本项目展示如何使用LlamaIndex使用基于向量搜索的方式搭建一个中国历史知识的RAG(检索增强生成系统)系统,这种系统可以根据询问来从历史语料库中检索到相关的历史资料片段,从而使模型给出更可靠的回答。有两种具体的构建方案,一种采用在本地搭建向量数据库的Milvus方案,一种是采用在云端进行索引构建的Zilliz Pipeline方案。
OpenAI token
Milvus==2.3.3
LlamaIndex==0.9.22
Docker
python3
| Command | Flag(s) | Description |
|---|---|---|
| build | 将目录或者文件进行索引构建,Milvus模式下为本地文件,Pipeline下为Url |
|
| build | -overwrite | 同上,但是进行覆盖构建,已有索引将被清空 |
| ask | 进入问答模式,输入quit退出该模式 |
|
| ask | -d | 同上,但是开启Debug模式,将返回出来搜索出来的语料信息 |
| quit | 退出当前状态 |
在开始之前,确保你有有效的OpenAI token。如果没有,请参考OpenAI的文档获取。并在环境变量中添加
export OPENAI_API_KEY=sk-xxxxxxxx你的tokenxxxxxxxxx启动向量数据库Milvus, 默认端口为19530
cd db
sudo docker compose up -dpip install -r requirements.txt利用文本语料库构建方便进行RAG的向量索引。执行交互程序cli.py,选择milvus模式,然后输入要构建的语料,build ./history24/会将该目录下所有文件进行索引构建,会消耗大量算力抽取向量,针对大规模语料库建议使用Pipeline方案。
python cli.py
milvus
build ./history24/baihuasanguozhi.txt输入ask进入提问模式。输入我们感兴趣的问题。
ask
'问题:关公刮骨疗毒是真的吗'在开始之前,确保你有有效的OpenAI token。如果没有,请参考OpenAI的文档获取。并在环境变量中添加
export OPENAI_API_KEY=sk-xxxxxxxx你的tokenxxxxxxxxx注册Zilliz Cloud账号,获取相应的配置,这个方案可以利用云端的算力进行大量文档的处理。更加详细的用例在这里。
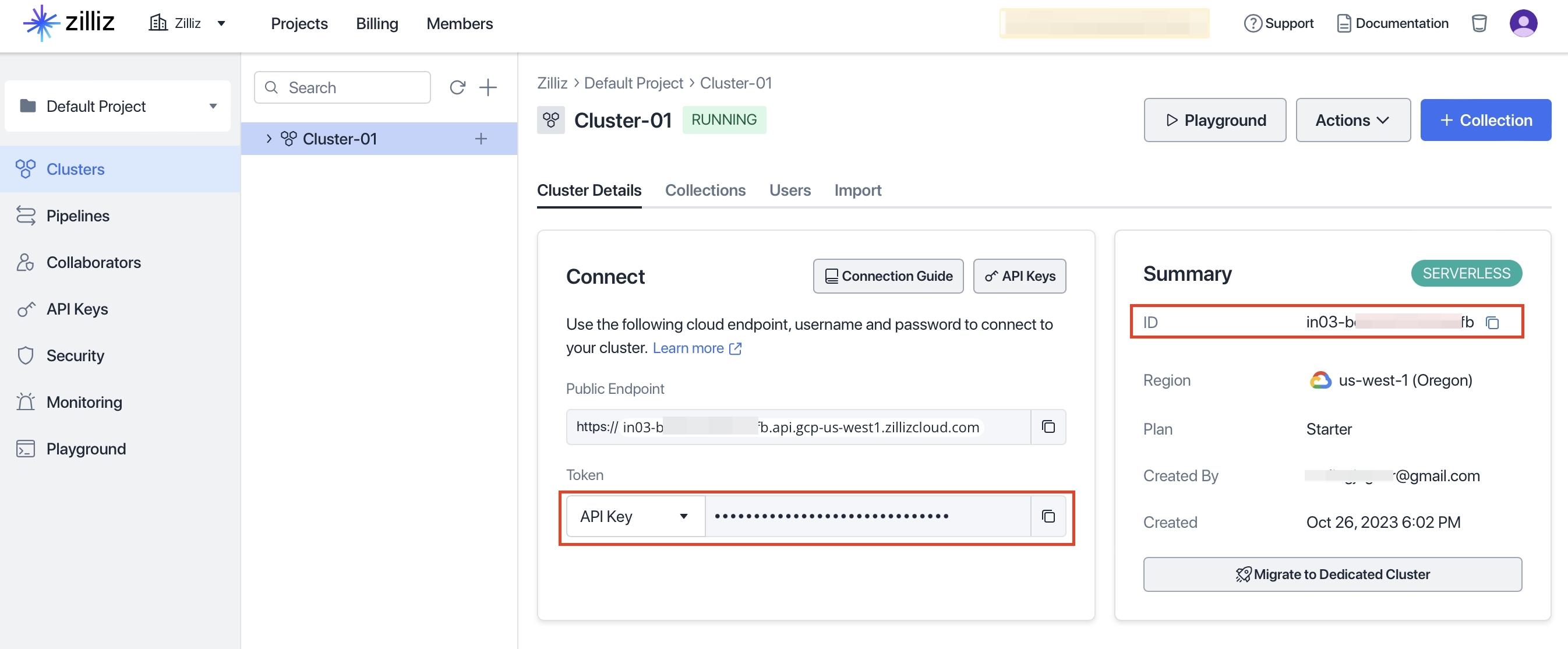 同样在环境变量中添加
同样在环境变量中添加
export ZILLIZ_TOKEN=左边红框的信息
export ZILLIZ_CLUSTER_ID=右边红框的信息pip install -r requirements.txt利用文本语料库构建方便进行RAG的向量索引。执行交互程序cli.py,选择pipeline模式,然后输入要构建的语料,build https://github.com/wxywb/history_rag/tree/master/data/history_24/会将该目录下所有文件进行索引构建, Pipeline方案目前仅支持Url,不支持本地文件。
python cli.py
pipeline
build https://github.com/wxywb/history_rag/tree/master/data/history_24/baihuasanguozhi.txt 输入ask进入提问模式。输入我们感兴趣的问题。
ask
'问题:关公刮骨疗毒是真的吗'