Let us consider a simple example, if apple looks more similar to peach, pear, and cherry (fruits) than monkey, cat or a rat (animals), then most likely apple is a fruit.
It is a Supervised Machine Learning Algorithm that used in the variety of applications such as finance, healthcare, political science, handwriting detection, image recognition and video recognition. In Credit ratings, financial institutes will predict the credit rating of customers.
KNN can be used for both clasification and regression problems. It is based on feature similaritiy approach.
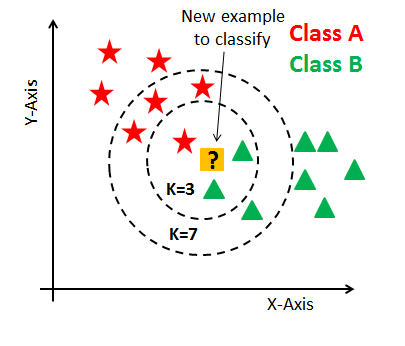
What is the Algorithm? It's basically classifies a data point based on how its neighbours are classified.
- Load the data
- Initialise the value of k
- For getting the predicted class, iterate from 1 to total number of training data points.
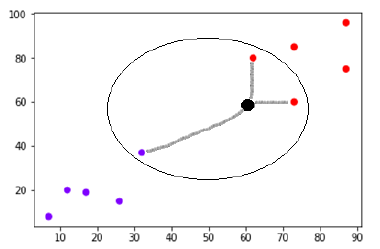
- Calculate the distance between test data and each row of training data.

- Sort the calculated distances in ascending order based on distance values
- Get top k rows from the sorted array
- Get the most frequent class of these rows
- Return the predicted class.
The k in KNN is the nearest neighbors. K is the core deciding factor, also the preformance of the model depends upon the value of k.
There is no optimal number of neighbors suits all kind of data sets. Each dataset has it's own requirements. In the case of a small number of neighbors, the noise will have a higher influence on the result, and a large number of neighbors make it computationally expensive.

In real life scenarios, K-NN is widely used as it is non-parametric which means it does not make any underlying assumptions about the distributions of data.
K-NN algorithm can be used for applications which require high accuracy as it makes highly accurate predictions. The quality of predictions is completely dependent on the distance measure. Thus, this algorithm is suitable for applications for which you have sufficient domain knowledge so that it can help you select an appropriate measure.
It is an instance-based learning or lazy learning as it uses the entire training dataset which gives more time for testing at the cost of memory.
The target is predicted by local interpolation of the targets associated of the nearest neighbors in the training set.Again, this k-neighbors regression use n_neighbors, you can use more than the single closest neighbor for regression, and the prediction is the average or mean of relevant neighbors.

KNN works well with a small number of input variables, but struggles when the number of inputs is very large. As the number of dimensions increases the volume of the input space increases at an exponential rate. In high dimensions, points that may be similar may have very large distances.
Now that we have we have seen how KNN works, let us look into some of the practical applications of K-NN.
- recommending products to people with similar interests, recommending movies and TV shows as per viewer’s choice and interest.
- recommending hotels and other accommodation facilities while you are travelling based on your previous bookings.
- Some advanced examples could include handwriting detection (like OCR), image recognition and even video recognition.