######### 模版 #############
week1 同一周在同一个level的bar上
[日期]-[first]-[论文标题]-[来源](附带链接,链接可选,时间倒序)\
论文框架图(有助于一眼就能想起论文内容),宽度设置为512
论文简述 (一两句话总结精华,切勿过长)
[日期]-[second]-[论文标题]-[来源](附带链接,链接可选,时间倒序)\
论文框架图(有助于一眼就能想起论文内容)
论文简述 (一两句话总结精华,切勿过长)
week2
######### 模版 #############
==> 时间倒序,本次更新插入位置 <==
[2024-8-11]-[徐赟博]-Layout-aware Dreamer for Embodied Referring Expression Grounding

论文简述:本文介绍了一种在导航任务中引入房间类型特征的方法,并且根据新特征设计了两个新的预训练任务。其中房间特征是通过GLIDE+Prompt构建的,对整个数据集中的view都抽取一次房间类型,然后选择频率高于0.8的类型作为最后使用的房间类型codebook。模型使用的基础架构也是DUET,额外增加的一个分支是将DUET的图像拓扑结构和房间类型CodeBook做点乘,与Ground Truth的房间类型做交叉熵损失。另一个预训练任务是将普通的Object Grounding转换成了使用该模型略加修改的OG任务。
[2024-8-4]-[徐赟博]-Sub-Instruction Aware Vision-and-Language Navigation(2020)

论文简述:本文是我目前关注的使用CLIP弥合LLM预训练数据和导航数据的domain gap的一个前身工作。如果直接对齐导航轨迹和指令,那么智能体有不能理解目前的观察图像如何对应到完整指令的某一部分的潜在问题。作者提出的办法是将指令拆解成一系列子指令,更好的让智能体在导航过程中关注到移动的细节。智能体在导航过程中不再使用完整的指令进行注意力操作,而是换成子指令,按照子指令和当前观察预测下一步移动。同时,在导航过程中需要判定是否要对子指令的顺序作shift,代表该部分子指令已经被完成。子指令拆解使用的是standford parser,shift则将当前的隐藏状态和子指令、观察图像做注意力得到预测分数。
[2024-7-21]-[陈银]-[比赛DDL,没有精读论文]
[2024-7-21]-[张雪松]-Depth-Aware Vision-and-Language Navigation using Scene Query_Attention Network-[ICRA-2022]

论文简述: 直接使用深度图像作为输入的dual-stream方式对模型导航的提升很小,现有新的特征(如detector region等)也是基于RGB observation,会引入语义不相干的纹理细节,使得模型过拟合访问过的环境。 本文试图通过通过深度信息 与RGB observations结合构建语义map(一种高水平的抽象的表示)防止模型过度拟合;另外端到端地引入并构建这种语义map也会带来更多的参数导致过拟合,所以本文预训练一个map encoder(类似detr的方式)。


[2024-7-14]-[张宇]-[本周因外出和家中琐事,没有精读论文]
[2024-7-14]-[聂建涛]-[Detection and Localization of Facial Expression Manipulations]-paper

论文简述:
这篇论文提出了一个基于面部表情识别系统的图像/视频面部表情操纵检测方法(EMD)。主要使用面部表情识别(FER)系统提取面部表情相关的特征。该FER系统包含共享层和集成层,能够学习面部表情信息。将FER系统的特征图与图像编码器-解码器网络相结合,进行图像操纵检测。编码器将图像映射到低维空间,然后与FER系统的特征图进行组合,最后解码器进行操纵区域的定位。
[2024-7-14]-[何艺超]-[Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis]-EMNLP2023

论文简介:
1.BERT,librosa,openface提取不同模态的表示信息。2.三个独立的transformer(1层)分别作用于三模态,为每个模态随机初始化一个低维令牌token(根据作者实验结论:将基本模态信息转移到初始化的低维令牌有利于减少与人类情感无关的冗余信息。从而以较小的参数实现更高的效率)3.将生成的不同模态的tokens输入到AHL(自适应超模态学习模块):原理是text模态及其transformer特征作为Q与其他两模态的K和V交互,然后将归一化后的生成与text经过两个transformer层的特征concat(AHL计算三次,也就是text指导三次),然后模态融合。最终在cmu-mosei,cmu-mosi等数据集的情感分析任务中达到sota。
[2024-7-14]-[陈银]-[CEPrompt: Cross-Modal Emotion-Aware Prompting for Facial Expression Recognition]-TCSVT
论文框架:

论文简介:
本文提出了一种新的对方法,将 CLIP 的视觉编码器知识蒸馏到一个新的 ViT 上面,并且进行 Global 和 Local 上的视觉语言对齐;此外还学习 CoOp 的方法, 把语言的 embedding 投影到视觉里面共同学习,作为一种引导 prompt,在多个静态数据集上取得了显著的效果。
[待补充]-[张雪松]-Diagnosing Vision-and-Language Navigation: What Really Matters-[ACL-2022]
论文简述:
[2024-7-14]-[徐赟博-[Sim-to-Real Transfer via 3D Feature Fields for Vision-and-Language Navigation]-arXiv

论文简述:本文介绍了一种在连续环境下使用3D图像特征进行导航的框架。与离散视觉语言导航框架不同的是,需要设计一个航点预测器来预测下一步移动的方向和距离。在该航点预测器的设计中,作者采用了3D特征的来进行编码解码。首先是需要预测一个语义图特征,将RGB图像经过UNET架构进行语义分割,按照不同的类别进行分割,从而对房间内的物体的范围语义有一定的了解。其次需要一个占用map特征,将深度图经过另一个UNET架构预测可占用map特征。两个特征与ground truth进行交叉熵损失。并且合并得到最终的一个可穿越性图。另外,作者还通过HNR Model(待阅读)将2D视觉特征和深度图转化为3D特征,为现实世界的单目机器人提供了全景感知能力。



[2024-7-7]-[贾朋]-[本周因家中琐事,没有精读论文]
[2024-7-7]-[何艺超]-[本周忙于videomae多分类头代码修改及多数据集微调,没有精读论文]
[2024-7-7]-[张宇]-[OUS: Scene-Guided Dynamic Facial Expression Recognition]-arXiv

论文简述:
本文所设计的策略在DFER任务中打破了僵化认知(面部区域作为可学习的内容,而人物背景则视为噪声),提出了一种新的学习策略,即将环境信息也作为学习信号辅助模型进行判断从而区分并非标注产生的模棱两可的情绪。在区分环境信息和面部信息时,使用的是一个冻结的人脸识别器提取人脸,剩下的则是环境信息,环境和人脸特征共享一个视觉编码器提取初级特征,而对于环境信息继续剥离分为场景特征和场景极性(积极、中性、消极),稍作修改交叉注意力使用可学习的q矩阵拉进环境特征和人脸特征之间的距离生成相似度损失,而场景极性是环境特征经过MLP得到的分类情况生成极性损失,值得注意的是本文也使用了CoOP可学习的token提示,人脸和环境融合后的特征可与固定的类级文本特征做余弦相似度得到对比损失,共计三个损失,相加之和作为总损失,在DFEW和FERv39k上达到了SOTA,并验证了在本文模型下无环境辅助会掉大概3个点(DFEW和FERv39k)。
[2024-7-6]-[陈银]-[FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs]-ArXiv
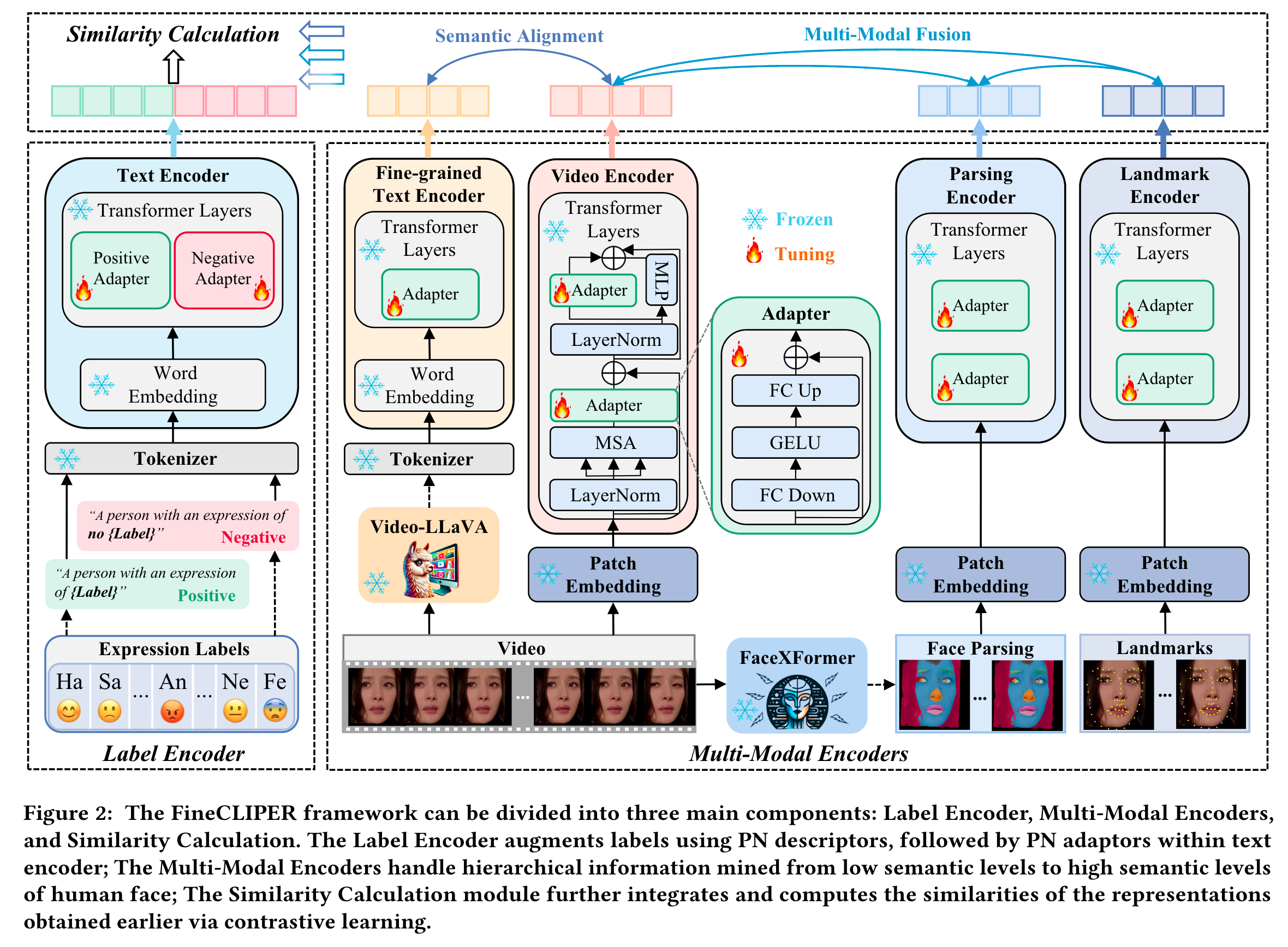
论文简述:
还是沿着vision-language的方式做的,组合式创新论文。相比于之前的只用简单的postive class description, 本文使用了postive-negative 文本描述;此外还使用了landmark和Parsing的特征,更使用了Video-LLaVA来生成细粒度的文本描述,最后将这些特征全部融合到一起与文本描述做一个有监督的学习。在有监督和zero-shot上面都取得了SOTA的成绩,值得注意的是引入negative文本描述以后,在UAR上表现很好,减少了表情的模糊性。
[2024-7-6]-[聂建涛]-[PAtt-Lite: Lightweight Patch and Attention MobileNet for Challenging Facial Expression Recognition]-paper-code暂未开源

论文简述:
本文提出一种基于MobileNetV1的轻量级补丁和注意力网络,称为PAtt-Lite,以改善在复杂条件下的FER表现。该方法利用截断的ImageNet预训练MobileNetV1作为骨干特征提取器。在截断层的位置上,提出了一个补丁提取块,用于提取重要的局部面部特征,以增强MobileNetV1的表示,特别是在复杂条件下。还提出了一个注意力分类器,以改善来自极轻量级特征提取器的这些补丁特征图的学习。
[2024-7-6]-[张雪松]-[Explore until Confident: Efficient Exploration for Embodied Question Answering]-paper-project-code

论文简述:(阅读动机)EQA包含了之前研究过的VQA和VLN两个任务,而且本文也试图calibrate VLM的 confident,且使用VLM。(当前挑战:)因为当前在EQA任务上使用VLM涉及两个难点:1)VLM仅利用预训练的知识去探索环境,不会随着时间去探索和存储场景的map。2)由于自信度confidence是mismiscalibrated,可能导致提前停止或者过度探索。(本文贡献):1)本文首先基于深度信息和通过VLM的视觉提示prompting来构建场景的语义地图——利用其对场景相关区域的丰富知识进行探索。2)本文使用conformal预测来校准VLM的问题回答置信度,让机器人知道何时停止探索——从而产生一个更经过校准和更有效的探索策略。3)本文还提供了一个新的EQA数据集,其中包含了基于Habitat-Matterport数据集(HM3D)的不同的、真实的人机场景和场景。模拟和真实的机器人实验都表明,我们提出的方法提高没有利用VLM进行探索或没有校准其置信度基线的性能和效率。
[2024-7-6]-[崔凯]-[A Cross-Modal Adaptive Masked Autoencoder for Decoding Emotions With Multimodal Data]-arxiv

论文简述:本文提出了一种称为跨模态自适应屏蔽自动编码器(CMA-MAE)的统一模型,用于不完整的多模态学习。CMA-MAE 模型包括跨模态自适应融合编码器(CMAFE)和多视图自适应编码器(MVAE),用于捕获和融合多模态特征之间的异质性和相关性。此外,我们设计了一个卷积解码器,它可以进行渐进式上采样并与模态不变特征融合,以从部分可观察的数据中生成强大的情感特征。为了有效地利用完整和不完整模式的数据进行特征学习,采用端到端方法,同时优化分类和重建任务。
[2024-7-5]-[徐赟博]-[Why Only Text: Empowering Vision-and-Language Navigation with Multi-modal Prompts]-arxiv

论文简述:
本文介绍了一种为VLN数据集建立多模态Prompt的pipeline,主要方式是通过预训练大模型为指令抽取landmark,并在图像中选中相似度最高的图像,将原始纯文本指令扩展为文本landmark+相似度最高的图像的形式。同时,作者也提出了使用这样的多模态Prompt的方式,包括按照插入顺序将Prompt中的文本landmark和图像分别抽离送入不同的transformer,编码后加上不同的类型embedding和位置embedding后可进行跨模态注意力。根据相似度的高低为每种landmark制作了三种不同的prompt,包括语义最相近的Align级别,需要找到语义相似度最大的图像,并要求图像覆盖整个指令;Related级别:找到相关语义的图像,不要求和指令有关,只要找到对应的landmark即可;Terminal级别:只有和最终的停止位置需要找到的landmark有关。作者在R2R,RXR,REVERIE和CVDN四个数据集上扩充了多模态Prompt,并在HAMT-baseline上进行了实验,发现在Valid Seen上可以出现比较不错的性能提升,但是在Valid Unseen上进步有限



[2024-6-30]-[贾朋]-[ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision]-arxiv

论文简述:
目前的VLP方法在很大程度上依赖于图像特征提取过程,其中大多数涉及region super-vision区域监督(如对象检测)和卷积结构(如ResNet),效率和表达能力都欠佳,本文提出了一个最小的VLP模型,Vision-and-Language Transformer(ViLT),视觉输入的处理被简化为与处理文本输入相同的无卷积方式。ViLT使用预训练的ViT来初始化交互的transformer。实验使用Microsoft COCO(MSCOCO), Visual Genome(VG), SBU Captions(SBU), Google Conceptual Caption(GCC)数据集用于预训练,在两种广泛探索的视觉和语言下游任务上评估了 ViLT:对于分类使用 VQAv2和 NLVR2,对于检索使用 MSCOCO 和 Flickr30K (F30K),ViLT-B/32 在两个数据集上都保持了有竞争力的性能。
[2024-6-30]-[张雪松]
未精读,修改VQA论文,只略读几篇vqa论文
[2024-6-30]-[何艺超]-[Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning]-arxiv

论文简述:
本文使用MER2023数据集,利用视频,音频,转录文本,微调了一个以minigpt4和llama2的多模态情感识别大模型,其中视频特征由MAE,VideoMAE提取(1024维度),音频特征由Hubert-Chinese-large提取(1024维,并且取最后一层的输出),将其concat以后输入至多模态模型minigpt4中,然后结合转录文本,输入至llama2中(由于llama2预训练的语料库是英文语料库,所以即使MER2023中的视频均是中文,作者也将其转换为英文翻译进行输入,而音频特征由Hubert-Chinese-large提取是为了更好贴合MER2023的中文属性),最终在mer2023数据集达到了0.9的准确率。
[2024-6-30]-[张宇]-MultiMediate 2023: Engagement Level Detection using Audio and Video Features

论文简述:
解决方案更加偏重于数据的预处理,对于Noxi数据集只用到了音频和视觉模态,使用音响、音高和谐波噪声比三个特征代表音频模态,并统一对其进行PCA降维,而视觉模态只考虑人体姿态特征不考虑面部表情特征,根据姿态特征值的特点将其归纳为6类情况转换为基于统计的视频特征,也采用了在一定的时间窗口内(5秒或10秒,静态)进行样本预测的策略,不同于滑动窗口实时进行时序信息的计算,其中使用parent的数据并不是注意力交叉计算而是直接拼接,模型则是使用最简单的线性层和前馈神经网络,说明对数据探究处理的好也能在最终结果达到较高的水准。
[2024-6-30]-[聂建涛]-LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis

论文简述:
本文介绍了LibreFace,用于面部表情分析。通过深度学习模型提供面部行为的实时和离线分析,包括面部动作单元(AU)检测、AU强度估计和面部表情识别。为了实现这一点,我们采用了一系列技术,包括使用大规模预训练网络、特征方面的知识蒸馏和任务特定的微调。
[2024-6-29]-[徐赟博]-[MAGIC: Meta-Ability Guided Interactive Chain-of-Distillation for Effective-and-Efficient Vision-and-Language Navigation]

论文简述:本文介绍了一种meta-ability引导的视觉语言导航模型的知识蒸馏方法。将进行视觉语言导航的智能体定义五个基本的meta-abality。分别是视觉感知-语言翻译-跨模态局部全景图匹配-跨模态全局拓扑定位-行为决策五种能力。每种能力背后是一种任务,有对应的loss。整个方法的框架由四部分组成,分别是1.meta-abality知识蒸馏:遵循了知识蒸馏的总体框架,定义了学生怎么通过五种meta-abality从老师处学的知识 2.随机权值:和多任务学习一样,本文的方法每种能力的训练也需要赋予对应的权值,初始化阶段为每种能力生成了高斯分布的权值,然后进行归一化生成新的非负权值。3.控制错误传播:因为老师作为一个模型不可能百分百正确,错误有可能被传播。教师模型在输出logits之前,需要将自身的输出和ground truth做交叉熵来作为自己本次推断的不确定度,将不确定度加权给样本调节样本的权重。防止错误传播。4.分阶段蒸馏:参考人的学习过程和VLN的多stage训练过程,该方法也进行了分阶段蒸馏。1阶段教师模型和学生模型各自输出2.训练一个学生模型,使用之前的框架3.学生和老师交替训练,轮流作为老师。4.让训好的学生模型作为老师训一个更小的模型。最终的结果是在学生模型仅有老师模型5%参数量的条件下,保证性能下降不显著,并且保证了对其他非sota方法性能的超越。(Teacher模型已是VLN目前sota)
[2024-6-29]-[陈银]-[Seeking Certainty In Uncertainty: Dual-Stage Unified Framework Solving Uncertainty in Dynamic Facial Expression Recognition ]-ArxiV )

论文简述: 提出了一个即插即用的模块自动的选择滤除野外DFER数据集中的噪声样本,并对某些错误的样本进行纠正。主要分为两个步骤:第一个步骤,根据预测概率分数过滤不可用的样本;第二个步骤,纠正错误标记的样本(在连续的 T 个 iter 里面预测标签保持一致,并且预测标签和 gt 不一样,并且预测的概率比 gt 的概率大于一个预值,就纠错)。在几个简单的backbone上都达到了提点,但是不知道在更强大的backbone上是否有效果。





[2024-6-23]-[贾朋] Language-agnostic BERT Sentence Embedding
论文简述:多语言嵌入向量模型是一种功能强大的工具,可以将不同语言的文本编码到共享的嵌入向量空间,可应用于下游一系列任务,例如文本分类、聚类等,同时还能够利用语义信息理解语言。在语言无关 BERT 句子嵌入向量(Language-agnostic BERT Sentence Embedding)中,本文提出一种名为 LaBSE 的多语言BERT嵌入向量模型,可为 109 种语言生成语言无关的跨语言句子嵌入向量。LaBSE 在 170 亿个单语句子和 60 亿个双语句子对上使用 MLM 和 TLM 进行了预训练,训练出的模型,对训练期间没有可用数据的低资源语言也有效。此外,该模型还在多个并行文本检索任务上建立了SOTA水平。
[2024-6-23]-[于洋晨]
本周因竞赛进度推进以及私事去天津,没有精读
[2024-6-23]-[张雪松]-Roses are Red, Violets are Blue... But Should VQA expect Them To?(CVPR2021)

论文简述:
类比VQA-CP v2,本文重新组织了GQA数据集,使得其能够评估模型在OOD条件下的表现。作者通过提出acc-tail, acc-head, acc-all等指标分析了当前的几个sota模型并表明这些方法或多或少的利用了数据集偏差,并表明缓解bias在vqa任务上仍有提高的空间。
[2024-6-23]-[程浩]-Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning-Arxiv
论文简述: 一个利用开源大模型进行多模态情感识别的工作, 作者想利用到多模态(AVT)和大模型的通用表征进行情感识别,于是考虑到把A,V的信息进行embedding之后利用他的Multimodal Prompt Template"[INST]<AudioFeature><VideoFeature>[Task Identifier]Prompt[/INST]"输入到大模型之中进行处理. 具体陈列为以下几点: 1.实际上没有考虑到转录文本或者描述文本, 虽然以LLM作为backbone. 2.对于使用到的音频编码器(hubert), 视觉编码器(mae, videomae, EVA) , LLM模型都是冻结的, 所以是在特征维度上进行处理, 训练代价极小. 3.作者没有指明使用的几个编码器是通用的还是在情感数据集上微调过的. 论文的方法比较简单, 看样子是他们去年参加MER2023的过程中没来得及实现的一个想法. 不过论文中的效果非常好.[2024-6-23]-[陈银]
本周在回复论文评审意见,没有精读论文
[2024-6-23]-[徐赟博]-[Correctable Landmark Discovery via Large Models for Vision-Language Navigation]

论文简述:现有的VLN中的大模型方法可以获益于训练数据中广泛的V-L数据集中的先验知识,但V-L数据集和用于导航的特定数据集存在巨大的domain-gap。本文是第一个尝试去解决这种domian-gap的方法。具体而言,该论文把VLN建模成一个landmark序列寻找的任务,我们可以把每次决策去对应landmark的依据看成一个不同landmark间的共现关系。比如看到客厅去想沙发, 看到沙发去想枕头。其中,大模型在自身训练过程中已经获得了对于不同物体-场景之间共现关系的先验。但这在导航场景中并不是万能通用的,我们需要针对每轮特定的导航场景来动态修改不同landmark间的先验关系。而搭建这个动态共现关系的方法就是CLIP。通过对每轮的观察通过CLIP对对应landmark进行编码,同时大模型在每轮观察中对观察到的物体进行共现先验知识的生成。用CLIP动态修改大模型的共现先验。本方法已经可以接近大多数基于学习的VLN模型的性能。但是暂时不敌引入太多特征的VLN方法。
[2024-6-23]-[崔凯]-Semi-Supervised End-To-End Contrastive Learning For Time Series Classification
论文简述:
现有对比学习方法中的流行方法由两个独立的阶段组成:在未标记数据集上预训练编码器,并在小规模标记数据集上微调训练有素的模型。然而,这种两阶段方法存在一些缺点,例如无监督的预训练对比损失无法直接影响下游的微调分类器,以及缺乏利用有价值的地面事实指导的分类损失。在本文中提出了一种称为 SLOTS(时间分类的半监督学习)的端到端模型。 SLOTS接收半标记数据集,包括大量未标记样本和一小部分标记样本,并通过编码器将它们映射到嵌入空间。不仅计算无监督对比损失,还测量具有真实值的样本的监督对比损失。学习到的嵌入被输入到分类器中,并使用可用的真实标签来计算分类损失。无监督、监督对比损失和分类损失联合用于优化编码器和分类器。
[2024-6-23]-[张宇]-DCTM: Dilated Convolutional Transformer Model for Multimodal Engagement Estimation in Conversation

论文简述:
对于参与度估计任务,在Noxi数据集上与其他工作不同,该工作并没有考虑搭档情况,而是直接使用被试者的多模态特征,音频、姿态和面部特征分别经过扩张卷积层进行增强,然后使用策略进行融合(交互注意力或自注意力),融合后的特征进入transformer和线性层从而得到结果,然而最后的实验显示交互注意力的效果并没有另一个融合策略好,可能是模型太过复杂发生了过拟合,总之在Noxi上取得了不错的效果。
[2024-6-23]-[聂建涛]-D3Net: Dual-Branch Disturbance Disentangling Network for Facial Expression Recognition

论文简述:
本文提出了一种名为D3Net的双分支网络,旨在有效识别面部表情,通过分离扰动因素来提高识别性能。D3Net包括表情分支和扰动分支,扰动分支中设计了标签感知子分支(LAS)和标签自由子分支(LFS)来处理不同类型的扰动因素。通过引入 Indian Buffet Process(IBP)先验来建模潜在扰动因素的分布,并利用对抗性训练增强扰动特征与表情特征的区别。
[2024-6-23]-[何艺超]-[videollama2:Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs]arxiv

论文简述:
videollama2由视觉语言模块,音频语言模块组成。主要创新在于在视觉模块设计了STC连接器,视频帧首先逐帧编码为特征,然后通过STC连接器(两个空间交互模块和一个时空聚合模块)进行处理。其中,采用RegStage实现“空间交互”,采用3D卷积实现“时空聚合”,而RegStage是一个自动探索和优化卷积网络配置的一个方法。
##########------------------------------ - 周分界线 - -------------------------------##########





[2024-6-16]-[陈银]-[Label-Guided Dynamic Spatial-Temporal Fusion for Video-Based Facial Expression Recognition)

论文简述:
作者提出了一种新的方法,称为标签引导的动态时空融合(LG-DSTF)。该方法将视频标签分配给每一帧,以增强空间特征的判别能力,并指导时间融合过程。通过构建两个辅助分类损失函数,引导不同层次的空间特征学习。通过测量空间特征的标签分布与均匀分布之间的交叉熵来评估每一帧的分类置信度。根据这些置信度值作为动态权重,在时空特征融合过程中强调关键帧。
[2024-6-16]-[何艺超]-[MultiMAE-DER: Multimodal Masked Autoencoder for Dynamic Emotion Recognition]-arxiv

论文简述:
本文以MAE-DFER(vit-large)为backbone,探索mfcc和video结合的六种策略(都是前期融合),并在下游任务上微调,发现在时空序列上融合多模式数据并通过捕获跨域数据之间的相关性显著提高了模型性能
[2024-6-16]-[崔凯]-[Incongruity-aware multimodal physiology signals fusion for emotion recognition]-Information Fusion
论文简述:
该文提出一种融合模型,该模型可以消除不同生理信号之间的不协调性,在一定程度上减少信息冗余。首先,由于一种生理信号在情绪识别中的突出表现,选择其作为主要模态,其余生理信号被视为辅助模态。其次,采用跨模态transformer(CMT)通过消除辅助模态之间的不协调来优化辅助模态的特征,然后进行低秩融合(LRF)以消除融合带来的信息冗余;然后,构建了改进的CMT(MCMT),通过优化后的辅助模态特征增强了主要模态的特征;第四,对所有增强的主要模态特征的串联结果进行自注意transformer(SAT),以充分利用它们之间的共同和互补性质来表示情绪状态。最后,通过串联融合增强的主要模态特征和优化的辅助特征,进行情感识别。
[2024-6-9]-[何艺超]-[Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition]-arxiv

论文简述:
这是第一项研究音频和视觉模型之间不一致问题(弱互补关系)的工作:A-V融合在一方噪声影响明显时会恶化融合表现(通过可视化CA来提供这一观点的可解释性),作者提出不一致感知交叉注意(IACA)模型,通过两阶段门控机制自适应选择特征来处理弱互补关系,核心是关注显著模态来进一步细化从第一门控层获得的特征,以抑制极度损坏或缺失模态的影响。
[2024-6-2]-[张宇]-[LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition ]-arxiv

论文简述:
总体来说本文为了解决DFER中局部特征不充分和长程依赖计算效率高之间的矛盾,首先将输入的视频帧通过ResNet18提取出高层特征图,随后将这些特征图展平并添加时空位置嵌入,形成特征序列,将该序列输入多个由局部和全局注意机制组成的Transformer块中,划分特征图为许多固定大小的窗口,局部注意在非重叠窗口内捕捉短程依赖(有点像swing transformer处理过程),计算完之后再次组装成原来的整体特征图,而全局注意通过池化方法将重组的特征图在全局范围内捕捉长程依赖,从而降低计算复杂度,最后通过一个预先添加的分类令牌输出分类结果。
[2024-6-2]-[崔凯]-[Multimodal Adaptive Emotion Transformer with Flexible Modality Inputs on A Novel Dataset with Continuous Labels]-[MM ’23](https: //doi.org/10.1145/3581783.3613797)

论文简述:
提出了一种新颖的多模态情感数据集,该数据集结合了脑电图(EEG)和眼动信号来系统地探索人类情感。通过大量视频引出七种基本情绪(快乐、悲伤、恐惧、厌恶、惊讶、愤怒和中性),并通过连续标签指示相应情绪的强度进行充分研究。此外,提出了一种新颖的多模态自适应情感转换器(MAET),它可以灵活地处理单模态和多模态输入。 MAET 使用对抗性训练来减轻主题差异,从而增强领域泛化。
[2024-6-1]-[何艺超]-[本周因毕业答辩事务繁忙,本周没有精读论文]
[2024-5-31]-[陈银]-MmAP : Multi-Modal Alignment Prompt for Cross-Domain Multi-Task Learning 知乎 PPT

论文简述:
本文提出了多模态对齐的Prompt, 使得CLIP在下游微调时保持文本和图像的对齐。具体来说,使用了task-specific prompts和group prompts, 将相似性高的任务分组来做,共享一个group prompts。并且通过克罗内克积 来生成文本和图像的prompts, 减少了参数量,并最大化保持了原有参数的信息,有利于模态对齐。


[2024-5-26]-[聂建涛]-UVCGAN:UNet Vision Transformer cycle-consistent GAN for unpaired image-to-image translation 知乎
论文简述:
这篇文章介绍了一种名为UVCGAN的未配对图像到图像的转换方法。UVCGAN是一种结合了UNet、Vision Transformer和Cycle-Consistent GAN的模型,旨在通过先进的生成对抗网络技术实现更好的图像到图像的翻译效果,实现两个未配对图像域之间的一对一映射。
[2024-5-26]-程浩-[The Platonic Representation Hypothesis]-ICML 2024
论文简述: 本文提出了一个假设,即随着模型规模增大、表征能力增强和不同任务的限制,各个不同模态的模型对于相应模态数据的内部表征正趋于一个对真实世界的统计投影,称之为柏拉图假设。作者在ImageNET、WiKiPedia数据集上使用CNN、transfomer等模型做了实验,部分程度上证明了这个假设的存在,但仍然存在一些问题,比如在某些无法利用除文本外其他模态表示的抽象概念。如果此理论得到证实,可以作为我们把单模态预训练好的模型拿来用在多模态任务上的的理论支撑。
[2024-5-26]-[何艺超]-[Semi-Supervised Multimodal Emotion Recognition with Class-Balanced Pseudo-labeling]-ACM MM 2023

论文简述:
本文提出了MER2023-Semi的解决方案,实现过程如下:1.特征提取:文本(MacBERT)、语音(HuBERT)、视频(在BP4D上预训练的ResNet50)2.时序建模:采用Transformer对不同模态提取到的特征进行时序建模 3.采用注意力的方式融合不同模态的特征 4.伪标签生成:上述模型先在有标签数据集训练,然后拿到没有标签的数据集中,设计了类平衡策略,即上述的单模态也会输出分类结果,将单模态和多模态结果进行比对,相同时才将其视为有效(说白了是找易分类质量高的样本),有效样本按标签被分为不同类后,选择置信度前top-k个样本作为真正的样本,拿到训练集中再次重复1.2.3步骤。
[2024-5-26]-[陈银]-Task-adaptive Q-Face

论文简述:
目前现有的人脸分析问题还是独立分析为主,没有从相关的任务中获益。本文提出了一种新颖的任务自适应多任务面部分析方法,即查询驱动的面部分析方法(Q-Face)。Q-Face 可以同时使用统一模型执行多个面部分析任务,并利用任务相关性来增强面部特征,从而从相关任务重获益,增强表征能力。
[2024-5-25]-[张宇]-[MSSTNet: A Multi-Scale Spatio-Temporal CNN-Transformer Network for Dynamic Facial Expression Recognition]-arxiv

论文简述:
对于DFER任务,还是分为空间特征和时间特征两个方向,空间上用ResNet50提取特征,时间上用Transformer模拟时序,和其他工作不同的地方就在于并不是将空间上层层提取的最后最小尺度特征用Tra整合,而是保留中间各个尺度的特征图,从低到中到高每个阶段提取的特征图都会经过时间端进行注意力计算,逐级相加(3级),直到最后一个时间端才会进行平均,即T个特征变成1个特征,固前面的时间端只是进行注意力计算,并不会改变向量的形状,这也是本篇工作的新颖之处。
[2024-5-24]-[张雪松]-[Vision-and-Language Navigation via Causal Learning]-Applied Soft Computing

论文简述:
本文的动机是默认了VLN数据集中存在bias和potential spurious correlations,但是没有详细分析。然后从因果的角度出发进行Back‐door Adjustment Causal Learning (BACL)和 Front‐door Adjustment Causal Learning (FACL),其实就是借助之前的一些因果策略,分别处理不同模态中重要的部分和不重要的部分(论文中称为Observable和unobservable),baseline还是duet。另一贡献是使用clip中的对比学习方式再pretraining阶段进行cross-modal feature pooling。实现结果目前sota,但是来源于作者额外的信息提取以及使用了更好的视觉,文本提取器和预训练权重,甚至减少了transformer layers层数防止模型过拟合。
[2024-5-23]-[崔凯]-[EEG emotion recognition based on the TimesNet fusion model]-Applied Soft Computing

论文简述:
该文提出了一种多尺度情感识别方法(MS-ERM)。首先,将脑电信号划分为不同频段0.5 s的时间窗口,提取微分熵特征,并将该特征嵌入脑电极图中,表达空间信息;然后,将每个段的功能用作模型 (MSTimesNet) 的输入。该模型结合多尺度卷积和TimesNet网络,有效提取二维空间中的动态时间特征、跨通道空间特征和复杂时间特征。



##########------------------------------ - 周分界线 - -------------------------------##########
[2024-5-19]-[程浩]-[Ensemble Pretrained Models for Multimodal Sentiment Analysis using Textual and Video Data Fusion]-WWW '24 Companion
只贴出IFFSA模型架构,BFSA和TBJE仅替换部分模块
\
论文简述:
视频+文本的多模态情感分析,基于TBJE(Transformer-based joint-encoding)模型,替换其中的特征提取、特征融合和一个类似特征处理的模块,设计出了两个IFFSA(Intermediate Feature Fusion Sentiment Analysis)和BFSA(Bilinear Fusion Sentiment Analysis)模型,三个模型的输出进行一个特征集成。整体模型有多次直觉上不必要的特征融合,且IFFSA和BFSA作替换的原因也未阐述。结果部分对比的SOTA不是最新,如果对比paper with code上的sota的话仅能在F1 score上做到领先。但消融实验可以看出文章使用的特征融合方法确实有效。

[2024-5-19]-[徐赟博]-[GridMM: Grid Memory Map for Vision-and-Language Navigation]
\
论文简述:
本文介绍了一种新型的视觉特征-GridMemory(网格记忆特征),该特征不同于深度图中的鸟瞰图,可以自适应的根据当前观察修改已建立的拓扑映射网格大小的尺寸。通过RGB深度图像和二维图像对坐标进行动态变换。在每个导航步骤的时间步中,通过CLIP编码当前观察中的视觉特征,然后将特征根据当前指令文本的相似度进行聚合。在跨模态推理的时候,作为key和value的是指令特征,query则是GridMM特征和导航轨迹concat在一起
[2024-5-19]-[张雪松]-
[赶论文实验-未精读]
[2024-5-19]-[聂建涛]-SimSwap: An Efficient Framework For High Fidelity Face Swapping

论文简述:
这篇文章提出了一种高效的人脸交换框架,名为Simple Swap(SimSwap),旨在实现通用和高保真的人脸交换。与之前的方法不同,这些方法要么缺乏对任意身份的泛化能力,要么无法保留面部表情和 gaze 方向等属性,而我们的框架能够将任意源人脸的身份转移到任意目标人脸,同时保留目标人脸的属性。具体来说,通过以下两种方式克服了上述缺陷:首先,提出了 ID 注入模块(IIM),在特征级别将源人脸的身份信息注入到目标人脸中。通过使用此模块,我们将特定于身份的人脸交换算法的架构扩展为适用于任意人脸交换的框架。其次,提出了弱特征匹配损失,该损失有效地帮助我们的框架以隐式方式保留面部属性。
[2024-5-18]-[何艺超]-[Semi-Supervised Multimodal Emotion Recognition with Expression MAE]-ACM MM 2023

论文简述:
利用半监督方法进行多模态情感识别,核心是3模态1数据(处理):1.数据层面:考虑到数据稀缺性不平衡分布,使用一个小的训练集从各种模态中提取特征后进行特征融合,进而训练分类器,为未标记的数据生成伪标签,并将它们合并到训练集中。2.视觉模态:为了结合静态和动态特征的优势,使用未标记的数据从头开始训练基于图像和基于视频的MAE,称为expMAE。3.文本和语音模态:使用MacBERT和HuBERT提取文本、语音特征,考虑到文本模态的性能相对较弱,使用CLIP和Tacotron的跨特征模型使得图像与文本、音频与文本交互整合。4.模态融合:使用FBP模块融合每个上下文相关的特征,生成融合的特征
[2024-5-18]-[张宇]-[Frame Level Emotion Guided Dynamic Facial Expression Recognition with Emotion Grouping]-CVPR2023

论文简述:
在DFER任务上提出了一种较为新颖的学习范式,利用在静态数据集RAF上预训练的ResNet18先对视频帧中的每个单帧进行分类,生成伪标签辅助主体进行识别,主体则还是利用预训练的R18提取3次特征图,分别送进Transformer模拟时序关系,用高级语义+低级语义特征作为最终的分类向量,并且在最终分类标签上使用组级标签学习的方式,即先分为积极、中性和消极,最后实现标准的归纳,在当时的DFER数据集上达到了不错的水平。
[2024-5-18]-[陈银]-[Task Adaptive Parameter Sharing for Multi-Task Learning]CVPR2022
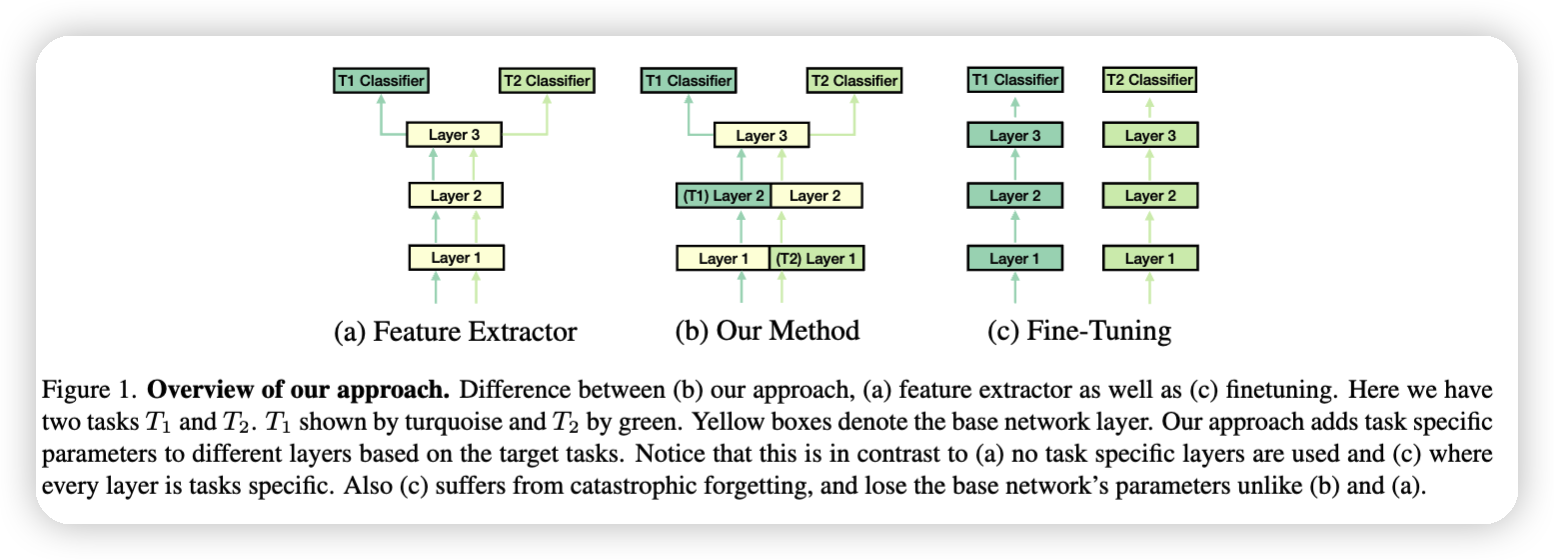
论文简述:
本文为多任务学习提出了一种自适应参数共享的方法,可以使得模型在进行多任务学习或者增量学习时避免了灾难性遗忘。并且提出了一种稀疏性惩罚的方法,促进基本模型的权重共享。



[2024-5-17]-[崔凯]-[Hypercomplex Multimodal Emotion Recognition from EEG and Peripheral Physiological Signals ]-IEEEXplore

论文简述:
在本文中提出了一种超复多模态网络,该网络配备了一个由参数化超复数乘法组成的新型融合模块。事实上,通过在超复数域中操作,操作遵循代数规则,这些规则允许对学习特征维度之间的潜在关系进行建模,以实现更有效的融合步骤。
##########------------------------------ - 周分界线 - -------------------------------########## [2024-5-12]-[聂建涛]-BlendFace: Re-designing Identity Encoders for Face-Swapping

论文简述:
这篇文章提出了一种新的身份编码器BlendFace,用于更一致的面部交换。主要方法是训练人脸识别模型在合成图像上交换属性,以消除属性偏差,并将其应用于面部交换模型中。具体来说,在训练过程中以一定概率替换输入图像的属性,迫使模型只关注面部内部特征,可以生成更分离的身份和属性,保留目标图像的属性,如表情、姿态和视线,同时提高生成的视觉一致性。
[2024-5-12]-[徐赟博]-[AdaTask: A Task-aware Adaptive Learning Rate Approach to Multi-task Learning]-[https://arxiv.org/pdf/2211.15055] 无核心流程图 主要是公式
论文简述:多任务学习中可能会存在某个任务主导的情况,即某个任务起到的作用远强于其他任务,从而导致性能下降。本文提出利用每个任务的损失梯度来衡量主导程度并根据损失值进行自适应权值下降,通过对相应任务的参数的平方更新的指数衰减平均值。分离累积梯度,从而得到自适应学习率(中每个参数的每个任务的学习率)。
[2024-5-12]-[张雪松]-[History Aware Multimodal Transformer for Vision-and-Language Navigation]-paper-NeurIPS 2021

论文简述: 在DUET论文被提出之前,VLN流行的决策范式还是进行“局部决策”(即agent只能选择其与其当前位置相邻的可导航点),并使用Transformer结构建模导航历史的空间或时间上的关系。本文提出的HAMT将这一范式发挥到了极致。 具体来说,(1)编码所有历史view的成本是巨大的,本文提出了hierarchical vision transformer能够逐步学习全景图中每一个view之间的空间关系,然后建模跨越全景图的基于历史observation的时间关系(2)本文提出了SAP训练方式,使得模型能够端到端的使用强化学习的方式训练大规模的transformer。(3)提出了两种新的VLN范式:R2R-Back要求agent到达destination后,返回起始点,R2R-Last仿照REVERIE,指令只使用原始R2R指令的最后一句。
[2024-5-11]-[何艺超]-[MMER:Multimodal Multi-task Learning for Speech Emotion Recognition]-arxiv

论文简述:
在SER任务中,多任务学习是一个没有被广泛探索的领域,作者提出了MMER网络结构。在SER中,针对语音和文本多模态,在基础transformer上交换语音和文本的查询q,并再次用原始查询q进行配对以拉近不同模态的距离,并设计声控门g控制语音冗余信息。除此之外,对通过反翻译,文本生成语音得到的原始数据的重制数据再次进行上述操作,对应网络的权重与原始数据网络权重共享,命名为增强对比学习。然后通过4个任务:最小化交叉墒损失,最小化CTC损失,原数据的监督对比学习,以及原数据和重置数据的增强对比学习,进一步通过加权的损失函数将多任务结合增强模型性能。在IEMOCAP4分类(快乐,愤怒,中性,悲伤)达到SOTA。
[2024-5-10]-[崔凯]-[Joint Contrastive Learning with Feature Alignment for Cross-Corpus EEG-based Emotion Recognition]-arXiv

论文简述:
提出了一种新颖的具有特征对齐(JCFA)的联合对比学习框架来解决基于跨语料库脑电图的情感识别。 JCFA 模型的运作分为两个主要阶段。在预训练阶段,引入联合域对比学习策略来表征脑电图信号的可泛化时频表示,而不使用标记数据。它为每个脑电图样本提取基于时间和基于频率的嵌入,然后将它们在共享的潜在时频空间内对齐。在微调阶段,JCFA 结合下游任务进行细化,其中考虑脑电极之间的结构连接。该模型的能力可以进一步增强,以应用于情绪检测和解释。
[2024-5-9]-[程浩]-[Mamba: Linear-Time Sequence Modeling with Selective State Spaces]-arxiv
论文简述:对s4模型做了一个seletive的改进,使得ssm模型可以实现与注意力机制相似的功能,称之为s6模型(mamba),同时设计了一个硬件感知算法,可以在显卡的多级存储机制上做操作,实现更快的计算和更小的显存占用。
[2024-5-8]-[张宇]-[FER-former: Multi-modal Transformer for Facial Expression Recognition]-arXiv-知乎

论文简述:
通过设计MEGI模块有效的发挥了CNN和Transformer结合效果,重要的是通过设计HDSS模块,利用文本作为监督信号,缓解了传统硬标签带来的注释模糊性问题,在推理阶段提出了这种很新的学习范式(传统分类损失+图文匹配损失),并且有效证明了文本辅助识别能够提升模型的性能,虽然只做了SFER,但是利用这种结论,可以应用到DFER任务中,得到的结论和本文的工作是其余研究工作中模型涨点不错的借鉴思想。
[2024-5-8]-[陈银]-[MultiMAE-DER: Multimodal Masked Autoencoder for Dynamic Emotion Recognition]-ICPR 2024


论文简述:
本文提出了一种多模态的 MAE方法做 DFER, 在 VideoMAE预训练权重的(来自 MAE-DFER)的基础上,加入音频数据进行微调,在几个实验室条件下的数据集上取得了不错的效果。使用了几种简单的策略,将音频数据和视频数据联合输入视频预训练的模型。消融实验说明,基于视频预训练的模型,使用音频数据微调也有用。




##########------------------------------ - 周分界线 - -------------------------------########## 五一放假
[2024-5-5]-[崔凯]-[GANSER: A Self-Supervised Data Augmentation Framework for EEG-Based Emotion Recognition]-IEEE TRANSACTIONS ON AFFECTIVE COMPUTING 2023

论文简述:
本文提出了一种数据增强框架,称为基于生成对抗网络的自监督数据增强(GANSER),该框架生成了高质量和高多样性的模拟脑电图样本。特别是利用对抗性训练来学习脑电图生成器,并迫使生成的脑电图信号接近真实样本的分布,从而确保增强样本的质量。采用变换操作来屏蔽部分脑电图信号,并迫使发生器根据未屏蔽部分合成潜在的脑电图信号,以产生各种样本。引入变换期间的掩蔽可能性作为先验知识,以概括增强样本空间的分类器。
##########------------------------------ - 周分界线 - -------------------------------##########
[2024-4-29]-[徐赟博]-[Vision-and-Language Navigation via Causal Learning] 论文框架:
论文简述: 本文从数据集存在的隐藏偏差和可能存在的虚假相关性入手,提出借助因果学习来消除智能体从多模态数据集中学习到的虚假相关性。其中,定义前门调整和后门调整,以及数据集中存在的可观测和不可观测到的混淆因子来对数据集进行无偏学习。作者在DSRG的基础上(作者本身也就是DSRG的作者),新加入了后门调整、前面调整、以及跨模态特征池化模块(对比学习),在视觉语言导航常用的数据集上全都大幅战胜了目前的SOTA。
[2024-4-28]-[张雪松]-Look and Answer the Question:On the Role of Vision in Embodied Question Answering
论文框架:
论文简述: 本文主要关注具身问答(EQA)任务,数据集和模型。具体来说,作者发现提供不同的视觉扰动(不一致的,黑色的,随机的)图像,模型仍然能够从general的视觉模式中稳定的学习。作者认为应该使用更好的数据和模型来完成这个任务。本文结果表明,尽管模型有在使用视觉模式进行预测更加准确,但是干扰视觉或者完全移除视觉信息不会影响模型的总体表现,而且表明模型更依赖语言(即语言模态更加stronger)。[2024-4-28]-[程浩]-[MMA-DFER: MultiModal Adaptation of unimodal models for Dynamic Facial Expression Recognition in-the-wild]-CVPR 2024 ABAW Workshop
论文框架:
论文简述:
通过三种方式: 模态内的adaptation,模态间的alignment和时间维度的adaptation, 来对已经预训练好的单模态encoder进行adaptation。具体使用到了audioMAE和faceMAE。接下来详细讲讲他所使用的三种方式:1.在单模态内的每一个transfomer层都加入可学习的prompt。2.设计了一个fusion bottlemeck模块来对两个模态的encoder做fusion,这里对多帧的处理就是全局平均池化。3.取每个帧的cls token和频谱图的cls token做cat。最终在可训练的参数很少的情况下,在mafw和dfew上实现了sota。[2024-4-27]-[何艺超]-UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition

论文简述:
作者从MSA和ERC任务长期分离研究的角度出发,提出了一种基于特征、标签、模型的联合处理MSA和ERC任务的框架,探索了两种任务的相似性及互补性,从音视频中分别抽取MSA和ERC任务的标签并将其统一为Universal Labels,语音模态利用librosa抽取梅尔频谱、视频模态利用EfficientNet模型提取特征,二者均利用LSTM处理上下文信息,并在T5模型加入多模态融合层,融合A+V+T,其中通过对比学习拉近A和T,V和T的关系,最后通过decoder输出标签,达到多个多模态数据集SOTA。
[2024-4-27]-[张宇]-Former-DFER: Dynamic Facial Expression Recognition Transformer

论文简述:
属于较早将Transformer应用在DFER任务上的工作,在处理遮挡和非正面姿态的DFER数据集时,CS-Former用来学习空间特征,T-Former用来学习时间关系,其中CS-Former由前4层是卷积层,第5层有N个Transformer编码器,最后一层还是卷积层,是Transformer与CNN搭配的架构,而T-Former就是普通的Transformer编码器用来模拟时序关系,这种结构的搭配也算是较为新颖,并在当时取得了不错的效果。
[2024-4-26]-[聂建涛]-Face2Exp: Combating Data Biases for Facial Expression Recognition

论文简述:
文章提出了Meta-Face2Exp框架,用于面部表情识别任务,通过元优化框架利用未标记的FR数据来增强FER。作者观察到FER数据存在类别不平衡问题,以及FR数据和FER数据之间存在分布不匹配。关键部分是基础网络和适配网络通过电路反馈范式不断相互补充,提取去偏置的知识。特别是去偏机制可以有效产生低方差和高均值的准确性。
[2024-4-26]-[崔凯]-[Self-supervised Group Meiosis Contrastive Learning for EEG-Based Emotion Recognition]-arXiv

论文简述:
本文提出了一种基于人类脑电信号刺激一致的自监督群体减数分裂对比学习框架(SGMC)。 SGMC 开发了一种新颖的受遗传学启发的数据增强方法,称为减数分裂。它利用组中脑电图样本之间的刺激对齐,通过配对、交叉交换和分离来生成增强组。该模型采用群体投影仪从相同情感视频刺激触发的群体脑电图样本中提取群体级特征表示。然后采用对比学习来最大化具有相同刺激的增强组的组级表示的相似性。
[2024-4-25]-[陈银]-[Multi-Task Multi-Modal Self-Supervised Learning for Facial Expression Recognition]-CVPRW2024, 知乎,博客
论文框架图
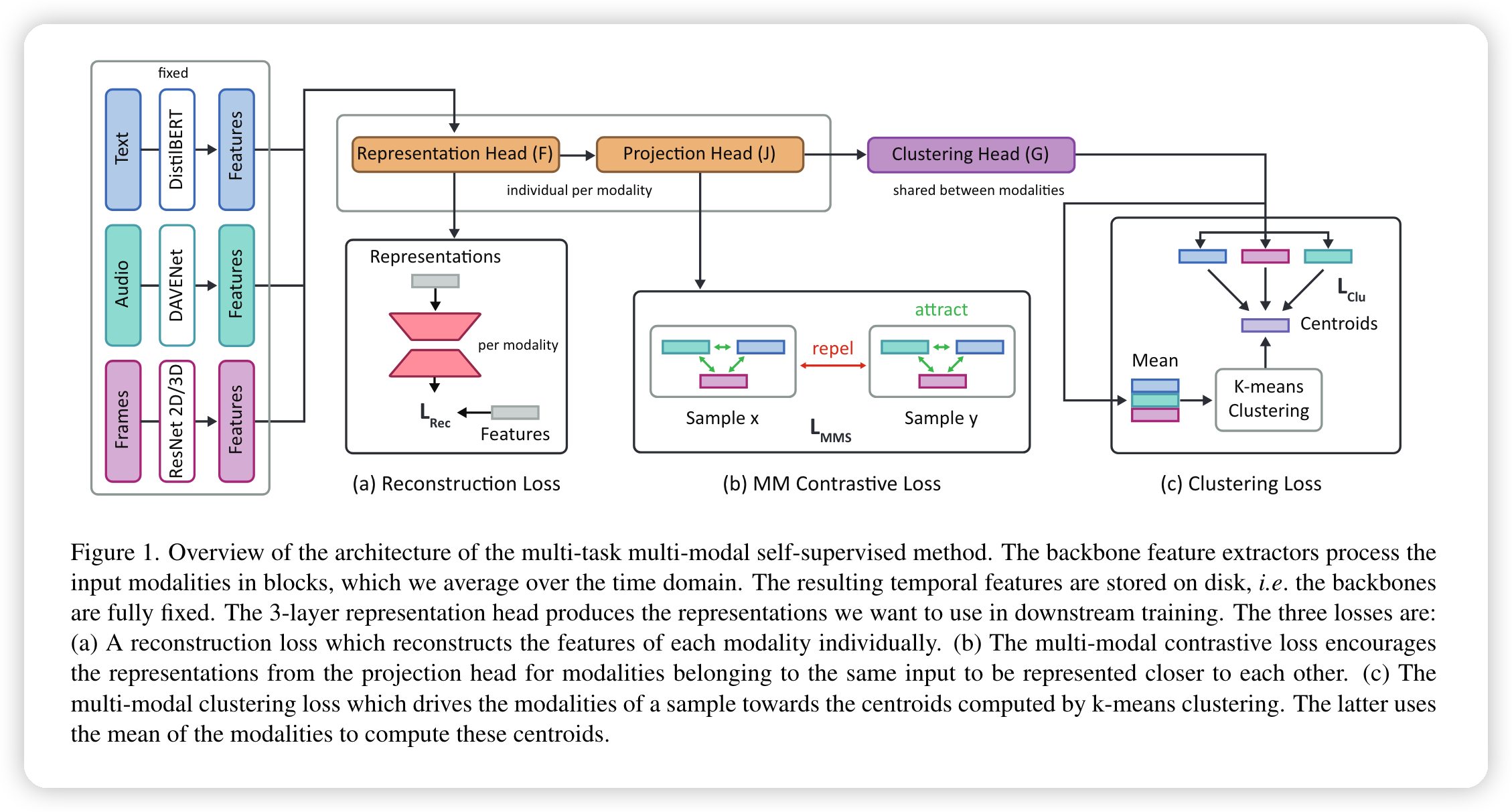
论文简述: 使用多任务多模态自监督的方法做面部表情识别,减少对标注数据的依赖。主要使用了三个损失函数:多模态对比损失对齐不同模态的特征;多模态聚类损失,保留空间输入数据的语义结构;多模态数据重建损失,增强encoder 表征能力。
[2024-4-24]-程浩-[INTER-MODALITY AND INTRA-SAMPLE ALIGNMENT FOR MULTI-MODAL EMOTION RECOGNITION]-ICASSP
论文框架图:
论文简述:
仍然是AV两个模态的模态对齐的工作,考虑到在在保持模态内部多样性的同时对齐两个模态,模型与cav-mae比较相似,但在对比阶段多了模态内的对比和一个监督对比。总体会有三个对比损失。





[2024-4-21]-[聂建涛]-FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio

论文简述:
这篇文章提出了一个新的说话人脸生成任务,即直接从音频中想象出符合音频特征的多样化动态说话人脸,而常规的该任务需要给定一张参考人脸。具体来说,该任务涉及到两个核心的挑战,首先如何从音频中解耦出说话人的身份(性别、年龄等语义信息以及脸型等结构信息)、说话内容以及说话人传递的情绪,其次是如何根据这些信息生成多样化的符合条件的视频,同时保持视频内的一致性。文章首先挖掘了三个人脸相关要素之间的联系,设计了一个渐进式音频解耦模块,以此降低解耦难度,并且提高了各个解耦因子的准确性。同时基于Latent DIffusion Models (LDMs)提出了一个可控一致帧生成模块,继承了LDMs的多样化生成能力,并设计了相应模块将音频中的信息准确的表达在生成的动态人脸上,缓解了LDMs可控性差的局限。
[2024-4-21]-[张雪松]-Diagnosing the Environment Bias in Vision-and-Language Navigation
论文简述:之前的研究发现vln模型倾向于拟合训练集,在unseen场景中的表现差,但是这种关于环境bias的发现没有被清楚的分析和验证。在这项工作中,作者通过环境重新分割设计了新的诊断实验和特征替换,探讨了环境偏差的可能原因。作者观察到,影响代理模型并导致结果中的环境偏见的既不是语言,也不是底层的导航图,而是通过ResNet特征传达的low-level视觉表现,作者还注意到有噪声但更高层次的语义特征可以有效地减少性能差距,同时在不同的VLN数据集上保持适度的性能。根据这一观察结果,作者探索了几种包含较少的低级视觉信息的语义表示,因此,利用这些特征学习到的代理可以更好地推广到看不见的测试环境中。
[2024-4.21]-[陈银]-[PTH-Net: Dynamic Facial Expression Recognition without Face Detection and Alignment]-[IEEE](PTH-Net: Dynamic Facial Expression Recognition without Face Detection and Alignmen, 知乎
论文框架图

论文简述: 本文提出了一个金字塔时间层次网络(PTH-Net), 可以直接应用于原始视频,无需进行面部检测和对齐。传统的先检测再对齐的方法,可能会丢失一些有用的关键信息, PTH-Net优势在于它在特征层面区分背景和目标,保留了更多关键信息,并且是一个端到端的网络,更加灵活。
[2024-4-20]-[何艺超]-[COGMEN: COntextualized GNN based Multimodal Emotion recognitioN]-NAACL 2022-知乎
论文简述:
在多人交互式对话多模态任务中,考虑到说话者与说话者之间、说话者与说话者本身会相互影响,作者提出使用Transformer+RGNN建模一段对话中的复杂依赖(局部(local)和全局(global)信息),并在IEMOCAP和MOSEI数据集中取得了SOTA结果。
[2024-4-20]-[张宇]-TransFER: Learning Relation-aware Facial Expression Representations with Transformers

论文简述:
本文指出不同的面部表情可能在某些部位存在相同的动作,而使用标准的Transformer对Patch相同注意力计算时候会误导模型的判断,固提出了MAD模块随机丢弃某些注意力图(对一个图片多次提取得到多个注意力图随机设置一些branch为0),并且利用MASD模块(包含MAD)随机丢弃自我注意模块,通过对标准的Transformer结构做改动实现对FER任务的适应。
[2024-4-20]-[崔凯]-[EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization]-2023 IEEE TRANSACTIONS ON NEURAL SYSTEMS AND REHABILITATION ENGINEERING

论文简述:
本文提出了一种紧凑的卷积Transformer,名为 EEG Conformer,将局部和全局特征封装在统一的 EEG 分类框架中。具体来说,卷积模块学习整个一维时间和空间卷积层的低级局部特征。自注意力模块直接连接以提取局部时间特征内的全局相关性。随后,基于全连接层的简单分类器模块来预测脑电图信号的类别。为了增强可解释性,还设计了一种可视化策略,将类激活映射投影到大脑地形上。



##########------------------------------ - 周分界线 - -------------------------------##########
[2024-4-14]-[张雪松]-Depth-guided adain and shift attention network for vision-and-language navigation
论文简述:
本文首次在VLN任务中显示地引入深度信息,从而提高智能体在unseen场景的鲁棒性。并进一步提出了一个转移注意力模块来模拟注意地图中的相对方向。这种简单增加深度信息的方式并没有显著提升agent的成功率,后续研究对这种方法进行了改进。值得一提的是,和当时的rgb图像一样,本文的深度图像也是通过Resnet152(在imagenet上预训练)提取。最近的论文提出使用Resnet50(在Gibson上预训练),但是这种方式主要应用在连续的导航任务中。
[2024-4-14]-[聂建涛]-Fine-Grained Face Swapping via Regional GAN Inversion

论文简述:
在这篇文章中,提出了一种新的人脸交换框架E4S,该框架明确地分解了每个人脸成分的形状和纹理,并将人脸交换重新定义为一个简化的纹理和形状交换问题。同时为了寻求这种解纠缠以及高分辨率和高保真,提出了一种新的区域GAN反演(RGI)方法。 具体来说,多尺度mask引导编码器将输入脸投射到每个区域样式的代码中。 此外,mask引导注入模块使用样式码根据给定的masks操作生成器中的特征映射。
[2024-4-13]-[陈银]-[Landmark-based Facial Self-supervised Learning for Face Recognition]-CVPR2024
论文简述:
本文提出了一种名为LAFS(基于landmark的面部自监督学习)的自监督学习策略,利用未标记的面部图像来学习并提高人脸识别性能。框架使用的是 DINO的学习方法,与在预训练中使用随机裁剪的图像块构建增强不同,LAFS利用通过提取的面部landmark 提取 patchs, 并引入了两种Landmark-based Augmantions(随机打乱 patchs 的顺序,和加入扰动),显著提升了人脸识别的性能。
[2024-4-13]-[张宇]-[Rethinking the Learning Paradigm for Dynamic Facial Expression Recognition]-CVPR 2023

论文简述:
本文的思想在于处理动态表情一系列视频帧序列时,认为将非目标帧视为嘈杂帧太过绝对,应当被归结为弱监督问题,所以提出了多实例学习(MIL)来处理不准确的标签,利用3DCNN提取特征,利用动态长期实例聚合模块(DLIAM)模拟时间关系并且动态聚合实例,从而能解决不同样本中目标帧出现的时间长短不一造成的影响,在DFER任务中引入多实例学习的方法属于比较有新意的学习范式,该方法在当时DFER数据集上达到了SOTA。
[2024-4-13]-[崔凯]-[A Multitask Framework for Emotion Recognition Using EEG and Eye Movement Signals with Adversarial Training and Attention Mechanism]-2023 IEEE International Conference on Bioinformatics and Biomedicine
论文简述: 在本文提出了一种具有对抗性训练和注意机制(ATAM)的多任务框架,用于使用脑电图和眼动信号进行情绪识别。对抗性训练方案是通过最大化相同模态内的互信息损失并最小化不同模态之间的余弦相似性损失来设计的。通过这种设计,所提出的 ATAM 不仅保留了脑电图和眼动信号中的情感信息,而且还保留了这两种模式之间的互补特性。再使用注意力机制自适应地融合多模态特征。
[2024-4-12]-[何艺超]-[Unsupervised Feature Learning for Speech Emotion Recognition Based on Autoencoder]-Electronics
论文简述:
作者设计了一种语音情感数据分割和增强方法,通过不同的时间偏移来分割情感语音数据,使得每个分割的数据集在情感类别上分布更加均衡。分析了不同自编码器包括简单自编码器、去噪自编码器和对抗自编码器在IEMOCAP数据集上的分类结果,并发现对抗自编码器模型在特征细节重建方面表现更好。
[2024-4-11]-[程浩]-[Beyond Text: Frozen Large Language Models in Visual Signal Comprehension]-CVPR 2024
论文简述:
idea为将图片视作一个外语,从而利用冻结的LLM去做多模态任务,如VQA,Image Caption. 具体来说,这篇论文提出V2L模型, 类似一个分词器,把图片转换到LLM的"token空间" (即把图片转化成LLM词汇表里面的Token), 然后把这些Token输入到冻结的LLM模型,从而可以让LLM模型理解图片. 接着在每种下游任务上都有小设计,但也都基于llm对图片的理解.




##########------------------------------ - 周分界线 - -------------------------------##########
[2024-4-7]-[聂建涛]-Reinforced Disentanglement for Face Swapping without Skip Connection

论文简述:
这篇论文的主要方法是提出了一个新的框架,通过网络结构和正则化损失的视角来解决之前工作中ID和非ID表示纠缠的问题。具体来说,作者提出了两个编码器,分别捕获目标图像的面部非ID属性和语义级非面部属性,每个编码器都被设计为专门捕获其期望的表示,而不需要相互妥协。同时,使用目标身份移除损失和几个非ID属性保留损失来补偿由于缺少跳过连接而丢失的细节。
[2024-4-6]-[张雪松]-DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
论文简述:
本文在两个level上将跨模态的对比学习应用到VLN任务中。具体来说,作者在视觉和文本指令在融合前,进行指令-历史level的对齐以及landmark-observation level上的对比学习,从而进行语义关联。实验在R2R,RxR等lowlevel的指令数据集上进行。
[2024-4-5]-[崔凯]-Spatial-frequency convolutional self-attention network for EEG emotion recognition
论文简述:
提出了一种空间频率卷积自注意力网络(SFCSAN)来整合脑电信号空间和频域的特征学习。在该模型中,采用频带内自注意力来学习每个频带的频率信息,频带间映射进一步将它们映射到最终的注意力表示中,以学习它们的互补频率信息。此外,还使用并行卷积神经网络(PCNN)层来挖掘脑电图信号的空间信息。
[2024-4-5]-[何艺超]-VIVIT:A video vision transformer
论文简述:
相对general的文章,情感计算领域可用。其主要提出了4种图像ViT扩展到视频的范式,分别是1.embedding to tokens中的token拼接 2.空间encoder输出至时间encoder 3.修改block结构,先计算空间MSA再计算时间MSA 4.修改block结构,将多头注意力分解成空间和时间两部分。除此之外,还提出了图像预训练ViT模型迁移到上述VideoViT上的方法。
[2024-4-5]-[张宇]-Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild

论文简述:
针对于DFER任务大多数据集忽略了同一类样本之间表达强度的差异这一问题,本文设计了一个新颖的全局注意力块GCA(重新缩放通道抑制不相关的目标)和一种新的强度感知损失IAL,从而帮助网络从硬标签DFER数据集(DFEW,FERv39K,MAFW等)获得更多的信息,减少类内差异,增加类间差异,并在当时在各个流行的DFER数据集上达到了SOTA。
[2024-4-5]-[陈银】-Cluster-Guided Asymmetric Contrastive Learning for Unsupervised Person Re-Identification, TIP
论文框架图

论文简述: 行人重识别的基于实例的对比学习容易让模型学习到RGB颜色特征上去,对任务造成干扰。本文提出了通过利用聚类信息在对比学习框架中指导特征学习,有效地利用了不同数据增强视图之间的不变性,学习到了超越RGB主导的有效特征。此外还提出来一种聚类信息精细化的方法,进一步提高模型的性能。
[2024-4-5]-[王会雅]-Spontaneous Facial Micro-Expression Recognition using 3D Spatiotemporal Convolutional Neural Networks ,知乎
论文简述: 作者提出了两种三维卷积神经网络(MicroExpSTCNN和MicroExpFuseNet)用于视频微表情识别,MicroExpSTCNN考虑的是面部全部区域,而MicroExpFuseNet考虑的则是眼睛和嘴巴区域。通过实验可知,MicroExpSTCNN的性能要优于MicroExpFuseNet,也就是除了眼睛和嘴巴区域外,其他一些显著的面部区域也有助于微表情识别
[2024-4-1]-[聂建涛]-[DPE: Disentanglement of Pose and Expression for General Video Portrait Editing]-Paper

论文简述:
本文提出了一种新的自监督解耦框架,用于在不需要3DMM和配对数据的情况下解耦姿态和表达。通过将人脸投影到一个可分离姿态运动和表达运动的强大可编辑潜在空间中,该方法可以通过附加操作方便地在该空间中执行姿势或表情转移。此外,该方法还提出了一种双向循环训练策略,通过精心设计的约束来保证解耦的实现。通过这种训练策略,可以在没有配对数据的情况下实现姿态和表达的解耦。
2024-4-1-程浩-MAViL: Masked Audio-Video Learners-NuerIPS 2023

论文简述:
在MAE和对比学习结合的CAV-MAE的基础上,借鉴知识蒸馏的思想,把原始MAE的代理任务由重建raw data转变为重建教师模型的表征。State-1对教师模型的训练用raw data作为target,State-2利用教师模型来对学生模型进行训练,两阶段掩码率都可达到80%。最终在Event Classification,Retrieval和单模态的任务上都达到SOTA。




##########------------------------------ - 周分界线 - -------------------------------########## [2024-3-30]-[崔凯]-Dynamic Confidence-Aware Multi-Modal Emotion Recognition
论文简述
提出了一个具有注意机制的多通道 LSTM 特征网络,可以同时对齐异构多模态特征并自适应预测时间层面的情绪不确定性。同时又设计了一种基于真实类别概率的置信回归网络来估计模态层面的情绪预测不确定性,它允许通过置信权重进行更可解释和更可靠的多模式情感融合识别。 在进行融合网络的优化过程中,采用自定进度学习来提高所提出模型的鲁棒性。
[2024-3-30]-[王会雅]-Micro-expression recognition based on 3D flow convolutional neural network
论文简述:
本文提出了具有12层(5对卷积层和池化层,一个完全连接层,一个softmax层)的3D FCNN模型,将光流(动态信息)和标准灰度帧(外观信息)作为网络的输入数据,对所有池化层的输入应用零填充,并使用更小的三维卷积核来表示局部区域的微小变化。
[2024-3-29]-[张宇]-NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition

论文简述:
在处理DFER任务上,本文没有遵循直接对序列整体特征的学习这一方式,而是提出了可以区分噪声帧和关键帧的网络NR-DFERNet,设计了一个动态-静态融合模块(DSF)以学习更加有效的特征,并且在时空阶段引入新的动态token(DCT)抑制无关帧(非neutral序列上过多neutral序列),最后通过SF过滤器对判别结果进行加强,在DFEW和AFEW上达到了当时的SOTA。
[2024-3-29]-[何艺超]-Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition
论文简述:
提出用于多标签识别的TAILOR,通过单模态特征抽取(Transformer编码器)、对抗多模态提取公有和私有表征(公有特征用于加噪、私有特征用于判别器识别原模态从而获得不同模态之间的共性和特有表示)、标签-模态对齐三个步骤,旨在细化多标签多模态表示。
[2024-3-28]-[张雪松]-Are You Looking? Grounding to Multiple Modalities in Vision-and-Language Navigation
论文简述:
本文在调查VLN的SOTA方法时有两个惊人的发现,(1)视觉模态对VLN任务会伤害模型导航的泛化表现,不使用视觉输入(视觉模态置为0)模型在unseen场景下的表现更好。(2)作者使用MoE(mixture-of-experts)的方法解耦视觉模态,路径结构和目标检测的特征,鼓励模型对齐每一种模态,并极大的提高了模型的导航表现。(本文来自2019ACL,视觉模态使用ResNet提取的特征,且仅在R2R数据集上进行实验,作者在文中指出类似的情况在VQA任务也有出现)
[2023-3-27]-[陈银]-Vi2CLR: Video and Image for Visual Contrastive Learning of Representation ,博客

论文简述:
核心还是使用对比学习,采用聚类的方法来构建正负样本对。 以往的对比学习正样本对构建都是通过不同的 view, 使用momentum Encoder来提取特征,或者采用memory bank。而本文采用了聚类的形式,将 Image 和 Video Encoder 输出的 concat 在一起,然后在特征空间做聚类。


##########------------------------------ - 周分界线 - -------------------------------##########
[2024-3-24]-[聂建涛]-[High-resolution face swapping via latent semantics disentanglement]-Paper

论文简述:
本文提出了一种基于预训练的GAN模型的高分辨率面部交换方法。该方法通过分离源图像和目标图像在生成器中的潜在语义,明确地分离了潜在的语义,从浅层获得结构属性,从深层获得外观属性,实现结构属性和外观属性的单独处理。
[2023-3-24]-[何艺超]-[MERBench: A Unified Evaluation Benchmark for Multimodal Emotion Recognition]-Paper,知乎
论文简述:
多模态情感识别领域模型方法研究的不一致性(数据集不一致,模型不一致,实验设置不一致)带来的难以公平评测不同模型能力的问题,后来的研究者难以轻松地选择适合自己的模型研究,这种不一致限制了多模态情感识别的发展,于是制作了MER2023 benchmark数据集,和一套模型测试方法,并在众多已有的模型上测试,给出了多指标的测试结果,方便后期工作者了解不同模型的性能。
[2023-3-23]-[崔凯]-[PR-PL: A Novel Prototypical Representation based Pairwise Learning Framework for Emotion Recognition Using EEG Signals]-Paper, GitHub

论文简述:
我们提出了一种新颖的迁移学习框架,该框架具有基于原型表示的成对学习(PR-PL)。学习区分性和广义的脑电图特征以揭示个体之间的情绪,并将情绪识别任务制定为成对学习,以提高模型对噪声标签的耐受性。更具体地说,开发了一种原型学习来编码脑电图数据固有的与情感相关的语义结构,并在考虑源域和目标域的特征可分离性的情况下将个体的脑电图特征对齐到共享的公共特征空间。
[2023-3-23]-[王会雅]-[Facial micro-expression spotting and recognition using time contrasted feature with visual memory]-Arxiv
论文简述:
本文使用时间网络与使用DeepLab v1的空间网络给出的更高层次微表情图像编码进行对比得出微表情相关的特征,GRU模块利用这种对比特征来记忆和预测微表情片段时间框架中的微表情的类别和强度,此方法不仅提高了从不明显的面部运动中识别微表情的能力,相对于传统识别方法还具有更高的准确性。
[2023-3-23]-[陈银]-[Unmasked Teacher: Towards Training-Efficient Video Foundation Model]-Paper, GitHub

论文简述:
基于像素重建的 VideoMAE预训练方式学习到的特征与下游任务存在较大的 gap, 而 CLIP 基于图像文本预训练包含更 hifh-level 的语义信息。本文提出一个新的框架,将 CLIP 预训练的 Image encoder 作为 Teacher, 指导 video model (Student)的学习, 使student model 既具备了时空捕捉能力,又学到了更接近下游任务的 high-level 知识。在下游的多个任务上达到 sota, 并且 student的性能超过了 teacher.
[2023-3-22]-[张雪松]-[Mind the Gap: Improving Success Rate of Vision-and-Language Navigation by Revisiting Oracle Success Routes]-Paper, 知乎

论文简述: 本文基于已有方法提供的指令和轨迹(不是智能体主动采样得到的),设计了一个基于tansformer多模块的框架,旨在找到轨迹中和指令描述匹配的目标位置,从而提高导航成功率,减少SR和OSR之间的差距。
[2023-3-20]-[张宇]-[EmoCLIP: A Vision-Language Method for Zero-Shot Video Facial Expression Recognition]-Arxiv 知乎
论文简述:
在CLIP的基础上进行改进实现对DFER进行zero-shot,加入ViT模型模拟时间维度,首个在DFER上提出使用样本级视频-文本数据集进行训练,在其余流行的DFER数据集上进行zero-shot进行测试,区别于VLM在DFER上CLIPER和DFER-CLIP的类级学习范式,微调了CLIP的image端和text端,使其对人脸表情以及表情描述文本更加敏感。
[2023-3-19]-[程浩]-[Self-supervised Cross-modal Pretraining for Speech Emotion Recognition and Sentiment Analysis]-EMNLP 2022
论文简述:
利用Textual modality现成的一个类Bert但更General的模型RoBERTa和Acoustic modality中一个较General的模型HuBERT分别作为两个模态的Embedding, 接着在特征层面进行Mask and Reconstruction的学习,模型对于两个模态分别设计了两个Transformer模块,并利用Cross-attention机制进行模态间的特征融合,最终在IEMOCAP和MOSEI两个数据集上达到了SOTA。

##########------------------------------ - 周分界线 - -------------------------------##########
[2023-3-17]-[崔凯]-[TSception: Capturing Temporal Dynamics and Spatial Asymmetry From EEG for Emotion Recognition]-ieee.org
论文简述
针对EEG信号的high temporal resolution和the asymmetric spatial activations属性,作者设计了具有多尺度卷积核Dynamic Temporal Layer以及Asymmetric Spatial Layer,以此来捕捉EEG的时间动态性和空间不对称性,实现更准确和更具备泛化的情绪识别。
[2023-3-13]-[陈银]-[A
$^3$ lign-DFER: Pioneering Comprehensive Dynamic Affective Alignment for Dynamic Facial Expression Recognition with CLIP]-Arxiv 知乎论文简述:
在CLIP的基础上,提出多个模块,从affective, dynamic和bidirectional三个角度实现了动态情感对齐,达到了较高的performance。相比于之前的prompt learning , 把text embeding增加了一个时间上的维度。在clip-based模型里达到了SOTA。