From 0efc6a5f6c6c0e432913e5ac0cd7a97354e26d2a Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 13:39:32 -0400
Subject: [PATCH 01/16] Create where-do-i-start section, and move table of
contents to beginning of document
---
README.md | 38 +++++++++++++++++++++++++-------------
1 file changed, 25 insertions(+), 13 deletions(-)
diff --git a/README.md b/README.md
index aeb81354..3ba2bac7 100644
--- a/README.md
+++ b/README.md
@@ -16,7 +16,25 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
+## Table of Contents
+
+- [What is Data Science?](#what-is-data-science)
+- [Where do I Start?](#where-do-i-start)
+- [Algorithms](#algorithms)
+- [Colleges](#colleges)
+- [MOOC's](#moocs)
+- [Podcasts](#podcasts)
+- [Books](#books)
+- [Book Deals](#book-deals-affiliated-🛍)
+- [YouTube Videos & Channels](#youtube-videos--channels)
+- [Toolboxes - Environment](#toolboxes---environment)
+- [Journals, Publications and Magazines](#journals-publications-and-magazines)
+- [Presentations](#presentations)
+- [Tutorials](#tutorials)
+
+
## What is Data Science?
+**[`^ back to top ^`](#awesome-data-science)**
Data Science is one of the hottest topics on the Computer and Internet farmland nowadays. People have gathered data from applications and systems until today and now is the time to analyze them. The next steps are producing suggestions from the data and creating predictions about the future. [Here](https://www.quora.com/Data-Science/What-is-data-science) you can find the biggest question for **Data Science** and hundreds of answers from experts.
@@ -31,22 +49,16 @@ Data Science is one of the hottest topics on the Computer and Internet farmland
| [a very short history of #datascience](https://www.forbes.com/sites/gilpress/2013/05/28/a-very-short-history-of-data-science/) | _The story of how data scientists became sexy is mostly the story of the coupling of the mature discipline of statistics with a very young one--computer science. The term “Data Science” has emerged only recently to specifically designate a new profession that is expected to make sense of the vast stores of big data. But making sense of data has a long history and has been discussed by scientists, statisticians, librarians, computer scientists and others for years. The following timeline traces the evolution of the term “Data Science” and its use, attempts to define it, and related terms._ |
|[Software Development Resources for Data Scientists](https://www.rstudio.com/blog/software-development-resources-for-data-scientists/)|Data scientists concentrate on making sense of data through exploratory analysis, statistics, and models. Software developers apply a separate set of knowledge with different tools. Although their focus may seem unrelated, data science teams can benefit from adopting software development best practices. Version control, automated testing, and other dev skills help create reproducible, production-ready code and tools.|
+## Where do I Start?
+**[`^ back to top ^`](#awesome-data-science)**
-## Learn Data Science
+While not strictly necessary, having a programming language is a crucial skill to be effective as a data scientist. Currently, the most popular language is _Python_, closely followed by _R_. Python is a general-purpose scripting language which sees applications in a wide variety of fields. R is a domain-specific language for statistics, which contains a lot of common statistics tools out of the box.
-Our favorite programming language is _Python_ nowadays for #DataScience. Python's - [Pandas](https://pandas.pydata.org/) library has full functionalities for collecting and analyzing data. We use [Anaconda](https://www.anaconda.com) to play with data and to create applications.
+Python is by far the most popular language in science, due in no small part to the ease at which it can be used and the vibrant ecosystem of user-generated packages. To install packages, there are two main methods: Pip (invoked as `pip install`), the package manager that comes bundled with Python, and [Anaconda](https://www.anaconda.com) (invoked as `conda install`), a powerful package manager that can install packages for Python, R, and can download executables like Git.
-- [Algorithms](#algorithms)
-- [Colleges](#colleges)
-- [MOOC's](#moocs)
-- [Podcasts](#podcasts)
-- [Books](#books)
-- [Book Deals](#book-deals-affiliated-🛍)
-- [YouTube Videos & Channels](#youtube-videos--channels)
-- [Toolboxes - Environment](#toolboxes---environment)
-- [Journals, Publications and Magazines](#journals-publications-and-magazines)
-- [Presentations](#presentations)
-- [Tutorials](#tutorials)
+Unlike R, Python was not built from the ground up with data science in mind, but there are plenty of third party libraries to make up for this. A much more exhaustive list of packages can be found later in this document, but these four packages are a good set of choices to start your data science journey with: [Scikit-Learn](https://scikit-learn.org/stable/index.html) is a general-purpose data science package which implements the most popular algorithms - it also includes rich documentation, tutorials, and examples of the models it implements. Even if you prefer to write your own implementations, Scikit-Learn is a valuable reference to the nuts-and-bolts behind many of the common algorithms you'll find. With [Pandas](https://pandas.pydata.org/), one can collect and analyze their data into a convenient table format. [Numpy](https://numpy.org/) provides very fast tooling for mathematical operations, with a focus on vectors and matrices. [Seaborn](https://seaborn.pydata.org/), itself based on the [Matplotlib](https://matplotlib.org/) package, is a quick way to generate beautiful visualizations of your data, with many good defaults available out of the box, as well as a gallery showing how to produce many commmon visualizations of your data.
+
+ When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the [Free courses](#free-courses) we've listed below!
## Algorithms
**[`^ back to top ^`](#awesome-data-science)**
From 023105a7a9def4a8f12f051ef7c691cf6d600ce0 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 13:59:03 -0400
Subject: [PATCH 02/16] Create training resources section with colleges, mooc,
and tutorials moved in
---
README.md | 100 ++++++++++++++++++++++++++++++------------------------
1 file changed, 55 insertions(+), 45 deletions(-)
diff --git a/README.md b/README.md
index 3ba2bac7..34657730 100644
--- a/README.md
+++ b/README.md
@@ -21,8 +21,7 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [What is Data Science?](#what-is-data-science)
- [Where do I Start?](#where-do-i-start)
- [Algorithms](#algorithms)
-- [Colleges](#colleges)
-- [MOOC's](#moocs)
+- [Training Resources](#training-resources)
- [Podcasts](#podcasts)
- [Books](#books)
- [Book Deals](#book-deals-affiliated-🛍)
@@ -30,7 +29,6 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Toolboxes - Environment](#toolboxes---environment)
- [Journals, Publications and Magazines](#journals-publications-and-magazines)
- [Presentations](#presentations)
-- [Tutorials](#tutorials)
## What is Data Science?
@@ -140,29 +138,44 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- Transformer
- Conditional Random Field (CRF)
-## COLLEGES
+## Training Resources
**[`^ back to top ^`](#awesome-data-science)**
-- [A list of colleges and universities offering degrees in data science.](https://github.com/ryanswanstrom/awesome-datascience-colleges)
-- [Data Science Degree @ Berkeley](https://ischoolonline.berkeley.edu/data-science/)
-- [Data Science Degree @ UVA](https://datascience.virginia.edu/)
-- [Data Science Degree @ Wisconsin](https://datasciencedegree.wisconsin.edu/)
-- [MS in Computer Information Systems @ Boston University](https://www.bu.edu/online/programs/graduate-programs/computer-information-systems-masters-degree/)
-- [MS in Business Analytics @ ASU Online](https://asuonline.asu.edu/online-degree-programs/graduate/master-science-business-analytics/)
-- [MS in Applied Data Science @ Syracuse](https://ischool.syr.edu/academics/applied-data-science-masters-degree/)
-- [M.S. Management & Data Science @ Leuphana](https://www.leuphana.de/en/graduate-school/masters-programmes/management-data-science.html)
-- [Master of Data Science @ Melbourne University](https://study.unimelb.edu.au/find/courses/graduate/master-of-data-science/#overview)
-- [Msc in Data Science @ The University of Edinburgh](https://www.ed.ac.uk/studying/postgraduate/degrees/index.php?r=site/view&id=902)
-- [Master of Management Analytics @ Queen's University](https://smith.queensu.ca/grad_studies/mma/index.php)
-- [Master of Data Science @ Illinois Institute of Technology](https://www.iit.edu/academics/programs/data-science-mas)
-- [Master of Applied Data Science @ The University of Michigan](https://www.si.umich.edu/programs/master-applied-data-science-online)
-- [Master Data Science and Artificial Intelligence @ Eindhoven University of Technology](https://www.tue.nl/en/education/graduate-school/master-data-science-and-artificial-intelligence/)
-- [Master's Degree in Data Science and Computer Engineering @ University of Granada](https://masteres.ugr.es/datcom/)
+How do you learn data science? By doing data science, of course! Okay, okay - that might not be particularly helpful when you're first starting out. In this section, we've listed some learning resources, in a rough order from least to greatest commitment - [Tutorials](#tutorials), [Massively Open Online Courses (MOOCs)](#moocs), [Intensive Programs](#intensive-programs), and [colleges](#colleges).
+
+
+### Tutorials
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [1000 Data Science Projects](https://cloud.blobcity.com/#/ps/explore) you can run on the browser with ipyton.
+- [#tidytuesday](https://github.com/rfordatascience/tidytuesday) A weekly data project aimed at the R ecosystem.
+- [Data science your way](https://github.com/jadianes/data-science-your-way)
+- [PySpark Cheatsheet](https://github.com/kevinschaich/pyspark-cheatsheet)
+- [Machine Learning, Data Science and Deep Learning with Python ](https://www.manning.com/livevideo/machine-learning-data-science-and-deep-learning-with-python)
+- [How To Label Data](https://www.lighttag.io/how-to-label-data/)
+- [Your Guide to Latent Dirichlet Allocation](https://medium.com/@lettier/how-does-lda-work-ill-explain-using-emoji-108abf40fa7d)
+- [Over 1000 Data Science Online Courses at Classpert Online Search Engine](https://classpert.com/search/data-science)
+- [Tutorials of source code from the book Genetic Algorithms with Python by Clinton Sheppard](https://github.com/handcraftsman/GeneticAlgorithmsWithPython)
+- [Tutorials to get started on signal processings for machine learning](https://github.com/jinglescode/python-signal-processing)
+- [Realtime deployment](https://www.microprediction.com/python-1) Tutorial on Python time-series model deployment.
+- [Python for Data Science: A Beginner’s Guide](https://learntocodewith.me/posts/python-for-data-science/)
+- [Minimum Viable Study Plan for Machine Learning Interviews](https://github.com/khangich/machine-learning-interview)
+- [Understand and Know Machine Learning Engineering by Building Solid Projects](http://mlzoomcamp.com/)
+
+
+### Free Courses
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [Data Scientist with R](https://www.datacamp.com/tracks/data-scientist-with-r)
+- [Data Scientist with Python](https://www.datacamp.com/tracks/data-scientist-with-python)
+- [Genetic Algorithms OCW Course](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/lecture-1-introduction-and-scope/)
+- [AI Expert Roadmap](https://github.com/AMAI-GmbH/AI-Expert-Roadmap) - Roadmap to becoming an Artificial Intelligence Expert
+- [Convex Optimization](https://www.edx.org/course/convex-optimization) - Convex Optimization (basics of convex analysis; least-squares, linear and quadratic programs, semidefinite programming, minimax, extremal volume, and other problems; optimality conditions, duality theory...)
+- [Skillcombo - Data Science](https://skillcombo.com/courses/development/data-science/free/) - 1000+ free online Data Science courses
+- [Learning from Data](https://home.work.caltech.edu/telecourse.html) - Introduction to machine learning covering basic theory, algorithms and applications
-## Intensive Programs
-- [S2DS](https://www.s2ds.org/)
-## MOOC's
+### MOOC's
**[`^ back to top ^`](#awesome-data-science)**
- [Coursera Introduction to Data Science](https://www.coursera.org/specializations/data-science)
@@ -203,33 +216,30 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- [Data Scientist with Python](https://app.datacamp.com/learn/career-tracks/data-scientist-with-python)
-## Tutorials
+### Intensive Programs
**[`^ back to top ^`](#awesome-data-science)**
-- [1000 Data Science Projects](https://cloud.blobcity.com/#/ps/explore) you can run on the browser with ipyton.
-- [#tidytuesday](https://github.com/rfordatascience/tidytuesday) A weekly data project aimed at the R ecosystem.
-- [Data science your way](https://github.com/jadianes/data-science-your-way)
-- [PySpark Cheatsheet](https://github.com/kevinschaich/pyspark-cheatsheet)
-- [Machine Learning, Data Science and Deep Learning with Python ](https://www.manning.com/livevideo/machine-learning-data-science-and-deep-learning-with-python)
-- [How To Label Data](https://www.lighttag.io/how-to-label-data/)
-- [Your Guide to Latent Dirichlet Allocation](https://medium.com/@lettier/how-does-lda-work-ill-explain-using-emoji-108abf40fa7d)
-- [Over 1000 Data Science Online Courses at Classpert Online Search Engine](https://classpert.com/search/data-science)
-- [Tutorials of source code from the book Genetic Algorithms with Python by Clinton Sheppard](https://github.com/handcraftsman/GeneticAlgorithmsWithPython)
-- [Tutorials to get started on signal processings for machine learning](https://github.com/jinglescode/python-signal-processing)
-- [Realtime deployment](https://www.microprediction.com/python-1) Tutorial on Python time-series model deployment.
-- [Python for Data Science: A Beginner’s Guide](https://learntocodewith.me/posts/python-for-data-science/)
-- [Minimum Viable Study Plan for Machine Learning Interviews](https://github.com/khangich/machine-learning-interview)
-- [Understand and Know Machine Learning Engineering by Building Solid Projects](http://mlzoomcamp.com/)
+- [S2DS](https://www.s2ds.org/)
-### Free Courses
-- [Data Scientist with R](https://www.datacamp.com/tracks/data-scientist-with-r)
-- [Data Scientist with Python](https://www.datacamp.com/tracks/data-scientist-with-python)
-- [Genetic Algorithms OCW Course](https://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-034-artificial-intelligence-fall-2010/lecture-videos/lecture-1-introduction-and-scope/)
-- [AI Expert Roadmap](https://github.com/AMAI-GmbH/AI-Expert-Roadmap) - Roadmap to becoming an Artificial Intelligence Expert
-- [Convex Optimization](https://www.edx.org/course/convex-optimization) - Convex Optimization (basics of convex analysis; least-squares, linear and quadratic programs, semidefinite programming, minimax, extremal volume, and other problems; optimality conditions, duality theory...)
-- [Skillcombo - Data Science](https://skillcombo.com/courses/development/data-science/free/) - 1000+ free online Data Science courses
-- [Learning from Data](https://home.work.caltech.edu/telecourse.html) - Introduction to machine learning covering basic theory, algorithms and applications
+### Colleges
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [A list of colleges and universities offering degrees in data science.](https://github.com/ryanswanstrom/awesome-datascience-colleges)
+- [Data Science Degree @ Berkeley](https://ischoolonline.berkeley.edu/data-science/)
+- [Data Science Degree @ UVA](https://datascience.virginia.edu/)
+- [Data Science Degree @ Wisconsin](https://datasciencedegree.wisconsin.edu/)
+- [MS in Computer Information Systems @ Boston University](https://www.bu.edu/online/programs/graduate-programs/computer-information-systems-masters-degree/)
+- [MS in Business Analytics @ ASU Online](https://asuonline.asu.edu/online-degree-programs/graduate/master-science-business-analytics/)
+- [MS in Applied Data Science @ Syracuse](https://ischool.syr.edu/academics/applied-data-science-masters-degree/)
+- [M.S. Management & Data Science @ Leuphana](https://www.leuphana.de/en/graduate-school/masters-programmes/management-data-science.html)
+- [Master of Data Science @ Melbourne University](https://study.unimelb.edu.au/find/courses/graduate/master-of-data-science/#overview)
+- [Msc in Data Science @ The University of Edinburgh](https://www.ed.ac.uk/studying/postgraduate/degrees/index.php?r=site/view&id=902)
+- [Master of Management Analytics @ Queen's University](https://smith.queensu.ca/grad_studies/mma/index.php)
+- [Master of Data Science @ Illinois Institute of Technology](https://www.iit.edu/academics/programs/data-science-mas)
+- [Master of Applied Data Science @ The University of Michigan](https://www.si.umich.edu/programs/master-applied-data-science-online)
+- [Master Data Science and Artificial Intelligence @ Eindhoven University of Technology](https://www.tue.nl/en/education/graduate-school/master-data-science-and-artificial-intelligence/)
+- [Master's Degree in Data Science and Computer Engineering @ University of Granada](https://masteres.ugr.es/datcom/)
## Toolboxes - Environment
From 537319ad1696c08170151049e152e7a63686de28 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 14:01:02 -0400
Subject: [PATCH 03/16] Fix capitalization in section titles
---
README.md | 8 ++++----
1 file changed, 4 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index 34657730..eab006c8 100644
--- a/README.md
+++ b/README.md
@@ -141,7 +141,7 @@ These are some Machine Learning and Data Mining algorithms and models help you t
## Training Resources
**[`^ back to top ^`](#awesome-data-science)**
-How do you learn data science? By doing data science, of course! Okay, okay - that might not be particularly helpful when you're first starting out. In this section, we've listed some learning resources, in a rough order from least to greatest commitment - [Tutorials](#tutorials), [Massively Open Online Courses (MOOCs)](#moocs), [Intensive Programs](#intensive-programs), and [colleges](#colleges).
+How do you learn data science? By doing data science, of course! Okay, okay - that might not be particularly helpful when you're first starting out. In this section, we've listed some learning resources, in a rough order from least to greatest commitment - [Tutorials](#tutorials), [Massively Open Online Courses (MOOCs)](#moocs), [Intensive Programs](#intensive-programs), and [Colleges](#colleges).
### Tutorials
@@ -373,7 +373,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
## Deep Learning
-### pytorch
+### PyTorch
* [PyTorch](https://github.com/pytorch/pytorch)
* [torchvision](https://github.com/pytorch/vision)
* [torchtext](https://github.com/pytorch/text)
@@ -388,7 +388,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [pyro](https://github.com/pyro-ppl/pyro)
* [Catalyst](https://github.com/catalyst-team/catalyst)
* [pytorch_tabular](https://github.com/manujosephv/pytorch_tabular)
-### tensorflow
+### TensorFlow
* [TensorFlow](https://github.com/tensorflow/tensorflow)
* [TensorLayer](https://github.com/tensorlayer/TensorLayer)
* [TFLearn](https://github.com/tflearn/tflearn)
@@ -407,7 +407,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [TF-Agents](https://github.com/tensorflow/agents)
* [TensorForce](https://github.com/tensorforce/tensorforce)
-### keras
+### Keras
* [Keras](https://keras.io)
* [keras-contrib](https://github.com/keras-team/keras-contrib)
From 462dd10035f91819f6a00954c466a2f787916375 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 14:53:04 -0400
Subject: [PATCH 04/16] Fix section header levels
---
README.md | 33 +++++++++++++++++++--------------
1 file changed, 19 insertions(+), 14 deletions(-)
diff --git a/README.md b/README.md
index eab006c8..1e51e429 100644
--- a/README.md
+++ b/README.md
@@ -592,7 +592,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Dive into Deep Learning](https://d2l.ai/)
- [Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/) - Free GitHub version
-# Book Deals (Affiliated) 🛍
+## Book Deals (Affiliated) 🛍
- [eBook sale - Save up to 45% on eBooks!](https://www.manning.com/?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=ebook_sale_8_8_22)
@@ -602,18 +602,22 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Causal Inference for Data Science](https://www.manning.com/books/causal-inference-for-data-science?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=book_ruizdevilla_causal_6_6_22)
- [Data for All](https://www.manning.com/books/data-for-all?utm_source=mikrobusiness&utm_medium=affiliate)
-# Socialize
+## Socialize
**[`^ back to top ^`](#awesome-data-science)**
+Below are some Social Media links. Connect with other data scientists!
+
- [Bloggers](#bloggers)
- [Facebook Accounts](#facebook-accounts)
- [Twitter Accounts](#twitter-accounts)
- [Newsletters](#newsletters)
+- [YouTube Videos and Channels](#youtube-videos--channels)
- [Telegram Channels](#telegram-channels)
- [Slack Communities](#slack-communities)
+- [GitHub Groups](#github-groups)
- [Data Science Competitions](#competitions)
-## Bloggers
+### Bloggers
**[`^ back to top ^`](#awesome-data-science)**
- [Wes McKinney](https://wesmckinney.com/archives.html) - Wes McKinney Archives.
@@ -702,7 +706,8 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Maria Khalusova](https://www.mariakhalusova.com/) - Data science blog
- [Aditi Rastogi](https://medium.com/@aditi2507rastogi) - ML,DL,Data Science blog
-## Facebook Accounts
+
+### Facebook Accounts
**[`^ back to top ^`](#awesome-data-science)**
- [Data](https://www.facebook.com/data)
@@ -728,7 +733,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [The Data Science Blog](https://www.facebook.com/theDataScienceBlog/)
-## Twitter Accounts
+### Twitter Accounts
**[`^ back to top ^`](#awesome-data-science)**
| Twitter | Description |
@@ -800,7 +805,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
| [Alexey Grigorev](https://twitter.com/Al_Grigor) | Data science author |
-## Newsletters
+### Newsletters
**[`^ back to top ^`](#awesome-data-science)**
- [AI Digest](https://aidigest.net/). A weekly newsletter to keep up to date with AI, machine learning, and data science. [Archive](https://aidigest.net/digests).
@@ -808,7 +813,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [The Analytics Engineering Roundup](https://roundup.getdbt.com/about). A newsletter about data science. [Archive](https://roundup.getdbt.com/archive).
-## Youtube Videos & Channels
+### YouTube Videos & Channels
**[`^ back to top ^`](#awesome-data-science)**
- [What is machine learning?](https://www.youtube.com/watch?v=WXHM_i-fgGo)
@@ -842,7 +847,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
-## Telegram Channels
+### Telegram Channels
**[`^ back to top ^`](#awesome-data-science)**
- [Open Data Science](https://t.me/opendatascience) – First Telegram Data Science channel. Covering all technical and popular staff about anything related to Data Science: AI, Big Data, Machine Learning, Statistics, general Math and the applications of former.
@@ -850,13 +855,13 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Machinelearning](https://t.me/ai_machinelearning_big_data) – Daily ML news.
-## Slack Communities
+### Slack Communities
[top](#awesome-data-science)
- [DataTalks.Club](https://datatalks.club)
-# Github Groups
+## GitHub Groups
- [Berkeley Institute for Data Science](https://github.com/BIDS)
@@ -871,14 +876,14 @@ Some data mining competition platforms
- [Microprediction](https://www.microprediction.com/python-1)
-# Fun
+## Fun
- [Infographic](#infographic)
- [Data Sets](#data-sets)
- [Comics](#comics)
-## Infographic
+### Infographic
**[`^ back to top ^`](#awesome-data-science)**
| Preview | Description |
@@ -897,7 +902,7 @@ Some data mining competition platforms
| [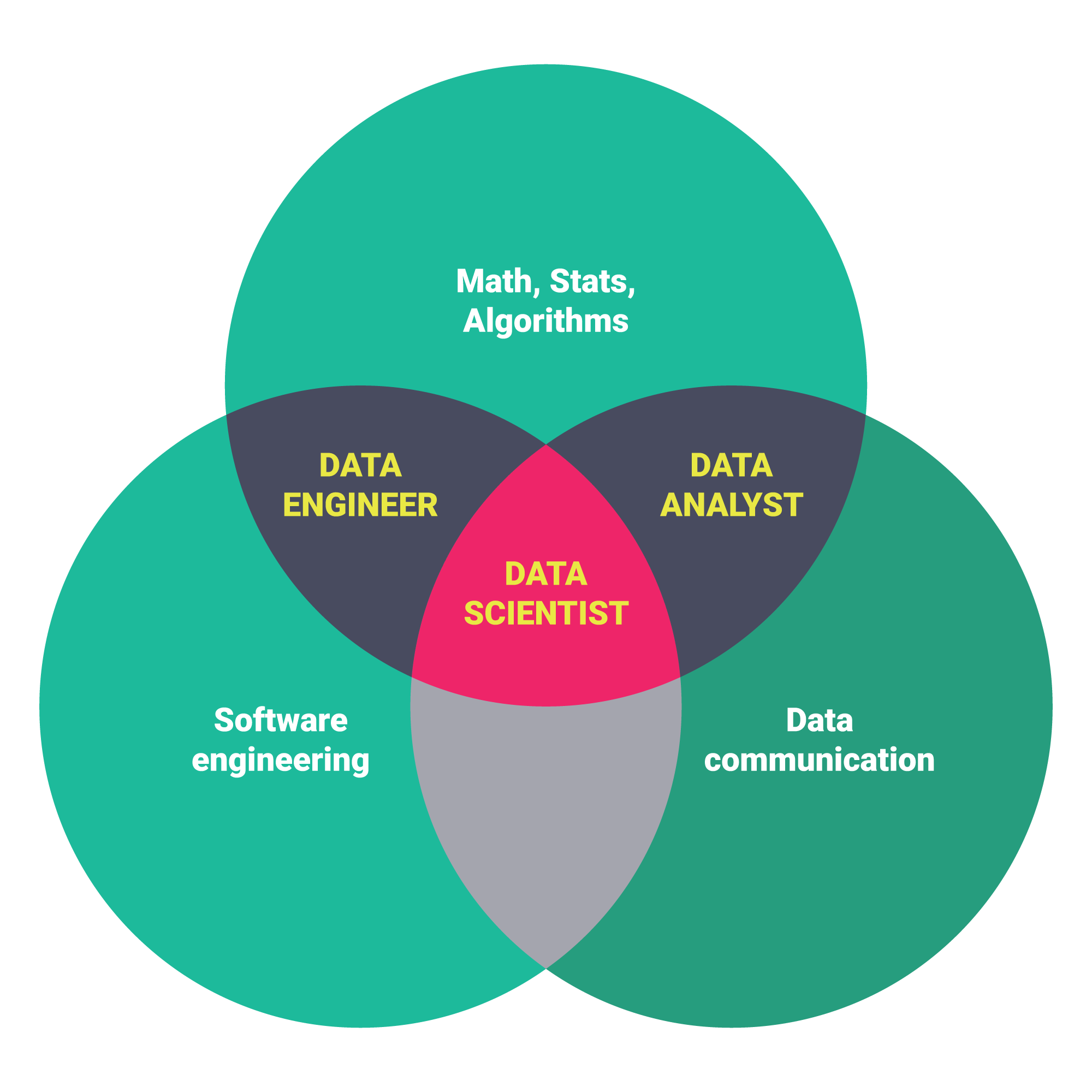 ](https://www.springboard.com/blog/wp-content/uploads/2016/03/20160324_springboard_vennDiagram.png) | Different Data Science Skills and Roles from [this article](https://www.springboard.com/blog/data-science-career-paths-different-roles-industry/) by Springboard |
| [
](https://www.springboard.com/blog/wp-content/uploads/2016/03/20160324_springboard_vennDiagram.png) | Different Data Science Skills and Roles from [this article](https://www.springboard.com/blog/data-science-career-paths-different-roles-industry/) by Springboard |
| [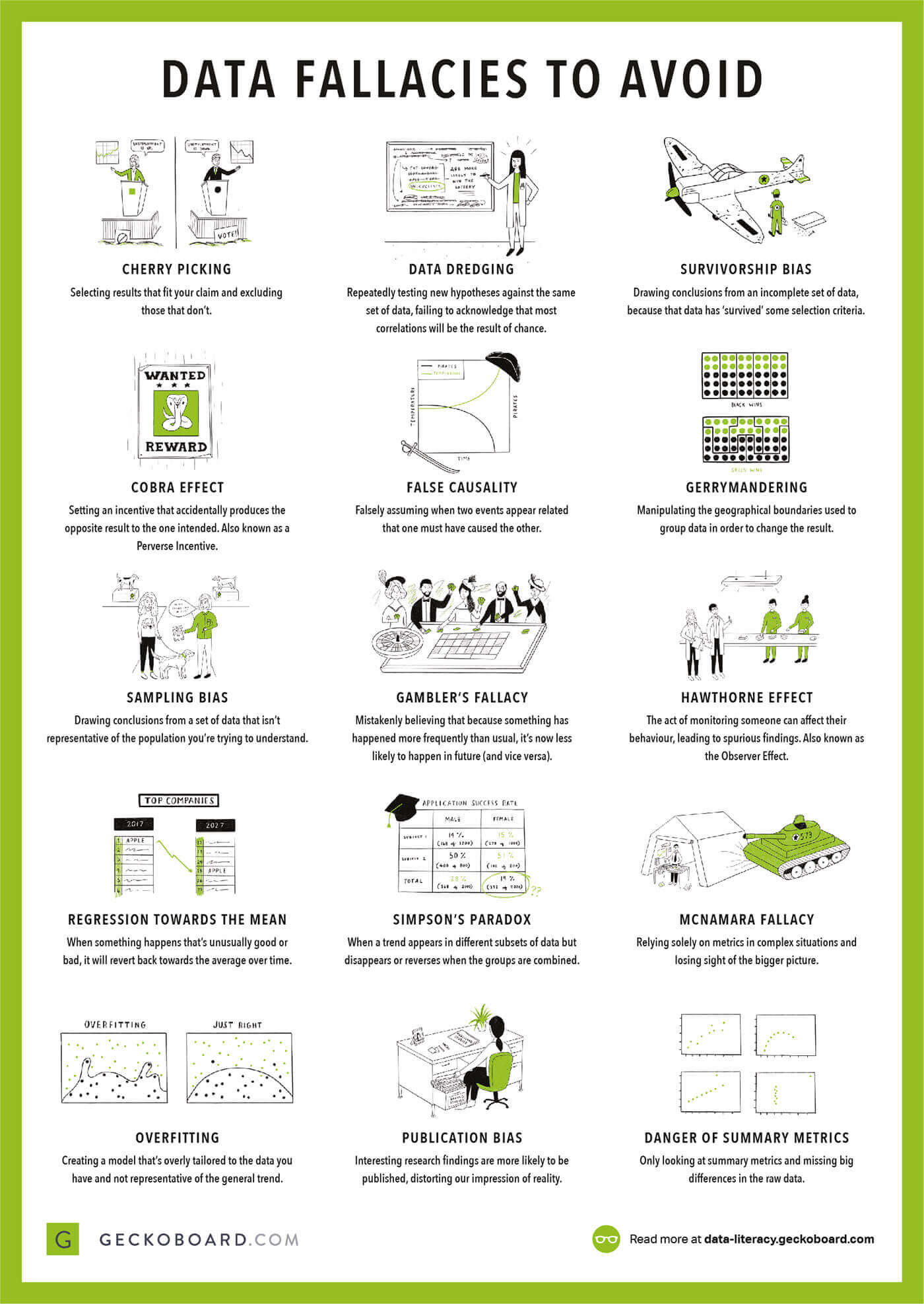 ](https://data-literacy.geckoboard.com/poster/) | A simple and friendly way of teaching your non-data scientist/non-statistician colleagues [how to avoid mistakes with data](https://data-literacy.geckoboard.com/poster/). From Geckoboard's [Data Literacy Lessons](https://data-literacy.geckoboard.com/). |
-## Data Sets
+### Data Sets
**[`^ back to top ^`](#awesome-data-science)**
- [Academic Torrents](https://academictorrents.com/)
@@ -954,7 +959,7 @@ Some data mining competition platforms
- [Enron Email Dataset](https://www.cs.cmu.edu/~./enron/)
- [5000 Images of Clothes](https://github.com/alexeygrigorev/clothing-dataset)
-## Comics
+### Comics
**[`^ back to top ^`](#awesome-data-science)**
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
From d6c0dafcb52ff29c1feba11818b9490cc05b6aaa Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:03:22 -0400
Subject: [PATCH 05/16] Update table of contents
---
README.md | 8 ++++++--
1 file changed, 6 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 1e51e429..39234e7f 100644
--- a/README.md
+++ b/README.md
@@ -20,13 +20,17 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [What is Data Science?](#what-is-data-science)
- [Where do I Start?](#where-do-i-start)
-- [Algorithms](#algorithms)
- [Training Resources](#training-resources)
+ - [Tutorials](#tutorials)
+ - [Free Courses](#free-courses)
+ - [Massively Open Online Courses](#moocs)
+ - [Intensive Programs](#intensive-programs)
+ - [Colleges](#colleges)
+- [The Data Science Toolbox](#the-data-science-toolbox)
- [Podcasts](#podcasts)
- [Books](#books)
- [Book Deals](#book-deals-affiliated-🛍)
- [YouTube Videos & Channels](#youtube-videos--channels)
-- [Toolboxes - Environment](#toolboxes---environment)
- [Journals, Publications and Magazines](#journals-publications-and-magazines)
- [Presentations](#presentations)
From db7d8861b03b70b81b099cf064080a6778ce5438 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:10:27 -0400
Subject: [PATCH 06/16] Re-order software section and update TOC
---
README.md | 377 ++++++++++++++++++++++++++++--------------------------
1 file changed, 196 insertions(+), 181 deletions(-)
diff --git a/README.md b/README.md
index 39234e7f..8b504d38 100644
--- a/README.md
+++ b/README.md
@@ -27,6 +27,20 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Intensive Programs](#intensive-programs)
- [Colleges](#colleges)
- [The Data Science Toolbox](#the-data-science-toolbox)
+ - [Algorithms](#algorithms)
+ - [Supervised Learning](#supervised-learning)
+ - [Unsupervised Learning](#unsupervised-learning)
+ - [Semi-Supervised Learning](#semi-supervised-learning)
+ - [Reinforcement Learning](#reinforcement-learning)
+ - [Data Mining Algorithms](#data-mining-algorithms)
+ - [Deep Learning Architectures](#deep-learning-architectures)
+ - [General Machine Learning Packages](#general-machine-learning-packages)
+ - [Deep Learning Packages](#deep-learning-packages)
+ - [PyTorch Ecosystem](#pytorch-ecosystem)
+ - [TensorFlow Ecosystem](#tensorflow-ecosystem)
+ - [Keras Ecosystem](#keras-ecosystem)
+ - [Visualization Tools](#visualization-tools)
+ - [Miscellaneous Tools](#miscellaneous-tools)
- [Podcasts](#podcasts)
- [Books](#books)
- [Book Deals](#book-deals-affiliated-🛍)
@@ -60,87 +74,7 @@ Python is by far the most popular language in science, due in no small part to t
Unlike R, Python was not built from the ground up with data science in mind, but there are plenty of third party libraries to make up for this. A much more exhaustive list of packages can be found later in this document, but these four packages are a good set of choices to start your data science journey with: [Scikit-Learn](https://scikit-learn.org/stable/index.html) is a general-purpose data science package which implements the most popular algorithms - it also includes rich documentation, tutorials, and examples of the models it implements. Even if you prefer to write your own implementations, Scikit-Learn is a valuable reference to the nuts-and-bolts behind many of the common algorithms you'll find. With [Pandas](https://pandas.pydata.org/), one can collect and analyze their data into a convenient table format. [Numpy](https://numpy.org/) provides very fast tooling for mathematical operations, with a focus on vectors and matrices. [Seaborn](https://seaborn.pydata.org/), itself based on the [Matplotlib](https://matplotlib.org/) package, is a quick way to generate beautiful visualizations of your data, with many good defaults available out of the box, as well as a gallery showing how to produce many commmon visualizations of your data.
- When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the [Free courses](#free-courses) we've listed below!
-
-## Algorithms
-**[`^ back to top ^`](#awesome-data-science)**
-
-These are some Machine Learning and Data Mining algorithms and models help you to understand your data and derive meaning from it.
-
-### Supervised Learning
-
-- Regression
-- [Linear Regression](https://en.wikipedia.org/wiki/Linear_regression)
-- Ordinary Least Squares
-- Logistic Regression
-- Stepwise Regression
-- Multivariate Adaptive Regression Splines
-- Locally Estimated Scatterplot Smoothing
-- Classification
- - k-nearest neighbor
- - Support Vector Machines
- - Decision Trees
- - ID3 algorithm
- - C4.5 algorithm
-- Ensemble Learning
-- Boosting
-- Bagging
-- Random Forest
-- AdaBoost
-
-### Unsupervised Learning
-- Clustering
- - Hierchical clustering
- - k-means
- - Fuzzy clustering
- - Mixture models
-- Dimension Reduction
- - Principal Component Analysis (PCA)
- - t-SNE
-- Neural Networks
-- Self-organizing map
-- Adaptive resonance theory
-- Hidden Markov Models (HMM)
-
-### Semi-Supervised Learning
-
-- S3VM
-- Clustering
-- Generative models
-- Low-density separation
-- Laplacian regularization
-- Heuristic approaches
-
-### Reinforcement Learning
-
-- Q Learning
-- SARSA (State-Action-Reward-State-Action) algorithm
-- Temporal difference learning
-
-### Data Mining Algorithms
-
-- C4.5
-- k-Means
-- SVM
-- Apriori
-- EM
-- PageRank
-- AdaBoost
-- kNN
-- Naive Bayes
-- CART
-
-### Deep Learning architectures
-
-- Multilayer Perceptron
-- Convolutional Neural Network (CNN)
-- Recurrent Neural Network (RNN)
-- Boltzmann Machines
-- Autoencoder
-- Generative Adversarial Network (GAN)
-- Self-Organized Maps
-- Transformer
-- Conditional Random Field (CRF)
+ When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the [Free courses](#free-courses) we've listed below!
## Training Resources
**[`^ back to top ^`](#awesome-data-science)**
@@ -245,104 +179,92 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Master Data Science and Artificial Intelligence @ Eindhoven University of Technology](https://www.tue.nl/en/education/graduate-school/master-data-science-and-artificial-intelligence/)
- [Master's Degree in Data Science and Computer Engineering @ University of Granada](https://masteres.ugr.es/datcom/)
+## The Data Science Toolbox
+**[`^ back to top ^`](#awesome-data-science)**
+
+This section is a collection of packages, tools, algorithms, and other useful items in the data science world.
-## Toolboxes - Environment
+### Algorithms
**[`^ back to top ^`](#awesome-data-science)**
-| Link | Description |
-| --- | --- |
-| [The Data Science Lifecycle Process](https://github.com/dslp/dslp) | The Data Science Lifecycle Process is a process for taking data science teams from Idea to Value repeatedly and sustainably. The process is documented in this repo |
-| [Data Science Lifecycle Template Repo](https://github.com/dslp/dslp-repo-template) | Template repository for data science lifecycle project |
-| [RexMex](https://github.com/AstraZeneca/rexmex) | A general purpose recommender metrics library for fair evaluation. |
-| [ChemicalX](https://github.com/AstraZeneca/chemicalx) | A PyTorch based deep learning library for drug pair scoring. |
-| [PyTorch Geometric Temporal](https://github.com/benedekrozemberczki/pytorch_geometric_temporal) | Representation learning on dynamic graphs. |
-| [Little Ball of Fur](https://github.com/benedekrozemberczki/littleballoffur) | A graph sampling library for NetworkX with a Scikit-Learn like API. |
-| [Karate Club](https://github.com/benedekrozemberczki/karateclub) | An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API. |
-| [ML Workspace](https://github.com/ml-tooling/ml-workspace) | All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code) |
-| [Neptune.ai](https://neptune.ai) | Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility. |
-| [steppy](https://github.com/minerva-ml/steppy) | Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design. |
-| [steppy-toolkit](https://github.com/minerva-ml/steppy-toolkit) | Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective. |
-| [Datalab from Google](https://cloud.google.com/datalab/docs/) | easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively. |
-| [Hortonworks Sandbox](https://www.cloudera.com/downloads/hortonworks-sandbox.html) | is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials. |
-| [R](https://www.r-project.org/) | is a free software environment for statistical computing and graphics. |
-| [Tidyverse](https://www.tidyverse.org/) | is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. |
-| [RStudio](https://www.rstudio.com) | IDE – powerful user interface for R. It’s free and open source, works on Windows, Mac, and Linux. |
-| [Python - Pandas - Anaconda](https://www.anaconda.com) | Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing |
-| [Pandas GUI](https://github.com/adrotog/PandasGUI) | Pandas GUI |
-| [Scikit-Learn](https://scikit-learn.org/stable/) | Machine Learning in Python |
-| [NumPy](https://numpy.org/) | NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays. |
-| [Vaex](https://vaex.io/) | Vaex is a Python library that allows you to visualize large datasets and calculate statistics at high speeds. |
-| [SciPy](https://scipy.org/) | SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization.
-| [Data Science Toolbox](https://www.coursera.org/learn/data-scientists-tools) | Coursera Course |
-| [Data Science Toolbox](https://datasciencetoolbox.org/) | Blog |
-| [Wolfram Data Science Platform](https://www.wolfram.com/data-science-platform/) | Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generating rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language. |
-| [Datadog](https://www.datadoghq.com/) | Solutions, code, and devops for high-scale data science. |
-| [Variance](https://variancecharts.com/) | Build powerful data visualizations for the web without writing JavaScript |
-| [Kite Development Kit](https://kitesdk.org/docs/current/index.html) | The Kite Software Development Kit (Apache License, Version 2.0) , or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem. |
-| [Domino Data Labs](https://www.dominodatalab.com) | Run, scale, share, and deploy your models — without any infrastructure or setup. |
-| [Apache Flink](https://flink.apache.org/) | A platform for efficient, distributed, general-purpose data processing. |
-| [Apache Hama](https://hama.apache.org/) | Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce. |
-| [Weka](https://www.cs.waikato.ac.nz/ml/weka/) | Weka is a collection of machine learning algorithms for data mining tasks. |
-| [Octave](https://www.gnu.org/software/octave/) | GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab) |
-| [Apache Spark](https://spark.apache.org/) | Lightning-fast cluster computing |
-| [Hydrosphere Mist](https://github.com/Hydrospheredata/mist) | a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services. |
-| [Data Mechanics](https://www.datamechanics.co) | A data science and engineering platform making Apache Spark more developer-friendly and cost-effective. |
-| [Caffe](https://caffe.berkeleyvision.org/) | Deep Learning Framework |
-| [Torch](https://torch.ch/) | A SCIENTIFIC COMPUTING FRAMEWORK FOR LUAJIT |
-| [Nervana's python based Deep Learning Framework](https://github.com/NervanaSystems/neon) | . |
-| [Skale](https://github.com/skale-me/skale) | High performance distributed data processing in NodeJS |
-| [Aerosolve](https://airbnb.io/aerosolve/) | A machine learning package built for humans. |
-| [Intel framework](https://github.com/intel/idlf) | Intel® Deep Learning Framework |
-| [Datawrapper](https://www.datawrapper.de/) | An open source data visualization platform helping everyone to create simple, correct and embeddable charts. Also at [github.com](https://github.com/datawrapper/datawrapper) |
-| [Tensor Flow](https://www.tensorflow.org/) | TensorFlow is an Open Source Software Library for Machine Intelligence |
-| [Natural Language Toolkit](https://www.nltk.org/) | An introductory yet powerful toolkit for natural language processing and classification |
-| [Annotation Lab](https://www.johnsnowlabs.com/annotation-lab/) | Free End-to-End No-Code platform for text annotation and DL model training/tuning. Out-of-the-box support for Named Entity Recognition, Classification, Relation extraction and Assertion Status Spark NLP models. Unlimited support for users, teams, projects, documents. |
-| [nlp-toolkit for node.js](https://www.npmjs.com/package/nlp-toolkit) | . |
-| [Julia](https://julialang.org) | high-level, high-performance dynamic programming language for technical computing |
-| [IJulia](https://github.com/JuliaLang/IJulia.jl) | a Julia-language backend combined with the Jupyter interactive environment |
-| [Apache Zeppelin](https://zeppelin.apache.org/) | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more |
-| [Featuretools](https://github.com/alteryx/featuretools) | An open source framework for automated feature engineering written in python |
-| [Optimus](https://github.com/hi-primus/optimus) | Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend. |
-| [Albumentations](https://github.com/albumentations-team/albumentations) | А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops. |
-| [DVC](https://github.com/iterative/dvc) | An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files. |
-| [Lambdo](https://github.com/asavinov/lambdo) | is a workflow engine which significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation. |
-| [Feast](https://github.com/feast-dev/feast) | A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving. |
-| [Polyaxon](https://github.com/polyaxon/polyaxon) | A platform for reproducible and scalable machine learning and deep learning. |
-| [LightTag](https://www.lighttag.io/) | Text Annotation Tool for teams |
-| [UBIAI](https://ubiai.tools) | Easy-to-use text annotation tool for teams with most comprehensive auto-annotation features. Supports NER, relations and document classification as well as OCR annotation for invoice labeling |
-| [Trains](https://github.com/allegroai/clearml) | Auto-Magical Experiment Manager, Version Control & DevOps for AI |
-| [Hopsworks](https://github.com/logicalclocks/hopsworks) | Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale. |
-| [MindsDB](https://github.com/mindsdb/mindsdb) | MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code. |
-| [Lightwood](https://github.com/mindsdb/lightwood) | A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code. |
-| [AWS Data Wrangler](https://github.com/awslabs/aws-data-wrangler) | An open-source Python package that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services (Amazon Redshift, AWS Glue, Amazon Athena, Amazon EMR, etc). |
-| [Amazon Rekognition](https://aws.amazon.com/rekognition/) | AWS Rekognition is a service that lets developers working with Amazon Web Services add image analysis to their applications. Catalog assets, automate workflows, and extract meaning from your media and applications.|
-| [Amazon Textract](https://aws.amazon.com/textract/) | Automatically extract printed text, handwriting, and data from any document. |
-| [Amazon Lookout for Vision](https://aws.amazon.com/lookout-for-vision/) | Spot product defects using computer vision to automate quality inspection. Identify missing product components, vehicle and structure damage, and irregularities for comprehensive quality control.|
-| [Amazon CodeGuru](https://aws.amazon.com/codeguru/) | Automate code reviews and optimize application performance with ML-powered recommendations.|
-| [CML](https://github.com/iterative/cml) | An open source toolkit for using continuous integration in data science projects. Automatically train and test models in production-like environments with GitHub Actions & GitLab CI, and autogenerate visual reports on pull/merge requests. |
-| [Dask](https://dask.org/) | An open source Python library to painlessly transition your analytics code to distributed computing systems (Big Data) |
-| [Statsmodels](https://www.statsmodels.org/stable/index.html) | A Python-based inferential statistics, hypothesis testing and regression framework |
-| [Gensim](https://radimrehurek.com/gensim/) | An open-source library for topic modeling of natural language text |
-| [spaCy](https://spacy.io/) | A performant natural language processing toolkit |
-| [Grid Studio](https://github.com/ricklamers/gridstudio) | Grid studio is a web-based spreadsheet application with full integration of the Python programming language. |
-|[Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook)|Python Data Science Handbook: full text in Jupyter Notebooks|
-| [Shapley](https://github.com/benedekrozemberczki/shapley) | A data-driven framework to quantify the value of classifiers in a machine learning ensemble. |
-| [DAGsHub](https://dagshub.com) | A platform built on open source tools for data, model and pipeline management. |
-| [Deepnote](https://deepnote.com) | A new kind of data science notebook. Jupyter-compatible, with real-time collaboration and running in the cloud. |
-| [Valohai](https://valohai.com) | An MLOps platform that handles machine orchestration, automatic reproducibility and deployment. |
-| [PyMC3](https://docs.pymc.io/) | A Python Library for Probabalistic Programming (Bayesian Inference and Machine Learning) |
-| [PyStan](https://pypi.org/project/pystan/) | Python interface to Stan (Bayesian inference and modeling) |
-| [hmmlearn](https://pypi.org/project/hmmlearn/) | Unsupervised learning and inference of Hidden Markov Models |
-| [Chaos Genius](https://github.com/chaos-genius/chaos_genius/) | ML powered analytics engine for outlier/anomaly detection and root cause analysis |
-| [Nimblebox](https://nimblebox.ai/) | A full-stack MLOps platform designed to help data scientists and machine learning practitioners around the world discover, create, and launch multi-cloud apps from their web browser. |
-| [Towhee](https://github.com/towhee-io/towhee) | A Python library that helps you encode your unstructured data into embeddings. |
-| [LineaPy](https://github.com/LineaLabs/lineapy) | Ever been frustrated with cleaning up long, messy Jupyter notebooks? With LineaPy, an open source Python library, it takes as little as two lines of code to transform messy development code into production pipelines. |
-| [envd](https://github.com/tensorchord/envd) | 🏕️ machine learning development environment for data science and AI/ML engineering teams |
-| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
-| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
+These are some Machine Learning and Data Mining algorithms and models help you to understand your data and derive meaning from it.
+
+#### Supervised Learning
+
+- Regression
+- [Linear Regression](https://en.wikipedia.org/wiki/Linear_regression)
+- Ordinary Least Squares
+- Logistic Regression
+- Stepwise Regression
+- Multivariate Adaptive Regression Splines
+- Locally Estimated Scatterplot Smoothing
+- Classification
+ - k-nearest neighbor
+ - Support Vector Machines
+ - Decision Trees
+ - ID3 algorithm
+ - C4.5 algorithm
+- Ensemble Learning
+- Boosting
+- Bagging
+- Random Forest
+- AdaBoost
+
+#### Unsupervised Learning
+- Clustering
+ - Hierchical clustering
+ - k-means
+ - Fuzzy clustering
+ - Mixture models
+- Dimension Reduction
+ - Principal Component Analysis (PCA)
+ - t-SNE
+- Neural Networks
+- Self-organizing map
+- Adaptive resonance theory
+- Hidden Markov Models (HMM)
+
+#### Semi-Supervised Learning
+
+- S3VM
+- Clustering
+- Generative models
+- Low-density separation
+- Laplacian regularization
+- Heuristic approaches
+#### Reinforcement Learning
-## Machine Learning in General Purpose
+- Q Learning
+- SARSA (State-Action-Reward-State-Action) algorithm
+- Temporal difference learning
+
+#### Data Mining Algorithms
+
+- C4.5
+- k-Means
+- SVM
+- Apriori
+- EM
+- PageRank
+- AdaBoost
+- kNN
+- Naive Bayes
+- CART
+
+#### Deep Learning architectures
+
+- Multilayer Perceptron
+- Convolutional Neural Network (CNN)
+- Recurrent Neural Network (RNN)
+- Boltzmann Machines
+- Autoencoder
+- Generative Adversarial Network (GAN)
+- Self-Organized Maps
+- Transformer
+- Conditional Random Field (CRF)
+
+### General Machine Learning Packages
**[`^ back to top ^`](#awesome-data-science)**
* [scikit-learn](https://scikit-learn.org/)
@@ -374,10 +296,9 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [pyGAM](https://github.com/dswah/pyGAM)
* [Deepchecks](https://github.com/deepchecks/deepchecks)
+### Deep Learning Packages
-## Deep Learning
-
-### PyTorch
+#### PyTorch Ecosystem
* [PyTorch](https://github.com/pytorch/pytorch)
* [torchvision](https://github.com/pytorch/vision)
* [torchtext](https://github.com/pytorch/text)
@@ -392,7 +313,8 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [pyro](https://github.com/pyro-ppl/pyro)
* [Catalyst](https://github.com/catalyst-team/catalyst)
* [pytorch_tabular](https://github.com/manujosephv/pytorch_tabular)
-### TensorFlow
+
+#### TensorFlow Ecosystem
* [TensorFlow](https://github.com/tensorflow/tensorflow)
* [TensorLayer](https://github.com/tensorlayer/TensorLayer)
* [TFLearn](https://github.com/tflearn/tflearn)
@@ -411,7 +333,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [TF-Agents](https://github.com/tensorflow/agents)
* [TensorForce](https://github.com/tensorforce/tensorforce)
-### Keras
+#### Keras Ecosystem
* [Keras](https://keras.io)
* [keras-contrib](https://github.com/keras-team/keras-contrib)
@@ -423,8 +345,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [keras-rl](https://github.com/keras-rl/keras-rl)
* [Talos](https://github.com/autonomio/talos)
-
-## Visualization Tools - Environments
+#### Visualization Tools
**[`^ back to top ^`](#awesome-data-science)**
- [altair](https://altair-viz.github.io/)
@@ -466,6 +387,100 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [C3](https://c3js.org/)
- [TensorWatch](https://github.com/microsoft/tensorwatch)
+### Miscellaneous Tools
+**[`^ back to top ^`](#awesome-data-science)**
+
+| Link | Description |
+| --- | --- |
+| [The Data Science Lifecycle Process](https://github.com/dslp/dslp) | The Data Science Lifecycle Process is a process for taking data science teams from Idea to Value repeatedly and sustainably. The process is documented in this repo |
+| [Data Science Lifecycle Template Repo](https://github.com/dslp/dslp-repo-template) | Template repository for data science lifecycle project |
+| [RexMex](https://github.com/AstraZeneca/rexmex) | A general purpose recommender metrics library for fair evaluation. |
+| [ChemicalX](https://github.com/AstraZeneca/chemicalx) | A PyTorch based deep learning library for drug pair scoring. |
+| [PyTorch Geometric Temporal](https://github.com/benedekrozemberczki/pytorch_geometric_temporal) | Representation learning on dynamic graphs. |
+| [Little Ball of Fur](https://github.com/benedekrozemberczki/littleballoffur) | A graph sampling library for NetworkX with a Scikit-Learn like API. |
+| [Karate Club](https://github.com/benedekrozemberczki/karateclub) | An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API. |
+| [ML Workspace](https://github.com/ml-tooling/ml-workspace) | All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code) |
+| [Neptune.ai](https://neptune.ai) | Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility. |
+| [steppy](https://github.com/minerva-ml/steppy) | Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design. |
+| [steppy-toolkit](https://github.com/minerva-ml/steppy-toolkit) | Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective. |
+| [Datalab from Google](https://cloud.google.com/datalab/docs/) | easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively. |
+| [Hortonworks Sandbox](https://www.cloudera.com/downloads/hortonworks-sandbox.html) | is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials. |
+| [R](https://www.r-project.org/) | is a free software environment for statistical computing and graphics. |
+| [Tidyverse](https://www.tidyverse.org/) | is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. |
+| [RStudio](https://www.rstudio.com) | IDE – powerful user interface for R. It’s free and open source, works on Windows, Mac, and Linux. |
+| [Python - Pandas - Anaconda](https://www.anaconda.com) | Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing |
+| [Pandas GUI](https://github.com/adrotog/PandasGUI) | Pandas GUI |
+| [Scikit-Learn](https://scikit-learn.org/stable/) | Machine Learning in Python |
+| [NumPy](https://numpy.org/) | NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays. |
+| [Vaex](https://vaex.io/) | Vaex is a Python library that allows you to visualize large datasets and calculate statistics at high speeds. |
+| [SciPy](https://scipy.org/) | SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization.
+| [Data Science Toolbox](https://www.coursera.org/learn/data-scientists-tools) | Coursera Course |
+| [Data Science Toolbox](https://datasciencetoolbox.org/) | Blog |
+| [Wolfram Data Science Platform](https://www.wolfram.com/data-science-platform/) | Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generating rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language. |
+| [Datadog](https://www.datadoghq.com/) | Solutions, code, and devops for high-scale data science. |
+| [Variance](https://variancecharts.com/) | Build powerful data visualizations for the web without writing JavaScript |
+| [Kite Development Kit](https://kitesdk.org/docs/current/index.html) | The Kite Software Development Kit (Apache License, Version 2.0) , or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem. |
+| [Domino Data Labs](https://www.dominodatalab.com) | Run, scale, share, and deploy your models — without any infrastructure or setup. |
+| [Apache Flink](https://flink.apache.org/) | A platform for efficient, distributed, general-purpose data processing. |
+| [Apache Hama](https://hama.apache.org/) | Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce. |
+| [Weka](https://www.cs.waikato.ac.nz/ml/weka/) | Weka is a collection of machine learning algorithms for data mining tasks. |
+| [Octave](https://www.gnu.org/software/octave/) | GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab) |
+| [Apache Spark](https://spark.apache.org/) | Lightning-fast cluster computing |
+| [Hydrosphere Mist](https://github.com/Hydrospheredata/mist) | a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services. |
+| [Data Mechanics](https://www.datamechanics.co) | A data science and engineering platform making Apache Spark more developer-friendly and cost-effective. |
+| [Caffe](https://caffe.berkeleyvision.org/) | Deep Learning Framework |
+| [Torch](https://torch.ch/) | A SCIENTIFIC COMPUTING FRAMEWORK FOR LUAJIT |
+| [Nervana's python based Deep Learning Framework](https://github.com/NervanaSystems/neon) | . |
+| [Skale](https://github.com/skale-me/skale) | High performance distributed data processing in NodeJS |
+| [Aerosolve](https://airbnb.io/aerosolve/) | A machine learning package built for humans. |
+| [Intel framework](https://github.com/intel/idlf) | Intel® Deep Learning Framework |
+| [Datawrapper](https://www.datawrapper.de/) | An open source data visualization platform helping everyone to create simple, correct and embeddable charts. Also at [github.com](https://github.com/datawrapper/datawrapper) |
+| [Tensor Flow](https://www.tensorflow.org/) | TensorFlow is an Open Source Software Library for Machine Intelligence |
+| [Natural Language Toolkit](https://www.nltk.org/) | An introductory yet powerful toolkit for natural language processing and classification |
+| [Annotation Lab](https://www.johnsnowlabs.com/annotation-lab/) | Free End-to-End No-Code platform for text annotation and DL model training/tuning. Out-of-the-box support for Named Entity Recognition, Classification, Relation extraction and Assertion Status Spark NLP models. Unlimited support for users, teams, projects, documents. |
+| [nlp-toolkit for node.js](https://www.npmjs.com/package/nlp-toolkit) | . |
+| [Julia](https://julialang.org) | high-level, high-performance dynamic programming language for technical computing |
+| [IJulia](https://github.com/JuliaLang/IJulia.jl) | a Julia-language backend combined with the Jupyter interactive environment |
+| [Apache Zeppelin](https://zeppelin.apache.org/) | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more |
+| [Featuretools](https://github.com/alteryx/featuretools) | An open source framework for automated feature engineering written in python |
+| [Optimus](https://github.com/hi-primus/optimus) | Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend. |
+| [Albumentations](https://github.com/albumentations-team/albumentations) | А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops. |
+| [DVC](https://github.com/iterative/dvc) | An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files. |
+| [Lambdo](https://github.com/asavinov/lambdo) | is a workflow engine which significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation. |
+| [Feast](https://github.com/feast-dev/feast) | A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving. |
+| [Polyaxon](https://github.com/polyaxon/polyaxon) | A platform for reproducible and scalable machine learning and deep learning. |
+| [LightTag](https://www.lighttag.io/) | Text Annotation Tool for teams |
+| [UBIAI](https://ubiai.tools) | Easy-to-use text annotation tool for teams with most comprehensive auto-annotation features. Supports NER, relations and document classification as well as OCR annotation for invoice labeling |
+| [Trains](https://github.com/allegroai/clearml) | Auto-Magical Experiment Manager, Version Control & DevOps for AI |
+| [Hopsworks](https://github.com/logicalclocks/hopsworks) | Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale. |
+| [MindsDB](https://github.com/mindsdb/mindsdb) | MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code. |
+| [Lightwood](https://github.com/mindsdb/lightwood) | A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code. |
+| [AWS Data Wrangler](https://github.com/awslabs/aws-data-wrangler) | An open-source Python package that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services (Amazon Redshift, AWS Glue, Amazon Athena, Amazon EMR, etc). |
+| [Amazon Rekognition](https://aws.amazon.com/rekognition/) | AWS Rekognition is a service that lets developers working with Amazon Web Services add image analysis to their applications. Catalog assets, automate workflows, and extract meaning from your media and applications.|
+| [Amazon Textract](https://aws.amazon.com/textract/) | Automatically extract printed text, handwriting, and data from any document. |
+| [Amazon Lookout for Vision](https://aws.amazon.com/lookout-for-vision/) | Spot product defects using computer vision to automate quality inspection. Identify missing product components, vehicle and structure damage, and irregularities for comprehensive quality control.|
+| [Amazon CodeGuru](https://aws.amazon.com/codeguru/) | Automate code reviews and optimize application performance with ML-powered recommendations.|
+| [CML](https://github.com/iterative/cml) | An open source toolkit for using continuous integration in data science projects. Automatically train and test models in production-like environments with GitHub Actions & GitLab CI, and autogenerate visual reports on pull/merge requests. |
+| [Dask](https://dask.org/) | An open source Python library to painlessly transition your analytics code to distributed computing systems (Big Data) |
+| [Statsmodels](https://www.statsmodels.org/stable/index.html) | A Python-based inferential statistics, hypothesis testing and regression framework |
+| [Gensim](https://radimrehurek.com/gensim/) | An open-source library for topic modeling of natural language text |
+| [spaCy](https://spacy.io/) | A performant natural language processing toolkit |
+| [Grid Studio](https://github.com/ricklamers/gridstudio) | Grid studio is a web-based spreadsheet application with full integration of the Python programming language. |
+|[Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook)|Python Data Science Handbook: full text in Jupyter Notebooks|
+| [Shapley](https://github.com/benedekrozemberczki/shapley) | A data-driven framework to quantify the value of classifiers in a machine learning ensemble. |
+| [DAGsHub](https://dagshub.com) | A platform built on open source tools for data, model and pipeline management. |
+| [Deepnote](https://deepnote.com) | A new kind of data science notebook. Jupyter-compatible, with real-time collaboration and running in the cloud. |
+| [Valohai](https://valohai.com) | An MLOps platform that handles machine orchestration, automatic reproducibility and deployment. |
+| [PyMC3](https://docs.pymc.io/) | A Python Library for Probabalistic Programming (Bayesian Inference and Machine Learning) |
+| [PyStan](https://pypi.org/project/pystan/) | Python interface to Stan (Bayesian inference and modeling) |
+| [hmmlearn](https://pypi.org/project/hmmlearn/) | Unsupervised learning and inference of Hidden Markov Models |
+| [Chaos Genius](https://github.com/chaos-genius/chaos_genius/) | ML powered analytics engine for outlier/anomaly detection and root cause analysis |
+| [Nimblebox](https://nimblebox.ai/) | A full-stack MLOps platform designed to help data scientists and machine learning practitioners around the world discover, create, and launch multi-cloud apps from their web browser. |
+| [Towhee](https://github.com/towhee-io/towhee) | A Python library that helps you encode your unstructured data into embeddings. |
+| [LineaPy](https://github.com/LineaLabs/lineapy) | Ever been frustrated with cleaning up long, messy Jupyter notebooks? With LineaPy, an open source Python library, it takes as little as two lines of code to transform messy development code into production pipelines. |
+| [envd](https://github.com/tensorchord/envd) | 🏕️ machine learning development environment for data science and AI/ML engineering teams |
+| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
+| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
## Journals, Publications and Magazines
**[`^ back to top ^`](#awesome-data-science)**
From f78c0b84f6761b500a4322b1c09f245c779f8181 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:22:33 -0400
Subject: [PATCH 07/16] Add Literature and Media section, put relevant sections
inside
---
README.md | 246 +++++++++++++++++++++++++++---------------------------
1 file changed, 124 insertions(+), 122 deletions(-)
diff --git a/README.md b/README.md
index 8b504d38..dd7badc5 100644
--- a/README.md
+++ b/README.md
@@ -41,12 +41,15 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Keras Ecosystem](#keras-ecosystem)
- [Visualization Tools](#visualization-tools)
- [Miscellaneous Tools](#miscellaneous-tools)
-- [Podcasts](#podcasts)
-- [Books](#books)
-- [Book Deals](#book-deals-affiliated-🛍)
-- [YouTube Videos & Channels](#youtube-videos--channels)
-- [Journals, Publications and Magazines](#journals-publications-and-magazines)
-- [Presentations](#presentations)
+- [Literature and Media](#literature-and-media)
+ - [Books](#books)
+ - [Book Deals (Affiliated)](#book-deals-affiliated-)
+ - [Journals, Publications, and Magazines](#journals-publications-and-magazines)
+ - [Newsletters](#newsletters)
+ - [Bloggers](#bloggers)
+ - [Presentations](#presentations)
+ - [Podcasts](#podcasts)]
+ - [YouTube Videos & Channels](#youtube-videos--channels)
## What is Data Science?
@@ -482,70 +485,12 @@ These are some Machine Learning and Data Mining algorithms and models help you t
| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
-## Journals, Publications and Magazines
+## Literature and Media
**[`^ back to top ^`](#awesome-data-science)**
-- [ICML](https://icml.cc/2015/) - International Conference on Machine Learning
-- [GECCO](https://gecco-2019.sigevo.org/index.html/HomePage) - The Genetic and Evolutionary Computation Conference (GECCO)
-- [epjdatascience](https://epjdatascience.springeropen.com/)
-- [Journal of Data Science](https://jds-online.org/journal/JDS) - an international journal devoted to applications of statistical methods at large
-- [Big Data Research](https://www.journals.elsevier.com/big-data-research)
-- [Journal of Big Data](https://journalofbigdata.springeropen.com/)
-- [Big Data & Society](https://journals.sagepub.com/home/bds)
-- [Data Science Journal](https://www.jstage.jst.go.jp/browse/dsj)
-- [datatau.com/news](https://www.datatau.com/news) - Like Hacker News, but for data
-- [Data Science Trello Board](https://trello.com/b/rbpEfMld/data-science)
-- [Medium Data Science Topic](https://medium.com/tag/data-science) - Data Science related publications on medium
-- [Towards Data Science Genetic Algorithm Topic](https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3#:~:text=A%20genetic%20algorithm%20is%20a,offspring%20of%20the%20next%20generation.) -Genetic Algorithm related Publications onTowards Data Science
-- [all AI news](https://allainews.com/) - The AI/ML/Big Data news aggregator platform
-
-## Presentations
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [How to Become a Data Scientist](https://www.slideshare.net/ryanorban/how-to-become-a-data-scientist)
-- [Introduction to Data Science](https://www.slideshare.net/NikoVuokko/introduction-to-data-science-25391618)
-- [Intro to Data Science for Enterprise Big Data](https://www.slideshare.net/pacoid/intro-to-data-science-for-enterprise-big-data)
-- [How to Interview a Data Scientist](https://www.slideshare.net/dtunkelang/how-to-interview-a-data-scientist)
-- [How to Share Data with a Statistician](https://github.com/jtleek/datasharing)
-- [The Science of a Great Career in Data Science](https://www.slideshare.net/katemats/the-science-of-a-great-career-in-data-science)
-- [What Does a Data Scientist Do?](https://www.slideshare.net/datasciencelondon/big-data-sorry-data-science-what-does-a-data-scientist-do)
-- [Building Data Start-Ups: Fast, Big, and Focused](https://www.slideshare.net/medriscoll/driscoll-strata-buildingdatastartups25may2011clean)
-- [How to win data science competitions with Deep Learning](https://www.slideshare.net/0xdata/how-to-win-data-science-competitions-with-deep-learning)
-- [Full-Stack Data Scientist](https://www.slideshare.net/AlexeyGrigorev/fullstack-data-scientist)
-
-
-## Podcasts
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [AI at Home](https://podcasts.apple.com/us/podcast/data-science-at-home/id1069871378)
-- [AI Today](https://www.cognilytica.com/aitoday/)
-- [Adversarial Learning](https://adversariallearning.com/)
-- [Becoming a Data Scientist](https://www.becomingadatascientist.com/category/podcast/)
-- [Chai time Data Science](https://www.youtube.com/playlist?list=PLLvvXm0q8zUbiNdoIazGzlENMXvZ9bd3x)
-- [Data Crunch](https://datacrunchcorp.com/data-crunch-podcast/)
-- [Data Engineering Podcast](https://www.dataengineeringpodcast.com/)
-- [Data Science at Home](https://datascienceathome.com/)
-- [Data Science Mixer](https://community.alteryx.com/t5/Data-Science-Mixer/bg-p/mixer)
-- [Data Skeptic](https://dataskeptic.com/)
-- [Data Stories](https://datastori.es/)
-- [Datacast](https://jameskle.com/writes/category/Datacast)
-- [DataFramed](https://www.datacamp.com/community/podcast)
-- [DataTalks.Club](https://anchor.fm/datatalksclub)
-- [Gradient Dissent](https://wandb.ai/fully-connected/gradient-dissent)
-- [Learning Machines 101](https://www.learningmachines101.com/)
-- [Let's Data (Brazil)](https://www.youtube.com/playlist?list=PLn_z5E4dh_Lj5eogejMxfOiNX3nOhmhmM)
-- [Linear Digressions](https://lineardigressions.com/)
-- [Not So Standard Deviations](https://nssdeviations.com/)
-- [O'Reilly Data Show Podcast](https://www.oreilly.com/radar/topics/oreilly-data-show-podcast/)
-- [Partially Derivative](https://partiallyderivative.com/)
-- [Superdatascience](https://www.superdatascience.com/podcast/)
-- [The Data Engineering Show](https://www.dataengineeringshow.com/)
-- [The Radical AI Podcast](https://www.radicalai.org/)
-- [The Robot Brains Podcast](https://www.therobotbrains.ai/)
-- [What's The Point](https://fivethirtyeight.com/tag/whats-the-point/)
-- [How AI Built This](https://how-ai-built-this.captivate.fm/)
+This section includes some additional reading material, channels to watch, and talks to listen to.
-## Books
+### Books
**[`^ back to top ^`](#awesome-data-science)**
- [Data Science From Scratch: First Principles with Python](https://www.amazon.com/Data-Science-Scratch-Principles-Python-dp-1492041130/dp/1492041130/ref=dp_ob_title_bk)
@@ -611,7 +556,7 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- [Dive into Deep Learning](https://d2l.ai/)
- [Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/) - Free GitHub version
-## Book Deals (Affiliated) 🛍
+#### Book Deals (Affiliated) 🛍
- [eBook sale - Save up to 45% on eBooks!](https://www.manning.com/?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=ebook_sale_8_8_22)
@@ -621,20 +566,29 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- [Causal Inference for Data Science](https://www.manning.com/books/causal-inference-for-data-science?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=book_ruizdevilla_causal_6_6_22)
- [Data for All](https://www.manning.com/books/data-for-all?utm_source=mikrobusiness&utm_medium=affiliate)
-## Socialize
+### Journals, Publications and Magazines
**[`^ back to top ^`](#awesome-data-science)**
-Below are some Social Media links. Connect with other data scientists!
+- [ICML](https://icml.cc/2015/) - International Conference on Machine Learning
+- [GECCO](https://gecco-2019.sigevo.org/index.html/HomePage) - The Genetic and Evolutionary Computation Conference (GECCO)
+- [epjdatascience](https://epjdatascience.springeropen.com/)
+- [Journal of Data Science](https://jds-online.org/journal/JDS) - an international journal devoted to applications of statistical methods at large
+- [Big Data Research](https://www.journals.elsevier.com/big-data-research)
+- [Journal of Big Data](https://journalofbigdata.springeropen.com/)
+- [Big Data & Society](https://journals.sagepub.com/home/bds)
+- [Data Science Journal](https://www.jstage.jst.go.jp/browse/dsj)
+- [datatau.com/news](https://www.datatau.com/news) - Like Hacker News, but for data
+- [Data Science Trello Board](https://trello.com/b/rbpEfMld/data-science)
+- [Medium Data Science Topic](https://medium.com/tag/data-science) - Data Science related publications on medium
+- [Towards Data Science Genetic Algorithm Topic](https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3#:~:text=A%20genetic%20algorithm%20is%20a,offspring%20of%20the%20next%20generation.) -Genetic Algorithm related Publications onTowards Data Science
+- [all AI news](https://allainews.com/) - The AI/ML/Big Data news aggregator platform
-- [Bloggers](#bloggers)
-- [Facebook Accounts](#facebook-accounts)
-- [Twitter Accounts](#twitter-accounts)
-- [Newsletters](#newsletters)
-- [YouTube Videos and Channels](#youtube-videos--channels)
-- [Telegram Channels](#telegram-channels)
-- [Slack Communities](#slack-communities)
-- [GitHub Groups](#github-groups)
-- [Data Science Competitions](#competitions)
+### Newsletters
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [AI Digest](https://aidigest.net/). A weekly newsletter to keep up to date with AI, machine learning, and data science. [Archive](https://aidigest.net/digests).
+- [DataTalks.Club](https://datatalks.club). A weekly newsletter about data-related things. [Archive](https://us19.campaign-archive.com/home/?u=0d7822ab98152f5afc118c176&id=97178021aa).
+- [The Analytics Engineering Roundup](https://roundup.getdbt.com/about). A newsletter about data science. [Archive](https://roundup.getdbt.com/archive).
### Bloggers
**[`^ back to top ^`](#awesome-data-science)**
@@ -725,6 +679,97 @@ Below are some Social Media links. Connect with other data scientists!
- [Maria Khalusova](https://www.mariakhalusova.com/) - Data science blog
- [Aditi Rastogi](https://medium.com/@aditi2507rastogi) - ML,DL,Data Science blog
+### Presentations
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [How to Become a Data Scientist](https://www.slideshare.net/ryanorban/how-to-become-a-data-scientist)
+- [Introduction to Data Science](https://www.slideshare.net/NikoVuokko/introduction-to-data-science-25391618)
+- [Intro to Data Science for Enterprise Big Data](https://www.slideshare.net/pacoid/intro-to-data-science-for-enterprise-big-data)
+- [How to Interview a Data Scientist](https://www.slideshare.net/dtunkelang/how-to-interview-a-data-scientist)
+- [How to Share Data with a Statistician](https://github.com/jtleek/datasharing)
+- [The Science of a Great Career in Data Science](https://www.slideshare.net/katemats/the-science-of-a-great-career-in-data-science)
+- [What Does a Data Scientist Do?](https://www.slideshare.net/datasciencelondon/big-data-sorry-data-science-what-does-a-data-scientist-do)
+- [Building Data Start-Ups: Fast, Big, and Focused](https://www.slideshare.net/medriscoll/driscoll-strata-buildingdatastartups25may2011clean)
+- [How to win data science competitions with Deep Learning](https://www.slideshare.net/0xdata/how-to-win-data-science-competitions-with-deep-learning)
+- [Full-Stack Data Scientist](https://www.slideshare.net/AlexeyGrigorev/fullstack-data-scientist)
+
+### Podcasts
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [AI at Home](https://podcasts.apple.com/us/podcast/data-science-at-home/id1069871378)
+- [AI Today](https://www.cognilytica.com/aitoday/)
+- [Adversarial Learning](https://adversariallearning.com/)
+- [Becoming a Data Scientist](https://www.becomingadatascientist.com/category/podcast/)
+- [Chai time Data Science](https://www.youtube.com/playlist?list=PLLvvXm0q8zUbiNdoIazGzlENMXvZ9bd3x)
+- [Data Crunch](https://datacrunchcorp.com/data-crunch-podcast/)
+- [Data Engineering Podcast](https://www.dataengineeringpodcast.com/)
+- [Data Science at Home](https://datascienceathome.com/)
+- [Data Science Mixer](https://community.alteryx.com/t5/Data-Science-Mixer/bg-p/mixer)
+- [Data Skeptic](https://dataskeptic.com/)
+- [Data Stories](https://datastori.es/)
+- [Datacast](https://jameskle.com/writes/category/Datacast)
+- [DataFramed](https://www.datacamp.com/community/podcast)
+- [DataTalks.Club](https://anchor.fm/datatalksclub)
+- [Gradient Dissent](https://wandb.ai/fully-connected/gradient-dissent)
+- [Learning Machines 101](https://www.learningmachines101.com/)
+- [Let's Data (Brazil)](https://www.youtube.com/playlist?list=PLn_z5E4dh_Lj5eogejMxfOiNX3nOhmhmM)
+- [Linear Digressions](https://lineardigressions.com/)
+- [Not So Standard Deviations](https://nssdeviations.com/)
+- [O'Reilly Data Show Podcast](https://www.oreilly.com/radar/topics/oreilly-data-show-podcast/)
+- [Partially Derivative](https://partiallyderivative.com/)
+- [Superdatascience](https://www.superdatascience.com/podcast/)
+- [The Data Engineering Show](https://www.dataengineeringshow.com/)
+- [The Radical AI Podcast](https://www.radicalai.org/)
+- [The Robot Brains Podcast](https://www.therobotbrains.ai/)
+- [What's The Point](https://fivethirtyeight.com/tag/whats-the-point/)
+- [How AI Built This](https://how-ai-built-this.captivate.fm/)
+
+### YouTube Videos & Channels
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [What is machine learning?](https://www.youtube.com/watch?v=WXHM_i-fgGo)
+- [Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning](https://www.youtube.com/watch?v=n1ViNeWhC24)
+- [Data36 - Data Science for Beginners by Tomi Mester](https://www.youtube.com/c/TomiMesterData36comDataScienceForBeginners)
+- [Deep Learning: Intelligence from Big Data](https://www.youtube.com/watch?v=czLI3oLDe8M)
+- [Interview with Google's AI and Deep Learning 'Godfather' Geoffrey Hinton](https://www.youtube.com/watch?v=1Wp3IIpssEc)
+- [Introduction to Deep Learning with Python](https://www.youtube.com/watch?v=S75EdAcXHKk)
+- [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk)
+- [Data School](https://www.youtube.com/channel/UCnVzApLJE2ljPZSeQylSEyg) - Data Science Education
+- [Neural Nets for Newbies by Melanie Warrick (May 2015)](https://www.youtube.com/watch?v=Cu6A96TUy_o)
+- [Neural Networks video series by Hugo Larochelle](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH)
+- [Google DeepMind co-founder Shane Legg - Machine Super Intelligence](https://www.youtube.com/watch?v=evNCyRL3DOU)
+- [Data Science Primer](https://www.youtube.com/watch?v=cHzvYxBN9Ls&list=PLPqVjP3T4RIRsjaW07zoGzH-Z4dBACpxY)
+- [Data Science with Genetic Algorithms](https://www.youtube.com/watch?v=lpD38NxTOnk)
+- [Data Science for Beginners](https://www.youtube.com/playlist?list=PL2zq7klxX5ATMsmyRazei7ZXkP1GHt-vs)
+- [DataTalks.Club](https://www.youtube.com/channel/UCDvErgK0j5ur3aLgn6U-LqQ)
+- [Mildlyoverfitted - Tutorials on intermediate ML/DL topics](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
+- [mlops.community - Interviews of industry experts about production ML](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
+- [ML Street Talk - Unabashedly technical and non-commercial, so you will hear no annoying pitches.](https://www.youtube.com/c/machinelearningstreettalk)
+- [Neural networks by 3Blue1Brown ](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi)
+- [Neural networks from scratch by Sentdex](https://www.youtube.com/playlist?list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3)
+- [Manning Publications YouTube channel](https://www.youtube.com/c/ManningPublications/featured)
+- [Ask Dr Chong: How to Lead in Data Science - Part 1](https://youtu.be/JYuQZii5o58)
+- [Ask Dr Chong: How to Lead in Data Science - Part 2](https://youtu.be/SzqIXV-O-ko)
+- [Ask Dr Chong: How to Lead in Data Science - Part 3](https://youtu.be/Ogwm7k_smTA)
+- [Ask Dr Chong: How to Lead in Data Science - Part 4](https://youtu.be/a9usjdzTxTU)
+- [Ask Dr Chong: How to Lead in Data Science - Part 5](https://youtu.be/MYdQq-F3Ws0)
+- [Ask Dr Chong: How to Lead in Data Science - Part 6](https://youtu.be/LOOt4OVC3hY)
+- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
+- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
+
+
+## Socialize
+**[`^ back to top ^`](#awesome-data-science)**
+*
+Below are some Social Media links. Connect with other data scientists!
+
+- [Facebook Accounts](#facebook-accounts)
+- [Twitter Accounts](#twitter-accounts)
+- [Telegram Channels](#telegram-channels)
+- [Slack Communities](#slack-communities)
+- [GitHub Groups](#github-groups)
+- [Data Science Competitions](#competitions)
+
### Facebook Accounts
**[`^ back to top ^`](#awesome-data-science)**
@@ -824,48 +869,6 @@ Below are some Social Media links. Connect with other data scientists!
| [Alexey Grigorev](https://twitter.com/Al_Grigor) | Data science author |
-### Newsletters
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [AI Digest](https://aidigest.net/). A weekly newsletter to keep up to date with AI, machine learning, and data science. [Archive](https://aidigest.net/digests).
-- [DataTalks.Club](https://datatalks.club). A weekly newsletter about data-related things. [Archive](https://us19.campaign-archive.com/home/?u=0d7822ab98152f5afc118c176&id=97178021aa).
-- [The Analytics Engineering Roundup](https://roundup.getdbt.com/about). A newsletter about data science. [Archive](https://roundup.getdbt.com/archive).
-
-
-### YouTube Videos & Channels
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [What is machine learning?](https://www.youtube.com/watch?v=WXHM_i-fgGo)
-- [Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning](https://www.youtube.com/watch?v=n1ViNeWhC24)
-- [Data36 - Data Science for Beginners by Tomi Mester](https://www.youtube.com/c/TomiMesterData36comDataScienceForBeginners)
-- [Deep Learning: Intelligence from Big Data](https://www.youtube.com/watch?v=czLI3oLDe8M)
-- [Interview with Google's AI and Deep Learning 'Godfather' Geoffrey Hinton](https://www.youtube.com/watch?v=1Wp3IIpssEc)
-- [Introduction to Deep Learning with Python](https://www.youtube.com/watch?v=S75EdAcXHKk)
-- [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk)
-- [Data School](https://www.youtube.com/channel/UCnVzApLJE2ljPZSeQylSEyg) - Data Science Education
-- [Neural Nets for Newbies by Melanie Warrick (May 2015)](https://www.youtube.com/watch?v=Cu6A96TUy_o)
-- [Neural Networks video series by Hugo Larochelle](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH)
-- [Google DeepMind co-founder Shane Legg - Machine Super Intelligence](https://www.youtube.com/watch?v=evNCyRL3DOU)
-- [Data Science Primer](https://www.youtube.com/watch?v=cHzvYxBN9Ls&list=PLPqVjP3T4RIRsjaW07zoGzH-Z4dBACpxY)
-- [Data Science with Genetic Algorithms](https://www.youtube.com/watch?v=lpD38NxTOnk)
-- [Data Science for Beginners](https://www.youtube.com/playlist?list=PL2zq7klxX5ATMsmyRazei7ZXkP1GHt-vs)
-- [DataTalks.Club](https://www.youtube.com/channel/UCDvErgK0j5ur3aLgn6U-LqQ)
-- [Mildlyoverfitted - Tutorials on intermediate ML/DL topics](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
-- [mlops.community - Interviews of industry experts about production ML](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
-- [ML Street Talk - Unabashedly technical and non-commercial, so you will hear no annoying pitches.](https://www.youtube.com/c/machinelearningstreettalk)
-- [Neural networks by 3Blue1Brown ](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi)
-- [Neural networks from scratch by Sentdex](https://www.youtube.com/playlist?list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3)
-- [Manning Publications YouTube channel](https://www.youtube.com/c/ManningPublications/featured)
-- [Ask Dr Chong: How to Lead in Data Science - Part 1](https://youtu.be/JYuQZii5o58)
-- [Ask Dr Chong: How to Lead in Data Science - Part 2](https://youtu.be/SzqIXV-O-ko)
-- [Ask Dr Chong: How to Lead in Data Science - Part 3](https://youtu.be/Ogwm7k_smTA)
-- [Ask Dr Chong: How to Lead in Data Science - Part 4](https://youtu.be/a9usjdzTxTU)
-- [Ask Dr Chong: How to Lead in Data Science - Part 5](https://youtu.be/MYdQq-F3Ws0)
-- [Ask Dr Chong: How to Lead in Data Science - Part 6](https://youtu.be/LOOt4OVC3hY)
-- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
-- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
-
-
### Telegram Channels
**[`^ back to top ^`](#awesome-data-science)**
@@ -879,7 +882,6 @@ Below are some Social Media links. Connect with other data scientists!
- [DataTalks.Club](https://datatalks.club)
-
## GitHub Groups
- [Berkeley Institute for Data Science](https://github.com/BIDS)
From a398fd1ca24d0878e1a1b6ad544f13e660cb733e Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:25:20 -0400
Subject: [PATCH 08/16] Update TOC to include "Socialize" section, adjust
header names in "socialize" section
---
README.md | 14 ++++++++++----
1 file changed, 10 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index dd7badc5..6609f66c 100644
--- a/README.md
+++ b/README.md
@@ -50,6 +50,13 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Presentations](#presentations)
- [Podcasts](#podcasts)]
- [YouTube Videos & Channels](#youtube-videos--channels)
+- [Socialize](#socialize)
+ - [Facebook Accounts](#facebook-accounts)
+ - [Twitter Accounts](#twitter-accounts)
+ - [Telegram Channels](#telegram-channels)
+ - [Slack Communities](#slack-communities)
+ - [GitHub Groups](#github-groups)
+ - [Data Science Competitions](#data-science-competitions)
## What is Data Science?
@@ -768,7 +775,7 @@ Below are some Social Media links. Connect with other data scientists!
- [Telegram Channels](#telegram-channels)
- [Slack Communities](#slack-communities)
- [GitHub Groups](#github-groups)
-- [Data Science Competitions](#competitions)
+- [Data Science Competitions](#data-science-competitions)
### Facebook Accounts
@@ -882,11 +889,10 @@ Below are some Social Media links. Connect with other data scientists!
- [DataTalks.Club](https://datatalks.club)
-## GitHub Groups
+### GitHub Groups
- [Berkeley Institute for Data Science](https://github.com/BIDS)
-
-## Competitions
+### Data Science Competitions
Some data mining competition platforms
From 1e9e1ec81e3b46dc69bd421d8456711412302631 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:27:52 -0400
Subject: [PATCH 09/16] Add remaining sections into TOC
---
README.md | 19 +++++++++++--------
1 file changed, 11 insertions(+), 8 deletions(-)
diff --git a/README.md b/README.md
index 6609f66c..1e8978f9 100644
--- a/README.md
+++ b/README.md
@@ -57,7 +57,13 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Slack Communities](#slack-communities)
- [GitHub Groups](#github-groups)
- [Data Science Competitions](#data-science-competitions)
-
+- [Fun](#fun)
+ - [Infographics](#infographics)
+ - [Datasets](#datasets)
+ - [Comics](#comics)
+- [Awesome Data Science](#awesome-data-science)
+- [Hobby](#hobby)
+- [Other Lists](#other-lists)
## What is Data Science?
**[`^ back to top ^`](#awesome-data-science)**
@@ -764,7 +770,6 @@ This section includes some additional reading material, channels to watch, and t
- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
-
## Socialize
**[`^ back to top ^`](#awesome-data-science)**
*
@@ -902,15 +907,14 @@ Some data mining competition platforms
- [InnoCentive](https://www.innocentive.com/)
- [Microprediction](https://www.microprediction.com/python-1)
-
## Fun
-- [Infographic](#infographic)
-- [Data Sets](#data-sets)
+- [Infographic](#infographics)
+- [Datasets](#datasets)
- [Comics](#comics)
-### Infographic
+### Infographics
**[`^ back to top ^`](#awesome-data-science)**
| Preview | Description |
@@ -929,7 +933,7 @@ Some data mining competition platforms
| [](https://www.springboard.com/blog/wp-content/uploads/2016/03/20160324_springboard_vennDiagram.png) | Different Data Science Skills and Roles from [this article](https://www.springboard.com/blog/data-science-career-paths-different-roles-industry/) by Springboard |
| [](https://data-literacy.geckoboard.com/poster/) | A simple and friendly way of teaching your non-data scientist/non-statistician colleagues [how to avoid mistakes with data](https://data-literacy.geckoboard.com/poster/). From Geckoboard's [Data Literacy Lessons](https://data-literacy.geckoboard.com/). |
-### Data Sets
+### Datasets
**[`^ back to top ^`](#awesome-data-science)**
- [Academic Torrents](https://academictorrents.com/)
@@ -992,7 +996,6 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-
## Awesome Data Science
[](https://github.com/sindresorhus/awesome) [](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
From 8ad41401c8bec83cc6d7a6736cafbb764197f3ae Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:30:55 -0400
Subject: [PATCH 10/16] Move awesome badge to top of project
---
README.md | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 1e8978f9..db71eea3 100644
--- a/README.md
+++ b/README.md
@@ -2,6 +2,8 @@
# AWESOME DATA SCIENCE
+[](https://github.com/sindresorhus/awesome)
+
**An open source Data Science repository to learn and apply towards solving real world problems.**
This is a shortcut path to start studying **Data Science**. Just follow the steps to answer the questions, "What is Data Science and what should I study to learn Data Science?"
@@ -998,7 +1000,7 @@ Some data mining competition platforms
## Awesome Data Science
-[](https://github.com/sindresorhus/awesome) [](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
+[](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
## Hobby
- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
From 0401fcb1c78a1c8c827626eec735ad9fa618b345 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:31:33 -0400
Subject: [PATCH 11/16] Remove dead "subscribe to new links" URL
---
README.md | 4 ----
1 file changed, 4 deletions(-)
diff --git a/README.md b/README.md
index db71eea3..15e005ea 100644
--- a/README.md
+++ b/README.md
@@ -998,10 +998,6 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-## Awesome Data Science
-
-[](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
-
## Hobby
- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
From 49399d8b0e94e926744caaa20c50fedc251c1dc2 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:32:58 -0400
Subject: [PATCH 12/16] Rename "Other Lists" to "Other Awesome Lists", move
"hobby section" as a subsection, and update TOC
---
README.md | 13 ++++++-------
1 file changed, 6 insertions(+), 7 deletions(-)
diff --git a/README.md b/README.md
index 15e005ea..c260989f 100644
--- a/README.md
+++ b/README.md
@@ -63,9 +63,8 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Infographics](#infographics)
- [Datasets](#datasets)
- [Comics](#comics)
-- [Awesome Data Science](#awesome-data-science)
-- [Hobby](#hobby)
-- [Other Lists](#other-lists)
+- [Other Awesome Lists](#other-lists)
+ - [Hobby](#hobby)
## What is Data Science?
**[`^ back to top ^`](#awesome-data-science)**
@@ -998,10 +997,7 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-## Hobby
-- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
-
-## Other Lists
+## Other Awesome Lists
- Other amazingly awesome lists can be found in the [awesome-awesomeness](https://github.com/bayandin/awesome-awesomeness)
- [Awesome Machine Learning](https://github.com/josephmisiti/awesome-machine-learning)
@@ -1031,6 +1027,9 @@ Some data mining competition platforms
- [Top Data Science Interview Questions](https://www.interviewbit.com/data-science-interview-questions/)
- [Awesome Drug Synergy, Interaction and Polypharmacy Prediction](https://github.com/AstraZeneca/awesome-drug-pair-scoring)
+### Hobby
+- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
+
](https://data-literacy.geckoboard.com/poster/) | A simple and friendly way of teaching your non-data scientist/non-statistician colleagues [how to avoid mistakes with data](https://data-literacy.geckoboard.com/poster/). From Geckoboard's [Data Literacy Lessons](https://data-literacy.geckoboard.com/). |
-## Data Sets
+### Data Sets
**[`^ back to top ^`](#awesome-data-science)**
- [Academic Torrents](https://academictorrents.com/)
@@ -954,7 +959,7 @@ Some data mining competition platforms
- [Enron Email Dataset](https://www.cs.cmu.edu/~./enron/)
- [5000 Images of Clothes](https://github.com/alexeygrigorev/clothing-dataset)
-## Comics
+### Comics
**[`^ back to top ^`](#awesome-data-science)**
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
From d6c0dafcb52ff29c1feba11818b9490cc05b6aaa Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:03:22 -0400
Subject: [PATCH 05/16] Update table of contents
---
README.md | 8 ++++++--
1 file changed, 6 insertions(+), 2 deletions(-)
diff --git a/README.md b/README.md
index 1e51e429..39234e7f 100644
--- a/README.md
+++ b/README.md
@@ -20,13 +20,17 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [What is Data Science?](#what-is-data-science)
- [Where do I Start?](#where-do-i-start)
-- [Algorithms](#algorithms)
- [Training Resources](#training-resources)
+ - [Tutorials](#tutorials)
+ - [Free Courses](#free-courses)
+ - [Massively Open Online Courses](#moocs)
+ - [Intensive Programs](#intensive-programs)
+ - [Colleges](#colleges)
+- [The Data Science Toolbox](#the-data-science-toolbox)
- [Podcasts](#podcasts)
- [Books](#books)
- [Book Deals](#book-deals-affiliated-🛍)
- [YouTube Videos & Channels](#youtube-videos--channels)
-- [Toolboxes - Environment](#toolboxes---environment)
- [Journals, Publications and Magazines](#journals-publications-and-magazines)
- [Presentations](#presentations)
From db7d8861b03b70b81b099cf064080a6778ce5438 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:10:27 -0400
Subject: [PATCH 06/16] Re-order software section and update TOC
---
README.md | 377 ++++++++++++++++++++++++++++--------------------------
1 file changed, 196 insertions(+), 181 deletions(-)
diff --git a/README.md b/README.md
index 39234e7f..8b504d38 100644
--- a/README.md
+++ b/README.md
@@ -27,6 +27,20 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Intensive Programs](#intensive-programs)
- [Colleges](#colleges)
- [The Data Science Toolbox](#the-data-science-toolbox)
+ - [Algorithms](#algorithms)
+ - [Supervised Learning](#supervised-learning)
+ - [Unsupervised Learning](#unsupervised-learning)
+ - [Semi-Supervised Learning](#semi-supervised-learning)
+ - [Reinforcement Learning](#reinforcement-learning)
+ - [Data Mining Algorithms](#data-mining-algorithms)
+ - [Deep Learning Architectures](#deep-learning-architectures)
+ - [General Machine Learning Packages](#general-machine-learning-packages)
+ - [Deep Learning Packages](#deep-learning-packages)
+ - [PyTorch Ecosystem](#pytorch-ecosystem)
+ - [TensorFlow Ecosystem](#tensorflow-ecosystem)
+ - [Keras Ecosystem](#keras-ecosystem)
+ - [Visualization Tools](#visualization-tools)
+ - [Miscellaneous Tools](#miscellaneous-tools)
- [Podcasts](#podcasts)
- [Books](#books)
- [Book Deals](#book-deals-affiliated-🛍)
@@ -60,87 +74,7 @@ Python is by far the most popular language in science, due in no small part to t
Unlike R, Python was not built from the ground up with data science in mind, but there are plenty of third party libraries to make up for this. A much more exhaustive list of packages can be found later in this document, but these four packages are a good set of choices to start your data science journey with: [Scikit-Learn](https://scikit-learn.org/stable/index.html) is a general-purpose data science package which implements the most popular algorithms - it also includes rich documentation, tutorials, and examples of the models it implements. Even if you prefer to write your own implementations, Scikit-Learn is a valuable reference to the nuts-and-bolts behind many of the common algorithms you'll find. With [Pandas](https://pandas.pydata.org/), one can collect and analyze their data into a convenient table format. [Numpy](https://numpy.org/) provides very fast tooling for mathematical operations, with a focus on vectors and matrices. [Seaborn](https://seaborn.pydata.org/), itself based on the [Matplotlib](https://matplotlib.org/) package, is a quick way to generate beautiful visualizations of your data, with many good defaults available out of the box, as well as a gallery showing how to produce many commmon visualizations of your data.
- When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the [Free courses](#free-courses) we've listed below!
-
-## Algorithms
-**[`^ back to top ^`](#awesome-data-science)**
-
-These are some Machine Learning and Data Mining algorithms and models help you to understand your data and derive meaning from it.
-
-### Supervised Learning
-
-- Regression
-- [Linear Regression](https://en.wikipedia.org/wiki/Linear_regression)
-- Ordinary Least Squares
-- Logistic Regression
-- Stepwise Regression
-- Multivariate Adaptive Regression Splines
-- Locally Estimated Scatterplot Smoothing
-- Classification
- - k-nearest neighbor
- - Support Vector Machines
- - Decision Trees
- - ID3 algorithm
- - C4.5 algorithm
-- Ensemble Learning
-- Boosting
-- Bagging
-- Random Forest
-- AdaBoost
-
-### Unsupervised Learning
-- Clustering
- - Hierchical clustering
- - k-means
- - Fuzzy clustering
- - Mixture models
-- Dimension Reduction
- - Principal Component Analysis (PCA)
- - t-SNE
-- Neural Networks
-- Self-organizing map
-- Adaptive resonance theory
-- Hidden Markov Models (HMM)
-
-### Semi-Supervised Learning
-
-- S3VM
-- Clustering
-- Generative models
-- Low-density separation
-- Laplacian regularization
-- Heuristic approaches
-
-### Reinforcement Learning
-
-- Q Learning
-- SARSA (State-Action-Reward-State-Action) algorithm
-- Temporal difference learning
-
-### Data Mining Algorithms
-
-- C4.5
-- k-Means
-- SVM
-- Apriori
-- EM
-- PageRank
-- AdaBoost
-- kNN
-- Naive Bayes
-- CART
-
-### Deep Learning architectures
-
-- Multilayer Perceptron
-- Convolutional Neural Network (CNN)
-- Recurrent Neural Network (RNN)
-- Boltzmann Machines
-- Autoencoder
-- Generative Adversarial Network (GAN)
-- Self-Organized Maps
-- Transformer
-- Conditional Random Field (CRF)
+ When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the [Free courses](#free-courses) we've listed below!
## Training Resources
**[`^ back to top ^`](#awesome-data-science)**
@@ -245,104 +179,92 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [Master Data Science and Artificial Intelligence @ Eindhoven University of Technology](https://www.tue.nl/en/education/graduate-school/master-data-science-and-artificial-intelligence/)
- [Master's Degree in Data Science and Computer Engineering @ University of Granada](https://masteres.ugr.es/datcom/)
+## The Data Science Toolbox
+**[`^ back to top ^`](#awesome-data-science)**
+
+This section is a collection of packages, tools, algorithms, and other useful items in the data science world.
-## Toolboxes - Environment
+### Algorithms
**[`^ back to top ^`](#awesome-data-science)**
-| Link | Description |
-| --- | --- |
-| [The Data Science Lifecycle Process](https://github.com/dslp/dslp) | The Data Science Lifecycle Process is a process for taking data science teams from Idea to Value repeatedly and sustainably. The process is documented in this repo |
-| [Data Science Lifecycle Template Repo](https://github.com/dslp/dslp-repo-template) | Template repository for data science lifecycle project |
-| [RexMex](https://github.com/AstraZeneca/rexmex) | A general purpose recommender metrics library for fair evaluation. |
-| [ChemicalX](https://github.com/AstraZeneca/chemicalx) | A PyTorch based deep learning library for drug pair scoring. |
-| [PyTorch Geometric Temporal](https://github.com/benedekrozemberczki/pytorch_geometric_temporal) | Representation learning on dynamic graphs. |
-| [Little Ball of Fur](https://github.com/benedekrozemberczki/littleballoffur) | A graph sampling library for NetworkX with a Scikit-Learn like API. |
-| [Karate Club](https://github.com/benedekrozemberczki/karateclub) | An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API. |
-| [ML Workspace](https://github.com/ml-tooling/ml-workspace) | All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code) |
-| [Neptune.ai](https://neptune.ai) | Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility. |
-| [steppy](https://github.com/minerva-ml/steppy) | Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design. |
-| [steppy-toolkit](https://github.com/minerva-ml/steppy-toolkit) | Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective. |
-| [Datalab from Google](https://cloud.google.com/datalab/docs/) | easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively. |
-| [Hortonworks Sandbox](https://www.cloudera.com/downloads/hortonworks-sandbox.html) | is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials. |
-| [R](https://www.r-project.org/) | is a free software environment for statistical computing and graphics. |
-| [Tidyverse](https://www.tidyverse.org/) | is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. |
-| [RStudio](https://www.rstudio.com) | IDE – powerful user interface for R. It’s free and open source, works on Windows, Mac, and Linux. |
-| [Python - Pandas - Anaconda](https://www.anaconda.com) | Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing |
-| [Pandas GUI](https://github.com/adrotog/PandasGUI) | Pandas GUI |
-| [Scikit-Learn](https://scikit-learn.org/stable/) | Machine Learning in Python |
-| [NumPy](https://numpy.org/) | NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays. |
-| [Vaex](https://vaex.io/) | Vaex is a Python library that allows you to visualize large datasets and calculate statistics at high speeds. |
-| [SciPy](https://scipy.org/) | SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization.
-| [Data Science Toolbox](https://www.coursera.org/learn/data-scientists-tools) | Coursera Course |
-| [Data Science Toolbox](https://datasciencetoolbox.org/) | Blog |
-| [Wolfram Data Science Platform](https://www.wolfram.com/data-science-platform/) | Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generating rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language. |
-| [Datadog](https://www.datadoghq.com/) | Solutions, code, and devops for high-scale data science. |
-| [Variance](https://variancecharts.com/) | Build powerful data visualizations for the web without writing JavaScript |
-| [Kite Development Kit](https://kitesdk.org/docs/current/index.html) | The Kite Software Development Kit (Apache License, Version 2.0) , or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem. |
-| [Domino Data Labs](https://www.dominodatalab.com) | Run, scale, share, and deploy your models — without any infrastructure or setup. |
-| [Apache Flink](https://flink.apache.org/) | A platform for efficient, distributed, general-purpose data processing. |
-| [Apache Hama](https://hama.apache.org/) | Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce. |
-| [Weka](https://www.cs.waikato.ac.nz/ml/weka/) | Weka is a collection of machine learning algorithms for data mining tasks. |
-| [Octave](https://www.gnu.org/software/octave/) | GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab) |
-| [Apache Spark](https://spark.apache.org/) | Lightning-fast cluster computing |
-| [Hydrosphere Mist](https://github.com/Hydrospheredata/mist) | a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services. |
-| [Data Mechanics](https://www.datamechanics.co) | A data science and engineering platform making Apache Spark more developer-friendly and cost-effective. |
-| [Caffe](https://caffe.berkeleyvision.org/) | Deep Learning Framework |
-| [Torch](https://torch.ch/) | A SCIENTIFIC COMPUTING FRAMEWORK FOR LUAJIT |
-| [Nervana's python based Deep Learning Framework](https://github.com/NervanaSystems/neon) | . |
-| [Skale](https://github.com/skale-me/skale) | High performance distributed data processing in NodeJS |
-| [Aerosolve](https://airbnb.io/aerosolve/) | A machine learning package built for humans. |
-| [Intel framework](https://github.com/intel/idlf) | Intel® Deep Learning Framework |
-| [Datawrapper](https://www.datawrapper.de/) | An open source data visualization platform helping everyone to create simple, correct and embeddable charts. Also at [github.com](https://github.com/datawrapper/datawrapper) |
-| [Tensor Flow](https://www.tensorflow.org/) | TensorFlow is an Open Source Software Library for Machine Intelligence |
-| [Natural Language Toolkit](https://www.nltk.org/) | An introductory yet powerful toolkit for natural language processing and classification |
-| [Annotation Lab](https://www.johnsnowlabs.com/annotation-lab/) | Free End-to-End No-Code platform for text annotation and DL model training/tuning. Out-of-the-box support for Named Entity Recognition, Classification, Relation extraction and Assertion Status Spark NLP models. Unlimited support for users, teams, projects, documents. |
-| [nlp-toolkit for node.js](https://www.npmjs.com/package/nlp-toolkit) | . |
-| [Julia](https://julialang.org) | high-level, high-performance dynamic programming language for technical computing |
-| [IJulia](https://github.com/JuliaLang/IJulia.jl) | a Julia-language backend combined with the Jupyter interactive environment |
-| [Apache Zeppelin](https://zeppelin.apache.org/) | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more |
-| [Featuretools](https://github.com/alteryx/featuretools) | An open source framework for automated feature engineering written in python |
-| [Optimus](https://github.com/hi-primus/optimus) | Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend. |
-| [Albumentations](https://github.com/albumentations-team/albumentations) | А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops. |
-| [DVC](https://github.com/iterative/dvc) | An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files. |
-| [Lambdo](https://github.com/asavinov/lambdo) | is a workflow engine which significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation. |
-| [Feast](https://github.com/feast-dev/feast) | A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving. |
-| [Polyaxon](https://github.com/polyaxon/polyaxon) | A platform for reproducible and scalable machine learning and deep learning. |
-| [LightTag](https://www.lighttag.io/) | Text Annotation Tool for teams |
-| [UBIAI](https://ubiai.tools) | Easy-to-use text annotation tool for teams with most comprehensive auto-annotation features. Supports NER, relations and document classification as well as OCR annotation for invoice labeling |
-| [Trains](https://github.com/allegroai/clearml) | Auto-Magical Experiment Manager, Version Control & DevOps for AI |
-| [Hopsworks](https://github.com/logicalclocks/hopsworks) | Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale. |
-| [MindsDB](https://github.com/mindsdb/mindsdb) | MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code. |
-| [Lightwood](https://github.com/mindsdb/lightwood) | A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code. |
-| [AWS Data Wrangler](https://github.com/awslabs/aws-data-wrangler) | An open-source Python package that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services (Amazon Redshift, AWS Glue, Amazon Athena, Amazon EMR, etc). |
-| [Amazon Rekognition](https://aws.amazon.com/rekognition/) | AWS Rekognition is a service that lets developers working with Amazon Web Services add image analysis to their applications. Catalog assets, automate workflows, and extract meaning from your media and applications.|
-| [Amazon Textract](https://aws.amazon.com/textract/) | Automatically extract printed text, handwriting, and data from any document. |
-| [Amazon Lookout for Vision](https://aws.amazon.com/lookout-for-vision/) | Spot product defects using computer vision to automate quality inspection. Identify missing product components, vehicle and structure damage, and irregularities for comprehensive quality control.|
-| [Amazon CodeGuru](https://aws.amazon.com/codeguru/) | Automate code reviews and optimize application performance with ML-powered recommendations.|
-| [CML](https://github.com/iterative/cml) | An open source toolkit for using continuous integration in data science projects. Automatically train and test models in production-like environments with GitHub Actions & GitLab CI, and autogenerate visual reports on pull/merge requests. |
-| [Dask](https://dask.org/) | An open source Python library to painlessly transition your analytics code to distributed computing systems (Big Data) |
-| [Statsmodels](https://www.statsmodels.org/stable/index.html) | A Python-based inferential statistics, hypothesis testing and regression framework |
-| [Gensim](https://radimrehurek.com/gensim/) | An open-source library for topic modeling of natural language text |
-| [spaCy](https://spacy.io/) | A performant natural language processing toolkit |
-| [Grid Studio](https://github.com/ricklamers/gridstudio) | Grid studio is a web-based spreadsheet application with full integration of the Python programming language. |
-|[Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook)|Python Data Science Handbook: full text in Jupyter Notebooks|
-| [Shapley](https://github.com/benedekrozemberczki/shapley) | A data-driven framework to quantify the value of classifiers in a machine learning ensemble. |
-| [DAGsHub](https://dagshub.com) | A platform built on open source tools for data, model and pipeline management. |
-| [Deepnote](https://deepnote.com) | A new kind of data science notebook. Jupyter-compatible, with real-time collaboration and running in the cloud. |
-| [Valohai](https://valohai.com) | An MLOps platform that handles machine orchestration, automatic reproducibility and deployment. |
-| [PyMC3](https://docs.pymc.io/) | A Python Library for Probabalistic Programming (Bayesian Inference and Machine Learning) |
-| [PyStan](https://pypi.org/project/pystan/) | Python interface to Stan (Bayesian inference and modeling) |
-| [hmmlearn](https://pypi.org/project/hmmlearn/) | Unsupervised learning and inference of Hidden Markov Models |
-| [Chaos Genius](https://github.com/chaos-genius/chaos_genius/) | ML powered analytics engine for outlier/anomaly detection and root cause analysis |
-| [Nimblebox](https://nimblebox.ai/) | A full-stack MLOps platform designed to help data scientists and machine learning practitioners around the world discover, create, and launch multi-cloud apps from their web browser. |
-| [Towhee](https://github.com/towhee-io/towhee) | A Python library that helps you encode your unstructured data into embeddings. |
-| [LineaPy](https://github.com/LineaLabs/lineapy) | Ever been frustrated with cleaning up long, messy Jupyter notebooks? With LineaPy, an open source Python library, it takes as little as two lines of code to transform messy development code into production pipelines. |
-| [envd](https://github.com/tensorchord/envd) | 🏕️ machine learning development environment for data science and AI/ML engineering teams |
-| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
-| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
+These are some Machine Learning and Data Mining algorithms and models help you to understand your data and derive meaning from it.
+
+#### Supervised Learning
+
+- Regression
+- [Linear Regression](https://en.wikipedia.org/wiki/Linear_regression)
+- Ordinary Least Squares
+- Logistic Regression
+- Stepwise Regression
+- Multivariate Adaptive Regression Splines
+- Locally Estimated Scatterplot Smoothing
+- Classification
+ - k-nearest neighbor
+ - Support Vector Machines
+ - Decision Trees
+ - ID3 algorithm
+ - C4.5 algorithm
+- Ensemble Learning
+- Boosting
+- Bagging
+- Random Forest
+- AdaBoost
+
+#### Unsupervised Learning
+- Clustering
+ - Hierchical clustering
+ - k-means
+ - Fuzzy clustering
+ - Mixture models
+- Dimension Reduction
+ - Principal Component Analysis (PCA)
+ - t-SNE
+- Neural Networks
+- Self-organizing map
+- Adaptive resonance theory
+- Hidden Markov Models (HMM)
+
+#### Semi-Supervised Learning
+
+- S3VM
+- Clustering
+- Generative models
+- Low-density separation
+- Laplacian regularization
+- Heuristic approaches
+#### Reinforcement Learning
-## Machine Learning in General Purpose
+- Q Learning
+- SARSA (State-Action-Reward-State-Action) algorithm
+- Temporal difference learning
+
+#### Data Mining Algorithms
+
+- C4.5
+- k-Means
+- SVM
+- Apriori
+- EM
+- PageRank
+- AdaBoost
+- kNN
+- Naive Bayes
+- CART
+
+#### Deep Learning architectures
+
+- Multilayer Perceptron
+- Convolutional Neural Network (CNN)
+- Recurrent Neural Network (RNN)
+- Boltzmann Machines
+- Autoencoder
+- Generative Adversarial Network (GAN)
+- Self-Organized Maps
+- Transformer
+- Conditional Random Field (CRF)
+
+### General Machine Learning Packages
**[`^ back to top ^`](#awesome-data-science)**
* [scikit-learn](https://scikit-learn.org/)
@@ -374,10 +296,9 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [pyGAM](https://github.com/dswah/pyGAM)
* [Deepchecks](https://github.com/deepchecks/deepchecks)
+### Deep Learning Packages
-## Deep Learning
-
-### PyTorch
+#### PyTorch Ecosystem
* [PyTorch](https://github.com/pytorch/pytorch)
* [torchvision](https://github.com/pytorch/vision)
* [torchtext](https://github.com/pytorch/text)
@@ -392,7 +313,8 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [pyro](https://github.com/pyro-ppl/pyro)
* [Catalyst](https://github.com/catalyst-team/catalyst)
* [pytorch_tabular](https://github.com/manujosephv/pytorch_tabular)
-### TensorFlow
+
+#### TensorFlow Ecosystem
* [TensorFlow](https://github.com/tensorflow/tensorflow)
* [TensorLayer](https://github.com/tensorlayer/TensorLayer)
* [TFLearn](https://github.com/tflearn/tflearn)
@@ -411,7 +333,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [TF-Agents](https://github.com/tensorflow/agents)
* [TensorForce](https://github.com/tensorforce/tensorforce)
-### Keras
+#### Keras Ecosystem
* [Keras](https://keras.io)
* [keras-contrib](https://github.com/keras-team/keras-contrib)
@@ -423,8 +345,7 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
* [keras-rl](https://github.com/keras-rl/keras-rl)
* [Talos](https://github.com/autonomio/talos)
-
-## Visualization Tools - Environments
+#### Visualization Tools
**[`^ back to top ^`](#awesome-data-science)**
- [altair](https://altair-viz.github.io/)
@@ -466,6 +387,100 @@ How do you learn data science? By doing data science, of course! Okay, okay - th
- [C3](https://c3js.org/)
- [TensorWatch](https://github.com/microsoft/tensorwatch)
+### Miscellaneous Tools
+**[`^ back to top ^`](#awesome-data-science)**
+
+| Link | Description |
+| --- | --- |
+| [The Data Science Lifecycle Process](https://github.com/dslp/dslp) | The Data Science Lifecycle Process is a process for taking data science teams from Idea to Value repeatedly and sustainably. The process is documented in this repo |
+| [Data Science Lifecycle Template Repo](https://github.com/dslp/dslp-repo-template) | Template repository for data science lifecycle project |
+| [RexMex](https://github.com/AstraZeneca/rexmex) | A general purpose recommender metrics library for fair evaluation. |
+| [ChemicalX](https://github.com/AstraZeneca/chemicalx) | A PyTorch based deep learning library for drug pair scoring. |
+| [PyTorch Geometric Temporal](https://github.com/benedekrozemberczki/pytorch_geometric_temporal) | Representation learning on dynamic graphs. |
+| [Little Ball of Fur](https://github.com/benedekrozemberczki/littleballoffur) | A graph sampling library for NetworkX with a Scikit-Learn like API. |
+| [Karate Club](https://github.com/benedekrozemberczki/karateclub) | An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API. |
+| [ML Workspace](https://github.com/ml-tooling/ml-workspace) | All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code) |
+| [Neptune.ai](https://neptune.ai) | Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility. |
+| [steppy](https://github.com/minerva-ml/steppy) | Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design. |
+| [steppy-toolkit](https://github.com/minerva-ml/steppy-toolkit) | Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective. |
+| [Datalab from Google](https://cloud.google.com/datalab/docs/) | easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively. |
+| [Hortonworks Sandbox](https://www.cloudera.com/downloads/hortonworks-sandbox.html) | is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials. |
+| [R](https://www.r-project.org/) | is a free software environment for statistical computing and graphics. |
+| [Tidyverse](https://www.tidyverse.org/) | is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. |
+| [RStudio](https://www.rstudio.com) | IDE – powerful user interface for R. It’s free and open source, works on Windows, Mac, and Linux. |
+| [Python - Pandas - Anaconda](https://www.anaconda.com) | Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing |
+| [Pandas GUI](https://github.com/adrotog/PandasGUI) | Pandas GUI |
+| [Scikit-Learn](https://scikit-learn.org/stable/) | Machine Learning in Python |
+| [NumPy](https://numpy.org/) | NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays. |
+| [Vaex](https://vaex.io/) | Vaex is a Python library that allows you to visualize large datasets and calculate statistics at high speeds. |
+| [SciPy](https://scipy.org/) | SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization.
+| [Data Science Toolbox](https://www.coursera.org/learn/data-scientists-tools) | Coursera Course |
+| [Data Science Toolbox](https://datasciencetoolbox.org/) | Blog |
+| [Wolfram Data Science Platform](https://www.wolfram.com/data-science-platform/) | Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generating rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language. |
+| [Datadog](https://www.datadoghq.com/) | Solutions, code, and devops for high-scale data science. |
+| [Variance](https://variancecharts.com/) | Build powerful data visualizations for the web without writing JavaScript |
+| [Kite Development Kit](https://kitesdk.org/docs/current/index.html) | The Kite Software Development Kit (Apache License, Version 2.0) , or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem. |
+| [Domino Data Labs](https://www.dominodatalab.com) | Run, scale, share, and deploy your models — without any infrastructure or setup. |
+| [Apache Flink](https://flink.apache.org/) | A platform for efficient, distributed, general-purpose data processing. |
+| [Apache Hama](https://hama.apache.org/) | Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce. |
+| [Weka](https://www.cs.waikato.ac.nz/ml/weka/) | Weka is a collection of machine learning algorithms for data mining tasks. |
+| [Octave](https://www.gnu.org/software/octave/) | GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab) |
+| [Apache Spark](https://spark.apache.org/) | Lightning-fast cluster computing |
+| [Hydrosphere Mist](https://github.com/Hydrospheredata/mist) | a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services. |
+| [Data Mechanics](https://www.datamechanics.co) | A data science and engineering platform making Apache Spark more developer-friendly and cost-effective. |
+| [Caffe](https://caffe.berkeleyvision.org/) | Deep Learning Framework |
+| [Torch](https://torch.ch/) | A SCIENTIFIC COMPUTING FRAMEWORK FOR LUAJIT |
+| [Nervana's python based Deep Learning Framework](https://github.com/NervanaSystems/neon) | . |
+| [Skale](https://github.com/skale-me/skale) | High performance distributed data processing in NodeJS |
+| [Aerosolve](https://airbnb.io/aerosolve/) | A machine learning package built for humans. |
+| [Intel framework](https://github.com/intel/idlf) | Intel® Deep Learning Framework |
+| [Datawrapper](https://www.datawrapper.de/) | An open source data visualization platform helping everyone to create simple, correct and embeddable charts. Also at [github.com](https://github.com/datawrapper/datawrapper) |
+| [Tensor Flow](https://www.tensorflow.org/) | TensorFlow is an Open Source Software Library for Machine Intelligence |
+| [Natural Language Toolkit](https://www.nltk.org/) | An introductory yet powerful toolkit for natural language processing and classification |
+| [Annotation Lab](https://www.johnsnowlabs.com/annotation-lab/) | Free End-to-End No-Code platform for text annotation and DL model training/tuning. Out-of-the-box support for Named Entity Recognition, Classification, Relation extraction and Assertion Status Spark NLP models. Unlimited support for users, teams, projects, documents. |
+| [nlp-toolkit for node.js](https://www.npmjs.com/package/nlp-toolkit) | . |
+| [Julia](https://julialang.org) | high-level, high-performance dynamic programming language for technical computing |
+| [IJulia](https://github.com/JuliaLang/IJulia.jl) | a Julia-language backend combined with the Jupyter interactive environment |
+| [Apache Zeppelin](https://zeppelin.apache.org/) | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more |
+| [Featuretools](https://github.com/alteryx/featuretools) | An open source framework for automated feature engineering written in python |
+| [Optimus](https://github.com/hi-primus/optimus) | Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend. |
+| [Albumentations](https://github.com/albumentations-team/albumentations) | А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops. |
+| [DVC](https://github.com/iterative/dvc) | An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files. |
+| [Lambdo](https://github.com/asavinov/lambdo) | is a workflow engine which significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation. |
+| [Feast](https://github.com/feast-dev/feast) | A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving. |
+| [Polyaxon](https://github.com/polyaxon/polyaxon) | A platform for reproducible and scalable machine learning and deep learning. |
+| [LightTag](https://www.lighttag.io/) | Text Annotation Tool for teams |
+| [UBIAI](https://ubiai.tools) | Easy-to-use text annotation tool for teams with most comprehensive auto-annotation features. Supports NER, relations and document classification as well as OCR annotation for invoice labeling |
+| [Trains](https://github.com/allegroai/clearml) | Auto-Magical Experiment Manager, Version Control & DevOps for AI |
+| [Hopsworks](https://github.com/logicalclocks/hopsworks) | Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale. |
+| [MindsDB](https://github.com/mindsdb/mindsdb) | MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code. |
+| [Lightwood](https://github.com/mindsdb/lightwood) | A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code. |
+| [AWS Data Wrangler](https://github.com/awslabs/aws-data-wrangler) | An open-source Python package that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services (Amazon Redshift, AWS Glue, Amazon Athena, Amazon EMR, etc). |
+| [Amazon Rekognition](https://aws.amazon.com/rekognition/) | AWS Rekognition is a service that lets developers working with Amazon Web Services add image analysis to their applications. Catalog assets, automate workflows, and extract meaning from your media and applications.|
+| [Amazon Textract](https://aws.amazon.com/textract/) | Automatically extract printed text, handwriting, and data from any document. |
+| [Amazon Lookout for Vision](https://aws.amazon.com/lookout-for-vision/) | Spot product defects using computer vision to automate quality inspection. Identify missing product components, vehicle and structure damage, and irregularities for comprehensive quality control.|
+| [Amazon CodeGuru](https://aws.amazon.com/codeguru/) | Automate code reviews and optimize application performance with ML-powered recommendations.|
+| [CML](https://github.com/iterative/cml) | An open source toolkit for using continuous integration in data science projects. Automatically train and test models in production-like environments with GitHub Actions & GitLab CI, and autogenerate visual reports on pull/merge requests. |
+| [Dask](https://dask.org/) | An open source Python library to painlessly transition your analytics code to distributed computing systems (Big Data) |
+| [Statsmodels](https://www.statsmodels.org/stable/index.html) | A Python-based inferential statistics, hypothesis testing and regression framework |
+| [Gensim](https://radimrehurek.com/gensim/) | An open-source library for topic modeling of natural language text |
+| [spaCy](https://spacy.io/) | A performant natural language processing toolkit |
+| [Grid Studio](https://github.com/ricklamers/gridstudio) | Grid studio is a web-based spreadsheet application with full integration of the Python programming language. |
+|[Python Data Science Handbook](https://github.com/jakevdp/PythonDataScienceHandbook)|Python Data Science Handbook: full text in Jupyter Notebooks|
+| [Shapley](https://github.com/benedekrozemberczki/shapley) | A data-driven framework to quantify the value of classifiers in a machine learning ensemble. |
+| [DAGsHub](https://dagshub.com) | A platform built on open source tools for data, model and pipeline management. |
+| [Deepnote](https://deepnote.com) | A new kind of data science notebook. Jupyter-compatible, with real-time collaboration and running in the cloud. |
+| [Valohai](https://valohai.com) | An MLOps platform that handles machine orchestration, automatic reproducibility and deployment. |
+| [PyMC3](https://docs.pymc.io/) | A Python Library for Probabalistic Programming (Bayesian Inference and Machine Learning) |
+| [PyStan](https://pypi.org/project/pystan/) | Python interface to Stan (Bayesian inference and modeling) |
+| [hmmlearn](https://pypi.org/project/hmmlearn/) | Unsupervised learning and inference of Hidden Markov Models |
+| [Chaos Genius](https://github.com/chaos-genius/chaos_genius/) | ML powered analytics engine for outlier/anomaly detection and root cause analysis |
+| [Nimblebox](https://nimblebox.ai/) | A full-stack MLOps platform designed to help data scientists and machine learning practitioners around the world discover, create, and launch multi-cloud apps from their web browser. |
+| [Towhee](https://github.com/towhee-io/towhee) | A Python library that helps you encode your unstructured data into embeddings. |
+| [LineaPy](https://github.com/LineaLabs/lineapy) | Ever been frustrated with cleaning up long, messy Jupyter notebooks? With LineaPy, an open source Python library, it takes as little as two lines of code to transform messy development code into production pipelines. |
+| [envd](https://github.com/tensorchord/envd) | 🏕️ machine learning development environment for data science and AI/ML engineering teams |
+| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
+| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
## Journals, Publications and Magazines
**[`^ back to top ^`](#awesome-data-science)**
From f78c0b84f6761b500a4322b1c09f245c779f8181 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:22:33 -0400
Subject: [PATCH 07/16] Add Literature and Media section, put relevant sections
inside
---
README.md | 246 +++++++++++++++++++++++++++---------------------------
1 file changed, 124 insertions(+), 122 deletions(-)
diff --git a/README.md b/README.md
index 8b504d38..dd7badc5 100644
--- a/README.md
+++ b/README.md
@@ -41,12 +41,15 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Keras Ecosystem](#keras-ecosystem)
- [Visualization Tools](#visualization-tools)
- [Miscellaneous Tools](#miscellaneous-tools)
-- [Podcasts](#podcasts)
-- [Books](#books)
-- [Book Deals](#book-deals-affiliated-🛍)
-- [YouTube Videos & Channels](#youtube-videos--channels)
-- [Journals, Publications and Magazines](#journals-publications-and-magazines)
-- [Presentations](#presentations)
+- [Literature and Media](#literature-and-media)
+ - [Books](#books)
+ - [Book Deals (Affiliated)](#book-deals-affiliated-)
+ - [Journals, Publications, and Magazines](#journals-publications-and-magazines)
+ - [Newsletters](#newsletters)
+ - [Bloggers](#bloggers)
+ - [Presentations](#presentations)
+ - [Podcasts](#podcasts)]
+ - [YouTube Videos & Channels](#youtube-videos--channels)
## What is Data Science?
@@ -482,70 +485,12 @@ These are some Machine Learning and Data Mining algorithms and models help you t
| [Explore Data Science Libraries](https://kandi.openweaver.com/explore/data-science) | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
| [MLEM](https://github.com/iterative/mlem) | 🐶 Version and deploy your ML models following GitOps principles |
-## Journals, Publications and Magazines
+## Literature and Media
**[`^ back to top ^`](#awesome-data-science)**
-- [ICML](https://icml.cc/2015/) - International Conference on Machine Learning
-- [GECCO](https://gecco-2019.sigevo.org/index.html/HomePage) - The Genetic and Evolutionary Computation Conference (GECCO)
-- [epjdatascience](https://epjdatascience.springeropen.com/)
-- [Journal of Data Science](https://jds-online.org/journal/JDS) - an international journal devoted to applications of statistical methods at large
-- [Big Data Research](https://www.journals.elsevier.com/big-data-research)
-- [Journal of Big Data](https://journalofbigdata.springeropen.com/)
-- [Big Data & Society](https://journals.sagepub.com/home/bds)
-- [Data Science Journal](https://www.jstage.jst.go.jp/browse/dsj)
-- [datatau.com/news](https://www.datatau.com/news) - Like Hacker News, but for data
-- [Data Science Trello Board](https://trello.com/b/rbpEfMld/data-science)
-- [Medium Data Science Topic](https://medium.com/tag/data-science) - Data Science related publications on medium
-- [Towards Data Science Genetic Algorithm Topic](https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3#:~:text=A%20genetic%20algorithm%20is%20a,offspring%20of%20the%20next%20generation.) -Genetic Algorithm related Publications onTowards Data Science
-- [all AI news](https://allainews.com/) - The AI/ML/Big Data news aggregator platform
-
-## Presentations
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [How to Become a Data Scientist](https://www.slideshare.net/ryanorban/how-to-become-a-data-scientist)
-- [Introduction to Data Science](https://www.slideshare.net/NikoVuokko/introduction-to-data-science-25391618)
-- [Intro to Data Science for Enterprise Big Data](https://www.slideshare.net/pacoid/intro-to-data-science-for-enterprise-big-data)
-- [How to Interview a Data Scientist](https://www.slideshare.net/dtunkelang/how-to-interview-a-data-scientist)
-- [How to Share Data with a Statistician](https://github.com/jtleek/datasharing)
-- [The Science of a Great Career in Data Science](https://www.slideshare.net/katemats/the-science-of-a-great-career-in-data-science)
-- [What Does a Data Scientist Do?](https://www.slideshare.net/datasciencelondon/big-data-sorry-data-science-what-does-a-data-scientist-do)
-- [Building Data Start-Ups: Fast, Big, and Focused](https://www.slideshare.net/medriscoll/driscoll-strata-buildingdatastartups25may2011clean)
-- [How to win data science competitions with Deep Learning](https://www.slideshare.net/0xdata/how-to-win-data-science-competitions-with-deep-learning)
-- [Full-Stack Data Scientist](https://www.slideshare.net/AlexeyGrigorev/fullstack-data-scientist)
-
-
-## Podcasts
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [AI at Home](https://podcasts.apple.com/us/podcast/data-science-at-home/id1069871378)
-- [AI Today](https://www.cognilytica.com/aitoday/)
-- [Adversarial Learning](https://adversariallearning.com/)
-- [Becoming a Data Scientist](https://www.becomingadatascientist.com/category/podcast/)
-- [Chai time Data Science](https://www.youtube.com/playlist?list=PLLvvXm0q8zUbiNdoIazGzlENMXvZ9bd3x)
-- [Data Crunch](https://datacrunchcorp.com/data-crunch-podcast/)
-- [Data Engineering Podcast](https://www.dataengineeringpodcast.com/)
-- [Data Science at Home](https://datascienceathome.com/)
-- [Data Science Mixer](https://community.alteryx.com/t5/Data-Science-Mixer/bg-p/mixer)
-- [Data Skeptic](https://dataskeptic.com/)
-- [Data Stories](https://datastori.es/)
-- [Datacast](https://jameskle.com/writes/category/Datacast)
-- [DataFramed](https://www.datacamp.com/community/podcast)
-- [DataTalks.Club](https://anchor.fm/datatalksclub)
-- [Gradient Dissent](https://wandb.ai/fully-connected/gradient-dissent)
-- [Learning Machines 101](https://www.learningmachines101.com/)
-- [Let's Data (Brazil)](https://www.youtube.com/playlist?list=PLn_z5E4dh_Lj5eogejMxfOiNX3nOhmhmM)
-- [Linear Digressions](https://lineardigressions.com/)
-- [Not So Standard Deviations](https://nssdeviations.com/)
-- [O'Reilly Data Show Podcast](https://www.oreilly.com/radar/topics/oreilly-data-show-podcast/)
-- [Partially Derivative](https://partiallyderivative.com/)
-- [Superdatascience](https://www.superdatascience.com/podcast/)
-- [The Data Engineering Show](https://www.dataengineeringshow.com/)
-- [The Radical AI Podcast](https://www.radicalai.org/)
-- [The Robot Brains Podcast](https://www.therobotbrains.ai/)
-- [What's The Point](https://fivethirtyeight.com/tag/whats-the-point/)
-- [How AI Built This](https://how-ai-built-this.captivate.fm/)
+This section includes some additional reading material, channels to watch, and talks to listen to.
-## Books
+### Books
**[`^ back to top ^`](#awesome-data-science)**
- [Data Science From Scratch: First Principles with Python](https://www.amazon.com/Data-Science-Scratch-Principles-Python-dp-1492041130/dp/1492041130/ref=dp_ob_title_bk)
@@ -611,7 +556,7 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- [Dive into Deep Learning](https://d2l.ai/)
- [Interpretable Machine Learning: A Guide for Making Black Box Models Explainable](https://christophm.github.io/interpretable-ml-book/) - Free GitHub version
-## Book Deals (Affiliated) 🛍
+#### Book Deals (Affiliated) 🛍
- [eBook sale - Save up to 45% on eBooks!](https://www.manning.com/?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=ebook_sale_8_8_22)
@@ -621,20 +566,29 @@ These are some Machine Learning and Data Mining algorithms and models help you t
- [Causal Inference for Data Science](https://www.manning.com/books/causal-inference-for-data-science?utm_source=mikrobusiness&utm_medium=affiliate&utm_campaign=book_ruizdevilla_causal_6_6_22)
- [Data for All](https://www.manning.com/books/data-for-all?utm_source=mikrobusiness&utm_medium=affiliate)
-## Socialize
+### Journals, Publications and Magazines
**[`^ back to top ^`](#awesome-data-science)**
-Below are some Social Media links. Connect with other data scientists!
+- [ICML](https://icml.cc/2015/) - International Conference on Machine Learning
+- [GECCO](https://gecco-2019.sigevo.org/index.html/HomePage) - The Genetic and Evolutionary Computation Conference (GECCO)
+- [epjdatascience](https://epjdatascience.springeropen.com/)
+- [Journal of Data Science](https://jds-online.org/journal/JDS) - an international journal devoted to applications of statistical methods at large
+- [Big Data Research](https://www.journals.elsevier.com/big-data-research)
+- [Journal of Big Data](https://journalofbigdata.springeropen.com/)
+- [Big Data & Society](https://journals.sagepub.com/home/bds)
+- [Data Science Journal](https://www.jstage.jst.go.jp/browse/dsj)
+- [datatau.com/news](https://www.datatau.com/news) - Like Hacker News, but for data
+- [Data Science Trello Board](https://trello.com/b/rbpEfMld/data-science)
+- [Medium Data Science Topic](https://medium.com/tag/data-science) - Data Science related publications on medium
+- [Towards Data Science Genetic Algorithm Topic](https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3#:~:text=A%20genetic%20algorithm%20is%20a,offspring%20of%20the%20next%20generation.) -Genetic Algorithm related Publications onTowards Data Science
+- [all AI news](https://allainews.com/) - The AI/ML/Big Data news aggregator platform
-- [Bloggers](#bloggers)
-- [Facebook Accounts](#facebook-accounts)
-- [Twitter Accounts](#twitter-accounts)
-- [Newsletters](#newsletters)
-- [YouTube Videos and Channels](#youtube-videos--channels)
-- [Telegram Channels](#telegram-channels)
-- [Slack Communities](#slack-communities)
-- [GitHub Groups](#github-groups)
-- [Data Science Competitions](#competitions)
+### Newsletters
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [AI Digest](https://aidigest.net/). A weekly newsletter to keep up to date with AI, machine learning, and data science. [Archive](https://aidigest.net/digests).
+- [DataTalks.Club](https://datatalks.club). A weekly newsletter about data-related things. [Archive](https://us19.campaign-archive.com/home/?u=0d7822ab98152f5afc118c176&id=97178021aa).
+- [The Analytics Engineering Roundup](https://roundup.getdbt.com/about). A newsletter about data science. [Archive](https://roundup.getdbt.com/archive).
### Bloggers
**[`^ back to top ^`](#awesome-data-science)**
@@ -725,6 +679,97 @@ Below are some Social Media links. Connect with other data scientists!
- [Maria Khalusova](https://www.mariakhalusova.com/) - Data science blog
- [Aditi Rastogi](https://medium.com/@aditi2507rastogi) - ML,DL,Data Science blog
+### Presentations
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [How to Become a Data Scientist](https://www.slideshare.net/ryanorban/how-to-become-a-data-scientist)
+- [Introduction to Data Science](https://www.slideshare.net/NikoVuokko/introduction-to-data-science-25391618)
+- [Intro to Data Science for Enterprise Big Data](https://www.slideshare.net/pacoid/intro-to-data-science-for-enterprise-big-data)
+- [How to Interview a Data Scientist](https://www.slideshare.net/dtunkelang/how-to-interview-a-data-scientist)
+- [How to Share Data with a Statistician](https://github.com/jtleek/datasharing)
+- [The Science of a Great Career in Data Science](https://www.slideshare.net/katemats/the-science-of-a-great-career-in-data-science)
+- [What Does a Data Scientist Do?](https://www.slideshare.net/datasciencelondon/big-data-sorry-data-science-what-does-a-data-scientist-do)
+- [Building Data Start-Ups: Fast, Big, and Focused](https://www.slideshare.net/medriscoll/driscoll-strata-buildingdatastartups25may2011clean)
+- [How to win data science competitions with Deep Learning](https://www.slideshare.net/0xdata/how-to-win-data-science-competitions-with-deep-learning)
+- [Full-Stack Data Scientist](https://www.slideshare.net/AlexeyGrigorev/fullstack-data-scientist)
+
+### Podcasts
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [AI at Home](https://podcasts.apple.com/us/podcast/data-science-at-home/id1069871378)
+- [AI Today](https://www.cognilytica.com/aitoday/)
+- [Adversarial Learning](https://adversariallearning.com/)
+- [Becoming a Data Scientist](https://www.becomingadatascientist.com/category/podcast/)
+- [Chai time Data Science](https://www.youtube.com/playlist?list=PLLvvXm0q8zUbiNdoIazGzlENMXvZ9bd3x)
+- [Data Crunch](https://datacrunchcorp.com/data-crunch-podcast/)
+- [Data Engineering Podcast](https://www.dataengineeringpodcast.com/)
+- [Data Science at Home](https://datascienceathome.com/)
+- [Data Science Mixer](https://community.alteryx.com/t5/Data-Science-Mixer/bg-p/mixer)
+- [Data Skeptic](https://dataskeptic.com/)
+- [Data Stories](https://datastori.es/)
+- [Datacast](https://jameskle.com/writes/category/Datacast)
+- [DataFramed](https://www.datacamp.com/community/podcast)
+- [DataTalks.Club](https://anchor.fm/datatalksclub)
+- [Gradient Dissent](https://wandb.ai/fully-connected/gradient-dissent)
+- [Learning Machines 101](https://www.learningmachines101.com/)
+- [Let's Data (Brazil)](https://www.youtube.com/playlist?list=PLn_z5E4dh_Lj5eogejMxfOiNX3nOhmhmM)
+- [Linear Digressions](https://lineardigressions.com/)
+- [Not So Standard Deviations](https://nssdeviations.com/)
+- [O'Reilly Data Show Podcast](https://www.oreilly.com/radar/topics/oreilly-data-show-podcast/)
+- [Partially Derivative](https://partiallyderivative.com/)
+- [Superdatascience](https://www.superdatascience.com/podcast/)
+- [The Data Engineering Show](https://www.dataengineeringshow.com/)
+- [The Radical AI Podcast](https://www.radicalai.org/)
+- [The Robot Brains Podcast](https://www.therobotbrains.ai/)
+- [What's The Point](https://fivethirtyeight.com/tag/whats-the-point/)
+- [How AI Built This](https://how-ai-built-this.captivate.fm/)
+
+### YouTube Videos & Channels
+**[`^ back to top ^`](#awesome-data-science)**
+
+- [What is machine learning?](https://www.youtube.com/watch?v=WXHM_i-fgGo)
+- [Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning](https://www.youtube.com/watch?v=n1ViNeWhC24)
+- [Data36 - Data Science for Beginners by Tomi Mester](https://www.youtube.com/c/TomiMesterData36comDataScienceForBeginners)
+- [Deep Learning: Intelligence from Big Data](https://www.youtube.com/watch?v=czLI3oLDe8M)
+- [Interview with Google's AI and Deep Learning 'Godfather' Geoffrey Hinton](https://www.youtube.com/watch?v=1Wp3IIpssEc)
+- [Introduction to Deep Learning with Python](https://www.youtube.com/watch?v=S75EdAcXHKk)
+- [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk)
+- [Data School](https://www.youtube.com/channel/UCnVzApLJE2ljPZSeQylSEyg) - Data Science Education
+- [Neural Nets for Newbies by Melanie Warrick (May 2015)](https://www.youtube.com/watch?v=Cu6A96TUy_o)
+- [Neural Networks video series by Hugo Larochelle](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH)
+- [Google DeepMind co-founder Shane Legg - Machine Super Intelligence](https://www.youtube.com/watch?v=evNCyRL3DOU)
+- [Data Science Primer](https://www.youtube.com/watch?v=cHzvYxBN9Ls&list=PLPqVjP3T4RIRsjaW07zoGzH-Z4dBACpxY)
+- [Data Science with Genetic Algorithms](https://www.youtube.com/watch?v=lpD38NxTOnk)
+- [Data Science for Beginners](https://www.youtube.com/playlist?list=PL2zq7klxX5ATMsmyRazei7ZXkP1GHt-vs)
+- [DataTalks.Club](https://www.youtube.com/channel/UCDvErgK0j5ur3aLgn6U-LqQ)
+- [Mildlyoverfitted - Tutorials on intermediate ML/DL topics](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
+- [mlops.community - Interviews of industry experts about production ML](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
+- [ML Street Talk - Unabashedly technical and non-commercial, so you will hear no annoying pitches.](https://www.youtube.com/c/machinelearningstreettalk)
+- [Neural networks by 3Blue1Brown ](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi)
+- [Neural networks from scratch by Sentdex](https://www.youtube.com/playlist?list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3)
+- [Manning Publications YouTube channel](https://www.youtube.com/c/ManningPublications/featured)
+- [Ask Dr Chong: How to Lead in Data Science - Part 1](https://youtu.be/JYuQZii5o58)
+- [Ask Dr Chong: How to Lead in Data Science - Part 2](https://youtu.be/SzqIXV-O-ko)
+- [Ask Dr Chong: How to Lead in Data Science - Part 3](https://youtu.be/Ogwm7k_smTA)
+- [Ask Dr Chong: How to Lead in Data Science - Part 4](https://youtu.be/a9usjdzTxTU)
+- [Ask Dr Chong: How to Lead in Data Science - Part 5](https://youtu.be/MYdQq-F3Ws0)
+- [Ask Dr Chong: How to Lead in Data Science - Part 6](https://youtu.be/LOOt4OVC3hY)
+- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
+- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
+
+
+## Socialize
+**[`^ back to top ^`](#awesome-data-science)**
+*
+Below are some Social Media links. Connect with other data scientists!
+
+- [Facebook Accounts](#facebook-accounts)
+- [Twitter Accounts](#twitter-accounts)
+- [Telegram Channels](#telegram-channels)
+- [Slack Communities](#slack-communities)
+- [GitHub Groups](#github-groups)
+- [Data Science Competitions](#competitions)
+
### Facebook Accounts
**[`^ back to top ^`](#awesome-data-science)**
@@ -824,48 +869,6 @@ Below are some Social Media links. Connect with other data scientists!
| [Alexey Grigorev](https://twitter.com/Al_Grigor) | Data science author |
-### Newsletters
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [AI Digest](https://aidigest.net/). A weekly newsletter to keep up to date with AI, machine learning, and data science. [Archive](https://aidigest.net/digests).
-- [DataTalks.Club](https://datatalks.club). A weekly newsletter about data-related things. [Archive](https://us19.campaign-archive.com/home/?u=0d7822ab98152f5afc118c176&id=97178021aa).
-- [The Analytics Engineering Roundup](https://roundup.getdbt.com/about). A newsletter about data science. [Archive](https://roundup.getdbt.com/archive).
-
-
-### YouTube Videos & Channels
-**[`^ back to top ^`](#awesome-data-science)**
-
-- [What is machine learning?](https://www.youtube.com/watch?v=WXHM_i-fgGo)
-- [Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning](https://www.youtube.com/watch?v=n1ViNeWhC24)
-- [Data36 - Data Science for Beginners by Tomi Mester](https://www.youtube.com/c/TomiMesterData36comDataScienceForBeginners)
-- [Deep Learning: Intelligence from Big Data](https://www.youtube.com/watch?v=czLI3oLDe8M)
-- [Interview with Google's AI and Deep Learning 'Godfather' Geoffrey Hinton](https://www.youtube.com/watch?v=1Wp3IIpssEc)
-- [Introduction to Deep Learning with Python](https://www.youtube.com/watch?v=S75EdAcXHKk)
-- [What is machine learning, and how does it work?](https://www.youtube.com/watch?v=elojMnjn4kk)
-- [Data School](https://www.youtube.com/channel/UCnVzApLJE2ljPZSeQylSEyg) - Data Science Education
-- [Neural Nets for Newbies by Melanie Warrick (May 2015)](https://www.youtube.com/watch?v=Cu6A96TUy_o)
-- [Neural Networks video series by Hugo Larochelle](https://www.youtube.com/playlist?list=PL6Xpj9I5qXYEcOhn7TqghAJ6NAPrNmUBH)
-- [Google DeepMind co-founder Shane Legg - Machine Super Intelligence](https://www.youtube.com/watch?v=evNCyRL3DOU)
-- [Data Science Primer](https://www.youtube.com/watch?v=cHzvYxBN9Ls&list=PLPqVjP3T4RIRsjaW07zoGzH-Z4dBACpxY)
-- [Data Science with Genetic Algorithms](https://www.youtube.com/watch?v=lpD38NxTOnk)
-- [Data Science for Beginners](https://www.youtube.com/playlist?list=PL2zq7klxX5ATMsmyRazei7ZXkP1GHt-vs)
-- [DataTalks.Club](https://www.youtube.com/channel/UCDvErgK0j5ur3aLgn6U-LqQ)
-- [Mildlyoverfitted - Tutorials on intermediate ML/DL topics](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
-- [mlops.community - Interviews of industry experts about production ML](https://www.youtube.com/channel/UCYBSjwkGTK06NnDnFsOcR7g)
-- [ML Street Talk - Unabashedly technical and non-commercial, so you will hear no annoying pitches.](https://www.youtube.com/c/machinelearningstreettalk)
-- [Neural networks by 3Blue1Brown ](https://www.youtube.com/playlist?list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi)
-- [Neural networks from scratch by Sentdex](https://www.youtube.com/playlist?list=PLQVvvaa0QuDcjD5BAw2DxE6OF2tius3V3)
-- [Manning Publications YouTube channel](https://www.youtube.com/c/ManningPublications/featured)
-- [Ask Dr Chong: How to Lead in Data Science - Part 1](https://youtu.be/JYuQZii5o58)
-- [Ask Dr Chong: How to Lead in Data Science - Part 2](https://youtu.be/SzqIXV-O-ko)
-- [Ask Dr Chong: How to Lead in Data Science - Part 3](https://youtu.be/Ogwm7k_smTA)
-- [Ask Dr Chong: How to Lead in Data Science - Part 4](https://youtu.be/a9usjdzTxTU)
-- [Ask Dr Chong: How to Lead in Data Science - Part 5](https://youtu.be/MYdQq-F3Ws0)
-- [Ask Dr Chong: How to Lead in Data Science - Part 6](https://youtu.be/LOOt4OVC3hY)
-- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
-- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
-
-
### Telegram Channels
**[`^ back to top ^`](#awesome-data-science)**
@@ -879,7 +882,6 @@ Below are some Social Media links. Connect with other data scientists!
- [DataTalks.Club](https://datatalks.club)
-
## GitHub Groups
- [Berkeley Institute for Data Science](https://github.com/BIDS)
From a398fd1ca24d0878e1a1b6ad544f13e660cb733e Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:25:20 -0400
Subject: [PATCH 08/16] Update TOC to include "Socialize" section, adjust
header names in "socialize" section
---
README.md | 14 ++++++++++----
1 file changed, 10 insertions(+), 4 deletions(-)
diff --git a/README.md b/README.md
index dd7badc5..6609f66c 100644
--- a/README.md
+++ b/README.md
@@ -50,6 +50,13 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Presentations](#presentations)
- [Podcasts](#podcasts)]
- [YouTube Videos & Channels](#youtube-videos--channels)
+- [Socialize](#socialize)
+ - [Facebook Accounts](#facebook-accounts)
+ - [Twitter Accounts](#twitter-accounts)
+ - [Telegram Channels](#telegram-channels)
+ - [Slack Communities](#slack-communities)
+ - [GitHub Groups](#github-groups)
+ - [Data Science Competitions](#data-science-competitions)
## What is Data Science?
@@ -768,7 +775,7 @@ Below are some Social Media links. Connect with other data scientists!
- [Telegram Channels](#telegram-channels)
- [Slack Communities](#slack-communities)
- [GitHub Groups](#github-groups)
-- [Data Science Competitions](#competitions)
+- [Data Science Competitions](#data-science-competitions)
### Facebook Accounts
@@ -882,11 +889,10 @@ Below are some Social Media links. Connect with other data scientists!
- [DataTalks.Club](https://datatalks.club)
-## GitHub Groups
+### GitHub Groups
- [Berkeley Institute for Data Science](https://github.com/BIDS)
-
-## Competitions
+### Data Science Competitions
Some data mining competition platforms
From 1e9e1ec81e3b46dc69bd421d8456711412302631 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:27:52 -0400
Subject: [PATCH 09/16] Add remaining sections into TOC
---
README.md | 19 +++++++++++--------
1 file changed, 11 insertions(+), 8 deletions(-)
diff --git a/README.md b/README.md
index 6609f66c..1e8978f9 100644
--- a/README.md
+++ b/README.md
@@ -57,7 +57,13 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Slack Communities](#slack-communities)
- [GitHub Groups](#github-groups)
- [Data Science Competitions](#data-science-competitions)
-
+- [Fun](#fun)
+ - [Infographics](#infographics)
+ - [Datasets](#datasets)
+ - [Comics](#comics)
+- [Awesome Data Science](#awesome-data-science)
+- [Hobby](#hobby)
+- [Other Lists](#other-lists)
## What is Data Science?
**[`^ back to top ^`](#awesome-data-science)**
@@ -764,7 +770,6 @@ This section includes some additional reading material, channels to watch, and t
- [Regression Models: Applying simple Poisson regression](https://www.youtube.com/watch?v=9Hk8K8jhiOo)
- [Deep Learning Architectures](https://www.youtube.com/playlist?list=PLv8Cp2NvcY8DpVcsmOT71kymgMmcr59Mf)
-
## Socialize
**[`^ back to top ^`](#awesome-data-science)**
*
@@ -902,15 +907,14 @@ Some data mining competition platforms
- [InnoCentive](https://www.innocentive.com/)
- [Microprediction](https://www.microprediction.com/python-1)
-
## Fun
-- [Infographic](#infographic)
-- [Data Sets](#data-sets)
+- [Infographic](#infographics)
+- [Datasets](#datasets)
- [Comics](#comics)
-### Infographic
+### Infographics
**[`^ back to top ^`](#awesome-data-science)**
| Preview | Description |
@@ -929,7 +933,7 @@ Some data mining competition platforms
| [](https://www.springboard.com/blog/wp-content/uploads/2016/03/20160324_springboard_vennDiagram.png) | Different Data Science Skills and Roles from [this article](https://www.springboard.com/blog/data-science-career-paths-different-roles-industry/) by Springboard |
| [](https://data-literacy.geckoboard.com/poster/) | A simple and friendly way of teaching your non-data scientist/non-statistician colleagues [how to avoid mistakes with data](https://data-literacy.geckoboard.com/poster/). From Geckoboard's [Data Literacy Lessons](https://data-literacy.geckoboard.com/). |
-### Data Sets
+### Datasets
**[`^ back to top ^`](#awesome-data-science)**
- [Academic Torrents](https://academictorrents.com/)
@@ -992,7 +996,6 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-
## Awesome Data Science
[](https://github.com/sindresorhus/awesome) [](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
From 8ad41401c8bec83cc6d7a6736cafbb764197f3ae Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:30:55 -0400
Subject: [PATCH 10/16] Move awesome badge to top of project
---
README.md | 4 +++-
1 file changed, 3 insertions(+), 1 deletion(-)
diff --git a/README.md b/README.md
index 1e8978f9..db71eea3 100644
--- a/README.md
+++ b/README.md
@@ -2,6 +2,8 @@
# AWESOME DATA SCIENCE
+[](https://github.com/sindresorhus/awesome)
+
**An open source Data Science repository to learn and apply towards solving real world problems.**
This is a shortcut path to start studying **Data Science**. Just follow the steps to answer the questions, "What is Data Science and what should I study to learn Data Science?"
@@ -998,7 +1000,7 @@ Some data mining competition platforms
## Awesome Data Science
-[](https://github.com/sindresorhus/awesome) [](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
+[](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
## Hobby
- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
From 0401fcb1c78a1c8c827626eec735ad9fa618b345 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:31:33 -0400
Subject: [PATCH 11/16] Remove dead "subscribe to new links" URL
---
README.md | 4 ----
1 file changed, 4 deletions(-)
diff --git a/README.md b/README.md
index db71eea3..15e005ea 100644
--- a/README.md
+++ b/README.md
@@ -998,10 +998,6 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-## Awesome Data Science
-
-[](https://app.releasly.co/sites/academic/awesome-datascience?utm_source=github_badge)
-
## Hobby
- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
From 49399d8b0e94e926744caaa20c50fedc251c1dc2 Mon Sep 17 00:00:00 2001
From: James Dean <24254612+AcylSilane@users.noreply.github.com>
Date: Sat, 15 Oct 2022 15:32:58 -0400
Subject: [PATCH 12/16] Rename "Other Lists" to "Other Awesome Lists", move
"hobby section" as a subsection, and update TOC
---
README.md | 13 ++++++-------
1 file changed, 6 insertions(+), 7 deletions(-)
diff --git a/README.md b/README.md
index 15e005ea..c260989f 100644
--- a/README.md
+++ b/README.md
@@ -63,9 +63,8 @@ This is a shortcut path to start studying **Data Science**. Just follow the step
- [Infographics](#infographics)
- [Datasets](#datasets)
- [Comics](#comics)
-- [Awesome Data Science](#awesome-data-science)
-- [Hobby](#hobby)
-- [Other Lists](#other-lists)
+- [Other Awesome Lists](#other-lists)
+ - [Hobby](#hobby)
## What is Data Science?
**[`^ back to top ^`](#awesome-data-science)**
@@ -998,10 +997,7 @@ Some data mining competition platforms
- [Comic compilation](https://medium.com/@nikhil_garg/a-compilation-of-comics-explaining-statistics-data-science-and-machine-learning-eeefbae91277)
- [Cartoons](https://www.kdnuggets.com/websites/cartoons.html)
-## Hobby
-- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
-
-## Other Lists
+## Other Awesome Lists
- Other amazingly awesome lists can be found in the [awesome-awesomeness](https://github.com/bayandin/awesome-awesomeness)
- [Awesome Machine Learning](https://github.com/josephmisiti/awesome-machine-learning)
@@ -1031,6 +1027,9 @@ Some data mining competition platforms
- [Top Data Science Interview Questions](https://www.interviewbit.com/data-science-interview-questions/)
- [Awesome Drug Synergy, Interaction and Polypharmacy Prediction](https://github.com/AstraZeneca/awesome-drug-pair-scoring)
+### Hobby
+- [Awesome Music Production](https://github.com/ad-si/awesome-music-production)
+