Page Not Found
+ + + +This page doesn't exist yet! +Reach out if you think it should. +-
+
- + + + subscribe to our monthly newsletter + +
- + follow us on + + + + Twitter and + + + + LinkedIn + +
 +
++ I've spent my career developing ML applications across all scales and industries. Specifically over the last four years (through Made With ML), I’ve had the opportunity to help dozens of F500 companies + startups build out their ML platforms and launch high-impact ML applications on top of them. I started Made With ML to address the gaps in education and share the best practices on how to deliver value with ML in production. +
+ ++ While this was an amazing experience, it was also a humbling one because there were obstacles around scale, integrations and productionization that I didn’t have great solutions for. So, I decided to join a team that has been addressing these precise obstacles with some of the best ML teams in the world and has an even bigger vision I could stand behind. So I'm excited to announce that Made With ML is now part of Anyscale to accelerate the path towards production ML. +
+ + + +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In the RNN lesson, we were constrained to using the representation at the very end but what if we could give contextual weight to each encoded input (\(h_i\)) when making our prediction? This is also preferred because it can help mitigate the vanishing gradient issue which stems from processing very long sequences. Below is attention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
+ +
+| Variable | +Description | +
|---|---|
| \(N\) | +batch size | +
| \(M\) | +max sequence length in the batch | +
| \(H\) | +hidden dim, model dim, etc. | +
| \(h\) | +RNN outputs (or any group of outputs you want to attend to) \(\in \mathbb{R}^{NXMXH}\) | +
| \(\alpha_{t,i}\) | +alignment function context vector \(c_t\) (attention in our case) $ | +
| \(W_{attn}\) | +attention weights to learn \(\in \mathbb{R}^{HX1}\) | +
| \(c_t\) | +context vector that accounts for the different inputs with attention | +
Let's set our seed and device for our main task. +
1 +2 +3 +4 +5 +6 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
+
1 +2 +3 +4 +5 | |
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc. +
1 +2 +3 +4 | |
1 +2 +3 +4 | |
+[nltk_data] Downloading package stopwords to /root/nltk_data... +[nltk_data] Package stopwords is already up-to-date! +['i', 'me', 'my', 'myself', 'we'] ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 +2 +3 | |
+great week nyse ++
1 +2 +3 +4 | |
+Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says + +sharon accepts plan reduce gaza army operation haaretz says ++ +
Warning
+If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (84000,), y_train: (84000,) +X_val: (18000,), y_val: (18000,) +X_test: (18000,), y_test: (18000,) +Sample point: china battles north korea nuclear talks → World ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 +5 | |
+{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}
+
+1 +2 +3 +4 +5 +6 | |
+y_train[0]: World +y_train[0]: 3 ++
1 +2 +3 +4 | |
+counts: [21000 21000 21000 21000]
+weights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}
+
+
+We'll define a Tokenizer to convert our text input data into token indices.
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 | |
Warning
+It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
+1 +2 +3 +4 +5 | |
+<Tokenizer(num_tokens=5000)> + ++
1 +2 +3 | |
+[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]
+least freq token's freq: 14
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
+Text to indices: + (preprocessed) → china battles north korea nuclear talks + (tokenized) → [ 16 1491 285 142 114 24] ++ +
We'll need to do 2D padding to our tokenized text. +
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+(3, 6) +[[1.600e+01 1.491e+03 2.850e+02 1.420e+02 1.140e+02 2.400e+01] + [1.445e+03 2.300e+01 6.560e+02 2.197e+03 1.000e+00 0.000e+00] + [1.200e+02 1.400e+01 1.955e+03 1.005e+03 1.529e+03 4.014e+03]] ++ +
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Datasets: + Train dataset: <Dataset(N=84000)> + Val dataset: <Dataset(N=18000)> + Test dataset: <Dataset(N=18000)> +Sample point: + X: [ 16 1491 285 142 114 24] + seq_len: 6 + y: 3 ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 | |
+Sample batch: + X: [64, 14] + seq_lens: [64] + y: [64] +Sample point: + X: tensor([ 16, 1491, 285, 142, 114, 24, 0, 0, 0, 0, 0, 0, + 0, 0]) + seq_len: 6 + y: 3 ++ +
Let's create the Trainer class that we'll use to facilitate training for our experiments.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 | |
Attention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
+
+| Variable | +Description | +
|---|---|
| \(N\) | +batch size | +
| \(M\) | +max sequence length in the batch | +
| \(H\) | +hidden dim, model dim, etc. | +
| \(h\) | +RNN outputs (or any group of outputs you want to attend to) \(\in \mathbb{R}^{NXMXH}\) | +
| \(\alpha_{t,i}\) | +alignment function context vector \(c_t\) (attention in our case) $ | +
| \(W_{attn}\) | +attention weights to learn \(\in \mathbb{R}^{HX1}\) | +
| \(c_t\) | +context vector that accounts for the different inputs with attention | +
1 | |
The RNN will create an encoded representation for each word in our input resulting in a stacked vector that has dimensions \(NXMXH\), where N is the # of samples in the batch, M is the max sequence length in the batch, and H is the number of hidden units in the RNN.
+1 +2 +3 +4 | |
1 +2 | |
1 +2 +3 +4 +5 | |
+out: torch.Size([64, 8, 128]) +h_n: torch.Size([1, 64, 128]) ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+e: torch.Size([64, 8, 1]) +attn_vals: torch.Size([64, 8]) +attn_vals[0]: tensor([0.1131, 0.1161, 0.1438, 0.1181, 0.1244, 0.1234, 0.1351, 0.1261], + grad_fn=+ +) +sum(attn_vals[0]): tensor(1.0000, grad_fn= ) +c: torch.Size([64, 128]) +
1 +2 +3 +4 | |
+output: torch.Size([64, 4]) ++ +
++In a many-to-many task such as machine translation, our attentional interface will also account for the encoded representation of token in the output as well (via concatenation) so we can know which encoded inputs to attend to based on the encoded output we're focusing on. For more on this, be sure to explore Bahdanau's attention paper.
+
Now let's create our RNN based model but with the addition of the attention layer on top of the RNN's outputs.
+1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 | |
1 +2 +3 +4 +5 +6 +7 | |
+<bound method Module.named_parameters of RNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): RNN(100, 128, batch_first=True) + (attn): Linear(in_features=128, out_features=1, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=128, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++ +
1 | |
1 +2 +3 +4 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 1.21680, val_loss: 1.08622, lr: 1.00E-04, _patience: 10 +Epoch: 2 | train_loss: 1.00379, val_loss: 0.93546, lr: 1.00E-04, _patience: 10 +Epoch: 3 | train_loss: 0.87091, val_loss: 0.83399, lr: 1.00E-04, _patience: 10 +... +Epoch: 48 | train_loss: 0.35045, val_loss: 0.54718, lr: 1.00E-08, _patience: 10 +Epoch: 49 | train_loss: 0.35055, val_loss: 0.54718, lr: 1.00E-08, _patience: 10 +Epoch: 50 | train_loss: 0.35086, val_loss: 0.54717, lr: 1.00E-08, _patience: 10 +Stopping early! ++ +
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8133385428975775,
+ "recall": 0.8137222222222222,
+ "f1": 0.8133454847232977,
+ "num_samples": 18000.0
+}
+
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+RNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): RNN(100, 128, batch_first=True) + (attn): Linear(in_features=128, out_features=1, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=128, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++ +
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
+['final tennis tournament starts next week'] ++
1 +2 +3 +4 | |
+['Sports'] ++
1 +2 +3 | |
+{
+ "Sports": 0.9651875495910645,
+ "World": 0.03468644618988037,
+ "Sci/Tech": 8.490968320984393e-05,
+ "Business": 4.112234091735445e-05
+}
+
+
+Let's use the attention values to see which encoded tokens were most useful in predicting the appropriate label.
+1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 | |
1 +2 +3 +4 +5 +6 +7 | |
+InterpretAttn( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): RNN(100, 128, batch_first=True) + (attn): Linear(in_features=128, out_features=1, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=128, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++ +
1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 | |
 +
+The word tennis was attended to the most to result in the Sports label.
We'll briefly look at the different types of attention and when to use each them.
+Soft attention the type of attention we've implemented so far, where we attend to all encoded inputs when creating our context vector.
+Hard attention is focusing on a specific set of the encoded inputs at each time step.
+ +
+Local attention blends the advantages of soft and hard attention. It involves learning an aligned position vector and empirically determining a local window of encoded inputs to attend to.
+ +
+We can also use attention within the encoded input sequence to create a weighted representation that based on the similarity between input pairs. This will allow us to create rich representations of the input sequence that are aware of the relationships between each other. For example, in the image below you can see that when composing the representation of the token "its", this specific attention head will be incorporating signal from the token "Law" (it's learned that "its" is referring to the "Law").
+ +
+In the next lesson, we'll implement Transformers that leverage self-attention to create contextual representations of our inputs for downstream applications.
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+At the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
+ +
+Let's set our seed and device. +
1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
+
1 +2 +3 +4 +5 | |
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc. +
1 +2 +3 +4 | |
1 +2 +3 +4 | |
+[nltk_data] Downloading package stopwords to /root/nltk_data... +[nltk_data] Package stopwords is already up-to-date! +['i', 'me', 'my', 'myself', 'we'] ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 +2 +3 | |
+great week nyse ++
1 +2 +3 +4 | |
+Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says + +sharon accepts plan reduce gaza army operation haaretz says ++ +
1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (84000,), y_train: (84000,) +X_val: (18000,), y_val: (18000,) +X_test: (18000,), y_test: (18000,) +Sample point: china battles north korea nuclear talks → World ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 +5 | |
+{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}
+
+1 +2 +3 +4 +5 +6 | |
+y_train[0]: World +y_train[0]: 3 ++
1 +2 +3 +4 | |
+counts: [21000 21000 21000 21000]
+weights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}
+
+
+Our input data is text and we can't feed it directly to our models. So, we'll define a Tokenizer to convert our text input data into token indices. This means that every token (we can decide what a token is char, word, sub-word, etc.) is mapped to a unique index which allows us to represent our text as an array of indices.
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 | |
Tokenizer to the top 500 most frequent tokens (stop words already removed) because the full vocabulary size (~35K) is too large to run on Google Colab notebooks.
+1 +2 +3 +4 +5 | |
+Tokenizer(num_tokens=500) ++
1 +2 +3 | |
+[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]
+least freq token's freq: 166
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
+Text to indices: + (preprocessed) → china <UNK> north korea nuclear talks + (tokenized) → [ 16 1 285 142 114 24] ++ +
Did we need to split the data first?
+How come we applied the preprocessing functions to the entire dataset but tokenization after splitting the dataset? Does it matter?
+If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. So for the tokenization process, it's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well. However for global preprocessing steps, like the preprocessing function where we aren't learning anything from the data itself, we can perform before splitting the data.
+One-hot encoding creates a binary column for each unique value for the feature we're trying to map. All of the values in each token's array will be 0 except at the index that this specific token is represented by.
+There are 5 words in the vocabulary: +
1 +2 +3 +4 +5 +6 +7 | |
Then the text aou would be represented by:
+
1 +2 +3 | |
One-hot encoding allows us to represent our data in a way that our models can process the data and isn't biased by the actual value of the token (ex. if your labels were actual numbers).
+++We have already applied one-hot encoding in the previous lessons when we encoded our labels. Each label was represented by a unique index but when determining loss, we effectively use it's one hot representation and compared it to the predicted probability distribution. We never explicitly wrote this out since all of our previous tasks were multi-class which means every input had just one output class, so the 0s didn't affect the loss (though it did matter during back propagation).
+
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 +6 | |
+[ 16 1 285 142 114 24] +6 +[[0. 0. 0. ... 0. 0. 0.] + [0. 1. 0. ... 0. 0. 0.] + [0. 0. 0. ... 0. 0. 0.] + [0. 0. 0. ... 0. 0. 0.] + [0. 0. 0. ... 0. 0. 0.] + [0. 0. 0. ... 0. 0. 0.]] +(6, 500) ++
1 +2 +3 +4 +5 | |
Our inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
++One-hot encoding creates a batch of shape (
+N,max_seq_len,vocab_size) so we'll need to be able to pad 3D sequences.
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 | |
+(6, 500) (5, 500) (6, 500) +(3, 6, 500) ++ +
Is our pad_sequences function properly created?
Notice any assumptions that could lead to hidden bugs?
+By using np.zeros() to create our padded sequences, we're assuming that our pad token's index is 0. While this is the case for our project, someone could choose to use a different index and this can cause an error. Worst of all, this would be a silent error because all downstream operations would still run normally but our performance will suffer and it may not always be intuitive that this was the cause of issue!
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
+1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
+Datasets: + Train dataset: <Dataset(N=84000)> + Val dataset: <Dataset(N=18000)> + Test dataset: <Dataset(N=18000)> +Sample point: + X: [[0. 0. 0. ... 0. 0. 0.] + [0. 1. 0. ... 0. 0. 0.] + [0. 1. 0. ... 0. 0. 0.] + [0. 1. 0. ... 0. 0. 0.]] + y: 1 ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Sample batch: + X: [64, 14, 500] + y: [64] +Sample point: + X: tensor([[0., 0., 0., ..., 0., 0., 0.], + [0., 1., 0., ..., 0., 0., 0.], + [0., 1., 0., ..., 0., 0., 0.], + ..., + [0., 0., 0., ..., 0., 0., 0.], + [0., 0., 0., ..., 0., 0., 0.], + [0., 0., 0., ..., 0., 0., 0.]], device="cpu") + y: 1 ++ +
We're going to learn about CNNs by applying them on 1D text data.
+In the dummy example below, our inputs are composed of character tokens that are one-hot encoded. We have a batch of N samples, where each sample has 8 characters and each character is represented by an array of 10 values (vocab size=10). This gives our inputs the size (N, 8, 10).
++With PyTorch, when dealing with convolution, our inputs (X) need to have the channels as the second dimension, so our inputs will be
+(N, 10, 8).
1 +2 +3 +4 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+X: torch.Size([64, 8, 10]) +X: torch.Size([64, 10, 8]) ++ +
 +
+At the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
+We can see convolution in the diagram below where we simplified the filters and inputs to be 2D for ease of visualization. Also note that the values are 0/1s but in reality they can be any floating point value.
+
+Now let's return to our actual inputs x, which is of shape (8, 10) [max_seq_len, vocab_size] and we want to convolve on this input using filters. We will use 50 filters that are of size (1, 3) and has the same depth as the number of channels (num_channels = vocab_size = one_hot_size = 10). This gives our filter a shape of (3, 10, 50) [kernel_size, vocab_size, num_filters]
 +
+stride: amount the filters move from one convolution operation to the next.padding: values (typically zero) padded to the input, typically to create a volume with whole number dimensions.So far we've used a stride of 1 and VALID padding (no padding) but let's look at an example with a higher stride and difference between different padding approaches.
Padding types:
+VALID: no padding, the filters only use the "valid" values in the input. If the filter cannot reach all the input values (filters go left to right), the extra values on the right are dropped.SAME: adds padding evenly to the right (preferred) and left sides of the input so that all values in the input are processed. +
+We're going to use the Conv1d layer to process our inputs.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+conv: torch.Size([50, 10, 3]) ++
1 +2 +3 | |
+z: torch.Size([64, 50, 6]) ++
 +
+When we apply these filter on our inputs, we receive an output of shape (N, 6, 50). We get 50 for the output channel dim because we used 50 filters and 6 for the conv outputs because:
+| Variable | +Description | +
|---|---|
| \(W\) | +width of each input = 8 | +
| \(H\) | +height of each input = 1 | +
| \(D\) | +depth (# of channels) | +
| \(F\) | +filter size = 3 | +
| \(P\) | +padding = 0 | +
| \(S\) | +stride = 1 | +
Now we'll add padding so that the convolutional outputs are the same shape as our inputs. The amount of padding for the SAME padding can be determined using the same equation. We want out output to have the same width as our input, so we solve for P:
If \(P\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
1 +2 +3 +4 +5 +6 +7 +8 | |
+conv: torch.Size([50, 10, 3]) ++
1 +2 +3 +4 | |
+padding: (1, 1) ++
1 +2 +3 | |
+z: torch.Size([64, 50, 8]) ++ +
++We will explore larger dimensional convolution layers in subsequent lessons. For example, Conv2D is used with 3D inputs (images, char-level text, etc.) and Conv3D is used for 4D inputs (videos, time-series, etc.).
+
The result of convolving filters on an input is a feature map. Due to the nature of convolution and overlaps, our feature map will have lots of redundant information. Pooling is a way to summarize a high-dimensional feature map into a lower dimensional one for simplified downstream computation. The pooling operation can be the max value, average, etc. in a certain receptive field. Below is an example of pooling where the outputs from a conv layer are 4X4 and we're going to apply max pool filters of size 2X2.
 +
+| Variable | +Description | +
|---|---|
| \(W\) | +width of each input = 4 | +
| \(H\) | +height of each input = 4 | +
| \(D\) | +depth (# of channels) | +
| \(F\) | +filter size = 2 | +
| \(S\) | +stride = 2 | +
In our use case, we want to just take the one max value so we will use the MaxPool1D layer, so our max-pool filter size will be max_seq_len. +
1 +2 +3 | |
+Size: torch.Size([64, 50, 1]) ++ +
The last topic we'll cover before constructing our model is batch normalization. It's an operation that will standardize (mean=0, std=1) the activations from the previous layer. Recall that we used to standardize our inputs in previous notebooks so our model can optimize quickly with larger learning rates. It's the same concept here but we continue to maintain standardized values throughout the repeated forward passes to further aid optimization.
+1 +2 +3 +4 | |
+z: torch.Size([64, 50, 6]) ++
1 +2 | |
+mean: -0.00, std: 0.57 ++
1 +2 | |
+mean: 0.00, std: 1.00 ++ +
Let's visualize the model's forward pass.
+batch_size, max_seq_len).batch_size, max_seq_len, vocab_size).filter_size, vocab_size, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors. +
+1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 | |
1 +2 +3 +4 +5 | |
+<bound method Module.named_parameters of CNN( + (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,)) + (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) + (fc1): Linear(in_features=50, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++ +
++We used
+SAMEpadding (w/ stride=1) which means that the conv outputs will have the same width (max_seq_len) as our inputs. The amount of padding differs for each batch based on themax_seq_lenbut you can calculate it by solving for P in the equation below.
If \(P\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
Let's create the Trainer class that we'll use to facilitate training for our experiments. Notice that we're now moving the train function inside this class.
1 | |
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 0.87388, val_loss: 0.79013, lr: 1.00E-03, _patience: 3 +Epoch: 2 | train_loss: 0.78354, val_loss: 0.78657, lr: 1.00E-03, _patience: 3 +Epoch: 3 | train_loss: 0.77743, val_loss: 0.78433, lr: 1.00E-03, _patience: 3 +Epoch: 4 | train_loss: 0.77242, val_loss: 0.78260, lr: 1.00E-03, _patience: 3 +Epoch: 5 | train_loss: 0.76900, val_loss: 0.78169, lr: 1.00E-03, _patience: 3 +Epoch: 6 | train_loss: 0.76613, val_loss: 0.78064, lr: 1.00E-03, _patience: 3 +Epoch: 7 | train_loss: 0.76413, val_loss: 0.78019, lr: 1.00E-03, _patience: 3 +Epoch: 8 | train_loss: 0.76215, val_loss: 0.78016, lr: 1.00E-03, _patience: 3 +Epoch: 9 | train_loss: 0.76034, val_loss: 0.77974, lr: 1.00E-03, _patience: 3 +Epoch: 10 | train_loss: 0.75859, val_loss: 0.77978, lr: 1.00E-03, _patience: 2 ++ +
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.7120047175492572,
+ "recall": 0.6935,
+ "f1": 0.6931471439737603,
+ "num_samples": 18000.0
+}
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
+CNN( + (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,)) + (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) + (fc1): Linear(in_features=50, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+['day new <UNK> stock market go <UNK>'] ++
1 +2 +3 +4 | |
+['Business'] ++
1 +2 +3 | |
+{
+ "Business": 0.8670833110809326,
+ "Sci/Tech": 0.10699427127838135,
+ "World": 0.021050667390227318,
+ "Sports": 0.004871787969022989
+}
+
+
+We went through all the trouble of padding our inputs before convolution to result in outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
+1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+InterpretableCNN( + (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,)) + (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) + (fc1): Linear(in_features=50, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++
1 +2 | |
1 +2 +3 | |
+(50, 7) ++
1 +2 +3 | |
 +
+The filters have high values for the words stock and market which influenced the Business category classification.
Warning
+This is a crude technique loosely based off of more elaborate interpretability methods.
+To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In a nutshell, a machine learning model consumes input data and produces predictions. The quality of the predictions directly corresponds to the quality of data you train the model with; garbage in, garbage out. Check out this article on where it makes sense to use AI and how to properly apply it.
+We're going to go through all the concepts with concrete code examples and some synthesized data to train our models on. The task is to determine whether a tumor will be benign (harmless) or malignant (harmful) based on leukocyte (white blood cells) count and blood pressure. This is a synthetic dataset that we created and has no clinical relevance.
+We'll set our seeds for reproducibility. +
1 +2 | |
1 | |
1 +2 +3 | |
We'll first train a model with the entire dataset. Later we'll remove a subset of the dataset and see the effect it has on our model.
+1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+X: (1000, 2) +y: (1000,) ++
1 +2 +3 +4 +5 +6 +7 | |
 +
+We want to choose features that have strong predictive signal for our task. If you want to improve performance, you need to continuously do feature engineering by collecting and adding new signals. So you may run into a new feature that has high correlation (orthogonal signal) with your existing features but it may still possess some unique signal to boost your predictive performance. +
1 +2 +3 | |
 +
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (700, 2), y_train: (700,) +X_val: (150, 2), y_val: (150,) +X_test: (150, 2), y_test: (150,) +Sample point: [11.5066204 15.98030799] → malignant ++ +
1 | |
1 +2 | |
1 +2 +3 +4 | |
+classes: ["benign", "malignant"] ++
1 +2 +3 +4 +5 +6 | |
+y_train[0]: malignant +y_train[0]: 1 ++
1 +2 +3 +4 | |
+counts: [272 428]
+weights: {0: 0.003676470588235294, 1: 0.002336448598130841}
+
+
+1 | |
1 +2 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+X_test[0]: mean: 0.0, std: 1.0 +X_test[1]: mean: 0.0, std: 1.0 ++ +
1 +2 +3 | |
1 +2 | |
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 +3 | |
+<bound method Module.named_parameters of MLP( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=2, bias=True) +)> ++ +
1 | |
1 +2 +3 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 0.70, accuracy: 49.6 +Epoch: 10 | loss: 0.54, accuracy: 93.7 +Epoch: 20 | loss: 0.43, accuracy: 97.1 +Epoch: 30 | loss: 0.35, accuracy: 97.0 +Epoch: 40 | loss: 0.30, accuracy: 97.4 ++ +
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.9461538461538461,
+ "recall": 0.9619565217391304,
+ "f1": 0.9517707041477195,
+ "num_samples": 150.0
+ },
+ "class": {
+ "benign": {
+ "precision": 0.8923076923076924,
+ "recall": 1.0,
+ "f1": 0.9430894308943091,
+ "num_samples": 58.0
+ },
+ "malignant": {
+ "precision": 1.0,
+ "recall": 0.9239130434782609,
+ "f1": 0.96045197740113,
+ "num_samples": 92.0
+ }
+ }
+}
+
+
+We're going to plot a point, which we know belongs to the malignant tumor class. Our well trained model here would accurately predict that it is indeed a malignant tumor! +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 | |
 +
+Great! We received great performances on both our train and test data splits. We're going to use this dataset to show the importance of data quality.
+Let's remove some training data near the decision boundary and see how robust the model is now.
+1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+X: (720, 2) +y: (720,) ++
1 +2 +3 +4 +5 +6 +7 | |
 +
+1 +2 +3 +4 +5 +6 +7 | |
+X_train: (503, 2), y_train: (503,) +X_val: (108, 2), y_val: (108,) +X_test: (109, 2), y_test: (109,) +Sample point: [19.66235758 15.65939541] → benign ++ +
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+counts: [272 231]
+weights: {0: 0.003676470588235294, 1: 0.004329004329004329}
+
+
+1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 0.68, accuracy: 69.8 +Epoch: 10 | loss: 0.53, accuracy: 99.6 +Epoch: 20 | loss: 0.42, accuracy: 99.6 +Epoch: 30 | loss: 0.33, accuracy: 99.6 +Epoch: 40 | loss: 0.27, accuracy: 99.8 ++ +
1 +2 +3 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 1.0,
+ "recall": 1.0,
+ "f1": 1.0,
+ "num_samples": 109.0
+ },
+ "class": {
+ "benign": {
+ "precision": 1.0,
+ "recall": 1.0,
+ "f1": 1.0,
+ "num_samples": 59.0
+ },
+ "malignant": {
+ "precision": 1.0,
+ "recall": 1.0,
+ "f1": 1.0,
+ "num_samples": 50.0
+ }
+ }
+}
+
+
+Now let's see how the same inference point from earlier performs now on the model trained on the reduced dataset.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 | |
 +
+This is a very fragile but highly realistic scenario. Based on our reduced synthetic dataset, we have achieved a model that generalized really well on the test data. But when we ask for the prediction for the same point tested earlier (which we known is malignant), the prediction is now a benign tumor. We would have completely missed the tumor. To mitigate this, we can:
+Models are not crystal balls. So it's important that before any machine learning, we really look at our data and ask ourselves if it is truly representative for the task we want to solve. The model itself may fit really well and generalize well on your data but if the data is of poor quality to begin with, the model cannot be trusted.
+Once you are confident that your data is of good quality, you can finally start thinking about modeling. The type of model you choose depends on many factors, including the task, type of data, complexity required, etc.
+So once you figure out what type of model your task needs, start with simple models and then slowly add complexity. You don’t want to start with neural networks right away because that may not be right model for your data and task. Striking this balance in model complexity is one of the key tasks of your data scientists. simple models → complex models
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+While one-hot encoding allows us to preserve the structural information, it does poses two major disadvantages.
+In this notebook, we're going to motivate the need for embeddings and how they address all the shortcomings of one-hot encoding. The main idea of embeddings is to have fixed length representations for the tokens in a text regardless of the number of tokens in the vocabulary. With one-hot encoding, each token is represented by an array of size vocab_size, but with embeddings, each token now has the shape embed_dim. The values in the representation will are not fixed binary values but rather, changing floating points allowing for fine-grained learned representations.
We can learn embeddings by creating our models in PyTorch but first, we're going to use a library that specializes in embeddings and topic modeling called Gensim.
+1 +2 +3 +4 +5 | |
+[nltk_data] Downloading package punkt to /root/nltk_data... +[nltk_data] Unzipping tokenizers/punkt.zip. ++
1 | |
1 +2 | |
1 +2 +3 +4 +5 | |
+12443 sentences ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
1 +2 +3 +4 | |
+Snape nodded, but did not elaborate. +['snape', 'nodded', 'but', 'did', 'not', 'elaborate'] ++ +
But how do we learn the embeddings the first place? The intuition behind embeddings is that the definition of a token doesn't depend on the token itself but on its context. There are several different ways of doing this:
+All of these approaches involve create data to train our model on. Every word in a sentence becomes the target word and the context words are determines by a window. In the image below (skip-gram), the window size is 2 (2 words to the left and right of the target word). We repeat this for every sentence in our corpus and this results in our training data for the unsupervised task. This in an unsupervised learning technique since we don't have official labels for contexts. The idea is that similar target words will appear with similar contexts and we can learn this relationship by repeatedly training our mode with (context, target) pairs.
+ +
+We can learn embeddings using any of these approaches above and some work better than others. You can inspect the learned embeddings but the best way to choose an approach is to empirically validate the performance on a supervised task.
+When we have large vocabularies to learn embeddings for, things can get complex very quickly. Recall that the backpropagation with softmax updates both the correct and incorrect class weights. This becomes a massive computation for every backwards pass we do so a workaround is to use negative sampling which only updates the correct class and a few arbitrary incorrect classes (NEGATIVE_SAMPLING=20). We're able to do this because of the large amount of training data where we'll see the same word as the target class multiple times.
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 | |
+Word2Vec(vocab=4937, size=100, alpha=0.025) ++
1 +2 | |
+array([-0.11787166, -0.2702948 , 0.24332453, 0.07497228, -0.5299148 , + 0.17751476, -0.30183575, 0.17060578, -0.0342238 , -0.331856 , + -0.06467848, 0.02454215, 0.4524056 , -0.18918884, -0.22446074, + 0.04246538, 0.5784022 , 0.12316586, 0.03419832, 0.12895502, + -0.36260423, 0.06671549, -0.28563526, -0.06784113, -0.0838319 , + 0.16225453, 0.24313857, 0.04139925, 0.06982274, 0.59947336, + 0.14201492, -0.00841052, -0.14700615, -0.51149386, -0.20590985, + 0.00435914, 0.04931103, 0.3382509 , -0.06798466, 0.23954925, + -0.07505646, -0.50945646, -0.44729665, 0.16253233, 0.11114362, + 0.05604156, 0.26727834, 0.43738437, -0.2606872 , 0.16259147, + -0.28841105, -0.02349186, 0.00743417, 0.08558545, -0.0844396 , + -0.44747537, -0.30635086, -0.04186366, 0.11142804, 0.03187608, + 0.38674814, -0.2663519 , 0.35415238, 0.094676 , -0.13586426, + -0.35296437, -0.31428036, -0.02917303, 0.02518964, -0.59744245, + -0.11500382, 0.15761602, 0.30535367, -0.06207089, 0.21460988, + 0.17566076, 0.46426776, 0.15573359, 0.3675553 , -0.09043553, + 0.2774392 , 0.16967005, 0.32909656, 0.01422888, 0.4131812 , + 0.20034142, 0.13722987, 0.10324971, 0.14308734, 0.23772323, + 0.2513108 , 0.23396717, -0.10305202, -0.03343603, 0.14360961, + -0.01891198, 0.11430877, 0.30017182, -0.09570111, -0.10692801], + dtype=float32) ++
1 +2 | |
+[('pain', 0.9274871349334717),
+ ('forehead', 0.9020695686340332),
+ ('heart', 0.8953317999839783),
+ ('mouth', 0.8939940929412842),
+ ('throat', 0.8922691345214844)]
+
+1 +2 +3 | |
What happens when a word doesn't exist in our vocabulary? We could assign an UNK token which is used for all OOV (out of vocabulary) words or we could use FastText, which uses character-level n-grams to embed a word. This helps embed rare words, misspelled words, and also words that don't exist in our corpus but are similar to words in our corpus. +
1 | |
1 +2 +3 +4 +5 | |
+FastText(vocab=4937, size=100, alpha=0.025) ++
1 +2 | |
1 +2 | |
+[('sparkling', 0.9785991907119751),
+ ('coiling', 0.9770463705062866),
+ ('watering', 0.9759057760238647),
+ ('glittering', 0.9756022095680237),
+ ('dazzling', 0.9755154848098755)]
+
+1 +2 +3 | |
We can learn embeddings from scratch using one of the approaches above but we can also leverage pretrained embeddings that have been trained on millions of documents. Popular ones include Word2Vec (skip-gram) or GloVe (global word-word co-occurrence). We can validate that these embeddings captured meaningful semantic relationships by confirming them.
+1 +2 +3 +4 +5 +6 | |
1 +2 | |
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 | |
+['glove.6B.50d.txt', + 'glove.6B.100d.txt', + 'glove.6B.200d.txt', + 'glove.6B.300d.txt'] ++
1 +2 +3 | |
+/content/glove.6B.100d.txt ++
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
+word: the +embedding: +[-0.038194 -0.24487 0.72812 -0.39961 0.083172 0.043953 -0.39141 + 0.3344 -0.57545 0.087459 0.28787 -0.06731 0.30906 -0.26384 + -0.13231 -0.20757 0.33395 -0.33848 -0.31743 -0.48336 0.1464 + -0.37304 0.34577 0.052041 0.44946 -0.46971 0.02628 -0.54155 + -0.15518 -0.14107 -0.039722 0.28277 0.14393 0.23464 -0.31021 + 0.086173 0.20397 0.52624 0.17164 -0.082378 -0.71787 -0.41531 + 0.20335 -0.12763 0.41367 0.55187 0.57908 -0.33477 -0.36559 + -0.54857 -0.062892 0.26584 0.30205 0.99775 -0.80481 -3.0243 + 0.01254 -0.36942 2.2167 0.72201 -0.24978 0.92136 0.034514 + 0.46745 1.1079 -0.19358 -0.074575 0.23353 -0.052062 -0.22044 + 0.057162 -0.15806 -0.30798 -0.41625 0.37972 0.15006 -0.53212 + -0.2055 -1.2526 0.071624 0.70565 0.49744 -0.42063 0.26148 + -1.538 -0.30223 -0.073438 -0.28312 0.37104 -0.25217 0.016215 + -0.017099 -0.38984 0.87424 -0.72569 -0.51058 -0.52028 -0.1459 + 0.8278 0.27062 ] +embedding dim: 100 ++
1 +2 +3 | |
+(400000, 100) ++
1 +2 | |
1 +2 +3 | |
+[('queen', 0.7698541283607483),
+ ('monarch', 0.6843380928039551),
+ ('throne', 0.6755735874176025),
+ ('daughter', 0.6594556570053101),
+ ('princess', 0.6520534753799438)]
+
+1 +2 | |
+[('gohan', 0.7246542572975159),
+ ('bulma', 0.6497020125389099),
+ ('raistlin', 0.6443604230880737),
+ ('skaar', 0.6316742897033691),
+ ('guybrush', 0.6231324672698975)]
+
+1 +2 +3 +4 | |
1 +2 +3 +4 | |
 +
+1 +2 | |
+[('nurse', 0.7735227346420288),
+ ('physician', 0.7189429998397827),
+ ('doctors', 0.6824328303337097),
+ ('patient', 0.6750682592391968),
+ ('dentist', 0.6726033687591553)]
+
+
+Let's set our seed and device for our main task. +
1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
+
1 +2 +3 +4 +5 | |
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc. +
1 +2 +3 +4 | |
1 +2 +3 +4 | |
+[nltk_data] Downloading package stopwords to /root/nltk_data... +[nltk_data] Package stopwords is already up-to-date! +['i', 'me', 'my', 'myself', 'we'] ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 +2 +3 | |
+great week nyse ++
1 +2 +3 +4 | |
+Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says + +sharon accepts plan reduce gaza army operation haaretz says ++ +
Warning
+If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (84000,), y_train: (84000,) +X_val: (18000,), y_val: (18000,) +X_test: (18000,), y_test: (18000,) +Sample point: china battles north korea nuclear talks → World ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 +5 | |
+{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}
+
+1 +2 +3 +4 +5 +6 | |
+y_train[0]: World +y_train[0]: 3 ++
1 +2 +3 +4 | |
+counts: [21000 21000 21000 21000]
+weights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}
+
+
+We'll define a Tokenizer to convert our text input data into token indices.
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 | |
Warning
+It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
+1 +2 +3 +4 +5 | |
+<Tokenizer(num_tokens=5000)> + ++
1 +2 +3 | |
+[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]
+least freq token's freq: 14
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
+Text to indices: + (preprocessed) → nba wrap neal <UNK> 40 heat <UNK> wizards + (tokenized) → [ 299 359 3869 1 1648 734 1 2021] ++ +
We can embed our inputs using PyTorch's embedding layer.
+1 +2 +3 +4 +5 | |
+tensor([[2, 6, 5, 2, 6]]) +torch.Size([1, 5]) ++
1 +2 +3 | |
+torch.Size([10, 100]) ++
1 +2 | |
+torch.Size([1, 5, 100]) ++ +
Each token in the input is represented via embeddings (all out-of-vocabulary (OOV) tokens are given the embedding for UNK token.) In the model below, we'll see how to set these embeddings to be pretrained GloVe embeddings and how to choose whether to freeze (fixed embedding weights) those embeddings or not during training.
Our inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
++While embedding our input tokens will create a batch of shape (
+N,max_seq_len,embed_dim) we only need to provide a 2D matrix (N,max_seq_len) for using embeddings with PyTorch.
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+(3, 8) +[[2.990e+02 3.590e+02 3.869e+03 1.000e+00 1.648e+03 7.340e+02 1.000e+00 + 2.021e+03] + [4.977e+03 1.000e+00 8.070e+02 0.000e+00 0.000e+00 0.000e+00 0.000e+00 + 0.000e+00] + [5.900e+01 1.213e+03 1.160e+02 4.042e+03 2.040e+02 4.190e+02 1.000e+00 + 0.000e+00]] ++ +
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
+1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Datasets: + Train dataset: <Dataset(N=84000)> + Val dataset: <Dataset(N=18000)> + Test dataset: <Dataset(N=18000)> +Sample point: + X: [ 299 359 3869 1 1648 734 1 2021] + y: 2 ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Sample batch: + X: [64, 9] + y: [64] +Sample point: + X: tensor([ 299, 359, 3869, 1, 1648, 734, 1, 2021, 0], device="cpu") + y: 2 ++ +
We'll be using a convolutional neural network on top of our embedded tokens to extract meaningful spatial signal. This time, we'll be using many filter widths to act as n-gram feature extractors.
+Let's visualize the model's forward pass.
+batch_size, max_seq_len).batch_size, max_seq_len, embedding_dim).filter_size, embedding_dim, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors. We have three different filter sizes (2, 3 and 4) and they will act as bi-gram, tri-gram and 4-gram feature extractors, respectively. +
+1 +2 | |
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
We're going create some utility functions to be able to load the pretrained GloVe embeddings into our Embeddings layer.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 | |
+<Embeddings(words=5000, dim=100)> ++ +
We have first have to decide whether to use pretrained embeddings randomly initialized ones. Then, we can choose to freeze our embeddings or continue to train them using the supervised data (this could lead to overfitting). Here are the three experiments we're going to conduct:
+1 +2 +3 | |
1 +2 +3 +4 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+<bound method Module.named_parameters of CNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (conv): ModuleList( + (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,)) + (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,)) + (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,)) + ) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=150, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 0.77038, val_loss: 0.59683, lr: 1.00E-03, _patience: 3 +Epoch: 2 | train_loss: 0.49571, val_loss: 0.54363, lr: 1.00E-03, _patience: 3 +Epoch: 3 | train_loss: 0.40796, val_loss: 0.54551, lr: 1.00E-03, _patience: 2 +Epoch: 4 | train_loss: 0.34797, val_loss: 0.57950, lr: 1.00E-03, _patience: 1 +Stopping early! ++
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8070310520771562,
+ "recall": 0.7999444444444445,
+ "f1": 0.8012357147662316,
+ "num_samples": 18000.0
+}
+
+
+1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+<bound method Module.named_parameters of CNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (conv): ModuleList( + (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,)) + (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,)) + (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,)) + ) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=150, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 0.51510, val_loss: 0.47643, lr: 1.00E-03, _patience: 3 +Epoch: 2 | train_loss: 0.44220, val_loss: 0.46124, lr: 1.00E-03, _patience: 3 +Epoch: 3 | train_loss: 0.41204, val_loss: 0.46231, lr: 1.00E-03, _patience: 2 +Epoch: 4 | train_loss: 0.38733, val_loss: 0.46606, lr: 1.00E-03, _patience: 1 +Stopping early! ++
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8304874226557859,
+ "recall": 0.8281111111111111,
+ "f1": 0.828556487688813,
+ "num_samples": 18000.0
+}
+
+
+1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+<bound method Module.named_parameters of CNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (conv): ModuleList( + (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,)) + (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,)) + (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,)) + ) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=150, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 0.48908, val_loss: 0.44320, lr: 1.00E-03, _patience: 3 +Epoch: 2 | train_loss: 0.38986, val_loss: 0.43616, lr: 1.00E-03, _patience: 3 +Epoch: 3 | train_loss: 0.34403, val_loss: 0.45240, lr: 1.00E-03, _patience: 2 +Epoch: 4 | train_loss: 0.30224, val_loss: 0.49063, lr: 1.00E-03, _patience: 1 +Stopping early! ++
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8297157849772082,
+ "recall": 0.8263333333333334,
+ "f1": 0.8266579939871359,
+ "num_samples": 18000.0
+}
+
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
+CNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (conv): ModuleList( + (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,)) + (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,)) + (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,)) + ) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=150, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
+['final tennis tournament starts next week'] ++
1 +2 +3 +4 | |
+['Sports'] ++
1 +2 +3 | |
+{
+ "Sports": 0.9999998807907104,
+ "World": 6.336378532978415e-08,
+ "Sci/Tech": 2.107449992294619e-09,
+ "Business": 3.706519813295728e-10
+}
+
+
+We went through all the trouble of padding our inputs before convolution to result is outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
+1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+InterpretableCNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (conv): ModuleList( + (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,)) + (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,)) + (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,)) + ) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=150, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
+(3, 50, 6) ++
1 +2 +3 +4 | |
 +
+1D global max-pooling would extract the highest value from each of our num_filters for each filter_size. We could also follow this same approach to figure out which n-gram is most relevant but notice in the heatmap above that many filters don't have much variance. To mitigate this, this paper uses threshold values to determine which filters to use for interpretability. But to keep things simple, let's extract which tokens' filter outputs were extracted via max-pooling the most frequently.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
+Original text: +The final tennis tournament starts next week. + +Preprocessed text: +final tennis tournament starts next week + +Most important n-grams: +[1-gram]: tennis +[2-gram]: tennis tournament +[3-gram]: final tennis tournament ++ + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Our goal is to learn a linear model \(\hat{y}\) that models \(y\) given \(X\) using weights \(W\) and bias \(b\):
+| Variable | +Description | +
|---|---|
| \(N\) | +total numbers of samples | +
| \(\hat{y}\) | +predictions \(\in \mathbb{R}^{NX1}\) | +
| \(X\) | +inputs \(\in \mathbb{R}^{NXD}\) | +
| \(W\) | +weights \(\in \mathbb{R}^{DX1}\) | +
| \(b\) | +bias \(\in \mathbb{R}^{1}\) | +
We're going to generate some simple dummy data to apply linear regression on. It's going to create roughly linear data (y = 3.5X + noise); the random noise is added to create realistic data that doesn't perfectly align in a line. Our goal is to have the model converge to a similar linear equation (there will be slight variance since we added some noise).
+
1 +2 +3 | |
1 +2 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+[[ 0. -4.25441649] + [ 1. 12.16326313] + [ 2. 10.13183217] + [ 3. 24.06075751] + [ 4. 27.39927424]] ++
1 +2 +3 +4 +5 | |
1 +2 +3 +4 | |
 +
+Now that we have our data prepared, we'll first implement linear regression using just NumPy. This will let us really understand the underlying operations.
+Since our task is a regression task, we will randomly split our dataset into three sets: train, validation and test data splits.
+train: used to train our model.val : used to validate our model's performance during training.test: used to do an evaluation of our fully trained model.++Be sure to check out our entire lesson focused on properly splitting data in our MLOps course.
+
1 +2 +3 | |
1 +2 +3 +4 +5 | |
Warning
+Be careful not to shuffle \(X\) and \(y\) separately because then the inputs won't correspond to the outputs!
+1 +2 +3 +4 +5 +6 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+X_train: (35, 1), y_train: (35, 1) +X_val: (7, 1), y_test: (7, 1) +X_test: (8, 1), y_test: (8, 1) ++ +
We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights.
+| Variable | +Description | +
|---|---|
| \(z\) | +standardized value | +
| \(x_i\) | +inputs | +
| \(\mu\) | +mean | +
| \(\sigma\) | +standard deviation | +
1 +2 | |
1 +2 +3 +4 +5 | |
We need to treat the validation and test sets as if they were hidden datasets. So we only use the train set to determine the mean and std to avoid biasing our training process.
+1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+mean: -0.4, std: 0.9 +mean: -0.3, std: 1.0 ++ +
Our goal is to learn a linear model \(\hat{y}\) that models \(y\) given \(X\) using weights \(W\) and bias \(b\) → \(\hat{y} = XW + b\)
+Step 1: Randomly initialize the model's weights \(W\).
+
1 +2 | |
1 +2 +3 +4 +5 | |
+W: (1, 1) +b: (1, 1) ++ +
Step 2: Feed inputs \(X\) into the model to receive the predictions \(\hat{y}\)
+
1 +2 +3 | |
+y_pred: (35, 1) ++ +
Step 3: Compare the predictions \(\hat{y}\) with the actual target values \(y\) using the objective (cost) function to determine the loss \(J\). A common objective function for linear regression is mean squared error (MSE). This function calculates the difference between the predicted and target values and squares it.
1 +2 +3 +4 | |
+loss: 0.99 ++ +
Step 4: Calculate the gradient of loss \(J(\theta)\) w.r.t to the model weights.
1 +2 +3 | |
The gradient is the derivative, or the rate of change of a function. It's a vector that points in the direction of greatest increase of a function. For example the gradient of our loss function (\(J\)) with respect to our weights (\(W\)) will tell us how to change \(W\) so we can maximize \(J\). However, we want to minimize our loss so we subtract the gradient from \(W\).
+Step 5: Update the weights \(W\) using a small learning rate \(\alpha\).
1 | |
1 +2 +3 | |
++The learning rate \(\alpha\) is a way to control how much we update the weights by. If we choose a small learning rate, it may take a long time for our model to train. However, if we choose a large learning rate, we may overshoot and our training will never converge. The specific learning rate depends on our data and the type of models we use but it's typically good to explore in the range of \([1e^{-8}, 1e^{-1}]\). We'll explore learning rate update strategies in later lessons.
+
Step 6: Repeat steps 2 - 5 to minimize the loss and train the model.
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 | |
+Epoch: 0, loss: 0.990 +Epoch: 10, loss: 0.039 +Epoch: 20, loss: 0.028 +Epoch: 30, loss: 0.028 +Epoch: 40, loss: 0.028 +Epoch: 50, loss: 0.028 +Epoch: 60, loss: 0.028 +Epoch: 70, loss: 0.028 +Epoch: 80, loss: 0.028 +Epoch: 90, loss: 0.028 ++ +
++To keep the code simple, we're not calculating and displaying the validation loss after each epoch here. But in later lessons, the performance on the validation set will be crucial in influencing the learning process (learning rate, when to stop training, etc.).
+
Now we're ready to see how well our trained model will perform on our test (hold-out) data split. This will be our best measure on how well the model would perform on the real world, given that our dataset's distribution is close to unseen data. +
1 +2 +3 | |
1 +2 +3 +4 | |
+train_MSE: 0.03, test_MSE: 0.01 ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
 +
+Since we standardized our inputs and outputs, our weights were fit to those standardized values. So we need to unstandardize our weights so we can compare it to our true weight (3.5).
+++Note that both \(X\) and \(y\) were standardized.
+
| Variable | +Description | +
|---|---|
| \(y_{scaled}\) | +\(\frac{\hat{y} - \bar{y}}{\sigma_y}\) | +
| \(x_{scaled}\) | +\(\frac{x_j - \bar{x}_j}{\sigma_j}\) | +
In the expression above, we can see the expression:
+| Variable | +Description | +
|---|---|
| \(W_{unscaled}\) | +\({W}_j(\frac{\sigma_y}{\sigma_j})\) | +
| \(b_{unscaled}\) | +\(b_{scaled}\sigma_y + \bar{y} - \sum_{j=1}^{k} {W}_j(\frac{\sigma_y}{\sigma_j})\bar{x}_j\) | +
By substituting \(W_{unscaled}\) in \(b_{unscaled}\), it now becomes:
+1 +2 +3 +4 +5 | |
+[actual] y = 3.5X + noise +[model] y_hat = 3.4X + 7.8 ++ +
Now that we've implemented linear regression with Numpy, let's do the same with PyTorch. +
1 | |
1 +2 | |
++ ++
This time, instead of splitting data using indices, let's use scikit-learn's built in train_test_split function.
+
1 | |
1 +2 +3 | |
1 +2 | |
1 +2 | |
+train: 35 (0.70) +remaining: 15 (0.30) ++
1 +2 +3 | |
1 +2 +3 | |
+train: 35 (0.70) +val: 7 (0.14) +test: 8 (0.16) ++ +
This time we'll use scikit-learn's StandardScaler to standardize our data.
1 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 | |
+mean: -0.3, std: 0.7 +mean: -0.3, std: 0.6 ++ +
We will be using PyTorch's Linear layers in our MLP implementation. These layers will act as out weights (and biases).
+1 | |
1 +2 +3 +4 +5 | |
+torch.Size([3, 1]) +[[ 0.04613046] + [ 0.40240282] + [-1.0115291 ]] ++
1 +2 +3 +4 +5 | |
+Linear(in_features=1, out_features=1, bias=True) +weights (torch.Size([1, 1])): 0.35 +bias (torch.Size([1])): -0.34 ++
1 +2 +3 +4 | |
+torch.Size([3, 1]) +[[-0.32104054] + [-0.19719592] + [-0.68869597]] ++ +
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 | |
+Model: +<bound method Module.named_parameters of LinearRegression( + (fc1): Linear(in_features=1, out_features=1, bias=True) +)> ++ +
This time we're using PyTorch's loss functions, specifically MSELoss.
1 +2 +3 +4 +5 | |
+Loss: 0.75 ++ +
When we implemented linear regression with just NumPy, we used batch gradient descent to update our weights (used entire training set). But there are actually many different gradient descent optimization algorithms to choose from and it depends on the situation. However, the ADAM optimizer has become a standard algorithm for most cases.
+1 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
+Epoch: 0 | loss: 0.22 +Epoch: 20 | loss: 0.03 +Epoch: 40 | loss: 0.02 +Epoch: 60 | loss: 0.02 +Epoch: 80 | loss: 0.02 ++ +
Now we're ready to evaluate our trained model.
+1 +2 +3 | |
1 +2 +3 +4 +5 | |
+train_error: 0.02 +test_error: 0.01 ++ +
Since we only have one feature, it's easy to visually inspect the model. +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
 +
+After training a model, we can use it to predict on new data.
+1 +2 +3 +4 | |
Recall that we need to unstandardize our predictions.
+1 +2 +3 +4 | |
+35.73 (actual) → 42.11 (predicted) +59.34 (actual) → 59.17 (predicted) +97.04 (actual) → 93.30 (predicted) ++ +
Linear regression offers the great advantage of being highly interpretable. Each feature has a coefficient which signifies its importance/impact on the output variable y. We can interpret our coefficient as follows: by increasing X by 1 unit, we increase y by \(W\) (~3.65) units. +
1 +2 +3 +4 +5 +6 +7 | |
+[actual] y = 3.5X + noise +[model] y_hat = 3.4X + 8.0 ++ +
Regularization helps decrease overfitting. Below is L2 regularization (ridge regression). There are many forms of regularization but they all work to reduce overfitting in our models. With L2 regularization, we are penalizing large weight values by decaying them because having large weights will lead to preferential bias with the respective inputs and we want the model to work with all the inputs and not just a select few. There are also other types of regularization like L1 (lasso regression) which is useful for creating sparse models where some feature coefficients are zeroed out, or elastic which combines L1 and L2 penalties.
++Regularization is not just for linear regression. You can use it to regularize any model's weights including the ones we will look at in future lessons.
+
| Variable | +Description | +
|---|---|
| \(\lambda\) | +regularization coefficient | +
| \(\alpha\) | +learning rate | +
In PyTorch, we can add L2 regularization by adjusting our optimizer. The Adam optimizer has a weight_decay parameter which to control the L2 penalty.
1 | |
1 +2 | |
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
+Epoch: 0 | loss: 2.20 +Epoch: 20 | loss: 0.06 +Epoch: 40 | loss: 0.03 +Epoch: 60 | loss: 0.02 +Epoch: 80 | loss: 0.02 ++
1 +2 +3 | |
1 +2 +3 +4 +5 | |
+train_error: 0.02 +test_error: 0.01 ++ +
Regularization didn't make a difference in performance with this specific example because our data is generated from a perfect linear equation but for large realistic data, regularization can help our model generalize well.
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Logistic regression is an extension on linear regression (both are generalized linear methods). We will still learn to model a line (plane) that models \(y\) given \(X\). Except now we are dealing with classification problems as opposed to regression problems so we'll be predicting probability distributions as opposed to discrete values. We'll be using the softmax operation to normalize our logits (\(XW\)) to derive probabilities.
+Our goal is to learn a logistic model \(\hat{y}\) that models \(y\) given \(X\).
+| Variable | +Description | +
|---|---|
| \(N\) | +total numbers of samples | +
| \(C\) | +number of classes | +
| \(\hat{y}\) | +predictions \(\in \mathbb{R}^{NXC}\) | +
| \(X\) | +inputs \(\in \mathbb{R}^{NXD}\) | +
| \(W\) | +weights \(\in \mathbb{R}^{DXC}\) | +
(*) bias term (\(b\)) excluded to avoid crowding the notations
+This function is known as the multinomial logistic regression or the softmax classifier. The softmax classifier will use the linear equation (\(z=XW\)) and normalize it (using the softmax function) to produce the probability for class y given the inputs.
+We'll set our seeds for reproducibility. +
1 +2 | |
1 | |
1 +2 +3 | |
We'll used some synthesized data to train our models on. The task is to determine whether a tumor will be benign (harmless) or malignant (harmful) based on leukocyte (white blood cells) count and blood pressure. Note that this is a synthetic dataset that has no clinical relevance.
+1 +2 +3 | |
1 | |
1 +2 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
 +
+We want to split our dataset so that each of the three splits has the same distribution of classes so that we can train and evaluate properly. We can easily achieve this by telling scikit-learn's train_test_split function what to stratify on.
+
1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (700, 2), y_train: (700,) +X_val: (150, 2), y_val: (150,) +X_test: (150, 2), y_test: (150,) +Sample point: [11.5066204 15.98030799] → malignant ++
Now let's see how many samples per class each data split has: +
1 +2 +3 +4 | |
+Classes: {"malignant": 611, "benign": 389}
+m:b = 1.57
+
+1 +2 +3 +4 +5 +6 +7 | |
+train m:b = 1.57 +val m:b = 1.54 +test m:b = 1.59 ++ +
You'll notice that our class labels are text. We need to encode them into integers so we can use them in our models. We could scikit-learn's LabelEncoder to do this but we're going to write our own simple label encoder class so we can see what's happening under the hood.
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 | |
+{"benign": 0, "malignant": 1}
+
+1 +2 +3 +4 +5 +6 +7 | |
+y_train[0]: malignant +y_train[0]: 1 +decoded: ["malignant"] ++
We also want to calculate our class weights, which are useful for weighting the loss function during training. It tells the model to focus on samples from an under-represented class. The loss section below will show how to incorporate these weights. +
1 +2 +3 +4 | |
+counts: [272 428]
+weights: {0: 0.003676470588235294, 1: 0.002336448598130841}
+
+
+We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values. +
1 | |
1 +2 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+X_test[0]: mean: 0.0, std: 1.0 +X_test[1]: mean: 0.1, std: 1.0 ++ +
Now that we have our data prepared, we'll first implement logistic regression using just NumPy. This will let us really understand the underlying operations. It's normal to find the math and code in this section slightly complex. You can still read each of the steps to build intuition for when we implement this using PyTorch.
+Our goal is to learn a logistic model \(\hat{y}\) that models \(y\) given \(X\).
+++We are going to use multinomial logistic regression even though our task only involves two classes because you can generalize the softmax classifier to any number of classes.
+
Step 1: Randomly initialize the model's weights \(W\).
+
1 +2 | |
1 +2 +3 +4 +5 | |
+W: (2, 2) +b: (1, 2) ++ +
Step 2: Feed inputs \(X\) into the model to receive the logits (\(z=XW\)). Apply the softmax operation on the logits to get the class probabilities \(\hat{y}\) in one-hot encoded form. For example, if there are three classes, the predicted class probabilities could look like [0.3, 0.3, 0.4].
1 +2 +3 +4 | |
+logits: (722, 2) +sample: [0.01817675 0.00635562] ++ +
1 +2 +3 +4 +5 | |
+y_hat: (722, 2) +sample: [0.50295525 0.49704475] ++ +
Step 3: Compare the predictions \(\hat{y}\) (ex. [0.3, 0.3, 0.4]) with the actual target values \(y\) (ex. class 2 would look like [0, 0, 1]) with the objective (cost) function to determine loss \(J\). A common objective function for logistics regression is cross-entropy loss.
1 +2 +3 +4 | |
+loss: 0.69 ++ +
Step 4: Calculate the gradient of loss \(J(\theta)\) w.r.t to the model weights. Let's assume that our classes are mutually exclusive (a set of inputs could only belong to one class).
1 +2 +3 +4 +5 +6 | |
Step 5: Update the weights \(W\) using a small learning rate \(\alpha\). The updates will penalize the probability for the incorrect classes (j) and encourage a higher probability for the correct class (y).
1 | |
1 +2 +3 | |
Step 6: Repeat steps 2 - 5 to minimize the loss and train the model.
+
1 | |
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 | |
+Epoch: 0, loss: 0.684, accuracy: 0.889 +Epoch: 10, loss: 0.447, accuracy: 0.978 +Epoch: 20, loss: 0.348, accuracy: 0.978 +Epoch: 30, loss: 0.295, accuracy: 0.981 +Epoch: 40, loss: 0.260, accuracy: 0.981 ++ +
Now we're ready to evaluate our trained model on our test (hold-out) data split. +
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 | |
+train acc: 0.98, test acc: 0.94 ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+Now that we've implemented logistic regression with Numpy, let's do the same with PyTorch. +
1 | |
1 +2 | |
We will be using PyTorch's Linear layers to recreate the same model. +
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 | |
+<bound method Module.named_parameters of LogisticRegression( + (fc1): Linear(in_features=2, out_features=2, bias=True) +)> ++ +
Our loss will be the categorical crossentropy. +
1 +2 +3 +4 +5 +6 | |
+tensor([0, 0, 1]) +Loss: 1.6113080978393555 ++
In our case, we will also incorporate the class weights into our loss function to counter any class imbalances. +
1 +2 +3 | |
We'll compute accuracy as we train our model because just looking the loss value isn't super intuitive to look at. We'll look at other metrics (precision, recall, f1) in the evaluation section below. +
1 +2 +3 +4 +5 | |
1 +2 +3 | |
+Accuracy: 33.3 ++ +
We'll be sticking with our Adam optimizer from previous lessons. +
1 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 0.95, accuracy: 60.8 +Epoch: 10 | loss: 0.27, accuracy: 86.7 +Epoch: 20 | loss: 0.15, accuracy: 96.1 +Epoch: 30 | loss: 0.11, accuracy: 98.2 +Epoch: 40 | loss: 0.09, accuracy: 98.9 ++ +
First let's see the accuracy of our model on our test split. +
1 | |
1 +2 +3 +4 +5 +6 +7 | |
+sample probability: tensor([9.2047e-04, 9.9908e-01]) +sample class: 1 ++
1 +2 +3 +4 | |
+train acc: 0.98, test acc: 0.98 ++ +
We can also evaluate our model on other meaningful metrics such as precision and recall. These are especially useful when there is data imbalance present.
+| Variable | +Description | +
|---|---|
| \(TP\) | +# of samples truly predicted to be positive and were positive | +
| \(TN\) | +# of samples truly predicted to be negative and were negative | +
| \(FP\) | +# of samples falsely predicted to be positive but were negative | +
| \(FN\) | +# of samples falsely predicted to be negative but were positive | +
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.9754098360655737,
+ "recall": 0.9836956521739131,
+ "f1": 0.9791076651655137,
+ "num_samples": 150.0
+ },
+ "class": {
+ "benign": {
+ "precision": 0.9508196721311475,
+ "recall": 1.0,
+ "f1": 0.9747899159663865,
+ "num_samples": 58.0
+ },
+ "malignant": {
+ "precision": 1.0,
+ "recall": 0.967391304347826,
+ "f1": 0.9834254143646408,
+ "num_samples": 92.0
+ }
+ }
+}
+
+
+With logistic regression (extension of linear regression), the model creates a linear decision boundary that we can easily visualize. +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+1 +2 | |
1 +2 +3 | |
+[[-0.66523095 -3.08638693]] ++
1 +2 +3 +4 +5 | |
+The probability that you have a benign tumor is 93% ++ +
Note that only \(X\) was standardized.
+| Variable | +Description | +
|---|---|
| \(x_{scaled}\) | +\(\frac{x_j - \bar{x}_j}{\sigma_j}\) | +
| \(\hat{y}_{unscaled}\) | +\(b_{scaled} + \sum_{j=1}^{k} {W_{scaled}}_j (\frac{x_j - \bar{x}_j}{\sigma_j})\) | +
In the expression above, we can see the expression \(\hat{y}_{unscaled} = W_{unscaled}x + b_{unscaled}\), therefore:
+| Variable | +Description | +
|---|---|
| \(W_{unscaled}\) | +\(\frac{ {W_{scaled}}_j }{\sigma_j}\) | +
| \(b_{unscaled}\) | +\(b_{scaled} - \sum_{j=1}^{k} {W_{scaled}}_j\frac{\bar{x}_j}{\sigma_j}\) | +
1 +2 +3 +4 +5 +6 +7 | |
+[[ 0.61700419 -1.20196244] + [-0.95664431 0.89996245]] + [ 8.913242 10.183178] ++ + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Our goal is to learn a model \(\hat{y}\) that models \(y\) given \(X\) . You'll notice that neural networks are just extensions of the generalized linear methods we've seen so far but with non-linear activation functions since our data will be highly non-linear.
+ +
+| Variable | +Description | +
|---|---|
| \(N\) | +total numbers of samples | +
| \(D\) | +number of features | +
| \(H\) | +number of hidden units | +
| \(C\) | +number of classes | +
| \(W_1\) | +1st layer weights \(\in \mathbb{R}^{DXH}\) | +
| \(z_1\) | +outputs from first layer \(\in \mathbb{R}^{NXH}\) | +
| \(f\) | +non-linear activation function | +
| \(a_1\) | +activations from first layer \(\in \mathbb{R}^{NXH}\) | +
| \(W_2\) | +2nd layer weights \(\in \mathbb{R}^{HXC}\) | +
| \(z_2\) | +outputs from second layer \(\in \mathbb{R}^{NXC}\) | +
| \(\hat{y}\) | +prediction \(\in \mathbb{R}^{NXC}\) | +
(*) bias term (\(b\)) excluded to avoid crowding the notations
+We'll set our seeds for reproducibility. +
1 +2 | |
1 | |
1 +2 +3 | |
I created some non-linearly separable spiral data so let's go ahead and download it for our classification task. +
1 +2 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+X: (1500, 2) +y: (1500,) ++
1 +2 +3 +4 +5 | |
 +
+We'll shuffle our dataset (since it's ordered by class) and then create our data splits (stratified on class). +
1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (1050, 2), y_train: (1050,) +X_val: (225, 2), y_val: (225,) +X_test: (225, 2), y_test: (225,) +Sample point: [ 0.44688413 -0.07360876] → c1 ++ +
In the previous lesson we wrote our own label encoder class to see the inner functions but this time we'll use scikit-learn LabelEncoder class which does the same operations as ours.
+
1 | |
1 +2 | |
1 +2 +3 +4 | |
+classes: ["c1", "c2", "c3"] ++
1 +2 +3 +4 +5 +6 | |
+y_train[0]: c1 +y_train[0]: 0 ++
1 +2 +3 +4 | |
+counts: [350 350 350]
+weights: {0: 0.002857142857142857, 1: 0.002857142857142857, 2: 0.002857142857142857}
+
+
+We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values. +
1 | |
1 +2 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+X_test[0]: mean: -0.2, std: 0.8 +X_test[1]: mean: -0.2, std: 0.9 ++ +
Before we get to our neural network, we're going to motivate non-linear activation functions by implementing a generalized linear model (logistic regression). We'll see why linear models (with linear activations) won't suffice for our dataset.
+1 | |
1 +2 | |
We'll create our linear model using one layer of weights. +
1 +2 | |
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 +3 | |
+Model: +<bound method Module.named_parameters of LinearModel( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=3, bias=True) +)> ++ +
We'll go ahead and train our initialized model for a few epochs. +
1 | |
1 +2 +3 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 1.13, accuracy: 51.2 +Epoch: 1 | loss: 0.90, accuracy: 50.0 +Epoch: 2 | loss: 0.78, accuracy: 55.0 +Epoch: 3 | loss: 0.74, accuracy: 54.4 +Epoch: 4 | loss: 0.73, accuracy: 54.2 +Epoch: 5 | loss: 0.74, accuracy: 54.7 +Epoch: 6 | loss: 0.75, accuracy: 54.9 +Epoch: 7 | loss: 0.75, accuracy: 54.3 +Epoch: 8 | loss: 0.76, accuracy: 54.8 +Epoch: 9 | loss: 0.76, accuracy: 55.0 ++ +
Now let's see how well our linear model does on our non-linear spiral data. +
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 +4 +5 | |
+sample probability: tensor([0.9306, 0.0683, 0.0012]) +sample class: 0 ++
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.5027661968102707,
+ "recall": 0.49333333333333335,
+ "f1": 0.4942485399571228,
+ "num_samples": 225.0
+ },
+ "class": {
+ "c1": {
+ "precision": 0.5068493150684932,
+ "recall": 0.49333333333333335,
+ "f1": 0.5,
+ "num_samples": 75.0
+ },
+ "c2": {
+ "precision": 0.43478260869565216,
+ "recall": 0.5333333333333333,
+ "f1": 0.47904191616766467,
+ "num_samples": 75.0
+ },
+ "c3": {
+ "precision": 0.5666666666666667,
+ "recall": 0.4533333333333333,
+ "f1": 0.5037037037037037,
+ "num_samples": 75.0
+ }
+ }
+}
+
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+Using the generalized linear method (logistic regression) yielded poor results because of the non-linearity present in our data yet our activation functions were linear. We need to use an activation function that can allow our model to learn and map the non-linearity in our data. There are many different options so let's explore a few.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 | |
 +
+The ReLU activation function (\(max(0,z)\)) is by far the most widely used activation function for neural networks. But as you can see, each activation function has its own constraints so there are circumstances where you'll want to use different ones. For example, if we need to constrain our outputs between 0 and 1, then the sigmoid activation is the best choice.
+++In some cases, using a ReLU activation function may not be sufficient. For instance, when the outputs from our neurons are mostly negative, the activation function will produce zeros. This effectively creates a "dying ReLU" and a recovery is unlikely. To mitigate this effect, we could lower the learning rate or use alternative ReLU activations, ex. leaky ReLU or parametric ReLU (PReLU), which have a small slope for negative neuron outputs.
+
Now let's create our multilayer perceptron (MLP) which is going to be exactly like the logistic regression model but with the activation function to map the non-linearity in our data.
+++It's normal to find the math and code in this section slightly complex. You can still read each of the steps to build intuition for when we implement this using PyTorch.
+
Our goal is to learn a model \(\hat{y}\) that models \(y\) given \(X\). You'll notice that neural networks are just extensions of the generalized linear methods we've seen so far but with non-linear activation functions since our data will be highly non-linear.
+Step 1: Randomly initialize the model's weights \(W\) (we'll cover more effective initialization strategies later in this lesson).
+
1 +2 +3 +4 +5 | |
+W1: (2, 100) +b1: (1, 100) ++ +
Step 2: Feed inputs \(X\) into the model to do the forward pass and receive the probabilities.
+First we pass the inputs into the first layer.
1 +2 +3 | |
+z1: (1050, 100) ++
Next we apply the non-linear activation function, ReLU (\(max(0,z)\)) in this case.
+1 +2 +3 | |
+a_1: (1050, 100) ++
We pass the activations to the second layer to get our logits.
+1 +2 +3 +4 +5 | |
+W2: (100, 3) +b2: (1, 3) ++ +
1 +2 +3 +4 | |
+logits: (1050, 3) +sample: [-9.85444376e-05 1.67334360e-03 -6.31717987e-04] ++
We'll apply the softmax function to normalize the logits and obtain class probabilities.
+1 +2 +3 +4 +5 | |
+y_hat: (1050, 3) +sample: [0.33319557 0.33378647 0.33301796] ++ +
Step 3: Compare the predictions \(\hat{y}\) (ex. [0.3, 0.3, 0.4]) with the actual target values \(y\) (ex. class 2 would look like [0, 0, 1]) with the objective (cost) function to determine loss \(J\). A common objective function for classification tasks is cross-entropy loss.
1 +2 +3 +4 | |
+loss: 0.70 ++ +
Step 4: Calculate the gradient of loss \(J(\theta)\) w.r.t to the model weights.
The gradient of the loss w.r.t to $$ W_2 $$ is the same as the gradients from logistic regression since $\(hat{y} = softmax(z_2)\).
+The gradient of the loss w.r.t \(W_1\) is a bit trickier since we have to backpropagate through two sets of weights.
+1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 | |
Step 5: Update the weights \(W\) using a small learning rate \(\alpha\). The updates will penalize the probability for the incorrect classes (\(j\)) and encourage a higher probability for the correct class (\(y\)).
1 +2 +3 +4 +5 | |
Step 6: Repeat steps 2 - 4 until model performs well.
+
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 | |
+Epoch: 0, loss: 1.099, accuracy: 0.339 +Epoch: 100, loss: 0.549, accuracy: 0.678 +Epoch: 200, loss: 0.238, accuracy: 0.907 +Epoch: 300, loss: 0.151, accuracy: 0.946 +Epoch: 400, loss: 0.098, accuracy: 0.972 +Epoch: 500, loss: 0.074, accuracy: 0.985 +Epoch: 600, loss: 0.059, accuracy: 0.988 +Epoch: 700, loss: 0.050, accuracy: 0.991 +Epoch: 800, loss: 0.043, accuracy: 0.992 +Epoch: 900, loss: 0.038, accuracy: 0.993 ++ +
Now let's see how our model performs on the test (hold-out) data split.
+1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.9824531024531025,
+ "recall": 0.9822222222222222,
+ "f1": 0.982220641694326,
+ "num_samples": 225.0
+ },
+ "class": {
+ "c1": {
+ "precision": 1.0,
+ "recall": 0.9733333333333334,
+ "f1": 0.9864864864864865,
+ "num_samples": 75.0
+ },
+ "c2": {
+ "precision": 0.974025974025974,
+ "recall": 1.0,
+ "f1": 0.9868421052631579,
+ "num_samples": 75.0
+ },
+ "c3": {
+ "precision": 0.9733333333333334,
+ "recall": 0.9733333333333334,
+ "f1": 0.9733333333333334,
+ "num_samples": 75.0
+ }
+ }
+}
+
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+Now let's implement the same MLP in PyTorch.
+We'll be using two linear layers along with PyTorch Functional API's ReLU operation. +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 +3 | |
+<bound method Module.named_parameters of MLP( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=3, bias=True) +)> ++ +
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 1.11, accuracy: 21.9 +Epoch: 10 | loss: 0.66, accuracy: 59.8 +Epoch: 20 | loss: 0.50, accuracy: 73.0 +Epoch: 30 | loss: 0.38, accuracy: 89.8 +Epoch: 40 | loss: 0.28, accuracy: 92.3 +Epoch: 50 | loss: 0.21, accuracy: 93.8 +Epoch: 60 | loss: 0.17, accuracy: 95.2 +Epoch: 70 | loss: 0.14, accuracy: 96.1 +Epoch: 80 | loss: 0.12, accuracy: 97.4 +Epoch: 90 | loss: 0.10, accuracy: 97.8 ++ +
1 +2 +3 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.9706790123456791,
+ "recall": 0.9688888888888889,
+ "f1": 0.9690388976103262,
+ "num_samples": 225.0
+ },
+ "class": {
+ "c1": {
+ "precision": 1.0,
+ "recall": 0.96,
+ "f1": 0.9795918367346939,
+ "num_samples": 75.0
+ },
+ "c2": {
+ "precision": 0.9259259259259259,
+ "recall": 1.0,
+ "f1": 0.9615384615384615,
+ "num_samples": 75.0
+ },
+ "c3": {
+ "precision": 0.9861111111111112,
+ "recall": 0.9466666666666667,
+ "f1": 0.9659863945578231,
+ "num_samples": 75.0
+ }
+ }
+}
+
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+Let's look at the inference operations when using our trained model.
+1 +2 | |
1 +2 +3 | |
+[[0.22746497 0.29242354]] ++
1 +2 +3 +4 +5 | |
+The probability that you have c1 is 92% ++ +
So far we have been initializing weights with small random values but this isn't optimal for convergence during training. The objective is to initialize the appropriate weights such that our activations (outputs of layers) don't vanish (too small) or explode (too large), as either of these situations will hinder convergence. We can do this by sampling the weights uniformly from a bound distribution (many that take into account the precise activation function used) such that all activations have unit variance.
+++You may be wondering why we don't do this for every forward pass and that's a great question. We'll look at more advanced strategies that help with optimization like batch normalization, etc. in future lessons. Meanwhile you can check out other initializers here.
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
A great technique to have our models generalize (perform well on test data) is to increase the size of your data but this isn't always an option. Fortunately, there are methods like regularization and dropout that can help create a more robust model.
+Dropout is a technique (used only during training) that allows us to zero the outputs of neurons. We do this for dropout_p% of the total neurons in each layer and it changes every batch. Dropout prevents units from co-adapting too much to the data and acts as a sampling strategy since we drop a different set of neurons each time.
 +
+1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
1 +2 +3 +4 | |
+<bound method Module.named_parameters of MLP( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=3, bias=True) +)> ++ +
Though neural networks are great at capturing non-linear relationships they are highly susceptible to overfitting to the training data and failing to generalize on test data. Just take a look at the example below where we generate completely random data and are able to fit a model with \(2*N*C + D\) (where N = # of samples, C = # of classes and D = input dimension) hidden units. The training performance is good (~70%) but the overfitting leads to very poor test performance. We'll be covering strategies to tackle overfitting in future lessons.
1 +2 +3 +4 | |
1 +2 +3 +4 +5 | |
+X: (150, 2) +y: (150,) ++
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (105, 2), y_train: (105,) +X_val: (22, 2), y_val: (22,) +X_test: (23, 2), y_test: (23,) +Sample point: [0.52553355 0.33956916] → 0 ++
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+<bound method Module.named_parameters of MLP( + (fc1): Linear(in_features=2, out_features=302, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=302, out_features=3, bias=True) +)> ++
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
+Epoch: 0 | loss: 1.15, accuracy: 37.1 +Epoch: 20 | loss: 1.04, accuracy: 47.6 +Epoch: 40 | loss: 0.98, accuracy: 51.4 +Epoch: 60 | loss: 0.90, accuracy: 57.1 +Epoch: 80 | loss: 0.87, accuracy: 59.0 +Epoch: 100 | loss: 0.88, accuracy: 58.1 +Epoch: 120 | loss: 0.84, accuracy: 64.8 +Epoch: 140 | loss: 0.86, accuracy: 61.0 +Epoch: 160 | loss: 0.81, accuracy: 64.8 +Epoch: 180 | loss: 0.89, accuracy: 59.0 +Epoch: 200 | loss: 0.91, accuracy: 60.0 +Epoch: 220 | loss: 0.82, accuracy: 63.8 +Epoch: 240 | loss: 0.86, accuracy: 59.0 +Epoch: 260 | loss: 0.77, accuracy: 66.7 +Epoch: 280 | loss: 0.82, accuracy: 67.6 +Epoch: 300 | loss: 0.88, accuracy: 57.1 +Epoch: 320 | loss: 0.81, accuracy: 61.9 +Epoch: 340 | loss: 0.79, accuracy: 63.8 +Epoch: 360 | loss: 0.80, accuracy: 61.0 +Epoch: 380 | loss: 0.86, accuracy: 64.8 +Epoch: 400 | loss: 0.77, accuracy: 64.8 +Epoch: 420 | loss: 0.79, accuracy: 64.8 +Epoch: 440 | loss: 0.81, accuracy: 65.7 +Epoch: 460 | loss: 0.77, accuracy: 70.5 +Epoch: 480 | loss: 0.80, accuracy: 67.6 ++
1 +2 +3 | |
1 +2 +3 | |
+{
+ "overall": {
+ "precision": 0.17857142857142858,
+ "recall": 0.16666666666666666,
+ "f1": 0.1722222222222222,
+ "num_samples": 23.0
+ },
+ "class": {
+ "c1": {
+ "precision": 0.0,
+ "recall": 0.0,
+ "f1": 0.0,
+ "num_samples": 7.0
+ },
+ "c2": {
+ "precision": 0.2857142857142857,
+ "recall": 0.25,
+ "f1": 0.26666666666666666,
+ "num_samples": 8.0
+ },
+ "c3": {
+ "precision": 0.25,
+ "recall": 0.25,
+ "f1": 0.25,
+ "num_samples": 8.0
+ }
+ }
+}
+
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+It's important that we experiment, starting with simple models that underfit (high bias) and improve it towards a good fit. Starting with simple models (linear/logistic regression) let's us catch errors without the added complexity of more sophisticated models (neural networks).
+ +
+To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Copy of 01_Notebooks to 1_Notebooks). +
+  +
+Alternatives to Google Colab
+Alternatively, you can run these notebooks locally by using JupyterLab. You should first set up a directory for our project, create a virtual environment and install jupyterlab.
+mkdir mlops
+python3 -m venv venv
+source venv/bin/activate
+pip install jupyterlab
+jupyter lab
+Notebooks are made up of cells. There are two types of cells:
+code cell: used for writing and executing code.text cell: used for writing text, HTML, Markdown, etc.Click on a desired location in the notebook and create the cell by clicking on the ➕ TEXT (located in the top left corner).
 +
+Once you create the cell, click on it and type the following text inside it:
+### This is a header
+Hello world!
+Once you type inside the cell, press the SHIFT and RETURN (enter key) together to run the cell.
To edit a cell, double click on it and make any changes.
+Move a cell up and down by clicking on the cell and then pressing the ⬆ and ⬇ button on the top right of the cell.
+ +
+Delete the cell by clicking on it and pressing the trash can button 🗑️ on the top right corner of the cell. Alternatively, you can also press ⌘/Ctrl + M + D.
+ +
+Repeat the steps above to create and edit a code cell. You can create a code cell by clicking on the ➕ CODE (located in the top left corner).
 +
+Once you've created the code cell, double click on it, type the following inside it and then press Shift + Enter to execute the code. +
1 | |
+Hello world! ++ +
These are the basic concepts we'll need to use these notebooks but we'll learn few more tricks in subsequent lessons.
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+First we'll import the NumPy package and set seeds for reproducibility so that we can receive the exact same results every time.
+1 | |
1 +2 | |
 +
+1 +2 +3 +4 +5 +6 +7 | |
+x: 6 +x ndim: 0 +x shape: () +x size: 1 +x dtype: int64 ++
1 +2 +3 +4 +5 +6 +7 | |
+x: [1.3 2.2 1.7] +x ndim: 1 +x shape: (3,) +x size: 3 +x dtype: float64 ++
1 +2 +3 +4 +5 +6 +7 | |
+x: + [[1 2] + [3 4]] +x ndim: 2 +x shape: (2, 2) +x size: 4 +x dtype: int64 ++
1 +2 +3 +4 +5 +6 +7 | |
+x: + [[[1 2] + [3 4]] + + [[5 6] + [7 8]]] +x ndim: 3 +x shape: (2, 2, 2) +x size: 8 +x dtype: int64 ++ +
NumPy also comes with several functions that allow us to create tensors quickly. +
1 +2 +3 +4 +5 | |
+np.zeros((2,2)): + [[0. 0.] + [0. 0.]] +np.ones((2,2)): + [[1. 1.] + [1. 1.]] +np.eye((2)): + [[1. 0.] + [0. 1.]] +np.random.random((2,2)): + [[0.19151945 0.62210877] + [0.43772774 0.78535858]] ++ +
We can extract specific values from our tensors using indexing.
+++Keep in mind that when indexing the row and column, indices start at
+0. And like indexing with lists, we can use negative indices as well (where-1is the last item).
 +
+1 +2 +3 +4 +5 +6 | |
+x: [1 2 3] +x[0]: 1 +x: [0 2 3] ++
1 +2 +3 +4 +5 +6 | |
+[[ 1 2 3 4] + [ 5 6 7 8] + [ 9 10 11 12]] +x column 1: [ 2 6 10] +x row 0: [1 2 3 4] +x rows 0,1 & cols 1,2: + [[2 3] + [6 7]] ++
1 +2 +3 +4 +5 +6 +7 +8 | |
+[[ 1 2 3 4] + [ 5 6 7 8] + [ 9 10 11 12]] +rows_to_get: [0 1 2] +cols_to_get: [0 2 1] +indexed values: [ 1 7 10] ++
1 +2 +3 +4 +5 | |
+x: + [[1 2] + [3 4] + [5 6]] +x > 2: + [[False False] + [ True True] + [ True True]] +x[x > 2]: + [3 4 5 6] ++ +
1 +2 +3 +4 +5 +6 | |
+x + y: + [[2. 4.] + [6. 8.]] +x - y: + [[0. 0.] + [0. 0.]] +x * y: + [[ 1. 4.] + [ 9. 16.]] ++ +
One of the most common NumPy operations we’ll use in machine learning is matrix multiplication using the dot product. Suppose we wanted to take the dot product of two matrices with shapes [2 X 3] and [3 X 2]. We take the rows of our first matrix (2) and the columns of our second matrix (2) to determine the dot product, giving us an output of [2 X 2]. The only requirement is that the inside dimensions match, in this case the first matrix has 3 columns and the second matrix has 3 rows.
 +
+1 +2 +3 +4 +5 +6 | |
+(2, 3) · (3, 2) = (2, 2) +[[ 58. 64.] + [139. 154.]] ++ +
We can also do operations across a specific axis.
+ +
+1 +2 +3 +4 +5 +6 | |
+[[1 2] + [3 4]] +sum all: 10 +sum axis=0: [4 6] +sum axis=1: [3 7] ++
1 +2 +3 +4 +5 +6 | |
+min: 1 +max: 6 +min axis=0: [1 2 3] +min axis=1: [1 4] ++ +
What happens when we try to do operations with tensors with seemingly incompatible shapes? Their dimensions aren’t compatible as is but how does NumPy still gives us the right result? This is where broadcasting comes in. The scalar is broadcast across the vector so that they have compatible shapes.
+ +
+1 +2 +3 +4 +5 | |
+z: + [4 5] ++ +
In the situation below, what is the value of c and what are its dimensions?
1 +2 +3 | |
1 +2 +3 +4 | |
+array([[ 6, 7, 8], + [ 7, 8, 9], + [ 8, 9, 10]]) ++ +
How can we fix this? We need to be careful to ensure that a is the same shape as b if we don't want this unintentional broadcasting behavior.
+
1 +2 +3 +4 +5 | |
+array([[ 6], + [ 8], + [10]]) ++ +
This kind of unintended broadcasting happens more often then you'd think because this is exactly what happens when we create an array from a list. So we need to ensure that we apply the proper reshaping before using it for any operations.
+1 +2 +3 +4 | |
We often need to change the dimensions of our tensors for operations like the dot product. If we need to switch two dimensions, we can transpose +the tensor.
+ +
+1 +2 +3 +4 +5 +6 +7 | |
+x: + [[1 2 3] + [4 5 6]] +x.shape: (2, 3) +y: + [[1 4] + [2 5] + [3 6]] +y.shape: (3, 2) ++ +
Sometimes, we'll need to alter the dimensions of the matrix. Reshaping allows us to transform a tensor into different permissible shapes. Below, our reshaped tensor has the same number of values as the original tensor. (1X6 = 2X3). We can also use -1 on a dimension and NumPy will infer the dimension based on our input tensor.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+[[1 2 3 4 5 6]] +x.shape: (1, 6) +y: + [[1 2 3] + [4 5 6]] +y.shape: (2, 3) +z: + [[1 2 3] + [4 5 6]] +z.shape: (2, 3) ++ +
The way reshape works is by looking at each dimension of the new tensor and separating our original tensor into that many units. So here the dimension at index 0 of the new tensor is 2 so we divide our original tensor into 2 units, and each of those has 3 values.
+ +
+Unintended reshaping
+Though reshaping is very convenient to manipulate tensors, we must be careful of its pitfalls as well. Let's look at the example below. Suppose we have x, which has the shape [2 X 3 X 4].
1 +2 +3 +4 | |
+x: +[[[ 1 1 1 1] +[ 2 2 2 2] +[ 3 3 3 3]] ++[[10 10 10 10] +[20 20 20 20] +[30 30 30 30]]] +x.shape: (2, 3, 4) +
We want to reshape x so that it has shape [3 X 8] but we want the output to look like this:
+[[ 1 1 1 1 10 10 10 10] +[ 2 2 2 2 20 20 20 20] +[ 3 3 3 3 30 30 30 30]] ++
and not like:
++[[ 1 1 1 1 2 2 2 2] +[ 3 3 3 3 10 10 10 10] +[20 20 20 20 30 30 30 30]] ++
even though they both have the same shape [3X8]. What is the right way to reshape this?
When we naively do a reshape, we get the right shape but the values are not what we're looking for.
+ +
+1 +2 +3 +4 | |
+z_incorrect: +[[ 1 1 1 1 2 2 2 2] +[ 3 3 3 3 10 10 10 10] +[20 20 20 20 30 30 30 30]] +z_incorrect.shape: (3, 8) ++
Instead, if we transpose the tensor and then do a reshape, we get our desired tensor. Transpose allows us to put our two vectors that we want to combine together and then we use reshape to join them together. And as a general rule, we should always get our dimensions together before reshaping to combine them.
+ +
+1 +2 +3 +4 +5 +6 +7 | |
+y: +[[[ 1 1 1 1] +[10 10 10 10]] ++[[ 2 2 2 2] +[20 20 20 20]]
+[[ 3 3 3 3] +[30 30 30 30]]] +y.shape: (3, 2, 4) +z_correct: +[[ 1 1 1 1 10 10 10 10] +[ 2 2 2 2 20 20 20 20] +[ 3 3 3 3 30 30 30 30]] +z_correct.shape: (3, 8) +
++This becomes difficult when we're dealing with weight tensors with random values in many machine learning tasks. So a good idea is to always create a dummy example like this when you’re unsure about reshaping. Blindly going by the tensor shape can lead to lots of issues downstream.
+
We can also join our tensors via concatentation or stacking.
+1 +2 +3 | |
+[[0.79564718 0.73023418 0.92340453] + [0.24929281 0.0513762 0.66149188]] +(2, 3) ++ +
1 +2 +3 +4 | |
+[[0.79564718 0.73023418 0.92340453] + [0.24929281 0.0513762 0.66149188] + [0.79564718 0.73023418 0.92340453] + [0.24929281 0.0513762 0.66149188]] +(4, 3) ++ +
1 +2 +3 +4 | |
+[[[0.79564718 0.73023418 0.92340453] + [0.24929281 0.0513762 0.66149188]] + + [[0.79564718 0.73023418 0.92340453] + [0.24929281 0.0513762 0.66149188]]] +(2, 2, 3) ++ +
We can also easily add and remove dimensions to our tensors and we'll want to do this to make tensors compatible for certain operations.
+1 +2 +3 +4 +5 +6 +7 | |
+x: + [[1 2 3] + [4 5 6]] +x.shape: (2, 3) +y: + [[[1 2 3]] + [[4 5 6]]] +y.shape: (2, 1, 3) ++ +
1 +2 +3 +4 +5 +6 +7 | |
+x: + [[[1 2 3]] + [[4 5 6]]] +x.shape: (2, 1, 3) +y: + [[1 2 3] + [4 5 6]] +y.shape: (2, 3) ++ +
++ +Check out Dask for scaling NumPy workflows with minimal change to existing code.
+
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+First we'll import the NumPy and Pandas libraries and set seeds for reproducibility. We'll also download the dataset we'll be working with to disk. +
1 +2 | |
1 +2 | |
We're going to work with the Titanic dataset which has data on the people who embarked the RMS Titanic in 1912 and whether they survived the expedition or not. It's a very common and rich dataset which makes it very apt for exploratory data analysis with Pandas.
+Let's load the data from the CSV file into a Pandas dataframe. The header=0 signifies that the first row (0th index) is a header row which contains the names of each column in our dataset.
1 +2 +3 | |
1 +2 | |
These are the different features:
+class: class of travelname: full name of the passengersex: genderage: numerical agesibsp: # of siblings/spouse aboardparch: number of parents/child aboardticket: ticket numberfare: cost of the ticketcabin: location of roomembarked: port that the passenger embarked atsurvived: survival metric (0 - died, 1 - survived)Now that we loaded our data, we're ready to start exploring it to find interesting information.
+++Be sure to check out our entire lesson focused on EDA in our MLOps course.
+
1 | |
We can use .describe() to extract some standard details about our numerical features.
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
 +
+We can also use .hist() to view the histogram of values for each feature.
+
1 +2 | |
 +
+1 +2 | |
+array(['S', 'C', nan, 'Q'], dtype=object) ++ +
We can filter our data by features and even by specific values (or value ranges) within specific features. +
1 +2 | |
+0 Allen, Miss. Elisabeth Walton +1 Allison, Master. Hudson Trevor +2 Allison, Miss. Helen Loraine +3 Allison, Mr. Hudson Joshua Creighton +4 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) +Name: name, dtype: object ++
1 +2 | |
We can also sort our features in ascending or descending order. +
1 +2 | |
We can also get statistics across our features for certain groups. Here we wan to see the average of our continuous features based on whether the passenger survived or not. +
1 +2 +3 | |
We can use iloc to get rows or columns at particular positions in the dataframe.
+
1 +2 | |
+pclass 1 +name Allen, Miss. Elisabeth Walton +sex female +age 29 +sibsp 0 +parch 0 +ticket 24160 +fare 211.338 +cabin B5 +embarked S +survived 1 +Name: 0, dtype: object ++
1 +2 | |
+'Allen, Miss. Elisabeth Walton' ++ +
After exploring, we can clean and preprocess our dataset.
+++Be sure to check out our entire lesson focused on preprocessing in our MLOps course.
+
1 +2 | |
1 +2 +3 +4 | |
1 +2 +3 | |
1 +2 +3 +4 | |
We're now going to use feature engineering to create a column called family_size. We'll first define a function called get_family_size that will determine the family size using the number of parents and siblings.
+
1 +2 +3 +4 | |
lambda to apply that function on each row (using the numbers of siblings and parents in each row to determine the family size for each row).
+1 +2 | |
1 +2 +3 | |
Tip
+Feature engineering can be done in collaboration with domain experts that can guide us on what features to engineer and use.
+Finally, let's save our preprocessed data into a new CSV file to use later. +
1 +2 | |
1 +2 | |
+total 96 +-rw-r--r-- 1 root root 6975 Dec 3 17:36 processed_titanic.csv +drwxr-xr-x 1 root root 4096 Nov 21 16:30 sample_data +-rw-r--r-- 1 root root 85153 Dec 3 17:36 titanic.csv ++ +
When working with very large datasets, our Pandas DataFrames can become very large and it can be very slow or impossible to operate on them. This is where packages that can distribute workloads or run on more efficient hardware can come in handy.
+And, of course, we can combine these together (Dask-cuDF) to operate on partitions of a dataframe on the GPU.
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Variables are containers for holding data and they're defined by a name and value.
+ +
+1 +2 +3 +4 | |
+5 +<class 'int'> ++ +
++Here we use the variable name
+xin our examples but when you're working on a specific task, be sure to be explicit (ex.first_name) when creating variables (applies to functions, classes, etc. as well).
We can change the value of a variable by simply assigning a new value to it.
+1 +2 +3 +4 | |
+hello +<class 'str'> ++
There are many different types of variables: integers, floats, strings, boolean etc. +
1 +2 +3 | |
+5 <class 'int'> ++
1 +2 +3 | |
+5.0 <class 'float'> ++
1 +2 +3 | |
+5 <class 'str'> ++
1 +2 +3 | |
+True <class 'bool'> ++
We can also do operations with variables: +
1 +2 +3 +4 +5 | |
+3 ++ +
Know your types!
+We should always know what types of variables we're dealing with so we can do the right operations with them. Here's a common mistake that can happen if we're using the wrong variable type. +
1 +2 +3 +4 | |
+8 ++
1 +2 +3 +4 | |
+53 ++
Lists are an ordered, mutable (changeable) collection of values that are comma separated and enclosed by square brackets. A list can be comprised of many different types of variables. Below is a list with an integer, string and a float:
+1 +2 +3 | |
+[3, 'hello', 1.2] ++
1 +2 | |
+3 ++
We can add to a list by using the append function: +
1 +2 +3 +4 | |
+[3, 'hello', 1.2, 7] +4 ++
and just as easily replace existing items: +
1 +2 +3 | |
+[3, 'bye', 1.2, 7] ++
and perform operations with lists: +
1 +2 +3 +4 | |
+[3, 'bye', 1.2, 7, 2.4, 'world'] ++ +
Tuples are collections that are ordered and immutable (unchangeable). We will use tuples to store values that will never be changed. +
1 +2 +3 | |
+(3.0, 'hello') ++ +
1 +2 +3 | |
+(3.0, 'hello', 5.6, 4) ++ +
1 +2 | |
+--------------------------------------------------------------------------- +TypeError Traceback (most recent call last) +----> 1 x[0] = 1.2 +TypeError: 'tuple' object does not support item assignment ++ +
Sets are collections that are unordered and mutable. However, every item in a set much be unique.
+1 +2 +3 +4 | |
+{'e', 'M', ' ', "r", "w", 'd', 'a', 'h', 't', 'i', 'L', 'n', "w"}
+{'with', 'Learn', 'ML', 'Made', 'With'}
+
+
+Indexing and slicing from lists allow us to retrieve specific values within lists. Note that indices can be positive (starting from 0) or negative (-1 and lower, where -1 is the last item in the list).
+ +
+1 +2 +3 +4 +5 +6 | |
+x[0]: 3 +x[1]: hello +x[-1]: 1.2 +x[-2]: hello ++ +
1 +2 +3 +4 +5 | |
+x[:]: [3, 'hello', 1.2] +x[1:]: ['hello', 1.2] +x[1:2]: ['hello'] +x[:-1]: [3, 'hello'] ++ +
Indexing beyond length
+What happens if we try to index beyond the length of a list? +
1 +2 +3 | |
+[3, 'hello', 1.2] +3 ++Though this does produce results, we should always explicitly use the length of the list to index items from it to avoid incorrect assumptions for downstream processes. +
Dictionaries are an unordered, mutable collection of key-value pairs. You can retrieve values based on the key and a dictionary cannot have two of the same keys.
+ +
+1 +2 +3 +4 +5 +6 | |
+{"name": "Goku", "eye_color": "brown"}
+Goku
+brown
+
+
+1 +2 +3 | |
+{"name": "Goku", "eye_color": "green"}
+
+
+1 +2 +3 | |
+{"name": "Goku", "eye_color": "green", "age": 24}
+
+
+1 +2 | |
+3 ++ +
Sort of the structures
+See if you can recall and sort out the similarities and differences of the foundational data structures we've seen so far.
+| + | Mutable | +Ordered | +Indexable | +Unique | +
|---|---|---|---|---|
| List | +❓ | +❓ | +❓ | +❓ | +
| Tuple | +❓ | +❓ | +❓ | +❓ | +
| Set | +❓ | +❓ | +❓ | +❓ | +
| Dictionary | +❓ | +❓ | +❓ | +❓ | +
| + | Mutable | +Ordered | +Indexable | +Unique | +
|---|---|---|---|---|
| List | +✅ | +✅ | +✅ | +❌ | +
| Tuple | +❌ | +✅ | +✅ | +❌ | +
| Set | +✅ | +❌ | +❌ | +✅ | +
| Dictionary | +✅ | +❌ | +❌ | +✅ keys ❌ values |
+
But of course, there is pretty much a way to do accomplish anything with Python. For example, even though native dictionaries are unordered, we can leverage the OrderedDict data structure to change that (useful if we want to iterate through keys in a certain order, etc.).
+1 | |
1 +2 +3 +4 +5 +6 | |
+{'a': 2, 'c': 3, 'b': 1}
+
+++After Python 3.7+, native dictionaries are insertion ordered.
+
1 +2 | |
+dict_items([('a', 2), ('c', 3), ('b', 1)])
+
+1 +2 | |
+OrderedDict([('a', 2), ('b', 1), ('c', 3)])
+
+1 +2 | |
+OrderedDict([('b', 1), ('a', 2), ('c', 3)])
+
+
+We can use if statements to conditionally do something. The conditions are defined by the words if, elif (which stands for else if) and else. We can have as many elif statements as we want. The indented code below each condition is the code that will execute if the condition is True.
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
+medium ++ +
1 +2 +3 +4 | |
+it worked ++ +
A for loop can iterate over a collection of values (lists, tuples, dictionaries, etc.) The indented code is executed for each item in the collection of values.
+
1 +2 +3 +4 | |
+carrots +broccoli +beans ++ +
When the loop encounters the break command, the loop will terminate immediately. If there were more items in the list, they will not be processed. +
1 +2 +3 +4 +5 +6 | |
+carrots ++ +
When the loop encounters the continue command, the loop will skip all other operations for that item in the list only. If there were more items in the list, the loop will continue normally.
+
1 +2 +3 +4 +5 +6 | |
+carrots +beans ++ +
A while loop can perform repeatedly as long as a condition is True. We can use continue and break commands in while loops as well.
+
1 +2 +3 +4 +5 | |
+2 +1 +0 ++ +
We can combine our knowledge of lists and for loops to leverage list comprehensions to create succinct code.
+1 +2 +3 +4 +5 +6 +7 | |
+[3, 4, 5] ++ +
 +
+1 +2 +3 | |
+[3, 4, 5] ++ +
List comprehension for nested for loops
+For the nested for loop below, which list comprehension is correct?
+1 +2 +3 +4 +5 +6 +7 +8 | |
+['am', 'be'] ++
[word.lower() if len(word) < 3 for word in letter_list for letter_list in words][word.lower() for word in letter_list for letter_list in words if len(word) < 3][word.lower() for letter_list in words for word in letter_list if len(word) < 3]Python syntax is usually very straight forward, so the correct answer involves just directly copying the statements from the nested for loop from top to bottom!
+[word.lower() if len(word) < 3 for word in letter_list for letter_list in words][word.lower() for word in letter_list for letter_list in words if len(word) < 3][word.lower() for letter_list in words for word in letter_list if len(word) < 3]Functions are a way to modularize reusable pieces of code. They're defined by the keyword def which stands for definition and they can have the following components.
 +
+1 +2 +3 +4 +5 | |
Here are the components that may be required when we want to use the function. we need to ensure that the function name and the input parameters match with how we defined the function above.
+ +
+1 +2 +3 +4 | |
+2 ++ +
A function can have as many input parameters and outputs as we want. +
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 | |
+Goku Mohandas ++ +
++We can be even more explicit with our function definitions by specifying the types of our input and output arguments. We cover this in our documentation lesson because the typing information is automatically leveraged to create very intuitive documentation.
+
It's good practice to always use keyword argument when using a function so that it's very clear what input variable belongs to what function input parameter. On a related note, you will often see the terms *args and **kwargs which stand for arguments and keyword arguments. You can extract them when they are passed into a function. The significance of the * is that any number of arguments and keyword arguments can be passed into the function.
1 +2 +3 +4 | |
1 | |
+x: 5, y: 2 ++ +
Classes are object constructors and are a fundamental component of object oriented programming in Python. They are composed of a set of functions that define the class and it's operations.
+Classes can be customized with magic methods like __init__ and __str__, to enable powerful operations. These are also known as dunder methods (ex. dunder init), which stands for double underscores due to the leading and trailing underscores.
The __init__ function is used when an instance of the class is initialized.
+
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 | |
+<__main__.Pet object at 0x7fe487e9c358> +Scooby ++ +
The print (my_dog) command printed something not so relevant to us. Let's fix that with the __str__ function.
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
1 +2 +3 +4 +5 | |
+dog named Scooby +Scooby ++ +
++We'll be exploring additional built-in functions in subsequent notebooks (like
+__len__,__iter__and__getitem__, etc.) but if you're curious, here is a tutorial on more magic methods.
Besides these magic functions, classes can also have object functions. +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
1 +2 +3 +4 | |
+dog named Scooby +Scooby ++ +
1 +2 +3 +4 | |
+dog named Scrappy +Scrappy ++ +
We can also build classes on top of one another using inheritance, which allows us to inherit all the properties and methods from another class (the parent). +
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
+A Great Dane doggo named Scooby ++
1 +2 | |
+A Great Dane doggo named Scooby Doo ++ +
Notice how we inherited the initialized variables from the parent Pet class like species and name. We also inherited functions such as change_name().
Which function is executed?
+Which function is executed if the parent and child functions have functions with the same name?
+As you can see, both our parent class (Pet) and the child class (Dog) have different __str__ functions defined but share the same function name. The child class inherits everything from the parent classes but when there is conflict between function names, the child class' functions take precedence and overwrite the parent class' functions.
There are two important decorator methods to know about when it comes to classes: @classmethod and @staticmethod. We'll learn about decorators in the next section below but these specific methods pertain to classes so we'll cover them here.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
A @classmethod allows us to create class instances by passing in the uninstantiated class itself (cls). This is a great way to create (or load) classes from objects (ie. dictionaries).
1 +2 +3 +4 | |
+Border Collie named Cassie ++ +
A @staticmethod can be called from an uninstantiated class object so we can do things like this:
+
1 +2 | |
+True ++ +
Recall that functions allow us to modularize code and reuse them. However, we'll often want to add some functionality before or after the main function executes and we may want to do this for many different functions. Instead of adding more code to the original function, we can use decorators!
+Suppose we have a function called operations which increments the input value x by 1. +
1 +2 +3 +4 | |
1 | |
+2 ++ +
Now let's say we want to increment our input x by 1 before and after the operations function executes and, to illustrate this example, let's say the increments have to be separate steps. Here's how we would do it by changing the original code: +
1 +2 +3 +4 +5 +6 | |
1 | |
+4 ++ +
We were able to achieve what we want but we now increased the size of our operations function and if we want to do the same incrementing for any other function, we have to add the same code to all of those as well ... not very efficient. To solve this, let's create a decorator called add which increments x by 1 before and after the main function f executes.
The decorator function accepts a function f which is the function we wish to wrap around, in our case, it's operations(). The output of the decorator is its wrapper function which receives the arguments and keyword arguments passed to function f.
Inside the wrapper function, we can:
f.f is executedwrapper function returns some value(s), which is what the decorator returns as well since it returns wrapper.1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
We can use this decorator by simply adding it to the top of our main function preceded by the @ symbol.
+
1 +2 +3 +4 +5 | |
1 | |
+4 ++ +
Suppose we wanted to debug and see what function actually executed with operations().
+
1 | |
+('wrapper', 'Wrapper function for @add.')
+
+The function name and docstring are not what we're looking for but it appears this way because the wrapper function is what was executed. In order to fix this, Python offers functools.wraps which carries the main function's metadata.
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
1 +2 +3 +4 +5 | |
1 | |
+('operations', 'Basic operations.')
+
+Awesome! We were able to decorate our main function operation() to achieve the customization we wanted without actually altering the function. We can reuse our decorator for other functions that may need the same customization!
++This was a dummy example to show how decorators work but we'll be using them heavily during our MLOps lessons. A simple scenario would be using decorators to create uniform JSON responses from each API endpoint without including the bulky code in each endpoint.
+
Decorators allow for customized operations before and after the main function's execution but what about in between? Suppose we want to conditionally/situationally do some operations. Instead of writing a whole bunch of if-statements and make our functions bulky, we can use callbacks!
+Our callbacks will be classes that have functions with key names that will execute at various periods during the main function's execution. The function names are up to us but we need to invoke the same callback functions within our main function. +
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 | |
+2 ++
1 | |
+[1, 2] ++ +
What's the difference compared to a decorator?
+It seems like we've just done some operations before and after the function's main process? Isn't that what a decorator is for?
+With callbacks, it's easier to keep track of objects since it's all defined in a separate callback class. It's also now possible to interact with our function, not just before or after but throughout the entire process! Imagine a function with:
+decorators + callbacks = powerful customization before, during and after the main function’s execution without increasing its complexity. We will be using this duo to create powerful ML training scripts that are highly customizable in future lessons.
+1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 +3 | |
+3 ++
1 | |
+[1, 2, 3] ++ + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+We'll import PyTorch and set seeds for reproducibility. Note that PyTorch also required a seed since we will be generating random tensors. +
1 +2 | |
1 | |
1 +2 +3 | |
++ ++
We'll first cover some basics with PyTorch such as creating tensors and converting from common data structures (lists, arrays, etc.) to tensors. +
1 +2 +3 +4 +5 | |
+Type: torch.FloatTensor +Size: torch.Size([2, 3]) +Values: +tensor([[ 0.0461, 0.4024, -1.0115], + [ 0.2167, -0.6123, 0.5036]]) ++
1 +2 +3 +4 +5 | |
+tensor([[0., 0., 0.], + [0., 0., 0.]]) +tensor([[1., 1., 1.], + [1., 1., 1.]]) ++
1 +2 +3 +4 | |
+Size: torch.Size([2, 3]) +Values: +tensor([[1., 2., 3.], + [4., 5., 6.]]) ++
1 +2 +3 +4 | |
+Size: torch.Size([2, 3]) +Values: +tensor([[0.1915, 0.6221, 0.4377], + [0.7854, 0.7800, 0.2726]]) ++
1 +2 +3 +4 +5 | |
+Type: torch.FloatTensor +Type: torch.LongTensor ++ +
Now we'll explore some basic operations with tensors. +
1 +2 +3 +4 +5 +6 | |
+Size: torch.Size([2, 3]) +Values: +tensor([[ 0.0761, -0.6775, -0.3988], + [ 3.0633, -0.1589, 0.3514]]) ++
1 +2 +3 +4 +5 +6 | |
+Size: torch.Size([2, 2]) +Values: +tensor([[ 1.0796, -0.0759], + [ 1.2746, -0.5134]]) ++
1 +2 +3 +4 +5 +6 +7 | |
+Size: torch.Size([2, 3]) +Values: +tensor([[ 0.8042, -0.1383, 0.3196], + [-1.0187, -1.3147, 2.5228]]) +Size: torch.Size([3, 2]) +Values: +tensor([[ 0.8042, -1.0187], + [-0.1383, -1.3147], + [ 0.3196, 2.5228]]) ++
1 +2 +3 +4 +5 | |
+Size: torch.Size([3, 2]) +Values: +tensor([[ 0.4501, 0.2709], + [-0.8087, -0.0217], + [-1.0413, 0.0702]]) ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
+Size: torch.Size([2, 3, 4]) +x: +tensor([[[ 1, 1, 1, 1], + [ 2, 2, 2, 2], + [ 3, 3, 3, 3]], + + [[10, 10, 10, 10], + [20, 20, 20, 20], + [30, 30, 30, 30]]]) + + +Size: torch.Size([3, 8]) +a: +tensor([[ 1, 1, 1, 1, 2, 2, 2, 2], + [ 3, 3, 3, 3, 10, 10, 10, 10], + [20, 20, 20, 20, 30, 30, 30, 30]]) + + +Size: torch.Size([3, 2, 4]) +b: +tensor([[[ 1, 1, 1, 1], + [10, 10, 10, 10]], + + [[ 2, 2, 2, 2], + [20, 20, 20, 20]], + + [[ 3, 3, 3, 3], + [30, 30, 30, 30]]]) + + +Size: torch.Size([3, 8]) +c: +tensor([[ 1, 1, 1, 1, 10, 10, 10, 10], + [ 2, 2, 2, 2, 20, 20, 20, 20], + [ 3, 3, 3, 3, 30, 30, 30, 30]]) ++
1 +2 +3 +4 +5 +6 +7 | |
+Values: +tensor([[ 0.5797, -0.0599, 0.1816], + [-0.6797, -0.2567, -1.8189]]) +Values: +tensor([-0.1000, -0.3166, -1.6373]) +Values: +tensor([ 0.7013, -2.7553]) ++ +
Now we'll look at how to extract, separate and join values from our tensors. +
1 +2 +3 +4 | |
+x: +tensor([[ 0.2111, 0.3372, 0.6638, 1.0397], + [ 1.8434, 0.6588, -0.2349, -0.0306], + [ 1.7462, -0.0722, -1.6794, -1.7010]]) +x[:1]: +tensor([[0.2111, 0.3372, 0.6638, 1.0397]]) +x[:1, 1:3]: +tensor([[0.3372, 0.6638]]) ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Values: +tensor([[ 0.6486, 1.7653, 1.0812], + [ 1.2436, 0.8971, -0.0784]]) +Values: +tensor([[ 0.6486, 1.0812], + [ 1.2436, -0.0784]]) +Values: +tensor([ 0.6486, -0.0784]) ++ +
We can also combine our tensors via concatenation or stacking operations, which are consistent with NumPy's joining functions' behaviors as well.
+1 +2 +3 | |
+tensor([[-1.5944, -0.4218, -1.8219], + [ 1.7446, 1.2058, -0.7753]]) +torch.Size([2, 3]) ++ +
1 +2 +3 +4 | |
+tensor([[-1.5944, -0.4218, -1.8219], + [ 1.7446, 1.2058, -0.7753], + [-1.5944, -0.4218, -1.8219], + [ 1.7446, 1.2058, -0.7753]]) +torch.Size([4, 3]) ++ +
1 +2 +3 +4 | |
+tensor([[[-1.5944, -0.4218, -1.8219], + [ 1.7446, 1.2058, -0.7753]], + + [[-1.5944, -0.4218, -1.8219], + [ 1.7446, 1.2058, -0.7753]]]) +torch.Size([2, 2, 3]) ++ +
We can determine gradients (rate of change) of our tensors with respect to their constituents using gradient bookkeeping. The gradient is a vector that points in the direction of greatest increase of a function. We'll be using gradients in the next lesson to determine how to change our weights to affect a particular objective function (ex. loss).
+1 +2 +3 +4 +5 +6 +7 | |
+x: +tensor([[0.7379, 0.0846, 0.4245, 0.9778], + [0.6800, 0.3151, 0.3911, 0.8943], + [0.6889, 0.8389, 0.1780, 0.6442]], requires_grad=True) +x.grad: +tensor([[0.2500, 0.2500, 0.2500, 0.2500], + [0.2500, 0.2500, 0.2500, 0.2500], + [0.2500, 0.2500, 0.2500, 0.2500]]) ++ +
We also load our tensors onto the GPU for parallelized computation using CUDA (a parallel computing platform and API from Nvidia). +
1 +2 | |
+False ++ +
If False (CUDA is not available), let's change that by following these steps: Go to Runtime > Change runtime type > Change Hardware accelerator to GPU > Click Save +
1 | |
1 +2 | |
+True ++
1 +2 +3 | |
+cuda ++
1 +2 +3 +4 | |
+False +True ++ + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far we've processed inputs as whole (ex. applying filters across the entire input to extract features) but we can also process our inputs sequentially. For example we can think of each token in our text as an event in time (timestep). We can process each timestep, one at a time, and predict the class after the last timestep (token) has been processed. This is very powerful because the model now has a meaningful way to account for the sequential order of tokens in our sequence and predict accordingly.
+ +
+$$ \text{RNN forward pass for a single time step } X_t $$:
+| Variable | +Description | +
|---|---|
| \(N\) | +batch size | +
| \(E\) | +embeddings dimension | +
| \(H\) | +# of hidden units | +
| \(W_{hh}\) | +RNN weights \(\in \mathbb{R}^{HXH}\) | +
| \(h_{t-1}\) | +previous timestep's hidden state \(\in in \mathbb{R}^{NXH}\) | +
| \(W_{xh}\) | +input weights \(\in \mathbb{R}^{EXH}\) | +
| \(X_t\) | +input at time step \(t \in \mathbb{R}^{NXE}\) | +
| \(b_h\) | +hidden units bias \(\in \mathbb{R}^{HX1}\) | +
| \(h_t\) | +output from RNN for timestep \(t\) | +
Let's set our seed and device for our main task. +
1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
+
1 +2 +3 +4 +5 | |
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc. +
1 +2 +3 +4 | |
1 +2 +3 +4 | |
+[nltk_data] Downloading package stopwords to /root/nltk_data... +[nltk_data] Package stopwords is already up-to-date! +['i', 'me', 'my', 'myself', 'we'] ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 +2 +3 | |
+great week nyse ++
1 +2 +3 +4 | |
+Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says + +sharon accepts plan reduce gaza army operation haaretz says ++ +
Warning
+If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (84000,), y_train: (84000,) +X_val: (18000,), y_val: (18000,) +X_test: (18000,), y_test: (18000,) +Sample point: china battles north korea nuclear talks → World ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 +5 | |
+{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}
+
+1 +2 +3 +4 +5 +6 | |
+y_train[0]: World +y_train[0]: 3 ++
1 +2 +3 +4 | |
+counts: [21000 21000 21000 21000]
+weights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}
+
+
+We'll define a Tokenizer to convert our text input data into token indices.
1 +2 +3 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 | |
Warning
+It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
+1 +2 +3 +4 +5 | |
+<Tokenizer(num_tokens=5000)> + ++
1 +2 +3 | |
+[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]
+least freq token's freq: 14
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
+Text to indices: + (preprocessed) → china battles north korea nuclear talks + (tokenized) → [ 16 1491 285 142 114 24] ++ +
We'll need to do 2D padding to our tokenized text. +
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
+(3, 6) +[[1.600e+01 1.491e+03 2.850e+02 1.420e+02 1.140e+02 2.400e+01] + [1.445e+03 2.300e+01 6.560e+02 2.197e+03 1.000e+00 0.000e+00] + [1.200e+02 1.400e+01 1.955e+03 1.005e+03 1.529e+03 4.014e+03]] ++ +
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Datasets: + Train dataset: <Dataset(N=84000)> + Val dataset: <Dataset(N=18000)> + Test dataset: <Dataset(N=18000)> +Sample point: + X: [ 16 1491 285 142 114 24] + seq_len: 6 + y: 3 ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 | |
+Sample batch: + X: [64, 14] + seq_lens: [64] + y: [64] +Sample point: + X: tensor([ 16, 1491, 285, 142, 114, 24, 0, 0, 0, 0, 0, 0, + 0, 0]) + seq_len: 6 + y: 3 ++ +
Let's create the Trainer class that we'll use to facilitate training for our experiments.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 | |
Inputs to RNNs are sequential like text or time-series.
+1 +2 | |
1 +2 +3 +4 +5 +6 | |
+torch.Size([64, 8, 100]) +torch.Size([1, 64]) ++
+$$ \text{RNN forward pass for a single time step } X_t $$:
+| Variable | +Description | +
|---|---|
| \(N\) | +batch size | +
| \(E\) | +embeddings dimension | +
| \(H\) | +# of hidden units | +
| \(W_{hh}\) | +RNN weights \(\in \mathbb{R}^{HXH}\) | +
| \(h_{t-1}\) | +previous timestep's hidden state \(\in in \mathbb{R}^{NXH}\) | +
| \(W_{xh}\) | +input weights \(\in \mathbb{R}^{EXH}\) | +
| \(X_t\) | +input at time step \(t \in \mathbb{R}^{NXE}\) | +
| \(b_h\) | +hidden units bias \(\in \mathbb{R}^{HX1}\) | +
| \(h_t\) | +output from RNN for timestep \(t\) | +
++At the first time step, the previous hidden state \(h_{t-1}\) can either be a zero vector (unconditioned) or initialized (conditioned). If we are conditioning the RNN, the first hidden state \(h_0\) can belong to a specific condition or we can concat the specific condition to the randomly initialized hidden vectors at each time step. More on this in the subsequent notebooks on RNNs.
+
1 +2 | |
1 +2 +3 | |
+torch.Size([64, 128]) ++ +
We'll show how to create an RNN cell using PyTorch's RNNCell and the more abstracted RNN.
1 +2 +3 | |
+RNNCell(100, 128) ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
+torch.Size([64, 8, 128]) ++
1 +2 +3 +4 +5 +6 | |
+out: torch.Size([64, 8, 128]) +h_n: torch.Size([1, 64, 128]) ++
1 +2 +3 | |
+tensor([[-0.0359, -0.3819, 0.2162, ..., -0.3397, 0.0468, 0.1937], + [-0.4914, -0.3056, -0.0837, ..., -0.3507, -0.4320, 0.3593], + [-0.0989, -0.2852, 0.1170, ..., -0.0805, -0.0786, 0.3922], + ..., + [-0.3115, -0.4169, 0.2611, ..., -0.3214, 0.0620, 0.0338], + [-0.2455, -0.3380, 0.2048, ..., -0.4198, -0.0075, 0.0372], + [-0.2092, -0.4594, 0.1654, ..., -0.5397, -0.1709, 0.0023]], + grad_fn=<SliceBackward>) +tensor([[-0.0359, -0.3819, 0.2162, ..., -0.3397, 0.0468, 0.1937], + [-0.4914, -0.3056, -0.0837, ..., -0.3507, -0.4320, 0.3593], + [-0.0989, -0.2852, 0.1170, ..., -0.0805, -0.0786, 0.3922], + ..., + [-0.3115, -0.4169, 0.2611, ..., -0.3214, 0.0620, 0.0338], + [-0.2455, -0.3380, 0.2048, ..., -0.4198, -0.0075, 0.0372], + [-0.2092, -0.4594, 0.1654, ..., -0.5397, -0.1709, 0.0023]], + grad_fn=<SqueezeBackward1>) ++ +
In our model, we want to use the RNN's output after the last relevant token in the sentence is processed. The last relevant token doesn't refer the <PAD> tokens but to the last actual word in the sentence and its index is different for each input in the batch. This is why we included a seq_lens tensor in our batches.
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 | |
+torch.Size([64, 128]) ++ +
There are many different ways to use RNNs. So far we've processed our inputs one timestep at a time and we could either use the RNN's output at each time step or just use the final input timestep's RNN output. Let's look at a few other possibilities.
+ +
+1 | |
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 | |
1 +2 +3 +4 +5 +6 +7 | |
+<bound method Module.named_parameters of RNN( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): RNN(100, 128, batch_first=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=128, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++ +
1 | |
1 +2 +3 +4 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 1.25605, val_loss: 1.10880, lr: 1.00E-04, _patience: 10 +Epoch: 2 | train_loss: 1.03074, val_loss: 0.96749, lr: 1.00E-04, _patience: 10 +Epoch: 3 | train_loss: 0.90110, val_loss: 0.86424, lr: 1.00E-04, _patience: 10 +... +Epoch: 31 | train_loss: 0.32206, val_loss: 0.53581, lr: 1.00E-06, _patience: 3 +Epoch: 32 | train_loss: 0.32233, val_loss: 0.53587, lr: 1.00E-07, _patience: 2 +Epoch: 33 | train_loss: 0.32215, val_loss: 0.53572, lr: 1.00E-07, _patience: 1 +Stopping early! ++ +
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8171357577653572,
+ "recall": 0.8176111111111112,
+ "f1": 0.8171696173843819,
+ "num_samples": 18000.0
+}
+
+
+While our simple RNNs so far are great for sequentially processing our inputs, they have quite a few disadvantages. They commonly suffer from exploding or vanishing gradients as a result using the same set of weights (\(W_{xh}\) and \(W_{hh}\)) with each timestep's input. During backpropagation, this can cause gradients to explode (>1) or vanish (<1). If you multiply any number greater than 1 with itself over and over, it moves towards infinity (exploding gradients) and similarly, If you multiply any number less than 1 with itself over and over, it moves towards zero (vanishing gradients). To mitigate this issue, gated RNNs were devised to selectively retain information. If you're interested in learning more of the specifics, this post is a must-read.
+There are two popular types of gated RNNs: Long Short-term Memory (LSTMs) units and Gated Recurrent Units (GRUs).
+++When deciding between LSTMs and GRUs, empirical performance is the best factor but in general GRUs offer similar performance with less complexity (less weights).
+
 +
+1 +2 +3 +4 | |
+torch.Size([64, 8, 100]) ++
1 +2 | |
1 +2 +3 +4 | |
+out: torch.Size([64, 8, 128]) +h_n: torch.Size([1, 64, 128]) ++ +
We can also have RNNs that process inputs from both directions (first token to last token and vice versa) and combine their outputs. This architecture is known as a bidirectional RNN. +
1 +2 +3 | |
1 +2 +3 +4 | |
+out: torch.Size([64, 8, 256]) +h_n: torch.Size([2, 64, 128]) ++
Notice that the output for each sample at each timestamp has size 256 (double the RNN_HIDDEN_DIM). This is because this includes both the forward and backward directions from the BiRNN.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 | |
1 +2 +3 +4 +5 +6 +7 | |
+<bound method Module.named_parameters of GRU( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): GRU(100, 128, batch_first=True, bidirectional=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=256, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +)> ++ +
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 1.18125, val_loss: 0.93827, lr: 1.00E-04, _patience: 10 +Epoch: 2 | train_loss: 0.81291, val_loss: 0.72564, lr: 1.00E-04, _patience: 10 +Epoch: 3 | train_loss: 0.65413, val_loss: 0.64487, lr: 1.00E-04, _patience: 10 +... +Epoch: 23 | train_loss: 0.30351, val_loss: 0.53904, lr: 1.00E-06, _patience: 3 +Epoch: 24 | train_loss: 0.30332, val_loss: 0.53912, lr: 1.00E-07, _patience: 2 +Epoch: 25 | train_loss: 0.30300, val_loss: 0.53909, lr: 1.00E-07, _patience: 1 +Stopping early! ++ +
1 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8192635071011053,
+ "recall": 0.8196111111111111,
+ "f1": 0.8192710197821547,
+ "num_samples": 18000.0
+}
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+GRU( + (embeddings): Embedding(5000, 100, padding_idx=0) + (rnn): GRU(100, 128, batch_first=True, bidirectional=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc1): Linear(in_features=256, out_features=100, bias=True) + (fc2): Linear(in_features=100, out_features=4, bias=True) +) ++
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
+['final tennis tournament starts next week'] ++
1 +2 +3 +4 | |
+['Sports'] ++
1 +2 +3 | |
+{
+ "Sports": 0.49753469228744507,
+ "World": 0.2925860285758972,
+ "Business": 0.1932886838912964,
+ "Sci/Tech": 0.01659061387181282
+}
+
+
+++ +We will learn how to create more context-aware representations and a little bit of interpretability with RNNs in the next lesson on attention.
+
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Transformers are a very popular architecture that leverage and extend the concept of self-attention to create very useful representations of our input data for a downstream task.
+advantages:
+disadvantages:
+ +
+Let's set our seed and device for our main task. +
1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
+
1 +2 +3 +4 +5 | |
1 +2 +3 | |
+10000 ++ +
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc. +
1 +2 +3 +4 | |
1 +2 +3 +4 | |
+[nltk_data] Downloading package stopwords to /root/nltk_data... +[nltk_data] Package stopwords is already up-to-date! +['i', 'me', 'my', 'myself', 'we'] ++
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 +2 +3 | |
+great week nyse ++
1 +2 +3 +4 | |
+Sharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says + +sharon accepts plan reduce gaza army operation haaretz says ++ +
Warning
+If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (7000,), y_train: (7000,) +X_val: (1500,), y_val: (1500,) +X_test: (1500,), y_test: (1500,) +Sample point: lost flu paydays → Business ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 | |
1 +2 +3 +4 +5 | |
+{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}
+
+1 +2 +3 +4 | |
+counts: [1746 1723 1725 1806]
+weights: {0: 0.000572737686139748, 1: 0.0005803830528148578, 2: 0.0005797101449275362, 3: 0.0005537098560354374}
+
+1 +2 +3 +4 +5 +6 +7 | |
+y_train[0]: Business +y_train[0]: [1 0 0 0] +decode([y_train[0]]): ['Business'] ++ +
We'll be using the BertTokenizer to tokenize our input text in to sub-word tokens.
+1 +2 | |
1 +2 +3 +4 +5 | |
+31090 ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
+torch.Size([7000, 27]) torch.Size([7000, 27]) +torch.Size([1500, 21]) torch.Size([1500, 21]) +torch.Size([1500, 26]) torch.Size([1500, 26]) ++ +
1 +2 | |
+tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0]) +[CLS] lost flu paydays [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] ++ +
1 +2 | |
+['[CLS]', 'lost', 'flu', 'pay', '##days', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]'] ++ +
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Data splits: + Train dataset: <Dataset(N=7000)> + Val dataset: <Dataset(N=1500)> + Test dataset: <Dataset(N=1500)> +Sample point: + ids: tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0]) + masks: tensor([1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0]) + targets: tensor([1., 0., 0., 0.], device="cpu") ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
+Sample batch: + ids: torch.Size([128, 27]) + masks: torch.Size([128, 27]) + targets: torch.Size([128, 4]) ++ +
Let's create the Trainer class that we'll use to facilitate training for our experiments.
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 | |
We'll first learn about the unique components within the Transformer architecture and then implement one for our text classification task.
+The most popular type of self-attention is scaled dot-product attention from the widely-cited Attention is all you need paper. This type of attention involves projecting our encoded input sequences onto three matrices, queries (Q), keys (K) and values (V), whose weights we learn.
+| Variable | +Description | +
|---|---|
| \(X\) | +encoded inputs \(\in \mathbb{R}^{NXMXH}\) | +
| \(N\) | +batch size | +
| \(M\) | +max sequence length in the batch | +
| \(H\) | +hidden dim, model dim, etc. | +
| \(W_q\) | +query weights \(\in \mathbb{R}^{HXd_q}\) | +
| \(W_k\) | +key weights \(\in \mathbb{R}^{HXd_k}\) | +
| \(W_v\) | +value weights \(\in \mathbb{R}^{HXd_v}\) | +
Instead of applying self-attention only once across the entire encoded input, we can also separate the input and apply self-attention in parallel (heads) to each input section and concatenate them. This allows the different head to learn unique representations while maintaining the complexity since we split the input into smaller subspaces.
+| Variable | +Description | +
|---|---|
| \(h\) | +number of attention heads | +
| \(W_O\) | +multi-head attention weights \(\in \mathbb{R}^{hd_vXH}\) | +
| \(H\) | +hidden dim (or dimension of the model \(d_{model}\)) | +
With self-attention, we aren't able to account for the sequential position of our input tokens. To address this, we can use positional encoding to create a representation of the location of each token with respect to the entire sequence. This can either be learned (with weights) or we can use a fixed function that can better extend to create positional encoding for lengths during inference that were not observed during training.
+| Variable | +Description | +
|---|---|
| \(pos\) | +position of the token \((1...M)\) | +
| \(i\) | +hidden dim \((1..H)\) | +
This effectively allows us to represent each token's relative position using a fixed function for very large sequences. And because we've constrained the positional encodings to have the same dimensions as our encoded inputs, we can simply concatenate them before feeding them into the multi-head attention heads.
+And here's how it all fits together! It's an end-to-end architecture that creates these contextual representations and uses an encoder-decoder architecture to predict the outcomes (one-to-one, many-to-one, many-to-many, etc.) Due to the complexity of the architecture, they require massive amounts of data for training without overfitting, however, they can be leveraged as pretrained models to finetune with smaller datasets that are similar to the larger set it was initially trained on.
+
+++We're not going to the implement the Transformer from scratch but we will use the Hugging Face library to do so in the training lesson!
+
We're going to use a pretrained BertModel to act as a feature extractor. We'll only use the encoder to receive sequential and pooled outputs (is_decoder=False is default).
1 | |
1 +2 +3 +4 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
++We decided to work with the pooled output, but we could have just as easily worked with the sequential output (encoder representation for each sub-token) and applied a CNN (or other decoder options) on top of it.
+
1 +2 +3 +4 +5 +6 +7 | |
+<bound method Module.named_parameters of Transformer( + (transformer): BertModel( + (embeddings): BertEmbeddings( + (word_embeddings): Embedding(31090, 768, padding_idx=0) + (position_embeddings): Embedding(512, 768) + (token_type_embeddings): Embedding(2, 768) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + (encoder): BertEncoder( + (layer): ModuleList( + (0): BertLayer( + (attention): BertAttention( + (self): BertSelfAttention( + (query): Linear(in_features=768, out_features=768, bias=True) + (key): Linear(in_features=768, out_features=768, bias=True) + (value): Linear(in_features=768, out_features=768, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + (output): BertSelfOutput( + (dense): Linear(in_features=768, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + (intermediate): BertIntermediate( + (dense): Linear(in_features=768, out_features=3072, bias=True) + ) + (output): BertOutput( + (dense): Linear(in_features=3072, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + (1): BertLayer( + (attention): BertAttention( + (self): BertSelfAttention( + (query): Linear(in_features=768, out_features=768, bias=True) + (key): Linear(in_features=768, out_features=768, bias=True) + (value): Linear(in_features=768, out_features=768, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + (output): BertSelfOutput( + (dense): Linear(in_features=768, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + (intermediate): BertIntermediate( + (dense): Linear(in_features=768, out_features=3072, bias=True) + ) + (output): BertOutput( + (dense): Linear(in_features=3072, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + ... + 11 more BertLayers + ... + ) + ) + (pooler): BertPooler( + (dense): Linear(in_features=768, out_features=768, bias=True) + (activation): Tanh() + ) + ) + (dropout): Dropout(p=0.5, inplace=False) + (fc1): Linear(in_features=768, out_features=4, bias=True) +)> ++ +
1 +2 +3 +4 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 | |
+Epoch: 1 | train_loss: 0.00022, val_loss: 0.00017, lr: 1.00E-04, _patience: 10 +Epoch: 2 | train_loss: 0.00014, val_loss: 0.00016, lr: 1.00E-04, _patience: 10 +Epoch: 3 | train_loss: 0.00010, val_loss: 0.00017, lr: 1.00E-04, _patience: 9 +... +Epoch: 9 | train_loss: 0.00002, val_loss: 0.00022, lr: 1.00E-05, _patience: 3 +Epoch: 10 | train_loss: 0.00002, val_loss: 0.00022, lr: 1.00E-05, _patience: 2 +Epoch: 11 | train_loss: 0.00001, val_loss: 0.00022, lr: 1.00E-05, _patience: 1 +Stopping early! ++ +
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.8085194951783808,
+ "recall": 0.8086666666666666,
+ "f1": 0.8083051845125695,
+ "num_samples": 1500.0
+}
+
+
+1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Data splits: + Train dataset: <Dataset(N=7000)> + Val dataset: <Dataset(N=1500)> + Test dataset: <Dataset(N=1500)> +Sample point: + ids: tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0]) + masks: tensor([1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0]) + targets: tensor([1., 0., 0., 0.], device="cpu") ++ +
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
1 +2 +3 +4 | |
+Sports ++ +
1 +2 +3 | |
+{
+ "Sports": 0.9999359846115112,
+ "World": 4.0660612285137177e-05,
+ "Sci/Tech": 1.1774928680097219e-05,
+ "Business": 1.1545793313416652e-05
+}
+
+
+Let's visualize the self-attention weights from each of the attention heads in the encoder.
+1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 | |
+tensor([[ 102, 2531, 3617, 8869, 23589, 4972, 8553, 2205, 4082, 103]], + device="cpu") +['[CLS] final tennis tournament starts next week [SEP]'] ++ +
1 +2 +3 +4 | |
+12 +torch.Size([1, 12, 10, 10]) ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
1 +2 +3 +4 | |
 +
+Now we're ready to start the MLOps course to learn how to apply all this foundational modeling knowledge to responsibly develop, deploy and maintain production machine learning applications.
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+We're having to set a lot of seeds for reproducibility now, so let's wrap it all up in a function.
+1 +2 +3 +4 +5 | |
1 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
+cuda ++ +
We'll use the same spiral dataset from previous lessons to demonstrate our utilities. +
1 +2 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+X: (1500, 2) +y: (1500,) ++
1 +2 +3 +4 +5 | |
 +
+1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 | |
+X_train: (1050, 2), y_train: (1050,) +X_val: (225, 2), y_val: (225,) +X_test: (225, 2), y_test: (225,) +Sample point: [-0.63919105 -0.69724176] → c1 ++ +
Next we'll define a LabelEncoder to encode our text labels into unique indices. We're not going to use scikit-learn's LabelEncoder anymore because we want to be able to save and load our instances the way we want to.
+
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 | |
1 +2 +3 +4 | |
+{"c1": 0, "c2": 1, "c3": 2}
+
+1 +2 +3 +4 +5 +6 | |
+y_train[0]: c1 +y_train[0]: 0 ++
1 +2 +3 +4 | |
+counts: [350 350 350]
+weights: {0: 0.002857142857142857, 1: 0.002857142857142857, 2: 0.002857142857142857}
+
+
+We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values. We're going to compose our own StandardScaler class so we can easily save and load it later during inference.
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+X_test[0]: mean: 0.1, std: 0.9 +X_test[1]: mean: 0.0, std: 1.0 ++ +
We're going to place our data into a Dataset and use a DataLoader to efficiently create batches for training and evaluation.
1 | |
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 | |
collate_fn here but we wanted to make it transparent because we will need it when we want to do specific processing on our batch (ex. padding).
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
+Datasets: + Train dataset: <Dataset(N=1050)> + Val dataset: <Dataset(N=225)> + Test dataset: <Dataset(N=225)> +Sample point: + X: [-1.47355106 -1.67417243] + y: 0 ++
So far, we used batch gradient descent to update our weights. This means that we calculated the gradients using the entire training dataset. We also could've updated our weights using stochastic gradient descent (SGD) where we pass in one training example one at a time. The current standard is mini-batch gradient descent, which strikes a balance between batch and SGD, where we update the weights using a mini-batch of n (BATCH_SIZE) samples. This is where the DataLoader object comes in handy.
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+Sample batch: + X: [64, 2] + y: [64] +Sample point: + X: tensor([-1.4736, -1.6742]) + y: 0 ++ +
So far we've been running our operations on the CPU but when we have large datasets and larger models to train, we can benefit by parallelizing tensor operations on a GPU. In this notebook, you can use a GPU by going to Runtime > Change runtime type > Select GPU in the Hardware accelerator dropdown. We can what device we're using with the following line of code:
1 +2 +3 | |
1 +2 +3 | |
+cuda ++ +
Let's initialize the model we'll be using to show the capabilities of training utilities.
+1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
1 +2 +3 +4 +5 +6 | |
+<bound method Module.named_parameters of MLP( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=3, bias=True) +)> ++ +
So far we've been writing training loops that train only using the train data split and then we perform evaluation on our test set. But in reality, we would follow this process:
+We'll create a Trainer class to keep all of these processes organized.
The first function in the class is train_step which will train the model using batches from one epoch of the train data split.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 | |
Next we'll define the eval_step which will be used for processing both the validation and test data splits. This is because neither of them require gradient updates and display the same metrics.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 | |
The final function is the predict_step which will be used for inference. It's fairly similar to the eval_step except we don't calculate any metrics. We pass on the predictions which we can use to generate our performance scores.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
As our model starts to optimize and perform better, the loss will reduce and we'll need to make smaller adjustments. If we keep using a fixed learning rate, we'll be overshooting back and forth. Therefore, we're going to add a learning rate scheduler to our optimizer to adjust our learning rate during training. There are many schedulers schedulers to choose from but a popular one is ReduceLROnPlateau which reduces the learning rate when a metric (ex. validation loss) stops improving. In the example below we'll reduce the learning rate by a factor of 0.1 (factor=0.1) when our metric of interest (self.scheduler.step(val_loss)) stops decreasing (mode="min") for three (patience=3) straight epochs.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
We should never train our models for an arbitrary number of epochs but instead we should have explicit stopping criteria (even if you are bootstrapped by compute resources). Common stopping criteria include when validation performance stagnates for certain # of epochs (patience), desired performance is reached, etc.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
Let's put all of this together now to train our model.
+1 | |
1 +2 +3 | |
1 +2 +3 | |
1 +2 +3 +4 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+Epoch: 1 | train_loss: 0.73999, val_loss: 0.58441, lr: 1.00E-02, _patience: 3 +Epoch: 2 | train_loss: 0.52631, val_loss: 0.41542, lr: 1.00E-02, _patience: 3 +Epoch: 3 | train_loss: 0.40919, val_loss: 0.30673, lr: 1.00E-02, _patience: 3 +Epoch: 4 | train_loss: 0.31421, val_loss: 0.22428, lr: 1.00E-02, _patience: 3 +... +Epoch: 48 | train_loss: 0.04100, val_loss: 0.02100, lr: 1.00E-02, _patience: 2 +Epoch: 49 | train_loss: 0.04155, val_loss: 0.02008, lr: 1.00E-02, _patience: 3 +Epoch: 50 | train_loss: 0.05295, val_loss: 0.02094, lr: 1.00E-02, _patience: 2 +Epoch: 51 | train_loss: 0.04619, val_loss: 0.02179, lr: 1.00E-02, _patience: 1 +Stopping early! ++ +
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
1 +2 +3 | |
1 +2 +3 +4 | |
+{
+ "precision": 0.9956140350877193,
+ "recall": 0.9955555555555556,
+ "f1": 0.9955553580159119,
+ "num_samples": 225.0
+}
+
+
+Many tutorials never show you how to save the components you created so you can load them for inference.
+1 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
+MLP( + (fc1): Linear(in_features=2, out_features=100, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + (fc2): Linear(in_features=100, out_features=3, bias=True) +) ++
1 +2 | |
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 | |
+["c1"] ++ +
There are lots of other utilities to cover, such as:
+We'll explore these as we require them in future lessons including some in our MLOps course!
+ +To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Our CLI application made it much easier to interact with our models, especially for fellow team members who may not want to delve into the codebase. But there are several limitations to serving our models with a CLI:
+To address these issues, we're going to develop an application programming interface (API) that will anyone to interact with our application with a simple request.
+++The end user may not directly interact with our API but may use UI/UX components that send requests to our it.
+
APIs allow different applications to communicate with each other in real-time. But when it comes to serving predictions, we need to first decide if we'll do that in batches or real-time, which is entirely based on the feature space (finite vs. unbound).
+We can make batch predictions on a finite set of inputs which are then written to a database for low latency inference. When a user or downstream process sends an inference request in real-time, cached results from the database are returned.
+ +
+Batch serving tasks
+What are some tasks where batch serving is ideal?
+Recommend content that existing users will like based on their viewing history. However, new users may just receive some generic recommendations based on their explicit interests until we process their history the next day. And even if we're not doing batch serving, it might still be useful to cache very popular sets of input features (ex. combination of explicit interests leads to certain recommended content) so that we can serve those predictions faster.
+We can also serve live predictions, typically through a request to an API with the appropriate input data.
+ +
+In this lesson, we'll create the API required to enable real-time serving. The interactions in our situation involve the client (users, other applications, etc.) sending a request (ex. prediction request) with the appropriate inputs to the server (our application with a trained model) and receiving a response (ex. prediction) in return.
+ +
+Users will interact with our API in the form of a request. Let's take a look at the different components of a request:
+A uniform resource identifier (URI) is an identifier for a specific resource.
++https://localhost:8000/models/{modelId}/?filter=passed#details ++ +
| Parts of the URI | +Description | +
|---|---|
| scheme | +protocol definition | +
| domain | +address of the website | +
| port | +endpoint | +
| path | +location of the resource | +
| query string | +parameters to identify resources | +
| anchor | +location on webpage | +
| Parts of the path | +Description | +
|---|---|
/models |
+ collection resource of all models |
+
/models/{modelID} |
+ single resource from the models collection |
+
modelId |
+ path parameters | +
filter |
+ query parameter | +
The method is the operation to execute on the specific resource defined by the URI. There are many possible methods to choose from, but the four below are the most popular, which are often referred to as CRUD because they allow you to Create, Read, Update and Delete.
+GET: get a resource.POST: create or update a resource.PUT/PATCH: create or update a resource.DELETE: delete a resource.Note
+You could use either the POST or PUT request method to create and modify resources but the main difference is that PUT is idempotent which means you can call the method repeatedly and it'll produce the same state every time. Whereas, calling POST multiple times can result in creating multiple instance and so changes the overall state each time.
POST /models/<new_model> -d {} # error since we haven't created the `new_model` resource yet
+POST /models -d {} # creates a new model based on information provided in data
+POST /models/<existing_model> -d {} # updates an existing model based on information provided in data
+
+PUT /models/<new_model> -d {} # creates a new model based on information provided in data
+PUT /models/<existing_model> -d {} # updates an existing model based on information provided in data
+We can use cURL to execute our API calls with the following options:
+curl --help
++Usage: curl [options...]+ ++-X, --request HTTP method (ie. GET) +-H, --header headers to be sent to the request (ex. authentication) +-d, --data data to POST, PUT/PATCH, DELETE (usually JSON) +... +
For example, if we want to GET all models, our cURL command would look like this:
+
curl -X GET "http://localhost:8000/models"
+Headers contain information about a certain event and are usually found in both the client's request as well as the server's response. It can range from what type of format they'll send and receive, authentication and caching info, etc. +
curl -X GET "http://localhost:8000/" \ # method and URI
+ -H "accept: application/json" \ # client accepts JSON
+ -H "Content-Type: application/json" \ # client sends JSON
+The body contains information that may be necessary for the request to be processed. It's usually a JSON object sent during POST, PUT/PATCH, DELETE request methods.
curl -X POST "http://localhost:8000/models" \ # method and URI
+ -H "accept: application/json" \ # client accepts JSON
+ -H "Content-Type: application/json" \ # client sends JSON
+ -d "{'name': 'RoBERTa', ...}" # request body
+The response we receive from our server is the result of the request we sent. The response also includes headers and a body which should include the proper HTTP status code as well as explicit messages, data, etc.
+{
+ "message": "OK",
+ "method": "GET",
+ "status-code": 200,
+ "url": "http://localhost:8000/",
+ "data": {}
+}
+++We may also want to include other metadata in the response such as model version, datasets used, etc. Anything that the downstream consumer may be interested in or metadata that might be useful for inspection.
+
There are many HTTP status codes to choose from depending on the situation but here are the most common options:
+| Code | +Description | +
|---|---|
200 OK |
+method operation was successful. | +
201 CREATED |
+POST or PUT method successfully created a resource. |
+
202 ACCEPTED |
+the request was accepted for processing (but processing may not be done). | +
400 BAD REQUEST |
+server cannot process the request because of a client side error. | +
401 UNAUTHORIZED |
+you're missing required authentication. | +
403 FORBIDDEN |
+you're not allowed to do this operation. | +
404 NOT FOUND |
+the resource you're looking for was not found. | +
500 INTERNAL SERVER ERROR |
+there was a failure somewhere in the system process. | +
501 NOT IMPLEMENTED |
+this operation on the resource doesn't exist yet. | +
When designing our API, there are some best practices to follow:
+GET /users not ❌ GET /get_users).GET /users/{userId} not ❌ GET /user/{userID}).GET /nlp-models/?find_desc=bert).We're going to define our API in a separate app directory because, in the future, we may have additional packages like tagifai and we don't want our app to be attached to any one package. Inside our app directory, we'll create the follow scripts:
mkdir app
+cd app
+touch api.py gunicorn.py schemas.py
+cd ../
+app/
+├── api.py - FastAPI app
+├── gunicorn.py - WSGI script
+└── schemas.py - API model schemas
+api.py: the main script that will include our API initialization and endpoints.gunicorn.py: script for defining API worker configurations.schemas.py: definitions for the different objects we'll use in our resource endpoints.We're going to use FastAPI as our framework to build our API service. There are plenty of other framework options out there such as Flask, Django and even non-Python based options like Node, Angular, etc. FastAPI combines many of the advantages across these frameworks and is maturing quickly and becoming more widely adopted. It's notable advantages include:
+pip install fastapi==0.78.0
+# Add to requirements.txt
+fastapi==0.78.0
+++Your choice of framework also depends on your team's existing systems and processes. However, with the wide adoption of microservices, we can wrap our specific application in any framework we choose and expose the appropriate resources so all other systems can easily communicate with it.
+
The first step is to initialize our API in our api.py script` by defining metadata like the title, description and version:
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
Our first endpoint is going to be a simple one where we want to show that everything is working as intended. The path for the endpoint will just be / (when a user visit our base URI) and it'll be a GET request. This simple endpoint is often used as a health check to ensure that our application is indeed up and running properly.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
We let our application know that the endpoint is at / through the path operation decorator in line 4 and we return a JSON response with the 200 OK HTTP status code.
++In our actual
+api.pyscript, you'll notice that even our index function looks different. Don't worry, we're slowly adding components to our endpoints and justifying them along the way.
We're using Uvicorn, a fast ASGI server that can run asynchronous code in a single process to launch our application.
+pip install uvicorn==0.17.6
+# Add to requirements.txt
+uvicorn==0.17.6
+We can launch our application with the following command:
+uvicorn app.api:app \ # location of app (`app` directory > `api.py` script > `app` object)
+ --host 0.0.0.0 \ # localhost
+ --port 8000 \ # port 8000
+ --reload \ # reload every time we update
+ --reload-dir tagifai \ # only reload on updates to `tagifai` directory
+ --reload-dir app # and the `app` directory
++INFO: Will watch for changes in these directories: ['/Users/goku/Documents/madewithml/mlops/app', '/Users/goku/Documents/madewithml/mlops/tagifai'] +INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit) +INFO: Started reloader process [57609] using statreload +INFO: Started server process [57611] +INFO: Waiting for application startup. +INFO: Application startup complete. ++ +
++Notice that we only reload on changes to specific directories, as this is to avoid reloading on files that won't impact our application such as log files, etc.
+
If we want to manage multiple uvicorn workers to enable parallelism in our application, we can use Gunicorn in conjunction with Uvicorn. This will usually be done in a production environment where we'll be dealing with meaningful traffic. We've included a app/gunicorn.py script with the customizable configuration and we can launch all the workers with the follow command:
+
gunicorn -c config/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app
+We'll add both of these commands to our README.md file as well:
+
uvicorn app.api:app --host 0.0.0.0 --port 8000 --reload --reload-dir tagifai --reload-dir app # dev
+gunicorn -c app/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app # prod
+Now that we have our application running, we can submit our GET request using several different methods:
curl -X GET http://localhost:8000/
+1 +2 +3 +4 +5 | |
For all of these, we'll see the exact same response from our API:
+
+{
+ "message": "OK",
+ "status-code": 200,
+ "data": {}
+}
+
+
+In our GET \ request's response above, there was not a whole lot of information about the actual request, but it's useful to have details such as URL, timestamp, etc. But we don't want to do this individually for each endpoint, so let's use decorators to automatically add relevant metadata to our responses
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 | |
We're passing in a Request instance in line 10 so we can access information like the request method and URL. Therefore, our endpoint functions also need to have this Request object as an input argument. Once we receive the results from our endpoint function f, we can append the extra details and return a more informative response. To use this decorator, we just have to wrap our functions accordingly.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+{
+ message: "OK",
+ method: "GET",
+ status-code: 200,
+ timestamp: "2021-02-08T13:19:11.343801",
+ url: "http://localhost:8000/",
+ data: { }
+}
+
+
+There are also some built-in decorators we should be aware of. We've already seen the path operation decorator (ex. @app.get("/")) which defines the path for the endpoint as well as other attributes. There is also the events decorator (@app.on_event()) which we can use to startup and shutdown our application. For example, we use the (@app.on_event("startup")) event to load the artifacts for the model to use for inference. The advantage of doing this as an event is that our service won't start until this is complete and so no requests will be prematurely processed and cause errors. Similarly, we can perform shutdown events with (@app.on_event("shutdown")), such as saving logs, cleaning, etc.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
When we define an endpoint, FastAPI automatically generates some documentation (adhering to OpenAPI standards) based on the it's inputs, typing, outputs, etc. We can access the Swagger UI for our documentation by going to /docs endpoints on any browser while the api is running.
 +
+Click on an endpoint > Try it out > Execute to see what the server's response will look like. Since this was a GET request without any inputs, our request body was empty but for other method's we'll need to provide some information (we'll illustrate this when we do a POST request).
 +
+Notice that our endpoint is organized under sections in the UI. We can use tags when defining our endpoints in the script:
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
++You can also use
+/redocendpoint to view the ReDoc documentation or Postman to execute and manage tests that you can save and share with others.
When designing the resources for our API , we need to think about the following questions:
+[USERS]: Who are the end users? This will define what resources need to be exposed.
[ACTIONS]: What actions do our users want to be able to perform?
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
Notice that we're passing an optional query parameter filter here to indicate the subset of performance we care about. We can include this parameter in our GET request like so:
curl -X "GET" \
+ "http://localhost:8000/performance?filter=overall" \
+ -H "accept: application/json"
+And this will only produce the subset of the performance we indicated through the query parameter:
+{
+ "message": "OK",
+ "method": "GET",
+ "status-code": 200,
+ "timestamp": "2021-03-21T13:12:01.297630",
+ "url": "http://localhost:8000/performance?filter=overall",
+ "data": {
+ "performance": {
+ "precision": 0.8941372402587212,
+ "recall": 0.8333333333333334,
+ "f1": 0.8491658224308651,
+ "num_samples": 144
+ }
+ }
+}
+Our next endpoint will be to GET the arguments used to train the model. This time, we're using a path parameter args, which is a required field in the URI.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
We can perform our GET request like so, where the param is part of the request URI's path as opposed to being part of it's query string.
+
curl -X "GET" \
+ "http://localhost:8000/args/learning_rate" \
+ -H "accept: application/json"
+And we'd receive a response like this:
+{
+ "message": "OK",
+ "method": "GET",
+ "status-code": 200,
+ "timestamp": "2021-03-21T13:13:46.696429",
+ "url": "http://localhost:8000/params/hidden_dim",
+ "data": {
+ "learning_rate": 0.14688087680118794
+ }
+}
+We can also create an endpoint to produce all the arguments that were used:
+GET /args1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
We can perform our GET request like so, where the param is part of the request URI's path as opposed to being part of it's query string.
curl -X "GET" \
+"http://localhost:8000/args" \
+-H "accept: application/json"
+And we'd receive a response like this:
+{
+"message":"OK",
+"method":"GET",
+"status-code":200,
+"timestamp":"2022-05-25T11:56:37.344762",
+"url":"http://localhost:8001/args",
+"data":{
+ "args":{
+ "shuffle":true,
+ "subset":null,
+ "min_freq":75,
+ "lower":true,
+ "stem":false,
+ "analyzer":"char_wb",
+ "ngram_max_range":8,
+ "alpha":0.0001,
+ "learning_rate":0.14688087680118794,
+ "power_t":0.158985493618746
+ }
+ }
+}
+Now it's time to define our endpoint for prediction. We need to consume the inputs that we want to classify and so we need to define the schema that needs to be followed when defining those inputs.
+# app/schemas.py
+from typing import List
+from fastapi import Query
+from pydantic import BaseModel
+
+class Text(BaseModel):
+ text: str = Query(None, min_length=1)
+
+class PredictPayload(BaseModel):
+ texts: List[Text]
+Here we're defining a PredictPayload object as a List of Text objects called texts. Each Text object is a string that defaults to None and must have a minimum length of 1 character.
Note
+We could've just defined our PredictPayload like so:
+
1 +2 | |
We can now use this payload in our predict endpoint:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
We need to adhere to the PredictPayload schema when we want to user our /predict endpoint:
curl -X 'POST' 'http://0.0.0.0:8000/predict' \
+ -H 'accept: application/json' \
+ -H 'Content-Type: application/json' \
+ -d '{
+ "texts": [
+ {"text": "Transfer learning with transformers for text classification."},
+ {"text": "Generative adversarial networks for image generation."}
+ ]
+ }'
+
+{
+ "message":"OK",
+ "method":"POST",
+ "status-code":200,
+ "timestamp":"2022-05-25T12:23:34.381614",
+ "url":"http://0.0.0.0:8001/predict",
+ "data":{
+ "predictions":[
+ {
+ "input_text":"Transfer learning with transformers for text classification.",
+ "predicted_tag":"natural-language-processing"
+ },
+ {
+ "input_text":"Generative adversarial networks for image generation.",
+ "predicted_tag":"computer-vision"
+ }
+ ]
+ }
+}
+
+
+We're using pydantic's BaseModel object here because it offers built-in validation for all of our schemas. In our case, if a Text instance is less than 1 character, then our service will return the appropriate error message and code:
curl -X POST "http://localhost:8000/predict" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"texts\":[{\"text\":\"\"}]}"
+
+{
+ "detail": [
+ {
+ "loc": [
+ "body",
+ "texts",
+ 0,
+ "text"
+ ],
+ "msg": "ensure this value has at least 1 characters",
+ "type": "value_error.any_str.min_length",
+ "ctx": {
+ "limit_value": 1
+ }
+ }
+ ]
+}
+
+
+We can also add custom validation on a specific entity by using the @validator decorator, like we do to ensure that list of texts is not empty.
1 +2 +3 +4 +5 +6 +7 +8 | |
curl -X POST "http://localhost:8000/predict" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"texts\":[]}"
+
+{
+ "detail":[
+ {
+ "loc":[
+ "body",
+ "texts"
+ ],
+ "msg": "List of texts to classify cannot be empty.",
+ "type": "value_error"
+ }
+ ]
+}
+
+
+Lastly, we can add a schema_extra object under a Config class to depict what an example PredictPayload should look like. When we do this, it automatically appears in our endpoint's documentation (click Try it out).
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 | |
 +
+To make our API a standalone product, we'll need to create and manage a database for our users and resources. These users will have credentials which they will use for authentication and use their privileges to be able to communicate with our service. And of course, we can display a rendered frontend to make all of this seamless with HTML forms, buttons, etc. This is exactly how the old MWML platform was built and we leveraged FastAPI to deliver high performance for 500K+ daily service requests.
+If you are building a product, then I highly recommending forking this generation template to get started. It includes the backbone architecture you need for your product:
+However, for the majority of ML developers, thanks to the wide adoption of microservices, we don't need to do all of this. A well designed API service that can seamlessly communicate with all other services (framework agnostic) will fit into any process and add value to the overall product. Our main focus should be to ensure that our service is working as it should and constantly improve, which is exactly what the next cluster of lessons will focus on (testing and monitoring)
+Besides wrapping our models as separate, scalable microservices, we can also have a purpose-built model server to host our models. Model servers provide a registry with an API layer to seamlessly inspect, update, serve, rollback, etc. multiple versions of models. They also offer automatic scaling to meet throughput and latency needs. Popular options include BentoML, MLFlow, TorchServe, RedisAI, Nvidia Triton Inference Server, etc.
+++ +Model servers are experiencing a lot of adoption for their ability to standardize the model deployment and serving processes across the team -- enabling seamless upgrades, validation and integration.
+
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+We'll often want to increase the size and diversity of our training data split through data augmentation. It involves using the existing samples to generate synthetic, yet realistic, examples.
+Split the dataset. We want to split our dataset first because many augmentation techniques will cause a form of data leak if we allow the generated samples to be placed across different data splits.
+++For example, some augmentation involves generating synonyms for certain key tokens in a sentence. If we allow the generated sentences from the same origin sentence to go into different splits, we could be potentially leaking samples with nearly identical embedding representations across our different splits.
+
Augment the training split. We want to apply data augmentation on only the training set because our validation and testing splits should be used to provide an accurate estimate on actual data points.
+Inspect and validate. It's useless to augment just for the same of increasing our training sample size if the augmented data samples are not probable inputs that our model could encounter in production.
+The exact method of data augmentation depends largely on the type of data and the application. Here are a few ways different modalities of data can be augmented:
+ +
+Warning
+While the transformations on some data modalities, such as images, are easy to inspect and validate, others may introduce silent errors. For example, shifting the order of tokens in text can significantly alter the meaning (“this is really cool” → “is this really cool”). Therefore, it’s important to measure the noise that our augmentation policies will introduce and do have granular control over the transformations that take place.
+Depending on the feature types and tasks, there are many data augmentation libraries which allow us to extend our training data.
+Let's use the nlpaug library to augment our dataset and assess the quality of the generated samples.
+pip install nlpaug==1.1.0 transformers==3.0.2 -q
+pip install snorkel==0.9.8 -q
+1 | |
1 +2 +3 +4 | |
1 +2 | |
+hierarchical risk mapping using variational signals and gans. ++ +
Substitution doesn't seem like a great idea for us because there are certain keywords that provide strong signal for our tags so we don't want to alter those. Also, note that these augmentations are NOT deterministic and will vary every time we run them. Let's try insertion...
+1 +2 | |
+automated conditional inverse image generation algorithms using multiple variational autoencoders and gans. ++ +
A little better but still quite fragile and now it can potentially insert key words that can influence false positive tags to appear. Maybe instead of substituting or inserting new tokens, let's try simply swapping machine learning related keywords with their aliases. We'll use Snorkel's transformation functions to easily achieve this.
+1 +2 +3 | |
1 +2 +3 +4 +5 +6 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
1 +2 | |
+['nlp', 'nlproc'] +['nlproc', 'natural language processing'] ++ +
++For now we'll use tags and aliases as they are in
+aliases_by_tagbut we could account for plurality of tags using the inflect package or apply stemming before replacing aliases, etc.
1 +2 +3 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
+<re.Match object; span=(10, 13), match='gan'> +None ++ +
Now let's use snorkel's transformation_function to systematically apply this transformation to our data.
1 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+autogenerate vision apply jobs using nlp +autogenerate cv apply jobs using natural language processing +autogenerate cv apply jobs using nlproc ++ +
Now we'll define a augmentation policy to apply our transformation functions with certain rules (how many samples to generate, whether to keep the original data point, etc.)
+1 | |
1 +2 +3 +4 +5 +6 | |
1 | |
+(668, 913) ++ +
For now, we'll skip the data augmentation because it's quite fickle and empirically it doesn't improvement performance much. But we can see how this can be very effective once we can control what type of vocabulary to augment on and what exactly to augment with.
+Warning
+Regardless of what method we use, it's important to validate that we're not just augmenting for the sake of augmentation. We can do this by executing any existing data validation tests and even creating specific tests to apply on augmented data.
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In the previous lesson, we learned how to manually execute our ML workloads with Jobs and Services. However, we want to be able to automatically execute these workloads when certain events occur (new data, performance regressions, elapsed time, etc.) to ensure that our models are always up to date and increasing in quality. In this lesson, we'll learn how to create continuous integration and delivery (CI/CD) pipelines to achieve an application that is capable of continual learning.
+We're going to use GitHub Actions to create our CI/CD pipelines. GitHub Actions allow us to define workflows that are triggered by events (pull request, push, etc.) and execute a series of actions.
+ +
+Our GitHub Actions are defined under our repository's .github/workflows directory where we have workflows for documentation (documentation.yaml), workloads (workloads.yaml) to train/validate a model and a final workflow for serving our model (serve.yaml). Let's start by understanding the structure of a workflow.
Workflows are triggered by an event, which can be something that occurs on an event (like a push or pull request), schedule (cron), manually and many more. In our application, our workloads workflow is triggered on a pull request to the main branch and then our serve workflow and documentation workflows are triggered on a push to the main branch.
1 +2 +3 +4 +5 +6 +7 +8 | |
This creates for the following ideal workflow:
+main branch.workloads workflow is triggered and executes our model development workloads.main branch.serve workflow is triggered and deploys our application to production (along with an update to our documentation).Once the event is triggered, a set of jobs run on a runner (GitHub's infrastructure or self-hosted).
1 +2 +3 +4 +5 +6 | |
Tip
+Each of our workflows only have one job but if we had multiple, the jobs would all run in parallel. If we wanted to create dependent jobs, where if a particular job fails all it's dependent jobs will be skipped, then we'd use the needs keyword.
+Each job contains a series of steps which are executed in order. Each step has a name, as well as actions to use from the GitHub Action marketplace and/or commands we want to run. For example, here's a look at one of the steps in our workloads job inside our workloads.yaml workflow:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
Now that we understand the basic components of a GitHub Actions workflow, let's take a closer look at each of our workflows. Most of our workflows will require access to our Anyscale credentials so we'll start by setting those up. We can set these secrets for our repository under the Settings tab.
+ +
+And our first workflow will be our workloads workflow which will be triggered on a pull request to the main branch. This means that we'll need to push our local code changes to Git and then submit a pull request to the main branch. But in order to push our code to GitHub, we'll need to first authenticate with our credentials before pushing to our repository:
git config --global user.name $GITHUB_USERNAME
+git config --global user.email you@example.com # <-- CHANGE THIS to your email
+git add .
+git commit -m "" # <-- CHANGE THIS to your message
+git push origin dev
+Now you will be prompted to enter your username and password (personal access token). Follow these steps to get personal access token: New GitHub personal access token → Add a name → Toggle repo and workflow → Click Generate token (scroll down) → Copy the token and paste it when prompted for your password.
++Note that we should be on a
+devbranch, which we set up in our setup lesson. If you're not, go ahead and rungit checkout -b devfirst.
And when any of our GitHub Actions workflows execute, we will be able to view them under the Actions tab of our repository. Here we'll find all the workflows that have been executed and we can inspect each one to see the details of the execution.
Our workloads workflow is triggered on a pull request to the main branch. It contains a single job that runs our model development workloads with an Anyscale Job. The steps in this job are as follows:
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 | |
.github/workflows/json_to_md.py to convert our JSON results to markdown tables that we can comment on our PR.
+1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
So when this workloads workflow completes, we'll have a comment on our PR (example) with our training and evaluation results. We can now collaboratively analyze the details and decide if we want to merge the PR.
 +
+Tip
+We could easily extend this by retrieving evaluation results from our currently deployed model in production as well. Recall that we defined a /evaluate/ endpoint for our service that expects a dataset location and returns the evaluation results. And we can submit this request as a step in our workflow and save the results to a markdown table that we can comment on our PR.
curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $SECRET_TOKEN" -d '{
+ "dataset": "https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/holdout.csv"
+}' $SERVICE_ENDPOINT/evaluate/
+{
+ "results": {
+ "timestamp": "July 24, 2023 11:43:37 PM",
+ "run_id": "f1684a944d314bacabeaa90ff972775b",
+ "overall": {
+ "precision": 0.9536309870079502,
+ "recall": 0.9528795811518325,
+ "f1": 0.9525489716579315,
+ "num_samples": 191
+ },
+ }
+}
+If we like the results and we want to merge the PR and push to the main branch, our serve workflow will be triggered.
1 +2 +3 +4 +5 +6 +7 +8 | |
It contains a single job that serves our model with Anyscale Services. The steps in this job are as follows:
+1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 | |
So when this serve workflow completes, our model will be deployed to production and we can start making inference requests with it.
Note
+The anyscale service rollout command will update our existing service (if there was already one running) without changing the SECRET_TOKEN or SERVICE_ENDPOINT. So this means that our downstream applications that were making inference requests to our service can continue to do so without any changes.
Our documentation workflow is also triggered on a push to the main branch. It contains a single job that builds our docs. The steps in this job are as follows:
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 | |
And with that, we're able to automatically update our ML application when ever we make changes to the code and want to trigger a new deployment. We have fully control because we can decide not to trigger an event (ex. push to main branch) if we're not satisfied with the results of our model development workloads. We can easily extend this to include other events (ex. new data, performance regressions, etc.) to trigger our workflows, as well as, integrate with more functionality around orchestration (ex. Prefect, Kubeflow, etc.), monitoring, etc.
 +
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In the previous lesson, we organized our code from our notebook into individual Python scripts. We moved our functions and classes into their respective scripts and also created new workload functions to execute the main ML workloads (ex. train_model function from madewithml/train.py script). We now want to enable users to execute these workloads from the terminal without having to know anything about our code itself.
One way to execute these workloads is to import the functions in the Python script and execute them one at a time:
+1 +2 | |
++Caution: Don't forget to run
+export PYTHONPATH=$PYTHONPATH:$PWDin your terminal to ensure that Python can find the modules in our project.
While this may seem simple, it still requires us to import packages, identify the input arguments, etc. Therefore, another alternative is to place the main function call under a if __name__ == "__main__" conditional so that it's only executed when we run the script directly. Here we can pass in the input arguments directly into the function in the code.
1 +2 +3 | |
python madewithml/train.py
+However, the limitation here is that we can't choose which function from a particular script to execute. We have to set the one we want to execute under the if __name__ == "__main__" conditional. It's also very rigid since we have to set the input argument values in the code, unless we use a library like argparse.
1 +2 +3 +4 +5 +6 +7 +8 | |
--threshold is optional since it has a default value):
+python madewithml/serve.py --run_id $RUN_ID
+++We use argparse in our
+madewithml/serve.pyscript because it's the only workload in the script and it's a one-line function call (serve.run()).
Compared to using functions or the __main__ conditional, a much better user experience would be to execute these workloads from the terminal. In this lesson, we'll learn how to build a command-line interface (CLI) so that execute our main ML workloads.
We're going to create our CLI using Typer. It's as simple as initializing the app and then adding the appropriate decorator to each function operation we wish to use as a CLI command in our script:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
You may notice that our function inputs have a lot of information besides just the input name. We'll cover typing (str, List, etc.) in our documentation lesson but for now, just know that Annotated allows us to specify metadata about the input argument's type and details about the (required) option (typer.Option).
++We make all of our input arguments optional so that we can explicitly define them in our CLI commands (ex.
+--experiment-name).
We can also add some helpful information about the input parameter (with typer.Option(help="...")) and a default value (ex. None).
With our CLI commands defined and our input arguments enriched, we can execute our workloads. Let's start by executing our train_model function by assuming that we don't know what the required input parameters are. Instead of having to look in the code, we can just do the following:
python madewithml/train.py --help
++Usage: train.py [OPTIONS] +Main train function to train our model as a distributed workload. ++ +
 +
+We can follow this helpful message to execute our workload with the appropriate inputs.
+export EXPERIMENT_NAME="llm"
+export DATASET_LOC="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv"
+export TRAIN_LOOP_CONFIG='{"dropout_p": 0.5, "lr": 1e-4, "lr_factor": 0.8, "lr_patience": 3}'
+python madewithml/train.py \
+ --experiment-name "$EXPERIMENT_NAME" \
+ --dataset-loc "$DATASET_LOC" \
+ --train-loop-config "$TRAIN_LOOP_CONFIG" \
+ --num-workers 1 \
+ --cpu-per-worker 10 \
+ --gpu-per-worker 1 \
+ --num-epochs 10 \
+ --batch-size 256 \
+ --results-fp results/training_results.json
+++ +Be sure to check out our
+README.mdfile as it has examples of all the CLI commands for our ML workloads (train, tune, evaluate, inference and serve).
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+When developing an application, there are a lot of technical decisions and results (preprocessing, performance, etc.) that are integral to our system. How can we effectively communicate this to other developers and business stakeholders? One option is a Jupyter notebook but it's often cluttered with code and isn't very easy for non-technical team members to access and run. We need to create a dashboard that can be accessed without any technical prerequisites and effectively communicates key findings. It would be even more useful if our dashboard was interactive such that it provides utility even for the technical developers.
+There are some great tooling options, such as Dash, Gradio, Streamlit, Tableau, Looker, etc. for creating dashboards to deliver data oriented insights. Traditionally, interactive dashboards were exclusively created using front-end programming languages such as HTML Javascript, CSS, etc. However, given that many developers working in machine learning are using Python, the tooling landscape has evolved to bridge this gap. These tools now allow ML developers to create interactive dashboards and visualizations in Python while offering full customization via HTML, JS, and CSS. We'll be using Streamlit to create our dashboards because of it's intuitive API, sharing capabilities and increasing community adoption.
+With Streamlit, we can quickly create an empty application and as we develop, the UI will update as well. +
# Setup
+pip install streamlit==1.10.0
+mkdir streamlit
+touch streamlit/app.py
+streamlit run streamlit/app.py
++You can now view your Streamlit app in your browser. + + Local URL: http://localhost:8501 + Network URL: http://10.0.1.93:8501 ++ +
This will automatically open up the streamlit dashboard for us on http://localhost:8501.
+++Be sure to add this package and version to our
+requirements.txtfile.
Before we create a dashboard for our specific application, we need to learn about the different Streamlit components. Instead of going through them all in this lesson, take a few minutes and go through the API reference. It's quite short and we promise you'll be amazed at how many UI components (styled text, latex, tables, plots, etc.) you can create using just Python. We'll explore the different components in detail as they apply to creating different interactions for our specific dashboard below.
+We'll start by outlining the sections we want to have in our dashboard by editing our streamlit/app.py script:
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 +6 +7 | |
To see these changes on our dashboard, we can refresh our dashboard page (press R) or set it Always rerun (press A).
 +
+We're going to keep our dashboard simple, so we'll just display the labeled projects.
+1 +2 +3 +4 +5 | |
 +
+In this section, we'll display the performance of from our latest trained model. Again, we're going to keep it simple but we could also overlay more information such as improvements or regressions from previous deployments by accessing the model store.
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
 +
+With the inference section, we want to be able to quickly predict with the latest trained model.
+1 +2 +3 +4 +5 | |
 +
+Tip
+Our dashboard is quite simple but we can also more comprehensive dashboards that reflect some of the core topics we covered in our machine learning canvas.
+Sometimes we may have views that involve computationally heavy operations, such as loading data or model artifacts. It's best practice to cache these operations by wrapping them as a separate function with the @st.cache decorator. This calls for Streamlit to cache the function by the specific combination of it's inputs to deliver the respective outputs when the function is invoked with the same inputs.
1 +2 +3 +4 +5 | |
We have several different options for deploying and managing our Streamlit dashboard. We could use Streamlit's sharing feature (beta) which allows us to seamlessly deploy dashboards straight from GitHub. Our dashboard will continue to stay updated as we commit changes to our repository. Another option is to deploy the Streamlit dashboard along with our API service. We can use docker-compose to spin up a separate container or simply add it to the API service's Dockerfile's ENTRYPOINT with the appropriate ports exposed. The later might be ideal, especially if your dashboard isn't meant to be public and it you want added security, performance, etc.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far we've had the convenience of using local CSV files as data source but in reality, our data can come from many disparate sources. Additionally, our processes around transforming and testing our data should ideally be moved upstream so that many different downstream processes can benefit from them. Our ML use case being just one among the many potential downstream applications. To address these shortcomings, we're going to learn about the fundamentals of data engineering and construct a modern data stack that can scale and provide high quality data for our applications.
+++ + + +View the data-engineering repository for all the code.
+
At a high level, we're going to:
+This process is more commonly known as ELT, but there are variants such as ETL and reverse ETL, etc. They are all essentially the same underlying workflows but have slight differences in the order of data flow and where data is processed and stored.
+ +
+Utility and simplicity
+It can be enticing to set up a modern data stack in your organization, especially with all the hype. But it's very important to motivate utility and adding additional complexity:
+Before we start working with our data, it's important to understand the different types of systems that our data can live in. So far in this course we've worked with files, but there are several types of data systems that are widely adopted in industry for different purposes.
+ +
+A data lake is a flat data management system that stores raw objects. It's a great option for inexpensive storage and has the capability to hold all types of data (unstructured, semi-structured and structured). Object stores are becoming the standard for data lakes with default options across the popular cloud providers. Unfortunately, because data is stored as objects in a data lake, it's not designed for operating on structured data.
+++Popular data lake options include Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
+
Another popular storage option is a database (DB), which is an organized collection of structured data that adheres to either:
+A database is an online transaction processing (OLTP) system because it's typically used for day-to-day CRUD (create, read, update, delete) operations where typically information is accessed by rows. However, they're generally used to store data from one application and is not designed to hold data from across many sources for the purpose of analytics.
+++Popular database options include PostgreSQL, MySQL, MongoDB, Cassandra, etc.
+
A data warehouse (DWH) is a type of database that's designed for storing structured data from many different sources for downstream analytics and data science. It's an online analytical processing (OLAP) system that's optimized for performing operations across aggregating column values rather than accessing specific rows.
+++Popular data warehouse options include SnowFlake, Google BigQuery, Amazon RedShift, Hive, etc.
+
The first step in our data pipeline is to extract data from a source and load it into the appropriate destination. While we could construct custom scripts to do this manually or on a schedule, an ecosystem of data ingestion tools have already standardized the entire process. They all come equipped with connectors that allow for extraction, normalization, cleaning and loading between sources and destinations. And these pipelines can be scaled, monitored, etc. all with very little to no code.
+ +
+++Popular data ingestion tools include Fivetran, Airbyte, Stitch, etc.
+
We're going to use the open-source tool Airbyte to create connections between our data sources and destinations. Let's set up Airbyte and define our data sources. As we progress in this lesson, we'll set up our destinations and create connections to extract and load data.
+git clone https://github.com/airbytehq/airbyte.git
+cd airbyte
+docker-compose up
+Our data sources we want to extract from can be from anywhere. They could come from 3rd party apps, files, user click streams, physical devices, data lakes, databases, data warehouses, etc. But regardless of the source of our data, they type of data should fit into one of these categories:
+structured: organized data stored in an explicit structure (ex. tables)semi-structured: data with some structure but no formal schema or data types (web pages, CSV, JSON, etc.)unstructured: qualitative data with no formal structure (text, images, audio, etc.)For our application, we'll define two data sources:
+++Ideally, these data assets would be retrieved from a database that contains projects that we extracted and perhaps another database that stores labels from our labeling team's workflows. However, for simplicity we'll use CSV files to demonstrate how to define a data source.
+
We'll start our ELT process by defining the data source in Airbyte:
+Sources on the left menu. Then click the + New source button on the top right corner.Source type dropdown and choose File. This will open a view to define our file data source.
+Name: Projects
+URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv
+File Format: csv
+Storage Provider: HTTPS: Public Web
+Dataset Name: projects
+Set up source button and our data source will be tested and saved.Name: Tags
+URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv
+File Format: csv
+Storage Provider: HTTPS: Public Web
+Dataset Name: tags
+ +
+Once we know the source we want to extract data from, we need to decide the destination to load it. The choice depends on what our downstream applications want to be able to do with the data. And it's also common to store data in one location (ex. data lake) and move it somewhere else (ex. data warehouse) for specific processing.
+Our destination will be a data warehouse since we'll want to use the data for downstream analytical and machine learning applications. We're going to use Google BigQuery which is free under Google Cloud's free tier for up to 10 GB storage and 1TB of queries (which is significantly more than we'll ever need for our purpose).
+Go to console button.Project name: made-with-ml # Google will append a unique ID to the end of it
+Location: No organization
+# Google BigQuery projects
+├── made-with-ml-XXXXXX 👈 our project
+├── bigquery-publicdata
+├── imjasonh-storage
+└── nyc-tlc
+Console or code
+Most cloud providers will allow us to do everything via console but also programmatically via API, Python, etc. For example, we manually create a project but we could've also done so with code as shown here.
+Next, we need to establish the connection between Airbyte and BigQuery so that we can load the extracted data to the destination. In order to authenticate our access to BigQuery with Airbyte, we'll need to create a service account and generate a secret key. This is basically creating an identity with certain access that we can use for verification. Follow these instructions to create a service and generate the key file (JSON). Note down the location of this file because we'll be using it throughout this lesson. For example ours is /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json.
Destinations on the left menu. Then click the + New destination button on the top right corner.Destination type dropdown and choose BigQuery. This will open a view to define our file data source.
+Name: BigQuery
+Default Dataset ID: mlops_course # where our data will go inside our BigQuery project
+Project ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID
+Credentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location
+Dataset location: US # select US or EU, all other options will not be compatible with dbt later
+Set up destination button and our data destination will be tested and saved. +
+So we've set up our data sources (public CSV files) and destination (Google BigQuery data warehouse) but they haven't been connected yet. To create the connection, we need to think about a few aspects.
+How often do we want to extract data from the sources and load it into the destination?
+batch: extracting data in batches, usually following a schedule (ex. daily) or when an event of interest occurs (ex. new data count)streaming: extracting data in a continuous stream (using tools like Kafka, Kinesis, etc.)Micro-batch
+As we keep decreasing the time between batch ingestion (ex. towards 0), do we have stream ingestion? Not exactly. Batch processing is deliberately deciding to extract data from a source at a given interval. As that interval becomes <15 minutes, it's referred to as a micro-batch (many data warehouses allow for batch ingestion every 5 minutes). However, with stream ingestion, the extraction process is continuously on and events will keep being ingested.
+Start simple
+In general, it's a good idea to start with batch ingestion for most applications and slowly add the complexity of streaming ingestion (and additional infrastructure). This was we can prove that downstream applications are finding value from the data source and evolving to streaming later should only improve things.
+++We'll learn more about the different system design implications of batch vs. stream in our systems design lesson.
+
Now we're ready to create the connection between our sources and destination:
+Connections on the left menu. Then click the + New connection button on the top right corner.Select a existing source, click on the Source dropdown and choose Projects and click Use existing source.Select a existing destination, click on the Destination dropdown and choose BigQuery and click Use existing destination.
+Connection name: Projects <> BigQuery
+Replication frequency: Manual
+Destination Namespace: Mirror source structure
+Normalized tabular data: True # leave this selected
+Set up connection button and our connection will be tested and saved.Tags source with the same BigQuery destination.++Notice that our sync mode is
+Full refresh | Overwritewhich means that every time we sync data from our source, it'll overwrite the existing data in our destination. As opposed toFull refresh | Appendwhich will add entries from the source to bottom of the previous syncs.
 +
+Our replication frequency is Manual because we'll trigger the data syncs ourselves:
Connections on the left menu. Then click the Projects <> BigQuery connection we set up earlier.🔄 Sync now button and once it's completed we'll see that the projects are now in our BigQuery data warehouse.Tags <> BigQuery connection.# Inside our data warehouse
+made-with-ml-XXXXXX - Project
+└── mlops_course - Dataset
+│ ├── _airbyte_raw_projects - table
+│ ├── _airbyte_raw_tags - table
+│ ├── projects - table
+│ └── tags - table
+++In our orchestration lesson, we'll use Airflow to programmatically execute the data sync.
+
We can easily explore and query this data using SQL directly inside our warehouse:
+🔍 QUERY button and select In new tab.1 +2 +3 | |
+ ++ +
With the advent of cheap storage and cloud SaaS options to manage them, it's become a best practice to store raw data into data lakes. This allows for storage of raw, potentially unstructured, data without having to justify storage with downstream applications. When we do need to transform and process the data, we can move it to a data warehouse so can perform those operations efficiently.
+ +
+Once we've extracted and loaded our data, we need to transform the data so that it's ready for downstream applications. These transformations are different from the preprocessing we've seen before but are instead reflective of business logic that's agnostic to downstream applications. Common transformations include defining schemas, filtering, cleaning and joining data across tables, etc. While we could do all of these things with SQL in our data warehouse (save queries as tables or views), dbt delivers production functionality around version control, testing, documentation, packaging, etc. out of the box. This becomes crucial for maintaining observability and high quality data workflows.
+ +
+++Popular transformation tools include dbt, Matillion, custom jinja templated SQL, etc.
+
Note
+In addition to data transformations, we can also process the data using large-scale analytics engines like Spark, Flink, etc.
+Now we're ready to transform our data in our data warehouse using dbt. We'll be using a developer account on dbt Cloud (free), which provides us with an IDE, unlimited runs, etc.
+++We'll learn how to use the dbt-core in our orchestration lesson. Unlike dbt Cloud, dbt core is completely open-source and we can programmatically connect to our data warehouse and perform transformations.
+
continue and choose BigQuery as the database.Upload a Service Account JSON file and upload our file to autopopulate everything.Test > Continue.Managed repository and name it dbt-transforms (or anything else you want).Create > Continue > Skip and complete.>_ Start Developing button.🗂 initialize your project.Now we're ready to start developing our models:
+··· next to the models directory on the left menu.New folder called models/labeled_projects.New file under models/labeled_projects called labeled_projects.sql.models/labeled_projects called schema.yml.dbt-cloud-XXXXX-dbt-transforms
+├── ...
+├── models
+│ ├── example
+│ └── labeled_projects
+│ │ ├── labeled_projects.sql
+│ │ └── schema.yml
+├── ...
+└── README.md
+Inside our models/labeled_projects/labeled_projects.sql file we'll create a view that joins our project data with the appropriate tags. This will create the labeled data necessary for downstream applications such as machine learning models. Here we're joining based on the matching id between the projects and tags:
1 +2 +3 +4 +5 | |
We can view the queried results by clicking the Preview button and view the data lineage as well.
Inside our models/labeled_projects/schema.yml file we'll define the schemas for each of the features in our transformed data. We also define several tests that each feature should pass. View the full list of dbt tests but note that we'll use Great Expectations for more comprehensive tests when we orchestrate all these data workflows in our orchestration lesson.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
At the bottom of the IDE, we can execute runs based on the transformations we've defined. We'll run each of the following commands and once they finish, we can see the transformed data inside our data warehouse.
+dbt run
+dbt test
+Once these commands run successfully, we're ready to move our transformations to a production environment where we can insert this view in our data warehouse.
+In order to apply these transformations to the data in our data warehouse, it's best practice to create an Environment and then define Jobs:
+Environments on the left menu > New Environment button (top right corner) and fill out the details:
+Name: Production
+Type: Deployment
+...
+Dataset: mlops_course
+New Job with the following details and then click Save (top right corner).
+Name: Transform
+Environment: Production
+Commands: dbt run
+ dbt test
+Schedule: uncheck "RUN ON SCHEDULE"
+Run Now and view the transformed data in our data warehouse under a view called labeled_projects.# Inside our data warehouse
+made-with-ml-XXXXXX - Project
+└── mlops_course - Dataset
+│ ├── _airbyte_raw_projects - table
+│ ├── _airbyte_raw_tags - table
+│ ├── labeled_projects - view
+│ ├── projects - table
+│ └── tags - table
+ +
+++There is so much more to dbt so be sure to check out their official documentation to really customize any workflows. And be sure to check out our orchestration lesson where we'll programmatically create and execute our dbt transformations.
+
Hopefully we created our data stack for the purpose of gaining some actionable insight about our business, users, etc. Because it's these use cases that dictate which sources of data we extract from, how often and how that data is stored and transformed. Downstream applications of our data typically fall into one of these categories:
+data analytics: use cases focused on reporting trends, aggregate views, etc. via charts, dashboards, etc.for the purpose of providing operational insight for business stakeholders.+ ++
machine learning: use cases centered around using the transformed data to construct predictive models (forecasting, personalization, etc.).While it's very easy to extract data from our data warehouse:
+pip install google-cloud-bigquery==1.21.0
+from google.cloud import bigquery
+from google.oauth2 import service_account
+
+# Replace these with your own values
+project_id = "made-with-ml-XXXXXX" # REPLACE
+SERVICE_ACCOUNT_KEY_JSON = "/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json" # REPLACE
+
+# Establish connection
+credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)
+client = bigquery.Client(credentials= credentials, project=project_id)
+
+# Query data
+query_job = client.query("""
+ SELECT *
+ FROM mlops_course.labeled_projects""")
+results = query_job.result()
+results.to_dataframe().head()
+Warning
+Check out our notebook where we extract the transformed data from our data warehouse. We do this in a separate notebook because it requires the google-cloud-bigquery package and until dbt loosens it's Jinja versioning constraints... it'll have to be done in a separate environment. However, downstream applications are typically analytics or ML applications which have their own environments anyway so these conflicts are not inhibiting.
many of the analytics (ex. dashboards) and machine learning solutions (ex. feature stores) allow for easy connection to our data warehouses so that workflows can be triggered when an event occurs or on a schedule. We're going to take this a step further in the next lesson where we'll use a central orchestration platform to control all these workflows.
+Analytics first, then ML
+It's a good idea for the first several applications to be analytics and reporting based in order to establish a robust data stack. These use cases typically just involve displaying data aggregations and trends, as opposed to machine learning systems that involve additional complex infrastructure and workflows.
+When we create complex data workflows like this, observability becomes a top priority. Data observability is the general concept of understanding the condition of data in our system and it involves:
+data quality: testing and monitoring our data quality after every step (schemas, completeness, recency, etc.).data lineage: mapping the where data comes from and how it's being transformed as it moves through our pipelines.discoverability: enabling discovery of the different data sources and features for downstream applications.privacy + security: are the different data assets treated and restricted appropriately amongst the applications?++Popular observability tools include Monte Carlo, Bigeye, etc.
+
The data stack ecosystem to create the robust data workflows is growing and maturing. However, it can be overwhelming when it comes to choosing the best tooling options, especially as needs change over time. Here are a few important factors to consider when making a tooling decision in this space:
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far we've had the convenience of using local CSV files as data source but in reality, our data can come from many disparate sources. Additionally, our processes around transforming and testing our data should ideally be moved upstream so that many different downstream processes can benefit from them. Our ML use case being just one among the many potential downstream applications. To address these shortcomings, we're going to learn about the fundamentals of data engineering and construct a modern data stack that can scale and provide high quality data for our applications.
+++ + + +View the data-engineering repository for all the code.
+
At a high level, we're going to:
+This process is more commonly known as ELT, but there are variants such as ETL and reverse ETL, etc. They are all essentially the same underlying workflows but have slight differences in the order of data flow and where data is processed and stored.
+
+Utility and simplicity
+It can be enticing to set up a modern data stack in your organization, especially with all the hype. But it's very important to motivate utility and adding additional complexity:
+Before we start working with our data, it's important to understand the different types of systems that our data can live in. So far in this course we've worked with files, but there are several types of data systems that are widely adopted in industry for different purposes.
+
+A data lake is a flat data management system that stores raw objects. It's a great option for inexpensive storage and has the capability to hold all types of data (unstructured, semi-structured and structured). Object stores are becoming the standard for data lakes with default options across the popular cloud providers. Unfortunately, because data is stored as objects in a data lake, it's not designed for operating on structured data.
+++Popular data lake options include Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
+
Another popular storage option is a database (DB), which is an organized collection of structured data that adheres to either:
+A database is an online transaction processing (OLTP) system because it's typically used for day-to-day CRUD (create, read, update, delete) operations where typically information is accessed by rows. However, they're generally used to store data from one application and is not designed to hold data from across many sources for the purpose of analytics.
+++Popular database options include PostgreSQL, MySQL, MongoDB, Cassandra, etc.
+
A data warehouse (DWH) is a type of database that's designed for storing structured data from many different sources for downstream analytics and data science. It's an online analytical processing (OLAP) system that's optimized for performing operations across aggregating column values rather than accessing specific rows.
+++Popular data warehouse options include SnowFlake, Google BigQuery, Amazon RedShift, Hive, etc.
+
The first step in our data pipeline is to extract data from a source and load it into the appropriate destination. While we could construct custom scripts to do this manually or on a schedule, an ecosystem of data ingestion tools have already standardized the entire process. They all come equipped with connectors that allow for extraction, normalization, cleaning and loading between sources and destinations. And these pipelines can be scaled, monitored, etc. all with very little to no code.
+
+++Popular data ingestion tools include Fivetran, Airbyte, Stitch, etc.
+
We're going to use the open-source tool Airbyte to create connections between our data sources and destinations. Let's set up Airbyte and define our data sources. As we progress in this lesson, we'll set up our destinations and create connections to extract and load data.
+git clone https://github.com/airbytehq/airbyte.git
+cd airbyte
+docker-compose up
+Our data sources we want to extract from can be from anywhere. They could come from 3rd party apps, files, user click streams, physical devices, data lakes, databases, data warehouses, etc. But regardless of the source of our data, they type of data should fit into one of these categories:
+structured: organized data stored in an explicit structure (ex. tables)semi-structured: data with some structure but no formal schema or data types (web pages, CSV, JSON, etc.)unstructured: qualitative data with no formal structure (text, images, audio, etc.)For our application, we'll define two data sources:
+++Ideally, these data assets would be retrieved from a database that contains projects that we extracted and perhaps another database that stores labels from our labeling team's workflows. However, for simplicity we'll use CSV files to demonstrate how to define a data source.
+
We'll start our ELT process by defining the data source in Airbyte:
+Sources on the left menu. Then click the + New source button on the top right corner.Source type dropdown and choose File. This will open a view to define our file data source.
+Name: Projects
+URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv
+File Format: csv
+Storage Provider: HTTPS: Public Web
+Dataset Name: projects
+Set up source button and our data source will be tested and saved.Name: Tags
+URL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv
+File Format: csv
+Storage Provider: HTTPS: Public Web
+Dataset Name: tags
+Once we know the source we want to extract data from, we need to decide the destination to load it. The choice depends on what our downstream applications want to be able to do with the data. And it's also common to store data in one location (ex. data lake) and move it somewhere else (ex. data warehouse) for specific processing.
+Our destination will be a data warehouse since we'll want to use the data for downstream analytical and machine learning applications. We're going to use Google BigQuery which is free under Google Cloud's free tier for up to 10 GB storage and 1TB of queries (which is significantly more than we'll ever need for our purpose).
+Go to console button.Project name: made-with-ml # Google will append a unique ID to the end of it
+Location: No organization
+# Google BigQuery projects
+├── made-with-ml-XXXXXX 👈 our project
+├── bigquery-publicdata
+├── imjasonh-storage
+└── nyc-tlc
+Console or code
+Most cloud providers will allow us to do everything via console but also programmatically via API, Python, etc. For example, we manually create a project but we could've also done so with code as shown here.
+Next, we need to establish the connection between Airbyte and BigQuery so that we can load the extracted data to the destination. In order to authenticate our access to BigQuery with Airbyte, we'll need to create a service account and generate a secret key. This is basically creating an identity with certain access that we can use for verification. Follow these instructions to create a service and generate the key file (JSON). Note down the location of this file because we'll be using it throughout this lesson. For example ours is /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json.
Destinations on the left menu. Then click the + New destination button on the top right corner.Destination type dropdown and choose BigQuery. This will open a view to define our file data source.
+Name: BigQuery
+Default Dataset ID: mlops_course # where our data will go inside our BigQuery project
+Project ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID
+Credentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location
+Dataset location: US # select US or EU, all other options will not be compatible with dbt later
+Set up destination button and our data destination will be tested and saved.
+So we've set up our data sources (public CSV files) and destination (Google BigQuery data warehouse) but they haven't been connected yet. To create the connection, we need to think about a few aspects.
+How often do we want to extract data from the sources and load it into the destination?
+batch: extracting data in batches, usually following a schedule (ex. daily) or when an event of interest occurs (ex. new data count)streaming: extracting data in a continuous stream (using tools like Kafka, Kinesis, etc.)Micro-batch
+As we keep decreasing the time between batch ingestion (ex. towards 0), do we have stream ingestion? Not exactly. Batch processing is deliberately deciding to extract data from a source at a given interval. As that interval becomes <15 minutes, it's referred to as a micro-batch (many data warehouses allow for batch ingestion every 5 minutes). However, with stream ingestion, the extraction process is continuously on and events will keep being ingested.
+Start simple
+In general, it's a good idea to start with batch ingestion for most applications and slowly add the complexity of streaming ingestion (and additional infrastructure). This was we can prove that downstream applications are finding value from the data source and evolving to streaming later should only improve things.
+++We'll learn more about the different system design implications of batch vs. stream in our systems design lesson.
+
Now we're ready to create the connection between our sources and destination:
+Connections on the left menu. Then click the + New connection button on the top right corner.Select a existing source, click on the Source dropdown and choose Projects and click Use existing source.Select a existing destination, click on the Destination dropdown and choose BigQuery and click Use existing destination.
+Connection name: Projects <> BigQuery
+Replication frequency: Manual
+Destination Namespace: Mirror source structure
+Normalized tabular data: True # leave this selected
+Set up connection button and our connection will be tested and saved.Tags source with the same BigQuery destination.++Notice that our sync mode is
+Full refresh | Overwritewhich means that every time we sync data from our source, it'll overwrite the existing data in our destination. As opposed toFull refresh | Appendwhich will add entries from the source to bottom of the previous syncs.
+Our replication frequency is Manual because we'll trigger the data syncs ourselves:
Connections on the left menu. Then click the Projects <> BigQuery connection we set up earlier.🔄 Sync now button and once it's completed we'll see that the projects are now in our BigQuery data warehouse.Tags <> BigQuery connection.# Inside our data warehouse
+made-with-ml-XXXXXX - Project
+└── mlops_course - Dataset
+│ ├── _airbyte_raw_projects - table
+│ ├── _airbyte_raw_tags - table
+│ ├── projects - table
+│ └── tags - table
+++In our orchestration lesson, we'll use Airflow to programmatically execute the data sync.
+
We can easily explore and query this data using SQL directly inside our warehouse:
+🔍 QUERY button and select In new tab.1 +2 +3 | |
+ ++ +
With the advent of cheap storage and cloud SaaS options to manage them, it's become a best practice to store raw data into data lakes. This allows for storage of raw, potentially unstructured, data without having to justify storage with downstream applications. When we do need to transform and process the data, we can move it to a data warehouse so can perform those operations efficiently.
+
+Once we've extracted and loaded our data, we need to transform the data so that it's ready for downstream applications. These transformations are different from the preprocessing we've seen before but are instead reflective of business logic that's agnostic to downstream applications. Common transformations include defining schemas, filtering, cleaning and joining data across tables, etc. While we could do all of these things with SQL in our data warehouse (save queries as tables or views), dbt delivers production functionality around version control, testing, documentation, packaging, etc. out of the box. This becomes crucial for maintaining observability and high quality data workflows.
+
+++Popular transformation tools include dbt, Matillion, custom jinja templated SQL, etc.
+
Note
+In addition to data transformations, we can also process the data using large-scale analytics engines like Spark, Flink, etc.
+Now we're ready to transform our data in our data warehouse using dbt. We'll be using a developer account on dbt Cloud (free), which provides us with an IDE, unlimited runs, etc.
+++We'll learn how to use the dbt-core in our orchestration lesson. Unlike dbt Cloud, dbt core is completely open-source and we can programmatically connect to our data warehouse and perform transformations.
+
continue and choose BigQuery as the database.Upload a Service Account JSON file and upload our file to autopopulate everything.Test > Continue.Managed repository and name it dbt-transforms (or anything else you want).Create > Continue > Skip and complete.>_ Start Developing button.🗂 initialize your project.Now we're ready to start developing our models:
+··· next to the models directory on the left menu.New folder called models/labeled_projects.New file under models/labeled_projects called labeled_projects.sql.models/labeled_projects called schema.yml.dbt-cloud-XXXXX-dbt-transforms
+├── ...
+├── models
+│ ├── example
+│ └── labeled_projects
+│ │ ├── labeled_projects.sql
+│ │ └── schema.yml
+├── ...
+└── README.md
+Inside our models/labeled_projects/labeled_projects.sql file we'll create a view that joins our project data with the appropriate tags. This will create the labeled data necessary for downstream applications such as machine learning models. Here we're joining based on the matching id between the projects and tags:
1 +2 +3 +4 +5 | |
We can view the queried results by clicking the Preview button and view the data lineage as well.
Inside our models/labeled_projects/schema.yml file we'll define the schemas for each of the features in our transformed data. We also define several tests that each feature should pass. View the full list of dbt tests but note that we'll use Great Expectations for more comprehensive tests when we orchestrate all these data workflows in our orchestration lesson.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
At the bottom of the IDE, we can execute runs based on the transformations we've defined. We'll run each of the following commands and once they finish, we can see the transformed data inside our data warehouse.
+dbt run
+dbt test
+Once these commands run successfully, we're ready to move our transformations to a production environment where we can insert this view in our data warehouse.
+In order to apply these transformations to the data in our data warehouse, it's best practice to create an Environment and then define Jobs:
+Environments on the left menu > New Environment button (top right corner) and fill out the details:
+Name: Production
+Type: Deployment
+...
+Dataset: mlops_course
+New Job with the following details and then click Save (top right corner).
+Name: Transform
+Environment: Production
+Commands: dbt run
+ dbt test
+Schedule: uncheck "RUN ON SCHEDULE"
+Run Now and view the transformed data in our data warehouse under a view called labeled_projects.# Inside our data warehouse
+made-with-ml-XXXXXX - Project
+└── mlops_course - Dataset
+│ ├── _airbyte_raw_projects - table
+│ ├── _airbyte_raw_tags - table
+│ ├── labeled_projects - view
+│ ├── projects - table
+│ └── tags - table
+++There is so much more to dbt so be sure to check out their official documentation to really customize any workflows. And be sure to check out our orchestration lesson where we'll programmatically create and execute our dbt transformations.
+
Hopefully we created our data stack for the purpose of gaining some actionable insight about our business, users, etc. Because it's these use cases that dictate which sources of data we extract from, how often and how that data is stored and transformed. Downstream applications of our data typically fall into one of these categories:
+data analytics: use cases focused on reporting trends, aggregate views, etc. via charts, dashboards, etc.for the purpose of providing operational insight for business stakeholders.+ ++
machine learning: use cases centered around using the transformed data to construct predictive models (forecasting, personalization, etc.).While it's very easy to extract data from our data warehouse:
+pip install google-cloud-bigquery==1.21.0
+from google.cloud import bigquery
+from google.oauth2 import service_account
+
+# Replace these with your own values
+project_id = "made-with-ml-XXXXXX" # REPLACE
+SERVICE_ACCOUNT_KEY_JSON = "/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json" # REPLACE
+
+# Establish connection
+credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)
+client = bigquery.Client(credentials= credentials, project=project_id)
+
+# Query data
+query_job = client.query("""
+ SELECT *
+ FROM mlops_course.labeled_projects""")
+results = query_job.result()
+results.to_dataframe().head()
+Warning
+Check out our notebook where we extract the transformed data from our data warehouse. We do this in a separate notebook because it requires the google-cloud-bigquery package and until dbt loosens it's Jinja versioning constraints... it'll have to be done in a separate environment. However, downstream applications are typically analytics or ML applications which have their own environments anyway so these conflicts are not inhibiting.
many of the analytics (ex. dashboards) and machine learning solutions (ex. feature stores) allow for easy connection to our data warehouses so that workflows can be triggered when an event occurs or on a schedule. We're going to take this a step further in the next lesson where we'll use a central orchestration platform to control all these workflows.
+Analytics first, then ML
+It's a good idea for the first several applications to be analytics and reporting based in order to establish a robust data stack. These use cases typically just involve displaying data aggregations and trends, as opposed to machine learning systems that involve additional complex infrastructure and workflows.
+When we create complex data workflows like this, observability becomes a top priority. Data observability is the general concept of understanding the condition of data in our system and it involves:
+data quality: testing and monitoring our data quality after every step (schemas, completeness, recency, etc.).data lineage: mapping the where data comes from and how it's being transformed as it moves through our pipelines.discoverability: enabling discovery of the different data sources and features for downstream applications.privacy + security: are the different data assets treated and restricted appropriately amongst the applications?++Popular observability tools include Monte Carlo, Bigeye, etc.
+
The data stack ecosystem to create the robust data workflows is growing and maturing. However, it can be overwhelming when it comes to choosing the best tooling options, especially as needs change over time. Here are a few important factors to consider when making a tooling decision in this space:
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far we've performed our data processing operations on a single machine. Our dataset was able to fit into a single Pandas DataFrame and we were able to perform our operations in a single Python process. But what if our dataset was too large to fit into a single machine? We would need to distribute our data processing operations across multiple machines. And with the increasing trend in ML for larger unstructured datasets and larger models (LLMs), we can quickly outgrow our single machine constraints and will need to go distributed.
+Note
+Our dataset is intentionally small for this course so that we can quickly execute the code. But with our distributed set up in this lesson, we can easily switch to a mcuh larger dataset and the code will continue to execute perfectly. And if we add more compute resources, we can scale our data processing operations to be even faster with no changes to our code.
+There are many frameworks for distributed computing, such as Ray, Dask, Modin, Spark, etc. All of these are great options but for our application we want to choose a framework that is will allow us to scale our data processing operations with minimal changes to our existing code and all in Python. We also want to choose a framework that will integrate well when we want to distributed our downstream workloads (training, tuning, serving, etc.).
+To address these needs, we'll be using Ray, a distributed computing framework that makes it easy to scale your Python applications. It's a general purpose framework that can be used for a variety of applications but we'll be using it for our data processing operations first (and more later). And it also has great integrations with the previously mentioned distributed data processing frameworks (Dask, Modin, Spark).
+ +
+The only setup we have to do is set Ray to preserve order when acting on our data. This is important for ensuring reproducible and deterministic results.
+1 | |
We'll start by ingesting our dataset. Ray has a range of input/output functions that supports all major data formats and sources.
+1 +2 +3 +4 | |
+[{'id': 2166,
+ 'created_on': datetime.datetime(2020, 8, 17, 5, 19, 41),
+ 'title': 'Pix2Pix',
+ 'description': 'Tensorflow 2.0 Implementation of the paper Image-to-Image Translation using Conditional GANs by Philip Isola, Jun-Yan Zhu, Tinghui Zhou and Alexei A. Efros.',
+ 'tag': 'computer-vision'}]
+
+
+Next, we'll split our dataset into our training and validation splits. Ray has a built-in train_test_split function but we're using a modified version so that we can stratify our split based on the tag column.
1 +2 +3 | |
1 +2 +3 | |
And finally, we're ready to preprocess our data splits. One of the advantages of using Ray is that we won't have to change anything to our original Pandas-based preprocessing function we implemented in the previous lesson. Instead, we can use it directly with Ray's map_batches utility to map our preprocessing function across batches in our data in a distributed manner.
1 +2 +3 | |
1 +2 +3 +4 +5 +6 | |
+{'ids': array([ 102, 5800, 14982, 1422, 4958, 14982, 437, 3294, 3577,
+ 12574, 2747, 1262, 7222, 103, 0, 0, 0, 0,
+ 0, 0, 0, 0, 0, 0, 0, 0]), 'masks': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
+ 0, 0, 0, 0]), 'targets': 2}
+
+
+
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+The last step in achieving reproducibility is to deploy our versioned code and artifacts in a reproducible environment. This goes well beyond the virtual environment we configured for our Python applications because there are system-level specifications (operating system, required implicit packages, etc.) we aren't capturing. We want to be able to encapsulate all the requirements we need so that there are no external dependencies that would prevent someone else from reproducing our exact application.
+There are actually quite a few solutions for system-level reproducibility (VMs, container engines, etc.) but the Docker container engine is by far the most popular for several key advantages:
+We're going to use Docker to deploy our application locally in an isolated, reproducible and scalable fashion. Once we do this, any machine with the Docker engine installed can reproduce our work. However, there is so much more to Docker, which you can explore in the docs, that goes beyond what we'll need.
+Before we install Docker, let's take a look at how the container engine works on top our operating system, which can be our local hardware or something managed on the cloud.
+ +
+The Docker container engine is responsible for spinning up configured containers, which contains our application and it's dependencies (binaries, libraries, etc.). The container engine is very efficient in that it doesn't need to create a separate operating system for each containerized application. This also means that our containers can share the system's resources via the Docker engine.
+Now we're ready to install Docker based on our operating system. Once installed, we can start the Docker Desktop which will allow us to create and deploy our containerized applications.
+docker --version
++Docker version 20.10.8, build 3967b7d ++ +
The first step is to build a docker image which has the application and all it's specified dependencies. We can create this image using a Dockerfile which outlines a set of instructions. These instructions essentially build read-only image layers on top of each other to construct our entire image. Let's take a look at our application's Dockerfile and the image layers it creates.
+We'll start by creating a Dockerfile:
+touch Dockerfile
+The first line we'll write in our Dockerfile specifies the base image we want to pull FROM. Here we want to use the base image for running Python based applications and specifically for Python 3.7 with the slim variant. Since we're only deploying a Python application, this slim variant with minimal packages satisfies our requirements while keeping the size of the image layer low.
# Base image
+FROM python:3.7-slim
+Next we're going to install our application dependencies. First, we'll COPY the required files from our local file system so we can use them for installation. Alternatively, if we were running on some remote infrastructure, we could've pulled from a remote git host. Once we have our files, we can install the packages required to install our application's dependencies using the RUN command. Once we're done using the packages, we can remove them to keep our image layer's size to a minimum.
+# Install dependencies
+WORKDIR /mlops
+COPY setup.py setup.py
+COPY requirements.txt requirements.txt
+RUN apt-get update \
+ && apt-get install -y --no-install-recommends gcc build-essential \
+ && rm -rf /var/lib/apt/lists/* \
+ && python3 -m pip install --upgrade pip setuptools wheel \
+ && python3 -m pip install -e . --no-cache-dir \
+ && python3 -m pip install protobuf==3.20.1 --no-cache-dir \
+ && apt-get purge -y --auto-remove gcc build-essential
+Next we're ready to COPY over the required files to actually RUN our application.
+# Copy
+COPY tagifai tagifai
+COPY app app
+COPY data data
+COPY config config
+COPY stores stores
+
+# Pull assets from S3
+RUN dvc init --no-scm
+RUN dvc remote add -d storage stores/blob
+RUN dvc pull
+Since our application (API) requires PORT 8000 to be open, we need to specify in our Dockerfile to expose it. +
# Export ports
+EXPOSE 8000
+The final step in building our image is to specify the executable to be run when a container is built from our image. For our application, we want to launch our API with gunicorn since this Dockerfile may be used to deploy our service to production at scale.
+# Start app
+ENTRYPOINT ["gunicorn", "-c", "app/gunicorn.py", "-k", "uvicorn.workers.UvicornWorker", "app.api:app"]
+++There are many more commands available for us to use in the Dockerfile, such as using environment variables (ENV) and arguments (ARG), command arguments (CMD), specifying volumes (VOLUME), setting the working directory (WORKDIR) and many more, all of which you can explore through the official docs.
+
Once we're done composing the Dockerfile, we're ready to build our image using the build command which allows us to add a tag and specify the location of the Dockerfile to use.
+docker build -t tagifai:latest -f Dockerfile .
+We can inspect all built images and their attributes like so: +
docker images
++REPOSITORY TAG IMAGE ID CREATED SIZE +tagifai latest 02c88c95dd4c 23 minutes ago 2.57GB ++ +
We can also remove any or all images based on their unique IDs.
+docker rmi <IMAGE_ID> # remove an image
+docker rmi $(docker images -a -q) # remove all images
+Once we've built our image, we're ready to run a container using that image with the run command which allows us to specify the image, port forwarding, etc.
+docker run -p 8000:8000 --name tagifai tagifai:latest
+Once we have our container running, we can use the API thanks for the port we're sharing (8000):
+curl -X 'POST' \
+ 'http://localhost:8000/predict' \
+ -H 'accept: application/json' \
+ -H 'Content-Type: application/json' \
+ -d '{
+ "texts": [
+ {
+ "text": "Transfer learning with transformers for text classification."
+ }
+ ]
+}'
+We can inspect all containers (running or stopped) like so: +
docker ps # running containers
+docker ps -a # stopped containers
++CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES +ee5f1b08abd5 tagifai:latest "gunicorn -c config…" 19 minutes ago Created 0.0.0.0:8000->8000/tcp tagifai ++ +
We can also stop and remove any or all containers based on their unique IDs:
+docker stop <CONTAINER_ID> # stop a running container
+docker rm <CONTAINER_ID> # remove a container
+docker stop $(docker ps -a -q) # stop all containers
+docker rm $(docker ps -a -q) # remove all containers
+++If our application required multiple containers for different services (API, database, etc.) then we can bring them all up at once using the docker compose functionality and scale and manage them using a container orchestration system like Kubernetes (K8s). If we're specifically deploying ML workflows, we can use a toolkit like KubeFlow to help us manage and scale.
+
In the event that we run into errors while building our image layers, a very easy way to debug the issue is to run the container with the image layers that have been build so far. We can do this by only including the commands that have ran successfully so far (and all COPY statements) in the Dockerfile. And then we need to rebuild the image (since we altered the Dockerfile) and run the container:
docker build -t tagifai:latest -f Dockerfile .
+docker run -p 8000:8000 -it tagifai /bin/bash
+Once we have our container running, we can use our application as we would on our local machine but now it's reproducible on any operating system that can run the Docker container engine. We've covered just what we need from Docker to deploy our application but there is so much more to Docker, which you can explore in the docs.
+This Dockerfile is commonly the end artifact a data scientist or ML engineer delivers to their DevOps teams to deploy and scale their services, with a few changes:
git clone.All of these changes would involve using the proper credentials (via encrypted secrets and can even be automatically deployed via CI/CD workflows. But, of course, there are subsequent responsibilities such as monitoring.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+++Code tells you how, comments tell you why. -- Jeff Atwood
+
We can really improve the quality of our codebase by documenting it to make it easier for others (and our future selves) to easily navigate and extend it. We know our code base best the moment we finish writing it but fortunately documenting it will allow us to quickly get back to that familiar state of mind. Documentation can mean many different things to developers, so let's define the most common components:
+comments: short descriptions as to why a piece of code exists.typing: specification of a function's inputs and outputs' data types, providing information pertaining to what a function consumes and produces.docstrings: meaningful descriptions for functions and classes that describe overall utility, arguments, returns, etc.docs: rendered webpage that summarizes all the functions, classes, workflows, examples, etc.It's important to be as explicit as possible with our code. We've already discussed choosing explicit names for variables, functions but another way we can be explicit is by defining the types for our function's inputs and outputs by using the typing library.
+So far, our functions have looked like this: +
1 +2 | |
But we can incorporate so much more information using typing: +
1 +2 +3 | |
Here we've defined:
+a is a listb is an integer with default value 0c is a NumPy arrayThere are many other data types that we can work with, including List, Set, Dict, Tuple, Sequence and more, as well as included types such as int, float, etc. You can also use types from packages we install (ex. np.ndarray) and even from our own defined classes (ex. LabelEncoder).
++Starting from Python 3.9+, common types are built in so we don't need to import them with
+from typing import List, Set, Dict, Tuple, Sequenceanymore.
We can make our code even more explicit by adding docstrings to describe overall utility, arguments, returns, exceptions and more. Let's take a look at an example:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
Let's unpack the different parts of this function's docstring:
+[Line 3]: Summary of the overall utility of the function.[Lines 5-12]: Example of how to use our function.[Lines 14-16]: Description of the function's input arguments.[Lines 18-19]: Any exceptions that may be raised in the function.[Lines 21-22]: Description of the function's output(s).We'll render these docstrings in the docs section below to produce this:
+ +
+Take a look at the docstrings of different functions and classes in our repository.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
Tip
+If using Visual Studio Code, be sure to use the Python Docstrings Generator extension so you can type """ under a function and then hit the Shift key to generate a template docstring. It will autofill parts of the docstring using the typing information and even exception in your code!
So we're going through all this effort of including typing and docstrings to our functions but it's all tucked away inside our scripts. What if we can collect all this effort and automatically surface it as documentation? Well that's exactly what we'll do with the following open-source packages → final result here.
+Initialize mkdocs +
python3 -m mkdocs new .
+.
+├─ docs/
+│ └─ index.md
+└─ mkdocs.yml
+We'll start by overwriting the default index.md file in our docs directory with information specific to our project:
+
| index.md | |
|---|---|
1 +2 +3 +4 +5 +6 +7 +8 | |
Next we'll create documentation files for each script in our madewithml directory:
+
mkdir docs/madewithml
+cd docs/madewithml
+touch config.md data.md evaluate.md models.md predict.md serve.md train.md tune.md util.md
+cd ../../
+Tip
+It's helpful to have the docs directory structure mimic our project's structure as much as possible.
Next we'll add madewithml.<SCRIPT_NAME> to each file under docs/madewithml. This will populate the file with information about the functions and classes (using their docstrings) from madewithml/<SCRIPT_NAME>.py thanks to the mkdocstrings plugin.
++Be sure to check out the complete list of mkdocs plugins. +
+# docs/madewithml/data.md +::: madewithml.data +
Finally, we'll add some configurations to our mkdocs.yml file that mkdocs automatically created:
+
site_name: Made With ML
+site_url: https://madewithml.com/
+repo_url: https://github.com/GokuMohandas/Made-With-ML/
+nav:
+ - Home: index.md
+ - madewithml:
+ - data: madewithml/data.md
+ - models: madewithml/models.md
+ - train: madewithml/train.md
+ - tune: madewithml/tune.md
+ - evaluate: madewithml/evaluate.md
+ - predict: madewithml/predict.md
+ - serve: madewithml/serve.md
+ - utils: madewithml/utils.md
+theme: readthedocs
+plugins:
+ - mkdocstrings
+watch:
+ - . # reload docs for any file changes
+Serve our documentation locally: +
python3 -m mkdocs serve
+This will serve our docs at http://localhost:8000/:
+ +
+
+
+We can easily serve our documentation for free using GitHub pages for public repositories as wells as private documentation for private repositories. And we can even host it on a custom domain (ex. company's subdomain).
+++Be sure to check out the auto-generated documentation page for our repository. We'll learn how to automatically generate and update this docs page every time we make changes to our codebase later in our CI/CD lesson.
+
In the next lesson, we'll learn how to style and format our codebase in a consistent manner.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Evaluation is an integral part of modeling and it's one that's often glossed over. We'll often find evaluation to involve simply computing the accuracy or other global metrics but for many real work applications, a much more nuanced evaluation process is required. However, before evaluating our model, we always want to:
+Let's start by setting up our metrics dictionary that we'll fill in as we go along and all the data we'll need for evaluation: grounds truth labels (y_test, predicted labels (y_pred) and predicted probabilities (y_prob).
1 +2 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 | |
1 +2 +3 +4 | |
1 +2 +3 +4 +5 | |
While we were developing our models, our evaluation process involved computing the coarse-grained metrics such as overall precision, recall and f1 metrics.
+ +
+1 | |
1 +2 +3 +4 +5 +6 +7 | |
+{
+ "precision": 0.916248340770615,
+ "recall": 0.9109947643979057,
+ "f1": 0.9110623702438432,
+ "num_samples": 191.0
+}
+
+
+Note
+The precision_recall_fscore_support() function from scikit-learn has an input parameter called average which has the following options below. We'll be using the different averaging methods for different metric granularities.
None: metrics are calculated for each unique class.binary: used for binary classification tasks where the pos_label is specified.micro: metrics are calculated using global TP, FP, and FN.macro: per-class metrics which are averaged without accounting for class imbalance.weighted: per-class metrics which are averaged by accounting for class imbalance.samples: metrics are calculated at the per-sample level.Inspecting these coarse-grained, overall metrics is a start but we can go deeper by evaluating the same fine-grained metrics at the categorical feature levels.
+1 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
1 +2 +3 | |
+{
+ "precision": 0.9036144578313253,
+ "recall": 0.9615384615384616,
+ "f1": 0.9316770186335404,
+ "num_samples": 78.0
+}
+
+
+1 +2 +3 +4 +5 | |
+[
+ "natural-language-processing",
+ {
+ "precision": 0.9036144578313253,
+ "recall": 0.9615384615384616,
+ "f1": 0.9316770186335404,
+ "num_samples": 78.0
+ }
+]
+[
+ "computer-vision",
+ {
+ "precision": 0.9838709677419355,
+ "recall": 0.8591549295774648,
+ "f1": 0.9172932330827067,
+ "num_samples": 71.0
+ }
+]
+[
+ "other",
+ {
+ "precision": 0.8333333333333334,
+ "recall": 0.9615384615384616,
+ "f1": 0.8928571428571429,
+ "num_samples": 26.0
+ }
+]
+[
+ "mlops",
+ {
+ "precision": 0.8125,
+ "recall": 0.8125,
+ "f1": 0.8125,
+ "num_samples": 16.0
+ }
+]
+
+
+Besides just inspecting the metrics for each class, we can also identify the true positives, false positives and false negatives. Each of these will give us insight about our model beyond what the metrics can provide.
+++It's a good to have our FP/FN samples feed back into our annotation pipelines in the event we want to fix their labels and have those changes be reflected everywhere.
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
1 +2 +3 | |
+[4, 9, 12, 17, 19, 23, 25, 26, 29, 30, 31, 32, 33, 34, 42, 47, 49, 50, 54, 56, 65, 66, 68, 71, 75, 76, 77, 78, 79, 82, 92, 94, 95, 97, 99, 101, 109, 113, 114, 118, 120, 122, 126, 128, 129, 130, 131, 133, 134, 135, 138, 139, 140, 141, 142, 144, 148, 149, 152, 159, 160, 161, 163, 166, 170, 172, 173, 174, 177, 179, 183, 184, 187, 189, 190] +[41, 44, 73, 102, 110, 150, 154, 165] +[16, 112, 115] ++ +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
+=== True positives === +Mention Classifier Category prediction model +This repo contains AllenNLP model for prediction of Named Entity categories by its mentions. + true: natural-language-processing + pred: natural-language-processing + +Finetune: Scikit-learn Style Model Finetuning for NLP Finetune is a library that allows users to leverage state-of-the-art pretrained NLP models for a wide variety of downstream tasks. + true: natural-language-processing + pred: natural-language-processing + +Finetuning Transformers with JAX + Haiku Walking through a port of the RoBERTa pre-trained model to JAX + Haiku, then fine-tuning the model to solve a downstream task. + true: natural-language-processing + pred: natural-language-processing + + +=== False positives === +How Docker Can Help You Become A More Effective Data Scientist A look at Docker from the perspective of a data scientist. + true: mlops + pred: natural-language-processing + +Transfer Learning & Fine-Tuning With Keras Your 100% up-to-date guide to transfer learning & fine-tuning with Keras. + true: computer-vision + pred: natural-language-processing + +Exploratory Data Analysis on MS COCO Style Datasets A Simple Toolkit to do exploratory data analysis on MS COCO style formatted datasets. + true: computer-vision + pred: natural-language-processing + + +=== False negatives === +The Unreasonable Effectiveness of Recurrent Neural Networks A close look at how RNNs are able to perform so well. + true: natural-language-processing + pred: other + +Machine Learning Projects This Repo contains projects done by me while learning the basics. All the familiar types of regression, classification, and clustering methods have been used. + true: natural-language-processing + pred: other + +BERT Distillation with Catalyst How to distill BERT with Catalyst. + true: natural-language-processing + pred: mlops + ++ +
Tip
+It's a really good idea to do this kind of analysis using our rule-based approach to catch really obvious labeling errors.
+While the confusion-matrix sample analysis was a coarse-grained process, we can also use fine-grained confidence based approaches to identify potentially mislabeled samples. Here we’re going to focus on the specific labeling quality as opposed to the final model predictions.
+Simple confidence based techniques include identifying samples whose:
+Categorical
+Continuous
+1 +2 +3 +4 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
1 | |
+[{'text': 'The Unreasonable Effectiveness of Recurrent Neural Networks A close look at how RNNs are able to perform so well.',
+ 'true': 'natural-language-processing',
+ 'pred': 'other',
+ 'prob': 0.0023471832},
+ {'text': 'Machine Learning Projects This Repo contains projects done by me while learning the basics. All the familiar types of regression, classification, and clustering methods have been used.',
+ 'true': 'natural-language-processing',
+ 'pred': 'other',
+ 'prob': 0.0027675298},
+ {'text': 'BERT Distillation with Catalyst How to distill BERT with Catalyst.',
+ 'true': 'natural-language-processing',
+ 'pred': 'mlops',
+ 'prob': 0.37908182}]
+
+
+But these are fairly crude techniques because neural networks are easily overconfident and so their confidences cannot be used without calibrating them.
+ +
+Recent work on confident learning (cleanlab) focuses on identifying noisy labels (with calibration), which can then be properly relabeled and used for training.
+1 +2 | |
1 +2 +3 | |
Not all of these are necessarily labeling errors but situations where the predicted probabilities were not so confident. Therefore, it will be useful to attach the predicted outcomes along side results. This way, we can know if we need to relabel, upsample, etc. as mitigation strategies to improve our performance.
+++The operations in this section can be applied to entire labeled dataset to discover labeling errors via confidence learning.
+
Just inspecting the overall and class metrics isn't enough to deploy our new version to production. There may be key slices of our dataset that we need to do really well on:
+An easy way to create and evaluate slices is to define slicing functions.
+1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 | |
Here we're using Snorkel's slicing_function to create our different slices. We can visualize our slices by applying this slicing function to a relevant DataFrame using slice_dataframe.
1 +2 | |
1 +2 | |
We can define even more slicing functions and create a slices record array using the PandasSFApplier. The slices array has N (# of data points) items and each item has S (# of slicing functions) items, indicating whether that data point is part of that slice. Think of this record array as a masking layer for each slicing function on our data.
1 +2 +3 +4 +5 | |
+rec.array([(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0),
+ (1, 0) (0, 0) (0, 1) (0, 0) (0, 0) (1, 0) (0, 0) (0, 0) (0, 1) (0, 0)
+ ...
+ (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 1),
+ (0, 0), (0, 0)],
+ dtype=[('nlp_cnn', '<i8'), ('short_text', '<i8')])
+
+
+To calculate metrics for our slices, we could use snorkel.analysis.Scorer but we've implemented a version that will work for multiclass or multilabel scenarios.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
1 | |
+{
+ "nlp_llm": {
+ "precision": 0.9642857142857143,
+ "recall": 0.9642857142857143,
+ "f1": 0.9642857142857143,
+ "num_samples": 28
+ },
+ "short_text": {
+ "precision": 1.0,
+ "recall": 1.0,
+ "f1": 1.0,
+ "num_samples": 7
+ }
+}
+
+
+Slicing can help identify sources of bias in our data. For example, our model has most likely learned to associated algorithms with certain applications such as CNNs used for computer vision or transformers used for NLP projects. However, these algorithms are not being applied beyond their initial use cases. We’d need ensure that our model learns to focus on the application over algorithm. This could be learned with:
+Besides just comparing predicted outputs with ground truth values, we can also inspect the inputs to our models. What aspects of the input are more influential towards the prediction? If the focus is not on the relevant features of our input, then we need to explore if there is a hidden pattern we're missing or if our model has learned to overfit on the incorrect features. We can use techniques such as SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) to inspect feature importance. On a high level, these techniques learn which features have the most signal by assessing the performance in their absence. These inspections can be performed on a global level (ex. per-class) or on a local level (ex. single prediction).
+1 +2 | |
LimeTextExplainer.explain_instance function requires a classifier_fn that takes in a list of strings and outputs the predicted probabilities.
1 +2 +3 +4 +5 | |
1 +2 +3 +4 | |
 +
+++We can also use model-specific approaches to interpretability we we did in our embeddings lesson to identify the most influential n-grams in our text.
+
Besides just looking at metrics, we also want to conduct some behavioral sanity tests. Behavioral testing is the process of testing input data and expected outputs while treating the model as a black box. They don't necessarily have to be adversarial in nature but more along the types of perturbations we'll see in the real world once our model is deployed. A landmark paper on this topic is Beyond Accuracy: Behavioral Testing of NLP Models with CheckList which breaks down behavioral testing into three types of tests:
+invariance: Changes should not affect outputs.
+1 +2 +3 +4 | |
+['natural-language-processing', 'natural-language-processing'] ++
directional: Change should affect outputs.
+1 +2 +3 +4 | |
+['natural-language-processing', 'computer-vision'] ++
minimum functionality: Simple combination of inputs and expected outputs.
+1 +2 +3 +4 | |
+['natural-language-processing', 'mlops'] ++ +
++We'll learn how to systematically create tests in our testing lesson.
+
Once we've evaluated our model's ability to perform on a static dataset we can run several types of online evaluation techniques to determine performance on actual production data. It can be performed using labels or, in the event we don't readily have labels, proxy signals.
+And there are many different experimentation strategies we can use to measure real-time performance before committing to replace our existing version of the system.
+AB testing involves sending production traffic to our current system (control group) and the new version (treatment group) and measuring if there is a statistical difference between the values for two metrics. There are several common issues with AB testing such as accounting for different sources of bias, such as the novelty effect of showing some users the new system. We also need to ensure that the same users continue to interact with the same systems so we can compare the results without contamination.
+ +
+++In many cases, if we're simply trying to compare the different versions for a certain metric, AB testing can take while before we reach statical significance since traffic is evenly split between the different groups. In this scenario, multi-armed bandits will be a better approach since they continuously assign traffic to the better performing version.
+
Canary tests involve sending most of the production traffic to the currently deployed system but sending traffic from a small cohort of users to the new system we're trying to evaluate. Again we need to make sure that the same users continue to interact with the same system as we gradually roll out the new system.
+ +
+Shadow testing involves sending the same production traffic to the different systems. We don't have to worry about system contamination and it's very safe compared to the previous approaches since the new system's results are not served. However, we do need to ensure that we're replicating as much of the production system as possible so we can catch issues that are unique to production early on. But overall, shadow testing is easy to monitor, validate operational consistency, etc.
+ +
+What can go wrong?
+If shadow tests allow us to test our updated system without having to actually serve the new results, why doesn't everyone adopt it?
+With shadow deployment, we'll miss out on any live feedback signals (explicit/implicit) from our users since users are not directly interacting with the product using our new version.
+We also need to ensure that we're replicating as much of the production system as possible so we can catch issues that are unique to production early on. This is rarely possible because, while your ML system may be a standalone microservice, it ultimately interacts with an intricate production environment that has many dependencies.
+We've seen the many different metrics that we'll want to calculate when it comes to evaluating our model but not all metrics mean the same thing. And this becomes very important when it comes to choosing the "best" model(s).
+While capability (ex. loss) and alignment (ex. accuracy) metrics may seem to be aligned, their differences can indicate issues in our data:
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far, we've been training and evaluating our different baselines but haven't really been tracking these experiments. We'll fix this but defining a proper process for experiment tracking which we'll use for all future experiments (including hyperparameter optimization). Experiment tracking is the process of managing all the different experiments and their components, such as parameters, metrics, models and other artifacts and it enables us to:
+There are many options for experiment tracking but we're going to use MLFlow (100% free and open-source) because it has all the functionality we'll need. We can run MLFlow on our own servers and databases so there are no storage cost / limitations, making it one of the most popular options and is used by Microsoft, Facebook, Databricks and others. There are also several popular options such as a Comet ML (used by Google AI, HuggingFace, etc.), Neptune (used by Roche, NewYorker, etc.), Weights and Biases (used by Open AI, Toyota Research, etc.). These are fully managed solutions that provide features like dashboards, reports, etc.
+We'll start by setting up our model registry where all of our experiments and their artifacts will be stores.
+1 +2 +3 +4 | |
1 +2 +3 +4 +5 +6 | |
+file:///tmp/mlflow ++ +
++On Windows, the tracking URI should have three forwards slashes: +
+
1MLFLOW_TRACKING_URI = "file:///" + str(MODEL_REGISTRY.absolute()) +
Note
+In this course, our MLflow artifact and backend store will both be on our local machine. In a production setting, these would be remote such as S3 for the artifact store and a database service (ex. PostgreSQL RDS) as our backend store.
+While we could use MLflow directly to log metrics, artifacts and parameters:
+1 +2 +3 +4 | |
We'll instead use Ray to integrate with MLflow. Specifically we'll use the MLflowLoggerCallback which will automatically log all the necessary components of our experiments to the location specified in our MLFLOW_TRACKING_URI. We of course can still use MLflow directly if we want to log something that's not automatically logged by the callback. And if we're using other experiment trackers, Ray has integrations for those as well.
1 +2 +3 +4 +5 +6 | |
Once we have the callback defined, all we have to do is update our RunConfig to include it.
1 +2 +3 +4 +5 | |
With our updated RunConfig, with the MLflow callback, we can now train our model and all the necessary components will be logged to MLflow. This is the exact same training workflow we've been using so far from the training lesson.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 | |
1 | |
We're going to use the search_runs function from the MLflow python API to identify the best run in our experiment so far (we' only done one run so far so it will be the run from above).
1 +2 +3 | |
+run_id 8e473b640d264808a89914e8068587fb +experiment_id 853333311265913081 +status FINISHED +... +tags.mlflow.runName TorchTrainer_077f9_00000 +Name: 0, dtype: object ++ +
Once we're done training, we can use the MLflow dashboard to visualize our results. To do so, we'll use the mlflow server command to launch the MLflow dashboard and navigate to the experiment we just created.
mlflow server -h 0.0.0.0 -p 8080 --backend-store-uri /tmp/mlflow/
+View the dashboard
+If you're on Anyscale Workspaces, then we need to first expose the port of the MLflow server. Run the following command on your Anyscale Workspace terminal to generate the public URL to your MLflow server.
+APP_PORT=8080
+echo https://$APP_PORT-port-$ANYSCALE_SESSION_DOMAIN
+If you're running this notebook on your local laptop then head on over to http://localhost:8080/ to view your MLflow dashboard.
+MLFlow creates a main dashboard with all your experiments and their respective runs. We can sort runs by clicking on the column headers.
+
And within each run, we can view metrics, parameters, artifacts, etc.
+
And we can even create custom plots to help us visualize our results.
+
After inspection and once we've identified an experiment that we like, we can load the model for evaluation and inference.
+1 +2 | |
We're going to create a small utility function that uses an MLflow run's artifact path to load a Ray Result object. We'll then use the Result object to load the best checkpoint.
1 +2 +3 +4 | |
With a particular run's best checkpoint, we can load the model from it and use it.
+1 +2 +3 +4 +5 | |
+{
+ "precision": 0.9281010510531216,
+ "recall": 0.9267015706806283,
+ "f1": 0.9269438615952555
+}
+
+
+Before we can use our model for inference, we need to load the preprocessor from our predictor and apply it to our input data.
+1 +2 | |
1 +2 +3 +4 +5 | |
+[{'prediction': 'natural-language-processing',
+ 'probabilities': {'computer-vision': 0.00038025028,
+ 'mlops': 0.00038209034,
+ 'natural-language-processing': 0.998792,
+ 'other': 0.00044562898}}]
+
+
+In the next lesson we'll learn how to tune our models and use our MLflow dashboard to compare the results.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Exploratory data analysis (EDA) to understand the signals and nuances of our dataset. It's a cyclical process that can be done at various points of our development process (before/after labeling, preprocessing, etc. depending on how well the problem is defined. For example, if we're unsure how to label or preprocess our data, we can use EDA to figure it out.
+We're going to start our project with EDA, a vital (and fun) process that's often misconstrued. Here's how to think about EDA:
+Let's answer a few key questions using EDA.
+1 +2 +3 +4 +5 | |
How many data points do we have per tag? We'll use the Counter class to get counts for all the different tags.
1 +2 +3 | |
+[('natural-language-processing', 310),
+ ('computer-vision', 285),
+ ('other', 106),
+ ('mlops', 63)]
+
+
+We can then separate the tags and from their respective counts and plot them using Plotly.
+1 +2 +3 +4 +5 +6 +7 +8 | |
 +
+++We do have some data imbalance but it's not too bad. If we did want to account for this, there are many strategies, including over-sampling less frequent classes and under-sampling popular classes, class weights in the loss function, etc.
+
Is there enough signal in the title and description that's unique to each tag? This is important to know because we want to verify our initial hypothesis that the project's title and description are high quality features for predicting the tag. And to visualize this, we're going to use a wordcloud. We also use a jupyter widget, which you can view in the notebook, to interactively select a tag and see the wordcloud for that tag.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
 +
+Looks like the title text feature has some good signal for the respective classes and matches our intuition. We can repeat this for the description text feature as well and see similar quality signals. This information will become useful when we decide how to use our features for modeling.
There's a lot more exploratory data analysis that we can do but for now we've answered our questions around our class distributions and the quality of our text features. In the next lesson we'll preprocess our dataset in preparation for model training.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Let's motivate the need for a feature store by chronologically looking at what challenges developers face in their current workflows. Suppose we had a task where we needed to predict something for an entity (ex. user) using their features.
+Solution: create a central feature repository where the entire team contributes maintained features that anyone can use for any application.Solution: create features using a unified pipeline and store them in a central location that the training and serving pipelines pull from.Solution: retrieve input features for the respective outcomes by pulling what's available when a prediction would be made.Point-in-time correctness refers to mapping the appropriately up-to-date input feature values to an observed outcome at \(t_{n+1}\). This involves knowing the time (\(t_n\)) that a prediction is needed so we can collect feature values (\(X\)) at that time.
+ +
+When actually constructing our feature store, there are several core components we need to have to address these challenges:
+Each of these components is fairly easy to set up but connecting them all together requires a managed service, SDK layer for interactions, etc. Instead of building from scratch, it's best to leverage one of the production-ready, feature store options such as Feast, Hopsworks, Tecton, Rasgo, etc. And of course, the large cloud providers have their own feature store options as well (Amazon's SageMaker Feature Store, Google's Vertex AI, etc.)
+Tip
+We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the feature-store repository for a quick overview with an interactive notebook.
+Not all machine learning platforms require a feature store. In fact, our use case is a perfect example of a task that does not benefit from a feature store. All of our data points are independent, stateless, from client-side and there is no entity that has changing features over time. The real utility of a feature store shines when we need to have up-to-date features for an entity that we continually generate predictions for. For example, a user's behavior (clicks, purchases, etc.) on an e-commerce platform or the deliveries a food runner recently made in the last hour, etc.
+To answer this question, let's revisit the main challenges that a feature store addresses:
+Note
+Additionally, if the transformations are compute intensive, then they'll incur a lot of costs by running on duplicate datasets across different applications (as opposed to having a central location with upt-o-date transformed features).
+Skew: similar to duplication of efforts, if our transformations can be tied to the model or as a standalone function, then we can just reuse the same pipelines to produce the feature values for training and serving. But this becomes complex and compute intensive as the number of applications, features and transformations grow.
+Value: if we aren't working with features that need to be computed server-side (batch or streaming), then we don't have to worry about concepts like point-in-time, etc. However, if we are, a feature store can allow us to retrieve the appropriate feature values across all data sources without the developer having to worry about using disparate tools for different sources (batch, streaming, etc.)
+We're going to leverage Feast as the feature store for our application for it's ease of local setup, SDK for training/serving, etc.
+# Install Feast and dependencies
+pip install feast==0.10.5 PyYAML==5.3.1 -q
+++👉 Follow along interactive notebook in the feature-store repository as we implement the concepts below.
+
We're going to create a feature repository at the root of our project. Feast will create a configuration file for us and we're going to add an additional features.py file to define our features.
+++Traditionally, the feature repository would be it's own isolated repository that other services will use to read/write features from.
+
mkdir -p stores/feature
+mkdir -p data
+feast init --minimal --template local features
+cd features
+touch features.py
++Creating a new Feast repository in /content/features. ++ +
The initialized feature repository (with the additional file we've added) will include:
+features/
+├── feature_store.yaml - configuration
+└── features.py - feature definitions
+We're going to configure the locations for our registry and online store (SQLite) in our feature_store.yaml file.
 +
+If all our feature definitions look valid, Feast will sync the metadata about Feast objects to the registry. The registry is a tiny database storing most of the same information you have in the feature repository. This step is necessary because the production feature serving infrastructure won't be able to access Python files in the feature repository at run time, but it will be able to efficiently and securely read the feature definitions from the registry.
+++When we run Feast locally, the offline store is effectively represented via Pandas point-in-time joins. Whereas, in production, the offline store can be something more robust like Google BigQuery, Amazon RedShift, etc.
+
We'll go ahead and paste this into our features/feature_store.yaml file (the notebook cell is automatically do this):
project: features
+registry: ../stores/feature/registry.db
+provider: local
+online_store:
+ path: ../stores/feature/online_store.db
+The first step is to establish connections with our data sources (databases, data warehouse, etc.). Feast requires it's data sources to either come from a file (Parquet), data warehouse (BigQuery) or data stream (Kafka / Kinesis). We'll convert our generated features file from the DataOps pipeline (features.json) into a Parquet file, which is a column-major data format that allows fast feature retrieval and caching benefits (contrary to row-major data formats such as CSV where we have to traverse every single row to collect feature values).
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
+ ++ +
1 +2 | |
1 +2 +3 +4 +5 +6 +7 | |
Now that we have our data source prepared, we can define our features for the feature store.
+1 +2 +3 +4 +5 | |
The first step is to define the location of the features (FileSource in our case) and the timestamp column for each data point.
+1 +2 +3 +4 +5 +6 | |
Next, we need to define the main entity that each data point pertains to. In our case, each project has a unique ID with features such as text and tags.
+1 +2 +3 +4 +5 +6 | |
Finally, we're ready to create a FeatureView that loads specific features (features), of various value types, from a data source (input) for a specific period of time (ttl).
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
So let's go ahead and define our feature views by moving this code into our features/features.py script (the notebook cell is automatically do this):
from datetime import datetime
+from pathlib import Path
+
+from feast import Entity, Feature, FeatureView, ValueType
+from feast.data_source import FileSource
+from google.protobuf.duration_pb2 import Duration
+
+
+# Read data
+START_TIME = "2020-02-17"
+project_details = FileSource(
+ path="/content/data/features.parquet",
+ event_timestamp_column="created_on",
+)
+
+# Define an entity for the project
+project = Entity(
+ name="id",
+ value_type=ValueType.INT64,
+ description="project id",
+)
+
+# Define a Feature View for each project
+# Can be used for fetching historical data and online serving
+project_details_view = FeatureView(
+ name="project_details",
+ entities=["id"],
+ ttl=Duration(
+ seconds=(datetime.today() - datetime.strptime(START_TIME, "%Y-%m-%d")).days * 24 * 60 * 60
+ ),
+ features=[
+ Feature(name="text", dtype=ValueType.STRING),
+ Feature(name="tag", dtype=ValueType.STRING),
+ ],
+ online=True,
+ input=project_details,
+ tags={},
+)
+Once we've defined our feature views, we can apply it to push a version controlled definition of our features to the registry for fast access. It will also configure our registry and online stores that we've defined in our feature_store.yaml.
cd features
+feast apply
++Registered entity id +Registered feature view project_details +Deploying infrastructure for project_details ++ +
Once we've registered our feature definition, along with the data source, entity definition, etc., we can use it to fetch historical features. This is done via joins using the provided timestamps using pandas for our local setup or BigQuery, Hive, etc. as an offline DB for production.
+1 +2 | |
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 +6 +7 | |
For online inference, we want to retrieve features very quickly via our online store, as opposed to fetching them from slow joins. However, the features are not in our online store just yet, so we'll need to materialize them first.
+cd features
+CURRENT_TIME=$(date -u +"%Y-%m-%dT%H:%M:%S")
+feast materialize-incremental $CURRENT_TIME
++Materializing 1 feature views to 2022-06-23 19:16:05+00:00 into the sqlite online store. +project_details from 2020-02-17 19:16:06+00:00 to 2022-06-23 19:16:05+00:00: +100%|██████████████████████████████████████████████████████████| 955/955 [00:00<00:00, 10596.97it/s] ++ +
This has moved the features for all of our projects into the online store since this was first time materializing to the online store. When we subsequently run the materialize-incremental command, Feast keeps track of previous materializations and so we'll only materialize the new data since the last attempt.
Once we've materialized the features (or directly sent to the online store in the stream scenario), we can use the online store to retrieve features.
+1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 | |
The feature store we implemented above assumes that our task requires batch processing. This means that inference requests on specific entity instances can use features that have been materialized from the offline store. Note that they may not be the most recent feature values for that entity.
+
+Warning
+Had our entity (projects) had features that change over time, we would materialize them to the online store incrementally. But since they don't, this would be considered over engineering but it's important to know how to leverage a feature store for entities with changing features over time.
+Some applications may require stream processing where we require near real-time feature values to deliver up-to-date predictions at low latency. While we'll still utilize an offline store for retrieving historical data, our application's real-time event data will go directly through our data streams to an online store for serving. An example where stream processing would be needed is when we want to retrieve real-time user session behavior (clicks, purchases) in an e-commerce platform so that we can recommend the appropriate items from our catalog.
+ +
+++There are a few more components we're not visualizing here such as the unified ingestion layer (Spark), that connects data from the varied data sources (warehouse, DB, etc.) to the offline/online stores, or low latency serving (<10 ms). We can read more about all of these in the official Feast Documentation, which also has guides to set up a feature store with Feast with AWS, GCP, etc.
+
Additional functionality that many feature store providers are currently (or recently) trying to integrate within the feature store platform include:
+Current solution: apply transformations as a separate Spark, Python, etc. workflow task before writing to the feature store.Current solution: apply data testing and monitoring as upstream workflow tasks before they are written to the feature store.Current solution: add a data discovery engine, such as Amundsen, on top of our feature store to enable others to search for features.Though we could continue to version our training data with DVC whenever we release a version of the model, it might not be necessary. When we pull data from source or compute features, should they save the data itself or just the operations?
+Regardless of the choice above, feature stores are very useful here. Instead of coupling data pulls and feature compute with the time of modeling, we can separate these two processes so that features are up-to-date when we need them. And we can still achieve reproducibility via efficient point-in-time correctness, low latency snapshots, etc. This essentially creates the ability to work with any version of the dataset at any point in time.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Whether we're working individually or with a team, it's important that we have a system to track changes to our projects so that we can revert to previous versions and so that others can reproduce our work and contribute to it. Git is a distributed versional control system that allows us do exactly this. Git runs locally on our computer and it keeps track of our files and their histories. To enable collaboration with others, we can use a remote host (GitHub, GitLab, BitBucket, etc.) to host our files and their histories. We'll use git to push our local changes and pull other's changes to and from the remote host.
+++Git is traditionally used to store and version small files <100MB (scripts, READMEs, etc.), however, we can still version large artifacts (datasets, model weights, etc.) using text pointers pointing to blob stores. These pointers will contain information such as where the asset is located, it's specific contents/version (ex. via hashing), etc.
+
 +
+Initialize a local repository (.git directory) to track our files:
+
git init
++Initialized empty Git repository in /Users/goku/Documents/madewithml/MLOps/.git/ ++ +
We can see what files are untracked or yet to be committed:
+git status
++On branch main + +No commits yet + +Untracked files: + (use "git add+ +..." to include in what will be committed) + .flake8 + .vscode/ + Makefile + ... +
We can see that we have some files that we don't want to push to a remote host, such as our virtual environment, logs, large data files, etc. We can create a .gitignore file to make sure we aren't checking in these files.
touch .gitignore
+We'll add the following files to the file:
+# Data
+logs/
+stores/
+data/
+
+# Packaging
+venv/
+*.egg-info/
+__pycache__/
+
+# Misc
+.DS_Store
+For now, we're going to add data to our .gitignore file as well but this means that others will not be able to produce the same data assets when they pull from our remote host. To address this, we'll push pointers to our data files in our versioning lesson so that the data too can be reproduced exactly as we have it locally.
Tip
+Check out our project's .gitignore for a more complete example that also includes lots of other system artifacts that we would normally not want to push to a remote repository. Our complete .gitignore file is based on GitHub's Python template and we're using a Mac, so we added the relevant global file names as well.
If we run git status now, we should no longer see the files we've defined in our .gitignore file.
Next, we'll add our work from the working directory to the staging area.
+git add <filename>
+git add .
+Now running git status will show us all the staged files:
git status
++On branch main + +No commits yet + +Changes to be committed: + (use "git rm --cached+ +..." to unstage) + new file: .flake8 + new file: .gitignore + new file: Makefile + ... +
Now we're ready to commit the files in the staging area to the local repository. The default branch (a version of our project) will be called main.
git commit -m "added project files"
++[main (root-commit) 704d99c] added project files + 47 files changed, 50651 insertions(+) + create mode 100644 .flake8 + create mode 100644 .gitignore + create mode 100644 Makefile + ... ++ +
The commit requires a message indicating what changes took place. We can use git commit --amend to edit the commit message if needed. If we do a git status check we'll see that there is nothing else to commit from our staging area.
git status
++On branch main +nothing to commit, working tree clean ++ +
Now we're ready to push the updates from our local repository to a remote repository. Start by creating an account on GitHub (or any other remote repository) and follow the instructions to create a remote repository (it can be private or public). Inside our local repository, we're going to set our username and email credentials so that we can push changes from our local to the remote repository.
+# Set credentials via terminal
+git config --global user.name <USERNAME>
+git config --global user.email <EMAIL>
+# Check credentials
+git config --global user.name
+git config --global user.email
+Next, we need to establish the connection between our local and remote repositories:
+# Push to remote
+git remote add origin https://github.com/<USERNAME>/<REPOSITORY_NAME>.git
+git push -u origin main # pushing the contents of our local repo to the remote repo
+ # origin signifies the remote repository
+Now we're ready to start adding to our project and committing the changes.
+If we (or someone else) doesn't already have the local repository set up and connected with the remote host, we can use the clone command:
+git clone <REMOTE_REPO_URL> <PATH_TO_PROJECT_DIR>
+And we can clone a specific branch of a repository as well:
+git clone -b <BRANCH> <REMOTE_REPO_URL> <PATH_TO_PROJECT_DIR>
+<REMOTE_REPO_URL> is the location of the remote repo (ex. https://github.com/GokuMohandas/Made-With-ML).<PATH_TO_PROJECT_DIR> is the name of the local directory you want to clone the project into.When we want to add or change something, such as adding a feature, fixing a bug, etc., it's always a best practice to create a separate branch before developing. This is especially crucial when working with a team so we can cleanly merge our work with the main branch after discussions and reviews.
We'll start by creating a new branch:
+git checkout -b <NEW_BRANCH_NAME>
+We can see all the branches we've created with the following command where the * indicates our current branch:
+git branch
++* convnet +main ++ +
We can easily switch between existing branches using:
+git checkout <BRANCH_NAME>
+Once we're in a branch, we can make changes to our project and commit those changes.
+git add .
+git commit -m "update model to a convnet"
+git push origin convnet
+Note that we are pushing this branch to our remote repository, which doesn't yet exist there, so GitHub will create it accordingly.
+When we push our new branch to the remote repository, we'll need to create a pull request (PR) to merge with another branch (ex. our main branch in this case). When merging our work with another branch (ex. main), it's called a pull request because we're requesting the branch to pull our committed work. We can create the pull request using steps outlined here: Creating a pull request.
 +
+Note
+We can merge branches and resolve conflicts using git CLI commands but it's preferred to use the online interface because we can easily visualize the changes, have discussion with teammates, etc. +
# Merge via CLI
+git push origin convnet
+git checkout main
+git merge convnet
+git push origin main
+Once we accepted the pull request, our main branch is now updated with our changes. However, the update only happened on the remote repository so we should pull those changes to our local main branch as well.
git checkout main
+git pull origin main
+Once we're done working with a branch, we can delete it to prevent our repository from cluttering up. We can easily delete both the local and remote versions of the branch with the following commands: +
# Delete branches
+git branch -d <BRANCH_NAME> # local
+git push origin --delete <BRANCH_NAME> # remote
+So far, the workflows for integrating our iterative development has been very smooth but in a collaborative setting, we may need to resolve conflicts. Let's say there are two branches (a and b) that were created from the main branch. Here's what we're going to try and simulate:
main branch to make some changesmain branch.main.When we try to merge the second PR, we have to resolve the conflicts between this new PR and what already exists in the main branch.
 +
+We can resolve the conflict by choosing which content (current main which merged with the a branch or this b branch) to keep and delete the other one. Then we can merge the PR successfully and update our local main branch.
<<<<<< BRANCH_A
+<CHANGES FROM BRANCH A>
+======
+<CHANGES FROM BRANCH B>
+>>>>>> BRANCH_B
+Once the conflicts have been resolved and we merge the PR, we can update our local repository to reflect the decisions.
+git checkout main
+git pull origin main
+Note
+We only have a conflict because both branches were forked from a previous version of the main branch and they both happened to alter the same content. Had we created one branch first and then updated main before creating the second branch, we wouldn't have any conflicts. But in a collaborative setting, different developers may fork off the same version of the branch anytime.
++A few more important commands to know include rebase and stash.
+
Git allows us to inspect the current and previous states of our work at many different levels. Let's explore the most commonly used commands.
+We've used the status command quite a bit already as it's very useful to quickly see the status of our working tree.
+# Status
+git status
+git status -s # short format
+If we want to see the log of all our commits, we can do so using the log command. We can also do the same by inspecting specific branch histories on the Git online interface.
+# Log
+git log
+git log --oneline # short version
++704d99c (HEAD -> main) added project files ++ +
++Commit IDs are 40 characters long but we can represent them with the first few (seven digits is the default for a Git SHA). If there is ambiguity, Git will notify us and we can simply add more of the commit ID.
+
If we want to know the difference between two commits, we can use the diff command.
+# Diff
+git diff # all changes between current working tree and previous commit
+git diff <COMMIT_A> <COMMIT_B> # diff b/w two commits
+git diff <COMMIT_A>:<PATH_TO_FILE> <COMMIT_B>:<PATH_TO_FILE> # file diff b/w two commits
+
+diff --git a/.gitignore b/.gitignore
+index 288973d..028aa13 100644
+--- a/.gitignore
++++ b/.gitignore
+@@ -1,7 +1,6 @@
+ # Data
+ logs/
+ stores/
+-data/
+
+
+One of the most useful inspection commands is blame, which allows us to see what commit was responsible for every single line in a file. +
# Blame
+git blame <PATH_TO_FILE>
+git blame -L 1,3 <PATH_TO_FILE> # blame for lines 1 and 3
+Sometimes we may have done something we wish we could change. It's not always possible to do this in life, but in the world of Git, it is!
+Sometimes we may just want to undo adding or staging a file, which we can easily do with the restore command. +
# Restore
+git restore -- <PATH_TO_FILE> <PATH_TO_FILE> # will undo any changes
+git restore --stage <PATH_TO_FILE> # will remove from stage (won't undo changes)
+Now if we already made the commit but haven't pushed to remote yet, we can reset to the previous commit by moving the branch pointer to that commit. Note that this will undo all changes made since the previous commit. +
# Reset
+git reset <PREVIOUS_COMMIT_ID> # or HEAD^
++++
HEADis a quick way to refer to the previous commit. BothHEADand any previous commit ID can be accompanied with a^or~symbol which acts as a relative reference.^n refers to the nth parent of the commit while~n refers to the nth grandparent. Of course we can always just explicitly use commit IDs but these short hands can come in handy for quick checks without doinggit logto retrieve commit IDs.
But instead of moving the branch pointer to a previous commit, we can continue to move forward by adding a new commit to revert certain previous commits.
+# Revert
+git revert <COMMIT_ID> ... # rollback specific commits
+git revert <COMMIT_TO_ROLLBACK_TO>..<COMMIT_TO_ROLLBACK_FROM> # range
+Sometimes we may want to temporarily switch back to a previous commit just to explore or commit some changes. It's best practice to do this in a separate branch and if we want to save our changes, we need to create a separate PR. Note that if you do checkout a previous commit and submit a PR, you may override the commits in between. +
# Checkout
+git checkout -b <BRANCH_NAME> <COMMIT_ID>
+There so many different works to work with git and sometimes it can became quickly unruly when fellow developers follow different practices. Here are a few, widely accepted, best practices when it comes to working with commits and branches.
+# Tags
+git tag -a v0.1 -m "initial release"
+main branch very easy.main branch as the "demo ready" branch that always works.main branch).Leverage git tags to mark significant release commits. We can create tags either through the terminal or the online remote interface and this can be done to previous commits as well (in case we forgot).
+# Tags
+git tag # view all existing tags
+git tag -a <TAG_NAME> -m "SGD" # create a tag
+git checkout -b <BRANCH_NAME> <TAG_NAME> # checkout a specific tag
+git tag -d <TAG_NAME> # delete local tag
+git push origin --delete <TAG_NAME> # delete remote tag
+git fetch --all --tags # fetch all tags from remote
+++ +Tag names usually adhere to version naming conventions, such as
+v1.4.2where the numbers indicate major, minor and bug changes from left to right.
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Live cohort
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Our ML workloads have been responsible for everything from data ingestion to model validation:
+ +
+We can execute these workloads as standalone CLI commands:
+1 +2 +3 +4 +5 +6 +7 | |
With all of our ML workloads implemented (and tested), we're ready to go to production. In this lesson, we'll learn how to convert our ML workloads from CLI commands into a scalable, fault-tolerant and reproducible workflow.
+ +
+Since we have our CLI commands for our ML workloads, we could just execute them one-by-one on our local machine or Workspace. But for efficiency, we're going to combine them all into one script. We'll organize this under a workloads.sh bash script inside our deploy/jobs directory. Here the workloads are very similar to our CLI commands but we have some additional steps to print and save the logs from each of our workloads. For example, our data validation workload looks like this:
# deploy/jobs/workloads.sh
+export RESULTS_FILE=results/test_data_results.txt
+export DATASET_LOC="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv"
+pytest --dataset-loc=$DATASET_LOC tests/data --verbose --disable-warnings > $RESULTS_FILE
+cat $RESULTS_FILE
+At the end of our workloads.sh script, we save our model registry (with our saved model artifacts) and the results from the different workloads to S3. We'll use these artifacts and results later on when we deploy our model as a Service.
# Save to S3
+export MODEL_REGISTRY=$(python -c "from madewithml import config; print(config.MODEL_REGISTRY)")
+aws s3 cp $MODEL_REGISTRY s3://madewithml/$GITHUB_USERNAME/mlflow/ --recursive
+aws s3 cp results/ s3://madewithml/$GITHUB_USERNAME/results/ --recursive
+Note
+If you're doing this lesson on your local laptop, you'll have to add the proper AWS credentials and up the S3 buckets for our workloads script to run successfully. +
export AWS_ACCESS_KEY_ID=""
+export AWS_SECRET_ACCESS_KEY=""
+export AWS_SESSION_TOKEN=""
+Now that we have our single script to execute all workloads, we can execute it with one command (./deploy/jobs/workloads.sh). But even better way is to use Anyscale Jobs to get features like automatic failure handling, email alerts and persisted logs all out of the box for our workloads. And with our cluster_env.yaml, cluster_compute.yaml and workloads.sh files, we can create the configuration for our Anyscale Job with an workloads.yaml file:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
Line 2: name of our Anyscale JobLine 3: name of our Anyscale Project (we're organizing it all under the same madewithml project we used for our Workspace setup)Line 4: name of our cluster environmentLine 5: name of our compute configurationLine 6-10: runtime environment for our Anyscale Job. The runtime_env here specifies that we should upload our current working_dir to an S3 bucket so that all of our workers when we execute an Anyscale Job have access to the code to use. We also set some environment variables that our workloads will have access to.Line 11: entrypoint for our Anyscale Job. This is the command that will be executed when we submit our Anyscale Job.Line 12: maximum number of retries for our Anyscale Job. If our Anyscale Job fails, it will automatically retry up to this number of times.Warning
+Be sure to update the $GITHUB_USERNAME slots inside our deploy/jobs/workloads.yaml configuration to your own GitHub username. This is used to save your model registry and results to a unique path on our shared S3 bucket (s3://madewithml).
Because we're using the exact same cluster environment and compute configuration, what worked during development will work in production. This is a huge benefit of using Anyscale Jobs because we don't have to worry about any environment discrepanices when we deploy our workloads to production. This makes going to production much easier and faster!
+And now we can execute our Anyscale Job in one line:
+anyscale job submit deploy/jobs/workloads.yaml
++Authenticating + +Output +(anyscale +8.8s) Maximum uptime is disabled for clusters launched by this job. +(anyscale +8.8s) Job prodjob_zqj3k99va8a5jtd895u3ygraup has been successfully submitted. Current state of job: PENDING. +(anyscale +8.8s) Query the status of the job with `anyscale job list --job-id prodjob_zqj3k99va8a5jtd895u3ygraup`. +(anyscale +8.8s) Get the logs for the job with `anyscale job logs --job-id prodjob_zqj3k99va8a5jtd895u3ygraup --follow`. +(anyscale +8.8s) View the job in the UI at https://console.anyscale.com/jobs/prodjob_zqj3k99va8a5jtd895u3ygraup +(anyscale +8.8s) Use --follow to stream the output of the job when submitting a job. ++ +
Tip
+When we run anyscale cli commands inside our Workspaces, we automatically have our credentials set up for us. But if we're running anyscale cli commands on our local laptop, we'll have to set up the appropriate credentials. +
export ANYSCALE_HOST=https://console.anyscale.com ANYSCALE_CLI_TOKEN=your_cli_token
+We can now go to thie UI link that was provided to us to view the status, logs, etc. of our Anyscale Job.
+ +
+And if we inspect our S3 buckets, we'll can see all the artifacts that have been saved from this Anyscale Job.
+ +
+Since we use the exact same cluster (environment and compute) for production as we did for development, we're significantly less likely to run into the environment discrepancy issues that typically arise when going from development to production. However, there can always be small issues that arize from missing credentials, etc. We can easily debug our Anyscale Jobs by inspecting the jobs: Jobs page > choose job > View console logs at the bottom > View Ray workers logs > paste command > Open job-logs directory > View job-driver-raysubmit_XYZ.log. Alternatively, we can also run our Anyscale Job as a Workspace by clicking on the Duplicate as Workspace button the top of a particular Job's page.
After we execute our Anyscale Job, we will have saved our model artifacts to a particular location. We'll now use Anyscale Services to pull from this location to serve our models in production behind a scalable rest endpoint
+Similar to Anyscale Jobs, we'll start by creating a serve_model.py and a serve_model.yaml configuration:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 | |
In this script, we first pull our previously saved artifacts from our S3 bucket to our local storage and then define the entrypoint for our model.
+Tip
+Recall that we have the option to scale when we define our service inside out madewithml/serve.py script. And we can scale our compute configuration to meet those demands.
1 +2 +3 +4 +5 | |
We can now use this entrypoint that we defined to serve our application:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
Line 2: name of our Anyscale ServiceLine 3: name of our Anyscale Project (we're organizing it all under the same madewithml project we used for our Workspace setup)Line 4: name of our cluster environmentLine 5: name of our compute configurationLine 6-12: serving configuration that specifies our entry point and details about the working directory, environment variables, etc.Line 13: rollout strategy for our Anyscale Service. We can either rollout a new version of our service or replace the existing version with the new one.Warning
+Be sure to update the $GITHUB_USERNAME slots inside our deploy/services/serve_model.yaml configuration to your own GitHub username. This is used to pull model artifacts and results from our shared S3 bucket (s3://madewithml).
And now we can execute our Anyscale Service in one line:
+# Rollout service
+anyscale service rollout -f deploy/services/serve_model.yaml
++Authenticating + +Output +(anyscale +7.3s) Service service2_xwmyv1wcm3i7qan2sahsmybymw has been deployed. Service is transitioning towards: RUNNING. +(anyscale +7.3s) View the service in the UI at https://console.anyscale.com/services/service2_xwmyv1wcm3i7qan2sahsmybymw ++ +
Note
+If we chose the ROLLOUT strategy, we get a canary rollout (increasingly serving traffic to the new version of our service) by default.
Once our service is up and running, we can query it:
+# Query
+curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $SECRET_TOKEN" -d '{
+ "title": "Transfer learning with transformers",
+ "description": "Using transformers for transfer learning on text classification tasks."
+}' $SERVICE_ENDPOINT/predict/
+{
+ "results": [
+ {
+ "prediction": "natural-language-processing",
+ "probabilities": {
+ "computer-vision": 3.175719175487757E-4,
+ "mlops": 4.065348766744137E-4,
+ "natural-language-processing": 0.9989110231399536,
+ "other": 3.6489960621111095E-4
+ }
+ }
+ ]
+}
+And we can just as easily rollback to a previous version of our service or terminate it altogether:
+# Rollback (to previous version of the Service)
+anyscale service rollback -f $SERVICE_CONFIG --name $SERVICE_NAME
+
+# Terminate
+anyscale service terminate --name $SERVICE_NAME
+Once we rollout our service, we have several different dashboards that we can use to monitor our service. We can access these dashboards by going to the Services page > choose service > Click the Dashboard button (top right corner) > Ray Dashboard. Here we'll able to see the logs from our Service, metrics, etc.
 +
+On the same Dashboard button, we also have a Metrics option that will take us to a Grafana Dashboard. This view has a lot more metrics on incoming requests, latency, errors, etc.
+ +
+Serving our models may not always work as intended. Even if our model serving logic is correct, there are external dependencies that could causes errors --- such as our model not being stored where it should be, trouble accessing our model registry, etc. For all these cases and more, it's very important to know how to be able to debug our Services.
+Services page > choose service > Go to Resource usage section > Click on the cluster link (cluster_for_service_XYZ) > Ray logs (tab at bottom) > paste command > Open worker-XYZ directory > View combined_worker.log
The combination of using Workspaces for development and Job & Services for production make it extremely easy and fast to make the transition. The cluster environment and compute configurations are the exact same so the code that's executing runs on the same conditions. However, we may sometimes want to scale up our production compute configurations to execute Jobs faster or meet the availability/latency demands for our Services. We could address this by creating a new compute configuration:
+# Compute config
+export CLUSTER_COMPUTE_NAME="madewithml-cluster-compute-prod"
+anyscale cluster-compute create deploy/cluster_compute_prod.yaml --name $CLUSTER_COMPUTE_NAME # uses new config with prod compute requirements
+or by using a one-off configuration to specify the compute changes, where instead of pointing to a previously existing compute configuration, we can define it directly in our Jobs/Services yaml configuration:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
And with that, we're able to completely productionize our ML workloads! We have a working service that we can use to make predictions using our trained model. However, what happens when we receive new data or our model's performance regresses over time? With our current approach here, we have to manually execute our Jobs and Services again to udpate our application. In the next lesson, we'll learn how to automate this process with CI/CD workflows that execute our Jobs and Services based on an event (e.g. new data).
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Labeling (or annotation) is the process of identifying the inputs and outputs that are worth modeling (not just what could be modeled).
+It's really important to get our labeling workflows in place before we start performing downstream tasks such as data augmentation, model training, etc.
+Warning
+Be careful not to include features in the dataset that will not be available during prediction, causing data leaks.
+What else can we learn?
+It's not just about identifying and labeling our initial dataset. What else can we learn from it?
+It's also the phase where we can use our deep understanding of the problem to:
+- augment the training data split
+- enhance using auxiliary datasets
+- simplify using constraints
+- remove noisy samples
+- improve the labeling process
+Regardless of whether we have a custom labeling platform or we choose a generalized platform, the process of labeling and all it's related workflows (QA, data import/export, etc.) follow a similar approach.
+[WHAT] Decide what needs to be labeled:[WHERE] Design the labeling interface:[HOW] Compose labeling instructions: +
+[IMPORT] new data for annotation[EXPORT] annotated data for QA, testing, modeling, etc. +
+For the purpose of this course, our data is already labeled, so we'll perform a basic version of ELT (extract, load, transform) to construct the labeled dataset.
+++In our data-stack and orchestration lessons, we'll construct a modern data stack and programmatically deliver high quality data via DataOps workflows.
+
Recall that our objective was to classify incoming content so that the community can discover them easily. These data assets will act as the training data for our first model.
+We'll start by extracting data from our sources (external CSV files). Traditionally, our data assets will be stored, versioned and updated in a database, warehouse, etc. We'll learn more about these different data systems later, but for now, we'll load our data as a stand-alone CSV file.
+1 | |
1 +2 +3 +4 | |
+ ++ +
We'll also load the labels (tag category) for our projects.
+1 +2 +3 +4 | |
+ ++ +
Apply basic transformations to create our labeled dataset.
+1 +2 +3 | |
+ ++ +
1 | |
Finally, we'll load our transformed data locally so that we can use it for our machine learning application.
+1 +2 | |
We could have used the user provided tags as our labels but what if the user added a wrong tag or forgot to add a relevant one. To remove this dependency on the user to provide the gold standard labels, we can leverage labeling tools and platforms. These tools allow for quick and organized labeling of the dataset to ensure its quality. And instead of starting from scratch and asking our labeler to provide all the relevant tags for a given project, we can provide the author's original tags and ask the labeler to add / remove as necessary. The specific labeling tool may be something that needs to be custom built or leverages something from the ecosystem.
+++As our platform grows, so too will our dataset and labeling needs so it's imperative to use the proper tooling that supports the workflows we'll depend on.
+
Generalized labeling solutions
+What criteria should we use to evaluate what labeling platform to use?
+It's important to pick a generalized platform that has all the major labeling features for your data modality with the capability to easily customize the experience.
+However, as an industry trend, this balance between generalization and specificity is difficult to strike. So many teams put in the upfront effort to create bespoke labeling platforms or used industry specific, niche, labeling tools.
+Even with a powerful labeling tool and established workflows, it's easy to see how involved and expensive labeling can be. Therefore, many teams employ active learning to iteratively label the dataset and evaluate the model.
+++This can be significantly more cost-effective and faster than labeling the entire dataset.
+
 +
+If we had samples that needed labeling or if we simply wanted to validate existing labels, we can use weak supervision to generate labels as opposed to hand labeling all of them. We could utilize weak supervision via labeling functions to label our existing and new data, where we can create constructs based on keywords, pattern expressions, knowledge bases, etc. And we can add to the labeling functions over time and even mitigate conflicts amongst the different labeling functions. We'll use these labeling functions to create and evaluate slices of our data in the evaluation lesson.
+1 +2 +3 +4 +5 +6 | |
++An easy way to validate our labels (before modeling) is to use the aliases in our auxillary datasets to create labeling functions for the different classes. Then we can look for false positives and negatives to identify potentially mislabeled samples. We'll actually implement a similar kind of inspection approach, but using a trained model as a heuristic, in our dashboards lesson.
+
Labeling isn't just a one time event or something we repeat identically. As new data is available, we'll want to strategically label the appropriate samples and improve slices of our data that are lacking in quality. Once new data is labeled, we can have workflows that are triggered to start the (re)training process to deploy a new version of our system.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Logging is the process of tracking and recording key events that occur in our applications for the purpose of inspection, debugging, etc. They're a whole lot more powerful than print statements because they allow us to send specific pieces of information to specific locations with custom formatting, shared interfaces, etc. This makes logging a key proponent in being able to surface insightful information from the internal processes of our application.
There are a few overarching concepts to be aware of:
+Logger: emits the log messages from our application.Handler: sends log records to a specific location.Formatter: formats and styles the log records.There is so much more to logging such as filters, exception logging, etc. but these basics will allows us to do everything we need for our application.
+Before we create our specialized, configured logger, let's look at what logged messages look like by using the basic configuration. +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+DEBUG:root:Used for debugging your code. +INFO:root:Informative messages from your code. +WARNING:root:Everything works but there is something to be aware of. +ERROR:root:There's been a mistake with the process. +CRITICAL:root:There is something terribly wrong and process may terminate. ++ +
These are the basic levels of logging, where DEBUG is the lowest priority and CRITICAL is the highest. We defined our logger using basicConfig to emit log messages to stdout (ie. our terminal console), but we also could've written to any other stream or even a file. We also defined our logging to be sensitive to log messages starting from level DEBUG. This means that all of our logged messages will be displayed since DEBUG is the lowest level. Had we made the level ERROR, then only ERROR and CRITICAL log message would be displayed.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
+ERROR:root:There's been a mistake with the process. +CRITICAL:root:There is something terribly wrong and process may terminate. ++ +
First we'll set the location of our logs in our config.py script:
1 +2 +3 | |
Next, we'll configure the logger for our application:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 | |
[Lines 6-11]: define two different Formatters (determine format and style of log messages), minimal and detailed, which use various LogRecord attributes to create a formatting template for log messages.[Lines 12-35]: define the different Handlers (details about location of where to send log messages):console: sends log messages (using the minimal formatter) to the stdout stream for messages above level DEBUG (ie. all logged messages).info: send log messages (using the detailed formatter) to logs/info.log (a file that can be up to 1 MB and we'll backup the last 10 versions of it) for messages above level INFO.error: send log messages (using the detailed formatter) to logs/error.log (a file that can be up to 1 MB and we'll backup the last 10 versions of it) for messages above level ERROR.[Lines 36-40]: attach our different handlers to our root Logger.We chose to use a dictionary to configure our logger but there are other ways such as Python script, configuration file, etc. Click on the different options below to expand and view the respective implementation.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 | |
Place this inside a logging.config file:
+
[formatters]
+keys=minimal,detailed
+
+[formatter_minimal]
+format=%(message)s
+
+[formatter_detailed]
+format=
+ %(levelname)s %(asctime)s [%(name)s:%(filename)s:%(funcName)s:%(lineno)d]
+ %(message)s
+
+[handlers]
+keys=console,info,error
+
+[handler_console]
+class=StreamHandler
+level=DEBUG
+formatter=minimal
+args=(sys.stdout,)
+
+[handler_info]
+class=handlers.RotatingFileHandler
+level=INFO
+formatter=detailed
+backupCount=10
+maxBytes=10485760
+args=("logs/info.log",)
+
+[handler_error]
+class=handlers.RotatingFileHandler
+level=ERROR
+formatter=detailed
+backupCount=10
+maxBytes=10485760
+args=("logs/error.log",)
+
+[loggers]
+keys=root
+
+[logger_root]
+level=INFO
+handlers=console,info,error
+Place this inside your Python script: +
1 +2 +3 +4 +5 +6 +7 +8 | |
We can load our logger configuration dict like so:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
+DEBUG Used for debugging your code. config.py:71 +INFO Informative messages from your code. config.py:72 +WARNING Everything works but there is something to be aware of. config.py:73 +ERROR There's been a mistake with the process. config.py:74 +CRITICAL There is something terribly wrong and process may terminate. config.py:75 ++ +
Our logged messages become stored inside the respective files in our logs directory:
+logs/
+ ├── info.log
+ └── error.log
+And since we defined a detailed formatter, we would see informative log messages like these:
++INFO 2020-10-21 11:18:42,102 [config.py:module:72] +Informative messages from your code. ++ +
In our project, we can replace all of our print statements into logging statements:
+1 | |
1 +2 | |
All of our log messages are at the INFO level but while developing we may have had to use DEBUG levels and we also add some ERROR or CRITICAL log messages if our system behaves in an unintended manner.
what: log all the necessary details you want to surface from our application that will be useful during development and afterwards for retrospective inspection.
+where: a best practice is to not clutter our modular functions with log statements. Instead we should log messages outside of small functions and inside larger workflows. For example, there are no log messages inside any of our scripts except the main.py and train.py files. This is because these scripts use the smaller functions defined in the other scripts (data.py, evaluate.py, etc.). If we ever feel that we the need to log within our other functions, then it usually indicates that the function needs to be broken down further.
++When it comes to saving our logs, we could simply upload our logs to a cloud blog storage (ex. S3 or Google Cloud Storage). Or for a more production-grade logging option, we could consider the Elastic stack.
+
In the next lesson, we'll learn how to document our code and automatically generate high quality docs for our application.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Throughout our development so far, there are so many different commands to keep track of. To help organize everything, we're going to use a Makefile which is a automation tool that organizes our commands. We'll start by create this file in our project's root directory.
touch Makefile
+At the top of our Makefile we need to specify the shell environment we want all of our commands to execute in:
# Makefile
+SHELL = /bin/bash
+Inside our Makefile, we'll be creating a list of rules. These rules have a target which can sometimes have prerequisites that need to be met (can be other targets) and on the next line a Tab followed by a recipe which specifies how to create the target.
# Makefile
+target: prerequisites
+<TAB> recipe
+For example, if we wanted to create a rule for styling our files, we would add the following to our Makefile:
# Styling
+style:
+ black .
+ flake8
+ python3 -m isort .
+Tabs vs. spaces
+Makefiles require that indention be done with a
+Makefile:
+Luckily, editors like VSCode automatically change indentation to tabs even if other files use spaces.
We can execute any of the rules by typing make <target> in the terminal:
# Make a target
+$ make style
++black . +All done! ✨ 🍰 ✨ +8 files left unchanged. +flake8 +python3 -m isort . +Skipped 1 files ++ +
Similarly, we can set up our Makefile for creating a virtual environment:
# Environment
+venv:
+ python3 -m venv venv
+ source venv/bin/activate && \
+ python3 -m pip install pip setuptools wheel && \
+ python3 -m pip install -e .
++++
&&signifies that we want these commands to execute in one shell (more on this below).
A Makefile is called as such because traditionally the targets are supposed to be files we can make. However, Makefiles are also commonly used as command shortcuts, which can lead to confusion when a Makefile target and a file share the same name! For example if we have a file called venv (which we do) and a target in your Makefile called venv, when you run make venv we'll get this message:
$ make venv
++make: `venv' is up to date. ++ +
In this situation, this is the intended behavior because if a virtual environment already exists, then we don't want ot make that target again. However, sometimes, we'll name our targets and want them to execute whether it exists as an actual file or not. In these scenarios, we want to define a PHONY target in our makefile by adding this line above the target:
+
.PHONY: <target_name>
+Most of the rules in our Makefile will require the PHONY target because we want them to execute even if there is a file sharing the target's name.
# Styling
+.PHONY: style
+style:
+ black .
+ flake8
+ isort .
+Before we make a target, we can attach prerequisites to them. These can either be file targets that must exist or PHONY target commands that need to be executed prior to making this target. For example, we'll set the style target as a prerequisite for the clean target so that all files are formatted appropriately prior to cleaning them.
+# Cleaning
+.PHONY: clean
+clean: style
+ find . -type f -name "*.DS_Store" -ls -delete
+ find . | grep -E "(__pycache__|\.pyc|\.pyo)" | xargs rm -rf
+ find . | grep -E ".pytest_cache" | xargs rm -rf
+ find . | grep -E ".ipynb_checkpoints" | xargs rm -rf
+ find . | grep -E ".trash" | xargs rm -rf
+ rm -f .coverage
+We can also set and use variables inside our Makefile to organize all of our rules.
+We can set the variables directly inside the Makefile. If the variable isn't defined in the Makefile, then it would default to any environment variable with the same name. +
# Set variable
+MESSAGE := "hello world"
+
+# Use variable
+greeting:
+ @echo ${MESSAGE}
+We can also use variables passed in when executing the rule like so (ensure that the variable is not overridden inside the Makefile): +
make greeting MESSAGE="hi"
+Each line in a recipe for a rule will execute in a separate sub-shell. However for certain recipes such as activating a virtual environment and loading packages, we want to execute all steps in one shell. To do this, we can add the .ONESHELL special target above any target.
# Environment
+.ONESHELL:
+venv:
+ python3 -m venv venv
+ source venv/bin/activate
+ python3 -m pip install pip setuptools wheel
+ python3 -m pip install -e .
+However this is only available in Make version 3.82 and above and most Macs currently use version 3.81. You can either update to the current version or chain your commands with && as we did previously:
# Environment
+venv:
+ python3 -m venv venv
+ source venv/bin/activate && \
+ python3 -m pip install pip setuptools wheel && \
+ python3 -m pip install -e .
+The last thing we'll add to our Makefile (for now at least) is a help target to the very top. This rule will provide an informative message for this Makefile's capabilities:
.PHONY: help
+help:
+ @echo "Commands:"
+ @echo "venv : creates a virtual environment."
+ @echo "style : executes style formatting."
+ @echo "clean : cleans all unnecessary files."
+make help
++Commands: +venv : creates a virtual environment. +style : executes style formatting. +clean : cleans all unnecessary files. ++ +
++ +There's a whole lot more to Makefiles but this is plenty for most applied ML projects.
+
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Even though we've trained and thoroughly evaluated our model, the real work begins once we deploy to production. This is one of the fundamental differences between traditional software engineering and ML development. Traditionally, with rule based, deterministic, software, the majority of the work occurs at the initial stage and once deployed, our system works as we've defined it. But with machine learning, we haven't explicitly defined how something works but used data to architect a probabilistic solution. This approach is subject to natural performance degradation over time, as well as unintended behavior, since the data exposed to the model will be different from what it has been trained on. This isn't something we should be trying to avoid but rather understand and mitigate as much as possible. In this lesson, we'll understand the short comings from attempting to capture performance degradation in order to motivate the need for drift detection.
+Tip
+We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the monitoring-ml repository for a quick overview with an interactive notebook.
+The first step to insure that our model is performing well is to ensure that the actual system is up and running as it should. This can include metrics specific to service requests such as latency, throughput, error rates, etc. as well as infrastructure utilization such as CPU/GPU utilization, memory, etc.
+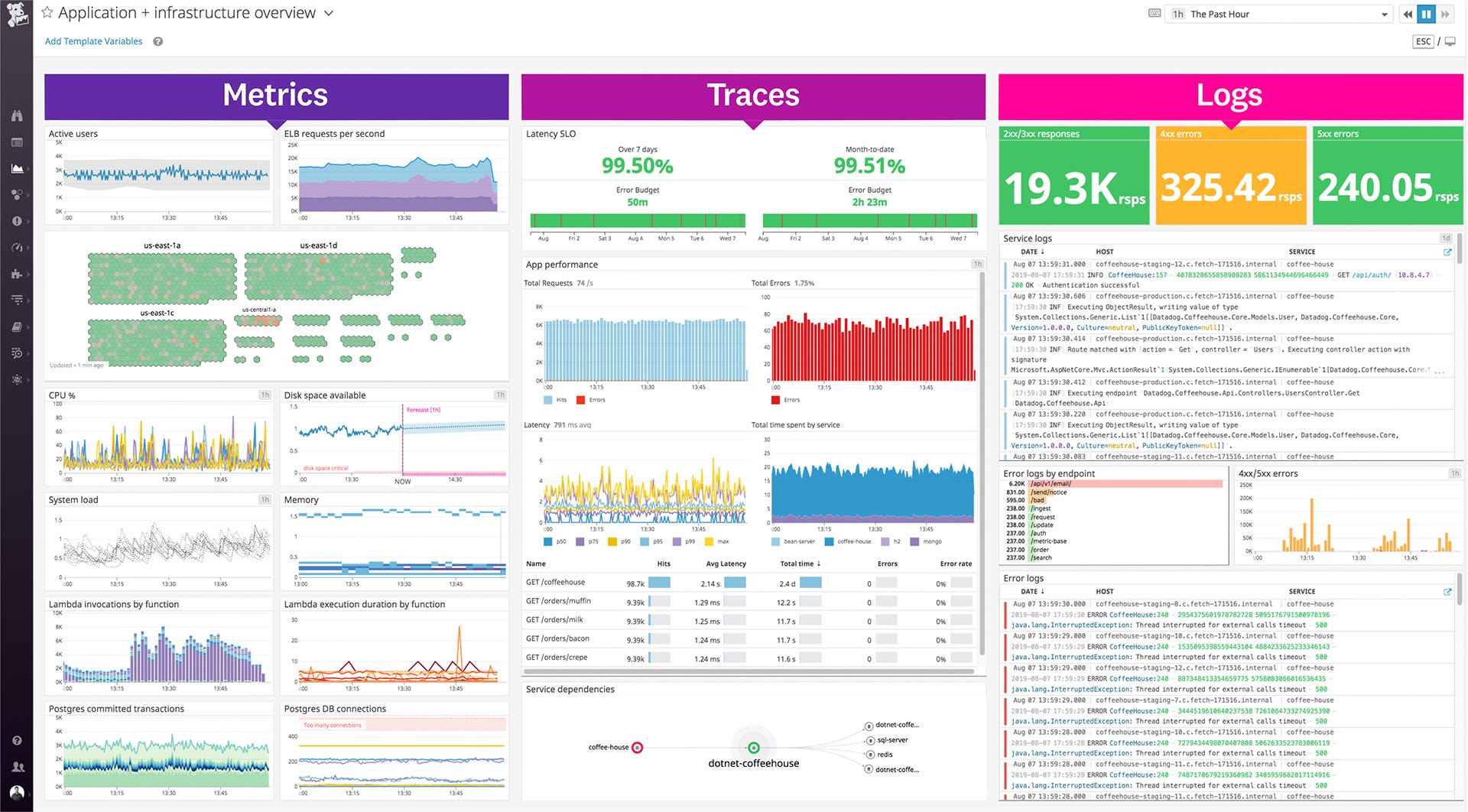 +
+Fortunately, most cloud providers and even orchestration layers will provide this insight into our system's health for free through a dashboard. In the event we don't, we can easily use Grafana, Datadog, etc. to ingest system performance metrics from logs to create a customized dashboard and set alerts.
+Unfortunately, just monitoring the system's health won't be enough to capture the underlying issues with our model. So, naturally, the next layer of metrics to monitor involves the model's performance. These could be quantitative evaluation metrics that we used during model evaluation (accuracy, precision, f1, etc.) but also key business metrics that the model influences (ROI, click rate, etc.).
+It's usually never enough to just analyze the cumulative performance metrics across the entire span of time since the model has been deployed. Instead, we should also inspect performance across a period of time that's significant for our application (ex. daily). These sliding metrics might be more indicative of our system's health and we might be able to identify issues faster by not obscuring them with historical data.
+++👉 Follow along interactive notebook in the monitoring-ml repository as we implement the concepts below.
+
1 +2 +3 +4 | |
1 +2 +3 +4 +5 | |
1 +2 +3 | |
+Average cumulative f1 on the last day: 93.7 ++
1 +2 +3 +4 | |
+Average sliding f1 on the last day: 88.6 ++
1 +2 +3 +4 +5 | |
 +
+++We may need to monitor metrics at various window sizes to catch performance degradation as soon as possible. Here we're monitoring the overall f1 but we can do the same for slices of data, individual classes, etc. For example, if we monitor the performance on a specific tag, we may be able to quickly catch new algorithms that were released for that tag (ex. new transformer architecture).
+
We may not always have the ground-truth outcomes available to determine the model's performance on production inputs. This is especially true if there is significant lag or annotation is required on the real-world data. To mitigate this, we could:
+However, approximate signals are not always available for every situation because there is no feedback on the ML system’s outputs or it’s too delayed. For these situations, a recent line of research relies on the only component that’s available in all situations: the input data.
+ +
+The core idea is to develop slicing functions that may potentially capture the ways our data may experience distribution shift. These slicing functions should capture obvious slices such as class labels or different categorical feature values but also slices based on implicit metadata (hidden aspects of the data that are not explicit feature columns). These slicing functions are then applied to our labeled dataset to create matrices with the corresponding labels. The same slicing functions are applied to our unlabeled production data to approximate what the weighted labels would be. With this, we can determine the approximate performance! The intuition here is that we can better approximate performance on our unlabeled dataset based on the similarity between the labeled slice matrix and unlabeled slice matrix. A core dependency of this assumption is that our slicing functions are comprehensive enough that they capture the causes of distributional shift.
+Warning
+If we wait to catch the model decay based on the performance, it may have already caused significant damage to downstream business pipelines that are dependent on it. We need to employ more fine-grained monitoring to identify the sources of model drift prior to actual performance degradation.
+We need to first understand the different types of issues that can cause our model's performance to decay (model drift). The best way to do this is to look at all the moving pieces of what we're trying to model and how each one can experience drift.
+| Entity | +Description | +Drift | +
|---|---|---|
| \(X\) | +inputs (features) | +data drift \(\rightarrow P(X) \neq P_{ref}(X)\) | +
| \(y\) | +outputs (ground-truth) | +target drift \(\rightarrow P(y) \neq P_{ref}(y)\) | +
| \(P(y \vert X)\) | +actual relationship between \(X\) and \(y\) | +concept drift \(\rightarrow P(y \vert X) \neq P_{ref}(y \vert X)\) | +
Data drift, also known as feature drift or covariate shift, occurs when the distribution of the production data is different from the training data. The model is not equipped to deal with this drift in the feature space and so, it's predictions may not be reliable. The actual cause of drift can be attributed to natural changes in the real-world but also to systemic issues such as missing data, pipeline errors, schema changes, etc. It's important to inspect the drifted data and trace it back along it's pipeline to identify when and where the drift was introduced.
+Warning
+Besides just looking at the distribution of our input data, we also want to ensure that the workflows to retrieve and process our input data is the same during training and serving to avoid training-serving skew. However, we can skip this step if we retrieve our features from the same source location for both training and serving, ie. from a feature store.
+ +
+++As data starts to drift, we may not yet notice significant decay in our model's performance, especially if the model is able to interpolate well. However, this is a great opportunity to potentially retrain before the drift starts to impact performance.
+
Besides just the input data changing, as with data drift, we can also experience drift in our outcomes. This can be a shift in the distributions but also the removal or addition of new classes with categorical tasks. Though retraining can mitigate the performance decay caused target drift, it can often be avoided with proper inter-pipeline communication about new classes, schema changes, etc.
+Besides the input and output data drifting, we can have the actual relationship between them drift as well. This concept drift renders our model ineffective because the patterns it learned to map between the original inputs and outputs are no longer relevant. Concept drift can be something that occurs in various patterns:
+ +
+++All the different types of drift we discussed can can occur simultaneously which can complicated identifying the sources of drift.
+
Now that we've identified the different types of drift, we need to learn how to locate and how often to measure it. Here are the constraints we need to consider:
+Since we're dealing with online drift detection (ie. detecting drift in live production data as opposed to past batch data), we can employ either a fixed or sliding window approach to identify our set of points for comparison. Typically, the reference window is a fixed, recent subset of the training data while the test window slides over time.
+Scikit-multiflow provides a toolkit for concept drift detection techniques directly on streaming data. The package offers windowed, moving average functionality (including dynamic preprocessing) and even methods around concepts like gradual concept drift.
+++We can also compare across various window sizes simultaneously to ensure smaller cases of drift aren't averaged out by large window sizes.
+
Once we have the window of points we wish to compare, we need to know how to compare them.
+1 +2 +3 +4 | |
1 +2 +3 +4 +5 +6 +7 | |
+ ++ +
The first form of measurement can be rule-based such as validating expectations around missing values, data types, value ranges, etc. as we did in our data testing lesson. The difference now is that we'll be validating these expectations on live production data.
+1 +2 | |
1 +2 +3 +4 | |
1 +2 | |
+{'evaluated_expectations': 2,
+ 'success_percent': 100.0,
+ 'successful_expectations': 2,
+ 'unsuccessful_expectations': 0}
+
+1 +2 | |
+{'evaluated_expectations': 2,
+ 'success_percent': 50.0,
+ 'successful_expectations': 1,
+ 'unsuccessful_expectations': 1}
+
+
+Once we've validated our rule-based expectations, we need to quantitatively measure drift across the different features in our data.
+Our task may involve univariate (1D) features that we will want to monitor. While there are many types of hypothesis tests we can use, a popular option is the Kolmogorov-Smirnov (KS) test.
+The KS test determines the maximum distance between two distribution's cumulative density functions. Here, we'll measure if there is any drift on the size of our input text feature between two different data subsets.
+Tip
+While text is a direct feature in our task, we can also monitor other implicit features such as % of unknown tokens in text (need to maintain a training vocabulary), etc. While they may not be used for our machine learning model, they can be great indicators for detecting drift.
+1 | |
1 +2 +3 +4 +5 +6 | |
1 +2 | |
1 +2 +3 +4 +5 +6 | |
 +
+1 | |
+{'data': {'distance': array([0.09], dtype=float32),
+ 'is_drift': 0,
+ 'p_val': array([0.3927307], dtype=float32),
+ 'threshold': 0.01},
+ 'meta': {'data_type': None,
+ 'detector_type': 'offline',
+ 'name': 'KSDrift',
+ 'version': '0.9.1'}}
+
+
+++↓ p-value = ↑ confident that the distributions are different.
+
1 +2 +3 +4 +5 +6 | |
 +
+1 | |
+{'data': {'distance': array([0.63], dtype=float32),
+ 'is_drift': 1,
+ 'p_val': array([6.7101775e-35], dtype=float32),
+ 'threshold': 0.01},
+ 'meta': {'data_type': None,
+ 'detector_type': 'offline',
+ 'name': 'KSDrift',
+ 'version': '0.9.1'}}
+
+
+Similarly, for categorical data (input features, targets, etc.), we can apply the Pearson's chi-squared test to determine if a frequency of events in production is consistent with a reference distribution.
+++We're creating a categorical variable for the # of tokens in our text feature but we could very very apply it to the tag distribution itself, individual tags (binary), slices of tags, etc.
+
1 | |
1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 +4 +5 +6 | |
 +
+1 | |
+{'data': {'distance': array([4.135522], dtype=float32),
+ 'is_drift': 0,
+ 'p_val': array([0.12646863], dtype=float32),
+ 'threshold': 0.01},
+ 'meta': {'data_type': None,
+ 'detector_type': 'offline',
+ 'name': 'ChiSquareDrift',
+ 'version': '0.9.1'}}
+
+
+1 +2 +3 +4 +5 +6 | |
 +
+1 | |
+{'data': {'is_drift': 1,
+ 'distance': array([118.03355], dtype=float32),
+ 'p_val': array([2.3406739e-26], dtype=float32),
+ 'threshold': 0.01},
+ 'meta': {'name': 'ChiSquareDrift',
+ 'detector_type': 'offline',
+ 'data_type': None}}
+
+
+As we can see, measuring drift is fairly straightforward for univariate data but difficult for multivariate data. We'll summarize the reduce and measure approach outlined in the following paper: Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift.
+ +
+We vectorized our text using tf-idf (to keep modeling simple), which has high dimensionality and is not semantically rich in context. However, typically with text, word/char embeddings are used. So to illustrate what drift detection on multivariate data would look like, let's represent our text using pretrained embeddings.
+++Be sure to refer to our embeddings and transformers lessons to learn more about these topics. But note that detecting drift on multivariate text embeddings is still quite difficult so it's typically more common to use these methods applied to tabular features or images.
+
We'll start by loading the tokenizer from a pretrained model.
+1 | |
1 +2 +3 +4 | |
+31090 ++ +
1 +2 +3 +4 | |
1 +2 | |
+tensor([ 102, 2029, 467, 1778, 609, 137, 6446, 4857, 191, 1332, + 2399, 13572, 19125, 1983, 147, 1954, 165, 6240, 205, 185, + 300, 3717, 7434, 1262, 121, 537, 201, 137, 1040, 111, + 545, 121, 4714, 205, 103, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, + 0]) +[CLS] comparison between yolo and rcnn on real world videos bringing theory to experiment is cool. we can easily train models in colab and find the results in minutes. [SEP] [PAD] [PAD] ... ++ +
1 +2 | |
+['[CLS]', 'comparison', 'between', 'yo', '##lo', 'and', 'rc', '##nn', 'on', 'real', 'world', 'videos', 'bringing', 'theory', 'to', 'experiment', 'is', 'cool', '.', 'we', 'can', 'easily', 'train', 'models', 'in', 'col', '##ab', 'and', 'find', 'the', 'results', 'in', 'minutes', '.', '[SEP]', '[PAD]', '[PAD]', ...] ++ +
Next, we'll load the pretrained model's weights and use the TransformerEmbedding object to extract the embeddings from the hidden state (averaged across tokens).
1 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+768 ++ +
Now we need to use a dimensionality reduction method to reduce our representations dimensions into something more manageable (ex. 32 dim) so we can run our two-sample tests on to detect drift. Popular options include:
+1 +2 | |
1 +2 +3 | |
+cuda ++ +
1 +2 +3 +4 +5 +6 +7 +8 | |
We can wrap all of the operations above into one preprocessing function that will consume input text and produce the reduced representation.
+1 +2 | |
1 +2 +3 +4 +5 | |
After applying dimensionality reduction techniques on our multivariate data, we can use different statistical tests to calculate drift. A popular option is Maximum Mean Discrepancy (MMD), a kernel-based approach that determines the distance between two distributions by computing the distance between the mean embeddings of the features from both distributions.
+1 | |
1 +2 | |
1 +2 +3 | |
+{'data': {'distance': 0.0021169185638427734,
+ 'distance_threshold': 0.0032651424,
+ 'is_drift': 0,
+ 'p_val': 0.05999999865889549,
+ 'threshold': 0.01},
+ 'meta': {'backend': 'pytorch',
+ 'data_type': None,
+ 'detector_type': 'offline',
+ 'name': 'MMDDriftTorch',
+ 'version': '0.9.1'}}
+
+
+1 +2 +3 | |
+{'data': {'distance': 0.014705955982208252,
+ 'distance_threshold': 0.003908038,
+ 'is_drift': 1,
+ 'p_val': 0.0,
+ 'threshold': 0.01},
+ 'meta': {'backend': 'pytorch',
+ 'data_type': None,
+ 'detector_type': 'offline',
+ 'name': 'MMDDriftTorch',
+ 'version': '0.9.1'}}
+
+
+So far we've applied our drift detection methods on offline data to try and understand what reference window sizes should be, what p-values are appropriate, etc. However, we'll need to apply these methods in the online production setting so that we can catch drift as easy as possible.
+++Many monitoring libraries and platforms come with online equivalents for their detection methods.
+
Typically, reference windows are large so that we have a proper benchmark to compare our production data points to. As for the test window, the smaller it is, the more quickly we can catch sudden drift. Whereas, a larger test window will allow us to identify more subtle/gradual drift. So it's best to compose windows of different sizes to regularly monitor.
+1 | |
1 +2 +3 +4 | |
+Generating permutations of kernel matrix.. +100%|██████████| 1000/1000 [00:00<00:00, 13784.22it/s] +Computing thresholds: 100%|██████████| 200/200 [00:32<00:00, 6.11it/s] ++ +
As data starts to flow in, we can use the detector to predict drift at every point. Our detector should detect drift sooner in our drifter dataset than in our normal data.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
1 +2 +3 | |
+27 steps ++ +
1 +2 +3 | |
+11 steps ++ +
There are also several considerations around how often to refresh both the reference and test windows. We could base in on the number of new observations or time without drift, etc. We can also adjust the various thresholds (ERT, window size, etc.) based on what we learn about our system through monitoring.
+With drift, we're comparing a window of production data with reference data as opposed to looking at any one specific data point. While each individual point may not be an anomaly or outlier, the group of points may cause a drift. The easiest way to illustrate this is to imagine feeding our live model the same input data point repeatedly. The actual data point may not have anomalous features but feeding it repeatedly will cause the feature distribution to change and lead to drift.
+ +
+Unfortunately, it's not very easy to detect outliers because it's hard to constitute the criteria for an outlier. Therefore the outlier detection task is typically unsupervised and requires a stochastic streaming algorithm to identify potential outliers. Luckily, there are several powerful libraries such as PyOD, Alibi Detect, WhyLogs (uses Apache DataSketches), etc. that offer a suite of outlier detection functionality (largely for tabular and image data for now).
+Typically, outlier detection algorithms fit (ex. via reconstruction) to the training set to understand what normal data looks like and then we can use a threshold to predict outliers. If we have a small labeled dataset with outliers, we can empirically choose our threshold but if not, we can choose some reasonable tolerance.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
++When we identify outliers, we may want to let the end user know that the model's response may not be reliable. Additionally, we may want to remove the outliers from the next training set or further inspect them and upsample them in case they're early signs of what future distributions of incoming features will look like.
+
It's not enough to just be able to measure drift or identify outliers but to also be able to act on it. We want to be able to alert on drift, inspect it and then act on it.
+Once we've identified outliers and/or measured statistically significant drift, we need to a devise a workflow to notify stakeholders of the issues. A negative connotation with monitoring is fatigue stemming from false positive alerts. This can be mitigated by choosing the appropriate constraints (ex. alerting thresholds) based on what's important to our specific application. For example, thresholds could be:
+1 +2 | |
1 +2 | |
1 +2 | |
Once we have our carefully crafted alerting workflows in place, we can notify stakeholders as issues arise via email, Slack, PageDuty, etc. The stakeholders can be of various levels (core engineers, managers, etc.) and they can subscribe to the alerts that are relevant for them.
+Once we receive an alert, we need to inspect it before acting on it. An alert needs several components in order for us to completely inspect it:
+# Sample alerting ticket
+{
+ "triggered_alerts": ["text_length_drift"],
+ "threshold": 0.05,
+ "measurement": "KSDrift",
+ "distance": 0.86,
+ "p_val": 0.03,
+ "reference": [],
+ "target": [],
+ "logs": ...
+}
+With these pieces of information, we can work backwards from the alert towards identifying the root cause of the issue. Root cause analysis (RCA) is an important first step when it comes to monitoring because we want to prevent the same issue from impacting our system again. Often times, many alerts are triggered but they maybe all actually be caused by the same underlying issue. In this case, we'd want to intelligently trigger just one alert that pinpoints the core issue. For example, let's say we receive an alert that our overall user satisfaction ratings are reducing but we also receive another alert that our North American users also have low satisfaction ratings. Here's the system would automatically assess for drift in user satisfaction ratings across many different slices and aggregations to discover that only users in a specific area are experiencing the issue but because it's a popular user base, it ends up triggering all aggregate downstream alerts as well!
+There are many different ways we can act to drift based on the situation. An initial impulse may be to retrain our model on the new data but it may not always solve the underlying issue.
+Since detecting drift and outliers can involve compute intensive operations, we need a solution that can execute serverless workloads on top of our event data streams (ex. Kafka). Typically these solutions will ingest payloads (ex. model's inputs and outputs) and can trigger monitoring workloads. This allows us to segregate the resources for monitoring from our actual ML application and scale them as needed.
+ +
+When it actually comes to implementing a monitoring system, we have several options, ranging from fully managed to from-scratch. Several popular managed solutions are Arize, Arthur, Fiddler, Gantry, Mona, WhyLabs, etc., all of which allow us to create custom monitoring views, trigger alerts, etc. There are even several great open-source solutions such as EvidentlyAI, TorchDrift, WhyLogs, etc.
+We'll often notice that monitoring solutions are offered as part of the larger deployment option such as Sagemaker, TensorFlow Extended (TFX), TorchServe, etc. And if we're already working with Kubernetes, we could use KNative or Kubeless for serverless workload management. But we could also use a higher level framework such as KFServing or Seldon core that natively use a serverless framework like KNative.
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+So far we've implemented our DataOps (ELT, validation, etc.) and MLOps (optimization, training, evaluation, etc.) workflows as Python function calls. This has worked well since our dataset is static and small. But happens when we need to:
+We'll need to break down our end-to-end ML pipeline into individual workflows that can be orchestrated as needed. There are several tools that can help us so this such as Airflow, Prefect, Dagster, Luigi, Orchest and even some ML focused options such as Metaflow, Flyte, KubeFlow Pipelines, Vertex pipelines, etc. We'll be creating our workflows using AirFlow for its:
+++We'll be running Airflow locally but we can easily scale it by running on a managed cluster platform where we can run Python, Hadoop, Spark, etc. on large batch processing jobs (AWS EMR, Google Cloud's Dataproc, on-prem hardware, etc.).
+
Before we create our specific pipelines, let's understand and implement Airflow's overarching concepts that will allow us to "author, schedule, and monitor workflows".
+Separate repository
+Our work in this lesson will live in a separate repository so create a new directory (outside our mlops-course repository) called data-engineering. All the work in this lesson can be found in our data-engineering repository.
To install and run Airflow, we can either do so locally or with Docker. If using docker-compose to run Airflow inside Docker containers, we'll want to allocate at least 4 GB in memory.
# Configurations
+export AIRFLOW_HOME=${PWD}/airflow
+AIRFLOW_VERSION=2.3.3
+PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
+CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
+
+# Install Airflow (may need to upgrade pip)
+pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
+
+# Initialize DB (SQLite by default)
+airflow db init
+This will create an airflow directory with the following components:
airflow/
+├── logs/
+├── airflow.cfg
+├── airflow.db
+├── unittests.cfg
+└── webserver_config.py
+We're going to edit the airflow.cfg file to best fit our needs: +
# Inside airflow.cfg
+enable_xcom_pickling = True # needed for Great Expectations airflow provider
+load_examples = False # don't clutter webserver with examples
+And we'll perform a reset to implement these configuration changes.
+airflow db reset -y
+Now we're ready to initialize our database with an admin user, which we'll use to login to access our workflows in the webserver.
+# We'll be prompted to enter a password
+airflow users create \
+ --username admin \
+ --firstname FIRSTNAME \
+ --lastname LASTNAME \
+ --role Admin \
+ --email EMAIL
+Once we've created a user, we're ready to launch the webserver and log in using our credentials.
+# Launch webserver
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+airflow webserver --port 8080 # http://localhost:8080
+The webserver allows us to run and inspect workflows, establish connections to external data storage, manager users, etc. through a UI. Similarly, we could also use Airflow's REST API or Command-line interface (CLI) to perform the same operations. However, we'll be using the webserver because it's convenient to visually inspect our workflows.
+ +
+We'll explore the different components of the webserver as we learn about Airflow and implement our workflows.
+Next, we need to launch our scheduler, which will execute and monitor the tasks in our workflows. The schedule executes tasks by reading from the metadata database and ensures the task has what it needs to finish running. We'll go ahead and execute the following commands on the separate terminal window:
+# Launch scheduler (in separate terminal)
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
+airflow scheduler
+As our scheduler reads from the metadata database, the executor determines what worker processes are necessary for the task to run to completion. Since our default database SQLlite, which can't support multiple connections, our default executor is the Sequential Executor. However, if we choose a more production-grade database option such as PostgresSQL or MySQL, we can choose scalable Executor backends Celery, Kubernetes, etc. For example, running Airflow with Docker uses PostgresSQL as the database and so uses the Celery Executor backend to run tasks in parallel.
+Workflows are defined by directed acyclic graphs (DAGs), whose nodes represent tasks and edges represent the data flow relationship between the tasks. Direct and acyclic implies that workflows can only execute in one direction and a previous, upstream task cannot run again once a downstream task has started.
+ +
+DAGs can be defined inside Python workflow scripts inside the airflow/dags directory and they'll automatically appear (and continuously be updated) on the webserver. Before we start creating our DataOps and MLOps workflows, we'll learn about Airflow's concepts via an example DAG outlined in airflow/dags/example.py. Execute the following commands in a new (3rd) terminal window:
mkdir airflow/dags
+touch airflow/dags/example.py
+Inside each workflow script, we can define some default arguments that will apply to all DAGs within that workflow.
+1 +2 +3 +4 | |
++Typically, our DAGs are not the only ones running in an Airflow cluster. However, it can be messy and sometimes impossible to execute different workflows when they require different resources, package versions, etc. For teams with multiple projects, it’s a good idea to use something like the KubernetesPodOperator to execute each job using an isolated docker image.
+
We can initialize DAGs with many parameters (which will override the same parameters in default_args) and in several different ways:
using a with statement +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
using the dag decorator +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
++There are many parameters that we can initialize our DAGs with, including a
+start_dateand aschedule_interval. While we could have our workflows execute on a temporal cadence, many ML workflows are initiated by events, which we can map using sensors and hooks to external databases, file systems, etc.
Tasks are the operations that are executed in a workflow and are represented by nodes in a DAG. Each task should be a clearly defined single operation and it should be idempotent, which means we can execute it multiple times and expect the same result and system state. This is important in the event we need to retry a failed task and don't have to worry about resetting the state of our system. Like DAGs, there are several different ways to implement tasks:
+using the task decorator +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 | |
using Operators +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
++Though the graphs are directed, we can establish certain trigger rules for each task to execute on conditional successes or failures of the parent tasks.
+
The first method of creating tasks involved using Operators, which defines what exactly the task will be doing. Airflow has many built-in Operators such as the BashOperator or PythonOperator, which allow us to execute bash and Python commands respectively.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
There are also many other Airflow native Operators (email, S3, MySQL, Hive, etc.), as well as community maintained provider packages (Kubernetes, Snowflake, Azure, AWS, Salesforce, Tableau, etc.), to execute tasks specific to certain platforms or tools.
+++We can also create our own custom Operators by extending the BashOperator class.
+
Once we've defined our tasks using Operators or as decorated functions, we need to define the relationships between them (edges). The way we define the relationships depends on how our tasks were defined:
+using decorated functions +
1 +2 +3 | |
using Operators +
1 +2 +3 | |
In both scenarios, we'll setting task_2 as the downstream task to task_1.
Note
+We can even create intricate DAGs by using these notations to define the relationships.
+1 +2 +3 | |
 +
+When we use task decorators, we can see how values can be passed between tasks. But, how can we pass values when using Operators? Airflow uses XComs (cross communications) objects, defined with a key, value, timestamp and task_id, to push and pull values between tasks. When we use decorated functions, XComs are being used under the hood but it's abstracted away, allowing us to pass values amongst Python functions seamlessly. But when using Operators, we'll need to explicitly push and pull the values as we need it.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 | |
We can also view our XComs on the webserver by going to Admin >> XComs:
+ +
+Warning
+The data we pass between tasks should be small (metadata, metrics, etc.) because Airflow's metadata database is not equipped to hold large artifacts. However, if we do need to store and use the large results of our tasks, it's best to use an external data storage (blog storage, model registry, etc.) and perform heavy processing using Spark or inside data systems like a data warehouse.
+Once we've defined the tasks and their relationships, we're ready to run our DAGs. We'll start defining our DAG like so: +
1 +2 +3 | |
The new DAG will have appeared when we refresh our Airflow webserver.
+Our DAG is initially paused since we specified dags_are_paused_at_creation = True inside our airflow.cfg configuration, so we'll have to manually execute this DAG by clicking on it > unpausing it (toggle) > triggering it (button). To view the logs for any of the tasks in our DAG run, we can click on the task > Log.
 +
+Note
+We could also use Airflow's REST API (will configured authorization) or Command-line interface (CLI) to inspect and trigger workflows (and a whole lot more). Or we could even use the trigger_dagrun Operator to trigger DAGs from within another workflow.
# CLI to run dags
+airflow dags trigger <DAG_ID>
+Had we specified a start_date and schedule_interval when defining the DAG, it would have have automatically executed at the appropriate times. For example, the DAG below will have started two days ago and will be triggered at the start of every day.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
Warning
+Depending on the start_date and schedule_interval, our workflow should have been triggered several times and Airflow will try to catchup to the current time. We can avoid this by setting catchup=False when defining the DAG. We can also set this configuration as part of the default arguments:
1 +2 +3 +4 | |
However, if we did want to run particular runs in the past, we can manually backfill what we need.
+We could also specify a cron expression for our schedule_interval parameter or even use cron presets.
++Airflow's Scheduler will run our workflows one
+schedule_intervalfrom thestart_date. For example, if we want our workflow to start on01-01-1983and run@daily, then the first run will be immediately after01-01-1983T11:59.
While it may make sense to execute many data processing workflows on a scheduled interval, machine learning workflows may require more nuanced triggers. We shouldn't be wasting compute by running executing our workflows just in case we have new data. Instead, we can use sensors to trigger workflows when some external condition is met. For example, we can initiate data processing when a new batch of annotated data appears in a database or when a specific file appears in a file system, etc.
+++There's so much more to Airflow (monitoring, Task groups, smart senors, etc.) so be sure to explore them as you need them by using the official documentation.
+
Now that we've reviewed Airflow's major concepts, we're ready to create the DataOps workflows. It's the exact same workflow we defined in our data stack lesson -- extract, load and transform -- but this time we'll be doing everything programmatically and orchestrating it with Airflow.
+ +
+We'll start by creating the script where we'll define our workflows:
+touch airflow/dags/workflows.py
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
In two separate terminals, activate the virtual environment and spin up the Airflow webserver and scheduler:
+# Airflow webserver
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+export GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+airflow webserver --port 8080
+# Go to http://localhost:8080
+# Airflow scheduler
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
+export GOOGLE_APPLICATION_CREDENTIALS=~/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+airflow scheduler
+We're going to use the Airbyte connections we set up in our data-stack lesson but this time we're going to programmatically trigger the data syncs with Airflow. First, let's ensure that Airbyte is running on a separate terminal in it's repository:
+git clone https://github.com/airbytehq/airbyte.git # skip if already create in data-stack lesson
+cd airbyte
+docker-compose up
+Next, let's install the required packages and establish the connection between Airbyte and Airflow:
+pip install apache-airflow-providers-airbyte==3.1.0
+Admin > Connections > ➕Connection ID: airbyte
+Connection Type: HTTP
+Host: localhost
+Port: 8000
+++We could also establish connections programmatically but it’s good to use the UI to understand what’s happening under the hood.
+
In order to execute our extract and load data syncs, we can use the AirbyteTriggerSyncOperator:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 | |
We can find the connection_id for each Airbyte connection by:
Connections on the left menu.https://demo.airbyte.io/workspaces/<WORKSPACE_ID>/connections/<CONNECTION_ID>/status
+CONNECTION_ID position is the connection's id.We can trigger our DAG right now and view the extracted data be loaded into our BigQuery data warehouse but we'll continue developing and execute our DAG once the entire DataOps workflow has been defined.
+The specific process of where and how we extract our data can be bespoke but what's important is that we have validation at every step of the way. We'll once again use Great Expectations, as we did in our testing lesson, to validate our extracted and loaded data before transforming it.
+With the Airflow concepts we've learned so far, there are many ways to use our data validation library to validate our data. Regardless of what data validation tool we use (ex. Great Expectations, TFX, AWS Deequ, etc.) we could use the BashOperator, PythonOperator, etc. to run our tests. However, Great Expectations has a Airflow Provider package to make it even easier to validate our data. This package contains a GreatExpectationsOperator which we can use to execute specific checkpoints as tasks.
pip install airflow-provider-great-expectations==0.1.1 great-expectations==0.15.19
+great_expectations init
+This will create the following directory within our data-engineering repository:
+tests/great_expectations/
+├── checkpoints/
+├── expectations/
+├── plugins/
+├── uncommitted/
+├── .gitignore
+└── great_expectations.yml
+But first, before we can create our tests, we need to define a new datasource within Great Expectations for our Google BigQuery data warehouse. This will require several packages and exports:
pip install pybigquery==0.10.2 sqlalchemy_bigquery==1.4.4
+export GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+great_expectations datasource new
+What data would you like Great Expectations to connect to?
+ 1. Files on a filesystem (for processing with Pandas or Spark)
+ 2. Relational database (SQL) 👈
+What are you processing your files with?
+1. MySQL
+2. Postgres
+3. Redshift
+4. Snowflake
+5. BigQuery 👈
+6. other - Do you have a working SQLAlchemy connection string?
+This will open up an interactive notebook where we can fill in the following details: +
datasource_name = “dwh"
+connection_string = “bigquery://made-with-ml-359923/mlops_course”
+Next, we can create a suite of expectations for our data assets:
+great_expectations suite new
+How would you like to create your Expectation Suite?
+ 1. Manually, without interacting with a sample batch of data (default)
+ 2. Interactively, with a sample batch of data 👈
+ 3. Automatically, using a profiler
+Select a datasource
+ 1. dwh 👈
+Which data asset (accessible by data connector "default_inferred_data_connector_name") would you like to use?
+ 1. mlops_course.projects 👈
+ 2. mlops_course.tags
+Name the new Expectation Suite [mlops.projects.warning]: projects
+This will open up an interactive notebook where we can define our expectations. Repeat the same for creating a suite for our tags data asset as well.
+mlops_course.projectsTable expectations +
1 +2 | |
Column expectations: +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
mlops_course.tagsColumn expectations: +
1 +2 +3 +4 +5 +6 | |
Once we have our suite of expectations, we're ready to check checkpoints to execute these expectations:
+great_expectations checkpoint new projects
+This will, of course, open up an interactive notebook. Just ensure that the following information is correct (the default values may not be): +
datasource_name: dwh
+data_asset_name: mlops_course.projects
+expectation_suite_name: projects
+And repeat the same for creating a checkpoint for our tags suite.
+With our checkpoints defined, we're ready to apply them to our data assets in our warehouse.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
Once we've validated our extracted and loaded data, we're ready to transform it. Our DataOps workflows are not specific to any particular downstream application so the transformation must be globally relevant (ex. cleaning missing data, aggregation, etc.). Just like in our data stack lesson, we're going to use dbt to transform our data. However, this time, we're going to do everything programmatically using the open-source dbt-core package.
+In the root of our data-engineering repository, initialize our dbt directory with the following command: +
dbt init dbf_transforms
+Which database would you like to use?
+[1] bigquery 👈
+Desired authentication method option:
+[1] oauth
+[2] service_account 👈
+keyfile: /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+project (GCP project id): made-with-ml-XXXXXX # REPLACE
+dataset: mlops_course
+threads: 1
+job_execution_timeout_seconds: 300
+Desired location option:
+[1] US 👈 # or what you picked when defining your dataset in Airbyte DWH destination setup
+[2] EU
+We'll prepare our dbt models as we did using the dbt Cloud IDE in the previous lesson.
+cd dbt_transforms
+rm -rf models/example
+mkdir models/labeled_projects
+touch models/labeled_projects/labeled_projects.sql
+touch models/labeled_projects/schema.yml
+and add the following code to our model files:
+1 +2 +3 +4 +5 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
And we can use the BashOperator to execute our dbt commands like so:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
Programmatically using dbt Cloud
+While we developed locally, we could just as easily use Airflow’s dbt cloud provider to connect to our dbt cloud and use the different operators to schedule jobs. This is recommended for production because we can design jobs with proper environment, authentication, schemas, etc.
+Go to Admin > Connections > + +
Connection ID: dbt_cloud_default
+Connection Type: dbt Cloud
+Account ID: View in URL of https://cloud.getdbt.com/
+API Token: View in https://cloud.getdbt.com/#/profile/api/
+pip install apache-airflow-providers-dbt-cloud==2.1.0
+1 +2 +3 +4 +5 +6 +7 +8 | |
And of course, we'll want to validate our transformations beyond dbt's built-in methods, using great expectations. We'll create a suite and checkpoint as we did above for our projects and tags data assets. +
great_expectations suite new # for mlops_course.labeled_projects
+mlops_course.labeled_projectsTable expectations +
1 +2 | |
Column expectations: +
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 | |
great_expectations checkpoint new labeled_projects
+datasource_name: dwh
+data_asset_name: mlops_course.labeled_projects
+expectation_suite_name: labeled_projects
+and just like how we added the validation task for our extracted and loaded data, we can do the same for our transformed data in Airflow:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
Now we have our entire DataOps DAG define and executing it will prepare our data from extraction to loading to transformation (and with validation at every step of the way) for downstream applications.
+ +
+++Typically we'll use sensors to trigger workflows when a condition is met or trigger them directly from the external source via API calls, etc. For our ML use cases, this could be at regular intervals or when labeling or monitoring workflows trigger retraining, etc.
+
Once we have our data prepared, we're ready to create one of the many potential downstream applications that will depend on it. Let's head back to our mlops-course project and follow the same set up instructions for Airflow (you can stop the Airflow webserver and scheduler from our data-engineering project since we'll reuse PORT 8000).
# Airflow webserver
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+export GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+airflow webserver --port 8080
+# Go to http://localhost:8080
+# Airflow scheduler
+source venv/bin/activate
+export AIRFLOW_HOME=${PWD}/airflow
+export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES
+export GOOGLE_APPLICATION_CREDENTIALS=~/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE
+airflow scheduler
+touch airflow/dags/workflows.py
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 | |
We already had an tagifai.elt_data function defined to prepare our data but if we want to leverage the data inside our data warehouse, we'll want to connect to it.
pip install google-cloud-bigquery==1.21.0
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 | |
Next, we'll use Great Expectations to validate our data. Even though we've already validated our data, it's a best practice to test for data quality whenever there is a hand-off of data from one place to another. We've already created a checkpoint for our labeled_projects in our testing lesson so we'll just leverage that inside our MLOps DAG.
pip install airflow-provider-great-expectations==0.1.1 great-expectations==0.15.19
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
Finally, we'll optimize and train a model using our validated data.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 | |
And with that we have our MLOps workflow defined that uses the prepared data from our DataOps workflow. At this point, we can add additional tasks for offline/online evaluation, deployment, etc. with the same process as above.
+ +
+The DataOps and MLOps workflows connect to create an ML system that's capable of continually learning. Such a system will guide us with when to update, what exactly to update and how to update it (easily).
+++We use the word continual (repeat with breaks) instead of continuous (repeat without interruption / intervention) because we're not trying to create a system that will automatically update with new incoming data without human intervention.
+
Our production system is live and monitored. When an event of interest occurs (ex. drift), one of several events needs to be triggered:
+continue: with the currently deployed model without any updates. However, an alert was raised so it should analyzed later to reduce false positive alerts.improve: by retraining the model to avoid performance degradation causes by meaningful drift (data, target, concept, etc.).inspect: to make a decision. Typically expectations are reassessed, schemas are reevaluated for changes, slices are reevaluated, etc.rollback: to a previous version of the model because of an issue with the current deployment. Typically these can be avoided using robust deployment strategies (ex. dark canary).If we need to improve on the existing version of the model, it's not just the matter of fact of rerunning the model creation workflow on the new dataset. We need to carefully compose the training data in order to avoid issues such as catastrophic forgetting (forget previously learned patterns when presented with new data).
+labeling: new incoming data may need to be properly labeled before being used (we cannot just depend on proxy labels).active learning: we may not be able to explicitly label every single new data point so we have to leverage active learning workflows to complete the labeling process.QA: quality assurance workflows to ensure that labeling is accurate, especially for known false positives/negatives and historically poorly performing slices of data.augmentation: increasing our training set with augmented data that's representative of the original dataset.sampling: upsampling and downsampling to address imbalanced data slices.evaluation: creation of an evaluation dataset that's representative of what the model will encounter once deployed.Once we have the proper dataset for retraining, we can kickoff the workflows to update our system!
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Before performing a commit to our local repository, there are a lot of items on our mental todo list, ranging from styling, formatting, testing, etc. And it's very easy to forget some of these steps, especially when we want to "push to quick fix". To help us manage all these important steps, we can use pre-commit hooks, which will automatically be triggered when we try to perform a commit. These hooks can ensure that certain rules are followed or specific actions are executed successfully and if any of them fail, the commit will be aborted.
+We'll be using the Pre-commit framework to help us automatically perform important checks via hooks when we make a commit.
+++We'll start by installing and autoupdating pre-commit (we only have to do this once). +
+pre-commit install +pre-commit autoupdate +
We define our pre-commit hooks via a .pre-commit-config.yaml configuration file. We can either create our yaml configuration from scratch or use the pre-commit CLI to create a sample configuration which we can add to.
# Simple config
+pre-commit sample-config > .pre-commit-config.yaml
+cat .pre-commit-config.yaml
+When it comes to creating and using hooks, we have several options to choose from.
+Inside the sample configuration, we can see that pre-commit has added some default hooks from it's repository. It specifies the location of the repository, version as well as the specific hook ids to use. We can read about the function of these hooks and add even more by exploring pre-commit's built-in hooks. Many of them also have additional arguments that we can configure to customize the hook.
+1 +2 +3 +4 +5 +6 | |
++Be sure to explore the many other built-in hooks because there are some really useful ones that we use in our project. For example,
+check-merge-conflictto see if there are any lingering merge conflict strings ordetect-aws-credentialsif we accidentally left our credentials exposed in a file, and so much more.
And we can also exclude certain files from being processed by the hooks by using the optional exclude key. There are many other optional keys we can configure for each hook ID.
+1 +2 +3 +4 +5 | |
Besides pre-commit's built-in hooks, there are also many custom, 3rd party popular hooks that we can choose from. For example, if we want to apply formatting checks with Black as a hook, we can leverage Black's pre-commit hook.
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
This specific hook is defined under a .pre-commit-hooks.yaml inside Black's repository, as are other custom hooks under their respective package repositories.
+We can also create our own local hooks without configuring a separate .pre-commit-hooks.yaml. Here we're defining two pre-commit hooks, test-non-training and clean, to run some commands that we've defined in our Makefile. Similarly, we can run any entry command with arguments to create hooks very quickly.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
Our pre-commit hooks will automatically execute when we try to make a commit. We'll be able to see if each hook passed or failed and make any changes. If any of the hooks fail, we have to fix the errors ourselves or, in many instances, reformatting will occur automatically.
++check yaml..............................................PASSED +clean...................................................FAILED ++ +
In the event that any of the hooks failed, we need to add and commit again to ensure that all hooks are passed.
git add .
+git commit -m <MESSAGE>
+ +
+Though pre-commit hooks are meant to run before (pre) a commit, we can manually trigger all or individual hooks on all or a set of files.
+# Run
+pre-commit run --all-files # run all hooks on all files
+pre-commit run <HOOK_ID> --all-files # run one hook on all files
+pre-commit run --files <PATH_TO_FILE> # run all hooks on a file
+pre-commit run <HOOK_ID> --files <PATH_TO_FILE> # run one hook on a file
+It is highly not recommended to skip running any of the pre-commit hooks because they are there for a reason. But for some highly urgent, world saving commits, we can use the no-verify flag.
+# Commit without hooks
+git commit -m <MESSAGE> --no-verify
+++Highly recommend not doing this because no commit deserves to be force pushed no matter how "small" your change was. If you accidentally did this and want to clear the cache, run
+pre-commit run --all-filesand execute the commit message operation again.
In our .pre-commit-config.yaml configuration files, we've had to specify the versions for each of the repositories so we can use their latest hooks. Pre-commit has an autoupdate CLI command which will update these versions as they become available.
# Autoupdate
+pre-commit autoupdate
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+We'll start by first preparing our data by ingesting it from source and splitting it into training, validation and test data splits.
+Our data could reside in many different places (databases, files, etc.) and exist in different formats (CSV, JSON, Parquet, etc.). For our application, we'll load the data from a CSV file to a Pandas DataFrame using the read_csv function.
++Here is a quick refresher on the Pandas library.
+
1 | |
1 +2 +3 +4 | |
++In our data engineering lesson we'll look at how to continually ingest data from more complex sources (ex. data warehouses)
+
Next, we need to split our training dataset into train and val data splits.
train split to train the model.++Here the model will have access to both inputs (features) and outputs (labels) to optimize its internal weights.
+
val split to determine the model's performance.++Here the model will not use the labels to optimize its weights but instead, we will use the validation performance to optimize training hyperparameters such as the learning rate, etc.
+
test dataset to determine the model's performance after training.++This is our best measure of how the model may behave on new, unseen data that is from a similar distribution to our training dataset.
+
Tip
+For our application, we will have a training dataset to split into train and val splits and a separate testing dataset for the test set. While we could have one large dataset and split that into the three splits, it's a good idea to have a separate test dataset. Over time, our training data may grow and our test splits will look different every time. This will make it difficult to compare models against other models and against each other.
We can view the class counts in our dataset by using the pandas.DataFrame.value_counts function:
1 | |
1 +2 | |
+tag +natural-language-processing 310 +computer-vision 285 +other 106 +mlops 63 +Name: count, dtype: int64 ++ +
For our multi-class task (where each project has exactly one tag), we want to ensure that the data splits have similar class distributions. We can achieve this by specifying how to stratify the split by using the stratify keyword argument with sklearn's train_test_split() function.
Creating proper data splits
+What are the criteria we should focus on to ensure proper data splits?
+time-series)1 +2 +3 | |
How can we validate that our data splits have similar class distributions? We can view the frequency of each class in each split:
+1 +2 | |
+tag +natural-language-processing 248 +computer-vision 228 +other 85 +mlops 50 +Name: count, dtype: int64 ++ +
Before we view our validation split's class counts, recall that our validation split is only test_size of the entire dataset. So we need to adjust the value counts so that we can compare it to the training split's class counts.
1 +2 | |
+tag +natural-language-processing 248 +computer-vision 228 +other 84 +mlops 52 +Name: count, dtype: int64 ++ +
These adjusted counts looks very similar to our train split's counts. Now we're ready to explore our dataset!
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Data preprocessing can be categorized into two types of processes: preparation and transformation. We'll explore common preprocessing techniques and then we'll preprocess our dataset.
+Warning
+Certain preprocessing steps are global (don't depend on our dataset, ex. lower casing text, removing stop words, etc.) and others are local (constructs are learned only from the training split, ex. vocabulary, standardization, etc.). For the local, dataset-dependent preprocessing steps, we want to ensure that we split the data first before preprocessing to avoid data leaks.
Preparing the data involves organizing and cleaning the data.
+Performing SQL joins with existing data tables to organize all the relevant data you need into one view. This makes working with our dataset a whole lot easier.
+1 +2 | |
Warning
+We need to be careful to perform point-in-time valid joins to avoid data leaks. For example, if Table B may have features for objects in Table A that were not available at the time inference would have been needed.
+First, we'll have to identify the rows with missing values and once we do, there are several approaches to dealing with them.
+omit samples with missing values (if only a small subset are missing it) +
1 +2 +3 +4 +5 +6 | |
omit the entire feature (if too many samples are missing the value) +
1 +2 | |
fill in missing values for features (using domain knowledge, heuristics, etc.) +
1 +2 | |
may not always seem "missing" (ex. 0, null, NA, etc.) +
1 +2 +3 | |
1 +2 | |
Feature engineering involves combining features in unique ways to draw out signal.
+1 +2 | |
Tip
+Feature engineering can be done in collaboration with domain experts that can guide us on what features to engineer and use.
+Cleaning our data involves apply constraints to make it easier for our models to extract signal from the data.
+1 +2 +3 +4 | |
1 +2 | |
Transforming the data involves feature encoding and engineering.
+don't blindly scale features (ex. categorical features)
+standardization: rescale values to mean 0, std 1
+1 +2 +3 +4 +5 +6 +7 +8 | |
+x: [0.36769939 0.82302265 0.9891467 0.56200803] +mean: 0.69, std: 0.24 +x_standardized: [-1.33285946 0.57695671 1.27375049 -0.51784775] +mean: 0.00, std: 1.00 ++
min-max: rescale values between a min and max
+1 +2 +3 +4 +5 +6 +7 +8 | |
+x: [0.20195674 0.99108855 0.73005081 0.02540603] +min: 0.03, max: 0.99 +x_scaled: [0.18282479 1. 0.72968575 0. ] +min: 0.00, max: 1.00 ++
binning: convert a continuous feature into categorical using bins
+1 +2 +3 +4 +5 +6 +7 +8 | |
+x: [0.54906364 0.1051404 0.2737904 0.2926313 ] +bins: [0. 0.25 0.5 0.75 1. ] +binned: [3 1 2 2] ++
and many more!
+allows for representing data efficiently (maintains signal) and effectively (learns patterns, ex. one-hot vs embeddings)
+label: unique index for categorical value
+1 +2 +3 +4 +5 +6 +7 +8 | |
+array([2, 2, 1]) ++
one-hot: representation as binary vector
+1 +2 | |
+array([1, 0, 0, 1, 0, ..., 0]) ++
embeddings: dense representations capable of representing context
+1 +2 +3 +4 +5 | |
+(len(X), embedding_dim) ++
and many more!
+autoencoders: learn to encode inputs for compressed knowledge representation
+principle component analysis (PCA): linear dimensionality reduction to project data in a lower dimensional space.
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
+[[-1.44245791 -0.1744313 ] + [-0.1148688 0.31291575] + [ 1.55732672 -0.13848446]] +[0.96838847 0.03161153] +[2.12582835 0.38408396] ++
counts (ngram): sparse representation of text as matrix of token counts — useful if feature values have lot's of meaningful, separable signal.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
+['acetone', 'acetyl', 'chloride', 'hydroxide'] +[[1 1 0 0] + [0 1 1 0] + [0 0 1 1]] ++
similarity: similar to count vectorization but based on similarities in tokens
+++We'll often was to retrieve feature values for an entity (user, item, etc.) over time and reuse the same features across different projects. To ensure that we're retrieving the proper feature values and to avoid duplication of efforts, we can use a feature store.
+
Curse of dimensionality
+What can we do if a feature has lots of unique values but enough data points for each unique value (ex. URL as a feature)?
+We can encode our data with hashing or using it's attributes instead of the exact entity itself. For example, representing a user by their location and favorites as opposed to using their user ID or representing a webpage with it's domain as opposed to the exact url. This methods effectively decrease the total number of unique feature values and increase the number of data points for each.
+For our application, we'll be implementing a few of these preprocessing steps that are relevant for our dataset.
+1 +2 +3 +4 +5 | |
We can combine existing input features to create new meaningful signal for helping the model learn. However, there's usually no simple way to know if certain feature combinations will help or not without empirically experimenting with the different combinations. Here, we could use a project's title and description separately as features but we'll combine them to create one input feature.
+1 +2 | |
Since we're dealing with text data, we can apply some common text preprocessing operations. Here, we'll be using Python's built-in regular expressions library re and the Natural Language Toolkit nltk.
1 +2 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 | |
Note
+We could definitely try and include emojis, punctuations, etc. because they do have a lot of signal for the task but it's best to simplify the initial feature set we use to just what we think are the most influential and then we can slowly introduce other features and assess utility.
+Once we're defined our function, we can apply it to each row in our dataframe via pandas.DataFrame.apply.
1 +2 +3 +4 | |
+Comparison between YOLO and RCNN on real world videos Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes. +comparison yolo rcnn real world videos bringing theory experiment cool easily train models colab find results minutes ++ +
Warning
+We'll want to introduce less frequent features as they become more frequent or encode them in a clever way (ex. binning, extract general attributes, common n-grams, mean encoding using other feature values, etc.) so that we can mitigate the feature value dimensionality issue until we're able to collect more data.
+We'll wrap up our cleaning operation by removing columns (pandas.DataFrame.drop) and rows with null tag values (pandas.DataFrame.dropna).
1 +2 +3 +4 +5 | |
We need to encode our data into numerical values so that our models can process them. We'll start by encoding our text labels into unique indices.
+1 +2 +3 +4 +5 | |
+{'mlops': 0,
+ 'natural-language-processing': 1,
+ 'computer-vision': 2,
+ 'other': 3}
+
+
+Next, we can use the pandas.Series.map function to map our class_to_index dictionary on our tag column to encode our labels.
1 +2 +3 | |
We'll also want to be able to decode our predictions back into text labels. We can do this by creating an index_to_class dictionary and using that to convert encoded labels back into text labels.
1 +2 | |
1 +2 | |
+['computer-vision', 'computer-vision', 'other', 'other', 'other'] ++ +
Next we'll encode our text as well. Instead of using a random dictionary, we'll use a tokenizer that was used for a pretrained LLM (scibert) to tokenize our text. We'll be fine-tuning this exact model later when we train our model.
+++Here is a quick refresher on attention and Transformers.
+
1 +2 | |
The tokenizer will convert our input text into a list of token ids and a list of attention masks. The token ids are the indices of the tokens in the vocabulary. The attention mask is a binary mask indicating the position of the token indices so that the model can attend to them (and ignore the pad tokens).
+1 +2 +3 +4 +5 +6 +7 | |
+input_ids: [[ 102 2268 1904 190 29155 168 3267 2998 205 103]] +attention_mask: [[1 1 1 1 1 1 1 1 1 1]] +[CLS] transfer learning with transformers for text classification. [SEP] ++ +
++Note that we use
+padding="longest"in our tokenizer function to pad our inputs to the longest item in the batch. This becomes important when we use batches of inputs later and want to create a uniform input size, where shorted text sequences will be padded with zeros to meet the length of the longest input in the batch.
We'll wrap our tokenization into a tokenize function that we can use to tokenize batches of our data.
1 +2 +3 +4 | |
1 +2 | |
+{'ids': array([[ 102, 2029, 1778, 609, 6446, 4857, 1332, 2399, 13572,
+ 19125, 1983, 1954, 6240, 3717, 7434, 1262, 537, 201,
+ 1040, 545, 4714, 103]]),
+ 'masks': array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
+ 'targets': array([2])}
+
+
+We'll wrap up by combining all of our preprocessing operations into function. This way we can easily apply it to different datasets (training, inference, etc.)
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
1 +2 | |
+{'ids': array([[ 102, 856, 532, ..., 0, 0, 0],
+ [ 102, 2177, 29155, ..., 0, 0, 0],
+ [ 102, 2180, 3241, ..., 0, 0, 0],
+ ...,
+ [ 102, 453, 2068, ..., 5730, 432, 103],
+ [ 102, 11268, 1782, ..., 0, 0, 0],
+ [ 102, 1596, 122, ..., 0, 0, 0]]),
+ 'masks': array([[1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0],
+ ...,
+ [1, 1, 1, ..., 1, 1, 1],
+ [1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0]]),
+ 'targets': array([0, 1, 1, ... 0, 2, 3])}
+
+
+
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Before we start developing any machine learning models, we need to first motivate and design our application. While this is a technical course, this initial product design process is extremely crucial for creating great products. We'll focus on the product design aspects of our application in this lesson and the systems design aspects in the next lesson.
+The template below is designed to guide machine learning product development. It involves both the product and systems design (next lesson) aspects of our application:
+Product design (What & Why) → Systems design (How)
+ +
+++👉 Download a PDF of the ML canvas to use for your own products → ml-canvas.pdf (right click the link and hit "Save Link As...")
+
Motivate the need for the product and outline the objectives and impact.
+Note
+Each section below has a part called "Our task", which will discuss how the specific topic relates to the application that we will be building.
+Set the scene for what we're trying to do through a user-centric approach:
+users: profile/persona of our usersgoals: our users' main goalspains: obstacles preventing our users from achieving their goalsOur task
+users: machine learning developers and researchers.goals: stay up-to-date on ML content for work, knowledge, etc.pains: too much unlabeled content scattered around the internet.Propose the value we can create through a product-centric approach:
+product: what needs to be built to help our users reach their goals?alleviates: how will the product reduce pains?advantages: how will the product create gains?Our task
+We will build a platform that helps machine learning developers and researchers stay up-to-date on ML content. We'll do this by discovering and categorizing content from popular sources (Reddit, Twitter, etc.) and displaying it on our platform. For simplicity, assume that we already have a pipeline that delivers ML content from popular sources to our platform. We will just focus on developing the ML service that can correctly categorize the content.
+product: a service that discovers and categorizes ML content from popular sources.alleviates: display categorized content for users to discover.advantages: when users visit our platform to stay up-to-date on ML content, they don't waste time searching for that content themselves in the noisy internet. +
+Breakdown the product into key objectives that we want to focus on.
+Our task
+Describe the solution required to meet our objectives, including its:
+core features: key features that will be developed.integration: how the product will integrate with other services.alternatives: alternative solutions that we should considered.constraints: limitations that we need to be aware of.out-of-scope.: features that we will not be developing for now.Our task
+Develop a model that can classify the content so that it can be organized by category (tag) on our platform.
+Core features:
Integrations:
Alternatives:
Constraints:
Out-of-scope:
natural-language-processing, computer-vision, mlops and other).How feasible is our solution and do we have the required resources to deliver it (data, $, team, etc.)?
+Our task
+We have a dataset with ML content that has been labeled. We'll need to assess if it has the necessary signals to meet our objectives.
+| Sample data point | |
|---|---|
1 +2 +3 +4 +5 +6 +7 | |
Now that we've set up the product design requirements for our ML service, let's move on to the systems design requirements in the next lesson.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In this lesson, we'll discuss how to migrate and organize code from our notebook to Python scripts. We'll be using VSCode in this course, but feel free to use any editor you feel comfortable with.
+Notebooks have been great so far for development. They're interactive, stateful (don't have to rerun code), and allow us to visualize outputs. However, when we want to a develop quality codebase, we need to move to scripts. Here are some reasons why:
+stateless: when we run code in a notebook, it's automatically saved to the global state (memory). This is great for experimentation because code and variables will be readily available across different cells. However, this can be very problematic as well because there can be hidden state that we're not aware of. Scripts, on the other hand, are stateless and we have to explicitly pass variables to functions and classes.
+linear: in notebooks, the order in which we execute cells matter. This can be problematic because we can easily execute cells out of order. Scripts, on the other hand, are linear and we have to explicitly execute code for each workload.
+testing: As we'll see in our testing lesson, it's significantly easier to compose and run tests on scripts, as opposed to Jupyter notebooks. This is crucial for ensuring that we have quality code that works as expected.
+We already have all the scripts provided in our repository so let's discuss how this was all organized.
+It's always a good idea to start organizing our scripts with a README.md file. This is where we can organize all of the instructions necessary to walkthrough our codebase. Our README has information on how to set up our environment, how to run our scripts, etc.
++The contents of the
+README.mdfile is what everyone will see when they visit your repository on GitHub. So, it's a good idea to keep it updated with the latest information.
Let's start by moving our code from notebooks to scripts. We're going to start by creating the different files and directories that we'll need for our project. The exact number and name of these scripts is entirely up to us, however, it's best to organize and choose names that relate to a specific workload. For example, data.py will have all of our data related functions and classes. And we can also have scripts for configurations (config.py), shared utilities (utils.py), etc.
madewithml/
+├── config.py
+├── data.py
+├── evaluate.py
+├── models.py
+├── predict.py
+├── serve.py
+├── train.py
+├── tune.py
+└── utils.py
+++Don't worry about the contents in these files that aren't from our notebooks just yet or if our code looks significantly more documented. We'll be taking a closer look at those in the respective lessons.
+
Once we have these ready, we can start moving code from our notebooks to the appropriate scripts. It should intuitive in which script a particular function or class belongs to. If not, we need to rethink how the names of our scripts. For example, train.py has functions from our notebook such as train_step, val_step, train_loop_per_worker, etc.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
Recall that for training a model, we wrote code in our notebook for setting configurations, training, etc. that was freeform in a code cell:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
These code cells are not part of a function or class, so we need to wrap them around a function so that we can easily execute that workload. For example, all of this training logic is wrapped inside a train_model function in train.py that has all the required inputs to execute the workload:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 | |
++In the next lesson on command-line interfaces (CLI), we'll learn how to execute these main workloads in our scripts from the command line.
+
In addition to our core workload scripts, recall that we also have a config.py script. This file will include all of the setup and configuration that all/most of our workloads depend on. For example, setting up our model registry:
1 +2 +3 +4 +5 | |
++We wouldn't have configurations like our
+ScalingConfighere because that's specific to our training workload. Theconfig.pyscript is for configurations that are shared across different workloads.
Similarly, we also have a utils.py script to include components that will be reused across different scripts. It's a good idea to organize these shared components here as opposed to the core scripts to avoid circular dependency conflicts (two scripts call on functions from each other). Here is an example of one of our utility functions, set_seeds, that's used in both our train.py and tune.py scripts.
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
Recall in our setup lesson that we initialized Ray inside our notebooks. We still need to initialize Ray before executing our ML workloads via scripts but we can decide to do this only for the scripts with Ray dependent workloads. For example, at the bottom of our train.py script, we have:
1 +2 +3 +4 +5 +6 | |
Now that we've set up our scripts, we can start executing them from the command line. In the next lesson, we'll learn how to do this with command-line interfaces (CLI).
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In this lesson, we're going to serve the machine learning models that we have developed so that we can use them to make predictions on unseen data. And we want to be able to serve our models in a scalable and robust manner so it can deliver high throughput (handle many requests) and low latency (quickly respond to each request). In an effort to be comprehensive, we will implement both batch inference (offline) and online inference (real-time), though we will focus on the latter in the remaining lessons as it's more appropriate for our application.
+There are many frameworks to choose from when it comes to model serving, such as Ray Serve, Nvidia Triton, HuggingFace, Bento ML, etc. When choosing between these frameworks, we want to choose the option that will allow us to:
+To address all of these requirements (and more), we will be using Ray Serve to create our service. While we'll be specifically using it's integration with FastAPI, there are many other integrations you might want to explore based on your stack (LangChain, Kubernetes, etc.).
+We will first implement batch inference (or offline inference), which is when we make predictions on a large batch of data. This is useful when we don't need to serve a model's prediction on input data as soon as the input data is received. For example, our service can be used to make predictions once at the end of every day on the batches of content collected throughout the day. This can be more efficient than making predictions on each content individually if we don't need that kind of low latency.
+Let's take a look at our how we can easily implement batch inference with Ray Serve. We'll start with some setup and load the best checkpoint from our training run.
+1 +2 +3 | |
1 +2 +3 | |
Next, we'll define a Predictor class that will load the model from our checkpoint and then define the __call__ method that will be used to make predictions on our input data.
1 +2 +3 +4 +5 +6 +7 +8 | |
++The
__call__function in Python defines the logic that will be executed when our object is called like a function. ++
predictor = Predictor() +prediction = predictor(batch) +
To do batch inference, we'll be using the map_batches functionality. We previously used map_batches to map (or apply) a preprocessing function across batches (chunks) of our data. We're now using the same concept to apply our predictor across batches of our inference data.
1 +2 +3 +4 +5 +6 +7 | |
++Note that
+best_checkpointas a keyword argument to ourPredictorclass so that we can load the model from that checkpoint. We can pass this in via thefn_constructor_kwargsargument in ourmap_batchesfunction.
1 +2 | |
+[{'prediction': 'computer-vision'},
+ {'prediction': 'other'},
+ {'prediction': 'other'}]
+
+
+While we can achieve batch inference at scale, many models will need to be served in an real-time manner where we may need to deliver predictions for many incoming requests (high throughput) with low latency. We want to use online inference for our application over batch inference because we want to quickly categorize content as they are received/submitted to our platform so that the community can discover them quickly.
+1 +2 +3 +4 | |
We'll start by defining our FastAPI application which involves initializing a predictor (and preprocessor) from the best checkpoint for a particular run (specified by run_id). We'll also define a predict function that will be used to make predictions on our input data.
1 +2 +3 +4 +5 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
+++
async defrefers to an asynchronous function (when we call the function we don't have to wait for the function to complete executing). Theawaitkeyword is used inside an asynchronous function to wait for the completion of therequest.json()operation.
We can now combine our FastAPI application with Ray Serve by simply wrapping our application with the serve.ingress decorator. We can further wrap all of this with the serve.deployment decorator to define our deployment configuration (ex. number of replicas, compute resources, etc.). These configurations allow us to easily scale our service as needed.
1 +2 +3 +4 | |
Now let's run our service and perform some real-time inference.
+1 +2 +3 +4 | |
+Started detached Serve instance in namespace "serve". +Deployment 'default_ModelDeployment:IcuFap' is ready at `http://127.0.0.1:8000/`. component=serve deployment=default_ModelDeployment +RayServeSyncHandle(deployment='default_ModelDeployment') ++ +
1 +2 +3 +4 +5 | |
+{'results': [{'prediction': 'natural-language-processing',
+ 'probabilities': {'computer-vision': 0.00038025027606636286,
+ 'mlops': 0.0003820903366431594,
+ 'natural-language-processing': 0.9987919926643372,
+ 'other': 0.00044562897528521717}}]}
+
+
+The issue with neural networks (and especially LLMs) is that they are notoriously overconfident. For every input, they will always make some prediction. And to account for this, we have an other class but that class only has projects that are not in our accepted tags but are still machine learning related nonetheless. Here's what happens when we input complete noise as our input:
1 +2 +3 +4 | |
+{'results': [{'prediction': 'natural-language-processing',
+ 'probabilities': {'computer-vision': 0.11885979026556015,
+ 'mlops': 0.09778415411710739,
+ 'natural-language-processing': 0.6735526323318481,
+ 'other': 0.1098034456372261}}]}
+
+
+Let's shutdown our service before we fixed this issue.
+1 +2 | |
To make our service a bit more robust, let's add some custom logic to predict the other class if the probability of the predicted class is below a certain threshold probability.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 | |
Tip
+It's easier to incorporate custom logic instead of altering the model itself. This way, we won't have to collect new data. change the model's architecture or retrain it. This also makes it really easy to change the custom logic as our product specifications may change (clean separation of product and machine learning).
+1 +2 | |
+Started detached Serve instance in namespace "serve". +Deployment 'default_ModelDeploymentRobust:RTbrNg' is ready at `http://127.0.0.1:8000/`. component=serve deployment=default_ModelDeploymentRobust +RayServeSyncHandle(deployment='default_ModelDeploymentRobust') ++ +
Now let's see how we perform on the same random noise with our custom logic incorporate into the service.
+1 +2 +3 +4 | |
+{'results': [{'prediction': 'other',
+ 'probabilities': {'computer-vision': 0.11885979026556015,
+ 'mlops': 0.09778415411710739,
+ 'natural-language-processing': 0.6735526323318481,
+ 'other': 0.1098034456372261}}]}
+
+
+1 +2 | |
We'll learn how to deploy our service to production in our Jobs and Services lesson a bit later.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In this lesson, we'll setup the development environment that we'll be using in all of our lessons. We'll have instructions for both local laptop and remote scalable clusters (Anyscale). While everything will work locally on your laptop, you can sign up to join one of our upcoming live cohorts where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day → sign up here.
+We'll start with defining our cluster, which refers to a group of servers that come together to form one system. Our clusters will have a head node that manages the cluster and it will be connected to a set of worker nodes that will execute workloads for us. These clusters can be fixed in size or autoscale based on our application's compute needs, which makes them highly scalable and performant. We'll create our cluster by defining a compute configuration and an environment.
+We'll start by defining our cluster environment which will specify the software dependencies that we'll need for our workloads.
+💻 Local
+Your personal laptop will need to have Python installed and we highly recommend using Python 3.10. You can use a tool like pyenv (mac) or pyenv-win (windows) to easily download and switch between Python versions.
pyenv install 3.10.11 # install
+pyenv global 3.10.11 # set default
+Once we have our Python version, we can create a virtual environment to install our dependencies. We'll download our Python dependencies after we clone our repository from git shortly.
+mkdir madewithml
+cd madewithml
+python3 -m venv venv # create virtual environment
+source venv/bin/activate # on Windows: venv\Scripts\activate
+python3 -m pip install --upgrade pip setuptools wheel
+🚀 Anyscale
+Our cluster environment will be defined inside a cluster_env.yaml file. Here we specify some details around our base image (anyscale/ray:2.6.0-py310-cu118) that has our Python version, GPU dependencies, etc.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 | |
We could specify any python packages inside pip_packages or conda_packages but we're going to use a requirements.txt file to load our dependencies under post_build_cmds.
Next, we'll define our compute configuration, which will specify our hardware dependencies (head and worker nodes) that we'll need for our workloads.
+💻 Local
+Your personal laptop (single machine) will act as the cluster, where one CPU will be the head node and some of the remaining CPU will be the worker nodes (no GPUs required). All of the code in this course will work in any personal laptop though it will be slower than executing the same workloads on a larger cluster.
+🚀 Anyscale
+Our cluster compute will be defined inside a cluster_compute.yaml file. Here we specify some details around where our compute resources will come from (cloud computing platform like AWS), types of nodes and their counts, etc.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
Our worker nodes will be GPU-enabled so we can train our models faster and we set min_workers to 0 so that we can autoscale these workers only when they're needed (up to a maximum of max_workers). This will help us significantly reduce our compute costs without having to manage the infrastructure ourselves.
With our compute and environment defined, we're ready to create our cluster workspace. This is where we'll be developing our ML application on top of our compute, environment and storage.
+💻 Local
+Your personal laptop will need to have an interactive development environment (IDE) installed, such as VS Code. For bash commands in this course, you're welcome to use the terminal on VSCode or a separate one.
+🚀 Anyscale
+We're going to launch an Anyscale Workspace to do all of our development in. Workspaces allow us to use development tools such as VSCode, Jupyter notebooks, web terminal, etc. on top of our cluster compute, environment and storage. This create an "infinite laptop" experience that feels like a local laptop experience but on a powerful, scalable cluster.
+ +
+We have the option to create our Workspace using a CLI but we're going to create it using the web UI (you will receive the required credentials during the cohort). On the UI, we can fill in the following information:
+- Workspace name: `madewithml`
+- Project: `madewithml`
+- Cluster environment name: `madewithml-cluster-env`
+# Toggle `Select from saved configurations`
+- Compute config: `madewithml-cluster-compute`
+- Click on the **Start** button to launch the Workspace
+ +
+We have already saved created our Project, cluster environment and compute config so we can select them from the dropdowns but we could just as easily create new ones / update these using the CLI.
+# Set credentials
+export ANYSCALE_HOST=https://console.anyscale.com
+export ANYSCALE_CLI_TOKEN=$YOUR_CLI_TOKEN # retrieved from Anyscale credentials page
+
+# Create project
+export PROJECT_NAME="madewithml"
+anyscale project create --name $PROJECT_NAME
+
+# Cluster environment
+export CLUSTER_ENV_NAME="madewithml-cluster-env"
+anyscale cluster-env build deploy/cluster_env.yaml --name $CLUSTER_ENV_NAME
+
+# Compute config
+export CLUSTER_COMPUTE_NAME="madewithml-cluster-compute"
+anyscale cluster-compute create deploy/cluster_compute.yaml --name $CLUSTER_COMPUTE_NAME
+With our development workspace all set up, we're ready to start developing. We'll start by following these instructions to create a repository:
+Made-With-MLAdd a README file (very important as this creates a main branch)Create repositoryNow we're ready to clone the Made With ML repository's contents from GitHub inside our madewithml directory.
export GITHUB_USERNAME="YOUR_GITHUB_UESRNAME" # <-- CHANGE THIS to your username
+git clone https://github.com/GokuMohandas/Made-With-ML.git .
+git remote set-url origin https://github.com/$GITHUB_USERNAME/Made-With-ML.git
+git checkout -b dev
+export PYTHONPATH=$PYTHONPATH:$PWD # so we can import modules from our scripts
+💻 Local
+Recall that we created our virtual environment earlier but didn't actually load any Python dependencies yet. We'll clone our repository and then install the packages using the requirements.txt file.
python3 -m pip install -r requirements.txt
+++Caution: make sure that we're installing our Python packages inside our virtual environment.
+
🚀 Anyscale
+Our environment with the appropriate Python version and libraries is already all set for us through the cluster environment we used when setting up our Anyscale Workspace. But if we want to install additional Python packages as we develop, we need to do pip install with the --user flag inside our Workspaces (via terminal) to ensure that our head and all worker nodes receive the package. And then we should also add it to our requirements file so it becomes part of the cluster environment build process next time.
pip install --user <package_name>:<version>
+Now we're ready to launch our Jupyter notebook to interactively develop our ML application.
+💻 Local
+We already installed jupyter through our requirements.txt file in the previous step, so we can just launch it.
jupyter lab notebooks/madewithml.ipynb
+🚀 Anyscale
+Click on the Jupyter icon ![]() at the top right corner of our Anyscale Workspace page and this will open up our JupyterLab instance in a new tab. Then navigate to the
at the top right corner of our Anyscale Workspace page and this will open up our JupyterLab instance in a new tab. Then navigate to the notebooks directory and open up the madewithml.ipynb notebook.
 +
+We'll be using Ray to scale and productionize our ML application. Ray consists of a core distributed runtime along with libraries for scaling ML workloads and has companies like OpenAI, Spotify, Netflix, Instacart, Doordash + many more using it to develop their ML applications. We're going to start by initializing Ray inside our notebooks:
+1 | |
1 +2 +3 +4 | |
We can also view our cluster resources to view the available compute resources:
+1 | |
💻 Local
+If you are running this on a local laptop (no GPU), use the CPU count from ray.cluster_resources() to set your resources. For example if your machine has 10 CPUs:
+{'CPU': 10.0,
+ 'object_store_memory': 2147483648.0,
+ 'node:127.0.0.1': 1.0}
+
+num_workers = 6 # prefer to do a few less than total available CPU (1 for head node + 1 for background tasks)
+resources_per_worker={"CPU": 1, "GPU": 0}
+🚀 Anyscale
+On our Anyscale Workspace, the ray.cluster_resources() command will produce:
+{'CPU': 8.0,
+'node:internal_head': 1.0,
+'node:10.0.56.150': 1.0,
+'memory': 34359738368.0,
+'object_store_memory': 9492578304.0}
+
+These cluster resources only reflect our head node (1 m5.2xlarge). But recall earlier in our compute configuration that we also added g4dn.xlarge worker nodes (each has 1 GPU and 4 CPU) to our cluster. But because we set min_workers=0, our worker nodes will autoscale ( up to max_workers) as they're needed for specific workloads (ex. training). So we can set the # of workers and resources by worker based on this insight:
# Workers (1 g4dn.xlarge)
+num_workers = 1
+resources_per_worker={"CPU": 3, "GPU": 1}
+Head on over to the next lesson, where we'll motivate the specific application that we're trying to build from a product and systems design perspective. And after that, we're ready to start developing!
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+To determine the efficacy of our models, we need to have an unbiased measuring approach. To do this, we split our dataset into training, validation, and testing data splits.
++Here the model will have access to both inputs and outputs to optimize its internal weights.
+
++Here the model will not use the outputs to optimize its weights but instead, we will use the performance to optimize training hyperparameters such as the learning rate, etc.
+
++This is our best measure of how the model may behave on new, unseen data. Note that training stops when the performance improvement is not significant or any other stopping criteria that we may have specified.
+
Creating proper data splits
+What are the criteria we should focus on to ensure proper data splits?
+time-series)++We need to clean our data first before splitting, at least for the features that splitting depends on. So the process is more like: preprocessing (global, cleaning) → splitting → preprocessing (local, transformations).
+
We'll start by splitting our dataset into three data splits for training, validation and testing.
+1 | |
1 +2 +3 +4 | |
For our multi-class task (each input has one label), we want to ensure that each data split has similar class distributions. We can achieve this by specifying how to stratify the split by adding the stratify keyword argument.
1 +2 +3 | |
1 +2 | |
+train: 668 (0.70) +remaining: 287 (0.30) ++
1 +2 +3 | |
1 +2 +3 | |
+train: 668 (0.70) +val: 143 (0.15) +test: 144 (0.15) ++
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 | |
It's hard to compare these because our train and test proportions are different. Let's see what the distribution looks like once we balance it out. What do we need to multiply our test ratio by so that we have the same amount as our train ratio?
+1 +2 +3 +4 +5 +6 +7 | |
1 +2 +3 +4 +5 +6 | |
We can see how much deviance there is in our naive data splits by computing the standard deviation of each split's class counts from the mean (ideal split).
+1 +2 | |
+0.9851056877051131 ++ +
1 +2 +3 +4 +5 | |
Multi-label classification
+If we had a multi-label classification task, then we would've applied iterative stratification via the skmultilearn library, which essentially splits each input into subsets (where each label is considered individually) and then it distributes the samples starting with fewest "positive" samples and working up to the inputs that have the most labels.
+from skmultilearn.model_selection import IterativeStratification
+def iterative_train_test_split(X, y, train_size):
+ """Custom iterative train test split which
+ 'maintains balanced representation with respect
+ to order-th label combinations.'
+ """
+ stratifier = IterativeStratification(
+ n_splits=2, order=1, sample_distribution_per_fold=[1.0-train_size, train_size, ])
+ train_indices, test_indices = next(stratifier.split(X, y))
+ X_train, y_train = X[train_indices], y[train_indices]
+ X_test, y_test = X[test_indices], y[test_indices]
+ return X_train, X_test, y_train, y_test
+Iterative stratification essentially creates splits while "trying to maintain balanced representation with respect to order-th label combinations". We used to an order=1 for our iterative split which means we cared about providing representative distribution of each tag across the splits. But we can account for higher-order label relationships as well where we may care about the distribution of label combinations.
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+++Code is read more often than it is written. -- Guido Van Rossum (author of Python)
+
When we write a piece of code, it's almost never the last time we see it or the last time it's edited. So we need to explain what's going on (via documentation) and make it easy to read. One of the easiest ways to make code more readable is to follow consistent style and formatting conventions. There are many options when it comes to Python style conventions to adhere to, but most are based on PEP8 conventions. Different teams follow different conventions and that's perfectly alright. The most important aspects are:
+consistency: everyone follows the same standards.automation: formatting should be largely effortless after initial configuration.We will be using a very popular blend of style and formatting conventions that makes some very opinionated decisions on our behalf (with configurable options).
+Black: an in-place reformatter that (mostly) adheres to PEP8.isort: sorts and formats import statements inside Python scripts.flake8: a code linter with stylistic conventions that adhere to PEP8.Before we can properly use these tools, we'll have to configure them because they may have some discrepancies amongst them since they follow slightly different conventions that extend from PEP8.
+To configure Black, we could just pass in options using the CLI method, but it's much cleaner to do this through our pyproject.toml file.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 | |
Here we're telling Black what our maximum line length should and to include and exclude certain file extensions.
+++The pyproject.toml was created to establish a more human-readable configuration file that is meant to replace a
+setup.pyorsetup.cfgfile and is increasingly adopted by many open-source libraries.
Next, we're going to configure isort in our pyproject.toml file (just below Black's configurations):
1 +2 +3 +4 +5 +6 +7 | |
Though there is a complete list of configuration options for isort, we've decided to set these explicitly so there are no conflicts with Black.
+Lastly, we'll set up flake8 by also adding it's configuration details to out pyproject.toml file.
1 +2 +3 +4 +5 +6 | |
Here we're including an ignore option to ignore certain flake8 rules so everything works with our Black and isort configurations. And besides defining configuration options here, which are applied globally, we can also choose to specifically ignore certain conventions on a line-by-line basis. Here is an example of how we utilize this:
1 +2 | |
By placing the # NOQA: <error-code> on a line, we're telling flake8 to do NO Quality Assurance for that particular error on this line.
To use these tools that we've configured, we have to execute them from the project directory: +
black .
+flake8
+isort .
++black . +All done! ✨ 🍰 ✨ +9 files left unchanged. +flake8 +python3 -m isort . isort . +Fixing ... ++ +
Take a look at your files to see all the changes that have been made!
+++the
+.signifies that the configuration file for that package is in the current directory
Remembering these three lines to style our code is a bit cumbersome so it's a good idea to create a Makefile. This file can be used to define a set of commands that can be executed with a single command. Here's what our Makefile looks like:
+# Makefile
+SHELL = /bin/bash
+
+# Styling
+.PHONY: style
+style:
+ black .
+ flake8
+ python3 -m isort .
+ pyupgrade
+
+# Cleaning
+.PHONY: clean
+clean: style
+ find . -type f -name "*.DS_Store" -ls -delete
+ find . | grep -E "(__pycache__|\.pyc|\.pyo)" | xargs rm -rf
+ find . | grep -E ".pytest_cache" | xargs rm -rf
+ find . | grep -E ".ipynb_checkpoints" | xargs rm -rf
+ rm -rf .coverage*
+++Notice that the
+cleancommand depends on thestylecommand (clean: style), which means thatstylewill be executed first beforecleanis executed.
.PHONY
+As the name suggests, a Makefile is typically used to make a file, where if a file with the name already exists, then the commands below won't be executed. But we're using it in a way where we want to execute some commands with a single alias. Therefore, the .PHONY: $FILENAME lines indicate that even if there is a file called $FILENAME, go ahead and execute the commands below anyway.
In the next lesson on pre-commit we'll learn how to automatically execute this formatting whenever we make changes to our code.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In the previous lesson, we covered the product design process for our ML application. In this lesson, we'll cover the systems design process where we'll learn how to design the ML system that will address our product objectives.
+The template below is designed to guide machine learning product development. It involves both the product and systems design aspects of our application:
+Product design (What & Why) → Systems design (How)
+
+++👉 Download a PDF of the ML canvas to use for your own products → ml-canvas.pdf (right click the link and hit "Save Link As...")
+
How can we engineer our approach for building the product? We need to account for everything from data ingestion to model serving.
+
+Describe the training and production (batches/streams) sources of data.
+ + +Our task
+| Assumption | +Reality | +Reason | +
|---|---|---|
| All of our incoming data is only machine learning related (no spam). | +We would need a filter to remove spam content that's not ML related. | +To simplify our ML task, we will assume all the data is ML content. | +
Describe the labeling process (ingestions, QA, etc.) and how we decided on the features and labels.
+
+Our task
+Labels: categories of machine learning (for simplification, we've restricted the label space to the following tags: natural-language-processing, computer-vision, mlops and other).
Features: text features (title and description) that describe the content.
+| Assumption | +Reality | +Reason | +
|---|---|---|
| Content can only belong to one category (multiclass). | +Content can belong to more than one category (multilabel). | +For simplicity and many libraries don't support or complicate multilabel scenarios. | +
One of the hardest challenges with ML systems is tying our core objectives, many of which may be qualitative, with quantitative metrics that our model can optimize towards.
+Our task
+For our task, we want to have both high precision and recall, so we'll optimize for f1 score (weighted combination of precision and recall). We'll determine these metrics for the overall dataset, as well as specific classes or slices of data.
+
+What are our priorities
+How do we decide which metrics to prioritize?
+It entirely depends on the specific task. For example, in an email spam detector, precision is very important because it's better than we some spam then completely miss an important email. Overtime, we need to iterate on our solution so all evaluation metrics improve but it's important to know which one's we can't comprise on from the get-go.
+Once we have our metrics defined, we need to think about when and how we'll evaluate our model.
+Offline evaluation requires a gold standard holdout dataset that we can use to benchmark all of our models.
+Our task
+We'll be using this holdout dataset for offline evaluation. We'll also be creating slices of data that we want to evaluate in isolation.
+Online evaluation ensures that our model continues to perform well in production and can be performed using labels or, in the event we don't readily have labels, proxy signals.
+Our task
+It's important that we measure real-time performance before committing to replace our existing version of the system.
+++Not all releases have to be high stakes and external facing. We can always include internal releases, gather feedback and iterate until we’re ready to increase the scope.
+
While the specific methodology we employ can differ based on the problem, there are core principles we always want to follow:
+Our task
+| Assumption | +Reality | +Reason | +
|---|---|---|
| Solution needs to involve ML due to unstructured data and ineffectiveness of rule-based systems for this task. | +An iterative approach where we start with simple rule-based solutions and slowly add complexity. | +This course is about responsibly delivering value with ML, so we'll jump to it right away. | +
Utility in starting simple
+Some of the earlier, simpler, approaches may not deliver on a certain performance objective. What are some advantages of still starting simple?
+Once we have a model we're satisfied with, we need to think about whether we want to perform batch (offline) or real-time (online) inference.
+We can use our models to make batch predictions on a finite set of inputs which are then written to a database for low latency inference. When a user or downstream service makes an inference request, cached results from the database are returned. In this scenario, our trained model can directly be loaded and used for inference in the code. It doesn't have to be served as a separate service.
+ +
+Batch serving tasks
+What are some tasks where batch serving is ideal?
+Recommend content that existing users will like based on their viewing history. However, new users may just receive some generic recommendations based on their explicit interests until we process their history the next day. And even if we're not doing batch serving, it might still be useful to cache very popular sets of input features (ex. combination of explicit interests leads to certain recommended content) so that we can serve those predictions faster.
+We can also serve real-time predictions where input features are fed to the model to retrieve predictions. In this scenario, our model will need to be served as a separate service (ex. api endpoint) that can handle incoming requests.
+ +
+Online inference tasks
+In our example task for batch inference above, how can online inference significantly improve content recommendations?
+With batch processing, we generate content recommendations for users offline using their history. These recommendations won't change until we process the batch the next day using the updated user features. But what is the user's taste significantly changes during the day (ex. user is searching for horror movies to watch). With real-time serving, we can use these recent features to recommend highly relevant content based on the immediate searches.
+Our task
+For our task, we'll be serving our model as a separate service to handle real-time requests. We want to be able to perform online inference so that we can quickly categorize ML content as they become available. However, we will also demonstrate how to do batch inference for the sake of completeness.
+How do we receive feedback on our system and incorporate it into the next iteration? This can involve both human-in-the-loop feedback as well as automatic feedback via monitoring, etc.
+Our task
+Always return to the value proposition
+While it's important to iterate and optimize on our models, it's even more important to ensure that our ML systems are actually making an impact. We need to constantly engage with our users to iterate on why our ML system exists and how it can be made better.
+ +
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In this lesson, we'll learn how to test code, data and machine learning models to construct a machine learning system that we can reliably iterate on. Tests are a way for us to ensure that something works as intended. We're incentivized to implement tests and discover sources of error as early in the development cycle as possible so that we can decrease downstream costs and wasted time. Once we've designed our tests, we can automatically execute them every time we change or add to our codebase.
+Tip
+We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the testing-ml repository for a quick overview with an interactive notebook.
+There are four majors types of tests which are utilized at different points in the development cycle:
+Unit tests: tests on individual components that each have a single responsibility (ex. function that filters a list).Integration tests: tests on the combined functionality of individual components (ex. data processing).System tests: tests on the design of a system for expected outputs given inputs (ex. training, inference, etc.).Acceptance tests: tests to verify that requirements have been met, usually referred to as User Acceptance Testing (UAT).Regression tests: tests based on errors we've seen before to ensure new changes don't reintroduce them.While ML systems are probabilistic in nature, they are composed of many deterministic components that can be tested in a similar manner as traditional software systems. The distinction between testing ML systems begins when we move from testing code to testing the data and models.
+ +
+++There are many other types of functional and non-functional tests as well, such as smoke tests (quick health checks), performance tests (load, stress), security tests, etc. but we can generalize all of these under the system tests above.
+
The framework to use when composing tests is the Arrange Act Assert methodology.
+Arrange: set up the different inputs to test on.Act: apply the inputs on the component we want to test.Assert: confirm that we received the expected output.+++
Cleaningis an unofficial fourth step to this methodology because it's important to not leave remnants of a previous test which may affect subsequent tests. We can use packages such as pytest-randomly to test against state dependency by executing tests randomly.
In Python, there are many tools, such as unittest, pytest, etc. that allow us to easily implement our tests while adhering to the Arrange Act Assert framework. These tools come with powerful built-in functionality such as parametrization, filters, and more, to test many conditions at scale.
+When arranging our inputs and asserting our expected outputs, what are some aspects of our inputs and outputs that we should be testing for?
+++👉 We'll cover specific details pertaining to what to test for regarding our data and models below.
+
Regardless of the framework we use, it's important to strongly tie testing into the development process.
+atomic: when creating functions and classes, we need to ensure that they have a single responsibility so that we can easily test them. If not, we'll need to split them into more granular components.compose: when we create new components, we want to compose tests to validate their functionality. It's a great way to ensure reliability and catch errors early on.reuse: we should maintain central repositories where core functionality is tested at the source and reused across many projects. This significantly reduces testing efforts for each new project's code base.regression: we want to account for new errors we come across with a regression test so we can ensure we don't reintroduce the same errors in the future.coverage: we want to ensure 100% coverage for our codebase. This doesn't mean writing a test for every single line of code but rather accounting for every single line.automate: in the event we forget to run our tests before committing to a repository, we want to auto run tests when we make changes to our codebase. We'll learn how to do this locally using pre-commit hooks and remotely via GitHub actions in subsequent lessons.In our codebase, we'll be testing the code, data and models.
+tests/
+├── code/
+│ ├── conftest.py
+│ ├── test_data.py
+│ ├── test_predict.py
+│ ├── test_train.py
+│ ├── test_tune.py
+│ ├── test_utils.py
+│ └── utils.py
+├── data/
+│ ├── conftest.py
+│ └── test_dataset.py
+└── models/
+│ ├── conftest.py
+│ └── test_behavioral.py
+++Note that we aren't testing
+evaluate.pyandserve.pybecause it involves complicated testing that's based on the data and models. We'll be testing these components as part of our integration tests when we test our system end-to-end.
We'll start by testing our code and we'll use pytest as our testing framework for it's powerful builtin features such as parametrization, fixtures, markers and more.
+Pytest expects tests to be organized under a tests directory by default. However, we can also add to our existing pyproject.toml file to configure any other test directories as well. Once in the directory, pytest looks for python scripts starting with tests_*.py but we can configure it to read any other file patterns as well.
1 +2 +3 +4 | |
Let's see what a sample test and it's results look like. Assume we have a simple function that decodes a list of indices into their respective classes using a dictionary mapping.
+1 +2 +3 | |
To test this function, we can use assert statements to map inputs with expected outputs. The statement following the word assert must return True.
1 +2 +3 +4 +5 +6 | |
++We can also have assertions about exceptions like we do in lines 6-8 where all the operations under the with statement are expected to raise the specified exception.
+
We can execute our tests above using several different levels of granularity:
+python3 -m pytest # all tests
+python3 -m pytest tests/code # tests under a directory
+python3 -m pytest tests/code/test_predict.py # tests for a single file
+python3 -m pytest tests/code/test_predict.py::test_decode # tests for a single function
+Running our specific test above would produce the following output: +
python3 -m pytest tests/code/test_predict.py::test_decode --verbose --disable-warnings
+
+tests/code/test_predict.py::test_decode PASSED [100%]
+
+
+Had any of our assertions in this test failed, we would see the failed assertions, along with the expected and actual output from our function.
++tests/code/test_predict.py::test_decode FAILED [100%] + + def test_decode(): + decoded = predict.decode( + indices=[0, 1, 1], + index_to_class={0: "x", 1: "y"}) +> assert decoded == ["x", "x", "y"] +E AssertionError: assert ['x', 'y', 'y'] == ['x', 'x', 'y'] +E At index 1 diff: 'y' != 'x' ++ +
Tip
+It's important to test for the variety of inputs and expected outputs that we outlined above and to never assume that a test is trivial. In our example above, it's important that we test for both "apple" and "Apple" in the event that our function didn't account for casing!
+We can also test classes and their respective functions.
+1 +2 +3 +4 +5 | |
++There are also more xunit-style testing options available as well for more involved testing with classes.
+
So far, in our tests, we've had to create individual assert statements to validate different combinations of inputs and expected outputs. However, there's a bit of redundancy here because the inputs always feed into our functions as arguments and the outputs are compared with our expected outputs. To remove this redundancy, pytest has the @pytest.mark.parametrize decorator which allows us to represent our inputs and outputs as parameters.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
[Line 2]: define the names of the parameters under the decorator, ex. "fruit, crisp" (note that this is one string).[Lines 3-7]: provide a list of combinations of values for the parameters from Step 1.[Line 9]: pass in parameter names to the test function.[Line 10]: include necessary assert statements which will be executed for each of the combinations in the list from Step 2.Similarly, we could pass in an exception as the expected result as well:
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
Parametrization allows us to reduce redundancy inside test functions but what about reducing redundancy across different test functions? For example, suppose that different test functions all have a common component (ex. preprocessor). Here, we can use pytest's builtin fixture, which is a function that is executed before the test function. Let's rewrite our test_fit_transform function from above using a fixture:
1 +2 +3 +4 | |
where dataset_loc and preprocessor are fixtures defined in our tests/code/conftest.py script:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
All of our test scripts know to look inside a conftest.py script in the same directory for any fixtures. Note that the name of the fixture and the input argument to our function have to be the same.
Fixture scopes
+Fixtures can have different scopes depending on how we want to use them. For example our df fixture has the module scope because we don't want to keep recreating it after every test but, instead, we want to create it just once for all the tests in our module (tests/test_data.py).
function: fixture is destroyed after every test. [default]class: fixture is destroyed after the last test in the class.module: fixture is destroyed after the last test in the module (script).package: fixture is destroyed after the last test in the package.session: fixture is destroyed after the last test of the session.We've been able to execute our tests at various levels of granularity (all tests, script, function, etc.) but we can create custom granularity by using markers. We've already used one type of marker (parametrize) but there are several other builtin markers as well. For example, the skipif marker allows us to skip execution of a test if a condition is met. For example, supposed we only wanted to test training our model if a GPU is available:
1 +2 +3 +4 +5 +6 | |
We can also create our own custom markers with the exception of a few reserved marker names.
+1 +2 +3 | |
We can execute them by using the -m flag which requires a (case-sensitive) marker expression like below:
pytest -m "training" # runs all tests marked with `training`
+pytest -m "not training" # runs all tests besides those marked with `training`
+Tip
+The proper way to use markers is to explicitly list the ones we've created in our pyproject.toml file. Here we can specify that all markers must be defined in this file with the --strict-markers flag and then declare our markers (with some info about them) in our markers list:
1 +2 +3 | |
1 +2 +3 +4 +5 +6 +7 +8 | |
pytest --markers and we'll receive an error when we're trying to use a new marker that's not defined here.
+As we're developing tests for our application's components, it's important to know how well we're covering our code base and to know if we've missed anything. We can use the Coverage library to track and visualize how much of our codebase our tests account for. With pytest, it's even easier to use this package thanks to the pytest-cov plugin.
+python3 -m pytest tests/code --cov madewithml --cov-report html --disable-warnings
+ +
+Here we're asking to run all tests under tests/code and to check for coverage for all the code in our madewithml directory. When we run this, we'll see the tests from our tests directory executing while the coverage plugin is keeping tracking of which lines in our application are being executed. Once our tests are done, we can view the generated report either through the terminal:
coverage report -m
++Name Stmts Miss Cover Missing +----------------------------------------------------- +madewithml/config.py 16 0 100% +madewithml/data.py 51 0 100% +madewithml/models.py 2 0 100% +madewithml/predict.py 23 0 100% +madewithml/train.py 45 0 100% +madewithml/tune.py 51 0 100% +madewithml/utils.py 39 0 100% +----------------------------------------------------- +TOTAL 227 0 100% ++ +
but a more interactive way is to view it through the htmlcov/index.html on a browser. Here we can click on individual files to see which parts were not covered by any tests.
 +
+Warning
+Though we have 100% coverage, this does not mean that our application is perfect. Coverage only indicates that a piece of code executed in a test, not necessarily that every part of it was tested, let alone thoroughly tested. Therefore, coverage should never be used as a representation of correctness. However, it is very useful to maintain coverage at 100% so we can know when new functionality has yet to be tested. In our CI/CD lesson, we'll see how to use GitHub actions to make 100% coverage a requirement when pushing to specific branches.
+Sometimes it doesn't make sense to write tests to cover every single line in our application yet we still want to account for these lines so we can maintain 100% coverage. We have two levels of purview when applying exclusions:
+Excusing lines by adding this comment # pragma: no cover, <MESSAGE>
+
1 +2 | |
Excluding files by specifying them in our pyproject.toml configuration:
1 +2 +3 | |
++The main point is that we were able to add justification to these exclusions through comments so our team can follow our reasoning.
+
Now that we have a foundation for testing traditional software, let's dive into testing our data and models in the context of machine learning systems.
+So far, we've used unit and integration tests to test the functions that interact with our data but we haven't tested the validity of the data itself. We're going to use the great expectations library to test what our data is expected to look like. It's a library that allows us to create expectations as to what our data should look like in a standardized way. It also provides modules to seamlessly connect with backend data sources such as local file systems, S3, databases, etc. Let's explore the library by implementing the expectations we'll need for our application.
+++👉 Follow along interactive notebook in the testing-ml repository as we implement the concepts below.
+
First we'll load the data we'd like to apply our expectations on. We can load our data from a variety of sources (filesystem, database, cloud etc.) which we can then wrap around a Dataset module (Pandas / Spark DataFrame, SQLAlchemy). Since multiple data tests may want access to this data, we'll create a fixture for it.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
When it comes to creating expectations as to what our data should look like, we want to think about our entire dataset and all the features (columns) within it.
+column_list = ["id", "created_on", "title", "description", "tag"]
+df.expect_table_columns_to_match_ordered_list(column_list=column_list) # schema adherence
+tags = ["computer-vision", "natural-language-processing", "mlops", "other"]
+df.expect_column_values_to_be_in_set(column="tag", value_set=tags) # expected labels
+df.expect_compound_columns_to_be_unique(column_list=["title", "description"]) # data leaks
+df.expect_column_values_to_not_be_null(column="tag") # missing values
+df.expect_column_values_to_be_unique(column="id") # unique values
+df.expect_column_values_to_be_of_type(column="title", type_="str") # type adherence
+Each of these expectations will create an output with details about success or failure, expected and observed values, expectations raised, etc. For example, the expectation df.expect_column_values_to_be_of_type(column="title", type_="str") would produce the following if successful:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 | |
and if we have a failed expectation (ex. df.expect_column_values_to_be_of_type(column="title", type_="int")), we'd receive this output(notice the counts and examples for what caused the failure):
+
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 | |
There are just a few of the different expectations that we can create. Be sure to explore all the expectations, including custom expectations. Here are some other popular expectations that don't pertain to our specific dataset but are widely applicable:
+expect_column_pair_values_a_to_be_greater_than_bexpect_column_mean_to_be_betweenInstead of running each of these individually, we can combine them all into an expectation suite.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
We can now execute these data tests just like a code test.
+export DATASET_LOC="https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv"
+pytest --dataset-loc=$DATASET_LOC tests/data --verbose --disable-warnings
+Note
+We've added a --dataset-loc flag to pytest by specifying in our tests/data/conftest.py script. This allows us to pass in the dataset location as an argument to our tests.
1 +2 +3 | |
++We're keeping things simple by using our expectations with pytest but Great expectations also has a lot more functionality around connecting to data sources, Checkpoints to execute suites across various parts of the pipeline, data docs to generate reports, etc.
+
While we're validating our datasets inside our machine learning applications, in most production scenarios, the data validation happens much further upstream. Our dataset may not be used just for our specific application and may actually be feeding into many other downstream application (ML and otherwise). Therefore, it's a great idea to execute these data validation tests as up stream as possible so that downstream applications can reliably use the data.
+
+++Learn more about different data systems in our data engineering lesson if you're not familiar with them.
+
The final aspect of testing ML systems involves how to test machine learning models during training, evaluation, inference and deployment.
+We want to write tests iteratively while we're developing our training pipelines so we can catch errors quickly. This is especially important because, unlike traditional software, ML systems can run to completion without throwing any exceptions / errors but can produce incorrect systems. We also want to catch errors quickly to save on time and compute.
+1 | |
1 | |
1 +2 | |
1 +2 +3 | |
1 +2 | |
Note
+You can mark the compute intensive tests with a pytest marker and only execute them when there is a change being made to system affecting the model. +
1 +2 +3 | |
Behavioral testing is the process of testing input data and expected outputs while treating the model as a black box (model agnostic evaluation). They don't necessarily have to be adversarial in nature but more along the types of perturbations we may expect to see in the real world once our model is deployed. A landmark paper on this topic is Beyond Accuracy: Behavioral Testing of NLP Models with CheckList which breaks down behavioral testing into three types of tests:
+invariance: Changes should not affect outputs.
+1 +2 +3 | |
+'natural-language-processing' +'natural-language-processing' ++
directional: Change should affect outputs.
+1 +2 +3 +4 | |
+'natural-language-processing' +'computer-vision' +'natural-language-processing' ++
minimum functionality: Simple combination of inputs and expected outputs.
+1 +2 +3 +4 | |
+'natural-language-processing' +'mlops' +'other' ++ +
And we can convert these tests into proper parameterized tests by first defining from fixtures in our tests/model/conftest.py and our tests/model/utils.py scripts:
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
And now, we can use these components to create our behavioral tests:
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 | |
And we can execute them just like any other test:
+# Model tests
+export EXPERIMENT_NAME="llm"
+export RUN_ID=$(python madewithml/predict.py get-best-run-id --experiment-name $EXPERIMENT_NAME --metric val_loss --mode ASC)
+pytest --run-id=$RUN_ID tests/model --verbose --disable-warnings
+We'll conclude by talking about the similarities and distinctions between testing and monitoring. They're both integral parts of the ML development pipeline and depend on each other for iteration. Testing is assuring that our system (code, data and models) passes the expectations that we've established offline. Whereas, monitoring involves that these expectations continue to pass online on live production data while also ensuring that their data distributions are comparable to the reference window (typically subset of training data) through \(t_n\). When these conditions no longer hold true, we need to inspect more closely (retraining may not always fix our root problem).
+With monitoring, there are quite a few distinct concerns that we didn't have to consider during testing since it involves (live) data we have yet to see.
+++We'll cover all of these concepts in much more depth (and code) in our monitoring lesson.
+
Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Now that we have our data prepared, we can start training our models to optimize on our objective. Ideally, we would start with the simplest possible baseline and slowly add complexity to our models:
+++Since we have four classes, we may expect a random model to be correct around 25% of the time but recall that not all of our classes have equal counts.
+
++We could build a list of common words for each class and if a word in the input matches a word in the list, we can predict that class.
+
++We could start with a simple term frequency (TF-IDF) mode and then move onto embeddings with CNNs, RNNs, Transformers, etc.
+
We're going to skip straight to step 3 of developing a complex model because this task involves unstructured data and rule-based systems are not well suited for this. And with the increase adoption of large language models (LLMs) as a proven model architecture for NLP tasks, we'll fine-tune a pretrained LLM on our dataset.
+Iterate on the data
+Instead of using a fixed dataset and iterating on the models, we could keep the model constant and iterate on the dataset. This is useful to improve the quality of our datasets.
+With the rapid increase in data (unstructured) and model sizes (ex. LLMs), it's becoming increasingly difficult to train models on a single machine. We need to be able to distribute our training across multiple machines in order to train our models in a reasonable amount of time. And we want to be able to do this without having to:
+To address all of these concerns, we'll be using Ray Train here in order to create a training workflow that can scale across multiple machines. While there are many options to choose from for distributed training, such as Pytorch Distributed Data Parallel (DDP), Horovod, etc., none of them allow us to scale across different machines with ease and do so with minimal changes to our single-machine training code as Ray does.
+Primer on distributed training
+With distributed training, there will be a head node that's responsible for orchestrating the training process. While the worker nodes that will be responsible for training the model and communicating results back to the head node. From a user's perspective, Ray abstracts away all of this complexity and we can simply define our training functionality with minimal changes to our code (as if we were training on a single machine).
+In this lesson, we're going to be fine-tuning a pretrained large language model (LLM) using our labeled dataset. The specific class of LLMs we'll be using is called BERT. Bert models are encoder-only models and are the gold-standard for supervised NLP tasks. However, you may be wondering how do all the (much larger) LLM, created for generative applications, fare (GPT 4, Falcon 40B, Llama 2, etc.)?
+++We chose the smaller BERT model for our course because it's easier to train and fine-tune. However, the workflow for fine-tuning the larger LLMs are quite similar as well. They do require much more compute but Ray abstracts away the scaling complexities involved with that.
+
Note
+All the code for this section can be found in our separate benchmarks.ipynb notebook.
+You'll need to first sign up for an OpenAI account and then grab your API key from here.
+1 +2 | |
We'll first load the our training and inference data into dataframes.
+1 | |
1 +2 +3 +4 | |
1 +2 +3 | |
+['computer-vision', 'other', 'natural-language-processing', 'mlops'] ++ +
1 +2 +3 | |
We'll define a few utility functions to make the OpenAI request and to store our predictions. While we could perform batch prediction by loading samples until the context length is reached, we'll just perform one at a time since it's not too many data points and we can have fully deterministic behavior (if you insert new data, etc.). We'll also added some reliability in case we overload the endpoints with too many request at once.
+1 +2 +3 +4 +5 +6 +7 | |
We'll first define what a sample call to the OpenAI endpoint looks like. We'll pass in:
+- system_content that has information about how the LLM should behave.
+- assistant_content for any additional context it should have for answering our questions.
+- user_content that has our message or query to the LLM.
+- model should specify which specific model we want to send our request to.
We can pass all of this information in through the openai.ChatCompletion.create function to receive our response.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
+I'm doing just fine, so glad you ask, +Rhyming away, up to the task. +How about you, my dear friend? +Tell me how your day did ascend. ++ +
Now, let's create a function that can predict tags for a given sample.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
+natural-language-processing ++ +
Next, let's create a function that can predict tags for a list of inputs.
+1 +2 +3 | |
+[{'title': 'Diffusion to Vector',
+ 'description': 'Reference implementation of Diffusion2Vec (Complenet 2018) built on Gensim and NetworkX. '},
+ {'title': 'Graph Wavelet Neural Network',
+ 'description': 'A PyTorch implementation of "Graph Wavelet Neural Network" (ICLR 2019) '},
+ {'title': 'Capsule Graph Neural Network',
+ 'description': 'A PyTorch implementation of "Capsule Graph Neural Network" (ICLR 2019).'}]
+
+
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 | |
1 +2 | |
+100%|██████████| 3/3 [00:01<00:00, 2.96its] +['computer-vision', 'computer-vision', 'computer-vision'] ++ +
Next we'll define a function that can clean our predictions in the event that it's not the proper format or has hallucinated a tag outside of our expected tags.
+1 +2 +3 +4 +5 +6 +7 | |
Tip
+Open AI has now released function calling and custom instructions which is worth exploring to avoid this manual cleaning.
+Next, we'll define a function that will plot our ground truth labels and predictions.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
And finally, we'll define a function that will combine all the utilities above to predict, clean and plot our results.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
Now we're ready to start benchmarking our different LLMs with different context.
+1 +2 | |
We'll start with zero-shot learning which involves providing the model with the system_content that tells it how to behave but no examples of the behavior (no assistant_content).
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 | |
+100%|██████████| 191/191 [11:01<00:00, 3.46s/it]
+{
+ "precision": 0.7919133278407181,
+ "recall": 0.806282722513089,
+ "f1": 0.7807530967691199
+}
+
+
+ +
+1 +2 +3 +4 +5 | |
+100%|██████████| 191/191 [02:28<00:00, 1.29it/s]
+{
+ "precision": 0.9314722577069027,
+ "recall": 0.9267015706806283,
+ "f1": 0.9271956481845013
+}
+
+
+ +
+Now, we'll be adding a assistant_context with a few samples from our training data for each class. The intuition here is that we're giving the model a few examples (few-shot learning) of what each class looks like so that it can learn to generalize better.
1 +2 +3 +4 +5 +6 +7 +8 | |
+[{'title': 'Comparison between YOLO and RCNN on real world videos',
+ 'description': 'Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes.',
+ 'tag': 'computer-vision'},
+ {'title': 'Show, Infer & Tell: Contextual Inference for Creative Captioning',
+ 'description': 'The beauty of the work lies in the way it architects the fundamental idea that humans look at the overall image and then individual pieces of it.\r\n',
+ 'tag': 'computer-vision'},
+ {'title': 'Awesome Graph Classification',
+ 'description': 'A collection of important graph embedding, classification and representation learning papers with implementations.',
+ 'tag': 'other'},
+ {'title': 'Awesome Monte Carlo Tree Search',
+ 'description': 'A curated list of Monte Carlo tree search papers with implementations. ',
+ 'tag': 'other'},
+ {'title': 'Rethinking Batch Normalization in Transformers',
+ 'description': 'We found that NLP batch statistics exhibit large variance throughout training, which leads to poor BN performance.',
+ 'tag': 'natural-language-processing'},
+ {'title': 'ELECTRA: Pre-training Text Encoders as Discriminators',
+ 'description': 'PyTorch implementation of the electra model from the paper: ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators',
+ 'tag': 'natural-language-processing'},
+ {'title': 'Pytest Board',
+ 'description': 'Continuous pytest runner with awesome visualization.',
+ 'tag': 'mlops'},
+ {'title': 'Debugging Neural Networks with PyTorch and W&B',
+ 'description': 'A closer look at debugging common issues when training neural networks.',
+ 'tag': 'mlops'}]
+
+
+1 +2 +3 | |
+Here are some examples with the correct labels: [{'title': 'Comparison between YOLO and RCNN on real world videos', ... 'description': 'A closer look at debugging common issues when training neural networks.', 'tag': 'mlops'}]
+
+
+Tip
+We could increase the number of samples by increasing the context length. We could also retrieve better few-shot samples by extracting examples from the training data that are similar to the current sample (ex. similar unique vocabulary).
+1 +2 +3 +4 +5 +6 | |
+100%|██████████| 191/191 [04:18<00:00, 1.35s/it]
+{
+ "precision": 0.8435247936255214,
+ "recall": 0.8586387434554974,
+ "f1": 0.8447984162323493
+}
+
+
+ +
+1 +2 +3 +4 +5 +6 | |
+100%|██████████| 191/191 [02:11<00:00, 1.46it/s]
+{
+ "precision": 0.9407759040163695,
+ "recall": 0.9267015706806283,
+ "f1": 0.9302632275594479
+}
+
+
+ +
+As we can see, few shot learning performs better than it's respective zero shot counter part. GPT 4 has had considerable improvements in reducing hallucinations but for our supervised task this comes at an expense of high precision but lower recall and f1 scores. When GPT 4 is not confident, it would rather predict other.
So far, we've only been using closed-source models from OpenAI. While these are currently the gold-standard, there are many open-source models that are rapidly catching up (Falcon 40B, Llama 2, etc.). Before we see how these models perform on our task, let's first consider a few reasons why we should care about open-source models.
+1 | |
Now let's compare all the results from our generative AI LLM benchmarks:
+1 | |
{
+ "zero_shot": {
+ "gpt-3.5-turbo-0613": {
+ "precision": 0.7919133278407181,
+ "recall": 0.806282722513089,
+ "f1": 0.7807530967691199
+ },
+ "gpt-4-0613": {
+ "precision": 0.9314722577069027,
+ "recall": 0.9267015706806283,
+ "f1": 0.9271956481845013
+ }
+ },
+ "few_shot": {
+ "gpt-3.5-turbo-0613": {
+ "precision": 0.8435247936255214,
+ "recall": 0.8586387434554974,
+ "f1": 0.8447984162323493
+ },
+ "gpt-4-0613": {
+ "precision": 0.9407759040163695,
+ "recall": 0.9267015706806283,
+ "f1": 0.9302632275594479
+ }
+ }
+}
+And we can plot these on a bar plot to compare them visually.
+1 +2 +3 +4 +5 +6 | |
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 | |
 +
+Our best model is GPT 4 with few shot learning at an f1 score of ~93%. We will see, in the rest of the course, how fine-tuning an LLM with a proper training dataset to change the actual weights of the last N layers (as opposed to the hard prompt tuning here) will yield similar/slightly better results to GPT 4 (at a fraction of the model size and inference costs).
+However, the best system might actually be a combination of using these few-shot hard prompt LLMs alongside fine-tuned LLMs. For example, our fine-tuned LLMs in the course will perform well when the test data is similar to the training data (similar distributions of vocabulary, etc.) but may not perform well on out of distribution. Whereas, these hard prompted LLMs, by themselves or augmented with additional context (ex. arXiv plugins in our case), could be used when our primary fine-tuned model is not so confident.
+We'll start by defining some setup utilities and configuring our model.
+1 +2 +3 +4 | |
We'll define a set_seeds function that will set the seeds for reproducibility across our libraries (np.random.seed, random.seed, torch.manual_seed and torch.cuda.manual_seed). We'll also set the behavior for some torch backends to ensure deterministic results when we run our workloads on GPUs.
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
Next, we'll define a simple load_data function to ingest our data from source (CSV files) and load it as a Ray Dataset.
1 +2 +3 +4 +5 | |
Tip
+When working with very large datasets, it's a good idea to limit the number of samples in our dataset so that we can execute our code quickly and iterate on bugs, etc. This is why we have a num_samples input argument in our load_data function (None = no limit, all samples).
We'll also define a custom preprocessor class that we'll to conveniently preprocess our dataset but also to save/load for later. When defining a preprocessor, we'll need to define a _fit method to learn how to fit to our dataset and a _transform_{pandas|numpy} method to preprocess the dataset using any components from the _fit method. We can either define a _transform_pandas method to apply our preprocessing to a Pandas DataFrame or a _transform_numpy method to apply our preprocessing to a NumPy array. We'll define the _transform_pandas method since our preprocessing function expects a batch of data as a Pandas DataFrame.
1 +2 +3 +4 +5 +6 +7 +8 | |
Now we're ready to start defining our model architecture. We'll start by loading a pretrained LLM and then defining the components needed for fine-tuning it on our dataset. Our pretrained LLM here is a transformer-based model that has been pretrained on a large corpus of scientific text called scibert.
+ +
+++If you're not familiar with transformer-based models like LLMs, be sure to check out the attention and Transformers lessons.
+
1 +2 | |
We can load our pretrained model by using the from_pretrained` method.
+1 +2 +3 | |
Once our model is loaded, we can tokenize an input text, convert it to torch tensors and pass it through our model to get a sequence and pooled representation of the text.
+1 +2 +3 +4 +5 +6 | |
+(torch.Size([1, 10, 768]), torch.Size([1, 768])) ++ +
We're going to use this pretrained model to represent our input text features and add additional layers (linear classifier) on top of it for our specific classification task. In short, the pretrained LLM will process the tokenized text and return a sequence (one representation after each token) and pooled (combined) representation of the text. We'll use the pooled representation as input to our final fully-connection layer (fc1) to result in a vector of size num_classes (number of classes) that we can use to make predictions.
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 | |
Let's initialize our model and inspect its layers:
+1 +2 +3 | |
+(llm): BertModel( +(embeddings): BertEmbeddings( + (word_embeddings): Embedding(31090, 768, padding_idx=0) + (position_embeddings): Embedding(512, 768) + (token_type_embeddings): Embedding(2, 768) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) +) +(encoder): BertEncoder( + (layer): ModuleList( + (0-11): 12 x BertLayer( + (attention): BertAttention( + (self): BertSelfAttention( + (query): Linear(in_features=768, out_features=768, bias=True) + (key): Linear(in_features=768, out_features=768, bias=True) + (value): Linear(in_features=768, out_features=768, bias=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + (output): BertSelfOutput( + (dense): Linear(in_features=768, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + (intermediate): BertIntermediate( + (dense): Linear(in_features=768, out_features=3072, bias=True) + (intermediate_act_fn): GELUActivation() + ) + (output): BertOutput( + (dense): Linear(in_features=3072, out_features=768, bias=True) + (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) + (dropout): Dropout(p=0.1, inplace=False) + ) + ) + ) +) +(pooler): BertPooler( + (dense): Linear(in_features=768, out_features=768, bias=True) + (activation): Tanh() +) +) +(dropout): Dropout(p=0.5, inplace=False) +(fc1): Linear(in_features=768, out_features=4, bias=True) ++ +
We can iterate through our dataset in batches however we may have batches of different sizes. Recall that our tokenizer padded the inputs to the longest item in the batch (padding="longest"). However, our batches for training will be smaller than our large data processing batches and so our batches here may have inputs with different lengths. To address this, we're going to define a custom collate_fn to repad the items in our training batches.
1 | |
Our pad_array function will take an array of arrays and pad the inner arrays to the longest length.
1 +2 +3 +4 +5 +6 | |
And our collate_fn will take a batch of data to pad them and convert them to the appropriate PyTorch tensor types.
1 +2 +3 +4 +5 +6 +7 +8 | |
Let's test our collate_fn on a sample batch from our dataset.
1 +2 +3 | |
+{'ids': tensor([[ 102, 5800, 14982, ..., 0, 0, 0],
+ [ 102, 7746, 2824, ..., 0, 0, 0],
+ [ 102, 502, 1371, ..., 0, 0, 0],
+ ...,
+ [ 102, 10431, 160, ..., 0, 0, 0],
+ [ 102, 124, 132, ..., 0, 0, 0],
+ [ 102, 12459, 28196, ..., 0, 0, 0]], dtype=torch.int32),
+ 'masks': tensor([[1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0],
+ ...,
+ [1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0],
+ [1, 1, 1, ..., 0, 0, 0]], dtype=torch.int32),
+ 'targets': tensor([2, 0, 3, 2, 0, 3, 2, 0, 2, 0, 2, 2, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2,
+ 0, 1, 1, 0, 2, 0, 3, 2, 0, 3, 2, 0, 2, 0, 2, 2, 0, 2, 0, 3, 2, 0, 3, 2,
+ 0, 2, 0, 2, 2, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 3, 0, 0,
+ 0, 3, 0, 1, 1, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 3, 2, 0,
+ 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 2, 0, 2, 2, 0, 2, 2, 0, 2, 0, 1, 1,
+ 0, 0, 0, 1, 0, 0, 1, 0])}
+
+
+Next, we'll implement set the necessary utility functions for distributed training.
+ +
+1 +2 +3 +4 +5 | |
We'll start by defining what one step (or iteration) of training looks like. This will be a function that takes in a batch of data, a model, a loss function, and an optimizer. It will then perform a forward pass, compute the loss, and perform a backward pass to update the model's weights. And finally, it will return the loss.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 | |
++Note: We're using the
+ray.data.iter_torch_batchesmethod instead oftorch.utils.data.DataLoaderto create a generator that will yield batches of data. In fact, this is the only line that's different from a typical PyTorch training loop and the actual training workflow remains untouched. Ray supports many other ways to load/consume data for different frameworks as well.
The validation step is quite similar to the training step but we don't need to perform a backward pass or update the model's weights.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
Next, we'll define the train_loop_per_worker which defines the overall training loop for each worker. It's important that we include operations like loading the datasets, models, etc. so that each worker will have its own copy of these objects. Ray takes care of combining all the workers' results at the end of each iteration, so from the user's perspective, it's the exact same as training on a single machine!
The only additional lines of code we need to add compared to a typical PyTorch training loop are the following:
+session.get_dataset_shard("train") and session.get_dataset_shard("val") to load the data splits (session.get_dataset_shard).model = train.torch.prepare_model(model) to prepare the torch model for distributed execution (train.torch.prepare_model).batch_size_per_worker = batch_size // session.get_world_size() to adjust the batch size for each worker (session.get_world_size).session.report(metrics, checkpoint=checkpoint) to report metrics and save our model checkpoint (session.report).All the other lines of code are the same as a typical PyTorch training loop!
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 | |
+
Class imbalance
+Our dataset doesn't suffer from horrible class imbalance, but if it did, we could easily account for it through our loss function. There are also other strategies such as over-sampling less frequent classes and under-sampling popular classes.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
Next, we'll define some configurations that will be used to train our model.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
Next we'll define our scaling configuration (ScalingConfig) that will specify how we want to scale our training workload. We specify the number of workers (num_workers), whether to use GPU or not (use_gpu), the resources per worker (resources_per_worker) and how much CPU each worker is allowed to use (_max_cpu_fraction_per_node).
1 +2 +3 +4 +5 +6 +7 | |
+++
_max_cpu_fraction_per_node=0.8indicates that 20% of CPU is reserved for non-training workloads that our workers will do such as data preprocessing (which we do prior to training anyway).
Next, we'll define our CheckpointConfig which will specify how we want to checkpoint our model. Here we will just save one checkpoint (num_to_keep) based on the checkpoint with the min val_loss. We'll also configure a RunConfig which will specify the name of our run and where we want to save our checkpoints.
1 +2 +3 | |
We'll be naming our experiment llm and saving our results to ~/ray_results, so a sample directory structure for our trained models would look like this:
/home/ray/ray_results/llm
+├── TorchTrainer_fd40a_00000_0_2023-07-20_18-14-50/
+├── basic-variant-state-2023-07-20_18-14-50.json
+├── experiment_state-2023-07-20_18-14-50.json
+├── trainer.pkl
+└── tuner.pkl
+The TorchTrainer_ objects are the individuals runs in this experiment and each one will have the following contents:
/home/ray/ray_results/TorchTrainer_fd40a_00000_0_2023-07-20_18-14-50/
+├── checkpoint_000009/ # we only save one checkpoint (the best)
+├── events.out.tfevents.1689902160.ip-10-0-49-200
+├── params.json
+├── params.pkl
+├── progress.csv
+└── result.json
+++There are several other configs that we could set with Ray (ex. failure handling) so be sure to check them out here.
+
Stopping criteria
+While we'll just let our experiments run for a certain number of epochs and stop automatically, our RunConfig accepts an optional stopping criteria (stop) which determines the conditions our training should stop for. It's entirely customizable and common examples include a certain metric value, elapsed time or even a custom class.
Now we're finally ready to train our model using all the components we've setup above.
+1 +2 +3 | |
1 +2 +3 +4 +5 +6 | |
++Calling materialize here is important because it will cache the preprocessed data in memory. This will allow us to train our model without having to reprocess the data each time.
+
Because we've preprocessed the data prior to training, we can use the fit=False and transform=False flags in our dataset config. This will allow us to skip the preprocessing step during training.
1 +2 +3 +4 +5 | |
We'll pass all of our functions and configs to the TorchTrainer class to start training. Ray supports a wide variety of framework Trainers so if you're using other frameworks, you can use the corresponding Trainer class instead.
 +
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 | |
Now let's fit our model to the data.
+1 +2 | |
1 | |
1 | |
+[(TorchCheckpoint(local_path=/home/ray/ray_results/llm/TorchTrainer_8c960_00000_0_2023-07-10_16-14-41/checkpoint_000009),
+ {'epoch': 9,
+ 'lr': 0.0001,
+ 'train_loss': 0.0005496611799268673,
+ 'val_loss': 0.0011818759376183152,
+ 'timestamp': 1689030958,
+ 'time_this_iter_s': 6.604866981506348,
+ 'should_checkpoint': True,
+ 'done': True,
+ 'training_iteration': 10,
+ 'trial_id': '8c960_00000',
+ 'date': '2023-07-10_16-16-01',
+ 'time_total_s': 76.30888652801514,
+ 'pid': 68577,
+ 'hostname': 'ip-10-0-18-44',
+ 'node_ip': '10.0.18.44',
+ 'config': {'train_loop_config': {'dropout_p': 0.5,
+ 'lr': 0.0001,
+ 'lr_factor': 0.8,
+ 'lr_patience': 3,
+ 'num_epochs': 10,
+ 'batch_size': 256,
+ 'num_classes': 4}},
+ 'time_since_restore': 76.30888652801514,
+ 'iterations_since_restore': 10,
+ 'experiment_tag': '0'})]
+
+
+While our model is training, we can inspect our Ray dashboard to observe how our compute resources are being utilized.
+💻 Local
+We can inspect our Ray dashboard by opening http://127.0.0.1:8265 on a browser window. Click on Cluster on the top menu bar and then we will be able to see a list of our nodes (head and worker) and their utilizations.
+🚀 Anyscale
+On Anyscale Workspaces, we can head over to the top right menu and click on 🛠️ Tools → Ray Dashboard and this will open our dashboard on a new tab. Click on Cluster on the top menu bar and then we will be able to see a list of our nodes (head and worker) and their utilizations.
+ +
+++Learn about all the other observability features on the Ray Dashboard through this video.
+
Now that we've trained our model, we can evaluate it on a separate holdout test set. We'll cover the topic of evaluation much more extensively in our evaluation lesson but for now we'll calculate some quick overall metrics.
+1 +2 | |
We'll define a function that can take in a dataset and a predictor and return the performance metrics.
+1 +2 +3 +4 | |
1 +2 +3 +4 +5 | |
+[{'ids': array([ 102, 4905, 2069, 2470, 2848, 4905, 30132, 22081, 691,
+ 4324, 7491, 5896, 341, 6136, 934, 30137, 103, 0,
+ 0, 0, 0]),
+ 'masks': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]),
+ 'targets': 3}]
+
+targets column by using ray.data.Dataset.select_column:
+1 +2 +3 +4 | |
+[3 3 3 0 2 0 0 0 0 2 0 0 2 3 0 0 2 2 3 2 3 0 3 2 0 2 2 1 1 2 2 2 2 2 2 0 0 + 0 0 0 1 1 2 0 0 3 1 2 0 2 2 3 3 0 2 3 2 3 3 3 3 0 0 0 0 2 2 0 2 1 0 2 3 0 + 0 2 2 2 2 2 0 0 2 0 1 0 0 0 0 3 0 0 2 0 2 2 3 2 0 2 0 2 0 3 0 0 0 0 0 2 0 + 0 2 2 2 2 3 0 2 0 2 0 2 3 3 3 2 0 2 2 2 2 0 2 2 2 0 1 2 2 2 2 2 1 2 0 3 0 + 2 2 1 1 2 0 0 0 0 0 0 2 2 2 0 2 1 1 2 0 0 1 2 3 2 2 2 0 0 2 0 2 0 3 0 2 2 + 0 1 2 1 2 2] ++
predictor. Note that the predictor will automatically take care of the preprocessing for us.
+1 +2 +3 +4 | |
+[3 3 3 0 2 0 0 0 0 2 0 0 2 3 0 0 0 2 3 2 3 0 3 2 0 0 2 1 1 2 2 2 2 2 2 0 0 + 0 0 0 1 2 2 0 2 3 1 2 0 2 2 3 3 0 2 1 2 3 3 3 3 2 0 0 0 2 2 0 2 1 0 2 3 1 + 0 2 2 2 2 2 0 0 2 1 1 0 0 0 0 3 0 0 2 0 2 2 3 2 0 2 0 2 2 0 2 0 0 3 0 2 0 + 0 1 2 2 2 3 0 2 0 2 0 2 3 3 3 2 0 2 2 2 2 0 2 2 2 0 1 2 2 2 2 2 1 2 0 3 0 + 2 2 2 1 2 0 2 0 0 0 0 2 2 2 0 2 1 2 2 0 0 1 2 3 2 2 2 0 0 2 0 2 1 3 0 2 2 + 0 1 2 1 2 2] ++
1 +2 +3 | |
+{'precision': 0.9147673308349523,
+ 'recall': 0.9109947643979057,
+ 'f1': 0.9115810676649443}
+
+
+We're going to encapsulate all of these steps into one function so that we can call on it as we train more models soon.
+1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 | |
Now let's load our trained model for inference on new data. We'll create a few utility functions to format the probabilities into a dictionary for each class and to return predictions for each item in a dataframe.
+1 | |
1 +2 +3 +4 +5 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
We'll load our predictor from the best checkpoint and load it's preprocessor.
1 +2 +3 | |
And now we're ready to apply our model to new data. We'll create a sample dataframe with a title and description and then use our predict_with_proba function to get the predictions. Note that we use a placeholder value for tag since our input dataframe will automatically be preprocessed (and it expects a value in the tag column).
1 +2 +3 +4 +5 | |
+[{'prediction': 'natural-language-processing',
+ 'probabilities': {'computer-vision': 0.0007296873,
+ 'mlops': 0.0008382588,
+ 'natural-language-processing': 0.997829,
+ 'other': 0.00060295867}}]
+
+
+Distributed training strategies are great for when our data or models are too large for training but there are additional strategies to make the models itself smaller for serving. The following model compression techniques are commonly used to reduce the size of the model:
+ +
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Hyperparameter tuning is the process of discovering a set of performant parameter values for our model. It can be a computationally involved process depending on the number of parameters, search space and model architectures. Hyperparameters don't just include the model's parameters but could also include parameters related to preprocessing, splitting, etc. When we look at all the different parameters that can be tuned, it quickly becomes a very large search space. However, just because something is a hyperparameter doesn't mean we need to tune it.
+lower=True] during preprocessing).We want to optimize our hyperparameters so that we can understand how each of them affects our objective. By running many trials across a reasonable search space, we can determine near ideal values for our different parameters.
+There are many options for hyperparameter tuning (Ray tune, Optuna, Hyperopt, etc.). We'll be using Ray Tune with it's HyperOpt integration for it's simplicity and general popularity. Ray Tune also has a wide variety of support for many other tune search algorithms (Optuna, Bayesian, etc.).
+There are many factors to consider when performing hyperparameter tuning. We'll be conducting a small study where we'll tune just a few key hyperparameters across a few trials. Feel free to include additional parameters and to increase the number trials in the tuning experiment.
+1 +2 | |
We'll start with some the set up, data and model prep as we've done in previous lessons.
+1 +2 +3 +4 +5 | |
1 +2 | |
1 +2 +3 | |
1 +2 +3 +4 +5 +6 | |
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
1 +2 +3 +4 +5 | |
We can think of tuning as training across different combinations of parameters. For this, we'll need to define several configurations around when to stop tuning (stopping criteria), how to define the next set of parameters to train with (search algorithm) and even the different values that the parameters can take (search space).
+We'll start by defining our CheckpointConfig and RunConfig as we did for training:
1 +2 +3 +4 +5 +6 | |
++Notice that we use the same
+mlflow_callbackfrom our experiment tracking lesson so all of our runs will be tracked to MLflow automatically.
Next, we're going to set the initial parameter values and the search algorithm (HyperOptSearch) for our tuning experiment. We're also going to set the maximum number of trials that can be run concurrently (ConcurrencyLimiter) based on the compute resources we have.
1 +2 +3 +4 | |
Tip
+It's a good idea to start with some initial parameter values that you think might be reasonable. This can help speed up the tuning process and also guarantee at least one experiment that will perform decently well.
+Next, we're going to define the parameter search space by choosing the parameters, their distribution and range of values. Depending on the parameter type, we have many different distributions to choose from.
+1 +2 +3 +4 +5 +6 +7 +8 +9 | |
Next, we're going to define a scheduler to prune unpromising trials. We'll be using AsyncHyperBandScheduler (ASHA), which is a very popular and aggressive early-stopping algorithm. Due to our aggressive scheduler, we'll set a grace_period to allow the trials to run for at least a few epochs before pruning and a maximum of max_t epochs.
1 +2 +3 +4 +5 | |
Finally, we're going to define a TuneConfig that will combine the search_alg and scheduler we've defined above.
1 +2 +3 +4 +5 +6 +7 +8 | |
And now, we'll pass in our trainer object with our configurations to create a Tuner object that we can run.
1 +2 +3 +4 +5 +6 +7 | |
1 +2 | |
1 +2 | |
And on our MLflow dashboard, we can create useful plots like a parallel coordinates plot to visualize the different hyperparameters and their values across the different trials.
+ +
+And from these results, we can extract the best trial and its hyperparameters:
+1 +2 +3 | |
1 +2 | |
+{'dropout_p': 0.5, 'lr': 0.0001, 'lr_factor': 0.8, 'lr_patience': 3.0}
+
+
+And now we'll load the best run from our experiment, which includes all the runs we've done so far (before and including the tuning runs).
+1 +2 +3 | |
From this we can load the best checkpoint from the best run and evaluate it on the test split.
+1 +2 +3 +4 +5 +6 | |
+{
+ "precision": 0.9487609194455242,
+ "recall": 0.9476439790575916,
+ "f1": 0.9471734167970421
+}
+
+
+And, just as we did in previous lessons, use our model for inference.
+1 +2 | |
1 +2 +3 +4 +5 | |
+[{'prediction': 'natural-language-processing',
+ 'probabilities': {'computer-vision': 0.0003628606,
+ 'mlops': 0.0002862369,
+ 'natural-language-processing': 0.99908364,
+ 'other': 0.0002672623}}]
+
+
+Now that we're tuned our model, in the next lesson, we're going to perform a much more intensive evaluation on our model compared to just viewing it's overall metrics on a test set.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+In this lesson, we're going to learn how to version our code, data and models to ensure reproducible behavior in our ML systems. It's imperative that we can reproduce our results and track changes to our system so we can debug and improve our application. Without it, it would be difficult to share our work, recreate our models in the event of system failures and fallback to previous versions in the event of regressions.
+To version our code, we'll be using git, which is a widely adopted version control system. In fact, when we cloned our repository in the setup lesson, we pulled code from a git repository that we had prepared for you.
+git clone https://github.com/GokuMohandas/Made-With-ML.git .
+We can then make changes to the code and Git, which is running locally on our computer, will keep track of our files and it's versions as we add and commit our changes. But it's not enough to just version our code locally, we need to push our work to a central location that can be pulled by us and others we want to grant access to. This is where remote repositories like GitHub, GitLab, BitBucket, etc. provide a remote location to hold our versioned code in.
+Here's a simplified workflow for how we version our code using GitHub:
+[make changes to code]
+git add .
+git commit -m "message"
+git push origin <branch-name>
+Tip
+If you're not familiar with Git, we highly recommend going through our Git lesson to learn the basics.
+While Git is ideal for saving our code, it's not ideal for saving artifacts like our datasets (especially unstructured data like text or images) and models. Also, recall that Git stores every version of our files and so large files that change frequently can very quickly take up space. So instead, it would be ideal if we can save locations (pointers) to these large artifacts in our code as opposed to the artifacts themselves. This way, we can version the locations of our artifacts and pull them as they're needed.
+ +
+While we're saving our dataset on GitHub for easy course access (and because our dataset is small), in a production setting, we would use a remote blob storage like S3 or a data warehouse like Snowflake. There are also many tools available for versioning our data, such as GitLFS, Dolt, Pachyderm, DVC, etc. With any of these solutions, we would be pointing to our remote storage location and versioning the pointer locations (ex. S3 bucket path) to our data instead of the data itself.
+And similarly, we currently store our models locally where the MLflow artifact and backend store are local directories.
+1 +2 +3 +4 +5 +6 | |
In a production setting, these would be remote such as S3 for the artifact store and a database service (ex. PostgreSQL RDS) as our backend store. This way, our models can be versioned and others, with the appropriate access credentials, can pull the model artifacts and deploy them.
+ +Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
 +
+ Design · Develop · Deploy · Iterate
+ +Learn how to combine machine learning with software engineering to design, develop, deploy and iterate on production ML applications. → GokuMohandas/Made-With-ML
+Live cohort
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
Machine learning is not a separate industry, instead, it's a powerful way of thinking about data that's not reserved for any one type of person.
+ +
++ I've spent my career developing ML applications across all scales and industries. Specifically over the last four years (through Made With ML), I’ve had the opportunity to help dozens of F500 companies + startups build out their ML platforms and launch high-impact ML applications on top of them. I started Made With ML to address the gaps in education and share the best practices on how to deliver value with ML in production. +
+ ++ While this was an amazing experience, it was also a humbling one because there were obstacles around scale, integrations and productionization that I didn’t have great solutions for. So, I decided to join a team that has been addressing these precise obstacles with some of the best ML teams in the world and has an even bigger vision I could stand behind. So I'm excited to announce that Made With ML is now part of Anyscale to accelerate the path towards production ML. +
+ + + +See what the community has to say about Made With ML.
+ + +
+ "Made with ML is one of the best courses I’ve ever taken. The material covered is very practical; I get to apply some of them to my job right away."
+ +
+ "This course has given me the know-how to make optimal choices around design & implementation of ML engineering for a variety of real-world use-cases."
+ +
+ "This will be a great journey for those interested in deploying machine learning models which lead to a positive impact on the product."
+ +
+ "This course really mimics the production ML thought process by providing alternative options with different levels of complexity & weighing on the pros/cons."
+ +
+ "For production ML, I cannot possibly think of a better resource out there ... this resource is the gold standard."
+ +
+ "One of the best places where you can learn the fundamentals of ML, then practice MLOps by building production grade products and delivering value!"
+ +
+ "Coming from academia with purely model-specific knowledge, Made With ML set the expectations right when it comes to how ML is being applied in the industry."
+ +
+ "Built some machine learning models? Want to take them to the next level? I do. And I’m using @madewithml to learn how. Outstanding MLOps lessons!"
+ +
+ "This is not a usual ML class, it covers productionalization part of ML projects - the most important part from a business point of view."
+ +
+ "Following all through, it's really amazing to see how you demonstrated best practices in building an ML driven application."
+ +
+ "The best MLOps resource that I've come across on the web. Goes over whys, hows, tradeoffs, tools & their alternatives via high-quality explanations and code."
+ +
+ "Completely sold out on the clean code and detailed writeup. This is one of the few ML courses which doesn't stop on just training a model but goes beyond."
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
You should know how to code in Python and the basics of machine learning.
+To cite this content, please use:
+1 +2 +3 +4 +5 +6 | |
Thank you for subscribing to our newsletter! A confirmation email was sent to the email address you provided. Please click on the confirmation button in the email to complete your subscription. If you don’t see it within a few minutes, be sure to check your promotions/spam/junk folder (and mark it Not junk so you receive our future emails).
We created Made With ML to educate and enable the community to responsibly develop, deploy and maintain production machine learning applications. While there are many facets to this mission, at its core are the relationships with teams who share this mission. We want to work together to help the community discover and use the best tools for their context and start the flywheel to make the tools even better.
+A few numbers that reflect the 100% organic traction we've had over the past few years and the need it's filled in the community for bringing ML to production:
+All of our lessons focus on first principles when approaching a concept. This helps develop the foundational understanding to be able to adapt to any stack. But to really solidify the understanding, we implement everything in code within the context of an end-to-end project. This helps understand the implicit value a tool provides and develop the decision making framework for constructing the appropriate stack. And because the community adopts what they've learned for their own use cases in industry, it's imperative that we use tools that can offer that enterprise maturity.
+ + +Your product will be deeply integrated into the MLOps course, where thousands of developers everyday will use and assess your product for their industry contexts. All of this visibility and traction is invaluable for industry adoption, standing out in the competitive landscape and using the feedback to improve the product.
+++We also have many downstream projects in progress to add more value on top of the content (async video course, private community, university labs, corporate onboarding, talent platform).
+
If your team is interested in joining our mission, reach out to us via email to learn more!
+ + + +Instructions
+After you've applied and been accepted to the next cohort, copy and paste this email template below to send to your manager for reimbursement for the course. Feel free to add any additional details as you see fit.
+Subject: Reimbursement for Made With ML's MLOps Course
+Hi,
+Hope you're doing well. I was recently accepted into Made With ML's MLOps course, which is an interactive project-based course on MLOps fundamentals. The course costs $1,250 but the value I'll gain for myself and our team/company will pay for the course almost immediately. I added some key information about the course below and would love to get this career development opportunity reimbursed.
+Course page: https://madewithml.com/
+An interactive project-based course to learn and apply the fundamentals of MLOps. I'll be learning to combine machine learning with software engineering best practices which I want to extend to build and improve our own systems. This course brings all of the MLOps best practices into one place, allowing me to quickly (and properly) learn it. And best of all, the course can be done before and after work, so it won't be interfering during work hours.
+Here's a quick look at the curriculum:
+ +
+The course is from Made With ML, one of the top ML repositories on GitHub (30K+ stars) with a growing community (30K+) and is a highly recommended resource used by industry. Their content not only covers MLOps concepts but they go deep into actually implementing everything with production quality code.
+I'll be learning the foundation I need to responsibly develop ML systems. This includes producing clean, production-grade code, testing my work, understanding MLOps (experiment management, monitoring, systems design, etc.) and data engineering (data stack, orchestration, feature stores) concepts.
+What I learn will directly translate to better quality ML systems in our products. I'll also be able to engage in conversations with peers and management as we traverse this space to build what's right for us. And, most important of all, I'll be able to pass on what I learn as I collaborate with others in our team so we're all working towards building reliable ML systems.
+Thank you
+ + + +You're all set!
+1. Resource links
+2. Say hello
+Send me an email at goku@madewithml.com to say hi, a bit about yourself and what you're currently learning or working on. I personally respond to all emails and always love to meet people from the community.
+Upcoming live cohorts
+Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day. + +
Subscribe to our newsletter
+📬 Receive new lessons straight to your inbox (once a month) and join 40K+ + developers in learning how to responsibly deliver value with ML.
+Join 40K+ developers in learning how to responsibly deliver value with ML!
Subscribe View lessons"},{"location":"#course","title":"ML for DevelopersWho is this content for?","text":"Design \u00b7 Develop \u00b7 Deploy \u00b7 Iterate
Learn how to combine machine learning with software engineering to design, develop, deploy and iterate on production ML applications. \u2192 GokuMohandas/Made-With-ML
1. \ud83c\udfa8 DesignLive cohort
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn more \u00a0 While the specific task in this course involves fine-tuning an LLM for a supervised task, everything we learn easily extends to all applications (NLP, CV, time-series, etc.), models (regression \u2192 LLMs), data modalities (tabular, text, etc.), cloud platforms (AWS, GCP) and scale (local laptop \u2192 distributed cluster). First principles Before we jump straight into the code, we develop a first principles understanding for every machine learning concept. Best practices Implement software engineering best practices as we develop and deploy our machine learning models. Scale Easily scale ML workloads (data, train, tune, serve) in Python without having to learn completely new languages. MLOps Connect MLOps components (tracking, testing, serving, orchestration, etc.) as we build an end-to-end machine learning system. Dev to Prod Learn how to quickly and reliably go from development to production without any changes to our code or infra management. CI/CD Learn how to create mature CI/CD workflows to continuously train and deploy better models in a modular way that integrates with any stack.Machine learning is not a separate industry, instead, it's a powerful way of thinking about data that's not reserved for any one type of person.
\ud83d\udc69\u200d\ud83d\udcbb\u00a0 All developers Whether software/infra engineer or data scientist, ML is increasingly becoming a key part of the products that you'll be developing. \ud83d\udc69\u200d\ud83c\udf93\u00a0 College graduates Learn the practical skills required for industry and bridge gap between the university curriculum and what industry expects. \ud83d\udc69\u200d\ud83d\udcbc\u00a0 Product/Leadership who want to develop a technical foundation so that they can build amazing (and reliable) products powered by machine learning."},{"location":"#instructor","title":"Meet your instructor","text":"Hi, I'm Goku MohandasI've spent my career developing ML applications across all scales and industries. Specifically over the last four years (through Made With ML), I\u2019ve had the opportunity to help dozens of F500 companies + startups build out their ML platforms and launch high-impact ML applications on top of them. I started Made With ML to address the gaps in education and share the best practices on how to deliver value with ML in production.
While this was an amazing experience, it was also a humbling one because there were obstacles around scale, integrations and productionization that I didn\u2019t have great solutions for. So, I decided to join a team that has been addressing these precise obstacles with some of the best ML teams in the world and has an even bigger vision I could stand behind. So I'm excited to announce that Made With ML is now part of Anyscale to accelerate the path towards production ML.
\ud83c\udf89\u00a0 Made With ML is now part of Anyscale, read more about it here!"},{"location":"#wall-of-love","title":"\u2764\ufe0f Wall of LoveFrequently Asked Questions (FAQ)","text":"See what the community has to say about Made With ML.
Sherry Wang Senior ML Engineer - Cars.com\"Made with ML is one of the best courses I\u2019ve ever taken. The material covered is very practical; I get to apply some of them to my job right away.\"
Deepak Jayakumaran Lead Data Scientist - Grab\"This course has given me the know-how to make optimal choices around design & implementation of ML engineering for a variety of real-world use-cases.\"
Jeremy Jordan Senior ML Engineer - Duo Security\"This will be a great journey for those interested in deploying machine learning models which lead to a positive impact on the product.\"
Clara Matos Head of AI Eng - Sword Health\"This course really mimics the production ML thought process by providing alternative options with different levels of complexity & weighing on the pros/cons.\"
Ritchie Ng PyTorch Keynote Speaker\"For production ML, I cannot possibly think of a better resource out there ... this resource is the gold standard.\"
Greg Coquillo AI Product - Amazon\"One of the best places where you can learn the fundamentals of ML, then practice MLOps by building production grade products and delivering value!\"
Kavin Veerapandian Senior Analyst - Citi\"Coming from academia with purely model-specific knowledge, Made With ML set the expectations right when it comes to how ML is being applied in the industry.\"
Daniel Bourke Founder - Mrdbourke\"Built some machine learning models? Want to take them to the next level? I do. And I\u2019m using @madewithml to learn how. Outstanding MLOps lessons!\"
Dmitry Petrov Co-Founder, CEO - DVC\"This is not a usual ML class, it covers productionalization part of ML projects - the most important part from a business point of view.\"
Lawrence Okegbemi ML Engineer - Enterscale\"Following all through, it's really amazing to see how you demonstrated best practices in building an ML driven application.\"
Laxman Tomar ML Engineer - Robofied\"The best MLOps resource that I've come across on the web. Goes over whys, hows, tradeoffs, tools & their alternatives via high-quality explanations and code.\"
Satyabrata Pal Julia Community\"Completely sold out on the clean code and detailed writeup. This is one of the few ML courses which doesn't stop on just training a model but goes beyond.\"
\u2039 \u203aUpcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn more Who is this course for? Machine learning is not a separate industry, instead, it's a powerful way of thinking about data that's not reserved for any one type of person.You should know how to code in Python and the basics of machine learning.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Home - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nI've spent my career developing ML applications across all scales and industries. Specifically over the last four years (through Made With ML), I\u2019ve had the opportunity to help dozens of F500 companies + startups build out their ML platforms and launch high-impact ML applications on top of them. I started Made With ML to address the gaps in education and share the best practices on how to deliver value with ML in production.
While this was an amazing experience, it was also a humbling one because there were obstacles around scale, integrations and productionization that I didn\u2019t have great solutions for. So, I decided to join a team that has been addressing these precise obstacles with some of the best ML teams in the world and has an even bigger vision I could stand behind. So I'm excited to announce that Made With ML is now part of Anyscale to accelerate the path towards production ML.
\ud83c\udf89\u00a0 Made With ML is now part of Anyscale, read more about it here!Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn more "},{"location":"courses/foundations/","title":"Foundations","text":"1. \ud83d\udee0 ToolkitTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Foundations - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nLive cohort
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn more \u00a0 While the specific task in this course involves fine-tuning an LLM for a supervised task, everything we learn easily extends to all applications (NLP, CV, time-series, etc.), models (regression \u2192 LLMs), data modalities (tabular, text, etc.), cloud platforms (AWS, GCP) and scale (local laptop \u2192 distributed cluster).Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { MLOps Course - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn the RNN lesson, we were constrained to using the representation at the very end but what if we could give contextual weight to each encoded input (\\(h_i\\)) when making our prediction? This is also preferred because it can help mitigate the vanishing gradient issue which stems from processing very long sequences. Below is attention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
\\[ \\alpha = softmax(W_{attn}h) \\] \\[ c_t = \\sum_{i=1}^{n} \\alpha_{t,i}h_i \\]Variable Description \\(N\\) batch size \\(M\\) max sequence length in the batch \\(H\\) hidden dim, model dim, etc. \\(h\\) RNN outputs (or any group of outputs you want to attend to) \\(\\in \\mathbb{R}^{NXMXH}\\) \\(\\alpha_{t,i}\\) alignment function context vector \\(c_t\\) (attention in our case) $ \\(W_{attn}\\) attention weights to learn \\(\\in \\mathbb{R}^{HX1}\\) \\(c_t\\) context vector that accounts for the different inputs with attention
Let's set our seed and device for our main task.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/attention/#load-data","title":"Load data","text":"
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\nWe're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nnltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\nprint (STOPWORDS[:5])\nporter = PorterStemmer()\n\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n['i', 'me', 'my', 'myself', 'we']\n
def preprocess(text, stopwords=STOPWORDS):\n\"\"\"Conditional preprocessing on our text unique to our task.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r\"\\b(\" + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub(\"\", text)\n\n # Remove words in parenthesis\n text = re.sub(r\"\\([^)]*\\)\", \"\", text)\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text)\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n return text\n# Sample\ntext = \"Great week for the NYSE!\"\npreprocess(text=text)\n\ngreat week nyse\n
# Apply to dataframe\npreprocessed_df = df.copy()\npreprocessed_df.title = preprocessed_df.title.apply(preprocess)\nprint (f\"{df.title.values[0]}\\n\\n{preprocessed_df.title.values[0]}\")\n\nSharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says\n\nsharon accepts plan reduce gaza army operation haaretz says\n
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
"},{"location":"courses/foundations/attention/#split-data","title":"Split data","text":"import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Data\nX = preprocessed_df[\"title\"].values\ny = preprocessed_df[\"category\"].values\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (84000,), y_train: (84000,)\nX_val: (18000,), y_val: (18000,)\nX_test: (18000,), y_test: (18000,)\nSample point: china battles north korea nuclear talks \u2192 World\n"},{"location":"courses/foundations/attention/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nNUM_CLASSES = len(label_encoder)\nlabel_encoder.class_to_index\n\n{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: World\ny_train[0]: 3\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [21000 21000 21000 21000]\nweights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}\n"},{"location":"courses/foundations/attention/#tokenizer","title":"Tokenizer","text":"We'll define a Tokenizer to convert our text input data into token indices.
import json\nfrom collections import Counter\nfrom more_itertools import take\nclass Tokenizer(object):\n def __init__(self, char_level, num_tokens=None,\n pad_token=\"<PAD>\", oov_token=\"<UNK>\",\n token_to_index=None):\n self.char_level = char_level\n self.separator = \"\" if self.char_level else \" \"\n if num_tokens: num_tokens -= 2 # pad + unk tokens\n self.num_tokens = num_tokens\n self.pad_token = pad_token\n self.oov_token = oov_token\n if not token_to_index:\n token_to_index = {pad_token: 0, oov_token: 1}\n self.token_to_index = token_to_index\n self.index_to_token = {v: k for k, v in self.token_to_index.items()}\n\n def __len__(self):\n return len(self.token_to_index)\n\n def __str__(self):\n return f\"<Tokenizer(num_tokens={len(self)})>\"\n\n def fit_on_texts(self, texts):\n if not self.char_level:\n texts = [text.split(\" \") for text in texts]\n all_tokens = [token for text in texts for token in text]\n counts = Counter(all_tokens).most_common(self.num_tokens)\n self.min_token_freq = counts[-1][1]\n for token, count in counts:\n index = len(self)\n self.token_to_index[token] = index\n self.index_to_token[index] = token\n return self\n\n def texts_to_sequences(self, texts):\n sequences = []\n for text in texts:\n if not self.char_level:\n text = text.split(\" \")\n sequence = []\n for token in text:\n sequence.append(self.token_to_index.get(\n token, self.token_to_index[self.oov_token]))\n sequences.append(np.asarray(sequence))\n return sequences\n\n def sequences_to_texts(self, sequences):\n texts = []\n for sequence in sequences:\n text = []\n for index in sequence:\n text.append(self.index_to_token.get(index, self.oov_token))\n texts.append(self.separator.join([token for token in text]))\n return texts\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {\n \"char_level\": self.char_level,\n \"oov_token\": self.oov_token,\n \"token_to_index\": self.token_to_index\n }\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\nWarning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Tokenize\ntokenizer = Tokenizer(char_level=False, num_tokens=5000)\ntokenizer.fit_on_texts(texts=X_train)\nVOCAB_SIZE = len(tokenizer)\nprint (tokenizer)\n\n<Tokenizer(num_tokens=5000)>\n\n
# Sample of tokens\nprint (take(5, tokenizer.token_to_index.items()))\nprint (f\"least freq token's freq: {tokenizer.min_token_freq}\") # use this to adjust num_tokens\n\n[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]\nleast freq token's freq: 14\n # Convert texts to sequences of indices\nX_train = tokenizer.texts_to_sequences(X_train)\nX_val = tokenizer.texts_to_sequences(X_val)\nX_test = tokenizer.texts_to_sequences(X_test)\npreprocessed_text = tokenizer.sequences_to_texts([X_train[0]])[0]\nprint (\"Text to indices:\\n\"\n f\" (preprocessed) \u2192 {preprocessed_text}\\n\"\n f\" (tokenized) \u2192 {X_train[0]}\")\n\nText to indices:\n (preprocessed) \u2192 china battles north korea nuclear talks\n (tokenized) \u2192 [ 16 1491 285 142 114 24]\n"},{"location":"courses/foundations/attention/#padding","title":"Padding","text":"
We'll need to do 2D padding to our tokenized text.
def pad_sequences(sequences, max_seq_len=0):\n\"\"\"Pad sequences to max length in sequence.\"\"\"\n max_seq_len = max(max_seq_len, max(len(sequence) for sequence in sequences))\n padded_sequences = np.zeros((len(sequences), max_seq_len))\n for i, sequence in enumerate(sequences):\n padded_sequences[i][:len(sequence)] = sequence\n return padded_sequences\n# 2D sequences\npadded = pad_sequences(X_train[0:3])\nprint (padded.shape)\nprint (padded)\n\n(3, 6)\n[[1.600e+01 1.491e+03 2.850e+02 1.420e+02 1.140e+02 2.400e+01]\n [1.445e+03 2.300e+01 6.560e+02 2.197e+03 1.000e+00 0.000e+00]\n [1.200e+02 1.400e+01 1.955e+03 1.005e+03 1.529e+03 4.014e+03]]\n"},{"location":"courses/foundations/attention/#datasets","title":"Datasets","text":"
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
class Dataset(torch.utils.data.Dataset):\n def __init__(self, X, y):\n self.X = X\n self.y = y\n\n def __len__(self):\n return len(self.y)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n X = self.X[index]\n y = self.y[index]\n return [X, len(X), y]\n\n def collate_fn(self, batch):\n\"\"\"Processing on a batch.\"\"\"\n # Get inputs\n batch = np.array(batch)\n X = batch[:, 0]\n seq_lens = batch[:, 1]\n y = batch[:, 2]\n\n # Pad inputs\n X = pad_sequences(sequences=X)\n\n # Cast\n X = torch.LongTensor(X.astype(np.int32))\n seq_lens = torch.LongTensor(seq_lens.astype(np.int32))\n y = torch.LongTensor(y.astype(np.int32))\n\n return X, seq_lens, y\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,\n shuffle=shuffle, drop_last=drop_last, pin_memory=True)\n# Create datasets\ntrain_dataset = Dataset(X=X_train, y=y_train)\nval_dataset = Dataset(X=X_val, y=y_val)\ntest_dataset = Dataset(X=X_test, y=y_test)\nprint (\"Datasets:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" X: {train_dataset[0][0]}\\n\"\n f\" seq_len: {train_dataset[0][1]}\\n\"\n f\" y: {train_dataset[0][2]}\")\n\nDatasets:\n Train dataset: <Dataset(N=84000)>\n Val dataset: <Dataset(N=18000)>\n Test dataset: <Dataset(N=18000)>\nSample point:\n X: [ 16 1491 285 142 114 24]\n seq_len: 6\n y: 3\n
# Create dataloaders\nbatch_size = 64\ntrain_dataloader = train_dataset.create_dataloader(\n batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(\n batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(\n batch_size=batch_size)\nbatch_X, batch_seq_lens, batch_y = next(iter(train_dataloader))\nprint (\"Sample batch:\\n\"\n f\" X: {list(batch_X.size())}\\n\"\n f\" seq_lens: {list(batch_seq_lens.size())}\\n\"\n f\" y: {list(batch_y.size())}\\n\"\n \"Sample point:\\n\"\n f\" X: {batch_X[0]}\\n\"\n f\" seq_len: {batch_seq_lens[0]}\\n\"\n f\" y: {batch_y[0]}\")\n\nSample batch:\n X: [64, 14]\n seq_lens: [64]\n y: [64]\nSample point:\n X: tensor([ 16, 1491, 285, 142, 114, 24, 0, 0, 0, 0, 0, 0,\n 0, 0])\n seq_len: 6\n y: 3\n"},{"location":"courses/foundations/attention/#trainer","title":"Trainer","text":"
Let's create the Trainer class that we'll use to facilitate training for our experiments.
class Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = torch.sigmoid(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n y_prob = F.softmax(model(inputs), dim=1)\n\n # Store outputs\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\nAttention applied to the outputs from an RNN. In theory, the outputs can come from anywhere where we want to learn how to weight amongst them but since we're working with the context of an RNN from the previous lesson , we'll continue with that.
\\[ \\alpha = softmax(W_{attn}h) \\] \\[ c_t = \\sum_{i=1}^{n} \\alpha_{t,i}h_i \\]Variable Description \\(N\\) batch size \\(M\\) max sequence length in the batch \\(H\\) hidden dim, model dim, etc. \\(h\\) RNN outputs (or any group of outputs you want to attend to) \\(\\in \\mathbb{R}^{NXMXH}\\) \\(\\alpha_{t,i}\\) alignment function context vector \\(c_t\\) (attention in our case) $ \\(W_{attn}\\) attention weights to learn \\(\\in \\mathbb{R}^{HX1}\\) \\(c_t\\) context vector that accounts for the different inputs with attention
import torch.nn.functional as F\nThe RNN will create an encoded representation for each word in our input resulting in a stacked vector that has dimensions \\(NXMXH\\), where N is the # of samples in the batch, M is the max sequence length in the batch, and H is the number of hidden units in the RNN.
BATCH_SIZE = 64\nSEQ_LEN = 8\nEMBEDDING_DIM = 100\nRNN_HIDDEN_DIM = 128\n# Embed\nx = torch.rand((BATCH_SIZE, SEQ_LEN, EMBEDDING_DIM))\n# Encode\nrnn = nn.RNN(EMBEDDING_DIM, RNN_HIDDEN_DIM, batch_first=True)\nout, h_n = rnn(x) # h_n is the last hidden state\nprint (\"out: \", out.shape)\nprint (\"h_n: \", h_n.shape)\n\nout: torch.Size([64, 8, 128])\nh_n: torch.Size([1, 64, 128])\n
# Attend\nattn = nn.Linear(RNN_HIDDEN_DIM, 1)\ne = attn(out)\nattn_vals = F.softmax(e.squeeze(2), dim=1)\nc = torch.bmm(attn_vals.unsqueeze(1), out).squeeze(1)\nprint (\"e: \", e.shape)\nprint (\"attn_vals: \", attn_vals.shape)\nprint (\"attn_vals[0]: \", attn_vals[0])\nprint (\"sum(attn_vals[0]): \", sum(attn_vals[0]))\nprint (\"c: \", c.shape)\n\ne: torch.Size([64, 8, 1])\nattn_vals: torch.Size([64, 8])\nattn_vals[0]: tensor([0.1131, 0.1161, 0.1438, 0.1181, 0.1244, 0.1234, 0.1351, 0.1261],\n grad_fn=)\nsum(attn_vals[0]): tensor(1.0000, grad_fn=)\nc: torch.Size([64, 128])\n\n\n\n# Predict\nfc1 = nn.Linear(RNN_HIDDEN_DIM, NUM_CLASSES)\noutput = F.softmax(fc1(c), dim=1)\nprint (\"output: \", output.shape)\n\noutput: torch.Size([64, 4])\n\n\nIn a many-to-many task such as machine translation, our attentional interface will also account for the encoded representation of token in the output as well (via concatenation) so we can know which encoded inputs to attend to based on the encoded output we're focusing on. For more on this, be sure to explore Bahdanau's attention paper.
"},{"location":"courses/foundations/attention/#model","title":"Model","text":"Now let's create our RNN based model but with the addition of the attention layer on top of the RNN's outputs.
\n\nRNN_HIDDEN_DIM = 128\nDROPOUT_P = 0.1\nHIDDEN_DIM = 100\n\nclass RNN(nn.Module):\n def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,\n hidden_dim, dropout_p, num_classes, padding_idx=0):\n super(RNN, self).__init__()\n\n # Initialize embeddings\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx)\n\n # RNN\n self.rnn = nn.RNN(embedding_dim, rnn_hidden_dim, batch_first=True)\n\n # Attention\n self.attn = nn.Linear(rnn_hidden_dim, 1)\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(rnn_hidden_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs):\n # Embed\n x_in, seq_lens = inputs\n x_in = self.embeddings(x_in)\n\n # Encode\n out, h_n = self.rnn(x_in)\n\n # Attend\n e = self.attn(out)\n attn_vals = F.softmax(e.squeeze(2), dim=1)\n c = torch.bmm(attn_vals.unsqueeze(1), out).squeeze(1)\n\n # Predict\n z = self.fc1(c)\n z = self.dropout(z)\n z = self.fc2(z)\n\n return z\n\n# Simple RNN cell\nmodel = RNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of RNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): RNN(100, 128, batch_first=True)\n (attn): Linear(in_features=128, out_features=1, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=128, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n"},{"location":"courses/foundations/attention/#training","title":"Training","text":"\nfrom torch.optim import Adam\n\nNUM_LAYERS = 1\nLEARNING_RATE = 1e-4\nPATIENCE = 10\nNUM_EPOCHS = 50\n\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 1.21680, val_loss: 1.08622, lr: 1.00E-04, _patience: 10\nEpoch: 2 | train_loss: 1.00379, val_loss: 0.93546, lr: 1.00E-04, _patience: 10\nEpoch: 3 | train_loss: 0.87091, val_loss: 0.83399, lr: 1.00E-04, _patience: 10\n...\nEpoch: 48 | train_loss: 0.35045, val_loss: 0.54718, lr: 1.00E-08, _patience: 10\nEpoch: 49 | train_loss: 0.35055, val_loss: 0.54718, lr: 1.00E-08, _patience: 10\nEpoch: 50 | train_loss: 0.35086, val_loss: 0.54717, lr: 1.00E-08, _patience: 10\nStopping early!\n"},{"location":"courses/foundations/attention/#evaluation","title":"Evaluation","text":"\nimport json\nfrom sklearn.metrics import precision_recall_fscore_support\n\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8133385428975775,\n \"recall\": 0.8137222222222222,\n \"f1\": 0.8133454847232977,\n \"num_samples\": 18000.0\n}\n"},{"location":"courses/foundations/attention/#inference","title":"Inference","text":"\ndef get_probability_distribution(y_prob, classes):\n\"\"\"Create a dict of class probabilities from an array.\"\"\"\n results = {}\n for i, class_ in enumerate(classes):\n results[class_] = np.float64(y_prob[i])\n sorted_results = {k: v for k, v in sorted(\n results.items(), key=lambda item: item[1], reverse=True)}\n return sorted_results\n\n# Load artifacts\ndevice = torch.device(\"cpu\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\ntokenizer = Tokenizer.load(fp=Path(dir, 'tokenizer.json'))\nmodel = GRU(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device)\n\nRNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): RNN(100, 128, batch_first=True)\n (attn): Linear(in_features=128, out_features=1, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=128, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n\n\n\n# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n\n# Dataloader\ntext = \"The final tennis tournament starts next week.\"\nX = tokenizer.texts_to_sequences([preprocess(text)])\nprint (tokenizer.sequences_to_texts(X))\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))\ndataset = Dataset(X=X, y=y_filler)\ndataloader = dataset.create_dataloader(batch_size=batch_size)\n\n['final tennis tournament starts next week']\n\n\n# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.decode(y_pred)\n\n['Sports']\n\n\n# Class distributions\nprob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)\nprint (json.dumps(prob_dist, indent=2))\n\n{\n \"Sports\": 0.9651875495910645,\n \"World\": 0.03468644618988037,\n \"Sci/Tech\": 8.490968320984393e-05,\n \"Business\": 4.112234091735445e-05\n}\n"},{"location":"courses/foundations/attention/#interpretability","title":"Interpretability","text":"Let's use the attention values to see which encoded tokens were most useful in predicting the appropriate label.
\n\nimport collections\nimport seaborn as sns\n\nclass InterpretAttn(nn.Module):\n def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,\n hidden_dim, dropout_p, num_classes, padding_idx=0):\n super(InterpretAttn, self).__init__()\n\n # Initialize embeddings\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx)\n\n # RNN\n self.rnn = nn.RNN(embedding_dim, rnn_hidden_dim, batch_first=True)\n\n # Attention\n self.attn = nn.Linear(rnn_hidden_dim, 1)\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(rnn_hidden_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs):\n # Embed\n x_in, seq_lens = inputs\n x_in = self.embeddings(x_in)\n\n # Encode\n out, h_n = self.rnn(x_in)\n\n # Attend\n e = self.attn(out) # could add optional activation function (ex. tanh)\n attn_vals = F.softmax(e.squeeze(2), dim=1)\n\n return attn_vals\n\n# Initialize model\ninterpretable_model = InterpretAttn(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\ninterpretable_model.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\ninterpretable_model.to(device)\n\nInterpretAttn(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): RNN(100, 128, batch_first=True)\n (attn): Linear(in_features=128, out_features=1, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=128, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n\n\n\n# Initialize trainer\ninterpretable_trainer = Trainer(model=interpretable_model, device=device)\n\n# Get attention values\nattn_vals = interpretable_trainer.predict_step(dataloader)\nprint (attn_vals.shape) # (N, max_seq_len)\n\n# Visualize a bi-gram filter's outputs\nsns.set(rc={\"figure.figsize\":(10, 1)})\ntokens = tokenizer.sequences_to_texts(X)[0].split(\" \")\nsns.heatmap(attn_vals, xticklabels=tokens)\nThe word
"},{"location":"courses/foundations/attention/#types-of-attention","title":"Types of attention","text":"tenniswas attended to the most to result in theSportslabel.We'll briefly look at the different types of attention and when to use each them.
"},{"location":"courses/foundations/attention/#soft-global-attention","title":"Soft (global) attention","text":"Soft attention the type of attention we've implemented so far, where we attend to all encoded inputs when creating our context vector.
\n
Hard attention is focusing on a specific set of the encoded inputs at each time step.
\nLocal attention blends the advantages of soft and hard attention. It involves learning an aligned position vector and empirically determining a local window of encoded inputs to attend to.
\nWe can also use attention within the encoded input sequence to create a weighted representation that based on the similarity between input pairs. This will allow us to create rich representations of the input sequence that are aware of the relationships between each other. For example, in the image below you can see that when composing the representation of the token \"its\", this specific attention head will be incorporating signal from the token \"Law\" (it's learned that \"its\" is referring to the \"Law\").
\nAttention Is All You Need\nIn the next lesson, we'll implement Transformers that leverage self-attention to create contextual representations of our inputs for downstream applications.
\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Attention - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nAt the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
Let's set our seed and device.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/convolutional-neural-networks/#load-data","title":"Load data","text":"
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\nWe're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nnltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\nprint (STOPWORDS[:5])\nporter = PorterStemmer()\n\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n['i', 'me', 'my', 'myself', 'we']\n
def preprocess(text, stopwords=STOPWORDS):\n\"\"\"Conditional preprocessing on our text unique to our task.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r\"\\b(\" + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub(\"\", text)\n\n # Remove words in parenthesis\n text = re.sub(r\"\\([^)]*\\)\", \"\", text)\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text) # separate punctuation tied to words\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n return text\n# Sample\ntext = \"Great week for the NYSE!\"\npreprocess(text=text)\n\ngreat week nyse\n
# Apply to dataframe\npreprocessed_df = df.copy()\npreprocessed_df.title = preprocessed_df.title.apply(preprocess)\nprint (f\"{df.title.values[0]}\\n\\n{preprocessed_df.title.values[0]}\")\n\nSharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says\n\nsharon accepts plan reduce gaza army operation haaretz says\n"},{"location":"courses/foundations/convolutional-neural-networks/#split-data","title":"Split data","text":"
import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Data\nX = preprocessed_df[\"title\"].values\ny = preprocessed_df[\"category\"].values\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (84000,), y_train: (84000,)\nX_val: (18000,), y_val: (18000,)\nX_test: (18000,), y_test: (18000,)\nSample point: china battles north korea nuclear talks \u2192 World\n"},{"location":"courses/foundations/convolutional-neural-networks/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nNUM_CLASSES = len(label_encoder)\nlabel_encoder.class_to_index\n\n{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: World\ny_train[0]: 3\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [21000 21000 21000 21000]\nweights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}\n"},{"location":"courses/foundations/convolutional-neural-networks/#tokenizer","title":"Tokenizer","text":"Our input data is text and we can't feed it directly to our models. So, we'll define a Tokenizer to convert our text input data into token indices. This means that every token (we can decide what a token is char, word, sub-word, etc.) is mapped to a unique index which allows us to represent our text as an array of indices.
import json\nfrom collections import Counter\nfrom more_itertools import take\nclass Tokenizer(object):\n def __init__(self, char_level, num_tokens=None,\n pad_token=\"<PAD>\", oov_token=\"<UNK>\",\n token_to_index=None):\n self.char_level = char_level\n self.separator = \"\" if self.char_level else \" \"\n if num_tokens: num_tokens -= 2 # pad + unk tokens\n self.num_tokens = num_tokens\n self.pad_token = pad_token\n self.oov_token = oov_token\n if not token_to_index:\n token_to_index = {pad_token: 0, oov_token: 1}\n self.token_to_index = token_to_index\n self.index_to_token = {v: k for k, v in self.token_to_index.items()}\n\n def __len__(self):\n return len(self.token_to_index)\n\n def __str__(self):\n return f\"<Tokenizer(num_tokens={len(self)})>\"\n\n def fit_on_texts(self, texts):\n if not self.char_level:\n texts = [text.split(\" \") for text in texts]\n all_tokens = [token for text in texts for token in text]\n counts = Counter(all_tokens).most_common(self.num_tokens)\n self.min_token_freq = counts[-1][1]\n for token, count in counts:\n index = len(self)\n self.token_to_index[token] = index\n self.index_to_token[index] = token\n return self\n\n def texts_to_sequences(self, texts):\n sequences = []\n for text in texts:\n if not self.char_level:\n text = text.split(\" \")\n sequence = []\n for token in text:\n sequence.append(self.token_to_index.get(\n token, self.token_to_index[self.oov_token]))\n sequences.append(np.asarray(sequence))\n return sequences\n\n def sequences_to_texts(self, sequences):\n texts = []\n for sequence in sequences:\n text = []\n for index in sequence:\n text.append(self.index_to_token.get(index, self.oov_token))\n texts.append(self.separator.join([token for token in text]))\n return texts\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {\n \"char_level\": self.char_level,\n \"oov_token\": self.oov_token,\n \"token_to_index\": self.token_to_index\n }\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\nTokenizer to the top 500 most frequent tokens (stop words already removed) because the full vocabulary size (~35K) is too large to run on Google Colab notebooks. # Tokenize\ntokenizer = Tokenizer(char_level=False, num_tokens=500)\ntokenizer.fit_on_texts(texts=X_train)\nVOCAB_SIZE = len(tokenizer)\nprint (tokenizer)\n\nTokenizer(num_tokens=500)\n
# Sample of tokens\nprint (take(5, tokenizer.token_to_index.items()))\nprint (f\"least freq token's freq: {tokenizer.min_token_freq}\") # use this to adjust num_tokens\n\n[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]\nleast freq token's freq: 166\n # Convert texts to sequences of indices\nX_train = tokenizer.texts_to_sequences(X_train)\nX_val = tokenizer.texts_to_sequences(X_val)\nX_test = tokenizer.texts_to_sequences(X_test)\npreprocessed_text = tokenizer.sequences_to_texts([X_train[0]])[0]\nprint (\"Text to indices:\\n\"\n f\" (preprocessed) \u2192 {preprocessed_text}\\n\"\n f\" (tokenized) \u2192 {X_train[0]}\")\n\nText to indices:\n (preprocessed) \u2192 china <UNK> north korea nuclear talks\n (tokenized) \u2192 [ 16 1 285 142 114 24]\n
Did we need to split the data first?
How come we applied the preprocessing functions to the entire dataset but tokenization after splitting the dataset? Does it matter?
Show answerIf you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. So for the tokenization process, it's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well. However for global preprocessing steps, like the preprocessing function where we aren't learning anything from the data itself, we can perform before splitting the data.
"},{"location":"courses/foundations/convolutional-neural-networks/#one-hot-encoding","title":"One-hot encoding","text":"One-hot encoding creates a binary column for each unique value for the feature we're trying to map. All of the values in each token's array will be 0 except at the index that this specific token is represented by.
There are 5 words in the vocabulary:
{\n\"a\": 0,\n\"e\": 1,\n\"i\": 2,\n\"o\": 3,\n\"u\": 4\n}\nThen the text aou would be represented by:
[[1. 0. 0. 0. 0.]\n [0. 0. 0. 1. 0.]\n [0. 0. 0. 0. 1.]]\nOne-hot encoding allows us to represent our data in a way that our models can process the data and isn't biased by the actual value of the token (ex. if your labels were actual numbers).
We have already applied one-hot encoding in the previous lessons when we encoded our labels. Each label was represented by a unique index but when determining loss, we effectively use it's one hot representation and compared it to the predicted probability distribution. We never explicitly wrote this out since all of our previous tasks were multi-class which means every input had just one output class, so the 0s didn't affect the loss (though it did matter during back propagation).
def to_categorical(seq, num_classes):\n\"\"\"One-hot encode a sequence of tokens.\"\"\"\n one_hot = np.zeros((len(seq), num_classes))\n for i, item in enumerate(seq):\n one_hot[i, item] = 1.\n return one_hot\n# One-hot encoding\nprint (X_train[0])\nprint (len(X_train[0]))\ncat = to_categorical(seq=X_train[0], num_classes=len(tokenizer))\nprint (cat)\nprint (cat.shape)\n\n[ 16 1 285 142 114 24]\n6\n[[0. 0. 0. ... 0. 0. 0.]\n [0. 1. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]\n [0. 0. 0. ... 0. 0. 0.]]\n(6, 500)\n
# Convert tokens to one-hot\nvocab_size = len(tokenizer)\nX_train = [to_categorical(seq, num_classes=vocab_size) for seq in X_train]\nX_val = [to_categorical(seq, num_classes=vocab_size) for seq in X_val]\nX_test = [to_categorical(seq, num_classes=vocab_size) for seq in X_test]\nOur inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
One-hot encoding creates a batch of shape (N, max_seq_len, vocab_size) so we'll need to be able to pad 3D sequences.
def pad_sequences(sequences, max_seq_len=0):\n\"\"\"Pad sequences to max length in sequence.\"\"\"\n max_seq_len = max(max_seq_len, max(len(sequence) for sequence in sequences))\n num_classes = sequences[0].shape[-1]\n padded_sequences = np.zeros((len(sequences), max_seq_len, num_classes))\n for i, sequence in enumerate(sequences):\n padded_sequences[i][:len(sequence)] = sequence\n return padded_sequences\n# 3D sequences\nprint (X_train[0].shape, X_train[1].shape, X_train[2].shape)\npadded = pad_sequences(X_train[0:3])\nprint (padded.shape)\n\n(6, 500) (5, 500) (6, 500)\n(3, 6, 500)\n
Is our pad_sequences function properly created?
Notice any assumptions that could lead to hidden bugs?
Show answerBy using np.zeros() to create our padded sequences, we're assuming that our pad token's index is 0. While this is the case for our project, someone could choose to use a different index and this can cause an error. Worst of all, this would be a silent error because all downstream operations would still run normally but our performance will suffer and it may not always be intuitive that this was the cause of issue!
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
FILTER_SIZE = 1 # unigram\nclass Dataset(torch.utils.data.Dataset):\n def __init__(self, X, y, max_filter_size):\n self.X = X\n self.y = y\n self.max_filter_size = max_filter_size\n\n def __len__(self):\n return len(self.y)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n X = self.X[index]\n y = self.y[index]\n return [X, y]\n\n def collate_fn(self, batch):\n\"\"\"Processing on a batch.\"\"\"\n # Get inputs\n batch = np.array(batch)\n X = batch[:, 0]\n y = batch[:, 1]\n\n # Pad sequences\n X = pad_sequences(X, max_seq_len=self.max_filter_size)\n\n # Cast\n X = torch.FloatTensor(X.astype(np.int32))\n y = torch.LongTensor(y.astype(np.int32))\n\n return X, y\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,\n shuffle=shuffle, drop_last=drop_last, pin_memory=True)\n# Create datasets for embedding\ntrain_dataset = Dataset(X=X_train, y=y_train, max_filter_size=FILTER_SIZE)\nval_dataset = Dataset(X=X_val, y=y_val, max_filter_size=FILTER_SIZE)\ntest_dataset = Dataset(X=X_test, y=y_test, max_filter_size=FILTER_SIZE)\nprint (\"Datasets:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" X: {test_dataset[0][0]}\\n\"\n f\" y: {test_dataset[0][1]}\")\n\nDatasets:\n Train dataset: <Dataset(N=84000)>\n Val dataset: <Dataset(N=18000)>\n Test dataset: <Dataset(N=18000)>\nSample point:\n X: [[0. 0. 0. ... 0. 0. 0.]\n [0. 1. 0. ... 0. 0. 0.]\n [0. 1. 0. ... 0. 0. 0.]\n [0. 1. 0. ... 0. 0. 0.]]\n y: 1\n
# Create dataloaders\nbatch_size = 64\ntrain_dataloader = train_dataset.create_dataloader(batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(batch_size=batch_size)\nbatch_X, batch_y = next(iter(test_dataloader))\nprint (\"Sample batch:\\n\"\n f\" X: {list(batch_X.size())}\\n\"\n f\" y: {list(batch_y.size())}\\n\"\n \"Sample point:\\n\"\n f\" X: {batch_X[0]}\\n\"\n f\" y: {batch_y[0]}\")\n\nSample batch:\n X: [64, 14, 500]\n y: [64]\nSample point:\n X: tensor([[0., 0., 0., ..., 0., 0., 0.],\n [0., 1., 0., ..., 0., 0., 0.],\n [0., 1., 0., ..., 0., 0., 0.],\n ...,\n [0., 0., 0., ..., 0., 0., 0.],\n [0., 0., 0., ..., 0., 0., 0.],\n [0., 0., 0., ..., 0., 0., 0.]], device=\"cpu\")\n y: 1\n"},{"location":"courses/foundations/convolutional-neural-networks/#cnn","title":"CNN","text":"
We're going to learn about CNNs by applying them on 1D text data.
"},{"location":"courses/foundations/convolutional-neural-networks/#inputs","title":"Inputs","text":"In the dummy example below, our inputs are composed of character tokens that are one-hot encoded. We have a batch of N samples, where each sample has 8 characters and each character is represented by an array of 10 values (vocab size=10). This gives our inputs the size (N, 8, 10).
With PyTorch, when dealing with convolution, our inputs (X) need to have the channels as the second dimension, so our inputs will be (N, 10, 8).
import math\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n# Assume all our inputs are padded to have the same # of words\nbatch_size = 64\nmax_seq_len = 8 # words per input\nvocab_size = 10 # one hot size\nx = torch.randn(batch_size, max_seq_len, vocab_size)\nprint(f\"X: {x.shape}\")\nx = x.transpose(1, 2)\nprint(f\"X: {x.shape}\")\n\nX: torch.Size([64, 8, 10])\nX: torch.Size([64, 10, 8])\nThis diagram above is for char-level tokens but extends to any level of tokenization."},{"location":"courses/foundations/convolutional-neural-networks/#filters","title":"Filters","text":"
At the core of CNNs are filters (aka weights, kernels, etc.) which convolve (slide) across our input to extract relevant features. The filters are initialized randomly but learn to act as feature extractors via parameter sharing.
We can see convolution in the diagram below where we simplified the filters and inputs to be 2D for ease of visualization. Also note that the values are 0/1s but in reality they can be any floating point value.
Now let's return to our actual inputs x, which is of shape (8, 10) [max_seq_len, vocab_size] and we want to convolve on this input using filters. We will use 50 filters that are of size (1, 3) and has the same depth as the number of channels (num_channels = vocab_size = one_hot_size = 10). This gives our filter a shape of (3, 10, 50) [kernel_size, vocab_size, num_filters]
stride: amount the filters move from one convolution operation to the next.padding: values (typically zero) padded to the input, typically to create a volume with whole number dimensions.So far we've used a stride of 1 and VALID padding (no padding) but let's look at an example with a higher stride and difference between different padding approaches.
Padding types:
VALID: no padding, the filters only use the \"valid\" values in the input. If the filter cannot reach all the input values (filters go left to right), the extra values on the right are dropped.SAME: adds padding evenly to the right (preferred) and left sides of the input so that all values in the input are processed.We're going to use the Conv1d layer to process our inputs.
# Convolutional filters (VALID padding)\nvocab_size = 10 # one hot size\nnum_filters = 50 # num filters\nfilter_size = 3 # filters are 3X3\nstride = 1\npadding = 0 # valid padding (no padding)\nconv1 = nn.Conv1d(in_channels=vocab_size, out_channels=num_filters,\n kernel_size=filter_size, stride=stride,\n padding=padding, padding_mode=\"zeros\")\nprint(\"conv: {}\".format(conv1.weight.shape))\n\nconv: torch.Size([50, 10, 3])\n
# Forward pass\nz = conv1(x)\nprint (f\"z: {z.shape}\")\n\nz: torch.Size([64, 50, 6])\n
When we apply these filter on our inputs, we receive an output of shape (N, 6, 50). We get 50 for the output channel dim because we used 50 filters and 6 for the conv outputs because:
\\[ W_1 = \\frac{W_2 - F + 2P}{S} + 1 = \\frac{8 - 3 + 2(0)}{1} + 1 = 6 \\] \\[ H_1 = \\frac{H_2 - F + 2P}{S} + 1 = \\frac{1 - 1 + 2(0)}{1} + 1 = 1 \\] \\[ D_2 = D_1 \\]Variable Description \\(W\\) width of each input = 8 \\(H\\) height of each input = 1 \\(D\\) depth (# of channels) \\(F\\) filter size = 3 \\(P\\) padding = 0 \\(S\\) stride = 1
Now we'll add padding so that the convolutional outputs are the same shape as our inputs. The amount of padding for the SAME padding can be determined using the same equation. We want out output to have the same width as our input, so we solve for P:
If \\(P\\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
# Convolutional filters (SAME padding)\nvocab_size = 10 # one hot size\nnum_filters = 50 # num filters\nfilter_size = 3 # filters are 3X3\nstride = 1\nconv = nn.Conv1d(in_channels=vocab_size, out_channels=num_filters,\n kernel_size=filter_size, stride=stride)\nprint(\"conv: {}\".format(conv.weight.shape))\n\nconv: torch.Size([50, 10, 3])\n
# `SAME` padding\npadding_left = int((conv.stride[0]*(max_seq_len-1) - max_seq_len + filter_size)/2)\npadding_right = int(math.ceil((conv.stride[0]*(max_seq_len-1) - max_seq_len + filter_size)/2))\nprint (f\"padding: {(padding_left, padding_right)}\")\n\npadding: (1, 1)\n
# Forward pass\nz = conv(F.pad(x, (padding_left, padding_right)))\nprint (f\"z: {z.shape}\")\n\nz: torch.Size([64, 50, 8])\n
We will explore larger dimensional convolution layers in subsequent lessons. For example, Conv2D is used with 3D inputs (images, char-level text, etc.) and Conv3D is used for 4D inputs (videos, time-series, etc.).
"},{"location":"courses/foundations/convolutional-neural-networks/#pooling","title":"Pooling","text":"The result of convolving filters on an input is a feature map. Due to the nature of convolution and overlaps, our feature map will have lots of redundant information. Pooling is a way to summarize a high-dimensional feature map into a lower dimensional one for simplified downstream computation. The pooling operation can be the max value, average, etc. in a certain receptive field. Below is an example of pooling where the outputs from a conv layer are 4X4 and we're going to apply max pool filters of size 2X2.
Variable Description \\(W\\) width of each input = 4 \\(H\\) height of each input = 4 \\(D\\) depth (# of channels) \\(F\\) filter size = 2 \\(S\\) stride = 2
In our use case, we want to just take the one max value so we will use the MaxPool1D layer, so our max-pool filter size will be max_seq_len.
# Max pooling\npool_output = F.max_pool1d(z, z.size(2))\nprint(\"Size: {}\".format(pool_output.shape))\n\nSize: torch.Size([64, 50, 1])\n"},{"location":"courses/foundations/convolutional-neural-networks/#batch-normalization","title":"Batch normalization","text":"
The last topic we'll cover before constructing our model is batch normalization. It's an operation that will standardize (mean=0, std=1) the activations from the previous layer. Recall that we used to standardize our inputs in previous notebooks so our model can optimize quickly with larger learning rates. It's the same concept here but we continue to maintain standardized values throughout the repeated forward passes to further aid optimization.
# Batch normalization\nbatch_norm = nn.BatchNorm1d(num_features=num_filters)\nz = batch_norm(conv(x)) # applied to activations (after conv layer & before pooling)\nprint (f\"z: {z.shape}\")\n\nz: torch.Size([64, 50, 6])\n
# Mean and std before batchnorm\nprint (f\"mean: {torch.mean(conv(x)):.2f}, std: {torch.std(conv(x)):.2f}\")\n\nmean: -0.00, std: 0.57\n
# Mean and std after batchnorm\nprint (f\"mean: {torch.mean(z):.2f}, std: {torch.std(z):.2f}\")\n\nmean: 0.00, std: 1.00\n"},{"location":"courses/foundations/convolutional-neural-networks/#modeling","title":"Modeling","text":""},{"location":"courses/foundations/convolutional-neural-networks/#model","title":"Model","text":"
Let's visualize the model's forward pass.
batch_size, max_seq_len).batch_size, max_seq_len, vocab_size).filter_size, vocab_size, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors.NUM_FILTERS = 50\nHIDDEN_DIM = 100\nDROPOUT_P = 0.1\nclass CNN(nn.Module):\n def __init__(self, vocab_size, num_filters, filter_size,\n hidden_dim, dropout_p, num_classes):\n super(CNN, self).__init__()\n\n # Convolutional filters\n self.filter_size = filter_size\n self.conv = nn.Conv1d(\n in_channels=vocab_size, out_channels=num_filters,\n kernel_size=filter_size, stride=1, padding=0, padding_mode=\"zeros\")\n self.batch_norm = nn.BatchNorm1d(num_features=num_filters)\n\n # FC layers\n self.fc1 = nn.Linear(num_filters, hidden_dim)\n self.dropout = nn.Dropout(dropout_p)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs, channel_first=False,):\n\n # Rearrange input so num_channels is in dim 1 (N, C, L)\n x_in, = inputs\n if not channel_first:\n x_in = x_in.transpose(1, 2)\n\n # Padding for `SAME` padding\n max_seq_len = x_in.shape[2]\n padding_left = int((self.conv.stride[0]*(max_seq_len-1) - max_seq_len + self.filter_size)/2)\n padding_right = int(math.ceil((self.conv.stride[0]*(max_seq_len-1) - max_seq_len + self.filter_size)/2))\n\n # Conv outputs\n z = self.conv(F.pad(x_in, (padding_left, padding_right)))\n z = F.max_pool1d(z, z.size(2)).squeeze(2)\n\n # FC layer\n z = self.fc1(z)\n z = self.dropout(z)\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = CNN(vocab_size=VOCAB_SIZE, num_filters=NUM_FILTERS, filter_size=FILTER_SIZE,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of CNN(\n (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,))\n (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (fc1): Linear(in_features=50, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n
We used SAME padding (w/ stride=1) which means that the conv outputs will have the same width (max_seq_len) as our inputs. The amount of padding differs for each batch based on the max_seq_len but you can calculate it by solving for P in the equation below.
If \\(P\\) is not a whole number, we round up (using math.ceil) and place the extra padding on the right side.
Let's create the Trainer class that we'll use to facilitate training for our experiments. Notice that we're now moving the train function inside this class.
from torch.optim import Adam\nLEARNING_RATE = 1e-3\nPATIENCE = 5\nNUM_EPOCHS = 10\nclass Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.87388, val_loss: 0.79013, lr: 1.00E-03, _patience: 3\nEpoch: 2 | train_loss: 0.78354, val_loss: 0.78657, lr: 1.00E-03, _patience: 3\nEpoch: 3 | train_loss: 0.77743, val_loss: 0.78433, lr: 1.00E-03, _patience: 3\nEpoch: 4 | train_loss: 0.77242, val_loss: 0.78260, lr: 1.00E-03, _patience: 3\nEpoch: 5 | train_loss: 0.76900, val_loss: 0.78169, lr: 1.00E-03, _patience: 3\nEpoch: 6 | train_loss: 0.76613, val_loss: 0.78064, lr: 1.00E-03, _patience: 3\nEpoch: 7 | train_loss: 0.76413, val_loss: 0.78019, lr: 1.00E-03, _patience: 3\nEpoch: 8 | train_loss: 0.76215, val_loss: 0.78016, lr: 1.00E-03, _patience: 3\nEpoch: 9 | train_loss: 0.76034, val_loss: 0.77974, lr: 1.00E-03, _patience: 3\nEpoch: 10 | train_loss: 0.75859, val_loss: 0.77978, lr: 1.00E-03, _patience: 2\n"},{"location":"courses/foundations/convolutional-neural-networks/#evaluation","title":"Evaluation","text":"
import json\nfrom pathlib import Path\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.7120047175492572,\n \"recall\": 0.6935,\n \"f1\": 0.6931471439737603,\n \"num_samples\": 18000.0\n}\n # Save artifacts\ndir = Path(\"cnn\")\ndir.mkdir(parents=True, exist_ok=True)\nlabel_encoder.save(fp=Path(dir, \"label_encoder.json\"))\ntokenizer.save(fp=Path(dir, 'tokenizer.json'))\ntorch.save(best_model.state_dict(), Path(dir, \"model.pt\"))\nwith open(Path(dir, 'performance.json'), \"w\") as fp:\n json.dump(performance, indent=2, sort_keys=False, fp=fp)\ndef get_probability_distribution(y_prob, classes):\n\"\"\"Create a dict of class probabilities from an array.\"\"\"\n results = {}\n for i, class_ in enumerate(classes):\n results[class_] = np.float64(y_prob[i])\n sorted_results = {k: v for k, v in sorted(\n results.items(), key=lambda item: item[1], reverse=True)}\n return sorted_results\n# Load artifacts\ndevice = torch.device(\"cpu\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\ntokenizer = Tokenizer.load(fp=Path(dir, 'tokenizer.json'))\nmodel = CNN(\n vocab_size=VOCAB_SIZE, num_filters=NUM_FILTERS, filter_size=FILTER_SIZE,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device)\n\nCNN(\n (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,))\n (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (fc1): Linear(in_features=50, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n
# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n# Dataloader\ntext = \"What a day for the new york stock market to go bust!\"\nsequences = tokenizer.texts_to_sequences([preprocess(text)])\nprint (tokenizer.sequences_to_texts(sequences))\nX = [to_categorical(seq, num_classes=len(tokenizer)) for seq in sequences]\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))\ndataset = Dataset(X=X, y=y_filler, max_filter_size=FILTER_SIZE)\ndataloader = dataset.create_dataloader(batch_size=batch_size)\n\n['day new <UNK> stock market go <UNK>']\n
# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.decode(y_pred)\n\n['Business']\n
# Class distributions\nprob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)\nprint (json.dumps(prob_dist, indent=2))\n\n{\n \"Business\": 0.8670833110809326,\n \"Sci/Tech\": 0.10699427127838135,\n \"World\": 0.021050667390227318,\n \"Sports\": 0.004871787969022989\n}\n"},{"location":"courses/foundations/convolutional-neural-networks/#interpretability","title":"Interpretability","text":"We went through all the trouble of padding our inputs before convolution to result in outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
import collections\nimport seaborn as sns\nclass InterpretableCNN(nn.Module):\n def __init__(self, vocab_size, num_filters, filter_size,\n hidden_dim, dropout_p, num_classes):\n super(InterpretableCNN, self).__init__()\n\n # Convolutional filters\n self.filter_size = filter_size\n self.conv = nn.Conv1d(\n in_channels=vocab_size, out_channels=num_filters,\n kernel_size=filter_size, stride=1, padding=0, padding_mode=\"zeros\")\n self.batch_norm = nn.BatchNorm1d(num_features=num_filters)\n\n # FC layers\n self.fc1 = nn.Linear(num_filters, hidden_dim)\n self.dropout = nn.Dropout(dropout_p)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs, channel_first=False):\n\n # Rearrange input so num_channels is in dim 1 (N, C, L)\n x_in, = inputs\n if not channel_first:\n x_in = x_in.transpose(1, 2)\n\n # Padding for `SAME` padding\n max_seq_len = x_in.shape[2]\n padding_left = int((self.conv.stride[0]*(max_seq_len-1) - max_seq_len + self.filter_size)/2)\n padding_right = int(math.ceil((self.conv.stride[0]*(max_seq_len-1) - max_seq_len + self.filter_size)/2))\n\n # Conv outputs\n z = self.conv(F.pad(x_in, (padding_left, padding_right)))\n return z\n# Initialize\ninterpretable_model = InterpretableCNN(\n vocab_size=len(tokenizer), num_filters=NUM_FILTERS, filter_size=FILTER_SIZE,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\n# Load weights (same architecture)\ninterpretable_model.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\ninterpretable_model.to(device)\n\nInterpretableCNN(\n (conv): Conv1d(500, 50, kernel_size=(1,), stride=(1,))\n (batch_norm): BatchNorm1d(50, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (fc1): Linear(in_features=50, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n
# Initialize trainer\ninterpretable_trainer = Trainer(model=interpretable_model, device=device)\n# Get conv outputs\nconv_outputs = interpretable_trainer.predict_step(dataloader)\nprint (conv_outputs.shape) # (num_filters, max_seq_len)\n\n(50, 7)\n
# Visualize a bi-gram filter's outputs\ntokens = tokenizer.sequences_to_texts(sequences)[0].split(\" \")\nsns.heatmap(conv_outputs, xticklabels=tokens)\nThe filters have high values for the words stock and market which influenced the Business category classification.
Warning
This is a crude technique loosely based off of more elaborate interpretability methods.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { CNNs - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn a nutshell, a machine learning model consumes input data and produces predictions. The quality of the predictions directly corresponds to the quality of data you train the model with; garbage in, garbage out. Check out this article on where it makes sense to use AI and how to properly apply it.
We're going to go through all the concepts with concrete code examples and some synthesized data to train our models on. The task is to determine whether a tumor will be benign (harmless) or malignant (harmful) based on leukocyte (white blood cells) count and blood pressure. This is a synthetic dataset that we created and has no clinical relevance.
"},{"location":"courses/foundations/data-quality/#set-up","title":"Set up","text":"We'll set our seeds for reproducibility.
import numpy as np\nimport random\nSEED = 1234\n# Set seed for reproducibility\nnp.random.seed(SEED)\nrandom.seed(SEED)\nWe'll first train a model with the entire dataset. Later we'll remove a subset of the dataset and see the effect it has on our model.
"},{"location":"courses/foundations/data-quality/#load-data","title":"Load data","text":"import matplotlib.pyplot as plt\nimport pandas as pd\nfrom pandas.plotting import scatter_matrix\n# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\n# Define X and y\nX = df[[\"leukocyte_count\", \"blood_pressure\"]].values\ny = df[\"tumor_class\"].values\nprint (\"X: \", np.shape(X))\nprint (\"y: \", np.shape(y))\n\nX: (1000, 2)\ny: (1000,)\n
# Plot data\ncolors = {\"benign\": \"red\", \"malignant\": \"blue\"}\nplt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], s=25, edgecolors=\"k\")\nplt.xlabel(\"leukocyte count\")\nplt.ylabel(\"blood pressure\")\nplt.legend([\"malignant\", \"benign\"], loc=\"upper right\")\nplt.show()\nWe want to choose features that have strong predictive signal for our task. If you want to improve performance, you need to continuously do feature engineering by collecting and adding new signals. So you may run into a new feature that has high correlation (orthogonal signal) with your existing features but it may still possess some unique signal to boost your predictive performance.
# Correlation matrix\nscatter_matrix(df, figsize=(5, 5));\ndf.corr()\nimport collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.70\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (700, 2), y_train: (700,)\nX_val: (150, 2), y_val: (150,)\nX_test: (150, 2), y_test: (150,)\nSample point: [11.5066204 15.98030799] \u2192 malignant\n"},{"location":"courses/foundations/data-quality/#label-encoding","title":"Label encoding","text":"
from sklearn.preprocessing import LabelEncoder\n# Output vectorizer\nlabel_encoder = LabelEncoder()\n# Fit on train data\nlabel_encoder = label_encoder.fit(y_train)\nclasses = list(label_encoder.classes_)\nprint (f\"classes: {classes}\")\n\nclasses: [\"benign\", \"malignant\"]\n
# Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.transform(y_train)\ny_val = label_encoder.transform(y_val)\ny_test = label_encoder.transform(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: malignant\ny_train[0]: 1\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [272 428]\nweights: {0: 0.003676470588235294, 1: 0.002336448598130841}\n"},{"location":"courses/foundations/data-quality/#standardize-data","title":"Standardize data","text":"from sklearn.preprocessing import StandardScaler\n# Standardize the data (mean=0, std=1) using training data\nX_scaler = StandardScaler().fit(X_train)\n# Apply scaler on training and test data (don't standardize outputs for classification)\nX_train = X_scaler.transform(X_train)\nX_val = X_scaler.transform(X_val)\nX_test = X_scaler.transform(X_test)\n# Check (means should be ~0 and std should be ~1)\nprint (f\"X_test[0]: mean: {np.mean(X_test[:, 0], axis=0):.1f}, std: {np.std(X_test[:, 0], axis=0):.1f}\")\nprint (f\"X_test[1]: mean: {np.mean(X_test[:, 1], axis=0):.1f}, std: {np.std(X_test[:, 1], axis=0):.1f}\")\n\nX_test[0]: mean: 0.0, std: 1.0\nX_test[1]: mean: 0.0, std: 1.0\n"},{"location":"courses/foundations/data-quality/#model","title":"Model","text":"
import torch\nfrom torch import nn\nimport torch.nn.functional as F\n# Set seed for reproducibility\ntorch.manual_seed(SEED)\nINPUT_DIM = 2 # X is 2-dimensional\nHIDDEN_DIM = 100\nNUM_CLASSES = 2\nclass MLP(nn.Module):\n def __init__(self, input_dim, hidden_dim, num_classes):\n super(MLP, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, x_in):\n z = F.relu(self.fc1(x_in)) # ReLU activation function added!\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of MLP(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=2, bias=True)\n)>\n"},{"location":"courses/foundations/data-quality/#training","title":"Training","text":"
from torch.optim import Adam\nLEARNING_RATE = 1e-3\nNUM_EPOCHS = 5\nBATCH_SIZE = 32\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values()))\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Accuracy\ndef accuracy_fn(y_pred, y_true):\n n_correct = torch.eq(y_pred, y_true).sum().item()\n accuracy = (n_correct / len(y_pred)) * 100\n return accuracy\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Training\nfor epoch in range(NUM_EPOCHS*10):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%10==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 0.70, accuracy: 49.6\nEpoch: 10 | loss: 0.54, accuracy: 93.7\nEpoch: 20 | loss: 0.43, accuracy: 97.1\nEpoch: 30 | loss: 0.35, accuracy: 97.0\nEpoch: 40 | loss: 0.30, accuracy: 97.4\n"},{"location":"courses/foundations/data-quality/#evaluation","title":"Evaluation","text":"
import json\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Predictions\ny_prob = F.softmax(model(X_test), dim=1)\ny_pred = y_prob.max(dim=1)[1]\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.9461538461538461,\n \"recall\": 0.9619565217391304,\n \"f1\": 0.9517707041477195,\n \"num_samples\": 150.0\n },\n \"class\": {\n \"benign\": {\n \"precision\": 0.8923076923076924,\n \"recall\": 1.0,\n \"f1\": 0.9430894308943091,\n \"num_samples\": 58.0\n },\n \"malignant\": {\n \"precision\": 1.0,\n \"recall\": 0.9239130434782609,\n \"f1\": 0.96045197740113,\n \"num_samples\": 92.0\n }\n }\n}\n"},{"location":"courses/foundations/data-quality/#inference","title":"Inference","text":"We're going to plot a point, which we know belongs to the malignant tumor class. Our well trained model here would accurately predict that it is indeed a malignant tumor!
def plot_multiclass_decision_boundary(model, X, y):\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))\n cmap = plt.cm.Spectral\n\n X_test = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float()\n y_pred = F.softmax(model(X_test), dim=1)\n _, y_pred = y_pred.max(dim=1)\n y_pred = y_pred.reshape(xx.shape)\n plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n# Visualize the decision boundary\nplt.figure(figsize=(8,5))\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\n\n# Sample point near the decision boundary\nmean_leukocyte_count, mean_blood_pressure = X_scaler.transform(\n [[np.mean(df.leukocyte_count), np.mean(df.blood_pressure)]])[0]\nplt.scatter(mean_leukocyte_count+0.05, mean_blood_pressure-0.05, s=200,\n c=\"b\", edgecolor=\"w\", linewidth=2)\n\n# Annotate\nplt.annotate(\"true: malignant,\\npred: malignant\",\n color=\"white\",\n xy=(mean_leukocyte_count, mean_blood_pressure),\n xytext=(0.4, 0.65),\n textcoords=\"figure fraction\",\n fontsize=16,\n arrowprops=dict(facecolor=\"white\", shrink=0.1))\nplt.show()\nGreat! We received great performances on both our train and test data splits. We're going to use this dataset to show the importance of data quality.
"},{"location":"courses/foundations/data-quality/#reduced-dataset","title":"Reduced dataset","text":"Let's remove some training data near the decision boundary and see how robust the model is now.
"},{"location":"courses/foundations/data-quality/#load-data_1","title":"Load data","text":"# Raw reduced data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors_reduced.csv\"\ndf_reduced = pd.read_csv(url, header=0) # load\ndf_reduced = df_reduced.sample(frac=1).reset_index(drop=True) # shuffle\ndf_reduced.head()\n# Define X and y\nX = df_reduced[[\"leukocyte_count\", \"blood_pressure\"]].values\ny = df_reduced[\"tumor_class\"].values\nprint (\"X: \", np.shape(X))\nprint (\"y: \", np.shape(y))\n\nX: (720, 2)\ny: (720,)\n
# Plot data\ncolors = {\"benign\": \"red\", \"malignant\": \"blue\"}\nplt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], s=25, edgecolors=\"k\")\nplt.xlabel(\"leukocyte count\")\nplt.ylabel(\"blood pressure\")\nplt.legend([\"malignant\", \"benign\"], loc=\"upper right\")\nplt.show()\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (503, 2), y_train: (503,)\nX_val: (108, 2), y_val: (108,)\nX_test: (109, 2), y_test: (109,)\nSample point: [19.66235758 15.65939541] \u2192 benign\n"},{"location":"courses/foundations/data-quality/#label-encoding_1","title":"Label encoding","text":"
# Encode class labels\nlabel_encoder = LabelEncoder()\nlabel_encoder = label_encoder.fit(y_train)\nnum_classes = len(label_encoder.classes_)\ny_train = label_encoder.transform(y_train)\ny_val = label_encoder.transform(y_val)\ny_test = label_encoder.transform(y_test)\n# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [272 231]\nweights: {0: 0.003676470588235294, 1: 0.004329004329004329}\n"},{"location":"courses/foundations/data-quality/#standardize-data_1","title":"Standardize data","text":"# Standardize inputs using training data\nX_scaler = StandardScaler().fit(X_train)\nX_train = X_scaler.transform(X_train)\nX_val = X_scaler.transform(X_val)\nX_test = X_scaler.transform(X_test)\n# Initialize model\nmodel = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values()))\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Training\nfor epoch in range(NUM_EPOCHS*10):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%10==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 0.68, accuracy: 69.8\nEpoch: 10 | loss: 0.53, accuracy: 99.6\nEpoch: 20 | loss: 0.42, accuracy: 99.6\nEpoch: 30 | loss: 0.33, accuracy: 99.6\nEpoch: 40 | loss: 0.27, accuracy: 99.8\n"},{"location":"courses/foundations/data-quality/#evaluation_1","title":"Evaluation","text":"
# Predictions\ny_prob = F.softmax(model(X_test), dim=1)\ny_pred = y_prob.max(dim=1)[1]\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 1.0,\n \"recall\": 1.0,\n \"f1\": 1.0,\n \"num_samples\": 109.0\n },\n \"class\": {\n \"benign\": {\n \"precision\": 1.0,\n \"recall\": 1.0,\n \"f1\": 1.0,\n \"num_samples\": 59.0\n },\n \"malignant\": {\n \"precision\": 1.0,\n \"recall\": 1.0,\n \"f1\": 1.0,\n \"num_samples\": 50.0\n }\n }\n}\n"},{"location":"courses/foundations/data-quality/#inference_1","title":"Inference","text":"Now let's see how the same inference point from earlier performs now on the model trained on the reduced dataset.
# Visualize the decision boundary\nplt.figure(figsize=(8,5))\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\n\n# Sample point near the decision boundary (same point as before)\nplt.scatter(mean_leukocyte_count+0.05, mean_blood_pressure-0.05, s=200,\n c=\"b\", edgecolor=\"w\", linewidth=2)\n\n# Annotate\nplt.annotate(\"true: malignant,\\npred: benign\",\n color=\"white\",\n xy=(mean_leukocyte_count, mean_blood_pressure),\n xytext=(0.45, 0.60),\n textcoords=\"figure fraction\",\n fontsize=16,\n arrowprops=dict(facecolor=\"white\", shrink=0.1))\nplt.show()\nThis is a very fragile but highly realistic scenario. Based on our reduced synthetic dataset, we have achieved a model that generalized really well on the test data. But when we ask for the prediction for the same point tested earlier (which we known is malignant), the prediction is now a benign tumor. We would have completely missed the tumor. To mitigate this, we can:
Models are not crystal balls. So it's important that before any machine learning, we really look at our data and ask ourselves if it is truly representative for the task we want to solve. The model itself may fit really well and generalize well on your data but if the data is of poor quality to begin with, the model cannot be trusted.
Once you are confident that your data is of good quality, you can finally start thinking about modeling. The type of model you choose depends on many factors, including the task, type of data, complexity required, etc.
So once you figure out what type of model your task needs, start with simple models and then slowly add complexity. You don\u2019t want to start with neural networks right away because that may not be right model for your data and task. Striking this balance in model complexity is one of the key tasks of your data scientists. simple models \u2192 complex models
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Data quality - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWhile one-hot encoding allows us to preserve the structural information, it does poses two major disadvantages.
In this notebook, we're going to motivate the need for embeddings and how they address all the shortcomings of one-hot encoding. The main idea of embeddings is to have fixed length representations for the tokens in a text regardless of the number of tokens in the vocabulary. With one-hot encoding, each token is represented by an array of size vocab_size, but with embeddings, each token now has the shape embed_dim. The values in the representation will are not fixed binary values but rather, changing floating points allowing for fine-grained learned representations.
We can learn embeddings by creating our models in PyTorch but first, we're going to use a library that specializes in embeddings and topic modeling called Gensim.
import nltk\nnltk.download(\"punkt\");\nimport numpy as np\nimport re\nimport urllib\n\n[nltk_data] Downloading package punkt to /root/nltk_data...\n[nltk_data] Unzipping tokenizers/punkt.zip.\n
SEED = 1234\n# Set seed for reproducibility\nnp.random.seed(SEED)\n# Split text into sentences\ntokenizer = nltk.data.load(\"tokenizers/punkt/english.pickle\")\nbook = urllib.request.urlopen(url=\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/harrypotter.txt\")\nsentences = tokenizer.tokenize(str(book.read()))\nprint (f\"{len(sentences)} sentences\")\n\n12443 sentences\n
def preprocess(text):\n\"\"\"Conditional preprocessing on our text.\"\"\"\n # Lower\n text = text.lower()\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text)\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n # Separate into word tokens\n text = text.split(\" \")\n\n return text\n# Preprocess sentences\nprint (sentences[11])\nsentences = [preprocess(sentence) for sentence in sentences]\nprint (sentences[11])\n\nSnape nodded, but did not elaborate.\n['snape', 'nodded', 'but', 'did', 'not', 'elaborate']\n
But how do we learn the embeddings the first place? The intuition behind embeddings is that the definition of a token doesn't depend on the token itself but on its context. There are several different ways of doing this:
All of these approaches involve create data to train our model on. Every word in a sentence becomes the target word and the context words are determines by a window. In the image below (skip-gram), the window size is 2 (2 words to the left and right of the target word). We repeat this for every sentence in our corpus and this results in our training data for the unsupervised task. This in an unsupervised learning technique since we don't have official labels for contexts. The idea is that similar target words will appear with similar contexts and we can learn this relationship by repeatedly training our mode with (context, target) pairs.
We can learn embeddings using any of these approaches above and some work better than others. You can inspect the learned embeddings but the best way to choose an approach is to empirically validate the performance on a supervised task.
"},{"location":"courses/foundations/embeddings/#word2vec","title":"Word2Vec","text":"When we have large vocabularies to learn embeddings for, things can get complex very quickly. Recall that the backpropagation with softmax updates both the correct and incorrect class weights. This becomes a massive computation for every backwards pass we do so a workaround is to use negative sampling which only updates the correct class and a few arbitrary incorrect classes (NEGATIVE_SAMPLING=20). We're able to do this because of the large amount of training data where we'll see the same word as the target class multiple times.
import gensim\nfrom gensim.models import KeyedVectors\nfrom gensim.models import Word2Vec\nEMBEDDING_DIM = 100\nWINDOW = 5\nMIN_COUNT = 3 # Ignores all words with total frequency lower than this\nSKIP_GRAM = 1 # 0 = CBOW\nNEGATIVE_SAMPLING = 20\n# Super fast because of optimized C code under the hood\nw2v = Word2Vec(\n sentences=sentences, size=EMBEDDING_DIM,\n window=WINDOW, min_count=MIN_COUNT,\n sg=SKIP_GRAM, negative=NEGATIVE_SAMPLING)\nprint (w2v)\n\nWord2Vec(vocab=4937, size=100, alpha=0.025)\n
# Vector for each word\nw2v.wv.get_vector(\"potter\")\n\narray([-0.11787166, -0.2702948 , 0.24332453, 0.07497228, -0.5299148 ,\n 0.17751476, -0.30183575, 0.17060578, -0.0342238 , -0.331856 ,\n -0.06467848, 0.02454215, 0.4524056 , -0.18918884, -0.22446074,\n 0.04246538, 0.5784022 , 0.12316586, 0.03419832, 0.12895502,\n -0.36260423, 0.06671549, -0.28563526, -0.06784113, -0.0838319 ,\n 0.16225453, 0.24313857, 0.04139925, 0.06982274, 0.59947336,\n 0.14201492, -0.00841052, -0.14700615, -0.51149386, -0.20590985,\n 0.00435914, 0.04931103, 0.3382509 , -0.06798466, 0.23954925,\n -0.07505646, -0.50945646, -0.44729665, 0.16253233, 0.11114362,\n 0.05604156, 0.26727834, 0.43738437, -0.2606872 , 0.16259147,\n -0.28841105, -0.02349186, 0.00743417, 0.08558545, -0.0844396 ,\n -0.44747537, -0.30635086, -0.04186366, 0.11142804, 0.03187608,\n 0.38674814, -0.2663519 , 0.35415238, 0.094676 , -0.13586426,\n -0.35296437, -0.31428036, -0.02917303, 0.02518964, -0.59744245,\n -0.11500382, 0.15761602, 0.30535367, -0.06207089, 0.21460988,\n 0.17566076, 0.46426776, 0.15573359, 0.3675553 , -0.09043553,\n 0.2774392 , 0.16967005, 0.32909656, 0.01422888, 0.4131812 ,\n 0.20034142, 0.13722987, 0.10324971, 0.14308734, 0.23772323,\n 0.2513108 , 0.23396717, -0.10305202, -0.03343603, 0.14360961,\n -0.01891198, 0.11430877, 0.30017182, -0.09570111, -0.10692801],\n dtype=float32)\n
# Get nearest neighbors (excluding itself)\nw2v.wv.most_similar(positive=\"scar\", topn=5)\n\n[('pain', 0.9274871349334717),\n ('forehead', 0.9020695686340332),\n ('heart', 0.8953317999839783),\n ('mouth', 0.8939940929412842),\n ('throat', 0.8922691345214844)]\n # Saving and loading\nw2v.wv.save_word2vec_format(\"model.bin\", binary=True)\nw2v = KeyedVectors.load_word2vec_format(\"model.bin\", binary=True)\nWhat happens when a word doesn't exist in our vocabulary? We could assign an UNK token which is used for all OOV (out of vocabulary) words or we could use FastText, which uses character-level n-grams to embed a word. This helps embed rare words, misspelled words, and also words that don't exist in our corpus but are similar to words in our corpus.
from gensim.models import FastText\n# Super fast because of optimized C code under the hood\nft = FastText(sentences=sentences, size=EMBEDDING_DIM,\n window=WINDOW, min_count=MIN_COUNT,\n sg=SKIP_GRAM, negative=NEGATIVE_SAMPLING)\nprint (ft)\n\nFastText(vocab=4937, size=100, alpha=0.025)\n
# This word doesn't exist so the word2vec model will error out\nw2v.wv.most_similar(positive=\"scarring\", topn=5)\n# FastText will use n-grams to embed an OOV word\nft.wv.most_similar(positive=\"scarring\", topn=5)\n\n[('sparkling', 0.9785991907119751),\n ('coiling', 0.9770463705062866),\n ('watering', 0.9759057760238647),\n ('glittering', 0.9756022095680237),\n ('dazzling', 0.9755154848098755)]\n # Save and loading\nft.wv.save(\"model.bin\")\nft = KeyedVectors.load(\"model.bin\")\nWe can learn embeddings from scratch using one of the approaches above but we can also leverage pretrained embeddings that have been trained on millions of documents. Popular ones include Word2Vec (skip-gram) or GloVe (global word-word co-occurrence). We can validate that these embeddings captured meaningful semantic relationships by confirming them.
from gensim.scripts.glove2word2vec import glove2word2vec\nfrom io import BytesIO\nimport matplotlib.pyplot as plt\nfrom sklearn.decomposition import PCA\nfrom urllib.request import urlopen\nfrom zipfile import ZipFile\n# Arguments\nEMBEDDING_DIM = 100\ndef plot_embeddings(words, embeddings, pca_results):\n for word in words:\n index = embeddings.index2word.index(word)\n plt.scatter(pca_results[index, 0], pca_results[index, 1])\n plt.annotate(word, xy=(pca_results[index, 0], pca_results[index, 1]))\n plt.show()\n# Unzip the file (may take ~3-5 minutes)\nresp = urlopen(\"http://nlp.stanford.edu/data/glove.6B.zip\")\nzipfile = ZipFile(BytesIO(resp.read()))\nzipfile.namelist()\n\n['glove.6B.50d.txt',\n 'glove.6B.100d.txt',\n 'glove.6B.200d.txt',\n 'glove.6B.300d.txt']\n
# Write embeddings to file\nembeddings_file = \"glove.6B.{0}d.txt\".format(EMBEDDING_DIM)\nzipfile.extract(embeddings_file)\n\n/content/glove.6B.100d.txt\n
# Preview of the GloVe embeddings file\nwith open(embeddings_file, \"r\") as fp:\n line = next(fp)\n values = line.split()\n word = values[0]\n embedding = np.asarray(values[1:], dtype='float32')\n print (f\"word: {word}\")\n print (f\"embedding:\\n{embedding}\")\n print (f\"embedding dim: {len(embedding)}\")\n\nword: the\nembedding:\n[-0.038194 -0.24487 0.72812 -0.39961 0.083172 0.043953 -0.39141\n 0.3344 -0.57545 0.087459 0.28787 -0.06731 0.30906 -0.26384\n -0.13231 -0.20757 0.33395 -0.33848 -0.31743 -0.48336 0.1464\n -0.37304 0.34577 0.052041 0.44946 -0.46971 0.02628 -0.54155\n -0.15518 -0.14107 -0.039722 0.28277 0.14393 0.23464 -0.31021\n 0.086173 0.20397 0.52624 0.17164 -0.082378 -0.71787 -0.41531\n 0.20335 -0.12763 0.41367 0.55187 0.57908 -0.33477 -0.36559\n -0.54857 -0.062892 0.26584 0.30205 0.99775 -0.80481 -3.0243\n 0.01254 -0.36942 2.2167 0.72201 -0.24978 0.92136 0.034514\n 0.46745 1.1079 -0.19358 -0.074575 0.23353 -0.052062 -0.22044\n 0.057162 -0.15806 -0.30798 -0.41625 0.37972 0.15006 -0.53212\n -0.2055 -1.2526 0.071624 0.70565 0.49744 -0.42063 0.26148\n -1.538 -0.30223 -0.073438 -0.28312 0.37104 -0.25217 0.016215\n -0.017099 -0.38984 0.87424 -0.72569 -0.51058 -0.52028 -0.1459\n 0.8278 0.27062 ]\nembedding dim: 100\n
# Save GloVe embeddings to local directory in word2vec format\nword2vec_output_file = \"{0}.word2vec\".format(embeddings_file)\nglove2word2vec(embeddings_file, word2vec_output_file)\n\n(400000, 100)\n
# Load embeddings (may take a minute)\nglove = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False)\n# (king - man) + woman = ?\n# king - man = ? - woman\nglove.most_similar(positive=[\"woman\", \"king\"], negative=[\"man\"], topn=5)\n\n[('queen', 0.7698541283607483),\n ('monarch', 0.6843380928039551),\n ('throne', 0.6755735874176025),\n ('daughter', 0.6594556570053101),\n ('princess', 0.6520534753799438)]\n # Get nearest neighbors (excluding itself)\nglove.wv.most_similar(positive=\"goku\", topn=5)\n\n[('gohan', 0.7246542572975159),\n ('bulma', 0.6497020125389099),\n ('raistlin', 0.6443604230880737),\n ('skaar', 0.6316742897033691),\n ('guybrush', 0.6231324672698975)]\n # Reduce dimensionality for plotting\nX = glove[glove.wv.vocab]\npca = PCA(n_components=2)\npca_results = pca.fit_transform(X)\n# Visualize\nplot_embeddings(\n words=[\"king\", \"queen\", \"man\", \"woman\"], embeddings=glove,\n pca_results=pca_results)\n# Bias in embeddings\nglove.most_similar(positive=[\"woman\", \"doctor\"], negative=[\"man\"], topn=5)\n\n[('nurse', 0.7735227346420288),\n ('physician', 0.7189429998397827),\n ('doctors', 0.6824328303337097),\n ('patient', 0.6750682592391968),\n ('dentist', 0.6726033687591553)]\n"},{"location":"courses/foundations/embeddings/#setup","title":"Set up","text":"Let's set our seed and device for our main task.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/embeddings/#load-data","title":"Load data","text":"
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\nWe're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nnltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\nprint (STOPWORDS[:5])\nporter = PorterStemmer()\n\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n['i', 'me', 'my', 'myself', 'we']\n
def preprocess(text, stopwords=STOPWORDS):\n\"\"\"Conditional preprocessing on our text unique to our task.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r\"\\b(\" + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub(\"\", text)\n\n # Remove words in parenthesis\n text = re.sub(r\"\\([^)]*\\)\", \"\", text)\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text)\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n return text\n# Sample\ntext = \"Great week for the NYSE!\"\npreprocess(text=text)\n\ngreat week nyse\n
# Apply to dataframe\npreprocessed_df = df.copy()\npreprocessed_df.title = preprocessed_df.title.apply(preprocess)\nprint (f\"{df.title.values[0]}\\n\\n{preprocessed_df.title.values[0]}\")\n\nSharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says\n\nsharon accepts plan reduce gaza army operation haaretz says\n
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
"},{"location":"courses/foundations/embeddings/#split-data","title":"Split data","text":"import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Data\nX = preprocessed_df[\"title\"].values\ny = preprocessed_df[\"category\"].values\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (84000,), y_train: (84000,)\nX_val: (18000,), y_val: (18000,)\nX_test: (18000,), y_test: (18000,)\nSample point: china battles north korea nuclear talks \u2192 World\n"},{"location":"courses/foundations/embeddings/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nNUM_CLASSES = len(label_encoder)\nlabel_encoder.class_to_index\n\n{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: World\ny_train[0]: 3\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [21000 21000 21000 21000]\nweights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}\n"},{"location":"courses/foundations/embeddings/#tokenizer","title":"Tokenizer","text":"We'll define a Tokenizer to convert our text input data into token indices.
import json\nfrom collections import Counter\nfrom more_itertools import take\nclass Tokenizer(object):\n def __init__(self, char_level, num_tokens=None,\n pad_token=\"<PAD>\", oov_token=\"<UNK>\",\n token_to_index=None):\n self.char_level = char_level\n self.separator = \"\" if self.char_level else \" \"\n if num_tokens: num_tokens -= 2 # pad + unk tokens\n self.num_tokens = num_tokens\n self.pad_token = pad_token\n self.oov_token = oov_token\n if not token_to_index:\n token_to_index = {pad_token: 0, oov_token: 1}\n self.token_to_index = token_to_index\n self.index_to_token = {v: k for k, v in self.token_to_index.items()}\n\n def __len__(self):\n return len(self.token_to_index)\n\n def __str__(self):\n return f\"<Tokenizer(num_tokens={len(self)})>\"\n\n def fit_on_texts(self, texts):\n if not self.char_level:\n texts = [text.split(\" \") for text in texts]\n all_tokens = [token for text in texts for token in text]\n counts = Counter(all_tokens).most_common(self.num_tokens)\n self.min_token_freq = counts[-1][1]\n for token, count in counts:\n index = len(self)\n self.token_to_index[token] = index\n self.index_to_token[index] = token\n return self\n\n def texts_to_sequences(self, texts):\n sequences = []\n for text in texts:\n if not self.char_level:\n text = text.split(\" \")\n sequence = []\n for token in text:\n sequence.append(self.token_to_index.get(\n token, self.token_to_index[self.oov_token]))\n sequences.append(np.asarray(sequence))\n return sequences\n\n def sequences_to_texts(self, sequences):\n texts = []\n for sequence in sequences:\n text = []\n for index in sequence:\n text.append(self.index_to_token.get(index, self.oov_token))\n texts.append(self.separator.join([token for token in text]))\n return texts\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {\n \"char_level\": self.char_level,\n \"oov_token\": self.oov_token,\n \"token_to_index\": self.token_to_index\n }\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\nWarning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Tokenize\ntokenizer = Tokenizer(char_level=False, num_tokens=5000)\ntokenizer.fit_on_texts(texts=X_train)\nVOCAB_SIZE = len(tokenizer)\nprint (tokenizer)\n\n<Tokenizer(num_tokens=5000)>\n\n
# Sample of tokens\nprint (take(5, tokenizer.token_to_index.items()))\nprint (f\"least freq token's freq: {tokenizer.min_token_freq}\") # use this to adjust num_tokens\n\n[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]\nleast freq token's freq: 14\n # Convert texts to sequences of indices\nX_train = tokenizer.texts_to_sequences(X_train)\nX_val = tokenizer.texts_to_sequences(X_val)\nX_test = tokenizer.texts_to_sequences(X_test)\npreprocessed_text = tokenizer.sequences_to_texts([X_train[0]])[0]\nprint (\"Text to indices:\\n\"\n f\" (preprocessed) \u2192 {preprocessed_text}\\n\"\n f\" (tokenized) \u2192 {X_train[0]}\")\n\nText to indices:\n (preprocessed) \u2192 nba wrap neal <UNK> 40 heat <UNK> wizards\n (tokenized) \u2192 [ 299 359 3869 1 1648 734 1 2021]\n"},{"location":"courses/foundations/embeddings/#embedding-layer","title":"Embedding layer","text":"
We can embed our inputs using PyTorch's embedding layer.
# Input\nvocab_size = 10\nx = torch.randint(high=vocab_size, size=(1,5))\nprint (x)\nprint (x.shape)\n\ntensor([[2, 6, 5, 2, 6]])\ntorch.Size([1, 5])\n
# Embedding layer\nembeddings = nn.Embedding(embedding_dim=100, num_embeddings=vocab_size)\nprint (embeddings.weight.shape)\n\ntorch.Size([10, 100])\n
# Embed the input\nembeddings(x).shape\n\ntorch.Size([1, 5, 100])\n
Each token in the input is represented via embeddings (all out-of-vocabulary (OOV) tokens are given the embedding for UNK token.) In the model below, we'll see how to set these embeddings to be pretrained GloVe embeddings and how to choose whether to freeze (fixed embedding weights) those embeddings or not during training.
Our inputs are all of varying length but we need each batch to be uniformly shaped. Therefore, we will use padding to make all the inputs in the batch the same length. Our padding index will be 0 (note that this is consistent with the <PAD> token defined in our Tokenizer).
While embedding our input tokens will create a batch of shape (N, max_seq_len, embed_dim) we only need to provide a 2D matrix (N, max_seq_len) for using embeddings with PyTorch.
def pad_sequences(sequences, max_seq_len=0):\n\"\"\"Pad sequences to max length in sequence.\"\"\"\n max_seq_len = max(max_seq_len, max(len(sequence) for sequence in sequences))\n padded_sequences = np.zeros((len(sequences), max_seq_len))\n for i, sequence in enumerate(sequences):\n padded_sequences[i][:len(sequence)] = sequence\n return padded_sequences\n# 2D sequences\npadded = pad_sequences(X_train[0:3])\nprint (padded.shape)\nprint (padded)\n\n(3, 8)\n[[2.990e+02 3.590e+02 3.869e+03 1.000e+00 1.648e+03 7.340e+02 1.000e+00\n 2.021e+03]\n [4.977e+03 1.000e+00 8.070e+02 0.000e+00 0.000e+00 0.000e+00 0.000e+00\n 0.000e+00]\n [5.900e+01 1.213e+03 1.160e+02 4.042e+03 2.040e+02 4.190e+02 1.000e+00\n 0.000e+00]]\n"},{"location":"courses/foundations/embeddings/#dataset","title":"Dataset","text":"
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
FILTER_SIZES = list(range(1, 4)) # uni, bi and tri grams\nclass Dataset(torch.utils.data.Dataset):\n def __init__(self, X, y, max_filter_size):\n self.X = X\n self.y = y\n self.max_filter_size = max_filter_size\n\n def __len__(self):\n return len(self.y)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n X = self.X[index]\n y = self.y[index]\n return [X, y]\n\n def collate_fn(self, batch):\n\"\"\"Processing on a batch.\"\"\"\n # Get inputs\n batch = np.array(batch)\n X = batch[:, 0]\n y = batch[:, 1]\n\n # Pad sequences\n X = pad_sequences(X)\n\n # Cast\n X = torch.LongTensor(X.astype(np.int32))\n y = torch.LongTensor(y.astype(np.int32))\n\n return X, y\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,\n shuffle=shuffle, drop_last=drop_last, pin_memory=True)\n# Create datasets\nmax_filter_size = max(FILTER_SIZES)\ntrain_dataset = Dataset(X=X_train, y=y_train, max_filter_size=max_filter_size)\nval_dataset = Dataset(X=X_val, y=y_val, max_filter_size=max_filter_size)\ntest_dataset = Dataset(X=X_test, y=y_test, max_filter_size=max_filter_size)\nprint (\"Datasets:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" X: {train_dataset[0][0]}\\n\"\n f\" y: {train_dataset[0][1]}\")\n\nDatasets:\n Train dataset: <Dataset(N=84000)>\n Val dataset: <Dataset(N=18000)>\n Test dataset: <Dataset(N=18000)>\nSample point:\n X: [ 299 359 3869 1 1648 734 1 2021]\n y: 2\n
# Create dataloaders\nbatch_size = 64\ntrain_dataloader = train_dataset.create_dataloader(batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(batch_size=batch_size)\nbatch_X, batch_y = next(iter(train_dataloader))\nprint (\"Sample batch:\\n\"\n f\" X: {list(batch_X.size())}\\n\"\n f\" y: {list(batch_y.size())}\\n\"\n \"Sample point:\\n\"\n f\" X: {batch_X[0]}\\n\"\n f\" y: {batch_y[0]}\")\n\nSample batch:\n X: [64, 9]\n y: [64]\nSample point:\n X: tensor([ 299, 359, 3869, 1, 1648, 734, 1, 2021, 0], device=\"cpu\")\n y: 2\n"},{"location":"courses/foundations/embeddings/#model","title":"Model","text":"
We'll be using a convolutional neural network on top of our embedded tokens to extract meaningful spatial signal. This time, we'll be using many filter widths to act as n-gram feature extractors.
Let's visualize the model's forward pass.
batch_size, max_seq_len).batch_size, max_seq_len, embedding_dim).filter_size, embedding_dim, num_filters) followed by batch normalization. Our filters act as character level n-gram detectors. We have three different filter sizes (2, 3 and 4) and they will act as bi-gram, tri-gram and 4-gram feature extractors, respectively.import math\nimport torch.nn.functional as F\nEMBEDDING_DIM = 100\nHIDDEN_DIM = 100\nDROPOUT_P = 0.1\nclass CNN(nn.Module):\n def __init__(self, embedding_dim, vocab_size, num_filters,\n filter_sizes, hidden_dim, dropout_p, num_classes,\n pretrained_embeddings=None, freeze_embeddings=False,\n padding_idx=0):\n super(CNN, self).__init__()\n\n # Filter sizes\n self.filter_sizes = filter_sizes\n\n # Initialize embeddings\n if pretrained_embeddings is None:\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx)\n else:\n pretrained_embeddings = torch.from_numpy(pretrained_embeddings).float()\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx, _weight=pretrained_embeddings)\n\n # Freeze embeddings or not\n if freeze_embeddings:\n self.embeddings.weight.requires_grad = False\n\n # Conv weights\n self.conv = nn.ModuleList(\n [nn.Conv1d(in_channels=embedding_dim,\n out_channels=num_filters,\n kernel_size=f) for f in filter_sizes])\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(num_filters*len(filter_sizes), hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs, channel_first=False):\n\n # Embed\n x_in, = inputs\n x_in = self.embeddings(x_in)\n\n # Rearrange input so num_channels is in dim 1 (N, C, L)\n if not channel_first:\n x_in = x_in.transpose(1, 2)\n\n # Conv outputs\n z = []\n max_seq_len = x_in.shape[2]\n for i, f in enumerate(self.filter_sizes):\n # `SAME` padding\n padding_left = int((self.conv[i].stride[0]*(max_seq_len-1) - max_seq_len + self.filter_sizes[i])/2)\n padding_right = int(math.ceil((self.conv[i].stride[0]*(max_seq_len-1) - max_seq_len + self.filter_sizes[i])/2))\n\n # Conv + pool\n _z = self.conv[i](F.pad(x_in, (padding_left, padding_right)))\n _z = F.max_pool1d(_z, _z.size(2)).squeeze(2)\n z.append(_z)\n\n # Concat conv outputs\n z = torch.cat(z, 1)\n\n # FC layers\n z = self.fc1(z)\n z = self.dropout(z)\n z = self.fc2(z)\n return z\nWe're going create some utility functions to be able to load the pretrained GloVe embeddings into our Embeddings layer.
def load_glove_embeddings(embeddings_file):\n\"\"\"Load embeddings from a file.\"\"\"\n embeddings = {}\n with open(embeddings_file, \"r\") as fp:\n for index, line in enumerate(fp):\n values = line.split()\n word = values[0]\n embedding = np.asarray(values[1:], dtype='float32')\n embeddings[word] = embedding\n return embeddings\ndef make_embeddings_matrix(embeddings, word_index, embedding_dim):\n\"\"\"Create embeddings matrix to use in Embedding layer.\"\"\"\n embedding_matrix = np.zeros((len(word_index), embedding_dim))\n for word, i in word_index.items():\n embedding_vector = embeddings.get(word)\n if embedding_vector is not None:\n embedding_matrix[i] = embedding_vector\n return embedding_matrix\n# Create embeddings\nembeddings_file = 'glove.6B.{0}d.txt'.format(EMBEDDING_DIM)\nglove_embeddings = load_glove_embeddings(embeddings_file=embeddings_file)\nembedding_matrix = make_embeddings_matrix(\n embeddings=glove_embeddings, word_index=tokenizer.token_to_index,\n embedding_dim=EMBEDDING_DIM)\nprint (f\"<Embeddings(words={embedding_matrix.shape[0]}, dim={embedding_matrix.shape[1]})>\")\n\n<Embeddings(words=5000, dim=100)>\n"},{"location":"courses/foundations/embeddings/#experiments","title":"Experiments","text":"
We have first have to decide whether to use pretrained embeddings randomly initialized ones. Then, we can choose to freeze our embeddings or continue to train them using the supervised data (this could lead to overfitting). Here are the three experiments we're going to conduct:
import json\nfrom sklearn.metrics import precision_recall_fscore_support\nfrom torch.optim import Adam\nNUM_FILTERS = 50\nLEARNING_RATE = 1e-3\nPATIENCE = 5\nNUM_EPOCHS = 10\nclass Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\nPRETRAINED_EMBEDDINGS = None\nFREEZE_EMBEDDINGS = False\n# Initialize model\nmodel = CNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n num_filters=NUM_FILTERS, filter_sizes=FILTER_SIZES,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES,\n pretrained_embeddings=PRETRAINED_EMBEDDINGS, freeze_embeddings=FREEZE_EMBEDDINGS)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of CNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (conv): ModuleList(\n (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,))\n (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,))\n (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,))\n )\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=150, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.77038, val_loss: 0.59683, lr: 1.00E-03, _patience: 3\nEpoch: 2 | train_loss: 0.49571, val_loss: 0.54363, lr: 1.00E-03, _patience: 3\nEpoch: 3 | train_loss: 0.40796, val_loss: 0.54551, lr: 1.00E-03, _patience: 2\nEpoch: 4 | train_loss: 0.34797, val_loss: 0.57950, lr: 1.00E-03, _patience: 1\nStopping early!\n
# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8070310520771562,\n \"recall\": 0.7999444444444445,\n \"f1\": 0.8012357147662316,\n \"num_samples\": 18000.0\n}\n"},{"location":"courses/foundations/embeddings/#glove-frozen","title":"Glove (frozen)","text":"PRETRAINED_EMBEDDINGS = embedding_matrix\nFREEZE_EMBEDDINGS = True\n# Initialize model\nmodel = CNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n num_filters=NUM_FILTERS, filter_sizes=FILTER_SIZES,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES,\n pretrained_embeddings=PRETRAINED_EMBEDDINGS, freeze_embeddings=FREEZE_EMBEDDINGS)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of CNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (conv): ModuleList(\n (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,))\n (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,))\n (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,))\n )\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=150, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.51510, val_loss: 0.47643, lr: 1.00E-03, _patience: 3\nEpoch: 2 | train_loss: 0.44220, val_loss: 0.46124, lr: 1.00E-03, _patience: 3\nEpoch: 3 | train_loss: 0.41204, val_loss: 0.46231, lr: 1.00E-03, _patience: 2\nEpoch: 4 | train_loss: 0.38733, val_loss: 0.46606, lr: 1.00E-03, _patience: 1\nStopping early!\n
# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8304874226557859,\n \"recall\": 0.8281111111111111,\n \"f1\": 0.828556487688813,\n \"num_samples\": 18000.0\n}\n"},{"location":"courses/foundations/embeddings/#glove-fine-tuned","title":"Glove (fine-tuned)","text":"PRETRAINED_EMBEDDINGS = embedding_matrix\nFREEZE_EMBEDDINGS = False\n# Initialize model\nmodel = CNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n num_filters=NUM_FILTERS, filter_sizes=FILTER_SIZES,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES,\n pretrained_embeddings=PRETRAINED_EMBEDDINGS, freeze_embeddings=FREEZE_EMBEDDINGS)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of CNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (conv): ModuleList(\n (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,))\n (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,))\n (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,))\n )\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=150, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.48908, val_loss: 0.44320, lr: 1.00E-03, _patience: 3\nEpoch: 2 | train_loss: 0.38986, val_loss: 0.43616, lr: 1.00E-03, _patience: 3\nEpoch: 3 | train_loss: 0.34403, val_loss: 0.45240, lr: 1.00E-03, _patience: 2\nEpoch: 4 | train_loss: 0.30224, val_loss: 0.49063, lr: 1.00E-03, _patience: 1\nStopping early!\n
# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8297157849772082,\n \"recall\": 0.8263333333333334,\n \"f1\": 0.8266579939871359,\n \"num_samples\": 18000.0\n}\n # Save artifacts\nfrom pathlib import Path\ndir = Path(\"cnn\")\ndir.mkdir(parents=True, exist_ok=True)\nlabel_encoder.save(fp=Path(dir, \"label_encoder.json\"))\ntokenizer.save(fp=Path(dir, \"tokenizer.json\"))\ntorch.save(best_model.state_dict(), Path(dir, \"model.pt\"))\nwith open(Path(dir, \"performance.json\"), \"w\") as fp:\n json.dump(performance, indent=2, sort_keys=False, fp=fp)\ndef get_probability_distribution(y_prob, classes):\n\"\"\"Create a dict of class probabilities from an array.\"\"\"\n results = {}\n for i, class_ in enumerate(classes):\n results[class_] = np.float64(y_prob[i])\n sorted_results = {k: v for k, v in sorted(\n results.items(), key=lambda item: item[1], reverse=True)}\n return sorted_results\n# Load artifacts\ndevice = torch.device(\"cpu\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\ntokenizer = Tokenizer.load(fp=Path(dir, \"tokenizer.json\"))\nmodel = CNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n num_filters=NUM_FILTERS, filter_sizes=FILTER_SIZES,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES,\n pretrained_embeddings=PRETRAINED_EMBEDDINGS, freeze_embeddings=FREEZE_EMBEDDINGS)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device)\n\nCNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (conv): ModuleList(\n (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,))\n (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,))\n (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,))\n )\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=150, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n
# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n# Dataloader\ntext = \"The final tennis tournament starts next week.\"\nX = tokenizer.texts_to_sequences([preprocess(text)])\nprint (tokenizer.sequences_to_texts(X))\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))\ndataset = Dataset(X=X, y=y_filler, max_filter_size=max_filter_size)\ndataloader = dataset.create_dataloader(batch_size=batch_size)\n\n['final tennis tournament starts next week']\n
# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.decode(y_pred)\n\n['Sports']\n
# Class distributions\nprob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)\nprint (json.dumps(prob_dist, indent=2))\n\n{\n \"Sports\": 0.9999998807907104,\n \"World\": 6.336378532978415e-08,\n \"Sci/Tech\": 2.107449992294619e-09,\n \"Business\": 3.706519813295728e-10\n}\n"},{"location":"courses/foundations/embeddings/#interpretability","title":"Interpretability","text":"We went through all the trouble of padding our inputs before convolution to result is outputs of the same shape as our inputs so we can try to get some interpretability. Since every token is mapped to a convolutional output on which we apply max pooling, we can see which token's output was most influential towards the prediction. We first need to get the conv outputs from our model:
import collections\nimport seaborn as sns\nclass InterpretableCNN(nn.Module):\n def __init__(self, embedding_dim, vocab_size, num_filters,\n filter_sizes, hidden_dim, dropout_p, num_classes,\n pretrained_embeddings=None, freeze_embeddings=False,\n padding_idx=0):\n super(InterpretableCNN, self).__init__()\n\n # Filter sizes\n self.filter_sizes = filter_sizes\n\n # Initialize embeddings\n if pretrained_embeddings is None:\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx)\n else:\n pretrained_embeddings = torch.from_numpy(pretrained_embeddings).float()\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx, _weight=pretrained_embeddings)\n\n # Freeze embeddings or not\n if freeze_embeddings:\n self.embeddings.weight.requires_grad = False\n\n # Conv weights\n self.conv = nn.ModuleList(\n [nn.Conv1d(in_channels=embedding_dim,\n out_channels=num_filters,\n kernel_size=f) for f in filter_sizes])\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(num_filters*len(filter_sizes), hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs, channel_first=False):\n\n # Embed\n x_in, = inputs\n x_in = self.embeddings(x_in)\n\n # Rearrange input so num_channels is in dim 1 (N, C, L)\n if not channel_first:\n x_in = x_in.transpose(1, 2)\n\n # Conv outputs\n z = []\n max_seq_len = x_in.shape[2]\n for i, f in enumerate(self.filter_sizes):\n # `SAME` padding\n padding_left = int((self.conv[i].stride[0]*(max_seq_len-1) - max_seq_len + self.filter_sizes[i])/2)\n padding_right = int(math.ceil((self.conv[i].stride[0]*(max_seq_len-1) - max_seq_len + self.filter_sizes[i])/2))\n\n # Conv + pool\n _z = self.conv[i](F.pad(x_in, (padding_left, padding_right)))\n z.append(_z.cpu().numpy())\n\n return z\nPRETRAINED_EMBEDDINGS = embedding_matrix\nFREEZE_EMBEDDINGS = False\n# Initialize model\ninterpretable_model = InterpretableCNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n num_filters=NUM_FILTERS, filter_sizes=FILTER_SIZES,\n hidden_dim=HIDDEN_DIM, dropout_p=DROPOUT_P, num_classes=NUM_CLASSES,\n pretrained_embeddings=PRETRAINED_EMBEDDINGS, freeze_embeddings=FREEZE_EMBEDDINGS)\ninterpretable_model.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\ninterpretable_model.to(device)\n\nInterpretableCNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (conv): ModuleList(\n (0): Conv1d(100, 50, kernel_size=(1,), stride=(1,))\n (1): Conv1d(100, 50, kernel_size=(2,), stride=(1,))\n (2): Conv1d(100, 50, kernel_size=(3,), stride=(1,))\n )\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=150, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n
# Get conv outputs\ninterpretable_model.eval()\nconv_outputs = []\nwith torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = interpretable_model(inputs)\n\n # Store conv outputs\n conv_outputs.extend(z)\n\nconv_outputs = np.vstack(conv_outputs)\nprint (conv_outputs.shape) # (len(filter_sizes), num_filters, max_seq_len)\n\n(3, 50, 6)\n
# Visualize a bi-gram filter's outputs\ntokens = tokenizer.sequences_to_texts(X)[0].split(\" \")\nfilter_size = 2\nsns.heatmap(conv_outputs[filter_size-1][:, len(tokens)], xticklabels=tokens)\n1D global max-pooling would extract the highest value from each of our num_filters for each filter_size. We could also follow this same approach to figure out which n-gram is most relevant but notice in the heatmap above that many filters don't have much variance. To mitigate this, this paper uses threshold values to determine which filters to use for interpretability. But to keep things simple, let's extract which tokens' filter outputs were extracted via max-pooling the most frequently.
sample_index = 0\nprint (f\"Original text:\\n{text}\")\nprint (f\"\\nPreprocessed text:\\n{tokenizer.sequences_to_texts(X)[0]}\")\nprint (\"\\nMost important n-grams:\")\n# Process conv outputs for each unique filter size\nfor i, filter_size in enumerate(FILTER_SIZES):\n\n # Identify most important n-gram (excluding last token)\n popular_indices = collections.Counter([np.argmax(conv_output) \\\n for conv_output in conv_outputs[i]])\n\n # Get corresponding text\n start = popular_indices.most_common(1)[-1][0]\n n_gram = \" \".join([token for token in tokens[start:start+filter_size]])\n print (f\"[{filter_size}-gram]: {n_gram}\")\n\nOriginal text:\nThe final tennis tournament starts next week.\n\nPreprocessed text:\nfinal tennis tournament starts next week\n\nMost important n-grams:\n[1-gram]: tennis\n[2-gram]: tennis tournament\n[3-gram]: final tennis tournament\n
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Embeddings - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nOur goal is to learn a linear model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\) using weights \\(W\\) and bias \\(b\\):
\\[ \\hat{y} = XW + b \\]Variable Description \\(N\\) total numbers of samples \\(\\hat{y}\\) predictions \\(\\in \\mathbb{R}^{NX1}\\) \\(X\\) inputs \\(\\in \\mathbb{R}^{NXD}\\) \\(W\\) weights \\(\\in \\mathbb{R}^{DX1}\\) \\(b\\) bias \\(\\in \\mathbb{R}^{1}\\)
We're going to generate some simple dummy data to apply linear regression on. It's going to create roughly linear data (y = 3.5X + noise); the random noise is added to create realistic data that doesn't perfectly align in a line. Our goal is to have the model converge to a similar linear equation (there will be slight variance since we added some noise).
import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nSEED = 1234\nNUM_SAMPLES = 50\n# Set seed for reproducibility\nnp.random.seed(SEED)\n# Generate synthetic data\ndef generate_data(num_samples):\n\"\"\"Generate dummy data for linear regression.\"\"\"\n X = np.array(range(num_samples))\n random_noise = np.random.uniform(-10, 20, size=num_samples)\n y = 3.5*X + random_noise # add some noise\n return X, y\n# Generate random (linear) data\nX, y = generate_data(num_samples=NUM_SAMPLES)\ndata = np.vstack([X, y]).T\nprint (data[:5])\n\n[[ 0. -4.25441649]\n [ 1. 12.16326313]\n [ 2. 10.13183217]\n [ 3. 24.06075751]\n [ 4. 27.39927424]]\n
# Load into a Pandas DataFrame\ndf = pd.DataFrame(data, columns=[\"X\", \"y\"])\nX = df[[\"X\"]].values\ny = df[[\"y\"]].values\ndf.head()\n# Scatter plot\nplt.title(\"Generated data\")\nplt.scatter(x=df[\"X\"], y=df[\"y\"])\nplt.show()\nNow that we have our data prepared, we'll first implement linear regression using just NumPy. This will let us really understand the underlying operations.
"},{"location":"courses/foundations/linear-regression/#split-data","title":"Split data","text":"Since our task is a regression task, we will randomly split our dataset into three sets: train, validation and test data splits.
train: used to train our model.val : used to validate our model's performance during training.test: used to do an evaluation of our fully trained model.Be sure to check out our entire lesson focused on properly splitting data in our MLOps course.
TRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\n# Shuffle data\nindices = list(range(NUM_SAMPLES))\nnp.random.shuffle(indices)\nX = X[indices]\ny = y[indices]\nWarning
Be careful not to shuffle \\(X\\) and \\(y\\) separately because then the inputs won't correspond to the outputs!
# Split indices\ntrain_start = 0\ntrain_end = int(0.7*NUM_SAMPLES)\nval_start = train_end\nval_end = int((TRAIN_SIZE+VAL_SIZE)*NUM_SAMPLES)\ntest_start = val_end\n# Split data\nX_train = X[train_start:train_end]\ny_train = y[train_start:train_end]\nX_val = X[val_start:val_end]\ny_val = y[val_start:val_end]\nX_test = X[test_start:]\ny_test = y[test_start:]\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_test: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\n\nX_train: (35, 1), y_train: (35, 1)\nX_val: (7, 1), y_test: (7, 1)\nX_test: (8, 1), y_test: (8, 1)\n"},{"location":"courses/foundations/linear-regression/#standardize-data","title":"Standardize data","text":"
We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights.
\\[ z = \\frac{x_i - \\mu}{\\sigma} \\]Variable Description \\(z\\) standardized value \\(x_i\\) inputs \\(\\mu\\) mean \\(\\sigma\\) standard deviation
def standardize_data(data, mean, std):\n return (data - mean)/std\n# Determine means and stds\nX_mean = np.mean(X_train)\nX_std = np.std(X_train)\ny_mean = np.mean(y_train)\ny_std = np.std(y_train)\nWe need to treat the validation and test sets as if they were hidden datasets. So we only use the train set to determine the mean and std to avoid biasing our training process.
# Standardize\nX_train = standardize_data(X_train, X_mean, X_std)\ny_train = standardize_data(y_train, y_mean, y_std)\nX_val = standardize_data(X_val, X_mean, X_std)\ny_val = standardize_data(y_val, y_mean, y_std)\nX_test = standardize_data(X_test, X_mean, X_std)\ny_test = standardize_data(y_test, y_mean, y_std)\n# Check (means should be ~0 and std should be ~1)\n# Check (means should be ~0 and std should be ~1)\nprint (f\"mean: {np.mean(X_test, axis=0)[0]:.1f}, std: {np.std(X_test, axis=0)[0]:.1f}\")\nprint (f\"mean: {np.mean(y_test, axis=0)[0]:.1f}, std: {np.std(y_test, axis=0)[0]:.1f}\")\n\nmean: -0.4, std: 0.9\nmean: -0.3, std: 1.0\n"},{"location":"courses/foundations/linear-regression/#weights","title":"Weights","text":"
Our goal is to learn a linear model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\) using weights \\(W\\) and bias \\(b\\) \u2192 \\(\\hat{y} = XW + b\\)
Step 1: Randomly initialize the model's weights \\(W\\).
INPUT_DIM = X_train.shape[1] # X is 1-dimensional\nOUTPUT_DIM = y_train.shape[1] # y is 1-dimensional\n# Initialize random weights\nW = 0.01 * np.random.randn(INPUT_DIM, OUTPUT_DIM)\nb = np.zeros((1, 1))\nprint (f\"W: {W.shape}\")\nprint (f\"b: {b.shape}\")\n\nW: (1, 1)\nb: (1, 1)\n"},{"location":"courses/foundations/linear-regression/#model","title":"Model","text":"
Step 2: Feed inputs \\(X\\) into the model to receive the predictions \\(\\hat{y}\\)
# Forward pass [NX1] \u00b7 [1X1] = [NX1]\ny_pred = np.dot(X_train, W) + b\nprint (f\"y_pred: {y_pred.shape}\")\n\ny_pred: (35, 1)\n"},{"location":"courses/foundations/linear-regression/#loss","title":"Loss","text":"
Step 3: Compare the predictions \\(\\hat{y}\\) with the actual target values \\(y\\) using the objective (cost) function to determine the loss \\(J\\). A common objective function for linear regression is mean squared error (MSE). This function calculates the difference between the predicted and target values and squares it.
bias term (\\(b\\)) excluded to avoid crowding the notations
# Loss\nN = len(y_train)\nloss = (1/N) * np.sum((y_train - y_pred)**2)\nprint (f\"loss: {loss:.2f}\")\n\nloss: 0.99\n"},{"location":"courses/foundations/linear-regression/#gradients","title":"Gradients","text":"
Step 4: Calculate the gradient of loss \\(J(\\theta)\\) w.r.t to the model weights.
# Backpropagation\ndW = -(2/N) * np.sum((y_train - y_pred) * X_train)\ndb = -(2/N) * np.sum((y_train - y_pred) * 1)\nThe gradient is the derivative, or the rate of change of a function. It's a vector that points in the direction of greatest increase of a function. For example the gradient of our loss function (\\(J\\)) with respect to our weights (\\(W\\)) will tell us how to change \\(W\\) so we can maximize \\(J\\). However, we want to minimize our loss so we subtract the gradient from \\(W\\).
"},{"location":"courses/foundations/linear-regression/#update-weights","title":"Update weights","text":"Step 5: Update the weights \\(W\\) using a small learning rate \\(\\alpha\\).
LEARNING_RATE = 1e-1\n# Update weights\nW += -LEARNING_RATE * dW\nb += -LEARNING_RATE * db\nThe learning rate \\(\\alpha\\) is a way to control how much we update the weights by. If we choose a small learning rate, it may take a long time for our model to train. However, if we choose a large learning rate, we may overshoot and our training will never converge. The specific learning rate depends on our data and the type of models we use but it's typically good to explore in the range of \\([1e^{-8}, 1e^{-1}]\\). We'll explore learning rate update strategies in later lessons.
"},{"location":"courses/foundations/linear-regression/#training","title":"Training","text":"Step 6: Repeat steps 2 - 5 to minimize the loss and train the model.
NUM_EPOCHS = 100\n# Initialize random weights\nW = 0.01 * np.random.randn(INPUT_DIM, OUTPUT_DIM)\nb = np.zeros((1, ))\n\n# Training loop\nfor epoch_num in range(NUM_EPOCHS):\n\n # Forward pass [NX1] \u00b7 [1X1] = [NX1]\n y_pred = np.dot(X_train, W) + b\n\n # Loss\n loss = (1/len(y_train)) * np.sum((y_train - y_pred)**2)\n\n # Show progress\n if epoch_num%10 == 0:\n print (f\"Epoch: {epoch_num}, loss: {loss:.3f}\")\n\n # Backpropagation\n dW = -(2/N) * np.sum((y_train - y_pred) * X_train)\n db = -(2/N) * np.sum((y_train - y_pred) * 1)\n\n # Update weights\n W += -LEARNING_RATE * dW\n b += -LEARNING_RATE * db\n\nEpoch: 0, loss: 0.990\nEpoch: 10, loss: 0.039\nEpoch: 20, loss: 0.028\nEpoch: 30, loss: 0.028\nEpoch: 40, loss: 0.028\nEpoch: 50, loss: 0.028\nEpoch: 60, loss: 0.028\nEpoch: 70, loss: 0.028\nEpoch: 80, loss: 0.028\nEpoch: 90, loss: 0.028\n
To keep the code simple, we're not calculating and displaying the validation loss after each epoch here. But in later lessons, the performance on the validation set will be crucial in influencing the learning process (learning rate, when to stop training, etc.).
"},{"location":"courses/foundations/linear-regression/#evaluation","title":"Evaluation","text":"Now we're ready to see how well our trained model will perform on our test (hold-out) data split. This will be our best measure on how well the model would perform on the real world, given that our dataset's distribution is close to unseen data.
# Predictions\npred_train = W*X_train + b\npred_test = W*X_test + b\n# Train and test MSE\ntrain_mse = np.mean((y_train - pred_train) ** 2)\ntest_mse = np.mean((y_test - pred_test) ** 2)\nprint (f\"train_MSE: {train_mse:.2f}, test_MSE: {test_mse:.2f}\")\n\ntrain_MSE: 0.03, test_MSE: 0.01\n
# Figure size\nplt.figure(figsize=(15,5))\n\n# Plot train data\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplt.scatter(X_train, y_train, label=\"y_train\")\nplt.plot(X_train, pred_train, color=\"red\", linewidth=1, linestyle=\"-\", label=\"model\")\nplt.legend(loc=\"lower right\")\n\n# Plot test data\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplt.scatter(X_test, y_test, label='y_test')\nplt.plot(X_test, pred_test, color=\"red\", linewidth=1, linestyle=\"-\", label=\"model\")\nplt.legend(loc=\"lower right\")\n\n# Show plots\nplt.show()\nSince we standardized our inputs and outputs, our weights were fit to those standardized values. So we need to unstandardize our weights so we can compare it to our true weight (3.5).
Note that both \\(X\\) and \\(y\\) were standardized.
\\[ \\hat{y}_{scaled} = b_{scaled} + \\sum_{j=1}^{k}{W_{scaled}}_j{x_{scaled}}_j \\]Variable Description \\(y_{scaled}\\) \\(\\frac{\\hat{y} - \\bar{y}}{\\sigma_y}\\) \\(x_{scaled}\\) \\(\\frac{x_j - \\bar{x}_j}{\\sigma_j}\\)
\\[ \\frac{\\hat{y} - \\bar{y}}{\\sigma_y} = b_{scaled} + \\sum_{j=1}^{k}{W_{scaled}}_j\\frac{x_j - \\bar{x}_j}{\\sigma_j} \\] \\[ \\hat{y}_{scaled} = \\frac{\\hat{y}_{unscaled} - \\bar{y}}{\\sigma_y} = {b_{scaled}} + \\sum_{j=1}^{k} {W_{scaled}}_j (\\frac{x_j - \\bar{x}_j}{\\sigma_j}) \\] \\[ \\hat{y}_{unscaled} = b_{scaled}\\sigma_y + \\bar{y} - \\sum_{j=1}^{k} {W_{scaled}}_j(\\frac{\\sigma_y}{\\sigma_j})\\bar{x}_j + \\sum_{j=1}^{k}{W_{scaled}}_j(\\frac{\\sigma_y}{\\sigma_j})x_j \\]In the expression above, we can see the expression:
\\[ \\hat{y}_{unscaled} = b_{unscaled} + W_{unscaled}x \\]Variable Description \\(W_{unscaled}\\) \\({W}_j(\\frac{\\sigma_y}{\\sigma_j})\\) \\(b_{unscaled}\\) \\(b_{scaled}\\sigma_y + \\bar{y} - \\sum_{j=1}^{k} {W}_j(\\frac{\\sigma_y}{\\sigma_j})\\bar{x}_j\\)
By substituting \\(W_{unscaled}\\) in \\(b_{unscaled}\\), it now becomes:
\\[ b_{unscaled} = b_{scaled}\\sigma_y + \\bar{y} - \\sum_{j=1}^{k} W_{unscaled}\\bar{x}_j \\]# Unscaled weights\nW_unscaled = W * (y_std/X_std)\nb_unscaled = b * y_std + y_mean - np.sum(W_unscaled*X_mean)\nprint (\"[actual] y = 3.5X + noise\")\nprint (f\"[model] y_hat = {W_unscaled[0][0]:.1f}X + {b_unscaled[0]:.1f}\")\n\n[actual] y = 3.5X + noise\n[model] y_hat = 3.4X + 7.8\n"},{"location":"courses/foundations/linear-regression/#pytorch","title":"PyTorch","text":"
Now that we've implemented linear regression with Numpy, let's do the same with PyTorch.
import torch\n# Set seed for reproducibility\ntorch.manual_seed(SEED)\n"},{"location":"courses/foundations/linear-regression/#split-data_1","title":"Split data","text":"This time, instead of splitting data using indices, let's use scikit-learn's built in train_test_split function.\n
from sklearn.model_selection import train_test_split\n
\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\n
\n# Split (train)\nX_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE)\n
\nprint (f\"train: {len(X_train)} ({(len(X_train) / len(X)):.2f})\\n\"\n f\"remaining: {len(X_)} ({(len(X_) / len(X)):.2f})\")\n
\n\ntrain: 35 (0.70)\nremaining: 15 (0.30)\n
\n# Split (test)\nX_val, X_test, y_val, y_test = train_test_split(\n X_, y_, train_size=0.5)\n
\nprint(f\"train: {len(X_train)} ({len(X_train)/len(X):.2f})\\n\"\n f\"val: {len(X_val)} ({len(X_val)/len(X):.2f})\\n\"\n f\"test: {len(X_test)} ({len(X_test)/len(X):.2f})\")\n
\n\ntrain: 35 (0.70)\nval: 7 (0.14)\ntest: 8 (0.16)\n
"},{"location":"courses/foundations/linear-regression/#standardize-data_1","title":"Standardize data","text":"This time we'll use scikit-learn's StandardScaler to standardize our data.
\nfrom sklearn.preprocessing import StandardScaler\n
\n# Standardize the data (mean=0, std=1) using training data\nX_scaler = StandardScaler().fit(X_train)\ny_scaler = StandardScaler().fit(y_train)\n
\n# Apply scaler on training and test data\nX_train = X_scaler.transform(X_train)\ny_train = y_scaler.transform(y_train).ravel().reshape(-1, 1)\nX_val = X_scaler.transform(X_val)\ny_val = y_scaler.transform(y_val).ravel().reshape(-1, 1)\nX_test = X_scaler.transform(X_test)\ny_test = y_scaler.transform(y_test).ravel().reshape(-1, 1)\n
\n# Check (means should be ~0 and std should be ~1)\nprint (f\"mean: {np.mean(X_test, axis=0)[0]:.1f}, std: {np.std(X_test, axis=0)[0]:.1f}\")\nprint (f\"mean: {np.mean(y_test, axis=0)[0]:.1f}, std: {np.std(y_test, axis=0)[0]:.1f}\")\n
\n\nmean: -0.3, std: 0.7\nmean: -0.3, std: 0.6\n
"},{"location":"courses/foundations/linear-regression/#weights_1","title":"Weights","text":"We will be using PyTorch's Linear layers in our MLP implementation. These layers will act as out weights (and biases).
\n\\[ z = XW \\]\nfrom torch import nn\n
\n# Inputs\nN = 3 # num samples\nx = torch.randn(N, INPUT_DIM)\nprint (x.shape)\nprint (x.numpy())\n
\n\ntorch.Size([3, 1])\n[[ 0.04613046]\n [ 0.40240282]\n [-1.0115291 ]]\n
\n# Weights\nm = nn.Linear(INPUT_DIM, OUTPUT_DIM)\nprint (m)\nprint (f\"weights ({m.weight.shape}): {m.weight[0][0]}\")\nprint (f\"bias ({m.bias.shape}): {m.bias[0]}\")\n
\n\nLinear(in_features=1, out_features=1, bias=True)\nweights (torch.Size([1, 1])): 0.35\nbias (torch.Size([1])): -0.34\n
\n# Forward pass\nz = m(x)\nprint (z.shape)\nprint (z.detach().numpy())\n
\n\ntorch.Size([3, 1])\n[[-0.32104054]\n [-0.19719592]\n [-0.68869597]]\n
"},{"location":"courses/foundations/linear-regression/#model_1","title":"Model","text":"\\[ \\hat{y} = XW + b \\]\nclass LinearRegression(nn.Module):\n def __init__(self, input_dim, output_dim):\n super(LinearRegression, self).__init__()\n self.fc1 = nn.Linear(input_dim, output_dim)\n\n def forward(self, x_in):\n y_pred = self.fc1(x_in)\n return y_pred\n
\n# Initialize model\nmodel = LinearRegression(input_dim=INPUT_DIM, output_dim=OUTPUT_DIM)\nprint (model.named_parameters)\n
\n\nModel:\n<bound method Module.named_parameters of LinearRegression(\n (fc1): Linear(in_features=1, out_features=1, bias=True)\n)>\n
"},{"location":"courses/foundations/linear-regression/#loss_1","title":"Loss","text":"This time we're using PyTorch's loss functions, specifically MSELoss.
\nloss_fn = nn.MSELoss()\ny_pred = torch.Tensor([0., 0., 1., 1.])\ny_true = torch.Tensor([1., 1., 1., 0.])\nloss = loss_fn(y_pred, y_true)\nprint(\"Loss: \", loss.numpy())\n
\n\nLoss: 0.75\n
"},{"location":"courses/foundations/linear-regression/#optimizer","title":"Optimizer","text":"When we implemented linear regression with just NumPy, we used batch gradient descent to update our weights (used entire training set). But there are actually many different gradient descent optimization algorithms to choose from and it depends on the situation. However, the ADAM optimizer has become a standard algorithm for most cases.
\nfrom torch.optim import Adam\n
\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n
"},{"location":"courses/foundations/linear-regression/#training_1","title":"Training","text":"# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.Tensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.Tensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.Tensor(y_test)\n
\n# Training\nfor epoch in range(NUM_EPOCHS):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%20==0:\n print (f\"Epoch: {epoch} | loss: {loss:.2f}\")\n
\n\nEpoch: 0 | loss: 0.22\nEpoch: 20 | loss: 0.03\nEpoch: 40 | loss: 0.02\nEpoch: 60 | loss: 0.02\nEpoch: 80 | loss: 0.02\n
"},{"location":"courses/foundations/linear-regression/#evaluation_1","title":"Evaluation","text":"Now we're ready to evaluate our trained model.
\n# Predictions\npred_train = model(X_train)\npred_test = model(X_test)\n
\n# Performance\ntrain_error = loss_fn(pred_train, y_train)\ntest_error = loss_fn(pred_test, y_test)\nprint(f\"train_error: {train_error:.2f}\")\nprint(f\"test_error: {test_error:.2f}\")\n
\n\ntrain_error: 0.02\ntest_error: 0.01\n
\n\nSince we only have one feature, it's easy to visually inspect the model.\n
# Figure size\nplt.figure(figsize=(15,5))\n\n# Plot train data\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplt.scatter(X_train, y_train, label=\"y_train\")\nplt.plot(X_train, pred_train.detach().numpy(), color=\"red\", linewidth=1, linestyle=\"-\", label=\"model\")\nplt.legend(loc=\"lower right\")\n\n# Plot test data\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplt.scatter(X_test, y_test, label='y_test')\nplt.plot(X_test, pred_test.detach().numpy(), color=\"red\", linewidth=1, linestyle=\"-\", label=\"model\")\nplt.legend(loc=\"lower right\")\n\n# Show plots\nplt.show()\n
"},{"location":"courses/foundations/linear-regression/#inference","title":"Inference","text":"After training a model, we can use it to predict on new data.
\n# Feed in your own inputs\nsample_indices = [10, 15, 25]\nX_infer = np.array(sample_indices, dtype=np.float32)\nX_infer = torch.Tensor(X_scaler.transform(X_infer.reshape(-1, 1)))\n
\nRecall that we need to unstandardize our predictions.
\n\\[ \\hat{y}_{scaled} = \\frac{\\hat{y} - \\mu_{\\hat{y}}}{\\sigma_{\\hat{y}}} \\]\n\\[ \\hat{y} = \\hat{y}_{scaled} * \\sigma_{\\hat{y}} + \\mu_{\\hat{y}} \\]\n# Unstandardize predictions\npred_infer = model(X_infer).detach().numpy() * np.sqrt(y_scaler.var_) + y_scaler.mean_\nfor i, index in enumerate(sample_indices):\n print (f\"{df.iloc[index][\"y\"]:.2f} (actual) \u2192 {pred_infer[i][0]:.2f} (predicted)\")\n
\n\n35.73 (actual) \u2192 42.11 (predicted)\n59.34 (actual) \u2192 59.17 (predicted)\n97.04 (actual) \u2192 93.30 (predicted)\n
"},{"location":"courses/foundations/linear-regression/#interpretability_1","title":"Interpretability","text":"Linear regression offers the great advantage of being highly interpretable. Each feature has a coefficient which signifies its importance/impact on the output variable y. We can interpret our coefficient as follows: by increasing X by 1 unit, we increase y by \\(W\\) (~3.65) units.\n
# Unstandardize coefficients\nW = model.fc1.weight.data.numpy()[0][0]\nb = model.fc1.bias.data.numpy()[0]\nW_unscaled = W * (y_scaler.scale_/X_scaler.scale_)\nb_unscaled = b * y_scaler.scale_ + y_scaler.mean_ - np.sum(W_unscaled*X_scaler.mean_)\nprint (\"[actual] y = 3.5X + noise\")\nprint (f\"[model] y_hat = {W_unscaled[0]:.1f}X + {b_unscaled[0]:.1f}\")\n
\n\n[actual] y = 3.5X + noise\n[model] y_hat = 3.4X + 8.0\n
"},{"location":"courses/foundations/linear-regression/#regularization","title":"Regularization","text":"Regularization helps decrease overfitting. Below is L2 regularization (ridge regression). There are many forms of regularization but they all work to reduce overfitting in our models. With L2 regularization, we are penalizing large weight values by decaying them because having large weights will lead to preferential bias with the respective inputs and we want the model to work with all the inputs and not just a select few. There are also other types of regularization like L1 (lasso regression) which is useful for creating sparse models where some feature coefficients are zeroed out, or elastic which combines L1 and L2 penalties.
\nRegularization is not just for linear regression. You can use it to regularize any model's weights including the ones we will look at in future lessons.
\n\\[ J(\\theta) = \\frac{1}{2}\\sum_{i}(X_iW - y_i)^2 + \\frac{\\lambda}{2}W^TW \\]\n\\[ \\frac{\\partial{J}}{\\partial{W}} = X (\\hat{y} - y) + \\lambda W \\]\n\\[ W = W - \\alpha\\frac{\\partial{J}}{\\partial{W}} \\]\n\nVariable\nDescription\n\\(\\lambda\\)\nregularization coefficient\n\\(\\alpha\\)\nlearning rate\n
\nIn PyTorch, we can add L2 regularization by adjusting our optimizer. The Adam optimizer has a weight_decay parameter which to control the L2 penalty.
\nL2_LAMBDA = 1e-2\n
\n# Initialize model\nmodel = LinearRegression(input_dim=INPUT_DIM, output_dim=OUTPUT_DIM)\n
\n# Optimizer (w/ L2 regularization)\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=L2_LAMBDA)\n
\n# Training\nfor epoch in range(NUM_EPOCHS):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%20==0:\n print (f\"Epoch: {epoch} | loss: {loss:.2f}\")\n
\n\nEpoch: 0 | loss: 2.20\nEpoch: 20 | loss: 0.06\nEpoch: 40 | loss: 0.03\nEpoch: 60 | loss: 0.02\nEpoch: 80 | loss: 0.02\n
\n# Predictions\npred_train = model(X_train)\npred_test = model(X_test)\n
\n# Performance\ntrain_error = loss_fn(pred_train, y_train)\ntest_error = loss_fn(pred_test, y_test)\nprint(f\"train_error: {train_error:.2f}\")\nprint(f\"test_error: {test_error:.2f}\")\n
\n\ntrain_error: 0.02\ntest_error: 0.01\n
\n\nRegularization didn't make a difference in performance with this specific example because our data is generated from a perfect linear equation but for large realistic data, regularization can help our model generalize well.
\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Linear regression - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\n
"},{"location":"courses/foundations/logistic-regression/","title":"Logistic Regression","text":""},{"location":"courses/foundations/logistic-regression/#overview","title":"Overview","text":"Logistic regression is an extension on linear regression (both are generalized linear methods). We will still learn to model a line (plane) that models \\(y\\) given \\(X\\). Except now we are dealing with classification problems as opposed to regression problems so we'll be predicting probability distributions as opposed to discrete values. We'll be using the softmax operation to normalize our logits (\\(XW\\)) to derive probabilities.
Our goal is to learn a logistic model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\).
\\[ \\hat{y} = \\frac{e^{XW_y}}{\\sum_j e^{XW}} \\] Variable Description \\(N\\) total numbers of samples \\(C\\) number of classes \\(\\hat{y}\\) predictions \\(\\in \\mathbb{R}^{NXC}\\) \\(X\\) inputs \\(\\in \\mathbb{R}^{NXD}\\) \\(W\\) weights \\(\\in \\mathbb{R}^{DXC}\\)
(*) bias term (\\(b\\)) excluded to avoid crowding the notations
This function is known as the multinomial logistic regression or the softmax classifier. The softmax classifier will use the linear equation (\\(z=XW\\)) and normalize it (using the softmax function) to produce the probability for class y given the inputs.
We'll set our seeds for reproducibility.
import numpy as np\nimport random\nSEED = 1234\n# Set seed for reproducibility\nnp.random.seed(SEED)\nrandom.seed(SEED)\nWe'll used some synthesized data to train our models on. The task is to determine whether a tumor will be benign (harmless) or malignant (harmful) based on leukocyte (white blood cells) count and blood pressure. Note that this is a synthetic dataset that has no clinical relevance.
import matplotlib.pyplot as plt\nimport pandas as pd\nfrom pandas.plotting import scatter_matrix\nSEED = 1234\n# Set seed for reproducibility\nnp.random.seed(SEED)\n# Read from CSV to Pandas DataFrame\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tumors.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\n# Define X and y\nX = df[[\"leukocyte_count\", \"blood_pressure\"]].values\ny = df[\"tumor_class\"].values\n# Plot data\ncolors = {\"benign\": \"red\", \"malignant\": \"blue\"}\nplt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], s=25, edgecolors=\"k\")\nplt.xlabel(\"leukocyte count\")\nplt.ylabel(\"blood pressure\")\nplt.legend([\"malignant\", \"benign\"], loc=\"upper right\")\nplt.show()\nWe want to split our dataset so that each of the three splits has the same distribution of classes so that we can train and evaluate properly. We can easily achieve this by telling scikit-learn's train_test_split function what to stratify on.
import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (700, 2), y_train: (700,)\nX_val: (150, 2), y_val: (150,)\nX_test: (150, 2), y_test: (150,)\nSample point: [11.5066204 15.98030799] \u2192 malignant\n
Now let's see how many samples per class each data split has:
# Overall class distribution\nclass_counts = dict(collections.Counter(y))\nprint (f\"Classes: {class_counts}\")\nprint (f'm:b = {class_counts[\"malignant\"]/class_counts[\"benign\"]:.2f}')\n\nClasses: {\"malignant\": 611, \"benign\": 389}\nm:b = 1.57\n # Per data split class distribution\ntrain_class_counts = dict(collections.Counter(y_train))\nval_class_counts = dict(collections.Counter(y_val))\ntest_class_counts = dict(collections.Counter(y_test))\nprint (f'train m:b = {train_class_counts[\"malignant\"]/train_class_counts[\"benign\"]:.2f}')\nprint (f'val m:b = {val_class_counts[\"malignant\"]/val_class_counts[\"benign\"]:.2f}')\nprint (f'test m:b = {test_class_counts[\"malignant\"]/test_class_counts[\"benign\"]:.2f}')\n\ntrain m:b = 1.57\nval m:b = 1.54\ntest m:b = 1.59\n"},{"location":"courses/foundations/logistic-regression/#label-encoding","title":"Label encoding","text":"
You'll notice that our class labels are text. We need to encode them into integers so we can use them in our models. We could scikit-learn's LabelEncoder to do this but we're going to write our own simple label encoder class so we can see what's happening under the hood.
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Fit\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nlabel_encoder.class_to_index\n\n{\"benign\": 0, \"malignant\": 1}\n # Encoder\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\nprint (f\"decoded: {label_encoder.decode([y_train[0]])}\")\n\ny_train[0]: malignant\ny_train[0]: 1\ndecoded: [\"malignant\"]\n
We also want to calculate our class weights, which are useful for weighting the loss function during training. It tells the model to focus on samples from an under-represented class. The loss section below will show how to incorporate these weights.
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [272 428]\nweights: {0: 0.003676470588235294, 1: 0.002336448598130841}\n"},{"location":"courses/foundations/logistic-regression/#standardize-data","title":"Standardize data","text":"We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values.
from sklearn.preprocessing import StandardScaler\n# Standardize the data (mean=0, std=1) using training data\nX_scaler = StandardScaler().fit(X_train)\n# Apply scaler on training and test data (don't standardize outputs for classification)\nX_train = X_scaler.transform(X_train)\nX_val = X_scaler.transform(X_val)\nX_test = X_scaler.transform(X_test)\n# Check (means should be ~0 and std should be ~1)\nprint (f\"X_test[0]: mean: {np.mean(X_test[:, 0], axis=0):.1f}, std: {np.std(X_test[:, 0], axis=0):.1f}\")\nprint (f\"X_test[1]: mean: {np.mean(X_test[:, 1], axis=0):.1f}, std: {np.std(X_test[:, 1], axis=0):.1f}\")\n\nX_test[0]: mean: 0.0, std: 1.0\nX_test[1]: mean: 0.1, std: 1.0\n"},{"location":"courses/foundations/logistic-regression/#numpy","title":"NumPy","text":"
Now that we have our data prepared, we'll first implement logistic regression using just NumPy. This will let us really understand the underlying operations. It's normal to find the math and code in this section slightly complex. You can still read each of the steps to build intuition for when we implement this using PyTorch.
Our goal is to learn a logistic model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\).
\\[ \\hat{y} = \\frac{e^{XW_y}}{\\sum_j e^{XW}} \\]We are going to use multinomial logistic regression even though our task only involves two classes because you can generalize the softmax classifier to any number of classes.
"},{"location":"courses/foundations/logistic-regression/#initialize-weights","title":"Initialize weights","text":"Step 1: Randomly initialize the model's weights \\(W\\).
INPUT_DIM = X_train.shape[1] # X is 2-dimensional\nNUM_CLASSES = len(label_encoder.classes) # y has two possibilities (benign or malignant)\n# Initialize random weights\nW = 0.01 * np.random.randn(INPUT_DIM, NUM_CLASSES)\nb = np.zeros((1, NUM_CLASSES))\nprint (f\"W: {W.shape}\")\nprint (f\"b: {b.shape}\")\n\nW: (2, 2)\nb: (1, 2)\n"},{"location":"courses/foundations/logistic-regression/#model","title":"Model","text":"
Step 2: Feed inputs \\(X\\) into the model to receive the logits (\\(z=XW\\)). Apply the softmax operation on the logits to get the class probabilities \\(\\hat{y}\\) in one-hot encoded form. For example, if there are three classes, the predicted class probabilities could look like [0.3, 0.3, 0.4].
# Forward pass [NX2] \u00b7 [2X2] + [1,2] = [NX2]\nlogits = np.dot(X_train, W) + b\nprint (f\"logits: {logits.shape}\")\nprint (f\"sample: {logits[0]}\")\n\nlogits: (722, 2)\nsample: [0.01817675 0.00635562]\n
# Normalization via softmax to obtain class probabilities\nexp_logits = np.exp(logits)\ny_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\nprint (f\"y_hat: {y_hat.shape}\")\nprint (f\"sample: {y_hat[0]}\")\n\ny_hat: (722, 2)\nsample: [0.50295525 0.49704475]\n"},{"location":"courses/foundations/logistic-regression/#loss","title":"Loss","text":"
Step 3: Compare the predictions \\(\\hat{y}\\) (ex. [0.3, 0.3, 0.4]) with the actual target values \\(y\\) (ex. class 2 would look like [0, 0, 1]) with the objective (cost) function to determine loss \\(J\\). A common objective function for logistics regression is cross-entropy loss.
bias term (\\(b\\)) excluded to avoid crowding the notations
# Loss\ncorrect_class_logprobs = -np.log(y_hat[range(len(y_hat)), y_train])\nloss = np.sum(correct_class_logprobs) / len(y_train)\nprint (f\"loss: {loss:.2f}\")\n\nloss: 0.69\n"},{"location":"courses/foundations/logistic-regression/#gradients","title":"Gradients","text":"
Step 4: Calculate the gradient of loss \\(J(\\theta)\\) w.r.t to the model weights. Let's assume that our classes are mutually exclusive (a set of inputs could only belong to one class).
# Backpropagation\ndscores = y_hat\ndscores[range(len(y_hat)), y_train] -= 1\ndscores /= len(y_train)\ndW = np.dot(X_train.T, dscores)\ndb = np.sum(dscores, axis=0, keepdims=True)\nStep 5: Update the weights \\(W\\) using a small learning rate \\(\\alpha\\). The updates will penalize the probability for the incorrect classes (j) and encourage a higher probability for the correct class (y).
LEARNING_RATE = 1e-1\n# Update weights\nW += -LEARNING_RATE * dW\nb += -LEARNING_RATE * db\nStep 6: Repeat steps 2 - 5 to minimize the loss and train the model.
NUM_EPOCHS = 50\n# Initialize random weights\nW = 0.01 * np.random.randn(INPUT_DIM, NUM_CLASSES)\nb = np.zeros((1, NUM_CLASSES))\n# Training loop\nfor epoch_num in range(NUM_EPOCHS):\n\n # Forward pass [NX2] \u00b7 [2X2] = [NX2]\n logits = np.dot(X_train, W) + b\n\n # Normalization via softmax to obtain class probabilities\n exp_logits = np.exp(logits)\n y_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\n\n # Loss\n correct_class_logprobs = -np.log(y_hat[range(len(y_hat)), y_train])\n loss = np.sum(correct_class_logprobs) / len(y_train)\n\n # show progress\n if epoch_num%10 == 0:\n # Accuracy\n y_pred = np.argmax(logits, axis=1)\n accuracy = np.mean(np.equal(y_train, y_pred))\n print (f\"Epoch: {epoch_num}, loss: {loss:.3f}, accuracy: {accuracy:.3f}\")\n\n # Backpropagation\n dscores = y_hat\n dscores[range(len(y_hat)), y_train] -= 1\n dscores /= len(y_train)\n dW = np.dot(X_train.T, dscores)\n db = np.sum(dscores, axis=0, keepdims=True)\n\n # Update weights\n W += -LEARNING_RATE * dW\n b += -LEARNING_RATE * db\n\nEpoch: 0, loss: 0.684, accuracy: 0.889\nEpoch: 10, loss: 0.447, accuracy: 0.978\nEpoch: 20, loss: 0.348, accuracy: 0.978\nEpoch: 30, loss: 0.295, accuracy: 0.981\nEpoch: 40, loss: 0.260, accuracy: 0.981\n"},{"location":"courses/foundations/logistic-regression/#evaluation","title":"Evaluation","text":"
Now we're ready to evaluate our trained model on our test (hold-out) data split.
class LogisticRegressionFromScratch():\n def predict(self, x):\n logits = np.dot(x, W) + b\n exp_logits = np.exp(logits)\n y_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\n return y_hat\n# Evaluation\nmodel = LogisticRegressionFromScratch()\nlogits_train = model.predict(X_train)\npred_train = np.argmax(logits_train, axis=1)\nlogits_test = model.predict(X_test)\npred_test = np.argmax(logits_test, axis=1)\n# Training and test accuracy\ntrain_acc = np.mean(np.equal(y_train, pred_train))\ntest_acc = np.mean(np.equal(y_test, pred_test))\nprint (f\"train acc: {train_acc:.2f}, test acc: {test_acc:.2f}\")\n\ntrain acc: 0.98, test acc: 0.94\n
def plot_multiclass_decision_boundary(model, X, y, savefig_fp=None):\n\"\"\"Plot the multiclass decision boundary for a model that accepts 2D inputs.\n Credit: https://cs231n.github.io/neural-networks-case-study/\n\n Arguments:\n model {function} -- trained model with function model.predict(x_in).\n X {numpy.ndarray} -- 2D inputs with shape (N, 2).\n y {numpy.ndarray} -- 1D outputs with shape (N,).\n \"\"\"\n # Axis boundaries\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101),\n np.linspace(y_min, y_max, 101))\n\n # Create predictions\n x_in = np.c_[xx.ravel(), yy.ravel()]\n y_pred = model.predict(x_in)\n y_pred = np.argmax(y_pred, axis=1).reshape(xx.shape)\n\n # Plot decision boundary\n plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n\n # Plot\n if savefig_fp:\n plt.savefig(savefig_fp, format=\"png\")\n# Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\nplt.show()\nNow that we've implemented logistic regression with Numpy, let's do the same with PyTorch.
import torch\n# Set seed for reproducibility\ntorch.manual_seed(SEED)\nWe will be using PyTorch's Linear layers to recreate the same model.
from torch import nn\nimport torch.nn.functional as F\nclass LogisticRegression(nn.Module):\n def __init__(self, input_dim, num_classes):\n super(LogisticRegression, self).__init__()\n self.fc1 = nn.Linear(input_dim, num_classes)\n\n def forward(self, x_in):\n z = self.fc1(x_in)\n return z\n# Initialize model\nmodel = LogisticRegression(input_dim=INPUT_DIM, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of LogisticRegression(\n (fc1): Linear(in_features=2, out_features=2, bias=True)\n)>\n"},{"location":"courses/foundations/logistic-regression/#loss_1","title":"Loss","text":"
Our loss will be the categorical crossentropy.
loss_fn = nn.CrossEntropyLoss()\ny_pred = torch.randn(3, NUM_CLASSES, requires_grad=False)\ny_true = torch.empty(3, dtype=torch.long).random_(NUM_CLASSES)\nprint (y_true)\nloss = loss_fn(y_pred, y_true)\nprint(f\"Loss: {loss.numpy()}\")\n\ntensor([0, 0, 1])\nLoss: 1.6113080978393555\n
In our case, we will also incorporate the class weights into our loss function to counter any class imbalances.
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values()))\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\nWe'll compute accuracy as we train our model because just looking the loss value isn't super intuitive to look at. We'll look at other metrics (precision, recall, f1) in the evaluation section below.
# Accuracy\ndef accuracy_fn(y_pred, y_true):\n n_correct = torch.eq(y_pred, y_true).sum().item()\n accuracy = (n_correct / len(y_pred)) * 100\n return accuracy\ny_pred = torch.Tensor([0, 0, 1])\ny_true = torch.Tensor([1, 1, 1])\nprint(\"Accuracy: {accuracy_fn(y_pred, y_true):.1f}\")\n\nAccuracy: 33.3\n"},{"location":"courses/foundations/logistic-regression/#optimizer","title":"Optimizer","text":"
We'll be sticking with our Adam optimizer from previous lessons.
from torch.optim import Adam\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Training\nfor epoch in range(NUM_EPOCHS):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%10==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 0.95, accuracy: 60.8\nEpoch: 10 | loss: 0.27, accuracy: 86.7\nEpoch: 20 | loss: 0.15, accuracy: 96.1\nEpoch: 30 | loss: 0.11, accuracy: 98.2\nEpoch: 40 | loss: 0.09, accuracy: 98.9\n"},{"location":"courses/foundations/logistic-regression/#evaluation_1","title":"Evaluation","text":"
First let's see the accuracy of our model on our test split.
from sklearn.metrics import accuracy_score\n# Predictions\npred_train = F.softmax(model(X_train), dim=1)\npred_test = F.softmax(model(X_test), dim=1)\nprint (f\"sample probability: {pred_test[0]}\")\npred_train = pred_train.max(dim=1)[1]\npred_test = pred_test.max(dim=1)[1]\nprint (f\"sample class: {pred_test[0]}\")\n\nsample probability: tensor([9.2047e-04, 9.9908e-01])\nsample class: 1\n
# Accuracy (could've also used our own accuracy function)\ntrain_acc = accuracy_score(y_train, pred_train)\ntest_acc = accuracy_score(y_test, pred_test)\nprint (f\"train acc: {train_acc:.2f}, test acc: {test_acc:.2f}\")\n\ntrain acc: 0.98, test acc: 0.98\n
We can also evaluate our model on other meaningful metrics such as precision and recall. These are especially useful when there is data imbalance present.
\\[ \\text{accuracy} = \\frac{TP+TN}{TP+TN+FP+FN} \\] \\[ \\text{recall} = \\frac{TP}{TP+FN} \\] \\[ \\text{precision} = \\frac{TP}{TP+FP} \\] \\[ F_1 = 2 * \\frac{\\text{precision } * \\text{ recall}}{\\text{precision } + \\text{ recall}} \\]Variable Description \\(TP\\) # of samples truly predicted to be positive and were positive \\(TN\\) # of samples truly predicted to be negative and were negative \\(FP\\) # of samples falsely predicted to be positive but were negative \\(FN\\) # of samples falsely predicted to be negative but were positive
import json\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=pred_test, classes=label_encoder.classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.9754098360655737,\n \"recall\": 0.9836956521739131,\n \"f1\": 0.9791076651655137,\n \"num_samples\": 150.0\n },\n \"class\": {\n \"benign\": {\n \"precision\": 0.9508196721311475,\n \"recall\": 1.0,\n \"f1\": 0.9747899159663865,\n \"num_samples\": 58.0\n },\n \"malignant\": {\n \"precision\": 1.0,\n \"recall\": 0.967391304347826,\n \"f1\": 0.9834254143646408,\n \"num_samples\": 92.0\n }\n }\n}\n With logistic regression (extension of linear regression), the model creates a linear decision boundary that we can easily visualize.
def plot_multiclass_decision_boundary(model, X, y):\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))\n cmap = plt.cm.Spectral\n\n X_test = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float()\n y_pred = F.softmax(model(X_test), dim=1)\n _, y_pred = y_pred.max(dim=1)\n y_pred = y_pred.reshape(xx.shape)\n plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n# Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\nplt.show()\n# Inputs for inference\nX_infer = pd.DataFrame([{\"leukocyte_count\": 13, \"blood_pressure\": 12}])\n# Standardize\nX_infer = X_scaler.transform(X_infer)\nprint (X_infer)\n\n[[-0.66523095 -3.08638693]]\n
# Predict\ny_infer = F.softmax(model(torch.Tensor(X_infer)), dim=1)\nprob, _class = y_infer.max(dim=1)\nlabel = label_encoder.decode(_class.detach().numpy())[0]\nprint (f\"The probability that you have a {label} tumor is {prob.detach().numpy()[0]*100.0:.0f}%\")\n\nThe probability that you have a benign tumor is 93%\n"},{"location":"courses/foundations/logistic-regression/#unscaled-weights","title":"Unscaled weights","text":"
Note that only \\(X\\) was standardized.
\\[ \\hat{y}_{unscaled} = b_{scaled} + \\sum_{j=1}^{k}{W_{scaled}}_j{x_{scaled}}_j \\]Variable Description \\(x_{scaled}\\) \\(\\frac{x_j - \\bar{x}_j}{\\sigma_j}\\) \\(\\hat{y}_{unscaled}\\) \\(b_{scaled} + \\sum_{j=1}^{k} {W_{scaled}}_j (\\frac{x_j - \\bar{x}_j}{\\sigma_j})\\)
\\[ \\hat{y}_{unscaled} = (b_{scaled} - \\sum_{j=1}^{k} {W_{scaled}}_j \\frac{\\bar{x}_j}{\\sigma_j}) + \\sum_{j=1}^{k} (\\frac{ {W_{scaled}}_j }{\\sigma_j})x_j \\]In the expression above, we can see the expression \\(\\hat{y}_{unscaled} = W_{unscaled}x + b_{unscaled}\\), therefore:
Variable Description \\(W_{unscaled}\\) \\(\\frac{ {W_{scaled}}_j }{\\sigma_j}\\) \\(b_{unscaled}\\) \\(b_{scaled} - \\sum_{j=1}^{k} {W_{scaled}}_j\\frac{\\bar{x}_j}{\\sigma_j}\\)
# Unstandardize weights\nW = model.fc1.weight.data.numpy()\nb = model.fc1.bias.data.numpy()\nW_unscaled = W / X_scaler.scale_\nb_unscaled = b - np.sum((W_unscaled * X_scaler.mean_))\nprint (W_unscaled)\nprint (b_unscaled)\n\n[[ 0.61700419 -1.20196244]\n [-0.95664431 0.89996245]]\n [ 8.913242 10.183178]\n
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Logistic regression - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nOur goal is to learn a model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\) . You'll notice that neural networks are just extensions of the generalized linear methods we've seen so far but with non-linear activation functions since our data will be highly non-linear.
\\[ z_1 = XW_1 \\] \\[ a_1 = f(z_1) \\] \\[ z_2 = a_1W_2 \\] \\[ \\hat{y} = softmax(z_2) \\]Variable Description \\(N\\) total numbers of samples \\(D\\) number of features \\(H\\) number of hidden units \\(C\\) number of classes \\(W_1\\) 1st layer weights \\(\\in \\mathbb{R}^{DXH}\\) \\(z_1\\) outputs from first layer \\(\\in \\mathbb{R}^{NXH}\\) \\(f\\) non-linear activation function \\(a_1\\) activations from first layer \\(\\in \\mathbb{R}^{NXH}\\) \\(W_2\\) 2nd layer weights \\(\\in \\mathbb{R}^{HXC}\\) \\(z_2\\) outputs from second layer \\(\\in \\mathbb{R}^{NXC}\\) \\(\\hat{y}\\) prediction \\(\\in \\mathbb{R}^{NXC}\\)
(*) bias term (\\(b\\)) excluded to avoid crowding the notations
We'll set our seeds for reproducibility.
import numpy as np\nimport random\nSEED = 1234\n# Set seed for reproducibility\nnp.random.seed(SEED)\nrandom.seed(SEED)\nI created some non-linearly separable spiral data so let's go ahead and download it for our classification task.
import matplotlib.pyplot as plt\nimport pandas as pd\n# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/spiral.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\n# Data shapes\nX = df[[\"X1\", \"X2\"]].values\ny = df[\"color\"].values\nprint (\"X: \", np.shape(X))\nprint (\"y: \", np.shape(y))\n\nX: (1500, 2)\ny: (1500,)\n
# Visualize data\nplt.title(\"Generated non-linear data\")\ncolors = {\"c1\": \"red\", \"c2\": \"yellow\", \"c3\": \"blue\"}\nplt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], edgecolors=\"k\", s=25)\nplt.show()\nWe'll shuffle our dataset (since it's ordered by class) and then create our data splits (stratified on class).
import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (1050, 2), y_train: (1050,)\nX_val: (225, 2), y_val: (225,)\nX_test: (225, 2), y_test: (225,)\nSample point: [ 0.44688413 -0.07360876] \u2192 c1\n"},{"location":"courses/foundations/neural-networks/#label-encoding","title":"Label encoding","text":"
In the previous lesson we wrote our own label encoder class to see the inner functions but this time we'll use scikit-learn LabelEncoder class which does the same operations as ours.
from sklearn.preprocessing import LabelEncoder\n# Output vectorizer\nlabel_encoder = LabelEncoder()\n# Fit on train data\nlabel_encoder = label_encoder.fit(y_train)\nclasses = list(label_encoder.classes_)\nprint (f\"classes: {classes}\")\n\nclasses: [\"c1\", \"c2\", \"c3\"]\n
# Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.transform(y_train)\ny_val = label_encoder.transform(y_val)\ny_test = label_encoder.transform(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: c1\ny_train[0]: 0\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [350 350 350]\nweights: {0: 0.002857142857142857, 1: 0.002857142857142857, 2: 0.002857142857142857}\n"},{"location":"courses/foundations/neural-networks/#standardize-data","title":"Standardize data","text":"We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values.
from sklearn.preprocessing import StandardScaler\n# Standardize the data (mean=0, std=1) using training data\nX_scaler = StandardScaler().fit(X_train)\n# Apply scaler on training and test data (don't standardize outputs for classification)\nX_train = X_scaler.transform(X_train)\nX_val = X_scaler.transform(X_val)\nX_test = X_scaler.transform(X_test)\n# Check (means should be ~0 and std should be ~1)\nprint (f\"X_test[0]: mean: {np.mean(X_test[:, 0], axis=0):.1f}, std: {np.std(X_test[:, 0], axis=0):.1f}\")\nprint (f\"X_test[1]: mean: {np.mean(X_test[:, 1], axis=0):.1f}, std: {np.std(X_test[:, 1], axis=0):.1f}\")\n\nX_test[0]: mean: -0.2, std: 0.8\nX_test[1]: mean: -0.2, std: 0.9\n"},{"location":"courses/foundations/neural-networks/#linear-model","title":"Linear model","text":"
Before we get to our neural network, we're going to motivate non-linear activation functions by implementing a generalized linear model (logistic regression). We'll see why linear models (with linear activations) won't suffice for our dataset.
import torch\n# Set seed for reproducibility\ntorch.manual_seed(SEED)\nWe'll create our linear model using one layer of weights.
from torch import nn\nimport torch.nn.functional as F\nINPUT_DIM = X_train.shape[1] # X is 2-dimensional\nHIDDEN_DIM = 100\nNUM_CLASSES = len(classes) # 3 classes\nclass LinearModel(nn.Module):\n def __init__(self, input_dim, hidden_dim, num_classes):\n super(LinearModel, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, x_in):\n z = self.fc1(x_in) # linear activation\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = LinearModel(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\nModel:\n<bound method Module.named_parameters of LinearModel(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=3, bias=True)\n)>\n"},{"location":"courses/foundations/neural-networks/#training","title":"Training","text":"
We'll go ahead and train our initialized model for a few epochs.
from torch.optim import Adam\nLEARNING_RATE = 1e-2\nNUM_EPOCHS = 10\nBATCH_SIZE = 32\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values()))\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Accuracy\ndef accuracy_fn(y_pred, y_true):\n n_correct = torch.eq(y_pred, y_true).sum().item()\n accuracy = (n_correct / len(y_pred)) * 100\n return accuracy\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Training\nfor epoch in range(NUM_EPOCHS):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%1==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 1.13, accuracy: 51.2\nEpoch: 1 | loss: 0.90, accuracy: 50.0\nEpoch: 2 | loss: 0.78, accuracy: 55.0\nEpoch: 3 | loss: 0.74, accuracy: 54.4\nEpoch: 4 | loss: 0.73, accuracy: 54.2\nEpoch: 5 | loss: 0.74, accuracy: 54.7\nEpoch: 6 | loss: 0.75, accuracy: 54.9\nEpoch: 7 | loss: 0.75, accuracy: 54.3\nEpoch: 8 | loss: 0.76, accuracy: 54.8\nEpoch: 9 | loss: 0.76, accuracy: 55.0\n"},{"location":"courses/foundations/neural-networks/#evaluation","title":"Evaluation","text":"
Now let's see how well our linear model does on our non-linear spiral data.
import json\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Predictions\ny_prob = F.softmax(model(X_test), dim=1)\nprint (f\"sample probability: {y_prob[0]}\")\ny_pred = y_prob.max(dim=1)[1]\nprint (f\"sample class: {y_pred[0]}\")\n\nsample probability: tensor([0.9306, 0.0683, 0.0012])\nsample class: 0\n
# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.5027661968102707,\n \"recall\": 0.49333333333333335,\n \"f1\": 0.4942485399571228,\n \"num_samples\": 225.0\n },\n \"class\": {\n \"c1\": {\n \"precision\": 0.5068493150684932,\n \"recall\": 0.49333333333333335,\n \"f1\": 0.5,\n \"num_samples\": 75.0\n },\n \"c2\": {\n \"precision\": 0.43478260869565216,\n \"recall\": 0.5333333333333333,\n \"f1\": 0.47904191616766467,\n \"num_samples\": 75.0\n },\n \"c3\": {\n \"precision\": 0.5666666666666667,\n \"recall\": 0.4533333333333333,\n \"f1\": 0.5037037037037037,\n \"num_samples\": 75.0\n }\n }\n}\n def plot_multiclass_decision_boundary(model, X, y):\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101), np.linspace(y_min, y_max, 101))\n cmap = plt.cm.Spectral\n\n X_test = torch.from_numpy(np.c_[xx.ravel(), yy.ravel()]).float()\n y_pred = F.softmax(model(X_test), dim=1)\n _, y_pred = y_pred.max(dim=1)\n y_pred = y_pred.reshape(xx.shape)\n plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n# Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\nplt.show()\nUsing the generalized linear method (logistic regression) yielded poor results because of the non-linearity present in our data yet our activation functions were linear. We need to use an activation function that can allow our model to learn and map the non-linearity in our data. There are many different options so let's explore a few.
# Fig size\nplt.figure(figsize=(12,3))\n\n# Data\nx = torch.arange(-5., 5., 0.1)\n\n# Sigmoid activation (constrain a value between 0 and 1.)\nplt.subplot(1, 3, 1)\nplt.title(\"Sigmoid activation\")\ny = torch.sigmoid(x)\nplt.plot(x.numpy(), y.numpy())\n\n# Tanh activation (constrain a value between -1 and 1.)\nplt.subplot(1, 3, 2)\ny = torch.tanh(x)\nplt.title(\"Tanh activation\")\nplt.plot(x.numpy(), y.numpy())\n\n# Relu (clip the negative values to 0)\nplt.subplot(1, 3, 3)\ny = F.relu(x)\nplt.title(\"ReLU activation\")\nplt.plot(x.numpy(), y.numpy())\n\n# Show plots\nplt.show()\nThe ReLU activation function (\\(max(0,z)\\)) is by far the most widely used activation function for neural networks. But as you can see, each activation function has its own constraints so there are circumstances where you'll want to use different ones. For example, if we need to constrain our outputs between 0 and 1, then the sigmoid activation is the best choice.
In some cases, using a ReLU activation function may not be sufficient. For instance, when the outputs from our neurons are mostly negative, the activation function will produce zeros. This effectively creates a \"dying ReLU\" and a recovery is unlikely. To mitigate this effect, we could lower the learning rate or use alternative ReLU activations, ex. leaky ReLU or parametric ReLU (PReLU), which have a small slope for negative neuron outputs.
"},{"location":"courses/foundations/neural-networks/#numpy","title":"NumPy","text":"Now let's create our multilayer perceptron (MLP) which is going to be exactly like the logistic regression model but with the activation function to map the non-linearity in our data.
It's normal to find the math and code in this section slightly complex. You can still read each of the steps to build intuition for when we implement this using PyTorch.
Our goal is to learn a model \\(\\hat{y}\\) that models \\(y\\) given \\(X\\). You'll notice that neural networks are just extensions of the generalized linear methods we've seen so far but with non-linear activation functions since our data will be highly non-linear.
\\[ z_1 = XW_1 \\] \\[ a_1 = f(z_1) \\] \\[ z_2 = a_1W_2 \\] \\[ \\hat{y} = softmax(z_2) \\]"},{"location":"courses/foundations/neural-networks/#initialize-weights","title":"Initialize weights","text":"Step 1: Randomly initialize the model's weights \\(W\\) (we'll cover more effective initialization strategies later in this lesson).
# Initialize first layer's weights\nW1 = 0.01 * np.random.randn(INPUT_DIM, HIDDEN_DIM)\nb1 = np.zeros((1, HIDDEN_DIM))\nprint (f\"W1: {W1.shape}\")\nprint (f\"b1: {b1.shape}\")\n\nW1: (2, 100)\nb1: (1, 100)\n"},{"location":"courses/foundations/neural-networks/#model_1","title":"Model","text":"
Step 2: Feed inputs \\(X\\) into the model to do the forward pass and receive the probabilities. First we pass the inputs into the first layer.
# z1 = [NX2] \u00b7 [2X100] + [1X100] = [NX100]\nz1 = np.dot(X_train, W1) + b1\nprint (f\"z1: {z1.shape}\")\n\nz1: (1050, 100)\n
Next we apply the non-linear activation function, ReLU (\\(max(0,z)\\)) in this case.
\\[ a_1 = f(z_1) \\]# Apply activation function\na1 = np.maximum(0, z1) # ReLU\nprint (f\"a_1: {a1.shape}\")\n\na_1: (1050, 100)\n
We pass the activations to the second layer to get our logits.
\\[ z_2 = a_1W_2 \\]# Initialize second layer's weights\nW2 = 0.01 * np.random.randn(HIDDEN_DIM, NUM_CLASSES)\nb2 = np.zeros((1, NUM_CLASSES))\nprint (f\"W2: {W2.shape}\")\nprint (f\"b2: {b2.shape}\")\n\nW2: (100, 3)\nb2: (1, 3)\n
# z2 = logits = [NX100] \u00b7 [100X3] + [1X3] = [NX3]\nlogits = np.dot(a1, W2) + b2\nprint (f\"logits: {logits.shape}\")\nprint (f\"sample: {logits[0]}\")\n\nlogits: (1050, 3)\nsample: [-9.85444376e-05 1.67334360e-03 -6.31717987e-04]\n
We'll apply the softmax function to normalize the logits and obtain class probabilities.
\\[ \\hat{y} = softmax(z_2) \\]# Normalization via softmax to obtain class probabilities\nexp_logits = np.exp(logits)\ny_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\nprint (f\"y_hat: {y_hat.shape}\")\nprint (f\"sample: {y_hat[0]}\")\n\ny_hat: (1050, 3)\nsample: [0.33319557 0.33378647 0.33301796]\n"},{"location":"courses/foundations/neural-networks/#loss","title":"Loss","text":"
Step 3: Compare the predictions \\(\\hat{y}\\) (ex. [0.3, 0.3, 0.4]) with the actual target values \\(y\\) (ex. class 2 would look like [0, 0, 1]) with the objective (cost) function to determine loss \\(J\\). A common objective function for classification tasks is cross-entropy loss.
(*) bias term (\\(b\\)) excluded to avoid crowding the notations
# Loss\ncorrect_class_logprobs = -np.log(y_hat[range(len(y_hat)), y_train])\nloss = np.sum(correct_class_logprobs) / len(y_train)\nprint (f\"loss: {loss:.2f}\")\n\nloss: 0.70\n"},{"location":"courses/foundations/neural-networks/#gradients","title":"Gradients","text":"
Step 4: Calculate the gradient of loss \\(J(\\theta)\\) w.r.t to the model weights.
The gradient of the loss w.r.t to $$ W_2 $$ is the same as the gradients from logistic regression since $\\(hat{y} = softmax(z_2)\\).
\\[ \\frac{\\partial{J}}{\\partial{W_{2j}}} = \\frac{\\partial{J}}{\\partial{\\hat{y}}}\\frac{\\partial{\\hat{y}}}{\\partial{W_{2j}}} = - \\frac{1}{\\hat{y}}\\frac{\\partial{\\hat{y}}}{\\partial{W_{2j}}} = \\] \\[ = - \\frac{1}{\\frac{e^{W_{2y}a_1}}{\\sum_j e^{a_1W}}}\\frac{\\sum_j e^{a_1W}e^{a_1W_{2y}}0 - e^{a_1W_{2y}}e^{a_1W_{2j}}a_1}{(\\sum_j e^{a_1W})^2} = \\frac{a_1e^{a_1W_{2j}}}{\\sum_j e^{a_1W}} = a_1\\hat{y} \\] \\[ \\frac{\\partial{J}}{\\partial{W_{2y}}} = \\frac{\\partial{J}}{\\partial{\\hat{y}}}\\frac{\\partial{\\hat{y}}}{\\partial{W_{2y}}} = - \\frac{1}{\\hat{y}}\\frac{\\partial{\\hat{y}}}{\\partial{W_{2y}}} = \\] \\[ = - \\frac{1}{\\frac{e^{W_{2y}a_1}}{\\sum_j e^{a_1W}}}\\frac{\\sum_j e^{a_1W}e^{a_1W_{2y}}a_1 - e^{a_1W_{2y}}e^{a_1W_{2y}}a_1}{(\\sum_j e^{a_1W})^2} = -\\frac{1}{\\hat{y}}(a_1\\hat{y} - a_1\\hat{y}^2) = a_1(\\hat{y}-1) \\]The gradient of the loss w.r.t \\(W_1\\) is a bit trickier since we have to backpropagate through two sets of weights.
\\[ \\frac{\\partial{J}}{\\partial{W_1}} = \\frac{\\partial{J}}{\\partial{\\hat{y}}} \\frac{\\partial{\\hat{y}}}{\\partial{a_1}} \\frac{\\partial{a_1}}{\\partial{z_1}} \\frac{\\partial{z_1}}{\\partial{W_1}} = W_2(\\partial{scores})(\\partial{ReLU})X \\]# dJ/dW2\ndscores = y_hat\ndscores[range(len(y_hat)), y_train] -= 1\ndscores /= len(y_train)\ndW2 = np.dot(a1.T, dscores)\ndb2 = np.sum(dscores, axis=0, keepdims=True)\n# dJ/dW1\ndhidden = np.dot(dscores, W2.T)\ndhidden[a1 <= 0] = 0 # ReLu backprop\ndW1 = np.dot(X_train.T, dhidden)\ndb1 = np.sum(dhidden, axis=0, keepdims=True)\nStep 5: Update the weights \\(W\\) using a small learning rate \\(\\alpha\\). The updates will penalize the probability for the incorrect classes (\\(j\\)) and encourage a higher probability for the correct class (\\(y\\)).
# Update weights\nW1 += -LEARNING_RATE * dW1\nb1 += -LEARNING_RATE * db1\nW2 += -LEARNING_RATE * dW2\nb2 += -LEARNING_RATE * db2\nStep 6: Repeat steps 2 - 4 until model performs well.
# Convert tensors to NumPy arrays\nX_train = X_train.numpy()\ny_train = y_train.numpy()\nX_val = X_val.numpy()\ny_val = y_val.numpy()\nX_test = X_test.numpy()\ny_test = y_test.numpy()\n# Initialize random weights\nW1 = 0.01 * np.random.randn(INPUT_DIM, HIDDEN_DIM)\nb1 = np.zeros((1, HIDDEN_DIM))\nW2 = 0.01 * np.random.randn(HIDDEN_DIM, NUM_CLASSES)\nb2 = np.zeros((1, NUM_CLASSES))\n\n# Training loop\nfor epoch_num in range(1000):\n\n # First layer forward pass [NX2] \u00b7 [2X100] = [NX100]\n z1 = np.dot(X_train, W1) + b1\n\n # Apply activation function\n a1 = np.maximum(0, z1) # ReLU\n\n # z2 = logits = [NX100] \u00b7 [100X3] = [NX3]\n logits = np.dot(a1, W2) + b2\n\n # Normalization via softmax to obtain class probabilities\n exp_logits = np.exp(logits)\n y_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\n\n # Loss\n correct_class_logprobs = -np.log(y_hat[range(len(y_hat)), y_train])\n loss = np.sum(correct_class_logprobs) / len(y_train)\n\n # show progress\n if epoch_num%100 == 0:\n # Accuracy\n y_pred = np.argmax(logits, axis=1)\n accuracy = np.mean(np.equal(y_train, y_pred))\n print (f\"Epoch: {epoch_num}, loss: {loss:.3f}, accuracy: {accuracy:.3f}\")\n\n # dJ/dW2\n dscores = y_hat\n dscores[range(len(y_hat)), y_train] -= 1\n dscores /= len(y_train)\n dW2 = np.dot(a1.T, dscores)\n db2 = np.sum(dscores, axis=0, keepdims=True)\n\n # dJ/dW1\n dhidden = np.dot(dscores, W2.T)\n dhidden[a1 <= 0] = 0 # ReLu backprop\n dW1 = np.dot(X_train.T, dhidden)\n db1 = np.sum(dhidden, axis=0, keepdims=True)\n\n # Update weights\n W1 += -1e0 * dW1\n b1 += -1e0 * db1\n W2 += -1e0 * dW2\n b2 += -1e0 * db2\n\nEpoch: 0, loss: 1.099, accuracy: 0.339\nEpoch: 100, loss: 0.549, accuracy: 0.678\nEpoch: 200, loss: 0.238, accuracy: 0.907\nEpoch: 300, loss: 0.151, accuracy: 0.946\nEpoch: 400, loss: 0.098, accuracy: 0.972\nEpoch: 500, loss: 0.074, accuracy: 0.985\nEpoch: 600, loss: 0.059, accuracy: 0.988\nEpoch: 700, loss: 0.050, accuracy: 0.991\nEpoch: 800, loss: 0.043, accuracy: 0.992\nEpoch: 900, loss: 0.038, accuracy: 0.993\n"},{"location":"courses/foundations/neural-networks/#evaluation_1","title":"Evaluation","text":"
Now let's see how our model performs on the test (hold-out) data split.
class MLPFromScratch():\n def predict(self, x):\n z1 = np.dot(x, W1) + b1\n a1 = np.maximum(0, z1)\n logits = np.dot(a1, W2) + b2\n exp_logits = np.exp(logits)\n y_hat = exp_logits / np.sum(exp_logits, axis=1, keepdims=True)\n return y_hat\n# Evaluation\nmodel = MLPFromScratch()\ny_prob = model.predict(X_test)\ny_pred = np.argmax(y_prob, axis=1)\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.9824531024531025,\n \"recall\": 0.9822222222222222,\n \"f1\": 0.982220641694326,\n \"num_samples\": 225.0\n },\n \"class\": {\n \"c1\": {\n \"precision\": 1.0,\n \"recall\": 0.9733333333333334,\n \"f1\": 0.9864864864864865,\n \"num_samples\": 75.0\n },\n \"c2\": {\n \"precision\": 0.974025974025974,\n \"recall\": 1.0,\n \"f1\": 0.9868421052631579,\n \"num_samples\": 75.0\n },\n \"c3\": {\n \"precision\": 0.9733333333333334,\n \"recall\": 0.9733333333333334,\n \"f1\": 0.9733333333333334,\n \"num_samples\": 75.0\n }\n }\n}\n def plot_multiclass_decision_boundary_numpy(model, X, y, savefig_fp=None):\n\"\"\"Plot the multiclass decision boundary for a model that accepts 2D inputs.\n Credit: https://cs231n.github.io/neural-networks-case-study/\n\n Arguments:\n model {function} -- trained model with function model.predict(x_in).\n X {numpy.ndarray} -- 2D inputs with shape (N, 2).\n y {numpy.ndarray} -- 1D outputs with shape (N,).\n \"\"\"\n # Axis boundaries\n x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1\n y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1\n xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101),\n np.linspace(y_min, y_max, 101))\n\n # Create predictions\n x_in = np.c_[xx.ravel(), yy.ravel()]\n y_pred = model.predict(x_in)\n y_pred = np.argmax(y_pred, axis=1).reshape(xx.shape)\n\n # Plot decision boundary\n plt.contourf(xx, yy, y_pred, cmap=plt.cm.Spectral, alpha=0.8)\n plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n\n # Plot\n if savefig_fp:\n plt.savefig(savefig_fp, format=\"png\")\n# Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary_numpy(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary_numpy(model=model, X=X_test, y=y_test)\nplt.show()\nNow let's implement the same MLP in PyTorch.
"},{"location":"courses/foundations/neural-networks/#model_2","title":"Model","text":"We'll be using two linear layers along with PyTorch Functional API's ReLU operation.
class MLP(nn.Module):\n def __init__(self, input_dim, hidden_dim, num_classes):\n super(MLP, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, x_in):\n z = F.relu(self.fc1(x_in)) # ReLU activation function added!\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of MLP(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=3, bias=True)\n)>\n"},{"location":"courses/foundations/neural-networks/#training_2","title":"Training","text":"
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values()))\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Accuracy\ndef accuracy_fn(y_pred, y_true):\n n_correct = torch.eq(y_pred, y_true).sum().item()\n accuracy = (n_correct / len(y_pred)) * 100\n return accuracy\n# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Training\nfor epoch in range(NUM_EPOCHS*10):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%10==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 1.11, accuracy: 21.9\nEpoch: 10 | loss: 0.66, accuracy: 59.8\nEpoch: 20 | loss: 0.50, accuracy: 73.0\nEpoch: 30 | loss: 0.38, accuracy: 89.8\nEpoch: 40 | loss: 0.28, accuracy: 92.3\nEpoch: 50 | loss: 0.21, accuracy: 93.8\nEpoch: 60 | loss: 0.17, accuracy: 95.2\nEpoch: 70 | loss: 0.14, accuracy: 96.1\nEpoch: 80 | loss: 0.12, accuracy: 97.4\nEpoch: 90 | loss: 0.10, accuracy: 97.8\n"},{"location":"courses/foundations/neural-networks/#evaluation_2","title":"Evaluation","text":"
# Predictions\ny_prob = F.softmax(model(X_test), dim=1)\ny_pred = y_prob.max(dim=1)[1]\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.9706790123456791,\n \"recall\": 0.9688888888888889,\n \"f1\": 0.9690388976103262,\n \"num_samples\": 225.0\n },\n \"class\": {\n \"c1\": {\n \"precision\": 1.0,\n \"recall\": 0.96,\n \"f1\": 0.9795918367346939,\n \"num_samples\": 75.0\n },\n \"c2\": {\n \"precision\": 0.9259259259259259,\n \"recall\": 1.0,\n \"f1\": 0.9615384615384615,\n \"num_samples\": 75.0\n },\n \"c3\": {\n \"precision\": 0.9861111111111112,\n \"recall\": 0.9466666666666667,\n \"f1\": 0.9659863945578231,\n \"num_samples\": 75.0\n }\n }\n}\n # Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\nplt.show()\nLet's look at the inference operations when using our trained model.
# Inputs for inference\nX_infer = pd.DataFrame([{\"X1\": 0.1, \"X2\": 0.1}])\n# Standardize\nX_infer = X_scaler.transform(X_infer)\nprint (X_infer)\n\n[[0.22746497 0.29242354]]\n
# Predict\ny_infer = F.softmax(model(torch.Tensor(X_infer)), dim=1)\nprob, _class = y_infer.max(dim=1)\nlabel = label_encoder.inverse_transform(_class.detach().numpy())[0]\nprint (f\"The probability that you have {label} is {prob.detach().numpy()[0]*100.0:.0f}%\")\n\nThe probability that you have c1 is 92%\n"},{"location":"courses/foundations/neural-networks/#initializing-weights","title":"Initializing weights","text":"
So far we have been initializing weights with small random values but this isn't optimal for convergence during training. The objective is to initialize the appropriate weights such that our activations (outputs of layers) don't vanish (too small) or explode (too large), as either of these situations will hinder convergence. We can do this by sampling the weights uniformly from a bound distribution (many that take into account the precise activation function used) such that all activations have unit variance.
You may be wondering why we don't do this for every forward pass and that's a great question. We'll look at more advanced strategies that help with optimization like batch normalization, etc. in future lessons. Meanwhile you can check out other initializers here.
from torch.nn import init\nclass MLP(nn.Module):\n def __init__(self, input_dim, hidden_dim, num_classes):\n super(MLP, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def init_weights(self):\n init.xavier_normal(self.fc1.weight, gain=init.calculate_gain(\"relu\"))\n\n def forward(self, x_in):\n z = F.relu(self.fc1(x_in)) # ReLU activation function added!\n z = self.fc2(z)\n return z\nA great technique to have our models generalize (perform well on test data) is to increase the size of your data but this isn't always an option. Fortunately, there are methods like regularization and dropout that can help create a more robust model.
Dropout is a technique (used only during training) that allows us to zero the outputs of neurons. We do this for dropout_p% of the total neurons in each layer and it changes every batch. Dropout prevents units from co-adapting too much to the data and acts as a sampling strategy since we drop a different set of neurons each time.
DROPOUT_P = 0.1 # percentage of weights that are dropped each pass\nclass MLP(nn.Module):\n def __init__(self, input_dim, hidden_dim, dropout_p, num_classes):\n super(MLP, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.dropout = nn.Dropout(dropout_p) # dropout\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def init_weights(self):\n init.xavier_normal(self.fc1.weight, gain=init.calculate_gain(\"relu\"))\n\n def forward(self, x_in):\n z = F.relu(self.fc1(x_in))\n z = self.dropout(z) # dropout\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of MLP(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=3, bias=True)\n)>\n"},{"location":"courses/foundations/neural-networks/#overfitting","title":"Overfitting","text":"
Though neural networks are great at capturing non-linear relationships they are highly susceptible to overfitting to the training data and failing to generalize on test data. Just take a look at the example below where we generate completely random data and are able to fit a model with \\(2*N*C + D\\) (where N = # of samples, C = # of classes and D = input dimension) hidden units. The training performance is good (~70%) but the overfitting leads to very poor test performance. We'll be covering strategies to tackle overfitting in future lessons.
NUM_EPOCHS = 500\nNUM_SAMPLES_PER_CLASS = 50\nLEARNING_RATE = 1e-1\nHIDDEN_DIM = 2 * NUM_SAMPLES_PER_CLASS * NUM_CLASSES + INPUT_DIM # 2*N*C + D\n# Generate random data\nX = np.random.rand(NUM_SAMPLES_PER_CLASS * NUM_CLASSES, INPUT_DIM)\ny = np.array([[i]*NUM_SAMPLES_PER_CLASS for i in range(NUM_CLASSES)]).reshape(-1)\nprint (\"X: \", format(np.shape(X)))\nprint (\"y: \", format(np.shape(y)))\n\nX: (150, 2)\ny: (150,)\n
# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (105, 2), y_train: (105,)\nX_val: (22, 2), y_val: (22,)\nX_test: (23, 2), y_test: (23,)\nSample point: [0.52553355 0.33956916] \u2192 0\n
# Standardize the inputs (mean=0, std=1) using training data\nX_scaler = StandardScaler().fit(X_train)\nX_train = X_scaler.transform(X_train)\nX_val = X_scaler.transform(X_val)\nX_test = X_scaler.transform(X_test)\n# Convert data to tensors\nX_train = torch.Tensor(X_train)\ny_train = torch.LongTensor(y_train)\nX_val = torch.Tensor(X_val)\ny_val = torch.LongTensor(y_val)\nX_test = torch.Tensor(X_test)\ny_test = torch.LongTensor(y_test)\n# Initialize model\nmodel = MLP(input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of MLP(\n (fc1): Linear(in_features=2, out_features=302, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=302, out_features=3, bias=True)\n)>\n
# Optimizer\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\n# Training\nfor epoch in range(NUM_EPOCHS):\n # Forward pass\n y_pred = model(X_train)\n\n # Loss\n loss = loss_fn(y_pred, y_train)\n\n # Zero all gradients\n optimizer.zero_grad()\n\n # Backward pass\n loss.backward()\n\n # Update weights\n optimizer.step()\n\n if epoch%20==0:\n predictions = y_pred.max(dim=1)[1] # class\n accuracy = accuracy_fn(y_pred=predictions, y_true=y_train)\n print (f\"Epoch: {epoch} | loss: {loss:.2f}, accuracy: {accuracy:.1f}\")\n\nEpoch: 0 | loss: 1.15, accuracy: 37.1\nEpoch: 20 | loss: 1.04, accuracy: 47.6\nEpoch: 40 | loss: 0.98, accuracy: 51.4\nEpoch: 60 | loss: 0.90, accuracy: 57.1\nEpoch: 80 | loss: 0.87, accuracy: 59.0\nEpoch: 100 | loss: 0.88, accuracy: 58.1\nEpoch: 120 | loss: 0.84, accuracy: 64.8\nEpoch: 140 | loss: 0.86, accuracy: 61.0\nEpoch: 160 | loss: 0.81, accuracy: 64.8\nEpoch: 180 | loss: 0.89, accuracy: 59.0\nEpoch: 200 | loss: 0.91, accuracy: 60.0\nEpoch: 220 | loss: 0.82, accuracy: 63.8\nEpoch: 240 | loss: 0.86, accuracy: 59.0\nEpoch: 260 | loss: 0.77, accuracy: 66.7\nEpoch: 280 | loss: 0.82, accuracy: 67.6\nEpoch: 300 | loss: 0.88, accuracy: 57.1\nEpoch: 320 | loss: 0.81, accuracy: 61.9\nEpoch: 340 | loss: 0.79, accuracy: 63.8\nEpoch: 360 | loss: 0.80, accuracy: 61.0\nEpoch: 380 | loss: 0.86, accuracy: 64.8\nEpoch: 400 | loss: 0.77, accuracy: 64.8\nEpoch: 420 | loss: 0.79, accuracy: 64.8\nEpoch: 440 | loss: 0.81, accuracy: 65.7\nEpoch: 460 | loss: 0.77, accuracy: 70.5\nEpoch: 480 | loss: 0.80, accuracy: 67.6\n
# Predictions\ny_prob = F.softmax(model(X_test), dim=1)\ny_pred = y_prob.max(dim=1)[1]\n# # Performance\nperformance = get_metrics(y_true=y_test, y_pred=y_pred, classes=classes)\nprint (json.dumps(performance, indent=2))\n\n{\n \"overall\": {\n \"precision\": 0.17857142857142858,\n \"recall\": 0.16666666666666666,\n \"f1\": 0.1722222222222222,\n \"num_samples\": 23.0\n },\n \"class\": {\n \"c1\": {\n \"precision\": 0.0,\n \"recall\": 0.0,\n \"f1\": 0.0,\n \"num_samples\": 7.0\n },\n \"c2\": {\n \"precision\": 0.2857142857142857,\n \"recall\": 0.25,\n \"f1\": 0.26666666666666666,\n \"num_samples\": 8.0\n },\n \"c3\": {\n \"precision\": 0.25,\n \"recall\": 0.25,\n \"f1\": 0.25,\n \"num_samples\": 8.0\n }\n }\n}\n # Visualize the decision boundary\nplt.figure(figsize=(12,5))\nplt.subplot(1, 2, 1)\nplt.title(\"Train\")\nplot_multiclass_decision_boundary(model=model, X=X_train, y=y_train)\nplt.subplot(1, 2, 2)\nplt.title(\"Test\")\nplot_multiclass_decision_boundary(model=model, X=X_test, y=y_test)\nplt.show()\nIt's important that we experiment, starting with simple models that underfit (high bias) and improve it towards a good fit. Starting with simple models (linear/logistic regression) let's us catch errors without the added complexity of more sophisticated models (neural networks).
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Neural networks - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nCopy of 01_Notebooks to 1_Notebooks).Alternatives to Google Colab
Alternatively, you can run these notebooks locally by using JupyterLab. You should first set up a directory for our project, create a virtual environment and install jupyterlab.
mkdir mlops\npython3 -m venv venv\nsource venv/bin/activate\npip install jupyterlab\njupyter lab\nNotebooks are made up of cells. There are two types of cells:
code cell: used for writing and executing code.text cell: used for writing text, HTML, Markdown, etc.Click on a desired location in the notebook and create the cell by clicking on the \u2795 TEXT (located in the top left corner).
Once you create the cell, click on it and type the following text inside it:
### This is a header\nHello world!\nOnce you type inside the cell, press the SHIFT and RETURN (enter key) together to run the cell.
To edit a cell, double click on it and make any changes.
"},{"location":"courses/foundations/notebooks/#move-a-cell","title":"Move a cell","text":"Move a cell up and down by clicking on the cell and then pressing the \u2b06 and \u2b07 button on the top right of the cell.
"},{"location":"courses/foundations/notebooks/#delete-a-cell","title":"Delete a cell","text":"Delete the cell by clicking on it and pressing the trash can button \ud83d\uddd1\ufe0f on the top right corner of the cell. Alternatively, you can also press \u2318/Ctrl + M + D.
"},{"location":"courses/foundations/notebooks/#code-cells","title":"Code cells","text":"Repeat the steps above to create and edit a code cell. You can create a code cell by clicking on the \u2795 CODE (located in the top left corner).
Once you've created the code cell, double click on it, type the following inside it and then press Shift + Enter to execute the code.
print (\"Hello world!\")\n\nHello world!\n
These are the basic concepts we'll need to use these notebooks but we'll learn few more tricks in subsequent lessons.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Notebooks - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nFirst we'll import the NumPy package and set seeds for reproducibility so that we can receive the exact same results every time.
import numpy as np\n# Set seed for reproducibility\nnp.random.seed(seed=1234)\n# Scalar\nx = np.array(6)\nprint (\"x: \", x)\nprint (\"x ndim: \", x.ndim) # number of dimensions\nprint (\"x shape:\", x.shape) # dimensions\nprint (\"x size: \", x.size) # size of elements\nprint (\"x dtype: \", x.dtype) # data type\n\nx: 6\nx ndim: 0\nx shape: ()\nx size: 1\nx dtype: int64\n
# Vector\nx = np.array([1.3 , 2.2 , 1.7])\nprint (\"x: \", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype) # notice the float datatype\n\nx: [1.3 2.2 1.7]\nx ndim: 1\nx shape: (3,)\nx size: 3\nx dtype: float64\n
# Matrix\nx = np.array([[1,2], [3,4]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)\n\nx:\n [[1 2]\n [3 4]]\nx ndim: 2\nx shape: (2, 2)\nx size: 4\nx dtype: int64\n
# 3-D Tensor\nx = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)\n\nx:\n [[[1 2]\n [3 4]]\n\n [[5 6]\n [7 8]]]\nx ndim: 3\nx shape: (2, 2, 2)\nx size: 8\nx dtype: int64\n
NumPy also comes with several functions that allow us to create tensors quickly.
# Functions\nprint (\"np.zeros((2,2)):\\n\", np.zeros((2,2)))\nprint (\"np.ones((2,2)):\\n\", np.ones((2,2)))\nprint (\"np.eye((2)):\\n\", np.eye((2))) # identity matrix\nprint (\"np.random.random((2,2)):\\n\", np.random.random((2,2)))\n\nnp.zeros((2,2)):\n [[0. 0.]\n [0. 0.]]\nnp.ones((2,2)):\n [[1. 1.]\n [1. 1.]]\nnp.eye((2)):\n [[1. 0.]\n [0. 1.]]\nnp.random.random((2,2)):\n [[0.19151945 0.62210877]\n [0.43772774 0.78535858]]\n"},{"location":"courses/foundations/numpy/#indexing","title":"Indexing","text":"
We can extract specific values from our tensors using indexing.
Keep in mind that when indexing the row and column, indices start at 0. And like indexing with lists, we can use negative indices as well (where -1 is the last item).
# Indexing\nx = np.array([1, 2, 3])\nprint (\"x: \", x)\nprint (\"x[0]: \", x[0])\nx[0] = 0\nprint (\"x: \", x)\n\nx: [1 2 3]\nx[0]: 1\nx: [0 2 3]\n
# Slicing\nx = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\nprint (x)\nprint (\"x column 1: \", x[:, 1])\nprint (\"x row 0: \", x[0, :])\nprint (\"x rows 0,1 & cols 1,2: \\n\", x[0:2, 1:3])\n\n[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nx column 1: [ 2 6 10]\nx row 0: [1 2 3 4]\nx rows 0,1 & cols 1,2:\n [[2 3]\n [6 7]]\n
# Integer array indexing\nprint (x)\nrows_to_get = np.array([0, 1, 2])\nprint (\"rows_to_get: \", rows_to_get)\ncols_to_get = np.array([0, 2, 1])\nprint (\"cols_to_get: \", cols_to_get)\n# Combine sequences above to get values to get\nprint (\"indexed values: \", x[rows_to_get, cols_to_get]) # (0, 0), (1, 2), (2, 1)\n\n[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nrows_to_get: [0 1 2]\ncols_to_get: [0 2 1]\nindexed values: [ 1 7 10]\n
# Boolean array indexing\nx = np.array([[1, 2], [3, 4], [5, 6]])\nprint (\"x:\\n\", x)\nprint (\"x > 2:\\n\", x > 2)\nprint (\"x[x > 2]:\\n\", x[x > 2])\n\nx:\n [[1 2]\n [3 4]\n [5 6]]\nx > 2:\n [[False False]\n [ True True]\n [ True True]]\nx[x > 2]:\n [3 4 5 6]\n"},{"location":"courses/foundations/numpy/#arithmetic","title":"Arithmetic","text":"
# Basic math\nx = np.array([[1,2], [3,4]], dtype=np.float64)\ny = np.array([[1,2], [3,4]], dtype=np.float64)\nprint (\"x + y:\\n\", np.add(x, y)) # or x + y\nprint (\"x - y:\\n\", np.subtract(x, y)) # or x - y\nprint (\"x * y:\\n\", np.multiply(x, y)) # or x * y\n\nx + y:\n [[2. 4.]\n [6. 8.]]\nx - y:\n [[0. 0.]\n [0. 0.]]\nx * y:\n [[ 1. 4.]\n [ 9. 16.]]\n"},{"location":"courses/foundations/numpy/#dot-product","title":"Dot product","text":"
One of the most common NumPy operations we\u2019ll use in machine learning is matrix multiplication using the dot product. Suppose we wanted to take the dot product of two matrices with shapes [2 X 3] and [3 X 2]. We take the rows of our first matrix (2) and the columns of our second matrix (2) to determine the dot product, giving us an output of [2 X 2]. The only requirement is that the inside dimensions match, in this case the first matrix has 3 columns and the second matrix has 3 rows.
# Dot product\na = np.array([[1,2,3], [4,5,6]], dtype=np.float64) # we can specify dtype\nb = np.array([[7,8], [9,10], [11, 12]], dtype=np.float64)\nc = a.dot(b)\nprint (f\"{a.shape} \u00b7 {b.shape} = {c.shape}\")\nprint (c)\n\n(2, 3) \u00b7 (3, 2) = (2, 2)\n[[ 58. 64.]\n [139. 154.]]\n"},{"location":"courses/foundations/numpy/#axis-operations","title":"Axis operations","text":"
We can also do operations across a specific axis.
# Sum across a dimension\nx = np.array([[1,2],[3,4]])\nprint (x)\nprint (\"sum all: \", np.sum(x)) # adds all elements\nprint (\"sum axis=0: \", np.sum(x, axis=0)) # sum across rows\nprint (\"sum axis=1: \", np.sum(x, axis=1)) # sum across columns\n\n[[1 2]\n [3 4]]\nsum all: 10\nsum axis=0: [4 6]\nsum axis=1: [3 7]\n
# Min/max\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"min: \", x.min())\nprint (\"max: \", x.max())\nprint (\"min axis=0: \", x.min(axis=0))\nprint (\"min axis=1: \", x.min(axis=1))\n\nmin: 1\nmax: 6\nmin axis=0: [1 2 3]\nmin axis=1: [1 4]\n"},{"location":"courses/foundations/numpy/#broadcast","title":"Broadcast","text":"
What happens when we try to do operations with tensors with seemingly incompatible shapes? Their dimensions aren\u2019t compatible as is but how does NumPy still gives us the right result? This is where broadcasting comes in. The scalar is broadcast across the vector so that they have compatible shapes.
# Broadcasting\nx = np.array([1,2]) # vector\ny = np.array(3) # scalar\nz = x + y\nprint (\"z:\\n\", z)\n\nz:\n [4 5]\n"},{"location":"courses/foundations/numpy/#gotchas","title":"Gotchas","text":"
In the situation below, what is the value of c and what are its dimensions?
a = np.array((3, 4, 5))\nb = np.expand_dims(a, axis=1)\nc = a + b\na.shape # (3,)\nb.shape # (3, 1)\nc.shape # (3, 3)\nprint (c)\n\narray([[ 6, 7, 8],\n [ 7, 8, 9],\n [ 8, 9, 10]])\n
How can we fix this? We need to be careful to ensure that a is the same shape as b if we don't want this unintentional broadcasting behavior.
a = a.reshape(-1, 1)\na.shape # (3, 1)\nc = a + b\nc.shape # (3, 1)\nprint (c)\n\narray([[ 6],\n [ 8],\n [10]])\n
This kind of unintended broadcasting happens more often then you'd think because this is exactly what happens when we create an array from a list. So we need to ensure that we apply the proper reshaping before using it for any operations.
a = np.array([3, 4, 5])\na.shape # (3,)\na = a.reshape(-1, 1)\na.shape # (3, 1)\nWe often need to change the dimensions of our tensors for operations like the dot product. If we need to switch two dimensions, we can transpose the tensor.
# Transposing\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.transpose(x, (1,0)) # flip dimensions at index 0 and 1\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)\n\nx:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny:\n [[1 4]\n [2 5]\n [3 6]]\ny.shape: (3, 2)\n"},{"location":"courses/foundations/numpy/#reshape","title":"Reshape","text":"
Sometimes, we'll need to alter the dimensions of the matrix. Reshaping allows us to transform a tensor into different permissible shapes. Below, our reshaped tensor has the same number of values as the original tensor. (1X6 = 2X3). We can also use -1 on a dimension and NumPy will infer the dimension based on our input tensor.
# Reshaping\nx = np.array([[1,2,3,4,5,6]])\nprint (x)\nprint (\"x.shape: \", x.shape)\ny = np.reshape(x, (2, 3))\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape)\nz = np.reshape(x, (2, -1))\nprint (\"z: \\n\", z)\nprint (\"z.shape: \", z.shape)\n\n[[1 2 3 4 5 6]]\nx.shape: (1, 6)\ny:\n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\nz:\n [[1 2 3]\n [4 5 6]]\nz.shape: (2, 3)\n
The way reshape works is by looking at each dimension of the new tensor and separating our original tensor into that many units. So here the dimension at index 0 of the new tensor is 2 so we divide our original tensor into 2 units, and each of those has 3 values.
Unintended reshaping
Though reshaping is very convenient to manipulate tensors, we must be careful of its pitfalls as well. Let's look at the example below. Suppose we have x, which has the shape [2 X 3 X 4].
x = np.array([[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],\n [[10, 10, 10, 10], [20, 20, 20, 20], [30, 30, 30, 30]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\n\nx:\n[[[ 1 1 1 1]\n[ 2 2 2 2]\n[ 3 3 3 3]]\n[[10 10 10 10]\n[20 20 20 20]\n[30 30 30 30]]]\nx.shape: (2, 3, 4)\n
\nWe want to reshape x so that it has shape
\n[3 X 8]but we want the output to look like this:\n[[ 1 1 1 1 10 10 10 10]\n[ 2 2 2 2 20 20 20 20]\n[ 3 3 3 3 30 30 30 30]]\n\nand not like:
\n\n[[ 1 1 1 1 2 2 2 2]\n[ 3 3 3 3 10 10 10 10]\n[20 20 20 20 30 30 30 30]]\n\neven though they both have the same shape
\nShow answer\n[3X8]. What is the right way to reshape this?When we naively do a reshape, we get the right shape but the values are not what we're looking for.
\n\n
\n\n# Unintended reshaping\nz_incorrect = np.reshape(x, (x.shape[1], -1))\nprint (\"z_incorrect:\\n\", z_incorrect)\nprint (\"z_incorrect.shape: \", z_incorrect.shape)\n\nz_incorrect:\n[[ 1 1 1 1 2 2 2 2]\n[ 3 3 3 3 10 10 10 10]\n[20 20 20 20 30 30 30 30]]\nz_incorrect.shape: (3, 8)\n\nInstead, if we transpose the tensor and then do a reshape, we get our desired tensor. Transpose allows us to put our two vectors that we want to combine together and then we use reshape to join them together. And as a general rule, we should always get our dimensions together before reshaping to combine them.
\n\n
\n\n# Intended reshaping\ny = np.transpose(x, (1,0,2))\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)\nz_correct = np.reshape(y, (y.shape[0], -1))\nprint (\"z_correct:\\n\", z_correct)\nprint (\"z_correct.shape: \", z_correct.shape)\n\ny:\n[[[ 1 1 1 1]\n[10 10 10 10]]\n[[ 2 2 2 2]\n[20 20 20 20]]
\n[[ 3 3 3 3]\n[30 30 30 30]]]\ny.shape: (3, 2, 4)\nz_correct:\n[[ 1 1 1 1 10 10 10 10]\n[ 2 2 2 2 20 20 20 20]\n[ 3 3 3 3 30 30 30 30]]\nz_correct.shape: (3, 8)\n
\nThis becomes difficult when we're dealing with weight tensors with random values in many machine learning tasks. So a good idea is to always create a dummy example like this when you\u2019re unsure about reshaping. Blindly going by the tensor shape can lead to lots of issues downstream.
"},{"location":"courses/foundations/numpy/#joining","title":"Joining","text":"We can also join our tensors via concatentation or stacking.
\n\nx = np.random.random((2, 3))\nprint (x)\nprint (x.shape)\n\n[[0.79564718 0.73023418 0.92340453]\n [0.24929281 0.0513762 0.66149188]]\n(2, 3)\n\n\n\n# Concatenation\ny = np.concatenate([x, x], axis=0) # concat on a specified axis\nprint (y)\nprint (y.shape)\n\n[[0.79564718 0.73023418 0.92340453]\n [0.24929281 0.0513762 0.66149188]\n [0.79564718 0.73023418 0.92340453]\n [0.24929281 0.0513762 0.66149188]]\n(4, 3)\n\n\n\n# Stacking\nz = np.stack([x, x], axis=0) # stack on new axis\nprint (z)\nprint (z.shape)\n\n[[[0.79564718 0.73023418 0.92340453]\n [0.24929281 0.0513762 0.66149188]]\n\n [[0.79564718 0.73023418 0.92340453]\n [0.24929281 0.0513762 0.66149188]]]\n(2, 2, 3)\n"},{"location":"courses/foundations/numpy/#expanding-reducing","title":"Expanding / reducing","text":"We can also easily add and remove dimensions to our tensors and we'll want to do this to make tensors compatible for certain operations.
\n\n# Adding dimensions\nx = np.array([[1,2,3],[4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.expand_dims(x, 1) # expand dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are added\n\nx:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny:\n [[[1 2 3]]\n [[4 5 6]]]\ny.shape: (2, 1, 3)\n\n\n\n# Removing dimensions\nx = np.array([[[1,2,3]],[[4,5,6]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.squeeze(x, 1) # squeeze dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are gone\n\nx:\n [[[1 2 3]]\n [[4 5 6]]]\nx.shape: (2, 1, 3)\ny:\n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\n\n\nCheck out Dask for scaling NumPy workflows with minimal change to existing code.
\nTo cite this content, please use:
\n"},{"location":"courses/foundations/pandas/","title":"Pandas for Machine Learning","text":""},{"location":"courses/foundations/pandas/#set-up","title":"Set up","text":"@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { NumPy - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nFirst we'll import the NumPy and Pandas libraries and set seeds for reproducibility. We'll also download the dataset we'll be working with to disk.
import numpy as np\nimport pandas as pd\n"},{"location":"courses/foundations/pandas/#load-data","title":"Load data","text":"# Set seed for reproducibility\nnp.random.seed(seed=1234)\nWe're going to work with the Titanic dataset which has data on the people who embarked the RMS Titanic in 1912 and whether they survived the expedition or not. It's a very common and rich dataset which makes it very apt for exploratory data analysis with Pandas.
Let's load the data from the CSV file into a Pandas dataframe. The
header=0signifies that the first row (0th index) is a header row which contains the names of each column in our dataset.# Read from CSV to Pandas DataFrame\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/titanic.csv\"\ndf = pd.read_csv(url, header=0)\npclass name sex age sibsp parch ticket fare cabin embarked survived 0 1 Allen, Miss. Elisabeth Walton female 29.0000 0 0 24160 211.3375 B5 S 1 1 1 Allison, Master. Hudson Trevor male 0.9167 1 2 113781 151.5500 C22 C26 S 1 2 1 Allison, Miss. Helen Loraine female 2.0000 1 2 113781 151.5500 C22 C26 S 0# First few items\ndf.head(3)\nThese are the different features:
class: class of travelname: full name of the passengersex: genderage: numerical agesibsp: # of siblings/spouse aboardparch: number of parents/child aboardticket: ticket numberfare: cost of the ticketcabin: location of roomembarked: port that the passenger embarked atsurvived: survival metric (0 - died, 1 - survived)Now that we loaded our data, we're ready to start exploring it to find interesting information.
Be sure to check out our entire lesson focused on EDA in our MLOps course.
import matplotlib.pyplot as plt\nWe can use .describe() to extract some standard details about our numerical features.
# Describe features\ndf.describe()\n# Correlation matrix\nplt.matshow(df.corr())\ncontinuous_features = df.describe().columns\nplt.xticks(range(len(continuous_features)), continuous_features, rotation=\"45\")\nplt.yticks(range(len(continuous_features)), continuous_features, rotation=\"45\")\nplt.colorbar()\nplt.show()\nWe can also use .hist() to view the histogram of values for each feature.
# Histograms\ndf[\"age\"].hist()\n# Unique values\ndf[\"embarked\"].unique()\n\narray(['S', 'C', nan, 'Q'], dtype=object)\n"},{"location":"courses/foundations/pandas/#filtering","title":"Filtering","text":"
We can filter our data by features and even by specific values (or value ranges) within specific features.
# Selecting data by feature\ndf[\"name\"].head()\n\n0 Allen, Miss. Elisabeth Walton\n1 Allison, Master. Hudson Trevor\n2 Allison, Miss. Helen Loraine\n3 Allison, Mr. Hudson Joshua Creighton\n4 Allison, Mrs. Hudson J C (Bessie Waldo Daniels)\nName: name, dtype: object\n
# Filtering\ndf[df[\"sex\"]==\"female\"].head() # only the female data appear\nWe can also sort our features in ascending or descending order.
# Sorting\ndf.sort_values(\"age\", ascending=False).head()\nWe can also get statistics across our features for certain groups. Here we wan to see the average of our continuous features based on whether the passenger survived or not.
# Grouping\nsurvived_group = df.groupby(\"survived\")\nsurvived_group.mean()\nWe can use iloc to get rows or columns at particular positions in the dataframe.
# Selecting row 0\ndf.iloc[0, :]\n\npclass 1\nname Allen, Miss. Elisabeth Walton\nsex female\nage 29\nsibsp 0\nparch 0\nticket 24160\nfare 211.338\ncabin B5\nembarked S\nsurvived 1\nName: 0, dtype: object\n
# Selecting a specific value\ndf.iloc[0, 1]\n\n'Allen, Miss. Elisabeth Walton'\n"},{"location":"courses/foundations/pandas/#preprocessing","title":"Preprocessing","text":"
After exploring, we can clean and preprocess our dataset.
Be sure to check out our entire lesson focused on preprocessing in our MLOps course.
# Rows with at least one NaN value\ndf[pd.isnull(df).any(axis=1)].head()\n# Drop rows with Nan values\ndf = df.dropna() # removes rows with any NaN values\ndf = df.reset_index() # reset's row indexes in case any rows were dropped\ndf.head()\n# Dropping multiple columns\ndf = df.drop([\"name\", \"cabin\", \"ticket\"], axis=1) # we won't use text features for our initial basic models\ndf.head()\n# Map feature values\ndf[\"sex\"] = df[\"sex\"].map( {\"female\": 0, \"male\": 1} ).astype(int)\ndf[\"embarked\"] = df[\"embarked\"].dropna().map( {\"S\":0, \"C\":1, \"Q\":2} ).astype(int)\ndf.head()\nWe're now going to use feature engineering to create a column called family_size. We'll first define a function called get_family_size that will determine the family size using the number of parents and siblings.
# Lambda expressions to create new features\ndef get_family_size(sibsp, parch):\n family_size = sibsp + parch\n return family_size\nlambda to apply that function on each row (using the numbers of siblings and parents in each row to determine the family size for each row). df[\"family_size\"] = df[[\"sibsp\", \"parch\"]].apply(lambda x: get_family_size(x[\"sibsp\"], x[\"parch\"]), axis=1)\ndf.head()\n# Reorganize headers\ndf = df[[\"pclass\", \"sex\", \"age\", \"sibsp\", \"parch\", \"family_size\", \"fare\", '\"mbarked\", \"survived\"]]\ndf.head()\nTip
Feature engineering can be done in collaboration with domain experts that can guide us on what features to engineer and use.
"},{"location":"courses/foundations/pandas/#save-data","title":"Save data","text":"Finally, let's save our preprocessed data into a new CSV file to use later.
# Saving dataframe to CSV\ndf.to_csv(\"processed_titanic.csv\", index=False)\n# See the saved file\n!ls -l\n\ntotal 96\n-rw-r--r-- 1 root root 6975 Dec 3 17:36 processed_titanic.csv\ndrwxr-xr-x 1 root root 4096 Nov 21 16:30 sample_data\n-rw-r--r-- 1 root root 85153 Dec 3 17:36 titanic.csv\n"},{"location":"courses/foundations/pandas/#scaling","title":"Scaling","text":"
When working with very large datasets, our Pandas DataFrames can become very large and it can be very slow or impossible to operate on them. This is where packages that can distribute workloads or run on more efficient hardware can come in handy.
And, of course, we can combine these together (Dask-cuDF) to operate on partitions of a dataframe on the GPU.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Pandas - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nVariables are containers for holding data and they're defined by a name and value.
# Integer variable\nx = 5\nprint (x)\nprint (type(x))\n\n5\n<class 'int'>\n
Here we use the variable name x in our examples but when you're working on a specific task, be sure to be explicit (ex. first_name) when creating variables (applies to functions, classes, etc. as well).
We can change the value of a variable by simply assigning a new value to it.
# String variable\nx = \"hello\"\nprint (x)\nprint (type(x))\n\nhello\n<class 'str'>\n
There are many different types of variables: integers, floats, strings, boolean etc.
# int variable\nx = 5\nprint (x, type(x))\n\n5 <class 'int'>\n
# float variable\nx = 5.0\nprint (x, type(x))\n\n5.0 <class 'float'>\n
# text variable\nx = \"5\"\nprint (x, type(x))\n\n5 <class 'str'>\n
# boolean variable\nx = True\nprint (x, type(x))\n\nTrue <class 'bool'>\n
We can also do operations with variables:
# Variables can be used with each other\na = 1\nb = 2\nc = a + b\nprint (c)\n\n3\n
Know your types!
We should always know what types of variables we're dealing with so we can do the right operations with them. Here's a common mistake that can happen if we're using the wrong variable type.
# int variables\na = 5\nb = 3\nprint (a + b)\n\n8\n
# string variables\na = \"5\"\nb = \"3\"\nprint (a + b)\n\n53\n"},{"location":"courses/foundations/python/#lists","title":"Lists","text":"
Lists are an ordered, mutable (changeable) collection of values that are comma separated and enclosed by square brackets. A list can be comprised of many different types of variables. Below is a list with an integer, string and a float:
# Creating a list\nx = [3, \"hello\", 1.2]\nprint (x)\n\n[3, 'hello', 1.2]\n
# Length of a list\nlen(x)\n\n3\n
We can add to a list by using the append function:
# Adding to a list\nx.append(7)\nprint (x)\nprint (len(x))\n\n[3, 'hello', 1.2, 7]\n4\n
and just as easily replace existing items:
# Replacing items in a list\nx[1] = \"bye\"\nprint (x)\n\n[3, 'bye', 1.2, 7]\n
and perform operations with lists:
# Operations\ny = [2.4, \"world\"]\nz = x + y\nprint (z)\n\n[3, 'bye', 1.2, 7, 2.4, 'world']\n"},{"location":"courses/foundations/python/#tuples","title":"Tuples","text":"
Tuples are collections that are ordered and immutable (unchangeable). We will use tuples to store values that will never be changed.
# Creating a tuple\nx = (3.0, \"hello\") # tuples start and end with ()\nprint (x)\n\n(3.0, 'hello')\n
# Adding values to a tuple\nx = x + (5.6, 4)\nprint (x)\n\n(3.0, 'hello', 5.6, 4)\n
# Try to change (it won't work and we get an error)\nx[0] = 1.2\n\n---------------------------------------------------------------------------\nTypeError Traceback (most recent call last)\n----> 1 x[0] = 1.2\nTypeError: 'tuple' object does not support item assignment\n"},{"location":"courses/foundations/python/#sets","title":"Sets","text":"
Sets are collections that are unordered and mutable. However, every item in a set much be unique.
# Sets\ntext = \"Learn ML with Made With ML\"\nprint (set(text))\nprint (set(text.split(\" \")))\n\n{'e', 'M', ' ', \"r\", \"w\", 'd', 'a', 'h', 't', 'i', 'L', 'n', \"w\"}\n{'with', 'Learn', 'ML', 'Made', 'With'}\n"},{"location":"courses/foundations/python/#indexing","title":"Indexing","text":"Indexing and slicing from lists allow us to retrieve specific values within lists. Note that indices can be positive (starting from 0) or negative (-1 and lower, where -1 is the last item in the list).
# Indexing\nx = [3, \"hello\", 1.2]\nprint (\"x[0]: \", x[0])\nprint (\"x[1]: \", x[1])\nprint (\"x[-1]: \", x[-1]) # the last item\nprint (\"x[-2]: \", x[-2]) # the second to last item\n\nx[0]: 3\nx[1]: hello\nx[-1]: 1.2\nx[-2]: hello\n
# Slicing\nprint (\"x[:]: \", x[:]) # all indices\nprint (\"x[1:]: \", x[1:]) # index 1 to the end of the list\nprint (\"x[1:2]: \", x[1:2]) # index 1 to index 2 (not including index 2)\nprint (\"x[:-1]: \", x[:-1]) # index 0 to last index (not including last index)\n\nx[:]: [3, 'hello', 1.2]\nx[1:]: ['hello', 1.2]\nx[1:2]: ['hello']\nx[:-1]: [3, 'hello']\n
Indexing beyond length
What happens if we try to index beyond the length of a list?
x = [3, \"hello\", 1.2]\nprint (x[:100])\nprint (len(x[:100]))\n\n[3, 'hello', 1.2]\n3\nThough this does produce results, we should always explicitly use the length of the list to index items from it to avoid incorrect assumptions for downstream processes."},{"location":"courses/foundations/python/#dictionaries","title":"Dictionaries","text":"
Dictionaries are an unordered, mutable collection of key-value pairs. You can retrieve values based on the key and a dictionary cannot have two of the same keys.
# Creating a dictionary\nperson = {\"name\": \"Goku\",\n \"eye_color\": \"brown\"}\nprint (person)\nprint (person[\"name\"])\nprint (person[\"eye_color\"])\n\n{\"name\": \"Goku\", \"eye_color\": \"brown\"}\nGoku\nbrown\n # Changing the value for a key\nperson[\"eye_color\"] = \"green\"\nprint (person)\n\n{\"name\": \"Goku\", \"eye_color\": \"green\"}\n # Adding new key-value pairs\nperson[\"age\"] = 24\nprint (person)\n\n{\"name\": \"Goku\", \"eye_color\": \"green\", \"age\": 24}\n # Length of a dictionary\nprint (len(person))\n\n3\n
Sort of the structures
See if you can recall and sort out the similarities and differences of the foundational data structures we've seen so far.
Mutable Ordered Indexable Unique List \u2753 \u2753 \u2753 \u2753 Tuple \u2753 \u2753 \u2753 \u2753 Set \u2753 \u2753 \u2753 \u2753 Dictionary \u2753 \u2753 \u2753 \u2753 Show answer Mutable Ordered Indexable Unique List \u2705 \u2705 \u2705 \u274c Tuple \u274c \u2705 \u2705 \u274c Set \u2705 \u274c \u274c \u2705 Dictionary \u2705 \u274c \u274c \u2705 \u00a0keys\u274c \u00a0valuesBut of course, there is pretty much a way to do accomplish anything with Python. For example, even though native dictionaries are unordered, we can leverage the OrderedDict data structure to change that (useful if we want to iterate through keys in a certain order, etc.).
from collections import OrderedDict\n# Native dict\nd = {}\nd[\"a\"] = 2\nd[\"c\"] = 3\nd[\"b\"] = 1\nprint (d)\n\n{'a': 2, 'c': 3, 'b': 1}\n After Python 3.7+, native dictionaries are insertion ordered.
# Dictionary items\nprint (d.items())\n\ndict_items([('a', 2), ('c', 3), ('b', 1)])\n # Order by keys\nprint (OrderedDict(sorted(d.items())))\n\nOrderedDict([('a', 2), ('b', 1), ('c', 3)])\n # Order by values\nprint (OrderedDict(sorted(d.items(), key=lambda x: x[1])))\n\nOrderedDict([('b', 1), ('a', 2), ('c', 3)])\n"},{"location":"courses/foundations/python/#if-statements","title":"If statements","text":"We can use if statements to conditionally do something. The conditions are defined by the words if, elif (which stands for else if) and else. We can have as many elif statements as we want. The indented code below each condition is the code that will execute if the condition is True.
# If statement\nx = 4\nif x < 1:\n score = \"low\"\nelif x <= 4: # elif = else if\n score = \"medium\"\nelse:\n score = \"high\"\nprint (score)\n\nmedium\n
# If statement with a boolean\nx = True\nif x:\n print (\"it worked\")\n\nit worked\n"},{"location":"courses/foundations/python/#loops","title":"Loops","text":""},{"location":"courses/foundations/python/#for-loops","title":"For loops","text":"
A for loop can iterate over a collection of values (lists, tuples, dictionaries, etc.) The indented code is executed for each item in the collection of values.
# For loop\nveggies = [\"carrots\", \"broccoli\", \"beans\"]\nfor veggie in veggies:\n print (veggie)\n\ncarrots\nbroccoli\nbeans\n
When the loop encounters the break command, the loop will terminate immediately. If there were more items in the list, they will not be processed.
# `break` from a for loop\nveggies = [\"carrots\", \"broccoli\", \"beans\"]\nfor veggie in veggies:\n if veggie == \"broccoli\":\n break\n print (veggie)\n\ncarrots\n
When the loop encounters the continue command, the loop will skip all other operations for that item in the list only. If there were more items in the list, the loop will continue normally.
# `continue` to the next iteration\nveggies = [\"carrots\", \"broccoli\", \"beans\"]\nfor veggie in veggies:\n if veggie == \"broccoli\":\n continue\n print (veggie)\n\ncarrots\nbeans\n"},{"location":"courses/foundations/python/#while-loops","title":"While loops","text":"
A while loop can perform repeatedly as long as a condition is True. We can use continue and break commands in while loops as well.
# While loop\nx = 3\nwhile x > 0:\n x -= 1 # same as x = x - 1\n print (x)\n\n2\n1\n0\n"},{"location":"courses/foundations/python/#list-comprehension","title":"List comprehension","text":"
We can combine our knowledge of lists and for loops to leverage list comprehensions to create succinct code.
# For loop\nx = [1, 2, 3, 4, 5]\ny = []\nfor item in x:\n if item > 2:\n y.append(item)\nprint (y)\n\n[3, 4, 5]\n
# List comprehension\ny = [item for item in x if item > 2]\nprint (y)\n\n[3, 4, 5]\n
List comprehension for nested for loops
For the nested for loop below, which list comprehension is correct?
# Nested for loops\nwords = [[\"Am\", \"ate\", \"ATOM\", \"apple\"], [\"bE\", \"boy\", \"ball\", \"bloom\"]]\nsmall_words = []\nfor letter_list in words:\n for word in letter_list:\n if len(word) < 3:\n small_words.append(word.lower())\nprint (small_words)\n\n['am', 'be']\n
[word.lower() if len(word) < 3 for word in letter_list for letter_list in words][word.lower() for word in letter_list for letter_list in words if len(word) < 3][word.lower() for letter_list in words for word in letter_list if len(word) < 3]Python syntax is usually very straight forward, so the correct answer involves just directly copying the statements from the nested for loop from top to bottom!
[word.lower() if len(word) < 3 for word in letter_list for letter_list in words][word.lower() for word in letter_list for letter_list in words if len(word) < 3][word.lower() for letter_list in words for word in letter_list if len(word) < 3]Functions are a way to modularize reusable pieces of code. They're defined by the keyword def which stands for definition and they can have the following components.
# Define the function\ndef add_two(x):\n\"\"\"Increase x by 2.\"\"\"\n x += 2\n return x\nHere are the components that may be required when we want to use the function. we need to ensure that the function name and the input parameters match with how we defined the function above.
# Use the function\nscore = 0\nnew_score = add_two(x=score)\nprint (new_score)\n\n2\n
A function can have as many input parameters and outputs as we want.
# Function with multiple inputs\ndef join_name(first_name, last_name):\n\"\"\"Combine first name and last name.\"\"\"\n joined_name = first_name + \" \" + last_name\n return joined_name\n# Use the function\nfirst_name = \"Goku\"\nlast_name = \"Mohandas\"\njoined_name = join_name(\n first_name=first_name, last_name=last_name)\nprint (joined_name)\n\nGoku Mohandas\n
We can be even more explicit with our function definitions by specifying the types of our input and output arguments. We cover this in our documentation lesson because the typing information is automatically leveraged to create very intuitive documentation.
It's good practice to always use keyword argument when using a function so that it's very clear what input variable belongs to what function input parameter. On a related note, you will often see the terms *args and **kwargs which stand for arguments and keyword arguments. You can extract them when they are passed into a function. The significance of the * is that any number of arguments and keyword arguments can be passed into the function.
def f(*args, **kwargs):\n x = args[0]\n y = kwargs.get(\"y\")\n print (f\"x: {x}, y: {y}\")\nf(5, y=2)\n\nx: 5, y: 2\n"},{"location":"courses/foundations/python/#classes","title":"Classes","text":"
Classes are object constructors and are a fundamental component of object oriented programming in Python. They are composed of a set of functions that define the class and it's operations.
"},{"location":"courses/foundations/python/#magic-methods","title":"Magic methods","text":"Classes can be customized with magic methods like __init__ and __str__, to enable powerful operations. These are also known as dunder methods (ex. dunder init), which stands for double underscores due to the leading and trailing underscores.
The __init__ function is used when an instance of the class is initialized.
# Creating the class\nclass Pet(object):\n\"\"\"Class object for a pet.\"\"\"\n\n def __init__(self, species, name):\n\"\"\"Initialize a Pet.\"\"\"\n self.species = species\n self.name = name\n# Creating an instance of a class\nmy_dog = Pet(species=\"dog\",\n name=\"Scooby\")\nprint (my_dog)\nprint (my_dog.name)\n\n<__main__.Pet object at 0x7fe487e9c358>\nScooby\n
The print (my_dog) command printed something not so relevant to us. Let's fix that with the __str__ function.
# Creating the class\n# Creating the class\nclass Pet(object):\n\"\"\"Class object for a pet.\"\"\"\n\n def __init__(self, species, name):\n\"\"\"Initialize a Pet.\"\"\"\n self.species = species\n self.name = name\n\n def __str__(self):\n\"\"\"Output when printing an instance of a Pet.\"\"\"\n return f\"{self.species} named {self.name}\"\n# Creating an instance of a class\nmy_dog = Pet(species=\"dog\",\n name=\"Scooby\")\nprint (my_dog)\nprint (my_dog.name)\n\ndog named Scooby\nScooby\n
We'll be exploring additional built-in functions in subsequent notebooks (like __len__, __iter__ and __getitem__, etc.) but if you're curious, here is a tutorial on more magic methods.
Besides these magic functions, classes can also have object functions.
# Creating the class\nclass Pet(object):\n\"\"\"Class object for a pet.\"\"\"\n\n def __init__(self, species, name):\n\"\"\"Initialize a Pet.\"\"\"\n self.species = species\n self.name = name\n\n def __str__(self):\n\"\"\"Output when printing an instance of a Pet.\"\"\"\n return f\"{self.species} named {self.name}\"\n\n def change_name(self, new_name):\n\"\"\"Change the name of your Pet.\"\"\"\n self.name = new_name\n# Creating an instance of a class\nmy_dog = Pet(species=\"dog\", name=\"Scooby\")\nprint (my_dog)\nprint (my_dog.name)\n\ndog named Scooby\nScooby\n
# Using a class's function\nmy_dog.change_name(new_name=\"Scrappy\")\nprint (my_dog)\nprint (my_dog.name)\n\ndog named Scrappy\nScrappy\n"},{"location":"courses/foundations/python/#inheritance","title":"Inheritance","text":"
We can also build classes on top of one another using inheritance, which allows us to inherit all the properties and methods from another class (the parent).
class Dog(Pet):\n def __init__(self, name, breed):\n super().__init__(species=\"dog\", name=name)\n self.breed = breed\n\n def __str__(self):\n return f\"A {self.breed} doggo named {self.name}\"\nscooby = Dog(species=\"dog\", breed=\"Great Dane\", name=\"Scooby\")\nprint (scooby)\n\nA Great Dane doggo named Scooby\n
scooby.change_name(\"Scooby Doo\")\nprint (scooby)\n\nA Great Dane doggo named Scooby Doo\n
Notice how we inherited the initialized variables from the parent Pet class like species and name. We also inherited functions such as change_name().
Which function is executed?
Which function is executed if the parent and child functions have functions with the same name?
Show answerAs you can see, both our parent class (Pet) and the child class (Dog) have different __str__ functions defined but share the same function name. The child class inherits everything from the parent classes but when there is conflict between function names, the child class' functions take precedence and overwrite the parent class' functions.
There are two important decorator methods to know about when it comes to classes: @classmethod and @staticmethod. We'll learn about decorators in the next section below but these specific methods pertain to classes so we'll cover them here.
class Dog(Pet):\n def __init__(self, name, breed):\n super().__init__(species=\"dog\", name=name)\n self.breed = breed\n\n def __str__(self):\n return f\"{self.breed} named {self.name}\"\n\n @classmethod\n def from_dict(cls, d):\n return cls(name=d[\"name\"], breed=d[\"breed\"])\n\n @staticmethod\n def is_cute(breed):\n return True # all animals are cute!\nA @classmethod allows us to create class instances by passing in the uninstantiated class itself (cls). This is a great way to create (or load) classes from objects (ie. dictionaries).
# Create instance\nd = {\"name\": \"Cassie\", \"breed\": \"Border Collie\"}\ncassie = Dog.from_dict(d=d)\nprint(cassie)\n\nBorder Collie named Cassie\n
A @staticmethod can be called from an uninstantiated class object so we can do things like this:
# Static method\nDog.is_cute(breed=\"Border Collie\")\n\nTrue\n"},{"location":"courses/foundations/python/#decorators","title":"Decorators","text":"
Recall that functions allow us to modularize code and reuse them. However, we'll often want to add some functionality before or after the main function executes and we may want to do this for many different functions. Instead of adding more code to the original function, we can use decorators!
Suppose we have a function called operations which increments the input value x by 1.
def operations(x):\n\"\"\"Basic operations.\"\"\"\n x += 1\n return x\noperations(x=1)\n\n2\n
Now let's say we want to increment our input x by 1 before and after the operations function executes and, to illustrate this example, let's say the increments have to be separate steps. Here's how we would do it by changing the original code:
def operations(x):\n\"\"\"Basic operations.\"\"\"\n x += 1\n x += 1\n x += 1\n return x\noperations(x=1)\n\n4\n
We were able to achieve what we want but we now increased the size of our operations function and if we want to do the same incrementing for any other function, we have to add the same code to all of those as well ... not very efficient. To solve this, let's create a decorator called add which increments x by 1 before and after the main function f executes.
The decorator function accepts a function f which is the function we wish to wrap around, in our case, it's operations(). The output of the decorator is its wrapper function which receives the arguments and keyword arguments passed to function f.
Inside the wrapper function, we can:
f.f is executedwrapper function returns some value(s), which is what the decorator returns as well since it returns wrapper.# Decorator\ndef add(f):\n def wrapper(*args, **kwargs):\n\"\"\"Wrapper function for @add.\"\"\"\n x = kwargs.pop(\"x\") # .get() if not altering x\n x += 1 # executes before function f\n x = f(*args, **kwargs, x=x)\n x += 1 # executes after function f\n return x\n return wrapper\nWe can use this decorator by simply adding it to the top of our main function preceded by the @ symbol.
@add\ndef operations(x):\n\"\"\"Basic operations.\"\"\"\n x += 1\n return x\noperations(x=1)\n\n4\n
Suppose we wanted to debug and see what function actually executed with operations().
operations.__name__, operations.__doc__\n\n('wrapper', 'Wrapper function for @add.')\n The function name and docstring are not what we're looking for but it appears this way because the wrapper function is what was executed. In order to fix this, Python offers functools.wraps which carries the main function's metadata.
from functools import wraps\n# Decorator\ndef add(f):\n @wraps(f)\n def wrap(*args, **kwargs):\n\"\"\"Wrapper function for @add.\"\"\"\n x = kwargs.pop(\"x\")\n x += 1\n x = f(*args, **kwargs, x=x)\n x += 1\n return x\n return wrap\n@add\ndef operations(x):\n\"\"\"Basic operations.\"\"\"\n x += 1\n return x\noperations.__name__, operations.__doc__\n\n('operations', 'Basic operations.')\n Awesome! We were able to decorate our main function operation() to achieve the customization we wanted without actually altering the function. We can reuse our decorator for other functions that may need the same customization!
This was a dummy example to show how decorators work but we'll be using them heavily during our MLOps lessons. A simple scenario would be using decorators to create uniform JSON responses from each API endpoint without including the bulky code in each endpoint.
"},{"location":"courses/foundations/python/#callbacks","title":"Callbacks","text":"Decorators allow for customized operations before and after the main function's execution but what about in between? Suppose we want to conditionally/situationally do some operations. Instead of writing a whole bunch of if-statements and make our functions bulky, we can use callbacks!
Our callbacks will be classes that have functions with key names that will execute at various periods during the main function's execution. The function names are up to us but we need to invoke the same callback functions within our main function.
# Callback\nclass x_tracker(object):\n def __init__(self, x):\n self.history = []\n def at_start(self, x):\n self.history.append(x)\n def at_end(self, x):\n self.history.append(x)\ndef operations(x, callbacks=[]):\n\"\"\"Basic operations.\"\"\"\n for callback in callbacks:\n callback.at_start(x)\n x += 1\n for callback in callbacks:\n callback.at_end(x)\n return x\nx = 1\ntracker = x_tracker(x=x)\noperations(x=x, callbacks=[tracker])\n\n2\n
tracker.history\n\n[1, 2]\n
What's the difference compared to a decorator?
It seems like we've just done some operations before and after the function's main process? Isn't that what a decorator is for?
Show answerWith callbacks, it's easier to keep track of objects since it's all defined in a separate callback class. It's also now possible to interact with our function, not just before or after but throughout the entire process! Imagine a function with:
decorators + callbacks = powerful customization before, during and after the main function\u2019s execution without increasing its complexity. We will be using this duo to create powerful ML training scripts that are highly customizable in future lessons.
from functools import wraps\n# Decorator\ndef add(f):\n @wraps(f)\n def wrap(*args, **kwargs):\n\"\"\"Wrapper function for @add.\"\"\"\n x = kwargs.pop(\"x\") # .get() if not altering x\n x += 1 # executes before function f\n x = f(*args, **kwargs, x=x)\n # can do things post function f as well\n return x\n return wrap\n# Callback\nclass x_tracker(object):\n def __init__(self, x):\n self.history = [x]\n def at_start(self, x):\n self.history.append(x)\n def at_end(self, x):\n self.history.append(x)\n# Main function\n@add\ndef operations(x, callbacks=[]):\n\"\"\"Basic operations.\"\"\"\n for callback in callbacks:\n callback.at_start(x)\n x += 1\n for callback in callbacks:\n callback.at_end(x)\n return x\nx = 1\ntracker = x_tracker(x=x)\noperations(x=x, callbacks=[tracker])\n\n3\n
tracker.history\n\n[1, 2, 3]\n
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Python - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWe'll import PyTorch and set seeds for reproducibility. Note that PyTorch also required a seed since we will be generating random tensors.
import numpy as np\nimport torch\nSEED = 1234\n# Set seed for reproducibility\nnp.random.seed(seed=SEED)\ntorch.manual_seed(SEED)\n"},{"location":"courses/foundations/pytorch/#basics","title":"Basics","text":"We'll first cover some basics with PyTorch such as creating tensors and converting from common data structures (lists, arrays, etc.) to tensors.\n
# Creating a random tensor\nx = torch.randn(2, 3) # normal distribution (rand(2,3) -> uniform distribution)\nprint(f\"Type: {x.type()}\")\nprint(f\"Size: {x.shape}\")\nprint(f\"Values: \\n{x}\")\n
\n\nType: torch.FloatTensor\nSize: torch.Size([2, 3])\nValues:\ntensor([[ 0.0461, 0.4024, -1.0115],\n [ 0.2167, -0.6123, 0.5036]])\n
\n# Zero and Ones tensor\nx = torch.zeros(2, 3)\nprint (x)\nx = torch.ones(2, 3)\nprint (x)\n
\n\ntensor([[0., 0., 0.],\n [0., 0., 0.]])\ntensor([[1., 1., 1.],\n [1., 1., 1.]])\n
\n# List \u2192 Tensor\nx = torch.Tensor([[1, 2, 3],[4, 5, 6]])\nprint(f\"Size: {x.shape}\")\nprint(f\"Values: \\n{x}\")\n
\n\nSize: torch.Size([2, 3])\nValues:\ntensor([[1., 2., 3.],\n [4., 5., 6.]])\n
\n# NumPy array \u2192 Tensor\nx = torch.Tensor(np.random.rand(2, 3))\nprint(f\"Size: {x.shape}\")\nprint(f\"Values: \\n{x}\")\n
\n\nSize: torch.Size([2, 3])\nValues:\ntensor([[0.1915, 0.6221, 0.4377],\n [0.7854, 0.7800, 0.2726]])\n
\n# Changing tensor type\nx = torch.Tensor(3, 4)\nprint(f\"Type: {x.type()}\")\nx = x.long()\nprint(f\"Type: {x.type()}\")\n
\n\nType: torch.FloatTensor\nType: torch.LongTensor\n
"},{"location":"courses/foundations/pytorch/#operations","title":"Operations","text":"Now we'll explore some basic operations with tensors.\n
# Addition\nx = torch.randn(2, 3)\ny = torch.randn(2, 3)\nz = x + y\nprint(f\"Size: {z.shape}\")\nprint(f\"Values: \\n{z}\")\n
\n\nSize: torch.Size([2, 3])\nValues:\ntensor([[ 0.0761, -0.6775, -0.3988],\n [ 3.0633, -0.1589, 0.3514]])\n
\n# Dot product\nx = torch.randn(2, 3)\ny = torch.randn(3, 2)\nz = torch.mm(x, y)\nprint(f\"Size: {z.shape}\")\nprint(f\"Values: \\n{z}\")\n
\n\nSize: torch.Size([2, 2])\nValues:\ntensor([[ 1.0796, -0.0759],\n [ 1.2746, -0.5134]])\n
\n# Transpose\nx = torch.randn(2, 3)\nprint(f\"Size: {x.shape}\")\nprint(f\"Values: \\n{x}\")\ny = torch.t(x)\nprint(f\"Size: {y.shape}\")\nprint(f\"Values: \\n{y}\")\n
\n\nSize: torch.Size([2, 3])\nValues:\ntensor([[ 0.8042, -0.1383, 0.3196],\n [-1.0187, -1.3147, 2.5228]])\nSize: torch.Size([3, 2])\nValues:\ntensor([[ 0.8042, -1.0187],\n [-0.1383, -1.3147],\n [ 0.3196, 2.5228]])\n
\n# Reshape\nx = torch.randn(2, 3)\nz = x.view(3, 2)\nprint(f\"Size: {z.shape}\")\nprint(f\"Values: \\n{z}\")\n
\n\nSize: torch.Size([3, 2])\nValues:\ntensor([[ 0.4501, 0.2709],\n [-0.8087, -0.0217],\n [-1.0413, 0.0702]])\n
\n# Dangers of reshaping (unintended consequences)\nx = torch.tensor([\n [[1,1,1,1], [2,2,2,2], [3,3,3,3]],\n [[10,10,10,10], [20,20,20,20], [30,30,30,30]]\n])\nprint(f\"Size: {x.shape}\")\nprint(f\"x: \\n{x}\\n\")\n\na = x.view(x.size(1), -1)\nprint(f\"\\nSize: {a.shape}\")\nprint(f\"a: \\n{a}\\n\")\n\nb = x.transpose(0,1).contiguous()\nprint(f\"\\nSize: {b.shape}\")\nprint(f\"b: \\n{b}\\n\")\n\nc = b.view(b.size(0), -1)\nprint(f\"\\nSize: {c.shape}\")\nprint(f\"c: \\n{c}\")\n
\n\nSize: torch.Size([2, 3, 4])\nx:\ntensor([[[ 1, 1, 1, 1],\n [ 2, 2, 2, 2],\n [ 3, 3, 3, 3]],\n\n [[10, 10, 10, 10],\n [20, 20, 20, 20],\n [30, 30, 30, 30]]])\n\n\nSize: torch.Size([3, 8])\na:\ntensor([[ 1, 1, 1, 1, 2, 2, 2, 2],\n [ 3, 3, 3, 3, 10, 10, 10, 10],\n [20, 20, 20, 20, 30, 30, 30, 30]])\n\n\nSize: torch.Size([3, 2, 4])\nb:\ntensor([[[ 1, 1, 1, 1],\n [10, 10, 10, 10]],\n\n [[ 2, 2, 2, 2],\n [20, 20, 20, 20]],\n\n [[ 3, 3, 3, 3],\n [30, 30, 30, 30]]])\n\n\nSize: torch.Size([3, 8])\nc:\ntensor([[ 1, 1, 1, 1, 10, 10, 10, 10],\n [ 2, 2, 2, 2, 20, 20, 20, 20],\n [ 3, 3, 3, 3, 30, 30, 30, 30]])\n
\n# Dimensional operations\nx = torch.randn(2, 3)\nprint(f\"Values: \\n{x}\")\ny = torch.sum(x, dim=0) # add each row's value for every column\nprint(f\"Values: \\n{y}\")\nz = torch.sum(x, dim=1) # add each columns's value for every row\nprint(f\"Values: \\n{z}\")\n
\n\nValues:\ntensor([[ 0.5797, -0.0599, 0.1816],\n [-0.6797, -0.2567, -1.8189]])\nValues:\ntensor([-0.1000, -0.3166, -1.6373])\nValues:\ntensor([ 0.7013, -2.7553])\n
"},{"location":"courses/foundations/pytorch/#indexing","title":"Indexing","text":"Now we'll look at how to extract, separate and join values from our tensors.\n
x = torch.randn(3, 4)\nprint (f\"x: \\n{x}\")\nprint (f\"x[:1]: \\n{x[:1]}\")\nprint (f\"x[:1, 1:3]: \\n{x[:1, 1:3]}\")\n
\n\nx:\ntensor([[ 0.2111, 0.3372, 0.6638, 1.0397],\n [ 1.8434, 0.6588, -0.2349, -0.0306],\n [ 1.7462, -0.0722, -1.6794, -1.7010]])\nx[:1]:\ntensor([[0.2111, 0.3372, 0.6638, 1.0397]])\nx[:1, 1:3]:\ntensor([[0.3372, 0.6638]])\n
"},{"location":"courses/foundations/pytorch/#slicing","title":"Slicing","text":"# Select with dimensional indices\nx = torch.randn(2, 3)\nprint(f\"Values: \\n{x}\")\n\ncol_indices = torch.LongTensor([0, 2])\nchosen = torch.index_select(x, dim=1, index=col_indices) # values from column 0 & 2\nprint(f\"Values: \\n{chosen}\")\n\nrow_indices = torch.LongTensor([0, 1])\ncol_indices = torch.LongTensor([0, 2])\nchosen = x[row_indices, col_indices] # values from (0, 0) & (1, 2)\nprint(f\"Values: \\n{chosen}\")\n
\n\nValues:\ntensor([[ 0.6486, 1.7653, 1.0812],\n [ 1.2436, 0.8971, -0.0784]])\nValues:\ntensor([[ 0.6486, 1.0812],\n [ 1.2436, -0.0784]])\nValues:\ntensor([ 0.6486, -0.0784])\n
"},{"location":"courses/foundations/pytorch/#joining","title":"Joining","text":"We can also combine our tensors via concatenation or stacking operations, which are consistent with NumPy's joining functions' behaviors as well.
\nx = torch.randn(2, 3)\nprint (x)\nprint (x.shape)\n
\n\ntensor([[-1.5944, -0.4218, -1.8219],\n [ 1.7446, 1.2058, -0.7753]])\ntorch.Size([2, 3])\n
\n\n# Concatenation\ny = torch.cat([x, x], dim=0) # concat on a specified dimension\nprint (y)\nprint (y.shape)\n
\n\ntensor([[-1.5944, -0.4218, -1.8219],\n [ 1.7446, 1.2058, -0.7753],\n [-1.5944, -0.4218, -1.8219],\n [ 1.7446, 1.2058, -0.7753]])\ntorch.Size([4, 3])\n
\n\n# Stacking\nz = torch.stack([x, x], dim=0) # stack on new dimension\nprint (z)\nprint (z.shape)\n
\n\ntensor([[[-1.5944, -0.4218, -1.8219],\n [ 1.7446, 1.2058, -0.7753]],\n\n [[-1.5944, -0.4218, -1.8219],\n [ 1.7446, 1.2058, -0.7753]]])\ntorch.Size([2, 2, 3])\n
"},{"location":"courses/foundations/pytorch/#gradients","title":"Gradients","text":"We can determine gradients (rate of change) of our tensors with respect to their constituents using gradient bookkeeping. The gradient is a vector that points in the direction of greatest increase of a function. We'll be using gradients in the next lesson to determine how to change our weights to affect a particular objective function (ex. loss).
\n\\[ y = 3x + 2 \\]\n\\[ z = \\sum{y}/N \\]\n\\[ \\frac{\\partial(z)}{\\partial(x)} = \\frac{\\partial(z)}{\\partial(y)} \\frac{\\partial(y)}{\\partial(x)} = \\frac{1}{N} * 3 = \\frac{1}{12} * 3 = 0.25 \\]\n# Tensors with gradient bookkeeping\nx = torch.rand(3, 4, requires_grad=True)\ny = 3*x + 2\nz = y.mean()\nz.backward() # z has to be scalar\nprint(f\"x: \\n{x}\")\nprint(f\"x.grad: \\n{x.grad}\")\n
\n\nx:\ntensor([[0.7379, 0.0846, 0.4245, 0.9778],\n [0.6800, 0.3151, 0.3911, 0.8943],\n [0.6889, 0.8389, 0.1780, 0.6442]], requires_grad=True)\nx.grad:\ntensor([[0.2500, 0.2500, 0.2500, 0.2500],\n [0.2500, 0.2500, 0.2500, 0.2500],\n [0.2500, 0.2500, 0.2500, 0.2500]])\n
"},{"location":"courses/foundations/pytorch/#cuda","title":"CUDA","text":"We also load our tensors onto the GPU for parallelized computation using CUDA (a parallel computing platform and API from Nvidia).\n
# Is CUDA available?\nprint (torch.cuda.is_available())\n
\n\nFalse\n
\n\nIf False (CUDA is not available), let's change that by following these steps: Go to Runtime > Change runtime type > Change Hardware accelerator to GPU > Click Save\n
import torch\n
\n# Is CUDA available now?\nprint (torch.cuda.is_available())\n
\n\nTrue\n
\n# Set device\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nprint (device)\n
\n\ncuda\n
\nx = torch.rand(2,3)\nprint (x.is_cuda)\nx = torch.rand(2,3).to(device) # Tensor is stored on the GPU\nprint (x.is_cuda)\n
\n\nFalse\nTrue\n
\n\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { PyTorch - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\n
"},{"location":"courses/foundations/recurrent-neural-networks/","title":"Recurrent Neural Networks (RNN)","text":""},{"location":"courses/foundations/recurrent-neural-networks/#overview","title":"Overview","text":"So far we've processed inputs as whole (ex. applying filters across the entire input to extract features) but we can also process our inputs sequentially. For example we can think of each token in our text as an event in time (timestep). We can process each timestep, one at a time, and predict the class after the last timestep (token) has been processed. This is very powerful because the model now has a meaningful way to account for the sequential order of tokens in our sequence and predict accordingly.
$$ \\text{RNN forward pass for a single time step } X_t $$:
\\[ h_t = tanh(W_{hh}h_{t-1} + W_{xh}X_t+b_h) \\] Variable Description \\(N\\) batch size \\(E\\) embeddings dimension \\(H\\) # of hidden units \\(W_{hh}\\) RNN weights \\(\\in \\mathbb{R}^{HXH}\\) \\(h_{t-1}\\) previous timestep's hidden state \\(\\in in \\mathbb{R}^{NXH}\\) \\(W_{xh}\\) input weights \\(\\in \\mathbb{R}^{EXH}\\) \\(X_t\\) input at time step \\(t \\in \\mathbb{R}^{NXE}\\) \\(b_h\\) hidden units bias \\(\\in \\mathbb{R}^{HX1}\\) \\(h_t\\) output from RNN for timestep \\(t\\)
Let's set our seed and device for our main task.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/recurrent-neural-networks/#load-data","title":"Load data","text":"
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\nWe're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nnltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\nprint (STOPWORDS[:5])\nporter = PorterStemmer()\n\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n['i', 'me', 'my', 'myself', 'we']\n
def preprocess(text, stopwords=STOPWORDS):\n\"\"\"Conditional preprocessing on our text unique to our task.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r\"\\b(\" + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub(\"\", text)\n\n # Remove words in parenthesis\n text = re.sub(r\"\\([^)]*\\)\", \"\", text)\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text)\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n return text\n# Sample\ntext = \"Great week for the NYSE!\"\npreprocess(text=text)\n\ngreat week nyse\n
# Apply to dataframe\npreprocessed_df = df.copy()\npreprocessed_df.title = preprocessed_df.title.apply(preprocess)\nprint (f\"{df.title.values[0]}\\n\\n{preprocessed_df.title.values[0]}\")\n\nSharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says\n\nsharon accepts plan reduce gaza army operation haaretz says\n
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
"},{"location":"courses/foundations/recurrent-neural-networks/#split-data","title":"Split data","text":"import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Data\nX = preprocessed_df[\"title\"].values\ny = preprocessed_df[\"category\"].values\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (84000,), y_train: (84000,)\nX_val: (18000,), y_val: (18000,)\nX_test: (18000,), y_test: (18000,)\nSample point: china battles north korea nuclear talks \u2192 World\n"},{"location":"courses/foundations/recurrent-neural-networks/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nNUM_CLASSES = len(label_encoder)\nlabel_encoder.class_to_index\n\n{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: World\ny_train[0]: 3\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [21000 21000 21000 21000]\nweights: {0: 4.761904761904762e-05, 1: 4.761904761904762e-05, 2: 4.761904761904762e-05, 3: 4.761904761904762e-05}\n"},{"location":"courses/foundations/recurrent-neural-networks/#tokenizer","title":"Tokenizer","text":"We'll define a Tokenizer to convert our text input data into token indices.
import json\nfrom collections import Counter\nfrom more_itertools import take\nclass Tokenizer(object):\n def __init__(self, char_level, num_tokens=None,\n pad_token=\"<PAD>\", oov_token=\"<UNK>\",\n token_to_index=None):\n self.char_level = char_level\n self.separator = \"\" if self.char_level else \" \"\n if num_tokens: num_tokens -= 2 # pad + unk tokens\n self.num_tokens = num_tokens\n self.pad_token = pad_token\n self.oov_token = oov_token\n if not token_to_index:\n token_to_index = {pad_token: 0, oov_token: 1}\n self.token_to_index = token_to_index\n self.index_to_token = {v: k for k, v in self.token_to_index.items()}\n\n def __len__(self):\n return len(self.token_to_index)\n\n def __str__(self):\n return f\"<Tokenizer(num_tokens={len(self)})>\"\n\n def fit_on_texts(self, texts):\n if not self.char_level:\n texts = [text.split(\" \") for text in texts]\n all_tokens = [token for text in texts for token in text]\n counts = Counter(all_tokens).most_common(self.num_tokens)\n self.min_token_freq = counts[-1][1]\n for token, count in counts:\n index = len(self)\n self.token_to_index[token] = index\n self.index_to_token[index] = token\n return self\n\n def texts_to_sequences(self, texts):\n sequences = []\n for text in texts:\n if not self.char_level:\n text = text.split(\" \")\n sequence = []\n for token in text:\n sequence.append(self.token_to_index.get(\n token, self.token_to_index[self.oov_token]))\n sequences.append(np.asarray(sequence))\n return sequences\n\n def sequences_to_texts(self, sequences):\n texts = []\n for sequence in sequences:\n text = []\n for index in sequence:\n text.append(self.index_to_token.get(index, self.oov_token))\n texts.append(self.separator.join([token for token in text]))\n return texts\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {\n \"char_level\": self.char_level,\n \"oov_token\": self.oov_token,\n \"token_to_index\": self.token_to_index\n }\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\nWarning
It's important that we only fit using our train data split because during inference, our model will not always know every token so it's important to replicate that scenario with our validation and test splits as well.
# Tokenize\ntokenizer = Tokenizer(char_level=False, num_tokens=5000)\ntokenizer.fit_on_texts(texts=X_train)\nVOCAB_SIZE = len(tokenizer)\nprint (tokenizer)\n\n<Tokenizer(num_tokens=5000)>\n\n
# Sample of tokens\nprint (take(5, tokenizer.token_to_index.items()))\nprint (f\"least freq token's freq: {tokenizer.min_token_freq}\") # use this to adjust num_tokens\n\n[('<PAD>', 0), ('<UNK>', 1), ('39', 2), ('b', 3), ('gt', 4)]\nleast freq token's freq: 14\n # Convert texts to sequences of indices\nX_train = tokenizer.texts_to_sequences(X_train)\nX_val = tokenizer.texts_to_sequences(X_val)\nX_test = tokenizer.texts_to_sequences(X_test)\npreprocessed_text = tokenizer.sequences_to_texts([X_train[0]])[0]\nprint (\"Text to indices:\\n\"\n f\" (preprocessed) \u2192 {preprocessed_text}\\n\"\n f\" (tokenized) \u2192 {X_train[0]}\")\n\nText to indices:\n (preprocessed) \u2192 china battles north korea nuclear talks\n (tokenized) \u2192 [ 16 1491 285 142 114 24]\n"},{"location":"courses/foundations/recurrent-neural-networks/#padding","title":"Padding","text":"
We'll need to do 2D padding to our tokenized text.
def pad_sequences(sequences, max_seq_len=0):\n\"\"\"Pad sequences to max length in sequence.\"\"\"\n max_seq_len = max(max_seq_len, max(len(sequence) for sequence in sequences))\n padded_sequences = np.zeros((len(sequences), max_seq_len))\n for i, sequence in enumerate(sequences):\n padded_sequences[i][:len(sequence)] = sequence\n return padded_sequences\n# 2D sequences\npadded = pad_sequences(X_train[0:3])\nprint (padded.shape)\nprint (padded)\n\n(3, 6)\n[[1.600e+01 1.491e+03 2.850e+02 1.420e+02 1.140e+02 2.400e+01]\n [1.445e+03 2.300e+01 6.560e+02 2.197e+03 1.000e+00 0.000e+00]\n [1.200e+02 1.400e+01 1.955e+03 1.005e+03 1.529e+03 4.014e+03]]\n"},{"location":"courses/foundations/recurrent-neural-networks/#datasets","title":"Datasets","text":"
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
class Dataset(torch.utils.data.Dataset):\n def __init__(self, X, y):\n self.X = X\n self.y = y\n\n def __len__(self):\n return len(self.y)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n X = self.X[index]\n y = self.y[index]\n return [X, len(X), y]\n\n def collate_fn(self, batch):\n\"\"\"Processing on a batch.\"\"\"\n # Get inputs\n batch = np.array(batch)\n X = batch[:, 0]\n seq_lens = batch[:, 1]\n y = batch[:, 2]\n\n # Pad inputs\n X = pad_sequences(sequences=X)\n\n # Cast\n X = torch.LongTensor(X.astype(np.int32))\n seq_lens = torch.LongTensor(seq_lens.astype(np.int32))\n y = torch.LongTensor(y.astype(np.int32))\n\n return X, seq_lens, y\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,\n shuffle=shuffle, drop_last=drop_last, pin_memory=True)\n# Create datasets\ntrain_dataset = Dataset(X=X_train, y=y_train)\nval_dataset = Dataset(X=X_val, y=y_val)\ntest_dataset = Dataset(X=X_test, y=y_test)\nprint (\"Datasets:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" X: {train_dataset[0][0]}\\n\"\n f\" seq_len: {train_dataset[0][1]}\\n\"\n f\" y: {train_dataset[0][2]}\")\n\nDatasets:\n Train dataset: <Dataset(N=84000)>\n Val dataset: <Dataset(N=18000)>\n Test dataset: <Dataset(N=18000)>\nSample point:\n X: [ 16 1491 285 142 114 24]\n seq_len: 6\n y: 3\n
# Create dataloaders\nbatch_size = 64\ntrain_dataloader = train_dataset.create_dataloader(\n batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(\n batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(\n batch_size=batch_size)\nbatch_X, batch_seq_lens, batch_y = next(iter(train_dataloader))\nprint (\"Sample batch:\\n\"\n f\" X: {list(batch_X.size())}\\n\"\n f\" seq_lens: {list(batch_seq_lens.size())}\\n\"\n f\" y: {list(batch_y.size())}\\n\"\n \"Sample point:\\n\"\n f\" X: {batch_X[0]}\\n\"\n f\" seq_len: {batch_seq_lens[0]}\\n\"\n f\" y: {batch_y[0]}\")\n\nSample batch:\n X: [64, 14]\n seq_lens: [64]\n y: [64]\nSample point:\n X: tensor([ 16, 1491, 285, 142, 114, 24, 0, 0, 0, 0, 0, 0,\n 0, 0])\n seq_len: 6\n y: 3\n"},{"location":"courses/foundations/recurrent-neural-networks/#trainer","title":"Trainer","text":"
Let's create the Trainer class that we'll use to facilitate training for our experiments.
class Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\nInputs to RNNs are sequential like text or time-series.
BATCH_SIZE = 64\nEMBEDDING_DIM = 100\n# Input\nsequence_size = 8 # words per input\nx = torch.rand((BATCH_SIZE, sequence_size, EMBEDDING_DIM))\nseq_lens = torch.randint(high=sequence_size, size=(BATCH_SIZE, ))\nprint (x.shape)\nprint (seq_lens.shape)\n\ntorch.Size([64, 8, 100])\ntorch.Size([1, 64])\n
$$ \\text{RNN forward pass for a single time step } X_t $$:
\\[ h_t = tanh(W_{hh}h_{t-1} + W_{xh}X_t+b_h) \\]Variable Description \\(N\\) batch size \\(E\\) embeddings dimension \\(H\\) # of hidden units \\(W_{hh}\\) RNN weights \\(\\in \\mathbb{R}^{HXH}\\) \\(h_{t-1}\\) previous timestep's hidden state \\(\\in in \\mathbb{R}^{NXH}\\) \\(W_{xh}\\) input weights \\(\\in \\mathbb{R}^{EXH}\\) \\(X_t\\) input at time step \\(t \\in \\mathbb{R}^{NXE}\\) \\(b_h\\) hidden units bias \\(\\in \\mathbb{R}^{HX1}\\) \\(h_t\\) output from RNN for timestep \\(t\\)
At the first time step, the previous hidden state \\(h_{t-1}\\) can either be a zero vector (unconditioned) or initialized (conditioned). If we are conditioning the RNN, the first hidden state \\(h_0\\) can belong to a specific condition or we can concat the specific condition to the randomly initialized hidden vectors at each time step. More on this in the subsequent notebooks on RNNs.
RNN_HIDDEN_DIM = 128\nDROPOUT_P = 0.1\n# Initialize hidden state\nhidden_t = torch.zeros((BATCH_SIZE, RNN_HIDDEN_DIM))\nprint (hidden_t.size())\n\ntorch.Size([64, 128])\n
We'll show how to create an RNN cell using PyTorch's RNNCell and the more abstracted RNN.
# Initialize RNN cell\nrnn_cell = nn.RNNCell(EMBEDDING_DIM, RNN_HIDDEN_DIM)\nprint (rnn_cell)\n\nRNNCell(100, 128)\n
# Forward pass through RNN\nx = x.permute(1, 0, 2) # RNN needs batch_size to be at dim 1\n\n# Loop through the inputs time steps\nhiddens = []\nfor t in range(sequence_size):\n hidden_t = rnn_cell(x[t], hidden_t)\n hiddens.append(hidden_t)\nhiddens = torch.stack(hiddens)\nhiddens = hiddens.permute(1, 0, 2) # bring batch_size back to dim 0\nprint (hiddens.size())\n\ntorch.Size([64, 8, 128])\n
# We also could've used a more abstracted layer\nx = torch.rand((BATCH_SIZE, sequence_size, EMBEDDING_DIM))\nrnn = nn.RNN(EMBEDDING_DIM, RNN_HIDDEN_DIM, batch_first=True)\nout, h_n = rnn(x) # h_n is the last hidden state\nprint (\"out: \", out.shape)\nprint (\"h_n: \", h_n.shape)\n\nout: torch.Size([64, 8, 128])\nh_n: torch.Size([1, 64, 128])\n
# The same tensors\nprint (out[:,-1,:])\nprint (h_n.squeeze(0))\n\ntensor([[-0.0359, -0.3819, 0.2162, ..., -0.3397, 0.0468, 0.1937],\n [-0.4914, -0.3056, -0.0837, ..., -0.3507, -0.4320, 0.3593],\n [-0.0989, -0.2852, 0.1170, ..., -0.0805, -0.0786, 0.3922],\n ...,\n [-0.3115, -0.4169, 0.2611, ..., -0.3214, 0.0620, 0.0338],\n [-0.2455, -0.3380, 0.2048, ..., -0.4198, -0.0075, 0.0372],\n [-0.2092, -0.4594, 0.1654, ..., -0.5397, -0.1709, 0.0023]],\n grad_fn=<SliceBackward>)\ntensor([[-0.0359, -0.3819, 0.2162, ..., -0.3397, 0.0468, 0.1937],\n [-0.4914, -0.3056, -0.0837, ..., -0.3507, -0.4320, 0.3593],\n [-0.0989, -0.2852, 0.1170, ..., -0.0805, -0.0786, 0.3922],\n ...,\n [-0.3115, -0.4169, 0.2611, ..., -0.3214, 0.0620, 0.0338],\n [-0.2455, -0.3380, 0.2048, ..., -0.4198, -0.0075, 0.0372],\n [-0.2092, -0.4594, 0.1654, ..., -0.5397, -0.1709, 0.0023]],\n grad_fn=<SqueezeBackward1>)\n
In our model, we want to use the RNN's output after the last relevant token in the sentence is processed. The last relevant token doesn't refer the <PAD> tokens but to the last actual word in the sentence and its index is different for each input in the batch. This is why we included a seq_lens tensor in our batches.
def gather_last_relevant_hidden(hiddens, seq_lens):\n\"\"\"Extract and collect the last relevant\n hidden state based on the sequence length.\"\"\"\n seq_lens = seq_lens.long().detach().cpu().numpy() - 1\n out = []\n for batch_index, column_index in enumerate(seq_lens):\n out.append(hiddens[batch_index, column_index])\n return torch.stack(out)\n# Get the last relevant hidden state\ngather_last_relevant_hidden(hiddens=out, seq_lens=seq_lens).squeeze(0).shape\n\ntorch.Size([64, 128])\n
There are many different ways to use RNNs. So far we've processed our inputs one timestep at a time and we could either use the RNN's output at each time step or just use the final input timestep's RNN output. Let's look at a few other possibilities.
"},{"location":"courses/foundations/recurrent-neural-networks/#model","title":"Model","text":"import torch.nn.functional as F\nHIDDEN_DIM = 100\nclass RNN(nn.Module):\n def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,\n hidden_dim, dropout_p, num_classes, padding_idx=0):\n super(RNN, self).__init__()\n\n # Initialize embeddings\n self.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size,\n padding_idx=padding_idx)\n\n # RNN\n self.rnn = nn.RNN(embedding_dim, rnn_hidden_dim, batch_first=True)\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(rnn_hidden_dim, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs):\n # Embed\n x_in, seq_lens = inputs\n x_in = self.embeddings(x_in)\n\n # Rnn outputs\n out, h_n = self.rnn(x_in)\n z = gather_last_relevant_hidden(hiddens=out, seq_lens=seq_lens)\n\n # FC layers\n z = self.fc1(z)\n z = self.dropout(z)\n z = self.fc2(z)\n return z\n# Simple RNN cell\nmodel = RNN(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of RNN(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): RNN(100, 128, batch_first=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=128, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n"},{"location":"courses/foundations/recurrent-neural-networks/#training","title":"Training","text":"
from torch.optim import Adam\nNUM_LAYERS = 1\nLEARNING_RATE = 1e-4\nPATIENCE = 10\nNUM_EPOCHS = 50\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 1.25605, val_loss: 1.10880, lr: 1.00E-04, _patience: 10\nEpoch: 2 | train_loss: 1.03074, val_loss: 0.96749, lr: 1.00E-04, _patience: 10\nEpoch: 3 | train_loss: 0.90110, val_loss: 0.86424, lr: 1.00E-04, _patience: 10\n...\nEpoch: 31 | train_loss: 0.32206, val_loss: 0.53581, lr: 1.00E-06, _patience: 3\nEpoch: 32 | train_loss: 0.32233, val_loss: 0.53587, lr: 1.00E-07, _patience: 2\nEpoch: 33 | train_loss: 0.32215, val_loss: 0.53572, lr: 1.00E-07, _patience: 1\nStopping early!\n"},{"location":"courses/foundations/recurrent-neural-networks/#evaluation","title":"Evaluation","text":"
import json\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8171357577653572,\n \"recall\": 0.8176111111111112,\n \"f1\": 0.8171696173843819,\n \"num_samples\": 18000.0\n}\n"},{"location":"courses/foundations/recurrent-neural-networks/#gated-rnn","title":"Gated RNN","text":"While our simple RNNs so far are great for sequentially processing our inputs, they have quite a few disadvantages. They commonly suffer from exploding or vanishing gradients as a result using the same set of weights (\\(W_{xh}\\) and \\(W_{hh}\\)) with each timestep's input. During backpropagation, this can cause gradients to explode (>1) or vanish (<1). If you multiply any number greater than 1 with itself over and over, it moves towards infinity (exploding gradients) and similarly, If you multiply any number less than 1 with itself over and over, it moves towards zero (vanishing gradients). To mitigate this issue, gated RNNs were devised to selectively retain information. If you're interested in learning more of the specifics, this post is a must-read.
There are two popular types of gated RNNs: Long Short-term Memory (LSTMs) units and Gated Recurrent Units (GRUs).
When deciding between LSTMs and GRUs, empirical performance is the best factor but in general GRUs offer similar performance with less complexity (less weights).
Understanding LSTM Networks - Chris Olah# Input\nsequence_size = 8 # words per input\nx = torch.rand((BATCH_SIZE, sequence_size, EMBEDDING_DIM))\nprint (x.shape)\n\ntorch.Size([64, 8, 100])\n
# GRU\ngru = nn.GRU(input_size=EMBEDDING_DIM, hidden_size=RNN_HIDDEN_DIM, batch_first=True)\n# Forward pass\nout, h_n = gru(x)\nprint (f\"out: {out.shape}\")\nprint (f\"h_n: {h_n.shape}\")\n\nout: torch.Size([64, 8, 128])\nh_n: torch.Size([1, 64, 128])\n"},{"location":"courses/foundations/recurrent-neural-networks/#bidirectional-rnn","title":"Bidirectional RNN","text":"
We can also have RNNs that process inputs from both directions (first token to last token and vice versa) and combine their outputs. This architecture is known as a bidirectional RNN.
# GRU\ngru = nn.GRU(input_size=EMBEDDING_DIM, hidden_size=RNN_HIDDEN_DIM,\n batch_first=True, bidirectional=True)\n# Forward pass\nout, h_n = gru(x)\nprint (f\"out: {out.shape}\")\nprint (f\"h_n: {h_n.shape}\")\n\nout: torch.Size([64, 8, 256])\nh_n: torch.Size([2, 64, 128])\n
Notice that the output for each sample at each timestamp has size 256 (double the RNN_HIDDEN_DIM). This is because this includes both the forward and backward directions from the BiRNN.
class GRU(nn.Module):\n def __init__(self, embedding_dim, vocab_size, rnn_hidden_dim,\n hidden_dim, dropout_p, num_classes, padding_idx=0):\n super(GRU, self).__init__()\n\n # Initialize embeddings\n self.embeddings = nn.Embedding(embedding_dim=embedding_dim,\n num_embeddings=vocab_size,\n padding_idx=padding_idx)\n\n # RNN\n self.rnn = nn.GRU(embedding_dim, rnn_hidden_dim,\n batch_first=True, bidirectional=True)\n\n # FC weights\n self.dropout = nn.Dropout(dropout_p)\n self.fc1 = nn.Linear(rnn_hidden_dim*2, hidden_dim)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs:\n # Embed\n x_in, seq_lens = inputs\n x_in = self.embeddings(x_in)\n\n # Rnn outputs\n out, h_n = self.rnn(x_in)\n z = gather_last_relevant_hidden(hiddens=out, seq_lens=seq_lens)\n\n # FC layers\n z = self.fc1(z)\n z = self.dropout(z)\n z = self.fc2(z)\n return z\n# Simple RNN cell\nmodel = GRU(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of GRU(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): GRU(100, 128, batch_first=True, bidirectional=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=256, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)>\n"},{"location":"courses/foundations/recurrent-neural-networks/#training_1","title":"Training","text":"
# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 1.18125, val_loss: 0.93827, lr: 1.00E-04, _patience: 10\nEpoch: 2 | train_loss: 0.81291, val_loss: 0.72564, lr: 1.00E-04, _patience: 10\nEpoch: 3 | train_loss: 0.65413, val_loss: 0.64487, lr: 1.00E-04, _patience: 10\n...\nEpoch: 23 | train_loss: 0.30351, val_loss: 0.53904, lr: 1.00E-06, _patience: 3\nEpoch: 24 | train_loss: 0.30332, val_loss: 0.53912, lr: 1.00E-07, _patience: 2\nEpoch: 25 | train_loss: 0.30300, val_loss: 0.53909, lr: 1.00E-07, _patience: 1\nStopping early!\n"},{"location":"courses/foundations/recurrent-neural-networks/#evaluation_1","title":"Evaluation","text":"
from pathlib import Path\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8192635071011053,\n \"recall\": 0.8196111111111111,\n \"f1\": 0.8192710197821547,\n \"num_samples\": 18000.0\n}\n # Save artifacts\ndir = Path(\"gru\")\ndir.mkdir(parents=True, exist_ok=True)\nlabel_encoder.save(fp=Path(dir, \"label_encoder.json\"))\ntokenizer.save(fp=Path(dir, 'tokenizer.json'))\ntorch.save(best_model.state_dict(), Path(dir, \"model.pt\"))\nwith open(Path(dir, 'performance.json'), \"w\") as fp:\n json.dump(performance, indent=2, sort_keys=False, fp=fp)\ndef get_probability_distribution(y_prob, classes):\n\"\"\"Create a dict of class probabilities from an array.\"\"\"\n results = {}\n for i, class_ in enumerate(classes):\n results[class_] = np.float64(y_prob[i])\n sorted_results = {k: v for k, v in sorted(\n results.items(), key=lambda item: item[1], reverse=True)}\n return sorted_results\n# Load artifacts\ndevice = torch.device(\"cpu\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\ntokenizer = Tokenizer.load(fp=Path(dir, 'tokenizer.json'))\nmodel = GRU(\n embedding_dim=EMBEDDING_DIM, vocab_size=VOCAB_SIZE,\n rnn_hidden_dim=RNN_HIDDEN_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device)\n\nGRU(\n (embeddings): Embedding(5000, 100, padding_idx=0)\n (rnn): GRU(100, 128, batch_first=True, bidirectional=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc1): Linear(in_features=256, out_features=100, bias=True)\n (fc2): Linear(in_features=100, out_features=4, bias=True)\n)\n
# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n# Dataloader\ntext = \"The final tennis tournament starts next week.\"\nX = tokenizer.texts_to_sequences([preprocess(text)])\nprint (tokenizer.sequences_to_texts(X))\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))\ndataset = Dataset(X=X, y=y_filler)\ndataloader = dataset.create_dataloader(batch_size=batch_size)\n\n['final tennis tournament starts next week']\n
# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.decode(y_pred)\n\n['Sports']\n
# Class distributions\nprob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)\nprint (json.dumps(prob_dist, indent=2))\n\n{\n \"Sports\": 0.49753469228744507,\n \"World\": 0.2925860285758972,\n \"Business\": 0.1932886838912964,\n \"Sci/Tech\": 0.01659061387181282\n}\n We will learn how to create more context-aware representations and a little bit of interpretability with RNNs in the next lesson on attention.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { RNNs - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nTransformers are a very popular architecture that leverage and extend the concept of self-attention to create very useful representations of our input data for a downstream task.
advantages:
disadvantages:
Let's set our seed and device for our main task.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/transformers/#load-data","title":"Load data","text":"
We will download the AG News dataset, which consists of 120K text samples from 4 unique classes (Business, Sci/Tech, Sports, World)
# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/news.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\n# Reduce data size (too large to fit in Colab's limited memory)\ndf = df[:10000]\nprint (len(df))\n\n10000\n"},{"location":"courses/foundations/transformers/#preprocessing","title":"Preprocessing","text":"
We're going to clean up our input data first by doing operations such as lower text, removing stop (filler) words, filters using regular expressions, etc.
import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nnltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\nprint (STOPWORDS[:5])\nporter = PorterStemmer()\n\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n['i', 'me', 'my', 'myself', 'we']\n
def preprocess(text, stopwords=STOPWORDS):\n\"\"\"Conditional preprocessing on our text unique to our task.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r\"\\b(\" + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub(\"\", text)\n\n # Remove words in parenthesis\n text = re.sub(r\"\\([^)]*\\)\", \"\", text)\n\n # Spacing and filters\n text = re.sub(r\"([-;;.,!?<=>])\", r\" \\1 \", text)\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip()\n\n return text\n# Sample\ntext = \"Great week for the NYSE!\"\npreprocess(text=text)\n\ngreat week nyse\n
# Apply to dataframe\npreprocessed_df = df.copy()\npreprocessed_df.title = preprocessed_df.title.apply(preprocess)\nprint (f\"{df.title.values[0]}\\n\\n{preprocessed_df.title.values[0]}\")\n\nSharon Accepts Plan to Reduce Gaza Army Operation, Haaretz Says\n\nsharon accepts plan reduce gaza army operation haaretz says\n
Warning
If you have preprocessing steps like standardization, etc. that are calculated, you need to separate the training and test set first before applying those operations. This is because we cannot apply any knowledge gained from the test set accidentally (data leak) during preprocessing/training. However for global preprocessing steps like the function above where we aren't learning anything from the data itself, we can perform before splitting the data.
"},{"location":"courses/foundations/transformers/#split-data","title":"Split data","text":"import collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Data\nX = preprocessed_df[\"title\"].values\ny = preprocessed_df[\"category\"].values\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (7000,), y_train: (7000,)\nX_val: (1500,), y_val: (1500,)\nX_test: (1500,), y_test: (1500,)\nSample point: lost flu paydays \u2192 Business\n"},{"location":"courses/foundations/transformers/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n y_one_hot = np.zeros((len(y), len(self.class_to_index)), dtype=int)\n for i, item in enumerate(y):\n y_one_hot[i][self.class_to_index[item]] = 1\n return y_one_hot\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n index = np.where(item == 1)[0][0]\n classes.append(self.index_to_class[index])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nNUM_CLASSES = len(label_encoder)\nlabel_encoder.class_to_index\n\n{'Business': 0, 'Sci/Tech': 1, 'Sports': 2, 'World': 3}\n # Class weights\ncounts = np.bincount([label_encoder.class_to_index[class_] for class_ in y_train])\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [1746 1723 1725 1806]\nweights: {0: 0.000572737686139748, 1: 0.0005803830528148578, 2: 0.0005797101449275362, 3: 0.0005537098560354374}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\nprint (f\"decode([y_train[0]]): {label_encoder.decode([y_train[0]])}\")\n\ny_train[0]: Business\ny_train[0]: [1 0 0 0]\ndecode([y_train[0]]): ['Business']\n"},{"location":"courses/foundations/transformers/#tokenizer","title":"Tokenizer","text":"
We'll be using the BertTokenizer to tokenize our input text in to sub-word tokens.
from transformers import DistilBertTokenizer\nfrom transformers import BertTokenizer\n# Load tokenizer and model\n# tokenizer = DistilBertTokenizer.from_pretrained(\"distilbert-base-uncased\")\ntokenizer = BertTokenizer.from_pretrained(\"allenai/scibert_scivocab_uncased\")\nvocab_size = len(tokenizer)\nprint (vocab_size)\n\n31090\n
# Tokenize inputs\nencoded_input = tokenizer(X_train.tolist(), return_tensors=\"pt\", padding=True)\nX_train_ids = encoded_input[\"input_ids\"]\nX_train_masks = encoded_input[\"attention_mask\"]\nprint (X_train_ids.shape, X_train_masks.shape)\nencoded_input = tokenizer(X_val.tolist(), return_tensors=\"pt\", padding=True)\nX_val_ids = encoded_input[\"input_ids\"]\nX_val_masks = encoded_input[\"attention_mask\"]\nprint (X_val_ids.shape, X_val_masks.shape)\nencoded_input = tokenizer(X_test.tolist(), return_tensors=\"pt\", padding=True)\nX_test_ids = encoded_input[\"input_ids\"]\nX_test_masks = encoded_input[\"attention_mask\"]\nprint (X_test_ids.shape, X_test_masks.shape)\n\ntorch.Size([7000, 27]) torch.Size([7000, 27])\ntorch.Size([1500, 21]) torch.Size([1500, 21])\ntorch.Size([1500, 26]) torch.Size([1500, 26])\n
# Decode\nprint (f\"{X_train_ids[0]}\\n{tokenizer.decode(X_train_ids[0])}\")\n\ntensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0])\n[CLS] lost flu paydays [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]\n
# Sub-word tokens\nprint (tokenizer.convert_ids_to_tokens(ids=X_train_ids[0]))\n\n['[CLS]', 'lost', 'flu', 'pay', '##days', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']\n"},{"location":"courses/foundations/transformers/#datasets","title":"Datasets","text":"
We're going to create Datasets and DataLoaders to be able to efficiently create batches with our data splits.
class TransformerTextDataset(torch.utils.data.Dataset):\n def __init__(self, ids, masks, targets):\n self.ids = ids\n self.masks = masks\n self.targets = targets\n\n def __len__(self):\n return len(self.targets)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n ids = torch.tensor(self.ids[index], dtype=torch.long)\n masks = torch.tensor(self.masks[index], dtype=torch.long)\n targets = torch.FloatTensor(self.targets[index])\n return ids, masks, targets\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self,\n batch_size=batch_size,\n shuffle=shuffle,\n drop_last=drop_last,\n pin_memory=False)\n# Create datasets\ntrain_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)\nval_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)\ntest_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)\nprint (\"Data splits:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" ids: {train_dataset[0][0]}\\n\"\n f\" masks: {train_dataset[0][1]}\\n\"\n f\" targets: {train_dataset[0][2]}\")\n\nData splits:\n Train dataset: <Dataset(N=7000)>\n Val dataset: <Dataset(N=1500)>\n Test dataset: <Dataset(N=1500)>\nSample point:\n ids: tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0])\n masks: tensor([1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0])\n targets: tensor([1., 0., 0., 0.], device=\"cpu\")\n
# Create dataloaders\nbatch_size = 128\ntrain_dataloader = train_dataset.create_dataloader(\n batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(\n batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(\n batch_size=batch_size)\nbatch = next(iter(train_dataloader))\nprint (\"Sample batch:\\n\"\n f\" ids: {batch[0].size()}\\n\"\n f\" masks: {batch[1].size()}\\n\"\n f\" targets: {batch[2].size()}\")\n\nSample batch:\n ids: torch.Size([128, 27])\n masks: torch.Size([128, 27])\n targets: torch.Size([128, 4])\n"},{"location":"courses/foundations/transformers/#trainer","title":"Trainer","text":"
Let's create the Trainer class that we'll use to facilitate training for our experiments.
import torch.nn.functional as F\nclass Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\nWe'll first learn about the unique components within the Transformer architecture and then implement one for our text classification task.
"},{"location":"courses/foundations/transformers/#scaled-dot-product-attention","title":"Scaled dot-product attention","text":"The most popular type of self-attention is scaled dot-product attention from the widely-cited Attention is all you need paper. This type of attention involves projecting our encoded input sequences onto three matrices, queries (Q), keys (K) and values (V), whose weights we learn.
\\[ Q = XW_q \\text{ where } W_q \\in \\mathbb{R}^{HXd_q} \\] \\[ K = XW_k \\text{ where } W_k \\in \\mathbb{R}^{HXd_k} \\] \\[ V = XW_v \\text{ where } W_v \\in \\mathbb{R}^{HXd_v} \\] \\[ attention (Q, K, V) = softmax( \\frac{Q K^{T}}{\\sqrt{d_k}} ) V \\in \\mathbb{R}^{MXd_v} \\]Variable Description \\(X\\) encoded inputs \\(\\in \\mathbb{R}^{NXMXH}\\) \\(N\\) batch size \\(M\\) max sequence length in the batch \\(H\\) hidden dim, model dim, etc. \\(W_q\\) query weights \\(\\in \\mathbb{R}^{HXd_q}\\) \\(W_k\\) key weights \\(\\in \\mathbb{R}^{HXd_k}\\) \\(W_v\\) value weights \\(\\in \\mathbb{R}^{HXd_v}\\)
"},{"location":"courses/foundations/transformers/#multi-head-attention","title":"Multi-head attention","text":"Instead of applying self-attention only once across the entire encoded input, we can also separate the input and apply self-attention in parallel (heads) to each input section and concatenate them. This allows the different head to learn unique representations while maintaining the complexity since we split the input into smaller subspaces.
\\[ MultiHead(Q, K, V) = concat({head}_1, ..., {head}_{h})W_O \\] \\[ {head}_i = attention(Q_i, K_i, V_i) \\]Variable Description \\(h\\) number of attention heads \\(W_O\\) multi-head attention weights \\(\\in \\mathbb{R}^{hd_vXH}\\) \\(H\\) hidden dim (or dimension of the model \\(d_{model}\\))
"},{"location":"courses/foundations/transformers/#positional-encoding","title":"Positional encoding","text":"With self-attention, we aren't able to account for the sequential position of our input tokens. To address this, we can use positional encoding to create a representation of the location of each token with respect to the entire sequence. This can either be learned (with weights) or we can use a fixed function that can better extend to create positional encoding for lengths during inference that were not observed during training.
\\[ PE_{(pos,2i)} = sin({pos}/{10000^{2i/H}}) \\] \\[ PE_{(pos,2i+1)} = cos({pos}/{10000^{2i/H}}) \\]Variable Description \\(pos\\) position of the token \\((1...M)\\) \\(i\\) hidden dim \\((1..H)\\)
This effectively allows us to represent each token's relative position using a fixed function for very large sequences. And because we've constrained the positional encodings to have the same dimensions as our encoded inputs, we can simply concatenate them before feeding them into the multi-head attention heads.
"},{"location":"courses/foundations/transformers/#architecture","title":"Architecture","text":"And here's how it all fits together! It's an end-to-end architecture that creates these contextual representations and uses an encoder-decoder architecture to predict the outcomes (one-to-one, many-to-one, many-to-many, etc.) Due to the complexity of the architecture, they require massive amounts of data for training without overfitting, however, they can be leveraged as pretrained models to finetune with smaller datasets that are similar to the larger set it was initially trained on.
Attention Is All You NeedWe're not going to the implement the Transformer from scratch but we will use the Hugging Face library to do so in the training lesson!
"},{"location":"courses/foundations/transformers/#model","title":"Model","text":"We're going to use a pretrained BertModel to act as a feature extractor. We'll only use the encoder to receive sequential and pooled outputs (is_decoder=False is default).
from transformers import BertModel\n# transformer = BertModel.from_pretrained(\"distilbert-base-uncased\")\n# embedding_dim = transformer.config.dim\ntransformer = BertModel.from_pretrained(\"allenai/scibert_scivocab_uncased\")\nembedding_dim = transformer.config.hidden_size\nclass Transformer(nn.Module):\n def __init__(self, transformer, dropout_p, embedding_dim, num_classes):\n super(Transformer, self).__init__()\n self.transformer = transformer\n self.dropout = torch.nn.Dropout(dropout_p)\n self.fc1 = torch.nn.Linear(embedding_dim, num_classes)\n\n def forward(self, inputs):\n ids, masks = inputs\n seq, pool = self.transformer(input_ids=ids, attention_mask=masks)\n z = self.dropout(pool)\n z = self.fc1(z)\n return z\nWe decided to work with the pooled output, but we could have just as easily worked with the sequential output (encoder representation for each sub-token) and applied a CNN (or other decoder options) on top of it.
# Initialize model\ndropout_p = 0.5\nmodel = Transformer(\n transformer=transformer, dropout_p=dropout_p,\n embedding_dim=embedding_dim, num_classes=num_classes)\nmodel = model.to(device)\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of Transformer(\n (transformer): BertModel(\n (embeddings): BertEmbeddings(\n (word_embeddings): Embedding(31090, 768, padding_idx=0)\n (position_embeddings): Embedding(512, 768)\n (token_type_embeddings): Embedding(2, 768)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n (encoder): BertEncoder(\n (layer): ModuleList(\n (0): BertLayer(\n (attention): BertAttention(\n (self): BertSelfAttention(\n (query): Linear(in_features=768, out_features=768, bias=True)\n (key): Linear(in_features=768, out_features=768, bias=True)\n (value): Linear(in_features=768, out_features=768, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n (output): BertSelfOutput(\n (dense): Linear(in_features=768, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n (intermediate): BertIntermediate(\n (dense): Linear(in_features=768, out_features=3072, bias=True)\n )\n (output): BertOutput(\n (dense): Linear(in_features=3072, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n (1): BertLayer(\n (attention): BertAttention(\n (self): BertSelfAttention(\n (query): Linear(in_features=768, out_features=768, bias=True)\n (key): Linear(in_features=768, out_features=768, bias=True)\n (value): Linear(in_features=768, out_features=768, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n (output): BertSelfOutput(\n (dense): Linear(in_features=768, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n (intermediate): BertIntermediate(\n (dense): Linear(in_features=768, out_features=3072, bias=True)\n )\n (output): BertOutput(\n (dense): Linear(in_features=3072, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n ...\n 11 more BertLayers\n ...\n )\n )\n (pooler): BertPooler(\n (dense): Linear(in_features=768, out_features=768, bias=True)\n (activation): Tanh()\n )\n )\n (dropout): Dropout(p=0.5, inplace=False)\n (fc1): Linear(in_features=768, out_features=4, bias=True)\n)>\n"},{"location":"courses/foundations/transformers/#training","title":"Training","text":"
# Arguments\nlr = 1e-4\nnum_epochs = 10\npatience = 10\n# Define loss\nclass_weights_tensor = torch.Tensor(np.array(list(class_weights.values())))\nloss_fn = nn.BCEWithLogitsLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = torch.optim.Adam(model.parameters(), lr=lr)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=5)\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(num_epochs, patience, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.00022, val_loss: 0.00017, lr: 1.00E-04, _patience: 10\nEpoch: 2 | train_loss: 0.00014, val_loss: 0.00016, lr: 1.00E-04, _patience: 10\nEpoch: 3 | train_loss: 0.00010, val_loss: 0.00017, lr: 1.00E-04, _patience: 9\n...\nEpoch: 9 | train_loss: 0.00002, val_loss: 0.00022, lr: 1.00E-05, _patience: 3\nEpoch: 10 | train_loss: 0.00002, val_loss: 0.00022, lr: 1.00E-05, _patience: 2\nEpoch: 11 | train_loss: 0.00001, val_loss: 0.00022, lr: 1.00E-05, _patience: 1\nStopping early!\n"},{"location":"courses/foundations/transformers/#evaluation","title":"Evaluation","text":"
import json\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_performance(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_performance(\n y_true=np.argmax(y_true, axis=1), y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.8085194951783808,\n \"recall\": 0.8086666666666666,\n \"f1\": 0.8083051845125695,\n \"num_samples\": 1500.0\n}\n # Save artifacts\nfrom pathlib import Path\ndir = Path(\"transformers\")\ndir.mkdir(parents=True, exist_ok=True)\nlabel_encoder.save(fp=Path(dir, \"label_encoder.json\"))\ntorch.save(best_model.state_dict(), Path(dir, \"model.pt\"))\nwith open(Path(dir, \"performance.json\"), \"w\") as fp:\n json.dump(performance, indent=2, sort_keys=False, fp=fp)\ndef get_probability_distribution(y_prob, classes):\n\"\"\"Create a dict of class probabilities from an array.\"\"\"\n results = {}\n for i, class_ in enumerate(classes):\n results[class_] = np.float64(y_prob[i])\n sorted_results = {k: v for k, v in sorted(\n results.items(), key=lambda item: item[1], reverse=True)}\n return sorted_results\n# Load artifacts\ndevice = torch.device(\"cpu\")\ntokenizer = BertTokenizer.from_pretrained(\"allenai/scibert_scivocab_uncased\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\ntransformer = BertModel.from_pretrained(\"allenai/scibert_scivocab_uncased\")\nembedding_dim = transformer.config.hidden_size\nmodel = Transformer(\n transformer=transformer, dropout_p=dropout_p,\n embedding_dim=embedding_dim, num_classes=num_classes)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device);\n# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n# Create datasets\ntrain_dataset = TransformerTextDataset(ids=X_train_ids, masks=X_train_masks, targets=y_train)\nval_dataset = TransformerTextDataset(ids=X_val_ids, masks=X_val_masks, targets=y_val)\ntest_dataset = TransformerTextDataset(ids=X_test_ids, masks=X_test_masks, targets=y_test)\nprint (\"Data splits:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" ids: {train_dataset[0][0]}\\n\"\n f\" masks: {train_dataset[0][1]}\\n\"\n f\" targets: {train_dataset[0][2]}\")\n\nData splits:\n Train dataset: <Dataset(N=7000)>\n Val dataset: <Dataset(N=1500)>\n Test dataset: <Dataset(N=1500)>\nSample point:\n ids: tensor([ 102, 6677, 1441, 3982, 17973, 103, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0])\n masks: tensor([1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0])\n targets: tensor([1., 0., 0., 0.], device=\"cpu\")\n
# Dataloader\ntext = \"The final tennis tournament starts next week.\"\nX = preprocess(text)\nencoded_input = tokenizer(X, return_tensors=\"pt\", padding=True).to(torch.device(\"cpu\"))\nids = encoded_input[\"input_ids\"]\nmasks = encoded_input[\"attention_mask\"]\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(ids))\ndataset = TransformerTextDataset(ids=ids, masks=masks, targets=y_filler)\ndataloader = dataset.create_dataloader(batch_size=int(batch_size))\n# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.index_to_class[y_pred[0]]\n\nSports\n
# Class distributions\nprob_dist = get_probability_distribution(y_prob=y_prob[0], classes=label_encoder.classes)\nprint (json.dumps(prob_dist, indent=2))\n\n{\n \"Sports\": 0.9999359846115112,\n \"World\": 4.0660612285137177e-05,\n \"Sci/Tech\": 1.1774928680097219e-05,\n \"Business\": 1.1545793313416652e-05\n}\n"},{"location":"courses/foundations/transformers/#interpretability","title":"Interpretability","text":"Let's visualize the self-attention weights from each of the attention heads in the encoder.
import sys\n!rm -r bertviz_repo\n!test -d bertviz_repo || git clone https://github.com/jessevig/bertviz bertviz_repo\nif not \"bertviz_repo\" in sys.path:\n sys.path += [\"bertviz_repo\"]\nfrom bertviz import head_view\n# Print input ids\nprint (ids)\nprint (tokenizer.batch_decode(ids))\n\ntensor([[ 102, 2531, 3617, 8869, 23589, 4972, 8553, 2205, 4082, 103]],\n device=\"cpu\")\n['[CLS] final tennis tournament starts next week [SEP]']\n
# Get encoder attentions\nseq, pool, attn = model.transformer(input_ids=ids, attention_mask=masks, output_attentions=True)\nprint (len(attn)) # 12 attention layers (heads)\nprint (attn[0].shape)\n\n12\ntorch.Size([1, 12, 10, 10])\n
# HTML set up\ndef call_html():\n import IPython\n display(IPython.core.display.HTML('''\n <script src=\"/static/components/requirejs/require.js\"></script>\n <script>\n requirejs.config({\n paths: {\n base: '/static/base',\n \"d3\": \"https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min\",\n jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',\n },\n });\n </script>\n '''))\n# Visualize self-attention weights\ncall_html()\ntokens = tokenizer.convert_ids_to_tokens(ids[0])\nhead_view(attention=attn, tokens=tokens)\nNow we're ready to start the MLOps course to learn how to apply all this foundational modeling knowledge to responsibly develop, deploy and maintain production machine learning applications.
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Transformers - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWe're having to set a lot of seeds for reproducibility now, so let's wrap it all up in a function.
import numpy as np\nimport pandas as pd\nimport random\nimport torch\nimport torch.nn as nn\nSEED = 1234\ndef set_seeds(seed=1234):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n torch.cuda.manual_seed_all(seed) # multi-GPU\n# Set seeds for reproducibility\nset_seeds(seed=SEED)\n# Set device\ncuda = True\ndevice = torch.device(\"cuda\" if (\n torch.cuda.is_available() and cuda) else \"cpu\")\ntorch.set_default_tensor_type(\"torch.FloatTensor\")\nif device.type == \"cuda\":\n torch.set_default_tensor_type(\"torch.cuda.FloatTensor\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/utilities/#load-data","title":"Load data","text":"
We'll use the same spiral dataset from previous lessons to demonstrate our utilities.
import matplotlib.pyplot as plt\nimport pandas as pd\n# Load data\nurl = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/spiral.csv\"\ndf = pd.read_csv(url, header=0) # load\ndf = df.sample(frac=1).reset_index(drop=True) # shuffle\ndf.head()\n# Data shapes\nX = df[[\"X1\", \"X2\"]].values\ny = df[\"color\"].values\nprint (\"X: \", np.shape(X))\nprint (\"y: \", np.shape(y))\n\nX: (1500, 2)\ny: (1500,)\n
# Visualize data\nplt.title(\"Generated non-linear data\")\ncolors = {\"c1\": \"red\", \"c2\": \"yellow\", \"c3\": \"blue\"}\nplt.scatter(X[:, 0], X[:, 1], c=[colors[_y] for _y in y], edgecolors=\"k\", s=25)\nplt.show()\nimport collections\nfrom sklearn.model_selection import train_test_split\nTRAIN_SIZE = 0.7\nVAL_SIZE = 0.15\nTEST_SIZE = 0.15\ndef train_val_test_split(X, y, train_size):\n\"\"\"Split dataset into data splits.\"\"\"\n X_train, X_, y_train, y_ = train_test_split(X, y, train_size=TRAIN_SIZE, stratify=y)\n X_val, X_test, y_val, y_test = train_test_split(X_, y_, train_size=0.5, stratify=y_)\n return X_train, X_val, X_test, y_train, y_val, y_test\n# Create data splits\nX_train, X_val, X_test, y_train, y_val, y_test = train_val_test_split(\n X=X, y=y, train_size=TRAIN_SIZE)\nprint (f\"X_train: {X_train.shape}, y_train: {y_train.shape}\")\nprint (f\"X_val: {X_val.shape}, y_val: {y_val.shape}\")\nprint (f\"X_test: {X_test.shape}, y_test: {y_test.shape}\")\nprint (f\"Sample point: {X_train[0]} \u2192 {y_train[0]}\")\n\nX_train: (1050, 2), y_train: (1050,)\nX_val: (225, 2), y_val: (225,)\nX_test: (225, 2), y_test: (225,)\nSample point: [-0.63919105 -0.69724176] \u2192 c1\n"},{"location":"courses/foundations/utilities/#label-encoding","title":"Label encoding","text":"
Next we'll define a LabelEncoder to encode our text labels into unique indices. We're not going to use scikit-learn's LabelEncoder anymore because we want to be able to save and load our instances the way we want to.
import itertools\nclass LabelEncoder(object):\n\"\"\"Label encoder for tag labels.\"\"\"\n def __init__(self, class_to_index={}):\n self.class_to_index = class_to_index or {} # mutable defaults ;)\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n\n def __len__(self):\n return len(self.class_to_index)\n\n def __str__(self):\n return f\"<LabelEncoder(num_classes={len(self)})>\"\n\n def fit(self, y):\n classes = np.unique(y)\n for i, class_ in enumerate(classes):\n self.class_to_index[class_] = i\n self.index_to_class = {v: k for k, v in self.class_to_index.items()}\n self.classes = list(self.class_to_index.keys())\n return self\n\n def encode(self, y):\n encoded = np.zeros((len(y)), dtype=int)\n for i, item in enumerate(y):\n encoded[i] = self.class_to_index[item]\n return encoded\n\n def decode(self, y):\n classes = []\n for i, item in enumerate(y):\n classes.append(self.index_to_class[item])\n return classes\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {'class_to_index': self.class_to_index}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Encode\nlabel_encoder = LabelEncoder()\nlabel_encoder.fit(y_train)\nlabel_encoder.class_to_index\n\n{\"c1\": 0, \"c2\": 1, \"c3\": 2}\n # Convert labels to tokens\nprint (f\"y_train[0]: {y_train[0]}\")\ny_train = label_encoder.encode(y_train)\ny_val = label_encoder.encode(y_val)\ny_test = label_encoder.encode(y_test)\nprint (f\"y_train[0]: {y_train[0]}\")\n\ny_train[0]: c1\ny_train[0]: 0\n
# Class weights\ncounts = np.bincount(y_train)\nclass_weights = {i: 1.0/count for i, count in enumerate(counts)}\nprint (f\"counts: {counts}\\nweights: {class_weights}\")\n\ncounts: [350 350 350]\nweights: {0: 0.002857142857142857, 1: 0.002857142857142857, 2: 0.002857142857142857}\n"},{"location":"courses/foundations/utilities/#standardize-data","title":"Standardize data","text":"We need to standardize our data (zero mean and unit variance) so a specific feature's magnitude doesn't affect how the model learns its weights. We're only going to standardize the inputs X because our outputs y are class values. We're going to compose our own StandardScaler class so we can easily save and load it later during inference.
class StandardScaler(object):\n def __init__(self, mean=None, std=None):\n self.mean = np.array(mean)\n self.std = np.array(std)\n\n def fit(self, X):\n self.mean = np.mean(X_train, axis=0)\n self.std = np.std(X_train, axis=0)\n\n def scale(self, X):\n return (X - self.mean) / self.std\n\n def unscale(self, X):\n return (X * self.std) + self.mean\n\n def save(self, fp):\n with open(fp, \"w\") as fp:\n contents = {\"mean\": self.mean.tolist(), \"std\": self.std.tolist()}\n json.dump(contents, fp, indent=4, sort_keys=False)\n\n @classmethod\n def load(cls, fp):\n with open(fp, \"r\") as fp:\n kwargs = json.load(fp=fp)\n return cls(**kwargs)\n# Standardize the data (mean=0, std=1) using training data\nX_scaler = StandardScaler()\nX_scaler.fit(X_train)\n# Apply scaler on training and test data (don't standardize outputs for classification)\nX_train = X_scaler.scale(X_train)\nX_val = X_scaler.scale(X_val)\nX_test = X_scaler.scale(X_test)\n# Check (means should be ~0 and std should be ~1)\nprint (f\"X_test[0]: mean: {np.mean(X_test[:, 0], axis=0):.1f}, std: {np.std(X_test[:, 0], axis=0):.1f}\")\nprint (f\"X_test[1]: mean: {np.mean(X_test[:, 1], axis=0):.1f}, std: {np.std(X_test[:, 1], axis=0):.1f}\")\n\nX_test[0]: mean: 0.1, std: 0.9\nX_test[1]: mean: 0.0, std: 1.0\n"},{"location":"courses/foundations/utilities/#dataloader","title":"DataLoader","text":"
We're going to place our data into a Dataset and use a DataLoader to efficiently create batches for training and evaluation.
import torch\n# Seed seed for reproducibility\ntorch.manual_seed(SEED)\nclass Dataset(torch.utils.data.Dataset):\n def __init__(self, X, y):\n self.X = X\n self.y = y\n\n def __len__(self):\n return len(self.y)\n\n def __str__(self):\n return f\"<Dataset(N={len(self)})>\"\n\n def __getitem__(self, index):\n X = self.X[index]\n y = self.y[index]\n return [X, y]\n\n def collate_fn(self, batch):\n\"\"\"Processing on a batch.\"\"\"\n # Get inputs\n batch = np.array(batch)\n X = np.stack(batch[:, 0], axis=0)\n y = batch[:, 1]\n\n # Cast\n X = torch.FloatTensor(X.astype(np.float32))\n y = torch.LongTensor(y.astype(np.int32))\n\n return X, y\n\n def create_dataloader(self, batch_size, shuffle=False, drop_last=False):\n return torch.utils.data.DataLoader(\n dataset=self, batch_size=batch_size, collate_fn=self.collate_fn,\n shuffle=shuffle, drop_last=drop_last, pin_memory=True)\ncollate_fn here but we wanted to make it transparent because we will need it when we want to do specific processing on our batch (ex. padding). # Create datasets\ntrain_dataset = Dataset(X=X_train, y=y_train)\nval_dataset = Dataset(X=X_val, y=y_val)\ntest_dataset = Dataset(X=X_test, y=y_test)\nprint (\"Datasets:\\n\"\n f\" Train dataset:{train_dataset.__str__()}\\n\"\n f\" Val dataset: {val_dataset.__str__()}\\n\"\n f\" Test dataset: {test_dataset.__str__()}\\n\"\n \"Sample point:\\n\"\n f\" X: {train_dataset[0][0]}\\n\"\n f\" y: {train_dataset[0][1]}\")\n\nDatasets:\n Train dataset: <Dataset(N=1050)>\n Val dataset: <Dataset(N=225)>\n Test dataset: <Dataset(N=225)>\nSample point:\n X: [-1.47355106 -1.67417243]\n y: 0\n
So far, we used batch gradient descent to update our weights. This means that we calculated the gradients using the entire training dataset. We also could've updated our weights using stochastic gradient descent (SGD) where we pass in one training example one at a time. The current standard is mini-batch gradient descent, which strikes a balance between batch and SGD, where we update the weights using a mini-batch of n (BATCH_SIZE) samples. This is where the DataLoader object comes in handy.
# Create dataloaders\nbatch_size = 64\ntrain_dataloader = train_dataset.create_dataloader(batch_size=batch_size)\nval_dataloader = val_dataset.create_dataloader(batch_size=batch_size)\ntest_dataloader = test_dataset.create_dataloader(batch_size=batch_size)\nbatch_X, batch_y = next(iter(train_dataloader))\nprint (\"Sample batch:\\n\"\n f\" X: {list(batch_X.size())}\\n\"\n f\" y: {list(batch_y.size())}\\n\"\n \"Sample point:\\n\"\n f\" X: {batch_X[0]}\\n\"\n f\" y: {batch_y[0]}\")\n\nSample batch:\n X: [64, 2]\n y: [64]\nSample point:\n X: tensor([-1.4736, -1.6742])\n y: 0\n"},{"location":"courses/foundations/utilities/#device","title":"Device","text":"
So far we've been running our operations on the CPU but when we have large datasets and larger models to train, we can benefit by parallelizing tensor operations on a GPU. In this notebook, you can use a GPU by going to Runtime > Change runtime type > Select GPU in the Hardware accelerator dropdown. We can what device we're using with the following line of code:
# Set CUDA seeds\ntorch.cuda.manual_seed(SEED)\ntorch.cuda.manual_seed_all(SEED) # multi-GPU\n# Device configuration\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nprint (device)\n\ncuda\n"},{"location":"courses/foundations/utilities/#model","title":"Model","text":"
Let's initialize the model we'll be using to show the capabilities of training utilities.
import math\nfrom torch import nn\nimport torch.nn.functional as F\nINPUT_DIM = X_train.shape[1] # 2D\nHIDDEN_DIM = 100\nDROPOUT_P = 0.1\nNUM_CLASSES = len(label_encoder.classes)\nNUM_EPOCHS = 10\nclass MLP(nn.Module):\n def __init__(self, input_dim, hidden_dim, dropout_p, num_classes):\n super(MLP, self).__init__()\n self.fc1 = nn.Linear(input_dim, hidden_dim)\n self.dropout = nn.Dropout(dropout_p)\n self.fc2 = nn.Linear(hidden_dim, num_classes)\n\n def forward(self, inputs):\n x_in, = inputs\n z = F.relu(self.fc1(x_in))\n z = self.dropout(z)\n z = self.fc2(z)\n return z\n# Initialize model\nmodel = MLP(\n input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel = model.to(device) # set device\nprint (model.named_parameters)\n\n<bound method Module.named_parameters of MLP(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=3, bias=True)\n)>\n"},{"location":"courses/foundations/utilities/#trainer","title":"Trainer","text":"
So far we've been writing training loops that train only using the train data split and then we perform evaluation on our test set. But in reality, we would follow this process:
We'll create a Trainer class to keep all of these processes organized.
The first function in the class is train_step which will train the model using batches from one epoch of the train data split.
def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\nNext we'll define the eval_step which will be used for processing both the validation and test data splits. This is because neither of them require gradient updates and display the same metrics.
def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\nThe final function is the predict_step which will be used for inference. It's fairly similar to the eval_step except we don't calculate any metrics. We pass on the predictions which we can use to generate our performance scores.
def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\nAs our model starts to optimize and perform better, the loss will reduce and we'll need to make smaller adjustments. If we keep using a fixed learning rate, we'll be overshooting back and forth. Therefore, we're going to add a learning rate scheduler to our optimizer to adjust our learning rate during training. There are many schedulers schedulers to choose from but a popular one is ReduceLROnPlateau which reduces the learning rate when a metric (ex. validation loss) stops improving. In the example below we'll reduce the learning rate by a factor of 0.1 (factor=0.1) when our metric of interest (self.scheduler.step(val_loss)) stops decreasing (mode=\"min\") for three (patience=3) straight epochs.
# Initialize the LR scheduler\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\n...\ntrain_loop():\n ...\n # Steps\n train_loss = trainer.train_step(dataloader=train_dataloader)\n val_loss, _, _ = trainer.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n ...\nWe should never train our models for an arbitrary number of epochs but instead we should have explicit stopping criteria (even if you are bootstrapped by compute resources). Common stopping criteria include when validation performance stagnates for certain # of epochs (patience), desired performance is reached, etc.
# Early stopping\nif val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = trainer.model\n _patience = patience # reset _patience\nelse:\n _patience -= 1\nif not _patience: # 0\n print(\"Stopping early!\")\n break\nLet's put all of this together now to train our model.
from torch.optim import Adam\nLEARNING_RATE = 1e-2\nNUM_EPOCHS = 100\nPATIENCE = 3\n# Define Loss\nclass_weights_tensor = torch.Tensor(list(class_weights.values())).to(device)\nloss_fn = nn.CrossEntropyLoss(weight=class_weights_tensor)\n# Define optimizer & scheduler\noptimizer = Adam(model.parameters(), lr=LEARNING_RATE)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=3)\nclass Trainer(object):\n def __init__(self, model, device, loss_fn=None, optimizer=None, scheduler=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n\n def train_step(self, dataloader):\n\"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, targets = batch[:-1], batch[-1]\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, targets) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n\"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Step\n batch = [item.to(self.device) for item in batch] # Set device\n inputs, y_true = batch[:-1], batch[-1]\n z = self.model(inputs) # Forward pass\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n\"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch[:-1], batch[-1]\n z = self.model(inputs)\n\n # Store outputs\n y_prob = F.softmax(z).cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n\n def train(self, num_epochs, patience, train_dataloader, val_dataloader):\n best_val_loss = np.inf\n for epoch in range(num_epochs):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Logging\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n return best_model\n# Trainer module\ntrainer = Trainer(\n model=model, device=device, loss_fn=loss_fn,\n optimizer=optimizer, scheduler=scheduler)\n# Train\nbest_model = trainer.train(\n NUM_EPOCHS, PATIENCE, train_dataloader, val_dataloader)\n\nEpoch: 1 | train_loss: 0.73999, val_loss: 0.58441, lr: 1.00E-02, _patience: 3\nEpoch: 2 | train_loss: 0.52631, val_loss: 0.41542, lr: 1.00E-02, _patience: 3\nEpoch: 3 | train_loss: 0.40919, val_loss: 0.30673, lr: 1.00E-02, _patience: 3\nEpoch: 4 | train_loss: 0.31421, val_loss: 0.22428, lr: 1.00E-02, _patience: 3\n...\nEpoch: 48 | train_loss: 0.04100, val_loss: 0.02100, lr: 1.00E-02, _patience: 2\nEpoch: 49 | train_loss: 0.04155, val_loss: 0.02008, lr: 1.00E-02, _patience: 3\nEpoch: 50 | train_loss: 0.05295, val_loss: 0.02094, lr: 1.00E-02, _patience: 2\nEpoch: 51 | train_loss: 0.04619, val_loss: 0.02179, lr: 1.00E-02, _patience: 1\nStopping early!\n"},{"location":"courses/foundations/utilities/#evaluation","title":"Evaluation","text":"
import json\nfrom sklearn.metrics import precision_recall_fscore_support\ndef get_metrics(y_true, y_pred, classes):\n\"\"\"Per-class performance metrics.\"\"\"\n # Performance\n performance = {\"overall\": {}, \"class\": {}}\n\n # Overall performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance[\"overall\"][\"precision\"] = metrics[0]\n performance[\"overall\"][\"recall\"] = metrics[1]\n performance[\"overall\"][\"f1\"] = metrics[2]\n performance[\"overall\"][\"num_samples\"] = np.float64(len(y_true))\n\n # Per-class performance\n metrics = precision_recall_fscore_support(y_true, y_pred, average=None)\n for i in range(len(classes)):\n performance[\"class\"][classes[i]] = {\n \"precision\": metrics[0][i],\n \"recall\": metrics[1][i],\n \"f1\": metrics[2][i],\n \"num_samples\": np.float64(metrics[3][i]),\n }\n\n return performance\n# Get predictions\ntest_loss, y_true, y_prob = trainer.eval_step(dataloader=test_dataloader)\ny_pred = np.argmax(y_prob, axis=1)\n# Determine performance\nperformance = get_metrics(\n y_true=y_test, y_pred=y_pred, classes=label_encoder.classes)\nprint (json.dumps(performance[\"overall\"], indent=2))\n\n{\n \"precision\": 0.9956140350877193,\n \"recall\": 0.9955555555555556,\n \"f1\": 0.9955553580159119,\n \"num_samples\": 225.0\n}\n"},{"location":"courses/foundations/utilities/#saving-loading","title":"Saving & loading","text":"Many tutorials never show you how to save the components you created so you can load them for inference.
from pathlib import Path\n# Save artifacts\ndir = Path(\"mlp\")\ndir.mkdir(parents=True, exist_ok=True)\nlabel_encoder.save(fp=Path(dir, \"label_encoder.json\"))\nX_scaler.save(fp=Path(dir, \"X_scaler.json\"))\ntorch.save(best_model.state_dict(), Path(dir, \"model.pt\"))\nwith open(Path(dir, 'performance.json'), \"w\") as fp:\n json.dump(performance, indent=2, sort_keys=False, fp=fp)\n# Load artifacts\ndevice = torch.device(\"cpu\")\nlabel_encoder = LabelEncoder.load(fp=Path(dir, \"label_encoder.json\"))\nX_scaler = StandardScaler.load(fp=Path(dir, \"X_scaler.json\"))\nmodel = MLP(\n input_dim=INPUT_DIM, hidden_dim=HIDDEN_DIM,\n dropout_p=DROPOUT_P, num_classes=NUM_CLASSES)\nmodel.load_state_dict(torch.load(Path(dir, \"model.pt\"), map_location=device))\nmodel.to(device)\n\nMLP(\n (fc1): Linear(in_features=2, out_features=100, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n (fc2): Linear(in_features=100, out_features=3, bias=True)\n)\n
# Initialize trainer\ntrainer = Trainer(model=model, device=device)\n# Dataloader\nsample = [[0.106737, 0.114197]] # c1\nX = X_scaler.scale(sample)\ny_filler = label_encoder.encode([label_encoder.classes[0]]*len(X))\ndataset = Dataset(X=X, y=y_filler)\ndataloader = dataset.create_dataloader(batch_size=batch_size)\n# Inference\ny_prob = trainer.predict_step(dataloader)\ny_pred = np.argmax(y_prob, axis=1)\nlabel_encoder.decode(y_pred)\n\n[\"c1\"]\n"},{"location":"courses/foundations/utilities/#miscellaneous","title":"Miscellaneous","text":"
There are lots of other utilities to cover, such as:
We'll explore these as we require them in future lessons including some in our MLOps course!
To cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Utilities - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nOur CLI application made it much easier to interact with our models, especially for fellow team members who may not want to delve into the codebase. But there are several limitations to serving our models with a CLI:
To address these issues, we're going to develop an application programming interface (API) that will anyone to interact with our application with a simple request.
The end user may not directly interact with our API but may use UI/UX components that send requests to our it.
"},{"location":"courses/mlops/api/#serving","title":"Serving","text":"APIs allow different applications to communicate with each other in real-time. But when it comes to serving predictions, we need to first decide if we'll do that in batches or real-time, which is entirely based on the feature space (finite vs. unbound).
"},{"location":"courses/mlops/api/#batch-serving","title":"Batch serving","text":"We can make batch predictions on a finite set of inputs which are then written to a database for low latency inference. When a user or downstream process sends an inference request in real-time, cached results from the database are returned.
Batch serving tasks
What are some tasks where batch serving is ideal?
Show answerRecommend content that existing users will like based on their viewing history. However, new users may just receive some generic recommendations based on their explicit interests until we process their history the next day. And even if we're not doing batch serving, it might still be useful to cache very popular sets of input features (ex. combination of explicit interests leads to certain recommended content) so that we can serve those predictions faster.
"},{"location":"courses/mlops/api/#real-time-serving","title":"Real-time serving","text":"We can also serve live predictions, typically through a request to an API with the appropriate input data.
In this lesson, we'll create the API required to enable real-time serving. The interactions in our situation involve the client (users, other applications, etc.) sending a request (ex. prediction request) with the appropriate inputs to the server (our application with a trained model) and receiving a response (ex. prediction) in return.
"},{"location":"courses/mlops/api/#request","title":"Request","text":"Users will interact with our API in the form of a request. Let's take a look at the different components of a request:
"},{"location":"courses/mlops/api/#uri","title":"URI","text":"A uniform resource identifier (URI) is an identifier for a specific resource.
\nhttps://localhost:8000/models/{modelId}/?filter=passed#details\n Parts of the URI Description scheme protocol definition domain address of the website port endpoint path location of the resource query string parameters to identify resources anchor location on webpage Parts of the path Description /models collection resource of all models /models/{modelID} single resource from the models collection modelId path parameters filter query parameter"},{"location":"courses/mlops/api/#method","title":"Method","text":"The method is the operation to execute on the specific resource defined by the URI. There are many possible methods to choose from, but the four below are the most popular, which are often referred to as CRUD because they allow you to Create, Read, Update and Delete.
GET: get a resource.POST: create or update a resource.PUT/PATCH: create or update a resource.DELETE: delete a resource.Note
You could use either the POST or PUT request method to create and modify resources but the main difference is that PUT is idempotent which means you can call the method repeatedly and it'll produce the same state every time. Whereas, calling POST multiple times can result in creating multiple instance and so changes the overall state each time.
POST /models/<new_model> -d {} # error since we haven't created the `new_model` resource yet\nPOST /models -d {} # creates a new model based on information provided in data\nPOST /models/<existing_model> -d {} # updates an existing model based on information provided in data\n\nPUT /models/<new_model> -d {} # creates a new model based on information provided in data\nPUT /models/<existing_model> -d {} # updates an existing model based on information provided in data\nWe can use cURL to execute our API calls with the following options:
curl --help\n\nUsage: curl [options...] \n-X, --request HTTP method (ie. GET)\n-H, --header headers to be sent to the request (ex. authentication)\n-d, --data data to POST, PUT/PATCH, DELETE (usually JSON)\n...\n\n\nFor example, if we want to GET all
models, our cURL command would look like this:\n\n"},{"location":"courses/mlops/api/#headers","title":"Headers","text":"curl -X GET \"http://localhost:8000/models\"\nHeaders contain information about a certain event and are usually found in both the client's request as well as the server's response. It can range from what type of format they'll send and receive, authentication and caching info, etc.\n
\n"},{"location":"courses/mlops/api/#body","title":"Body","text":"curl -X GET \"http://localhost:8000/\" \\ # method and URI\n-H \"accept: application/json\" \\ # client accepts JSON\n-H \"Content-Type: application/json\" \\ # client sends JSON\nThe body contains information that may be necessary for the request to be processed. It's usually a JSON object sent during
\nPOST,PUT/PATCH,DELETErequest methods.\n"},{"location":"courses/mlops/api/#response","title":"Response","text":"curl -X POST \"http://localhost:8000/models\" \\ # method and URI\n-H \"accept: application/json\" \\ # client accepts JSON\n-H \"Content-Type: application/json\" \\ # client sends JSON\n-d \"{'name': 'RoBERTa', ...}\" # request body\nThe response we receive from our server is the result of the request we sent. The response also includes headers and a body which should include the proper HTTP status code as well as explicit messages, data, etc.
\n\n{\n\"message\": \"OK\",\n \"method\": \"GET\",\n \"status-code\": 200,\n \"url\": \"http://localhost:8000/\",\n \"data\": {}\n}\nWe may also want to include other metadata in the response such as model version, datasets used, etc. Anything that the downstream consumer may be interested in or metadata that might be useful for inspection.
\nThere are many HTTP status codes to choose from depending on the situation but here are the most common options:
\n\nCode\nDescription\n
"},{"location":"courses/mlops/api/#best-practices","title":"Best practices","text":"200 OK\nmethod operation was successful.\n201 CREATED\nPOSTorPUTmethod successfully created a resource.\n202 ACCEPTED\nthe request was accepted for processing (but processing may not be done).\n400 BAD REQUEST\nserver cannot process the request because of a client side error.\n401 UNAUTHORIZED\nyou're missing required authentication.\n403 FORBIDDEN\nyou're not allowed to do this operation.\n404 NOT FOUND\nthe resource you're looking for was not found.\n500 INTERNAL SERVER ERROR\nthere was a failure somewhere in the system process.\n501 NOT IMPLEMENTED\nthis operation on the resource doesn't exist yet.\nWhen designing our API, there are some best practices to follow:
\n
GET /users not \u274c\u00a0 GET /get_users).GET /users/{userId} not \u274c\u00a0 GET /user/{userID}).GET /nlp-models/?find_desc=bert).We're going to define our API in a separate app directory because, in the future, we may have additional packages like tagifai and we don't want our app to be attached to any one package. Inside our app directory, we'll create the follow scripts:
mkdir app\ncd app\ntouch api.py gunicorn.py schemas.py\ncd ../\napp/\n\u251c\u2500\u2500 api.py - FastAPI app\n\u251c\u2500\u2500 gunicorn.py - WSGI script\n\u2514\u2500\u2500 schemas.py - API model schemas\napi.py: the main script that will include our API initialization and endpoints.gunicorn.py: script for defining API worker configurations.schemas.py: definitions for the different objects we'll use in our resource endpoints.We're going to use FastAPI as our framework to build our API service. There are plenty of other framework options out there such as Flask, Django and even non-Python based options like Node, Angular, etc. FastAPI combines many of the advantages across these frameworks and is maturing quickly and becoming more widely adopted. It's notable advantages include:
\npip install fastapi==0.78.0\n# Add to requirements.txt\nfastapi==0.78.0\nYour choice of framework also depends on your team's existing systems and processes. However, with the wide adoption of microservices, we can wrap our specific application in any framework we choose and expose the appropriate resources so all other systems can easily communicate with it.
"},{"location":"courses/mlops/api/#initialization","title":"Initialization","text":"The first step is to initialize our API in our api.py script` by defining metadata like the title, description and version:
# app/api.py\nfrom fastapi import FastAPI\n\n# Define application\napp = FastAPI(\n title=\"TagIfAI - Made With ML\",\n description=\"Classify machine learning projects.\",\n version=\"0.1\",\n)\nOur first endpoint is going to be a simple one where we want to show that everything is working as intended. The path for the endpoint will just be / (when a user visit our base URI) and it'll be a GET request. This simple endpoint is often used as a health check to ensure that our application is indeed up and running properly.
# app/api.py\nfrom http import HTTPStatus\nfrom typing import Dict\n@app.get(\"/\")\ndef _index() -> Dict:\n\"\"\"Health check.\"\"\"\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {},\n }\n return response\nWe let our application know that the endpoint is at / through the path operation decorator in line 4 and we return a JSON response with the 200 OK HTTP status code.
In our actual api.py script, you'll notice that even our index function looks different. Don't worry, we're slowly adding components to our endpoints and justifying them along the way.
We're using Uvicorn, a fast ASGI server that can run asynchronous code in a single process to launch our application.
\npip install uvicorn==0.17.6\n# Add to requirements.txt\nuvicorn==0.17.6\nWe can launch our application with the following command:
\nuvicorn app.api:app \\ # location of app (`app` directory > `api.py` script > `app` object)\n--host 0.0.0.0 \\ # localhost\n--port 8000 \\ # port 8000\n--reload \\ # reload every time we update\n--reload-dir tagifai \\ # only reload on updates to `tagifai` directory\n--reload-dir app # and the `app` directory\n\nINFO: Will watch for changes in these directories: ['/Users/goku/Documents/madewithml/mlops/app', '/Users/goku/Documents/madewithml/mlops/tagifai']\nINFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)\nINFO: Started reloader process [57609] using statreload\nINFO: Started server process [57611]\nINFO: Waiting for application startup.\nINFO: Application startup complete.\n\n\n
Notice that we only reload on changes to specific directories, as this is to avoid reloading on files that won't impact our application such as log files, etc.
\nIf we want to manage multiple uvicorn workers to enable parallelism in our application, we can use Gunicorn in conjunction with Uvicorn. This will usually be done in a production environment where we'll be dealing with meaningful traffic. We've included a app/gunicorn.py script with the customizable configuration and we can launch all the workers with the follow command:\n
gunicorn -c config/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app\nWe'll add both of these commands to our README.md file as well:\n
uvicorn app.api:app --host 0.0.0.0 --port 8000 --reload --reload-dir tagifai --reload-dir app # dev\ngunicorn -c app/gunicorn.py -k uvicorn.workers.UvicornWorker app.api:app # prod\nNow that we have our application running, we can submit our GET request using several different methods:
curl -X GET http://localhost:8000/\nimport json\nimport requests\n\nresponse = requests.get(\"http://localhost:8000/\")\nprint (json.loads(response.text))\nFor all of these, we'll see the exact same response from our API:
\n\n{\n \"message\": \"OK\",\n \"status-code\": 200,\n \"data\": {}\n}\n"},{"location":"courses/mlops/api/#decorators","title":"Decorators","text":"In our GET \\ request's response above, there was not a whole lot of information about the actual request, but it's useful to have details such as URL, timestamp, etc. But we don't want to do this individually for each endpoint, so let's use decorators to automatically add relevant metadata to our responses
# app/api.py\nfrom datetime import datetime\nfrom functools import wraps\nfrom fastapi import FastAPI, Request\n\ndef construct_response(f):\n\"\"\"Construct a JSON response for an endpoint.\"\"\"\n\n @wraps(f)\ndef wrap(request: Request, *args, **kwargs) -> Dict:\nresults = f(request, *args, **kwargs)\n response = {\n \"message\": results[\"message\"],\n \"method\": request.method,\n \"status-code\": results[\"status-code\"],\n \"timestamp\": datetime.now().isoformat(),\n \"url\": request.url._url,\n }\n if \"data\" in results:\n response[\"data\"] = results[\"data\"]\n return response\n\n return wrap\nWe're passing in a Request instance in line 10 so we can access information like the request method and URL. Therefore, our endpoint functions also need to have this Request object as an input argument. Once we receive the results from our endpoint function f, we can append the extra details and return a more informative response. To use this decorator, we just have to wrap our functions accordingly.
@app.get(\"/\")\n@construct_response\ndef _index(request: Request) -> Dict:\n\"\"\"Health check.\"\"\"\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {},\n }\n return response\n\n{\n message: \"OK\",\n method: \"GET\",\n status-code: 200,\n timestamp: \"2021-02-08T13:19:11.343801\",\n url: \"http://localhost:8000/\",\n data: { }\n}\n\n\nThere are also some built-in decorators we should be aware of. We've already seen the path operation decorator (ex. @app.get(\"/\")) which defines the path for the endpoint as well as other attributes. There is also the events decorator (@app.on_event()) which we can use to startup and shutdown our application. For example, we use the (@app.on_event(\"startup\")) event to load the artifacts for the model to use for inference. The advantage of doing this as an event is that our service won't start until this is complete and so no requests will be prematurely processed and cause errors. Similarly, we can perform shutdown events with (@app.on_event(\"shutdown\")), such as saving logs, cleaning, etc.
from pathlib import Path\nfrom config import logger\nfrom tagifai import main\n\n@app.on_event(\"startup\")\ndef load_artifacts():\nglobal artifacts\n run_id = open(Path(config.CONFIG_DIR, \"run_id.txt\")).read()\n artifacts = main.load_artifacts(model_dir=config.MODEL_DIR)\n logger.info(\"Ready for inference!\")\nWhen we define an endpoint, FastAPI automatically generates some documentation (adhering to OpenAPI standards) based on the it's inputs, typing, outputs, etc. We can access the Swagger UI for our documentation by going to /docs endpoints on any browser while the api is running.
Click on an endpoint > Try it out > Execute to see what the server's response will look like. Since this was a GET request without any inputs, our request body was empty but for other method's we'll need to provide some information (we'll illustrate this when we do a POST request).
Notice that our endpoint is organized under sections in the UI. We can use tags when defining our endpoints in the script:\n
@app.get(\"/\", tags=[\"General\"])\n@construct_response\ndef _index(request: Request) -> Dict:\n\"\"\"Health check.\"\"\"\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {},\n }\n return response\nYou can also use /redoc endpoint to view the ReDoc documentation or Postman to execute and manage tests that you can save and share with others.
When designing the resources for our API , we need to think about the following questions:
\n[USERS]: Who are the end users? This will define what resources need to be exposed.
[ACTIONS]: What actions do our users want to be able to perform?
@app.get(\"/performance\", tags=[\"Performance\"])\n@construct_response\ndef _performance(request: Request, filter: str = None) -> Dict:\n\"\"\"Get the performance metrics.\"\"\"\n performance = artifacts[\"performance\"]\n data = {\"performance\":performance.get(filter, performance)}\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": data,\n }\n return response\nNotice that we're passing an optional query parameter filter here to indicate the subset of performance we care about. We can include this parameter in our GET request like so:
curl -X \"GET\" \\\n\"http://localhost:8000/performance?filter=overall\" \\\n-H \"accept: application/json\"\nAnd this will only produce the subset of the performance we indicated through the query parameter:
\n{\n\"message\": \"OK\",\n\"method\": \"GET\",\n\"status-code\": 200,\n\"timestamp\": \"2021-03-21T13:12:01.297630\",\n\"url\": \"http://localhost:8000/performance?filter=overall\",\n\"data\": {\n\"performance\": {\n\"precision\": 0.8941372402587212,\n\"recall\": 0.8333333333333334,\n\"f1\": 0.8491658224308651,\n\"num_samples\": 144\n}\n}\n}\nOur next endpoint will be to GET the arguments used to train the model. This time, we're using a path parameter args, which is a required field in the URI.
@app.get(\"/args/{arg}\", tags=[\"Arguments\"])\n@construct_response\ndef _arg(request: Request, arg: str) -> Dict:\n\"\"\"Get a specific parameter's value used for the run.\"\"\"\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {\n arg: vars(artifacts[\"args\"]).get(arg, \"\"),\n },\n }\n return response\nWe can perform our GET request like so, where the param is part of the request URI's path as opposed to being part of it's query string.\n
curl -X \"GET\" \\\n\"http://localhost:8000/args/learning_rate\" \\\n-H \"accept: application/json\"\nAnd we'd receive a response like this:
\n{\n\"message\": \"OK\",\n\"method\": \"GET\",\n\"status-code\": 200,\n\"timestamp\": \"2021-03-21T13:13:46.696429\",\n\"url\": \"http://localhost:8000/params/hidden_dim\",\n\"data\": {\n\"learning_rate\": 0.14688087680118794\n}\n}\nWe can also create an endpoint to produce all the arguments that were used:
\nViewGET /args\n@app.get(\"/args\", tags=[\"Arguments\"])\n@construct_response\ndef _args(request: Request) -> Dict:\n\"\"\"Get all arguments used for the run.\"\"\"\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {\n \"args\": vars(artifacts[\"args\"]),\n },\n }\n return response\nWe can perform our GET request like so, where the param is part of the request URI's path as opposed to being part of it's query string.
curl -X \"GET\" \\\n\"http://localhost:8000/args\" \\\n-H \"accept: application/json\"\nAnd we'd receive a response like this:
\n{\n\"message\":\"OK\",\n\"method\":\"GET\",\n\"status-code\":200,\n\"timestamp\":\"2022-05-25T11:56:37.344762\",\n\"url\":\"http://localhost:8001/args\",\n\"data\":{\n\"args\":{\n\"shuffle\":true,\n\"subset\":null,\n\"min_freq\":75,\n\"lower\":true,\n\"stem\":false,\n\"analyzer\":\"char_wb\",\n\"ngram_max_range\":8,\n\"alpha\":0.0001,\n\"learning_rate\":0.14688087680118794,\n\"power_t\":0.158985493618746\n}\n}\n}\nNow it's time to define our endpoint for prediction. We need to consume the inputs that we want to classify and so we need to define the schema that needs to be followed when defining those inputs.
\n# app/schemas.py\nfrom typing import List\nfrom fastapi import Query\nfrom pydantic import BaseModel\n\nclass Text(BaseModel):\n text: str = Query(None, min_length=1)\n\nclass PredictPayload(BaseModel):\n texts: List[Text]\nHere we're defining a PredictPayload object as a List of Text objects called texts. Each Text object is a string that defaults to None and must have a minimum length of 1 character.
Note
\nWe could've just defined our PredictPayload like so:\n
class PredictPayload(BaseModel):\n texts: List[str] = Query(None, min_length=1)\nWe can now use this payload in our predict endpoint:
\nfrom app.schemas import PredictPayload\nfrom tagifai import predict\n\n@app.post(\"/predict\", tags=[\"Prediction\"])\n@construct_response\ndef _predict(request: Request, payload: PredictPayload) -> Dict:\n\"\"\"Predict tags for a list of texts.\"\"\"\n texts = [item.text for item in payload.texts]\n predictions = predict.predict(texts=texts, artifacts=artifacts)\n response = {\n \"message\": HTTPStatus.OK.phrase,\n \"status-code\": HTTPStatus.OK,\n \"data\": {\"predictions\": predictions},\n }\n return response\nWe need to adhere to the PredictPayload schema when we want to user our /predict endpoint:
curl -X 'POST' 'http://0.0.0.0:8000/predict' \\\n-H 'accept: application/json' \\\n-H 'Content-Type: application/json' \\\n-d '{\n \"texts\": [\n {\"text\": \"Transfer learning with transformers for text classification.\"},\n {\"text\": \"Generative adversarial networks for image generation.\"}\n ]\n }'\n\n{\n \"message\":\"OK\",\n \"method\":\"POST\",\n \"status-code\":200,\n \"timestamp\":\"2022-05-25T12:23:34.381614\",\n \"url\":\"http://0.0.0.0:8001/predict\",\n \"data\":{\n \"predictions\":[\n {\n \"input_text\":\"Transfer learning with transformers for text classification.\",\n \"predicted_tag\":\"natural-language-processing\"\n },\n {\n \"input_text\":\"Generative adversarial networks for image generation.\",\n \"predicted_tag\":\"computer-vision\"\n }\n ]\n }\n}\n"},{"location":"courses/mlops/api/#validation","title":"Validation","text":""},{"location":"courses/mlops/api/#built-in","title":"Built-in","text":"We're using pydantic's BaseModel object here because it offers built-in validation for all of our schemas. In our case, if a Text instance is less than 1 character, then our service will return the appropriate error message and code:
curl -X POST \"http://localhost:8000/predict\" -H \"accept: application/json\" -H \"Content-Type: application/json\" -d \"{\\\"texts\\\":[{\\\"text\\\":\\\"\\\"}]}\"\n\n{\n \"detail\": [\n {\n \"loc\": [\n \"body\",\n \"texts\",\n 0,\n \"text\"\n ],\n \"msg\": \"ensure this value has at least 1 characters\",\n \"type\": \"value_error.any_str.min_length\",\n \"ctx\": {\n \"limit_value\": 1\n }\n }\n ]\n}\n"},{"location":"courses/mlops/api/#custom","title":"Custom","text":"We can also add custom validation on a specific entity by using the @validator decorator, like we do to ensure that list of texts is not empty.
class PredictPayload(BaseModel):\n texts: List[Text]\n\n@validator(\"texts\")\ndef list_must_not_be_empty(cls, value):\nif not len(value):\nraise ValueError(\"List of texts to classify cannot be empty.\")\nreturn value\ncurl -X POST \"http://localhost:8000/predict\" -H \"accept: application/json\" -H \"Content-Type: application/json\" -d \"{\\\"texts\\\":[]}\"\n\n{\n \"detail\":[\n {\n \"loc\":[\n \"body\",\n \"texts\"\n ],\n \"msg\": \"List of texts to classify cannot be empty.\",\n \"type\": \"value_error\"\n }\n ]\n}\n"},{"location":"courses/mlops/api/#extras","title":"Extras","text":"Lastly, we can add a schema_extra object under a Config class to depict what an example PredictPayload should look like. When we do this, it automatically appears in our endpoint's documentation (click Try it out).
class PredictPayload(BaseModel):\n texts: List[Text]\n\n @validator(\"texts\")\n def list_must_not_be_empty(cls, value):\n if not len(value):\n raise ValueError(\"List of texts to classify cannot be empty.\")\n return value\n\nclass Config:\nschema_extra = {\n\"example\": {\n\"texts\": [\n{\"text\": \"Transfer learning with transformers for text classification.\"},\n{\"text\": \"Generative adversarial networks in both PyTorch and TensorFlow.\"},\n]\n}\n}\nTo make our API a standalone product, we'll need to create and manage a database for our users and resources. These users will have credentials which they will use for authentication and use their privileges to be able to communicate with our service. And of course, we can display a rendered frontend to make all of this seamless with HTML forms, buttons, etc. This is exactly how the old MWML platform was built and we leveraged FastAPI to deliver high performance for 500K+ daily service requests.
\nIf you are building a product, then I highly recommending forking this generation template to get started. It includes the backbone architecture you need for your product:
\nHowever, for the majority of ML developers, thanks to the wide adoption of microservices, we don't need to do all of this. A well designed API service that can seamlessly communicate with all other services (framework agnostic) will fit into any process and add value to the overall product. Our main focus should be to ensure that our service is working as it should and constantly improve, which is exactly what the next cluster of lessons will focus on (testing and monitoring)
"},{"location":"courses/mlops/api/#model-server","title":"Model server","text":"Besides wrapping our models as separate, scalable microservices, we can also have a purpose-built model server to host our models. Model servers provide a registry with an API layer to seamlessly inspect, update, serve, rollback, etc. multiple versions of models. They also offer automatic scaling to meet throughput and latency needs. Popular options include BentoML, MLFlow, TorchServe, RedisAI, Nvidia Triton Inference Server, etc.
\nModel servers are experiencing a lot of adoption for their ability to standardize the model deployment and serving processes across the team -- enabling seamless upgrades, validation and integration.
\nUpcoming live cohorts
\nSign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.\n\n
\n Learn more\n\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { APIs for Model Serving - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWe'll often want to increase the size and diversity of our training data split through data augmentation. It involves using the existing samples to generate synthetic, yet realistic, examples.
Split the dataset. We want to split our dataset first because many augmentation techniques will cause a form of data leak if we allow the generated samples to be placed across different data splits.
For example, some augmentation involves generating synonyms for certain key tokens in a sentence. If we allow the generated sentences from the same origin sentence to go into different splits, we could be potentially leaking samples with nearly identical embedding representations across our different splits.
Augment the training split. We want to apply data augmentation on only the training set because our validation and testing splits should be used to provide an accurate estimate on actual data points.
Inspect and validate. It's useless to augment just for the same of increasing our training sample size if the augmented data samples are not probable inputs that our model could encounter in production.
The exact method of data augmentation depends largely on the type of data and the application. Here are a few ways different modalities of data can be augmented:
Data Augmentation with SnorkelWarning
While the transformations on some data modalities, such as images, are easy to inspect and validate, others may introduce silent errors. For example, shifting the order of tokens in text can significantly alter the meaning (\u201cthis is really cool\u201d \u2192 \u201cis this really cool\u201d). Therefore, it\u2019s important to measure the noise that our augmentation policies will introduce and do have granular control over the transformations that take place.
"},{"location":"courses/mlops/augmentation/#libraries","title":"Libraries","text":"Depending on the feature types and tasks, there are many data augmentation libraries which allow us to extend our training data.
"},{"location":"courses/mlops/augmentation/#natural-language-processing-nlp","title":"Natural language processing (NLP)","text":"Let's use the nlpaug library to augment our dataset and assess the quality of the generated samples.
pip install nlpaug==1.1.0 transformers==3.0.2 -q\npip install snorkel==0.9.8 -q\nimport nlpaug.augmenter.word as naw\n# Load tokenizers and transformers\nsubstitution = naw.ContextualWordEmbsAug(model_path=\"distilbert-base-uncased\", action=\"substitute\")\ninsertion = naw.ContextualWordEmbsAug(model_path=\"distilbert-base-uncased\", action=\"insert\")\ntext = \"Conditional image generation using Variational Autoencoders and GANs.\"\n# Substitutions\nsubstitution.augment(text)\n\nhierarchical risk mapping using variational signals and gans.\n
Substitution doesn't seem like a great idea for us because there are certain keywords that provide strong signal for our tags so we don't want to alter those. Also, note that these augmentations are NOT deterministic and will vary every time we run them. Let's try insertion...
# Insertions\ninsertion.augment(text)\n\nautomated conditional inverse image generation algorithms using multiple variational autoencoders and gans.\n
A little better but still quite fragile and now it can potentially insert key words that can influence false positive tags to appear. Maybe instead of substituting or inserting new tokens, let's try simply swapping machine learning related keywords with their aliases. We'll use Snorkel's transformation functions to easily achieve this.
# Replace dashes from tags & aliases\ndef replace_dash(x):\n return x.replace(\"-\", \" \")\n# Aliases\naliases_by_tag = {\n \"computer-vision\": [\"cv\", \"vision\"],\n \"mlops\": [\"production\"],\n \"natural-language-processing\": [\"nlp\", \"nlproc\"]\n}\n# Flatten dict\nflattened_aliases = {}\nfor tag, aliases in aliases_by_tag.items():\n tag = replace_dash(x=tag)\n if len(aliases):\n flattened_aliases[tag] = aliases\n for alias in aliases:\n _aliases = aliases + [tag]\n _aliases.remove(alias)\n flattened_aliases[alias] = _aliases\nprint (flattened_aliases[\"natural language processing\"])\nprint (flattened_aliases[\"nlp\"])\n\n['nlp', 'nlproc']\n['nlproc', 'natural language processing']\n
For now we'll use tags and aliases as they are in aliases_by_tag but we could account for plurality of tags using the inflect package or apply stemming before replacing aliases, etc.
# We want to match with the whole word only\nprint (\"gan\" in \"This is a gan.\")\nprint (\"gan\" in \"This is gandalf.\")\n# \\b matches spaces\ndef find_word(word, text):\n word = word.replace(\"+\", \"\\+\")\n pattern = re.compile(fr\"\\b({word})\\b\", flags=re.IGNORECASE)\n return pattern.search(text)\n# Correct behavior (single instance)\nprint (find_word(\"gan\", \"This is a gan.\"))\nprint (find_word(\"gan\", \"This is gandalf.\"))\n\n<re.Match object; span=(10, 13), match='gan'>\nNone\n
Now let's use snorkel's transformation_function to systematically apply this transformation to our data.
from snorkel.augmentation import transformation_function\n@transformation_function()\ndef swap_aliases(x):\n\"\"\"Swap ML keywords with their aliases.\"\"\"\n # Find all matches\n matches = []\n for i, tag in enumerate(flattened_aliases):\n match = find_word(tag, x.text)\n if match:\n matches.append(match)\n # Swap a random match with a random alias\n if len(matches):\n match = random.choice(matches)\n tag = x.text[match.start():match.end()]\n x.text = f\"{x.text[:match.start()]}{random.choice(flattened_aliases[tag])}{x.text[match.end():]}\"\n return x\n# Swap\nfor i in range(3):\n sample_df = pd.DataFrame([{\"text\": \"a survey of reinforcement learning for nlp tasks.\"}])\n sample_df.text = sample_df.text.apply(clean_text, lower=True, stem=False)\n print (swap_aliases(sample_df.iloc[0]).text)\n# Undesired behavior (needs contextual insight)\nfor i in range(3):\n sample_df = pd.DataFrame([{\"text\": \"Autogenerate your CV to apply for jobs using NLP.\"}])\n sample_df.text = sample_df.text.apply(clean_text, lower=True, stem=False)\n print (swap_aliases(sample_df.iloc[0]).text)\n\nautogenerate vision apply jobs using nlp\nautogenerate cv apply jobs using natural language processing\nautogenerate cv apply jobs using nlproc\n
Now we'll define a augmentation policy to apply our transformation functions with certain rules (how many samples to generate, whether to keep the original data point, etc.)
from snorkel.augmentation import ApplyOnePolicy, PandasTFApplier\n# Transformation function (TF) policy\npolicy = ApplyOnePolicy(n_per_original=5, keep_original=True)\ntf_applier = PandasTFApplier([swap_aliases], policy)\ntrain_df_augmented = tf_applier.apply(train_df)\ntrain_df_augmented.drop_duplicates(subset=[\"text\"], inplace=True)\ntrain_df_augmented.head()\nlen(train_df), len(train_df_augmented)\n\n(668, 913)\n
For now, we'll skip the data augmentation because it's quite fickle and empirically it doesn't improvement performance much. But we can see how this can be very effective once we can control what type of vocabulary to augment on and what exactly to augment with.
Warning
Regardless of what method we use, it's important to validate that we're not just augmenting for the sake of augmentation. We can do this by executing any existing data validation tests and even creating specific tests to apply on augmented data.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Data Augmentation - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn the previous lesson, we learned how to manually execute our ML workloads with Jobs and Services. However, we want to be able to automatically execute these workloads when certain events occur (new data, performance regressions, elapsed time, etc.) to ensure that our models are always up to date and increasing in quality. In this lesson, we'll learn how to create continuous integration and delivery (CI/CD) pipelines to achieve an application that is capable of continual learning.
"},{"location":"courses/mlops/cicd/#github-actions","title":"GitHub Actions","text":"We're going to use GitHub Actions to create our CI/CD pipelines. GitHub Actions allow us to define workflows that are triggered by events (pull request, push, etc.) and execute a series of actions.
Our GitHub Actions are defined under our repository's .github/workflows directory where we have workflows for documentation (documentation.yaml), workloads (workloads.yaml) to train/validate a model and a final workflow for serving our model (serve.yaml). Let's start by understanding the structure of a workflow.
Workflows are triggered by an event, which can be something that occurs on an event (like a push or pull request), schedule (cron), manually and many more. In our application, our workloads workflow is triggered on a pull request to the main branch and then our serve workflow and documentation workflows are triggered on a push to the main branch.
# .github/workflows/workloads.yaml\nname: workloads\non:\nworkflow_dispatch: # manual\npull_request:\nbranches:\n- main\n...\nThis creates for the following ideal workflow:
main branch.workloads workflow is triggered and executes our model development workloads.main branch.serve workflow is triggered and deploys our application to production (along with an update to our documentation).Once the event is triggered, a set of jobs run on a runner (GitHub's infrastructure or self-hosted).
# .github/workflows/workloads.yaml\n...\njobs:\nworkloads:\nruns-on: ubuntu-22.04\n...\nTip
Each of our workflows only have one job but if we had multiple, the jobs would all run in parallel. If we wanted to create dependent jobs, where if a particular job fails all it's dependent jobs will be skipped, then we'd use the needs keyword.
"},{"location":"courses/mlops/cicd/#steps","title":"Steps","text":"Each job contains a series of steps which are executed in order. Each step has a name, as well as actions to use from the GitHub Action marketplace and/or commands we want to run. For example, here's a look at one of the steps in our workloads job inside our workloads.yaml workflow:
# .github/workflows/testing.yml\njobs:\nworkloads:\nruns-on: ubuntu-22.04\nsteps:\n...\n# Run workloads\n- name: Workloads\nrun: |\nexport ANYSCALE_HOST=$\\{\\{ secrets.ANYSCALE_HOST \\}\\}\nexport ANYSCALE_CLI_TOKEN=$\\{\\{ secrets.ANYSCALE_CLI_TOKEN \\}\\}\nanyscale jobs submit deploy/jobs/workloads.yaml --wait\n...\nNow that we understand the basic components of a GitHub Actions workflow, let's take a closer look at each of our workflows. Most of our workflows will require access to our Anyscale credentials so we'll start by setting those up. We can set these secrets for our repository under the Settings tab.
And our first workflow will be our workloads workflow which will be triggered on a pull request to the main branch. This means that we'll need to push our local code changes to Git and then submit a pull request to the main branch. But in order to push our code to GitHub, we'll need to first authenticate with our credentials before pushing to our repository:
git config --global user.name $GITHUB_USERNAME\ngit config --global user.email you@example.com # <-- CHANGE THIS to your email\ngit add .\ngit commit -m \"\" # <-- CHANGE THIS to your message\ngit push origin dev\nNow you will be prompted to enter your username and password (personal access token). Follow these steps to get personal access token: New GitHub personal access token \u2192 Add a name \u2192 Toggle repo and workflow \u2192 Click Generate token (scroll down) \u2192 Copy the token and paste it when prompted for your password.
Note that we should be on a dev branch, which we set up in our setup lesson. If you're not, go ahead and run git checkout -b dev first.
And when any of our GitHub Actions workflows execute, we will be able to view them under the Actions tab of our repository. Here we'll find all the workflows that have been executed and we can inspect each one to see the details of the execution.
Our workloads workflow is triggered on a pull request to the main branch. It contains a single job that runs our model development workloads with an Anyscale Job. The steps in this job are as follows:
# Configure AWS credentials\n- name: Configure AWS credentials\nuses: aws-actions/configure-aws-credentials@v2\nwith:\nrole-to-assume: arn:aws:iam::593241322649:role/github-actions-madewithml\nrole-session-name: s3access\naws-region: us-west-2\n# Set up dependencies\n- uses: actions/checkout@v3\n- uses: actions/setup-python@v4\nwith:\npython-version: '3.10.11'\ncache: 'pip'\n- run: python3 -m pip install anyscale==0.5.128 typer==0.9.0\n# Run workloads\n- name: Workloads\nrun: |\nexport ANYSCALE_HOST=$\\{\\{ secrets.ANYSCALE_HOST \\}\\}\nexport ANYSCALE_CLI_TOKEN=$\\{\\{ secrets.ANYSCALE_CLI_TOKEN \\}\\}\nanyscale jobs submit deploy/jobs/workloads.yaml --wait\n.github/workflows/json_to_md.py to convert our JSON results to markdown tables that we can comment on our PR. # Read results from S3\n- name: Read results from S3\nrun: |\nmkdir results\naws s3 cp s3://madewithml/$\\{\\{ github.actor \\}\\}/results/ results/ --recursive\npython .github/workflows/json_to_md.py results/training_results.json results/training_results.md\npython .github/workflows/json_to_md.py results/evaluation_results.json results/evaluation_results.md\n# Comment results to PR\n- name: Comment training results on PR\nuses: thollander/actions-comment-pull-request@v2\nwith:\nfilePath: results/training_results.md\n- name: Comment evaluation results on PR\nuses: thollander/actions-comment-pull-request@v2\nwith:\nfilePath: results/evaluation_results.md\nSo when this workloads workflow completes, we'll have a comment on our PR (example) with our training and evaluation results. We can now collaboratively analyze the details and decide if we want to merge the PR.
Tip
We could easily extend this by retrieving evaluation results from our currently deployed model in production as well. Recall that we defined a /evaluate/ endpoint for our service that expects a dataset location and returns the evaluation results. And we can submit this request as a step in our workflow and save the results to a markdown table that we can comment on our PR.
curl -X POST -H \"Content-Type: application/json\" -H \"Authorization: Bearer $SECRET_TOKEN\" -d '{\n \"dataset\": \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/holdout.csv\"\n}' $SERVICE_ENDPOINT/evaluate/\n{\n\"results\": {\n\"timestamp\": \"July 24, 2023 11:43:37 PM\",\n\"run_id\": \"f1684a944d314bacabeaa90ff972775b\",\n\"overall\": {\n\"precision\": 0.9536309870079502,\n\"recall\": 0.9528795811518325,\n\"f1\": 0.9525489716579315,\n\"num_samples\": 191\n},\n}\n}\nIf we like the results and we want to merge the PR and push to the main branch, our serve workflow will be triggered.
# .github/workflows/serve.yaml\nname: serve\non:\nworkflow_dispatch: # manual\npush:\nbranches:\n- main\n...\nIt contains a single job that serves our model with Anyscale Services. The steps in this job are as follows:
# Configure AWS credentials\n- name: Configure AWS credentials\nuses: aws-actions/configure-aws-credentials@v2\nwith:\nrole-to-assume: arn:aws:iam::593241322649:role/github-actions-madewithml\nrole-session-name: s3access\naws-region: us-west-2\n# Set up dependencies\n- uses: actions/checkout@v3\n- uses: actions/setup-python@v4\nwith:\npython-version: '3.10.11'\ncache: 'pip'\n- run: python3 -m pip install anyscale==0.5.128 typer==0.9.0\n# Run workloads\n- name: Workloads\nrun: |\nexport ANYSCALE_HOST=$\\{\\{ secrets.ANYSCALE_HOST \\}\\}\nexport ANYSCALE_CLI_TOKEN=$\\{\\{ secrets.ANYSCALE_CLI_TOKEN \\}\\}\nanyscale service rollout --service-config-file deploy/services/serve_model.yaml\nSo when this serve workflow completes, our model will be deployed to production and we can start making inference requests with it.
Note
The anyscale service rollout command will update our existing service (if there was already one running) without changing the SECRET_TOKEN or SERVICE_ENDPOINT. So this means that our downstream applications that were making inference requests to our service can continue to do so without any changes.
Our documentation workflow is also triggered on a push to the main branch. It contains a single job that builds our docs. The steps in this job are as follows:
# Set up dependencies\n- uses: actions/checkout@v3\n- uses: actions/setup-python@v4\nwith:\npython-version: '3.10.11'\ncache: 'pip'\n- run: python3 -m pip install mkdocs==1.4.2 mkdocstrings==0.21.2 \"mkdocstrings[python]>=0.18\"\n# Deploy docs\n- name: Deploy documentation\nrun: mkdocs gh-deploy --force\nAnd with that, we're able to automatically update our ML application when ever we make changes to the code and want to trigger a new deployment. We have fully control because we can decide not to trigger an event (ex. push to main branch) if we're not satisfied with the results of our model development workloads. We can easily extend this to include other events (ex. new data, performance regressions, etc.) to trigger our workflows, as well as, integrate with more functionality around orchestration (ex. Prefect, Kubeflow, etc.), monitoring, etc.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { CI/CD workflows - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn the previous lesson, we organized our code from our notebook into individual Python scripts. We moved our functions and classes into their respective scripts and also created new workload functions to execute the main ML workloads (ex. train_model function from madewithml/train.py script). We now want to enable users to execute these workloads from the terminal without having to know anything about our code itself.
One way to execute these workloads is to import the functions in the Python script and execute them one at a time:
from madewithml import train\ntrain.train_model(experiment_name=\"llm\", ...)\nCaution: Don't forget to run export PYTHONPATH=$PYTHONPATH:$PWD in your terminal to ensure that Python can find the modules in our project.
While this may seem simple, it still requires us to import packages, identify the input arguments, etc. Therefore, another alternative is to place the main function call under a if __name__ == \"__main__\" conditional so that it's only executed when we run the script directly. Here we can pass in the input arguments directly into the function in the code.
# madewithml/train.py\nif __name__ == \"__main__\":\n train_model(experiment_name=\"llm\", ...)\npython madewithml/train.py\nHowever, the limitation here is that we can't choose which function from a particular script to execute. We have to set the one we want to execute under the if __name__ == \"__main__\" conditional. It's also very rigid since we have to set the input argument values in the code, unless we use a library like argparse.
# madewithml/serve.py\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--run_id\", help=\"run ID to use for serving.\")\n parser.add_argument(\"--threshold\", type=float, default=0.9, help=\"threshold for `other` class.\")\n args = parser.parse_args()\n ray.init()\n serve.run(ModelDeployment.bind(run_id=args.run_id, threshold=args.threshold))\n--threshold is optional since it has a default value): python madewithml/serve.py --run_id $RUN_ID\nWe use argparse in our madewithml/serve.py script because it's the only workload in the script and it's a one-line function call (serve.run()).
Compared to using functions or the __main__ conditional, a much better user experience would be to execute these workloads from the terminal. In this lesson, we'll learn how to build a command-line interface (CLI) so that execute our main ML workloads.
We're going to create our CLI using Typer. It's as simple as initializing the app and then adding the appropriate decorator to each function operation we wish to use as a CLI command in our script:
import typer\nfrom typing_extensions import Annotated\napp = typer.Typer()\n\n@app.command()\ndef train_model(\n experiment_name: Annotated[str, typer.Option(help=\"name of the experiment.\")] = None,\n ...):\n pass\n\nif __name__ == \"__main__\":\n app()\nYou may notice that our function inputs have a lot of information besides just the input name. We'll cover typing (str, List, etc.) in our documentation lesson but for now, just know that Annotated allows us to specify metadata about the input argument's type and details about the (required) option (typer.Option).
We make all of our input arguments optional so that we can explicitly define them in our CLI commands (ex. --experiment-name).
We can also add some helpful information about the input parameter (with typer.Option(help=\"...\")) and a default value (ex. None).
With our CLI commands defined and our input arguments enriched, we can execute our workloads. Let's start by executing our train_model function by assuming that we don't know what the required input parameters are. Instead of having to look in the code, we can just do the following:
python madewithml/train.py --help\n\nUsage: train.py [OPTIONS]\nMain train function to train our model as a distributed workload.\n
We can follow this helpful message to execute our workload with the appropriate inputs.
export EXPERIMENT_NAME=\"llm\"\nexport DATASET_LOC=\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\nexport TRAIN_LOOP_CONFIG='{\"dropout_p\": 0.5, \"lr\": 1e-4, \"lr_factor\": 0.8, \"lr_patience\": 3}'\npython madewithml/train.py \\\n--experiment-name \"$EXPERIMENT_NAME\" \\\n--dataset-loc \"$DATASET_LOC\" \\\n--train-loop-config \"$TRAIN_LOOP_CONFIG\" \\\n--num-workers 1 \\\n--cpu-per-worker 10 \\\n--gpu-per-worker 1 \\\n--num-epochs 10 \\\n--batch-size 256 \\\n--results-fp results/training_results.json\nBe sure to check out our README.md file as it has examples of all the CLI commands for our ML workloads (train, tune, evaluate, inference and serve).
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { CLI - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWhen developing an application, there are a lot of technical decisions and results (preprocessing, performance, etc.) that are integral to our system. How can we effectively communicate this to other developers and business stakeholders? One option is a Jupyter notebook but it's often cluttered with code and isn't very easy for non-technical team members to access and run. We need to create a dashboard that can be accessed without any technical prerequisites and effectively communicates key findings. It would be even more useful if our dashboard was interactive such that it provides utility even for the technical developers.
"},{"location":"courses/mlops/dashboard/#streamlit","title":"Streamlit","text":"There are some great tooling options, such as Dash, Gradio, Streamlit, Tableau, Looker, etc. for creating dashboards to deliver data oriented insights. Traditionally, interactive dashboards were exclusively created using front-end programming languages such as HTML Javascript, CSS, etc. However, given that many developers working in machine learning are using Python, the tooling landscape has evolved to bridge this gap. These tools now allow ML developers to create interactive dashboards and visualizations in Python while offering full customization via HTML, JS, and CSS. We'll be using Streamlit to create our dashboards because of it's intuitive API, sharing capabilities and increasing community adoption.
"},{"location":"courses/mlops/dashboard/#set-up","title":"Set up","text":"With Streamlit, we can quickly create an empty application and as we develop, the UI will update as well.
# Setup\npip install streamlit==1.10.0\nmkdir streamlit\ntouch streamlit/app.py\nstreamlit run streamlit/app.py\n\nYou can now view your Streamlit app in your browser.\n\n Local URL: http://localhost:8501\n Network URL: http://10.0.1.93:8501\n
This will automatically open up the streamlit dashboard for us on http://localhost:8501.
Be sure to add this package and version to our requirements.txt file.
Before we create a dashboard for our specific application, we need to learn about the different Streamlit components. Instead of going through them all in this lesson, take a few minutes and go through the API reference. It's quite short and we promise you'll be amazed at how many UI components (styled text, latex, tables, plots, etc.) you can create using just Python. We'll explore the different components in detail as they apply to creating different interactions for our specific dashboard below.
"},{"location":"courses/mlops/dashboard/#sections","title":"Sections","text":"We'll start by outlining the sections we want to have in our dashboard by editing our streamlit/app.py script:
import pandas as pd\nfrom pathlib import Path\nimport streamlit as st\n\nfrom config import config\nfrom tagifai import main, utils\n# Title\nst.title(\"MLOps Course \u00b7 Made With ML\")\n\n# Sections\nst.header(\"\ud83d\udd22 Data\")\nst.header(\"\ud83d\udcca Performance\")\nst.header(\"\ud83d\ude80 Inference\")\nTo see these changes on our dashboard, we can refresh our dashboard page (press R) or set it Always rerun (press A).
We're going to keep our dashboard simple, so we'll just display the labeled projects.
st.header(\"Data\")\nprojects_fp = Path(config.DATA_DIR, \"labeled_projects.csv\")\ndf = pd.read_csv(projects_fp)\nst.text(f\"Projects (count: {len(df)})\")\nst.write(df)\nIn this section, we'll display the performance of from our latest trained model. Again, we're going to keep it simple but we could also overlay more information such as improvements or regressions from previous deployments by accessing the model store.
st.header(\"\ud83d\udcca Performance\")\nperformance_fp = Path(config.CONFIG_DIR, \"performance.json\")\nperformance = utils.load_dict(filepath=performance_fp)\nst.text(\"Overall:\")\nst.write(performance[\"overall\"])\ntag = st.selectbox(\"Choose a tag: \", list(performance[\"class\"].keys()))\nst.write(performance[\"class\"][tag])\ntag = st.selectbox(\"Choose a slice: \", list(performance[\"slices\"].keys()))\nst.write(performance[\"slices\"][tag])\nWith the inference section, we want to be able to quickly predict with the latest trained model.
st.header(\"\ud83d\ude80 Inference\")\ntext = st.text_input(\"Enter text:\", \"Transfer learning with transformers for text classification.\")\nrun_id = st.text_input(\"Enter run ID:\", open(Path(config.CONFIG_DIR, \"run_id.txt\")).read())\nprediction = main.predict_tag(text=text, run_id=run_id)\nst.write(prediction)\nTip
Our dashboard is quite simple but we can also more comprehensive dashboards that reflect some of the core topics we covered in our machine learning canvas.
Sometimes we may have views that involve computationally heavy operations, such as loading data or model artifacts. It's best practice to cache these operations by wrapping them as a separate function with the @st.cache decorator. This calls for Streamlit to cache the function by the specific combination of it's inputs to deliver the respective outputs when the function is invoked with the same inputs.
@st.cache()\ndef load_data():\n projects_fp = Path(config.DATA_DIR, \"labeled_projects.csv\")\n df = pd.read_csv(projects_fp)\n return df\nWe have several different options for deploying and managing our Streamlit dashboard. We could use Streamlit's sharing feature (beta) which allows us to seamlessly deploy dashboards straight from GitHub. Our dashboard will continue to stay updated as we commit changes to our repository. Another option is to deploy the Streamlit dashboard along with our API service. We can use docker-compose to spin up a separate container or simply add it to the API service's Dockerfile's ENTRYPOINT with the appropriate ports exposed. The later might be ideal, especially if your dashboard isn't meant to be public and it you want added security, performance, etc.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Dashboard - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nSo far we've had the convenience of using local CSV files as data source but in reality, our data can come from many disparate sources. Additionally, our processes around transforming and testing our data should ideally be moved upstream so that many different downstream processes can benefit from them. Our ML use case being just one among the many potential downstream applications. To address these shortcomings, we're going to learn about the fundamentals of data engineering and construct a modern data stack that can scale and provide high quality data for our applications.
View the data-engineering repository for all the code.
At a high level, we're going to:
This process is more commonly known as ELT, but there are variants such as ETL and reverse ETL, etc. They are all essentially the same underlying workflows but have slight differences in the order of data flow and where data is processed and stored.
Utility and simplicity
It can be enticing to set up a modern data stack in your organization, especially with all the hype. But it's very important to motivate utility and adding additional complexity:
Before we start working with our data, it's important to understand the different types of systems that our data can live in. So far in this course we've worked with files, but there are several types of data systems that are widely adopted in industry for different purposes.
"},{"location":"courses/mlops/data-engineering/#data-lake","title":"Data lake","text":"A data lake is a flat data management system that stores raw objects. It's a great option for inexpensive storage and has the capability to hold all types of data (unstructured, semi-structured and structured). Object stores are becoming the standard for data lakes with default options across the popular cloud providers. Unfortunately, because data is stored as objects in a data lake, it's not designed for operating on structured data.
Popular data lake options include Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
"},{"location":"courses/mlops/data-engineering/#database","title":"Database","text":"Another popular storage option is a database (DB), which is an organized collection of structured data that adheres to either:
A database is an online transaction processing (OLTP) system because it's typically used for day-to-day CRUD (create, read, update, delete) operations where typically information is accessed by rows. However, they're generally used to store data from one application and is not designed to hold data from across many sources for the purpose of analytics.
Popular database options include PostgreSQL, MySQL, MongoDB, Cassandra, etc.
"},{"location":"courses/mlops/data-engineering/#data-warehouse","title":"Data warehouse","text":"A data warehouse (DWH) is a type of database that's designed for storing structured data from many different sources for downstream analytics and data science. It's an online analytical processing (OLAP) system that's optimized for performing operations across aggregating column values rather than accessing specific rows.
Popular data warehouse options include SnowFlake, Google BigQuery, Amazon RedShift, Hive, etc.
"},{"location":"courses/mlops/data-engineering/#extract-and-load","title":"Extract and load","text":"The first step in our data pipeline is to extract data from a source and load it into the appropriate destination. While we could construct custom scripts to do this manually or on a schedule, an ecosystem of data ingestion tools have already standardized the entire process. They all come equipped with connectors that allow for extraction, normalization, cleaning and loading between sources and destinations. And these pipelines can be scaled, monitored, etc. all with very little to no code.
Popular data ingestion tools include Fivetran, Airbyte, Stitch, etc.
We're going to use the open-source tool Airbyte to create connections between our data sources and destinations. Let's set up Airbyte and define our data sources. As we progress in this lesson, we'll set up our destinations and create connections to extract and load data.
git clone https://github.com/airbytehq/airbyte.git\ncd airbyte\ndocker-compose up\nOur data sources we want to extract from can be from anywhere. They could come from 3rd party apps, files, user click streams, physical devices, data lakes, databases, data warehouses, etc. But regardless of the source of our data, they type of data should fit into one of these categories:
structured: organized data stored in an explicit structure (ex. tables)semi-structured: data with some structure but no formal schema or data types (web pages, CSV, JSON, etc.)unstructured: qualitative data with no formal structure (text, images, audio, etc.)For our application, we'll define two data sources:
Ideally, these data assets would be retrieved from a database that contains projects that we extracted and perhaps another database that stores labels from our labeling team's workflows. However, for simplicity we'll use CSV files to demonstrate how to define a data source.
"},{"location":"courses/mlops/data-engineering/#define-file-source-in-airbyte","title":"Define file source in Airbyte","text":"We'll start our ELT process by defining the data source in Airbyte:
Sources on the left menu. Then click the + New source button on the top right corner.Source type dropdown and choose File. This will open a view to define our file data source. Name: Projects\nURL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv\nFile Format: csv\nStorage Provider: HTTPS: Public Web\nDataset Name: projects\nSet up source button and our data source will be tested and saved.Name: Tags\nURL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv\nFile Format: csv\nStorage Provider: HTTPS: Public Web\nDataset Name: tags\nOnce we know the source we want to extract data from, we need to decide the destination to load it. The choice depends on what our downstream applications want to be able to do with the data. And it's also common to store data in one location (ex. data lake) and move it somewhere else (ex. data warehouse) for specific processing.
"},{"location":"courses/mlops/data-engineering/#set-up-google-bigquery","title":"Set up Google BigQuery","text":"Our destination will be a data warehouse since we'll want to use the data for downstream analytical and machine learning applications. We're going to use Google BigQuery which is free under Google Cloud's free tier for up to 10 GB storage and 1TB of queries (which is significantly more than we'll ever need for our purpose).
Go to console button.Project name: made-with-ml # Google will append a unique ID to the end of it\nLocation: No organization\n# Google BigQuery projects\n\u251c\u2500\u2500 made-with-ml-XXXXXX \ud83d\udc48 our project\n\u251c\u2500\u2500 bigquery-publicdata\n\u251c\u2500\u2500 imjasonh-storage\n\u2514\u2500\u2500 nyc-tlc\nConsole or code
Most cloud providers will allow us to do everything via console but also programmatically via API, Python, etc. For example, we manually create a project but we could've also done so with code as shown here.
"},{"location":"courses/mlops/data-engineering/#define-bigquery-destination-in-airbyte","title":"Define BigQuery destination in Airbyte","text":"Next, we need to establish the connection between Airbyte and BigQuery so that we can load the extracted data to the destination. In order to authenticate our access to BigQuery with Airbyte, we'll need to create a service account and generate a secret key. This is basically creating an identity with certain access that we can use for verification. Follow these instructions to create a service and generate the key file (JSON). Note down the location of this file because we'll be using it throughout this lesson. For example ours is /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json.
Destinations on the left menu. Then click the + New destination button on the top right corner.Destination type dropdown and choose BigQuery. This will open a view to define our file data source. Name: BigQuery\nDefault Dataset ID: mlops_course # where our data will go inside our BigQuery project\nProject ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID\nCredentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location\nDataset location: US # select US or EU, all other options will not be compatible with dbt later\nSet up destination button and our data destination will be tested and saved.So we've set up our data sources (public CSV files) and destination (Google BigQuery data warehouse) but they haven't been connected yet. To create the connection, we need to think about a few aspects.
"},{"location":"courses/mlops/data-engineering/#frequency","title":"Frequency","text":"How often do we want to extract data from the sources and load it into the destination?
batch: extracting data in batches, usually following a schedule (ex. daily) or when an event of interest occurs (ex. new data count)streaming: extracting data in a continuous stream (using tools like Kafka, Kinesis, etc.)Micro-batch
As we keep decreasing the time between batch ingestion (ex. towards 0), do we have stream ingestion? Not exactly. Batch processing is deliberately deciding to extract data from a source at a given interval. As that interval becomes <15 minutes, it's referred to as a micro-batch (many data warehouses allow for batch ingestion every 5 minutes). However, with stream ingestion, the extraction process is continuously on and events will keep being ingested.
Start simple
In general, it's a good idea to start with batch ingestion for most applications and slowly add the complexity of streaming ingestion (and additional infrastructure). This was we can prove that downstream applications are finding value from the data source and evolving to streaming later should only improve things.
We'll learn more about the different system design implications of batch vs. stream in our systems design lesson.
"},{"location":"courses/mlops/data-engineering/#connecting-file-source-to-bigquery-destination","title":"Connecting File source to BigQuery destination","text":"Now we're ready to create the connection between our sources and destination:
Connections on the left menu. Then click the + New connection button on the top right corner.Select a existing source, click on the Source dropdown and choose Projects and click Use existing source.Select a existing destination, click on the Destination dropdown and choose BigQuery and click Use existing destination. Connection name: Projects <> BigQuery\nReplication frequency: Manual\nDestination Namespace: Mirror source structure\nNormalized tabular data: True # leave this selected\nSet up connection button and our connection will be tested and saved.Tags source with the same BigQuery destination.Notice that our sync mode is Full refresh | Overwrite which means that every time we sync data from our source, it'll overwrite the existing data in our destination. As opposed to Full refresh | Append which will add entries from the source to bottom of the previous syncs.
Our replication frequency is Manual because we'll trigger the data syncs ourselves:
Connections on the left menu. Then click the Projects <> BigQuery connection we set up earlier.\ud83d\udd04 Sync now button and once it's completed we'll see that the projects are now in our BigQuery data warehouse.Tags <> BigQuery connection.# Inside our data warehouse\nmade-with-ml-XXXXXX - Project\n\u2514\u2500\u2500 mlops_course - Dataset\n\u2502 \u251c\u2500\u2500 _airbyte_raw_projects - table\n\u2502 \u251c\u2500\u2500 _airbyte_raw_tags - table\n\u2502 \u251c\u2500\u2500 projects - table\n\u2502 \u2514\u2500\u2500 tags - table\nIn our orchestration lesson, we'll use Airflow to programmatically execute the data sync.
We can easily explore and query this data using SQL directly inside our warehouse:
\ud83d\udd0d QUERY button and select In new tab.SELECT *\nFROM `made-with-ml-XXXXXX.mlops_course.projects`\nLIMIT 1000\n\nid\n created_on\n title\n description\n 0\n 6\n 2020-02-20 06:43:18\n Comparison between YOLO and RCNN on real world...\n Bringing theory to experiment is cool. We can ...\n 1\n 7\n 2020-02-20 06:47:21\n Show, Infer & Tell: Contextual Inference for C...\n The beauty of the work lies in the way it arch...\n 2\n 9\n 2020-02-24 16:24:45\n Awesome Graph Classification\n A collection of important graph embedding, cla...\n 3\n 15\n 2020-02-28 23:55:26\n Awesome Monte Carlo Tree Search\n A curated list of Monte Carlo tree search papers...\n 4\n 19\n 2020-03-03 13:54:31\n Diffusion to Vector\n Reference implementation of Diffusion2Vec (Com...\n"},{"location":"courses/mlops/data-engineering/#best-practices","title":"Best practices","text":"
With the advent of cheap storage and cloud SaaS options to manage them, it's become a best practice to store raw data into data lakes. This allows for storage of raw, potentially unstructured, data without having to justify storage with downstream applications. When we do need to transform and process the data, we can move it to a data warehouse so can perform those operations efficiently.
"},{"location":"courses/mlops/data-engineering/#transform","title":"Transform","text":"Once we've extracted and loaded our data, we need to transform the data so that it's ready for downstream applications. These transformations are different from the preprocessing we've seen before but are instead reflective of business logic that's agnostic to downstream applications. Common transformations include defining schemas, filtering, cleaning and joining data across tables, etc. While we could do all of these things with SQL in our data warehouse (save queries as tables or views), dbt delivers production functionality around version control, testing, documentation, packaging, etc. out of the box. This becomes crucial for maintaining observability and high quality data workflows.
Popular transformation tools include dbt, Matillion, custom jinja templated SQL, etc.
Note
In addition to data transformations, we can also process the data using large-scale analytics engines like Spark, Flink, etc.
"},{"location":"courses/mlops/data-engineering/#dbt-cloud","title":"dbt Cloud","text":"Now we're ready to transform our data in our data warehouse using dbt. We'll be using a developer account on dbt Cloud (free), which provides us with an IDE, unlimited runs, etc.
We'll learn how to use the dbt-core in our orchestration lesson. Unlike dbt Cloud, dbt core is completely open-source and we can programmatically connect to our data warehouse and perform transformations.
continue and choose BigQuery as the database.Upload a Service Account JSON file and upload our file to autopopulate everything.Test > Continue.Managed repository and name it dbt-transforms (or anything else you want).Create > Continue > Skip and complete.>_ Start Developing button.\ud83d\uddc2 initialize your project.Now we're ready to start developing our models:
\u00b7\u00b7\u00b7 next to the models directory on the left menu.New folder called models/labeled_projects.New file under models/labeled_projects called labeled_projects.sql.models/labeled_projects called schema.yml.dbt-cloud-XXXXX-dbt-transforms\n\u251c\u2500\u2500 ...\n\u251c\u2500\u2500 models\n\u2502 \u251c\u2500\u2500 example\n\u2502 \u2514\u2500\u2500 labeled_projects\n\u2502 \u2502 \u251c\u2500\u2500 labeled_projects.sql\n\u2502 \u2502 \u2514\u2500\u2500 schema.yml\n\u251c\u2500\u2500 ...\n\u2514\u2500\u2500 README.md\nInside our models/labeled_projects/labeled_projects.sql file we'll create a view that joins our project data with the appropriate tags. This will create the labeled data necessary for downstream applications such as machine learning models. Here we're joining based on the matching id between the projects and tags:
-- models/labeled_projects/labeled_projects.sql\nSELECT p.id, created_on, title, description, tag\nFROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE\nLEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE\nON p.id = t.id\nWe can view the queried results by clicking the Preview button and view the data lineage as well.
Inside our models/labeled_projects/schema.yml file we'll define the schemas for each of the features in our transformed data. We also define several tests that each feature should pass. View the full list of dbt tests but note that we'll use Great Expectations for more comprehensive tests when we orchestrate all these data workflows in our orchestration lesson.
# models/labeled_projects/schema.yml\n\nversion: 2\n\nmodels:\n- name: labeled_projects\ndescription: \"Tags for all projects\"\ncolumns:\n- name: id\ndescription: \"Unique ID of the project.\"\ntests:\n- unique\n- not_null\n- name: title\ndescription: \"Title of the project.\"\ntests:\n- not_null\n- name: description\ndescription: \"Description of the project.\"\ntests:\n- not_null\n- name: tag\ndescription: \"Labeled tag for the project.\"\ntests:\n- not_null\nAt the bottom of the IDE, we can execute runs based on the transformations we've defined. We'll run each of the following commands and once they finish, we can see the transformed data inside our data warehouse.
dbt run\ndbt test\nOnce these commands run successfully, we're ready to move our transformations to a production environment where we can insert this view in our data warehouse.
"},{"location":"courses/mlops/data-engineering/#jobs","title":"Jobs","text":"In order to apply these transformations to the data in our data warehouse, it's best practice to create an Environment and then define Jobs:
Environments on the left menu > New Environment button (top right corner) and fill out the details: Name: Production\nType: Deployment\n...\nDataset: mlops_course\nNew Job with the following details and then click Save (top right corner). Name: Transform\nEnvironment: Production\nCommands: dbt run\ndbt test\nSchedule: uncheck \"RUN ON SCHEDULE\"\nRun Now and view the transformed data in our data warehouse under a view called labeled_projects.# Inside our data warehouse\nmade-with-ml-XXXXXX - Project\n\u2514\u2500\u2500 mlops_course - Dataset\n\u2502 \u251c\u2500\u2500 _airbyte_raw_projects - table\n\u2502 \u251c\u2500\u2500 _airbyte_raw_tags - table\n\u2502 \u251c\u2500\u2500 labeled_projects - view\n\u2502 \u251c\u2500\u2500 projects - table\n\u2502 \u2514\u2500\u2500 tags - table\nThere is so much more to dbt so be sure to check out their official documentation to really customize any workflows. And be sure to check out our orchestration lesson where we'll programmatically create and execute our dbt transformations.
"},{"location":"courses/mlops/data-engineering/#implementations","title":"Implementations","text":"Hopefully we created our data stack for the purpose of gaining some actionable insight about our business, users, etc. Because it's these use cases that dictate which sources of data we extract from, how often and how that data is stored and transformed. Downstream applications of our data typically fall into one of these categories:
data analytics: use cases focused on reporting trends, aggregate views, etc. via charts, dashboards, etc.for the purpose of providing operational insight for business stakeholders. \ud83d\udee0\u00a0 Popular tools: Tableau, Looker, Metabase, Superset, etc.
machine learning: use cases centered around using the transformed data to construct predictive models (forecasting, personalization, etc.).While it's very easy to extract data from our data warehouse:
pip install google-cloud-bigquery==1.21.0\nfrom google.cloud import bigquery\nfrom google.oauth2 import service_account\n\n# Replace these with your own values\nproject_id = \"made-with-ml-XXXXXX\" # REPLACE\nSERVICE_ACCOUNT_KEY_JSON = \"/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json\" # REPLACE\n\n# Establish connection\ncredentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)\nclient = bigquery.Client(credentials= credentials, project=project_id)\n\n# Query data\nquery_job = client.query(\"\"\"\n SELECT *\n FROM mlops_course.labeled_projects\"\"\")\nresults = query_job.result()\nresults.to_dataframe().head()\nWarning
Check out our notebook where we extract the transformed data from our data warehouse. We do this in a separate notebook because it requires the google-cloud-bigquery package and until dbt loosens it's Jinja versioning constraints... it'll have to be done in a separate environment. However, downstream applications are typically analytics or ML applications which have their own environments anyway so these conflicts are not inhibiting.
many of the analytics (ex. dashboards) and machine learning solutions (ex. feature stores) allow for easy connection to our data warehouses so that workflows can be triggered when an event occurs or on a schedule. We're going to take this a step further in the next lesson where we'll use a central orchestration platform to control all these workflows.
Analytics first, then ML
It's a good idea for the first several applications to be analytics and reporting based in order to establish a robust data stack. These use cases typically just involve displaying data aggregations and trends, as opposed to machine learning systems that involve additional complex infrastructure and workflows.
"},{"location":"courses/mlops/data-engineering/#observability","title":"Observability","text":"When we create complex data workflows like this, observability becomes a top priority. Data observability is the general concept of understanding the condition of data in our system and it involves:
data quality: testing and monitoring our data quality after every step (schemas, completeness, recency, etc.).data lineage: mapping the where data comes from and how it's being transformed as it moves through our pipelines.discoverability: enabling discovery of the different data sources and features for downstream applications.privacy + security: are the different data assets treated and restricted appropriately amongst the applications?Popular observability tools include Monte Carlo, Bigeye, etc.
"},{"location":"courses/mlops/data-engineering/#considerations","title":"Considerations","text":"The data stack ecosystem to create the robust data workflows is growing and maturing. However, it can be overwhelming when it comes to choosing the best tooling options, especially as needs change over time. Here are a few important factors to consider when making a tooling decision in this space:
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Data engineering - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nSo far we've had the convenience of using local CSV files as data source but in reality, our data can come from many disparate sources. Additionally, our processes around transforming and testing our data should ideally be moved upstream so that many different downstream processes can benefit from them. Our ML use case being just one among the many potential downstream applications. To address these shortcomings, we're going to learn about the fundamentals of data engineering and construct a modern data stack that can scale and provide high quality data for our applications.
View the data-engineering repository for all the code.
At a high level, we're going to:
This process is more commonly known as ELT, but there are variants such as ETL and reverse ETL, etc. They are all essentially the same underlying workflows but have slight differences in the order of data flow and where data is processed and stored.
Utility and simplicity
It can be enticing to set up a modern data stack in your organization, especially with all the hype. But it's very important to motivate utility and adding additional complexity:
Before we start working with our data, it's important to understand the different types of systems that our data can live in. So far in this course we've worked with files, but there are several types of data systems that are widely adopted in industry for different purposes.
"},{"location":"courses/mlops/data-stack/#data-lake","title":"Data lake","text":"A data lake is a flat data management system that stores raw objects. It's a great option for inexpensive storage and has the capability to hold all types of data (unstructured, semi-structured and structured). Object stores are becoming the standard for data lakes with default options across the popular cloud providers. Unfortunately, because data is stored as objects in a data lake, it's not designed for operating on structured data.
Popular data lake options include Amazon S3, Azure Blob Storage, Google Cloud Storage, etc.
"},{"location":"courses/mlops/data-stack/#database","title":"Database","text":"Another popular storage option is a database (DB), which is an organized collection of structured data that adheres to either:
A database is an online transaction processing (OLTP) system because it's typically used for day-to-day CRUD (create, read, update, delete) operations where typically information is accessed by rows. However, they're generally used to store data from one application and is not designed to hold data from across many sources for the purpose of analytics.
Popular database options include PostgreSQL, MySQL, MongoDB, Cassandra, etc.
"},{"location":"courses/mlops/data-stack/#data-warehouse","title":"Data warehouse","text":"A data warehouse (DWH) is a type of database that's designed for storing structured data from many different sources for downstream analytics and data science. It's an online analytical processing (OLAP) system that's optimized for performing operations across aggregating column values rather than accessing specific rows.
Popular data warehouse options include SnowFlake, Google BigQuery, Amazon RedShift, Hive, etc.
"},{"location":"courses/mlops/data-stack/#extract-and-load","title":"Extract and load","text":"The first step in our data pipeline is to extract data from a source and load it into the appropriate destination. While we could construct custom scripts to do this manually or on a schedule, an ecosystem of data ingestion tools have already standardized the entire process. They all come equipped with connectors that allow for extraction, normalization, cleaning and loading between sources and destinations. And these pipelines can be scaled, monitored, etc. all with very little to no code.
Popular data ingestion tools include Fivetran, Airbyte, Stitch, etc.
We're going to use the open-source tool Airbyte to create connections between our data sources and destinations. Let's set up Airbyte and define our data sources. As we progress in this lesson, we'll set up our destinations and create connections to extract and load data.
git clone https://github.com/airbytehq/airbyte.git\ncd airbyte\ndocker-compose up\nOur data sources we want to extract from can be from anywhere. They could come from 3rd party apps, files, user click streams, physical devices, data lakes, databases, data warehouses, etc. But regardless of the source of our data, they type of data should fit into one of these categories:
structured: organized data stored in an explicit structure (ex. tables)semi-structured: data with some structure but no formal schema or data types (web pages, CSV, JSON, etc.)unstructured: qualitative data with no formal structure (text, images, audio, etc.)For our application, we'll define two data sources:
Ideally, these data assets would be retrieved from a database that contains projects that we extracted and perhaps another database that stores labels from our labeling team's workflows. However, for simplicity we'll use CSV files to demonstrate how to define a data source.
"},{"location":"courses/mlops/data-stack/#define-file-source-in-airbyte","title":"Define file source in Airbyte","text":"We'll start our ELT process by defining the data source in Airbyte:
Sources on the left menu. Then click the + New source button on the top right corner.Source type dropdown and choose File. This will open a view to define our file data source. Name: Projects\nURL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv\nFile Format: csv\nStorage Provider: HTTPS: Public Web\nDataset Name: projects\nSet up source button and our data source will be tested and saved.Name: Tags\nURL: https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv\nFile Format: csv\nStorage Provider: HTTPS: Public Web\nDataset Name: tags\nOnce we know the source we want to extract data from, we need to decide the destination to load it. The choice depends on what our downstream applications want to be able to do with the data. And it's also common to store data in one location (ex. data lake) and move it somewhere else (ex. data warehouse) for specific processing.
"},{"location":"courses/mlops/data-stack/#set-up-google-bigquery","title":"Set up Google BigQuery","text":"Our destination will be a data warehouse since we'll want to use the data for downstream analytical and machine learning applications. We're going to use Google BigQuery which is free under Google Cloud's free tier for up to 10 GB storage and 1TB of queries (which is significantly more than we'll ever need for our purpose).
Go to console button.Project name: made-with-ml # Google will append a unique ID to the end of it\nLocation: No organization\n# Google BigQuery projects\n\u251c\u2500\u2500 made-with-ml-XXXXXX \ud83d\udc48 our project\n\u251c\u2500\u2500 bigquery-publicdata\n\u251c\u2500\u2500 imjasonh-storage\n\u2514\u2500\u2500 nyc-tlc\nConsole or code
Most cloud providers will allow us to do everything via console but also programmatically via API, Python, etc. For example, we manually create a project but we could've also done so with code as shown here.
"},{"location":"courses/mlops/data-stack/#define-bigquery-destination-in-airbyte","title":"Define BigQuery destination in Airbyte","text":"Next, we need to establish the connection between Airbyte and BigQuery so that we can load the extracted data to the destination. In order to authenticate our access to BigQuery with Airbyte, we'll need to create a service account and generate a secret key. This is basically creating an identity with certain access that we can use for verification. Follow these instructions to create a service and generate the key file (JSON). Note down the location of this file because we'll be using it throughout this lesson. For example ours is /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json.
Destinations on the left menu. Then click the + New destination button on the top right corner.Destination type dropdown and choose BigQuery. This will open a view to define our file data source. Name: BigQuery\nDefault Dataset ID: mlops_course # where our data will go inside our BigQuery project\nProject ID: made-with-ml-XXXXXX # REPLACE this with your Google BiqQuery Project ID\nCredentials JSON: SERVICE-ACCOUNT-KEY.json # REPLACE this with your service account JSON location\nDataset location: US # select US or EU, all other options will not be compatible with dbt later\nSet up destination button and our data destination will be tested and saved.So we've set up our data sources (public CSV files) and destination (Google BigQuery data warehouse) but they haven't been connected yet. To create the connection, we need to think about a few aspects.
"},{"location":"courses/mlops/data-stack/#frequency","title":"Frequency","text":"How often do we want to extract data from the sources and load it into the destination?
batch: extracting data in batches, usually following a schedule (ex. daily) or when an event of interest occurs (ex. new data count)streaming: extracting data in a continuous stream (using tools like Kafka, Kinesis, etc.)Micro-batch
As we keep decreasing the time between batch ingestion (ex. towards 0), do we have stream ingestion? Not exactly. Batch processing is deliberately deciding to extract data from a source at a given interval. As that interval becomes <15 minutes, it's referred to as a micro-batch (many data warehouses allow for batch ingestion every 5 minutes). However, with stream ingestion, the extraction process is continuously on and events will keep being ingested.
Start simple
In general, it's a good idea to start with batch ingestion for most applications and slowly add the complexity of streaming ingestion (and additional infrastructure). This was we can prove that downstream applications are finding value from the data source and evolving to streaming later should only improve things.
We'll learn more about the different system design implications of batch vs. stream in our systems design lesson.
"},{"location":"courses/mlops/data-stack/#connecting-file-source-to-bigquery-destination","title":"Connecting File source to BigQuery destination","text":"Now we're ready to create the connection between our sources and destination:
Connections on the left menu. Then click the + New connection button on the top right corner.Select a existing source, click on the Source dropdown and choose Projects and click Use existing source.Select a existing destination, click on the Destination dropdown and choose BigQuery and click Use existing destination. Connection name: Projects <> BigQuery\nReplication frequency: Manual\nDestination Namespace: Mirror source structure\nNormalized tabular data: True # leave this selected\nSet up connection button and our connection will be tested and saved.Tags source with the same BigQuery destination.Notice that our sync mode is Full refresh | Overwrite which means that every time we sync data from our source, it'll overwrite the existing data in our destination. As opposed to Full refresh | Append which will add entries from the source to bottom of the previous syncs.
Our replication frequency is Manual because we'll trigger the data syncs ourselves:
Connections on the left menu. Then click the Projects <> BigQuery connection we set up earlier.\ud83d\udd04 Sync now button and once it's completed we'll see that the projects are now in our BigQuery data warehouse.Tags <> BigQuery connection.# Inside our data warehouse\nmade-with-ml-XXXXXX - Project\n\u2514\u2500\u2500 mlops_course - Dataset\n\u2502 \u251c\u2500\u2500 _airbyte_raw_projects - table\n\u2502 \u251c\u2500\u2500 _airbyte_raw_tags - table\n\u2502 \u251c\u2500\u2500 projects - table\n\u2502 \u2514\u2500\u2500 tags - table\nIn our orchestration lesson, we'll use Airflow to programmatically execute the data sync.
We can easily explore and query this data using SQL directly inside our warehouse:
\ud83d\udd0d QUERY button and select In new tab.SELECT *\nFROM `made-with-ml-XXXXXX.mlops_course.projects`\nLIMIT 1000\n\nid\n created_on\n title\n description\n 0\n 6\n 2020-02-20 06:43:18\n Comparison between YOLO and RCNN on real world...\n Bringing theory to experiment is cool. We can ...\n 1\n 7\n 2020-02-20 06:47:21\n Show, Infer & Tell: Contextual Inference for C...\n The beauty of the work lies in the way it arch...\n 2\n 9\n 2020-02-24 16:24:45\n Awesome Graph Classification\n A collection of important graph embedding, cla...\n 3\n 15\n 2020-02-28 23:55:26\n Awesome Monte Carlo Tree Search\n A curated list of Monte Carlo tree search papers...\n 4\n 19\n 2020-03-03 13:54:31\n Diffusion to Vector\n Reference implementation of Diffusion2Vec (Com...\n"},{"location":"courses/mlops/data-stack/#best-practices","title":"Best practices","text":"
With the advent of cheap storage and cloud SaaS options to manage them, it's become a best practice to store raw data into data lakes. This allows for storage of raw, potentially unstructured, data without having to justify storage with downstream applications. When we do need to transform and process the data, we can move it to a data warehouse so can perform those operations efficiently.
"},{"location":"courses/mlops/data-stack/#transform","title":"Transform","text":"Once we've extracted and loaded our data, we need to transform the data so that it's ready for downstream applications. These transformations are different from the preprocessing we've seen before but are instead reflective of business logic that's agnostic to downstream applications. Common transformations include defining schemas, filtering, cleaning and joining data across tables, etc. While we could do all of these things with SQL in our data warehouse (save queries as tables or views), dbt delivers production functionality around version control, testing, documentation, packaging, etc. out of the box. This becomes crucial for maintaining observability and high quality data workflows.
Popular transformation tools include dbt, Matillion, custom jinja templated SQL, etc.
Note
In addition to data transformations, we can also process the data using large-scale analytics engines like Spark, Flink, etc.
"},{"location":"courses/mlops/data-stack/#dbt-cloud","title":"dbt Cloud","text":"Now we're ready to transform our data in our data warehouse using dbt. We'll be using a developer account on dbt Cloud (free), which provides us with an IDE, unlimited runs, etc.
We'll learn how to use the dbt-core in our orchestration lesson. Unlike dbt Cloud, dbt core is completely open-source and we can programmatically connect to our data warehouse and perform transformations.
continue and choose BigQuery as the database.Upload a Service Account JSON file and upload our file to autopopulate everything.Test > Continue.Managed repository and name it dbt-transforms (or anything else you want).Create > Continue > Skip and complete.>_ Start Developing button.\ud83d\uddc2 initialize your project.Now we're ready to start developing our models:
\u00b7\u00b7\u00b7 next to the models directory on the left menu.New folder called models/labeled_projects.New file under models/labeled_projects called labeled_projects.sql.models/labeled_projects called schema.yml.dbt-cloud-XXXXX-dbt-transforms\n\u251c\u2500\u2500 ...\n\u251c\u2500\u2500 models\n\u2502 \u251c\u2500\u2500 example\n\u2502 \u2514\u2500\u2500 labeled_projects\n\u2502 \u2502 \u251c\u2500\u2500 labeled_projects.sql\n\u2502 \u2502 \u2514\u2500\u2500 schema.yml\n\u251c\u2500\u2500 ...\n\u2514\u2500\u2500 README.md\nInside our models/labeled_projects/labeled_projects.sql file we'll create a view that joins our project data with the appropriate tags. This will create the labeled data necessary for downstream applications such as machine learning models. Here we're joining based on the matching id between the projects and tags:
-- models/labeled_projects/labeled_projects.sql\nSELECT p.id, created_on, title, description, tag\nFROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE\nLEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE\nON p.id = t.id\nWe can view the queried results by clicking the Preview button and view the data lineage as well.
Inside our models/labeled_projects/schema.yml file we'll define the schemas for each of the features in our transformed data. We also define several tests that each feature should pass. View the full list of dbt tests but note that we'll use Great Expectations for more comprehensive tests when we orchestrate all these data workflows in our orchestration lesson.
# models/labeled_projects/schema.yml\n\nversion: 2\n\nmodels:\n- name: labeled_projects\ndescription: \"Tags for all projects\"\ncolumns:\n- name: id\ndescription: \"Unique ID of the project.\"\ntests:\n- unique\n- not_null\n- name: title\ndescription: \"Title of the project.\"\ntests:\n- not_null\n- name: description\ndescription: \"Description of the project.\"\ntests:\n- not_null\n- name: tag\ndescription: \"Labeled tag for the project.\"\ntests:\n- not_null\nAt the bottom of the IDE, we can execute runs based on the transformations we've defined. We'll run each of the following commands and once they finish, we can see the transformed data inside our data warehouse.
dbt run\ndbt test\nOnce these commands run successfully, we're ready to move our transformations to a production environment where we can insert this view in our data warehouse.
"},{"location":"courses/mlops/data-stack/#jobs","title":"Jobs","text":"In order to apply these transformations to the data in our data warehouse, it's best practice to create an Environment and then define Jobs:
Environments on the left menu > New Environment button (top right corner) and fill out the details: Name: Production\nType: Deployment\n...\nDataset: mlops_course\nNew Job with the following details and then click Save (top right corner). Name: Transform\nEnvironment: Production\nCommands: dbt run\ndbt test\nSchedule: uncheck \"RUN ON SCHEDULE\"\nRun Now and view the transformed data in our data warehouse under a view called labeled_projects.# Inside our data warehouse\nmade-with-ml-XXXXXX - Project\n\u2514\u2500\u2500 mlops_course - Dataset\n\u2502 \u251c\u2500\u2500 _airbyte_raw_projects - table\n\u2502 \u251c\u2500\u2500 _airbyte_raw_tags - table\n\u2502 \u251c\u2500\u2500 labeled_projects - view\n\u2502 \u251c\u2500\u2500 projects - table\n\u2502 \u2514\u2500\u2500 tags - table\nThere is so much more to dbt so be sure to check out their official documentation to really customize any workflows. And be sure to check out our orchestration lesson where we'll programmatically create and execute our dbt transformations.
"},{"location":"courses/mlops/data-stack/#implementations","title":"Implementations","text":"Hopefully we created our data stack for the purpose of gaining some actionable insight about our business, users, etc. Because it's these use cases that dictate which sources of data we extract from, how often and how that data is stored and transformed. Downstream applications of our data typically fall into one of these categories:
data analytics: use cases focused on reporting trends, aggregate views, etc. via charts, dashboards, etc.for the purpose of providing operational insight for business stakeholders. \ud83d\udee0\u00a0 Popular tools: Tableau, Looker, Metabase, Superset, etc.
machine learning: use cases centered around using the transformed data to construct predictive models (forecasting, personalization, etc.).While it's very easy to extract data from our data warehouse:
pip install google-cloud-bigquery==1.21.0\nfrom google.cloud import bigquery\nfrom google.oauth2 import service_account\n\n# Replace these with your own values\nproject_id = \"made-with-ml-XXXXXX\" # REPLACE\nSERVICE_ACCOUNT_KEY_JSON = \"/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json\" # REPLACE\n\n# Establish connection\ncredentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)\nclient = bigquery.Client(credentials= credentials, project=project_id)\n\n# Query data\nquery_job = client.query(\"\"\"\n SELECT *\n FROM mlops_course.labeled_projects\"\"\")\nresults = query_job.result()\nresults.to_dataframe().head()\nWarning
Check out our notebook where we extract the transformed data from our data warehouse. We do this in a separate notebook because it requires the google-cloud-bigquery package and until dbt loosens it's Jinja versioning constraints... it'll have to be done in a separate environment. However, downstream applications are typically analytics or ML applications which have their own environments anyway so these conflicts are not inhibiting.
many of the analytics (ex. dashboards) and machine learning solutions (ex. feature stores) allow for easy connection to our data warehouses so that workflows can be triggered when an event occurs or on a schedule. We're going to take this a step further in the next lesson where we'll use a central orchestration platform to control all these workflows.
Analytics first, then ML
It's a good idea for the first several applications to be analytics and reporting based in order to establish a robust data stack. These use cases typically just involve displaying data aggregations and trends, as opposed to machine learning systems that involve additional complex infrastructure and workflows.
"},{"location":"courses/mlops/data-stack/#observability","title":"Observability","text":"When we create complex data workflows like this, observability becomes a top priority. Data observability is the general concept of understanding the condition of data in our system and it involves:
data quality: testing and monitoring our data quality after every step (schemas, completeness, recency, etc.).data lineage: mapping the where data comes from and how it's being transformed as it moves through our pipelines.discoverability: enabling discovery of the different data sources and features for downstream applications.privacy + security: are the different data assets treated and restricted appropriately amongst the applications?Popular observability tools include Monte Carlo, Bigeye, etc.
"},{"location":"courses/mlops/data-stack/#considerations","title":"Considerations","text":"The data stack ecosystem to create the robust data workflows is growing and maturing. However, it can be overwhelming when it comes to choosing the best tooling options, especially as needs change over time. Here are a few important factors to consider when making a tooling decision in this space:
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Data Stack for Machine Learning - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nSo far we've performed our data processing operations on a single machine. Our dataset was able to fit into a single Pandas DataFrame and we were able to perform our operations in a single Python process. But what if our dataset was too large to fit into a single machine? We would need to distribute our data processing operations across multiple machines. And with the increasing trend in ML for larger unstructured datasets and larger models (LLMs), we can quickly outgrow our single machine constraints and will need to go distributed.
Note
Our dataset is intentionally small for this course so that we can quickly execute the code. But with our distributed set up in this lesson, we can easily switch to a mcuh larger dataset and the code will continue to execute perfectly. And if we add more compute resources, we can scale our data processing operations to be even faster with no changes to our code.
"},{"location":"courses/mlops/distributed-data/#implementation","title":"Implementation","text":"There are many frameworks for distributed computing, such as Ray, Dask, Modin, Spark, etc. All of these are great options but for our application we want to choose a framework that is will allow us to scale our data processing operations with minimal changes to our existing code and all in Python. We also want to choose a framework that will integrate well when we want to distributed our downstream workloads (training, tuning, serving, etc.).
To address these needs, we'll be using Ray, a distributed computing framework that makes it easy to scale your Python applications. It's a general purpose framework that can be used for a variety of applications but we'll be using it for our data processing operations first (and more later). And it also has great integrations with the previously mentioned distributed data processing frameworks (Dask, Modin, Spark).
"},{"location":"courses/mlops/distributed-data/#setup","title":"Setup","text":"The only setup we have to do is set Ray to preserve order when acting on our data. This is important for ensuring reproducible and deterministic results.
ray.data.DatasetContext.get_current().execution_options.preserve_order = True # deterministic\nWe'll start by ingesting our dataset. Ray has a range of input/output functions that supports all major data formats and sources.
# Data ingestion\nds = ray.data.read_csv(DATASET_LOC)\nds = ds.random_shuffle(seed=1234)\nds.take(1)\n\n[{'id': 2166,\n 'created_on': datetime.datetime(2020, 8, 17, 5, 19, 41),\n 'title': 'Pix2Pix',\n 'description': 'Tensorflow 2.0 Implementation of the paper Image-to-Image Translation using Conditional GANs by Philip Isola, Jun-Yan Zhu, Tinghui Zhou and Alexei A. Efros.',\n 'tag': 'computer-vision'}]\n"},{"location":"courses/mlops/distributed-data/#splitting","title":"Splitting","text":"Next, we'll split our dataset into our training and validation splits. Ray has a built-in train_test_split function but we're using a modified version so that we can stratify our split based on the tag column.
import sys\nsys.path.append(\"..\")\nfrom madewithml.data import stratify_split\n# Split dataset\ntest_size = 0.2\ntrain_ds, val_ds = stratify_split(ds, stratify=\"tag\", test_size=test_size)\nAnd finally, we're ready to preprocess our data splits. One of the advantages of using Ray is that we won't have to change anything to our original Pandas-based preprocessing function we implemented in the previous lesson. Instead, we can use it directly with Ray's map_batches utility to map our preprocessing function across batches in our data in a distributed manner.
# Mapping\ntags = train_ds.unique(column=\"tag\")\nclass_to_index = {tag: i for i, tag in enumerate(tags)}\n# Distributed preprocessing\nsample_ds = train_ds.map_batches(\n preprocess,\n fn_kwargs={\"class_to_index\": class_to_index},\n batch_format=\"pandas\")\nsample_ds.show(1)\n\n{'ids': array([ 102, 5800, 14982, 1422, 4958, 14982, 437, 3294, 3577,\n 12574, 2747, 1262, 7222, 103, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0]), 'masks': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0]), 'targets': 2}\n Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Distributed - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nThe last step in achieving reproducibility is to deploy our versioned code and artifacts in a reproducible environment. This goes well beyond the virtual environment we configured for our Python applications because there are system-level specifications (operating system, required implicit packages, etc.) we aren't capturing. We want to be able to encapsulate all the requirements we need so that there are no external dependencies that would prevent someone else from reproducing our exact application.
"},{"location":"courses/mlops/docker/#docker","title":"Docker","text":"There are actually quite a few solutions for system-level reproducibility (VMs, container engines, etc.) but the Docker container engine is by far the most popular for several key advantages:
We're going to use Docker to deploy our application locally in an isolated, reproducible and scalable fashion. Once we do this, any machine with the Docker engine installed can reproduce our work. However, there is so much more to Docker, which you can explore in the docs, that goes beyond what we'll need.
"},{"location":"courses/mlops/docker/#architecture","title":"Architecture","text":"Before we install Docker, let's take a look at how the container engine works on top our operating system, which can be our local hardware or something managed on the cloud.
The Docker container engine is responsible for spinning up configured containers, which contains our application and it's dependencies (binaries, libraries, etc.). The container engine is very efficient in that it doesn't need to create a separate operating system for each containerized application. This also means that our containers can share the system's resources via the Docker engine.
"},{"location":"courses/mlops/docker/#set-up","title":"Set up","text":"Now we're ready to install Docker based on our operating system. Once installed, we can start the Docker Desktop which will allow us to create and deploy our containerized applications.
docker --version\n\nDocker version 20.10.8, build 3967b7d\n"},{"location":"courses/mlops/docker/#images","title":"Images","text":"
The first step is to build a docker image which has the application and all it's specified dependencies. We can create this image using a Dockerfile which outlines a set of instructions. These instructions essentially build read-only image layers on top of each other to construct our entire image. Let's take a look at our application's Dockerfile and the image layers it creates.
"},{"location":"courses/mlops/docker/#dockerfile","title":"Dockerfile","text":"We'll start by creating a Dockerfile:
touch Dockerfile\nThe first line we'll write in our Dockerfile specifies the base image we want to pull FROM. Here we want to use the base image for running Python based applications and specifically for Python 3.7 with the slim variant. Since we're only deploying a Python application, this slim variant with minimal packages satisfies our requirements while keeping the size of the image layer low.
# Base image\nFROM python:3.7-slim\nNext we're going to install our application dependencies. First, we'll COPY the required files from our local file system so we can use them for installation. Alternatively, if we were running on some remote infrastructure, we could've pulled from a remote git host. Once we have our files, we can install the packages required to install our application's dependencies using the RUN command. Once we're done using the packages, we can remove them to keep our image layer's size to a minimum.
# Install dependencies\nWORKDIR /mlops\nCOPY setup.py setup.py\nCOPY requirements.txt requirements.txt\nRUN apt-get update \\\n&& apt-get install -y --no-install-recommends gcc build-essential \\\n&& rm -rf /var/lib/apt/lists/* \\\n&& python3 -m pip install --upgrade pip setuptools wheel \\\n&& python3 -m pip install -e . --no-cache-dir \\\n&& python3 -m pip install protobuf==3.20.1 --no-cache-dir \\\n&& apt-get purge -y --auto-remove gcc build-essential\nNext we're ready to COPY over the required files to actually RUN our application.
# Copy\nCOPY tagifai tagifai\nCOPY app app\nCOPY data data\nCOPY config config\nCOPY stores stores\n\n# Pull assets from S3\nRUN dvc init --no-scm\nRUN dvc remote add -d storage stores/blob\nRUN dvc pull\nSince our application (API) requires PORT 8000 to be open, we need to specify in our Dockerfile to expose it.
# Export ports\nEXPOSE 8000\nThe final step in building our image is to specify the executable to be run when a container is built from our image. For our application, we want to launch our API with gunicorn since this Dockerfile may be used to deploy our service to production at scale.
# Start app\nENTRYPOINT [\"gunicorn\", \"-c\", \"app/gunicorn.py\", \"-k\", \"uvicorn.workers.UvicornWorker\", \"app.api:app\"]\nThere are many more commands available for us to use in the Dockerfile, such as using environment variables (ENV) and arguments (ARG), command arguments (CMD), specifying volumes (VOLUME), setting the working directory (WORKDIR) and many more, all of which you can explore through the official docs.
"},{"location":"courses/mlops/docker/#build-images","title":"Build images","text":"Once we're done composing the Dockerfile, we're ready to build our image using the build command which allows us to add a tag and specify the location of the Dockerfile to use.
docker build -t tagifai:latest -f Dockerfile .\nWe can inspect all built images and their attributes like so:
docker images\n\nREPOSITORY TAG IMAGE ID CREATED SIZE\ntagifai latest 02c88c95dd4c 23 minutes ago 2.57GB\n
We can also remove any or all images based on their unique IDs.
docker rmi <IMAGE_ID> # remove an image\ndocker rmi $(docker images -a -q) # remove all images\nOnce we've built our image, we're ready to run a container using that image with the run command which allows us to specify the image, port forwarding, etc.
docker run -p 8000:8000 --name tagifai tagifai:latest\nOnce we have our container running, we can use the API thanks for the port we're sharing (8000):
curl -X 'POST' \\\n'http://localhost:8000/predict' \\\n-H 'accept: application/json' \\\n-H 'Content-Type: application/json' \\\n-d '{\n \"texts\": [\n {\n \"text\": \"Transfer learning with transformers for text classification.\"\n }\n ]\n}'\nWe can inspect all containers (running or stopped) like so:
docker ps # running containers\ndocker ps -a # stopped containers\n\nCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\nee5f1b08abd5 tagifai:latest \"gunicorn -c config\u2026\" 19 minutes ago Created 0.0.0.0:8000->8000/tcp tagifai\n
We can also stop and remove any or all containers based on their unique IDs:
docker stop <CONTAINER_ID> # stop a running container\ndocker rm <CONTAINER_ID> # remove a container\ndocker stop $(docker ps -a -q) # stop all containers\ndocker rm $(docker ps -a -q) # remove all containers\nIf our application required multiple containers for different services (API, database, etc.) then we can bring them all up at once using the docker compose functionality and scale and manage them using a container orchestration system like Kubernetes (K8s). If we're specifically deploying ML workflows, we can use a toolkit like KubeFlow to help us manage and scale.
"},{"location":"courses/mlops/docker/#debug","title":"Debug","text":"In the event that we run into errors while building our image layers, a very easy way to debug the issue is to run the container with the image layers that have been build so far. We can do this by only including the commands that have ran successfully so far (and all COPY statements) in the Dockerfile. And then we need to rebuild the image (since we altered the Dockerfile) and run the container:
docker build -t tagifai:latest -f Dockerfile .\ndocker run -p 8000:8000 -it tagifai /bin/bash\nOnce we have our container running, we can use our application as we would on our local machine but now it's reproducible on any operating system that can run the Docker container engine. We've covered just what we need from Docker to deploy our application but there is so much more to Docker, which you can explore in the docs.
"},{"location":"courses/mlops/docker/#production","title":"Production","text":"This Dockerfile is commonly the end artifact a data scientist or ML engineer delivers to their DevOps teams to deploy and scale their services, with a few changes:
git clone.All of these changes would involve using the proper credentials (via encrypted secrets and can even be automatically deployed via CI/CD workflows. But, of course, there are subsequent responsibilities such as monitoring.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Docker - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nCode tells you how, comments tell you why. -- Jeff Atwood
We can really improve the quality of our codebase by documenting it to make it easier for others (and our future selves) to easily navigate and extend it. We know our code base best the moment we finish writing it but fortunately documenting it will allow us to quickly get back to that familiar state of mind. Documentation can mean many different things to developers, so let's define the most common components:
comments: short descriptions as to why a piece of code exists.typing: specification of a function's inputs and outputs' data types, providing information pertaining to what a function consumes and produces.docstrings: meaningful descriptions for functions and classes that describe overall utility, arguments, returns, etc.docs: rendered webpage that summarizes all the functions, classes, workflows, examples, etc.It's important to be as explicit as possible with our code. We've already discussed choosing explicit names for variables, functions but another way we can be explicit is by defining the types for our function's inputs and outputs by using the typing library.
So far, our functions have looked like this:
def some_function(a, b):\n return c\nBut we can incorporate so much more information using typing:
from typing import List\ndef some_function(a: List, b: int = 0) -> np.ndarray:\n return c\nHere we've defined:
a is a listb is an integer with default value 0c is a NumPy arrayThere are many other data types that we can work with, including List, Set, Dict, Tuple, Sequence and more, as well as included types such as int, float, etc. You can also use types from packages we install (ex. np.ndarray) and even from our own defined classes (ex. LabelEncoder).
Starting from Python 3.9+, common types are built in so we don't need to import them with from typing import List, Set, Dict, Tuple, Sequence anymore.
We can make our code even more explicit by adding docstrings to describe overall utility, arguments, returns, exceptions and more. Let's take a look at an example:
from typing import List\ndef some_function(a: List, b: int = 0) -> np.ndarray:\n\"\"\"Function description.\n\n ```python\n c = some_function(a=[], b=0)\n print (c)\n ```\n <pre>\n [[1 2]\n [3 4]]\n </pre>\n\n Args:\n a (List): description of `a`.\n b (int, optional): description of `b`. Defaults to 0.\n\n Raises:\n ValueError: Input list is not one-dimensional.\n\n Returns:\n np.ndarray: Description of `c`.\n\n \"\"\"\n return c\nLet's unpack the different parts of this function's docstring:
[Line 3]: Summary of the overall utility of the function.[Lines 5-12]: Example of how to use our function.[Lines 14-16]: Description of the function's input arguments.[Lines 18-19]: Any exceptions that may be raised in the function.[Lines 21-22]: Description of the function's output(s).We'll render these docstrings in the docs section below to produce this:
Take a look at the docstrings of different functions and classes in our repository.
# madewithml/data.py\nfrom typing import List\n\ndef clean_text(text: str, stopwords: List = STOPWORDS) -> str:\n\"\"\"Clean raw text string.\n Args:\n text (str): Raw text to clean.\n stopwords (List, optional): list of words to filter out. Defaults to STOPWORDS.\n\n Returns:\n str: cleaned text.\n \"\"\"\n pass\nTip
If using Visual Studio Code, be sure to use the Python Docstrings Generator extension so you can type \"\"\" under a function and then hit the Shift key to generate a template docstring. It will autofill parts of the docstring using the typing information and even exception in your code!
So we're going through all this effort of including typing and docstrings to our functions but it's all tucked away inside our scripts. What if we can collect all this effort and automatically surface it as documentation? Well that's exactly what we'll do with the following open-source packages \u2192 final result here.
Initialize mkdocs
python3 -m mkdocs new .\n.\n\u251c\u2500 docs/\n\u2502 \u2514\u2500 index.md\n\u2514\u2500 mkdocs.yml\nWe'll start by overwriting the default index.md file in our docs directory with information specific to our project: index.md
## Documentation\n- [madewithml](madewithml/config.md): documentation for functions and classes.\n\n## Course\nLearn how to combine machine learning with software engineering to design, develop, deploy and iterate on production ML applications.\n\n- Lessons: [https://madewithml.com/](https://madewithml.com/#course)\n- Code: [GokuMohandas/Made-With-ML](https://github.com/GokuMohandas/Made-With-ML)\nNext we'll create documentation files for each script in our madewithml directory:
mkdir docs/madewithml\ncd docs/madewithml\ntouch config.md data.md evaluate.md models.md predict.md serve.md train.md tune.md util.md\ncd ../../\nTip
It's helpful to have the docs directory structure mimic our project's structure as much as possible.
Next we'll add madewithml.<SCRIPT_NAME> to each file under docs/madewithml. This will populate the file with information about the functions and classes (using their docstrings) from madewithml/<SCRIPT_NAME>.py thanks to the mkdocstrings plugin.
Be sure to check out the complete list of mkdocs plugins.
# docs/madewithml/data.md\n::: madewithml.data\nFinally, we'll add some configurations to our mkdocs.yml file that mkdocs automatically created:
site_name: Made With ML\nsite_url: https://madewithml.com/\nrepo_url: https://github.com/GokuMohandas/Made-With-ML/\nnav:\n- Home: index.md\n- madewithml:\n- data: madewithml/data.md\n- models: madewithml/models.md\n- train: madewithml/train.md\n- tune: madewithml/tune.md\n- evaluate: madewithml/evaluate.md\n- predict: madewithml/predict.md\n- serve: madewithml/serve.md\n- utils: madewithml/utils.md\ntheme: readthedocs\nplugins:\n- mkdocstrings\nwatch:\n- . # reload docs for any file changes\nServe our documentation locally:
python3 -m mkdocs serve\nThis will serve our docs at http://localhost:8000/:
"},{"location":"courses/mlops/documentation/#publishing","title":"Publishing","text":"We can easily serve our documentation for free using GitHub pages for public repositories as wells as private documentation for private repositories. And we can even host it on a custom domain (ex. company's subdomain).
Be sure to check out the auto-generated documentation page for our repository. We'll learn how to automatically generate and update this docs page every time we make changes to our codebase later in our CI/CD lesson.
In the next lesson, we'll learn how to style and format our codebase in a consistent manner.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Documentation - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nEvaluation is an integral part of modeling and it's one that's often glossed over. We'll often find evaluation to involve simply computing the accuracy or other global metrics but for many real work applications, a much more nuanced evaluation process is required. However, before evaluating our model, we always want to:
Let's start by setting up our metrics dictionary that we'll fill in as we go along and all the data we'll need for evaluation: grounds truth labels (y_test, predicted labels (y_pred) and predicted probabilities (y_prob).
# Metrics\nmetrics = {\"overall\": {}, \"class\": {}}\n# y_test\npreprocessor = predictor.get_preprocessor()\npreprocessed_ds = preprocessor.transform(test_ds)\nvalues = preprocessed_ds.select_columns(cols=[\"targets\"]).take_all()\ny_test = np.stack([item[\"targets\"] for item in values])\n# y_pred\ntest_df = test_ds.to_pandas()\nz = predictor.predict(data=test_df)[\"predictions\"] # adds text column (in-memory)\ny_pred = np.stack(z).argmax(1)\n# y_prob\ny_prob = torch.tensor(np.stack(z)).softmax(dim=1).numpy()\nprint (np.shape(y_test))\nprint (np.shape(y_prob))\n# Add columns (for convenience)\ntest_df = test_ds.to_pandas()\ntest_df[\"text\"] = test_df[\"title\"] + \" \" + test_df[\"description\"]\ntest_df[\"prediction\"] = test_df.index.map(lambda i: preprocessor.index_to_class[y_pred[i]])\ntest_df.head()\nWhile we were developing our models, our evaluation process involved computing the coarse-grained metrics such as overall precision, recall and f1 metrics.
from sklearn.metrics import precision_recall_fscore_support\n# Overall metrics\noverall_metrics = precision_recall_fscore_support(y_test, y_pred, average=\"weighted\")\nmetrics[\"overall\"][\"precision\"] = overall_metrics[0]\nmetrics[\"overall\"][\"recall\"] = overall_metrics[1]\nmetrics[\"overall\"][\"f1\"] = overall_metrics[2]\nmetrics[\"overall\"][\"num_samples\"] = np.float64(len(y_test))\nprint (json.dumps(metrics[\"overall\"], indent=4))\n\n{\n \"precision\": 0.916248340770615,\n \"recall\": 0.9109947643979057,\n \"f1\": 0.9110623702438432,\n \"num_samples\": 191.0\n}\n Note
The precision_recall_fscore_support() function from scikit-learn has an input parameter called average which has the following options below. We'll be using the different averaging methods for different metric granularities.
None: metrics are calculated for each unique class.binary: used for binary classification tasks where the pos_label is specified.micro: metrics are calculated using global TP, FP, and FN.macro: per-class metrics which are averaged without accounting for class imbalance.weighted: per-class metrics which are averaged by accounting for class imbalance.samples: metrics are calculated at the per-sample level.Inspecting these coarse-grained, overall metrics is a start but we can go deeper by evaluating the same fine-grained metrics at the categorical feature levels.
from collections import OrderedDict\n# Per-class metrics\nclass_metrics = precision_recall_fscore_support(y_test, y_pred, average=None)\nfor i, _class in enumerate(preprocessor.class_to_index):\n metrics[\"class\"][_class] = {\n \"precision\": class_metrics[0][i],\n \"recall\": class_metrics[1][i],\n \"f1\": class_metrics[2][i],\n \"num_samples\": np.float64(class_metrics[3][i]),\n }\n# Metrics for a specific class\ntag=\"natural-language-processing\"\nprint (json.dumps(metrics[\"class\"][tag], indent=2))\n\n{\n \"precision\": 0.9036144578313253,\n \"recall\": 0.9615384615384616,\n \"f1\": 0.9316770186335404,\n \"num_samples\": 78.0\n}\n # Sorted tags\nsorted_tags_by_f1 = OrderedDict(sorted(\n metrics[\"class\"].items(), key=lambda tag: tag[1][\"f1\"], reverse=True))\nfor item in sorted_tags_by_f1.items():\n print (json.dumps(item, indent=2))\n\n[\n \"natural-language-processing\",\n {\n \"precision\": 0.9036144578313253,\n \"recall\": 0.9615384615384616,\n \"f1\": 0.9316770186335404,\n \"num_samples\": 78.0\n }\n]\n[\n \"computer-vision\",\n {\n \"precision\": 0.9838709677419355,\n \"recall\": 0.8591549295774648,\n \"f1\": 0.9172932330827067,\n \"num_samples\": 71.0\n }\n]\n[\n \"other\",\n {\n \"precision\": 0.8333333333333334,\n \"recall\": 0.9615384615384616,\n \"f1\": 0.8928571428571429,\n \"num_samples\": 26.0\n }\n]\n[\n \"mlops\",\n {\n \"precision\": 0.8125,\n \"recall\": 0.8125,\n \"f1\": 0.8125,\n \"num_samples\": 16.0\n }\n]\n"},{"location":"courses/mlops/evaluation/#confusion-matrix","title":"Confusion matrix","text":"Besides just inspecting the metrics for each class, we can also identify the true positives, false positives and false negatives. Each of these will give us insight about our model beyond what the metrics can provide.
It's a good to have our FP/FN samples feed back into our annotation pipelines in the event we want to fix their labels and have those changes be reflected everywhere.
# TP, FP, FN samples\ntag = \"natural-language-processing\"\nindex = preprocessor.class_to_index[tag]\ntp, fp, fn = [], [], []\nfor i, true in enumerate(y_test):\n pred = y_pred[i]\n if index==true==pred:\n tp.append(i)\n elif index!=true and index==pred:\n fp.append(i)\n elif index==true and index!=pred:\n fn.append(i)\nprint (tp)\nprint (fp)\nprint (fn)\n\n[4, 9, 12, 17, 19, 23, 25, 26, 29, 30, 31, 32, 33, 34, 42, 47, 49, 50, 54, 56, 65, 66, 68, 71, 75, 76, 77, 78, 79, 82, 92, 94, 95, 97, 99, 101, 109, 113, 114, 118, 120, 122, 126, 128, 129, 130, 131, 133, 134, 135, 138, 139, 140, 141, 142, 144, 148, 149, 152, 159, 160, 161, 163, 166, 170, 172, 173, 174, 177, 179, 183, 184, 187, 189, 190]\n[41, 44, 73, 102, 110, 150, 154, 165]\n[16, 112, 115]\n
# Samples\nnum_samples = 3\ncm = [(tp, \"True positives\"), (fp, \"False positives\"), (fn, \"False negatives\")]\nfor item in cm:\n if len(item[0]):\n print (f\"\\n=== {item[1]} ===\")\n for index in item[0][:num_samples]:\n print (f\"{test_df.iloc[index].text}\")\n print (f\" true: {test_df.tag[index]}\")\n print (f\" pred: {test_df.prediction[index]}\\n\")\n\n=== True positives ===\nMention Classifier Category prediction model\nThis repo contains AllenNLP model for prediction of Named Entity categories by its mentions.\n true: natural-language-processing\n pred: natural-language-processing\n\nFinetune: Scikit-learn Style Model Finetuning for NLP Finetune is a library that allows users to leverage state-of-the-art pretrained NLP models for a wide variety of downstream tasks.\n true: natural-language-processing\n pred: natural-language-processing\n\nFinetuning Transformers with JAX + Haiku Walking through a port of the RoBERTa pre-trained model to JAX + Haiku, then fine-tuning the model to solve a downstream task.\n true: natural-language-processing\n pred: natural-language-processing\n\n\n=== False positives ===\nHow Docker Can Help You Become A More Effective Data Scientist A look at Docker from the perspective of a data scientist.\n true: mlops\n pred: natural-language-processing\n\nTransfer Learning & Fine-Tuning With Keras Your 100% up-to-date guide to transfer learning & fine-tuning with Keras.\n true: computer-vision\n pred: natural-language-processing\n\nExploratory Data Analysis on MS COCO Style Datasets A Simple Toolkit to do exploratory data analysis on MS COCO style formatted datasets.\n true: computer-vision\n pred: natural-language-processing\n\n\n=== False negatives ===\nThe Unreasonable Effectiveness of Recurrent Neural Networks A close look at how RNNs are able to perform so well.\n true: natural-language-processing\n pred: other\n\nMachine Learning Projects This Repo contains projects done by me while learning the basics. All the familiar types of regression, classification, and clustering methods have been used.\n true: natural-language-processing\n pred: other\n\nBERT Distillation with Catalyst How to distill BERT with Catalyst.\n true: natural-language-processing\n pred: mlops\n\n
Tip
It's a really good idea to do this kind of analysis using our rule-based approach to catch really obvious labeling errors.
"},{"location":"courses/mlops/evaluation/#confidence-learning","title":"Confidence learning","text":"While the confusion-matrix sample analysis was a coarse-grained process, we can also use fine-grained confidence based approaches to identify potentially mislabeled samples. Here we\u2019re going to focus on the specific labeling quality as opposed to the final model predictions.
Simple confidence based techniques include identifying samples whose:
Categorical
Continuous
# Tag to inspect\ntag = \"natural-language-processing\"\nindex = class_to_index[tag]\nindices = np.where(y_test==index)[0]\n# Confidence score for the correct class is below a threshold\nlow_confidence = []\nmin_threshold = 0.5\nfor i in indices:\n prob = y_prob[i][index]\n if prob <= 0.5:\n low_confidence.append({\n \"text\": f\"{test_df.iloc[i].text}\",\n \"true\": test_df.tag[i],\n \"pred\": test_df.prediction[i],\n \"prob\": prob})\nlow_confidence[0:3]\n\n[{'text': 'The Unreasonable Effectiveness of Recurrent Neural Networks A close look at how RNNs are able to perform so well.',\n 'true': 'natural-language-processing',\n 'pred': 'other',\n 'prob': 0.0023471832},\n {'text': 'Machine Learning Projects This Repo contains projects done by me while learning the basics. All the familiar types of regression, classification, and clustering methods have been used.',\n 'true': 'natural-language-processing',\n 'pred': 'other',\n 'prob': 0.0027675298},\n {'text': 'BERT Distillation with Catalyst How to distill BERT with Catalyst.',\n 'true': 'natural-language-processing',\n 'pred': 'mlops',\n 'prob': 0.37908182}]\n But these are fairly crude techniques because neural networks are easily overconfident and so their confidences cannot be used without calibrating them.
Modern (large) neural networks result in higher accuracies but are over confident.On Calibration of Modern Neural NetworksRecent work on confident learning (cleanlab) focuses on identifying noisy labels (with calibration), which can then be properly relabeled and used for training.
import cleanlab\nfrom cleanlab.filter import find_label_issues\n# Find label issues\nlabel_issues = find_label_issues(labels=y_test, pred_probs=y_prob, return_indices_ranked_by=\"self_confidence\")\ntest_df.iloc[label_issues].drop(columns=[\"text\"]).head()\nNot all of these are necessarily labeling errors but situations where the predicted probabilities were not so confident. Therefore, it will be useful to attach the predicted outcomes along side results. This way, we can know if we need to relabel, upsample, etc. as mitigation strategies to improve our performance.
The operations in this section can be applied to entire labeled dataset to discover labeling errors via confidence learning.
"},{"location":"courses/mlops/evaluation/#slicing","title":"Slicing","text":"Just inspecting the overall and class metrics isn't enough to deploy our new version to production. There may be key slices of our dataset that we need to do really well on:
An easy way to create and evaluate slices is to define slicing functions.
from snorkel.slicing import PandasSFApplier\nfrom snorkel.slicing import slice_dataframe\nfrom snorkel.slicing import slicing_function\n@slicing_function()\ndef nlp_llm(x):\n\"\"\"NLP projects that use LLMs.\"\"\"\n nlp_project = \"natural-language-processing\" in x.tag\n llm_terms = [\"transformer\", \"llm\", \"bert\"]\n llm_project = any(s.lower() in x.text.lower() for s in llm_terms)\n return (nlp_project and llm_project)\n@slicing_function()\ndef short_text(x):\n\"\"\"Projects with short titles and descriptions.\"\"\"\n return len(x.text.split()) < 8 # less than 8 words\nHere we're using Snorkel's slicing_function to create our different slices. We can visualize our slices by applying this slicing function to a relevant DataFrame using slice_dataframe.
nlp_llm_df = slice_dataframe(test_df, nlp_llm)\nnlp_llm_df[[\"text\", \"tag\"]].head()\nshort_text_df = slice_dataframe(test_df, short_text)\nshort_text_df[[\"text\", \"tag\"]].head()\nWe can define even more slicing functions and create a slices record array using the PandasSFApplier. The slices array has N (# of data points) items and each item has S (# of slicing functions) items, indicating whether that data point is part of that slice. Think of this record array as a masking layer for each slicing function on our data.
# Slices\nslicing_functions = [nlp_llm, short_text]\napplier = PandasSFApplier(slicing_functions)\nslices = applier.apply(test_df)\nslices\n\nrec.array([(0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0),\n (1, 0) (0, 0) (0, 1) (0, 0) (0, 0) (1, 0) (0, 0) (0, 0) (0, 1) (0, 0)\n ...\n (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 0), (0, 1),\n (0, 0), (0, 0)],\n dtype=[('nlp_cnn', '<i8'), ('short_text', '<i8')])\n To calculate metrics for our slices, we could use snorkel.analysis.Scorer but we've implemented a version that will work for multiclass or multilabel scenarios.
# Score slices\nmetrics[\"slices\"] = {}\nfor slice_name in slices.dtype.names:\n mask = slices[slice_name].astype(bool)\n if sum(mask):\n slice_metrics = precision_recall_fscore_support(\n y_test[mask], y_pred[mask], average=\"micro\"\n )\n metrics[\"slices\"][slice_name] = {}\n metrics[\"slices\"][slice_name][\"precision\"] = slice_metrics[0]\n metrics[\"slices\"][slice_name][\"recall\"] = slice_metrics[1]\n metrics[\"slices\"][slice_name][\"f1\"] = slice_metrics[2]\n metrics[\"slices\"][slice_name][\"num_samples\"] = len(y_test[mask])\nprint(json.dumps(metrics[\"slices\"], indent=2))\n\n{\n \"nlp_llm\": {\n \"precision\": 0.9642857142857143,\n \"recall\": 0.9642857142857143,\n \"f1\": 0.9642857142857143,\n \"num_samples\": 28\n },\n \"short_text\": {\n \"precision\": 1.0,\n \"recall\": 1.0,\n \"f1\": 1.0,\n \"num_samples\": 7\n }\n}\n Slicing can help identify sources of bias in our data. For example, our model has most likely learned to associated algorithms with certain applications such as CNNs used for computer vision or transformers used for NLP projects. However, these algorithms are not being applied beyond their initial use cases. We\u2019d need ensure that our model learns to focus on the application over algorithm. This could be learned with:
Besides just comparing predicted outputs with ground truth values, we can also inspect the inputs to our models. What aspects of the input are more influential towards the prediction? If the focus is not on the relevant features of our input, then we need to explore if there is a hidden pattern we're missing or if our model has learned to overfit on the incorrect features. We can use techniques such as SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) to inspect feature importance. On a high level, these techniques learn which features have the most signal by assessing the performance in their absence. These inspections can be performed on a global level (ex. per-class) or on a local level (ex. single prediction).
from lime.lime_text import LimeTextExplainer\nfrom sklearn.pipeline import make_pipeline\nLimeTextExplainer.explain_instance function requires a classifier_fn that takes in a list of strings and outputs the predicted probabilities.
def classifier_fn(texts):\n df = pd.DataFrame({\"title\": texts, \"description\": \"\", \"tag\": \"other\"})\n z = predictor.predict(data=df)[\"predictions\"]\n y_prob = torch.tensor(np.stack(z)).softmax(dim=1).numpy()\n return y_prob\n# Explain instance\ntext = \"Using pretrained convolutional neural networks for object detection.\"\nexplainer = LimeTextExplainer(class_names=list(class_to_index.keys()))\nexplainer.explain_instance(text, classifier_fn=classifier_fn, top_labels=1).show_in_notebook(text=True)\nWe can also use model-specific approaches to interpretability we we did in our embeddings lesson to identify the most influential n-grams in our text.
"},{"location":"courses/mlops/evaluation/#behavioral-testing","title":"Behavioral testing","text":"Besides just looking at metrics, we also want to conduct some behavioral sanity tests. Behavioral testing is the process of testing input data and expected outputs while treating the model as a black box. They don't necessarily have to be adversarial in nature but more along the types of perturbations we'll see in the real world once our model is deployed. A landmark paper on this topic is Beyond Accuracy: Behavioral Testing of NLP Models with CheckList which breaks down behavioral testing into three types of tests:
invariance: Changes should not affect outputs. # INVariance via verb injection (changes should not affect outputs)\ntokens = [\"revolutionized\", \"disrupted\"]\ntexts = [f\"Transformers applied to NLP have {token} the ML field.\" for token in tokens]\n[preprocessor.index_to_class[y_prob.argmax()] for y_prob in classifier_fn(texts=texts)]\n\n['natural-language-processing', 'natural-language-processing']\n
directional: Change should affect outputs. # DIRectional expectations (changes with known outputs)\ntokens = [\"text classification\", \"image classification\"]\ntexts = [f\"ML applied to {token}.\" for token in tokens]\n[preprocessor.index_to_class[y_prob.argmax()] for y_prob in classifier_fn(texts=texts)]\n\n['natural-language-processing', 'computer-vision']\n
minimum functionality: Simple combination of inputs and expected outputs. # Minimum Functionality Tests (simple input/output pairs)\ntokens = [\"natural language processing\", \"mlops\"]\ntexts = [f\"{token} is the next big wave in machine learning.\" for token in tokens]\n[preprocessor.index_to_class[y_prob.argmax()] for y_prob in classifier_fn(texts=texts)]\n\n['natural-language-processing', 'mlops']\n
We'll learn how to systematically create tests in our testing lesson.
"},{"location":"courses/mlops/evaluation/#online-evaluation","title":"Online evaluation","text":"Once we've evaluated our model's ability to perform on a static dataset we can run several types of online evaluation techniques to determine performance on actual production data. It can be performed using labels or, in the event we don't readily have labels, proxy signals.
And there are many different experimentation strategies we can use to measure real-time performance before committing to replace our existing version of the system.
"},{"location":"courses/mlops/evaluation/#ab-tests","title":"AB tests","text":"AB testing involves sending production traffic to our current system (control group) and the new version (treatment group) and measuring if there is a statistical difference between the values for two metrics. There are several common issues with AB testing such as accounting for different sources of bias, such as the novelty effect of showing some users the new system. We also need to ensure that the same users continue to interact with the same systems so we can compare the results without contamination.
In many cases, if we're simply trying to compare the different versions for a certain metric, AB testing can take while before we reach statical significance since traffic is evenly split between the different groups. In this scenario, multi-armed bandits will be a better approach since they continuously assign traffic to the better performing version.
"},{"location":"courses/mlops/evaluation/#canary-tests","title":"Canary tests","text":"Canary tests involve sending most of the production traffic to the currently deployed system but sending traffic from a small cohort of users to the new system we're trying to evaluate. Again we need to make sure that the same users continue to interact with the same system as we gradually roll out the new system.
"},{"location":"courses/mlops/evaluation/#shadow-tests","title":"Shadow tests","text":"Shadow testing involves sending the same production traffic to the different systems. We don't have to worry about system contamination and it's very safe compared to the previous approaches since the new system's results are not served. However, we do need to ensure that we're replicating as much of the production system as possible so we can catch issues that are unique to production early on. But overall, shadow testing is easy to monitor, validate operational consistency, etc.
What can go wrong?
If shadow tests allow us to test our updated system without having to actually serve the new results, why doesn't everyone adopt it?
Show answerWith shadow deployment, we'll miss out on any live feedback signals (explicit/implicit) from our users since users are not directly interacting with the product using our new version.
We also need to ensure that we're replicating as much of the production system as possible so we can catch issues that are unique to production early on. This is rarely possible because, while your ML system may be a standalone microservice, it ultimately interacts with an intricate production environment that has many dependencies.
"},{"location":"courses/mlops/evaluation/#capability-vs-alignment","title":"Capability vs. alignment","text":"We've seen the many different metrics that we'll want to calculate when it comes to evaluating our model but not all metrics mean the same thing. And this becomes very important when it comes to choosing the \"best\" model(s).
While capability (ex. loss) and alignment (ex. accuracy) metrics may seem to be aligned, their differences can indicate issues in our data:
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Evaluation - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nSo far, we've been training and evaluating our different baselines but haven't really been tracking these experiments. We'll fix this but defining a proper process for experiment tracking which we'll use for all future experiments (including hyperparameter optimization). Experiment tracking is the process of managing all the different experiments and their components, such as parameters, metrics, models and other artifacts and it enables us to:
There are many options for experiment tracking but we're going to use MLFlow (100% free and open-source) because it has all the functionality we'll need. We can run MLFlow on our own servers and databases so there are no storage cost / limitations, making it one of the most popular options and is used by Microsoft, Facebook, Databricks and others. There are also several popular options such as a Comet ML (used by Google AI, HuggingFace, etc.), Neptune (used by Roche, NewYorker, etc.), Weights and Biases (used by Open AI, Toyota Research, etc.). These are fully managed solutions that provide features like dashboards, reports, etc.
"},{"location":"courses/mlops/experiment-tracking/#setup","title":"Setup","text":"We'll start by setting up our model registry where all of our experiments and their artifacts will be stores.
import mlflow\nfrom pathlib import Path\nfrom ray.air.integrations.mlflow import MLflowLoggerCallback\nimport time\n# Config MLflow\nMODEL_REGISTRY = Path(\"/tmp/mlflow\")\nPath(MODEL_REGISTRY).mkdir(parents=True, exist_ok=True)\nMLFLOW_TRACKING_URI = \"file://\" + str(MODEL_REGISTRY.absolute())\nmlflow.set_tracking_uri(MLFLOW_TRACKING_URI)\nprint (mlflow.get_tracking_uri())\n\nfile:///tmp/mlflow\n
On Windows, the tracking URI should have three forwards slashes:
MLFLOW_TRACKING_URI = \"file:///\" + str(MODEL_REGISTRY.absolute())\nNote
In this course, our MLflow artifact and backend store will both be on our local machine. In a production setting, these would be remote such as S3 for the artifact store and a database service (ex. PostgreSQL RDS) as our backend store.
"},{"location":"courses/mlops/experiment-tracking/#integration","title":"Integration","text":"While we could use MLflow directly to log metrics, artifacts and parameters:
# Example mlflow calls\nmlflow.log_metrics({\"train_loss\": train_loss, \"val_loss\": val_loss}, step=epoch)\nmlflow.log_artifacts(dir)\nmlflow.log_params(config)\nWe'll instead use Ray to integrate with MLflow. Specifically we'll use the MLflowLoggerCallback which will automatically log all the necessary components of our experiments to the location specified in our MLFLOW_TRACKING_URI. We of course can still use MLflow directly if we want to log something that's not automatically logged by the callback. And if we're using other experiment trackers, Ray has integrations for those as well.
# MLflow callback\nexperiment_name = f\"llm-{int(time.time())}\"\nmlflow_callback = MLflowLoggerCallback(\n tracking_uri=MLFLOW_TRACKING_URI,\n experiment_name=experiment_name,\n save_artifact=True)\nOnce we have the callback defined, all we have to do is update our RunConfig to include it.
# Run configuration with MLflow callback\nrun_config = RunConfig(\n callbacks=[mlflow_callback],\n checkpoint_config=checkpoint_config,\n)\nWith our updated RunConfig, with the MLflow callback, we can now train our model and all the necessary components will be logged to MLflow. This is the exact same training workflow we've been using so far from the training lesson.
# Dataset\nds = load_data()\ntrain_ds, val_ds = stratify_split(ds, stratify=\"tag\", test_size=test_size)\n\n# Preprocess\npreprocessor = CustomPreprocessor()\ntrain_ds = preprocessor.fit_transform(train_ds)\nval_ds = preprocessor.transform(val_ds)\ntrain_ds = train_ds.materialize()\nval_ds = val_ds.materialize()\n\n# Trainer\ntrainer = TorchTrainer(\n train_loop_per_worker=train_loop_per_worker,\n train_loop_config=train_loop_config,\n scaling_config=scaling_config,\n run_config=run_config, # uses RunConfig with MLflow callback\n datasets={\"train\": train_ds, \"val\": val_ds},\n dataset_config=dataset_config,\n preprocessor=preprocessor,\n)\n\n# Train\nresults = trainer.fit()\nresults.metrics_dataframe\nWe're going to use the search_runs function from the MLflow python API to identify the best run in our experiment so far (we' only done one run so far so it will be the run from above).
# Sorted runs\nsorted_runs = mlflow.search_runs(experiment_names=[experiment_name], order_by=[\"metrics.val_loss ASC\"])\nsorted_runs\n\nrun_id 8e473b640d264808a89914e8068587fb\nexperiment_id 853333311265913081\nstatus FINISHED\n...\ntags.mlflow.runName TorchTrainer_077f9_00000\nName: 0, dtype: object\n"},{"location":"courses/mlops/experiment-tracking/#dashboard","title":"Dashboard","text":"
Once we're done training, we can use the MLflow dashboard to visualize our results. To do so, we'll use the mlflow server command to launch the MLflow dashboard and navigate to the experiment we just created.
mlflow server -h 0.0.0.0 -p 8080 --backend-store-uri /tmp/mlflow/\nView the dashboard
AnyscaleLocalIf you're on Anyscale Workspaces, then we need to first expose the port of the MLflow server. Run the following command on your Anyscale Workspace terminal to generate the public URL to your MLflow server.
APP_PORT=8080\necho https://$APP_PORT-port-$ANYSCALE_SESSION_DOMAIN\nIf you're running this notebook on your local laptop then head on over to http://localhost:8080/ to view your MLflow dashboard.
MLFlow creates a main dashboard with all your experiments and their respective runs. We can sort runs by clicking on the column headers.
And within each run, we can view metrics, parameters, artifacts, etc.
And we can even create custom plots to help us visualize our results.
"},{"location":"courses/mlops/experiment-tracking/#loading","title":"Loading","text":"After inspection and once we've identified an experiment that we like, we can load the model for evaluation and inference.
from ray.air import Result\nfrom urllib.parse import urlparse\nWe're going to create a small utility function that uses an MLflow run's artifact path to load a Ray Result object. We'll then use the Result object to load the best checkpoint.
def get_best_checkpoint(run_id):\n artifact_dir = urlparse(mlflow.get_run(run_id).info.artifact_uri).path # get path from mlflow\n results = Result.from_path(artifact_dir)\n return results.best_checkpoints[0][0]\nWith a particular run's best checkpoint, we can load the model from it and use it.
# Evaluate on test split\nbest_checkpoint = get_best_checkpoint(run_id=best_run.run_id)\npredictor = TorchPredictor.from_checkpoint(best_checkpoint)\nperformance = evaluate(ds=test_ds, predictor=predictor)\nprint (json.dumps(performance, indent=2))\n\n{\n \"precision\": 0.9281010510531216,\n \"recall\": 0.9267015706806283,\n \"f1\": 0.9269438615952555\n}\n Before we can use our model for inference, we need to load the preprocessor from our predictor and apply it to our input data.
# Preprocessor\npreprocessor = predictor.get_preprocessor()\n# Predict on sample\ntitle = \"Transfer learning with transformers\"\ndescription = \"Using transformers for transfer learning on text classification tasks.\"\nsample_df = pd.DataFrame([{\"title\": title, \"description\": description, \"tag\": \"other\"}])\npredict_with_proba(df=sample_df, predictor=predictor)\n\n[{'prediction': 'natural-language-processing',\n 'probabilities': {'computer-vision': 0.00038025028,\n 'mlops': 0.00038209034,\n 'natural-language-processing': 0.998792,\n 'other': 0.00044562898}}]\n In the next lesson we'll learn how to tune our models and use our MLflow dashboard to compare the results.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Tracking - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nExploratory data analysis (EDA) to understand the signals and nuances of our dataset. It's a cyclical process that can be done at various points of our development process (before/after labeling, preprocessing, etc. depending on how well the problem is defined. For example, if we're unsure how to label or preprocess our data, we can use EDA to figure it out.
We're going to start our project with EDA, a vital (and fun) process that's often misconstrued. Here's how to think about EDA:
Let's answer a few key questions using EDA.
from collections import Counter\nimport matplotlib.pyplot as plt\nimport seaborn as sns; sns.set_theme()\nimport warnings; warnings.filterwarnings(\"ignore\")\nfrom wordcloud import WordCloud, STOPWORDS\nHow many data points do we have per tag? We'll use the Counter class to get counts for all the different tags.
# Most common tags\nall_tags = Counter(df.tag)\nall_tags.most_common()\n\n[('natural-language-processing', 310),\n ('computer-vision', 285),\n ('other', 106),\n ('mlops', 63)]\n We can then separate the tags and from their respective counts and plot them using Plotly.
# Plot tag frequencies\ntags, tag_counts = zip(*all_tags.most_common())\nplt.figure(figsize=(10, 3))\nax = sns.barplot(x=list(tags), y=list(tag_counts))\nax.set_xticklabels(tags, rotation=0, fontsize=8)\nplt.title(\"Tag distribution\", fontsize=14)\nplt.ylabel(\"# of projects\", fontsize=12)\nplt.show()\nWe do have some data imbalance but it's not too bad. If we did want to account for this, there are many strategies, including over-sampling less frequent classes and under-sampling popular classes, class weights in the loss function, etc.
"},{"location":"courses/mlops/exploratory-data-analysis/#wordcloud","title":"Wordcloud","text":"Is there enough signal in the title and description that's unique to each tag? This is important to know because we want to verify our initial hypothesis that the project's title and description are high quality features for predicting the tag. And to visualize this, we're going to use a wordcloud. We also use a jupyter widget, which you can view in the notebook, to interactively select a tag and see the wordcloud for that tag.
# Most frequent tokens for each tag\ntag=\"natural-language-processing\"\nplt.figure(figsize=(10, 3))\nsubset = df[df.tag==tag]\ntext = subset.title.values\ncloud = WordCloud(\n stopwords=STOPWORDS, background_color=\"black\", collocations=False,\n width=500, height=300).generate(\" \".join(text))\nplt.axis(\"off\")\nplt.imshow(cloud)\nLooks like the title text feature has some good signal for the respective classes and matches our intuition. We can repeat this for the description text feature as well and see similar quality signals. This information will become useful when we decide how to use our features for modeling.
There's a lot more exploratory data analysis that we can do but for now we've answered our questions around our class distributions and the quality of our text features. In the next lesson we'll preprocess our dataset in preparation for model training.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Exploration - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nLet's motivate the need for a feature store by chronologically looking at what challenges developers face in their current workflows. Suppose we had a task where we needed to predict something for an entity (ex. user) using their features.
Solution: create a central feature repository where the entire team contributes maintained features that anyone can use for any application.Solution: create features using a unified pipeline and store them in a central location that the training and serving pipelines pull from.Solution: retrieve input features for the respective outcomes by pulling what's available when a prediction would be made.Point-in-time correctness refers to mapping the appropriately up-to-date input feature values to an observed outcome at \\(t_{n+1}\\). This involves knowing the time (\\(t_n\\)) that a prediction is needed so we can collect feature values (\\(X\\)) at that time.
When actually constructing our feature store, there are several core components we need to have to address these challenges:
Each of these components is fairly easy to set up but connecting them all together requires a managed service, SDK layer for interactions, etc. Instead of building from scratch, it's best to leverage one of the production-ready, feature store options such as Feast, Hopsworks, Tecton, Rasgo, etc. And of course, the large cloud providers have their own feature store options as well (Amazon's SageMaker Feature Store, Google's Vertex AI, etc.)
Tip
We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the feature-store repository for a quick overview with an interactive notebook.
"},{"location":"courses/mlops/feature-store/#over-engineering","title":"Over-engineering","text":"Not all machine learning platforms require a feature store. In fact, our use case is a perfect example of a task that does not benefit from a feature store. All of our data points are independent, stateless, from client-side and there is no entity that has changing features over time. The real utility of a feature store shines when we need to have up-to-date features for an entity that we continually generate predictions for. For example, a user's behavior (clicks, purchases, etc.) on an e-commerce platform or the deliveries a food runner recently made in the last hour, etc.
"},{"location":"courses/mlops/feature-store/#when-do-i-need-a-feature-store","title":"When do I need a feature store?","text":"To answer this question, let's revisit the main challenges that a feature store addresses:
Note
Additionally, if the transformations are compute intensive, then they'll incur a lot of costs by running on duplicate datasets across different applications (as opposed to having a central location with upt-o-date transformed features).
Skew: similar to duplication of efforts, if our transformations can be tied to the model or as a standalone function, then we can just reuse the same pipelines to produce the feature values for training and serving. But this becomes complex and compute intensive as the number of applications, features and transformations grow.
Value: if we aren't working with features that need to be computed server-side (batch or streaming), then we don't have to worry about concepts like point-in-time, etc. However, if we are, a feature store can allow us to retrieve the appropriate feature values across all data sources without the developer having to worry about using disparate tools for different sources (batch, streaming, etc.)
We're going to leverage Feast as the feature store for our application for it's ease of local setup, SDK for training/serving, etc.
# Install Feast and dependencies\npip install feast==0.10.5 PyYAML==5.3.1 -q\n\ud83d\udc49 \u00a0 Follow along interactive notebook in the feature-store repository as we implement the concepts below.
"},{"location":"courses/mlops/feature-store/#set-up","title":"Set up","text":"We're going to create a feature repository at the root of our project. Feast will create a configuration file for us and we're going to add an additional features.py file to define our features.
Traditionally, the feature repository would be it's own isolated repository that other services will use to read/write features from.
mkdir -p stores/feature\nmkdir -p data\nfeast init --minimal --template local features\ncd features\ntouch features.py\n\nCreating a new Feast repository in /content/features.\n
The initialized feature repository (with the additional file we've added) will include:
features/\n\u251c\u2500\u2500 feature_store.yaml - configuration\n\u2514\u2500\u2500 features.py - feature definitions\nWe're going to configure the locations for our registry and online store (SQLite) in our feature_store.yaml file.
If all our feature definitions look valid, Feast will sync the metadata about Feast objects to the registry. The registry is a tiny database storing most of the same information you have in the feature repository. This step is necessary because the production feature serving infrastructure won't be able to access Python files in the feature repository at run time, but it will be able to efficiently and securely read the feature definitions from the registry.
When we run Feast locally, the offline store is effectively represented via Pandas point-in-time joins. Whereas, in production, the offline store can be something more robust like Google BigQuery, Amazon RedShift, etc.
We'll go ahead and paste this into our features/feature_store.yaml file (the notebook cell is automatically do this):
project: features\nregistry: ../stores/feature/registry.db\nprovider: local\nonline_store:\npath: ../stores/feature/online_store.db\nThe first step is to establish connections with our data sources (databases, data warehouse, etc.). Feast requires it's data sources to either come from a file (Parquet), data warehouse (BigQuery) or data stream (Kafka / Kinesis). We'll convert our generated features file from the DataOps pipeline (features.json) into a Parquet file, which is a column-major data format that allows fast feature retrieval and caching benefits (contrary to row-major data formats such as CSV where we have to traverse every single row to collect feature values).
import os\nimport pandas as pd\n# Load labeled projects\nprojects = pd.read_csv(\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv\")\ntags = pd.read_csv(\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv\")\ndf = pd.merge(projects, tags, on=\"id\")\ndf[\"text\"] = df.title + \" \" + df.description\ndf.drop([\"title\", \"description\"], axis=1, inplace=True)\ndf.head(5)\n\nid\n created_on\n tag\n text\n 0\n 6\n 2020-02-20 06:43:18\n computer-vision\n Comparison between YOLO and RCNN on real world...\n 1\n 7\n 2020-02-20 06:47:21\n computer-vision\n Show, Infer & Tell: Contextual Inference for C...\n 2\n 9\n 2020-02-24 16:24:45\n graph-learning\n Awesome Graph Classification A collection of i...\n 3\n 15\n 2020-02-28 23:55:26\n reinforcement-learning\n Awesome Monte Carlo Tree Search A curated list...\n 4\n 19\n 2020-03-03 13:54:31\n graph-learning\n Diffusion to Vector Reference implementation o...\n
# Format timestamp\ndf.created_on = pd.to_datetime(df.created_on)\n# Convert to parquet\nDATA_DIR = Path(os.getcwd(), \"data\")\ndf.to_parquet(\n Path(DATA_DIR, \"features.parquet\"),\n compression=None,\n allow_truncated_timestamps=True,\n)\nNow that we have our data source prepared, we can define our features for the feature store.
from datetime import datetime\nfrom pathlib import Path\nfrom feast import Entity, Feature, FeatureView, ValueType\nfrom feast.data_source import FileSource\nfrom google.protobuf.duration_pb2 import Duration\nThe first step is to define the location of the features (FileSource in our case) and the timestamp column for each data point.
# Read data\nSTART_TIME = \"2020-02-17\"\nproject_details = FileSource(\n path=str(Path(DATA_DIR, \"features.parquet\")),\n event_timestamp_column=\"created_on\",\n)\nNext, we need to define the main entity that each data point pertains to. In our case, each project has a unique ID with features such as text and tags.
# Define an entity\nproject = Entity(\n name=\"id\",\n value_type=ValueType.INT64,\n description=\"project id\",\n)\nFinally, we're ready to create a FeatureView that loads specific features (features), of various value types, from a data source (input) for a specific period of time (ttl).
# Define a Feature View for each project\nproject_details_view = FeatureView(\n name=\"project_details\",\n entities=[\"id\"],\nttl=Duration(\nseconds=(datetime.today() - datetime.strptime(START_TIME, \"%Y-%m-%d\")).days * 24 * 60 * 60\n ),\nfeatures=[\nFeature(name=\"text\", dtype=ValueType.STRING),\n Feature(name=\"tag\", dtype=ValueType.STRING),\n ],\n online=True,\ninput=project_details,\ntags={},\n)\nSo let's go ahead and define our feature views by moving this code into our features/features.py script (the notebook cell is automatically do this):
from datetime import datetime\nfrom pathlib import Path\n\nfrom feast import Entity, Feature, FeatureView, ValueType\nfrom feast.data_source import FileSource\nfrom google.protobuf.duration_pb2 import Duration\n\n\n# Read data\nSTART_TIME = \"2020-02-17\"\nproject_details = FileSource(\n path=\"/content/data/features.parquet\",\n event_timestamp_column=\"created_on\",\n)\n\n# Define an entity for the project\nproject = Entity(\n name=\"id\",\n value_type=ValueType.INT64,\n description=\"project id\",\n)\n\n# Define a Feature View for each project\n# Can be used for fetching historical data and online serving\nproject_details_view = FeatureView(\n name=\"project_details\",\n entities=[\"id\"],\n ttl=Duration(\n seconds=(datetime.today() - datetime.strptime(START_TIME, \"%Y-%m-%d\")).days * 24 * 60 * 60\n ),\n features=[\n Feature(name=\"text\", dtype=ValueType.STRING),\n Feature(name=\"tag\", dtype=ValueType.STRING),\n ],\n online=True,\n input=project_details,\n tags={},\n)\nOnce we've defined our feature views, we can apply it to push a version controlled definition of our features to the registry for fast access. It will also configure our registry and online stores that we've defined in our feature_store.yaml.
cd features\nfeast apply\n\nRegistered entity id\nRegistered feature view project_details\nDeploying infrastructure for project_details\n"},{"location":"courses/mlops/feature-store/#historical-features","title":"Historical features","text":"
Once we've registered our feature definition, along with the data source, entity definition, etc., we can use it to fetch historical features. This is done via joins using the provided timestamps using pandas for our local setup or BigQuery, Hive, etc. as an offline DB for production.
import pandas as pd\nfrom feast import FeatureStore\n# Identify entities\nproject_ids = df.id[0:3].to_list()\nnow = datetime.now()\ntimestamps = [datetime(now.year, now.month, now.day)]*len(project_ids)\nentity_df = pd.DataFrame.from_dict({\"id\": project_ids, \"event_timestamp\": timestamps})\nentity_df.head()\n# Get historical features\nstore = FeatureStore(repo_path=\"features\")\ntraining_df = store.get_historical_features(\n entity_df=entity_df,\n feature_refs=[\"project_details:text\", \"project_details:tag\"],\n).to_df()\ntraining_df.head()\nFor online inference, we want to retrieve features very quickly via our online store, as opposed to fetching them from slow joins. However, the features are not in our online store just yet, so we'll need to materialize them first.
cd features\nCURRENT_TIME=$(date -u +\"%Y-%m-%dT%H:%M:%S\")\nfeast materialize-incremental $CURRENT_TIME\n\nMaterializing 1 feature views to 2022-06-23 19:16:05+00:00 into the sqlite online store.\nproject_details from 2020-02-17 19:16:06+00:00 to 2022-06-23 19:16:05+00:00:\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 955/955 [00:00<00:00, 10596.97it/s]\n
This has moved the features for all of our projects into the online store since this was first time materializing to the online store. When we subsequently run the materialize-incremental command, Feast keeps track of previous materializations and so we'll only materialize the new data since the last attempt.
Once we've materialized the features (or directly sent to the online store in the stream scenario), we can use the online store to retrieve features.
# Get online features\nstore = FeatureStore(repo_path=\"features\")\nfeature_vector = store.get_online_features(\n feature_refs=[\"project_details:text\", \"project_details:tag\"],\n entity_rows=[{\"id\": 6}],\n).to_dict()\nfeature_vector\n{'id': [6],\n 'project_details__tag': ['computer-vision'],\n 'project_details__text': ['Comparison between YOLO and RCNN on real world videos Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes.']}\nThe feature store we implemented above assumes that our task requires batch processing. This means that inference requests on specific entity instances can use features that have been materialized from the offline store. Note that they may not be the most recent feature values for that entity.
Warning
Had our entity (projects) had features that change over time, we would materialize them to the online store incrementally. But since they don't, this would be considered over engineering but it's important to know how to leverage a feature store for entities with changing features over time.
"},{"location":"courses/mlops/feature-store/#stream-processing","title":"Stream processing","text":"Some applications may require stream processing where we require near real-time feature values to deliver up-to-date predictions at low latency. While we'll still utilize an offline store for retrieving historical data, our application's real-time event data will go directly through our data streams to an online store for serving. An example where stream processing would be needed is when we want to retrieve real-time user session behavior (clicks, purchases) in an e-commerce platform so that we can recommend the appropriate items from our catalog.
There are a few more components we're not visualizing here such as the unified ingestion layer (Spark), that connects data from the varied data sources (warehouse, DB, etc.) to the offline/online stores, or low latency serving (<10 ms). We can read more about all of these in the official Feast Documentation, which also has guides to set up a feature store with Feast with AWS, GCP, etc.
"},{"location":"courses/mlops/feature-store/#additional-functionality","title":"Additional functionality","text":"Additional functionality that many feature store providers are currently (or recently) trying to integrate within the feature store platform include:
Current solution: apply transformations as a separate Spark, Python, etc. workflow task before writing to the feature store.Current solution: apply data testing and monitoring as upstream workflow tasks before they are written to the feature store.Current solution: add a data discovery engine, such as Amundsen, on top of our feature store to enable others to search for features.Though we could continue to version our training data with DVC whenever we release a version of the model, it might not be necessary. When we pull data from source or compute features, should they save the data itself or just the operations?
Regardless of the choice above, feature stores are very useful here. Instead of coupling data pulls and feature compute with the time of modeling, we can separate these two processes so that features are up-to-date when we need them. And we can still achieve reproducibility via efficient point-in-time correctness, low latency snapshots, etc. This essentially creates the ability to work with any version of the dataset at any point in time.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Feature Store - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWhether we're working individually or with a team, it's important that we have a system to track changes to our projects so that we can revert to previous versions and so that others can reproduce our work and contribute to it. Git is a distributed versional control system that allows us do exactly this. Git runs locally on our computer and it keeps track of our files and their histories. To enable collaboration with others, we can use a remote host (GitHub, GitLab, BitBucket, etc.) to host our files and their histories. We'll use git to push our local changes and pull other's changes to and from the remote host.
Git is traditionally used to store and version small files <100MB (scripts, READMEs, etc.), however, we can still version large artifacts (datasets, model weights, etc.) using text pointers pointing to blob stores. These pointers will contain information such as where the asset is located, it's specific contents/version (ex. via hashing), etc.
"},{"location":"courses/mlops/git/#set-up","title":"Set up","text":""},{"location":"courses/mlops/git/#initialize-git","title":"Initialize git","text":"Initialize a local repository (.git directory) to track our files:
git init\n\nInitialized empty Git repository in /Users/goku/Documents/madewithml/MLOps/.git/\n
We can see what files are untracked or yet to be committed:
git status\n\nOn branch main\n\nNo commits yet\n\nUntracked files:\n (use \"git add ...\" to include in what will be committed)\n .flake8\n .vscode/\n Makefile\n ..."},{"location":"courses/mlops/git/#gitignore","title":".gitignore","text":"We can see that we have some files that we don't want to push to a remote host, such as our virtual environment, logs, large data files, etc. We can create a .gitignore file to make sure we aren't checking in these files.
\ntouch .gitignore\n
\nWe'll add the following files to the file:
\n# Data\nlogs/\nstores/\ndata/\n\n# Packaging\nvenv/\n*.egg-info/\n__pycache__/\n\n# Misc\n.DS_Store\n
\nFor now, we're going to add data to our .gitignore file as well but this means that others will not be able to produce the same data assets when they pull from our remote host. To address this, we'll push pointers to our data files in our versioning lesson so that the data too can be reproduced exactly as we have it locally.
\nTip
\nCheck out our project's .gitignore for a more complete example that also includes lots of other system artifacts that we would normally not want to push to a remote repository. Our complete .gitignore file is based on GitHub's Python template and we're using a Mac, so we added the relevant global file names as well.
\nIf we run git status now, we should no longer see the files we've defined in our .gitignore file.
"},{"location":"courses/mlops/git/#add-to-stage","title":"Add to stage","text":"Next, we'll add our work from the working directory to the staging area.
\ngit add <filename>\ngit add .\nNow running git status will show us all the staged files:
git status\n\nOn branch main\n\nNo commits yet\n\nChanges to be committed:\n (use \"git rm --cached ...\" to unstage)\n new file: .flake8\n new file: .gitignore\n new file: Makefile\n ..."},{"location":"courses/mlops/git/#commit-to-repo","title":"Commit to repo","text":"Now we're ready to commit the files in the staging area to the local repository. The default branch (a version of our project) will be called main.
\ngit commit -m \"added project files\"\n
\n\n[main (root-commit) 704d99c] added project files\n 47 files changed, 50651 insertions(+)\n create mode 100644 .flake8\n create mode 100644 .gitignore\n create mode 100644 Makefile\n ...\n
\n\nThe commit requires a message indicating what changes took place. We can use git commit --amend to edit the commit message if needed. If we do a git status check we'll see that there is nothing else to commit from our staging area.
\ngit status\n
\n\nOn branch main\nnothing to commit, working tree clean\n
"},{"location":"courses/mlops/git/#push-to-remote","title":"Push to remote","text":"Now we're ready to push the updates from our local repository to a remote repository. Start by creating an account on GitHub (or any other remote repository) and follow the instructions to create a remote repository (it can be private or public). Inside our local repository, we're going to set our username and email credentials so that we can push changes from our local to the remote repository.
\n# Set credentials via terminal\ngit config --global user.name <USERNAME>\ngit config --global user.email <EMAIL>\n
\nWe can quickly validate that we set the proper credentials like so:\n# Check credentials\ngit config --global user.name\ngit config --global user.email\n
\nNext, we need to establish the connection between our local and remote repositories:
\n# Push to remote\ngit remote add origin https://github.com/<USERNAME>/<REPOSITORY_NAME>.git\ngit push -u origin main # pushing the contents of our local repo to the remote repo\n# origin signifies the remote repository\n
"},{"location":"courses/mlops/git/#developing","title":"Developing","text":"Now we're ready to start adding to our project and committing the changes.
"},{"location":"courses/mlops/git/#cloning","title":"Cloning","text":"If we (or someone else) doesn't already have the local repository set up and connected with the remote host, we can use the clone command:
\ngit clone <REMOTE_REPO_URL> <PATH_TO_PROJECT_DIR>\n
\nAnd we can clone a specific branch of a repository as well:
\ngit clone -b <BRANCH> <REMOTE_REPO_URL> <PATH_TO_PROJECT_DIR>\n
\n<REMOTE_REPO_URL> is the location of the remote repo (ex. https://github.com/GokuMohandas/Made-With-ML).<PATH_TO_PROJECT_DIR> is the name of the local directory you want to clone the project into.When we want to add or change something, such as adding a feature, fixing a bug, etc., it's always a best practice to create a separate branch before developing. This is especially crucial when working with a team so we can cleanly merge our work with the main branch after discussions and reviews.
We'll start by creating a new branch:
\ngit checkout -b <NEW_BRANCH_NAME>\nWe can see all the branches we've created with the following command where the * indicates our current branch:
\ngit branch\n\n* convnet\nmain\n\n\n
We can easily switch between existing branches using:
\ngit checkout <BRANCH_NAME>\nOnce we're in a branch, we can make changes to our project and commit those changes.
\ngit add .\ngit commit -m \"update model to a convnet\"\ngit push origin convnet\nNote that we are pushing this branch to our remote repository, which doesn't yet exist there, so GitHub will create it accordingly.
"},{"location":"courses/mlops/git/#pull-request-pr","title":"Pull request (PR)","text":"When we push our new branch to the remote repository, we'll need to create a pull request (PR) to merge with another branch (ex. our main branch in this case). When merging our work with another branch (ex. main), it's called a pull request because we're requesting the branch to pull our committed work. We can create the pull request using steps outlined here: Creating a pull request.
Note
\nWe can merge branches and resolve conflicts using git CLI commands but it's preferred to use the online interface because we can easily visualize the changes, have discussion with teammates, etc.\n
# Merge via CLI\ngit push origin convnet\ngit checkout main\ngit merge convnet\ngit push origin main\nOnce we accepted the pull request, our main branch is now updated with our changes. However, the update only happened on the remote repository so we should pull those changes to our local main branch as well.
git checkout main\ngit pull origin main\nOnce we're done working with a branch, we can delete it to prevent our repository from cluttering up. We can easily delete both the local and remote versions of the branch with the following commands:\n
# Delete branches\ngit branch -d <BRANCH_NAME> # local\ngit push origin --delete <BRANCH_NAME> # remote\nSo far, the workflows for integrating our iterative development has been very smooth but in a collaborative setting, we may need to resolve conflicts. Let's say there are two branches (a and b) that were created from the main branch. Here's what we're going to try and simulate:
main branch to make some changesmain branch.main.When we try to merge the second PR, we have to resolve the conflicts between this new PR and what already exists in the main branch.
We can resolve the conflict by choosing which content (current main which merged with the a branch or this b branch) to keep and delete the other one. Then we can merge the PR successfully and update our local main branch.
<<<<<< BRANCH_A\n<CHANGES FROM BRANCH A>\n======\n<CHANGES FROM BRANCH B>\n>>>>>> BRANCH_B\nOnce the conflicts have been resolved and we merge the PR, we can update our local repository to reflect the decisions.
\ngit checkout main\ngit pull origin main\nNote
\nWe only have a conflict because both branches were forked from a previous version of the main branch and they both happened to alter the same content. Had we created one branch first and then updated main before creating the second branch, we wouldn't have any conflicts. But in a collaborative setting, different developers may fork off the same version of the branch anytime.
A few more important commands to know include rebase and stash.
"},{"location":"courses/mlops/git/#inspection","title":"Inspection","text":"Git allows us to inspect the current and previous states of our work at many different levels. Let's explore the most commonly used commands.
"},{"location":"courses/mlops/git/#status","title":"Status","text":"We've used the status command quite a bit already as it's very useful to quickly see the status of our working tree.
\n# Status\ngit status\ngit status -s # short format\nIf we want to see the log of all our commits, we can do so using the log command. We can also do the same by inspecting specific branch histories on the Git online interface.
\n# Log\ngit log\ngit log --oneline # short version\n\n704d99c (HEAD -> main) added project files\n\n\n
Commit IDs are 40 characters long but we can represent them with the first few (seven digits is the default for a Git SHA). If there is ambiguity, Git will notify us and we can simply add more of the commit ID.
"},{"location":"courses/mlops/git/#diff","title":"Diff","text":"If we want to know the difference between two commits, we can use the diff command.
\n# Diff\ngit diff # all changes between current working tree and previous commit\ngit diff <COMMIT_A> <COMMIT_B> # diff b/w two commits\ngit diff <COMMIT_A>:<PATH_TO_FILE> <COMMIT_B>:<PATH_TO_FILE> # file diff b/w two commits\n\ndiff --git a/.gitignore b/.gitignore\nindex 288973d..028aa13 100644\n--- a/.gitignore\n+++ b/.gitignore\n@@ -1,7 +1,6 @@\n # Data\n logs/\n stores/\n-data/\n"},{"location":"courses/mlops/git/#blame","title":"Blame","text":"
One of the most useful inspection commands is blame, which allows us to see what commit was responsible for every single line in a file.\n
# Blame\ngit blame <PATH_TO_FILE>\ngit blame -L 1,3 <PATH_TO_FILE> # blame for lines 1 and 3\nSometimes we may have done something we wish we could change. It's not always possible to do this in life, but in the world of Git, it is!
"},{"location":"courses/mlops/git/#restore","title":"Restore","text":"Sometimes we may just want to undo adding or staging a file, which we can easily do with the restore command.\n
# Restore\ngit restore -- <PATH_TO_FILE> <PATH_TO_FILE> # will undo any changes\ngit restore --stage <PATH_TO_FILE> # will remove from stage (won't undo changes)\nNow if we already made the commit but haven't pushed to remote yet, we can reset to the previous commit by moving the branch pointer to that commit. Note that this will undo all changes made since the previous commit.\n
# Reset\ngit reset <PREVIOUS_COMMIT_ID> # or HEAD^\nHEAD is a quick way to refer to the previous commit. Both HEAD and any previous commit ID can be accompanied with a ^ or ~ symbol which acts as a relative reference. ^n refers to the nth parent of the commit while ~n refers to the nth grandparent. Of course we can always just explicitly use commit IDs but these short hands can come in handy for quick checks without doing git log to retrieve commit IDs."},{"location":"courses/mlops/git/#revert","title":"Revert","text":"
But instead of moving the branch pointer to a previous commit, we can continue to move forward by adding a new commit to revert certain previous commits.
\n# Revert\ngit revert <COMMIT_ID> ... # rollback specific commits\ngit revert <COMMIT_TO_ROLLBACK_TO>..<COMMIT_TO_ROLLBACK_FROM> # range\nSometimes we may want to temporarily switch back to a previous commit just to explore or commit some changes. It's best practice to do this in a separate branch and if we want to save our changes, we need to create a separate PR. Note that if you do checkout a previous commit and submit a PR, you may override the commits in between.\n
# Checkout\ngit checkout -b <BRANCH_NAME> <COMMIT_ID>\nThere so many different works to work with git and sometimes it can became quickly unruly when fellow developers follow different practices. Here are a few, widely accepted, best practices when it comes to working with commits and branches.
"},{"location":"courses/mlops/git/#commits","title":"Commits","text":"# Tags\ngit tag -a v0.1 -m \"initial release\"\nmain branch very easy.main branch as the \"demo ready\" branch that always works.main branch).Leverage git tags to mark significant release commits. We can create tags either through the terminal or the online remote interface and this can be done to previous commits as well (in case we forgot).
\n# Tags\ngit tag # view all existing tags\ngit tag -a <TAG_NAME> -m \"SGD\" # create a tag\ngit checkout -b <BRANCH_NAME> <TAG_NAME> # checkout a specific tag\ngit tag -d <TAG_NAME> # delete local tag\ngit push origin --delete <TAG_NAME> # delete remote tag\ngit fetch --all --tags # fetch all tags from remote\nTag names usually adhere to version naming conventions, such as v1.4.2 where the numbers indicate major, minor and bug changes from left to right.
Upcoming live cohorts
\nSign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.\n\n
\n Learn more\n\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Git - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nOur ML workloads have been responsible for everything from data ingestion to model validation:
We can execute these workloads as standalone CLI commands:
# ML workloads (simplified)\npytest --dataset-loc=$DATASET_LOC tests/data ... # test data\npython -m pytest tests/code --verbose --disable-warnings # test code\npython madewithml/train.py --experiment-name \"llm\" ... # train model\npython madewithml/evaluate.py --run-id $RUN_ID ... # evaluate model\npytest --run-id=$RUN_ID tests/model ... # test model\npython madewithml/serve.py --run_id $RUN_ID # serve model\nWith all of our ML workloads implemented (and tested), we're ready to go to production. In this lesson, we'll learn how to convert our ML workloads from CLI commands into a scalable, fault-tolerant and reproducible workflow.
Since we have our CLI commands for our ML workloads, we could just execute them one-by-one on our local machine or Workspace. But for efficiency, we're going to combine them all into one script. We'll organize this under a workloads.sh bash script inside our deploy/jobs directory. Here the workloads are very similar to our CLI commands but we have some additional steps to print and save the logs from each of our workloads. For example, our data validation workload looks like this:
# deploy/jobs/workloads.sh\nexport RESULTS_FILE=results/test_data_results.txt\nexport DATASET_LOC=\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\npytest --dataset-loc=$DATASET_LOC tests/data --verbose --disable-warnings > $RESULTS_FILE\ncat $RESULTS_FILE\nAt the end of our workloads.sh script, we save our model registry (with our saved model artifacts) and the results from the different workloads to S3. We'll use these artifacts and results later on when we deploy our model as a Service.
# Save to S3\nexport MODEL_REGISTRY=$(python -c \"from madewithml import config; print(config.MODEL_REGISTRY)\")\naws s3 cp $MODEL_REGISTRY s3://madewithml/$GITHUB_USERNAME/mlflow/ --recursive\naws s3 cp results/ s3://madewithml/$GITHUB_USERNAME/results/ --recursive\nNote
If you're doing this lesson on your local laptop, you'll have to add the proper AWS credentials and up the S3 buckets for our workloads script to run successfully.
export AWS_ACCESS_KEY_ID=\"\"\nexport AWS_SECRET_ACCESS_KEY=\"\"\nexport AWS_SESSION_TOKEN=\"\"\nNow that we have our single script to execute all workloads, we can execute it with one command (./deploy/jobs/workloads.sh). But even better way is to use Anyscale Jobs to get features like automatic failure handling, email alerts and persisted logs all out of the box for our workloads. And with our cluster_env.yaml, cluster_compute.yaml and workloads.sh files, we can create the configuration for our Anyscale Job with an workloads.yaml file:
# deploy/jobs/workloads.yaml\nname: workloads\nproject_id: prj_v9izs5t1d6b512ism8c5rkq4wm\ncluster_env: madewithml-cluster-env\ncompute_config: madewithml-cluster-compute\nruntime_env:\nworking_dir: .\nupload_path: s3://madewithml/GokuMohandas/jobs # <--- CHANGE USERNAME (case-sensitive)\nenv_vars:\nGITHUB_USERNAME: GokuMohandas # <--- CHANGE USERNAME (case-sensitive)\nentrypoint: bash deploy/jobs/workloads.sh\nmax_retries: 0\nLine 2: name of our Anyscale JobLine 3: name of our Anyscale Project (we're organizing it all under the same madewithml project we used for our Workspace setup)Line 4: name of our cluster environmentLine 5: name of our compute configurationLine 6-10: runtime environment for our Anyscale Job. The runtime_env here specifies that we should upload our current working_dir to an S3 bucket so that all of our workers when we execute an Anyscale Job have access to the code to use. We also set some environment variables that our workloads will have access to.Line 11: entrypoint for our Anyscale Job. This is the command that will be executed when we submit our Anyscale Job.Line 12: maximum number of retries for our Anyscale Job. If our Anyscale Job fails, it will automatically retry up to this number of times.Warning
Be sure to update the $GITHUB_USERNAME slots inside our deploy/jobs/workloads.yaml configuration to your own GitHub username. This is used to save your model registry and results to a unique path on our shared S3 bucket (s3://madewithml).
Because we're using the exact same cluster environment and compute configuration, what worked during development will work in production. This is a huge benefit of using Anyscale Jobs because we don't have to worry about any environment discrepanices when we deploy our workloads to production. This makes going to production much easier and faster!
"},{"location":"courses/mlops/jobs-and-services/#execution","title":"Execution","text":"And now we can execute our Anyscale Job in one line:
anyscale job submit deploy/jobs/workloads.yaml\n\nAuthenticating\n\nOutput\n(anyscale +8.8s) Maximum uptime is disabled for clusters launched by this job.\n(anyscale +8.8s) Job prodjob_zqj3k99va8a5jtd895u3ygraup has been successfully submitted. Current state of job: PENDING.\n(anyscale +8.8s) Query the status of the job with `anyscale job list --job-id prodjob_zqj3k99va8a5jtd895u3ygraup`.\n(anyscale +8.8s) Get the logs for the job with `anyscale job logs --job-id prodjob_zqj3k99va8a5jtd895u3ygraup --follow`.\n(anyscale +8.8s) View the job in the UI at https://console.anyscale.com/jobs/prodjob_zqj3k99va8a5jtd895u3ygraup\n(anyscale +8.8s) Use --follow to stream the output of the job when submitting a job.\n
Tip
When we run anyscale cli commands inside our Workspaces, we automatically have our credentials set up for us. But if we're running anyscale cli commands on our local laptop, we'll have to set up the appropriate credentials.
export ANYSCALE_HOST=https://console.anyscale.com ANYSCALE_CLI_TOKEN=your_cli_token\nWe can now go to thie UI link that was provided to us to view the status, logs, etc. of our Anyscale Job.
And if we inspect our S3 buckets, we'll can see all the artifacts that have been saved from this Anyscale Job.
"},{"location":"courses/mlops/jobs-and-services/#debugging","title":"Debugging","text":"Since we use the exact same cluster (environment and compute) for production as we did for development, we're significantly less likely to run into the environment discrepancy issues that typically arise when going from development to production. However, there can always be small issues that arize from missing credentials, etc. We can easily debug our Anyscale Jobs by inspecting the jobs: Jobs page > choose job > View console logs at the bottom > View Ray workers logs > paste command > Open job-logs directory > View job-driver-raysubmit_XYZ.log. Alternatively, we can also run our Anyscale Job as a Workspace by clicking on the Duplicate as Workspace button the top of a particular Job's page.
After we execute our Anyscale Job, we will have saved our model artifacts to a particular location. We'll now use Anyscale Services to pull from this location to serve our models in production behind a scalable rest endpoint
"},{"location":"courses/mlops/jobs-and-services/#script_1","title":"Script","text":"Similar to Anyscale Jobs, we'll start by creating a serve_model.py and a serve_model.yaml configuration:
# deploy/services/serve_model.py\n\nimport os\nimport subprocess\nfrom madewithml.config import MODEL_REGISTRY # NOQA: E402\nfrom madewithml.serve import ModelDeployment # NOQA: E402\n\n# Copy from S3\ngithub_username = os.environ.get(\"GITHUB_USERNAME\")\nsubprocess.check_output([\"aws\", \"s3\", \"cp\", f\"s3://madewithml/{github_username}/mlflow/\", str(MODEL_REGISTRY), \"--recursive\"])\nsubprocess.check_output([\"aws\", \"s3\", \"cp\", f\"s3://madewithml/{github_username}/results/\", \"./\", \"--recursive\"])\n\n# Entrypoint\nrun_id = [line.strip() for line in open(\"run_id.txt\")][0]\nentrypoint = ModelDeployment.bind(run_id=run_id, threshold=0.9)\n\n# Inference\ndata = {\"query\": \"What is the default batch size for map_batches?\"}\nresponse = requests.post(\"http://127.0.0.1:8000/query\", json=data)\nprint(response.json())\n\n\n# Inference\ndata = {\"query\": \"What is the default batch size for map_batches?\"}\nresponse = requests.post(\"http://127.0.0.1:8000/query\", json=data)\nprint(response.json())\nIn this script, we first pull our previously saved artifacts from our S3 bucket to our local storage and then define the entrypoint for our model.
Tip
Recall that we have the option to scale when we define our service inside out madewithml/serve.py script. And we can scale our compute configuration to meet those demands.
# madewithml/serve.py\n@serve.deployment(route_prefix=\"/\", num_replicas=\"1\", ray_actor_options={\"num_cpus\": 8, \"num_gpus\": 0})\n@serve.ingress(app)\nclass ModelDeployment:\n pass\nWe can now use this entrypoint that we defined to serve our application:
# deploy/services/serve_model.yaml\nname: madewithml\nproject_id: prj_v9izs5t1d6b512ism8c5rkq4wm\ncluster_env: madewithml-cluster-env\ncompute_config: madewithml-cluster-compute\nray_serve_config:\nimport_path: deploy.services.serve_model:entrypoint\nruntime_env:\nworking_dir: .\nupload_path: s3://madewithml/GokuMohandas/services # <--- CHANGE USERNAME (case-sensitive)\nenv_vars:\nGITHUB_USERNAME: GokuMohandas # <--- CHANGE USERNAME (case-sensitive)\nrollout_strategy: ROLLOUT # ROLLOUT or IN_PLACE\nLine 2: name of our Anyscale ServiceLine 3: name of our Anyscale Project (we're organizing it all under the same madewithml project we used for our Workspace setup)Line 4: name of our cluster environmentLine 5: name of our compute configurationLine 6-12: serving configuration that specifies our entry point and details about the working directory, environment variables, etc.Line 13: rollout strategy for our Anyscale Service. We can either rollout a new version of our service or replace the existing version with the new one.Warning
Be sure to update the $GITHUB_USERNAME slots inside our deploy/services/serve_model.yaml configuration to your own GitHub username. This is used to pull model artifacts and results from our shared S3 bucket (s3://madewithml).
And now we can execute our Anyscale Service in one line:
# Rollout service\nanyscale service rollout -f deploy/services/serve_model.yaml\n\nAuthenticating\n\nOutput\n(anyscale +7.3s) Service service2_xwmyv1wcm3i7qan2sahsmybymw has been deployed. Service is transitioning towards: RUNNING.\n(anyscale +7.3s) View the service in the UI at https://console.anyscale.com/services/service2_xwmyv1wcm3i7qan2sahsmybymw\n
Note
If we chose the ROLLOUT strategy, we get a canary rollout (increasingly serving traffic to the new version of our service) by default.
Once our service is up and running, we can query it:
# Query\ncurl -X POST -H \"Content-Type: application/json\" -H \"Authorization: Bearer $SECRET_TOKEN\" -d '{\n \"title\": \"Transfer learning with transformers\",\n \"description\": \"Using transformers for transfer learning on text classification tasks.\"\n}' $SERVICE_ENDPOINT/predict/\n{\n\"results\": [\n{\n\"prediction\": \"natural-language-processing\",\n\"probabilities\": {\n\"computer-vision\": 3.175719175487757E-4,\n\"mlops\": 4.065348766744137E-4,\n\"natural-language-processing\": 0.9989110231399536,\n\"other\": 3.6489960621111095E-4\n}\n}\n]\n}\nAnd we can just as easily rollback to a previous version of our service or terminate it altogether:
# Rollback (to previous version of the Service)\nanyscale service rollback -f $SERVICE_CONFIG --name $SERVICE_NAME\n\n# Terminate\nanyscale service terminate --name $SERVICE_NAME\nOnce we rollout our service, we have several different dashboards that we can use to monitor our service. We can access these dashboards by going to the Services page > choose service > Click the Dashboard button (top right corner) > Ray Dashboard. Here we'll able to see the logs from our Service, metrics, etc.
On the same Dashboard button, we also have a Metrics option that will take us to a Grafana Dashboard. This view has a lot more metrics on incoming requests, latency, errors, etc.
"},{"location":"courses/mlops/jobs-and-services/#debugging_1","title":"Debugging","text":"Serving our models may not always work as intended. Even if our model serving logic is correct, there are external dependencies that could causes errors --- such as our model not being stored where it should be, trouble accessing our model registry, etc. For all these cases and more, it's very important to know how to be able to debug our Services.
Services page > choose service > Go to Resource usage section > Click on the cluster link (cluster_for_service_XYZ) > Ray logs (tab at bottom) > paste command > Open worker-XYZ directory > View combined_worker.log
The combination of using Workspaces for development and Job & Services for production make it extremely easy and fast to make the transition. The cluster environment and compute configurations are the exact same so the code that's executing runs on the same conditions. However, we may sometimes want to scale up our production compute configurations to execute Jobs faster or meet the availability/latency demands for our Services. We could address this by creating a new compute configuration:
# Compute config\nexport CLUSTER_COMPUTE_NAME=\"madewithml-cluster-compute-prod\"\nanyscale cluster-compute create deploy/cluster_compute_prod.yaml --name $CLUSTER_COMPUTE_NAME # uses new config with prod compute requirements\nor by using a one-off configuration to specify the compute changes, where instead of pointing to a previously existing compute configuration, we can define it directly in our Jobs/Services yaml configuration:
name: madewithml\nproject_id: prj_v9izs5t1d6b512ism8c5rkq4wm\ncluster_env: madewithml-cluster-env\ncompute_config:\ncloud: anyscale-v2-cloud-fast-startup\nmax_workers: 20\nhead_node_type:\nname: head_node_type\ninstance_type: m5.4xlarge\nworker_node_types:\n- name: gpu_worker\ninstance_type: g4dn.4xlarge\nmin_workers: 1\nmax_workers: 8\naws:\nBlockDeviceMappings:\n- DeviceName: \"/dev/sda1\"\nEbs:\nVolumeSize: 500\nDeleteOnTermination: true\n...\nAnd with that, we're able to completely productionize our ML workloads! We have a working service that we can use to make predictions using our trained model. However, what happens when we receive new data or our model's performance regresses over time? With our current approach here, we have to manually execute our Jobs and Services again to udpate our application. In the next lesson, we'll learn how to automate this process with CI/CD workflows that execute our Jobs and Services based on an event (e.g. new data).
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Jobs & Services - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nLabeling (or annotation) is the process of identifying the inputs and outputs that are worth modeling (not just what could be modeled).
It's really important to get our labeling workflows in place before we start performing downstream tasks such as data augmentation, model training, etc.
Warning
Be careful not to include features in the dataset that will not be available during prediction, causing data leaks.
What else can we learn?
It's not just about identifying and labeling our initial dataset. What else can we learn from it?
Show answerIt's also the phase where we can use our deep understanding of the problem to:
- augment the training data split\n- enhance using auxiliary datasets\n- simplify using constraints\n- remove noisy samples\n- improve the labeling process\nRegardless of whether we have a custom labeling platform or we choose a generalized platform, the process of labeling and all it's related workflows (QA, data import/export, etc.) follow a similar approach.
"},{"location":"courses/mlops/labeling/#preliminary-steps","title":"Preliminary steps","text":"[WHAT] Decide what needs to be labeled:[WHERE] Design the labeling interface:[HOW] Compose labeling instructions:[IMPORT] new data for annotation[EXPORT] annotated data for QA, testing, modeling, etc.For the purpose of this course, our data is already labeled, so we'll perform a basic version of ELT (extract, load, transform) to construct the labeled dataset.
In our data-stack and orchestration lessons, we'll construct a modern data stack and programmatically deliver high quality data via DataOps workflows.
Recall that our objective was to classify incoming content so that the community can discover them easily. These data assets will act as the training data for our first model.
"},{"location":"courses/mlops/labeling/#extract","title":"Extract","text":"We'll start by extracting data from our sources (external CSV files). Traditionally, our data assets will be stored, versioned and updated in a database, warehouse, etc. We'll learn more about these different data systems later, but for now, we'll load our data as a stand-alone CSV file.
import pandas as pd\n# Extract projects\nPROJECTS_URL = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv\"\nprojects = pd.read_csv(PROJECTS_URL)\nprojects.head(5)\n\nid\n created_on\n title\n description\n 0\n 6\n 2020-02-20 06:43:18\n Comparison between YOLO and RCNN on real world...\n Bringing theory to experiment is cool. We can ...\n 1\n 7\n 2020-02-20 06:47:21\n Show, Infer & Tell: Contextual Inference for C...\n The beauty of the work lies in the way it arch...\n 2\n 9\n 2020-02-24 16:24:45\n Awesome Graph Classification\n A collection of important graph embedding, cla...\n 3\n 15\n 2020-02-28 23:55:26\n Awesome Monte Carlo Tree Search\n A curated list of Monte Carlo tree search papers...\n 4\n 19\n 2020-03-03 13:54:31\n Diffusion to Vector\n Reference implementation of Diffusion2Vec (Com...\n
We'll also load the labels (tag category) for our projects.
# Extract tags\nTAGS_URL = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv\"\ntags = pd.read_csv(TAGS_URL)\ntags.head(5)\n\nid\n tag\n 0\n 6\n computer-vision\n 1\n 7\n computer-vision\n 2\n 9\n graph-learning\n 3\n 15\n reinforcement-learning\n 4\n 19\n graph-learning\n"},{"location":"courses/mlops/labeling/#transform","title":"Transform","text":"
Apply basic transformations to create our labeled dataset.
# Join projects and tags\ndf = pd.merge(projects, tags, on=\"id\")\ndf.head()\n\nid\n created_on\n title\n description\n tag\n 0\n 6\n 2020-02-20 06:43:18\n Comparison between YOLO and RCNN on real world...\n Bringing theory to experiment is cool. We can ...\n computer-vision\n 1\n 7\n 2020-02-20 06:47:21\n Show, Infer & Tell: Contextual Inference for C...\n The beauty of the work lies in the way it arch...\n computer-vision\n 2\n 9\n 2020-02-24 16:24:45\n Awesome Graph Classification\n A collection of important graph embedding, cla...\n graph-learning\n 3\n 15\n 2020-02-28 23:55:26\n Awesome Monte Carlo Tree Search\n A curated list of Monte Carlo tree search papers...\n reinforcement-learning\n 4\n 19\n 2020-03-03 13:54:31\n Diffusion to Vector\n Reference implementation of Diffusion2Vec (Com...\n graph-learning\n
df = df[df.tag.notnull()] # remove projects with no tag\nFinally, we'll load our transformed data locally so that we can use it for our machine learning application.
# Save locally\ndf.to_csv(\"labeled_projects.csv\", index=False)\nWe could have used the user provided tags as our labels but what if the user added a wrong tag or forgot to add a relevant one. To remove this dependency on the user to provide the gold standard labels, we can leverage labeling tools and platforms. These tools allow for quick and organized labeling of the dataset to ensure its quality. And instead of starting from scratch and asking our labeler to provide all the relevant tags for a given project, we can provide the author's original tags and ask the labeler to add / remove as necessary. The specific labeling tool may be something that needs to be custom built or leverages something from the ecosystem.
As our platform grows, so too will our dataset and labeling needs so it's imperative to use the proper tooling that supports the workflows we'll depend on.
"},{"location":"courses/mlops/labeling/#general","title":"General","text":"Generalized labeling solutions
What criteria should we use to evaluate what labeling platform to use?
Show answerIt's important to pick a generalized platform that has all the major labeling features for your data modality with the capability to easily customize the experience.
However, as an industry trend, this balance between generalization and specificity is difficult to strike. So many teams put in the upfront effort to create bespoke labeling platforms or used industry specific, niche, labeling tools.
"},{"location":"courses/mlops/labeling/#active-learning","title":"Active learning","text":"Even with a powerful labeling tool and established workflows, it's easy to see how involved and expensive labeling can be. Therefore, many teams employ active learning to iteratively label the dataset and evaluate the model.
This can be significantly more cost-effective and faster than labeling the entire dataset.
Active Learning Literature Survey"},{"location":"courses/mlops/labeling/#libraries_1","title":"Libraries","text":"If we had samples that needed labeling or if we simply wanted to validate existing labels, we can use weak supervision to generate labels as opposed to hand labeling all of them. We could utilize weak supervision via labeling functions to label our existing and new data, where we can create constructs based on keywords, pattern expressions, knowledge bases, etc. And we can add to the labeling functions over time and even mitigate conflicts amongst the different labeling functions. We'll use these labeling functions to create and evaluate slices of our data in the evaluation lesson.
from snorkel.labeling import labeling_function\n\n@labeling_function()\ndef contains_tensorflow(text):\n condition = any(tag in text.lower() for tag in (\"tensorflow\", \"tf\"))\n return \"tensorflow\" if condition else None\nAn easy way to validate our labels (before modeling) is to use the aliases in our auxillary datasets to create labeling functions for the different classes. Then we can look for false positives and negatives to identify potentially mislabeled samples. We'll actually implement a similar kind of inspection approach, but using a trained model as a heuristic, in our dashboards lesson.
"},{"location":"courses/mlops/labeling/#iteration","title":"Iteration","text":"Labeling isn't just a one time event or something we repeat identically. As new data is available, we'll want to strategically label the appropriate samples and improve slices of our data that are lacking in quality. Once new data is labeled, we can have workflows that are triggered to start the (re)training process to deploy a new version of our system.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Data Labeling - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nLogging is the process of tracking and recording key events that occur in our applications for the purpose of inspection, debugging, etc. They're a whole lot more powerful than print statements because they allow us to send specific pieces of information to specific locations with custom formatting, shared interfaces, etc. This makes logging a key proponent in being able to surface insightful information from the internal processes of our application.
There are a few overarching concepts to be aware of:
Logger: emits the log messages from our application.Handler: sends log records to a specific location.Formatter: formats and styles the log records.There is so much more to logging such as filters, exception logging, etc. but these basics will allows us to do everything we need for our application.
"},{"location":"courses/mlops/logging/#levels","title":"Levels","text":"Before we create our specialized, configured logger, let's look at what logged messages look like by using the basic configuration.
import logging\nimport sys\n\n# Create super basic logger\nlogging.basicConfig(stream=sys.stdout, level=logging.DEBUG)\n\n# Logging levels (from lowest to highest priority)\nlogging.debug(\"Used for debugging your code.\")\nlogging.info(\"Informative messages from your code.\")\nlogging.warning(\"Everything works but there is something to be aware of.\")\nlogging.error(\"There's been a mistake with the process.\")\nlogging.critical(\"There is something terribly wrong and process may terminate.\")\n\nDEBUG:root:Used for debugging your code.\nINFO:root:Informative messages from your code.\nWARNING:root:Everything works but there is something to be aware of.\nERROR:root:There's been a mistake with the process.\nCRITICAL:root:There is something terribly wrong and process may terminate.\n
These are the basic levels of logging, where DEBUG is the lowest priority and CRITICAL is the highest. We defined our logger using basicConfig to emit log messages to stdout (ie. our terminal console), but we also could've written to any other stream or even a file. We also defined our logging to be sensitive to log messages starting from level DEBUG. This means that all of our logged messages will be displayed since DEBUG is the lowest level. Had we made the level ERROR, then only ERROR and CRITICAL log message would be displayed.
import logging\nimport sys\n\n# Create super basic logger\nlogging.basicConfig(stream=sys.stdout, level=logging.ERROR)\n# Logging levels (from lowest to highest priority)\nlogging.debug(\"Used for debugging your code.\")\nlogging.info(\"Informative messages from your code.\")\nlogging.warning(\"Everything works but there is something to be aware of.\")\nlogging.error(\"There's been a mistake with the process.\")\nlogging.critical(\"There is something terribly wrong and process may terminate.\")\n\nERROR:root:There's been a mistake with the process.\nCRITICAL:root:There is something terribly wrong and process may terminate.\n"},{"location":"courses/mlops/logging/#configuration","title":"Configuration","text":"
First we'll set the location of our logs in our config.py script:
# madewithml/config.py\nLOGS_DIR = Path(BASE_DIR, \"logs\")\nLOGS_DIR.mkdir(parents=True, exist_ok=True)\nNext, we'll configure the logger for our application:
# madewithml/config.py\nimport logging\nimport sys\nlogging_config = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"formatters\": {\n \"minimal\": {\"format\": \"%(message)s\"},\n \"detailed\": {\n \"format\": \"%(levelname)s %(asctime)s [%(name)s:%(filename)s:%(funcName)s:%(lineno)d]\\n%(message)s\\n\"\n },\n },\n \"handlers\": {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"stream\": sys.stdout,\n \"formatter\": \"minimal\",\n \"level\": logging.DEBUG,\n },\n \"info\": {\n \"class\": \"logging.handlers.RotatingFileHandler\",\n \"filename\": Path(LOGS_DIR, \"info.log\"),\n \"maxBytes\": 10485760, # 1 MB\n \"backupCount\": 10,\n \"formatter\": \"detailed\",\n \"level\": logging.INFO,\n },\n \"error\": {\n \"class\": \"logging.handlers.RotatingFileHandler\",\n \"filename\": Path(LOGS_DIR, \"error.log\"),\n \"maxBytes\": 10485760, # 1 MB\n \"backupCount\": 10,\n \"formatter\": \"detailed\",\n \"level\": logging.ERROR,\n },\n },\n \"root\": {\n \"handlers\": [\"console\", \"info\", \"error\"],\n \"level\": logging.INFO,\n \"propagate\": True,\n },\n}\n[Lines 6-11]: define two different Formatters (determine format and style of log messages), minimal and detailed, which use various LogRecord attributes to create a formatting template for log messages.[Lines 12-35]: define the different Handlers (details about location of where to send log messages):console: sends log messages (using the minimal formatter) to the stdout stream for messages above level DEBUG (ie. all logged messages).info: send log messages (using the detailed formatter) to logs/info.log (a file that can be up to 1 MB and we'll backup the last 10 versions of it) for messages above level INFO.error: send log messages (using the detailed formatter) to logs/error.log (a file that can be up to 1 MB and we'll backup the last 10 versions of it) for messages above level ERROR.[Lines 36-40]: attach our different handlers to our root Logger.We chose to use a dictionary to configure our logger but there are other ways such as Python script, configuration file, etc. Click on the different options below to expand and view the respective implementation.
Python scriptimport logging\nfrom rich.logging import RichHandler\n\n# Get root logger\nlogger = logging.getLogger()\nlogger.setLevel(logging.DEBUG)\n\n# Create handlers\nconsole_handler = RichHandler(markup=True)\nconsole_handler.setLevel(logging.DEBUG)\ninfo_handler = logging.handlers.RotatingFileHandler(\n filename=Path(LOGS_DIR, \"info.log\"),\n maxBytes=10485760, # 1 MB\n backupCount=10,\n)\ninfo_handler.setLevel(logging.INFO)\nerror_handler = logging.handlers.RotatingFileHandler(\n filename=Path(LOGS_DIR, \"error.log\"),\n maxBytes=10485760, # 1 MB\n backupCount=10,\n)\nerror_handler.setLevel(logging.ERROR)\n\n# Create formatters\nminimal_formatter = logging.Formatter(fmt=\"%(message)s\")\ndetailed_formatter = logging.Formatter(\n fmt=\"%(levelname)s %(asctime)s [%(name)s:%(filename)s:%(funcName)s:%(lineno)d]\\n%(message)s\\n\"\n)\n\n# Hook it all up\nconsole_handler.setFormatter(fmt=minimal_formatter)\ninfo_handler.setFormatter(fmt=detailed_formatter)\nerror_handler.setFormatter(fmt=detailed_formatter)\nlogger.addHandler(hdlr=console_handler)\nlogger.addHandler(hdlr=info_handler)\nlogger.addHandler(hdlr=error_handler)\nPlace this inside a logging.config file:
[formatters]\nkeys=minimal,detailed\n\n[formatter_minimal]\nformat=%(message)s\n\n[formatter_detailed]\nformat=\n %(levelname)s %(asctime)s [%(name)s:%(filename)s:%(funcName)s:%(lineno)d]\n %(message)s\n\n[handlers]\nkeys=console,info,error\n\n[handler_console]\nclass=StreamHandler\nlevel=DEBUG\nformatter=minimal\nargs=(sys.stdout,)\n\n[handler_info]\nclass=handlers.RotatingFileHandler\nlevel=INFO\nformatter=detailed\nbackupCount=10\nmaxBytes=10485760\nargs=(\"logs/info.log\",)\n\n[handler_error]\nclass=handlers.RotatingFileHandler\nlevel=ERROR\nformatter=detailed\nbackupCount=10\nmaxBytes=10485760\nargs=(\"logs/error.log\",)\n\n[loggers]\nkeys=root\n\n[logger_root]\nlevel=INFO\nhandlers=console,info,error\nPlace this inside your Python script:
import logging\nimport logging.config\nfrom rich.logging import RichHandler\n\n# Use config file to initialize logger\nlogging.config.fileConfig(Path(CONFIG_DIR, \"logging.config\"))\nlogger = logging.getLogger()\nlogger.handlers[0] = RichHandler(markup=True) # set rich handler\nWe can load our logger configuration dict like so:
# madewithml/config.py\nimport logging\n\n# Logger\nlogging_config = {...}\nlogging.config.dictConfig(logging_config)\nlogger = logging.getLogger()\n\n# Sample messages (note that we use configured `logger` now)\nlogger.debug(\"Used for debugging your code.\")\nlogger.info(\"Informative messages from your code.\")\nlogger.warning(\"Everything works but there is something to be aware of.\")\nlogger.error(\"There's been a mistake with the process.\")\nlogger.critical(\"There is something terribly wrong and process may terminate.\")\n\nDEBUG Used for debugging your code. config.py:71\nINFO Informative messages from your code. config.py:72\nWARNING Everything works but there is something to be aware of. config.py:73\nERROR There's been a mistake with the process. config.py:74\nCRITICAL There is something terribly wrong and process may terminate. config.py:75\n
Our logged messages become stored inside the respective files in our logs directory:
logs/\n \u251c\u2500\u2500 info.log\n \u2514\u2500\u2500 error.log\nAnd since we defined a detailed formatter, we would see informative log messages like these:
\nINFO 2020-10-21 11:18:42,102 [config.py:module:72]\nInformative messages from your code.\n"},{"location":"courses/mlops/logging/#implementation","title":"Implementation","text":"
In our project, we can replace all of our print statements into logging statements:
print(\"\u2705 Training complete!\")\nfrom config import logger\nlogger.info(\"\u2705 Training complete!\")\nAll of our log messages are at the INFO level but while developing we may have had to use DEBUG levels and we also add some ERROR or CRITICAL log messages if our system behaves in an unintended manner.
what: log all the necessary details you want to surface from our application that will be useful during development and afterwards for retrospective inspection.
where: a best practice is to not clutter our modular functions with log statements. Instead we should log messages outside of small functions and inside larger workflows. For example, there are no log messages inside any of our scripts except the main.py and train.py files. This is because these scripts use the smaller functions defined in the other scripts (data.py, evaluate.py, etc.). If we ever feel that we the need to log within our other functions, then it usually indicates that the function needs to be broken down further.
When it comes to saving our logs, we could simply upload our logs to a cloud blog storage (ex. S3 or Google Cloud Storage). Or for a more production-grade logging option, we could consider the Elastic stack.
In the next lesson, we'll learn how to document our code and automatically generate high quality docs for our application.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Logging - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nThroughout our development so far, there are so many different commands to keep track of. To help organize everything, we're going to use a Makefile which is a automation tool that organizes our commands. We'll start by create this file in our project's root directory.
touch Makefile\nAt the top of our Makefile we need to specify the shell environment we want all of our commands to execute in:
# Makefile\nSHELL = /bin/bash\nInside our Makefile, we'll be creating a list of rules. These rules have a target which can sometimes have prerequisites that need to be met (can be other targets) and on the next line a Tab followed by a recipe which specifies how to create the target.
# Makefile\ntarget: prerequisites\n<TAB> recipe\nFor example, if we wanted to create a rule for styling our files, we would add the following to our Makefile:
# Styling\nstyle:\n black .\n flake8\n python3 -m isort .\nTabs vs. spaces
Makefiles require that indention be done with a , instead of spaces where we'll receive an error:
\nMakefile:: *** missing separator. Stop.\n\nLuckily, editors like VSCode automatically change indentation to tabs even if other files use spaces."},{"location":"courses/mlops/makefile/#targets","title":"Targets","text":"We can execute any of the rules by typing make <target> in the terminal:
\n# Make a target\n$ make style\n
\n\nblack .\nAll done! \u2728 \ud83c\udf70 \u2728\n8 files left unchanged.\nflake8\npython3 -m isort .\nSkipped 1 files\n
\n\nSimilarly, we can set up our Makefile for creating a virtual environment:
\n# Environment\nvenv:\n python3 -m venv venv\n source venv/bin/activate && \\\npython3 -m pip install pip setuptools wheel && \\\npython3 -m pip install -e .\n
\n&& signifies that we want these commands to execute in one shell (more on this below).
"},{"location":"courses/mlops/makefile/#phony","title":"PHONY","text":"A Makefile is called as such because traditionally the targets are supposed to be files we can make. However, Makefiles are also commonly used as command shortcuts, which can lead to confusion when a Makefile target and a file share the same name! For example if we have a file called venv (which we do) and a target in your Makefile called venv, when you run make venv we'll get this message:
\n$ make venv\n
\n\nmake: `venv' is up to date.\n
\n\nIn this situation, this is the intended behavior because if a virtual environment already exists, then we don't want ot make that target again. However, sometimes, we'll name our targets and want them to execute whether it exists as an actual file or not. In these scenarios, we want to define a PHONY target in our makefile by adding this line above the target:\n
.PHONY: <target_name>\n
\nMost of the rules in our Makefile will require the PHONY target because we want them to execute even if there is a file sharing the target's name.
\n# Styling\n.PHONY: style\nstyle:\n black .\n flake8\n isort .\n
"},{"location":"courses/mlops/makefile/#prerequisites","title":"Prerequisites","text":"Before we make a target, we can attach prerequisites to them. These can either be file targets that must exist or PHONY target commands that need to be executed prior to making this target. For example, we'll set the style target as a prerequisite for the clean target so that all files are formatted appropriately prior to cleaning them.
\n# Cleaning\n.PHONY: clean\nclean: style\n find . -type f -name \"*.DS_Store\" -ls -delete\n find . | grep -E \"(__pycache__|\\.pyc|\\.pyo)\" | xargs rm -rf\n find . | grep -E \".pytest_cache\" | xargs rm -rf\n find . | grep -E \".ipynb_checkpoints\" | xargs rm -rf\n find . | grep -E \".trash\" | xargs rm -rf\n rm -f .coverage\n
"},{"location":"courses/mlops/makefile/#variables","title":"Variables","text":"We can also set and use variables inside our Makefile to organize all of our rules.
\nWe can set the variables directly inside the Makefile. If the variable isn't defined in the Makefile, then it would default to any environment variable with the same name.\n
# Set variable\nMESSAGE := \"hello world\"\n\n# Use variable\ngreeting:\n @echo ${MESSAGE}\nWe can also use variables passed in when executing the rule like so (ensure that the variable is not overridden inside the Makefile):\n
make greeting MESSAGE=\"hi\"\nEach line in a recipe for a rule will execute in a separate sub-shell. However for certain recipes such as activating a virtual environment and loading packages, we want to execute all steps in one shell. To do this, we can add the .ONESHELL special target above any target.
# Environment\n.ONESHELL:\nvenv:\n python3 -m venv venv\n source venv/bin/activate\n python3 -m pip install pip setuptools wheel\n python3 -m pip install -e .\nHowever this is only available in Make version 3.82 and above and most Macs currently use version 3.81. You can either update to the current version or chain your commands with && as we did previously:
# Environment\nvenv:\n python3 -m venv venv\n source venv/bin/activate && \\\npython3 -m pip install pip setuptools wheel && \\\npython3 -m pip install -e .\nThe last thing we'll add to our Makefile (for now at least) is a help target to the very top. This rule will provide an informative message for this Makefile's capabilities:
.PHONY: help\nhelp:\n @echo \"Commands:\"\n@echo \"venv : creates a virtual environment.\"\n@echo \"style : executes style formatting.\"\n@echo \"clean : cleans all unnecessary files.\"\nmake help\n\nCommands:\nvenv : creates a virtual environment.\nstyle : executes style formatting.\nclean : cleans all unnecessary files.\n\n\n
There's a whole lot more to Makefiles but this is plenty for most applied ML projects.
\nUpcoming live cohorts
\nSign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.\n\n
\n Learn more\n\nTo cite this content, please use:
\n@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Makefiles - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nEven though we've trained and thoroughly evaluated our model, the real work begins once we deploy to production. This is one of the fundamental differences between traditional software engineering and ML development. Traditionally, with rule based, deterministic, software, the majority of the work occurs at the initial stage and once deployed, our system works as we've defined it. But with machine learning, we haven't explicitly defined how something works but used data to architect a probabilistic solution. This approach is subject to natural performance degradation over time, as well as unintended behavior, since the data exposed to the model will be different from what it has been trained on. This isn't something we should be trying to avoid but rather understand and mitigate as much as possible. In this lesson, we'll understand the short comings from attempting to capture performance degradation in order to motivate the need for drift detection.
Tip
We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the monitoring-ml repository for a quick overview with an interactive notebook.
"},{"location":"courses/mlops/monitoring/#system-health","title":"System health","text":"The first step to insure that our model is performing well is to ensure that the actual system is up and running as it should. This can include metrics specific to service requests such as latency, throughput, error rates, etc. as well as infrastructure utilization such as CPU/GPU utilization, memory, etc.
Fortunately, most cloud providers and even orchestration layers will provide this insight into our system's health for free through a dashboard. In the event we don't, we can easily use Grafana, Datadog, etc. to ingest system performance metrics from logs to create a customized dashboard and set alerts.
"},{"location":"courses/mlops/monitoring/#performance","title":"Performance","text":"Unfortunately, just monitoring the system's health won't be enough to capture the underlying issues with our model. So, naturally, the next layer of metrics to monitor involves the model's performance. These could be quantitative evaluation metrics that we used during model evaluation (accuracy, precision, f1, etc.) but also key business metrics that the model influences (ROI, click rate, etc.).
It's usually never enough to just analyze the cumulative performance metrics across the entire span of time since the model has been deployed. Instead, we should also inspect performance across a period of time that's significant for our application (ex. daily). These sliding metrics might be more indicative of our system's health and we might be able to identify issues faster by not obscuring them with historical data.
\ud83d\udc49 \u00a0 Follow along interactive notebook in the monitoring-ml repository as we implement the concepts below.
import matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\nsns.set_theme()\n# Generate data\nhourly_f1 = list(np.random.randint(low=94, high=98, size=24*20)) + \\\n list(np.random.randint(low=92, high=96, size=24*5)) + \\\n list(np.random.randint(low=88, high=96, size=24*5)) + \\\n list(np.random.randint(low=86, high=92, size=24*5))\n# Cumulative f1\ncumulative_f1 = [np.mean(hourly_f1[:n]) for n in range(1, len(hourly_f1)+1)]\nprint (f\"Average cumulative f1 on the last day: {np.mean(cumulative_f1[-24:]):.1f}\")\n\nAverage cumulative f1 on the last day: 93.7\n
# Sliding f1\nwindow_size = 24\nsliding_f1 = np.convolve(hourly_f1, np.ones(window_size)/window_size, mode=\"valid\")\nprint (f\"Average sliding f1 on the last day: {np.mean(sliding_f1[-24:]):.1f}\")\n\nAverage sliding f1 on the last day: 88.6\n
plt.ylim([80, 100])\nplt.hlines(y=90, xmin=0, xmax=len(hourly_f1), colors=\"blue\", linestyles=\"dashed\", label=\"threshold\")\nplt.plot(cumulative_f1, label=\"cumulative\")\nplt.plot(sliding_f1, label=\"sliding\")\nplt.legend()\nWe may need to monitor metrics at various window sizes to catch performance degradation as soon as possible. Here we're monitoring the overall f1 but we can do the same for slices of data, individual classes, etc. For example, if we monitor the performance on a specific tag, we may be able to quickly catch new algorithms that were released for that tag (ex. new transformer architecture).
"},{"location":"courses/mlops/monitoring/#delayed-outcomes","title":"Delayed outcomes","text":"We may not always have the ground-truth outcomes available to determine the model's performance on production inputs. This is especially true if there is significant lag or annotation is required on the real-world data. To mitigate this, we could:
However, approximate signals are not always available for every situation because there is no feedback on the ML system\u2019s outputs or it\u2019s too delayed. For these situations, a recent line of research relies on the only component that\u2019s available in all situations: the input data.
Mandoline: Model Evaluation under Distribution ShiftThe core idea is to develop slicing functions that may potentially capture the ways our data may experience distribution shift. These slicing functions should capture obvious slices such as class labels or different categorical feature values but also slices based on implicit metadata (hidden aspects of the data that are not explicit feature columns). These slicing functions are then applied to our labeled dataset to create matrices with the corresponding labels. The same slicing functions are applied to our unlabeled production data to approximate what the weighted labels would be. With this, we can determine the approximate performance! The intuition here is that we can better approximate performance on our unlabeled dataset based on the similarity between the labeled slice matrix and unlabeled slice matrix. A core dependency of this assumption is that our slicing functions are comprehensive enough that they capture the causes of distributional shift.
Warning
If we wait to catch the model decay based on the performance, it may have already caused significant damage to downstream business pipelines that are dependent on it. We need to employ more fine-grained monitoring to identify the sources of model drift prior to actual performance degradation.
"},{"location":"courses/mlops/monitoring/#drift","title":"Drift","text":"We need to first understand the different types of issues that can cause our model's performance to decay (model drift). The best way to do this is to look at all the moving pieces of what we're trying to model and how each one can experience drift.
Entity Description Drift \\(X\\) inputs (features) data drift \\(\\rightarrow P(X) \\neq P_{ref}(X)\\) \\(y\\) outputs (ground-truth) target drift \\(\\rightarrow P(y) \\neq P_{ref}(y)\\) \\(P(y \\vert X)\\) actual relationship between \\(X\\) and \\(y\\) concept drift \\(\\rightarrow P(y \\vert X) \\neq P_{ref}(y \\vert X)\\)
"},{"location":"courses/mlops/monitoring/#data-drift","title":"Data drift","text":"Data drift, also known as feature drift or covariate shift, occurs when the distribution of the production data is different from the training data. The model is not equipped to deal with this drift in the feature space and so, it's predictions may not be reliable. The actual cause of drift can be attributed to natural changes in the real-world but also to systemic issues such as missing data, pipeline errors, schema changes, etc. It's important to inspect the drifted data and trace it back along it's pipeline to identify when and where the drift was introduced.
Warning
Besides just looking at the distribution of our input data, we also want to ensure that the workflows to retrieve and process our input data is the same during training and serving to avoid training-serving skew. However, we can skip this step if we retrieve our features from the same source location for both training and serving, ie. from a feature store.
Data drift can occur in either continuous or categorical features.As data starts to drift, we may not yet notice significant decay in our model's performance, especially if the model is able to interpolate well. However, this is a great opportunity to potentially retrain before the drift starts to impact performance.
"},{"location":"courses/mlops/monitoring/#target-drift","title":"Target drift","text":"Besides just the input data changing, as with data drift, we can also experience drift in our outcomes. This can be a shift in the distributions but also the removal or addition of new classes with categorical tasks. Though retraining can mitigate the performance decay caused target drift, it can often be avoided with proper inter-pipeline communication about new classes, schema changes, etc.
"},{"location":"courses/mlops/monitoring/#concept-drift","title":"Concept drift","text":"Besides the input and output data drifting, we can have the actual relationship between them drift as well. This concept drift renders our model ineffective because the patterns it learned to map between the original inputs and outputs are no longer relevant. Concept drift can be something that occurs in various patterns:
All the different types of drift we discussed can can occur simultaneously which can complicated identifying the sources of drift.
"},{"location":"courses/mlops/monitoring/#locating-drift","title":"Locating drift","text":"Now that we've identified the different types of drift, we need to learn how to locate and how often to measure it. Here are the constraints we need to consider:
Since we're dealing with online drift detection (ie. detecting drift in live production data as opposed to past batch data), we can employ either a fixed or sliding window approach to identify our set of points for comparison. Typically, the reference window is a fixed, recent subset of the training data while the test window slides over time.
Scikit-multiflow provides a toolkit for concept drift detection techniques directly on streaming data. The package offers windowed, moving average functionality (including dynamic preprocessing) and even methods around concepts like gradual concept drift.
We can also compare across various window sizes simultaneously to ensure smaller cases of drift aren't averaged out by large window sizes.
"},{"location":"courses/mlops/monitoring/#measuring-drift","title":"Measuring drift","text":"Once we have the window of points we wish to compare, we need to know how to compare them.
import great_expectations as ge\nimport json\nimport pandas as pd\nfrom urllib.request import urlopen\n# Load labeled projects\nprojects = pd.read_csv(\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/projects.csv\")\ntags = pd.read_csv(\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/tags.csv\")\ndf = ge.dataset.PandasDataset(pd.merge(projects, tags, on=\"id\"))\ndf[\"text\"] = df.title + \" \" + df.description\ndf.drop([\"title\", \"description\"], axis=1, inplace=True)\ndf.head(5)\n\nid\n created_on\n tag\n text\n 0\n 6\n 2020-02-20 06:43:18\n computer-vision\n Comparison between YOLO and RCNN on real world...\n 1\n 7\n 2020-02-20 06:47:21\n computer-vision\n Show, Infer & Tell: Contextual Inference for C...\n 2\n 9\n 2020-02-24 16:24:45\n graph-learning\n Awesome Graph Classification A collection of i...\n 3\n 15\n 2020-02-28 23:55:26\n reinforcement-learning\n Awesome Monte Carlo Tree Search A curated list...\n 4\n 19\n 2020-03-03 13:54:31\n graph-learning\n Diffusion to Vector Reference implementation o...\n"},{"location":"courses/mlops/monitoring/#expectations","title":"Expectations","text":"
The first form of measurement can be rule-based such as validating expectations around missing values, data types, value ranges, etc. as we did in our data testing lesson. The difference now is that we'll be validating these expectations on live production data.
# Simulated production data\nprod_df = ge.dataset.PandasDataset([{\"text\": \"hello\"}, {\"text\": 0}, {\"text\": \"world\"}])\n# Expectation suite\ndf.expect_column_values_to_not_be_null(column=\"text\")\ndf.expect_column_values_to_be_of_type(column=\"text\", type_=\"str\")\nexpectation_suite = df.get_expectation_suite()\n# Validate reference data\ndf.validate(expectation_suite=expectation_suite, only_return_failures=True)[\"statistics\"]\n\n{'evaluated_expectations': 2,\n 'success_percent': 100.0,\n 'successful_expectations': 2,\n 'unsuccessful_expectations': 0}\n # Validate production data\nprod_df.validate(expectation_suite=expectation_suite, only_return_failures=True)[\"statistics\"]\n\n{'evaluated_expectations': 2,\n 'success_percent': 50.0,\n 'successful_expectations': 1,\n 'unsuccessful_expectations': 1}\n Once we've validated our rule-based expectations, we need to quantitatively measure drift across the different features in our data.
"},{"location":"courses/mlops/monitoring/#univariate","title":"Univariate","text":"Our task may involve univariate (1D) features that we will want to monitor. While there are many types of hypothesis tests we can use, a popular option is the Kolmogorov-Smirnov (KS) test.
"},{"location":"courses/mlops/monitoring/#kolmogorov-smirnov-ks-test","title":"Kolmogorov-Smirnov (KS) test","text":"The KS test determines the maximum distance between two distribution's cumulative density functions. Here, we'll measure if there is any drift on the size of our input text feature between two different data subsets.
Tip
While text is a direct feature in our task, we can also monitor other implicit features such as % of unknown tokens in text (need to maintain a training vocabulary), etc. While they may not be used for our machine learning model, they can be great indicators for detecting drift.
from alibi_detect.cd import KSDrift\n# Reference\ndf[\"num_tokens\"] = df.text.apply(lambda x: len(x.split(\" \")))\nref = df[\"num_tokens\"][0:200].to_numpy()\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.legend()\nplt.show()\n# Initialize drift detector\nlength_drift_detector = KSDrift(ref, p_val=0.01)\n# No drift\nno_drift = df[\"num_tokens\"][200:400].to_numpy()\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.hist(no_drift, alpha=0.5, label=\"test\")\nplt.legend()\nplt.show()\nlength_drift_detector.predict(no_drift, return_p_val=True, return_distance=True)\n\n{'data': {'distance': array([0.09], dtype=float32),\n 'is_drift': 0,\n 'p_val': array([0.3927307], dtype=float32),\n 'threshold': 0.01},\n 'meta': {'data_type': None,\n 'detector_type': 'offline',\n 'name': 'KSDrift',\n 'version': '0.9.1'}}\n \u2193 p-value = \u2191 confident that the distributions are different.
# Drift\ndrift = np.random.normal(30, 5, len(ref))\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.hist(drift, alpha=0.5, label=\"test\")\nplt.legend()\nplt.show()\nlength_drift_detector.predict(drift, return_p_val=True, return_distance=True)\n\n{'data': {'distance': array([0.63], dtype=float32),\n 'is_drift': 1,\n 'p_val': array([6.7101775e-35], dtype=float32),\n 'threshold': 0.01},\n 'meta': {'data_type': None,\n 'detector_type': 'offline',\n 'name': 'KSDrift',\n 'version': '0.9.1'}}\n"},{"location":"courses/mlops/monitoring/#chi-squared-test","title":"Chi-squared test","text":"Similarly, for categorical data (input features, targets, etc.), we can apply the Pearson's chi-squared test to determine if a frequency of events in production is consistent with a reference distribution.
We're creating a categorical variable for the # of tokens in our text feature but we could very very apply it to the tag distribution itself, individual tags (binary), slices of tags, etc.
from alibi_detect.cd import ChiSquareDrift\n# Reference\ndf.token_count = df.num_tokens.apply(lambda x: \"small\" if x <= 10 else (\"medium\" if x <=25 else \"large\"))\nref = df.token_count[0:200].to_numpy()\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.legend()\n# Initialize drift detector\ntarget_drift_detector = ChiSquareDrift(ref, p_val=0.01)\n# No drift\nno_drift = df.token_count[200:400].to_numpy()\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.hist(no_drift, alpha=0.5, label=\"test\")\nplt.legend()\nplt.show()\ntarget_drift_detector.predict(no_drift, return_p_val=True, return_distance=True)\n\n{'data': {'distance': array([4.135522], dtype=float32),\n 'is_drift': 0,\n 'p_val': array([0.12646863], dtype=float32),\n 'threshold': 0.01},\n 'meta': {'data_type': None,\n 'detector_type': 'offline',\n 'name': 'ChiSquareDrift',\n 'version': '0.9.1'}}\n # Drift\ndrift = np.array([\"small\"]*80 + [\"medium\"]*40 + [\"large\"]*80)\nplt.hist(ref, alpha=0.75, label=\"reference\")\nplt.hist(drift, alpha=0.5, label=\"test\")\nplt.legend()\nplt.show()\ntarget_drift_detector.predict(drift, return_p_val=True, return_distance=True)\n\n{'data': {'is_drift': 1,\n 'distance': array([118.03355], dtype=float32),\n 'p_val': array([2.3406739e-26], dtype=float32),\n 'threshold': 0.01},\n 'meta': {'name': 'ChiSquareDrift',\n 'detector_type': 'offline',\n 'data_type': None}}\n"},{"location":"courses/mlops/monitoring/#multivariate","title":"Multivariate","text":"As we can see, measuring drift is fairly straightforward for univariate data but difficult for multivariate data. We'll summarize the reduce and measure approach outlined in the following paper: Failing Loudly: An Empirical Study of Methods for Detecting Dataset Shift.
We vectorized our text using tf-idf (to keep modeling simple), which has high dimensionality and is not semantically rich in context. However, typically with text, word/char embeddings are used. So to illustrate what drift detection on multivariate data would look like, let's represent our text using pretrained embeddings.
Be sure to refer to our embeddings and transformers lessons to learn more about these topics. But note that detecting drift on multivariate text embeddings is still quite difficult so it's typically more common to use these methods applied to tabular features or images.
We'll start by loading the tokenizer from a pretrained model.
from transformers import AutoTokenizer\nmodel_name = \"allenai/scibert_scivocab_uncased\"\ntokenizer = AutoTokenizer.from_pretrained(model_name)\nvocab_size = len(tokenizer)\nprint (vocab_size)\n\n31090\n
# Tokenize inputs\nencoded_input = tokenizer(df.text.tolist(), return_tensors=\"pt\", padding=True)\nids = encoded_input[\"input_ids\"]\nmasks = encoded_input[\"attention_mask\"]\n# Decode\nprint (f\"{ids[0]}\\n{tokenizer.decode(ids[0])}\")\n\ntensor([ 102, 2029, 467, 1778, 609, 137, 6446, 4857, 191, 1332,\n 2399, 13572, 19125, 1983, 147, 1954, 165, 6240, 205, 185,\n 300, 3717, 7434, 1262, 121, 537, 201, 137, 1040, 111,\n 545, 121, 4714, 205, 103, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n 0])\n[CLS] comparison between yolo and rcnn on real world videos bringing theory to experiment is cool. we can easily train models in colab and find the results in minutes. [SEP] [PAD] [PAD] ...\n
# Sub-word tokens\nprint (tokenizer.convert_ids_to_tokens(ids=ids[0]))\n\n['[CLS]', 'comparison', 'between', 'yo', '##lo', 'and', 'rc', '##nn', 'on', 'real', 'world', 'videos', 'bringing', 'theory', 'to', 'experiment', 'is', 'cool', '.', 'we', 'can', 'easily', 'train', 'models', 'in', 'col', '##ab', 'and', 'find', 'the', 'results', 'in', 'minutes', '.', '[SEP]', '[PAD]', '[PAD]', ...]\n
Next, we'll load the pretrained model's weights and use the TransformerEmbedding object to extract the embeddings from the hidden state (averaged across tokens).
from alibi_detect.models.pytorch import TransformerEmbedding\n# Embedding layer\nemb_type = \"hidden_state\"\nlayers = [-x for x in range(1, 9)] # last 8 layers\nembedding_layer = TransformerEmbedding(model_name, emb_type, layers)\n# Embedding dimension\nembedding_dim = embedding_layer.model.embeddings.word_embeddings.embedding_dim\nembedding_dim\n\n768\n"},{"location":"courses/mlops/monitoring/#dimensionality-reduction","title":"Dimensionality reduction","text":"
Now we need to use a dimensionality reduction method to reduce our representations dimensions into something more manageable (ex. 32 dim) so we can run our two-sample tests on to detect drift. Popular options include:
import torch\nimport torch.nn as nn\n# Device\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nprint(device)\n\ncuda\n
# Untrained autoencoder (UAE) reducer\nencoder_dim = 32\nreducer = nn.Sequential(\n embedding_layer,\n nn.Linear(embedding_dim, 256),\n nn.ReLU(),\n nn.Linear(256, encoder_dim)\n).to(device).eval()\nWe can wrap all of the operations above into one preprocessing function that will consume input text and produce the reduced representation.
from alibi_detect.cd.pytorch import preprocess_drift\nfrom functools import partial\n# Preprocessing with the reducer\nmax_len = 100\nbatch_size = 32\npreprocess_fn = partial(preprocess_drift, model=reducer, tokenizer=tokenizer,\n max_len=max_len, batch_size=batch_size, device=device)\nAfter applying dimensionality reduction techniques on our multivariate data, we can use different statistical tests to calculate drift. A popular option is Maximum Mean Discrepancy (MMD), a kernel-based approach that determines the distance between two distributions by computing the distance between the mean embeddings of the features from both distributions.
from alibi_detect.cd import MMDDrift\n# Initialize drift detector\nmmd_drift_detector = MMDDrift(ref, backend=\"pytorch\", p_val=.01, preprocess_fn=preprocess_fn)\n# No drift\nno_drift = df.text[200:400].to_list()\nmmd_drift_detector.predict(no_drift)\n\n{'data': {'distance': 0.0021169185638427734,\n 'distance_threshold': 0.0032651424,\n 'is_drift': 0,\n 'p_val': 0.05999999865889549,\n 'threshold': 0.01},\n 'meta': {'backend': 'pytorch',\n 'data_type': None,\n 'detector_type': 'offline',\n 'name': 'MMDDriftTorch',\n 'version': '0.9.1'}}\n # Drift\ndrift = [\"UNK \" + text for text in no_drift]\nmmd_drift_detector.predict(drift)\n\n{'data': {'distance': 0.014705955982208252,\n 'distance_threshold': 0.003908038,\n 'is_drift': 1,\n 'p_val': 0.0,\n 'threshold': 0.01},\n 'meta': {'backend': 'pytorch',\n 'data_type': None,\n 'detector_type': 'offline',\n 'name': 'MMDDriftTorch',\n 'version': '0.9.1'}}\n"},{"location":"courses/mlops/monitoring/#online","title":"Online","text":"So far we've applied our drift detection methods on offline data to try and understand what reference window sizes should be, what p-values are appropriate, etc. However, we'll need to apply these methods in the online production setting so that we can catch drift as easy as possible.
Many monitoring libraries and platforms come with online equivalents for their detection methods.
Typically, reference windows are large so that we have a proper benchmark to compare our production data points to. As for the test window, the smaller it is, the more quickly we can catch sudden drift. Whereas, a larger test window will allow us to identify more subtle/gradual drift. So it's best to compose windows of different sizes to regularly monitor.
from alibi_detect.cd import MMDDriftOnline\n# Online MMD drift detector\nref = df.text[0:800].to_list()\nonline_mmd_drift_detector = MMDDriftOnline(\n ref, ert=400, window_size=200, backend=\"pytorch\", preprocess_fn=preprocess_fn)\n\nGenerating permutations of kernel matrix..\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 1000/1000 [00:00<00:00, 13784.22it/s]\nComputing thresholds: 100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 200/200 [00:32<00:00, 6.11it/s]\n
As data starts to flow in, we can use the detector to predict drift at every point. Our detector should detect drift sooner in our drifter dataset than in our normal data.
def simulate_production(test_window):\n i = 0\n online_mmd_drift_detector.reset()\n for text in test_window:\n result = online_mmd_drift_detector.predict(text)\n is_drift = result[\"data\"][\"is_drift\"]\n if is_drift:\n break\n else:\n i += 1\n print (f\"{i} steps\")\n# Normal\ntest_window = df.text[800:]\nsimulate_production(test_window)\n\n27 steps\n
# Drift\ntest_window = \"UNK\" * len(df.text[800:])\nsimulate_production(test_window)\n\n11 steps\n
There are also several considerations around how often to refresh both the reference and test windows. We could base in on the number of new observations or time without drift, etc. We can also adjust the various thresholds (ERT, window size, etc.) based on what we learn about our system through monitoring.
"},{"location":"courses/mlops/monitoring/#outliers","title":"Outliers","text":"With drift, we're comparing a window of production data with reference data as opposed to looking at any one specific data point. While each individual point may not be an anomaly or outlier, the group of points may cause a drift. The easiest way to illustrate this is to imagine feeding our live model the same input data point repeatedly. The actual data point may not have anomalous features but feeding it repeatedly will cause the feature distribution to change and lead to drift.
Unfortunately, it's not very easy to detect outliers because it's hard to constitute the criteria for an outlier. Therefore the outlier detection task is typically unsupervised and requires a stochastic streaming algorithm to identify potential outliers. Luckily, there are several powerful libraries such as PyOD, Alibi Detect, WhyLogs (uses Apache DataSketches), etc. that offer a suite of outlier detection functionality (largely for tabular and image data for now).
Typically, outlier detection algorithms fit (ex. via reconstruction) to the training set to understand what normal data looks like and then we can use a threshold to predict outliers. If we have a small labeled dataset with outliers, we can empirically choose our threshold but if not, we can choose some reasonable tolerance.
from alibi_detect.od import OutlierVAE\nX_train = (n_samples, n_features)\noutlier_detector = OutlierVAE(\n threshold=0.05,\n encoder_net=encoder,\n decoder_net=decoder,\n latent_dim=512\n)\noutlier_detector.fit(X_train, epochs=50)\noutlier_detector.infer_threshold(X, threshold_perc=95) # infer from % outliers\npreds = outlier_detector.predict(X, outlier_type=\"instance\", outlier_perc=75)\nWhen we identify outliers, we may want to let the end user know that the model's response may not be reliable. Additionally, we may want to remove the outliers from the next training set or further inspect them and upsample them in case they're early signs of what future distributions of incoming features will look like.
"},{"location":"courses/mlops/monitoring/#solutions","title":"Solutions","text":"It's not enough to just be able to measure drift or identify outliers but to also be able to act on it. We want to be able to alert on drift, inspect it and then act on it.
"},{"location":"courses/mlops/monitoring/#alert","title":"Alert","text":"Once we've identified outliers and/or measured statistically significant drift, we need to a devise a workflow to notify stakeholders of the issues. A negative connotation with monitoring is fatigue stemming from false positive alerts. This can be mitigated by choosing the appropriate constraints (ex. alerting thresholds) based on what's important to our specific application. For example, thresholds could be:
if percentage_unk_tokens > 5%:\n trigger_alert()\nif current_f1 < forecast_f1(current_time):\n trigger_alert()\nfrom alibi_detect.cd import KSDrift\nlength_drift_detector = KSDrift(reference, p_val=0.01)\nOnce we have our carefully crafted alerting workflows in place, we can notify stakeholders as issues arise via email, Slack, PageDuty, etc. The stakeholders can be of various levels (core engineers, managers, etc.) and they can subscribe to the alerts that are relevant for them.
"},{"location":"courses/mlops/monitoring/#inspect","title":"Inspect","text":"Once we receive an alert, we need to inspect it before acting on it. An alert needs several components in order for us to completely inspect it:
# Sample alerting ticket\n{\n\"triggered_alerts\": [\"text_length_drift\"],\n \"threshold\": 0.05,\n \"measurement\": \"KSDrift\",\n \"distance\": 0.86,\n \"p_val\": 0.03,\n \"reference\": [],\n \"target\": [],\n \"logs\": ...\n}\nWith these pieces of information, we can work backwards from the alert towards identifying the root cause of the issue. Root cause analysis (RCA) is an important first step when it comes to monitoring because we want to prevent the same issue from impacting our system again. Often times, many alerts are triggered but they maybe all actually be caused by the same underlying issue. In this case, we'd want to intelligently trigger just one alert that pinpoints the core issue. For example, let's say we receive an alert that our overall user satisfaction ratings are reducing but we also receive another alert that our North American users also have low satisfaction ratings. Here's the system would automatically assess for drift in user satisfaction ratings across many different slices and aggregations to discover that only users in a specific area are experiencing the issue but because it's a popular user base, it ends up triggering all aggregate downstream alerts as well!
"},{"location":"courses/mlops/monitoring/#act","title":"Act","text":"There are many different ways we can act to drift based on the situation. An initial impulse may be to retrain our model on the new data but it may not always solve the underlying issue.
Since detecting drift and outliers can involve compute intensive operations, we need a solution that can execute serverless workloads on top of our event data streams (ex. Kafka). Typically these solutions will ingest payloads (ex. model's inputs and outputs) and can trigger monitoring workloads. This allows us to segregate the resources for monitoring from our actual ML application and scale them as needed.
When it actually comes to implementing a monitoring system, we have several options, ranging from fully managed to from-scratch. Several popular managed solutions are Arize, Arthur, Fiddler, Gantry, Mona, WhyLabs, etc., all of which allow us to create custom monitoring views, trigger alerts, etc. There are even several great open-source solutions such as EvidentlyAI, TorchDrift, WhyLogs, etc.
We'll often notice that monitoring solutions are offered as part of the larger deployment option such as Sagemaker, TensorFlow Extended (TFX), TorchServe, etc. And if we're already working with Kubernetes, we could use KNative or Kubeless for serverless workload management. But we could also use a higher level framework such as KFServing or Seldon core that natively use a serverless framework like KNative.
"},{"location":"courses/mlops/monitoring/#references","title":"References","text":"Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Monitoring - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nSo far we've implemented our DataOps (ELT, validation, etc.) and MLOps (optimization, training, evaluation, etc.) workflows as Python function calls. This has worked well since our dataset is static and small. But happens when we need to:
We'll need to break down our end-to-end ML pipeline into individual workflows that can be orchestrated as needed. There are several tools that can help us so this such as Airflow, Prefect, Dagster, Luigi, Orchest and even some ML focused options such as Metaflow, Flyte, KubeFlow Pipelines, Vertex pipelines, etc. We'll be creating our workflows using AirFlow for its:
We'll be running Airflow locally but we can easily scale it by running on a managed cluster platform where we can run Python, Hadoop, Spark, etc. on large batch processing jobs (AWS EMR, Google Cloud's Dataproc, on-prem hardware, etc.).
"},{"location":"courses/mlops/orchestration/#airflow","title":"Airflow","text":"Before we create our specific pipelines, let's understand and implement Airflow's overarching concepts that will allow us to \"author, schedule, and monitor workflows\".
Separate repository
Our work in this lesson will live in a separate repository so create a new directory (outside our mlops-course repository) called data-engineering. All the work in this lesson can be found in our data-engineering repository.
To install and run Airflow, we can either do so locally or with Docker. If using docker-compose to run Airflow inside Docker containers, we'll want to allocate at least 4 GB in memory.
# Configurations\nexport AIRFLOW_HOME=${PWD}/airflow\nAIRFLOW_VERSION=2.3.3\nPYTHON_VERSION=\"$(python --version | cut -d \" \" -f 2 | cut -d \".\" -f 1-2)\"\nCONSTRAINT_URL=\"https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt\"\n\n# Install Airflow (may need to upgrade pip)\npip install \"apache-airflow==${AIRFLOW_VERSION}\" --constraint \"${CONSTRAINT_URL}\"\n\n# Initialize DB (SQLite by default)\nairflow db init\nThis will create an airflow directory with the following components:
airflow/\n\u251c\u2500\u2500 logs/\n\u251c\u2500\u2500 airflow.cfg\n\u251c\u2500\u2500 airflow.db\n\u251c\u2500\u2500 unittests.cfg\n\u2514\u2500\u2500 webserver_config.py\nWe're going to edit the airflow.cfg file to best fit our needs:
# Inside airflow.cfg\nenable_xcom_pickling = True # needed for Great Expectations airflow provider\nload_examples = False # don't clutter webserver with examples\nAnd we'll perform a reset to implement these configuration changes.
airflow db reset -y\nNow we're ready to initialize our database with an admin user, which we'll use to login to access our workflows in the webserver.
# We'll be prompted to enter a password\nairflow users create \\\n--username admin \\\n--firstname FIRSTNAME \\\n--lastname LASTNAME \\\n--role Admin \\\n--email EMAIL\nOnce we've created a user, we're ready to launch the webserver and log in using our credentials.
# Launch webserver\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nairflow webserver --port 8080 # http://localhost:8080\nThe webserver allows us to run and inspect workflows, establish connections to external data storage, manager users, etc. through a UI. Similarly, we could also use Airflow's REST API or Command-line interface (CLI) to perform the same operations. However, we'll be using the webserver because it's convenient to visually inspect our workflows.
We'll explore the different components of the webserver as we learn about Airflow and implement our workflows.
"},{"location":"courses/mlops/orchestration/#scheduler","title":"Scheduler","text":"Next, we need to launch our scheduler, which will execute and monitor the tasks in our workflows. The schedule executes tasks by reading from the metadata database and ensures the task has what it needs to finish running. We'll go ahead and execute the following commands on the separate terminal window:
# Launch scheduler (in separate terminal)\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nexport OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES\nairflow scheduler\nAs our scheduler reads from the metadata database, the executor determines what worker processes are necessary for the task to run to completion. Since our default database SQLlite, which can't support multiple connections, our default executor is the Sequential Executor. However, if we choose a more production-grade database option such as PostgresSQL or MySQL, we can choose scalable Executor backends Celery, Kubernetes, etc. For example, running Airflow with Docker uses PostgresSQL as the database and so uses the Celery Executor backend to run tasks in parallel.
"},{"location":"courses/mlops/orchestration/#dags","title":"DAGs","text":"Workflows are defined by directed acyclic graphs (DAGs), whose nodes represent tasks and edges represent the data flow relationship between the tasks. Direct and acyclic implies that workflows can only execute in one direction and a previous, upstream task cannot run again once a downstream task has started.
DAGs can be defined inside Python workflow scripts inside the airflow/dags directory and they'll automatically appear (and continuously be updated) on the webserver. Before we start creating our DataOps and MLOps workflows, we'll learn about Airflow's concepts via an example DAG outlined in airflow/dags/example.py. Execute the following commands in a new (3rd) terminal window:
mkdir airflow/dags\ntouch airflow/dags/example.py\nInside each workflow script, we can define some default arguments that will apply to all DAGs within that workflow.
# Default DAG args\ndefault_args = {\n \"owner\": \"airflow\",\n}\nTypically, our DAGs are not the only ones running in an Airflow cluster. However, it can be messy and sometimes impossible to execute different workflows when they require different resources, package versions, etc. For teams with multiple projects, it\u2019s a good idea to use something like the KubernetesPodOperator to execute each job using an isolated docker image.
We can initialize DAGs with many parameters (which will override the same parameters in default_args) and in several different ways:
using a with statement
from airflow import DAG\n\nwith DAG(\n dag_id=\"example\",\n description=\"Example DAG\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"example\"],\n) as example:\n # Define tasks\n pass\nusing the dag decorator
from airflow.decorators import dag\n\n@dag(\n dag_id=\"example\",\n description=\"Example DAG\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"example\"],\n)\ndef example():\n # Define tasks\n pass\nThere are many parameters that we can initialize our DAGs with, including a start_date and a schedule_interval. While we could have our workflows execute on a temporal cadence, many ML workflows are initiated by events, which we can map using sensors and hooks to external databases, file systems, etc.
Tasks are the operations that are executed in a workflow and are represented by nodes in a DAG. Each task should be a clearly defined single operation and it should be idempotent, which means we can execute it multiple times and expect the same result and system state. This is important in the event we need to retry a failed task and don't have to worry about resetting the state of our system. Like DAGs, there are several different ways to implement tasks:
using the task decorator
from airflow.decorators import dag, task\nfrom airflow.utils.dates import days_ago\n\n@dag(\n dag_id=\"example\",\n description=\"Example DAG with task decorators\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"example\"],\n)\ndef example():\n @task\n def task_1():\n return 1\n @task\n def task_2(x):\n return x+1\nusing Operators
from airflow.decorators import dag\nfrom airflow.operators.bash_operator import BashOperator\nfrom airflow.utils.dates import days_ago\n\n@dag(\n dag_id=\"example\",\n description=\"Example DAG with Operators\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"example\"],\n)\ndef example():\n # Define tasks\n task_1 = BashOperator(task_id=\"task_1\", bash_command=\"echo 1\")\n task_2 = BashOperator(task_id=\"task_2\", bash_command=\"echo 2\")\nThough the graphs are directed, we can establish certain trigger rules for each task to execute on conditional successes or failures of the parent tasks.
"},{"location":"courses/mlops/orchestration/#operators","title":"Operators","text":"The first method of creating tasks involved using Operators, which defines what exactly the task will be doing. Airflow has many built-in Operators such as the BashOperator or PythonOperator, which allow us to execute bash and Python commands respectively.
# BashOperator\nfrom airflow.operators.bash_operator import BashOperator\ntask_1 = BashOperator(task_id=\"task_1\", bash_command=\"echo 1\")\n\n# PythonOperator\nfrom airflow.operators.python import PythonOperator\ntask_2 = PythonOperator(\n task_id=\"task_2\",\n python_callable=foo,\n op_kwargs={\"arg1\": ...})\nThere are also many other Airflow native Operators (email, S3, MySQL, Hive, etc.), as well as community maintained provider packages (Kubernetes, Snowflake, Azure, AWS, Salesforce, Tableau, etc.), to execute tasks specific to certain platforms or tools.
We can also create our own custom Operators by extending the BashOperator class.
"},{"location":"courses/mlops/orchestration/#relationships","title":"Relationships","text":"Once we've defined our tasks using Operators or as decorated functions, we need to define the relationships between them (edges). The way we define the relationships depends on how our tasks were defined:
using decorated functions
# Task relationships\nx = task_1()\ny = task_2(x=x)\nusing Operators
# Task relationships\ntask_1 >> task_2 # same as task_1.set_downstream(task_2) or\n # task_2.set_upstream(task_1)\nIn both scenarios, we'll setting task_2 as the downstream task to task_1.
Note
We can even create intricate DAGs by using these notations to define the relationships.
task_1 >> [task_2_1, task_2_2] >> task_3\ntask_2_2 >> task_4\n[task_3, task_4] >> task_5\nWhen we use task decorators, we can see how values can be passed between tasks. But, how can we pass values when using Operators? Airflow uses XComs (cross communications) objects, defined with a key, value, timestamp and task_id, to push and pull values between tasks. When we use decorated functions, XComs are being used under the hood but it's abstracted away, allowing us to pass values amongst Python functions seamlessly. But when using Operators, we'll need to explicitly push and pull the values as we need it.
def _task_1(ti):\n x = 2\nti.xcom_push(key=\"x\", value=x)\ndef _task_2(ti):\nx = ti.xcom_pull(key=\"x\", task_ids=[\"task_1\"])[0]\ny = x + 3\nti.xcom_push(key=\"y\", value=y)\n@dag(\n dag_id=\"example\",\n description=\"Example DAG\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"example\"],\n)\ndef example2():\n # Tasks\n task_1 = PythonOperator(task_id=\"task_1\", python_callable=_task_1)\n task_2 = PythonOperator(task_id=\"task_2\", python_callable=_task_2)\n task_1 >> task_2\nWe can also view our XComs on the webserver by going to Admin >> XComs:
Warning
The data we pass between tasks should be small (metadata, metrics, etc.) because Airflow's metadata database is not equipped to hold large artifacts. However, if we do need to store and use the large results of our tasks, it's best to use an external data storage (blog storage, model registry, etc.) and perform heavy processing using Spark or inside data systems like a data warehouse.
"},{"location":"courses/mlops/orchestration/#dag-runs","title":"DAG runs","text":"Once we've defined the tasks and their relationships, we're ready to run our DAGs. We'll start defining our DAG like so:
# Run DAGs\nexample1_dag = example_1()\nexample2_dag = example_2()\nThe new DAG will have appeared when we refresh our Airflow webserver.
"},{"location":"courses/mlops/orchestration/#manual","title":"Manual","text":"Our DAG is initially paused since we specified dags_are_paused_at_creation = True inside our airflow.cfg configuration, so we'll have to manually execute this DAG by clicking on it > unpausing it (toggle) > triggering it (button). To view the logs for any of the tasks in our DAG run, we can click on the task > Log.
Note
We could also use Airflow's REST API (will configured authorization) or Command-line interface (CLI) to inspect and trigger workflows (and a whole lot more). Or we could even use the trigger_dagrun Operator to trigger DAGs from within another workflow.
# CLI to run dags\nairflow dags trigger <DAG_ID>\nHad we specified a start_date and schedule_interval when defining the DAG, it would have have automatically executed at the appropriate times. For example, the DAG below will have started two days ago and will be triggered at the start of every day.
from airflow.decorators import dag\nfrom airflow.utils.dates import days_ago\nfrom datetime import timedelta\n\n@dag(\n dag_id=\"example\",\n default_args=default_args,\n schedule_interval=timedelta(days=1),\n start_date=days_ago(2),\n tags=[\"example\"],\n catch_up=False,\n)\nWarning
Depending on the start_date and schedule_interval, our workflow should have been triggered several times and Airflow will try to catchup to the current time. We can avoid this by setting catchup=False when defining the DAG. We can also set this configuration as part of the default arguments:
default_args = {\n \"owner\": \"airflow\",\n\"catch_up\": False,\n}\nHowever, if we did want to run particular runs in the past, we can manually backfill what we need.
We could also specify a cron expression for our schedule_interval parameter or even use cron presets.
Airflow's Scheduler will run our workflows one schedule_interval from the start_date. For example, if we want our workflow to start on 01-01-1983 and run @daily, then the first run will be immediately after 01-01-1983T11:59.
While it may make sense to execute many data processing workflows on a scheduled interval, machine learning workflows may require more nuanced triggers. We shouldn't be wasting compute by running executing our workflows just in case we have new data. Instead, we can use sensors to trigger workflows when some external condition is met. For example, we can initiate data processing when a new batch of annotated data appears in a database or when a specific file appears in a file system, etc.
There's so much more to Airflow (monitoring, Task groups, smart senors, etc.) so be sure to explore them as you need them by using the official documentation.
"},{"location":"courses/mlops/orchestration/#dataops","title":"DataOps","text":"Now that we've reviewed Airflow's major concepts, we're ready to create the DataOps workflows. It's the exact same workflow we defined in our data stack lesson -- extract, load and transform -- but this time we'll be doing everything programmatically and orchestrating it with Airflow.
We'll start by creating the script where we'll define our workflows:
touch airflow/dags/workflows.py\nfrom pathlib import Path\nfrom airflow.decorators import dag\nfrom airflow.utils.dates import days_ago\n\n# Default DAG args\ndefault_args = {\n \"owner\": \"airflow\",\n \"catch_up\": False,\n}\nBASE_DIR = Path(__file__).parent.parent.parent.absolute()\n\n@dag(\n dag_id=\"dataops\",\n description=\"DataOps workflows.\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"dataops\"],\n)\ndef dataops():\n\"\"\"DataOps workflows.\"\"\"\n pass\n\n# Run DAG\ndo = dataops()\nIn two separate terminals, activate the virtual environment and spin up the Airflow webserver and scheduler:
# Airflow webserver\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nexport GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\nairflow webserver --port 8080\n# Go to http://localhost:8080\n# Airflow scheduler\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nexport OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES\nexport GOOGLE_APPLICATION_CREDENTIALS=~/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\nairflow scheduler\nWe're going to use the Airbyte connections we set up in our data-stack lesson but this time we're going to programmatically trigger the data syncs with Airflow. First, let's ensure that Airbyte is running on a separate terminal in it's repository:
git clone https://github.com/airbytehq/airbyte.git # skip if already create in data-stack lesson\ncd airbyte\ndocker-compose up\nNext, let's install the required packages and establish the connection between Airbyte and Airflow:
pip install apache-airflow-providers-airbyte==3.1.0\nAdmin > Connections > \u2795Connection ID: airbyte\nConnection Type: HTTP\nHost: localhost\nPort: 8000\nWe could also establish connections programmatically but it\u2019s good to use the UI to understand what\u2019s happening under the hood.
In order to execute our extract and load data syncs, we can use the AirbyteTriggerSyncOperator:
@dag(...)\ndef dataops():\n\"\"\"Production DataOps workflows.\"\"\"\n # Extract + Load\n extract_and_load_projects = AirbyteTriggerSyncOperator(\n task_id=\"extract_and_load_projects\",\n airbyte_conn_id=\"airbyte\",\n connection_id=\"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX\", # REPLACE\n asynchronous=False,\n timeout=3600,\n wait_seconds=3,\n )\n extract_and_load_tags = AirbyteTriggerSyncOperator(\n task_id=\"extract_and_load_tags\",\n airbyte_conn_id=\"airbyte\",\n connection_id=\"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX\", # REPLACE\n asynchronous=False,\n timeout=3600,\n wait_seconds=3,\n )\n\n # Define DAG\n extract_and_load_projects\n extract_and_load_tags\nWe can find the connection_id for each Airbyte connection by:
Connections on the left menu.https://demo.airbyte.io/workspaces/<WORKSPACE_ID>/connections/<CONNECTION_ID>/status\nCONNECTION_ID position is the connection's id.We can trigger our DAG right now and view the extracted data be loaded into our BigQuery data warehouse but we'll continue developing and execute our DAG once the entire DataOps workflow has been defined.
"},{"location":"courses/mlops/orchestration/#validate","title":"Validate","text":"The specific process of where and how we extract our data can be bespoke but what's important is that we have validation at every step of the way. We'll once again use Great Expectations, as we did in our testing lesson, to validate our extracted and loaded data before transforming it.
With the Airflow concepts we've learned so far, there are many ways to use our data validation library to validate our data. Regardless of what data validation tool we use (ex. Great Expectations, TFX, AWS Deequ, etc.) we could use the BashOperator, PythonOperator, etc. to run our tests. However, Great Expectations has a Airflow Provider package to make it even easier to validate our data. This package contains a GreatExpectationsOperator which we can use to execute specific checkpoints as tasks.
pip install airflow-provider-great-expectations==0.1.1 great-expectations==0.15.19\ngreat_expectations init\nThis will create the following directory within our data-engineering repository:
tests/great_expectations/\n\u251c\u2500\u2500 checkpoints/\n\u251c\u2500\u2500 expectations/\n\u251c\u2500\u2500 plugins/\n\u251c\u2500\u2500 uncommitted/\n\u251c\u2500\u2500 .gitignore\n\u2514\u2500\u2500 great_expectations.yml\nBut first, before we can create our tests, we need to define a new datasource within Great Expectations for our Google BigQuery data warehouse. This will require several packages and exports:
pip install pybigquery==0.10.2 sqlalchemy_bigquery==1.4.4\nexport GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\ngreat_expectations datasource new\nWhat data would you like Great Expectations to connect to?\n 1. Files on a filesystem (for processing with Pandas or Spark)\n2. Relational database (SQL) \ud83d\udc48\nWhat are you processing your files with?\n1. MySQL\n2. Postgres\n3. Redshift\n4. Snowflake\n5. BigQuery \ud83d\udc48\n6. other - Do you have a working SQLAlchemy connection string?\nThis will open up an interactive notebook where we can fill in the following details:
datasource_name = \u201cdwh\"\nconnection_string = \u201cbigquery://made-with-ml-359923/mlops_course\u201d\nNext, we can create a suite of expectations for our data assets:
great_expectations suite new\nHow would you like to create your Expectation Suite?\n 1. Manually, without interacting with a sample batch of data (default)\n2. Interactively, with a sample batch of data \ud83d\udc48\n 3. Automatically, using a profiler\nSelect a datasource\n 1. dwh \ud83d\udc48\nWhich data asset (accessible by data connector \"default_inferred_data_connector_name\") would you like to use?\n 1. mlops_course.projects \ud83d\udc48\n 2. mlops_course.tags\nName the new Expectation Suite [mlops.projects.warning]: projects\nThis will open up an interactive notebook where we can define our expectations. Repeat the same for creating a suite for our tags data asset as well.
Expectations formlops_course.projects Table expectations
# data leak\nvalidator.expect_compound_columns_to_be_unique(column_list=[\"title\", \"description\"])\nColumn expectations:
# id\nvalidator.expect_column_values_to_be_unique(column=\"id\")\n\n# create_on\nvalidator.expect_column_values_to_not_be_null(column=\"created_on\")\n\n# title\nvalidator.expect_column_values_to_not_be_null(column=\"title\")\nvalidator.expect_column_values_to_be_of_type(column=\"title\", type_=\"STRING\")\n\n# description\nvalidator.expect_column_values_to_not_be_null(column=\"description\")\nvalidator.expect_column_values_to_be_of_type(column=\"description\", type_=\"STRING\")\nmlops_course.tags Column expectations:
# id\nvalidator.expect_column_values_to_be_unique(column=\"id\")\n\n# tag\nvalidator.expect_column_values_to_not_be_null(column=\"tag\")\nvalidator.expect_column_values_to_be_of_type(column=\"tag\", type_=\"STRING\")\nOnce we have our suite of expectations, we're ready to check checkpoints to execute these expectations:
great_expectations checkpoint new projects\nThis will, of course, open up an interactive notebook. Just ensure that the following information is correct (the default values may not be):
datasource_name: dwh\ndata_asset_name: mlops_course.projects\nexpectation_suite_name: projects\nAnd repeat the same for creating a checkpoint for our tags suite.
"},{"location":"courses/mlops/orchestration/#tasks_1","title":"Tasks","text":"With our checkpoints defined, we're ready to apply them to our data assets in our warehouse.
GE_ROOT_DIR = Path(BASE_DIR, \"great_expectations\")\n\n@dag(...)\ndef dataops():\n ...\n validate_projects = GreatExpectationsOperator(\n task_id=\"validate_projects\",\n checkpoint_name=\"projects\",\n data_context_root_dir=GE_ROOT_DIR,\n fail_task_on_validation_failure=True,\n )\n validate_tags = GreatExpectationsOperator(\n task_id=\"validate_tags\",\n checkpoint_name=\"tags\",\n data_context_root_dir=GE_ROOT_DIR,\n fail_task_on_validation_failure=True,\n )\n\n # Define DAG\n extract_and_load_projects >> validate_projects\n extract_and_load_tags >> validate_tags\nOnce we've validated our extracted and loaded data, we're ready to transform it. Our DataOps workflows are not specific to any particular downstream application so the transformation must be globally relevant (ex. cleaning missing data, aggregation, etc.). Just like in our data stack lesson, we're going to use dbt to transform our data. However, this time, we're going to do everything programmatically using the open-source dbt-core package.
In the root of our data-engineering repository, initialize our dbt directory with the following command:
dbt init dbf_transforms\nWhich database would you like to use?\n[1] bigquery \ud83d\udc48\nDesired authentication method option:\n[1] oauth\n[2] service_account \ud83d\udc48\nkeyfile: /Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\nproject (GCP project id): made-with-ml-XXXXXX # REPLACE\ndataset: mlops_course\nthreads: 1\njob_execution_timeout_seconds: 300\nDesired location option:\n[1] US \ud83d\udc48 # or what you picked when defining your dataset in Airbyte DWH destination setup\n[2] EU\nWe'll prepare our dbt models as we did using the dbt Cloud IDE in the previous lesson.
cd dbt_transforms\nrm -rf models/example\nmkdir models/labeled_projects\ntouch models/labeled_projects/labeled_projects.sql\ntouch models/labeled_projects/schema.yml\nand add the following code to our model files:
-- models/labeled_projects/labeled_projects.sql\nSELECT p.id, created_on, title, description, tag\nFROM `made-with-ml-XXXXXX.mlops_course.projects` p -- REPLACE\nLEFT JOIN `made-with-ml-XXXXXX.mlops_course.tags` t -- REPLACE\nON p.id = t.id\n# models/labeled_projects/schema.yml\n\nversion: 2\n\nmodels:\n- name: labeled_projects\ndescription: \"Tags for all projects\"\ncolumns:\n- name: id\ndescription: \"Unique ID of the project.\"\ntests:\n- unique\n- not_null\n- name: title\ndescription: \"Title of the project.\"\ntests:\n- not_null\n- name: description\ndescription: \"Description of the project.\"\ntests:\n- not_null\n- name: tag\ndescription: \"Labeled tag for the project.\"\ntests:\n- not_null\nAnd we can use the BashOperator to execute our dbt commands like so:
DBT_ROOT_DIR = Path(BASE_DIR, \"dbt_transforms\")\n\n@dag(...)\ndef dataops():\n ...\n # Transform\n transform = BashOperator(task_id=\"transform\", bash_command=f\"cd {DBT_ROOT_DIR} && dbt run && dbt test\")\n\n # Define DAG\n extract_and_load_projects >> validate_projects\n extract_and_load_tags >> validate_tags\n [validate_projects, validate_tags] >> transform\nProgrammatically using dbt Cloud
While we developed locally, we could just as easily use Airflow\u2019s dbt cloud provider to connect to our dbt cloud and use the different operators to schedule jobs. This is recommended for production because we can design jobs with proper environment, authentication, schemas, etc.
Go to Admin > Connections > +
Connection ID: dbt_cloud_default\nConnection Type: dbt Cloud\nAccount ID: View in URL of https://cloud.getdbt.com/\nAPI Token: View in https://cloud.getdbt.com/#/profile/api/\npip install apache-airflow-providers-dbt-cloud==2.1.0\nfrom airflow.providers.dbt.cloud.operators.dbt import DbtCloudRunJobOperator\ntransform = DbtCloudRunJobOperator(\n task_id=\"transform\",\n job_id=118680, # Go to dbt UI > click left menu > Jobs > Transform > job_id in URL\n wait_for_termination=True, # wait for job to finish running\n check_interval=10, # check job status\n timeout=300, # max time for job to execute\n)\nAnd of course, we'll want to validate our transformations beyond dbt's built-in methods, using great expectations. We'll create a suite and checkpoint as we did above for our projects and tags data assets.
great_expectations suite new # for mlops_course.labeled_projects\nmlops_course.labeled_projects Table expectations
# data leak\nvalidator.expect_compound_columns_to_be_unique(column_list=[\"title\", \"description\"])\nColumn expectations:
# id\nvalidator.expect_column_values_to_be_unique(column=\"id\")\n\n# create_on\nvalidator.expect_column_values_to_not_be_null(column=\"created_on\")\n\n# title\nvalidator.expect_column_values_to_not_be_null(column=\"title\")\nvalidator.expect_column_values_to_be_of_type(column=\"title\", type_=\"STRING\")\n\n# description\nvalidator.expect_column_values_to_not_be_null(column=\"description\")\nvalidator.expect_column_values_to_be_of_type(column=\"description\", type_=\"STRING\")\n\n# tag\nvalidator.expect_column_values_to_not_be_null(column=\"tag\")\nvalidator.expect_column_values_to_be_of_type(column=\"tag\", type_=\"STRING\")\ngreat_expectations checkpoint new labeled_projects\ndatasource_name: dwh\ndata_asset_name: mlops_course.labeled_projects\nexpectation_suite_name: labeled_projects\nand just like how we added the validation task for our extracted and loaded data, we can do the same for our transformed data in Airflow:
@dag(...)\ndef dataops():\n ...\n # Transform\n transform = BashOperator(task_id=\"transform\", bash_command=f\"cd {DBT_ROOT_DIR} && dbt run && dbt test\")\n validate_transforms = GreatExpectationsOperator(\n task_id=\"validate_transforms\",\n checkpoint_name=\"labeled_projects\",\n data_context_root_dir=GE_ROOT_DIR,\n fail_task_on_validation_failure=True,\n )\n\n # Define DAG\n extract_and_load_projects >> validate_projects\n extract_and_load_tags >> validate_tags\n [validate_projects, validate_tags] >> transform >> validate_transforms\nNow we have our entire DataOps DAG define and executing it will prepare our data from extraction to loading to transformation (and with validation at every step of the way) for downstream applications.
Typically we'll use sensors to trigger workflows when a condition is met or trigger them directly from the external source via API calls, etc. For our ML use cases, this could be at regular intervals or when labeling or monitoring workflows trigger retraining, etc.
"},{"location":"courses/mlops/orchestration/#mlops","title":"MLOps","text":"Once we have our data prepared, we're ready to create one of the many potential downstream applications that will depend on it. Let's head back to our mlops-course project and follow the same set up instructions for Airflow (you can stop the Airflow webserver and scheduler from our data-engineering project since we'll reuse PORT 8000).
# Airflow webserver\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nexport GOOGLE_APPLICATION_CREDENTIALS=/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\nairflow webserver --port 8080\n# Go to http://localhost:8080\n# Airflow scheduler\nsource venv/bin/activate\nexport AIRFLOW_HOME=${PWD}/airflow\nexport OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YES\nexport GOOGLE_APPLICATION_CREDENTIALS=~/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json # REPLACE\nairflow scheduler\ntouch airflow/dags/workflows.py\n# airflow/dags/workflows.py\nfrom pathlib import Path\nfrom airflow.decorators import dag\nfrom airflow.utils.dates import days_ago\n\n# Default DAG args\ndefault_args = {\n \"owner\": \"airflow\",\n \"catch_up\": False,\n}\n\n@dag(\n dag_id=\"mlops\",\n description=\"MLOps tasks.\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"mlops\"],\n)\ndef mlops():\n\"\"\"MLOps workflows.\"\"\"\n pass\n\n# Run DAG\nml = mlops()\nWe already had an tagifai.elt_data function defined to prepare our data but if we want to leverage the data inside our data warehouse, we'll want to connect to it.
pip install google-cloud-bigquery==1.21.0\n# airflow/dags/workflows.py\nfrom google.cloud import bigquery\nfrom google.oauth2 import service_account\n\nPROJECT_ID = \"made-with-ml-XXXXX\" # REPLACE\nSERVICE_ACCOUNT_KEY_JSON = \"/Users/goku/Downloads/made-with-ml-XXXXXX-XXXXXXXXXXXX.json\" # REPLACE\n\ndef _extract_from_dwh():\n\"\"\"Extract labeled data from\n our BigQuery data warehouse and\n save it locally.\"\"\"\n # Establish connection to DWH\n credentials = service_account.Credentials.from_service_account_file(SERVICE_ACCOUNT_KEY_JSON)\n client = bigquery.Client(credentials=credentials, project=PROJECT_ID)\n\n # Query data\n query_job = client.query(\"\"\"\n SELECT *\n FROM mlops_course.labeled_projects\"\"\")\n results = query_job.result()\n results.to_dataframe().to_csv(Path(config.DATA_DIR, \"labeled_projects.csv\"), index=False)\n\n@dag(\n dag_id=\"mlops\",\n description=\"MLOps tasks.\",\n default_args=default_args,\n schedule_interval=None,\n start_date=days_ago(2),\n tags=[\"mlops\"],\n)\ndef mlops():\n\"\"\"MLOps workflows.\"\"\"\n extract_from_dwh = PythonOperator(\n task_id=\"extract_data\",\n python_callable=_extract_from_dwh,\n )\n\n # Define DAG\n extract_from_dwh\nNext, we'll use Great Expectations to validate our data. Even though we've already validated our data, it's a best practice to test for data quality whenever there is a hand-off of data from one place to another. We've already created a checkpoint for our labeled_projects in our testing lesson so we'll just leverage that inside our MLOps DAG.
pip install airflow-provider-great-expectations==0.1.1 great-expectations==0.15.19\nfrom great_expectations_provider.operators.great_expectations import GreatExpectationsOperator\nfrom config import config\n\nGE_ROOT_DIR = Path(config.BASE_DIR, \"tests\", \"great_expectations\")\n\n@dag(...)\ndef mlops():\n\"\"\"MLOps workflows.\"\"\"\n extract_from_dwh = PythonOperator(\n task_id=\"extract_data\",\n python_callable=_extract_from_dwh,\n )\n validate = GreatExpectationsOperator(\n task_id=\"validate\",\n checkpoint_name=\"labeled_projects\",\n data_context_root_dir=GE_ROOT_DIR,\n fail_task_on_validation_failure=True,\n )\n\n # Define DAG\n extract_from_dwh >> validate\nFinally, we'll optimize and train a model using our validated data.
from airflow.operators.python_operator import PythonOperator\nfrom config import config\nfrom tagifai import main\n\n@dag(...)\ndef mlops():\n\"\"\"MLOps workflows.\"\"\"\n ...\n optimize = PythonOperator(\n task_id=\"optimize\",\n python_callable=main.optimize,\n op_kwargs={\n \"args_fp\": Path(config.CONFIG_DIR, \"args.json\"),\n \"study_name\": \"optimization\",\n \"num_trials\": 1,\n },\n )\n train = PythonOperator(\n task_id=\"train\",\n python_callable=main.train_model,\n op_kwargs={\n \"args_fp\": Path(config.CONFIG_DIR, \"args.json\"),\n \"experiment_name\": \"baselines\",\n \"run_name\": \"sgd\",\n },\n )\nAnd with that we have our MLOps workflow defined that uses the prepared data from our DataOps workflow. At this point, we can add additional tasks for offline/online evaluation, deployment, etc. with the same process as above.
"},{"location":"courses/mlops/orchestration/#continual-learning","title":"Continual learning","text":"The DataOps and MLOps workflows connect to create an ML system that's capable of continually learning. Such a system will guide us with when to update, what exactly to update and how to update it (easily).
We use the word continual (repeat with breaks) instead of continuous (repeat without interruption / intervention) because we're not trying to create a system that will automatically update with new incoming data without human intervention.
"},{"location":"courses/mlops/orchestration/#monitoring","title":"Monitoring","text":"Our production system is live and monitored. When an event of interest occurs (ex. drift), one of several events needs to be triggered:
continue: with the currently deployed model without any updates. However, an alert was raised so it should analyzed later to reduce false positive alerts.improve: by retraining the model to avoid performance degradation causes by meaningful drift (data, target, concept, etc.).inspect: to make a decision. Typically expectations are reassessed, schemas are reevaluated for changes, slices are reevaluated, etc.rollback: to a previous version of the model because of an issue with the current deployment. Typically these can be avoided using robust deployment strategies (ex. dark canary).If we need to improve on the existing version of the model, it's not just the matter of fact of rerunning the model creation workflow on the new dataset. We need to carefully compose the training data in order to avoid issues such as catastrophic forgetting (forget previously learned patterns when presented with new data).
labeling: new incoming data may need to be properly labeled before being used (we cannot just depend on proxy labels).active learning: we may not be able to explicitly label every single new data point so we have to leverage active learning workflows to complete the labeling process.QA: quality assurance workflows to ensure that labeling is accurate, especially for known false positives/negatives and historically poorly performing slices of data.augmentation: increasing our training set with augmented data that's representative of the original dataset.sampling: upsampling and downsampling to address imbalanced data slices.evaluation: creation of an evaluation dataset that's representative of what the model will encounter once deployed.Once we have the proper dataset for retraining, we can kickoff the workflows to update our system!
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Orchestration for Machine Learning - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nBefore performing a commit to our local repository, there are a lot of items on our mental todo list, ranging from styling, formatting, testing, etc. And it's very easy to forget some of these steps, especially when we want to \"push to quick fix\". To help us manage all these important steps, we can use pre-commit hooks, which will automatically be triggered when we try to perform a commit. These hooks can ensure that certain rules are followed or specific actions are executed successfully and if any of them fail, the commit will be aborted.
"},{"location":"courses/mlops/pre-commit/#installation","title":"Installation","text":"We'll be using the Pre-commit framework to help us automatically perform important checks via hooks when we make a commit.
We'll start by installing and autoupdating pre-commit (we only have to do this once).
pre-commit install\npre-commit autoupdate\nWe define our pre-commit hooks via a .pre-commit-config.yaml configuration file. We can either create our yaml configuration from scratch or use the pre-commit CLI to create a sample configuration which we can add to.
# Simple config\npre-commit sample-config > .pre-commit-config.yaml\ncat .pre-commit-config.yaml\nWhen it comes to creating and using hooks, we have several options to choose from.
"},{"location":"courses/mlops/pre-commit/#built-in","title":"Built-in","text":"Inside the sample configuration, we can see that pre-commit has added some default hooks from it's repository. It specifies the location of the repository, version as well as the specific hook ids to use. We can read about the function of these hooks and add even more by exploring pre-commit's built-in hooks. Many of them also have additional arguments that we can configure to customize the hook.
# Inside .pre-commit-config.yaml\n...\n- id: check-added-large-files\nargs: ['--maxkb=1000']\nexclude: \"notebooks\"\n...\nBe sure to explore the many other built-in hooks because there are some really useful ones that we use in our project. For example, check-merge-conflict to see if there are any lingering merge conflict strings or detect-aws-credentials if we accidentally left our credentials exposed in a file, and so much more.
And we can also exclude certain files from being processed by the hooks by using the optional exclude key. There are many other optional keys we can configure for each hook ID.
# Inside .pre-commit-config.yaml\n...\n- id: check-yaml\nexclude: \"mkdocs.yml\"\n...\nBesides pre-commit's built-in hooks, there are also many custom, 3rd party popular hooks that we can choose from. For example, if we want to apply formatting checks with Black as a hook, we can leverage Black's pre-commit hook.
# Inside .pre-commit-config.yaml\n...\n- repo: https://github.com/psf/black\nrev: 20.8b1\nhooks:\n- id: black\nargs: []\nfiles: .\n...\nThis specific hook is defined under a .pre-commit-hooks.yaml inside Black's repository, as are other custom hooks under their respective package repositories.
"},{"location":"courses/mlops/pre-commit/#local","title":"Local","text":"We can also create our own local hooks without configuring a separate .pre-commit-hooks.yaml. Here we're defining two pre-commit hooks, test-non-training and clean, to run some commands that we've defined in our Makefile. Similarly, we can run any entry command with arguments to create hooks very quickly.
# Inside .pre-commit-config.yaml\n...\n- repo: local\nhooks:\n- id: clean\nname: clean\nentry: make\nargs: [\"clean\"]\nlanguage: system\npass_filenames: false\nOur pre-commit hooks will automatically execute when we try to make a commit. We'll be able to see if each hook passed or failed and make any changes. If any of the hooks fail, we have to fix the errors ourselves or, in many instances, reformatting will occur automatically.
\ncheck yaml..............................................PASSED\nclean...................................................FAILED\n
In the event that any of the hooks failed, we need to add and commit again to ensure that all hooks are passed.
git add .\ngit commit -m <MESSAGE>\nThough pre-commit hooks are meant to run before (pre) a commit, we can manually trigger all or individual hooks on all or a set of files.
# Run\npre-commit run --all-files # run all hooks on all files\npre-commit run <HOOK_ID> --all-files # run one hook on all files\npre-commit run --files <PATH_TO_FILE> # run all hooks on a file\npre-commit run <HOOK_ID> --files <PATH_TO_FILE> # run one hook on a file\nIt is highly not recommended to skip running any of the pre-commit hooks because they are there for a reason. But for some highly urgent, world saving commits, we can use the no-verify flag.
# Commit without hooks\ngit commit -m <MESSAGE> --no-verify\nHighly recommend not doing this because no commit deserves to be force pushed no matter how \"small\" your change was. If you accidentally did this and want to clear the cache, run pre-commit run --all-files and execute the commit message operation again.
In our .pre-commit-config.yaml configuration files, we've had to specify the versions for each of the repositories so we can use their latest hooks. Pre-commit has an autoupdate CLI command which will update these versions as they become available.
# Autoupdate\npre-commit autoupdate\nUpcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Pre-commit - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nWe'll start by first preparing our data by ingesting it from source and splitting it into training, validation and test data splits.
"},{"location":"courses/mlops/preparation/#ingestion","title":"Ingestion","text":"Our data could reside in many different places (databases, files, etc.) and exist in different formats (CSV, JSON, Parquet, etc.). For our application, we'll load the data from a CSV file to a Pandas DataFrame using the read_csv function.
Here is a quick refresher on the Pandas library.
import pandas as pd\n# Data ingestion\nDATASET_LOC = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\ndf = pd.read_csv(DATASET_LOC)\ndf.head()\nIn our data engineering lesson we'll look at how to continually ingest data from more complex sources (ex. data warehouses)
"},{"location":"courses/mlops/preparation/#splitting","title":"Splitting","text":"Next, we need to split our training dataset into train and val data splits.
train split to train the model. Here the model will have access to both inputs (features) and outputs (labels) to optimize its internal weights.
val split to determine the model's performance. Here the model will not use the labels to optimize its weights but instead, we will use the validation performance to optimize training hyperparameters such as the learning rate, etc.
test dataset to determine the model's performance after training. This is our best measure of how the model may behave on new, unseen data that is from a similar distribution to our training dataset.
Tip
For our application, we will have a training dataset to split into train and val splits and a separate testing dataset for the test set. While we could have one large dataset and split that into the three splits, it's a good idea to have a separate test dataset. Over time, our training data may grow and our test splits will look different every time. This will make it difficult to compare models against other models and against each other.
We can view the class counts in our dataset by using the pandas.DataFrame.value_counts function:
from sklearn.model_selection import train_test_split\n# Value counts\ndf.tag.value_counts()\n\ntag\nnatural-language-processing 310\ncomputer-vision 285\nother 106\nmlops 63\nName: count, dtype: int64\n
For our multi-class task (where each project has exactly one tag), we want to ensure that the data splits have similar class distributions. We can achieve this by specifying how to stratify the split by using the stratify keyword argument with sklearn's train_test_split() function.
Creating proper data splits
What are the criteria we should focus on to ensure proper data splits?
Show answertime-series)# Split dataset\ntest_size = 0.2\ntrain_df, val_df = train_test_split(df, stratify=df.tag, test_size=test_size, random_state=1234)\nHow can we validate that our data splits have similar class distributions? We can view the frequency of each class in each split:
# Train value counts\ntrain_df.tag.value_counts()\n\ntag\nnatural-language-processing 248\ncomputer-vision 228\nother 85\nmlops 50\nName: count, dtype: int64\n
Before we view our validation split's class counts, recall that our validation split is only test_size of the entire dataset. So we need to adjust the value counts so that we can compare it to the training split's class counts.
# Validation (adjusted) value counts\nval_df.tag.value_counts() * int((1-test_size) / test_size)\n\ntag\nnatural-language-processing 248\ncomputer-vision 228\nother 84\nmlops 52\nName: count, dtype: int64\n
These adjusted counts looks very similar to our train split's counts. Now we're ready to explore our dataset!
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Preparation - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nData preprocessing can be categorized into two types of processes: preparation and transformation. We'll explore common preprocessing techniques and then we'll preprocess our dataset.
Warning
Certain preprocessing steps are global (don't depend on our dataset, ex. lower casing text, removing stop words, etc.) and others are local (constructs are learned only from the training split, ex. vocabulary, standardization, etc.). For the local, dataset-dependent preprocessing steps, we want to ensure that we split the data first before preprocessing to avoid data leaks.
Preparing the data involves organizing and cleaning the data.
"},{"location":"courses/mlops/preprocessing/#joins","title":"Joins","text":"Performing SQL joins with existing data tables to organize all the relevant data you need into one view. This makes working with our dataset a whole lot easier.
SELECT * FROM A\nINNER JOIN B on A.id == B.id\nWarning
We need to be careful to perform point-in-time valid joins to avoid data leaks. For example, if Table B may have features for objects in Table A that were not available at the time inference would have been needed.
"},{"location":"courses/mlops/preprocessing/#missing-values","title":"Missing values","text":"First, we'll have to identify the rows with missing values and once we do, there are several approaches to dealing with them.
omit samples with missing values (if only a small subset are missing it)
# Drop a row (sample) by index\ndf.drop([4, 10, ...])\n# Conditionally drop rows (samples)\ndf = df[df.value > 0]\n# Drop samples with any missing feature\ndf = df[df.isnull().any(axis=1)]\nomit the entire feature (if too many samples are missing the value)
# Drop a column (feature)\ndf.drop([\"A\"], axis=1)\nfill in missing values for features (using domain knowledge, heuristics, etc.)
# Fill in missing values with mean\ndf.A = df.A.fillna(df.A.mean())\nmay not always seem \"missing\" (ex. 0, null, NA, etc.)
# Replace zeros to NaNs\nimport numpy as np\ndf.A = df.A.replace({\"0\": np.nan, 0: np.nan})\n# Ex. Feature value must be within 2 standard deviations\ndf[np.abs(df.A - df.A.mean()) <= (2 * df.A.std())]\nFeature engineering involves combining features in unique ways to draw out signal.
# Input\ndf.C = df.A + df.B\nTip
Feature engineering can be done in collaboration with domain experts that can guide us on what features to engineer and use.
"},{"location":"courses/mlops/preprocessing/#cleaning","title":"Cleaning","text":"Cleaning our data involves apply constraints to make it easier for our models to extract signal from the data.
# Resize\nimport cv2\ndims = (height, width)\nresized_img = cv2.resize(src=img, dsize=dims, interpolation=cv2.INTER_LINEAR)\n# Lower case the text\ntext = text.lower()\nTransforming the data involves feature encoding and engineering.
"},{"location":"courses/mlops/preprocessing/#scaling","title":"Scaling","text":"don't blindly scale features (ex. categorical features)
standardization: rescale values to mean 0, std 1
# Standardization\nimport numpy as np\nx = np.random.random(4) # values between 0 and 1\nprint (\"x:\\n\", x)\nprint (f\"mean: {np.mean(x):.2f}, std: {np.std(x):.2f}\")\nx_standardized = (x - np.mean(x)) / np.std(x)\nprint (\"x_standardized:\\n\", x_standardized)\nprint (f\"mean: {np.mean(x_standardized):.2f}, std: {np.std(x_standardized):.2f}\")\n\nx: [0.36769939 0.82302265 0.9891467 0.56200803]\nmean: 0.69, std: 0.24\nx_standardized: [-1.33285946 0.57695671 1.27375049 -0.51784775]\nmean: 0.00, std: 1.00\n
min-max: rescale values between a min and max
# Min-max\nimport numpy as np\nx = np.random.random(4) # values between 0 and 1\nprint (\"x:\", x)\nprint (f\"min: {x.min():.2f}, max: {x.max():.2f}\")\nx_scaled = (x - x.min()) / (x.max() - x.min())\nprint (\"x_scaled:\", x_scaled)\nprint (f\"min: {x_scaled.min():.2f}, max: {x_scaled.max():.2f}\")\n\nx: [0.20195674 0.99108855 0.73005081 0.02540603]\nmin: 0.03, max: 0.99\nx_scaled: [0.18282479 1. 0.72968575 0. ]\nmin: 0.00, max: 1.00\n
binning: convert a continuous feature into categorical using bins
# Binning\nimport numpy as np\nx = np.random.random(4) # values between 0 and 1\nprint (\"x:\", x)\nbins = np.linspace(0, 1, 5) # bins between 0 and 1\nprint (\"bins:\", bins)\nbinned = np.digitize(x, bins)\nprint (\"binned:\", binned)\n\nx: [0.54906364 0.1051404 0.2737904 0.2926313 ]\nbins: [0. 0.25 0.5 0.75 1. ]\nbinned: [3 1 2 2]\n
and many more!
allows for representing data efficiently (maintains signal) and effectively (learns patterns, ex. one-hot vs embeddings)
label: unique index for categorical value
# Label encoding\nlabel_encoder.class_to_index = {\n\"attention\": 0,\n\"autoencoders\": 1,\n\"convolutional-neural-networks\": 2,\n\"data-augmentation\": 3,\n... }\nlabel_encoder.transform([\"attention\", \"data-augmentation\"])\n\narray([2, 2, 1])\n
one-hot: representation as binary vector
# One-hot encoding\none_hot_encoder.transform([\"attention\", \"data-augmentation\"])\n\narray([1, 0, 0, 1, 0, ..., 0])\n
embeddings: dense representations capable of representing context
# Embeddings\nself.embeddings = nn.Embedding(\n embedding_dim=embedding_dim, num_embeddings=vocab_size)\nx_in = self.embeddings(x_in)\nprint (x_in.shape)\n\n(len(X), embedding_dim)\n
and many more!
autoencoders: learn to encode inputs for compressed knowledge representation
principle component analysis (PCA): linear dimensionality reduction to project data in a lower dimensional space.
# PCA\nimport numpy as np\nfrom sklearn.decomposition import PCA\nX = np.array([[-1, -1, 3], [-2, -1, 2], [-3, -2, 1]])\npca = PCA(n_components=2)\npca.fit(X)\nprint (pca.transform(X))\nprint (pca.explained_variance_ratio_)\nprint (pca.singular_values_)\n\n[[-1.44245791 -0.1744313 ]\n [-0.1148688 0.31291575]\n [ 1.55732672 -0.13848446]]\n[0.96838847 0.03161153]\n[2.12582835 0.38408396]\n
counts (ngram): sparse representation of text as matrix of token counts \u2014 useful if feature values have lot's of meaningful, separable signal.
# Counts (ngram)\nfrom sklearn.feature_extraction.text import CountVectorizer\ny = [\n \"acetyl acetone\",\n \"acetyl chloride\",\n \"chloride hydroxide\",\n]\nvectorizer = CountVectorizer()\ny = vectorizer.fit_transform(y)\nprint (vectorizer.get_feature_names())\nprint (y.toarray())\n# \ud83d\udca1 Repeat above with char-level ngram vectorizer\n# vectorizer = CountVectorizer(analyzer='char', ngram_range=(1, 3)) # uni, bi and trigrams\n\n['acetone', 'acetyl', 'chloride', 'hydroxide']\n[[1 1 0 0]\n [0 1 1 0]\n [0 0 1 1]]\n
similarity: similar to count vectorization but based on similarities in tokens
We'll often was to retrieve feature values for an entity (user, item, etc.) over time and reuse the same features across different projects. To ensure that we're retrieving the proper feature values and to avoid duplication of efforts, we can use a feature store.
Curse of dimensionality
What can we do if a feature has lots of unique values but enough data points for each unique value (ex. URL as a feature)?
Show answerWe can encode our data with hashing or using it's attributes instead of the exact entity itself. For example, representing a user by their location and favorites as opposed to using their user ID or representing a webpage with it's domain as opposed to the exact url. This methods effectively decrease the total number of unique feature values and increase the number of data points for each.
"},{"location":"courses/mlops/preprocessing/#implementation","title":"Implementation","text":"For our application, we'll be implementing a few of these preprocessing steps that are relevant for our dataset.
import json\nimport nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem import PorterStemmer\nimport re\nWe can combine existing input features to create new meaningful signal for helping the model learn. However, there's usually no simple way to know if certain feature combinations will help or not without empirically experimenting with the different combinations. Here, we could use a project's title and description separately as features but we'll combine them to create one input feature.
# Input\ndf[\"text\"] = df.title + \" \" + df.description\nSince we're dealing with text data, we can apply some common text preprocessing operations. Here, we'll be using Python's built-in regular expressions library re and the Natural Language Toolkit nltk.
nltk.download(\"stopwords\")\nSTOPWORDS = stopwords.words(\"english\")\ndef clean_text(text, stopwords=STOPWORDS):\n\"\"\"Clean raw text string.\"\"\"\n # Lower\n text = text.lower()\n\n # Remove stopwords\n pattern = re.compile(r'\\b(' + r\"|\".join(stopwords) + r\")\\b\\s*\")\n text = pattern.sub('', text)\n\n # Spacing and filters\n text = re.sub(r\"([!\\\"'#$%&()*\\+,-./:;<=>?@\\\\\\[\\]^_`{|}~])\", r\" \\1 \", text) # add spacing\n text = re.sub(\"[^A-Za-z0-9]+\", \" \", text) # remove non alphanumeric chars\n text = re.sub(\" +\", \" \", text) # remove multiple spaces\n text = text.strip() # strip white space at the ends\n text = re.sub(r\"http\\S+\", \"\", text) # remove links\n\n return text\nNote
We could definitely try and include emojis, punctuations, etc. because they do have a lot of signal for the task but it's best to simplify the initial feature set we use to just what we think are the most influential and then we can slowly introduce other features and assess utility.
Once we're defined our function, we can apply it to each row in our dataframe via pandas.DataFrame.apply.
# Apply to dataframe\noriginal_df = df.copy()\ndf.text = df.text.apply(clean_text)\nprint (f\"{original_df.text.values[0]}\\n{df.text.values[0]}\")\n\nComparison between YOLO and RCNN on real world videos Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes.\ncomparison yolo rcnn real world videos bringing theory experiment cool easily train models colab find results minutes\n
Warning
We'll want to introduce less frequent features as they become more frequent or encode them in a clever way (ex. binning, extract general attributes, common n-grams, mean encoding using other feature values, etc.) so that we can mitigate the feature value dimensionality issue until we're able to collect more data.
We'll wrap up our cleaning operation by removing columns (pandas.DataFrame.drop) and rows with null tag values (pandas.DataFrame.dropna).
# DataFrame cleanup\ndf = df.drop(columns=[\"id\", \"created_on\", \"title\", \"description\"], errors=\"ignore\") # drop cols\ndf = df.dropna(subset=[\"tag\"]) # drop nulls\ndf = df[[\"text\", \"tag\"]] # rearrange cols\ndf.head()\nWe need to encode our data into numerical values so that our models can process them. We'll start by encoding our text labels into unique indices.
# Label to index\ntags = train_df.tag.unique().tolist()\nnum_classes = len(tags)\nclass_to_index = {tag: i for i, tag in enumerate(tags)}\nclass_to_index\n\n{'mlops': 0,\n 'natural-language-processing': 1,\n 'computer-vision': 2,\n 'other': 3}\n Next, we can use the pandas.Series.map function to map our class_to_index dictionary on our tag column to encode our labels.
# Encode labels\ndf[\"tag\"] = df[\"tag\"].map(class_to_index)\ndf.head()\nWe'll also want to be able to decode our predictions back into text labels. We can do this by creating an index_to_class dictionary and using that to convert encoded labels back into text labels.
def decode(indices, index_to_class):\n return [index_to_class[index] for index in indices]\nindex_to_class = {v:k for k, v in class_to_index.items()}\ndecode(df.head()[\"tag\"].values, index_to_class=index_to_class)\n\n['computer-vision', 'computer-vision', 'other', 'other', 'other']\n"},{"location":"courses/mlops/preprocessing/#tokenizer","title":"Tokenizer","text":"
Next we'll encode our text as well. Instead of using a random dictionary, we'll use a tokenizer that was used for a pretrained LLM (scibert) to tokenize our text. We'll be fine-tuning this exact model later when we train our model.
Here is a quick refresher on attention and Transformers.
import numpy as np\nfrom transformers import BertTokenizer\nThe tokenizer will convert our input text into a list of token ids and a list of attention masks. The token ids are the indices of the tokens in the vocabulary. The attention mask is a binary mask indicating the position of the token indices so that the model can attend to them (and ignore the pad tokens).
# Bert tokenizer\ntokenizer = BertTokenizer.from_pretrained(\"allenai/scibert_scivocab_uncased\", return_dict=False)\ntext = \"Transfer learning with transformers for text classification.\"\nencoded_inputs = tokenizer([text], return_tensors=\"np\", padding=\"longest\") # pad to longest item in batch\nprint (\"input_ids:\", encoded_inputs[\"input_ids\"])\nprint (\"attention_mask:\", encoded_inputs[\"attention_mask\"])\nprint (tokenizer.decode(encoded_inputs[\"input_ids\"][0]))\n\ninput_ids: [[ 102 2268 1904 190 29155 168 3267 2998 205 103]]\nattention_mask: [[1 1 1 1 1 1 1 1 1 1]]\n[CLS] transfer learning with transformers for text classification. [SEP]\n
Note that we use padding=\"longest\" in our tokenizer function to pad our inputs to the longest item in the batch. This becomes important when we use batches of inputs later and want to create a uniform input size, where shorted text sequences will be padded with zeros to meet the length of the longest input in the batch.
We'll wrap our tokenization into a tokenize function that we can use to tokenize batches of our data.
def tokenize(batch):\n tokenizer = BertTokenizer.from_pretrained(\"allenai/scibert_scivocab_uncased\", return_dict=False)\n encoded_inputs = tokenizer(batch[\"text\"].tolist(), return_tensors=\"np\", padding=\"longest\")\n return dict(ids=encoded_inputs[\"input_ids\"], masks=encoded_inputs[\"attention_mask\"], targets=np.array(batch[\"tag\"]))\n# Tokenization\ntokenize(df.head(1))\n\n{'ids': array([[ 102, 2029, 1778, 609, 6446, 4857, 1332, 2399, 13572,\n 19125, 1983, 1954, 6240, 3717, 7434, 1262, 537, 201,\n 1040, 545, 4714, 103]]),\n 'masks': array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),\n 'targets': array([2])}\n"},{"location":"courses/mlops/preprocessing/#best-practices","title":"Best practices","text":"We'll wrap up by combining all of our preprocessing operations into function. This way we can easily apply it to different datasets (training, inference, etc.)
def preprocess(df, class_to_index):\n\"\"\"Preprocess the data.\"\"\"\n df[\"text\"] = df.title + \" \" + df.description # feature engineering\n df[\"text\"] = df.text.apply(clean_text) # clean text\n df = df.drop(columns=[\"id\", \"created_on\", \"title\", \"description\"], errors=\"ignore\") # clean dataframe\n df = df[[\"text\", \"tag\"]] # rearrange columns\n df[\"tag\"] = df[\"tag\"].map(class_to_index) # label encoding\n outputs = tokenize(df)\n return outputs\n# Apply\npreprocess(df=train_df, class_to_index=class_to_index)\n\n{'ids': array([[ 102, 856, 532, ..., 0, 0, 0],\n [ 102, 2177, 29155, ..., 0, 0, 0],\n [ 102, 2180, 3241, ..., 0, 0, 0],\n ...,\n [ 102, 453, 2068, ..., 5730, 432, 103],\n [ 102, 11268, 1782, ..., 0, 0, 0],\n [ 102, 1596, 122, ..., 0, 0, 0]]),\n 'masks': array([[1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0],\n ...,\n [1, 1, 1, ..., 1, 1, 1],\n [1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0]]),\n 'targets': array([0, 1, 1, ... 0, 2, 3])}\n Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Preprocessing - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nBefore we start developing any machine learning models, we need to first motivate and design our application. While this is a technical course, this initial product design process is extremely crucial for creating great products. We'll focus on the product design aspects of our application in this lesson and the systems design aspects in the next lesson.
"},{"location":"courses/mlops/product-design/#template","title":"Template","text":"The template below is designed to guide machine learning product development. It involves both the product and systems design (next lesson) aspects of our application:
Product design (What & Why) \u2192 Systems design (How)
\ud83d\udc49 \u00a0 Download a PDF of the ML canvas to use for your own products \u2192 ml-canvas.pdf (right click the link and hit \"Save Link As...\")
"},{"location":"courses/mlops/product-design/#product-design","title":"Product design","text":"Motivate the need for the product and outline the objectives and impact.
Note
Each section below has a part called \"Our task\", which will discuss how the specific topic relates to the application that we will be building.
"},{"location":"courses/mlops/product-design/#background","title":"Background","text":"Set the scene for what we're trying to do through a user-centric approach:
users: profile/persona of our usersgoals: our users' main goalspains: obstacles preventing our users from achieving their goalsOur task
users: machine learning developers and researchers.goals: stay up-to-date on ML content for work, knowledge, etc.pains: too much unlabeled content scattered around the internet.Propose the value we can create through a product-centric approach:
product: what needs to be built to help our users reach their goals?alleviates: how will the product reduce pains?advantages: how will the product create gains?Our task
We will build a platform that helps machine learning developers and researchers stay up-to-date on ML content. We'll do this by discovering and categorizing content from popular sources (Reddit, Twitter, etc.) and displaying it on our platform. For simplicity, assume that we already have a pipeline that delivers ML content from popular sources to our platform. We will just focus on developing the ML service that can correctly categorize the content.
product: a service that discovers and categorizes ML content from popular sources.alleviates: display categorized content for users to discover.advantages: when users visit our platform to stay up-to-date on ML content, they don't waste time searching for that content themselves in the noisy internet."},{"location":"courses/mlops/product-design/#objectives","title":"Objectives","text":"
Breakdown the product into key objectives that we want to focus on.
Our task
Describe the solution required to meet our objectives, including its:
core features: key features that will be developed.integration: how the product will integrate with other services.alternatives: alternative solutions that we should considered.constraints: limitations that we need to be aware of.out-of-scope.: features that we will not be developing for now.Our task
Develop a model that can classify the content so that it can be organized by category (tag) on our platform.
Core features:
Integrations:
Alternatives:
Constraints:
Out-of-scope:
natural-language-processing, computer-vision, mlops and other).How feasible is our solution and do we have the required resources to deliver it (data, $, team, etc.)?
Our task
We have a dataset with ML content that has been labeled. We'll need to assess if it has the necessary signals to meet our objectives.
Sample data point{\n\"id\": 443,\n\"created_on\": \"2020-04-10 17:51:39\",\n\"title\": \"AllenNLP Interpret\",\n\"description\": \"A Framework for Explaining Predictions of NLP Models\",\n\"tag\": \"natural-language-processing\"\n}\nNow that we've set up the product design requirements for our ML service, let's move on to the systems design requirements in the next lesson.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Product - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn this lesson, we'll discuss how to migrate and organize code from our notebook to Python scripts. We'll be using VSCode in this course, but feel free to use any editor you feel comfortable with.
Notebooks have been great so far for development. They're interactive, stateful (don't have to rerun code), and allow us to visualize outputs. However, when we want to a develop quality codebase, we need to move to scripts. Here are some reasons why:
stateless: when we run code in a notebook, it's automatically saved to the global state (memory). This is great for experimentation because code and variables will be readily available across different cells. However, this can be very problematic as well because there can be hidden state that we're not aware of. Scripts, on the other hand, are stateless and we have to explicitly pass variables to functions and classes.
linear: in notebooks, the order in which we execute cells matter. This can be problematic because we can easily execute cells out of order. Scripts, on the other hand, are linear and we have to explicitly execute code for each workload.
testing: As we'll see in our testing lesson, it's significantly easier to compose and run tests on scripts, as opposed to Jupyter notebooks. This is crucial for ensuring that we have quality code that works as expected.
We already have all the scripts provided in our repository so let's discuss how this was all organized.
"},{"location":"courses/mlops/scripting/#readme","title":"README","text":"It's always a good idea to start organizing our scripts with a README.md file. This is where we can organize all of the instructions necessary to walkthrough our codebase. Our README has information on how to set up our environment, how to run our scripts, etc.
The contents of the README.md file is what everyone will see when they visit your repository on GitHub. So, it's a good idea to keep it updated with the latest information.
Let's start by moving our code from notebooks to scripts. We're going to start by creating the different files and directories that we'll need for our project. The exact number and name of these scripts is entirely up to us, however, it's best to organize and choose names that relate to a specific workload. For example, data.py will have all of our data related functions and classes. And we can also have scripts for configurations (config.py), shared utilities (utils.py), etc.
madewithml/\n\u251c\u2500\u2500 config.py\n\u251c\u2500\u2500 data.py\n\u251c\u2500\u2500 evaluate.py\n\u251c\u2500\u2500 models.py\n\u251c\u2500\u2500 predict.py\n\u251c\u2500\u2500 serve.py\n\u251c\u2500\u2500 train.py\n\u251c\u2500\u2500 tune.py\n\u2514\u2500\u2500 utils.py\nDon't worry about the contents in these files that aren't from our notebooks just yet or if our code looks significantly more documented. We'll be taking a closer look at those in the respective lessons.
"},{"location":"courses/mlops/scripting/#functions-and-classes","title":"Functions and classes","text":"Once we have these ready, we can start moving code from our notebooks to the appropriate scripts. It should intuitive in which script a particular function or class belongs to. If not, we need to rethink how the names of our scripts. For example, train.py has functions from our notebook such as train_step, val_step, train_loop_per_worker, etc.
# madewithml/train.py\ndef train_step(...):\n pass\n\ndef val_step(...):\n pass\n\ndef train_loop_per_worker(...):\n pass\n\n...\nRecall that for training a model, we wrote code in our notebook for setting configurations, training, etc. that was freeform in a code cell:
# Scaling config\nscaling_config = ScalingConfig(\n num_workers=num_workers,\n use_gpu=bool(resources_per_worker[\"GPU\"]),\n resources_per_worker=resources_per_worker,\n _max_cpu_fraction_per_node=0.8,\n)\n\n# Checkpoint config\ncheckpoint_config = CheckpointConfig(\n num_to_keep=1,\n checkpoint_score_attribute=\"val_loss\",\n checkpoint_score_order=\"min\",\n)\n\n...\nThese code cells are not part of a function or class, so we need to wrap them around a function so that we can easily execute that workload. For example, all of this training logic is wrapped inside a train_model function in train.py that has all the required inputs to execute the workload:
# madewithml/train.py\ndef train_model(experiment_name, dataset_loc, ...):\n ...\n\n # Scaling config\n scaling_config = ScalingConfig(\n num_workers=num_workers,\n use_gpu=bool(gpu_per_worker),\n resources_per_worker={\"CPU\": cpu_per_worker, \"GPU\": gpu_per_worker},\n _max_cpu_fraction_per_node=0.8,\n )\n\n # Checkpoint config\n checkpoint_config = CheckpointConfig(\n num_to_keep=1,\n checkpoint_score_attribute=\"val_loss\",\n checkpoint_score_order=\"min\",\n )\n\n ...\nIn the next lesson on command-line interfaces (CLI), we'll learn how to execute these main workloads in our scripts from the command line.
"},{"location":"courses/mlops/scripting/#config","title":"Config","text":"In addition to our core workload scripts, recall that we also have a config.py script. This file will include all of the setup and configuration that all/most of our workloads depend on. For example, setting up our model registry:
# Config MLflow\nMODEL_REGISTRY = Path(\"/tmp/mlflow\")\nPath(MODEL_REGISTRY).mkdir(parents=True, exist_ok=True)\nMLFLOW_TRACKING_URI = \"file://\" + str(MODEL_REGISTRY.absolute())\nmlflow.set_tracking_uri(MLFLOW_TRACKING_URI)\nWe wouldn't have configurations like our ScalingConfig here because that's specific to our training workload. The config.py script is for configurations that are shared across different workloads.
Similarly, we also have a utils.py script to include components that will be reused across different scripts. It's a good idea to organize these shared components here as opposed to the core scripts to avoid circular dependency conflicts (two scripts call on functions from each other). Here is an example of one of our utility functions, set_seeds, that's used in both our train.py and tune.py scripts.
def set_seeds(seed: int = 42):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n eval(\"setattr(torch.backends.cudnn, 'deterministic', True)\")\n eval(\"setattr(torch.backends.cudnn, 'benchmark', False)\")\n os.environ[\"PYTHONHASHSEED\"] = str(seed)\nRecall in our setup lesson that we initialized Ray inside our notebooks. We still need to initialize Ray before executing our ML workloads via scripts but we can decide to do this only for the scripts with Ray dependent workloads. For example, at the bottom of our train.py script, we have:
# madewithml/train.py\nif __name__ == \"__main__\":\n if ray.is_initialized():\n ray.shutdown()\n ray.init()\n app() # initialize Typer app\nNow that we've set up our scripts, we can start executing them from the command line. In the next lesson, we'll learn how to do this with command-line interfaces (CLI).
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Scripting - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn this lesson, we're going to serve the machine learning models that we have developed so that we can use them to make predictions on unseen data. And we want to be able to serve our models in a scalable and robust manner so it can deliver high throughput (handle many requests) and low latency (quickly respond to each request). In an effort to be comprehensive, we will implement both batch inference (offline) and online inference (real-time), though we will focus on the latter in the remaining lessons as it's more appropriate for our application.
"},{"location":"courses/mlops/serving/#frameworks","title":"Frameworks","text":"There are many frameworks to choose from when it comes to model serving, such as Ray Serve, Nvidia Triton, HuggingFace, Bento ML, etc. When choosing between these frameworks, we want to choose the option that will allow us to:
To address all of these requirements (and more), we will be using Ray Serve to create our service. While we'll be specifically using it's integration with FastAPI, there are many other integrations you might want to explore based on your stack (LangChain, Kubernetes, etc.).
"},{"location":"courses/mlops/serving/#batch-inference","title":"Batch inference","text":"We will first implement batch inference (or offline inference), which is when we make predictions on a large batch of data. This is useful when we don't need to serve a model's prediction on input data as soon as the input data is received. For example, our service can be used to make predictions once at the end of every day on the batches of content collected throughout the day. This can be more efficient than making predictions on each content individually if we don't need that kind of low latency.
Let's take a look at our how we can easily implement batch inference with Ray Serve. We'll start with some setup and load the best checkpoint from our training run.
import ray.data\nfrom ray.train.torch import TorchPredictor\nfrom ray.data import ActorPoolStrategy\n# Load predictor\nrun_id = sorted_runs.iloc[0].run_id\nbest_checkpoint = get_best_checkpoint(run_id=run_id)\nNext, we'll define a Predictor class that will load the model from our checkpoint and then define the __call__ method that will be used to make predictions on our input data.
class Predictor:\n def __init__(self, checkpoint):\n self.predictor = TorchPredictor.from_checkpoint(checkpoint)\n def __call__(self, batch):\n z = self.predictor.predict(batch)[\"predictions\"]\n y_pred = np.stack(z).argmax(1)\n prediction = decode(y_pred, preprocessor.index_to_class)\n return {\"prediction\": prediction}\nThe __call__ function in Python defines the logic that will be executed when our object is called like a function.
predictor = Predictor()\nprediction = predictor(batch)\nTo do batch inference, we'll be using the map_batches functionality. We previously used map_batches to map (or apply) a preprocessing function across batches (chunks) of our data. We're now using the same concept to apply our predictor across batches of our inference data.
# Batch predict\npredictions = test_ds.map_batches(\n Predictor,\n batch_size=128,\n compute=ActorPoolStrategy(min_size=1, max_size=2), # scaling\n batch_format=\"pandas\",\n fn_constructor_kwargs={\"checkpoint\": best_checkpoint})\nNote that best_checkpoint as a keyword argument to our Predictor class so that we can load the model from that checkpoint. We can pass this in via the fn_constructor_kwargs argument in our map_batches function.
# Sample predictions\npredictions.take(3)\n\n[{'prediction': 'computer-vision'},\n {'prediction': 'other'},\n {'prediction': 'other'}]\n"},{"location":"courses/mlops/serving/#online-inference","title":"Online inference","text":"While we can achieve batch inference at scale, many models will need to be served in an real-time manner where we may need to deliver predictions for many incoming requests (high throughput) with low latency. We want to use online inference for our application over batch inference because we want to quickly categorize content as they are received/submitted to our platform so that the community can discover them quickly.
from fastapi import FastAPI\nfrom ray import serve\nimport requests\nfrom starlette.requests import Request\nWe'll start by defining our FastAPI application which involves initializing a predictor (and preprocessor) from the best checkpoint for a particular run (specified by run_id). We'll also define a predict function that will be used to make predictions on our input data.
# Define application\napp = FastAPI(\n title=\"Made With ML\",\n description=\"Classify machine learning projects.\",\n version=\"0.1\")\nclass ModelDeployment:\n\n def __init__(self, run_id):\n\"\"\"Initialize the model.\"\"\"\n self.run_id = run_id\n mlflow.set_tracking_uri(MLFLOW_TRACKING_URI) # so workers have access to model registry\n best_checkpoint = get_best_checkpoint(run_id=run_id)\n self.predictor = TorchPredictor.from_checkpoint(best_checkpoint)\n self.preprocessor = self.predictor.get_preprocessor()\n\n @app.post(\"/predict/\")\n async def _predict(self, request: Request):\n data = await request.json()\n df = pd.DataFrame([{\"title\": data.get(\"title\", \"\"), \"description\": data.get(\"description\", \"\"), \"tag\": \"\"}])\n results = predict_with_proba(df=df, predictor=self.predictor)\n return {\"results\": results}\nasync def refers to an asynchronous function (when we call the function we don't have to wait for the function to complete executing). The await keyword is used inside an asynchronous function to wait for the completion of the request.json() operation.
We can now combine our FastAPI application with Ray Serve by simply wrapping our application with the serve.ingress decorator. We can further wrap all of this with the serve.deployment decorator to define our deployment configuration (ex. number of replicas, compute resources, etc.). These configurations allow us to easily scale our service as needed.
@serve.deployment(route_prefix=\"/\", num_replicas=\"1\", ray_actor_options={\"num_cpus\": 8, \"num_gpus\": 0})\n@serve.ingress(app)\nclass ModelDeployment:\n pass\nNow let's run our service and perform some real-time inference.
# Run service\nsorted_runs = mlflow.search_runs(experiment_names=[experiment_name], order_by=[\"metrics.val_loss ASC\"])\nrun_id = sorted_runs.iloc[0].run_id\nserve.run(ModelDeployment.bind(run_id=run_id))\n\nStarted detached Serve instance in namespace \"serve\".\nDeployment 'default_ModelDeployment:IcuFap' is ready at `http://127.0.0.1:8000/`. component=serve deployment=default_ModelDeployment\nRayServeSyncHandle(deployment='default_ModelDeployment')\n
# Query\ntitle = \"Transfer learning with transformers\"\ndescription = \"Using transformers for transfer learning on text classification tasks.\"\njson_data = json.dumps({\"title\": title, \"description\": description})\nrequests.post(\"http://127.0.0.1:8000/predict/\", data=json_data).json()\n\n{'results': [{'prediction': 'natural-language-processing',\n 'probabilities': {'computer-vision': 0.00038025027606636286,\n 'mlops': 0.0003820903366431594,\n 'natural-language-processing': 0.9987919926643372,\n 'other': 0.00044562897528521717}}]}\n The issue with neural networks (and especially LLMs) is that they are notoriously overconfident. For every input, they will always make some prediction. And to account for this, we have an other class but that class only has projects that are not in our accepted tags but are still machine learning related nonetheless. Here's what happens when we input complete noise as our input:
# Query (noise)\ntitle = \" 65n7r5675\" # random noise\njson_data = json.dumps({\"title\": title, \"description\": \"\"})\nrequests.post(\"http://127.0.0.1:8000/predict/\", data=json_data).json()\n\n{'results': [{'prediction': 'natural-language-processing',\n 'probabilities': {'computer-vision': 0.11885979026556015,\n 'mlops': 0.09778415411710739,\n 'natural-language-processing': 0.6735526323318481,\n 'other': 0.1098034456372261}}]}\n Let's shutdown our service before we fixed this issue.
# Shutdown\nserve.shutdown()\nTo make our service a bit more robust, let's add some custom logic to predict the other class if the probability of the predicted class is below a certain threshold probability.
@serve.deployment(route_prefix=\"/\", num_replicas=\"1\", ray_actor_options={\"num_cpus\": 8, \"num_gpus\": 0})\n@serve.ingress(app)\nclass ModelDeploymentRobust:\n\n def __init__(self, run_id, threshold=0.9):\n\"\"\"Initialize the model.\"\"\"\n self.run_id = run_id\n self.threshold = threshold\n mlflow.set_tracking_uri(MLFLOW_TRACKING_URI) # so workers have access to model registry\n best_checkpoint = get_best_checkpoint(run_id=run_id)\n self.predictor = TorchPredictor.from_checkpoint(best_checkpoint)\n self.preprocessor = self.predictor.get_preprocessor()\n\n @app.post(\"/predict/\")\n async def _predict(self, request: Request):\n data = await request.json()\n df = pd.DataFrame([{\"title\": data.get(\"title\", \"\"), \"description\": data.get(\"description\", \"\"), \"tag\": \"\"}])\n results = predict_with_proba(df=df, predictor=self.predictor)\n\n # Apply custom logic\n for i, result in enumerate(results):\n pred = result[\"prediction\"]\n prob = result[\"probabilities\"]\n if prob[pred] < self.threshold:\n results[i][\"prediction\"] = \"other\"\n\n return {\"results\": results}\nTip
It's easier to incorporate custom logic instead of altering the model itself. This way, we won't have to collect new data. change the model's architecture or retrain it. This also makes it really easy to change the custom logic as our product specifications may change (clean separation of product and machine learning).
# Run service\nserve.run(ModelDeploymentRobust.bind(run_id=run_id, threshold=0.9))\n\nStarted detached Serve instance in namespace \"serve\".\nDeployment 'default_ModelDeploymentRobust:RTbrNg' is ready at `http://127.0.0.1:8000/`. component=serve deployment=default_ModelDeploymentRobust\nRayServeSyncHandle(deployment='default_ModelDeploymentRobust')\n
Now let's see how we perform on the same random noise with our custom logic incorporate into the service.
# Query (noise)\ntitle = \" 65n7r5675\" # random noise\njson_data = json.dumps({\"title\": title, \"description\": \"\"})\nrequests.post(\"http://127.0.0.1:8000/predict/\", data=json_data).json()\n\n{'results': [{'prediction': 'other',\n 'probabilities': {'computer-vision': 0.11885979026556015,\n 'mlops': 0.09778415411710739,\n 'natural-language-processing': 0.6735526323318481,\n 'other': 0.1098034456372261}}]}\n # Shutdown\nserve.shutdown()\nWe'll learn how to deploy our service to production in our Jobs and Services lesson a bit later.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Serving - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn this lesson, we'll setup the development environment that we'll be using in all of our lessons. We'll have instructions for both local laptop and remote scalable clusters (Anyscale). While everything will work locally on your laptop, you can sign up to join one of our upcoming live cohorts where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day \u2192 sign up here.
"},{"location":"courses/mlops/setup/#cluster","title":"Cluster","text":"We'll start with defining our cluster, which refers to a group of servers that come together to form one system. Our clusters will have a head node that manages the cluster and it will be connected to a set of worker nodes that will execute workloads for us. These clusters can be fixed in size or autoscale based on our application's compute needs, which makes them highly scalable and performant. We'll create our cluster by defining a compute configuration and an environment.
"},{"location":"courses/mlops/setup/#environment","title":"Environment","text":"We'll start by defining our cluster environment which will specify the software dependencies that we'll need for our workloads.
\ud83d\udcbb Local
Your personal laptop will need to have Python installed and we highly recommend using Python 3.10. You can use a tool like pyenv (mac) or pyenv-win (windows) to easily download and switch between Python versions.
pyenv install 3.10.11 # install\npyenv global 3.10.11 # set default\nOnce we have our Python version, we can create a virtual environment to install our dependencies. We'll download our Python dependencies after we clone our repository from git shortly.
mkdir madewithml\ncd madewithml\npython3 -m venv venv # create virtual environment\nsource venv/bin/activate # on Windows: venv\\Scripts\\activate\npython3 -m pip install --upgrade pip setuptools wheel\n\ud83d\ude80 Anyscale
Our cluster environment will be defined inside a cluster_env.yaml file. Here we specify some details around our base image (anyscale/ray:2.6.0-py310-cu118) that has our Python version, GPU dependencies, etc.
base_image: anyscale/ray:2.6.0-py310-cu118\nenv_vars: {}\ndebian_packages:\n- curl\n\npython:\npip_packages: []\nconda_packages: []\n\npost_build_cmds:\n- python3 -m pip install --upgrade pip setuptools wheel\n- python3 -m pip install -r https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/requirements.txt\nWe could specify any python packages inside pip_packages or conda_packages but we're going to use a requirements.txt file to load our dependencies under post_build_cmds.
Next, we'll define our compute configuration, which will specify our hardware dependencies (head and worker nodes) that we'll need for our workloads.
\ud83d\udcbb Local
Your personal laptop (single machine) will act as the cluster, where one CPU will be the head node and some of the remaining CPU will be the worker nodes (no GPUs required). All of the code in this course will work in any personal laptop though it will be slower than executing the same workloads on a larger cluster.
\ud83d\ude80 Anyscale
Our cluster compute will be defined inside a cluster_compute.yaml file. Here we specify some details around where our compute resources will come from (cloud computing platform like AWS), types of nodes and their counts, etc.
cloud: madewithml-us-east-2\nregion: us-east2\nhead_node_type:\nname: head_node_type\ninstance_type: m5.2xlarge # 8 CPU, 0 GPU, 32 GB RAM\nworker_node_types:\n- name: gpu_worker\ninstance_type: g4dn.xlarge # 4 CPU, 1 GPU, 16 GB RAM\nmin_workers: 0\nmax_workers: 1\n...\nOur worker nodes will be GPU-enabled so we can train our models faster and we set min_workers to 0 so that we can autoscale these workers only when they're needed (up to a maximum of max_workers). This will help us significantly reduce our compute costs without having to manage the infrastructure ourselves.
With our compute and environment defined, we're ready to create our cluster workspace. This is where we'll be developing our ML application on top of our compute, environment and storage.
\ud83d\udcbb Local
Your personal laptop will need to have an interactive development environment (IDE) installed, such as VS Code. For bash commands in this course, you're welcome to use the terminal on VSCode or a separate one.
\ud83d\ude80 Anyscale
We're going to launch an Anyscale Workspace to do all of our development in. Workspaces allow us to use development tools such as VSCode, Jupyter notebooks, web terminal, etc. on top of our cluster compute, environment and storage. This create an \"infinite laptop\" experience that feels like a local laptop experience but on a powerful, scalable cluster.
We have the option to create our Workspace using a CLI but we're going to create it using the web UI (you will receive the required credentials during the cohort). On the UI, we can fill in the following information:
- Workspace name: `madewithml`\n- Project: `madewithml`\n- Cluster environment name: `madewithml-cluster-env`\n# Toggle `Select from saved configurations`\n- Compute config: `madewithml-cluster-compute`\n- Click on the **Start** button to launch the Workspace\n
We have already saved created our Project, cluster environment and compute config so we can select them from the dropdowns but we could just as easily create new ones / update these using the CLI.
CLI method# Set credentials\nexport ANYSCALE_HOST=https://console.anyscale.com\nexport ANYSCALE_CLI_TOKEN=$YOUR_CLI_TOKEN # retrieved from Anyscale credentials page\n\n# Create project\nexport PROJECT_NAME=\"madewithml\"\nanyscale project create --name $PROJECT_NAME\n\n# Cluster environment\nexport CLUSTER_ENV_NAME=\"madewithml-cluster-env\"\nanyscale cluster-env build deploy/cluster_env.yaml --name $CLUSTER_ENV_NAME\n\n# Compute config\nexport CLUSTER_COMPUTE_NAME=\"madewithml-cluster-compute\"\nanyscale cluster-compute create deploy/cluster_compute.yaml --name $CLUSTER_COMPUTE_NAME\nWith our development workspace all set up, we're ready to start developing. We'll start by following these instructions to create a repository:
Made-With-MLAdd a README file (very important as this creates a main branch)Create repositoryNow we're ready to clone the Made With ML repository's contents from GitHub inside our madewithml directory.
export GITHUB_USERNAME=\"YOUR_GITHUB_UESRNAME\" # <-- CHANGE THIS to your username\ngit clone https://github.com/GokuMohandas/Made-With-ML.git .\ngit remote set-url origin https://github.com/$GITHUB_USERNAME/Made-With-ML.git\ngit checkout -b dev\nexport PYTHONPATH=$PYTHONPATH:$PWD # so we can import modules from our scripts\n\ud83d\udcbb Local
Recall that we created our virtual environment earlier but didn't actually load any Python dependencies yet. We'll clone our repository and then install the packages using the requirements.txt file.
python3 -m pip install -r requirements.txt\nCaution: make sure that we're installing our Python packages inside our virtual environment.
\ud83d\ude80 Anyscale
Our environment with the appropriate Python version and libraries is already all set for us through the cluster environment we used when setting up our Anyscale Workspace. But if we want to install additional Python packages as we develop, we need to do pip install with the --user flag inside our Workspaces (via terminal) to ensure that our head and all worker nodes receive the package. And then we should also add it to our requirements file so it becomes part of the cluster environment build process next time.
pip install --user <package_name>:<version>\nNow we're ready to launch our Jupyter notebook to interactively develop our ML application.
\ud83d\udcbb Local
We already installed jupyter through our requirements.txt file in the previous step, so we can just launch it.
jupyter lab notebooks/madewithml.ipynb\n\ud83d\ude80 Anyscale
Click on the Jupyter icon \u00a0\u00a0 at the top right corner of our Anyscale Workspace page and this will open up our JupyterLab instance in a new tab. Then navigate to the notebooks directory and open up the madewithml.ipynb notebook.
"},{"location":"courses/mlops/setup/#ray","title":"Ray","text":"
We'll be using Ray to scale and productionize our ML application. Ray consists of a core distributed runtime along with libraries for scaling ML workloads and has companies like OpenAI, Spotify, Netflix, Instacart, Doordash + many more using it to develop their ML applications. We're going to start by initializing Ray inside our notebooks:
import ray\n# Initialize Ray\nif ray.is_initialized():\n ray.shutdown()\nray.init()\nWe can also view our cluster resources to view the available compute resources:
ray.cluster_resources()\n\ud83d\udcbb Local
If you are running this on a local laptop (no GPU), use the CPU count from ray.cluster_resources() to set your resources. For example if your machine has 10 CPUs:
\n{'CPU': 10.0,\n 'object_store_memory': 2147483648.0,\n 'node:127.0.0.1': 1.0}\n num_workers = 6 # prefer to do a few less than total available CPU (1 for head node + 1 for background tasks)\nresources_per_worker={\"CPU\": 1, \"GPU\": 0}\n\ud83d\ude80 Anyscale
On our Anyscale Workspace, the ray.cluster_resources() command will produce:
\n{'CPU': 8.0,\n'node:internal_head': 1.0,\n'node:10.0.56.150': 1.0,\n'memory': 34359738368.0,\n'object_store_memory': 9492578304.0}\n These cluster resources only reflect our head node (1 m5.2xlarge). But recall earlier in our compute configuration that we also added g4dn.xlarge worker nodes (each has 1 GPU and 4 CPU) to our cluster. But because we set min_workers=0, our worker nodes will autoscale ( up to max_workers) as they're needed for specific workloads (ex. training). So we can set the # of workers and resources by worker based on this insight:
# Workers (1 g4dn.xlarge)\nnum_workers = 1\nresources_per_worker={\"CPU\": 3, \"GPU\": 1}\nHead on over to the next lesson, where we'll motivate the specific application that we're trying to build from a product and systems design perspective. And after that, we're ready to start developing!
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Setup - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nTo determine the efficacy of our models, we need to have an unbiased measuring approach. To do this, we split our dataset into training, validation, and testing data splits.
Here the model will have access to both inputs and outputs to optimize its internal weights.
Here the model will not use the outputs to optimize its weights but instead, we will use the performance to optimize training hyperparameters such as the learning rate, etc.
This is our best measure of how the model may behave on new, unseen data. Note that training stops when the performance improvement is not significant or any other stopping criteria that we may have specified.
Creating proper data splits
What are the criteria we should focus on to ensure proper data splits?
Show answertime-series)We need to clean our data first before splitting, at least for the features that splitting depends on. So the process is more like: preprocessing (global, cleaning) \u2192 splitting \u2192 preprocessing (local, transformations).
"},{"location":"courses/mlops/splitting/#naive-split","title":"Naive split","text":"We'll start by splitting our dataset into three data splits for training, validation and testing.
from sklearn.model_selection import train_test_split\n# Split sizes\ntrain_size = 0.7\nval_size = 0.15\ntest_size = 0.15\nFor our multi-class task (each input has one label), we want to ensure that each data split has similar class distributions. We can achieve this by specifying how to stratify the split by adding the stratify keyword argument.
# Split (train)\nX_train, X_, y_train, y_ = train_test_split(\n X, y, train_size=train_size, stratify=y)\nprint (f\"train: {len(X_train)} ({(len(X_train) / len(X)):.2f})\\n\"\n f\"remaining: {len(X_)} ({(len(X_) / len(X)):.2f})\")\n\ntrain: 668 (0.70)\nremaining: 287 (0.30)\n
# Split (test)\nX_val, X_test, y_val, y_test = train_test_split(\n X_, y_, train_size=0.5, stratify=y_)\nprint(f\"train: {len(X_train)} ({len(X_train)/len(X):.2f})\\n\"\n f\"val: {len(X_val)} ({len(X_val)/len(X):.2f})\\n\"\n f\"test: {len(X_test)} ({len(X_test)/len(X):.2f})\")\n\ntrain: 668 (0.70)\nval: 143 (0.15)\ntest: 144 (0.15)\n
# Get counts for each class\ncounts = {}\ncounts[\"train_counts\"] = {tag: label_encoder.decode(y_train).count(tag) for tag in label_encoder.classes}\ncounts[\"val_counts\"] = {tag: label_encoder.decode(y_val).count(tag) for tag in label_encoder.classes}\ncounts[\"test_counts\"] = {tag: label_encoder.decode(y_test).count(tag) for tag in label_encoder.classes}\n# View distributions\npd.DataFrame({\n \"train\": counts[\"train_counts\"],\n \"val\": counts[\"val_counts\"],\n \"test\": counts[\"test_counts\"]\n}).T.fillna(0)\nIt's hard to compare these because our train and test proportions are different. Let's see what the distribution looks like once we balance it out. What do we need to multiply our test ratio by so that we have the same amount as our train ratio?
\\[ \\alpha * N_{test} = N_{train} \\] \\[ \\alpha = \\frac{N_{train}}{N_{test}} \\]# Adjust counts across splits\nfor k in counts[\"val_counts\"].keys():\n counts[\"val_counts\"][k] = int(counts[\"val_counts\"][k] * \\\n (train_size/val_size))\nfor k in counts[\"test_counts\"].keys():\n counts[\"test_counts\"][k] = int(counts[\"test_counts\"][k] * \\\n (train_size/test_size))\ndist_df = pd.DataFrame({\n \"train\": counts[\"train_counts\"],\n \"val\": counts[\"val_counts\"],\n \"test\": counts[\"test_counts\"]\n}).T.fillna(0)\ndist_df\nWe can see how much deviance there is in our naive data splits by computing the standard deviation of each split's class counts from the mean (ideal split).
\\[ \\sigma = \\sqrt{\\frac{(x - \\bar{x})^2}{N}} \\]# Standard deviation\nnp.mean(np.std(dist_df.to_numpy(), axis=0))\n\n0.9851056877051131\n
# Split DataFrames\ntrain_df = pd.DataFrame({\"text\": X_train, \"tag\": label_encoder.decode(y_train)})\nval_df = pd.DataFrame({\"text\": X_val, \"tag\": label_encoder.decode(y_val)})\ntest_df = pd.DataFrame({\"text\": X_test, \"tag\": label_encoder.decode(y_test)})\ntrain_df.head()\nMulti-label classification
If we had a multi-label classification task, then we would've applied iterative stratification via the skmultilearn library, which essentially splits each input into subsets (where each label is considered individually) and then it distributes the samples starting with fewest \"positive\" samples and working up to the inputs that have the most labels.
from skmultilearn.model_selection import IterativeStratification\ndef iterative_train_test_split(X, y, train_size):\n\"\"\"Custom iterative train test split which\n 'maintains balanced representation with respect\n to order-th label combinations.'\n \"\"\"\n stratifier = IterativeStratification(\n n_splits=2, order=1, sample_distribution_per_fold=[1.0-train_size, train_size, ])\n train_indices, test_indices = next(stratifier.split(X, y))\n X_train, y_train = X[train_indices], y[train_indices]\n X_test, y_test = X[test_indices], y[test_indices]\n return X_train, X_test, y_train, y_test\nIterative stratification essentially creates splits while \"trying to maintain balanced representation with respect to order-th label combinations\". We used to an order=1 for our iterative split which means we cared about providing representative distribution of each tag across the splits. But we can account for higher-order label relationships as well where we may care about the distribution of label combinations.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Splitting a Dataset for Machine Learning - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nCode is read more often than it is written. -- Guido Van Rossum (author of Python)
When we write a piece of code, it's almost never the last time we see it or the last time it's edited. So we need to explain what's going on (via documentation) and make it easy to read. One of the easiest ways to make code more readable is to follow consistent style and formatting conventions. There are many options when it comes to Python style conventions to adhere to, but most are based on PEP8 conventions. Different teams follow different conventions and that's perfectly alright. The most important aspects are:
consistency: everyone follows the same standards.automation: formatting should be largely effortless after initial configuration.We will be using a very popular blend of style and formatting conventions that makes some very opinionated decisions on our behalf (with configurable options).
Black: an in-place reformatter that (mostly) adheres to PEP8.isort: sorts and formats import statements inside Python scripts.flake8: a code linter with stylistic conventions that adhere to PEP8.Before we can properly use these tools, we'll have to configure them because they may have some discrepancies amongst them since they follow slightly different conventions that extend from PEP8.
"},{"location":"courses/mlops/styling/#black","title":"Black","text":"To configure Black, we could just pass in options using the CLI method, but it's much cleaner to do this through our pyproject.toml file.
# Black formatting\n[tool.black]\nline-length = 150\ninclude = '\\.pyi?$'\nexclude = '''\n/(\n .eggs # exclude a few common directories in the\n | .git # root of the project\n | .hg\n | .mypy_cache\n | .tox\n | venv\n | _build\n | buck-out\n | build\n | dist\n )/\n'''\nHere we're telling Black what our maximum line length should and to include and exclude certain file extensions.
The pyproject.toml was created to establish a more human-readable configuration file that is meant to replace a setup.py or setup.cfg file and is increasingly adopted by many open-source libraries.
Next, we're going to configure isort in our pyproject.toml file (just below Black's configurations):
# iSort\n[tool.isort]\nprofile = \"black\"\nline_length = 79\nmulti_line_output = 3\ninclude_trailing_comma = true\nvirtual_env = \"venv\"\nThough there is a complete list of configuration options for isort, we've decided to set these explicitly so there are no conflicts with Black.
"},{"location":"courses/mlops/styling/#flake8","title":"flake8","text":"Lastly, we'll set up flake8 by also adding it's configuration details to out pyproject.toml file.
[tool.flake8]\nexclude = \"venv\"\nignore = [\"E501\", \"W503\", \"E226\"]\n# E501: Line too long\n# W503: Line break occurred before binary operator\n# E226: Missing white space around arithmetic operator\nHere we're including an ignore option to ignore certain flake8 rules so everything works with our Black and isort configurations. And besides defining configuration options here, which are applied globally, we can also choose to specifically ignore certain conventions on a line-by-line basis. Here is an example of how we utilize this:
# madewithml/config.py\nimport pretty_errors # NOQA: F401 (imported but unused)\nBy placing the # NOQA: <error-code> on a line, we're telling flake8 to do NO Quality Assurance for that particular error on this line.
To use these tools that we've configured, we have to execute them from the project directory:
black .\nflake8\nisort .\n\nblack .\nAll done! \u2728 \ud83c\udf70 \u2728\n9 files left unchanged.\nflake8\npython3 -m isort . isort .\nFixing ...\n
Take a look at your files to see all the changes that have been made!
the . signifies that the configuration file for that package is in the current directory
Remembering these three lines to style our code is a bit cumbersome so it's a good idea to create a Makefile. This file can be used to define a set of commands that can be executed with a single command. Here's what our Makefile looks like:
# Makefile\nSHELL = /bin/bash\n\n# Styling\n.PHONY: style\nstyle:\nblack .\n flake8\n python3 -m isort .\n pyupgrade\n\n# Cleaning\n.PHONY: clean\nclean: style\nfind . -type f -name \"*.DS_Store\" -ls -delete\n find . | grep -E \"(__pycache__|\\.pyc|\\.pyo)\" | xargs rm -rf\n find . | grep -E \".pytest_cache\" | xargs rm -rf\n find . | grep -E \".ipynb_checkpoints\" | xargs rm -rf\n rm -rf .coverage*\nNotice that the clean command depends on the style command (clean: style), which means that style will be executed first before clean is executed.
.PHONY
As the name suggests, a Makefile is typically used to make a file, where if a file with the name already exists, then the commands below won't be executed. But we're using it in a way where we want to execute some commands with a single alias. Therefore, the .PHONY: $FILENAME lines indicate that even if there is a file called $FILENAME, go ahead and execute the commands below anyway.
In the next lesson on pre-commit we'll learn how to automatically execute this formatting whenever we make changes to our code.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Styling - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn the previous lesson, we covered the product design process for our ML application. In this lesson, we'll cover the systems design process where we'll learn how to design the ML system that will address our product objectives.
"},{"location":"courses/mlops/systems-design/#template","title":"Template","text":"The template below is designed to guide machine learning product development. It involves both the product and systems design aspects of our application:
Product design (What & Why) \u2192 Systems design (How)
\ud83d\udc49 \u00a0 Download a PDF of the ML canvas to use for your own products \u2192 ml-canvas.pdf (right click the link and hit \"Save Link As...\")
"},{"location":"courses/mlops/systems-design/#systems-design","title":"Systems design","text":"How can we engineer our approach for building the product? We need to account for everything from data ingestion to model serving.
"},{"location":"courses/mlops/systems-design/#data","title":"Data","text":"Describe the training and production (batches/streams) sources of data.
id created_on title description tag 0 6 2020-02-20 06:43:18 Comparison between YOLO and RCNN on real world ... Bringing theory to experiment is cool. We can ... computer-vision 1 89 2020-03-20 18:17:31 Rethinking Batch Normalization in Transformers We found that NLP batch statistics exhibit large ... natural-language-processing 2 1274 2020-06-10 05:21:00 Getting Machine Learning to Production Machine learning is hard and there are a lot, a lot of ... mlops 4 19 2020-03-03 13:54:31 Diffusion to Vector Reference implementation of Diffusion2Vec ... otherOur task
Assumption Reality Reason All of our incoming data is only machine learning related (no spam). We would need a filter to remove spam content that's not ML related. To simplify our ML task, we will assume all the data is ML content.
"},{"location":"courses/mlops/systems-design/#labeling","title":"Labeling","text":"Describe the labeling process (ingestions, QA, etc.) and how we decided on the features and labels.
Our task
Labels: categories of machine learning (for simplification, we've restricted the label space to the following tags: natural-language-processing, computer-vision, mlops and other).
Features: text features (title and description) that describe the content.
Assumption Reality Reason Content can only belong to one category (multiclass). Content can belong to more than one category (multilabel). For simplicity and many libraries don't support or complicate multilabel scenarios.
"},{"location":"courses/mlops/systems-design/#metrics","title":"Metrics","text":"One of the hardest challenges with ML systems is tying our core objectives, many of which may be qualitative, with quantitative metrics that our model can optimize towards.
Our task
For our task, we want to have both high precision and recall, so we'll optimize for f1 score (weighted combination of precision and recall). We'll determine these metrics for the overall dataset, as well as specific classes or slices of data.
What are our priorities
How do we decide which metrics to prioritize?
Show answerIt entirely depends on the specific task. For example, in an email spam detector, precision is very important because it's better than we some spam then completely miss an important email. Overtime, we need to iterate on our solution so all evaluation metrics improve but it's important to know which one's we can't comprise on from the get-go.
"},{"location":"courses/mlops/systems-design/#evaluation","title":"Evaluation","text":"Once we have our metrics defined, we need to think about when and how we'll evaluate our model.
"},{"location":"courses/mlops/systems-design/#offline-evaluation","title":"Offline evaluation","text":"Offline evaluation requires a gold standard holdout dataset that we can use to benchmark all of our models.
Our task
We'll be using this holdout dataset for offline evaluation. We'll also be creating slices of data that we want to evaluate in isolation.
"},{"location":"courses/mlops/systems-design/#online-evaluation","title":"Online evaluation","text":"Online evaluation ensures that our model continues to perform well in production and can be performed using labels or, in the event we don't readily have labels, proxy signals.
Our task
It's important that we measure real-time performance before committing to replace our existing version of the system.
Not all releases have to be high stakes and external facing. We can always include internal releases, gather feedback and iterate until we\u2019re ready to increase the scope.
"},{"location":"courses/mlops/systems-design/#modeling","title":"Modeling","text":"While the specific methodology we employ can differ based on the problem, there are core principles we always want to follow:
Our task
Assumption Reality Reason Solution needs to involve ML due to unstructured data and ineffectiveness of rule-based systems for this task. An iterative approach where we start with simple rule-based solutions and slowly add complexity. This course is about responsibly delivering value with ML, so we'll jump to it right away.
Utility in starting simple
Some of the earlier, simpler, approaches may not deliver on a certain performance objective. What are some advantages of still starting simple?
Show answerOnce we have a model we're satisfied with, we need to think about whether we want to perform batch (offline) or real-time (online) inference.
"},{"location":"courses/mlops/systems-design/#batch-inference","title":"Batch inference","text":"We can use our models to make batch predictions on a finite set of inputs which are then written to a database for low latency inference. When a user or downstream service makes an inference request, cached results from the database are returned. In this scenario, our trained model can directly be loaded and used for inference in the code. It doesn't have to be served as a separate service.
Batch serving tasks
What are some tasks where batch serving is ideal?
Show answerRecommend content that existing users will like based on their viewing history. However, new users may just receive some generic recommendations based on their explicit interests until we process their history the next day. And even if we're not doing batch serving, it might still be useful to cache very popular sets of input features (ex. combination of explicit interests leads to certain recommended content) so that we can serve those predictions faster.
"},{"location":"courses/mlops/systems-design/#online-inference","title":"Online inference","text":"We can also serve real-time predictions where input features are fed to the model to retrieve predictions. In this scenario, our model will need to be served as a separate service (ex. api endpoint) that can handle incoming requests.
Online inference tasks
In our example task for batch inference above, how can online inference significantly improve content recommendations?
Show answerWith batch processing, we generate content recommendations for users offline using their history. These recommendations won't change until we process the batch the next day using the updated user features. But what is the user's taste significantly changes during the day (ex. user is searching for horror movies to watch). With real-time serving, we can use these recent features to recommend highly relevant content based on the immediate searches.
Our task
For our task, we'll be serving our model as a separate service to handle real-time requests. We want to be able to perform online inference so that we can quickly categorize ML content as they become available. However, we will also demonstrate how to do batch inference for the sake of completeness.
"},{"location":"courses/mlops/systems-design/#feedback","title":"Feedback","text":"How do we receive feedback on our system and incorporate it into the next iteration? This can involve both human-in-the-loop feedback as well as automatic feedback via monitoring, etc.
Our task
Always return to the value proposition
While it's important to iterate and optimize on our models, it's even more important to ensure that our ML systems are actually making an impact. We need to constantly engage with our users to iterate on why our ML system exists and how it can be made better.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Systems - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn this lesson, we'll learn how to test code, data and machine learning models to construct a machine learning system that we can reliably iterate on. Tests are a way for us to ensure that something works as intended. We're incentivized to implement tests and discover sources of error as early in the development cycle as possible so that we can decrease downstream costs and wasted time. Once we've designed our tests, we can automatically execute them every time we change or add to our codebase.
Tip
We highly recommend that you explore this lesson after completing the previous lessons since the topics (and code) are iteratively developed. We did, however, create the testing-ml repository for a quick overview with an interactive notebook.
"},{"location":"courses/mlops/testing/#types-of-tests","title":"Types of tests","text":"There are four majors types of tests which are utilized at different points in the development cycle:
Unit tests: tests on individual components that each have a single responsibility (ex. function that filters a list).Integration tests: tests on the combined functionality of individual components (ex. data processing).System tests: tests on the design of a system for expected outputs given inputs (ex. training, inference, etc.).Acceptance tests: tests to verify that requirements have been met, usually referred to as User Acceptance Testing (UAT).Regression tests: tests based on errors we've seen before to ensure new changes don't reintroduce them.While ML systems are probabilistic in nature, they are composed of many deterministic components that can be tested in a similar manner as traditional software systems. The distinction between testing ML systems begins when we move from testing code to testing the data and models.
There are many other types of functional and non-functional tests as well, such as smoke tests (quick health checks), performance tests (load, stress), security tests, etc. but we can generalize all of these under the system tests above.
"},{"location":"courses/mlops/testing/#how-should-we-test","title":"How should we test?","text":"The framework to use when composing tests is the Arrange Act Assert methodology.
Arrange: set up the different inputs to test on.Act: apply the inputs on the component we want to test.Assert: confirm that we received the expected output.Cleaning is an unofficial fourth step to this methodology because it's important to not leave remnants of a previous test which may affect subsequent tests. We can use packages such as pytest-randomly to test against state dependency by executing tests randomly.
In Python, there are many tools, such as unittest, pytest, etc. that allow us to easily implement our tests while adhering to the Arrange Act Assert framework. These tools come with powerful built-in functionality such as parametrization, filters, and more, to test many conditions at scale.
"},{"location":"courses/mlops/testing/#what-should-we-test","title":"What should we test?","text":"When arranging our inputs and asserting our expected outputs, what are some aspects of our inputs and outputs that we should be testing for?
\ud83d\udc49 \u00a0We'll cover specific details pertaining to what to test for regarding our data and models below.
"},{"location":"courses/mlops/testing/#best-practices","title":"Best practices","text":"Regardless of the framework we use, it's important to strongly tie testing into the development process.
atomic: when creating functions and classes, we need to ensure that they have a single responsibility so that we can easily test them. If not, we'll need to split them into more granular components.compose: when we create new components, we want to compose tests to validate their functionality. It's a great way to ensure reliability and catch errors early on.reuse: we should maintain central repositories where core functionality is tested at the source and reused across many projects. This significantly reduces testing efforts for each new project's code base.regression: we want to account for new errors we come across with a regression test so we can ensure we don't reintroduce the same errors in the future.coverage: we want to ensure 100% coverage for our codebase. This doesn't mean writing a test for every single line of code but rather accounting for every single line.automate: in the event we forget to run our tests before committing to a repository, we want to auto run tests when we make changes to our codebase. We'll learn how to do this locally using pre-commit hooks and remotely via GitHub actions in subsequent lessons.In our codebase, we'll be testing the code, data and models.
tests/\n\u251c\u2500\u2500 code/\n\u2502 \u251c\u2500\u2500 conftest.py\n\u2502 \u251c\u2500\u2500 test_data.py\n\u2502 \u251c\u2500\u2500 test_predict.py\n\u2502 \u251c\u2500\u2500 test_train.py\n\u2502 \u251c\u2500\u2500 test_tune.py\n\u2502 \u251c\u2500\u2500 test_utils.py\n\u2502 \u2514\u2500\u2500 utils.py\n\u251c\u2500\u2500 data/\n\u2502 \u251c\u2500\u2500 conftest.py\n\u2502 \u2514\u2500\u2500 test_dataset.py\n\u2514\u2500\u2500 models/\n\u2502 \u251c\u2500\u2500 conftest.py\n\u2502 \u2514\u2500\u2500 test_behavioral.py\nNote that we aren't testing evaluate.py and serve.py because it involves complicated testing that's based on the data and models. We'll be testing these components as part of our integration tests when we test our system end-to-end.
We'll start by testing our code and we'll use pytest as our testing framework for it's powerful builtin features such as parametrization, fixtures, markers and more.
"},{"location":"courses/mlops/testing/#configuration","title":"Configuration","text":"Pytest expects tests to be organized under a tests directory by default. However, we can also add to our existing pyproject.toml file to configure any other test directories as well. Once in the directory, pytest looks for python scripts starting with tests_*.py but we can configure it to read any other file patterns as well.
# Pytest\n[tool.pytest.ini_options]\ntestpaths = [\"tests\"]\npython_files = \"test_*.py\"\nLet's see what a sample test and it's results look like. Assume we have a simple function that decodes a list of indices into their respective classes using a dictionary mapping.
# madewithml/predict.py\ndef decode(indices: Iterable[Any], index_to_class: Dict) -> List:\n return [index_to_class[index] for index in indices]\nTo test this function, we can use assert statements to map inputs with expected outputs. The statement following the word assert must return True.
# tests/code/test_predict.py\ndef test_decode():\ndecoded = predict.decode(\n indices=[0, 1, 1],\n index_to_class={0: \"x\", 1: \"y\"})\nassert decoded == [\"x\", \"y\", \"y\"]\nWe can also have assertions about exceptions like we do in lines 6-8 where all the operations under the with statement are expected to raise the specified exception.
"},{"location":"courses/mlops/testing/#execution","title":"Execution","text":"We can execute our tests above using several different levels of granularity:
python3 -m pytest # all tests\npython3 -m pytest tests/code # tests under a directory\npython3 -m pytest tests/code/test_predict.py # tests for a single file\npython3 -m pytest tests/code/test_predict.py::test_decode # tests for a single function\nRunning our specific test above would produce the following output:
python3 -m pytest tests/code/test_predict.py::test_decode --verbose --disable-warnings\n\ntests/code/test_predict.py::test_decode PASSED [100%]\n
Had any of our assertions in this test failed, we would see the failed assertions, along with the expected and actual output from our function.
\ntests/code/test_predict.py::test_decode FAILED [100%]\n\n def test_decode():\n decoded = predict.decode(\n indices=[0, 1, 1],\n index_to_class={0: \"x\", 1: \"y\"})\n> assert decoded == [\"x\", \"x\", \"y\"]\nE AssertionError: assert ['x', 'y', 'y'] == ['x', 'x', 'y']\nE At index 1 diff: 'y' != 'x'\n Tip
It's important to test for the variety of inputs and expected outputs that we outlined above and to never assume that a test is trivial. In our example above, it's important that we test for both \"apple\" and \"Apple\" in the event that our function didn't account for casing!
"},{"location":"courses/mlops/testing/#classes","title":"Classes","text":"We can also test classes and their respective functions.
def test_fit_transform():\n preprocessor = data.CustomPreprocessor()\n ds = data.load_data(dataset_loc=\"...\")\n preprocessor.fit_transform(ds)\n assert len(preprocessor.class_to_index) == 4\nThere are also more xunit-style testing options available as well for more involved testing with classes.
"},{"location":"courses/mlops/testing/#parametrize","title":"Parametrize","text":"So far, in our tests, we've had to create individual assert statements to validate different combinations of inputs and expected outputs. However, there's a bit of redundancy here because the inputs always feed into our functions as arguments and the outputs are compared with our expected outputs. To remove this redundancy, pytest has the @pytest.mark.parametrize decorator which allows us to represent our inputs and outputs as parameters.
@pytest.mark.parametrize(\n \"text, sw, clean_text\",\n [\n (\"hi\", [], \"hi\"),\n (\"hi you\", [\"you\"], \"hi\"),\n (\"hi yous\", [\"you\"], \"hi yous\"),\n ],\n)\ndef test_clean_text(text, sw, clean_text):\n assert data.clean_text(text=text, stopwords=sw) == clean_text\n[Line 2]: define the names of the parameters under the decorator, ex. \"fruit, crisp\" (note that this is one string).[Lines 3-7]: provide a list of combinations of values for the parameters from Step 1.[Line 9]: pass in parameter names to the test function.[Line 10]: include necessary assert statements which will be executed for each of the combinations in the list from Step 2.Similarly, we could pass in an exception as the expected result as well:
@pytest.mark.parametrize(\n \"x, exception\",\n [\n (1, ValueError),\n ],\n)\ndef test_foo(x, exception):\n with pytest.raises(exception):\n foo(x=x)\nParametrization allows us to reduce redundancy inside test functions but what about reducing redundancy across different test functions? For example, suppose that different test functions all have a common component (ex. preprocessor). Here, we can use pytest's builtin fixture, which is a function that is executed before the test function. Let's rewrite our test_fit_transform function from above using a fixture:
def test_fit_transform(dataset_loc, preprocessor):\n ds = data.load_data(dataset_loc=dataset_loc)\n preprocessor.fit_transform(ds)\n assert len(preprocessor.class_to_index) == 4\nwhere dataset_loc and preprocessor are fixtures defined in our tests/code/conftest.py script:
# tests/code/conftest.py\nimport pytest\nfrom madewithml.data import CustomPreprocessor\n\n@pytest.fixture\ndef dataset_loc():\n return \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\n\n@pytest.fixture\ndef preprocessor():\n return CustomPreprocessor()\nAll of our test scripts know to look inside a conftest.py script in the same directory for any fixtures. Note that the name of the fixture and the input argument to our function have to be the same.
Fixture scopes
Fixtures can have different scopes depending on how we want to use them. For example our df fixture has the module scope because we don't want to keep recreating it after every test but, instead, we want to create it just once for all the tests in our module (tests/test_data.py).
function: fixture is destroyed after every test. [default]class: fixture is destroyed after the last test in the class.module: fixture is destroyed after the last test in the module (script).package: fixture is destroyed after the last test in the package.session: fixture is destroyed after the last test of the session.We've been able to execute our tests at various levels of granularity (all tests, script, function, etc.) but we can create custom granularity by using markers. We've already used one type of marker (parametrize) but there are several other builtin markers as well. For example, the skipif marker allows us to skip execution of a test if a condition is met. For example, supposed we only wanted to test training our model if a GPU is available:
@pytest.mark.skipif(\n not torch.cuda.is_available(),\n reason=\"Full training tests require a GPU.\"\n)\ndef test_training():\n pass\nWe can also create our own custom markers with the exception of a few reserved marker names.
@pytest.mark.training\ndef test_train_model(dataset_loc):\n pass\nWe can execute them by using the -m flag which requires a (case-sensitive) marker expression like below:
pytest -m \"training\" # runs all tests marked with `training`\npytest -m \"not training\" # runs all tests besides those marked with `training`\nTip
The proper way to use markers is to explicitly list the ones we've created in our pyproject.toml file. Here we can specify that all markers must be defined in this file with the --strict-markers flag and then declare our markers (with some info about them) in our markers list:
@pytest.mark.training\ndef test_train_model():\n assert ...\n# Pytest\n[tool.pytest.ini_options]\ntestpaths = [\"tests\"]\npython_files = \"test_*.py\"\naddopts = \"--strict-markers --disable-pytest-warnings\"\nmarkers = [\n\"training: tests that involve training\",\n]\npytest --markers and we'll receive an error when we're trying to use a new marker that's not defined here."},{"location":"courses/mlops/testing/#coverage","title":"Coverage","text":"As we're developing tests for our application's components, it's important to know how well we're covering our code base and to know if we've missed anything. We can use the Coverage library to track and visualize how much of our codebase our tests account for. With pytest, it's even easier to use this package thanks to the pytest-cov plugin.
python3 -m pytest tests/code --cov madewithml --cov-report html --disable-warnings\nHere we're asking to run all tests under tests/code and to check for coverage for all the code in our madewithml directory. When we run this, we'll see the tests from our tests directory executing while the coverage plugin is keeping tracking of which lines in our application are being executed. Once our tests are done, we can view the generated report either through the terminal:
coverage report -m\n\nName Stmts Miss Cover Missing\n-----------------------------------------------------\nmadewithml/config.py 16 0 100%\nmadewithml/data.py 51 0 100%\nmadewithml/models.py 2 0 100%\nmadewithml/predict.py 23 0 100%\nmadewithml/train.py 45 0 100%\nmadewithml/tune.py 51 0 100%\nmadewithml/utils.py 39 0 100%\n-----------------------------------------------------\nTOTAL 227 0 100%\n
but a more interactive way is to view it through the htmlcov/index.html on a browser. Here we can click on individual files to see which parts were not covered by any tests.
Warning
Though we have 100% coverage, this does not mean that our application is perfect. Coverage only indicates that a piece of code executed in a test, not necessarily that every part of it was tested, let alone thoroughly tested. Therefore, coverage should never be used as a representation of correctness. However, it is very useful to maintain coverage at 100% so we can know when new functionality has yet to be tested. In our CI/CD lesson, we'll see how to use GitHub actions to make 100% coverage a requirement when pushing to specific branches.
"},{"location":"courses/mlops/testing/#exclusions","title":"Exclusions","text":"Sometimes it doesn't make sense to write tests to cover every single line in our application yet we still want to account for these lines so we can maintain 100% coverage. We have two levels of purview when applying exclusions:
Excusing lines by adding this comment # pragma: no cover, <MESSAGE>
if results_fp: # pragma: no cover, saving results\n utils.save_dict(d, results_fp)\nExcluding files by specifying them in our pyproject.toml configuration:
# Pytest cov\n[tool.coverage.run]\nomit=[\"madewithml/evaluate.py\", \"madewithml/serve.py\"]\nThe main point is that we were able to add justification to these exclusions through comments so our team can follow our reasoning.
Now that we have a foundation for testing traditional software, let's dive into testing our data and models in the context of machine learning systems.
"},{"location":"courses/mlops/testing/#data","title":"\ud83d\udd22\u00a0 Data","text":"So far, we've used unit and integration tests to test the functions that interact with our data but we haven't tested the validity of the data itself. We're going to use the great expectations library to test what our data is expected to look like. It's a library that allows us to create expectations as to what our data should look like in a standardized way. It also provides modules to seamlessly connect with backend data sources such as local file systems, S3, databases, etc. Let's explore the library by implementing the expectations we'll need for our application.
\ud83d\udc49 \u00a0 Follow along interactive notebook in the testing-ml repository as we implement the concepts below.
First we'll load the data we'd like to apply our expectations on. We can load our data from a variety of sources (filesystem, database, cloud etc.) which we can then wrap around a Dataset module (Pandas / Spark DataFrame, SQLAlchemy). Since multiple data tests may want access to this data, we'll create a fixture for it.
# tests/data/conftest.py\nimport great_expectations as ge\nimport pandas as pd\nimport pytest\n\n@pytest.fixture(scope=\"module\")\ndef df(request):\n dataset_loc = request.config.getoption(\"--dataset-loc\")\n df = ge.dataset.PandasDataset(pd.read_csv(dataset_loc))\n return df\nWhen it comes to creating expectations as to what our data should look like, we want to think about our entire dataset and all the features (columns) within it.
column_list = [\"id\", \"created_on\", \"title\", \"description\", \"tag\"]\ndf.expect_table_columns_to_match_ordered_list(column_list=column_list) # schema adherence\ntags = [\"computer-vision\", \"natural-language-processing\", \"mlops\", \"other\"]\ndf.expect_column_values_to_be_in_set(column=\"tag\", value_set=tags) # expected labels\ndf.expect_compound_columns_to_be_unique(column_list=[\"title\", \"description\"]) # data leaks\ndf.expect_column_values_to_not_be_null(column=\"tag\") # missing values\ndf.expect_column_values_to_be_unique(column=\"id\") # unique values\ndf.expect_column_values_to_be_of_type(column=\"title\", type_=\"str\") # type adherence\nEach of these expectations will create an output with details about success or failure, expected and observed values, expectations raised, etc. For example, the expectation df.expect_column_values_to_be_of_type(column=\"title\", type_=\"str\") would produce the following if successful:
{\n\"exception_info\": {\n\"raised_exception\": false,\n\"exception_traceback\": null,\n\"exception_message\": null\n},\n\"success\": true,\n\"meta\": {},\n\"expectation_config\": {\n\"kwargs\": {\n\"column\": \"title\",\n\"type_\": \"str\",\n\"result_format\": \"BASIC\"\n},\n\"meta\": {},\n\"expectation_type\": \"_expect_column_values_to_be_of_type__map\"\n},\n\"result\": {\n\"element_count\": 955,\n\"missing_count\": 0,\n\"missing_percent\": 0.0,\n\"unexpected_count\": 0,\n\"unexpected_percent\": 0.0,\n\"unexpected_percent_nonmissing\": 0.0,\n\"partial_unexpected_list\": []\n}\n}\nand if we have a failed expectation (ex. df.expect_column_values_to_be_of_type(column=\"title\", type_=\"int\")), we'd receive this output(notice the counts and examples for what caused the failure):
{\n\"success\": false,\n\"exception_info\": {\n\"raised_exception\": false,\n\"exception_traceback\": null,\n\"exception_message\": null\n},\n\"expectation_config\": {\n\"meta\": {},\n\"kwargs\": {\n\"column\": \"title\",\n\"type_\": \"int\",\n\"result_format\": \"BASIC\"\n},\n\"expectation_type\": \"_expect_column_values_to_be_of_type__map\"\n},\n\"result\": {\n\"element_count\": 955,\n\"missing_count\": 0,\n\"missing_percent\": 0.0,\n\"unexpected_count\": 955,\n\"unexpected_percent\": 100.0,\n\"unexpected_percent_nonmissing\": 100.0,\n\"partial_unexpected_list\": [\n\"How to Deal with Files in Google Colab: What You Need to Know\",\n\"Machine Learning Methods Explained (+ Examples)\",\n\"OpenMMLab Computer Vision\",\n\"...\",\n]\n},\n\"meta\": {}\n}\nThere are just a few of the different expectations that we can create. Be sure to explore all the expectations, including custom expectations. Here are some other popular expectations that don't pertain to our specific dataset but are widely applicable:
expect_column_pair_values_a_to_be_greater_than_bexpect_column_mean_to_be_betweenInstead of running each of these individually, we can combine them all into an expectation suite.
# tests/data/test_dataset.py\ndef test_dataset(df):\n\"\"\"Test dataset quality and integrity.\"\"\"\n column_list = [\"id\", \"created_on\", \"title\", \"description\", \"tag\"]\n df.expect_table_columns_to_match_ordered_list(column_list=column_list) # schema adherence\n tags = [\"computer-vision\", \"natural-language-processing\", \"mlops\", \"other\"]\n df.expect_column_values_to_be_in_set(column=\"tag\", value_set=tags) # expected labels\n df.expect_compound_columns_to_be_unique(column_list=[\"title\", \"description\"]) # data leaks\n df.expect_column_values_to_not_be_null(column=\"tag\") # missing values\n df.expect_column_values_to_be_unique(column=\"id\") # unique values\n df.expect_column_values_to_be_of_type(column=\"title\", type_=\"str\") # type adherence\n\n # Expectation suite\nexpectation_suite = df.get_expectation_suite(discard_failed_expectations=False)\nresults = df.validate(expectation_suite=expectation_suite, only_return_failures=True).to_json_dict()\nassert results[\"success\"]\nWe can now execute these data tests just like a code test.
export DATASET_LOC=\"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\npytest --dataset-loc=$DATASET_LOC tests/data --verbose --disable-warnings\nNote
We've added a --dataset-loc flag to pytest by specifying in our tests/data/conftest.py script. This allows us to pass in the dataset location as an argument to our tests.
# tests/data/conftest.py\ndef pytest_addoption(parser):\n parser.addoption(\"--dataset-loc\", action=\"store\", default=None, help=\"Dataset location.\")\nWe're keeping things simple by using our expectations with pytest but Great expectations also has a lot more functionality around connecting to data sources, Checkpoints to execute suites across various parts of the pipeline, data docs to generate reports, etc.
"},{"location":"courses/mlops/testing/#production","title":"Production","text":"While we're validating our datasets inside our machine learning applications, in most production scenarios, the data validation happens much further upstream. Our dataset may not be used just for our specific application and may actually be feeding into many other downstream application (ML and otherwise). Therefore, it's a great idea to execute these data validation tests as up stream as possible so that downstream applications can reliably use the data.
Learn more about different data systems in our data engineering lesson if you're not familiar with them.
"},{"location":"courses/mlops/testing/#models","title":"\ud83e\udd16\u00a0 Models","text":"The final aspect of testing ML systems involves how to test machine learning models during training, evaluation, inference and deployment.
"},{"location":"courses/mlops/testing/#training","title":"Training","text":"We want to write tests iteratively while we're developing our training pipelines so we can catch errors quickly. This is especially important because, unlike traditional software, ML systems can run to completion without throwing any exceptions / errors but can produce incorrect systems. We also want to catch errors quickly to save on time and compute.
assert model(inputs).shape == torch.Size([len(inputs), num_classes])\nassert epoch_loss < prev_epoch_loss\naccuracy = train(model, inputs=batches[0])\nassert accuracy == pytest.approx(0.95, abs=0.05) # 0.95 \u00b1 0.05\ntrain(model)\nassert learning_rate >= min_learning_rate\nassert artifacts\nassert train(model, device=torch.device(\"cpu\"))\nassert train(model, device=torch.device(\"cuda\"))\nNote
You can mark the compute intensive tests with a pytest marker and only execute them when there is a change being made to system affecting the model.
@pytest.mark.training\ndef test_train_model():\n ...\nBehavioral testing is the process of testing input data and expected outputs while treating the model as a black box (model agnostic evaluation). They don't necessarily have to be adversarial in nature but more along the types of perturbations we may expect to see in the real world once our model is deployed. A landmark paper on this topic is Beyond Accuracy: Behavioral Testing of NLP Models with CheckList which breaks down behavioral testing into three types of tests:
invariance: Changes should not affect outputs. # INVariance via verb injection (changes should not affect outputs)\nget_label(text=\"Transformers applied to NLP have revolutionized machine learning.\", predictor=predictor)\nget_label(text=\"Transformers applied to NLP have disrupted machine learning.\", predictor=predictor)\n\n'natural-language-processing'\n'natural-language-processing'\n
directional: Change should affect outputs. # DIRectional expectations (changes with known outputs)\nget_label(text=\"ML applied to text classification.\", predictor=predictor)\nget_label(text=\"ML applied to image classification.\", predictor=predictor)\nget_label(text=\"CNNs for text classification.\", predictor=predictor)\n\n'natural-language-processing'\n'computer-vision'\n'natural-language-processing'\n
minimum functionality: Simple combination of inputs and expected outputs. # Minimum Functionality Tests (simple input/output pairs)\nget_label(text=\"Natural language processing is the next big wave in machine learning.\", predictor=predictor)\nget_label(text=\"MLOps is the next big wave in machine learning.\", predictor=predictor)\nget_label(text=\"This is about graph neural networks.\", predictor=predictor)\n\n'natural-language-processing'\n'mlops'\n'other'\n
And we can convert these tests into proper parameterized tests by first defining from fixtures in our tests/model/conftest.py and our tests/model/utils.py scripts:
# tests/model/conftest.py\nimport pytest\nfrom ray.train.torch.torch_predictor import TorchPredictor\nfrom madewithml import predict\n\ndef pytest_addoption(parser):\n parser.addoption(\"--run-id\", action=\"store\", default=None, help=\"Run ID of model to use.\")\n\n\n@pytest.fixture(scope=\"module\")\ndef run_id(request):\n return request.config.getoption(\"--run-id\")\n\n\n@pytest.fixture(scope=\"module\")\ndef predictor(run_id):\n best_checkpoint = predict.get_best_checkpoint(run_id=run_id)\n predictor = TorchPredictor.from_checkpoint(best_checkpoint)\n return predictor\n# tests/model/utils.py\nimport numpy as np\nimport pandas as pd\nfrom madewithml import predict\n\ndef get_label(text, predictor):\n df = pd.DataFrame({\"title\": [text], \"description\": \"\", \"tag\": \"other\"})\n z = predictor.predict(data=df)[\"predictions\"]\n preprocessor = predictor.get_preprocessor()\n label = predict.decode(np.stack(z).argmax(1), preprocessor.index_to_class)[0]\n return label\nAnd now, we can use these components to create our behavioral tests:
# tests/model/test_behavioral.py\n@pytest.mark.parametrize(\n \"input_a, input_b, label\",\n [\n (\n \"Transformers applied to NLP have revolutionized machine learning.\",\n \"Transformers applied to NLP have disrupted machine learning.\",\n \"natural-language-processing\",\n ),\n ],\n)\ndef test_invariance(input_a, input_b, label, predictor):\n\"\"\"INVariance via verb injection (changes should not affect outputs).\"\"\"\n label_a = utils.get_label(text=input_a, predictor=predictor)\n label_b = utils.get_label(text=input_b, predictor=predictor)\n assert label_a == label_b == label\n# tests/model/test_behavioral.py\n@pytest.mark.parametrize(\n \"input, label\",\n [\n (\n \"ML applied to text classification.\",\n \"natural-language-processing\",\n ),\n (\n \"ML applied to image classification.\",\n \"computer-vision\",\n ),\n (\n \"CNNs for text classification.\",\n \"natural-language-processing\",\n ),\n ],\n)\ndef test_directional(input, label, predictor):\n\"\"\"DIRectional expectations (changes with known outputs).\"\"\"\n prediction = utils.get_label(text=input, predictor=predictor)\n assert label == prediction\n# tests/model/test_behavioral.py\n@pytest.mark.parametrize(\n \"input, label\",\n [\n (\n \"Natural language processing is the next big wave in machine learning.\",\n \"natural-language-processing\",\n ),\n (\n \"MLOps is the next big wave in machine learning.\",\n \"mlops\",\n ),\n (\n \"This is about graph neural networks.\",\n \"other\",\n ),\n ],\n)\ndef test_mft(input, label, predictor):\n\"\"\"Minimum Functionality Tests (simple input/output pairs).\"\"\"\n prediction = utils.get_label(text=input, predictor=predictor)\n assert label == prediction\nAnd we can execute them just like any other test:
# Model tests\nexport EXPERIMENT_NAME=\"llm\"\nexport RUN_ID=$(python madewithml/predict.py get-best-run-id --experiment-name $EXPERIMENT_NAME --metric val_loss --mode ASC)\npytest --run-id=$RUN_ID tests/model --verbose --disable-warnings\nWe'll conclude by talking about the similarities and distinctions between testing and monitoring. They're both integral parts of the ML development pipeline and depend on each other for iteration. Testing is assuring that our system (code, data and models) passes the expectations that we've established offline. Whereas, monitoring involves that these expectations continue to pass online on live production data while also ensuring that their data distributions are comparable to the reference window (typically subset of training data) through \\(t_n\\). When these conditions no longer hold true, we need to inspect more closely (retraining may not always fix our root problem).
With monitoring, there are quite a few distinct concerns that we didn't have to consider during testing since it involves (live) data we have yet to see.
We'll cover all of these concepts in much more depth (and code) in our monitoring lesson.
"},{"location":"courses/mlops/testing/#resources","title":"Resources","text":"Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Code - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nNow that we have our data prepared, we can start training our models to optimize on our objective. Ideally, we would start with the simplest possible baseline and slowly add complexity to our models:
Since we have four classes, we may expect a random model to be correct around 25% of the time but recall that not all of our classes have equal counts.
We could build a list of common words for each class and if a word in the input matches a word in the list, we can predict that class.
We could start with a simple term frequency (TF-IDF) mode and then move onto embeddings with CNNs, RNNs, Transformers, etc.
We're going to skip straight to step 3 of developing a complex model because this task involves unstructured data and rule-based systems are not well suited for this. And with the increase adoption of large language models (LLMs) as a proven model architecture for NLP tasks, we'll fine-tune a pretrained LLM on our dataset.
Iterate on the data
Instead of using a fixed dataset and iterating on the models, we could keep the model constant and iterate on the dataset. This is useful to improve the quality of our datasets.
With the rapid increase in data (unstructured) and model sizes (ex. LLMs), it's becoming increasingly difficult to train models on a single machine. We need to be able to distribute our training across multiple machines in order to train our models in a reasonable amount of time. And we want to be able to do this without having to:
To address all of these concerns, we'll be using Ray Train here in order to create a training workflow that can scale across multiple machines. While there are many options to choose from for distributed training, such as Pytorch Distributed Data Parallel (DDP), Horovod, etc., none of them allow us to scale across different machines with ease and do so with minimal changes to our single-machine training code as Ray does.
Primer on distributed training
With distributed training, there will be a head node that's responsible for orchestrating the training process. While the worker nodes that will be responsible for training the model and communicating results back to the head node. From a user's perspective, Ray abstracts away all of this complexity and we can simply define our training functionality with minimal changes to our code (as if we were training on a single machine).
"},{"location":"courses/mlops/training/#generative-ai","title":"Generative AI","text":"In this lesson, we're going to be fine-tuning a pretrained large language model (LLM) using our labeled dataset. The specific class of LLMs we'll be using is called BERT. Bert models are encoder-only models and are the gold-standard for supervised NLP tasks. However, you may be wondering how do all the (much larger) LLM, created for generative applications, fare (GPT 4, Falcon 40B, Llama 2, etc.)?
We chose the smaller BERT model for our course because it's easier to train and fine-tune. However, the workflow for fine-tuning the larger LLMs are quite similar as well. They do require much more compute but Ray abstracts away the scaling complexities involved with that.
Note
All the code for this section can be found in our separate benchmarks.ipynb notebook.
"},{"location":"courses/mlops/training/#set-up","title":"Set up","text":"You'll need to first sign up for an OpenAI account and then grab your API key from here.
import openai\nopenai.api_key = \"YOUR_API_KEY\"\nWe'll first load the our training and inference data into dataframes.
import pandas as pd\n# Load training data\nDATASET_LOC = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/dataset.csv\"\ntrain_df = pd.read_csv(DATASET_LOC)\ntrain_df.head()\n# Unique labels\ntags = train_df.tag.unique().tolist()\ntags\n\n['computer-vision', 'other', 'natural-language-processing', 'mlops']\n
# Load inference dataset\nHOLDOUT_LOC = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/holdout.csv\"\ntest_df = pd.read_csv(HOLDOUT_LOC)\nWe'll define a few utility functions to make the OpenAI request and to store our predictions. While we could perform batch prediction by loading samples until the context length is reached, we'll just perform one at a time since it's not too many data points and we can have fully deterministic behavior (if you insert new data, etc.). We'll also added some reliability in case we overload the endpoints with too many request at once.
import json\nfrom collections import Counter\nimport matplotlib.pyplot as plt\nimport seaborn as sns; sns.set_theme()\nfrom sklearn.metrics import precision_recall_fscore_support\nimport time\nfrom tqdm import tqdm\nWe'll first define what a sample call to the OpenAI endpoint looks like. We'll pass in: - system_content that has information about how the LLM should behave. - assistant_content for any additional context it should have for answering our questions. - user_content that has our message or query to the LLM. - model should specify which specific model we want to send our request to.
We can pass all of this information in through the openai.ChatCompletion.create function to receive our response.
# Query OpenAI endpoint\nsystem_content = \"you only answer in rhymes\" # system content (behavior)\nassistant_content = \"\" # assistant content (context)\nuser_content = \"how are you\" # user content (message)\nresponse = openai.ChatCompletion.create(\n model=\"gpt-3.5-turbo-0613\",\n messages=[\n {\"role\": \"system\", \"content\": system_content},\n {\"role\": \"assistant\", \"content\": assistant_content},\n {\"role\": \"user\", \"content\": user_content},\n ],\n)\nprint (response.to_dict()[\"choices\"][0].to_dict()[\"message\"][\"content\"])\n\nI'm doing just fine, so glad you ask,\nRhyming away, up to the task.\nHow about you, my dear friend?\nTell me how your day did ascend.\n
Now, let's create a function that can predict tags for a given sample.
def get_tag(model, system_content=\"\", assistant_content=\"\", user_content=\"\"):\n try:\n # Get response from OpenAI\n response = openai.ChatCompletion.create(\n model=model,\n messages=[\n {\"role\": \"system\", \"content\": system_content},\n {\"role\": \"assistant\", \"content\": assistant_content},\n {\"role\": \"user\", \"content\": user_content},\n ],\n )\n predicted_tag = response.to_dict()[\"choices\"][0].to_dict()[\"message\"][\"content\"]\n return predicted_tag\n\n except (openai.error.ServiceUnavailableError, openai.error.APIError) as e:\n return None\n# Get tag\nmodel = \"gpt-3.5-turbo-0613\"\nsystem_context = f\"\"\"\n You are a NLP prediction service that predicts the label given an input's title and description.\n You must choose between one of the following labels for each input: {tags}.\n Only respond with the label name and nothing else.\n \"\"\"\nassistant_content = \"\"\nuser_context = \"Transfer learning with transformers: Using transformers for transfer learning on text classification tasks.\"\ntag = get_tag(model=model, system_content=system_context, assistant_content=assistant_content, user_content=user_context)\nprint (tag)\n\nnatural-language-processing\n
Next, let's create a function that can predict tags for a list of inputs.
# List of dicts w/ {title, description} (just the first 3 samples for now)\nsamples = test_df[[\"title\", \"description\"]].to_dict(orient=\"records\")[:3]\nsamples\n\n[{'title': 'Diffusion to Vector',\n 'description': 'Reference implementation of Diffusion2Vec (Complenet 2018) built on Gensim and NetworkX. '},\n {'title': 'Graph Wavelet Neural Network',\n 'description': 'A PyTorch implementation of \"Graph Wavelet Neural Network\" (ICLR 2019) '},\n {'title': 'Capsule Graph Neural Network',\n 'description': 'A PyTorch implementation of \"Capsule Graph Neural Network\" (ICLR 2019).'}]\n def get_predictions(inputs, model, system_content, assistant_content=\"\"):\n y_pred = []\n for item in tqdm(inputs):\n # Convert item dict to string\n user_content = str(item)\n\n # Get prediction\n predicted_tag = get_tag(\n model=model, system_content=system_content,\n assistant_content=assistant_content, user_content=user_content)\n\n # If error, try again after pause (repeatedly until success)\n while predicted_tag is None:\n time.sleep(30) # could also do exponential backoff\n predicted_tag = get_tag(\n model=model, system_content=system_content,\n assistant_content=assistant_content, user_content=user_content)\n\n # Add to list of predictions\n y_pred.append(predicted_tag)\n\n return y_pred\n# Get predictions for a list of inputs\nget_predictions(inputs=samples, model=model, system_content=system_context)\n\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 3/3 [00:01<00:00, 2.96its]\n['computer-vision', 'computer-vision', 'computer-vision']\n
Next we'll define a function that can clean our predictions in the event that it's not the proper format or has hallucinated a tag outside of our expected tags.
def clean_predictions(y_pred, tags, default=\"other\"):\n for i, item in enumerate(y_pred):\n if item not in tags: # hallucinations\n y_pred[i] = default\n if item.startswith(\"'\") and item.endswith(\"'\"): # GPT 4 likes to places quotes\n y_pred[i] = item[1:-1]\n return y_pred\nTip
Open AI has now released function calling and custom instructions which is worth exploring to avoid this manual cleaning.
Next, we'll define a function that will plot our ground truth labels and predictions.
def plot_tag_dist(y_true, y_pred):\n # Distribution of tags\n true_tag_freq = dict(Counter(y_true))\n pred_tag_freq = dict(Counter(y_pred))\n df_true = pd.DataFrame({\"tag\": list(true_tag_freq.keys()), \"freq\": list(true_tag_freq.values()), \"source\": \"true\"})\n df_pred = pd.DataFrame({\"tag\": list(pred_tag_freq.keys()), \"freq\": list(pred_tag_freq.values()), \"source\": \"pred\"})\n df = pd.concat([df_true, df_pred], ignore_index=True)\n\n # Plot\n plt.figure(figsize=(10, 3))\n plt.title(\"Tag distribution\", fontsize=14)\n ax = sns.barplot(x=\"tag\", y=\"freq\", hue=\"source\", data=df)\n ax.set_xticklabels(list(true_tag_freq.keys()), rotation=0, fontsize=8)\n plt.legend()\n plt.show()\nAnd finally, we'll define a function that will combine all the utilities above to predict, clean and plot our results.
def evaluate(test_df, model, system_content, assistant_content=\"\", tags):\n # Predictions\n y_test = test_df.tag.to_list()\n test_samples = test_df[[\"title\", \"description\"]].to_dict(orient=\"records\")\n y_pred = get_predictions(\n inputs=test_samples, model=model,\n system_content=system_content, assistant_content=assistant_content)\n y_pred = clean_predictions(y_pred=y_pred, tags=tags)\n\n # Performance\n metrics = precision_recall_fscore_support(y_test, y_pred, average=\"weighted\")\n performance = {\"precision\": metrics[0], \"recall\": metrics[1], \"f1\": metrics[2]}\n print(json.dumps(performance, indent=2))\n plot_tag_dist(y_true=y_test, y_pred=y_pred)\n return y_pred, performance\nNow we're ready to start benchmarking our different LLMs with different context.
y_pred = {\"zero_shot\": {}, \"few_shot\": {}}\nperformance = {\"zero_shot\": {}, \"few_shot\": {}}\nWe'll start with zero-shot learning which involves providing the model with the system_content that tells it how to behave but no examples of the behavior (no assistant_content).
system_content = f\"\"\"\n You are a NLP prediction service that predicts the label given an input's title and description.\n You must choose between one of the following labels for each input: {tags}.\n Only respond with the label name and nothing else.\n \"\"\"\n# Zero-shot with GPT 3.5\nmethod = \"zero_shot\"\nmodel = \"gpt-3.5-turbo-0613\"\ny_pred[method][model], performance[method][model] = evaluate(\n test_df=test_df, model=model, system_content=system_content, tags=tags)\n\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 191/191 [11:01<00:00, 3.46s/it]\n{\n \"precision\": 0.7919133278407181,\n \"recall\": 0.806282722513089,\n \"f1\": 0.7807530967691199\n}\n # Zero-shot with GPT 4\nmethod = \"zero_shot\"\nmodel = \"gpt-4-0613\"\ny_pred[method][model], performance[method][model] = evaluate(\n test_df=test_df, model=model, system_content=system_content, tags=tags)\n\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 191/191 [02:28<00:00, 1.29it/s]\n{\n \"precision\": 0.9314722577069027,\n \"recall\": 0.9267015706806283,\n \"f1\": 0.9271956481845013\n}\n"},{"location":"courses/mlops/training/#few-shot-learning","title":"Few-shot learning","text":"Now, we'll be adding a assistant_context with a few samples from our training data for each class. The intuition here is that we're giving the model a few examples (few-shot learning) of what each class looks like so that it can learn to generalize better.
# Create additional context with few samples from each class\nnum_samples = 2\nadditional_context = []\ncols_to_keep = [\"title\", \"description\", \"tag\"]\nfor tag in tags:\n samples = train_df[cols_to_keep][train_df.tag == tag][:num_samples].to_dict(orient=\"records\")\n additional_context.extend(samples)\nadditional_context\n\n[{'title': 'Comparison between YOLO and RCNN on real world videos',\n 'description': 'Bringing theory to experiment is cool. We can easily train models in colab and find the results in minutes.',\n 'tag': 'computer-vision'},\n {'title': 'Show, Infer & Tell: Contextual Inference for Creative Captioning',\n 'description': 'The beauty of the work lies in the way it architects the fundamental idea that humans look at the overall image and then individual pieces of it.\\r\\n',\n 'tag': 'computer-vision'},\n {'title': 'Awesome Graph Classification',\n 'description': 'A collection of important graph embedding, classification and representation learning papers with implementations.',\n 'tag': 'other'},\n {'title': 'Awesome Monte Carlo Tree Search',\n 'description': 'A curated list of Monte Carlo tree search papers with implementations. ',\n 'tag': 'other'},\n {'title': 'Rethinking Batch Normalization in Transformers',\n 'description': 'We found that NLP batch statistics exhibit large variance throughout training, which leads to poor BN performance.',\n 'tag': 'natural-language-processing'},\n {'title': 'ELECTRA: Pre-training Text Encoders as Discriminators',\n 'description': 'PyTorch implementation of the electra model from the paper: ELECTRA - Pre-training Text Encoders as Discriminators Rather Than Generators',\n 'tag': 'natural-language-processing'},\n {'title': 'Pytest Board',\n 'description': 'Continuous pytest runner with awesome visualization.',\n 'tag': 'mlops'},\n {'title': 'Debugging Neural Networks with PyTorch and W&B',\n 'description': 'A closer look at debugging common issues when training neural networks.',\n 'tag': 'mlops'}]\n # Add assistant context\nassistant_content = f\"\"\"Here are some examples with the correct labels: {additional_context}\"\"\"\nprint (assistant_content)\n\nHere are some examples with the correct labels: [{'title': 'Comparison between YOLO and RCNN on real world videos', ... 'description': 'A closer look at debugging common issues when training neural networks.', 'tag': 'mlops'}]\n Tip
We could increase the number of samples by increasing the context length. We could also retrieve better few-shot samples by extracting examples from the training data that are similar to the current sample (ex. similar unique vocabulary).
# Few-shot with GPT 3.5\nmethod = \"few_shot\"\nmodel = \"gpt-3.5-turbo-0613\"\ny_pred[method][model], performance[method][model] = evaluate(\n test_df=test_df, model=model, system_content=system_content,\n assistant_content=assistant_content, tags=tags)\n\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 191/191 [04:18<00:00, 1.35s/it]\n{\n \"precision\": 0.8435247936255214,\n \"recall\": 0.8586387434554974,\n \"f1\": 0.8447984162323493\n}\n # Few-shot with GPT 4\nmethod = \"few_shot\"\nmodel = \"gpt-4-0613\"\ny_pred[method][model], performance[method][model] = evaluate(\n test_df=test_df, model=model, system_content=few_shot_context,\n assistant_content=assistant_content, tags=tags)\n\n100%|\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 191/191 [02:11<00:00, 1.46it/s]\n{\n \"precision\": 0.9407759040163695,\n \"recall\": 0.9267015706806283,\n \"f1\": 0.9302632275594479\n}\n As we can see, few shot learning performs better than it's respective zero shot counter part. GPT 4 has had considerable improvements in reducing hallucinations but for our supervised task this comes at an expense of high precision but lower recall and f1 scores. When GPT 4 is not confident, it would rather predict other.
So far, we've only been using closed-source models from OpenAI. While these are currently the gold-standard, there are many open-source models that are rapidly catching up (Falcon 40B, Llama 2, etc.). Before we see how these models perform on our task, let's first consider a few reasons why we should care about open-source models.
# Coming soon in August!\nNow let's compare all the results from our generative AI LLM benchmarks:
print(json.dumps(performance, indent=2))\n{\n\"zero_shot\": {\n\"gpt-3.5-turbo-0613\": {\n\"precision\": 0.7919133278407181,\n\"recall\": 0.806282722513089,\n\"f1\": 0.7807530967691199\n},\n\"gpt-4-0613\": {\n\"precision\": 0.9314722577069027,\n\"recall\": 0.9267015706806283,\n\"f1\": 0.9271956481845013\n}\n},\n\"few_shot\": {\n\"gpt-3.5-turbo-0613\": {\n\"precision\": 0.8435247936255214,\n\"recall\": 0.8586387434554974,\n\"f1\": 0.8447984162323493\n},\n\"gpt-4-0613\": {\n\"precision\": 0.9407759040163695,\n\"recall\": 0.9267015706806283,\n\"f1\": 0.9302632275594479\n}\n}\n}\nAnd we can plot these on a bar plot to compare them visually.
# Transform data into a new dictionary with four keys\nby_model_and_context = {}\nfor context_type, models_data in performance.items():\n for model, metrics in models_data.items():\n key = f\"{model}_{context_type}\"\n by_model_and_context[key] = metrics\n# Extracting the model names and the metric values\nmodels = list(by_model_and_context.keys())\nmetrics = list(by_model_and_context[models[0]].keys())\n\n# Plotting the bar chart with metric scores on top of each bar\nfig, ax = plt.subplots(figsize=(10, 4))\nwidth = 0.2\nx = range(len(models))\n\nfor i, metric in enumerate(metrics):\n metric_values = [by_model_and_context[model][metric] for model in models]\n ax.bar([pos + width * i for pos in x], metric_values, width, label=metric)\n # Displaying the metric scores on top of each bar\n for pos, val in zip(x, metric_values):\n ax.text(pos + width * i, val, f'{val:.3f}', ha='center', va='bottom', fontsize=9)\n\nax.set_xticks([pos + width for pos in x])\nax.set_xticklabels(models, rotation=0, ha='center', fontsize=8)\nax.set_ylabel('Performance')\nax.set_title('GPT Benchmarks')\nax.legend(loc='upper left', bbox_to_anchor=(1, 1))\n\nplt.tight_layout()\nplt.show()\nOur best model is GPT 4 with few shot learning at an f1 score of ~93%. We will see, in the rest of the course, how fine-tuning an LLM with a proper training dataset to change the actual weights of the last N layers (as opposed to the hard prompt tuning here) will yield similar/slightly better results to GPT 4 (at a fraction of the model size and inference costs).
However, the best system might actually be a combination of using these few-shot hard prompt LLMs alongside fine-tuned LLMs. For example, our fine-tuned LLMs in the course will perform well when the test data is similar to the training data (similar distributions of vocabulary, etc.) but may not perform well on out of distribution. Whereas, these hard prompted LLMs, by themselves or augmented with additional context (ex. arXiv plugins in our case), could be used when our primary fine-tuned model is not so confident.
"},{"location":"courses/mlops/training/#setup","title":"Setup","text":"We'll start by defining some setup utilities and configuring our model.
import os\nimport random\nimport torch\nfrom ray.data.preprocessor import Preprocessor\nWe'll define a set_seeds function that will set the seeds for reproducibility across our libraries (np.random.seed, random.seed, torch.manual_seed and torch.cuda.manual_seed). We'll also set the behavior for some torch backends to ensure deterministic results when we run our workloads on GPUs.
def set_seeds(seed=42):\n\"\"\"Set seeds for reproducibility.\"\"\"\n np.random.seed(seed)\n random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed(seed)\n eval(\"setattr(torch.backends.cudnn, 'deterministic', True)\")\n eval(\"setattr(torch.backends.cudnn, 'benchmark', False)\")\n os.environ[\"PYTHONHASHSEED\"] = str(seed)\nNext, we'll define a simple load_data function to ingest our data from source (CSV files) and load it as a Ray Dataset.
def load_data(num_samples=None):\n ds = ray.data.read_csv(DATASET_LOC)\n ds = ds.random_shuffle(seed=1234)\n ds = ray.data.from_items(ds.take(num_samples)) if num_samples else ds\n return ds\nTip
When working with very large datasets, it's a good idea to limit the number of samples in our dataset so that we can execute our code quickly and iterate on bugs, etc. This is why we have a num_samples input argument in our load_data function (None = no limit, all samples).
We'll also define a custom preprocessor class that we'll to conveniently preprocess our dataset but also to save/load for later. When defining a preprocessor, we'll need to define a _fit method to learn how to fit to our dataset and a _transform_{pandas|numpy} method to preprocess the dataset using any components from the _fit method. We can either define a _transform_pandas method to apply our preprocessing to a Pandas DataFrame or a _transform_numpy method to apply our preprocessing to a NumPy array. We'll define the _transform_pandas method since our preprocessing function expects a batch of data as a Pandas DataFrame.
class CustomPreprocessor(Preprocessor):\n\"\"\"Custom preprocessor class.\"\"\"\n def _fit(self, ds):\n tags = ds.unique(column=\"tag\")\n self.class_to_index = {tag: i for i, tag in enumerate(tags)}\n self.index_to_class = {v:k for k, v in self.class_to_index.items()}\n def _transform_pandas(self, batch): # could also do _transform_numpy\n return preprocess(batch, class_to_index=self.class_to_index)\nNow we're ready to start defining our model architecture. We'll start by loading a pretrained LLM and then defining the components needed for fine-tuning it on our dataset. Our pretrained LLM here is a transformer-based model that has been pretrained on a large corpus of scientific text called scibert.
If you're not familiar with transformer-based models like LLMs, be sure to check out the attention and Transformers lessons.
import torch.nn as nn\nfrom transformers import BertModel\nWe can load our pretrained model by using the from_pretrained` method.
# Pretrained LLM\nllm = BertModel.from_pretrained(\"allenai/scibert_scivocab_uncased\", return_dict=False)\nembedding_dim = llm.config.hidden_size\nOnce our model is loaded, we can tokenize an input text, convert it to torch tensors and pass it through our model to get a sequence and pooled representation of the text.
# Sample\ntext = \"Transfer learning with transformers for text classification.\"\nbatch = tokenizer([text], return_tensors=\"np\", padding=\"longest\")\nbatch = {k:torch.tensor(v) for k,v in batch.items()} # convert to torch tensors\nseq, pool = llm(input_ids=batch[\"input_ids\"], attention_mask=batch[\"attention_mask\"])\nnp.shape(seq), np.shape(pool)\n\n(torch.Size([1, 10, 768]), torch.Size([1, 768]))\n
We're going to use this pretrained model to represent our input text features and add additional layers (linear classifier) on top of it for our specific classification task. In short, the pretrained LLM will process the tokenized text and return a sequence (one representation after each token) and pooled (combined) representation of the text. We'll use the pooled representation as input to our final fully-connection layer (fc1) to result in a vector of size num_classes (number of classes) that we can use to make predictions.
class FinetunedLLM(nn.Module):\n def __init__(self, llm, dropout_p, embedding_dim, num_classes):\n super(FinetunedLLM, self).__init__()\n self.llm = llm\n self.dropout = torch.nn.Dropout(dropout_p)\n self.fc1 = torch.nn.Linear(embedding_dim, num_classes)\n\n def forward(self, batch):\n ids, masks = batch[\"ids\"], batch[\"masks\"]\n seq, pool = self.llm(input_ids=ids, attention_mask=masks)\n z = self.dropout(pool)\n z = self.fc1(z)\n return z\n\n @torch.inference_mode()\n def predict(self, batch):\n self.eval()\n z = self(inputs)\n y_pred = torch.argmax(z, dim=1).cpu().numpy()\n return y_pred\n\n @torch.inference_mode()\n def predict_proba(self, batch):\n self.eval()\n z = self(batch)\n y_probs = F.softmax(z).cpu().numpy()\n return y_probs\nLet's initialize our model and inspect its layers:
# Initialize model\nmodel = FinetunedLLM(llm=llm, dropout_p=0.5, embedding_dim=embedding_dim, num_classes=num_classes)\nprint (model.named_parameters)\n\n(llm): BertModel(\n(embeddings): BertEmbeddings(\n (word_embeddings): Embedding(31090, 768, padding_idx=0)\n (position_embeddings): Embedding(512, 768)\n (token_type_embeddings): Embedding(2, 768)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n)\n(encoder): BertEncoder(\n (layer): ModuleList(\n (0-11): 12 x BertLayer(\n (attention): BertAttention(\n (self): BertSelfAttention(\n (query): Linear(in_features=768, out_features=768, bias=True)\n (key): Linear(in_features=768, out_features=768, bias=True)\n (value): Linear(in_features=768, out_features=768, bias=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n (output): BertSelfOutput(\n (dense): Linear(in_features=768, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n (intermediate): BertIntermediate(\n (dense): Linear(in_features=768, out_features=3072, bias=True)\n (intermediate_act_fn): GELUActivation()\n )\n (output): BertOutput(\n (dense): Linear(in_features=3072, out_features=768, bias=True)\n (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)\n (dropout): Dropout(p=0.1, inplace=False)\n )\n )\n )\n)\n(pooler): BertPooler(\n (dense): Linear(in_features=768, out_features=768, bias=True)\n (activation): Tanh()\n)\n)\n(dropout): Dropout(p=0.5, inplace=False)\n(fc1): Linear(in_features=768, out_features=4, bias=True)\n"},{"location":"courses/mlops/training/#batching","title":"Batching","text":"
We can iterate through our dataset in batches however we may have batches of different sizes. Recall that our tokenizer padded the inputs to the longest item in the batch (padding=\"longest\"). However, our batches for training will be smaller than our large data processing batches and so our batches here may have inputs with different lengths. To address this, we're going to define a custom collate_fn to repad the items in our training batches.
from ray.train.torch import get_device\nOur pad_array function will take an array of arrays and pad the inner arrays to the longest length.
def pad_array(arr, dtype=np.int32):\n max_len = max(len(row) for row in arr)\n padded_arr = np.zeros((arr.shape[0], max_len), dtype=dtype)\n for i, row in enumerate(arr):\n padded_arr[i][:len(row)] = row\n return padded_arr\nAnd our collate_fn will take a batch of data to pad them and convert them to the appropriate PyTorch tensor types.
def collate_fn(batch):\n batch[\"ids\"] = pad_array(batch[\"ids\"])\n batch[\"masks\"] = pad_array(batch[\"masks\"])\n dtypes = {\"ids\": torch.int32, \"masks\": torch.int32, \"targets\": torch.int64}\n tensor_batch = {}\n for key, array in batch.items():\n tensor_batch[key] = torch.as_tensor(array, dtype=dtypes[key], device=get_device())\n return tensor_batch\nLet's test our collate_fn on a sample batch from our dataset.
# Sample batch\nsample_batch = sample_ds.take_batch(batch_size=128)\ncollate_fn(batch=sample_batch)\n\n{'ids': tensor([[ 102, 5800, 14982, ..., 0, 0, 0],\n [ 102, 7746, 2824, ..., 0, 0, 0],\n [ 102, 502, 1371, ..., 0, 0, 0],\n ...,\n [ 102, 10431, 160, ..., 0, 0, 0],\n [ 102, 124, 132, ..., 0, 0, 0],\n [ 102, 12459, 28196, ..., 0, 0, 0]], dtype=torch.int32),\n 'masks': tensor([[1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0],\n ...,\n [1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0],\n [1, 1, 1, ..., 0, 0, 0]], dtype=torch.int32),\n 'targets': tensor([2, 0, 3, 2, 0, 3, 2, 0, 2, 0, 2, 2, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2,\n 0, 1, 1, 0, 2, 0, 3, 2, 0, 3, 2, 0, 2, 0, 2, 2, 0, 2, 0, 3, 2, 0, 3, 2,\n 0, 2, 0, 2, 2, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 3, 0, 0,\n 0, 3, 0, 1, 1, 0, 3, 2, 0, 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 3, 2, 0,\n 2, 3, 0, 2, 2, 0, 2, 2, 0, 1, 1, 0, 2, 0, 2, 2, 0, 2, 2, 0, 2, 0, 1, 1,\n 0, 0, 0, 1, 0, 0, 1, 0])}\n"},{"location":"courses/mlops/training/#utilities_1","title":"Utilities","text":"Next, we'll implement set the necessary utility functions for distributed training.
from ray.air import Checkpoint, session\nfrom ray.air.config import CheckpointConfig, DatasetConfig, RunConfig, ScalingConfig\nimport ray.train as train\nfrom ray.train.torch import TorchCheckpoint, TorchTrainer\nimport torch.nn.functional as F\nWe'll start by defining what one step (or iteration) of training looks like. This will be a function that takes in a batch of data, a model, a loss function, and an optimizer. It will then perform a forward pass, compute the loss, and perform a backward pass to update the model's weights. And finally, it will return the loss.
def train_step(ds, batch_size, model, num_classes, loss_fn, optimizer):\n\"\"\"Train step.\"\"\"\n model.train()\n loss = 0.0\nds_generator = ds.iter_torch_batches(batch_size=batch_size, collate_fn=collate_fn)\nfor i, batch in enumerate(ds_generator):\n optimizer.zero_grad() # reset gradients\n z = model(batch) # forward pass\n targets = F.one_hot(batch[\"targets\"], num_classes=num_classes).float() # one-hot (for loss_fn)\n J = loss_fn(z, targets) # define loss\n J.backward() # backward pass\n optimizer.step() # update weights\n loss += (J.detach().item() - loss) / (i + 1) # cumulative loss\n return loss\nNote: We're using the ray.data.iter_torch_batches method instead of torch.utils.data.DataLoader to create a generator that will yield batches of data. In fact, this is the only line that's different from a typical PyTorch training loop and the actual training workflow remains untouched. Ray supports many other ways to load/consume data for different frameworks as well.
The validation step is quite similar to the training step but we don't need to perform a backward pass or update the model's weights.
def eval_step(ds, batch_size, model, num_classes, loss_fn):\n\"\"\"Eval step.\"\"\"\n model.eval()\n loss = 0.0\n y_trues, y_preds = [], []\nds_generator = ds.iter_torch_batches(batch_size=batch_size, collate_fn=collate_fn)\nwith torch.inference_mode():\n for i, batch in enumerate(ds_generator):\n z = model(batch)\n targets = F.one_hot(batch[\"targets\"], num_classes=num_classes).float() # one-hot (for loss_fn)\n J = loss_fn(z, targets).item()\n loss += (J - loss) / (i + 1)\n y_trues.extend(batch[\"targets\"].cpu().numpy())\n y_preds.extend(torch.argmax(z, dim=1).cpu().numpy())\n return loss, np.vstack(y_trues), np.vstack(y_preds)\nNext, we'll define the train_loop_per_worker which defines the overall training loop for each worker. It's important that we include operations like loading the datasets, models, etc. so that each worker will have its own copy of these objects. Ray takes care of combining all the workers' results at the end of each iteration, so from the user's perspective, it's the exact same as training on a single machine!
The only additional lines of code we need to add compared to a typical PyTorch training loop are the following:
session.get_dataset_shard(\"train\") and session.get_dataset_shard(\"val\") to load the data splits (session.get_dataset_shard).model = train.torch.prepare_model(model) to prepare the torch model for distributed execution (train.torch.prepare_model).batch_size_per_worker = batch_size // session.get_world_size() to adjust the batch size for each worker (session.get_world_size).session.report(metrics, checkpoint=checkpoint) to report metrics and save our model checkpoint (session.report).All the other lines of code are the same as a typical PyTorch training loop!
# Training loop\ndef train_loop_per_worker(config):\n # Hyperparameters\n dropout_p = config[\"dropout_p\"]\n lr = config[\"lr\"]\n lr_factor = config[\"lr_factor\"]\n lr_patience = config[\"lr_patience\"]\n num_epochs = config[\"num_epochs\"]\n batch_size = config[\"batch_size\"]\n num_classes = config[\"num_classes\"]\n\n # Get datasets\n set_seeds()\ntrain_ds = session.get_dataset_shard(\"train\")\nval_ds = session.get_dataset_shard(\"val\")\n# Model\n llm = BertModel.from_pretrained(\"allenai/scibert_scivocab_uncased\", return_dict=False)\n model = FinetunedLLM(llm=llm, dropout_p=dropout_p, embedding_dim=llm.config.hidden_size, num_classes=num_classes)\nmodel = train.torch.prepare_model(model)\n# Training components\n loss_fn = nn.BCEWithLogitsLoss()\n optimizer = torch.optim.Adam(model.parameters(), lr=lr)\n scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode=\"min\", factor=lr_factor, patience=lr_patience)\n\n # Training\nbatch_size_per_worker = batch_size // session.get_world_size()\nfor epoch in range(num_epochs):\n # Step\n train_loss = train_step(train_ds, batch_size_per_worker, model, num_classes, loss_fn, optimizer)\n val_loss, _, _ = eval_step(val_ds, batch_size_per_worker, model, num_classes, loss_fn)\n scheduler.step(val_loss)\n\n # Checkpoint\n metrics = dict(epoch=epoch, lr=optimizer.param_groups[0][\"lr\"], train_loss=train_loss, val_loss=val_loss)\n checkpoint = TorchCheckpoint.from_model(model=model)\nsession.report(metrics, checkpoint=checkpoint)\nClass imbalance
Our dataset doesn't suffer from horrible class imbalance, but if it did, we could easily account for it through our loss function. There are also other strategies such as over-sampling less frequent classes and under-sampling popular classes.
# Class weights\nbatch_counts = []\nfor batch in train_ds.iter_torch_batches(batch_size=256, collate_fn=collate_fn):\n batch_counts.append(np.bincount(batch[\"targets\"].cpu().numpy()))\ncounts = [sum(count) for count in zip(*batch_counts)]\nclass_weights = np.array([1.0/count for i, count in enumerate(counts)])\nclass_weights_tensor = torch.Tensor(class_weights).to(get_device())\n\n# Training components\nloss_fn = nn.BCEWithLogitsLoss(weight=class_weights_tensor)\n...\nNext, we'll define some configurations that will be used to train our model.
# Train loop config\ntrain_loop_config = {\n \"dropout_p\": 0.5,\n \"lr\": 1e-4,\n \"lr_factor\": 0.8,\n \"lr_patience\": 3,\n \"num_epochs\": 10,\n \"batch_size\": 256,\n \"num_classes\": num_classes,\n}\nNext we'll define our scaling configuration (ScalingConfig) that will specify how we want to scale our training workload. We specify the number of workers (num_workers), whether to use GPU or not (use_gpu), the resources per worker (resources_per_worker) and how much CPU each worker is allowed to use (_max_cpu_fraction_per_node).
# Scaling config\nscaling_config = ScalingConfig(\n num_workers=num_workers,\n use_gpu=bool(resources_per_worker[\"GPU\"]),\n resources_per_worker=resources_per_worker,\n _max_cpu_fraction_per_node=0.8,\n)\n_max_cpu_fraction_per_node=0.8 indicates that 20% of CPU is reserved for non-training workloads that our workers will do such as data preprocessing (which we do prior to training anyway).
Next, we'll define our CheckpointConfig which will specify how we want to checkpoint our model. Here we will just save one checkpoint (num_to_keep) based on the checkpoint with the min val_loss. We'll also configure a RunConfig which will specify the name of our run and where we want to save our checkpoints.
# Run config\ncheckpoint_config = CheckpointConfig(num_to_keep=1, checkpoint_score_attribute=\"val_loss\", checkpoint_score_order=\"min\")\nrun_config = RunConfig(name=\"llm\", checkpoint_config=checkpoint_config, local_dir=\"~/ray_results\")\nWe'll be naming our experiment llm and saving our results to ~/ray_results, so a sample directory structure for our trained models would look like this:
/home/ray/ray_results/llm\n\u251c\u2500\u2500 TorchTrainer_fd40a_00000_0_2023-07-20_18-14-50/\n\u251c\u2500\u2500 basic-variant-state-2023-07-20_18-14-50.json\n\u251c\u2500\u2500 experiment_state-2023-07-20_18-14-50.json\n\u251c\u2500\u2500 trainer.pkl\n\u2514\u2500\u2500 tuner.pkl\nThe TorchTrainer_ objects are the individuals runs in this experiment and each one will have the following contents:
/home/ray/ray_results/TorchTrainer_fd40a_00000_0_2023-07-20_18-14-50/\n\u251c\u2500\u2500 checkpoint_000009/ # we only save one checkpoint (the best)\n\u251c\u2500\u2500 events.out.tfevents.1689902160.ip-10-0-49-200\n\u251c\u2500\u2500 params.json\n\u251c\u2500\u2500 params.pkl\n\u251c\u2500\u2500 progress.csv\n\u2514\u2500\u2500 result.json\nThere are several other configs that we could set with Ray (ex. failure handling) so be sure to check them out here.
Stopping criteria
While we'll just let our experiments run for a certain number of epochs and stop automatically, our RunConfig accepts an optional stopping criteria (stop) which determines the conditions our training should stop for. It's entirely customizable and common examples include a certain metric value, elapsed time or even a custom class.
Now we're finally ready to train our model using all the components we've setup above.
# Load and split data\nds = load_data()\ntrain_ds, val_ds = stratify_split(ds, stratify=\"tag\", test_size=test_size)\n# Preprocess\npreprocessor = CustomPreprocessor()\ntrain_ds = preprocessor.fit_transform(train_ds)\nval_ds = preprocessor.transform(val_ds)\ntrain_ds = train_ds.materialize()\nval_ds = val_ds.materialize()\nCalling materialize here is important because it will cache the preprocessed data in memory. This will allow us to train our model without having to reprocess the data each time.
Because we've preprocessed the data prior to training, we can use the fit=False and transform=False flags in our dataset config. This will allow us to skip the preprocessing step during training.
# Dataset config\ndataset_config = {\n \"train\": DatasetConfig(fit=False, transform=False, randomize_block_order=False),\n \"val\": DatasetConfig(fit=False, transform=False, randomize_block_order=False),\n}\nWe'll pass all of our functions and configs to the TorchTrainer class to start training. Ray supports a wide variety of framework Trainers so if you're using other frameworks, you can use the corresponding Trainer class instead.
# Trainer\ntrainer = TorchTrainer(\n train_loop_per_worker=train_loop_per_worker,\n train_loop_config=train_loop_config,\n scaling_config=scaling_config,\n run_config=run_config,\n datasets={\"train\": train_ds, \"val\": val_ds},\n dataset_config=dataset_config,\n preprocessor=preprocessor,\n)\nNow let's fit our model to the data.
# Train\nresults = trainer.fit()\nresults.metrics_dataframe\nresults.best_checkpoints\n\n[(TorchCheckpoint(local_path=/home/ray/ray_results/llm/TorchTrainer_8c960_00000_0_2023-07-10_16-14-41/checkpoint_000009),\n {'epoch': 9,\n 'lr': 0.0001,\n 'train_loss': 0.0005496611799268673,\n 'val_loss': 0.0011818759376183152,\n 'timestamp': 1689030958,\n 'time_this_iter_s': 6.604866981506348,\n 'should_checkpoint': True,\n 'done': True,\n 'training_iteration': 10,\n 'trial_id': '8c960_00000',\n 'date': '2023-07-10_16-16-01',\n 'time_total_s': 76.30888652801514,\n 'pid': 68577,\n 'hostname': 'ip-10-0-18-44',\n 'node_ip': '10.0.18.44',\n 'config': {'train_loop_config': {'dropout_p': 0.5,\n 'lr': 0.0001,\n 'lr_factor': 0.8,\n 'lr_patience': 3,\n 'num_epochs': 10,\n 'batch_size': 256,\n 'num_classes': 4}},\n 'time_since_restore': 76.30888652801514,\n 'iterations_since_restore': 10,\n 'experiment_tag': '0'})]\n"},{"location":"courses/mlops/training/#observability","title":"Observability","text":"While our model is training, we can inspect our Ray dashboard to observe how our compute resources are being utilized.
\ud83d\udcbb Local
We can inspect our Ray dashboard by opening http://127.0.0.1:8265 on a browser window. Click on Cluster on the top menu bar and then we will be able to see a list of our nodes (head and worker) and their utilizations.
\ud83d\ude80 Anyscale
On Anyscale Workspaces, we can head over to the top right menu and click on \ud83d\udee0\ufe0f Tools \u2192 Ray Dashboard and this will open our dashboard on a new tab. Click on Cluster on the top menu bar and then we will be able to see a list of our nodes (head and worker) and their utilizations.
Learn about all the other observability features on the Ray Dashboard through this video.
"},{"location":"courses/mlops/training/#evaluation","title":"Evaluation","text":"Now that we've trained our model, we can evaluate it on a separate holdout test set. We'll cover the topic of evaluation much more extensively in our evaluation lesson but for now we'll calculate some quick overall metrics.
from ray.train.torch import TorchPredictor\nfrom sklearn.metrics import precision_recall_fscore_support\nWe'll define a function that can take in a dataset and a predictor and return the performance metrics.
# Predictor\nbest_checkpoint = results.best_checkpoints[0][0]\npredictor = TorchPredictor.from_checkpoint(best_checkpoint)\npreprocessor = predictor.get_preprocessor()\n# Test (holdout) dataset\nHOLDOUT_LOC = \"https://raw.githubusercontent.com/GokuMohandas/Made-With-ML/main/datasets/holdout.csv\"\ntest_ds = ray.data.read_csv(HOLDOUT_LOC)\npreprocessed_ds = preprocessor.transform(test_ds)\npreprocessed_ds.take(1)\n\n[{'ids': array([ 102, 4905, 2069, 2470, 2848, 4905, 30132, 22081, 691,\n 4324, 7491, 5896, 341, 6136, 934, 30137, 103, 0,\n 0, 0, 0]),\n 'masks': array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]),\n 'targets': 3}]\n targets column by using ray.data.Dataset.select_column: # y_true\nvalues = preprocessed_ds.select_columns(cols=[\"targets\"]).take_all()\ny_true = np.stack([item[\"targets\"] for item in values])\nprint (y_true)\n\n[3 3 3 0 2 0 0 0 0 2 0 0 2 3 0 0 2 2 3 2 3 0 3 2 0 2 2 1 1 2 2 2 2 2 2 0 0\n 0 0 0 1 1 2 0 0 3 1 2 0 2 2 3 3 0 2 3 2 3 3 3 3 0 0 0 0 2 2 0 2 1 0 2 3 0\n 0 2 2 2 2 2 0 0 2 0 1 0 0 0 0 3 0 0 2 0 2 2 3 2 0 2 0 2 0 3 0 0 0 0 0 2 0\n 0 2 2 2 2 3 0 2 0 2 0 2 3 3 3 2 0 2 2 2 2 0 2 2 2 0 1 2 2 2 2 2 1 2 0 3 0\n 2 2 1 1 2 0 0 0 0 0 0 2 2 2 0 2 1 1 2 0 0 1 2 3 2 2 2 0 0 2 0 2 0 3 0 2 2\n 0 1 2 1 2 2]\n
predictor. Note that the predictor will automatically take care of the preprocessing for us. # y_pred\nz = predictor.predict(data=test_ds.to_pandas())[\"predictions\"]\ny_pred = np.stack(z).argmax(1)\nprint (y_pred)\n\n[3 3 3 0 2 0 0 0 0 2 0 0 2 3 0 0 0 2 3 2 3 0 3 2 0 0 2 1 1 2 2 2 2 2 2 0 0\n 0 0 0 1 2 2 0 2 3 1 2 0 2 2 3 3 0 2 1 2 3 3 3 3 2 0 0 0 2 2 0 2 1 0 2 3 1\n 0 2 2 2 2 2 0 0 2 1 1 0 0 0 0 3 0 0 2 0 2 2 3 2 0 2 0 2 2 0 2 0 0 3 0 2 0\n 0 1 2 2 2 3 0 2 0 2 0 2 3 3 3 2 0 2 2 2 2 0 2 2 2 0 1 2 2 2 2 2 1 2 0 3 0\n 2 2 2 1 2 0 2 0 0 0 0 2 2 2 0 2 1 2 2 0 0 1 2 3 2 2 2 0 0 2 0 2 1 3 0 2 2\n 0 1 2 1 2 2]\n
# Evaluate\nmetrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n{\"precision\": metrics[0], \"recall\": metrics[1], \"f1\": metrics[2]}\n\n{'precision': 0.9147673308349523,\n 'recall': 0.9109947643979057,\n 'f1': 0.9115810676649443}\n We're going to encapsulate all of these steps into one function so that we can call on it as we train more models soon.
def evaluate(ds, predictor):\n # y_true\n preprocessor = predictor.get_preprocessor()\n preprocessed_ds = preprocessor.transform(ds)\n values = preprocessed_ds.select_columns(cols=[\"targets\"]).take_all()\n y_true = np.stack([item[\"targets\"] for item in values])\n\n # y_pred\n z = predictor.predict(data=ds.to_pandas())[\"predictions\"]\n y_pred = np.stack(z).argmax(1)\n\n # Evaluate\n metrics = precision_recall_fscore_support(y_true, y_pred, average=\"weighted\")\n performance = {\"precision\": metrics[0], \"recall\": metrics[1], \"f1\": metrics[2]}\n return performance\nNow let's load our trained model for inference on new data. We'll create a few utility functions to format the probabilities into a dictionary for each class and to return predictions for each item in a dataframe.
import pandas as pd\ndef format_prob(prob, index_to_class):\n d = {}\n for i, item in enumerate(prob):\n d[index_to_class[i]] = item\n return d\ndef predict_with_proba(df, predictor):\n preprocessor = predictor.get_preprocessor()\n z = predictor.predict(data=df)[\"predictions\"]\n y_prob = torch.tensor(np.stack(z)).softmax(dim=1).numpy()\n results = []\n for i, prob in enumerate(y_prob):\n tag = decode([z[i].argmax()], preprocessor.index_to_class)[0]\n results.append({\"prediction\": tag, \"probabilities\": format_prob(prob, preprocessor.index_to_class)})\n return results\nWe'll load our predictor from the best checkpoint and load it's preprocessor.
# Preprocessor\npredictor = TorchPredictor.from_checkpoint(best_checkpoint)\npreprocessor = predictor.get_preprocessor()\nAnd now we're ready to apply our model to new data. We'll create a sample dataframe with a title and description and then use our predict_with_proba function to get the predictions. Note that we use a placeholder value for tag since our input dataframe will automatically be preprocessed (and it expects a value in the tag column).
# Predict on sample\ntitle = \"Transfer learning with transformers\"\ndescription = \"Using transformers for transfer learning on text classification tasks.\"\nsample_df = pd.DataFrame([{\"title\": title, \"description\": description, \"tag\": \"other\"}])\npredict_with_proba(df=sample_df, predictor=predictor)\n\n[{'prediction': 'natural-language-processing',\n 'probabilities': {'computer-vision': 0.0007296873,\n 'mlops': 0.0008382588,\n 'natural-language-processing': 0.997829,\n 'other': 0.00060295867}}]\n"},{"location":"courses/mlops/training/#optimization","title":"Optimization","text":"Distributed training strategies are great for when our data or models are too large for training but there are additional strategies to make the models itself smaller for serving. The following model compression techniques are commonly used to reduce the size of the model:
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Training - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nHyperparameter tuning is the process of discovering a set of performant parameter values for our model. It can be a computationally involved process depending on the number of parameters, search space and model architectures. Hyperparameters don't just include the model's parameters but could also include parameters related to preprocessing, splitting, etc. When we look at all the different parameters that can be tuned, it quickly becomes a very large search space. However, just because something is a hyperparameter doesn't mean we need to tune it.
lower=True] during preprocessing).We want to optimize our hyperparameters so that we can understand how each of them affects our objective. By running many trials across a reasonable search space, we can determine near ideal values for our different parameters.
"},{"location":"courses/mlops/tuning/#frameworks","title":"Frameworks","text":"There are many options for hyperparameter tuning (Ray tune, Optuna, Hyperopt, etc.). We'll be using Ray Tune with it's HyperOpt integration for it's simplicity and general popularity. Ray Tune also has a wide variety of support for many other tune search algorithms (Optuna, Bayesian, etc.).
"},{"location":"courses/mlops/tuning/#set-up","title":"Set up","text":"There are many factors to consider when performing hyperparameter tuning. We'll be conducting a small study where we'll tune just a few key hyperparameters across a few trials. Feel free to include additional parameters and to increase the number trials in the tuning experiment.
# Number of trials (small sample)\nnum_runs = 2\nWe'll start with some the set up, data and model prep as we've done in previous lessons.
from ray import tune\nfrom ray.tune import Tuner\nfrom ray.tune.schedulers import AsyncHyperBandScheduler\nfrom ray.tune.search import ConcurrencyLimiter\nfrom ray.tune.search.hyperopt import HyperOptSearch\n# Set up\nset_seeds()\n# Dataset\nds = load_data()\ntrain_ds, val_ds = stratify_split(ds, stratify=\"tag\", test_size=test_size)\n# Preprocess\npreprocessor = CustomPreprocessor()\ntrain_ds = preprocessor.fit_transform(train_ds)\nval_ds = preprocessor.transform(val_ds)\ntrain_ds = train_ds.materialize()\nval_ds = val_ds.materialize()\n# Trainer\ntrainer = TorchTrainer(\n train_loop_per_worker=train_loop_per_worker,\n train_loop_config=train_loop_config,\n scaling_config=scaling_config,\n datasets={\"train\": train_ds, \"val\": val_ds},\n dataset_config=dataset_config,\n preprocessor=preprocessor,\n)\n# MLflow callback\nmlflow_callback = MLflowLoggerCallback(\n tracking_uri=MLFLOW_TRACKING_URI,\n experiment_name=experiment_name,\n save_artifact=True)\nWe can think of tuning as training across different combinations of parameters. For this, we'll need to define several configurations around when to stop tuning (stopping criteria), how to define the next set of parameters to train with (search algorithm) and even the different values that the parameters can take (search space).
We'll start by defining our CheckpointConfig and RunConfig as we did for training:
# Run configuration\ncheckpoint_config = CheckpointConfig(num_to_keep=1, checkpoint_score_attribute=\"val_loss\", checkpoint_score_order=\"min\")\nrun_config = RunConfig(\n callbacks=[mlflow_callback],\n checkpoint_config=checkpoint_config\n)\nNotice that we use the same mlflow_callback from our experiment tracking lesson so all of our runs will be tracked to MLflow automatically.
Next, we're going to set the initial parameter values and the search algorithm (HyperOptSearch) for our tuning experiment. We're also going to set the maximum number of trials that can be run concurrently (ConcurrencyLimiter) based on the compute resources we have.
# Hyperparameters to start with\ninitial_params = [{\"train_loop_config\": {\"dropout_p\": 0.5, \"lr\": 1e-4, \"lr_factor\": 0.8, \"lr_patience\": 3}}]\nsearch_alg = HyperOptSearch(points_to_evaluate=initial_params)\nsearch_alg = ConcurrencyLimiter(search_alg, max_concurrent=2)\nTip
It's a good idea to start with some initial parameter values that you think might be reasonable. This can help speed up the tuning process and also guarantee at least one experiment that will perform decently well.
"},{"location":"courses/mlops/tuning/#search-space","title":"Search space","text":"Next, we're going to define the parameter search space by choosing the parameters, their distribution and range of values. Depending on the parameter type, we have many different distributions to choose from.
# Parameter space\nparam_space = {\n \"train_loop_config\": {\n \"dropout_p\": tune.uniform(0.3, 0.9),\n \"lr\": tune.loguniform(1e-5, 5e-4),\n \"lr_factor\": tune.uniform(0.1, 0.9),\n \"lr_patience\": tune.uniform(1, 10),\n }\n}\nNext, we're going to define a scheduler to prune unpromising trials. We'll be using AsyncHyperBandScheduler (ASHA), which is a very popular and aggressive early-stopping algorithm. Due to our aggressive scheduler, we'll set a grace_period to allow the trials to run for at least a few epochs before pruning and a maximum of max_t epochs.
# Scheduler\nscheduler = AsyncHyperBandScheduler(\n max_t=train_loop_config[\"num_epochs\"], # max epoch (<time_attr>) per trial\n grace_period=5, # min epoch (<time_attr>) per trial\n)\nFinally, we're going to define a TuneConfig that will combine the search_alg and scheduler we've defined above.
# Tune config\ntune_config = tune.TuneConfig(\n metric=\"val_loss\",\n mode=\"min\",\n search_alg=search_alg,\n scheduler=scheduler,\n num_samples=num_runs,\n)\nAnd now, we'll pass in our trainer object with our configurations to create a Tuner object that we can run.
# Tuner\ntuner = Tuner(\n trainable=trainer,\n run_config=run_config,\n param_space=param_space,\n tune_config=tune_config,\n)\n# Tune\nresults = tuner.fit()\n# All trials in experiment\nresults.get_dataframe()\nAnd on our MLflow dashboard, we can create useful plots like a parallel coordinates plot to visualize the different hyperparameters and their values across the different trials.
"},{"location":"courses/mlops/tuning/#best-trial","title":"Best trial","text":"And from these results, we can extract the best trial and its hyperparameters:
# Best trial's epochs\nbest_trial = results.get_best_result(metric=\"val_loss\", mode=\"min\")\nbest_trial.metrics_dataframe\n# Best trial's hyperparameters\nbest_trial.config[\"train_loop_config\"]\n\n{'dropout_p': 0.5, 'lr': 0.0001, 'lr_factor': 0.8, 'lr_patience': 3.0}\n And now we'll load the best run from our experiment, which includes all the runs we've done so far (before and including the tuning runs).
# Sorted runs\nsorted_runs = mlflow.search_runs(experiment_names=[experiment_name], order_by=[\"metrics.val_loss ASC\"])\nsorted_runs\nFrom this we can load the best checkpoint from the best run and evaluate it on the test split.
# Evaluate on test split\nrun_id = sorted_runs.iloc[0].run_id\nbest_checkpoint = get_best_checkpoint(run_id=run_id)\npredictor = TorchPredictor.from_checkpoint(best_checkpoint)\nperformance = evaluate(ds=test_ds, predictor=predictor)\nprint (json.dumps(performance, indent=2))\n\n{\n \"precision\": 0.9487609194455242,\n \"recall\": 0.9476439790575916,\n \"f1\": 0.9471734167970421\n}\n And, just as we did in previous lessons, use our model for inference.
# Preprocessor\npreprocessor = predictor.get_preprocessor()\n# Predict on sample\ntitle = \"Transfer learning with transformers\"\ndescription = \"Using transformers for transfer learning on text classification tasks.\"\nsample_df = pd.DataFrame([{\"title\": title, \"description\": description, \"tag\": \"other\"}])\npredict_with_proba(df=sample_df, predictor=predictor)\n\n[{'prediction': 'natural-language-processing',\n 'probabilities': {'computer-vision': 0.0003628606,\n 'mlops': 0.0002862369,\n 'natural-language-processing': 0.99908364,\n 'other': 0.0002672623}}]\n Now that we're tuned our model, in the next lesson, we're going to perform a much more intensive evaluation on our model compared to just viewing it's overall metrics on a test set.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Tuning - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nIn this lesson, we're going to learn how to version our code, data and models to ensure reproducible behavior in our ML systems. It's imperative that we can reproduce our results and track changes to our system so we can debug and improve our application. Without it, it would be difficult to share our work, recreate our models in the event of system failures and fallback to previous versions in the event of regressions.
"},{"location":"courses/mlops/versioning/#code","title":"Code","text":"To version our code, we'll be using git, which is a widely adopted version control system. In fact, when we cloned our repository in the setup lesson, we pulled code from a git repository that we had prepared for you.
git clone https://github.com/GokuMohandas/Made-With-ML.git .\nWe can then make changes to the code and Git, which is running locally on our computer, will keep track of our files and it's versions as we add and commit our changes. But it's not enough to just version our code locally, we need to push our work to a central location that can be pulled by us and others we want to grant access to. This is where remote repositories like GitHub, GitLab, BitBucket, etc. provide a remote location to hold our versioned code in.
Here's a simplified workflow for how we version our code using GitHub:
[make changes to code]\ngit add .\ngit commit -m \"message\"\ngit push origin <branch-name>\nTip
If you're not familiar with Git, we highly recommend going through our Git lesson to learn the basics.
"},{"location":"courses/mlops/versioning/#artifacts","title":"Artifacts","text":"While Git is ideal for saving our code, it's not ideal for saving artifacts like our datasets (especially unstructured data like text or images) and models. Also, recall that Git stores every version of our files and so large files that change frequently can very quickly take up space. So instead, it would be ideal if we can save locations (pointers) to these large artifacts in our code as opposed to the artifacts themselves. This way, we can version the locations of our artifacts and pull them as they're needed.
"},{"location":"courses/mlops/versioning/#data","title":"Data","text":"While we're saving our dataset on GitHub for easy course access (and because our dataset is small), in a production setting, we would use a remote blob storage like S3 or a data warehouse like Snowflake. There are also many tools available for versioning our data, such as GitLFS, Dolt, Pachyderm, DVC, etc. With any of these solutions, we would be pointing to our remote storage location and versioning the pointer locations (ex. S3 bucket path) to our data instead of the data itself.
"},{"location":"courses/mlops/versioning/#models","title":"Models","text":"And similarly, we currently store our models locally where the MLflow artifact and backend store are local directories.
# Config MLflow\nMODEL_REGISTRY = Path(\"/tmp/mlflow\")\nPath(MODEL_REGISTRY).mkdir(parents=True, exist_ok=True)\nMLFLOW_TRACKING_URI = \"file://\" + str(MODEL_REGISTRY.absolute())\nmlflow.set_tracking_uri(MLFLOW_TRACKING_URI)\nprint (mlflow.get_tracking_uri())\nIn a production setting, these would be remote such as S3 for the artifact store and a database service (ex. PostgreSQL RDS) as our backend store. This way, our models can be versioned and others, with the appropriate access credentials, can pull the model artifacts and deploy them.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn moreTo cite this content, please use:
@article{madewithml,\nauthor = {Goku Mohandas},\ntitle = { Versioning - Made With ML },\nhowpublished = {\\url{https://madewithml.com/}},\nyear = {2023}\n}\nThis content will be coming soon! Be sure to subscribe and follow us on Twitter and LinkedIn for updates and tips.
"},{"location":"misc/confirmation/","title":"\ud83d\udcec Check your email","text":""},{"location":"misc/confirmation/#_1","title":"\ud83d\udcec Check your email","text":"Thank you for subscribing to our newsletter! A confirmation email was sent to the email address you provided. Please click on the confirmation button in the email to complete your subscription. If you don\u2019t see it within a few minutes, be sure to check your promotions/spam/junk folder (and mark it Not junk so you receive our future emails).
\u2190\u00a0 Return to home
"},{"location":"misc/newsletter/","title":"Newsletter","text":""},{"location":"misc/partnerships/","title":"Partnerships","text":""},{"location":"misc/partnerships/#_1","title":"Partnerships","text":""},{"location":"misc/partnerships/#our-mission","title":"Our Mission","text":"We created Made With ML to educate and enable the community to responsibly develop, deploy and maintain production machine learning applications. While there are many facets to this mission, at its core are the relationships with teams who share this mission. We want to work together to help the community discover and use the best tools for their context and start the flywheel to make the tools even better.
"},{"location":"misc/partnerships/#brand","title":"Brand","text":"A few numbers that reflect the 100% organic traction we've had over the past few years and the need it's filled in the community for bringing ML to production:
All of our lessons focus on first principles when approaching a concept. This helps develop the foundational understanding to be able to adapt to any stack. But to really solidify the understanding, we implement everything in code within the context of an end-to-end project. This helps understand the implicit value a tool provides and develop the decision making framework for constructing the appropriate stack. And because the community adopts what they've learned for their own use cases in industry, it's imperative that we use tools that can offer that enterprise maturity.
Your product will be deeply integrated into the MLOps course, where thousands of developers everyday will use and assess your product for their industry contexts. All of this visibility and traction is invaluable for industry adoption, standing out in the competitive landscape and using the feedback to improve the product.
We also have many downstream projects in progress to add more value on top of the content (async video course, private community, university labs, corporate onboarding, talent platform).
"},{"location":"misc/partnerships/#join-us","title":"Join us","text":"If your team is interested in joining our mission, reach out to us via email to learn more!
"},{"location":"misc/reimbursement/","title":"Reimbursement Template","text":""},{"location":"misc/reimbursement/#_1","title":"Reimbursement Template","text":"Instructions
After you've applied and been accepted to the next cohort, copy and paste this email template below to send to your manager for reimbursement for the course. Feel free to add any additional details as you see fit.
Subject: Reimbursement for Made With ML's MLOps Course
Hi,
Hope you're doing well. I was recently accepted into Made With ML's MLOps course, which is an interactive project-based course on MLOps fundamentals. The course costs $1,250 but the value I'll gain for myself and our team/company will pay for the course almost immediately. I added some key information about the course below and would love to get this career development opportunity reimbursed.
Course page: https://madewithml.com/
"},{"location":"misc/reimbursement/#what-is-the-course","title":"What is the course?","text":"An interactive project-based course to learn and apply the fundamentals of MLOps. I'll be learning to combine machine learning with software engineering best practices which I want to extend to build and improve our own systems. This course brings all of the MLOps best practices into one place, allowing me to quickly (and properly) learn it. And best of all, the course can be done before and after work, so it won't be interfering during work hours.
Here's a quick look at the curriculum:
"},{"location":"misc/reimbursement/#whos-teaching-the-course","title":"Who's teaching the course?","text":"The course is from Made With ML, one of the top ML repositories on GitHub (30K+ stars) with a growing community (30K+) and is a highly recommended resource used by industry. Their content not only covers MLOps concepts but they go deep into actually implementing everything with production quality code.
"},{"location":"misc/reimbursement/#how-will-this-help-me","title":"How will this help me?","text":"I'll be learning the foundation I need to responsibly develop ML systems. This includes producing clean, production-grade code, testing my work, understanding MLOps (experiment management, monitoring, systems design, etc.) and data engineering (data stack, orchestration, feature stores) concepts.
"},{"location":"misc/reimbursement/#how-will-this-help-our-company","title":"How will this help our company?","text":"What I learn will directly translate to better quality ML systems in our products. I'll also be able to engage in conversations with peers and management as we traverse this space to build what's right for us. And, most important of all, I'll be able to pass on what I learn as I collaborate with others in our team so we're all working towards building reliable ML systems.
Thank you
"},{"location":"misc/subscribed/","title":"\u2705 Subscription confirmed","text":""},{"location":"misc/subscribed/#_1","title":"\u2705 Subscription confirmed","text":"You're all set!
1. Resource links
2. Say hello
Send me an email at goku@madewithml.com to say hi, a bit about yourself and what you're currently learning or working on. I personally respond to all emails and always love to meet people from the community.
Upcoming live cohorts
Sign up for our upcoming live cohort, where we'll provide live lessons + QA, compute (GPUs) and community to learn everything in one day.
Learn more "},{"location":"styles/lesson/","title":"Lesson","text":""},{"location":"styles/page/","title":"Page","text":""}]} \ No newline at end of file diff --git a/sitemap.xml b/sitemap.xml new file mode 100644 index 00000000..45b918a7 --- /dev/null +++ b/sitemap.xml @@ -0,0 +1,318 @@ + +