Sequence to Sequence Architectures
One of the goals of the Tarteel ML team is to convert spoken recitation to Arabic text. In order to develop these kinds of models, we use sequence-to-sequence neural networks. These networks convert a sequence of one type (in our case, audio MFCC coefficients) to to a sequence of another type (one-hot encoded vectors of Arabic characters). Sequence-to-sequence networks differ from conventional networks because the latter are restricted to taking input shapes of a fixed size and producing a fixed-size output.
A common sequence-to-sequence machine learning architecture is based on LSTM encoders and decoders. Such a model is illustrated below, for the task of converting English to French (image credit: Keras blog).
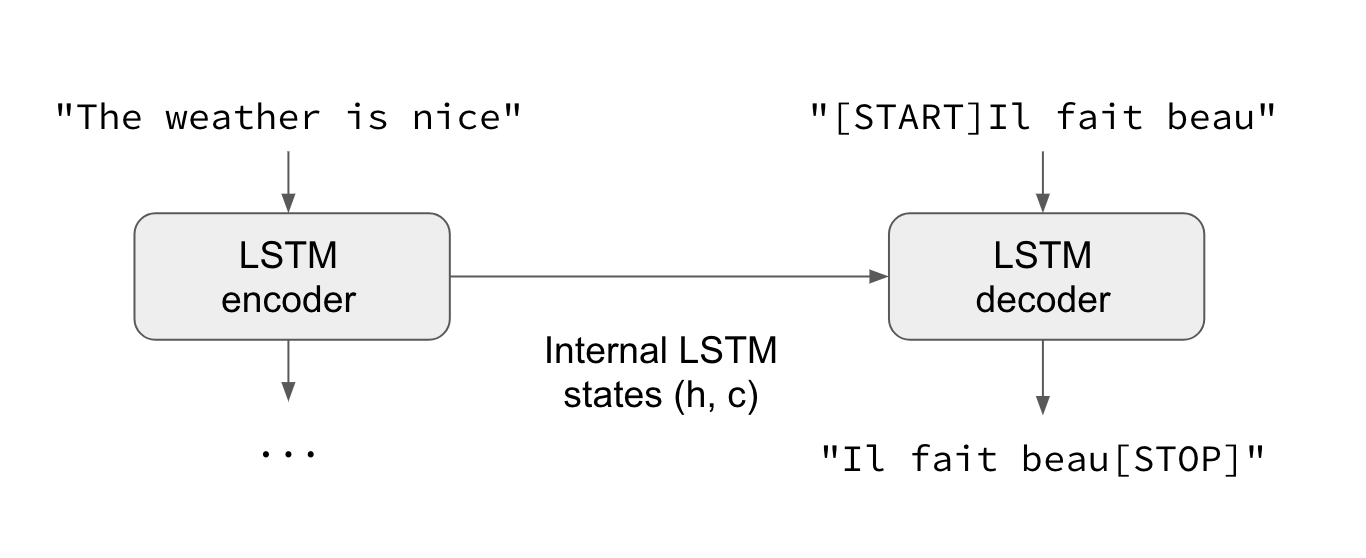
We define a similar LSTM sequence-to-sequence model in our file seq2seq.py:
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder = LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
# We discard `encoder_outputs` and only keep the states.
encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state.
decoder_inputs = Input(shape=(None, num_decoder_tokens))
# We set up our decoder to return full output sequences,
# and to return internal states as well. We don't use the
# return states in the training model, but we will use them in inference.
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
# Define the model that will turn
# `encoder_input_data` & `decoder_input_data` into `decoder_target_data`
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)Training such sequence-to-sequence models is difficult, so we use a process called teacher forcing to help the neural network. The basic idea is to not only feed the relevant portion of the audio files, but also the previous character, which makes it a little easier for the model to predict the next character.
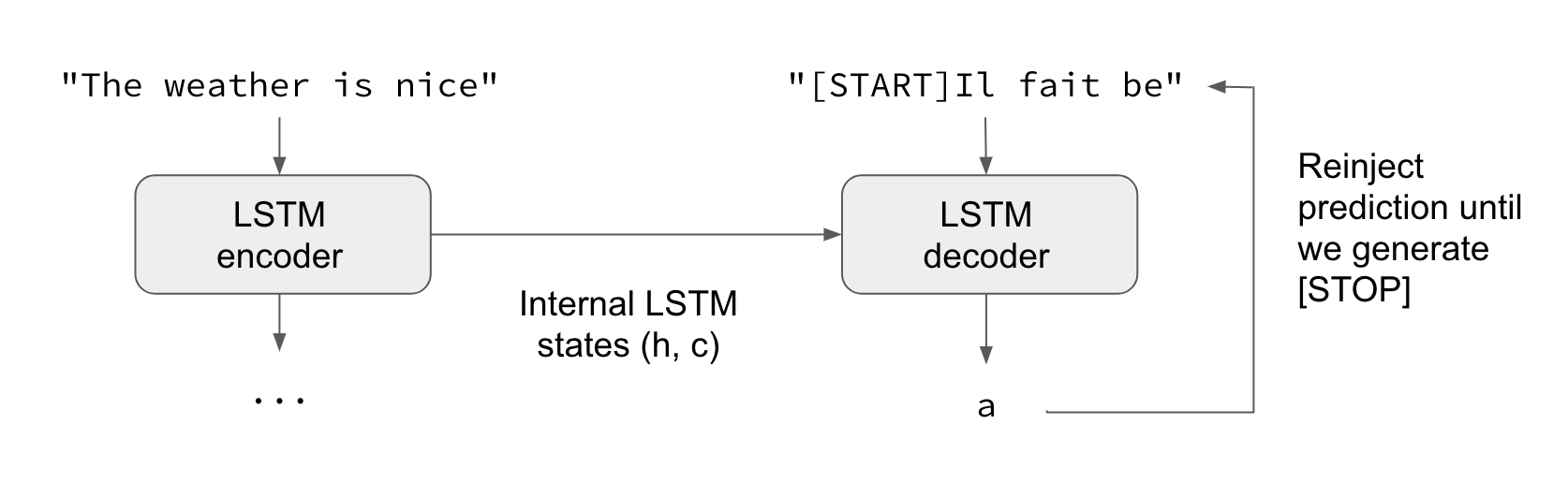
Teacher forcing is built into both the training and inference scripts (see seq2seq.py).
Our preliminary experiments show that the LSTM decoder is quite good at generating realistic outputs of the Qur'anic verses. We are able to produce the first verse of Surah Fatihah quite consistently -- however, it is produced regardless of what audio input is fed into the model. Thus, it seems we need to work on improving the LSTM encoder and having it used by the LSTM decoder.
Next steps include understanding how to improve the sequence-to-sequence model training
- How does increasing the latent dimensionality of the LSTM improve results?
- How does adding more layers to the model improve results?
- How does increasing the size of the dataset fed into the model improve results?
- What if we remove teacher forcing?
- How about other architectures, such as Transformers?