Replies: 9 comments 1 reply
-
|
I think some of the points were discussed in #225 |
Beta Was this translation helpful? Give feedback.
-
|
I apologize on closing this issue, as it was not intended. I'm quite new to using GitHub. Regarding the other issue, yes, I do agree some points are quite similar. Thank you for sharing! NoisyLatentCompositionExample.json This workflow is meant to introduce noisy latent composition as a method to place an apple exactly on the middle of the table, feel free to try it out! In a regular diffusion workflow, you'd prompt for an apple in the middle on the table, however, it would be much harder to get consistent and reliable results on the position of the apple. Besides, prompting for specific positions for multiple objects does not scale well. In the attached workflow, I've been getting consistent results on the apple position, although the image still isn't perfect. Therefore, it's still necessary to iteratively edit and manipulate the image. All in all, this method seems to scale very well with multiple objects and prompts, does not require any custom nodes and works as a layer of control, while still maintaining an iterative and controllable workflow. This is what I initially meant with the issue, a simple, scalable and modular solution to help solve a complicated problem. The goal is to reduce the total number of steps, and therefore compute power and time needed to generate a precise image, all while still abiding to the plugin's goals and intentions. |
Beta Was this translation helpful? Give feedback.
-
|
I did some searching about how to create regional prompts (instead of inpainting) to get more control over specific parts of the image (area composition). E.g., the SD WebUI has a Regional Prompter extension (but I haven't looked any further into how that works yet). Your solution looks interesting, because I found a workflow that should do the same but in a different way. Your workflow (Noisy Latent Composition/LatentComposite):
What I found (ConditioningSetArea+ ConditioningCombine):
I would assume that with Krita's inbuild selection tool it should not be too difficult to get the coordinates of regional promt areas... |

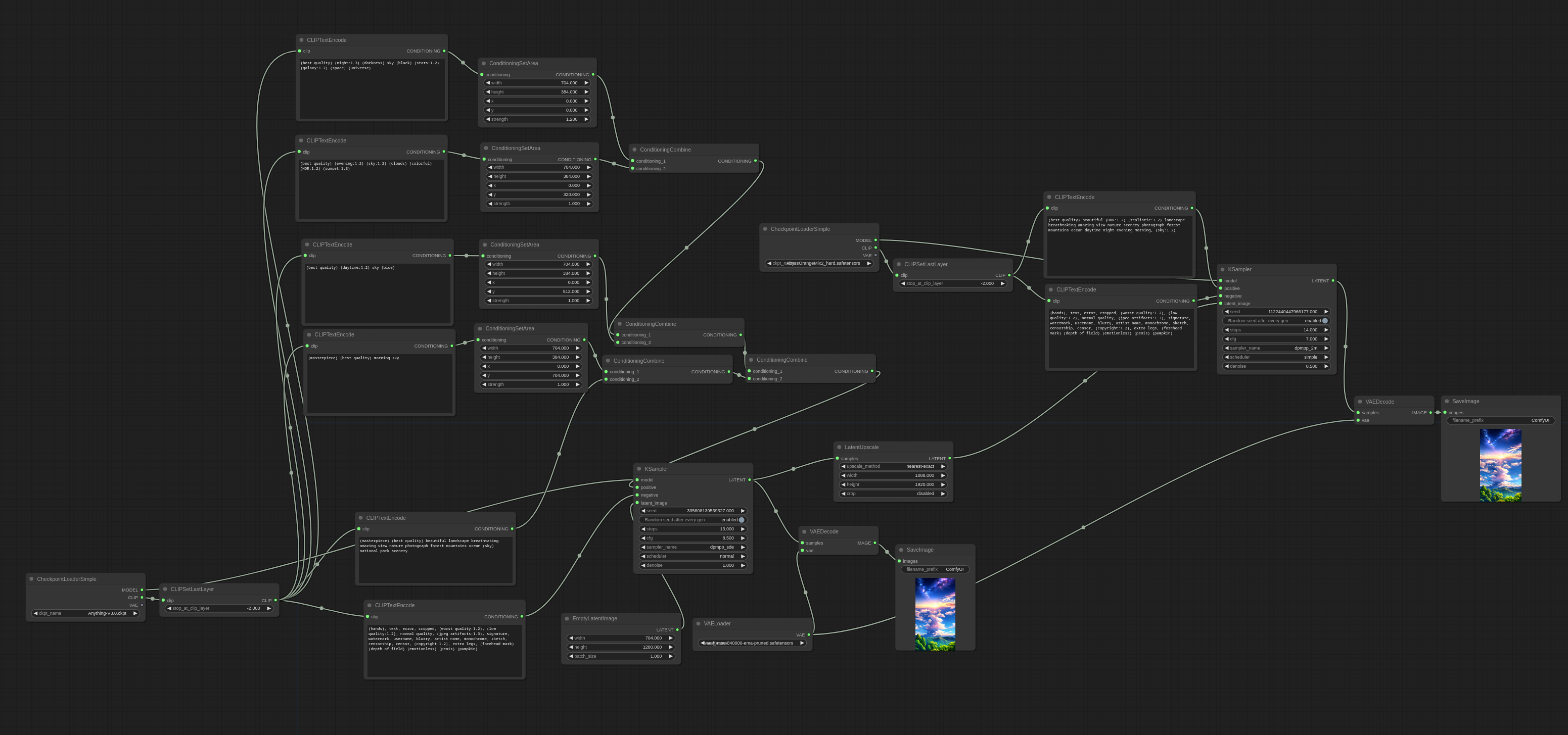
Beta Was this translation helpful? Give feedback.
-
|
As to the Krita part of this integration, I'm heavily unsure on the complexity of the approach, as I really do not have experience with making Krita plugins, however, I would also assume that it wouldn't be too difficult if it were to be implemented as a new control layer of sorts taking a condition and mask layer? As to the Noisy Latent Composition workflow, it's simply an adaptation from this example: https://comfyanonymous.github.io/ComfyUI_examples/noisy_latent_composition/ Both the latent composite workflow and the area conditioning workflow would work very well and augment artist control. I simply chose to show the latent composite method because it works by pasting latents during the denoising process. The first few steps are used mostly to determine general shapes, therefore, this method works sort of like informing the model about object positioning, shape and specifications using what I believe are different latents, then compositing them together early in the denoising process. Further image detailing is made for the image as a whole, since it's sampling using a general prompt for the entire image. Some details such as shape are already defined, so it builds upon that. Of course, this does have a speed drawback. I would say it's about 10% slower in simple cases such as the workflow I provideded earlier. That's where area conditioning comes in place, by defining specific details that do not rely on shape nor position. Since I believe it's only a concatenated string, there seems to be negligible performance loss, while still allowing for sparse control over the result. The result of the workflow you found produces great results in terms of regional prompting, however it lacks on general image coherency, as seen by the lacking representation of the sky in the end result. I'd like to propose that this solution should not just be a single method such as the latent composite workflow, but a combination of methods that can complement each other, towards the end goal of a simple, intuitive and iterative regional conditioning pipeline. Perhaps latent composition can be used alongside prompt concatenation to achieve a better result. Meanwhile, I'll be thoroughly researching methods that would allow us to achieve an optimal regional prompting workflow. If anyone's interested in this and would like to share a technique, workflow or paper, please do so! Thanks! EDIT: fixed link |
Beta Was this translation helpful? Give feedback.
-
|
Hm, I tried the ConditioningSetArea/ConditioningCombine approach, but it didn't worked out as expected. Apparently, overlapping areas will blend into each other. 
ConditioningCombine.json Using a ConditioningConcat instead of a ConditioningCombine node (using the "empty table" prompt and the "single red apple" prompts) generates an image that a single "empty table, single red apple" would generate (an empty table with actually two apples on it). Seems like the LatentComposite approach is more promising. |
Beta Was this translation helpful? Give feedback.
-
|
Well, my initial thought was something like, Krita is a painting app, so just paint it Yes the simple example isn't doing you any favours here and area text prompts would be more useful as the subjects become more complex and therefore more time consuming to sketch. That being said, I've tried area conditioning for more complex scenarios, and it becomes quite difficult to predict where things end up in the image, it won't necessarily turn out in a way where the areas make sense. It just feels all too nebulous and unconcrete to me to plan an image ahead like that without having any feedback or guarantee that SD will understand it. I like to go step by step, with intermediate generation. I like building up on actual pixels. Speaking of pixels, that's where Krita is strong, they may come from a photo, something you sketch or paint, photo-bash, etc. Generating from scratch is just one option, and not a primary focus of the plugin. Personally, I'm really interested in how SD/gen-AI can be better integrated and become more fluid and intuitive in image workflows. Like a more prcecise tool to manipulate an image. Ideas from this discussion go a bit into the opposite direction, it's more technical setup for one big do-everything generation. Still, it's not like there is no overlap, and separate prompt/image/control setups for different areas of the image do make sense throughout the process of working on an image. Storing masks and going back and forth between subjects is useful, and it would be nice to have a more automated way to restore the SD setup that was previously used for a certain part of the image. If that kind of structure is built of successively, it could also be used via area conditioning on full image passes. Latent composite I'm not sure, it loses its purpose at lower denoise strength, even though detailed prompts for certain areas could still make sense for the later diffusion stages. |

Beta Was this translation helpful? Give feedback.
-
|
I've started the development of PR #639, do you think it would be helpful for your needs ? |
Beta Was this translation helpful? Give feedback.
-
|
I noticed your PR some minutes ago. Looks quite promising! |
Beta Was this translation helpful? Give feedback.
-
|
Invoke AI has implemented something similar recently: https://support.invoke.ai/support/solutions/articles/151000189477 |
Beta Was this translation helpful? Give feedback.
-
|
Regions are released: v1.18.0 |
Beta Was this translation helpful? Give feedback.
-
The issue
Although very capable, diffusion models currently struggle with object position and precise artistic control over an image. As an example, there are currently very few ways to tell the model where the sun should be in an image. Using this tool, the few ways I can think this could work would be through ControlNET and/or inpainting, albeit this would require an extra model pass for the latter, slowing down generation incrementally for each detail that the artist chooses to change. Furthermore, in specific cases it might even require an extra model pass to increase coherency with the entire image, be it lighting or style.
How to solve it
Recent work such as "RPG-DiffusionMaster" and "LLM-groundedDiffusion" suggest the use of LLMs to provide conditioning context boxes using tools such as GLIGEN or regional prompting to further augment diffusion model capabilities on precise object placement. However, I do not see the use of LLMs fit in this project as practical, since they require a lot of RAM/VRAM, nor do they augment artistic capabilities, since they reduce artistic control on placement. Instead, I suggest the use of context/conditioning mask layers with optional prompt conditioning, delegating the LLM work to the end user, increasing artistic control over precise object placement.
How to integrate the solution seamlessly
Although the solution would bring various benefits, it is complex to imagine how this would work with the current workflow. In order to keep breaking changes to a minimum, I suggest the addition of a modular regional conditioning tab, similar to ControlNET. This would still be a breaking change, having in sight the history tab is based on a single prompt, styles are also based on a single prompt, so on and so forth. Therefore, I would like to ask for feedback regarding this topic in this issue, be it from users or the project lead, who has thorough knowledge of the codebase and project design.
What tools to use in this implementation
I suggest either GLIGEN, Noisy Latent Composition or regular regional conditioning. I believe it is out of scope of this issue to explain this techniques, but two of them are explained thoroughly on ComfyUI examples. Some of them require extra custom nodes, some of them do not. It would be a pleasure to hear feedback about which one of these seems fit for this solution and integration to the plugin. As for the Krita segment, I would suggest mask layers. Pretty simple, I believe, since this is already available as discussed in other issues such as SDXL inpainting context.
Further discussion
I would greatly appreciate any discussion in this issue, as I believe this solution would be a vital component of any artist's workflow. Although I sometimes code in Python, I'm not knowledgeable on the codebase, therefore I'm refraining from suggesting code architecture changes, since I don't even know how it's structured to begin with. If there is any interest in discussing about any component of this suggestion or suggestions to change anything, I would wholeheartedly respond with my current knowledge about diffusion models, ComfyUI or whatever else may be needed.
Thank you for your attention!
Beta Was this translation helpful? Give feedback.
All reactions