Home
in which we explored the problem of emotion recognition from dialogues. Our vision has been evolving a lot during the summer. The final approach described below is building a multi-modal machine learning model utilizing several modalities to make the best prediction.
Using an IEMOCAP (The Interactive Emotional Dyadic Motion Capture) data set comprising (among others) audio recordings and transcripts aligned word by word with the speech, we could split audio into short functional utterances. This allowed us for using a hierarchical Long Short-Term Memory (LSTM) model that firstly analyses an audio segment corresponding to one word, then combines information extracted from all of the words from the sentence and based on the collective knowledge makes a prediction about the emotional load of the whole sentence. We hoped that this approach could offer currently not available insights letting us understand better what is it exactly that makes a sequence of audio features evoke a particular emotional response. As for now (29 th of August), we are still in a process of training the network, fine tuning parameters etc. etc., therefore we will not share a pre-trained model. On the other hand, the TensorFlow model and records with data are ready to clone and run and have no extra requirements (other than tf).
This wiki is a part of a final GSOC submission and presents data preprocessing steps, the detailed architecture of the model and preliminary results of training.
TL;DR
You don't need to do all of the data preprocessing steps yourself in order to run the model, since TensorFlow record files are a part of the repository. If you would like to test the model with other data sets, you can do it by writing your data to binaries of the same structure as the ones used here. XXXXXX file will help you figuring out how to do it. Yet, it may be valuable to read this lengthy section in order to understand our motivation in constructing data files the way we did.
The IEMOCAP data set consists of multi-modal data collected during over 12 hours of interactions between two actors. In our experiments we used only a part of available data: sentences separated from longer dialogues, corresponding transcripts and emotional evaluations. From those we discarded sentences for which there were no matching transcripts as well as these with an ambiguous or 'rare' emotional assignment. The emotions used for the training (happiness, sadness, excitation, frustration, anger and neutral) are marked yellow in the histogram.

We extracted short term features (zero crossing rate, energy, entropy of energy, spectral centroid, spectral spread, spectral entropy, spectral flux, spectral rolloff, MFCCs, chroma vector and chroma deviation - together 34 digits per frame) from *.wav files representing single sentences with pyAudioAnalysis library. For calculations we used a 20 ms window with a 10 ms overlap. This step can be done automatically over a big amount of files with the script data_preprocessing.sh (modified according to paths on your computer).
![]()
Since files with aligned transcripts included the timing in units corresponding to 10 ms, we were able to precisely extract features corresponding to single words from transcripts. All frames containing no words and described as 'silence', 'breathing', 'laughter' etc., were excluded from the data.

We excluded all the words that lasted more than 600 ms. This meant discarding some 2.6 % of spoken words and, since a typical speech speed is estimated to be 225 words per minute - meaning a mean duration of a word (excluding pauses) about 266 ms and a slow speech 100 words per minute - with one word lasting 600 ms, seemed to be a valid cut-off for getting rid of possibly misaligned words. Importantly, there was not a single word completely lost in the procedure - all of the rejected words had also 'shorter' realizations that were kept.
Similarly, we restricted the number of words in the sentence. Since the sentence length distribution had a long tail of outliers, we decided to keep sentences not longer than 25 words in order to decrease the computation time. This resulted in using 88 % of the data for the further analysis. For both words and sentences shorter than the threshold we used zero padding to keep the input size fixed.
While it is possible to use the sequence length as a parameter of the tf.nn.bidirectional_dynamic_rnn function used to initialize the network, it turned out that restricting the length of sequences was beneficial in terms of both computational efficiency and network's performance.
We used the gensim python library and precomputed embeddings (DOWNLOAD HERE). Words that were not the part of the model dictionary were assigned a zero embedding vector (precisely the length of embeddings is 300, so the zero embedding means a vector with 300 zeros).
After the alignment words and audio features separate into two information streams in the model.
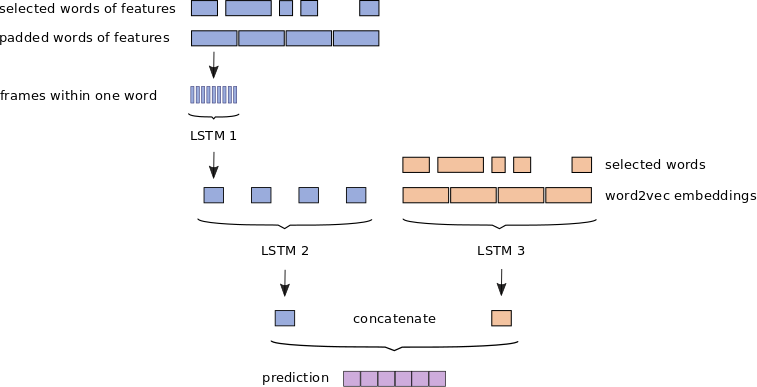
Audio features are processed in the hierarchical manner. LSTM 1 processes features of a single word. This is repeated for all of the words in the sentence. The output of this first layer is then passed as an input sequence to the LSTM 2. The second part of the model consists of a single LSTM 3 that is passed the sequence of word2vec embeddings. Outputs of these streams are then concatenated and regressed on the prediction vector.