diff --git a/.circleci/test.yml b/.circleci/test.yml
index 81af82a14e4..0eefb195dd6 100644
--- a/.circleci/test.yml
+++ b/.circleci/test.yml
@@ -136,6 +136,8 @@ jobs:
machine:
image: ubuntu-2004-cuda-11.4:202110-01
resource_class: gpu.nvidia.small
+ environment:
+ MKL_SERVICE_FORCE_INTEL: 1
parameters:
torch:
type: string
diff --git a/.dev_scripts/fill_metafile.py b/.dev_scripts/fill_metafile.py
index d0f49a84a8a..2541d763b22 100644
--- a/.dev_scripts/fill_metafile.py
+++ b/.dev_scripts/fill_metafile.py
@@ -20,8 +20,10 @@
MMCLS_ROOT = Path(__file__).absolute().parents[1].resolve().absolute()
console = Console()
-dataset_completer = FuzzyWordCompleter(
- ['ImageNet-1k', 'ImageNet-21k', 'CIFAR-10', 'CIFAR-100'])
+dataset_completer = FuzzyWordCompleter([
+ 'ImageNet-1k', 'ImageNet-21k', 'CIFAR-10', 'CIFAR-100', 'RefCOCO', 'VQAv2',
+ 'COCO', 'OpenImages', 'Object365', 'CC3M', 'CC12M', 'YFCC100M', 'VG'
+])
def prompt(message,
@@ -83,53 +85,57 @@ def parse_args():
return args
-def get_flops(config_path):
+def get_flops_params(config_path):
import numpy as np
import torch
- from fvcore.nn import FlopCountAnalysis, parameter_count
- from mmengine.config import Config
+ from mmengine.analysis import FlopAnalyzer, parameter_count
from mmengine.dataset import Compose
from mmengine.model.utils import revert_sync_batchnorm
from mmengine.registry import DefaultScope
- import mmpretrain.datasets # noqa: F401
- from mmpretrain.apis import init_model
-
- cfg = Config.fromfile(config_path)
-
- if 'test_dataloader' in cfg:
- # build the data pipeline
- test_dataset = cfg.test_dataloader.dataset
- if test_dataset.pipeline[0]['type'] == 'LoadImageFromFile':
- test_dataset.pipeline.pop(0)
- if test_dataset.type in ['CIFAR10', 'CIFAR100']:
- # The image shape of CIFAR is (32, 32, 3)
- test_dataset.pipeline.insert(1, dict(type='Resize', scale=32))
-
- with DefaultScope.overwrite_default_scope('mmpretrain'):
- data = Compose(test_dataset.pipeline)({
- 'img':
- np.random.randint(0, 256, (224, 224, 3), dtype=np.uint8)
- })
- resolution = tuple(data['inputs'].shape[-2:])
- else:
- # For configs only for get model.
- resolution = (224, 224)
+ from mmpretrain.apis import get_model
+ from mmpretrain.models.utils import no_load_hf_pretrained_model
- model = init_model(cfg, device='cpu')
+ with no_load_hf_pretrained_model():
+ model = get_model(config_path, device='cpu')
model = revert_sync_batchnorm(model)
model.eval()
-
- with torch.no_grad():
- model.forward = model.extract_feat
- model.to('cpu')
- inputs = (torch.randn((1, 3, *resolution)), )
- analyzer = FlopCountAnalysis(model, inputs)
- analyzer.unsupported_ops_warnings(False)
- analyzer.uncalled_modules_warnings(False)
- flops = analyzer.total()
- params = parameter_count(model)['']
- return int(flops), int(params)
+ params = int(parameter_count(model)[''])
+
+ # get flops
+ try:
+ if 'test_dataloader' in model._config:
+ # build the data pipeline
+ test_dataset = model._config.test_dataloader.dataset
+ if test_dataset.pipeline[0]['type'] == 'LoadImageFromFile':
+ test_dataset.pipeline.pop(0)
+ if test_dataset.type in ['CIFAR10', 'CIFAR100']:
+ # The image shape of CIFAR is (32, 32, 3)
+ test_dataset.pipeline.insert(1, dict(type='Resize', scale=32))
+
+ with DefaultScope.overwrite_default_scope('mmpretrain'):
+ data = Compose(test_dataset.pipeline)({
+ 'img':
+ np.random.randint(0, 256, (224, 224, 3), dtype=np.uint8)
+ })
+ resolution = tuple(data['inputs'].shape[-2:])
+ else:
+ # For configs only for get model.
+ resolution = (224, 224)
+
+ with torch.no_grad():
+ # Skip flops if the model doesn't have `extract_feat` method.
+ model.forward = model.extract_feat
+ model.to('cpu')
+ inputs = (torch.randn((1, 3, *resolution)), )
+ analyzer = FlopAnalyzer(model, inputs)
+ analyzer.unsupported_ops_warnings(False)
+ analyzer.uncalled_modules_warnings(False)
+ flops = int(analyzer.total())
+ except Exception:
+ print('Unable to calculate flops.')
+ flops = None
+ return flops, params
def fill_collection(collection: dict):
@@ -202,12 +208,9 @@ def fill_model_by_prompt(model: dict, defaults: dict):
params = model.get('Metadata', {}).get('Parameters')
if model.get('Config') is not None and (
MMCLS_ROOT / model['Config']).exists() and (flops is None
- or params is None):
- try:
- print('Automatically compute FLOPs and Parameters from config.')
- flops, params = get_flops(str(MMCLS_ROOT / model['Config']))
- except Exception:
- print('Failed to compute FLOPs and Parameters.')
+ and params is None):
+ print('Automatically compute FLOPs and Parameters from config.')
+ flops, params = get_flops_params(str(MMCLS_ROOT / model['Config']))
if flops is None:
flops = prompt('Please specify the [red]FLOPs[/]: ')
@@ -222,7 +225,8 @@ def fill_model_by_prompt(model: dict, defaults: dict):
model['Metadata'].setdefault('FLOPs', flops)
model['Metadata'].setdefault('Parameters', params)
- if model.get('Metadata', {}).get('Training Data') is None:
+ if 'Training Data' not in model.get('Metadata', {}) and \
+ 'Training Data' not in defaults.get('Metadata', {}):
training_data = prompt(
'Please input all [red]training dataset[/], '
'include pre-training (input empty to finish): ',
@@ -259,12 +263,11 @@ def fill_model_by_prompt(model: dict, defaults: dict):
for metric in metrics_list:
k, v = metric.split('=')[:2]
metrics[k] = round(float(v), 2)
- if len(metrics) > 0:
- results = [{
- 'Dataset': test_dataset,
- 'Metrics': metrics,
- 'Task': task
- }]
+ results = [{
+ 'Task': task,
+ 'Dataset': test_dataset,
+ 'Metrics': metrics or None,
+ }]
model['Results'] = results
weights = model.get('Weights')
@@ -274,7 +277,7 @@ def fill_model_by_prompt(model: dict, defaults: dict):
if model.get('Converted From') is None and model.get(
'Weights') is not None:
- if Confirm.ask(
+ if '3rdparty' in model['Name'] or Confirm.ask(
'Is the checkpoint is converted '
'from [red]other repository[/]?',
default=False):
@@ -317,9 +320,9 @@ def update_model_by_dict(model: dict, update_dict: dict, defaults: dict):
# Metadata.Flops, Metadata.Parameters
flops = model.get('Metadata', {}).get('FLOPs')
params = model.get('Metadata', {}).get('Parameters')
- if config_updated or (flops is None or params is None):
+ if config_updated or (flops is None and params is None):
print(f'Automatically compute FLOPs and Parameters of {model["Name"]}')
- flops, params = get_flops(str(MMCLS_ROOT / model['Config']))
+ flops, params = get_flops_params(str(MMCLS_ROOT / model['Config']))
model.setdefault('Metadata', {})
model['Metadata']['FLOPs'] = flops
@@ -409,10 +412,15 @@ def format_model(model: dict):
def order_models(model):
order = []
+ # Pre-trained model
order.append(int('Downstream' not in model))
+ # non-3rdparty model
order.append(int('3rdparty' in model['Name']))
+ # smaller model
order.append(model.get('Metadata', {}).get('Parameters', 0))
+ # faster model
order.append(model.get('Metadata', {}).get('FLOPs', 0))
+ # name order
order.append(len(model['Name']))
return tuple(order)
@@ -442,7 +450,10 @@ def main():
collection = fill_collection(collection)
if ori_collection != collection:
console.print(format_collection(collection))
- model_defaults = {'In Collection': collection['Name']}
+ model_defaults = {
+ 'In Collection': collection['Name'],
+ 'Metadata': collection.get('Metadata', {}),
+ }
models = content.get('Models', [])
updated_models = []
diff --git a/.dev_scripts/generate_readme.py b/.dev_scripts/generate_readme.py
index 2fd0a5a2a48..e80d691a19c 100644
--- a/.dev_scripts/generate_readme.py
+++ b/.dev_scripts/generate_readme.py
@@ -331,6 +331,12 @@ def add_models(metafile):
'Image Classification',
'Image Retrieval',
'Multi-Label Classification',
+ 'Image Caption',
+ 'Visual Grounding',
+ 'Visual Question Answering',
+ 'Image-To-Text Retrieval',
+ 'Text-To-Image Retrieval',
+ 'NLVR',
]
for task in tasks:
diff --git a/README.md b/README.md
index ea24969459d..e6a0afbe21d 100644
--- a/README.md
+++ b/README.md
@@ -70,11 +70,19 @@ The `main` branch works with **PyTorch 1.8+**.
### Major features
- Various backbones and pretrained models
-- Rich training strategies(supervised learning, self-supervised learning, etc.)
+- Rich training strategies (supervised learning, self-supervised learning, multi-modality learning etc.)
- Bag of training tricks
- Large-scale training configs
- High efficiency and extensibility
- Powerful toolkits for model analysis and experiments
+- Various out-of-box inference tasks.
+ - Image Classification
+ - Image Caption
+ - Visual Question Answering
+ - Visual Grounding
+ - Retrieval (Image-To-Image, Text-To-Image, Image-To-Text)
+
+https://github.com/open-mmlab/mmpretrain/assets/26739999/e4dcd3a2-f895-4d1b-a351-fbc74a04e904
## What's new
@@ -117,6 +125,12 @@ mim install -e .
Please refer to [installation documentation](https://mmpretrain.readthedocs.io/en/latest/get_started.html) for more detailed installation and dataset preparation.
+For multi-modality models support, please install the extra dependencies by:
+
+```shell
+mim install -e ".[multimodal]"
+```
+
## User Guides
We provided a series of tutorials about the basic usage of MMPreTrain for new users:
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 0576df108b7..50426aca2a2 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -68,11 +68,19 @@ MMPreTrain 是一款基于 PyTorch 的开源深度学习预训练工具箱,是
### 主要特性
- 支持多样的主干网络与预训练模型
-- 支持多种训练策略(有监督学习,无监督学习等)
+- 支持多种训练策略(有监督学习,无监督学习,多模态学习等)
- 提供多种训练技巧
- 大量的训练配置文件
- 高效率和高可扩展性
- 功能强大的工具箱,有助于模型分析和实验
+- 支持多种开箱即用的推理任务
+ - 图像分类
+ - 图像描述(Image Caption)
+ - 视觉问答(Visual Question Answering)
+ - 视觉定位(Visual Grounding)
+ - 检索(图搜图,图搜文,文搜图)
+
+https://github.com/open-mmlab/mmpretrain/assets/26739999/e4dcd3a2-f895-4d1b-a351-fbc74a04e904
## 更新日志
@@ -114,6 +122,12 @@ mim install -e .
更详细的步骤请参考 [安装指南](https://mmpretrain.readthedocs.io/zh_CN/latest/get_started.html) 进行安装。
+如果需要多模态模型,请使用如下方式安装额外的依赖:
+
+```shell
+mim install -e ".[multimodal]"
+```
+
## 基础教程
我们为新用户提供了一系列基础教程:
diff --git a/configs/_base_/datasets/coco_caption.py b/configs/_base_/datasets/coco_caption.py
new file mode 100644
index 00000000000..05d49349ce1
--- /dev/null
+++ b/configs/_base_/datasets/coco_caption.py
@@ -0,0 +1,69 @@
+# data settings
+
+data_preprocessor = dict(
+ type='MultiModalDataPreprocessor',
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=384,
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(type='CleanCaption', keys='gt_caption'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['gt_caption'],
+ meta_keys=['image_id'],
+ ),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(384, 384),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='PackInputs', meta_keys=['image_id']),
+]
+
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=5,
+ dataset=dict(
+ type='COCOCaption',
+ data_root='data/coco',
+ ann_file='annotations/coco_karpathy_train.json',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ persistent_workers=True,
+ drop_last=True,
+)
+
+val_dataloader = dict(
+ batch_size=16,
+ num_workers=5,
+ dataset=dict(
+ type='COCOCaption',
+ data_root='data/coco',
+ ann_file='annotations/coco_karpathy_val.json',
+ pipeline=test_pipeline,
+ ),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+)
+
+val_evaluator = dict(
+ type='COCOCaption',
+ ann_file='data/coco/annotations/coco_karpathy_val_gt.json',
+)
+
+# # If you want standard test, please manually configure the test dataset
+test_dataloader = val_dataloader
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/coco_retrieval.py b/configs/_base_/datasets/coco_retrieval.py
new file mode 100644
index 00000000000..8bc1c1f6754
--- /dev/null
+++ b/configs/_base_/datasets/coco_retrieval.py
@@ -0,0 +1,95 @@
+# data settings
+data_preprocessor = dict(
+ type='MultiModalDataPreprocessor',
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+rand_increasing_policies = [
+ dict(type='AutoContrast'),
+ dict(type='Equalize'),
+ dict(type='Rotate', magnitude_key='angle', magnitude_range=(0, 30)),
+ dict(
+ type='Brightness', magnitude_key='magnitude',
+ magnitude_range=(0, 0.0)),
+ dict(type='Sharpness', magnitude_key='magnitude', magnitude_range=(0, 0)),
+ dict(
+ type='Shear',
+ magnitude_key='magnitude',
+ magnitude_range=(0, 0.3),
+ direction='horizontal'),
+ dict(
+ type='Shear',
+ magnitude_key='magnitude',
+ magnitude_range=(0, 0.3),
+ direction='vertical'),
+]
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=384,
+ crop_ratio_range=(0.5, 1.0),
+ interpolation='bicubic'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies=rand_increasing_policies,
+ num_policies=2,
+ magnitude_level=5),
+ dict(type='CleanCaption', keys='text'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text', 'is_matched'],
+ meta_keys=['image_id']),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(384, 384),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='CleanCaption', keys='text'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text', 'gt_text_id', 'gt_image_id'],
+ meta_keys=['image_id']),
+]
+
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=16,
+ dataset=dict(
+ type='COCORetrieval',
+ data_root='data/coco',
+ ann_file='annotations/caption_karpathy_train2014.json',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ persistent_workers=True,
+ drop_last=True,
+)
+
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=16,
+ dataset=dict(
+ type='COCORetrieval',
+ data_root='data/coco',
+ ann_file='annotations/caption_karpathy_val2014.json',
+ pipeline=test_pipeline,
+ # This is required for evaluation
+ test_mode=True,
+ ),
+ sampler=dict(type='SequentialSampler', subsample_type='sequential'),
+ persistent_workers=True,
+)
+
+val_evaluator = dict(type='RetrievalRecall', topk=(1, 5, 10))
+
+# If you want standard test, please manually configure the test dataset
+test_dataloader = val_dataloader
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/coco_vg_vqa.py b/configs/_base_/datasets/coco_vg_vqa.py
new file mode 100644
index 00000000000..7ba0eac4685
--- /dev/null
+++ b/configs/_base_/datasets/coco_vg_vqa.py
@@ -0,0 +1,96 @@
+# data settings
+data_preprocessor = dict(
+ type='MultiModalDataPreprocessor',
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=(480, 480),
+ crop_ratio_range=(0.5, 1.0),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ dict(
+ type='RandAugment',
+ policies='simple_increasing', # slightly different from LAVIS
+ num_policies=2,
+ magnitude_level=5),
+ dict(type='CleanCaption', keys=['question', 'gt_answer']),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['question', 'gt_answer', 'gt_answer_weight']),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(480, 480),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='CleanCaption', keys=['question']),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['question'],
+ meta_keys=['question_id']),
+]
+
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=8,
+ dataset=dict(
+ type='ConcatDataset',
+ datasets=[
+ # VQAv2 train
+ dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='train2014',
+ question_file=
+ 'annotations/v2_OpenEnded_mscoco_train2014_questions.json',
+ ann_file='annotations/v2_mscoco_train2014_annotations.json',
+ pipeline=train_pipeline,
+ ),
+ # VQAv2 val
+ dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='val2014',
+ question_file=
+ 'annotations/v2_OpenEnded_mscoco_val2014_questions.json',
+ ann_file='annotations/v2_mscoco_val2014_annotations.json',
+ pipeline=train_pipeline,
+ ),
+ # Visual Genome
+ dict(
+ type='VisualGenomeQA',
+ data_root='visual_genome',
+ data_prefix='image',
+ ann_file='question_answers.json',
+ pipeline=train_pipeline,
+ )
+ ]),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ persistent_workers=True,
+ drop_last=True,
+)
+
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=8,
+ dataset=dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='test2015',
+ question_file=
+ 'annotations/v2_OpenEnded_mscoco_test2015_questions.json', # noqa: E501
+ pipeline=test_pipeline,
+ ),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+)
+test_evaluator = dict(type='ReportVQA', file_path='vqa_test.json')
diff --git a/configs/_base_/datasets/coco_vqa.py b/configs/_base_/datasets/coco_vqa.py
new file mode 100644
index 00000000000..7fb16bd241b
--- /dev/null
+++ b/configs/_base_/datasets/coco_vqa.py
@@ -0,0 +1,84 @@
+# data settings
+
+data_preprocessor = dict(
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=384,
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['question', 'gt_answer', 'gt_answer_weight'],
+ meta_keys=['question_id', 'image_id'],
+ ),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(480, 480),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(
+ type='CleanCaption',
+ keys=['question'],
+ ),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['question', 'gt_answer', 'gt_answer_weight'],
+ meta_keys=['question_id', 'image_id'],
+ ),
+]
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='train2014',
+ question_file=
+ 'annotations/v2_OpenEnded_mscoco_train2014_questions.json',
+ ann_file='annotations/v2_mscoco_train2014_annotations.json',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ persistent_workers=True,
+ drop_last=True,
+)
+
+val_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='val2014',
+ question_file='annotations/v2_OpenEnded_mscoco_val2014_questions.json',
+ ann_file='annotations/v2_mscoco_val2014_annotations.json',
+ pipeline=test_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+)
+val_evaluator = dict(type='VQAAcc')
+
+test_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='COCOVQA',
+ data_root='data/coco',
+ data_prefix='test2015',
+ question_file= # noqa: E251
+ 'annotations/v2_OpenEnded_mscoco_test2015_questions.json',
+ pipeline=test_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+)
+test_evaluator = dict(type='ReportVQA', file_path='vqa_test.json')
diff --git a/configs/_base_/datasets/nlvr2.py b/configs/_base_/datasets/nlvr2.py
new file mode 100644
index 00000000000..2f5314bcd14
--- /dev/null
+++ b/configs/_base_/datasets/nlvr2.py
@@ -0,0 +1,86 @@
+# dataset settings
+data_preprocessor = dict(
+ type='MultiModalDataPreprocessor',
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(
+ type='ApplyToList',
+ # NLVR requires to load two images in task.
+ scatter_key='img_path',
+ transforms=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomResizedCrop',
+ scale=384,
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='RandomFlip', prob=0.5, direction='horizontal'),
+ ],
+ collate_keys=['img', 'scale_factor', 'ori_shape'],
+ ),
+ dict(type='CleanCaption', keys='text'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text'],
+ meta_keys=['image_id'],
+ ),
+]
+
+test_pipeline = [
+ dict(
+ type='ApplyToList',
+ # NLVR requires to load two images in task.
+ scatter_key='img_path',
+ transforms=[
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(384, 384),
+ interpolation='bicubic',
+ backend='pillow'),
+ ],
+ collate_keys=['img', 'scale_factor', 'ori_shape'],
+ ),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text'],
+ meta_keys=['image_id'],
+ ),
+]
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='NLVR2',
+ data_root='data/nlvr2',
+ ann_file='dev.json',
+ data_prefix='dev',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ persistent_workers=True,
+ drop_last=True,
+)
+
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=8,
+ dataset=dict(
+ type='NLVR2',
+ data_root='data/nlvr2',
+ ann_file='dev.json',
+ data_prefix='dev',
+ pipeline=test_pipeline,
+ ),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ persistent_workers=True,
+)
+val_evaluator = dict(type='Accuracy')
+
+# If you want standard test, please manually configure the test dataset
+test_dataloader = val_dataloader
+test_evaluator = val_evaluator
diff --git a/configs/_base_/datasets/refcoco.py b/configs/_base_/datasets/refcoco.py
new file mode 100644
index 00000000000..f698e76c032
--- /dev/null
+++ b/configs/_base_/datasets/refcoco.py
@@ -0,0 +1,105 @@
+# data settings
+
+data_preprocessor = dict(
+ mean=[122.770938, 116.7460125, 104.09373615],
+ std=[68.5005327, 66.6321579, 70.32316305],
+ to_rgb=True,
+)
+
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='RandomApply',
+ transforms=[
+ dict(
+ type='ColorJitter',
+ brightness=0.4,
+ contrast=0.4,
+ saturation=0.4,
+ hue=0.1,
+ backend='cv2')
+ ],
+ prob=0.5),
+ dict(
+ type='mmdet.RandomCrop',
+ crop_type='relative_range',
+ crop_size=(0.8, 0.8),
+ allow_negative_crop=False),
+ dict(
+ type='RandomChoiceResize',
+ scales=[(384, 384), (360, 360), (344, 344), (312, 312), (300, 300),
+ (286, 286), (270, 270)],
+ keep_ratio=False),
+ dict(
+ type='RandomTranslatePad',
+ size=384,
+ aug_translate=True,
+ ),
+ dict(type='CleanCaption', keys='text'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text', 'gt_bboxes', 'scale_factor'],
+ meta_keys=['image_id'],
+ ),
+]
+
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='Resize',
+ scale=(384, 384),
+ interpolation='bicubic',
+ backend='pillow'),
+ dict(type='CleanCaption', keys='text'),
+ dict(
+ type='PackInputs',
+ algorithm_keys=['text', 'gt_bboxes', 'scale_factor'],
+ meta_keys=['image_id'],
+ ),
+]
+
+train_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='RefCOCO',
+ data_root='data/coco',
+ data_prefix='train2014',
+ ann_file='refcoco/instances.json',
+ split_file='refcoco/refs(unc).p',
+ split='train',
+ pipeline=train_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ drop_last=True,
+)
+
+val_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='RefCOCO',
+ data_root='data/coco',
+ data_prefix='train2014',
+ ann_file='refcoco/instances.json',
+ split_file='refcoco/refs(unc).p',
+ split='val',
+ pipeline=test_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+)
+
+val_evaluator = dict(type='VisualGroundingMetric')
+
+test_dataloader = dict(
+ batch_size=16,
+ num_workers=8,
+ dataset=dict(
+ type='RefCOCO',
+ data_root='data/coco',
+ data_prefix='train2014',
+ ann_file='refcoco/instances.json',
+ split_file='refcoco/refs(unc).p',
+ split='testA', # or 'testB'
+ pipeline=test_pipeline),
+ sampler=dict(type='DefaultSampler', shuffle=False),
+)
+test_evaluator = val_evaluator
diff --git a/configs/blip/README.md b/configs/blip/README.md
new file mode 100644
index 00000000000..ac449248bc3
--- /dev/null
+++ b/configs/blip/README.md
@@ -0,0 +1,90 @@
+# BLIP
+
+> [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086)
+
+
+
+## Abstract
+
+Vision-Language Pre-training (VLP) has advanced the performance for many vision-language tasks. However, most existing pre-trained models only excel in either understanding-based tasks or generation-based tasks. Furthermore, performance improvement has been largely achieved by scaling up the dataset with noisy image-text pairs collected from the web, which is a suboptimal source of supervision. In this paper, we propose BLIP, a new VLP framework which transfers flexibly to both vision-language understanding and generation tasks. BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. We achieve state-of-the-art results on a wide range of vision-language tasks, such as image-text retrieval (+2.7% in average recall@1), image captioning (+2.8% in CIDEr), and VQA (+1.6% in VQA score). BLIP also demonstrates strong generalization ability when directly transferred to video-language tasks in a zero-shot manner.
+
+
+
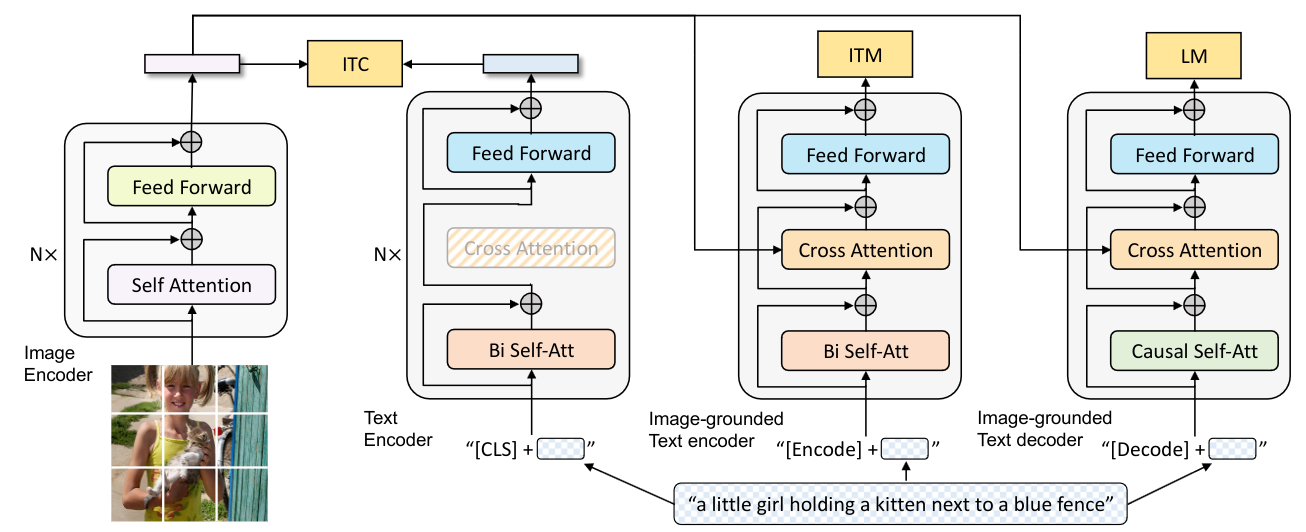
+
+
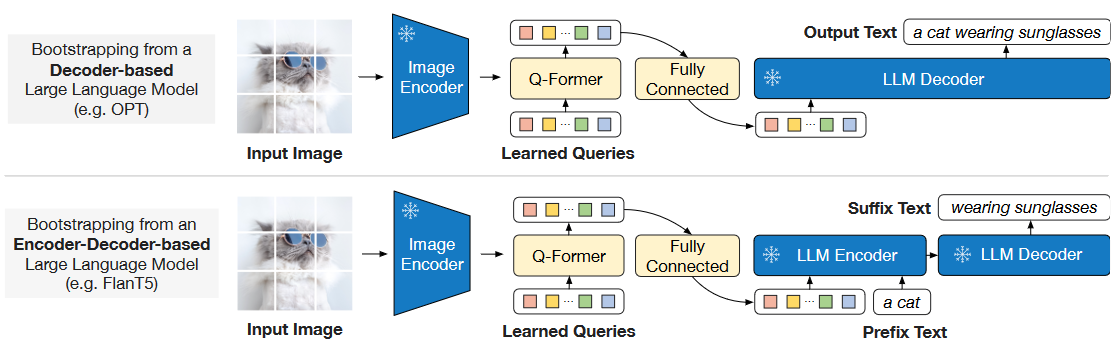
+
+
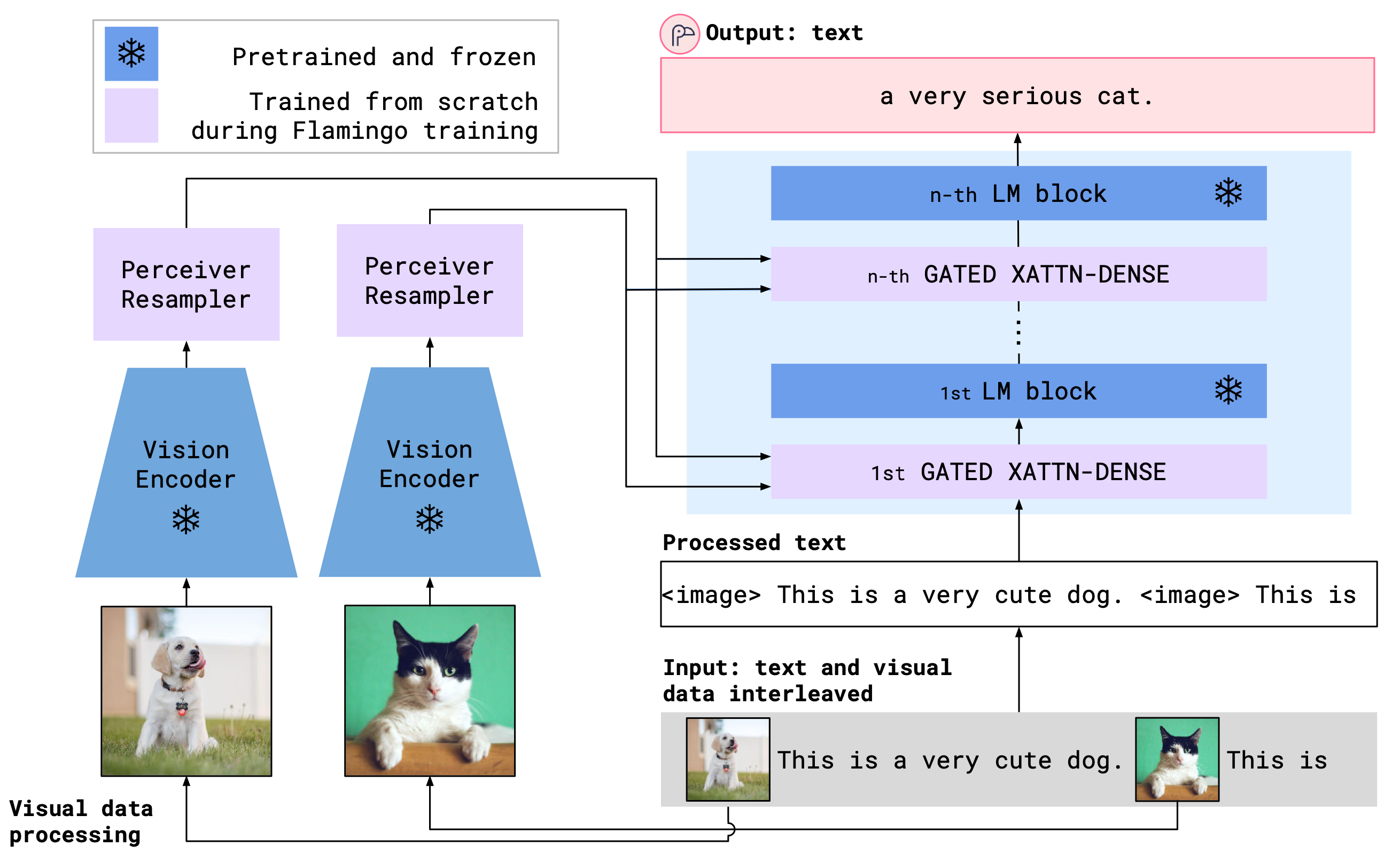
+
+
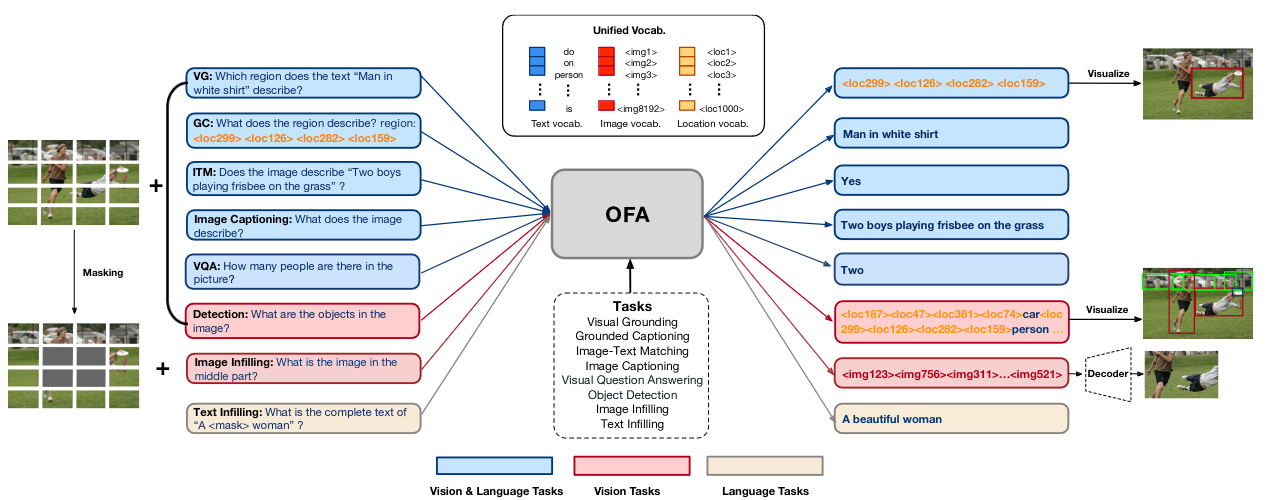
+
 +
## Extract Features From Image
Compared with `model.extract_feat`, `FeatureExtractor` is used to extract features from the image files directly, instead of a batch of tensors.
In a word, the input of `model.extract_feat` is `torch.Tensor`, the input of `FeatureExtractor` is images.
-```
+```python
>>> from mmpretrain import FeatureExtractor, get_model
>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
>>> extractor = FeatureExtractor(model)
diff --git a/docs/zh_CN/conf.py b/docs/zh_CN/conf.py
index a98d275c620..2c372a8ae59 100644
--- a/docs/zh_CN/conf.py
+++ b/docs/zh_CN/conf.py
@@ -223,6 +223,8 @@ def get_version():
'torch': ('https://pytorch.org/docs/stable/', None),
'mmcv': ('https://mmcv.readthedocs.io/zh_CN/2.x/', None),
'mmengine': ('https://mmengine.readthedocs.io/zh_CN/latest/', None),
+ 'transformers':
+ ('https://huggingface.co/docs/transformers/main/zh/', None),
}
napoleon_custom_sections = [
# Custom sections for data elements.
diff --git a/docs/zh_CN/get_started.md b/docs/zh_CN/get_started.md
index 6d77e426bac..c2100815aed 100644
--- a/docs/zh_CN/get_started.md
+++ b/docs/zh_CN/get_started.md
@@ -74,6 +74,18 @@ pip install -U openmim && mim install "mmpretrain>=1.0.0rc7"
`mim` 是一个轻量级的命令行工具,可以根据 PyTorch 和 CUDA 版本为 OpenMMLab 算法库配置合适的环境。同时它也提供了一些对于深度学习实验很有帮助的功能。
```
+## 安装多模态支持 (可选)
+
+MMPretrain 中的多模态模型需要额外的依赖项,要安装这些依赖项,请在安装过程中添加 `[multimodal]` 参数,如下所示:
+
+```shell
+# 从源码安装
+mim install -e ".[multimodal]"
+
+# 作为 Python 包安装
+mim install "mmpretrain[multimodal]>=1.0.0rc7"
+```
+
## 验证安装
为了验证 MMPretrain 的安装是否正确,我们提供了一些示例代码来执行模型推理。
diff --git a/docs/zh_CN/stat.py b/docs/zh_CN/stat.py
index 70ea692d531..29e57563ccf 100755
--- a/docs/zh_CN/stat.py
+++ b/docs/zh_CN/stat.py
@@ -173,7 +173,10 @@ def generate_summary_table(task, model_result_pairs, title=None):
continue
name = model.name
params = f'{model.metadata.parameters / 1e6:.2f}' # Params
- flops = f'{model.metadata.flops / 1e9:.2f}' # Params
+ if model.metadata.flops is not None:
+ flops = f'{model.metadata.flops / 1e9:.2f}' # Flops
+ else:
+ flops = None
readme = Path(model.collection.filepath).parent.with_suffix('.md').name
page = f'[链接]({PAPERS_ROOT / readme})'
model_metrics = []
diff --git a/docs/zh_CN/user_guides/inference.md b/docs/zh_CN/user_guides/inference.md
index a5efb8bd0f7..068e42e16de 100644
--- a/docs/zh_CN/user_guides/inference.md
+++ b/docs/zh_CN/user_guides/inference.md
@@ -2,25 +2,45 @@
本文将展示如何使用以下API:
-1. [**`list_models`**](mmpretrain.apis.list_models) 和 [**`get_model`**](mmpretrain.apis.get_model) :列出 MMPreTrain 中的模型并获取模型。
-2. [**`ImageClassificationInferencer`**](mmpretrain.apis.ImageClassificationInferencer): 在给定图像上进行推理。
-3. [**`FeatureExtractor`**](mmpretrain.apis.FeatureExtractor): 从图像文件直接提取特征。
-
-## 列出模型和获取模型
+- [**`list_models`**](mmpretrain.apis.list_models): 列举 MMPretrain 中所有可用模型名称
+- [**`get_model`**](mmpretrain.apis.get_model): 通过模型名称或模型配置文件获取模型
+- [**`inference_model`**](mmpretrain.apis.inference_model): 使用与模型相对应任务的推理器进行推理。主要用作快速
+ 展示。如需配置进阶用法,还需要直接使用下列推理器。
+- 推理器:
+ 1. [**`ImageClassificationInferencer`**](mmpretrain.apis.ImageClassificationInferencer):
+ 对给定图像执行图像分类。
+ 2. [**`ImageRetrievalInferencer`**](mmpretrain.apis.ImageRetrievalInferencer):
+ 从给定的一系列图像中,检索与给定图像最相似的图像。
+ 3. [**`ImageCaptionInferencer`**](mmpretrain.apis.ImageCaptionInferencer):
+ 生成给定图像的一段描述。
+ 4. [**`VisualQuestionAnsweringInferencer`**](mmpretrain.apis.VisualQuestionAnsweringInferencer):
+ 根据给定的图像回答问题。
+ 5. [**`VisualGroundingInferencer`**](mmpretrain.apis.VisualGroundingInferencer):
+ 根据一段描述,从给定图像中找到一个与描述对应的对象。
+ 6. [**`TextToImageRetrievalInferencer`**](mmpretrain.apis.TextToImageRetrievalInferencer):
+ 从给定的一系列图像中,检索与给定文本最相似的图像。
+ 7. [**`ImageToTextRetrievalInferencer`**](mmpretrain.apis.ImageToTextRetrievalInferencer):
+ 从给定的一系列文本中,检索与给定图像最相似的文本。
+ 8. [**`NLVRInferencer`**](mmpretrain.apis.NLVRInferencer):
+ 对给定的一对图像和一段文本进行自然语言视觉推理(NLVR 任务)。
+ 9. [**`FeatureExtractor`**](mmpretrain.apis.FeatureExtractor):
+ 通过视觉主干网络从图像文件提取特征。
+
+## 列举可用模型
列出 MMPreTrain 中的所有已支持的模型。
-```
+```python
>>> from mmpretrain import list_models
>>> list_models()
['barlowtwins_resnet50_8xb256-coslr-300e_in1k',
'beit-base-p16_beit-in21k-pre_3rdparty_in1k',
- .................]
+ ...]
```
-`list_models` 支持模糊匹配,您可以使用 **\*** 匹配任意字符。
+`list_models` 支持 Unix 文件名风格的模式匹配,你可以使用 \*\* * \*\* 匹配任意字符。
-```
+```python
>>> from mmpretrain import list_models
>>> list_models("*convnext-b*21k")
['convnext-base_3rdparty_in21k',
@@ -28,30 +48,43 @@
'convnext-base_in21k-pre_3rdparty_in1k']
```
-了解了已经支持了哪些模型后,你可以使用 `get_model` 获取特定模型。
+你还可以使用推理器的 `list_models` 方法获取对应任务可用的所有模型。
+```python
+>>> from mmpretrain import ImageCaptionInferencer
+>>> ImageCaptionInferencer.list_models()
+['blip-base_3rdparty_caption',
+ 'blip2-opt2.7b_3rdparty-zeroshot_caption',
+ 'flamingo_3rdparty-zeroshot_caption',
+ 'ofa-base_3rdparty-finetuned_caption']
```
+
+## 获取模型
+
+选定需要的模型后,你可以使用 `get_model` 获取特定模型。
+
+```python
>>> from mmpretrain import get_model
-# 没有预训练权重的模型
+# 不加载预训练权重的模型
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k")
-# 使用MMPreTrain中默认的权重
+# 加载默认的权重文件
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained=True)
-# 使用本地权重
+# 加载制定的权重文件
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained="your_local_checkpoint_path")
-# 您还可以做一些修改,例如修改 head 中的 num_classes。
+# 指定额外的模型初始化参数,例如修改 head 中的 num_classes。
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", head=dict(num_classes=10))
-# 您可以获得没有 neck,head 的模型,并直接从 backbone 中的 stage 1, 2, 3 输出
+# 另外一个例子:移除模型的 neck,head 模块,直接从 backbone 中的 stage 1, 2, 3 输出
>>> model_headless = get_model("resnet18_8xb32_in1k", head=None, neck=None, backbone=dict(out_indices=(1, 2, 3)))
```
-得到模型后,你可以进行推理:
+获得的模型是一个通常的 PyTorch Module
-```
+```python
>>> import torch
>>> from mmpretrain import get_model
>>> model = get_model('convnext-base_in21k-pre_3rdparty_in1k', pretrained=True)
@@ -63,45 +96,71 @@
## 在给定图像上进行推理
-这是一个使用 ImageNet-1k 预训练权重在给定图像上构建推理器的示例。
+这里是一个例子,我们将使用 ResNet-50 预训练模型对给定的 [图像](https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG) 进行分类。
+```python
+>>> from mmpretrain import inference_model
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> # 如果你没有图形界面,请设置 `show=False`
+>>> result = inference_model('resnet50_8xb32_in1k', image, show=True)
+>>> print(result['pred_class'])
+sea snake
```
->>> from mmpretrain import ImageClassificationInferencer
+上述 `inference_model` 接口可以快速进行模型推理,但它每次调用都需要重新初始化模型,也无法进行多个样本的推理。
+因此我们需要使用推理器来进行多次调用。
+
+```python
+>>> from mmpretrain import ImageClassificationInferencer
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
>>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
->>> results = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')
->>> print(results[0]['pred_class'])
+>>> # 注意推理器的输出始终为一个结果列表,即使输入只有一个样本
+>>> result = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> print(result['pred_class'])
sea snake
+>>>
+>>> # 你可以对多张图像进行批量推理
+>>> image_list = ['demo/demo.JPEG', 'demo/bird.JPEG'] * 16
+>>> results = inferencer(image_list, batch_size=8)
+>>> print(len(results))
+32
+>>> print(results[1]['pred_class'])
+house finch, linnet, Carpodacus mexicanus
```
-result 是一个包含 pred_label、pred_score、pred_scores 和 pred_class 的字典,结果如下:
+通常,每个样本的结果都是一个字典。比如图像分类的结果是一个包含了 `pred_label`、`pred_score`、`pred_scores`、`pred_class` 等字段的字典:
-```{text}
-{"pred_label":65,"pred_score":0.6649366617202759,"pred_class":"sea snake", "pred_scores": [..., 0.6649366617202759, ...]}
+```python
+{
+ "pred_label": 65,
+ "pred_score": 0.6649366617202759,
+ "pred_class":"sea snake",
+ "pred_scores": array([..., 0.6649366617202759, ...], dtype=float32)
+}
```
-如果你想使用自己的配置和权重:
+你可以为推理器配置额外的参数,比如使用你自己的配置文件和权重文件,在 CUDA 上进行推理:
-```
+```python
>>> from mmpretrain import ImageClassificationInferencer
->>> inferencer = ImageClassificationInferencer(
- model='configs/resnet/resnet50_8xb32_in1k.py',
- pretrained='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
- device='cuda')
->>> inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> config = 'configs/resnet/resnet50_8xb32_in1k.py'
+>>> checkpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth'
+>>> inferencer = ImageClassificationInferencer(model=config, pretrained=checkpoint, device='cuda')
+>>> result = inferencer(image)[0]
+>>> print(result['pred_class'])
+sea snake
```
-你还可以在CUDA上通过批处理进行多个图像的推理:
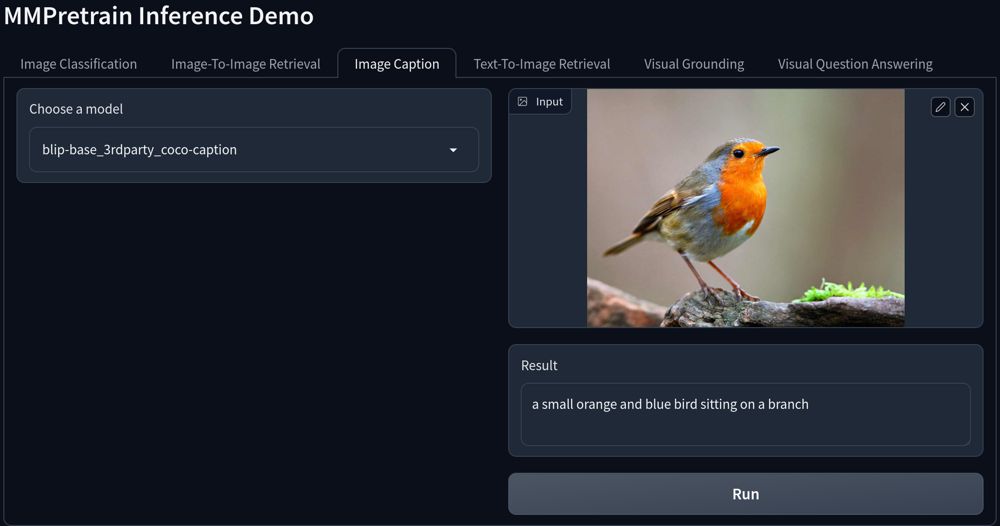
+## 使用 Gradio 推理示例
-```{python}
->>> from mmpretrain import ImageClassificationInferencer
+我们还提供了一个基于 gradio 的推理示例,提供了 MMPretrain 所支持的所有任务的推理展示功能,你可以在 [projects/gradio_demo/launch.py](https://github.com/open-mmlab/mmpretrain/blob/main/projects/gradio_demo/launch.py) 找到这一例程。
->>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k', device='cuda')
->>> imgs = ['https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'] * 5
->>> results = inferencer(imgs, batch_size=2)
->>> print(results[1]['pred_class'])
-sea snake
-```
+请首先使用 `pip install -U gradio` 安装 `gradio` 库。
+
+这里是界面效果预览:
+
+
## 从图像中提取特征
diff --git a/mmpretrain/apis/__init__.py b/mmpretrain/apis/__init__.py
index e82d897c9b3..6fbf443772a 100644
--- a/mmpretrain/apis/__init__.py
+++ b/mmpretrain/apis/__init__.py
@@ -1,12 +1,22 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseInferencer
from .feature_extractor import FeatureExtractor
+from .image_caption import ImageCaptionInferencer
from .image_classification import ImageClassificationInferencer
from .image_retrieval import ImageRetrievalInferencer
from .model import (ModelHub, get_model, inference_model, init_model,
list_models)
+from .multimodal_retrieval import (ImageToTextRetrievalInferencer,
+ TextToImageRetrievalInferencer)
+from .nlvr import NLVRInferencer
+from .visual_grounding import VisualGroundingInferencer
+from .visual_question_answering import VisualQuestionAnsweringInferencer
__all__ = [
'init_model', 'inference_model', 'list_models', 'get_model', 'ModelHub',
'ImageClassificationInferencer', 'ImageRetrievalInferencer',
- 'FeatureExtractor'
+ 'FeatureExtractor', 'ImageCaptionInferencer',
+ 'TextToImageRetrievalInferencer', 'VisualGroundingInferencer',
+ 'VisualQuestionAnsweringInferencer', 'ImageToTextRetrievalInferencer',
+ 'BaseInferencer', 'NLVRInferencer'
]
diff --git a/mmpretrain/apis/base.py b/mmpretrain/apis/base.py
new file mode 100644
index 00000000000..ee4f44490c6
--- /dev/null
+++ b/mmpretrain/apis/base.py
@@ -0,0 +1,388 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Callable, Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.config import Config
+from mmengine.dataset import default_collate
+from mmengine.fileio import get_file_backend
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track
+from .model import get_model, list_models
+
+ModelType = Union[BaseModel, str, Config]
+InputType = Union[str, np.ndarray, list]
+
+
+class BaseInferencer:
+ """Base inferencer for various tasks.
+
+ The BaseInferencer provides the standard workflow for inference as follows:
+
+ 1. Preprocess the input data by :meth:`preprocess`.
+ 2. Forward the data to the model by :meth:`forward`. ``BaseInferencer``
+ assumes the model inherits from :class:`mmengine.models.BaseModel` and
+ will call `model.test_step` in :meth:`forward` by default.
+ 3. Visualize the results by :meth:`visualize`.
+ 4. Postprocess and return the results by :meth:`postprocess`.
+
+ When we call the subclasses inherited from BaseInferencer (not overriding
+ ``__call__``), the workflow will be executed in order.
+
+ All subclasses of BaseInferencer could define the following class
+ attributes for customization:
+
+ - ``preprocess_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`preprocess`.
+ - ``forward_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`forward`
+ - ``visualize_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`visualize`
+ - ``postprocess_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`postprocess`
+
+ All attributes mentioned above should be a ``set`` of keys (strings),
+ and each key should not be duplicated. Actually, :meth:`__call__` will
+ dispatch all the arguments to the corresponding methods according to the
+ ``xxx_kwargs`` mentioned above.
+
+ Subclasses inherited from ``BaseInferencer`` should implement
+ :meth:`_init_pipeline`, :meth:`visualize` and :meth:`postprocess`:
+
+ - _init_pipeline: Return a callable object to preprocess the input data.
+ - visualize: Visualize the results returned by :meth:`forward`.
+ - postprocess: Postprocess the results returned by :meth:`forward` and
+ :meth:`visualize`.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``cls.list_models()`` and you can also query it in
+ :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str | torch.device | None): Transfer the model to the target
+ device. Defaults to None.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+ """
+
+ preprocess_kwargs: set = set()
+ forward_kwargs: set = set()
+ visualize_kwargs: set = set()
+ postprocess_kwargs: set = set()
+
+ def __init__(self,
+ model: ModelType,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ device_map=None,
+ offload_folder=None,
+ **kwargs) -> None:
+
+ if isinstance(model, BaseModel):
+ if isinstance(pretrained, str):
+ load_checkpoint(model, pretrained, map_location='cpu')
+ if device_map is not None:
+ from .utils import dispatch_model
+ model = dispatch_model(
+ model,
+ device_map=device_map,
+ offload_folder=offload_folder)
+ elif device is not None:
+ model.to(device)
+ else:
+ model = get_model(
+ model,
+ pretrained,
+ device=device,
+ device_map=device_map,
+ offload_folder=offload_folder,
+ **kwargs)
+
+ model.eval()
+
+ self.config = model._config
+ self.model = model
+ self.pipeline = self._init_pipeline(self.config)
+ self.visualizer = None
+
+ def __call__(
+ self,
+ inputs,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+ return_datasamples (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``, ``visualize_kwargs``
+ and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results.
+ """
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(**kwargs)
+
+ ori_inputs = self._inputs_to_list(inputs)
+ inputs = self.preprocess(
+ ori_inputs, batch_size=batch_size, **preprocess_kwargs)
+ preds = []
+ for data in track(inputs, 'Inference'):
+ preds.extend(self.forward(data, **forward_kwargs))
+ visualization = self.visualize(ori_inputs, preds, **visualize_kwargs)
+ results = self.postprocess(preds, visualization, return_datasamples,
+ **postprocess_kwargs)
+ return results
+
+ def _inputs_to_list(self, inputs: InputType) -> list:
+ """Preprocess the inputs to a list.
+
+ Cast the input data to a list of data.
+
+ - list or tuple: return inputs
+ - str:
+ - Directory path: return all files in the directory
+ - other cases: return a list containing the string. The string
+ could be a path to file, a url or other types of string according
+ to the task.
+ - other: return a list with one item.
+
+ Args:
+ inputs (str | array | list): Inputs for the inferencer.
+
+ Returns:
+ list: List of input for the :meth:`preprocess`.
+ """
+ if isinstance(inputs, str):
+ backend = get_file_backend(inputs)
+ if hasattr(backend, 'isdir') and backend.isdir(inputs):
+ # Backends like HttpsBackend do not implement `isdir`, so only
+ # those backends that implement `isdir` could accept the inputs
+ # as a directory
+ file_list = backend.list_dir_or_file(inputs, list_dir=False)
+ inputs = [
+ backend.join_path(inputs, file) for file in file_list
+ ]
+
+ if not isinstance(inputs, (list, tuple)):
+ inputs = [inputs]
+
+ return list(inputs)
+
+ def preprocess(self, inputs: InputType, batch_size: int = 1, **kwargs):
+ """Process the inputs into a model-feedable format.
+
+ Customize your preprocess by overriding this method. Preprocess should
+ return an iterable object, of which each item will be used as the
+ input of ``model.test_step``.
+
+ ``BaseInferencer.preprocess`` will return an iterable chunked data,
+ which will be used in __call__ like this:
+
+ .. code-block:: python
+
+ def __call__(self, inputs, batch_size=1, **kwargs):
+ chunked_data = self.preprocess(inputs, batch_size, **kwargs)
+ for batch in chunked_data:
+ preds = self.forward(batch, **kwargs)
+
+ Args:
+ inputs (InputsType): Inputs given by user.
+ batch_size (int): batch size. Defaults to 1.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``default_collate``.
+ """
+ chunked_data = self._get_chunk_data(
+ map(self.pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ @torch.no_grad()
+ def forward(self, inputs: Union[dict, tuple], **kwargs):
+ """Feed the inputs to the model."""
+ return self.model.test_step(inputs)
+
+ def visualize(self,
+ inputs: list,
+ preds: List[DataSample],
+ show: bool = False,
+ **kwargs) -> List[np.ndarray]:
+ """Visualize predictions.
+
+ Customize your visualization by overriding this method. visualize
+ should return visualization results, which could be np.ndarray or any
+ other objects.
+
+ Args:
+ inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
+ preds (Any): Predictions of the model.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+
+ Returns:
+ List[np.ndarray]: Visualization results.
+ """
+ if show:
+ raise NotImplementedError(
+ f'The `visualize` method of {self.__class__.__name__} '
+ 'is not implemented.')
+
+ @abstractmethod
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasample=False,
+ **kwargs,
+ ) -> dict:
+ """Process the predictions and visualization results from ``forward``
+ and ``visualize``.
+
+ This method should be responsible for the following tasks:
+
+ 1. Convert datasamples into a json-serializable dict if needed.
+ 2. Pack the predictions and visualization results and return them.
+ 3. Dump or log the predictions.
+
+ Customize your postprocess by overriding this method. Make sure
+ ``postprocess`` will return a dict with visualization results and
+ inference results.
+
+ Args:
+ preds (List[Dict]): Predictions of the model.
+ visualization (np.ndarray): Visualized predictions.
+ return_datasample (bool): Whether to return results as datasamples.
+ Defaults to False.
+
+ Returns:
+ dict: Inference and visualization results with key ``predictions``
+ and ``visualization``
+
+ - ``visualization (Any)``: Returned by :meth:`visualize`
+ - ``predictions`` (dict or DataSample): Returned by
+ :meth:`forward` and processed in :meth:`postprocess`.
+ If ``return_datasample=False``, it usually should be a
+ json-serializable dict containing only basic data elements such
+ as strings and numbers.
+ """
+
+ @abstractmethod
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ """Initialize the test pipeline.
+
+ Return a pipeline to handle various input data, such as ``str``,
+ ``np.ndarray``. It is an abstract method in BaseInferencer, and should
+ be implemented in subclasses.
+
+ The returned pipeline will be used to process a single data.
+ It will be used in :meth:`preprocess` like this:
+
+ .. code-block:: python
+ def preprocess(self, inputs, batch_size, **kwargs):
+ ...
+ dataset = map(self.pipeline, dataset)
+ ...
+ """
+
+ def _get_chunk_data(self, inputs: Iterable, chunk_size: int):
+ """Get batch data from dataset.
+
+ Args:
+ inputs (Iterable): An iterable dataset.
+ chunk_size (int): Equivalent to batch size.
+
+ Yields:
+ list: batch data.
+ """
+ inputs_iter = iter(inputs)
+ while True:
+ try:
+ chunk_data = []
+ for _ in range(chunk_size):
+ processed_data = next(inputs_iter)
+ chunk_data.append(processed_data)
+ yield chunk_data
+ except StopIteration:
+ if chunk_data:
+ yield chunk_data
+ break
+
+ def _dispatch_kwargs(self, **kwargs) -> Tuple[dict, dict, dict, dict]:
+ """Dispatch kwargs to preprocess(), forward(), visualize() and
+ postprocess() according to the actual demands.
+
+ Returns:
+ Tuple[Dict, Dict, Dict, Dict]: kwargs passed to preprocess,
+ forward, visualize and postprocess respectively.
+ """
+ # Ensure each argument only matches one function
+ method_kwargs = self.preprocess_kwargs | self.forward_kwargs | \
+ self.visualize_kwargs | self.postprocess_kwargs
+
+ union_kwargs = method_kwargs | set(kwargs.keys())
+ if union_kwargs != method_kwargs:
+ unknown_kwargs = union_kwargs - method_kwargs
+ raise ValueError(
+ f'unknown argument {unknown_kwargs} for `preprocess`, '
+ '`forward`, `visualize` and `postprocess`')
+
+ preprocess_kwargs = {}
+ forward_kwargs = {}
+ visualize_kwargs = {}
+ postprocess_kwargs = {}
+
+ for key, value in kwargs.items():
+ if key in self.preprocess_kwargs:
+ preprocess_kwargs[key] = value
+ if key in self.forward_kwargs:
+ forward_kwargs[key] = value
+ if key in self.visualize_kwargs:
+ visualize_kwargs[key] = value
+ if key in self.postprocess_kwargs:
+ postprocess_kwargs[key] = value
+
+ return (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ )
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List models defined in metafile of corresponding packages.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern)
diff --git a/mmpretrain/apis/feature_extractor.py b/mmpretrain/apis/feature_extractor.py
index 513717fc89f..b7c52c2fcbc 100644
--- a/mmpretrain/apis/feature_extractor.py
+++ b/mmpretrain/apis/feature_extractor.py
@@ -1,60 +1,43 @@
# Copyright (c) OpenMMLab. All rights reserved.
from typing import Callable, List, Optional, Union
-import numpy as np
import torch
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType
+from .model import list_models
class FeatureExtractor(BaseInferencer):
"""The inferencer for extract features.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
- by ``FeatureExtractor.list_models()``.
- pretrained (bool | str): When use name to specify model, you can
- use ``True`` to load the pre-defined pretrained weights. And you
- can also use a string to specify the path or link of weights to
- load. Defaults to True.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
- """
-
- def __init__(
- self,
- model: ModelType,
- pretrained: Union[bool, str] = True,
- device: Union[str, torch.device, None] = None,
- ) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ by ``FeatureExtractor.list_models()`` and you can also query it in
+ :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import FeatureExtractor
+ >>> inferencer = FeatureExtractor('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+ >>> feats = inferencer('demo/demo.JPEG', stage='backbone')[0]
+ >>> for feat in feats:
+ >>> print(feat.shape)
+ torch.Size([256, 56, 56])
+ torch.Size([512, 28, 28])
+ torch.Size([1024, 14, 14])
+ torch.Size([2048, 7, 7])
+ """ # noqa: E501
def __call__(self,
inputs: InputType,
@@ -122,7 +105,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self):
raise NotImplementedError(
diff --git a/mmpretrain/apis/image_caption.py b/mmpretrain/apis/image_caption.py
new file mode 100644
index 00000000000..aef21878112
--- /dev/null
+++ b/mmpretrain/apis/image_caption.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer, InputType
+from .model import list_models
+
+
+class ImageCaptionInferencer(BaseInferencer):
+ """The inferencer for image caption.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``ImageCaptionInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import ImageCaptionInferencer
+ >>> inferencer = ImageCaptionInferencer('blip-base_3rdparty_caption')
+ >>> inferencer('demo/cat-dog.png')[0]
+ {'pred_caption': 'a puppy and a cat sitting on a blanket'}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {'resize', 'show', 'show_dir', 'wait_time'}
+
+ def __call__(self,
+ images: InputType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(images, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[InputType], batch_size: int = 1):
+
+ def load_image(input_):
+ img = imread(input_)
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return dict(
+ img=img,
+ img_shape=img.shape[:2],
+ ori_shape=img.shape[:2],
+ )
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[InputType],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_)
+ if isinstance(input_, str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_image_caption(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({'pred_caption': data_sample.get('pred_caption')})
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Image Caption')
diff --git a/mmpretrain/apis/image_classification.py b/mmpretrain/apis/image_classification.py
index e261a568467..081672614c3 100644
--- a/mmpretrain/apis/image_classification.py
+++ b/mmpretrain/apis/image_classification.py
@@ -7,32 +7,28 @@
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
from mmpretrain.structures import DataSample
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType, ModelType
+from .model import list_models
class ImageClassificationInferencer(BaseInferencer):
"""The inferencer for image classification.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
by ``ImageClassificationInferencer.list_models()`` and you can also
query it in :doc:`/modelzoo_statistics`.
- pretrained (str, optional): Path to the checkpoint. If None, it will try
- to find a pre-defined weight from the model you specified
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
(only work if the ``model`` is a model name). Defaults to None.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
Example:
1. Use a pre-trained model in MMPreTrain to inference an image.
@@ -61,34 +57,20 @@ class ImageClassificationInferencer(BaseInferencer):
'wait_time'
}
- def __init__(
- self,
- model: ModelType,
- pretrained: Union[bool, str] = True,
- device: Union[str, torch.device, None] = None,
- classes=None,
- ) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ def __init__(self,
+ model: ModelType,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ classes=None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
if classes is not None:
self.classes = classes
else:
- self.classes = getattr(model, 'dataset_meta', {}).get('classes')
+ self.classes = getattr(self.model, '_dataset_meta',
+ {}).get('classes')
def __call__(self,
inputs: InputType,
@@ -120,8 +102,11 @@ def __call__(self,
Returns:
list: The inference results.
"""
- return super().__call__(inputs, return_datasamples, batch_size,
- **kwargs)
+ return super().__call__(
+ inputs,
+ return_datasamples=return_datasamples,
+ batch_size=batch_size,
+ **kwargs)
def _init_pipeline(self, cfg: Config) -> Callable:
test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
@@ -147,7 +132,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self,
ori_inputs: List[InputType],
diff --git a/mmpretrain/apis/image_retrieval.py b/mmpretrain/apis/image_retrieval.py
index f233877d605..980d65cc3c7 100644
--- a/mmpretrain/apis/image_retrieval.py
+++ b/mmpretrain/apis/image_retrieval.py
@@ -7,57 +7,56 @@
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import BaseDataset, Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
from mmpretrain.structures import DataSample
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType, ModelType
+from .model import list_models
class ImageRetrievalInferencer(BaseInferencer):
"""The inferencer for image to image retrieval.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
- by ``ImageClassificationInferencer.list_models()`` and you can also
+ by ``ImageRetrievalInferencer.list_models()`` and you can also
query it in :doc:`/modelzoo_statistics`.
- weights (str, optional): Path to the checkpoint. If None, it will try
- to find a pre-defined weight from the model you specified
+ prototype (str | list | dict | DataLoader, BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The directory of the the images.
+ - list: A list of path of the images.
+ - dict: A config dict of the a prototype dataset.
+ - BaseDataset: A prototype dataset.
+ - DataLoader: A data loader to load the prototype data.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
(only work if the ``model`` is a model name). Defaults to None.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
Example:
- 1. Use a pre-trained model in MMPreTrain to inference an image.
-
- >>> from mmpretrain import ImageClassificationInferencer
- >>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
- >>> inferencer('demo/demo.JPEG')
- [{'pred_score': array([...]),
- 'pred_label': 65,
- 'pred_score': 0.6649367809295654,
- 'pred_class': 'sea snake'}]
-
- 2. Use a config file and checkpoint to inference multiple images on GPU,
- and save the visualization results in a folder.
-
- >>> from mmpretrain import ImageClassificationInferencer
- >>> inferencer = ImageClassificationInferencer(
- model='configs/resnet/resnet50_8xb32_in1k.py',
- weights='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
- device='cuda')
- >>> inferencer(['demo/dog.jpg', 'demo/bird.JPEG'], show_dir="./visualize/")
+ >>> from mmpretrain import ImageRetrievalInferencer
+ >>> inferencer = ImageRetrievalInferencer(
+ ... 'resnet50-arcface_8xb32_inshop',
+ ... prototype='./demo/',
+ ... prototype_cache='img_retri.pth')
+ >>> inferencer('demo/cat-dog.png', topk=2)[0][1]
+ {'match_score': tensor(0.4088, device='cuda:0'),
+ 'sample_idx': 3,
+ 'sample': {'img_path': './demo/dog.jpg'}}
""" # noqa: E501
visualize_kwargs: set = {
- 'draw_score', 'resize', 'show_dir', 'show', 'wait_time'
+ 'draw_score', 'resize', 'show_dir', 'show', 'wait_time', 'topk'
}
postprocess_kwargs: set = {'topk'}
@@ -65,36 +64,19 @@ def __init__(
self,
model: ModelType,
prototype,
- prototype_vecs=None,
+ prototype_cache=None,
prepare_batch_size=8,
pretrained: Union[bool, str] = True,
device: Union[str, torch.device, None] = None,
+ **kwargs,
) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
self.prototype_dataset = self._prepare_prototype(
- prototype, prototype_vecs, prepare_batch_size)
-
- # An ugly hack to escape from the duplicated arguments check in the
- # base class
- self.visualize_kwargs.add('topk')
+ prototype, prototype_cache, prepare_batch_size)
- def _prepare_prototype(self, prototype, prototype_vecs=None, batch_size=8):
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
from mmengine.dataset import DefaultSampler
from torch.utils.data import DataLoader
@@ -102,23 +84,30 @@ def build_dataloader(dataset):
return DataLoader(
dataset,
batch_size=batch_size,
- collate_fn=self.collate_fn,
+ collate_fn=default_collate,
sampler=DefaultSampler(dataset, shuffle=False),
persistent_workers=False,
)
- test_pipeline = self.config.test_dataloader.dataset.pipeline
-
if isinstance(prototype, str):
# A directory path of images
- from mmpretrain.datasets import CustomDataset
- dataset = CustomDataset(
- data_root=prototype, pipeline=test_pipeline, with_label=False)
+ prototype = dict(
+ type='CustomDataset', with_label=False, data_root=prototype)
+
+ if isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
dataloader = build_dataloader(dataset)
elif isinstance(prototype, dict):
# A config of dataset
from mmpretrain.registry import DATASETS
- prototype.setdefault('pipeline', test_pipeline)
+ test_pipeline = [dict(type='LoadImageFromFile'), self.pipeline]
dataset = DATASETS.build(prototype)
dataloader = build_dataloader(dataset)
elif isinstance(prototype, DataLoader):
@@ -130,25 +119,25 @@ def build_dataloader(dataset):
else:
raise TypeError(f'Unsupported prototype type {type(prototype)}.')
- if prototype_vecs is not None and Path(prototype_vecs).exists():
- self.model.prototype = prototype_vecs
+ if cache is not None and Path(cache).exists():
+ self.model.prototype = cache
else:
self.model.prototype = dataloader
self.model.prepare_prototype()
from mmengine.logging import MMLogger
logger = MMLogger.get_current_instance()
- if prototype_vecs is None:
+ if cache is None:
logger.info('The prototype has been prepared, you can use '
- '`save_prototype_vecs` to dump it into a pickle '
+ '`save_prototype` to dump it into a pickle '
'file for the future usage.')
- elif not Path(prototype_vecs).exists():
- self.save_prototype_vecs(prototype_vecs)
- logger.info(f'The prototype has been saved at {prototype_vecs}.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
return dataset
- def save_prototype_vecs(self, path):
+ def save_prototype(self, path):
self.model.dump_prototype(path)
def __call__(self,
@@ -205,7 +194,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self,
ori_inputs: List[InputType],
@@ -294,49 +283,3 @@ def list_models(pattern: Optional[str] = None):
List[str]: a list of model names.
"""
return list_models(pattern=pattern, task='Image Retrieval')
-
- def _dispatch_kwargs(self, **kwargs):
- """Dispatch kwargs to preprocess(), forward(), visualize() and
- postprocess() according to the actual demands.
-
- Override this method to allow same argument for different methods.
-
- Returns:
- Tuple[Dict, Dict, Dict, Dict]: kwargs passed to preprocess,
- forward, visualize and postprocess respectively.
- """
- method_kwargs = set.union(
- self.preprocess_kwargs,
- self.forward_kwargs,
- self.visualize_kwargs,
- self.postprocess_kwargs,
- )
-
- union_kwargs = method_kwargs | set(kwargs.keys())
- if union_kwargs != method_kwargs:
- unknown_kwargs = union_kwargs - method_kwargs
- raise ValueError(
- f'unknown argument {unknown_kwargs} for `preprocess`, '
- '`forward`, `visualize` and `postprocess`')
-
- preprocess_kwargs = {}
- forward_kwargs = {}
- visualize_kwargs = {}
- postprocess_kwargs = {}
-
- for key, value in kwargs.items():
- if key in self.preprocess_kwargs:
- preprocess_kwargs[key] = value
- if key in self.forward_kwargs:
- forward_kwargs[key] = value
- if key in self.visualize_kwargs:
- visualize_kwargs[key] = value
- if key in self.postprocess_kwargs:
- postprocess_kwargs[key] = value
-
- return (
- preprocess_kwargs,
- forward_kwargs,
- visualize_kwargs,
- postprocess_kwargs,
- )
diff --git a/mmpretrain/apis/model.py b/mmpretrain/apis/model.py
index a36c553a1a3..eba475e7f79 100644
--- a/mmpretrain/apis/model.py
+++ b/mmpretrain/apis/model.py
@@ -2,10 +2,11 @@
import copy
import fnmatch
import os.path as osp
+import re
import warnings
from os import PathLike
from pathlib import Path
-from typing import List, Union
+from typing import List, Tuple, Union
from mmengine.config import Config
from modelindex.load_model_index import load
@@ -96,6 +97,9 @@ def has(cls, model_name):
def get_model(model: Union[str, Config],
pretrained: Union[str, bool] = False,
device=None,
+ device_map=None,
+ offload_folder=None,
+ url_mapping: Tuple[str, str] = None,
**kwargs):
"""Get a pre-defined model or create a model from config.
@@ -108,6 +112,18 @@ def get_model(model: Union[str, Config],
load. Defaults to False.
device (str | torch.device | None): Transfer the model to the target
device. Defaults to None.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ url_mapping (Tuple[str, str], optional): The mapping of pretrained
+ checkpoint link. For example, load checkpoint from a local dir
+ instead of download by ``('https://.*/', './checkpoint')``.
+ Defaults to None.
**kwargs: Other keyword arguments of the model config.
Returns:
@@ -136,11 +152,16 @@ def get_model(model: Union[str, Config],
>>> print(result['pred_class'])
'sea snake'
""" # noqa: E501
+ if device_map is not None:
+ from .utils import dispatch_model
+ dispatch_model._verify_require()
+
+ metainfo = None
if isinstance(model, Config):
config = copy.deepcopy(model)
if pretrained is True and 'load_from' in config:
pretrained = config.load_from
- elif isinstance(model, (str, PathLike)) and Path(model).suffix:
+ elif isinstance(model, (str, PathLike)) and Path(model).suffix == '.py':
config = Config.fromfile(model)
if pretrained is True and 'load_from' in config:
pretrained = config.load_from
@@ -164,14 +185,19 @@ def get_model(model: Union[str, Config],
config.model.setdefault('data_preprocessor',
config.get('data_preprocessor', None))
+ from mmengine.registry import DefaultScope
+
from mmpretrain.registry import MODELS
- model = MODELS.build(config.model)
+ with DefaultScope.overwrite_default_scope('mmpretrain'):
+ model = MODELS.build(config.model)
dataset_meta = {}
if pretrained:
# Mapping the weights to GPU may cause unexpected video memory leak
# which refers to https://github.com/open-mmlab/mmdetection/pull/6405
from mmengine.runner import load_checkpoint
+ if url_mapping is not None:
+ pretrained = re.sub(url_mapping[0], url_mapping[1], pretrained)
checkpoint = load_checkpoint(model, pretrained, map_location='cpu')
if 'dataset_meta' in checkpoint.get('meta', {}):
# mmpretrain 1.x
@@ -185,9 +211,15 @@ def get_model(model: Union[str, Config],
dataset_class = DATASETS.get(config.test_dataloader.dataset.type)
dataset_meta = getattr(dataset_class, 'METAINFO', {})
- model.dataset_meta = dataset_meta
- model.config = config # save the config in the model for convenience
- model.to(device)
+ if device_map is not None:
+ model = dispatch_model(
+ model, device_map=device_map, offload_folder=offload_folder)
+ elif device is not None:
+ model.to(device)
+
+ model._dataset_meta = dataset_meta # save the dataset meta
+ model._config = config # save the config in the model
+ model._metainfo = metainfo # save the metainfo in the model
model.eval()
return model
@@ -284,6 +316,8 @@ def list_models(pattern=None, exclude_patterns=None, task=None) -> List[str]:
metainfo = ModelHub._models_dict[key]
if metainfo.results is None and task == 'null':
task_matches.append(key)
+ elif metainfo.results is None:
+ continue
elif task in [result.task for result in metainfo.results]:
task_matches.append(key)
matches = task_matches
@@ -291,41 +325,84 @@ def list_models(pattern=None, exclude_patterns=None, task=None) -> List[str]:
return sorted(list(matches))
-def inference_model(model, input_, **kwargs):
+def inference_model(model, *args, **kwargs):
"""Inference an image with the inferencer.
Automatically select inferencer to inference according to the type of
model. It's a shortcut for a quick start, and for advanced usage, please
use the correspondding inferencer class.
- Here is the mapping from model type to inferencer:
+ Here is the mapping from task to inferencer:
- - :class:`~mmpretrain.models.ImageClassifier`: :class:`ImageClassificationInferencer`.
- - :class:`~mmpretrain.models.ImageToImageRetriever`: :class:`ImageToImageRetrievalInferencer`.
+ - Image Classification: :class:`ImageClassificationInferencer`
+ - Image Retrieval: :class:`ImageRetrievalInferencer`
+ - Image Caption: :class:`ImageCaptionInferencer`
+ - Visual Question Answering: :class:`VisualQuestionAnsweringInferencer`
+ - Visual Grounding: :class:`VisualGroundingInferencer`
+ - Text-To-Image Retrieval: :class:`TextToImageRetrievalInferencer`
+ - Image-To-Text Retrieval: :class:`ImageToTextRetrievalInferencer`
+ - NLVR: :class:`NLVRInferencer`
Args:
model (BaseModel | str | Config): The loaded model, the model
name or the config of the model.
- input_ (str | ndarray): The image path or loaded image.
- **kwargs: Other keyword arguments to initialize the correspondding
- inferencer.
+ *args: Positional arguments to call the inferencer.
+ **kwargs: Other keyword arguments to initialize and call the
+ correspondding inferencer.
Returns:
result (dict): The inference results.
""" # noqa: E501
from mmengine.model import BaseModel
- if not isinstance(model, BaseModel):
- model = get_model(model, pretrained=True)
+ if isinstance(model, BaseModel):
+ metainfo = getattr(model, '_metainfo', None)
+ else:
+ metainfo = ModelHub.get(model)
+
+ from inspect import signature
- import mmpretrain.models
+ from .image_caption import ImageCaptionInferencer
from .image_classification import ImageClassificationInferencer
from .image_retrieval import ImageRetrievalInferencer
-
- if isinstance(model, mmpretrain.models.ImageClassifier):
- inferencer = ImageClassificationInferencer(model, **kwargs)
- elif isinstance(model, mmpretrain.models.ImageToImageRetriever):
- inferencer = ImageRetrievalInferencer(model, **kwargs)
- else:
- raise NotImplementedError(f'No available inferencer for {type(model)}')
- return inferencer(input_)[0]
+ from .multimodal_retrieval import (ImageToTextRetrievalInferencer,
+ TextToImageRetrievalInferencer)
+ from .nlvr import NLVRInferencer
+ from .visual_grounding import VisualGroundingInferencer
+ from .visual_question_answering import VisualQuestionAnsweringInferencer
+ task_mapping = {
+ 'Image Classification': ImageClassificationInferencer,
+ 'Image Retrieval': ImageRetrievalInferencer,
+ 'Image Caption': ImageCaptionInferencer,
+ 'Visual Question Answering': VisualQuestionAnsweringInferencer,
+ 'Visual Grounding': VisualGroundingInferencer,
+ 'Text-To-Image Retrieval': TextToImageRetrievalInferencer,
+ 'Image-To-Text Retrieval': ImageToTextRetrievalInferencer,
+ 'NLVR': NLVRInferencer,
+ }
+
+ inferencer_type = None
+
+ if metainfo is not None and metainfo.results is not None:
+ tasks = set(result.task for result in metainfo.results)
+ inferencer_type = [
+ task_mapping.get(task) for task in tasks if task in task_mapping
+ ]
+ if len(inferencer_type) > 1:
+ inferencer_names = [cls.__name__ for cls in inferencer_type]
+ warnings.warn('The model supports multiple tasks, auto select '
+ f'{inferencer_names[0]}, you can also use other '
+ f'inferencer {inferencer_names} directly.')
+ inferencer_type = inferencer_type[0]
+
+ if inferencer_type is None:
+ raise NotImplementedError('No available inferencer for the model')
+
+ init_kwargs = {
+ k: kwargs.pop(k)
+ for k in list(kwargs)
+ if k in signature(inferencer_type).parameters.keys()
+ }
+
+ inferencer = inferencer_type(model, **init_kwargs)
+ return inferencer(*args, **kwargs)[0]
diff --git a/mmpretrain/apis/multimodal_retrieval.py b/mmpretrain/apis/multimodal_retrieval.py
new file mode 100644
index 00000000000..5eb9c859aca
--- /dev/null
+++ b/mmpretrain/apis/multimodal_retrieval.py
@@ -0,0 +1,603 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+from pathlib import Path
+from typing import Callable, List, Optional, Tuple, Union
+
+import mmengine
+import numpy as np
+import torch
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import BaseDataset, Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track
+from .base import BaseInferencer
+from .base import InputType as ImageType
+from .base import ModelType
+from .model import list_models
+
+
+def filter_transforms(transforms: list, data_info: dict):
+ """Filter pipeline to avoid KeyError with partial data info."""
+ data_info = deepcopy(data_info)
+ filtered_transforms = []
+ for t in transforms:
+ try:
+ data_info = t(data_info)
+ filtered_transforms.append(t)
+ except KeyError:
+ pass
+ return filtered_transforms
+
+
+class TextToImageRetrievalInferencer(BaseInferencer):
+ """The inferencer for text to image retrieval.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``TextToImageRetrievalInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ prototype (str | list | dict | DataLoader | BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The directory of the the images.
+ - list: A list of path of the images.
+ - dict: A config dict of the a prototype dataset.
+ - BaseDataset: A prototype dataset.
+ - DataLoader: A data loader to load the prototype data.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ fast_match (bool): Some algorithms will record extra image features for
+ further matching, which may consume large memory, set True to avoid
+ this behavior. Defaults to True.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import TextToImageRetrievalInferencer
+ >>> inferencer = TextToImageRetrievalInferencer(
+ ... 'blip-base_3rdparty_retrieval',
+ ... prototype='./demo/',
+ ... prototype_cache='t2i_retri.pth')
+ >>> inferencer('A cat and a dog.')[0]
+ {'match_score': tensor(0.3855, device='cuda:0'),
+ 'sample_idx': 1,
+ 'sample': {'img_path': './demo/cat-dog.png'}}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'draw_score', 'show_dir', 'show', 'wait_time', 'figsize', 'topk'
+ }
+ postprocess_kwargs: set = {'topk'}
+
+ def __init__(self,
+ model: ModelType,
+ prototype,
+ prototype_cache=None,
+ fast_match=True,
+ prepare_batch_size=8,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
+
+ self.img_pipeline, self.text_pipeline = self.pipeline
+
+ if hasattr(self.model, 'fast_match'):
+ self.model.fast_match = fast_match
+
+ self.prototype_dataset = self._prepare_prototype(
+ prototype, prototype_cache, batch_size=prepare_batch_size)
+
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
+ from mmengine.dataset import DefaultSampler
+ from torch.utils.data import DataLoader
+
+ def build_dataloader(dataset):
+ return DataLoader(
+ dataset,
+ batch_size=batch_size,
+ collate_fn=default_collate,
+ sampler=DefaultSampler(dataset, shuffle=False),
+ persistent_workers=False,
+ )
+
+ if isinstance(prototype, str):
+ # A directory path of images
+ prototype = dict(
+ type='CustomDataset', with_label=False, data_root=prototype)
+
+ if isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, dict):
+ # A config of dataset
+ from mmpretrain.registry import DATASETS
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ prototype.setdefault('pipeline', test_pipeline)
+ dataset = DATASETS.build(prototype)
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, DataLoader):
+ dataset = prototype.dataset
+ dataloader = prototype
+ elif isinstance(prototype, BaseDataset):
+ dataset = prototype
+ dataloader = build_dataloader(dataset)
+ else:
+ raise TypeError(f'Unsupported prototype type {type(prototype)}.')
+
+ if cache is not None and Path(cache).exists():
+ self.prototype = torch.load(cache)
+ else:
+ prototype = []
+ for data_batch in track(dataloader, 'Prepare prototype...'):
+ with torch.no_grad():
+ data_batch = self.model.data_preprocessor(
+ data_batch, False)
+ feats = self.model._run_forward(data_batch, mode='tensor')
+ prototype.append(feats)
+ prototype = {
+ k: torch.cat([d[k] for d in prototype])
+ for k in prototype[0]
+ }
+ self.prototype = prototype
+
+ from mmengine.logging import MMLogger
+ logger = MMLogger.get_current_instance()
+ if cache is None:
+ logger.info('The prototype has been prepared, you can use '
+ '`save_prototype` to dump it into a pickle '
+ 'file for the future usage.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
+
+ return dataset
+
+ def save_prototype(self, path):
+ torch.save(self.prototype, path)
+
+ def __call__(self,
+ inputs: ImageType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the match scores.
+ Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ @torch.no_grad()
+ def forward(self, data: dict, **kwargs):
+ """Feed the inputs to the model."""
+ data = self.model.data_preprocessor(data, False)
+ data_samples = data['data_samples']
+ feats = self.prototype.copy()
+ feats.update(self.model.extract_feat(data_samples=data_samples))
+ return self.model.predict_all(feats, data_samples, cal_i2t=False)[0]
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ test_transfroms = [TRANSFORMS.build(t) for t in test_pipeline_cfg]
+ img_info = {'img': np.zeros((224, 224, 3), dtype=np.uint8)}
+ text_info = {'text': 'example'}
+ img_pipeline = Compose(filter_transforms(test_transfroms, img_info))
+ text_pipeline = Compose(filter_transforms(test_transfroms, text_info))
+ return img_pipeline, text_pipeline
+
+ def preprocess(self, inputs: List[str], batch_size: int = 1):
+
+ def process_text(input_: str):
+ return self.text_pipeline({'text': input_})
+
+ chunked_data = self._get_chunk_data(
+ map(process_text, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[str],
+ preds: List[DataSample],
+ topk: int = 3,
+ figsize: Tuple[int, int] = (16, 9),
+ show: bool = False,
+ wait_time: int = 0,
+ draw_score=True,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (text, data_sample) in enumerate(zip(ori_inputs, preds)):
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_t2i_retrieval(
+ text,
+ data_sample,
+ self.prototype_dataset,
+ topk=topk,
+ fig_cfg=dict(figsize=figsize),
+ draw_score=draw_score,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False,
+ topk=1,
+ ) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ matches = []
+ for match_score, sample_idx in zip(match_scores, indices):
+ sample = self.prototype_dataset.get_data_info(
+ sample_idx.item())
+ sample_idx = sample.pop('sample_idx')
+ matches.append({
+ 'match_score': match_score,
+ 'sample_idx': sample_idx,
+ 'sample': sample
+ })
+ results.append(matches)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Text-To-Image Retrieval')
+
+
+class ImageToTextRetrievalInferencer(BaseInferencer):
+ """The inferencer for image to text retrieval.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``ImageToTextRetrievalInferencer.list_models()`` and you can
+ also query it in :doc:`/modelzoo_statistics`.
+ prototype (str | list | dict | DataLoader, BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The file path to load the string list.
+ - list: A list of string.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ fast_match (bool): Some algorithms will record extra image features for
+ further matching, which may consume large memory, set True to avoid
+ this behavior. Defaults to True.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import ImageToTextRetrievalInferencer
+ >>> inferencer = ImageToTextRetrievalInferencer(
+ ... 'blip-base_3rdparty_retrieval',
+ ... prototype=['cat', 'dog', 'snake', 'bird'],
+ ... prototype_cache='i2t_retri.pth')
+ >>> inferencer('demo/bird.JPEG')[0]
+ {'match_score': tensor(0.3855, device='cuda:0'),
+ 'sample_idx': 1,
+ 'sample': {'img_path': './demo/cat-dog.png'}}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'draw_score', 'resize', 'show_dir', 'show', 'wait_time', 'topk'
+ }
+ postprocess_kwargs: set = {'topk'}
+
+ def __init__(self,
+ model: ModelType,
+ prototype,
+ prototype_cache=None,
+ fast_match=True,
+ prepare_batch_size=8,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
+
+ self.img_pipeline, self.text_pipeline = self.pipeline
+
+ if hasattr(self.model, 'fast_match'):
+ self.model.fast_match = fast_match
+
+ self.prototype_dataset = self._prepare_prototype(
+ prototype, cache=prototype_cache, batch_size=prepare_batch_size)
+
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
+ from mmengine.dataset import DefaultSampler
+ from torch.utils.data import DataLoader
+
+ def build_dataloader(dataset):
+ return DataLoader(
+ [
+ self.text_pipeline({
+ 'sample_idx': i,
+ 'text': text
+ }) for i, text in enumerate(dataset)
+ ],
+ batch_size=batch_size,
+ collate_fn=default_collate,
+ sampler=DefaultSampler(dataset, shuffle=False),
+ persistent_workers=False,
+ )
+
+ if isinstance(prototype, str):
+ # A file path of a list of string
+ dataset = mmengine.list_from_file(prototype)
+ elif mmengine.utils.is_seq_of(prototype, str):
+ dataset = prototype
+ else:
+ raise TypeError(f'Unsupported prototype type {type(prototype)}.')
+
+ dataloader = build_dataloader(dataset)
+
+ if cache is not None and Path(cache).exists():
+ self.prototype = torch.load(cache)
+ else:
+ prototype = []
+ for data_batch in track(dataloader, 'Prepare prototype...'):
+ with torch.no_grad():
+ data_batch = self.model.data_preprocessor(
+ data_batch, False)
+ feats = self.model._run_forward(data_batch, mode='tensor')
+ prototype.append(feats)
+ prototype = {
+ k: torch.cat([d[k] for d in prototype])
+ for k in prototype[0]
+ }
+ self.prototype = prototype
+
+ from mmengine.logging import MMLogger
+ logger = MMLogger.get_current_instance()
+ if cache is None:
+ logger.info('The prototype has been prepared, you can use '
+ '`save_prototype` to dump it into a pickle '
+ 'file for the future usage.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
+
+ return dataset
+
+ def save_prototype(self, path):
+ torch.save(self.prototype, path)
+
+ def __call__(self,
+ inputs: ImageType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the match scores.
+ Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ @torch.no_grad()
+ def forward(self, data: dict, **kwargs):
+ """Feed the inputs to the model."""
+ data = self.model.data_preprocessor(data, False)
+ feats = self.prototype.copy()
+ feats.update(self.model.extract_feat(images=data['images']))
+ return self.model.predict_all(
+ feats, data['data_samples'], cal_t2i=False)[0]
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ test_transfroms = [TRANSFORMS.build(t) for t in test_pipeline_cfg]
+ img_info = {'img': np.zeros((224, 224, 3), dtype=np.uint8)}
+ text_info = {'text': 'example'}
+ img_pipeline = Compose(filter_transforms(test_transfroms, img_info))
+ text_pipeline = Compose(filter_transforms(test_transfroms, text_info))
+ return img_pipeline, text_pipeline
+
+ def preprocess(self, inputs: List[ImageType], batch_size: int = 1):
+
+ def load_image(input_):
+ img = imread(input_)
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return dict(
+ img=img,
+ img_shape=img.shape[:2],
+ ori_shape=img.shape[:2],
+ )
+
+ pipeline = Compose([load_image, self.img_pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[ImageType],
+ preds: List[DataSample],
+ topk: int = 3,
+ resize: Optional[int] = 224,
+ show: bool = False,
+ wait_time: int = 0,
+ draw_score=True,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_)
+ if isinstance(input_, str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_i2t_retrieval(
+ image,
+ data_sample,
+ self.prototype_dataset,
+ topk=topk,
+ resize=resize,
+ draw_score=draw_score,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False,
+ topk=1,
+ ) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ matches = []
+ for match_score, sample_idx in zip(match_scores, indices):
+ text = self.prototype_dataset[sample_idx.item()]
+ matches.append({
+ 'match_score': match_score,
+ 'sample_idx': sample_idx,
+ 'text': text
+ })
+ results.append(matches)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Image-To-Text Retrieval')
diff --git a/mmpretrain/apis/nlvr.py b/mmpretrain/apis/nlvr.py
new file mode 100644
index 00000000000..9977c3b06f3
--- /dev/null
+++ b/mmpretrain/apis/nlvr.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+InputType = Tuple[Union[str, np.ndarray], Union[str, np.ndarray], str]
+InputsType = Union[List[InputType], InputType]
+
+
+class NLVRInferencer(BaseInferencer):
+ """The inferencer for Natural Language for Visual Reasoning.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``NLVRInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+ """
+
+ visualize_kwargs: set = {
+ 'resize', 'draw_score', 'show', 'show_dir', 'wait_time'
+ }
+
+ def __call__(self,
+ inputs: InputsType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (tuple, List[tuple]): The input data tuples, every tuple
+ should include three items (left image, right image, text).
+ The image can be a path or numpy array.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ assert isinstance(inputs, (tuple, list))
+ if isinstance(inputs, tuple):
+ inputs = [inputs]
+ for input_ in inputs:
+ assert isinstance(input_, tuple)
+ assert len(input_) == 3
+
+ return super().__call__(
+ inputs,
+ return_datasamples=return_datasamples,
+ batch_size=batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ assert test_pipeline_cfg[0]['type'] == 'ApplyToList'
+
+ list_pipeline = deepcopy(test_pipeline_cfg[0])
+ if list_pipeline.scatter_key == 'img_path':
+ # Remove `LoadImageFromFile`
+ list_pipeline.transforms.pop(0)
+ list_pipeline.scatter_key = 'img'
+
+ test_pipeline = Compose(
+ [TRANSFORMS.build(list_pipeline)] +
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg[1:]])
+ return test_pipeline
+
+ def preprocess(self, inputs: InputsType, batch_size: int = 1):
+
+ def load_image(input_):
+ img1 = imread(input_[0])
+ img2 = imread(input_[1])
+ text = input_[2]
+ if img1 is None:
+ raise ValueError(f'Failed to read image {input_[0]}.')
+ if img2 is None:
+ raise ValueError(f'Failed to read image {input_[1]}.')
+ return dict(
+ img=[img1, img2],
+ img_shape=[img1.shape[:2], img2.shape[:2]],
+ ori_shape=[img1.shape[:2], img2.shape[:2]],
+ text=text,
+ )
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ pred_scores = data_sample.pred_score
+ pred_score = float(torch.max(pred_scores).item())
+ pred_label = torch.argmax(pred_scores).item()
+ result = {
+ 'pred_scores': pred_scores.detach().cpu().numpy(),
+ 'pred_label': pred_label,
+ 'pred_score': pred_score,
+ }
+ results.append(result)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='NLVR')
diff --git a/mmpretrain/apis/utils.py b/mmpretrain/apis/utils.py
new file mode 100644
index 00000000000..83e76325472
--- /dev/null
+++ b/mmpretrain/apis/utils.py
@@ -0,0 +1,270 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from collections import defaultdict
+from contextlib import contextmanager
+from itertools import chain
+from typing import Dict, List, Optional, Union
+
+import torch
+import torch.nn as nn
+
+from mmpretrain.utils import require
+
+
+@require('torch>=1.9.0', 'https://pytorch.org/get-started/locally/')
+@require('accelerate')
+def dispatch_model(
+ model,
+ device_map: Union[str, dict],
+ max_memory: Optional[dict] = None,
+ no_split_module_classes: Optional[List[str]] = None,
+ offload_folder: str = None,
+ offload_buffers: bool = False,
+ preload_module_classes: Optional[List[str]] = None,
+):
+ """Split and dispatch a model across devices.
+
+ The function depends on the `accelerate` package. Refers to
+ https://huggingface.co/docs/accelerate/main/en/usage_guides/big_modeling
+
+ Args:
+ model (torch.nn.Module): The model to dispatch.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ max_memory (dict | None): A dictionary device identifier to maximum
+ memory. Will default to the maximum memory available for each GPU
+ and the available CPU RAM if unset. Defaults to None.
+ no_split_module_classes (List[str] | None): A list of layer class names
+ that should never be split across device (for instance any layer
+ that has a residual connection). If None, try to get the settings
+ from the model class. Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ offload_buffers (bool): In the layers that are offloaded on the CPU
+ or the hard drive, whether or not to offload the buffers as
+ well as the parameters. Defaults to False.
+ preload_module_classes (List[str] | None): A list of classes whose
+ instances should load all their weights (even in the submodules) at
+ the beginning of the forward. This should only be used for classes
+ that have submodules which are registered but not called directly
+ during the forward, for instance if a `dense` linear layer is
+ registered, but at forward, `dense.weight` and `dense.bias` are
+ used in some operations instead of calling `dense` directly.
+ Defaults to None.
+ """
+ from accelerate import dispatch_model, infer_auto_device_map
+
+ # Check valid device_map string.
+ valid_map_option = ['auto', 'balanced', 'balanced_low_0', 'sequential']
+ if isinstance(device_map, str) and device_map not in valid_map_option:
+ raise ValueError('If passing a string for `device_map`, please choose '
+ f'from {valid_map_option}.')
+
+ # Generate device map automatically
+ if isinstance(device_map, str):
+ if no_split_module_classes is None:
+ no_split_module_classes = getattr(model, '_no_split_modules', None)
+ if no_split_module_classes is None:
+ raise ValueError(f'{model.__class__.__name__} does not support '
+ f"`device_map='{device_map}'` yet.")
+
+ if device_map != 'sequential':
+ from accelerate.utils import get_balanced_memory
+ max_memory = get_balanced_memory(
+ model,
+ max_memory=max_memory,
+ no_split_module_classes=no_split_module_classes,
+ dtype=None,
+ low_zero=(device_map == 'balanced_low_0'),
+ )
+ max_memory[0] *= 0.9
+ device_map = infer_auto_device_map(
+ model,
+ max_memory=max_memory,
+ no_split_module_classes=no_split_module_classes,
+ dtype=None,
+ )
+
+ if 'disk' in device_map.values():
+ if offload_folder is None:
+ raise ValueError(
+ 'The current `device_map` had weights offloaded to the disk. '
+ 'Please provide an `offload_folder` for them.')
+ os.makedirs(offload_folder, exist_ok=True)
+
+ main_device = next(
+ (d for d in device_map.values() if d not in ['cpu', 'disk']), 'cpu')
+
+ model = dispatch_model(
+ model,
+ device_map=device_map,
+ main_device=main_device,
+ offload_dir=offload_folder,
+ offload_buffers=offload_buffers,
+ preload_module_classes=preload_module_classes,
+ )
+ if hasattr(model, 'data_preprocessor'):
+ model.data_preprocessor._device = torch.device(main_device)
+ return model
+
+
+@contextmanager
+def init_empty_weights(include_buffers: bool = False):
+ """A context manager under which models are initialized with all parameters
+ on the meta device.
+
+ With this context manager, we can create an empty model. Useful when just
+ initializing the model would blow the available RAM.
+
+ Besides move the parameters to meta device, this method will also avoid
+ load checkpoint from `mmengine.runner.load_checkpoint` and
+ `transformers.PreTrainedModel.from_pretrained`.
+
+ Modified from https://github.com/huggingface/accelerate
+
+ Args:
+ include_buffers (bool): Whether put all buffers on the meta device
+ during initialization.
+ """
+ device = torch.device('meta')
+
+ # move parameter and buffer to meta device
+ old_register_parameter = nn.Module.register_parameter
+ if include_buffers:
+ old_register_buffer = nn.Module.register_buffer
+ # See https://github.com/huggingface/accelerate/pull/699
+ tensor_constructors_to_patch = {
+ torch_function_name: getattr(torch, torch_function_name)
+ for torch_function_name in ['empty', 'zeros', 'ones', 'full']
+ }
+
+ def register_parameter(module, name, param):
+ old_register_parameter(module, name, param)
+ if param is not None:
+ param_cls = type(module._parameters[name])
+ kwargs = module._parameters[name].__dict__
+ module._parameters[name] = param_cls(
+ module._parameters[name].to(device), **kwargs)
+
+ def register_buffer(module, name, buffer, *args, **kwargs):
+ old_register_buffer(module, name, buffer, *args, **kwargs)
+ if buffer is not None:
+ module._buffers[name] = module._buffers[name].to(device)
+
+ def patch_tensor_constructor(fn):
+
+ def wrapper(*args, **kwargs):
+ kwargs['device'] = device
+ return fn(*args, **kwargs)
+
+ return wrapper
+
+ # Patch load_checkpoint
+ import mmengine.runner.checkpoint as mmengine_load
+ old_load_checkpoint = mmengine_load.load_checkpoint
+
+ def patch_load_checkpoint(*args, **kwargs):
+ return {}
+
+ # Patch transformers from pretrained
+ try:
+ from transformers import PreTrainedModel
+ from transformers.models.auto.auto_factory import (AutoConfig,
+ _BaseAutoModelClass)
+ with_transformers = True
+ except ImportError:
+ with_transformers = False
+
+ @classmethod
+ def patch_auto_model(cls, pretrained_model_name_or_path, *model_args,
+ **kwargs):
+ cfg = AutoConfig.from_pretrained(pretrained_model_name_or_path,
+ *model_args, **kwargs)
+ return cls.from_config(cfg)
+
+ @classmethod
+ def patch_pretrained_model(cls, pretrained_model_name_or_path, *model_args,
+ **kwargs):
+ cfg = cls.config_class.from_pretrained(pretrained_model_name_or_path,
+ *model_args, **kwargs)
+ return cls(cfg)
+
+ if with_transformers:
+ old_pretrained_model = PreTrainedModel.from_pretrained
+ old_auto_model = _BaseAutoModelClass.from_pretrained
+
+ try:
+ nn.Module.register_parameter = register_parameter
+ mmengine_load.load_checkpoint = patch_load_checkpoint
+ if with_transformers:
+ PreTrainedModel.from_pretrained = patch_pretrained_model
+ _BaseAutoModelClass.from_pretrained = patch_auto_model
+ if include_buffers:
+ nn.Module.register_buffer = register_buffer
+ for func in tensor_constructors_to_patch.keys():
+ tensor_constructor = patch_tensor_constructor(
+ getattr(torch, func))
+ setattr(torch, func, tensor_constructor)
+ yield
+ finally:
+ nn.Module.register_parameter = old_register_parameter
+ mmengine_load.load_checkpoint = old_load_checkpoint
+ if with_transformers:
+ PreTrainedModel.from_pretrained = old_pretrained_model
+ _BaseAutoModelClass.from_pretrained = old_auto_model
+ if include_buffers:
+ nn.Module.register_buffer = old_register_buffer
+ for func, ori in tensor_constructors_to_patch.items():
+ setattr(torch, func, ori)
+
+
+def compute_module_sizes(
+ model: nn.Module,
+ dtype: Union[str, torch.dtype, None] = None,
+ special_dtypes: Optional[Dict[str, Union[str, torch.dtype]]] = None):
+ """Compute the size of each submodule of a given model."""
+
+ def get_dtype(dtype):
+ if isinstance(dtype, str):
+ dtype = getattr(torch, dtype)
+ if dtype is not None:
+ assert issubclass(dtype, torch.dtype)
+ return dtype
+
+ def dtype_bytes(dtype: torch.dtype):
+ if dtype is torch.bool:
+ return 1
+ if dtype.is_floating_point:
+ return torch.finfo(dtype).bits / 8
+ else:
+ return torch.iinfo(dtype).bits / 8
+
+ if dtype is not None:
+ dtype = get_dtype(dtype)
+ dtype_size = dtype_bytes(dtype)
+
+ if special_dtypes is not None:
+ special_dtypes = {
+ key: dtype_bytes(dtype)
+ for key, dtype in special_dtypes.items()
+ }
+
+ module_sizes = defaultdict(int)
+ for name, tensor in chain(
+ model.named_parameters(recurse=True),
+ model.named_buffers(recurse=True)):
+ if special_dtypes is not None and name in special_dtypes:
+ size = tensor.numel() * special_dtypes[name]
+ elif dtype is None:
+ size = tensor.numel() * tensor.element_size()
+ else:
+ size = tensor.numel() * min(dtype_size, tensor.element_size())
+ name_parts = name.split('.')
+ for idx in range(len(name_parts) + 1):
+ module_sizes['.'.join(name_parts[:idx])] += size
+
+ return module_sizes
diff --git a/mmpretrain/apis/visual_grounding.py b/mmpretrain/apis/visual_grounding.py
new file mode 100644
index 00000000000..59a6ba8b2cb
--- /dev/null
+++ b/mmpretrain/apis/visual_grounding.py
@@ -0,0 +1,180 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+
+class VisualGroundingInferencer(BaseInferencer):
+ """The inferencer for visual grounding.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``VisualGroundingInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import VisualGroundingInferencer
+ >>> inferencer = VisualGroundingInferencer('ofa-base_3rdparty_refcoco')
+ >>> inferencer('demo/cat-dog.png', 'dog')[0]
+ {'pred_bboxes': tensor([[ 36.6000, 29.6000, 355.8000, 395.2000]])}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'resize', 'show', 'show_dir', 'wait_time', 'line_width', 'bbox_color'
+ }
+
+ def __call__(self,
+ images: Union[str, np.ndarray, list],
+ texts: Union[str, list],
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ texts (str | list): The text to do visual grounding.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+ line_width (int): The line width of the bbox. Defaults to 3.
+ bbox_color (str | tuple): The color of the bbox.
+ Defaults to 'green'.
+
+ Returns:
+ list: The inference results.
+ """
+ if not isinstance(images, (list, tuple)):
+ assert isinstance(texts, str)
+ inputs = [{'img': images, 'text': texts}]
+ else:
+ inputs = []
+ for i in range(len(images)):
+ input_ = {'img': images[i], 'text': texts[i]}
+ inputs.append(input_)
+
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[dict], batch_size: int = 1):
+
+ def load_image(input_: dict):
+ img = imread(input_['img'])
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return {**input_, 'img': img}
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[dict],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ line_width: int = 3,
+ bbox_color: Union[str, tuple] = 'green',
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_['img'])
+ if isinstance(input_['img'], str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_['img']).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_visual_grounding(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ line_width=line_width,
+ bbox_color=bbox_color,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({'pred_bboxes': data_sample.get('pred_bboxes')})
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Visual Grounding')
diff --git a/mmpretrain/apis/visual_question_answering.py b/mmpretrain/apis/visual_question_answering.py
new file mode 100644
index 00000000000..2d056758f39
--- /dev/null
+++ b/mmpretrain/apis/visual_question_answering.py
@@ -0,0 +1,181 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+
+class VisualQuestionAnsweringInferencer(BaseInferencer):
+ """The inferencer for visual question answering.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``VisualQuestionAnsweringInferencer.list_models()`` and you can
+ also query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import VisualQuestionAnsweringInferencer
+ >>> inferencer = VisualQuestionAnsweringInferencer('ofa-base_3rdparty-zeroshot_vqa')
+ >>> inferencer('demo/cat-dog.png', "What's the animal next to the dog?")[0]
+ {'question': "What's the animal next to the dog?", 'pred_answer': 'cat'}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {'resize', 'show', 'show_dir', 'wait_time'}
+
+ def __call__(self,
+ images: Union[str, np.ndarray, list],
+ questions: Union[str, list],
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ objects: Optional[List[str]] = None,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ questions (str | list): The question to the correspondding image.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ objects (List[List[str]], optional): Some algorithms like OFA
+ fine-tuned VQA models requires extra object description list
+ for every image. Defaults to None.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ if not isinstance(images, (list, tuple)):
+ assert isinstance(questions, str)
+ inputs = [{'img': images, 'question': questions}]
+ if objects is not None:
+ assert isinstance(objects[0], str)
+ inputs[0]['objects'] = objects
+ else:
+ inputs = []
+ for i in range(len(images)):
+ input_ = {'img': images[i], 'question': questions[i]}
+ if objects is not None:
+ input_['objects'] = objects[i]
+ inputs.append(input_)
+
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[dict], batch_size: int = 1):
+
+ def load_image(input_: dict):
+ img = imread(input_['img'])
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return {**input_, 'img': img}
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[dict],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_['img'])
+ if isinstance(input_['img'], str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_['img']).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_vqa(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({
+ 'question': data_sample.get('question'),
+ 'pred_answer': data_sample.get('pred_answer'),
+ })
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Visual Question Answering')
diff --git a/mmpretrain/datasets/__init__.py b/mmpretrain/datasets/__init__.py
index e3807830785..b680fb83abb 100644
--- a/mmpretrain/datasets/__init__.py
+++ b/mmpretrain/datasets/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
from .base_dataset import BaseDataset
from .builder import build_dataset
from .caltech101 import Caltech101
@@ -15,6 +16,7 @@
from .mnist import MNIST, FashionMNIST
from .multi_label import MultiLabelDataset
from .multi_task import MultiTaskDataset
+from .nlvr2 import NLVR2
from .oxfordiiitpet import OxfordIIITPet
from .places205 import Places205
from .samplers import * # noqa: F401,F403
@@ -24,9 +26,29 @@
from .voc import VOC
__all__ = [
- 'BaseDataset', 'ImageNet', 'CIFAR10', 'CIFAR100', 'MNIST', 'FashionMNIST',
- 'VOC', 'build_dataset', 'ImageNet21k', 'KFoldDataset', 'CUB',
- 'CustomDataset', 'MultiLabelDataset', 'MultiTaskDataset', 'InShop',
- 'Places205', 'Flowers102', 'OxfordIIITPet', 'DTD', 'FGVCAircraft',
- 'StanfordCars', 'SUN397', 'Caltech101', 'Food101'
+ 'BaseDataset', 'CIFAR10', 'CIFAR100', 'CUB', 'Caltech101', 'CustomDataset',
+ 'DTD', 'FGVCAircraft', 'FashionMNIST', 'Flowers102', 'Food101', 'ImageNet',
+ 'ImageNet21k', 'InShop', 'KFoldDataset', 'MNIST', 'MultiLabelDataset',
+ 'MultiTaskDataset', 'NLVR2', 'OxfordIIITPet', 'Places205', 'SUN397',
+ 'StanfordCars', 'VOC', 'build_dataset'
]
+
+if WITH_MULTIMODAL:
+ from .coco_caption import COCOCaption
+ from .coco_retrieval import COCORetrieval
+ from .coco_vqa import COCOVQA
+ from .flamingo import FlamingoEvalCOCOCaption, FlamingoEvalCOCOVQA
+ from .refcoco import RefCOCO
+ from .scienceqa import ScienceQA
+ from .visual_genome import VisualGenomeQA
+
+ __all__.extend([
+ 'COCOCaption',
+ 'COCORetrieval',
+ 'COCOVQA',
+ 'FlamingoEvalCOCOCaption',
+ 'FlamingoEvalCOCOVQA',
+ 'RefCOCO',
+ 'VisualGenomeQA',
+ 'ScienceQA',
+ ])
diff --git a/mmpretrain/datasets/coco_caption.py b/mmpretrain/datasets/coco_caption.py
new file mode 100644
index 00000000000..541cda80398
--- /dev/null
+++ b/mmpretrain/datasets/coco_caption.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import get_file_backend
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class COCOCaption(BaseDataset):
+ """COCO Caption dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``..
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ img_prefix = self.data_prefix['img_path']
+ annotations = mmengine.load(self.ann_file)
+ file_backend = get_file_backend(img_prefix)
+
+ data_list = []
+ for ann in annotations:
+ data_info = {
+ 'image_id': Path(ann['image']).stem.split('_')[-1],
+ 'img_path': file_backend.join_path(img_prefix, ann['image']),
+ 'gt_caption': ann['caption'],
+ }
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/coco_retrieval.py b/mmpretrain/datasets/coco_retrieval.py
new file mode 100644
index 00000000000..60d1586ad86
--- /dev/null
+++ b/mmpretrain/datasets/coco_retrieval.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from collections import OrderedDict
+from typing import List
+
+from mmengine import get_file_backend
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class COCORetrieval(BaseDataset):
+ """COCO Retrieval dataset.
+
+ Args:
+ ann_file (str): Annotation file path.
+ test_mode (bool): Whether dataset is used for evaluation. This will
+ decide the annotation format in data list annotations.
+ Defaults to False.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (str | dict): Prefix for training data. Defaults to ''.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ # get file backend
+ img_prefix = self.data_prefix['img_path']
+ file_backend = get_file_backend(img_prefix)
+
+ anno_info = json.load(open(self.ann_file, 'r'))
+ # mapping img_id to img filename
+ img_dict = OrderedDict()
+ for idx, img in enumerate(anno_info['images']):
+ if img['id'] not in img_dict:
+ img_rel_path = img['coco_url'].rsplit('/', 2)[-2:]
+ img_path = file_backend.join_path(img_prefix, *img_rel_path)
+
+ # create new idx for image
+ img_dict[img['id']] = dict(
+ ori_id=img['id'],
+ image_id=idx, # will be used for evaluation
+ img_path=img_path,
+ text=[],
+ gt_text_id=[],
+ gt_image_id=[],
+ )
+
+ train_list = []
+ for idx, anno in enumerate(anno_info['annotations']):
+ anno['text'] = anno.pop('caption')
+ anno['ori_id'] = anno.pop('id')
+ anno['text_id'] = idx # will be used for evaluation
+ # 1. prepare train data list item
+ train_data = anno.copy()
+ train_image = img_dict[train_data['image_id']]
+ train_data['img_path'] = train_image['img_path']
+ train_data['image_ori_id'] = train_image['ori_id']
+ train_data['image_id'] = train_image['image_id']
+ train_data['is_matched'] = True
+ train_list.append(train_data)
+ # 2. prepare eval data list item based on img dict
+ img_dict[anno['image_id']]['gt_text_id'].append(anno['text_id'])
+ img_dict[anno['image_id']]['text'].append(anno['text'])
+ img_dict[anno['image_id']]['gt_image_id'].append(
+ train_image['image_id'])
+
+ self.img_size = len(img_dict)
+ self.text_size = len(anno_info['annotations'])
+
+ # return needed format data list
+ if self.test_mode:
+ return list(img_dict.values())
+ return train_list
diff --git a/mmpretrain/datasets/coco_vqa.py b/mmpretrain/datasets/coco_vqa.py
new file mode 100644
index 00000000000..85f4bdcf39e
--- /dev/null
+++ b/mmpretrain/datasets/coco_vqa.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import re
+from collections import Counter
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class COCOVQA(BaseDataset):
+ """VQAv2 dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix``, ``ann_file``
+ and ``question_file``.
+ data_prefix (str): The directory of images.
+ question_file (str): Question file path.
+ ann_file (str, optional): Annotation file path for training and
+ validation. Defaults to an empty string.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ data_prefix: str,
+ question_file: str,
+ ann_file: str = '',
+ **kwarg):
+ self.question_file = question_file
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwarg,
+ )
+
+ def _join_prefix(self):
+ if not mmengine.is_abs(self.question_file) and self.question_file:
+ self.question_file = osp.join(self.data_root, self.question_file)
+
+ return super()._join_prefix()
+
+ def _create_image_index(self):
+ img_prefix = self.data_prefix['img_path']
+
+ files = mmengine.list_dir_or_file(img_prefix, list_dir=False)
+ image_index = {}
+ for file in files:
+ image_id = re.findall(r'\d{12}', file)
+ if len(image_id) > 0:
+ image_id = int(image_id[-1])
+ image_index[image_id] = mmengine.join_path(img_prefix, file)
+
+ return image_index
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ questions = mmengine.load(self.question_file)['questions']
+ if self.ann_file:
+ annotations = mmengine.load(self.ann_file)['annotations']
+ assert len(questions) == len(annotations)
+ else:
+ annotations = [None] * len(questions)
+
+ # The original VQAv2 annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ data_list = []
+ for question, ann in zip(questions, annotations):
+ # question example
+ # {
+ # 'image_id': 262144,
+ # 'question': "Is the ball flying towards the batter?",
+ # 'question_id': 262144000
+ # }
+ #
+ # ann example
+ # {
+ # 'question_type': "what are the",
+ # 'answer_type': "other",
+ # 'answers': [
+ # {'answer': 'watching',
+ # 'answer_id': 1,
+ # 'answer_confidence': 'yes'},
+ # ...
+ # ],
+ # 'image_id': 262148,
+ # 'question_id': 262148000,
+ # 'multiple_choice_answer': 'watching',
+ # 'answer_type': 'other',
+ # }
+
+ data_info = question
+ data_info['img_path'] = self.image_index[question['image_id']]
+
+ if ann is not None:
+ assert ann['question_id'] == question['question_id']
+
+ # add answer_weight & answer_count, delete duplicate answer
+ answers = [item['answer'] for item in ann.pop('answers')]
+ count = Counter(answers)
+ answer_weight = [i / len(answers) for i in count.values()]
+ data_info['gt_answer'] = list(count.keys())
+ data_info['gt_answer_weight'] = answer_weight
+ data_info.update(ann)
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/flamingo.py b/mmpretrain/datasets/flamingo.py
new file mode 100644
index 00000000000..3b5745a1437
--- /dev/null
+++ b/mmpretrain/datasets/flamingo.py
@@ -0,0 +1,295 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from abc import abstractmethod
+from collections import Counter
+from typing import List
+
+import mmengine
+import numpy as np
+from mmengine.dataset import BaseDataset
+from pycocotools.coco import COCO
+
+from mmpretrain.registry import DATASETS
+from .coco_vqa import COCOVQA
+
+
+class FlamingoFewShotMixin:
+ """Flamingo fewshot eval dataset minin.
+
+ Args:
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ Note: 0 does not mean a strict zero-shot in Flamingo setting.
+ It will use 2 only-text prompt without in context images.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ incontext_prompt_temp (str): In context prompt template for few shot
+ examples. Defaults to ''.
+ final_prompt_temp (str): Final query prompt template. Defaults to ''.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ incontext_prompt_temp: str = '',
+ final_prompt_temp: str = '',
+ **kwarg):
+ self.num_shots = num_shots
+ self.num_support_examples = num_support_examples
+ self.num_query_examples = num_query_examples
+ self.incontext_prompt_temp = incontext_prompt_temp
+ self.final_prompt_temp = final_prompt_temp
+ super().__init__(**kwarg)
+
+ def get_subset_idx(self, total_num):
+ random_idx = np.random.choice(
+ total_num,
+ self.num_support_examples + self.num_query_examples,
+ replace=False)
+
+ support_idx = random_idx[:self.num_support_examples]
+ query_idx = random_idx[self.num_support_examples:]
+ return support_idx, query_idx
+
+ @abstractmethod
+ def parse_basic_anno(self, anno: dict) -> dict:
+ """Parse basic annotation for support and query set."""
+ pass
+
+ @abstractmethod
+ def parse_fewshot_anno(self, anno: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list."""
+ pass
+
+
+@DATASETS.register_module()
+class FlamingoEvalCOCOVQA(FlamingoFewShotMixin, COCOVQA):
+ """Flamingo few shot VQAv2 dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ ann_file (str): Annotation file path.
+ question_file (str): Question file path.
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ Note: 0 does not mean a strict zero-shot in Flamingo setting.
+ It will use 2 only-text prompt without in context images.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ question_file: str,
+ ann_file: str = '',
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ question_file=question_file,
+ ann_file=ann_file,
+ num_shots=num_shots,
+ num_support_examples=num_support_examples,
+ num_query_examples=num_query_examples,
+ **kwarg)
+
+ def parse_basic_anno(self, ann: dict) -> dict:
+ """Parse basic annotation for support and query set.
+
+ Args:
+ anno (dict): Annotation for single example.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ if ann is None:
+ return {}
+
+ answers = [a['answer'] for a in ann['answers']]
+ count = Counter(answers)
+ answer_weight = [i / len(answers) for i in count.values()]
+ answer_info = {
+ 'gt_answer': list(count.keys()),
+ 'gt_answer_weight': answer_weight
+ }
+ return answer_info
+
+ def parse_fewshot_anno(self, query: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list.
+
+ Args:
+ anno (dict): Annotation for single example.
+ support_list (List): List of support subset to subsample few shots.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ # prepare n shots examples
+ shots = random.sample(support_list, self.num_shots)
+
+ # append image path for n shots
+ img_path = [shot['img_path'] for shot in shots]
+ img_path.append(query['img_path'])
+ query['img_path'] = img_path
+
+ query['shots'] = [
+ dict(
+ question=item['question'],
+ answer=item['gt_answer'][0],
+ ) for item in shots
+ ]
+ return query
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ questions = mmengine.load(self.question_file)['questions']
+ if self.ann_file:
+ annotations = mmengine.load(self.ann_file)['annotations']
+ assert len(questions) == len(annotations)
+ else:
+ annotations = [None] * len(questions)
+ if self.num_shots > 0:
+ raise ValueError('Unable to construct few-shot examples '
+ 'since no annotation file.')
+
+ # The original VQAv2 annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ num_data = len(questions)
+ support_idx, query_idx = self.get_subset_idx(num_data)
+
+ # prepare support subset
+ if self.num_shots > 0:
+ support_list = []
+ for idx in support_idx:
+ question = questions[idx]
+ ann = annotations[idx]
+ support = {**question, **self.parse_basic_anno(ann)}
+ support['img_path'] = self.image_index[question['image_id']]
+ support_list.append(support)
+
+ # prepare query subset
+ data_list = []
+ for idx in query_idx:
+ question = questions[idx]
+ ann = annotations[idx]
+ data_info = {**question, **self.parse_basic_anno(ann)}
+ data_info['img_path'] = self.image_index[question['image_id']]
+ if self.num_shots > 0:
+ data_info = self.parse_fewshot_anno(data_info, support_list)
+ data_list.append(data_info)
+
+ return data_list
+
+
+@DATASETS.register_module()
+class FlamingoEvalCOCOCaption(FlamingoFewShotMixin, BaseDataset):
+ """Flamingo few shot COCO Caption dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ ann_file: str,
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ ann_file=ann_file,
+ num_shots=num_shots,
+ num_support_examples=num_support_examples,
+ num_query_examples=num_query_examples,
+ **kwarg)
+
+ def parse_basic_anno(self, ann: dict, coco: COCO) -> dict:
+ """Parse basic annotation for support and query set.
+
+ Args:
+ anno (dict): Annotation for single example.
+ coco (COCO): The coco dataset.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ img_prefix = self.data_prefix['img_path']
+ img = coco.imgs[ann['image_id']]
+ data_info = dict(
+ img_path=mmengine.join_path(img_prefix, img['file_name']),
+ gt_caption=ann['caption'],
+ image_id=ann['image_id'],
+ )
+ return data_info
+
+ def parse_fewshot_anno(self, query: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list.
+
+ Args:
+ query (dict): Annotation for single example.
+ support_list (List): List of support subset to subsample few shots.
+ coco (COCO): The coco dataset.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ # prepare n shots examples
+ shots = random.sample(support_list, self.num_shots)
+
+ # append image path for n shots
+ img_path = [shot['img_path'] for shot in shots]
+ img_path.append(query['img_path'])
+ query['img_path'] = img_path
+
+ query['shots'] = [dict(caption=item['gt_caption']) for item in shots]
+ return query
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ with mmengine.get_local_path(self.ann_file) as ann_file:
+ coco = COCO(ann_file)
+
+ num_data = len(coco.anns)
+ support_idx, query_idx = self.get_subset_idx(num_data)
+ ann_ids = list(coco.anns)
+
+ # prepare support subset
+ if self.num_shots > 0:
+ support_list = []
+ for idx in support_idx:
+ support = self.parse_basic_anno(coco.anns[ann_ids[idx]], coco)
+ support_list.append(support)
+
+ # prepare query subset
+ query_list = []
+ for idx in query_idx:
+ data_info = self.parse_basic_anno(coco.anns[ann_ids[idx]], coco)
+ if self.num_shots > 0:
+ data_info = self.parse_fewshot_anno(data_info, support_list)
+ query_list.append(data_info)
+
+ return query_list
diff --git a/mmpretrain/datasets/multi_label.py b/mmpretrain/datasets/multi_label.py
index 252b2318ff0..58a9c7cd5f0 100644
--- a/mmpretrain/datasets/multi_label.py
+++ b/mmpretrain/datasets/multi_label.py
@@ -12,9 +12,6 @@ class MultiLabelDataset(BaseDataset):
This dataset support annotation file in `OpenMMLab 2.0 style annotation
format`.
- .. _OpenMMLab 2.0 style annotation format:
- https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html
-
The annotation format is shown as follows.
.. code-block:: none
diff --git a/mmpretrain/datasets/nlvr2.py b/mmpretrain/datasets/nlvr2.py
new file mode 100644
index 00000000000..00630906577
--- /dev/null
+++ b/mmpretrain/datasets/nlvr2.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import List
+
+from mmengine.fileio import get_file_backend, list_from_file
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class NLVR2(BaseDataset):
+ """COCO Caption dataset."""
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+
+ data_list = []
+ img_prefix = self.data_prefix['img_path']
+ file_backend = get_file_backend(img_prefix)
+ examples = list_from_file(self.ann_file)
+
+ for example in examples:
+ example = json.loads(example)
+ prefix = example['identifier'].rsplit('-', 1)[0]
+ train_data = {}
+ train_data['text'] = example['sentence']
+ train_data['gt_label'] = {'True': 1, 'False': 0}[example['label']]
+ train_data['img_path'] = [
+ file_backend.join_path(img_prefix, prefix + f'-img{i}.png')
+ for i in range(2)
+ ]
+
+ data_list.append(train_data)
+
+ return data_list
diff --git a/mmpretrain/datasets/refcoco.py b/mmpretrain/datasets/refcoco.py
new file mode 100644
index 00000000000..f4f2a943f73
--- /dev/null
+++ b/mmpretrain/datasets/refcoco.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List
+
+import mmengine
+import numpy as np
+from mmengine.dataset import BaseDataset
+from pycocotools.coco import COCO
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class RefCOCO(BaseDataset):
+ """RefCOCO dataset.
+
+ Args:
+ ann_file (str): Annotation file path.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (str): Prefix for training data.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root,
+ ann_file,
+ data_prefix,
+ split_file,
+ split='train',
+ **kwargs):
+ self.split_file = split_file
+ self.split = split
+
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwargs,
+ )
+
+ def _join_prefix(self):
+ if not mmengine.is_abs(self.split_file) and self.split_file:
+ self.split_file = osp.join(self.data_root, self.split_file)
+
+ return super()._join_prefix()
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ with mmengine.get_local_path(self.ann_file) as ann_file:
+ coco = COCO(ann_file)
+ splits = mmengine.load(self.split_file, file_format='pkl')
+ img_prefix = self.data_prefix['img_path']
+
+ data_list = []
+ join_path = mmengine.fileio.get_file_backend(img_prefix).join_path
+ for refer in splits:
+ if refer['split'] != self.split:
+ continue
+
+ ann = coco.anns[refer['ann_id']]
+ img = coco.imgs[ann['image_id']]
+ sentences = refer['sentences']
+ bbox = np.array(ann['bbox'], dtype=np.float32)
+ bbox[2:4] = bbox[0:2] + bbox[2:4] # XYWH -> XYXY
+
+ for sent in sentences:
+ data_info = {
+ 'img_path': join_path(img_prefix, img['file_name']),
+ 'image_id': ann['image_id'],
+ 'ann_id': ann['id'],
+ 'text': sent['sent'],
+ 'gt_bboxes': bbox[None, :],
+ }
+ data_list.append(data_info)
+
+ if len(data_list) == 0:
+ raise ValueError(f'No sample in split "{self.split}".')
+
+ return data_list
diff --git a/mmpretrain/datasets/samplers/__init__.py b/mmpretrain/datasets/samplers/__init__.py
index 9ef45b23fc1..2bccf9c3465 100644
--- a/mmpretrain/datasets/samplers/__init__.py
+++ b/mmpretrain/datasets/samplers/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .repeat_aug import RepeatAugSampler
+from .sequential import SequentialSampler
-__all__ = ('RepeatAugSampler', )
+__all__ = ['RepeatAugSampler', 'SequentialSampler']
diff --git a/mmpretrain/datasets/samplers/sequential.py b/mmpretrain/datasets/samplers/sequential.py
new file mode 100644
index 00000000000..e3b940c2eab
--- /dev/null
+++ b/mmpretrain/datasets/samplers/sequential.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Iterator
+
+import torch
+from mmengine.dataset import DefaultSampler
+
+from mmpretrain.registry import DATA_SAMPLERS
+
+
+@DATA_SAMPLERS.register_module()
+class SequentialSampler(DefaultSampler):
+ """Sequential sampler which supports different subsample policy.
+
+ Args:
+ dataset (Sized): The dataset.
+ round_up (bool): Whether to add extra samples to make the number of
+ samples evenly divisible by the world size. Defaults to True.
+ subsample_type (str): The method to subsample data on different rank.
+ Supported type:
+
+ - ``'default'``: Original torch behavior. Sample the examples one
+ by one for each GPU in terms. For instance, 8 examples on 2 GPUs,
+ GPU0: [0,2,4,8], GPU1: [1,3,5,7]
+ - ``'sequential'``: Subsample all examples to n chunk sequntially.
+ For instance, 8 examples on 2 GPUs,
+ GPU0: [0,1,2,3], GPU1: [4,5,6,7]
+ """
+
+ def __init__(self, subsample_type: str = 'default', **kwargs) -> None:
+ super().__init__(shuffle=False, **kwargs)
+
+ if subsample_type not in ['default', 'sequential']:
+ raise ValueError(f'Unsupported subsample typer "{subsample_type}",'
+ ' please choose from ["default", "sequential"]')
+ self.subsample_type = subsample_type
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ indices = torch.arange(len(self.dataset)).tolist()
+
+ # add extra samples to make it evenly divisible
+ if self.round_up:
+ indices = (
+ indices *
+ int(self.total_size / len(indices) + 1))[:self.total_size]
+
+ # subsample
+ if self.subsample_type == 'default':
+ indices = indices[self.rank:self.total_size:self.world_size]
+ elif self.subsample_type == 'sequential':
+ num_samples_per_rank = self.total_size // self.world_size
+ indices = indices[self.rank *
+ num_samples_per_rank:(self.rank + 1) *
+ num_samples_per_rank]
+
+ return iter(indices)
diff --git a/mmpretrain/datasets/scienceqa.py b/mmpretrain/datasets/scienceqa.py
new file mode 100644
index 00000000000..391f7e1acc0
--- /dev/null
+++ b/mmpretrain/datasets/scienceqa.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from typing import Callable, List, Sequence
+
+import mmengine
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import get_file_backend
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class ScienceQA(BaseDataset):
+ """ScienceQA dataset.
+
+ This dataset is used to load the multimodal data of ScienceQA dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ split (str): The split of dataset. Options: ``train``, ``val``,
+ ``test``, ``trainval``, ``minival``, and ``minitest``.
+ split_file (str): The split file of dataset, which contains the
+ ids of data samples in the split.
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ split: str,
+ split_file: str,
+ ann_file: str,
+ data_prefix: dict = dict(img_path=''),
+ pipeline: Sequence[Callable] = (),
+ **kwargs):
+
+ assert split in [
+ 'train', 'val', 'test', 'trainval', 'minival', 'minitest'
+ ], f'Invalid split {split}'
+ self.split = split
+ self.split_file = os.path.join(data_root, split_file)
+
+ super().__init__(
+ data_root=data_root,
+ ann_file=ann_file,
+ data_prefix=data_prefix,
+ pipeline=pipeline,
+ **kwargs)
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ img_prefix = self.data_prefix['img_path']
+ annotations = mmengine.load(self.ann_file)
+ current_data_split = mmengine.load(self.split_file)[self.split] # noqa
+
+ file_backend = get_file_backend(img_prefix)
+
+ data_list = []
+ for data_id in current_data_split:
+ ann = annotations[data_id]
+ if ann['image'] is not None:
+ data_info = {
+ 'image_id':
+ data_id,
+ 'question':
+ ann['question'],
+ 'choices':
+ ann['choices'],
+ 'answer':
+ ann['answer'],
+ 'hint':
+ ann['hint'],
+ 'image_name':
+ ann['image'],
+ 'task':
+ ann['task'],
+ 'grade':
+ ann['grade'],
+ 'subject':
+ ann['subject'],
+ 'topic':
+ ann['topic'],
+ 'category':
+ ann['category'],
+ 'skill':
+ ann['skill'],
+ 'lecture':
+ ann['lecture'],
+ 'solution':
+ ann['solution'],
+ 'split':
+ ann['split'],
+ 'img_path':
+ file_backend.join_path(img_prefix, data_id,
+ ann['image']), # noqa
+ }
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/transforms/__init__.py b/mmpretrain/datasets/transforms/__init__.py
index 583303cc206..88c72ca18b2 100644
--- a/mmpretrain/datasets/transforms/__init__.py
+++ b/mmpretrain/datasets/transforms/__init__.py
@@ -10,11 +10,12 @@
SolarizeAdd, Translate)
from .formatting import (Collect, NumpyToPIL, PackInputs, PackMultiTaskInputs,
PILToNumpy, Transpose)
-from .processing import (Albumentations, BEiTMaskGenerator, ColorJitter,
- EfficientNetCenterCrop, EfficientNetRandomCrop,
- Lighting, RandomCrop, RandomErasing,
- RandomResizedCrop, ResizeEdge, SimMIMMaskGenerator)
-from .wrappers import MultiView
+from .processing import (Albumentations, BEiTMaskGenerator, CleanCaption,
+ ColorJitter, EfficientNetCenterCrop,
+ EfficientNetRandomCrop, Lighting, RandomCrop,
+ RandomErasing, RandomResizedCrop, RandomTranslatePad,
+ ResizeEdge, SimMIMMaskGenerator)
+from .wrappers import ApplyToList, MultiView
for t in (CenterCrop, LoadImageFromFile, Normalize, RandomFlip,
RandomGrayscale, RandomResize, Resize):
@@ -30,5 +31,6 @@
'EfficientNetCenterCrop', 'ResizeEdge', 'BaseAugTransform',
'PackMultiTaskInputs', 'GaussianBlur', 'BEiTMaskGenerator',
'SimMIMMaskGenerator', 'CenterCrop', 'LoadImageFromFile', 'Normalize',
- 'RandomFlip', 'RandomGrayscale', 'RandomResize', 'Resize', 'MultiView'
+ 'RandomFlip', 'RandomGrayscale', 'RandomResize', 'Resize', 'MultiView',
+ 'ApplyToList', 'CleanCaption', 'RandomTranslatePad'
]
diff --git a/mmpretrain/datasets/transforms/auto_augment.py b/mmpretrain/datasets/transforms/auto_augment.py
index 1d169ed5fc8..03b057b850a 100644
--- a/mmpretrain/datasets/transforms/auto_augment.py
+++ b/mmpretrain/datasets/transforms/auto_augment.py
@@ -1234,4 +1234,11 @@ def __repr__(self):
dict(type='Translate', magnitude_range=(0, 0.45), direction='horizontal'),
dict(type='Translate', magnitude_range=(0, 0.45), direction='vertical'),
],
+ 'simple_increasing': [
+ dict(type='AutoContrast'),
+ dict(type='Equalize'),
+ dict(type='Rotate', magnitude_range=(0, 30)),
+ dict(type='Shear', magnitude_range=(0, 0.3), direction='horizontal'),
+ dict(type='Shear', magnitude_range=(0, 0.3), direction='vertical'),
+ ],
}
diff --git a/mmpretrain/datasets/transforms/formatting.py b/mmpretrain/datasets/transforms/formatting.py
index 30480b7d99f..e4d331636a8 100644
--- a/mmpretrain/datasets/transforms/formatting.py
+++ b/mmpretrain/datasets/transforms/formatting.py
@@ -129,6 +129,7 @@ def format_input(input_):
def transform(self, results: dict) -> dict:
"""Method to pack the input data."""
+
packed_results = dict()
if self.input_key in results:
input_ = results[self.input_key]
diff --git a/mmpretrain/datasets/transforms/processing.py b/mmpretrain/datasets/transforms/processing.py
index 9e41ed1db02..ad753c16fbb 100644
--- a/mmpretrain/datasets/transforms/processing.py
+++ b/mmpretrain/datasets/transforms/processing.py
@@ -3,6 +3,7 @@
import math
import numbers
import re
+import string
import traceback
from enum import EnumMeta
from numbers import Number
@@ -1624,3 +1625,138 @@ def __repr__(self) -> str:
repr_str += f'scale={self.scale}, '
repr_str += f'ratio={self.ratio})'
return repr_str
+
+
+@TRANSFORMS.register_module()
+class CleanCaption(BaseTransform):
+ """Clean caption text.
+
+ Remove some useless punctuation for the caption task.
+
+ **Required Keys:**
+
+ - ``*keys``
+
+ **Modified Keys:**
+
+ - ``*keys``
+
+ Args:
+ keys (Sequence[str], optional): The keys of text to be cleaned.
+ Defaults to 'gt_caption'.
+ remove_chars (str): The characters to be removed. Defaults to
+ :py:attr:`string.punctuation`.
+ lowercase (bool): Whether to convert the text to lowercase.
+ Defaults to True.
+ remove_dup_space (bool): Whether to remove duplicated whitespaces.
+ Defaults to True.
+ strip (bool): Whether to remove leading and trailing whitespaces.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ keys='gt_caption',
+ remove_chars=string.punctuation,
+ lowercase=True,
+ remove_dup_space=True,
+ strip=True,
+ ):
+ if isinstance(keys, str):
+ keys = [keys]
+ self.keys = keys
+ self.transtab = str.maketrans({ch: None for ch in remove_chars})
+ self.lowercase = lowercase
+ self.remove_dup_space = remove_dup_space
+ self.strip = strip
+
+ def _clean(self, text):
+ """Perform text cleaning before tokenizer."""
+
+ if self.strip:
+ text = text.strip()
+
+ text = text.translate(self.transtab)
+
+ if self.remove_dup_space:
+ text = re.sub(r'\s{2,}', ' ', text)
+
+ if self.lowercase:
+ text = text.lower()
+
+ return text
+
+ def clean(self, text):
+ """Perform text cleaning before tokenizer."""
+ if isinstance(text, (list, tuple)):
+ return [self._clean(item) for item in text]
+ elif isinstance(text, str):
+ return self._clean(text)
+ else:
+ raise TypeError('text must be a string or a list of strings')
+
+ def transform(self, results: dict) -> dict:
+ """Method to clean the input text data."""
+ for key in self.keys:
+ results[key] = self.clean(results[key])
+ return results
+
+
+@TRANSFORMS.register_module()
+class OFAAddObjects(BaseTransform):
+
+ def transform(self, results: dict) -> dict:
+ if 'objects' not in results:
+ raise ValueError(
+ 'Some OFA fine-tuned models requires `objects` field in the '
+ 'dataset, which is generated by VinVL. Or please use '
+ 'zero-shot configs. See '
+ 'https://github.com/OFA-Sys/OFA/issues/189')
+
+ if 'question' in results:
+ prompt = '{} object: {}'.format(
+ results['question'],
+ ' '.join(results['objects']),
+ )
+ results['decoder_prompt'] = prompt
+ results['question'] = prompt
+
+
+@TRANSFORMS.register_module()
+class RandomTranslatePad(BaseTransform):
+
+ def __init__(self, size=640, aug_translate=False):
+ self.size = size
+ self.aug_translate = aug_translate
+
+ @cache_randomness
+ def rand_translate_params(self, dh, dw):
+ top = np.random.randint(0, dh)
+ left = np.random.randint(0, dw)
+ return top, left
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ h, w = img.shape[:-1]
+ dw = self.size - w
+ dh = self.size - h
+ if self.aug_translate:
+ top, left = self.rand_translate_params(dh, dw)
+ else:
+ top = round(dh / 2.0 - 0.1)
+ left = round(dw / 2.0 - 0.1)
+
+ out_img = np.zeros((self.size, self.size, 3), dtype=np.float32)
+ out_img[top:top + h, left:left + w, :] = img
+ results['img'] = out_img
+ results['img_shape'] = (self.size, self.size)
+
+ # translate box
+ if 'gt_bboxes' in results.keys():
+ for i in range(len(results['gt_bboxes'])):
+ box = results['gt_bboxes'][i]
+ box[0], box[2] = box[0] + left, box[2] + left
+ box[1], box[3] = box[1] + top, box[3] + top
+ results['gt_bboxes'][i] = box
+
+ return results
diff --git a/mmpretrain/datasets/transforms/wrappers.py b/mmpretrain/datasets/transforms/wrappers.py
index 93bc31d1237..c0dfd730b4d 100644
--- a/mmpretrain/datasets/transforms/wrappers.py
+++ b/mmpretrain/datasets/transforms/wrappers.py
@@ -95,3 +95,50 @@ def __repr__(self) -> str:
repr_str += str(p)
repr_str += ')'
return repr_str
+
+
+@TRANSFORMS.register_module()
+class ApplyToList(BaseTransform):
+ """A transform wrapper to apply the wrapped transforms to a list of items.
+ For example, to load and resize a list of images.
+
+ Args:
+ transforms (list[dict | callable]): Sequence of transform config dict
+ to be wrapped.
+ scatter_key (str): The key to scatter data dict. If the field is a
+ list, scatter the list to multiple data dicts to do transformation.
+ collate_keys (List[str]): The keys to collate from multiple data dicts.
+ The fields in ``collate_keys`` will be composed into a list after
+ transformation, and the other fields will be adopted from the
+ first data dict.
+ """
+
+ def __init__(self, transforms, scatter_key, collate_keys):
+ super().__init__()
+
+ self.transforms = Compose([TRANSFORMS.build(t) for t in transforms])
+ self.scatter_key = scatter_key
+ self.collate_keys = set(collate_keys)
+ self.collate_keys.add(self.scatter_key)
+
+ def transform(self, results: dict):
+ scatter_field = results.get(self.scatter_key)
+
+ if isinstance(scatter_field, list):
+ scattered_results = []
+ for item in scatter_field:
+ single_results = copy.deepcopy(results)
+ single_results[self.scatter_key] = item
+ scattered_results.append(self.transforms(single_results))
+
+ final_output = scattered_results[0]
+
+ # merge output list to single output
+ for key in scattered_results[0].keys():
+ if key in self.collate_keys:
+ final_output[key] = [
+ single[key] for single in scattered_results
+ ]
+ return final_output
+ else:
+ return self.transforms(results)
diff --git a/mmpretrain/datasets/vg_vqa.py b/mmpretrain/datasets/vg_vqa.py
new file mode 100644
index 00000000000..2d83884c804
--- /dev/null
+++ b/mmpretrain/datasets/vg_vqa.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+from mmengine.fileio import load
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class VGVQA(BaseDataset):
+ """Visual Genome VQA dataset."""
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list.
+
+ Compare to BaseDataset, the only difference is that coco_vqa annotation
+ file is already a list of data. There is no 'metainfo'.
+ """
+
+ raw_data_list = load(self.ann_file)
+ if not isinstance(raw_data_list, list):
+ raise TypeError(
+ f'The VQA annotations loaded from annotation file '
+ f'should be a dict, but got {type(raw_data_list)}!')
+
+ # load and parse data_infos.
+ data_list = []
+ for raw_data_info in raw_data_list:
+ # parse raw data information to target format
+ data_info = self.parse_data_info(raw_data_info)
+ if isinstance(data_info, dict):
+ # For VQA tasks, each `data_info` looks like:
+ # {
+ # "question_id": 986769,
+ # "question": "How many people are there?",
+ # "answer": "two",
+ # "image": "image/1.jpg",
+ # "dataset": "vg"
+ # }
+
+ # change 'image' key to 'img_path'
+ # TODO: This process will be removed, after the annotation file
+ # is preprocess.
+ data_info['img_path'] = data_info['image']
+ del data_info['image']
+
+ if 'answer' in data_info:
+ # add answer_weight & answer_count, delete duplicate answer
+ if data_info['dataset'] == 'vqa':
+ answer_weight = {}
+ for answer in data_info['answer']:
+ if answer in answer_weight.keys():
+ answer_weight[answer] += 1 / len(
+ data_info['answer'])
+ else:
+ answer_weight[answer] = 1 / len(
+ data_info['answer'])
+
+ data_info['answer'] = list(answer_weight.keys())
+ data_info['answer_weight'] = list(
+ answer_weight.values())
+ data_info['answer_count'] = len(answer_weight)
+
+ elif data_info['dataset'] == 'vg':
+ data_info['answers'] = [data_info['answer']]
+ data_info['answer_weight'] = [0.2]
+ data_info['answer_count'] = 1
+
+ data_list.append(data_info)
+
+ else:
+ raise TypeError(
+ f'Each VQA data element loaded from annotation file '
+ f'should be a dict, but got {type(data_info)}!')
+
+ return data_list
diff --git a/mmpretrain/datasets/visual_genome.py b/mmpretrain/datasets/visual_genome.py
new file mode 100644
index 00000000000..8c33b86c4f8
--- /dev/null
+++ b/mmpretrain/datasets/visual_genome.py
@@ -0,0 +1,95 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from itertools import chain
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class VisualGenomeQA(BaseDataset):
+ """Visual Genome Question Answering dataset.
+
+ dataset structure: ::
+
+ data_root
+ ├── image
+ │ ├── 1.jpg
+ │ ├── 2.jpg
+ │ └── ...
+ └── question_answers.json
+
+ Args:
+ data_root (str): The root directory for ``data_prefix``, ``ann_file``
+ and ``question_file``.
+ data_prefix (str): The directory of images. Defaults to ``"image"``.
+ ann_file (str, optional): Annotation file path for training and
+ validation. Defaults to ``"question_answers.json"``.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ data_prefix: str = 'image',
+ ann_file: str = 'question_answers.json',
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwarg,
+ )
+
+ def _create_image_index(self):
+ img_prefix = self.data_prefix['img_path']
+
+ files = mmengine.list_dir_or_file(img_prefix, list_dir=False)
+ image_index = {}
+ for file in files:
+ image_id = re.findall(r'\d+', file)
+ if len(image_id) > 0:
+ image_id = int(image_id[-1])
+ image_index[image_id] = mmengine.join_path(img_prefix, file)
+
+ return image_index
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ annotations = mmengine.load(self.ann_file)
+
+ # The original Visual Genome annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ data_list = []
+ for qas in chain.from_iterable(ann['qas'] for ann in annotations):
+ # ann example
+ # {
+ # 'id': 1,
+ # 'qas': [
+ # {
+ # 'a_objects': [],
+ # 'question': 'What color is the clock?',
+ # 'image_id': 1,
+ # 'qa_id': 986768,
+ # 'answer': 'Two.',
+ # 'q_objects': [],
+ # }
+ # ...
+ # ]
+ # }
+
+ data_info = {
+ 'img_path': self.image_index[qas['image_id']],
+ 'quesiton': qas['quesiton'],
+ 'question_id': qas['question_id'],
+ 'image_id': qas['image_id'],
+ 'gt_answer': [qas['answer']],
+ }
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/engine/__init__.py b/mmpretrain/engine/__init__.py
index e04835b27e4..7785da7b259 100644
--- a/mmpretrain/engine/__init__.py
+++ b/mmpretrain/engine/__init__.py
@@ -1,3 +1,4 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .hooks import * # noqa: F401, F403
from .optimizers import * # noqa: F401, F403
+from .runners import * # noqa: F401, F403
diff --git a/mmpretrain/engine/hooks/__init__.py b/mmpretrain/engine/hooks/__init__.py
index 090d7652192..bc9e22be7e9 100644
--- a/mmpretrain/engine/hooks/__init__.py
+++ b/mmpretrain/engine/hooks/__init__.py
@@ -9,10 +9,11 @@
from .swav_hook import SwAVHook
from .switch_recipe_hook import SwitchRecipeHook
from .visualization_hook import VisualizationHook
+from .warmup_param_hook import WarmupParamHook
__all__ = [
'ClassNumCheckHook', 'PreciseBNHook', 'VisualizationHook',
'SwitchRecipeHook', 'PrepareProtoBeforeValLoopHook',
'SetAdaptiveMarginsHook', 'EMAHook', 'SimSiamHook', 'DenseCLHook',
- 'SwAVHook'
+ 'SwAVHook', 'WarmupParamHook'
]
diff --git a/mmpretrain/engine/hooks/warmup_param_hook.py b/mmpretrain/engine/hooks/warmup_param_hook.py
new file mode 100644
index 00000000000..b45d8918dbb
--- /dev/null
+++ b/mmpretrain/engine/hooks/warmup_param_hook.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import operator as op
+from typing import Any, Optional, Union
+
+from mmengine.hooks import Hook
+
+from mmpretrain.registry import HOOKS
+from mmpretrain.utils import get_ori_model
+
+
+@HOOKS.register_module()
+class WarmupParamHook(Hook):
+ """This is a hook used for changing the parameters other than optimizations
+ that need to warmup inside the module.
+
+ This hook can extend with more detailed warmup rule if necessary.
+
+ Args:
+ param_name (str): The parameter name that needs to be altered.
+ module_name (str): Module name that belongs to the model. Such as
+ `head`, `head.loss`, etc.
+ warmup_epochs (int): The warmup epochs for this parameter.
+ """
+
+ def __init__(
+ self,
+ param_name: str,
+ module_name: str,
+ warmup_epochs: int,
+ ) -> None:
+ self.param_name = param_name
+ self.warmup_epochs = warmup_epochs
+ # getter for module which saves the changed parameter
+ self.module_getter = op.attrgetter(module_name)
+
+ def get_param(self, runner) -> Any:
+ """Get the parameter."""
+ try:
+ module = self.module_getter(get_ori_model(runner.model))
+ return getattr(module, self.param_name)
+ except AttributeError as e:
+ raise AttributeError(f'{e}. Please check hook settings.')
+
+ def set_param(self, runner, value) -> None:
+ """Set the parameter."""
+ try:
+ module = self.module_getter(get_ori_model(runner.model))
+ setattr(module, self.param_name, value)
+ except AttributeError as e:
+ raise AttributeError(f'{e}. Please check hook settings.')
+
+ def before_train(self, runner) -> None:
+ """Get the original value before train."""
+ self.ori_val = self.get_param(runner)
+
+ def before_train_iter(
+ self,
+ runner,
+ batch_idx: int,
+ data_batch: Optional[Union[dict, tuple, list]] = None) -> None:
+ """Set the warmup value before each train iter."""
+ cur_iter = runner.iter
+ iters_per_epoch = runner.max_iters / runner.max_epochs
+ new_val = self.ori_val * min(
+ 1, cur_iter / (self.warmup_epochs * iters_per_epoch))
+ self.set_param(runner, new_val)
diff --git a/mmpretrain/engine/runners/__init__.py b/mmpretrain/engine/runners/__init__.py
new file mode 100644
index 00000000000..23206e1ea7c
--- /dev/null
+++ b/mmpretrain/engine/runners/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .retrieval_loop import RetrievalTestLoop, RetrievalValLoop
+
+__all__ = ['RetrievalTestLoop', 'RetrievalValLoop']
diff --git a/mmpretrain/engine/runners/retrieval_loop.py b/mmpretrain/engine/runners/retrieval_loop.py
new file mode 100644
index 00000000000..d15387eddeb
--- /dev/null
+++ b/mmpretrain/engine/runners/retrieval_loop.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import torch
+from mmengine.model import is_model_wrapper
+from mmengine.runner import TestLoop, ValLoop, autocast
+
+from mmpretrain.registry import LOOPS
+
+
+@LOOPS.register_module()
+class RetrievalValLoop(ValLoop):
+ """Loop for multimodal retrieval val.
+
+ Args:
+ runner (Runner): A reference of runner.
+ dataloader (Dataloader or dict): A dataloader object or a dict to
+ build a dataloader.
+ evaluator (Evaluator or dict or list): Used for computing metrics.
+ fp16 (bool): Whether to enable fp16 valing. Defaults to
+ False.
+ """
+
+ def run(self) -> dict:
+ """Launch val."""
+ self.runner.call_hook('before_val')
+ self.runner.call_hook('before_val_epoch')
+ self.runner.model.eval()
+
+ feats_local = []
+ data_samples_local = []
+
+ for idx, data_batch in enumerate(self.dataloader):
+ with torch.no_grad():
+ self.runner.call_hook(
+ 'before_val_iter', batch_idx=idx, data_batch=data_batch)
+ # predictions should be sequence of BaseDataElement
+ with autocast(enabled=self.fp16):
+ if is_model_wrapper(self.runner.model):
+ data_preprocessor = self.runner.model.module.data_preprocessor # noqa: E501
+ else:
+ data_preprocessor = self.runner.model.data_preprocessor
+
+ # get features for retrieval instead of data samples
+ data_batch = data_preprocessor(data_batch, False)
+ feats = self.runner.model._run_forward(
+ data_batch, mode='tensor')
+ feats_local.append(feats)
+ data_samples_local.extend(data_batch['data_samples'])
+ self.runner.call_hook(
+ 'after_val_iter',
+ batch_idx=idx,
+ data_batch=data_batch,
+ outputs=feats)
+
+ # concatenate different features
+ feats_local = {
+ k: torch.cat([dic[k] for dic in feats_local])
+ for k in feats_local[0]
+ }
+
+ # get predictions
+ if is_model_wrapper(self.runner.model):
+ predict_all_fn = self.runner.model.module.predict_all
+ else:
+ predict_all_fn = self.runner.model.predict_all
+
+ img_size = self.dataloader.dataset.img_size
+ text_size = self.dataloader.dataset.text_size
+ with torch.no_grad():
+ i2t_data_samples, t2i_data_samples = predict_all_fn(
+ feats_local,
+ data_samples_local,
+ num_images=img_size,
+ num_texts=text_size,
+ )
+
+ # process in evaluator and compute metrics
+ self.evaluator.process(i2t_data_samples, None)
+ i2t_metrics = self.evaluator.evaluate(img_size)
+ i2t_metrics = {f'i2t/{k}': v for k, v in i2t_metrics.items()}
+ self.evaluator.process(t2i_data_samples, None)
+ t2i_metrics = self.evaluator.evaluate(text_size)
+ t2i_metrics = {f't2i/{k}': v for k, v in t2i_metrics.items()}
+ metrics = {**i2t_metrics, **t2i_metrics}
+
+ self.runner.call_hook('after_val_epoch', metrics=metrics)
+ self.runner.call_hook('after_val')
+ return metrics
+
+
+@LOOPS.register_module()
+class RetrievalTestLoop(TestLoop):
+ """Loop for multimodal retrieval test.
+
+ Args:
+ runner (Runner): A reference of runner.
+ dataloader (Dataloader or dict): A dataloader object or a dict to
+ build a dataloader.
+ evaluator (Evaluator or dict or list): Used for computing metrics.
+ fp16 (bool): Whether to enable fp16 testing. Defaults to
+ False.
+ """
+
+ def run(self) -> dict:
+ """Launch test."""
+ self.runner.call_hook('before_test')
+ self.runner.call_hook('before_test_epoch')
+ self.runner.model.eval()
+
+ feats_local = []
+ data_samples_local = []
+
+ for idx, data_batch in enumerate(self.dataloader):
+ with torch.no_grad():
+ self.runner.call_hook(
+ 'before_test_iter', batch_idx=idx, data_batch=data_batch)
+ # predictions should be sequence of BaseDataElement
+ with autocast(enabled=self.fp16):
+ if is_model_wrapper(self.runner.model):
+ data_preprocessor = self.runner.model.module.data_preprocessor # noqa: E501
+ else:
+ data_preprocessor = self.runner.model.data_preprocessor
+ # get features for retrieval instead of data samples
+ data_batch = data_preprocessor(data_batch, False)
+ feats = self.runner.model._run_forward(
+ data_batch, mode='tensor')
+ feats_local.append(feats)
+ data_samples_local.extend(data_batch['data_samples'])
+ self.runner.call_hook(
+ 'after_test_iter',
+ batch_idx=idx,
+ data_batch=data_batch,
+ outputs=feats)
+
+ # concatenate different features
+ feats_local = {
+ k: torch.cat([dic[k] for dic in feats_local])
+ for k in feats_local[0]
+ }
+
+ # get predictions
+ if is_model_wrapper(self.runner.model):
+ predict_all_fn = self.runner.model.module.predict_all
+ else:
+ predict_all_fn = self.runner.model.predict_all
+
+ img_size = self.dataloader.dataset.img_size
+ text_size = self.dataloader.dataset.text_size
+ with torch.no_grad():
+ i2t_data_samples, t2i_data_samples = predict_all_fn(
+ feats_local,
+ data_samples_local,
+ num_images=img_size,
+ num_texts=text_size,
+ )
+
+ # process in evaluator and compute metrics
+ self.evaluator.process(i2t_data_samples, None)
+ i2t_metrics = self.evaluator.evaluate(img_size)
+ i2t_metrics = {f'i2t/{k}': v for k, v in i2t_metrics.items()}
+ self.evaluator.process(t2i_data_samples, None)
+ t2i_metrics = self.evaluator.evaluate(text_size)
+ t2i_metrics = {f't2i/{k}': v for k, v in t2i_metrics.items()}
+ metrics = {**i2t_metrics, **t2i_metrics}
+
+ self.runner.call_hook('after_test_epoch', metrics=metrics)
+ self.runner.call_hook('after_test')
+ return metrics
diff --git a/mmpretrain/evaluation/metrics/__init__.py b/mmpretrain/evaluation/metrics/__init__.py
index 25fed7242e4..683cf72bed0 100644
--- a/mmpretrain/evaluation/metrics/__init__.py
+++ b/mmpretrain/evaluation/metrics/__init__.py
@@ -1,12 +1,16 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .caption import COCOCaption
from .multi_label import AveragePrecision, MultiLabelMetric
from .multi_task import MultiTasksMetric
from .retrieval import RetrievalRecall
from .single_label import Accuracy, ConfusionMatrix, SingleLabelMetric
+from .visual_grounding_eval import VisualGroundingMetric
from .voc_multi_label import VOCAveragePrecision, VOCMultiLabelMetric
+from .vqa import ReportVQA, VQAAcc
__all__ = [
'Accuracy', 'SingleLabelMetric', 'MultiLabelMetric', 'AveragePrecision',
'MultiTasksMetric', 'VOCAveragePrecision', 'VOCMultiLabelMetric',
- 'ConfusionMatrix', 'RetrievalRecall'
+ 'ConfusionMatrix', 'RetrievalRecall', 'VQAAcc', 'ReportVQA', 'COCOCaption',
+ 'VisualGroundingMetric'
]
diff --git a/mmpretrain/evaluation/metrics/caption.py b/mmpretrain/evaluation/metrics/caption.py
new file mode 100644
index 00000000000..c4bffabfa97
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/caption.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os
+import tempfile
+from typing import List, Optional
+
+from mmengine.evaluator import BaseMetric
+from mmengine.utils import track_iter_progress
+
+from mmpretrain.registry import METRICS
+from mmpretrain.utils import require
+
+try:
+ from pycocoevalcap.eval import COCOEvalCap
+ from pycocotools.coco import COCO
+except ImportError:
+ COCOEvalCap = None
+ COCO = None
+
+
+@METRICS.register_module()
+class COCOCaption(BaseMetric):
+ """Coco Caption evaluation wrapper.
+
+ Save the generated captions and transform into coco format.
+ Calling COCO API for caption metrics.
+
+ Args:
+ ann_file (str): the path for the COCO format caption ground truth
+ json file, load for evaluations.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+
+ @require('pycocoevalcap')
+ def __init__(self,
+ ann_file: str,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.ann_file = ann_file
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+
+ for data_sample in data_samples:
+ result = dict()
+
+ result['caption'] = data_sample.get('pred_caption')
+ result['image_id'] = int(data_sample.get('image_id'))
+
+ # Save the result to `self.results`.
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ # NOTICE: don't access `self.results` from the method.
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+
+ eval_result_file = save_result(
+ result=results,
+ result_dir=temp_dir,
+ filename='m4-caption_pred',
+ remove_duplicate='image_id',
+ )
+
+ coco_val = coco_caption_eval(eval_result_file, self.ann_file)
+
+ return coco_val
+
+
+def save_result(result, result_dir, filename, remove_duplicate=''):
+ """Saving predictions as json file for evaluation."""
+
+ # combine results from all processes
+ result_new = []
+
+ if remove_duplicate:
+ result_new = []
+ id_list = []
+ for res in track_iter_progress(result):
+ if res[remove_duplicate] not in id_list:
+ id_list.append(res[remove_duplicate])
+ result_new.append(res)
+ result = result_new
+
+ final_result_file_url = os.path.join(result_dir, '%s.json' % filename)
+ print(f'result file saved to {final_result_file_url}')
+ json.dump(result, open(final_result_file_url, 'w'))
+
+ return final_result_file_url
+
+
+def coco_caption_eval(results_file, ann_file):
+ """Evaluation between gt json and prediction json files."""
+ # create coco object and coco_result object
+ coco = COCO(ann_file)
+ coco_result = coco.loadRes(results_file)
+
+ # create coco_eval object by taking coco and coco_result
+ coco_eval = COCOEvalCap(coco, coco_result)
+
+ # make sure the image ids are the same
+ coco_eval.params['image_id'] = coco_result.getImgIds()
+
+ # This will take some times at the first run
+ coco_eval.evaluate()
+
+ # print output evaluation scores
+ for metric, score in coco_eval.eval.items():
+ print(f'{metric}: {score:.3f}')
+
+ return coco_eval.eval
diff --git a/mmpretrain/evaluation/metrics/visual_grounding_eval.py b/mmpretrain/evaluation/metrics/visual_grounding_eval.py
new file mode 100644
index 00000000000..ad16e5adf46
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/visual_grounding_eval.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torchvision.ops.boxes as boxes
+from mmengine.evaluator import BaseMetric
+
+from mmpretrain.registry import METRICS
+
+
+def aligned_box_iou(boxes1: torch.Tensor, boxes2: torch.Tensor):
+ area1 = boxes.box_area(boxes1)
+ area2 = boxes.box_area(boxes2)
+
+ lt = torch.max(boxes1[:, :2], boxes2[:, :2]) # (B, 2)
+ rb = torch.min(boxes1[:, 2:], boxes2[:, 2:]) # (B, 2)
+
+ wh = boxes._upcast(rb - lt).clamp(min=0) # (B, 2)
+ inter = wh[:, 0] * wh[:, 1] # (B, )
+
+ union = area1 + area2 - inter
+ iou = inter / union
+ return iou
+
+
+@METRICS.register_module()
+class VisualGroundingMetric(BaseMetric):
+ """Visual Grounding evaluator.
+
+ Calculate the box mIOU and box grounding accuracy for visual grounding
+ model.
+
+ Args:
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+ default_prefix = 'visual-grounding'
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ for preds in data_samples:
+
+ pred_box = preds['pred_bboxes'].squeeze()
+ box_gt = torch.Tensor(preds['gt_bboxes']).squeeze()
+
+ result = {
+ 'box': pred_box.to('cpu').squeeze(),
+ 'box_target': box_gt.squeeze(),
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ pred_boxes = torch.stack([each['box'] for each in results])
+ gt_boxes = torch.stack([each['box_target'] for each in results])
+ iou = aligned_box_iou(pred_boxes, gt_boxes)
+ accu_num = torch.sum(iou >= 0.5)
+
+ miou = torch.mean(iou)
+ acc = accu_num / len(gt_boxes)
+ coco_val = {'miou': miou, 'acc': acc}
+ return coco_val
diff --git a/mmpretrain/evaluation/metrics/vqa.py b/mmpretrain/evaluation/metrics/vqa.py
new file mode 100644
index 00000000000..fd77ba9bc23
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/vqa.py
@@ -0,0 +1,315 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Partly adopted from https://github.com/GT-Vision-Lab/VQA
+# Copyright (c) 2014, Aishwarya Agrawal
+from typing import List, Optional
+
+import mmengine
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpretrain.registry import METRICS
+
+
+def _process_punctuation(inText):
+ import re
+ outText = inText
+ punct = [
+ ';', r'/', '[', ']', '"', '{', '}', '(', ')', '=', '+', '\\', '_', '-',
+ '>', '<', '@', '`', ',', '?', '!'
+ ]
+ commaStrip = re.compile('(\d)(,)(\d)') # noqa: W605
+ periodStrip = re.compile('(?!<=\d)(\.)(?!\d)') # noqa: W605
+ for p in punct:
+ if (p + ' ' in inText or ' ' + p in inText) or (re.search(
+ commaStrip, inText) is not None):
+ outText = outText.replace(p, '')
+ else:
+ outText = outText.replace(p, ' ')
+ outText = periodStrip.sub('', outText, re.UNICODE)
+ return outText
+
+
+def _process_digit_article(inText):
+ outText = []
+ tempText = inText.lower().split()
+ articles = ['a', 'an', 'the']
+ manualMap = {
+ 'none': '0',
+ 'zero': '0',
+ 'one': '1',
+ 'two': '2',
+ 'three': '3',
+ 'four': '4',
+ 'five': '5',
+ 'six': '6',
+ 'seven': '7',
+ 'eight': '8',
+ 'nine': '9',
+ 'ten': '10',
+ }
+ contractions = {
+ 'aint': "ain't",
+ 'arent': "aren't",
+ 'cant': "can't",
+ 'couldve': "could've",
+ 'couldnt': "couldn't",
+ "couldn'tve": "couldn't've",
+ "couldnt've": "couldn't've",
+ 'didnt': "didn't",
+ 'doesnt': "doesn't",
+ 'dont': "don't",
+ 'hadnt': "hadn't",
+ "hadnt've": "hadn't've",
+ "hadn'tve": "hadn't've",
+ 'hasnt': "hasn't",
+ 'havent': "haven't",
+ 'hed': "he'd",
+ "hed've": "he'd've",
+ "he'dve": "he'd've",
+ 'hes': "he's",
+ 'howd': "how'd",
+ 'howll': "how'll",
+ 'hows': "how's",
+ "Id've": "I'd've",
+ "I'dve": "I'd've",
+ 'Im': "I'm",
+ 'Ive': "I've",
+ 'isnt': "isn't",
+ 'itd': "it'd",
+ "itd've": "it'd've",
+ "it'dve": "it'd've",
+ 'itll': "it'll",
+ "let's": "let's",
+ 'maam': "ma'am",
+ 'mightnt': "mightn't",
+ "mightnt've": "mightn't've",
+ "mightn'tve": "mightn't've",
+ 'mightve': "might've",
+ 'mustnt': "mustn't",
+ 'mustve': "must've",
+ 'neednt': "needn't",
+ 'notve': "not've",
+ 'oclock': "o'clock",
+ 'oughtnt': "oughtn't",
+ "ow's'at": "'ow's'at",
+ "'ows'at": "'ow's'at",
+ "'ow'sat": "'ow's'at",
+ 'shant': "shan't",
+ "shed've": "she'd've",
+ "she'dve": "she'd've",
+ "she's": "she's",
+ 'shouldve': "should've",
+ 'shouldnt': "shouldn't",
+ "shouldnt've": "shouldn't've",
+ "shouldn'tve": "shouldn't've",
+ "somebody'd": 'somebodyd',
+ "somebodyd've": "somebody'd've",
+ "somebody'dve": "somebody'd've",
+ 'somebodyll': "somebody'll",
+ 'somebodys': "somebody's",
+ 'someoned': "someone'd",
+ "someoned've": "someone'd've",
+ "someone'dve": "someone'd've",
+ 'someonell': "someone'll",
+ 'someones': "someone's",
+ 'somethingd': "something'd",
+ "somethingd've": "something'd've",
+ "something'dve": "something'd've",
+ 'somethingll': "something'll",
+ 'thats': "that's",
+ 'thered': "there'd",
+ "thered've": "there'd've",
+ "there'dve": "there'd've",
+ 'therere': "there're",
+ 'theres': "there's",
+ 'theyd': "they'd",
+ "theyd've": "they'd've",
+ "they'dve": "they'd've",
+ 'theyll': "they'll",
+ 'theyre': "they're",
+ 'theyve': "they've",
+ 'twas': "'twas",
+ 'wasnt': "wasn't",
+ "wed've": "we'd've",
+ "we'dve": "we'd've",
+ 'weve': "we've",
+ 'werent': "weren't",
+ 'whatll': "what'll",
+ 'whatre': "what're",
+ 'whats': "what's",
+ 'whatve': "what've",
+ 'whens': "when's",
+ 'whered': "where'd",
+ 'wheres': "where's",
+ 'whereve': "where've",
+ 'whod': "who'd",
+ "whod've": "who'd've",
+ "who'dve": "who'd've",
+ 'wholl': "who'll",
+ 'whos': "who's",
+ 'whove': "who've",
+ 'whyll': "why'll",
+ 'whyre': "why're",
+ 'whys': "why's",
+ 'wont': "won't",
+ 'wouldve': "would've",
+ 'wouldnt': "wouldn't",
+ "wouldnt've": "wouldn't've",
+ "wouldn'tve": "wouldn't've",
+ 'yall': "y'all",
+ "yall'll": "y'all'll",
+ "y'allll": "y'all'll",
+ "yall'd've": "y'all'd've",
+ "y'alld've": "y'all'd've",
+ "y'all'dve": "y'all'd've",
+ 'youd': "you'd",
+ "youd've": "you'd've",
+ "you'dve": "you'd've",
+ 'youll': "you'll",
+ 'youre': "you're",
+ 'youve': "you've",
+ }
+ for word in tempText:
+ word = manualMap.setdefault(word, word)
+ if word not in articles:
+ outText.append(word)
+ for wordId, word in enumerate(outText):
+ if word in contractions:
+ outText[wordId] = contractions[word]
+ outText = ' '.join(outText)
+ return outText
+
+
+@METRICS.register_module()
+class VQAAcc(BaseMetric):
+ '''VQA Acc metric.
+ Args:
+
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ '''
+ default_prefix = 'VQA'
+
+ def __init__(self,
+ full_score_weight: float = 0.3,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.full_score_weight = full_score_weight
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ for sample in data_samples:
+ gt_answer = sample.get('gt_answer')
+ gt_answer_weight = sample.get('gt_answer_weight')
+ if isinstance(gt_answer, str):
+ gt_answer = [gt_answer]
+ if gt_answer_weight is None:
+ gt_answer_weight = [1. / (len(gt_answer))] * len(gt_answer)
+
+ result = {
+ 'pred_answer': sample.get('pred_answer'),
+ 'gt_answer': gt_answer,
+ 'gt_answer_weight': gt_answer_weight,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ acc = []
+ for result in results:
+ pred_answer = self._process_answer(result['pred_answer'])
+ gt_answer = [
+ self._process_answer(answer) for answer in result['gt_answer']
+ ]
+ answer_weight = result['gt_answer_weight']
+
+ weight_sum = 0
+ for i, gt in enumerate(gt_answer):
+ if gt == pred_answer:
+ weight_sum += answer_weight[i]
+ vqa_acc = min(1.0, weight_sum / self.full_score_weight)
+ acc.append(vqa_acc)
+
+ accuracy = sum(acc) / len(acc) * 100
+
+ metrics = {'acc': accuracy}
+ return metrics
+
+ def _process_answer(self, answer):
+ answer = answer.replace('\n', ' ')
+ answer = answer.replace('\t', ' ')
+ answer = answer.strip()
+ answer = _process_punctuation(answer)
+ answer = _process_digit_article(answer)
+ return answer
+
+
+@METRICS.register_module()
+class ReportVQA(BaseMetric):
+ """Dump VQA result to the standard json format for VQA evaluation.
+
+ Args:
+ file_path (str): The file path to save the result file.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+ default_prefix = 'VQA'
+
+ def __init__(self,
+ file_path: str,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ if not file_path.endswith('.json'):
+ raise ValueError('The output file must be a json file.')
+ self.file_path = file_path
+
+ def process(self, data_batch, data_samples) -> None:
+ """transfer tensors in predictions to CPU."""
+ for sample in data_samples:
+ question_id = sample['question_id']
+ pred_answer = sample['pred_answer']
+
+ result = {
+ 'question_id': int(question_id),
+ 'answer': pred_answer,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Dump the result to json file."""
+ mmengine.dump(results, self.file_path)
+ logger = MMLogger.get_current_instance()
+ logger.info(f'Results has been saved to {self.file_path}.')
+ return {}
diff --git a/mmpretrain/models/__init__.py b/mmpretrain/models/__init__.py
index 767bbaa2a00..ba05735b26a 100644
--- a/mmpretrain/models/__init__.py
+++ b/mmpretrain/models/__init__.py
@@ -6,6 +6,7 @@
from .classifiers import * # noqa: F401,F403
from .heads import * # noqa: F401,F403
from .losses import * # noqa: F401,F403
+from .multimodal import * # noqa: F401,F403
from .necks import * # noqa: F401,F403
from .retrievers import * # noqa: F401,F403
from .selfsup import * # noqa: F401,F403
diff --git a/mmpretrain/models/backbones/timm_backbone.py b/mmpretrain/models/backbones/timm_backbone.py
index 69169b4a81b..51ecbdbb077 100644
--- a/mmpretrain/models/backbones/timm_backbone.py
+++ b/mmpretrain/models/backbones/timm_backbone.py
@@ -4,6 +4,7 @@
from mmengine.logging import MMLogger
from mmpretrain.registry import MODELS
+from mmpretrain.utils import require
from .base_backbone import BaseBackbone
@@ -55,6 +56,7 @@ class TIMMBackbone(BaseBackbone):
**kwargs: Other timm & model specific arguments.
"""
+ @require('timm')
def __init__(self,
model_name,
features_only=False,
@@ -63,11 +65,7 @@ def __init__(self,
in_channels=3,
init_cfg=None,
**kwargs):
- try:
- import timm
- except ImportError:
- raise ImportError(
- 'Failed to import timm. Please run "pip install timm".')
+ import timm
if not isinstance(pretrained, bool):
raise TypeError('pretrained must be bool, not str for model path')
@@ -79,7 +77,12 @@ def __init__(self,
super(TIMMBackbone, self).__init__(init_cfg)
if 'norm_layer' in kwargs:
- kwargs['norm_layer'] = MODELS.get(kwargs['norm_layer'])
+ norm_class = MODELS.get(kwargs['norm_layer'])
+
+ def build_norm(*args, **kwargs):
+ return norm_class(*args, **kwargs)
+
+ kwargs['norm_layer'] = build_norm
self.timm_model = timm.create_model(
model_name=model_name,
features_only=features_only,
diff --git a/mmpretrain/models/classifiers/hugging_face.py b/mmpretrain/models/classifiers/hugging_face.py
index f10f22621b9..26a8fda51b0 100644
--- a/mmpretrain/models/classifiers/hugging_face.py
+++ b/mmpretrain/models/classifiers/hugging_face.py
@@ -9,6 +9,7 @@
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
+from mmpretrain.utils import require
from .base import BaseClassifier
@@ -66,6 +67,7 @@ class HuggingFaceClassifier(BaseClassifier):
torch.Size([1, 1000])
""" # noqa: E501
+ @require('transformers')
def __init__(self,
model_name,
pretrained=False,
diff --git a/mmpretrain/models/classifiers/timm.py b/mmpretrain/models/classifiers/timm.py
index e33100b8537..d777b2e039d 100644
--- a/mmpretrain/models/classifiers/timm.py
+++ b/mmpretrain/models/classifiers/timm.py
@@ -9,6 +9,7 @@
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
+from mmpretrain.utils import require
from .base import BaseClassifier
@@ -59,6 +60,7 @@ class TimmClassifier(BaseClassifier):
torch.Size([1, 1000])
""" # noqa: E501
+ @require('timm')
def __init__(self,
*args,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
diff --git a/mmpretrain/models/heads/__init__.py b/mmpretrain/models/heads/__init__.py
index 42b257e2daf..7d2c1ae0f02 100644
--- a/mmpretrain/models/heads/__init__.py
+++ b/mmpretrain/models/heads/__init__.py
@@ -7,6 +7,9 @@
from .contrastive_head import ContrastiveHead
from .deit_head import DeiTClsHead
from .efficientformer_head import EfficientFormerClsHead
+from .grounding_head import GroundingHead
+from .itc_head import ITCHead
+from .itm_head import ITMHead
from .latent_heads import LatentCrossCorrelationHead, LatentPredictHead
from .levit_head import LeViTClsHead
from .linear_head import LinearClsHead
@@ -19,11 +22,13 @@
from .multi_label_csra_head import CSRAClsHead
from .multi_label_linear_head import MultiLabelLinearClsHead
from .multi_task_head import MultiTaskHead
+from .seq_gen_head import SeqGenerationHead
from .simmim_head import SimMIMHead
from .stacked_head import StackedLinearClsHead
from .swav_head import SwAVHead
from .vig_head import VigClsHead
from .vision_transformer_head import VisionTransformerClsHead
+from .vqa_head import VQAGenerationHead
__all__ = [
'ClsHead',
@@ -52,4 +57,9 @@
'MoCoV3Head',
'MIMHead',
'SimMIMHead',
+ 'SeqGenerationHead',
+ 'VQAGenerationHead',
+ 'ITCHead',
+ 'ITMHead',
+ 'GroundingHead',
]
diff --git a/mmpretrain/models/heads/grounding_head.py b/mmpretrain/models/heads/grounding_head.py
new file mode 100644
index 00000000000..a47512ef593
--- /dev/null
+++ b/mmpretrain/models/heads/grounding_head.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+
+from mmpretrain.models.utils.box_utils import (box_cxcywh_to_xyxy,
+ generalized_box_iou)
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+@MODELS.register_module()
+class GroundingHead(BaseModule):
+ """bbox Coordination generation head for multi-modal pre-trained task,
+ adapted by BLIP. Normally used for visual grounding.
+
+ Args:
+ loss: dict,
+ decoder: dict,
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ decoder: dict = None,
+ tokenizer: dict = None,
+ box_l1_loss_coeff=4.0,
+ box_giou_loss_coeff=2.0,
+ init_cfg: Optional[dict] = None,
+ ) -> None:
+ super(GroundingHead, self).__init__(init_cfg=init_cfg)
+ ''' init the decoder from med_config'''
+ self.decoder = None
+ if decoder:
+ self.decoder = MODELS.build(decoder)
+ self.loss_fn = torch.nn.CrossEntropyLoss(
+ reduction='none', ignore_index=-100)
+
+ self.box_l1_loss_coeff = box_l1_loss_coeff
+ self.box_giou_loss_coeff = box_giou_loss_coeff
+
+ if isinstance(tokenizer, dict):
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+
+ self.image_res = 640
+ prefix_ids = torch.tensor(
+ self.tokenizer.convert_tokens_to_ids(['[unused339]']))
+ target_ids = torch.tensor(
+ self.tokenizer.convert_tokens_to_ids(
+ [f'[unused{340+_}]' for _ in range(self.image_res + 1)]))
+ self.register_buffer('prefix_ids', prefix_ids)
+ self.register_buffer('target_ids', target_ids)
+
+ bbox_prob_mask = torch.zeros(len(self.tokenizer))
+ bbox_prob_mask[self.target_ids[0]:self.target_ids[-1] + 1] = 1
+ bbox_prob_mask = (1.0 - bbox_prob_mask) * -10000.0
+ self.register_buffer('bbox_prob_mask', bbox_prob_mask)
+ self.bin_start_idx = self.target_ids[0]
+
+ def forward(self, text_embedding, text_embedding_mask,
+ encoder_hidden_states, encoder_attention_mask):
+
+ # localize prompt token, text embedding
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ loc_prompt = self.prompt.weight.T
+ loc_prompt = torch.repeat_interleave(loc_prompt,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(1)
+
+ loc_prompt_mask = torch.ones(loc_prompt.shape[:-1]).long().to(
+ loc_prompt.device)
+
+ decoder_out = self.decoder(
+ inputs_embeds=loc_prompt,
+ attention_mask=loc_prompt_mask,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ output_hidden_states=True,
+ labels=None,
+ )
+ decoder_hs = decoder_out.hidden_states[-1][:, 0, :]
+ box_pred = self.box_head(decoder_hs)
+ return decoder_out, decoder_hs, box_pred
+
+ def loss(self,
+ text_embedding,
+ text_embedding_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ decoder_targets,
+ return_scores=False):
+ """Calculate losses from the extracted features.
+
+ Args:
+ feats (dict): The features extracted from the backbone.
+ data_samples (List[BaseDataElement]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ answer_targets = (decoder_targets *
+ self.image_res).long() + self.bin_start_idx
+ prefix_ids = torch.repeat_interleave(self.prefix_ids,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(-1)
+ prefix_ids = torch.cat([prefix_ids, answer_targets], dim=1)
+
+ answer_output = self.decoder(
+ prefix_ids,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ labels=None,
+ return_dict=True,
+ )
+ prob_mask = self.bbox_prob_mask.view(1, 1,
+ self.bbox_prob_mask.shape[-1])
+ prediction_scores = answer_output.logits + prob_mask
+
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = prefix_ids[:, 1:].contiguous()
+ vocab_size = len(self.tokenizer)
+ loss_seq_init = self.loss_fn(
+ shifted_prediction_scores.view(-1, vocab_size), labels.view(-1))
+
+ with torch.no_grad():
+ pred_box = (torch.argmax(
+ prediction_scores[:, :-1, :].contiguous(), dim=-1) -
+ self.bin_start_idx) / self.image_res
+ weight_bbox = F.l1_loss(
+ pred_box, decoder_targets, reduction='none').clamp(
+ 0, 5) * self.box_l1_loss_coeff
+ weight_giou = (1 - torch.diag(
+ generalized_box_iou(
+ box_cxcywh_to_xyxy(pred_box),
+ box_cxcywh_to_xyxy(decoder_targets)))
+ ) * self.box_giou_loss_coeff
+ bs = text_embedding.shape[0]
+ loss_seq = loss_seq_init[:].view(bs, -1, 4)
+ loss_seq = loss_seq * weight_bbox
+ loss_seq = loss_seq * weight_giou.unsqueeze(1)
+
+ loss_seq = loss_seq.mean()
+
+ losses = {
+ 'loss_seq': loss_seq,
+ 'loss_seq_init': loss_seq_init.mean(),
+ 'loss': loss_seq,
+ 'box_l1': weight_bbox.mean(-1).mean().detach(),
+ 'box_giou': weight_giou.mean().detach()
+ }
+
+ return losses
+
+ def predict(
+ self,
+ text_embedding,
+ text_embedding_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ """Generates the bbox coordinates at inference time."""
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ prefix_ids = torch.repeat_interleave(self.prefix_ids,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(-1)
+
+ for _ in range(4):
+ decoder_output = self.decoder(
+ prefix_ids,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ labels=None,
+ return_dict=True,
+ )
+ prob_mask = self.bbox_prob_mask.view(1, 1,
+ self.bbox_prob_mask.shape[-1])
+ prediction_scores = decoder_output.logits + prob_mask
+
+ prefix_ids = torch.cat([
+ prefix_ids,
+ torch.argmax(prediction_scores[:, -1, :], dim=-1).unsqueeze(1)
+ ],
+ dim=1)
+
+ pred_box = self.process_bbox(prefix_ids[:, 1:]) # xywh 0-1 to xyxy 0-1
+
+ return pred_box
+
+ @torch.no_grad()
+ def process_bbox(self, bbox):
+ bbox = bbox - self.bin_start_idx
+ bbox = torch.true_divide(bbox, self.image_res)
+ bbox = box_cxcywh_to_xyxy(bbox)
+ bbox = torch.clip(bbox, 0, 1)
+ assert torch.all(bbox <= 1)
+ return bbox
diff --git a/mmpretrain/models/heads/itc_head.py b/mmpretrain/models/heads/itc_head.py
new file mode 100644
index 00000000000..006d52c76d9
--- /dev/null
+++ b/mmpretrain/models/heads/itc_head.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.dist import all_gather
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class ITCHead(BaseModule):
+ """Image-text matching head for multi-modal pre-trained task. Adapted by
+ BLIP, ALBEF. Normally used for retrieval task.
+
+ Args:
+ embed_dim (int): Embed channel size for queue.
+ queue_size (int): Queue size for image and text. Defaults to 57600.
+ temperature (float): Temperature to calculate the similarity.
+ Defaults to 0.07.
+ use_distill (bool): Whether to use distill to calculate loss.
+ Defaults to True.
+ alpha (float): Weight for momentum similarity. Defaults to 0.4.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dim: int,
+ queue_size: int = 57600,
+ temperature: float = 0.07,
+ use_distill: bool = True,
+ alpha: float = 0.4,
+ init_cfg: Optional[dict] = None):
+ super(ITCHead, self).__init__(init_cfg=init_cfg)
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+ self.use_distill = use_distill
+ if self.use_distill:
+ # create the queue
+ self.register_buffer('image_queue',
+ torch.randn(embed_dim, queue_size))
+ self.register_buffer('text_queue',
+ torch.randn(embed_dim, queue_size))
+ self.register_buffer('idx_queue', torch.full((1, queue_size),
+ -100))
+ self.register_buffer('queue_ptr', torch.zeros(1, dtype=torch.long))
+
+ self.image_queue = F.normalize(self.image_queue, dim=0)
+ self.text_queue = F.normalize(self.text_queue, dim=0)
+
+ self.queue_size = queue_size
+ # This value will be warmup by `WarmupParamHook`
+ self.alpha = alpha
+
+ def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
+ """The forward process."""
+ return feats[-1]
+
+ def loss(self, feats: Tuple[torch.Tensor], data_samples, **kwargs) -> dict:
+ """Calculate losses from the classification score.
+
+ Args:
+ feats (tuple[Tensor]): The features extracted from the backbone.
+ Multiple stage inputs are acceptable but only the last stage
+ will be used to classify. The shape of every item should be
+ ``(num_samples, num_classes)``.
+ data_samples (List[ClsDataSample]): The annotation data of
+ every samples.
+ **kwargs: Other keyword arguments to forward the loss module.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ # The part can be traced by torch.fx
+ img_feats, text_feats, img_feats_m, text_feats_m = self(feats)
+
+ img_feats_all = torch.cat(
+ [img_feats_m.t(),
+ self.image_queue.clone().detach()], dim=1)
+ text_feats_all = torch.cat(
+ [text_feats_m.t(),
+ self.text_queue.clone().detach()], dim=1)
+
+ # The part can not be traced by torch.fx
+ losses = self._get_loss(img_feats, text_feats, img_feats_m,
+ text_feats_m, img_feats_all, text_feats_all,
+ data_samples, **kwargs)
+ return losses
+
+ def _get_loss(self, img_feats, text_feats, img_feats_m, text_feats_m,
+ img_feats_all, text_feats_all, data_samples, **kwargs):
+ """Unpack data samples and compute loss."""
+
+ idx = torch.tensor([ds.image_id
+ for ds in data_samples]).to(img_feats.device)
+ idx = idx.view(-1, 1)
+ idx_all = torch.cat([idx.t(), self.idx_queue.clone().detach()], dim=1)
+ pos_idx = torch.eq(idx, idx_all).float()
+ sim_targets = pos_idx / pos_idx.sum(1, keepdim=True)
+
+ with torch.no_grad():
+ if self.use_distill:
+ sim_i2t_m = img_feats_m @ text_feats_all / self.temp
+ sim_t2i_m = text_feats_m @ img_feats_all / self.temp
+
+ sim_i2t_targets = (
+ self.alpha * F.softmax(sim_i2t_m, dim=1) +
+ (1 - self.alpha) * sim_targets)
+ sim_t2i_targets = (
+ self.alpha * F.softmax(sim_t2i_m, dim=1) +
+ (1 - self.alpha) * sim_targets)
+
+ sim_i2t = img_feats @ text_feats_all / self.temp
+ sim_t2i = text_feats @ img_feats_all / self.temp
+
+ if self.use_distill:
+ loss_i2t = -torch.sum(
+ F.log_softmax(sim_i2t, dim=1) * sim_i2t_targets, dim=1).mean()
+ loss_t2i = -torch.sum(
+ F.log_softmax(sim_t2i, dim=1) * sim_t2i_targets, dim=1).mean()
+ else:
+ loss_i2t = -torch.sum(
+ F.log_softmax(sim_i2t, dim=1) * sim_targets, dim=1).mean()
+ loss_t2i = -torch.sum(
+ F.log_softmax(sim_t2i, dim=1) * sim_targets, dim=1).mean()
+
+ # compute loss
+ losses = dict()
+
+ losses['itc_loss'] = (loss_i2t + loss_t2i) / 2
+ self._dequeue_and_enqueue(img_feats_m, text_feats_m, idx)
+ return losses
+
+ @torch.no_grad()
+ def _dequeue_and_enqueue(self, image_feat, text_feat, idxs=None):
+ # gather keys before updating queue
+ image_feats = torch.cat(all_gather(image_feat))
+ text_feats = torch.cat(all_gather(text_feat))
+
+ batch_size = image_feats.shape[0]
+
+ ptr = int(self.queue_ptr)
+ assert self.queue_size % batch_size == 0 # for simplicity
+
+ # replace the keys at ptr (dequeue and enqueue)
+ self.image_queue[:, ptr:ptr + batch_size] = image_feats.T
+ self.text_queue[:, ptr:ptr + batch_size] = text_feats.T
+
+ if idxs is not None:
+ idxs = torch.cat(all_gather(idxs))
+ self.idx_queue[:, ptr:ptr + batch_size] = idxs.T
+
+ ptr = (ptr + batch_size) % self.queue_size # move pointer
+ self.queue_ptr[0] = ptr
diff --git a/mmpretrain/models/heads/itm_head.py b/mmpretrain/models/heads/itm_head.py
new file mode 100644
index 00000000000..c7b42f3f684
--- /dev/null
+++ b/mmpretrain/models/heads/itm_head.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+from mmpretrain.evaluation import Accuracy
+from mmpretrain.registry import MODELS
+
+
+class Pooler(nn.Module):
+
+ def __init__(self, hidden_size):
+ super().__init__()
+ self.dense = nn.Linear(hidden_size, hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+@MODELS.register_module()
+class ITMHead(BaseModule):
+ """Image-text matching head for multi-modal pre-trained task. Adapted by
+ BLIP, FLAVA.
+
+ Args:
+ hidden_size (int): Hidden channel size out input features.
+ with_pooler (bool): Whether a pooler is added. Defaults to True.
+ loss (dict): Config of global contrasive loss. Defaults to
+ ``dict(type='GlobalContrasiveLoss')``.
+ cal_acc (bool): Whether to calculate accuracy during training.
+ If you use batch augmentations like Mixup and CutMix during
+ training, it is pointless to calculate accuracy.
+ Defaults to False.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ hidden_size: int,
+ with_pooler: bool = True,
+ loss: dict = dict(type='CrossEntropyLoss', loss_weight=1.0),
+ cal_acc: bool = False,
+ init_cfg: Optional[dict] = None):
+ super(ITMHead, self).__init__(init_cfg=init_cfg)
+ self.hidden_size = hidden_size
+
+ if with_pooler:
+ self.pooler = Pooler(hidden_size=self.hidden_size)
+ else:
+ self.pooler = nn.Identity()
+ self.fc = nn.Linear(self.hidden_size, 2)
+
+ self.loss_module = MODELS.build(loss)
+ self.cal_acc = cal_acc
+
+ def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
+ """The forward process."""
+ pre_logits = self.pooler(feats[-1])
+ itm_logits = self.fc(pre_logits)
+ return itm_logits
+
+ def loss(self, feats: Tuple[torch.Tensor], data_samples, **kwargs) -> dict:
+ """Calculate losses from the classification score.
+
+ Args:
+ feats (tuple[Tensor]): The features extracted from the backbone.
+ Multiple stage inputs are acceptable but only the last stage
+ will be used to classify. The shape of every item should be
+ ``(num_samples, num_classes)``.
+ data_samples (List[ClsDataSample]): The annotation data of
+ every samples.
+ **kwargs: Other keyword arguments to forward the loss module.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ # The part can be traced by torch.fx
+ itm_logits = self(feats)
+
+ # deal with query
+ if itm_logits.ndim == 3:
+ itm_logits = itm_logits.mean(dim=1)
+
+ # The part can not be traced by torch.fx
+ losses = self._get_loss(itm_logits, data_samples, **kwargs)
+ return losses
+
+ def _get_loss(self, itm_logits: torch.Tensor, data_samples, **kwargs):
+ """Unpack data samples and compute loss."""
+ # Unpack data samples and pack targets
+ # use `itm_label` in here temporarily
+ target = torch.tensor([i.is_matched
+ for i in data_samples]).to(itm_logits.device)
+
+ # compute loss
+ losses = dict()
+
+ loss = self.loss_module(
+ itm_logits, target.long(), avg_factor=itm_logits.size(0), **kwargs)
+ losses['itm_loss'] = loss
+
+ # compute accuracy
+ if self.cal_acc:
+ # topk is meaningless for matching task
+ acc = Accuracy.calculate(itm_logits, target)
+ # acc is warpped with two lists of topk and thrs
+ # which are unnecessary here
+ losses.update({'itm_accuracy': acc[0][0]})
+
+ return losses
diff --git a/mmpretrain/models/heads/seq_gen_head.py b/mmpretrain/models/heads/seq_gen_head.py
new file mode 100644
index 00000000000..b2e9b10efe6
--- /dev/null
+++ b/mmpretrain/models/heads/seq_gen_head.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class SeqGenerationHead(BaseModule):
+ """Generation head for multi-modal pre-trained task, adopted by BLIP.
+ Normally used for generation task.
+
+ Args:
+ decoder (dict): Decoder for blip generation head.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ decoder: dict,
+ ignore_index=-100,
+ loss: dict = dict(type='LabelSmoothLoss', label_smooth_val=0.1),
+ init_cfg: Optional[dict] = None,
+ ) -> None:
+ super(SeqGenerationHead, self).__init__(init_cfg=init_cfg)
+ self.decoder = MODELS.build(decoder)
+ self.loss_fn = MODELS.build(loss)
+ self.ignore_index = ignore_index
+
+ def forward(self, input_ids: torch.Tensor,
+ encoder_hidden_states: torch.Tensor,
+ encoder_attention_mask: torch.Tensor, labels: torch.Tensor):
+ """Forward to get decoder output.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ encoder_attention_mask (torch.Tensor): Image embeddings hidden
+ states attention mask.
+ labels (torch.Tensor): Decoder target for calculate loss.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of decoder outputs.
+ """
+
+ decoder_out = self.decoder(
+ input_ids=input_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ labels=labels,
+ return_dict=True,
+ )
+ return decoder_out
+
+ def loss(self, input_ids, encoder_hidden_states, encoder_attention_mask,
+ labels):
+ """Calculate losses from the extracted features.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ encoder_attention_mask (torch.Tensor): Image embeddings hidden
+ states attention mask.
+ labels (torch.Tensor): Decoder target for calculate loss.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+
+ decoder_out = self(
+ input_ids=input_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ labels=labels,
+ )
+ prediction_scores = decoder_out['logits']
+ # we are doing next-token prediction;
+ # shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+
+ vocab_size = prediction_scores.shape[-1]
+
+ # mask ignored index
+ if (labels == self.ignore_index).any():
+ labels = labels.view(-1).clone()
+ ignore_mask = (labels == self.ignore_index)
+ labels.masked_fill_(ignore_mask, 0)
+ weight = torch.logical_not(ignore_mask)
+ avg_factor = max(weight.sum(), 1)
+ else:
+ weight = None
+ avg_factor = labels.size(0)
+
+ lm_loss = self.loss_fn(
+ shifted_prediction_scores.view(-1, vocab_size),
+ labels,
+ weight=weight,
+ avg_factor=avg_factor,
+ )
+ losses = {
+ 'seq_gen_lm_loss': lm_loss,
+ }
+
+ return losses
+
+ def predict(self,
+ input_ids,
+ encoder_hidden_states,
+ sep_token_id,
+ pad_token_id,
+ use_nucleus_sampling=False,
+ num_beams=3,
+ max_length=20,
+ min_length=2,
+ top_p=0.9,
+ repetition_penalty=1.0,
+ **kwargs):
+ """Decoder prediction method.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ sep_token_id (int): Tokenid of separation token.
+ pad_token_id (int): Tokenid of pad token.
+ use_nucleus_sampling (bool): Whether to use nucleus sampling in
+ prediction. Defaults to False.
+ num_beams (int): Number of beams used in predition.
+ Defaults to 3.
+ max_length (int): Max length of generated text in predition.
+ Defaults to 20.
+ min_length (int): Min length of generated text in predition.
+ Defaults to 20.
+ top_p (float):
+ If < 1.0, only keep the top tokens with cumulative probability
+ >= top_p (nucleus filtering). Defaults to 0.9.
+ repetition_penalty (float): The parameter for repetition penalty.
+ Defaults to 1.0.
+ **kwarg: Other arguments that might used in generation.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of generation outputs.
+ """
+ device = encoder_hidden_states.device
+
+ # TODO: In old version of transformers
+ # Additional repeat interleave of hidden states should be add here.
+ image_atts = torch.ones(
+ encoder_hidden_states.size()[:-1], dtype=torch.long).to(device)
+
+ model_kwargs = {
+ 'encoder_hidden_states': encoder_hidden_states,
+ 'encoder_attention_mask': image_atts,
+ }
+ model_kwargs.update(kwargs)
+
+ if use_nucleus_sampling:
+ # nucleus sampling
+ outputs = self.decoder.generate(
+ input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ do_sample=True,
+ top_p=top_p,
+ num_return_sequences=1,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=1.1,
+ **model_kwargs)
+ else:
+ # beam search
+ outputs = self.decoder.generate(
+ input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ num_beams=num_beams,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=repetition_penalty,
+ **model_kwargs)
+
+ return outputs
diff --git a/mmpretrain/models/heads/vqa_head.py b/mmpretrain/models/heads/vqa_head.py
new file mode 100644
index 00000000000..c7b5fe53287
--- /dev/null
+++ b/mmpretrain/models/heads/vqa_head.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import mmengine
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class VQAGenerationHead(BaseModule):
+ """Generation head for multi-modal pre-trained task, adapted by BLIP.
+ Normally used for qa generation task (open-set)
+
+ Args:
+ decoder (dict): Decoder for decoding answers.
+ inference_method (str): Inference method. One of 'rank', 'generate'.
+ - If 'rank', the model will return answers with the highest
+ probability from the answer list.
+ - If 'generate', the model will generate answers.
+ - Only for test, not for train / val.
+ num_beams (int): Number of beams for beam search. 1 means no beam
+ search. Only support when inference_method=='generate'.
+ Defaults to 3.
+ num_ans_candidates (int): Number of answer candidates, used to filter
+ out answers with low probability. Only support when
+ inference_method=='rank'. Defaults to 128.
+ loss (dict or nn.Module): Config of loss or module of loss. Defaults to
+ ``nn.CrossEntropyLoss(reduction='none', ignore_index=-100)``.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ answer_list_path (str, optional): Path to `answer_list.json`
+ (json file of a answer list). Required when
+ inference_method=='rank'.
+
+
+ TODO: `mmcls.LabelSmoothLoss` has not support `ignore_index` param.
+ Now using `nn.CrossEntropyLoss`, without label_smoothing, in order to
+ maintain compatibility with torch < 1.10.0
+ """
+
+ def __init__(
+ self,
+ decoder: dict,
+ inference_method: str = 'generate',
+ num_beams: int = 3,
+ num_ans_candidates: int = 128,
+ loss: Union[dict, nn.Module] = nn.CrossEntropyLoss(
+ reduction='none', ignore_index=-100),
+ init_cfg: Optional[dict] = None,
+ answer_list_path: Optional[str] = None,
+ ) -> None:
+
+ super(VQAGenerationHead, self).__init__(init_cfg=init_cfg)
+ self.decoder = MODELS.build(decoder)
+
+ if inference_method == 'generate':
+ assert isinstance(num_beams, int), \
+ 'for VQA `generate` mode, `num_beams` must be a int.'
+ self.num_beams = num_beams
+ self.num_ans_candidates = None
+ self.answer_list = None
+
+ elif inference_method == 'rank':
+ assert isinstance(num_ans_candidates, int), \
+ 'for VQA `rank` mode, `num_ans_candidates` must be a int.'
+ assert isinstance(answer_list_path, str), \
+ 'for VQA `rank` mode, `answer_list_path` must be set as ' \
+ 'the path to `answer_list.json`.'
+ self.num_beams = None
+ self.answer_list = mmengine.load(answer_list_path)
+ if isinstance(self.answer_list, dict):
+ self.answer_list = list(self.answer_list.keys())
+ assert isinstance(self.answer_list, list) and all(
+ isinstance(item, str) for item in self.answer_list), \
+ 'for VQA `rank` mode, `answer_list.json` must be a list of str'
+ self.num_ans_candidates = min(num_ans_candidates,
+ len(self.answer_list))
+
+ else:
+ raise AssertionError(
+ 'for VQA, `inference_method` must be "generate" or "rank", '
+ 'got {}.'.format(inference_method))
+
+ self.inference_method = inference_method
+ if not isinstance(loss, nn.Module):
+ loss = MODELS.build(loss)
+ self.loss_module = loss
+
+ def forward(self, feats: dict):
+ prediction_logits = self.decoder(
+ feats['answer_input_ids'],
+ attention_mask=feats['answer_attention_mask'],
+ encoder_hidden_states=feats['question_states'],
+ encoder_attention_mask=feats['question_atts'],
+ labels=feats['answer_targets'],
+ return_dict=True,
+ return_logits=True, # directly return logits, not computing loss
+ reduction='none',
+ )
+ return prediction_logits
+
+ def loss(self, feats: dict, data_samples=None):
+ """Calculate losses from the extracted features.
+
+ Args:
+ feats (dict): The features extracted from the backbone.
+ data_samples (List[BaseDataElement]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ shifted_prediction_scores = self(feats)
+ labels = feats['answer_targets']
+ lm_loss = None
+
+ # we are doing next-token prediction;
+ # shift prediction scores and input ids by one
+ labels = labels[:, 1:].contiguous()
+ lm_loss = self.loss_module(
+ shifted_prediction_scores.view(-1,
+ self.decoder.med_config.vocab_size),
+ labels.view(-1))
+ lm_loss = lm_loss.view(shifted_prediction_scores.size(0), -1).sum(1)
+ # compute weighted loss
+ losses = dict()
+ loss = feats['answer_weight'] * lm_loss
+ loss = loss.sum() / feats['batch_size']
+ losses['vqa_loss'] = loss
+
+ return losses
+
+ def predict_rank(self, feats: dict, data_samples=None):
+ """Predict rank in a close-set answer list."""
+ question_states = feats['multimodal_embeds']
+ question_atts = feats['question_atts']
+ answer_candidates = feats['answer_candidates']
+ assert answer_candidates is not None
+
+ answer_ids = answer_candidates.input_ids
+ answer_atts = answer_candidates.attention_mask
+ num_ques = question_states.size(0)
+ start_ids = answer_ids[0, 0].repeat(num_ques, 1) # bos token
+
+ start_output = self.decoder(
+ start_ids,
+ encoder_hidden_states=question_states,
+ encoder_attention_mask=question_atts,
+ return_dict=True,
+ reduction='none',
+ )
+ logits = start_output.logits[:, 0, :] # first token's logit
+
+ # topk_probs: top-k probability
+ # topk_ids: [num_question, k]
+ answer_first_token = answer_ids[:, 1]
+ prob_first_token = F.softmax(
+ logits, dim=1).index_select(
+ dim=1, index=answer_first_token)
+ topk_probs, topk_ids = prob_first_token.topk(
+ self.num_ans_candidates, dim=1)
+
+ # answer input: [num_question*k, answer_len]
+ input_ids = []
+ input_atts = []
+ for b, topk_id in enumerate(topk_ids):
+ input_ids.append(answer_ids.index_select(dim=0, index=topk_id))
+ input_atts.append(answer_atts.index_select(dim=0, index=topk_id))
+ input_ids = torch.cat(input_ids, dim=0)
+ input_atts = torch.cat(input_atts, dim=0)
+
+ targets_ids = input_ids.masked_fill(input_ids == feats['pad_token_id'],
+ -100)
+
+ def tile(x, dim, n_tile):
+ init_dim = x.size(dim)
+ repeat_idx = [1] * x.dim()
+ repeat_idx[dim] = n_tile
+ x = x.repeat(*(repeat_idx))
+ order_index = torch.LongTensor(
+ np.concatenate([
+ init_dim * np.arange(n_tile) + i for i in range(init_dim)
+ ]))
+ return torch.index_select(x, dim, order_index.to(x.device))
+
+ # repeat encoder's output for top-k answers
+ question_states = tile(question_states, 0, self.num_ans_candidates)
+ question_atts = tile(question_atts, 0, self.num_ans_candidates)
+
+ output = self.decoder(
+ input_ids,
+ attention_mask=input_atts,
+ encoder_hidden_states=question_states,
+ encoder_attention_mask=question_atts,
+ labels=targets_ids,
+ return_dict=True,
+ reduction='none',
+ )
+
+ log_probs_sum = -output.loss
+ log_probs_sum = log_probs_sum.view(num_ques, self.num_ans_candidates)
+
+ max_topk_ids = log_probs_sum.argmax(dim=1)
+ max_ids = topk_ids[max_topk_ids >= 0, max_topk_ids]
+
+ answers = [self.answer_list[max_id] for max_id in max_ids]
+
+ return answers
+
+ def predict_generate(self, feats: dict, data_samples=None):
+ """Predict answers in a generation manner."""
+ device = feats['multimodal_embeds'].device
+ question_states = feats['multimodal_embeds']
+ question_atts = torch.ones(
+ question_states.size()[:-1], dtype=torch.long).to(device)
+ model_kwargs = {
+ 'encoder_hidden_states': question_states,
+ 'encoder_attention_mask': question_atts
+ }
+
+ bos_ids = torch.full((feats['multimodal_embeds'].shape[0], 1),
+ fill_value=feats['bos_token_id'],
+ device=device)
+
+ outputs = self.decoder.generate(
+ input_ids=bos_ids,
+ max_length=10,
+ min_length=1,
+ num_beams=self.num_beams,
+ eos_token_id=feats['sep_token_id'],
+ pad_token_id=feats['pad_token_id'],
+ **model_kwargs)
+
+ return outputs
+
+ def predict(self, feats: dict, data_samples=None):
+ """Predict results from the extracted features."""
+ if self.inference_method == 'generate':
+ return self.predict_generate(feats, data_samples)
+ elif self.inference_method == 'rank':
+ return self.predict_rank(feats, data_samples)
diff --git a/mmpretrain/models/losses/label_smooth_loss.py b/mmpretrain/models/losses/label_smooth_loss.py
index b53b9913ce7..f117df33b07 100644
--- a/mmpretrain/models/losses/label_smooth_loss.py
+++ b/mmpretrain/models/losses/label_smooth_loss.py
@@ -62,7 +62,9 @@ def __init__(self,
use_sigmoid=None,
mode='original',
reduction='mean',
- loss_weight=1.0):
+ loss_weight=1.0,
+ class_weight=None,
+ pos_weight=None):
super().__init__()
self.num_classes = num_classes
self.loss_weight = loss_weight
@@ -101,7 +103,11 @@ def __init__(self,
use_sigmoid = False if use_sigmoid is None else use_sigmoid
self.ce = CrossEntropyLoss(
- use_sigmoid=use_sigmoid, use_soft=not use_sigmoid)
+ use_sigmoid=use_sigmoid,
+ use_soft=not use_sigmoid,
+ reduction=reduction,
+ class_weight=class_weight,
+ pos_weight=pos_weight)
def generate_one_hot_like_label(self, label):
"""This function takes one-hot or index label vectors and computes one-
diff --git a/mmpretrain/models/multimodal/__init__.py b/mmpretrain/models/multimodal/__init__.py
new file mode 100644
index 00000000000..bda7087a4a5
--- /dev/null
+++ b/mmpretrain/models/multimodal/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
+
+if WITH_MULTIMODAL:
+ from .blip import * # noqa: F401,F403
+ from .blip2 import * # noqa: F401,F403
+ from .flamingo import * # noqa: F401, F403
+ from .ofa import * # noqa: F401, F403
+else:
+ from mmpretrain.registry import MODELS
+ from mmpretrain.utils.dependency import register_multimodal_placeholder
+
+ register_multimodal_placeholder([
+ 'Blip2Caption', 'Blip2Retrieval', 'Blip2VQA', 'BlipCaption',
+ 'BlipNLVR', 'BlipRetrieval', 'BlipGrounding', 'BlipVQA', 'Flamingo',
+ 'OFA'
+ ], MODELS)
diff --git a/mmpretrain/models/multimodal/blip/__init__.py b/mmpretrain/models/multimodal/blip/__init__.py
new file mode 100644
index 00000000000..ebbc0da6e0d
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .blip_caption import BlipCaption
+from .blip_grounding import BlipGrounding
+from .blip_nlvr import BlipNLVR
+from .blip_retrieval import BlipRetrieval
+from .blip_vqa import BlipVQA
+from .language_model import BertLMHeadModel, XBertEncoder, XBertLMHeadDecoder
+
+__all__ = [
+ 'BertLMHeadModel', 'BlipCaption', 'BlipGrounding', 'BlipNLVR',
+ 'BlipRetrieval', 'BlipVQA', 'XBertEncoder', 'XBertLMHeadDecoder'
+]
diff --git a/mmpretrain/models/multimodal/blip/blip_caption.py b/mmpretrain/models/multimodal/blip/blip_caption.py
new file mode 100644
index 00000000000..9af3e2408da
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_caption.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class BlipCaption(BaseModel):
+ """BLIP Caption.
+
+ Args:
+ vision_encoder (dict): Encoder for extracting image features.
+ decoder_head (dict): The decoder head module to forward and
+ calculate loss from processed features.
+ tokenizer: (Optional[dict]): The config for tokenizer.
+ Defaults to None.
+ prompt (str): Prompt used for training and eval.
+ Defaults to ''.
+ max_txt_len (int): Max text length of input text.
+ num_captions (int): Number of captions to be generated for each image.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_encoder: dict,
+ decoder_head: dict,
+ tokenizer: Optional[dict] = None,
+ prompt: str = '',
+ max_txt_len: int = 20,
+ num_captions: int = 1,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipCaption, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.visual_encoder = MODELS.build(vision_encoder)
+ self.seq_gen_head = MODELS.build(decoder_head)
+
+ self.prompt = prompt
+ self.prompt_length = len(self.tokenizer(self.prompt).input_ids) - 1
+ self.max_txt_len = max_txt_len
+ self.num_captions = num_captions
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "predict" and "loss":
+
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): pre_processed img tensor (N, C, ...).
+ data_samples (List[DataSample], optional): Data samples with
+ additional infos.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self, images, data_samples=None, **kwargs):
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input images tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ # prepare inputs for decoder generation.
+ image_embeds = self.visual_encoder(images)[0]
+ image_embeds = torch.repeat_interleave(image_embeds, self.num_captions,
+ 0)
+
+ prompt = [self.prompt] * image_embeds.size(0)
+ prompt = self.tokenizer(
+ prompt, padding='longest',
+ return_tensors='pt').to(image_embeds.device)
+
+ prompt.input_ids[:, 0] = self.tokenizer.bos_token_id
+ prompt.input_ids = prompt.input_ids[:, :-1]
+
+ decoder_out = self.seq_gen_head.predict(
+ input_ids=prompt.input_ids,
+ encoder_hidden_states=image_embeds,
+ sep_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ output_attentions=True,
+ return_dict_in_generate=True,
+ )
+
+ decode_tokens = self.tokenizer.batch_decode(
+ decoder_out.sequences, skip_special_tokens=True)
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None for _ in range(len(decode_tokens))]
+
+ for data_sample, decode_token in zip(data_samples, decode_tokens):
+ if data_sample is None:
+ data_sample = DataSample()
+ data_sample.pred_caption = decode_token[len(self.prompt):]
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
+
+ def loss(self, images, data_samples):
+ """Calculate losses from a batch of images and data samples.
+
+ Args:
+ images (torch.Tensor): The input images tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[ImageTextDataSample]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+ image_embeds = self.visual_encoder(images)[0]
+ raw_text = [self.prompt + ds.gt_caption for ds in data_samples]
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+ text.input_ids[:, 0] = self.tokenizer.bos_token_id
+
+ # prepare targets for forwarding decoder
+ labels = text.input_ids.masked_fill(
+ text.input_ids == self.tokenizer.pad_token_id, -100)
+ labels[:, :self.prompt_length] = -100
+ # forward decoder
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(image_embeds.device)
+
+ losses = self.seq_gen_head.loss(
+ input_ids=text.input_ids,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ labels=labels,
+ )
+ return losses
diff --git a/mmpretrain/models/multimodal/blip/blip_grounding.py b/mmpretrain/models/multimodal/blip/blip_grounding.py
new file mode 100644
index 00000000000..cb087287220
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_grounding.py
@@ -0,0 +1,248 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.models.utils.box_utils import box_xyxy_to_cxcywh
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures.data_sample import DataSample
+
+
+@MODELS.register_module()
+class BlipGrounding(BaseModel):
+ """BLIP Grounding.
+
+ Args:
+ visual_encoder (dict): Backbone for extracting image features.
+ text_encoder (dict): Backbone for extracting text features.
+ but we integrate the vqa text extractor
+ into the tokenizer part in datasets/transform/
+ so we don't need text_backbone
+ multimodal_encoder (Optional[dict]): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ neck (Optional[dict]): The neck module to process features from
+ backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed features. See :mod:`mmpretrain.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ tokenizer: Optional[dict] = None,
+ visual_encoder: Optional[dict] = None,
+ text_encoder: Optional[dict] = None,
+ multimodal_encoder: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipGrounding, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.prompt = 'localize instance: '
+ self.visual_encoder = MODELS.build(visual_encoder)
+ self.text_encoder = MODELS.build(text_encoder)
+ self.multimodal_encoder = MODELS.build(multimodal_encoder)
+ head.setdefault('tokenizer', self.tokenizer)
+ self.grounding_head = MODELS.build(head)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor, tuple): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[VQADataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract features from the input tensor with shape (N, C, ...).
+
+ Args:
+ inputs (Tensor): A batch of inputs. The shape of it should be
+ ``(num_samples, num_channels, *img_shape)``.
+ Returns:
+ image_embeds (Tensor): The output features.
+ """
+ image_embeds = self.visual_encoder(images)[0]
+ return image_embeds
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples=None,
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
+ """generate train_loss from the input tensor and data_samples.
+
+ Args:
+ inputs (Tensor): A batch of inputs. The shape of it should be
+ ``(num_samples, num_channels, *img_shape)``.
+ data_samples (List[VQADataSample], optional): The annotation
+ data of every samples..
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+
+ # extract image feature
+ image_embeds = self.extract_feat(images)
+ image_atts = image_embeds.new_ones(
+ image_embeds.size()[:-1], dtype=torch.long)
+
+ raw_text = []
+ box_targets = []
+ for ds in data_samples:
+
+ raw_text.append(ds.text)
+ box_t = copy.deepcopy(ds.box) * 1.0
+ box_t[1] /= ds.img_shape[0]
+ box_t[3] /= ds.img_shape[0]
+ box_t[0] /= ds.img_shape[1]
+ box_t[2] /= ds.img_shape[1]
+
+ box_targets.append(box_t)
+
+ box_targets = image_embeds.new_tensor(np.stack(box_targets))
+ box_targets = box_xyxy_to_cxcywh(box_targets) # xywh 0-1
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=128,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+
+ text_embeds = self.text_encoder(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ mode='text',
+ return_dict=True) # bz, seq_len, hid
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_encoder(
+ encoder_embeds=text_embeds.last_hidden_state,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ losses = self.grounding_head.loss(
+ text_embedding=multimodal_embeds.last_hidden_state,
+ text_embedding_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ decoder_targets=box_targets,
+ )
+
+ return losses
+
+ def predict(self, images, data_samples=None):
+ """"""
+
+ # extract image feature
+ image_embeds = self.extract_feat(images)
+ image_atts = image_embeds.new_ones(
+ image_embeds.size()[:-1], dtype=torch.long)
+
+ raw_text = []
+ for ds in data_samples:
+ raw_text.append(ds.text)
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=128,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+
+ text_embeds = self.text_encoder(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ mode='text',
+ return_dict=True) # bz, seq_len, hid
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_encoder(
+ encoder_embeds=text_embeds.last_hidden_state,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ output_boxes = self.grounding_head.predict(
+ text_embedding=multimodal_embeds.last_hidden_state,
+ text_embedding_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ ) # xyxy 0-1
+
+ out_data_samples = []
+ for bbox, data_sample, img in zip(output_boxes, data_samples, images):
+ if data_sample is None:
+ data_sample = DataSample()
+
+ img_size = img.shape[-2:]
+ scale_factor = data_sample.get('scale_factor', (1, 1))
+ bbox[0::2] = bbox[0::2] * img_size[1] / scale_factor[0]
+ bbox[1::2] = bbox[1::2] * img_size[0] / scale_factor[1]
+ bbox = bbox[None, :]
+ data_sample.pred_bboxes = bbox
+
+ if 'gt_bboxes' in data_sample:
+ gt_bboxes = torch.Tensor(data_sample.get('gt_bboxes'))
+ gt_bboxes[:, 0::2] /= scale_factor[0]
+ gt_bboxes[:, 1::2] /= scale_factor[1]
+ data_sample.gt_bboxes = gt_bboxes
+
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/blip/blip_nlvr.py b/mmpretrain/models/multimodal/blip/blip_nlvr.py
new file mode 100644
index 00000000000..f96e3cce237
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_nlvr.py
@@ -0,0 +1,205 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+@MODELS.register_module()
+class BlipNLVR(BaseModel):
+ """BLIP NLVR.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ but we integrate the vqa text extractor into the tokenizer part in
+ datasets/transform/ so we don't need text_backbone
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ neck (Optional[dict]): The neck module to process features from
+ backbone. Defaults to None.
+ head (Optional[dict]): The head module to calculate
+ loss from processed features. See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ tokenizer: (Optional[dict]): The config for tokenizer
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ multimodal_backbone: dict,
+ tokenizer: Optional[dict] = None,
+ max_txt_len: int = 35,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+ if tokenizer is not None:
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.max_txt_len = max_txt_len
+
+ # For simplity, directly use head definition here.
+ # If more complex head is designed, move this and loss to a new
+ # head module.
+ hidden_size = self.multimodal_backbone.config.hidden_size
+ self.head = nn.Sequential(
+ nn.Linear(hidden_size, hidden_size),
+ nn.ReLU(),
+ nn.Linear(hidden_size, 2),
+ )
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def preprocess_text(self, data_samples):
+
+ sample_item = data_samples[0]
+
+ if sample_item is not None and 'text' in sample_item:
+ texts = [sample.get('text') for sample in data_samples]
+ else:
+ return None
+
+ # perform tokenize first if satisfied conditions
+ texts = self.tokenizer(
+ texts,
+ padding='longest',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(self.device)
+
+ return texts
+
+ def forward(
+ self,
+ images: dict,
+ data_samples: Optional[List] = None,
+ mode: str = 'tensor',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ images and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (dict of torch.Tensor):
+ img: pre_processed img tensor (N, C, ...).
+ text: tokenized text (N, L)
+ data_samples (List[CaptionDataSample], optional):
+ The annotation data of every samples.
+ 'image': raw image data
+ 'text' tokenized text
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ # B, T, C, H, W to T*B, C, H, W
+ images = images.permute(1, 0, 2, 3, 4).flatten(0, 1)
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self, images, data_samples=None):
+ """Predict caption."""
+ # prepare inputs for decoder generation.
+ image_embeds = self.vision_backbone(images)[0]
+ texts = self.preprocess_text(data_samples)
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ image0_embeds, image1_embeds = torch.split(image_embeds,
+ texts.input_ids.size(0))
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ texts.input_ids,
+ attention_mask=texts.attention_mask,
+ encoder_hidden_states=[image0_embeds, image1_embeds],
+ encoder_attention_mask=[
+ image_atts[:image0_embeds.size(0)],
+ image_atts[image0_embeds.size(0):],
+ ],
+ return_dict=True,
+ )
+
+ # get prediction
+ outputs = self.head(multimodal_embeds.last_hidden_state[:, 0, :])
+
+ pred_scores = F.softmax(outputs, dim=1)
+
+ for pred_score, data_sample in zip(pred_scores, data_samples):
+ data_sample.set_pred_score(pred_score)
+ data_sample.set_pred_label(pred_score.argmax(dim=0))
+
+ return data_samples
+
+ def loss(self, images, data_samples):
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[ImageTextDataSample]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+ # prepare inputs for decoder generation.
+ image_embeds = self.vision_backbone(images)[0]
+ texts = self.preprocess_text(data_samples)
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+ image0_embeds, image1_embeds = torch.split(image_embeds,
+ texts.input_ids.size(0))
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ texts.input_ids,
+ attention_mask=texts.attention_mask,
+ encoder_hidden_states=[image0_embeds, image1_embeds],
+ encoder_attention_mask=[
+ image_atts[:image0_embeds.size(0)],
+ image_atts[image0_embeds.size(0):],
+ ],
+ return_dict=True,
+ )
+
+ # get prediction
+ outputs = self.head(multimodal_embeds.last_hidden_state[:, 0, :])
+
+ targets = torch.tensor([i.gt_label
+ for i in data_samples]).to(outputs.device)
+ loss = F.cross_entropy(outputs, targets)
+ return {'loss': loss}
diff --git a/mmpretrain/models/multimodal/blip/blip_retrieval.py b/mmpretrain/models/multimodal/blip/blip_retrieval.py
new file mode 100644
index 00000000000..8983e63e208
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_retrieval.py
@@ -0,0 +1,716 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import ChainMap
+from copy import deepcopy
+from typing import Dict, List, Optional, Tuple, Union
+
+import mmengine.dist as dist
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+from torch import distributed as torch_dist
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track_on_main_process
+
+
+def all_gather_concat(data: torch.Tensor) -> torch.Tensor:
+ """Gather tensors with different first-dimension size and concat to one
+ tenosr.
+
+ Note:
+ Only the first dimension should be different.
+
+ Args:
+ data (Tensor): Tensor to be gathered.
+
+ Returns:
+ torch.Tensor: The concatenated tenosr.
+ """
+ if dist.get_world_size() == 1:
+ return data
+
+ data_size = torch.tensor(data.size(0), device=data.device)
+ sizes_list = dist.all_gather(data_size)
+
+ max_length = max(sizes_list)
+ size_diff = max_length.item() - data_size.item()
+ if size_diff:
+ padding = torch.zeros(
+ size_diff, *data.size()[1:], device=data.device, dtype=data.dtype)
+ data = torch.cat((data, padding))
+
+ gather_list = dist.all_gather(data)
+
+ all_data = []
+ for tensor, size in zip(gather_list, sizes_list):
+
+ all_data.append(tensor[:size])
+
+ return torch.concat(all_data)
+
+
+@MODELS.register_module()
+class BlipRetrieval(BaseModel):
+ """BLIP Retriever.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features.
+ vision_neck (Optional[dict]): The neck module to process image features
+ from vision backbone. Defaults to None.
+ text_neck (Optional[dict]): The neck module to process text features
+ from text backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed single modality features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ multimodal_head (Optional[Union[List[dict], dict]]): The multi-modal
+ head module to calculate loss from processed multimodal features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ momentum (float): Momentum used for momentum contrast.
+ Defaults to .995.
+ negative_all_rank (bool): Whether to sample negative data from all
+ ranks for image text matching in training. Defaults to True.
+ temperature (float): Temperature parameter that controls the
+ concentration level of the distribution. Defaults to 0.07.
+ fast_match (bool): If False, select topk similarity as candidates and
+ compute the matching score. If True, return the similarity as the
+ matching score directly. Defaults to False.
+ topk (int): Select topk similarity as candidates for compute matching
+ scores. Notice that this is not the topk in evaluation.
+ Defaults to 256.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: dict,
+ multimodal_backbone: Optional[dict] = None,
+ vision_neck: Optional[dict] = None,
+ text_neck: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ multimodal_head: Optional[Union[List[dict], dict]] = None,
+ tokenizer: Optional[dict] = None,
+ momentum: float = .995,
+ negative_all_rank: bool = True,
+ temperature: float = 0.07,
+ fast_match: bool = False,
+ topk: int = 256,
+ max_txt_len: int = 20,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.text_backbone = MODELS.build(text_backbone)
+
+ if multimodal_backbone is not None:
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+
+ if vision_neck is not None:
+ self.vision_neck = MODELS.build(vision_neck)
+
+ if text_neck is not None:
+ self.text_neck = MODELS.build(text_neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+
+ if multimodal_head is not None:
+ self.multimodal_head = MODELS.build(multimodal_head)
+
+ if tokenizer is not None:
+ self.tokenizer = TOKENIZER.build(tokenizer)
+
+ self.momentum = momentum
+ self.negative_all_rank = negative_all_rank
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+ # Shares the same para
+ self.head.temp = self.temp
+
+ # create the momentum encoder
+ self.vision_backbone_m = deepcopy(self.vision_backbone)
+ self.text_backbone_m = deepcopy(self.text_backbone)
+
+ self.vision_neck_m = deepcopy(self.vision_neck)
+ self.text_neck_m = deepcopy(self.text_neck)
+
+ self.model_pairs = [
+ [self.vision_backbone, self.vision_backbone_m],
+ [self.text_backbone, self.text_backbone_m],
+ [self.vision_neck, self.vision_neck_m],
+ [self.text_neck, self.text_neck_m],
+ ]
+ self.copy_params()
+
+ # multimodal backone shares weights with text backbone in BLIP
+ # No need to set up
+
+ # Notice that this topk is used for select k candidate to compute
+ # image-text score, but not the final metric topk in evaluation.
+ self.fast_match = fast_match
+ self.topk = topk
+
+ self.max_txt_len = max_txt_len
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def preprocess_text(self, data_samples):
+ sample_item = data_samples[0]
+
+ if sample_item is not None and 'text' in sample_item:
+ if isinstance(sample_item.get('text'), (list, tuple)):
+ texts = []
+ for sample in data_samples:
+ texts.extend(sample.get('text'))
+ elif isinstance(sample_item.get('text'), str):
+ texts = [sample.get('text') for sample in data_samples]
+ else:
+ raise TypeError('text must be a string or a list of strings')
+ else:
+ return None
+
+ # perform tokenize first if satisfied conditions
+ texts = self.tokenizer(
+ texts,
+ padding='max_length',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(self.device)
+
+ return texts
+
+ def forward(self,
+ images: torch.tensor = None,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'tensor') -> Union[Tuple, dict]:
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "tensor", and "loss":
+
+ - "tensor": Forward the whole network and return tensor without any
+ post-processing, same as a common nn.Module.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ For unified "predict" mode in other mm repos. It is noticed that
+ image-text retrieval cannot perform batch prediction since it will go
+ through all the samples. A standard process of retrieval evaluation is
+ to extract and collect all feats, and then predict all samples.
+ Therefore the `predict` mode here is remained as a trigger
+ to inform use to choose the right configurations.
+
+ Args:
+ images (torch.Tensor): The input inputs tensor of shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="tensor"``, return a tuple.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'tensor':
+ return self.extract_feat(images, data_samples)
+ elif mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(
+ self,
+ images: torch.Tensor = None,
+ data_samples: List[DataSample] = None,
+ return_texts=True,
+ return_embeds=None,
+ ) -> Dict[str, torch.Tensor]:
+ """Extract features from the input dict.
+
+ Args:
+ images (tensor, optional): The images to extract features.
+ Defaults to None.
+ data_samples (list, optional): The data samples containing texts
+ to extract features. Defaults to None.
+ return_texts (bool): Whether to return the tokenized text and the
+ corresponding attention masks. Defaults to True.
+ return_embeds (bool): Whether to return the text embedding and
+ image embedding. Defaults to None, which means to use
+ ``self.fast_match``.
+
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ If multimodal_backbone is not exist, tuple of torch.Tensor
+ will be returned.
+ """
+ if data_samples is not None:
+ texts = self.preprocess_text(data_samples)
+ else:
+ texts = None
+
+ assert images is not None or texts is not None, \
+ 'At least single modality should be passed as inputs.'
+
+ results = {}
+ if texts is not None and return_texts:
+ results.update({
+ 'text_ids': texts.input_ids,
+ 'text_attn_mask': texts.attention_mask,
+ })
+
+ if return_embeds is None:
+ return_embeds = not self.fast_match
+
+ # extract image features
+ if images is not None:
+ output = self._extract_feat(images, modality='images')
+ results['image_feat'] = output['image_feat']
+ if return_embeds:
+ results['image_embeds'] = output['image_embeds']
+
+ # extract text features
+ if texts is not None:
+ output = self._extract_feat(texts, modality='texts')
+ results['text_feat'] = output['text_feat']
+ if return_embeds:
+ results['text_embeds'] = output['text_embeds']
+
+ return results
+
+ def _extract_feat(self, inputs: Union[torch.Tensor, dict],
+ modality: str) -> Tuple[torch.Tensor]:
+ """Extract features from the single modality.
+
+ Args:
+ inputs (Union[torch.Tensor, dict]): A batch of inputs.
+ For image, a tensor of shape (N, C, ...) in general.
+ For text, a dict of tokenized text inputs.
+ modality (str): Modality feature to be extracted. Only two
+ options are supported.
+
+ - ``images``: Only extract image features, mostly used for
+ inference.
+ - ``texts``: Only extract text features, mostly used for
+ inference.
+
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ """
+
+ if modality == 'images':
+ # extract image features
+ image_embeds = self.vision_backbone(inputs)[0]
+ image_feat = F.normalize(
+ self.vision_neck(image_embeds[:, 0, :]), dim=-1)
+ return {'image_embeds': image_embeds, 'image_feat': image_feat}
+ elif modality == 'texts':
+ # extract text features
+ text_output = self.text_backbone(
+ inputs.input_ids,
+ attention_mask=inputs.attention_mask,
+ token_type_ids=None,
+ return_dict=True,
+ mode='text',
+ )
+ text_embeds = text_output.last_hidden_state
+ text_feat = F.normalize(
+ self.text_neck(text_embeds[:, 0, :]), dim=-1)
+ return {'text_embeds': text_embeds, 'text_feat': text_feat}
+ else:
+ raise RuntimeError(f'Invalid modality "{modality}".')
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Dict[str, torch.tensor]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (dict): A batch of inputs. The input tensor with of
+ at least one modality. For image, the value is a tensor
+ of shape (N, C, ...) in general.
+ For text, the value is a dict of tokenized text inputs.
+ data_samples (Optional[List[DataSample]]):
+ The annotation data of every samples. Defaults to None.
+
+ Returns:
+ Dict[str, torch.tensor]: a dictionary of loss components of
+ both head and multimodal head.
+ """
+ output = self.extract_feat(images, data_samples, return_embeds=True)
+
+ text_ids = output['text_ids']
+ text_attn_mask = output['text_attn_mask']
+ image_embeds = output['image_embeds']
+ image_feat = output['image_feat']
+ text_feat = output['text_feat']
+
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ # get momentum features
+ with torch.no_grad():
+ self._momentum_update()
+ image_embeds_m = self.vision_backbone_m(images)[0]
+ image_feat_m = F.normalize(
+ self.vision_neck_m(image_embeds_m[:, 0, :]), dim=-1)
+
+ text_output_m = self.text_backbone_m(
+ text_ids,
+ attention_mask=text_attn_mask,
+ token_type_ids=None,
+ return_dict=True,
+ mode='text',
+ )
+ text_embeds_m = text_output_m.last_hidden_state
+ text_feat_m = F.normalize(
+ self.text_neck_m(text_embeds_m[:, 0, :]), dim=-1)
+
+ loss = self.head.loss(
+ ([image_feat, text_feat, image_feat_m, text_feat_m], ),
+ data_samples)
+
+ # prepare for itm
+ encoder_input_ids = text_ids.clone()
+ encoder_input_ids[:,
+ 0] = self.tokenizer.additional_special_tokens_ids[0]
+ output_pos = self.text_backbone(
+ encoder_input_ids,
+ attention_mask=text_attn_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ idx = torch.tensor([i.image_id for i in data_samples]).view(-1, 1)
+ bs = idx.size(0)
+ idxs = torch.cat(dist.all_gather(idx))
+ if self.negative_all_rank:
+ # compute sample similarity
+ with torch.no_grad():
+ mask = torch.eq(idx, idxs.t()).to(self.device)
+
+ image_feat_world = torch.cat(dist.all_gather(image_feat))
+ text_feat_world = torch.cat(dist.all_gather(text_feat))
+
+ sim_i2t = image_feat @ text_feat_world.t() / self.temp
+ sim_t2i = text_feat @ image_feat_world.t() / self.temp
+
+ weights_i2t = F.softmax(sim_i2t, dim=1)
+ weights_i2t.masked_fill_(mask, 0)
+
+ weights_t2i = F.softmax(sim_t2i, dim=1)
+ weights_t2i.masked_fill_(mask, 0)
+
+ world_size = dist.get_world_size()
+ if world_size == 1:
+ image_embeds_world = image_embeds
+ else:
+ image_embeds_world = torch.cat(
+ torch_dist.nn.all_gather(image_embeds))
+
+ # select a negative image (from all ranks) for each text
+ image_embeds_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_t2i[b], 1).item()
+ image_embeds_neg.append(image_embeds_world[neg_idx])
+ image_embeds_neg = torch.stack(image_embeds_neg, dim=0)
+
+ # select a negative text (from all ranks) for each image
+ input_ids_world = torch.cat(dist.all_gather(encoder_input_ids))
+ att_mask_world = torch.cat(dist.all_gather(text_attn_mask))
+
+ text_ids_neg = []
+ text_atts_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_i2t[b], 1).item()
+ text_ids_neg.append(input_ids_world[neg_idx])
+ text_atts_neg.append(att_mask_world[neg_idx])
+
+ text_ids_neg = torch.stack(text_ids_neg, dim=0)
+ text_atts_neg = torch.stack(text_atts_neg, dim=0)
+
+ text_ids_all = torch.cat([encoder_input_ids, text_ids_neg], dim=0)
+ text_atts_all = torch.cat([text_attn_mask, text_atts_neg], dim=0)
+
+ image_embeds_all = torch.cat([image_embeds_neg, image_embeds], dim=0)
+ image_atts_all = torch.cat([image_atts, image_atts], dim=0)
+
+ output_neg = self.text_backbone(
+ text_ids_all,
+ attention_mask=text_atts_all,
+ encoder_hidden_states=image_embeds_all,
+ encoder_attention_mask=image_atts_all,
+ return_dict=True,
+ )
+
+ vl_embeddings = torch.cat(
+ [
+ output_pos.last_hidden_state[:, 0, :],
+ output_neg.last_hidden_state[:, 0, :],
+ ],
+ dim=0,
+ )
+
+ # create false data samples
+ data_samples.extend(
+ [DataSample(is_matched=False) for _ in range(2 * bs)])
+ loss_multimodal = self.multimodal_head.loss((vl_embeddings, ),
+ data_samples)
+
+ return dict(ChainMap(loss, loss_multimodal))
+
+ def predict(self, images, data_samples, cal_i2t=True, cal_t2i=True):
+ feats = self.extract_feat(images, data_samples)
+
+ return self.predict_all(
+ feats, data_samples, cal_i2t=cal_i2t, cal_t2i=cal_t2i)
+
+ def predict_all(self,
+ feats,
+ data_samples,
+ num_images=None,
+ num_texts=None,
+ cal_i2t=True,
+ cal_t2i=True):
+ text_ids = feats['text_ids']
+ text_ids[:, 0] = self.tokenizer.additional_special_tokens_ids[0]
+ text_attn_mask = feats['text_attn_mask']
+ image_embeds = feats.get('image_embeds', None)
+ image_feat = feats['image_feat']
+ text_feat = feats['text_feat']
+
+ num_images = num_images or image_feat.size(0)
+ num_texts = num_texts or text_feat.size(0)
+
+ if not self.fast_match:
+ image_embeds_all = all_gather_concat(image_embeds)[:num_images]
+ else:
+ image_embeds_all = None
+ image_feat_all = all_gather_concat(image_feat)[:num_images]
+ text_feat_all = all_gather_concat(text_feat)[:num_texts]
+ text_ids_all = all_gather_concat(text_ids)[:num_texts]
+ text_attn_mask_all = all_gather_concat(text_attn_mask)[:num_texts]
+
+ results = []
+ if cal_i2t:
+ result_i2t = self.compute_score_matrix_i2t(
+ image_feat,
+ image_embeds,
+ text_feat_all,
+ text_ids_all,
+ text_attn_mask_all,
+ )
+ results.append(
+ self._get_predictions(result_i2t, data_samples, mode='i2t'))
+ if cal_t2i:
+ result_t2i = self.compute_score_matrix_t2i(
+ image_feat_all,
+ image_embeds_all,
+ text_feat,
+ text_ids,
+ text_attn_mask,
+ )
+ results.append(
+ self._get_predictions(result_t2i, data_samples, mode='t2i'))
+ return tuple(results)
+
+ def compute_score_matrix_i2t(self, img_feats, img_embeds, text_feats,
+ text_ids, text_atts):
+ """Compare the score matrix for image-to-text retrieval. Every image
+ should compare to all the text features.
+
+ Args:
+ img_feats (torch.Tensor): The input img feats tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ img_embeds (torch.Tensor): The input img embeds tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ text_feats (torch.Tensor): The input text feats tensor with shape
+ (N, C). N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (N, C).
+ text_atts (torch.Tensor): The input tensor with shape (N, C).
+
+ Returns:
+ torch.Tensor: Score matrix of image-to-text retrieval.
+ """
+
+ # compute i2t sim matrix
+ sim_matrix_i2t = img_feats @ text_feats.t()
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_i2t = torch.full((img_feats.size(0), text_feats.size(0)),
+ -100.0).to(self.device)
+ for i in track_on_main_process(
+ range(img_feats.size(0)), 'Compute I2T scores...'):
+ sims = sim_matrix_i2t[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+
+ encoder_output = img_embeds[i].repeat(self.topk, 1, 1)
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ output = self.text_backbone(
+ text_ids[topk_idx],
+ attention_mask=text_atts[topk_idx],
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, 0, :], ))[:, 1]
+ score_matrix_i2t[i, topk_idx] = score + topk_sim
+
+ return score_matrix_i2t
+
+ def compute_score_matrix_t2i(self, img_feats, img_embeds, text_feats,
+ text_ids, text_atts):
+ """Compare the score matrix for text-to-image retrieval. Every text
+ should compare to all the image features.
+
+ Args:
+ img_feats (torch.Tensor): The input img feats tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ img_embeds (torch.Tensor): The input img embeds tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ text_feats (torch.Tensor): The input text feats tensor with shape
+ (N, C). N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (M, C).
+ text_atts (torch.Tensor): The input tensor with shape (M, C).
+
+ Returns:
+ torch.Tensor: Score matrix of text-to-image retrieval.
+ """
+
+ # compute t2i sim matrix
+ sim_matrix_t2i = text_feats @ img_feats.t()
+ if self.fast_match:
+ return sim_matrix_t2i
+
+ score_matrix_t2i = torch.full((text_feats.size(0), img_feats.size(0)),
+ -100.0).to(self.device)
+ for i in track_on_main_process(
+ range(text_feats.size(0)), 'Compute T2I scores...'):
+ sims = sim_matrix_t2i[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+
+ encoder_output = img_embeds[topk_idx]
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ output = self.text_backbone(
+ text_ids[i].repeat(self.topk, 1),
+ attention_mask=text_atts[i].repeat(self.topk, 1),
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, 0, :], ))[:, 1]
+ score_matrix_t2i[i, topk_idx] = score + topk_sim
+
+ return score_matrix_t2i
+
+ def _get_predictions(self,
+ result: torch.Tensor,
+ data_samples: List[DataSample],
+ mode: str = 'i2t'):
+ """Post-process the output of retriever.
+
+ Args:
+ result (torch.Tensor): Score matrix of single retrieve,
+ either from image or text.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+ mode (str): Retrieve mode, either `i2t` for image to text, or `t2i`
+ text to image. Defaults to `i2t`.
+
+ Returns:
+ List[DataSample]: the raw data_samples with
+ the predicted results.
+ """
+
+ # create data sample if not exists
+ if data_samples is None:
+ data_samples = [DataSample() for _ in range(result.size(0))]
+ elif mode == 't2i':
+ # Process data samples to align with the num of texts.
+ new_data_samples = []
+ for sample in data_samples:
+ if isinstance(sample.text, (list, tuple)):
+ texts = sample.text
+ else:
+ texts = [sample.text]
+ for i, text in enumerate(texts):
+ new_sample = DataSample(text=text)
+ if 'gt_image_id' in sample:
+ new_sample.gt_label = sample.gt_image_id[i]
+ new_data_samples.append(new_sample)
+ assert len(new_data_samples) == result.size(0)
+ data_samples = new_data_samples
+ elif mode == 'i2t':
+ for sample in data_samples:
+ if 'gt_text_id' in sample:
+ sample.gt_label = sample.gt_text_id
+ else:
+ raise ValueError(f'Type {mode} is not supported.')
+
+ for data_sample, score in zip(data_samples, result):
+ idx = score.argmax(keepdim=True).detach()
+
+ data_sample.set_pred_score(score)
+ data_sample.set_pred_label(idx)
+ return data_samples
+
+ # TODO: add temperaily
+ @torch.no_grad()
+ def copy_params(self):
+ for model_pair in self.model_pairs:
+ for param, param_m in zip(model_pair[0].parameters(),
+ model_pair[1].parameters()):
+ param_m.data.copy_(param.data) # initialize
+ param_m.requires_grad = False # not update by gradient
+
+ @torch.no_grad()
+ def _momentum_update(self):
+ for model_pair in self.model_pairs:
+ for (name,
+ param), (name_m,
+ param_m) in zip(model_pair[0].named_parameters(),
+ model_pair[1].named_parameters()):
+ # hack to behave the same
+ if any([i in name for i in ['8', '9', '10', '11']
+ ]) and 'layers' in name and any(
+ [i in name for i in ['attn', 'ffn']]):
+ param_m.data = param.data
+ else:
+ param_m.data = param_m.data * self.momentum + \
+ param.data * (1.0 - self.momentum)
diff --git a/mmpretrain/models/multimodal/blip/blip_vqa.py b/mmpretrain/models/multimodal/blip/blip_vqa.py
new file mode 100644
index 00000000000..d0f4e5861b5
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_vqa.py
@@ -0,0 +1,265 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class BlipVQA(BaseModel):
+ """BLIP VQA.
+
+ Args:
+ tokenizer: (dict): The config for tokenizer.
+ vision_backbone (dict): Encoder for extracting image features.
+ multimodal_backbone (dict): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ head (dict): The head module to calculate
+ loss from processed features.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ `MutimodalDataPreprocessor` as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ tokenizer: dict,
+ vision_backbone: dict,
+ multimodal_backbone: dict,
+ head: dict,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipVQA, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.vqa_head = MODELS.build(head)
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+
+ - "loss": For training. Forward and return a dict of losses according
+ to the given inputs and data samples. Note that this method doesn't
+ handle neither back propagation nor optimizer updating, which are
+ done in the :meth:`train_step`.
+ - "predict": For testing. Forward and return a list of data_sample that
+ contains pred_answer for each question.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation data of
+ every samples. Required when ``mode="loss"``. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ - If ``mode="predict"``, return a list of `DataSample`
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract features from the input tensor with shape (N, C, ..).
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+
+ Returns:
+ visual_embeds (Tensor): The output features.
+ """
+ # extract visual feature
+ if images.ndim == 4:
+ visual_embeds = self.vision_backbone(images)[0]
+ elif images.ndim == 5:
+ # [batch, T, C, H, W] -> [batch * T, C, H, W]
+ bs = images.size(0)
+ images = images.reshape(-1, *images.shape[2:])
+ visual_embeds = self.vision_backbone(images)[0]
+ # [batch * num_segs, L, dim] -> [batch, num_segs * L, dim]
+ visual_embeds = visual_embeds.reshape(bs, -1,
+ *visual_embeds.shape[2:])
+ else:
+ raise ValueError(
+ f'Images with {images.ndim} dims is not supported.')
+ return visual_embeds
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
+ """generate train_loss from the input tensor and data_samples.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+ visual_embeds = self.extract_feat(images)
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ questions = []
+ for sample in data_samples:
+ questions.append(sample.get('question'))
+ questions = self.tokenizer(
+ questions, padding='longest', return_tensors='pt').to(self.device)
+
+ questions.input_ids[:, 0] = \
+ self.tokenizer.additional_special_tokens_ids[0]
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ questions.input_ids,
+ attention_mask=questions.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ answer_raw_text = []
+ for sample in data_samples:
+ answer_raw_text.extend(sample.gt_answer)
+ answer = self.tokenizer(
+ answer_raw_text, padding='longest',
+ return_tensors='pt').to(self.device)
+ answer_targets = answer.input_ids.masked_fill(
+ answer.input_ids == self.tokenizer.pad_token_id, -100)
+ for sample in data_samples:
+ # follow BLIP setting, set answer_weight to 0.2 for VG dataset.
+ if not hasattr(sample, 'gt_answer_weight'):
+ sample.gt_answer_weight = torch.tensor([0.2])
+ else:
+ sample.gt_answer_weight = torch.tensor(sample.gt_answer_weight)
+ answer_weight = torch.cat(
+ [sample.gt_answer_weight for sample in data_samples],
+ dim=0).to(self.device)
+ answer_count = torch.tensor(
+ [len(sample.gt_answer) for sample in data_samples]).to(self.device)
+
+ question_states, question_atts = [], []
+ for b, n in enumerate(answer_count):
+ question_states += [multimodal_embeds.last_hidden_state[b]] * n
+ question_atts += [questions.attention_mask[b]] * n
+
+ question_states = torch.stack(question_states, dim=0).to(self.device)
+ question_atts = torch.stack(question_atts, dim=0).to(self.device)
+
+ head_feats = dict(
+ answer_input_ids=answer.input_ids,
+ answer_attention_mask=answer.attention_mask,
+ answer_weight=answer_weight,
+ answer_targets=answer_targets,
+ question_states=question_states,
+ question_atts=question_atts,
+ batch_size=len(data_samples),
+ )
+
+ losses = self.vqa_head.loss(head_feats)
+
+ return losses
+
+ def predict(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ):
+ """update data_samples that contain pred_answer for each question.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+ visual_embeds = self.extract_feat(images)
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ questions = []
+ for sample in data_samples:
+ questions.append(sample.get('question'))
+ questions = self.tokenizer(
+ questions, padding='longest', return_tensors='pt').to(self.device)
+
+ questions.input_ids[:, 0] = \
+ self.tokenizer.additional_special_tokens_ids[0]
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ questions.input_ids,
+ attention_mask=questions.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ if self.vqa_head.inference_method == 'rank':
+ answer_candidates = self.tokenizer(
+ self.vqa_head.answer_list,
+ padding='longest',
+ return_tensors='pt').to(self.device)
+ answer_candidates.input_ids[:, 0] = self.tokenizer.bos_token_id
+ elif self.vqa_head.inference_method == 'generate':
+ answer_candidates = None
+
+ head_feats = dict(
+ multimodal_embeds=multimodal_embeds.last_hidden_state,
+ question_atts=questions.attention_mask,
+ answer_candidates=answer_candidates,
+ bos_token_id=self.tokenizer.bos_token_id,
+ sep_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ )
+
+ if self.vqa_head.inference_method == 'rank':
+ answers = self.vqa_head.predict(head_feats)
+ for answer, data_sample in zip(answers, data_samples):
+ data_sample.pred_answer = answer
+
+ elif self.vqa_head.inference_method == 'generate':
+ outputs = self.vqa_head.predict(head_feats)
+ for output, data_sample in zip(outputs, data_samples):
+ data_sample.pred_answer = self.tokenizer.decode(
+ output, skip_special_tokens=True)
+
+ return data_samples
diff --git a/mmpretrain/models/multimodal/blip/language_model.py b/mmpretrain/models/multimodal/blip/language_model.py
new file mode 100644
index 00000000000..48605a95f60
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/language_model.py
@@ -0,0 +1,1320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# flake8: noqa
+
+import math
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+from torch import Tensor, device
+
+try:
+ from transformers.activations import ACT2FN
+ from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions)
+ from transformers.modeling_utils import (PreTrainedModel,
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ prune_linear_layer)
+ from transformers.models.bert.configuration_bert import BertConfig
+except:
+ ACT2FN = None
+ BaseModelOutputWithPastAndCrossAttentions = None
+ BaseModelOutputWithPoolingAndCrossAttentions = None
+ CausalLMOutputWithCrossAttentions = None
+ PreTrainedModel = None
+ apply_chunking_to_forward = None
+ find_pruneable_heads_and_indices = None
+ prune_linear_layer = None
+ BertConfig = None
+
+from mmpretrain.registry import MODELS
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word and position embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(
+ config.vocab_size,
+ config.hidden_size,
+ padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings,
+ config.hidden_size)
+
+ if config.add_type_embeddings:
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size,
+ config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ 'position_ids',
+ torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+
+ self.config = config
+
+ def forward(
+ self,
+ input_ids=None,
+ token_type_ids=None,
+ position_ids=None,
+ inputs_embeds=None,
+ past_key_values_length=0,
+ ):
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length:
+ seq_length +
+ past_key_values_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ if token_type_ids is not None:
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ else:
+ embeddings = inputs_embeds
+
+ if self.position_embedding_type == 'absolute':
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertPooler(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class BertPreTrainedModel(PreTrainedModel):
+ """An abstract class to handle weights initialization and a simple
+ interface for downloading and loading pretrained models."""
+
+ config_class = BertConfig
+ base_model_prefix = 'bert'
+ _keys_to_ignore_on_load_missing = [r'position_ids']
+
+ def _init_weights(self, module):
+ """Initialize the weights."""
+ if isinstance(module, (nn.Linear, nn.Embedding)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(
+ mean=0.0, std=self.config.initializer_range)
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+
+class BertSelfAttention(nn.Module):
+
+ def __init__(self, config, is_cross_attention):
+ super().__init__()
+ self.config = config
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(
+ config, 'embedding_size'):
+ raise ValueError(
+ 'The hidden size (%d) is not a multiple of the number of attention '
+ 'heads (%d)' %
+ (config.hidden_size, config.num_attention_heads))
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size /
+ config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ if is_cross_attention:
+ self.key = nn.Linear(config.encoder_width, self.all_head_size)
+ self.value = nn.Linear(config.encoder_width, self.all_head_size)
+ else:
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+ if (self.position_embedding_type == 'relative_key'
+ or self.position_embedding_type == 'relative_key_query'):
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(
+ 2 * config.max_position_embeddings - 1,
+ self.attention_head_size)
+ self.save_attention = False
+
+ def save_attn_gradients(self, attn_gradients):
+ self.attn_gradients = attn_gradients
+
+ def get_attn_gradients(self):
+ return self.attn_gradients
+
+ def save_attention_map(self, attention_map):
+ self.attention_map = attention_map
+
+ def get_attention_map(self):
+ return self.attention_map
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (
+ self.num_attention_heads,
+ self.attention_head_size,
+ )
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention:
+ key_layer = self.transpose_for_scores(
+ self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(
+ self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer,
+ key_layer.transpose(-1, -2))
+
+ if (self.position_embedding_type == 'relative_key'
+ or self.position_embedding_type == 'relative_key_query'):
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(
+ seq_length, dtype=torch.long,
+ device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(
+ seq_length, dtype=torch.long,
+ device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(
+ distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(
+ dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == 'relative_key':
+ relative_position_scores = torch.einsum(
+ 'bhld,lrd->bhlr', query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == 'relative_key_query':
+ relative_position_scores_query = torch.einsum(
+ 'bhld,lrd->bhlr', query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum(
+ 'bhrd,lrd->bhlr', key_layer, positional_embedding)
+ attention_scores = (
+ attention_scores + relative_position_scores_query +
+ relative_position_scores_key)
+
+ attention_scores = attention_scores / math.sqrt(
+ self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ if is_cross_attention and self.save_attention:
+ self.save_attention_map(attention_probs)
+ attention_probs.register_hook(self.save_attn_gradients)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs_dropped = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs_dropped = attention_probs_dropped * head_mask
+
+ context_layer = torch.matmul(attention_probs_dropped, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (
+ self.all_head_size, )
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = ((context_layer, attention_probs) if output_attentions else
+ (context_layer, ))
+
+ outputs = outputs + (past_key_value, )
+ return outputs
+
+
+class BertSelfOutput(nn.Module):
+
+ def __init__(self, config, twin=False, merge=False):
+ super().__init__()
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ if twin:
+ self.dense0 = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dense1 = nn.Linear(config.hidden_size, config.hidden_size)
+ else:
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if merge:
+ self.act = ACT2FN[config.hidden_act]
+ self.merge_layer = nn.Linear(config.hidden_size * 2,
+ config.hidden_size)
+ self.merge = True
+ else:
+ self.merge = False
+
+ def forward(self, hidden_states, input_tensor):
+ if type(hidden_states) == list:
+ hidden_states0 = self.dense0(hidden_states[0])
+ hidden_states1 = self.dense1(hidden_states[1])
+ if self.merge:
+ hidden_states = self.merge_layer(
+ torch.cat([hidden_states0, hidden_states1], dim=-1))
+ else:
+ hidden_states = (hidden_states0 + hidden_states1) / 2
+ else:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertAttention(nn.Module):
+
+ def __init__(self, config, is_cross_attention=False, layer_num=-1):
+ super().__init__()
+ is_nlvr = is_cross_attention and getattr(config, 'nlvr', False)
+ if is_nlvr:
+ self.self0 = BertSelfAttention(config, is_nlvr)
+ self.self1 = BertSelfAttention(config, is_nlvr)
+ else:
+ self.self = BertSelfAttention(config, is_cross_attention)
+ self.output = BertSelfOutput(
+ config,
+ twin=is_nlvr,
+ merge=(is_nlvr and layer_num >= 6),
+ )
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads,
+ self.self.num_attention_heads,
+ self.self.attention_head_size,
+ self.pruned_heads,
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(
+ heads)
+ self.self.all_head_size = (
+ self.self.attention_head_size * self.self.num_attention_heads)
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ if type(encoder_hidden_states) == list:
+ self_outputs0 = self.self0(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states[0],
+ encoder_attention_mask[0],
+ past_key_value,
+ output_attentions,
+ )
+ self_outputs1 = self.self1(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states[1],
+ encoder_attention_mask[1],
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(
+ [self_outputs0[0], self_outputs1[0]], hidden_states)
+
+ outputs = (attention_output, ) + self_outputs0[
+ 1:] # add attentions if we output them
+ else:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,
+ ) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertIntermediate(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class BertOutput(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertLayer(nn.Module):
+
+ def __init__(self, config, layer_num):
+ super().__init__()
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = BertAttention(config)
+ self.layer_num = layer_num
+
+ # compatibility for ALBEF and BLIP
+ try:
+ # ALBEF & ALPRO
+ fusion_layer = self.config.fusion_layer
+ add_cross_attention = (
+ fusion_layer <= layer_num and self.config.add_cross_attention)
+
+ self.fusion_layer = fusion_layer
+ except AttributeError:
+ # BLIP
+ self.fusion_layer = self.config.num_hidden_layers
+ add_cross_attention = self.config.add_cross_attention
+
+ # if self.config.add_cross_attention:
+ if self.config.add_cross_attention:
+ self.crossattention = BertAttention(
+ config,
+ is_cross_attention=self.config.add_cross_attention,
+ layer_num=layer_num,
+ )
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ mode=None,
+ ):
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = (
+ past_key_value[:2] if past_key_value is not None else None)
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+
+ # TODO line 482 in albef/models/xbert.py
+ # compatibility for ALBEF and BLIP
+ if mode in ['multimodal', 'fusion'] and hasattr(
+ self, 'crossattention'):
+ assert (
+ encoder_hidden_states is not None
+ ), 'encoder_hidden_states must be given for cross-attention layers'
+
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = (outputs + cross_attention_outputs[1:-1]
+ ) # add cross attentions if we output attention weights
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output,
+ )
+ outputs = (layer_output, ) + outputs
+
+ outputs = outputs + (present_key_value, )
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+class BertEncoder(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList(
+ [BertLayer(config, i) for i in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ mode='multimodal',
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = (() if output_attentions
+ and self.config.add_cross_attention else None)
+
+ next_decoder_cache = () if use_cache else None
+
+ try:
+ # ALBEF
+ fusion_layer = self.config.fusion_layer
+ except AttributeError:
+ # BLIP
+ fusion_layer = self.config.num_hidden_layers
+
+ if mode == 'text':
+ start_layer = 0
+ # output_layer = self.config.fusion_layer
+ output_layer = fusion_layer
+
+ elif mode == 'fusion':
+ # start_layer = self.config.fusion_layer
+ start_layer = fusion_layer
+ output_layer = self.config.num_hidden_layers
+
+ elif mode == 'multimodal':
+ start_layer = 0
+ output_layer = self.config.num_hidden_layers
+
+ # compatibility for ALBEF and BLIP
+ # for i in range(self.config.num_hidden_layers):
+ for i in range(start_layer, output_layer):
+ layer_module = self.layer[i]
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[
+ i] if past_key_values is not None else None
+
+ # TODO pay attention to this.
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ # TODO: logger here
+ # logger.warn(
+ # "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ # )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value,
+ output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ mode=mode,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ mode=mode,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1], )
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (
+ layer_outputs[1], )
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ] if v is not None)
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class BertPredictionHeadTransform(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if isinstance(config.hidden_act, str):
+ self.transform_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.transform_act_fn = config.hidden_act
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.transform_act_fn(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+
+class BertLMPredictionHead(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.transform = BertPredictionHeadTransform(config)
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+
+ self.bias = nn.Parameter(torch.zeros(config.vocab_size))
+
+ # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
+ self.decoder.bias = self.bias
+
+ def forward(self, hidden_states):
+ hidden_states = self.transform(hidden_states)
+ hidden_states = self.decoder(hidden_states)
+ return hidden_states
+
+
+class BertOnlyMLMHead(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.predictions = BertLMPredictionHead(config)
+
+ def forward(self, sequence_output):
+ prediction_scores = self.predictions(sequence_output)
+ return prediction_scores
+
+
+@MODELS.register_module()
+class BertModel(BertPreTrainedModel):
+ """The model can behave as an encoder (with only self-attention) as well as
+ a decoder, in which case a layer of cross-attention is added between the
+ self-attention layers, following the architecture described in `Attention
+ is all you need `__ by Ashish Vaswani,
+ Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N.
+
+ Gomez, Lukasz Kaiser and Illia Polosukhin. argument and
+ :obj:`add_cross_attention` set to :obj:`True`; an
+ :obj:`encoder_hidden_states` is then expected as an input to the forward
+ pass.
+ """
+
+ def __init__(self, config, add_pooling_layer=True):
+ if not isinstance(config, BertConfig):
+ config = BertConfig.from_dict(config)
+
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = BertEmbeddings(config)
+
+ self.encoder = BertEncoder(config)
+
+ self.pooler = BertPooler(config) if add_pooling_layer else None
+
+ self.init_weights()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """Prunes heads of the model.
+
+ heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def get_extended_attention_mask(
+ self,
+ attention_mask: Tensor,
+ input_shape: Tuple[int],
+ device: device,
+ is_decoder: bool,
+ ) -> Tensor:
+ """Makes broadcastable attention and causal masks so that future and
+ masked tokens are ignored.
+
+ Arguments:
+ attention_mask (:obj:`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (:obj:`Tuple[int]`):
+ The shape of the input to the model.
+ device: (:obj:`torch.device`):
+ The device of the input to the model.
+
+ Returns:
+ :obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
+ """
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if is_decoder:
+ batch_size, seq_length = input_shape
+
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = (
+ seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <=
+ seq_ids[None, :, None])
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[
+ 1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones(
+ (batch_size, seq_length, prefix_seq_len),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = (
+ causal_mask[:, None, :, :] *
+ attention_mask[:, None, None, :])
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ 'Wrong shape for input_ids (shape {}) or attention_mask (shape {})'
+ .format(input_shape, attention_mask.shape))
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(
+ dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+ return extended_attention_mask
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ is_decoder=False,
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ if is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both input_ids and inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ batch_size, seq_length = input_shape
+ device = input_ids.device
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = inputs_embeds.device
+ elif encoder_embeds is not None:
+ input_shape = encoder_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = encoder_embeds.device
+ else:
+ raise ValueError(
+ 'You have to specify either input_ids or inputs_embeds or encoder_embeds'
+ )
+
+ # past_key_values_length
+ past_key_values_length = (
+ past_key_values[0][0].shape[2]
+ if past_key_values is not None else 0)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ ((batch_size, seq_length + past_key_values_length)),
+ device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(
+ attention_mask, input_shape, device, is_decoder)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if encoder_hidden_states is not None:
+ if type(encoder_hidden_states) == list:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[
+ 0].size()
+ else:
+ (
+ encoder_batch_size,
+ encoder_sequence_length,
+ _,
+ ) = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size,
+ encoder_sequence_length)
+
+ if type(encoder_attention_mask) == list:
+ encoder_extended_attention_mask = [
+ self.invert_attention_mask(mask)
+ for mask in encoder_attention_mask
+ ]
+ elif encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(
+ encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask,
+ self.config.num_hidden_layers)
+
+ if encoder_embeds is None:
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+ else:
+ embedding_output = encoder_embeds
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ mode=mode,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = (
+ self.pooler(sequence_output) if self.pooler is not None else None)
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+class BaseEncoder(nn.Module):
+ """Base class for primitive encoders, such as ViT, TimeSformer, etc."""
+
+ def __init__(self):
+ super().__init__()
+
+ def forward_features(self, samples, **kwargs):
+ raise NotImplementedError
+
+ @property
+ def device(self):
+ return list(self.parameters())[0].device
+
+
+@MODELS.register_module()
+class XBertEncoder(BertModel, BaseEncoder):
+
+ def __init__(self, med_config, from_pretrained=False):
+
+ med_config = BertConfig.from_dict(med_config)
+ super().__init__(config=med_config, add_pooling_layer=False)
+
+ def forward_automask(self, tokenized_text, visual_embeds, **kwargs):
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ text = tokenized_text
+ text_output = super().forward(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ return text_output
+
+ def forward_text(self, tokenized_text, **kwargs):
+ text = tokenized_text
+ token_type_ids = kwargs.get('token_type_ids', None)
+
+ text_output = super().forward(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ token_type_ids=token_type_ids,
+ return_dict=True,
+ mode='text',
+ )
+
+ return text_output
+
+
+@MODELS.register_module()
+class Linear(torch.nn.Linear):
+ """Wrapper for linear function."""
+
+
+@MODELS.register_module()
+class BertLMHeadModel(BertPreTrainedModel):
+
+ _keys_to_ignore_on_load_unexpected = [r'pooler']
+ _keys_to_ignore_on_load_missing = [
+ r'position_ids', r'predictions.decoder.bias'
+ ]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.bert = BertModel(config, add_pooling_layer=False)
+ self.cls = BertOnlyMLMHead(config)
+
+ self.init_weights()
+
+ def get_output_embeddings(self):
+ return self.cls.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings):
+ self.cls.predictions.decoder = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ labels=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ return_logits=False,
+ is_decoder=True,
+ reduction='mean',
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
+ ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ Returns:
+ Example::
+ >>> from transformers import BertTokenizer,
+ BertLMHeadModel, BertConfig
+ >>> import torch
+ >>> tokenizer = BertTokenizer.from_pretrained(
+ 'bert-base-cased')
+ >>> config = BertConfig.from_pretrained(
+ "bert-base-cased")
+ >>> model = BertLMHeadModel.from_pretrained(
+ 'bert-base-cased', config=config)
+ >>> inputs = tokenizer(
+ "Hello, my dog is cute",
+ return_tensors="pt")
+ >>> outputs = model(**inputs)
+ >>> prediction_logits = outputs.logits
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+ if labels is not None:
+ use_cache = False
+
+ outputs = self.bert(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ is_decoder=is_decoder,
+ mode=mode,
+ )
+
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ if return_logits:
+ return prediction_scores[:, :-1, :].contiguous()
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :
+ -1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = torch.nn.CrossEntropyLoss(
+ reduction=reduction, label_smoothing=0.1)
+ lm_loss = loss_fct(
+ shifted_prediction_scores.view(-1, self.config.vocab_size),
+ labels.view(-1))
+ if reduction == 'none':
+ lm_loss = lm_loss.view(prediction_scores.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (prediction_scores, ) + outputs[2:]
+ return ((lm_loss, ) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ input_ids,
+ past=None,
+ attention_mask=None,
+ **model_kwargs):
+ input_shape = input_ids.shape
+ # if model is used as a decoder in encoder-decoder model,
+ # the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ 'input_ids':
+ input_ids,
+ 'attention_mask':
+ attention_mask,
+ 'past_key_values':
+ past,
+ 'encoder_hidden_states':
+ model_kwargs.get('encoder_hidden_states', None),
+ 'encoder_attention_mask':
+ model_kwargs.get('encoder_attention_mask', None),
+ 'is_decoder':
+ True,
+ }
+
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@MODELS.register_module()
+class XBertLMHeadDecoder(BertLMHeadModel):
+ """This class decouples the decoder forward logic from the VL model.
+
+ In this way, different VL models can share this decoder as long as they
+ feed encoder_embeds as required.
+ """
+
+ def __init__(self, med_config):
+ self.med_config = BertConfig.from_dict(med_config)
+ super(XBertLMHeadDecoder, self).__init__(config=self.med_config)
+
+ def generate_from_encoder(self,
+ tokenized_prompt,
+ visual_embeds,
+ sep_token_id,
+ pad_token_id,
+ use_nucleus_sampling=False,
+ num_beams=3,
+ max_length=30,
+ min_length=10,
+ top_p=0.9,
+ repetition_penalty=1.0,
+ **kwargs):
+
+ if not use_nucleus_sampling:
+ num_beams = num_beams
+ visual_embeds = visual_embeds.repeat_interleave(num_beams, dim=0)
+
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ model_kwargs = {
+ 'encoder_hidden_states': visual_embeds,
+ 'encoder_attention_mask': image_atts,
+ }
+
+ if use_nucleus_sampling:
+ # nucleus sampling
+ outputs = self.generate(
+ input_ids=tokenized_prompt.input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ do_sample=True,
+ top_p=top_p,
+ num_return_sequences=1,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=1.1,
+ **model_kwargs)
+ else:
+ # beam search
+ outputs = self.generate(
+ input_ids=tokenized_prompt.input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ num_beams=num_beams,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=repetition_penalty,
+ **model_kwargs)
+
+ return outputs
diff --git a/mmpretrain/models/multimodal/blip2/Qformer.py b/mmpretrain/models/multimodal/blip2/Qformer.py
new file mode 100644
index 00000000000..2b85f9ee660
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/Qformer.py
@@ -0,0 +1,772 @@
+# flake8: noqa
+"""
+ * Copyright (c) 2023, salesforce.com, inc.
+"""
+from typing import Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import Tensor, device, nn
+from torch.nn import CrossEntropyLoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions)
+from transformers.modeling_utils import apply_chunking_to_forward
+from transformers.models.bert.configuration_bert import BertConfig
+from transformers.utils import logging
+
+from mmpretrain.registry import MODELS
+from ..blip.language_model import (BertAttention, BertIntermediate,
+ BertOnlyMLMHead, BertOutput, BertPooler,
+ BertPreTrainedModel)
+
+logger = logging.get_logger(__name__)
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word and position embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(
+ config.vocab_size,
+ config.hidden_size,
+ padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings,
+ config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ 'position_ids',
+ torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+
+ self.config = config
+
+ def forward(
+ self,
+ input_ids=None,
+ position_ids=None,
+ query_embeds=None,
+ past_key_values_length=0,
+ ):
+ if input_ids is not None:
+ seq_length = input_ids.size()[1]
+ else:
+ seq_length = 0
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length:
+ seq_length +
+ past_key_values_length].clone()
+
+ if input_ids is not None:
+ embeddings = self.word_embeddings(input_ids)
+ if self.position_embedding_type == 'absolute':
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings = embeddings + position_embeddings
+
+ if query_embeds is not None:
+ embeddings = torch.cat((query_embeds, embeddings), dim=1)
+ else:
+ embeddings = query_embeds
+
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertLayer(nn.Module):
+
+ def __init__(self, config, layer_num):
+ super().__init__()
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = BertAttention(config)
+ self.layer_num = layer_num
+ if (self.config.add_cross_attention
+ and layer_num % self.config.cross_attention_freq == 0):
+ self.crossattention = BertAttention(
+ config, is_cross_attention=self.config.add_cross_attention)
+ self.has_cross_attention = True
+ else:
+ self.has_cross_attention = False
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ self.intermediate_query = BertIntermediate(config)
+ self.output_query = BertOutput(config)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ query_length=0,
+ ):
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = (
+ past_key_value[:2] if past_key_value is not None else None)
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:-1]
+
+ present_key_value = self_attention_outputs[-1]
+
+ if query_length > 0:
+ query_attention_output = attention_output[:, :query_length, :]
+
+ if self.has_cross_attention:
+ assert (
+ encoder_hidden_states is not None
+ ), 'encoder_hidden_states must be given for cross-attention layers'
+ cross_attention_outputs = self.crossattention(
+ query_attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ output_attentions=output_attentions,
+ )
+ query_attention_output = cross_attention_outputs[0]
+ outputs = (
+ outputs + cross_attention_outputs[1:-1]
+ ) # add cross attentions if we output attention weights
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk_query,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ query_attention_output,
+ )
+ if attention_output.shape[1] > query_length:
+ layer_output_text = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output[:, query_length:, :],
+ )
+ layer_output = torch.cat([layer_output, layer_output_text],
+ dim=1)
+ else:
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output,
+ )
+ outputs = (layer_output, ) + outputs
+
+ outputs = outputs + (present_key_value, )
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+ def feed_forward_chunk_query(self, attention_output):
+ intermediate_output = self.intermediate_query(attention_output)
+ layer_output = self.output_query(intermediate_output, attention_output)
+ return layer_output
+
+
+class BertEncoder(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList(
+ [BertLayer(config, i) for i in range(config.num_hidden_layers)])
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ query_length=0,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = (() if output_attentions
+ and self.config.add_cross_attention else None)
+
+ next_decoder_cache = () if use_cache else None
+
+ for i in range(self.config.num_hidden_layers):
+ layer_module = self.layer[i]
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[
+ i] if past_key_values is not None else None
+
+ if getattr(self.config, 'gradient_checkpointing',
+ False) and self.training:
+
+ if use_cache:
+ logger.warn(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value,
+ output_attentions, query_length)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ query_length,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1], )
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (
+ layer_outputs[1], )
+ all_cross_attentions = all_cross_attentions + (
+ layer_outputs[2], )
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ] if v is not None)
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class BertModel(BertPreTrainedModel):
+ """The model can behave as an encoder (with only self-attention) as well as
+ a decoder, in which case a layer of cross-attention is added between the
+ self-attention layers, following the architecture described in `Attention
+ is all you need `__ by Ashish Vaswani,
+ Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N.
+
+ Gomez, Lukasz Kaiser and Illia Polosukhin. argument and
+ :obj:`add_cross_attention` set to :obj:`True`; an
+ :obj:`encoder_hidden_states` is then expected as an input to the forward
+ pass.
+ """
+
+ def __init__(self, config, add_pooling_layer=False):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = BertEmbeddings(config)
+
+ self.encoder = BertEncoder(config)
+
+ self.pooler = BertPooler(config) if add_pooling_layer else None
+
+ self.init_weights()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """Prunes heads of the model.
+
+ heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def get_extended_attention_mask(
+ self,
+ attention_mask: Tensor,
+ input_shape: Tuple[int],
+ device: device,
+ is_decoder: bool,
+ has_query: bool = False,
+ ) -> Tensor:
+ """Makes broadcastable attention and causal masks so that future and
+ masked tokens are ignored.
+
+ Arguments:
+ attention_mask (:obj:`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (:obj:`Tuple[int]`):
+ The shape of the input to the model.
+ device: (:obj:`torch.device`):
+ The device of the input to the model.
+
+ Returns:
+ :obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
+ """
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if is_decoder:
+ batch_size, seq_length = input_shape
+
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = (
+ seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <=
+ seq_ids[None, :, None])
+
+ # add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[
+ 1] - causal_mask.shape[1]
+ if has_query: # UniLM style attention mask
+ causal_mask = torch.cat(
+ [
+ torch.zeros(
+ (batch_size, prefix_seq_len, seq_length),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=1,
+ )
+ causal_mask = torch.cat(
+ [
+ torch.ones(
+ (batch_size, causal_mask.shape[1],
+ prefix_seq_len),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+ extended_attention_mask = (
+ causal_mask[:, None, :, :] *
+ attention_mask[:, None, None, :])
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ 'Wrong shape for input_ids (shape {}) or attention_mask (shape {})'
+ .format(input_shape, attention_mask.shape))
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(
+ dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+ return extended_attention_mask
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ query_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ is_decoder=False,
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # use_cache = use_cache if use_cache is not None else self.config.use_cache
+ if input_ids is None:
+ assert (
+ query_embeds is not None
+ ), 'You have to specify query_embeds when input_ids is None'
+
+ # past_key_values_length
+ past_key_values_length = (
+ past_key_values[0][0].shape[2] -
+ self.config.query_length if past_key_values is not None else 0)
+
+ query_length = query_embeds.shape[1] if query_embeds is not None else 0
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ query_embeds=query_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ input_shape = embedding_output.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = embedding_output.device
+
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ ((batch_size, seq_length + past_key_values_length)),
+ device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if is_decoder:
+ extended_attention_mask = self.get_extended_attention_mask(
+ attention_mask,
+ input_ids.shape,
+ device,
+ is_decoder,
+ has_query=(query_embeds is not None),
+ )
+ else:
+ extended_attention_mask = self.get_extended_attention_mask(
+ attention_mask, input_shape, device, is_decoder)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if encoder_hidden_states is not None:
+ if type(encoder_hidden_states) == list:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[
+ 0].size()
+ else:
+ (
+ encoder_batch_size,
+ encoder_sequence_length,
+ _,
+ ) = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size,
+ encoder_sequence_length)
+
+ if type(encoder_attention_mask) == list:
+ encoder_extended_attention_mask = [
+ self.invert_attention_mask(mask)
+ for mask in encoder_attention_mask
+ ]
+ elif encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(
+ encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask,
+ self.config.num_hidden_layers)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ query_length=query_length,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = (
+ self.pooler(sequence_output) if self.pooler is not None else None)
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+class BertLMHeadModel(BertPreTrainedModel):
+
+ _keys_to_ignore_on_load_unexpected = [r'pooler']
+ _keys_to_ignore_on_load_missing = [
+ r'position_ids', r'predictions.decoder.bias'
+ ]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.bert = BertModel(config, add_pooling_layer=False)
+ self.cls = BertOnlyMLMHead(config)
+
+ self.init_weights()
+
+ def get_output_embeddings(self):
+ return self.cls.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings):
+ self.cls.predictions.decoder = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ query_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ labels=None,
+ past_key_values=None,
+ use_cache=True,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ return_logits=False,
+ is_decoder=True,
+ reduction='mean',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
+ ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4
+ tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ Returns:
+ Example::
+ >>> from transformers import BertTokenizer, BertLMHeadModel, BertConfig
+ >>> import torch
+ >>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
+ >>> config = BertConfig.from_pretrained("bert-base-cased")
+ >>> model = BertLMHeadModel.from_pretrained('bert-base-cased', config=config)
+ >>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+ >>> outputs = model(**inputs)
+ >>> prediction_logits = outputs.logits
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+ if labels is not None:
+ use_cache = False
+ if past_key_values is not None:
+ query_embeds = None
+
+ outputs = self.bert(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ query_embeds=query_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ is_decoder=is_decoder,
+ )
+
+ sequence_output = outputs[0]
+ if query_embeds is not None:
+ sequence_output = outputs[0][:, query_embeds.shape[1]:, :]
+ prediction_scores = self.cls(sequence_output)
+
+ if return_logits:
+ return prediction_scores[:, :-1, :].contiguous()
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :
+ -1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = CrossEntropyLoss(
+ reduction=reduction, label_smoothing=0.1)
+ lm_loss = loss_fct(
+ shifted_prediction_scores.view(-1, self.config.vocab_size),
+ labels.view(-1),
+ )
+ if reduction == 'none':
+ lm_loss = lm_loss.view(prediction_scores.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (prediction_scores, ) + outputs[2:]
+ return ((lm_loss, ) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ input_ids,
+ query_embeds,
+ past=None,
+ attention_mask=None,
+ **model_kwargs):
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+ query_mask = input_ids.new_ones(query_embeds.shape[:-1])
+ attention_mask = torch.cat([query_mask, attention_mask], dim=-1)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ 'input_ids':
+ input_ids,
+ 'query_embeds':
+ query_embeds,
+ 'attention_mask':
+ attention_mask,
+ 'past_key_values':
+ past,
+ 'encoder_hidden_states':
+ model_kwargs.get('encoder_hidden_states', None),
+ 'encoder_attention_mask':
+ model_kwargs.get('encoder_attention_mask', None),
+ 'is_decoder':
+ True,
+ }
+
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@MODELS.register_module()
+class Qformer(BertLMHeadModel):
+
+ def __init__(self, model_style: str, vision_model_width: int,
+ add_cross_attention: bool, cross_attention_freq: int,
+ num_query_token: int) -> None:
+
+ config = BertConfig.from_pretrained(model_style)
+ config.add_cross_attention = add_cross_attention
+ config.encoder_width = vision_model_width
+ config.cross_attention_freq = cross_attention_freq
+ config.query_length = num_query_token
+ super().__init__(config)
diff --git a/mmpretrain/models/multimodal/blip2/__init__.py b/mmpretrain/models/multimodal/blip2/__init__.py
new file mode 100644
index 00000000000..b5695f236ca
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .blip2_caption import Blip2Caption
+from .blip2_opt_vqa import Blip2VQA
+from .blip2_retriever import Blip2Retrieval
+from .modeling_opt import OPTForCausalLM
+from .Qformer import Qformer
+
+__all__ = [
+ 'Blip2Caption', 'Blip2Retrieval', 'Blip2VQA', 'OPTForCausalLM', 'Qformer'
+]
diff --git a/mmpretrain/models/multimodal/blip2/blip2_caption.py b/mmpretrain/models/multimodal/blip2/blip2_caption.py
new file mode 100644
index 00000000000..7b409b07acb
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_caption.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+from torch import nn
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class Blip2Caption(BaseModel):
+ """BLIP2 Caption.
+
+ Module for BLIP2 Caption task.
+
+ Args:
+ vision_backbone (dict): The config dict for vision backbone.
+ text_backbone (dict): The config dict for text backbone.
+ multimodal_backbone (dict): The config dict for multimodal backbone.
+ vision_neck (dict): The config dict for vision neck.
+ tokenizer: (Optional[dict]): The config for tokenizer.
+ Defaults to None.
+ prompt (str): Prompt used for training and eval.
+ Defaults to ''.
+ max_txt_len (int): Max text length of input text.
+ num_captions (int): Number of captions to be generated for each image.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type.
+ See :class:`MultiModalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+ _no_split_modules = ['BEiTViT', 'OPTDecoderLayer', 'BertLayer']
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: dict,
+ multimodal_backbone: dict,
+ vision_neck: dict,
+ tokenizer: Optional[dict] = None,
+ prompt: str = '',
+ max_txt_len: int = 20,
+ num_captions: int = 1,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.eos_token_id = self.tokenizer(
+ '\n', add_special_tokens=False).input_ids[0]
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.ln_vision_backbone = nn.LayerNorm(self.vision_backbone.embed_dims)
+
+ self.vision_neck = MODELS.build(vision_neck)
+
+ self.text_backbone = MODELS.build(text_backbone)
+
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.multimodal_backbone.cls = None
+ self.multimodal_backbone.bert.embeddings.word_embeddings = None
+ self.multimodal_backbone.bert.embeddings.position_embeddings = None
+ for layer in self.multimodal_backbone.bert.encoder.layer:
+ layer.output = None
+ layer.intermediate = None
+
+ self.prompt = prompt
+ self.max_txt_len = max_txt_len
+ self.num_captions = num_captions
+ prompt_tokens = self.tokenizer(prompt, return_tensors='pt')
+ self.prompt_length = prompt_tokens.attention_mask.sum(1)
+
+ self.query_tokens = nn.Parameter(
+ torch.zeros(1, self.multimodal_backbone.bert.config.query_length,
+ self.multimodal_backbone.bert.config.hidden_size))
+ self.query_tokens.data.normal_(
+ mean=0.0,
+ std=self.multimodal_backbone.bert.config.initializer_range)
+
+ # freeze the text backbone
+ for _, param in self.text_backbone.named_parameters():
+ param.requires_grad = False
+
+ if hasattr(self, 'register_load_state_dict_post_hook'):
+ self.register_load_state_dict_post_hook(self._ignore_llm_keys_hook)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List] = None,
+ mode: str = 'loss',
+ ) -> List[DataSample]:
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "predict" and "loss":
+
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): pre_processed img tensor (N, C, ...).
+ data_samples (List[DataSample], optional):
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ **kwargs) -> List[DataSample]:
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+
+ # extract image features from
+ image_embeds = self.ln_vision_backbone(self.vision_backbone(images)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1],
+ dtype=torch.long,
+ ).to(images.device)
+
+ # distill image features to query tokens
+ query_tokens = self.query_tokens.expand(image_embeds.size(0), -1, -1)
+ query_outputs = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+ inputs_opt = self.vision_neck([query_outputs.last_hidden_state])
+ attns_opt = torch.ones(
+ inputs_opt.size()[:-1], dtype=torch.long).to(images.device)
+
+ prompt = [self.prompt] * image_embeds.size(0)
+
+ opt_tokens = self.tokenizer(
+ prompt, return_tensors='pt').to(images.device)
+ input_ids = opt_tokens.input_ids
+ attention_mask = torch.cat([attns_opt, opt_tokens.attention_mask],
+ dim=1)
+
+ query_embeds = inputs_opt
+
+ outputs = self.text_backbone.generate(
+ input_ids=input_ids,
+ query_embeds=query_embeds,
+ attention_mask=attention_mask,
+ do_sample=False,
+ top_p=0.9,
+ temperature=1.,
+ num_beams=5,
+ max_new_tokens=self.max_txt_len,
+ min_length=1,
+ eos_token_id=self.eos_token_id,
+ repetition_penalty=1.0,
+ length_penalty=1.0,
+ num_return_sequences=self.num_captions,
+ )
+
+ output_text = self.tokenizer.batch_decode(
+ outputs[:, self.prompt_length:], skip_special_tokens=True)
+ output_text = [text.strip() for text in output_text]
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None for _ in range(len(output_text))]
+
+ for data_sample, decode_token in zip(data_samples, output_text):
+ if data_sample is None:
+ data_sample = DataSample()
+ data_sample.pred_caption = decode_token
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
+
+ @staticmethod
+ def _ignore_llm_keys_hook(module, incompatible_keys):
+ """Avoid warning missing keys of the LLM model."""
+ import re
+ llm_pattern = '^text_backbone'
+ for key in list(incompatible_keys.missing_keys):
+ if re.match(llm_pattern, key):
+ incompatible_keys.missing_keys.remove(key)
diff --git a/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py b/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py
new file mode 100644
index 00000000000..20e439fa826
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+
+from mmpretrain.registry import MODELS
+from mmpretrain.structures import DataSample
+from .blip2_caption import Blip2Caption
+
+
+@MODELS.register_module()
+class Blip2VQA(Blip2Caption):
+ """BLIP2 VQA.
+
+ Module for BLIP2 VQA task. For more details about the initialization
+ params, please refer to :class:`Blip2Caption`.
+ """
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ **kwargs) -> List[DataSample]:
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ questions = [d.question for d in data_samples]
+
+ # extract image features from
+ image_embeds = self.ln_vision_backbone(self.vision_backbone(images)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1],
+ dtype=torch.long,
+ ).to(images.device)
+
+ # distill image features to query tokens
+ query_tokens = self.query_tokens.expand(image_embeds.size(0), -1, -1)
+ query_outputs = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+ inputs_opt = self.vision_neck([query_outputs.last_hidden_state])
+ attns_opt = torch.ones(
+ inputs_opt.size()[:-1], dtype=torch.long).to(images.device)
+
+ prompt = [self.prompt.format(q) for q in questions]
+
+ # use left padding
+ self.tokenizer.padding_side = 'left'
+
+ opt_tokens = self.tokenizer(
+ prompt, return_tensors='pt', padding='longest').to(images.device)
+ input_ids = opt_tokens.input_ids
+ attention_mask = torch.cat([attns_opt, opt_tokens.attention_mask],
+ dim=1)
+
+ inputs_embeds = self.text_backbone.model.decoder.embed_tokens(
+ input_ids)
+ inputs_embeds = torch.cat([inputs_opt, inputs_embeds], dim=1)
+
+ outputs = self.text_backbone.generate(
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ do_sample=False,
+ num_beams=5,
+ max_new_tokens=self.max_txt_len,
+ min_length=1,
+ eos_token_id=self.eos_token_id,
+ length_penalty=-1.0,
+ )
+
+ output_text = self.tokenizer.batch_decode(
+ outputs, skip_special_tokens=True)
+ output_text = [text.strip() for text in output_text]
+
+ out_data_samples = []
+ for data_sample, decode_token in zip(data_samples, output_text):
+ data_sample.pred_answer = decode_token
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/blip2/blip2_retriever.py b/mmpretrain/models/multimodal/blip2/blip2_retriever.py
new file mode 100644
index 00000000000..e626404a4cd
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_retriever.py
@@ -0,0 +1,505 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import mmengine.dist as dist
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.utils import track_iter_progress
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from ..blip.blip_retrieval import BlipRetrieval, all_gather_concat
+
+
+@MODELS.register_module()
+class Blip2Retrieval(BlipRetrieval):
+ """BLIP2 Retriever.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features.
+ vision_neck (Optional[dict]): The neck module to process image features
+ from vision backbone. Defaults to None.
+ text_neck (Optional[dict]): The neck module to process text features
+ from text backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed single modality features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ multimodal_head (Optional[Union[List[dict], dict]]): The multi-modal
+ head module to calculate loss from processed multimodal features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ tokenizer (Optional[dict]): The config for tokenizer. Defaults to None.
+ temperature (float): Temperature parameter that controls the
+ concentration level of the distribution. Defaults to 0.07.
+ fast_match (bool): If False, select topk similarity as candidates and
+ compute the matching score. If True, return the similarity as the
+ matching score directly. Defaults to False.
+ topk (int): Select topk similarity as candidates for compute matching
+ scores. Notice that this is not the topk in evaluation.
+ Defaults to 256.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type.
+ See :class:`MultiModalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: Optional[dict] = None,
+ multimodal_backbone: Optional[dict] = None,
+ vision_neck: Optional[dict] = None,
+ text_neck: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ multimodal_head: Optional[Union[List[dict], dict]] = None,
+ tokenizer: Optional[dict] = None,
+ temperature: float = 0.07,
+ fast_match: bool = False,
+ topk: int = 256,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ # Skip BlipRetrieval init
+ super(BlipRetrieval, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.ln_vision_backbone = nn.LayerNorm(self.vision_backbone.embed_dims)
+ self.tokenizer = TOKENIZER.build(tokenizer)
+
+ if text_backbone is not None:
+ self.text_backbone = MODELS.build(text_backbone)
+
+ if multimodal_backbone is not None:
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.multimodal_backbone.resize_token_embeddings(
+ len(self.tokenizer))
+ self.query_tokens = nn.Parameter(
+ torch.zeros(1, self.multimodal_backbone.bert.config.query_length,
+ self.multimodal_backbone.bert.config.hidden_size))
+ self.query_tokens.data.normal_(
+ mean=0.0,
+ std=self.multimodal_backbone.bert.config.initializer_range)
+
+ if vision_neck is not None:
+ self.vision_neck = MODELS.build(vision_neck)
+
+ if text_neck is not None:
+ self.text_neck = MODELS.build(text_neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+
+ if multimodal_head is not None:
+ self.multimodal_head = MODELS.build(multimodal_head)
+
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+
+ # Notice that this topk is used for select k candidate to compute
+ # image-text score, but not the final metric topk in evaluation.
+ self.fast_match = fast_match
+ self.topk = topk
+
+ def _extract_feat(self, inputs: Union[torch.Tensor, dict],
+ modality: str) -> Tuple[torch.Tensor]:
+ """Extract features from the single modality.
+ Args:
+ inputs (Union[torch.Tensor, dict]): A batch of inputs.
+ For image, a tensor of shape (N, C, ...) in general.
+ For text, a dict of tokenized text inputs.
+ modality (str): Modality feature to be extracted. Only two
+ options are supported.
+
+ - ``images``: Only extract image features, mostly used for
+ inference.
+ - ``texts``: Only extract text features, mostly used for
+ inference.
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ """
+ if modality == 'images':
+ # extract image features
+ # TODO:
+ # Add layernorm inside backbone and handle the concat outside
+ image_embeds = self.ln_vision_backbone(
+ self.vision_backbone(inputs)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1,
+ -1)
+ query_output = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ use_cache=True,
+ return_dict=True,
+ )
+ image_feat = F.normalize(
+ self.vision_neck([query_output.last_hidden_state]), dim=-1)
+ return {
+ 'image_embeds': image_embeds,
+ 'image_feat': image_feat,
+ 'query_output': query_output
+ }
+ elif modality == 'texts':
+ # extract text features
+ text_output = self.multimodal_backbone.bert(
+ inputs.input_ids,
+ attention_mask=inputs.attention_mask,
+ return_dict=True,
+ )
+ text_embeds = text_output.last_hidden_state
+ text_feat = F.normalize(
+ self.text_neck([text_embeds[:, 0, :]]), dim=-1)
+ return {'text_embeds': text_embeds, 'text_feat': text_feat}
+ else:
+ raise RuntimeError(f'Invalid modality "{modality}".')
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Dict[str, torch.tensor]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (dict): A batch of inputs. The input tensor with of
+ at least one modality. For image, the value is a tensor
+ of shape (N, C, ...) in general.
+ For text, the value is a dict of tokenized text inputs.
+ data_samples (Optional[List[DataSample]]):
+ The annotation data of every samples. Defaults to None.
+
+ Returns:
+ Dict[str, torch.tensor]: a dictionary of loss components of
+ both head and multimodal head.
+ """
+ output = self.extract_feat(images, data_samples)
+
+ text_ids = output['text_ids']
+ text_attn_mask = output['text_attn_mask']
+ image_embeds = output['image_embeds']
+ image_feat = output['image_feat']
+ text_feat = output['text_feat']
+ query_output = output['query_output']
+
+ # ITC Loss
+ # B*world_size, num_query, D
+ image_feat_all = torch.cat(dist.all_gather(image_feat))
+ # B*world_size, D
+ text_feat_all = torch.cat(dist.all_gather(text_feat))
+
+ # B, B*world_size, num_query
+ sim_q2t = torch.matmul(
+ image_feat.unsqueeze(1), text_feat_all.unsqueeze(-1)).squeeze()
+
+ # image to text similarity
+ sim_i2t, _ = sim_q2t.max(-1)
+ sim_i2t = sim_i2t / self.temp
+
+ # B, B*world_size, num_query
+ sim_t2q = torch.matmul(
+ text_feat.unsqueeze(1).unsqueeze(1),
+ image_feat_all.permute(0, 2, 1)).squeeze()
+
+ # text-image similarity
+ sim_t2i, _ = sim_t2q.max(-1)
+ sim_t2i = sim_t2i / self.temp
+
+ rank = dist.get_rank()
+ bs = images.size(0)
+ targets = torch.linspace(
+ rank * bs, rank * bs + bs - 1, bs, dtype=int).to(self.device)
+
+ itc_loss = (F.cross_entropy(sim_i2t, targets, label_smoothing=0.1) +
+ F.cross_entropy(sim_t2i, targets, label_smoothing=0.1)) / 2
+
+ # prepare for itm
+ text_input_ids_world = torch.cat(dist.all_gather(text_ids))
+ text_attention_mask_world = torch.cat(dist.all_gather(text_attn_mask))
+ image_embeds_world = torch.cat(dist.all_gather(image_embeds))
+ with torch.no_grad():
+ weights_t2i = F.softmax(sim_t2i, dim=1) + 1e-4
+ weights_t2i[:, rank * bs:rank * bs + bs].fill_diagonal_(0)
+ weights_i2t = F.softmax(sim_i2t, dim=1) + 1e-4
+ weights_i2t[:, rank * bs:rank * bs + bs].fill_diagonal_(0)
+
+ # select a negative image for each text
+ image_embeds_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_t2i[b], 1).item()
+ image_embeds_neg.append(image_embeds_world[neg_idx])
+ image_embeds_neg = torch.stack(image_embeds_neg, dim=0)
+
+ # select a negative text for each image
+ text_ids_neg = []
+ text_atts_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_i2t[b], 1).item()
+ text_ids_neg.append(text_input_ids_world[neg_idx])
+ text_atts_neg.append(text_attention_mask_world[neg_idx])
+
+ text_ids_neg = torch.stack(text_ids_neg, dim=0)
+ text_atts_neg = torch.stack(text_atts_neg, dim=0)
+
+ text_ids_all = torch.cat([text_ids, text_ids, text_ids_neg],
+ dim=0) # pos, pos, neg
+ text_atts_all = torch.cat(
+ [text_attn_mask, text_attn_mask, text_atts_neg],
+ dim=0,
+ )
+
+ query_tokens_itm = self.query_tokens.expand(text_ids_all.shape[0], -1,
+ -1)
+ query_atts_itm = torch.ones(
+ query_tokens_itm.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask_all = torch.cat([query_atts_itm, text_atts_all], dim=1)
+
+ image_embeds_all = torch.cat(
+ [image_embeds, image_embeds_neg, image_embeds],
+ dim=0) # pos, neg, pos
+ image_atts_all = torch.ones(
+ image_embeds_all.size()[:-1], dtype=torch.long).to(self.device)
+
+ output_itm = self.multimodal_backbone.bert(
+ text_ids_all,
+ query_embeds=query_tokens_itm,
+ attention_mask=attention_mask_all,
+ encoder_hidden_states=image_embeds_all,
+ encoder_attention_mask=image_atts_all,
+ return_dict=True,
+ )
+
+ vl_embeddings = output_itm.last_hidden_state[:, :query_tokens_itm.
+ size(1), :]
+
+ # create false data samples
+ data_samples.extend(
+ [DataSample(is_matched=False) for _ in range(2 * bs)])
+ loss_multimodal = self.multimodal_head.loss((vl_embeddings, ),
+ data_samples)
+
+ # LM loss
+ decoder_input_ids = text_ids.clone()
+ decoder_input_ids[:, 0] = self.tokenizer.bos_token_id
+ labels = decoder_input_ids.masked_fill(
+ decoder_input_ids == self.tokenizer.pad_token_id, -100)
+
+ query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat([query_atts, text_attn_mask], dim=1)
+ lm_output = self.multimodal_backbone(
+ decoder_input_ids,
+ attention_mask=attention_mask,
+ past_key_values=query_output.past_key_values,
+ return_dict=True,
+ labels=labels,
+ )
+
+ return dict(
+ itc_loss=itc_loss, **loss_multimodal, lm_loss=lm_output.loss)
+
+ def predict_all(self,
+ feats: Dict[str, torch.Tensor],
+ data_samples: List[DataSample],
+ num_images: int = None,
+ num_texts: int = None,
+ cal_i2t: bool = True,
+ cal_t2i: bool = True) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Compute similarity matrix between images and texts across all ranks.
+
+ Args:
+ feats (Dict[str, torch.Tensor]): Features from the current rank.
+ data_samples (List[DataSample]): Data samples from the current
+ rank.
+ num_images (int, optional): Number of images to use.
+ Defaults to None.
+ num_texts (int, optional): Number of texts to use.
+ Defaults to None.
+ cal_i2t (bool, optional): Whether to compute image-to-text
+ similarity. Defaults to True.
+ cal_t2i (bool, optional): Whether to compute text-to-image
+ similarity. Defaults to True.
+
+ Returns:
+ Tuple[torch.Tensor, torch.Tensor]: Image-to-text and text-to-image
+ similarity matrices.
+ """
+ text_ids = feats['text_ids']
+ text_attn_mask = feats['text_attn_mask']
+ image_embeds = feats.get('image_embeds', None)
+ image_feat = feats['image_feat']
+ text_feat = feats['text_feat']
+
+ num_images = num_images or image_feat.size(0)
+ num_texts = num_texts or text_feat.size(0)
+
+ if not self.fast_match:
+ image_embeds_all = all_gather_concat(image_embeds)[:num_images]
+ else:
+ image_embeds_all = None
+ image_feat_all = all_gather_concat(image_feat)[:num_images]
+ text_feat_all = all_gather_concat(text_feat)[:num_texts]
+ text_ids_all = all_gather_concat(text_ids)[:num_texts]
+ text_attn_mask_all = all_gather_concat(text_attn_mask)[:num_texts]
+
+ results = []
+ if cal_i2t:
+ result_i2t = self.compute_score_matrix_i2t(
+ image_feat,
+ image_embeds,
+ text_feat_all,
+ text_ids_all,
+ text_attn_mask_all,
+ )
+ results.append(
+ self._get_predictions(result_i2t, data_samples, mode='i2t'))
+ if cal_t2i:
+ result_t2i = self.compute_score_matrix_t2i(
+ image_feat_all,
+ image_embeds_all,
+ text_feat,
+ text_ids,
+ text_attn_mask,
+ )
+ results.append(
+ self._get_predictions(result_t2i, data_samples, mode='t2i'))
+ return tuple(results)
+
+ def compute_score_matrix_i2t(self, img_feats: torch.Tensor,
+ img_embeds: List[torch.Tensor],
+ text_feats: torch.Tensor,
+ text_ids: torch.Tensor,
+ text_atts: torch.Tensor) -> torch.Tensor:
+ """Compare the score matrix for image-to-text retrieval. Every image
+ should compare to all the text features.
+
+ Args:
+ img_feats (torch.Tensor): The input tensor with shape (M, C).
+ M stands for numbers of samples on a single GPU.
+ img_embeds (List[torch.Tensor]): Image features from each layer of
+ the vision backbone.
+ text_feats (torch.Tensor): The input tensor with shape (N, C).
+ N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (N, C).
+ text_atts (torch.Tensor): The input tensor with shape (N, C).
+
+ Returns:
+ torch.Tensor: Score matrix of image-to-text retrieval.
+ """
+
+ # compute i2t sim matrix
+ # TODO: check correctness
+ sim_matrix_i2t, _ = (img_feats @ text_feats.t()).max(1)
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_i2t = torch.full((img_feats.size(0), text_feats.size(0)),
+ -100.0).to(self.device)
+
+ for i in track_iter_progress(range(img_feats.size(0))):
+ sims = sim_matrix_i2t[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+ # get repeated image embeddings
+ encoder_output = img_embeds[i].repeat(self.topk, 1, 1)
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ # query embeds and attention masks
+ query_tokens = self.query_tokens.expand(encoder_output.shape[0],
+ -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat([query_atts, text_atts[topk_idx]],
+ dim=1)
+ output = self.multimodal_backbone.bert(
+ text_ids[topk_idx],
+ query_embeds=query_tokens,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, :query_tokens.size(1), :],
+ ))[:, :, 1].mean(dim=1)
+ score_matrix_i2t[i, topk_idx] = score + topk_sim
+
+ return score_matrix_i2t
+
+ def compute_score_matrix_t2i(self, img_feats: torch.Tensor,
+ img_embeds: List[torch.Tensor],
+ text_feats: torch.Tensor,
+ text_ids: torch.Tensor,
+ text_atts: torch.Tensor) -> torch.Tensor:
+ """Compare the score matrix for text-to-image retrieval.
+
+ Every text should compare to all the image features.
+
+ Args:
+ img_feats (torch.Tensor): The input tensor with shape (N, C).
+ N stands for numbers of all samples on all GPUs.
+ img_embeds (List[torch.Tensor]): Image features from each layer of
+ the vision backbone.
+ text_feats (torch.Tensor): The input tensor with shape (M, C).
+ M stands for numbers of samples on a single GPU.
+ text_ids (torch.Tensor): The input tensor with shape (M, C).
+ text_atts (torch.Tensor): The input tensor with shape (M, C).
+
+ Returns:
+ torch.Tensor: Score matrix of text-to-image retrieval.
+ """
+
+ # compute t2i sim matrix
+ # TODO: check correctness
+ sim_matrix_i2t, _ = (img_feats @ text_feats.t()).max(1)
+ sim_matrix_t2i = sim_matrix_i2t.t()
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_t2i = torch.full((text_feats.size(0), img_feats.size(0)),
+ -100.0).to(self.device)
+
+ for i in track_iter_progress(range(text_feats.size(0))):
+ sims = sim_matrix_t2i[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+ # get topk image embeddings
+ encoder_output = img_embeds[topk_idx]
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ # get query embeds and attention masks
+ query_tokens = self.query_tokens.expand(encoder_output.shape[0],
+ -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat(
+ [query_atts, text_atts[i].repeat(self.topk, 1)], dim=1)
+ output = self.multimodal_backbone.bert(
+ text_ids[i].repeat(self.topk, 1),
+ query_embeds=query_tokens,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, :query_tokens.size(1), :],
+ ))[:, :, 1].mean(dim=1)
+ score_matrix_t2i[i, topk_idx] = score + topk_sim
+
+ return score_matrix_t2i
diff --git a/mmpretrain/models/multimodal/blip2/modeling_opt.py b/mmpretrain/models/multimodal/blip2/modeling_opt.py
new file mode 100644
index 00000000000..7cde0d76a20
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/modeling_opt.py
@@ -0,0 +1,1083 @@
+# flake8: noqa
+# Copyright 2022 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch OPT model."""
+import random
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (BaseModelOutputWithPast,
+ CausalLMOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.utils import (add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward, logging,
+ replace_return_docstrings)
+
+from mmpretrain.models.utils import register_hf_model
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = 'facebook/opt-350m'
+_CONFIG_FOR_DOC = 'OPTConfig'
+_TOKENIZER_FOR_DOC = 'GPT2Tokenizer'
+
+# Base model docstring
+_EXPECTED_OUTPUT_SHAPE = [1, 8, 1024]
+
+OPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ 'facebook/opt-125m',
+ 'facebook/opt-350m',
+ 'facebook/opt-1.3b',
+ 'facebook/opt-2.7b',
+ 'facebook/opt-6.7b',
+ 'facebook/opt-13b',
+ 'facebook/opt-30b',
+ # See all OPT models at https://huggingface.co/models?filter=opt
+]
+
+
+def _make_causal_mask(input_ids_shape: torch.Size,
+ dtype: torch.dtype,
+ past_key_values_length: int = 0):
+ """Make causal mask used for bi-directional self-attention."""
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min))
+ mask_cond = torch.arange(mask.size(-1))
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat(
+ [torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask],
+ dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len,
+ tgt_len + past_key_values_length)
+
+
+def _expand_mask(mask: torch.Tensor,
+ dtype: torch.dtype,
+ tgt_len: Optional[int] = None):
+ """Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len,
+ src_seq_len]`."""
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len,
+ src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(
+ inverted_mask.to(torch.bool),
+ torch.finfo(dtype).min)
+
+
+class OPTLearnedPositionalEmbedding(nn.Embedding):
+ """This module learns positional embeddings up to a fixed maximum size."""
+
+ def __init__(self, num_embeddings: int, embedding_dim: int):
+ # OPT is set up so that if padding_idx is specified then offset the embedding ids by 2
+ # and adjust num_embeddings appropriately. Other models don't have this hack
+ self.offset = 2
+ super().__init__(num_embeddings + self.offset, embedding_dim)
+
+ def forward(self,
+ attention_mask: torch.LongTensor,
+ past_key_values_length: int = 0):
+ """`input_ids_shape` is expected to be [bsz x seqlen]."""
+ attention_mask = attention_mask.long()
+
+ # create positions depending on attention_mask
+ positions = (
+ torch.cumsum(attention_mask, dim=1).type_as(attention_mask) *
+ attention_mask).long() - 1
+
+ # cut positions if `past_key_values_length` is > 0
+ positions = positions[:, past_key_values_length:]
+
+ return super().forward(positions + self.offset)
+
+
+class OPTAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper."""
+
+ def __init__(
+ self,
+ embed_dim: int,
+ num_heads: int,
+ dropout: float = 0.0,
+ is_decoder: bool = False,
+ bias: bool = True,
+ ):
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.dropout = dropout
+ self.head_dim = embed_dim // num_heads
+
+ if (self.head_dim * num_heads) != self.embed_dim:
+ raise ValueError(
+ f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}'
+ f' and `num_heads`: {num_heads}).')
+ self.scaling = self.head_dim**-0.5
+ self.is_decoder = is_decoder
+
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return (tensor.view(bsz, seq_len, self.num_heads,
+ self.head_dim).transpose(1, 2).contiguous())
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel."""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scaling
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len,
+ bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is'
+ f' {attn_weights.size()}')
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}'
+ )
+ attn_weights = (
+ attn_weights.view(bsz, self.num_heads, tgt_len, src_len) +
+ attention_mask)
+ attn_weights = torch.max(
+ attn_weights,
+ torch.tensor(torch.finfo(attn_weights.dtype).min))
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len,
+ src_len)
+
+ # upcast to fp32 if the weights are in fp16. Please see https://github.com/huggingface/transformers/pull/17437
+ if attn_weights.dtype == torch.float16:
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(torch.float16)
+ else:
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads, ):
+ raise ValueError(
+ f'Head mask for a single layer should be of size {(self.num_heads,)}, but is'
+ f' {layer_head_mask.size()}')
+ attn_weights = layer_head_mask.view(
+ 1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len,
+ src_len)
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len,
+ src_len)
+
+ if output_attentions:
+ # this operation is a bit awkward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to be reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads,
+ tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads,
+ tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(
+ attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len,
+ self.head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len,
+ self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned aross GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped, past_key_value
+
+
+class OPTDecoderLayer(nn.Module):
+
+ def __init__(self, config: OPTConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = OPTAttention(
+ embed_dim=self.embed_dim,
+ num_heads=config.num_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ )
+ self.do_layer_norm_before = config.do_layer_norm_before
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.fc1 = nn.Linear(self.embed_dim, config.ffn_dim)
+ self.fc2 = nn.Linear(config.ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(
+ hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ hidden_states_shape = hidden_states.shape
+ hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(
+ hidden_states, p=self.dropout, training=self.training)
+
+ hidden_states = (residual + hidden_states).view(hidden_states_shape)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ return outputs
+
+
+OPT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`OPTConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare OPT Model outputting raw hidden-states without any specific head on top.',
+ OPT_START_DOCSTRING,
+)
+class OPTPreTrainedModel(PreTrainedModel):
+
+ config_class = OPTConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['OPTDecoderLayer']
+ _keys_to_ignore_on_load_unexpected = [r'decoder\.version']
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (OPTDecoder)):
+ module.gradient_checkpointing = value
+
+
+OPT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`GPT2Tokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+class OPTDecoder(OPTPreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`OPTDecoderLayer`]
+
+ Args:
+ config: OPTConfig
+ """
+
+ def __init__(self, config: OPTConfig):
+ super().__init__(config)
+ self.dropout = config.dropout
+ self.layerdrop = config.layerdrop
+ self.padding_idx = config.pad_token_id
+ self.max_target_positions = config.max_position_embeddings
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size,
+ config.word_embed_proj_dim,
+ self.padding_idx)
+ self.embed_positions = OPTLearnedPositionalEmbedding(
+ config.max_position_embeddings, config.hidden_size)
+
+ if config.word_embed_proj_dim != config.hidden_size:
+ self.project_out = nn.Linear(
+ config.hidden_size, config.word_embed_proj_dim, bias=False)
+ else:
+ self.project_out = None
+
+ if config.word_embed_proj_dim != config.hidden_size:
+ self.project_in = nn.Linear(
+ config.word_embed_proj_dim, config.hidden_size, bias=False)
+ else:
+ self.project_in = None
+
+ # Note that the only purpose of `config._remove_final_layer_norm` is to keep backward compatibility
+ # with checkpoints that have been fine-tuned before transformers v4.20.1
+ # see https://github.com/facebookresearch/metaseq/pull/164
+ if config.do_layer_norm_before and not config._remove_final_layer_norm:
+ self.final_layer_norm = nn.LayerNorm(config.hidden_size)
+ else:
+ self.final_layer_norm = None
+
+ self.layers = nn.ModuleList(
+ [OPTDecoderLayer(config) for _ in range(config.num_hidden_layers)])
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape,
+ inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ past_key_values_length=past_key_values_length,
+ ).to(inputs_embeds.device)
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(
+ attention_mask, inputs_embeds.dtype,
+ tgt_len=input_shape[-1]).to(inputs_embeds.device)
+ combined_attention_mask = (
+ expanded_attn_mask if combined_attention_mask is None else
+ expanded_attn_mask + combined_attention_mask)
+
+ return combined_attention_mask
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
+ provide it.
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(num_hidden_layers, num_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
+ cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
+ that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
+ all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError(
+ 'You have to specify either decoder_input_ids or decoder_inputs_embeds'
+ )
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if query_embeds is not None:
+ inputs_embeds = torch.cat([query_embeds, inputs_embeds], dim=1)
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ input_shape = (batch_size, seq_length)
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ inputs_embeds.shape[:2],
+ dtype=torch.bool,
+ device=inputs_embeds.device)
+ pos_embeds = self.embed_positions(attention_mask,
+ past_key_values_length)
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past),
+ dtype=torch.bool,
+ device=inputs_embeds.device)
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, input_shape, inputs_embeds, past_key_values_length)
+
+ if self.project_in is not None:
+ inputs_embeds = self.project_in(inputs_embeds)
+
+ hidden_states = inputs_embeds + pos_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ # check if head_mask has a correct number of layers specified if desired
+ for attn_mask, mask_name in zip([head_mask], ['head_mask']):
+ if attn_mask is not None:
+ if attn_mask.size()[0] != (len(self.layers)):
+ raise ValueError(
+ f'The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for'
+ f' {head_mask.size()[0]}.')
+
+ for idx, decoder_layer in enumerate(self.layers):
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ dropout_probability = random.uniform(0, 1)
+ if self.training and (dropout_probability < self.layerdrop):
+ continue
+
+ past_key_value = (
+ past_key_values[idx] if past_key_values is not None else None)
+
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ logger.warning(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ head_mask[idx] if head_mask is not None else None,
+ None,
+ )
+ else:
+
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=(head_mask[idx]
+ if head_mask is not None else None),
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (
+ layer_outputs[2 if output_attentions else 1], )
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ if self.final_layer_norm is not None:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if self.project_out is not None:
+ hidden_states = self.project_out(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(
+ v for v in
+ [hidden_states, next_cache, all_hidden_states, all_self_attns]
+ if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+@add_start_docstrings(
+ 'The bare OPT Model outputting raw hidden-states without any specific head on top.',
+ OPT_START_DOCSTRING,
+)
+class OPTModel(OPTPreTrainedModel):
+
+ def __init__(self, config: OPTConfig):
+ super().__init__(config)
+ self.decoder = OPTDecoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.decoder.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.decoder.embed_tokens = value
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(OPT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_TOKENIZER_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPast,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
+ decoder_outputs = self.decoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ query_embeds=query_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ return decoder_outputs
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ hidden_states=decoder_outputs.hidden_states,
+ attentions=decoder_outputs.attentions,
+ )
+
+
+@register_hf_model()
+class OPTForCausalLM(OPTPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r'lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = OPTModel(config)
+
+ # the lm_head weight is automatically tied to the embed tokens weight
+ self.lm_head = nn.Linear(
+ config.word_embed_proj_dim, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.decoder.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.decoder.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model.decoder = decoder
+
+ def get_decoder(self):
+ return self.model.decoder
+
+ @replace_return_docstrings(
+ output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ reduction: Optional[str] = 'mean',
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
+ provide it.
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(num_hidden_layers, num_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
+ shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`. The two additional
+ tensors are only required when the model is used as a decoder in a Sequence to Sequence model.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
+ cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
+ that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
+ all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import GPT2Tokenizer, OPTForCausalLM
+
+ >>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
+ >>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
+
+ >>> prompt = "Hey, are you consciours? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
+ ```"""
+
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model.decoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ query_embeds=query_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ logits = self.lm_head(outputs[0]).contiguous()
+
+ loss = None
+ if labels is not None:
+ logits = logits[:, -labels.size(1):, :]
+
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss(reduction=reduction)
+ loss = loss_fct(
+ shift_logits.view(-1, self.config.vocab_size),
+ shift_labels.view(-1))
+ if reduction == 'none':
+ loss = loss.view(shift_logits.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids=None,
+ inputs_embeds=None,
+ query_embeds=None,
+ past_key_values=None,
+ attention_mask=None,
+ use_cache=None,
+ **kwargs,
+ ):
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ if input_ids is not None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+ if past_key_values:
+ input_ids = input_ids[:, -1:]
+ query_embeds = None
+ # first step, decoder_cached_states are empty
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'query_embeds': query_embeds,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'use_cache': use_cache,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
diff --git a/mmpretrain/models/multimodal/flamingo/__init__.py b/mmpretrain/models/multimodal/flamingo/__init__.py
new file mode 100644
index 00000000000..e0bfd63b657
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .adapter import FlamingoLMAdapter
+from .flamingo import Flamingo
+
+__all__ = ['Flamingo', 'FlamingoLMAdapter']
diff --git a/mmpretrain/models/multimodal/flamingo/adapter.py b/mmpretrain/models/multimodal/flamingo/adapter.py
new file mode 100644
index 00000000000..69a635c2ecd
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/adapter.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+
+import torch.nn as nn
+
+from mmpretrain.registry import MODELS
+from .modules import FlamingoLayer, GatedCrossAttentionBlock
+from .utils import getattr_recursive, setattr_recursive
+
+
+@MODELS.register_module()
+class FlamingoLMAdapter:
+ """Mixin to add cross-attention layers to a language model."""
+
+ @classmethod
+ def extend_init(
+ cls,
+ base: object,
+ vis_hidden_size: int,
+ cross_attn_every_n_layers: int,
+ use_media_placement_augmentation: bool,
+ ):
+ """Initialize Flamingo by adding a new gated cross attn to the decoder.
+
+ Store the media token id for computing the media locations.
+
+ Args:
+ base (object): Base module could be any object that represent
+ a instance of language model.
+ vis_hidden_size: (int): Hidden size of vision embeddings.
+ cross_attn_every_n_layers: (int): Additional cross attn for
+ every n layers.
+ use_media_placement_augmentation: (bool): Whether to use media
+ placement augmentation.
+ """
+ base.set_decoder_layers_attr_name('model.layers')
+ gated_cross_attn_layers = nn.ModuleList([
+ GatedCrossAttentionBlock(
+ dim=base.config.hidden_size, dim_visual=vis_hidden_size) if
+ (layer_idx + 1) % cross_attn_every_n_layers == 0 else None
+ for layer_idx, _ in enumerate(base._get_decoder_layers())
+ ])
+ base._set_decoder_layers(
+ nn.ModuleList([
+ FlamingoLayer(gated_cross_attn_layer, decoder_layer)
+ for gated_cross_attn_layer, decoder_layer in zip(
+ gated_cross_attn_layers, base._get_decoder_layers())
+ ]))
+ base.use_media_placement_augmentation = use_media_placement_augmentation # noqa
+ base.initialized_flamingo = True
+ return base
+
+ def set_decoder_layers_attr_name(self, decoder_layers_attr_name):
+ """Set decoder layers attribute name."""
+ self.decoder_layers_attr_name = decoder_layers_attr_name
+
+ def _get_decoder_layers(self):
+ """Get decoder layers according to attribute name."""
+ return getattr_recursive(self, self.decoder_layers_attr_name)
+
+ def _set_decoder_layers(self, value):
+ """Set decoder layers according to attribute name."""
+ setattr_recursive(self, self.decoder_layers_attr_name, value)
+
+ def forward(self, *input, **kwargs):
+ """Condition the Flamingo layers on the media locations before forward
+ function."""
+ input_ids = kwargs['input_ids'] if 'input_ids' in kwargs else input[0]
+ media_locations = input_ids == self.media_token_id
+ attend_previous = ((random.random() < 0.5)
+ if self.use_media_placement_augmentation else False)
+
+ for layer in self.get_decoder().layers:
+ layer.condition_media_locations(media_locations)
+ layer.condition_attend_previous(attend_previous)
+
+ return super().forward(
+ *input, **kwargs) # Call the other parent's forward method
+
+ def is_conditioned(self) -> bool:
+ """Check whether all decoder layers are already conditioned."""
+ return all(layer.is_conditioned()
+ for layer in self._get_decoder_layers())
+
+ def clear_conditioned_layers(self):
+ """Clear all conditional layers."""
+ for layer in self._get_decoder_layers():
+ layer.condition_vis_x(None)
+ layer.condition_media_locations(None)
+ layer.condition_attend_previous(None)
diff --git a/mmpretrain/models/multimodal/flamingo/flamingo.py b/mmpretrain/models/multimodal/flamingo/flamingo.py
new file mode 100644
index 00000000000..abdd03328f4
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/flamingo.py
@@ -0,0 +1,322 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from .modules import PerceiverResampler
+from .utils import ExtendModule
+
+
+@MODELS.register_module()
+class Flamingo(BaseModel):
+ """The Open Flamingo model for multiple tasks.
+
+ Args:
+ vision_encoder (dict): The config of the vision encoder.
+ lang_encoder (dict): The config of the language encoder.
+ tokenizer (dict): The tokenizer to encode the text.
+ task (int): The task to perform prediction.
+ zeroshot_prompt (str): Prompt used for zero-shot inference.
+ Defaults to 'Output:'.
+ shot_prompt_tmpl (str): Prompt used for few-shot inference.
+ Defaults to 'Output:{caption}<|endofchunk|>'.
+ final_prompt_tmpl (str): Final part of prompt used for inference.
+ Defaults to 'Output:'.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of [~`transformers.GenerationConfig`].
+ Defaults to an empty dict.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ support_tasks = {'caption', 'vqa'}
+ _no_split_modules = [
+ 'TransformerEncoderLayer', 'PerceiverAttention',
+ 'GatedCrossAttentionBlock', 'FlamingoLayer'
+ ]
+
+ def __init__(
+ self,
+ vision_encoder: dict,
+ lang_encoder: dict,
+ tokenizer: dict,
+ task: str = 'caption',
+ zeroshot_prompt: str = 'Output:',
+ shot_prompt_tmpl: str = 'Output:{caption}<|endofchunk|>',
+ final_prompt_tmpl: str = 'Output:',
+ generation_cfg: dict = dict(),
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ if task not in self.support_tasks:
+ raise ValueError(f'Unsupported task {task}, please select '
+ f'the task from {self.support_tasks}.')
+ self.task = task
+
+ # init tokenizer
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ # add Flamingo special tokens to the tokenizer
+ self.tokenizer.add_special_tokens(
+ {'additional_special_tokens': ['<|endofchunk|>', '']})
+ self.tokenizer.bos_token_id = 1
+ if self.tokenizer.pad_token is None:
+ # Issue: GPT models don't have a pad token, which we use to
+ # modify labels for the loss.
+ self.tokenizer.add_special_tokens({'pad_token': ''})
+
+ # Template to format the prompt input
+ self.zeroshot_prompt = zeroshot_prompt
+ self.shot_prompt_tmpl = shot_prompt_tmpl
+ self.final_prompt_tmpl = final_prompt_tmpl
+
+ # init vision encoder related modules
+ vision_encoder_weight = vision_encoder.pop('pretrained', None)
+ self.vision_encoder = MODELS.build(vision_encoder)
+ if vision_encoder_weight is not None:
+ from mmengine.runner.checkpoint import load_checkpoint
+ load_checkpoint(
+ self.vision_encoder,
+ vision_encoder_weight,
+ map_location='cpu',
+ revise_keys=[(r'^backbone\.', '')],
+ )
+
+ self.perceiver = PerceiverResampler(dim=self.vision_encoder.embed_dims)
+
+ # init language encoder related modules
+ self.lang_encoder = ExtendModule(**lang_encoder)
+ self.lang_encoder.resize_token_embeddings(len(self.tokenizer))
+ self.lang_encoder.media_token_id = self.tokenizer.encode('')[-1]
+
+ # other necessary parameters
+ self.eoc_token_id = self.tokenizer.encode('<|endofchunk|>')[-1]
+ self.generation_cfg = {
+ 'num_beams': 1,
+ 'max_new_tokens': None,
+ 'temperature': 1.0,
+ 'top_k': 0,
+ 'top_p': 1.0,
+ 'no_repeat_ngram_size': 0,
+ 'prefix_allowed_tokens_fn': None,
+ 'length_penalty': 1.0,
+ 'num_return_sequences': 1,
+ 'do_sample': False,
+ 'early_stopping': False,
+ **generation_cfg,
+ }
+
+ if hasattr(self, 'register_load_state_dict_post_hook'):
+ self.register_load_state_dict_post_hook(self._load_adapter_hook)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): The input image tensor with different ndim
+ according to the inputs.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_vision_feats(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract vision features.
+
+ Args:
+ images (torch.Tensor): For zero-shot, the input images tensor is
+ with shape (B, C, H, W), for few-shot, which is
+ (B, T_img, C, H, W) in general. Images in the same chunk
+ are collated along T_img. Video data is not supported yet.
+
+ Returns:
+ torch.Tensor: Return extracted features.
+ """
+ if images.ndim == 4:
+ # (B, C, H, W) -> (B, 1, C, H, W) for zero-shot.
+ images = images.unsqueeze(1)
+ b, T = images.shape[:2]
+ # b T c h w -> (b T) c h w
+ images = images.view(b * T, *images.shape[-3:])
+
+ with torch.no_grad():
+ vision_feats = self.vision_encoder(images)[-1][:, 1:]
+
+ # (b T F) v d -> b T F v d Only support F=1 here
+ vision_feats = vision_feats.view(b, T, 1, *vision_feats.shape[-2:])
+
+ vision_feats = self.perceiver(vision_feats) # reshapes to (b, T, n, d)
+ return vision_feats
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ **generation_cfg):
+ """Predict generation results from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): For zero-shot, the input images tensor is
+ with shape (B, C, H, W), for few-shot, which is
+ (B, T_img, C, H, W) in general. Images in the same chunk
+ are collated along T_img. Video data is not supported yet.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **generation_cfg: Other keyword arguments accepted by the
+ ``generate`` method of :attr:`lang_encoder`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ # generation_cfg in prediction should be dominant
+ generation_cfg = {**self.generation_cfg, **generation_cfg}
+ num_beams = generation_cfg['num_beams']
+
+ if num_beams > 1:
+ images = images.repeat_interleave(num_beams, dim=0)
+
+ # extra vision feats and set as language condition feats
+ vision_x = self.extract_vision_feats(images)
+ for layer in self.lang_encoder._get_decoder_layers():
+ layer.condition_vis_x(vision_x)
+
+ input_text = self.preprocess_text(data_samples, device=images.device)
+
+ outputs = self.lang_encoder.generate(
+ input_text.input_ids,
+ attention_mask=input_text.attention_mask,
+ eos_token_id=self.eoc_token_id,
+ **generation_cfg)
+
+ # clear conditioned layers for language models
+ self.lang_encoder.clear_conditioned_layers()
+
+ # remove prefix
+ outputs = outputs[:, len(input_text.input_ids[0]):]
+
+ return self.post_process(outputs, data_samples)
+
+ def preprocess_text(self, data_samples: List[DataSample],
+ device: torch.device) -> List[DataSample]:
+ """Preprocess text in advance before fed into language model.
+
+ Args:
+ data_samples (List[DataSample]): The annotation
+ data of every samples. Defaults to None.
+ device (torch.device): Device for text to put on.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ prompts = []
+ for sample in data_samples:
+ if 'shots' in sample:
+ # few-shot
+ shot_prompt = ''.join([
+ self.shot_prompt_tmpl.format(**shot)
+ for shot in sample.get('shots')
+ ])
+ else:
+ # zero-shot
+ shot_prompt = self.zeroshot_prompt
+
+ # add final prompt
+ final_prompt = self.final_prompt_tmpl.format(**sample.to_dict())
+ prompts.append(shot_prompt + final_prompt)
+
+ self.tokenizer.padding_side = 'left'
+ input_text = self.tokenizer(
+ prompts,
+ padding='longest',
+ truncation=True,
+ return_tensors='pt',
+ max_length=2000,
+ ).to(device)
+ return input_text
+
+ def post_process(
+ self, outputs: torch.Tensor,
+ data_samples: Optional[List[DataSample]]) -> List[DataSample]:
+ """Perform post process for outputs for different task.
+
+ Args:
+ outputs (torch.Tensor): The generated outputs.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ outputs = self.tokenizer.batch_decode(
+ outputs, skip_special_tokens=True)
+
+ if data_samples is None:
+ data_samples = [DataSample() for _ in range(len(outputs))]
+
+ for output, data_sample in zip(outputs, data_samples):
+ # remove text pattern
+ if self.task == 'caption':
+ data_sample.pred_caption = re.split('Output', output,
+ 1)[0].replace('"', '')
+ elif self.task == 'vqa':
+ data_sample.pred_answer = re.split('Question|Answer', output,
+ 1)[0]
+
+ return data_samples
+
+ @staticmethod
+ def _load_adapter_hook(module, incompatible_keys):
+ """Avoid warning missing keys except adapter keys."""
+ adapter_patterns = [
+ '^perceiver',
+ 'lang_encoder.*embed_tokens',
+ 'lang_encoder.*gated_cross_attn_layers',
+ 'lang_encoder.*rotary_emb',
+ ]
+ for key in list(incompatible_keys.missing_keys):
+ if not any(re.match(pattern, key) for pattern in adapter_patterns):
+ incompatible_keys.missing_keys.remove(key)
+
+ for key in list(incompatible_keys.unexpected_keys):
+ if 'position_ids' in key:
+ incompatible_keys.unexpected_keys.remove(key)
+ if 'lang_encoder.gated_cross_attn_layers' in key:
+ incompatible_keys.unexpected_keys.remove(key)
diff --git a/mmpretrain/models/multimodal/flamingo/modules.py b/mmpretrain/models/multimodal/flamingo/modules.py
new file mode 100644
index 00000000000..730c61b68a8
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/modules.py
@@ -0,0 +1,398 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Taken from https://github.com/lucidrains/flamingo-pytorch."""
+
+from typing import Optional
+
+import torch
+from einops import rearrange, repeat
+from torch import einsum, nn
+
+
+def FeedForward(dim, mult: int = 4):
+ """Feedforward layers.
+
+ Args:
+ mult (int): Layer expansion muliplier. Defaults to 4.
+ """
+ inner_dim = int(dim * mult)
+ return nn.Sequential(
+ nn.LayerNorm(dim),
+ nn.Linear(dim, inner_dim, bias=False),
+ nn.GELU(),
+ nn.Linear(inner_dim, dim, bias=False),
+ )
+
+
+class PerceiverAttention(nn.Module):
+ """Perceiver attetion layers.
+
+ Args:
+ dim (int): Input dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ """
+
+ def __init__(self, *, dim: int, dim_head: int = 64, heads: int = 8):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ inner_dim = dim_head * heads
+
+ self.norm_media = nn.LayerNorm(dim)
+ self.norm_latents = nn.LayerNorm(dim)
+
+ self.to_q = nn.Linear(dim, inner_dim, bias=False)
+ self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
+ self.to_out = nn.Linear(inner_dim, dim, bias=False)
+
+ def forward(self, x: torch.Tensor, latents: torch.Tensor):
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): image features of shape (b, T, n1, D).
+ latent (torch.Tensor): latent features of shape (b, T, n2, D).
+ """
+ x = self.norm_media(x)
+ latents = self.norm_latents(latents)
+
+ h = self.heads
+
+ q = self.to_q(latents)
+ kv_input = torch.cat((x, latents), dim=-2)
+ k, v = self.to_kv(kv_input).chunk(2, dim=-1)
+ q = rearrange(q, 'b t n (h d) -> b h t n d', h=h)
+ k = rearrange(k, 'b t n (h d) -> b h t n d', h=h)
+ v = rearrange(v, 'b t n (h d) -> b h t n d', h=h)
+ q = q * self.scale
+
+ # attention
+ sim = einsum('... i d, ... j d -> ... i j', q, k)
+ sim = sim - sim.amax(dim=-1, keepdim=True).detach()
+ attn = sim.softmax(dim=-1)
+
+ out = einsum('... i j, ... j d -> ... i d', attn, v)
+ out = rearrange(out, 'b h t n d -> b t n (h d)', h=h)
+ return self.to_out(out)
+
+
+class PerceiverResampler(nn.Module):
+ """Perceiver resampler layers.
+
+ Args:
+ dim (int): Input dimensions.
+ depth (int): Depth of resampler. Defaults to 6.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ num_latents (int): Number of latents. Defaults to 64.
+ max_num_media (int, optional): Max number of media.
+ Defaults to None.
+ max_num_frames (int, optional): Max number of frames.
+ Defaults to None.
+ ff_mult (int): Feed forward multiplier. Defaults to 4.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ depth: int = 6,
+ dim_head: int = 64,
+ heads: int = 8,
+ num_latents: int = 64,
+ max_num_media: Optional[int] = None,
+ max_num_frames: Optional[int] = None,
+ ff_mult: int = 4,
+ ):
+ super().__init__()
+ self.latents = nn.Parameter(torch.randn(num_latents, dim))
+ self.frame_embs = (
+ nn.Parameter(torch.randn(max_num_frames, dim))
+ if max_num_frames is not None else None)
+ self.media_time_embs = (
+ nn.Parameter(torch.randn(max_num_media, 1, dim))
+ if max_num_media is not None else None)
+
+ self.layers = nn.ModuleList([])
+ for _ in range(depth):
+ self.layers.append(
+ nn.ModuleList([
+ PerceiverAttention(
+ dim=dim, dim_head=dim_head, heads=heads),
+ FeedForward(dim=dim, mult=ff_mult),
+ ]))
+
+ self.norm = nn.LayerNorm(dim)
+
+ def forward(self, x: torch.Tensor):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): image features of shape (b, T, F, v, D)
+
+ Returns:
+ torch.Tensor: shape (b, T, n, D) where n is self.num_latents
+ """
+ b, T, F, v = x.shape[:4]
+
+ # frame and media time embeddings
+ if self.frame_embs is not None:
+ frame_embs = repeat(
+ self.frame_embs[:F], 'F d -> b T F v d', b=b, T=T, v=v)
+ x = x + frame_embs
+ x = rearrange(x, 'b T F v d -> b T (F v) d'
+ ) # flatten the frame and spatial dimensions
+ if self.media_time_embs is not None:
+ x = x + self.media_time_embs[:T]
+
+ # blocks
+ latents = repeat(self.latents, 'n d -> b T n d', b=b, T=T)
+ for attn, ff in self.layers:
+ latents = attn(x, latents) + latents
+ latents = ff(latents) + latents
+ return self.norm(latents)
+
+
+class MaskedCrossAttention(nn.Module):
+ """Masked cross attention layers.
+
+ Args:
+ dim (int): Input text feature dimensions.
+ dim_visual (int): Input visual feature dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ only_attend_immediate_media (bool): Whether attend immediate media.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ dim_visual: int,
+ dim_head: int = 64,
+ heads: int = 8,
+ only_attend_immediate_media: bool = True,
+ ):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ inner_dim = dim_head * heads
+
+ self.norm = nn.LayerNorm(dim)
+
+ self.to_q = nn.Linear(dim, inner_dim, bias=False)
+ self.to_kv = nn.Linear(dim_visual, inner_dim * 2, bias=False)
+ self.to_out = nn.Linear(inner_dim, dim, bias=False)
+
+ # whether for text to only attend to immediate preceding image
+ # or all previous images
+ self.only_attend_immediate_media = only_attend_immediate_media
+
+ def forward(self,
+ x: torch.Tensor,
+ media: torch.Tensor,
+ media_locations: Optional[torch.Tensor] = None,
+ attend_previous: bool = True):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): text features of shape (B, T_txt, D_txt).
+ media (torch.Tensor): image features of shape
+ (B, T_img, n, D_img) where n is the dim of the latents.
+ media_locations (torch.Tensor, optional): boolean mask identifying
+ the media tokens in x of shape (B, T_txt). Defaults to None.
+ attend_previous (bool): If false, ignores immediately preceding
+ image and starts attending when following image.
+ Defaults to True.
+ """
+ _, T_img, n = media.shape[:3]
+ h = self.heads
+
+ x = self.norm(x)
+
+ q = self.to_q(x)
+ media = rearrange(media, 'b t n d -> b (t n) d')
+
+ k, v = self.to_kv(media).chunk(2, dim=-1)
+ q = rearrange(q, 'b n (h d) -> b h n d', h=h)
+ k = rearrange(k, 'b n (h d) -> b h n d', h=h)
+ v = rearrange(v, 'b n (h d) -> b h n d', h=h)
+
+ q = q * self.scale
+
+ sim = einsum('... i d, ... j d -> ... i j', q, k)
+
+ if media_locations is not None:
+ # at each boolean of True, increment the time counter
+ # (relative to media time)
+ text_time = media_locations.cumsum(dim=-1)
+ media_time = torch.arange(T_img, device=x.device) + 1
+
+ if not attend_previous:
+ text_time[~media_locations] += 1
+ # make sure max is still the number of images in the sequence
+ text_time[text_time > repeat(
+ torch.count_nonzero(media_locations, dim=1),
+ 'b -> b i',
+ i=text_time.shape[1],
+ )] = 0
+
+ # text time must equal media time if only attending to most
+ # immediate image otherwise, as long as text time is greater than
+ # media time (if attending to all previous images / media)
+ mask_op = torch.eq if self.only_attend_immediate_media else torch.ge # noqa
+
+ text_to_media_mask = mask_op(
+ rearrange(text_time, 'b i -> b 1 i 1'),
+ repeat(media_time, 'j -> 1 1 1 (j n)', n=n),
+ )
+ sim = sim.masked_fill(~text_to_media_mask,
+ -torch.finfo(sim.dtype).max)
+
+ sim = sim - sim.amax(dim=-1, keepdim=True).detach()
+ attn = sim.softmax(dim=-1)
+
+ if media_locations is not None and self.only_attend_immediate_media:
+ # any text without a preceding media needs to have
+ # attention zeroed out
+ text_without_media_mask = text_time == 0
+ text_without_media_mask = rearrange(text_without_media_mask,
+ 'b i -> b 1 i 1')
+ attn = attn.masked_fill(text_without_media_mask, 0.0)
+
+ out = einsum('... i j, ... j d -> ... i d', attn, v)
+ out = rearrange(out, 'b h n d -> b n (h d)')
+ return self.to_out(out)
+
+
+class GatedCrossAttentionBlock(nn.Module):
+ """Gated cross attention layers.
+
+ Args:
+ dim (int): Input text feature dimensions.
+ dim_visual (int): Input visual feature dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ ff_mult (int): Feed forward multiplier. Defaults to 4.
+ only_attend_immediate_media (bool): Whether attend immediate media.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ dim_visual: int,
+ dim_head: int = 64,
+ heads: int = 8,
+ ff_mult: int = 4,
+ only_attend_immediate_media: bool = True,
+ ):
+ super().__init__()
+ self.attn = MaskedCrossAttention(
+ dim=dim,
+ dim_visual=dim_visual,
+ dim_head=dim_head,
+ heads=heads,
+ only_attend_immediate_media=only_attend_immediate_media,
+ )
+ self.attn_gate = nn.Parameter(torch.tensor([0.0]))
+
+ self.ff = FeedForward(dim, mult=ff_mult)
+ self.ff_gate = nn.Parameter(torch.tensor([0.0]))
+
+ def forward(self,
+ x: torch.Tensor,
+ media: torch.Tensor,
+ media_locations: Optional[torch.Tensor] = None,
+ attend_previous: bool = True):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): text features of shape (B, T_txt, D_txt).
+ media (torch.Tensor): image features of shape
+ (B, T_img, n, D_img) where n is the dim of the latents.
+ media_locations (torch.Tensor, optional): boolean mask identifying
+ the media tokens in x of shape (B, T_txt). Defaults to None.
+ attend_previous (bool): If false, ignores immediately preceding
+ image and starts attending when following image.
+ Defaults to True.
+ """
+ x = (
+ self.attn(
+ x,
+ media,
+ media_locations=media_locations,
+ attend_previous=attend_previous,
+ ) * self.attn_gate.tanh() + x)
+ x = self.ff(x) * self.ff_gate.tanh() + x
+
+ return x
+
+
+class FlamingoLayer(nn.Module):
+ """Faminogo layers.
+
+ Args:
+ gated_cross_attn_layer (nn.Module): Gated cross attention layer.
+ decoder_layer (nn.Module): Decoder layer.
+ """
+
+ def __init__(self, gated_cross_attn_layer: nn.Module,
+ decoder_layer: nn.Module):
+ super().__init__()
+ self.gated_cross_attn_layer = gated_cross_attn_layer
+ self.decoder_layer = decoder_layer
+ self.vis_x = None
+ self.media_locations = None
+
+ def is_conditioned(self) -> bool:
+ """Check whether the layer is conditioned."""
+ return self.vis_x is not None
+
+ def condition_vis_x(self, vis_x):
+ """Set condition vision features."""
+ self.vis_x = vis_x
+
+ def condition_media_locations(self, media_locations):
+ """Set condition media locations."""
+ self.media_locations = media_locations
+
+ def condition_attend_previous(self, attend_previous):
+ """Set attend previous."""
+ self.attend_previous = attend_previous
+
+ def forward(
+ self,
+ lang_x: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ **decoder_layer_kwargs,
+ ):
+ """Forward function.
+
+ Args:
+ lang_x (torch.Tensor): language inputs.
+ attention_mask (torch.Tensor, optional): text attention mask.
+ Defaults to None.
+ **decoder_layer_kwargs: Other decoder layer keyword arguments.
+ """
+ if self.gated_cross_attn_layer is None:
+ return self.decoder_layer(
+ lang_x, attention_mask=attention_mask, **decoder_layer_kwargs)
+
+ if self.vis_x is None:
+ raise ValueError('vis_x must be conditioned before forward pass')
+
+ if self.media_locations is None:
+ raise ValueError(
+ 'media_locations must be conditioned before forward pass')
+
+ lang_x = self.gated_cross_attn_layer(
+ lang_x,
+ self.vis_x,
+ media_locations=self.media_locations,
+ attend_previous=self.attend_previous,
+ )
+ lang_x = self.decoder_layer(
+ lang_x, attention_mask=attention_mask, **decoder_layer_kwargs)
+ return lang_x
diff --git a/mmpretrain/models/multimodal/flamingo/utils.py b/mmpretrain/models/multimodal/flamingo/utils.py
new file mode 100644
index 00000000000..1077e145a7d
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/utils.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Type
+
+from mmpretrain.registry import MODELS
+
+
+class ExtendModule:
+ """Combine the base language model with adapter. This module will create a
+ instance from base with extended functions in adapter.
+
+ Args:
+ base (object): Base module could be any object that represent
+ a instance of language model or a dict that can build the
+ base module.
+ adapter: (dict): Dict to build the adapter.
+ """
+
+ def __new__(cls, base: object, adapter: dict):
+
+ if isinstance(base, dict):
+ base = MODELS.build(base)
+
+ adapter_module = MODELS.get(adapter.pop('type'))
+ cls.extend_instance(base, adapter_module)
+ return adapter_module.extend_init(base, **adapter)
+
+ @classmethod
+ def extend_instance(cls, base: object, mixin: Type[Any]):
+ """Apply mixins to a class instance after creation.
+
+ Args:
+ base (object): Base module instance.
+ mixin: (Type[Any]): Adapter class type to mixin.
+ """
+ base_cls = base.__class__
+ base_cls_name = base.__class__.__name__
+ base.__class__ = type(
+ base_cls_name, (mixin, base_cls),
+ {}) # mixin needs to go first for our forward() logic to work
+
+
+def getattr_recursive(obj, att):
+ """
+ Return nested attribute of obj
+ Example: getattr_recursive(obj, 'a.b.c') is equivalent to obj.a.b.c
+ """
+ if att == '':
+ return obj
+ i = att.find('.')
+ if i < 0:
+ return getattr(obj, att)
+ else:
+ return getattr_recursive(getattr(obj, att[:i]), att[i + 1:])
+
+
+def setattr_recursive(obj, att, val):
+ """
+ Set nested attribute of obj
+ Example: setattr_recursive(obj, 'a.b.c', val)
+ is equivalent to obj.a.b.c = val
+ """
+ if '.' in att:
+ obj = getattr_recursive(obj, '.'.join(att.split('.')[:-1]))
+ setattr(obj, att.split('.')[-1], val)
diff --git a/mmpretrain/models/multimodal/ofa/__init__.py b/mmpretrain/models/multimodal/ofa/__init__.py
new file mode 100644
index 00000000000..bcb3f45f09b
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ofa import OFA
+from .ofa_modules import OFADecoder, OFAEncoder, OFAEncoderDecoder
+
+__all__ = ['OFAEncoderDecoder', 'OFA', 'OFAEncoder', 'OFADecoder']
diff --git a/mmpretrain/models/multimodal/ofa/ofa.py b/mmpretrain/models/multimodal/ofa/ofa.py
new file mode 100644
index 00000000000..e15787a60d6
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/ofa.py
@@ -0,0 +1,320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import string
+from collections import defaultdict
+from functools import partial
+from typing import Optional, Union
+
+import mmengine
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.datasets import CleanCaption
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from .ofa_modules import OFAEncoderDecoder
+
+
+class TreeNode():
+
+ def __init__(self):
+ self.child = defaultdict(TreeNode)
+
+
+class Trie:
+
+ def __init__(self, eos):
+ self.root = TreeNode()
+ self.eos = eos
+
+ def insert(self, word):
+ cur = self.root
+ for c in word:
+ cur = cur.child[c]
+
+ def get_next_layer(self, word):
+ cur = self.root
+ for c in word:
+ cur = cur.child.get(c)
+ if cur is None:
+ return [self.eos]
+ return list(cur.child.keys())
+
+
+def apply_constraint(
+ input_ids: torch.Tensor,
+ logits: torch.Tensor,
+ decoder_prompts: Optional[list],
+ num_beams: int,
+ constraint_trie: Trie = None,
+):
+ if decoder_prompts is None and constraint_trie is None:
+ return logits
+
+ mask = logits.new_zeros(logits[:, -1, :].size(), dtype=torch.bool)
+ input_ids = input_ids.view(-1, num_beams, input_ids.shape[-1])
+ for batch_id, beam_sent in enumerate(input_ids):
+ for beam_id, sent in enumerate(beam_sent):
+ if decoder_prompts is None:
+ prompt_len = 0
+ else:
+ prompt_len = len(decoder_prompts[batch_id])
+
+ if sent.size(0) - 1 < prompt_len:
+ allowed_tokens = [decoder_prompts[batch_id][sent.size(0) - 1]]
+ mask[batch_id * num_beams + beam_id, allowed_tokens] = True
+ elif constraint_trie is not None:
+ answer_tokens = [0] + sent[prompt_len + 1:].tolist()
+ allowed_tokens = constraint_trie.get_next_layer(answer_tokens)
+ mask[batch_id * num_beams + beam_id, allowed_tokens] = True
+ else:
+ mask[batch_id * num_beams + beam_id, :] = True
+ logits[:, -1, :].masked_fill_(~mask, float('-inf'))
+ return logits
+
+
+@MODELS.register_module()
+class OFA(BaseModel):
+ """The OFA model for multiple tasks.
+
+ Args:
+ encoder_cfg (dict): The config of the encoder, accept the keyword
+ arguments of :class:`OFAEncoder`.
+ decoder_cfg (dict): The config of the decoder, accept the keyword
+ arguments of :class:`OFADecoder`.
+ vocab_size (int): The size of the vocabulary.
+ embedding_dim (int): The embedding dimensions of both the encoder
+ and the decoder.
+ tokenizer (dict | PreTrainedTokenizer): The tokenizer to encode
+ the text.
+ task (str): The task name, supported tasks are "caption", "vqa" and
+ "refcoco".
+ prompt (str, optional): The prompt template for the following tasks,
+ If None, use default prompt:
+
+ - **caption**: ' what does the image describe?'
+ - **refcoco**: ' which region does the text " {} " describe?'
+
+ Defaults to None
+ ans2label (str | Sequence | None): The answer to label mapping for
+ the vqa task. If a string, it should be a pickle or json file.
+ The sequence constrains the output answers. Defaults to None,
+ which means no constraint.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of :class:`~transformers.GenerationConfig`.
+ Defaults to an empty dict.
+ data_preprocessor (dict, optional): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type. See :class:
+ `MultiModalDataPreprocessor` for more details. Defaults to None.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+ support_tasks = {'caption', 'vqa', 'refcoco'}
+
+ def __init__(
+ self,
+ encoder_cfg,
+ decoder_cfg,
+ vocab_size,
+ embedding_dim,
+ tokenizer,
+ task,
+ prompt=None,
+ ans2label: Union[dict, str, None] = None,
+ generation_cfg=dict(),
+ data_preprocessor: Optional[dict] = None,
+ init_cfg=None,
+ ):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ if isinstance(tokenizer, dict):
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+
+ if task not in self.support_tasks:
+ raise ValueError(f'Unsupported task {task}, please select '
+ f'the task from {self.support_tasks}.')
+
+ self.prompt = prompt
+ self.task = task
+
+ if isinstance(ans2label, str):
+ self.ans2label = mmengine.load(ans2label)
+ else:
+ self.ans2label = ans2label
+
+ if self.task == 'vqa' and self.ans2label is not None:
+ self.constraint_trie = Trie(eos=self.tokenizer.eos_token_id)
+ answers = [f' {answer}' for answer in self.ans2label]
+ answer_tokens = self.tokenizer(answers, padding=False)
+ for answer_token in answer_tokens['input_ids']:
+ self.constraint_trie.insert(answer_token)
+ else:
+ self.constraint_trie = None
+
+ generation_cfg = {
+ 'num_beams': 5,
+ 'max_new_tokens': 20,
+ 'no_repeat_ngram_size': 3,
+ **generation_cfg,
+ }
+ self.model = OFAEncoderDecoder(
+ encoder_cfg=encoder_cfg,
+ decoder_cfg=decoder_cfg,
+ padding_idx=self.tokenizer.pad_token_id,
+ vocab_size=vocab_size,
+ embedding_dim=embedding_dim,
+ generation_cfg=generation_cfg,
+ )
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ mode: str = 'predict',
+ **kwargs,
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method accepts the following modes:
+
+ - "predict": Forward and return a list of data samples contain the
+ predict results.
+
+ Args:
+ images (torch.Tensor): the preprocessed image tensor of shape
+ ``(N, C, H, W)``.
+ data_samples (List[DataSample], optional): The annotation data
+ of every samples. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'predict'.
+ """
+ if mode == 'predict':
+ return self.predict(images, data_samples, **kwargs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(
+ self,
+ images,
+ data_samples=None,
+ post_process=True,
+ **generation_config,
+ ):
+ text_tokens = self.preprocess_text(data_samples, images.size(0),
+ images.device)
+
+ if 'images_mask' in data_samples[0]:
+ images_mask = torch.tensor([
+ sample.get('images_mask') for sample in data_samples
+ ]).bool().to(images.device)
+ else:
+ images_mask = None
+
+ num_beams = generation_config.get(
+ 'num_beams', getattr(self.model.generation_config, 'num_beams'))
+ decoder_prompts = self.get_decoder_prompts(data_samples)
+ constrain_fn = partial(
+ apply_constraint,
+ constraint_trie=self.constraint_trie,
+ decoder_prompts=decoder_prompts,
+ num_beams=num_beams,
+ )
+
+ outputs = self.model.generate(
+ input_ids=text_tokens,
+ images=images,
+ images_mask=images_mask,
+ constrain_fn=constrain_fn,
+ **generation_config,
+ )
+
+ if decoder_prompts is not None:
+ # Remove the prefix decoder prompt.
+ for prompt_ids, token in zip(decoder_prompts, outputs):
+ token[1:len(prompt_ids) + 1] = self.tokenizer.pad_token_id
+
+ if post_process:
+ return self.post_process(outputs, data_samples)
+ else:
+ return outputs
+
+ def get_decoder_prompts(self, data_samples):
+ decoder_prompts = []
+ if 'decoder_prompt' not in data_samples[0]:
+ return None
+ for sample in data_samples:
+ prompt = ' ' + sample.get('decoder_prompt')
+ prompt_ids = self.tokenizer(prompt, add_special_tokens=False)
+ prompt_ids = prompt_ids['input_ids']
+ decoder_prompts.append(prompt_ids)
+ return decoder_prompts
+
+ def preprocess_text(self, data_samples, batch_size, device):
+ if self.task == 'caption':
+ prompt = self.prompt or ' what does the image describe?'
+ prompts = [prompt] * batch_size
+ prompts = self.tokenizer(prompts, return_tensors='pt')
+ return prompts.input_ids.to(device)
+ elif self.task == 'vqa':
+ prompts = []
+ for sample in data_samples:
+ assert 'question' in sample
+ prompt = ' ' + sample.get('question')
+ prompts.append(prompt)
+ prompts = self.tokenizer(
+ prompts, return_tensors='pt', padding=True)
+ return prompts.input_ids.to(device)
+ elif self.task == 'refcoco':
+ prompt_template = self.prompt or \
+ ' which region does the text " {} " describe?'
+ prompts = []
+ for sample in data_samples:
+ assert 'text' in sample
+ prompt = prompt_template.format(sample.get('text'))
+ prompts.append(prompt)
+ prompts = self.tokenizer(
+ prompts, return_tensors='pt', padding=True)
+ return prompts.input_ids.to(device)
+
+ def post_process(self, outputs, data_samples):
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None] * outputs.size(0)
+
+ for data_sample, token in zip(data_samples, outputs):
+ if data_sample is None:
+ data_sample = DataSample()
+
+ if self.task == 'caption':
+ text = self.tokenizer.decode(token, skip_special_tokens=True)
+ text = CleanCaption(
+ lowercase=False,
+ remove_chars=string.punctuation).clean(text)
+ data_sample.pred_caption = text
+ elif self.task == 'vqa':
+ text = self.tokenizer.decode(token, skip_special_tokens=True)
+ data_sample.pred_answer = text.strip()
+ elif self.task == 'refcoco':
+ bbox = token[1:5] - self.tokenizer.bin_offset
+ # During training, the bbox is normalized by 512. It's related
+ # to the `max_image_size` config in the official repo.
+ bbox = bbox / self.tokenizer.num_bins * 512
+ scale_factor = data_sample.get('scale_factor', (1, 1))
+ bbox[0::2] /= scale_factor[0]
+ bbox[1::2] /= scale_factor[1]
+ data_sample.pred_bboxes = bbox.unsqueeze(0)
+ if 'gt_bboxes' in data_sample:
+ gt_bboxes = bbox.new_tensor(data_sample.gt_bboxes)
+ gt_bboxes[:, 0::2] /= scale_factor[0]
+ gt_bboxes[:, 1::2] /= scale_factor[1]
+ data_sample.gt_bboxes = gt_bboxes
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/ofa/ofa_modules.py b/mmpretrain/models/multimodal/ofa/ofa_modules.py
new file mode 100644
index 00000000000..1c79049b617
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/ofa_modules.py
@@ -0,0 +1,1612 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from dataclasses import dataclass
+from functools import partial
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn.bricks import DropPath
+from mmengine.model import BaseModule
+from mmengine.utils import digit_version
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions, ModelOutput, Seq2SeqLMOutput)
+from transformers.modeling_utils import (GenerationConfig, GenerationMixin,
+ PretrainedConfig)
+
+from mmpretrain.registry import MODELS
+from ...backbones.resnet import Bottleneck, ResNet
+
+if digit_version(torch.__version__) >= digit_version('1.10.0'):
+ torch_meshgrid = partial(torch.meshgrid, indexing='ij')
+else:
+ torch_meshgrid = torch.meshgrid
+
+
+def make_token_bucket_position(bucket_size, max_position=1024):
+ context_pos = torch.arange(max_position, dtype=torch.long)[:, None]
+ memory_pos = torch.arange(max_position, dtype=torch.long)[None, :]
+ relative_pos = context_pos - memory_pos
+ sign = torch.sign(relative_pos)
+ mid = bucket_size // 2
+ abs_pos = torch.where((relative_pos < mid) & (relative_pos > -mid),
+ mid - 1, torch.abs(relative_pos))
+ log_pos = torch.ceil(
+ torch.log(abs_pos / mid) / math.log(
+ (max_position - 1) / mid) * (mid - 1)) + mid
+ log_pos = log_pos.int()
+ bucket_pos = torch.where(abs_pos.le(mid), relative_pos,
+ log_pos * sign).long()
+ return bucket_pos + bucket_size - 1
+
+
+def make_image_bucket_position(bucket_size, num_relative_distance):
+ coords_h = torch.arange(bucket_size)
+ coords_w = torch.arange(bucket_size)
+ # (2, h, w)
+ coords = torch.stack(torch_meshgrid([coords_h, coords_w]))
+ # (2, h*w)
+ coords_flatten = torch.flatten(coords, 1)
+ # (2, h*w, h*w)
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
+ # (h*w, h*w, 2)
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous()
+ relative_coords[:, :, 0] += bucket_size - 1 # shift to start from 0
+ relative_coords[:, :, 1] += bucket_size - 1
+ relative_coords[:, :, 0] *= 2 * bucket_size - 1
+ relative_position_index = torch.zeros(
+ size=(bucket_size * bucket_size + 1, ) * 2,
+ dtype=relative_coords.dtype)
+ # (h*w, h*w)
+ relative_position_index[1:, 1:] = relative_coords.sum(-1)
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+
+def _make_causal_mask(input_ids_shape: torch.Size,
+ dtype: torch.dtype,
+ past_key_values_length: int = 0):
+ """Make causal mask used for uni-directional self-attention."""
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), float('-inf'))
+ mask_cond = torch.arange(mask.size(-1))
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat(
+ [torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask],
+ dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len,
+ tgt_len + past_key_values_length)
+
+
+def _expand_mask(mask: torch.Tensor,
+ dtype: torch.dtype,
+ tgt_len: Optional[int] = None):
+ """Expands attention_mask from ``[B, L_s]`` to ``[B, 1, L_t, L_s]``.
+
+ Where ``B`` is batch_size, `L_s`` is the source sequence length, and
+ ``L_t`` is the target sequence length.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len,
+ src_len).to(dtype)
+ return expanded_mask.masked_fill(expanded_mask.bool(),
+ torch.finfo(dtype).min)
+
+
+class MultiheadAttention(BaseModule):
+ """Multi-head Attention Module for OFA.
+
+ Args:
+ embedding_dim (int): The embedding dimension of query.
+ num_heads (int): Parallel attention heads.
+ kdim (int, optional): The embedding dimension of key.
+ Defaults to None, which means the same as the `embedding_dim`.
+ vdim (int, optional): The embedding dimension of value.
+ Defaults to None, which means the same as the `embedding_dim`.
+ attn_drop (float): Dropout rate of the dropout layer after the
+ attention calculation of query and key. Defaults to 0.
+ qkv_bias (bool): If True, add a learnable bias to q, k, v.
+ Defaults to True.
+ scale_factor (float): The scale of qk will be
+ ``(head_dim * scale_factor) ** -0.5``. Defaults to 1.
+ proj_bias (bool) If True, add a learnable bias to output projection.
+ Defaults to True.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ kdim=None,
+ vdim=None,
+ attn_drop=0.,
+ scale_factor=1.,
+ qkv_bias=True,
+ proj_bias=True,
+ scale_heads=False,
+ init_cfg=None):
+ super(MultiheadAttention, self).__init__(init_cfg=init_cfg)
+
+ self.embedding_dim = embedding_dim
+ self.num_heads = num_heads
+ self.kdim = kdim or embedding_dim
+ self.vdim = vdim or embedding_dim
+
+ self.head_dim = embedding_dim // num_heads
+ self.scale = (self.head_dim * scale_factor)**-0.5
+
+ self.q_proj = nn.Linear(embedding_dim, embedding_dim, bias=qkv_bias)
+ self.k_proj = nn.Linear(self.kdim, embedding_dim, bias=qkv_bias)
+ self.v_proj = nn.Linear(self.vdim, embedding_dim, bias=qkv_bias)
+ self.out_proj = nn.Linear(embedding_dim, embedding_dim, bias=proj_bias)
+
+ self.attn_drop = nn.Dropout(p=attn_drop)
+
+ if scale_heads:
+ self.c_attn = nn.Parameter(torch.ones(num_heads))
+ else:
+ self.c_attn = None
+
+ def forward(
+ self,
+ query,
+ key_value=None,
+ attn_mask=None,
+ attn_bias=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ B, _, C = query.shape
+ assert C == self.head_dim * self.num_heads
+
+ is_cross_attention = key_value is not None
+ if key_value is None:
+ key_value = query
+
+ # (B, L, C) -> (B, num_heads, L, head_dims)
+ q = self.q_proj(query).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ if is_cross_attention and past_key_value is not None:
+ # Reuse key and value in cross_attentions
+ k, v = past_key_value
+ else:
+ k = self.k_proj(key_value).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ v = self.v_proj(key_value).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ if past_key_value is not None:
+ past_key, past_value = past_key_value
+ k = torch.cat([past_key, k], dim=2)
+ v = torch.cat([past_value, v], dim=2)
+
+ past_key_value = (k, v)
+
+ attn_weights = q @ k.transpose(-2, -1) * self.scale
+
+ if attn_bias is not None:
+ src_len = k.size(2)
+ attn_weights[:, :, -src_len:] += attn_bias[:, :, -src_len:]
+
+ if attn_mask is not None:
+ attn_weights += attn_mask
+ attn_weights = torch.softmax(attn_weights, dim=-1)
+ attn = self.attn_drop(attn_weights) @ v
+
+ if self.c_attn is not None:
+ attn = torch.einsum('bhlc,h->bhlc', attn, self.c_attn)
+
+ # (B, num_heads, L, head_dims) -> (B, L, C)
+ attn = attn.transpose(1, 2).reshape(B, -1, self.embedding_dim)
+ attn = self.out_proj(attn)
+
+ if output_attentions:
+ return attn, attn_weights, past_key_value
+ else:
+ return attn, None, past_key_value
+
+
+@MODELS.register_module(force=True)
+class OFAResNet(ResNet):
+ """ResNet module for OFA.
+
+ The ResNet in OFA has only three stages.
+ """
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6)),
+ 101: (Bottleneck, (3, 4, 23)),
+ 152: (Bottleneck, (3, 8, 36)),
+ }
+
+ def __init__(self, depth, *args, **kwargs):
+ super().__init__(
+ depth=depth,
+ *args,
+ num_stages=3,
+ out_indices=(2, ),
+ dilations=(1, 1, 1),
+ strides=(1, 2, 2),
+ **kwargs)
+
+
+@dataclass
+class OFAEncoderOutput(ModelOutput):
+ """OFA encoder outputs.
+
+ Args:
+ last_hidden_state (torch.tensor): The hidden-states of the output at
+ the last layer of the model. The shape is (B, L, C).
+ hidden_states (Tuple[torch.tensor]): The initial embedding and the
+ output of each layer. The shape of every item is (B, L, C).
+ attentions (Tuple[torch.tensor]): The attention weights after the
+ attention softmax, used to compute the weighted average in the
+ self-attention heads. The shape of every item is
+ (B, num_heads, L, L).
+ position_embedding (torch.tensor): The positional embeddings of the
+ inputs. The shape is (B, L, C).
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ padding_mask: torch.Tensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ position_embedding: Optional[torch.FloatTensor] = None
+
+
+class OFAEncoderLayer(nn.Module):
+ """OFAEncoder layer block."""
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ attn_drop=0.,
+ act_drop=0.,
+ scale_factor=2.,
+ mlp_ratio=4.,
+ scale_heads=True,
+ normformer=True,
+ pre_norm=True,
+ act_cfg=dict(type='GELU')):
+ super().__init__()
+ self.embedding_dim = embedding_dim
+ self.pre_norm = pre_norm
+
+ self.attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ mid_channels = int(embedding_dim * mlp_ratio)
+ self.fc1 = nn.Linear(embedding_dim, mid_channels)
+ self.fc2 = nn.Linear(mid_channels, embedding_dim)
+ self.act = MODELS.build(act_cfg)
+ self.act_drop = nn.Dropout(
+ act_drop) if act_drop > 0. else nn.Identity()
+
+ # LayerNorm between attention block and ffn block.
+ self.attn_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_ln = nn.LayerNorm(embedding_dim)
+
+ # Extra LayerNorm
+ self.normformer = normformer
+ if self.normformer:
+ self.attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_mid_ln = nn.LayerNorm(mid_channels)
+
+ self.dropout = nn.Dropout(dropout_rate)
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
+
+ def forward(self,
+ x,
+ attention_mask=None,
+ attn_bias=None,
+ output_attentions=False):
+ """Forward the encoder layer.
+
+ Args:
+ x (torch.tensor): The input to the layer of shape ``(B, L, C)``.
+ attention_mask (torch.Tensor, optional): The attention mask of size
+ ``(B, 1, L, L)``, where padding elements are indicated by very
+ large negative values. Defaults to None.
+ attn_bias (torch.tensor, optional): The bias for positional
+ information. Defaults to None.
+ output_attentions (bool): Whether to return the attentions tensors
+ of the attention layer.
+
+ Returns:
+ List[torch.tensor]: The first element is the encoded output of
+ shape ``(B, L, C)``. And the second element is the output
+ attentions if ``output_attentions=True``.
+ """
+ residual = x
+
+ # Attention block
+ if self.pre_norm:
+ x = self.attn_ln(x)
+ x, attn_weights, _ = self.attn(
+ query=x,
+ attn_mask=attention_mask,
+ attn_bias=attn_bias,
+ output_attentions=output_attentions)
+ if self.normformer:
+ x = self.attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.attn_ln(x)
+
+ residual = x
+
+ # FFN block
+ if self.pre_norm:
+ x = self.ffn_ln(x)
+ x = self.act(self.fc1(x))
+ x = self.act_drop(x)
+ if self.normformer:
+ x = self.ffn_mid_ln(x)
+ x = self.fc2(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.ffn_ln(x)
+
+ if output_attentions:
+ return [x, attn_weights]
+ else:
+ return [x]
+
+
+class OFADecoderLayer(nn.Module):
+ """OFADecoder layer block."""
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ attn_drop=0.,
+ act_drop=0.,
+ scale_factor=2.,
+ mlp_ratio=4.,
+ encoder_embed_dim=None,
+ scale_heads=True,
+ normformer=True,
+ pre_norm=True,
+ act_cfg=dict(type='GELU')):
+ super().__init__()
+ self.embedding_dim = embedding_dim
+ self.pre_norm = pre_norm
+
+ self.self_attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ self.cross_attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ kdim=encoder_embed_dim,
+ vdim=encoder_embed_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ mid_channels = int(embedding_dim * mlp_ratio)
+ self.fc1 = nn.Linear(embedding_dim, mid_channels)
+ self.fc2 = nn.Linear(mid_channels, embedding_dim)
+ self.act = MODELS.build(act_cfg)
+ self.act_drop = nn.Dropout(
+ act_drop) if act_drop > 0. else nn.Identity()
+
+ # LayerNorm between attention block and ffn block.
+ self.self_attn_ln = nn.LayerNorm(embedding_dim)
+ self.cross_attn_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_ln = nn.LayerNorm(embedding_dim)
+
+ # Extra LayerNorm
+ self.normformer = normformer
+ if self.normformer:
+ self.self_attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.cross_attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_mid_ln = nn.LayerNorm(mid_channels)
+
+ self.dropout = nn.Dropout(dropout_rate)
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
+
+ def forward(
+ self,
+ x,
+ attention_mask=None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[List[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ self_attn_bias: Optional[torch.Tensor] = None,
+ cross_attn_bias: Optional[torch.Tensor] = None,
+ ):
+ """Forward the decoder layer.
+
+ Args:
+ x (torch.tensor): The input to the layer of shape ``(B, L, C)``.
+ attention_mask (torch.Tensor, optional): The attention mask of size
+ ``(B, 1, L, L)``, where padding elements are indicated by very
+ large negative values. Defaults to None.
+ encoder_hidden_states (torch.Tensor, optional): The cross attention
+ input to the layer of size ``(B, L, C)``. Defaults to None.
+ encoder_attention_mask (torch.Tensor, optional): The cross
+ attention mask where padding elements are indicated by very
+ large negative values. Defaults to None.
+ past_key_value (Tuple[torch.tensor], optional): The cached past key
+ and value projection states. Defaults to none.
+ output_attentions (bool): whether to return the attentions tensors
+ of all attention layers. Defaults to False.
+ use_cache (bool, optional): Whether to use cache.
+ Defaults to False.
+ self_attn_bias (torch.Tensor, optional): The self attention bias
+ for positional information. Defaults to None.
+ cross_attn_bias (torch.Tensor, optional): The cross attention bias
+ for positional information. Defaults to None.
+
+ Returns:
+ List[torch.tensor]: The first element is the encoded output of
+ shape ``(B, L, C)``. The following two elements can be the output
+ self-attentions and cross-attentions if ``output_attentions=True``.
+ The following one element can be the cached past key and value
+ projection states.
+ """
+ residual = x
+
+ if past_key_value is not None:
+ self_past_key_value = past_key_value[:2]
+ cross_past_key_value = past_key_value[2:]
+ else:
+ self_past_key_value, cross_past_key_value = None, None
+
+ # Self-Attention block
+ if self.pre_norm:
+ x = self.self_attn_ln(x)
+ x, self_attn_weights, present_key_value = self.self_attn(
+ query=x,
+ past_key_value=self_past_key_value,
+ attn_mask=attention_mask,
+ output_attentions=output_attentions,
+ attn_bias=self_attn_bias,
+ )
+ if self.normformer:
+ x = self.self_attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.self_attn_ln(x)
+
+ # Cross-Attention block
+ if encoder_hidden_states is not None:
+ residual = x
+ if self.pre_norm:
+ x = self.cross_attn_ln(x)
+ x, cross_attn_weights, cross_key_value = self.cross_attn.forward(
+ query=x,
+ key_value=encoder_hidden_states,
+ attn_mask=encoder_attention_mask,
+ past_key_value=cross_past_key_value,
+ output_attentions=output_attentions,
+ attn_bias=cross_attn_bias)
+ if self.normformer:
+ x = self.cross_attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.cross_attn_ln(x)
+
+ present_key_value = present_key_value + cross_key_value
+
+ residual = x
+
+ # FFN block
+ if self.pre_norm:
+ x = self.ffn_ln(x)
+ x = self.act(self.fc1(x))
+ x = self.act_drop(x)
+ if self.normformer:
+ x = self.ffn_mid_ln(x)
+ x = self.fc2(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.ffn_ln(x)
+
+ outputs = [x]
+
+ if output_attentions:
+ outputs.extend([self_attn_weights, cross_attn_weights])
+
+ if use_cache:
+ outputs.append(present_key_value)
+
+ return outputs
+
+
+class OFAEncoder(BaseModule):
+ """The encoder module of OFA.
+
+ Args:
+ embed_tokens (nn.Embedding): The embedding module to embed the
+ input tokens.
+ embed_images (dict | nn.Module): The module to embed the input
+ images into features. The output number of channels should
+ be 1024.
+ num_layers (int): The number of encoder layers. Defaults to 6.
+ num_heads (int): The number of heads of attention. Defaults to 12.
+ dropout_rate (float): The prob of dropout for embedding and
+ transformer layers. Defaults to 0.
+ drop_path_rate (float): The prob of droppath for transformer layers.
+ Defaults to 0.
+ max_source_positions (int): The maximum length of the input tokens.
+ Defaults to 1024.
+ token_bucket_size (int): The token bucket size, it's used as the
+ maximum relative position index in relative position embedding
+ of input tokens. Defaults to 256.
+ image_bucket_size (int): The image bucket size, it's used to generate
+ the image relative position embedding table. It should be larger
+ than the shape of image feature map. Defaults to 42.
+ attn_scale_factor (float): The scale factor to calculate qk scale in
+ attentions. Defaults to 2.
+ scale_embedding (bool): Whether to scale the embeddings by the square
+ root of the dimension. Defaults to False.
+ add_embedding_ln (bool): Whether to add an extra layer norm for token
+ embeddings. Defaults to True.
+ add_image_embedding_ln (bool): Whether to add an extra layer norm for
+ image embeddings. Defaults to True.
+ pre_norm (bool): Whether to do layer norm before attention and ffn
+ blocks in transformer layers. Defaults to True.
+ entangle_position_embedding (bool): Whether to add the position
+ embedding on the embeddings directly. Defaults to False.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ embed_tokens,
+ embed_images: dict,
+ num_layers=6,
+ num_heads=12,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ max_source_positions=1024,
+ token_bucket_size=256,
+ image_bucket_size=42,
+ attn_scale_factor=2.,
+ scale_embedding=False,
+ add_embedding_ln=True,
+ add_type_embed=True,
+ add_image_embedding_ln=True,
+ pre_norm=True,
+ entangle_position_embedding=False,
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_layers = num_layers
+ embedding_dim = embed_tokens.embedding_dim
+ self.embedding_dim = embedding_dim
+ self.padding_idx = embed_tokens.padding_idx
+ self.max_source_positions = max_source_positions
+ self.num_heads = num_heads
+
+ # Build embedding process components
+ self.embed_tokens = embed_tokens
+ self.embedding_scale = math.sqrt(
+ embedding_dim) if scale_embedding else 1.0
+
+ if not isinstance(embed_images, nn.Module):
+ self.embed_images = MODELS.build(embed_images)
+ else:
+ self.embed_images = embed_images
+ self.image_proj = nn.Linear(1024, embedding_dim)
+
+ if add_embedding_ln:
+ self.embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.embedding_ln = None
+
+ if add_type_embed:
+ self.embed_type = nn.Embedding(2, embedding_dim)
+ else:
+ self.embed_type = None
+
+ if add_image_embedding_ln:
+ self.image_embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.image_embedding_ln = None
+
+ self.entangle_position_embedding = entangle_position_embedding
+
+ # Build position embedding
+ self.embed_positions = nn.Embedding(self.max_source_positions + 2,
+ embedding_dim)
+ self.pos_ln = nn.LayerNorm(embedding_dim)
+ self.embed_image_positions = nn.Embedding(image_bucket_size**2 + 1,
+ embedding_dim)
+ self.image_pos_ln = nn.LayerNorm(embedding_dim)
+
+ self.pos_scaling = float(embedding_dim / num_heads *
+ attn_scale_factor)**-0.5
+ self.pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+
+ self.dropout = nn.Dropout(
+ dropout_rate) if dropout_rate > 0. else nn.Identity()
+
+ # Register token relative position embedding table
+ self.token_bucket_size = token_bucket_size
+ token_num_rel_dis = 2 * token_bucket_size - 1
+ token_rp_bucket = make_token_bucket_position(token_bucket_size,
+ self.max_source_positions)
+ self.register_buffer('token_rp_bucket', token_rp_bucket)
+ self.token_rel_pos_table_list = nn.ModuleList()
+
+ # Register image relative position embedding table
+ self.image_bucket_size = image_bucket_size
+ image_num_rel_dis = (2 * image_bucket_size -
+ 1) * (2 * image_bucket_size - 1) + 3
+ image_rp_bucket = make_image_bucket_position(image_bucket_size,
+ image_num_rel_dis)
+ self.register_buffer('image_rp_bucket', image_rp_bucket)
+ self.image_rel_pos_table_list = nn.ModuleList()
+
+ # Build encoder layers
+ self.layers = nn.ModuleList()
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ for index in range(self.num_layers):
+ layer = OFAEncoderLayer(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ dropout_rate=dropout_rate,
+ drop_path_rate=dpr[index],
+ scale_factor=attn_scale_factor,
+ pre_norm=pre_norm,
+ )
+ self.layers.append(layer)
+ token_pos_table = nn.Embedding(token_num_rel_dis, self.num_heads)
+ image_pos_table = nn.Embedding(image_num_rel_dis, self.num_heads)
+ nn.init.constant_(token_pos_table.weight, 0.)
+ nn.init.constant_(image_pos_table.weight, 0.)
+ self.token_rel_pos_table_list.append(token_pos_table)
+ self.image_rel_pos_table_list.append(image_pos_table)
+
+ if pre_norm:
+ self.final_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.final_ln = None
+
+ main_input_name = 'input_ids'
+
+ def forward(self,
+ input_ids,
+ images,
+ images_mask,
+ output_attentions=False,
+ output_hidden_states=False,
+ sample_patch_num=None):
+ padding_mask = input_ids.eq(self.padding_idx)
+ has_pads = padding_mask.any()
+ token_embedding = self.embed_tokens(input_ids)
+ token_embedding = self.embedding_scale * token_embedding
+
+ # Embed the token position
+ src_pos_idx = torch.arange(input_ids.size(-1), device=input_ids.device)
+ src_pos_idx = src_pos_idx.expand(*input_ids.shape).contiguous()
+ pos_embedding = self.embed_positions(src_pos_idx)
+
+ # Embed the input tokens
+ x = self.process_embedding(
+ embedding=token_embedding,
+ type_tokens=input_ids.new_zeros(token_embedding.shape[:2]),
+ pos_embedding=pos_embedding,
+ embedding_ln=self.embedding_ln,
+ )
+ pos_embedding = self.pos_ln(pos_embedding)
+
+ # Embed the input images
+ if images is not None:
+ (image_tokens, image_padding_mask, image_position_ids,
+ image_pos_embedding) = self.get_image_tokens(
+ images,
+ sample_patch_num,
+ images_mask,
+ )
+ image_embedding = self.image_proj(image_tokens)
+
+ image_x = self.process_embedding(
+ embedding=image_embedding,
+ type_tokens=input_ids.new_ones(image_embedding.shape[:2]),
+ pos_embedding=image_pos_embedding,
+ embedding_ln=self.image_embedding_ln,
+ )
+ image_pos_embedding = self.image_pos_ln(image_pos_embedding)
+
+ x = torch.cat([image_x, x], dim=1)
+ padding_mask = torch.cat([image_padding_mask, padding_mask], dim=1)
+ pos_embedding = torch.cat([image_pos_embedding, pos_embedding],
+ dim=1)
+
+ # account for padding while computing the representation
+ if has_pads:
+ x = x * (1 - padding_mask.unsqueeze(-1).type_as(x))
+
+ # Decoupled position embedding
+ B, L = pos_embedding.shape[:2]
+ pos_q = self.pos_q_linear(pos_embedding).view(
+ B, L, self.num_heads, -1).transpose(1, 2) * self.pos_scaling
+ pos_k = self.pos_k_linear(pos_embedding).view(B, L, self.num_heads,
+ -1).transpose(1, 2)
+ abs_pos_bias = torch.matmul(pos_q, pos_k.transpose(2, 3))
+
+ all_hidden_states = [] if output_hidden_states else None
+ all_attentions = [] if output_attentions else None
+
+ for idx, layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ self_attn_bias = abs_pos_bias.clone()
+ # Add decoupled position embedding for input tokens.
+ token_len = input_ids.size(1)
+ rel_pos_bias = self.get_rel_pos_bias(input_ids, idx)
+ self_attn_bias[:, :, -token_len:, -token_len:] += rel_pos_bias
+
+ # Add decoupled position embedding for images
+ if images is not None:
+ token_len = image_tokens.size(1)
+ rel_pos_bias = self.get_image_rel_pos_bias(
+ image_position_ids, idx)
+ self_attn_bias[:, :, :token_len, :token_len] += rel_pos_bias
+
+ if has_pads:
+ attention_mask = _expand_mask(padding_mask, dtype=x.dtype)
+ else:
+ attention_mask = None
+
+ out = layer(
+ x,
+ attention_mask=attention_mask,
+ attn_bias=self_attn_bias,
+ output_attentions=output_attentions)
+ x = out[0]
+
+ if output_attentions:
+ all_attentions.append(out[1])
+
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ if self.final_ln is not None:
+ x = self.final_ln(x)
+
+ return OFAEncoderOutput(
+ last_hidden_state=x, # (B, L, C)
+ padding_mask=padding_mask, # (B, L)
+ position_embedding=pos_embedding, # (B, L, C)
+ hidden_states=all_hidden_states, # list of (B, L, C)
+ attentions=all_attentions, # list of (B, num_heads, L, head_dims)
+ )
+
+ def get_image_tokens(self, images, sample_patch_num, images_mask):
+ image_embedding = self.embed_images(images)[-1]
+ B, C, H, W = image_embedding.shape
+ num_patches = H * W
+
+ padding_mask = images.new_zeros((B, num_patches)).bool()
+ position_col = torch.arange(W).unsqueeze(0)
+ position_row = torch.arange(H).unsqueeze(1) * self.image_bucket_size
+ position_idx = (position_col + position_row + 1).view(-1)
+ position_idx = position_idx.to(images.device).expand(B, num_patches)
+
+ # (B, C, H, W) -> (B, C, H*W) -> (B, H*W, C)
+ image_embedding = image_embedding.flatten(2).transpose(1, 2)
+ if sample_patch_num is not None:
+ patch_orders = torch.stack([
+ torch.randperm(num_patches)[:sample_patch_num]
+ for _ in range(B)
+ ])
+ num_patches = sample_patch_num
+ image_embedding = image_embedding.gather(
+ dim=1, index=patch_orders.unsqueeze(2).expand(-1, -1, C))
+ padding_mask = padding_mask.gather(1, patch_orders)
+ position_idx = position_idx.gather(1, patch_orders)
+
+ pos_embedding = self.embed_image_positions(position_idx)
+ padding_mask[~images_mask] = True
+ return image_embedding, padding_mask, position_idx, pos_embedding
+
+ def process_embedding(self,
+ embedding,
+ pos_embedding=None,
+ type_tokens=None,
+ embedding_ln=None):
+ if self.entangle_position_embedding and pos_embedding is not None:
+ embedding += pos_embedding
+ if self.embed_type is not None:
+ embedding += self.embed_type(type_tokens)
+ if embedding_ln is not None:
+ embedding = embedding_ln(embedding)
+ embedding = self.dropout(embedding)
+
+ return embedding
+
+ def get_rel_pos_bias(self, x, idx):
+ seq_len = x.size(1)
+ rp_bucket = self.token_rp_bucket[:seq_len, :seq_len]
+ values = F.embedding(rp_bucket,
+ self.token_rel_pos_table_list[idx].weight)
+ values = values.unsqueeze(0).expand(x.size(0), -1, -1, -1)
+ values = values.permute([0, 3, 1, 2])
+ return values.contiguous()
+
+ def get_image_rel_pos_bias(self, image_position_ids, idx):
+ bsz, seq_len = image_position_ids.shape
+ rp_bucket_size = self.image_rp_bucket.size(1)
+
+ rp_bucket = self.image_rp_bucket.unsqueeze(0).expand(
+ bsz, rp_bucket_size, rp_bucket_size).gather(
+ 1, image_position_ids[:, :, None].expand(
+ bsz, seq_len, rp_bucket_size)).gather(
+ 2, image_position_ids[:, None, :].expand(
+ bsz, seq_len, seq_len))
+ values = F.embedding(rp_bucket,
+ self.image_rel_pos_table_list[idx].weight)
+ values = values.permute(0, 3, 1, 2)
+ return values
+
+
+class OFADecoder(BaseModule):
+ """The decoder module of OFA.
+
+ Args:
+ embed_tokens (nn.Embedding): The embedding module to embed the
+ input tokens.
+ num_layers (int): The number of decoder layers. Defaults to 6.
+ num_heads (int): The number of heads of attention. Defaults to 12.
+ dropout_rate (float): The prob of dropout for embedding and
+ transformer layers. Defaults to 0.
+ drop_path_rate (float): The prob of droppath for transformer layers.
+ Defaults to 0.
+ max_target_positions (int): The maximum length of the input tokens.
+ Defaults to 1024.
+ code_image_size (int): The resolution of the generated image in the
+ image infilling task. Defaults to 128.
+ token_bucket_size (int): The token bucket size, it's used as the
+ maximum relative position index in relative position embedding
+ of input tokens. Defaults to 256.
+ image_bucket_size (int): The image bucket size, it's used to generate
+ the image relative position embedding table. It should be larger
+ than the shape of image feature map. Defaults to 42.
+ attn_scale_factor (float): The scale factor to calculate qk scale in
+ attentions. Defaults to 2.
+ scale_embedding (bool): Whether to scale the embeddings by the square
+ root of the dimension. Defaults to False.
+ add_embedding_ln (bool): Whether to add an extra layer norm for token
+ embeddings. Defaults to True.
+ add_code_embedding_ln (bool): Whether to add an extra layer norm for
+ code embeddings. Defaults to True.
+ pre_norm (bool): Whether to do layer norm before attention and ffn
+ blocks in transformer layers. Defaults to True.
+ entangle_position_embedding (bool): Whether to add the position
+ embedding on the embeddings directly. Defaults to False.
+ share_input_output_embed (bool): Share the weights of the input token
+ embedding module and the output projection module.
+ Defaults to True.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ embed_tokens,
+ num_layers=6,
+ num_heads=12,
+ dropout_rate=0.,
+ drop_layer_rate=0.,
+ drop_path_rate=0.,
+ max_target_positions=1024,
+ code_image_size=128,
+ token_bucket_size=256,
+ image_bucket_size=42,
+ attn_scale_factor=2.,
+ scale_embedding=False,
+ add_embedding_ln=True,
+ add_code_embedding_ln=True,
+ pre_norm=True,
+ entangle_position_embedding=False,
+ share_input_output_embed=True,
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+ self._future_mask = torch.empty(0)
+
+ self.num_layers = num_layers
+ embedding_dim = embed_tokens.embedding_dim
+ self.embedding_dim = embedding_dim
+ self.padding_idx = embed_tokens.padding_idx
+ self.max_target_positions = max_target_positions
+ self.num_heads = num_heads
+
+ # Build embedding process components
+ self.embed_tokens = embed_tokens
+ self.embedding_scale = math.sqrt(
+ embedding_dim) if scale_embedding else 1.0
+
+ if add_embedding_ln:
+ self.embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.embedding_ln = None
+
+ if add_code_embedding_ln:
+ self.code_embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.code_embedding_ln = None
+
+ # Build position embedding
+ self.embed_positions = nn.Embedding(self.max_target_positions + 2,
+ embedding_dim)
+ self.pos_ln = nn.LayerNorm(embedding_dim)
+ self.embed_image_positions = nn.Embedding(image_bucket_size**2 + 1,
+ embedding_dim)
+ self.image_pos_ln = nn.LayerNorm(embedding_dim)
+
+ self.pos_scaling = float(embedding_dim / num_heads *
+ attn_scale_factor)**-0.5
+ self.self_pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.self_pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.cross_pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.cross_pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+
+ self.entangle_position_embedding = entangle_position_embedding
+
+ self.dropout = nn.Dropout(
+ dropout_rate) if dropout_rate > 0. else nn.Identity()
+ if drop_layer_rate > 0.:
+ raise NotImplementedError
+
+ # Register token relative position embedding table
+ self.token_bucket_size = token_bucket_size
+ token_num_rel_dis = 2 * token_bucket_size - 1
+ token_rp_bucket = make_token_bucket_position(token_bucket_size)
+ self.register_buffer('token_rp_bucket', token_rp_bucket)
+ self.token_rel_pos_table_list = nn.ModuleList()
+
+ # Register image relative position embedding table
+ self.image_bucket_size = image_bucket_size
+ image_num_rel_dis = (2 * image_bucket_size -
+ 1) * (2 * image_bucket_size - 1) + 3
+ image_rp_bucket = make_image_bucket_position(image_bucket_size,
+ image_num_rel_dis)
+ self.register_buffer('image_rp_bucket', image_rp_bucket)
+ self.image_rel_pos_table_list = nn.ModuleList()
+
+ self.window_size = code_image_size // 8
+
+ position_col = torch.arange(self.window_size).unsqueeze(0)
+ position_row = torch.arange(
+ self.window_size).unsqueeze(1) * self.image_bucket_size
+ image_position_idx = (position_col + position_row + 1)
+ image_position_idx = torch.cat(
+ [torch.tensor([0]), image_position_idx.view(-1)])
+ image_position_idx = torch.cat(
+ [image_position_idx,
+ torch.tensor([1024] * 768)])
+ self.register_buffer('image_position_idx', image_position_idx)
+
+ # Build decoder layers
+ self.layers = nn.ModuleList()
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ for index in range(self.num_layers):
+ layer = OFADecoderLayer(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ dropout_rate=dropout_rate,
+ drop_path_rate=dpr[index],
+ scale_factor=attn_scale_factor,
+ pre_norm=pre_norm,
+ )
+ self.layers.append(layer)
+ token_pos_table = nn.Embedding(token_num_rel_dis, self.num_heads)
+ image_pos_table = nn.Embedding(image_num_rel_dis, self.num_heads)
+ nn.init.constant_(token_pos_table.weight, 0.)
+ nn.init.constant_(image_pos_table.weight, 0.)
+ self.token_rel_pos_table_list.append(token_pos_table)
+ self.image_rel_pos_table_list.append(image_pos_table)
+
+ if pre_norm:
+ self.final_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.final_ln = None
+
+ # Build output projection
+ if share_input_output_embed:
+ self.output_projection = nn.Linear(
+ self.embed_tokens.weight.shape[1],
+ self.embed_tokens.weight.shape[0],
+ bias=False,
+ )
+ self.output_projection.weight = self.embed_tokens.weight
+ else:
+ vocab_size = self.embed_tokens.num_embeddings
+ self.output_projection = nn.Linear(
+ embedding_dim, vocab_size, bias=False)
+ nn.init.normal_(
+ self.output_projection.weight,
+ mean=0,
+ std=embedding_dim**-0.5,
+ )
+
+ main_input_name = 'input_ids'
+
+ def forward(
+ self,
+ input_ids: torch.Tensor = None,
+ attention_mask: torch.Tensor = None,
+ encoder_hidden_states: torch.Tensor = None,
+ encoder_attention_mask: torch.Tensor = None,
+ code_masks: Optional[torch.Tensor] = None,
+ encoder_pos_embedding: Optional[torch.Tensor] = None,
+ past_key_values: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ):
+
+ if past_key_values is not None and len(past_key_values) > 0:
+ B, _, L_past, _ = past_key_values[0][0].shape
+ L = L_past + 1
+ else:
+ B, L = input_ids.shape
+ L_past = 0
+
+ # Embed the token position
+ target_pos_idx = torch.arange(
+ L, device=input_ids.device).expand([B, L]).contiguous()
+ pos_embedding = self.embed_positions(target_pos_idx)
+
+ # Embed the code positions
+ if code_masks is not None and torch.any(code_masks):
+ image_position_idx = self.image_position_idx[:input_ids.size(1)]
+ image_position_idx = image_position_idx.unsqueeze(0).expand(B, L)
+ pos_embedding[code_masks] = self.embed_image_positions(
+ image_position_idx)[code_masks]
+
+ # Self-attention position bias (B, num_heads, L_t, L_t)
+ self_abs_pos_bias = self.get_pos_info(self.pos_ln(pos_embedding))
+ if code_masks is not None and torch.any(code_masks):
+ self_image_abs_pos_bias = self.get_pos_info(
+ self.image_pos_ln(pos_embedding))
+ self_abs_pos_bias[code_masks] = self_image_abs_pos_bias[code_masks]
+
+ # Cross-attention position bias (B, num_heads, L_t, L_s)
+ cross_abs_pos_bias = self.get_pos_info(
+ self.pos_ln(pos_embedding), encoder_pos_embedding)
+ if code_masks is not None and torch.any(code_masks):
+ cross_image_abs_pos_bias = self.get_pos_info(
+ self.image_pos_ln(pos_embedding), encoder_pos_embedding)
+ cross_abs_pos_bias[code_masks] = cross_image_abs_pos_bias[
+ code_masks]
+
+ all_prev_output_tokens = input_ids.clone()
+ if past_key_values is not None and len(past_key_values) > 0:
+ input_ids = input_ids[:, -1:]
+ cross_abs_pos_bias = cross_abs_pos_bias[:, :, -1:, :]
+ pos_embedding = pos_embedding[:, -1:, :]
+
+ # Embed the input tokens
+ x = self.embed_tokens(input_ids) * self.embedding_scale
+
+ if self.entangle_position_embedding:
+ x += pos_embedding
+
+ if self.embedding_ln is not None:
+ if (code_masks is None or not code_masks.any()
+ or self.code_embedding_ln is None):
+ x = self.embedding_ln(x)
+ elif code_masks is not None and code_masks.all():
+ x = self.code_embedding_ln(x)
+ else:
+ x[~code_masks] = self.embedding_ln(x[~code_masks])
+ x[code_masks] = self.code_embedding_ln(x[code_masks])
+
+ x = self.dropout(x)
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, input_ids.shape, x.dtype, L_past)
+ attention_mask = attention_mask.to(x.device)
+
+ # decoder layers
+ all_hidden_states = [] if output_hidden_states else None
+ all_self_attns = [] if output_attentions else None
+ all_cross_attentions = [] if (
+ output_attentions and encoder_hidden_states is not None) else None
+ next_decoder_cache = [] if use_cache else None
+
+ for idx, layer in enumerate(self.layers):
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ if past_key_values is not None and len(past_key_values) > 0:
+ past_key_value = past_key_values[idx]
+ else:
+ past_key_value = None
+
+ self_attn_bias = self_abs_pos_bias.clone()
+ if code_masks is None or not code_masks.any():
+ self_attn_bias += self.get_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ elif code_masks is not None and code_masks.all():
+ self_attn_bias += self.get_image_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ else:
+ self_attn_bias[~code_masks] += self.get_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ self_attn_bias[code_masks] += self.get_image_rel_pos_bias(
+ all_prev_output_tokens, idx)
+
+ if past_key_value is not None:
+ self_attn_bias = self_attn_bias[:, :, -1:, :]
+
+ out = layer(
+ x,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ self_attn_bias=self_attn_bias,
+ cross_attn_bias=cross_abs_pos_bias,
+ )
+ x = out.pop(0)
+
+ if output_attentions:
+ all_self_attns.append(out.pop(0))
+ if encoder_hidden_states is not None:
+ all_cross_attentions.append(out.pop(0))
+
+ if use_cache:
+ next_decoder_cache.append(out.pop(0))
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (x, )
+
+ if self.final_ln is not None:
+ x = self.final_ln(x)
+
+ x = self.output_projection(x)
+
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=x,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ cross_attentions=all_cross_attentions,
+ )
+
+ def _prepare_decoder_attention_mask(
+ self,
+ attention_mask,
+ input_shape,
+ dtype,
+ past_key_values_length,
+ ):
+ r"""
+ Create causal mask for unidirectional decoding.
+ [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ """
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ dtype,
+ past_key_values_length=past_key_values_length).to(
+ attention_mask.device)
+
+ if attention_mask is not None:
+ # (B, L_s) -> (B, 1, L_t, L_s)
+ expanded_attention_mask = _expand_mask(
+ attention_mask, dtype, tgt_len=input_shape[-1])
+ combined_attention_mask = (
+ expanded_attention_mask if combined_attention_mask is None else
+ expanded_attention_mask + combined_attention_mask)
+
+ return combined_attention_mask
+
+ def get_pos_info(self, pos_embedding, src_pos_embedding=None):
+ B, tgt_len = pos_embedding.shape[:2]
+ if src_pos_embedding is not None:
+ src_len = src_pos_embedding.size(1)
+ pos_q = self.cross_pos_q_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+ pos_q = pos_q * self.pos_scaling
+ pos_k = self.cross_pos_k_linear(src_pos_embedding).view(
+ B, src_len, self.num_heads, -1).transpose(1, 2)
+ else:
+ pos_q = self.self_pos_q_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+ pos_q = pos_q * self.pos_scaling
+ pos_k = self.self_pos_k_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+
+ abs_pos_bias = torch.matmul(pos_q, pos_k.transpose(2, 3))
+
+ return abs_pos_bias
+
+ def get_rel_pos_bias(self, x, idx):
+ seq_len = x.size(1)
+ rp_bucket = self.token_rp_bucket[:seq_len, :seq_len]
+ values = F.embedding(rp_bucket,
+ self.token_rel_pos_table_list[idx].weight)
+ values = values.unsqueeze(0).expand(x.size(0), -1, -1, -1)
+ values = values.permute([0, 3, 1, 2])
+ return values.contiguous()
+
+ def get_image_rel_pos_bias(self, image_position_ids, idx):
+ bsz, seq_len = image_position_ids.shape
+ rp_bucket_size = self.image_rp_bucket.size(1)
+
+ rp_bucket = self.image_rp_bucket.unsqueeze(0).expand(
+ bsz, rp_bucket_size, rp_bucket_size).gather(
+ 1, image_position_ids[:, :, None].expand(
+ bsz, seq_len, rp_bucket_size)).gather(
+ 2, image_position_ids[:, None, :].expand(
+ bsz, seq_len, seq_len))
+ values = F.embedding(rp_bucket,
+ self.image_rel_pos_table_list[idx].weight)
+ values = values.permute(0, 3, 1, 2)
+ return values
+
+
+class OFAEncoderDecoder(BaseModule, GenerationMixin):
+ """The OFA main architecture with an encoder and a decoder.
+
+ Args:
+ encoder_cfg (dict): The config of the encoder, accept the keyword
+ arguments of :class:`OFAEncoder`.
+ decoder_cfg (dict): The config of the decoder, accept the keyword
+ arguments of :class:`OFADecoder`.
+ padding_idx (int): The index of the padding token.
+ vocab_size (int): The size of the vocabulary.
+ embedding_dim (int): The embedding dimensions of both the encoder
+ and the decoder.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of :class:`~transformers.GenerationConfig`.
+ Defaults to an empty dict.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ encoder_cfg,
+ decoder_cfg,
+ padding_idx,
+ vocab_size,
+ embedding_dim,
+ generation_cfg=dict(),
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.padding_idx = padding_idx
+ self.vocab_size = vocab_size
+ self.embedding_dim = embedding_dim
+ embed_tokens = nn.Embedding(vocab_size, embedding_dim, padding_idx)
+
+ self.encoder = OFAEncoder(embed_tokens, **encoder_cfg)
+ self.decoder = OFADecoder(embed_tokens, **decoder_cfg)
+
+ self.config = PretrainedConfig(
+ vocab_size=vocab_size,
+ embedding_dim=embedding_dim,
+ padding_idx=padding_idx,
+ bos_token_id=0,
+ decoder_start_token_id=0,
+ pad_token_id=1,
+ eos_token_id=2,
+ forced_eos_token_id=2,
+ use_cache=False,
+ is_encoder_decoder=True,
+ )
+ self.config.update(generation_cfg)
+
+ self.generation_config = GenerationConfig.from_model_config(
+ self.config)
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def can_generate(self):
+ return True
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ def max_decoder_positions(self):
+ """Maximum length supported by the decoder."""
+ return self.decoder.max_positions()
+
+ def get_normalized_probs(self, net_output, log_probs: bool, sample=None):
+ """Get normalized probabilities (or log probs) from a net's output."""
+ return self.get_normalized_probs_scriptable(net_output, log_probs,
+ sample)
+
+ def get_normalized_probs_scriptable(
+ self,
+ net_output,
+ log_probs: bool,
+ sample=None,
+ ):
+ """Scriptable helper function for get_normalized_probs in.
+
+ ~BaseFairseqModel.
+ """
+ if hasattr(self, 'decoder'):
+ return self.decoder.get_normalized_probs(net_output, log_probs,
+ sample)
+ elif torch.is_tensor(net_output):
+ # syntactic sugar for simple models which don't have a decoder
+ # (e.g., the classification tutorial)
+ logits = net_output.float()
+ if log_probs:
+ return F.log_softmax(logits, dim=-1)
+ else:
+ return F.softmax(logits, dim=-1)
+ raise NotImplementedError
+
+ main_input_name = 'input_ids'
+
+ def forward(self,
+ input_ids=None,
+ images=None,
+ images_mask=None,
+ sample_patch_num=None,
+ decoder_input_ids=None,
+ code_masks=None,
+ attention_mask=None,
+ encoder_outputs=None,
+ past_key_values=None,
+ use_cache=False,
+ output_attentions=False,
+ output_hidden_states=False,
+ constrain_fn=None,
+ return_dict=False):
+ """Forword the module.
+
+ Args:
+ input_ids (torch.Tensor): The indices of the input tokens in the
+ vocabulary, and padding will be ignored by default. The indices
+ can be obtained using :class:`OFATokenizer`.
+ The shape is (B, L).
+ images (torch.Tensor): The input images. The shape is (B, 3, H, W).
+ images_mask (torch.Tensor): The mask of all available images. The
+ shape is (B, ).
+ sample_patch_num (int): The number of patches to sample for the
+ images. Defaults to None, which means to use all patches.
+ decoder_input_ids (torch.Tensor): The indices of the input tokens
+ for the decoder.
+ code_masks (torch.Tensor): The mask of all samples for image
+ generation. The shape is (B, ).
+ attention_mask (torch.Tensor): The attention mask for decoding.
+ The shape is (B, L).
+ encoder_outputs (OFAEncoderOutput): The encoder outputs with hidden
+ states, positional embeddings, and padding masks.
+ past_key_values (Tuple[Tuple[torch.Tensor]]): If use cache, the
+ parameter is a tuple of length ``num_layers``. Every item is
+ also a tuple with four tensors, two for the key and value of
+ self-attention, two for the key and value of cross-attention.
+ use_cache (bool): Whether to use cache for faster inference.
+ Defaults to False.
+ output_attentions (bool): Whether to output attention weights.
+ Defaults to False.
+ output_hidden_states (bool): Whether to output hidden states.
+ Defaults to False.
+ constrain_fn (Callable, optional): The function to constrain the
+ output logits. Defaults to None.
+ return_dict (bool): Not used, it's only for compat with the
+ interface of the ``generate`` of ``transformers``.
+
+ Returns:
+ Seq2SeqLMOutput:
+
+ - logits (``torch.Tensor``): The last decoder hidden states.
+ The shape is (B, L, C).
+ - past_key_values (``Tuple[Tuple[torch.Tensor]]``): The past keys
+ and values for faster inference.
+ - decoder_hidden_states (``Tuple[torch.Tensor]``): the decoder
+ hidden states of all layers.
+ - decoder_attentions (``Tuple[torch.Tensor]``): The self-attention
+ weights of all layers in the decoder.
+ - cross_attentions (``Tuple[torch.Tensor]``): The cross-attention
+ weights of all layers in the decoder.
+ - encoder_last_hidden_state (``torch.Tensor``): The last encoder
+ hidden states.
+ - encoder_hidden_states (``Tuple[torch.Tensor]``): The encoder
+ hidden states of all layers, including the embeddings.
+ - encoder_attentions (``Tuple[torch.Tensor]``): The self-attention
+ weights of all layers in the encoder.
+ """
+
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ images=images,
+ images_mask=images_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ sample_patch_num=sample_patch_num,
+ )
+
+ if decoder_input_ids.eq(self.padding_idx).any():
+ attention_mask = decoder_input_ids.eq(self.padding_idx)
+
+ encoder_hidden_states = encoder_outputs.last_hidden_state
+ encoder_attention_mask = _expand_mask(encoder_outputs.padding_mask,
+ encoder_hidden_states.dtype,
+ decoder_input_ids.shape[-1])
+ src_pos_embed = encoder_outputs.position_embedding
+
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ code_masks=code_masks,
+ encoder_pos_embedding=src_pos_embed,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ # The constrain operation for fine-tuned model in OFA is applied
+ # before log_softmax, therefore we cannot use
+ # `prefix_allowed_tokens_fn` to implement it.
+ if constrain_fn is not None:
+ logits = constrain_fn(decoder_input_ids,
+ decoder_outputs.last_hidden_state)
+ else:
+ logits = decoder_outputs.last_hidden_state
+
+ return Seq2SeqLMOutput(
+ logits=logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ decoder_input_ids=None,
+ past=None,
+ attention_mask=None,
+ code_masks=None,
+ use_cache=False,
+ encoder_outputs=None,
+ constrain_fn=None,
+ **kwargs):
+ # if attention_mask is None:
+ attention_mask = decoder_input_ids.new_zeros(decoder_input_ids.shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ decoder_input_ids = decoder_input_ids[:, -1:]
+
+ return {
+ 'input_ids': None,
+ 'images': None,
+ 'images_mask': None,
+ 'sample_patch_num': None,
+ 'attention_mask': attention_mask,
+ 'encoder_outputs': encoder_outputs,
+ 'past_key_values': past,
+ 'decoder_input_ids': decoder_input_ids,
+ 'code_masks': code_masks,
+ 'use_cache': use_cache,
+ 'constrain_fn': constrain_fn,
+ }
+
+ def _prepare_encoder_decoder_kwargs_for_generation(
+ self,
+ inputs_tensor: torch.Tensor,
+ model_kwargs,
+ model_input_name: Optional[str] = None):
+ # 1. get encoder
+ encoder = self.get_encoder()
+
+ # 2. prepare encoder args and encoder kwargs from model kwargs
+ irrelevant_prefix = [
+ 'decoder_', 'cross_attn', 'use_cache', 'attention_mask',
+ 'constrain_fn'
+ ]
+ encoder_kwargs = {
+ argument: value
+ for argument, value in model_kwargs.items()
+ if not any(argument.startswith(p) for p in irrelevant_prefix)
+ }
+
+ if encoder_kwargs.get('images_mask') is None:
+ encoder_kwargs['images_mask'] = torch.tensor([True] *
+ inputs_tensor.size(0))
+
+ # 3. make sure that encoder returns `ModelOutput`
+ model_input_name = model_input_name or self.main_input_name
+ encoder_kwargs[model_input_name] = inputs_tensor
+ model_kwargs['encoder_outputs']: ModelOutput = encoder(
+ **encoder_kwargs)
+ model_kwargs['attention_mask'] = None
+
+ return model_kwargs
+
+ @staticmethod
+ def _reorder_cache(past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+ @staticmethod
+ def _expand_inputs_for_generation(
+ input_ids: torch.LongTensor,
+ expand_size: int = 1,
+ is_encoder_decoder: bool = False,
+ attention_mask: Optional[torch.LongTensor] = None,
+ encoder_outputs: Optional[ModelOutput] = None,
+ **model_kwargs,
+ ):
+ expanded_return_idx = (
+ torch.arange(input_ids.shape[0]).view(-1, 1).repeat(
+ 1, expand_size).view(-1).to(input_ids.device))
+ input_ids = input_ids.index_select(0, expanded_return_idx)
+
+ if attention_mask is not None:
+ model_kwargs['attention_mask'] = attention_mask.index_select(
+ 0, expanded_return_idx)
+
+ if is_encoder_decoder:
+ if encoder_outputs is None:
+ raise ValueError('If `is_encoder_decoder` is True, make '
+ 'sure that `encoder_outputs` is defined.')
+ encoder_outputs['last_hidden_state'] = encoder_outputs.\
+ last_hidden_state.index_select(0, expanded_return_idx)
+ encoder_outputs['position_embedding'] = encoder_outputs.\
+ position_embedding.index_select(0, expanded_return_idx)
+ encoder_outputs['padding_mask'] = encoder_outputs.\
+ padding_mask.index_select(0, expanded_return_idx)
+ model_kwargs['encoder_outputs'] = encoder_outputs
+ return input_ids, model_kwargs
diff --git a/mmpretrain/models/utils/__init__.py b/mmpretrain/models/utils/__init__.py
index b7df9e415eb..1f5c14c7aa1 100644
--- a/mmpretrain/models/utils/__init__.py
+++ b/mmpretrain/models/utils/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
from .attention import (BEiTAttention, ChannelMultiheadAttention,
CrossMultiheadAttention, LeAttention,
MultiheadAttention, PromptMultiheadAttention,
@@ -6,8 +7,10 @@
from .batch_augments import CutMix, Mixup, RandomBatchAugment, ResizeMix
from .batch_shuffle import batch_shuffle_ddp, batch_unshuffle_ddp
from .channel_shuffle import channel_shuffle
-from .clip_generator_helper import build_clip_model
-from .data_preprocessor import (ClsDataPreprocessor, SelfSupDataPreprocessor,
+from .clip_generator_helper import QuickGELU, build_clip_model
+from .data_preprocessor import (ClsDataPreprocessor,
+ MultiModalDataPreprocessor,
+ SelfSupDataPreprocessor,
TwoNormDataPreprocessor, VideoDataPreprocessor)
from .ema import CosineEMA
from .embed import (HybridEmbed, PatchEmbed, PatchMerging, resize_pos_embed,
@@ -70,7 +73,19 @@
'VideoDataPreprocessor',
'CosineEMA',
'ResLayerExtraNorm',
+ 'MultiModalDataPreprocessor',
+ 'QuickGELU',
'SwiGLUFFN',
'SwiGLUFFNFused',
'RotaryEmbeddingFast',
]
+
+if WITH_MULTIMODAL:
+ from .huggingface import (no_load_hf_pretrained_model, register_hf_model,
+ register_hf_tokenizer)
+ from .tokenizer import Blip2Tokenizer, BlipTokenizer, OFATokenizer
+
+ __all__.extend([
+ 'BlipTokenizer', 'OFATokenizer', 'Blip2Tokenizer', 'register_hf_model',
+ 'register_hf_tokenizer', 'no_load_hf_pretrained_model'
+ ])
diff --git a/mmpretrain/models/utils/box_utils.py b/mmpretrain/models/utils/box_utils.py
new file mode 100644
index 00000000000..79db516c990
--- /dev/null
+++ b/mmpretrain/models/utils/box_utils.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torchvision.ops.boxes as boxes
+
+
+def box_cxcywh_to_xyxy(x):
+ x_c, y_c, w, h = x.unbind(-1)
+ b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
+ return torch.stack(b, dim=-1)
+
+
+def box_xyxy_to_cxcywh(x):
+ x0, y0, x1, y1 = x.unbind(-1)
+ b = [(x0 + x1) / 2.0, (y0 + y1) / 2.0, (x1 - x0), (y1 - y0)]
+ return torch.stack(b, dim=-1)
+
+
+def box_iou(boxes1, boxes2):
+ """Return intersection-over-union (Jaccard index) between two sets of
+ boxes.
+
+ Both sets of boxes are expected to be in ``(x1, y1, x2, y2)`` format with
+ ``0 <= x1 < x2`` and ``0 <= y1 < y2``.
+
+ Args:
+ boxes1 (Tensor[N, 4]): first set of boxes
+ boxes2 (Tensor[M, 4]): second set of boxes
+
+ Returns:
+ Tensor[N, M]: the NxM matrix containing the pairwise IoU values for
+ every element in boxes1 and boxes2
+ """
+ return boxes.box_iou(boxes1, boxes2)
+
+
+def generalized_box_iou(boxes1, boxes2):
+ """Return generalized intersection-over-union (Jaccard index) between two
+ sets of boxes.
+
+ Both sets of boxes are expected to be in ``(x1, y1, x2, y2)`` format with
+ ``0 <= x1 < x2`` and ``0 <= y1 < y2``.
+
+ Args:
+ boxes1 (Tensor[N, 4]): first set of boxes
+ boxes2 (Tensor[M, 4]): second set of boxes
+
+ Returns:
+ Tensor[N, M]: the NxM matrix containing the pairwise generalized IoU
+ values for every element in boxes1 and boxes2
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+
+ return boxes.generalized_box_iou(boxes1, boxes2)
diff --git a/mmpretrain/models/utils/clip_generator_helper.py b/mmpretrain/models/utils/clip_generator_helper.py
index 90d7b483206..4f67f0ed697 100644
--- a/mmpretrain/models/utils/clip_generator_helper.py
+++ b/mmpretrain/models/utils/clip_generator_helper.py
@@ -8,6 +8,8 @@
from mmengine.logging import MMLogger
from torch import nn
+from mmpretrain.registry import MODELS
+
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
@@ -19,6 +21,7 @@ def forward(self, x: torch.Tensor) -> torch.Tensor:
return ret.type(orig_type)
+@MODELS.register_module()
class QuickGELU(nn.Module):
"""A faster version of GELU."""
diff --git a/mmpretrain/models/utils/data_preprocessor.py b/mmpretrain/models/utils/data_preprocessor.py
index 8f3fcb9f62c..c407bd4c936 100644
--- a/mmpretrain/models/utils/data_preprocessor.py
+++ b/mmpretrain/models/utils/data_preprocessor.py
@@ -515,3 +515,106 @@ def forward(
batch_inputs = (batch_inputs - self.mean) / self.std
return {'inputs': batch_inputs, 'data_samples': batch_data_samples}
+
+
+@MODELS.register_module()
+class MultiModalDataPreprocessor(BaseDataPreprocessor):
+ """Data pre-processor for image-text multimodality tasks.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Number = 0,
+ to_rgb: bool = False,
+ ):
+ super().__init__()
+ self.pad_size_divisor = pad_size_divisor
+ self.pad_value = pad_value
+ self.to_rgb = to_rgb
+
+ if mean is not None:
+ assert std is not None, 'To enable the normalization in ' \
+ 'preprocessing, please specify both `mean` and `std`.'
+ # Enable the normalization in preprocessing.
+ self._enable_normalize = True
+ self.register_buffer('mean',
+ torch.tensor(mean).view(-1, 1, 1), False)
+ self.register_buffer('std',
+ torch.tensor(std).view(-1, 1, 1), False)
+ else:
+ self._enable_normalize = False
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization, padding, bgr2rgb conversion and batch
+ augmentation based on ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ data = self.cast_data(data)
+
+ imgs = data.get('inputs', None)
+
+ def _process_img(img):
+ # ------ To RGB ------
+ if self.to_rgb and img.size(1) == 3:
+ img = img.flip(1)
+
+ # -- Normalization ---
+ img = img.float()
+ if self._enable_normalize:
+ img = (img - self.mean) / self.std
+
+ # ------ Padding -----
+ if self.pad_size_divisor > 1:
+ h, w = img.shape[-2:]
+
+ target_h = math.ceil(
+ h / self.pad_size_divisor) * self.pad_size_divisor
+ target_w = math.ceil(
+ w / self.pad_size_divisor) * self.pad_size_divisor
+ pad_h = target_h - h
+ pad_w = target_w - w
+ img = F.pad(img, (0, pad_w, 0, pad_h), 'constant',
+ self.pad_value)
+ return img
+
+ if isinstance(imgs, torch.Tensor):
+ imgs = _process_img(imgs)
+ elif isinstance(imgs, Sequence):
+ # B, T, C, H, W
+ imgs = torch.stack([_process_img(img) for img in imgs], dim=1)
+ elif imgs is not None:
+ raise ValueError(f'{type(imgs)} is not supported for imgs inputs.')
+
+ data_samples = data.get('data_samples', None)
+
+ return {'images': imgs, 'data_samples': data_samples}
diff --git a/mmpretrain/models/utils/huggingface.py b/mmpretrain/models/utils/huggingface.py
new file mode 100644
index 00000000000..e527315b26e
--- /dev/null
+++ b/mmpretrain/models/utils/huggingface.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import contextlib
+from typing import Optional
+
+import transformers
+from mmengine.registry import Registry
+from transformers import AutoConfig, PreTrainedModel
+from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+def register_hf_tokenizer(
+ cls: Optional[type] = None,
+ registry: Registry = TOKENIZER,
+):
+ """Register HuggingFace-style PreTrainedTokenizerBase class."""
+ if cls is None:
+
+ # use it as a decorator: @register_hf_tokenizer()
+ def _register(cls):
+ register_hf_tokenizer(cls=cls)
+ return cls
+
+ return _register
+
+ def from_pretrained(**kwargs):
+ if ('pretrained_model_name_or_path' not in kwargs
+ and 'name_or_path' not in kwargs):
+ raise TypeError(
+ f'{cls.__name__}.from_pretrained() missing required '
+ "argument 'pretrained_model_name_or_path' or 'name_or_path'.")
+ # `pretrained_model_name_or_path` is too long for config,
+ # add an alias name `name_or_path` here.
+ name_or_path = kwargs.pop('pretrained_model_name_or_path',
+ kwargs.pop('name_or_path'))
+ return cls.from_pretrained(name_or_path, **kwargs)
+
+ registry._register_module(module=from_pretrained, module_name=cls.__name__)
+ return cls
+
+
+_load_hf_pretrained_model = True
+
+
+@contextlib.contextmanager
+def no_load_hf_pretrained_model():
+ global _load_hf_pretrained_model
+ _load_hf_pretrained_model = False
+ yield
+ _load_hf_pretrained_model = True
+
+
+def register_hf_model(
+ cls: Optional[type] = None,
+ registry: Registry = MODELS,
+):
+ """Register HuggingFace-style PreTrainedModel class."""
+ if cls is None:
+
+ # use it as a decorator: @register_hf_tokenizer()
+ def _register(cls):
+ register_hf_model(cls=cls)
+ return cls
+
+ return _register
+
+ if issubclass(cls, _BaseAutoModelClass):
+ get_config = AutoConfig.from_pretrained
+ from_config = cls.from_config
+ elif issubclass(cls, PreTrainedModel):
+ get_config = cls.config_class.from_pretrained
+ from_config = cls
+ else:
+ raise TypeError('Not auto model nor pretrained model of huggingface.')
+
+ def build(**kwargs):
+ if ('pretrained_model_name_or_path' not in kwargs
+ and 'name_or_path' not in kwargs):
+ raise TypeError(
+ f'{cls.__name__} missing required argument '
+ '`pretrained_model_name_or_path` or `name_or_path`.')
+ # `pretrained_model_name_or_path` is too long for config,
+ # add an alias name `name_or_path` here.
+ name_or_path = kwargs.pop('pretrained_model_name_or_path',
+ kwargs.pop('name_or_path'))
+
+ if kwargs.pop('load_pretrained', True) and _load_hf_pretrained_model:
+ return cls.from_pretrained(name_or_path, **kwargs)
+ else:
+ cfg = get_config(name_or_path, **kwargs)
+ return from_config(cfg)
+
+ registry._register_module(module=build, module_name=cls.__name__)
+ return cls
+
+
+register_hf_model(transformers.AutoModelForCausalLM)
diff --git a/mmpretrain/models/utils/tokenizer.py b/mmpretrain/models/utils/tokenizer.py
new file mode 100644
index 00000000000..eb02f741126
--- /dev/null
+++ b/mmpretrain/models/utils/tokenizer.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+
+from transformers import (AutoTokenizer, BartTokenizer, BertTokenizer,
+ BertTokenizerFast, LlamaTokenizer)
+
+from .huggingface import register_hf_tokenizer
+
+register_hf_tokenizer(AutoTokenizer)
+register_hf_tokenizer(LlamaTokenizer)
+
+
+@register_hf_tokenizer()
+class BlipTokenizer(BertTokenizerFast):
+ """"BlipTokenizer inherit BertTokenizerFast (fast, Rust-based)."""
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ os.environ['TOKENIZERS_PARALLELISM'] = 'true'
+
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ tokenizer.add_special_tokens({'bos_token': '[DEC]'})
+ tokenizer.add_special_tokens({'additional_special_tokens': ['[ENC]']})
+ return tokenizer
+
+
+@register_hf_tokenizer()
+class Blip2Tokenizer(BertTokenizer):
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ tokenizer.add_special_tokens({'bos_token': '[DEC]'})
+ return tokenizer
+
+
+@register_hf_tokenizer()
+class OFATokenizer(BartTokenizer):
+
+ vocab_files_names = {
+ 'vocab_file': 'vocab.json',
+ 'merges_file': 'merges.txt'
+ }
+
+ pretrained_vocab_files_map = {
+ 'vocab_file': {
+ 'OFA-Sys/OFA-tiny':
+ 'https://huggingface.co/OFA-Sys/OFA-tiny/blob/main/vocab.json',
+ 'OFA-Sys/OFA-medium':
+ 'https://huggingface.co/OFA-Sys/OFA-medium/blob/main/vocab.json',
+ 'OFA-Sys/OFA-base':
+ 'https://huggingface.co/OFA-Sys/OFA-base/blob/main/vocab.json',
+ 'OFA-Sys/OFA-large':
+ 'https://huggingface.co/OFA-Sys/OFA-large/blob/main/vocab.json',
+ },
+ 'merges_file': {
+ 'OFA-Sys/OFA-tiny':
+ 'https://huggingface.co/OFA-Sys/OFA-tiny/blob/main/merges.txt',
+ 'OFA-Sys/OFA-medium':
+ 'https://huggingface.co/OFA-Sys/OFA-medium/blob/main/merges.txt',
+ 'OFA-Sys/OFA-base':
+ 'https://huggingface.co/OFA-Sys/OFA-base/blob/main/merges.txt',
+ 'OFA-Sys/OFA-large':
+ 'https://huggingface.co/OFA-Sys/OFA-large/blob/main/merges.txt',
+ },
+ }
+
+ max_model_input_sizes = {
+ 'OFA-Sys/OFA-tiny': 1024,
+ 'OFA-Sys/OFA-medium': 1024,
+ 'OFA-Sys/OFA-base': 1024,
+ 'OFA-Sys/OFA-large': 1024,
+ }
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ num_bins = kwargs.pop('num_bins', 1000)
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ length = len(tokenizer)
+ tokenizer.add_tokens([''.format(i) for i in range(8192)])
+ tokenizer.code_offset = length
+ tokenizer.add_tokens([''.format(i) for i in range(num_bins)])
+ tokenizer.bin_offset = length + 8192
+ tokenizer.num_bins = num_bins
+ return tokenizer
diff --git a/mmpretrain/registry.py b/mmpretrain/registry.py
index 45bd0cf5752..cac2bdad725 100644
--- a/mmpretrain/registry.py
+++ b/mmpretrain/registry.py
@@ -154,6 +154,11 @@
parent=MMENGINE_TASK_UTILS,
locations=['mmpretrain.models'],
)
+# Tokenizer to encode sequence
+TOKENIZER = Registry(
+ 'tokenizer',
+ locations=['mmpretrain.models'],
+)
#######################################################################
# mmpretrain.evaluation #
diff --git a/mmpretrain/utils/__init__.py b/mmpretrain/utils/__init__.py
index 328c01d72eb..991e3217d2f 100644
--- a/mmpretrain/utils/__init__.py
+++ b/mmpretrain/utils/__init__.py
@@ -1,11 +1,12 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .analyze import load_json_log
from .collect_env import collect_env
+from .dependency import require
from .misc import get_ori_model
-from .progress import track_on_main_process
+from .progress import track, track_on_main_process
from .setup_env import register_all_modules
__all__ = [
'collect_env', 'register_all_modules', 'track_on_main_process',
- 'load_json_log', 'get_ori_model'
+ 'load_json_log', 'get_ori_model', 'track', 'require'
]
diff --git a/mmpretrain/utils/dependency.py b/mmpretrain/utils/dependency.py
new file mode 100644
index 00000000000..0e3d8ae5df7
--- /dev/null
+++ b/mmpretrain/utils/dependency.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from functools import wraps
+from inspect import isfunction
+
+from importlib_metadata import PackageNotFoundError, distribution
+from mmengine.utils import digit_version
+
+
+def satisfy_requirement(dep):
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, dep, maxsplit=1)
+ parts = [p.strip() for p in parts]
+ package = parts[0]
+ if len(parts) > 1:
+ op, version = parts[1:]
+ op = {
+ '>=': '__ge__',
+ '==': '__eq__',
+ '>': '__gt__',
+ '<': '__lt__',
+ '<=': '__le__'
+ }[op]
+ else:
+ op, version = None, None
+
+ try:
+ dist = distribution(package)
+ if op is None or getattr(digit_version(dist.version), op)(
+ digit_version(version)):
+ return True
+ except PackageNotFoundError:
+ pass
+
+ return False
+
+
+def require(dep, install=None):
+ """A wrapper of function for extra package requirements.
+
+ Args:
+ dep (str): The dependency package name, like ``transformers``
+ or ``transformers>=4.28.0``.
+ install (str, optional): The installation command hint. Defaults
+ to None, which means to use "pip install dep".
+ """
+
+ def wrapper(fn):
+ assert isfunction(fn)
+
+ @wraps(fn)
+ def ask_install(*args, **kwargs):
+ name = fn.__qualname__.replace('.__init__', '')
+ ins = install or f'pip install "{dep}"'
+ raise ImportError(
+ f'{name} requires {dep}, please install it by `{ins}`.')
+
+ if satisfy_requirement(dep):
+ fn._verify_require = getattr(fn, '_verify_require', lambda: None)
+ return fn
+
+ ask_install._verify_require = ask_install
+ return ask_install
+
+ return wrapper
+
+
+WITH_MULTIMODAL = all(
+ satisfy_requirement(item)
+ for item in ['pycocotools', 'transformers>=4.28.0'])
+
+
+def register_multimodal_placeholder(names, registry):
+ for name in names:
+
+ def ask_install(*args, **kwargs):
+ raise ImportError(
+ f'{name} requires extra multi-modal dependencies, please '
+ 'install it by `pip install "mmpretrain[multimodal]"` '
+ 'or `pip install -e ".[multimodal]"`.')
+
+ registry.register_module(name=name, module=ask_install)
diff --git a/mmpretrain/utils/progress.py b/mmpretrain/utils/progress.py
index 66c6c32db25..bde7e558079 100644
--- a/mmpretrain/utils/progress.py
+++ b/mmpretrain/utils/progress.py
@@ -2,9 +2,18 @@
import mmengine.dist as dist
import rich.progress as progress
+disable_progress_bar = False
+
+
+def track(sequence, *args, **kwargs):
+ if disable_progress_bar:
+ return sequence
+ else:
+ return progress.track(sequence, *args, **kwargs)
+
def track_on_main_process(sequence, *args, **kwargs):
- if not dist.is_main_process():
+ if not dist.is_main_process() or disable_progress_bar:
yield from sequence
else:
yield from progress.track(sequence, *args, **kwargs)
diff --git a/mmpretrain/visualization/visualizer.py b/mmpretrain/visualization/visualizer.py
index abff913ca42..5d18ca87f6b 100644
--- a/mmpretrain/visualization/visualizer.py
+++ b/mmpretrain/visualization/visualizer.py
@@ -105,9 +105,9 @@ def visualize_cls(self,
if resize is not None:
h, w = image.shape[:2]
if w < h:
- image = mmcv.imresize(image, (resize, resize * h / w))
+ image = mmcv.imresize(image, (resize, resize * h // w))
else:
- image = mmcv.imresize(image, (resize * w / h, resize))
+ image = mmcv.imresize(image, (resize * w // h, resize))
elif rescale_factor is not None:
image = mmcv.imrescale(image, rescale_factor)
@@ -340,3 +340,438 @@ def visualize_masked_image(self,
self.add_image(name, drawn_img, step=step)
return drawn_img
+
+ @master_only
+ def visualize_image_caption(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize image caption result.
+
+ This method will draw the input image and the images caption.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ data_sample.get('pred_caption'),
+ wrap=True,
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_vqa(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize visual question answering result.
+
+ This method will draw the input image, question and answer.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ text = (f'Q: {data_sample.get("question")}\n'
+ f'A: {data_sample.get("pred_answer")}')
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ text,
+ wrap=True,
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_visual_grounding(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ line_width: Union[int, float] = 3,
+ bbox_color: Union[str, tuple] = 'green',
+ step: int = 0) -> None:
+ """Visualize visual grounding result.
+
+ This method will draw the input image, bbox and the object.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ gt_bboxes = data_sample.get('gt_bboxes')
+ pred_bboxes = data_sample.get('pred_bboxes')
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image, w_scale, h_scale = mmcv.imresize(
+ image, (resize, resize * h // w), return_scale=True)
+ else:
+ image, w_scale, h_scale = mmcv.imresize(
+ image, (resize * w // h, resize), return_scale=True)
+ pred_bboxes[:, ::2] *= w_scale
+ pred_bboxes[:, 1::2] *= h_scale
+ if gt_bboxes is not None:
+ gt_bboxes[:, ::2] *= w_scale
+ gt_bboxes[:, 1::2] *= h_scale
+
+ self.set_image(image)
+ # Avoid the line-width limit in the base classes.
+ self._default_font_size = 1e3
+ self.draw_bboxes(
+ pred_bboxes, line_widths=line_width, edge_colors=bbox_color)
+ if gt_bboxes is not None:
+ self.draw_bboxes(
+ gt_bboxes, line_widths=line_width, edge_colors='blue')
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+
+ text_positions = pred_bboxes[:, :2] + line_width
+ for i in range(pred_bboxes.size(0)):
+ self.ax_save.text(
+ text_positions[i, 0] + line_width,
+ text_positions[i, 1] + line_width,
+ data_sample.get('text'),
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_t2i_retrieval(self,
+ text: str,
+ data_sample: DataSample,
+ prototype_dataset: BaseDataset,
+ topk: int = 1,
+ draw_score: bool = True,
+ text_cfg: dict = dict(),
+ fig_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize Text-To-Image retrieval result.
+
+ This method will draw the input text and the images retrieved from the
+ prototype dataset.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ prototype_dataset (:obj:`BaseDataset`): The prototype dataset.
+ It should have `get_data_info` method and return a dict
+ includes `img_path`.
+ topk (int): To visualize the topk matching items. Defaults to 1.
+ draw_score (bool): Whether to draw the match scores of the
+ retrieved images. Defaults to True.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ fig_cfg (dict): Extra figure setting, which accepts arguments of
+ :func:`plt.Figure`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+
+ figure = create_figure(margin=True, **fig_cfg)
+ figure.suptitle(text)
+ gs = figure.add_gridspec(1, topk)
+
+ for k, (score, sample_idx) in enumerate(zip(match_scores, indices)):
+ sample = prototype_dataset.get_data_info(sample_idx.item())
+ value_image = mmcv.imread(sample['img_path'])[..., ::-1]
+ value_plot = figure.add_subplot(gs[0, k])
+ value_plot.axis(False)
+ value_plot.imshow(value_image)
+ if draw_score:
+ value_plot.text(
+ 5,
+ 5,
+ f'{score:.2f}',
+ **text_cfg,
+ )
+ drawn_img = img_from_canvas(figure.canvas)
+ self.set_image(drawn_img)
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_i2t_retrieval(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ prototype_dataset: Sequence[str],
+ topk: int = 1,
+ draw_score: bool = True,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: str = '',
+ step: int = 0) -> None:
+ """Visualize Image-To-Text retrieval result.
+
+ This method will draw the input image and the texts retrieved from the
+ prototype dataset.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ prototype_dataset (Sequence[str]): The prototype dataset.
+ It should be a list of texts.
+ topk (int): To visualize the topk matching items. Defaults to 1.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts
+ arguments of :meth:`mmengine.Visualizer.draw_texts`.
+ Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ texts = []
+ for score, sample_idx in zip(match_scores, indices):
+ text = prototype_dataset[sample_idx.item()]
+ if draw_score:
+ text = f'{score:.2f} ' + text
+ texts.append(text)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ '\n'.join(texts),
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
diff --git a/model-index.yml b/model-index.yml
index c960b360a27..f5f90b12833 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -66,8 +66,12 @@ Import:
- configs/cae/metafile.yml
- configs/maskfeat/metafile.yml
- configs/milan/metafile.yml
+ - configs/ofa/metafile.yml
- configs/riformer/metafile.yml
- configs/sam/metafile.yml
- configs/glip/metafile.yml
- configs/eva02/metafile.yml
- configs/dinov2/metafile.yml
+ - configs/blip/metafile.yml
+ - configs/flamingo/metafile.yml
+ - configs/blip2/metafile.yml
diff --git a/projects/gradio_demo/README.md b/projects/gradio_demo/README.md
new file mode 100644
index 00000000000..6799f865ad9
--- /dev/null
+++ b/projects/gradio_demo/README.md
@@ -0,0 +1,44 @@
+# MMPretrain Gradio Demo
+
+Here is a gradio demo for MMPretrain supported inference tasks.
+
+Currently supported tasks:
+
+- Image Classifiation
+- Image-To-Image Retrieval
+- Text-To-Image Retrieval (require multi-modality support)
+- Image Caption (require multi-modality support)
+- Visual Question Answering (require multi-modality support)
+- Visual Grounding (require multi-modality support)
+
+## Preview
+
+
+
+## Requirements
+
+To run the demo, you need to install MMPretrain at first. And please install with the extra multi-modality
+dependencies to enable multi-modality tasks.
+
+```shell
+# At the MMPretrain root folder
+pip install -e ".[multimodal]"
+```
+
+And then install the latest gradio package.
+
+```shell
+pip install "gradio>=3.31.0"
+```
+
+## Start
+
+Then, you can start the gradio server on the local machine by:
+
+```shell
+# At the project folder
+python launch.py
+```
+
+The demo will start a local server `http://127.0.0.1:7860` and you can browse it by your browser.
+And to share it to others, please set `share=True` in the `demo.launch()`.
diff --git a/projects/gradio_demo/launch.py b/projects/gradio_demo/launch.py
new file mode 100644
index 00000000000..bd4fa780d3a
--- /dev/null
+++ b/projects/gradio_demo/launch.py
@@ -0,0 +1,466 @@
+from functools import partial
+from pathlib import Path
+from typing import Callable
+
+import gradio as gr
+import torch
+from mmengine.logging import MMLogger
+
+import mmpretrain
+from mmpretrain.apis import (ImageCaptionInferencer,
+ ImageClassificationInferencer,
+ ImageRetrievalInferencer,
+ TextToImageRetrievalInferencer,
+ VisualGroundingInferencer,
+ VisualQuestionAnsweringInferencer)
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
+from mmpretrain.visualization import UniversalVisualizer
+
+mmpretrain.utils.progress.disable_progress_bar = True
+
+logger = MMLogger('mmpretrain', logger_name='mmpre')
+if torch.cuda.is_available():
+ gpus = [
+ torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())
+ ]
+ logger.info(f'Available GPUs: {len(gpus)}')
+else:
+ gpus = None
+ logger.info('No available GPU.')
+
+
+def get_free_device():
+ if gpus is None:
+ return torch.device('cpu')
+ if hasattr(torch.cuda, 'mem_get_info'):
+ free = [torch.cuda.mem_get_info(gpu)[0] for gpu in gpus]
+ select = max(zip(free, range(len(free))))[1]
+ else:
+ import random
+ select = random.randint(0, len(gpus) - 1)
+ return gpus[select]
+
+
+class InferencerCache:
+ max_size = 2
+ _cache = []
+
+ @classmethod
+ def get_instance(cls, instance_name, callback: Callable):
+ if len(cls._cache) > 0:
+ for i, cache in enumerate(cls._cache):
+ if cache[0] == instance_name:
+ # Re-insert to the head of list.
+ cls._cache.insert(0, cls._cache.pop(i))
+ logger.info(f'Use cached {instance_name}.')
+ return cache[1]
+
+ if len(cls._cache) == cls.max_size:
+ cls._cache.pop(cls.max_size - 1)
+ torch.cuda.empty_cache()
+ device = get_free_device()
+ instance = callback(device=device)
+ logger.info(f'New instance {instance_name} on {device}.')
+ cls._cache.insert(0, (instance_name, instance))
+ return instance
+
+
+class ImageCaptionTab:
+
+ def __init__(self) -> None:
+ self.model_list = ImageCaptionInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_caption_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='blip-base_3rdparty_coco-caption',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ caption_output = gr.Textbox(
+ label='Result',
+ lines=2,
+ elem_classes='caption_result',
+ interactive=False,
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input],
+ outputs=caption_output,
+ )
+
+ def inference(self, model, image):
+ image = image[:, :, ::-1]
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(ImageCaptionInferencer, model))
+
+ result = inferencer(image)[0]
+ return result['pred_caption']
+
+
+class ImageClassificationTab:
+
+ def __init__(self) -> None:
+ self.short_list = [
+ 'resnet50_8xb32_in1k',
+ 'resnet50_8xb256-rsb-a1-600e_in1k',
+ 'swin-base_16xb64_in1k',
+ 'convnext-base_32xb128_in1k',
+ 'vit-base-p16_32xb128-mae_in1k',
+ ]
+ self.long_list = ImageClassificationInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_classification_models',
+ elem_classes='select_model',
+ choices=self.short_list,
+ value='swin-base_16xb64_in1k',
+ )
+ expand = gr.Checkbox(label='Browse all models')
+
+ def browse_all_model(value):
+ models = self.long_list if value else self.short_list
+ return gr.update(choices=models)
+
+ expand.select(
+ fn=browse_all_model, inputs=expand, outputs=select_model)
+ with gr.Column():
+ in_image = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ out_cls = gr.Label(
+ label='Result',
+ num_top_classes=5,
+ elem_classes='cls_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, in_image],
+ outputs=out_cls,
+ )
+
+ def inference(self, model, image):
+ image = image[:, :, ::-1]
+
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(ImageClassificationInferencer, model))
+ result = inferencer(image)[0]['pred_scores'].tolist()
+
+ if inferencer.classes is not None:
+ classes = inferencer.classes
+ else:
+ classes = list(range(len(result)))
+
+ return dict(zip(classes, result))
+
+
+class ImageRetrievalTab:
+
+ def __init__(self) -> None:
+ self.model_list = ImageRetrievalInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_retri_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='resnet50-arcface_8xb32_inshop',
+ )
+ topk = gr.Slider(minimum=1, maximum=6, value=3, step=1)
+ with gr.Column():
+ prototype = gr.File(
+ label='Retrieve from',
+ file_count='multiple',
+ file_types=['image'])
+ image_input = gr.Image(
+ label='Query',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ retri_output = gr.Gallery(
+ label='Result',
+ elem_classes='img_retri_result',
+ ).style(
+ columns=[3], object_fit='contain', height='auto')
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, prototype, image_input, topk],
+ outputs=retri_output,
+ )
+
+ def inference(self, model, prototype, image, topk):
+ image = image[:, :, ::-1]
+
+ import hashlib
+
+ proto_signature = ''.join(file.name for file in prototype).encode()
+ proto_signature = hashlib.sha256(proto_signature).hexdigest()
+ inferencer_name = self.__class__.__name__ + model + proto_signature
+ tmp_dir = Path(prototype[0].name).parent
+ cache_file = tmp_dir / f'{inferencer_name}.pth'
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(
+ ImageRetrievalInferencer,
+ model,
+ prototype=[file.name for file in prototype],
+ prototype_cache=str(cache_file),
+ ),
+ )
+
+ result = inferencer(image, topk=min(topk, len(prototype)))[0]
+ return [(str(item['sample']['img_path']),
+ str(item['match_score'].cpu().item())) for item in result]
+
+
+class TextToImageRetrievalTab:
+
+ def __init__(self) -> None:
+ self.model_list = TextToImageRetrievalInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='t2i_retri_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='blip-base_3rdparty_coco-retrieval',
+ )
+ topk = gr.Slider(minimum=1, maximum=6, value=3, step=1)
+ with gr.Column():
+ prototype = gr.File(
+ file_count='multiple', file_types=['image'])
+ text_input = gr.Textbox(
+ label='Query',
+ elem_classes='input_text',
+ interactive=True,
+ )
+ retri_output = gr.Gallery(
+ label='Result',
+ elem_classes='img_retri_result',
+ ).style(
+ columns=[3], object_fit='contain', height='auto')
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, prototype, text_input, topk],
+ outputs=retri_output,
+ )
+
+ def inference(self, model, prototype, text, topk):
+ import hashlib
+
+ proto_signature = ''.join(file.name for file in prototype).encode()
+ proto_signature = hashlib.sha256(proto_signature).hexdigest()
+ inferencer_name = self.__class__.__name__ + model + proto_signature
+ tmp_dir = Path(prototype[0].name).parent
+ cache_file = tmp_dir / f'{inferencer_name}.pth'
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(
+ TextToImageRetrievalInferencer,
+ model,
+ prototype=[file.name for file in prototype],
+ prototype_cache=str(cache_file),
+ ),
+ )
+
+ result = inferencer(text, topk=min(topk, len(prototype)))[0]
+ return [(str(item['sample']['img_path']),
+ str(item['match_score'].cpu().item())) for item in result]
+
+
+class VisualGroundingTab:
+
+ def __init__(self) -> None:
+ self.model_list = VisualGroundingInferencer.list_models()
+ self.tab = self.create_ui()
+ self.visualizer = UniversalVisualizer(
+ fig_save_cfg=dict(figsize=(16, 9)))
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='vg_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='ofa-base_3rdparty_refcoco',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Image',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ text_input = gr.Textbox(
+ label='The object to search',
+ elem_classes='input_text',
+ interactive=True,
+ )
+ vg_output = gr.Image(
+ label='Result',
+ source='upload',
+ interactive=False,
+ elem_classes='vg_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input, text_input],
+ outputs=vg_output,
+ )
+
+ def inference(self, model, image, text):
+
+ inferencer_name = self.__class__.__name__ + model
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(VisualGroundingInferencer, model),
+ )
+
+ result = inferencer(
+ image[:, :, ::-1], text, return_datasamples=True)[0]
+ vis = self.visualizer.visualize_visual_grounding(
+ image, result, resize=512)
+ return vis
+
+
+class VisualQuestionAnsweringTab:
+
+ def __init__(self) -> None:
+ self.model_list = VisualQuestionAnsweringInferencer.list_models()
+ # The fine-tuned OFA vqa models requires extra object description.
+ self.model_list.remove('ofa-base_3rdparty-finetuned_vqa')
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='vqa_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='ofa-base_3rdparty-zeroshot_coco-vqa',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ question_input = gr.Textbox(
+ label='Question',
+ elem_classes='question_input',
+ )
+ answer_output = gr.Textbox(
+ label='Answer',
+ elem_classes='answer_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input, question_input],
+ outputs=answer_output,
+ )
+
+ def inference(self, model, image, question):
+ image = image[:, :, ::-1]
+
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(VisualQuestionAnsweringInferencer, model))
+
+ result = inferencer(image, question)[0]
+ return result['pred_answer']
+
+
+if __name__ == '__main__':
+ title = 'MMPretrain Inference Demo'
+ with gr.Blocks(analytics_enabled=False, title=title) as demo:
+ gr.Markdown(f'# {title}')
+ with gr.Tabs():
+ with gr.TabItem('Image Classification'):
+ ImageClassificationTab()
+ with gr.TabItem('Image-To-Image Retrieval'):
+ ImageRetrievalTab()
+ if WITH_MULTIMODAL:
+ with gr.TabItem('Image Caption'):
+ ImageCaptionTab()
+ with gr.TabItem('Text-To-Image Retrieval'):
+ TextToImageRetrievalTab()
+ with gr.TabItem('Visual Grounding'):
+ VisualGroundingTab()
+ with gr.TabItem('Visual Question Answering'):
+ VisualQuestionAnsweringTab()
+ else:
+ with gr.TabItem('Multi-modal tasks'):
+ gr.Markdown(
+ 'To inference multi-modal models, please install '
+ 'the extra multi-modal dependencies, please refer '
+ 'to https://mmpretrain.readthedocs.io/en/latest/'
+ 'get_started.html#installation')
+
+ demo.launch()
diff --git a/requirements/multimodal.txt b/requirements/multimodal.txt
new file mode 100644
index 00000000000..f6150b16d8e
--- /dev/null
+++ b/requirements/multimodal.txt
@@ -0,0 +1,2 @@
+pycocotools
+transformers>=4.28.0
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
index 6d7b3d2aeaf..145cedab5b8 100644
--- a/requirements/readthedocs.txt
+++ b/requirements/readthedocs.txt
@@ -1,5 +1,7 @@
--extra-index-url https://download.pytorch.org/whl/cpu
mmcv-lite>=2.0.0rc4
mmengine
+pycocotools
torch
torchvision
+transformers
diff --git a/setup.cfg b/setup.cfg
index 13c91624e9a..fe9c158b104 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -21,3 +21,12 @@ default_section = THIRDPARTY
skip = *.ipynb
quiet-level = 3
ignore-words-list = patten,confectionary,nd,ty,formating,dows
+
+[flake8]
+# The E251 check is conflict with yapf in some situation.
+# See https://github.com/google/yapf/issues/393
+extend-ignore = E251
+# The F401 check is wrong if the `__all__` variable is modified
+# in `__init__.py`
+per-file-ignores =
+ */__init__.py: F401
diff --git a/setup.py b/setup.py
index 925ce9b3ba5..6ed773f80dd 100644
--- a/setup.py
+++ b/setup.py
@@ -193,5 +193,6 @@ def add_mim_extension():
'tests': parse_requirements('requirements/tests.txt'),
'optional': parse_requirements('requirements/optional.txt'),
'mim': parse_requirements('requirements/mminstall.txt'),
+ 'multimodal': parse_requirements('requirements/multimodal.txt'),
},
zip_safe=False)
diff --git a/tests/test_apis/test_inference.py b/tests/test_apis/test_inference.py
index 1e9d7cbc4da..72b20e567c8 100644
--- a/tests/test_apis/test_inference.py
+++ b/tests/test_apis/test_inference.py
@@ -23,7 +23,7 @@ def test_init(self):
# test input BaseModel
model = get_model(MODEL)
inferencer = ImageClassificationInferencer(model)
- self.assertEqual(model.config, inferencer.config)
+ self.assertEqual(model._config, inferencer.config)
self.assertIsInstance(inferencer.model.backbone, MobileNetV3)
# test input model name
diff --git a/tests/test_tools.py b/tests/test_tools.py
index 4909de64b4e..013584d0da1 100644
--- a/tests/test_tools.py
+++ b/tests/test_tools.py
@@ -306,7 +306,7 @@ def setUp(self):
model = get_model('mobilevit-xxsmall_3rdparty_in1k')
self.config_file = self.dir / 'config.py'
- model.config.dump(self.config_file)
+ model._config.dump(self.config_file)
self.ckpt_file = self.dir / 'ckpt.pth'
torch.save(model.state_dict(), self.ckpt_file)
diff --git a/tools/model_converters/ofa.py b/tools/model_converters/ofa.py
new file mode 100644
index 00000000000..142c7ac3872
--- /dev/null
+++ b/tools/model_converters/ofa.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import re
+from collections import OrderedDict, namedtuple
+from pathlib import Path
+
+import torch
+
+prog_description = """\
+Convert OFA official models to MMPretrain format.
+"""
+
+MapItem = namedtuple(
+ 'MapItem', 'pattern repl key_action value_action', defaults=[None] * 4)
+
+
+def convert_by_mapdict(src_dict: dict, map_dict: Path):
+ dst_dict = OrderedDict()
+ convert_map_dict = dict()
+
+ for k, v in src_dict.items():
+ ori_k = k
+ for item in map_dict:
+ pattern = item.pattern
+ assert pattern is not None
+ match = next(re.finditer(pattern, k), None)
+ if match is None:
+ continue
+ match_group = match.groups()
+ repl = item.repl
+
+ key_action = item.key_action
+ if key_action is not None:
+ assert callable(key_action)
+ match_group = key_action(*match_group)
+ if isinstance(match_group, str):
+ match_group = (match_group, )
+ start, end = match.span(0)
+ if repl is not None:
+ k = k[:start] + repl.format(*match_group) + k[end:]
+ else:
+ for i, sub in enumerate(match_group):
+ start, end = match.span(i + 1)
+ k = k[:start] + str(sub) + k[end:]
+
+ value_action = item.value_action
+ if value_action is not None:
+ assert callable(value_action)
+ v = value_action(v)
+
+ if v is not None:
+ dst_dict[k] = v
+ convert_map_dict[k] = ori_k
+ return dst_dict, convert_map_dict
+
+
+map_dict = [
+ # Encoder modules
+ MapItem(r'\.type_embedding\.', '.embed_type.'),
+ MapItem(r'\.layernorm_embedding\.', '.embedding_ln.'),
+ MapItem(r'\.patch_layernorm_embedding\.', '.image_embedding_ln.'),
+ MapItem(r'encoder.layer_norm\.', 'encoder.final_ln.'),
+ # Encoder layers
+ MapItem(r'\.attn_ln\.', '.attn_mid_ln.'),
+ MapItem(r'\.ffn_layernorm\.', '.ffn_mid_ln.'),
+ MapItem(r'\.final_layer_norm', '.ffn_ln'),
+ MapItem(r'encoder.*(\.self_attn\.)', key_action=lambda _: '.attn.'),
+ MapItem(
+ r'encoder.*(\.self_attn_layer_norm\.)',
+ key_action=lambda _: '.attn_ln.'),
+ # Decoder modules
+ MapItem(r'\.code_layernorm_embedding\.', '.code_embedding_ln.'),
+ MapItem(r'decoder.layer_norm\.', 'decoder.final_ln.'),
+ # Decoder layers
+ MapItem(r'\.self_attn_ln', '.self_attn_mid_ln'),
+ MapItem(r'\.cross_attn_ln', '.cross_attn_mid_ln'),
+ MapItem(r'\.encoder_attn_layer_norm', '.cross_attn_ln'),
+ MapItem(r'\.encoder_attn', '.cross_attn'),
+ MapItem(
+ r'decoder.*(\.self_attn_layer_norm\.)',
+ key_action=lambda _: '.self_attn_ln.'),
+ # Remove version key
+ MapItem(r'version', '', value_action=lambda _: None),
+ # Add model prefix
+ MapItem(r'^', 'model.'),
+]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description=prog_description)
+ parser.add_argument('src', type=str, help='The official checkpoint path.')
+ parser.add_argument('dst', type=str, help='The save path.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ src = torch.load(args.src)
+ if 'extra_state' in src and 'ema' in src['extra_state']:
+ print('Use EMA weights.')
+ src = src['extra_state']['ema']
+ else:
+ src = src['model']
+ dst, _ = convert_by_mapdict(src, map_dict)
+ torch.save(dst, args.dst)
+ print('Done!!')
+
+
+if __name__ == '__main__':
+ main()
+
## Extract Features From Image
Compared with `model.extract_feat`, `FeatureExtractor` is used to extract features from the image files directly, instead of a batch of tensors.
In a word, the input of `model.extract_feat` is `torch.Tensor`, the input of `FeatureExtractor` is images.
-```
+```python
>>> from mmpretrain import FeatureExtractor, get_model
>>> model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
>>> extractor = FeatureExtractor(model)
diff --git a/docs/zh_CN/conf.py b/docs/zh_CN/conf.py
index a98d275c620..2c372a8ae59 100644
--- a/docs/zh_CN/conf.py
+++ b/docs/zh_CN/conf.py
@@ -223,6 +223,8 @@ def get_version():
'torch': ('https://pytorch.org/docs/stable/', None),
'mmcv': ('https://mmcv.readthedocs.io/zh_CN/2.x/', None),
'mmengine': ('https://mmengine.readthedocs.io/zh_CN/latest/', None),
+ 'transformers':
+ ('https://huggingface.co/docs/transformers/main/zh/', None),
}
napoleon_custom_sections = [
# Custom sections for data elements.
diff --git a/docs/zh_CN/get_started.md b/docs/zh_CN/get_started.md
index 6d77e426bac..c2100815aed 100644
--- a/docs/zh_CN/get_started.md
+++ b/docs/zh_CN/get_started.md
@@ -74,6 +74,18 @@ pip install -U openmim && mim install "mmpretrain>=1.0.0rc7"
`mim` 是一个轻量级的命令行工具,可以根据 PyTorch 和 CUDA 版本为 OpenMMLab 算法库配置合适的环境。同时它也提供了一些对于深度学习实验很有帮助的功能。
```
+## 安装多模态支持 (可选)
+
+MMPretrain 中的多模态模型需要额外的依赖项,要安装这些依赖项,请在安装过程中添加 `[multimodal]` 参数,如下所示:
+
+```shell
+# 从源码安装
+mim install -e ".[multimodal]"
+
+# 作为 Python 包安装
+mim install "mmpretrain[multimodal]>=1.0.0rc7"
+```
+
## 验证安装
为了验证 MMPretrain 的安装是否正确,我们提供了一些示例代码来执行模型推理。
diff --git a/docs/zh_CN/stat.py b/docs/zh_CN/stat.py
index 70ea692d531..29e57563ccf 100755
--- a/docs/zh_CN/stat.py
+++ b/docs/zh_CN/stat.py
@@ -173,7 +173,10 @@ def generate_summary_table(task, model_result_pairs, title=None):
continue
name = model.name
params = f'{model.metadata.parameters / 1e6:.2f}' # Params
- flops = f'{model.metadata.flops / 1e9:.2f}' # Params
+ if model.metadata.flops is not None:
+ flops = f'{model.metadata.flops / 1e9:.2f}' # Flops
+ else:
+ flops = None
readme = Path(model.collection.filepath).parent.with_suffix('.md').name
page = f'[链接]({PAPERS_ROOT / readme})'
model_metrics = []
diff --git a/docs/zh_CN/user_guides/inference.md b/docs/zh_CN/user_guides/inference.md
index a5efb8bd0f7..068e42e16de 100644
--- a/docs/zh_CN/user_guides/inference.md
+++ b/docs/zh_CN/user_guides/inference.md
@@ -2,25 +2,45 @@
本文将展示如何使用以下API:
-1. [**`list_models`**](mmpretrain.apis.list_models) 和 [**`get_model`**](mmpretrain.apis.get_model) :列出 MMPreTrain 中的模型并获取模型。
-2. [**`ImageClassificationInferencer`**](mmpretrain.apis.ImageClassificationInferencer): 在给定图像上进行推理。
-3. [**`FeatureExtractor`**](mmpretrain.apis.FeatureExtractor): 从图像文件直接提取特征。
-
-## 列出模型和获取模型
+- [**`list_models`**](mmpretrain.apis.list_models): 列举 MMPretrain 中所有可用模型名称
+- [**`get_model`**](mmpretrain.apis.get_model): 通过模型名称或模型配置文件获取模型
+- [**`inference_model`**](mmpretrain.apis.inference_model): 使用与模型相对应任务的推理器进行推理。主要用作快速
+ 展示。如需配置进阶用法,还需要直接使用下列推理器。
+- 推理器:
+ 1. [**`ImageClassificationInferencer`**](mmpretrain.apis.ImageClassificationInferencer):
+ 对给定图像执行图像分类。
+ 2. [**`ImageRetrievalInferencer`**](mmpretrain.apis.ImageRetrievalInferencer):
+ 从给定的一系列图像中,检索与给定图像最相似的图像。
+ 3. [**`ImageCaptionInferencer`**](mmpretrain.apis.ImageCaptionInferencer):
+ 生成给定图像的一段描述。
+ 4. [**`VisualQuestionAnsweringInferencer`**](mmpretrain.apis.VisualQuestionAnsweringInferencer):
+ 根据给定的图像回答问题。
+ 5. [**`VisualGroundingInferencer`**](mmpretrain.apis.VisualGroundingInferencer):
+ 根据一段描述,从给定图像中找到一个与描述对应的对象。
+ 6. [**`TextToImageRetrievalInferencer`**](mmpretrain.apis.TextToImageRetrievalInferencer):
+ 从给定的一系列图像中,检索与给定文本最相似的图像。
+ 7. [**`ImageToTextRetrievalInferencer`**](mmpretrain.apis.ImageToTextRetrievalInferencer):
+ 从给定的一系列文本中,检索与给定图像最相似的文本。
+ 8. [**`NLVRInferencer`**](mmpretrain.apis.NLVRInferencer):
+ 对给定的一对图像和一段文本进行自然语言视觉推理(NLVR 任务)。
+ 9. [**`FeatureExtractor`**](mmpretrain.apis.FeatureExtractor):
+ 通过视觉主干网络从图像文件提取特征。
+
+## 列举可用模型
列出 MMPreTrain 中的所有已支持的模型。
-```
+```python
>>> from mmpretrain import list_models
>>> list_models()
['barlowtwins_resnet50_8xb256-coslr-300e_in1k',
'beit-base-p16_beit-in21k-pre_3rdparty_in1k',
- .................]
+ ...]
```
-`list_models` 支持模糊匹配,您可以使用 **\*** 匹配任意字符。
+`list_models` 支持 Unix 文件名风格的模式匹配,你可以使用 \*\* * \*\* 匹配任意字符。
-```
+```python
>>> from mmpretrain import list_models
>>> list_models("*convnext-b*21k")
['convnext-base_3rdparty_in21k',
@@ -28,30 +48,43 @@
'convnext-base_in21k-pre_3rdparty_in1k']
```
-了解了已经支持了哪些模型后,你可以使用 `get_model` 获取特定模型。
+你还可以使用推理器的 `list_models` 方法获取对应任务可用的所有模型。
+```python
+>>> from mmpretrain import ImageCaptionInferencer
+>>> ImageCaptionInferencer.list_models()
+['blip-base_3rdparty_caption',
+ 'blip2-opt2.7b_3rdparty-zeroshot_caption',
+ 'flamingo_3rdparty-zeroshot_caption',
+ 'ofa-base_3rdparty-finetuned_caption']
```
+
+## 获取模型
+
+选定需要的模型后,你可以使用 `get_model` 获取特定模型。
+
+```python
>>> from mmpretrain import get_model
-# 没有预训练权重的模型
+# 不加载预训练权重的模型
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k")
-# 使用MMPreTrain中默认的权重
+# 加载默认的权重文件
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained=True)
-# 使用本地权重
+# 加载制定的权重文件
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained="your_local_checkpoint_path")
-# 您还可以做一些修改,例如修改 head 中的 num_classes。
+# 指定额外的模型初始化参数,例如修改 head 中的 num_classes。
>>> model = get_model("convnext-base_in21k-pre_3rdparty_in1k", head=dict(num_classes=10))
-# 您可以获得没有 neck,head 的模型,并直接从 backbone 中的 stage 1, 2, 3 输出
+# 另外一个例子:移除模型的 neck,head 模块,直接从 backbone 中的 stage 1, 2, 3 输出
>>> model_headless = get_model("resnet18_8xb32_in1k", head=None, neck=None, backbone=dict(out_indices=(1, 2, 3)))
```
-得到模型后,你可以进行推理:
+获得的模型是一个通常的 PyTorch Module
-```
+```python
>>> import torch
>>> from mmpretrain import get_model
>>> model = get_model('convnext-base_in21k-pre_3rdparty_in1k', pretrained=True)
@@ -63,45 +96,71 @@
## 在给定图像上进行推理
-这是一个使用 ImageNet-1k 预训练权重在给定图像上构建推理器的示例。
+这里是一个例子,我们将使用 ResNet-50 预训练模型对给定的 [图像](https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG) 进行分类。
+```python
+>>> from mmpretrain import inference_model
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> # 如果你没有图形界面,请设置 `show=False`
+>>> result = inference_model('resnet50_8xb32_in1k', image, show=True)
+>>> print(result['pred_class'])
+sea snake
```
->>> from mmpretrain import ImageClassificationInferencer
+上述 `inference_model` 接口可以快速进行模型推理,但它每次调用都需要重新初始化模型,也无法进行多个样本的推理。
+因此我们需要使用推理器来进行多次调用。
+
+```python
+>>> from mmpretrain import ImageClassificationInferencer
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
>>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
->>> results = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')
->>> print(results[0]['pred_class'])
+>>> # 注意推理器的输出始终为一个结果列表,即使输入只有一个样本
+>>> result = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
+>>> print(result['pred_class'])
sea snake
+>>>
+>>> # 你可以对多张图像进行批量推理
+>>> image_list = ['demo/demo.JPEG', 'demo/bird.JPEG'] * 16
+>>> results = inferencer(image_list, batch_size=8)
+>>> print(len(results))
+32
+>>> print(results[1]['pred_class'])
+house finch, linnet, Carpodacus mexicanus
```
-result 是一个包含 pred_label、pred_score、pred_scores 和 pred_class 的字典,结果如下:
+通常,每个样本的结果都是一个字典。比如图像分类的结果是一个包含了 `pred_label`、`pred_score`、`pred_scores`、`pred_class` 等字段的字典:
-```{text}
-{"pred_label":65,"pred_score":0.6649366617202759,"pred_class":"sea snake", "pred_scores": [..., 0.6649366617202759, ...]}
+```python
+{
+ "pred_label": 65,
+ "pred_score": 0.6649366617202759,
+ "pred_class":"sea snake",
+ "pred_scores": array([..., 0.6649366617202759, ...], dtype=float32)
+}
```
-如果你想使用自己的配置和权重:
+你可以为推理器配置额外的参数,比如使用你自己的配置文件和权重文件,在 CUDA 上进行推理:
-```
+```python
>>> from mmpretrain import ImageClassificationInferencer
->>> inferencer = ImageClassificationInferencer(
- model='configs/resnet/resnet50_8xb32_in1k.py',
- pretrained='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
- device='cuda')
->>> inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')
+>>> image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
+>>> config = 'configs/resnet/resnet50_8xb32_in1k.py'
+>>> checkpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth'
+>>> inferencer = ImageClassificationInferencer(model=config, pretrained=checkpoint, device='cuda')
+>>> result = inferencer(image)[0]
+>>> print(result['pred_class'])
+sea snake
```
-你还可以在CUDA上通过批处理进行多个图像的推理:
+## 使用 Gradio 推理示例
-```{python}
->>> from mmpretrain import ImageClassificationInferencer
+我们还提供了一个基于 gradio 的推理示例,提供了 MMPretrain 所支持的所有任务的推理展示功能,你可以在 [projects/gradio_demo/launch.py](https://github.com/open-mmlab/mmpretrain/blob/main/projects/gradio_demo/launch.py) 找到这一例程。
->>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k', device='cuda')
->>> imgs = ['https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'] * 5
->>> results = inferencer(imgs, batch_size=2)
->>> print(results[1]['pred_class'])
-sea snake
-```
+请首先使用 `pip install -U gradio` 安装 `gradio` 库。
+
+这里是界面效果预览:
+
+
## 从图像中提取特征
diff --git a/mmpretrain/apis/__init__.py b/mmpretrain/apis/__init__.py
index e82d897c9b3..6fbf443772a 100644
--- a/mmpretrain/apis/__init__.py
+++ b/mmpretrain/apis/__init__.py
@@ -1,12 +1,22 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .base import BaseInferencer
from .feature_extractor import FeatureExtractor
+from .image_caption import ImageCaptionInferencer
from .image_classification import ImageClassificationInferencer
from .image_retrieval import ImageRetrievalInferencer
from .model import (ModelHub, get_model, inference_model, init_model,
list_models)
+from .multimodal_retrieval import (ImageToTextRetrievalInferencer,
+ TextToImageRetrievalInferencer)
+from .nlvr import NLVRInferencer
+from .visual_grounding import VisualGroundingInferencer
+from .visual_question_answering import VisualQuestionAnsweringInferencer
__all__ = [
'init_model', 'inference_model', 'list_models', 'get_model', 'ModelHub',
'ImageClassificationInferencer', 'ImageRetrievalInferencer',
- 'FeatureExtractor'
+ 'FeatureExtractor', 'ImageCaptionInferencer',
+ 'TextToImageRetrievalInferencer', 'VisualGroundingInferencer',
+ 'VisualQuestionAnsweringInferencer', 'ImageToTextRetrievalInferencer',
+ 'BaseInferencer', 'NLVRInferencer'
]
diff --git a/mmpretrain/apis/base.py b/mmpretrain/apis/base.py
new file mode 100644
index 00000000000..ee4f44490c6
--- /dev/null
+++ b/mmpretrain/apis/base.py
@@ -0,0 +1,388 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from abc import abstractmethod
+from typing import Callable, Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.config import Config
+from mmengine.dataset import default_collate
+from mmengine.fileio import get_file_backend
+from mmengine.model import BaseModel
+from mmengine.runner import load_checkpoint
+
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track
+from .model import get_model, list_models
+
+ModelType = Union[BaseModel, str, Config]
+InputType = Union[str, np.ndarray, list]
+
+
+class BaseInferencer:
+ """Base inferencer for various tasks.
+
+ The BaseInferencer provides the standard workflow for inference as follows:
+
+ 1. Preprocess the input data by :meth:`preprocess`.
+ 2. Forward the data to the model by :meth:`forward`. ``BaseInferencer``
+ assumes the model inherits from :class:`mmengine.models.BaseModel` and
+ will call `model.test_step` in :meth:`forward` by default.
+ 3. Visualize the results by :meth:`visualize`.
+ 4. Postprocess and return the results by :meth:`postprocess`.
+
+ When we call the subclasses inherited from BaseInferencer (not overriding
+ ``__call__``), the workflow will be executed in order.
+
+ All subclasses of BaseInferencer could define the following class
+ attributes for customization:
+
+ - ``preprocess_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`preprocess`.
+ - ``forward_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`forward`
+ - ``visualize_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`visualize`
+ - ``postprocess_kwargs``: The keys of the kwargs that will be passed to
+ :meth:`postprocess`
+
+ All attributes mentioned above should be a ``set`` of keys (strings),
+ and each key should not be duplicated. Actually, :meth:`__call__` will
+ dispatch all the arguments to the corresponding methods according to the
+ ``xxx_kwargs`` mentioned above.
+
+ Subclasses inherited from ``BaseInferencer`` should implement
+ :meth:`_init_pipeline`, :meth:`visualize` and :meth:`postprocess`:
+
+ - _init_pipeline: Return a callable object to preprocess the input data.
+ - visualize: Visualize the results returned by :meth:`forward`.
+ - postprocess: Postprocess the results returned by :meth:`forward` and
+ :meth:`visualize`.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``cls.list_models()`` and you can also query it in
+ :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str | torch.device | None): Transfer the model to the target
+ device. Defaults to None.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+ """
+
+ preprocess_kwargs: set = set()
+ forward_kwargs: set = set()
+ visualize_kwargs: set = set()
+ postprocess_kwargs: set = set()
+
+ def __init__(self,
+ model: ModelType,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ device_map=None,
+ offload_folder=None,
+ **kwargs) -> None:
+
+ if isinstance(model, BaseModel):
+ if isinstance(pretrained, str):
+ load_checkpoint(model, pretrained, map_location='cpu')
+ if device_map is not None:
+ from .utils import dispatch_model
+ model = dispatch_model(
+ model,
+ device_map=device_map,
+ offload_folder=offload_folder)
+ elif device is not None:
+ model.to(device)
+ else:
+ model = get_model(
+ model,
+ pretrained,
+ device=device,
+ device_map=device_map,
+ offload_folder=offload_folder,
+ **kwargs)
+
+ model.eval()
+
+ self.config = model._config
+ self.model = model
+ self.pipeline = self._init_pipeline(self.config)
+ self.visualizer = None
+
+ def __call__(
+ self,
+ inputs,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs,
+ ) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (InputsType): Inputs for the inferencer.
+ return_datasamples (bool): Whether to return results as
+ :obj:`BaseDataElement`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ **kwargs: Key words arguments passed to :meth:`preprocess`,
+ :meth:`forward`, :meth:`visualize` and :meth:`postprocess`.
+ Each key in kwargs should be in the corresponding set of
+ ``preprocess_kwargs``, ``forward_kwargs``, ``visualize_kwargs``
+ and ``postprocess_kwargs``.
+
+ Returns:
+ dict: Inference and visualization results.
+ """
+ (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ ) = self._dispatch_kwargs(**kwargs)
+
+ ori_inputs = self._inputs_to_list(inputs)
+ inputs = self.preprocess(
+ ori_inputs, batch_size=batch_size, **preprocess_kwargs)
+ preds = []
+ for data in track(inputs, 'Inference'):
+ preds.extend(self.forward(data, **forward_kwargs))
+ visualization = self.visualize(ori_inputs, preds, **visualize_kwargs)
+ results = self.postprocess(preds, visualization, return_datasamples,
+ **postprocess_kwargs)
+ return results
+
+ def _inputs_to_list(self, inputs: InputType) -> list:
+ """Preprocess the inputs to a list.
+
+ Cast the input data to a list of data.
+
+ - list or tuple: return inputs
+ - str:
+ - Directory path: return all files in the directory
+ - other cases: return a list containing the string. The string
+ could be a path to file, a url or other types of string according
+ to the task.
+ - other: return a list with one item.
+
+ Args:
+ inputs (str | array | list): Inputs for the inferencer.
+
+ Returns:
+ list: List of input for the :meth:`preprocess`.
+ """
+ if isinstance(inputs, str):
+ backend = get_file_backend(inputs)
+ if hasattr(backend, 'isdir') and backend.isdir(inputs):
+ # Backends like HttpsBackend do not implement `isdir`, so only
+ # those backends that implement `isdir` could accept the inputs
+ # as a directory
+ file_list = backend.list_dir_or_file(inputs, list_dir=False)
+ inputs = [
+ backend.join_path(inputs, file) for file in file_list
+ ]
+
+ if not isinstance(inputs, (list, tuple)):
+ inputs = [inputs]
+
+ return list(inputs)
+
+ def preprocess(self, inputs: InputType, batch_size: int = 1, **kwargs):
+ """Process the inputs into a model-feedable format.
+
+ Customize your preprocess by overriding this method. Preprocess should
+ return an iterable object, of which each item will be used as the
+ input of ``model.test_step``.
+
+ ``BaseInferencer.preprocess`` will return an iterable chunked data,
+ which will be used in __call__ like this:
+
+ .. code-block:: python
+
+ def __call__(self, inputs, batch_size=1, **kwargs):
+ chunked_data = self.preprocess(inputs, batch_size, **kwargs)
+ for batch in chunked_data:
+ preds = self.forward(batch, **kwargs)
+
+ Args:
+ inputs (InputsType): Inputs given by user.
+ batch_size (int): batch size. Defaults to 1.
+
+ Yields:
+ Any: Data processed by the ``pipeline`` and ``default_collate``.
+ """
+ chunked_data = self._get_chunk_data(
+ map(self.pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ @torch.no_grad()
+ def forward(self, inputs: Union[dict, tuple], **kwargs):
+ """Feed the inputs to the model."""
+ return self.model.test_step(inputs)
+
+ def visualize(self,
+ inputs: list,
+ preds: List[DataSample],
+ show: bool = False,
+ **kwargs) -> List[np.ndarray]:
+ """Visualize predictions.
+
+ Customize your visualization by overriding this method. visualize
+ should return visualization results, which could be np.ndarray or any
+ other objects.
+
+ Args:
+ inputs (list): Inputs preprocessed by :meth:`_inputs_to_list`.
+ preds (Any): Predictions of the model.
+ show (bool): Whether to display the image in a popup window.
+ Defaults to False.
+
+ Returns:
+ List[np.ndarray]: Visualization results.
+ """
+ if show:
+ raise NotImplementedError(
+ f'The `visualize` method of {self.__class__.__name__} '
+ 'is not implemented.')
+
+ @abstractmethod
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasample=False,
+ **kwargs,
+ ) -> dict:
+ """Process the predictions and visualization results from ``forward``
+ and ``visualize``.
+
+ This method should be responsible for the following tasks:
+
+ 1. Convert datasamples into a json-serializable dict if needed.
+ 2. Pack the predictions and visualization results and return them.
+ 3. Dump or log the predictions.
+
+ Customize your postprocess by overriding this method. Make sure
+ ``postprocess`` will return a dict with visualization results and
+ inference results.
+
+ Args:
+ preds (List[Dict]): Predictions of the model.
+ visualization (np.ndarray): Visualized predictions.
+ return_datasample (bool): Whether to return results as datasamples.
+ Defaults to False.
+
+ Returns:
+ dict: Inference and visualization results with key ``predictions``
+ and ``visualization``
+
+ - ``visualization (Any)``: Returned by :meth:`visualize`
+ - ``predictions`` (dict or DataSample): Returned by
+ :meth:`forward` and processed in :meth:`postprocess`.
+ If ``return_datasample=False``, it usually should be a
+ json-serializable dict containing only basic data elements such
+ as strings and numbers.
+ """
+
+ @abstractmethod
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ """Initialize the test pipeline.
+
+ Return a pipeline to handle various input data, such as ``str``,
+ ``np.ndarray``. It is an abstract method in BaseInferencer, and should
+ be implemented in subclasses.
+
+ The returned pipeline will be used to process a single data.
+ It will be used in :meth:`preprocess` like this:
+
+ .. code-block:: python
+ def preprocess(self, inputs, batch_size, **kwargs):
+ ...
+ dataset = map(self.pipeline, dataset)
+ ...
+ """
+
+ def _get_chunk_data(self, inputs: Iterable, chunk_size: int):
+ """Get batch data from dataset.
+
+ Args:
+ inputs (Iterable): An iterable dataset.
+ chunk_size (int): Equivalent to batch size.
+
+ Yields:
+ list: batch data.
+ """
+ inputs_iter = iter(inputs)
+ while True:
+ try:
+ chunk_data = []
+ for _ in range(chunk_size):
+ processed_data = next(inputs_iter)
+ chunk_data.append(processed_data)
+ yield chunk_data
+ except StopIteration:
+ if chunk_data:
+ yield chunk_data
+ break
+
+ def _dispatch_kwargs(self, **kwargs) -> Tuple[dict, dict, dict, dict]:
+ """Dispatch kwargs to preprocess(), forward(), visualize() and
+ postprocess() according to the actual demands.
+
+ Returns:
+ Tuple[Dict, Dict, Dict, Dict]: kwargs passed to preprocess,
+ forward, visualize and postprocess respectively.
+ """
+ # Ensure each argument only matches one function
+ method_kwargs = self.preprocess_kwargs | self.forward_kwargs | \
+ self.visualize_kwargs | self.postprocess_kwargs
+
+ union_kwargs = method_kwargs | set(kwargs.keys())
+ if union_kwargs != method_kwargs:
+ unknown_kwargs = union_kwargs - method_kwargs
+ raise ValueError(
+ f'unknown argument {unknown_kwargs} for `preprocess`, '
+ '`forward`, `visualize` and `postprocess`')
+
+ preprocess_kwargs = {}
+ forward_kwargs = {}
+ visualize_kwargs = {}
+ postprocess_kwargs = {}
+
+ for key, value in kwargs.items():
+ if key in self.preprocess_kwargs:
+ preprocess_kwargs[key] = value
+ if key in self.forward_kwargs:
+ forward_kwargs[key] = value
+ if key in self.visualize_kwargs:
+ visualize_kwargs[key] = value
+ if key in self.postprocess_kwargs:
+ postprocess_kwargs[key] = value
+
+ return (
+ preprocess_kwargs,
+ forward_kwargs,
+ visualize_kwargs,
+ postprocess_kwargs,
+ )
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List models defined in metafile of corresponding packages.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern)
diff --git a/mmpretrain/apis/feature_extractor.py b/mmpretrain/apis/feature_extractor.py
index 513717fc89f..b7c52c2fcbc 100644
--- a/mmpretrain/apis/feature_extractor.py
+++ b/mmpretrain/apis/feature_extractor.py
@@ -1,60 +1,43 @@
# Copyright (c) OpenMMLab. All rights reserved.
from typing import Callable, List, Optional, Union
-import numpy as np
import torch
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType
+from .model import list_models
class FeatureExtractor(BaseInferencer):
"""The inferencer for extract features.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
- by ``FeatureExtractor.list_models()``.
- pretrained (bool | str): When use name to specify model, you can
- use ``True`` to load the pre-defined pretrained weights. And you
- can also use a string to specify the path or link of weights to
- load. Defaults to True.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
- """
-
- def __init__(
- self,
- model: ModelType,
- pretrained: Union[bool, str] = True,
- device: Union[str, torch.device, None] = None,
- ) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ by ``FeatureExtractor.list_models()`` and you can also query it in
+ :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import FeatureExtractor
+ >>> inferencer = FeatureExtractor('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
+ >>> feats = inferencer('demo/demo.JPEG', stage='backbone')[0]
+ >>> for feat in feats:
+ >>> print(feat.shape)
+ torch.Size([256, 56, 56])
+ torch.Size([512, 28, 28])
+ torch.Size([1024, 14, 14])
+ torch.Size([2048, 7, 7])
+ """ # noqa: E501
def __call__(self,
inputs: InputType,
@@ -122,7 +105,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self):
raise NotImplementedError(
diff --git a/mmpretrain/apis/image_caption.py b/mmpretrain/apis/image_caption.py
new file mode 100644
index 00000000000..aef21878112
--- /dev/null
+++ b/mmpretrain/apis/image_caption.py
@@ -0,0 +1,164 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer, InputType
+from .model import list_models
+
+
+class ImageCaptionInferencer(BaseInferencer):
+ """The inferencer for image caption.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``ImageCaptionInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import ImageCaptionInferencer
+ >>> inferencer = ImageCaptionInferencer('blip-base_3rdparty_caption')
+ >>> inferencer('demo/cat-dog.png')[0]
+ {'pred_caption': 'a puppy and a cat sitting on a blanket'}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {'resize', 'show', 'show_dir', 'wait_time'}
+
+ def __call__(self,
+ images: InputType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(images, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[InputType], batch_size: int = 1):
+
+ def load_image(input_):
+ img = imread(input_)
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return dict(
+ img=img,
+ img_shape=img.shape[:2],
+ ori_shape=img.shape[:2],
+ )
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[InputType],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_)
+ if isinstance(input_, str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_image_caption(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({'pred_caption': data_sample.get('pred_caption')})
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Image Caption')
diff --git a/mmpretrain/apis/image_classification.py b/mmpretrain/apis/image_classification.py
index e261a568467..081672614c3 100644
--- a/mmpretrain/apis/image_classification.py
+++ b/mmpretrain/apis/image_classification.py
@@ -7,32 +7,28 @@
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
from mmpretrain.structures import DataSample
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType, ModelType
+from .model import list_models
class ImageClassificationInferencer(BaseInferencer):
"""The inferencer for image classification.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
by ``ImageClassificationInferencer.list_models()`` and you can also
query it in :doc:`/modelzoo_statistics`.
- pretrained (str, optional): Path to the checkpoint. If None, it will try
- to find a pre-defined weight from the model you specified
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
(only work if the ``model`` is a model name). Defaults to None.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
Example:
1. Use a pre-trained model in MMPreTrain to inference an image.
@@ -61,34 +57,20 @@ class ImageClassificationInferencer(BaseInferencer):
'wait_time'
}
- def __init__(
- self,
- model: ModelType,
- pretrained: Union[bool, str] = True,
- device: Union[str, torch.device, None] = None,
- classes=None,
- ) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ def __init__(self,
+ model: ModelType,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ classes=None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
if classes is not None:
self.classes = classes
else:
- self.classes = getattr(model, 'dataset_meta', {}).get('classes')
+ self.classes = getattr(self.model, '_dataset_meta',
+ {}).get('classes')
def __call__(self,
inputs: InputType,
@@ -120,8 +102,11 @@ def __call__(self,
Returns:
list: The inference results.
"""
- return super().__call__(inputs, return_datasamples, batch_size,
- **kwargs)
+ return super().__call__(
+ inputs,
+ return_datasamples=return_datasamples,
+ batch_size=batch_size,
+ **kwargs)
def _init_pipeline(self, cfg: Config) -> Callable:
test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
@@ -147,7 +132,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self,
ori_inputs: List[InputType],
diff --git a/mmpretrain/apis/image_retrieval.py b/mmpretrain/apis/image_retrieval.py
index f233877d605..980d65cc3c7 100644
--- a/mmpretrain/apis/image_retrieval.py
+++ b/mmpretrain/apis/image_retrieval.py
@@ -7,57 +7,56 @@
from mmcv.image import imread
from mmengine.config import Config
from mmengine.dataset import BaseDataset, Compose, default_collate
-from mmengine.device import get_device
-from mmengine.infer import BaseInferencer
-from mmengine.model import BaseModel
-from mmengine.runner import load_checkpoint
from mmpretrain.registry import TRANSFORMS
from mmpretrain.structures import DataSample
-from .model import get_model, list_models
-
-ModelType = Union[BaseModel, str, Config]
-InputType = Union[str, np.ndarray, list]
+from .base import BaseInferencer, InputType, ModelType
+from .model import list_models
class ImageRetrievalInferencer(BaseInferencer):
"""The inferencer for image to image retrieval.
Args:
- model (BaseModel | str | Config): A model name or a path to the confi
+ model (BaseModel | str | Config): A model name or a path to the config
file, or a :obj:`BaseModel` object. The model name can be found
- by ``ImageClassificationInferencer.list_models()`` and you can also
+ by ``ImageRetrievalInferencer.list_models()`` and you can also
query it in :doc:`/modelzoo_statistics`.
- weights (str, optional): Path to the checkpoint. If None, it will try
- to find a pre-defined weight from the model you specified
+ prototype (str | list | dict | DataLoader, BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The directory of the the images.
+ - list: A list of path of the images.
+ - dict: A config dict of the a prototype dataset.
+ - BaseDataset: A prototype dataset.
+ - DataLoader: A data loader to load the prototype data.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
(only work if the ``model`` is a model name). Defaults to None.
- device (str, optional): Device to run inference. If None, use CPU or
- the device of the input model. Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
Example:
- 1. Use a pre-trained model in MMPreTrain to inference an image.
-
- >>> from mmpretrain import ImageClassificationInferencer
- >>> inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
- >>> inferencer('demo/demo.JPEG')
- [{'pred_score': array([...]),
- 'pred_label': 65,
- 'pred_score': 0.6649367809295654,
- 'pred_class': 'sea snake'}]
-
- 2. Use a config file and checkpoint to inference multiple images on GPU,
- and save the visualization results in a folder.
-
- >>> from mmpretrain import ImageClassificationInferencer
- >>> inferencer = ImageClassificationInferencer(
- model='configs/resnet/resnet50_8xb32_in1k.py',
- weights='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
- device='cuda')
- >>> inferencer(['demo/dog.jpg', 'demo/bird.JPEG'], show_dir="./visualize/")
+ >>> from mmpretrain import ImageRetrievalInferencer
+ >>> inferencer = ImageRetrievalInferencer(
+ ... 'resnet50-arcface_8xb32_inshop',
+ ... prototype='./demo/',
+ ... prototype_cache='img_retri.pth')
+ >>> inferencer('demo/cat-dog.png', topk=2)[0][1]
+ {'match_score': tensor(0.4088, device='cuda:0'),
+ 'sample_idx': 3,
+ 'sample': {'img_path': './demo/dog.jpg'}}
""" # noqa: E501
visualize_kwargs: set = {
- 'draw_score', 'resize', 'show_dir', 'show', 'wait_time'
+ 'draw_score', 'resize', 'show_dir', 'show', 'wait_time', 'topk'
}
postprocess_kwargs: set = {'topk'}
@@ -65,36 +64,19 @@ def __init__(
self,
model: ModelType,
prototype,
- prototype_vecs=None,
+ prototype_cache=None,
prepare_batch_size=8,
pretrained: Union[bool, str] = True,
device: Union[str, torch.device, None] = None,
+ **kwargs,
) -> None:
- device = device or get_device()
-
- if isinstance(model, BaseModel):
- if isinstance(pretrained, str):
- load_checkpoint(model, pretrained, map_location='cpu')
- model = model.to(device)
- else:
- model = get_model(model, pretrained, device)
-
- model.eval()
-
- self.config = model.config
- self.model = model
- self.pipeline = self._init_pipeline(self.config)
- self.collate_fn = default_collate
- self.visualizer = None
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
self.prototype_dataset = self._prepare_prototype(
- prototype, prototype_vecs, prepare_batch_size)
-
- # An ugly hack to escape from the duplicated arguments check in the
- # base class
- self.visualize_kwargs.add('topk')
+ prototype, prototype_cache, prepare_batch_size)
- def _prepare_prototype(self, prototype, prototype_vecs=None, batch_size=8):
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
from mmengine.dataset import DefaultSampler
from torch.utils.data import DataLoader
@@ -102,23 +84,30 @@ def build_dataloader(dataset):
return DataLoader(
dataset,
batch_size=batch_size,
- collate_fn=self.collate_fn,
+ collate_fn=default_collate,
sampler=DefaultSampler(dataset, shuffle=False),
persistent_workers=False,
)
- test_pipeline = self.config.test_dataloader.dataset.pipeline
-
if isinstance(prototype, str):
# A directory path of images
- from mmpretrain.datasets import CustomDataset
- dataset = CustomDataset(
- data_root=prototype, pipeline=test_pipeline, with_label=False)
+ prototype = dict(
+ type='CustomDataset', with_label=False, data_root=prototype)
+
+ if isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
dataloader = build_dataloader(dataset)
elif isinstance(prototype, dict):
# A config of dataset
from mmpretrain.registry import DATASETS
- prototype.setdefault('pipeline', test_pipeline)
+ test_pipeline = [dict(type='LoadImageFromFile'), self.pipeline]
dataset = DATASETS.build(prototype)
dataloader = build_dataloader(dataset)
elif isinstance(prototype, DataLoader):
@@ -130,25 +119,25 @@ def build_dataloader(dataset):
else:
raise TypeError(f'Unsupported prototype type {type(prototype)}.')
- if prototype_vecs is not None and Path(prototype_vecs).exists():
- self.model.prototype = prototype_vecs
+ if cache is not None and Path(cache).exists():
+ self.model.prototype = cache
else:
self.model.prototype = dataloader
self.model.prepare_prototype()
from mmengine.logging import MMLogger
logger = MMLogger.get_current_instance()
- if prototype_vecs is None:
+ if cache is None:
logger.info('The prototype has been prepared, you can use '
- '`save_prototype_vecs` to dump it into a pickle '
+ '`save_prototype` to dump it into a pickle '
'file for the future usage.')
- elif not Path(prototype_vecs).exists():
- self.save_prototype_vecs(prototype_vecs)
- logger.info(f'The prototype has been saved at {prototype_vecs}.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
return dataset
- def save_prototype_vecs(self, path):
+ def save_prototype(self, path):
self.model.dump_prototype(path)
def __call__(self,
@@ -205,7 +194,7 @@ def load_image(input_):
pipeline = Compose([load_image, self.pipeline])
chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
- yield from map(self.collate_fn, chunked_data)
+ yield from map(default_collate, chunked_data)
def visualize(self,
ori_inputs: List[InputType],
@@ -294,49 +283,3 @@ def list_models(pattern: Optional[str] = None):
List[str]: a list of model names.
"""
return list_models(pattern=pattern, task='Image Retrieval')
-
- def _dispatch_kwargs(self, **kwargs):
- """Dispatch kwargs to preprocess(), forward(), visualize() and
- postprocess() according to the actual demands.
-
- Override this method to allow same argument for different methods.
-
- Returns:
- Tuple[Dict, Dict, Dict, Dict]: kwargs passed to preprocess,
- forward, visualize and postprocess respectively.
- """
- method_kwargs = set.union(
- self.preprocess_kwargs,
- self.forward_kwargs,
- self.visualize_kwargs,
- self.postprocess_kwargs,
- )
-
- union_kwargs = method_kwargs | set(kwargs.keys())
- if union_kwargs != method_kwargs:
- unknown_kwargs = union_kwargs - method_kwargs
- raise ValueError(
- f'unknown argument {unknown_kwargs} for `preprocess`, '
- '`forward`, `visualize` and `postprocess`')
-
- preprocess_kwargs = {}
- forward_kwargs = {}
- visualize_kwargs = {}
- postprocess_kwargs = {}
-
- for key, value in kwargs.items():
- if key in self.preprocess_kwargs:
- preprocess_kwargs[key] = value
- if key in self.forward_kwargs:
- forward_kwargs[key] = value
- if key in self.visualize_kwargs:
- visualize_kwargs[key] = value
- if key in self.postprocess_kwargs:
- postprocess_kwargs[key] = value
-
- return (
- preprocess_kwargs,
- forward_kwargs,
- visualize_kwargs,
- postprocess_kwargs,
- )
diff --git a/mmpretrain/apis/model.py b/mmpretrain/apis/model.py
index a36c553a1a3..eba475e7f79 100644
--- a/mmpretrain/apis/model.py
+++ b/mmpretrain/apis/model.py
@@ -2,10 +2,11 @@
import copy
import fnmatch
import os.path as osp
+import re
import warnings
from os import PathLike
from pathlib import Path
-from typing import List, Union
+from typing import List, Tuple, Union
from mmengine.config import Config
from modelindex.load_model_index import load
@@ -96,6 +97,9 @@ def has(cls, model_name):
def get_model(model: Union[str, Config],
pretrained: Union[str, bool] = False,
device=None,
+ device_map=None,
+ offload_folder=None,
+ url_mapping: Tuple[str, str] = None,
**kwargs):
"""Get a pre-defined model or create a model from config.
@@ -108,6 +112,18 @@ def get_model(model: Union[str, Config],
load. Defaults to False.
device (str | torch.device | None): Transfer the model to the target
device. Defaults to None.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ url_mapping (Tuple[str, str], optional): The mapping of pretrained
+ checkpoint link. For example, load checkpoint from a local dir
+ instead of download by ``('https://.*/', './checkpoint')``.
+ Defaults to None.
**kwargs: Other keyword arguments of the model config.
Returns:
@@ -136,11 +152,16 @@ def get_model(model: Union[str, Config],
>>> print(result['pred_class'])
'sea snake'
""" # noqa: E501
+ if device_map is not None:
+ from .utils import dispatch_model
+ dispatch_model._verify_require()
+
+ metainfo = None
if isinstance(model, Config):
config = copy.deepcopy(model)
if pretrained is True and 'load_from' in config:
pretrained = config.load_from
- elif isinstance(model, (str, PathLike)) and Path(model).suffix:
+ elif isinstance(model, (str, PathLike)) and Path(model).suffix == '.py':
config = Config.fromfile(model)
if pretrained is True and 'load_from' in config:
pretrained = config.load_from
@@ -164,14 +185,19 @@ def get_model(model: Union[str, Config],
config.model.setdefault('data_preprocessor',
config.get('data_preprocessor', None))
+ from mmengine.registry import DefaultScope
+
from mmpretrain.registry import MODELS
- model = MODELS.build(config.model)
+ with DefaultScope.overwrite_default_scope('mmpretrain'):
+ model = MODELS.build(config.model)
dataset_meta = {}
if pretrained:
# Mapping the weights to GPU may cause unexpected video memory leak
# which refers to https://github.com/open-mmlab/mmdetection/pull/6405
from mmengine.runner import load_checkpoint
+ if url_mapping is not None:
+ pretrained = re.sub(url_mapping[0], url_mapping[1], pretrained)
checkpoint = load_checkpoint(model, pretrained, map_location='cpu')
if 'dataset_meta' in checkpoint.get('meta', {}):
# mmpretrain 1.x
@@ -185,9 +211,15 @@ def get_model(model: Union[str, Config],
dataset_class = DATASETS.get(config.test_dataloader.dataset.type)
dataset_meta = getattr(dataset_class, 'METAINFO', {})
- model.dataset_meta = dataset_meta
- model.config = config # save the config in the model for convenience
- model.to(device)
+ if device_map is not None:
+ model = dispatch_model(
+ model, device_map=device_map, offload_folder=offload_folder)
+ elif device is not None:
+ model.to(device)
+
+ model._dataset_meta = dataset_meta # save the dataset meta
+ model._config = config # save the config in the model
+ model._metainfo = metainfo # save the metainfo in the model
model.eval()
return model
@@ -284,6 +316,8 @@ def list_models(pattern=None, exclude_patterns=None, task=None) -> List[str]:
metainfo = ModelHub._models_dict[key]
if metainfo.results is None and task == 'null':
task_matches.append(key)
+ elif metainfo.results is None:
+ continue
elif task in [result.task for result in metainfo.results]:
task_matches.append(key)
matches = task_matches
@@ -291,41 +325,84 @@ def list_models(pattern=None, exclude_patterns=None, task=None) -> List[str]:
return sorted(list(matches))
-def inference_model(model, input_, **kwargs):
+def inference_model(model, *args, **kwargs):
"""Inference an image with the inferencer.
Automatically select inferencer to inference according to the type of
model. It's a shortcut for a quick start, and for advanced usage, please
use the correspondding inferencer class.
- Here is the mapping from model type to inferencer:
+ Here is the mapping from task to inferencer:
- - :class:`~mmpretrain.models.ImageClassifier`: :class:`ImageClassificationInferencer`.
- - :class:`~mmpretrain.models.ImageToImageRetriever`: :class:`ImageToImageRetrievalInferencer`.
+ - Image Classification: :class:`ImageClassificationInferencer`
+ - Image Retrieval: :class:`ImageRetrievalInferencer`
+ - Image Caption: :class:`ImageCaptionInferencer`
+ - Visual Question Answering: :class:`VisualQuestionAnsweringInferencer`
+ - Visual Grounding: :class:`VisualGroundingInferencer`
+ - Text-To-Image Retrieval: :class:`TextToImageRetrievalInferencer`
+ - Image-To-Text Retrieval: :class:`ImageToTextRetrievalInferencer`
+ - NLVR: :class:`NLVRInferencer`
Args:
model (BaseModel | str | Config): The loaded model, the model
name or the config of the model.
- input_ (str | ndarray): The image path or loaded image.
- **kwargs: Other keyword arguments to initialize the correspondding
- inferencer.
+ *args: Positional arguments to call the inferencer.
+ **kwargs: Other keyword arguments to initialize and call the
+ correspondding inferencer.
Returns:
result (dict): The inference results.
""" # noqa: E501
from mmengine.model import BaseModel
- if not isinstance(model, BaseModel):
- model = get_model(model, pretrained=True)
+ if isinstance(model, BaseModel):
+ metainfo = getattr(model, '_metainfo', None)
+ else:
+ metainfo = ModelHub.get(model)
+
+ from inspect import signature
- import mmpretrain.models
+ from .image_caption import ImageCaptionInferencer
from .image_classification import ImageClassificationInferencer
from .image_retrieval import ImageRetrievalInferencer
-
- if isinstance(model, mmpretrain.models.ImageClassifier):
- inferencer = ImageClassificationInferencer(model, **kwargs)
- elif isinstance(model, mmpretrain.models.ImageToImageRetriever):
- inferencer = ImageRetrievalInferencer(model, **kwargs)
- else:
- raise NotImplementedError(f'No available inferencer for {type(model)}')
- return inferencer(input_)[0]
+ from .multimodal_retrieval import (ImageToTextRetrievalInferencer,
+ TextToImageRetrievalInferencer)
+ from .nlvr import NLVRInferencer
+ from .visual_grounding import VisualGroundingInferencer
+ from .visual_question_answering import VisualQuestionAnsweringInferencer
+ task_mapping = {
+ 'Image Classification': ImageClassificationInferencer,
+ 'Image Retrieval': ImageRetrievalInferencer,
+ 'Image Caption': ImageCaptionInferencer,
+ 'Visual Question Answering': VisualQuestionAnsweringInferencer,
+ 'Visual Grounding': VisualGroundingInferencer,
+ 'Text-To-Image Retrieval': TextToImageRetrievalInferencer,
+ 'Image-To-Text Retrieval': ImageToTextRetrievalInferencer,
+ 'NLVR': NLVRInferencer,
+ }
+
+ inferencer_type = None
+
+ if metainfo is not None and metainfo.results is not None:
+ tasks = set(result.task for result in metainfo.results)
+ inferencer_type = [
+ task_mapping.get(task) for task in tasks if task in task_mapping
+ ]
+ if len(inferencer_type) > 1:
+ inferencer_names = [cls.__name__ for cls in inferencer_type]
+ warnings.warn('The model supports multiple tasks, auto select '
+ f'{inferencer_names[0]}, you can also use other '
+ f'inferencer {inferencer_names} directly.')
+ inferencer_type = inferencer_type[0]
+
+ if inferencer_type is None:
+ raise NotImplementedError('No available inferencer for the model')
+
+ init_kwargs = {
+ k: kwargs.pop(k)
+ for k in list(kwargs)
+ if k in signature(inferencer_type).parameters.keys()
+ }
+
+ inferencer = inferencer_type(model, **init_kwargs)
+ return inferencer(*args, **kwargs)[0]
diff --git a/mmpretrain/apis/multimodal_retrieval.py b/mmpretrain/apis/multimodal_retrieval.py
new file mode 100644
index 00000000000..5eb9c859aca
--- /dev/null
+++ b/mmpretrain/apis/multimodal_retrieval.py
@@ -0,0 +1,603 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+from pathlib import Path
+from typing import Callable, List, Optional, Tuple, Union
+
+import mmengine
+import numpy as np
+import torch
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import BaseDataset, Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track
+from .base import BaseInferencer
+from .base import InputType as ImageType
+from .base import ModelType
+from .model import list_models
+
+
+def filter_transforms(transforms: list, data_info: dict):
+ """Filter pipeline to avoid KeyError with partial data info."""
+ data_info = deepcopy(data_info)
+ filtered_transforms = []
+ for t in transforms:
+ try:
+ data_info = t(data_info)
+ filtered_transforms.append(t)
+ except KeyError:
+ pass
+ return filtered_transforms
+
+
+class TextToImageRetrievalInferencer(BaseInferencer):
+ """The inferencer for text to image retrieval.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``TextToImageRetrievalInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ prototype (str | list | dict | DataLoader | BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The directory of the the images.
+ - list: A list of path of the images.
+ - dict: A config dict of the a prototype dataset.
+ - BaseDataset: A prototype dataset.
+ - DataLoader: A data loader to load the prototype data.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ fast_match (bool): Some algorithms will record extra image features for
+ further matching, which may consume large memory, set True to avoid
+ this behavior. Defaults to True.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import TextToImageRetrievalInferencer
+ >>> inferencer = TextToImageRetrievalInferencer(
+ ... 'blip-base_3rdparty_retrieval',
+ ... prototype='./demo/',
+ ... prototype_cache='t2i_retri.pth')
+ >>> inferencer('A cat and a dog.')[0]
+ {'match_score': tensor(0.3855, device='cuda:0'),
+ 'sample_idx': 1,
+ 'sample': {'img_path': './demo/cat-dog.png'}}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'draw_score', 'show_dir', 'show', 'wait_time', 'figsize', 'topk'
+ }
+ postprocess_kwargs: set = {'topk'}
+
+ def __init__(self,
+ model: ModelType,
+ prototype,
+ prototype_cache=None,
+ fast_match=True,
+ prepare_batch_size=8,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
+
+ self.img_pipeline, self.text_pipeline = self.pipeline
+
+ if hasattr(self.model, 'fast_match'):
+ self.model.fast_match = fast_match
+
+ self.prototype_dataset = self._prepare_prototype(
+ prototype, prototype_cache, batch_size=prepare_batch_size)
+
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
+ from mmengine.dataset import DefaultSampler
+ from torch.utils.data import DataLoader
+
+ def build_dataloader(dataset):
+ return DataLoader(
+ dataset,
+ batch_size=batch_size,
+ collate_fn=default_collate,
+ sampler=DefaultSampler(dataset, shuffle=False),
+ persistent_workers=False,
+ )
+
+ if isinstance(prototype, str):
+ # A directory path of images
+ prototype = dict(
+ type='CustomDataset', with_label=False, data_root=prototype)
+
+ if isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, dict):
+ # A config of dataset
+ from mmpretrain.registry import DATASETS
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ prototype.setdefault('pipeline', test_pipeline)
+ dataset = DATASETS.build(prototype)
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, list):
+ test_pipeline = [dict(type='LoadImageFromFile'), self.img_pipeline]
+ dataset = BaseDataset(
+ lazy_init=True, serialize_data=False, pipeline=test_pipeline)
+ dataset.data_list = [{
+ 'sample_idx': i,
+ 'img_path': file
+ } for i, file in enumerate(prototype)]
+ dataset._fully_initialized = True
+ dataloader = build_dataloader(dataset)
+ elif isinstance(prototype, DataLoader):
+ dataset = prototype.dataset
+ dataloader = prototype
+ elif isinstance(prototype, BaseDataset):
+ dataset = prototype
+ dataloader = build_dataloader(dataset)
+ else:
+ raise TypeError(f'Unsupported prototype type {type(prototype)}.')
+
+ if cache is not None and Path(cache).exists():
+ self.prototype = torch.load(cache)
+ else:
+ prototype = []
+ for data_batch in track(dataloader, 'Prepare prototype...'):
+ with torch.no_grad():
+ data_batch = self.model.data_preprocessor(
+ data_batch, False)
+ feats = self.model._run_forward(data_batch, mode='tensor')
+ prototype.append(feats)
+ prototype = {
+ k: torch.cat([d[k] for d in prototype])
+ for k in prototype[0]
+ }
+ self.prototype = prototype
+
+ from mmengine.logging import MMLogger
+ logger = MMLogger.get_current_instance()
+ if cache is None:
+ logger.info('The prototype has been prepared, you can use '
+ '`save_prototype` to dump it into a pickle '
+ 'file for the future usage.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
+
+ return dataset
+
+ def save_prototype(self, path):
+ torch.save(self.prototype, path)
+
+ def __call__(self,
+ inputs: ImageType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the match scores.
+ Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ @torch.no_grad()
+ def forward(self, data: dict, **kwargs):
+ """Feed the inputs to the model."""
+ data = self.model.data_preprocessor(data, False)
+ data_samples = data['data_samples']
+ feats = self.prototype.copy()
+ feats.update(self.model.extract_feat(data_samples=data_samples))
+ return self.model.predict_all(feats, data_samples, cal_i2t=False)[0]
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ test_transfroms = [TRANSFORMS.build(t) for t in test_pipeline_cfg]
+ img_info = {'img': np.zeros((224, 224, 3), dtype=np.uint8)}
+ text_info = {'text': 'example'}
+ img_pipeline = Compose(filter_transforms(test_transfroms, img_info))
+ text_pipeline = Compose(filter_transforms(test_transfroms, text_info))
+ return img_pipeline, text_pipeline
+
+ def preprocess(self, inputs: List[str], batch_size: int = 1):
+
+ def process_text(input_: str):
+ return self.text_pipeline({'text': input_})
+
+ chunked_data = self._get_chunk_data(
+ map(process_text, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[str],
+ preds: List[DataSample],
+ topk: int = 3,
+ figsize: Tuple[int, int] = (16, 9),
+ show: bool = False,
+ wait_time: int = 0,
+ draw_score=True,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (text, data_sample) in enumerate(zip(ori_inputs, preds)):
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_t2i_retrieval(
+ text,
+ data_sample,
+ self.prototype_dataset,
+ topk=topk,
+ fig_cfg=dict(figsize=figsize),
+ draw_score=draw_score,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False,
+ topk=1,
+ ) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ matches = []
+ for match_score, sample_idx in zip(match_scores, indices):
+ sample = self.prototype_dataset.get_data_info(
+ sample_idx.item())
+ sample_idx = sample.pop('sample_idx')
+ matches.append({
+ 'match_score': match_score,
+ 'sample_idx': sample_idx,
+ 'sample': sample
+ })
+ results.append(matches)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Text-To-Image Retrieval')
+
+
+class ImageToTextRetrievalInferencer(BaseInferencer):
+ """The inferencer for image to text retrieval.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``ImageToTextRetrievalInferencer.list_models()`` and you can
+ also query it in :doc:`/modelzoo_statistics`.
+ prototype (str | list | dict | DataLoader, BaseDataset): The images to
+ be retrieved. It can be the following types:
+
+ - str: The file path to load the string list.
+ - list: A list of string.
+
+ prototype_cache (str, optional): The path of the generated prototype
+ features. If exists, directly load the cache instead of re-generate
+ the prototype features. If not exists, save the generated features
+ to the path. Defaults to None.
+ fast_match (bool): Some algorithms will record extra image features for
+ further matching, which may consume large memory, set True to avoid
+ this behavior. Defaults to True.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import ImageToTextRetrievalInferencer
+ >>> inferencer = ImageToTextRetrievalInferencer(
+ ... 'blip-base_3rdparty_retrieval',
+ ... prototype=['cat', 'dog', 'snake', 'bird'],
+ ... prototype_cache='i2t_retri.pth')
+ >>> inferencer('demo/bird.JPEG')[0]
+ {'match_score': tensor(0.3855, device='cuda:0'),
+ 'sample_idx': 1,
+ 'sample': {'img_path': './demo/cat-dog.png'}}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'draw_score', 'resize', 'show_dir', 'show', 'wait_time', 'topk'
+ }
+ postprocess_kwargs: set = {'topk'}
+
+ def __init__(self,
+ model: ModelType,
+ prototype,
+ prototype_cache=None,
+ fast_match=True,
+ prepare_batch_size=8,
+ pretrained: Union[bool, str] = True,
+ device: Union[str, torch.device, None] = None,
+ **kwargs) -> None:
+ super().__init__(
+ model=model, pretrained=pretrained, device=device, **kwargs)
+
+ self.img_pipeline, self.text_pipeline = self.pipeline
+
+ if hasattr(self.model, 'fast_match'):
+ self.model.fast_match = fast_match
+
+ self.prototype_dataset = self._prepare_prototype(
+ prototype, cache=prototype_cache, batch_size=prepare_batch_size)
+
+ def _prepare_prototype(self, prototype, cache=None, batch_size=8):
+ from mmengine.dataset import DefaultSampler
+ from torch.utils.data import DataLoader
+
+ def build_dataloader(dataset):
+ return DataLoader(
+ [
+ self.text_pipeline({
+ 'sample_idx': i,
+ 'text': text
+ }) for i, text in enumerate(dataset)
+ ],
+ batch_size=batch_size,
+ collate_fn=default_collate,
+ sampler=DefaultSampler(dataset, shuffle=False),
+ persistent_workers=False,
+ )
+
+ if isinstance(prototype, str):
+ # A file path of a list of string
+ dataset = mmengine.list_from_file(prototype)
+ elif mmengine.utils.is_seq_of(prototype, str):
+ dataset = prototype
+ else:
+ raise TypeError(f'Unsupported prototype type {type(prototype)}.')
+
+ dataloader = build_dataloader(dataset)
+
+ if cache is not None and Path(cache).exists():
+ self.prototype = torch.load(cache)
+ else:
+ prototype = []
+ for data_batch in track(dataloader, 'Prepare prototype...'):
+ with torch.no_grad():
+ data_batch = self.model.data_preprocessor(
+ data_batch, False)
+ feats = self.model._run_forward(data_batch, mode='tensor')
+ prototype.append(feats)
+ prototype = {
+ k: torch.cat([d[k] for d in prototype])
+ for k in prototype[0]
+ }
+ self.prototype = prototype
+
+ from mmengine.logging import MMLogger
+ logger = MMLogger.get_current_instance()
+ if cache is None:
+ logger.info('The prototype has been prepared, you can use '
+ '`save_prototype` to dump it into a pickle '
+ 'file for the future usage.')
+ elif not Path(cache).exists():
+ self.save_prototype(cache)
+ logger.info(f'The prototype has been saved at {cache}.')
+
+ return dataset
+
+ def save_prototype(self, path):
+ torch.save(self.prototype, path)
+
+ def __call__(self,
+ inputs: ImageType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (str | array | list): The image path or array, or a list of
+ images.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the match scores.
+ Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ @torch.no_grad()
+ def forward(self, data: dict, **kwargs):
+ """Feed the inputs to the model."""
+ data = self.model.data_preprocessor(data, False)
+ feats = self.prototype.copy()
+ feats.update(self.model.extract_feat(images=data['images']))
+ return self.model.predict_all(
+ feats, data['data_samples'], cal_t2i=False)[0]
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ test_transfroms = [TRANSFORMS.build(t) for t in test_pipeline_cfg]
+ img_info = {'img': np.zeros((224, 224, 3), dtype=np.uint8)}
+ text_info = {'text': 'example'}
+ img_pipeline = Compose(filter_transforms(test_transfroms, img_info))
+ text_pipeline = Compose(filter_transforms(test_transfroms, text_info))
+ return img_pipeline, text_pipeline
+
+ def preprocess(self, inputs: List[ImageType], batch_size: int = 1):
+
+ def load_image(input_):
+ img = imread(input_)
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return dict(
+ img=img,
+ img_shape=img.shape[:2],
+ ori_shape=img.shape[:2],
+ )
+
+ pipeline = Compose([load_image, self.img_pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[ImageType],
+ preds: List[DataSample],
+ topk: int = 3,
+ resize: Optional[int] = 224,
+ show: bool = False,
+ wait_time: int = 0,
+ draw_score=True,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_)
+ if isinstance(input_, str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_i2t_retrieval(
+ image,
+ data_sample,
+ self.prototype_dataset,
+ topk=topk,
+ resize=resize,
+ draw_score=draw_score,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(
+ self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False,
+ topk=1,
+ ) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ matches = []
+ for match_score, sample_idx in zip(match_scores, indices):
+ text = self.prototype_dataset[sample_idx.item()]
+ matches.append({
+ 'match_score': match_score,
+ 'sample_idx': sample_idx,
+ 'text': text
+ })
+ results.append(matches)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Image-To-Text Retrieval')
diff --git a/mmpretrain/apis/nlvr.py b/mmpretrain/apis/nlvr.py
new file mode 100644
index 00000000000..9977c3b06f3
--- /dev/null
+++ b/mmpretrain/apis/nlvr.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from copy import deepcopy
+from typing import Callable, List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+InputType = Tuple[Union[str, np.ndarray], Union[str, np.ndarray], str]
+InputsType = Union[List[InputType], InputType]
+
+
+class NLVRInferencer(BaseInferencer):
+ """The inferencer for Natural Language for Visual Reasoning.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``NLVRInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+ """
+
+ visualize_kwargs: set = {
+ 'resize', 'draw_score', 'show', 'show_dir', 'wait_time'
+ }
+
+ def __call__(self,
+ inputs: InputsType,
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ inputs (tuple, List[tuple]): The input data tuples, every tuple
+ should include three items (left image, right image, text).
+ The image can be a path or numpy array.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ assert isinstance(inputs, (tuple, list))
+ if isinstance(inputs, tuple):
+ inputs = [inputs]
+ for input_ in inputs:
+ assert isinstance(input_, tuple)
+ assert len(input_) == 3
+
+ return super().__call__(
+ inputs,
+ return_datasamples=return_datasamples,
+ batch_size=batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ assert test_pipeline_cfg[0]['type'] == 'ApplyToList'
+
+ list_pipeline = deepcopy(test_pipeline_cfg[0])
+ if list_pipeline.scatter_key == 'img_path':
+ # Remove `LoadImageFromFile`
+ list_pipeline.transforms.pop(0)
+ list_pipeline.scatter_key = 'img'
+
+ test_pipeline = Compose(
+ [TRANSFORMS.build(list_pipeline)] +
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg[1:]])
+ return test_pipeline
+
+ def preprocess(self, inputs: InputsType, batch_size: int = 1):
+
+ def load_image(input_):
+ img1 = imread(input_[0])
+ img2 = imread(input_[1])
+ text = input_[2]
+ if img1 is None:
+ raise ValueError(f'Failed to read image {input_[0]}.')
+ if img2 is None:
+ raise ValueError(f'Failed to read image {input_[1]}.')
+ return dict(
+ img=[img1, img2],
+ img_shape=[img1.shape[:2], img2.shape[:2]],
+ ori_shape=[img1.shape[:2], img2.shape[:2]],
+ text=text,
+ )
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ pred_scores = data_sample.pred_score
+ pred_score = float(torch.max(pred_scores).item())
+ pred_label = torch.argmax(pred_scores).item()
+ result = {
+ 'pred_scores': pred_scores.detach().cpu().numpy(),
+ 'pred_label': pred_label,
+ 'pred_score': pred_score,
+ }
+ results.append(result)
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='NLVR')
diff --git a/mmpretrain/apis/utils.py b/mmpretrain/apis/utils.py
new file mode 100644
index 00000000000..83e76325472
--- /dev/null
+++ b/mmpretrain/apis/utils.py
@@ -0,0 +1,270 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from collections import defaultdict
+from contextlib import contextmanager
+from itertools import chain
+from typing import Dict, List, Optional, Union
+
+import torch
+import torch.nn as nn
+
+from mmpretrain.utils import require
+
+
+@require('torch>=1.9.0', 'https://pytorch.org/get-started/locally/')
+@require('accelerate')
+def dispatch_model(
+ model,
+ device_map: Union[str, dict],
+ max_memory: Optional[dict] = None,
+ no_split_module_classes: Optional[List[str]] = None,
+ offload_folder: str = None,
+ offload_buffers: bool = False,
+ preload_module_classes: Optional[List[str]] = None,
+):
+ """Split and dispatch a model across devices.
+
+ The function depends on the `accelerate` package. Refers to
+ https://huggingface.co/docs/accelerate/main/en/usage_guides/big_modeling
+
+ Args:
+ model (torch.nn.Module): The model to dispatch.
+ device_map (str | dict | None): A map that specifies where each
+ submodule should go. It doesn't need to be refined to each
+ parameter/buffer name, once a given module name is inside, every
+ submodule of it will be sent to the same device. You can use
+ `device_map="auto"` to automatically generate the device map.
+ Defaults to None.
+ max_memory (dict | None): A dictionary device identifier to maximum
+ memory. Will default to the maximum memory available for each GPU
+ and the available CPU RAM if unset. Defaults to None.
+ no_split_module_classes (List[str] | None): A list of layer class names
+ that should never be split across device (for instance any layer
+ that has a residual connection). If None, try to get the settings
+ from the model class. Defaults to None.
+ offload_folder (str | None): If the `device_map` contains any value
+ `"disk"`, the folder where we will offload weights.
+ offload_buffers (bool): In the layers that are offloaded on the CPU
+ or the hard drive, whether or not to offload the buffers as
+ well as the parameters. Defaults to False.
+ preload_module_classes (List[str] | None): A list of classes whose
+ instances should load all their weights (even in the submodules) at
+ the beginning of the forward. This should only be used for classes
+ that have submodules which are registered but not called directly
+ during the forward, for instance if a `dense` linear layer is
+ registered, but at forward, `dense.weight` and `dense.bias` are
+ used in some operations instead of calling `dense` directly.
+ Defaults to None.
+ """
+ from accelerate import dispatch_model, infer_auto_device_map
+
+ # Check valid device_map string.
+ valid_map_option = ['auto', 'balanced', 'balanced_low_0', 'sequential']
+ if isinstance(device_map, str) and device_map not in valid_map_option:
+ raise ValueError('If passing a string for `device_map`, please choose '
+ f'from {valid_map_option}.')
+
+ # Generate device map automatically
+ if isinstance(device_map, str):
+ if no_split_module_classes is None:
+ no_split_module_classes = getattr(model, '_no_split_modules', None)
+ if no_split_module_classes is None:
+ raise ValueError(f'{model.__class__.__name__} does not support '
+ f"`device_map='{device_map}'` yet.")
+
+ if device_map != 'sequential':
+ from accelerate.utils import get_balanced_memory
+ max_memory = get_balanced_memory(
+ model,
+ max_memory=max_memory,
+ no_split_module_classes=no_split_module_classes,
+ dtype=None,
+ low_zero=(device_map == 'balanced_low_0'),
+ )
+ max_memory[0] *= 0.9
+ device_map = infer_auto_device_map(
+ model,
+ max_memory=max_memory,
+ no_split_module_classes=no_split_module_classes,
+ dtype=None,
+ )
+
+ if 'disk' in device_map.values():
+ if offload_folder is None:
+ raise ValueError(
+ 'The current `device_map` had weights offloaded to the disk. '
+ 'Please provide an `offload_folder` for them.')
+ os.makedirs(offload_folder, exist_ok=True)
+
+ main_device = next(
+ (d for d in device_map.values() if d not in ['cpu', 'disk']), 'cpu')
+
+ model = dispatch_model(
+ model,
+ device_map=device_map,
+ main_device=main_device,
+ offload_dir=offload_folder,
+ offload_buffers=offload_buffers,
+ preload_module_classes=preload_module_classes,
+ )
+ if hasattr(model, 'data_preprocessor'):
+ model.data_preprocessor._device = torch.device(main_device)
+ return model
+
+
+@contextmanager
+def init_empty_weights(include_buffers: bool = False):
+ """A context manager under which models are initialized with all parameters
+ on the meta device.
+
+ With this context manager, we can create an empty model. Useful when just
+ initializing the model would blow the available RAM.
+
+ Besides move the parameters to meta device, this method will also avoid
+ load checkpoint from `mmengine.runner.load_checkpoint` and
+ `transformers.PreTrainedModel.from_pretrained`.
+
+ Modified from https://github.com/huggingface/accelerate
+
+ Args:
+ include_buffers (bool): Whether put all buffers on the meta device
+ during initialization.
+ """
+ device = torch.device('meta')
+
+ # move parameter and buffer to meta device
+ old_register_parameter = nn.Module.register_parameter
+ if include_buffers:
+ old_register_buffer = nn.Module.register_buffer
+ # See https://github.com/huggingface/accelerate/pull/699
+ tensor_constructors_to_patch = {
+ torch_function_name: getattr(torch, torch_function_name)
+ for torch_function_name in ['empty', 'zeros', 'ones', 'full']
+ }
+
+ def register_parameter(module, name, param):
+ old_register_parameter(module, name, param)
+ if param is not None:
+ param_cls = type(module._parameters[name])
+ kwargs = module._parameters[name].__dict__
+ module._parameters[name] = param_cls(
+ module._parameters[name].to(device), **kwargs)
+
+ def register_buffer(module, name, buffer, *args, **kwargs):
+ old_register_buffer(module, name, buffer, *args, **kwargs)
+ if buffer is not None:
+ module._buffers[name] = module._buffers[name].to(device)
+
+ def patch_tensor_constructor(fn):
+
+ def wrapper(*args, **kwargs):
+ kwargs['device'] = device
+ return fn(*args, **kwargs)
+
+ return wrapper
+
+ # Patch load_checkpoint
+ import mmengine.runner.checkpoint as mmengine_load
+ old_load_checkpoint = mmengine_load.load_checkpoint
+
+ def patch_load_checkpoint(*args, **kwargs):
+ return {}
+
+ # Patch transformers from pretrained
+ try:
+ from transformers import PreTrainedModel
+ from transformers.models.auto.auto_factory import (AutoConfig,
+ _BaseAutoModelClass)
+ with_transformers = True
+ except ImportError:
+ with_transformers = False
+
+ @classmethod
+ def patch_auto_model(cls, pretrained_model_name_or_path, *model_args,
+ **kwargs):
+ cfg = AutoConfig.from_pretrained(pretrained_model_name_or_path,
+ *model_args, **kwargs)
+ return cls.from_config(cfg)
+
+ @classmethod
+ def patch_pretrained_model(cls, pretrained_model_name_or_path, *model_args,
+ **kwargs):
+ cfg = cls.config_class.from_pretrained(pretrained_model_name_or_path,
+ *model_args, **kwargs)
+ return cls(cfg)
+
+ if with_transformers:
+ old_pretrained_model = PreTrainedModel.from_pretrained
+ old_auto_model = _BaseAutoModelClass.from_pretrained
+
+ try:
+ nn.Module.register_parameter = register_parameter
+ mmengine_load.load_checkpoint = patch_load_checkpoint
+ if with_transformers:
+ PreTrainedModel.from_pretrained = patch_pretrained_model
+ _BaseAutoModelClass.from_pretrained = patch_auto_model
+ if include_buffers:
+ nn.Module.register_buffer = register_buffer
+ for func in tensor_constructors_to_patch.keys():
+ tensor_constructor = patch_tensor_constructor(
+ getattr(torch, func))
+ setattr(torch, func, tensor_constructor)
+ yield
+ finally:
+ nn.Module.register_parameter = old_register_parameter
+ mmengine_load.load_checkpoint = old_load_checkpoint
+ if with_transformers:
+ PreTrainedModel.from_pretrained = old_pretrained_model
+ _BaseAutoModelClass.from_pretrained = old_auto_model
+ if include_buffers:
+ nn.Module.register_buffer = old_register_buffer
+ for func, ori in tensor_constructors_to_patch.items():
+ setattr(torch, func, ori)
+
+
+def compute_module_sizes(
+ model: nn.Module,
+ dtype: Union[str, torch.dtype, None] = None,
+ special_dtypes: Optional[Dict[str, Union[str, torch.dtype]]] = None):
+ """Compute the size of each submodule of a given model."""
+
+ def get_dtype(dtype):
+ if isinstance(dtype, str):
+ dtype = getattr(torch, dtype)
+ if dtype is not None:
+ assert issubclass(dtype, torch.dtype)
+ return dtype
+
+ def dtype_bytes(dtype: torch.dtype):
+ if dtype is torch.bool:
+ return 1
+ if dtype.is_floating_point:
+ return torch.finfo(dtype).bits / 8
+ else:
+ return torch.iinfo(dtype).bits / 8
+
+ if dtype is not None:
+ dtype = get_dtype(dtype)
+ dtype_size = dtype_bytes(dtype)
+
+ if special_dtypes is not None:
+ special_dtypes = {
+ key: dtype_bytes(dtype)
+ for key, dtype in special_dtypes.items()
+ }
+
+ module_sizes = defaultdict(int)
+ for name, tensor in chain(
+ model.named_parameters(recurse=True),
+ model.named_buffers(recurse=True)):
+ if special_dtypes is not None and name in special_dtypes:
+ size = tensor.numel() * special_dtypes[name]
+ elif dtype is None:
+ size = tensor.numel() * tensor.element_size()
+ else:
+ size = tensor.numel() * min(dtype_size, tensor.element_size())
+ name_parts = name.split('.')
+ for idx in range(len(name_parts) + 1):
+ module_sizes['.'.join(name_parts[:idx])] += size
+
+ return module_sizes
diff --git a/mmpretrain/apis/visual_grounding.py b/mmpretrain/apis/visual_grounding.py
new file mode 100644
index 00000000000..59a6ba8b2cb
--- /dev/null
+++ b/mmpretrain/apis/visual_grounding.py
@@ -0,0 +1,180 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+
+class VisualGroundingInferencer(BaseInferencer):
+ """The inferencer for visual grounding.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``VisualGroundingInferencer.list_models()`` and you can also
+ query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import VisualGroundingInferencer
+ >>> inferencer = VisualGroundingInferencer('ofa-base_3rdparty_refcoco')
+ >>> inferencer('demo/cat-dog.png', 'dog')[0]
+ {'pred_bboxes': tensor([[ 36.6000, 29.6000, 355.8000, 395.2000]])}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {
+ 'resize', 'show', 'show_dir', 'wait_time', 'line_width', 'bbox_color'
+ }
+
+ def __call__(self,
+ images: Union[str, np.ndarray, list],
+ texts: Union[str, list],
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ texts (str | list): The text to do visual grounding.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+ line_width (int): The line width of the bbox. Defaults to 3.
+ bbox_color (str | tuple): The color of the bbox.
+ Defaults to 'green'.
+
+ Returns:
+ list: The inference results.
+ """
+ if not isinstance(images, (list, tuple)):
+ assert isinstance(texts, str)
+ inputs = [{'img': images, 'text': texts}]
+ else:
+ inputs = []
+ for i in range(len(images)):
+ input_ = {'img': images[i], 'text': texts[i]}
+ inputs.append(input_)
+
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[dict], batch_size: int = 1):
+
+ def load_image(input_: dict):
+ img = imread(input_['img'])
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return {**input_, 'img': img}
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[dict],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ line_width: int = 3,
+ bbox_color: Union[str, tuple] = 'green',
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_['img'])
+ if isinstance(input_['img'], str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_['img']).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_visual_grounding(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ line_width=line_width,
+ bbox_color=bbox_color,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({'pred_bboxes': data_sample.get('pred_bboxes')})
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Visual Grounding')
diff --git a/mmpretrain/apis/visual_question_answering.py b/mmpretrain/apis/visual_question_answering.py
new file mode 100644
index 00000000000..2d056758f39
--- /dev/null
+++ b/mmpretrain/apis/visual_question_answering.py
@@ -0,0 +1,181 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import Callable, List, Optional, Union
+
+import numpy as np
+from mmcv.image import imread
+from mmengine.config import Config
+from mmengine.dataset import Compose, default_collate
+
+from mmpretrain.registry import TRANSFORMS
+from mmpretrain.structures import DataSample
+from .base import BaseInferencer
+from .model import list_models
+
+
+class VisualQuestionAnsweringInferencer(BaseInferencer):
+ """The inferencer for visual question answering.
+
+ Args:
+ model (BaseModel | str | Config): A model name or a path to the config
+ file, or a :obj:`BaseModel` object. The model name can be found
+ by ``VisualQuestionAnsweringInferencer.list_models()`` and you can
+ also query it in :doc:`/modelzoo_statistics`.
+ pretrained (str, optional): Path to the checkpoint. If None, it will
+ try to find a pre-defined weight from the model you specified
+ (only work if the ``model`` is a model name). Defaults to None.
+ device (str, optional): Device to run inference. If None, the available
+ device will be automatically used. Defaults to None.
+ **kwargs: Other keyword arguments to initialize the model (only work if
+ the ``model`` is a model name).
+
+ Example:
+ >>> from mmpretrain import VisualQuestionAnsweringInferencer
+ >>> inferencer = VisualQuestionAnsweringInferencer('ofa-base_3rdparty-zeroshot_vqa')
+ >>> inferencer('demo/cat-dog.png', "What's the animal next to the dog?")[0]
+ {'question': "What's the animal next to the dog?", 'pred_answer': 'cat'}
+ """ # noqa: E501
+
+ visualize_kwargs: set = {'resize', 'show', 'show_dir', 'wait_time'}
+
+ def __call__(self,
+ images: Union[str, np.ndarray, list],
+ questions: Union[str, list],
+ return_datasamples: bool = False,
+ batch_size: int = 1,
+ objects: Optional[List[str]] = None,
+ **kwargs) -> dict:
+ """Call the inferencer.
+
+ Args:
+ images (str | array | list): The image path or array, or a list of
+ images.
+ questions (str | list): The question to the correspondding image.
+ return_datasamples (bool): Whether to return results as
+ :obj:`DataSample`. Defaults to False.
+ batch_size (int): Batch size. Defaults to 1.
+ objects (List[List[str]], optional): Some algorithms like OFA
+ fine-tuned VQA models requires extra object description list
+ for every image. Defaults to None.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ show (bool): Whether to display the visualization result in a
+ window. Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ show_dir (str, optional): If not None, save the visualization
+ results in the specified directory. Defaults to None.
+
+ Returns:
+ list: The inference results.
+ """
+ if not isinstance(images, (list, tuple)):
+ assert isinstance(questions, str)
+ inputs = [{'img': images, 'question': questions}]
+ if objects is not None:
+ assert isinstance(objects[0], str)
+ inputs[0]['objects'] = objects
+ else:
+ inputs = []
+ for i in range(len(images)):
+ input_ = {'img': images[i], 'question': questions[i]}
+ if objects is not None:
+ input_['objects'] = objects[i]
+ inputs.append(input_)
+
+ return super().__call__(inputs, return_datasamples, batch_size,
+ **kwargs)
+
+ def _init_pipeline(self, cfg: Config) -> Callable:
+ test_pipeline_cfg = cfg.test_dataloader.dataset.pipeline
+ if test_pipeline_cfg[0]['type'] == 'LoadImageFromFile':
+ # Image loading is finished in `self.preprocess`.
+ test_pipeline_cfg = test_pipeline_cfg[1:]
+ test_pipeline = Compose(
+ [TRANSFORMS.build(t) for t in test_pipeline_cfg])
+ return test_pipeline
+
+ def preprocess(self, inputs: List[dict], batch_size: int = 1):
+
+ def load_image(input_: dict):
+ img = imread(input_['img'])
+ if img is None:
+ raise ValueError(f'Failed to read image {input_}.')
+ return {**input_, 'img': img}
+
+ pipeline = Compose([load_image, self.pipeline])
+
+ chunked_data = self._get_chunk_data(map(pipeline, inputs), batch_size)
+ yield from map(default_collate, chunked_data)
+
+ def visualize(self,
+ ori_inputs: List[dict],
+ preds: List[DataSample],
+ show: bool = False,
+ wait_time: int = 0,
+ resize: Optional[int] = None,
+ show_dir=None):
+ if not show and show_dir is None:
+ return None
+
+ if self.visualizer is None:
+ from mmpretrain.visualization import UniversalVisualizer
+ self.visualizer = UniversalVisualizer()
+
+ visualization = []
+ for i, (input_, data_sample) in enumerate(zip(ori_inputs, preds)):
+ image = imread(input_['img'])
+ if isinstance(input_['img'], str):
+ # The image loaded from path is BGR format.
+ image = image[..., ::-1]
+ name = Path(input_['img']).stem
+ else:
+ name = str(i)
+
+ if show_dir is not None:
+ show_dir = Path(show_dir)
+ show_dir.mkdir(exist_ok=True)
+ out_file = str((show_dir / name).with_suffix('.png'))
+ else:
+ out_file = None
+
+ self.visualizer.visualize_vqa(
+ image,
+ data_sample,
+ resize=resize,
+ show=show,
+ wait_time=wait_time,
+ name=name,
+ out_file=out_file)
+ visualization.append(self.visualizer.get_image())
+ if show:
+ self.visualizer.close()
+ return visualization
+
+ def postprocess(self,
+ preds: List[DataSample],
+ visualization: List[np.ndarray],
+ return_datasamples=False) -> dict:
+ if return_datasamples:
+ return preds
+
+ results = []
+ for data_sample in preds:
+ results.append({
+ 'question': data_sample.get('question'),
+ 'pred_answer': data_sample.get('pred_answer'),
+ })
+
+ return results
+
+ @staticmethod
+ def list_models(pattern: Optional[str] = None):
+ """List all available model names.
+
+ Args:
+ pattern (str | None): A wildcard pattern to match model names.
+
+ Returns:
+ List[str]: a list of model names.
+ """
+ return list_models(pattern=pattern, task='Visual Question Answering')
diff --git a/mmpretrain/datasets/__init__.py b/mmpretrain/datasets/__init__.py
index e3807830785..b680fb83abb 100644
--- a/mmpretrain/datasets/__init__.py
+++ b/mmpretrain/datasets/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
from .base_dataset import BaseDataset
from .builder import build_dataset
from .caltech101 import Caltech101
@@ -15,6 +16,7 @@
from .mnist import MNIST, FashionMNIST
from .multi_label import MultiLabelDataset
from .multi_task import MultiTaskDataset
+from .nlvr2 import NLVR2
from .oxfordiiitpet import OxfordIIITPet
from .places205 import Places205
from .samplers import * # noqa: F401,F403
@@ -24,9 +26,29 @@
from .voc import VOC
__all__ = [
- 'BaseDataset', 'ImageNet', 'CIFAR10', 'CIFAR100', 'MNIST', 'FashionMNIST',
- 'VOC', 'build_dataset', 'ImageNet21k', 'KFoldDataset', 'CUB',
- 'CustomDataset', 'MultiLabelDataset', 'MultiTaskDataset', 'InShop',
- 'Places205', 'Flowers102', 'OxfordIIITPet', 'DTD', 'FGVCAircraft',
- 'StanfordCars', 'SUN397', 'Caltech101', 'Food101'
+ 'BaseDataset', 'CIFAR10', 'CIFAR100', 'CUB', 'Caltech101', 'CustomDataset',
+ 'DTD', 'FGVCAircraft', 'FashionMNIST', 'Flowers102', 'Food101', 'ImageNet',
+ 'ImageNet21k', 'InShop', 'KFoldDataset', 'MNIST', 'MultiLabelDataset',
+ 'MultiTaskDataset', 'NLVR2', 'OxfordIIITPet', 'Places205', 'SUN397',
+ 'StanfordCars', 'VOC', 'build_dataset'
]
+
+if WITH_MULTIMODAL:
+ from .coco_caption import COCOCaption
+ from .coco_retrieval import COCORetrieval
+ from .coco_vqa import COCOVQA
+ from .flamingo import FlamingoEvalCOCOCaption, FlamingoEvalCOCOVQA
+ from .refcoco import RefCOCO
+ from .scienceqa import ScienceQA
+ from .visual_genome import VisualGenomeQA
+
+ __all__.extend([
+ 'COCOCaption',
+ 'COCORetrieval',
+ 'COCOVQA',
+ 'FlamingoEvalCOCOCaption',
+ 'FlamingoEvalCOCOVQA',
+ 'RefCOCO',
+ 'VisualGenomeQA',
+ 'ScienceQA',
+ ])
diff --git a/mmpretrain/datasets/coco_caption.py b/mmpretrain/datasets/coco_caption.py
new file mode 100644
index 00000000000..541cda80398
--- /dev/null
+++ b/mmpretrain/datasets/coco_caption.py
@@ -0,0 +1,42 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from pathlib import Path
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import get_file_backend
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class COCOCaption(BaseDataset):
+ """COCO Caption dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``..
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ img_prefix = self.data_prefix['img_path']
+ annotations = mmengine.load(self.ann_file)
+ file_backend = get_file_backend(img_prefix)
+
+ data_list = []
+ for ann in annotations:
+ data_info = {
+ 'image_id': Path(ann['image']).stem.split('_')[-1],
+ 'img_path': file_backend.join_path(img_prefix, ann['image']),
+ 'gt_caption': ann['caption'],
+ }
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/coco_retrieval.py b/mmpretrain/datasets/coco_retrieval.py
new file mode 100644
index 00000000000..60d1586ad86
--- /dev/null
+++ b/mmpretrain/datasets/coco_retrieval.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from collections import OrderedDict
+from typing import List
+
+from mmengine import get_file_backend
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class COCORetrieval(BaseDataset):
+ """COCO Retrieval dataset.
+
+ Args:
+ ann_file (str): Annotation file path.
+ test_mode (bool): Whether dataset is used for evaluation. This will
+ decide the annotation format in data list annotations.
+ Defaults to False.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (str | dict): Prefix for training data. Defaults to ''.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ # get file backend
+ img_prefix = self.data_prefix['img_path']
+ file_backend = get_file_backend(img_prefix)
+
+ anno_info = json.load(open(self.ann_file, 'r'))
+ # mapping img_id to img filename
+ img_dict = OrderedDict()
+ for idx, img in enumerate(anno_info['images']):
+ if img['id'] not in img_dict:
+ img_rel_path = img['coco_url'].rsplit('/', 2)[-2:]
+ img_path = file_backend.join_path(img_prefix, *img_rel_path)
+
+ # create new idx for image
+ img_dict[img['id']] = dict(
+ ori_id=img['id'],
+ image_id=idx, # will be used for evaluation
+ img_path=img_path,
+ text=[],
+ gt_text_id=[],
+ gt_image_id=[],
+ )
+
+ train_list = []
+ for idx, anno in enumerate(anno_info['annotations']):
+ anno['text'] = anno.pop('caption')
+ anno['ori_id'] = anno.pop('id')
+ anno['text_id'] = idx # will be used for evaluation
+ # 1. prepare train data list item
+ train_data = anno.copy()
+ train_image = img_dict[train_data['image_id']]
+ train_data['img_path'] = train_image['img_path']
+ train_data['image_ori_id'] = train_image['ori_id']
+ train_data['image_id'] = train_image['image_id']
+ train_data['is_matched'] = True
+ train_list.append(train_data)
+ # 2. prepare eval data list item based on img dict
+ img_dict[anno['image_id']]['gt_text_id'].append(anno['text_id'])
+ img_dict[anno['image_id']]['text'].append(anno['text'])
+ img_dict[anno['image_id']]['gt_image_id'].append(
+ train_image['image_id'])
+
+ self.img_size = len(img_dict)
+ self.text_size = len(anno_info['annotations'])
+
+ # return needed format data list
+ if self.test_mode:
+ return list(img_dict.values())
+ return train_list
diff --git a/mmpretrain/datasets/coco_vqa.py b/mmpretrain/datasets/coco_vqa.py
new file mode 100644
index 00000000000..85f4bdcf39e
--- /dev/null
+++ b/mmpretrain/datasets/coco_vqa.py
@@ -0,0 +1,114 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+import re
+from collections import Counter
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class COCOVQA(BaseDataset):
+ """VQAv2 dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix``, ``ann_file``
+ and ``question_file``.
+ data_prefix (str): The directory of images.
+ question_file (str): Question file path.
+ ann_file (str, optional): Annotation file path for training and
+ validation. Defaults to an empty string.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ data_prefix: str,
+ question_file: str,
+ ann_file: str = '',
+ **kwarg):
+ self.question_file = question_file
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwarg,
+ )
+
+ def _join_prefix(self):
+ if not mmengine.is_abs(self.question_file) and self.question_file:
+ self.question_file = osp.join(self.data_root, self.question_file)
+
+ return super()._join_prefix()
+
+ def _create_image_index(self):
+ img_prefix = self.data_prefix['img_path']
+
+ files = mmengine.list_dir_or_file(img_prefix, list_dir=False)
+ image_index = {}
+ for file in files:
+ image_id = re.findall(r'\d{12}', file)
+ if len(image_id) > 0:
+ image_id = int(image_id[-1])
+ image_index[image_id] = mmengine.join_path(img_prefix, file)
+
+ return image_index
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ questions = mmengine.load(self.question_file)['questions']
+ if self.ann_file:
+ annotations = mmengine.load(self.ann_file)['annotations']
+ assert len(questions) == len(annotations)
+ else:
+ annotations = [None] * len(questions)
+
+ # The original VQAv2 annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ data_list = []
+ for question, ann in zip(questions, annotations):
+ # question example
+ # {
+ # 'image_id': 262144,
+ # 'question': "Is the ball flying towards the batter?",
+ # 'question_id': 262144000
+ # }
+ #
+ # ann example
+ # {
+ # 'question_type': "what are the",
+ # 'answer_type': "other",
+ # 'answers': [
+ # {'answer': 'watching',
+ # 'answer_id': 1,
+ # 'answer_confidence': 'yes'},
+ # ...
+ # ],
+ # 'image_id': 262148,
+ # 'question_id': 262148000,
+ # 'multiple_choice_answer': 'watching',
+ # 'answer_type': 'other',
+ # }
+
+ data_info = question
+ data_info['img_path'] = self.image_index[question['image_id']]
+
+ if ann is not None:
+ assert ann['question_id'] == question['question_id']
+
+ # add answer_weight & answer_count, delete duplicate answer
+ answers = [item['answer'] for item in ann.pop('answers')]
+ count = Counter(answers)
+ answer_weight = [i / len(answers) for i in count.values()]
+ data_info['gt_answer'] = list(count.keys())
+ data_info['gt_answer_weight'] = answer_weight
+ data_info.update(ann)
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/flamingo.py b/mmpretrain/datasets/flamingo.py
new file mode 100644
index 00000000000..3b5745a1437
--- /dev/null
+++ b/mmpretrain/datasets/flamingo.py
@@ -0,0 +1,295 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from abc import abstractmethod
+from collections import Counter
+from typing import List
+
+import mmengine
+import numpy as np
+from mmengine.dataset import BaseDataset
+from pycocotools.coco import COCO
+
+from mmpretrain.registry import DATASETS
+from .coco_vqa import COCOVQA
+
+
+class FlamingoFewShotMixin:
+ """Flamingo fewshot eval dataset minin.
+
+ Args:
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ Note: 0 does not mean a strict zero-shot in Flamingo setting.
+ It will use 2 only-text prompt without in context images.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ incontext_prompt_temp (str): In context prompt template for few shot
+ examples. Defaults to ''.
+ final_prompt_temp (str): Final query prompt template. Defaults to ''.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ incontext_prompt_temp: str = '',
+ final_prompt_temp: str = '',
+ **kwarg):
+ self.num_shots = num_shots
+ self.num_support_examples = num_support_examples
+ self.num_query_examples = num_query_examples
+ self.incontext_prompt_temp = incontext_prompt_temp
+ self.final_prompt_temp = final_prompt_temp
+ super().__init__(**kwarg)
+
+ def get_subset_idx(self, total_num):
+ random_idx = np.random.choice(
+ total_num,
+ self.num_support_examples + self.num_query_examples,
+ replace=False)
+
+ support_idx = random_idx[:self.num_support_examples]
+ query_idx = random_idx[self.num_support_examples:]
+ return support_idx, query_idx
+
+ @abstractmethod
+ def parse_basic_anno(self, anno: dict) -> dict:
+ """Parse basic annotation for support and query set."""
+ pass
+
+ @abstractmethod
+ def parse_fewshot_anno(self, anno: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list."""
+ pass
+
+
+@DATASETS.register_module()
+class FlamingoEvalCOCOVQA(FlamingoFewShotMixin, COCOVQA):
+ """Flamingo few shot VQAv2 dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ ann_file (str): Annotation file path.
+ question_file (str): Question file path.
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ Note: 0 does not mean a strict zero-shot in Flamingo setting.
+ It will use 2 only-text prompt without in context images.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ question_file: str,
+ ann_file: str = '',
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ question_file=question_file,
+ ann_file=ann_file,
+ num_shots=num_shots,
+ num_support_examples=num_support_examples,
+ num_query_examples=num_query_examples,
+ **kwarg)
+
+ def parse_basic_anno(self, ann: dict) -> dict:
+ """Parse basic annotation for support and query set.
+
+ Args:
+ anno (dict): Annotation for single example.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ if ann is None:
+ return {}
+
+ answers = [a['answer'] for a in ann['answers']]
+ count = Counter(answers)
+ answer_weight = [i / len(answers) for i in count.values()]
+ answer_info = {
+ 'gt_answer': list(count.keys()),
+ 'gt_answer_weight': answer_weight
+ }
+ return answer_info
+
+ def parse_fewshot_anno(self, query: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list.
+
+ Args:
+ anno (dict): Annotation for single example.
+ support_list (List): List of support subset to subsample few shots.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ # prepare n shots examples
+ shots = random.sample(support_list, self.num_shots)
+
+ # append image path for n shots
+ img_path = [shot['img_path'] for shot in shots]
+ img_path.append(query['img_path'])
+ query['img_path'] = img_path
+
+ query['shots'] = [
+ dict(
+ question=item['question'],
+ answer=item['gt_answer'][0],
+ ) for item in shots
+ ]
+ return query
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ questions = mmengine.load(self.question_file)['questions']
+ if self.ann_file:
+ annotations = mmengine.load(self.ann_file)['annotations']
+ assert len(questions) == len(annotations)
+ else:
+ annotations = [None] * len(questions)
+ if self.num_shots > 0:
+ raise ValueError('Unable to construct few-shot examples '
+ 'since no annotation file.')
+
+ # The original VQAv2 annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ num_data = len(questions)
+ support_idx, query_idx = self.get_subset_idx(num_data)
+
+ # prepare support subset
+ if self.num_shots > 0:
+ support_list = []
+ for idx in support_idx:
+ question = questions[idx]
+ ann = annotations[idx]
+ support = {**question, **self.parse_basic_anno(ann)}
+ support['img_path'] = self.image_index[question['image_id']]
+ support_list.append(support)
+
+ # prepare query subset
+ data_list = []
+ for idx in query_idx:
+ question = questions[idx]
+ ann = annotations[idx]
+ data_info = {**question, **self.parse_basic_anno(ann)}
+ data_info['img_path'] = self.image_index[question['image_id']]
+ if self.num_shots > 0:
+ data_info = self.parse_fewshot_anno(data_info, support_list)
+ data_list.append(data_info)
+
+ return data_list
+
+
+@DATASETS.register_module()
+class FlamingoEvalCOCOCaption(FlamingoFewShotMixin, BaseDataset):
+ """Flamingo few shot COCO Caption dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ num_shots (int): Number of shots to perform evaluation.
+ Defaults to 0.
+ num_support_examples (int): Number of support examples to get the
+ few shots from. Defaults to 2048.
+ num_query_examples (int): Number of query examples to perform the
+ final evaluation. Defaults to 5000.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ ann_file: str,
+ num_shots: int = 0,
+ num_support_examples: int = 2048,
+ num_query_examples: int = 5000,
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ ann_file=ann_file,
+ num_shots=num_shots,
+ num_support_examples=num_support_examples,
+ num_query_examples=num_query_examples,
+ **kwarg)
+
+ def parse_basic_anno(self, ann: dict, coco: COCO) -> dict:
+ """Parse basic annotation for support and query set.
+
+ Args:
+ anno (dict): Annotation for single example.
+ coco (COCO): The coco dataset.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ img_prefix = self.data_prefix['img_path']
+ img = coco.imgs[ann['image_id']]
+ data_info = dict(
+ img_path=mmengine.join_path(img_prefix, img['file_name']),
+ gt_caption=ann['caption'],
+ image_id=ann['image_id'],
+ )
+ return data_info
+
+ def parse_fewshot_anno(self, query: dict, support_list: List) -> dict:
+ """Parse fewshot related annotation for query set with support list.
+
+ Args:
+ query (dict): Annotation for single example.
+ support_list (List): List of support subset to subsample few shots.
+ coco (COCO): The coco dataset.
+
+ Return:
+ dict: Parsed annotation for single example.
+ """
+ # prepare n shots examples
+ shots = random.sample(support_list, self.num_shots)
+
+ # append image path for n shots
+ img_path = [shot['img_path'] for shot in shots]
+ img_path.append(query['img_path'])
+ query['img_path'] = img_path
+
+ query['shots'] = [dict(caption=item['gt_caption']) for item in shots]
+ return query
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ with mmengine.get_local_path(self.ann_file) as ann_file:
+ coco = COCO(ann_file)
+
+ num_data = len(coco.anns)
+ support_idx, query_idx = self.get_subset_idx(num_data)
+ ann_ids = list(coco.anns)
+
+ # prepare support subset
+ if self.num_shots > 0:
+ support_list = []
+ for idx in support_idx:
+ support = self.parse_basic_anno(coco.anns[ann_ids[idx]], coco)
+ support_list.append(support)
+
+ # prepare query subset
+ query_list = []
+ for idx in query_idx:
+ data_info = self.parse_basic_anno(coco.anns[ann_ids[idx]], coco)
+ if self.num_shots > 0:
+ data_info = self.parse_fewshot_anno(data_info, support_list)
+ query_list.append(data_info)
+
+ return query_list
diff --git a/mmpretrain/datasets/multi_label.py b/mmpretrain/datasets/multi_label.py
index 252b2318ff0..58a9c7cd5f0 100644
--- a/mmpretrain/datasets/multi_label.py
+++ b/mmpretrain/datasets/multi_label.py
@@ -12,9 +12,6 @@ class MultiLabelDataset(BaseDataset):
This dataset support annotation file in `OpenMMLab 2.0 style annotation
format`.
- .. _OpenMMLab 2.0 style annotation format:
- https://mmengine.readthedocs.io/en/latest/advanced_tutorials/basedataset.html
-
The annotation format is shown as follows.
.. code-block:: none
diff --git a/mmpretrain/datasets/nlvr2.py b/mmpretrain/datasets/nlvr2.py
new file mode 100644
index 00000000000..00630906577
--- /dev/null
+++ b/mmpretrain/datasets/nlvr2.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+from typing import List
+
+from mmengine.fileio import get_file_backend, list_from_file
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class NLVR2(BaseDataset):
+ """COCO Caption dataset."""
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+
+ data_list = []
+ img_prefix = self.data_prefix['img_path']
+ file_backend = get_file_backend(img_prefix)
+ examples = list_from_file(self.ann_file)
+
+ for example in examples:
+ example = json.loads(example)
+ prefix = example['identifier'].rsplit('-', 1)[0]
+ train_data = {}
+ train_data['text'] = example['sentence']
+ train_data['gt_label'] = {'True': 1, 'False': 0}[example['label']]
+ train_data['img_path'] = [
+ file_backend.join_path(img_prefix, prefix + f'-img{i}.png')
+ for i in range(2)
+ ]
+
+ data_list.append(train_data)
+
+ return data_list
diff --git a/mmpretrain/datasets/refcoco.py b/mmpretrain/datasets/refcoco.py
new file mode 100644
index 00000000000..f4f2a943f73
--- /dev/null
+++ b/mmpretrain/datasets/refcoco.py
@@ -0,0 +1,81 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os.path as osp
+from typing import List
+
+import mmengine
+import numpy as np
+from mmengine.dataset import BaseDataset
+from pycocotools.coco import COCO
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class RefCOCO(BaseDataset):
+ """RefCOCO dataset.
+
+ Args:
+ ann_file (str): Annotation file path.
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``. Defaults to ''.
+ data_prefix (str): Prefix for training data.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root,
+ ann_file,
+ data_prefix,
+ split_file,
+ split='train',
+ **kwargs):
+ self.split_file = split_file
+ self.split = split
+
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwargs,
+ )
+
+ def _join_prefix(self):
+ if not mmengine.is_abs(self.split_file) and self.split_file:
+ self.split_file = osp.join(self.data_root, self.split_file)
+
+ return super()._join_prefix()
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ with mmengine.get_local_path(self.ann_file) as ann_file:
+ coco = COCO(ann_file)
+ splits = mmengine.load(self.split_file, file_format='pkl')
+ img_prefix = self.data_prefix['img_path']
+
+ data_list = []
+ join_path = mmengine.fileio.get_file_backend(img_prefix).join_path
+ for refer in splits:
+ if refer['split'] != self.split:
+ continue
+
+ ann = coco.anns[refer['ann_id']]
+ img = coco.imgs[ann['image_id']]
+ sentences = refer['sentences']
+ bbox = np.array(ann['bbox'], dtype=np.float32)
+ bbox[2:4] = bbox[0:2] + bbox[2:4] # XYWH -> XYXY
+
+ for sent in sentences:
+ data_info = {
+ 'img_path': join_path(img_prefix, img['file_name']),
+ 'image_id': ann['image_id'],
+ 'ann_id': ann['id'],
+ 'text': sent['sent'],
+ 'gt_bboxes': bbox[None, :],
+ }
+ data_list.append(data_info)
+
+ if len(data_list) == 0:
+ raise ValueError(f'No sample in split "{self.split}".')
+
+ return data_list
diff --git a/mmpretrain/datasets/samplers/__init__.py b/mmpretrain/datasets/samplers/__init__.py
index 9ef45b23fc1..2bccf9c3465 100644
--- a/mmpretrain/datasets/samplers/__init__.py
+++ b/mmpretrain/datasets/samplers/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .repeat_aug import RepeatAugSampler
+from .sequential import SequentialSampler
-__all__ = ('RepeatAugSampler', )
+__all__ = ['RepeatAugSampler', 'SequentialSampler']
diff --git a/mmpretrain/datasets/samplers/sequential.py b/mmpretrain/datasets/samplers/sequential.py
new file mode 100644
index 00000000000..e3b940c2eab
--- /dev/null
+++ b/mmpretrain/datasets/samplers/sequential.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Iterator
+
+import torch
+from mmengine.dataset import DefaultSampler
+
+from mmpretrain.registry import DATA_SAMPLERS
+
+
+@DATA_SAMPLERS.register_module()
+class SequentialSampler(DefaultSampler):
+ """Sequential sampler which supports different subsample policy.
+
+ Args:
+ dataset (Sized): The dataset.
+ round_up (bool): Whether to add extra samples to make the number of
+ samples evenly divisible by the world size. Defaults to True.
+ subsample_type (str): The method to subsample data on different rank.
+ Supported type:
+
+ - ``'default'``: Original torch behavior. Sample the examples one
+ by one for each GPU in terms. For instance, 8 examples on 2 GPUs,
+ GPU0: [0,2,4,8], GPU1: [1,3,5,7]
+ - ``'sequential'``: Subsample all examples to n chunk sequntially.
+ For instance, 8 examples on 2 GPUs,
+ GPU0: [0,1,2,3], GPU1: [4,5,6,7]
+ """
+
+ def __init__(self, subsample_type: str = 'default', **kwargs) -> None:
+ super().__init__(shuffle=False, **kwargs)
+
+ if subsample_type not in ['default', 'sequential']:
+ raise ValueError(f'Unsupported subsample typer "{subsample_type}",'
+ ' please choose from ["default", "sequential"]')
+ self.subsample_type = subsample_type
+
+ def __iter__(self) -> Iterator[int]:
+ """Iterate the indices."""
+ indices = torch.arange(len(self.dataset)).tolist()
+
+ # add extra samples to make it evenly divisible
+ if self.round_up:
+ indices = (
+ indices *
+ int(self.total_size / len(indices) + 1))[:self.total_size]
+
+ # subsample
+ if self.subsample_type == 'default':
+ indices = indices[self.rank:self.total_size:self.world_size]
+ elif self.subsample_type == 'sequential':
+ num_samples_per_rank = self.total_size // self.world_size
+ indices = indices[self.rank *
+ num_samples_per_rank:(self.rank + 1) *
+ num_samples_per_rank]
+
+ return iter(indices)
diff --git a/mmpretrain/datasets/scienceqa.py b/mmpretrain/datasets/scienceqa.py
new file mode 100644
index 00000000000..391f7e1acc0
--- /dev/null
+++ b/mmpretrain/datasets/scienceqa.py
@@ -0,0 +1,103 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+from typing import Callable, List, Sequence
+
+import mmengine
+from mmengine.dataset import BaseDataset
+from mmengine.fileio import get_file_backend
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class ScienceQA(BaseDataset):
+ """ScienceQA dataset.
+
+ This dataset is used to load the multimodal data of ScienceQA dataset.
+
+ Args:
+ data_root (str): The root directory for ``data_prefix`` and
+ ``ann_file``.
+ split (str): The split of dataset. Options: ``train``, ``val``,
+ ``test``, ``trainval``, ``minival``, and ``minitest``.
+ split_file (str): The split file of dataset, which contains the
+ ids of data samples in the split.
+ ann_file (str): Annotation file path.
+ data_prefix (dict): Prefix for data field. Defaults to
+ ``dict(img_path='')``.
+ pipeline (Sequence): Processing pipeline. Defaults to an empty tuple.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ split: str,
+ split_file: str,
+ ann_file: str,
+ data_prefix: dict = dict(img_path=''),
+ pipeline: Sequence[Callable] = (),
+ **kwargs):
+
+ assert split in [
+ 'train', 'val', 'test', 'trainval', 'minival', 'minitest'
+ ], f'Invalid split {split}'
+ self.split = split
+ self.split_file = os.path.join(data_root, split_file)
+
+ super().__init__(
+ data_root=data_root,
+ ann_file=ann_file,
+ data_prefix=data_prefix,
+ pipeline=pipeline,
+ **kwargs)
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ img_prefix = self.data_prefix['img_path']
+ annotations = mmengine.load(self.ann_file)
+ current_data_split = mmengine.load(self.split_file)[self.split] # noqa
+
+ file_backend = get_file_backend(img_prefix)
+
+ data_list = []
+ for data_id in current_data_split:
+ ann = annotations[data_id]
+ if ann['image'] is not None:
+ data_info = {
+ 'image_id':
+ data_id,
+ 'question':
+ ann['question'],
+ 'choices':
+ ann['choices'],
+ 'answer':
+ ann['answer'],
+ 'hint':
+ ann['hint'],
+ 'image_name':
+ ann['image'],
+ 'task':
+ ann['task'],
+ 'grade':
+ ann['grade'],
+ 'subject':
+ ann['subject'],
+ 'topic':
+ ann['topic'],
+ 'category':
+ ann['category'],
+ 'skill':
+ ann['skill'],
+ 'lecture':
+ ann['lecture'],
+ 'solution':
+ ann['solution'],
+ 'split':
+ ann['split'],
+ 'img_path':
+ file_backend.join_path(img_prefix, data_id,
+ ann['image']), # noqa
+ }
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/datasets/transforms/__init__.py b/mmpretrain/datasets/transforms/__init__.py
index 583303cc206..88c72ca18b2 100644
--- a/mmpretrain/datasets/transforms/__init__.py
+++ b/mmpretrain/datasets/transforms/__init__.py
@@ -10,11 +10,12 @@
SolarizeAdd, Translate)
from .formatting import (Collect, NumpyToPIL, PackInputs, PackMultiTaskInputs,
PILToNumpy, Transpose)
-from .processing import (Albumentations, BEiTMaskGenerator, ColorJitter,
- EfficientNetCenterCrop, EfficientNetRandomCrop,
- Lighting, RandomCrop, RandomErasing,
- RandomResizedCrop, ResizeEdge, SimMIMMaskGenerator)
-from .wrappers import MultiView
+from .processing import (Albumentations, BEiTMaskGenerator, CleanCaption,
+ ColorJitter, EfficientNetCenterCrop,
+ EfficientNetRandomCrop, Lighting, RandomCrop,
+ RandomErasing, RandomResizedCrop, RandomTranslatePad,
+ ResizeEdge, SimMIMMaskGenerator)
+from .wrappers import ApplyToList, MultiView
for t in (CenterCrop, LoadImageFromFile, Normalize, RandomFlip,
RandomGrayscale, RandomResize, Resize):
@@ -30,5 +31,6 @@
'EfficientNetCenterCrop', 'ResizeEdge', 'BaseAugTransform',
'PackMultiTaskInputs', 'GaussianBlur', 'BEiTMaskGenerator',
'SimMIMMaskGenerator', 'CenterCrop', 'LoadImageFromFile', 'Normalize',
- 'RandomFlip', 'RandomGrayscale', 'RandomResize', 'Resize', 'MultiView'
+ 'RandomFlip', 'RandomGrayscale', 'RandomResize', 'Resize', 'MultiView',
+ 'ApplyToList', 'CleanCaption', 'RandomTranslatePad'
]
diff --git a/mmpretrain/datasets/transforms/auto_augment.py b/mmpretrain/datasets/transforms/auto_augment.py
index 1d169ed5fc8..03b057b850a 100644
--- a/mmpretrain/datasets/transforms/auto_augment.py
+++ b/mmpretrain/datasets/transforms/auto_augment.py
@@ -1234,4 +1234,11 @@ def __repr__(self):
dict(type='Translate', magnitude_range=(0, 0.45), direction='horizontal'),
dict(type='Translate', magnitude_range=(0, 0.45), direction='vertical'),
],
+ 'simple_increasing': [
+ dict(type='AutoContrast'),
+ dict(type='Equalize'),
+ dict(type='Rotate', magnitude_range=(0, 30)),
+ dict(type='Shear', magnitude_range=(0, 0.3), direction='horizontal'),
+ dict(type='Shear', magnitude_range=(0, 0.3), direction='vertical'),
+ ],
}
diff --git a/mmpretrain/datasets/transforms/formatting.py b/mmpretrain/datasets/transforms/formatting.py
index 30480b7d99f..e4d331636a8 100644
--- a/mmpretrain/datasets/transforms/formatting.py
+++ b/mmpretrain/datasets/transforms/formatting.py
@@ -129,6 +129,7 @@ def format_input(input_):
def transform(self, results: dict) -> dict:
"""Method to pack the input data."""
+
packed_results = dict()
if self.input_key in results:
input_ = results[self.input_key]
diff --git a/mmpretrain/datasets/transforms/processing.py b/mmpretrain/datasets/transforms/processing.py
index 9e41ed1db02..ad753c16fbb 100644
--- a/mmpretrain/datasets/transforms/processing.py
+++ b/mmpretrain/datasets/transforms/processing.py
@@ -3,6 +3,7 @@
import math
import numbers
import re
+import string
import traceback
from enum import EnumMeta
from numbers import Number
@@ -1624,3 +1625,138 @@ def __repr__(self) -> str:
repr_str += f'scale={self.scale}, '
repr_str += f'ratio={self.ratio})'
return repr_str
+
+
+@TRANSFORMS.register_module()
+class CleanCaption(BaseTransform):
+ """Clean caption text.
+
+ Remove some useless punctuation for the caption task.
+
+ **Required Keys:**
+
+ - ``*keys``
+
+ **Modified Keys:**
+
+ - ``*keys``
+
+ Args:
+ keys (Sequence[str], optional): The keys of text to be cleaned.
+ Defaults to 'gt_caption'.
+ remove_chars (str): The characters to be removed. Defaults to
+ :py:attr:`string.punctuation`.
+ lowercase (bool): Whether to convert the text to lowercase.
+ Defaults to True.
+ remove_dup_space (bool): Whether to remove duplicated whitespaces.
+ Defaults to True.
+ strip (bool): Whether to remove leading and trailing whitespaces.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ keys='gt_caption',
+ remove_chars=string.punctuation,
+ lowercase=True,
+ remove_dup_space=True,
+ strip=True,
+ ):
+ if isinstance(keys, str):
+ keys = [keys]
+ self.keys = keys
+ self.transtab = str.maketrans({ch: None for ch in remove_chars})
+ self.lowercase = lowercase
+ self.remove_dup_space = remove_dup_space
+ self.strip = strip
+
+ def _clean(self, text):
+ """Perform text cleaning before tokenizer."""
+
+ if self.strip:
+ text = text.strip()
+
+ text = text.translate(self.transtab)
+
+ if self.remove_dup_space:
+ text = re.sub(r'\s{2,}', ' ', text)
+
+ if self.lowercase:
+ text = text.lower()
+
+ return text
+
+ def clean(self, text):
+ """Perform text cleaning before tokenizer."""
+ if isinstance(text, (list, tuple)):
+ return [self._clean(item) for item in text]
+ elif isinstance(text, str):
+ return self._clean(text)
+ else:
+ raise TypeError('text must be a string or a list of strings')
+
+ def transform(self, results: dict) -> dict:
+ """Method to clean the input text data."""
+ for key in self.keys:
+ results[key] = self.clean(results[key])
+ return results
+
+
+@TRANSFORMS.register_module()
+class OFAAddObjects(BaseTransform):
+
+ def transform(self, results: dict) -> dict:
+ if 'objects' not in results:
+ raise ValueError(
+ 'Some OFA fine-tuned models requires `objects` field in the '
+ 'dataset, which is generated by VinVL. Or please use '
+ 'zero-shot configs. See '
+ 'https://github.com/OFA-Sys/OFA/issues/189')
+
+ if 'question' in results:
+ prompt = '{} object: {}'.format(
+ results['question'],
+ ' '.join(results['objects']),
+ )
+ results['decoder_prompt'] = prompt
+ results['question'] = prompt
+
+
+@TRANSFORMS.register_module()
+class RandomTranslatePad(BaseTransform):
+
+ def __init__(self, size=640, aug_translate=False):
+ self.size = size
+ self.aug_translate = aug_translate
+
+ @cache_randomness
+ def rand_translate_params(self, dh, dw):
+ top = np.random.randint(0, dh)
+ left = np.random.randint(0, dw)
+ return top, left
+
+ def transform(self, results: dict) -> dict:
+ img = results['img']
+ h, w = img.shape[:-1]
+ dw = self.size - w
+ dh = self.size - h
+ if self.aug_translate:
+ top, left = self.rand_translate_params(dh, dw)
+ else:
+ top = round(dh / 2.0 - 0.1)
+ left = round(dw / 2.0 - 0.1)
+
+ out_img = np.zeros((self.size, self.size, 3), dtype=np.float32)
+ out_img[top:top + h, left:left + w, :] = img
+ results['img'] = out_img
+ results['img_shape'] = (self.size, self.size)
+
+ # translate box
+ if 'gt_bboxes' in results.keys():
+ for i in range(len(results['gt_bboxes'])):
+ box = results['gt_bboxes'][i]
+ box[0], box[2] = box[0] + left, box[2] + left
+ box[1], box[3] = box[1] + top, box[3] + top
+ results['gt_bboxes'][i] = box
+
+ return results
diff --git a/mmpretrain/datasets/transforms/wrappers.py b/mmpretrain/datasets/transforms/wrappers.py
index 93bc31d1237..c0dfd730b4d 100644
--- a/mmpretrain/datasets/transforms/wrappers.py
+++ b/mmpretrain/datasets/transforms/wrappers.py
@@ -95,3 +95,50 @@ def __repr__(self) -> str:
repr_str += str(p)
repr_str += ')'
return repr_str
+
+
+@TRANSFORMS.register_module()
+class ApplyToList(BaseTransform):
+ """A transform wrapper to apply the wrapped transforms to a list of items.
+ For example, to load and resize a list of images.
+
+ Args:
+ transforms (list[dict | callable]): Sequence of transform config dict
+ to be wrapped.
+ scatter_key (str): The key to scatter data dict. If the field is a
+ list, scatter the list to multiple data dicts to do transformation.
+ collate_keys (List[str]): The keys to collate from multiple data dicts.
+ The fields in ``collate_keys`` will be composed into a list after
+ transformation, and the other fields will be adopted from the
+ first data dict.
+ """
+
+ def __init__(self, transforms, scatter_key, collate_keys):
+ super().__init__()
+
+ self.transforms = Compose([TRANSFORMS.build(t) for t in transforms])
+ self.scatter_key = scatter_key
+ self.collate_keys = set(collate_keys)
+ self.collate_keys.add(self.scatter_key)
+
+ def transform(self, results: dict):
+ scatter_field = results.get(self.scatter_key)
+
+ if isinstance(scatter_field, list):
+ scattered_results = []
+ for item in scatter_field:
+ single_results = copy.deepcopy(results)
+ single_results[self.scatter_key] = item
+ scattered_results.append(self.transforms(single_results))
+
+ final_output = scattered_results[0]
+
+ # merge output list to single output
+ for key in scattered_results[0].keys():
+ if key in self.collate_keys:
+ final_output[key] = [
+ single[key] for single in scattered_results
+ ]
+ return final_output
+ else:
+ return self.transforms(results)
diff --git a/mmpretrain/datasets/vg_vqa.py b/mmpretrain/datasets/vg_vqa.py
new file mode 100644
index 00000000000..2d83884c804
--- /dev/null
+++ b/mmpretrain/datasets/vg_vqa.py
@@ -0,0 +1,77 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+from mmengine.fileio import load
+
+from mmpretrain.registry import DATASETS
+from .base_dataset import BaseDataset
+
+
+@DATASETS.register_module()
+class VGVQA(BaseDataset):
+ """Visual Genome VQA dataset."""
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list.
+
+ Compare to BaseDataset, the only difference is that coco_vqa annotation
+ file is already a list of data. There is no 'metainfo'.
+ """
+
+ raw_data_list = load(self.ann_file)
+ if not isinstance(raw_data_list, list):
+ raise TypeError(
+ f'The VQA annotations loaded from annotation file '
+ f'should be a dict, but got {type(raw_data_list)}!')
+
+ # load and parse data_infos.
+ data_list = []
+ for raw_data_info in raw_data_list:
+ # parse raw data information to target format
+ data_info = self.parse_data_info(raw_data_info)
+ if isinstance(data_info, dict):
+ # For VQA tasks, each `data_info` looks like:
+ # {
+ # "question_id": 986769,
+ # "question": "How many people are there?",
+ # "answer": "two",
+ # "image": "image/1.jpg",
+ # "dataset": "vg"
+ # }
+
+ # change 'image' key to 'img_path'
+ # TODO: This process will be removed, after the annotation file
+ # is preprocess.
+ data_info['img_path'] = data_info['image']
+ del data_info['image']
+
+ if 'answer' in data_info:
+ # add answer_weight & answer_count, delete duplicate answer
+ if data_info['dataset'] == 'vqa':
+ answer_weight = {}
+ for answer in data_info['answer']:
+ if answer in answer_weight.keys():
+ answer_weight[answer] += 1 / len(
+ data_info['answer'])
+ else:
+ answer_weight[answer] = 1 / len(
+ data_info['answer'])
+
+ data_info['answer'] = list(answer_weight.keys())
+ data_info['answer_weight'] = list(
+ answer_weight.values())
+ data_info['answer_count'] = len(answer_weight)
+
+ elif data_info['dataset'] == 'vg':
+ data_info['answers'] = [data_info['answer']]
+ data_info['answer_weight'] = [0.2]
+ data_info['answer_count'] = 1
+
+ data_list.append(data_info)
+
+ else:
+ raise TypeError(
+ f'Each VQA data element loaded from annotation file '
+ f'should be a dict, but got {type(data_info)}!')
+
+ return data_list
diff --git a/mmpretrain/datasets/visual_genome.py b/mmpretrain/datasets/visual_genome.py
new file mode 100644
index 00000000000..8c33b86c4f8
--- /dev/null
+++ b/mmpretrain/datasets/visual_genome.py
@@ -0,0 +1,95 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from itertools import chain
+from typing import List
+
+import mmengine
+from mmengine.dataset import BaseDataset
+
+from mmpretrain.registry import DATASETS
+
+
+@DATASETS.register_module()
+class VisualGenomeQA(BaseDataset):
+ """Visual Genome Question Answering dataset.
+
+ dataset structure: ::
+
+ data_root
+ ├── image
+ │ ├── 1.jpg
+ │ ├── 2.jpg
+ │ └── ...
+ └── question_answers.json
+
+ Args:
+ data_root (str): The root directory for ``data_prefix``, ``ann_file``
+ and ``question_file``.
+ data_prefix (str): The directory of images. Defaults to ``"image"``.
+ ann_file (str, optional): Annotation file path for training and
+ validation. Defaults to ``"question_answers.json"``.
+ **kwargs: Other keyword arguments in :class:`BaseDataset`.
+ """
+
+ def __init__(self,
+ data_root: str,
+ data_prefix: str = 'image',
+ ann_file: str = 'question_answers.json',
+ **kwarg):
+ super().__init__(
+ data_root=data_root,
+ data_prefix=dict(img_path=data_prefix),
+ ann_file=ann_file,
+ **kwarg,
+ )
+
+ def _create_image_index(self):
+ img_prefix = self.data_prefix['img_path']
+
+ files = mmengine.list_dir_or_file(img_prefix, list_dir=False)
+ image_index = {}
+ for file in files:
+ image_id = re.findall(r'\d+', file)
+ if len(image_id) > 0:
+ image_id = int(image_id[-1])
+ image_index[image_id] = mmengine.join_path(img_prefix, file)
+
+ return image_index
+
+ def load_data_list(self) -> List[dict]:
+ """Load data list."""
+ annotations = mmengine.load(self.ann_file)
+
+ # The original Visual Genome annotation file and question file includes
+ # only image id but no image file paths.
+ self.image_index = self._create_image_index()
+
+ data_list = []
+ for qas in chain.from_iterable(ann['qas'] for ann in annotations):
+ # ann example
+ # {
+ # 'id': 1,
+ # 'qas': [
+ # {
+ # 'a_objects': [],
+ # 'question': 'What color is the clock?',
+ # 'image_id': 1,
+ # 'qa_id': 986768,
+ # 'answer': 'Two.',
+ # 'q_objects': [],
+ # }
+ # ...
+ # ]
+ # }
+
+ data_info = {
+ 'img_path': self.image_index[qas['image_id']],
+ 'quesiton': qas['quesiton'],
+ 'question_id': qas['question_id'],
+ 'image_id': qas['image_id'],
+ 'gt_answer': [qas['answer']],
+ }
+
+ data_list.append(data_info)
+
+ return data_list
diff --git a/mmpretrain/engine/__init__.py b/mmpretrain/engine/__init__.py
index e04835b27e4..7785da7b259 100644
--- a/mmpretrain/engine/__init__.py
+++ b/mmpretrain/engine/__init__.py
@@ -1,3 +1,4 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .hooks import * # noqa: F401, F403
from .optimizers import * # noqa: F401, F403
+from .runners import * # noqa: F401, F403
diff --git a/mmpretrain/engine/hooks/__init__.py b/mmpretrain/engine/hooks/__init__.py
index 090d7652192..bc9e22be7e9 100644
--- a/mmpretrain/engine/hooks/__init__.py
+++ b/mmpretrain/engine/hooks/__init__.py
@@ -9,10 +9,11 @@
from .swav_hook import SwAVHook
from .switch_recipe_hook import SwitchRecipeHook
from .visualization_hook import VisualizationHook
+from .warmup_param_hook import WarmupParamHook
__all__ = [
'ClassNumCheckHook', 'PreciseBNHook', 'VisualizationHook',
'SwitchRecipeHook', 'PrepareProtoBeforeValLoopHook',
'SetAdaptiveMarginsHook', 'EMAHook', 'SimSiamHook', 'DenseCLHook',
- 'SwAVHook'
+ 'SwAVHook', 'WarmupParamHook'
]
diff --git a/mmpretrain/engine/hooks/warmup_param_hook.py b/mmpretrain/engine/hooks/warmup_param_hook.py
new file mode 100644
index 00000000000..b45d8918dbb
--- /dev/null
+++ b/mmpretrain/engine/hooks/warmup_param_hook.py
@@ -0,0 +1,66 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import operator as op
+from typing import Any, Optional, Union
+
+from mmengine.hooks import Hook
+
+from mmpretrain.registry import HOOKS
+from mmpretrain.utils import get_ori_model
+
+
+@HOOKS.register_module()
+class WarmupParamHook(Hook):
+ """This is a hook used for changing the parameters other than optimizations
+ that need to warmup inside the module.
+
+ This hook can extend with more detailed warmup rule if necessary.
+
+ Args:
+ param_name (str): The parameter name that needs to be altered.
+ module_name (str): Module name that belongs to the model. Such as
+ `head`, `head.loss`, etc.
+ warmup_epochs (int): The warmup epochs for this parameter.
+ """
+
+ def __init__(
+ self,
+ param_name: str,
+ module_name: str,
+ warmup_epochs: int,
+ ) -> None:
+ self.param_name = param_name
+ self.warmup_epochs = warmup_epochs
+ # getter for module which saves the changed parameter
+ self.module_getter = op.attrgetter(module_name)
+
+ def get_param(self, runner) -> Any:
+ """Get the parameter."""
+ try:
+ module = self.module_getter(get_ori_model(runner.model))
+ return getattr(module, self.param_name)
+ except AttributeError as e:
+ raise AttributeError(f'{e}. Please check hook settings.')
+
+ def set_param(self, runner, value) -> None:
+ """Set the parameter."""
+ try:
+ module = self.module_getter(get_ori_model(runner.model))
+ setattr(module, self.param_name, value)
+ except AttributeError as e:
+ raise AttributeError(f'{e}. Please check hook settings.')
+
+ def before_train(self, runner) -> None:
+ """Get the original value before train."""
+ self.ori_val = self.get_param(runner)
+
+ def before_train_iter(
+ self,
+ runner,
+ batch_idx: int,
+ data_batch: Optional[Union[dict, tuple, list]] = None) -> None:
+ """Set the warmup value before each train iter."""
+ cur_iter = runner.iter
+ iters_per_epoch = runner.max_iters / runner.max_epochs
+ new_val = self.ori_val * min(
+ 1, cur_iter / (self.warmup_epochs * iters_per_epoch))
+ self.set_param(runner, new_val)
diff --git a/mmpretrain/engine/runners/__init__.py b/mmpretrain/engine/runners/__init__.py
new file mode 100644
index 00000000000..23206e1ea7c
--- /dev/null
+++ b/mmpretrain/engine/runners/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .retrieval_loop import RetrievalTestLoop, RetrievalValLoop
+
+__all__ = ['RetrievalTestLoop', 'RetrievalValLoop']
diff --git a/mmpretrain/engine/runners/retrieval_loop.py b/mmpretrain/engine/runners/retrieval_loop.py
new file mode 100644
index 00000000000..d15387eddeb
--- /dev/null
+++ b/mmpretrain/engine/runners/retrieval_loop.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+import torch
+from mmengine.model import is_model_wrapper
+from mmengine.runner import TestLoop, ValLoop, autocast
+
+from mmpretrain.registry import LOOPS
+
+
+@LOOPS.register_module()
+class RetrievalValLoop(ValLoop):
+ """Loop for multimodal retrieval val.
+
+ Args:
+ runner (Runner): A reference of runner.
+ dataloader (Dataloader or dict): A dataloader object or a dict to
+ build a dataloader.
+ evaluator (Evaluator or dict or list): Used for computing metrics.
+ fp16 (bool): Whether to enable fp16 valing. Defaults to
+ False.
+ """
+
+ def run(self) -> dict:
+ """Launch val."""
+ self.runner.call_hook('before_val')
+ self.runner.call_hook('before_val_epoch')
+ self.runner.model.eval()
+
+ feats_local = []
+ data_samples_local = []
+
+ for idx, data_batch in enumerate(self.dataloader):
+ with torch.no_grad():
+ self.runner.call_hook(
+ 'before_val_iter', batch_idx=idx, data_batch=data_batch)
+ # predictions should be sequence of BaseDataElement
+ with autocast(enabled=self.fp16):
+ if is_model_wrapper(self.runner.model):
+ data_preprocessor = self.runner.model.module.data_preprocessor # noqa: E501
+ else:
+ data_preprocessor = self.runner.model.data_preprocessor
+
+ # get features for retrieval instead of data samples
+ data_batch = data_preprocessor(data_batch, False)
+ feats = self.runner.model._run_forward(
+ data_batch, mode='tensor')
+ feats_local.append(feats)
+ data_samples_local.extend(data_batch['data_samples'])
+ self.runner.call_hook(
+ 'after_val_iter',
+ batch_idx=idx,
+ data_batch=data_batch,
+ outputs=feats)
+
+ # concatenate different features
+ feats_local = {
+ k: torch.cat([dic[k] for dic in feats_local])
+ for k in feats_local[0]
+ }
+
+ # get predictions
+ if is_model_wrapper(self.runner.model):
+ predict_all_fn = self.runner.model.module.predict_all
+ else:
+ predict_all_fn = self.runner.model.predict_all
+
+ img_size = self.dataloader.dataset.img_size
+ text_size = self.dataloader.dataset.text_size
+ with torch.no_grad():
+ i2t_data_samples, t2i_data_samples = predict_all_fn(
+ feats_local,
+ data_samples_local,
+ num_images=img_size,
+ num_texts=text_size,
+ )
+
+ # process in evaluator and compute metrics
+ self.evaluator.process(i2t_data_samples, None)
+ i2t_metrics = self.evaluator.evaluate(img_size)
+ i2t_metrics = {f'i2t/{k}': v for k, v in i2t_metrics.items()}
+ self.evaluator.process(t2i_data_samples, None)
+ t2i_metrics = self.evaluator.evaluate(text_size)
+ t2i_metrics = {f't2i/{k}': v for k, v in t2i_metrics.items()}
+ metrics = {**i2t_metrics, **t2i_metrics}
+
+ self.runner.call_hook('after_val_epoch', metrics=metrics)
+ self.runner.call_hook('after_val')
+ return metrics
+
+
+@LOOPS.register_module()
+class RetrievalTestLoop(TestLoop):
+ """Loop for multimodal retrieval test.
+
+ Args:
+ runner (Runner): A reference of runner.
+ dataloader (Dataloader or dict): A dataloader object or a dict to
+ build a dataloader.
+ evaluator (Evaluator or dict or list): Used for computing metrics.
+ fp16 (bool): Whether to enable fp16 testing. Defaults to
+ False.
+ """
+
+ def run(self) -> dict:
+ """Launch test."""
+ self.runner.call_hook('before_test')
+ self.runner.call_hook('before_test_epoch')
+ self.runner.model.eval()
+
+ feats_local = []
+ data_samples_local = []
+
+ for idx, data_batch in enumerate(self.dataloader):
+ with torch.no_grad():
+ self.runner.call_hook(
+ 'before_test_iter', batch_idx=idx, data_batch=data_batch)
+ # predictions should be sequence of BaseDataElement
+ with autocast(enabled=self.fp16):
+ if is_model_wrapper(self.runner.model):
+ data_preprocessor = self.runner.model.module.data_preprocessor # noqa: E501
+ else:
+ data_preprocessor = self.runner.model.data_preprocessor
+ # get features for retrieval instead of data samples
+ data_batch = data_preprocessor(data_batch, False)
+ feats = self.runner.model._run_forward(
+ data_batch, mode='tensor')
+ feats_local.append(feats)
+ data_samples_local.extend(data_batch['data_samples'])
+ self.runner.call_hook(
+ 'after_test_iter',
+ batch_idx=idx,
+ data_batch=data_batch,
+ outputs=feats)
+
+ # concatenate different features
+ feats_local = {
+ k: torch.cat([dic[k] for dic in feats_local])
+ for k in feats_local[0]
+ }
+
+ # get predictions
+ if is_model_wrapper(self.runner.model):
+ predict_all_fn = self.runner.model.module.predict_all
+ else:
+ predict_all_fn = self.runner.model.predict_all
+
+ img_size = self.dataloader.dataset.img_size
+ text_size = self.dataloader.dataset.text_size
+ with torch.no_grad():
+ i2t_data_samples, t2i_data_samples = predict_all_fn(
+ feats_local,
+ data_samples_local,
+ num_images=img_size,
+ num_texts=text_size,
+ )
+
+ # process in evaluator and compute metrics
+ self.evaluator.process(i2t_data_samples, None)
+ i2t_metrics = self.evaluator.evaluate(img_size)
+ i2t_metrics = {f'i2t/{k}': v for k, v in i2t_metrics.items()}
+ self.evaluator.process(t2i_data_samples, None)
+ t2i_metrics = self.evaluator.evaluate(text_size)
+ t2i_metrics = {f't2i/{k}': v for k, v in t2i_metrics.items()}
+ metrics = {**i2t_metrics, **t2i_metrics}
+
+ self.runner.call_hook('after_test_epoch', metrics=metrics)
+ self.runner.call_hook('after_test')
+ return metrics
diff --git a/mmpretrain/evaluation/metrics/__init__.py b/mmpretrain/evaluation/metrics/__init__.py
index 25fed7242e4..683cf72bed0 100644
--- a/mmpretrain/evaluation/metrics/__init__.py
+++ b/mmpretrain/evaluation/metrics/__init__.py
@@ -1,12 +1,16 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from .caption import COCOCaption
from .multi_label import AveragePrecision, MultiLabelMetric
from .multi_task import MultiTasksMetric
from .retrieval import RetrievalRecall
from .single_label import Accuracy, ConfusionMatrix, SingleLabelMetric
+from .visual_grounding_eval import VisualGroundingMetric
from .voc_multi_label import VOCAveragePrecision, VOCMultiLabelMetric
+from .vqa import ReportVQA, VQAAcc
__all__ = [
'Accuracy', 'SingleLabelMetric', 'MultiLabelMetric', 'AveragePrecision',
'MultiTasksMetric', 'VOCAveragePrecision', 'VOCMultiLabelMetric',
- 'ConfusionMatrix', 'RetrievalRecall'
+ 'ConfusionMatrix', 'RetrievalRecall', 'VQAAcc', 'ReportVQA', 'COCOCaption',
+ 'VisualGroundingMetric'
]
diff --git a/mmpretrain/evaluation/metrics/caption.py b/mmpretrain/evaluation/metrics/caption.py
new file mode 100644
index 00000000000..c4bffabfa97
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/caption.py
@@ -0,0 +1,136 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import json
+import os
+import tempfile
+from typing import List, Optional
+
+from mmengine.evaluator import BaseMetric
+from mmengine.utils import track_iter_progress
+
+from mmpretrain.registry import METRICS
+from mmpretrain.utils import require
+
+try:
+ from pycocoevalcap.eval import COCOEvalCap
+ from pycocotools.coco import COCO
+except ImportError:
+ COCOEvalCap = None
+ COCO = None
+
+
+@METRICS.register_module()
+class COCOCaption(BaseMetric):
+ """Coco Caption evaluation wrapper.
+
+ Save the generated captions and transform into coco format.
+ Calling COCO API for caption metrics.
+
+ Args:
+ ann_file (str): the path for the COCO format caption ground truth
+ json file, load for evaluations.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+
+ @require('pycocoevalcap')
+ def __init__(self,
+ ann_file: str,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.ann_file = ann_file
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+
+ for data_sample in data_samples:
+ result = dict()
+
+ result['caption'] = data_sample.get('pred_caption')
+ result['image_id'] = int(data_sample.get('image_id'))
+
+ # Save the result to `self.results`.
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ # NOTICE: don't access `self.results` from the method.
+
+ with tempfile.TemporaryDirectory() as temp_dir:
+
+ eval_result_file = save_result(
+ result=results,
+ result_dir=temp_dir,
+ filename='m4-caption_pred',
+ remove_duplicate='image_id',
+ )
+
+ coco_val = coco_caption_eval(eval_result_file, self.ann_file)
+
+ return coco_val
+
+
+def save_result(result, result_dir, filename, remove_duplicate=''):
+ """Saving predictions as json file for evaluation."""
+
+ # combine results from all processes
+ result_new = []
+
+ if remove_duplicate:
+ result_new = []
+ id_list = []
+ for res in track_iter_progress(result):
+ if res[remove_duplicate] not in id_list:
+ id_list.append(res[remove_duplicate])
+ result_new.append(res)
+ result = result_new
+
+ final_result_file_url = os.path.join(result_dir, '%s.json' % filename)
+ print(f'result file saved to {final_result_file_url}')
+ json.dump(result, open(final_result_file_url, 'w'))
+
+ return final_result_file_url
+
+
+def coco_caption_eval(results_file, ann_file):
+ """Evaluation between gt json and prediction json files."""
+ # create coco object and coco_result object
+ coco = COCO(ann_file)
+ coco_result = coco.loadRes(results_file)
+
+ # create coco_eval object by taking coco and coco_result
+ coco_eval = COCOEvalCap(coco, coco_result)
+
+ # make sure the image ids are the same
+ coco_eval.params['image_id'] = coco_result.getImgIds()
+
+ # This will take some times at the first run
+ coco_eval.evaluate()
+
+ # print output evaluation scores
+ for metric, score in coco_eval.eval.items():
+ print(f'{metric}: {score:.3f}')
+
+ return coco_eval.eval
diff --git a/mmpretrain/evaluation/metrics/visual_grounding_eval.py b/mmpretrain/evaluation/metrics/visual_grounding_eval.py
new file mode 100644
index 00000000000..ad16e5adf46
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/visual_grounding_eval.py
@@ -0,0 +1,85 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List
+
+import torch
+import torchvision.ops.boxes as boxes
+from mmengine.evaluator import BaseMetric
+
+from mmpretrain.registry import METRICS
+
+
+def aligned_box_iou(boxes1: torch.Tensor, boxes2: torch.Tensor):
+ area1 = boxes.box_area(boxes1)
+ area2 = boxes.box_area(boxes2)
+
+ lt = torch.max(boxes1[:, :2], boxes2[:, :2]) # (B, 2)
+ rb = torch.min(boxes1[:, 2:], boxes2[:, 2:]) # (B, 2)
+
+ wh = boxes._upcast(rb - lt).clamp(min=0) # (B, 2)
+ inter = wh[:, 0] * wh[:, 1] # (B, )
+
+ union = area1 + area2 - inter
+ iou = inter / union
+ return iou
+
+
+@METRICS.register_module()
+class VisualGroundingMetric(BaseMetric):
+ """Visual Grounding evaluator.
+
+ Calculate the box mIOU and box grounding accuracy for visual grounding
+ model.
+
+ Args:
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+ default_prefix = 'visual-grounding'
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ for preds in data_samples:
+
+ pred_box = preds['pred_bboxes'].squeeze()
+ box_gt = torch.Tensor(preds['gt_bboxes']).squeeze()
+
+ result = {
+ 'box': pred_box.to('cpu').squeeze(),
+ 'box_target': box_gt.squeeze(),
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ pred_boxes = torch.stack([each['box'] for each in results])
+ gt_boxes = torch.stack([each['box_target'] for each in results])
+ iou = aligned_box_iou(pred_boxes, gt_boxes)
+ accu_num = torch.sum(iou >= 0.5)
+
+ miou = torch.mean(iou)
+ acc = accu_num / len(gt_boxes)
+ coco_val = {'miou': miou, 'acc': acc}
+ return coco_val
diff --git a/mmpretrain/evaluation/metrics/vqa.py b/mmpretrain/evaluation/metrics/vqa.py
new file mode 100644
index 00000000000..fd77ba9bc23
--- /dev/null
+++ b/mmpretrain/evaluation/metrics/vqa.py
@@ -0,0 +1,315 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+# Partly adopted from https://github.com/GT-Vision-Lab/VQA
+# Copyright (c) 2014, Aishwarya Agrawal
+from typing import List, Optional
+
+import mmengine
+from mmengine.evaluator import BaseMetric
+from mmengine.logging import MMLogger
+
+from mmpretrain.registry import METRICS
+
+
+def _process_punctuation(inText):
+ import re
+ outText = inText
+ punct = [
+ ';', r'/', '[', ']', '"', '{', '}', '(', ')', '=', '+', '\\', '_', '-',
+ '>', '<', '@', '`', ',', '?', '!'
+ ]
+ commaStrip = re.compile('(\d)(,)(\d)') # noqa: W605
+ periodStrip = re.compile('(?!<=\d)(\.)(?!\d)') # noqa: W605
+ for p in punct:
+ if (p + ' ' in inText or ' ' + p in inText) or (re.search(
+ commaStrip, inText) is not None):
+ outText = outText.replace(p, '')
+ else:
+ outText = outText.replace(p, ' ')
+ outText = periodStrip.sub('', outText, re.UNICODE)
+ return outText
+
+
+def _process_digit_article(inText):
+ outText = []
+ tempText = inText.lower().split()
+ articles = ['a', 'an', 'the']
+ manualMap = {
+ 'none': '0',
+ 'zero': '0',
+ 'one': '1',
+ 'two': '2',
+ 'three': '3',
+ 'four': '4',
+ 'five': '5',
+ 'six': '6',
+ 'seven': '7',
+ 'eight': '8',
+ 'nine': '9',
+ 'ten': '10',
+ }
+ contractions = {
+ 'aint': "ain't",
+ 'arent': "aren't",
+ 'cant': "can't",
+ 'couldve': "could've",
+ 'couldnt': "couldn't",
+ "couldn'tve": "couldn't've",
+ "couldnt've": "couldn't've",
+ 'didnt': "didn't",
+ 'doesnt': "doesn't",
+ 'dont': "don't",
+ 'hadnt': "hadn't",
+ "hadnt've": "hadn't've",
+ "hadn'tve": "hadn't've",
+ 'hasnt': "hasn't",
+ 'havent': "haven't",
+ 'hed': "he'd",
+ "hed've": "he'd've",
+ "he'dve": "he'd've",
+ 'hes': "he's",
+ 'howd': "how'd",
+ 'howll': "how'll",
+ 'hows': "how's",
+ "Id've": "I'd've",
+ "I'dve": "I'd've",
+ 'Im': "I'm",
+ 'Ive': "I've",
+ 'isnt': "isn't",
+ 'itd': "it'd",
+ "itd've": "it'd've",
+ "it'dve": "it'd've",
+ 'itll': "it'll",
+ "let's": "let's",
+ 'maam': "ma'am",
+ 'mightnt': "mightn't",
+ "mightnt've": "mightn't've",
+ "mightn'tve": "mightn't've",
+ 'mightve': "might've",
+ 'mustnt': "mustn't",
+ 'mustve': "must've",
+ 'neednt': "needn't",
+ 'notve': "not've",
+ 'oclock': "o'clock",
+ 'oughtnt': "oughtn't",
+ "ow's'at": "'ow's'at",
+ "'ows'at": "'ow's'at",
+ "'ow'sat": "'ow's'at",
+ 'shant': "shan't",
+ "shed've": "she'd've",
+ "she'dve": "she'd've",
+ "she's": "she's",
+ 'shouldve': "should've",
+ 'shouldnt': "shouldn't",
+ "shouldnt've": "shouldn't've",
+ "shouldn'tve": "shouldn't've",
+ "somebody'd": 'somebodyd',
+ "somebodyd've": "somebody'd've",
+ "somebody'dve": "somebody'd've",
+ 'somebodyll': "somebody'll",
+ 'somebodys': "somebody's",
+ 'someoned': "someone'd",
+ "someoned've": "someone'd've",
+ "someone'dve": "someone'd've",
+ 'someonell': "someone'll",
+ 'someones': "someone's",
+ 'somethingd': "something'd",
+ "somethingd've": "something'd've",
+ "something'dve": "something'd've",
+ 'somethingll': "something'll",
+ 'thats': "that's",
+ 'thered': "there'd",
+ "thered've": "there'd've",
+ "there'dve": "there'd've",
+ 'therere': "there're",
+ 'theres': "there's",
+ 'theyd': "they'd",
+ "theyd've": "they'd've",
+ "they'dve": "they'd've",
+ 'theyll': "they'll",
+ 'theyre': "they're",
+ 'theyve': "they've",
+ 'twas': "'twas",
+ 'wasnt': "wasn't",
+ "wed've": "we'd've",
+ "we'dve": "we'd've",
+ 'weve': "we've",
+ 'werent': "weren't",
+ 'whatll': "what'll",
+ 'whatre': "what're",
+ 'whats': "what's",
+ 'whatve': "what've",
+ 'whens': "when's",
+ 'whered': "where'd",
+ 'wheres': "where's",
+ 'whereve': "where've",
+ 'whod': "who'd",
+ "whod've": "who'd've",
+ "who'dve": "who'd've",
+ 'wholl': "who'll",
+ 'whos': "who's",
+ 'whove': "who've",
+ 'whyll': "why'll",
+ 'whyre': "why're",
+ 'whys': "why's",
+ 'wont': "won't",
+ 'wouldve': "would've",
+ 'wouldnt': "wouldn't",
+ "wouldnt've": "wouldn't've",
+ "wouldn'tve": "wouldn't've",
+ 'yall': "y'all",
+ "yall'll": "y'all'll",
+ "y'allll": "y'all'll",
+ "yall'd've": "y'all'd've",
+ "y'alld've": "y'all'd've",
+ "y'all'dve": "y'all'd've",
+ 'youd': "you'd",
+ "youd've": "you'd've",
+ "you'dve": "you'd've",
+ 'youll': "you'll",
+ 'youre': "you're",
+ 'youve': "you've",
+ }
+ for word in tempText:
+ word = manualMap.setdefault(word, word)
+ if word not in articles:
+ outText.append(word)
+ for wordId, word in enumerate(outText):
+ if word in contractions:
+ outText[wordId] = contractions[word]
+ outText = ' '.join(outText)
+ return outText
+
+
+@METRICS.register_module()
+class VQAAcc(BaseMetric):
+ '''VQA Acc metric.
+ Args:
+
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ '''
+ default_prefix = 'VQA'
+
+ def __init__(self,
+ full_score_weight: float = 0.3,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ self.full_score_weight = full_score_weight
+
+ def process(self, data_batch, data_samples):
+ """Process one batch of data samples.
+
+ The processed results should be stored in ``self.results``, which will
+ be used to computed the metrics when all batches have been processed.
+
+ Args:
+ data_batch: A batch of data from the dataloader.
+ data_samples (Sequence[dict]): A batch of outputs from the model.
+ """
+ for sample in data_samples:
+ gt_answer = sample.get('gt_answer')
+ gt_answer_weight = sample.get('gt_answer_weight')
+ if isinstance(gt_answer, str):
+ gt_answer = [gt_answer]
+ if gt_answer_weight is None:
+ gt_answer_weight = [1. / (len(gt_answer))] * len(gt_answer)
+
+ result = {
+ 'pred_answer': sample.get('pred_answer'),
+ 'gt_answer': gt_answer,
+ 'gt_answer_weight': gt_answer_weight,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Compute the metrics from processed results.
+
+ Args:
+ results (dict): The processed results of each batch.
+
+ Returns:
+ Dict: The computed metrics. The keys are the names of the metrics,
+ and the values are corresponding results.
+ """
+ acc = []
+ for result in results:
+ pred_answer = self._process_answer(result['pred_answer'])
+ gt_answer = [
+ self._process_answer(answer) for answer in result['gt_answer']
+ ]
+ answer_weight = result['gt_answer_weight']
+
+ weight_sum = 0
+ for i, gt in enumerate(gt_answer):
+ if gt == pred_answer:
+ weight_sum += answer_weight[i]
+ vqa_acc = min(1.0, weight_sum / self.full_score_weight)
+ acc.append(vqa_acc)
+
+ accuracy = sum(acc) / len(acc) * 100
+
+ metrics = {'acc': accuracy}
+ return metrics
+
+ def _process_answer(self, answer):
+ answer = answer.replace('\n', ' ')
+ answer = answer.replace('\t', ' ')
+ answer = answer.strip()
+ answer = _process_punctuation(answer)
+ answer = _process_digit_article(answer)
+ return answer
+
+
+@METRICS.register_module()
+class ReportVQA(BaseMetric):
+ """Dump VQA result to the standard json format for VQA evaluation.
+
+ Args:
+ file_path (str): The file path to save the result file.
+ collect_device (str): Device name used for collecting results from
+ different ranks during distributed training. Must be 'cpu' or
+ 'gpu'. Defaults to 'cpu'.
+ prefix (str, optional): The prefix that will be added in the metric
+ names to disambiguate homonymous metrics of different evaluators.
+ If prefix is not provided in the argument, self.default_prefix
+ will be used instead. Should be modified according to the
+ `retrieval_type` for unambiguous results. Defaults to TR.
+ """
+ default_prefix = 'VQA'
+
+ def __init__(self,
+ file_path: str,
+ collect_device: str = 'cpu',
+ prefix: Optional[str] = None):
+ super().__init__(collect_device=collect_device, prefix=prefix)
+ if not file_path.endswith('.json'):
+ raise ValueError('The output file must be a json file.')
+ self.file_path = file_path
+
+ def process(self, data_batch, data_samples) -> None:
+ """transfer tensors in predictions to CPU."""
+ for sample in data_samples:
+ question_id = sample['question_id']
+ pred_answer = sample['pred_answer']
+
+ result = {
+ 'question_id': int(question_id),
+ 'answer': pred_answer,
+ }
+
+ self.results.append(result)
+
+ def compute_metrics(self, results: List):
+ """Dump the result to json file."""
+ mmengine.dump(results, self.file_path)
+ logger = MMLogger.get_current_instance()
+ logger.info(f'Results has been saved to {self.file_path}.')
+ return {}
diff --git a/mmpretrain/models/__init__.py b/mmpretrain/models/__init__.py
index 767bbaa2a00..ba05735b26a 100644
--- a/mmpretrain/models/__init__.py
+++ b/mmpretrain/models/__init__.py
@@ -6,6 +6,7 @@
from .classifiers import * # noqa: F401,F403
from .heads import * # noqa: F401,F403
from .losses import * # noqa: F401,F403
+from .multimodal import * # noqa: F401,F403
from .necks import * # noqa: F401,F403
from .retrievers import * # noqa: F401,F403
from .selfsup import * # noqa: F401,F403
diff --git a/mmpretrain/models/backbones/timm_backbone.py b/mmpretrain/models/backbones/timm_backbone.py
index 69169b4a81b..51ecbdbb077 100644
--- a/mmpretrain/models/backbones/timm_backbone.py
+++ b/mmpretrain/models/backbones/timm_backbone.py
@@ -4,6 +4,7 @@
from mmengine.logging import MMLogger
from mmpretrain.registry import MODELS
+from mmpretrain.utils import require
from .base_backbone import BaseBackbone
@@ -55,6 +56,7 @@ class TIMMBackbone(BaseBackbone):
**kwargs: Other timm & model specific arguments.
"""
+ @require('timm')
def __init__(self,
model_name,
features_only=False,
@@ -63,11 +65,7 @@ def __init__(self,
in_channels=3,
init_cfg=None,
**kwargs):
- try:
- import timm
- except ImportError:
- raise ImportError(
- 'Failed to import timm. Please run "pip install timm".')
+ import timm
if not isinstance(pretrained, bool):
raise TypeError('pretrained must be bool, not str for model path')
@@ -79,7 +77,12 @@ def __init__(self,
super(TIMMBackbone, self).__init__(init_cfg)
if 'norm_layer' in kwargs:
- kwargs['norm_layer'] = MODELS.get(kwargs['norm_layer'])
+ norm_class = MODELS.get(kwargs['norm_layer'])
+
+ def build_norm(*args, **kwargs):
+ return norm_class(*args, **kwargs)
+
+ kwargs['norm_layer'] = build_norm
self.timm_model = timm.create_model(
model_name=model_name,
features_only=features_only,
diff --git a/mmpretrain/models/classifiers/hugging_face.py b/mmpretrain/models/classifiers/hugging_face.py
index f10f22621b9..26a8fda51b0 100644
--- a/mmpretrain/models/classifiers/hugging_face.py
+++ b/mmpretrain/models/classifiers/hugging_face.py
@@ -9,6 +9,7 @@
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
+from mmpretrain.utils import require
from .base import BaseClassifier
@@ -66,6 +67,7 @@ class HuggingFaceClassifier(BaseClassifier):
torch.Size([1, 1000])
""" # noqa: E501
+ @require('transformers')
def __init__(self,
model_name,
pretrained=False,
diff --git a/mmpretrain/models/classifiers/timm.py b/mmpretrain/models/classifiers/timm.py
index e33100b8537..d777b2e039d 100644
--- a/mmpretrain/models/classifiers/timm.py
+++ b/mmpretrain/models/classifiers/timm.py
@@ -9,6 +9,7 @@
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
+from mmpretrain.utils import require
from .base import BaseClassifier
@@ -59,6 +60,7 @@ class TimmClassifier(BaseClassifier):
torch.Size([1, 1000])
""" # noqa: E501
+ @require('timm')
def __init__(self,
*args,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
diff --git a/mmpretrain/models/heads/__init__.py b/mmpretrain/models/heads/__init__.py
index 42b257e2daf..7d2c1ae0f02 100644
--- a/mmpretrain/models/heads/__init__.py
+++ b/mmpretrain/models/heads/__init__.py
@@ -7,6 +7,9 @@
from .contrastive_head import ContrastiveHead
from .deit_head import DeiTClsHead
from .efficientformer_head import EfficientFormerClsHead
+from .grounding_head import GroundingHead
+from .itc_head import ITCHead
+from .itm_head import ITMHead
from .latent_heads import LatentCrossCorrelationHead, LatentPredictHead
from .levit_head import LeViTClsHead
from .linear_head import LinearClsHead
@@ -19,11 +22,13 @@
from .multi_label_csra_head import CSRAClsHead
from .multi_label_linear_head import MultiLabelLinearClsHead
from .multi_task_head import MultiTaskHead
+from .seq_gen_head import SeqGenerationHead
from .simmim_head import SimMIMHead
from .stacked_head import StackedLinearClsHead
from .swav_head import SwAVHead
from .vig_head import VigClsHead
from .vision_transformer_head import VisionTransformerClsHead
+from .vqa_head import VQAGenerationHead
__all__ = [
'ClsHead',
@@ -52,4 +57,9 @@
'MoCoV3Head',
'MIMHead',
'SimMIMHead',
+ 'SeqGenerationHead',
+ 'VQAGenerationHead',
+ 'ITCHead',
+ 'ITMHead',
+ 'GroundingHead',
]
diff --git a/mmpretrain/models/heads/grounding_head.py b/mmpretrain/models/heads/grounding_head.py
new file mode 100644
index 00000000000..a47512ef593
--- /dev/null
+++ b/mmpretrain/models/heads/grounding_head.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+
+from mmpretrain.models.utils.box_utils import (box_cxcywh_to_xyxy,
+ generalized_box_iou)
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+@MODELS.register_module()
+class GroundingHead(BaseModule):
+ """bbox Coordination generation head for multi-modal pre-trained task,
+ adapted by BLIP. Normally used for visual grounding.
+
+ Args:
+ loss: dict,
+ decoder: dict,
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ decoder: dict = None,
+ tokenizer: dict = None,
+ box_l1_loss_coeff=4.0,
+ box_giou_loss_coeff=2.0,
+ init_cfg: Optional[dict] = None,
+ ) -> None:
+ super(GroundingHead, self).__init__(init_cfg=init_cfg)
+ ''' init the decoder from med_config'''
+ self.decoder = None
+ if decoder:
+ self.decoder = MODELS.build(decoder)
+ self.loss_fn = torch.nn.CrossEntropyLoss(
+ reduction='none', ignore_index=-100)
+
+ self.box_l1_loss_coeff = box_l1_loss_coeff
+ self.box_giou_loss_coeff = box_giou_loss_coeff
+
+ if isinstance(tokenizer, dict):
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+
+ self.image_res = 640
+ prefix_ids = torch.tensor(
+ self.tokenizer.convert_tokens_to_ids(['[unused339]']))
+ target_ids = torch.tensor(
+ self.tokenizer.convert_tokens_to_ids(
+ [f'[unused{340+_}]' for _ in range(self.image_res + 1)]))
+ self.register_buffer('prefix_ids', prefix_ids)
+ self.register_buffer('target_ids', target_ids)
+
+ bbox_prob_mask = torch.zeros(len(self.tokenizer))
+ bbox_prob_mask[self.target_ids[0]:self.target_ids[-1] + 1] = 1
+ bbox_prob_mask = (1.0 - bbox_prob_mask) * -10000.0
+ self.register_buffer('bbox_prob_mask', bbox_prob_mask)
+ self.bin_start_idx = self.target_ids[0]
+
+ def forward(self, text_embedding, text_embedding_mask,
+ encoder_hidden_states, encoder_attention_mask):
+
+ # localize prompt token, text embedding
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ loc_prompt = self.prompt.weight.T
+ loc_prompt = torch.repeat_interleave(loc_prompt,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(1)
+
+ loc_prompt_mask = torch.ones(loc_prompt.shape[:-1]).long().to(
+ loc_prompt.device)
+
+ decoder_out = self.decoder(
+ inputs_embeds=loc_prompt,
+ attention_mask=loc_prompt_mask,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ output_hidden_states=True,
+ labels=None,
+ )
+ decoder_hs = decoder_out.hidden_states[-1][:, 0, :]
+ box_pred = self.box_head(decoder_hs)
+ return decoder_out, decoder_hs, box_pred
+
+ def loss(self,
+ text_embedding,
+ text_embedding_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ decoder_targets,
+ return_scores=False):
+ """Calculate losses from the extracted features.
+
+ Args:
+ feats (dict): The features extracted from the backbone.
+ data_samples (List[BaseDataElement]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ answer_targets = (decoder_targets *
+ self.image_res).long() + self.bin_start_idx
+ prefix_ids = torch.repeat_interleave(self.prefix_ids,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(-1)
+ prefix_ids = torch.cat([prefix_ids, answer_targets], dim=1)
+
+ answer_output = self.decoder(
+ prefix_ids,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ labels=None,
+ return_dict=True,
+ )
+ prob_mask = self.bbox_prob_mask.view(1, 1,
+ self.bbox_prob_mask.shape[-1])
+ prediction_scores = answer_output.logits + prob_mask
+
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = prefix_ids[:, 1:].contiguous()
+ vocab_size = len(self.tokenizer)
+ loss_seq_init = self.loss_fn(
+ shifted_prediction_scores.view(-1, vocab_size), labels.view(-1))
+
+ with torch.no_grad():
+ pred_box = (torch.argmax(
+ prediction_scores[:, :-1, :].contiguous(), dim=-1) -
+ self.bin_start_idx) / self.image_res
+ weight_bbox = F.l1_loss(
+ pred_box, decoder_targets, reduction='none').clamp(
+ 0, 5) * self.box_l1_loss_coeff
+ weight_giou = (1 - torch.diag(
+ generalized_box_iou(
+ box_cxcywh_to_xyxy(pred_box),
+ box_cxcywh_to_xyxy(decoder_targets)))
+ ) * self.box_giou_loss_coeff
+ bs = text_embedding.shape[0]
+ loss_seq = loss_seq_init[:].view(bs, -1, 4)
+ loss_seq = loss_seq * weight_bbox
+ loss_seq = loss_seq * weight_giou.unsqueeze(1)
+
+ loss_seq = loss_seq.mean()
+
+ losses = {
+ 'loss_seq': loss_seq,
+ 'loss_seq_init': loss_seq_init.mean(),
+ 'loss': loss_seq,
+ 'box_l1': weight_bbox.mean(-1).mean().detach(),
+ 'box_giou': weight_giou.mean().detach()
+ }
+
+ return losses
+
+ def predict(
+ self,
+ text_embedding,
+ text_embedding_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ """Generates the bbox coordinates at inference time."""
+
+ merged_encode_hs = torch.cat([encoder_hidden_states, text_embedding],
+ 1)
+ merge_att_mask = torch.cat(
+ [encoder_attention_mask, text_embedding_mask], 1)
+
+ prefix_ids = torch.repeat_interleave(self.prefix_ids,
+ merge_att_mask.shape[0],
+ 0).unsqueeze(-1)
+
+ for _ in range(4):
+ decoder_output = self.decoder(
+ prefix_ids,
+ encoder_hidden_states=merged_encode_hs,
+ encoder_attention_mask=merge_att_mask,
+ labels=None,
+ return_dict=True,
+ )
+ prob_mask = self.bbox_prob_mask.view(1, 1,
+ self.bbox_prob_mask.shape[-1])
+ prediction_scores = decoder_output.logits + prob_mask
+
+ prefix_ids = torch.cat([
+ prefix_ids,
+ torch.argmax(prediction_scores[:, -1, :], dim=-1).unsqueeze(1)
+ ],
+ dim=1)
+
+ pred_box = self.process_bbox(prefix_ids[:, 1:]) # xywh 0-1 to xyxy 0-1
+
+ return pred_box
+
+ @torch.no_grad()
+ def process_bbox(self, bbox):
+ bbox = bbox - self.bin_start_idx
+ bbox = torch.true_divide(bbox, self.image_res)
+ bbox = box_cxcywh_to_xyxy(bbox)
+ bbox = torch.clip(bbox, 0, 1)
+ assert torch.all(bbox <= 1)
+ return bbox
diff --git a/mmpretrain/models/heads/itc_head.py b/mmpretrain/models/heads/itc_head.py
new file mode 100644
index 00000000000..006d52c76d9
--- /dev/null
+++ b/mmpretrain/models/heads/itc_head.py
@@ -0,0 +1,157 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.dist import all_gather
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class ITCHead(BaseModule):
+ """Image-text matching head for multi-modal pre-trained task. Adapted by
+ BLIP, ALBEF. Normally used for retrieval task.
+
+ Args:
+ embed_dim (int): Embed channel size for queue.
+ queue_size (int): Queue size for image and text. Defaults to 57600.
+ temperature (float): Temperature to calculate the similarity.
+ Defaults to 0.07.
+ use_distill (bool): Whether to use distill to calculate loss.
+ Defaults to True.
+ alpha (float): Weight for momentum similarity. Defaults to 0.4.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embed_dim: int,
+ queue_size: int = 57600,
+ temperature: float = 0.07,
+ use_distill: bool = True,
+ alpha: float = 0.4,
+ init_cfg: Optional[dict] = None):
+ super(ITCHead, self).__init__(init_cfg=init_cfg)
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+ self.use_distill = use_distill
+ if self.use_distill:
+ # create the queue
+ self.register_buffer('image_queue',
+ torch.randn(embed_dim, queue_size))
+ self.register_buffer('text_queue',
+ torch.randn(embed_dim, queue_size))
+ self.register_buffer('idx_queue', torch.full((1, queue_size),
+ -100))
+ self.register_buffer('queue_ptr', torch.zeros(1, dtype=torch.long))
+
+ self.image_queue = F.normalize(self.image_queue, dim=0)
+ self.text_queue = F.normalize(self.text_queue, dim=0)
+
+ self.queue_size = queue_size
+ # This value will be warmup by `WarmupParamHook`
+ self.alpha = alpha
+
+ def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
+ """The forward process."""
+ return feats[-1]
+
+ def loss(self, feats: Tuple[torch.Tensor], data_samples, **kwargs) -> dict:
+ """Calculate losses from the classification score.
+
+ Args:
+ feats (tuple[Tensor]): The features extracted from the backbone.
+ Multiple stage inputs are acceptable but only the last stage
+ will be used to classify. The shape of every item should be
+ ``(num_samples, num_classes)``.
+ data_samples (List[ClsDataSample]): The annotation data of
+ every samples.
+ **kwargs: Other keyword arguments to forward the loss module.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ # The part can be traced by torch.fx
+ img_feats, text_feats, img_feats_m, text_feats_m = self(feats)
+
+ img_feats_all = torch.cat(
+ [img_feats_m.t(),
+ self.image_queue.clone().detach()], dim=1)
+ text_feats_all = torch.cat(
+ [text_feats_m.t(),
+ self.text_queue.clone().detach()], dim=1)
+
+ # The part can not be traced by torch.fx
+ losses = self._get_loss(img_feats, text_feats, img_feats_m,
+ text_feats_m, img_feats_all, text_feats_all,
+ data_samples, **kwargs)
+ return losses
+
+ def _get_loss(self, img_feats, text_feats, img_feats_m, text_feats_m,
+ img_feats_all, text_feats_all, data_samples, **kwargs):
+ """Unpack data samples and compute loss."""
+
+ idx = torch.tensor([ds.image_id
+ for ds in data_samples]).to(img_feats.device)
+ idx = idx.view(-1, 1)
+ idx_all = torch.cat([idx.t(), self.idx_queue.clone().detach()], dim=1)
+ pos_idx = torch.eq(idx, idx_all).float()
+ sim_targets = pos_idx / pos_idx.sum(1, keepdim=True)
+
+ with torch.no_grad():
+ if self.use_distill:
+ sim_i2t_m = img_feats_m @ text_feats_all / self.temp
+ sim_t2i_m = text_feats_m @ img_feats_all / self.temp
+
+ sim_i2t_targets = (
+ self.alpha * F.softmax(sim_i2t_m, dim=1) +
+ (1 - self.alpha) * sim_targets)
+ sim_t2i_targets = (
+ self.alpha * F.softmax(sim_t2i_m, dim=1) +
+ (1 - self.alpha) * sim_targets)
+
+ sim_i2t = img_feats @ text_feats_all / self.temp
+ sim_t2i = text_feats @ img_feats_all / self.temp
+
+ if self.use_distill:
+ loss_i2t = -torch.sum(
+ F.log_softmax(sim_i2t, dim=1) * sim_i2t_targets, dim=1).mean()
+ loss_t2i = -torch.sum(
+ F.log_softmax(sim_t2i, dim=1) * sim_t2i_targets, dim=1).mean()
+ else:
+ loss_i2t = -torch.sum(
+ F.log_softmax(sim_i2t, dim=1) * sim_targets, dim=1).mean()
+ loss_t2i = -torch.sum(
+ F.log_softmax(sim_t2i, dim=1) * sim_targets, dim=1).mean()
+
+ # compute loss
+ losses = dict()
+
+ losses['itc_loss'] = (loss_i2t + loss_t2i) / 2
+ self._dequeue_and_enqueue(img_feats_m, text_feats_m, idx)
+ return losses
+
+ @torch.no_grad()
+ def _dequeue_and_enqueue(self, image_feat, text_feat, idxs=None):
+ # gather keys before updating queue
+ image_feats = torch.cat(all_gather(image_feat))
+ text_feats = torch.cat(all_gather(text_feat))
+
+ batch_size = image_feats.shape[0]
+
+ ptr = int(self.queue_ptr)
+ assert self.queue_size % batch_size == 0 # for simplicity
+
+ # replace the keys at ptr (dequeue and enqueue)
+ self.image_queue[:, ptr:ptr + batch_size] = image_feats.T
+ self.text_queue[:, ptr:ptr + batch_size] = text_feats.T
+
+ if idxs is not None:
+ idxs = torch.cat(all_gather(idxs))
+ self.idx_queue[:, ptr:ptr + batch_size] = idxs.T
+
+ ptr = (ptr + batch_size) % self.queue_size # move pointer
+ self.queue_ptr[0] = ptr
diff --git a/mmpretrain/models/heads/itm_head.py b/mmpretrain/models/heads/itm_head.py
new file mode 100644
index 00000000000..c7b42f3f684
--- /dev/null
+++ b/mmpretrain/models/heads/itm_head.py
@@ -0,0 +1,117 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+from mmengine.model import BaseModule
+
+from mmpretrain.evaluation import Accuracy
+from mmpretrain.registry import MODELS
+
+
+class Pooler(nn.Module):
+
+ def __init__(self, hidden_size):
+ super().__init__()
+ self.dense = nn.Linear(hidden_size, hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+@MODELS.register_module()
+class ITMHead(BaseModule):
+ """Image-text matching head for multi-modal pre-trained task. Adapted by
+ BLIP, FLAVA.
+
+ Args:
+ hidden_size (int): Hidden channel size out input features.
+ with_pooler (bool): Whether a pooler is added. Defaults to True.
+ loss (dict): Config of global contrasive loss. Defaults to
+ ``dict(type='GlobalContrasiveLoss')``.
+ cal_acc (bool): Whether to calculate accuracy during training.
+ If you use batch augmentations like Mixup and CutMix during
+ training, it is pointless to calculate accuracy.
+ Defaults to False.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ hidden_size: int,
+ with_pooler: bool = True,
+ loss: dict = dict(type='CrossEntropyLoss', loss_weight=1.0),
+ cal_acc: bool = False,
+ init_cfg: Optional[dict] = None):
+ super(ITMHead, self).__init__(init_cfg=init_cfg)
+ self.hidden_size = hidden_size
+
+ if with_pooler:
+ self.pooler = Pooler(hidden_size=self.hidden_size)
+ else:
+ self.pooler = nn.Identity()
+ self.fc = nn.Linear(self.hidden_size, 2)
+
+ self.loss_module = MODELS.build(loss)
+ self.cal_acc = cal_acc
+
+ def forward(self, feats: Tuple[torch.Tensor]) -> torch.Tensor:
+ """The forward process."""
+ pre_logits = self.pooler(feats[-1])
+ itm_logits = self.fc(pre_logits)
+ return itm_logits
+
+ def loss(self, feats: Tuple[torch.Tensor], data_samples, **kwargs) -> dict:
+ """Calculate losses from the classification score.
+
+ Args:
+ feats (tuple[Tensor]): The features extracted from the backbone.
+ Multiple stage inputs are acceptable but only the last stage
+ will be used to classify. The shape of every item should be
+ ``(num_samples, num_classes)``.
+ data_samples (List[ClsDataSample]): The annotation data of
+ every samples.
+ **kwargs: Other keyword arguments to forward the loss module.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+
+ # The part can be traced by torch.fx
+ itm_logits = self(feats)
+
+ # deal with query
+ if itm_logits.ndim == 3:
+ itm_logits = itm_logits.mean(dim=1)
+
+ # The part can not be traced by torch.fx
+ losses = self._get_loss(itm_logits, data_samples, **kwargs)
+ return losses
+
+ def _get_loss(self, itm_logits: torch.Tensor, data_samples, **kwargs):
+ """Unpack data samples and compute loss."""
+ # Unpack data samples and pack targets
+ # use `itm_label` in here temporarily
+ target = torch.tensor([i.is_matched
+ for i in data_samples]).to(itm_logits.device)
+
+ # compute loss
+ losses = dict()
+
+ loss = self.loss_module(
+ itm_logits, target.long(), avg_factor=itm_logits.size(0), **kwargs)
+ losses['itm_loss'] = loss
+
+ # compute accuracy
+ if self.cal_acc:
+ # topk is meaningless for matching task
+ acc = Accuracy.calculate(itm_logits, target)
+ # acc is warpped with two lists of topk and thrs
+ # which are unnecessary here
+ losses.update({'itm_accuracy': acc[0][0]})
+
+ return losses
diff --git a/mmpretrain/models/heads/seq_gen_head.py b/mmpretrain/models/heads/seq_gen_head.py
new file mode 100644
index 00000000000..b2e9b10efe6
--- /dev/null
+++ b/mmpretrain/models/heads/seq_gen_head.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class SeqGenerationHead(BaseModule):
+ """Generation head for multi-modal pre-trained task, adopted by BLIP.
+ Normally used for generation task.
+
+ Args:
+ decoder (dict): Decoder for blip generation head.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(
+ self,
+ decoder: dict,
+ ignore_index=-100,
+ loss: dict = dict(type='LabelSmoothLoss', label_smooth_val=0.1),
+ init_cfg: Optional[dict] = None,
+ ) -> None:
+ super(SeqGenerationHead, self).__init__(init_cfg=init_cfg)
+ self.decoder = MODELS.build(decoder)
+ self.loss_fn = MODELS.build(loss)
+ self.ignore_index = ignore_index
+
+ def forward(self, input_ids: torch.Tensor,
+ encoder_hidden_states: torch.Tensor,
+ encoder_attention_mask: torch.Tensor, labels: torch.Tensor):
+ """Forward to get decoder output.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ encoder_attention_mask (torch.Tensor): Image embeddings hidden
+ states attention mask.
+ labels (torch.Tensor): Decoder target for calculate loss.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of decoder outputs.
+ """
+
+ decoder_out = self.decoder(
+ input_ids=input_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ labels=labels,
+ return_dict=True,
+ )
+ return decoder_out
+
+ def loss(self, input_ids, encoder_hidden_states, encoder_attention_mask,
+ labels):
+ """Calculate losses from the extracted features.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ encoder_attention_mask (torch.Tensor): Image embeddings hidden
+ states attention mask.
+ labels (torch.Tensor): Decoder target for calculate loss.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+
+ decoder_out = self(
+ input_ids=input_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ labels=labels,
+ )
+ prediction_scores = decoder_out['logits']
+ # we are doing next-token prediction;
+ # shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+
+ vocab_size = prediction_scores.shape[-1]
+
+ # mask ignored index
+ if (labels == self.ignore_index).any():
+ labels = labels.view(-1).clone()
+ ignore_mask = (labels == self.ignore_index)
+ labels.masked_fill_(ignore_mask, 0)
+ weight = torch.logical_not(ignore_mask)
+ avg_factor = max(weight.sum(), 1)
+ else:
+ weight = None
+ avg_factor = labels.size(0)
+
+ lm_loss = self.loss_fn(
+ shifted_prediction_scores.view(-1, vocab_size),
+ labels,
+ weight=weight,
+ avg_factor=avg_factor,
+ )
+ losses = {
+ 'seq_gen_lm_loss': lm_loss,
+ }
+
+ return losses
+
+ def predict(self,
+ input_ids,
+ encoder_hidden_states,
+ sep_token_id,
+ pad_token_id,
+ use_nucleus_sampling=False,
+ num_beams=3,
+ max_length=20,
+ min_length=2,
+ top_p=0.9,
+ repetition_penalty=1.0,
+ **kwargs):
+ """Decoder prediction method.
+
+ Args:
+ input_ids (torch.Tensor): The tokenized input text tensor.
+ encoder_hidden_states (torch.Tensor): Hidden states from image
+ embeddings.
+ sep_token_id (int): Tokenid of separation token.
+ pad_token_id (int): Tokenid of pad token.
+ use_nucleus_sampling (bool): Whether to use nucleus sampling in
+ prediction. Defaults to False.
+ num_beams (int): Number of beams used in predition.
+ Defaults to 3.
+ max_length (int): Max length of generated text in predition.
+ Defaults to 20.
+ min_length (int): Min length of generated text in predition.
+ Defaults to 20.
+ top_p (float):
+ If < 1.0, only keep the top tokens with cumulative probability
+ >= top_p (nucleus filtering). Defaults to 0.9.
+ repetition_penalty (float): The parameter for repetition penalty.
+ Defaults to 1.0.
+ **kwarg: Other arguments that might used in generation.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of generation outputs.
+ """
+ device = encoder_hidden_states.device
+
+ # TODO: In old version of transformers
+ # Additional repeat interleave of hidden states should be add here.
+ image_atts = torch.ones(
+ encoder_hidden_states.size()[:-1], dtype=torch.long).to(device)
+
+ model_kwargs = {
+ 'encoder_hidden_states': encoder_hidden_states,
+ 'encoder_attention_mask': image_atts,
+ }
+ model_kwargs.update(kwargs)
+
+ if use_nucleus_sampling:
+ # nucleus sampling
+ outputs = self.decoder.generate(
+ input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ do_sample=True,
+ top_p=top_p,
+ num_return_sequences=1,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=1.1,
+ **model_kwargs)
+ else:
+ # beam search
+ outputs = self.decoder.generate(
+ input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ num_beams=num_beams,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=repetition_penalty,
+ **model_kwargs)
+
+ return outputs
diff --git a/mmpretrain/models/heads/vqa_head.py b/mmpretrain/models/heads/vqa_head.py
new file mode 100644
index 00000000000..c7b5fe53287
--- /dev/null
+++ b/mmpretrain/models/heads/vqa_head.py
@@ -0,0 +1,246 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional, Union
+
+import mmengine
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModule
+
+from mmpretrain.registry import MODELS
+
+
+@MODELS.register_module()
+class VQAGenerationHead(BaseModule):
+ """Generation head for multi-modal pre-trained task, adapted by BLIP.
+ Normally used for qa generation task (open-set)
+
+ Args:
+ decoder (dict): Decoder for decoding answers.
+ inference_method (str): Inference method. One of 'rank', 'generate'.
+ - If 'rank', the model will return answers with the highest
+ probability from the answer list.
+ - If 'generate', the model will generate answers.
+ - Only for test, not for train / val.
+ num_beams (int): Number of beams for beam search. 1 means no beam
+ search. Only support when inference_method=='generate'.
+ Defaults to 3.
+ num_ans_candidates (int): Number of answer candidates, used to filter
+ out answers with low probability. Only support when
+ inference_method=='rank'. Defaults to 128.
+ loss (dict or nn.Module): Config of loss or module of loss. Defaults to
+ ``nn.CrossEntropyLoss(reduction='none', ignore_index=-100)``.
+ init_cfg (dict, optional): the config to control the initialization.
+ Defaults to None.
+ answer_list_path (str, optional): Path to `answer_list.json`
+ (json file of a answer list). Required when
+ inference_method=='rank'.
+
+
+ TODO: `mmcls.LabelSmoothLoss` has not support `ignore_index` param.
+ Now using `nn.CrossEntropyLoss`, without label_smoothing, in order to
+ maintain compatibility with torch < 1.10.0
+ """
+
+ def __init__(
+ self,
+ decoder: dict,
+ inference_method: str = 'generate',
+ num_beams: int = 3,
+ num_ans_candidates: int = 128,
+ loss: Union[dict, nn.Module] = nn.CrossEntropyLoss(
+ reduction='none', ignore_index=-100),
+ init_cfg: Optional[dict] = None,
+ answer_list_path: Optional[str] = None,
+ ) -> None:
+
+ super(VQAGenerationHead, self).__init__(init_cfg=init_cfg)
+ self.decoder = MODELS.build(decoder)
+
+ if inference_method == 'generate':
+ assert isinstance(num_beams, int), \
+ 'for VQA `generate` mode, `num_beams` must be a int.'
+ self.num_beams = num_beams
+ self.num_ans_candidates = None
+ self.answer_list = None
+
+ elif inference_method == 'rank':
+ assert isinstance(num_ans_candidates, int), \
+ 'for VQA `rank` mode, `num_ans_candidates` must be a int.'
+ assert isinstance(answer_list_path, str), \
+ 'for VQA `rank` mode, `answer_list_path` must be set as ' \
+ 'the path to `answer_list.json`.'
+ self.num_beams = None
+ self.answer_list = mmengine.load(answer_list_path)
+ if isinstance(self.answer_list, dict):
+ self.answer_list = list(self.answer_list.keys())
+ assert isinstance(self.answer_list, list) and all(
+ isinstance(item, str) for item in self.answer_list), \
+ 'for VQA `rank` mode, `answer_list.json` must be a list of str'
+ self.num_ans_candidates = min(num_ans_candidates,
+ len(self.answer_list))
+
+ else:
+ raise AssertionError(
+ 'for VQA, `inference_method` must be "generate" or "rank", '
+ 'got {}.'.format(inference_method))
+
+ self.inference_method = inference_method
+ if not isinstance(loss, nn.Module):
+ loss = MODELS.build(loss)
+ self.loss_module = loss
+
+ def forward(self, feats: dict):
+ prediction_logits = self.decoder(
+ feats['answer_input_ids'],
+ attention_mask=feats['answer_attention_mask'],
+ encoder_hidden_states=feats['question_states'],
+ encoder_attention_mask=feats['question_atts'],
+ labels=feats['answer_targets'],
+ return_dict=True,
+ return_logits=True, # directly return logits, not computing loss
+ reduction='none',
+ )
+ return prediction_logits
+
+ def loss(self, feats: dict, data_samples=None):
+ """Calculate losses from the extracted features.
+
+ Args:
+ feats (dict): The features extracted from the backbone.
+ data_samples (List[BaseDataElement]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components
+ """
+ shifted_prediction_scores = self(feats)
+ labels = feats['answer_targets']
+ lm_loss = None
+
+ # we are doing next-token prediction;
+ # shift prediction scores and input ids by one
+ labels = labels[:, 1:].contiguous()
+ lm_loss = self.loss_module(
+ shifted_prediction_scores.view(-1,
+ self.decoder.med_config.vocab_size),
+ labels.view(-1))
+ lm_loss = lm_loss.view(shifted_prediction_scores.size(0), -1).sum(1)
+ # compute weighted loss
+ losses = dict()
+ loss = feats['answer_weight'] * lm_loss
+ loss = loss.sum() / feats['batch_size']
+ losses['vqa_loss'] = loss
+
+ return losses
+
+ def predict_rank(self, feats: dict, data_samples=None):
+ """Predict rank in a close-set answer list."""
+ question_states = feats['multimodal_embeds']
+ question_atts = feats['question_atts']
+ answer_candidates = feats['answer_candidates']
+ assert answer_candidates is not None
+
+ answer_ids = answer_candidates.input_ids
+ answer_atts = answer_candidates.attention_mask
+ num_ques = question_states.size(0)
+ start_ids = answer_ids[0, 0].repeat(num_ques, 1) # bos token
+
+ start_output = self.decoder(
+ start_ids,
+ encoder_hidden_states=question_states,
+ encoder_attention_mask=question_atts,
+ return_dict=True,
+ reduction='none',
+ )
+ logits = start_output.logits[:, 0, :] # first token's logit
+
+ # topk_probs: top-k probability
+ # topk_ids: [num_question, k]
+ answer_first_token = answer_ids[:, 1]
+ prob_first_token = F.softmax(
+ logits, dim=1).index_select(
+ dim=1, index=answer_first_token)
+ topk_probs, topk_ids = prob_first_token.topk(
+ self.num_ans_candidates, dim=1)
+
+ # answer input: [num_question*k, answer_len]
+ input_ids = []
+ input_atts = []
+ for b, topk_id in enumerate(topk_ids):
+ input_ids.append(answer_ids.index_select(dim=0, index=topk_id))
+ input_atts.append(answer_atts.index_select(dim=0, index=topk_id))
+ input_ids = torch.cat(input_ids, dim=0)
+ input_atts = torch.cat(input_atts, dim=0)
+
+ targets_ids = input_ids.masked_fill(input_ids == feats['pad_token_id'],
+ -100)
+
+ def tile(x, dim, n_tile):
+ init_dim = x.size(dim)
+ repeat_idx = [1] * x.dim()
+ repeat_idx[dim] = n_tile
+ x = x.repeat(*(repeat_idx))
+ order_index = torch.LongTensor(
+ np.concatenate([
+ init_dim * np.arange(n_tile) + i for i in range(init_dim)
+ ]))
+ return torch.index_select(x, dim, order_index.to(x.device))
+
+ # repeat encoder's output for top-k answers
+ question_states = tile(question_states, 0, self.num_ans_candidates)
+ question_atts = tile(question_atts, 0, self.num_ans_candidates)
+
+ output = self.decoder(
+ input_ids,
+ attention_mask=input_atts,
+ encoder_hidden_states=question_states,
+ encoder_attention_mask=question_atts,
+ labels=targets_ids,
+ return_dict=True,
+ reduction='none',
+ )
+
+ log_probs_sum = -output.loss
+ log_probs_sum = log_probs_sum.view(num_ques, self.num_ans_candidates)
+
+ max_topk_ids = log_probs_sum.argmax(dim=1)
+ max_ids = topk_ids[max_topk_ids >= 0, max_topk_ids]
+
+ answers = [self.answer_list[max_id] for max_id in max_ids]
+
+ return answers
+
+ def predict_generate(self, feats: dict, data_samples=None):
+ """Predict answers in a generation manner."""
+ device = feats['multimodal_embeds'].device
+ question_states = feats['multimodal_embeds']
+ question_atts = torch.ones(
+ question_states.size()[:-1], dtype=torch.long).to(device)
+ model_kwargs = {
+ 'encoder_hidden_states': question_states,
+ 'encoder_attention_mask': question_atts
+ }
+
+ bos_ids = torch.full((feats['multimodal_embeds'].shape[0], 1),
+ fill_value=feats['bos_token_id'],
+ device=device)
+
+ outputs = self.decoder.generate(
+ input_ids=bos_ids,
+ max_length=10,
+ min_length=1,
+ num_beams=self.num_beams,
+ eos_token_id=feats['sep_token_id'],
+ pad_token_id=feats['pad_token_id'],
+ **model_kwargs)
+
+ return outputs
+
+ def predict(self, feats: dict, data_samples=None):
+ """Predict results from the extracted features."""
+ if self.inference_method == 'generate':
+ return self.predict_generate(feats, data_samples)
+ elif self.inference_method == 'rank':
+ return self.predict_rank(feats, data_samples)
diff --git a/mmpretrain/models/losses/label_smooth_loss.py b/mmpretrain/models/losses/label_smooth_loss.py
index b53b9913ce7..f117df33b07 100644
--- a/mmpretrain/models/losses/label_smooth_loss.py
+++ b/mmpretrain/models/losses/label_smooth_loss.py
@@ -62,7 +62,9 @@ def __init__(self,
use_sigmoid=None,
mode='original',
reduction='mean',
- loss_weight=1.0):
+ loss_weight=1.0,
+ class_weight=None,
+ pos_weight=None):
super().__init__()
self.num_classes = num_classes
self.loss_weight = loss_weight
@@ -101,7 +103,11 @@ def __init__(self,
use_sigmoid = False if use_sigmoid is None else use_sigmoid
self.ce = CrossEntropyLoss(
- use_sigmoid=use_sigmoid, use_soft=not use_sigmoid)
+ use_sigmoid=use_sigmoid,
+ use_soft=not use_sigmoid,
+ reduction=reduction,
+ class_weight=class_weight,
+ pos_weight=pos_weight)
def generate_one_hot_like_label(self, label):
"""This function takes one-hot or index label vectors and computes one-
diff --git a/mmpretrain/models/multimodal/__init__.py b/mmpretrain/models/multimodal/__init__.py
new file mode 100644
index 00000000000..bda7087a4a5
--- /dev/null
+++ b/mmpretrain/models/multimodal/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
+
+if WITH_MULTIMODAL:
+ from .blip import * # noqa: F401,F403
+ from .blip2 import * # noqa: F401,F403
+ from .flamingo import * # noqa: F401, F403
+ from .ofa import * # noqa: F401, F403
+else:
+ from mmpretrain.registry import MODELS
+ from mmpretrain.utils.dependency import register_multimodal_placeholder
+
+ register_multimodal_placeholder([
+ 'Blip2Caption', 'Blip2Retrieval', 'Blip2VQA', 'BlipCaption',
+ 'BlipNLVR', 'BlipRetrieval', 'BlipGrounding', 'BlipVQA', 'Flamingo',
+ 'OFA'
+ ], MODELS)
diff --git a/mmpretrain/models/multimodal/blip/__init__.py b/mmpretrain/models/multimodal/blip/__init__.py
new file mode 100644
index 00000000000..ebbc0da6e0d
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/__init__.py
@@ -0,0 +1,12 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .blip_caption import BlipCaption
+from .blip_grounding import BlipGrounding
+from .blip_nlvr import BlipNLVR
+from .blip_retrieval import BlipRetrieval
+from .blip_vqa import BlipVQA
+from .language_model import BertLMHeadModel, XBertEncoder, XBertLMHeadDecoder
+
+__all__ = [
+ 'BertLMHeadModel', 'BlipCaption', 'BlipGrounding', 'BlipNLVR',
+ 'BlipRetrieval', 'BlipVQA', 'XBertEncoder', 'XBertLMHeadDecoder'
+]
diff --git a/mmpretrain/models/multimodal/blip/blip_caption.py b/mmpretrain/models/multimodal/blip/blip_caption.py
new file mode 100644
index 00000000000..9af3e2408da
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_caption.py
@@ -0,0 +1,184 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class BlipCaption(BaseModel):
+ """BLIP Caption.
+
+ Args:
+ vision_encoder (dict): Encoder for extracting image features.
+ decoder_head (dict): The decoder head module to forward and
+ calculate loss from processed features.
+ tokenizer: (Optional[dict]): The config for tokenizer.
+ Defaults to None.
+ prompt (str): Prompt used for training and eval.
+ Defaults to ''.
+ max_txt_len (int): Max text length of input text.
+ num_captions (int): Number of captions to be generated for each image.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_encoder: dict,
+ decoder_head: dict,
+ tokenizer: Optional[dict] = None,
+ prompt: str = '',
+ max_txt_len: int = 20,
+ num_captions: int = 1,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipCaption, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.visual_encoder = MODELS.build(vision_encoder)
+ self.seq_gen_head = MODELS.build(decoder_head)
+
+ self.prompt = prompt
+ self.prompt_length = len(self.tokenizer(self.prompt).input_ids) - 1
+ self.max_txt_len = max_txt_len
+ self.num_captions = num_captions
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "predict" and "loss":
+
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): pre_processed img tensor (N, C, ...).
+ data_samples (List[DataSample], optional): Data samples with
+ additional infos.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self, images, data_samples=None, **kwargs):
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input images tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ # prepare inputs for decoder generation.
+ image_embeds = self.visual_encoder(images)[0]
+ image_embeds = torch.repeat_interleave(image_embeds, self.num_captions,
+ 0)
+
+ prompt = [self.prompt] * image_embeds.size(0)
+ prompt = self.tokenizer(
+ prompt, padding='longest',
+ return_tensors='pt').to(image_embeds.device)
+
+ prompt.input_ids[:, 0] = self.tokenizer.bos_token_id
+ prompt.input_ids = prompt.input_ids[:, :-1]
+
+ decoder_out = self.seq_gen_head.predict(
+ input_ids=prompt.input_ids,
+ encoder_hidden_states=image_embeds,
+ sep_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ output_attentions=True,
+ return_dict_in_generate=True,
+ )
+
+ decode_tokens = self.tokenizer.batch_decode(
+ decoder_out.sequences, skip_special_tokens=True)
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None for _ in range(len(decode_tokens))]
+
+ for data_sample, decode_token in zip(data_samples, decode_tokens):
+ if data_sample is None:
+ data_sample = DataSample()
+ data_sample.pred_caption = decode_token[len(self.prompt):]
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
+
+ def loss(self, images, data_samples):
+ """Calculate losses from a batch of images and data samples.
+
+ Args:
+ images (torch.Tensor): The input images tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[ImageTextDataSample]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+ image_embeds = self.visual_encoder(images)[0]
+ raw_text = [self.prompt + ds.gt_caption for ds in data_samples]
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+ text.input_ids[:, 0] = self.tokenizer.bos_token_id
+
+ # prepare targets for forwarding decoder
+ labels = text.input_ids.masked_fill(
+ text.input_ids == self.tokenizer.pad_token_id, -100)
+ labels[:, :self.prompt_length] = -100
+ # forward decoder
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(image_embeds.device)
+
+ losses = self.seq_gen_head.loss(
+ input_ids=text.input_ids,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ labels=labels,
+ )
+ return losses
diff --git a/mmpretrain/models/multimodal/blip/blip_grounding.py b/mmpretrain/models/multimodal/blip/blip_grounding.py
new file mode 100644
index 00000000000..cb087287220
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_grounding.py
@@ -0,0 +1,248 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+from typing import List, Optional, Tuple, Union
+
+import numpy as np
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.models.utils.box_utils import box_xyxy_to_cxcywh
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures.data_sample import DataSample
+
+
+@MODELS.register_module()
+class BlipGrounding(BaseModel):
+ """BLIP Grounding.
+
+ Args:
+ visual_encoder (dict): Backbone for extracting image features.
+ text_encoder (dict): Backbone for extracting text features.
+ but we integrate the vqa text extractor
+ into the tokenizer part in datasets/transform/
+ so we don't need text_backbone
+ multimodal_encoder (Optional[dict]): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ neck (Optional[dict]): The neck module to process features from
+ backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed features. See :mod:`mmpretrain.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ tokenizer: Optional[dict] = None,
+ visual_encoder: Optional[dict] = None,
+ text_encoder: Optional[dict] = None,
+ multimodal_encoder: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipGrounding, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.prompt = 'localize instance: '
+ self.visual_encoder = MODELS.build(visual_encoder)
+ self.text_encoder = MODELS.build(text_encoder)
+ self.multimodal_encoder = MODELS.build(multimodal_encoder)
+ head.setdefault('tokenizer', self.tokenizer)
+ self.grounding_head = MODELS.build(head)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ inputs (torch.Tensor, tuple): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[VQADataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract features from the input tensor with shape (N, C, ...).
+
+ Args:
+ inputs (Tensor): A batch of inputs. The shape of it should be
+ ``(num_samples, num_channels, *img_shape)``.
+ Returns:
+ image_embeds (Tensor): The output features.
+ """
+ image_embeds = self.visual_encoder(images)[0]
+ return image_embeds
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples=None,
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
+ """generate train_loss from the input tensor and data_samples.
+
+ Args:
+ inputs (Tensor): A batch of inputs. The shape of it should be
+ ``(num_samples, num_channels, *img_shape)``.
+ data_samples (List[VQADataSample], optional): The annotation
+ data of every samples..
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+
+ # extract image feature
+ image_embeds = self.extract_feat(images)
+ image_atts = image_embeds.new_ones(
+ image_embeds.size()[:-1], dtype=torch.long)
+
+ raw_text = []
+ box_targets = []
+ for ds in data_samples:
+
+ raw_text.append(ds.text)
+ box_t = copy.deepcopy(ds.box) * 1.0
+ box_t[1] /= ds.img_shape[0]
+ box_t[3] /= ds.img_shape[0]
+ box_t[0] /= ds.img_shape[1]
+ box_t[2] /= ds.img_shape[1]
+
+ box_targets.append(box_t)
+
+ box_targets = image_embeds.new_tensor(np.stack(box_targets))
+ box_targets = box_xyxy_to_cxcywh(box_targets) # xywh 0-1
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=128,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+
+ text_embeds = self.text_encoder(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ mode='text',
+ return_dict=True) # bz, seq_len, hid
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_encoder(
+ encoder_embeds=text_embeds.last_hidden_state,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ losses = self.grounding_head.loss(
+ text_embedding=multimodal_embeds.last_hidden_state,
+ text_embedding_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ decoder_targets=box_targets,
+ )
+
+ return losses
+
+ def predict(self, images, data_samples=None):
+ """"""
+
+ # extract image feature
+ image_embeds = self.extract_feat(images)
+ image_atts = image_embeds.new_ones(
+ image_embeds.size()[:-1], dtype=torch.long)
+
+ raw_text = []
+ for ds in data_samples:
+ raw_text.append(ds.text)
+
+ text = self.tokenizer(
+ raw_text,
+ padding='longest',
+ truncation=True,
+ max_length=128,
+ return_tensors='pt',
+ ).to(image_embeds.device)
+
+ text_embeds = self.text_encoder(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ mode='text',
+ return_dict=True) # bz, seq_len, hid
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_encoder(
+ encoder_embeds=text_embeds.last_hidden_state,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ output_boxes = self.grounding_head.predict(
+ text_embedding=multimodal_embeds.last_hidden_state,
+ text_embedding_mask=text.attention_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ ) # xyxy 0-1
+
+ out_data_samples = []
+ for bbox, data_sample, img in zip(output_boxes, data_samples, images):
+ if data_sample is None:
+ data_sample = DataSample()
+
+ img_size = img.shape[-2:]
+ scale_factor = data_sample.get('scale_factor', (1, 1))
+ bbox[0::2] = bbox[0::2] * img_size[1] / scale_factor[0]
+ bbox[1::2] = bbox[1::2] * img_size[0] / scale_factor[1]
+ bbox = bbox[None, :]
+ data_sample.pred_bboxes = bbox
+
+ if 'gt_bboxes' in data_sample:
+ gt_bboxes = torch.Tensor(data_sample.get('gt_bboxes'))
+ gt_bboxes[:, 0::2] /= scale_factor[0]
+ gt_bboxes[:, 1::2] /= scale_factor[1]
+ data_sample.gt_bboxes = gt_bboxes
+
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/blip/blip_nlvr.py b/mmpretrain/models/multimodal/blip/blip_nlvr.py
new file mode 100644
index 00000000000..f96e3cce237
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_nlvr.py
@@ -0,0 +1,205 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+@MODELS.register_module()
+class BlipNLVR(BaseModel):
+ """BLIP NLVR.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ but we integrate the vqa text extractor into the tokenizer part in
+ datasets/transform/ so we don't need text_backbone
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ neck (Optional[dict]): The neck module to process features from
+ backbone. Defaults to None.
+ head (Optional[dict]): The head module to calculate
+ loss from processed features. See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ tokenizer: (Optional[dict]): The config for tokenizer
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ multimodal_backbone: dict,
+ tokenizer: Optional[dict] = None,
+ max_txt_len: int = 35,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+ if tokenizer is not None:
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.max_txt_len = max_txt_len
+
+ # For simplity, directly use head definition here.
+ # If more complex head is designed, move this and loss to a new
+ # head module.
+ hidden_size = self.multimodal_backbone.config.hidden_size
+ self.head = nn.Sequential(
+ nn.Linear(hidden_size, hidden_size),
+ nn.ReLU(),
+ nn.Linear(hidden_size, 2),
+ )
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def preprocess_text(self, data_samples):
+
+ sample_item = data_samples[0]
+
+ if sample_item is not None and 'text' in sample_item:
+ texts = [sample.get('text') for sample in data_samples]
+ else:
+ return None
+
+ # perform tokenize first if satisfied conditions
+ texts = self.tokenizer(
+ texts,
+ padding='longest',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(self.device)
+
+ return texts
+
+ def forward(
+ self,
+ images: dict,
+ data_samples: Optional[List] = None,
+ mode: str = 'tensor',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ images and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (dict of torch.Tensor):
+ img: pre_processed img tensor (N, C, ...).
+ text: tokenized text (N, L)
+ data_samples (List[CaptionDataSample], optional):
+ The annotation data of every samples.
+ 'image': raw image data
+ 'text' tokenized text
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ # B, T, C, H, W to T*B, C, H, W
+ images = images.permute(1, 0, 2, 3, 4).flatten(0, 1)
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self, images, data_samples=None):
+ """Predict caption."""
+ # prepare inputs for decoder generation.
+ image_embeds = self.vision_backbone(images)[0]
+ texts = self.preprocess_text(data_samples)
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ image0_embeds, image1_embeds = torch.split(image_embeds,
+ texts.input_ids.size(0))
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ texts.input_ids,
+ attention_mask=texts.attention_mask,
+ encoder_hidden_states=[image0_embeds, image1_embeds],
+ encoder_attention_mask=[
+ image_atts[:image0_embeds.size(0)],
+ image_atts[image0_embeds.size(0):],
+ ],
+ return_dict=True,
+ )
+
+ # get prediction
+ outputs = self.head(multimodal_embeds.last_hidden_state[:, 0, :])
+
+ pred_scores = F.softmax(outputs, dim=1)
+
+ for pred_score, data_sample in zip(pred_scores, data_samples):
+ data_sample.set_pred_score(pred_score)
+ data_sample.set_pred_label(pred_score.argmax(dim=0))
+
+ return data_samples
+
+ def loss(self, images, data_samples):
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[ImageTextDataSample]): The annotation data of
+ every samples.
+
+ Returns:
+ dict[str, Tensor]: a dictionary of loss components.
+ """
+ # prepare inputs for decoder generation.
+ image_embeds = self.vision_backbone(images)[0]
+ texts = self.preprocess_text(data_samples)
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+ image0_embeds, image1_embeds = torch.split(image_embeds,
+ texts.input_ids.size(0))
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ texts.input_ids,
+ attention_mask=texts.attention_mask,
+ encoder_hidden_states=[image0_embeds, image1_embeds],
+ encoder_attention_mask=[
+ image_atts[:image0_embeds.size(0)],
+ image_atts[image0_embeds.size(0):],
+ ],
+ return_dict=True,
+ )
+
+ # get prediction
+ outputs = self.head(multimodal_embeds.last_hidden_state[:, 0, :])
+
+ targets = torch.tensor([i.gt_label
+ for i in data_samples]).to(outputs.device)
+ loss = F.cross_entropy(outputs, targets)
+ return {'loss': loss}
diff --git a/mmpretrain/models/multimodal/blip/blip_retrieval.py b/mmpretrain/models/multimodal/blip/blip_retrieval.py
new file mode 100644
index 00000000000..8983e63e208
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_retrieval.py
@@ -0,0 +1,716 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from collections import ChainMap
+from copy import deepcopy
+from typing import Dict, List, Optional, Tuple, Union
+
+import mmengine.dist as dist
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.model import BaseModel
+from torch import distributed as torch_dist
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from mmpretrain.utils import track_on_main_process
+
+
+def all_gather_concat(data: torch.Tensor) -> torch.Tensor:
+ """Gather tensors with different first-dimension size and concat to one
+ tenosr.
+
+ Note:
+ Only the first dimension should be different.
+
+ Args:
+ data (Tensor): Tensor to be gathered.
+
+ Returns:
+ torch.Tensor: The concatenated tenosr.
+ """
+ if dist.get_world_size() == 1:
+ return data
+
+ data_size = torch.tensor(data.size(0), device=data.device)
+ sizes_list = dist.all_gather(data_size)
+
+ max_length = max(sizes_list)
+ size_diff = max_length.item() - data_size.item()
+ if size_diff:
+ padding = torch.zeros(
+ size_diff, *data.size()[1:], device=data.device, dtype=data.dtype)
+ data = torch.cat((data, padding))
+
+ gather_list = dist.all_gather(data)
+
+ all_data = []
+ for tensor, size in zip(gather_list, sizes_list):
+
+ all_data.append(tensor[:size])
+
+ return torch.concat(all_data)
+
+
+@MODELS.register_module()
+class BlipRetrieval(BaseModel):
+ """BLIP Retriever.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features.
+ vision_neck (Optional[dict]): The neck module to process image features
+ from vision backbone. Defaults to None.
+ text_neck (Optional[dict]): The neck module to process text features
+ from text backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed single modality features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ multimodal_head (Optional[Union[List[dict], dict]]): The multi-modal
+ head module to calculate loss from processed multimodal features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ momentum (float): Momentum used for momentum contrast.
+ Defaults to .995.
+ negative_all_rank (bool): Whether to sample negative data from all
+ ranks for image text matching in training. Defaults to True.
+ temperature (float): Temperature parameter that controls the
+ concentration level of the distribution. Defaults to 0.07.
+ fast_match (bool): If False, select topk similarity as candidates and
+ compute the matching score. If True, return the similarity as the
+ matching score directly. Defaults to False.
+ topk (int): Select topk similarity as candidates for compute matching
+ scores. Notice that this is not the topk in evaluation.
+ Defaults to 256.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: dict,
+ multimodal_backbone: Optional[dict] = None,
+ vision_neck: Optional[dict] = None,
+ text_neck: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ multimodal_head: Optional[Union[List[dict], dict]] = None,
+ tokenizer: Optional[dict] = None,
+ momentum: float = .995,
+ negative_all_rank: bool = True,
+ temperature: float = 0.07,
+ fast_match: bool = False,
+ topk: int = 256,
+ max_txt_len: int = 20,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.text_backbone = MODELS.build(text_backbone)
+
+ if multimodal_backbone is not None:
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+
+ if vision_neck is not None:
+ self.vision_neck = MODELS.build(vision_neck)
+
+ if text_neck is not None:
+ self.text_neck = MODELS.build(text_neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+
+ if multimodal_head is not None:
+ self.multimodal_head = MODELS.build(multimodal_head)
+
+ if tokenizer is not None:
+ self.tokenizer = TOKENIZER.build(tokenizer)
+
+ self.momentum = momentum
+ self.negative_all_rank = negative_all_rank
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+ # Shares the same para
+ self.head.temp = self.temp
+
+ # create the momentum encoder
+ self.vision_backbone_m = deepcopy(self.vision_backbone)
+ self.text_backbone_m = deepcopy(self.text_backbone)
+
+ self.vision_neck_m = deepcopy(self.vision_neck)
+ self.text_neck_m = deepcopy(self.text_neck)
+
+ self.model_pairs = [
+ [self.vision_backbone, self.vision_backbone_m],
+ [self.text_backbone, self.text_backbone_m],
+ [self.vision_neck, self.vision_neck_m],
+ [self.text_neck, self.text_neck_m],
+ ]
+ self.copy_params()
+
+ # multimodal backone shares weights with text backbone in BLIP
+ # No need to set up
+
+ # Notice that this topk is used for select k candidate to compute
+ # image-text score, but not the final metric topk in evaluation.
+ self.fast_match = fast_match
+ self.topk = topk
+
+ self.max_txt_len = max_txt_len
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def preprocess_text(self, data_samples):
+ sample_item = data_samples[0]
+
+ if sample_item is not None and 'text' in sample_item:
+ if isinstance(sample_item.get('text'), (list, tuple)):
+ texts = []
+ for sample in data_samples:
+ texts.extend(sample.get('text'))
+ elif isinstance(sample_item.get('text'), str):
+ texts = [sample.get('text') for sample in data_samples]
+ else:
+ raise TypeError('text must be a string or a list of strings')
+ else:
+ return None
+
+ # perform tokenize first if satisfied conditions
+ texts = self.tokenizer(
+ texts,
+ padding='max_length',
+ truncation=True,
+ max_length=self.max_txt_len,
+ return_tensors='pt',
+ ).to(self.device)
+
+ return texts
+
+ def forward(self,
+ images: torch.tensor = None,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'tensor') -> Union[Tuple, dict]:
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "tensor", and "loss":
+
+ - "tensor": Forward the whole network and return tensor without any
+ post-processing, same as a common nn.Module.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ For unified "predict" mode in other mm repos. It is noticed that
+ image-text retrieval cannot perform batch prediction since it will go
+ through all the samples. A standard process of retrieval evaluation is
+ to extract and collect all feats, and then predict all samples.
+ Therefore the `predict` mode here is remained as a trigger
+ to inform use to choose the right configurations.
+
+ Args:
+ images (torch.Tensor): The input inputs tensor of shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'tensor'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="tensor"``, return a tuple.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'tensor':
+ return self.extract_feat(images, data_samples)
+ elif mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(
+ self,
+ images: torch.Tensor = None,
+ data_samples: List[DataSample] = None,
+ return_texts=True,
+ return_embeds=None,
+ ) -> Dict[str, torch.Tensor]:
+ """Extract features from the input dict.
+
+ Args:
+ images (tensor, optional): The images to extract features.
+ Defaults to None.
+ data_samples (list, optional): The data samples containing texts
+ to extract features. Defaults to None.
+ return_texts (bool): Whether to return the tokenized text and the
+ corresponding attention masks. Defaults to True.
+ return_embeds (bool): Whether to return the text embedding and
+ image embedding. Defaults to None, which means to use
+ ``self.fast_match``.
+
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ If multimodal_backbone is not exist, tuple of torch.Tensor
+ will be returned.
+ """
+ if data_samples is not None:
+ texts = self.preprocess_text(data_samples)
+ else:
+ texts = None
+
+ assert images is not None or texts is not None, \
+ 'At least single modality should be passed as inputs.'
+
+ results = {}
+ if texts is not None and return_texts:
+ results.update({
+ 'text_ids': texts.input_ids,
+ 'text_attn_mask': texts.attention_mask,
+ })
+
+ if return_embeds is None:
+ return_embeds = not self.fast_match
+
+ # extract image features
+ if images is not None:
+ output = self._extract_feat(images, modality='images')
+ results['image_feat'] = output['image_feat']
+ if return_embeds:
+ results['image_embeds'] = output['image_embeds']
+
+ # extract text features
+ if texts is not None:
+ output = self._extract_feat(texts, modality='texts')
+ results['text_feat'] = output['text_feat']
+ if return_embeds:
+ results['text_embeds'] = output['text_embeds']
+
+ return results
+
+ def _extract_feat(self, inputs: Union[torch.Tensor, dict],
+ modality: str) -> Tuple[torch.Tensor]:
+ """Extract features from the single modality.
+
+ Args:
+ inputs (Union[torch.Tensor, dict]): A batch of inputs.
+ For image, a tensor of shape (N, C, ...) in general.
+ For text, a dict of tokenized text inputs.
+ modality (str): Modality feature to be extracted. Only two
+ options are supported.
+
+ - ``images``: Only extract image features, mostly used for
+ inference.
+ - ``texts``: Only extract text features, mostly used for
+ inference.
+
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ """
+
+ if modality == 'images':
+ # extract image features
+ image_embeds = self.vision_backbone(inputs)[0]
+ image_feat = F.normalize(
+ self.vision_neck(image_embeds[:, 0, :]), dim=-1)
+ return {'image_embeds': image_embeds, 'image_feat': image_feat}
+ elif modality == 'texts':
+ # extract text features
+ text_output = self.text_backbone(
+ inputs.input_ids,
+ attention_mask=inputs.attention_mask,
+ token_type_ids=None,
+ return_dict=True,
+ mode='text',
+ )
+ text_embeds = text_output.last_hidden_state
+ text_feat = F.normalize(
+ self.text_neck(text_embeds[:, 0, :]), dim=-1)
+ return {'text_embeds': text_embeds, 'text_feat': text_feat}
+ else:
+ raise RuntimeError(f'Invalid modality "{modality}".')
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Dict[str, torch.tensor]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (dict): A batch of inputs. The input tensor with of
+ at least one modality. For image, the value is a tensor
+ of shape (N, C, ...) in general.
+ For text, the value is a dict of tokenized text inputs.
+ data_samples (Optional[List[DataSample]]):
+ The annotation data of every samples. Defaults to None.
+
+ Returns:
+ Dict[str, torch.tensor]: a dictionary of loss components of
+ both head and multimodal head.
+ """
+ output = self.extract_feat(images, data_samples, return_embeds=True)
+
+ text_ids = output['text_ids']
+ text_attn_mask = output['text_attn_mask']
+ image_embeds = output['image_embeds']
+ image_feat = output['image_feat']
+ text_feat = output['text_feat']
+
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ # get momentum features
+ with torch.no_grad():
+ self._momentum_update()
+ image_embeds_m = self.vision_backbone_m(images)[0]
+ image_feat_m = F.normalize(
+ self.vision_neck_m(image_embeds_m[:, 0, :]), dim=-1)
+
+ text_output_m = self.text_backbone_m(
+ text_ids,
+ attention_mask=text_attn_mask,
+ token_type_ids=None,
+ return_dict=True,
+ mode='text',
+ )
+ text_embeds_m = text_output_m.last_hidden_state
+ text_feat_m = F.normalize(
+ self.text_neck_m(text_embeds_m[:, 0, :]), dim=-1)
+
+ loss = self.head.loss(
+ ([image_feat, text_feat, image_feat_m, text_feat_m], ),
+ data_samples)
+
+ # prepare for itm
+ encoder_input_ids = text_ids.clone()
+ encoder_input_ids[:,
+ 0] = self.tokenizer.additional_special_tokens_ids[0]
+ output_pos = self.text_backbone(
+ encoder_input_ids,
+ attention_mask=text_attn_mask,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ idx = torch.tensor([i.image_id for i in data_samples]).view(-1, 1)
+ bs = idx.size(0)
+ idxs = torch.cat(dist.all_gather(idx))
+ if self.negative_all_rank:
+ # compute sample similarity
+ with torch.no_grad():
+ mask = torch.eq(idx, idxs.t()).to(self.device)
+
+ image_feat_world = torch.cat(dist.all_gather(image_feat))
+ text_feat_world = torch.cat(dist.all_gather(text_feat))
+
+ sim_i2t = image_feat @ text_feat_world.t() / self.temp
+ sim_t2i = text_feat @ image_feat_world.t() / self.temp
+
+ weights_i2t = F.softmax(sim_i2t, dim=1)
+ weights_i2t.masked_fill_(mask, 0)
+
+ weights_t2i = F.softmax(sim_t2i, dim=1)
+ weights_t2i.masked_fill_(mask, 0)
+
+ world_size = dist.get_world_size()
+ if world_size == 1:
+ image_embeds_world = image_embeds
+ else:
+ image_embeds_world = torch.cat(
+ torch_dist.nn.all_gather(image_embeds))
+
+ # select a negative image (from all ranks) for each text
+ image_embeds_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_t2i[b], 1).item()
+ image_embeds_neg.append(image_embeds_world[neg_idx])
+ image_embeds_neg = torch.stack(image_embeds_neg, dim=0)
+
+ # select a negative text (from all ranks) for each image
+ input_ids_world = torch.cat(dist.all_gather(encoder_input_ids))
+ att_mask_world = torch.cat(dist.all_gather(text_attn_mask))
+
+ text_ids_neg = []
+ text_atts_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_i2t[b], 1).item()
+ text_ids_neg.append(input_ids_world[neg_idx])
+ text_atts_neg.append(att_mask_world[neg_idx])
+
+ text_ids_neg = torch.stack(text_ids_neg, dim=0)
+ text_atts_neg = torch.stack(text_atts_neg, dim=0)
+
+ text_ids_all = torch.cat([encoder_input_ids, text_ids_neg], dim=0)
+ text_atts_all = torch.cat([text_attn_mask, text_atts_neg], dim=0)
+
+ image_embeds_all = torch.cat([image_embeds_neg, image_embeds], dim=0)
+ image_atts_all = torch.cat([image_atts, image_atts], dim=0)
+
+ output_neg = self.text_backbone(
+ text_ids_all,
+ attention_mask=text_atts_all,
+ encoder_hidden_states=image_embeds_all,
+ encoder_attention_mask=image_atts_all,
+ return_dict=True,
+ )
+
+ vl_embeddings = torch.cat(
+ [
+ output_pos.last_hidden_state[:, 0, :],
+ output_neg.last_hidden_state[:, 0, :],
+ ],
+ dim=0,
+ )
+
+ # create false data samples
+ data_samples.extend(
+ [DataSample(is_matched=False) for _ in range(2 * bs)])
+ loss_multimodal = self.multimodal_head.loss((vl_embeddings, ),
+ data_samples)
+
+ return dict(ChainMap(loss, loss_multimodal))
+
+ def predict(self, images, data_samples, cal_i2t=True, cal_t2i=True):
+ feats = self.extract_feat(images, data_samples)
+
+ return self.predict_all(
+ feats, data_samples, cal_i2t=cal_i2t, cal_t2i=cal_t2i)
+
+ def predict_all(self,
+ feats,
+ data_samples,
+ num_images=None,
+ num_texts=None,
+ cal_i2t=True,
+ cal_t2i=True):
+ text_ids = feats['text_ids']
+ text_ids[:, 0] = self.tokenizer.additional_special_tokens_ids[0]
+ text_attn_mask = feats['text_attn_mask']
+ image_embeds = feats.get('image_embeds', None)
+ image_feat = feats['image_feat']
+ text_feat = feats['text_feat']
+
+ num_images = num_images or image_feat.size(0)
+ num_texts = num_texts or text_feat.size(0)
+
+ if not self.fast_match:
+ image_embeds_all = all_gather_concat(image_embeds)[:num_images]
+ else:
+ image_embeds_all = None
+ image_feat_all = all_gather_concat(image_feat)[:num_images]
+ text_feat_all = all_gather_concat(text_feat)[:num_texts]
+ text_ids_all = all_gather_concat(text_ids)[:num_texts]
+ text_attn_mask_all = all_gather_concat(text_attn_mask)[:num_texts]
+
+ results = []
+ if cal_i2t:
+ result_i2t = self.compute_score_matrix_i2t(
+ image_feat,
+ image_embeds,
+ text_feat_all,
+ text_ids_all,
+ text_attn_mask_all,
+ )
+ results.append(
+ self._get_predictions(result_i2t, data_samples, mode='i2t'))
+ if cal_t2i:
+ result_t2i = self.compute_score_matrix_t2i(
+ image_feat_all,
+ image_embeds_all,
+ text_feat,
+ text_ids,
+ text_attn_mask,
+ )
+ results.append(
+ self._get_predictions(result_t2i, data_samples, mode='t2i'))
+ return tuple(results)
+
+ def compute_score_matrix_i2t(self, img_feats, img_embeds, text_feats,
+ text_ids, text_atts):
+ """Compare the score matrix for image-to-text retrieval. Every image
+ should compare to all the text features.
+
+ Args:
+ img_feats (torch.Tensor): The input img feats tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ img_embeds (torch.Tensor): The input img embeds tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ text_feats (torch.Tensor): The input text feats tensor with shape
+ (N, C). N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (N, C).
+ text_atts (torch.Tensor): The input tensor with shape (N, C).
+
+ Returns:
+ torch.Tensor: Score matrix of image-to-text retrieval.
+ """
+
+ # compute i2t sim matrix
+ sim_matrix_i2t = img_feats @ text_feats.t()
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_i2t = torch.full((img_feats.size(0), text_feats.size(0)),
+ -100.0).to(self.device)
+ for i in track_on_main_process(
+ range(img_feats.size(0)), 'Compute I2T scores...'):
+ sims = sim_matrix_i2t[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+
+ encoder_output = img_embeds[i].repeat(self.topk, 1, 1)
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ output = self.text_backbone(
+ text_ids[topk_idx],
+ attention_mask=text_atts[topk_idx],
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, 0, :], ))[:, 1]
+ score_matrix_i2t[i, topk_idx] = score + topk_sim
+
+ return score_matrix_i2t
+
+ def compute_score_matrix_t2i(self, img_feats, img_embeds, text_feats,
+ text_ids, text_atts):
+ """Compare the score matrix for text-to-image retrieval. Every text
+ should compare to all the image features.
+
+ Args:
+ img_feats (torch.Tensor): The input img feats tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ img_embeds (torch.Tensor): The input img embeds tensor with shape
+ (M, C). M stands for numbers of samples on a single GPU.
+ text_feats (torch.Tensor): The input text feats tensor with shape
+ (N, C). N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (M, C).
+ text_atts (torch.Tensor): The input tensor with shape (M, C).
+
+ Returns:
+ torch.Tensor: Score matrix of text-to-image retrieval.
+ """
+
+ # compute t2i sim matrix
+ sim_matrix_t2i = text_feats @ img_feats.t()
+ if self.fast_match:
+ return sim_matrix_t2i
+
+ score_matrix_t2i = torch.full((text_feats.size(0), img_feats.size(0)),
+ -100.0).to(self.device)
+ for i in track_on_main_process(
+ range(text_feats.size(0)), 'Compute T2I scores...'):
+ sims = sim_matrix_t2i[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+
+ encoder_output = img_embeds[topk_idx]
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ output = self.text_backbone(
+ text_ids[i].repeat(self.topk, 1),
+ attention_mask=text_atts[i].repeat(self.topk, 1),
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, 0, :], ))[:, 1]
+ score_matrix_t2i[i, topk_idx] = score + topk_sim
+
+ return score_matrix_t2i
+
+ def _get_predictions(self,
+ result: torch.Tensor,
+ data_samples: List[DataSample],
+ mode: str = 'i2t'):
+ """Post-process the output of retriever.
+
+ Args:
+ result (torch.Tensor): Score matrix of single retrieve,
+ either from image or text.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+ mode (str): Retrieve mode, either `i2t` for image to text, or `t2i`
+ text to image. Defaults to `i2t`.
+
+ Returns:
+ List[DataSample]: the raw data_samples with
+ the predicted results.
+ """
+
+ # create data sample if not exists
+ if data_samples is None:
+ data_samples = [DataSample() for _ in range(result.size(0))]
+ elif mode == 't2i':
+ # Process data samples to align with the num of texts.
+ new_data_samples = []
+ for sample in data_samples:
+ if isinstance(sample.text, (list, tuple)):
+ texts = sample.text
+ else:
+ texts = [sample.text]
+ for i, text in enumerate(texts):
+ new_sample = DataSample(text=text)
+ if 'gt_image_id' in sample:
+ new_sample.gt_label = sample.gt_image_id[i]
+ new_data_samples.append(new_sample)
+ assert len(new_data_samples) == result.size(0)
+ data_samples = new_data_samples
+ elif mode == 'i2t':
+ for sample in data_samples:
+ if 'gt_text_id' in sample:
+ sample.gt_label = sample.gt_text_id
+ else:
+ raise ValueError(f'Type {mode} is not supported.')
+
+ for data_sample, score in zip(data_samples, result):
+ idx = score.argmax(keepdim=True).detach()
+
+ data_sample.set_pred_score(score)
+ data_sample.set_pred_label(idx)
+ return data_samples
+
+ # TODO: add temperaily
+ @torch.no_grad()
+ def copy_params(self):
+ for model_pair in self.model_pairs:
+ for param, param_m in zip(model_pair[0].parameters(),
+ model_pair[1].parameters()):
+ param_m.data.copy_(param.data) # initialize
+ param_m.requires_grad = False # not update by gradient
+
+ @torch.no_grad()
+ def _momentum_update(self):
+ for model_pair in self.model_pairs:
+ for (name,
+ param), (name_m,
+ param_m) in zip(model_pair[0].named_parameters(),
+ model_pair[1].named_parameters()):
+ # hack to behave the same
+ if any([i in name for i in ['8', '9', '10', '11']
+ ]) and 'layers' in name and any(
+ [i in name for i in ['attn', 'ffn']]):
+ param_m.data = param.data
+ else:
+ param_m.data = param_m.data * self.momentum + \
+ param.data * (1.0 - self.momentum)
diff --git a/mmpretrain/models/multimodal/blip/blip_vqa.py b/mmpretrain/models/multimodal/blip/blip_vqa.py
new file mode 100644
index 00000000000..d0f4e5861b5
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/blip_vqa.py
@@ -0,0 +1,265 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional, Tuple, Union
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class BlipVQA(BaseModel):
+ """BLIP VQA.
+
+ Args:
+ tokenizer: (dict): The config for tokenizer.
+ vision_backbone (dict): Encoder for extracting image features.
+ multimodal_backbone (dict): Backbone for extracting
+ multi-modal features. We apply this part as VQA fusion module.
+ head (dict): The head module to calculate
+ loss from processed features.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ `MutimodalDataPreprocessor` as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ tokenizer: dict,
+ vision_backbone: dict,
+ multimodal_backbone: dict,
+ head: dict,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super(BlipVQA, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.vqa_head = MODELS.build(head)
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+
+ - "loss": For training. Forward and return a dict of losses according
+ to the given inputs and data samples. Note that this method doesn't
+ handle neither back propagation nor optimizer updating, which are
+ done in the :meth:`train_step`.
+ - "predict": For testing. Forward and return a list of data_sample that
+ contains pred_answer for each question.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation data of
+ every samples. Required when ``mode="loss"``. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ - If ``mode="predict"``, return a list of `DataSample`
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_feat(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract features from the input tensor with shape (N, C, ..).
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+
+ Returns:
+ visual_embeds (Tensor): The output features.
+ """
+ # extract visual feature
+ if images.ndim == 4:
+ visual_embeds = self.vision_backbone(images)[0]
+ elif images.ndim == 5:
+ # [batch, T, C, H, W] -> [batch * T, C, H, W]
+ bs = images.size(0)
+ images = images.reshape(-1, *images.shape[2:])
+ visual_embeds = self.vision_backbone(images)[0]
+ # [batch * num_segs, L, dim] -> [batch, num_segs * L, dim]
+ visual_embeds = visual_embeds.reshape(bs, -1,
+ *visual_embeds.shape[2:])
+ else:
+ raise ValueError(
+ f'Images with {images.ndim} dims is not supported.')
+ return visual_embeds
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Union[torch.Tensor, Tuple[torch.Tensor]]:
+ """generate train_loss from the input tensor and data_samples.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+ visual_embeds = self.extract_feat(images)
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ questions = []
+ for sample in data_samples:
+ questions.append(sample.get('question'))
+ questions = self.tokenizer(
+ questions, padding='longest', return_tensors='pt').to(self.device)
+
+ questions.input_ids[:, 0] = \
+ self.tokenizer.additional_special_tokens_ids[0]
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ questions.input_ids,
+ attention_mask=questions.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ # put answer from data_samples into tensor form
+ answer_raw_text = []
+ for sample in data_samples:
+ answer_raw_text.extend(sample.gt_answer)
+ answer = self.tokenizer(
+ answer_raw_text, padding='longest',
+ return_tensors='pt').to(self.device)
+ answer_targets = answer.input_ids.masked_fill(
+ answer.input_ids == self.tokenizer.pad_token_id, -100)
+ for sample in data_samples:
+ # follow BLIP setting, set answer_weight to 0.2 for VG dataset.
+ if not hasattr(sample, 'gt_answer_weight'):
+ sample.gt_answer_weight = torch.tensor([0.2])
+ else:
+ sample.gt_answer_weight = torch.tensor(sample.gt_answer_weight)
+ answer_weight = torch.cat(
+ [sample.gt_answer_weight for sample in data_samples],
+ dim=0).to(self.device)
+ answer_count = torch.tensor(
+ [len(sample.gt_answer) for sample in data_samples]).to(self.device)
+
+ question_states, question_atts = [], []
+ for b, n in enumerate(answer_count):
+ question_states += [multimodal_embeds.last_hidden_state[b]] * n
+ question_atts += [questions.attention_mask[b]] * n
+
+ question_states = torch.stack(question_states, dim=0).to(self.device)
+ question_atts = torch.stack(question_atts, dim=0).to(self.device)
+
+ head_feats = dict(
+ answer_input_ids=answer.input_ids,
+ answer_attention_mask=answer.attention_mask,
+ answer_weight=answer_weight,
+ answer_targets=answer_targets,
+ question_states=question_states,
+ question_atts=question_atts,
+ batch_size=len(data_samples),
+ )
+
+ losses = self.vqa_head.loss(head_feats)
+
+ return losses
+
+ def predict(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ):
+ """update data_samples that contain pred_answer for each question.
+
+ Args:
+ images (Tensor): A batch of images. The shape of it should be
+ (B, C, H, W) for images and (B, T, C, H, W) for videos.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ Dict[torch.Tensor]: The losses features.
+ """
+ visual_embeds = self.extract_feat(images)
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ questions = []
+ for sample in data_samples:
+ questions.append(sample.get('question'))
+ questions = self.tokenizer(
+ questions, padding='longest', return_tensors='pt').to(self.device)
+
+ questions.input_ids[:, 0] = \
+ self.tokenizer.additional_special_tokens_ids[0]
+
+ # multimodal fusion
+ multimodal_embeds = self.multimodal_backbone(
+ questions.input_ids,
+ attention_mask=questions.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ if self.vqa_head.inference_method == 'rank':
+ answer_candidates = self.tokenizer(
+ self.vqa_head.answer_list,
+ padding='longest',
+ return_tensors='pt').to(self.device)
+ answer_candidates.input_ids[:, 0] = self.tokenizer.bos_token_id
+ elif self.vqa_head.inference_method == 'generate':
+ answer_candidates = None
+
+ head_feats = dict(
+ multimodal_embeds=multimodal_embeds.last_hidden_state,
+ question_atts=questions.attention_mask,
+ answer_candidates=answer_candidates,
+ bos_token_id=self.tokenizer.bos_token_id,
+ sep_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ )
+
+ if self.vqa_head.inference_method == 'rank':
+ answers = self.vqa_head.predict(head_feats)
+ for answer, data_sample in zip(answers, data_samples):
+ data_sample.pred_answer = answer
+
+ elif self.vqa_head.inference_method == 'generate':
+ outputs = self.vqa_head.predict(head_feats)
+ for output, data_sample in zip(outputs, data_samples):
+ data_sample.pred_answer = self.tokenizer.decode(
+ output, skip_special_tokens=True)
+
+ return data_samples
diff --git a/mmpretrain/models/multimodal/blip/language_model.py b/mmpretrain/models/multimodal/blip/language_model.py
new file mode 100644
index 00000000000..48605a95f60
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip/language_model.py
@@ -0,0 +1,1320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+
+# flake8: noqa
+
+import math
+from typing import Tuple
+
+import torch
+import torch.nn as nn
+from torch import Tensor, device
+
+try:
+ from transformers.activations import ACT2FN
+ from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions)
+ from transformers.modeling_utils import (PreTrainedModel,
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ prune_linear_layer)
+ from transformers.models.bert.configuration_bert import BertConfig
+except:
+ ACT2FN = None
+ BaseModelOutputWithPastAndCrossAttentions = None
+ BaseModelOutputWithPoolingAndCrossAttentions = None
+ CausalLMOutputWithCrossAttentions = None
+ PreTrainedModel = None
+ apply_chunking_to_forward = None
+ find_pruneable_heads_and_indices = None
+ prune_linear_layer = None
+ BertConfig = None
+
+from mmpretrain.registry import MODELS
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word and position embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(
+ config.vocab_size,
+ config.hidden_size,
+ padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings,
+ config.hidden_size)
+
+ if config.add_type_embeddings:
+ self.token_type_embeddings = nn.Embedding(config.type_vocab_size,
+ config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ 'position_ids',
+ torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+
+ self.config = config
+
+ def forward(
+ self,
+ input_ids=None,
+ token_type_ids=None,
+ position_ids=None,
+ inputs_embeds=None,
+ past_key_values_length=0,
+ ):
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length:
+ seq_length +
+ past_key_values_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ if token_type_ids is not None:
+ token_type_embeddings = self.token_type_embeddings(token_type_ids)
+
+ embeddings = inputs_embeds + token_type_embeddings
+ else:
+ embeddings = inputs_embeds
+
+ if self.position_embedding_type == 'absolute':
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertPooler(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class BertPreTrainedModel(PreTrainedModel):
+ """An abstract class to handle weights initialization and a simple
+ interface for downloading and loading pretrained models."""
+
+ config_class = BertConfig
+ base_model_prefix = 'bert'
+ _keys_to_ignore_on_load_missing = [r'position_ids']
+
+ def _init_weights(self, module):
+ """Initialize the weights."""
+ if isinstance(module, (nn.Linear, nn.Embedding)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(
+ mean=0.0, std=self.config.initializer_range)
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+
+class BertSelfAttention(nn.Module):
+
+ def __init__(self, config, is_cross_attention):
+ super().__init__()
+ self.config = config
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(
+ config, 'embedding_size'):
+ raise ValueError(
+ 'The hidden size (%d) is not a multiple of the number of attention '
+ 'heads (%d)' %
+ (config.hidden_size, config.num_attention_heads))
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size /
+ config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ if is_cross_attention:
+ self.key = nn.Linear(config.encoder_width, self.all_head_size)
+ self.value = nn.Linear(config.encoder_width, self.all_head_size)
+ else:
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+ if (self.position_embedding_type == 'relative_key'
+ or self.position_embedding_type == 'relative_key_query'):
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(
+ 2 * config.max_position_embeddings - 1,
+ self.attention_head_size)
+ self.save_attention = False
+
+ def save_attn_gradients(self, attn_gradients):
+ self.attn_gradients = attn_gradients
+
+ def get_attn_gradients(self):
+ return self.attn_gradients
+
+ def save_attention_map(self, attention_map):
+ self.attention_map = attention_map
+
+ def get_attention_map(self):
+ return self.attention_map
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (
+ self.num_attention_heads,
+ self.attention_head_size,
+ )
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention:
+ key_layer = self.transpose_for_scores(
+ self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(
+ self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer,
+ key_layer.transpose(-1, -2))
+
+ if (self.position_embedding_type == 'relative_key'
+ or self.position_embedding_type == 'relative_key_query'):
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(
+ seq_length, dtype=torch.long,
+ device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(
+ seq_length, dtype=torch.long,
+ device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(
+ distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(
+ dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == 'relative_key':
+ relative_position_scores = torch.einsum(
+ 'bhld,lrd->bhlr', query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == 'relative_key_query':
+ relative_position_scores_query = torch.einsum(
+ 'bhld,lrd->bhlr', query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum(
+ 'bhrd,lrd->bhlr', key_layer, positional_embedding)
+ attention_scores = (
+ attention_scores + relative_position_scores_query +
+ relative_position_scores_key)
+
+ attention_scores = attention_scores / math.sqrt(
+ self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ if is_cross_attention and self.save_attention:
+ self.save_attention_map(attention_probs)
+ attention_probs.register_hook(self.save_attn_gradients)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs_dropped = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs_dropped = attention_probs_dropped * head_mask
+
+ context_layer = torch.matmul(attention_probs_dropped, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (
+ self.all_head_size, )
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = ((context_layer, attention_probs) if output_attentions else
+ (context_layer, ))
+
+ outputs = outputs + (past_key_value, )
+ return outputs
+
+
+class BertSelfOutput(nn.Module):
+
+ def __init__(self, config, twin=False, merge=False):
+ super().__init__()
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+ if twin:
+ self.dense0 = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dense1 = nn.Linear(config.hidden_size, config.hidden_size)
+ else:
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if merge:
+ self.act = ACT2FN[config.hidden_act]
+ self.merge_layer = nn.Linear(config.hidden_size * 2,
+ config.hidden_size)
+ self.merge = True
+ else:
+ self.merge = False
+
+ def forward(self, hidden_states, input_tensor):
+ if type(hidden_states) == list:
+ hidden_states0 = self.dense0(hidden_states[0])
+ hidden_states1 = self.dense1(hidden_states[1])
+ if self.merge:
+ hidden_states = self.merge_layer(
+ torch.cat([hidden_states0, hidden_states1], dim=-1))
+ else:
+ hidden_states = (hidden_states0 + hidden_states1) / 2
+ else:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertAttention(nn.Module):
+
+ def __init__(self, config, is_cross_attention=False, layer_num=-1):
+ super().__init__()
+ is_nlvr = is_cross_attention and getattr(config, 'nlvr', False)
+ if is_nlvr:
+ self.self0 = BertSelfAttention(config, is_nlvr)
+ self.self1 = BertSelfAttention(config, is_nlvr)
+ else:
+ self.self = BertSelfAttention(config, is_cross_attention)
+ self.output = BertSelfOutput(
+ config,
+ twin=is_nlvr,
+ merge=(is_nlvr and layer_num >= 6),
+ )
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads,
+ self.self.num_attention_heads,
+ self.self.attention_head_size,
+ self.pruned_heads,
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(
+ heads)
+ self.self.all_head_size = (
+ self.self.attention_head_size * self.self.num_attention_heads)
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ if type(encoder_hidden_states) == list:
+ self_outputs0 = self.self0(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states[0],
+ encoder_attention_mask[0],
+ past_key_value,
+ output_attentions,
+ )
+ self_outputs1 = self.self1(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states[1],
+ encoder_attention_mask[1],
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(
+ [self_outputs0[0], self_outputs1[0]], hidden_states)
+
+ outputs = (attention_output, ) + self_outputs0[
+ 1:] # add attentions if we output them
+ else:
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,
+ ) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertIntermediate(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class BertOutput(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertLayer(nn.Module):
+
+ def __init__(self, config, layer_num):
+ super().__init__()
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = BertAttention(config)
+ self.layer_num = layer_num
+
+ # compatibility for ALBEF and BLIP
+ try:
+ # ALBEF & ALPRO
+ fusion_layer = self.config.fusion_layer
+ add_cross_attention = (
+ fusion_layer <= layer_num and self.config.add_cross_attention)
+
+ self.fusion_layer = fusion_layer
+ except AttributeError:
+ # BLIP
+ self.fusion_layer = self.config.num_hidden_layers
+ add_cross_attention = self.config.add_cross_attention
+
+ # if self.config.add_cross_attention:
+ if self.config.add_cross_attention:
+ self.crossattention = BertAttention(
+ config,
+ is_cross_attention=self.config.add_cross_attention,
+ layer_num=layer_num,
+ )
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ mode=None,
+ ):
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = (
+ past_key_value[:2] if past_key_value is not None else None)
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+
+ # TODO line 482 in albef/models/xbert.py
+ # compatibility for ALBEF and BLIP
+ if mode in ['multimodal', 'fusion'] and hasattr(
+ self, 'crossattention'):
+ assert (
+ encoder_hidden_states is not None
+ ), 'encoder_hidden_states must be given for cross-attention layers'
+
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = (outputs + cross_attention_outputs[1:-1]
+ ) # add cross attentions if we output attention weights
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output,
+ )
+ outputs = (layer_output, ) + outputs
+
+ outputs = outputs + (present_key_value, )
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+class BertEncoder(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList(
+ [BertLayer(config, i) for i in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ mode='multimodal',
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = (() if output_attentions
+ and self.config.add_cross_attention else None)
+
+ next_decoder_cache = () if use_cache else None
+
+ try:
+ # ALBEF
+ fusion_layer = self.config.fusion_layer
+ except AttributeError:
+ # BLIP
+ fusion_layer = self.config.num_hidden_layers
+
+ if mode == 'text':
+ start_layer = 0
+ # output_layer = self.config.fusion_layer
+ output_layer = fusion_layer
+
+ elif mode == 'fusion':
+ # start_layer = self.config.fusion_layer
+ start_layer = fusion_layer
+ output_layer = self.config.num_hidden_layers
+
+ elif mode == 'multimodal':
+ start_layer = 0
+ output_layer = self.config.num_hidden_layers
+
+ # compatibility for ALBEF and BLIP
+ # for i in range(self.config.num_hidden_layers):
+ for i in range(start_layer, output_layer):
+ layer_module = self.layer[i]
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[
+ i] if past_key_values is not None else None
+
+ # TODO pay attention to this.
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ # TODO: logger here
+ # logger.warn(
+ # "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ # )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value,
+ output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ mode=mode,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ mode=mode,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1], )
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (
+ layer_outputs[1], )
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ] if v is not None)
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class BertPredictionHeadTransform(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if isinstance(config.hidden_act, str):
+ self.transform_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.transform_act_fn = config.hidden_act
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.transform_act_fn(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+
+class BertLMPredictionHead(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.transform = BertPredictionHeadTransform(config)
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = nn.Linear(
+ config.hidden_size, config.vocab_size, bias=False)
+
+ self.bias = nn.Parameter(torch.zeros(config.vocab_size))
+
+ # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
+ self.decoder.bias = self.bias
+
+ def forward(self, hidden_states):
+ hidden_states = self.transform(hidden_states)
+ hidden_states = self.decoder(hidden_states)
+ return hidden_states
+
+
+class BertOnlyMLMHead(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.predictions = BertLMPredictionHead(config)
+
+ def forward(self, sequence_output):
+ prediction_scores = self.predictions(sequence_output)
+ return prediction_scores
+
+
+@MODELS.register_module()
+class BertModel(BertPreTrainedModel):
+ """The model can behave as an encoder (with only self-attention) as well as
+ a decoder, in which case a layer of cross-attention is added between the
+ self-attention layers, following the architecture described in `Attention
+ is all you need `__ by Ashish Vaswani,
+ Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N.
+
+ Gomez, Lukasz Kaiser and Illia Polosukhin. argument and
+ :obj:`add_cross_attention` set to :obj:`True`; an
+ :obj:`encoder_hidden_states` is then expected as an input to the forward
+ pass.
+ """
+
+ def __init__(self, config, add_pooling_layer=True):
+ if not isinstance(config, BertConfig):
+ config = BertConfig.from_dict(config)
+
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = BertEmbeddings(config)
+
+ self.encoder = BertEncoder(config)
+
+ self.pooler = BertPooler(config) if add_pooling_layer else None
+
+ self.init_weights()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """Prunes heads of the model.
+
+ heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def get_extended_attention_mask(
+ self,
+ attention_mask: Tensor,
+ input_shape: Tuple[int],
+ device: device,
+ is_decoder: bool,
+ ) -> Tensor:
+ """Makes broadcastable attention and causal masks so that future and
+ masked tokens are ignored.
+
+ Arguments:
+ attention_mask (:obj:`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (:obj:`Tuple[int]`):
+ The shape of the input to the model.
+ device: (:obj:`torch.device`):
+ The device of the input to the model.
+
+ Returns:
+ :obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
+ """
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if is_decoder:
+ batch_size, seq_length = input_shape
+
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = (
+ seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <=
+ seq_ids[None, :, None])
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[
+ 1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones(
+ (batch_size, seq_length, prefix_seq_len),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = (
+ causal_mask[:, None, :, :] *
+ attention_mask[:, None, None, :])
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ 'Wrong shape for input_ids (shape {}) or attention_mask (shape {})'
+ .format(input_shape, attention_mask.shape))
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(
+ dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+ return extended_attention_mask
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ token_type_ids=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ is_decoder=False,
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ if is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both input_ids and inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ batch_size, seq_length = input_shape
+ device = input_ids.device
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = inputs_embeds.device
+ elif encoder_embeds is not None:
+ input_shape = encoder_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = encoder_embeds.device
+ else:
+ raise ValueError(
+ 'You have to specify either input_ids or inputs_embeds or encoder_embeds'
+ )
+
+ # past_key_values_length
+ past_key_values_length = (
+ past_key_values[0][0].shape[2]
+ if past_key_values is not None else 0)
+
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ ((batch_size, seq_length + past_key_values_length)),
+ device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(
+ attention_mask, input_shape, device, is_decoder)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if encoder_hidden_states is not None:
+ if type(encoder_hidden_states) == list:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[
+ 0].size()
+ else:
+ (
+ encoder_batch_size,
+ encoder_sequence_length,
+ _,
+ ) = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size,
+ encoder_sequence_length)
+
+ if type(encoder_attention_mask) == list:
+ encoder_extended_attention_mask = [
+ self.invert_attention_mask(mask)
+ for mask in encoder_attention_mask
+ ]
+ elif encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(
+ encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask,
+ self.config.num_hidden_layers)
+
+ if encoder_embeds is None:
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ token_type_ids=token_type_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+ else:
+ embedding_output = encoder_embeds
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ mode=mode,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = (
+ self.pooler(sequence_output) if self.pooler is not None else None)
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+class BaseEncoder(nn.Module):
+ """Base class for primitive encoders, such as ViT, TimeSformer, etc."""
+
+ def __init__(self):
+ super().__init__()
+
+ def forward_features(self, samples, **kwargs):
+ raise NotImplementedError
+
+ @property
+ def device(self):
+ return list(self.parameters())[0].device
+
+
+@MODELS.register_module()
+class XBertEncoder(BertModel, BaseEncoder):
+
+ def __init__(self, med_config, from_pretrained=False):
+
+ med_config = BertConfig.from_dict(med_config)
+ super().__init__(config=med_config, add_pooling_layer=False)
+
+ def forward_automask(self, tokenized_text, visual_embeds, **kwargs):
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ text = tokenized_text
+ text_output = super().forward(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ encoder_hidden_states=visual_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+
+ return text_output
+
+ def forward_text(self, tokenized_text, **kwargs):
+ text = tokenized_text
+ token_type_ids = kwargs.get('token_type_ids', None)
+
+ text_output = super().forward(
+ text.input_ids,
+ attention_mask=text.attention_mask,
+ token_type_ids=token_type_ids,
+ return_dict=True,
+ mode='text',
+ )
+
+ return text_output
+
+
+@MODELS.register_module()
+class Linear(torch.nn.Linear):
+ """Wrapper for linear function."""
+
+
+@MODELS.register_module()
+class BertLMHeadModel(BertPreTrainedModel):
+
+ _keys_to_ignore_on_load_unexpected = [r'pooler']
+ _keys_to_ignore_on_load_missing = [
+ r'position_ids', r'predictions.decoder.bias'
+ ]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.bert = BertModel(config, add_pooling_layer=False)
+ self.cls = BertOnlyMLMHead(config)
+
+ self.init_weights()
+
+ def get_output_embeddings(self):
+ return self.cls.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings):
+ self.cls.predictions.decoder = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ labels=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ return_logits=False,
+ is_decoder=True,
+ reduction='mean',
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
+ ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ Returns:
+ Example::
+ >>> from transformers import BertTokenizer,
+ BertLMHeadModel, BertConfig
+ >>> import torch
+ >>> tokenizer = BertTokenizer.from_pretrained(
+ 'bert-base-cased')
+ >>> config = BertConfig.from_pretrained(
+ "bert-base-cased")
+ >>> model = BertLMHeadModel.from_pretrained(
+ 'bert-base-cased', config=config)
+ >>> inputs = tokenizer(
+ "Hello, my dog is cute",
+ return_tensors="pt")
+ >>> outputs = model(**inputs)
+ >>> prediction_logits = outputs.logits
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+ if labels is not None:
+ use_cache = False
+
+ outputs = self.bert(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ is_decoder=is_decoder,
+ mode=mode,
+ )
+
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ if return_logits:
+ return prediction_scores[:, :-1, :].contiguous()
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :
+ -1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = torch.nn.CrossEntropyLoss(
+ reduction=reduction, label_smoothing=0.1)
+ lm_loss = loss_fct(
+ shifted_prediction_scores.view(-1, self.config.vocab_size),
+ labels.view(-1))
+ if reduction == 'none':
+ lm_loss = lm_loss.view(prediction_scores.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (prediction_scores, ) + outputs[2:]
+ return ((lm_loss, ) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ input_ids,
+ past=None,
+ attention_mask=None,
+ **model_kwargs):
+ input_shape = input_ids.shape
+ # if model is used as a decoder in encoder-decoder model,
+ # the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ 'input_ids':
+ input_ids,
+ 'attention_mask':
+ attention_mask,
+ 'past_key_values':
+ past,
+ 'encoder_hidden_states':
+ model_kwargs.get('encoder_hidden_states', None),
+ 'encoder_attention_mask':
+ model_kwargs.get('encoder_attention_mask', None),
+ 'is_decoder':
+ True,
+ }
+
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@MODELS.register_module()
+class XBertLMHeadDecoder(BertLMHeadModel):
+ """This class decouples the decoder forward logic from the VL model.
+
+ In this way, different VL models can share this decoder as long as they
+ feed encoder_embeds as required.
+ """
+
+ def __init__(self, med_config):
+ self.med_config = BertConfig.from_dict(med_config)
+ super(XBertLMHeadDecoder, self).__init__(config=self.med_config)
+
+ def generate_from_encoder(self,
+ tokenized_prompt,
+ visual_embeds,
+ sep_token_id,
+ pad_token_id,
+ use_nucleus_sampling=False,
+ num_beams=3,
+ max_length=30,
+ min_length=10,
+ top_p=0.9,
+ repetition_penalty=1.0,
+ **kwargs):
+
+ if not use_nucleus_sampling:
+ num_beams = num_beams
+ visual_embeds = visual_embeds.repeat_interleave(num_beams, dim=0)
+
+ image_atts = torch.ones(
+ visual_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ model_kwargs = {
+ 'encoder_hidden_states': visual_embeds,
+ 'encoder_attention_mask': image_atts,
+ }
+
+ if use_nucleus_sampling:
+ # nucleus sampling
+ outputs = self.generate(
+ input_ids=tokenized_prompt.input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ do_sample=True,
+ top_p=top_p,
+ num_return_sequences=1,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=1.1,
+ **model_kwargs)
+ else:
+ # beam search
+ outputs = self.generate(
+ input_ids=tokenized_prompt.input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ num_beams=num_beams,
+ eos_token_id=sep_token_id,
+ pad_token_id=pad_token_id,
+ repetition_penalty=repetition_penalty,
+ **model_kwargs)
+
+ return outputs
diff --git a/mmpretrain/models/multimodal/blip2/Qformer.py b/mmpretrain/models/multimodal/blip2/Qformer.py
new file mode 100644
index 00000000000..2b85f9ee660
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/Qformer.py
@@ -0,0 +1,772 @@
+# flake8: noqa
+"""
+ * Copyright (c) 2023, salesforce.com, inc.
+"""
+from typing import Tuple
+
+import torch
+import torch.utils.checkpoint
+from torch import Tensor, device, nn
+from torch.nn import CrossEntropyLoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions)
+from transformers.modeling_utils import apply_chunking_to_forward
+from transformers.models.bert.configuration_bert import BertConfig
+from transformers.utils import logging
+
+from mmpretrain.registry import MODELS
+from ..blip.language_model import (BertAttention, BertIntermediate,
+ BertOnlyMLMHead, BertOutput, BertPooler,
+ BertPreTrainedModel)
+
+logger = logging.get_logger(__name__)
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word and position embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(
+ config.vocab_size,
+ config.hidden_size,
+ padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings,
+ config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(
+ config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer(
+ 'position_ids',
+ torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config,
+ 'position_embedding_type',
+ 'absolute')
+
+ self.config = config
+
+ def forward(
+ self,
+ input_ids=None,
+ position_ids=None,
+ query_embeds=None,
+ past_key_values_length=0,
+ ):
+ if input_ids is not None:
+ seq_length = input_ids.size()[1]
+ else:
+ seq_length = 0
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length:
+ seq_length +
+ past_key_values_length].clone()
+
+ if input_ids is not None:
+ embeddings = self.word_embeddings(input_ids)
+ if self.position_embedding_type == 'absolute':
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings = embeddings + position_embeddings
+
+ if query_embeds is not None:
+ embeddings = torch.cat((query_embeds, embeddings), dim=1)
+ else:
+ embeddings = query_embeds
+
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertLayer(nn.Module):
+
+ def __init__(self, config, layer_num):
+ super().__init__()
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = BertAttention(config)
+ self.layer_num = layer_num
+ if (self.config.add_cross_attention
+ and layer_num % self.config.cross_attention_freq == 0):
+ self.crossattention = BertAttention(
+ config, is_cross_attention=self.config.add_cross_attention)
+ self.has_cross_attention = True
+ else:
+ self.has_cross_attention = False
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ self.intermediate_query = BertIntermediate(config)
+ self.output_query = BertOutput(config)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ query_length=0,
+ ):
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = (
+ past_key_value[:2] if past_key_value is not None else None)
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:-1]
+
+ present_key_value = self_attention_outputs[-1]
+
+ if query_length > 0:
+ query_attention_output = attention_output[:, :query_length, :]
+
+ if self.has_cross_attention:
+ assert (
+ encoder_hidden_states is not None
+ ), 'encoder_hidden_states must be given for cross-attention layers'
+ cross_attention_outputs = self.crossattention(
+ query_attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ output_attentions=output_attentions,
+ )
+ query_attention_output = cross_attention_outputs[0]
+ outputs = (
+ outputs + cross_attention_outputs[1:-1]
+ ) # add cross attentions if we output attention weights
+
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk_query,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ query_attention_output,
+ )
+ if attention_output.shape[1] > query_length:
+ layer_output_text = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output[:, query_length:, :],
+ )
+ layer_output = torch.cat([layer_output, layer_output_text],
+ dim=1)
+ else:
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk,
+ self.chunk_size_feed_forward,
+ self.seq_len_dim,
+ attention_output,
+ )
+ outputs = (layer_output, ) + outputs
+
+ outputs = outputs + (present_key_value, )
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+ def feed_forward_chunk_query(self, attention_output):
+ intermediate_output = self.intermediate_query(attention_output)
+ layer_output = self.output_query(intermediate_output, attention_output)
+ return layer_output
+
+
+class BertEncoder(nn.Module):
+
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList(
+ [BertLayer(config, i) for i in range(config.num_hidden_layers)])
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ query_length=0,
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = (() if output_attentions
+ and self.config.add_cross_attention else None)
+
+ next_decoder_cache = () if use_cache else None
+
+ for i in range(self.config.num_hidden_layers):
+ layer_module = self.layer[i]
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[
+ i] if past_key_values is not None else None
+
+ if getattr(self.config, 'gradient_checkpointing',
+ False) and self.training:
+
+ if use_cache:
+ logger.warn(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value,
+ output_attentions, query_length)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ query_length,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1], )
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (
+ layer_outputs[1], )
+ all_cross_attentions = all_cross_attentions + (
+ layer_outputs[2], )
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states, )
+
+ if not return_dict:
+ return tuple(v for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ] if v is not None)
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class BertModel(BertPreTrainedModel):
+ """The model can behave as an encoder (with only self-attention) as well as
+ a decoder, in which case a layer of cross-attention is added between the
+ self-attention layers, following the architecture described in `Attention
+ is all you need `__ by Ashish Vaswani,
+ Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N.
+
+ Gomez, Lukasz Kaiser and Illia Polosukhin. argument and
+ :obj:`add_cross_attention` set to :obj:`True`; an
+ :obj:`encoder_hidden_states` is then expected as an input to the forward
+ pass.
+ """
+
+ def __init__(self, config, add_pooling_layer=False):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = BertEmbeddings(config)
+
+ self.encoder = BertEncoder(config)
+
+ self.pooler = BertPooler(config) if add_pooling_layer else None
+
+ self.init_weights()
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """Prunes heads of the model.
+
+ heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ def get_extended_attention_mask(
+ self,
+ attention_mask: Tensor,
+ input_shape: Tuple[int],
+ device: device,
+ is_decoder: bool,
+ has_query: bool = False,
+ ) -> Tensor:
+ """Makes broadcastable attention and causal masks so that future and
+ masked tokens are ignored.
+
+ Arguments:
+ attention_mask (:obj:`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (:obj:`Tuple[int]`):
+ The shape of the input to the model.
+ device: (:obj:`torch.device`):
+ The device of the input to the model.
+
+ Returns:
+ :obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
+ """
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if is_decoder:
+ batch_size, seq_length = input_shape
+
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = (
+ seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <=
+ seq_ids[None, :, None])
+
+ # add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[
+ 1] - causal_mask.shape[1]
+ if has_query: # UniLM style attention mask
+ causal_mask = torch.cat(
+ [
+ torch.zeros(
+ (batch_size, prefix_seq_len, seq_length),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=1,
+ )
+ causal_mask = torch.cat(
+ [
+ torch.ones(
+ (batch_size, causal_mask.shape[1],
+ prefix_seq_len),
+ device=device,
+ dtype=causal_mask.dtype,
+ ),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+ extended_attention_mask = (
+ causal_mask[:, None, :, :] *
+ attention_mask[:, None, None, :])
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ 'Wrong shape for input_ids (shape {}) or attention_mask (shape {})'
+ .format(input_shape, attention_mask.shape))
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(
+ dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+ return extended_attention_mask
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ query_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ is_decoder=False,
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # use_cache = use_cache if use_cache is not None else self.config.use_cache
+ if input_ids is None:
+ assert (
+ query_embeds is not None
+ ), 'You have to specify query_embeds when input_ids is None'
+
+ # past_key_values_length
+ past_key_values_length = (
+ past_key_values[0][0].shape[2] -
+ self.config.query_length if past_key_values is not None else 0)
+
+ query_length = query_embeds.shape[1] if query_embeds is not None else 0
+
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ query_embeds=query_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+
+ input_shape = embedding_output.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = embedding_output.device
+
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ ((batch_size, seq_length + past_key_values_length)),
+ device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if is_decoder:
+ extended_attention_mask = self.get_extended_attention_mask(
+ attention_mask,
+ input_ids.shape,
+ device,
+ is_decoder,
+ has_query=(query_embeds is not None),
+ )
+ else:
+ extended_attention_mask = self.get_extended_attention_mask(
+ attention_mask, input_shape, device, is_decoder)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if encoder_hidden_states is not None:
+ if type(encoder_hidden_states) == list:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[
+ 0].size()
+ else:
+ (
+ encoder_batch_size,
+ encoder_sequence_length,
+ _,
+ ) = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size,
+ encoder_sequence_length)
+
+ if type(encoder_attention_mask) == list:
+ encoder_extended_attention_mask = [
+ self.invert_attention_mask(mask)
+ for mask in encoder_attention_mask
+ ]
+ elif encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(
+ encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(
+ encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask,
+ self.config.num_hidden_layers)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ query_length=query_length,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = (
+ self.pooler(sequence_output) if self.pooler is not None else None)
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+class BertLMHeadModel(BertPreTrainedModel):
+
+ _keys_to_ignore_on_load_unexpected = [r'pooler']
+ _keys_to_ignore_on_load_missing = [
+ r'position_ids', r'predictions.decoder.bias'
+ ]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.bert = BertModel(config, add_pooling_layer=False)
+ self.cls = BertOnlyMLMHead(config)
+
+ self.init_weights()
+
+ def get_output_embeddings(self):
+ return self.cls.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings):
+ self.cls.predictions.decoder = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ query_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ labels=None,
+ past_key_values=None,
+ use_cache=True,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ return_logits=False,
+ is_decoder=True,
+ reduction='mean',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
+ ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4
+ tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ Returns:
+ Example::
+ >>> from transformers import BertTokenizer, BertLMHeadModel, BertConfig
+ >>> import torch
+ >>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
+ >>> config = BertConfig.from_pretrained("bert-base-cased")
+ >>> model = BertLMHeadModel.from_pretrained('bert-base-cased', config=config)
+ >>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+ >>> outputs = model(**inputs)
+ >>> prediction_logits = outputs.logits
+ """
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+ if labels is not None:
+ use_cache = False
+ if past_key_values is not None:
+ query_embeds = None
+
+ outputs = self.bert(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ query_embeds=query_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ is_decoder=is_decoder,
+ )
+
+ sequence_output = outputs[0]
+ if query_embeds is not None:
+ sequence_output = outputs[0][:, query_embeds.shape[1]:, :]
+ prediction_scores = self.cls(sequence_output)
+
+ if return_logits:
+ return prediction_scores[:, :-1, :].contiguous()
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :
+ -1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = CrossEntropyLoss(
+ reduction=reduction, label_smoothing=0.1)
+ lm_loss = loss_fct(
+ shifted_prediction_scores.view(-1, self.config.vocab_size),
+ labels.view(-1),
+ )
+ if reduction == 'none':
+ lm_loss = lm_loss.view(prediction_scores.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (prediction_scores, ) + outputs[2:]
+ return ((lm_loss, ) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ input_ids,
+ query_embeds,
+ past=None,
+ attention_mask=None,
+ **model_kwargs):
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+ query_mask = input_ids.new_ones(query_embeds.shape[:-1])
+ attention_mask = torch.cat([query_mask, attention_mask], dim=-1)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ 'input_ids':
+ input_ids,
+ 'query_embeds':
+ query_embeds,
+ 'attention_mask':
+ attention_mask,
+ 'past_key_values':
+ past,
+ 'encoder_hidden_states':
+ model_kwargs.get('encoder_hidden_states', None),
+ 'encoder_attention_mask':
+ model_kwargs.get('encoder_attention_mask', None),
+ 'is_decoder':
+ True,
+ }
+
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+
+@MODELS.register_module()
+class Qformer(BertLMHeadModel):
+
+ def __init__(self, model_style: str, vision_model_width: int,
+ add_cross_attention: bool, cross_attention_freq: int,
+ num_query_token: int) -> None:
+
+ config = BertConfig.from_pretrained(model_style)
+ config.add_cross_attention = add_cross_attention
+ config.encoder_width = vision_model_width
+ config.cross_attention_freq = cross_attention_freq
+ config.query_length = num_query_token
+ super().__init__(config)
diff --git a/mmpretrain/models/multimodal/blip2/__init__.py b/mmpretrain/models/multimodal/blip2/__init__.py
new file mode 100644
index 00000000000..b5695f236ca
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .blip2_caption import Blip2Caption
+from .blip2_opt_vqa import Blip2VQA
+from .blip2_retriever import Blip2Retrieval
+from .modeling_opt import OPTForCausalLM
+from .Qformer import Qformer
+
+__all__ = [
+ 'Blip2Caption', 'Blip2Retrieval', 'Blip2VQA', 'OPTForCausalLM', 'Qformer'
+]
diff --git a/mmpretrain/models/multimodal/blip2/blip2_caption.py b/mmpretrain/models/multimodal/blip2/blip2_caption.py
new file mode 100644
index 00000000000..7b409b07acb
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_caption.py
@@ -0,0 +1,217 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+from torch import nn
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+
+
+@MODELS.register_module()
+class Blip2Caption(BaseModel):
+ """BLIP2 Caption.
+
+ Module for BLIP2 Caption task.
+
+ Args:
+ vision_backbone (dict): The config dict for vision backbone.
+ text_backbone (dict): The config dict for text backbone.
+ multimodal_backbone (dict): The config dict for multimodal backbone.
+ vision_neck (dict): The config dict for vision neck.
+ tokenizer: (Optional[dict]): The config for tokenizer.
+ Defaults to None.
+ prompt (str): Prompt used for training and eval.
+ Defaults to ''.
+ max_txt_len (int): Max text length of input text.
+ num_captions (int): Number of captions to be generated for each image.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type.
+ See :class:`MultiModalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+ _no_split_modules = ['BEiTViT', 'OPTDecoderLayer', 'BertLayer']
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: dict,
+ multimodal_backbone: dict,
+ vision_neck: dict,
+ tokenizer: Optional[dict] = None,
+ prompt: str = '',
+ max_txt_len: int = 20,
+ num_captions: int = 1,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ self.eos_token_id = self.tokenizer(
+ '\n', add_special_tokens=False).input_ids[0]
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.ln_vision_backbone = nn.LayerNorm(self.vision_backbone.embed_dims)
+
+ self.vision_neck = MODELS.build(vision_neck)
+
+ self.text_backbone = MODELS.build(text_backbone)
+
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.multimodal_backbone.cls = None
+ self.multimodal_backbone.bert.embeddings.word_embeddings = None
+ self.multimodal_backbone.bert.embeddings.position_embeddings = None
+ for layer in self.multimodal_backbone.bert.encoder.layer:
+ layer.output = None
+ layer.intermediate = None
+
+ self.prompt = prompt
+ self.max_txt_len = max_txt_len
+ self.num_captions = num_captions
+ prompt_tokens = self.tokenizer(prompt, return_tensors='pt')
+ self.prompt_length = prompt_tokens.attention_mask.sum(1)
+
+ self.query_tokens = nn.Parameter(
+ torch.zeros(1, self.multimodal_backbone.bert.config.query_length,
+ self.multimodal_backbone.bert.config.hidden_size))
+ self.query_tokens.data.normal_(
+ mean=0.0,
+ std=self.multimodal_backbone.bert.config.initializer_range)
+
+ # freeze the text backbone
+ for _, param in self.text_backbone.named_parameters():
+ param.requires_grad = False
+
+ if hasattr(self, 'register_load_state_dict_post_hook'):
+ self.register_load_state_dict_post_hook(self._ignore_llm_keys_hook)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List] = None,
+ mode: str = 'loss',
+ ) -> List[DataSample]:
+ """The unified entry for a forward process in both training and test.
+ The method should accept two modes: "predict" and "loss":
+
+ - "predict": Forward and return the predictions, which are fully
+ processed to a list of :obj:`DataSample`.
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): pre_processed img tensor (N, C, ...).
+ data_samples (List[DataSample], optional):
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ **kwargs) -> List[DataSample]:
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+
+ # extract image features from
+ image_embeds = self.ln_vision_backbone(self.vision_backbone(images)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1],
+ dtype=torch.long,
+ ).to(images.device)
+
+ # distill image features to query tokens
+ query_tokens = self.query_tokens.expand(image_embeds.size(0), -1, -1)
+ query_outputs = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+ inputs_opt = self.vision_neck([query_outputs.last_hidden_state])
+ attns_opt = torch.ones(
+ inputs_opt.size()[:-1], dtype=torch.long).to(images.device)
+
+ prompt = [self.prompt] * image_embeds.size(0)
+
+ opt_tokens = self.tokenizer(
+ prompt, return_tensors='pt').to(images.device)
+ input_ids = opt_tokens.input_ids
+ attention_mask = torch.cat([attns_opt, opt_tokens.attention_mask],
+ dim=1)
+
+ query_embeds = inputs_opt
+
+ outputs = self.text_backbone.generate(
+ input_ids=input_ids,
+ query_embeds=query_embeds,
+ attention_mask=attention_mask,
+ do_sample=False,
+ top_p=0.9,
+ temperature=1.,
+ num_beams=5,
+ max_new_tokens=self.max_txt_len,
+ min_length=1,
+ eos_token_id=self.eos_token_id,
+ repetition_penalty=1.0,
+ length_penalty=1.0,
+ num_return_sequences=self.num_captions,
+ )
+
+ output_text = self.tokenizer.batch_decode(
+ outputs[:, self.prompt_length:], skip_special_tokens=True)
+ output_text = [text.strip() for text in output_text]
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None for _ in range(len(output_text))]
+
+ for data_sample, decode_token in zip(data_samples, output_text):
+ if data_sample is None:
+ data_sample = DataSample()
+ data_sample.pred_caption = decode_token
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
+
+ @staticmethod
+ def _ignore_llm_keys_hook(module, incompatible_keys):
+ """Avoid warning missing keys of the LLM model."""
+ import re
+ llm_pattern = '^text_backbone'
+ for key in list(incompatible_keys.missing_keys):
+ if re.match(llm_pattern, key):
+ incompatible_keys.missing_keys.remove(key)
diff --git a/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py b/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py
new file mode 100644
index 00000000000..20e439fa826
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_opt_vqa.py
@@ -0,0 +1,92 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Optional
+
+import torch
+
+from mmpretrain.registry import MODELS
+from mmpretrain.structures import DataSample
+from .blip2_caption import Blip2Caption
+
+
+@MODELS.register_module()
+class Blip2VQA(Blip2Caption):
+ """BLIP2 VQA.
+
+ Module for BLIP2 VQA task. For more details about the initialization
+ params, please refer to :class:`Blip2Caption`.
+ """
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ **kwargs) -> List[DataSample]:
+ """Predict captions from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): The input tensor with shape
+ (N, C, ...) in general.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **kwargs: Other keyword arguments accepted by the ``predict``
+ method of :attr:`head`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ questions = [d.question for d in data_samples]
+
+ # extract image features from
+ image_embeds = self.ln_vision_backbone(self.vision_backbone(images)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1],
+ dtype=torch.long,
+ ).to(images.device)
+
+ # distill image features to query tokens
+ query_tokens = self.query_tokens.expand(image_embeds.size(0), -1, -1)
+ query_outputs = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ return_dict=True,
+ )
+ inputs_opt = self.vision_neck([query_outputs.last_hidden_state])
+ attns_opt = torch.ones(
+ inputs_opt.size()[:-1], dtype=torch.long).to(images.device)
+
+ prompt = [self.prompt.format(q) for q in questions]
+
+ # use left padding
+ self.tokenizer.padding_side = 'left'
+
+ opt_tokens = self.tokenizer(
+ prompt, return_tensors='pt', padding='longest').to(images.device)
+ input_ids = opt_tokens.input_ids
+ attention_mask = torch.cat([attns_opt, opt_tokens.attention_mask],
+ dim=1)
+
+ inputs_embeds = self.text_backbone.model.decoder.embed_tokens(
+ input_ids)
+ inputs_embeds = torch.cat([inputs_opt, inputs_embeds], dim=1)
+
+ outputs = self.text_backbone.generate(
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ do_sample=False,
+ num_beams=5,
+ max_new_tokens=self.max_txt_len,
+ min_length=1,
+ eos_token_id=self.eos_token_id,
+ length_penalty=-1.0,
+ )
+
+ output_text = self.tokenizer.batch_decode(
+ outputs, skip_special_tokens=True)
+ output_text = [text.strip() for text in output_text]
+
+ out_data_samples = []
+ for data_sample, decode_token in zip(data_samples, output_text):
+ data_sample.pred_answer = decode_token
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/blip2/blip2_retriever.py b/mmpretrain/models/multimodal/blip2/blip2_retriever.py
new file mode 100644
index 00000000000..e626404a4cd
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/blip2_retriever.py
@@ -0,0 +1,505 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Dict, List, Optional, Tuple, Union
+
+import mmengine.dist as dist
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmengine.utils import track_iter_progress
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from ..blip.blip_retrieval import BlipRetrieval, all_gather_concat
+
+
+@MODELS.register_module()
+class Blip2Retrieval(BlipRetrieval):
+ """BLIP2 Retriever.
+
+ Args:
+ vision_backbone (dict): Backbone for extracting image features.
+ text_backbone (dict): Backbone for extracting text features.
+ multimodal_backbone (Optional[dict]): Backbone for extracting
+ multi-modal features.
+ vision_neck (Optional[dict]): The neck module to process image features
+ from vision backbone. Defaults to None.
+ text_neck (Optional[dict]): The neck module to process text features
+ from text backbone. Defaults to None.
+ head (Optional[Union[List[dict], dict]]): The head module to calculate
+ loss from processed single modality features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ multimodal_head (Optional[Union[List[dict], dict]]): The multi-modal
+ head module to calculate loss from processed multimodal features.
+ See :mod:`mmmultimodal.models.heads`.
+ Notice that if the head is not set, `loss` method cannot be used.
+ Defaults to None.
+ tokenizer (Optional[dict]): The config for tokenizer. Defaults to None.
+ temperature (float): Temperature parameter that controls the
+ concentration level of the distribution. Defaults to 0.07.
+ fast_match (bool): If False, select topk similarity as candidates and
+ compute the matching score. If True, return the similarity as the
+ matching score directly. Defaults to False.
+ topk (int): Select topk similarity as candidates for compute matching
+ scores. Notice that this is not the topk in evaluation.
+ Defaults to 256.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type.
+ See :class:`MultiModalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (Optional[dict]): the config to control the initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ vision_backbone: dict,
+ text_backbone: Optional[dict] = None,
+ multimodal_backbone: Optional[dict] = None,
+ vision_neck: Optional[dict] = None,
+ text_neck: Optional[dict] = None,
+ head: Optional[Union[List[dict], dict]] = None,
+ multimodal_head: Optional[Union[List[dict], dict]] = None,
+ tokenizer: Optional[dict] = None,
+ temperature: float = 0.07,
+ fast_match: bool = False,
+ topk: int = 256,
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None) -> None:
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ # Skip BlipRetrieval init
+ super(BlipRetrieval, self).__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ self.vision_backbone = MODELS.build(vision_backbone)
+ self.ln_vision_backbone = nn.LayerNorm(self.vision_backbone.embed_dims)
+ self.tokenizer = TOKENIZER.build(tokenizer)
+
+ if text_backbone is not None:
+ self.text_backbone = MODELS.build(text_backbone)
+
+ if multimodal_backbone is not None:
+ self.multimodal_backbone = MODELS.build(multimodal_backbone)
+ self.multimodal_backbone.resize_token_embeddings(
+ len(self.tokenizer))
+ self.query_tokens = nn.Parameter(
+ torch.zeros(1, self.multimodal_backbone.bert.config.query_length,
+ self.multimodal_backbone.bert.config.hidden_size))
+ self.query_tokens.data.normal_(
+ mean=0.0,
+ std=self.multimodal_backbone.bert.config.initializer_range)
+
+ if vision_neck is not None:
+ self.vision_neck = MODELS.build(vision_neck)
+
+ if text_neck is not None:
+ self.text_neck = MODELS.build(text_neck)
+
+ if head is not None:
+ self.head = MODELS.build(head)
+
+ if multimodal_head is not None:
+ self.multimodal_head = MODELS.build(multimodal_head)
+
+ self.temp = nn.Parameter(temperature * torch.ones([]))
+
+ # Notice that this topk is used for select k candidate to compute
+ # image-text score, but not the final metric topk in evaluation.
+ self.fast_match = fast_match
+ self.topk = topk
+
+ def _extract_feat(self, inputs: Union[torch.Tensor, dict],
+ modality: str) -> Tuple[torch.Tensor]:
+ """Extract features from the single modality.
+ Args:
+ inputs (Union[torch.Tensor, dict]): A batch of inputs.
+ For image, a tensor of shape (N, C, ...) in general.
+ For text, a dict of tokenized text inputs.
+ modality (str): Modality feature to be extracted. Only two
+ options are supported.
+
+ - ``images``: Only extract image features, mostly used for
+ inference.
+ - ``texts``: Only extract text features, mostly used for
+ inference.
+ Returns:
+ Tuple[torch.Tensor]: The output features.
+ """
+ if modality == 'images':
+ # extract image features
+ # TODO:
+ # Add layernorm inside backbone and handle the concat outside
+ image_embeds = self.ln_vision_backbone(
+ self.vision_backbone(inputs)[0])
+ image_atts = torch.ones(
+ image_embeds.size()[:-1], dtype=torch.long).to(self.device)
+
+ query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1,
+ -1)
+ query_output = self.multimodal_backbone.bert(
+ query_embeds=query_tokens,
+ encoder_hidden_states=image_embeds,
+ encoder_attention_mask=image_atts,
+ use_cache=True,
+ return_dict=True,
+ )
+ image_feat = F.normalize(
+ self.vision_neck([query_output.last_hidden_state]), dim=-1)
+ return {
+ 'image_embeds': image_embeds,
+ 'image_feat': image_feat,
+ 'query_output': query_output
+ }
+ elif modality == 'texts':
+ # extract text features
+ text_output = self.multimodal_backbone.bert(
+ inputs.input_ids,
+ attention_mask=inputs.attention_mask,
+ return_dict=True,
+ )
+ text_embeds = text_output.last_hidden_state
+ text_feat = F.normalize(
+ self.text_neck([text_embeds[:, 0, :]]), dim=-1)
+ return {'text_embeds': text_embeds, 'text_feat': text_feat}
+ else:
+ raise RuntimeError(f'Invalid modality "{modality}".')
+
+ def loss(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ ) -> Dict[str, torch.tensor]:
+ """Calculate losses from a batch of inputs and data samples.
+
+ Args:
+ inputs (dict): A batch of inputs. The input tensor with of
+ at least one modality. For image, the value is a tensor
+ of shape (N, C, ...) in general.
+ For text, the value is a dict of tokenized text inputs.
+ data_samples (Optional[List[DataSample]]):
+ The annotation data of every samples. Defaults to None.
+
+ Returns:
+ Dict[str, torch.tensor]: a dictionary of loss components of
+ both head and multimodal head.
+ """
+ output = self.extract_feat(images, data_samples)
+
+ text_ids = output['text_ids']
+ text_attn_mask = output['text_attn_mask']
+ image_embeds = output['image_embeds']
+ image_feat = output['image_feat']
+ text_feat = output['text_feat']
+ query_output = output['query_output']
+
+ # ITC Loss
+ # B*world_size, num_query, D
+ image_feat_all = torch.cat(dist.all_gather(image_feat))
+ # B*world_size, D
+ text_feat_all = torch.cat(dist.all_gather(text_feat))
+
+ # B, B*world_size, num_query
+ sim_q2t = torch.matmul(
+ image_feat.unsqueeze(1), text_feat_all.unsqueeze(-1)).squeeze()
+
+ # image to text similarity
+ sim_i2t, _ = sim_q2t.max(-1)
+ sim_i2t = sim_i2t / self.temp
+
+ # B, B*world_size, num_query
+ sim_t2q = torch.matmul(
+ text_feat.unsqueeze(1).unsqueeze(1),
+ image_feat_all.permute(0, 2, 1)).squeeze()
+
+ # text-image similarity
+ sim_t2i, _ = sim_t2q.max(-1)
+ sim_t2i = sim_t2i / self.temp
+
+ rank = dist.get_rank()
+ bs = images.size(0)
+ targets = torch.linspace(
+ rank * bs, rank * bs + bs - 1, bs, dtype=int).to(self.device)
+
+ itc_loss = (F.cross_entropy(sim_i2t, targets, label_smoothing=0.1) +
+ F.cross_entropy(sim_t2i, targets, label_smoothing=0.1)) / 2
+
+ # prepare for itm
+ text_input_ids_world = torch.cat(dist.all_gather(text_ids))
+ text_attention_mask_world = torch.cat(dist.all_gather(text_attn_mask))
+ image_embeds_world = torch.cat(dist.all_gather(image_embeds))
+ with torch.no_grad():
+ weights_t2i = F.softmax(sim_t2i, dim=1) + 1e-4
+ weights_t2i[:, rank * bs:rank * bs + bs].fill_diagonal_(0)
+ weights_i2t = F.softmax(sim_i2t, dim=1) + 1e-4
+ weights_i2t[:, rank * bs:rank * bs + bs].fill_diagonal_(0)
+
+ # select a negative image for each text
+ image_embeds_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_t2i[b], 1).item()
+ image_embeds_neg.append(image_embeds_world[neg_idx])
+ image_embeds_neg = torch.stack(image_embeds_neg, dim=0)
+
+ # select a negative text for each image
+ text_ids_neg = []
+ text_atts_neg = []
+ for b in range(bs):
+ neg_idx = torch.multinomial(weights_i2t[b], 1).item()
+ text_ids_neg.append(text_input_ids_world[neg_idx])
+ text_atts_neg.append(text_attention_mask_world[neg_idx])
+
+ text_ids_neg = torch.stack(text_ids_neg, dim=0)
+ text_atts_neg = torch.stack(text_atts_neg, dim=0)
+
+ text_ids_all = torch.cat([text_ids, text_ids, text_ids_neg],
+ dim=0) # pos, pos, neg
+ text_atts_all = torch.cat(
+ [text_attn_mask, text_attn_mask, text_atts_neg],
+ dim=0,
+ )
+
+ query_tokens_itm = self.query_tokens.expand(text_ids_all.shape[0], -1,
+ -1)
+ query_atts_itm = torch.ones(
+ query_tokens_itm.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask_all = torch.cat([query_atts_itm, text_atts_all], dim=1)
+
+ image_embeds_all = torch.cat(
+ [image_embeds, image_embeds_neg, image_embeds],
+ dim=0) # pos, neg, pos
+ image_atts_all = torch.ones(
+ image_embeds_all.size()[:-1], dtype=torch.long).to(self.device)
+
+ output_itm = self.multimodal_backbone.bert(
+ text_ids_all,
+ query_embeds=query_tokens_itm,
+ attention_mask=attention_mask_all,
+ encoder_hidden_states=image_embeds_all,
+ encoder_attention_mask=image_atts_all,
+ return_dict=True,
+ )
+
+ vl_embeddings = output_itm.last_hidden_state[:, :query_tokens_itm.
+ size(1), :]
+
+ # create false data samples
+ data_samples.extend(
+ [DataSample(is_matched=False) for _ in range(2 * bs)])
+ loss_multimodal = self.multimodal_head.loss((vl_embeddings, ),
+ data_samples)
+
+ # LM loss
+ decoder_input_ids = text_ids.clone()
+ decoder_input_ids[:, 0] = self.tokenizer.bos_token_id
+ labels = decoder_input_ids.masked_fill(
+ decoder_input_ids == self.tokenizer.pad_token_id, -100)
+
+ query_tokens = self.query_tokens.expand(image_embeds.shape[0], -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat([query_atts, text_attn_mask], dim=1)
+ lm_output = self.multimodal_backbone(
+ decoder_input_ids,
+ attention_mask=attention_mask,
+ past_key_values=query_output.past_key_values,
+ return_dict=True,
+ labels=labels,
+ )
+
+ return dict(
+ itc_loss=itc_loss, **loss_multimodal, lm_loss=lm_output.loss)
+
+ def predict_all(self,
+ feats: Dict[str, torch.Tensor],
+ data_samples: List[DataSample],
+ num_images: int = None,
+ num_texts: int = None,
+ cal_i2t: bool = True,
+ cal_t2i: bool = True) -> Tuple[torch.Tensor, torch.Tensor]:
+ """Compute similarity matrix between images and texts across all ranks.
+
+ Args:
+ feats (Dict[str, torch.Tensor]): Features from the current rank.
+ data_samples (List[DataSample]): Data samples from the current
+ rank.
+ num_images (int, optional): Number of images to use.
+ Defaults to None.
+ num_texts (int, optional): Number of texts to use.
+ Defaults to None.
+ cal_i2t (bool, optional): Whether to compute image-to-text
+ similarity. Defaults to True.
+ cal_t2i (bool, optional): Whether to compute text-to-image
+ similarity. Defaults to True.
+
+ Returns:
+ Tuple[torch.Tensor, torch.Tensor]: Image-to-text and text-to-image
+ similarity matrices.
+ """
+ text_ids = feats['text_ids']
+ text_attn_mask = feats['text_attn_mask']
+ image_embeds = feats.get('image_embeds', None)
+ image_feat = feats['image_feat']
+ text_feat = feats['text_feat']
+
+ num_images = num_images or image_feat.size(0)
+ num_texts = num_texts or text_feat.size(0)
+
+ if not self.fast_match:
+ image_embeds_all = all_gather_concat(image_embeds)[:num_images]
+ else:
+ image_embeds_all = None
+ image_feat_all = all_gather_concat(image_feat)[:num_images]
+ text_feat_all = all_gather_concat(text_feat)[:num_texts]
+ text_ids_all = all_gather_concat(text_ids)[:num_texts]
+ text_attn_mask_all = all_gather_concat(text_attn_mask)[:num_texts]
+
+ results = []
+ if cal_i2t:
+ result_i2t = self.compute_score_matrix_i2t(
+ image_feat,
+ image_embeds,
+ text_feat_all,
+ text_ids_all,
+ text_attn_mask_all,
+ )
+ results.append(
+ self._get_predictions(result_i2t, data_samples, mode='i2t'))
+ if cal_t2i:
+ result_t2i = self.compute_score_matrix_t2i(
+ image_feat_all,
+ image_embeds_all,
+ text_feat,
+ text_ids,
+ text_attn_mask,
+ )
+ results.append(
+ self._get_predictions(result_t2i, data_samples, mode='t2i'))
+ return tuple(results)
+
+ def compute_score_matrix_i2t(self, img_feats: torch.Tensor,
+ img_embeds: List[torch.Tensor],
+ text_feats: torch.Tensor,
+ text_ids: torch.Tensor,
+ text_atts: torch.Tensor) -> torch.Tensor:
+ """Compare the score matrix for image-to-text retrieval. Every image
+ should compare to all the text features.
+
+ Args:
+ img_feats (torch.Tensor): The input tensor with shape (M, C).
+ M stands for numbers of samples on a single GPU.
+ img_embeds (List[torch.Tensor]): Image features from each layer of
+ the vision backbone.
+ text_feats (torch.Tensor): The input tensor with shape (N, C).
+ N stands for numbers of all samples on all GPUs.
+ text_ids (torch.Tensor): The input tensor with shape (N, C).
+ text_atts (torch.Tensor): The input tensor with shape (N, C).
+
+ Returns:
+ torch.Tensor: Score matrix of image-to-text retrieval.
+ """
+
+ # compute i2t sim matrix
+ # TODO: check correctness
+ sim_matrix_i2t, _ = (img_feats @ text_feats.t()).max(1)
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_i2t = torch.full((img_feats.size(0), text_feats.size(0)),
+ -100.0).to(self.device)
+
+ for i in track_iter_progress(range(img_feats.size(0))):
+ sims = sim_matrix_i2t[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+ # get repeated image embeddings
+ encoder_output = img_embeds[i].repeat(self.topk, 1, 1)
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ # query embeds and attention masks
+ query_tokens = self.query_tokens.expand(encoder_output.shape[0],
+ -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat([query_atts, text_atts[topk_idx]],
+ dim=1)
+ output = self.multimodal_backbone.bert(
+ text_ids[topk_idx],
+ query_embeds=query_tokens,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, :query_tokens.size(1), :],
+ ))[:, :, 1].mean(dim=1)
+ score_matrix_i2t[i, topk_idx] = score + topk_sim
+
+ return score_matrix_i2t
+
+ def compute_score_matrix_t2i(self, img_feats: torch.Tensor,
+ img_embeds: List[torch.Tensor],
+ text_feats: torch.Tensor,
+ text_ids: torch.Tensor,
+ text_atts: torch.Tensor) -> torch.Tensor:
+ """Compare the score matrix for text-to-image retrieval.
+
+ Every text should compare to all the image features.
+
+ Args:
+ img_feats (torch.Tensor): The input tensor with shape (N, C).
+ N stands for numbers of all samples on all GPUs.
+ img_embeds (List[torch.Tensor]): Image features from each layer of
+ the vision backbone.
+ text_feats (torch.Tensor): The input tensor with shape (M, C).
+ M stands for numbers of samples on a single GPU.
+ text_ids (torch.Tensor): The input tensor with shape (M, C).
+ text_atts (torch.Tensor): The input tensor with shape (M, C).
+
+ Returns:
+ torch.Tensor: Score matrix of text-to-image retrieval.
+ """
+
+ # compute t2i sim matrix
+ # TODO: check correctness
+ sim_matrix_i2t, _ = (img_feats @ text_feats.t()).max(1)
+ sim_matrix_t2i = sim_matrix_i2t.t()
+ if self.fast_match:
+ return sim_matrix_i2t
+
+ score_matrix_t2i = torch.full((text_feats.size(0), img_feats.size(0)),
+ -100.0).to(self.device)
+
+ for i in track_iter_progress(range(text_feats.size(0))):
+ sims = sim_matrix_t2i[i]
+ topk_sim, topk_idx = sims.topk(k=self.topk, dim=0)
+ # get topk image embeddings
+ encoder_output = img_embeds[topk_idx]
+ encoder_att = torch.ones(
+ encoder_output.size()[:-1], dtype=torch.long).to(self.device)
+ # get query embeds and attention masks
+ query_tokens = self.query_tokens.expand(encoder_output.shape[0],
+ -1, -1)
+ query_atts = torch.ones(
+ query_tokens.size()[:-1], dtype=torch.long).to(self.device)
+ attention_mask = torch.cat(
+ [query_atts, text_atts[i].repeat(self.topk, 1)], dim=1)
+ output = self.multimodal_backbone.bert(
+ text_ids[i].repeat(self.topk, 1),
+ query_embeds=query_tokens,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_output,
+ encoder_attention_mask=encoder_att,
+ return_dict=True,
+ )
+ score = self.multimodal_head(
+ (output.last_hidden_state[:, :query_tokens.size(1), :],
+ ))[:, :, 1].mean(dim=1)
+ score_matrix_t2i[i, topk_idx] = score + topk_sim
+
+ return score_matrix_t2i
diff --git a/mmpretrain/models/multimodal/blip2/modeling_opt.py b/mmpretrain/models/multimodal/blip2/modeling_opt.py
new file mode 100644
index 00000000000..7cde0d76a20
--- /dev/null
+++ b/mmpretrain/models/multimodal/blip2/modeling_opt.py
@@ -0,0 +1,1083 @@
+# flake8: noqa
+# Copyright 2022 The Fairseq Authors and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch OPT model."""
+import random
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import (BaseModelOutputWithPast,
+ CausalLMOutputWithPast)
+from transformers.modeling_utils import PreTrainedModel
+from transformers.models.opt.configuration_opt import OPTConfig
+from transformers.utils import (add_code_sample_docstrings,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward, logging,
+ replace_return_docstrings)
+
+from mmpretrain.models.utils import register_hf_model
+
+logger = logging.get_logger(__name__)
+
+_CHECKPOINT_FOR_DOC = 'facebook/opt-350m'
+_CONFIG_FOR_DOC = 'OPTConfig'
+_TOKENIZER_FOR_DOC = 'GPT2Tokenizer'
+
+# Base model docstring
+_EXPECTED_OUTPUT_SHAPE = [1, 8, 1024]
+
+OPT_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ 'facebook/opt-125m',
+ 'facebook/opt-350m',
+ 'facebook/opt-1.3b',
+ 'facebook/opt-2.7b',
+ 'facebook/opt-6.7b',
+ 'facebook/opt-13b',
+ 'facebook/opt-30b',
+ # See all OPT models at https://huggingface.co/models?filter=opt
+]
+
+
+def _make_causal_mask(input_ids_shape: torch.Size,
+ dtype: torch.dtype,
+ past_key_values_length: int = 0):
+ """Make causal mask used for bi-directional self-attention."""
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min))
+ mask_cond = torch.arange(mask.size(-1))
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat(
+ [torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask],
+ dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len,
+ tgt_len + past_key_values_length)
+
+
+def _expand_mask(mask: torch.Tensor,
+ dtype: torch.dtype,
+ tgt_len: Optional[int] = None):
+ """Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len,
+ src_seq_len]`."""
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len,
+ src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(
+ inverted_mask.to(torch.bool),
+ torch.finfo(dtype).min)
+
+
+class OPTLearnedPositionalEmbedding(nn.Embedding):
+ """This module learns positional embeddings up to a fixed maximum size."""
+
+ def __init__(self, num_embeddings: int, embedding_dim: int):
+ # OPT is set up so that if padding_idx is specified then offset the embedding ids by 2
+ # and adjust num_embeddings appropriately. Other models don't have this hack
+ self.offset = 2
+ super().__init__(num_embeddings + self.offset, embedding_dim)
+
+ def forward(self,
+ attention_mask: torch.LongTensor,
+ past_key_values_length: int = 0):
+ """`input_ids_shape` is expected to be [bsz x seqlen]."""
+ attention_mask = attention_mask.long()
+
+ # create positions depending on attention_mask
+ positions = (
+ torch.cumsum(attention_mask, dim=1).type_as(attention_mask) *
+ attention_mask).long() - 1
+
+ # cut positions if `past_key_values_length` is > 0
+ positions = positions[:, past_key_values_length:]
+
+ return super().forward(positions + self.offset)
+
+
+class OPTAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper."""
+
+ def __init__(
+ self,
+ embed_dim: int,
+ num_heads: int,
+ dropout: float = 0.0,
+ is_decoder: bool = False,
+ bias: bool = True,
+ ):
+ super().__init__()
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.dropout = dropout
+ self.head_dim = embed_dim // num_heads
+
+ if (self.head_dim * num_heads) != self.embed_dim:
+ raise ValueError(
+ f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim}'
+ f' and `num_heads`: {num_heads}).')
+ self.scaling = self.head_dim**-0.5
+ self.is_decoder = is_decoder
+
+ self.k_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.v_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.q_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+ self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return (tensor.view(bsz, seq_len, self.num_heads,
+ self.head_dim).transpose(1, 2).contiguous())
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor],
+ Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel."""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get query proj
+ query_states = self.q_proj(hidden_states) * self.scaling
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self._shape(self.k_proj(key_value_states), -1, bsz)
+ value_states = self._shape(self.v_proj(key_value_states), -1, bsz)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+ else:
+ # self_attention
+ key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
+ value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ proj_shape = (bsz * self.num_heads, -1, self.head_dim)
+ query_states = self._shape(query_states, tgt_len,
+ bsz).view(*proj_shape)
+ key_states = key_states.view(*proj_shape)
+ value_states = value_states.view(*proj_shape)
+
+ src_len = key_states.size(1)
+ attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
+
+ if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
+ raise ValueError(
+ f'Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is'
+ f' {attn_weights.size()}')
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f'Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}'
+ )
+ attn_weights = (
+ attn_weights.view(bsz, self.num_heads, tgt_len, src_len) +
+ attention_mask)
+ attn_weights = torch.max(
+ attn_weights,
+ torch.tensor(torch.finfo(attn_weights.dtype).min))
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len,
+ src_len)
+
+ # upcast to fp32 if the weights are in fp16. Please see https://github.com/huggingface/transformers/pull/17437
+ if attn_weights.dtype == torch.float16:
+ attn_weights = nn.functional.softmax(
+ attn_weights, dim=-1, dtype=torch.float32).to(torch.float16)
+ else:
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1)
+
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads, ):
+ raise ValueError(
+ f'Head mask for a single layer should be of size {(self.num_heads,)}, but is'
+ f' {layer_head_mask.size()}')
+ attn_weights = layer_head_mask.view(
+ 1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len,
+ src_len)
+ attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len,
+ src_len)
+
+ if output_attentions:
+ # this operation is a bit awkward, but it's required to
+ # make sure that attn_weights keeps its gradient.
+ # In order to do so, attn_weights have to be reshaped
+ # twice and have to be reused in the following
+ attn_weights_reshaped = attn_weights.view(bsz, self.num_heads,
+ tgt_len, src_len)
+ attn_weights = attn_weights_reshaped.view(bsz * self.num_heads,
+ tgt_len, src_len)
+ else:
+ attn_weights_reshaped = None
+
+ attn_probs = nn.functional.dropout(
+ attn_weights, p=self.dropout, training=self.training)
+
+ attn_output = torch.bmm(attn_probs, value_states)
+
+ if attn_output.size() != (bsz * self.num_heads, tgt_len,
+ self.head_dim):
+ raise ValueError(
+ f'`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is'
+ f' {attn_output.size()}')
+
+ attn_output = attn_output.view(bsz, self.num_heads, tgt_len,
+ self.head_dim)
+ attn_output = attn_output.transpose(1, 2)
+
+ # Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
+ # partitioned aross GPUs when using tensor-parallelism.
+ attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, attn_weights_reshaped, past_key_value
+
+
+class OPTDecoderLayer(nn.Module):
+
+ def __init__(self, config: OPTConfig):
+ super().__init__()
+ self.embed_dim = config.hidden_size
+ self.self_attn = OPTAttention(
+ embed_dim=self.embed_dim,
+ num_heads=config.num_attention_heads,
+ dropout=config.attention_dropout,
+ is_decoder=True,
+ )
+ self.do_layer_norm_before = config.do_layer_norm_before
+ self.dropout = config.dropout
+ self.activation_fn = ACT2FN[config.activation_function]
+
+ self.self_attn_layer_norm = nn.LayerNorm(self.embed_dim)
+ self.fc1 = nn.Linear(self.embed_dim, config.ffn_dim)
+ self.fc2 = nn.Linear(config.ffn_dim, self.embed_dim)
+ self.final_layer_norm = nn.LayerNorm(self.embed_dim)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor,
+ torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = nn.functional.dropout(
+ hidden_states, p=self.dropout, training=self.training)
+ hidden_states = residual + hidden_states
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ hidden_states_shape = hidden_states.shape
+ hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = nn.functional.dropout(
+ hidden_states, p=self.dropout, training=self.training)
+
+ hidden_states = (residual + hidden_states).view(hidden_states_shape)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states, )
+
+ if output_attentions:
+ outputs += (self_attn_weights, )
+
+ if use_cache:
+ outputs += (present_key_value, )
+
+ return outputs
+
+
+OPT_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`OPTConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ 'The bare OPT Model outputting raw hidden-states without any specific head on top.',
+ OPT_START_DOCSTRING,
+)
+class OPTPreTrainedModel(PreTrainedModel):
+
+ config_class = OPTConfig
+ base_model_prefix = 'model'
+ supports_gradient_checkpointing = True
+ _no_split_modules = ['OPTDecoderLayer']
+ _keys_to_ignore_on_load_unexpected = [r'decoder\.version']
+
+ def _init_weights(self, module):
+ std = self.config.init_std
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, (OPTDecoder)):
+ module.gradient_checkpointing = value
+
+
+OPT_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`GPT2Tokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+ head_mask (`torch.Tensor` of shape `(encoder_layers, encoder_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+class OPTDecoder(OPTPreTrainedModel):
+ """Transformer decoder consisting of *config.num_hidden_layers* layers.
+ Each layer is a [`OPTDecoderLayer`]
+
+ Args:
+ config: OPTConfig
+ """
+
+ def __init__(self, config: OPTConfig):
+ super().__init__(config)
+ self.dropout = config.dropout
+ self.layerdrop = config.layerdrop
+ self.padding_idx = config.pad_token_id
+ self.max_target_positions = config.max_position_embeddings
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size,
+ config.word_embed_proj_dim,
+ self.padding_idx)
+ self.embed_positions = OPTLearnedPositionalEmbedding(
+ config.max_position_embeddings, config.hidden_size)
+
+ if config.word_embed_proj_dim != config.hidden_size:
+ self.project_out = nn.Linear(
+ config.hidden_size, config.word_embed_proj_dim, bias=False)
+ else:
+ self.project_out = None
+
+ if config.word_embed_proj_dim != config.hidden_size:
+ self.project_in = nn.Linear(
+ config.word_embed_proj_dim, config.hidden_size, bias=False)
+ else:
+ self.project_in = None
+
+ # Note that the only purpose of `config._remove_final_layer_norm` is to keep backward compatibility
+ # with checkpoints that have been fine-tuned before transformers v4.20.1
+ # see https://github.com/facebookresearch/metaseq/pull/164
+ if config.do_layer_norm_before and not config._remove_final_layer_norm:
+ self.final_layer_norm = nn.LayerNorm(config.hidden_size)
+ else:
+ self.final_layer_norm = None
+
+ self.layers = nn.ModuleList(
+ [OPTDecoderLayer(config) for _ in range(config.num_hidden_layers)])
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape,
+ inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ past_key_values_length=past_key_values_length,
+ ).to(inputs_embeds.device)
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(
+ attention_mask, inputs_embeds.dtype,
+ tgt_len=input_shape[-1]).to(inputs_embeds.device)
+ combined_attention_mask = (
+ expanded_attn_mask if combined_attention_mask is None else
+ expanded_attn_mask + combined_attention_mask)
+
+ return combined_attention_mask
+
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
+ provide it.
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(num_hidden_layers, num_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
+ cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
+ that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
+ all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ """
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError(
+ 'You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time'
+ )
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError(
+ 'You have to specify either decoder_input_ids or decoder_inputs_embeds'
+ )
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ if query_embeds is not None:
+ inputs_embeds = torch.cat([query_embeds, inputs_embeds], dim=1)
+ input_shape = inputs_embeds.size()[:-1]
+ else:
+ input_shape = (batch_size, seq_length)
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ inputs_embeds.shape[:2],
+ dtype=torch.bool,
+ device=inputs_embeds.device)
+ pos_embeds = self.embed_positions(attention_mask,
+ past_key_values_length)
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones((batch_size, seq_length_with_past),
+ dtype=torch.bool,
+ device=inputs_embeds.device)
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, input_shape, inputs_embeds, past_key_values_length)
+
+ if self.project_in is not None:
+ inputs_embeds = self.project_in(inputs_embeds)
+
+ hidden_states = inputs_embeds + pos_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ # check if head_mask has a correct number of layers specified if desired
+ for attn_mask, mask_name in zip([head_mask], ['head_mask']):
+ if attn_mask is not None:
+ if attn_mask.size()[0] != (len(self.layers)):
+ raise ValueError(
+ f'The `{mask_name}` should be specified for {len(self.layers)} layers, but it is for'
+ f' {head_mask.size()[0]}.')
+
+ for idx, decoder_layer in enumerate(self.layers):
+ # add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ dropout_probability = random.uniform(0, 1)
+ if self.training and (dropout_probability < self.layerdrop):
+ continue
+
+ past_key_value = (
+ past_key_values[idx] if past_key_values is not None else None)
+
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ logger.warning(
+ '`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...'
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ head_mask[idx] if head_mask is not None else None,
+ None,
+ )
+ else:
+
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=(head_mask[idx]
+ if head_mask is not None else None),
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (
+ layer_outputs[2 if output_attentions else 1], )
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1], )
+
+ if self.final_layer_norm is not None:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ if self.project_out is not None:
+ hidden_states = self.project_out(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states, )
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(
+ v for v in
+ [hidden_states, next_cache, all_hidden_states, all_self_attns]
+ if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+@add_start_docstrings(
+ 'The bare OPT Model outputting raw hidden-states without any specific head on top.',
+ OPT_START_DOCSTRING,
+)
+class OPTModel(OPTPreTrainedModel):
+
+ def __init__(self, config: OPTConfig):
+ super().__init__(config)
+ self.decoder = OPTDecoder(config)
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.decoder.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.decoder.embed_tokens = value
+
+ def get_decoder(self):
+ return self.decoder
+
+ @add_start_docstrings_to_model_forward(OPT_INPUTS_DOCSTRING)
+ @add_code_sample_docstrings(
+ processor_class=_TOKENIZER_FOR_DOC,
+ checkpoint=_CHECKPOINT_FOR_DOC,
+ output_type=BaseModelOutputWithPast,
+ config_class=_CONFIG_FOR_DOC,
+ expected_output=_EXPECTED_OUTPUT_SHAPE,
+ )
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, past_key_value, dec_hidden, dec_attn)
+ decoder_outputs = self.decoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ query_embeds=query_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ if not return_dict:
+ return decoder_outputs
+
+ return BaseModelOutputWithPast(
+ last_hidden_state=decoder_outputs.last_hidden_state,
+ past_key_values=decoder_outputs.past_key_values,
+ hidden_states=decoder_outputs.hidden_states,
+ attentions=decoder_outputs.attentions,
+ )
+
+
+@register_hf_model()
+class OPTForCausalLM(OPTPreTrainedModel):
+ _keys_to_ignore_on_load_missing = [r'lm_head.weight']
+
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = OPTModel(config)
+
+ # the lm_head weight is automatically tied to the embed tokens weight
+ self.lm_head = nn.Linear(
+ config.word_embed_proj_dim, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.decoder.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.decoder.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model.decoder = decoder
+
+ def get_decoder(self):
+ return self.model.decoder
+
+ @replace_return_docstrings(
+ output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ reduction: Optional[str] = 'mean',
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you
+ provide it.
+
+ Indices can be obtained using [`OPTTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+ head_mask (`torch.Tensor` of shape `(num_hidden_layers, num_attention_heads)`, *optional*):
+ Mask to nullify selected heads of the attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
+ shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of
+ shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`. The two additional
+ tensors are only required when the model is used as a decoder in a Sequence to Sequence model.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the
+ cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those
+ that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of
+ all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
+ This is useful if you want more control over how to convert `input_ids` indices into associated vectors
+ than the model's internal embedding lookup matrix.
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import GPT2Tokenizer, OPTForCausalLM
+
+ >>> model = OPTForCausalLM.from_pretrained("facebook/opt-350m")
+ >>> tokenizer = GPT2Tokenizer.from_pretrained("facebook/opt-350m")
+
+ >>> prompt = "Hey, are you consciours? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
+ ```"""
+
+ output_attentions = (
+ output_attentions if output_attentions is not None else
+ self.config.output_attentions)
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else
+ self.config.output_hidden_states)
+ return_dict = (
+ return_dict
+ if return_dict is not None else self.config.use_return_dict)
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model.decoder(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ head_mask=head_mask,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ query_embeds=query_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ logits = self.lm_head(outputs[0]).contiguous()
+
+ loss = None
+ if labels is not None:
+ logits = logits[:, -labels.size(1):, :]
+
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss(reduction=reduction)
+ loss = loss_fct(
+ shift_logits.view(-1, self.config.vocab_size),
+ shift_labels.view(-1))
+ if reduction == 'none':
+ loss = loss.view(shift_logits.size(0), -1).sum(1)
+
+ if not return_dict:
+ output = (logits, ) + outputs[1:]
+ return (loss, ) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self,
+ input_ids=None,
+ inputs_embeds=None,
+ query_embeds=None,
+ past_key_values=None,
+ attention_mask=None,
+ use_cache=None,
+ **kwargs,
+ ):
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ if input_ids is not None:
+ attention_mask = input_ids.new_ones(input_ids.shape)
+ if past_key_values:
+ input_ids = input_ids[:, -1:]
+ query_embeds = None
+ # first step, decoder_cached_states are empty
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {'inputs_embeds': inputs_embeds}
+ else:
+ model_inputs = {'input_ids': input_ids}
+
+ model_inputs.update({
+ 'query_embeds': query_embeds,
+ 'attention_mask': attention_mask,
+ 'past_key_values': past_key_values,
+ 'use_cache': use_cache,
+ })
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
diff --git a/mmpretrain/models/multimodal/flamingo/__init__.py b/mmpretrain/models/multimodal/flamingo/__init__.py
new file mode 100644
index 00000000000..e0bfd63b657
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .adapter import FlamingoLMAdapter
+from .flamingo import Flamingo
+
+__all__ = ['Flamingo', 'FlamingoLMAdapter']
diff --git a/mmpretrain/models/multimodal/flamingo/adapter.py b/mmpretrain/models/multimodal/flamingo/adapter.py
new file mode 100644
index 00000000000..69a635c2ecd
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/adapter.py
@@ -0,0 +1,90 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+
+import torch.nn as nn
+
+from mmpretrain.registry import MODELS
+from .modules import FlamingoLayer, GatedCrossAttentionBlock
+from .utils import getattr_recursive, setattr_recursive
+
+
+@MODELS.register_module()
+class FlamingoLMAdapter:
+ """Mixin to add cross-attention layers to a language model."""
+
+ @classmethod
+ def extend_init(
+ cls,
+ base: object,
+ vis_hidden_size: int,
+ cross_attn_every_n_layers: int,
+ use_media_placement_augmentation: bool,
+ ):
+ """Initialize Flamingo by adding a new gated cross attn to the decoder.
+
+ Store the media token id for computing the media locations.
+
+ Args:
+ base (object): Base module could be any object that represent
+ a instance of language model.
+ vis_hidden_size: (int): Hidden size of vision embeddings.
+ cross_attn_every_n_layers: (int): Additional cross attn for
+ every n layers.
+ use_media_placement_augmentation: (bool): Whether to use media
+ placement augmentation.
+ """
+ base.set_decoder_layers_attr_name('model.layers')
+ gated_cross_attn_layers = nn.ModuleList([
+ GatedCrossAttentionBlock(
+ dim=base.config.hidden_size, dim_visual=vis_hidden_size) if
+ (layer_idx + 1) % cross_attn_every_n_layers == 0 else None
+ for layer_idx, _ in enumerate(base._get_decoder_layers())
+ ])
+ base._set_decoder_layers(
+ nn.ModuleList([
+ FlamingoLayer(gated_cross_attn_layer, decoder_layer)
+ for gated_cross_attn_layer, decoder_layer in zip(
+ gated_cross_attn_layers, base._get_decoder_layers())
+ ]))
+ base.use_media_placement_augmentation = use_media_placement_augmentation # noqa
+ base.initialized_flamingo = True
+ return base
+
+ def set_decoder_layers_attr_name(self, decoder_layers_attr_name):
+ """Set decoder layers attribute name."""
+ self.decoder_layers_attr_name = decoder_layers_attr_name
+
+ def _get_decoder_layers(self):
+ """Get decoder layers according to attribute name."""
+ return getattr_recursive(self, self.decoder_layers_attr_name)
+
+ def _set_decoder_layers(self, value):
+ """Set decoder layers according to attribute name."""
+ setattr_recursive(self, self.decoder_layers_attr_name, value)
+
+ def forward(self, *input, **kwargs):
+ """Condition the Flamingo layers on the media locations before forward
+ function."""
+ input_ids = kwargs['input_ids'] if 'input_ids' in kwargs else input[0]
+ media_locations = input_ids == self.media_token_id
+ attend_previous = ((random.random() < 0.5)
+ if self.use_media_placement_augmentation else False)
+
+ for layer in self.get_decoder().layers:
+ layer.condition_media_locations(media_locations)
+ layer.condition_attend_previous(attend_previous)
+
+ return super().forward(
+ *input, **kwargs) # Call the other parent's forward method
+
+ def is_conditioned(self) -> bool:
+ """Check whether all decoder layers are already conditioned."""
+ return all(layer.is_conditioned()
+ for layer in self._get_decoder_layers())
+
+ def clear_conditioned_layers(self):
+ """Clear all conditional layers."""
+ for layer in self._get_decoder_layers():
+ layer.condition_vis_x(None)
+ layer.condition_media_locations(None)
+ layer.condition_attend_previous(None)
diff --git a/mmpretrain/models/multimodal/flamingo/flamingo.py b/mmpretrain/models/multimodal/flamingo/flamingo.py
new file mode 100644
index 00000000000..abdd03328f4
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/flamingo.py
@@ -0,0 +1,322 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from typing import List, Optional
+
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from .modules import PerceiverResampler
+from .utils import ExtendModule
+
+
+@MODELS.register_module()
+class Flamingo(BaseModel):
+ """The Open Flamingo model for multiple tasks.
+
+ Args:
+ vision_encoder (dict): The config of the vision encoder.
+ lang_encoder (dict): The config of the language encoder.
+ tokenizer (dict): The tokenizer to encode the text.
+ task (int): The task to perform prediction.
+ zeroshot_prompt (str): Prompt used for zero-shot inference.
+ Defaults to 'Output:'.
+ shot_prompt_tmpl (str): Prompt used for few-shot inference.
+ Defaults to 'Output:{caption}<|endofchunk|>'.
+ final_prompt_tmpl (str): Final part of prompt used for inference.
+ Defaults to 'Output:'.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of [~`transformers.GenerationConfig`].
+ Defaults to an empty dict.
+ data_preprocessor (Optional[dict]): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MutimodalDataPreprocessor" as type.
+ See :class:`MutimodalDataPreprocessor` for more details.
+ Defaults to None.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ support_tasks = {'caption', 'vqa'}
+ _no_split_modules = [
+ 'TransformerEncoderLayer', 'PerceiverAttention',
+ 'GatedCrossAttentionBlock', 'FlamingoLayer'
+ ]
+
+ def __init__(
+ self,
+ vision_encoder: dict,
+ lang_encoder: dict,
+ tokenizer: dict,
+ task: str = 'caption',
+ zeroshot_prompt: str = 'Output:',
+ shot_prompt_tmpl: str = 'Output:{caption}<|endofchunk|>',
+ final_prompt_tmpl: str = 'Output:',
+ generation_cfg: dict = dict(),
+ data_preprocessor: Optional[dict] = None,
+ init_cfg: Optional[dict] = None):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ if task not in self.support_tasks:
+ raise ValueError(f'Unsupported task {task}, please select '
+ f'the task from {self.support_tasks}.')
+ self.task = task
+
+ # init tokenizer
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ # add Flamingo special tokens to the tokenizer
+ self.tokenizer.add_special_tokens(
+ {'additional_special_tokens': ['<|endofchunk|>', '']})
+ self.tokenizer.bos_token_id = 1
+ if self.tokenizer.pad_token is None:
+ # Issue: GPT models don't have a pad token, which we use to
+ # modify labels for the loss.
+ self.tokenizer.add_special_tokens({'pad_token': ''})
+
+ # Template to format the prompt input
+ self.zeroshot_prompt = zeroshot_prompt
+ self.shot_prompt_tmpl = shot_prompt_tmpl
+ self.final_prompt_tmpl = final_prompt_tmpl
+
+ # init vision encoder related modules
+ vision_encoder_weight = vision_encoder.pop('pretrained', None)
+ self.vision_encoder = MODELS.build(vision_encoder)
+ if vision_encoder_weight is not None:
+ from mmengine.runner.checkpoint import load_checkpoint
+ load_checkpoint(
+ self.vision_encoder,
+ vision_encoder_weight,
+ map_location='cpu',
+ revise_keys=[(r'^backbone\.', '')],
+ )
+
+ self.perceiver = PerceiverResampler(dim=self.vision_encoder.embed_dims)
+
+ # init language encoder related modules
+ self.lang_encoder = ExtendModule(**lang_encoder)
+ self.lang_encoder.resize_token_embeddings(len(self.tokenizer))
+ self.lang_encoder.media_token_id = self.tokenizer.encode('')[-1]
+
+ # other necessary parameters
+ self.eoc_token_id = self.tokenizer.encode('<|endofchunk|>')[-1]
+ self.generation_cfg = {
+ 'num_beams': 1,
+ 'max_new_tokens': None,
+ 'temperature': 1.0,
+ 'top_k': 0,
+ 'top_p': 1.0,
+ 'no_repeat_ngram_size': 0,
+ 'prefix_allowed_tokens_fn': None,
+ 'length_penalty': 1.0,
+ 'num_return_sequences': 1,
+ 'do_sample': False,
+ 'early_stopping': False,
+ **generation_cfg,
+ }
+
+ if hasattr(self, 'register_load_state_dict_post_hook'):
+ self.register_load_state_dict_post_hook(self._load_adapter_hook)
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ mode: str = 'loss',
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method should accept only one mode "loss":
+
+ - "loss": Forward and return a dict of losses according to the given
+ inputs and data samples.
+
+ Note that this method doesn't handle neither back propagation nor
+ optimizer updating, which are done in the :meth:`train_step`.
+
+ Args:
+ images (torch.Tensor): The input image tensor with different ndim
+ according to the inputs.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. It's required if ``mode="loss"``.
+ Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'loss'.
+
+ Returns:
+ The return type depends on ``mode``.
+ - If ``mode="loss"``, return a dict of tensor.
+ """
+
+ if mode == 'loss':
+ return self.loss(images, data_samples)
+ elif mode == 'predict':
+ return self.predict(images, data_samples)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def extract_vision_feats(self, images: torch.Tensor) -> torch.Tensor:
+ """Extract vision features.
+
+ Args:
+ images (torch.Tensor): For zero-shot, the input images tensor is
+ with shape (B, C, H, W), for few-shot, which is
+ (B, T_img, C, H, W) in general. Images in the same chunk
+ are collated along T_img. Video data is not supported yet.
+
+ Returns:
+ torch.Tensor: Return extracted features.
+ """
+ if images.ndim == 4:
+ # (B, C, H, W) -> (B, 1, C, H, W) for zero-shot.
+ images = images.unsqueeze(1)
+ b, T = images.shape[:2]
+ # b T c h w -> (b T) c h w
+ images = images.view(b * T, *images.shape[-3:])
+
+ with torch.no_grad():
+ vision_feats = self.vision_encoder(images)[-1][:, 1:]
+
+ # (b T F) v d -> b T F v d Only support F=1 here
+ vision_feats = vision_feats.view(b, T, 1, *vision_feats.shape[-2:])
+
+ vision_feats = self.perceiver(vision_feats) # reshapes to (b, T, n, d)
+ return vision_feats
+
+ def predict(self,
+ images: torch.Tensor,
+ data_samples: Optional[List[DataSample]] = None,
+ **generation_cfg):
+ """Predict generation results from a batch of inputs.
+
+ Args:
+ images (torch.Tensor): For zero-shot, the input images tensor is
+ with shape (B, C, H, W), for few-shot, which is
+ (B, T_img, C, H, W) in general. Images in the same chunk
+ are collated along T_img. Video data is not supported yet.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples. Defaults to None.
+ **generation_cfg: Other keyword arguments accepted by the
+ ``generate`` method of :attr:`lang_encoder`.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ # generation_cfg in prediction should be dominant
+ generation_cfg = {**self.generation_cfg, **generation_cfg}
+ num_beams = generation_cfg['num_beams']
+
+ if num_beams > 1:
+ images = images.repeat_interleave(num_beams, dim=0)
+
+ # extra vision feats and set as language condition feats
+ vision_x = self.extract_vision_feats(images)
+ for layer in self.lang_encoder._get_decoder_layers():
+ layer.condition_vis_x(vision_x)
+
+ input_text = self.preprocess_text(data_samples, device=images.device)
+
+ outputs = self.lang_encoder.generate(
+ input_text.input_ids,
+ attention_mask=input_text.attention_mask,
+ eos_token_id=self.eoc_token_id,
+ **generation_cfg)
+
+ # clear conditioned layers for language models
+ self.lang_encoder.clear_conditioned_layers()
+
+ # remove prefix
+ outputs = outputs[:, len(input_text.input_ids[0]):]
+
+ return self.post_process(outputs, data_samples)
+
+ def preprocess_text(self, data_samples: List[DataSample],
+ device: torch.device) -> List[DataSample]:
+ """Preprocess text in advance before fed into language model.
+
+ Args:
+ data_samples (List[DataSample]): The annotation
+ data of every samples. Defaults to None.
+ device (torch.device): Device for text to put on.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ prompts = []
+ for sample in data_samples:
+ if 'shots' in sample:
+ # few-shot
+ shot_prompt = ''.join([
+ self.shot_prompt_tmpl.format(**shot)
+ for shot in sample.get('shots')
+ ])
+ else:
+ # zero-shot
+ shot_prompt = self.zeroshot_prompt
+
+ # add final prompt
+ final_prompt = self.final_prompt_tmpl.format(**sample.to_dict())
+ prompts.append(shot_prompt + final_prompt)
+
+ self.tokenizer.padding_side = 'left'
+ input_text = self.tokenizer(
+ prompts,
+ padding='longest',
+ truncation=True,
+ return_tensors='pt',
+ max_length=2000,
+ ).to(device)
+ return input_text
+
+ def post_process(
+ self, outputs: torch.Tensor,
+ data_samples: Optional[List[DataSample]]) -> List[DataSample]:
+ """Perform post process for outputs for different task.
+
+ Args:
+ outputs (torch.Tensor): The generated outputs.
+ data_samples (List[DataSample], optional): The annotation
+ data of every samples.
+
+ Returns:
+ List[DataSample]: Return list of data samples.
+ """
+ outputs = self.tokenizer.batch_decode(
+ outputs, skip_special_tokens=True)
+
+ if data_samples is None:
+ data_samples = [DataSample() for _ in range(len(outputs))]
+
+ for output, data_sample in zip(outputs, data_samples):
+ # remove text pattern
+ if self.task == 'caption':
+ data_sample.pred_caption = re.split('Output', output,
+ 1)[0].replace('"', '')
+ elif self.task == 'vqa':
+ data_sample.pred_answer = re.split('Question|Answer', output,
+ 1)[0]
+
+ return data_samples
+
+ @staticmethod
+ def _load_adapter_hook(module, incompatible_keys):
+ """Avoid warning missing keys except adapter keys."""
+ adapter_patterns = [
+ '^perceiver',
+ 'lang_encoder.*embed_tokens',
+ 'lang_encoder.*gated_cross_attn_layers',
+ 'lang_encoder.*rotary_emb',
+ ]
+ for key in list(incompatible_keys.missing_keys):
+ if not any(re.match(pattern, key) for pattern in adapter_patterns):
+ incompatible_keys.missing_keys.remove(key)
+
+ for key in list(incompatible_keys.unexpected_keys):
+ if 'position_ids' in key:
+ incompatible_keys.unexpected_keys.remove(key)
+ if 'lang_encoder.gated_cross_attn_layers' in key:
+ incompatible_keys.unexpected_keys.remove(key)
diff --git a/mmpretrain/models/multimodal/flamingo/modules.py b/mmpretrain/models/multimodal/flamingo/modules.py
new file mode 100644
index 00000000000..730c61b68a8
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/modules.py
@@ -0,0 +1,398 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+"""Taken from https://github.com/lucidrains/flamingo-pytorch."""
+
+from typing import Optional
+
+import torch
+from einops import rearrange, repeat
+from torch import einsum, nn
+
+
+def FeedForward(dim, mult: int = 4):
+ """Feedforward layers.
+
+ Args:
+ mult (int): Layer expansion muliplier. Defaults to 4.
+ """
+ inner_dim = int(dim * mult)
+ return nn.Sequential(
+ nn.LayerNorm(dim),
+ nn.Linear(dim, inner_dim, bias=False),
+ nn.GELU(),
+ nn.Linear(inner_dim, dim, bias=False),
+ )
+
+
+class PerceiverAttention(nn.Module):
+ """Perceiver attetion layers.
+
+ Args:
+ dim (int): Input dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ """
+
+ def __init__(self, *, dim: int, dim_head: int = 64, heads: int = 8):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ inner_dim = dim_head * heads
+
+ self.norm_media = nn.LayerNorm(dim)
+ self.norm_latents = nn.LayerNorm(dim)
+
+ self.to_q = nn.Linear(dim, inner_dim, bias=False)
+ self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
+ self.to_out = nn.Linear(inner_dim, dim, bias=False)
+
+ def forward(self, x: torch.Tensor, latents: torch.Tensor):
+ """Forward function.
+
+ Args:
+ x (torch.Tensor): image features of shape (b, T, n1, D).
+ latent (torch.Tensor): latent features of shape (b, T, n2, D).
+ """
+ x = self.norm_media(x)
+ latents = self.norm_latents(latents)
+
+ h = self.heads
+
+ q = self.to_q(latents)
+ kv_input = torch.cat((x, latents), dim=-2)
+ k, v = self.to_kv(kv_input).chunk(2, dim=-1)
+ q = rearrange(q, 'b t n (h d) -> b h t n d', h=h)
+ k = rearrange(k, 'b t n (h d) -> b h t n d', h=h)
+ v = rearrange(v, 'b t n (h d) -> b h t n d', h=h)
+ q = q * self.scale
+
+ # attention
+ sim = einsum('... i d, ... j d -> ... i j', q, k)
+ sim = sim - sim.amax(dim=-1, keepdim=True).detach()
+ attn = sim.softmax(dim=-1)
+
+ out = einsum('... i j, ... j d -> ... i d', attn, v)
+ out = rearrange(out, 'b h t n d -> b t n (h d)', h=h)
+ return self.to_out(out)
+
+
+class PerceiverResampler(nn.Module):
+ """Perceiver resampler layers.
+
+ Args:
+ dim (int): Input dimensions.
+ depth (int): Depth of resampler. Defaults to 6.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ num_latents (int): Number of latents. Defaults to 64.
+ max_num_media (int, optional): Max number of media.
+ Defaults to None.
+ max_num_frames (int, optional): Max number of frames.
+ Defaults to None.
+ ff_mult (int): Feed forward multiplier. Defaults to 4.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ depth: int = 6,
+ dim_head: int = 64,
+ heads: int = 8,
+ num_latents: int = 64,
+ max_num_media: Optional[int] = None,
+ max_num_frames: Optional[int] = None,
+ ff_mult: int = 4,
+ ):
+ super().__init__()
+ self.latents = nn.Parameter(torch.randn(num_latents, dim))
+ self.frame_embs = (
+ nn.Parameter(torch.randn(max_num_frames, dim))
+ if max_num_frames is not None else None)
+ self.media_time_embs = (
+ nn.Parameter(torch.randn(max_num_media, 1, dim))
+ if max_num_media is not None else None)
+
+ self.layers = nn.ModuleList([])
+ for _ in range(depth):
+ self.layers.append(
+ nn.ModuleList([
+ PerceiverAttention(
+ dim=dim, dim_head=dim_head, heads=heads),
+ FeedForward(dim=dim, mult=ff_mult),
+ ]))
+
+ self.norm = nn.LayerNorm(dim)
+
+ def forward(self, x: torch.Tensor):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): image features of shape (b, T, F, v, D)
+
+ Returns:
+ torch.Tensor: shape (b, T, n, D) where n is self.num_latents
+ """
+ b, T, F, v = x.shape[:4]
+
+ # frame and media time embeddings
+ if self.frame_embs is not None:
+ frame_embs = repeat(
+ self.frame_embs[:F], 'F d -> b T F v d', b=b, T=T, v=v)
+ x = x + frame_embs
+ x = rearrange(x, 'b T F v d -> b T (F v) d'
+ ) # flatten the frame and spatial dimensions
+ if self.media_time_embs is not None:
+ x = x + self.media_time_embs[:T]
+
+ # blocks
+ latents = repeat(self.latents, 'n d -> b T n d', b=b, T=T)
+ for attn, ff in self.layers:
+ latents = attn(x, latents) + latents
+ latents = ff(latents) + latents
+ return self.norm(latents)
+
+
+class MaskedCrossAttention(nn.Module):
+ """Masked cross attention layers.
+
+ Args:
+ dim (int): Input text feature dimensions.
+ dim_visual (int): Input visual feature dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ only_attend_immediate_media (bool): Whether attend immediate media.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ dim_visual: int,
+ dim_head: int = 64,
+ heads: int = 8,
+ only_attend_immediate_media: bool = True,
+ ):
+ super().__init__()
+ self.scale = dim_head**-0.5
+ self.heads = heads
+ inner_dim = dim_head * heads
+
+ self.norm = nn.LayerNorm(dim)
+
+ self.to_q = nn.Linear(dim, inner_dim, bias=False)
+ self.to_kv = nn.Linear(dim_visual, inner_dim * 2, bias=False)
+ self.to_out = nn.Linear(inner_dim, dim, bias=False)
+
+ # whether for text to only attend to immediate preceding image
+ # or all previous images
+ self.only_attend_immediate_media = only_attend_immediate_media
+
+ def forward(self,
+ x: torch.Tensor,
+ media: torch.Tensor,
+ media_locations: Optional[torch.Tensor] = None,
+ attend_previous: bool = True):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): text features of shape (B, T_txt, D_txt).
+ media (torch.Tensor): image features of shape
+ (B, T_img, n, D_img) where n is the dim of the latents.
+ media_locations (torch.Tensor, optional): boolean mask identifying
+ the media tokens in x of shape (B, T_txt). Defaults to None.
+ attend_previous (bool): If false, ignores immediately preceding
+ image and starts attending when following image.
+ Defaults to True.
+ """
+ _, T_img, n = media.shape[:3]
+ h = self.heads
+
+ x = self.norm(x)
+
+ q = self.to_q(x)
+ media = rearrange(media, 'b t n d -> b (t n) d')
+
+ k, v = self.to_kv(media).chunk(2, dim=-1)
+ q = rearrange(q, 'b n (h d) -> b h n d', h=h)
+ k = rearrange(k, 'b n (h d) -> b h n d', h=h)
+ v = rearrange(v, 'b n (h d) -> b h n d', h=h)
+
+ q = q * self.scale
+
+ sim = einsum('... i d, ... j d -> ... i j', q, k)
+
+ if media_locations is not None:
+ # at each boolean of True, increment the time counter
+ # (relative to media time)
+ text_time = media_locations.cumsum(dim=-1)
+ media_time = torch.arange(T_img, device=x.device) + 1
+
+ if not attend_previous:
+ text_time[~media_locations] += 1
+ # make sure max is still the number of images in the sequence
+ text_time[text_time > repeat(
+ torch.count_nonzero(media_locations, dim=1),
+ 'b -> b i',
+ i=text_time.shape[1],
+ )] = 0
+
+ # text time must equal media time if only attending to most
+ # immediate image otherwise, as long as text time is greater than
+ # media time (if attending to all previous images / media)
+ mask_op = torch.eq if self.only_attend_immediate_media else torch.ge # noqa
+
+ text_to_media_mask = mask_op(
+ rearrange(text_time, 'b i -> b 1 i 1'),
+ repeat(media_time, 'j -> 1 1 1 (j n)', n=n),
+ )
+ sim = sim.masked_fill(~text_to_media_mask,
+ -torch.finfo(sim.dtype).max)
+
+ sim = sim - sim.amax(dim=-1, keepdim=True).detach()
+ attn = sim.softmax(dim=-1)
+
+ if media_locations is not None and self.only_attend_immediate_media:
+ # any text without a preceding media needs to have
+ # attention zeroed out
+ text_without_media_mask = text_time == 0
+ text_without_media_mask = rearrange(text_without_media_mask,
+ 'b i -> b 1 i 1')
+ attn = attn.masked_fill(text_without_media_mask, 0.0)
+
+ out = einsum('... i j, ... j d -> ... i d', attn, v)
+ out = rearrange(out, 'b h n d -> b n (h d)')
+ return self.to_out(out)
+
+
+class GatedCrossAttentionBlock(nn.Module):
+ """Gated cross attention layers.
+
+ Args:
+ dim (int): Input text feature dimensions.
+ dim_visual (int): Input visual feature dimensions.
+ dim_head (int): Number of dimension heads. Defaults to 64.
+ heads (int): Number of heads. Defaults to 8.
+ ff_mult (int): Feed forward multiplier. Defaults to 4.
+ only_attend_immediate_media (bool): Whether attend immediate media.
+ Defaults to True.
+ """
+
+ def __init__(
+ self,
+ *,
+ dim: int,
+ dim_visual: int,
+ dim_head: int = 64,
+ heads: int = 8,
+ ff_mult: int = 4,
+ only_attend_immediate_media: bool = True,
+ ):
+ super().__init__()
+ self.attn = MaskedCrossAttention(
+ dim=dim,
+ dim_visual=dim_visual,
+ dim_head=dim_head,
+ heads=heads,
+ only_attend_immediate_media=only_attend_immediate_media,
+ )
+ self.attn_gate = nn.Parameter(torch.tensor([0.0]))
+
+ self.ff = FeedForward(dim, mult=ff_mult)
+ self.ff_gate = nn.Parameter(torch.tensor([0.0]))
+
+ def forward(self,
+ x: torch.Tensor,
+ media: torch.Tensor,
+ media_locations: Optional[torch.Tensor] = None,
+ attend_previous: bool = True):
+ """Forward function for perceiver sampler.
+
+ Args:
+ x (torch.Tensor): text features of shape (B, T_txt, D_txt).
+ media (torch.Tensor): image features of shape
+ (B, T_img, n, D_img) where n is the dim of the latents.
+ media_locations (torch.Tensor, optional): boolean mask identifying
+ the media tokens in x of shape (B, T_txt). Defaults to None.
+ attend_previous (bool): If false, ignores immediately preceding
+ image and starts attending when following image.
+ Defaults to True.
+ """
+ x = (
+ self.attn(
+ x,
+ media,
+ media_locations=media_locations,
+ attend_previous=attend_previous,
+ ) * self.attn_gate.tanh() + x)
+ x = self.ff(x) * self.ff_gate.tanh() + x
+
+ return x
+
+
+class FlamingoLayer(nn.Module):
+ """Faminogo layers.
+
+ Args:
+ gated_cross_attn_layer (nn.Module): Gated cross attention layer.
+ decoder_layer (nn.Module): Decoder layer.
+ """
+
+ def __init__(self, gated_cross_attn_layer: nn.Module,
+ decoder_layer: nn.Module):
+ super().__init__()
+ self.gated_cross_attn_layer = gated_cross_attn_layer
+ self.decoder_layer = decoder_layer
+ self.vis_x = None
+ self.media_locations = None
+
+ def is_conditioned(self) -> bool:
+ """Check whether the layer is conditioned."""
+ return self.vis_x is not None
+
+ def condition_vis_x(self, vis_x):
+ """Set condition vision features."""
+ self.vis_x = vis_x
+
+ def condition_media_locations(self, media_locations):
+ """Set condition media locations."""
+ self.media_locations = media_locations
+
+ def condition_attend_previous(self, attend_previous):
+ """Set attend previous."""
+ self.attend_previous = attend_previous
+
+ def forward(
+ self,
+ lang_x: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ **decoder_layer_kwargs,
+ ):
+ """Forward function.
+
+ Args:
+ lang_x (torch.Tensor): language inputs.
+ attention_mask (torch.Tensor, optional): text attention mask.
+ Defaults to None.
+ **decoder_layer_kwargs: Other decoder layer keyword arguments.
+ """
+ if self.gated_cross_attn_layer is None:
+ return self.decoder_layer(
+ lang_x, attention_mask=attention_mask, **decoder_layer_kwargs)
+
+ if self.vis_x is None:
+ raise ValueError('vis_x must be conditioned before forward pass')
+
+ if self.media_locations is None:
+ raise ValueError(
+ 'media_locations must be conditioned before forward pass')
+
+ lang_x = self.gated_cross_attn_layer(
+ lang_x,
+ self.vis_x,
+ media_locations=self.media_locations,
+ attend_previous=self.attend_previous,
+ )
+ lang_x = self.decoder_layer(
+ lang_x, attention_mask=attention_mask, **decoder_layer_kwargs)
+ return lang_x
diff --git a/mmpretrain/models/multimodal/flamingo/utils.py b/mmpretrain/models/multimodal/flamingo/utils.py
new file mode 100644
index 00000000000..1077e145a7d
--- /dev/null
+++ b/mmpretrain/models/multimodal/flamingo/utils.py
@@ -0,0 +1,64 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Any, Type
+
+from mmpretrain.registry import MODELS
+
+
+class ExtendModule:
+ """Combine the base language model with adapter. This module will create a
+ instance from base with extended functions in adapter.
+
+ Args:
+ base (object): Base module could be any object that represent
+ a instance of language model or a dict that can build the
+ base module.
+ adapter: (dict): Dict to build the adapter.
+ """
+
+ def __new__(cls, base: object, adapter: dict):
+
+ if isinstance(base, dict):
+ base = MODELS.build(base)
+
+ adapter_module = MODELS.get(adapter.pop('type'))
+ cls.extend_instance(base, adapter_module)
+ return adapter_module.extend_init(base, **adapter)
+
+ @classmethod
+ def extend_instance(cls, base: object, mixin: Type[Any]):
+ """Apply mixins to a class instance after creation.
+
+ Args:
+ base (object): Base module instance.
+ mixin: (Type[Any]): Adapter class type to mixin.
+ """
+ base_cls = base.__class__
+ base_cls_name = base.__class__.__name__
+ base.__class__ = type(
+ base_cls_name, (mixin, base_cls),
+ {}) # mixin needs to go first for our forward() logic to work
+
+
+def getattr_recursive(obj, att):
+ """
+ Return nested attribute of obj
+ Example: getattr_recursive(obj, 'a.b.c') is equivalent to obj.a.b.c
+ """
+ if att == '':
+ return obj
+ i = att.find('.')
+ if i < 0:
+ return getattr(obj, att)
+ else:
+ return getattr_recursive(getattr(obj, att[:i]), att[i + 1:])
+
+
+def setattr_recursive(obj, att, val):
+ """
+ Set nested attribute of obj
+ Example: setattr_recursive(obj, 'a.b.c', val)
+ is equivalent to obj.a.b.c = val
+ """
+ if '.' in att:
+ obj = getattr_recursive(obj, '.'.join(att.split('.')[:-1]))
+ setattr(obj, att.split('.')[-1], val)
diff --git a/mmpretrain/models/multimodal/ofa/__init__.py b/mmpretrain/models/multimodal/ofa/__init__.py
new file mode 100644
index 00000000000..bcb3f45f09b
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .ofa import OFA
+from .ofa_modules import OFADecoder, OFAEncoder, OFAEncoderDecoder
+
+__all__ = ['OFAEncoderDecoder', 'OFA', 'OFAEncoder', 'OFADecoder']
diff --git a/mmpretrain/models/multimodal/ofa/ofa.py b/mmpretrain/models/multimodal/ofa/ofa.py
new file mode 100644
index 00000000000..e15787a60d6
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/ofa.py
@@ -0,0 +1,320 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import string
+from collections import defaultdict
+from functools import partial
+from typing import Optional, Union
+
+import mmengine
+import torch
+from mmengine.model import BaseModel
+
+from mmpretrain.datasets import CleanCaption
+from mmpretrain.registry import MODELS, TOKENIZER
+from mmpretrain.structures import DataSample
+from .ofa_modules import OFAEncoderDecoder
+
+
+class TreeNode():
+
+ def __init__(self):
+ self.child = defaultdict(TreeNode)
+
+
+class Trie:
+
+ def __init__(self, eos):
+ self.root = TreeNode()
+ self.eos = eos
+
+ def insert(self, word):
+ cur = self.root
+ for c in word:
+ cur = cur.child[c]
+
+ def get_next_layer(self, word):
+ cur = self.root
+ for c in word:
+ cur = cur.child.get(c)
+ if cur is None:
+ return [self.eos]
+ return list(cur.child.keys())
+
+
+def apply_constraint(
+ input_ids: torch.Tensor,
+ logits: torch.Tensor,
+ decoder_prompts: Optional[list],
+ num_beams: int,
+ constraint_trie: Trie = None,
+):
+ if decoder_prompts is None and constraint_trie is None:
+ return logits
+
+ mask = logits.new_zeros(logits[:, -1, :].size(), dtype=torch.bool)
+ input_ids = input_ids.view(-1, num_beams, input_ids.shape[-1])
+ for batch_id, beam_sent in enumerate(input_ids):
+ for beam_id, sent in enumerate(beam_sent):
+ if decoder_prompts is None:
+ prompt_len = 0
+ else:
+ prompt_len = len(decoder_prompts[batch_id])
+
+ if sent.size(0) - 1 < prompt_len:
+ allowed_tokens = [decoder_prompts[batch_id][sent.size(0) - 1]]
+ mask[batch_id * num_beams + beam_id, allowed_tokens] = True
+ elif constraint_trie is not None:
+ answer_tokens = [0] + sent[prompt_len + 1:].tolist()
+ allowed_tokens = constraint_trie.get_next_layer(answer_tokens)
+ mask[batch_id * num_beams + beam_id, allowed_tokens] = True
+ else:
+ mask[batch_id * num_beams + beam_id, :] = True
+ logits[:, -1, :].masked_fill_(~mask, float('-inf'))
+ return logits
+
+
+@MODELS.register_module()
+class OFA(BaseModel):
+ """The OFA model for multiple tasks.
+
+ Args:
+ encoder_cfg (dict): The config of the encoder, accept the keyword
+ arguments of :class:`OFAEncoder`.
+ decoder_cfg (dict): The config of the decoder, accept the keyword
+ arguments of :class:`OFADecoder`.
+ vocab_size (int): The size of the vocabulary.
+ embedding_dim (int): The embedding dimensions of both the encoder
+ and the decoder.
+ tokenizer (dict | PreTrainedTokenizer): The tokenizer to encode
+ the text.
+ task (str): The task name, supported tasks are "caption", "vqa" and
+ "refcoco".
+ prompt (str, optional): The prompt template for the following tasks,
+ If None, use default prompt:
+
+ - **caption**: ' what does the image describe?'
+ - **refcoco**: ' which region does the text " {} " describe?'
+
+ Defaults to None
+ ans2label (str | Sequence | None): The answer to label mapping for
+ the vqa task. If a string, it should be a pickle or json file.
+ The sequence constrains the output answers. Defaults to None,
+ which means no constraint.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of :class:`~transformers.GenerationConfig`.
+ Defaults to an empty dict.
+ data_preprocessor (dict, optional): The config for preprocessing input
+ data. If None or no specified type, it will use
+ "MultiModalDataPreprocessor" as type. See :class:
+ `MultiModalDataPreprocessor` for more details. Defaults to None.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+ support_tasks = {'caption', 'vqa', 'refcoco'}
+
+ def __init__(
+ self,
+ encoder_cfg,
+ decoder_cfg,
+ vocab_size,
+ embedding_dim,
+ tokenizer,
+ task,
+ prompt=None,
+ ans2label: Union[dict, str, None] = None,
+ generation_cfg=dict(),
+ data_preprocessor: Optional[dict] = None,
+ init_cfg=None,
+ ):
+ if data_preprocessor is None:
+ data_preprocessor = {}
+ if isinstance(data_preprocessor, dict):
+ data_preprocessor.setdefault('type', 'MultiModalDataPreprocessor')
+ data_preprocessor = MODELS.build(data_preprocessor)
+
+ super().__init__(
+ init_cfg=init_cfg, data_preprocessor=data_preprocessor)
+
+ if isinstance(tokenizer, dict):
+ self.tokenizer = TOKENIZER.build(tokenizer)
+ else:
+ self.tokenizer = tokenizer
+
+ if task not in self.support_tasks:
+ raise ValueError(f'Unsupported task {task}, please select '
+ f'the task from {self.support_tasks}.')
+
+ self.prompt = prompt
+ self.task = task
+
+ if isinstance(ans2label, str):
+ self.ans2label = mmengine.load(ans2label)
+ else:
+ self.ans2label = ans2label
+
+ if self.task == 'vqa' and self.ans2label is not None:
+ self.constraint_trie = Trie(eos=self.tokenizer.eos_token_id)
+ answers = [f' {answer}' for answer in self.ans2label]
+ answer_tokens = self.tokenizer(answers, padding=False)
+ for answer_token in answer_tokens['input_ids']:
+ self.constraint_trie.insert(answer_token)
+ else:
+ self.constraint_trie = None
+
+ generation_cfg = {
+ 'num_beams': 5,
+ 'max_new_tokens': 20,
+ 'no_repeat_ngram_size': 3,
+ **generation_cfg,
+ }
+ self.model = OFAEncoderDecoder(
+ encoder_cfg=encoder_cfg,
+ decoder_cfg=decoder_cfg,
+ padding_idx=self.tokenizer.pad_token_id,
+ vocab_size=vocab_size,
+ embedding_dim=embedding_dim,
+ generation_cfg=generation_cfg,
+ )
+
+ def forward(
+ self,
+ images: torch.Tensor,
+ data_samples: Optional[list] = None,
+ mode: str = 'predict',
+ **kwargs,
+ ):
+ """The unified entry for a forward process in both training and test.
+ The method accepts the following modes:
+
+ - "predict": Forward and return a list of data samples contain the
+ predict results.
+
+ Args:
+ images (torch.Tensor): the preprocessed image tensor of shape
+ ``(N, C, H, W)``.
+ data_samples (List[DataSample], optional): The annotation data
+ of every samples. Defaults to None.
+ mode (str): Return what kind of value. Defaults to 'predict'.
+ """
+ if mode == 'predict':
+ return self.predict(images, data_samples, **kwargs)
+ else:
+ raise RuntimeError(f'Invalid mode "{mode}".')
+
+ def predict(
+ self,
+ images,
+ data_samples=None,
+ post_process=True,
+ **generation_config,
+ ):
+ text_tokens = self.preprocess_text(data_samples, images.size(0),
+ images.device)
+
+ if 'images_mask' in data_samples[0]:
+ images_mask = torch.tensor([
+ sample.get('images_mask') for sample in data_samples
+ ]).bool().to(images.device)
+ else:
+ images_mask = None
+
+ num_beams = generation_config.get(
+ 'num_beams', getattr(self.model.generation_config, 'num_beams'))
+ decoder_prompts = self.get_decoder_prompts(data_samples)
+ constrain_fn = partial(
+ apply_constraint,
+ constraint_trie=self.constraint_trie,
+ decoder_prompts=decoder_prompts,
+ num_beams=num_beams,
+ )
+
+ outputs = self.model.generate(
+ input_ids=text_tokens,
+ images=images,
+ images_mask=images_mask,
+ constrain_fn=constrain_fn,
+ **generation_config,
+ )
+
+ if decoder_prompts is not None:
+ # Remove the prefix decoder prompt.
+ for prompt_ids, token in zip(decoder_prompts, outputs):
+ token[1:len(prompt_ids) + 1] = self.tokenizer.pad_token_id
+
+ if post_process:
+ return self.post_process(outputs, data_samples)
+ else:
+ return outputs
+
+ def get_decoder_prompts(self, data_samples):
+ decoder_prompts = []
+ if 'decoder_prompt' not in data_samples[0]:
+ return None
+ for sample in data_samples:
+ prompt = ' ' + sample.get('decoder_prompt')
+ prompt_ids = self.tokenizer(prompt, add_special_tokens=False)
+ prompt_ids = prompt_ids['input_ids']
+ decoder_prompts.append(prompt_ids)
+ return decoder_prompts
+
+ def preprocess_text(self, data_samples, batch_size, device):
+ if self.task == 'caption':
+ prompt = self.prompt or ' what does the image describe?'
+ prompts = [prompt] * batch_size
+ prompts = self.tokenizer(prompts, return_tensors='pt')
+ return prompts.input_ids.to(device)
+ elif self.task == 'vqa':
+ prompts = []
+ for sample in data_samples:
+ assert 'question' in sample
+ prompt = ' ' + sample.get('question')
+ prompts.append(prompt)
+ prompts = self.tokenizer(
+ prompts, return_tensors='pt', padding=True)
+ return prompts.input_ids.to(device)
+ elif self.task == 'refcoco':
+ prompt_template = self.prompt or \
+ ' which region does the text " {} " describe?'
+ prompts = []
+ for sample in data_samples:
+ assert 'text' in sample
+ prompt = prompt_template.format(sample.get('text'))
+ prompts.append(prompt)
+ prompts = self.tokenizer(
+ prompts, return_tensors='pt', padding=True)
+ return prompts.input_ids.to(device)
+
+ def post_process(self, outputs, data_samples):
+
+ out_data_samples = []
+ if data_samples is None:
+ data_samples = [None] * outputs.size(0)
+
+ for data_sample, token in zip(data_samples, outputs):
+ if data_sample is None:
+ data_sample = DataSample()
+
+ if self.task == 'caption':
+ text = self.tokenizer.decode(token, skip_special_tokens=True)
+ text = CleanCaption(
+ lowercase=False,
+ remove_chars=string.punctuation).clean(text)
+ data_sample.pred_caption = text
+ elif self.task == 'vqa':
+ text = self.tokenizer.decode(token, skip_special_tokens=True)
+ data_sample.pred_answer = text.strip()
+ elif self.task == 'refcoco':
+ bbox = token[1:5] - self.tokenizer.bin_offset
+ # During training, the bbox is normalized by 512. It's related
+ # to the `max_image_size` config in the official repo.
+ bbox = bbox / self.tokenizer.num_bins * 512
+ scale_factor = data_sample.get('scale_factor', (1, 1))
+ bbox[0::2] /= scale_factor[0]
+ bbox[1::2] /= scale_factor[1]
+ data_sample.pred_bboxes = bbox.unsqueeze(0)
+ if 'gt_bboxes' in data_sample:
+ gt_bboxes = bbox.new_tensor(data_sample.gt_bboxes)
+ gt_bboxes[:, 0::2] /= scale_factor[0]
+ gt_bboxes[:, 1::2] /= scale_factor[1]
+ data_sample.gt_bboxes = gt_bboxes
+ out_data_samples.append(data_sample)
+
+ return out_data_samples
diff --git a/mmpretrain/models/multimodal/ofa/ofa_modules.py b/mmpretrain/models/multimodal/ofa/ofa_modules.py
new file mode 100644
index 00000000000..1c79049b617
--- /dev/null
+++ b/mmpretrain/models/multimodal/ofa/ofa_modules.py
@@ -0,0 +1,1612 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from dataclasses import dataclass
+from functools import partial
+from typing import List, Optional, Tuple
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from mmcv.cnn.bricks import DropPath
+from mmengine.model import BaseModule
+from mmengine.utils import digit_version
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions, ModelOutput, Seq2SeqLMOutput)
+from transformers.modeling_utils import (GenerationConfig, GenerationMixin,
+ PretrainedConfig)
+
+from mmpretrain.registry import MODELS
+from ...backbones.resnet import Bottleneck, ResNet
+
+if digit_version(torch.__version__) >= digit_version('1.10.0'):
+ torch_meshgrid = partial(torch.meshgrid, indexing='ij')
+else:
+ torch_meshgrid = torch.meshgrid
+
+
+def make_token_bucket_position(bucket_size, max_position=1024):
+ context_pos = torch.arange(max_position, dtype=torch.long)[:, None]
+ memory_pos = torch.arange(max_position, dtype=torch.long)[None, :]
+ relative_pos = context_pos - memory_pos
+ sign = torch.sign(relative_pos)
+ mid = bucket_size // 2
+ abs_pos = torch.where((relative_pos < mid) & (relative_pos > -mid),
+ mid - 1, torch.abs(relative_pos))
+ log_pos = torch.ceil(
+ torch.log(abs_pos / mid) / math.log(
+ (max_position - 1) / mid) * (mid - 1)) + mid
+ log_pos = log_pos.int()
+ bucket_pos = torch.where(abs_pos.le(mid), relative_pos,
+ log_pos * sign).long()
+ return bucket_pos + bucket_size - 1
+
+
+def make_image_bucket_position(bucket_size, num_relative_distance):
+ coords_h = torch.arange(bucket_size)
+ coords_w = torch.arange(bucket_size)
+ # (2, h, w)
+ coords = torch.stack(torch_meshgrid([coords_h, coords_w]))
+ # (2, h*w)
+ coords_flatten = torch.flatten(coords, 1)
+ # (2, h*w, h*w)
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
+ # (h*w, h*w, 2)
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous()
+ relative_coords[:, :, 0] += bucket_size - 1 # shift to start from 0
+ relative_coords[:, :, 1] += bucket_size - 1
+ relative_coords[:, :, 0] *= 2 * bucket_size - 1
+ relative_position_index = torch.zeros(
+ size=(bucket_size * bucket_size + 1, ) * 2,
+ dtype=relative_coords.dtype)
+ # (h*w, h*w)
+ relative_position_index[1:, 1:] = relative_coords.sum(-1)
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+
+def _make_causal_mask(input_ids_shape: torch.Size,
+ dtype: torch.dtype,
+ past_key_values_length: int = 0):
+ """Make causal mask used for uni-directional self-attention."""
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), float('-inf'))
+ mask_cond = torch.arange(mask.size(-1))
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat(
+ [torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask],
+ dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len,
+ tgt_len + past_key_values_length)
+
+
+def _expand_mask(mask: torch.Tensor,
+ dtype: torch.dtype,
+ tgt_len: Optional[int] = None):
+ """Expands attention_mask from ``[B, L_s]`` to ``[B, 1, L_t, L_s]``.
+
+ Where ``B`` is batch_size, `L_s`` is the source sequence length, and
+ ``L_t`` is the target sequence length.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len,
+ src_len).to(dtype)
+ return expanded_mask.masked_fill(expanded_mask.bool(),
+ torch.finfo(dtype).min)
+
+
+class MultiheadAttention(BaseModule):
+ """Multi-head Attention Module for OFA.
+
+ Args:
+ embedding_dim (int): The embedding dimension of query.
+ num_heads (int): Parallel attention heads.
+ kdim (int, optional): The embedding dimension of key.
+ Defaults to None, which means the same as the `embedding_dim`.
+ vdim (int, optional): The embedding dimension of value.
+ Defaults to None, which means the same as the `embedding_dim`.
+ attn_drop (float): Dropout rate of the dropout layer after the
+ attention calculation of query and key. Defaults to 0.
+ qkv_bias (bool): If True, add a learnable bias to q, k, v.
+ Defaults to True.
+ scale_factor (float): The scale of qk will be
+ ``(head_dim * scale_factor) ** -0.5``. Defaults to 1.
+ proj_bias (bool) If True, add a learnable bias to output projection.
+ Defaults to True.
+ init_cfg (dict, optional): The Config for initialization.
+ Defaults to None.
+ """
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ kdim=None,
+ vdim=None,
+ attn_drop=0.,
+ scale_factor=1.,
+ qkv_bias=True,
+ proj_bias=True,
+ scale_heads=False,
+ init_cfg=None):
+ super(MultiheadAttention, self).__init__(init_cfg=init_cfg)
+
+ self.embedding_dim = embedding_dim
+ self.num_heads = num_heads
+ self.kdim = kdim or embedding_dim
+ self.vdim = vdim or embedding_dim
+
+ self.head_dim = embedding_dim // num_heads
+ self.scale = (self.head_dim * scale_factor)**-0.5
+
+ self.q_proj = nn.Linear(embedding_dim, embedding_dim, bias=qkv_bias)
+ self.k_proj = nn.Linear(self.kdim, embedding_dim, bias=qkv_bias)
+ self.v_proj = nn.Linear(self.vdim, embedding_dim, bias=qkv_bias)
+ self.out_proj = nn.Linear(embedding_dim, embedding_dim, bias=proj_bias)
+
+ self.attn_drop = nn.Dropout(p=attn_drop)
+
+ if scale_heads:
+ self.c_attn = nn.Parameter(torch.ones(num_heads))
+ else:
+ self.c_attn = None
+
+ def forward(
+ self,
+ query,
+ key_value=None,
+ attn_mask=None,
+ attn_bias=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ B, _, C = query.shape
+ assert C == self.head_dim * self.num_heads
+
+ is_cross_attention = key_value is not None
+ if key_value is None:
+ key_value = query
+
+ # (B, L, C) -> (B, num_heads, L, head_dims)
+ q = self.q_proj(query).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+
+ if is_cross_attention and past_key_value is not None:
+ # Reuse key and value in cross_attentions
+ k, v = past_key_value
+ else:
+ k = self.k_proj(key_value).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ v = self.v_proj(key_value).reshape(B, -1, self.num_heads,
+ self.head_dim).transpose(1, 2)
+ if past_key_value is not None:
+ past_key, past_value = past_key_value
+ k = torch.cat([past_key, k], dim=2)
+ v = torch.cat([past_value, v], dim=2)
+
+ past_key_value = (k, v)
+
+ attn_weights = q @ k.transpose(-2, -1) * self.scale
+
+ if attn_bias is not None:
+ src_len = k.size(2)
+ attn_weights[:, :, -src_len:] += attn_bias[:, :, -src_len:]
+
+ if attn_mask is not None:
+ attn_weights += attn_mask
+ attn_weights = torch.softmax(attn_weights, dim=-1)
+ attn = self.attn_drop(attn_weights) @ v
+
+ if self.c_attn is not None:
+ attn = torch.einsum('bhlc,h->bhlc', attn, self.c_attn)
+
+ # (B, num_heads, L, head_dims) -> (B, L, C)
+ attn = attn.transpose(1, 2).reshape(B, -1, self.embedding_dim)
+ attn = self.out_proj(attn)
+
+ if output_attentions:
+ return attn, attn_weights, past_key_value
+ else:
+ return attn, None, past_key_value
+
+
+@MODELS.register_module(force=True)
+class OFAResNet(ResNet):
+ """ResNet module for OFA.
+
+ The ResNet in OFA has only three stages.
+ """
+ arch_settings = {
+ 50: (Bottleneck, (3, 4, 6)),
+ 101: (Bottleneck, (3, 4, 23)),
+ 152: (Bottleneck, (3, 8, 36)),
+ }
+
+ def __init__(self, depth, *args, **kwargs):
+ super().__init__(
+ depth=depth,
+ *args,
+ num_stages=3,
+ out_indices=(2, ),
+ dilations=(1, 1, 1),
+ strides=(1, 2, 2),
+ **kwargs)
+
+
+@dataclass
+class OFAEncoderOutput(ModelOutput):
+ """OFA encoder outputs.
+
+ Args:
+ last_hidden_state (torch.tensor): The hidden-states of the output at
+ the last layer of the model. The shape is (B, L, C).
+ hidden_states (Tuple[torch.tensor]): The initial embedding and the
+ output of each layer. The shape of every item is (B, L, C).
+ attentions (Tuple[torch.tensor]): The attention weights after the
+ attention softmax, used to compute the weighted average in the
+ self-attention heads. The shape of every item is
+ (B, num_heads, L, L).
+ position_embedding (torch.tensor): The positional embeddings of the
+ inputs. The shape is (B, L, C).
+ """
+
+ last_hidden_state: torch.FloatTensor = None
+ padding_mask: torch.Tensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+ position_embedding: Optional[torch.FloatTensor] = None
+
+
+class OFAEncoderLayer(nn.Module):
+ """OFAEncoder layer block."""
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ attn_drop=0.,
+ act_drop=0.,
+ scale_factor=2.,
+ mlp_ratio=4.,
+ scale_heads=True,
+ normformer=True,
+ pre_norm=True,
+ act_cfg=dict(type='GELU')):
+ super().__init__()
+ self.embedding_dim = embedding_dim
+ self.pre_norm = pre_norm
+
+ self.attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ mid_channels = int(embedding_dim * mlp_ratio)
+ self.fc1 = nn.Linear(embedding_dim, mid_channels)
+ self.fc2 = nn.Linear(mid_channels, embedding_dim)
+ self.act = MODELS.build(act_cfg)
+ self.act_drop = nn.Dropout(
+ act_drop) if act_drop > 0. else nn.Identity()
+
+ # LayerNorm between attention block and ffn block.
+ self.attn_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_ln = nn.LayerNorm(embedding_dim)
+
+ # Extra LayerNorm
+ self.normformer = normformer
+ if self.normformer:
+ self.attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_mid_ln = nn.LayerNorm(mid_channels)
+
+ self.dropout = nn.Dropout(dropout_rate)
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
+
+ def forward(self,
+ x,
+ attention_mask=None,
+ attn_bias=None,
+ output_attentions=False):
+ """Forward the encoder layer.
+
+ Args:
+ x (torch.tensor): The input to the layer of shape ``(B, L, C)``.
+ attention_mask (torch.Tensor, optional): The attention mask of size
+ ``(B, 1, L, L)``, where padding elements are indicated by very
+ large negative values. Defaults to None.
+ attn_bias (torch.tensor, optional): The bias for positional
+ information. Defaults to None.
+ output_attentions (bool): Whether to return the attentions tensors
+ of the attention layer.
+
+ Returns:
+ List[torch.tensor]: The first element is the encoded output of
+ shape ``(B, L, C)``. And the second element is the output
+ attentions if ``output_attentions=True``.
+ """
+ residual = x
+
+ # Attention block
+ if self.pre_norm:
+ x = self.attn_ln(x)
+ x, attn_weights, _ = self.attn(
+ query=x,
+ attn_mask=attention_mask,
+ attn_bias=attn_bias,
+ output_attentions=output_attentions)
+ if self.normformer:
+ x = self.attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.attn_ln(x)
+
+ residual = x
+
+ # FFN block
+ if self.pre_norm:
+ x = self.ffn_ln(x)
+ x = self.act(self.fc1(x))
+ x = self.act_drop(x)
+ if self.normformer:
+ x = self.ffn_mid_ln(x)
+ x = self.fc2(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.ffn_ln(x)
+
+ if output_attentions:
+ return [x, attn_weights]
+ else:
+ return [x]
+
+
+class OFADecoderLayer(nn.Module):
+ """OFADecoder layer block."""
+
+ def __init__(self,
+ embedding_dim,
+ num_heads,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ attn_drop=0.,
+ act_drop=0.,
+ scale_factor=2.,
+ mlp_ratio=4.,
+ encoder_embed_dim=None,
+ scale_heads=True,
+ normformer=True,
+ pre_norm=True,
+ act_cfg=dict(type='GELU')):
+ super().__init__()
+ self.embedding_dim = embedding_dim
+ self.pre_norm = pre_norm
+
+ self.self_attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ self.cross_attn = MultiheadAttention(
+ embedding_dim=embedding_dim,
+ kdim=encoder_embed_dim,
+ vdim=encoder_embed_dim,
+ num_heads=num_heads,
+ attn_drop=attn_drop,
+ scale_factor=scale_factor,
+ scale_heads=scale_heads,
+ )
+
+ mid_channels = int(embedding_dim * mlp_ratio)
+ self.fc1 = nn.Linear(embedding_dim, mid_channels)
+ self.fc2 = nn.Linear(mid_channels, embedding_dim)
+ self.act = MODELS.build(act_cfg)
+ self.act_drop = nn.Dropout(
+ act_drop) if act_drop > 0. else nn.Identity()
+
+ # LayerNorm between attention block and ffn block.
+ self.self_attn_ln = nn.LayerNorm(embedding_dim)
+ self.cross_attn_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_ln = nn.LayerNorm(embedding_dim)
+
+ # Extra LayerNorm
+ self.normformer = normformer
+ if self.normformer:
+ self.self_attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.cross_attn_mid_ln = nn.LayerNorm(embedding_dim)
+ self.ffn_mid_ln = nn.LayerNorm(mid_channels)
+
+ self.dropout = nn.Dropout(dropout_rate)
+ self.drop_path = DropPath(
+ drop_path_rate) if drop_path_rate > 0.0 else nn.Identity()
+
+ def forward(
+ self,
+ x,
+ attention_mask=None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[List[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ self_attn_bias: Optional[torch.Tensor] = None,
+ cross_attn_bias: Optional[torch.Tensor] = None,
+ ):
+ """Forward the decoder layer.
+
+ Args:
+ x (torch.tensor): The input to the layer of shape ``(B, L, C)``.
+ attention_mask (torch.Tensor, optional): The attention mask of size
+ ``(B, 1, L, L)``, where padding elements are indicated by very
+ large negative values. Defaults to None.
+ encoder_hidden_states (torch.Tensor, optional): The cross attention
+ input to the layer of size ``(B, L, C)``. Defaults to None.
+ encoder_attention_mask (torch.Tensor, optional): The cross
+ attention mask where padding elements are indicated by very
+ large negative values. Defaults to None.
+ past_key_value (Tuple[torch.tensor], optional): The cached past key
+ and value projection states. Defaults to none.
+ output_attentions (bool): whether to return the attentions tensors
+ of all attention layers. Defaults to False.
+ use_cache (bool, optional): Whether to use cache.
+ Defaults to False.
+ self_attn_bias (torch.Tensor, optional): The self attention bias
+ for positional information. Defaults to None.
+ cross_attn_bias (torch.Tensor, optional): The cross attention bias
+ for positional information. Defaults to None.
+
+ Returns:
+ List[torch.tensor]: The first element is the encoded output of
+ shape ``(B, L, C)``. The following two elements can be the output
+ self-attentions and cross-attentions if ``output_attentions=True``.
+ The following one element can be the cached past key and value
+ projection states.
+ """
+ residual = x
+
+ if past_key_value is not None:
+ self_past_key_value = past_key_value[:2]
+ cross_past_key_value = past_key_value[2:]
+ else:
+ self_past_key_value, cross_past_key_value = None, None
+
+ # Self-Attention block
+ if self.pre_norm:
+ x = self.self_attn_ln(x)
+ x, self_attn_weights, present_key_value = self.self_attn(
+ query=x,
+ past_key_value=self_past_key_value,
+ attn_mask=attention_mask,
+ output_attentions=output_attentions,
+ attn_bias=self_attn_bias,
+ )
+ if self.normformer:
+ x = self.self_attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.self_attn_ln(x)
+
+ # Cross-Attention block
+ if encoder_hidden_states is not None:
+ residual = x
+ if self.pre_norm:
+ x = self.cross_attn_ln(x)
+ x, cross_attn_weights, cross_key_value = self.cross_attn.forward(
+ query=x,
+ key_value=encoder_hidden_states,
+ attn_mask=encoder_attention_mask,
+ past_key_value=cross_past_key_value,
+ output_attentions=output_attentions,
+ attn_bias=cross_attn_bias)
+ if self.normformer:
+ x = self.cross_attn_mid_ln(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.cross_attn_ln(x)
+
+ present_key_value = present_key_value + cross_key_value
+
+ residual = x
+
+ # FFN block
+ if self.pre_norm:
+ x = self.ffn_ln(x)
+ x = self.act(self.fc1(x))
+ x = self.act_drop(x)
+ if self.normformer:
+ x = self.ffn_mid_ln(x)
+ x = self.fc2(x)
+ x = self.dropout(x)
+ x = residual + self.drop_path(x)
+ if not self.pre_norm:
+ x = self.ffn_ln(x)
+
+ outputs = [x]
+
+ if output_attentions:
+ outputs.extend([self_attn_weights, cross_attn_weights])
+
+ if use_cache:
+ outputs.append(present_key_value)
+
+ return outputs
+
+
+class OFAEncoder(BaseModule):
+ """The encoder module of OFA.
+
+ Args:
+ embed_tokens (nn.Embedding): The embedding module to embed the
+ input tokens.
+ embed_images (dict | nn.Module): The module to embed the input
+ images into features. The output number of channels should
+ be 1024.
+ num_layers (int): The number of encoder layers. Defaults to 6.
+ num_heads (int): The number of heads of attention. Defaults to 12.
+ dropout_rate (float): The prob of dropout for embedding and
+ transformer layers. Defaults to 0.
+ drop_path_rate (float): The prob of droppath for transformer layers.
+ Defaults to 0.
+ max_source_positions (int): The maximum length of the input tokens.
+ Defaults to 1024.
+ token_bucket_size (int): The token bucket size, it's used as the
+ maximum relative position index in relative position embedding
+ of input tokens. Defaults to 256.
+ image_bucket_size (int): The image bucket size, it's used to generate
+ the image relative position embedding table. It should be larger
+ than the shape of image feature map. Defaults to 42.
+ attn_scale_factor (float): The scale factor to calculate qk scale in
+ attentions. Defaults to 2.
+ scale_embedding (bool): Whether to scale the embeddings by the square
+ root of the dimension. Defaults to False.
+ add_embedding_ln (bool): Whether to add an extra layer norm for token
+ embeddings. Defaults to True.
+ add_image_embedding_ln (bool): Whether to add an extra layer norm for
+ image embeddings. Defaults to True.
+ pre_norm (bool): Whether to do layer norm before attention and ffn
+ blocks in transformer layers. Defaults to True.
+ entangle_position_embedding (bool): Whether to add the position
+ embedding on the embeddings directly. Defaults to False.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ embed_tokens,
+ embed_images: dict,
+ num_layers=6,
+ num_heads=12,
+ dropout_rate=0.,
+ drop_path_rate=0.,
+ max_source_positions=1024,
+ token_bucket_size=256,
+ image_bucket_size=42,
+ attn_scale_factor=2.,
+ scale_embedding=False,
+ add_embedding_ln=True,
+ add_type_embed=True,
+ add_image_embedding_ln=True,
+ pre_norm=True,
+ entangle_position_embedding=False,
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.num_layers = num_layers
+ embedding_dim = embed_tokens.embedding_dim
+ self.embedding_dim = embedding_dim
+ self.padding_idx = embed_tokens.padding_idx
+ self.max_source_positions = max_source_positions
+ self.num_heads = num_heads
+
+ # Build embedding process components
+ self.embed_tokens = embed_tokens
+ self.embedding_scale = math.sqrt(
+ embedding_dim) if scale_embedding else 1.0
+
+ if not isinstance(embed_images, nn.Module):
+ self.embed_images = MODELS.build(embed_images)
+ else:
+ self.embed_images = embed_images
+ self.image_proj = nn.Linear(1024, embedding_dim)
+
+ if add_embedding_ln:
+ self.embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.embedding_ln = None
+
+ if add_type_embed:
+ self.embed_type = nn.Embedding(2, embedding_dim)
+ else:
+ self.embed_type = None
+
+ if add_image_embedding_ln:
+ self.image_embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.image_embedding_ln = None
+
+ self.entangle_position_embedding = entangle_position_embedding
+
+ # Build position embedding
+ self.embed_positions = nn.Embedding(self.max_source_positions + 2,
+ embedding_dim)
+ self.pos_ln = nn.LayerNorm(embedding_dim)
+ self.embed_image_positions = nn.Embedding(image_bucket_size**2 + 1,
+ embedding_dim)
+ self.image_pos_ln = nn.LayerNorm(embedding_dim)
+
+ self.pos_scaling = float(embedding_dim / num_heads *
+ attn_scale_factor)**-0.5
+ self.pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+
+ self.dropout = nn.Dropout(
+ dropout_rate) if dropout_rate > 0. else nn.Identity()
+
+ # Register token relative position embedding table
+ self.token_bucket_size = token_bucket_size
+ token_num_rel_dis = 2 * token_bucket_size - 1
+ token_rp_bucket = make_token_bucket_position(token_bucket_size,
+ self.max_source_positions)
+ self.register_buffer('token_rp_bucket', token_rp_bucket)
+ self.token_rel_pos_table_list = nn.ModuleList()
+
+ # Register image relative position embedding table
+ self.image_bucket_size = image_bucket_size
+ image_num_rel_dis = (2 * image_bucket_size -
+ 1) * (2 * image_bucket_size - 1) + 3
+ image_rp_bucket = make_image_bucket_position(image_bucket_size,
+ image_num_rel_dis)
+ self.register_buffer('image_rp_bucket', image_rp_bucket)
+ self.image_rel_pos_table_list = nn.ModuleList()
+
+ # Build encoder layers
+ self.layers = nn.ModuleList()
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ for index in range(self.num_layers):
+ layer = OFAEncoderLayer(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ dropout_rate=dropout_rate,
+ drop_path_rate=dpr[index],
+ scale_factor=attn_scale_factor,
+ pre_norm=pre_norm,
+ )
+ self.layers.append(layer)
+ token_pos_table = nn.Embedding(token_num_rel_dis, self.num_heads)
+ image_pos_table = nn.Embedding(image_num_rel_dis, self.num_heads)
+ nn.init.constant_(token_pos_table.weight, 0.)
+ nn.init.constant_(image_pos_table.weight, 0.)
+ self.token_rel_pos_table_list.append(token_pos_table)
+ self.image_rel_pos_table_list.append(image_pos_table)
+
+ if pre_norm:
+ self.final_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.final_ln = None
+
+ main_input_name = 'input_ids'
+
+ def forward(self,
+ input_ids,
+ images,
+ images_mask,
+ output_attentions=False,
+ output_hidden_states=False,
+ sample_patch_num=None):
+ padding_mask = input_ids.eq(self.padding_idx)
+ has_pads = padding_mask.any()
+ token_embedding = self.embed_tokens(input_ids)
+ token_embedding = self.embedding_scale * token_embedding
+
+ # Embed the token position
+ src_pos_idx = torch.arange(input_ids.size(-1), device=input_ids.device)
+ src_pos_idx = src_pos_idx.expand(*input_ids.shape).contiguous()
+ pos_embedding = self.embed_positions(src_pos_idx)
+
+ # Embed the input tokens
+ x = self.process_embedding(
+ embedding=token_embedding,
+ type_tokens=input_ids.new_zeros(token_embedding.shape[:2]),
+ pos_embedding=pos_embedding,
+ embedding_ln=self.embedding_ln,
+ )
+ pos_embedding = self.pos_ln(pos_embedding)
+
+ # Embed the input images
+ if images is not None:
+ (image_tokens, image_padding_mask, image_position_ids,
+ image_pos_embedding) = self.get_image_tokens(
+ images,
+ sample_patch_num,
+ images_mask,
+ )
+ image_embedding = self.image_proj(image_tokens)
+
+ image_x = self.process_embedding(
+ embedding=image_embedding,
+ type_tokens=input_ids.new_ones(image_embedding.shape[:2]),
+ pos_embedding=image_pos_embedding,
+ embedding_ln=self.image_embedding_ln,
+ )
+ image_pos_embedding = self.image_pos_ln(image_pos_embedding)
+
+ x = torch.cat([image_x, x], dim=1)
+ padding_mask = torch.cat([image_padding_mask, padding_mask], dim=1)
+ pos_embedding = torch.cat([image_pos_embedding, pos_embedding],
+ dim=1)
+
+ # account for padding while computing the representation
+ if has_pads:
+ x = x * (1 - padding_mask.unsqueeze(-1).type_as(x))
+
+ # Decoupled position embedding
+ B, L = pos_embedding.shape[:2]
+ pos_q = self.pos_q_linear(pos_embedding).view(
+ B, L, self.num_heads, -1).transpose(1, 2) * self.pos_scaling
+ pos_k = self.pos_k_linear(pos_embedding).view(B, L, self.num_heads,
+ -1).transpose(1, 2)
+ abs_pos_bias = torch.matmul(pos_q, pos_k.transpose(2, 3))
+
+ all_hidden_states = [] if output_hidden_states else None
+ all_attentions = [] if output_attentions else None
+
+ for idx, layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ self_attn_bias = abs_pos_bias.clone()
+ # Add decoupled position embedding for input tokens.
+ token_len = input_ids.size(1)
+ rel_pos_bias = self.get_rel_pos_bias(input_ids, idx)
+ self_attn_bias[:, :, -token_len:, -token_len:] += rel_pos_bias
+
+ # Add decoupled position embedding for images
+ if images is not None:
+ token_len = image_tokens.size(1)
+ rel_pos_bias = self.get_image_rel_pos_bias(
+ image_position_ids, idx)
+ self_attn_bias[:, :, :token_len, :token_len] += rel_pos_bias
+
+ if has_pads:
+ attention_mask = _expand_mask(padding_mask, dtype=x.dtype)
+ else:
+ attention_mask = None
+
+ out = layer(
+ x,
+ attention_mask=attention_mask,
+ attn_bias=self_attn_bias,
+ output_attentions=output_attentions)
+ x = out[0]
+
+ if output_attentions:
+ all_attentions.append(out[1])
+
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ if self.final_ln is not None:
+ x = self.final_ln(x)
+
+ return OFAEncoderOutput(
+ last_hidden_state=x, # (B, L, C)
+ padding_mask=padding_mask, # (B, L)
+ position_embedding=pos_embedding, # (B, L, C)
+ hidden_states=all_hidden_states, # list of (B, L, C)
+ attentions=all_attentions, # list of (B, num_heads, L, head_dims)
+ )
+
+ def get_image_tokens(self, images, sample_patch_num, images_mask):
+ image_embedding = self.embed_images(images)[-1]
+ B, C, H, W = image_embedding.shape
+ num_patches = H * W
+
+ padding_mask = images.new_zeros((B, num_patches)).bool()
+ position_col = torch.arange(W).unsqueeze(0)
+ position_row = torch.arange(H).unsqueeze(1) * self.image_bucket_size
+ position_idx = (position_col + position_row + 1).view(-1)
+ position_idx = position_idx.to(images.device).expand(B, num_patches)
+
+ # (B, C, H, W) -> (B, C, H*W) -> (B, H*W, C)
+ image_embedding = image_embedding.flatten(2).transpose(1, 2)
+ if sample_patch_num is not None:
+ patch_orders = torch.stack([
+ torch.randperm(num_patches)[:sample_patch_num]
+ for _ in range(B)
+ ])
+ num_patches = sample_patch_num
+ image_embedding = image_embedding.gather(
+ dim=1, index=patch_orders.unsqueeze(2).expand(-1, -1, C))
+ padding_mask = padding_mask.gather(1, patch_orders)
+ position_idx = position_idx.gather(1, patch_orders)
+
+ pos_embedding = self.embed_image_positions(position_idx)
+ padding_mask[~images_mask] = True
+ return image_embedding, padding_mask, position_idx, pos_embedding
+
+ def process_embedding(self,
+ embedding,
+ pos_embedding=None,
+ type_tokens=None,
+ embedding_ln=None):
+ if self.entangle_position_embedding and pos_embedding is not None:
+ embedding += pos_embedding
+ if self.embed_type is not None:
+ embedding += self.embed_type(type_tokens)
+ if embedding_ln is not None:
+ embedding = embedding_ln(embedding)
+ embedding = self.dropout(embedding)
+
+ return embedding
+
+ def get_rel_pos_bias(self, x, idx):
+ seq_len = x.size(1)
+ rp_bucket = self.token_rp_bucket[:seq_len, :seq_len]
+ values = F.embedding(rp_bucket,
+ self.token_rel_pos_table_list[idx].weight)
+ values = values.unsqueeze(0).expand(x.size(0), -1, -1, -1)
+ values = values.permute([0, 3, 1, 2])
+ return values.contiguous()
+
+ def get_image_rel_pos_bias(self, image_position_ids, idx):
+ bsz, seq_len = image_position_ids.shape
+ rp_bucket_size = self.image_rp_bucket.size(1)
+
+ rp_bucket = self.image_rp_bucket.unsqueeze(0).expand(
+ bsz, rp_bucket_size, rp_bucket_size).gather(
+ 1, image_position_ids[:, :, None].expand(
+ bsz, seq_len, rp_bucket_size)).gather(
+ 2, image_position_ids[:, None, :].expand(
+ bsz, seq_len, seq_len))
+ values = F.embedding(rp_bucket,
+ self.image_rel_pos_table_list[idx].weight)
+ values = values.permute(0, 3, 1, 2)
+ return values
+
+
+class OFADecoder(BaseModule):
+ """The decoder module of OFA.
+
+ Args:
+ embed_tokens (nn.Embedding): The embedding module to embed the
+ input tokens.
+ num_layers (int): The number of decoder layers. Defaults to 6.
+ num_heads (int): The number of heads of attention. Defaults to 12.
+ dropout_rate (float): The prob of dropout for embedding and
+ transformer layers. Defaults to 0.
+ drop_path_rate (float): The prob of droppath for transformer layers.
+ Defaults to 0.
+ max_target_positions (int): The maximum length of the input tokens.
+ Defaults to 1024.
+ code_image_size (int): The resolution of the generated image in the
+ image infilling task. Defaults to 128.
+ token_bucket_size (int): The token bucket size, it's used as the
+ maximum relative position index in relative position embedding
+ of input tokens. Defaults to 256.
+ image_bucket_size (int): The image bucket size, it's used to generate
+ the image relative position embedding table. It should be larger
+ than the shape of image feature map. Defaults to 42.
+ attn_scale_factor (float): The scale factor to calculate qk scale in
+ attentions. Defaults to 2.
+ scale_embedding (bool): Whether to scale the embeddings by the square
+ root of the dimension. Defaults to False.
+ add_embedding_ln (bool): Whether to add an extra layer norm for token
+ embeddings. Defaults to True.
+ add_code_embedding_ln (bool): Whether to add an extra layer norm for
+ code embeddings. Defaults to True.
+ pre_norm (bool): Whether to do layer norm before attention and ffn
+ blocks in transformer layers. Defaults to True.
+ entangle_position_embedding (bool): Whether to add the position
+ embedding on the embeddings directly. Defaults to False.
+ share_input_output_embed (bool): Share the weights of the input token
+ embedding module and the output projection module.
+ Defaults to True.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ embed_tokens,
+ num_layers=6,
+ num_heads=12,
+ dropout_rate=0.,
+ drop_layer_rate=0.,
+ drop_path_rate=0.,
+ max_target_positions=1024,
+ code_image_size=128,
+ token_bucket_size=256,
+ image_bucket_size=42,
+ attn_scale_factor=2.,
+ scale_embedding=False,
+ add_embedding_ln=True,
+ add_code_embedding_ln=True,
+ pre_norm=True,
+ entangle_position_embedding=False,
+ share_input_output_embed=True,
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+ self._future_mask = torch.empty(0)
+
+ self.num_layers = num_layers
+ embedding_dim = embed_tokens.embedding_dim
+ self.embedding_dim = embedding_dim
+ self.padding_idx = embed_tokens.padding_idx
+ self.max_target_positions = max_target_positions
+ self.num_heads = num_heads
+
+ # Build embedding process components
+ self.embed_tokens = embed_tokens
+ self.embedding_scale = math.sqrt(
+ embedding_dim) if scale_embedding else 1.0
+
+ if add_embedding_ln:
+ self.embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.embedding_ln = None
+
+ if add_code_embedding_ln:
+ self.code_embedding_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.code_embedding_ln = None
+
+ # Build position embedding
+ self.embed_positions = nn.Embedding(self.max_target_positions + 2,
+ embedding_dim)
+ self.pos_ln = nn.LayerNorm(embedding_dim)
+ self.embed_image_positions = nn.Embedding(image_bucket_size**2 + 1,
+ embedding_dim)
+ self.image_pos_ln = nn.LayerNorm(embedding_dim)
+
+ self.pos_scaling = float(embedding_dim / num_heads *
+ attn_scale_factor)**-0.5
+ self.self_pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.self_pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.cross_pos_q_linear = nn.Linear(embedding_dim, embedding_dim)
+ self.cross_pos_k_linear = nn.Linear(embedding_dim, embedding_dim)
+
+ self.entangle_position_embedding = entangle_position_embedding
+
+ self.dropout = nn.Dropout(
+ dropout_rate) if dropout_rate > 0. else nn.Identity()
+ if drop_layer_rate > 0.:
+ raise NotImplementedError
+
+ # Register token relative position embedding table
+ self.token_bucket_size = token_bucket_size
+ token_num_rel_dis = 2 * token_bucket_size - 1
+ token_rp_bucket = make_token_bucket_position(token_bucket_size)
+ self.register_buffer('token_rp_bucket', token_rp_bucket)
+ self.token_rel_pos_table_list = nn.ModuleList()
+
+ # Register image relative position embedding table
+ self.image_bucket_size = image_bucket_size
+ image_num_rel_dis = (2 * image_bucket_size -
+ 1) * (2 * image_bucket_size - 1) + 3
+ image_rp_bucket = make_image_bucket_position(image_bucket_size,
+ image_num_rel_dis)
+ self.register_buffer('image_rp_bucket', image_rp_bucket)
+ self.image_rel_pos_table_list = nn.ModuleList()
+
+ self.window_size = code_image_size // 8
+
+ position_col = torch.arange(self.window_size).unsqueeze(0)
+ position_row = torch.arange(
+ self.window_size).unsqueeze(1) * self.image_bucket_size
+ image_position_idx = (position_col + position_row + 1)
+ image_position_idx = torch.cat(
+ [torch.tensor([0]), image_position_idx.view(-1)])
+ image_position_idx = torch.cat(
+ [image_position_idx,
+ torch.tensor([1024] * 768)])
+ self.register_buffer('image_position_idx', image_position_idx)
+
+ # Build decoder layers
+ self.layers = nn.ModuleList()
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_layers)]
+ for index in range(self.num_layers):
+ layer = OFADecoderLayer(
+ embedding_dim=embedding_dim,
+ num_heads=num_heads,
+ dropout_rate=dropout_rate,
+ drop_path_rate=dpr[index],
+ scale_factor=attn_scale_factor,
+ pre_norm=pre_norm,
+ )
+ self.layers.append(layer)
+ token_pos_table = nn.Embedding(token_num_rel_dis, self.num_heads)
+ image_pos_table = nn.Embedding(image_num_rel_dis, self.num_heads)
+ nn.init.constant_(token_pos_table.weight, 0.)
+ nn.init.constant_(image_pos_table.weight, 0.)
+ self.token_rel_pos_table_list.append(token_pos_table)
+ self.image_rel_pos_table_list.append(image_pos_table)
+
+ if pre_norm:
+ self.final_ln = nn.LayerNorm(embedding_dim)
+ else:
+ self.final_ln = None
+
+ # Build output projection
+ if share_input_output_embed:
+ self.output_projection = nn.Linear(
+ self.embed_tokens.weight.shape[1],
+ self.embed_tokens.weight.shape[0],
+ bias=False,
+ )
+ self.output_projection.weight = self.embed_tokens.weight
+ else:
+ vocab_size = self.embed_tokens.num_embeddings
+ self.output_projection = nn.Linear(
+ embedding_dim, vocab_size, bias=False)
+ nn.init.normal_(
+ self.output_projection.weight,
+ mean=0,
+ std=embedding_dim**-0.5,
+ )
+
+ main_input_name = 'input_ids'
+
+ def forward(
+ self,
+ input_ids: torch.Tensor = None,
+ attention_mask: torch.Tensor = None,
+ encoder_hidden_states: torch.Tensor = None,
+ encoder_attention_mask: torch.Tensor = None,
+ code_masks: Optional[torch.Tensor] = None,
+ encoder_pos_embedding: Optional[torch.Tensor] = None,
+ past_key_values: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ ):
+
+ if past_key_values is not None and len(past_key_values) > 0:
+ B, _, L_past, _ = past_key_values[0][0].shape
+ L = L_past + 1
+ else:
+ B, L = input_ids.shape
+ L_past = 0
+
+ # Embed the token position
+ target_pos_idx = torch.arange(
+ L, device=input_ids.device).expand([B, L]).contiguous()
+ pos_embedding = self.embed_positions(target_pos_idx)
+
+ # Embed the code positions
+ if code_masks is not None and torch.any(code_masks):
+ image_position_idx = self.image_position_idx[:input_ids.size(1)]
+ image_position_idx = image_position_idx.unsqueeze(0).expand(B, L)
+ pos_embedding[code_masks] = self.embed_image_positions(
+ image_position_idx)[code_masks]
+
+ # Self-attention position bias (B, num_heads, L_t, L_t)
+ self_abs_pos_bias = self.get_pos_info(self.pos_ln(pos_embedding))
+ if code_masks is not None and torch.any(code_masks):
+ self_image_abs_pos_bias = self.get_pos_info(
+ self.image_pos_ln(pos_embedding))
+ self_abs_pos_bias[code_masks] = self_image_abs_pos_bias[code_masks]
+
+ # Cross-attention position bias (B, num_heads, L_t, L_s)
+ cross_abs_pos_bias = self.get_pos_info(
+ self.pos_ln(pos_embedding), encoder_pos_embedding)
+ if code_masks is not None and torch.any(code_masks):
+ cross_image_abs_pos_bias = self.get_pos_info(
+ self.image_pos_ln(pos_embedding), encoder_pos_embedding)
+ cross_abs_pos_bias[code_masks] = cross_image_abs_pos_bias[
+ code_masks]
+
+ all_prev_output_tokens = input_ids.clone()
+ if past_key_values is not None and len(past_key_values) > 0:
+ input_ids = input_ids[:, -1:]
+ cross_abs_pos_bias = cross_abs_pos_bias[:, :, -1:, :]
+ pos_embedding = pos_embedding[:, -1:, :]
+
+ # Embed the input tokens
+ x = self.embed_tokens(input_ids) * self.embedding_scale
+
+ if self.entangle_position_embedding:
+ x += pos_embedding
+
+ if self.embedding_ln is not None:
+ if (code_masks is None or not code_masks.any()
+ or self.code_embedding_ln is None):
+ x = self.embedding_ln(x)
+ elif code_masks is not None and code_masks.all():
+ x = self.code_embedding_ln(x)
+ else:
+ x[~code_masks] = self.embedding_ln(x[~code_masks])
+ x[code_masks] = self.code_embedding_ln(x[code_masks])
+
+ x = self.dropout(x)
+
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, input_ids.shape, x.dtype, L_past)
+ attention_mask = attention_mask.to(x.device)
+
+ # decoder layers
+ all_hidden_states = [] if output_hidden_states else None
+ all_self_attns = [] if output_attentions else None
+ all_cross_attentions = [] if (
+ output_attentions and encoder_hidden_states is not None) else None
+ next_decoder_cache = [] if use_cache else None
+
+ for idx, layer in enumerate(self.layers):
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states.append(x)
+
+ if past_key_values is not None and len(past_key_values) > 0:
+ past_key_value = past_key_values[idx]
+ else:
+ past_key_value = None
+
+ self_attn_bias = self_abs_pos_bias.clone()
+ if code_masks is None or not code_masks.any():
+ self_attn_bias += self.get_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ elif code_masks is not None and code_masks.all():
+ self_attn_bias += self.get_image_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ else:
+ self_attn_bias[~code_masks] += self.get_rel_pos_bias(
+ all_prev_output_tokens, idx)
+ self_attn_bias[code_masks] += self.get_image_rel_pos_bias(
+ all_prev_output_tokens, idx)
+
+ if past_key_value is not None:
+ self_attn_bias = self_attn_bias[:, :, -1:, :]
+
+ out = layer(
+ x,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ self_attn_bias=self_attn_bias,
+ cross_attn_bias=cross_abs_pos_bias,
+ )
+ x = out.pop(0)
+
+ if output_attentions:
+ all_self_attns.append(out.pop(0))
+ if encoder_hidden_states is not None:
+ all_cross_attentions.append(out.pop(0))
+
+ if use_cache:
+ next_decoder_cache.append(out.pop(0))
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (x, )
+
+ if self.final_ln is not None:
+ x = self.final_ln(x)
+
+ x = self.output_projection(x)
+
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=x,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ cross_attentions=all_cross_attentions,
+ )
+
+ def _prepare_decoder_attention_mask(
+ self,
+ attention_mask,
+ input_shape,
+ dtype,
+ past_key_values_length,
+ ):
+ r"""
+ Create causal mask for unidirectional decoding.
+ [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ """
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ dtype,
+ past_key_values_length=past_key_values_length).to(
+ attention_mask.device)
+
+ if attention_mask is not None:
+ # (B, L_s) -> (B, 1, L_t, L_s)
+ expanded_attention_mask = _expand_mask(
+ attention_mask, dtype, tgt_len=input_shape[-1])
+ combined_attention_mask = (
+ expanded_attention_mask if combined_attention_mask is None else
+ expanded_attention_mask + combined_attention_mask)
+
+ return combined_attention_mask
+
+ def get_pos_info(self, pos_embedding, src_pos_embedding=None):
+ B, tgt_len = pos_embedding.shape[:2]
+ if src_pos_embedding is not None:
+ src_len = src_pos_embedding.size(1)
+ pos_q = self.cross_pos_q_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+ pos_q = pos_q * self.pos_scaling
+ pos_k = self.cross_pos_k_linear(src_pos_embedding).view(
+ B, src_len, self.num_heads, -1).transpose(1, 2)
+ else:
+ pos_q = self.self_pos_q_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+ pos_q = pos_q * self.pos_scaling
+ pos_k = self.self_pos_k_linear(pos_embedding).view(
+ B, tgt_len, self.num_heads, -1).transpose(1, 2)
+
+ abs_pos_bias = torch.matmul(pos_q, pos_k.transpose(2, 3))
+
+ return abs_pos_bias
+
+ def get_rel_pos_bias(self, x, idx):
+ seq_len = x.size(1)
+ rp_bucket = self.token_rp_bucket[:seq_len, :seq_len]
+ values = F.embedding(rp_bucket,
+ self.token_rel_pos_table_list[idx].weight)
+ values = values.unsqueeze(0).expand(x.size(0), -1, -1, -1)
+ values = values.permute([0, 3, 1, 2])
+ return values.contiguous()
+
+ def get_image_rel_pos_bias(self, image_position_ids, idx):
+ bsz, seq_len = image_position_ids.shape
+ rp_bucket_size = self.image_rp_bucket.size(1)
+
+ rp_bucket = self.image_rp_bucket.unsqueeze(0).expand(
+ bsz, rp_bucket_size, rp_bucket_size).gather(
+ 1, image_position_ids[:, :, None].expand(
+ bsz, seq_len, rp_bucket_size)).gather(
+ 2, image_position_ids[:, None, :].expand(
+ bsz, seq_len, seq_len))
+ values = F.embedding(rp_bucket,
+ self.image_rel_pos_table_list[idx].weight)
+ values = values.permute(0, 3, 1, 2)
+ return values
+
+
+class OFAEncoderDecoder(BaseModule, GenerationMixin):
+ """The OFA main architecture with an encoder and a decoder.
+
+ Args:
+ encoder_cfg (dict): The config of the encoder, accept the keyword
+ arguments of :class:`OFAEncoder`.
+ decoder_cfg (dict): The config of the decoder, accept the keyword
+ arguments of :class:`OFADecoder`.
+ padding_idx (int): The index of the padding token.
+ vocab_size (int): The size of the vocabulary.
+ embedding_dim (int): The embedding dimensions of both the encoder
+ and the decoder.
+ generation_cfg (dict): The extra generation config, accept the keyword
+ arguments of :class:`~transformers.GenerationConfig`.
+ Defaults to an empty dict.
+ init_cfg (dict, optional): The initialization config. Defaults to None.
+ """
+
+ def __init__(
+ self,
+ encoder_cfg,
+ decoder_cfg,
+ padding_idx,
+ vocab_size,
+ embedding_dim,
+ generation_cfg=dict(),
+ init_cfg=None,
+ ):
+ super().__init__(init_cfg=init_cfg)
+
+ self.padding_idx = padding_idx
+ self.vocab_size = vocab_size
+ self.embedding_dim = embedding_dim
+ embed_tokens = nn.Embedding(vocab_size, embedding_dim, padding_idx)
+
+ self.encoder = OFAEncoder(embed_tokens, **encoder_cfg)
+ self.decoder = OFADecoder(embed_tokens, **decoder_cfg)
+
+ self.config = PretrainedConfig(
+ vocab_size=vocab_size,
+ embedding_dim=embedding_dim,
+ padding_idx=padding_idx,
+ bos_token_id=0,
+ decoder_start_token_id=0,
+ pad_token_id=1,
+ eos_token_id=2,
+ forced_eos_token_id=2,
+ use_cache=False,
+ is_encoder_decoder=True,
+ )
+ self.config.update(generation_cfg)
+
+ self.generation_config = GenerationConfig.from_model_config(
+ self.config)
+
+ @property
+ def device(self):
+ return next(self.parameters()).device
+
+ def can_generate(self):
+ return True
+
+ def get_encoder(self):
+ return self.encoder
+
+ def get_decoder(self):
+ return self.decoder
+
+ def max_decoder_positions(self):
+ """Maximum length supported by the decoder."""
+ return self.decoder.max_positions()
+
+ def get_normalized_probs(self, net_output, log_probs: bool, sample=None):
+ """Get normalized probabilities (or log probs) from a net's output."""
+ return self.get_normalized_probs_scriptable(net_output, log_probs,
+ sample)
+
+ def get_normalized_probs_scriptable(
+ self,
+ net_output,
+ log_probs: bool,
+ sample=None,
+ ):
+ """Scriptable helper function for get_normalized_probs in.
+
+ ~BaseFairseqModel.
+ """
+ if hasattr(self, 'decoder'):
+ return self.decoder.get_normalized_probs(net_output, log_probs,
+ sample)
+ elif torch.is_tensor(net_output):
+ # syntactic sugar for simple models which don't have a decoder
+ # (e.g., the classification tutorial)
+ logits = net_output.float()
+ if log_probs:
+ return F.log_softmax(logits, dim=-1)
+ else:
+ return F.softmax(logits, dim=-1)
+ raise NotImplementedError
+
+ main_input_name = 'input_ids'
+
+ def forward(self,
+ input_ids=None,
+ images=None,
+ images_mask=None,
+ sample_patch_num=None,
+ decoder_input_ids=None,
+ code_masks=None,
+ attention_mask=None,
+ encoder_outputs=None,
+ past_key_values=None,
+ use_cache=False,
+ output_attentions=False,
+ output_hidden_states=False,
+ constrain_fn=None,
+ return_dict=False):
+ """Forword the module.
+
+ Args:
+ input_ids (torch.Tensor): The indices of the input tokens in the
+ vocabulary, and padding will be ignored by default. The indices
+ can be obtained using :class:`OFATokenizer`.
+ The shape is (B, L).
+ images (torch.Tensor): The input images. The shape is (B, 3, H, W).
+ images_mask (torch.Tensor): The mask of all available images. The
+ shape is (B, ).
+ sample_patch_num (int): The number of patches to sample for the
+ images. Defaults to None, which means to use all patches.
+ decoder_input_ids (torch.Tensor): The indices of the input tokens
+ for the decoder.
+ code_masks (torch.Tensor): The mask of all samples for image
+ generation. The shape is (B, ).
+ attention_mask (torch.Tensor): The attention mask for decoding.
+ The shape is (B, L).
+ encoder_outputs (OFAEncoderOutput): The encoder outputs with hidden
+ states, positional embeddings, and padding masks.
+ past_key_values (Tuple[Tuple[torch.Tensor]]): If use cache, the
+ parameter is a tuple of length ``num_layers``. Every item is
+ also a tuple with four tensors, two for the key and value of
+ self-attention, two for the key and value of cross-attention.
+ use_cache (bool): Whether to use cache for faster inference.
+ Defaults to False.
+ output_attentions (bool): Whether to output attention weights.
+ Defaults to False.
+ output_hidden_states (bool): Whether to output hidden states.
+ Defaults to False.
+ constrain_fn (Callable, optional): The function to constrain the
+ output logits. Defaults to None.
+ return_dict (bool): Not used, it's only for compat with the
+ interface of the ``generate`` of ``transformers``.
+
+ Returns:
+ Seq2SeqLMOutput:
+
+ - logits (``torch.Tensor``): The last decoder hidden states.
+ The shape is (B, L, C).
+ - past_key_values (``Tuple[Tuple[torch.Tensor]]``): The past keys
+ and values for faster inference.
+ - decoder_hidden_states (``Tuple[torch.Tensor]``): the decoder
+ hidden states of all layers.
+ - decoder_attentions (``Tuple[torch.Tensor]``): The self-attention
+ weights of all layers in the decoder.
+ - cross_attentions (``Tuple[torch.Tensor]``): The cross-attention
+ weights of all layers in the decoder.
+ - encoder_last_hidden_state (``torch.Tensor``): The last encoder
+ hidden states.
+ - encoder_hidden_states (``Tuple[torch.Tensor]``): The encoder
+ hidden states of all layers, including the embeddings.
+ - encoder_attentions (``Tuple[torch.Tensor]``): The self-attention
+ weights of all layers in the encoder.
+ """
+
+ if encoder_outputs is None:
+ encoder_outputs = self.encoder(
+ input_ids=input_ids,
+ images=images,
+ images_mask=images_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ sample_patch_num=sample_patch_num,
+ )
+
+ if decoder_input_ids.eq(self.padding_idx).any():
+ attention_mask = decoder_input_ids.eq(self.padding_idx)
+
+ encoder_hidden_states = encoder_outputs.last_hidden_state
+ encoder_attention_mask = _expand_mask(encoder_outputs.padding_mask,
+ encoder_hidden_states.dtype,
+ decoder_input_ids.shape[-1])
+ src_pos_embed = encoder_outputs.position_embedding
+
+ decoder_outputs = self.decoder(
+ input_ids=decoder_input_ids,
+ attention_mask=attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ code_masks=code_masks,
+ encoder_pos_embedding=src_pos_embed,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ # The constrain operation for fine-tuned model in OFA is applied
+ # before log_softmax, therefore we cannot use
+ # `prefix_allowed_tokens_fn` to implement it.
+ if constrain_fn is not None:
+ logits = constrain_fn(decoder_input_ids,
+ decoder_outputs.last_hidden_state)
+ else:
+ logits = decoder_outputs.last_hidden_state
+
+ return Seq2SeqLMOutput(
+ logits=logits,
+ past_key_values=decoder_outputs.past_key_values,
+ decoder_hidden_states=decoder_outputs.hidden_states,
+ decoder_attentions=decoder_outputs.attentions,
+ cross_attentions=decoder_outputs.cross_attentions,
+ encoder_last_hidden_state=encoder_outputs.last_hidden_state,
+ encoder_hidden_states=encoder_outputs.hidden_states,
+ encoder_attentions=encoder_outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(self,
+ decoder_input_ids=None,
+ past=None,
+ attention_mask=None,
+ code_masks=None,
+ use_cache=False,
+ encoder_outputs=None,
+ constrain_fn=None,
+ **kwargs):
+ # if attention_mask is None:
+ attention_mask = decoder_input_ids.new_zeros(decoder_input_ids.shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ decoder_input_ids = decoder_input_ids[:, -1:]
+
+ return {
+ 'input_ids': None,
+ 'images': None,
+ 'images_mask': None,
+ 'sample_patch_num': None,
+ 'attention_mask': attention_mask,
+ 'encoder_outputs': encoder_outputs,
+ 'past_key_values': past,
+ 'decoder_input_ids': decoder_input_ids,
+ 'code_masks': code_masks,
+ 'use_cache': use_cache,
+ 'constrain_fn': constrain_fn,
+ }
+
+ def _prepare_encoder_decoder_kwargs_for_generation(
+ self,
+ inputs_tensor: torch.Tensor,
+ model_kwargs,
+ model_input_name: Optional[str] = None):
+ # 1. get encoder
+ encoder = self.get_encoder()
+
+ # 2. prepare encoder args and encoder kwargs from model kwargs
+ irrelevant_prefix = [
+ 'decoder_', 'cross_attn', 'use_cache', 'attention_mask',
+ 'constrain_fn'
+ ]
+ encoder_kwargs = {
+ argument: value
+ for argument, value in model_kwargs.items()
+ if not any(argument.startswith(p) for p in irrelevant_prefix)
+ }
+
+ if encoder_kwargs.get('images_mask') is None:
+ encoder_kwargs['images_mask'] = torch.tensor([True] *
+ inputs_tensor.size(0))
+
+ # 3. make sure that encoder returns `ModelOutput`
+ model_input_name = model_input_name or self.main_input_name
+ encoder_kwargs[model_input_name] = inputs_tensor
+ model_kwargs['encoder_outputs']: ModelOutput = encoder(
+ **encoder_kwargs)
+ model_kwargs['attention_mask'] = None
+
+ return model_kwargs
+
+ @staticmethod
+ def _reorder_cache(past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(
+ past_state.index_select(0, beam_idx)
+ for past_state in layer_past), )
+ return reordered_past
+
+ @staticmethod
+ def _expand_inputs_for_generation(
+ input_ids: torch.LongTensor,
+ expand_size: int = 1,
+ is_encoder_decoder: bool = False,
+ attention_mask: Optional[torch.LongTensor] = None,
+ encoder_outputs: Optional[ModelOutput] = None,
+ **model_kwargs,
+ ):
+ expanded_return_idx = (
+ torch.arange(input_ids.shape[0]).view(-1, 1).repeat(
+ 1, expand_size).view(-1).to(input_ids.device))
+ input_ids = input_ids.index_select(0, expanded_return_idx)
+
+ if attention_mask is not None:
+ model_kwargs['attention_mask'] = attention_mask.index_select(
+ 0, expanded_return_idx)
+
+ if is_encoder_decoder:
+ if encoder_outputs is None:
+ raise ValueError('If `is_encoder_decoder` is True, make '
+ 'sure that `encoder_outputs` is defined.')
+ encoder_outputs['last_hidden_state'] = encoder_outputs.\
+ last_hidden_state.index_select(0, expanded_return_idx)
+ encoder_outputs['position_embedding'] = encoder_outputs.\
+ position_embedding.index_select(0, expanded_return_idx)
+ encoder_outputs['padding_mask'] = encoder_outputs.\
+ padding_mask.index_select(0, expanded_return_idx)
+ model_kwargs['encoder_outputs'] = encoder_outputs
+ return input_ids, model_kwargs
diff --git a/mmpretrain/models/utils/__init__.py b/mmpretrain/models/utils/__init__.py
index b7df9e415eb..1f5c14c7aa1 100644
--- a/mmpretrain/models/utils/__init__.py
+++ b/mmpretrain/models/utils/__init__.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
from .attention import (BEiTAttention, ChannelMultiheadAttention,
CrossMultiheadAttention, LeAttention,
MultiheadAttention, PromptMultiheadAttention,
@@ -6,8 +7,10 @@
from .batch_augments import CutMix, Mixup, RandomBatchAugment, ResizeMix
from .batch_shuffle import batch_shuffle_ddp, batch_unshuffle_ddp
from .channel_shuffle import channel_shuffle
-from .clip_generator_helper import build_clip_model
-from .data_preprocessor import (ClsDataPreprocessor, SelfSupDataPreprocessor,
+from .clip_generator_helper import QuickGELU, build_clip_model
+from .data_preprocessor import (ClsDataPreprocessor,
+ MultiModalDataPreprocessor,
+ SelfSupDataPreprocessor,
TwoNormDataPreprocessor, VideoDataPreprocessor)
from .ema import CosineEMA
from .embed import (HybridEmbed, PatchEmbed, PatchMerging, resize_pos_embed,
@@ -70,7 +73,19 @@
'VideoDataPreprocessor',
'CosineEMA',
'ResLayerExtraNorm',
+ 'MultiModalDataPreprocessor',
+ 'QuickGELU',
'SwiGLUFFN',
'SwiGLUFFNFused',
'RotaryEmbeddingFast',
]
+
+if WITH_MULTIMODAL:
+ from .huggingface import (no_load_hf_pretrained_model, register_hf_model,
+ register_hf_tokenizer)
+ from .tokenizer import Blip2Tokenizer, BlipTokenizer, OFATokenizer
+
+ __all__.extend([
+ 'BlipTokenizer', 'OFATokenizer', 'Blip2Tokenizer', 'register_hf_model',
+ 'register_hf_tokenizer', 'no_load_hf_pretrained_model'
+ ])
diff --git a/mmpretrain/models/utils/box_utils.py b/mmpretrain/models/utils/box_utils.py
new file mode 100644
index 00000000000..79db516c990
--- /dev/null
+++ b/mmpretrain/models/utils/box_utils.py
@@ -0,0 +1,56 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torchvision.ops.boxes as boxes
+
+
+def box_cxcywh_to_xyxy(x):
+ x_c, y_c, w, h = x.unbind(-1)
+ b = [(x_c - 0.5 * w), (y_c - 0.5 * h), (x_c + 0.5 * w), (y_c + 0.5 * h)]
+ return torch.stack(b, dim=-1)
+
+
+def box_xyxy_to_cxcywh(x):
+ x0, y0, x1, y1 = x.unbind(-1)
+ b = [(x0 + x1) / 2.0, (y0 + y1) / 2.0, (x1 - x0), (y1 - y0)]
+ return torch.stack(b, dim=-1)
+
+
+def box_iou(boxes1, boxes2):
+ """Return intersection-over-union (Jaccard index) between two sets of
+ boxes.
+
+ Both sets of boxes are expected to be in ``(x1, y1, x2, y2)`` format with
+ ``0 <= x1 < x2`` and ``0 <= y1 < y2``.
+
+ Args:
+ boxes1 (Tensor[N, 4]): first set of boxes
+ boxes2 (Tensor[M, 4]): second set of boxes
+
+ Returns:
+ Tensor[N, M]: the NxM matrix containing the pairwise IoU values for
+ every element in boxes1 and boxes2
+ """
+ return boxes.box_iou(boxes1, boxes2)
+
+
+def generalized_box_iou(boxes1, boxes2):
+ """Return generalized intersection-over-union (Jaccard index) between two
+ sets of boxes.
+
+ Both sets of boxes are expected to be in ``(x1, y1, x2, y2)`` format with
+ ``0 <= x1 < x2`` and ``0 <= y1 < y2``.
+
+ Args:
+ boxes1 (Tensor[N, 4]): first set of boxes
+ boxes2 (Tensor[M, 4]): second set of boxes
+
+ Returns:
+ Tensor[N, M]: the NxM matrix containing the pairwise generalized IoU
+ values for every element in boxes1 and boxes2
+ """
+ # degenerate boxes gives inf / nan results
+ # so do an early check
+ assert (boxes1[:, 2:] >= boxes1[:, :2]).all()
+ assert (boxes2[:, 2:] >= boxes2[:, :2]).all()
+
+ return boxes.generalized_box_iou(boxes1, boxes2)
diff --git a/mmpretrain/models/utils/clip_generator_helper.py b/mmpretrain/models/utils/clip_generator_helper.py
index 90d7b483206..4f67f0ed697 100644
--- a/mmpretrain/models/utils/clip_generator_helper.py
+++ b/mmpretrain/models/utils/clip_generator_helper.py
@@ -8,6 +8,8 @@
from mmengine.logging import MMLogger
from torch import nn
+from mmpretrain.registry import MODELS
+
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
@@ -19,6 +21,7 @@ def forward(self, x: torch.Tensor) -> torch.Tensor:
return ret.type(orig_type)
+@MODELS.register_module()
class QuickGELU(nn.Module):
"""A faster version of GELU."""
diff --git a/mmpretrain/models/utils/data_preprocessor.py b/mmpretrain/models/utils/data_preprocessor.py
index 8f3fcb9f62c..c407bd4c936 100644
--- a/mmpretrain/models/utils/data_preprocessor.py
+++ b/mmpretrain/models/utils/data_preprocessor.py
@@ -515,3 +515,106 @@ def forward(
batch_inputs = (batch_inputs - self.mean) / self.std
return {'inputs': batch_inputs, 'data_samples': batch_data_samples}
+
+
+@MODELS.register_module()
+class MultiModalDataPreprocessor(BaseDataPreprocessor):
+ """Data pre-processor for image-text multimodality tasks.
+
+ It provides the data pre-processing as follows
+
+ - Collate and move data to the target device.
+ - Pad inputs to the maximum size of current batch with defined
+ ``pad_value``. The padding size can be divisible by a defined
+ ``pad_size_divisor``
+ - Stack inputs to batch_inputs.
+ - Convert inputs from bgr to rgb if the shape of input is (3, H, W).
+ - Normalize image with defined std and mean.
+
+ Args:
+ mean (Sequence[Number], optional): The pixel mean of R, G, B channels.
+ Defaults to None.
+ std (Sequence[Number], optional): The pixel standard deviation of
+ R, G, B channels. Defaults to None.
+ pad_size_divisor (int): The size of padded image should be
+ divisible by ``pad_size_divisor``. Defaults to 1.
+ pad_value (Number): The padded pixel value. Defaults to 0.
+ to_rgb (bool): whether to convert image from BGR to RGB.
+ Defaults to False.
+ """
+
+ def __init__(
+ self,
+ mean: Sequence[Number] = None,
+ std: Sequence[Number] = None,
+ pad_size_divisor: int = 1,
+ pad_value: Number = 0,
+ to_rgb: bool = False,
+ ):
+ super().__init__()
+ self.pad_size_divisor = pad_size_divisor
+ self.pad_value = pad_value
+ self.to_rgb = to_rgb
+
+ if mean is not None:
+ assert std is not None, 'To enable the normalization in ' \
+ 'preprocessing, please specify both `mean` and `std`.'
+ # Enable the normalization in preprocessing.
+ self._enable_normalize = True
+ self.register_buffer('mean',
+ torch.tensor(mean).view(-1, 1, 1), False)
+ self.register_buffer('std',
+ torch.tensor(std).view(-1, 1, 1), False)
+ else:
+ self._enable_normalize = False
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization, padding, bgr2rgb conversion and batch
+ augmentation based on ``BaseDataPreprocessor``.
+
+ Args:
+ data (dict): data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ data = self.cast_data(data)
+
+ imgs = data.get('inputs', None)
+
+ def _process_img(img):
+ # ------ To RGB ------
+ if self.to_rgb and img.size(1) == 3:
+ img = img.flip(1)
+
+ # -- Normalization ---
+ img = img.float()
+ if self._enable_normalize:
+ img = (img - self.mean) / self.std
+
+ # ------ Padding -----
+ if self.pad_size_divisor > 1:
+ h, w = img.shape[-2:]
+
+ target_h = math.ceil(
+ h / self.pad_size_divisor) * self.pad_size_divisor
+ target_w = math.ceil(
+ w / self.pad_size_divisor) * self.pad_size_divisor
+ pad_h = target_h - h
+ pad_w = target_w - w
+ img = F.pad(img, (0, pad_w, 0, pad_h), 'constant',
+ self.pad_value)
+ return img
+
+ if isinstance(imgs, torch.Tensor):
+ imgs = _process_img(imgs)
+ elif isinstance(imgs, Sequence):
+ # B, T, C, H, W
+ imgs = torch.stack([_process_img(img) for img in imgs], dim=1)
+ elif imgs is not None:
+ raise ValueError(f'{type(imgs)} is not supported for imgs inputs.')
+
+ data_samples = data.get('data_samples', None)
+
+ return {'images': imgs, 'data_samples': data_samples}
diff --git a/mmpretrain/models/utils/huggingface.py b/mmpretrain/models/utils/huggingface.py
new file mode 100644
index 00000000000..e527315b26e
--- /dev/null
+++ b/mmpretrain/models/utils/huggingface.py
@@ -0,0 +1,98 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import contextlib
+from typing import Optional
+
+import transformers
+from mmengine.registry import Registry
+from transformers import AutoConfig, PreTrainedModel
+from transformers.models.auto.auto_factory import _BaseAutoModelClass
+
+from mmpretrain.registry import MODELS, TOKENIZER
+
+
+def register_hf_tokenizer(
+ cls: Optional[type] = None,
+ registry: Registry = TOKENIZER,
+):
+ """Register HuggingFace-style PreTrainedTokenizerBase class."""
+ if cls is None:
+
+ # use it as a decorator: @register_hf_tokenizer()
+ def _register(cls):
+ register_hf_tokenizer(cls=cls)
+ return cls
+
+ return _register
+
+ def from_pretrained(**kwargs):
+ if ('pretrained_model_name_or_path' not in kwargs
+ and 'name_or_path' not in kwargs):
+ raise TypeError(
+ f'{cls.__name__}.from_pretrained() missing required '
+ "argument 'pretrained_model_name_or_path' or 'name_or_path'.")
+ # `pretrained_model_name_or_path` is too long for config,
+ # add an alias name `name_or_path` here.
+ name_or_path = kwargs.pop('pretrained_model_name_or_path',
+ kwargs.pop('name_or_path'))
+ return cls.from_pretrained(name_or_path, **kwargs)
+
+ registry._register_module(module=from_pretrained, module_name=cls.__name__)
+ return cls
+
+
+_load_hf_pretrained_model = True
+
+
+@contextlib.contextmanager
+def no_load_hf_pretrained_model():
+ global _load_hf_pretrained_model
+ _load_hf_pretrained_model = False
+ yield
+ _load_hf_pretrained_model = True
+
+
+def register_hf_model(
+ cls: Optional[type] = None,
+ registry: Registry = MODELS,
+):
+ """Register HuggingFace-style PreTrainedModel class."""
+ if cls is None:
+
+ # use it as a decorator: @register_hf_tokenizer()
+ def _register(cls):
+ register_hf_model(cls=cls)
+ return cls
+
+ return _register
+
+ if issubclass(cls, _BaseAutoModelClass):
+ get_config = AutoConfig.from_pretrained
+ from_config = cls.from_config
+ elif issubclass(cls, PreTrainedModel):
+ get_config = cls.config_class.from_pretrained
+ from_config = cls
+ else:
+ raise TypeError('Not auto model nor pretrained model of huggingface.')
+
+ def build(**kwargs):
+ if ('pretrained_model_name_or_path' not in kwargs
+ and 'name_or_path' not in kwargs):
+ raise TypeError(
+ f'{cls.__name__} missing required argument '
+ '`pretrained_model_name_or_path` or `name_or_path`.')
+ # `pretrained_model_name_or_path` is too long for config,
+ # add an alias name `name_or_path` here.
+ name_or_path = kwargs.pop('pretrained_model_name_or_path',
+ kwargs.pop('name_or_path'))
+
+ if kwargs.pop('load_pretrained', True) and _load_hf_pretrained_model:
+ return cls.from_pretrained(name_or_path, **kwargs)
+ else:
+ cfg = get_config(name_or_path, **kwargs)
+ return from_config(cfg)
+
+ registry._register_module(module=build, module_name=cls.__name__)
+ return cls
+
+
+register_hf_model(transformers.AutoModelForCausalLM)
diff --git a/mmpretrain/models/utils/tokenizer.py b/mmpretrain/models/utils/tokenizer.py
new file mode 100644
index 00000000000..eb02f741126
--- /dev/null
+++ b/mmpretrain/models/utils/tokenizer.py
@@ -0,0 +1,112 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+
+from transformers import (AutoTokenizer, BartTokenizer, BertTokenizer,
+ BertTokenizerFast, LlamaTokenizer)
+
+from .huggingface import register_hf_tokenizer
+
+register_hf_tokenizer(AutoTokenizer)
+register_hf_tokenizer(LlamaTokenizer)
+
+
+@register_hf_tokenizer()
+class BlipTokenizer(BertTokenizerFast):
+ """"BlipTokenizer inherit BertTokenizerFast (fast, Rust-based)."""
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ os.environ['TOKENIZERS_PARALLELISM'] = 'true'
+
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ tokenizer.add_special_tokens({'bos_token': '[DEC]'})
+ tokenizer.add_special_tokens({'additional_special_tokens': ['[ENC]']})
+ return tokenizer
+
+
+@register_hf_tokenizer()
+class Blip2Tokenizer(BertTokenizer):
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ tokenizer.add_special_tokens({'bos_token': '[DEC]'})
+ return tokenizer
+
+
+@register_hf_tokenizer()
+class OFATokenizer(BartTokenizer):
+
+ vocab_files_names = {
+ 'vocab_file': 'vocab.json',
+ 'merges_file': 'merges.txt'
+ }
+
+ pretrained_vocab_files_map = {
+ 'vocab_file': {
+ 'OFA-Sys/OFA-tiny':
+ 'https://huggingface.co/OFA-Sys/OFA-tiny/blob/main/vocab.json',
+ 'OFA-Sys/OFA-medium':
+ 'https://huggingface.co/OFA-Sys/OFA-medium/blob/main/vocab.json',
+ 'OFA-Sys/OFA-base':
+ 'https://huggingface.co/OFA-Sys/OFA-base/blob/main/vocab.json',
+ 'OFA-Sys/OFA-large':
+ 'https://huggingface.co/OFA-Sys/OFA-large/blob/main/vocab.json',
+ },
+ 'merges_file': {
+ 'OFA-Sys/OFA-tiny':
+ 'https://huggingface.co/OFA-Sys/OFA-tiny/blob/main/merges.txt',
+ 'OFA-Sys/OFA-medium':
+ 'https://huggingface.co/OFA-Sys/OFA-medium/blob/main/merges.txt',
+ 'OFA-Sys/OFA-base':
+ 'https://huggingface.co/OFA-Sys/OFA-base/blob/main/merges.txt',
+ 'OFA-Sys/OFA-large':
+ 'https://huggingface.co/OFA-Sys/OFA-large/blob/main/merges.txt',
+ },
+ }
+
+ max_model_input_sizes = {
+ 'OFA-Sys/OFA-tiny': 1024,
+ 'OFA-Sys/OFA-medium': 1024,
+ 'OFA-Sys/OFA-base': 1024,
+ 'OFA-Sys/OFA-large': 1024,
+ }
+
+ @classmethod
+ def from_pretrained(
+ cls,
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ ):
+ num_bins = kwargs.pop('num_bins', 1000)
+ tokenizer = super().from_pretrained(
+ pretrained_model_name_or_path,
+ *init_inputs,
+ **kwargs,
+ )
+ length = len(tokenizer)
+ tokenizer.add_tokens([''.format(i) for i in range(8192)])
+ tokenizer.code_offset = length
+ tokenizer.add_tokens([''.format(i) for i in range(num_bins)])
+ tokenizer.bin_offset = length + 8192
+ tokenizer.num_bins = num_bins
+ return tokenizer
diff --git a/mmpretrain/registry.py b/mmpretrain/registry.py
index 45bd0cf5752..cac2bdad725 100644
--- a/mmpretrain/registry.py
+++ b/mmpretrain/registry.py
@@ -154,6 +154,11 @@
parent=MMENGINE_TASK_UTILS,
locations=['mmpretrain.models'],
)
+# Tokenizer to encode sequence
+TOKENIZER = Registry(
+ 'tokenizer',
+ locations=['mmpretrain.models'],
+)
#######################################################################
# mmpretrain.evaluation #
diff --git a/mmpretrain/utils/__init__.py b/mmpretrain/utils/__init__.py
index 328c01d72eb..991e3217d2f 100644
--- a/mmpretrain/utils/__init__.py
+++ b/mmpretrain/utils/__init__.py
@@ -1,11 +1,12 @@
# Copyright (c) OpenMMLab. All rights reserved.
from .analyze import load_json_log
from .collect_env import collect_env
+from .dependency import require
from .misc import get_ori_model
-from .progress import track_on_main_process
+from .progress import track, track_on_main_process
from .setup_env import register_all_modules
__all__ = [
'collect_env', 'register_all_modules', 'track_on_main_process',
- 'load_json_log', 'get_ori_model'
+ 'load_json_log', 'get_ori_model', 'track', 'require'
]
diff --git a/mmpretrain/utils/dependency.py b/mmpretrain/utils/dependency.py
new file mode 100644
index 00000000000..0e3d8ae5df7
--- /dev/null
+++ b/mmpretrain/utils/dependency.py
@@ -0,0 +1,82 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import re
+from functools import wraps
+from inspect import isfunction
+
+from importlib_metadata import PackageNotFoundError, distribution
+from mmengine.utils import digit_version
+
+
+def satisfy_requirement(dep):
+ pat = '(' + '|'.join(['>=', '==', '>']) + ')'
+ parts = re.split(pat, dep, maxsplit=1)
+ parts = [p.strip() for p in parts]
+ package = parts[0]
+ if len(parts) > 1:
+ op, version = parts[1:]
+ op = {
+ '>=': '__ge__',
+ '==': '__eq__',
+ '>': '__gt__',
+ '<': '__lt__',
+ '<=': '__le__'
+ }[op]
+ else:
+ op, version = None, None
+
+ try:
+ dist = distribution(package)
+ if op is None or getattr(digit_version(dist.version), op)(
+ digit_version(version)):
+ return True
+ except PackageNotFoundError:
+ pass
+
+ return False
+
+
+def require(dep, install=None):
+ """A wrapper of function for extra package requirements.
+
+ Args:
+ dep (str): The dependency package name, like ``transformers``
+ or ``transformers>=4.28.0``.
+ install (str, optional): The installation command hint. Defaults
+ to None, which means to use "pip install dep".
+ """
+
+ def wrapper(fn):
+ assert isfunction(fn)
+
+ @wraps(fn)
+ def ask_install(*args, **kwargs):
+ name = fn.__qualname__.replace('.__init__', '')
+ ins = install or f'pip install "{dep}"'
+ raise ImportError(
+ f'{name} requires {dep}, please install it by `{ins}`.')
+
+ if satisfy_requirement(dep):
+ fn._verify_require = getattr(fn, '_verify_require', lambda: None)
+ return fn
+
+ ask_install._verify_require = ask_install
+ return ask_install
+
+ return wrapper
+
+
+WITH_MULTIMODAL = all(
+ satisfy_requirement(item)
+ for item in ['pycocotools', 'transformers>=4.28.0'])
+
+
+def register_multimodal_placeholder(names, registry):
+ for name in names:
+
+ def ask_install(*args, **kwargs):
+ raise ImportError(
+ f'{name} requires extra multi-modal dependencies, please '
+ 'install it by `pip install "mmpretrain[multimodal]"` '
+ 'or `pip install -e ".[multimodal]"`.')
+
+ registry.register_module(name=name, module=ask_install)
diff --git a/mmpretrain/utils/progress.py b/mmpretrain/utils/progress.py
index 66c6c32db25..bde7e558079 100644
--- a/mmpretrain/utils/progress.py
+++ b/mmpretrain/utils/progress.py
@@ -2,9 +2,18 @@
import mmengine.dist as dist
import rich.progress as progress
+disable_progress_bar = False
+
+
+def track(sequence, *args, **kwargs):
+ if disable_progress_bar:
+ return sequence
+ else:
+ return progress.track(sequence, *args, **kwargs)
+
def track_on_main_process(sequence, *args, **kwargs):
- if not dist.is_main_process():
+ if not dist.is_main_process() or disable_progress_bar:
yield from sequence
else:
yield from progress.track(sequence, *args, **kwargs)
diff --git a/mmpretrain/visualization/visualizer.py b/mmpretrain/visualization/visualizer.py
index abff913ca42..5d18ca87f6b 100644
--- a/mmpretrain/visualization/visualizer.py
+++ b/mmpretrain/visualization/visualizer.py
@@ -105,9 +105,9 @@ def visualize_cls(self,
if resize is not None:
h, w = image.shape[:2]
if w < h:
- image = mmcv.imresize(image, (resize, resize * h / w))
+ image = mmcv.imresize(image, (resize, resize * h // w))
else:
- image = mmcv.imresize(image, (resize * w / h, resize))
+ image = mmcv.imresize(image, (resize * w // h, resize))
elif rescale_factor is not None:
image = mmcv.imrescale(image, rescale_factor)
@@ -340,3 +340,438 @@ def visualize_masked_image(self,
self.add_image(name, drawn_img, step=step)
return drawn_img
+
+ @master_only
+ def visualize_image_caption(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize image caption result.
+
+ This method will draw the input image and the images caption.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ data_sample.get('pred_caption'),
+ wrap=True,
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_vqa(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize visual question answering result.
+
+ This method will draw the input image, question and answer.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ text = (f'Q: {data_sample.get("question")}\n'
+ f'A: {data_sample.get("pred_answer")}')
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ text,
+ wrap=True,
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_visual_grounding(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ line_width: Union[int, float] = 3,
+ bbox_color: Union[str, tuple] = 'green',
+ step: int = 0) -> None:
+ """Visualize visual grounding result.
+
+ This method will draw the input image, bbox and the object.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ resize (int, optional): Resize the long edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ gt_bboxes = data_sample.get('gt_bboxes')
+ pred_bboxes = data_sample.get('pred_bboxes')
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image, w_scale, h_scale = mmcv.imresize(
+ image, (resize, resize * h // w), return_scale=True)
+ else:
+ image, w_scale, h_scale = mmcv.imresize(
+ image, (resize * w // h, resize), return_scale=True)
+ pred_bboxes[:, ::2] *= w_scale
+ pred_bboxes[:, 1::2] *= h_scale
+ if gt_bboxes is not None:
+ gt_bboxes[:, ::2] *= w_scale
+ gt_bboxes[:, 1::2] *= h_scale
+
+ self.set_image(image)
+ # Avoid the line-width limit in the base classes.
+ self._default_font_size = 1e3
+ self.draw_bboxes(
+ pred_bboxes, line_widths=line_width, edge_colors=bbox_color)
+ if gt_bboxes is not None:
+ self.draw_bboxes(
+ gt_bboxes, line_widths=line_width, edge_colors='blue')
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+
+ text_positions = pred_bboxes[:, :2] + line_width
+ for i in range(pred_bboxes.size(0)):
+ self.ax_save.text(
+ text_positions[i, 0] + line_width,
+ text_positions[i, 1] + line_width,
+ data_sample.get('text'),
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_t2i_retrieval(self,
+ text: str,
+ data_sample: DataSample,
+ prototype_dataset: BaseDataset,
+ topk: int = 1,
+ draw_score: bool = True,
+ text_cfg: dict = dict(),
+ fig_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: Optional[str] = '',
+ step: int = 0) -> None:
+ """Visualize Text-To-Image retrieval result.
+
+ This method will draw the input text and the images retrieved from the
+ prototype dataset.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ prototype_dataset (:obj:`BaseDataset`): The prototype dataset.
+ It should have `get_data_info` method and return a dict
+ includes `img_path`.
+ topk (int): To visualize the topk matching items. Defaults to 1.
+ draw_score (bool): Whether to draw the match scores of the
+ retrieved images. Defaults to True.
+ text_cfg (dict): Extra text setting, which accepts arguments of
+ :func:`plt.text`. Defaults to an empty dict.
+ fig_cfg (dict): Extra figure setting, which accepts arguments of
+ :func:`plt.Figure`. Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ text_cfg = {**self.DEFAULT_TEXT_CFG, **text_cfg}
+
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+
+ figure = create_figure(margin=True, **fig_cfg)
+ figure.suptitle(text)
+ gs = figure.add_gridspec(1, topk)
+
+ for k, (score, sample_idx) in enumerate(zip(match_scores, indices)):
+ sample = prototype_dataset.get_data_info(sample_idx.item())
+ value_image = mmcv.imread(sample['img_path'])[..., ::-1]
+ value_plot = figure.add_subplot(gs[0, k])
+ value_plot.axis(False)
+ value_plot.imshow(value_image)
+ if draw_score:
+ value_plot.text(
+ 5,
+ 5,
+ f'{score:.2f}',
+ **text_cfg,
+ )
+ drawn_img = img_from_canvas(figure.canvas)
+ self.set_image(drawn_img)
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
+
+ @master_only
+ def visualize_i2t_retrieval(self,
+ image: np.ndarray,
+ data_sample: DataSample,
+ prototype_dataset: Sequence[str],
+ topk: int = 1,
+ draw_score: bool = True,
+ resize: Optional[int] = None,
+ text_cfg: dict = dict(),
+ show: bool = False,
+ wait_time: float = 0,
+ out_file: Optional[str] = None,
+ name: str = '',
+ step: int = 0) -> None:
+ """Visualize Image-To-Text retrieval result.
+
+ This method will draw the input image and the texts retrieved from the
+ prototype dataset.
+
+ Args:
+ image (np.ndarray): The image to draw. The format should be RGB.
+ data_sample (:obj:`DataSample`): The annotation of the image.
+ prototype_dataset (Sequence[str]): The prototype dataset.
+ It should be a list of texts.
+ topk (int): To visualize the topk matching items. Defaults to 1.
+ draw_score (bool): Whether to draw the prediction scores
+ of prediction categories. Defaults to True.
+ resize (int, optional): Resize the short edge of the image to the
+ specified length before visualization. Defaults to None.
+ text_cfg (dict): Extra text setting, which accepts
+ arguments of :meth:`mmengine.Visualizer.draw_texts`.
+ Defaults to an empty dict.
+ show (bool): Whether to display the drawn image in a window, please
+ confirm your are able to access the graphical interface.
+ Defaults to False.
+ wait_time (float): The display time (s). Defaults to 0, which means
+ "forever".
+ out_file (str, optional): Extra path to save the visualization
+ result. If specified, the visualizer will only save the result
+ image to the out_file and ignore its storage backends.
+ Defaults to None.
+ name (str): The image identifier. It's useful when using the
+ storage backends of the visualizer to save or display the
+ image. Defaults to an empty string.
+ step (int): The global step value. It's useful to record a
+ series of visualization results for the same image with the
+ storage backends. Defaults to 0.
+
+ Returns:
+ np.ndarray: The visualization image.
+ """
+ if resize is not None:
+ h, w = image.shape[:2]
+ if w < h:
+ image = mmcv.imresize(image, (resize, resize * h // w))
+ else:
+ image = mmcv.imresize(image, (resize * w // h, resize))
+
+ self.set_image(image)
+
+ match_scores, indices = torch.topk(data_sample.pred_score, k=topk)
+ texts = []
+ for score, sample_idx in zip(match_scores, indices):
+ text = prototype_dataset[sample_idx.item()]
+ if draw_score:
+ text = f'{score:.2f} ' + text
+ texts.append(text)
+
+ img_scale = get_adaptive_scale(image.shape[:2])
+ text_cfg = {
+ 'size': int(img_scale * 7),
+ **self.DEFAULT_TEXT_CFG,
+ **text_cfg,
+ }
+ self.ax_save.text(
+ img_scale * 5,
+ img_scale * 5,
+ '\n'.join(texts),
+ **text_cfg,
+ )
+ drawn_img = self.get_image()
+
+ if show:
+ self.show(drawn_img, win_name=name, wait_time=wait_time)
+
+ if out_file is not None:
+ # save the image to the target file instead of vis_backends
+ mmcv.imwrite(drawn_img[..., ::-1], out_file)
+ else:
+ self.add_image(name, drawn_img, step=step)
+
+ return drawn_img
diff --git a/model-index.yml b/model-index.yml
index c960b360a27..f5f90b12833 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -66,8 +66,12 @@ Import:
- configs/cae/metafile.yml
- configs/maskfeat/metafile.yml
- configs/milan/metafile.yml
+ - configs/ofa/metafile.yml
- configs/riformer/metafile.yml
- configs/sam/metafile.yml
- configs/glip/metafile.yml
- configs/eva02/metafile.yml
- configs/dinov2/metafile.yml
+ - configs/blip/metafile.yml
+ - configs/flamingo/metafile.yml
+ - configs/blip2/metafile.yml
diff --git a/projects/gradio_demo/README.md b/projects/gradio_demo/README.md
new file mode 100644
index 00000000000..6799f865ad9
--- /dev/null
+++ b/projects/gradio_demo/README.md
@@ -0,0 +1,44 @@
+# MMPretrain Gradio Demo
+
+Here is a gradio demo for MMPretrain supported inference tasks.
+
+Currently supported tasks:
+
+- Image Classifiation
+- Image-To-Image Retrieval
+- Text-To-Image Retrieval (require multi-modality support)
+- Image Caption (require multi-modality support)
+- Visual Question Answering (require multi-modality support)
+- Visual Grounding (require multi-modality support)
+
+## Preview
+
+
+
+## Requirements
+
+To run the demo, you need to install MMPretrain at first. And please install with the extra multi-modality
+dependencies to enable multi-modality tasks.
+
+```shell
+# At the MMPretrain root folder
+pip install -e ".[multimodal]"
+```
+
+And then install the latest gradio package.
+
+```shell
+pip install "gradio>=3.31.0"
+```
+
+## Start
+
+Then, you can start the gradio server on the local machine by:
+
+```shell
+# At the project folder
+python launch.py
+```
+
+The demo will start a local server `http://127.0.0.1:7860` and you can browse it by your browser.
+And to share it to others, please set `share=True` in the `demo.launch()`.
diff --git a/projects/gradio_demo/launch.py b/projects/gradio_demo/launch.py
new file mode 100644
index 00000000000..bd4fa780d3a
--- /dev/null
+++ b/projects/gradio_demo/launch.py
@@ -0,0 +1,466 @@
+from functools import partial
+from pathlib import Path
+from typing import Callable
+
+import gradio as gr
+import torch
+from mmengine.logging import MMLogger
+
+import mmpretrain
+from mmpretrain.apis import (ImageCaptionInferencer,
+ ImageClassificationInferencer,
+ ImageRetrievalInferencer,
+ TextToImageRetrievalInferencer,
+ VisualGroundingInferencer,
+ VisualQuestionAnsweringInferencer)
+from mmpretrain.utils.dependency import WITH_MULTIMODAL
+from mmpretrain.visualization import UniversalVisualizer
+
+mmpretrain.utils.progress.disable_progress_bar = True
+
+logger = MMLogger('mmpretrain', logger_name='mmpre')
+if torch.cuda.is_available():
+ gpus = [
+ torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())
+ ]
+ logger.info(f'Available GPUs: {len(gpus)}')
+else:
+ gpus = None
+ logger.info('No available GPU.')
+
+
+def get_free_device():
+ if gpus is None:
+ return torch.device('cpu')
+ if hasattr(torch.cuda, 'mem_get_info'):
+ free = [torch.cuda.mem_get_info(gpu)[0] for gpu in gpus]
+ select = max(zip(free, range(len(free))))[1]
+ else:
+ import random
+ select = random.randint(0, len(gpus) - 1)
+ return gpus[select]
+
+
+class InferencerCache:
+ max_size = 2
+ _cache = []
+
+ @classmethod
+ def get_instance(cls, instance_name, callback: Callable):
+ if len(cls._cache) > 0:
+ for i, cache in enumerate(cls._cache):
+ if cache[0] == instance_name:
+ # Re-insert to the head of list.
+ cls._cache.insert(0, cls._cache.pop(i))
+ logger.info(f'Use cached {instance_name}.')
+ return cache[1]
+
+ if len(cls._cache) == cls.max_size:
+ cls._cache.pop(cls.max_size - 1)
+ torch.cuda.empty_cache()
+ device = get_free_device()
+ instance = callback(device=device)
+ logger.info(f'New instance {instance_name} on {device}.')
+ cls._cache.insert(0, (instance_name, instance))
+ return instance
+
+
+class ImageCaptionTab:
+
+ def __init__(self) -> None:
+ self.model_list = ImageCaptionInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_caption_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='blip-base_3rdparty_coco-caption',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ caption_output = gr.Textbox(
+ label='Result',
+ lines=2,
+ elem_classes='caption_result',
+ interactive=False,
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input],
+ outputs=caption_output,
+ )
+
+ def inference(self, model, image):
+ image = image[:, :, ::-1]
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(ImageCaptionInferencer, model))
+
+ result = inferencer(image)[0]
+ return result['pred_caption']
+
+
+class ImageClassificationTab:
+
+ def __init__(self) -> None:
+ self.short_list = [
+ 'resnet50_8xb32_in1k',
+ 'resnet50_8xb256-rsb-a1-600e_in1k',
+ 'swin-base_16xb64_in1k',
+ 'convnext-base_32xb128_in1k',
+ 'vit-base-p16_32xb128-mae_in1k',
+ ]
+ self.long_list = ImageClassificationInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_classification_models',
+ elem_classes='select_model',
+ choices=self.short_list,
+ value='swin-base_16xb64_in1k',
+ )
+ expand = gr.Checkbox(label='Browse all models')
+
+ def browse_all_model(value):
+ models = self.long_list if value else self.short_list
+ return gr.update(choices=models)
+
+ expand.select(
+ fn=browse_all_model, inputs=expand, outputs=select_model)
+ with gr.Column():
+ in_image = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ out_cls = gr.Label(
+ label='Result',
+ num_top_classes=5,
+ elem_classes='cls_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, in_image],
+ outputs=out_cls,
+ )
+
+ def inference(self, model, image):
+ image = image[:, :, ::-1]
+
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(ImageClassificationInferencer, model))
+ result = inferencer(image)[0]['pred_scores'].tolist()
+
+ if inferencer.classes is not None:
+ classes = inferencer.classes
+ else:
+ classes = list(range(len(result)))
+
+ return dict(zip(classes, result))
+
+
+class ImageRetrievalTab:
+
+ def __init__(self) -> None:
+ self.model_list = ImageRetrievalInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='image_retri_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='resnet50-arcface_8xb32_inshop',
+ )
+ topk = gr.Slider(minimum=1, maximum=6, value=3, step=1)
+ with gr.Column():
+ prototype = gr.File(
+ label='Retrieve from',
+ file_count='multiple',
+ file_types=['image'])
+ image_input = gr.Image(
+ label='Query',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ retri_output = gr.Gallery(
+ label='Result',
+ elem_classes='img_retri_result',
+ ).style(
+ columns=[3], object_fit='contain', height='auto')
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, prototype, image_input, topk],
+ outputs=retri_output,
+ )
+
+ def inference(self, model, prototype, image, topk):
+ image = image[:, :, ::-1]
+
+ import hashlib
+
+ proto_signature = ''.join(file.name for file in prototype).encode()
+ proto_signature = hashlib.sha256(proto_signature).hexdigest()
+ inferencer_name = self.__class__.__name__ + model + proto_signature
+ tmp_dir = Path(prototype[0].name).parent
+ cache_file = tmp_dir / f'{inferencer_name}.pth'
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(
+ ImageRetrievalInferencer,
+ model,
+ prototype=[file.name for file in prototype],
+ prototype_cache=str(cache_file),
+ ),
+ )
+
+ result = inferencer(image, topk=min(topk, len(prototype)))[0]
+ return [(str(item['sample']['img_path']),
+ str(item['match_score'].cpu().item())) for item in result]
+
+
+class TextToImageRetrievalTab:
+
+ def __init__(self) -> None:
+ self.model_list = TextToImageRetrievalInferencer.list_models()
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='t2i_retri_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='blip-base_3rdparty_coco-retrieval',
+ )
+ topk = gr.Slider(minimum=1, maximum=6, value=3, step=1)
+ with gr.Column():
+ prototype = gr.File(
+ file_count='multiple', file_types=['image'])
+ text_input = gr.Textbox(
+ label='Query',
+ elem_classes='input_text',
+ interactive=True,
+ )
+ retri_output = gr.Gallery(
+ label='Result',
+ elem_classes='img_retri_result',
+ ).style(
+ columns=[3], object_fit='contain', height='auto')
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, prototype, text_input, topk],
+ outputs=retri_output,
+ )
+
+ def inference(self, model, prototype, text, topk):
+ import hashlib
+
+ proto_signature = ''.join(file.name for file in prototype).encode()
+ proto_signature = hashlib.sha256(proto_signature).hexdigest()
+ inferencer_name = self.__class__.__name__ + model + proto_signature
+ tmp_dir = Path(prototype[0].name).parent
+ cache_file = tmp_dir / f'{inferencer_name}.pth'
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(
+ TextToImageRetrievalInferencer,
+ model,
+ prototype=[file.name for file in prototype],
+ prototype_cache=str(cache_file),
+ ),
+ )
+
+ result = inferencer(text, topk=min(topk, len(prototype)))[0]
+ return [(str(item['sample']['img_path']),
+ str(item['match_score'].cpu().item())) for item in result]
+
+
+class VisualGroundingTab:
+
+ def __init__(self) -> None:
+ self.model_list = VisualGroundingInferencer.list_models()
+ self.tab = self.create_ui()
+ self.visualizer = UniversalVisualizer(
+ fig_save_cfg=dict(figsize=(16, 9)))
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='vg_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='ofa-base_3rdparty_refcoco',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Image',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ text_input = gr.Textbox(
+ label='The object to search',
+ elem_classes='input_text',
+ interactive=True,
+ )
+ vg_output = gr.Image(
+ label='Result',
+ source='upload',
+ interactive=False,
+ elem_classes='vg_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input, text_input],
+ outputs=vg_output,
+ )
+
+ def inference(self, model, image, text):
+
+ inferencer_name = self.__class__.__name__ + model
+
+ inferencer = InferencerCache.get_instance(
+ inferencer_name,
+ partial(VisualGroundingInferencer, model),
+ )
+
+ result = inferencer(
+ image[:, :, ::-1], text, return_datasamples=True)[0]
+ vis = self.visualizer.visualize_visual_grounding(
+ image, result, resize=512)
+ return vis
+
+
+class VisualQuestionAnsweringTab:
+
+ def __init__(self) -> None:
+ self.model_list = VisualQuestionAnsweringInferencer.list_models()
+ # The fine-tuned OFA vqa models requires extra object description.
+ self.model_list.remove('ofa-base_3rdparty-finetuned_vqa')
+ self.tab = self.create_ui()
+
+ def create_ui(self):
+ with gr.Row():
+ with gr.Column():
+ select_model = gr.Dropdown(
+ label='Choose a model',
+ elem_id='vqa_models',
+ elem_classes='select_model',
+ choices=self.model_list,
+ value='ofa-base_3rdparty-zeroshot_coco-vqa',
+ )
+ with gr.Column():
+ image_input = gr.Image(
+ label='Input',
+ source='upload',
+ elem_classes='input_image',
+ interactive=True,
+ tool='editor',
+ )
+ question_input = gr.Textbox(
+ label='Question',
+ elem_classes='question_input',
+ )
+ answer_output = gr.Textbox(
+ label='Answer',
+ elem_classes='answer_result',
+ )
+ run_button = gr.Button(
+ 'Run',
+ elem_classes='run_button',
+ )
+ run_button.click(
+ self.inference,
+ inputs=[select_model, image_input, question_input],
+ outputs=answer_output,
+ )
+
+ def inference(self, model, image, question):
+ image = image[:, :, ::-1]
+
+ inferencer_name = self.__class__.__name__ + model
+ inferencer = InferencerCache.get_instance(
+ inferencer_name, partial(VisualQuestionAnsweringInferencer, model))
+
+ result = inferencer(image, question)[0]
+ return result['pred_answer']
+
+
+if __name__ == '__main__':
+ title = 'MMPretrain Inference Demo'
+ with gr.Blocks(analytics_enabled=False, title=title) as demo:
+ gr.Markdown(f'# {title}')
+ with gr.Tabs():
+ with gr.TabItem('Image Classification'):
+ ImageClassificationTab()
+ with gr.TabItem('Image-To-Image Retrieval'):
+ ImageRetrievalTab()
+ if WITH_MULTIMODAL:
+ with gr.TabItem('Image Caption'):
+ ImageCaptionTab()
+ with gr.TabItem('Text-To-Image Retrieval'):
+ TextToImageRetrievalTab()
+ with gr.TabItem('Visual Grounding'):
+ VisualGroundingTab()
+ with gr.TabItem('Visual Question Answering'):
+ VisualQuestionAnsweringTab()
+ else:
+ with gr.TabItem('Multi-modal tasks'):
+ gr.Markdown(
+ 'To inference multi-modal models, please install '
+ 'the extra multi-modal dependencies, please refer '
+ 'to https://mmpretrain.readthedocs.io/en/latest/'
+ 'get_started.html#installation')
+
+ demo.launch()
diff --git a/requirements/multimodal.txt b/requirements/multimodal.txt
new file mode 100644
index 00000000000..f6150b16d8e
--- /dev/null
+++ b/requirements/multimodal.txt
@@ -0,0 +1,2 @@
+pycocotools
+transformers>=4.28.0
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
index 6d7b3d2aeaf..145cedab5b8 100644
--- a/requirements/readthedocs.txt
+++ b/requirements/readthedocs.txt
@@ -1,5 +1,7 @@
--extra-index-url https://download.pytorch.org/whl/cpu
mmcv-lite>=2.0.0rc4
mmengine
+pycocotools
torch
torchvision
+transformers
diff --git a/setup.cfg b/setup.cfg
index 13c91624e9a..fe9c158b104 100644
--- a/setup.cfg
+++ b/setup.cfg
@@ -21,3 +21,12 @@ default_section = THIRDPARTY
skip = *.ipynb
quiet-level = 3
ignore-words-list = patten,confectionary,nd,ty,formating,dows
+
+[flake8]
+# The E251 check is conflict with yapf in some situation.
+# See https://github.com/google/yapf/issues/393
+extend-ignore = E251
+# The F401 check is wrong if the `__all__` variable is modified
+# in `__init__.py`
+per-file-ignores =
+ */__init__.py: F401
diff --git a/setup.py b/setup.py
index 925ce9b3ba5..6ed773f80dd 100644
--- a/setup.py
+++ b/setup.py
@@ -193,5 +193,6 @@ def add_mim_extension():
'tests': parse_requirements('requirements/tests.txt'),
'optional': parse_requirements('requirements/optional.txt'),
'mim': parse_requirements('requirements/mminstall.txt'),
+ 'multimodal': parse_requirements('requirements/multimodal.txt'),
},
zip_safe=False)
diff --git a/tests/test_apis/test_inference.py b/tests/test_apis/test_inference.py
index 1e9d7cbc4da..72b20e567c8 100644
--- a/tests/test_apis/test_inference.py
+++ b/tests/test_apis/test_inference.py
@@ -23,7 +23,7 @@ def test_init(self):
# test input BaseModel
model = get_model(MODEL)
inferencer = ImageClassificationInferencer(model)
- self.assertEqual(model.config, inferencer.config)
+ self.assertEqual(model._config, inferencer.config)
self.assertIsInstance(inferencer.model.backbone, MobileNetV3)
# test input model name
diff --git a/tests/test_tools.py b/tests/test_tools.py
index 4909de64b4e..013584d0da1 100644
--- a/tests/test_tools.py
+++ b/tests/test_tools.py
@@ -306,7 +306,7 @@ def setUp(self):
model = get_model('mobilevit-xxsmall_3rdparty_in1k')
self.config_file = self.dir / 'config.py'
- model.config.dump(self.config_file)
+ model._config.dump(self.config_file)
self.ckpt_file = self.dir / 'ckpt.pth'
torch.save(model.state_dict(), self.ckpt_file)
diff --git a/tools/model_converters/ofa.py b/tools/model_converters/ofa.py
new file mode 100644
index 00000000000..142c7ac3872
--- /dev/null
+++ b/tools/model_converters/ofa.py
@@ -0,0 +1,111 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import re
+from collections import OrderedDict, namedtuple
+from pathlib import Path
+
+import torch
+
+prog_description = """\
+Convert OFA official models to MMPretrain format.
+"""
+
+MapItem = namedtuple(
+ 'MapItem', 'pattern repl key_action value_action', defaults=[None] * 4)
+
+
+def convert_by_mapdict(src_dict: dict, map_dict: Path):
+ dst_dict = OrderedDict()
+ convert_map_dict = dict()
+
+ for k, v in src_dict.items():
+ ori_k = k
+ for item in map_dict:
+ pattern = item.pattern
+ assert pattern is not None
+ match = next(re.finditer(pattern, k), None)
+ if match is None:
+ continue
+ match_group = match.groups()
+ repl = item.repl
+
+ key_action = item.key_action
+ if key_action is not None:
+ assert callable(key_action)
+ match_group = key_action(*match_group)
+ if isinstance(match_group, str):
+ match_group = (match_group, )
+ start, end = match.span(0)
+ if repl is not None:
+ k = k[:start] + repl.format(*match_group) + k[end:]
+ else:
+ for i, sub in enumerate(match_group):
+ start, end = match.span(i + 1)
+ k = k[:start] + str(sub) + k[end:]
+
+ value_action = item.value_action
+ if value_action is not None:
+ assert callable(value_action)
+ v = value_action(v)
+
+ if v is not None:
+ dst_dict[k] = v
+ convert_map_dict[k] = ori_k
+ return dst_dict, convert_map_dict
+
+
+map_dict = [
+ # Encoder modules
+ MapItem(r'\.type_embedding\.', '.embed_type.'),
+ MapItem(r'\.layernorm_embedding\.', '.embedding_ln.'),
+ MapItem(r'\.patch_layernorm_embedding\.', '.image_embedding_ln.'),
+ MapItem(r'encoder.layer_norm\.', 'encoder.final_ln.'),
+ # Encoder layers
+ MapItem(r'\.attn_ln\.', '.attn_mid_ln.'),
+ MapItem(r'\.ffn_layernorm\.', '.ffn_mid_ln.'),
+ MapItem(r'\.final_layer_norm', '.ffn_ln'),
+ MapItem(r'encoder.*(\.self_attn\.)', key_action=lambda _: '.attn.'),
+ MapItem(
+ r'encoder.*(\.self_attn_layer_norm\.)',
+ key_action=lambda _: '.attn_ln.'),
+ # Decoder modules
+ MapItem(r'\.code_layernorm_embedding\.', '.code_embedding_ln.'),
+ MapItem(r'decoder.layer_norm\.', 'decoder.final_ln.'),
+ # Decoder layers
+ MapItem(r'\.self_attn_ln', '.self_attn_mid_ln'),
+ MapItem(r'\.cross_attn_ln', '.cross_attn_mid_ln'),
+ MapItem(r'\.encoder_attn_layer_norm', '.cross_attn_ln'),
+ MapItem(r'\.encoder_attn', '.cross_attn'),
+ MapItem(
+ r'decoder.*(\.self_attn_layer_norm\.)',
+ key_action=lambda _: '.self_attn_ln.'),
+ # Remove version key
+ MapItem(r'version', '', value_action=lambda _: None),
+ # Add model prefix
+ MapItem(r'^', 'model.'),
+]
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description=prog_description)
+ parser.add_argument('src', type=str, help='The official checkpoint path.')
+ parser.add_argument('dst', type=str, help='The save path.')
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ src = torch.load(args.src)
+ if 'extra_state' in src and 'ema' in src['extra_state']:
+ print('Use EMA weights.')
+ src = src['extra_state']['ema']
+ else:
+ src = src['model']
+ dst, _ = convert_by_mapdict(src, map_dict)
+ torch.save(dst, args.dst)
+ print('Done!!')
+
+
+if __name__ == '__main__':
+ main()