| title | category | tag | |
|---|---|---|---|
线性数据结构 |
计算机基础 |
|
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
数组的特点是:提供随机访问 并且容量有限。
假如数组的长度为 n。
访问:O(1)//访问特定位置的元素
插入:O(n )//最坏的情况发生在插入发生在数组的首部并需要移动所有元素时
删除:O(n)//最坏的情况发生在删除数组的开头发生并需要移动第一元素后面所有的元素时
链表(LinkedList) 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
常见链表分类:
- 单链表
- 双向链表
- 循环链表
- 双向循环链表
假如链表中有n个元素。
访问:O(n)//访问特定位置的元素
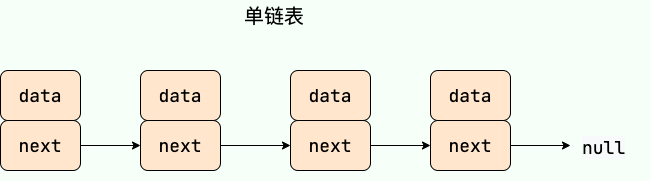
插入删除:O(1)//必须要要知道插入元素的位置单链表 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。
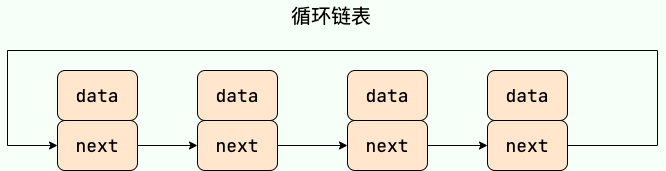
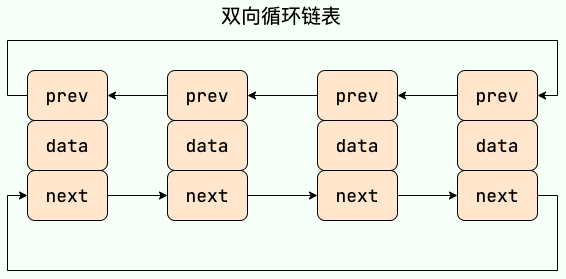
循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
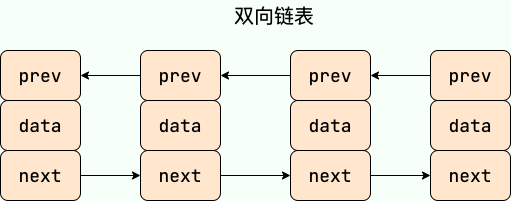
双向链表 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
- 如果需要支持随机访问的话,链表没办法做到。
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
- 数组支持随机访问,而链表不支持。
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
栈 (Stack) 只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈 。
假设堆栈中有n个元素。
访问:O(n)//最坏情况
插入删除:O(1)//顶端插入和删除元素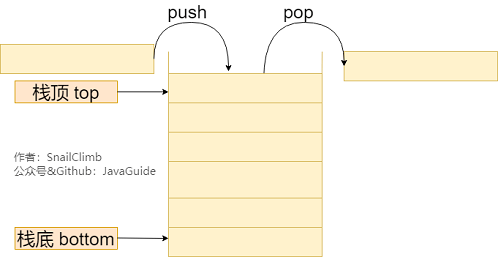
当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 后进先出(LIFO, Last In First Out) 的特性时,我们就可以使用栈这个数据结构。
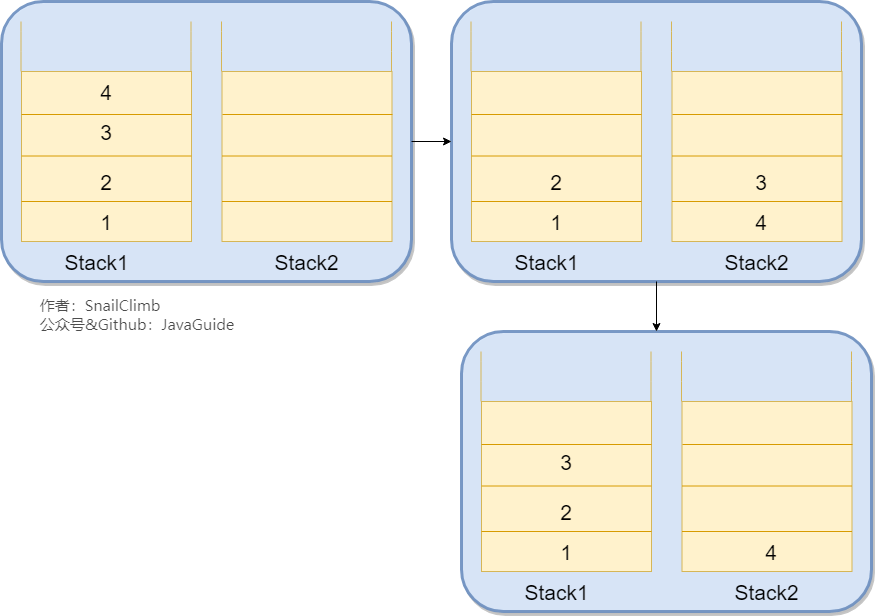
我们只需要使用两个栈(Stack1 和 Stack2)和就能实现这个功能。比如你按顺序查看了 1,2,3,4 这四个页面,我们依次把 1,2,3,4 这四个页面压入 Stack1 中。当你想回头看 2 这个页面的时候,你点击回退按钮,我们依次把 4,3 这两个页面从 Stack1 弹出,然后压入 Stack2 中。假如你又想回到页面 3,你点击前进按钮,我们将 3 页面从 Stack2 弹出,然后压入到 Stack1 中。示例图如下:
给定一个只包括
'(',')','{','}','[',']'的字符串,判断该字符串是否有效。有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]"、"([)]" 则不是。
这个问题实际是 Leetcode 的一道题目,我们可以利用栈 Stack 来解决这个问题。
- 首先我们将括号间的对应规则存放在
Map中,这一点应该毋容置疑; - 创建一个栈。遍历字符串,如果字符是左括号就直接加入
stack中,否则将stack的栈顶元素与这个括号做比较,如果不相等就直接返回 false。遍历结束,如果stack为空,返回true。
public boolean isValid(String s){
// 括号之间的对应规则
HashMap<Character, Character> mappings = new HashMap<Character, Character>();
mappings.put(')', '(');
mappings.put('}', '{');
mappings.put(']', '[');
Stack<Character> stack = new Stack<Character>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (mappings.containsKey(chars[i])) {
char topElement = stack.empty() ? '#' : stack.pop();
if (topElement != mappings.get(chars[i])) {
return false;
}
} else {
stack.push(chars[i]);
}
}
return stack.isEmpty();
}将字符串中的每个字符先入栈再出栈就可以了。
最后一个被调用的函数必须先完成执行,符合栈的 后进先出(LIFO, Last In First Out) 特性。
栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。
下面我们使用数组来实现一个栈,并且这个栈具有push()、pop()(返回栈顶元素并出栈)、peek() (返回栈顶元素不出栈)、isEmpty()、size()这些基本的方法。
提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用
Arrays.copyOf()进行扩容;
public class MyStack {
private int[] storage;//存放栈中元素的数组
private int capacity;//栈的容量
private int count;//栈中元素数量
private static final int GROW_FACTOR = 2;
//不带初始容量的构造方法。默认容量为8
public MyStack() {
this.capacity = 8;
this.storage=new int[8];
this.count = 0;
}
//带初始容量的构造方法
public MyStack(int initialCapacity) {
if (initialCapacity < 1)
throw new IllegalArgumentException("Capacity too small.");
this.capacity = initialCapacity;
this.storage = new int[initialCapacity];
this.count = 0;
}
//入栈
public void push(int value) {
if (count == capacity) {
ensureCapacity();
}
storage[count++] = value;
}
//确保容量大小
private void ensureCapacity() {
int newCapacity = capacity * GROW_FACTOR;
storage = Arrays.copyOf(storage, newCapacity);
capacity = newCapacity;
}
//返回栈顶元素并出栈
private int pop() {
if (count == 0)
throw new IllegalArgumentException("Stack is empty.");
count--;
return storage[count];
}
//返回栈顶元素不出栈
private int peek() {
if (count == 0){
throw new IllegalArgumentException("Stack is empty.");
}else {
return storage[count-1];
}
}
//判断栈是否为空
private boolean isEmpty() {
return count == 0;
}
//返回栈中元素的个数
private int size() {
return count;
}
}验证
MyStack myStack = new MyStack(3);
myStack.push(1);
myStack.push(2);
myStack.push(3);
myStack.push(4);
myStack.push(5);
myStack.push(6);
myStack.push(7);
myStack.push(8);
System.out.println(myStack.peek());//8
System.out.println(myStack.size());//8
for (int i = 0; i < 8; i++) {
System.out.println(myStack.pop());
}
System.out.println(myStack.isEmpty());//true
myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.队列(Queue) 是 先进先出 (FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
假设队列中有n个元素。
访问:O(n)//最坏情况
插入删除:O(1)//后端插入前端删除元素
单队列就是常见的队列, 每次添加元素时,都是添加到队尾。单队列又分为 顺序队列(数组实现) 和 链式队列(链表实现)。
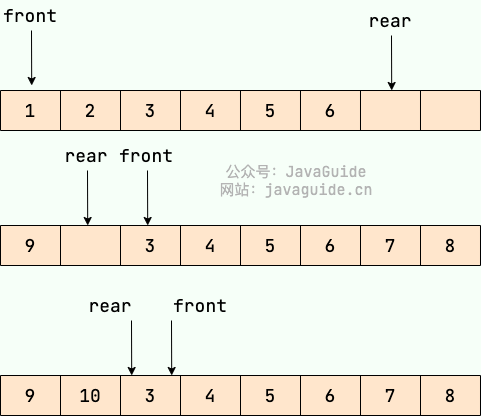
顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。
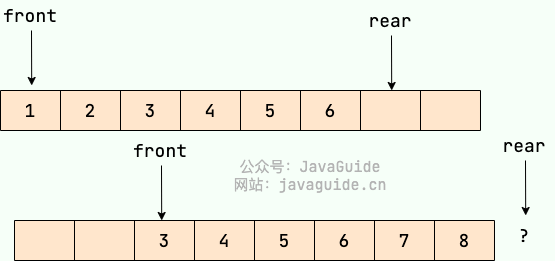
假设下图是一个顺序队列,我们将前两个元素 1,2 出队,并入队两个元素 7,8。当进行入队、出队操作的时候,front 和 rear 都会持续往后移动,当 rear 移动到最后的时候,我们无法再往队列中添加数据,即使数组中还有空余空间,这种现象就是 ”假溢出“ 。除了假溢出问题之外,如下图所示,当添加元素 8 的时候,rear 指针移动到数组之外(越界)。
为了避免当只有一个元素的时候,队头和队尾重合使处理变得麻烦,所以引入两个指针,front 指针指向对头元素,rear 指针指向队列最后一个元素的下一个位置,这样当 front 等于 rear 时,此队列不是还剩一个元素,而是空队列。——From 《大话数据结构》
循环队列可以解决顺序队列的假溢出和越界问题。解决办法就是:从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来。
还是用上面的图,我们将 rear 指针指向数组下标为 0 的位置就不会有越界问题了。当我们再向队列中添加元素的时候, rear 向后移动。
顺序队列中,我们说 front==rear 的时候队列为空,循环队列中则不一样,也可能为满,如上图所示。解决办法有两种:
- 可以设置一个标志变量
flag,当front==rear并且flag=0的时候队列为空,当front==rear并且flag=1的时候队列为满。 - 队列为空的时候就是
front==rear,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是:(rear+1) % QueueSize==front。
双端队列 (Deque) 是一种在队列的两端都可以进行插入和删除操作的队列,相比单队列来说更加灵活。
一般来说,我们可以对双端队列进行 addFirst、addLast、removeFirst 和 removeLast 操作。
优先队列 (Priority Queue) 从底层结构上来讲并非线性的数据结构,它一般是由堆来实现的。
- 在每个元素入队时,优先队列会将新元素其插入堆中并调整堆。
- 在队头出队时,优先队列会返回堆顶元素并调整堆。
关于堆的具体实现可以看堆这一节。
总而言之,不论我们进行什么操作,优先队列都能按照某种排序方式进行一系列堆的相关操作,从而保证整个集合的有序性。
虽然优先队列的底层并非严格的线性结构,但是在我们使用的过程中,我们是感知不到堆的,从使用者的眼中优先队列可以被认为是一种线性的数据结构:一种会自动排序的线性队列。
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
- 阻塞队列: 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
- 线程池中的请求/任务队列: 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:
FixedThreadPool使用无界队列LinkedBlockingQueue。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出java.util.concurrent.RejectedExecutionException异常。 - 栈:双端队列天生便可以实现栈的全部功能(
push、pop和peek),并且在Deque接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。 - Linux 内核进程队列(按优先级排队)
- 现实生活中的派对,播放器上的播放列表;
- 消息队列
- 等等......