[question] Myelin: attention fusion and FlashAttention #3243
Comments
|
@nvpohanh ^ ^ |
|
For now, you can only check the Nsight Systems profiles: https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#nvprof If the MHA is fused, there should be kernel names with In next TRT version, you will be able to get this info by using the IEngineInspector (or |
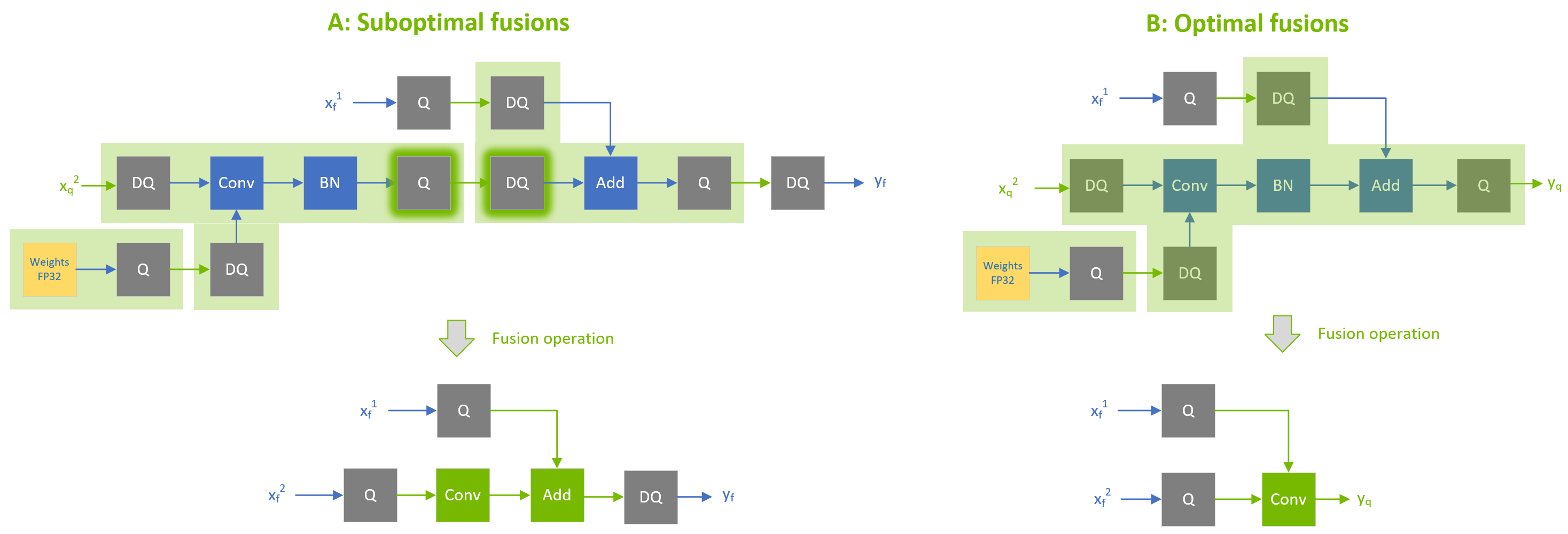
TRT's MHA fusion does not support implicit quantizations yet. Please use explicit quantization instead: Add Q/DQ ops before the two batch gemms in the MHA and also add Q/DQ ops before the ResidualAdd. Here is an ugly example: |

|
Hey, a couple questions to tack on:
|
|
The INT8 MHA fused kernels are already integrated in TRT 8.6. The only caveat is that SeqLen must be 512 or below. It does use flash attention if applicable.
For Transformers, it is recommended to add Q/DQs on both the inputs of the ResidualAdd. This is because in ConvNets, we fuse the ResidualAdd with the Conv, but for Transformers, we fuse the ResidualAdd with the LayerNorm that comes right after the ResidualAdd. |
|
Hey, one followup question. How does the fusion scheme work for pre-norm transformers (as the layer norm would only be applied to the residual branch, and not the identity branch)? Does a norm first transformer come with a performance penalty / less optimized kernels? |

|
TRT should be able to fuse the add_1 with norm2, so it should not cause any perf issue. |
@nvpohanh How about the int8 attention speed v.s. fp16? Do you have more detailed documents about how to conduct explicit quantization on attention? thanks! |
hi, I'm new to TRT and not familiear with TRT's docs. Is there somewhere we can view the features and constraints of all of TRT supported kernels/fuse pattern/plugins? Such as how to insert QDQ for MHA and its supported layout? |
Hi, @nvpohanh I try to convert this onnx to Tensorrt Engine. But there is no kernel name with _mha. |


|
@Aktcob Could you share your trtexec command and the ONNX? Also, could you try TRT 10.0.1.6 GA release and make sure you have enabled FP16? |
@nvpohanh Thanks for reply! I try it on Jetson Orin devkit. So I cannot try it with TRT 10.0.1.6 GA. Onnx File: https://wenshu.sankuai.com/file/share/download/35BB3D5239CBFD33D79A5FE4DA4F17BFF7B46221 |
|
@nvpohanh I try it on another SelfAttention Module without AttentionMask. And there is a kernel with name mha_v2 which fuses matmal + softmax + matmal. |
|
Does Myelin fuses the attention during runtime at engine running or Ahead of time at engine build? |
|
@nvpohanh Hi, I follow ur example and test my MHA module. And the onnx model is shown as: I test it on Jetson Orin Device, Tensorrt version is 8.6.0. And it can be built Tensorrt Engine with mha kernel. I use Nsys to show this. However, the INT8 mha kernel is much slower than the FP16 mha kernel.(800us vs 200us). How to solve this problem? Thanks for ur reply.
|


{kind=link}
Hi! When attention op gets fused in a single op with Myelin, it's not written in trex-tooltip if it's using FlashAttention / proper fusion or not (and if it's using quantization under the hood, especially for the implicit quantization mode). How can we know if it's using fused attention impl like FlashAttention? Thanks :)
The text was updated successfully, but these errors were encountered: