404
+Page not found
+Page not found
+
EC2 m5.4xlarge
+| Key | +Value | +
|---|---|
| vCPUs | +16 | +
| Memory (GiB) | +64.0 | +
| Memory per vCPU (GiB) | +4.0 | +
| Physical Processor | +Intel Xeon Platinum 8175 | +
| Clock Speed (GHz) | +3.1 | +
| CPU Architecture | +x86_64 | +
| Disk space | +256 Gb | +
Details about the instance type
+All the information provided for a default seed 42. Size on disk is a total size of compressed parquet files. An amount of rows depends of SEED that was used for generation of the data because an amount of transactions for each id (customer id) per day is sampled from binomial distribution.
+See src/lib.rs for details of the implementation.
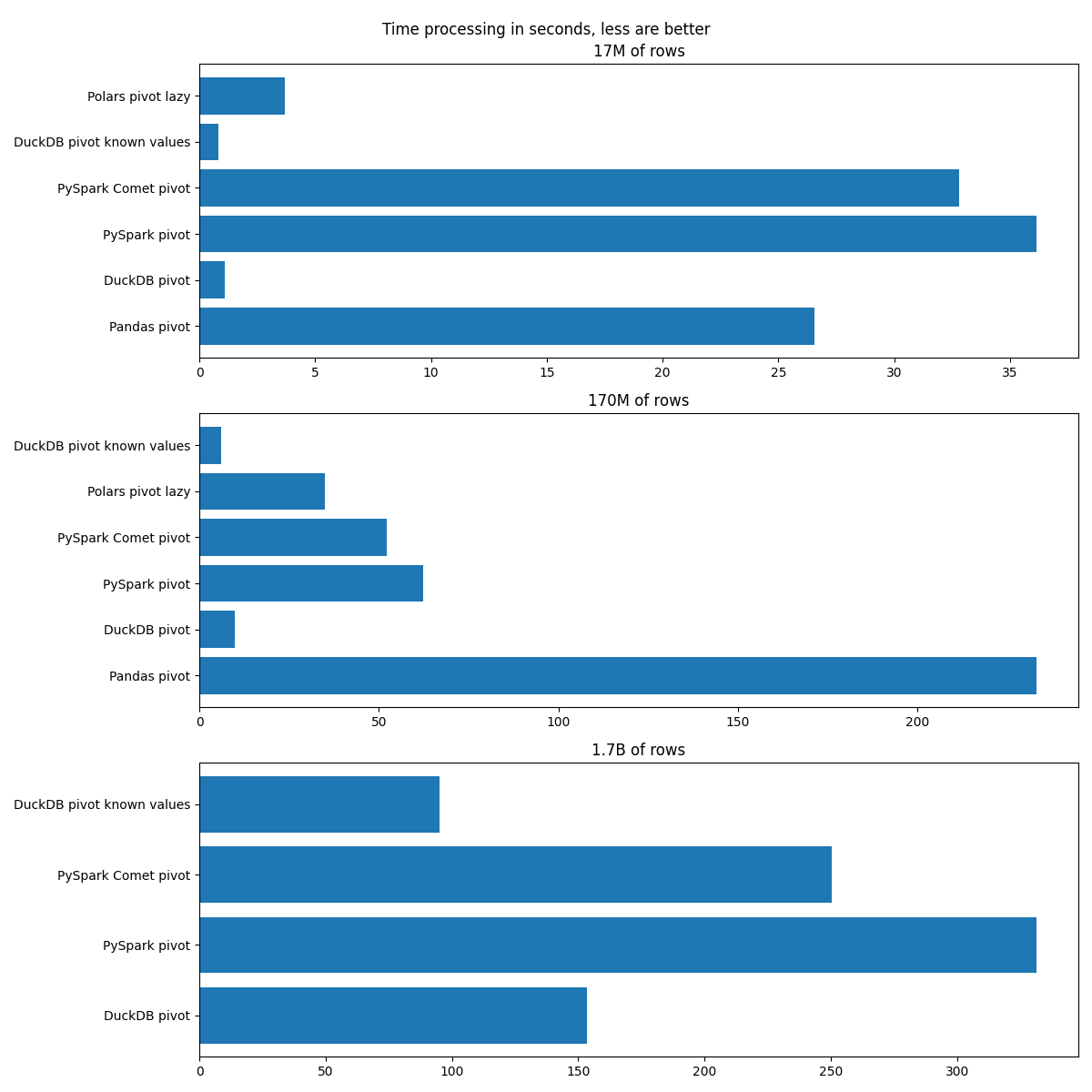
Amount of rows: 17,299,455
+Size on disk: 178 Mb
+Unique IDs: 1,000
+| Tool | +Time of processing in seconds | +
|---|---|
| PySpark pandas-udf | +78.31 | +
| PySpark case-when | +242.84 | +
| Pandas pivot | +23.91 | +
| Polars pivot | +4.54 | +
| DuckDB pivot | +4.10 | +
| DuckDB case-when | +36.59 | +
| PySpark Comet case-when | +94.06 | +
| PySpark-4 polars-udf | +53.06 | +
| PySpark pivot | +104.21 | +
Amount of rows: 172,925,732
+Size on disk: 1.8 Gb
+Unique IDs: 10,000
+| Tool | +Time of processing in seconds | +
|---|---|
| Pandas pivot | +214.67 | +
| Polars pivot | +41.20 | +
| DuckDB pivot | +28.60 | +
| DuckDB case-when | +304.52 | +
| PySpark pandas-udf | +516.38 | +
| PySpark case-when | +1808.99 | +
| PySpark Comet case-when | +729.75 | +
| PySpark-4 polars-udf | +356.19 | +
| PySpark pivot | +151.60 | +
Amount of rows: 1,717,414,863
+Size on disk: 18 Gb
+Unique IDs: 100,000
+| Tool | +Time of processing in seconds | +
|---|---|
| Pandas pivot | +OOM | +
| Polars pivot | +OOM | +
| DuckDB pivot | +2181.59 | +
| PySpark pandas-udf | +5983.14 | +
| PySpark case-when | +17653.46 | +
| PySpark Comet case-when | +4873.54 | +
| PySpark-4 polars-udf | +4704.73 | +
| PySpark pivot | +455.49 | +
(Linux)
+maturin build --release for build a wheelpython3 -m venv .venv (python3.11 is required)source .venv/bin/activatepip install target/wheels/data_generation-0.1.0-cp311-cp311-manylinux_2_34_x86_64.whl (choose one for your system)(Inside venv from the previous step)
generator --helpgenerator --prefix test_data_tiny (generate tiny data)generator --prefix test_data_small --size small (generate small data)Contributions are very welcome. I created that benchmark not to prove that one framework is better than other. Also, I'm not related anyhow to any company that develops one or another ETL tool. I have some preferences to Apache Spark because I like it, but results and benchmark is quite fair. For example, I'm not trying to hide how faster are Pandas compared to Spark on small datasets, that are fit into memory.
+What would be cool:
+Pandas;Spark;There is a lack of documentation for now, but I'm working on it. You may open an issue, open a PR or just contact me via email: mailto:ssinchenko@apache.org.
This project aims to create a DB-like benchmark of feature generation (or feature aggregation) task. Especially the task of generating ML-features from time-series data. In other words it is a benchmark of ETL tools on the task of generating the single partition of the Feature Store.
+Today, in the era of ML-driver approach to the business, each company on the market is trying to use the data about it's customers. For modern banks such a data is, for example, a history of transactions. In a mobile game it may be, for example, the history of in-game purchases. For an online shop it may be, for example, the history of orders.
+The typical ML-task on such a data may be, for example:
+And a lot of other interesting and useful for the business tasks. For a good overview you may check the book Introduction to Algorithmic Marketing.
+When we have time-series data, but need to make a prediction on the level of the primary key (customer ID, for example), we need to generate features first. A very common approach is just to compute different aggregations, like min, max, average, count, etc. But not on the level of the whole data, but on the level of different groupings and time windows. For example, we may want to calculate something like average customer spending in category "Health" from a Debit Card for the last three months.
+In a result the transforms to an ETL (Extract-Transform-Load) pipeline with a very specific profile, when we have a very long table with about 5 columns and we need to transform it to the short, but very wide table with about thousand of columns. Another problem is that such a pipeline is very hard to explain in pure SQL.
+Because generating thousand of features may be a complex task, it is a common way to create a table with precomputed features. That table is typically named "Feature Store".
+Such a table typically has a structure with two primary keys:
+| customer_id | +features_timestamp | +feature1 | +... | +featureN | +
|---|---|---|---|---|
| id1 | +2024-05-12 | +1 | +... | +1000 | +
| id1 | +2024-05-13 | +3 | +... | +500 | +
| id2 | +2024-05-12 | +-1 | +... | +750 | +
Where feature1, ..., featureN are aggregations per customer for different categories and for different time windows.
There is a well know TPC-H bechmark on which the most of ETL-tools are compete. The problem of that benchmark is that it is about DWH-like workload that is slightly different from ML-like Feature Generation workload.
+My benchmark is specified by the following:
+There is also a DB-like benchmark from H2O. Why my benchmark is different:
+As input we have the long table of customer transactions in the form of:
+| customer_id | +card_type | +trx_type | +channel | +trx_amnt | +t_minus | +part_col | +
|---|---|---|---|---|---|---|
| Long | +String | +String | +String | +Double | +Long | +String | +
customer_id
+Is a unique ID of our customer. Just an incremental Long value, started from zero. Amount of rows per customers depends of expected transactions per day.
+
card_type
+Is a category variable that may have values DC (Debit Card) and CC (Credit Card). DC appears with probability 75%:
+| DC | +CC | +
|---|---|
| 12,972,530 | +4,326,925 | +
(Distribution for tiny dataset)
+trx_type
+Is a category variable with 13 unique values. No skew.
+channel
+Is a category variable with 2 unique values (mobile, classic). Mobile appears with probability 75%:
+| mobile | +classic | +
|---|---|
| 12,976,058 | +4,323,397 | +
(Distribution for tiny dataset**
+trx_amnt
+Is a double variable that is used for next aggregations. Uniformly distributed random value from 100 to 10,000.
+t_minus
+Is a Long value that represents the time. It's value is an offset from the reference date.
+part_col
+Partition column. There are two reasons of that variable:
+Our goal is to generate the following aggregations:
+The aggregations are always computed for trx_amnt column.
+We should compute aggregations defined above for the following groups:
+We should compute all aggregations for all the groups defined above for the following intervals:
+import pandas as pd
+
+
+def generate_pivoted_batch(data: pd.DataFrame, t_minus: int, groups: list[str]) -> pd.DataFrame:
+ pre_agg = (
+ data.loc[data["t_minus"] <= t_minus]
+ .groupby(["customer_id"] + groups, as_index=False)["trx_amnt"]
+ .agg(["count", "mean", "sum", "min", "max"])
+ )
+ pivoted = pre_agg.pivot(
+ columns=groups,
+ index="customer_id",
+ values=["count", "mean", "sum", "min", "max"],
+ )
+ pivoted.columns = ["_".join(a[1:]) + f"_{t_minus}d_{a[0]}" for a in pivoted.columns.to_flat_index()]
+ return pivoted
+Such a function do the following:
+dfs_list = []
+
+for win in WINDOWS_IN_DAYS:
+ # Iterate over combination card_type + trx_type
+ dfs_list.append(generate_pivoted_batch(data, win, ["card_type", "trx_type"]))
+
+ # Iterate over combination channel + trx_type
+ dfs_list.append(generate_pivoted_batch(data, win, ["channel", "trx_type"]))
+
+(
+ reduce(lambda a, b: pd.merge(a, b, left_index=True, right_index=True), dfs_list)
+ .reset_index(drop=False)
+ .to_parquet("../tmp_out")
+)
+The last step is just to iterate over required time offset, compute batches and finally join all of them together using the fact, that customer_id is an index.