| title | layout | tab | order | tags |
|---|---|---|---|---|
Scoring |
true |
2 |
benchmark |
One of the unique things about OWASP Benchmark is that it is very easy to score a tool's security analysis results against it. Each test case in Benchmark has a single intentional CWE that is either a True or False Positive. These are documented in the expectedresults-1.2.csv file. The project includes automated scorecard generators for dozens of security tools that can automatically score a tool's results against Benchmark. The following describes the Benchmark scoring scheme, reporting format, and how to actually generate Benchmark scores for tools.
Security tools (SAST, DAST, and IAST) are amazing when they find a complex vulnerability in your code. But with widespread misunderstanding of the specific vulnerabilities automated tools cover, end users are often left with a false sense of security.
We are on a quest to measure just how good these tools are at discovering and properly diagnosing security problems in applications. We rely on the long history of military and medical evaluation of detection technology as a foundation for our research. Therefore, the test suite tests both real and fake vulnerabilities.
There are four possible test outcomes in the Benchmark:
- Tool correctly identifies a real vulnerability (True Positive - TP)
- Tool fails to identify a real vulnerability (False Negative - FN)
- Tool correctly ignores a false alarm (True Negative - TN)
- Tool fails to ignore a false alarm (False Positive - FP)
We can learn a lot about a tool from these four metrics. Consider a tool that simply flags every line of code as vulnerable. This tool will perfectly identify all vulnerabilities! But it will also have 100% false positives and thus adds no value. Similarly, consider a tool that reports absolutely nothing. This tool will have zero false positives, but will also identify zero real vulnerabilities and is also worthless. You can even imagine a tool that flips a coin to decide whether to report whether each test case contains a vulnerability. The result would be 50% true positives and 50% false positives. We need a way to distinguish valuable security tools from these trivial ones.
If you imagine the line that connects all these points, from 0,0 to 100,100 establishes a line that roughly translates to "random guessing." The ultimate measure of a security tool is how much better it can do than this line. The diagram below shows how we will evaluate security tools against the Benchmark.
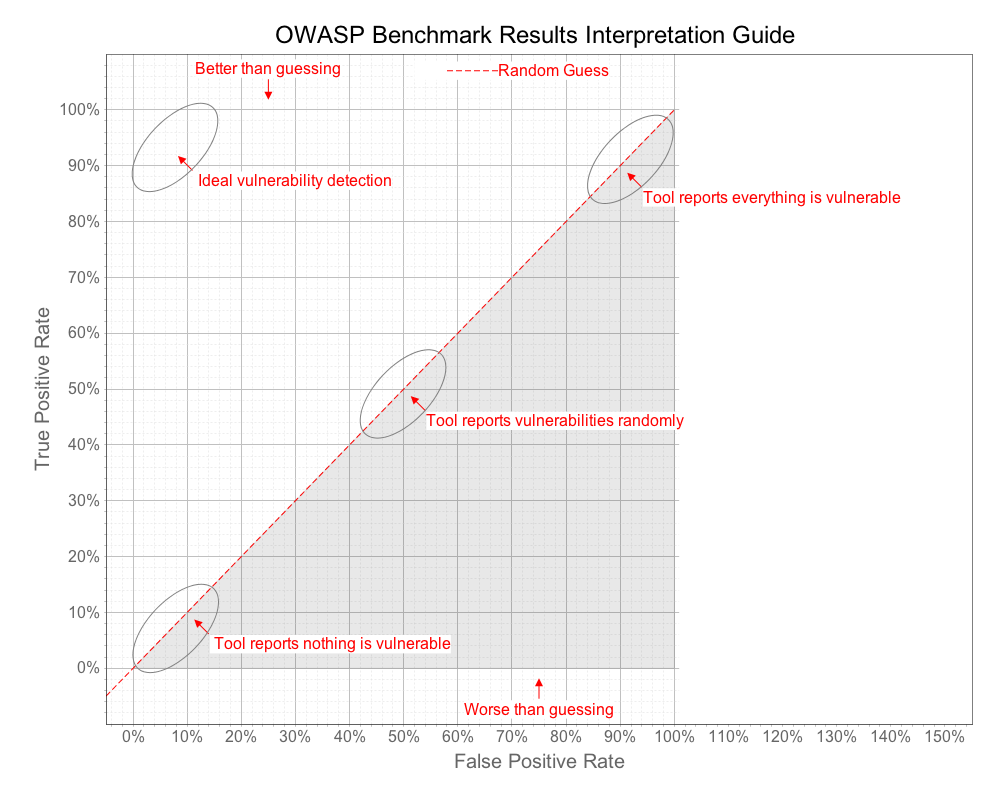 A point plotted on this chart provides a visual indication of how well a tool did considering both the True Positives the tool reported, as well as the False Positives it reported. We also want to compute an individual score for that point in the range 0 - 100, which we call the Benchmark Accuracy Score.
A point plotted on this chart provides a visual indication of how well a tool did considering both the True Positives the tool reported, as well as the False Positives it reported. We also want to compute an individual score for that point in the range 0 - 100, which we call the Benchmark Accuracy Score.
The Benchmark Accuracy Score is essentially a Youden Index, which is a standard way of summarizing the accuracy of a set of tests. Youden's index is one of the oldest measures for diagnostic accuracy. It is also a global measure of a test performance, used for the evaluation of overall discriminative power of a diagnostic procedure and for comparison of this test with other tests. Youden's index is calculated by deducting 1 from the sum of a test's sensitivity and specificity expressed not as percentage but as a part of a whole number: (sensitivity + specificity) - 1. For a test with poor diagnostic accuracy, Youden's index equals 0, and in a perfect test Youden's index equals 1.
code()
So for example, if a tool has a True Positive Rate (TPR) of .98 (i.e., 98%)
and False Positive Rate (FPR) of .05 (i.e., 5%)
Sensitivity = TPR (.98)
Specificity = 1-FPR (.95)
So the Youden Index is (.98+.95) - 1 = .93
And this would equate to a Benchmark score of 93 (since we normalize this to the range 0 - 100)
On the graph, the Benchmark Score is the length of the line from the point down to the diagonal "guessing" line. Note that a Benchmark score can actually be negative if the point is below the line. This is caused when the False Positive Rate is actually higher than the True Positive Rate.
Anyone can use this Benchmark to evaluate vulnerability detection tools. The basic steps are:
- Download the Benchmark from GitHub
- Run your tools against the Benchmark
- Run the BenchmarkScore tool on the reports from your tools That's it!
Full details on how to do this are at the bottom of the page on the Quick Start tab.
We encourage both vendors, open-source tools, and end users to verify their application security tools against the Benchmark. In order to ensure that the results are fair and useful, we ask that you follow a few simple rules when publishing results. We won't recognize any results that aren't easily reproducible:
- A description of the default "out-of-the-box" installation, version numbers, etc.
- Any and all configuration, tailoring, onboarding, etc. performed to make the tool run
- Any and all changes to default security rules, tests, or checks used to achieve the results
- Easily reproducible steps to run the tool
The Benchmark includes tools to interpret raw tool output, compare it to the expected results, and generate summary charts and graphs. We use the following table format in order to capture all the information generated during the evaluation.
| Security Category | TP | FN | TN | FP | Total | TPR | FPR | Score |
|---|---|---|---|---|---|---|---|---|
| General security category for test cases. | True Positives: Tests with real vulnerabilities that were correctly reported as vulnerable by the tool. | False Negative: Tests with real vulnerabilities that were not correctly reported as vulnerable by the tool. | True Negative: Tests with fake vulnerabilities that were correctly not reported as vulnerable by the tool. | False Positive: Tests with fake vulnerabilities that were incorrectly reported as vulnerable by the tool. | Total test cases for this category. | True Positive Rate: TP / ( TP + FN ) - Also referred to as Recall, as defined at Wikipedia. | False Positive Rate: FP / ( FP + TN ). | Normalized distance from the "guess line" TPR - FPR. |
| Command Injection | ... | ... | ... | ... | ... | ... | ... | ... |
| Etc. | ... | ... | ... | ... | ... | ... | ... | ... |
| Total TP | Total FN | Total TN | Total FP | Total TC | Average TPR | Average FPR | Average Score |
To be clear, the Benchmark tests are not exactly like real applications. The tests are derived from coding patterns observed in real applications, but the majority of them are considerably simpler than real applications. That is, most real-world applications will be considerably harder to successfully analyze than the OWASP Benchmark Test Suite. Although the tests are based on real code, it is possible that some tests may have coding patterns that don't occur frequently in real code.
Remember, we are trying to test the capabilities of the tools and make them explicit, so that users can make informed decisions about what tools to use, how to use them, and what results to expect. This is exactly aligned with the OWASP mission to make application security visible.