| layout |
|---|
default |
Back to Home;
Scarica le [slides](./resources/slides/2017-09-Game Engines Game Sound Techniques.pdf) delle lezioni!
{: class="dashed"}
Di seguito parte dei contenuti trattati durante le lezioni:
Il game engine (o motore di gioco) è un componente software usato per aiutare lo sviluppo l'esecuzione di un videogioco. Prima di esaminarlo in dettaglio conveniamo sulla definizione di videogioco.
Il videogioco è una moderna di declinazione del concetto di gioco. La sua particolarità risiede nel mezzo con cui si fruisce del gioco: uno schermo.

Un gioco è una narrazione guidata da scelte che uno o più giocatori compiono in conformità a un insieme di regole che limitano il campo d’azione.
Le sue caratteristiche sono:
- Intrattenimento (non solo: studi sull'impatto del videogioco sulla salute e le capacità cognitive)
- Interattività
- Multimedialità
Storicamente i videogiochi hanno visto i natali negli arcade (sale gioco), a cui si sono aggiunte le console e infine i PC. Un videogioco altro non è che un software, un insieme di codici contenenti le istruzioni comprensibili da una macchina.
Ogni macchina per le sue peculiarità (hardware, OS quando presente) comprende un particolare insieme di codici, non utilizzabili da altri macchinari, per quanto simili come finalità di utilizzo.
Inoltre, assieme alla complessità logica e grafica i giochi ci sono man mano diversificati anche in virtù di un genere di appartenenza.
La diversificazione dei generi non è stata solo uno sbocco naturale dovuto all'innovazione tecnologica ma anche una necessità dell'industria per far fronte ad una stagnazione del mercato, ormai saturo di giochi, uno clone dell'altro, sia negli arcade, console e primi pc. Uno su tutti è l'esempio di Pong il cui chip (l'AY-3-8500)

La saturazione del mercato fu causata anche da una mancanza di regolamentazione nel copyright associato al prodotto videoludico!
{: class="dashed"}
Di generi videoludici ne esistono moltissimi, possiamo qui esaminarne alcuni, come ad esempio un'avventura testuale o grafica, un RPG, un race game e un FPS. Tutti questi sono videogiochi, ma differiscono notevolmente tra di loro sia per quanto riguarda la logica interna sia per quanto riguarda la performance richiesta alla macchina.
- un'avventura testuale (come Colossal Cave Adventure del 1976) richiede un'efficienza in termini di parsing del testo (comprensione delle istruzioni digitate dall'utente), ma non ha grafica;
- un'avventura grafica (come Gabriel Knight della Sierra) invece richiede un render grafico, la possibilità di emettere suono e di gestire la fisica, e la gestione dell'input dell'utente attraverso interfaccia grafica (GUI);
- un RPG (come Ultima) richiede memoria per gestire le statistiche e i vari livelli durante il gioco. A differenza delle avventure testuali richiede anche la capacità di render grafico;
- un race game (come Indianapolis 500) si basa sulla simulazione, quindi saranno necessari modelli accurati e una corretta impostazione della fisica del gioco per poter riprodurre il più fedelemente possibile questi modelli nel gioco. A ciò si aggiunge il render grafico che deve essere accurato, una capacità responsiva veloce e una gestione di controller articolata;
- un FPS (come Wofenstein 3D) ha bisogno di un'ottima resa grafica, di un sistema di gestione delle collisioni ottimale, di un sistema di AI e di gestire l'input utente attraverso interfacce grafiche anche molto complesse.
Si vede che anche solo considerando pochi esempi di videogiochi, questi differscano non solo in genere, ma anche in risorse di cui necessitano.
Per capire perchè il game engine è importante...
Quindi ora, mettiamoci nei panni di una software house. Possiamo decidere di sviluppare ogni videogame da zero. Questo è dispendioso in termini di persone coinvolte e di tempo impiegato nella realizzazione del videogioco (concept, creazione degli asset, programmazione del gioco - interazione, fisica, grafica, suono, ottimizzazione per varie piattaforme - abbiamo visto prima che macchine diverse comprendono codici - o linguaggi - diversi).
Questa modalità a lungo andare non è efficiente. Allora ci domandiamo, perchè reinventare ogni volta la ruota?
Quando abbiamo realizzato un videogioco, ad esempio un RPG, abbiamo già a disposizione tutta una serie di strumenti software che possono essere riutilizzati in altri giochi RPG. Quello che cambierebbe allora sarebbero solo gli assets (grafiche, suoni, modelli, script,...). Questo è dispendioso solo in termini di rendere il pacchetto software già realizzato il più generico possibile, in modo da essere utilizzabile più e più volte per diversi giochi.
Una volta che si crea questo motore di gioco (game engine), lo sviluppo di ulteriori giochi è facilitato, si possono spender più tempo e soldi in termini di sviluppo asset e soprattutto in level design. Il tutto è ulteriormente semplificato dall'utilizzo di un'IDE grafica (interfaccia di sviluppo grafica) che rende trasparente il livello di programmazione.
I vari reparti interessati nello sviluppo del gioco lavorano ciascuno nel proprio ambito sulla medesima piattaforma di sviluppo (sullo stesso progetto) senza preoccuparsi di integrare le varie componenti tra di loro. Il reparto che si occupa di programmazione si occupa di collegare le risorse sia tra di loro sia con la logica sottostante utilizzando codice.
Ecco quindi che come software house abbiamo creato un nostro game engine ad uso interno.
Il nostro game engine è comunque lungi dall'essere un'innovazione nell'industria. Appoggiarsi a game engine (nel caso di sviluppo di videogiochi) o a porzioni di software già pronto (nella fase di sviluppo e creazione software) è una pratica vecchia quanto la computer science. Per quanto possibile non si reinventa la ruota. Si cerca, al più, di migliorarla.

A partire dagli arcade, passando per le prime console e quindi approdando ai PC, la tecnologia ha reso sempre più semplice e desiderabile riutilizzare software già scritto, testato, ottimizzato, sul quale è possibile costruire nuovi programmi in minor tempo e in modo più efficiente.
Ma se siamo sviluppatori indipendenti e non abbiamo un reparto che si occupa di programmazione e sviluppo software capace di creare dal nulla un game engine? Alcune software house importanti (Epic Games con "Unreal" e Id Software con "idTech") hanno rilasciato al pubblico i loro engine, entrambi utilizzati per la realizzazione di FPS, il genere di videogiochi più in voga al tempo.
Altre software house si sono specializzate nello sviluppo di game engine per terze parti. Negli ultimi anni si ha una vera e propria profusione di game engine di respiro più genrico, per cui oggi non si ha che l'imbarazzo della scelta.
Una nota: esistono game engine più generici (Unity3D, Godot,...) e altri pensati per la realizzaizone di una tipologia precisa di videogiochi (Inform, Unreal, ...). Alcuni game engine offrono molte risorse (render 3D, compatibilità con sistemi VR, gestione rete per multiplayer online, streaming video...), ma alle volte non tutte sono necessarie per il gioco che si vuole realizzare. Quindi si sceglie (visto che oggi lo si può fare) il game engine in funzione del gioco da realizzare.
Non uso Ableton Live per fare editing al campione, come non uso ProTools per fare una performance dal vivo che richiede flessibilità e affidabilità.
{: class="note"}
Come pro tools può essere espanso con plugin che ne amplificano le funzionalità, così i game engine possono essere ampliati in alcune loro funzionalità grazie all'uso di middleware (di cui avete già visto un esempio in Wwise). Ci sono middleware molto famosi, come Havok per la fisica e l'AI e Euphoria per la fisica e le collisioni.
| <iframe width="100%" src="https://www.youtube.com/embed/cIcg5eotZlY" frameborder="0" allowfullscreen></iframe> | <iframe width="100%" src="https://www.youtube.com/embed/wKLaMN9dnjQ" frameborder="0" allowfullscreen></iframe> |
Un'ulteriore nota di carattere generale: sebbene il livello di programmazione è trasparente all'utente del game engine, questo non scompare. Il gioco non cessa di essere software e il software altro non è che codice scritto in un linguaggio di programmazione. In parole povere, non si prescinde dal codice, ci sono sistemi semplificati di programmazione resi disponibili dai game engine, ma non esistono game engine in cui si può creare un gioco senza programmare. {: class="note"}
Abbiamo visto che il videogioco altro non è se non un software. Sebbene nei moderni sistemi di sviluppo non sia necessario essere in grado di programmare se si creano assets (ad esempio audio), è anche vero che ci si dovrà interfacciare con reparti tecnici che invece lavorano con il codice (ad esempio un DSP guy o audio programmer/coder). Quindi familiarizzare con un po' di nomenclatura facilita il lavoro di entrambi.
In sostanza, imparare i rudimenti della programmazione è fondamentale, soprattutro per operare nell'ambito multimediale, per i seguenti motivi:
- imparare a programmare fornisce un linguaggio comune spendibile in tutti i contesti in cui ci si debba interfacciare con un team di sviluppatori;
- imparare a programmare non implica che per forza si debba cercare uno sbocco professionale nel campo. Così come si impara a leggere e scrivere senza pensare di divenire scrittori, così programmare sta diventando l'equivalente dell'alfabetizzazione del secolo scorso.
Le nuove tecnologie si stanno evolvendo a ritmi sostenuti (esempi) e, se questo è da una parte salutato con entusiasmo, dall'altra è guardato con preoccupazione. L'unico modo per interfacciarsi serenamente con la tecnologia, ovvero non caderne vittima e non fuggirla come una minaccia è conoscerla! {: class="note"}
- inoltre, padroneggiare i principi di programmazione torna utile anche da un punto di vista creativo, rendendo possibile usare tool di sviluppo audio come SuperCollider o Chuck con cui si possono realizzare effetti audio e suoni inediti e del tutto originali. Inoltre questi strumenti sono utilizzabili durante live performances per creare jam con il codice (live coding). A tal proposito, rimandiamo all'interessante talk del creatore di Sonic Pi, Sam Aaron. Il movimento di riferimento è Algorave e il sito in cui trovare informazioni è toplap.
Per chi fosse interessato ad approfondire da subito il mondo della programmazione, consigliamo di seguire questa breve lezione tenuta da Daniel Shiffman, portabandiera della Processing Foundation. {: class="dashed"}
Cosa significa avere un sistema semplificato di programmazione come ho detto prima?
Il computer è una macchina universale. Significa che può compiere qualsiasi compito per il quale le si forniscano le corrette istruzioni. Il computer però non fa nulla da solo. Non è come una radio, che una volta accesa, capterà automaticamente le onde radio a una data frequenza e le renderà in forma di onda sonora. Il computer una volta acceso rimane in stand-by. Attende istruzioni.
Le istruzioni comprese dal computer sono in forma binaria. Significa che sono in forma di sequenze di caratteri 1 e 0.
E' possibile programmare, ovvero fornire istruzioni al computer, in forma binaria, ma non è molto efficiente. Questo per due motivi principali:
- le istruzioni raggiungono lunghezze considerevoli in breve tempo, quindi richiedo del tempo per essere redatte;
- la possibilità di errore cresce esponenzialmente con la lunghezza delle istruzioni così come la difficoltà di correggere l'errore.
Il vantaggio di programmare in binario è, però, l'assenza di livelli intermedi tra programmatore/software ed hardware. Per facilitare il compito del programmatore sono nati linguaggi di programmazione più vicini al linguaggio naturale, che grazie ad una macchina (l'assembler), vengono tradotti in binario. Ogni macchina comprende un particolare dialetto binario, quindi avrà un proprio assembly (il linguaggio compreso dall'assembler) dedicato. Non posso usare l'assembly per Intel su una macchina Motorola.
L'assembly è a tutti gli effetti quello che si chiama linguaggio a basso livello (ovvero, un linguaggio che usa simboli e alfabeto proprio degli esseri umani e che comunica in linea piuttosto diretta con l'hardware).
Per rendere la programmazione indipendente dalla macchina su cui si lavora (sviluppo un editor di testo che possa funzionare su DOS, Unix, Solaris, ...), sono stati creati dei linguaggi ancora più vicini al linguaggio naturale e che si avvantaggiano del compilatore, un software che traduce il file sorgente in un file scritto nell'assembly relativo alla macchina di destinazione, che a sua volta sarà reso in binario.

Parlando di linguaggi vicini al linguaggio naturale, forse diamo un'idea un po' fuorviante. In realtà un linguaggio di programmazione è un linguaggio formale, ovvero un linguaggio con una grammatica, una sintassi e dei fortemente vincolato. Al contrario del linguaggio naturale, l'ambiguità è inesistente, pena la non computabilità del file sorgente.
Infine, a un livello di astrazione ulteriore si situano i cosiddetti linguaggi di scripting, che richiedono un passaggio intermedio ulteriore rispetto ai linguaggi compilati per essere resi in binario

Più un linguaggio ha una grammatica e sintassi formale più si evitano ambiguità e più è semplice formulare istruzioni. Di contro, bisogna padroneggiare una buona percentuale del linguaggio prima di essere in grado di utilizzarlo. {: class="note"}
Ecco le principali funzionalità che non possono mancare in un qualsiasi game engine:
- rendering engine (motore di render): sia 2D che 3D, si occupa di raccogliere tutte le informazioni della scena e sintetizzarle a schermo in un'immagine coerente (camera, luci, occlusioni, colori, texture) responsiva dell'input dell'utente (60 fps). Render 3d: i modelli 3d si compongono di "facce" ovvero poligoni costruiti usando triangoli. Ciascun vertice di ciascun triangolo è sottoposto a forze, illuminazione, deformazione, movimento... Tutto questo viene calcolato per milioni di vertici 60 volte al secondo;
- physics engine (motore di fisica): 60 volte al secondo il sistema controlla le collisioni dei corpi, le interazioni tra questi, i movimenti - anche solo camminare - è determinato da un intervento sulla fisica:
s = s0 + v0*t + 1/2a*t^2; - sound engine (motore audio): generalmente si distingue un emitter (= altoparlante) e un listener (= microfono o array di microfoni) per la gestione dei suoni diegetici. Un player audio stereo o multicanale è utilizzato invece per i suoni extra-diegeteici (colonna sonora);
- interprete del linguaggio di scripting;
- AI engine (motore di intelligenza artificiale): i primi esempi di AI risalgono a PacMan, ma soprattutto al giorno d'oggi l'AI ha assunto un ruolo di rilievo in molti giochi. Chi si occupa di gestirla a livello software è il game engine;
- animation tools;
- particle systems;
- memory management (garbage collection);
- threading (physics engine e AI engine);
- video support (codecs);
- network management;
- UI/GUI ();
- VR;
- etc...
Interessate il progetto openHMD (open Head Mounted Display) che offre un set di librerie libere e open source pensate per la gestione del VR e AR. {: class="dashed"}
Prendiamo Godot come game engine di esempio.
<iframe width="100%" height="315" src="https://www.youtube.com/embed/XptlVErsL-o" frameborder="0" allowfullscreen></iframe>Perchè abbiamo scelto Godot:
- open source: posso modificarlo come voglio e c'è una community che amplia e consolida la piattaforma
- multipiattaforma: linux, Windows, Mac OS
- 2D e 3D: parimenti sviluppato per entrambi i formati di gioco
- leggero e veloce non pesa sulla memoria del sistema operativo
- GDScript è mutuato su Python (Godot3 ha porting per Python): è un linguaggio molto usato (dalla computer vision alla AI, al NLP)
- GUI
- visual programming (dalla versione 3)

Come è strutturata l'interfaccia di Godot:
- Filesystem: accesso a risorse sul computer e visualizzazione gererchia cartelle all'interno del progetto
- pannello risorse: le risorse usate nel gioco (file audio, file video, scene, sprite/modelli 3D, mesh, textures, immagini)
- hierarchy: gerarchia della scena (Nodo root, nodi figli, nodi fratelli, scripts associati ai singoli nodi, scene istanziate)
- properties: proprietà del nodo: variabili modificabili per il nodo (estendibili tramite script)
- Node Signals: segnali emessi/recepiti dal nodo (sistema di comunicazione fra vari elementi)
- Node Group: assegnazione dei nodi a gruppi per associare comportamento comune a più elementi (esempio enemies)
Quando siamo fruitori di opere di intrattenimento - libri, cinema, teatro, etc... - tra noi e gli autori dell'opera si instaura una sorta di tacito accordo.
Da una parte nasce (inconsciamente) in noi volontà di sospendere l'incredulità per mettere momentaneamente da parte le nostre facoltà critiche, ignorare le incongruenze secondarie e godere appieno dell'opera di fantasia. Come spettatori ci lasciamo guidare e ci abbandoniamo alla narrazione.
Dall'altra parte l'autore si impegna ad introdurci e nel guidarci attraverso un percorso comune per raccontare una storia.
La sospensione dell'incredulità nasce da un equilibrio molto sottile, tanto più difficile da creare quanto da mantenere da parte dell'autore dell'opera, soprattutto in epoca moderna dove si è bombardati da flussi continui di informazione e da moltissime forme diverse di intrattenimento.
Declinando il concetto al mondo videoludico, un suono ripetitivo viene riconosciuto dal nostro cervello come un pattern. Il nostro cervello è abilissimo ad identificare pattern, strutture ricorrenti di ogni tipo, è quando questo avviene il contratto si rompe.
Scott Selfon di Microsoft Corporation parla della ripetizione nel videogioco al GDC 2014 in un talk intitolato "Techniques for Fighting Repetition in Game Audio". {: class="dashed"}
La ripetizione è considerata un male nell'audio per il videogioco, perchè si rivela spesso causa della rottura dell'illusione.
Tuttavia la ripetizione non è sempre un male: al giocatore va data una sorta di feedback, una audio reward ad indicare che si sta facendo qualcosa di giusto o qualcosa che migliora la propria condizione (es. bere la pozione rinvigorente in "Prince of Persia").
 {: width="60%"}
{: width="60%"}
Anche nell'ambito dei suoni associati alla UI la ripetizione è quasi necessaria: un particolare suono sta ad indicare che si sta selezionando una opzione specifica e lo stesso suono ripetuto serve a sottolineare il fatto. Se l'interfaccia utente proponesse suoni diversi mentre l'utente si muove nell'interfaccia, anche interagendo con il medesimo pulsante, la cosa causerebbe non poca confuzione.
I casi in cui la ripetizione NON è bene sono quelli in cui causa la rottura dell'illusione: se il suono che udiamo è lo stesso che abbiamo già ascoltato, il nostro cervello intuisce immediatamente che qualcosa non funziona come dovrebbe.
Un suono che si ripete, sempre uguale a sé stesso, anche solo due volte di fila, è quanto di più innaturale si possa percepire.
La ripetizione può verificarsi nell'ambito dei:
- dialoghi: immaginiamo una situazione in cui affrontiamo uno schieramento di nemici e ognuno di essi pronunci un grido di battaglia assolutamente identico a quello pronunciato dai vicini;
- fooley: esempio tipico è quello dei footsteps, in cui lo stesso identico suono si sente ripetuto più e più volte durante il gioco. L'effetto suona innaturale e contribuisce a "buttare fuori" lo spettatore;
- fisica: se il physics engine lavora per simulare, ad esempio, una lattina che rotola al suolo, e l'integrazione prevede che un suono venga riprodotto a loop ad intervalli di tempo regolari, ecco che si ha lo stesso tipo di problema (indipendentemente che il suono ben si sposi con l'immagine renderizzata a schermo);
- suono senza corrispondenza visiva (o per meglio dire, con errata corrispondenza visiva): una cosa che accade tipicamente con i suoni d'ambiente, spesso pre-prodotti e inseriti nel gioco senza che ci sia una comunicazione tra i game e audio engines (discuteremo meglio questo aspetto fra poco).
La ripetizione può essere ovviata utilizzando diverse varianti dello stesso suono e riprodurre, di volta in volta, una versione diversa dalla precedente.
Il workflow comunce infatti può essere compreso se si pensa a come l'audio viene normalemnte implementato all'interno del videogioco: come un evento che corrisponde ad un determinato suono.
 {: width="60%"}
{: width="60%"}
Che cosa si intende per evento? All'interno del game engine, un evento potrebbe essere qualsiasi verificarsi di una qualche condizione. Ad esempio:
- il click del mouse;
- il raggiungimento di un determinato punteggio;
- il fatto di pronunciare una determinata frase oppure no;
- oppure ancora una collisione tra due corpi rilevata e riportata dall'engine di fisica.
 {: width="30%"}
{: width="30%"}
Ammesso che la relazione martello--> colpisce--> incudine produca lo stesso suono di incudine--> colpisce--> martello, gli assets audio da ricreare sono comunque tantissimi: la crescita è combinatoria!
 {: width="40%"}
{: width="40%"}
Se dovessimo realizzare un suono per ciascuna delle combinazioni possibili di due oggetti tra tutti quelli presenti all'interno del gioco ecco che ne servirebbero già un'ottantina in un caso come quello mostrato qui di seguito:

Senza contare che, come abbiamo già detto, un oggetto non ha solo un singolo modo di "suonare"!
Un oggetto può essere colpito in un particolare punto o subire un impatto da un corpo che poi rimane in contatto. Può essere strisciato e causare una eccitazione da frizione, soffiato per eccitarne eventuali cavità d'aria oppure scosso da una vicina sorgente ad esso accoppiata ed essere portato in risonanza.
Inoltre tutto questo può accadere in aria oppure sott'acqua il che modificherebbe la velocità del suono e la sua propagazione. Oppure può accadere mentre l'oggetto, l'ascoltatore o il mezzo di propagazione sono in movimento causando l'effetto Doppler, etc...
Per fare un altro esempio si potrebbe considerare ancora quello dei footsteps: senza troppo eccedere, potremmo supporre che il gioco contenga 20 diverse superfici calpestabili come legno, metallo, ghiaia, sabbia, cemento e così via.
Per ottenere il numero di file audio da produrre, dobbiamo moltiplicare questo numero per quello dei personaggi più importanti per il gioco, i quali hanno bisogno d'essere caratterizzati particolarmente nei loro movimenti.
Questi personaggi possono poi indossare diversi tipi di calzari e possono camminare a diverse velocità: anche questo incide sul suono (il correre non suona come il camminare).
All'interno dell'equazione potremmo poi inserire anche il paramtro peso, dovuto ad esempio dal numero di oggetti trasportati nell'inventario personale, oppure ancora considerare la pendenza del terreno, e così via...
{: class="note"}
Il lavoro del sound designer è quello di preparare un grand numero di assets sonori "riempiendo gli speadsheed" (derivati in fase di preproduzione dall'audio design document) e registrare centinaia se non migliaia di suoni diversi. Una matrice ad incroci enorme che richiede un sacco di tempo e risorse per essere prodotta.

Come si vede la matrice degli assets sonori in un caso come quelli illustrati diventerebbe davvero gigantesca e multidimensionale.
Un caso di studio interessante potrebbe essere quello illustrato da Alastair MacGregor della Rockstar games al GDC 2014 rigaurdo agli assets del gioco GTA V (vedi minuto 13:47)


TODO: argomenta suoni di impatto, dialoghi (walla), programmi radiofonici, etc...
Una possibile soluzione alla ripetizione, alla conseguente necessità di avere numerosissimi assets è quella di generare variazioni in realtime, usando, ove possibile, le capacità offerte dai dispositivi hardware della piattaforma oppure programmando via software le features necessarie.
Ecco le principali accortezze che si potrebbero avere:
Si tratta di un sistema facile ed economico da mettere in atto perchè comporta operazioni CPU base. Fornisce già una discreta illusione della profondità e della spazialità, tuttavia non è uno dei sistemi più incisivi per vincere la ripetitività;
TODO: cosa significa costo CPU? {: class="note"}
L'orecchio umano è meno abile nel riuscire a percepire differenze di intonazione. Inoltre questo sistema non è sempre applicabile, specie nelle linee di dialogo, per le quali invece una variazione di pitch risulterebbe particolarmente fastidiosa.
La causa di questo è da ricercare nel fatto che tutti questi cambiamenti nel pitch avvengono attraverso cambiamenti di sample rate, nel dominio del tempo quindi, con conseguente variazione nella durata.
Così facendo la voce diventa rapidamente innaturale (quando una voce è "pitchata" verso l'alto ad esempio si incorre nel problema legato alle armoniche superiori che, superata la frequenza di nyquist, finiscono per ripresentarsi nella parte bassa dello spettro, causando distorsioni e artifatti percepibili).
Inoltre da considerare la banda di trasferimento dati da disco a memorie/processore: con un pitch shift di un ottava sopra ci ritorviamo un audio dalla velocità raddoppiata il che necessità un più veloce accesso ai dati.
Pitch shifting più avanzati possono essee usati: si tratta dei pitch shifting che agiscono invece nel dominio della frequenza e si basano quindi sulla FFT. Sono pitch shifting con la preservazione delle formanti che garantiscono alle voci di mantenere la loro credibilità. Con questi tipi di pitch shifting inoltre lo streaming dei contenuti audio da disco resta coerente.
Spesso l'hardware dei dispositivi su cui il gioco verrà giocato permette di effettuare operazioni di filtraggio in modo diretto senza costi di alcun tipo. In caso questo non sia possibile invece è comunque semplice implementare lo stesso tipo di filtri base come un LPF o un banco di BPF, via codice DSP.
L'uso del filtro è fondamentale per restituire senzazioni come la distanza (un filtro passa basso è ottimo per ricalcare il naturale roll-off delle alte frequenze) oppure per sottolineare la presenza di elementi attenuanti come l'umidità ad esempio (ne parleremo meglio fra poco).
Applicare variazioni randomiche sul filtto di una voce inoltre, aiuta soprattutto a fornire la sensazione di direzionalità: nell'esperienza quotidiana, come ascoltatori ci accorgiamo che la nostra testa non è mai perfettamente ferma nello stesso punto e, anche piccole variazioni nella posizione, possono modificare lo spettro dell'audio percepito.
Usare i filtri sul sonoro e anche sulle voci permette di raggiungere un alto grado di variabilità. Non importa se il filtraggio non rispetta con accuratezza la fisica del fenomeno, il semplice fatto che ci sia un filtro fa suonare il tutto più naturale.
Anche questa è una tecnica relativamente economica da applicare.
Di nuovo in questo caso si può citare l'esempio dei footsteps. Il suono dei passi è infatti un suono molto articolato, per questo si può pensare di spezzarlo nelle sue componenti individuali e applicare variazioni casuali a ciascuna di queste per ottenere un risultato molto più ricco.
Un altro espediente è quello di variare il tempo che intercorre tra i vari elementi. In un suono ambientale che debba generare un tappeto costante di sottofondo, un particolare altamente riconoscibile come un ululato o il bubolare di un gufo può destare l'interesse dell'ascoltatore (il cervello si aggrappa a cose di questo tipo), pertanto una ripetizione a loop dell'audiofile, verrebbe immediatemente classificata come finta.
In questi casi meglio separe le diverse parti e lavorare con tempi diversi e casuali frapposti tra i suoni che possono essere più problematici.
Talvolta il silenzio può risultare un grande alleato quando si cerchi di sconfiggere la ripetitività.
Semplicemente contemplare il silenzio come una delle possibili opzioni nel ventaglio di delle possibilità, può aggiungere un po' di variazione in più!
Applicare curve di inviluppo su volume o frequenza di taglio dei filtri aggiungono ancora ulteriore variabilità.
La variazioni applicata al posizionamento dei suoni nell'ambiente è importante; in particolare per tutti quei suoni che non hanno un proprio corrispettivo visivo.
Il bubolare di un gufo nello scenario del bosco visto poco fa deve essere posizionato con cognizione e mantenere la propria posizione coerentemente con i movimenti del giocatore (la cosa potrebbe non essere scontata: pensiamo ad un audio ambientale prerenderizzato; mono, stereo o multicanale).
Inoltre, considerando che i suoni non sono quasi mai omnidirezionali, occorre considerare anche quale la direzione verso cui la sorgente sonora è orientata.
Un "epic fail" in questo caso sarebbe il percepire un gufo sul proprio lato destro quando, sopraggiungendo dal bosco, si sia ormai arrivati a costeggiare sulla destra un alto edificio.
L'ambiente deve interagire con il suono prodotto dagli emitter: il mondo 3D in cui siamo immersi può essere sfruttato per creare variazione.
Per continuare con l'esempio del muro, il suono dei nostri passi dovrebbe in questo caso essere arricchito da una serie di early reflection. Ascoltando il suono così realizzato non soltanto si avrebbe una percezione di variazione ma anche una maggiore sensazione di immedesimazione nell'ambiente.
Un esempio potrebbe essere il plug-in Reflect di Wwise il cui compito è proprio quello di realizzare le early reflection dinamicamente su base della struttura 3D del mondo.
Ad oggi la cosa può sembrare scontata ma, forse qualcuno se ne ricorderà, prima che il calcolo dinamico delle occlusioni diventasse possibile e venisse implementato massicciamente, poteva capitare che si sentisse il suono di un nemico sopraggiungere dal lato ma che, voltandosi verso la direzione di provenienza del suono, non ci fosse nulla se non un muro. Il nemico c'era ma aldilà della parete. {: class="dashed"}
{% comment %} TODO: nota sulla tecnologia
un'osservazione personalissima:
- grandi variazioni in ambito audio --> comportano piccole differenze nella percezione della verosimiglianza;
- piccole variazioni in ambito grafico --> comportano immani differenze nella percezione di cosa è verosimile. {: class="dashed"} {% endcomment %}
Aggiungere variazione non è sempre facile: il dialogo è la cosa più difficile da manipolare dinamicamente su cui è più difficile applicare quanto visto fino ad ora..
Per questo la variazione la si ottiene in fase di registrazione, con l'attore e il direttore del ADR che registrano battute con differenti intenzioni ed intonazioni.
Interessanti saranno i futuri sviluppi dell'intelligenza artificiale per la sintesi vocale la quale potrebbe presto soppiantare la necessità di disporre di voice talents in carne ed ossa per la registrazione di linee di dialogo (vedi il progetto WaveNet ad esempio). {: class="note"}
Nel caso dei dialoghi eventualmente si possono applicare modifiche in real-time come il voice-masking (usato tra l'altro per ridurre il gender gap (flip gender) nell interviste di lavoro on-line, inducendo un artificiale "gender flip") oppure ancora per una "radio-lizzazione" (voice coming from the radio).
In tale caso è possibile aggiungere più o meno rumore, crakcles o distorsione in modo dinamico e in termpo reale.
Altro esempio è il filtering real time che si applica per simulare la voce proveniente da una comunicazione telefonica. in genere utilizzando un filtro passabanda da 300Hz a 3000Hz. {: class="dashed"}
Resta comunque il fatto che la stessa frase non può essere mai detta identicamente 2 volte di fila! E' inaccettabile all'ascolto.
Un altro aspetto interessante che dovrebbe essere gestito è nell'interazione di più characters durante il dialogo: come individui nella quotidianità del mondo reale, siamo naturalmente in grado di ascoltarci l'un l'latro e aspettare il nostro turno per esprimere la nostra opinione. In caso di sovrapposzione è possibile interrompere l'interlocutore alzando la voce oppure restare in silenzio fino a che colui che parla non concluda.
Un gioco non è in grado di fare questo. Interessante sarebbe capire come ed in che modo introdurre sistemi intelligenti per simulare questo tipo di interazioni sociali per restituire una suono più verosimile.
Una nota va spesa per citare i sistemi di speech recognition come shortcut sostitutivi all'uso dei controller fisici per agire all'interno del gioco (implementati ad esempio in titoli come "Mass Effect 3", "The Elder Scrolls V: skyrim"). {: class="note"}
Importante comunque generare variazioni come la già citata positional variation considerando che il suono proveniente dalla bocca non è direzionale e pertanto va opportunamente filtrato a seconda dei movimenti.
Come già detto, le variazioni hanno ampia applicazione sugli effetti sonori.
Anche la musica è una elemento che può certo avvantaggiarsi delle tecniche di variazione fino ad ora discusse.
Un sistema davvero interessante è quello ideato dai compositori Michael Land e Peter McConnel nel 1991, quando all'epoca lavoravano ai videogiochi di avventura della LucasArts: iMuse.
Nasce nel 1991 (brevettato nel 1994); è un sistema che premette l'introduzione di componenti di audio dinamico in un linguaggio di scripting. Fondamentalmente iMuse è un database di sequenze musicali che possono contenere punti di decisione o markers all'interno delle tracce.
Il sistema, utilizzando eventi SysEx nei file MIDI, permette l'interazione tra le azioni del giocatore e il sonoro del gioco. Gli eventi in questione sono di due tipi: markers e hooks.
- Un marker viene inserito nel file MIDI nel punto che, una volta raggiunto dal lettore MIDI, deve triggerare l'esecuzione di un particolare comando da parte dello script del gioco. Il comando in questione è inserito in una lista (coda fifo) è ne viene attivata l'esecuzione non appena il MIDI player raggiunge un marker con un determinato ID. I comandi possono essere qualsiasi cosa, dal fade in/out alle pause;
- Un hook contiene un ID e l'azione da eseguire una volta che l'hook viene raggiunto. Lo script lancia un comando che si occupa di aspettare che un certo hook venga incontrato (callback), e quindi di mettere in esecuzione il comando contenuto in quest'ultimo. Gli hook si distinguono in vari tipi, quali ad esempio salti, trasposizioni, abilitazione/disabilitazione di strumenti.
Vediamone un paio di esempi sfruttando il motore ScummVM e giocando a Monkey Island 2: LeChuck revenge (nota: nella particolare dimostrazione usiamo una emulazione software della scheda Roland MT-32, all'epoca lo stato dell'arte dell'audio nel mondo videoludico);
 {: width="100%"}
{: width="100%"}
Per la musica si potrebbe aprire un intero capitolo a parte parlando di composizioni interattive, musica generativa/algoritmica, passando per iMuse, Farnell,
Forse in una lezione futura :)
Il game audio engine è una componente del game engine, oppure un modulo middleware da affiancare ad esso, che si occupa della gestione di tutto ciò che è suono all'interno di un videogioco.
Quali sono i compiti e le caratteristiche principali di un game audio engine tradizionale?
Logiche e meccanismi per dare priorità ai suoni da riprodurre e assegnare le voci disponibili, dal momento che si tratta di risorse limitate. Un esempio potrebbero essere i sintetizzatori dove si parla di voice stealing.
Un esempio di voice stealing nel videogioco lo si ha in Super Mario Bros, dove il sound engine agisce sulla voce assegnata alla melodia principale (il suono più acuto), deallocandola e riassegnandola per la sintesi degli effetti sonori delle monete.
<iframe width="100%" height="315" src="https://www.youtube.com/embed/Dp7fVUfj8oI?start=123" frameborder="0" allowfullscreen></iframe>Lo switching è guidato anche dal ruolo che il particolare suono riveste all'interno della narrazione: in una sitauzione in cui sono presenti molti suoni, sono quelli meno importanti ai fini di quanto si deve raccontare ad essere sacrificati per primi.
Ai suoni in riproduzione in un videogioco sono quasi sempre associati valori di priorità o rating in modo automatico o semi-automatico in base alle scelte del giocatore. Questi valori numerici sono fondamentali nella scelta di quali voci deallocare in un scenario di voice stealing/switching.
Come abbiamo ampiamente detto poco fa, la randomicità può essere una grande risorsa per aggiungere variabilità.
Il game audio engine dispone di una serie di strumenti integrati per aggiungere variabilità pressochè a ciascun parametro disponibile.
Il leitmotif è: le risorse sono limitate.
Crossfade parametrico tra campioni diversi, quello che nella sintesi prende il nome di multisampling. Questa tecnica è implementata in gran misura nei campionatori i quali infatti rispondono a diverse velocity di tocco con un mix tra campioni corrispondenti.

In un gioco, immaginiamo una caduta di un oggetto da diverse altezze; questo comporta intensità diversa ma non solo, anche variazione timbrica.
Molti game audio system incorporano un mixer del tutto analogo a quallo in uso nelle grandi produzioni: un banco large frame con gruppi, mandate e ritorni, etc...
La differenza è che, mentre per una produzione tradizionale la configurazione del banco rimane statica, praticamente invariata lungo tutta la durato di Un medesimo brano o album, nel caso di un videogioco il mixer deve spesso riconfigurarsi del tutto in pochi istanti.

|

|
Un esempio potrebbe essere il passaggio da una sitauzione in-game ad un menù di interfaccia (pausa o salvataggio).
Il game sound engine deve stabilire con il game engine un'interfaccia per ricevere (e inviare) parametri real time da utilizzarsi per controllare interattivamente controlli quali volume, pitch o frequenza di taglio.

Alcuni esempi di parametri utilizzabile per modificare i suoni i nriproduzione potrebbero essere:
- il livello di salute per il player;
- il carico per un automobile in corsa;
- il punteggio della partita a regolare il livello di eccitamento del pubblico sugli spalti dello stadio.
Come funziona l'audio in un gioco: emitters sono oggetti nello spazio tridimensionale che emettono suono e uno o più listeners (mono, stereo o multicanale; va pensato come un array di microfoni), in genere solidale col player.
Ogni emitter nel 3D world è caratterizzato dalla presenza due sfere ad esso concentriche che dividono lo spazio in 3 volumi.

Attenuazione e smorzamento: un discorso legato alla distanza tra emitter e listener, grandezza geometrica ricavata dal modello tridimensionale, in base alla quale viene modificato in tempo reale l'amplificatore di livello e/o la frequenza di taglio di un filtro passa basso.
Lo stesso si applica in casi in cui ci sia un ostacolo tra emittere e listener: occlusione ottenuta con filtri opportunamente settati. Materiali diversi
In altre parole si tratta di un sistema che si occupa di calcolare in run-time le funzioni di trasferimento e i filtri da applicare al suono riprodotto per dare all'ascoltatore la percezione che gli emettitori si trovino immersi nello spazio virtuale circostante.
Il panning "reale" è più complcato rispetto ad una semplice variazione di volume tra i canali. panning, multicanale (stereo, 5.1, 7.1, ambisonic (non usato), binaurale); {: class="nota"}
Un esempio interessante per quanto riguarda il posizionamento del suono nello spazio lo si ha ad esempio nel gioco "Hellblade: Senua's sacrifice", sviluppato da Ninja Theory e pubblicato pochi giorni fa.
In questo gioco l'audio binuaurale diventa importantissimo per rappresentare con efficacia le voci interiori della protagonista che soffre di un disturbo psichico.
<iframe width="100%" height="315" src="https://www.youtube.com/embed/LQQ2Jm2dgXk?list=PLbpkF8TRYizaT6GfMcKBG-RoUOQ6BJRXp" frameborder="0" allowfullscreen></iframe>A proposito di binuaurale, mai sentito parlare del fenomeno denominato ASMR? Ecco un interessante articolo a rigurdo. {: class="dashed"}
Nel gioco l'audio è talvolta utilizzato come mezzo (quasi) esclusivo per riuscire ad orientarsi nel mondo tridimensionale.
Parlando di sample, quando si registra si predilige il suono diretto e si fa di tutto per escludere quello riverberato Questo perchè il suono d'ambienza viene calcolato in tempo reale da processori dedicati (reverb, delay, doppler effect, filtering, fast realtime convolution).

Il game audio engine deve essere in grado di interfacciarsi e gestire complessi database di informazioni. Uno di questi è rappresentato dall'insieme degli audio file associati a tutte le varie linee di dialogo (in una o più lingue) presenti nel gioco.
Il game audio engine deve essere in grado di gestire l'eventuale colonna sonora musicale interattiva (vedi ad esempio il sistema iMuse).
Uno scenario in cui più giocatori prendono parte ad un partita multiplayer. Un server preposto al controllo e al master clock per la ricezione e ridistribuzione dei pacchetti. A seconda della contingeza ci possono essere latenze che si sommano e si accumulano, e possono essere diverse da caso a caso, e da giocatore a giocatore e cambiare nel tempo.
Il game engine, e più nello specifico l'audio engine per quanto concerne il suono, deve essere in grado di gestire situazioni come questa e di riordinare opportunamente i pacchetti in arrivo per dare un audio sempre corerente.
L'audio engine deve interfacciarsi con quella parte di software in carico di gestire gli accessi al disco e che si occupa del memory management. Da ricordare che l'audio è immagazzinato sul supporto in forma compressa in modo da risparmiare spazio di archiviazione, il che, nel momento della riproduzione, impone un pre fetching e un buffering per la decompressione prima dell'effettiva riproduzione.
alcuni esempi di codifice dei file audio potrebbero essere:
- PCM e ADPCM
- MP3
- Ogg Vorbis
- Speex
- Opus
- flac
- musepack
- per Xbox: XMA e WXMA
- per Playstation: Atrac AT9
TODO
Concetti di:
- "one project per game";
- uno o più game events possono essere associati al medesimo eevento in fmdo e triggerarne diverse istanze;
- modules --> sound modules --> one or more trigger regions (play until mouse leaves the trigger region);

- 3D panner
- min and max distance
- attenuation curve
- sound size
- min extent (eventualmente impiegato per sovrascrivere per sovrascrivere quanto impostato con gli altri parametri)
- pt motors / parametrization
- pt footsteps
- pt music
 {: width="40%"}
{: width="40%"}
A ben vedere nell'ultima parte della sua storia, come analizzato fino ad ora, il suono nel videogioco si presenta come un modello guidato dai dati (data driven model).
In altri termini, è costituito da una moltitudine di file audio raccolti in un database e che vengono messi in riproduzione all'occorrenza, in seguito al verificarsi di particolari eventi (event based).
{: width="60%"}
Ai sample che vengono riprodotti si possono certo applicare delle modificazioni in tempo reale come abbiamo già detto (attenuazione dovuta alla distanza, combinazioni e layering, random e granularità).
A ben vedere però questo sistema basato sui sample audio sembra in contraddizione netta con il dominio visivo, caratterizzato invece da un comportamento continuo e guidato da uno stream di parametri piuttosto che da eventi discreti.
In un gioco che si basi pesantemente sull'aspetto grafico, l'immagine mostrata a schermo è fondamentale per restituire la senzazione di realismo. Interessante notare comunque che l'immagine che vediamo quando giochiamo non esiste prima del run-time!
Consideriamo un semplice modello 3D costituito da 4 facce triangolari: occorrono 3 (OpenGL ne usa 4 in realtà) valori numerici corrispondenti ai 3 assi cartesiani per identificare la posizione di ciascuno dei suoi vertici nello spazio tridimensionale.
Un modello estrapolato da un moderno videogioco tuttavia è composto da una moltitudine di poligoni, centinaia se non migliaia (high poly). Questi vertici e la loro configurazione nello spazio costituisce la mesh del modello ma da sola, non basta per creare l'illusione di realismo.
Serve una texture da poter mappare sulla mesh che riproduca fedelmente le caratteristiche visive come colori e dettagli dell'oggetto (UV mapping).
Perchè il modello possa essere visto nel mondo tridimensionale occorrono luci: ogni oggetto dunque, colpito dai raggi irradiati da tutte le fonti di luce presenti nel mondo virtuale, verrà descritto in modo ancora più realistico, in più se il modello riporta alcuni valori per le grandezze fisice associate ai materiali di cui è composto, come coefficienti di riflessione e assorbimento, e così via, l'effetto potrà essere ancora migliore.
Moltiplichiamo il tutto per la moltitudine di modelli simultaneamente presenti all'interno del mondo 3D virtuale e avremo quanto computato da una componente del game engine, il rendering engine (che traspone il tutto su una superficie flat 2D: il nostro schermo), coadiuvato da una speciale componente hardware, la GPU, che aiuta accelerando e parallelizzando il processing.
L'interità dei modelli e delle loro mesh non sono fondamentali soltanto per ottenere una immagine 2D in uscita ma anche per creare la cosìdetta word geometry per il calcolo delle collisioni, indispensabili per prevedere e computare i comportamenti fisici.
Tutto questo è appannaggio del physics engine che non si occupa solo di collisioni ma valuta l'interà fisicità del mondo virtuale in cui siamo immersi: masse, densità, velocità e accelerazioni, forze, torsioni.
A tutto questo si aggiunge la componente di intelligenza artificiale che ha il compito di simulare comportamenti "intelligenti" per tutti quegli attori che, nel gioco, non sono comandati da un player umano.
Ebbene tutto questo viene calcolato di continuo, sempre in funzione dei dati di movimento ottenuti dalle azioni del giocatore, 60 se non più volte al secondo.
Quando la grafica 3D cominciava ad affermarsi nel mondo del videogioco (siamo agli inizi degli anni '90) i modelli erano composti da un numero limitato di poligoni (low poly) per una questione di limitazioni della capacità hardware delle macchine del tempo, PC o PlayStation 1 ad esempio.

|

|
Eppure negli stessi anni al cinema si poteva assistere alla proiezione di Toy Story, il primo film di animazione interamente realizzato in computer grafica. Nel film i modelli sono molto più definiti dei loro corrispettivi in ambito videogames, ma questo solo perchè i numerosi calcoli richiesti per renderizzare ciascuno dei frame erano svolti da grandi "render farm", niente di comparabile ad una contemporanea console per uso domestico. Inoltre il risultato di un rendering spesso era pronto dopo diverso tempo che i dati erano stati introdotti.
Sotto questa luce, il low poly dei primi videogiochi 3D diventa una prova evidente che la grafica dovesse (e deve) necessariamente essere calcolata in tempo reale!
Il sample audio è una registrazione, e come tale si tratta di un qualche cosa fissato nel tempo: una registrazione cattura la perturbazione della densità dell'aria, l'effetto di un movimento nello spazio in un particolare istante ma non ci dice nulla in merito al comportamento.
In questo senso l'audio fruito attraverso i campioni resta un procedimento statico, come un interruttore che può essere solamente acceso o spento, una fotografia fissa ed immutabile anzichè vivida e dinamica.
Ci potremmo chiedere quindi che significato ha la parola realismo? Premesso che il realismo non è una condizione indispensabile, anzi, ci sono videogiochi (basti pensare a PacMan, o a diverse produzioni indipendenti come Fez, Limbo, etc...) che tutt'altro ci propongono rispetto ad una esperienza "realistica", ce ne occupiamo perchè la ricerca del realismo sembra essere stata forse "IL" motore principale per lo sviluppo tecnologico nell'abito dei videogames.
Basti pensare che si è passati al massiccio uso della grafica tridimensionale non appena le tecnologie lo hanno permesso (questo vale anche per il mondo dell'animazione). Si ricerca sempre una maggiore definizione dei modelli. Ci si avvale del supporto di potenti motori di fisica per simulare fedelmente i comportamenti quali collisioni, esplosioni, attrazione gravitazionale, spinta del vento, forze etc...
L'intelligenza artificiale contribuisce a rendere sempre più credibili i movimenti e le azioni di attori e creature npc e la lista potrebbe continuare a lungo.
In abito audio invece quello che si fa, in pratica, è "premere il tasto play" quando serve, il che sembra un po' riduttivo, soprattutto per il fatto che:
- il suono riveste un ruolo importante di guida emotiva all'interno del gioco;
- l'audio è una parte importante anche per la narrazione;
- contribuisce alla percezione di verosimiglianza (vedi più avanti);
Un approccio event based/data driven in somma rende il suono malamente accoppiato con il motore di gioco sottostante, incoesivo con l'esperienza complessiva. Eppure non è sempre stato così.
All'inizio della storia dei videogame, delle console e dei computer, era l'audio la motivazione principale che ha guidato lo sviluppo tecnologico.
L'audio veniva generato in tempo reale e rispecchiava linearmente le azioni del giocatore e le reazioni dell'engine. L'audio veniva sintetizzato in tempo reale. Questa tendenza si è interrotta indicativamente attorno alla seconda metà degli anni '90, momento storico dove si può collocare la comparsa sul mercato dei prini CD e che vede il diffondersi dell'audio campionato ad alta qualità (44100@16bit).
Il SID (Sound Interface Device) era il chip sonoro utilizzato dal Vic20, C64 e C128, sviluppato da Robert Yannes di MOS technology il quale, oltre al background tecnico, ne sapeva molto anche di musica.
 {: width="60%"}
{: width="60%"}
Il suo intento era sviluppare un chip di sintesi sottrattiva totalemente differente dai sistemi sonori presenti nei computer dell'epoca e il risultato fu qualcosa di innovativo.
Il chip era programmabile in BASIC o in linguaggio macchina e possedeva molte caratteristiche interessanti, le principali elencate qui di seguito:
- 3 generatori di suono (voci);
- 4 diverse forme d'onda disponibili (sawtooth, triangle, rectangle w/ pulse width modulation, noise);
- 3 modulatori d'ampiezza (adsr);
- 1 controllo di Master volume (in 16 steps);
Erano possibili effetti come la ring modulation o l'hard sync tra gli oscillatori.
Inoltre il SID disponeva di un filtro programmabile (low pass, bandpass, high pass), con frequenza di taglio e risonanza selezionabile. Il funzionamento del filtro era possibile grazie alla presenza di alcuni componenti analogici che completavano il circuito: 2 capacitori. Questa caratteristica rendeva il suono del SID unico e difficilmente replicabile fedelmente, anche al giorno d'oggi.
Ecco qui di seguito un piccolo programma d'esempio:

Da ricordare che, usando l'istruzione poke del linguaggio di programmazione BASIC è possibile accedere e scrivere sui singoli registri interni del SID specificando sia l'indirizzo, sia il valore numerico da memorizzarvi.
Il programma usa la prima voce impostata come onda triangolare per riprodurre una nota A440 di durata pari a circa 500 millisecondi. Le istruzioni usate sono:
- indirizzamento del SID
SI=54272; - impostazione del volume master (registo 4:
L=SI+24con valori da 0 a 15, volume basso/alto); - impostazione dell'envelope con 4 bit per ciascuna fase = 2 byte per la memorizzazione (registri 5 e 6:
A=SI+5eH=SI+6, rispettivamente per attack/decay e sustain/release); - impostazione della frequenza (registri 0 e 1:
FL=SIeFH=SI+1) - selezione dell'onda (registro 4). Alcuni valori possibili sono:
- tringolare: 17;
- dente di sega: 33;
- rettangolare: 65 --> parametro addizionale "duty cycle" (registri 2 e 3
TL=SI+2,TL=SI+3); - noise: 129;
- ciclo for per la durata della nota.
Il SID è uno chip che dispone di sole 3 voci ma non è detto che nelle mani di capaci musicisti programmatori non possa ricreare la polifonia e la ricchezza timbrica di un ensamble molto più numeroso
<iframe width="100%" height="315" src="https://www.youtube.com/embed/pgPEaI0GHBI?list=PLXhLeiiveJmNhFf5ShVwwXspGfgt-ww8c" frameborder="0" allowfullscreen></iframe>Si tratta della in game music del gioco "Commando" uscito per C64 nel 1985. Ecco le tracce separate per apprezzare meglio la ricchezza di variazioni, il timing e intuire l'ingegnosità dei programmi scritti da Hubbard:
Anche dalle immagini che mostrano la forma d'onda della parte iniziale della prima voce si può comprendere la complessità della lavorazione:


Immagini e tracce sonore sono state estrapolate utilizzando il player SIDplay2 e Audacity.
mentre la musica di Hubbard proviene dal database High Voltage SID Collection. Il programma è stato scritto e eseguito utilizzando VICE, importante emulatore commodore. Qui altre interessanti informazioni sul SID: datasheet e wiki.
{: class="dashed"}
Il lavoro di Hubbard inoltre è un mirabile esempio di come spesso si riescano ad ottenere risultati ammirevoli partendo da risorse limitate o necessità stringenti. {: class="note"}
Attenzione, questo non significa che in passato i sample non venissero utilizzati; Nintendo, SEGA e ancora prima nelle coin-op, dove possibile, si inserivano sistemi DAC in grado di riprodurre, seppure non con la stessa qualità CD, campioni e sample pre-registrati, soprattutto per la voce. La ricerca del "realismo" tuttavia ha infine soppiantato i sistemi di sintesi tradizionale.
Sotto questa luce, i "trucchi" descritti poco fa, usati normalmente per ridurre o mascherare la ripetitività, sono in realtà dei rimedi temporanei.
Un modo alternativo, mutuato dalla storia del videogioco, è quello di pensare il sonoro come sintetico: in questo modo due suoni associati allo stesso evento non suonerebbero mai esattamente allo stesso modo.
Si tratta in fondo di una caratteristica peculiare della sintesi sottrattica, la quale fa uso del rumore come forma d'onda base.
Anche se le differenze potrebbero essere estremamente sottili, il nostro cervello ha la capacità particolare di riconoscere queste sorgenti come "vive".
Inoltre, un approccio data driven come questo ha i suoi svantaggi vediamo un paio di esempi:
Supponiamo di avvicinarci ad una abitazione sconosciuta. L'intento è quello di entravi senza destare l'attenzione di chi sta all'interno. Nel gioco guideremo il nostro avatar fin sulla soglia e, a questo punto, a seconda dell'ispirazione del momento, potremo aprire la porta di colpo e preciparci all'interno oppure socchiuderla lentamente e magari interromperci al primo sospetto di non essere soli.
 {: width="50%"}
{: width="50%"}
Secondo l'approccio tradizionale sample based un campione preregistrato di scricchiolio viene riprodoto non appena si verifica l'evento "collisione" tra il nostro avatar e l'oggetto porta. Specie se l'audio file è lungo si nota che la riproduzione dell'audio file prosegue, anche se l'azione sulla porta si interrompe dopo breve.
Anche nel caso il game sound engine utilizzasse meccanismi di dissolvenza in uscita per temporizzare correttamente il livello, comunque risulterebbe chiara la disomogeineità tra i domini grafico e uditivo.
Immaginiamo cosa accadrebbe se poi scostassimo la porta ripetutamente, avanti ed indietro...
Alcuni oggetti come le campane o i tubi creano differenti suoni in base al proprio stato. un tubo che è già in vibrazione e che venga colpito in un punto diverso, incorporerà le nuove eccitazioni nel pattern di vibrazione a creare un suono diverso rispetto a quello che avrebbe fatto se colpito in stato di quiete. Niente di simile è ottenibile usando i campioni.
 {: width="50%"}
{: width="50%"}
Immaginiamoci con un arma di fronte alla fortificazione di un piccolo bunker dal quale dobbiamo stanare i nostri nemici. Cominciamo a sparare e colpiamo ripetutamente una delle lastre di metallo che rivestono l'esterno della costruzione.
Ad ogni impatto (di un proiettile sulla lastra) la lastra viene eccitata e di tutti i possibili modi strutturali saranno quelli primari ad assorbire il maggior quantitativo di energia e, come risultato, percepiremo sempre più chiaramente le frequenze di risonanza della lastra mano a mano che i proiettili continuano ad incidere su essa.
Lo stesso effetto non è ottenibile riproducendo lo stesso audiofile ripetuttamente per ogni nuovo impatto.
Se, i videogiochi moderni hanno via via preferito i campioni, i paradigmi di audio sintetizzato, più tradizionali se vogliamo, sono sopravissuti in una parte del mercato legato all'audio: la musica e gli strumenti musicali. In questi campi ci si accorge subito delle limitazion intrinseche dell'audio per campioni (il sample è un tradimento della realtà), per questo la ricerca e lo sviluppo di nuovi sistemi di sintesi continua a progredire.
Nascono i primi sistemi di sintesi basati su modelli: i fenomeni della fisica del suono vengono studiati e sintetizzati in modelli matematici e poi innestati all'interno dei circuiti integrati o dei software per computer.
Quando si vuole simulare i suoni dei vecchi sintetizzatori analogici, si sviluppano tecnologie volte a riprodurre in digitale tutte le idiosincrasie dei componenti elettrici discreti che li costituivano e nascono i modelli virtual analog.

ad esempio:
- la tecnologia True Analog Emulation (TAE) di Arturia, usata in plugin come il mini V o l'arp-2600.
- Il Pod di Line6 implementa un suond engine in grado di simulare molti preamplificatori per chitarra e basso, cabinets e acustia degli ambienti.
- Anche l'italiana Acustica-Audio usa molta tecnologia interessante all'interno dei loro plugin come il Nebula3 ad esempio, che "is a multi-effect plug-in that is able to emulate and replicate several types of audio equipment and uses libraries which are created using a sophisticated “sampling approach” making it possible to “record” aspects of the sound of audio devices and play them back".
- Interessantissimi anche i lavori dell'italiana AudioThing;
- I virtual instruments della svizzera Togu Audio Line (Tal);
Quando invece si vuole simulare strumenti musicali acustici o elettroacustici nascono modelli volti a riprodurre i fenomeni fisici delle sollecitazioni, vibrazioni, attenuazioni dei materiali: nasce il physical modelling.

- Arturia Stage-73 V;
- i pianoforti virtuali di PianoTeq;
- Antares Auto-tune oppure Throath;
- Celemony Melodyne e Capstan, Izotope RX.
- Altri esempi potrebbero essere l'Aerophone AE-10 di Roland, che fa uso dell'engine di sintesi per modelli SuperNATURAL in parallelo con la tradizionale sintesi per campioni;
- Native Instruments B4, etc...
Solo un appunto interessante a proposito di Pianoteq: il peso del software è di soli 40MB. In confronto al Ravenscroft Virtual Piano 275 - che fa uso di 17.000 samples - che richiede 6GB per funzionare (perchè i dati sono compressi) e un HD a stato solido per garantire una performance ottimale! {: class="note"}
Esistono da diversi anni scuole di pensiero volte a traslare questi metodi di sintesi, da tempo diffusisi sul mercato e molto apprezzati per le loro qualità, nel mondo videoludico e dell'interazione più in generale.
Pionieri di questa filosofia di pensiero sono persone come Perry Cook e Andy Farnell, solo per citare i più noti, i quali ritengono possibile derivare dagli studi fatti fino ad ora, modelli finalizzati non tanto a simulare suoni appartenenti al dominio musicale ma piuttosto volti a sintetizzare una moltitudine di classi sonore associate ad oggetti e fenomeni più generali: così da rendere possibile la sintesi, potenziale, di ogni tipo di suono possibile.

|

|
Da questo punto di vista il suono nel videogioco diventa un modello inteso come processo (sound as a process), in contrasto con il paradigma precedente di event driven/data driven model.
Il termine spesso associato a questo paradigma è audio procedurale, eccone una definizione:
“Procedural audio is non-linear, often synthetic sound, created in real time according to a set of programmatic rules and live input.” – "An introduction to procedural audio and its application in computer games.” by Andy Farnell
Processo guidato da uno stream continuo di dati provenienti dall'interazione dell'utente, manipolati e usati come parametri per controllare in tempo reale una serie di algoritmi che sintetizzano audio.
A ben vedere il concetto di audio procedurale non ci è del tutto estraneo; un esempio a cui siamo abituati è il riverbero digitale che usiamo tutti i giorni sottoforma di plug-in o di outboard fisico in studio.
 {: width="30%" }
{: width="30%" }
Tra i vantaggi possiamo considerare:
Mentre l'atto di registrare un suono è un azione che fissa nel tempo senza lasciare alcune possibilità di intervento successivo, l'audio procedurale è dinamico e lascia che molte delle decisioni, anche strutturali, vengano rimandate al real-time.
Talvolta è semplicemente impossibile conoscere a priori quale sarà il suono che il gioco dovrà riprodurre e, di conseguenza, impossibile sapere come registrarlo o realizzarlo in fase di produzione. In un caso come questo, il moderno sound designer potrebbe avvantaggiarsi dell'audio procedurale e predisponendo un modello per il suono e lasciare che questo venga confezionato "durante" il gioco.
Un esempio pratico di quanto detto lo si trova nel videogame "No Man Sky". Il gioco si basa interamente su contenuti generati proceduralmente (non escluivamente sonori). Proprio per la natura del gioco, Paul Weir il suond designer di Hello Games, intento a risolvere il problema del suono delle creature, diversissime tra loro e inconoscibili prima della partita, ha realizzato il tool VocAlien: una sorta di plugin che integrato nel game audio engine si occupasse di sintetizzare i suoni necessari secondo dei parametri di volta in volta diversi, passatigli dall'engine di gioco. (ecco qui il talk).
Caratteristica fondamentale del suono procedurale che garantisce la possibilità pressochè completa di modificazione del suono in tempo reale e di produrre in questo modo risultati sonori anche molto diversi tra loro pur facendo capo ad uno stesso modello.
Dal momento che la crescita dei sounds assets è combinatoria, diventa difficile provvedere alla creazione di tutti i suond assets necessari mano a mano che il mondo virtuale cresce. Il vantaggio di un modello procedurale è che il suono può essere generato in modo automatico derivando le proprietà dagli oggetti presenti nel gioco. Questo non elimina la figura del sound designer, il quale interviene laddove alcuni suoni necessitino di particolari caratteristiche perchè più importanti per la narrazione, ma garantisce che ogni oggetto abbia sempre un suono di default associato, senza incorrere così nel rischio che qualche evento sonoro non possa essere triggerato.
Il suono sintetico si dimostra vincente rispetto all'approccio data driven quando si debbano descrive ampie scene con innumerevoli sorgenti sonore (tra 100 e 1000 sorgenti concorrenti).
I dati sottoforma di campione hanno un costo fisso (lo streaming dati da disco non cambia se il suono deve essere riprodotto completamente dry oppure deve subire real-time processings). Inoltre, la densità di suoni che possono essere riprodotti in una scena ha un limite:
- sia in termini di accuratezza del mix dei vari suoni (più suoni = più difficile sommarli tra loro, problemi di dinamica e saturazione);
- sia dal punto di vista psicoacustico (alcuni dei contibuti sonori sono inutili all'atto pratico perchè non posso essere uditi per via dei diversi mascheramenti, in tempo o in frequenza).
Già quando si arriva a sommare 100 suoni simultanei, si può vedere che il contributo di ogni nuovo suono aggiuntivo, in rapporto al costo computazionale associato, diminuisce.
D'altro canto, una approccio sintetico può offrire un costo variabile ad ogni sorgente: un esempio potrebbe essere il suono di un bicchiere che si infrange cadendo a terra.
Un metodo sintetico potrebbe produrre un suono molto "realistico" e mantenere ancora un alto grado di correlazione audio-video rimpiazzando i frammenti perimetrali con singoli segnali sinusoidali o granuli di rumore, fornendo un alto grado di dettaglio per quei frammenti che cadono vicino al player.
Il paradigma procedurale permette il LOAD - Level Of Audio Details - (che sfrutta le conoscenze in ambito di acustica e psico-acustica) caricamento dinamico sulla CPU esattamente come già fa la parte grafica cone il mipmapping.
Consideriamo una esempio quale potrebbe essere un suono in grande lontananza: nel caso di un motore audio tradizionale, al suono verrebbe applicato notevole processing DSP in tempo reale da far sì che il sample - attenuato e filtrato - dia l'impressione di provenire da lontano. Tuttavia, nonostante il suono ne risulti pesantemente modificato rispetto all'originale, comunque il costo in termini di risorse sarebbe invariato rispetto alla normale riproduzione di un audio file.
Nel caso il problema venga affrontato con il paradigma procedurale invece, soprattutto facendosi forti del fatto che il modello è stratificato e costituito da più parti indipendenti tra loro, il carico di lavoro potrebbe essere ridotto: certe componenti del suono, proprio per via del fatto che la sorgente sonora è ascoltata da grande distanza, potrebbero essere del tutto tralasciate rispetto ad altre. Il lavoro del processore sarebbe avvantaggato.
Lo stesso dicasi se il suono riprodotto da un modello si trova riprodotto in associazione con altri suoni che causerebbero il mascheramento nel tempo o in frequenza di alcune sue componenti.
Tra gli svantaggi:
Al momento attuale non sembra ci sia interesse nell'implementare quanto necessario per inserire questo paradigma nel workflow per la produzione di giochi. Spesso in questi casi ci si scontra con metodi di lavoro consolidati che sono difficili da modificare, soprattutto per via dei costi e dei tempi necessari per la transizione.
Il paradigma procedurale richiede personale che sappia operare in campo audio in nuovi modi. Studiare modelli derivati o ispirati dal mondo reale e implementarli poi in una forma hardware o software richiede abilità e competenze che normalmente non fanno parte del bagaglio culturale di un sound designer tradizionale.
Permane la falsa concezione che la sintesi audio sia, in qualche modo, sinonimo di finzione (sintesi = suono "di plastica") e, come tale, sia qualcosa di insoddisfacende, di deludente.
In realtà non è così, ne abbiamo avuto la prova più e più volte durante queste lezioni e, se anche lo fosse, il ragionamento non sta in piedi in quanto il realismo non serve! Lo sanno bene i sound designer e tutti coloro che, in generale, hanno già qualche esperienza nel mondo dell'intrattenimento, il realismo spesso delude.
Non c'è bisogno che il suono sia perfettamente fedele al fenomeno percepito nella realtà, quello che è veramente importante è il verosimile, è la resa (come dice molto bene Chion) o addirittura dell'hyperrealism ("more than reality").
"Il tutto è più grande della somma delle sue parti." (Aristotele, Metafisica)
Questo perchè suono ed immagine combinati assieme generano sempre un risultato inaspettato, assolutamente assente se lo si ricercasse in una sola delle sue componenti. E' questo il concetto del valore aggiunto di Chion.
Si tratta di una cosa che si può sperimentare anche quando si fa un mix: supponiamo di averne ottenuto uno che suoni davvero bene.
Tutto è al suo posto e si è ricavato la propria posizione sia nello spazio sterofonico che nel range dinamico e di frequenza. Non ci sono sovrapposizioni, conflitti di alcun genere e il tutto risulta comprensibile e omogeneo.
Ora, se tornassimo ad ascoltare una delle singole tracce che compongono il mix, magari la chitarra elettrica, il basso o il pianoforte, ci accorgeremmo molto probabilmente di quanto il suono processato, se preso singolarmente, risulti in realtà molto diverso da quello emesso dallo strumento reale.
Il suono è stato probabilmente filtrato, equalizzato, compresso, ripulito di eventuali fastidiose risonanze, emagari suona anche un po' più "piccolo" che nella realtà eppure, se reinserito nel mix, ecco che lo strumento riacquista di colpo tutte le sue componenti e trasmette un senso tutto diverso.
Questo è possibili grazie al fatto che lo strumento è affiancato ad altri, si fa forza dell'essere parte di un insieme, arricchisce, ed è arricchito al contempo di dignificati nuovi che, non avrebbe se preso singolarmente!
In un futuro presumibilmente non troppo lontano, il paradigma procedurale avrà preso ancora più piede e il mondo del lavoro nel settore dell'audio per videogiochi si arricchirà di tutta una serie di nuove figure professionali.

Proprio come negli ultimi 20 anni sono nate specializzazioni di ogni tipo nel mondo della computer grafica (professionisti che si occupano esclusivamente di rigging, textures, animazione, modellazione, light, visual fxs, compositing etc...), così anche nel mondo del sound design nasceranno nuove figure speciallizzate nella modellazione di suoni e fenomeni fisici differenti (acqua e bolle, fuoco, fracture sound, impatti, frizioni e sfregamenti, accartocciamenti, acustica delle stanze, etc...).
C'è addirittura chi si specializza nel processo inverso, ovvero nel ricreare animazioni basandosi sul suono in una sorta di inverse fooley, il che può portare a risultati davvero sorprendenti:
<iframe width="100%" height="315" src="https://www.youtube.com/embed/EGkQkdCKztM?start=130" frameborder="0" allowfullscreen></iframe>Se, come spesso accade, l'audio è considerato come accessorio e secondario rispetto alla parte grafica/visiva, ci sono tuttavia alcuni casi in cui questo andamento è ribaltato: event --> sound diviene qui sound --> event.
Automatic lip sync: un sistema studiato da moltissimo tempo per animare grafiche e modelli 3D in modo automatico basandosi sul segnale audio (vedi patent Sierra).

Procedural animation: Tom Clancy's Ghost Recon Advanced Warfighter 2 (Ubisoft 2007) case study: un aeroplano precipitato nel deserto esplode e continua a bruciare a terra. Le fiamme sono sferzate a destra e a sinistra da un vento irregolare. Polvere e fumo sono generati proceduralmetne in base al livello dell'audio pre-prodotto (vedi questo talk di Scott Selfon al minuto 23:14)!
TODO
tipologie di suono: classi sonore relativamente piccole, canne, lastre di metallo o corde possono essere programmate con relativa facilità usando sorgenti di tipo generico.
 {: width="80%"}
{: width="80%"}
physical modelling / physical informed modelling (differenze) Waveguide (difetto: uso della memoria per implementare delay per la propagazione e i risuonatori) MSD (Mass, Spring, damper)
tipologie di suono: questo approccio lavora bene per "dropped sound", collisions, tubi o lastre percosse, eccitazione di strutture fisse.
Utile l'analisi statistica della densità
tipologie di suono: suoni con struttura eterogenea, onde che si infrangono sulla spiaggia, pioggia, grandi gruppi di persone (ae esempio il suono degli applausi).
Abbiamo detto che il paradigma del suono procedurale prevede una stratificazione delle diverse fasi. Questo significa che ciascuna di esse può essere svolta con un particolare strumento hardware o software piuttosto che un altro, a seconda delle esigenze del progetto o delle particolari propensioni del suond designer.
{: width="40%"}
Tipico è il caso del layer di implementazione: in questa fase infatti qualsiasi strumento software può essere usato per implementare il modello. Esistono infatti svariati linguaggi che possono essere utilizzati per la fase di implementazione (Supercollider, Csound, Faust, C++ via STK, Chuck, etc...). Ogni linguaggio possiede determinate caratteristiche che lo rendono più indicato per un task specifico.
Parleremo di Pure data, che sembra essere un valido compromesso in termini di efficienza, facilità di apprendimento, di integrazione in altri tipi di sistema come può essere un game engine esistente (grazie in particolar modo a progetti software di integrazione come libpd, vedi sotto).
Pure Data, come Godot, è free software quindi aperto per essere modificato ed esteso liberamente.
Che cosa è PureData? PureData è un linguaggio di programmazione a nodi nato a metà degli anni '90 ad opera di Miller Puckette che all'epoca lavorava all'IRCAM di Parigi.
Pure Data è un linguaggio di programmazioni a paradigma dataflow e, sebbene manchi di ricorsione e di una effettiva accuratezza "al sample" nell'implementazione di filtri FIR, IIR, è uno strumento molto produttivo e permette di risolvere il 90% dei problemi di sound design sintetico.
Uno degli obiettivi cui si è interessati è quello di fare il minor uso possibile della memoria (evitando quindi, ove possibile, lookup table, ring buffers per dly, etc...). Si usano dunque i troncamenti delle approssimazioni in serie di Taylor delle varie funzioni anzichè ricorrere a lookup tables, il rumore è generato come numeri pseudo casuali, etc...
Perchè evitare l'uso della memoria? Uno dei motivi è quello di facilitare l'esecuzione del codice in un ambiente multithread, in cui i diversi thread sono distribuiti su più processori.
{: class="dashed"}
Vedremo ora alcuni esempi tratti dal lavoro di Andy Farnell, il quale usa PureData come linguaggio di programmazione (thanks to Andy Farnell, Alexey Reshetnikov and Rod Selfridge).
- telephone: bakelite resonators
Il vento in sè non produce suono (molto interessante a tale proposito il seminario "Squeezing out noise" di Chris Woolf, technical consultant per Rycote)
TODO
Vale la pena di sottolineare che tutti i suoni prodotti dalla macchine sono il risultato di un qualche tipo di inefficienza e di frizione: in teoria, la macchina perfetta non emette alcun rumore.
-
electric motors:
-
fans: il suono macchine come le ventole degli impianti di areazione, le quali funzionno di continuo, è più soggetto a problematiche di ripetizione. Se il suono viene generato per mezzo della sintesi (usando come base il rumore in questo caso) ecco che il problema è risolto: il suono acquista una caratteristica viva e il cervello non è più in grado di identificare alcun pattern.
-
elicopter:
-
clocks: Il suono di un orologio che ticchetta può essere realizzato sovrapponendo diverse componenti più semplici per ottenere un risultato finale organico. Interessante a tale proposito l'aneddoto raccontato dallo stesso Farnell in un seminario sull'audio procedurale all'AES nel 2013 in cui ricorda d'avere analizzato il suono di una sveglia dopo averlo registrato ad alta risoluzione e riprodotto a velocità ridotta.
-
creaking: movimento slip-stick. Un segnale di controllo (che simboleggi la forza impiegata nel movimento) che varia da 0 e 1 produce una serie di impulsi in uscita. Questi passano attraverso una serie di filtri passabanda per riprodurre le formanti di una struttura quadrata in legno.
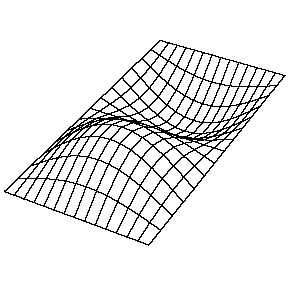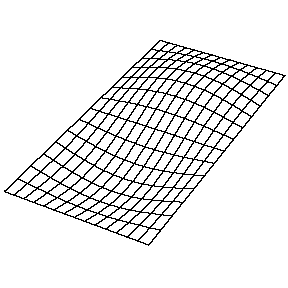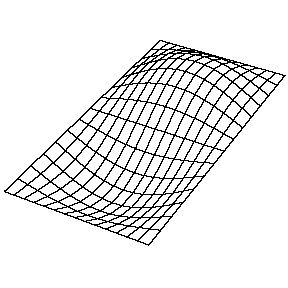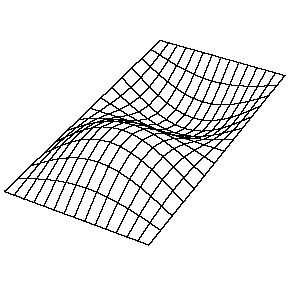
Di seguito alcune belle animazioni che mostrano i modi principali per una membrana rettangolare, tratte dalla pagina del professor Daniel Russel della Pennsylvania State University.

|
|

|

|

Sicuramente da approfondirne le caratteristiche: Frame3dd. Un software libero per studiare le dinamiche strutturali statiche e dinamiche. Che possa esserci utile nell'analisi dei modi? {: class="dashed"}
Maggiori informazioni sulle patch e sul loro utilizzo si trovano nel file README all'interno della apposita cartella del repository. {: class="dashed"}
{% comment %}
Per utilizzare questi esempi è necessaria l'installazione di PureData e delle seguenti librerie aggiuntive:
- list_abs (for the [list_dot] and [list_emath] objects);
- zexy (for the [>~] and [<~] object);
- iemlib ([prvu~], [init], [t3_bpe], [t3_line~] and [t3_delay] objects);
- motex ([ln~] object);
- lyonpotpourri ([adsr~] object);
- creb ([ead~] object);
- cxc, cyclone, purepd ([Uzi], [acos], [atan~], [delta~] objects);
- ggee ([image] object); {% endcomment %}
Godot è un game engine libero!

TODO: immagine audio server / audio player / stream / sample / architecture
Interrogato dal driver, l'audio server deve fornire lui tutti i samples (campioni audio 32 bit) di cui ha bisogno.
Per farlo deve copiare i dati immagazzinati nel proprio internal buffer sul p_buffer che il driver gli ha fornito.
Ad ogni richiestadel driver, l'audio server passa in rassegna tutte le voci (esaminandone con cura la coda dei comandi rispettiva in modo tale da sapere se la voce deve essere riprodotta, messa in pausa, eliminata dalla codam etc...) e chiede al mixer di mixarle. In seguito si passa ad analizzare gli stream e a scrivere infine sul p_buffer.
Il mixer elabora l'audio che passa attraverso i suoi canali provvedendo eventualmente a calcolare eventuali effetti da applicare sull'audio passante. Una volta fatto questo, copia i dati contenuti sul proprio internal_buffer a quello dell'audio_server.
L'audio player:
Lo stream player:
L'event player:
Il software libero è vincente in quanto consente l'accesso diretto al codice sorgente rendendo più veloci e agili integrazioni, modifiche e migliorie altrimenti impossibili in progetti software proprietari.
In questo modo ci è stato possibile avviare un progetto di integrazione in Godot dell'engine audio PureData grazie al wrapper libpd ideato da Peter Brinkmann.
 {: width="60%"}
{: width="60%"}
Il progetto è ancora in fase embrionale ma contiamo di refinirlo sempre più per poi rilasciarlo ufficialemtne al pubblico in modo che tutti possano avvantaggiarsi anche di un audio veramente procedurale all'interno di Godot.
Qui il link al repository sul quale limulo.net sta facendo i primi test: ogni contributo è benvenuto!
Vai alla pagina references per maggiori informazioni.
Gli argomenti sono tantissimi e nel poco tempo a disposizione non è sempre possibile trattare tutto con la dovuta attenzione e dovizia di particolari. Di seguito alcuni degli argomenti che avremo voluto illustrare a lezione ma che purtroppo, per i motivi di cui sopra, non hanno trovato spazio all'interno della trattazione.
Un videogioco a piattaforme ambientato in un intricato palazzo della Persia medievale, originariamente pubblicato per Apple II da Brøderbund nel 1989, e successivamente portato su molti altri sistemi.
Per maggiori informazioni su questo bel gioco vi rimandiamo a questo link. Inoltro, per chi fosse interessato, ecco il link al repository GitHub dove l'autore del gioco, Jordan Mechner, ha rilasciato il codice sorgente per MOS 6502 originale. Sul sito personale dell'autore si possono consultare anche il e i diari di sviluppo! {: class="dashed"}
I suoni si cui il gioco fa uso (almeno nella sua versione per PC-MSDOS) sono 32. Sono stati realizzati dal sound designer Tom Retting. Eccone la lista, come la si può leggere dal design document originale:
| Entrance door closes |
|
| Footsteps |
|
| Loose floor shakes (7 vers.) |
|
| Falling floor lands |
|
| Moveable floor |
|
| Gate coming down slow |
|
| Gate crashes down |
|
| Gate reaches bottom (Clang!) |
|
| Gate rising |
|
| Gate stops at top |
|
| Spikes coming out |
|
| Impaled by spikes |
|
| Slicer blades clash |
|
| Character gets sliced in half |
|
| Grab on to ledge |
|
| Unsheathe sword |
|
| Sword swipe |
|
| Sword clash |
|
| Stab opponent |
|
| Stabbed by opponent / Drink poison |
|
| Bones leap to life |
|
| Drink potion |
|
| Soft landing |
|
| Medium landing ("Oof!") |
|
| Hard landing (Splat!) |
|
| Bump soft |
|
| Jump through mirror |
|
| Exit door opening |
|
{% comment %}
-
Entrance door closes
-
Footsteps
-
Loose floor shakes (7 versions)
-
Falling floor lands
-
Movable floor
-
Gate coming down slow
-
Gate crashes down
-
Gate reaches bottom (Clang!)
-
Gate rising
-
Gate stops at top
-
Spikes-coming-out
-
Impaled by spikes
-
Slicer blades clash
-
Character gets sliced in half
-
Grab on to ledge
-
Unsheathe sword
-
Sword swipe
-
Sword clash
-
Stab opponent
-
Stabbed by opponent / Drink poison (lose 1 unit of strength)
-
Bones leap to life
-
Drink potion (glug glug)
-
Soft landing
-
Medium landing (“Oof!”)
-
Hard landing (Splat!)
-
Bump (soft)
-
Jump through mirror
-
Exit door opening {% endcomment %}