diff --git "a/week3/6\355\214\200_\354\236\204\354\204\270\355\233\210.md" "b/week3/6\355\214\200_\354\236\204\354\204\270\355\233\210.md"
new file mode 100644
index 0000000..51a38b3
--- /dev/null
+++ "b/week3/6\355\214\200_\354\236\204\354\204\270\355\233\210.md"
@@ -0,0 +1,82 @@
+# 트리 알고리즘
+___
+## 결정 트리
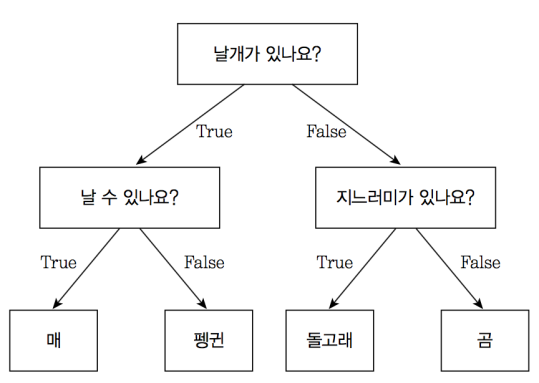
+> 결정 트리란?
+
+ 
+
+ - 조건문에 대한 참과 거짓으로 데이터를 판별
+ - 조건을 확인할 수 있기 때문에 직관적
+ - 조건에 따라 데이터를 분류하기 때문에 회귀보다는 분류 문제에 적합
+ - 탐욕 알고리즘의 일종
+
+>로지스틱 회귀와 다른 점
+
+ |로지스틱 회귀 | 결정 트리|
+ | :--:| :--: |
+ |선형 | 비선형 |
+ |데이터가 특정 범주에 속할 확률 확인|데이터가 특정 범주에 속하는 이유 확인|
+ | | |
+
+> 루트 노드와 리프 노드
+
+ - 노드 : 결정 트리를 구성하는 핵심 요소. 데이터의 특서엥 대한 테스트 표현
+
+ - 루트 노드 : 결정 트리의 맨 위에 있는 노드
+ - 리프 노드 : 결정 트리의 맨 아래 끝에 달린 노드
+
+> 노드를 이루는 구성 요소
+
+ - 테스트 조건 : 훈련 데이터에 대한 테스트를 표현하는 요소
+ - gini : 데이터가 얼마나 섞여있는지를 표현하는 요소(불순도)
+ - samples : 총 샘플의 수를 표현하는 요소
+ - value : 각 클래스 별의 샘플 수를 보여주는 요소
+
+> 불순도
+ - Criterion 매개변수에서 데이터의 분할 기준을 결정하는 값
+ - 기본값은 gini, 엔트로피와 같은 다른 불순도도 존재
+ - gini = 1-((음성 클래스 비율)^2 + (양성 클래스 비율)^2)
+ - 부모 노드와 자식 노드의 불순도 차를 크게 만드는 것이 좋음(정보 이득)
+ - 정보 이득 : 부모와 자식 노드 사이의 불순도 차이
+
+> 가지치기
+ - max_depth : 트리의 최대 깊이를 조절하는 하이퍼파라미터
+ - scikitlearn에서는 GridSearchCV()를 통해 자동으로 하이퍼파라미터를 탐색
+ - 최대 깊이가 커질수록 정확도가 높아지지만 너무 커지면 과대적합이 발생
+
+___
+## 교차 검증과 그리드 서치
+
+>Validation set(검증 세트) & Cross Validation(교차 검증)
+ - 기존의 훈련 세트를 한번 더 나누어서 과적합 문제를 방지
+ - 검증 세트를 떼어내고 교차 검증을 하면서 안정적인 검증 점수를 얻음
+ - k - 폴드 교차 검증 : 훈련 세트를 k개로 나누어서 검증 세트를 떼어내고 평가하는 과정을 반복
+
+
+ ___
+## 트리의 앙상블
+>RandomForest
+ - 랜덤하게 결정 트리를 형성해 여러 개의 결정 트리로 숲을 이루는 방식
+ - 각 결정 트리의 예측으로부터 최종 예측값을 도출
+ - 부트스트랩 샘플을 이용
+ - 부트스트랩 : 각각의 트리를 학습시키기 위해 학습 데이터를 중복을 허용하여 랜덤하게 뽑는 것
+
+>ExtraTree
+ - Randomforest와 동일하게 작용하지만 샘플을 뽑는 방식에서 차별점을 둠
+ - 무작위 분할 실행
+ - 앙상블의 다양성을 높이고, 과대적합을 방지하는 효과
+
+> Gradient Boosting
+ - 깊이가 낮은 트리 여러개를 사용
+ - 과대적합 방지, 일반화 성능 구현
+ - 경사 하강법과 유사한 과정
+ - max_depth 값을 점차 줄여나가며 이동
+ - 분류 문제는 로지스틱 손실 함수, 회귀 문제는 평균 제곱 오차 함수를 사용
+ - 성능이 좋지만 속도가 느리다는 단점
+
+> Histogram-based Gradient Boosting
+ - Gradient Boosting + Histogram
+ - 입력 특성을 256개의 구간으로 나눔
+ - 이중 하나는 누락된 값을 위하여 사용(누락된 값 전처리할 필요 X)
+ - Gradient Boosting에서 속도/성능 개선
+ - 머신러닝 알고리즘 중 가장 인기가 높음
\ No newline at end of file
diff --git "a/week5/1\355\214\200_\354\236\204\354\204\270\355\233\210.md" "b/week5/1\355\214\200_\354\236\204\354\204\270\355\233\210.md"
new file mode 100644
index 0000000..58f1dc3
--- /dev/null
+++ "b/week5/1\355\214\200_\354\236\204\354\204\270\355\233\210.md"
@@ -0,0 +1,78 @@
+# Ch.06 비지도 학습
+## 1. 비지도 학습 Unsupervised learning
+### 비지도 학습이란?
+ - 결과정보가 없는 데이터들에 대해 특정 패턴을 찾는 것
+ - 데이터의 잠재 구조, 계층 구조 찾기
+ - 숨겨진 사용자 집단 찾기
+ - 사용 패턴 찾기
+
+### 비지도 학습의 대상
+ 1. 군집화 Clustering
+ 2. 밀도 추정 Density estimation
+ 3. 차원 축소 Dementionality reduction
+ ___
+## 2. k-평균 알고리즘 k-Mean Clustering Algorithm
+
+### 원리
+1. 센트로이드 랜덤 선정
+2. 샘플에 레이블을 할당하고 센트로이드 업데이트
+3. 센트로이드 변화가 없을 때까지 2를 반복
+
+### 업데이트 방식
+- inertia
+ - 샘플과 센트로이드 가이의 거리를 측정하여 모델의 대략적인 성능 확인
+ - 특정 클러스터 개수에서 inertia 급격하게 감소
+
+### 최적의 클러스터 개수 찾기
+ - inertia가 급격하게 감소하는 지점의 클러스터 개수 찾기
+ - 실루엣 score가 1에 가까운 클러스터 개수 찾기
+
+### 문제점
+ - 변동성 문제
+ - 센트로이드의 초기값에 따라서 결과가 달라질 수 있음
+ - Outlier에 예민
+ - Outlier 하나하나에 센트로이드가 민감하게 반응
+ - 다양한 모양의 클러스터에 취약
+ - 거리만을 측정하여 센트로이드 값을 업데이트하기 때문
+___
+## 3. 차원 축소 Demensionally Reduction
+
+### 고차원 데이터의 문제점
+- 계산 복잡성 증가
+- 노이즈 발생 가능성 증가
+- 변수들의 상관관계가 많을 수록 모델 성능 감소
+
+### 해결책
+- 차원 축소
+ - 저차원에서도 데이터를 잘 설명하는 변수들만 사용
+___
+## 4. PCA Principal Component Analysis
+
+### 원리
+- 원본 데이터의 분산을 보존하는 수직인 기저 집합 찾기
+ - 데이터가 Projection된 이후에도 데이터의 분산 보존
+ - 차원 축소 이후 데이터의 분산이 큰 방향으로 진행
+- 공분산
+ - 어떤 변수의 증감에 따라 다른 변수가 따라가는 정도를 의미
+ - 이러한 관계를 수치적으로 표현
+
+### 과정
+1. Data Centering
+ - 데이터의 중심을 평균값으로 조정한다.
+ (이후 공분산을 계산할 때 유용)
+2. 최적화 문제 계산
+ - 벡터를 기저에 투영시켰을 때의 공분산을 계산
+ - 공분산이 큰 쪽으로 진행
+3. Lagrangian multiplier
+ - Lagrangian multiplier을 이용하여 Eigenvectors와 Eigenvalues를 구한다.
+4. 적용
+ - Eigenvectors, Eigenvalues를 통해 lambda값을 계산(lambda값에 따라 원 데이터의 분산이 잘 보존되는지 알 수 있음)
+
+### 데이터 재구성
+- 압축된 데이터셋에 PCA변환을 반대로 적용하면 원래 차원으로 되돌릴 수 있음
+- 이 경우 원본 데이터와의 차이(재구성 오차)가 발생
+
+### PCA 이외의 차원 축소 기법
+- Isomap, t-SNE, MDS 등
+- 각각의 기법에 따라 차원 축소 후의 결과가 다르게 나타남
+ ___
\ No newline at end of file