I would also like to see this misalignment happen naturally
=> @sjenning, I think it can happen under the below scenarios, it's a kind of resource exhausting case.
- Container requests 2 exclusive CPUs , 5GB Memory and 3x 1GB-Hugepages.
- deploy multiple sets of above container.
[Idle State Case]
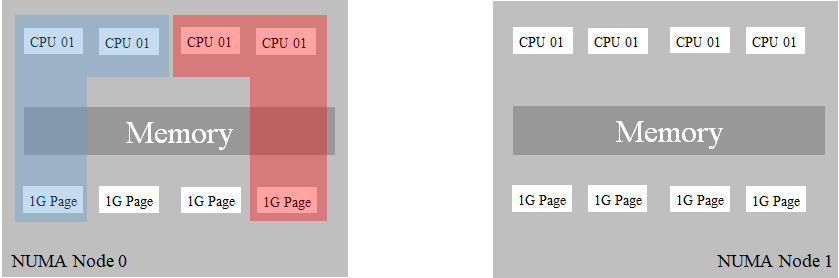 When containers are idle state, containers may consume one or two hugepages.
In this case, there is no problem, there is no remote access to memory.
If containers always consume the maximum size of hugepages, this case will not happen.
When containers are idle state, containers may consume one or two hugepages.
In this case, there is no problem, there is no remote access to memory.
If containers always consume the maximum size of hugepages, this case will not happen.
(Kernel allocates hugepages when a process allocates memory over mmap.
If the process allocates less size of 1GB memory, kernel will allocate one hugepage.
If process allocates 1.5GB memory, kernel will allocate two hugepages to process)
[Busy State Case]
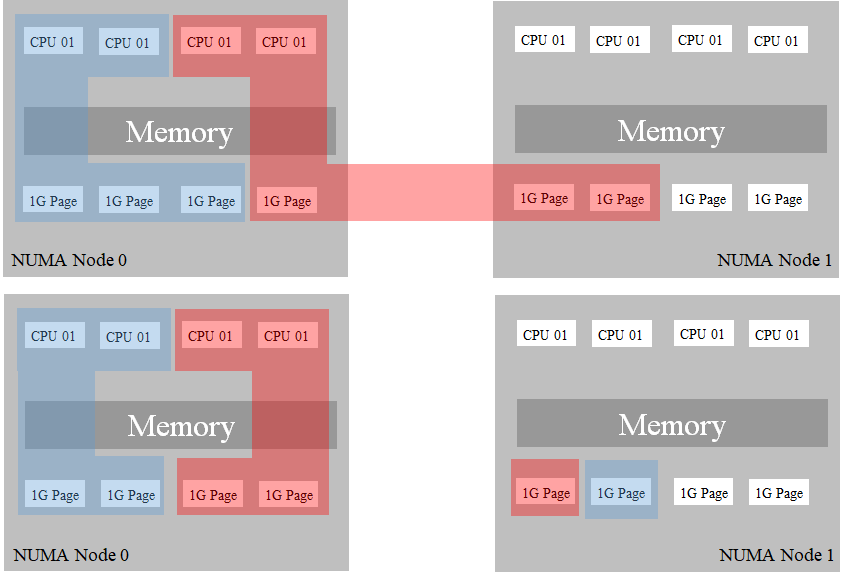 When the container is a busy state, the container may consume a maximum quantity of hugepages.
When the container is a busy state, the container may consume a maximum quantity of hugepages.
Here, it's three of 1GB-Hugepages.
In this case, if there are no extra hugepages on the local numa node, the container will consume hugepages on another NUMA node.
- Container Blue requests 2 exclusive CPUs, 95GB Memory and 3x 1GB-Hugepages.
- Container Red requests 2 exclusive CPUs, 5GB Memory and 3x 1GB-Hugepages.
[Idle State Case]
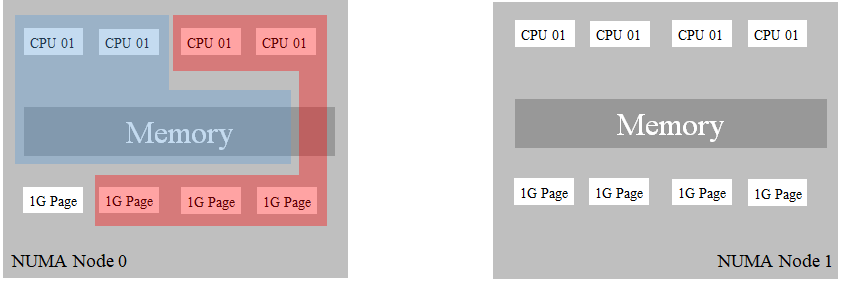
In this scenario, container blue can be such kind of In-Memory Database(redis).
Or it can be multiple containers that sharing CPUs.
When a container red is an idle state, there will be no remote access to memory.
[Busy State Case]
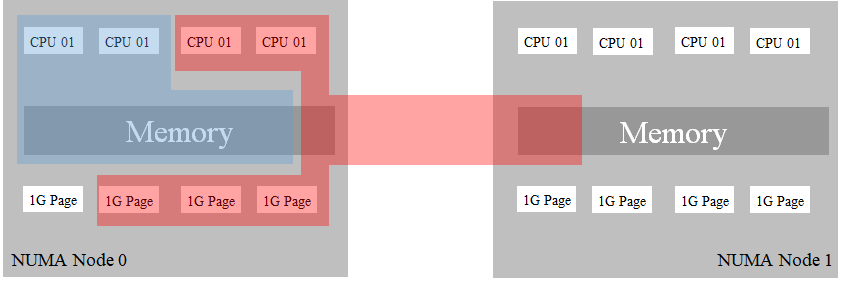
But when the container red is a busy state, there will be remote access to memory.
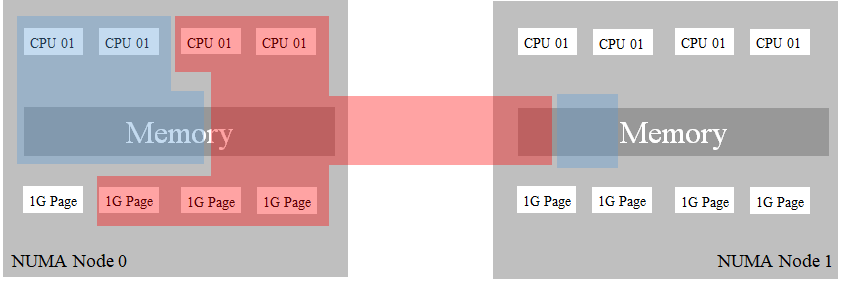 Maybe, this worst-case can happen, this case will reduce the performance of both containers.
Maybe, this worst-case can happen, this case will reduce the performance of both containers.
Maybe you guys would say that the above scenarios are not a normal case or it's just a corner case. But I want to say that it can happen because cgroup sets only limits of memory regardless of the memory capacity of NUMA node.
The point is kubelet does not consider the memory capacity of NUMA node.
Topology Manager, CPU Manager and Device Manager (will) does it for CPU and devices(such as NIC and GPU), but there is no consideration of Memory(including Hugepages) at all.
As @sjenning mentioned above, it seems that numa_balancing can cover most general cases(like idle state in scenarios).
But it cannot guarantee local access of memory for a container.
Without guaranteeing local access of memory, we cannot guarantee the performance of DPDK containers.
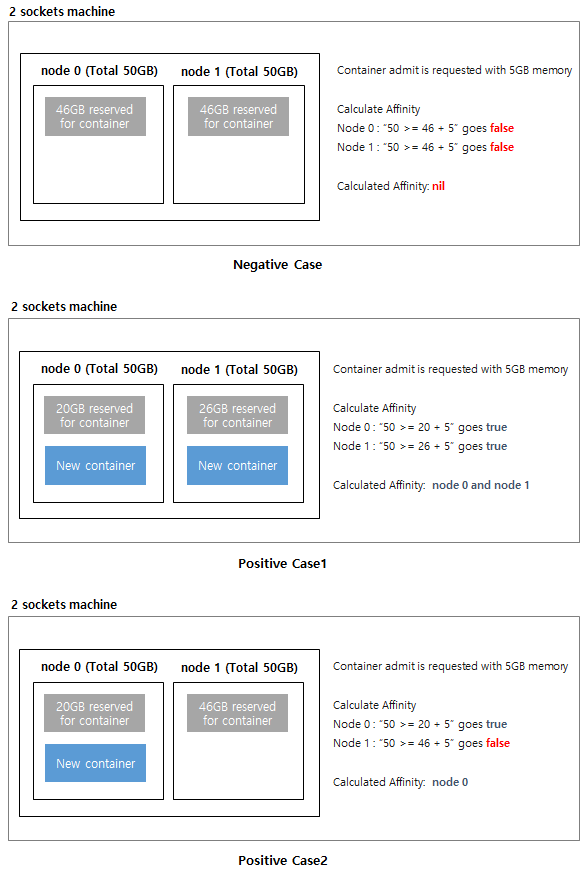
To guarantee local access to memory, kubelet should schedule a container to a NUMA node based on the container's memory request.
Then enforce container to consume memory on a NUMA node using a cupset.mems.
The below image shows the concept of scheduling.
Otherwise, Openstack which is used to run VNF(DPDK) fully guarantee it, through hw:numa_memproperty, see here and here.
Moreover, OpenStack also supports that VM takes a certain amount of memory from multiple NUMA nodes, see table 3.2 here.
It seems that the Libvirt driver supports it, but I'm not sure, I was just one of the users of Openstack.
Example
Example when the instance has 8 vCPUs and 4GB RAM:
hw:numa_nodes=2
hw:numa_cpus.0=0,1,2,3,4,5
hw:numa_cpus.1=6,7
hw:numa_mem.0=3 //Mapping 3 GB of RAM to NUMA node 0
hw:numa_mem.1=1 //Mapping 1 GB of RAM to NUMA node 1.