From c7fd9a52139d784585cc801b7b778037db47648d Mon Sep 17 00:00:00 2001
From: Michelle <97082656+MichelleMa8@users.noreply.github.com>
Date: Thu, 30 Nov 2023 22:55:52 +0800
Subject: [PATCH] [ColossalQA] refactor server and webui & add new feature
(#5138)
* refactor server and webui & add new feature
* add requirements
* modify readme and ui
---
applications/ColossalQA/README.md | 2 +-
.../colossalqa/data_loader/document_loader.py | 8 +
.../ColossalQA/colossalqa/prompt/prompt.py | 20 +-
.../ColossalQA/colossalqa/retriever.py | 19 +-
.../examples/webui_demo/RAG_ChatBot.py | 101 +++++----
.../ColossalQA/examples/webui_demo/README.md | 91 +++++++-
.../ColossalQA/examples/webui_demo/config.py | 58 ++++++
.../examples/webui_demo/requirements.txt | 3 +
.../ColossalQA/examples/webui_demo/server.py | 195 ++++++++----------
.../examples/webui_demo/start_colossal_qa.sh | 43 ----
.../ColossalQA/examples/webui_demo/utils.py | 6 +
.../ColossalQA/examples/webui_demo/webui.py | 91 ++++----
12 files changed, 380 insertions(+), 257 deletions(-)
create mode 100644 applications/ColossalQA/examples/webui_demo/config.py
create mode 100644 applications/ColossalQA/examples/webui_demo/requirements.txt
delete mode 100755 applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh
create mode 100644 applications/ColossalQA/examples/webui_demo/utils.py
diff --git a/applications/ColossalQA/README.md b/applications/ColossalQA/README.md
index a12f2c47a6bd..a031f9ae0713 100644
--- a/applications/ColossalQA/README.md
+++ b/applications/ColossalQA/README.md
@@ -121,7 +121,7 @@ Read comments under ./colossalqa/data_loader for more detail regarding supported
### Run The Script
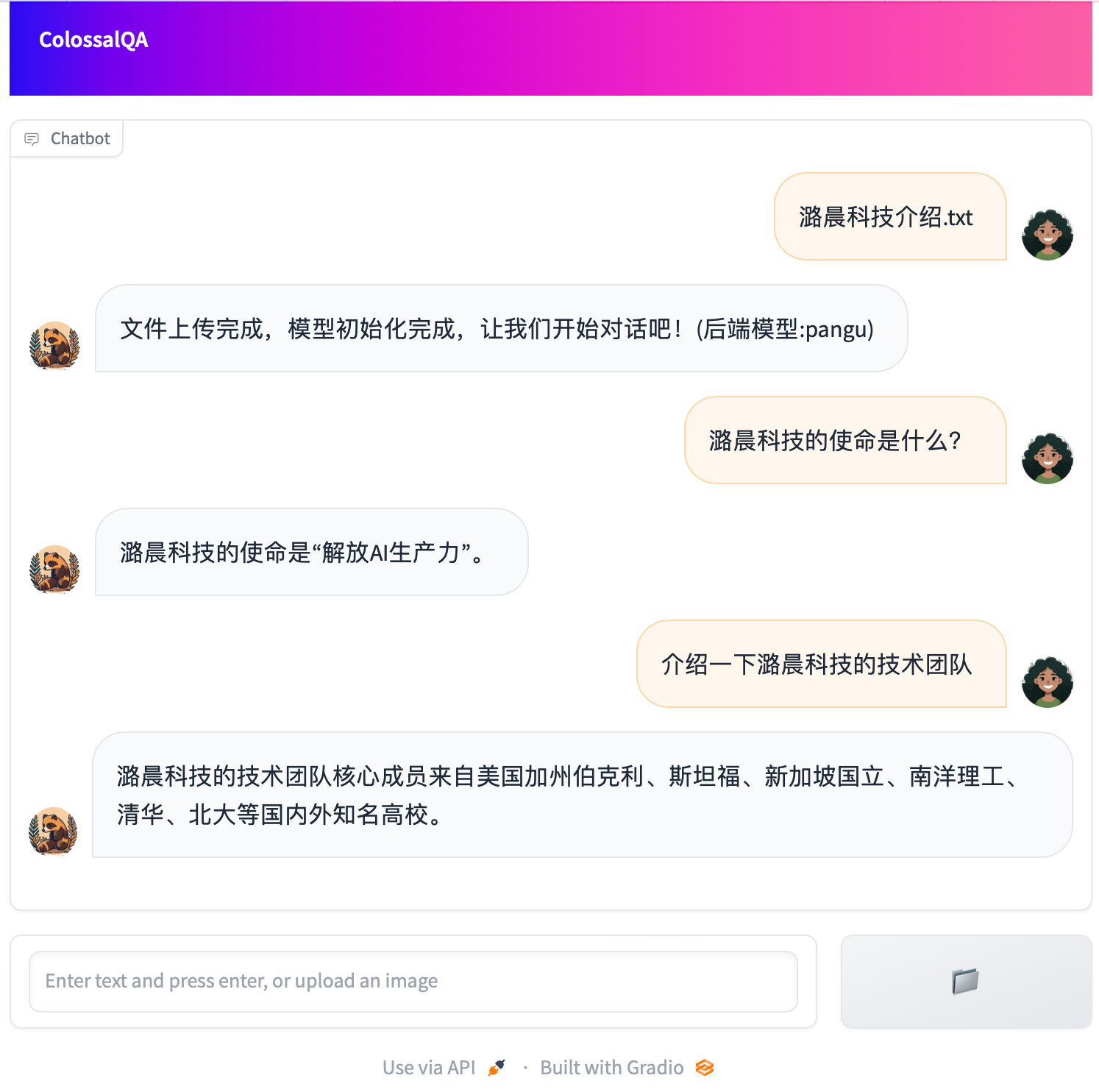
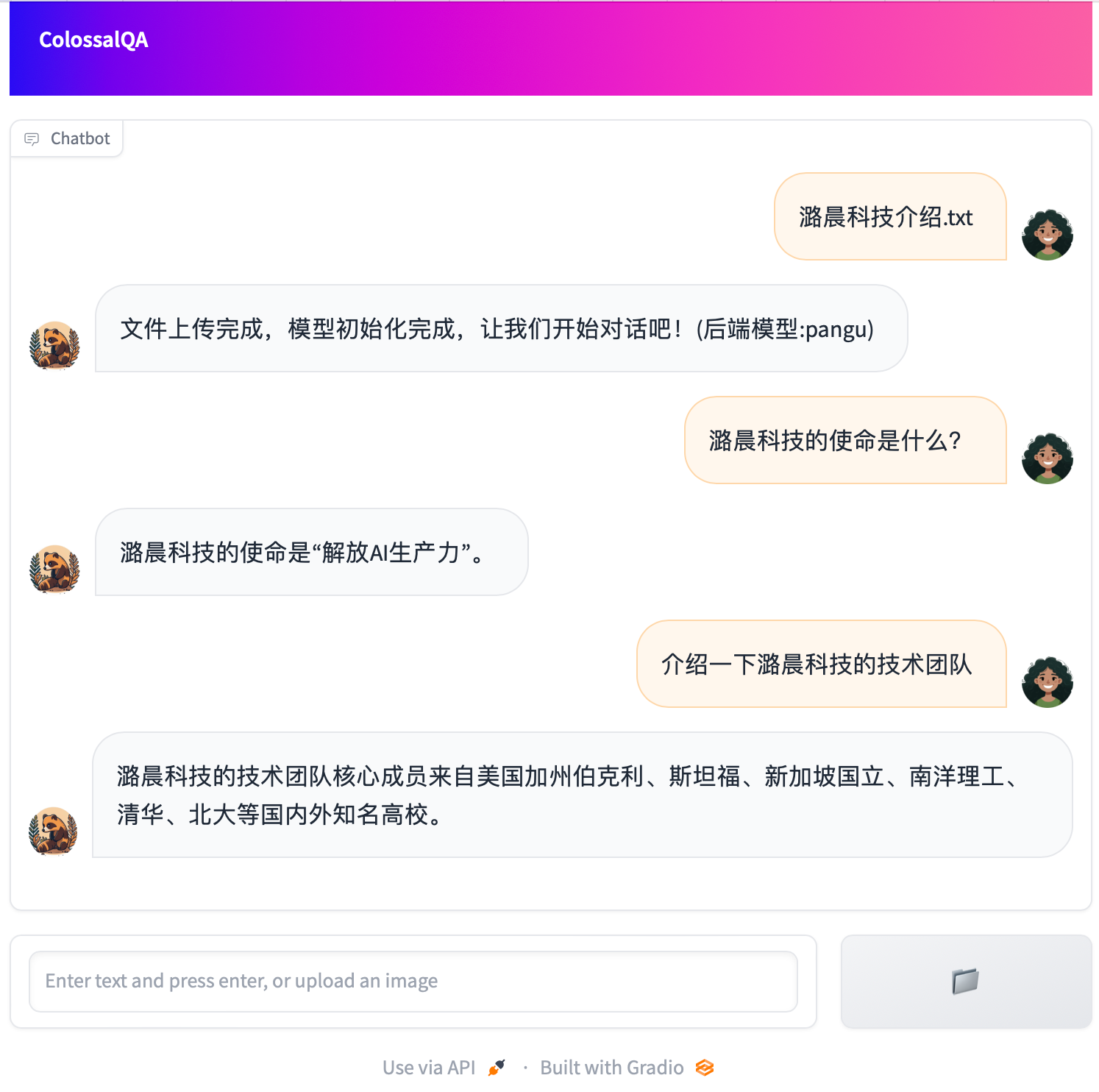
We provide a simple Web UI demo of ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser. More details can be found [here](examples/webui_demo/README.md)
-
+
We also provided some scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality. The Bi-lingual one is a high-level wrapper for the other two classes. We write different scripts for different languages because retrieval QA requires different embedding models, LLMs, prompts for different language setting. For now, we use LLaMa2 for English retrieval QA and ChatGLM2 for Chinese retrieval QA for better performance.
diff --git a/applications/ColossalQA/colossalqa/data_loader/document_loader.py b/applications/ColossalQA/colossalqa/data_loader/document_loader.py
index 0fe1e4d1a00c..4ddbf2b9d249 100644
--- a/applications/ColossalQA/colossalqa/data_loader/document_loader.py
+++ b/applications/ColossalQA/colossalqa/data_loader/document_loader.py
@@ -126,3 +126,11 @@ def load_data(self, path: str) -> None:
else:
# May ba a directory, we strictly follow the glob path and will not load files in subdirectories
pass
+
+ def clear(self):
+ """
+ Clear loaded data.
+ """
+ self.data = {}
+ self.kwargs = {}
+ self.all_data = []
diff --git a/applications/ColossalQA/colossalqa/prompt/prompt.py b/applications/ColossalQA/colossalqa/prompt/prompt.py
index a7723078689e..533f0bd552b9 100644
--- a/applications/ColossalQA/colossalqa/prompt/prompt.py
+++ b/applications/ColossalQA/colossalqa/prompt/prompt.py
@@ -4,6 +4,9 @@
from langchain.prompts.prompt import PromptTemplate
+
+# Below are Chinese retrieval qa prompts
+
_CUSTOM_SUMMARIZER_TEMPLATE_ZH = """请递进式地总结所提供的当前对话,将当前对话的摘要内容添加到先前已有的摘要上,返回一个融合了当前对话的新的摘要。
例1:
@@ -27,8 +30,6 @@
新的摘要:"""
-# Chinese retrieval qa prompt
-
_ZH_RETRIEVAL_QA_PROMPT = """<指令>根据下列支持文档和对话历史,简洁和专业地来回答问题。如果无法从支持文档中得到答案,请说 “根据已知信息无法回答该问题”。回答中请不要涉及支持文档中没有提及的信息,答案请使用中文。
{context}
@@ -70,7 +71,8 @@
句子: {input}
消除歧义的句子:"""
-# English retrieval qa prompt
+
+# Below are English retrieval qa prompts
_EN_RETRIEVAL_QA_PROMPT = """[INST] <>Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist content.
If the answer cannot be infered based on the given context, please say "I cannot answer the question based on the information given.".<>
@@ -105,20 +107,24 @@
disambiguated sentence:"""
+# Prompt templates
+
+# English retrieval prompt, the model generates answer based on this prompt
PROMPT_RETRIEVAL_QA_EN = PromptTemplate(
template=_EN_RETRIEVAL_QA_PROMPT, input_variables=["question", "chat_history", "context"]
)
-
+# English disambigate prompt, which replace any ambiguous references in the user's input with the specific names or entities mentioned in the chat history
PROMPT_DISAMBIGUATE_EN = PromptTemplate(template=_EN_DISAMBIGUATION_PROMPT, input_variables=["chat_history", "input"])
+# Chinese summary prompt, which summarize the chat history
SUMMARY_PROMPT_ZH = PromptTemplate(input_variables=["summary", "new_lines"], template=_CUSTOM_SUMMARIZER_TEMPLATE_ZH)
-
+# Chinese disambigate prompt, which replace any ambiguous references in the user's input with the specific names or entities mentioned in the chat history
PROMPT_DISAMBIGUATE_ZH = PromptTemplate(template=_ZH_DISAMBIGUATION_PROMPT, input_variables=["chat_history", "input"])
-
+# Chinese retrieval prompt, the model generates answer based on this prompt
PROMPT_RETRIEVAL_QA_ZH = PromptTemplate(
template=_ZH_RETRIEVAL_QA_PROMPT, input_variables=["question", "chat_history", "context"]
)
-
+# Chinese retrieval prompt for a use case to analyze fault causes
PROMPT_RETRIEVAL_CLASSIFICATION_USE_CASE_ZH = PromptTemplate(
template=_ZH_RETRIEVAL_CLASSIFICATION_USE_CASE, input_variables=["question", "context"]
)
diff --git a/applications/ColossalQA/colossalqa/retriever.py b/applications/ColossalQA/colossalqa/retriever.py
index 9ea6d5b080cd..c891cb613bd6 100644
--- a/applications/ColossalQA/colossalqa/retriever.py
+++ b/applications/ColossalQA/colossalqa/retriever.py
@@ -73,6 +73,7 @@ def add_documents(
data_by_source[doc.metadata["source"]].append(doc)
elif mode == "merge":
data_by_source["merged"] = docs
+
for source in data_by_source:
if source not in self.vector_stores:
hash_encoding = hashlib.sha3_224(source.encode()).hexdigest()
@@ -81,8 +82,10 @@ def add_documents(
os.remove(f"{self.sql_file_path}/{hash_encoding}.db")
# Create a new sql database to store indexes, sql files are stored in the same directory as the source file
sql_path = f"sqlite:///{self.sql_file_path}/{hash_encoding}.db"
- self.vector_stores[source] = Chroma(embedding_function=embedding, collection_name=hash_encoding)
+ # to record the sql database with their source as index
self.sql_index_database[source] = f"{self.sql_file_path}/{hash_encoding}.db"
+
+ self.vector_stores[source] = Chroma(embedding_function=embedding, collection_name=hash_encoding)
self.record_managers[source] = SQLRecordManager(source, db_url=sql_path)
self.record_managers[source].create_schema()
index(
@@ -93,6 +96,20 @@ def add_documents(
source_id_key="source",
)
+ def clear_documents(self):
+ """Clear all document vectors from database"""
+ for source in self.vector_stores:
+ index(
+ [],
+ self.record_managers[source],
+ self.vector_stores[source],
+ cleanup="full",
+ source_id_key="source"
+ )
+ self.vector_stores = {}
+ self.sql_index_database = {}
+ self.record_managers = {}
+
def __del__(self):
for source in self.sql_index_database:
if os.path.exists(self.sql_index_database[source]):
diff --git a/applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py b/applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py
index 0ad547c0093a..c58be9c33477 100644
--- a/applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py
+++ b/applications/ColossalQA/examples/webui_demo/RAG_ChatBot.py
@@ -1,3 +1,4 @@
+import os
from typing import Dict, Tuple
from colossalqa.chain.retrieval_qa.base import RetrievalQA
@@ -12,29 +13,11 @@
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
)
from colossalqa.retriever import CustomRetriever
-from colossalqa.text_splitter import ChineseTextSplitter
from langchain import LLMChain
from langchain.embeddings import HuggingFaceEmbeddings
logger = get_logger()
-DEFAULT_RAG_CFG = {
- "retri_top_k": 3,
- "retri_kb_file_path": "./",
- "verbose": True,
- "mem_summary_prompt": SUMMARY_PROMPT_ZH,
- "mem_human_prefix": "用户",
- "mem_ai_prefix": "Assistant",
- "mem_max_tokens": 2000,
- "mem_llm_kwargs": {"max_new_tokens": 50, "temperature": 1, "do_sample": True},
- "disambig_prompt": PROMPT_DISAMBIGUATE_ZH,
- "disambig_llm_kwargs": {"max_new_tokens": 30, "temperature": 1, "do_sample": True},
- "embed_model_name_or_path": "moka-ai/m3e-base",
- "embed_model_device": {"device": "cpu"},
- "gen_llm_kwargs": {"max_new_tokens": 100, "temperature": 1, "do_sample": True},
- "gen_qa_prompt": PROMPT_RETRIEVAL_QA_ZH,
-}
-
class RAG_ChatBot:
def __init__(
@@ -44,13 +27,16 @@ def __init__(
) -> None:
self.llm = llm
self.rag_config = rag_config
- self.set_embed_model(**self.rag_config)
- self.set_text_splitter(**self.rag_config)
- self.set_memory(**self.rag_config)
- self.set_info_retriever(**self.rag_config)
- self.set_rag_chain(**self.rag_config)
- if self.rag_config.get("disambig_prompt", None):
- self.set_disambig_retriv(**self.rag_config)
+ self.set_embed_model(**self.rag_config["embed"])
+ self.set_text_splitter(**self.rag_config["splitter"])
+ self.set_memory(**self.rag_config["chain"])
+ self.set_info_retriever(**self.rag_config["retrieval"])
+ self.set_rag_chain(**self.rag_config["chain"])
+ if self.rag_config["chain"].get("disambig_prompt", None):
+ self.set_disambig_retriv(**self.rag_config["chain"])
+
+ self.documents = []
+ self.docs_names = []
def set_embed_model(self, **kwargs):
self.embed_model = HuggingFaceEmbeddings(
@@ -61,7 +47,7 @@ def set_embed_model(self, **kwargs):
def set_text_splitter(self, **kwargs):
# Initialize text_splitter
- self.text_splitter = ChineseTextSplitter()
+ self.text_splitter = kwargs["name"]()
def set_memory(self, **kwargs):
params = {"llm_kwargs": kwargs["mem_llm_kwargs"]} if kwargs.get("mem_llm_kwargs", None) else {}
@@ -91,10 +77,6 @@ def set_rag_chain(self, **kwargs):
**params,
)
- def split_docs(self, documents):
- doc_splits = self.text_splitter.split_documents(documents)
- return doc_splits
-
def set_disambig_retriv(self, **kwargs):
params = {"llm_kwargs": kwargs["disambig_llm_kwargs"]} if kwargs.get("disambig_llm_kwargs", None) else {}
self.llm_chain_disambiguate = LLMChain(llm=self.llm, prompt=kwargs["disambig_prompt"], **params)
@@ -106,42 +88,50 @@ def disambiguity(input: str):
self.info_retriever.set_rephrase_handler(disambiguity)
def load_doc_from_console(self, json_parse_args: Dict = {}):
- documents = []
- print("Select files for constructing Chinese retriever")
+ print("Select files for constructing the retriever")
while True:
file = input("Enter a file path or press Enter directly without input to exit:").strip()
if file == "":
break
data_name = input("Enter a short description of the data:")
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
- documents.extend(docs)
- self.documents = documents
- self.split_docs_and_add_to_mem(**self.rag_config)
+ self.documents.extend(docs)
+ self.docs_names.append(data_name)
+ self.split_docs_and_add_to_mem(**self.rag_config["chain"])
def load_doc_from_files(self, files, data_name="default_kb", json_parse_args: Dict = {}):
- documents = []
for file in files:
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
- documents.extend(docs)
- self.documents = documents
- self.split_docs_and_add_to_mem(**self.rag_config)
+ self.documents.extend(docs)
+ self.docs_names.append(os.path.basename(file))
+ self.split_docs_and_add_to_mem(**self.rag_config["chain"])
def split_docs_and_add_to_mem(self, **kwargs):
- self.doc_splits = self.split_docs(self.documents)
+ doc_splits = self.split_docs(self.documents)
self.info_retriever.add_documents(
- docs=self.doc_splits, cleanup="incremental", mode="by_source", embedding=self.embed_model
+ docs=doc_splits, cleanup="incremental", mode="by_source", embedding=self.embed_model
)
self.memory.initiate_document_retrieval_chain(self.llm, kwargs["gen_qa_prompt"], self.info_retriever)
+ def split_docs(self, documents):
+ doc_splits = self.text_splitter.split_documents(documents)
+ return doc_splits
+
+ def clear_docs(self, **kwargs):
+ self.documents = []
+ self.docs_names = []
+ self.info_retriever.clear_documents()
+ self.memory.initiate_document_retrieval_chain(self.llm, kwargs["gen_qa_prompt"], self.info_retriever)
+
def reset_config(self, rag_config):
self.rag_config = rag_config
- self.set_embed_model(**self.rag_config)
- self.set_text_splitter(**self.rag_config)
- self.set_memory(**self.rag_config)
- self.set_info_retriever(**self.rag_config)
- self.set_rag_chain(**self.rag_config)
- if self.rag_config.get("disambig_prompt", None):
- self.set_disambig_retriv(**self.rag_config)
+ self.set_embed_model(**self.rag_config["embed"])
+ self.set_text_splitter(**self.rag_config["splitter"])
+ self.set_memory(**self.rag_config["chain"])
+ self.set_info_retriever(**self.rag_config["retrieval"])
+ self.set_rag_chain(**self.rag_config["chain"])
+ if self.rag_config["chain"].get("disambig_prompt", None):
+ self.set_disambig_retriv(**self.rag_config["chain"])
def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[str, ConversationBufferWithSummary]:
if memory:
@@ -153,7 +143,7 @@ def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[s
rejection_trigger_keywrods=ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
rejection_answer=ZH_RETRIEVAL_QA_REJECTION_ANSWER,
)
- return result.split("\n")[0], memory
+ return result, memory
def start_test_session(self):
"""
@@ -170,15 +160,18 @@ def start_test_session(self):
if __name__ == "__main__":
# Initialize an Langchain LLM(here we use ChatGPT as an example)
+ import config
from langchain.llms import OpenAI
- llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
+ # you need to: export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
+ llm = OpenAI(openai_api_key=os.getenv("OPENAI_API_KEY"))
# chatgpt cannot control temperature, do_sample, etc.
- DEFAULT_RAG_CFG["mem_llm_kwargs"] = None
- DEFAULT_RAG_CFG["disambig_llm_kwargs"] = None
- DEFAULT_RAG_CFG["gen_llm_kwargs"] = None
+ all_config = config.ALL_CONFIG
+ all_config["chain"]["mem_llm_kwargs"] = None
+ all_config["chain"]["disambig_llm_kwargs"] = None
+ all_config["chain"]["gen_llm_kwargs"] = None
- rag = RAG_ChatBot(llm, DEFAULT_RAG_CFG)
+ rag = RAG_ChatBot(llm, all_config)
rag.load_doc_from_console()
rag.start_test_session()
diff --git a/applications/ColossalQA/examples/webui_demo/README.md b/applications/ColossalQA/examples/webui_demo/README.md
index 15ce6b5b71be..1942cd45ee50 100644
--- a/applications/ColossalQA/examples/webui_demo/README.md
+++ b/applications/ColossalQA/examples/webui_demo/README.md
@@ -16,22 +16,103 @@ cd ColossalAI/applications/ColossalQA/
pip install -e .
```
+Install the dependencies for ColossalQA webui demo:
+```sh
+pip install -r requirements.txt
+```
+
## Configure the RAG Chain
-Customize the RAG Chain settings, such as the embedding model (default: moka-ai/m3e) and the language model, in the `start_colossal_qa.sh` script.
+Customize the RAG Chain settings, such as the embedding model (default: moka-ai/m3e), the language model, and the prompts, in the `config.py`. Please refer to [`Prepare configuration file`](#prepare-configuration-file) for the details of `config.py`.
For API-based language models (like ChatGPT or Huawei Pangu), provide your API key for authentication. For locally-run models, indicate the path to the model's checkpoint file.
-If you want to customize prompts in the RAG Chain, you can have a look at the `RAG_ChatBot.py` file to modify them.
+## Prepare configuration file
+
+All configs are defined in `ColossalQA/examples/webui_demo/config.py`.
+
+- embed:
+ - embed_name: the embedding model name
+ - embed_model_name_or_path: path to embedding model, could be a local path or a huggingface path
+ - embed_model_device: device to load the embedding model
+- model:
+ - mode: "local" for loading models, "api" for using model api
+ - model_name: "chatgpt_api", "pangu_api", or your local model name
+ - model_path: path to the model, could be a local path or a huggingface path. don't need if mode="api"
+ - device: device to load the LLM
+- splitter:
+ - name: text splitter class name, the class should be imported at the beginning of `config.py`
+- retrieval:
+ - retri_top_k: number of retrieval text which will be provided to the model
+ - retri_kb_file_path: path to store database files
+ - verbose: Boolean type, to control the level of detail in program output
+- chain:
+ - mem_summary_prompt: summary prompt template
+ - mem_human_prefix: human prefix for prompt
+ - mem_ai_prefix: AI assistant prefix for prompt
+ - mem_max_tokens: max tokens for history information
+ - mem_llm_kwargs: model's generation kwargs for summarizing history
+ - max_new_tokens: int
+ - temperature: int
+ - do_sample: bool
+ - disambig_prompt: disambiguate prompt template
+ - disambig_llm_kwargs: model's generation kwargs for disambiguating user's input
+ - max_new_tokens: int
+ - temperature": int
+ - do_sample: bool
+ - gen_llm_kwargs: model's generation kwargs
+ - max_new_tokens: int
+ - temperature: int
+ - do_sample: bool
+ - gen_qa_prompt: generation prompt template
+ - verbose: Boolean type, to control the level of detail in program output
-## Run WebUI Demo
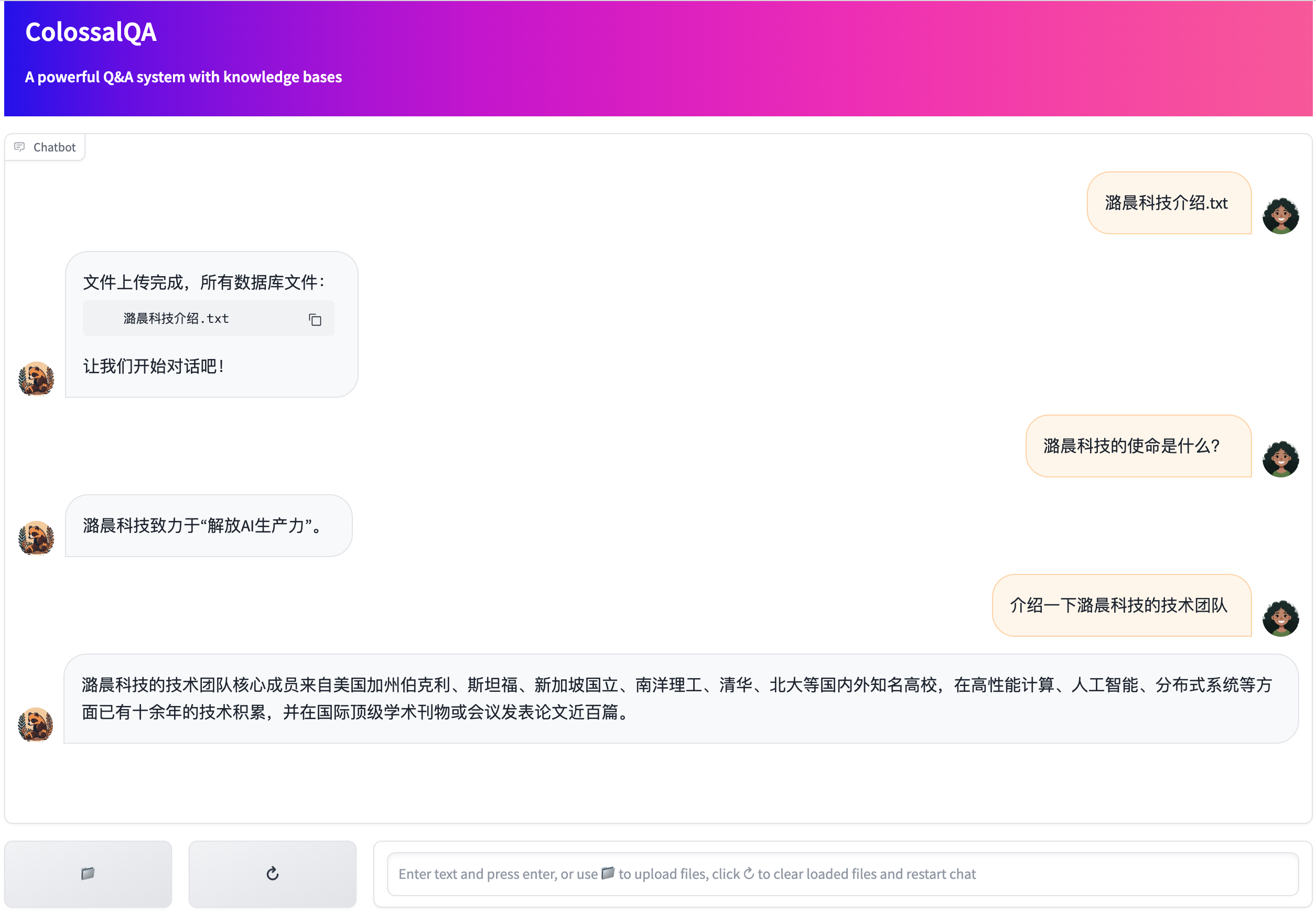
+## Run WebUI Demo
Execute the following command to start the demo:
+1. If you want to use a local model as the backend model, you need to specify the model name and model path in `config.py` and run the following commands.
+
```sh
-bash start_colossal_qa.sh
+export TMP="path/to/store/tmp/files"
+# start the backend server
+python server.py --http_host "host" --http_port "port"
+
+# in an another terminal, start the ui
+python webui.py --http_host "your-backend-api-host" --http_port "your-backend-api-port"
+```
+
+2. If you want to use pangu api as the backend model, you need to change the model mode to "api", change the model name to "chatgpt_api" in `config.py`, and run the following commands.
+```sh
+export TMP="path/to/store/tmp/files"
+
+# Auth info for OpenAI API
+export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
+
+# start the backend server
+python server.py --http_host "host" --http_port "port"
+
+# in an another terminal, start the ui
+python webui.py --http_host "your-backend-api-host" --http_port "your-backend-api-port"
+```
+
+3. If you want to use pangu api as the backend model, you need to change the model mode to "api", change the model name to "pangu_api" in `config.py`, and run the following commands.
+```sh
+export TMP="path/to/store/tmp/files"
+
+# Auth info for Pangu API
+export URL=""
+export USERNAME=""
+export PASSWORD=""
+export DOMAIN_NAME=""
+
+# start the backend server
+python server.py --http_host "host" --http_port "port"
+
+# in an another terminal, start the ui
+python webui.py --http_host "your-backend-api-host" --http_port "your-backend-api-port"
```
After launching the script, you can upload files and engage with the chatbot through your web browser.
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/applications/ColossalQA/examples/webui_demo/config.py b/applications/ColossalQA/examples/webui_demo/config.py
new file mode 100644
index 000000000000..ef90fab62589
--- /dev/null
+++ b/applications/ColossalQA/examples/webui_demo/config.py
@@ -0,0 +1,58 @@
+from colossalqa.prompt.prompt import (
+ PROMPT_DISAMBIGUATE_ZH,
+ PROMPT_RETRIEVAL_QA_ZH,
+ SUMMARY_PROMPT_ZH,
+ ZH_RETRIEVAL_QA_REJECTION_ANSWER,
+ ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
+)
+from colossalqa.text_splitter import ChineseTextSplitter
+
+ALL_CONFIG = {
+ "embed": {
+ "embed_name": "m3e", # embedding model name
+ "embed_model_name_or_path": "moka-ai/m3e-base", # path to embedding model, could be a local path or a huggingface path
+ "embed_model_device": {
+ "device": "cpu"
+ }
+ },
+ "model": {
+ "mode": "api", # "local" for loading models, "api" for using model api
+ "model_name": "chatgpt_api", # local model name, "chatgpt_api" or "pangu_api"
+ "model_path": "", # path to the model, could be a local path or a huggingface path. don't need if using an api
+ "device": {
+ "device": "cuda"
+ }
+ },
+ "splitter": {
+ "name": ChineseTextSplitter
+ },
+ "retrieval": {
+ "retri_top_k": 3,
+ "retri_kb_file_path": "./", # path to store database files
+ "verbose": True
+ },
+ "chain": {
+ "mem_summary_prompt": SUMMARY_PROMPT_ZH, # summary prompt template
+ "mem_human_prefix": "用户",
+ "mem_ai_prefix": "Assistant",
+ "mem_max_tokens": 2000,
+ "mem_llm_kwargs": {
+ "max_new_tokens": 50,
+ "temperature": 1,
+ "do_sample": True
+ },
+ "disambig_prompt": PROMPT_DISAMBIGUATE_ZH, # disambiguate prompt template
+ "disambig_llm_kwargs": {
+ "max_new_tokens": 30,
+ "temperature": 1,
+ "do_sample": True
+ },
+ "gen_llm_kwargs": {
+ "max_new_tokens": 100,
+ "temperature": 1,
+ "do_sample": True
+ },
+ "gen_qa_prompt": PROMPT_RETRIEVAL_QA_ZH, # generation prompt template
+ "verbose": True
+ }
+}
\ No newline at end of file
diff --git a/applications/ColossalQA/examples/webui_demo/requirements.txt b/applications/ColossalQA/examples/webui_demo/requirements.txt
new file mode 100644
index 000000000000..84168cbd6f78
--- /dev/null
+++ b/applications/ColossalQA/examples/webui_demo/requirements.txt
@@ -0,0 +1,3 @@
+fastapi==0.99.1
+uvicorn>=0.24.0
+pydantic==1.10.13
diff --git a/applications/ColossalQA/examples/webui_demo/server.py b/applications/ColossalQA/examples/webui_demo/server.py
index c3147594fc89..050994567570 100644
--- a/applications/ColossalQA/examples/webui_demo/server.py
+++ b/applications/ColossalQA/examples/webui_demo/server.py
@@ -1,117 +1,98 @@
import argparse
-import copy
-import json
import os
-import random
-import string
-from http.server import BaseHTTPRequestHandler, HTTPServer
+from typing import List, Union
+
+
from colossalqa.local.llm import ColossalAPI, ColossalLLM
from colossalqa.data_loader.document_loader import DocumentLoader
+from colossalqa.mylogging import get_logger
from colossalqa.retrieval_conversation_zh import ChineseRetrievalConversation
from colossalqa.retriever import CustomRetriever
+from enum import Enum
+from fastapi import FastAPI, Request
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
-from RAG_ChatBot import RAG_ChatBot, DEFAULT_RAG_CFG
-
-# Define the mapping between embed_model_name(passed from Front End) and the actual path on the back end server
-EMBED_MODEL_DICT = {
- "m3e": os.environ.get("EMB_MODEL_PATH", DEFAULT_RAG_CFG["embed_model_name_or_path"])
-}
-# Define the mapping between LLM_name(passed from Front End) and the actual path on the back end server
-LLM_DICT = {
- "chatglm2": os.environ.get("CHAT_LLM_PATH", "THUDM/chatglm-6b"),
- "pangu": "Pangu_API",
- "chatgpt": "OpenAI_API"
-}
-
-def randomword(length):
- letters = string.ascii_lowercase
- return "".join(random.choice(letters) for i in range(length))
-
-class ColossalQAServerRequestHandler(BaseHTTPRequestHandler):
- chatbot = None
- def _set_response(self):
- """
- set http header for response
- """
- self.send_response(200)
- self.send_header("Content-type", "application/json")
- self.end_headers()
-
- def do_POST(self):
- content_length = int(self.headers["Content-Length"])
- post_data = self.rfile.read(content_length)
- received_json = json.loads(post_data.decode("utf-8"))
- print(received_json)
- # conversation_ready is False(user's first request): Need to upload files and initialize the RAG chain
- if received_json["conversation_ready"] is False:
- self.rag_config = DEFAULT_RAG_CFG.copy()
- try:
- assert received_json["embed_model_name"] in EMBED_MODEL_DICT
- assert received_json["llm_name"] in LLM_DICT
- self.docs_files = received_json["docs"]
- embed_model_name, llm_name = received_json["embed_model_name"], received_json["llm_name"]
-
- # Find the embed_model/llm ckpt path on the back end server.
- embed_model_path, llm_path = EMBED_MODEL_DICT[embed_model_name], LLM_DICT[llm_name]
- self.rag_config["embed_model_name_or_path"] = embed_model_path
-
- # Create the storage path for knowledge base files
- self.rag_config["retri_kb_file_path"] = os.path.join(os.environ["TMP"], "colossalqa_kb/"+randomword(20))
- if not os.path.exists(self.rag_config["retri_kb_file_path"]):
- os.makedirs(self.rag_config["retri_kb_file_path"])
-
- if (embed_model_path is not None) and (llm_path is not None):
- # ---- Intialize LLM, QA_chatbot here ----
- print("Initializing LLM...")
- if llm_path == "Pangu_API":
- from colossalqa.local.pangu_llm import Pangu
- self.llm = Pangu(id=1)
- self.llm.set_auth_config() # verify user's auth info here
- self.rag_config["mem_llm_kwargs"] = None
- self.rag_config["disambig_llm_kwargs"] = None
- self.rag_config["gen_llm_kwargs"] = None
- elif llm_path == "OpenAI_API":
- from langchain.llms import OpenAI
- self.llm = OpenAI()
- self.rag_config["mem_llm_kwargs"] = None
- self.rag_config["disambig_llm_kwargs"] = None
- self.rag_config["gen_llm_kwargs"] = None
- else:
- # ** (For Testing Only) **
- # In practice, all LLMs will run on the cloud platform and accessed by API, instead of running locally.
- # initialize model from model_path by using ColossalLLM
- self.rag_config["mem_llm_kwargs"] = {"max_new_tokens": 50, "temperature": 1, "do_sample": True}
- self.rag_config["disambig_llm_kwargs"] = {"max_new_tokens": 30, "temperature": 1, "do_sample": True}
- self.rag_config["gen_llm_kwargs"] = {"max_new_tokens": 100, "temperature": 1, "do_sample": True}
- self.colossal_api = ColossalAPI(llm_name, llm_path)
- self.llm = ColossalLLM(n=1, api=self.colossal_api)
-
- print(f"Initializing RAG Chain...")
- print("RAG_CONFIG: ", self.rag_config)
- self.__class__.chatbot = RAG_ChatBot(self.llm, self.rag_config)
- print("Loading Files....\n", self.docs_files)
- self.__class__.chatbot.load_doc_from_files(self.docs_files)
- # -----------------------------------------------------------------------------------
- res = {"response": f"文件上传完成,模型初始化完成,让我们开始对话吧!(后端模型:{llm_name})", "error": "", "conversation_ready": True}
- except Exception as e:
- res = {"response": "文件上传或模型初始化有误,无法开始对话。",
- "error": f"Error in File Uploading and/or RAG initialization. Error details: {e}",
- "conversation_ready": False}
- # conversation_ready is True: Chatbot and docs are all set. Ready to chat.
- else:
- user_input = received_json["user_input"]
- chatbot_response, self.__class__.chatbot.memory = self.__class__.chatbot.run(user_input, self.__class__.chatbot.memory)
- res = {"response": chatbot_response, "error": "", "conversation_ready": True}
- self._set_response()
- self.wfile.write(json.dumps(res).encode("utf-8"))
+from pydantic import BaseModel, Field
+import uvicorn
+
+import config
+from RAG_ChatBot import RAG_ChatBot
+from utils import DocAction
+
+
+logger = get_logger()
+
+def parseArgs():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--http_host", default="0.0.0.0")
+ parser.add_argument("--http_port", type=int, default=13666)
+ return parser.parse_args()
+
+
+app = FastAPI()
+
+
+class DocUpdateReq(BaseModel):
+ doc_files: Union[List[str], str, None] = None
+ action: DocAction = DocAction.ADD
+
+class GenerationTaskReq(BaseModel):
+ user_input: str
+
+
+@app.post("/update")
+def update_docs(data: DocUpdateReq, request: Request):
+ if data.action == "add":
+ if isinstance(data.doc_files, str):
+ data.doc_files = [data.doc_files]
+ chatbot.load_doc_from_files(files = data.doc_files)
+ all_docs = ""
+ for doc in chatbot.docs_names:
+ all_docs += f"\t{doc}\n\n"
+ return {"response": f"文件上传完成,所有数据库文件:\n\n{all_docs}让我们开始对话吧!"}
+ elif data.action == "clear":
+ chatbot.clear_docs(**all_config["chain"])
+ return {"response": f"已清空数据库。"}
+
+
+@app.post("/generate")
+def generate(data: GenerationTaskReq, request: Request):
+ try:
+ chatbot_response, chatbot.memory = chatbot.run(data.user_input, chatbot.memory)
+ return {"response": chatbot_response, "error": ""}
+ except Exception as e:
+ return {"response": "模型生成回答有误", "error": f"Error in generating answers, details: {e}"}
+
if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Chinese retrieval based conversation system")
- parser.add_argument("--port", type=int, default=13666, help="port on localhost to start the server")
- args = parser.parse_args()
- server_address = ("localhost", args.port)
- httpd = HTTPServer(server_address, ColossalQAServerRequestHandler)
- print(f"Starting server on port {args.port}...")
- httpd.serve_forever()
-
+ args = parseArgs()
+
+ all_config = config.ALL_CONFIG
+ model_name = all_config["model"]["model_name"]
+
+ # initialize chatbot
+ logger.info(f"Initialize the chatbot from {model_name}")
+
+ if all_config["model"]["mode"] == "local":
+ colossal_api = ColossalAPI(model_name, all_config["model"]["model_path"])
+ llm = ColossalLLM(n=1, api=colossal_api)
+ elif all_config["model"]["mode"] == "api":
+ all_config["chain"]["mem_llm_kwargs"] = None
+ all_config["chain"]["disambig_llm_kwargs"] = None
+ all_config["chain"]["gen_llm_kwargs"] = None
+ if model_name == "pangu_api":
+ from colossalqa.local.pangu_llm import Pangu
+ llm = Pangu(id=1)
+ llm.set_auth_config() # verify user's auth info here
+ elif model_name == "chatgpt_api":
+ from langchain.llms import OpenAI
+ llm = OpenAI()
+ else:
+ raise ValueError("Unsupported mode.")
+
+ # initialize chatbot
+ chatbot = RAG_ChatBot(llm, all_config)
+
+ app_config = uvicorn.Config(app, host=args.http_host, port=args.http_port)
+ server = uvicorn.Server(config=app_config)
+ server.run()
diff --git a/applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh b/applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh
deleted file mode 100755
index c9c7b71c3e90..000000000000
--- a/applications/ColossalQA/examples/webui_demo/start_colossal_qa.sh
+++ /dev/null
@@ -1,43 +0,0 @@
-#!/bin/bash
-cleanup() {
- echo "Caught Signal ... cleaning up."
- pkill -P $$ # kill all subprocess of this script
- exit 1 # exit script
-}
-# 'cleanup' is trigered when receive SIGINT(Ctrl+C) OR SIGTERM(kill) signal
-trap cleanup INT TERM
-
-# Disable your proxy
-# unset HTTP_PROXY HTTPS_PROXY http_proxy https_proxy
-
-# Path to store knowledge base(Home Directory by default)
-export TMP=$HOME
-
-# Use m3e as embedding model
-export EMB_MODEL="m3e" # moka-ai/m3e-base model will be download automatically
-# export EMB_MODEL_PATH="PATH_TO_LOCAL_CHECKPOINT/m3e-base" # you can also specify the local path to embedding model
-
-# Choose a backend LLM
-# - ChatGLM2
-# export CHAT_LLM="chatglm2"
-# export CHAT_LLM_PATH="PATH_TO_LOCAL_CHECKPOINT/chatglm2-6b"
-
-# - ChatGPT
-export CHAT_LLM="chatgpt"
-# Auth info for OpenAI API
-export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
-
-# - Pangu
-# export CHAT_LLM="pangu"
-# # Auth info for Pangu API
-# export URL=""
-# export USERNAME=""
-# export PASSWORD=""
-# export DOMAIN_NAME=""
-
-# Run server.py and colossalqa_webui.py in the background
-python server.py &
-python webui.py &
-
-# Wait for all processes to finish
-wait
diff --git a/applications/ColossalQA/examples/webui_demo/utils.py b/applications/ColossalQA/examples/webui_demo/utils.py
new file mode 100644
index 000000000000..c1dcbfa6c6a7
--- /dev/null
+++ b/applications/ColossalQA/examples/webui_demo/utils.py
@@ -0,0 +1,6 @@
+from enum import Enum
+
+
+class DocAction(str, Enum):
+ ADD = "add"
+ CLEAR = "clear"
diff --git a/applications/ColossalQA/examples/webui_demo/webui.py b/applications/ColossalQA/examples/webui_demo/webui.py
index 2d2910b5adce..cd3b5fd5da4b 100644
--- a/applications/ColossalQA/examples/webui_demo/webui.py
+++ b/applications/ColossalQA/examples/webui_demo/webui.py
@@ -1,17 +1,21 @@
+import argparse
import json
import os
-import gradio as gr
import requests
-RAG_STATE = {"conversation_ready": False, # Conversation is not ready until files are uploaded and RAG chain is initialized
- "embed_model_name": os.environ.get("EMB_MODEL", "m3e"),
- "llm_name": os.environ.get("CHAT_LLM", "chatgpt")}
-URL = "http://localhost:13666"
+import gradio as gr
+
+from utils import DocAction
+
+def parseArgs():
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--http_host", default="0.0.0.0")
+ parser.add_argument("--http_port", type=int, default=13666)
+ return parser.parse_args()
-def get_response(client_data, URL):
+def get_response(data, url):
headers = {"Content-type": "application/json"}
- print(f"Sending request to server url: {URL}")
- response = requests.post(URL, data=json.dumps(client_data), headers=headers)
+ response = requests.post(url, json=data, headers=headers)
response = json.loads(response.content)
return response
@@ -19,41 +23,43 @@ def add_text(history, text):
history = history + [(text, None)]
return history, gr.update(value=None, interactive=True)
+
def add_file(history, files):
- global RAG_STATE
- RAG_STATE["conversation_ready"] = False # after adding new files, reset the ChatBot
- RAG_STATE["upload_files"]=[file.name for file in files]
- files_string = "\n".join([os.path.basename(path) for path in RAG_STATE["upload_files"]])
- print(files_string)
- history = history + [(files_string, None)]
+ files_string = "\n".join([os.path.basename(file.name) for file in files])
+
+ doc_files = [file.name for file in files]
+ data = {
+ "doc_files": doc_files,
+ "action": DocAction.ADD
+ }
+ response = get_response(data, update_url)["response"]
+ history = history + [(files_string, response)]
return history
-def bot(history):
- print(history)
- global RAG_STATE
- if not RAG_STATE["conversation_ready"]:
- # Upload files and initialize models
- client_data = {
- "docs": RAG_STATE["upload_files"],
- "embed_model_name": RAG_STATE["embed_model_name"], # Select embedding model name here
- "llm_name": RAG_STATE["llm_name"], # Select LLM model name here. ["pangu", "chatglm2"]
- "conversation_ready": RAG_STATE["conversation_ready"]
- }
- else:
- client_data = {}
- client_data["conversation_ready"] = RAG_STATE["conversation_ready"]
- client_data["user_input"] = history[-1][0].strip()
-
- response = get_response(client_data, URL) # TODO: async request, to avoid users waiting the model initialization too long
- print(response)
+def bot(history):
+ data = {
+ "user_input": history[-1][0].strip()
+ }
+ response = get_response(data, gen_url)
+
if response["error"] != "":
raise gr.Error(response["error"])
- RAG_STATE["conversation_ready"] = response["conversation_ready"]
history[-1][1] = response["response"]
yield history
+def restart(chatbot, txt):
+ # Reset the conversation state and clear the chat history
+ data = {
+ "doc_files": "",
+ "action": DocAction.CLEAR
+ }
+ response = get_response(data, update_url)
+
+ return gr.update(value=None), gr.update(value=None, interactive=True)
+
+
CSS = """
.contain { display: flex; flex-direction: column; height: 100vh }
#component-0 { height: 100%; }
@@ -63,7 +69,7 @@ def bot(history):
header_html = """
ColossalQA
- ColossalQA
+ A powerful Q&A system with knowledge bases
"""
@@ -78,25 +84,32 @@ def bot(history):
(os.path.join(os.path.dirname(__file__), "img/avatar_ai.png")),
),
)
-
with gr.Row():
+ btn = gr.UploadButton("📁", file_types=["file"], file_count="multiple", size="sm")
+ restart_btn = gr.Button(str("\u21BB"), elem_id="restart-btn", scale=1)
txt = gr.Textbox(
- scale=4,
+ scale=8,
show_label=False,
- placeholder="Enter text and press enter, or upload an image",
+ placeholder="Enter text and press enter, or use 📁 to upload files, click \u21BB to clear loaded files and restart chat",
container=True,
autofocus=True,
)
- btn = gr.UploadButton("📁", file_types=["file"], file_count="multiple")
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)
# Clear the original textbox
txt_msg.then(lambda: gr.update(value=None, interactive=True), None, [txt], queue=False)
# Click Upload Button: 1. upload files 2. send config to backend, initalize model 3. get response "conversation_ready" = True/False
- file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False).then(bot, chatbot, chatbot)
+ file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False)
+ # restart
+ restart_msg = restart_btn.click(restart, [chatbot, txt], [chatbot, txt], queue=False)
if __name__ == "__main__":
+ args = parseArgs()
+
+ update_url = f"http://{args.http_host}:{args.http_port}/update"
+ gen_url = f"http://{args.http_host}:{args.http_port}/generate"
+
demo.queue()
demo.launch(share=True) # share=True will release a public link of the demo