
| Category | -Metric Name | -Definition | -Data Required | -Use Scenarios and Recommended Practices | -Value | -
|---|---|---|---|---|---|
| Delivery Velocity | -Requirement Count | -Number of issues in type "Requirement" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process.
- 2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. - 3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. - 4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. |
- 1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources.
- 2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. |
-
| Requirement Delivery Rate | -Ratio of delivered requirements to all requirements | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -|||
| Requirement Lead Time | -Lead time of issues with type "Requirement" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the trend of requirement lead time to observe if it has improved over time.
- 2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time. - 3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow. |
- 1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays
- 2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks. |
- |
| Requirement Granularity | -Number of story points associated with an issue | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal.
- 2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents) |
- 1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team.
- 2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management. |
- |
| Commit Count | -Number of Commits | -Source Code Management entities: Git/GitHub/GitLab commits | -
-1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison
- 2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents) |
- 1. Identify potential bottlenecks that may affect output
- 2. Encourage R&D practices of small step submissions and develop excellent coding habits |
- |
| Added Lines of Code | -Accumulated number of added lines of code | -Source Code Management entities: Git/GitHub/GitLab commits | -
-1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate
- 2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model. - 3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison. |
- 1. identify potential bottlenecks that may affect the output
- 2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits |
- |
| Deleted Lines of Code | -Accumulated number of deleted lines of code | -Source Code Management entities: Git/GitHub/GitLab commits | -|||
| Pull Request Review Time | -Time from Pull/Merge created time until merged | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | --1. Observe the mean and distribution of code review time from the project/team/individual dimension to assess the rationality of the review time | -1. Take inventory of project/team code review resources to avoid lack of resources and backlog of review sessions, resulting in long waiting time
- 2. Encourage teams to implement an efficient and responsive code review mechanism |
- |
| Bug Age | -Lead time of issues in type "Bug" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Observe the trend of bug age and locate the key reasons. -2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of bug and incident age. |
- 1. Help the team to establish an effective hierarchical response mechanism for bugs and incidents. Focus on the resolution of important problems in the backlog. -2. Improve team's and individual's bug/incident fixing efficiency. Identify good/to-be-improved practices that affect bug age or incident age |
- |
| Incident Age | -Lead time of issues in type "Incident" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -|||
| Delivery Quality | -Pull Request Count | -Number of Pull/Merge Requests | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -
-1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. |
- 1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation |
-
| Pull Request Pass Rate | -Ratio of Pull/Merge Review requests to merged | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Pull Request Review Rounds | -Number of cycles of commits followed by comments/final merge | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Pull Request Review Count | -Number of Pull/Merge Reviewers | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -1. As a secondary indicator, assess the cost of labor invested in the code review process | -1. Take inventory of project/team code review resources to avoid long waits for review sessions due to insufficient resource input | -|
| Bug Count | -Number of bugs found during testing | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc. -2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality -3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points -4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values |
- 1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process -2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts -3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects |
- |
| Incident Count | -Number of Incidents found after shipping | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Bugs Count per 1k Lines of Code | -Amount of bugs per 1,000 lines of code | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Incidents Count per 1k Lines of Code | -Amount of incidents per 1,000 lines of code | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Delivery Cost | -Commit Author Count | -Number of Contributors who have committed code | -Source Code Management entities: Git/GitHub/GitLab commits | -1. As a secondary indicator, this helps assess the labor cost of participating in coding | -1. Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment | -
| Delivery Capability | -Build Count | -The number of builds started | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -1. From the project dimension, compare the number of builds and success rate by combining the project phase and the complexity of tasks -2. From the time dimension, analyze the trend of the number of builds and success rate to see if it has improved over time |
- 1. As a process indicator, it reflects the value flow efficiency of upstream production and research links -2. Identify excellent/to-be-improved practices that impact the build, and drive the team to precipitate reusable tools and mechanisms to build infrastructure for fast and high-frequency delivery |
-
| Build Duration | -The duration of successful builds | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -|||
| Build Success Rate | -The percentage of successful builds | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -
DevLake Components
- -A DevLake installation typically consists of the following components: - -- Config UI: A handy user interface to create, trigger, and debug data pipelines. -- API Server: The main programmatic interface of DevLake. -- Runner: The runner does all the heavy-lifting for executing tasks. In the default DevLake installation, it runs within the API Server, but DevLake provides a temporal-based runner (beta) for production environments. -- Database: The database stores both DevLake's metadata and user data collected by data pipelines. DevLake supports MySQL and PostgreSQL as of v0.11. -- Plugins: Plugins enable DevLake to collect and analyze dev data from any DevOps tools with an accessible API. DevLake community is actively adding plugins for popular DevOps tools, but if your preferred tool is not covered yet, feel free to open a GitHub issue to let us know or check out our doc on how to build a new plugin by yourself. -- Dashboards: Dashboards deliver data and insights to DevLake users. A dashboard is simply a collection of SQL queries along with corresponding visualization configurations. DevLake's official dashboard tool is Grafana and pre-built dashboards are shipped in Grafana's JSON format. Users are welcome to swap for their own choice of dashboard/BI tool if desired. - -## Dataflow - -
DevLake Dataflow
- -A typical plugin's dataflow is illustrated below: - -1. The Raw layer stores the API responses from data sources (DevOps tools) in JSON. This saves developers' time if the raw data is to be transformed differently later on. Please note that communicating with data sources' APIs is usually the most time-consuming step. -2. The Tool layer extracts raw data from JSONs into a relational schema that's easier to consume by analytical tasks. Each DevOps tool would have a schema that's tailored to their data structure, hence the name, the Tool layer. -3. The Domain layer attempts to build a layer of abstraction on top of the Tool layer so that analytics logics can be re-used across different tools. For example, GitHub's Pull Request (PR) and GitLab's Merge Request (MR) are similar entities. They each have their own table name and schema in the Tool layer, but they're consolidated into a single entity in the Domain layer, so that developers only need to implement metrics like Cycle Time and Code Review Rounds once against the domain layer schema. - -## Principles - -1. Extensible: DevLake's plugin system allows users to integrate with any DevOps tool. DevLake also provides a dbt plugin that enables users to define their own data transformation and analysis workflows. -2. Portable: DevLake has a modular design and provides multiple options for each module. Users of different setups can freely choose the right configuration for themselves. -3. Robust: DevLake provides an SDK to help plugins efficiently and reliably collect data from data sources while respecting their API rate limits and constraints. - - -
-## Project Metrics This Covers
-
-| Metric Name | Description |
-|:------------------------------------|:--------------------------------------------------------------------------------------------------|
-| Requirement Count | Number of issues with type "Requirement" |
-| Requirement Lead Time | Lead time of issues with type "Requirement" |
-| Requirement Delivery Rate | Ratio of delivered requirements to all requirements |
-| Requirement Granularity | Number of story points associated with an issue |
-| Bug Count | Number of issues with type "Bug"
-
-## Project Metrics This Covers
-
-| Metric Name | Description |
-|:------------------------------------|:--------------------------------------------------------------------------------------------------|
-| Requirement Count | Number of issues with type "Requirement" |
-| Requirement Lead Time | Lead time of issues with type "Requirement" |
-| Requirement Delivery Rate | Ratio of delivered requirements to all requirements |
-| Requirement Granularity | Number of story points associated with an issue |
-| Bug Count | Number of issues with type "Bug"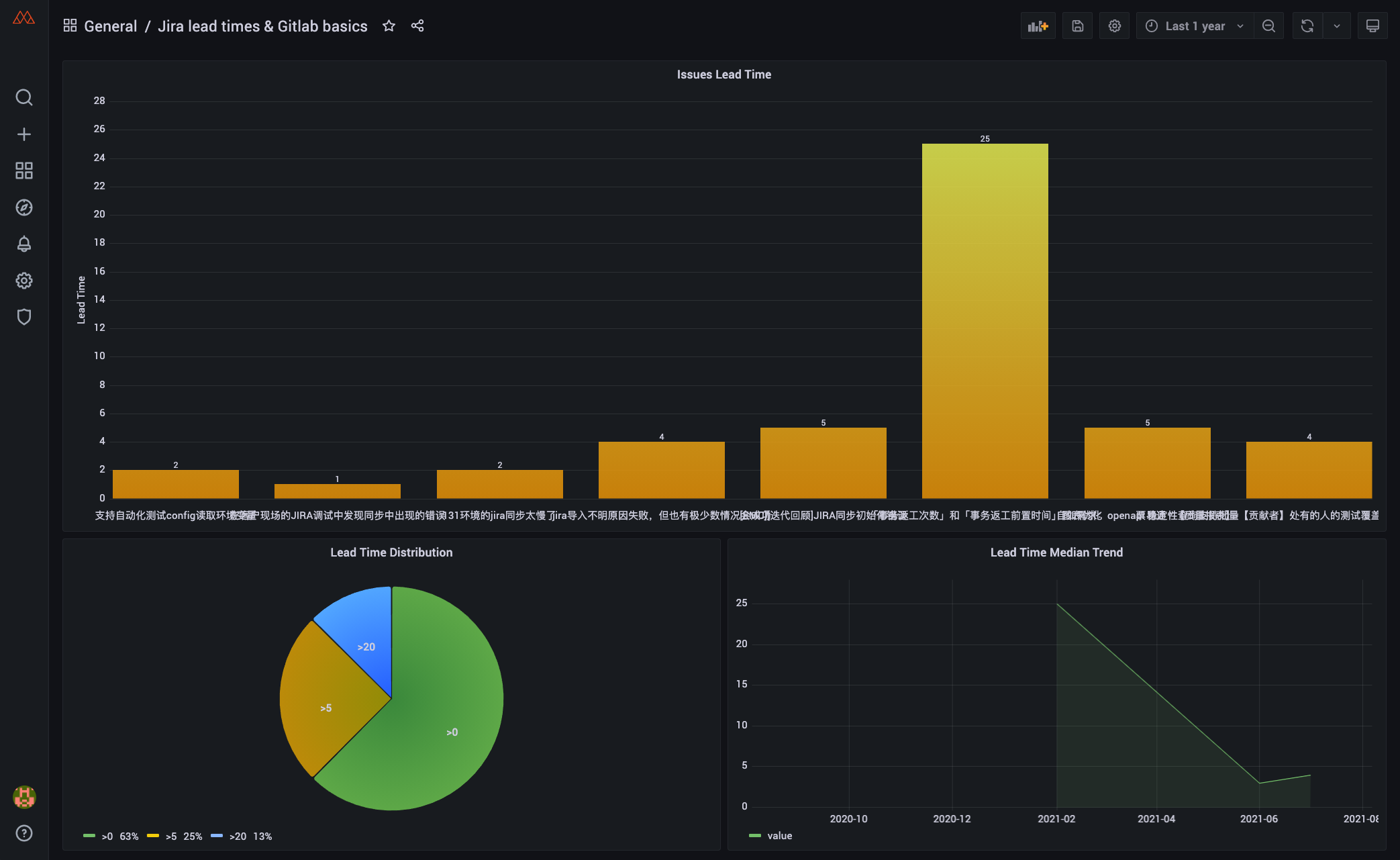 -
-When first visiting Grafana, you will be provided with a sample dashboard with some basic charts setup from the database.
-
-## Contents
-
-Section | Link
-:------------ | :-------------
-Logging In | [View Section](#logging-in)
-Viewing All Dashboards | [View Section](#viewing-all-dashboards)
-Customizing a Dashboard | [View Section](#customizing-a-dashboard)
-Dashboard Settings | [View Section](#dashboard-settings)
-Provisioning a Dashboard | [View Section](#provisioning-a-dashboard)
-Troubleshooting DB Connection | [View Section](#troubleshooting-db-connection)
-
-## Logging In
-
-Once the app is up and running, visit `http://localhost:3002` to view the Grafana dashboard.
-
-Default login credentials are:
-
-- Username: `admin`
-- Password: `admin`
-
-## Viewing All Dashboards
-
-To see all dashboards created in Grafana visit `/dashboards`
-
-Or, use the sidebar and click on **Manage**:
-
-
-
-
-## Customizing a Dashboard
-
-When viewing a dashboard, click the top bar of a panel, and go to **edit**
-
-
-
-**Edit Dashboard Panel Page:**
-
-
-
-### 1. Preview Area
-- **Top Left** is the variable select area (custom dashboard variables, used for switching projects, or grouping data)
-- **Top Right** we have a toolbar with some buttons related to the display of the data:
- - View data results in a table
- - Time range selector
- - Refresh data button
-- **The Main Area** will display the chart and should update in real time
-
-> Note: Data should refresh automatically, but may require a refresh using the button in some cases
-
-### 2. Query Builder
-Here we form the SQL query to pull data into our chart, from our database
-- Ensure the **Data Source** is the correct database
-
- 
-
-- Select **Format as Table**, and **Edit SQL** buttons to write/edit queries as SQL
-
- 
-
-- The **Main Area** is where the queries are written, and in the top right is the **Query Inspector** button (to inspect returned data)
-
- 
-
-### 3. Main Panel Toolbar
-In the top right of the window are buttons for:
-- Dashboard settings (regarding entire dashboard)
-- Save/apply changes (to specific panel)
-
-### 4. Grafana Parameter Sidebar
-- Change chart style (bar/line/pie chart etc)
-- Edit legends, chart parameters
-- Modify chart styling
-- Other Grafana specific settings
-
-## Dashboard Settings
-
-When viewing a dashboard click on the settings icon to view dashboard settings. Here are 2 important sections to use:
-
-
-
-- Variables
- - Create variables to use throughout the dashboard panels, that are also built on SQL queries
-
- 
-
-- JSON Model
- - Copy `json` code here and save it to a new file in `/grafana/dashboards/` with a unique name in the `lake` repo. This will allow us to persist dashboards when we load the app
-
- 
-
-## Provisioning a Dashboard
-
-To save a dashboard in the `lake` repo and load it:
-
-1. Create a dashboard in browser (visit `/dashboard/new`, or use sidebar)
-2. Save dashboard (in top right of screen)
-3. Go to dashboard settings (in top right of screen)
-4. Click on _JSON Model_ in sidebar
-5. Copy code into a new `.json` file in `/grafana/dashboards`
-
-## Troubleshooting DB Connection
-
-To ensure we have properly connected our database to the data source in Grafana, check database settings in `./grafana/datasources/datasource.yml`, specifically:
-- `database`
-- `user`
-- `secureJsonData/password`
diff --git a/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md b/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md
deleted file mode 100644
index ce82b1eb00d..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-title: "Recurring Pipelines"
-sidebar_position: 3
-description: >
- Recurring Pipelines
----
-
-## How to create recurring pipelines?
-
-Once you've verified that a pipeline works, most likely you'll want to run that pipeline periodically to keep data fresh, and DevLake's pipeline blueprint feature have got you covered.
-
-
-1. Click 'Create Pipeline Run' and
- - Toggle the plugins you'd like to run, here we use GitHub and GitExtractor plugin as an example
- - Toggle on Automate Pipeline
- 
-
-
-2. Click 'Add Blueprint'. Fill in the form and 'Save Blueprint'.
-
- - **NOTE**: The schedule syntax is standard unix cron syntax, [Crontab.guru](https://crontab.guru/) is an useful reference
- - **IMPORANT**: The scheduler is running using the `UTC` timezone. If you want data collection to happen at 3 AM New York time (UTC-04:00) every day, use **Custom Shedule** and set it to `0 7 * * *`
-
- 
-
-3. Click 'Save Blueprint'.
-
-4. Click 'Pipeline Blueprints', you can view and edit the new blueprint in the blueprint list.
-
- 
\ No newline at end of file
diff --git a/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md b/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md
deleted file mode 100644
index f893a830dfd..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md
+++ /dev/null
@@ -1,35 +0,0 @@
----
-title: "Temporal Setup"
-sidebar_position: 5
-description: >
- The steps to install DevLake in Temporal mode.
----
-
-
-Normally, DevLake would execute pipelines on a local machine (we call it `local mode`), it is sufficient most of the time. However, when you have too many pipelines that need to be executed in parallel, it can be problematic, as the horsepower and throughput of a single machine is limited.
-
-`temporal mode` was added to support distributed pipeline execution, you can fire up arbitrary workers on multiple machines to carry out those pipelines in parallel to overcome the limitations of a single machine.
-
-But, be careful, many API services like JIRA/GITHUB have a request rate limit mechanism. Collecting data in parallel against the same API service with the same identity would most likely hit such limit.
-
-## How it works
-
-1. DevLake Server and Workers connect to the same temporal server by setting up `TEMPORAL_URL`
-2. DevLake Server sends a `pipeline` to the temporal server, and one of the Workers pick it up and execute it
-
-
-**IMPORTANT: This feature is in early stage of development. Please use with caution**
-
-
-## Temporal Demo
-
-### Requirements
-
-- [Docker](https://docs.docker.com/get-docker)
-- [docker-compose](https://docs.docker.com/compose/install/)
-- [temporalio](https://temporal.io/)
-
-### How to setup
-
-1. Clone and fire up [temporalio](https://temporal.io/) services
-2. Clone this repo, and fire up DevLake with command `docker-compose -f docker-compose-temporal.yml up -d`
\ No newline at end of file
diff --git a/versioned_docs/version-v0.11/UserManuals/_category_.json b/versioned_docs/version-v0.11/UserManuals/_category_.json
deleted file mode 100644
index b47bdfd7d09..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "User Manuals",
- "position": 3
-}
diff --git a/versioned_docs/version-v0.12/DataModels/DataSupport.md b/versioned_docs/version-v0.12/DataModels/DataSupport.md
deleted file mode 100644
index 4cb4b619131..00000000000
--- a/versioned_docs/version-v0.12/DataModels/DataSupport.md
+++ /dev/null
@@ -1,59 +0,0 @@
----
-title: "Data Support"
-description: >
- Data sources that DevLake supports
-sidebar_position: 1
----
-
-
-## Data Sources and Data Plugins
-DevLake supports the following data sources. The data from each data source is collected with one or more plugins. There are 9 data plugins in total: `ae`, `feishu`, `gitextractor`, `github`, `gitlab`, `jenkins`, `jira`, `refdiff` and `tapd`.
-
-
-| Data Source | Versions | Plugins |
-|-------------|--------------------------------------|-------- |
-| AE | | `ae` |
-| Feishu | Cloud |`feishu` |
-| GitHub | Cloud |`github`, `gitextractor`, `refdiff` |
-| Gitlab | Cloud, Community Edition 13.x+ |`gitlab`, `gitextractor`, `refdiff` |
-| Jenkins | 2.263.x+ |`jenkins` |
-| Jira | Cloud, Server 8.x+, Data Center 8.x+ |`jira` |
-| TAPD | Cloud | `tapd` |
-
-
-
-## Data Collection Scope By Each Plugin
-This table shows the entities collected by each plugin. Domain layer entities in this table are consistent with the entities [here](./DevLakeDomainLayerSchema.md).
-
-| Domain Layer Entities | ae | gitextractor | github | gitlab | jenkins | jira | refdiff | tapd |
-| --------------------- | -------------- | ------------ | -------------- | ------- | ------- | ------- | ------- | ------- |
-| commits | update commits | default | not-by-default | default | | | | |
-| commit_parents | | default | | | | | | |
-| commit_files | | default | | | | | | |
-| pull_requests | | | default | default | | | | |
-| pull_request_commits | | | default | default | | | | |
-| pull_request_comments | | | default | default | | | | |
-| pull_request_labels | | | default | | | | | |
-| refs | | default | | | | | | |
-| refs_commits_diffs | | | | | | | default | |
-| refs_issues_diffs | | | | | | | default | |
-| ref_pr_cherry_picks | | | | | | | default | |
-| repos | | | default | default | | | | |
-| repo_commits | | default | default | | | | | |
-| board_repos | | | | | | | | |
-| issue_commits | | | | | | | | |
-| issue_repo_commits | | | | | | | | |
-| pull_request_issues | | | | | | | | |
-| refs_issues_diffs | | | | | | | | |
-| boards | | | default | | | default | | default |
-| board_issues | | | default | | | default | | default |
-| issue_changelogs | | | | | | default | | default |
-| issues | | | default | | | default | | default |
-| issue_comments | | | | | | default | | default |
-| issue_labels | | | default | | | | | |
-| sprints | | | | | | default | | default |
-| issue_worklogs | | | | | | default | | default |
-| users o | | | default | | | default | | default |
-| builds | | | | | default | | | |
-| jobs | | | | | default | | | |
-
diff --git a/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md b/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md
deleted file mode 100644
index 10c80d907a1..00000000000
--- a/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md
+++ /dev/null
@@ -1,544 +0,0 @@
----
-title: "Domain Layer Schema"
-description: >
- DevLake Domain Layer Schema
-sidebar_position: 2
----
-
-## Summary
-
-This document describes the entities in DevLake's domain layer schema and their relationships.
-
-Data in the domain layer is transformed from the data in the tool layer. The tool layer schema is based on the data from specific tools such as Jira, GitHub, Gitlab, Jenkins, etc. The domain layer schema can be regarded as an abstraction of tool-layer schemas.
-
-Domain layer schema itself includes 2 logical layers: a `DWD` layer and a `DWM` layer. The DWD layer stores the detailed data points, while the DWM is the slight aggregation and operation of DWD to store more organized details or middle-level metrics.
-
-
-## Use Cases
-1. Users can make customized Grafana dashboards based on the domain layer schema.
-2. Contributors can complete the ETL logic when adding new data source plugins refering to this data model.
-
-
-## Data Models
-
-This is the up-to-date domain layer schema for DevLake v0.10.x. Tables (entities) are categorized into 5 domains.
-1. Issue tracking domain entities: Jira issues, GitHub issues, GitLab issues, etc.
-2. Source code management domain entities: Git/GitHub/Gitlab commits and refs(tags and branches), etc.
-3. Code review domain entities: GitHub PRs, Gitlab MRs, etc.
-4. CI/CD domain entities: Jenkins jobs & builds, etc.
-5. Cross-domain entities: entities that map entities from different domains to break data isolation.
-
-
-### Schema Diagram
-
-
-When reading the schema, you'll notice that many tables' primary key is called `id`. Unlike auto-increment id or UUID, `id` is a string composed of several parts to uniquely identify similar entities (e.g. repo) from different platforms (e.g. Github/Gitlab) and allow them to co-exist in a single table.
-
-Tables that end with WIP are still under development.
-
-
-### Naming Conventions
-
-1. The name of a table is in plural form. Eg. boards, issues, etc.
-2. The name of a table which describe the relation between 2 entities is in the form of [BigEntity in singular form]\_[SmallEntity in plural form]. Eg. board_issues, sprint_issues, pull_request_comments, etc.
-3. Value of the field in enum type are in capital letters. Eg. [table.issues.type](https://merico.feishu.cn/docs/doccnvyuG9YpVc6lvmWkmmbZtUc#ZDCw9k) has 3 values, REQUIREMENT, BUG, INCIDENT. Values that are phrases, such as 'IN_PROGRESS' of [table.issues.status](https://merico.feishu.cn/docs/doccnvyuG9YpVc6lvmWkmmbZtUc#ZDCw9k), are separated with underscore '\_'.
-
-
-
-When first visiting Grafana, you will be provided with a sample dashboard with some basic charts setup from the database.
-
-## Contents
-
-Section | Link
-:------------ | :-------------
-Logging In | [View Section](#logging-in)
-Viewing All Dashboards | [View Section](#viewing-all-dashboards)
-Customizing a Dashboard | [View Section](#customizing-a-dashboard)
-Dashboard Settings | [View Section](#dashboard-settings)
-Provisioning a Dashboard | [View Section](#provisioning-a-dashboard)
-Troubleshooting DB Connection | [View Section](#troubleshooting-db-connection)
-
-## Logging In
-
-Once the app is up and running, visit `http://localhost:3002` to view the Grafana dashboard.
-
-Default login credentials are:
-
-- Username: `admin`
-- Password: `admin`
-
-## Viewing All Dashboards
-
-To see all dashboards created in Grafana visit `/dashboards`
-
-Or, use the sidebar and click on **Manage**:
-
-
-
-
-## Customizing a Dashboard
-
-When viewing a dashboard, click the top bar of a panel, and go to **edit**
-
-
-
-**Edit Dashboard Panel Page:**
-
-
-
-### 1. Preview Area
-- **Top Left** is the variable select area (custom dashboard variables, used for switching projects, or grouping data)
-- **Top Right** we have a toolbar with some buttons related to the display of the data:
- - View data results in a table
- - Time range selector
- - Refresh data button
-- **The Main Area** will display the chart and should update in real time
-
-> Note: Data should refresh automatically, but may require a refresh using the button in some cases
-
-### 2. Query Builder
-Here we form the SQL query to pull data into our chart, from our database
-- Ensure the **Data Source** is the correct database
-
- 
-
-- Select **Format as Table**, and **Edit SQL** buttons to write/edit queries as SQL
-
- 
-
-- The **Main Area** is where the queries are written, and in the top right is the **Query Inspector** button (to inspect returned data)
-
- 
-
-### 3. Main Panel Toolbar
-In the top right of the window are buttons for:
-- Dashboard settings (regarding entire dashboard)
-- Save/apply changes (to specific panel)
-
-### 4. Grafana Parameter Sidebar
-- Change chart style (bar/line/pie chart etc)
-- Edit legends, chart parameters
-- Modify chart styling
-- Other Grafana specific settings
-
-## Dashboard Settings
-
-When viewing a dashboard click on the settings icon to view dashboard settings. Here are 2 important sections to use:
-
-
-
-- Variables
- - Create variables to use throughout the dashboard panels, that are also built on SQL queries
-
- 
-
-- JSON Model
- - Copy `json` code here and save it to a new file in `/grafana/dashboards/` with a unique name in the `lake` repo. This will allow us to persist dashboards when we load the app
-
- 
-
-## Provisioning a Dashboard
-
-To save a dashboard in the `lake` repo and load it:
-
-1. Create a dashboard in browser (visit `/dashboard/new`, or use sidebar)
-2. Save dashboard (in top right of screen)
-3. Go to dashboard settings (in top right of screen)
-4. Click on _JSON Model_ in sidebar
-5. Copy code into a new `.json` file in `/grafana/dashboards`
-
-## Troubleshooting DB Connection
-
-To ensure we have properly connected our database to the data source in Grafana, check database settings in `./grafana/datasources/datasource.yml`, specifically:
-- `database`
-- `user`
-- `secureJsonData/password`
diff --git a/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md b/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md
deleted file mode 100644
index ce82b1eb00d..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/RecurringPipelines.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-title: "Recurring Pipelines"
-sidebar_position: 3
-description: >
- Recurring Pipelines
----
-
-## How to create recurring pipelines?
-
-Once you've verified that a pipeline works, most likely you'll want to run that pipeline periodically to keep data fresh, and DevLake's pipeline blueprint feature have got you covered.
-
-
-1. Click 'Create Pipeline Run' and
- - Toggle the plugins you'd like to run, here we use GitHub and GitExtractor plugin as an example
- - Toggle on Automate Pipeline
- 
-
-
-2. Click 'Add Blueprint'. Fill in the form and 'Save Blueprint'.
-
- - **NOTE**: The schedule syntax is standard unix cron syntax, [Crontab.guru](https://crontab.guru/) is an useful reference
- - **IMPORANT**: The scheduler is running using the `UTC` timezone. If you want data collection to happen at 3 AM New York time (UTC-04:00) every day, use **Custom Shedule** and set it to `0 7 * * *`
-
- 
-
-3. Click 'Save Blueprint'.
-
-4. Click 'Pipeline Blueprints', you can view and edit the new blueprint in the blueprint list.
-
- 
\ No newline at end of file
diff --git a/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md b/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md
deleted file mode 100644
index f893a830dfd..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/TemporalSetup.md
+++ /dev/null
@@ -1,35 +0,0 @@
----
-title: "Temporal Setup"
-sidebar_position: 5
-description: >
- The steps to install DevLake in Temporal mode.
----
-
-
-Normally, DevLake would execute pipelines on a local machine (we call it `local mode`), it is sufficient most of the time. However, when you have too many pipelines that need to be executed in parallel, it can be problematic, as the horsepower and throughput of a single machine is limited.
-
-`temporal mode` was added to support distributed pipeline execution, you can fire up arbitrary workers on multiple machines to carry out those pipelines in parallel to overcome the limitations of a single machine.
-
-But, be careful, many API services like JIRA/GITHUB have a request rate limit mechanism. Collecting data in parallel against the same API service with the same identity would most likely hit such limit.
-
-## How it works
-
-1. DevLake Server and Workers connect to the same temporal server by setting up `TEMPORAL_URL`
-2. DevLake Server sends a `pipeline` to the temporal server, and one of the Workers pick it up and execute it
-
-
-**IMPORTANT: This feature is in early stage of development. Please use with caution**
-
-
-## Temporal Demo
-
-### Requirements
-
-- [Docker](https://docs.docker.com/get-docker)
-- [docker-compose](https://docs.docker.com/compose/install/)
-- [temporalio](https://temporal.io/)
-
-### How to setup
-
-1. Clone and fire up [temporalio](https://temporal.io/) services
-2. Clone this repo, and fire up DevLake with command `docker-compose -f docker-compose-temporal.yml up -d`
\ No newline at end of file
diff --git a/versioned_docs/version-v0.11/UserManuals/_category_.json b/versioned_docs/version-v0.11/UserManuals/_category_.json
deleted file mode 100644
index b47bdfd7d09..00000000000
--- a/versioned_docs/version-v0.11/UserManuals/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "User Manuals",
- "position": 3
-}
diff --git a/versioned_docs/version-v0.12/DataModels/DataSupport.md b/versioned_docs/version-v0.12/DataModels/DataSupport.md
deleted file mode 100644
index 4cb4b619131..00000000000
--- a/versioned_docs/version-v0.12/DataModels/DataSupport.md
+++ /dev/null
@@ -1,59 +0,0 @@
----
-title: "Data Support"
-description: >
- Data sources that DevLake supports
-sidebar_position: 1
----
-
-
-## Data Sources and Data Plugins
-DevLake supports the following data sources. The data from each data source is collected with one or more plugins. There are 9 data plugins in total: `ae`, `feishu`, `gitextractor`, `github`, `gitlab`, `jenkins`, `jira`, `refdiff` and `tapd`.
-
-
-| Data Source | Versions | Plugins |
-|-------------|--------------------------------------|-------- |
-| AE | | `ae` |
-| Feishu | Cloud |`feishu` |
-| GitHub | Cloud |`github`, `gitextractor`, `refdiff` |
-| Gitlab | Cloud, Community Edition 13.x+ |`gitlab`, `gitextractor`, `refdiff` |
-| Jenkins | 2.263.x+ |`jenkins` |
-| Jira | Cloud, Server 8.x+, Data Center 8.x+ |`jira` |
-| TAPD | Cloud | `tapd` |
-
-
-
-## Data Collection Scope By Each Plugin
-This table shows the entities collected by each plugin. Domain layer entities in this table are consistent with the entities [here](./DevLakeDomainLayerSchema.md).
-
-| Domain Layer Entities | ae | gitextractor | github | gitlab | jenkins | jira | refdiff | tapd |
-| --------------------- | -------------- | ------------ | -------------- | ------- | ------- | ------- | ------- | ------- |
-| commits | update commits | default | not-by-default | default | | | | |
-| commit_parents | | default | | | | | | |
-| commit_files | | default | | | | | | |
-| pull_requests | | | default | default | | | | |
-| pull_request_commits | | | default | default | | | | |
-| pull_request_comments | | | default | default | | | | |
-| pull_request_labels | | | default | | | | | |
-| refs | | default | | | | | | |
-| refs_commits_diffs | | | | | | | default | |
-| refs_issues_diffs | | | | | | | default | |
-| ref_pr_cherry_picks | | | | | | | default | |
-| repos | | | default | default | | | | |
-| repo_commits | | default | default | | | | | |
-| board_repos | | | | | | | | |
-| issue_commits | | | | | | | | |
-| issue_repo_commits | | | | | | | | |
-| pull_request_issues | | | | | | | | |
-| refs_issues_diffs | | | | | | | | |
-| boards | | | default | | | default | | default |
-| board_issues | | | default | | | default | | default |
-| issue_changelogs | | | | | | default | | default |
-| issues | | | default | | | default | | default |
-| issue_comments | | | | | | default | | default |
-| issue_labels | | | default | | | | | |
-| sprints | | | | | | default | | default |
-| issue_worklogs | | | | | | default | | default |
-| users o | | | default | | | default | | default |
-| builds | | | | | default | | | |
-| jobs | | | | | default | | | |
-
diff --git a/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md b/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md
deleted file mode 100644
index 10c80d907a1..00000000000
--- a/versioned_docs/version-v0.12/DataModels/DevLakeDomainLayerSchema.md
+++ /dev/null
@@ -1,544 +0,0 @@
----
-title: "Domain Layer Schema"
-description: >
- DevLake Domain Layer Schema
-sidebar_position: 2
----
-
-## Summary
-
-This document describes the entities in DevLake's domain layer schema and their relationships.
-
-Data in the domain layer is transformed from the data in the tool layer. The tool layer schema is based on the data from specific tools such as Jira, GitHub, Gitlab, Jenkins, etc. The domain layer schema can be regarded as an abstraction of tool-layer schemas.
-
-Domain layer schema itself includes 2 logical layers: a `DWD` layer and a `DWM` layer. The DWD layer stores the detailed data points, while the DWM is the slight aggregation and operation of DWD to store more organized details or middle-level metrics.
-
-
-## Use Cases
-1. Users can make customized Grafana dashboards based on the domain layer schema.
-2. Contributors can complete the ETL logic when adding new data source plugins refering to this data model.
-
-
-## Data Models
-
-This is the up-to-date domain layer schema for DevLake v0.10.x. Tables (entities) are categorized into 5 domains.
-1. Issue tracking domain entities: Jira issues, GitHub issues, GitLab issues, etc.
-2. Source code management domain entities: Git/GitHub/Gitlab commits and refs(tags and branches), etc.
-3. Code review domain entities: GitHub PRs, Gitlab MRs, etc.
-4. CI/CD domain entities: Jenkins jobs & builds, etc.
-5. Cross-domain entities: entities that map entities from different domains to break data isolation.
-
-
-### Schema Diagram
-
-
-When reading the schema, you'll notice that many tables' primary key is called `id`. Unlike auto-increment id or UUID, `id` is a string composed of several parts to uniquely identify similar entities (e.g. repo) from different platforms (e.g. Github/Gitlab) and allow them to co-exist in a single table.
-
-Tables that end with WIP are still under development.
-
-
-### Naming Conventions
-
-1. The name of a table is in plural form. Eg. boards, issues, etc.
-2. The name of a table which describe the relation between 2 entities is in the form of [BigEntity in singular form]\_[SmallEntity in plural form]. Eg. board_issues, sprint_issues, pull_request_comments, etc.
-3. Value of the field in enum type are in capital letters. Eg. [table.issues.type](https://merico.feishu.cn/docs/doccnvyuG9YpVc6lvmWkmmbZtUc#ZDCw9k) has 3 values, REQUIREMENT, BUG, INCIDENT. Values that are phrases, such as 'IN_PROGRESS' of [table.issues.status](https://merico.feishu.cn/docs/doccnvyuG9YpVc6lvmWkmmbZtUc#ZDCw9k), are separated with underscore '\_'.
-
-| Category | -Metric Name | -Definition | -Data Required | -Use Scenarios and Recommended Practices | -Value | -
|---|---|---|---|---|---|
| Delivery Velocity | -Requirement Count | -Number of issues in type "Requirement" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process.
- 2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. - 3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. - 4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. |
- 1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources.
- 2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. |
-
| Requirement Delivery Rate | -Ratio of delivered requirements to all requirements | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -|||
| Requirement Lead Time | -Lead time of issues with type "Requirement" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the trend of requirement lead time to observe if it has improved over time.
- 2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time. - 3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow. |
- 1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays
- 2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks. |
- |
| Requirement Granularity | -Number of story points associated with an issue | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal.
- 2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents) |
- 1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team.
- 2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management. |
- |
| Commit Count | -Number of Commits | -Source Code Management entities: Git/GitHub/GitLab commits | -
-1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison
- 2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents) |
- 1. Identify potential bottlenecks that may affect output
- 2. Encourage R&D practices of small step submissions and develop excellent coding habits |
- |
| Added Lines of Code | -Accumulated number of added lines of code | -Source Code Management entities: Git/GitHub/GitLab commits | -
-1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate
- 2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model. - 3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison. |
- 1. identify potential bottlenecks that may affect the output
- 2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits |
- |
| Deleted Lines of Code | -Accumulated number of deleted lines of code | -Source Code Management entities: Git/GitHub/GitLab commits | -|||
| Pull Request Review Time | -Time from Pull/Merge created time until merged | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | --1. Observe the mean and distribution of code review time from the project/team/individual dimension to assess the rationality of the review time | -1. Take inventory of project/team code review resources to avoid lack of resources and backlog of review sessions, resulting in long waiting time
- 2. Encourage teams to implement an efficient and responsive code review mechanism |
- |
| Bug Age | -Lead time of issues in type "Bug" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. Observe the trend of bug age and locate the key reasons. -2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of bug and incident age. |
- 1. Help the team to establish an effective hierarchical response mechanism for bugs and incidents. Focus on the resolution of important problems in the backlog. -2. Improve team's and individual's bug/incident fixing efficiency. Identify good/to-be-improved practices that affect bug age or incident age |
- |
| Incident Age | -Lead time of issues in type "Incident" | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -|||
| Delivery Quality | -Pull Request Count | -Number of Pull/Merge Requests | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -
-1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. |
- 1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation |
-
| Pull Request Pass Rate | -Ratio of Pull/Merge Review requests to merged | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Pull Request Review Rounds | -Number of cycles of commits followed by comments/final merge | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Pull Request Review Count | -Number of Pull/Merge Reviewers | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -1. As a secondary indicator, assess the cost of labor invested in the code review process | -1. Take inventory of project/team code review resources to avoid long waits for review sessions due to insufficient resource input | -|
| Bug Count | -Number of bugs found during testing | -Issue/Task Management entities: Jira issues, GitHub issues, etc | -
-1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc. -2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality -3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points -4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values |
- 1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process -2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts -3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects |
- |
| Incident Count | -Number of Incidents found after shipping | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Bugs Count per 1k Lines of Code | -Amount of bugs per 1,000 lines of code | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Incidents Count per 1k Lines of Code | -Amount of incidents per 1,000 lines of code | -Source Code Management entities: GitHub PRs, GitLab MRs, etc | -|||
| Delivery Cost | -Commit Author Count | -Number of Contributors who have committed code | -Source Code Management entities: Git/GitHub/GitLab commits | -1. As a secondary indicator, this helps assess the labor cost of participating in coding | -1. Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment | -
| Delivery Capability | -Build Count | -The number of builds started | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -1. From the project dimension, compare the number of builds and success rate by combining the project phase and the complexity of tasks -2. From the time dimension, analyze the trend of the number of builds and success rate to see if it has improved over time |
- 1. As a process indicator, it reflects the value flow efficiency of upstream production and research links -2. Identify excellent/to-be-improved practices that impact the build, and drive the team to precipitate reusable tools and mechanisms to build infrastructure for fast and high-frequency delivery |
-
| Build Duration | -The duration of successful builds | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -|||
| Build Success Rate | -The percentage of successful builds | -CI/CD entities: Jenkins PRs, GitLabCI MRs, etc | -
DevLake Components
- -A DevLake installation typically consists of the following components: - -- Config UI: A handy user interface to create, trigger, and debug Blueprints. A Blueprint specifies the where (data connection), what (data scope), how (transformation rule), and when (sync frequency) of a data pipeline. -- API Server: The main programmatic interface of DevLake. -- Runner: The runner does all the heavy-lifting for executing tasks. In the default DevLake installation, it runs within the API Server, but DevLake provides a temporal-based runner (beta) for production environments. -- Database: The database stores both DevLake's metadata and user data collected by data pipelines. DevLake supports MySQL and PostgreSQL as of v0.11. -- Plugins: Plugins enable DevLake to collect and analyze dev data from any DevOps tools with an accessible API. DevLake community is actively adding plugins for popular DevOps tools, but if your preferred tool is not covered yet, feel free to open a GitHub issue to let us know or check out our doc on how to build a new plugin by yourself. -- Dashboards: Dashboards deliver data and insights to DevLake users. A dashboard is simply a collection of SQL queries along with corresponding visualization configurations. DevLake's official dashboard tool is Grafana and pre-built dashboards are shipped in Grafana's JSON format. Users are welcome to swap for their own choice of dashboard/BI tool if desired. - -## Dataflow - -
DevLake Dataflow
- -A typical plugin's dataflow is illustrated below: - -1. The Raw layer stores the API responses from data sources (DevOps tools) in JSON. This saves developers' time if the raw data is to be transformed differently later on. Please note that communicating with data sources' APIs is usually the most time-consuming step. -2. The Tool layer extracts raw data from JSONs into a relational schema that's easier to consume by analytical tasks. Each DevOps tool would have a schema that's tailored to their data structure, hence the name, the Tool layer. -3. The Domain layer attempts to build a layer of abstraction on top of the Tool layer so that analytics logics can be re-used across different tools. For example, GitHub's Pull Request (PR) and GitLab's Merge Request (MR) are similar entities. They each have their own table name and schema in the Tool layer, but they're consolidated into a single entity in the Domain layer, so that developers only need to implement metrics like Cycle Time and Code Review Rounds once against the domain layer schema. - -## Principles - -1. Extensible: DevLake's plugin system allows users to integrate with any DevOps tool. DevLake also provides a dbt plugin that enables users to define their own data transformation and analysis workflows. -2. Portable: DevLake has a modular design and provides multiple options for each module. Users of different setups can freely choose the right configuration for themselves. -3. Robust: DevLake provides an SDK to help plugins efficiently and reliably collect data from data sources while respecting their API rate limits and constraints. - -
-
-## Project Metrics This Covers
-
-| Metric Name | Description |
-|:------------------------------------|:--------------------------------------------------------------------------------------------------|
-| Requirement Count | Number of issues with type "Requirement" |
-| Requirement Lead Time | Lead time of issues with type "Requirement" |
-| Requirement Delivery Rate | Ratio of delivered requirements to all requirements |
-| Requirement Granularity | Number of story points associated with an issue |
-| Bug Count | Number of issues with type "Bug"
-
-When first visiting Grafana, you will be provided with a sample dashboard with some basic charts setup from the database.
-
-## Contents
-
-Section | Link
-:------------ | :-------------
-Logging In | [View Section](#logging-in)
-Viewing All Dashboards | [View Section](#viewing-all-dashboards)
-Customizing a Dashboard | [View Section](#customizing-a-dashboard)
-Dashboard Settings | [View Section](#dashboard-settings)
-Provisioning a Dashboard | [View Section](#provisioning-a-dashboard)
-Troubleshooting DB Connection | [View Section](#troubleshooting-db-connection)
-
-## Logging In
-
-Once the app is up and running, visit `http://localhost:3002` to view the Grafana dashboard.
-
-Default login credentials are:
-
-- Username: `admin`
-- Password: `admin`
-
-## Viewing All Dashboards
-
-To see all dashboards created in Grafana visit `/dashboards`
-
-Or, use the sidebar and click on **Manage**:
-
-
-
-
-## Customizing a Dashboard
-
-When viewing a dashboard, click the top bar of a panel, and go to **edit**
-
-
-
-**Edit Dashboard Panel Page:**
-
-
-
-### 1. Preview Area
-- **Top Left** is the variable select area (custom dashboard variables, used for switching projects, or grouping data)
-- **Top Right** we have a toolbar with some buttons related to the display of the data:
- - View data results in a table
- - Time range selector
- - Refresh data button
-- **The Main Area** will display the chart and should update in real time
-
-> Note: Data should refresh automatically, but may require a refresh using the button in some cases
-
-### 2. Query Builder
-Here we form the SQL query to pull data into our chart, from our database
-- Ensure the **Data Source** is the correct database
-
- 
-
-- Select **Format as Table**, and **Edit SQL** buttons to write/edit queries as SQL
-
- 
-
-- The **Main Area** is where the queries are written, and in the top right is the **Query Inspector** button (to inspect returned data)
-
- 
-
-### 3. Main Panel Toolbar
-In the top right of the window are buttons for:
-- Dashboard settings (regarding entire dashboard)
-- Save/apply changes (to specific panel)
-
-### 4. Grafana Parameter Sidebar
-- Change chart style (bar/line/pie chart etc)
-- Edit legends, chart parameters
-- Modify chart styling
-- Other Grafana specific settings
-
-## Dashboard Settings
-
-When viewing a dashboard click on the settings icon to view dashboard settings. Here are 2 important sections to use:
-
-
-
-- Variables
- - Create variables to use throughout the dashboard panels, that are also built on SQL queries
-
- 
-
-- JSON Model
- - Copy `json` code here and save it to a new file in `/grafana/dashboards/` with a unique name in the `lake` repo. This will allow us to persist dashboards when we load the app
-
- 
-
-## Provisioning a Dashboard
-
-To save a dashboard in the `lake` repo and load it:
-
-1. Create a dashboard in browser (visit `/dashboard/new`, or use sidebar)
-2. Save dashboard (in top right of screen)
-3. Go to dashboard settings (in top right of screen)
-4. Click on _JSON Model_ in sidebar
-5. Copy code into a new `.json` file in `/grafana/dashboards`
-
-## Troubleshooting DB Connection
-
-To ensure we have properly connected our database to the data source in Grafana, check database settings in `./grafana/datasources/datasource.yml`, specifically:
-- `database`
-- `user`
-- `secureJsonData/password`
diff --git a/versioned_docs/version-v0.12/UserManuals/Dashboards/_category_.json b/versioned_docs/version-v0.12/UserManuals/Dashboards/_category_.json
deleted file mode 100644
index 0db83c6e9b8..00000000000
--- a/versioned_docs/version-v0.12/UserManuals/Dashboards/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Dashboards",
- "position": 5
-}
diff --git a/versioned_docs/version-v0.12/UserManuals/TeamConfiguration.md b/versioned_docs/version-v0.12/UserManuals/TeamConfiguration.md
deleted file mode 100644
index b81df20001b..00000000000
--- a/versioned_docs/version-v0.12/UserManuals/TeamConfiguration.md
+++ /dev/null
@@ -1,188 +0,0 @@
----
-title: "Team Configuration"
-sidebar_position: 7
-description: >
- Team Configuration
----
-## What is 'Team Configuration' and how it works?
-
-To organize and display metrics by `team`, Apache DevLake needs to know about the team configuration in an organization, specifically:
-
-1. What are the teams?
-2. Who are the users(unified identities)?
-3. Which users belong to a team?
-4. Which accounts(identities in specific tools) belong to the same user?
-
-Each of the questions above corresponds to a table in DevLake's schema, illustrated below:
-
-
-
-1. `teams` table stores all the teams in the organization.
-2. `users` table stores the organization's roster. An entry in the `users` table corresponds to a person in the org.
-3. `team_users` table stores which users belong to a team.
-4. `user_accounts` table stores which accounts belong to a user. An `account` refers to an identiy in a DevOps tool and is automatically created when importing data from that tool. For example, a `user` may have a GitHub `account` as well as a Jira `account`.
-
-Apache DevLake uses a simple heuristic algorithm based on emails and names to automatically map accounts to users and populate the `user_accounts` table.
-When Apache DevLake cannot confidently map an `account` to a `user` due to insufficient information, it allows DevLake users to manually configure the mapping to ensure accuracy and integrity.
-
-## A step-by-step guide
-
-In the following sections, we'll walk through how to configure teams and create the five aforementioned tables (`teams`, `users`, `team_users`, `accounts`, and `user_accounts`).
-The overall workflow is:
-
-1. Create the `teams` table
-2. Create the `users` and `team_users` table
-3. Populate the `accounts` table via data collection
-4. Run a heuristic algorithm to populate `user_accounts` table
-5. Manually update `user_accounts` when the algorithm can't catch everything
-
-Note:
-
-1. Please replace `/path/to/*.csv` with the absolute path of the CSV file you'd like to upload.
-2. Please replace `127.0.0.1:8080` with your actual Apache DevLake service IP and port number.
-
-## Step 1 - Create the `teams` table
-
-You can create the `teams` table by sending a PUT request to `/plugins/org/teams.csv` with a `teams.csv` file. To jumpstart the process, you can download a template `teams.csv` from `/plugins/org/teams.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `teams.csv` file
-
- i. GET http://127.0.0.1:8080/plugins/org/teams.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:8080/plugins/org/teams.csv?fake_data=true'
-
-
-b. Fill out `teams.csv` file and upload it to DevLake
-
- i. Fill out `teams.csv` with your org data. Please don't modify the column headers or the file suffix.
-
- ii. Upload `teams.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:8080/plugins/org/teams.csv' --form 'file=@"/path/to/teams.csv"'
-
- iii. The PUT request would populate the `teams` table with data from `teams.csv` file.
- You can connect to the database and verify the data in the `teams` table.
- See Appendix for how to connect to the database.
-
-
-
-
-## Step 2 - Create the `users` and `team_users` table
-
-You can create the `users` and `team_users` table by sending a single PUT request to `/plugins/org/users.csv` with a `users.csv` file. To jumpstart the process, you can download a template `users.csv` from `/plugins/org/users.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `users.csv` file
-
- i. GET http://127.0.0.1:8080/plugins/org/users.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:8080/plugins/org/users.csv?fake_data=true'
-
-
-b. Fill out `users.csv` and upload to DevLake
-
- i. Fill out `users.csv` with your org data. Please don't modify the column headers or the file suffix
-
- ii. Upload `users.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:8080/plugins/org/users.csv' --form 'file=@"/path/to/users.csv"'
-
- iii. The PUT request would populate the `users` table along with the `team_users` table with data from `users.csv` file.
- You can connect to the database and verify these two tables.
-
-
-
-
-
-c. If you ever want to update `team_users` or `users` table, simply upload the updated `users.csv` to DevLake again following step b.
-
-## Step 3 - Populate the `accounts` table via data collection
-
-The `accounts` table is automatically populated when you collect data from data sources like GitHub and Jira through DevLake.
-
-For example, the GitHub plugin would create one entry in the `accounts` table for each GitHub user involved in your repository.
-For demo purposes, we'll insert some mock data into the `accounts` table using SQL:
-
-```
-INSERT INTO `accounts` (`id`, `created_at`, `updated_at`, `_raw_data_params`, `_raw_data_table`, `_raw_data_id`, `_raw_data_remark`, `email`, `full_name`, `user_name`, `avatar_url`, `organization`, `created_date`, `status`)
-VALUES
- ('github:GithubAccount:1:1234', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"Owner\":\"apache\",\"Repo\":\"incubator-devlake\"}', '_raw_github_api_pull_request_reviews', 28, '', 'TyroneKCummings@teleworm.us', '', 'Tyrone K. Cummings', 'https://avatars.githubusercontent.com/u/101256042?u=a6e460fbaffce7514cbd65ac739a985f5158dabc&v=4', '', NULL, 0),
- ('jira:JiraAccount:1:629cdf', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"BoardId\":\"76\"}', '_raw_jira_api_users', 5, '', 'DorothyRUpdegraff@dayrep.com', '', 'Dorothy R. Updegraff', 'https://avatars.jiraxxxx158dabc&v=4', '', NULL, 0);
-
-```
-
-
-
-## Step 4 - Run a heuristic algorithm to populate `user_accounts` table
-
-Now that we have data in both the `users` and `accounts` table, we can tell DevLake to infer the mappings between `users` and `accounts` with a simple heuristic algorithm based on names and emails.
-
-a. Send an API request to DevLake to run the mapping algorithm
-
-```
-curl --location --request POST '127.0.0.1:8080/pipelines' \
---header 'Content-Type: application/json' \
---data-raw '{
- "name": "test",
- "plan":[
- [
- {
- "plugin": "org",
- "subtasks":["connectUserAccountsExact"],
- "options":{
- "connectionId":1
- }
- }
- ]
- ]
-}'
-```
-
-b. After successful execution, you can verify the data in `user_accounts` in the database.
-
-
-
-## Step 5 - Manually update `user_accounts` when the algorithm can't catch everything
-
-It is recommended to examine the generated `user_accounts` table after running the algorithm.
-We'll demonstrate how to manually update `user_accounts` when the mapping is inaccurate/incomplete in this section.
-To make manual verification easier, DevLake provides an API for users to download `user_accounts` as a CSV file.
-Alternatively, you can verify and modify `user_accounts` all by SQL, see Appendix for more info.
-
-a. GET http://127.0.0.1:8080/plugins/org/user_account_mapping.csv(pasting the URL into your browser will download the file). If you prefer using curl:
-```
-curl --location --request GET 'http://127.0.0.1:8080/plugins/org/user_account_mapping.csv'
-```
-
-
-
-b. If you find the mapping inaccurate or incomplete, you can modify the `user_account_mapping.csv` file and then upload it to DevLake.
-For example, here we change the `UserId` of row 'Id=github:GithubAccount:1:1234' in the `user_account_mapping.csv` file to 2.
-Then we upload the updated `user_account_mapping.csv` file with the following curl command:
-
-```
-curl --location --request PUT 'http://127.0.0.1:8080/plugins/org/user_account_mapping.csv' --form 'file=@"/path/to/user_account_mapping.csv"'
-```
-
-c. You can verify the data in the `user_accounts` table has been updated.
-
-
-
-## Appendix A: how to connect to the database
-
-Here we use MySQL as an example. You can install database management tools like Sequel Ace, DataGrip, MySQLWorkbench, etc.
-
-
-Or through the command line:
-
-```
-mysql -h 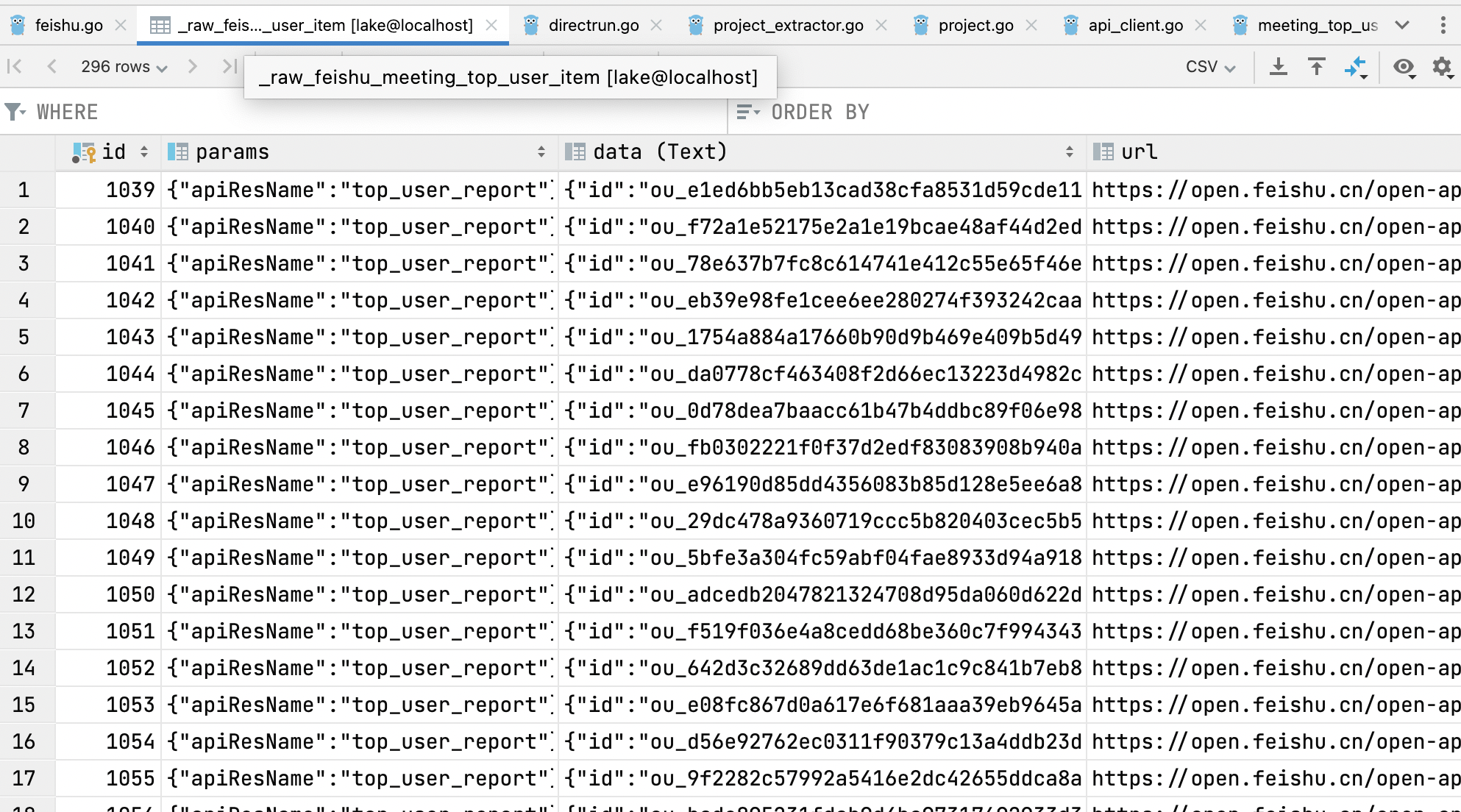 -Ok, the data has now been saved to the `_raw_feishu_*` table, and the `data` column is the return information from the plugin. Here we only collected data for the last 2 days. The data information is not much, but it also covers a variety of situations. That is, the same person has data on different days.
-
-It is also worth mentioning that the plugin runs two tasks, `collectMeetingTopUserItem` and `extractMeetingTopUserItem`. The former is the task of collecting, which is needed to run this time, and the latter is the task of extracting data. It doesn't matter whether the extractor runs in the prepared data session.
-
-Next, we need to export the data to .csv format. This step can be done in a variety of different ways - you can show your skills. I will only introduce a few common methods here.
-
-### DevLake Code Generator Export
-
-Run `go run generator/main.go create-e2e-raw` directly and follow the guidelines to complete the export. This solution is the simplest, but has some limitations, such as the exported fields being fixed. You can refer to the next solutions if you need more customisation options.
-
-
-
-### GoLand Database export
-
-
-
-This solution is very easy to use and will not cause problems using Postgres or MySQL.
-
-The success criteria for csv export is that the go program can read it without errors, so several points are worth noticing.
-
-1. the values in the csv file should be wrapped in double quotes to avoid special symbols such as commas in the values that break the csv format
-2. double quotes in csv files are escaped. generally `""` represents a double quote
-3. pay attention to whether the column `data` is the actual value, not the value after base64 or hex
-
-After exporting, move the .csv file to `plugins/feishu/e2e/raw_tables/_raw_feishu_meeting_top_user_item.csv`.
-
-### MySQL Select Into Outfile
-
-This is MySQL's solution for exporting query results to a file. The MySQL currently started in docker-compose.yml comes with the --security parameter, so it does not allow `select ... into outfile`. The first step is to turn off the security parameter, which is done roughly as follows.
-
-After closing it, use `select ... into outfile` to export the csv file. The export result is rough as follows.
-
-Notice that the data field has extra hexsha fields, which need to be manually converted to literal quantities.
-
-### Vscode Database
-
-This is Vscode's solution for exporting query results to a file, but it is not easy to use. Here is the export result without any configuration changes
-
-However, it is obvious that the escape symbol does not conform to the csv specification, and the data is not successfully exported. After adjusting the configuration and manually replacing `\"` with `""`, we get the following result.
-
-The data field of this file is encoded in base64, so it needs to be decoded manually to a literal amount before using it.
-
-### MySQL workerbench
-
-This tool must write the SQL yourself to complete the data export, which can be rewritten by imitating the following SQL.
-```sql
-SELECT id, params, CAST(`data` as char) as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item;
-```
-
-Select csv as the save format and export it for use.
-
-### Postgres Copy with csv header
-
-`Copy(SQL statement) to '/var/lib/postgresql/data/raw.csv' with csv header;` is a common export method for PG to export csv, which can also be used here.
-```sql
-COPY (
-SELECT id, params, convert_from(data, 'utf-8') as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item
-) to '/var/lib/postgresql/data/raw.csv' with csv header;
-```
-Use the above statement to complete the export of the file. If pg runs in docker, just use the command `docker cp` to export the file to the host.
-
-## Writing E2E tests
-
-First, create a test environment. For example, let's create `meeting_test.go`.
-
-Then enter the test preparation code in it as follows. The code is to create an instance of the `feishu` plugin and then call `ImportCsvIntoRawTable` to import the data from the csv file into the `_raw_feishu_meeting_top_user_item` table.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-}
-```
-The signature of the import function is as follows.
-```func (t *DataFlowTester) ImportCsvIntoRawTable(csvRelPath string, rawTableName string)```
-It has a twin, with only slight differences in parameters.
-```func (t *DataFlowTester) ImportCsvIntoTabler(csvRelPath string, dst schema.Tabler)```
-The former is used to import tables in the raw layer. The latter is used to import arbitrary tables.
-**Note:** These two functions will delete the db table and use `gorm.AutoMigrate` to re-create a new table to clear data in it.
-After importing the data is complete, run this tester and it must be PASS without any test logic at this moment. Then write the logic for calling the call to the extractor task in `TestMeetingDataFlow`.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- taskData := &tasks.FeishuTaskData{
- Options: &tasks.FeishuOptions{
- ConnectionId: 1,
- },
- }
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-
- // verify extraction
- dataflowTester.FlushTabler(&models.FeishuMeetingTopUserItem{})
- dataflowTester.Subtask(tasks.ExtractMeetingTopUserItemMeta, taskData)
-
-}
-```
-The added code includes a call to `dataflowTester.FlushTabler` to clear the table `_tool_feishu_meeting_top_user_items` and a call to `dataflowTester.Subtask` to simulate the running of the subtask `ExtractMeetingTopUserItemMeta`.
-
-Now run it and see if the subtask `ExtractMeetingTopUserItemMeta` completes without errors. The data results of the `extract` run generally come from the raw table, so the plugin subtask will run correctly if written without errors. We can observe if the data is successfully parsed in the db table in the tool layer. In this case the `_tool_feishu_meeting_top_user_items` table has the correct data.
-
-If the run is incorrect, maybe you can troubleshoot the problem with the plugin itself before moving on to the next step.
-
-## Verify that the results of the task are correct
-
-Let's continue writing the test and add the following code at the end of the test function
-```go
-func TestMeetingDataFlow(t *testing.T) {
- ......
-
- dataflowTester.VerifyTable(
- models.FeishuMeetingTopUserItem{},
- "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv",
- []string{
- "meeting_count",
- "meeting_duration",
- "user_type",
- "_raw_data_params",
- "_raw_data_table",
- "_raw_data_id",
- "_raw_data_remark",
- },
- )
-}
-```
-Its purpose is to call `dataflowTester.VerifyTable` to complete the validation of the data results. The third parameter is all the fields of the table that need to be verified.
-The data used for validation exists in `. /snapshot_tables/_tool_feishu_meeting_top_user_items.csv`, but of course, this file does not exist yet.
-
-There is a twin, more generalized function, that could be used instead:
-```go
-dataflowTester.VerifyTableWithOptions(models.FeishuMeetingTopUserItem{},
- dataflowTester.TableOptions{
- CSVRelPath: "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv"
- },
- )
-
-```
-The above usage will default to validating against all fields of the ```models.FeishuMeetingTopUserItem``` model. There are additional fields on ```TableOptions``` that can be specified
-to limit which fields on that model to perform validation on.
-
-To facilitate the generation of the file mentioned above, DevLake has adopted a testing technique called `Snapshot`, which will automatically generate the file based on the run results when the `VerifyTable` or `VerifyTableWithOptions` functions are called without the csv existing.
-
-But note! Please do two things after the snapshot is created: 1. check if the file is generated correctly 2. re-run it to make sure there are no errors between the generated results and the re-run results.
-These two operations are critical and directly related to the quality of test writing. We should treat the snapshot file in `.csv' format like a code file.
-
-If there is a problem with this step, there are usually 2 ways to solve it.
-1. The validated fields contain fields like create_at runtime or self-incrementing ids, which cannot be repeatedly validated and should be excluded.
-2. there is `\n` or `\r\n` or other escape mismatch fields in the run results. Generally, when parsing the `httpResponse` error, you can follow these solutions:
- 1. modify the field type of the content in the api model to `json.
- 2. convert it to string when parsing
- 3. so that the `\n` symbol can be kept intact, avoiding the parsing of line breaks by the database or the operating system
-
-
-For example, in the `github` plugin, this is how it is handled.
-
-
-
-Well, at this point, the E2E writing is done. We have added a total of 3 new files to complete the testing of the meeting length collection task. It's pretty easy.
-
-
-## Run E2E tests for all plugins like CI
-
-It's straightforward. Just run `make e2e-plugins` because DevLake has already solidified it into a script~
-
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md b/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md
deleted file mode 100644
index 23456b4f1e7..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: "Notifications"
-description: >
- Notifications
-sidebar_position: 4
----
-
-## Request
-Example request
-```
-POST /lake/notify?nouce=3-FDXxIootApWxEVtz&sign=424c2f6159bd9e9828924a53f9911059433dc14328a031e91f9802f062b495d5
-
-{"TaskID":39,"PluginName":"jenkins","CreatedAt":"2021-09-30T15:28:00.389+08:00","UpdatedAt":"2021-09-30T15:28:00.785+08:00"}
-```
-
-## Configuration
-If you want to use the notification feature, you should add two configuration key to `.env` file.
-```shell
-# .env
-# notification request url, e.g.: http://example.com/lake/notify
-NOTIFICATION_ENDPOINT=
-# secret is used to calculate signature
-NOTIFICATION_SECRET=
-```
-
-## Signature
-You should check the signature before accepting the notification request. We use sha256 algorithm to calculate the checksum.
-```go
-// calculate checksum
-sum := sha256.Sum256([]byte(requestBody + NOTIFICATION_SECRET + nouce))
-return hex.EncodeToString(sum[:])
-```
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md b/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md
deleted file mode 100644
index b478a4ddd43..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md
+++ /dev/null
@@ -1,339 +0,0 @@
----
-title: "Plugin Implementation"
-sidebar_position: 2
-description: >
- Plugin Implementation
----
-
-If your favorite DevOps tool is not yet supported by DevLake, don't worry. It's not difficult to implement a DevLake plugin. In this post, we'll go through the basics of DevLake plugins and build an example plugin from scratch together.
-
-## What is a plugin?
-
-A DevLake plugin is a shared library built with Go's `plugin` package that hooks up to DevLake core at run-time.
-
-A plugin may extend DevLake's capability in three ways:
-
-1. Integrating with new data sources
-2. Transforming/enriching existing data
-3. Exporting DevLake data to other data systems
-
-
-## How do plugins work?
-
-A plugin mainly consists of a collection of subtasks that can be executed by DevLake core. For data source plugins, a subtask may be collecting a single entity from the data source (e.g., issues from Jira). Besides the subtasks, there're hooks that a plugin can implement to customize its initialization, migration, and more. See below for a list of the most important interfaces:
-
-1. [PluginMeta](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_meta.go) contains the minimal interface that a plugin should implement, with only two functions
- - Description() returns the description of a plugin
- - RootPkgPath() returns the root package path of a plugin
-2. [PluginInit](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_init.go) allows a plugin to customize its initialization
-3. [PluginTask](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_task.go) enables a plugin to prepare data prior to subtask execution
-4. [PluginApi](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_api.go) lets a plugin exposes some self-defined APIs
-5. [PluginMigration](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_migration.go) is where a plugin manages its database migrations
-6. [PluginModel](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_model.go) allows other plugins to get the model information of all database tables of the current plugin through the GetTablesInfo() method.If you need to access Domain Layer Models,please visit [DomainLayerSchema](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/)
-
-The diagram below shows the control flow of executing a plugin:
-
-```mermaid
-flowchart TD;
- subgraph S4[Step4 sub-task extractor running process];
- direction LR;
- D4[DevLake];
- D4 -- "Step4.1 create a new\n ApiExtractor\n and execute it" --> E["ExtractXXXMeta.\nEntryPoint"];
- E <-- "Step4.2 read from\n raw table" --> E2["RawDataSubTaskArgs\n.Table"];
- E -- "Step4.3 call with RawData" --> ApiExtractor.Extract;
- ApiExtractor.Extract -- "decode and return gorm models" --> E
- end
- subgraph S3[Step3 sub-task collector running process]
- direction LR
- D3[DevLake]
- D3 -- "Step3.1 create a new\n ApiCollector\n and execute it" --> C["CollectXXXMeta.\nEntryPoint"];
- C <-- "Step3.2 create\n raw table" --> C2["RawDataSubTaskArgs\n.RAW_BBB_TABLE"];
- C <-- "Step3.3 build query\n before sending requests" --> ApiCollectorArgs.\nQuery/UrlTemplate;
- C <-. "Step3.4 send requests by ApiClient \n and return HTTP response" .-> A1["HTTP APIs"];
- C <-- "Step3.5 call and \nreturn decoded data \nfrom HTTP response" --> ResponseParser;
- end
- subgraph S2[Step2 DevLake register custom plugin]
- direction LR
- D2[DevLake]
- D2 <-- "Step2.1 function \`Init\` \nneed to do init jobs" --> plugin.Init;
- D2 <-- "Step2.2 (Optional) call \nand return migration scripts" --> plugin.MigrationScripts;
- D2 <-- "Step2.3 (Optional) call \nand return taskCtx" --> plugin.PrepareTaskData;
- D2 <-- "Step2.4 call and \nreturn subTasks for execting" --> plugin.SubTaskContext;
- end
- subgraph S1[Step1 Run DevLake]
- direction LR
- main -- "Transfer of control \nby \`runner.DirectRun\`" --> D1[DevLake];
- end
- S1-->S2-->S3-->S4
-```
-There's a lot of information in the diagram but we don't expect you to digest it right away, simply use it as a reference when you go through the example below.
-
-## A step-by-step guide towards your first plugin
-
-In this section, we will describe how to create a data collection plugin from scratch. The data to be collected is the information about all Committers and Contributors of the Apache project, in order to check whether they have signed the CLA. We are going to
-
-* request `https://people.apache.org/public/icla-info.json` to get the Committers' information
-* request the `mailing list` to get the Contributors' information
-
-We will focus on demonstrating how to request and cache information about all Committers through the Apache API and extract structured data from it. The collection of Contributors will only be briefly described.
-
-### Step 1: Bootstrap the new plugin
-
-**Note:** Please make sure you have DevLake up and running before proceeding.
-
-> More info about plugin:
-> Generally, we need these folders in plugin folders: `api`, `models` and `tasks`
-> `api` interacts with `config-ui` for test/get/save connection of data source
-> - connection [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/api/connection.go)
-> - connection model [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/models/connection.go)
-> `models` stores all `data entities` and `data migration scripts`.
-> - entity
-> - data migrations [template](https://github.com/apache/incubator-devlake/tree/main/generator/template/migrationscripts)
-> `tasks` contains all of our `sub tasks` for a plugin
-> - task data [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data.go-template)
-> - api client [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data_with_api_client.go-template)
-
-Don't worry if you cannot figure out what these concepts mean immediately. We'll explain them one by one later.
-
-DevLake provides a generator to create a plugin conveniently. Let's scaffold our new plugin by running `go run generator/main.go create-plugin icla`, which would ask for `with_api_client` and `Endpoint`.
-
-* `with_api_client` is used for choosing if we need to request HTTP APIs by api_client.
-* `Endpoint` use in which site we will request, in our case, it should be `https://people.apache.org/`.
-
-
-
-Now we have three files in our plugin. `api_client.go` and `task_data.go` are in subfolder `tasks/`.
-
-
-Have a try to run this plugin by function `main` in `plugin_main.go`. When you see result like this:
-```
-$go run plugins/icla/plugin_main.go
-[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-02 18:07:30] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-02 18:07:30] INFO [icla] total step: 0
-```
-How exciting. It works! The plugin defined and initiated in `plugin_main.go` use some options in `task_data.go`. They are made up as the most straightforward plugin in Apache DevLake, and `api_client.go` will be used in the next step to request HTTP APIs.
-
-### Step 2: Create a sub-task for data collection
-Before we start, it is helpful to know how collection task is executed:
-1. First, Apache DevLake would call `plugin_main.PrepareTaskData()` to prepare needed data before any sub-tasks. We need to create an API client here.
-2. Then Apache DevLake will call the sub-tasks returned by `plugin_main.SubTaskMetas()`. Sub-task is an independent task to do some job, like requesting API, processing data, etc.
-
-> Each sub-task must be defined as a SubTaskMeta, and implement SubTaskEntryPoint of SubTaskMeta. SubTaskEntryPoint is defined as
-> ```go
-> type SubTaskEntryPoint func(c SubTaskContext) error
-> ```
-> More info at: https://devlake.apache.org/blog/how-DevLake-is-up-and-running/
-
-#### Step 2.1: Create a sub-task(Collector) for data collection
-
-Let's run `go run generator/main.go create-collector icla committer` and confirm it. This sub-task is activated by registering in `plugin_main.go/SubTaskMetas` automatically.
-
-
-
-> - Collector will collect data from HTTP or other data sources, and save the data into the raw layer.
-> - Inside the func `SubTaskEntryPoint` of `Collector`, we use `helper.NewApiCollector` to create an object of [ApiCollector](https://github.com/apache/incubator-devlake/blob/main/backend/generator/template/plugin/tasks/api_collector.go-template), then call `execute()` to do the job.
-
-Now you can notice `data.ApiClient` is initiated in `plugin_main.go/PrepareTaskData.ApiClient`. `PrepareTaskData` create a new `ApiClient`, which is a tool Apache DevLake suggests to request data from HTTP Apis. This tool support some valuable features for HttpApi, like rateLimit, proxy and retry. Of course, if you like, you may use the lib `http` instead, but it will be more tedious.
-
-Let's move forward to use it.
-
-1. To collect data from `https://people.apache.org/public/icla-info.json`,
-we have filled `https://people.apache.org/` into `tasks/api_client.go/ENDPOINT` in Step 1.
-
-
-
-2. Fill `public/icla-info.json` into `UrlTemplate`, delete the unnecessary iterator and add `println("receive data:", res)` in `ResponseParser` to see if collection was successful.
-
-
-
-Ok, now the collector sub-task has been added to the plugin, and we can kick it off by running `main` again. If everything goes smoothly, the output should look like this:
-```bash
-[2022-06-06 12:24:52] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 12:24:52] INFO [icla] total step: 1
-[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
-receive data: 0x140005763f0
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1
-```
-
-Great! Now we can see data pulled from the server without any problem. The last step is to decode the response body in `ResponseParser` and return it to the framework, so it can be stored in the database.
-```go
-ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
- body := &struct {
- LastUpdated string `json:"last_updated"`
- Committers json.RawMessage `json:"committers"`
- }{}
- err := helper.UnmarshalResponse(res, body)
- if err != nil {
- return nil, err
- }
- println("receive data:", len(body.Committers))
- return []json.RawMessage{body.Committers}, nil
-},
-
-```
-Ok, run the function `main` once again, then it turned out like this, and we should be able see some records show up in the table `_raw_icla_committer`.
-```bash
-……
-receive data: 272956 /* <- the number means 272956 models received */
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
-```
-
-
-
-#### Step 2.2: Create a sub-task(Extractor) to extract data from the raw layer
-
-> - Extractor will extract data from raw layer and save it into tool db table.
-> - Except for some pre-processing, the main flow is similar to the collector.
-
-We have already collected data from HTTP API and saved them into the DB table `_raw_XXXX`. In this step, we will extract the names of committers from the raw data. As you may infer from the name, raw tables are temporary and not easy to use directly.
-
-Now Apache DevLake suggests to save data by [gorm](https://gorm.io/docs/index.html), so we will create a model by gorm and add it into `plugin_main.go/AutoMigrate()`.
-
-plugins/icla/models/committer.go
-```go
-package models
-
-import (
- "github.com/apache/incubator-devlake/models/common"
-)
-
-type IclaCommitter struct {
- UserName string `gorm:"primaryKey;type:varchar(255)"`
- Name string `gorm:"primaryKey;type:varchar(255)"`
- common.NoPKModel
-}
-
-func (IclaCommitter) TableName() string {
- return "_tool_icla_committer"
-}
-```
-
-plugins/icla/plugin_main.go
-
-
-
-Ok, run the plugin, and table `_tool_icla_committer` will be created automatically just like the snapshot below:
-
-
-Next, let's run `go run generator/main.go create-extractor icla committer` and type in what the command prompt asks for to create a new sub-task.
-
-
-
-Let's look at the function `extract` in `committer_extractor.go` created just now, and the code that needs to be written here. It's obvious that `resData.data` is the raw data, so we could json-decode each row add a new `IclaCommitter` for each and save them.
-```go
-Extract: func(resData *helper.RawData) ([]interface{}, error) {
- names := &map[string]string{}
- err := json.Unmarshal(resData.Data, names)
- if err != nil {
- return nil, err
- }
- extractedModels := make([]interface{}, 0)
- for userName, name := range *names {
- extractedModels = append(extractedModels, &models.IclaCommitter{
- UserName: userName,
- Name: name,
- })fco
- }
- return extractedModels, nil
-},
-```
-
-Ok, run it then we get:
-```
-[2022-06-06 15:39:40] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 15:39:40] INFO [icla] total step: 2
-[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
-receive data: 272956
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
-[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
-[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
-[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2
-```
-Now committer data have been saved in _tool_icla_committer.
-
-
-#### Step 2.3: Convertor
-
-Notes: The goal of Converters is to create a vendor-agnostic model out of the vendor-dependent ones created by the Extractors.
-They are not necessary to have per se, but we encourage it because converters and the domain layer will significantly help with building dashboards. More info about the domain layer [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/).
-
-In short:
-
-> - Convertor will convert data from the tool layer and save it into the domain layer.
-> - We use `helper.NewDataConverter` to create an object of DataConvertor, then call `execute()`.
-
-#### Step 2.4: Let's try it
-Sometimes OpenApi will be protected by token or other auth types, and we need to log in to gain a token to visit it. For example, only after logging in `private@apahce.com` could we gather the data about contributors signing ICLA. Here we briefly introduce how to authorize DevLake to collect data.
-
-Let's look at `api_client.go`. `NewIclaApiClient` load config `ICLA_TOKEN` by `.env`, so we can add `ICLA_TOKEN=XXXXXX` in `.env` and use it in `apiClient.SetHeaders()` to mock the login status. Code as below:
-
-
-Of course, we can use `username/password` to get a token after login mockery. Just try and adjust according to the actual situation.
-
-Look for more related details at https://github.com/apache/incubator-devlake
-
-#### Step 2.5: Implement the GetTablesInfo() method of the PluginModel interface
-
-As shown in the following gitlab plugin example,
-add all models that need to be accessed by external plugins to the return value.
-
-```go
-var _ core.PluginModel = (*Gitlab)(nil)
-
-func (plugin Gitlab) GetTablesInfo() []core.Tabler {
- return []core.Tabler{
- &models.GitlabConnection{},
- &models.GitlabAccount{},
- &models.GitlabCommit{},
- &models.GitlabIssue{},
- &models.GitlabIssueLabel{},
- &models.GitlabJob{},
- &models.GitlabMergeRequest{},
- &models.GitlabMrComment{},
- &models.GitlabMrCommit{},
- &models.GitlabMrLabel{},
- &models.GitlabMrNote{},
- &models.GitlabPipeline{},
- &models.GitlabProject{},
- &models.GitlabProjectCommit{},
- &models.GitlabReviewer{},
- &models.GitlabTag{},
- }
-}
-```
-
-You can use it as follows:
-
-```go
-if pm, ok := plugin.(core.PluginModel); ok {
- tables := pm.GetTablesInfo()
- for _, table := range tables {
- // do something
- }
-}
-
-```
-
-#### Final step: Submit the code as open source code
-We encourage ideas and contributions ~ Let's use migration scripts, domain layers and other discussed concepts to write normative and platform-neutral code. More info at [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema) or contact us for ebullient help.
-
-
-## Done!
-
-Congratulations! The first plugin has been created! 🎖
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md b/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md
deleted file mode 100644
index 9e020d4a8b3..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md
+++ /dev/null
@@ -1,111 +0,0 @@
-# Devlake release guide
-
-**Please make sure your public key was included in the https://downloads.apache.org/incubator/devlake/KEYS , if not, please update https://downloads.apache.org/incubator/devlake/KEYS first.**
-## How to update KEYS
-1. Clone the svn repository
- ```shell
- svn co https://dist.apache.org/repos/dist/dev/incubator/devlake
- ```
-2. Append your public key to the KEYS file
- ```shell
- cd devlake
- (gpg --list-sigs
-Ok, the data has now been saved to the `_raw_feishu_*` table, and the `data` column is the return information from the plugin. Here we only collected data for the last 2 days. The data information is not much, but it also covers a variety of situations. That is, the same person has data on different days.
-
-It is also worth mentioning that the plugin runs two tasks, `collectMeetingTopUserItem` and `extractMeetingTopUserItem`. The former is the task of collecting, which is needed to run this time, and the latter is the task of extracting data. It doesn't matter whether the extractor runs in the prepared data session.
-
-Next, we need to export the data to .csv format. This step can be done in a variety of different ways - you can show your skills. I will only introduce a few common methods here.
-
-### DevLake Code Generator Export
-
-Run `go run generator/main.go create-e2e-raw` directly and follow the guidelines to complete the export. This solution is the simplest, but has some limitations, such as the exported fields being fixed. You can refer to the next solutions if you need more customisation options.
-
-
-
-### GoLand Database export
-
-
-
-This solution is very easy to use and will not cause problems using Postgres or MySQL.
-
-The success criteria for csv export is that the go program can read it without errors, so several points are worth noticing.
-
-1. the values in the csv file should be wrapped in double quotes to avoid special symbols such as commas in the values that break the csv format
-2. double quotes in csv files are escaped. generally `""` represents a double quote
-3. pay attention to whether the column `data` is the actual value, not the value after base64 or hex
-
-After exporting, move the .csv file to `plugins/feishu/e2e/raw_tables/_raw_feishu_meeting_top_user_item.csv`.
-
-### MySQL Select Into Outfile
-
-This is MySQL's solution for exporting query results to a file. The MySQL currently started in docker-compose.yml comes with the --security parameter, so it does not allow `select ... into outfile`. The first step is to turn off the security parameter, which is done roughly as follows.
-
-After closing it, use `select ... into outfile` to export the csv file. The export result is rough as follows.
-
-Notice that the data field has extra hexsha fields, which need to be manually converted to literal quantities.
-
-### Vscode Database
-
-This is Vscode's solution for exporting query results to a file, but it is not easy to use. Here is the export result without any configuration changes
-
-However, it is obvious that the escape symbol does not conform to the csv specification, and the data is not successfully exported. After adjusting the configuration and manually replacing `\"` with `""`, we get the following result.
-
-The data field of this file is encoded in base64, so it needs to be decoded manually to a literal amount before using it.
-
-### MySQL workerbench
-
-This tool must write the SQL yourself to complete the data export, which can be rewritten by imitating the following SQL.
-```sql
-SELECT id, params, CAST(`data` as char) as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item;
-```
-
-Select csv as the save format and export it for use.
-
-### Postgres Copy with csv header
-
-`Copy(SQL statement) to '/var/lib/postgresql/data/raw.csv' with csv header;` is a common export method for PG to export csv, which can also be used here.
-```sql
-COPY (
-SELECT id, params, convert_from(data, 'utf-8') as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item
-) to '/var/lib/postgresql/data/raw.csv' with csv header;
-```
-Use the above statement to complete the export of the file. If pg runs in docker, just use the command `docker cp` to export the file to the host.
-
-## Writing E2E tests
-
-First, create a test environment. For example, let's create `meeting_test.go`.
-
-Then enter the test preparation code in it as follows. The code is to create an instance of the `feishu` plugin and then call `ImportCsvIntoRawTable` to import the data from the csv file into the `_raw_feishu_meeting_top_user_item` table.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-}
-```
-The signature of the import function is as follows.
-```func (t *DataFlowTester) ImportCsvIntoRawTable(csvRelPath string, rawTableName string)```
-It has a twin, with only slight differences in parameters.
-```func (t *DataFlowTester) ImportCsvIntoTabler(csvRelPath string, dst schema.Tabler)```
-The former is used to import tables in the raw layer. The latter is used to import arbitrary tables.
-**Note:** These two functions will delete the db table and use `gorm.AutoMigrate` to re-create a new table to clear data in it.
-After importing the data is complete, run this tester and it must be PASS without any test logic at this moment. Then write the logic for calling the call to the extractor task in `TestMeetingDataFlow`.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- taskData := &tasks.FeishuTaskData{
- Options: &tasks.FeishuOptions{
- ConnectionId: 1,
- },
- }
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-
- // verify extraction
- dataflowTester.FlushTabler(&models.FeishuMeetingTopUserItem{})
- dataflowTester.Subtask(tasks.ExtractMeetingTopUserItemMeta, taskData)
-
-}
-```
-The added code includes a call to `dataflowTester.FlushTabler` to clear the table `_tool_feishu_meeting_top_user_items` and a call to `dataflowTester.Subtask` to simulate the running of the subtask `ExtractMeetingTopUserItemMeta`.
-
-Now run it and see if the subtask `ExtractMeetingTopUserItemMeta` completes without errors. The data results of the `extract` run generally come from the raw table, so the plugin subtask will run correctly if written without errors. We can observe if the data is successfully parsed in the db table in the tool layer. In this case the `_tool_feishu_meeting_top_user_items` table has the correct data.
-
-If the run is incorrect, maybe you can troubleshoot the problem with the plugin itself before moving on to the next step.
-
-## Verify that the results of the task are correct
-
-Let's continue writing the test and add the following code at the end of the test function
-```go
-func TestMeetingDataFlow(t *testing.T) {
- ......
-
- dataflowTester.VerifyTable(
- models.FeishuMeetingTopUserItem{},
- "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv",
- []string{
- "meeting_count",
- "meeting_duration",
- "user_type",
- "_raw_data_params",
- "_raw_data_table",
- "_raw_data_id",
- "_raw_data_remark",
- },
- )
-}
-```
-Its purpose is to call `dataflowTester.VerifyTable` to complete the validation of the data results. The third parameter is all the fields of the table that need to be verified.
-The data used for validation exists in `. /snapshot_tables/_tool_feishu_meeting_top_user_items.csv`, but of course, this file does not exist yet.
-
-There is a twin, more generalized function, that could be used instead:
-```go
-dataflowTester.VerifyTableWithOptions(models.FeishuMeetingTopUserItem{},
- dataflowTester.TableOptions{
- CSVRelPath: "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv"
- },
- )
-
-```
-The above usage will default to validating against all fields of the ```models.FeishuMeetingTopUserItem``` model. There are additional fields on ```TableOptions``` that can be specified
-to limit which fields on that model to perform validation on.
-
-To facilitate the generation of the file mentioned above, DevLake has adopted a testing technique called `Snapshot`, which will automatically generate the file based on the run results when the `VerifyTable` or `VerifyTableWithOptions` functions are called without the csv existing.
-
-But note! Please do two things after the snapshot is created: 1. check if the file is generated correctly 2. re-run it to make sure there are no errors between the generated results and the re-run results.
-These two operations are critical and directly related to the quality of test writing. We should treat the snapshot file in `.csv' format like a code file.
-
-If there is a problem with this step, there are usually 2 ways to solve it.
-1. The validated fields contain fields like create_at runtime or self-incrementing ids, which cannot be repeatedly validated and should be excluded.
-2. there is `\n` or `\r\n` or other escape mismatch fields in the run results. Generally, when parsing the `httpResponse` error, you can follow these solutions:
- 1. modify the field type of the content in the api model to `json.
- 2. convert it to string when parsing
- 3. so that the `\n` symbol can be kept intact, avoiding the parsing of line breaks by the database or the operating system
-
-
-For example, in the `github` plugin, this is how it is handled.
-
-
-
-Well, at this point, the E2E writing is done. We have added a total of 3 new files to complete the testing of the meeting length collection task. It's pretty easy.
-
-
-## Run E2E tests for all plugins like CI
-
-It's straightforward. Just run `make e2e-plugins` because DevLake has already solidified it into a script~
-
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md b/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md
deleted file mode 100644
index 23456b4f1e7..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/Notifications.md
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: "Notifications"
-description: >
- Notifications
-sidebar_position: 4
----
-
-## Request
-Example request
-```
-POST /lake/notify?nouce=3-FDXxIootApWxEVtz&sign=424c2f6159bd9e9828924a53f9911059433dc14328a031e91f9802f062b495d5
-
-{"TaskID":39,"PluginName":"jenkins","CreatedAt":"2021-09-30T15:28:00.389+08:00","UpdatedAt":"2021-09-30T15:28:00.785+08:00"}
-```
-
-## Configuration
-If you want to use the notification feature, you should add two configuration key to `.env` file.
-```shell
-# .env
-# notification request url, e.g.: http://example.com/lake/notify
-NOTIFICATION_ENDPOINT=
-# secret is used to calculate signature
-NOTIFICATION_SECRET=
-```
-
-## Signature
-You should check the signature before accepting the notification request. We use sha256 algorithm to calculate the checksum.
-```go
-// calculate checksum
-sum := sha256.Sum256([]byte(requestBody + NOTIFICATION_SECRET + nouce))
-return hex.EncodeToString(sum[:])
-```
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md b/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md
deleted file mode 100644
index b478a4ddd43..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/PluginImplementation.md
+++ /dev/null
@@ -1,339 +0,0 @@
----
-title: "Plugin Implementation"
-sidebar_position: 2
-description: >
- Plugin Implementation
----
-
-If your favorite DevOps tool is not yet supported by DevLake, don't worry. It's not difficult to implement a DevLake plugin. In this post, we'll go through the basics of DevLake plugins and build an example plugin from scratch together.
-
-## What is a plugin?
-
-A DevLake plugin is a shared library built with Go's `plugin` package that hooks up to DevLake core at run-time.
-
-A plugin may extend DevLake's capability in three ways:
-
-1. Integrating with new data sources
-2. Transforming/enriching existing data
-3. Exporting DevLake data to other data systems
-
-
-## How do plugins work?
-
-A plugin mainly consists of a collection of subtasks that can be executed by DevLake core. For data source plugins, a subtask may be collecting a single entity from the data source (e.g., issues from Jira). Besides the subtasks, there're hooks that a plugin can implement to customize its initialization, migration, and more. See below for a list of the most important interfaces:
-
-1. [PluginMeta](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_meta.go) contains the minimal interface that a plugin should implement, with only two functions
- - Description() returns the description of a plugin
- - RootPkgPath() returns the root package path of a plugin
-2. [PluginInit](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_init.go) allows a plugin to customize its initialization
-3. [PluginTask](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_task.go) enables a plugin to prepare data prior to subtask execution
-4. [PluginApi](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_api.go) lets a plugin exposes some self-defined APIs
-5. [PluginMigration](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_migration.go) is where a plugin manages its database migrations
-6. [PluginModel](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_model.go) allows other plugins to get the model information of all database tables of the current plugin through the GetTablesInfo() method.If you need to access Domain Layer Models,please visit [DomainLayerSchema](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/)
-
-The diagram below shows the control flow of executing a plugin:
-
-```mermaid
-flowchart TD;
- subgraph S4[Step4 sub-task extractor running process];
- direction LR;
- D4[DevLake];
- D4 -- "Step4.1 create a new\n ApiExtractor\n and execute it" --> E["ExtractXXXMeta.\nEntryPoint"];
- E <-- "Step4.2 read from\n raw table" --> E2["RawDataSubTaskArgs\n.Table"];
- E -- "Step4.3 call with RawData" --> ApiExtractor.Extract;
- ApiExtractor.Extract -- "decode and return gorm models" --> E
- end
- subgraph S3[Step3 sub-task collector running process]
- direction LR
- D3[DevLake]
- D3 -- "Step3.1 create a new\n ApiCollector\n and execute it" --> C["CollectXXXMeta.\nEntryPoint"];
- C <-- "Step3.2 create\n raw table" --> C2["RawDataSubTaskArgs\n.RAW_BBB_TABLE"];
- C <-- "Step3.3 build query\n before sending requests" --> ApiCollectorArgs.\nQuery/UrlTemplate;
- C <-. "Step3.4 send requests by ApiClient \n and return HTTP response" .-> A1["HTTP APIs"];
- C <-- "Step3.5 call and \nreturn decoded data \nfrom HTTP response" --> ResponseParser;
- end
- subgraph S2[Step2 DevLake register custom plugin]
- direction LR
- D2[DevLake]
- D2 <-- "Step2.1 function \`Init\` \nneed to do init jobs" --> plugin.Init;
- D2 <-- "Step2.2 (Optional) call \nand return migration scripts" --> plugin.MigrationScripts;
- D2 <-- "Step2.3 (Optional) call \nand return taskCtx" --> plugin.PrepareTaskData;
- D2 <-- "Step2.4 call and \nreturn subTasks for execting" --> plugin.SubTaskContext;
- end
- subgraph S1[Step1 Run DevLake]
- direction LR
- main -- "Transfer of control \nby \`runner.DirectRun\`" --> D1[DevLake];
- end
- S1-->S2-->S3-->S4
-```
-There's a lot of information in the diagram but we don't expect you to digest it right away, simply use it as a reference when you go through the example below.
-
-## A step-by-step guide towards your first plugin
-
-In this section, we will describe how to create a data collection plugin from scratch. The data to be collected is the information about all Committers and Contributors of the Apache project, in order to check whether they have signed the CLA. We are going to
-
-* request `https://people.apache.org/public/icla-info.json` to get the Committers' information
-* request the `mailing list` to get the Contributors' information
-
-We will focus on demonstrating how to request and cache information about all Committers through the Apache API and extract structured data from it. The collection of Contributors will only be briefly described.
-
-### Step 1: Bootstrap the new plugin
-
-**Note:** Please make sure you have DevLake up and running before proceeding.
-
-> More info about plugin:
-> Generally, we need these folders in plugin folders: `api`, `models` and `tasks`
-> `api` interacts with `config-ui` for test/get/save connection of data source
-> - connection [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/api/connection.go)
-> - connection model [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/models/connection.go)
-> `models` stores all `data entities` and `data migration scripts`.
-> - entity
-> - data migrations [template](https://github.com/apache/incubator-devlake/tree/main/generator/template/migrationscripts)
-> `tasks` contains all of our `sub tasks` for a plugin
-> - task data [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data.go-template)
-> - api client [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data_with_api_client.go-template)
-
-Don't worry if you cannot figure out what these concepts mean immediately. We'll explain them one by one later.
-
-DevLake provides a generator to create a plugin conveniently. Let's scaffold our new plugin by running `go run generator/main.go create-plugin icla`, which would ask for `with_api_client` and `Endpoint`.
-
-* `with_api_client` is used for choosing if we need to request HTTP APIs by api_client.
-* `Endpoint` use in which site we will request, in our case, it should be `https://people.apache.org/`.
-
-
-
-Now we have three files in our plugin. `api_client.go` and `task_data.go` are in subfolder `tasks/`.
-
-
-Have a try to run this plugin by function `main` in `plugin_main.go`. When you see result like this:
-```
-$go run plugins/icla/plugin_main.go
-[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-02 18:07:30] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-02 18:07:30] INFO [icla] total step: 0
-```
-How exciting. It works! The plugin defined and initiated in `plugin_main.go` use some options in `task_data.go`. They are made up as the most straightforward plugin in Apache DevLake, and `api_client.go` will be used in the next step to request HTTP APIs.
-
-### Step 2: Create a sub-task for data collection
-Before we start, it is helpful to know how collection task is executed:
-1. First, Apache DevLake would call `plugin_main.PrepareTaskData()` to prepare needed data before any sub-tasks. We need to create an API client here.
-2. Then Apache DevLake will call the sub-tasks returned by `plugin_main.SubTaskMetas()`. Sub-task is an independent task to do some job, like requesting API, processing data, etc.
-
-> Each sub-task must be defined as a SubTaskMeta, and implement SubTaskEntryPoint of SubTaskMeta. SubTaskEntryPoint is defined as
-> ```go
-> type SubTaskEntryPoint func(c SubTaskContext) error
-> ```
-> More info at: https://devlake.apache.org/blog/how-DevLake-is-up-and-running/
-
-#### Step 2.1: Create a sub-task(Collector) for data collection
-
-Let's run `go run generator/main.go create-collector icla committer` and confirm it. This sub-task is activated by registering in `plugin_main.go/SubTaskMetas` automatically.
-
-
-
-> - Collector will collect data from HTTP or other data sources, and save the data into the raw layer.
-> - Inside the func `SubTaskEntryPoint` of `Collector`, we use `helper.NewApiCollector` to create an object of [ApiCollector](https://github.com/apache/incubator-devlake/blob/main/backend/generator/template/plugin/tasks/api_collector.go-template), then call `execute()` to do the job.
-
-Now you can notice `data.ApiClient` is initiated in `plugin_main.go/PrepareTaskData.ApiClient`. `PrepareTaskData` create a new `ApiClient`, which is a tool Apache DevLake suggests to request data from HTTP Apis. This tool support some valuable features for HttpApi, like rateLimit, proxy and retry. Of course, if you like, you may use the lib `http` instead, but it will be more tedious.
-
-Let's move forward to use it.
-
-1. To collect data from `https://people.apache.org/public/icla-info.json`,
-we have filled `https://people.apache.org/` into `tasks/api_client.go/ENDPOINT` in Step 1.
-
-
-
-2. Fill `public/icla-info.json` into `UrlTemplate`, delete the unnecessary iterator and add `println("receive data:", res)` in `ResponseParser` to see if collection was successful.
-
-
-
-Ok, now the collector sub-task has been added to the plugin, and we can kick it off by running `main` again. If everything goes smoothly, the output should look like this:
-```bash
-[2022-06-06 12:24:52] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 12:24:52] INFO [icla] total step: 1
-[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
-receive data: 0x140005763f0
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1
-```
-
-Great! Now we can see data pulled from the server without any problem. The last step is to decode the response body in `ResponseParser` and return it to the framework, so it can be stored in the database.
-```go
-ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
- body := &struct {
- LastUpdated string `json:"last_updated"`
- Committers json.RawMessage `json:"committers"`
- }{}
- err := helper.UnmarshalResponse(res, body)
- if err != nil {
- return nil, err
- }
- println("receive data:", len(body.Committers))
- return []json.RawMessage{body.Committers}, nil
-},
-
-```
-Ok, run the function `main` once again, then it turned out like this, and we should be able see some records show up in the table `_raw_icla_committer`.
-```bash
-……
-receive data: 272956 /* <- the number means 272956 models received */
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
-```
-
-
-
-#### Step 2.2: Create a sub-task(Extractor) to extract data from the raw layer
-
-> - Extractor will extract data from raw layer and save it into tool db table.
-> - Except for some pre-processing, the main flow is similar to the collector.
-
-We have already collected data from HTTP API and saved them into the DB table `_raw_XXXX`. In this step, we will extract the names of committers from the raw data. As you may infer from the name, raw tables are temporary and not easy to use directly.
-
-Now Apache DevLake suggests to save data by [gorm](https://gorm.io/docs/index.html), so we will create a model by gorm and add it into `plugin_main.go/AutoMigrate()`.
-
-plugins/icla/models/committer.go
-```go
-package models
-
-import (
- "github.com/apache/incubator-devlake/models/common"
-)
-
-type IclaCommitter struct {
- UserName string `gorm:"primaryKey;type:varchar(255)"`
- Name string `gorm:"primaryKey;type:varchar(255)"`
- common.NoPKModel
-}
-
-func (IclaCommitter) TableName() string {
- return "_tool_icla_committer"
-}
-```
-
-plugins/icla/plugin_main.go
-
-
-
-Ok, run the plugin, and table `_tool_icla_committer` will be created automatically just like the snapshot below:
-
-
-Next, let's run `go run generator/main.go create-extractor icla committer` and type in what the command prompt asks for to create a new sub-task.
-
-
-
-Let's look at the function `extract` in `committer_extractor.go` created just now, and the code that needs to be written here. It's obvious that `resData.data` is the raw data, so we could json-decode each row add a new `IclaCommitter` for each and save them.
-```go
-Extract: func(resData *helper.RawData) ([]interface{}, error) {
- names := &map[string]string{}
- err := json.Unmarshal(resData.Data, names)
- if err != nil {
- return nil, err
- }
- extractedModels := make([]interface{}, 0)
- for userName, name := range *names {
- extractedModels = append(extractedModels, &models.IclaCommitter{
- UserName: userName,
- Name: name,
- })fco
- }
- return extractedModels, nil
-},
-```
-
-Ok, run it then we get:
-```
-[2022-06-06 15:39:40] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 15:39:40] INFO [icla] total step: 2
-[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
-receive data: 272956
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
-[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
-[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
-[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2
-```
-Now committer data have been saved in _tool_icla_committer.
-
-
-#### Step 2.3: Convertor
-
-Notes: The goal of Converters is to create a vendor-agnostic model out of the vendor-dependent ones created by the Extractors.
-They are not necessary to have per se, but we encourage it because converters and the domain layer will significantly help with building dashboards. More info about the domain layer [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/).
-
-In short:
-
-> - Convertor will convert data from the tool layer and save it into the domain layer.
-> - We use `helper.NewDataConverter` to create an object of DataConvertor, then call `execute()`.
-
-#### Step 2.4: Let's try it
-Sometimes OpenApi will be protected by token or other auth types, and we need to log in to gain a token to visit it. For example, only after logging in `private@apahce.com` could we gather the data about contributors signing ICLA. Here we briefly introduce how to authorize DevLake to collect data.
-
-Let's look at `api_client.go`. `NewIclaApiClient` load config `ICLA_TOKEN` by `.env`, so we can add `ICLA_TOKEN=XXXXXX` in `.env` and use it in `apiClient.SetHeaders()` to mock the login status. Code as below:
-
-
-Of course, we can use `username/password` to get a token after login mockery. Just try and adjust according to the actual situation.
-
-Look for more related details at https://github.com/apache/incubator-devlake
-
-#### Step 2.5: Implement the GetTablesInfo() method of the PluginModel interface
-
-As shown in the following gitlab plugin example,
-add all models that need to be accessed by external plugins to the return value.
-
-```go
-var _ core.PluginModel = (*Gitlab)(nil)
-
-func (plugin Gitlab) GetTablesInfo() []core.Tabler {
- return []core.Tabler{
- &models.GitlabConnection{},
- &models.GitlabAccount{},
- &models.GitlabCommit{},
- &models.GitlabIssue{},
- &models.GitlabIssueLabel{},
- &models.GitlabJob{},
- &models.GitlabMergeRequest{},
- &models.GitlabMrComment{},
- &models.GitlabMrCommit{},
- &models.GitlabMrLabel{},
- &models.GitlabMrNote{},
- &models.GitlabPipeline{},
- &models.GitlabProject{},
- &models.GitlabProjectCommit{},
- &models.GitlabReviewer{},
- &models.GitlabTag{},
- }
-}
-```
-
-You can use it as follows:
-
-```go
-if pm, ok := plugin.(core.PluginModel); ok {
- tables := pm.GetTablesInfo()
- for _, table := range tables {
- // do something
- }
-}
-
-```
-
-#### Final step: Submit the code as open source code
-We encourage ideas and contributions ~ Let's use migration scripts, domain layers and other discussed concepts to write normative and platform-neutral code. More info at [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema) or contact us for ebullient help.
-
-
-## Done!
-
-Congratulations! The first plugin has been created! 🎖
diff --git a/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md b/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md
deleted file mode 100644
index 9e020d4a8b3..00000000000
--- a/versioned_docs/version-v0.13/DeveloperManuals/Release-SOP.md
+++ /dev/null
@@ -1,111 +0,0 @@
-# Devlake release guide
-
-**Please make sure your public key was included in the https://downloads.apache.org/incubator/devlake/KEYS , if not, please update https://downloads.apache.org/incubator/devlake/KEYS first.**
-## How to update KEYS
-1. Clone the svn repository
- ```shell
- svn co https://dist.apache.org/repos/dist/dev/incubator/devlake
- ```
-2. Append your public key to the KEYS file
- ```shell
- cd devlake
- (gpg --list-sigs Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on: -- `Deployments` collected in one of the following ways: - - Open APIs of Jenkins, GitLab, GitHub, etc. - - Webhook for general CI tools. - - Releases and PR/MRs from GitHub, GitLab APIs, etc. -- `Incidents` collected in one of the following ways: - - Issue tracking tools such as Jira, TAPD, GitHub, etc. - - Incident or Service Monitoring tools such as PagerDuty, ServiceNow, etc. - -Transformation Rules Required - -This metric relies on: -- Deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as `Deployments`. -- Incident configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - -## How to improve? -- Add unit tests for all new feature -- "Shift left", start QA early and introduce more automated tests -- Enforce code review if it's not strictly executed diff --git a/versioned_docs/version-v0.13/Metrics/CodingTime.md b/versioned_docs/version-v0.13/Metrics/CodingTime.md deleted file mode 100644 index d788474810c..00000000000 --- a/versioned_docs/version-v0.13/Metrics/CodingTime.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "PR Coding Time" -description: > - PR Coding Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from the first commit until a PR is issued. - -## Why is it important? -It is recommended that you keep every task on a workable and manageable scale for a reasonably short amount of coding time. The average coding time of most engineering teams is around 3-4 days. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -Divide coding tasks into workable and manageable pieces. diff --git a/versioned_docs/version-v0.13/Metrics/CommitAuthorCount.md b/versioned_docs/version-v0.13/Metrics/CommitAuthorCount.md deleted file mode 100644 index 3be4ad20633..00000000000 --- a/versioned_docs/version-v0.13/Metrics/CommitAuthorCount.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "Commit Author Count" -description: > - Commit Author Count -sidebar_position: 14 ---- - -## What is this metric? -The number of commit authors who have committed code. - -## Why is it important? -Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment. - - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -This metric is calculated by counting the number of commit authors in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - - -## How to improve? -As a secondary indicator, this helps assess the labor cost of participating in coding. diff --git a/versioned_docs/version-v0.13/Metrics/CommitCount.md b/versioned_docs/version-v0.13/Metrics/CommitCount.md deleted file mode 100644 index ae85af8d2cd..00000000000 --- a/versioned_docs/version-v0.13/Metrics/CommitCount.md +++ /dev/null @@ -1,55 +0,0 @@ ---- -title: "Commit Count" -description: > - Commit Count -sidebar_position: 6 ---- - -## What is this metric? -The number of commits created. - -## Why is it important? -1. Identify potential bottlenecks that may affect output -2. Encourage R&D practices of small step submissions and develop excellent coding habits - -## Which dashboard(s) does it exist in -- GitHub Release Quality and Contribution Analysis -- Demo-Is this month more productive than last? -- Demo-Commit Count by Author - -## How is it calculated? -This metric is calculated by counting the number of commits in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -SQL Queries - -If you want to see the monthly trend, run the following SQL -``` - with _commits as( - SELECT - DATE_ADD(date(authored_date), INTERVAL -DAY(date(authored_date))+1 DAY) as time, - count(*) as commit_count - FROM commits - WHERE - message not like '%Merge%' - and $__timeFilter(authored_date) - group by 1 - ) - - SELECT - date_format(time,'%M %Y') as month, - commit_count as "Commit Count" - FROM _commits - ORDER BY time -``` - -## How to improve? -1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison -2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents) diff --git a/versioned_docs/version-v0.13/Metrics/CycleTime.md b/versioned_docs/version-v0.13/Metrics/CycleTime.md deleted file mode 100644 index bbc98349ab8..00000000000 --- a/versioned_docs/version-v0.13/Metrics/CycleTime.md +++ /dev/null @@ -1,40 +0,0 @@ ---- -title: "PR Cycle Time" -description: > - PR Cycle Time -sidebar_position: 2 ---- - -## What is this metric? -PR Cycle Time is the sum of PR Coding Time, Pickup TIme, Review Time and Deploy Time. It is the total time from the first commit to when the PR is deployed. - -## Why is it important? -PR Cycle Time indicate the overall speed of the delivery progress in terms of PR. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -You can define `deployment` based on your actual practice. For a full list of `deployment`'s definitions that DevLake support, please refer to [Deployment Frequency](/docs/Metrics/DeploymentFrequency.md). - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Divide coding tasks into workable and manageable pieces; -2. Use DevLake's dashboards to monitor your delivery progress; -3. Have a habit to check for hanging PRs regularly; -4. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued; -2. Use automated tests for the initial work; -5. Reduce PR size; -6. Analyze the causes for long reviews. \ No newline at end of file diff --git a/versioned_docs/version-v0.13/Metrics/DeletedLinesOfCode.md b/versioned_docs/version-v0.13/Metrics/DeletedLinesOfCode.md deleted file mode 100644 index 218ceae0c54..00000000000 --- a/versioned_docs/version-v0.13/Metrics/DeletedLinesOfCode.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "Deleted Lines of Code" -description: > - Deleted Lines of Code -sidebar_position: 8 ---- - -## What is this metric? -The accumulated number of deleted lines of code. - -## Why is it important? -1. identify potential bottlenecks that may affect the output -2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits - -## Which dashboard(s) does it exist in -N/A - -## How is it calculated? -This metric is calculated by summing the deletions of commits in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -## How to improve? -1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate -2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model. -3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison. diff --git a/versioned_docs/version-v0.13/Metrics/DeployTime.md b/versioned_docs/version-v0.13/Metrics/DeployTime.md deleted file mode 100644 index d908480829f..00000000000 --- a/versioned_docs/version-v0.13/Metrics/DeployTime.md +++ /dev/null @@ -1,30 +0,0 @@ ---- -title: "PR Deploy Time" -description: > - PR Deploy Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is merged to when it is deployed. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in? - - -## How is it calculated? -You can define `deployment` based on your actual practice. For a full list of `deployment`'s definitions that DevLake support, please refer to [Deployment Frequency](/docs/Metrics/DeploymentFrequency.md). - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -## How to improve? - diff --git a/versioned_docs/version-v0.13/Metrics/DeploymentFrequency.md b/versioned_docs/version-v0.13/Metrics/DeploymentFrequency.md deleted file mode 100644 index 6b318535c51..00000000000 --- a/versioned_docs/version-v0.13/Metrics/DeploymentFrequency.md +++ /dev/null @@ -1,45 +0,0 @@ ---- -title: "DORA - Deployment Frequency(WIP)" -description: > - DORA - Deployment Frequency -sidebar_position: 18 ---- - -## What is this metric? -How often an organization deploys code to production or release it to end users. - -## Why is it important? -Deployment frequency reflects the efficiency of a team's deployment. A team that deploys more frequently can deliver the product faster and users' feature requirements can be met faster. - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -Deployment frequency is calculated based on the number of deployment days, not the number of deployments, e.g.,daily, weekly, monthly, yearly. - -| Groups | Benchmarks | -| -----------------| -------------------------------------| -| Elite performers | Multiple times a day | -| High performers | Once a week to once a month | -| Medium performers| Once a month to once every six months| -| Low performers | Less than once every six months | - -Source: 2021 Accelerate State of DevOps, Google
- - -Data Sources Required - -This metric relies on deployments collected in multiple ways: -- Open APIs of Jenkins, GitLab, GitHub, etc. -- Webhook for general CI tools. -- Releases and PR/MRs from GitHub, GitLab APIs, etc. - -Transformation Rules Required - -This metric relies on the deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as deployments. - -## How to improve? -- Trunk development. Work in small batches and often merge their work into shared trunks. -- Integrate CI/CD tools for automated deployment -- Improve automated test coverage diff --git a/versioned_docs/version-v0.13/Metrics/IncidentAge.md b/versioned_docs/version-v0.13/Metrics/IncidentAge.md deleted file mode 100644 index 4cd5e60cbb5..00000000000 --- a/versioned_docs/version-v0.13/Metrics/IncidentAge.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "Incident Age" -description: > - Incident Age -sidebar_position: 10 ---- - -## What is this metric? -The amount of time it takes a incident to fix. - -## Why is it important? -1. Help the team to establish an effective hierarchical response mechanism for incidents. Focus on the resolution of important problems in the backlog. -2. Improve team's and individual's incident fixing efficiency. Identify good/to-be-improved practices that affect incident age - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -This metric equals to `resolution_date` - `created_date` of issues in type "INCIDENT". - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-incident' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - - -## How to improve? -1. Observe the trend of incident age and locate the key reasons. -2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of incident age. \ No newline at end of file diff --git a/versioned_docs/version-v0.13/Metrics/IncidentCountPer1kLinesOfCode.md b/versioned_docs/version-v0.13/Metrics/IncidentCountPer1kLinesOfCode.md deleted file mode 100644 index 9ad92787780..00000000000 --- a/versioned_docs/version-v0.13/Metrics/IncidentCountPer1kLinesOfCode.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Incident Count per 1k Lines of Code" -description: > - Incident Count per 1k Lines of Code -sidebar_position: 13 ---- - -## What is this metric? -Amount of incidents per 1,000 lines of code. - -## Why is it important? -1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process -2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts -3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -The number of incidents divided by total accumulated lines of code (additions + deletions) in the given data range. - -Data Sources Required - -This metric relies on -- issues collected from Jira, GitHub or TAPD. -- commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -This metric relies on -- "Issue type mapping" in Jira, GitHub or TAPD's transformation rules page to let DevLake know what type(s) of issues can be regarded as incidents. -- "PR-Issue Mapping" in GitHub, GitLab's transformation rules page to let DevLake know the bugs are fixed by which PR/MRs. - -## How to improve? -1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc. -2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality -3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points -4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values diff --git a/versioned_docs/version-v0.13/Metrics/LeadTimeForChanges.md b/versioned_docs/version-v0.13/Metrics/LeadTimeForChanges.md deleted file mode 100644 index b964f2009e0..00000000000 --- a/versioned_docs/version-v0.13/Metrics/LeadTimeForChanges.md +++ /dev/null @@ -1,56 +0,0 @@ ---- -title: "DORA - Lead Time for Changes(WIP)" -description: > - DORA - Lead Time for Changes -sidebar_position: 19 ---- - -## What is this metric? -The median amount of time for a commit to be deployed into production. - -## Why is it important? -This metric measures the time it takes to commit code to the production environment and reflects the speed of software delivery. A lower average change preparation time means that your team is efficient at coding and deploying your project. - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -This metric can be calculated in two ways: -- If a deployment can be linked to PRs, then the lead time for changes of a deployment is the average cycle time of its associated PRs. For instance, - - Compared to the previous deployment `deploy-1`, `deploy-2` deployed three new commits `commit-1`, `commit-2` and `commit-3`. - - `commit-1` is linked to `pr-1`, `commit-2` is linked to `pr-2` and `pr-3`, `commit-3` is not linked to any PR. Then, `deploy-2` is associated with `pr-1`, `pr-2` and `pr-3`. - - `Deploy-2`'s lead time for changes = average cycle time of `pr-1`, `pr-2` and `pr-3`. -- If a deployment can't be linked to PRs, then the lead time for changes is computed based on its associated commits. For instance, - - Compared to the previous deployment `deploy-1`, `deploy-2` deployed three new commits `commit-1`, `commit-2` and `commit-3`. - - None of `commit-1`, `commit-2` and `commit-3` is linked to any PR. - - Calculate each commit's lead time for changes, which equals to `deploy-2`'s deployed_at - commit's authored_date - - `Deploy-2`'s Lead time for changes = average lead time for changes of `commit-1`, `commit-2` and `commit-3`. - -Below are the benchmarks for different development teams: - -| Groups | Benchmarks | -| -----------------| -------------------------------------| -| Elite performers | Less than one hour | -| High performers | Between one day and one week | -| Medium performers| Between one month and six months | -| Low performers | More than six months | - -Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on deployments collected in multiple ways: -- Open APIs of Jenkins, GitLab, GitHub, etc. -- Webhook for general CI tools. -- Releases and PR/MRs from GitHub, GitLab APIs, etc. - -Transformation Rules Required - -This metric relies on the deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as deployments. - -## How to improve? -- Break requirements into smaller, more manageable deliverables -- Optimize the code review process -- "Shift left", start QA early and introduce more automated tests -- Integrate CI/CD tools to automate the deployment process diff --git a/versioned_docs/version-v0.13/Metrics/MTTR.md b/versioned_docs/version-v0.13/Metrics/MTTR.md deleted file mode 100644 index f76be2490f8..00000000000 --- a/versioned_docs/version-v0.13/Metrics/MTTR.md +++ /dev/null @@ -1,55 +0,0 @@ ---- -title: "DORA - Mean Time to Restore Service" -description: > - DORA - Mean Time to Restore Service -sidebar_position: 20 ---- - -## What is this metric? -The time to restore service after service incidents, rollbacks, or any type of production failure happened. - -## Why is it important? -This metric is essential to measure the disaster control capability of your team and the robustness of the software. - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -MTTR = Total [incident age](./IncidentAge.md) (in hours)/number of incidents. - -If you have three incidents that happened in the given data range, one lasting 1 hour, one lasting 2 hours and one lasting 3 hours. Your MTTR will be: (1 + 2 + 3) / 3 = 2 hours. - -Below are the benchmarks for different development teams: - -| Groups | Benchmarks | -| -----------------| -------------------------------------| -| Elite performers | Less than one hour | -| High performers | Less one day | -| Medium performers| Between one day and one week | -| Low performers | More than six months | - -Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on: -- `Deployments` collected in one of the following ways: - - Open APIs of Jenkins, GitLab, GitHub, etc. - - Webhook for general CI tools. - - Releases and PR/MRs from GitHub, GitLab APIs, etc. -- `Incidents` collected in one of the following ways: - - Issue tracking tools such as Jira, TAPD, GitHub, etc. - - Incident or Service Monitoring tools such as PagerDuty, ServiceNow, etc. - -Transformation Rules Required - -This metric relies on: -- Deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as `Deployments`. -- Incident configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - -## How to improve? -- Use automated tools to quickly report failure -- Prioritize recovery when a failure happens -- Establish a go-to action plan to respond to failures immediately -- Reduce the deployment time for failure-fixing diff --git a/versioned_docs/version-v0.13/Metrics/MergeRate.md b/versioned_docs/version-v0.13/Metrics/MergeRate.md deleted file mode 100644 index c8c274338c9..00000000000 --- a/versioned_docs/version-v0.13/Metrics/MergeRate.md +++ /dev/null @@ -1,40 +0,0 @@ ---- -title: "PR Merge Rate" -description: > - Pull Request Merge Rate -sidebar_position: 12 ---- - -## What is this metric? -The ratio of PRs/MRs that get merged. - -## Why is it important? -1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- GitLab -- Weekly Community Retro -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -The number of merged PRs divided by the number of all PRs in the given data range. - -Data Sources Required - -This metric relies on PRs/MRs collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - - -## How to improve? -1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. diff --git a/versioned_docs/version-v0.13/Metrics/PRCount.md b/versioned_docs/version-v0.13/Metrics/PRCount.md deleted file mode 100644 index 4521e78617a..00000000000 --- a/versioned_docs/version-v0.13/Metrics/PRCount.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Pull Request Count" -description: > - Pull Request Count -sidebar_position: 11 ---- - -## What is this metric? -The number of pull requests created. - -## Why is it important? -1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- GitLab -- Weekly Community Retro -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is calculated by counting the number of PRs in the given data range. - -Data Sources Required - -This metric relies on PRs/MRs collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -## How to improve? -1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. diff --git a/versioned_docs/version-v0.13/Metrics/PRSize.md b/versioned_docs/version-v0.13/Metrics/PRSize.md deleted file mode 100644 index bf6a87d82d9..00000000000 --- a/versioned_docs/version-v0.13/Metrics/PRSize.md +++ /dev/null @@ -1,35 +0,0 @@ ---- -title: "PR Size" -description: > - PR Size -sidebar_position: 2 ---- - -## What is this metric? -The average code changes (in Lines of Code) of PRs in the selected time range. - -## Why is it important? -Small PRs can reduce risks of introducing new bugs and increase code review quality, as problems may often be hidden in big chuncks of code and difficult to identify. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is calculated by counting the total number of code changes (in LOC) divided by the total number of PRs in the selected time range. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Divide coding tasks into workable and manageable pieces; -1. Encourage developers to submit small PRs and only keep related changes in the same PR. diff --git a/versioned_docs/version-v0.13/Metrics/PickupTime.md b/versioned_docs/version-v0.13/Metrics/PickupTime.md deleted file mode 100644 index 07242ae772b..00000000000 --- a/versioned_docs/version-v0.13/Metrics/PickupTime.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "PR Pickup Time" -description: > - PR Pickup Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is issued until the first comment is added to that PR. - -## Why is it important? -PR Pickup Time shows how engaged your team is in collaborative work by identifying the delay in picking up PRs. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboard to monitor your delivery progress; -2. Have a habit to check for hanging PRs regularly; -3. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued. diff --git a/versioned_docs/version-v0.13/Metrics/RequirementCount.md b/versioned_docs/version-v0.13/Metrics/RequirementCount.md deleted file mode 100644 index e9a6bd32981..00000000000 --- a/versioned_docs/version-v0.13/Metrics/RequirementCount.md +++ /dev/null @@ -1,68 +0,0 @@ ---- -title: "Requirement Count" -description: > - Requirement Count -sidebar_position: 2 ---- - -## What is this metric? -The number of delivered requirements or features. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -This metric is calculated by counting the number of delivered issues in type "REQUIREMENT" in the given data range. - -Data Sources Required - -This metric relies on the issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - -SQL Queries - -If you want to see a single count, run the following SQL in Grafana -``` - select - count(*) as "Requirement Count" - from issues i - join board_issues bi on i.id = bi.issue_id - where - i.type = 'REQUIREMENT' - and i.status = 'DONE' - -- this is the default variable in Grafana - and $__timeFilter(i.created_date) - and bi.board_id in ($board_id) -``` - -If you want to see the monthly trend, run the following SQL -``` - SELECT - DATE_ADD(date(i.created_date), INTERVAL -DAYOFMONTH(date(i.created_date))+1 DAY) as time, - count(distinct case when status != 'DONE' then i.id else null end) as "Number of Open Issues", - count(distinct case when status = 'DONE' then i.id else null end) as "Number of Delivered Issues" - FROM issues i - join board_issues bi on i.id = bi.issue_id - join boards b on bi.board_id = b.id - WHERE - i.type = 'REQUIREMENT' - and i.status = 'DONE' - and $__timeFilter(i.created_date) - and bi.board_id in ($board_id) - GROUP by 1 -``` - -## How to improve? -1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process. -2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. -3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. -4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. diff --git a/versioned_docs/version-v0.13/Metrics/RequirementDeliveryRate.md b/versioned_docs/version-v0.13/Metrics/RequirementDeliveryRate.md deleted file mode 100644 index eb0a03133d5..00000000000 --- a/versioned_docs/version-v0.13/Metrics/RequirementDeliveryRate.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "Requirement Delivery Rate" -description: > - Requirement Delivery Rate -sidebar_position: 3 ---- - -## What is this metric? -The ratio of delivered requirements to all requirements. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -The number of delivered requirements divided by the total number of requirements in the given data range. - -Data Sources Required - -This metric relies on the issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process. -2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. -3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. -4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. diff --git a/versioned_docs/version-v0.13/Metrics/RequirementGranularity.md b/versioned_docs/version-v0.13/Metrics/RequirementGranularity.md deleted file mode 100644 index 03bb91767f5..00000000000 --- a/versioned_docs/version-v0.13/Metrics/RequirementGranularity.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "Requirement Granularity" -description: > - Requirement Granularity -sidebar_position: 5 ---- - -## What is this metric? -The average number of story points per requirement. - -## Why is it important? -1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team. -2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -The average story points of issues in type "REQUIREMENT" in the given data range. - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal. -2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents) diff --git a/versioned_docs/version-v0.13/Metrics/RequirementLeadTime.md b/versioned_docs/version-v0.13/Metrics/RequirementLeadTime.md deleted file mode 100644 index 74061d63dec..00000000000 --- a/versioned_docs/version-v0.13/Metrics/RequirementLeadTime.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "Requirement Lead Time" -description: > - Requirement Lead Time -sidebar_position: 4 ---- - -## What is this metric? -The amount of time it takes a requirement to deliver. - -## Why is it important? -1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays -2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks. - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- Community Experience - - -## How is it calculated? -This metric equals to `resolution_date` - `created_date` of issues in type "REQUIREMENT". - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the trend of requirement lead time to observe if it has improved over time. -2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time. -3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow. \ No newline at end of file diff --git a/versioned_docs/version-v0.13/Metrics/ReviewDepth.md b/versioned_docs/version-v0.13/Metrics/ReviewDepth.md deleted file mode 100644 index 59bcfbe876c..00000000000 --- a/versioned_docs/version-v0.13/Metrics/ReviewDepth.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "PR Review Depth" -description: > - PR Review Depth -sidebar_position: 2 ---- - -## What is this metric? -The average number of comments of PRs in the selected time range. - -## Why is it important? -PR Review Depth (in Comments per RR) is related to the quality of code review, indicating how thorough your team reviews PRs. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - -## How is it calculated? -This metric is calculated by counting the total number of PR comments divided by the total number of PRs in the selected time range. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Encourage multiple reviewers to review a PR; -2. Review Depth is an indicator for generally how thorough your PRs are reviewed, but it does not mean the deeper the better. In some cases, spending an excessive amount of resources on reviewing PRs is also not recommended. \ No newline at end of file diff --git a/versioned_docs/version-v0.13/Metrics/ReviewTime.md b/versioned_docs/version-v0.13/Metrics/ReviewTime.md deleted file mode 100644 index 8cfe080b0cc..00000000000 --- a/versioned_docs/version-v0.13/Metrics/ReviewTime.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "PR Review Time" -description: > - PR Review Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes to complete a code review of a PR before it gets merged. - -## Why is it important? -Code review should be conducted almost in real-time and usually take less than two days. Abnormally long PR Review Time may indicate one or more of the following problems: -1. The PR size is too large that makes it difficult to review. -2. The team is too busy to review code. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is the time frame between when the first comment is added to a PR, to when the PR is merged. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboards to monitor your delivery progress; -2. Use automated tests for the initial work; -3. Reduce PR size; -4. Analyze the causes for long reviews. \ No newline at end of file diff --git a/versioned_docs/version-v0.13/Metrics/TimeToMerge.md b/versioned_docs/version-v0.13/Metrics/TimeToMerge.md deleted file mode 100644 index 04a39225fe0..00000000000 --- a/versioned_docs/version-v0.13/Metrics/TimeToMerge.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "PR Time To Merge" -description: > - PR Time To Merge -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is issued to when it is merged. Essentially, PR Time to Merge = PR Pickup Time + PR Review Time. - -## Why is it important? -The delay of reviewing and waiting to review PRs has large impact on delivery speed, while reasonably short PR Time to Merge can indicate frictionless teamwork. Improving on this metric is the key to reduce PR cycle time. - -## Which dashboard(s) does it exist in? -- GitHub Basic Metrics -- Bi-weekly Community Retro - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboards to monitor your delivery progress; -2. Have a habit to check for hanging PRs regularly; -3. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued; -4. Reduce PR size; -5. Analyze the causes for long reviews. diff --git a/versioned_docs/version-v0.13/Metrics/_category_.json b/versioned_docs/version-v0.13/Metrics/_category_.json deleted file mode 100644 index e944147d528..00000000000 --- a/versioned_docs/version-v0.13/Metrics/_category_.json +++ /dev/null @@ -1,8 +0,0 @@ -{ - "label": "Metrics", - "position": 5, - "link":{ - "type": "generated-index", - "slug": "Metrics" - } -} diff --git a/versioned_docs/version-v0.13/Overview/Architecture.md b/versioned_docs/version-v0.13/Overview/Architecture.md deleted file mode 100755 index d4c6a9c5340..00000000000 --- a/versioned_docs/version-v0.13/Overview/Architecture.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Architecture" -description: > - Understand the architecture of Apache DevLake -sidebar_position: 2 ---- - -## Architecture Overview - -
DevLake Components
- -A DevLake installation typically consists of the following components: - -- Config UI: A handy user interface to create, trigger, and debug Blueprints. A Blueprint specifies the where (data connection), what (data scope), how (transformation rule), and when (sync frequency) of a data pipeline. -- API Server: The main programmatic interface of DevLake. -- Runner: The runner does all the heavy-lifting for executing tasks. In the default DevLake installation, it runs within the API Server, but DevLake provides a temporal-based runner (beta) for production environments. -- Database: The database stores both DevLake's metadata and user data collected by data pipelines. DevLake supports MySQL and PostgreSQL as of v0.11. -- Plugins: Plugins enable DevLake to collect and analyze dev data from any DevOps tools with an accessible API. DevLake community is actively adding plugins for popular DevOps tools, but if your preferred tool is not covered yet, feel free to open a GitHub issue to let us know or check out our doc on how to build a new plugin by yourself. -- Dashboards: Dashboards deliver data and insights to DevLake users. A dashboard is simply a collection of SQL queries along with corresponding visualization configurations. DevLake's official dashboard tool is Grafana and pre-built dashboards are shipped in Grafana's JSON format. Users are welcome to swap for their own choice of dashboard/BI tool if desired. - -## Dataflow - -
DevLake Dataflow
- -A typical plugin's dataflow is illustrated below: - -1. The Raw layer stores the API responses from data sources (DevOps tools) in JSON. This saves developers' time if the raw data is to be transformed differently later on. Please note that communicating with data sources' APIs is usually the most time-consuming step. -2. The Tool layer extracts raw data from JSONs into a relational schema that's easier to consume by analytical tasks. Each DevOps tool would have a schema that's tailored to their data structure, hence the name, the Tool layer. -3. The Domain layer attempts to build a layer of abstraction on top of the Tool layer so that analytics logics can be re-used across different tools. For example, GitHub's Pull Request (PR) and GitLab's Merge Request (MR) are similar entities. They each have their own table name and schema in the Tool layer, but they're consolidated into a single entity in the Domain layer, so that developers only need to implement metrics like Cycle Time and Code Review Rounds once against the domain layer schema. - -## Principles - -1. Extensible: DevLake's plugin system allows users to integrate with any DevOps tool. DevLake also provides a dbt plugin that enables users to define their own data transformation and analysis workflows. -2. Portable: DevLake has a modular design and provides multiple options for each module. Users of different setups can freely choose the right configuration for themselves. -3. Robust: DevLake provides an SDK to help plugins efficiently and reliably collect data from data sources while respecting their API rate limits and constraints. - -
-
-## Project Metrics This Covers
-
-| Metric Name | Description |
-|:------------------------------------|:--------------------------------------------------------------------------------------------------|
-| Requirement Count | Number of issues with type "Requirement" |
-| Requirement Lead Time | Lead time of issues with type "Requirement" |
-| Requirement Delivery Rate | Ratio of delivered requirements to all requirements |
-| Requirement Granularity | Number of story points associated with an issue |
-| Bug Count | Number of issues with type "Bug"
-
-When first visiting Grafana, you will be provided with a sample dashboard with some basic charts setup from the database.
-
-## Contents
-
-Section | Link
-:------------ | :-------------
-Logging In | [View Section](#logging-in)
-Viewing All Dashboards | [View Section](#viewing-all-dashboards)
-Customizing a Dashboard | [View Section](#customizing-a-dashboard)
-Dashboard Settings | [View Section](#dashboard-settings)
-Provisioning a Dashboard | [View Section](#provisioning-a-dashboard)
-Troubleshooting DB Connection | [View Section](#troubleshooting-db-connection)
-
-## Logging In
-
-Once the app is up and running, visit `http://localhost:3002` to view the Grafana dashboard.
-
-Default login credentials are:
-
-- Username: `admin`
-- Password: `admin`
-
-## Viewing All Dashboards
-
-To see all dashboards created in Grafana visit `/dashboards`
-
-Or, use the sidebar and click on **Manage**:
-
-
-
-
-## Customizing a Dashboard
-
-When viewing a dashboard, click the top bar of a panel, and go to **edit**
-
-
-
-**Edit Dashboard Panel Page:**
-
-
-
-### 1. Preview Area
-- **Top Left** is the variable select area (custom dashboard variables, used for switching projects, or grouping data)
-- **Top Right** we have a toolbar with some buttons related to the display of the data:
- - View data results in a table
- - Time range selector
- - Refresh data button
-- **The Main Area** will display the chart and should update in real time
-
-> Note: Data should refresh automatically, but may require a refresh using the button in some cases
-
-### 2. Query Builder
-Here we form the SQL query to pull data into our chart, from our database
-- Ensure the **Data Source** is the correct database
-
- 
-
-- Select **Format as Table**, and **Edit SQL** buttons to write/edit queries as SQL
-
- 
-
-- The **Main Area** is where the queries are written, and in the top right is the **Query Inspector** button (to inspect returned data)
-
- 
-
-### 3. Main Panel Toolbar
-In the top right of the window are buttons for:
-- Dashboard settings (regarding entire dashboard)
-- Save/apply changes (to specific panel)
-
-### 4. Grafana Parameter Sidebar
-- Change chart style (bar/line/pie chart etc)
-- Edit legends, chart parameters
-- Modify chart styling
-- Other Grafana specific settings
-
-## Dashboard Settings
-
-When viewing a dashboard click on the settings icon to view dashboard settings. Here are 2 important sections to use:
-
-
-
-- Variables
- - Create variables to use throughout the dashboard panels, that are also built on SQL queries
-
- 
-
-- JSON Model
- - Copy `json` code here and save it to a new file in `/grafana/dashboards/` with a unique name in the `lake` repo. This will allow us to persist dashboards when we load the app
-
- 
-
-## Provisioning a Dashboard
-
-To save a dashboard in the `lake` repo and load it:
-
-1. Create a dashboard in browser (visit `/dashboard/new`, or use sidebar)
-2. Save dashboard (in top right of screen)
-3. Go to dashboard settings (in top right of screen)
-4. Click on _JSON Model_ in sidebar
-5. Copy code into a new `.json` file in `/grafana/dashboards`
-
-## Troubleshooting DB Connection
-
-To ensure we have properly connected our database to the data source in Grafana, check database settings in `./grafana/datasources/datasource.yml`, specifically:
-- `database`
-- `user`
-- `secureJsonData/password`
diff --git a/versioned_docs/version-v0.13/UserManuals/Dashboards/_category_.json b/versioned_docs/version-v0.13/UserManuals/Dashboards/_category_.json
deleted file mode 100644
index 0db83c6e9b8..00000000000
--- a/versioned_docs/version-v0.13/UserManuals/Dashboards/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Dashboards",
- "position": 5
-}
diff --git a/versioned_docs/version-v0.13/UserManuals/TeamConfiguration.md b/versioned_docs/version-v0.13/UserManuals/TeamConfiguration.md
deleted file mode 100644
index c8ade3eabcf..00000000000
--- a/versioned_docs/version-v0.13/UserManuals/TeamConfiguration.md
+++ /dev/null
@@ -1,188 +0,0 @@
----
-title: "Team Configuration"
-sidebar_position: 7
-description: >
- Team Configuration
----
-## What is 'Team Configuration' and how it works?
-
-To organize and display metrics by `team`, Apache DevLake needs to know about the team configuration in an organization, specifically:
-
-1. What are the teams?
-2. Who are the users(unified identities)?
-3. Which users belong to a team?
-4. Which accounts(identities in specific tools) belong to the same user?
-
-Each of the questions above corresponds to a table in DevLake's schema, illustrated below:
-
-
-
-1. `teams` table stores all the teams in the organization.
-2. `users` table stores the organization's roster. An entry in the `users` table corresponds to a person in the org.
-3. `team_users` table stores which users belong to a team.
-4. `user_accounts` table stores which accounts belong to a user. An `account` refers to an identiy in a DevOps tool and is automatically created when importing data from that tool. For example, a `user` may have a GitHub `account` as well as a Jira `account`.
-
-Apache DevLake uses a simple heuristic algorithm based on emails and names to automatically map accounts to users and populate the `user_accounts` table.
-When Apache DevLake cannot confidently map an `account` to a `user` due to insufficient information, it allows DevLake users to manually configure the mapping to ensure accuracy and integrity.
-
-## A step-by-step guide
-
-In the following sections, we'll walk through how to configure teams and create the five aforementioned tables (`teams`, `users`, `team_users`, `accounts`, and `user_accounts`).
-The overall workflow is:
-
-1. Create the `teams` table
-2. Create the `users` and `team_users` table
-3. Populate the `accounts` table via data collection
-4. Run a heuristic algorithm to populate `user_accounts` table
-5. Manually update `user_accounts` when the algorithm can't catch everything
-
-Note:
-
-1. Please replace `/path/to/*.csv` with the absolute path of the CSV file you'd like to upload.
-2. Please replace `127.0.0.1:4000` with your actual Apache DevLake ConfigUI service IP and port number.
-
-## Step 1 - Create the `teams` table
-
-You can create the `teams` table by sending a PUT request to `/plugins/org/teams.csv` with a `teams.csv` file. To jumpstart the process, you can download a template `teams.csv` from `/plugins/org/teams.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `teams.csv` file
-
- i. GET http://127.0.0.1:4000/api/plugins/org/teams.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/teams.csv?fake_data=true'
-
-
-b. Fill out `teams.csv` file and upload it to DevLake
-
- i. Fill out `teams.csv` with your org data. Please don't modify the column headers or the file suffix.
-
- ii. Upload `teams.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/teams.csv' --form 'file=@"/path/to/teams.csv"'
-
- iii. The PUT request would populate the `teams` table with data from `teams.csv` file.
- You can connect to the database and verify the data in the `teams` table.
- See Appendix for how to connect to the database.
-
-
-
-
-## Step 2 - Create the `users` and `team_users` table
-
-You can create the `users` and `team_users` table by sending a single PUT request to `/plugins/org/users.csv` with a `users.csv` file. To jumpstart the process, you can download a template `users.csv` from `/plugins/org/users.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `users.csv` file
-
- i. GET http://127.0.0.1:4000/api/plugins/org/users.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/users.csv?fake_data=true'
-
-
-b. Fill out `users.csv` and upload to DevLake
-
- i. Fill out `users.csv` with your org data. Please don't modify the column headers or the file suffix
-
- ii. Upload `users.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/users.csv' --form 'file=@"/path/to/users.csv"'
-
- iii. The PUT request would populate the `users` table along with the `team_users` table with data from `users.csv` file.
- You can connect to the database and verify these two tables.
-
-
-
-
-
-c. If you ever want to update `team_users` or `users` table, simply upload the updated `users.csv` to DevLake again following step b.
-
-## Step 3 - Populate the `accounts` table via data collection
-
-The `accounts` table is automatically populated when you collect data from data sources like GitHub and Jira through DevLake.
-
-For example, the GitHub plugin would create one entry in the `accounts` table for each GitHub user involved in your repository.
-For demo purposes, we'll insert some mock data into the `accounts` table using SQL:
-
-```
-INSERT INTO `accounts` (`id`, `created_at`, `updated_at`, `_raw_data_params`, `_raw_data_table`, `_raw_data_id`, `_raw_data_remark`, `email`, `full_name`, `user_name`, `avatar_url`, `organization`, `created_date`, `status`)
-VALUES
- ('github:GithubAccount:1:1234', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"Owner\":\"apache\",\"Repo\":\"incubator-devlake\"}', '_raw_github_api_pull_request_reviews', 28, '', 'TyroneKCummings@teleworm.us', '', 'Tyrone K. Cummings', 'https://avatars.githubusercontent.com/u/101256042?u=a6e460fbaffce7514cbd65ac739a985f5158dabc&v=4', '', NULL, 0),
- ('jira:JiraAccount:1:629cdf', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"BoardId\":\"76\"}', '_raw_jira_api_users', 5, '', 'DorothyRUpdegraff@dayrep.com', '', 'Dorothy R. Updegraff', 'https://avatars.jiraxxxx158dabc&v=4', '', NULL, 0);
-
-```
-
-
-
-## Step 4 - Run a heuristic algorithm to populate `user_accounts` table
-
-Now that we have data in both the `users` and `accounts` table, we can tell DevLake to infer the mappings between `users` and `accounts` with a simple heuristic algorithm based on names and emails.
-
-a. Send an API request to DevLake to run the mapping algorithm
-
-```
-curl --location --request POST '127.0.0.1:4000/api/pipelines' \
---header 'Content-Type: application/json' \
---data-raw '{
- "name": "test",
- "plan":[
- [
- {
- "plugin": "org",
- "subtasks":["connectUserAccountsExact"],
- "options":{
- "connectionId":1
- }
- }
- ]
- ]
-}'
-```
-
-b. After successful execution, you can verify the data in `user_accounts` in the database.
-
-
-
-## Step 5 - Manually update `user_accounts` when the algorithm can't catch everything
-
-It is recommended to examine the generated `user_accounts` table after running the algorithm.
-We'll demonstrate how to manually update `user_accounts` when the mapping is inaccurate/incomplete in this section.
-To make manual verification easier, DevLake provides an API for users to download `user_accounts` as a CSV file.
-Alternatively, you can verify and modify `user_accounts` all by SQL, see Appendix for more info.
-
-a. GET http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv(pasting the URL into your browser will download the file). If you prefer using curl:
-```
-curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv'
-```
-
-
-
-b. If you find the mapping inaccurate or incomplete, you can modify the `user_account_mapping.csv` file and then upload it to DevLake.
-For example, here we change the `UserId` of row 'Id=github:GithubAccount:1:1234' in the `user_account_mapping.csv` file to 2.
-Then we upload the updated `user_account_mapping.csv` file with the following curl command:
-
-```
-curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv' --form 'file=@"/path/to/user_account_mapping.csv"'
-```
-
-c. You can verify the data in the `user_accounts` table has been updated.
-
-
-
-## Appendix A: how to connect to the database
-
-Here we use MySQL as an example. You can install database management tools like Sequel Ace, DataGrip, MySQLWorkbench, etc.
-
-
-Or through the command line:
-
-```
-mysql -h
-Ok, the data has now been saved to the `_raw_feishu_*` table, and the `data` column is the return information from the plugin. Here we only collected data for the last 2 days. The data information is not much, but it also covers a variety of situations. That is, the same person has data on different days.
-
-It is also worth mentioning that the plugin runs two tasks, `collectMeetingTopUserItem` and `extractMeetingTopUserItem`. The former is the task of collecting, which is needed to run this time, and the latter is the task of extracting data. It doesn't matter whether the extractor runs in the prepared data session.
-
-Next, we need to export the data to .csv format. This step can be done in a variety of different ways - you can show your skills. I will only introduce a few common methods here.
-
-### DevLake Code Generator Export
-
-Run `go run generator/main.go create-e2e-raw` directly and follow the guidelines to complete the export. This solution is the simplest, but has some limitations, such as the exported fields being fixed. You can refer to the next solutions if you need more customisation options.
-
-
-
-### GoLand Database export
-
-
-
-This solution is very easy to use and will not cause problems using Postgres or MySQL.
-
-The success criteria for csv export is that the go program can read it without errors, so several points are worth noticing.
-
-1. the values in the csv file should be wrapped in double quotes to avoid special symbols such as commas in the values that break the csv format
-2. double quotes in csv files are escaped. generally `""` represents a double quote
-3. pay attention to whether the column `data` is the actual value, not the value after base64 or hex
-
-After exporting, move the .csv file to `plugins/feishu/e2e/raw_tables/_raw_feishu_meeting_top_user_item.csv`.
-
-### MySQL Select Into Outfile
-
-This is MySQL's solution for exporting query results to a file. The MySQL currently started in docker-compose.yml comes with the --security parameter, so it does not allow `select ... into outfile`. The first step is to turn off the security parameter, which is done roughly as follows.
-
-After closing it, use `select ... into outfile` to export the csv file. The export result is rough as follows.
-
-Notice that the data field has extra hexsha fields, which need to be manually converted to literal quantities.
-
-### Vscode Database
-
-This is Vscode's solution for exporting query results to a file, but it is not easy to use. Here is the export result without any configuration changes
-
-However, it is obvious that the escape symbol does not conform to the csv specification, and the data is not successfully exported. After adjusting the configuration and manually replacing `\"` with `""`, we get the following result.
-
-The data field of this file is encoded in base64, so it needs to be decoded manually to a literal amount before using it.
-
-### MySQL workbench
-
-This tool must write the SQL yourself to complete the data export, which can be rewritten by imitating the following SQL.
-```sql
-SELECT id, params, CAST(`data` as char) as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item;
-```
-
-Select csv as the save format and export it for use.
-
-### Postgres Copy with csv header
-
-`Copy(SQL statement) to '/var/lib/postgresql/data/raw.csv' with csv header;` is a common export method for PG to export csv, which can also be used here.
-```sql
-COPY (
-SELECT id, params, convert_from(data, 'utf-8') as data, url, input,created_at FROM _raw_feishu_meeting_top_user_item
-) to '/var/lib/postgresql/data/raw.csv' with csv header;
-```
-Use the above statement to complete the export of the file. If pg runs in docker, just use the command `docker cp` to export the file to the host.
-
-## Writing E2E tests
-
-First, create a test environment. For example, let's create `meeting_test.go`.
-
-Then enter the test preparation code in it as follows. The code is to create an instance of the `feishu` plugin and then call `ImportCsvIntoRawTable` to import the data from the csv file into the `_raw_feishu_meeting_top_user_item` table.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-}
-```
-The signature of the import function is as follows.
-```func (t *DataFlowTester) ImportCsvIntoRawTable(csvRelPath string, rawTableName string)```
-It has a twin, with only slight differences in parameters.
-```func (t *DataFlowTester) ImportCsvIntoTabler(csvRelPath string, dst schema.Tabler)```
-The former is used to import tables in the raw layer. The latter is used to import arbitrary tables.
-**Note:** These two functions will delete the db table and use `gorm.AutoMigrate` to re-create a new table to clear data in it.
-After importing the data is complete, run this tester and it must be PASS without any test logic at this moment. Then write the logic for calling the call to the extractor task in `TestMeetingDataFlow`.
-
-```go
-func TestMeetingDataFlow(t *testing.T) {
- var plugin impl.Feishu
- dataflowTester := e2ehelper.NewDataFlowTester(t, "feishu", plugin)
-
- taskData := &tasks.FeishuTaskData{
- Options: &tasks.FeishuOptions{
- ConnectionId: 1,
- },
- }
-
- // import raw data table
- dataflowTester.ImportCsvIntoRawTable("./raw_tables/_raw_feishu_meeting_top_user_item.csv", "_raw_feishu_meeting_top_user_item")
-
- // verify extraction
- dataflowTester.FlushTabler(&models.FeishuMeetingTopUserItem{})
- dataflowTester.Subtask(tasks.ExtractMeetingTopUserItemMeta, taskData)
-
-}
-```
-The added code includes a call to `dataflowTester.FlushTabler` to clear the table `_tool_feishu_meeting_top_user_items` and a call to `dataflowTester.Subtask` to simulate the running of the subtask `ExtractMeetingTopUserItemMeta`.
-
-Now run it and see if the subtask `ExtractMeetingTopUserItemMeta` completes without errors. The data results of the `extract` run generally come from the raw table, so the plugin subtask will run correctly if written without errors. We can observe if the data is successfully parsed in the db table in the tool layer. In this case the `_tool_feishu_meeting_top_user_items` table has the correct data.
-
-If the run is incorrect, maybe you can troubleshoot the problem with the plugin itself before moving on to the next step.
-
-## Verify that the results of the task are correct
-
-Let's continue writing the test and add the following code at the end of the test function
-```go
-func TestMeetingDataFlow(t *testing.T) {
- ......
-
- dataflowTester.VerifyTable(
- models.FeishuMeetingTopUserItem{},
- "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv",
- []string{
- "meeting_count",
- "meeting_duration",
- "user_type",
- "_raw_data_params",
- "_raw_data_table",
- "_raw_data_id",
- "_raw_data_remark",
- },
- )
-}
-```
-Its purpose is to call `dataflowTester.VerifyTable` to complete the validation of the data results. The third parameter is all the fields of the table that need to be verified.
-The data used for validation exists in `. /snapshot_tables/_tool_feishu_meeting_top_user_items.csv`, but of course, this file does not exist yet.
-
-There is a twin, more generalized function, that could be used instead:
-```go
-dataflowTester.VerifyTableWithOptions(models.FeishuMeetingTopUserItem{},
- dataflowTester.TableOptions{
- CSVRelPath: "./snapshot_tables/_tool_feishu_meeting_top_user_items.csv"
- },
- )
-
-```
-The above usage will be default to validating against all fields of the `models.FeishuMeetingTopUserItem` model. There are additional fields on `TableOptions` that can be specified to limit which fields on that model to perform validation on.
-
-To facilitate the generation of the file mentioned above, DevLake has adopted a testing technique called `Snapshot`, which will automatically generate the file based on the run results when the `VerifyTable` or `VerifyTableWithOptions` functions are called without the csv existing.
-
-But note! Please do two things after the snapshot is created: 1. check if the file is generated correctly 2. re-run it to make sure there are no errors between the generated results and the re-run results.
-These two operations are critical and directly related to the quality of test writing. We should treat the snapshot file in `.csv` format like a code file.
-
-If there is a problem with this step, there are usually 2 ways to solve it.
-1. The validated fields contain fields like create_at runtime or self-incrementing ids, which cannot be repeatedly validated and should be excluded.
-2. there is `\n` or `\r\n` or other escape mismatch fields in the run results. Generally, when parsing the `httpResponse` error, you can follow these solutions:
- 1. modify the field type of the content in the api model to `json.
- 2. convert it to string when parsing
- 3. so that the `\n` symbol can be kept intact, avoiding the parsing of line breaks by the database or the operating system
-
-
-For example, in the `github` plugin, this is how it is handled.
-
-
-
-Well, at this point, the E2E writing is done. We have added a total of 3 new files to complete the testing of the meeting length collection task. It's pretty easy.
-
-
-## Run E2E tests for all plugins like CI
-
-It's straightforward. Just run `make e2e-plugins` because DevLake has already solidified it into a script~
-
diff --git a/versioned_docs/version-v0.14/DeveloperManuals/Notifications.md b/versioned_docs/version-v0.14/DeveloperManuals/Notifications.md
deleted file mode 100644
index 23456b4f1e7..00000000000
--- a/versioned_docs/version-v0.14/DeveloperManuals/Notifications.md
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: "Notifications"
-description: >
- Notifications
-sidebar_position: 4
----
-
-## Request
-Example request
-```
-POST /lake/notify?nouce=3-FDXxIootApWxEVtz&sign=424c2f6159bd9e9828924a53f9911059433dc14328a031e91f9802f062b495d5
-
-{"TaskID":39,"PluginName":"jenkins","CreatedAt":"2021-09-30T15:28:00.389+08:00","UpdatedAt":"2021-09-30T15:28:00.785+08:00"}
-```
-
-## Configuration
-If you want to use the notification feature, you should add two configuration key to `.env` file.
-```shell
-# .env
-# notification request url, e.g.: http://example.com/lake/notify
-NOTIFICATION_ENDPOINT=
-# secret is used to calculate signature
-NOTIFICATION_SECRET=
-```
-
-## Signature
-You should check the signature before accepting the notification request. We use sha256 algorithm to calculate the checksum.
-```go
-// calculate checksum
-sum := sha256.Sum256([]byte(requestBody + NOTIFICATION_SECRET + nouce))
-return hex.EncodeToString(sum[:])
-```
diff --git a/versioned_docs/version-v0.14/DeveloperManuals/PluginImplementation.md b/versioned_docs/version-v0.14/DeveloperManuals/PluginImplementation.md
deleted file mode 100644
index b6264991c28..00000000000
--- a/versioned_docs/version-v0.14/DeveloperManuals/PluginImplementation.md
+++ /dev/null
@@ -1,339 +0,0 @@
----
-title: "Plugin Implementation"
-sidebar_position: 2
-description: >
- Plugin Implementation
----
-
-If your favorite DevOps tool is not yet supported by DevLake, don't worry. It's not difficult to implement a DevLake plugin. In this post, we'll go through the basics of DevLake plugins and build an example plugin from scratch together.
-
-## What is a plugin?
-
-A DevLake plugin is a shared library built with Go's `plugin` package that hooks up to DevLake core at run-time.
-
-A plugin may extend DevLake's capability in three ways:
-
-1. Integrating with new data sources
-2. Transforming/enriching existing data
-3. Exporting DevLake data to other data systems
-
-
-## How do plugins work?
-
-A plugin mainly consists of a collection of subtasks that can be executed by DevLake core. For data source plugins, a subtask may be collecting a single entity from the data source (e.g., issues from Jira). Besides the subtasks, there're hooks that a plugin can implement to customize its initialization, migration, and more. See below for a list of the most important interfaces:
-
-1. [PluginMeta](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_meta.go) contains the minimal interface that a plugin should implement, with only two functions
- - Description() returns the description of a plugin
- - RootPkgPath() returns the root package path of a plugin
-2. [PluginInit](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_init.go) allows a plugin to customize its initialization
-3. [PluginTask](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_task.go) enables a plugin to prepare data prior to subtask execution
-4. [PluginApi](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_api.go) lets a plugin exposes some self-defined APIs
-5. [PluginMigration](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_migration.go) is where a plugin manages its database migrations
-6. [PluginModel](https://github.com/apache/incubator-devlake/blob/main/backend/core/plugin/plugin_model.go) allows other plugins to get the model information of all database tables of the current plugin through the GetTablesInfo() method.If you need to access Domain Layer Models,please visit [DomainLayerSchema](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/)
-
-The diagram below shows the control flow of executing a plugin:
-
-```mermaid
-flowchart TD;
- subgraph S4[Step4 sub-task extractor running process];
- direction LR;
- D4[DevLake];
- D4 -- "Step4.1 create a new\n ApiExtractor\n and execute it" --> E["ExtractXXXMeta.\nEntryPoint"];
- E <-- "Step4.2 read from\n raw table" --> E2["RawDataSubTaskArgs\n.Table"];
- E -- "Step4.3 call with RawData" --> ApiExtractor.Extract;
- ApiExtractor.Extract -- "decode and return gorm models" --> E
- end
- subgraph S3[Step3 sub-task collector running process]
- direction LR
- D3[DevLake]
- D3 -- "Step3.1 create a new\n ApiCollector\n and execute it" --> C["CollectXXXMeta.\nEntryPoint"];
- C <-- "Step3.2 create\n raw table" --> C2["RawDataSubTaskArgs\n.RAW_BBB_TABLE"];
- C <-- "Step3.3 build query\n before sending requests" --> ApiCollectorArgs.\nQuery/UrlTemplate;
- C <-. "Step3.4 send requests by ApiClient \n and return HTTP response" .-> A1["HTTP APIs"];
- C <-- "Step3.5 call and \nreturn decoded data \nfrom HTTP response" --> ResponseParser;
- end
- subgraph S2[Step2 DevLake register custom plugin]
- direction LR
- D2[DevLake]
- D2 <-- "Step2.1 function \`Init\` \nneed to do init jobs" --> plugin.Init;
- D2 <-- "Step2.2 (Optional) call \nand return migration scripts" --> plugin.MigrationScripts;
- D2 <-- "Step2.3 (Optional) call \nand return taskCtx" --> plugin.PrepareTaskData;
- D2 <-- "Step2.4 call and \nreturn subTasks for execting" --> plugin.SubTaskContext;
- end
- subgraph S1[Step1 Run DevLake]
- direction LR
- main -- "Transfer of control \nby \`runner.DirectRun\`" --> D1[DevLake];
- end
- S1-->S2-->S3-->S4
-```
-There's a lot of information in the diagram, but we don't expect you to digest it right away. You can simply use it as a reference when you go through the example below.
-
-## A step-by-step guide towards your first plugin
-
-In this section, we will describe how to create a data collection plugin from scratch. The data to be collected is the information about all Committers and Contributors of the Apache project, in order to check whether they have signed the CLA. We are going to
-
-* request `https://people.apache.org/public/icla-info.json` to get the Committers' information
-* request the `mailing list` to get the Contributors' information
-
-We will focus on demonstrating how to request and cache information about all Committers through the Apache API and extract structured data from it. The collection of Contributors will only be briefly described.
-
-### Step 1: Bootstrap the new plugin
-
-**Note:** Please make sure you have DevLake up and running before proceeding.
-
-> More info about plugin:
-> Generally, we need these folders in plugin folders: `api`, `models` and `tasks`
-> `api` interacts with `config-ui` for test/get/save connection of data source
-> - connection [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/api/connection.go)
-> - connection model [example](https://github.com/apache/incubator-devlake/blob/main/plugins/gitlab/models/connection.go)
-> `models` stores all `data entities` and `data migration scripts`.
-> - entity
-> - data migrations [template](https://github.com/apache/incubator-devlake/tree/main/generator/template/migrationscripts)
-> `tasks` contains all of our `sub tasks` for a plugin
-> - task data [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data.go-template)
-> - api client [template](https://github.com/apache/incubator-devlake/blob/main/generator/template/plugin/tasks/task_data_with_api_client.go-template)
-
-Don't worry if you cannot figure out what these concepts mean immediately. We'll explain them one by one later.
-
-DevLake provides a generator to create a plugin conveniently. Let's scaffold our new plugin by running `go run generator/main.go create-plugin icla`, which would ask for `with_api_client` and `Endpoint`.
-
-* `with_api_client` is used for choosing if we need to request HTTP APIs by api_client.
-* `Endpoint` use in which site we will request, in our case, it should be `https://people.apache.org/`.
-
-
-
-Now we have three files in our plugin. `api_client.go` and `task_data.go` are in subfolder `tasks/`.
-
-
-Have a try to run this plugin by function `main` in `plugin_main.go`. When you see result like this:
-```
-$go run plugins/icla/plugin_main.go
-[2022-06-02 18:07:30] INFO failed to create dir logs: mkdir logs: file exists
-press `c` to send cancel signal
-[2022-06-02 18:07:30] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-02 18:07:30] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-02 18:07:30] INFO [icla] total step: 0
-```
-How exciting. It works! The plugin defined and initiated in `plugin_main.go` use some options in `task_data.go`. They are made up as the most straightforward plugin in Apache DevLake, and `api_client.go` will be used in the next step to request HTTP APIs.
-
-### Step 2: Create a sub-task for data collection
-Before we start, it is helpful to know how collection task is executed:
-1. First, Apache DevLake would call `plugin_main.PrepareTaskData()` to prepare needed data before any sub-tasks. We need to create an API client here.
-2. Then Apache DevLake will call the sub-tasks returned by `plugin_main.SubTaskMetas()`. Sub-task is an independent task to do some job, like requesting API, processing data, etc.
-
-> Each sub-task must be defined as a SubTaskMeta, and implement SubTaskEntryPoint of SubTaskMeta. SubTaskEntryPoint is defined as
-> ```go
-> type SubTaskEntryPoint func(c SubTaskContext) error
-> ```
-> More info at: https://devlake.apache.org/blog/how-DevLake-is-up-and-running/
-
-#### Step 2.1: Create a sub-task(Collector) for data collection
-
-Let's run `go run generator/main.go create-collector icla committer` and confirm it. This sub-task is activated by registering in `plugin_main.go/SubTaskMetas` automatically.
-
-
-
-> - Collector will collect data from HTTP or other data sources, and save the data into the raw layer.
-> - Inside the func `SubTaskEntryPoint` of `Collector`, we use `helper.NewApiCollector` to create an object of [ApiCollector](https://github.com/apache/incubator-devlake/blob/main/backend/generator/template/plugin/tasks/api_collector.go-template), then call `execute()` to do the job.
-
-Now you can notice `data.ApiClient` is initiated in `plugin_main.go/PrepareTaskData.ApiClient`. `PrepareTaskData` create a new `ApiClient`, which is a tool Apache DevLake suggests to request data from HTTP Apis. This tool support some valuable features for HttpApi, like rateLimit, proxy and retry. Of course, if you like, you may use the lib `http` instead, but it will be more tedious.
-
-Let's move forward to use it.
-
-1. To collect data from `https://people.apache.org/public/icla-info.json`,
-we have filled `https://people.apache.org/` into `tasks/api_client.go/ENDPOINT` in Step 1.
-
-
-
-2. Fill `public/icla-info.json` into `UrlTemplate`, delete the unnecessary iterator and add `println("receive data:", res)` in `ResponseParser` to see if collection was successful.
-
-
-
-Ok, now the collector sub-task has been added to the plugin, and we can kick it off by running `main` again. If everything goes smoothly, the output should look like this:
-```bash
-[2022-06-06 12:24:52] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 12:24:52] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 12:24:52] INFO [icla] total step: 1
-[2022-06-06 12:24:52] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 12:24:52] INFO [icla] [CollectCommitter] start api collection
-receive data: 0x140005763f0
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 12:24:55] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 12:24:55] INFO [icla] finished step: 1 / 1
-```
-
-Great! Now we can see data pulled from the server without any problem. The last step is to decode the response body in `ResponseParser` and return it to the framework, so it can be stored in the database.
-```go
-ResponseParser: func(res *http.Response) ([]json.RawMessage, error) {
- body := &struct {
- LastUpdated string `json:"last_updated"`
- Committers json.RawMessage `json:"committers"`
- }{}
- err := helper.UnmarshalResponse(res, body)
- if err != nil {
- return nil, err
- }
- println("receive data:", len(body.Committers))
- return []json.RawMessage{body.Committers}, nil
-},
-
-```
-Ok, run the function `main` once again, then it turned out like this, and we should be able to see some records show up in the table `_raw_icla_committer`.
-```bash
-……
-receive data: 272956 /* <- the number means 272956 models received */
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 13:46:57] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 13:46:57] INFO [icla] finished step: 1 / 1
-```
-
-
-
-#### Step 2.2: Create a sub-task(Extractor) to extract data from the raw layer
-
-> - Extractor will extract data from raw layer and save it into tool db table.
-> - Except for some pre-processing, the main flow is similar to the collector.
-
-We have already collected data from HTTP API and saved them into the DB table `_raw_XXXX`. In this step, we will extract the names of committers from the raw data. As you may infer from the name, raw tables are temporary and not easy to use directly.
-
-Now Apache DevLake suggests to save data by [gorm](https://gorm.io/docs/index.html), so we will create a model by gorm and add it into `plugin_main.go/AutoMigrate()`.
-
-plugins/icla/models/committer.go
-```go
-package models
-
-import (
- "github.com/apache/incubator-devlake/models/common"
-)
-
-type IclaCommitter struct {
- UserName string `gorm:"primaryKey;type:varchar(255)"`
- Name string `gorm:"primaryKey;type:varchar(255)"`
- common.NoPKModel
-}
-
-func (IclaCommitter) TableName() string {
- return "_tool_icla_committer"
-}
-```
-
-plugins/icla/plugin_main.go
-
-
-
-Ok, run the plugin, and table `_tool_icla_committer` will be created automatically just like the snapshot below:
-
-
-Next, let's run `go run generator/main.go create-extractor icla committer` and type in what the command prompt asks for to create a new sub-task.
-
-
-
-Let's look at the function `extract` in `committer_extractor.go` created just now, and the code that needs to be written here. It's obvious that `resData.data` is the raw data, so we could json-decode each row add a new `IclaCommitter` for each and save them.
-```go
-Extract: func(resData *helper.RawData) ([]interface{}, error) {
- names := &map[string]string{}
- err := json.Unmarshal(resData.Data, names)
- if err != nil {
- return nil, err
- }
- extractedModels := make([]interface{}, 0)
- for userName, name := range *names {
- extractedModels = append(extractedModels, &models.IclaCommitter{
- UserName: userName,
- Name: name,
- })fco
- }
- return extractedModels, nil
-},
-```
-
-Ok, run it then we get:
-```
-[2022-06-06 15:39:40] INFO [icla] start plugin
-invalid ICLA_TOKEN, but ignore this error now
-[2022-06-06 15:39:40] INFO [icla] scheduler for api https://people.apache.org/ worker: 25, request: 18000, duration: 1h0m0s
-[2022-06-06 15:39:40] INFO [icla] total step: 2
-[2022-06-06 15:39:40] INFO [icla] executing subtask CollectCommitter
-[2022-06-06 15:39:40] INFO [icla] [CollectCommitter] start api collection
-receive data: 272956
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] finished records: 1
-[2022-06-06 15:39:44] INFO [icla] [CollectCommitter] end api collection
-[2022-06-06 15:39:44] INFO [icla] finished step: 1 / 2
-[2022-06-06 15:39:44] INFO [icla] executing subtask ExtractCommitter
-[2022-06-06 15:39:46] INFO [icla] [ExtractCommitter] finished records: 1
-[2022-06-06 15:39:46] INFO [icla] finished step: 2 / 2
-```
-Now committer data have been saved in _tool_icla_committer.
-
-
-#### Step 2.3: Convertor
-
-Notes: The goal of Converters is to create a vendor-agnostic model out of the vendor-dependent ones created by the Extractors.
-They are not necessary to have per se, but we encourage it because converters and the domain layer will significantly help with building dashboards. More info about the domain layer [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/).
-
-In short:
-
-> - Convertor will convert data from the tool layer and save it into the domain layer.
-> - We use `helper.NewDataConverter` to create an object of DataConvertor, then call `execute()`.
-
-#### Step 2.4: Let's try it
-Sometimes OpenApi will be protected by token or other auth types, and we need to log in to gain a token to visit it. For example, only after logging in `private@apahce.com` could we gather the data about contributors signing ICLA. Here we briefly introduce how to authorize DevLake to collect data.
-
-Let's look at `api_client.go`. `NewIclaApiClient` load config `ICLA_TOKEN` by `.env`, so we can add `ICLA_TOKEN=XXXXXX` in `.env` and use it in `apiClient.SetHeaders()` to mock the login status. Code as below:
-
-
-Of course, we can use `username/password` to get a token after login mockery. Just try and adjust according to the actual situation.
-
-Look for more related details at https://github.com/apache/incubator-devlake
-
-#### Step 2.5: Implement the GetTablesInfo() method of the PluginModel interface
-
-As shown in the following gitlab plugin example,
-add all models that need to be accessed by external plugins to the return value.
-
-```go
-var _ core.PluginModel = (*Gitlab)(nil)
-
-func (plugin Gitlab) GetTablesInfo() []core.Tabler {
- return []core.Tabler{
- &models.GitlabConnection{},
- &models.GitlabAccount{},
- &models.GitlabCommit{},
- &models.GitlabIssue{},
- &models.GitlabIssueLabel{},
- &models.GitlabJob{},
- &models.GitlabMergeRequest{},
- &models.GitlabMrComment{},
- &models.GitlabMrCommit{},
- &models.GitlabMrLabel{},
- &models.GitlabMrNote{},
- &models.GitlabPipeline{},
- &models.GitlabProject{},
- &models.GitlabProjectCommit{},
- &models.GitlabReviewer{},
- &models.GitlabTag{},
- }
-}
-```
-
-You can use it as follows:
-
-```go
-if pm, ok := plugin.(core.PluginModel); ok {
- tables := pm.GetTablesInfo()
- for _, table := range tables {
- // do something
- }
-}
-
-```
-
-#### Final step: Submit the code as open source code
-We encourage ideas and contributions ~ Let's use migration scripts, domain layers and other discussed concepts to write normative and platform-neutral code. More info at [here](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema) or contact us for ebullient help.
-
-
-## Done!
-
-Congratulations! The first plugin has been created! 🎖
diff --git a/versioned_docs/version-v0.14/DeveloperManuals/Release-SOP.md b/versioned_docs/version-v0.14/DeveloperManuals/Release-SOP.md
deleted file mode 100644
index e63f317f5bd..00000000000
--- a/versioned_docs/version-v0.14/DeveloperManuals/Release-SOP.md
+++ /dev/null
@@ -1,117 +0,0 @@
-# DevLake Release Guide
-
-**Please make sure your public key was included in the https://downloads.apache.org/incubator/devlake/KEYS , if not, please update this file first.**
-## How to update KEYS
-1. Clone the svn repository
- ```shell
- svn co https://dist.apache.org/repos/dist/dev/incubator/devlake
- ```
-2. Append your public key to the KEYS file
- ```shell
- cd devlake
- (gpg --list-sigs Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on: -- `Deployments` collected in one of the following ways: - - Open APIs of Jenkins, GitLab, GitHub, etc. - - Webhook for general CI tools. - - Releases and PR/MRs from GitHub, GitLab APIs, etc. -- `Incidents` collected in one of the following ways: - - Issue tracking tools such as Jira, TAPD, GitHub, etc. - - Incident or Service Monitoring tools such as PagerDuty, ServiceNow, etc. - -Transformation Rules Required - -This metric relies on: -- Deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as `Deployments`. -- Incident configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - -SQL Queries - -If you want to measure the monthly trend of change failure rate as the picture shown below, run the following SQL in Grafana. - - - -``` -with _deployments as ( --- get the deployment count each month - SELECT - date_format(finished_date,'%y/%m') as month, - COUNT(distinct id) AS deployment_count - FROM - cicd_tasks - WHERE - type = 'DEPLOYMENT' - and result = 'SUCCESS' - GROUP BY 1 -), - -_incidents as ( --- get the incident count each month - SELECT - date_format(created_date,'%y/%m') as month, - COUNT(distinct id) AS incident_count - FROM - issues - WHERE - type = 'INCIDENT' - GROUP BY 1 -), - -_calendar_months as( --- deal with the month with no incidents - SELECT date_format(CAST((SYSDATE()-INTERVAL (month_index) MONTH) AS date), '%y/%m') as month - FROM ( SELECT 0 month_index - UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 - UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 - UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 - UNION ALL SELECT 10 UNION ALL SELECT 11 - ) month_index - WHERE (SYSDATE()-INTERVAL (month_index) MONTH) > SYSDATE()-INTERVAL 6 MONTH -) - -SELECT - cm.month, - case - when d.deployment_count is null or i.incident_count is null then 0 - else i.incident_count/d.deployment_count end as change_failure_rate -FROM - _calendar_months cm - left join _incidents i on cm.month = i.month - left join _deployments d on cm.month = d.month -ORDER BY 1 -``` - -If you want to measure in which category your team falls into as the picture shown below, run the following SQL in Grafana. - - - -``` -with _deployment_count as ( --- get the deployment deployed within the selected time period in the top-right corner - SELECT - COUNT(distinct id) AS deployment_count - FROM - cicd_tasks - WHERE - type = 'DEPLOYMENT' - and result = 'SUCCESS' - and $__timeFilter(finished_date) -), - -_incident_count as ( --- get the incident created within the selected time period in the top-right corner - SELECT - COUNT(distinct id) AS incident_count - FROM - issues - WHERE - type = 'INCIDENT' - and $__timeFilter(created_date) -) - -SELECT - case - when deployment_count is null or incident_count is null or deployment_count = 0 then NULL - when incident_count/deployment_count <= .15 then "0-15%" - when incident_count/deployment_count <= .20 then "16%-20%" - when incident_count/deployment_count <= .30 then "21%-30%" - else "> 30%" - end as change_failure_rate -FROM - _deployment_count, _incident_count -``` - -## How to improve? -- Add unit tests for all new feature -- "Shift left", start QA early and introduce more automated tests -- Enforce code review if it's not strictly executed diff --git a/versioned_docs/version-v0.14/Metrics/CodingTime.md b/versioned_docs/version-v0.14/Metrics/CodingTime.md deleted file mode 100644 index d788474810c..00000000000 --- a/versioned_docs/version-v0.14/Metrics/CodingTime.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "PR Coding Time" -description: > - PR Coding Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from the first commit until a PR is issued. - -## Why is it important? -It is recommended that you keep every task on a workable and manageable scale for a reasonably short amount of coding time. The average coding time of most engineering teams is around 3-4 days. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -Divide coding tasks into workable and manageable pieces. diff --git a/versioned_docs/version-v0.14/Metrics/CommitAuthorCount.md b/versioned_docs/version-v0.14/Metrics/CommitAuthorCount.md deleted file mode 100644 index 3be4ad20633..00000000000 --- a/versioned_docs/version-v0.14/Metrics/CommitAuthorCount.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "Commit Author Count" -description: > - Commit Author Count -sidebar_position: 14 ---- - -## What is this metric? -The number of commit authors who have committed code. - -## Why is it important? -Take inventory of project/team R&D resource inputs, assess input-output ratio, and rationalize resource deployment. - - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -This metric is calculated by counting the number of commit authors in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - - -## How to improve? -As a secondary indicator, this helps assess the labor cost of participating in coding. diff --git a/versioned_docs/version-v0.14/Metrics/CommitCount.md b/versioned_docs/version-v0.14/Metrics/CommitCount.md deleted file mode 100644 index ae85af8d2cd..00000000000 --- a/versioned_docs/version-v0.14/Metrics/CommitCount.md +++ /dev/null @@ -1,55 +0,0 @@ ---- -title: "Commit Count" -description: > - Commit Count -sidebar_position: 6 ---- - -## What is this metric? -The number of commits created. - -## Why is it important? -1. Identify potential bottlenecks that may affect output -2. Encourage R&D practices of small step submissions and develop excellent coding habits - -## Which dashboard(s) does it exist in -- GitHub Release Quality and Contribution Analysis -- Demo-Is this month more productive than last? -- Demo-Commit Count by Author - -## How is it calculated? -This metric is calculated by counting the number of commits in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -SQL Queries - -If you want to see the monthly trend, run the following SQL -``` - with _commits as( - SELECT - DATE_ADD(date(authored_date), INTERVAL -DAY(date(authored_date))+1 DAY) as time, - count(*) as commit_count - FROM commits - WHERE - message not like '%Merge%' - and $__timeFilter(authored_date) - group by 1 - ) - - SELECT - date_format(time,'%M %Y') as month, - commit_count as "Commit Count" - FROM _commits - ORDER BY time -``` - -## How to improve? -1. Identify the main reasons for the unusual number of commits and the possible impact on the number of commits through comparison -2. Evaluate whether the number of commits is reasonable in conjunction with more microscopic workload metrics (e.g. lines of code/code equivalents) diff --git a/versioned_docs/version-v0.14/Metrics/CycleTime.md b/versioned_docs/version-v0.14/Metrics/CycleTime.md deleted file mode 100644 index bbc98349ab8..00000000000 --- a/versioned_docs/version-v0.14/Metrics/CycleTime.md +++ /dev/null @@ -1,40 +0,0 @@ ---- -title: "PR Cycle Time" -description: > - PR Cycle Time -sidebar_position: 2 ---- - -## What is this metric? -PR Cycle Time is the sum of PR Coding Time, Pickup TIme, Review Time and Deploy Time. It is the total time from the first commit to when the PR is deployed. - -## Why is it important? -PR Cycle Time indicate the overall speed of the delivery progress in terms of PR. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -You can define `deployment` based on your actual practice. For a full list of `deployment`'s definitions that DevLake support, please refer to [Deployment Frequency](/docs/Metrics/DeploymentFrequency.md). - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Divide coding tasks into workable and manageable pieces; -2. Use DevLake's dashboards to monitor your delivery progress; -3. Have a habit to check for hanging PRs regularly; -4. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued; -2. Use automated tests for the initial work; -5. Reduce PR size; -6. Analyze the causes for long reviews. \ No newline at end of file diff --git a/versioned_docs/version-v0.14/Metrics/DeletedLinesOfCode.md b/versioned_docs/version-v0.14/Metrics/DeletedLinesOfCode.md deleted file mode 100644 index 218ceae0c54..00000000000 --- a/versioned_docs/version-v0.14/Metrics/DeletedLinesOfCode.md +++ /dev/null @@ -1,32 +0,0 @@ ---- -title: "Deleted Lines of Code" -description: > - Deleted Lines of Code -sidebar_position: 8 ---- - -## What is this metric? -The accumulated number of deleted lines of code. - -## Why is it important? -1. identify potential bottlenecks that may affect the output -2. Encourage the team to implement a development model that matches the business requirements; develop excellent coding habits - -## Which dashboard(s) does it exist in -N/A - -## How is it calculated? -This metric is calculated by summing the deletions of commits in the given data range. - -Data Sources Required - -This metric relies on commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -## How to improve? -1. From the project/team dimension, observe the accumulated change in Added lines to assess the team activity and code growth rate -2. From version cycle dimension, observe the active time distribution of code changes, and evaluate the effectiveness of project development model. -3. From the member dimension, observe the trend and stability of code output of each member, and identify the key points that affect code output by comparison. diff --git a/versioned_docs/version-v0.14/Metrics/DeployTime.md b/versioned_docs/version-v0.14/Metrics/DeployTime.md deleted file mode 100644 index d908480829f..00000000000 --- a/versioned_docs/version-v0.14/Metrics/DeployTime.md +++ /dev/null @@ -1,30 +0,0 @@ ---- -title: "PR Deploy Time" -description: > - PR Deploy Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is merged to when it is deployed. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in? - - -## How is it calculated? -You can define `deployment` based on your actual practice. For a full list of `deployment`'s definitions that DevLake support, please refer to [Deployment Frequency](/docs/Metrics/DeploymentFrequency.md). - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -## How to improve? - diff --git a/versioned_docs/version-v0.14/Metrics/DeploymentFrequency.md b/versioned_docs/version-v0.14/Metrics/DeploymentFrequency.md deleted file mode 100644 index 90459adc593..00000000000 --- a/versioned_docs/version-v0.14/Metrics/DeploymentFrequency.md +++ /dev/null @@ -1,169 +0,0 @@ ---- -title: "DORA - Deployment Frequency" -description: > - DORA - Deployment Frequency -sidebar_position: 18 ---- - -## What is this metric? -How often an organization deploys code to production or release it to end users. - -## Why is it important? -Deployment frequency reflects the efficiency of a team's deployment. A team that deploys more frequently can deliver the product faster and users' feature requirements can be met faster. - -## Which dashboard(s) does it exist in -DORA dashboard. See [live demo](https://grafana-lake.demo.devlake.io/grafana/d/qNo8_0M4z/dora?orgId=1). - - -## How is it calculated? -Deployment frequency is calculated based on the number of deployment days, not the number of deployments, e.g.,daily, weekly, monthly, yearly. - -Below are the benchmarks for different development teams from Google's report. DevLake uses the same benchmarks. - -| Groups | Benchmarks | DevLake Benchmarks | -| -----------------| --------------------------------------------- | ---------------------------------------------- | -| Elite performers | On-demand (multiple deploys per day) | On-demand | -| High performers | Between once per week and once per month | Between once per week and once per month | -| Medium performers| Between once per month and once every 6 months| Between once per month and once every 6 months | -| Low performers | Fewer than once per six months | Fewer than once per six months | - -Source: 2021 Accelerate State of DevOps, Google
- - -Data Sources Required - -This metric relies on deployments collected in multiple ways: -- Open APIs of Jenkins, GitLab, GitHub, etc. -- Webhook for general CI tools. -- Releases and PR/MRs from GitHub, GitLab APIs, etc. - -Transformation Rules Required - -This metric relies on the deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as deployments. - -SQL Queries - -If you want to measure the monthly trend of deployment count as the picture shown below, run the following SQL in Grafana. - - - -``` -with _deployments as ( --- get the deployment count each month - SELECT - date_format(finished_date,'%y/%m') as month, - COUNT(distinct id) AS deployment_count - FROM - cicd_tasks - WHERE - type = 'DEPLOYMENT' - and result = 'SUCCESS' - GROUP BY 1 -), - -_calendar_months as( --- deal with the month with no deployments - SELECT date_format(CAST((SYSDATE()-INTERVAL (month_index) MONTH) AS date), '%y/%m') as month - FROM ( SELECT 0 month_index - UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 - UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 - UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 - UNION ALL SELECT 10 UNION ALL SELECT 11 - ) month_index - WHERE (SYSDATE()-INTERVAL (month_index) MONTH) > SYSDATE()-INTERVAL 6 MONTH -) - -SELECT - cm.month, - case when d.deployment_count is null then 0 else d.deployment_count end as deployment_count -FROM - _calendar_months cm - left join _deployments d on cm.month = d.month -ORDER BY 1 -``` - -If you want to measure in which category your team falls into as the picture shown below, run the following SQL in Grafana. - - - -``` -with last_few_calendar_months as( --- get the last few months within the selected time period in the top-right corner - SELECT CAST((SYSDATE()-INTERVAL (H+T+U) DAY) AS date) day - FROM ( SELECT 0 H - UNION ALL SELECT 100 UNION ALL SELECT 200 UNION ALL SELECT 300 - ) H CROSS JOIN ( SELECT 0 T - UNION ALL SELECT 10 UNION ALL SELECT 20 UNION ALL SELECT 30 - UNION ALL SELECT 40 UNION ALL SELECT 50 UNION ALL SELECT 60 - UNION ALL SELECT 70 UNION ALL SELECT 80 UNION ALL SELECT 90 - ) T CROSS JOIN ( SELECT 0 U - UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 - UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 - UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 - ) U - WHERE - (SYSDATE()-INTERVAL (H+T+U) DAY) > $__timeFrom() -), - -_days_weeks_deploy as( - SELECT - date(DATE_ADD(last_few_calendar_months.day, INTERVAL -WEEKDAY(last_few_calendar_months.day) DAY)) as week, - MAX(if(deployments.day is not null, 1, 0)) as week_deployed, - COUNT(distinct deployments.day) as days_deployed - FROM - last_few_calendar_months - LEFT JOIN( - SELECT - DATE(finished_date) AS day, - id - FROM cicd_tasks - WHERE - type = 'DEPLOYMENT' - and result = 'SUCCESS') deployments ON deployments.day = last_few_calendar_months.day - GROUP BY week - ), - -_monthly_deploy as( - SELECT - date(DATE_ADD(last_few_calendar_months.day, INTERVAL -DAY(last_few_calendar_months.day)+1 DAY)) as month, - MAX(if(deployments.day is not null, 1, 0)) as months_deployed - FROM - last_few_calendar_months - LEFT JOIN( - SELECT - DATE(finished_date) AS day, - id - FROM cicd_tasks - WHERE - type = 'DEPLOYMENT' - and result = 'SUCCESS') deployments ON deployments.day = last_few_calendar_months.day - GROUP BY month - ), - -_median_number_of_deployment_days_per_week as ( - SELECT x.days_deployed as median_number_of_deployment_days_per_week from _days_weeks_deploy x, _days_weeks_deploy y - GROUP BY x.days_deployed - HAVING SUM(SIGN(1-SIGN(y.days_deployed-x.days_deployed)))/COUNT(*) > 0.5 - LIMIT 1 -), - -_median_number_of_deployment_days_per_month as ( - SELECT x.months_deployed as median_number_of_deployment_days_per_month from _monthly_deploy x, _monthly_deploy y - GROUP BY x.months_deployed - HAVING SUM(SIGN(1-SIGN(y.months_deployed-x.months_deployed)))/COUNT(*) > 0.5 - LIMIT 1 -) - -SELECT - CASE - WHEN median_number_of_deployment_days_per_week >= 3 THEN 'On-demand' - WHEN median_number_of_deployment_days_per_week >= 1 THEN 'Between once per week and once per month' - WHEN median_number_of_deployment_days_per_month >= 1 THEN 'Between once per month and once every 6 months' - ELSE 'Fewer than once per six months' END AS 'Deployment Frequency' -FROM _median_number_of_deployment_days_per_week, _median_number_of_deployment_days_per_month -``` - -## How to improve? -- Trunk development. Work in small batches and often merge their work into shared trunks. -- Integrate CI/CD tools for automated deployment -- Improve automated test coverage diff --git a/versioned_docs/version-v0.14/Metrics/IncidentAge.md b/versioned_docs/version-v0.14/Metrics/IncidentAge.md deleted file mode 100644 index 4cd5e60cbb5..00000000000 --- a/versioned_docs/version-v0.14/Metrics/IncidentAge.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "Incident Age" -description: > - Incident Age -sidebar_position: 10 ---- - -## What is this metric? -The amount of time it takes a incident to fix. - -## Why is it important? -1. Help the team to establish an effective hierarchical response mechanism for incidents. Focus on the resolution of important problems in the backlog. -2. Improve team's and individual's incident fixing efficiency. Identify good/to-be-improved practices that affect incident age - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -This metric equals to `resolution_date` - `created_date` of issues in type "INCIDENT". - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-incident' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - - -## How to improve? -1. Observe the trend of incident age and locate the key reasons. -2. According to the severity level, type (business, functional classification), affected module, source of bugs, count and observe the length of incident age. \ No newline at end of file diff --git a/versioned_docs/version-v0.14/Metrics/IncidentCountPer1kLinesOfCode.md b/versioned_docs/version-v0.14/Metrics/IncidentCountPer1kLinesOfCode.md deleted file mode 100644 index 9ad92787780..00000000000 --- a/versioned_docs/version-v0.14/Metrics/IncidentCountPer1kLinesOfCode.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Incident Count per 1k Lines of Code" -description: > - Incident Count per 1k Lines of Code -sidebar_position: 13 ---- - -## What is this metric? -Amount of incidents per 1,000 lines of code. - -## Why is it important? -1. Defect drill-down analysis to inform the development of design and code review strategies and to improve the internal QA process -2. Assist teams to locate projects/modules with higher defect severity and density, and clean up technical debts -3. Analyze critical points, identify good/to-be-improved practices that affect defect count or defect rate, to reduce the amount of future defects - -## Which dashboard(s) does it exist in -N/A - - -## How is it calculated? -The number of incidents divided by total accumulated lines of code (additions + deletions) in the given data range. - -Data Sources Required - -This metric relies on -- issues collected from Jira, GitHub or TAPD. -- commits collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -This metric relies on -- "Issue type mapping" in Jira, GitHub or TAPD's transformation rules page to let DevLake know what type(s) of issues can be regarded as incidents. -- "PR-Issue Mapping" in GitHub, GitLab's transformation rules page to let DevLake know the bugs are fixed by which PR/MRs. - -## How to improve? -1. From the project or team dimension, observe the statistics on the total number of defects, the distribution of the number of defects in each severity level/type/owner, the cumulative trend of defects, and the change trend of the defect rate in thousands of lines, etc. -2. From version cycle dimension, observe the statistics on the cumulative trend of the number of defects/defect rate, which can be used to determine whether the growth rate of defects is slowing down, showing a flat convergence trend, and is an important reference for judging the stability of software version quality -3. From the time dimension, analyze the trend of the number of test defects, defect rate to locate the key items/key points -4. Evaluate whether the software quality and test plan are reasonable by referring to CMMI standard values diff --git a/versioned_docs/version-v0.14/Metrics/LeadTimeForChanges.md b/versioned_docs/version-v0.14/Metrics/LeadTimeForChanges.md deleted file mode 100644 index 0c8dfc764bf..00000000000 --- a/versioned_docs/version-v0.14/Metrics/LeadTimeForChanges.md +++ /dev/null @@ -1,167 +0,0 @@ ---- -title: "DORA - Lead Time for Changes" -description: > - DORA - Lead Time for Changes -sidebar_position: 19 ---- - -## What is this metric? -The median amount of time for a commit to be deployed into production. - -## Why is it important? -This metric measures the time it takes to commit code to the production environment and reflects the speed of software delivery. A lower average change preparation time means that your team is efficient at coding and deploying your project. - -## Which dashboard(s) does it exist in -DORA dashboard. See [live demo](https://grafana-lake.demo.devlake.io/grafana/d/qNo8_0M4z/dora?orgId=1). - - -## How is it calculated? -This metric is calculated by the median cycle time of the PRs deployed in a time range. A PR's cycle time is equal to the time a PR was deployed minus the PR's first commit's authored_date. - - - -See the picture above, there were three deployments in the last month: Deploy-1, Deploy-2 and Deploy-3. Six PRs were deployed during the same period. - - Median Lead Time for Changes = The median cycle time of PR-1, PR-2, PR-3, PR-4, PR-5, PR-6 - -The way to calculate PR cycle time: -- PR-1 cycle time = Deploy-1's finished_date - PR-1's first commit's authored_date -- PR-2 cycle time = Deploy-2's finished_date - PR-2's first commit's authored_date -- PR-3 cycle time = Deploy-2's finished_date - PR-3's first commit's authored_date -- PR-4 cycle time = Deploy-3's finished_date - PR-4's first commit's authored_date -- PR-5 cycle time = Deploy-3's finished_date - PR-5's first commit's authored_date -- PR-6 cycle time = Deploy-3's finished_date - PR-6's first commit's authored_date - -PR cycle time is pre-calculated when dora plugin is triggered. You can connect to DevLake's database and find it in the field `change_timespan` in [table.pull_requests](https://devlake.apache.org/docs/DataModels/DevLakeDomainLayerSchema/#pull_requests). - - -Below are the benchmarks for different development teams from Google's report. However, it's difficult to tell which group a team falls into when the team's median lead time for changes is `between one week and one month`. Therefore, DevLake provides its own benchmarks to address this problem: - -| Groups | Benchmarks | DevLake Benchmarks -| -----------------| -------------------------------------| --------------------------------| -| Elite performers | Less than one hour | Less than one hour | -| High performers | Between one day and one week | Less than one week | -| Medium performers| Between one month and six months | Between one week and six months | -| Low performers | More than six months | More than six months | - -Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on deployments collected in multiple ways: -- Open APIs of Jenkins, GitLab, GitHub, etc. -- Webhook for general CI tools. -- Releases and PR/MRs from GitHub, GitLab APIs, etc. - -Transformation Rules Required - -This metric relies on the deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as deployments. - -SQL Queries - -If you want to measure the monthly trend of median lead time for changes as the picture shown below, run the following SQL in Grafana. - - - -``` -with _pr_stats as ( --- get PRs' cycle lead time in each month - SELECT - pr.id, - date_format(pr.merged_date,'%y/%m') as month, - pr.change_timespan as pr_cycle_time - FROM - pull_requests pr - WHERE - pr.merged_date is not null - and pr.change_timespan is not null - and $__timeFilter(pr.merged_date) -), - -_find_median_clt_each_month as ( - SELECT x.month, x.pr_cycle_time as med_change_lead_time - FROM _pr_stats x JOIN _pr_stats y ON x.month = y.month - GROUP BY x.month, x.pr_cycle_time - HAVING SUM(SIGN(1-SIGN(y.pr_cycle_time-x.pr_cycle_time)))/COUNT(*) > 0.5 -), - -_find_clt_rank_each_month as ( - SELECT - *, - rank() over(PARTITION BY month ORDER BY med_change_lead_time) as _rank - FROM - _find_median_clt_each_month -), - -_clt as ( - SELECT - month, - med_change_lead_time - from _find_clt_rank_each_month - WHERE _rank = 1 -), - -_calendar_months as( --- to deal with the month with no incidents - SELECT date_format(CAST((SYSDATE()-INTERVAL (month_index) MONTH) AS date), '%y/%m') as month - FROM ( SELECT 0 month_index - UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 - UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 - UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 - UNION ALL SELECT 10 UNION ALL SELECT 11 - ) month_index - WHERE (SYSDATE()-INTERVAL (month_index) MONTH) > SYSDATE()-INTERVAL 6 MONTH -) - -SELECT - cm.month, - case - when _clt.med_change_lead_time is null then 0 - else _clt.med_change_lead_time/60 end as med_change_lead_time_in_hour -FROM - _calendar_months cm - left join _clt on cm.month = _clt.month -ORDER BY 1 -``` - -If you want to measure in which category your team falls into as the picture shown below, run the following SQL in Grafana. - - - -``` -with _pr_stats as ( --- get PRs' cycle time in the selected period - SELECT - pr.id, - pr.change_timespan as pr_cycle_time - FROM - pull_requests pr - WHERE - pr.merged_date is not null - and pr.change_timespan is not null - and $__timeFilter(pr.merged_date) -), - -_median_change_lead_time as ( --- use median PR cycle time as the median change lead time - SELECT x.pr_cycle_time as median_change_lead_time from _pr_stats x, _pr_stats y - GROUP BY x.pr_cycle_time - HAVING SUM(SIGN(1-SIGN(y.pr_cycle_time-x.pr_cycle_time)))/COUNT(*) > 0.5 - LIMIT 1 -) - -SELECT - CASE - WHEN median_change_lead_time < 60 then "Less than one hour" - WHEN median_change_lead_time < 7 * 24 * 60 then "Less than one week" - WHEN median_change_lead_time < 180 * 24 * 60 then "Between one week and six months" - ELSE "More than six months" - END as median_change_lead_time -FROM _median_change_lead_time -``` - -## How to improve? -- Break requirements into smaller, more manageable deliverables -- Optimize the code review process -- "Shift left", start QA early and introduce more automated tests -- Integrate CI/CD tools to automate the deployment process diff --git a/versioned_docs/version-v0.14/Metrics/MTTR.md b/versioned_docs/version-v0.14/Metrics/MTTR.md deleted file mode 100644 index 8fa33fb6b91..00000000000 --- a/versioned_docs/version-v0.14/Metrics/MTTR.md +++ /dev/null @@ -1,158 +0,0 @@ ---- -title: "DORA - Median Time to Restore Service" -description: > - DORA - Median Time to Restore Service -sidebar_position: 20 ---- - -## What is this metric? -The time to restore service after service incidents, rollbacks, or any type of production failure happened. - -## Why is it important? -This metric is essential to measure the disaster control capability of your team and the robustness of the software. - -## Which dashboard(s) does it exist in -DORA dashboard. See [live demo](https://grafana-lake.demo.devlake.io/grafana/d/qNo8_0M4z/dora?orgId=1). - - -## How is it calculated? -MTTR = Total [incident age](./IncidentAge.md) (in hours)/number of incidents. - -If you have three incidents that happened in the given data range, one lasting 1 hour, one lasting 2 hours and one lasting 3 hours. Your MTTR will be: (1 + 2 + 3) / 3 = 2 hours. - -Below are the benchmarks for different development teams from Google's report. However, it's difficult to tell which group a team falls into when the team's median time to restore service is `between one week and six months`. Therefore, DevLake provides its own benchmarks to address this problem: - -| Groups | Benchmarks | DevLake Benchmarks -| -----------------| -------------------------------------| -------------------------------| -| Elite performers | Less than one hour | Less than one hour | -| High performers | Less one day | Less than one day | -| Medium performers| Between one day and one week | Between one day and one week | -| Low performers | More than six months | More than one week | - -Source: 2021 Accelerate State of DevOps, Google
- -Data Sources Required - -This metric relies on: -- `Deployments` collected in one of the following ways: - - Open APIs of Jenkins, GitLab, GitHub, etc. - - Webhook for general CI tools. - - Releases and PR/MRs from GitHub, GitLab APIs, etc. -- `Incidents` collected in one of the following ways: - - Issue tracking tools such as Jira, TAPD, GitHub, etc. - - Incident or Service Monitoring tools such as PagerDuty, ServiceNow, etc. - -Transformation Rules Required - -This metric relies on: -- Deployment configuration in Jenkins, GitLab or GitHub transformation rules to let DevLake know what CI builds/jobs can be regarded as `Deployments`. -- Incident configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Incidents`. - -SQL Queries - -If you want to measure the monthly trend of median time to restore service as the picture shown below, run the following SQL in Grafana. - - - -``` -with _incidents as ( --- get the incident count each month - SELECT - date_format(created_date,'%y/%m') as month, - cast(lead_time_minutes as signed) as lead_time_minutes - FROM - issues - WHERE - type = 'INCIDENT' -), - -_find_median_mttr_each_month as ( - SELECT - x.* - from _incidents x join _incidents y on x.month = y.month - WHERE x.lead_time_minutes is not null and y.lead_time_minutes is not null - GROUP BY x.month, x.lead_time_minutes - HAVING SUM(SIGN(1-SIGN(y.lead_time_minutes-x.lead_time_minutes)))/COUNT(*) > 0.5 -), - -_find_mttr_rank_each_month as ( - SELECT - *, - rank() over(PARTITION BY month ORDER BY lead_time_minutes) as _rank - FROM - _find_median_mttr_each_month -), - -_mttr as ( - SELECT - month, - lead_time_minutes as med_time_to_resolve - from _find_mttr_rank_each_month - WHERE _rank = 1 -), - -_calendar_months as( --- deal with the month with no incidents - SELECT date_format(CAST((SYSDATE()-INTERVAL (month_index) MONTH) AS date), '%y/%m') as month - FROM ( SELECT 0 month_index - UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 - UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 - UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9 - UNION ALL SELECT 10 UNION ALL SELECT 11 - ) month_index - WHERE (SYSDATE()-INTERVAL (month_index) MONTH) > SYSDATE()-INTERVAL 6 MONTH -) - -SELECT - cm.month, - case - when m.med_time_to_resolve is null then 0 - else m.med_time_to_resolve/60 end as med_time_to_resolve_in_hour -FROM - _calendar_months cm - left join _mttr m on cm.month = m.month -ORDER BY 1 -``` - -If you want to measure in which category your team falls into as the picture shown below, run the following SQL in Grafana. - - - -``` -with _incidents as ( --- get the incidents created within the selected time period in the top-right corner - SELECT - cast(lead_time_minutes as signed) as lead_time_minutes - FROM - issues - WHERE - type = 'INCIDENT' - and $__timeFilter(created_date) -), - -_median_mttr as ( - SELECT - x.lead_time_minutes as med_time_to_resolve - from _incidents x, _incidents y - WHERE x.lead_time_minutes is not null and y.lead_time_minutes is not null - GROUP BY x.lead_time_minutes - HAVING SUM(SIGN(1-SIGN(y.lead_time_minutes-x.lead_time_minutes)))/COUNT(*) > 0.5 - LIMIT 1 -) - -SELECT - case - WHEN med_time_to_resolve < 60 then "Less than one hour" - WHEN med_time_to_resolve < 24 * 60 then "Less than one Day" - WHEN med_time_to_resolve < 7 * 24 * 60 then "Between one day and one week" - ELSE "More than one week" - END as med_time_to_resolve -FROM - _median_mttr -``` - -## How to improve? -- Use automated tools to quickly report failure -- Prioritize recovery when a failure happens -- Establish a go-to action plan to respond to failures immediately -- Reduce the deployment time for failure-fixing diff --git a/versioned_docs/version-v0.14/Metrics/MergeRate.md b/versioned_docs/version-v0.14/Metrics/MergeRate.md deleted file mode 100644 index c8c274338c9..00000000000 --- a/versioned_docs/version-v0.14/Metrics/MergeRate.md +++ /dev/null @@ -1,40 +0,0 @@ ---- -title: "PR Merge Rate" -description: > - Pull Request Merge Rate -sidebar_position: 12 ---- - -## What is this metric? -The ratio of PRs/MRs that get merged. - -## Why is it important? -1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- GitLab -- Weekly Community Retro -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -The number of merged PRs divided by the number of all PRs in the given data range. - -Data Sources Required - -This metric relies on PRs/MRs collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - - -## How to improve? -1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. diff --git a/versioned_docs/version-v0.14/Metrics/PRCount.md b/versioned_docs/version-v0.14/Metrics/PRCount.md deleted file mode 100644 index 4521e78617a..00000000000 --- a/versioned_docs/version-v0.14/Metrics/PRCount.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Pull Request Count" -description: > - Pull Request Count -sidebar_position: 11 ---- - -## What is this metric? -The number of pull requests created. - -## Why is it important? -1. Code review metrics are process indicators to provide quick feedback on developers' code quality -2. Promote the team to establish a unified coding specification and standardize the code review criteria -3. Identify modules with low-quality risks in advance, optimize practices, and precipitate into reusable knowledge and tools to avoid technical debt accumulation - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- GitLab -- Weekly Community Retro -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is calculated by counting the number of PRs in the given data range. - -Data Sources Required - -This metric relies on PRs/MRs collected from GitHub, GitLab or BitBucket. - -Transformation Rules Required - -N/A - -## How to improve? -1. From the developer dimension, we evaluate the code quality of developers by combining the task complexity with the metrics related to the number of review passes and review rounds. -2. From the reviewer dimension, we observe the reviewer's review style by taking into account the task complexity, the number of passes and the number of review rounds. -3. From the project/team dimension, we combine the project phase and team task complexity to aggregate the metrics related to the number of review passes and review rounds, and identify the modules with abnormal code review process and possible quality risks. diff --git a/versioned_docs/version-v0.14/Metrics/PRSize.md b/versioned_docs/version-v0.14/Metrics/PRSize.md deleted file mode 100644 index bf6a87d82d9..00000000000 --- a/versioned_docs/version-v0.14/Metrics/PRSize.md +++ /dev/null @@ -1,35 +0,0 @@ ---- -title: "PR Size" -description: > - PR Size -sidebar_position: 2 ---- - -## What is this metric? -The average code changes (in Lines of Code) of PRs in the selected time range. - -## Why is it important? -Small PRs can reduce risks of introducing new bugs and increase code review quality, as problems may often be hidden in big chuncks of code and difficult to identify. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is calculated by counting the total number of code changes (in LOC) divided by the total number of PRs in the selected time range. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Divide coding tasks into workable and manageable pieces; -1. Encourage developers to submit small PRs and only keep related changes in the same PR. diff --git a/versioned_docs/version-v0.14/Metrics/PickupTime.md b/versioned_docs/version-v0.14/Metrics/PickupTime.md deleted file mode 100644 index 07242ae772b..00000000000 --- a/versioned_docs/version-v0.14/Metrics/PickupTime.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "PR Pickup Time" -description: > - PR Pickup Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is issued until the first comment is added to that PR. - -## Why is it important? -PR Pickup Time shows how engaged your team is in collaborative work by identifying the delay in picking up PRs. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboard to monitor your delivery progress; -2. Have a habit to check for hanging PRs regularly; -3. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued. diff --git a/versioned_docs/version-v0.14/Metrics/RequirementCount.md b/versioned_docs/version-v0.14/Metrics/RequirementCount.md deleted file mode 100644 index e9a6bd32981..00000000000 --- a/versioned_docs/version-v0.14/Metrics/RequirementCount.md +++ /dev/null @@ -1,68 +0,0 @@ ---- -title: "Requirement Count" -description: > - Requirement Count -sidebar_position: 2 ---- - -## What is this metric? -The number of delivered requirements or features. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -This metric is calculated by counting the number of delivered issues in type "REQUIREMENT" in the given data range. - -Data Sources Required - -This metric relies on the issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - -SQL Queries - -If you want to see a single count, run the following SQL in Grafana -``` - select - count(*) as "Requirement Count" - from issues i - join board_issues bi on i.id = bi.issue_id - where - i.type = 'REQUIREMENT' - and i.status = 'DONE' - -- this is the default variable in Grafana - and $__timeFilter(i.created_date) - and bi.board_id in ($board_id) -``` - -If you want to see the monthly trend, run the following SQL -``` - SELECT - DATE_ADD(date(i.created_date), INTERVAL -DAYOFMONTH(date(i.created_date))+1 DAY) as time, - count(distinct case when status != 'DONE' then i.id else null end) as "Number of Open Issues", - count(distinct case when status = 'DONE' then i.id else null end) as "Number of Delivered Issues" - FROM issues i - join board_issues bi on i.id = bi.issue_id - join boards b on bi.board_id = b.id - WHERE - i.type = 'REQUIREMENT' - and i.status = 'DONE' - and $__timeFilter(i.created_date) - and bi.board_id in ($board_id) - GROUP by 1 -``` - -## How to improve? -1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process. -2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. -3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. -4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. diff --git a/versioned_docs/version-v0.14/Metrics/RequirementDeliveryRate.md b/versioned_docs/version-v0.14/Metrics/RequirementDeliveryRate.md deleted file mode 100644 index eb0a03133d5..00000000000 --- a/versioned_docs/version-v0.14/Metrics/RequirementDeliveryRate.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "Requirement Delivery Rate" -description: > - Requirement Delivery Rate -sidebar_position: 3 ---- - -## What is this metric? -The ratio of delivered requirements to all requirements. - -## Why is it important? -1. Based on historical data, establish a baseline of the delivery capacity of a single iteration to improve the organization and planning of R&D resources. -2. Evaluate whether the delivery capacity matches the business phase and demand scale. Identify key bottlenecks and reasonably allocate resources. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -The number of delivered requirements divided by the total number of requirements in the given data range. - -Data Sources Required - -This metric relies on the issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the number of requirements and delivery rate of different time cycles to find the stability and trend of the development process. -2. Analyze and compare the number of requirements delivered and delivery rate of each project/team, and compare the scale of requirements of different projects. -3. Based on historical data, establish a baseline of the delivery capacity of a single iteration (optimistic, probable and pessimistic values) to provide a reference for iteration estimation. -4. Drill down to analyze the number and percentage of requirements in different phases of SDLC. Analyze rationality and identify the requirements stuck in the backlog. diff --git a/versioned_docs/version-v0.14/Metrics/RequirementGranularity.md b/versioned_docs/version-v0.14/Metrics/RequirementGranularity.md deleted file mode 100644 index 03bb91767f5..00000000000 --- a/versioned_docs/version-v0.14/Metrics/RequirementGranularity.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "Requirement Granularity" -description: > - Requirement Granularity -sidebar_position: 5 ---- - -## What is this metric? -The average number of story points per requirement. - -## Why is it important? -1. Promote product teams to split requirements carefully, improve requirements quality, help developers understand requirements clearly, deliver efficiently and with high quality, and improve the project management capability of the team. -2. Establish a data-supported workload estimation model to help R&D teams calibrate their estimation methods and more accurately assess the granularity of requirements, which is useful to achieve better issue planning in project management. - -## Which dashboard(s) does it exist in -- Jira -- GitHub - - -## How is it calculated? -The average story points of issues in type "REQUIREMENT" in the given data range. - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the story points/requirement lead time of requirements to evaluate whether the ticket size, ie. requirement complexity is optimal. -2. Compare the estimated requirement granularity with the actual situation and evaluate whether the difference is reasonable by combining more microscopic workload metrics (e.g. lines of code/code equivalents) diff --git a/versioned_docs/version-v0.14/Metrics/RequirementLeadTime.md b/versioned_docs/version-v0.14/Metrics/RequirementLeadTime.md deleted file mode 100644 index 74061d63dec..00000000000 --- a/versioned_docs/version-v0.14/Metrics/RequirementLeadTime.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "Requirement Lead Time" -description: > - Requirement Lead Time -sidebar_position: 4 ---- - -## What is this metric? -The amount of time it takes a requirement to deliver. - -## Why is it important? -1. Analyze key projects and critical points, identify good/to-be-improved practices that affect requirement lead time, and reduce the risk of delays -2. Focus on the end-to-end velocity of value delivery process; coordinate different parts of R&D to avoid efficiency shafts; make targeted improvements to bottlenecks. - -## Which dashboard(s) does it exist in -- Jira -- GitHub -- Community Experience - - -## How is it calculated? -This metric equals to `resolution_date` - `created_date` of issues in type "REQUIREMENT". - -Data Sources Required - -This metric relies on issues collected from Jira, GitHub, or TAPD. - -Transformation Rules Required - -This metric relies on the 'type-requirement' configuration in Jira, GitHub or TAPD transformation rules to let DevLake know what CI builds/jobs can be regarded as `Requirements`. - - -## How to improve? -1. Analyze the trend of requirement lead time to observe if it has improved over time. -2. Analyze and compare the requirement lead time of each project/team to identify key projects with abnormal lead time. -3. Drill down to analyze a requirement's staying time in different phases of SDLC. Analyze the bottleneck of delivery velocity and improve the workflow. \ No newline at end of file diff --git a/versioned_docs/version-v0.14/Metrics/ReviewDepth.md b/versioned_docs/version-v0.14/Metrics/ReviewDepth.md deleted file mode 100644 index 59bcfbe876c..00000000000 --- a/versioned_docs/version-v0.14/Metrics/ReviewDepth.md +++ /dev/null @@ -1,34 +0,0 @@ ---- -title: "PR Review Depth" -description: > - PR Review Depth -sidebar_position: 2 ---- - -## What is this metric? -The average number of comments of PRs in the selected time range. - -## Why is it important? -PR Review Depth (in Comments per RR) is related to the quality of code review, indicating how thorough your team reviews PRs. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - -## How is it calculated? -This metric is calculated by counting the total number of PR comments divided by the total number of PRs in the selected time range. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Encourage multiple reviewers to review a PR; -2. Review Depth is an indicator for generally how thorough your PRs are reviewed, but it does not mean the deeper the better. In some cases, spending an excessive amount of resources on reviewing PRs is also not recommended. \ No newline at end of file diff --git a/versioned_docs/version-v0.14/Metrics/ReviewTime.md b/versioned_docs/version-v0.14/Metrics/ReviewTime.md deleted file mode 100644 index 8cfe080b0cc..00000000000 --- a/versioned_docs/version-v0.14/Metrics/ReviewTime.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "PR Review Time" -description: > - PR Review Time -sidebar_position: 2 ---- - -## What is this metric? -The time it takes to complete a code review of a PR before it gets merged. - -## Why is it important? -Code review should be conducted almost in real-time and usually take less than two days. Abnormally long PR Review Time may indicate one or more of the following problems: -1. The PR size is too large that makes it difficult to review. -2. The team is too busy to review code. - -## Which dashboard(s) does it exist in? -- Engineering Throughput and Cycle Time -- Engineering Throughput and Cycle Time - Team View - - -## How is it calculated? -This metric is the time frame between when the first comment is added to a PR, to when the PR is merged. - -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboards to monitor your delivery progress; -2. Use automated tests for the initial work; -3. Reduce PR size; -4. Analyze the causes for long reviews. \ No newline at end of file diff --git a/versioned_docs/version-v0.14/Metrics/TimeToMerge.md b/versioned_docs/version-v0.14/Metrics/TimeToMerge.md deleted file mode 100644 index 04a39225fe0..00000000000 --- a/versioned_docs/version-v0.14/Metrics/TimeToMerge.md +++ /dev/null @@ -1,36 +0,0 @@ ---- -title: "PR Time To Merge" -description: > - PR Time To Merge -sidebar_position: 2 ---- - -## What is this metric? -The time it takes from when a PR is issued to when it is merged. Essentially, PR Time to Merge = PR Pickup Time + PR Review Time. - -## Why is it important? -The delay of reviewing and waiting to review PRs has large impact on delivery speed, while reasonably short PR Time to Merge can indicate frictionless teamwork. Improving on this metric is the key to reduce PR cycle time. - -## Which dashboard(s) does it exist in? -- GitHub Basic Metrics -- Bi-weekly Community Retro - - -## How is it calculated? -Data Sources Required - -This metric relies on PR/MRs collected from GitHub or GitLab. - -Transformation Rules Required - -N/A - -SQL Queries - - -## How to improve? -1. Use DevLake's dashboards to monitor your delivery progress; -2. Have a habit to check for hanging PRs regularly; -3. Set up alerts for your communication tools (e.g. Slack, Lark) when new PRs are issued; -4. Reduce PR size; -5. Analyze the causes for long reviews. diff --git a/versioned_docs/version-v0.14/Metrics/_category_.json b/versioned_docs/version-v0.14/Metrics/_category_.json deleted file mode 100644 index e944147d528..00000000000 --- a/versioned_docs/version-v0.14/Metrics/_category_.json +++ /dev/null @@ -1,8 +0,0 @@ -{ - "label": "Metrics", - "position": 5, - "link":{ - "type": "generated-index", - "slug": "Metrics" - } -} diff --git a/versioned_docs/version-v0.14/Overview/Architecture.md b/versioned_docs/version-v0.14/Overview/Architecture.md deleted file mode 100755 index 47bd4b48e03..00000000000 --- a/versioned_docs/version-v0.14/Overview/Architecture.md +++ /dev/null @@ -1,39 +0,0 @@ ---- -title: "Architecture" -description: > - Understand the architecture of Apache DevLake -sidebar_position: 2 ---- - -## Overview - -
DevLake Components
- -A DevLake installation typically consists of the following components: - -- Config UI: A handy user interface to create, trigger, and debug Blueprints. A Blueprint specifies the where (data connection), what (data scope), how (transformation rule), and when (sync frequency) of a data pipeline. -- API Server: The main programmatic interface of DevLake. -- Runner: The runner does all the heavy-lifting for executing tasks. In the default DevLake installation, it runs within the API Server, but DevLake provides a temporal-based runner (beta) for production environments. -- Database: The database stores both DevLake's metadata and user data collected by data pipelines. DevLake supports MySQL and PostgreSQL as of v0.11. -- Plugins: Plugins enable DevLake to collect and analyze dev data from any DevOps tools with an accessible API. DevLake community is actively adding plugins for popular DevOps tools, but if your preferred tool is not covered yet, feel free to open a GitHub issue to let us know or check out our doc on how to build a new plugin by yourself. -- Dashboards: Dashboards deliver data and insights to DevLake users. A dashboard is simply a collection of SQL queries along with corresponding visualization configurations. DevLake's official dashboard tool is Grafana and pre-built dashboards are shipped in Grafana's JSON format. Users are welcome to swap for their own choice of dashboard/BI tool if desired. - -## Dataflow - -
DevLake Dataflow
- -A typical plugin's dataflow is illustrated below: - -1. The Raw layer stores the API responses from data sources (DevOps tools) in JSON. This saves developers' time if the raw data is to be transformed differently later on. Please note that communicating with data sources' APIs is usually the most time-consuming step. -2. The Tool layer extracts raw data from JSONs into a relational schema that's easier to consume by analytical tasks. Each DevOps tool would have a schema that's tailored to their data structure, hence the name, the Tool layer. -3. The Domain layer attempts to build a layer of abstraction on top of the Tool layer so that analytics logics can be re-used across different tools. For example, GitHub's Pull Request (PR) and GitLab's Merge Request (MR) are similar entities. They each have their own table name and schema in the Tool layer, but they're consolidated into a single entity in the Domain layer, so that developers only need to implement metrics like Cycle Time and Code Review Rounds once against the domain layer schema. - -## Principles - -1. Extensible: DevLake's plugin system allows users to integrate with any DevOps tool. DevLake also provides a dbt plugin that enables users to define their own data transformation and analysis workflows. -2. Portable: DevLake has a modular design and provides multiple options for each module. Users of different setups can freely choose the right configuration for themselves. -3. Robust: DevLake provides an SDK to help plugins efficiently and reliably collect data from data sources while respecting their API rate limits and constraints. - -
-
-## Project Metrics This Covers
-
-| Metric Name | Description |
-|:------------------------------------|:--------------------------------------------------------------------------------------------------|
-| Requirement Count | Number of issues with type "Requirement" |
-| Requirement Lead Time | Lead time of issues with type "Requirement" |
-| Requirement Delivery Rate | Ratio of delivered requirements to all requirements |
-| Requirement Granularity | Number of story points associated with an issue |
-| Bug Count | Number of issues with type "Bug"
-
-When first visiting Grafana, you will be provided with a sample dashboard with some basic charts setup from the database.
-
-## Contents
-
-Section | Link
-:------------ | :-------------
-Logging In | [View Section](#logging-in)
-Viewing All Dashboards | [View Section](#viewing-all-dashboards)
-Customizing a Dashboard | [View Section](#customizing-a-dashboard)
-Dashboard Settings | [View Section](#dashboard-settings)
-Provisioning a Dashboard | [View Section](#provisioning-a-dashboard)
-Troubleshooting DB Connection | [View Section](#troubleshooting-db-connection)
-
-## Logging In
-
-Once the app is up and running, visit `http://localhost:3002` to view the Grafana dashboard.
-
-Default login credentials are:
-
-- Username: `admin`
-- Password: `admin`
-
-## Viewing All Dashboards
-
-To see all dashboards created in Grafana visit `/dashboards`
-
-Or, use the sidebar and click on **Manage**:
-
-
-
-
-## Customizing a Dashboard
-
-When viewing a dashboard, click the top bar of a panel, and go to **edit**
-
-
-
-**Edit Dashboard Panel Page:**
-
-
-
-### 1. Preview Area
-- **Top Left** is the variable select area (custom dashboard variables, used for switching projects, or grouping data)
-- **Top Right** we have a toolbar with some buttons related to the display of the data:
- - View data results in a table
- - Time range selector
- - Refresh data button
-- **The Main Area** will display the chart and should update in real time
-
-> Note: Data should refresh automatically, but may require a refresh using the button in some cases
-
-### 2. Query Builder
-Here we form the SQL query to pull data into our chart, from our database
-- Ensure the **Data Source** is the correct database
-
- 
-
-- Select **Format as Table**, and **Edit SQL** buttons to write/edit queries as SQL
-
- 
-
-- The **Main Area** is where the queries are written, and in the top right is the **Query Inspector** button (to inspect returned data)
-
- 
-
-### 3. Main Panel Toolbar
-In the top right of the window are buttons for:
-- Dashboard settings (regarding entire dashboard)
-- Save/apply changes (to specific panel)
-
-### 4. Grafana Parameter Sidebar
-- Change chart style (bar/line/pie chart etc)
-- Edit legends, chart parameters
-- Modify chart styling
-- Other Grafana specific settings
-
-## Dashboard Settings
-
-When viewing a dashboard click on the settings icon to view dashboard settings. Here are 2 important sections to use:
-
-
-
-- Variables
- - Create variables to use throughout the dashboard panels, that are also built on SQL queries
-
- 
-
-- JSON Model
- - Copy `json` code here and save it to a new file in `/grafana/dashboards/` with a unique name in the `lake` repo. This will allow us to persist dashboards when we load the app
-
- 
-
-## Provisioning a Dashboard
-
-To save a dashboard in the `lake` repo and load it:
-
-1. Create a dashboard in browser (visit `/dashboard/new`, or use sidebar)
-2. Save dashboard (in top right of screen)
-3. Go to dashboard settings (in top right of screen)
-4. Click on _JSON Model_ in sidebar
-5. Copy code into a new `.json` file in `/grafana/dashboards`
-
-## Troubleshooting DB Connection
-
-To ensure we have properly connected our database to the data source in Grafana, check database settings in `./grafana/datasources/datasource.yml`, specifically:
-- `database`
-- `user`
-- `secureJsonData/password`
diff --git a/versioned_docs/version-v0.14/UserManuals/Dashboards/_category_.json b/versioned_docs/version-v0.14/UserManuals/Dashboards/_category_.json
deleted file mode 100644
index 0db83c6e9b8..00000000000
--- a/versioned_docs/version-v0.14/UserManuals/Dashboards/_category_.json
+++ /dev/null
@@ -1,4 +0,0 @@
-{
- "label": "Dashboards",
- "position": 5
-}
diff --git a/versioned_docs/version-v0.14/UserManuals/TeamConfiguration.md b/versioned_docs/version-v0.14/UserManuals/TeamConfiguration.md
deleted file mode 100644
index 84c9c6ac08b..00000000000
--- a/versioned_docs/version-v0.14/UserManuals/TeamConfiguration.md
+++ /dev/null
@@ -1,188 +0,0 @@
----
-title: "Team Configuration"
-sidebar_position: 9
-description: >
- Team Configuration
----
-## What is 'Team Configuration' and how it works?
-
-To organize and display metrics by `team`, Apache DevLake needs to know about the team configuration in an organization, specifically:
-
-1. What are the teams?
-2. Who are the users(unified identities)?
-3. Which users belong to a team?
-4. Which accounts(identities in specific tools) belong to the same user?
-
-Each of the questions above corresponds to a table in DevLake's schema, illustrated below:
-
-
-
-1. `teams` table stores all the teams in the organization.
-2. `users` table stores the organization's roster. An entry in the `users` table corresponds to a person in the org.
-3. `team_users` table stores which users belong to a team.
-4. `user_accounts` table stores which accounts belong to a user. An `account` refers to an identiy in a DevOps tool and is automatically created when importing data from that tool. For example, a `user` may have a GitHub `account` as well as a Jira `account`.
-
-Apache DevLake uses a simple heuristic algorithm based on emails and names to automatically map accounts to users and populate the `user_accounts` table.
-When Apache DevLake cannot confidently map an `account` to a `user` due to insufficient information, it allows DevLake users to manually configure the mapping to ensure accuracy and integrity.
-
-## A step-by-step guide
-
-In the following sections, we'll walk through how to configure teams and create the five aforementioned tables (`teams`, `users`, `team_users`, `accounts`, and `user_accounts`).
-The overall workflow is:
-
-1. Create the `teams` table
-2. Create the `users` and `team_users` table
-3. Populate the `accounts` table via data collection
-4. Run a heuristic algorithm to populate `user_accounts` table
-5. Manually update `user_accounts` when the algorithm can't catch everything
-
-Note:
-
-1. Please replace `/path/to/*.csv` with the absolute path of the CSV file you'd like to upload.
-2. Please replace `127.0.0.1:4000` with your actual Apache DevLake ConfigUI service IP and port number.
-
-## Step 1 - Create the `teams` table
-
-You can create the `teams` table by sending a PUT request to `/plugins/org/teams.csv` with a `teams.csv` file. To jumpstart the process, you can download a template `teams.csv` from `/plugins/org/teams.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `teams.csv` file
-
- i. GET http://127.0.0.1:4000/api/plugins/org/teams.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/teams.csv?fake_data=true'
-
-
-b. Fill out `teams.csv` file and upload it to DevLake
-
- i. Fill out `teams.csv` with your org data. Please don't modify the column headers or the file suffix.
-
- ii. Upload `teams.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/teams.csv' --form 'file=@"/path/to/teams.csv"'
-
- iii. The PUT request would populate the `teams` table with data from `teams.csv` file.
- You can connect to the database and verify the data in the `teams` table.
- See Appendix for how to connect to the database.
-
-
-
-
-## Step 2 - Create the `users` and `team_users` table
-
-You can create the `users` and `team_users` table by sending a single PUT request to `/plugins/org/users.csv` with a `users.csv` file. To jumpstart the process, you can download a template `users.csv` from `/plugins/org/users.csv?fake_data=true`. Below are the detailed instructions:
-
-a. Download the template `users.csv` file
-
- i. GET http://127.0.0.1:4000/api/plugins/org/users.csv?fake_data=true (pasting the URL into your browser will download the template)
-
- ii. If you prefer using curl:
- curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/users.csv?fake_data=true'
-
-
-b. Fill out `users.csv` and upload to DevLake
-
- i. Fill out `users.csv` with your org data. Please don't modify the column headers or the file suffix
-
- ii. Upload `users.csv` to DevLake with the following curl command:
- curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/users.csv' --form 'file=@"/path/to/users.csv"'
-
- iii. The PUT request would populate the `users` table along with the `team_users` table with data from `users.csv` file.
- You can connect to the database and verify these two tables.
-
-
-
-
-
-c. If you ever want to update `team_users` or `users` table, simply upload the updated `users.csv` to DevLake again following step b.
-
-## Step 3 - Populate the `accounts` table via data collection
-
-The `accounts` table is automatically populated when you collect data from data sources like GitHub and Jira through DevLake.
-
-For example, the GitHub plugin would create one entry in the `accounts` table for each GitHub user involved in your repository.
-For demo purposes, we'll insert some mock data into the `accounts` table using SQL:
-
-```
-INSERT INTO `accounts` (`id`, `created_at`, `updated_at`, `_raw_data_params`, `_raw_data_table`, `_raw_data_id`, `_raw_data_remark`, `email`, `full_name`, `user_name`, `avatar_url`, `organization`, `created_date`, `status`)
-VALUES
- ('github:GithubAccount:1:1234', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"Owner\":\"apache\",\"Repo\":\"incubator-devlake\"}', '_raw_github_api_pull_request_reviews', 28, '', 'TyroneKCummings@teleworm.us', '', 'Tyrone K. Cummings', 'https://avatars.githubusercontent.com/u/101256042?u=a6e460fbaffce7514cbd65ac739a985f5158dabc&v=4', '', NULL, 0),
- ('jira:JiraAccount:1:629cdf', '2022-07-12 10:54:09.632', '2022-07-12 10:54:09.632', '{\"ConnectionId\":1,\"BoardId\":\"76\"}', '_raw_jira_api_users', 5, '', 'DorothyRUpdegraff@dayrep.com', '', 'Dorothy R. Updegraff', 'https://avatars.jiraxxxx158dabc&v=4', '', NULL, 0);
-
-```
-
-
-
-## Step 4 - Run a heuristic algorithm to populate `user_accounts` table
-
-Now that we have data in both the `users` and `accounts` table, we can tell DevLake to infer the mappings between `users` and `accounts` with a simple heuristic algorithm based on names and emails.
-
-a. Send an API request to DevLake to run the mapping algorithm
-
-```
-curl --location --request POST '127.0.0.1:4000/api/pipelines' \
---header 'Content-Type: application/json' \
---data-raw '{
- "name": "test",
- "plan":[
- [
- {
- "plugin": "org",
- "subtasks":["connectUserAccountsExact"],
- "options":{
- "connectionId":1
- }
- }
- ]
- ]
-}'
-```
-
-b. After successful execution, you can verify the data in `user_accounts` in the database.
-
-
-
-## Step 5 - Manually update `user_accounts` when the algorithm can't catch everything
-
-It is recommended to examine the generated `user_accounts` table after running the algorithm.
-We'll demonstrate how to manually update `user_accounts` when the mapping is inaccurate/incomplete in this section.
-To make manual verification easier, DevLake provides an API for users to download `user_accounts` as a CSV file.
-Alternatively, you can verify and modify `user_accounts` all by SQL, see Appendix for more info.
-
-a. GET http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv(pasting the URL into your browser will download the file). If you prefer using curl:
-```
-curl --location --request GET 'http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv'
-```
-
-
-
-b. If you find the mapping inaccurate or incomplete, you can modify the `user_account_mapping.csv` file and then upload it to DevLake.
-For example, here we change the `UserId` of row 'Id=github:GithubAccount:1:1234' in the `user_account_mapping.csv` file to 2.
-Then we upload the updated `user_account_mapping.csv` file with the following curl command:
-
-```
-curl --location --request PUT 'http://127.0.0.1:4000/api/plugins/org/user_account_mapping.csv' --form 'file=@"/path/to/user_account_mapping.csv"'
-```
-
-c. You can verify the data in the `user_accounts` table has been updated.
-
-
-
-## Appendix A: how to connect to the database
-
-Here we use MySQL as an example. You can install database management tools like Sequel Ace, DataGrip, MySQLWorkbench, etc.
-
-
-Or through the command line:
-
-```
-mysql -h