- R4DS chapter 14
- P4DA chapter 7.4
- RegEx Cheat Sheet
You can find examples and motivation in the resources.
In this lecture, we are going to learn how to use RegEx to pattern match strings. We will see how powerful it is to use RegEx to bulk search for patterns. It is industry standard and can be used in all of the tools we have used so far, i.e Git, Python/R and SQL.
Regular Expressions (RegEx) is a powerful tool used in computer science and programming for pattern matching within strings. It provides a concise and flexible means of searching, matching, and manipulating text based on patterns.
A regular expression is a sequence of characters (a type of query) that defines a search pattern. These patterns can include a variety of elements such as literal characters, metacharacters (special characters with specific meanings), and quantifiers (to specify the number of occurrences). Regex is commonly used in tasks like text searching, validation, and text manipulation.
Before diving in to the syntax of RegEx, let's look at a simple example.
Consider a scenario where you want to extract email addresses from a text, for instance the following text.
Please contact [email protected] for assistance. For general inquiries, you can email [email protected].
We can use the following RegEx to extract the emails in this text by matching them to a specific format.
\b[\w._%+-]+@[\w.-]+\.[A-Za-z]{2,4}\bThe expression above might look daunting but it will make sense when you get thet gist of RegEx. Lets break down this expression.
- \b: Word boundary to ensure that the match is a whole word and not part of a
larger sequence. For instance,
\bcat\bwill match the word cat but not scattered. - [\w._%+-]+: Matches the username part of the email address, allowing
alphanumeric characters, dots, underscores, percent signs, plus signs, and
hyphens. Here
\wis a metacharacter which is short forA-Za-z0-9.+outside of the brackets matches 1 or more of the proceeding character. - @: Matches the at symbol.
- [\w.-]+: Matches the domain name, allowing alphanumeric characters, dots, and hyphens.
- .: Matches the dot before the top-level domain.
- [A-Z|a-z]{2,4}: Matches the top-level domain (eg. .com) with at least two and at most 4 characters .
- \b: Word boundary to complete the match.
To summarise The following image illustrates what we have done.
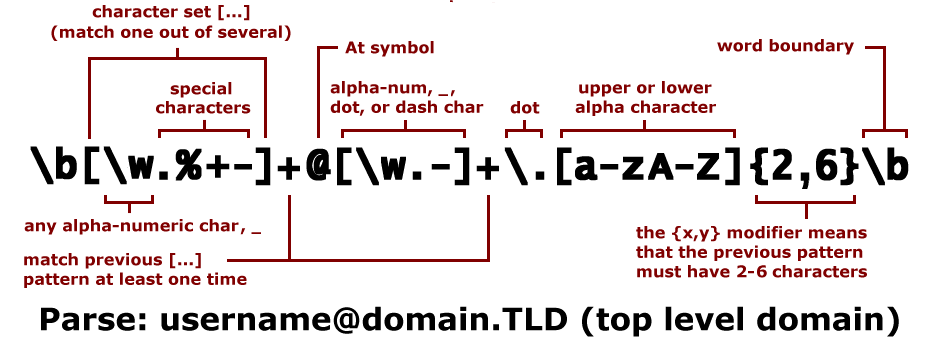
Image from: https://kottke.org/21/07/a-history-of-regular-expressions-and-artificial-intelligence
Even if it does not make sense yet that is fine.
Some important definitions in regex are the following.
Characters in a regex pattern that match themselves. For example, the regex abc will match the string "abc" in the input.
Special characters with a specific meaning in regex. Some common metacharacters include:
.(dot): Matches any single character except a newline.^: Anchors the regex at the start of the string.$: Anchors the regex at the end of the string.*: Matches 0 or more occurrences of the preceding character or group.+: Matches 1 or more occurrences of the preceding character or group.?: Matches 0 or 1 occurrence of the preceding character or group.|: Acts like a logical OR, allowing alternatives. For example,a|bmatches either "a" or "b".(): Groups characters together. For example,(abc)+matches one or more occurrences of "abc".
[ ]: Defines a character class. For example,[aeiou]matches any vowel.[^ ]: Negates a character class. For example,[^0-9]matches any non-digit character.
Control the number of occurrences of a character or group.
{n}: Matches exactly n occurrences.{n,}: Matches n or more occurrences.{n,m}: Matches between n and m occurrences.
Use a backslash \ to escape a metacharacter, allowing it to be treated as a literal character. For example, \. matches a literal period.
\d: Matches any digit (equivalent to[0-9]).\D: Matches any non-digit.\w: Matches any word character (alphanumeric + underscore).\W: Matches any non-word character.\s: Matches any whitespace character.\S: Matches any non-whitespace character.
Specify the position in the string where a match must occur.
\b: Word boundary.\B: Non-word boundary.^: Start of a line.$: End of a line.
i: Case-insensitive matching.g: Global matching (find all matches, not just the first).
.* is a common pattern to match any character (except newline) zero or more times.
I strongly believe that you learn regex by examples. So let's look a typical example of regex.
Suppose you have a list of email addresses:
Now, let's say you want to extract all the email addresses from the domain example.com. You can use the following regex:
\b[A-Za-z0-9._%+-]+@example\.com\bExplanation:
\b: Word boundary to ensure that we match the entire domain, not just a part of it. [A-Za-z0-9._%+-]+: Matches the username part of the email address, allowing letters, numbers, dots, underscores, percent signs, plus signs, and hyphens. @example.com: Matches the domain part, specifically example.com.
This pattern will match the following strings.
This is a simple example of regex that is meant to illustrate the power of it.
Here are some excersises, try them out on your own!
[email protected]
[email protected]
[email protected]
invalid.email@domainOutput should be:
Valid Email Addresses:
- [email protected]
- [email protected]
- [email protected]
Invalid Email Addresses:
- invalid.email@domainPhone numbers:
123-456-7890,
(555) 987-6543,
9876543210, 555-1234
Invalid:
12-345-6789,
555-98765,
abcdefghOuput should be:
Valid Phone Numbers:
- 123-456-7890
- (555) 987-6543
- 9876543210
- 555-1234
Invalid Phone Numbers:
- 12-345-6789
- 555-98765
- abcdefgh<p class="intro">This is a <strong>sample</strong> paragraph.</p>
<p>No class here.</p>
<div id="container" class="main">
<h1>Title</h1>
<p>Content</p>
</div>Output should be:
HTML Tags and Attributes:
- <p class="intro">
- <strong>
Attributes in <div>:
- id="container"
- class="main"You can execute RegEx using Python or R. Look at the resources for how to do this!