主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中SLDA(Sentence-LDA)是主题模型的一种。SLDA是LDA主题模型的扩展,LDA假设每个单词对应一个主题,而SLDA假设每个句子对应一个主题。本Module基于的数据集为百度自建的小说领域数据集。
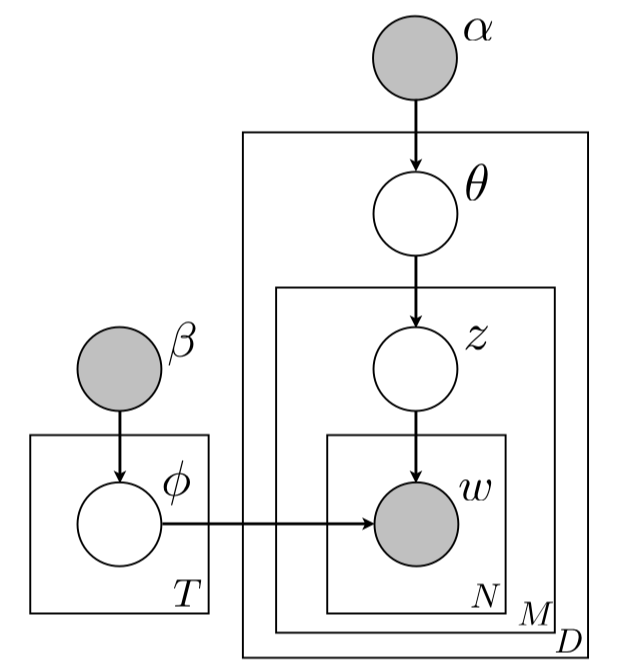
更多详情请参考SLDA论文。
注:该Module由第三方开发者DesmonDay贡献。
用于推理出文档的主题分布。
参数
- document(str): 输入文档。
返回
- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
参数
- topic_id(int): 主题ID。
- k(int): 需要知道对应主题的前k个关键词。
返回
- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
这里展示部分API的使用示例。
import paddlehub as hub
slda_novel = hub.Module(name="slda_novel")
topic_dist = slda_novel.infer_doc_topic_distribution("妈妈告诉女儿,今天爸爸过生日,放学后要早点回家一起庆祝")
# [{'topic id': 222, 'distribution': 0.5}, {'topic id': 362, 'distribution': 0.5}]
keywords = slda_novel.show_topic_keywords(topic_id=222)
# {'回来': 0.044502306717752,
# '回去': 0.036457065533017245,
# '回家': 0.029136327306669554,
# '明天': 0.028762575780517493,
# '休息': 0.022904260192395567,
# '晚上': 0.021970839714261954,
# '时间': 0.020756626422891028,
# '好好': 0.019726413882856498,
# '电话': 0.017195445214734463,
# '吃饭': 0.01521839547511471}https://github.com/baidu/Familia
paddlepaddle >= 1.8.2
paddlehub >= 1.8.0
-
1.0.0
初始发布