Adoption of containers and container orchestration technologies allow proliferation of modern microservice-based architectures.
Containers solve the packaging problem - non-network runtime dependencies bundled into a standardized container allow developers to ensure programs can run on any machine, regardless of dependencies, frameworks, languages, etc. Increases the reproducibility of workloads.
Container orchestration solves the problem of mapping containers to machines that execute these containers. Using container orchestration technologies allow you to minimize the deploy-time and infrastructure costs of 1 -> 10 -> 100 services.
Isolated namespaces and restricted processes
- Namespaces provide the first and most straightforward form of isolation: processes running within a container cannot see, and even less affect, processes running in another container, or in the host system.
- Control Groups are another key component of Linux Containers. They implement resource accounting and limiting. They provide many useful metrics, but they also help ensure that each container gets its fair share of memory, CPU, disk I/O; and, more importantly, that a single container cannot bring the system down by exhausting one of those resources.
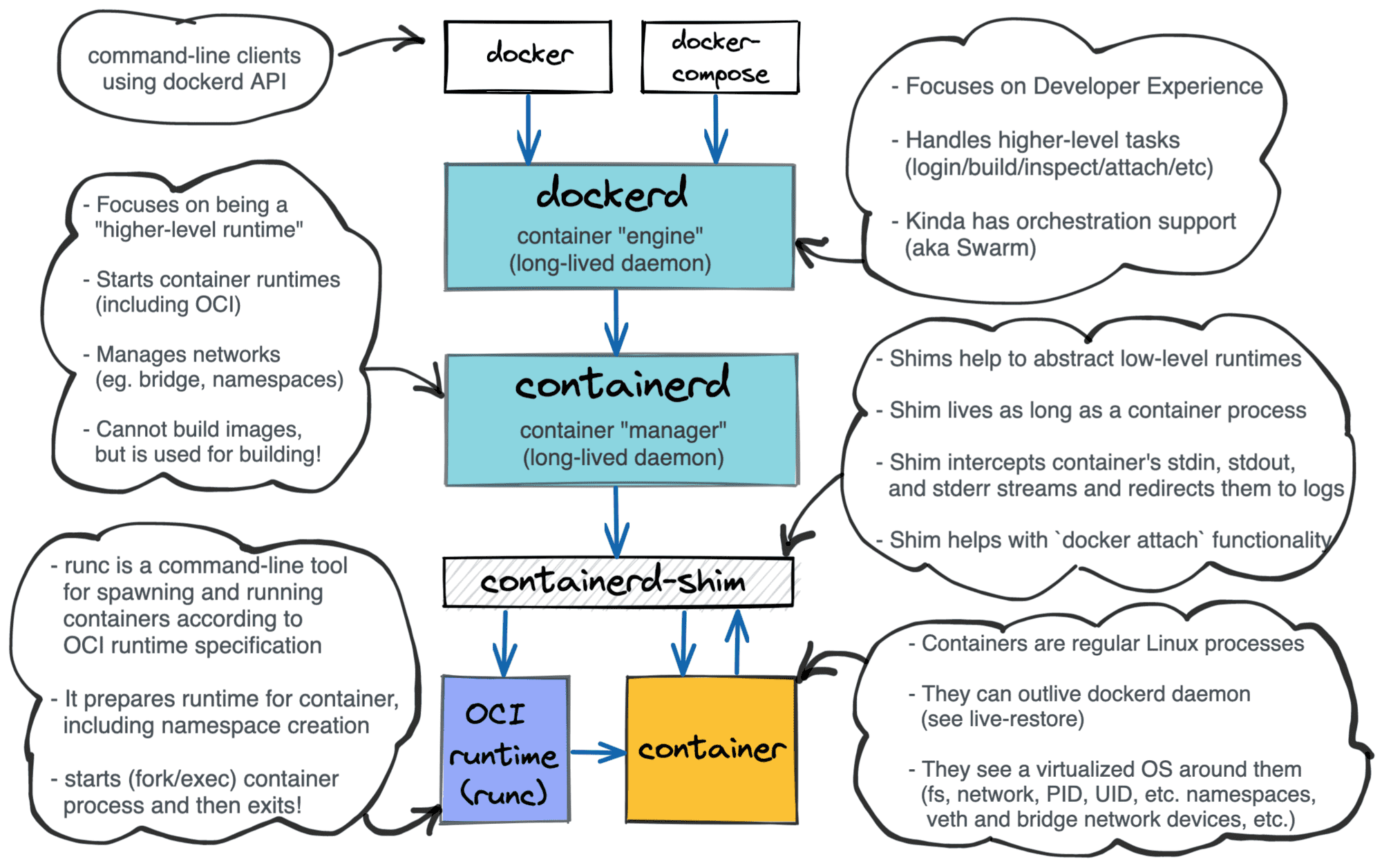
- Each container has its own network stack. You can enable networking through exposing public ports for your containers. Container runtimes - dockerd, containerd, runc Just some processes running on a Linux host - not necessarily an operating system
Docker breakdown:
- dockerd - higher-level daemon in front of containerd daemon
- docker - cli client to interact with dockerd It can:
- build/push/pull/scan images
- launch/pause/inspect/kill containers
- create networks/port forward
Pods
- Allows packaging of sidecars with main containers
- Native communication between containers in a pod (e.g. via
localhost) - Containers can remain isolated
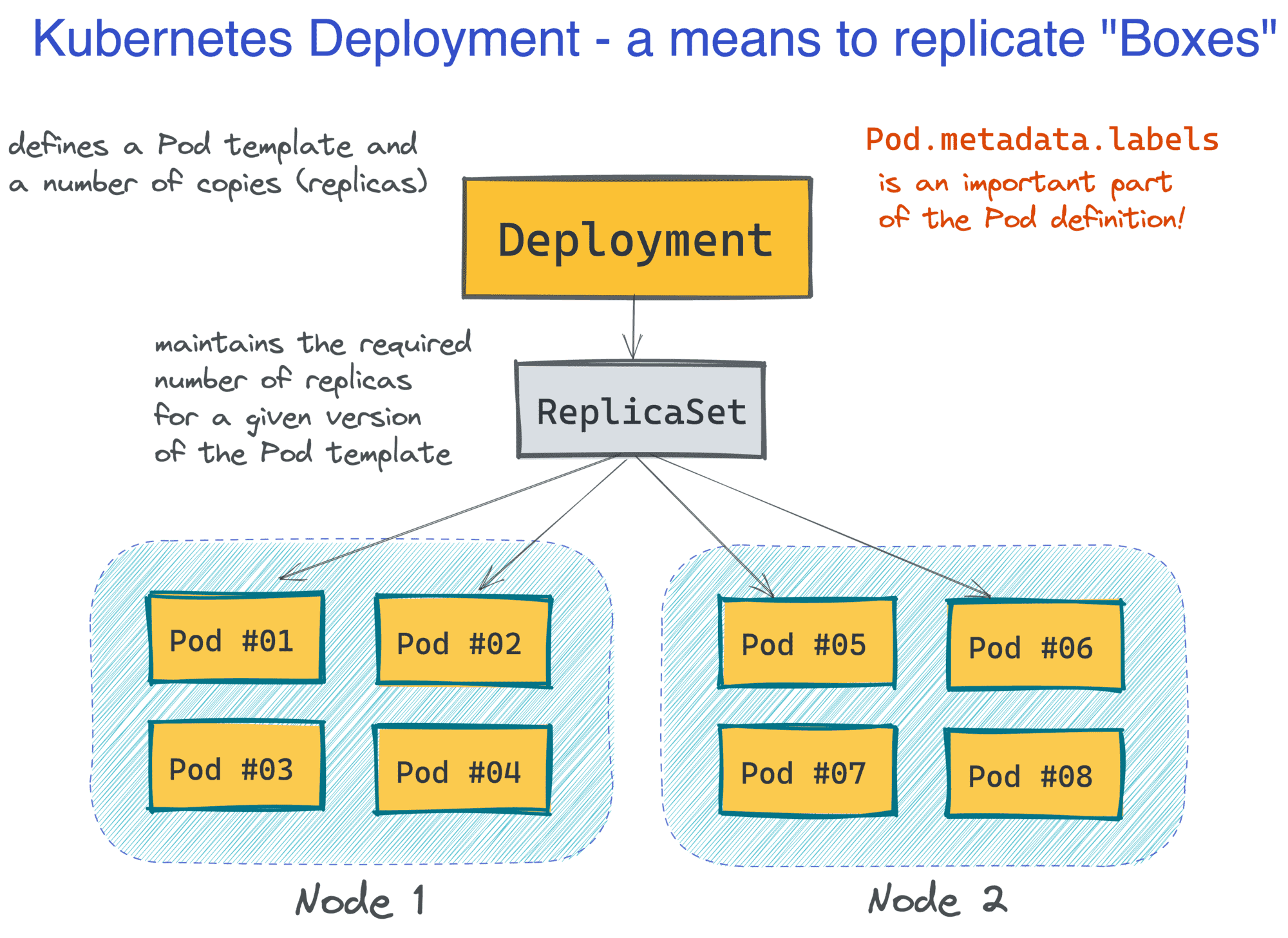
Deployments, a Kubernetes abstraction, allow you to specify the desired number of Pod replicas. Kubernetes is declarative by nature; users specify the desired end state and Kubernetes figures out the implementation details. In the example of scaling, the desired end state is defined in a manifest/resource, and pod distribution happens automatically across cluster nodes.
Objects
- Represents state of cluster
- Which applications are running? How many resources are available? Policies such as restart/upgrade/fault-tolerance
specto describe desired statestatusto describe current state
ReplicaSet
- A Kubernetes resource
- Ensures a specified number of pod replicas are running at all times
- Define a desired state for a set of pods, rather than an individual one.
- If a pod dies or becomes unavailable, the ReplicaSet will create a new pod to replace it
- If the number of running pods exceeds the desired number, the ReplicaSet will delete the extra pods.
- Self-healing, monitors health of pods and restarts/replaces unresponsive ones
StatefulSet
- Manages stateful applications
- Provides guarentees about the ordering and uniqueness of these pods
- Usage:
- Stable persistant storage
- Ordered and graceful deployment and scaling
- Ordered automatic rolling updates
Controller
- Tracks Kubernetes resource types
specfield to describe desired state- Kubernetes Job
- Creates pods to completion
- Autoscaling pods in clusters (Horizontal, Vertical)
Operator
- Kubernetes API Client - acts as a controller for a Custom Resource
- Usage:
- deploying applications on demand
- restoring application state from a backup
- handling upgrades of application code (database schemas, configuration)
- chaos engineering
- choosing a leader for a distributed system without an internal election process
- We used operators at Coinbase from open source tooling to automate database and schema migrations.
Problem: clients need to figure out the IP address and port it should use. In modern web services, there are multiple copies of a service in production at the same time.
Solution: service discovery. common solutions include a load balancer/reverse proxy like NGINX or HAProxy, using a single endpoint for the client which can route subsequent traffic to multiple instances of services. reverse proxies and load balancers utilize a service registry to determine the location and availability of a service. (a load balancer's routing rules are dynamically updated depending on this service registry)
Load balancers = single point of failure, potential throughput bottleneck + extra network hop on request path
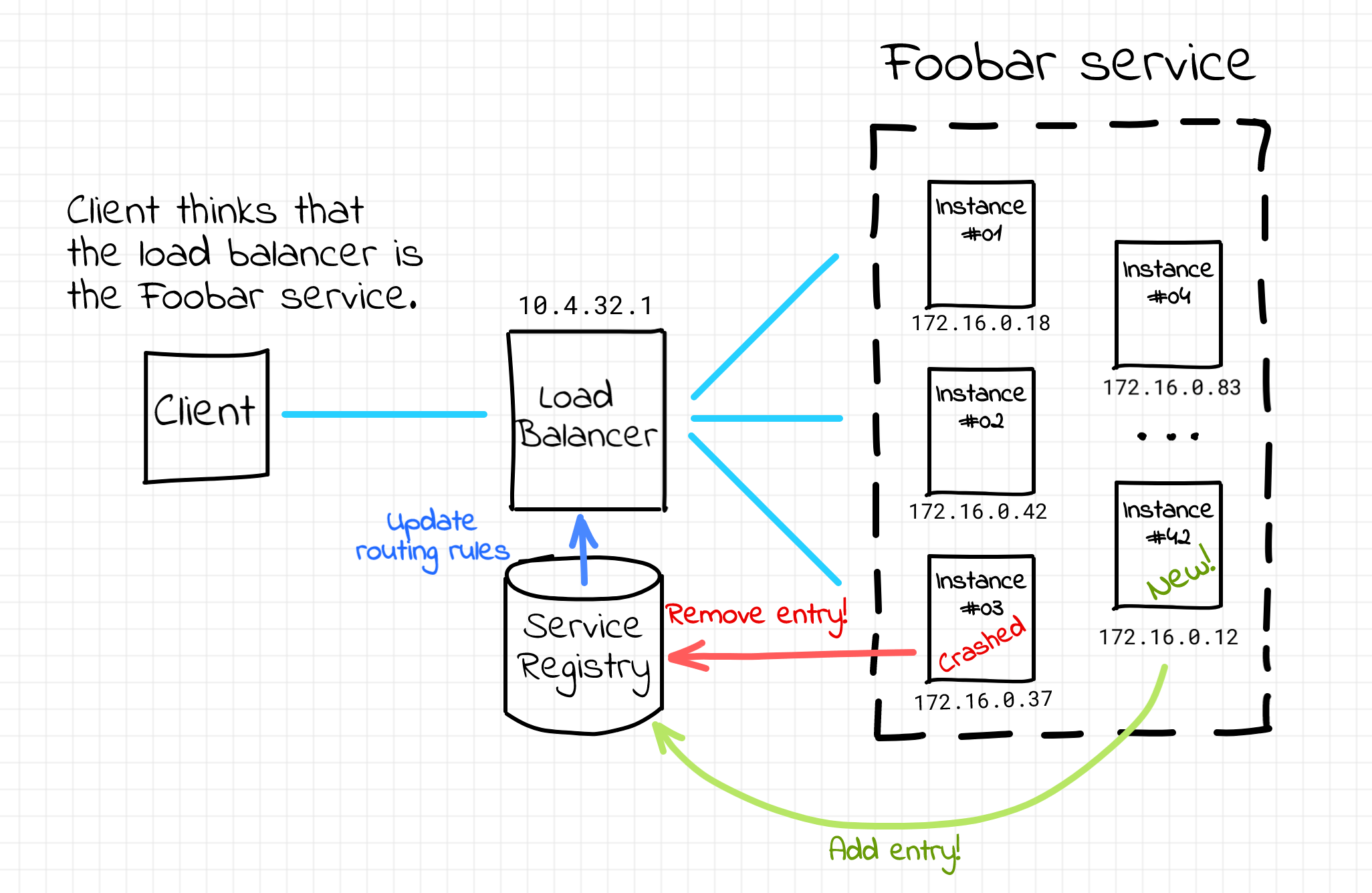
Client-side and round robin DNS can also be used as an alternative (not studying this further as it doesn't seem to be industry standard)
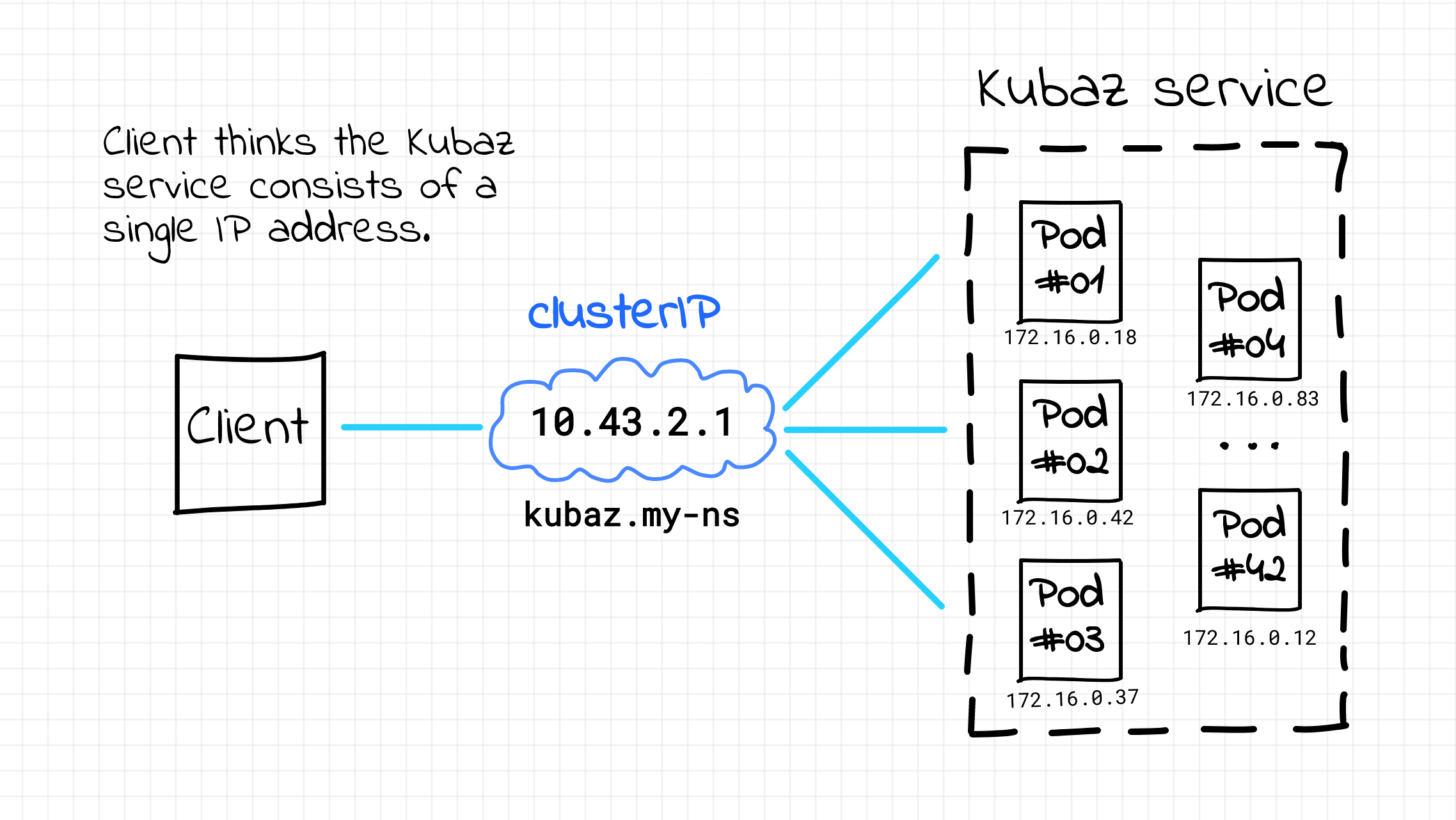
Kubernetes has built-in service discovery!
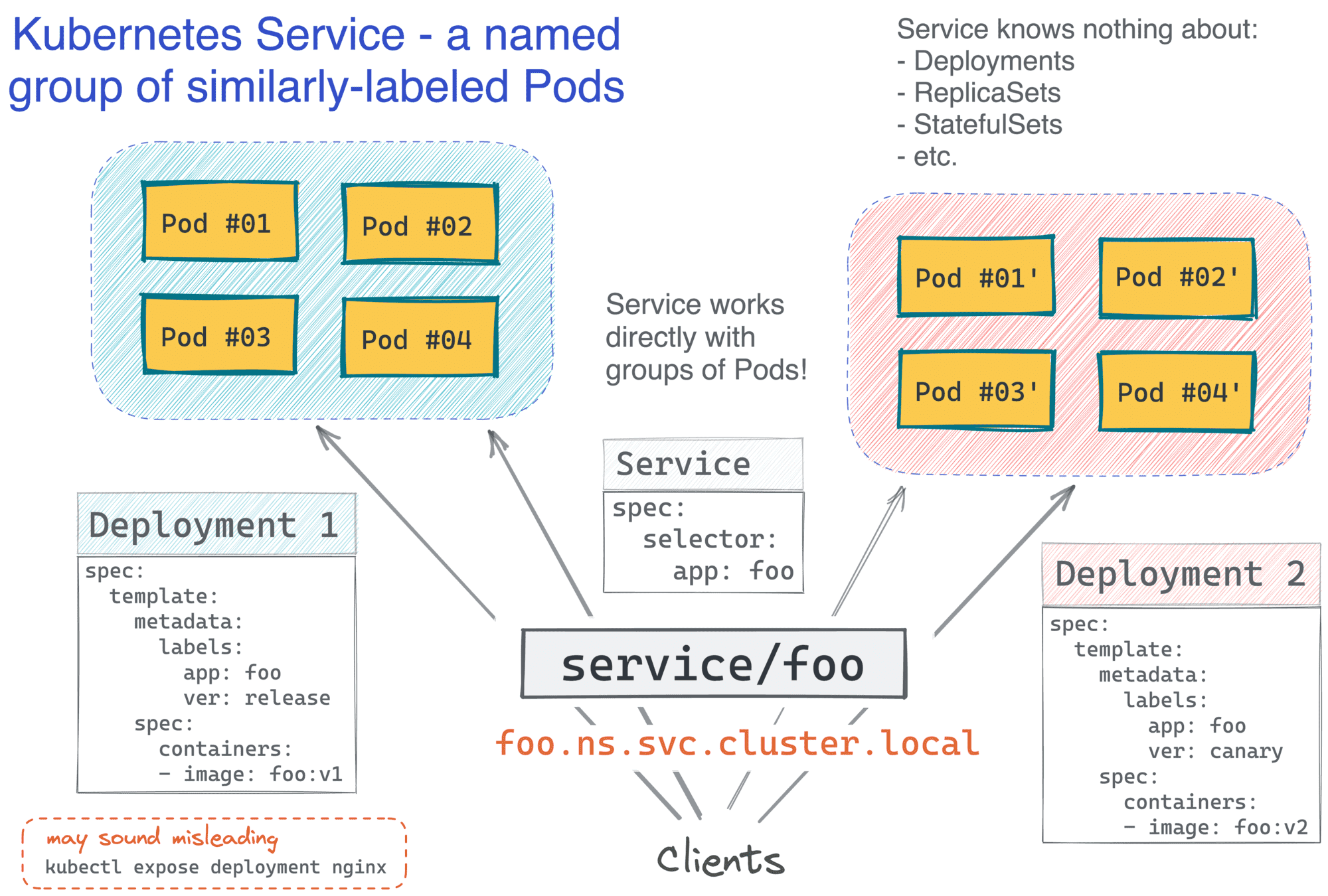
Kubernetes service
- A microservice
- Defines a set of pods and policies to access them
- pods are ephemeral
- name must include a valid DNS label name
Kubernetes service discovery is similar to DNS service discovery, but introduces the concept of clusterIP , which can be used to access pods in the service. Clients are able to learn the clusterIP for a service by inspecting its environment variables. When a pod is created, it is automatically assigned a unique IP address within the cluster. Services are also assigned unique IP addresses, and they can be used to access the pods that they represent.
Upon a pod startup, for every running service Kubernetes injects a couple of env variables looking like `<service-name>_SERVICE_HOST` and `<service-name>_SERVICE_PORT`.
REDIS_PRIMARY_SERVICE_HOST=10.0.0.11
REDIS_PRIMARY_SERVICE_PORT=6379
REDIS_PRIMARY_PORT=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_PRIMARY_PORT_6379_TCP_PROTO=tcp
REDIS_PRIMARY_PORT_6379_TCP_PORT=6379
REDIS_PRIMARY_PORT_6379_TCP_ADDR=10.0.0.11
Managed offerings like Amazon EKS (Elastic Kubernetes Service) allow automatic provisioning, scaling, and maintaining the control plane and worker nodes to meet application demand.
In Amazon EKS, the service discovery is implemented using the Kubernetes DNS, which is automatically deployed and configured when the cluster is created. The DNS service runs as a pod inside the cluster and provides the service discovery functionality. Additionally, the Amazon EKS also uses AWS's internal DNS service (Route 53) to provide a seamless service discovery across the different availability zones.
Argo rollouts
- Open-source Kubernetes extension for advanced deployments
- Manage the creation, scaling, and deletion of
ReplicaSetobjects. - Useful for:
- Canary deployments
- Blue/green deployments
- Progressive delivery
You can optionally integrate argo rollouts with an ingress controller and service mesh to perform canary and blue/green deployments.
While Kubernetes provides RollingUpdate in its native Deployment Object, users are unable to control the speed, traffic flow, readiness probes, external metrics, or abort/rollback the deployment. Therefore, in large-scale high-volume production environments it's recommended to use an Argo rollout.