-Anshul Sharma, IIT Kharagpur



The main cause of poor performance in machine learning is either overfitting or underfitting of the data by the model. In this post, you will discover the problems of overfitting and underfitting.
Overfitting refers to a model that fits the training data too well or almost perfectly. It happens when a model learns the detail and noise and outliers in the training data to the extent that it adversley impacts the performance of the model on test data. The problem is that these concepts do not apply to new data and thus the model is not able to generalize. Commonly, In the case of overfitting, training error is less than test error. Look at the following images for reference.
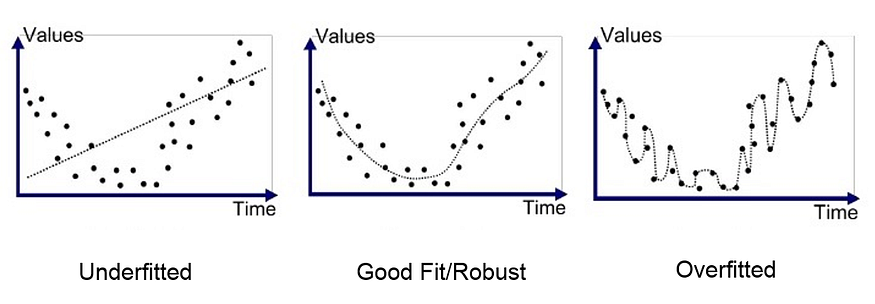
For example, decision trees are very flexible and are subject to overfitting train data. This problem can be addressed by pruning a tree after it has learned in order to remove some of the detail
Underfitting refers to a model that can neither fit the training data nor generalize to new data. An underfit machine learning model is not a suitable model and will be obvious as it will have poor performance on the training data. Underfitting is often not discussed as it is easy to detect given a good performance metric. The remedy is to move on and try alternate machine learning algorithms. Nevertheless, it does provide a good contrast to the problem of overfitting.
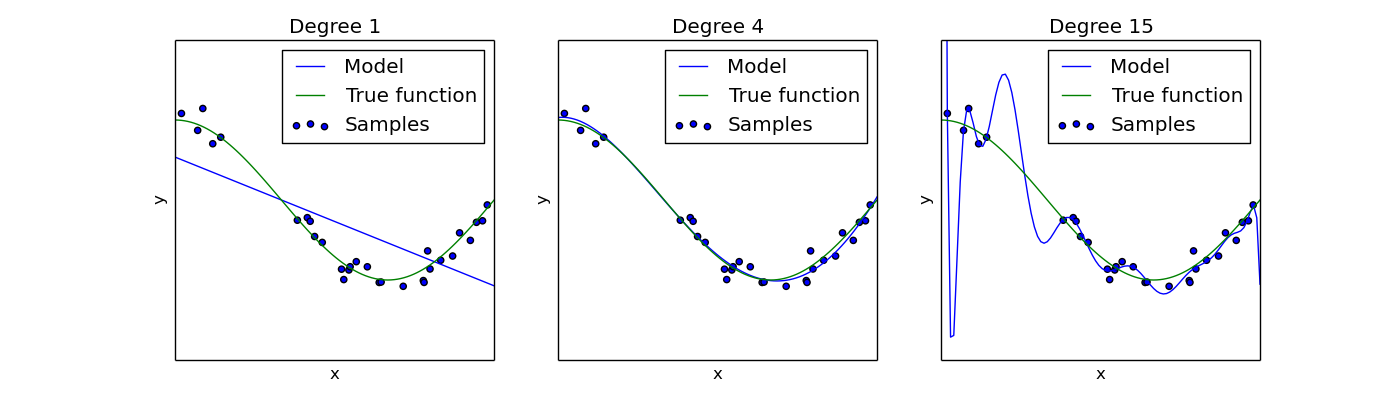
Overfitting is such a problem because the evaluation of machine learning algorithms on training data is different from the evaluation we actually care. The model fails to perform on the training data. To overcome this, we can use the followung techniques:
- Use a resampling technique like cross validation to estimate the performance.
- Make a validation dataset.
A validation dataset is simply a subset of your training data that you hold back from your machine learning algorithms until the very end of your project. After you have selected the machine learning algorithms, you can evaluate the models on the validation dataset to get a final objective idea of how the models might perform on unseen data.
- DevIncept Mentor
- Google for images
- Medium blog posts
- Wikipedia
- UCI Machine learning datset repository