| title | category | tag | ||
|---|---|---|---|---|
MySQL隐式转换造成索引失效 |
数据库 |
|
本次测试使用的 MySQL 版本是
5.7.26,随着 MySQL 版本的更新某些特性可能会发生改变,本文不代表所述观点和结论于 MySQL 所有版本均准确无误,版本差异请自行甄别。
数据库优化是一个任重而道远的任务,想要做优化必须深入理解数据库的各种特性。在开发过程中我们经常会遇到一些原因很简单但造成的后果却很严重的疑难杂症,这类问题往往还不容易定位,排查费时费力最后发现是一个很小的疏忽造成的,又或者是因为不了解某个技术特性产生的。
于数据库层面,最常见的恐怕就是索引失效了,且一开始因为数据量小还不易被发现。但随着业务的拓展数据量的提升,性能问题慢慢的就体现出来了,处理不及时还很容易造成雪球效应,最终导致数据库卡死甚至瘫痪。造成索引失效的原因可能有很多种,相关技术博客已经有太多了,今天我要记录的是隐式转换造成的索引失效。
首先使用存储过程生成 1000 万条测试数据,
测试表一共建立了 7 个字段(包括主键),num1和num2保存的是和ID一样的顺序数字,其中num2是字符串类型。
type1和type2保存的都是主键对 5 的取模,目的是模拟实际应用中常用类似 type 类型的数据,但是type2是没有建立索引的。
str1和str2都是保存了一个 20 位长度的随机字符串,str1不能为NULL,str2允许为NULL,相应的生成测试数据的时候我也会在str2字段生产少量NULL值(每 100 条数据产生一个NULL值)。
-- 创建测试数据表
DROP TABLE IF EXISTS test1;
CREATE TABLE `test1` (
`id` int(11) NOT NULL,
`num1` int(11) NOT NULL DEFAULT '0',
`num2` varchar(11) NOT NULL DEFAULT '',
`type1` int(4) NOT NULL DEFAULT '0',
`type2` int(4) NOT NULL DEFAULT '0',
`str1` varchar(100) NOT NULL DEFAULT '',
`str2` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `num1` (`num1`),
KEY `num2` (`num2`),
KEY `type1` (`type1`),
KEY `str1` (`str1`),
KEY `str2` (`str2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 创建存储过程
DROP PROCEDURE IF EXISTS pre_test1;
DELIMITER //
CREATE PROCEDURE `pre_test1`()
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
WHILE i < 10000000 DO
SET i = i + 1;
SET @str1 = SUBSTRING(MD5(RAND()),1,20);
-- 每100条数据str2产生一个null值
IF i % 100 = 0 THEN
SET @str2 = NULL;
ELSE
SET @str2 = @str1;
END IF;
INSERT INTO test1 (`id`, `num1`, `num2`,
`type1`, `type2`, `str1`, `str2`)
VALUES (CONCAT('', i), CONCAT('', i),
CONCAT('', i), i%5, i%5, @str1, @str2);
-- 事务优化,每一万条数据提交一次事务
IF i % 10000 = 0 THEN
COMMIT;
END IF;
END WHILE;
END;
// DELIMITER ;
-- 执行存储过程
CALL pre_test1();数据量比较大,还涉及使用MD5生成随机字符串,所以速度有点慢,稍安勿躁,耐心等待即可。
1000 万条数据,我用了 33 分钟才跑完(实际时间跟你电脑硬件配置有关)。这里贴几条生成的数据,大致长这样。
先来看这组 SQL,一共四条,我们的测试数据表num1是int类型,num2是varchar类型,但是存储的数据都是跟主键id一样的顺序数字,两个字段都建立有索引。
1: SELECT * FROM `test1` WHERE num1 = 10000;
2: SELECT * FROM `test1` WHERE num1 = '10000';
3: SELECT * FROM `test1` WHERE num2 = 10000;
4: SELECT * FROM `test1` WHERE num2 = '10000';这四条 SQL 都是有针对性写的,12 查询的字段是 int 类型,34 查询的字段是varchar类型。12 或 34 查询的字段虽然都相同,但是一个条件是数字,一个条件是用引号引起来的字符串。这样做有什么区别呢?先不看下边的测试结果你能猜出这四条 SQL 的效率顺序吗?
经测试这四条 SQL 最后的执行结果却相差很大,其中 124 三条 SQL 基本都是瞬间出结果,大概在 0.0010.005 秒,在千万级的数据量下这样的结果可以判定这三条 SQL 性能基本没差别了。但是第三条 SQL,多次测试耗时基本在 4.54.8 秒之间。
为什么 34 两条 SQL 效率相差那么大,但是同样做对比的 12 两条 SQL 却没什么差别呢?查看一下执行计划,下边分别 1234 条 SQL 的执行计划数据:

可以看到,124 三条 SQL 都能使用到索引,连接类型都为ref,扫描行数都为 1,所以效率非常高。再看看第三条 SQL,没有用上索引,所以为全表扫描,rows直接到达 1000 万了,所以性能差别才那么大。
仔细观察你会发现,34 两条 SQL 查询的字段num2是varchar类型的,查询条件等号右边加引号的第 4 条 SQL 是用到索引的,那么是查询的数据类型和字段数据类型不一致造成的吗?如果是这样那 12 两条 SQL 查询的字段num1是int类型,但是第 2 条 SQL 查询条件右边加了引号为什么还能用上索引呢。
查阅 MySQL 相关文档发现是隐式转换造成的,看一下官方的描述:
官方文档:12.2 Type Conversion in Expression Evaluation
当操作符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。以下规则描述了比较操作的转换方式:
- 两个参数至少有一个是
NULL时,比较的结果也是NULL,特殊的情况是使用<=>对两个NULL做比较时会返回1,这两种情况都不需要做类型转换- 两个参数都是字符串,会按照字符串来比较,不做类型转换
- 两个参数都是整数,按照整数来比较,不做类型转换
- 十六进制的值和非数字做比较时,会被当做二进制串
- 有一个参数是
TIMESTAMP或DATETIME,并且另外一个参数是常量,常量会被转换为timestamp- 有一个参数是
decimal类型,如果另外一个参数是decimal或者整数,会将整数转换为decimal后进行比较,如果另外一个参数是浮点数,则会把decimal转换为浮点数进行比较- 所有其他情况下,两个参数都会被转换为浮点数再进行比较
根据官方文档的描述,我们的第 23 两条 SQL 都发生了隐式转换,第 2 条 SQL 的查询条件num1 = '10000',左边是int类型右边是字符串,第 3 条 SQL 相反,那么根据官方转换规则第 7 条,左右两边都会转换为浮点数再进行比较。
先看第 2 条 SQL:SELECT * FROMtest1WHERE num1 = '10000'; 左边为 int 类型10000,转换为浮点数还是10000,右边字符串类型'10000',转换为浮点数也是10000。两边的转换结果都是唯一确定的,所以不影响使用索引。
第 3 条 SQL:SELECT * FROMtest1WHERE num2 = 10000; 左边是字符串类型'10000',转浮点数为 10000 是唯一的,右边int类型10000转换结果也是唯一的。但是,因为左边是检索条件,'10000'转到10000虽然是唯一,但是其他字符串也可以转换为10000,比如'10000a','010000','10000'等等都能转为浮点数10000,这样的情况下,是不能用到索引的。
关于这个隐式转换我们可以通过查询测试验证一下,先插入几条数据,其中num2='10000a'、'010000'和'10000':
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000001', '10000', '10000a', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000002', '10000', '010000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000003', '10000', ' 10000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');然后使用第三条 SQL 语句SELECT * FROMtest1WHERE num2 = 10000;进行查询:
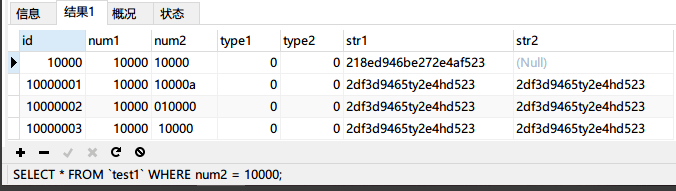
从结果可以看到,后面插入的三条数据也都匹配上了。那么这个字符串隐式转换的规则是什么呢?为什么num2='10000a'、'010000'和'10000'这三种情形都能匹配上呢?查阅相关资料发现规则如下:
- 不以数字开头的字符串都将转换为
0。如'abc'、'a123bc'、'abc123'都会转化为0; - 以数字开头的字符串转换时会进行截取,从第一个字符截取到第一个非数字内容为止。比如
'123abc'会转换为123,'012abc'会转换为012也就是12,'5.3a66b78c'会转换为5.3,其他同理。
现对以上规则做如下测试验证:

如此也就印证了之前的查询结果了。
再次写一条 SQL 查询 str1 字段:SELECT * FROMtest1WHERE str1 = 1234;
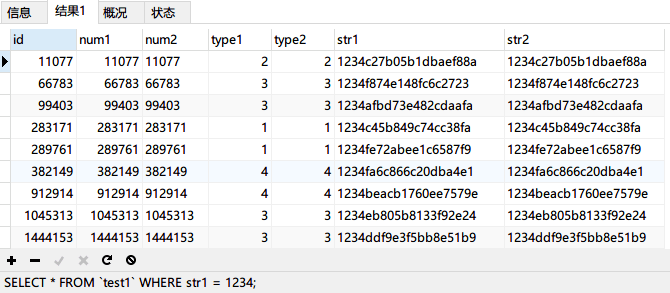
通过上面的测试我们发现 MySQL 使用操作符的一些特性:
- 当操作符左右两边的数据类型不一致时,会发生隐式转换。
- 当 where 查询操作符左边为数值类型时发生了隐式转换,那么对效率影响不大,但还是不推荐这么做。
- 当 where 查询操作符左边为字符类型时发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低。
- 字符串转换为数值类型时,非数字开头的字符串会转化为
0,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果。
所以,我们在写 SQL 时一定要养成良好的习惯,查询的字段是什么类型,等号右边的条件就写成对应的类型。特别当查询的字段是字符串时,等号右边的条件一定要用引号引起来标明这是一个字符串,否则会造成索引失效触发全表扫描。