| isOriginal | category | tag | |
|---|---|---|---|
true |
云原生 |
|
集群内网络架构为,基于Calico BGP 的路由模式,直接与交互机建联。
影响范围
线下环境 node-xx 物理机上 Pod 网络不可用
影响时间线(2023-07-23 22:09 ~ 22:14)
[22:13] 收到网工反馈 Peer Down

[22:14] Calico 故障自愈(自动重启)
1)查看 calico 事件信息:kubectl -n kube-system describe pod calico-node-xx

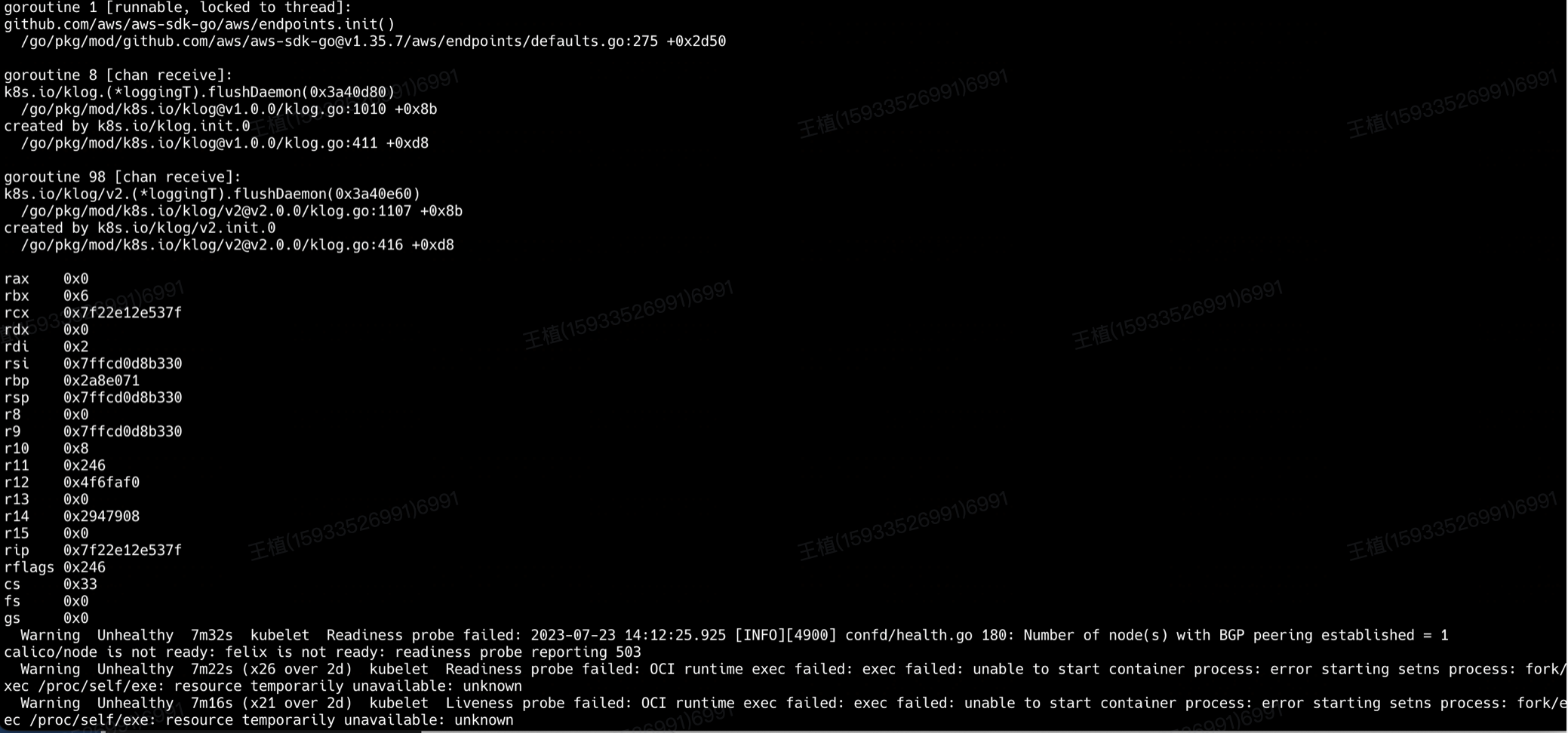

ok , 从上面事件日志可得找到以下关键信息:
Readiness probe failed、Liveness probe failed 就绪探针、存活探针 探测失败 → 查看探测方式,是使用 exec 进行探测(fork 新命令方式)→ 具体错误信息 Resource temporarily unavailable
2)查看 kubelet 系统日志 journalctl -u kubelet.service --since "2023-07-23 22:00:00"
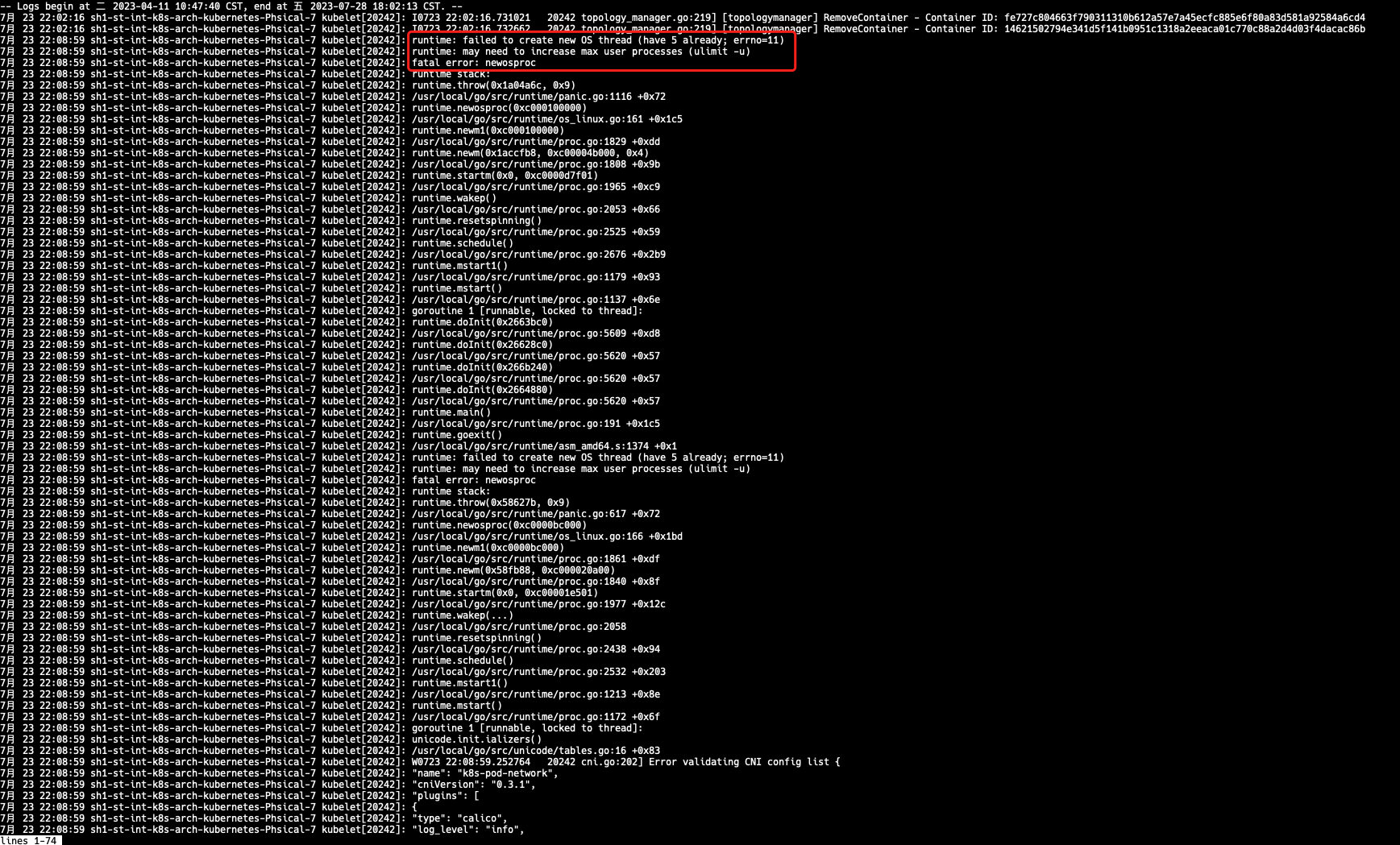
从上面日志可以得到以下关键信息: runtime: failed to create new OS thread (have 5 already; errno=11) runtime: may need to increase max user processes (ulimit -u) fatal error: newosproc
3)查看 Node-exporter 监控大盘,Processes 相关监控
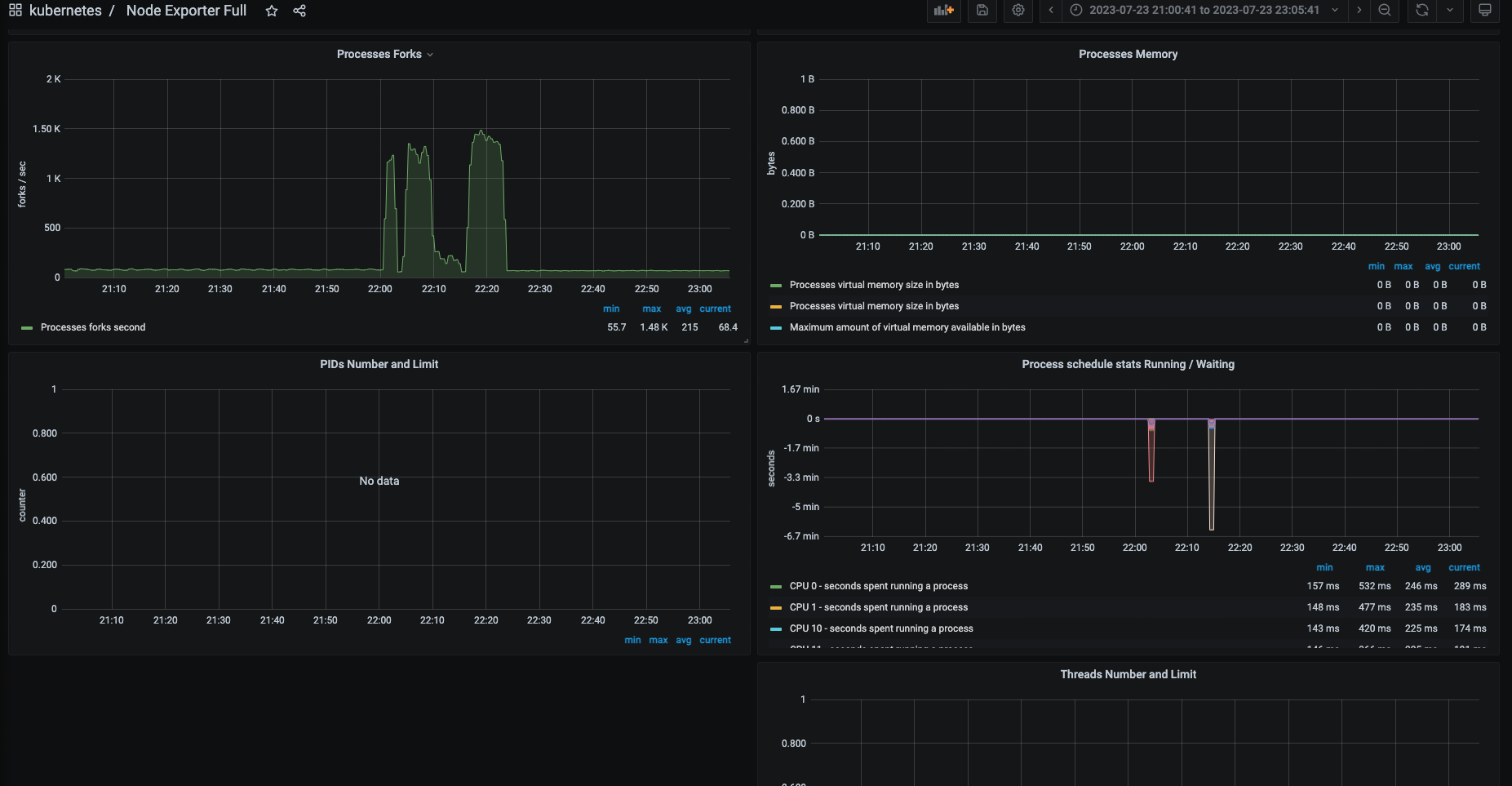
从监控大盘可以分析出来:
从22点开始出现了大量的 Processes Forks, 没收集到 PIDs Number 和 Threads Number
4)有没有可能是 PID 跑满了,由于没有收集到 PIDs Number 和 Threads Number,所以换个思路,看看容器 cadvisor 是否有收集 Processes 相关信息,是不是容器捣的鬼,使用 promql 查询 node-xx 容器线程趋势 sum(container_threads{node="node-xx"})
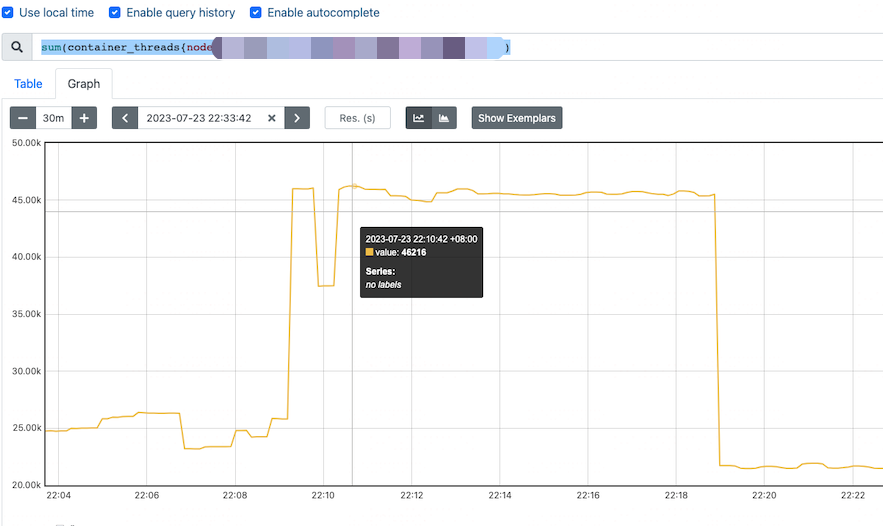
查询到 22点多 容器总线程量达到 46k
总结一下,上述现象的有用信息
- calico-node 使用 exec 进行监控探测,探测失败,Resource temporarily unavailable
- kubelet 无法初始化线程,需要增加所处运行用户的进程限制,大致意思就是需要调整ulimit -u
- 22 点有大量的 process forks,node-xx 容器总线程 突增到 46k,无法确定当时宿主机的总线程数,可以通过 如下命令实时计算
ps -eLf | wc -l
继续分析,登录服务查看 ulimit -u 的限制数 204k ,46k 比 204k 还差得远
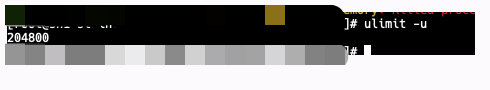
因为ulimit是针对于每用户而言的,具体还要验证每个用户的limit的配置,如下
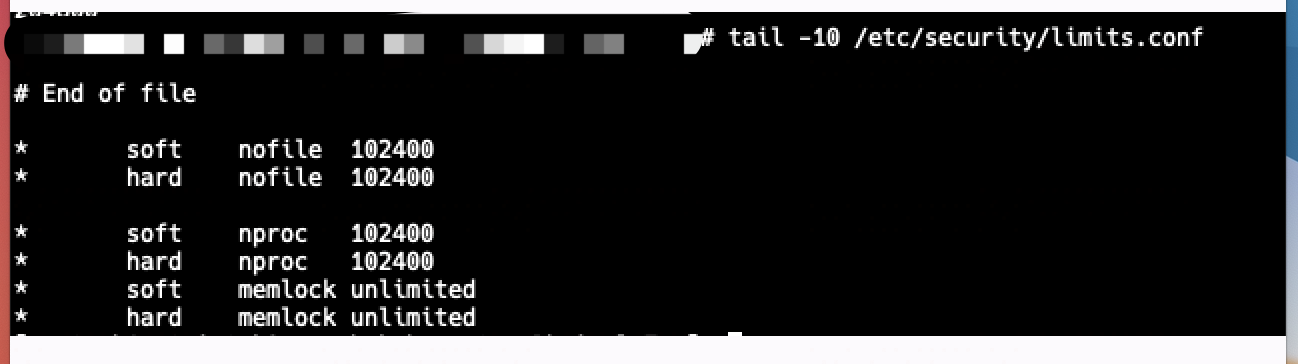
根据以下配置判断,并没有超出设定的范围,最后的取值是会取 /etc/security/limits.d/20-nofile.conf 里面的值(优先级高) ,还是 204k

-→ 继续找 Google Resource temporarily unavailable 错误,翻阅linux内核文档,搜索PID相关字段,其中找到如下相关的PID参数 kernel.pid_max
https://www.kernel.org/doc/html/latest/admin-guide/sysctl/kernel.html#pid-max
参数大致意思是,kernel允许当前系统分配的最大PID identify,如果kernel 在fork时hit到这个值时,kernel会wrap back到内核定义的minimum PID identify,意思就是不能分配大于该参数设定的值+1,该参数边界范围是全局的,属于系统全局边界
同理,还有threads-max 参数
OK,安排,确认当前的 PID 限制,检查全局 PID 最大限制: cat /proc/sys/kernel/pid_max 49k,没错,应该就是它了,49k = 46k(容器总线程) + 非容器线程数
也检查下线程数限制:cat /proc/sys/kernel/threads-max 1545k


结论:全局 PID(/proc/sys/kernel/pid_max ) 达到上限,导入 calico 无法 fork 进程,进而监控检查失败,存活探针自动重启
等等,还没完,到底是谁把 PID 耗尽了呢,还要找出真凶,容器总线程 突增,说明是某个容器造成的,安排promql 查,container_threads{node="node-xx"}
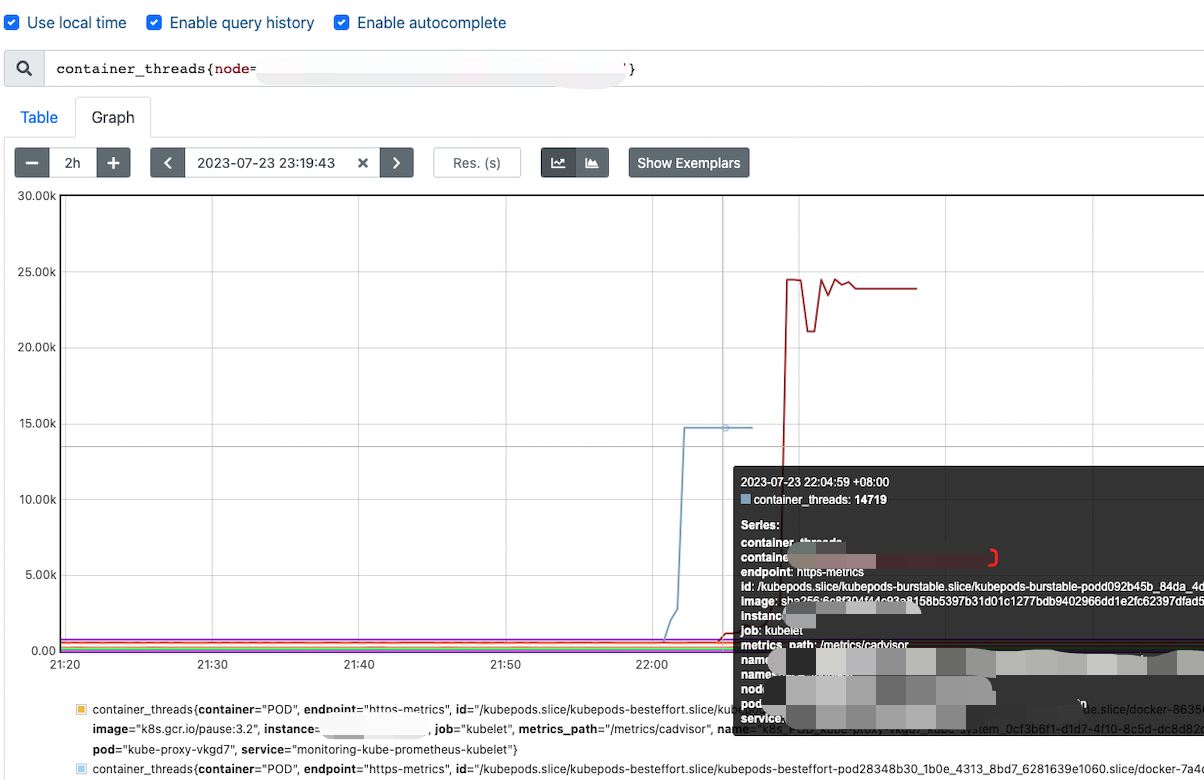
至此,结案了,联系开发改代码,有线程泄露。
1)导致问题的直接原因是什么?
Xxx 应用线程泄露,导致全局 PID 耗尽,进而导致 calico 监控检查失败,自动重启。
2)K8s Pod 中没有限制 PID 数吗?
默认 K8s Pod 是不对 PID 数进行限制的。

3)为何排查问题耗时较长?
未收集物理机 Processes 的相关监控指标,也未设置 PID 使用百分比触发器
4)全局PID限制,为何比用户PID限制要小?
参数设置不合理,未进行调优
1)调整 pid_max 参数
2)开启 Node-exporter Process 监控并补全告警
node-exporter 启动参数中新增 --collector.processes,并添加告警规则 (node_processes_threads / on(instance) min by(instance) (node_processes_max_processes or node_processes_max_threads) > 0.8)
3)评估业务是否需要开始 Pod PID 限制:https://kubernetes.io/zh-cn/docs/concepts/policy/pid-limiting/
我是 Clay,下期见 👋
欢迎订阅我的公众号「SRE运维进阶之路」或关注我的 Github https://github.com/clay-wangzhi/wiki 查看最新文章
欢迎加我微信
sre-k8s-ai,与我讨论云原生、稳定性相关内容
