![]()
rcognita is a flexibly configurable framework for agent-enviroment simulation with a menu of predictive and safe reinforcement learning controllers.
A detailed documentation is available here.
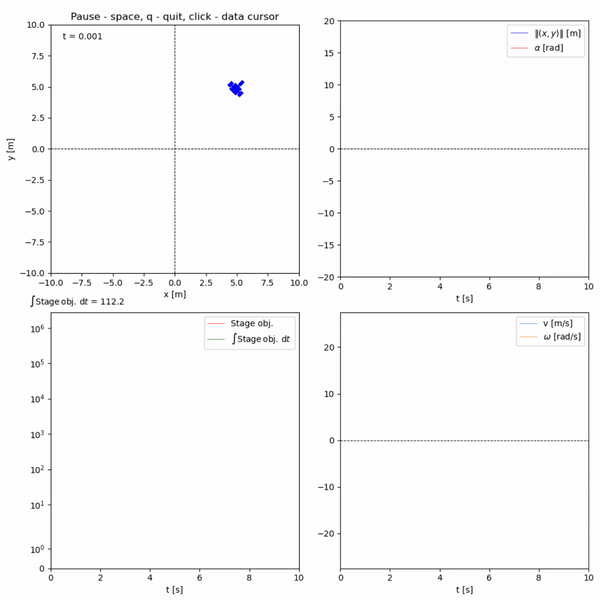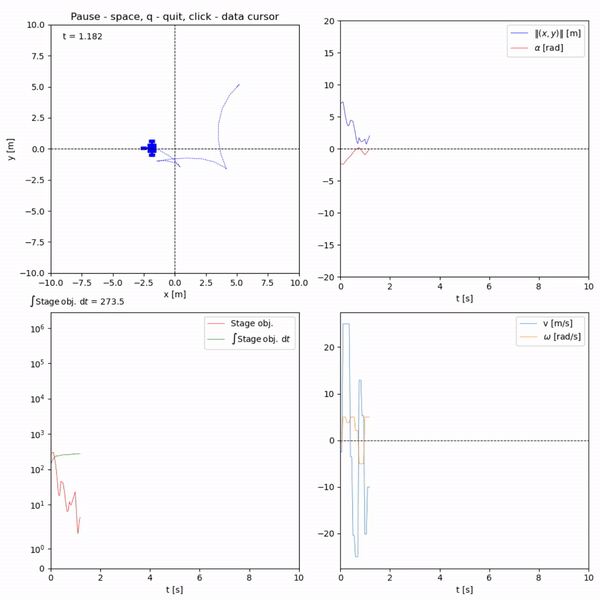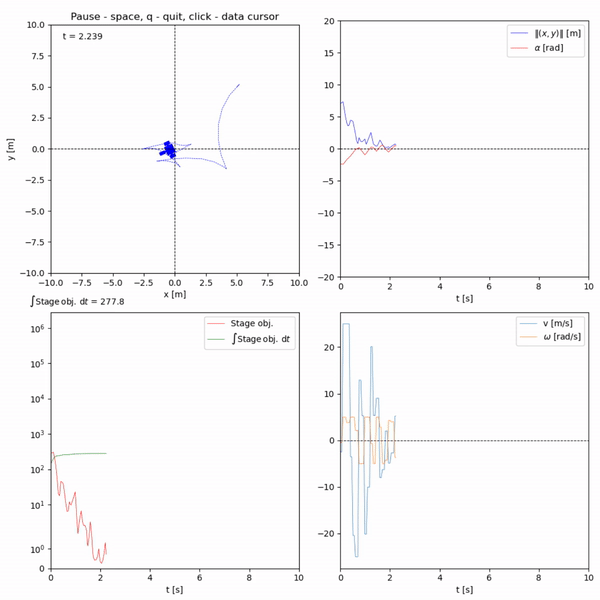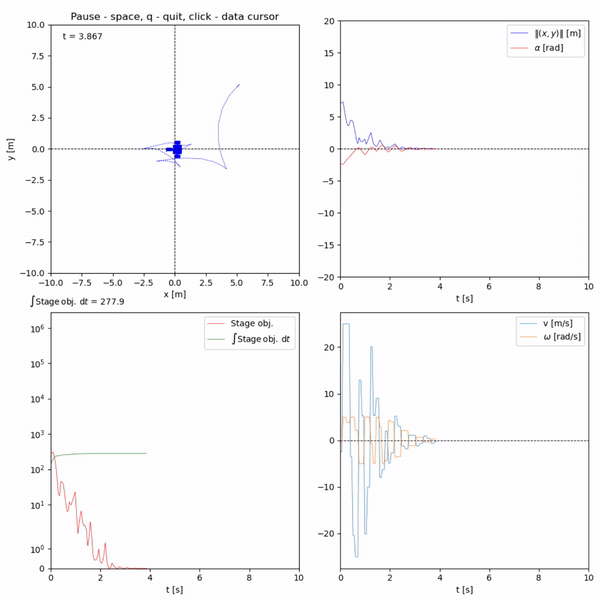
Run in terminal:
pip3 install rcognita
Alternatively, one can install the package direcly form the master branch. The following instruction is for Unix-based systems, assuming a terminal and Python3 interpreter.
git clone https://github.com/AIDynamicAction/rcognita cd rcognita python3 setup.py install
Notice that your Python 3 interpreter might be called something else,
say, just python.
The package was tested with online model estimation using
SIPPY. The respective
functionality is implemented and enabled via is_est_model. Related
parameters can be found in the documentation of the CtrlOptPred
class.
To install SIPPY, first take care of the dependencies:
sudo apt-get install -y build-essential gfortran cmake libopenblas-dev
pacman -Sy gcc gcc-fortran cmake base-devel openblas
pip install scikit-build
or, using Anaconda,
conda install scikit-build
pip3 install rcognita[SIPPY]
rcognita Python package is designed for hybrid simulation of agents
and environments (generally speaking, not necessarily reinforcement
learning agents). Its main idea is to have an explicit implementation of
sampled controls with user-defined sampling time specification. The
package consists of several modules, namely, controllers,
loggers, models, simulator, systems, utilities,
visuals and a collection of main modules (presets) for each
agent-environment configuration.
This flowchart
shows interaction of the core rcognita classes contained in the said
modules (the latter are not shown on the diagram).
The main module is a preset, on the flowchart a 3-wheel robot. It
initializes the system (the environment), the controllers (the agents,
e. g., a safe agent, a benchmarking agent, a reinforcement learning
agent etc.), the visualization engine called animator, the logger and
the simulator. The latter is a multi-purpose device for simulating
agent-environment loops of different types (specified by sys_type).
Depending on sys_type, the environment can either be described by a
differential equation (including stochastic ones), a difference equation
(for discrete-time systems), or by a probability distribution (for,
e.g., Markov decision processes).
The parameter dt determines the maximal step size for the numerical
solver in case of differential equations. The main method of this class
is sim_step which performs one solver step, whereas reset
re-initializes the simulator after an episode.
The Logger class is an interface defining stubs of a
print-to-console method print sim step, and print-to-file method log
data row, respectively. Concrete loggers realize these methods.
A similar class inheritance scheme is used in Animator, and
System. The core data of Animator’s subclasses are
objects, which include entities to be updated on the screen, and
their parameters stored in pars.
A concrete realization of a system interface must realize sys_dyn,
which is the “right-handside” of the environment description, optionally
disturbance dynamics via disturb_dyn, optionally controller dynamics
(if the latter is, e.g., time-varying), and the output function out.
The method receive_action gets a control action and stores it.
Everything is packed together in the closed_loop_rhs for the use in
Simulator.
Finally, the controllers module contains various agent types. One of
them is CtrlOptPred – the class of predictive objective-optimizing
agents (model-predictive control and predictive reinforcement learning)
as shown in this
flowchart. Notice
it contains an explicit specification of the sampling time dt.
The method _critic computes a model of something related to the
value, e.g., value function, Q-function or advantage. In turn,
_critic_cost defines a cost (loss) function to fir the critic
(commonly based on temporal errors). The method _critic_optimizer
actually optimizes the critic cost. The principle is analogous with the
actor, except that it optimizes an objective along a prediction horizon.
The details can be found in the code documentation. The method
compute_action essentially watches the internal clock and performs
an action updates when a time sample has elapsed.
Auxiliary modules of the package are models and utilities which
provide auxiliary functions and data structures, such as neural
networks.
After the package is installed, you may just python run one of the
presets found here, say,
python3 main_3wrobot_NI.py
This will call the preset with default settings, description of which can be found in the preset accordingly.
The naming convention is main_ACRONYM, where ACRONYM is actually
related to the system (environment). You may create your own by analogy.
For configuration of hyper-parameters, just call help on the required preset, say,
python3 main_3wrobot_NI.py -h
Some key settings are described below (full description is available via
-h option).
| Parameter | Type | Description |
|---|---|---|
ctrl_mode |
string | Controller mode |
dt |
number | Controller sampling time |
t1 |
number | Final time |
state_init |
list | Initial state |
is_log_data |
binary | Flag to log data |
is_visualization |
binary | Flag to produce graphical output |
is_print_sim_step |
binary | Flag to print simulation step data |
is_est_model |
binary | If a model of the system is to be estimated online |
Nactor |
integer | Horizon length (in steps) for predictive controllers |
stage_obj_struct |
string | Structure of running objective function |
Ncritic |
integer | Critic stack size (number of TDs) |
gamma |
number | Discount factor |
critic_struct |
string | Structure of critic features |
actor_struct |
string | Structure of actor features |
- Custom environments: realize
systeminterface in thesystemsmodule. You might need nominal controllers for that, as well as an animator, a logger etc. - Custom running cost: adjust
rcostin controllers - Custom AC method: simplest way -- by adding a new mode and
updating
_actor_cost,_critic_costand, possibly,_actor,_critic. For deep net AC structures, use, say, PyTorch - Custom model estimator: so far, the framework offers a state-space model structure. You may use any other one. In case of neural nets, use, e.g., PyTorch
An interface for dynamical controllers, which can be considered as
extensions of the system state vector, is provided in _ctrl_dyn of
the systems module. RL is usually understood as a static controller,
i.e., a one which assigns actions directly to outputs. A dynamical
controller does this indirectly, via an internal state as intermediate
link. ynamical controllers can overcome some limitations of static
controllers.
- Online actor-critic via stacked Q-learning and Kalman filter for model estimation
- More on fusion of model-predictive control and reinforcement learing
- More on "JACS", joint actor-critic (stabilizing)
- Some comparison of model-predictive control vs. stacked Q-learning
Please contact me for any inquiries and don't forget to give me credit for usage of this code. If you are interested in stacked Q-learning, kindly read the paper.
Original author: P. Osinenko, 2020
@misc{rcognita2020,
author = {Pavel Osinenko},
title = {Rcognita: a framework for hybrid agent-enviroment simultion},
howpublished = {\url{https://github.com/AIDynamicAction/rcognita}},
year = {2020}
}