- Flexible: Encodes the entire HTTP protocol in Apache Spark for full control of web requests
- Performant: Fully distributed across workers, built in support for multi-threaded buffering, batching, and asynchronous request concurrency.
- Easy to Use: High-level APIs for automatic parsing of requests, abstracting all HTTP knowledge to under the hood.
- Accessible from Multiple Languages: Usable in Python and Scala. Native integration with Scala's Apache HTTP Core. Native integration with Python Requests library coming soon!
- Composable: Pipeline Stage APIs allow users to embed and compose web services with SparkML machine learning models.
import mmlspark
from mmlspark.io.http import SimpleHTTPTransformer, JSONOutputParser
from pyspark.sql.types import StructType, StringType
df = sc.parallelize([(x, ) for x in range(100)]).toDF("data")
client = SimpleHTTPTransformer() \
.setInputCol("data") \
.setOutputParser(JSONOutputParser() \
.setDataType(StructType().add("replies", StringType))) \
.setUrl("www.my_service_url.com/any_api_here") \
.setOutputCol("results")
responses = client.transform(df)The Simple HTTP transformer provides options for batching request bodies and asynchronous request sending. For simplicity and easier debugging, these options are not enabled by default.
-
maxBatchSize: Parameter that enables buffered minibatching. If this parameter is set, a background thread will fetch up to at mostmaxBatchSizerequests. These requests's are combined by creating an array of their entity data. The method sends up tomaxBatchSizerequests, rapid iterator materialization will result in smaller batches as the background thread does not have enough time to materialize a full batch. In other words, each new request sends all of the new data that has accumulated at this stage of the pipeline. -
concurrency: This parameter allows one to send up toconcurrencyrequests simultaneously using Scala futures under the hood. If this parameter is set to 1 (default), then no Scala futures are used. -
concurrentTimeout: Ifconcurrency>1, requests will fail if they do not receive a response withinconcurrentTimeoutseconds. -
handlingStrategy: ("basic", or"advanced") advanced handling uses exponential backoff on the retires and can handle responses that instruct clients to throttle or retry again.
SimpleHTTPTransformer() \
.setMaxBatchSize(100) \
.setConcurrency(5) \
.setConcurrentTimeout(30.0) \
.setHandlingStrategy("advanced")HTTP on Spark encapsulates the entire HTTP protocol within Spark's datatypes. Uses can create flexible web clients that communicate with a wide variety of endpoints. MMLSpark provides methods to convert between Scala case classes, Spark types, and Apache HTTP Core types. A common representation makes it easy to work with HTTP on spark from Scala, Python, or any other spark compatible language. This common representation is serializable allowing for complex operations like SQL joins and repartitons.
In HTTP on Spark, each partition manages a running web client that sends requests. A schematic representation can be seen below:
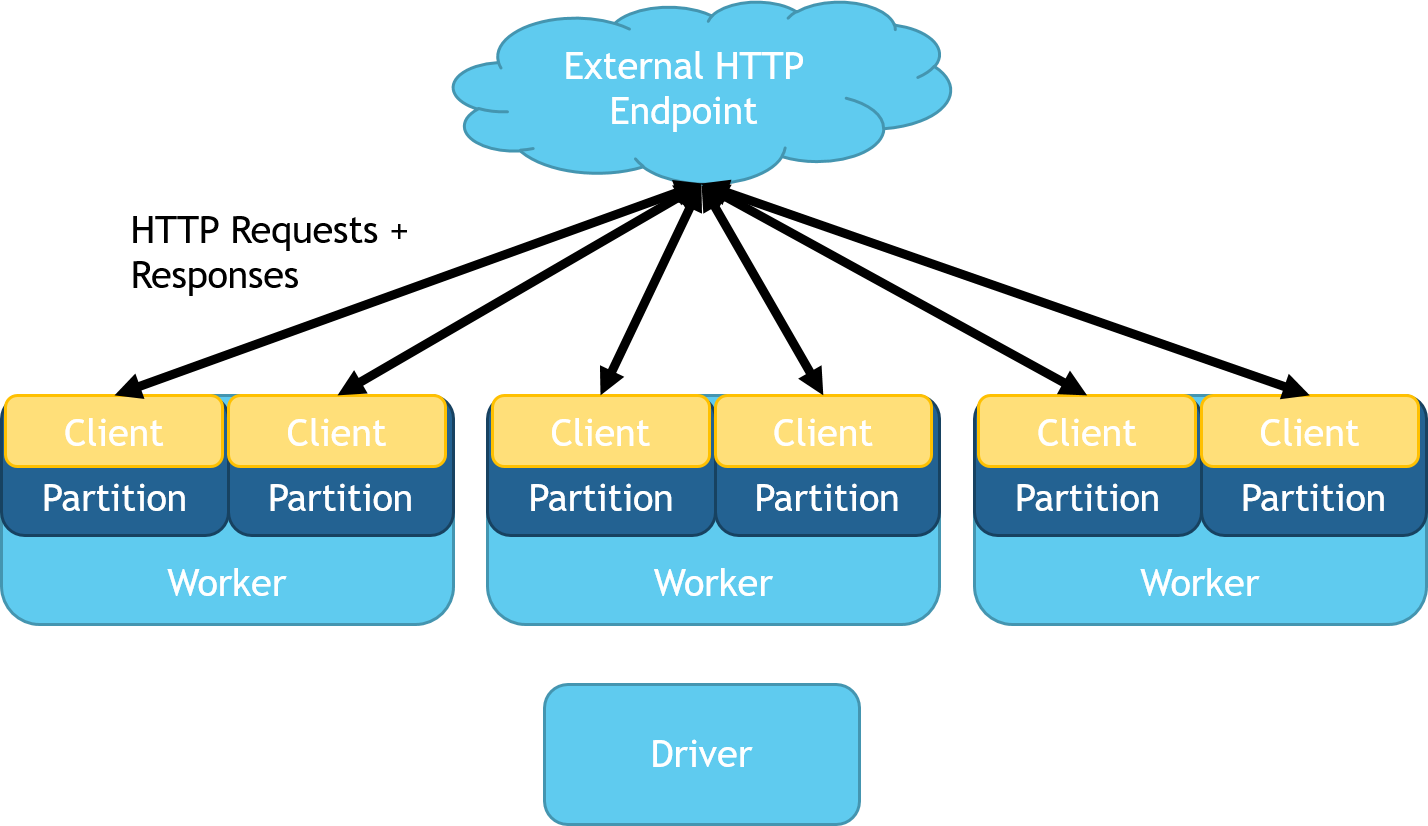
This library adds Spark types that faithfully represent the HTTP protocol for requests and responses. MMLSpark provides several ways to create these objects from the apache HTTP core library, and from a set of case classes.
The schema for a complete HTTP request looks like:
request: struct (nullable = true)
+-- requestLine: struct (nullable = true)
| +-- method: string (nullable = true)
| +-- uri: string (nullable = true)
| +-- protoclVersion: struct (nullable = true)
| +-- protocol: string (nullable = true)
| +-- major: integer (nullable = false)
| +-- minor: integer (nullable = false)
+-- headers: array (nullable = true)
| +-- element: struct (containsNull = true)
| +-- name: string (nullable = true)
| +-- value: string (nullable = true)
+-- entity: struct (nullable = true)
+-- content: binary (nullable = true)
+-- contentEncoding: struct (nullable = true)
| +-- name: string (nullable = true)
| +-- value: string (nullable = true)
+-- contentLenth: long (nullable = false)
+-- contentType: struct (nullable = true)
| +-- name: string (nullable = true)
| +-- value: string (nullable = true)
+-- isChunked: boolean (nullable = false)
+-- isRepeatable: boolean (nullable = false)
+-- isStreaming: boolean (nullable = false)
And the schema for a complete response looks like:
response: struct (nullable = true)
+-- headers: array (nullable = true)
| +-- element: struct (containsNull = true)
| +-- name: string (nullable = true)
| +-- value: string (nullable = true)
+-- entity: struct (nullable = true)
| +-- content: binary (nullable = true)
| +-- contentEncoding: struct (nullable = true)
| | +-- name: string (nullable = true)
| | +-- value: string (nullable = true)
| +-- contentLenth: long (nullable = false)
| +-- contentType: struct (nullable = true)
| | +-- name: string (nullable = true)
| | +-- value: string (nullable = true)
| +-- isChunked: boolean (nullable = false)
| +-- isRepeatable: boolean (nullable = false)
| +-- isStreaming: boolean (nullable = false)
+-- statusLine: struct (nullable = true)
| +-- protocolVersion: struct (nullable = true)
| | +-- protocol: string (nullable = true)
| | +-- major: integer (nullable = false)
| | +-- minor: integer (nullable = false)
| +-- statusCode: integer (nullable = false)
| +-- reasonPhrase: string (nullable = true)
+-- locale: string (nullable = true)