- TCP 是面向连接的:需要进行三次握手,在创建的连接上进行数据传输
- TCP 提供可靠交付:通过 TCP 连接传输的数据,无差错、不丢失、不重复、并且按序到达
- TCP 面向字节流:IP 包可不是一个流,而是一个个的 IP 包,TCP 实现的流发送
- TCP 可以拥塞控制:根据网络环境调整发送数据的多少与快慢
- TCP 是有状态服务:精确记录发送接收结果,发送序号
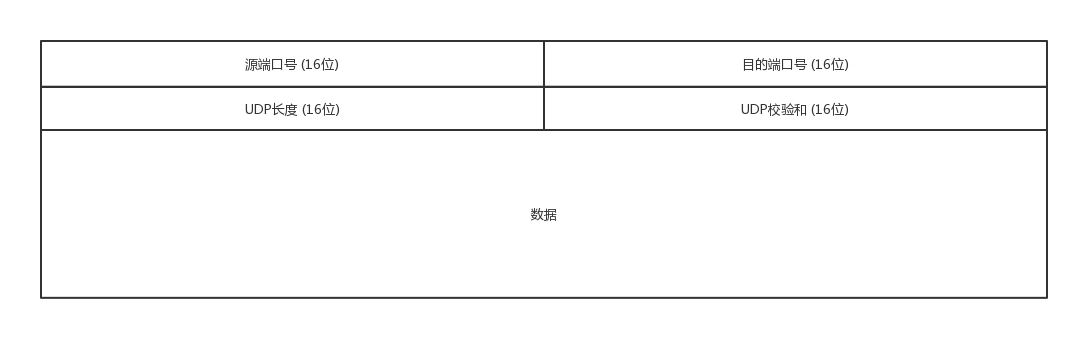
- UDP 是面向无连接的
- UDP 继承了 IP 包的特性,不保证不丢失,不保证按顺序到达
- UDP 继承了 IP 的特性,基于数据报的,一个一个地发,一个一个地收
- UDP 没有拥塞控制,应用让我发,我就发,管它洪水滔天
- UDP 则是无状态服务,不做其他的准确性发送控制
当我发送的 UDP 包到达目标机器后,发现 MAC 地址匹配,于是就取下来,将剩下的包传给处理 IP 层的代码。把 IP 头取下来,发现目标 IP 匹配,IP 头里面有个 8 位协议,这里会存放数据里面到底是 TCP 还是 UDP,如果我们知道 UDP 头的格式,就能从数据里面,将它解析出来。处理完传输层的事情,内核的事情基本就干完了,里面的数据应该交给应用程序自己去处理论,应用程序写的使用 TCP 传数据,还是 UDP 传数据,都要监听一个端口。根据端口号,将数据交给相应的应用程序。
- 沟通简单,因为没有大量的数据结构、处理逻辑、包头字段
- 没有信任机制,因为不会建立连接,虽然有端口号,但是监听在这个地方,谁都可以传给他数据,他也可以传给任何人数据,甚至可以同时传给多个人数据
- 不会进行发送变通,因为它不会根据网络的情况进行发包的拥塞控制,无论网络丢包丢成啥样了
- 需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用
- 不需要一对一沟通,建立连接,而是可以广播的应用,如 DHCP 就是一种广播的形式,就是基于 UDP 协议的
- 需要处理速度快,时延低,可以容忍少数丢包,但是要求即便网络拥塞,也毫不退缩,一往无前的时候
- QUIC:Google提出的一种基于UDP改进的快速UDP互联网连接通信协议 QUIC,其目的是降低网络通信的延迟,提供更好的用户互动体验。
- 流媒体的协议:很多直播应用,都基于 UDP 实现了自己的视频传输协议,视频的连续帧里面,有的帧重要,有的不重要,如果必须要丢包,隔几个帧丢一个,其实看视频的人不会感知
- 实时游戏:实时游戏中客户端和服务端要建立长连接,来保证实时传输。游戏玩家很多,服务器却不多。一台机器能够支撑的TCP连接数目是有限的,然后UDP由于是没有连接的。游戏对实时要求较为严格的情况下,采用自定义的可靠UDP协议,自定义重传策略,能够把丢包产生的延迟降到最低,尽量减少网络问题对游戏性造成的影响。
- 移动通信领域:4G网络里,移动流量上网的数据面对的协议GTP-U是基于UDP的。
网络环境是恶劣的,丢包、乱序、重传,拥塞都是常有的事情,所以需要从算法层面来保证可靠性。
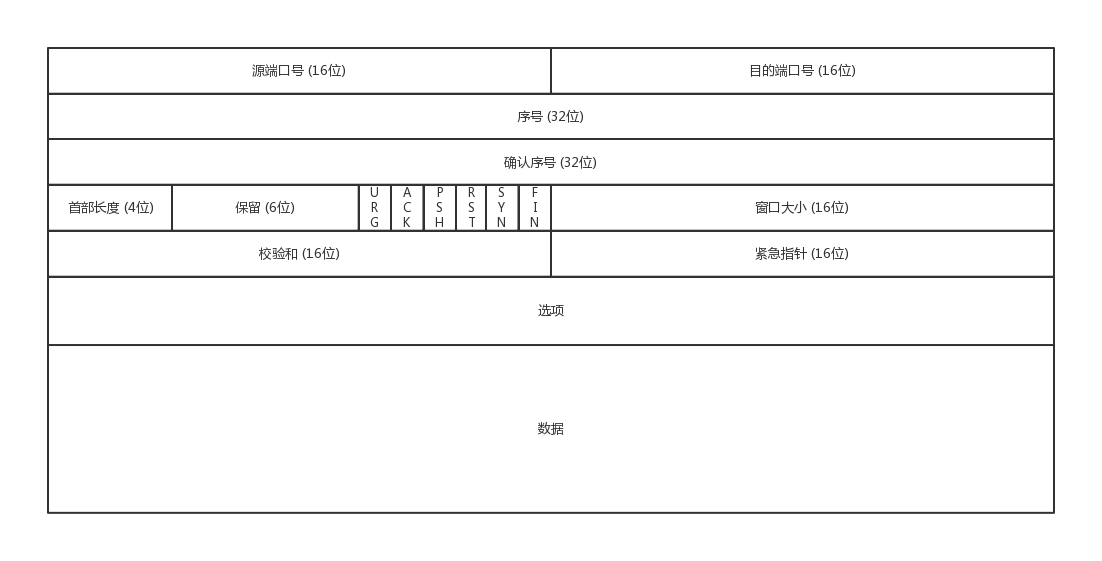
- 端口号:需要有端对端端口号,这样数据才知道应该发给哪个应用。
- 包的序号:编号是为了解决乱序问题【顺序问题 ,稳重不乱】。
- 确认序号:发出去的包应该有确认序号,来确认对方有没有收到,没有收到就应该重新发送,直到送达。可以解决不丢包的问题。【丢包问题,承诺靠谱】
- 状态位:SYN发起一个连接,ACK回复,RST重新连接,FIN结束连接等。TCP是面向连接的,因而双方要维护连接的状态,这些带状态位的包的发送,会引起双方的状态变更。【连接维护,有始有终】
- 窗口大小:TCP要做流量控制,通信双方各声明一个窗口,标识自己当前能够的处理能力。【流量控制,把握分寸,拥塞控制,知进知退】
使用序号,对收到的TCP报文段进行排序以及检测重复的数据;使用校验和来检测报文段的错误;使用确认和计时器来检测和纠正丢包或延时。TCP头部,总长度20字节:
typedef struct _tcp_hdr
{
unsigned short src_port; //源端口号
unsigned short dst_port; //目的端口号
unsigned int seq_no; //序列号
unsigned int ack_no; //确认号
#if LITTLE_ENDIAN
unsigned char reserved_1:4; //保留6位中的4位首部长度
unsigned char thl:4; //tcp头部长度
unsigned char flag:6; //6位标志
unsigned char reseverd_2:2; //保留6位中的2位
#else
unsigned char thl:4; //tcp头部长度
unsigned char reserved_1:4; //保留6位中的4位首部长度
unsigned char reseverd_2:2; //保留6位中的2位
unsigned char flag:6; //6位标志
#endif
unsigned short wnd_size; //16位窗口大小
unsigned short chk_sum; //16位TCP检验和
unsigned short urgt_p; //16为紧急指针
}tcp_hdr; TCP 是靠谱的协议,但是这不能说明它面临的网络环境好。从 IP 层面来讲,如果网络状况的确那么差,是没有任何可靠性保证的,而作为 IP 的上一层 TCP 也无能为力,唯一能做的就是更加努力,不断重传,通过各种算法保证。也就是说,对于 TCP 来讲,IP 层你丢不丢包,我管不着,但是我在我的层面上,会努力保证可靠性。
在公网上传输数据,公网往往是不可靠的,因而需要很多的机制去保证传输的可靠性:
为了保证顺序性,每一个包都有一个ID。在建立连接的时候,会商定起始的ID是什么,然后按照ID一个个发送。
客户端每发送的一个包,服务器端都应该有个回复,如果服务器端超过一定的时间没有回复,客户端就会重新发送这个包,直到有回复。这种节制叫累计确认。
接收端会给发送端报一个窗口的大小,叫Advertised window。
发送端需要保持下面的数据结构:
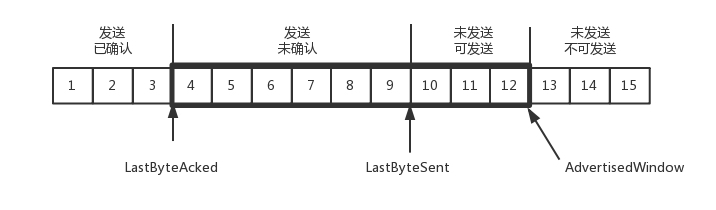
- LastByteAcked:第一部分和第二部分的分界线
- LastByteSent:第二部分和第三部分的分界线
- LastByteAcked + AdvertisedWindow:第三部分和第四部分的分界线
对于接收端缓存里记录的内容:
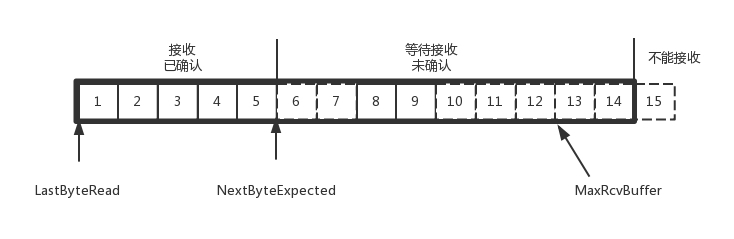
- MaxRcvBuffer:最大缓存的量;
- LastByteRead:之后是已经接收了,但是还没被应用层读取的;
- NextByteExpected:是第一部分和第二部分的分界线。
AdvertisedWindow=MaxRcvBuffer-((NextByteExpected-1)-LastByteRead)
- 超时重试:每一个发送了,但是没有ACK的包,都有设一个定时器,超过了一定的时间(往返时间),就重新尝试。这里用的是自适应重传算法,TCP通过采样RTT的时间,然后进行加权平均,算出一个值(往返时间),而且这个值还是要不断变化的,因为网络状况不断的变化。
- 超时间隔加倍:每当遇到一次超时重传的时候,都会将下一次超时时间间隔设为先前值的两倍**。**两次超时,就说明网络环境差,不宜频繁反复发送。
- SACK:需要在TCP头里加一个SACK的东西,可以将缓存的地图发送给发送方。例如可以发送ACK6、SACK8、SACK9,有了地图,发送方一下子就能看出来是7丢了。
拥塞控制的问题,也是通过窗口的大小来控制的。滑动窗口rwnd是怕发送方把接收方缓存塞满,而拥塞窗口cwnd,是怕把网络塞满。
这里有一个公式 LastByteSent - LastByteAcked <= min {cwnd, rwnd} ,是拥塞窗口和滑动窗口共同控制发送的速度。
TCP 的拥塞控制就是在不堵塞,不丢包的情况下,尽量发挥带宽(每秒钟能够发送多少数据,端到端的时延)。所以:通道的容量 = 带宽 × 往返延迟。
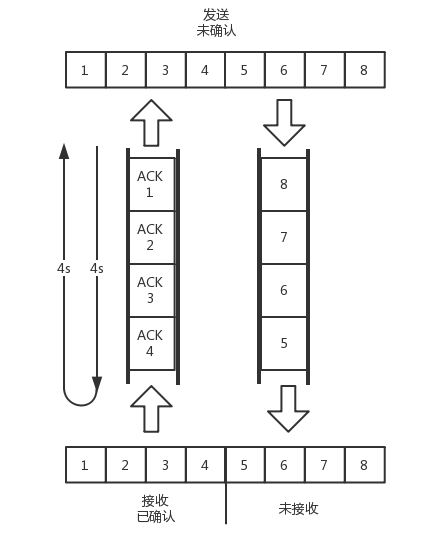
如上图:往返时间为 8s,去 4s,回 4s,每秒发送一个包,每个包 1024 byte。已经过去了 8 s,则 8 个包都发出去了,其中前 4 个包已经到达接收端,但是 ACK 还没有返回,不能算发送成功。5 - 8 后四个包还在路上,还没被接收。这个时候,整个管道正好撑满,在发送端,已发送未确认的为 8 个包,正好等于带宽,也即每秒发送 1 个包,乘以来回时间 8s。
保丢失:
如果发送的更加快速,则单位时间内,会有更多的包到达这些中间设备,这些设备还是只能每秒处理一个包的话,多出来的包就会被丢弃。
超时重传:
可以中间设备上加缓存,处理不过来的在队列里面排着,这样包就不会丢失,但是缺点是会增加时延,这个缓存的包,4s 肯定到达不了接收端了,如果时延达到一定程度,就会超时重传。
于是 TCP 的拥塞控制主要来避免两种现象,包丢失和超时重传。一旦出现了这些现象就说明,发送速度太快了,要慢一点。
但是一开始我怎么知道速度多快呢,我怎么知道应该把窗口调整到多大呢?
慢启动:
一条TCP连接开始,cwnd设置为一个报文段,一次只能发送一个;当收到这一个确认的时候,cwnd加一,于是一次能够发送两个;当这两个的确认到来的时候,每个确认cwnd加一,两个确认cwnd加二,于是一次能够发送四个;当这四个的确认到来的时候,每个确认cwnd加一,四个确认cwnd加四,于是一次能够发送八个。可以看出这是指数性的增长。
超过值ssthresh 65535 时,每收到一个确认后,cwnd增加1/cwnd,我们接着上面的过程来,一次发送八个,当八个确认到来的时候,每个确认增加1/8,八个确认一共cwnd增加1,于是一次能够发送九个,变成了线性增长。
如此以来,终会有网络通道塞满的时候,这样会有两个问题:
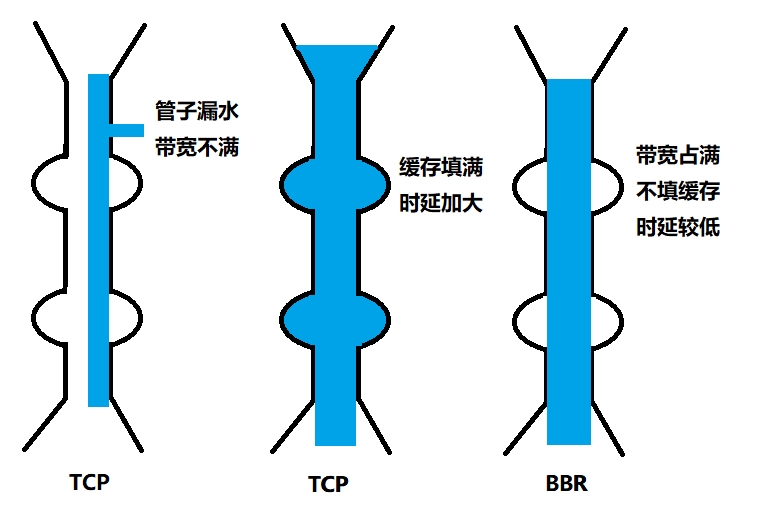
- 第一个问题是丢包并不代表着通道满了,也可能是管子本来就漏水。例如公网上带宽不满也会丢包,这个时候就认为拥塞了,退缩了,其实是不对的。
- 第二个问题是TCP的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实TCP只要填满管道就可以了,不应该接着填,直到连缓存也填满。
为了优化这两个问题,后来有了TCP BBR拥塞算法。它企图找到一个平衡点,就是通过不断的加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
- S1:慢启动开始时,以前期的延迟时间为延迟最小值Tmin。然后监控延迟值是否达到Tmin的n倍,达到这个阀值后,判断带宽已经消耗尽且使用了一定的缓存,进入排空阶段
- S2:指数降低发送速率,直至延迟不再降低。这个过程的原理同S1
- S3:协议进入稳定运行状态。交替探测带宽和延迟,且大多数时间下都处于带宽探测阶段


- 物理层:将数据转化成 0 和 1 的二进制电信号,利用传输介质为数据链路层提供物理连接,实现比特流的透明传输
- 数据链路层(ARP/RARP协议在这层):规定 0 和 1 的分包形式,确定了网络数据包的形式;通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路
- 网络层(IP ICMP 协议在这层):负责在源和终点之间建立连接,通过IPv4,IPv6确定计算机的位置;通过路由选择算法,为报文或分组通过通信子网选择最适当的路径【路由器】
- 传输层(TCP UDP 协议在这层):向高层提供可靠的端到端的网络数据流服务,每一个应用程序都会在网卡注册一个端口号,该层就是端口与端口的通信;向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输
- 会话层:自动的网络寻址,向两个实体的表示层提供建立和使用连接的方法
- 表示层:用于应用层数据编码和转化,对来自应用层的命令和数据进行解释,以确保以一个系统应用层发送的信息可以被另一个系统应用层识别,如解决不同系统之间的通信:Linux 下的 QQ 和 Windows 下的 QQ 可以通信【网桥,交换机】
- 应用层(HTTP FTP SMTP DNS 协议在这层):他是各种应用程序和网络之间的接口,规定数据的传输协议【网卡,网线,集线器,中继器,调制解调器】
OSI 七层模型通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯,因此其最主要的功能就是帮助不同类型的主机实现数据传输 。
┌────------────┐┌─ ┬─ ┬ -┬─ ┬─ ┬─ ┬─┬─ ┬─-┬─┬─-┐ │ ││D│F│W│F│H│G│T│I│S│U│ │ │ ││N│I│H│T│T│O│E│R│M│S│其│ │第四层,应用层 ││S│N│O│P│T│P│L│C│T│E│ │ │ ││ │G│I│ │P│H│N│ │P│N│ │ │ ││ │E│S│ │ │E│E│ │ │E│它│ │ ││ │R│ │ │ │R│T│ │ │T│ │ └───────------─┘└─ ┴ ─┴─-┴─┴─-┴─ ┴─-┴─ ┴─┴─ ┴-─┘ ┌───────-----─┐┌─────────-------┬──--------─────────┐ │第三层,传输层 ││ TCP │ UDP │ └───────-----─┘└────────-------─┴──────────--------─┘ ┌───────-----─┐┌───----── ┬───---─ ┬────────-------─┐ │ ││ │ICMP│ │ │第二层,网络层 ││ └──---──┘ │ │ ││ IP │ └────────-----┘└────────────────────-------------─-┘ ┌────────-----┐┌─────────-------┬──────--------─────┐ │第一层,网络接口││ARP/RARP│ 其它 │ └────────------┘└─────────------┴─────--------──────┘
