-Anshul Sharma, IIT Kharagpur



You will get to know about the Bias-Variance Trade-Off and how to use it to get better performance on your data in this post.
The basic goal of the Machine Learning model is to learn from the given data and generate predictions on unseen data. However, we need to continuously make improvements and evaluate our models. We also measure the model’s performance using metrics like Accuracy, Mean Squared Error(MSE), etc. The prediction error can be broken down broadly into three parts:

- Bias Error
- Variance Error
- Irreducible Error
The irreducible error cannot be reduced as may be due to reasons that are unknown, like if the attributes have no relation with the target values or excessive noise in the data. You would like to gather new data or use that only.
Bias are the assumptions made by a model to make the target function easier to learn, model may assume that the data is simple in representation to determine the target function fast. When it is introduced to the unseen data, these assumptions may not always be correct. Commonly, linear algorithms like linear regression have a high bias making them fast learners. Because of that sometimes, they may have poor performance on the validation/test data.
- Low Bias: model makes less assumptions about the data.
- High-Bias: model makes more assumptions about the data.
Examples of low-bias machine learning algorithms include: Decision Trees, k-Nearest Neighbors and Support Vector Machines. (They are also some most powerful machine learning algorithms today 😃😃)
Variance is quit opposite to bias. It happens is when the model takes into account the noise in the data. The target function is calculated mathematically from the training data, so we should expect the algorithm to have some ability to capture noise. But, it should generalize over new data. Machine learning algorithms that have a high variance are strongly influenced by the noise of the training data.
- Low Variance: model makes small changes to the target function with changes to the training dataset.
- High Variance: model makes large changes to the target function with changes to the training dataset.
- Linear algorithms often have a high bias but a low variance.
- Nonlinear algorithms often have a low bias but a high variance.
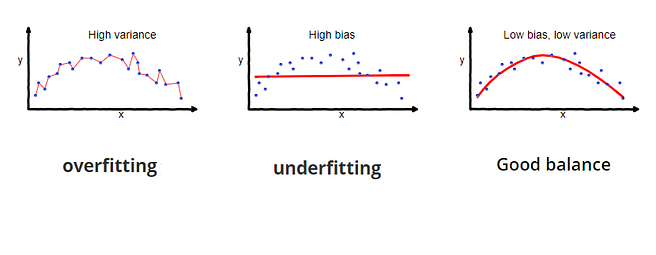
If you decrease bias, variance will increase and vice versa. So, there is a trade off. You have to choose optimum values for both such that the error is less. Bias and Variance provide the tools to understand the behavior of machine learning algorithms in the terms of performance.
- DevIncept Mentor
- Google for images
- Medium blog posts