This Streamlit application uses Selenium to interact with the eCourts website for a specific District Court, scrape the daily cause lists for a selected date and court, and generate structured PDF reports using ReportLab.
newdelhi.dcourts.gov.in). Excessive, automated scraping or activities that may disrupt the website's service are strictly prohibited. Always check the site's robots.txt and legal guidelines.
- Date Selection: Easily select the desired cause list date.
- Court Selection: Select the Court Complex and specific Court Number.
- CAPTCHA Handling: Captures the on-screen CAPTCHA for manual user entry within the Streamlit interface.
- Data Scraper: Uses Selenium to navigate, input details, submit the form, and extract tabular data.
- PDF Generation: Generates print-ready, landscape A4 PDF reports for each scraped court list using ReportLab, ensuring text wrapping and proper column sizing.
You need Python 3.x installed.
# Clone the repository (if applicable)
# git clone <your-repo-link>
# cd <your-project-folder>
# Create and activate a virtual environment (recommended)
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activateInstall the required Python packages:
pip install streamlit selenium pandas reportlabThis application uses Google Chrome and Chromedriver.
- Download Chromedriver: Download the appropriate
chromedriverbinary for your version of Google Chrome from the Chromedriver website. - Path Configuration:
- The provided code expects
chromedriverto be located at/usr/local/bin/chromedriver. - If you are on Windows or your driver is in a different location, you must change the line:
to the correct path for your system, e.g.,
driver_path = Service("/usr/local/bin/chromedriver")
Service("C:/Users/User/Downloads/chromedriver.exe").
- The provided code expects
- Save the provided Python code as a file (e.g.,
main.py). - Run the application from your terminal:
streamlit run main.pyThe app will automatically open in your web browser.
- Select Date: Choose the desired date for the cause list using the date picker.
- Fetch Cause List: Click the "Fetch Cause List" button.
- A Chrome browser instance will launch.
- The script will navigate to the site, select the Court Complex and Court Number, and input the date.
- It will then capture the security CAPTCHA image.
- Enter CAPTCHA: An image of the CAPTCHA will be displayed in the Streamlit app.
- Enter the characters shown in the image into the input box.
- Submit Captcha: Click "Submit Captcha".
- The script submits the form on the website.
- Upon successful verification, the results are scraped.
- View and Save Results:
- The scraped data will be displayed in a table format within the Streamlit app.
- A PDF report for each section is automatically generated and saved in a new folder structure:
CauseLists/DD-MM-YYYY/.
A video demonstration of the scraping process, from input to PDF generation.
Click the image below to watch the demo on YouTube:
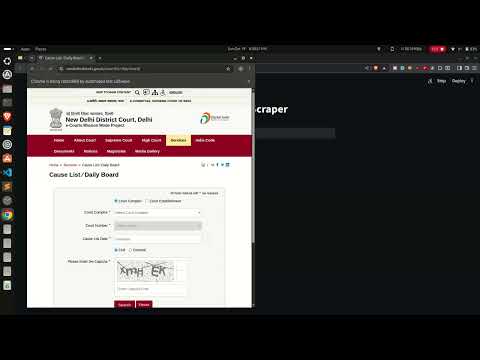
The generated files are saved into a dated directory structure:
ECORTS_SCRAPER/
├── main.py # The Streamlit application code
├── captcha/
│ └── ecourts_captcha.png # Temporary file for the current CAPTCHA image
└── CauseLists/
└── 18-10-2025/ # Folder created dynamically based on the selected date (DD-MM-YYYY)
├── Arguments.pdf # PDF report for 'Arguments' section
├── Misc.__Appearance.pdf # PDF report for 'Misc. / Appearance' section
└── Misc.__Arguments.pdf # PDF report for 'Misc. / Arguments' section