Thrift整体架构图:
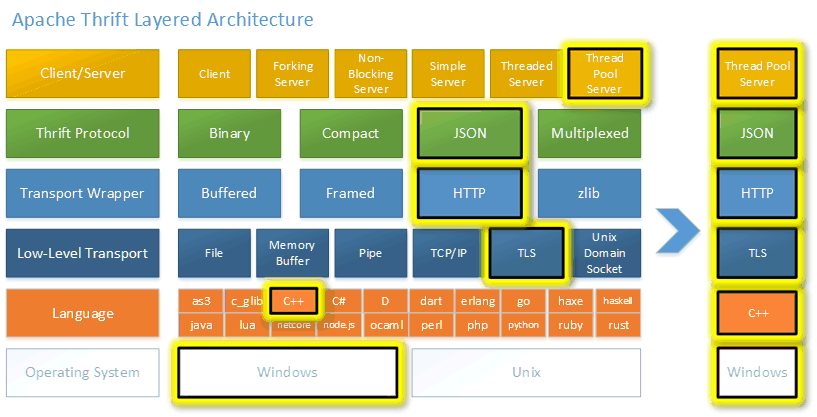
Thrift是一套包含序列化功能和支持服务通信的RPC框架,主要包含三大部分:代码生成、序列化框架、RPC框架,大致相当于protoc + protobuffer + grpc,并且支持大量语言,保证常用功能在跨语言间功能一致,是一套全栈式的RPC解决方案。Thrift最初由FaceBook开发,之后由ASF管理。
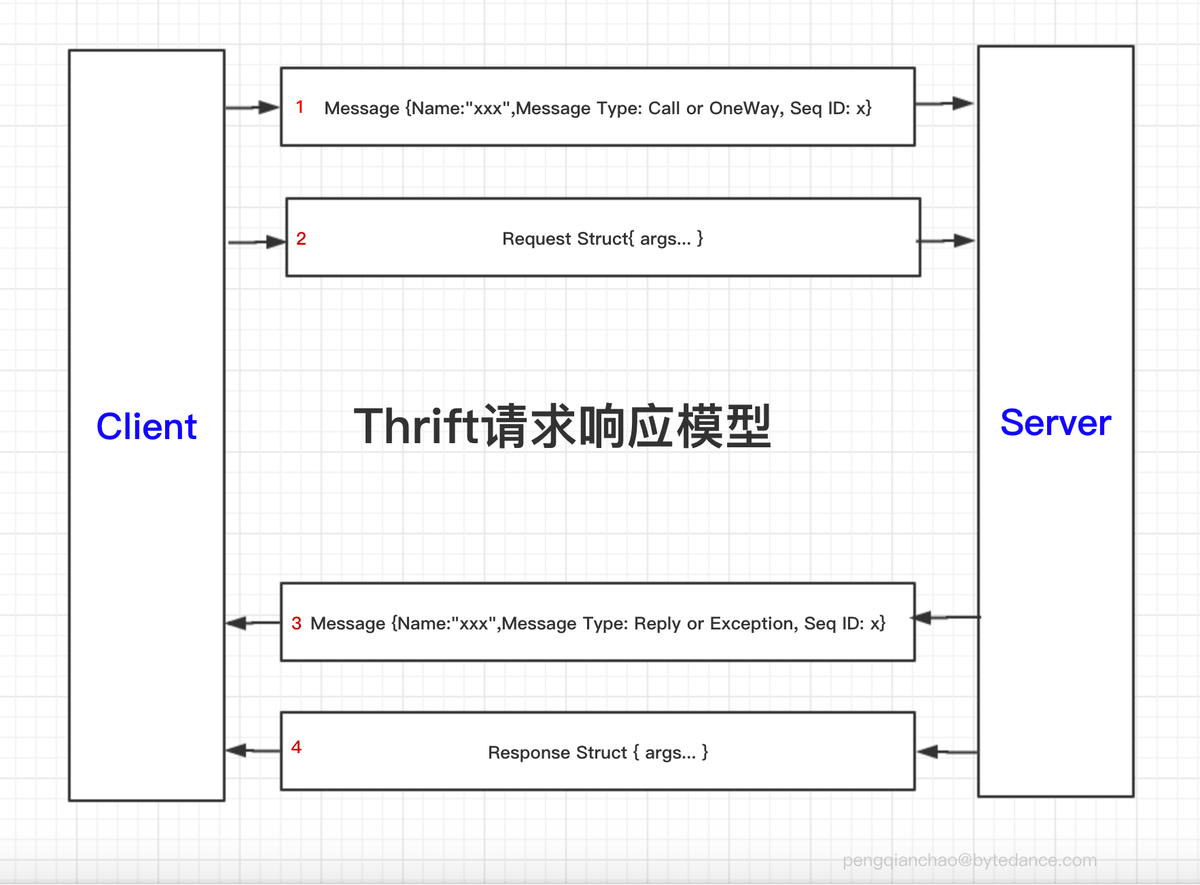
在Thrift的官方Doc中将Thrift的RPC请求响应描述为上面的四个步骤。图中,最外层只有Message和Struct。 这里可以将Message和Struct类比为TCP中的首部和负载。Message中放的是传递的元信息(metadata),Struct则包含的是具体传递的数据(payload)
注意这里不要理解成了Client,Server在一个TCP上Send了两次,而应该理解为字节流,2的数据紧跟在1的数据后面,4的数据紧跟在3的数据后面。
Message中主要包含Name,Message Type,Sequence ID等数据。
-
Name:为调用的方法名
-
Message Type:有Call, OneWay, Reply, Exception四种,在实际传递的时候,传递的是Type ID,这四种Type对应的Type ID如下
Call ---> 1 OneWay ---> 2 Reply ---> 3 Exception ---> 4
其中Call、OneWay用于Request, Reply、 Exception用于Response中。 四者的含义如下:
- Call: 调用远程方法,并且期待对方发送响应。
- OneWay: 调用远程方法,不期待响应。即没有步骤3,4。
- Reply: 表明处理完成,响应正常返回。
- Exception:表明出理出错。
- Sequence ID : 序列号, 有符号的四字节整数。在一个传输层的连接上所有未完成的请求必须有唯一的序列号,客户端使用序列号来处理响应的失序到达,实现请求和响应的匹配。服务端不需要检查该序列号,也不能对序列号有任何的逻辑依赖,只需要响应的时候将其原样返回即可。这里注意将Thrift序列号和我们常用的用于防止非幂等请求多次提交的unique ID区分开来。
在上面的Thrift请求响应模型中,有两种Struct:
- Request Struct
- Response Struct 这两种Struct的结构是一样的,都是由多个Field组成。关于Struct的详细在下面讲Thrift序列化的时候会讲到,所以接着往下看哦 :>)
Thrift支持多种序列化协议,常用的有: Binary、Compact、JSON。这里我们主要分析Binary和Compact。
binary序列化是一种二进制的序列化方式。不可读,但传输效率高。头条的绝大部分kite服务采用的都是Binary序列化的方式。
Message的序列化分为两种,strict encoding和old encoding。 在有些实现中,会通过 检查Thrift消息的第一个bit来判断使用了那种encoding:
- 1 —-> strict encoding
- 0 —-> old encoding
Message的Binary序列化下面的一张图就够了:

Struct装的是Thrift通信的实际参数,一个Struct由很多基本类型组合而成,要了解Struct怎么序列化的必须知道这些基本类型的序列化。下面我们就由大到小来逐一分析这些基本类型:
| 类型名 | idl类型名 | 占用字节数 | 类型ID |
|---|---|---|---|
| bool | bool | 1 | 2 |
| byte | byte | 1 | 3 |
| short | i16 | 2 | 6 |
| int | i32 | 4 | 8 |
| long | i64 | 8 | 10 |
| double | double | 8 | 4 |
| string | string | 4+N | 11 |
| []byte | binary | 4+N | |
| list | list | 1+4+N | 15 |
| set | set | 1+4+N | 14 |
| map | map | 1+1+4+NX+NY | 13 |
| field | 1+2+X | ||
| struct | struct | N*X | 12 |
| enum | |||
| union | |||
| exception |
上表中的 bool, byte, short, int, long, double采用的都是固定字节数编码,各类型占用的字节数见上。




struct的编码,一个struct就是由多个field编码而成,最后一个field排列完成之后是一个stop field,这个field是一个8bit全为0的字节,它标志着一条Thrift消息的结束。这也是上面思考题的答案。
---------------------------------------------
| field1 | field2 |...| fieldN | stop field | stop field: 00000000
| M | M |...| M | | 所以Message Type编码的时候不能用0
---------------------------------------------
thrift序列化的时候并没有将字段名给序列化进去,所以在idl文件中更改字段名是没有任何影响的。有些同学可能有疑问。那字段名是怎么在客户端和服务端统一的呢?答案是客户端和服务端使用的是同一个idl文件呀,自己想一想,是不是?
Compact序列化也是一种二进制的序列化,不同于Binary的点主要在于整数类型采用了zigzag 和 varint压缩编码实现,这里简要介绍下zigzag 和 varint整数编码。
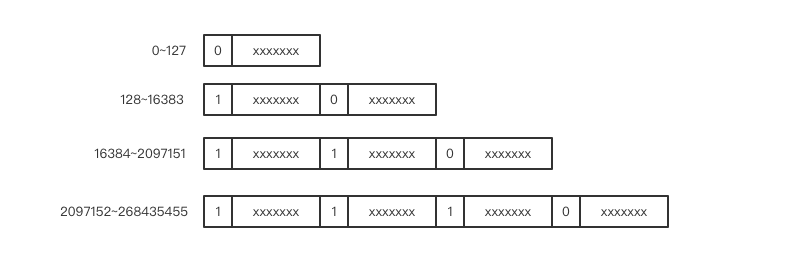
对于一个整形数字,一般使用 4 个字节来表示一个整数值。但是经过研究发现,消息传递中大部分使用的整数值都是很小的非负整数,如果全部使用 4 个字节来表示一个整数会很浪费。比如数字1用四字节表示就是这样: 00000000 00000000 00000000 00000001 对较小整数来说,这种固定字节数编码很浪费bit。所以人们就发明了一个类型叫变长整数varint。数值非常小时,只需要使用一个字节来存储,数值稍微大一点可以使用 2 个字节,再大一点就是 3 个字节,它还可以超过 4 个字节用来表达长整形数字。
其原理也很简单,就是保留每个字节的最高位的bit来标识后一个字节是否属于该bit,1表示属于,0表示不属于。
示意图如下:
那么对于负数怎么办呢?大家知道负数在计算机中是以补码的形式存在的。
10000000 00000000 00000000 00000001 -1的原码
11111111 11111111 11111111 11111110 -1的反码
11111111 11111111 11111111 11111111 -1的补码
所以-1在计算机中就是11111111 11111111 11111111,如果按照Varint编码,那么需要6个字节才能存的下,但是在现实生活中,-1却是个常用的整数。越大的负数越常见,编码需要的字节数越大,这显然是不能容忍的。为了解决这个问题, 就要使用ZigZag编码压缩技术了。
zigzag 编码专门用来解决负数编码问题。zigzag 编码将整数范围一一映射到自然数范围,然后再进行 varint 编码。
0 => 0
-1 => 1
1 => 2
-2 => 3
2 => 4
-3 => 5
3 => 6
zigzag 将负数编码成正奇数,正数编码成偶数。解码的时候遇到偶数直接除 2 就是原值,遇到奇数就加 1 除 2 再取负就是原值。
Compact编码——压缩的二进制。Compact序列化的实现大致逻辑和Binary序列化实现是一样的,就是将i16、i32、i64三种类型使用zigzag+varint编码实现,string、binary、map、list、set复合类型的长度只采用varint编码没使用zigzag,其他逻辑几乎一样。
首先,基于帧与不基于帧是在二进制协议的情况下谈的,文本协议不谈这个。
早期, Thrift使用的是不基于帧的传输(unFramedTransport), 在这种情况下,处理器是直接向socket中读写数据。
之后, Thrift中引入了基于帧的传输(FramedTransport):Client/Server会首先在内存中缓存完整的请求/响应,当将request struct/response struct的最后一个字节缓存完成之后,会计算该消息的长度,然后向socket中写入该长度(4字节有符号整数),接着写入消息的实际内容。长度前缀+消息内容就组成了一个帧(Frame)。
基于帧的传输主要是为了简化异步处理器的实现。
BufferedTransport资料貌似比较少,有的文档里说thrift0.8以上就不支持BufferedTransport了, 但是在go的lib中确实还是有BufferedTransport的。
这里我们可以确定的是BufferedTransport一定是unFrame的。
提问?
抓包演示:
sudo tcpdump -i any -Xvv dst port 5678 and tcp
0x0000: 0200 0000 4500 00d6 0000 4000 4006 0000 ....E.....@.@...
0x0010: 7f00 0001 7f00 0001 fe07 162e b53b 387a .............;8z
0x0020: 96c2 0195 8018 31d7 feca 0000 0101 080a ......1.........
0x0030: 43da 11ca 43da 11c9 8001 0001 0000 0003 C...C...........
0x0040: 4164 6400 0000 010c 0001 0a00 0100 0000 Add.............
0x0050: 0000 0000 640a 0002 0000 0000 0000 00c8 ....d...........
0x0060: 0c00 ff0b 0001 0000 0021 3230 3139 3032 .........!201902
0x0070: 3232 3134 3336 3032 3031 3030 3934 3039 2214360201009409
0x0080: 3432 3339 3530 3538 4135 410b 0002 0000 42395058A5A.....
0x0090: 0001 2d0b 0003 0000 000c 3130 2e39 342e ..-.......10.94.
0x00a0: 3934 2e32 3339 0b00 0400 0000 000d 0006 94.239..........
0x00b0: 0b0b 0000 0002 0000 0007 636c 7573 7465 ..........cluste
0x00c0: 7200 0000 0764 6566 6175 6c74 0000 0003 r....default....
0x00d0: 656e 7600 0000 0000 0000 env.......
Thrift Official Doc: https://github.com/apache/thrift/tree/master/doc/specs Wikimore’s Blog: https://wikimore.github.io/2016/04/04/thrift-protocol/ Thrift官网: http://thrift.apache.org/docs/