In this way, we would like to unite the power of StreamPipes to easily connect to and read from different data sources, especially in the IoT domain,
and the amazing universe of data analytics libraries in Python.
-
-
-
-
StreamPipes Python is in beta
-
The current version of this Python library is still a beta version.
-This means that it is still heavily under development, which may result in frequent and extensive API changes, unstable behavior, etc.
diff --git a/docs-python/dev/search/search_index.json b/docs-python/dev/search/search_index.json
index e22082102..2ac931609 100644
--- a/docs-python/dev/search/search_index.json
+++ b/docs-python/dev/search/search_index.json
@@ -1 +1 @@
-{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"\ud83c\udfe1 Home","text":"StreamPipes is a self-service (Industrial) IoT toolbox to enable non-technical users to connect, analyze and explore IoT data streams. Apache StreamPipes for Python \ud83d\udc0d
Apache StreamPipes meets Python! We are working highly motivated on a Python library to interact with StreamPipes. In this way, we would like to unite the power of StreamPipes to easily connect to and read from different data sources, especially in the IoT domain, and the amazing universe of data analytics libraries in Python.
StreamPipes Python is in beta
The current version of this Python library is still a beta version. This means that it is still heavily under development, which may result in frequent and extensive API changes, unstable behavior, etc.
As a quick example, we demonstrate how to set up and configure a StreamPipes client. In addition, we will get the available data lake measures out of StreamPipes.
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nconfig = StreamPipesClientConfig(\n credential_provider = StreamPipesApiKeyCredentials(\n username = \"test@streampipes.apache.org\",\n api_key = \"DEMO-KEY\",\n ),\n host_address = \"localhost\",\n https_disabled = True,\n port = 80\n)\n\nclient = StreamPipesClient(client_config=config)\n\n# get all available datat lake measures\nmeasures = client.dataLakeMeasureApi.all()\n\n# get amount of retrieved measures\nlen(measures)\n
Output:
1\n
# inspect the data lake measures as pandas dataframe\nmeasures.to_pandas()\n
Output:
measure_name timestamp_field ... pipeline_is_running num_event_properties\n0 test s0::timestamp ... False 2\n[1 rows x 6 columns]\n
Alternatively, you can provide your credentials via environment variables. Simply define your credential provider as follows:
from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nStreamPipesApiKeyCredentials()\n
This requires to set the following environment variables: SP_API_KEY and SP_USERNAME
username is always the username that is used to log in into StreamPipes.
How to get your StreamPipes API key
The api_key can be generated within the UI as demonstrated below:
"},{"location":"getting-started/developing/","title":"Developing & Contributing","text":""},{"location":"getting-started/developing/#development-guide","title":"\ud83d\udcd6 Development Guide","text":"
This document describes how to easily set up your local dev environment to work on StreamPipes Python \ud83d\udc0d.
"},{"location":"getting-started/developing/#first-steps","title":"\ud83d\ude80 First Steps","text":"
1) Set up your Python environment
Create a virtual Python environment using a tool of your choice. To manage dependencies, we use Poetry, so please install poetry in your local environment, e.g. via
pip install poetry\n
Once poetry is installed you can simply finalize your Python environment by running:
poetry install --with dev,stubs # install everything that is required for the development\npoetry install --with docs # install everything to work with the documentation\npoetry install --with dev,stubs,docs # install all optional dependencies related to development\n
2) Install pre-commit hook
The pre-commit hook is run before every commit and takes care about code style, linting, type hints, import sorting, etc. It will stop your commit in case the changes do not apply the expected format. Always check to have the recent version of the pre-commit hook installed otherwise the CI build might fail. If you are interested, you can have a deeper look on the underlying library: pre-commit.
pre-commit install\n
The definition of the pre-commit hook can be found in .pre-commit-config.yaml. "},{"location":"getting-started/developing/#conventions","title":"\ud83d\udc4f Conventions","text":"
Below we list some conventions that we have agreed on for creating StreamPipes Python. Please comply to them when you plan to contribute to this project. If you have any other suggestions or would like to discuss them, we would be happy to hear from you on our mailing list dev@streampipes.apache.org or in our discussions on GitHub.
1) Use numpy style for Python docstrings \ud83d\udcc4 Please stick to the numpy style when writing docstrings, as we require this for generating our documentation.
2) Provide tests \u2705 We are aiming for broad test coverage for the Python package and have therefore set a requirement of at least 90% unit test coverage. Therefore, please remember to write (unit) tests already during development. If you have problems with writing tests, don't hesitate to ask us for help directly in the PR or even before that via our mailing list (see above).
3) Build a similar API as the Java client provides \ud83d\udd04 Whenever possible, please try to develop the API of the Python library the same as the Java client or Java SDK. By doing so, we would like to provide a consistent developer experience and the basis for automated testing in the future.
To build our documentation, we use Materials for MkDocs. All files can be found within the docs directory. To pre-view your local version of the documentation, you can use the following command:
Before opening a pull request, review the Get Involved page. It lists information that is required for contributing to StreamPipes.
When you contribute code, you affirm that the contribution is your original work and that you license the work to the project under the project's open source license. Whether or not you state this explicitly, by submitting any copyrighted material via pull request, email, or other means you agree to license the material under the project's open source license and warrant that you have the legal authority to do so.
The StreamPipes Python library is meant to work with Python 3.8 and above. Installation can be done via pip: You can install the latest development version from GitHub, as so:
pip install streampipes\n\n# if you want to have the current development state you can also execute\npip install git+https://github.com/apache/streampipes.git#subdirectory=streampipes-client-python\n# the corresponding documentation can be found here: https://streampipes.apache.org/docs/docs/python/dev/\n
"},{"location":"getting-started/first-steps/#setting-up-streampipes","title":"\u2b06\ufe0f Setting up StreamPipes","text":"
When working with the StreamPipes Python library it is inevitable to have a running StreamPipes instance to connect and interact with. In case you don't have a running instance at hand, you can easily set up one on your local machine. Hereby you need to consider that StreamPipes supports different message broker (e.g., Kafka, NATS). We will demonstrate below how you can easily set up StreamPipes for both supported message brokers.
"},{"location":"getting-started/first-steps/#start-streampipes-via-docker-compose","title":"\ud83d\udc33 Start StreamPipes via Docker Compose","text":"
The easiest and therefore recommend way to get StreamPipes started is by using docker compose. Therefore, you need Docker running. You can check if Docker is ready on your machine by executing.
docker ps\n
If this results in an output similar to the following, Docker is ready to continue.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\n... ... ... ... ... ... ...\n
Otherwise, you need to start docker first. Please read the full guide on how to start StreamPipes with docker compose here."},{"location":"getting-started/first-steps/#setup-streampipes-with-nats-as-message-broker","title":"Setup StreamPipes with NATS as message broker","text":"
The following shows how you can set up a StreamPipes instance that uses NATS as messaging layer. So in this scenario, we will go with docker-compose.nats.yml. Thereby, when running locally, we need to add the following port mapping entry to services.nats.ports:
- 4222:4222\n
After this modification is applied, StreamPipes can simply be started with this command:
docker-compose -f docker-compose.nats.yml up -d\n
Once all services are started, you can access StreamPipes via http://localhost.
"},{"location":"getting-started/first-steps/#setup-streampipes-with-kafka-as-message-broker","title":"Setup StreamPipes with Kafka as message broker","text":"
Alternatively, you can use docker-compose.yml to start StreamPipes with Kafka as messaging layer. When running locally we have to modify services.kafka.environment and add the ports to services.kafka.ports:
As a quick example, we demonstrate how to set up and configure a StreamPipes client. In addition, we will get the available data lake measures out of StreamPipes.
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nconfig = StreamPipesClientConfig(\n credential_provider = StreamPipesApiKeyCredentials(\n username = \"test@streampipes.apache.org\",\n api_key = \"DEMO-KEY\",\n ),\n host_address = \"localhost\",\n https_disabled = True,\n port = 80\n)\n\nclient = StreamPipesClient(client_config=config)\n\n# get all available datat lake measures\nmeasures = client.dataLakeMeasureApi.all()\n\n# get amount of retrieved measures\nlen(measures)\n
Output:
1\n
# inspect the data lake measures as pandas dataframe\nmeasures.to_pandas()\n
Output:
measure_name timestamp_field ... pipeline_is_running num_event_properties\n0 test s0::timestamp ... False 2\n[1 rows x 6 columns]\n
Alternatively, you can provide your credentials via environment variables. Simply define your credential provider as follows:
from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nStreamPipesApiKeyCredentials()\n
This requires to set the following environment variables: SP_API_KEY and SP_USERNAME
username is always the username that is used to log in into StreamPipes. The api_key can be generated within the UI as demonstrated below:
Implementation of the StreamPipes client. The client is designed as the central point of interaction with the StreamPipes API and provides all functionalities to communicate with the API.
This is the central point of contact with StreamPipes and provides all the functionalities to interact with it.
The client provides so-called \"endpoints\" each of which refers to an endpoint of the StreamPipes API, e.g. .dataLakeMeasureApi. An endpoint provides the actual methods to interact with StreamPipes API.
PARAMETER DESCRIPTION client_config
Configures the client to connect properly to the StreamPipes instance.
TYPE: StreamPipesClientConfig
logging_level
Influences the log messages emitted by the StreamPipesClient
TYPE: Optional[int] DEFAULT: INFO
ATTRIBUTE DESCRIPTION dataLakeMeasureApi
Instance of the data lake measure endpoint
TYPE: DataLakeMeasureEndpoint
dataStreamApi
Instance of the data stream endpoint
TYPE: DataStreamEndpoint
RAISES DESCRIPTION AttributeError:
In case an invalid configuration of the StreamPipesClientConfig is passed
Examples:
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
The HTTP headers are composed of the authentication headers supplied by the credential provider and additional required headers (currently this is only the application header).
RETURNS DESCRIPTION http_headers
header information for HTTP requests as string key-value pairs.
Prints a short description of the connected StreamPipes instance and the available resources to the console.
RETURNS DESCRIPTION None
Examples:
client.describe()\n
Output:
Hi there!\nYou are connected to a StreamPipes instance running at http://localhost:80.\nThe following StreamPipes resources are available with this client:\n6x DataStreams\n1x DataLakeMeasures\n
Implementation of credential providers. A credential provider supplies the specified sort of credentials in the appropriate HTTP header format. The headers are then used by the client to connect to StreamPipes.
Creates the HTTP headers for the specific credential provider.
Concrete authentication headers must be defined in the implementation of a credential provider.
PARAMETER DESCRIPTION http_headers
Additional HTTP headers the generated headers are extended by.
TYPE: Optional[Dict[str, str]] DEFAULT: None
RETURNS DESCRIPTION https_headers
Dictionary with header information as string key-value pairs. Contains all pairs given as parameter plus the header pairs for authentication determined by the credential provider.
A credential provider that allows authentication via a StreamPipes API Token.
The required token can be generated via the StreamPipes UI (see the description on our start-page.
Both parameters can either be passed as arguments or remain unset. If they are not passed, they are retrieved from environment variables:
SP_USERNAME is expected to contain the username
SP_API_KEY is expected to contain the API key
PARAMETER DESCRIPTION username
The username to which the API token is granted, e.g., demo-user@streampipes.apche.org. If not passed, the username is retrieved from environment variable SP_USERNAME.
TYPE: Optional[str] DEFAULT: None
api_key
The StreamPipes API key as it is displayed in the UI. If not passed, the api key is retrieved from environment variable SP_API_KEY
General implementation for an endpoint. Provided classes and assets are aimed to be used for developing endpoints. An endpoint provides all options to communicate with ad dedicated part of StreamPipes in a handy way.
Serves as template for all endpoints of the StreamPipes API. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
Abstract implementation of a StreamPipes endpoint.
Serves as template for all endpoints used for interaction with a StreamPipes instance. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
PARAMETER DESCRIPTION parent_client
This parameter expects the instance of StreamPipesClient the endpoint is attached to.
Abstract implementation of a StreamPipes messaging endpoint.
Serves as template for all endpoints used for interacting with the StreamPipes messaging layer directly. Therefore, they need to provide the functionality to talk with the broker system running in StreamPipes. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
Defines the broker instance that is used to connect to StreamPipes' messaging layer.
This instance enables the client to authenticate to the broker used in the target StreamPipes instance, to consume messages from and to write messages to the broker.
Exception that indicates that an instance of a messaging endpoint has not been configured.
This error occurs when an instance of a messaging endpoint is used before the broker instance to be used is configured by passing it to the configure() method.
PARAMETER DESCRIPTION endpoint_name
The name of the endpoint that caused the error
TYPE: str
"},{"location":"reference/endpoint/api/data_lake_measure/","title":"Data lake measure","text":"
Specific implementation of the StreamPipes API's data lake measure endpoints. This endpoint allows to consume data stored in StreamPipes' data lake.
# get all existing data lake measures from StreamPipes\ndata_lake_measures = client.dataLakeMeasureApi.all()\n\n# let's take a look how many we got\nlen(data_lake_measures)\n
5\n
# Retrieve a specific data lake measure as a pandas DataFrame\nflow_rate_pd = client.dataLakeMeasureApi.get(identifier=\"flow-rate\").to_pandas()\nflow_rate_pd\n
Queries the specified data lake measure from the API.
By default, the maximum number of returned records is 1000. This behaviour can be influenced by passing the parameter limit with a different value (see MeasurementGetQueryConfig).
PARAMETER DESCRIPTION identifier
The identifier of the data lake measure to be queried.
TYPE: str
**kwargs
keyword arguments can be used to provide additional query parameters. The available query parameters are defined by the MeasurementGetQueryConfig.
Config class describing the parameters of the get() method for measurements.
This config class is used to validate the provided query parameters for the GET endpoint of measurements. Additionally, it takes care of the conversion to a proper HTTP query string. Thereby, parameter names are adapted to the naming of the StreamPipes API, for which Pydantic aliases are used.
ATTRIBUTE DESCRIPTION columns
A comma separated list of column names (e.g., time,value) If provided, the returned data only consists of the given columns. Please be aware that the column time as an index is always included.
TYPE: Optional[List[str]]
end_date
Restricts queried data to be younger than the specified time.
TYPE: Optional[datetime]
limit
Amount of records returned at maximum (default: 1000) This needs to be at least 1
TYPE: Optional[int]
offset
Offset to be applied to returned data This needs to be at least 0
TYPE: Optional[int]
order
Ordering of query results Allowed values: ASC and DESC (default: ASC)
TYPE: Optional[str]
page_no
Page number used for paging operation This needs to be at least 1
TYPE: Optional[int]
start_date
Restricts queried data to be older than the specified time
This method returns an HTTP query string for the invoking config. It follows the following structure ?param1=value1¶m2=value2.... This query string is not an entire URL, instead it needs to appended to an API path.
This endpoint provides metadata about the StreamPipes version of the connected instance. It only allows to apply the get() method with an empty string as identifier.
PARAMETER DESCRIPTION parent_client
The instance of StreamPipesClient the endpoint is attached to.
TYPE: StreamPipesClient
Examples:
>>> from streampipes.client import StreamPipesClient\n>>> from streampipes.client.config import StreamPipesClientConfig\n>>> from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
Usually, this method returns information about all resources provided by this endpoint. However, this endpoint does not support this kind of operation.
RAISES DESCRIPTION NotImplementedError
this endpoint does not return multiple entries, therefore this method is not available
Usually, this method allows to create via this endpoint. Since the data represented by this endpoint is immutable, it does not support this kind of operation.
RAISES DESCRIPTION NotImplementedError
this endpoint does not allow for POST requests, therefore this method is not available
Wrapper class to enable an easy usage for Online Machine Learning models of the River library.
It creates a StreamPipesFunction to train a model with the incoming events of a data stream and creates an output data stream that publishes the prediction to StreamPipes.
PARAMETER DESCRIPTION client
The client for the StreamPipes API.
TYPE: StreamPipesClient
stream_ids
The ids of the data stream to train the model.
TYPE: List[str]
model
The model to train. It meant to be a River model/pipeline, but can be every model with a 'learn_one' and 'predict_one' methode.
TYPE: Any
prediction_type
The data type of the prediction. Is only needed when you continue to work with the prediction in StreamPipes.
TYPE: str DEFAULT: value
supervised
Define if the model is supervised or unsupervised.
TYPE: bool DEFAULT: False
target_label
Define the name of the target attribute if the model is supervised.
TYPE: Optional[str] DEFAULT: None
on_start
A function to be called when this StreamPipesFunction gets started.
The function handler manages the StreamPipes Functions.
It controls the connection to the brokers, starts the functions, manages the broadcast of the live data and is able to stop the connection to the brokers and functions.
PARAMETER DESCRIPTION registration
The registration, that contains the StreamPipesFunctions.
A StreamPipesFunction allows users to get the data of a StreamPipes data streams easily. It makes it possible to work with the live data in python and enables to use the powerful data analytics libraries there.
PARAMETER DESCRIPTION function_definition
the definition of the function that contains metadata about the connected function
TYPE: Optional[FunctionDefinition] DEFAULT: None
ATTRIBUTE DESCRIPTION output_collectors
List of all output collectors which are created based on the provided function definitions.
Collector for output events. The events are published to an output data stream. Therefore, the output collector establishes a connection to the broker.
PARAMETER DESCRIPTION data_stream
The output data stream that will receive the events.
TYPE: DataStream
ATTRIBUTE DESCRIPTION publisher
The publisher instance that sends the data to StreamPipes
RETURNS DESCRIPTION None"},{"location":"reference/functions/utils/async_iter_handler/","title":"Async iter handler","text":""},{"location":"reference/functions/utils/async_iter_handler/#streampipes.functions.utils.async_iter_handler.AsyncIterHandler","title":"AsyncIterHandler","text":"
Handles asynchronous iterators to get every message after another in parallel.
Implementation of the resource container for the data lake measures endpoint.
This resource container is a collection of data lake measures returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried DataLakeMeasure. Furthermore, the resource container makes them accessible in a pythonic manner.
Implementation of the resource container for the data stream endpoint.
This resource container is a collection of data streams returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried DataStream. Furthermore, the resource container makes them accessible in a pythonic manner.
General and abstract implementation for a resource container.
A resource container is a collection of resources returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried resources. Furthermore, the resource container makes them accessible in a pythonic manner.
General and abstract implementation for a resource container.
A resource container is a collection of resources returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried resources. Furthermore, the resource container makes them accessible in a pythonic manner.
PARAMETER DESCRIPTION resources
A list of resources to be contained in the ResourceContainer.
Implementation of the resource container for the versions endpoint.
This resource container is a collection of versions returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried Version. Furthermore, the resource container makes them accessible in a pythonic manner.
PARAMETER DESCRIPTION resources
A list of resources (Version) to be contained in the ResourceContainer.
TYPE: List[Resource]
"},{"location":"reference/model/resource/data_lake_measure/","title":"Data lake measure","text":""},{"location":"reference/model/resource/data_lake_measure/#streampipes.model.resource.data_lake_measure.DataLakeMeasure","title":"DataLakeMeasure","text":"
Bases: Resource
Implementation of a resource for data lake measures.
This resource defines the data model used by resource container (model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response, and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns the dictionary representation of a data lake measure to be used when creating a pandas Dataframe.
It excludes the following fields: element_id, event_schema, schema_version. Instead of the whole event schema the number of event properties contained is returned with the column name num_event_properties.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Implementation of a resource for data series. This resource defines the data model used by its resource container(model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Notes
This class will only exist temporarily in it its current appearance since\nthere are some inconsistencies in the StreamPipes API.\n
Creates an instance of DataSeries from a given JSON string.
This method is used by the resource container to parse the JSON response of the StreamPipes API. Currently, it only supports data lake series that consist of exactly one series of data.
PARAMETER DESCRIPTION json_string
The JSON string the data lake series should be created on.
TYPE: str
RETURNS DESCRIPTION DataSeries
Instance of DataSeries that is created based on the given JSON string.
This resource defines the data model used by resource container (model.container.DataStreams). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns the dictionary representation of a data stream to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
This class maps to the FunctionDefinition class in the StreamPipes model. It contains all metadata that are required to register a function at the StreamPipes backend.
PARAMETER DESCRIPTION consumed_streams
List of data streams the function is consuming from
function_id
identifier object of a StreamPipes function
ATTRIBUTE DESCRIPTION output_data_streams
Map off all output data streams added to the function definition
Returns the dictionary representation of a function definition to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Implementation of a resource for query result. This resource defines the data model used by its resource container(model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
General and abstract implementation for a resource.
A resource defines the data model used by a resource container (model.container.resourceContainer). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns a dictionary representation to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Validates the backend version of the StreamPipes. Sets 'development' if none is returned since this the behavior of StreamPipes backend running in development mode.
Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
In\u00a0[\u00a0]: Copied!
from pathlib import Path\n
from pathlib import Path In\u00a0[\u00a0]: Copied!
import mkdocs_gen_files\n
import mkdocs_gen_files In\u00a0[\u00a0]: Copied!
nav = mkdocs_gen_files.Nav()\n
nav = mkdocs_gen_files.Nav() In\u00a0[\u00a0]: Copied!
for path in sorted(Path(\"streampipes\").rglob(\"*.py\")):\n module_path = path.relative_to(\"streampipes\").with_suffix(\"\")\n doc_path = path.relative_to(\"streampipes\").with_suffix(\".md\")\n full_doc_path = Path(\"reference\", doc_path)\n\n parts = list(module_path.parts)\n\n if parts[-1] == \"__init__\":\n # parts = parts[:-1]\n continue\n elif parts[-1] == \"__version__\":\n continue\n elif parts[-1] == \"__main__\":\n continue\n elif parts[-1] == \" \":\n continue\n\n nav[parts] = doc_path.as_posix()\n\n with mkdocs_gen_files.open(full_doc_path, \"w+\") as fd:\n identifier = \".\".join(parts)\n print(f\"::: streampipes.{identifier}\", file=fd)\n\n mkdocs_gen_files.set_edit_path(full_doc_path, path)\n
for path in sorted(Path(\"streampipes\").rglob(\"*.py\")): module_path = path.relative_to(\"streampipes\").with_suffix(\"\") doc_path = path.relative_to(\"streampipes\").with_suffix(\".md\") full_doc_path = Path(\"reference\", doc_path) parts = list(module_path.parts) if parts[-1] == \"__init__\": # parts = parts[:-1] continue elif parts[-1] == \"__version__\": continue elif parts[-1] == \"__main__\": continue elif parts[-1] == \" \": continue nav[parts] = doc_path.as_posix() with mkdocs_gen_files.open(full_doc_path, \"w+\") as fd: identifier = \".\".join(parts) print(f\"::: streampipes.{identifier}\", file=fd) mkdocs_gen_files.set_edit_path(full_doc_path, path)
with mkdocs_gen_files.open(\"reference/SUMMARY.md\", \"w+\") as nav_file: nav_file.writelines(nav.build_literate_nav())
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/","title":"Introduction to StreamPipes Python","text":"In\u00a0[\u00a0]: Copied!
%pip install streampipes\n
%pip install streampipes
If you want to have the current development state you can also execute:
The corresponding documentation can be found here.
In\u00a0[\u00a0]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
Please be aware that connecting to StreamPipes via a https connection is currently not supported by the Python client.
Providing secrets like the api_key as plaintext in the source code is an anti-pattern. This is why the StreamPipes client also supports passing the required secrets as environment variables. To do so, you must initialize the credential provider like the following:
In\u00a0[\u00a0]: Copied!
StreamPipesApiKeyCredentials()\n
StreamPipesApiKeyCredentials()
To ensure that the above code works, you must set the environment variables as expected. This can be done like following:
That's already it. You can check if everything works out by using the following command:
In\u00a0[6]: Copied!
client.describe()\n
client.describe()
2023-02-24 17:05:49,398 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:167] [_make_request] - Successfully retrieved all resources.\n2023-02-24 17:05:49,457 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:167] [_make_request] - Successfully retrieved all resources.\n\nHi there!\nYou are connected to a StreamPipes instance running at http://localhost:80.\nThe following StreamPipes resources are available with this client:\n1x DataLakeMeasures\n1x DataStreams\n
This prints you a short textual description of the connected StreamPipes instance to the console.
The created client instance serves as the central point of interaction with StreamPipes. You can invoke a variety of commands directly on this object.
Are you curious now how you actually can get data out of StreamPipes and make use of it with Python? Then check out the next tutorial on extracting Data from the StreamPipes data lake.
Thanks for reading this introductory tutorial. We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#Introduction-to-StreamPipes-Python","title":"Introduction to StreamPipes Python\u00b6","text":""},{"location":"tutorials/1-introduction-to-streampipes-python-client/#Why-there-is-an-extra-Python-library-for-StreamPipes?","title":"Why there is an extra Python library for StreamPipes?\u00b6","text":"
Apache StreamPipes aims to enable non-technical users to connect and analyze IoT data streams. To this end, it provides an easy-to-use and convenient user interface that allows one to connect to an IoT data source and create some visual graphs within a few minutes. Although this is the main use case of Apache StreamPipes, it can also provide great value for people who are eager to work on data analysis or data science with IoT data, but don't we do get in touch with all the hassle associated with extracting data from devices in a suitable format. In this scenario, StreamPipes helps you connect to your data source and extract the data for you. You then can make the data available outside StreamPipes by writing it into an external source, such as a database, Kafka, etc. While this requires another component, you can also extract your data directly from StreamPipes programmatically using the StreamPipes API. For convenience, we also provide you with a StreamPipes client both available for Java and Python. Specifically with StreamPipes Python, we want to address the amazing data analytics and data science community in Python and benefit from the great universe of Python libraries out there.
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-install-StreamPipes-Python?","title":"How to install StreamPipes Python?\u00b6","text":"
Simply use the following pip command:
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-prepare-the-tutorials","title":"How to prepare the tutorials\u00b6","text":"
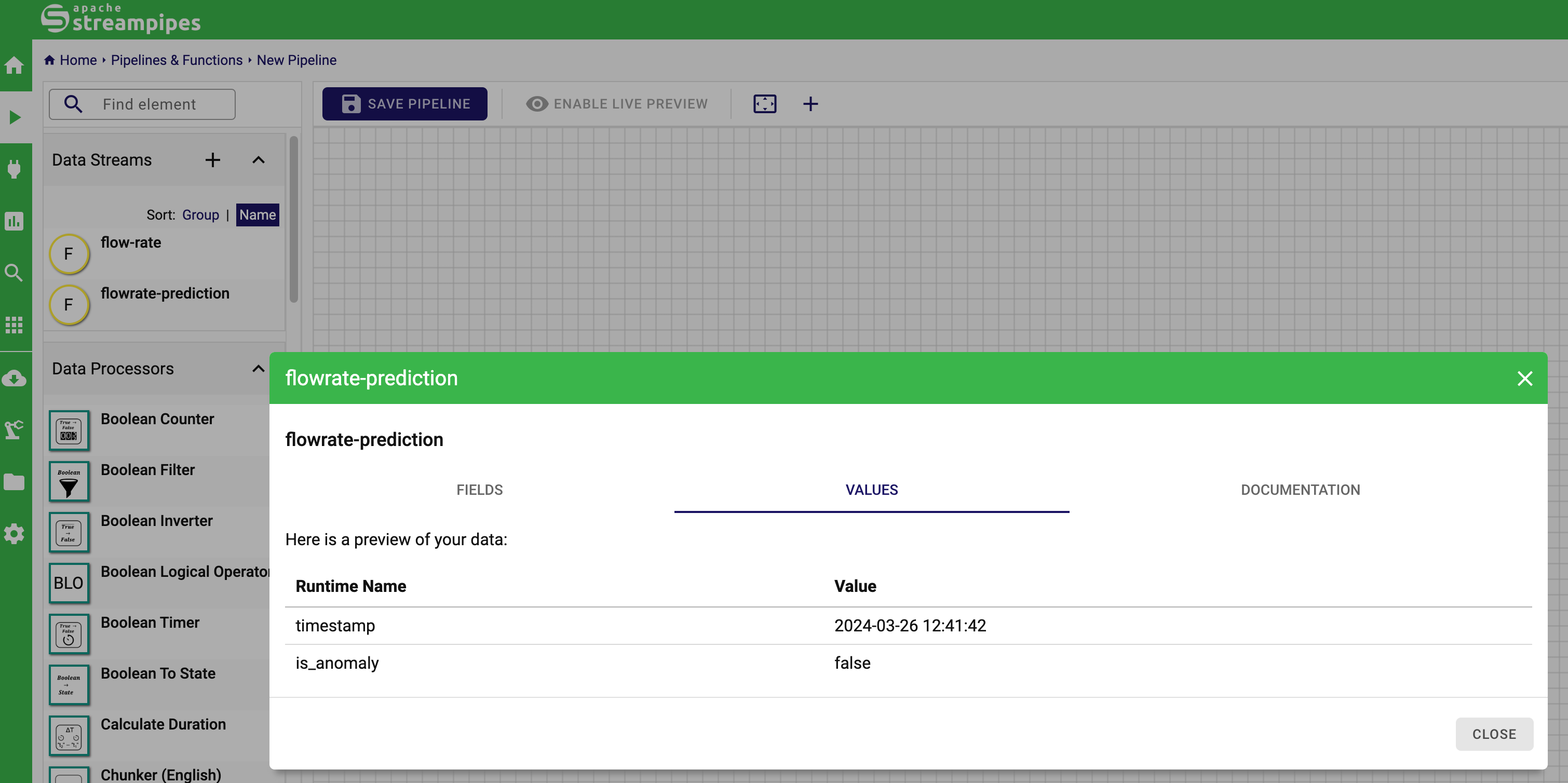
In case you want to reproduce the first two tutorials exactly on your end, you need to create a simple pipeline in StreamPipes like demonstrated below.
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-configure-the-Python-client","title":"How to configure the Python client\u00b6","text":"
In order to access the resources available in StreamPipes, one must be able to authenticate against the backend. For this purpose, the client sofar only supports the authentication via an API token that can be generated via the StreamPipes UI, as you see below.
Having generated the API token, one can directly start initializing a client instance as follows:
"},{"location":"tutorials/2-extracting-data-from-the-streampipes-data-lake/","title":"Extracting Data from the StreamPipes data lake","text":"In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# if you want all necessary dependencies required for this tutorial to be installed,\n# you can simply execute the following command\n%pip install matplotlib streampipes\n
# if you want all necessary dependencies required for this tutorial to be installed, # you can simply execute the following command %pip install matplotlib streampipes In\u00a0[2]: Copied!
As a first step, we want to get an overview about all data available in the data lake. The data is stored as so-called measures, which refer to a data stream stored in the data lake. For his purpose we use the all() method of the dataLakeMeasure endpoint.
So far, we have only retrieved metadata about the available data lake measure. In the following, we will access the actual data of the measure flow-rate.
For this purpose, we will use the get() method of the dataLakeMeasure endpoint.
For further processing, the easiest way is to turn the data measure into a pandas DataFrame.
In\u00a0[10]: Copied!
flow_rate_pd = flow_rate_measure.to_pandas()\n
flow_rate_pd = flow_rate_measure.to_pandas()
Let's see how many data points we got...
In\u00a0[11]: Copied!
len(flow_rate_pd)\n
len(flow_rate_pd) Out[11]:
1000
... and get a first overview
In\u00a0[12]: Copied!
flow_rate_pd.describe()\n
flow_rate_pd.describe() Out[12]: density mass_flow temperature volume_flow count 1000.000000 1000.000000 1000.000000 1000.000000 mean 45.560337 5.457014 45.480231 5.659558 std 3.201544 3.184959 3.132878 3.122437 min 40.007698 0.004867 40.000992 0.039422 25% 42.819497 2.654101 42.754623 3.021625 50% 45.679264 5.382355 45.435944 5.572553 75% 48.206881 8.183144 48.248473 8.338209 max 50.998310 10.986015 50.964909 10.998676
As a final step, we want to create a plot of both attributes
In\u00a0[13]: Copied!
import matplotlib.pyplot as plt\nflow_rate_pd.plot(y=[\"mass_flow\", \"temperature\"])\nplt.show()\n
import matplotlib.pyplot as plt flow_rate_pd.plot(y=[\"mass_flow\", \"temperature\"]) plt.show()
For data lake measurements, the get() method is even more powerful than simply returning all the data for a given data lake measurement. We will look at a selection of these below. The full list of supported parameters can be found in the docs. Let's start by referring to the graph we created above, where we use only two columns of our data lake measurement. If we already know this, we can directly restrict the queried data to a subset of columns by using the columns parameter. columns takes a list of column names as a comma-separated string:
By default, the client returns only the first one thousand records of a Data Lake measurement. This can be changed by passing a concrete value for the limit parameter:
If you want your data to be selected by time of occurrence rather than quantity, you can specify your time window by passing the start_date and end_date parameters:
... from this point on we leave all future processing of the data up to your creativity. Keep in mind: the general syntax used in this tutorial (all(), to_pandas(), get()) applies to all endpoints and associated resources of the StreamPipes Python client.
If you get further and create exiting stuff with data extracted from StreamPipes please let us know. We are thrilled to see what you as a community will build with the provided client. Furthermore, don't hesitate to discuss feature requests to extend the current functionality with us.
For now, that's all about the StreamPipes client. Read the next tutorial (Getting live data from the StreamPipes data stream) if you are interested in making use of the powerful StreamPipes functions to interact with StreamPipes event-based.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/2-extracting-data-from-the-streampipes-data-lake/#Extracting-Data-from-the-StreamPipes-data-lake","title":"Extracting Data from the StreamPipes data lake\u00b6","text":"
In the first tutorial (Introduction to the StreamPipes Python client) we took the first steps with the StreamPipes Python client and learned how to set everything up. Now we are ready to get started and want to retrieve some data out of StreamPipes. In this tutorial, we'll focus on the StreamPipes Data Lake, the component where StreamPipes stores data internally. To get started, we'll use the client instance created in the first tutorial.
"},{"location":"tutorials/3-getting-live-data-from-the-streampipes-data-stream/","title":"Getting live data from the StreamPipes data stream","text":"
Note As of now we mainly developed the support for StreamPipes functions using NATS as messaging protocol. Consequently, this setup is tested most and should work flawlessly. Visit our first-steps page to see how to start StreamPipes accordingly. Anyhow, you can also use the other brokers that are currently supported in StreamPipes Python. In case you observe any problems, please reach out to us and file us an issue on GitHub.
In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# You can install all required libraries for this tutorial with the following command\n%pip install matplotlib ipython streampipes\n
# You can install all required libraries for this tutorial with the following command %pip install matplotlib ipython streampipes In\u00a0[2]: Copied!
import os\n\nos.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\"\nos.environ[\"SP_API_KEY\"] = \"XXX\"\n\n# Use this if you work locally:\nos.environ[\"BROKER-HOST\"] = \"localhost\" \nos.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker. If Kafka is not running on localhost, KAFKA_ADVERTISED_LISTENERS should be adjusted to the external address\n
import os os.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\" os.environ[\"SP_API_KEY\"] = \"XXX\" # Use this if you work locally: os.environ[\"BROKER-HOST\"] = \"localhost\" os.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker. If Kafka is not running on localhost, KAFKA_ADVERTISED_LISTENERS should be adjusted to the external address In\u00a0[3]: Copied!
Next we can create a StreamPipesFunction. For this we need to implement the 3 following methods:
onServiceStarted is called when the function gets started. There you can use the given meta information of the FunctionContext to initialize the function.
onEvent is called when ever a new event arrives. The event contains the live data and you can use the streamId to identify a stream if the function is connected to multiple data streams.
onServiceStopped is called when the function gets stopped.
For this tutorial we just create a function that saves every new event in a pandas DataFrame and plots the first column of the DataFrame when the function gets stopped.
(If you want to use the same structure as in Java you can overwrite the getFunctionId and requiredStreamIds methods instead of using the FunctionDefinition)
In\u00a0[5]: Copied!
from typing import Dict, Any\nimport pandas as pd\nfrom datetime import datetime\nimport matplotlib.pyplot as plt\nfrom streampipes.functions.function_handler import FunctionHandler\nfrom streampipes.functions.registration import Registration\nfrom streampipes.functions.streampipes_function import StreamPipesFunction\nfrom streampipes.functions.utils.function_context import FunctionContext\nfrom streampipes.model.resource.function_definition import FunctionDefinition, FunctionId\n\nclass ExampleFunction(StreamPipesFunction):\n def __init__(self, function_definition: FunctionDefinition) -> None:\n super().__init__(function_definition)\n # Create the Dataframe to save the live data\n self.df = pd.DataFrame()\n\n def onServiceStarted(self, context: FunctionContext):\n # Get the name of the timestamp field\n for event_property in context.schema[context.streams[0]].event_schema.event_properties:\n if event_property.property_scope == \"HEADER_PROPERTY\":\n self.timestamp = event_property.runtime_name\n\n def onEvent(self, event: Dict[str, Any], streamId: str):\n # Convert the unix timestamp to datetime\n event[self.timestamp] = datetime.fromtimestamp(event[self.timestamp] / 1000)\n # Add every value of the event to the DataFrame\n self.df = pd.concat(\n [self.df, pd.DataFrame({key: [event[key]] for key in event.keys()}).set_index(self.timestamp)]\n )\n\n def onServiceStopped(self):\n # Plot the first column of the Dataframe\n plt.figure(figsize=(10, 5))\n plt.xlabel(self.timestamp)\n plt.ylabel(self.df.columns[0])\n plt.plot(self.df.iloc[:, 0])\n plt.show()\n
from typing import Dict, Any import pandas as pd from datetime import datetime import matplotlib.pyplot as plt from streampipes.functions.function_handler import FunctionHandler from streampipes.functions.registration import Registration from streampipes.functions.streampipes_function import StreamPipesFunction from streampipes.functions.utils.function_context import FunctionContext from streampipes.model.resource.function_definition import FunctionDefinition, FunctionId class ExampleFunction(StreamPipesFunction): def __init__(self, function_definition: FunctionDefinition) -> None: super().__init__(function_definition) # Create the Dataframe to save the live data self.df = pd.DataFrame() def onServiceStarted(self, context: FunctionContext): # Get the name of the timestamp field for event_property in context.schema[context.streams[0]].event_schema.event_properties: if event_property.property_scope == \"HEADER_PROPERTY\": self.timestamp = event_property.runtime_name def onEvent(self, event: Dict[str, Any], streamId: str): # Convert the unix timestamp to datetime event[self.timestamp] = datetime.fromtimestamp(event[self.timestamp] / 1000) # Add every value of the event to the DataFrame self.df = pd.concat( [self.df, pd.DataFrame({key: [event[key]] for key in event.keys()}).set_index(self.timestamp)] ) def onServiceStopped(self): # Plot the first column of the Dataframe plt.figure(figsize=(10, 5)) plt.xlabel(self.timestamp) plt.ylabel(self.df.columns[0]) plt.plot(self.df.iloc[:, 0]) plt.show()
Now we can start the function. First we create an instance of the ExampleFunction and insert the element_id of the stream which data we want to consume. Then we have to register this function and we can start all functions by initializing the FunctionHandler. (it's also possible to register multiple functions with .register(...).register(...))
The while loop just displays the the DataFrame every second until the cell is stopped. We could achieve the same result manually by executing example_function.df repeatedly.
You can stop the functions whenever you want by executing the command below.
That's enough for this tutorial. Now you can try to write your own StreamPipesFunction. All you need to do is creating a new class, implementing the 4 required methods and registering the function.
Want to see more exciting use cases you can achieve with StreamPipes functions in Python? Then don't hesitate and jump to our next tutorial on applying online machine learning algorithms to StreamPipes data streams with River.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/3-getting-live-data-from-the-streampipes-data-stream/#Getting-live-data-from-the-StreamPipes-data-stream","title":"Getting live data from the StreamPipes data stream\u00b6","text":"
In the last tutorial (Extracting Data from the StreamPipes data lake) we learned how to extract the stored data from a StreamPipes data lake. This tutorial is about the StreamPipes data stream and shows how to get the live data from StreamPipes into Python. Therefore, we first create the client instance as before.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/","title":"Using Online Machine Learning on a StreamPipes data stream","text":"In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# you can install all required dependecies for this tutorial by executing the following command\n%pip install river streampipes\n
# you can install all required dependecies for this tutorial by executing the following command %pip install river streampipes In\u00a0[2]: Copied!
import os\n\nos.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\"\nos.environ[\"SP_API_KEY\"] = \"XXX\"\n\n# Use this if you work locally:\nos.environ[\"BROKER-HOST\"] = \"localhost\" \nos.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker\n
import os os.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\" os.environ[\"SP_API_KEY\"] = \"XXX\" # Use this if you work locally: os.environ[\"BROKER-HOST\"] = \"localhost\" os.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker In\u00a0[3]: Copied!
import pickle\nfrom river import compose, tree\nfrom streampipes.function_zoo.river_function import OnlineML\nfrom streampipes.functions.utils.data_stream_generator import RuntimeType\n\nhoeffding_tree = compose.Pipeline(\n (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")),\n (\"hoeffding_tree\", tree.HoeffdingTreeRegressor(grace_period=5)),\n)\n\n\ndef draw_tree(self, event, streamId):\n\"\"\"Draw the tree and save the image.\"\"\"\n if self.learning:\n if self.model[1].n_nodes != None:\n self.model[1].draw().render(\"hoeffding_tree\", format=\"png\", cleanup=True)\n\n\ndef save_model(self):\n\"\"\"Save the trained model.\"\"\"\n with open(\"hoeffding_tree.pkl\", \"wb\") as f:\n pickle.dump(self.model, f)\n\n\nregressor = OnlineML(\n client=client,\n stream_ids=[\"sp:spdatastream:xboBFK\"],\n model=hoeffding_tree,\n prediction_type=RuntimeType.FLOAT.value,\n supervised=True,\n target_label=\"temperature\",\n on_event=draw_tree,\n on_stop=save_model,\n)\nregressor.start()\n
import pickle from river import compose, tree from streampipes.function_zoo.river_function import OnlineML from streampipes.functions.utils.data_stream_generator import RuntimeType hoeffding_tree = compose.Pipeline( (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")), (\"hoeffding_tree\", tree.HoeffdingTreeRegressor(grace_period=5)), ) def draw_tree(self, event, streamId): \"\"\"Draw the tree and save the image.\"\"\" if self.learning: if self.model[1].n_nodes != None: self.model[1].draw().render(\"hoeffding_tree\", format=\"png\", cleanup=True) def save_model(self): \"\"\"Save the trained model.\"\"\" with open(\"hoeffding_tree.pkl\", \"wb\") as f: pickle.dump(self.model, f) regressor = OnlineML( client=client, stream_ids=[\"sp:spdatastream:xboBFK\"], model=hoeffding_tree, prediction_type=RuntimeType.FLOAT.value, supervised=True, target_label=\"temperature\", on_event=draw_tree, on_stop=save_model, ) regressor.start() In\u00a0[9]: Copied!
import pickle\nfrom river import compose, tree\nfrom streampipes.function_zoo.river_function import OnlineML\nfrom streampipes.functions.utils.data_stream_generator import RuntimeType\n\ndecision_tree = compose.Pipeline(\n (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")),\n (\"decision_tree\", tree.ExtremelyFastDecisionTreeClassifier(grace_period=5)),\n)\n\n\ndef draw_tree(self, event, streamId):\n\"\"\"Draw the tree and save the image.\"\"\"\n if self.learning:\n if self.model[1].n_nodes != None:\n self.model[1].draw().render(\"decicion_tree\", format=\"png\", cleanup=True)\n\n\ndef save_model(self):\n\"\"\"Save the trained model.\"\"\"\n with open(\"decision_tree.pkl\", \"wb\") as f:\n pickle.dump(self.model, f)\n\n\nclassifier = OnlineML(\n client=client,\n stream_ids=[\"sp:spdatastream:xboBFK\"],\n model=decision_tree,\n prediction_type=RuntimeType.BOOLEAN.value,\n supervised=True,\n target_label=\"sensor_fault_flags\",\n on_event=draw_tree,\n on_stop=save_model,\n)\nclassifier.start()\n
import pickle from river import compose, tree from streampipes.function_zoo.river_function import OnlineML from streampipes.functions.utils.data_stream_generator import RuntimeType decision_tree = compose.Pipeline( (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")), (\"decision_tree\", tree.ExtremelyFastDecisionTreeClassifier(grace_period=5)), ) def draw_tree(self, event, streamId): \"\"\"Draw the tree and save the image.\"\"\" if self.learning: if self.model[1].n_nodes != None: self.model[1].draw().render(\"decicion_tree\", format=\"png\", cleanup=True) def save_model(self): \"\"\"Save the trained model.\"\"\" with open(\"decision_tree.pkl\", \"wb\") as f: pickle.dump(self.model, f) classifier = OnlineML( client=client, stream_ids=[\"sp:spdatastream:xboBFK\"], model=decision_tree, prediction_type=RuntimeType.BOOLEAN.value, supervised=True, target_label=\"sensor_fault_flags\", on_event=draw_tree, on_stop=save_model, ) classifier.start() In\u00a0[12]: Copied!
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#Using-Online-Machine-Learning-on-a-StreamPipes-data-stream","title":"Using Online Machine Learning on a StreamPipes data stream\u00b6","text":"
The last tutorial (Getting live data from the StreamPipes data stream) showed how we can connect to a data stream, and it would be possible to use Online Machine Learning with this approach and train a model with the incoming events at the onEvent method. However, the StreamPipes client also provides an easier way to do this with the use of the River library for Online Machine Learning. We will have a look at this now.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#How-to-use-Online-Machine-Learning-with-StreamPipes","title":"How to use Online Machine Learning with StreamPipes\u00b6","text":"
After we configured the client as usual, we can start with the new part. The approach is straight forward and you can start with the ML part in just 3 steps:
Create a pipeline with River and insert the preprocessing steps and model of your choice.
Configure the OnlineML wrapper to fit to your model and insert the client and required data stream ids.
Start the wrapper and let the learning begin.
A StreamPipesFunction is then started, which trains the model for each new event. It also creates an output data stream which will send the prediction of the model back to StreamPipes. This output stream can be seen when creating a new pipeline and can be used like every other data source. So you can use it in a pipeline and save the predictions in a Data Lake. You can also stop and start the training with the method set_learning. To stop the whole function use the stop methode and if you want to delete the output stream entirely, you can go to the Pipeline Element Installer in StreamPipes and uninstall it.
Now let's take a look at some examples. If you want to execute the examples below you have to create an adapter for the Machine Data Simulator, select the flowrate sensor and insert the stream id of this stream.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#KMeans","title":"KMeans\u00b6","text":""},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#HoeffdingTreeRegressor","title":"HoeffdingTreeRegressor\u00b6","text":""},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#DecisionTreeClassifier","title":"DecisionTreeClassifier\u00b6","text":""}]}
\ No newline at end of file
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"\ud83c\udfe1 Home","text":"StreamPipes is a self-service (Industrial) IoT toolbox to enable non-technical users to connect, analyze and explore IoT data streams. Apache StreamPipes for Python \ud83d\udc0d
Apache StreamPipes meets Python! We are working highly motivated on a Python library to interact with StreamPipes. In this way, we would like to unite the power of StreamPipes to easily connect to and read from different data sources, especially in the IoT domain, and the amazing universe of data analytics libraries in Python.
As a quick example, we demonstrate how to set up and configure a StreamPipes client. In addition, we will get the available data lake measures out of StreamPipes.
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nconfig = StreamPipesClientConfig(\n credential_provider = StreamPipesApiKeyCredentials(\n username = \"test@streampipes.apache.org\",\n api_key = \"DEMO-KEY\",\n ),\n host_address = \"localhost\",\n https_disabled = True,\n port = 80\n)\n\nclient = StreamPipesClient(client_config=config)\n\n# get all available datat lake measures\nmeasures = client.dataLakeMeasureApi.all()\n\n# get amount of retrieved measures\nlen(measures)\n
Output:
1\n
# inspect the data lake measures as pandas dataframe\nmeasures.to_pandas()\n
Output:
measure_name timestamp_field ... pipeline_is_running num_event_properties\n0 test s0::timestamp ... False 2\n[1 rows x 6 columns]\n
Alternatively, you can provide your credentials via environment variables. Simply define your credential provider as follows:
from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nStreamPipesApiKeyCredentials()\n
This requires to set the following environment variables: SP_API_KEY and SP_USERNAME
username is always the username that is used to log in into StreamPipes.
How to get your StreamPipes API key
The api_key can be generated within the UI as demonstrated below:
"},{"location":"getting-started/developing/","title":"Developing & Contributing","text":""},{"location":"getting-started/developing/#development-guide","title":"\ud83d\udcd6 Development Guide","text":"
This document describes how to easily set up your local dev environment to work on StreamPipes Python \ud83d\udc0d.
"},{"location":"getting-started/developing/#first-steps","title":"\ud83d\ude80 First Steps","text":"
1) Set up your Python environment
Create a virtual Python environment using a tool of your choice. To manage dependencies, we use Poetry, so please install poetry in your local environment, e.g. via
pip install poetry\n
Once poetry is installed you can simply finalize your Python environment by running:
poetry install --with dev,stubs # install everything that is required for the development\npoetry install --with docs # install everything to work with the documentation\npoetry install --with dev,stubs,docs # install all optional dependencies related to development\n
2) Install pre-commit hook
The pre-commit hook is run before every commit and takes care about code style, linting, type hints, import sorting, etc. It will stop your commit in case the changes do not apply the expected format. Always check to have the recent version of the pre-commit hook installed otherwise the CI build might fail. If you are interested, you can have a deeper look on the underlying library: pre-commit.
pre-commit install\n
The definition of the pre-commit hook can be found in .pre-commit-config.yaml. "},{"location":"getting-started/developing/#conventions","title":"\ud83d\udc4f Conventions","text":"
Below we list some conventions that we have agreed on for creating StreamPipes Python. Please comply to them when you plan to contribute to this project. If you have any other suggestions or would like to discuss them, we would be happy to hear from you on our mailing list dev@streampipes.apache.org or in our discussions on GitHub.
1) Use numpy style for Python docstrings \ud83d\udcc4 Please stick to the numpy style when writing docstrings, as we require this for generating our documentation.
2) Provide tests \u2705 We are aiming for broad test coverage for the Python package and have therefore set a requirement of at least 90% unit test coverage. Therefore, please remember to write (unit) tests already during development. If you have problems with writing tests, don't hesitate to ask us for help directly in the PR or even before that via our mailing list (see above).
3) Build a similar API as the Java client provides \ud83d\udd04 Whenever possible, please try to develop the API of the Python library the same as the Java client or Java SDK. By doing so, we would like to provide a consistent developer experience and the basis for automated testing in the future.
To build our documentation, we use Materials for MkDocs. All files can be found within the docs directory. To pre-view your local version of the documentation, you can use the following command:
Before opening a pull request, review the Get Involved page. It lists information that is required for contributing to StreamPipes.
When you contribute code, you affirm that the contribution is your original work and that you license the work to the project under the project's open source license. Whether or not you state this explicitly, by submitting any copyrighted material via pull request, email, or other means you agree to license the material under the project's open source license and warrant that you have the legal authority to do so.
The StreamPipes Python library is meant to work with Python 3.8 and above. Installation can be done via pip: You can install the latest development version from GitHub, as so:
pip install streampipes\n\n# if you want to have the current development state you can also execute\npip install git+https://github.com/apache/streampipes.git#subdirectory=streampipes-client-python\n# the corresponding documentation can be found here: https://streampipes.apache.org/docs/docs/python/dev/\n
"},{"location":"getting-started/first-steps/#setting-up-streampipes","title":"\u2b06\ufe0f Setting up StreamPipes","text":"
When working with the StreamPipes Python library it is inevitable to have a running StreamPipes instance to connect and interact with. In case you don't have a running instance at hand, you can easily set up one on your local machine. Hereby you need to consider that StreamPipes supports different message broker (e.g., Kafka, NATS). We will demonstrate below how you can easily set up StreamPipes for both supported message brokers.
"},{"location":"getting-started/first-steps/#start-streampipes-via-docker-compose","title":"\ud83d\udc33 Start StreamPipes via Docker Compose","text":"
The easiest and therefore recommend way to get StreamPipes started is by using docker compose. Therefore, you need Docker running. You can check if Docker is ready on your machine by executing.
docker ps\n
If this results in an output similar to the following, Docker is ready to continue.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\n... ... ... ... ... ... ...\n
Otherwise, you need to start docker first. Please read the full guide on how to start StreamPipes with docker compose here."},{"location":"getting-started/first-steps/#setup-streampipes-with-nats-as-message-broker","title":"Setup StreamPipes with NATS as message broker","text":"
The following shows how you can set up a StreamPipes instance that uses NATS as messaging layer. So in this scenario, we will go with docker-compose.nats.yml. Thereby, when running locally, we need to add the following port mapping entry to services.nats.ports:
- 4222:4222\n
After this modification is applied, StreamPipes can simply be started with this command:
docker-compose -f docker-compose.nats.yml up -d\n
Once all services are started, you can access StreamPipes via http://localhost.
"},{"location":"getting-started/first-steps/#setup-streampipes-with-kafka-as-message-broker","title":"Setup StreamPipes with Kafka as message broker","text":"
Alternatively, you can use docker-compose.yml to start StreamPipes with Kafka as messaging layer. When running locally we have to modify services.kafka.environment and add the ports to services.kafka.ports:
As a quick example, we demonstrate how to set up and configure a StreamPipes client. In addition, we will get the available data lake measures out of StreamPipes.
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nconfig = StreamPipesClientConfig(\n credential_provider = StreamPipesApiKeyCredentials(\n username = \"test@streampipes.apache.org\",\n api_key = \"DEMO-KEY\",\n ),\n host_address = \"localhost\",\n https_disabled = True,\n port = 80\n)\n\nclient = StreamPipesClient(client_config=config)\n\n# get all available datat lake measures\nmeasures = client.dataLakeMeasureApi.all()\n\n# get amount of retrieved measures\nlen(measures)\n
Output:
1\n
# inspect the data lake measures as pandas dataframe\nmeasures.to_pandas()\n
Output:
measure_name timestamp_field ... pipeline_is_running num_event_properties\n0 test s0::timestamp ... False 2\n[1 rows x 6 columns]\n
Alternatively, you can provide your credentials via environment variables. Simply define your credential provider as follows:
from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n\nStreamPipesApiKeyCredentials()\n
This requires to set the following environment variables: SP_API_KEY and SP_USERNAME
username is always the username that is used to log in into StreamPipes. The api_key can be generated within the UI as demonstrated below:
Implementation of the StreamPipes client. The client is designed as the central point of interaction with the StreamPipes API and provides all functionalities to communicate with the API.
This is the central point of contact with StreamPipes and provides all the functionalities to interact with it.
The client provides so-called \"endpoints\" each of which refers to an endpoint of the StreamPipes API, e.g. .dataLakeMeasureApi. An endpoint provides the actual methods to interact with StreamPipes API.
PARAMETER DESCRIPTION client_config
Configures the client to connect properly to the StreamPipes instance.
TYPE: StreamPipesClientConfig
logging_level
Influences the log messages emitted by the StreamPipesClient
TYPE: Optional[int] DEFAULT: INFO
ATTRIBUTE DESCRIPTION dataLakeMeasureApi
Instance of the data lake measure endpoint
TYPE: DataLakeMeasureEndpoint
dataStreamApi
Instance of the data stream endpoint
TYPE: DataStreamEndpoint
RAISES DESCRIPTION AttributeError:
In case an invalid configuration of the StreamPipesClientConfig is passed
Examples:
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
The HTTP headers are composed of the authentication headers supplied by the credential provider and additional required headers (currently this is only the application header).
RETURNS DESCRIPTION http_headers
header information for HTTP requests as string key-value pairs.
Prints a short description of the connected StreamPipes instance and the available resources to the console.
RETURNS DESCRIPTION None
Examples:
client.describe()\n
Output:
Hi there!\nYou are connected to a StreamPipes instance running at http://localhost:80.\nThe following StreamPipes resources are available with this client:\n6x DataStreams\n1x DataLakeMeasures\n
Implementation of credential providers. A credential provider supplies the specified sort of credentials in the appropriate HTTP header format. The headers are then used by the client to connect to StreamPipes.
Creates the HTTP headers for the specific credential provider.
Concrete authentication headers must be defined in the implementation of a credential provider.
PARAMETER DESCRIPTION http_headers
Additional HTTP headers the generated headers are extended by.
TYPE: Optional[Dict[str, str]] DEFAULT: None
RETURNS DESCRIPTION https_headers
Dictionary with header information as string key-value pairs. Contains all pairs given as parameter plus the header pairs for authentication determined by the credential provider.
A credential provider that allows authentication via a StreamPipes API Token.
The required token can be generated via the StreamPipes UI (see the description on our start-page.
Both parameters can either be passed as arguments or remain unset. If they are not passed, they are retrieved from environment variables:
SP_USERNAME is expected to contain the username
SP_API_KEY is expected to contain the API key
PARAMETER DESCRIPTION username
The username to which the API token is granted, e.g., demo-user@streampipes.apche.org. If not passed, the username is retrieved from environment variable SP_USERNAME.
TYPE: Optional[str] DEFAULT: None
api_key
The StreamPipes API key as it is displayed in the UI. If not passed, the api key is retrieved from environment variable SP_API_KEY
General implementation for an endpoint. Provided classes and assets are aimed to be used for developing endpoints. An endpoint provides all options to communicate with ad dedicated part of StreamPipes in a handy way.
Serves as template for all endpoints of the StreamPipes API. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
Abstract implementation of a StreamPipes endpoint.
Serves as template for all endpoints used for interaction with a StreamPipes instance. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
PARAMETER DESCRIPTION parent_client
This parameter expects the instance of StreamPipesClient the endpoint is attached to.
Abstract implementation of a StreamPipes messaging endpoint.
Serves as template for all endpoints used for interacting with the StreamPipes messaging layer directly. Therefore, they need to provide the functionality to talk with the broker system running in StreamPipes. By design, endpoints are only instantiated within the __init__ method of the StreamPipesClient.
Defines the broker instance that is used to connect to StreamPipes' messaging layer.
This instance enables the client to authenticate to the broker used in the target StreamPipes instance, to consume messages from and to write messages to the broker.
Exception that indicates that an instance of a messaging endpoint has not been configured.
This error occurs when an instance of a messaging endpoint is used before the broker instance to be used is configured by passing it to the configure() method.
PARAMETER DESCRIPTION endpoint_name
The name of the endpoint that caused the error
TYPE: str
"},{"location":"reference/endpoint/api/data_lake_measure/","title":"Data lake measure","text":"
Specific implementation of the StreamPipes API's data lake measure endpoints. This endpoint allows to consume data stored in StreamPipes' data lake.
# get all existing data lake measures from StreamPipes\ndata_lake_measures = client.dataLakeMeasureApi.all()\n\n# let's take a look how many we got\nlen(data_lake_measures)\n
5\n
# Retrieve a specific data lake measure as a pandas DataFrame\nflow_rate_pd = client.dataLakeMeasureApi.get(identifier=\"flow-rate\").to_pandas()\nflow_rate_pd\n
Queries the specified data lake measure from the API.
By default, the maximum number of returned records is 1000. This behaviour can be influenced by passing the parameter limit with a different value (see MeasurementGetQueryConfig).
PARAMETER DESCRIPTION identifier
The identifier of the data lake measure to be queried.
TYPE: str
**kwargs
keyword arguments can be used to provide additional query parameters. The available query parameters are defined by the MeasurementGetQueryConfig.
Config class describing the parameters of the get() method for measurements.
This config class is used to validate the provided query parameters for the GET endpoint of measurements. Additionally, it takes care of the conversion to a proper HTTP query string. Thereby, parameter names are adapted to the naming of the StreamPipes API, for which Pydantic aliases are used.
ATTRIBUTE DESCRIPTION columns
A comma separated list of column names (e.g., time,value) If provided, the returned data only consists of the given columns. Please be aware that the column time as an index is always included.
TYPE: Optional[List[str]]
end_date
Restricts queried data to be younger than the specified time.
TYPE: Optional[datetime]
limit
Amount of records returned at maximum (default: 1000) This needs to be at least 1
TYPE: Optional[int]
offset
Offset to be applied to returned data This needs to be at least 0
TYPE: Optional[int]
order
Ordering of query results Allowed values: ASC and DESC (default: ASC)
TYPE: Optional[str]
page_no
Page number used for paging operation This needs to be at least 1
TYPE: Optional[int]
start_date
Restricts queried data to be older than the specified time
This method returns an HTTP query string for the invoking config. It follows the following structure ?param1=value1¶m2=value2.... This query string is not an entire URL, instead it needs to appended to an API path.
This endpoint provides metadata about the StreamPipes version of the connected instance. It only allows to apply the get() method with an empty string as identifier.
PARAMETER DESCRIPTION parent_client
The instance of StreamPipesClient the endpoint is attached to.
TYPE: StreamPipesClient
Examples:
>>> from streampipes.client import StreamPipesClient\n>>> from streampipes.client.config import StreamPipesClientConfig\n>>> from streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
Usually, this method returns information about all resources provided by this endpoint. However, this endpoint does not support this kind of operation.
RAISES DESCRIPTION NotImplementedError
this endpoint does not return multiple entries, therefore this method is not available
Usually, this method allows to create via this endpoint. Since the data represented by this endpoint is immutable, it does not support this kind of operation.
RAISES DESCRIPTION NotImplementedError
this endpoint does not allow for POST requests, therefore this method is not available
Wrapper class to enable an easy usage for Online Machine Learning models of the River library.
It creates a StreamPipesFunction to train a model with the incoming events of a data stream and creates an output data stream that publishes the prediction to StreamPipes.
PARAMETER DESCRIPTION client
The client for the StreamPipes API.
TYPE: StreamPipesClient
stream_ids
The ids of the data stream to train the model.
TYPE: List[str]
model
The model to train. It meant to be a River model/pipeline, but can be every model with a 'learn_one' and 'predict_one' methode.
TYPE: Any
prediction_type
The data type of the prediction. Is only needed when you continue to work with the prediction in StreamPipes.
TYPE: str DEFAULT: value
supervised
Define if the model is supervised or unsupervised.
TYPE: bool DEFAULT: False
target_label
Define the name of the target attribute if the model is supervised.
TYPE: Optional[str] DEFAULT: None
on_start
A function to be called when this StreamPipesFunction gets started.
The function handler manages the StreamPipes Functions.
It controls the connection to the brokers, starts the functions, manages the broadcast of the live data and is able to stop the connection to the brokers and functions.
PARAMETER DESCRIPTION registration
The registration, that contains the StreamPipesFunctions.
A StreamPipesFunction allows users to get the data of a StreamPipes data streams easily. It makes it possible to work with the live data in python and enables to use the powerful data analytics libraries there.
PARAMETER DESCRIPTION function_definition
the definition of the function that contains metadata about the connected function
TYPE: Optional[FunctionDefinition] DEFAULT: None
ATTRIBUTE DESCRIPTION output_collectors
List of all output collectors which are created based on the provided function definitions.
Collector for output events. The events are published to an output data stream. Therefore, the output collector establishes a connection to the broker.
PARAMETER DESCRIPTION data_stream
The output data stream that will receive the events.
TYPE: DataStream
ATTRIBUTE DESCRIPTION publisher
The publisher instance that sends the data to StreamPipes
RETURNS DESCRIPTION None"},{"location":"reference/functions/utils/async_iter_handler/","title":"Async iter handler","text":""},{"location":"reference/functions/utils/async_iter_handler/#streampipes.functions.utils.async_iter_handler.AsyncIterHandler","title":"AsyncIterHandler","text":"
Handles asynchronous iterators to get every message after another in parallel.
Implementation of the resource container for the data lake measures endpoint.
This resource container is a collection of data lake measures returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried DataLakeMeasure. Furthermore, the resource container makes them accessible in a pythonic manner.
Implementation of the resource container for the data stream endpoint.
This resource container is a collection of data streams returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried DataStream. Furthermore, the resource container makes them accessible in a pythonic manner.
General and abstract implementation for a resource container.
A resource container is a collection of resources returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried resources. Furthermore, the resource container makes them accessible in a pythonic manner.
General and abstract implementation for a resource container.
A resource container is a collection of resources returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried resources. Furthermore, the resource container makes them accessible in a pythonic manner.
PARAMETER DESCRIPTION resources
A list of resources to be contained in the ResourceContainer.
Implementation of the resource container for the versions endpoint.
This resource container is a collection of versions returned by the StreamPipes API. It is capable of parsing the response content directly into a list of queried Version. Furthermore, the resource container makes them accessible in a pythonic manner.
PARAMETER DESCRIPTION resources
A list of resources (Version) to be contained in the ResourceContainer.
TYPE: List[Resource]
"},{"location":"reference/model/resource/data_lake_measure/","title":"Data lake measure","text":""},{"location":"reference/model/resource/data_lake_measure/#streampipes.model.resource.data_lake_measure.DataLakeMeasure","title":"DataLakeMeasure","text":"
Bases: Resource
Implementation of a resource for data lake measures.
This resource defines the data model used by resource container (model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response, and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns the dictionary representation of a data lake measure to be used when creating a pandas Dataframe.
It excludes the following fields: element_id, event_schema, schema_version. Instead of the whole event schema the number of event properties contained is returned with the column name num_event_properties.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Implementation of a resource for data series. This resource defines the data model used by its resource container(model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Notes
This class will only exist temporarily in it its current appearance since\nthere are some inconsistencies in the StreamPipes API.\n
Creates an instance of DataSeries from a given JSON string.
This method is used by the resource container to parse the JSON response of the StreamPipes API. Currently, it only supports data lake series that consist of exactly one series of data.
PARAMETER DESCRIPTION json_string
The JSON string the data lake series should be created on.
TYPE: str
RETURNS DESCRIPTION DataSeries
Instance of DataSeries that is created based on the given JSON string.
This resource defines the data model used by resource container (model.container.DataStreams). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns the dictionary representation of a data stream to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
This class maps to the FunctionDefinition class in the StreamPipes model. It contains all metadata that are required to register a function at the StreamPipes backend.
PARAMETER DESCRIPTION consumed_streams
List of data streams the function is consuming from
function_id
identifier object of a StreamPipes function
ATTRIBUTE DESCRIPTION output_data_streams
Map off all output data streams added to the function definition
Returns the dictionary representation of a function definition to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Implementation of a resource for query result. This resource defines the data model used by its resource container(model.container.DataLakeMeasures). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
General and abstract implementation for a resource.
A resource defines the data model used by a resource container (model.container.resourceContainer). It inherits from Pydantic's BaseModel to get all its superpowers, which are used to parse, validate the API response and to easily switch between the Python representation (both serialized and deserialized) and Java representation (serialized only).
Returns a dictionary representation to be used when creating a pandas Dataframe.
RETURNS DESCRIPTION pandas_repr
Pandas representation of the resource as a dictionary, which is then used by the respource container to create a data frame from a collection of resources.
Validates the backend version of the StreamPipes. Sets 'development' if none is returned since this the behavior of StreamPipes backend running in development mode.
Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
In\u00a0[\u00a0]: Copied!
from pathlib import Path\n
from pathlib import Path In\u00a0[\u00a0]: Copied!
import mkdocs_gen_files\n
import mkdocs_gen_files In\u00a0[\u00a0]: Copied!
nav = mkdocs_gen_files.Nav()\n
nav = mkdocs_gen_files.Nav() In\u00a0[\u00a0]: Copied!
for path in sorted(Path(\"streampipes\").rglob(\"*.py\")):\n module_path = path.relative_to(\"streampipes\").with_suffix(\"\")\n doc_path = path.relative_to(\"streampipes\").with_suffix(\".md\")\n full_doc_path = Path(\"reference\", doc_path)\n\n parts = list(module_path.parts)\n\n if parts[-1] == \"__init__\":\n # parts = parts[:-1]\n continue\n elif parts[-1] == \"__version__\":\n continue\n elif parts[-1] == \"__main__\":\n continue\n elif parts[-1] == \" \":\n continue\n\n nav[parts] = doc_path.as_posix()\n\n with mkdocs_gen_files.open(full_doc_path, \"w+\") as fd:\n identifier = \".\".join(parts)\n print(f\"::: streampipes.{identifier}\", file=fd)\n\n mkdocs_gen_files.set_edit_path(full_doc_path, path)\n
for path in sorted(Path(\"streampipes\").rglob(\"*.py\")): module_path = path.relative_to(\"streampipes\").with_suffix(\"\") doc_path = path.relative_to(\"streampipes\").with_suffix(\".md\") full_doc_path = Path(\"reference\", doc_path) parts = list(module_path.parts) if parts[-1] == \"__init__\": # parts = parts[:-1] continue elif parts[-1] == \"__version__\": continue elif parts[-1] == \"__main__\": continue elif parts[-1] == \" \": continue nav[parts] = doc_path.as_posix() with mkdocs_gen_files.open(full_doc_path, \"w+\") as fd: identifier = \".\".join(parts) print(f\"::: streampipes.{identifier}\", file=fd) mkdocs_gen_files.set_edit_path(full_doc_path, path)
with mkdocs_gen_files.open(\"reference/SUMMARY.md\", \"w+\") as nav_file: nav_file.writelines(nav.build_literate_nav())
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/","title":"Introduction to StreamPipes Python","text":"In\u00a0[\u00a0]: Copied!
%pip install streampipes\n
%pip install streampipes
If you want to have the current development state you can also execute:
The corresponding documentation can be found here.
In\u00a0[\u00a0]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
Please be aware that connecting to StreamPipes via a https connection is currently not supported by the Python client.
Providing secrets like the api_key as plaintext in the source code is an anti-pattern. This is why the StreamPipes client also supports passing the required secrets as environment variables. To do so, you must initialize the credential provider like the following:
In\u00a0[\u00a0]: Copied!
StreamPipesApiKeyCredentials()\n
StreamPipesApiKeyCredentials()
To ensure that the above code works, you must set the environment variables as expected. This can be done like following:
That's already it. You can check if everything works out by using the following command:
In\u00a0[6]: Copied!
client.describe()\n
client.describe()
2023-02-24 17:05:49,398 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:167] [_make_request] - Successfully retrieved all resources.\n2023-02-24 17:05:49,457 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:167] [_make_request] - Successfully retrieved all resources.\n\nHi there!\nYou are connected to a StreamPipes instance running at http://localhost:80.\nThe following StreamPipes resources are available with this client:\n1x DataLakeMeasures\n1x DataStreams\n
This prints you a short textual description of the connected StreamPipes instance to the console.
The created client instance serves as the central point of interaction with StreamPipes. You can invoke a variety of commands directly on this object.
Are you curious now how you actually can get data out of StreamPipes and make use of it with Python? Then check out the next tutorial on extracting Data from the StreamPipes data lake.
Thanks for reading this introductory tutorial. We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#Introduction-to-StreamPipes-Python","title":"Introduction to StreamPipes Python\u00b6","text":""},{"location":"tutorials/1-introduction-to-streampipes-python-client/#Why-there-is-an-extra-Python-library-for-StreamPipes?","title":"Why there is an extra Python library for StreamPipes?\u00b6","text":"
Apache StreamPipes aims to enable non-technical users to connect and analyze IoT data streams. To this end, it provides an easy-to-use and convenient user interface that allows one to connect to an IoT data source and create some visual graphs within a few minutes. Although this is the main use case of Apache StreamPipes, it can also provide great value for people who are eager to work on data analysis or data science with IoT data, but don't we do get in touch with all the hassle associated with extracting data from devices in a suitable format. In this scenario, StreamPipes helps you connect to your data source and extract the data for you. You then can make the data available outside StreamPipes by writing it into an external source, such as a database, Kafka, etc. While this requires another component, you can also extract your data directly from StreamPipes programmatically using the StreamPipes API. For convenience, we also provide you with a StreamPipes client both available for Java and Python. Specifically with StreamPipes Python, we want to address the amazing data analytics and data science community in Python and benefit from the great universe of Python libraries out there.
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-install-StreamPipes-Python?","title":"How to install StreamPipes Python?\u00b6","text":"
Simply use the following pip command:
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-prepare-the-tutorials","title":"How to prepare the tutorials\u00b6","text":"
In case you want to reproduce the first two tutorials exactly on your end, you need to create a simple pipeline in StreamPipes like demonstrated below.
"},{"location":"tutorials/1-introduction-to-streampipes-python-client/#How-to-configure-the-Python-client","title":"How to configure the Python client\u00b6","text":"
In order to access the resources available in StreamPipes, one must be able to authenticate against the backend. For this purpose, the client sofar only supports the authentication via an API token that can be generated via the StreamPipes UI, as you see below.
Having generated the API token, one can directly start initializing a client instance as follows:
"},{"location":"tutorials/2-extracting-data-from-the-streampipes-data-lake/","title":"Extracting Data from the StreamPipes data lake","text":"In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# if you want all necessary dependencies required for this tutorial to be installed,\n# you can simply execute the following command\n%pip install matplotlib streampipes\n
# if you want all necessary dependencies required for this tutorial to be installed, # you can simply execute the following command %pip install matplotlib streampipes In\u00a0[2]: Copied!
As a first step, we want to get an overview about all data available in the data lake. The data is stored as so-called measures, which refer to a data stream stored in the data lake. For his purpose we use the all() method of the dataLakeMeasure endpoint.
So far, we have only retrieved metadata about the available data lake measure. In the following, we will access the actual data of the measure flow-rate.
For this purpose, we will use the get() method of the dataLakeMeasure endpoint.
For further processing, the easiest way is to turn the data measure into a pandas DataFrame.
In\u00a0[10]: Copied!
flow_rate_pd = flow_rate_measure.to_pandas()\n
flow_rate_pd = flow_rate_measure.to_pandas()
Let's see how many data points we got...
In\u00a0[11]: Copied!
len(flow_rate_pd)\n
len(flow_rate_pd) Out[11]:
1000
... and get a first overview
In\u00a0[12]: Copied!
flow_rate_pd.describe()\n
flow_rate_pd.describe() Out[12]: density mass_flow temperature volume_flow count 1000.000000 1000.000000 1000.000000 1000.000000 mean 45.560337 5.457014 45.480231 5.659558 std 3.201544 3.184959 3.132878 3.122437 min 40.007698 0.004867 40.000992 0.039422 25% 42.819497 2.654101 42.754623 3.021625 50% 45.679264 5.382355 45.435944 5.572553 75% 48.206881 8.183144 48.248473 8.338209 max 50.998310 10.986015 50.964909 10.998676
As a final step, we want to create a plot of both attributes
In\u00a0[13]: Copied!
import matplotlib.pyplot as plt\nflow_rate_pd.plot(y=[\"mass_flow\", \"temperature\"])\nplt.show()\n
import matplotlib.pyplot as plt flow_rate_pd.plot(y=[\"mass_flow\", \"temperature\"]) plt.show()
For data lake measurements, the get() method is even more powerful than simply returning all the data for a given data lake measurement. We will look at a selection of these below. The full list of supported parameters can be found in the docs. Let's start by referring to the graph we created above, where we use only two columns of our data lake measurement. If we already know this, we can directly restrict the queried data to a subset of columns by using the columns parameter. columns takes a list of column names as a comma-separated string:
By default, the client returns only the first one thousand records of a Data Lake measurement. This can be changed by passing a concrete value for the limit parameter:
If you want your data to be selected by time of occurrence rather than quantity, you can specify your time window by passing the start_date and end_date parameters:
... from this point on we leave all future processing of the data up to your creativity. Keep in mind: the general syntax used in this tutorial (all(), to_pandas(), get()) applies to all endpoints and associated resources of the StreamPipes Python client.
If you get further and create exiting stuff with data extracted from StreamPipes please let us know. We are thrilled to see what you as a community will build with the provided client. Furthermore, don't hesitate to discuss feature requests to extend the current functionality with us.
For now, that's all about the StreamPipes client. Read the next tutorial (Getting live data from the StreamPipes data stream) if you are interested in making use of the powerful StreamPipes functions to interact with StreamPipes event-based.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/2-extracting-data-from-the-streampipes-data-lake/#Extracting-Data-from-the-StreamPipes-data-lake","title":"Extracting Data from the StreamPipes data lake\u00b6","text":"
In the first tutorial (Introduction to the StreamPipes Python client) we took the first steps with the StreamPipes Python client and learned how to set everything up. Now we are ready to get started and want to retrieve some data out of StreamPipes. In this tutorial, we'll focus on the StreamPipes Data Lake, the component where StreamPipes stores data internally. To get started, we'll use the client instance created in the first tutorial.
"},{"location":"tutorials/3-getting-live-data-from-the-streampipes-data-stream/","title":"Getting live data from the StreamPipes data stream","text":"
Note As of now we mainly developed the support for StreamPipes functions using NATS as messaging protocol. Consequently, this setup is tested most and should work flawlessly. Visit our first-steps page to see how to start StreamPipes accordingly. Anyhow, you can also use the other brokers that are currently supported in StreamPipes Python. In case you observe any problems, please reach out to us and file us an issue on GitHub.
In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# You can install all required libraries for this tutorial with the following command\n%pip install matplotlib ipython streampipes\n
# You can install all required libraries for this tutorial with the following command %pip install matplotlib ipython streampipes In\u00a0[2]: Copied!
import os\n\nos.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\"\nos.environ[\"SP_API_KEY\"] = \"XXX\"\n\n# Use this if you work locally:\nos.environ[\"BROKER-HOST\"] = \"localhost\" \nos.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker. If Kafka is not running on localhost, KAFKA_ADVERTISED_LISTENERS should be adjusted to the external address\n
import os os.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\" os.environ[\"SP_API_KEY\"] = \"XXX\" # Use this if you work locally: os.environ[\"BROKER-HOST\"] = \"localhost\" os.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker. If Kafka is not running on localhost, KAFKA_ADVERTISED_LISTENERS should be adjusted to the external address In\u00a0[3]: Copied!
Next we can create a StreamPipesFunction. For this we need to implement the 3 following methods:
onServiceStarted is called when the function gets started. There you can use the given meta information of the FunctionContext to initialize the function.
onEvent is called when ever a new event arrives. The event contains the live data and you can use the streamId to identify a stream if the function is connected to multiple data streams.
onServiceStopped is called when the function gets stopped.
For this tutorial we just create a function that saves every new event in a pandas DataFrame and plots the first column of the DataFrame when the function gets stopped.
(If you want to use the same structure as in Java you can overwrite the getFunctionId and requiredStreamIds methods instead of using the FunctionDefinition)
In\u00a0[5]: Copied!
from typing import Dict, Any\nimport pandas as pd\nfrom datetime import datetime\nimport matplotlib.pyplot as plt\nfrom streampipes.functions.function_handler import FunctionHandler\nfrom streampipes.functions.registration import Registration\nfrom streampipes.functions.streampipes_function import StreamPipesFunction\nfrom streampipes.functions.utils.function_context import FunctionContext\nfrom streampipes.model.resource.function_definition import FunctionDefinition, FunctionId\n\nclass ExampleFunction(StreamPipesFunction):\n def __init__(self, function_definition: FunctionDefinition) -> None:\n super().__init__(function_definition)\n # Create the Dataframe to save the live data\n self.df = pd.DataFrame()\n\n def onServiceStarted(self, context: FunctionContext):\n # Get the name of the timestamp field\n for event_property in context.schema[context.streams[0]].event_schema.event_properties:\n if event_property.property_scope == \"HEADER_PROPERTY\":\n self.timestamp = event_property.runtime_name\n\n def onEvent(self, event: Dict[str, Any], streamId: str):\n # Convert the unix timestamp to datetime\n event[self.timestamp] = datetime.fromtimestamp(event[self.timestamp] / 1000)\n # Add every value of the event to the DataFrame\n self.df = pd.concat(\n [self.df, pd.DataFrame({key: [event[key]] for key in event.keys()}).set_index(self.timestamp)]\n )\n\n def onServiceStopped(self):\n # Plot the first column of the Dataframe\n plt.figure(figsize=(10, 5))\n plt.xlabel(self.timestamp)\n plt.ylabel(self.df.columns[0])\n plt.plot(self.df.iloc[:, 0])\n plt.show()\n
from typing import Dict, Any import pandas as pd from datetime import datetime import matplotlib.pyplot as plt from streampipes.functions.function_handler import FunctionHandler from streampipes.functions.registration import Registration from streampipes.functions.streampipes_function import StreamPipesFunction from streampipes.functions.utils.function_context import FunctionContext from streampipes.model.resource.function_definition import FunctionDefinition, FunctionId class ExampleFunction(StreamPipesFunction): def __init__(self, function_definition: FunctionDefinition) -> None: super().__init__(function_definition) # Create the Dataframe to save the live data self.df = pd.DataFrame() def onServiceStarted(self, context: FunctionContext): # Get the name of the timestamp field for event_property in context.schema[context.streams[0]].event_schema.event_properties: if event_property.property_scope == \"HEADER_PROPERTY\": self.timestamp = event_property.runtime_name def onEvent(self, event: Dict[str, Any], streamId: str): # Convert the unix timestamp to datetime event[self.timestamp] = datetime.fromtimestamp(event[self.timestamp] / 1000) # Add every value of the event to the DataFrame self.df = pd.concat( [self.df, pd.DataFrame({key: [event[key]] for key in event.keys()}).set_index(self.timestamp)] ) def onServiceStopped(self): # Plot the first column of the Dataframe plt.figure(figsize=(10, 5)) plt.xlabel(self.timestamp) plt.ylabel(self.df.columns[0]) plt.plot(self.df.iloc[:, 0]) plt.show()
Now we can start the function. First we create an instance of the ExampleFunction and insert the element_id of the stream which data we want to consume. Then we have to register this function and we can start all functions by initializing the FunctionHandler. (it's also possible to register multiple functions with .register(...).register(...))
The while loop just displays the the DataFrame every second until the cell is stopped. We could achieve the same result manually by executing example_function.df repeatedly.
You can stop the functions whenever you want by executing the command below.
That's enough for this tutorial. Now you can try to write your own StreamPipesFunction. All you need to do is creating a new class, implementing the 4 required methods and registering the function.
Want to see more exciting use cases you can achieve with StreamPipes functions in Python? Then don't hesitate and jump to our next tutorial on applying online machine learning algorithms to StreamPipes data streams with River.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/3-getting-live-data-from-the-streampipes-data-stream/#Getting-live-data-from-the-StreamPipes-data-stream","title":"Getting live data from the StreamPipes data stream\u00b6","text":"
In the last tutorial (Extracting Data from the StreamPipes data lake) we learned how to extract the stored data from a StreamPipes data lake. This tutorial is about the StreamPipes data stream and shows how to get the live data from StreamPipes into Python. Therefore, we first create the client instance as before.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/","title":"Using Online Machine Learning on a StreamPipes data stream","text":"In\u00a0[1]: Copied!
from streampipes.client import StreamPipesClient\nfrom streampipes.client.config import StreamPipesClientConfig\nfrom streampipes.client.credential_provider import StreamPipesApiKeyCredentials\n
from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials In\u00a0[\u00a0]: Copied!
# you can install all required dependencies for this tutorial by executing the following command\n%pip install river streampipes\n
# you can install all required dependencies for this tutorial by executing the following command %pip install river streampipes In\u00a0[2]: Copied!
import os\n\nos.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\"\nos.environ[\"SP_API_KEY\"] = \"XXX\"\n\n# Use this if you work locally:\nos.environ[\"BROKER-HOST\"] = \"localhost\" \nos.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker\n
import os os.environ[\"SP_USERNAME\"] = \"admin@streampipes.apache.org\" os.environ[\"SP_API_KEY\"] = \"XXX\" # Use this if you work locally: os.environ[\"BROKER-HOST\"] = \"localhost\" os.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker In\u00a0[3]: Copied!
import pickle\nfrom river import compose, tree\nfrom streampipes.function_zoo.river_function import OnlineML\nfrom streampipes.functions.utils.data_stream_generator import RuntimeType\n\nhoeffding_tree = compose.Pipeline(\n (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")),\n (\"hoeffding_tree\", tree.HoeffdingTreeRegressor(grace_period=5)),\n)\n\n\ndef draw_tree(self, event, streamId):\n\"\"\"Draw the tree and save the image.\"\"\"\n if self.learning:\n if self.model[1].n_nodes != None:\n self.model[1].draw().render(\"hoeffding_tree\", format=\"png\", cleanup=True)\n\n\ndef save_model(self):\n\"\"\"Save the trained model.\"\"\"\n with open(\"hoeffding_tree.pkl\", \"wb\") as f:\n pickle.dump(self.model, f)\n\n\nregressor = OnlineML(\n client=client,\n stream_ids=[\"sp:spdatastream:xboBFK\"],\n model=hoeffding_tree,\n prediction_type=RuntimeType.FLOAT.value,\n supervised=True,\n target_label=\"temperature\",\n on_event=draw_tree,\n on_stop=save_model,\n)\nregressor.start()\n
import pickle from river import compose, tree from streampipes.function_zoo.river_function import OnlineML from streampipes.functions.utils.data_stream_generator import RuntimeType hoeffding_tree = compose.Pipeline( (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")), (\"hoeffding_tree\", tree.HoeffdingTreeRegressor(grace_period=5)), ) def draw_tree(self, event, streamId): \"\"\"Draw the tree and save the image.\"\"\" if self.learning: if self.model[1].n_nodes != None: self.model[1].draw().render(\"hoeffding_tree\", format=\"png\", cleanup=True) def save_model(self): \"\"\"Save the trained model.\"\"\" with open(\"hoeffding_tree.pkl\", \"wb\") as f: pickle.dump(self.model, f) regressor = OnlineML( client=client, stream_ids=[\"sp:spdatastream:xboBFK\"], model=hoeffding_tree, prediction_type=RuntimeType.FLOAT.value, supervised=True, target_label=\"temperature\", on_event=draw_tree, on_stop=save_model, ) regressor.start() In\u00a0[9]: Copied!
import pickle\nfrom river import compose, tree\nfrom streampipes.function_zoo.river_function import OnlineML\nfrom streampipes.functions.utils.data_stream_generator import RuntimeType\n\ndecision_tree = compose.Pipeline(\n (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")),\n (\"decision_tree\", tree.ExtremelyFastDecisionTreeClassifier(grace_period=5)),\n)\n\n\ndef draw_tree(self, event, streamId):\n\"\"\"Draw the tree and save the image.\"\"\"\n if self.learning:\n if self.model[1].n_nodes != None:\n self.model[1].draw().render(\"decicion_tree\", format=\"png\", cleanup=True)\n\n\ndef save_model(self):\n\"\"\"Save the trained model.\"\"\"\n with open(\"decision_tree.pkl\", \"wb\") as f:\n pickle.dump(self.model, f)\n\n\nclassifier = OnlineML(\n client=client,\n stream_ids=[\"sp:spdatastream:xboBFK\"],\n model=decision_tree,\n prediction_type=RuntimeType.BOOLEAN.value,\n supervised=True,\n target_label=\"sensor_fault_flags\",\n on_event=draw_tree,\n on_stop=save_model,\n)\nclassifier.start()\n
import pickle from river import compose, tree from streampipes.function_zoo.river_function import OnlineML from streampipes.functions.utils.data_stream_generator import RuntimeType decision_tree = compose.Pipeline( (\"drop_features\", compose.Discard(\"sensorId\", \"timestamp\")), (\"decision_tree\", tree.ExtremelyFastDecisionTreeClassifier(grace_period=5)), ) def draw_tree(self, event, streamId): \"\"\"Draw the tree and save the image.\"\"\" if self.learning: if self.model[1].n_nodes != None: self.model[1].draw().render(\"decicion_tree\", format=\"png\", cleanup=True) def save_model(self): \"\"\"Save the trained model.\"\"\" with open(\"decision_tree.pkl\", \"wb\") as f: pickle.dump(self.model, f) classifier = OnlineML( client=client, stream_ids=[\"sp:spdatastream:xboBFK\"], model=decision_tree, prediction_type=RuntimeType.BOOLEAN.value, supervised=True, target_label=\"sensor_fault_flags\", on_event=draw_tree, on_stop=save_model, ) classifier.start() In\u00a0[12]: Copied!
That's already it! Isn't it truly easy to apply Online ML with StreamPipes and River? Please go ahead and apply it to your own use cases. We would be happy to hear about them!
Want to see more exciting use cases you can achieve with StreamPipes functions in Python? Then don\u2019t hesitate and jump to our next tutorial on using interoperable machine learning algorithm models with StreamPipes Python and ONNX.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#Using-Online-Machine-Learning-on-a-StreamPipes-data-stream","title":"Using Online Machine Learning on a StreamPipes data stream\u00b6","text":"
The last tutorial (Getting live data from the StreamPipes data stream) showed how we can connect to a data stream, and it would be possible to use Online Machine Learning with this approach and train a model with the incoming events at the onEvent method. However, the StreamPipes client also provides an easier way to do this with the use of the River library for Online Machine Learning. We will have a look at this now.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#How-to-use-Online-Machine-Learning-with-StreamPipes","title":"How to use Online Machine Learning with StreamPipes\u00b6","text":"
After we configured the client as usual, we can start with the new part. The approach is straight forward and you can start with the ML part in just 3 steps:
Create a pipeline with River and insert the preprocessing steps and model of your choice.
Configure the OnlineML wrapper to fit to your model and insert the client and required data stream ids.
Start the wrapper and let the learning begin.
A StreamPipesFunction is then started, which trains the model for each new event. It also creates an output data stream which will send the prediction of the model back to StreamPipes. This output stream can be seen when creating a new pipeline and can be used like every other data source. So you can use it in a pipeline and save the predictions in a Data Lake. You can also stop and start the training with the method set_learning. To stop the whole function use the stop methode and if you want to delete the output stream entirely, you can go to the Pipeline Element Installer in StreamPipes and uninstall it.
Now let's take a look at some examples. If you want to execute the examples below you have to create an adapter for the Machine Data Simulator, select the flowrate sensor and insert the stream id of this stream.
"},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#KMeans","title":"KMeans\u00b6","text":""},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#HoeffdingTreeRegressor","title":"HoeffdingTreeRegressor\u00b6","text":""},{"location":"tutorials/4-using-online-machine-learning-on-a-streampipes-data-stream/#DecisionTreeClassifier","title":"DecisionTreeClassifier\u00b6","text":""},{"location":"tutorials/5-applying-interoperable-machine-learning-in-streampipes/","title":"Applying Interoperable Machine Learning in StreamPipes","text":"In\u00a0[\u00a0]: Copied!
import os from streampipes.client import StreamPipesClient from streampipes.client.config import StreamPipesClientConfig from streampipes.client.credential_provider import StreamPipesApiKeyCredentials os.environ[\"BROKER-HOST\"] = \"localhost\" os.environ[\"KAFKA-PORT\"] = \"9094\" # When using Kafka as message broker config = StreamPipesClientConfig( credential_provider=StreamPipesApiKeyCredentials( username=\"admin@streampipes.apache.org\", api_key=\"TOKEN\", ), host_address=\"localhost\", https_disabled=True, port=80 ) client = StreamPipesClient(client_config=config)
2024-03-26 10:21:38,538 - streampipes.client.client - [INFO] - [client.py:198] [_set_up_logging] - Logging successfully initialized with logging level INFO.\n2024-03-26 10:21:38,632 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.\n2024-03-26 10:21:38,634 - streampipes.client.client - [INFO] - [client.py:171] [_get_server_version] - The StreamPipes version was successfully retrieved from the backend: 0.95.0. By means of that, authentication via the provided credentials is also tested successfully.\n
The main objective of this tutorial is to demonstrate how to make predictions with an existing and pre-trained ML model using a StreamPipes function and ONNX. Therefore, you can skip the following sections on use case and model training if you already have an existing ONNX model and are only interested in applying it using StreamPipes.
from sklearn.ensemble import IsolationForest\n\nmodel = IsolationForest(contamination=0.01)\nmodel.fit(X)\n
from sklearn.ensemble import IsolationForest model = IsolationForest(contamination=0.01) model.fit(X) Out[14]:
IsolationForest(contamination=0.01)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.\u00a0\u00a0IsolationForest?Documentation for IsolationForestiFitted
IsolationForest(contamination=0.01)
The contamination parameter models the proportion of outliers in the data. See the scikit-learn documentation for more information.
Before we convert the model to an ONNX representation, let's do a quick visual analysis of the model results:
Let's dive a little deeper into the different parts of the function
__init__: First, we need to take care about the data stream that is required to send the predictions from our function to StreamPipes. Thus, we create a dedicated output data stream which we need to provide with the attributes our event will consist of (a timestamp attribute is always added automatically). This output data stream needs to be registered at the function definition which is to be passed to the parent class. Lastly, we need to define some instance variables that are mainly required for the ONNX runtime.
onServiceStarted: Here we prepare the ONNX runtime session by creating an InferenceSession and retrieving the corresponding configuration parameters.
onEvent: Following the parameter names specified by self.feature_names, we extract all feature values from the current event. Subsequently, the corresponding feature vector is transmitted to the ONNX runtime session. The resulting prediction is then converted into our output event, where a value of -1 signifies an anomaly. Finally, the generated output event is forwarded to StreamPipes.
Having the function code in place, we can start the function with the following:
In\u00a0[25]: Copied!
from streampipes.functions.registration import Registration\nfrom streampipes.functions.function_handler import FunctionHandler\n\nstream = [\n stream\n for stream\n in client.dataStreamApi.all()\n if stream.name == \"flow-rate\"\n][0]\n\nfunction = ONNXFunction(\n feature_names=[\"volume_flow\"],\n input_stream=stream\n)\n\nregistration = Registration()\nregistration.register(function)\nfunction_handler = FunctionHandler(registration, client)\nfunction_handler.initializeFunctions()\n
from streampipes.functions.registration import Registration from streampipes.functions.function_handler import FunctionHandler stream = [ stream for stream in client.dataStreamApi.all() if stream.name == \"flow-rate\" ][0] function = ONNXFunction( feature_names=[\"volume_flow\"], input_stream=stream ) registration = Registration() registration.register(function) function_handler = FunctionHandler(registration, client) function_handler.initializeFunctions()
2024-03-26 12:39:50,443 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.\n2024-03-26 12:39:50,502 - streampipes.functions.function_handler - [INFO] - [function_handler.py:76] [initializeFunctions] - The data stream could not be created.\n2024-03-26 12:39:50,503 - streampipes.functions.function_handler - [INFO] - [function_handler.py:78] [initializeFunctions] - This is due to the fact that this data stream already exists. Continuing with the existing data stream.\n2024-03-26 12:39:50,503 - streampipes.functions.function_handler - [INFO] - [function_handler.py:84] [initializeFunctions] - Using output data stream 'sp:spdatastream:flowrate-prediction' for function '7c06fa31-9534-4f91-9c50-b7a3607ec3dc'\n2024-03-26 12:39:50,548 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.\n2024-03-26 12:39:50,549 - streampipes.functions.function_handler - [INFO] - [function_handler.py:100] [initializeFunctions] - Using KafkaConsumer for ONNXFunction\n
We can now access the live values of the prediction in the StreamPipes UI, e.g., in the pipeline editor.
That's already it. We hope this tutorial serves as an illustration how ML models can be utilized in StreamPipes with the help of ONNX.
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
"},{"location":"tutorials/5-applying-interoperable-machine-learning-in-streampipes/#Applying-Interoperable-Machine-Learning-in-StreamPipes","title":"Applying Interoperable Machine Learning in StreamPipes\u00b6","text":"
The last tutorial (Using Online Machine Learning on a StreamPipes data stream) demonstrated how patterns in streaming data can be learned online. In contrast, this tutorial demonstrates how one can apply a pre-trained machine learning (ML) model to a StreamPipes data stream making use of ONNX. We will show how StreamPipes can be used for both: extracting historical data for training purposes and using model inference on live data with a pre-trained model.
The following lines configure the client and establish a connection to the StreamPipes instance. If you're not familiar with it or anything is unclear, please have a look at our first tutorial.
"},{"location":"tutorials/5-applying-interoperable-machine-learning-in-streampipes/#Machine-Learning-Use-Case","title":"Machine Learning Use Case\u00b6","text":"
In this tutorial, we will use data generated by the Machine Data Simulator adapter. More specifically, we will focus on the flowrate data, which consists of various sensor values coming from a water pipe system. Our goal is keep an eye on the parameter volume_flow, which represents the current volume flow in cubic meters/second. For this parameter, we want to detect anomalies that could indicate problems such as leaks, blockages, etc.
To get the concerned data, we simply need to create an instance of the machine data simulator and persist the data in the data lake:
If you choose to perform the model training step yourself, you will need to wait approximately 15 minutes for enough data to be available for model training. If you want to speed this up, you can configure a lower wait time when creating the adapter. Please be aware that this also influences the inference scenario.
"},{"location":"tutorials/5-applying-interoperable-machine-learning-in-streampipes/#Model-Training-with-Historic-Data","title":"Model Training with Historic Data\u00b6","text":"
As said above, the aim of our model is to detect anomalies of the volume_flow parameter. For this task, we will use Isolation Forests. Please note that the focus of the tutorial is not on training the model, so please be patient even though the training is very simplified and lacks important preparation steps such as standardization.
As a first step, lets query the flowrate data from the StreamPipes data lake and extract the values of volume_flow as a feature:
"},{"location":"tutorials/5-applying-interoperable-machine-learning-in-streampipes/#Model-Inference-with-Live-Data","title":"Model Inference with Live Data\u00b6","text":"
Utilizing a pre-trained model within StreamPipes becomes seamless with the ONNX interoperability standard, enabling effortless application of your existing model on live data streams.
Interacting with live data from StreamPipes is facilitated through StreamPipes functions. Below, we'll create a Python StreamPipes function that leverages an ONNX model to generate predictions for each incoming event, making the results accessible as a data stream within StreamPipes for subsequent steps.
So let's create an ONNXFunction that is capable of applying a model in ONNX representation to a StreamPipes data stream. If you'd like to read more details about how functions are defined, refer to our third tutorial.
Want to see more exciting use cases you can achieve with StreamPipes functions in Python? Then don’t hesitate and jump to our next tutorial on using interoperable machine learning algorithm models with StreamPipes Python and ONNX.
+
+
+
+
+
+
+
+
+
+
How do you like this tutorial?
We hope you like it and would love to receive some feedback from you.
Just go to our GitHub discussion page and let us know your impression.
diff --git a/docs-python/dev/tutorials/5-applying-interoperable-machine-learning-in-streampipes/index.html b/docs-python/dev/tutorials/5-applying-interoperable-machine-learning-in-streampipes/index.html
new file mode 100644
index 000000000..56185f7b4
--- /dev/null
+++ b/docs-python/dev/tutorials/5-applying-interoperable-machine-learning-in-streampipes/index.html
@@ -0,0 +1,4495 @@
+
+
+
+
+
+
+
Applying Interoperable Machine Learning in StreamPipes¶
The last tutorial (Using Online Machine Learning on a StreamPipes data stream) demonstrated how patterns in streaming data can be learned online. In contrast, this tutorial demonstrates how one can apply a pre-trained machine learning (ML) model to a StreamPipes data stream making use of ONNX. We will show how StreamPipes can be used for both: extracting historical data for training purposes and using model inference on live data with a pre-trained model.
The following lines configure the client and establish a connection to the StreamPipes instance. If you're not familiar with it or anything is unclear, please have a look at our first tutorial.
2024-03-26 10:21:38,538 - streampipes.client.client - [INFO] - [client.py:198] [_set_up_logging] - Logging successfully initialized with logging level INFO.
+2024-03-26 10:21:38,632 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.
+2024-03-26 10:21:38,634 - streampipes.client.client - [INFO] - [client.py:171] [_get_server_version] - The StreamPipes version was successfully retrieved from the backend: 0.95.0. By means of that, authentication via the provided credentials is also tested successfully.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
The main objective of this tutorial is to demonstrate how to make predictions with an existing and pre-trained ML model using a StreamPipes function and ONNX. Therefore, you can skip the following sections on use case and model training if you already have an existing ONNX model and are only interested in applying it using StreamPipes.
In this tutorial, we will use data generated by the Machine Data Simulator adapter. More specifically, we will focus on the flowrate data, which consists of various sensor values coming from a water pipe system. Our goal is keep an eye on the parameter volume_flow, which represents the current volume flow in cubic meters/second. For this parameter, we want to detect anomalies that could indicate problems such as leaks, blockages, etc.
+
To get the concerned data, we simply need to create an instance of the machine data simulator and persist the data in the data lake:
+
+
+
+
If you choose to perform the model training step yourself, you will need to wait approximately 15 minutes for enough data to be available for model training. If you want to speed this up, you can configure a lower wait time when creating the adapter. Please be aware that this also influences the inference scenario.
As said above, the aim of our model is to detect anomalies of the volume_flow parameter. For this task, we will use Isolation Forests.
+Please note that the focus of the tutorial is not on training the model, so please be patient even though the training is very simplified and lacks important preparation steps such as standardization.
+
As a first step, lets query the flowrate data from the StreamPipes data lake and extract the values of volume_flow as a feature:
from sklearn.ensemble import IsolationForest
+
+model = IsolationForest(contamination=0.01)
+model.fit(X)
+
+
+
+
+
+
+
+
+
+
Out[14]:
+
+
IsolationForest(contamination=0.01)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
IsolationForest(contamination=0.01)
+
+
+
+
+
+
+
+
+
+
+
+
+
The contamination parameter models the proportion of outliers in the data. See the scikit-learn documentation for more information.
+
+
+
+
+
+
+
+
+
+
+
Before we convert the model to an ONNX representation, let's do a quick visual analysis of the model results:
Utilizing a pre-trained model within StreamPipes becomes seamless with the ONNX interoperability standard, enabling effortless application of your existing model on live data streams.
+
Interacting with live data from StreamPipes is facilitated through StreamPipes functions. Below, we'll create a Python StreamPipes function that leverages an ONNX model to generate predictions for each incoming event, making the results accessible as a data stream within StreamPipes for subsequent steps.
+
So let's create an ONNXFunction that is capable of applying a model in ONNX representation to a StreamPipes data stream. If you'd like to read more details about how functions are defined, refer to our third tutorial.
Let's dive a little deeper into the different parts of the function
+
+
__init__: First, we need to take care about the data stream that is required to send the predictions from our function to StreamPipes. Thus, we create a dedicated output data stream which we need to provide with the attributes our event will consist of (a timestamp attribute is always added automatically). This output data stream needs to be registered at the function definition which is to be passed to the parent class. Lastly, we need to define some instance variables that are mainly required for the ONNX runtime.
+
+
onServiceStarted: Here we prepare the ONNX runtime session by creating an InferenceSession and retrieving the corresponding configuration parameters.
+
+
onEvent: Following the parameter names specified by self.feature_names, we extract all feature values from the current event. Subsequently, the corresponding feature vector is transmitted to the ONNX runtime session. The resulting prediction is then converted into our output event, where a value of -1 signifies an anomaly. Finally, the generated output event is forwarded to StreamPipes.
+
+
+
Having the function code in place, we can start the function with the following:
2024-03-26 12:39:50,443 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.
+2024-03-26 12:39:50,502 - streampipes.functions.function_handler - [INFO] - [function_handler.py:76] [initializeFunctions] - The data stream could not be created.
+2024-03-26 12:39:50,503 - streampipes.functions.function_handler - [INFO] - [function_handler.py:78] [initializeFunctions] - This is due to the fact that this data stream already exists. Continuing with the existing data stream.
+2024-03-26 12:39:50,503 - streampipes.functions.function_handler - [INFO] - [function_handler.py:84] [initializeFunctions] - Using output data stream 'sp:spdatastream:flowrate-prediction' for function '7c06fa31-9534-4f91-9c50-b7a3607ec3dc'
+2024-03-26 12:39:50,548 - streampipes.endpoint.endpoint - [INFO] - [endpoint.py:164] [_make_request] - Successfully retrieved all resources.
+2024-03-26 12:39:50,549 - streampipes.functions.function_handler - [INFO] - [function_handler.py:100] [initializeFunctions] - Using KafkaConsumer for ONNXFunction
+
+
+
+
+
+
+
+
+
+
+
+
+
+
We can now access the live values of the prediction in the StreamPipes UI, e.g., in the pipeline editor.
+
+
+
+
+
+
+
+
+
+
+
+
+
That's already it. We hope this tutorial serves as an illustration how ML models can be utilized in StreamPipes with the help of ONNX.
+
+
+
+
+
+
+
+
+
+
+
How do you like this tutorial? We hope you like it and would love to receive some feedback from you. Just go to our GitHub discussion page and let us know your impression. We'll read and react to them all, we promise!
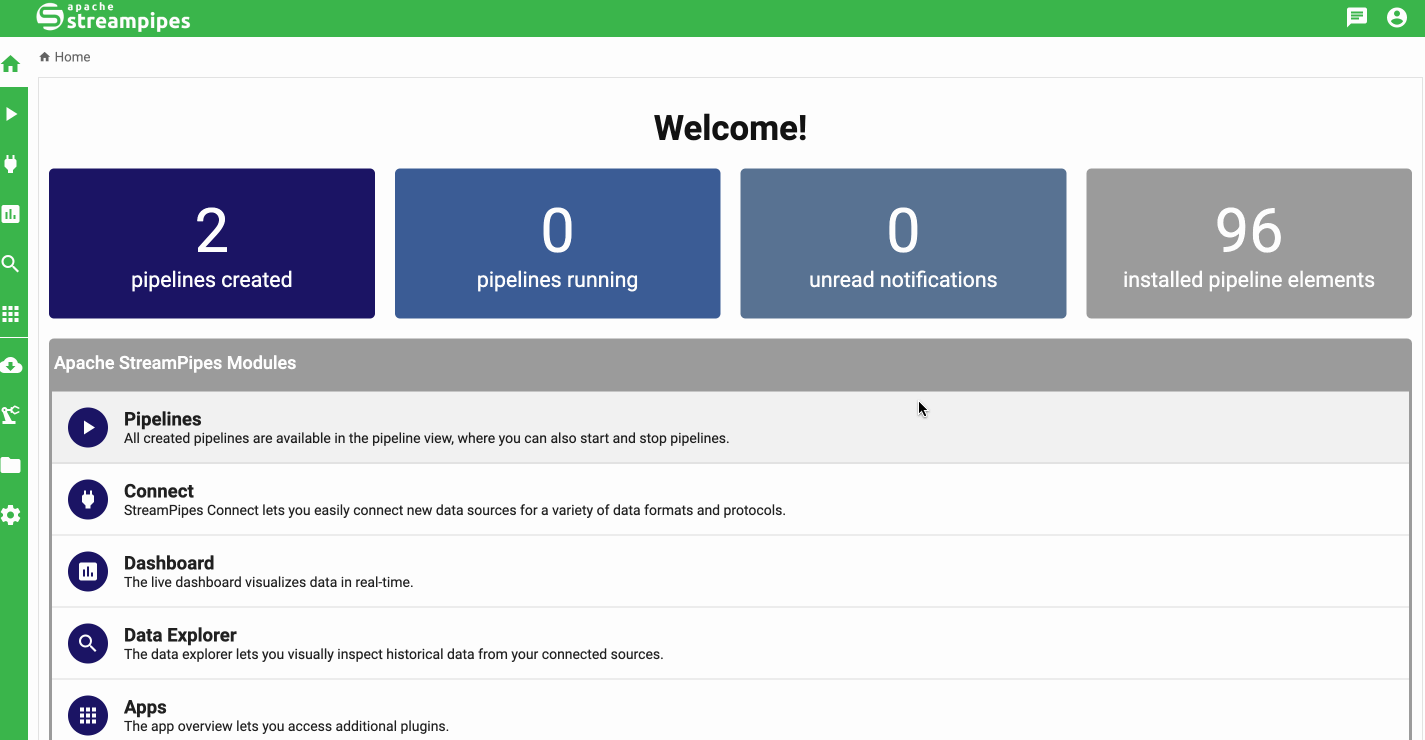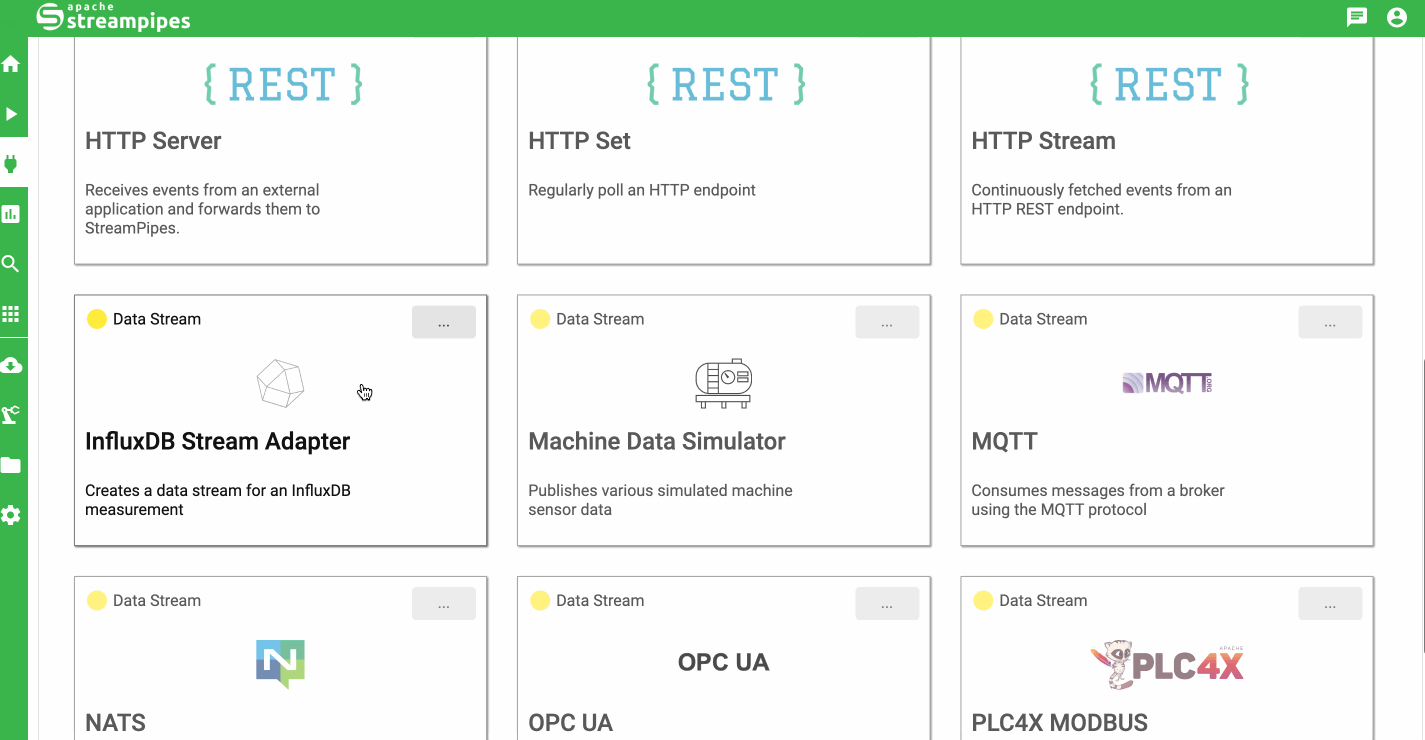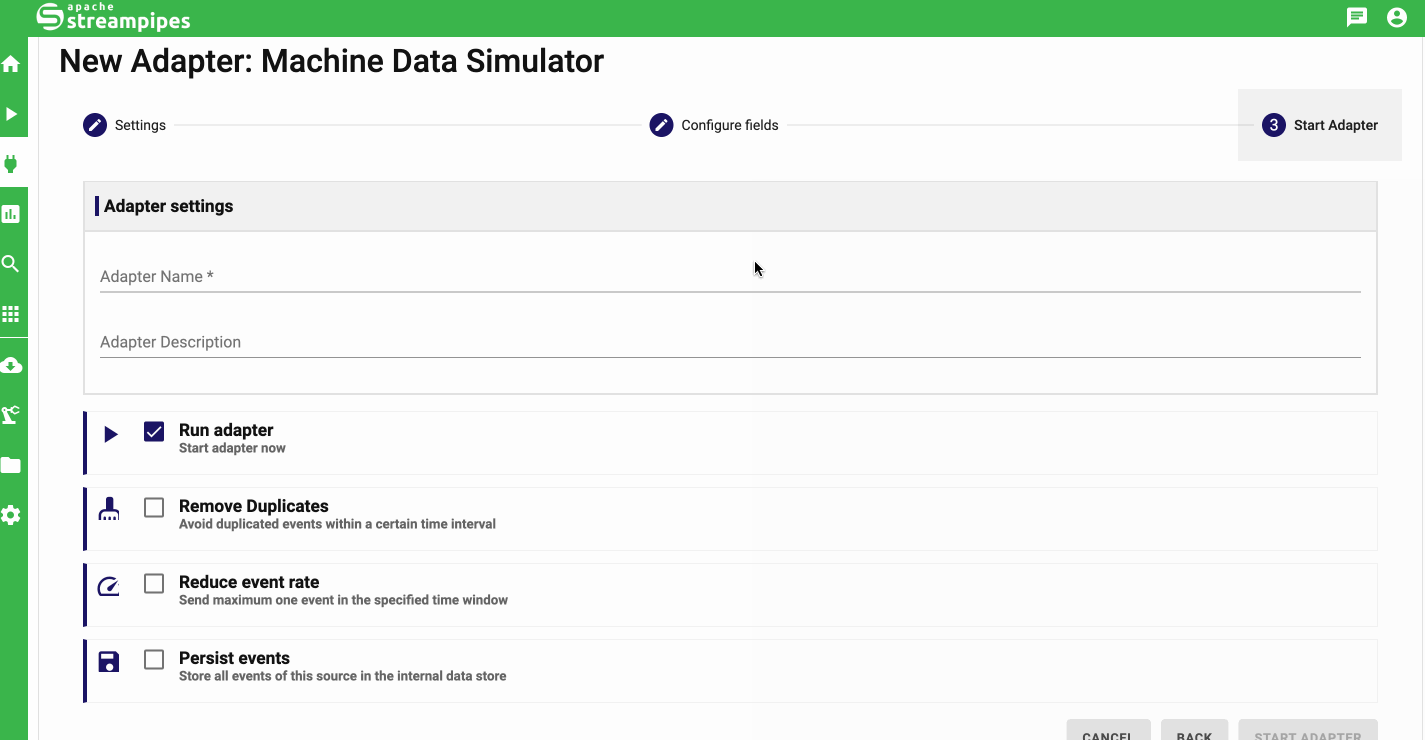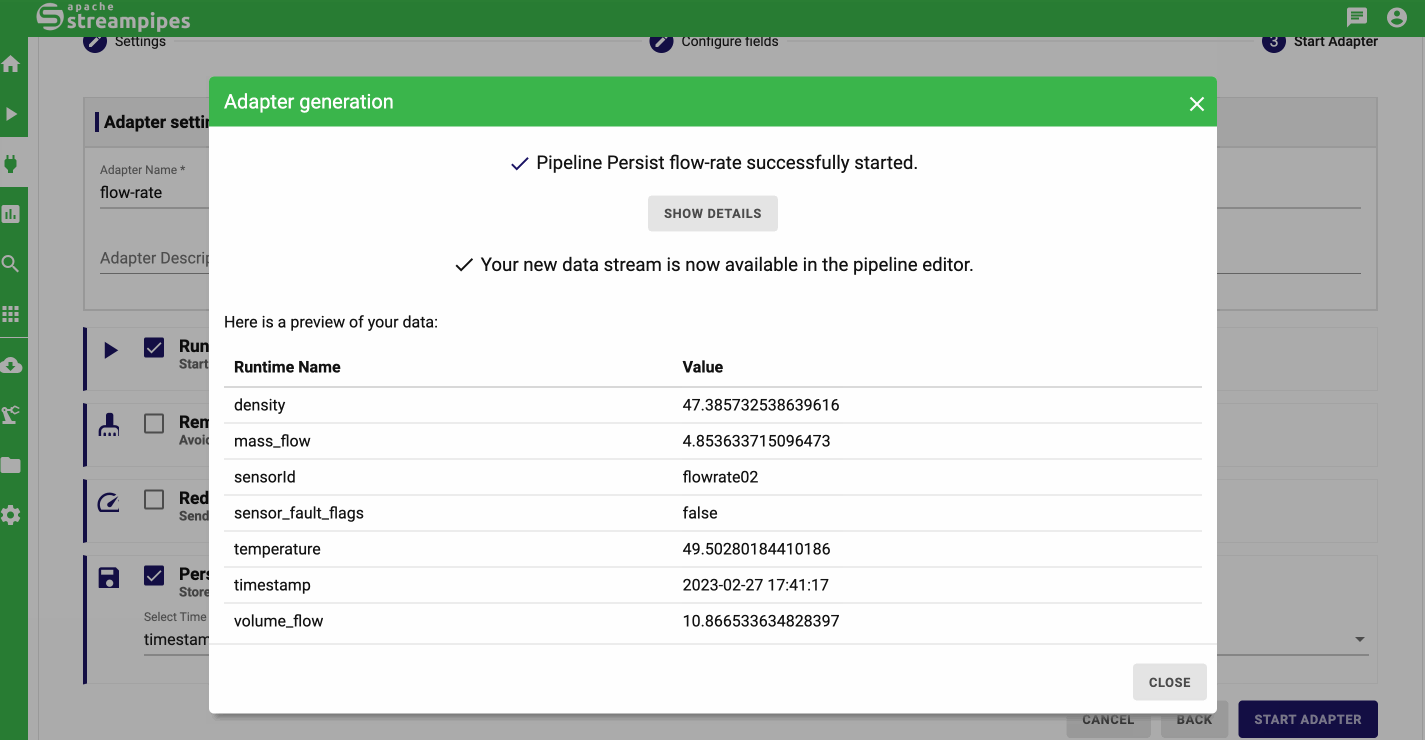
 +
+