电影推荐项目实战(双塔模型) #45
Comments
|
有个问题不解,按预设的业务场景,应该是通过训练数据做出模型来对一个新用户(未出现在训练数据中)进行预测。那么需要对模型进行输入这个用户的行为(该用户对某几部电影的评分)从而输出该用户对其他电影的预测评价,以达到推荐的目的,但是你的代码中在预测环节只输入了用户信息,可以理解为只将用户-电影两者,没有具体行为,那么这个结果如何算作推荐结果 |
训练的时候 是用户-电影数据作为x,评分作为y,双塔的目的是算相关性。 |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
一、推荐的技术方法
推荐系统简单来说就是, 高效地达成用户与意向对象的匹配。具体可见之前文章:【一窥推荐系统的原理】。而技术上实现两者匹配,简单来说有两类方法:
1.1 基于分类方法
分类的方法很好理解,可以训练一个意向物品的多分类模型,预测用户偏好那一类物品。或者将用户+物品等全方面特征作为拼接训练二分类模型,预测为是否偏好(如下经典的CTR模型,以用户物品特征及对应的标签 0或 1 构建分类模型,预测该用户是否会点击这物品,)。

基于分类的方法,精度较高,常用于推荐的排序阶段(如粗排、精排)。
1.2 基于相似度方法
利用计算物与物或人与人、人与物的距离,将物品推荐给喜好相似的人。
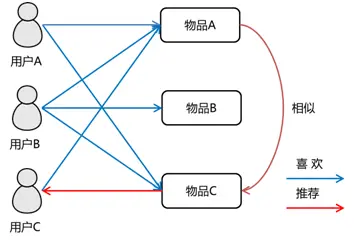
如关联规则推荐,可以将物与物共现度看做为某种的相似度;协同过滤算法可以基于物品或者基于用户计算相似用户或物品;以及本文谈到的双塔模型,通过计算物品与用户之间的相似度距离并做推荐。
利用相似度的方法效率快、准确度差一些常用于推荐中的粗排、召回阶段。
2. DSSM双塔模型
2.1 DSSM模型的原理
DSSM(Deep Structured Semantic Models)也叫深度语义匹配模型,最早是微软发表的一篇应用于NLP领域中计算语义相似度任务的文章。
DSSM深度语义匹配模型原理很简单:获取搜索引擎中的用户搜索query和doc的海量曝光和点击日志数据,训练阶段分别用复杂的深度学习网络构建query侧特征的query embedding和doc侧特征的doc embedding,线上infer时通过计算两个语义向量的cos距离来表示语义相似度,最终获得语义相似模型。这个模型既可以获得语句的低维语义向量表达sentence embedding,还可以预测两句话的语义相似度。
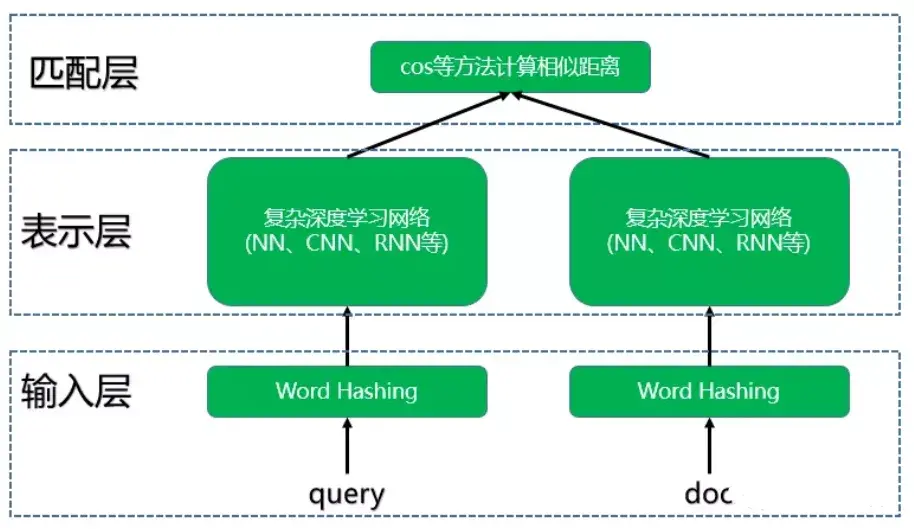
2.2 DSSM模型结构
DSSM模型总的来说可以分成三层结构,分别是输入层、表示层和匹配层。
结构如下图所示:
3.双塔模型代码实践
(END)
文章首发公众号“算法进阶”,公众号阅读原文可访问文章相关数据代码及资料
The text was updated successfully, but these errors were encountered: