` afterwards to install a package and\nsave it as a dependency in the package.json file.\n\nPress ^C at any time to quit.\npackage name: (weapp-utils)\nversion: (1.0.0)\ndescription: some foundmental utils for weapp\nentry point: (lib/index.js)\ntest command:\ngit repository:\nkeywords: weapp,utils\nauthor: tusi666\nlicense: (ISC) MIT\nAbout to write to D:\\robin\\lib\\weapp-utils\\package.json:\n\n{\n \"name\": \"weapp-utils\",\n \"version\": \"1.0.0\",\n \"description\": \"some foundmental utils for weapp\",\n \"main\": \"lib/index.js\",\n \"scripts\": {\n \"test\": \"echo \\\"Error: no test specified\\\" && exit 1\"\n },\n \"keywords\": [\n \"weapp\",\n \"utils\"\n ],\n \"author\": \"tusi666\",\n \"license\": \"MIT\"\n}\n```\n\n其中`main`字段是入口文件\n\n# 写好README\n\n一个完备的`README`文件是必要的,以便别人了解你的包是做什么用途。\n\n# 确认registry\n\n一般我们开发时会修改`npm registry`为`https://registry.npm.taobao.org`。\n\n但是发布`npm`包时,我们需要将其改回来,不然是会报错的。\n\n```shell\nnpm config set registry http://registry.npmjs.org/\n```\n\n# npm注册账号\n\n打开`npm`[官网](https://www.npmjs.com/),开始注册账号。\n\n**ps:**记得要验证邮箱哦!\n\n# 添加npm账户\n\n使用`npm adduser`添加账户,别名`npm login`\n\n```\nD:\\robin\\lib\\weapp-utils>npm adduser\nUsername: tusi666\nPassword:\nEmail: (this IS public) cumtrobin@163.com\nLogged in as tusi666 on https://registry.npm.taobao.org/.\n```\n\n# 添加github仓库\n\n在`package.json`添加配置项,不加也没事,看自己需求。\n\n```json\n\"repository\": {\n \"type\": \"git\",\n \"url\": \"https://github.com/xxx/zqh_test2.git\"\n}\n```\n\n# 发布\n\n```shell\nnpm publish\n```\n\n如果发布时报这样的错,\n\n```shell\nThe operation was rejected by your operating system.\nnpm ERR! It\'s possible that the file was already in use (by a text editor or antivirus),\nnpm ERR! or that you lack permissions to access it.\n```\n\n建议还是检查下`registry`,或者`npm adduser`是不是成功了。\n\n发布成功,会有这样的提示,\n\n```shell\nnpm notice\nnpm notice package: weapp-utils@1.0.0\nnpm notice === Tarball Contents ===\nnpm notice 397B package.json\nnpm notice 1.1kB LICENSE\nnpm notice 2.7kB README.md\nnpm notice 12.9kB lib/index.js\nnpm notice === Tarball Details ===\nnpm notice name: weapp-utils\nnpm notice version: 1.0.0\nnpm notice package size: 5.1 kB\nnpm notice unpacked size: 17.1 kB\nnpm notice shasum: a7f2f428d9334dd1dd749d2a492dbc4df7195d0d\nnpm notice integrity: sha512-Cp8jPhOMq73y6[...]bfofe7X+4cLeg==\nnpm notice total files: 4\nnpm notice\n+ weapp-utils@1.0.0\n```\n\n上`npm`搜索`weapp-utils`,发现有了!\n\n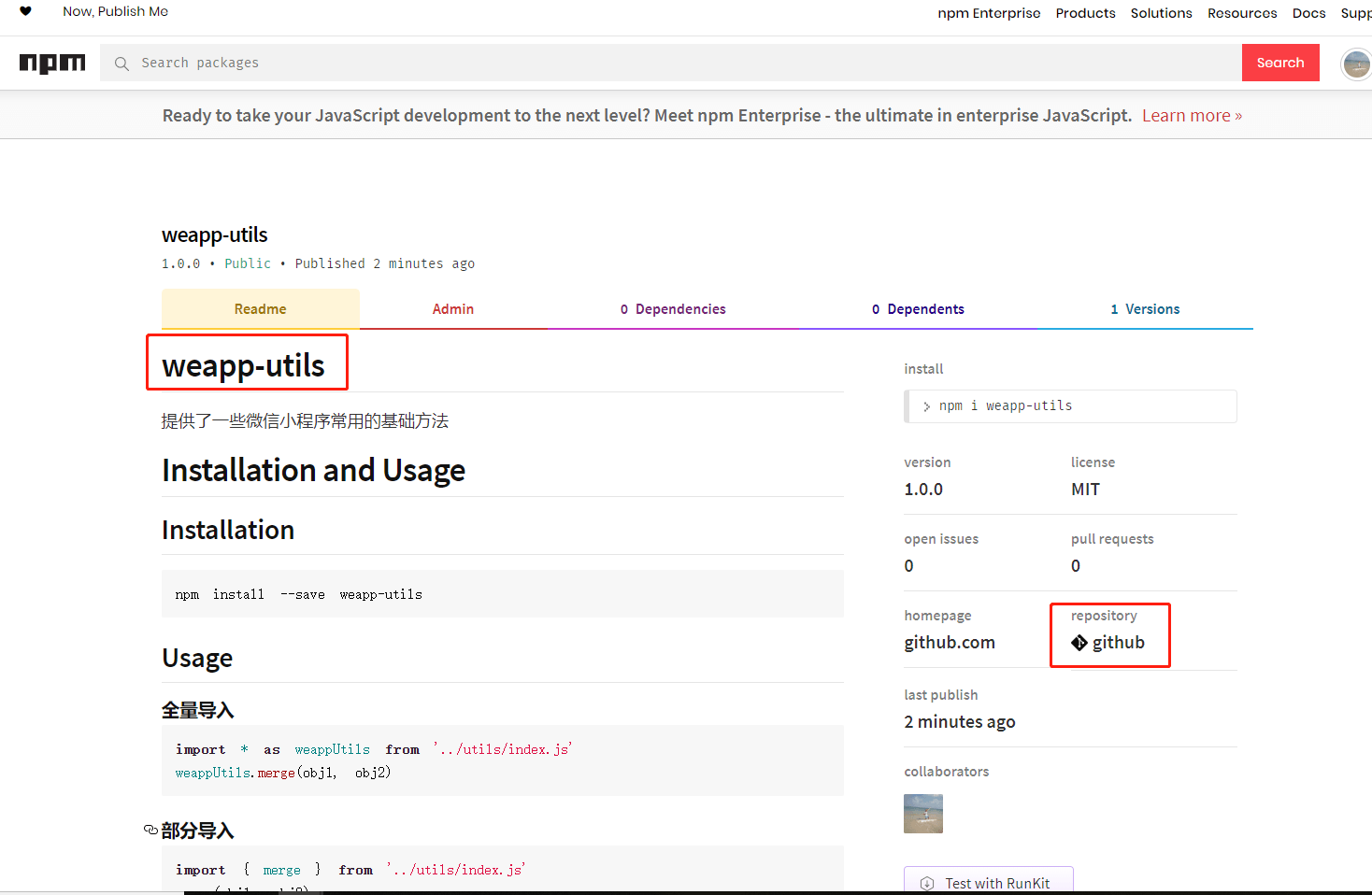\n\n# 调用\n\n发布成功了,也要验证下,是否可正常使用。\n\n```javascript\nimport { merge } from \"weapp-utils\"\n\nlet mergedOptions = merge(DEFAULT_OPTIONS, options)\n```', '2019-09-21 15:19:42', '2024-09-02 17:10:24', 1, 48, 0, '本文简单地记录了发布一个简单npm包的过程,以便后续参考使用。', 'https://qncdn.wbjiang.cn/npm%E9%80%9A%E7%94%A8.jpg', 0, 0);
-INSERT INTO `article` VALUES (188, '块级元素和行内元素', '最近给自己定了一个小目标,一周温习一个基础知识点,并输出一篇手记。看自己是否能坚持下去。^_^\n\n# 块级元素\n\n块级元素占据独立的空间,有以下特点:\n\n- 独占一行或多行\n- 宽度,高度,内外边距可以设置,且有效\n- 宽度默认是父容器的100%\n- 可以作为其他块级元素和行内元素的父容器(文本类块级元素不建议作为其他块级元素的容器,如`p, h1~h6`)\n\n\n\n常见的块级元素有:`div, h1~h6, hgroup, p, table, form, ul, ol, hr, header, main, footer, aside, article, section, video, audio, canvas, pre, option` \n\n# 行内元素\n\n行内元素不占据独立空间,依靠自身内容撑开宽高,与同属一个父容器的其他行内元素在同一行上依次排列,根据`white-space`属性值来决定是否换行。它们具备以下特征:\n\n- 不独占一行,但内容过长时会根据`white-space`控制换行。\n\n- 宽度,高度的设置是无效的。内外边距只能设置左右方向(设置`padding-top`, `padding-bottom`, `margin-top`, `margin-bottom`是无效的)。但是有一点要注意,`padding-top`和`padding-bottom`对自身有表现效果,但是不影响周围元素的布局,看图说话:\n\n \n\n- 宽度由自身内容决定。\n\n- 行内元素不建议作为块级元素的容器(`a`标签例外)\n\n常见的行内元素有:`span, i, code, strong, a, br, sub, sup, label ` \n\n对于不确定的元素,可以设置`width`来测试下,如果`width`不生效,说明是行内元素啦。\n\n# 行内块级元素\n\n行内块级元素也不会独占一行,但是可设置宽高,内外边距等。\n\n常见的行内块级元素有:`input, button, img, select, textarea `\n\n# CSS显示转换\n\n## display: block;\n\n让元素表现为块级元素\n\n## display: inline;\n\n让元素表现为行内元素\n\n## display: inline-block;\n\n让元素表现为行内块级元素\n\n------', '2019-09-26 12:44:51', '2024-09-04 00:52:12', 1, 25, 0, '最近给自己定了一个小目标,一周温习一个基础知识点,并输出一篇手记。看自己是否能坚持下去。^_^', 'https://qncdn.wbjiang.cn/tag_480x270.png', 0, 0);
-INSERT INTO `article` VALUES (189, '耐人寻味的CSS属性white-space', '《耐人寻味的CSS属性white-space》,本文说的`white-space`是一个控制换行和空白处理的`CSS`属性。我曾经被这个属性烦死,一直没记住,今天决定还是写下来好好琢磨下。\n\n# 属性值\n\n## normal\n\n**默认值**,正常换行,空白和换行符会被浏览器忽略。啥意思呢?\n\n- 正常换行的意思是,单词间会正常换行,如果下一个单词太长,不足以在当前行剩余部分完整展示,则会在下一行显示。哪些情况算一个单词呢?\n\n - 一个中文字\n\n - 一个英文单词\n\n ```\n // 这是两个单词\n Tusi Blog\n // 这只算一个单词\n TusiBlog\n ```\n\n - 连续的数字或符号也只算一个单词\n\n ```\n // 这只算一个单词,如果超长也不会换行,会挤出横向滚动条\n 10000000000000000000000+2000000000000000000*200000000000000\n ```\n\n- 空白和换行符会被浏览器忽略。就是你输入连续的空格,只会表现出一个空格的效果;如果敲了回车,也不会换行。\n\n```html\n\n00000000 00000000000000000>
\n\n00000000 00000000000000000\n```\n\n## pre\n\n- 行为方式类似`HTML`中的`pre`标签。`pre`标签一般用来包裹源代码。\n- 不会自动换行(想想,你写代码时,不回车会换行吗?),除非在文本中遇到换行符(敲了回车)或使用了`br`标签。\n- 空白会被浏览器保留。意思就是连续的空格会被保留,不会合并成一个。\n\n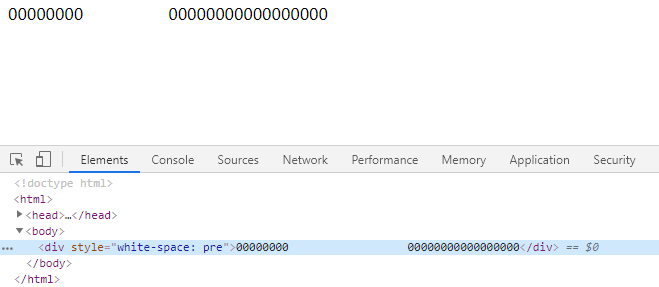\n\n## nowrap\n\n- 不换行,内容再多也不换行。\n\n- 忽略换行符,也就是说回车也不会换行,直到遇到`br`标签为止。\n\n## pre-wrap\n\n- 正常换行\n- 连续的空白符会被保留\n- 换行符(回车)也是有效的\n\n## pre-line\n\n- 正常换行\n- 连续空白符会被合并成一个\n- 换行符(回车)也有效\n\n## inherit\n\n继承父元素的`white-space`属性值\n\n# 总结\n\n可以从几个方面来对比下这几种属性值的差异。\n\n| / | 是否正常换行 | 是否合并连续空白符 | 换行符是否有效 |\n| -------- | ------------ | ------------------ | -------------- |\n| normal | 是 | 是 | 否 |\n| pre | 否 | 否 | 是 |\n| nowrap | 否 | 是 | 否 |\n| pre-wrap | 是 | 否 | 是 |\n| pre-line | 是 | 是 | 是 |\n\n妈呀,还是挺难记的,多多复习!', '2019-10-13 11:18:18', '2024-08-08 03:57:45', 1, 37, 0, '《耐人寻味的CSS属性white-space》,本文说的white-space是一个控制换行和空白处理的CSS属性。我曾经被这个属性烦死,一直没记住,今天决定还是写下来好好琢磨下。', 'https://qncdn.wbjiang.cn/css.jpg', 0, 0);
-INSERT INTO `article` VALUES (190, '如何判断IE OCX插件正常安装?', '项目中用到了一个第三方的`ie ocx`控件,而经常遇到客户和测试小伙伴反馈相关功能无法正常使用,也没有友好提示。考虑到这个问题,必须要有一个`ie ocx`控件的检查机制。\n\n# 检查原理\n\n创建`ActiveXObject`对象去检查`ocx`控件\n\n```javascript\nlet newObj = new ActiveXObject(servername, typename[, location]) \n```\n\n# 参数问题\n\n看起来很简单的,但是用起来我懵逼了,应用程序对象名称`servername`这个参数怎么填呢?\n\n插件供应商只提供了控件安装包,示例程序,`clsid`\n\n```html\n
\n \n\n\n```\n\n# 静态展示\n\n任何事都不是一蹴而就的,我们首先来实现一个静态的效果,然后再实现动画效果,甚至是复杂的控制逻辑。\n\n## 确定画布大小\n\n第一步是确定画布大小。从设计稿我们可以直观地看到,整个环形进度条的最外围是由进度圆点确定的,而进度圆点的圆心在圆环圆周上。\n\n\n\n因此我们得出伪代码如下:\n\n```javascript\n// canvasSize: canvas宽度/高度\n// outerRadius: 外围半径\n// pointRadius: 圆点半径\n// pointRadius: 圆环半径\ncanvasSize = 2 * outerRadius = 2 * (pointRadius + circleRadius)\n```\n\n据此我们可以定义如下组件属性:\n\n```javascript\nprops: {\n circleRadius: {\n type: Number,\n default: 40\n },\n pointRadius: {\n type: Number,\n default: 6\n }\n},\ncomputed: {\n // 外围半径\n outerRadius() {\n return this.circleRadius + this.pointRadius\n },\n // canvas宽/高\n canvasSize() {\n return 2 * this.outerRadius + \'px\'\n }\n}\n```\n\n那么`canvas`大小也可以先进行绑定了\n\n```html\n\n \n```\n\n## 获取绘图上下文\n\n` getContext(\'2d\') `方法返回一个用于在`canvas`上绘图的环境,支持一系列`2d`绘图`API`。 \n\n```javascript\nmounted() {\n // 在$nextTick初始化画布,不然dom还未渲染好\n this.$nextTick(() => {\n this.initCanvas()\n })\n},\nmethods: {\n initCanvas() {\n var canvas = this.$refs.canvasDemo;\n var ctx = canvas.getContext(\'2d\');\n }\n}\n```\n\n## 画底色圆环\n\n完成了上述步骤后,我们就可以着手画各个元素了。我们先画圆环,这时我们还要定义两个属性,分别是圆环线宽`circleWidth`和圆环颜色`circleColor`。\n\n```javascript\ncircleWidth: {\n type: Number,\n default: 2\n},\ncircleColor: {\n type: String,\n default: \'#3B77E3\'\n}\n```\n\n`canvas`提供的画圆弧的方法是`ctx.arc()`,需要提供圆心坐标,半径,起止弧度,是否逆时针等参数。\n\n```javascript\nctx.arc(x, y, radius, startAngle, endAngle, anticlockwise);\n```\n\n 我们知道,`Web`网页中的坐标系是这样的,从绝对定位的设置上其实就能看出来(`top`,`left`设置正负值会发生什么变化),而且原点`(0, 0)`是在盒子(比如说`canvas`)的左上角哦。 \n\n\n\n对于角度而言,`0°`是`x`轴正向,默认是顺时针方向旋转。\n\n圆环的圆心就是`canvas`的中心,所以`x `, `y` 取`outerRadius`的值就可以了。\n\n```javascript\nctx.strokeStyle = this.circleColor;\nctx.lineWidth = this.circleWidth;\nctx.beginPath();\nctx.arc(this.outerRadius, this.outerRadius, this.circleRadius, 0, this.deg2Arc(360));\nctx.stroke();\n```\n\n注意`arc`传的是弧度参数,而不是我们常理解的`360°`这种概念,因此我们需要将我们理解的`360°`转为弧度。\n\n```javascript\n// deg转弧度\ndeg2Arc(deg) {\n return deg / 180 * Math.PI\n}\n```\n\n\n\n## 画文字\n\n调用`fillText`绘制文字,利用`canvas.clientWidth / 2`和`canvas.clientWidth / 2`取得中点坐标,结合控制文字对齐的两个属性`textAlign`和`textBaseline`,我们可以将文字绘制在画布中央。文字的值由`label`属性接收,字体大小由`fontSize`属性接收,颜色则取的`fontColor`。\n\n```javascript\nif (this.label) {\n ctx.font = `${this.fontSize}px Arial,\"Microsoft YaHei\"`\n ctx.fillStyle = this.fontColor;\n ctx.textAlign = \'center\'\n ctx.textBaseline = \'middle\'\n ctx.fillText(this.label, canvas.clientWidth / 2, canvas.clientWidth / 2);\n}\n```\n\n\n\n## 画进度弧\n\n支持普通颜色和渐变色,`withGradient`默认为`true`,代表使用渐变色绘制进度弧,渐变方向我默认给的从上到下。如果希望使用普通颜色,`withGradient`传`false`即可,并可以通过`lineColor`自定义颜色。\n\n```javascript\nif (this.withGradient) {\n this.gradient = ctx.createLinearGradient(this.circleRadius, 0, this.circleRadius, this.circleRadius * 2);\n this.lineColorStops.forEach(item => {\n this.gradient.addColorStop(item.percent, item.color);\n });\n}\n```\n\n其中`lineColorStops`是渐变色的颜色偏移断点,由父组件传入,可传入任意个颜色断点,格式如下:\n\n```javascript\ncolorStops2: [\n { percent: 0, color: \'#FF9933\' },\n { percent: 1, color: \'#FF4949\' }\n]\n```\n\n画一条从上到下的进度弧,即`270°`到`90°`\n\n```javascript\nctx.strokeStyle = this.withGradient ? this.gradient : this.lineColor;\nctx.lineWidth = this.lineWidth;\nctx.beginPath();\nctx.arc(this.outerRadius, this.outerRadius, this.circleRadius, this.deg2Arc(270), this.deg2Arc(90));\nctx.stroke();\n```\n\n\n\n其中`lineWidth`是弧线的宽度,由父组件传入\n\n```javascript\nlineWidth: {\n type: Number,\n default: 8\n}\n```\n\n## 画进度圆点\n\n最后我们需要把进度圆点补上,我们先写死一个角度`90°`,显而易见,圆点坐标为`(this.outerRadius, this.outerRadius + this.circleRadius)`\n\n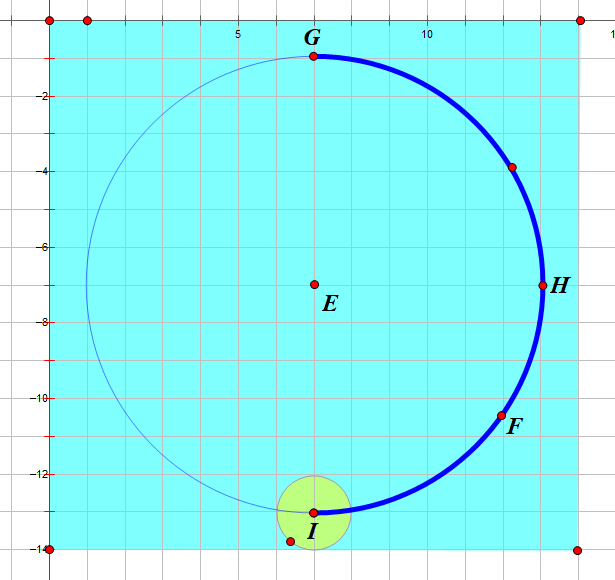\n\n画圆点的代码如下:\n\n```javascript\nctx.fillStyle = this.pointColor;\nctx.beginPath();\nctx.arc(this.outerRadius, this.outerRadius + this.circleRadius, this.pointRadius, 0, this.deg2Arc(360));\nctx.fill();\n```\n\n其中`pointRadius`是圆点的半径,由父组件传入:\n\n```javascript\npointRadius: {\n type: Number,\n default: 6\n}\n```\n\n\n\n## 角度自定义\n\n当然,进度条的角度是灵活定义的,包括开始角度,结束角度,都应该由调用者随意给出。因此我们再定义一个属性`angleRange`,用于接收起止角度。\n\n```javascript\nangleRange: {\n type: Array,\n default: function() {\n return [270, 90]\n }\n}\n```\n\n有了这个属性,我们就可以随意地画进度弧和圆点了,哈哈哈哈。\n\n\n\n老哥,这种圆点坐标怎么求?\n\n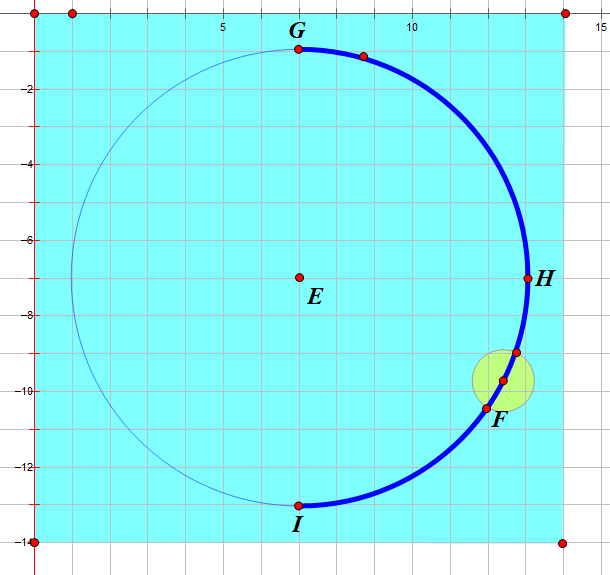\n\n噗......看来高兴过早了,最重要的是根据不同角度求得圆点的圆心坐标,这让我顿时犯了难。\n\n\n\n经过冷静思考,我脑子里闪过了一个利用正余弦公式求坐标的思路,但前提是坐标系原点如果在圆环外接矩形的左上角才好算。仔细想想,冇问题啦,我先给坐标系平移一下,最后求出来结果,再补个平移差值不就行了嘛。\n\n\n\n画图工具不是很熟练,这里图没画好,线歪了,请忽略细节。\n\n好的,我们先给坐标系向右下方平移`pointRadius`,最后求得结果再加上`pointRadius`就好了。伪代码如下:\n\n```javascript\n// realx:真实的x坐标\n// realy:真实的y坐标\n// resultx:平移后求取的x坐标\n// resultx:平移后求取的y坐标\n// pointRadius 圆点半径\nrealx = resultx + pointRadius\nrealy = resulty + pointRadius\n```\n\n求解坐标的思路大概如下,分四个范围判断,得出求解公式,应该还可以化简,不过我数学太菜了,先这样吧。\n\n```javascript\ngetPositionsByDeg(deg) {\n let x = 0;\n let y = 0;\n if (deg >= 0 && deg <= 90) {\n // 0~90度\n x = this.circleRadius * (1 + Math.cos(this.deg2Arc(deg)))\n y = this.circleRadius * (1 + Math.sin(this.deg2Arc(deg)))\n } else if (deg > 90 && deg <= 180) {\n // 90~180度\n x = this.circleRadius * (1 - Math.cos(this.deg2Arc(180 - deg)))\n y = this.circleRadius * (1 + Math.sin(this.deg2Arc(180 - deg)))\n } else if (deg > 180 && deg <= 270) {\n // 180~270度\n x = this.circleRadius * (1 - Math.sin(this.deg2Arc(270 - deg)))\n y = this.circleRadius * (1 - Math.cos(this.deg2Arc(270 - deg)))\n } else {\n // 270~360度\n x = this.circleRadius * (1 + Math.cos(this.deg2Arc(360 - deg)))\n y = this.circleRadius * (1 - Math.sin(this.deg2Arc(360 - deg)))\n }\n return { x, y }\n}\n```\n\n最后再补上偏移值即可。\n\n```javascript\nconst pointPosition = this.getPositionsByDeg(nextDeg);\nctx.arc(pointPosition.x + this.pointRadius, pointPosition.y + this.pointRadius, this.pointRadius, 0, this.deg2Arc(360));\n```\n\n\n\n这样,一个基本的`canvas`环形进度条就成型了。\n\n# 动画展示\n\n静态的东西逼格自然是不够的,因此我们需要再搞点动画效果装装逼。\n\n## 基础动画\n\n我们先简单实现一个线性的动画效果。基本思路是把开始角度和结束角度的差值分为`N`段,利用`window.requestAnimationFrame`依次执行动画。\n\n比如从`30°`到`90°`,我给它分为6段,每次画`10°`。要注意`canvas`画这种动画过程一般是要重复地清空画布并重绘的,所以第一次我画的弧线范围就是`30°~40°`,第二次我画的弧线范围就是`30°~50°`,以此类推......\n\n基本的代码结构如下,具体代码请参考[vue-awesome-progress]( https://github.com/cumt-robin/vue-awesome-progress ) `v1.1.0`版本,如果顺手帮忙点个`star`也是极好的。\n\n```javascript\nanimateDrawArc(canvas, ctx, startDeg, endDeg, nextDeg, step) {\n window.requestAnimationFrame(() => {\n // 清空画布\n ctx.clearRect(0, 0, canvas.clientWidth, canvas.clientHeight);\n // 求下一个目标角度\n nextDeg = this.getTargetDeg(nextDeg || startDeg, endDeg, step);\n // 画圆环\n // 画文字\n // 画进度弧线\n // 画进度圆点\n if (nextDeg !== endDeg) {\n // 满足条件继续调用动画,否则结束动画\n this.animateDrawArc(canvas, ctx, startDeg, endDeg, nextDeg, step)\n }\n }\n}\n```\n\n\n\n## 缓动效果\n\n线性动画显得有点单调,可操作性不大,因此我考虑引入贝塞尔缓动函数`easing`,并且支持传入动画执行时间周期`duration`,增强了可定制性,使用体验更好。这里不列出实现代码了,请前往[vue-awesome-progress]( https://github.com/cumt-robin/vue-awesome-progress )查看。\n\n```html\n\n\n// 省略部分...\n\n\n```\n\n\n\n可以看到,当传入不同的动画周期`duration`和缓动参数`easing`时,动画效果各异,完全取决于使用者自己。\n\n# 其他效果\n\n当然根据组件支持的属性,我们也可以定制出其他效果,比如不显示文字,不显示圆点,弧线线宽与圆环线宽一样,不使用渐变色,不需要动画,等等。我们后续也会考虑支持更多能力,比如控制进度,数字动态增长等!具体使用方法,请参考[vue-awesome-progress]( https://github.com/cumt-robin/vue-awesome-progress )。\n\n\n\n# 更新日志\n\n**2020年04月10日更新**\n\n支持进度控制,只需要修改组件的属性值`percentage`即可。\n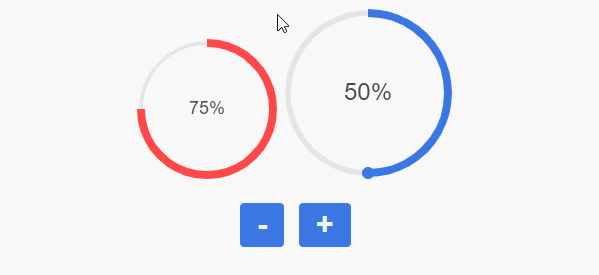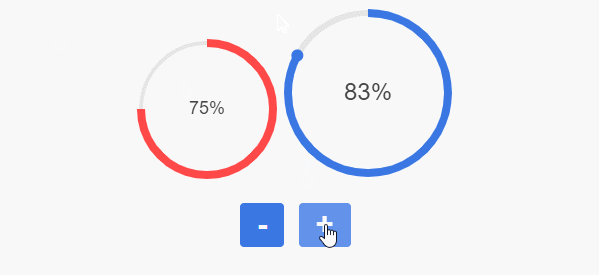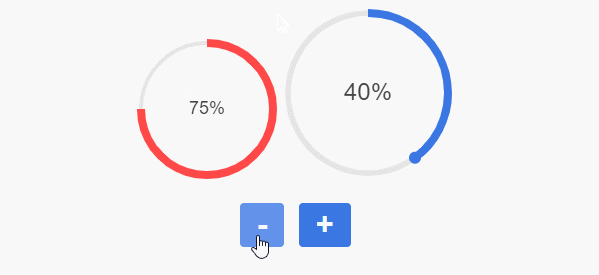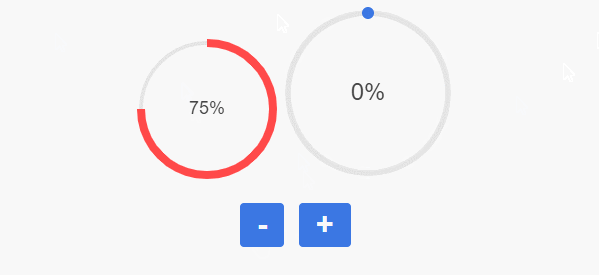\n\n------\n**2019年11月10日更新**\n\n由于我从业务场景出发做了这个组件,没有考虑到大部分场景都是传百分比控制进度的,因此在`v1.4.0`版本做了如下修正:\n\n1. 废弃`angle-range`,改用`percentage`控制进度,同时提供`start-deg`属性控制起始角度;\n\n2. `with-gradient`改为`use-gradient`\n\n3. 通过`show-text`控制是否显示进度文字\n\n4. 支持通过`format`函数自定义显示文字的规则\n\n\n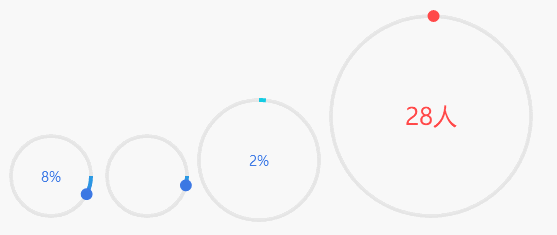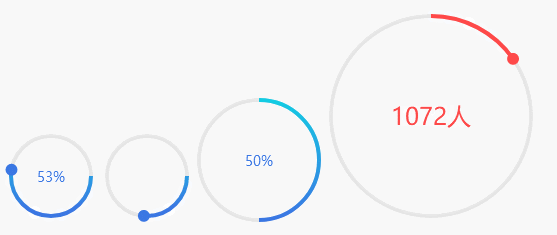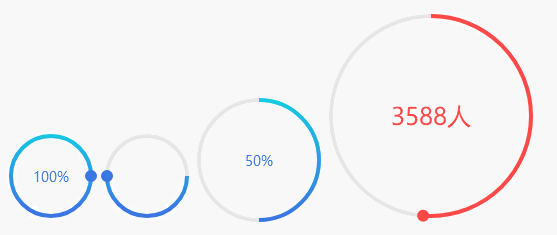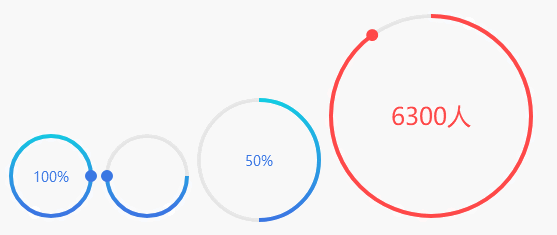\n\n# 结语\n\n写完这个组件有让我感觉到,程序员最终不是输给了代码和技术的快速迭代,而是输给了自己的逻辑思维能力和数学功底。就[vue-awesome-progress]( https://github.com/cumt-robin/vue-awesome-progress )这个组件而言,根据这个思路,我们也能迅速开发出适用于`React`,`Angular`以及其他框架生态下的组件。工作三年有余,接触了不少框架和技术,经历了`MVVM`,`Hybrid`,`小程序`,`跨平台`,`大前端`,` serverless `的大火,也时常感慨“学不动了”,在这个快速演进的代码世界里常常感到失落。好在自己还没有丢掉分析问题的能力,而不仅仅是调用各种`API`和插件,这可能是程序员最宝贵的财富吧。前路坎坷,我辈当不忘初心,愿你出走半生,归来仍是少年!\n\n------', '2019-11-09 12:25:01', '2024-08-11 00:51:54', 1, 82, 0, '周末好,今天给大家带来一款接地气的环形进度条组件vue-awesome-progress。', 'https://qncdn.wbjiang.cn/vue-awesome-progress.png', 0, 0);
-INSERT INTO `article` VALUES (197, '因为new Date(),我给IE跪了', '处理日期格式是日常工作中的常事,我们经常会对日期字符串和日期对象之间进行转换。今天在`IE`浏览器就踩了这么一个日期转换的坑。\n\n# new Date()的坑\n\n后端返回的日期字符串格式为:`yyyy-MM-dd HH:mm:ss`,看到这个格式,大部分人都会觉得这应该是标准格式吧,我也是这么认为的,觉得没有任何兼容问题。转换语句如下:\n\n```javascript\nvar str2DateObj = new Date(\'2019-11-04 10:10:10\')\nconsole.log(str2DateObj)\n// 输出:VM796:2 Mon Nov 04 2019 10:10:10 GMT+0800 (中国标准时间)\n```\n\n但是`IE`就是这么`diao`,我就不支持这个格式。\n\n```javascript\nvar str2DateObj = new Date(\'2019-11-04 10:10:10\')\nconsole.log(str2DateObj)\n[date] Invalid Date[date] Invalid Date\n```\n\n# 解决方案\n\n## 自行解析\n\n将得到的日期字符串进行拆分解析,分别得到年月日时分秒,然后再`new Date`\n\n```javascript\n// 注意,月是从0开始的\nnew Date(2019, 10, 4, 10, 10, 10)\n```\n\n## 借助外力\n\n正好项目也用了`moment`这个日期时间库,那就交给它处理吧。\n\n```javascript\n// no problem\nmoment(\'2019-11-04 10:10:10\')\n```', '2019-11-15 09:50:00', '2024-08-16 14:16:29', 1, 40, 0, '处理日期格式是日常工作中的常事,我们经常会对日期字符串和日期对象之间进行转换。今天在IE浏览器就踩了这么一个日期转换的坑。', 'https://qncdn.wbjiang.cn/IE%E4%BD%A0%E5%88%AB%E8%B7%91.jpg', 0, 0);
-INSERT INTO `article` VALUES (198, '解决办公IP变化后git无法推送远程仓库的问题', '最近公司乔迁新址,在提交代码时遇到了无法`git push`的问题。报错如下:\n\n```\nThe RSA host key for github.com has changed,\nand the key for the corresponding IP address 42.243.156.48\nis unknown. This could either mean that\nDNS SPOOFING is happening or the IP address for the host\nand its host key have changed at the same time.\n```\n\n经检查,`ssh`密钥对是没有问题的,问题出在了`known_hosts`文件,办公`ip`变化了,而`known_hosts`中保留的是原来的`ip`,导致不识别当前`ip`而验证失败。\n\n解决方法也很简单,首先找到`.ssh`目录,我的是\n\n```\nC:\\Users\\Jiang.Wenbin\\.ssh\n```\n\n我们删除掉`known_hosts`文件,然后打开`git bash`,视个人情况选择性输入如下命令:\n\n```shell\n// 连接github\nssh -T git@github.com\n// 连接gitee\nssh -T git@gitee.com\n// 连接coding.net\nssh -T git@git.coding.net\n```\n\n在弹出询问后输入`yes`即可。\n\n这里在连接`github`时比较特殊,遇到了一个报错\n\n```\ngit@github.com: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).\n```\n\n其实是我开启了网络代理或者`fanqiang`工具引起的,关闭后正常了。\n\n再次`git push`代码就没问题了。', '2019-11-17 15:54:24', '2024-08-14 05:40:08', 1, 53, 0, '最近公司乔迁新址,在提交代码时遇到了无法git push的问题。', 'https://qncdn.wbjiang.cn/abstract_city_600x400.png', 0, 0);
-INSERT INTO `article` VALUES (199, 'Git多个远程仓库不同步时的补救办法', '`git`本地仓库是可以与多个远程仓库关联的,如果想知道怎么配置,请参考[Git如何使用多个托管平台管理代码](http://hexo.wbjiang.cn/干货!Git-如何使用多个托管平台管理代码.html) 。\n\n当`git remote`关联了多个远程仓库时,总会遇到一些问题。今天就遇到了两个远程仓库不一致导致无法`push`的情况。\n\n\n# 远程仓库间出现差异\n\n大概情况是这样的,我是一个本地仓库关联了`github`和`gitee`两个远程仓库。\n\n```shell\ngit remote add all git@github.com:cumt-robin/BlogFrontEnd.git\ngit remote set-url --add all git@gitee.com:tusi/BlogFrontEnd.git\n```\n\n由于不小心在远程仓库`gitee`上手动修改了`README.md`文件,导致两个远程仓库出现了差异。所以当我在本地完成了一部分功能,准备提交到远程仓库时,出现了报错。\n\n```shell\n$ git push all --all\nEverything up-to-date\nTo gitee.com:tusi/BlogFrontEnd.git\n ! [rejected] master -> master (fetch first)\nerror: failed to push some refs to \'git@gitee.com:tusi/BlogFrontEnd.git\'\nhint: Updates were rejected because the remote contains work that you do\nhint: not have locally. This is usually caused by another repository pushing\nhint: to the same ref. You may want to first integrate the remote changes\nhint: (e.g., \'git pull ...\') before pushing again.\nhint: See the \'Note about fast-forwards\' in \'git push --help\' for details.\n```\n\n# 解决方案\n\n由于是`gitee`的仓库多修改了一点东西,因此在本地再加一个`remote`,单独关联`gitee`。\n\n```shell\n$ git remote add gitee git@gitee.com:tusi/BlogFrontEnd.git\n```\n\n将`gitee`的代码拉到本地`master`。\n\n```shell\n$ git pull gitee master\nremote: Enumerating objects: 1, done.\nremote: Counting objects: 100% (1/1), done.\nremote: Total 1 (delta 0), reused 0 (delta 0)\nUnpacking objects: 100% (1/1), done.\nFrom gitee.com:tusi/BlogFrontEnd\n * branch master -> FETCH_HEAD\n * [new branch] master -> gitee/master\nAlready up to date!\nMerge made by the \'recursive\' strategy.\n```\n\n再将本地`master`推送到远程`all`。\n\n```shell\n$ git push all --all\nEnumerating objects: 2, done.\nCounting objects: 100% (2/2), done.\nDelta compression using up to 6 threads\nCompressing objects: 100% (2/2), done.\nWriting objects: 100% (2/2), 499 bytes | 499.00 KiB/s, done.\nTotal 2 (delta 0), reused 0 (delta 0)\nTo github.com:cumt-robin/BlogFrontEnd.git\n 1557ece..8391333 master -> master\nEnumerating objects: 2, done.\nCounting objects: 100% (2/2), done.\nDelta compression using up to 6 threads\nCompressing objects: 100% (2/2), done.\nWriting objects: 100% (2/2), 917 bytes | 917.00 KiB/s, done.\nTotal 2 (delta 0), reused 0 (delta 0)\nremote: Powered By Gitee.com\nTo gitee.com:tusi/BlogFrontEnd.git\n 8912ff5..8391333 master -> master\n```\n\n问题得以解决!\n\n------', '2019-11-19 18:40:23', '2024-07-25 08:06:35', 1, 34, 0, '当git remote关联了多个远程仓库时,总会遇到一些问题。今天就遇到了两个远程仓库不一致导致无法push的情况。', 'https://qncdn.wbjiang.cn/git%E5%A4%9A%E4%BB%93%E5%BA%93%E5%B7%AE%E5%BC%82.png', 0, 0);
-INSERT INTO `article` VALUES (200, '前端API层架构,也许你做得还不够', '上午好,今天为大家分享下个人对于前端`API`层架构的一点经验和看法。架构设计是一条永远走不完的路,没有最好,只有更好。这个道理适用于软件设计的各个场景,前端`API`层的设计也不例外,如果您觉得在调用接口时还存在诸多槽点,那就说明您的接口层架构还待优化。今天我以`vue + axios`为例,为大家梳理下我的一些经历和设想。\n\n# 石器时代,痛苦\n\n直接调用`axios`,真的痛苦,每个调用的地方都要进行响应状态的判断,冗余代码超级多。\n\n```javascript\nimport axios from \"axios\"\n\naxios.get(\'/usercenter/user/page?pageNo=1&pageSize=10\').then(res => {\n const data = res.data\n // 判断请求状态,success字段为true代表成功,视前后端约束而定\n if (data.success) {\n // 结果成功后的业务代码\n } else {\n // 结果失败后的业务代码\n }\n})\n```\n\n看起来确实很难受,每调用一次接口,就有这么多重复的工作!\n\n# 青铜器时代,中规中矩\n\n为了解决直接调用`axios`的痛点,我们一般会利用`Promise`对`axios`二次封装,对接口响应状态进行集中判断,对外暴露`get`, `post`, `put`, `delete`等`http`方法。\n\n## axios二次封装\n\n```javascript\nimport axios from \"axios\"\nimport router from \"@/router\"\nimport { BASE_URL } from \"@/router/base-url\"\nimport { errorMsg } from \"@/utils/msg\";\nimport { stringify } from \"@/utils/helper\";\n// 创建axios实例\nconst v3api = axios.create({\n baseURL: process.env.BASE_API,\n timeout: 10000\n});\n// axios实例默认配置\nv3api.defaults.headers.common[\'Content-Type\'] = \'application/x-www-form-urlencoded\';\nv3api.defaults.transformRequest = data => {\n return stringify(data)\n}\n// 返回状态拦截,进行状态的集中判断\nv3api.interceptors.response.use(\n response => {\n const res = response.data;\n if (res.success) {\n return Promise.resolve(res)\n } else {\n // 内部错误码处理\n if (res.code === 1401) {\n errorMsg(res.message || \'登录已过期,请重新登录!\')\n router.replace({ path: `${BASE_URL}/login` })\n } else {\n // 默认的错误提示\n errorMsg(res.message || \'网络异常,请稍后重试!\')\n }\n return Promise.reject(res);\n }\n },\n error => {\n if (/timeout\\sof\\s\\d+ms\\sexceeded/.test(error.message)) {\n // 超时\n errorMsg(\'网络出了点问题,请稍后重试!\')\n }\n if (error.response) {\n // http状态码判断\n switch (error.response.status) {\n // http status handler\n case 404:\n errorMsg(\'请求的资源不存在!\')\n break\n case 500:\n errorMsg(\'内部错误,请稍后重试!\')\n break\n case 503:\n errorMsg(\'服务器正在维护,请稍等!\')\n break\n }\n }\n return Promise.reject(error.response)\n }\n)\n\n// 处理get请求\nconst get = (url, params, config = {}) => v3api.get(url, { ...config, params })\n// 处理delete请求,为了防止和关键词delete冲突,方法名定义为deletes\nconst deletes = (url, params, config = {}) => v3api.delete(url, { ...config, params })\n// 处理post请求\nconst post = (url, params, config = {}) => v3api.post(url, params, config)\n// 处理put请求\nconst put = (url, params, config = {}) => v3api.put(url, params, config)\nexport default {\n get,\n deletes,\n post,\n put\n}\n```\n\n## 调用者不再判断请求状态\n\n```javascript\nimport api from \"@/api\";\n\nmethods: {\n getUserPageData() {\n api.get(\'/usercenter/user/page?pageNo=1&pageSize=10\').then(res => {\n // 状态已经集中判断了,这里直接写成功的逻辑\n // 业务代码......\n const result = res.result;\n }).catch(res => {\n // 失败的情况写在catch中\n })\n }\n}\n```\n\n## async/await改造\n\n使用语义化的异步函数\n\n```javascript\nmethods: {\n async getUserPageData() {\n try {\n const res = await api.get(\'/usercenter/user/page?pageNo=1&pageSize=10\') \n // 业务代码......\n const { result } = res;\n } catch(error) {\n // 失败的情况写在catch中\n }\n }\n}\n```\n\n## 存在的问题\n\n- 语义化程度有限,调用接口还是需要查询接口`url`\n- 前端`api`层难以维护,如后端接口发生改动,前端每处都需要大改。\n- 如果`UI`组件的数据模型与后端接口要求的数据结构存在差异,每处调用接口前都需要进行数据处理,抹平差异,比如`[1,2,3]`转`1,2,3`这种(当然,这只是最简单的一个例子)。这样如果数据处理不慎,调用者出错几率太高!\n- 难以满足特殊化场景,举个例子,一个查询的场景,后端要求,如果输入了搜索关键词`keyword`,必须调用`/user/search`接口,如果没有输入关键词,只能调用`/user/page`接口。如果每个调用者都要判断是不是输入了关键词,再决定调用哪个接口,你觉得出错几率有多大,用起来烦不烦?\n- 产品说,这些场景需要优化,默认按创建时间降序排序。我擦,又一个个改一遍?\n- ......\n\n那么怎么解决这些问题呢?请耐心接着看......\n\n# 铁器时代,it\'s cool\n\n我想到的方案是在底层封装和调用者之间再增加一层`API`适配层(适配层,取量身定制之意),在适配层做统一处理,包括参数处理,请求头处理,特殊化处理等,提炼出更语义化的方法,让调用者“傻瓜式”调用,不再为了查找接口`url`和处理数据结构这些重复的工作而烦恼,把`ViewModel`层绑定的数据模型直接丢给适配层统一处理。\n\n## 对齐微服务架构\n\n 首先,为了对齐后端微服务架构,在前端将`API`调用分为三个模块。 \n\n```\n├─api\n index.js axios底层封装\n ├─base 负责调用基础服务,basecenter\n ├─iot 负责调用物联网服务,iotcenter\n └─user 负责调用用户相关服务,usercenter\n```\n\n 每个模块下都定义了统一的微服务命名空间,例如`/src/api/user/index.js`: \n\n```javascript\nexport const namespace = \'usercenter\';\n```\n\n## 特性模块\n\n每个功能特性都有独立的`js`模块,以角色管理相关接口为例,模块是`/src/api/user/role.js` \n\n```javascript\nimport api from \'../index\'\nimport { paramsFilter } from \"@/utils/helper\";\nimport { namespace } from \"./index\"\nconst feature = \'role\'\n\n// 添加角色\nexport const addRole = params => api.post(`/${namespace}/${feature}/add`, paramsFilter(params));\n// 删除角色\nexport const deleteRole = id => api.deletes(`/${namespace}/${feature}/delete`, { id });\n// 更新角色\nexport const updateRole = params => api.put(`/${namespace}/${feature}/update`, paramsFilter(params));\n// 条件查询角色\nexport const findRoles = params => api.get(`/${namespace}/${feature}/find`, paramsFilter(params));\n// 查询所有角色,不传参调用find接口代表查询所有角色\nexport const getAllRoles = () => findRoles();\n// 获取角色详情\nexport const getRoleDetail = id => api.get(`/${namespace}/${feature}/detail`, { id });\n// 分页查询角色\nexport const getRolePage = params => api.get(`/${namespace}/${feature}/page`, paramsFilter(params));\n// 搜索角色\nexport const searchRole = params => params.keyword ? api.get(`/${namespace}/${feature}/search`, paramsFilter(params)) : getRolePage(params);\n```\n\n- 每一条接口都根据`RESTful`风格,调用增(`api.post`)删(`api.deletes`)改(`api.put`)查(`api.get`)的底层方法,对外输出语义化方法。\n- 调用的`url`由三部分组成,格式:`/微服务命名空间/特性命名空间/方法`\n- 接口适配层函数命名规范:\n\n- - 新增:`addXXX`\n - 删除:`deleteXXX`\n - 更新:`updateXXX`\n - 根据ID查询记录:`getXXXDetail`\n - 条件查询一条记录:`findOneXXX`\n - 条件查询:`findXXXs`\n - 查询所有记录:`getAllXXXs`\n - 分页查询:`getXXXPage`\n - 搜索:`searchXXX`\n - 其余个性化接口根据语义进行命名\n\n## 解决问题\n\n- 语义化程度更高,配合`vscode`的代码提示功能,用起来不要太爽!\n\n- 迅速响应接口改动,适配层统一处理\n\n- 集中进行数据处理(对于公用的数据处理,我们用`paramsFilter`解决,对于特殊的情况,再另行处理),调用者安心做业务即可\n\n- 满足特殊场景,佛系应对后端和产品朋友\n\n - 针对上节提到的关键字查询场景,我们在适配层通过在入参中判断是否有`keyword`字段,决定调用`search`还是`page`接口。对外我们只需暴露`searchRole`方法,调用者只需要调用`searchRole`方法即可,无需做其他考虑。\n\n ```javascript\n export const searchRole = params => params.keyword ? api.get(`/${namespace}/${feature}/search`, paramsFilter(params)) : getRolePage(params);\n ```\n\n - 针对产品突然加的排序需求,我们可以在适配层去做默认入参的处理。\n\n 首先,我们新建一个专门管理默认参数的`js`,如`src/api/default-options.js`\n\n ```javascript\n // 默认按创建时间降序的参数对象\n export const SORT_BY_CREATETIME_OPTIONS = {\n sortField: \'createTime\',\n // desc代表降序,asc是升序\n sortType: \'desc\'\n }\n ```\n\n 接着,我们在接口适配层做集中化处理\n\n ```javascript\n import api from \'../index\'\n import { SORT_BY_CREATETIME_OPTIONS } from \"../default-options\"\n import { paramsFilter } from \"@/utils/helper\";\n import { namespace } from \"./index\"\n const feature = \'role\'\n \n export const getRolePage = params => api.get(`/${namespace}/${feature}/page`, paramsFilter({ ...SORT_BY_CREATETIME_OPTIONS, ...params }));\n ```\n\n `SORT_BY_CREATETIME_OPTIONS`放在前面,是为了满足如果出现其他排序需求,调用者传入的排序字段能覆盖掉默认参数。\n\n## mock先行\n\n一个完善的`API`层设计,肯定是离不开`mock`的。在后端提供接口之前,前端必须通过模拟数据并行开发,否则进度无法保证。那么如何设计一个跟真实接口契合度高的`mock`系统呢?我这里简单做下分享。\n\n- 首先,创建`mock`专用的`axios`实例\n\n我们在`src`目录下新建`mock`目录,并在`src/mock/index.js`简单封装一个`axios`实例\n\n```javascript\n// 仅限模拟数据使用\nimport axios from \"axios\"\nconst mock = axios.create({\n baseURL: \'\'\n});\n// 返回状态拦截\nmock.interceptors.response.use(\n response => {\n return Promise.resolve(response.data)\n },\n error => {\n return Promise.reject(error.response)\n }\n)\n\nexport default mock\n```\n\n- `mock`同样也要分模块,以`usercenter`微服务下的角色管理`mock`接口为例\n\n```\n├─mock\n index.js mock底层axios封装\n ├─user 负责调用基础服务,usercenter\n ├─role\n ├─index.js\n```\n\n我们在`src/mock/user/role/index.js`中简单模拟一个获取所有角色的接口`getAllRoles`\n\n```javascript\nimport mock from \"@/mock\";\n\nexport const getAllRoles = () => mock.get(\'/static/mock/user/role/getAllRoles.json\')\n```\n\n可以看到,我们是在`mock`接口中获取了`static/mock`目录下的`json`数据。因此我们需要根据接口文档或者约定好的数据结构准备好`getAllRoles.json`数据\n\n```\n{\n \"success\": true,\n \"result\": {\n \"pageNo\": 1,\n \"pageSize\": 10,\n \"total\": 2,\n \"list\": [\n {\n \"id\": 1,\n \"createTime\": \"2019-11-19 12:53:05\",\n \"updateTime\": \"2019-12-03 09:53:41\",\n \"name\": \"管理员\",\n \"code\": \"管理员\",\n \"description\": \"一个拥有部分权限的管理员角色\",\n \"sort\": 1,\n \"menuIds\": \"789,2,55,983,54\",\n \"menuNames\": \"数据字典, 后台, 账户信息, 修改密码, 账户中心\"\n },\n {\n \"id\": 2,\n \"createTime\": \"2019-11-27 17:18:54\",\n \"updateTime\": \"2019-12-01 19:14:30\",\n \"name\": \"前台测试\",\n \"code\": \"前台测试\",\n \"description\": \"一个拥有部分权限的前台测试角色\",\n \"sort\": 2,\n \"menuIds\": \"15,4,1\",\n \"menuNames\": \"油耗统计, 车联网, 物联网监管系统\"\n }\n ]\n },\n \"message\": \"请求成功\",\n \"code\": 0\n}\n```\n\n- 我们来看看`mock`是怎么做的\n\n先看下真实接口的调用方式\n\n```javascript\nimport { getAllRoles } from \"@/api/user/role\";\n\ncreated() {\n this.getAllRolesData()\n},\nmethods: {\n async getAllRolesData() {\n const res = await getAllRoles()\n console.log(res)\n }\n}\n```\n\n那么`mock`时怎么做呢?非常简单,只要将`mock`中提供的方法替代掉`api`提供的方法即可。\n\n```javascript\n// import { getAllRoles } from \"@/api/user/role\";\nimport { getAllRoles } from \"@/mock/user/role\";\n```\n\n可以看到,这种`mock`方式与调用真实接口的契合度还是挺高的,正式调试接口时,只需将注释的代码调整即可,过渡非常平滑!\n\n- 注意,在生产环境下,为了防止打包时将`static/mock`目录下的内容`copy`到`dist`目录下,我们需要配置下`CopyWebpackPlugin`,以`vue-cli@2`为例,我们修改`webpack.base.conf.js`即可。\n\n```javascript\nconst devMode = process.env.NODE_ENV === \'development\';\n\nnew CopyWebpackPlugin([\n {\n from: path.resolve(__dirname, \'../static\'),\n to: devMode ? config.dev.assetsSubDirectory : config.build.assetsSubDirectory,\n ignore: devMode ? \'\' : \'mock/**/*\'\n }\n])\n```\n\n# 蒸汽时代,真香\n\n下一步的设想,使用类型安全的`typescript`,让前端`API`层真正做到面向接口文档编程,规范入参,出参,可选参数,等等,提高可维护性,在编码阶段就大大降低出错几率。虽然还在重构阶段,但是我想说,重拾`typescript`是真香,突然怀念使用`Angular`的那两年了,期待`vue3.0`能将`typescript`结合得更加完美......\n\n# 电气时代,更多畅想\n\n未来还有无限可能,面对日渐复杂和多样化的业务场景,我们会提炼出更好的架构和设计模式。目前有一个不成熟的设想,是否能在接口设计上做到更规范化,后端输出接口文档的同时,提炼出`API json`之类的数据结构?前端拿到`API json`,通过`nodejs`文件编程的能力,自动化生成前端接口层代码,解放双手。 \n\n# 结语\n\n当然,以上只是我的一点点经验和设想,是在我能力范围内能想到的东西,希望能帮助到一些有需要的同学。如果大佬们有更好的经验,可以指点一二。\n\n------\n[首发链接](https://juejin.im/post/5de7169451882512454b18d8)\n\n------\n\n往期精彩:\n\n- [用初中数学知识撸一个canvas环形进度条]( https://juejin.im/post/5dc626125188253aec025a60 )', '2019-12-04 10:18:33', '2024-08-11 21:27:24', 1, 91, 0, '上午好,今天为大家分享下个人对于前端API层架构的一点经验和看法。架构设计是一条永远走不完的路,没有最好,只有更好。这个道理适用于软件设计的各个场景,前端API层的设计也不例外。', 'https://qncdn.wbjiang.cn/%E5%89%8D%E7%AB%AFAPI%E5%B1%82%E6%9E%B6%E6%9E%84.png', 0, 0);
-INSERT INTO `article` VALUES (201, '从一道面试题简单谈谈发布订阅和观察者模式', '今天的话题是`javascript`中常被提及的「发布订阅模式和观察者模式」,提到这,我不由得想起了一次面试。记得在去年的一次求职面试过程中,面试官问我,“你在项目中是怎么处理非父子组件之间的通信的?”。我答道,“有用到`vuex`,有的场景也会用`EventEmitter2`”。面试官继续问,“那你能手写代码,实现一个简单的`EventEmitter`吗?”\n\n# 手写EventEmitter\n\n我犹豫了一会儿,想到使用`EventEmitter2`时,主要是用`emit`发事件,用`on`监听事件,还有`off`销毁事件监听者,`removeAllListeners`销毁指定事件的所有监听者,还有`once`之类的方法。考虑到时间关系,我想着就先实现发事件,监听事件,移除监听者这几个功能。当时可能有点紧张,不过有惊无险,在面试官给了一点提示后,顺利地写出来了!现在把这部分代码也记下来。\n\n```javascript\nclass EventEmitter {\n constructor() {\n // 维护事件及监听者\n this.listeners = {}\n }\n /**\n * 注册事件监听者\n * @param {String} type 事件类型\n * @param {Function} cb 回调函数\n */\n on(type, cb) {\n if (!this.listeners[type]) {\n this.listeners[type] = []\n }\n this.listeners[type].push(cb)\n }\n /**\n * 发布事件\n * @param {String} type 事件类型\n * @param {...any} args 参数列表,把emit传递的参数赋给回调函数\n */\n emit(type, ...args) {\n if (this.listeners[type]) {\n this.listeners[type].forEach(cb => {\n cb(...args)\n })\n }\n }\n /**\n * 移除某个事件的一个监听者\n * @param {String} type 事件类型\n * @param {Function} cb 回调函数\n */\n off(type, cb) {\n if (this.listeners[type]) {\n const targetIndex = this.listeners[type].findIndex(item => item === cb)\n if (targetIndex !== -1) {\n this.listeners[type].splice(targetIndex, 1)\n }\n if (this.listeners[type].length === 0) {\n delete this.listeners[type]\n }\n }\n }\n /**\n * 移除某个事件的所有监听者\n * @param {String} type 事件类型\n */\n offAll(type) {\n if (this.listeners[type]) {\n delete this.listeners[type]\n }\n }\n}\n// 创建事件管理器实例\nconst ee = new EventEmitter()\n// 注册一个chifan事件监听者\nee.on(\'chifan\', function() { console.log(\'吃饭了,我们走!\') })\n// 发布事件chifan\nee.emit(\'chifan\')\n// 也可以emit传递参数\nee.on(\'chifan\', function(address, food) { console.log(`吃饭了,我们去${address}吃${food}!`) })\nee.emit(\'chifan\', \'三食堂\', \'铁板饭\') // 此时会打印两条信息,因为前面注册了两个chifan事件的监听者\n\n// 测试移除事件监听\nconst toBeRemovedListener = function() { console.log(\'我是一个可以被移除的监听者\') }\nee.on(\'testoff\', toBeRemovedListener)\nee.emit(\'testoff\')\nee.off(\'testoff\', toBeRemovedListener)\nee.emit(\'testoff\') // 此时事件监听已经被移除,不会再有console.log打印出来了\n\n// 测试移除chifan的所有事件监听\nee.offAll(\'chifan\')\nconsole.log(ee) // 此时可以看到ee.listeners已经变成空对象了,再emit发送chifan事件也不会有反应了\n```\n\n有了这个自己写的简单版本的`EventEmitter`,我们就不用依赖第三方库啦。对了,`vue`也可以帮我们做这样的事情。\n\n```javascript\nconst ee = new Vue();\nee.$on(\'chifan\', function(address, food) { console.log(`吃饭了,我们去${address}吃${food}!`) })\nee.$emit(\'chifan\', \'三食堂\', \'铁板饭\')\n```\n\n所以我们可以单独`new`一个`Vue`的实例,作为事件管理器导出给外部使用。想测试的朋友可以直接打开`vue`官网,在控制台试试,也可以在自己的`vue`项目中实践下哦。\n\n# 发布订阅模式\n\n其实仔细看看,`EventEmitter`就是一个典型的发布订阅模式,实现了事件调度中心。发布订阅模式中,包含发布者,事件调度中心,订阅者三个角色。我们刚刚实现的`EventEmitter`的一个实例`ee`就是一个事件调度中心,发布者和订阅者是松散耦合的,互不关心对方是否存在,他们关注的是事件本身。发布者借用事件调度中心提供的`emit`方法发布事件,而订阅者则通过`on`进行订阅。\n\n如果还不是很清楚的话,我们把代码换下单词,是不是变得容易理解一点呢?\n\n```javascript\nclass PubSub {\n constructor() {\n // 维护事件及订阅行为\n this.events = {}\n }\n /**\n * 注册事件订阅行为\n * @param {String} type 事件类型\n * @param {Function} cb 回调函数\n */\n subscribe(type, cb) {\n if (!this.events[type]) {\n this.events[type] = []\n }\n this.events[type].push(cb)\n }\n /**\n * 发布事件\n * @param {String} type 事件类型\n * @param {...any} args 参数列表\n */\n publish(type, ...args) {\n if (this.events[type]) {\n this.events[type].forEach(cb => {\n cb(...args)\n })\n }\n }\n /**\n * 移除某个事件的一个订阅行为\n * @param {String} type 事件类型\n * @param {Function} cb 回调函数\n */\n unsubscribe(type, cb) {\n if (this.events[type]) {\n const targetIndex = this.events[type].findIndex(item => item === cb)\n if (targetIndex !== -1) {\n this.events[type].splice(targetIndex, 1)\n }\n if (this.events[type].length === 0) {\n delete this.events[type]\n }\n }\n }\n /**\n * 移除某个事件的所有订阅行为\n * @param {String} type 事件类型\n */\n unsubscribeAll(type) {\n if (this.events[type]) {\n delete this.events[type]\n }\n }\n}\n```\n\n## 画图分析\n\n最后,我们画个图加深下理解:\n\n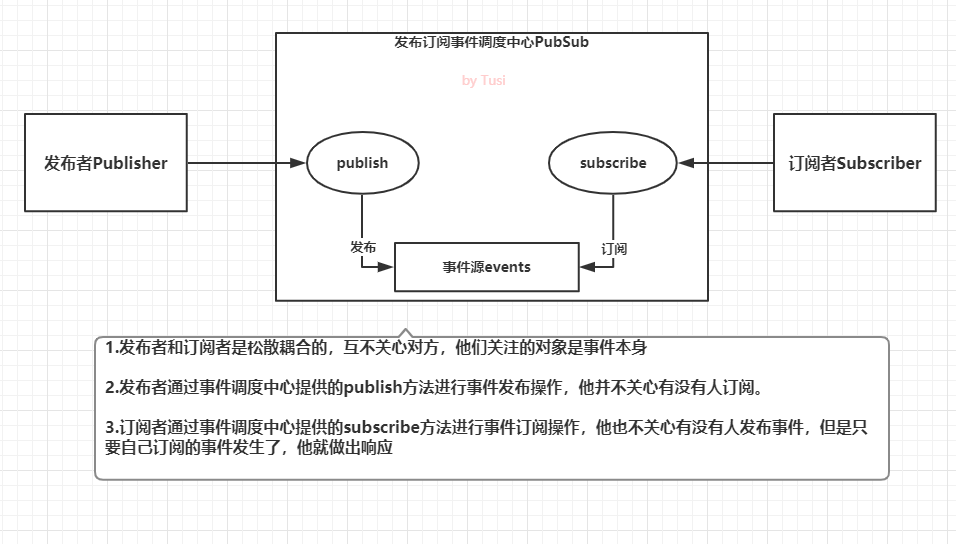\n\n## 特点\n\n- 发布订阅模式中,对于发布者`Publisher`和订阅者`Subscriber`没有特殊的约束,他们好似是匿名活动,借助事件调度中心提供的接口发布和订阅事件,互不了解对方是谁。\n- 松散耦合,灵活度高,常用作事件总线\n- 易理解,可类比于`DOM`事件中的`dispatchEvent`和`addEventListener`。\n\n## 缺点\n\n- 当事件类型越来越多时,难以维护,需要考虑事件命名的规范,也要防范数据流混乱。\n\n# 观察者模式\n\n观察者模式与发布订阅模式相比,耦合度更高,通常用来实现一些响应式的效果。在观察者模式中,只有两个主体,分别是目标对象`Subject`,观察者`Observer`。\n\n- 观察者需`Observer`要实现`update`方法,供目标对象调用。`update`方法中可以执行自定义的业务代码。\n- 目标对象`Subject`也通常被叫做被观察者或主题,它的职能很单一,可以理解为,它只管理一种事件。`Subject`需要维护自身的观察者数组`observerList`,当自身发生变化时,通过调用自身的`notify`方法,依次通知每一个观察者执行`update`方法。\n\n按照这种定义,我们可以实现一个简单版本的观察者模式。\n\n```javascript\n// 观察者\nclass Observer {\n /**\n * 构造器\n * @param {Function} cb 回调函数,收到目标对象通知时执行\n */\n constructor(cb){\n if (typeof cb === \'function\') {\n this.cb = cb\n } else {\n throw new Error(\'Observer构造器必须传入函数类型!\')\n }\n }\n /**\n * 被目标对象通知时执行\n */\n update() {\n this.cb()\n }\n}\n\n// 目标对象\nclass Subject {\n constructor() {\n // 维护观察者列表\n this.observerList = []\n }\n /**\n * 添加一个观察者\n * @param {Observer} observer Observer实例\n */\n addObserver(observer) {\n this.observerList.push(observer)\n }\n /**\n * 通知所有的观察者\n */\n notify() {\n this.observerList.forEach(observer => {\n observer.update()\n })\n }\n}\n\nconst observerCallback = function() {\n console.log(\'我被通知了\')\n}\nconst observer = new Observer(observerCallback)\n\nconst subject = new Subject();\nsubject.addObserver(observer);\nsubject.notify();\n```\n\n## 画图分析\n\n最后也整张图理解下观察者模式:\n\n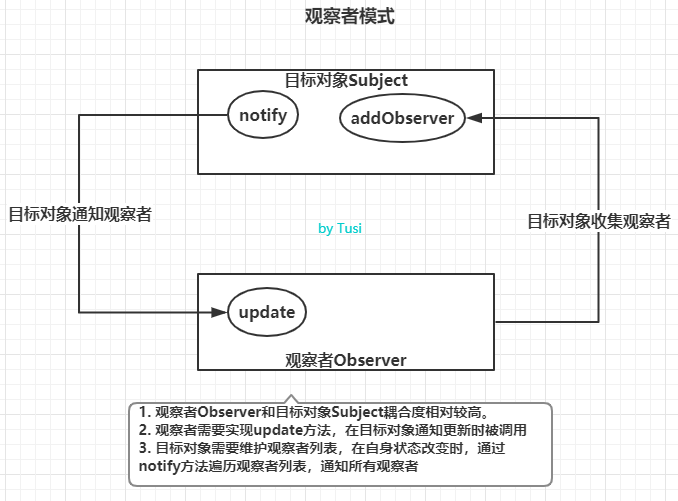\n\n## 特点\n\n- 角色很明确,没有事件调度中心作为中间者,目标对象`Subject`和观察者`Observer`都要实现约定的成员方法。\n- 双方联系更紧密,目标对象的主动性很强,自己收集和维护观察者,并在状态变化时主动通知观察者更新。\n\n## 缺点\n\n我还没体会到,这里不做评价\n\n# 结语\n\n关于这个话题,网上文章挺多的,观点上可能也有诸多分歧。重复造轮子,纯属帮助自己加深理解。\n\n本人水平有限,以上仅是个人观点,如有错误之处,还请斧正!如果能帮到您理解发布订阅模式和观察者模式,非常荣幸!\n\n如果有兴趣看看我这糟糕的代码,请点击[github](https://github.com/cumt-robin/just-demos),祝大家生活愉快!\n\n------', '2019-12-12 10:47:36', '2024-08-03 20:28:50', 1, 105, 0, '今天的话题是javascript中常被提及的「发布订阅模式和观察者模式」,提到这,我不由得想起了一次面试。', 'https://qncdn.wbjiang.cn/%E5%8F%91%E5%B8%83%E8%AE%A2%E9%98%85&%E8%A7%82%E5%AF%9F%E8%80%85.png', 0, 0);
-INSERT INTO `article` VALUES (202, '入门babel,我们需要了解些什么', '说实话,我从工作开始就一直在接触`babel`,然而对于`babel`并没有一个清晰的认识,只知道`babel`是用于编译`javascript`,让开发者能使用超前的`ES6+`语法进行开发。自己配置`babel`的时候,总是遇到很多困惑,下面我就以`babel@7`为例,重新简单认识下`babel`。\n\n# 什么是babel\n\n> Babel 是一个工具链,主要用于将 ECMAScript 2015+ 版本的代码转换为向后兼容的 JavaScript 语法,以便能够运行在当前和旧版本的浏览器或其他环境中。\n\n`babel`的配置文件一般是根目录下的`.babelrc`,`babel@7`目前已经支持`babel.config.js`,不妨用`babel.config.js`试试。\n\n# 泰拳警告\n\n\n\n`babel`提供的基础能力是语法转换,或者叫语法糖转换。比如把箭头函数转为普通的`function`,而对于`ES6`新引入的全局对象是默认不做处理的,如`Promise`, `Map`, `Set`, `Reflect`, `Proxy`等。对于这些全局对象和新的`API`,需要用垫片`polyfill`处理,`core-js`有提供这些内容。\n\n所以`babel`做的事情主要是:\n\n1. 根据你的配置做语法糖解析,转换\n2. 根据你的配置塞入垫片`polyfill`\n\n如果不搞清楚这点,`babel`的文档看起来会很吃力!\n\n# 必须掌握的概念\n\n## plugins\n\n`babel`默认不做任何处理,需要借助插件来完成语法的解析,转换,输出。\n\n插件分为语法插件`Syntax Plugins`和转换插件`Transform Plugins`。\n\n### 语法插件\n\n语法插件仅允许`babel`解析语法,不做转换操作。我们主要关注的是转换插件。\n\n### 转换插件\n\n转换插件,顾名思义,负责的是语法转换。\n\n> 转换插件将启用相应的语法插件,如果启用了某个语法的转换插件,则不必再另行指定相应的语法插件了。\n\n语法转换插件有很多,从`ES3`到`ES2018`,甚至是一些实验性的语法和相关框架生态下的语法,都有相关的插件支持。\n\n语法转换插件主要做的事情有:\n\n利用`@babel/parser`进行词法分析和语法分析,转换为`AST` **-->** 利用`babel-traverse`进行`AST`转换(涉及添加,更新及移除节点等操作) **-->** 利用`babel-generator`生成目标环境`js`代码\n\n### 插件简写\n\n`babel@7`之前的缩写形式是这样的:\n\n```javascript\n// 完整写法\nplugins: [\n \"babel-plugin-transform-runtime\"\n]\n// 简写形式\nplugins: [\n \"transform-runtime\"\n]\n```\n\n而在`babel@7`之后,由于`plugins`都归到了`@babel`目录下,所以简写形式也有所改变:\n\n```java\n// babel@7插件完整写法\nplugins: [\n \"@babel/plugin-transform-runtime\"\n]\n// 简写形式,需要保留目录\nplugins: [\n \"@babel/transform-runtime\"\n]\n```\n\n### 插件开发\n\n我们自己也可以开发插件,官网上的一个非常简单的小例子:\n\n```javascript\nexport default function() {\n return {\n visitor: {\n Identifier(path) {\n const name = path.node.name;\n // reverse the name: JavaScript -> tpircSavaJ\n path.node.name = name\n .split(\"\")\n .reverse()\n .join(\"\");\n },\n },\n };\n}\n```\n\n## presets\n\n`preset`,意为“预设”,其实是一组`plugin`的集合。我的理解是,根据这项配置,`babel`会为你预设(或称为“内置”)好一些`ECMA`标准,草案,或提案下的语法或`API`,甚至是你自己写的一些语法规则。当然,这都是基于`plugin`实现的。\n\n### 官方presets\n\n- [@babel/preset-env](https://babeljs.io/docs/en/babel-preset-env)\n- [@babel/preset-flow](https://babeljs.io/docs/en/babel-preset-flow)\n- [@babel/preset-react](https://babeljs.io/docs/en/babel-preset-react)\n- [@babel/preset-typescript](https://babeljs.io/docs/en/babel-preset-typescript)\n\n### @babel/preset-env\n\n`@babel/preset-env`提供了一种智能的预设,根据配置的`options`来决定支持哪些能力。\n\n我们看看关键的`options`有哪些。\n\n- targets\n\n描述你的项目要支持的目标环境。写法源于开源项目[browserslist](https://github.com/browserslist/browserslist)。这项配置应该根据你需要兼容的浏览器而设置,不必与其他人一模一样。示例如下:\n\n```javascript\n\"targets\": {\n \"browsers\": [\"> 1%\", \"last 2 versions\", \"not ie <= 9\"]\n}\n```\n\n- loose\n\n可以直译为“松散模式”,默认为`false`,即为`normal`模式。简单地说,就是`normal`模式转换出来的代码更贴合`ES6`风格,更严谨;而`loose`模式更像我们平时的写法。以`class`写法举例:\n\n我们先写个简单的`class`:\n\n```javascript\nclass TestBabelLoose {\n constractor(name) {\n this.name = name\n }\n getName() {\n return this.name\n }\n}\n\nnew TestBabelLoose(\'Tusi\')\n```\n\n使用`normal`模式编译得到结果如下:\n\n```javascript\nfunction _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError(\"Cannot call a class as a function\"); } }\n\nfunction _defineProperties(target, props) { for (var i = 0; i < props.length; i++) { var descriptor = props[i]; descriptor.enumerable = descriptor.enumerable || false; descriptor.configurable = true; if (\"value\" in descriptor) descriptor.writable = true; Object.defineProperty(target, descriptor.key, descriptor); } }\n\nfunction _createClass(Constructor, protoProps, staticProps) { if (protoProps) _defineProperties(Constructor.prototype, protoProps); if (staticProps) _defineProperties(Constructor, staticProps); return Constructor; }\n\nvar TestBabelLoose =\n/*#__PURE__*/\nfunction () {\n function TestBabelLoose() {\n _classCallCheck(this, TestBabelLoose);\n }\n\n _createClass(TestBabelLoose, [{\n key: \"constractor\",\n value: function constractor(name) {\n this.name = name;\n }\n }, {\n key: \"getName\",\n value: function getName() {\n return this.name;\n }\n }]);\n\n return TestBabelLoose;\n}();\n\nnew TestBabelLoose(\'Tusi\');\n```\n\n而使用`loose`模式编译得到结果是这样的,是不是更符合我们用`prototype`实现类的写法?\n\n```javascript\n\"use strict\";\n\nvar TestBabelLoose =\n/*#__PURE__*/\nfunction () {\n function TestBabelLoose() {}\n\n var _proto = TestBabelLoose.prototype;\n\n _proto.constractor = function constractor(name) {\n this.name = name;\n };\n\n _proto.getName = function getName() {\n return this.name;\n };\n\n return TestBabelLoose;\n}();\n\nnew TestBabelLoose(\'Tusi\');\n```\n\n个人推荐配置`loose: false`,当然也要结合项目实际去考量哪种模式更合适。\n\n- modules\n\n可选值有:`\"amd\" | \"umd\" | \"systemjs\" | \"commonjs\" | \"cjs\" | \"auto\" | false`,默认是`auto`\n\n该配置将决定是否把`ES6`模块语法转换为其他模块类型。注意,`cjs`是`commonjs`的别名。\n\n其实我一直有个疑惑,为什么我看到的开源组件中,基本都是设置的`modules: false`?后面终于明白了,原来这样做的目的是把转换模块类型的处理权交给了`webpack`,由`webpack`去处理这项任务。所以,如果你也使用`webpack`,那么设置`modules: false`就没错啦。\n\n- useBuiltIns\n\n可选值有:`\"entry\" | \"usage\" | false`,默认是`false`\n\n该配置将决定`@babel/preset-env`如何去处理`polyfill`\n\n`\"entry\"`\n\n如果`useBuiltIns`设置为`\"entry\"`,我们需要安装`@babel/polyfill`,并且在入口文件引入`@babel/polyfill`,最终会被转换为`core-js`模块和`regenerator-runtime/runtime`。对了,`@babel/polyfill`也不会处理`stage <=3`的提案。\n\n我们用一段包含了`Promise`的代码来做下测试:\n\n```javascript\nimport \"@babel/polyfill\";\n\nclass TestBabelLoose {\n constractor(name) {\n this.name = name\n }\n getName() {\n return this.name\n }\n testPromise() {\n return new Promise(resolve => {\n resolve()\n })\n }\n}\nnew TestBabelLoose(\'Tusi\')\n```\n\n但是编译后,貌似引入了很多`polyfill`啊,一共149个,怎么不是按需引入呢?嗯...你需要往下看了。\n\n```javascript\nimport \"core-js/modules/es6.array.map\";\nimport \"core-js/modules/es6.map\";\nimport \"core-js/modules/es6.promise\";\nimport \"core-js/modules/es7.promise.finally\";\nimport \"regenerator-runtime/runtime\";\n// 此处省略了144个包。。。\n```\n\n`\"usage\"`\n\n如果`useBuiltIns`设置为`\"usage\"`,我们无需安装`@babel/polyfill`,`babel`会根据你实际用到的语法特性导入相应的`polyfill`,有点按需加载的意思。\n\n```javascript\n// 上个例子中,如果改用useBuiltIns: \'usage\',最终转换的结果,只有四个模块\nimport \"core-js/modules/es6.object.define-property\";\nimport \"core-js/modules/es6.promise\";\nimport \"core-js/modules/es6.object.to-string\";\nimport \"core-js/modules/es6.function.name\";\n```\n\n配置`\"usage\"`时,常搭配`corejs`选项来指定`core-js`主版本号\n\n```javascript\nuseBuiltIns: \"usage\",\ncorejs: 3\n```\n\n`false`\n\n如果`useBuiltIns`设置为`false`,`babel`不会自动为每个文件加上`polyfill`,也不会把`import \"@babel/polyfill\"`转为一个个独立的`core-js`模块。\n\n- `@babel/preset-env`还有一些配置,自己慢慢去折腾吧......\n\n### stage-x\n\n`stage-x`描述的是`ECMA`标准相关的内容。根据`TC39`(`ECMA`39号技术专家委员会)的提案划分界限,`stage-x`大致分为以下几个阶段:\n\n- stage-0:`strawman`,还只是一种设想,只能由`TC39`成员或者`TC39`贡献者提出。\n- stage-1:`proposal`,提案阶段,比较正式的提议,只能由`TC39`成员发起,这个提案要解决的问题须有正式的书面描述,一般会提出一些案例,以及`API`,语法,算法的雏形。\n- stage-2:`draft`,草案,有了初始规范,必须对功能的语法和语义进行正式描述,包括一些实验性的实现,也可以提出一些待办事项。\n- stage-3:`condidate`,候选,该提议基本已经实现,需要等待实践验证,用户反馈及验收测试通过。\n- stage-4:`finished`,已完成,必须通过`Test262`验收测试,下一步就是纳入到`ECMA`标准中。比如一些`ES2016`,`ES2017`的语法就是通过这个阶段被合入`ECMA`标准中了。\n\n有兴趣了解的可以关注[ecma262](https://github.com/tc39/ecma262)。\n\n> 需要注意的是,babel@7已经移除了stage-x的preset,stage-4部分的功能已经被@babel/preset-env集成了,而如果你需要stage <= 3部分的功能,则需要自行通过plugins组装。\n\n```\nAs of v7.0.0-beta.55, we\'ve removed Babel\'s Stage presets.\nPlease consider reading our blog post on this decision at\nhttps://babeljs.io/blog/2018/07/27/removing-babels-stage-presets\nfor more details. TL;DR is that it\'s more beneficial in the long run to explicitly add which proposals to use.\nIf you want the same configuration as before:\n{\n \"plugins\": [\n // Stage 2\n [\"@babel/plugin-proposal-decorators\", { \"legacy\": true }],\n \"@babel/plugin-proposal-function-sent\",\n \"@babel/plugin-proposal-export-namespace-from\",\n \"@babel/plugin-proposal-numeric-separator\",\n \"@babel/plugin-proposal-throw-expressions\",\n // Stage 3\n \"@babel/plugin-syntax-dynamic-import\",\n \"@babel/plugin-syntax-import-meta\",\n [\"@babel/plugin-proposal-class-properties\", { \"loose\": false }],\n \"@babel/plugin-proposal-json-strings\"\n ]\n}\n```\n\n### 自己写preset\n\n如需创建一个自己的`preset`,只需导出一份配置即可,主要是通过写`plugins`来实现`preset`。此外,我们也可以在自己的`preset`中包含第三方的`preset`。\n\n```javascript\nmodule.exports = function() {\n return {\n // 增加presets项去包含别人的preset\n presets: [\n require(\"@babel/preset-env\")\n ],\n // 用插件来包装成自己的preset\n plugins: [\n \"pluginA\",\n \"pluginB\",\n \"pluginC\"\n ]\n };\n}\n```\n\n# @babel/runtime\n\n`babel`运行时,很重要的一个东西,它一定程度上决定了你产出的包的大小!一般适合于组件库开发,而不是应用级的产品开发。\n\n## 说明\n\n这里有两个东西要注意,一个是`@babel/runtime`,它包含了大量的语法转换包,会根据情况被按需引入。另一个是`@babel/plugin-transform-runtime`,它是插件,负责在`babel`转换代码时分析词法语法,分析出你真正用到的`ES6+`语法,然后在`transformed code`中引入对应的`@babel/runtime`中的包,实现按需引入。\n\n举个例子,我用到了展开运算符`...`,那么经过`@babel/plugin-transform-runtime`处理后的结果是这样的:\n\n```javascript\n/* 0 */\n/***/ (function(module, exports, __webpack_require__) {\n\nvar arrayWithoutHoles = __webpack_require__(2);\n\nvar iterableToArray = __webpack_require__(3);\n\nvar nonIterableSpread = __webpack_require__(4);\n\nfunction _toConsumableArray(arr) {\n return arrayWithoutHoles(arr) || iterableToArray(arr) || nonIterableSpread();\n}\n\nmodule.exports = _toConsumableArray;\n \n// EXTERNAL MODULE: ../node_modules/@babel/runtime/helpers/toConsumableArray.js\nvar toConsumableArray = __webpack_require__(0);\nvar toConsumableArray_default = /*#__PURE__*/__webpack_require__.n(toConsumableArray);\n```\n\n## 安装和简单配置\n\n`@babel/runtime`是需要按需引入到生产环境中的,而`@babel/plugin-transform-runtime`是`babel`辅助插件。因此安装方式如下:\n\n```\nnpm i --save @babel/runtime\nnpm i --save-dev @babel/plugin-transform-runtime\n```\n\n配置时也挺简单:\n\n```javascript\nconst buildConfig = {\n presets: [\n // ......\n ],\n plugins: [\n \"@babel/plugin-transform-runtime\"\n ],\n // ......\n}\n```\n\n## @babel/runtime和useBuiltIns: \'usage\'有什么区别?\n\n两者看起来都实现了按需加载的能力,但是实际上作用是不一样的。`@babel/runtime`处理的是语法支持,把新的语法糖转为目标环境支持的语法;而`useBuiltIns: \'usage\'`处理的是垫片`polyfill`,为旧的环境提供新的全局对象,如`Promise`等,提供新的原型方法支持,如`Array.prototype.includes`等。如果你开发的是组件库,一般不建议处理`polyfill`的,应该由调用者去做这些支持,防止重复的`polyfill`。\n\n- 开发组件时,如果仅使用`@babel/plugin-transform-runtime`\n\n\n\n- 加上`useBuiltIns: \'usage\'`,多了很多不必要的包。\n\n\n\n# babel@7要注意的地方\n\n最后简单地提一下使用`babel@7`要注意的地方,当然更详细的内容还是要看[babel官方](https://babeljs.io/docs/en/v7-migration)。\n\n- `babel@7`相关的包命名都改了,基本是`@babel/plugin-xxx`, `@babel/preset-xxx`这种形式。这是开发插件体系时一个比较标准的命名和目录组织规范。\n- 建议用`babel.config.js`代替`.babelrc`,这在你要支持不同环境时特别有用。\n- `babel@7`已经移除了`stage-x`的`presets`,也不鼓励再使用`@babel/polyfill`。\n- 不要再使用`babel-preset-es2015`, `babel-preset-es2016`等`preset`了,应该用`@babel/preset-env`代替。\n- ......\n\n# 结语\n\n本人只是对`babel`有个粗略的认识,所以这是一篇`babel`入门的简单介绍,并没有提到深入的内容,可能也存在错误之处。自己翻来覆去也看过好几遍`babel`的文档了,一直觉得收获不大,也没理解到什么东西,在与`webpack`配合使用的过程中,还是有很多疑惑没搞懂的。其实错在自己不该在复杂的项目中直接去实践。在最近重新学习`webpack`和`babel`的过程中,我觉得,对于不是很懂的东西,我们不妨从写一个`hello world`开始,因为不是每个人都是理解能力超群的天才......\n\n-----', '2019-12-17 09:43:47', '2024-08-03 12:21:07', 1, 44, 0, '说实话,我从工作开始就一直在接触babel,然而对于babel并没有一个清晰的认识,只知道babel是用于编译javascript,让开发者能使用超前的ES6+语法进行开发。自己配置babel的时候,总是遇到很多困惑,下面我就以babel@7为例,重新简单认识下babel。', 'https://qncdn.wbjiang.cn/babel.png', 0, 0);
-INSERT INTO `article` VALUES (203, '自动化部署的一小步,前端搬砖的一大步', '在`nodejs`日渐普及的大背景下,**前端工程化**的发展可谓日新月异。构建打包这种日常任务脚本化已经是常态了,`webpack`和`gulp`已经家喻户晓自然不必多说,而**持续集成/持续交付/持续部署**也越来越得到各个前端`Team`的重视,业界也有了很多成熟的概念或者方案,如`Hudson`, `Jenkins`, `Travis CI `, `Circle CI`, `DevOps`, `git hook`。然而对于小白来讲,如果直接上手这些内容,很容易混淆概念,陷入迷茫。如果为了用`Jenkins`而用`Jenkins`,那不是我的做事风格,我必须搞清楚这项技术能给我带来什么。所以我干脆回归问题本质,从最简单的**工作流**入手,先**解决手动部署的效率问题**。\n\n> 前面说这么多废话纯属凑字数,对了,本文讲的内容比较简单,不适合工作流已经很完善的同学\n\n# 自动构建\n\n**构建不是本文的重点**,也不是一篇短文能够讲清楚的,这里就一笔带过了。\n\n## 构建工具\n\n使用主流的构建工具如`webpack`, `gulp`, `rollup`等。\n\n## 构建目标\n\n通过脚本化的形式组织`代码检查`,`编译`,`压缩`,`混淆`,`资源处理`,`devServer`等工作流事务。\n\n# 手动部署\n\n## 踩过的坑\n\n本人曾经也尝试过两种手动部署的方法。\n\n- 搬砖模式,将构建完毕的文件夹通过`xftp`传输到服务器`/usr/share/nginx/html`目录下。\n- 将构建完毕的文件夹用`git`分支管理起来,推送到远程仓库,然后在`linux`服务器上拉取这部分代码。\n\n第一种方法显然已经属于刀耕火种模式了,不过我竟然用了很久。唉,没办法,业务缠身的我只能挤出时间来优化工作流。\n\n第二种方法我自己私下也用过,后来一想,好像可以用[git hook](https://www.git-scm.com/book/zh/v2/自定义-Git-Git-钩子)来改造优化下,也是实现自动部署的好方法。有兴趣的同学可以试试`git hook`。\n\n# 自动部署\n\n## 写脚本\n\n先写个自动构建部署的脚本,主要是包含了切`git`分支,拉取最新代码,构建打包,传输文件到服务器这些步骤。\n\n> scp 命令用于 Linux 之间复制文件和目录\n\n```shell\n#!/bin/bash\ngit checkout develop\ngit pull\nnpm run build:test\nscp -r ./dist/. username@162.81.49.85:/usr/share/nginx/html/projectname/\n```\n\n**ps:**`ip`已经被我胡乱改了一把,别试着攻击我了。\n\n然而我发现在使用部署脚本的过程中,**每次操作都要输入密码**,很烦人。\n\n## ssh认证\n\n虽然很讨厌输密码,但是密码是安全的保证,如果不输入密码,只能通过`ssh`安全访问了。\n\n首先是在自己工作电脑的`~/.ssh`目录下**创建密钥对**。\n\n```shell\nssh-keygen -t rsa\n```\n\n根据个人情况按需修改密钥对的文件名,输入密码时回车即可,代表不需要使用密码\n\n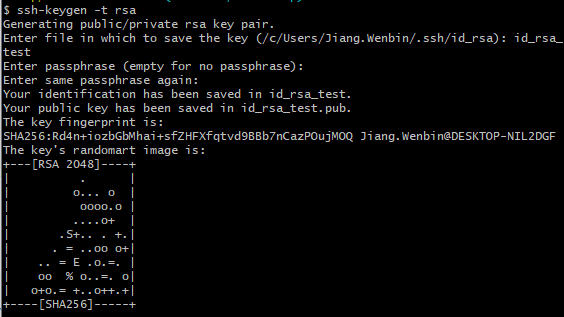\n\n接着要**把公钥传输到服务器**上\n\n```shell\nscp ~/.ssh/id_rsa.pub username@162.81.49.85:/home/username/.ssh/authorized_keys\n```\n\n> 如果服务器已经存在`authorized_keys`文件,那么可以直接在服务器上修改`authorized_keys`文件,在文件末加入你自己的`id_rsa.pub`内容即可。\n\n然后我们再修改部署脚本,改用`ssh`认证方式向`linux`服务器传输文件。\n\n```shell\n#!/bin/bash\ngit checkout develop\nnpm run build:test\nscp -i ~/.ssh/id_rsa -r ./dist/. username@162.81.49.85:/usr/share/nginx/html/projectname/\n```\n\n> `scp`的`-i`参数指定传输时使用的密钥文件,这样就可以通过`ssh`安全访问,而不用再每次输入密码了。`-r`参数则是`recursive`,代表递归复制整个目录。\n\n最后我们可以修改下`package.json`,通过`npm scripts`来执行`sh`\n\n```json\n\"scripts\": {\n \"deploy:test\": \"deploy-test.sh\"\n}\n```\n\n配合`vscode`的`npm scripts`快捷方式,用起来就很舒服了。\n\n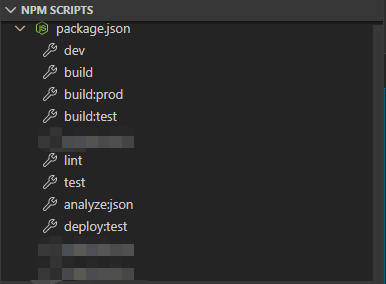\n\n注意,如果`linux`文件**权限不够**也可能报错的,别忘了给`authorized_keys`文件赋予权限,**拥有者可读可写**即可。\n\n```shell\nchmod 600 authorized_keys\n```\n\n好了,按下那个`deploy:test`,静静等待一会吧。此时别忘了扭扭脖子,按按腰啊,程序员还是要注意身体,对自己好一点。\n\n\n\n随着`bash`窗口的自动关闭,部署工作也画上了句号。\n\n\n\n# last but not least\n\n这里还要考虑的一个问题是,部署过程中会不会造成用户访问问题?\n\n答案是**会影响用户访问**。比如部署脚本执行过程中,已经替换了`index.html`,正在部署静态资源,此时用户正好进入网站,新的`index.html`却访问不到新的静态资源,网页白屏报错。\n\n解决方法是**先上静态资源,再上页面**。因为静态资源经`webpack`构建后都带上了`hash`值,先上静态资源不会影响原有的版本,所以我们还需要再优化下部署脚本,分解下传输过程。\n\n很头疼的是`scp`命令竟然不能忽略文件,这就有点麻烦了。\n\n如果打包后的`dist`根目录文件不算很多,可以考虑手动列举的方式来排列传输顺序。举个例子:\n\n```shell\n#!/bin/bash\ngit checkout develop\ngit pull\nnpm run build:test\nscp -i ~/.ssh/id_rsa -r ./dist/static username@162.81.49.85:/usr/share/nginx/html/projectname/\nscp -i ~/.ssh/id_rsa ./dist/favicon.ico username@162.81.49.85:/usr/share/nginx/html/projectname/favicon.ico\nscp -i ~/.ssh/id_rsa ./dist/element-icons.ttf username@162.81.49.85:/usr/share/nginx/html/projectname/element-icons.ttf\nscp -i ~/.ssh/id_rsa ./dist/element-icons.woff username@162.81.49.85:/usr/share/nginx/html/projectname/element-icons.woff\nscp -i ~/.ssh/id_rsa ./dist/index.html username@162.81.49.85:/usr/share/nginx/html/projectname/index.html\n```\n\n如果觉得这样很傻X,那么可以考虑下`rsync`了,`rsync`是可以通过`--exclude`忽略文件的,这样的话理论上只需要写两条传输命令即可,也不用考虑后续构建可能会新增的内容。不过在`windows`和`linux`之间用`rsync`还是蛮复杂的,留给各位大佬自己探索啦。', '2020-01-16 22:07:18', '2024-10-31 16:41:24', 1, 59, 0, '手撸一个前端自动部署脚本', 'https://qncdn.wbjiang.cn/前端自动化部署海报.png', 0, 0);
-INSERT INTO `article` VALUES (204, '前端自动化部署的深度实践', '年前我也在**自动化部署**这方面下了点功夫,将自己的学习所得在[自动化部署的一小步,前端搬砖的一大步](https://juejin.im/post/5e206168f265da3e2b2d7560)这篇博客中做了分享。感谢两位网友`@_shanks`和`@TomCzHen`的意见,让我有了继续优化部署流程的动力。本文主要是在自动化部署流程中,对**版本管理**和**流程合理性**等方面做了一些改进,配合规范的工作流,使用体验更佳!\n\n# 更新日志自动生成\n\n之前我都是手动修改`CHANGELOG.md`,用来记录更新日志,感觉操作起来有点心累,也不是很规范。好在已有前人种树,于是我就考虑利用`conventional-changelog-cli`自动生成和更新`CHANGELOG.md`,真的好用!\n\n.gif)\n\n## 什么是conventional-changelog\n\n> Generate a changelog from git metadata\n\n根据`git`元数据生成更新日志,而`conventional-changelog-cli`则是相关的命令行工具。\n\n## 安装conventional-changelog-cli\n\n```shell\nnpm install -g conventional-changelog-cli\n```\n\n## 初始化生成CHANGELOG.md\n\n```shell\ncd my-project\nconventional-changelog -p angular -i CHANGELOG.md -s\n```\n\n以上命令是基于最后一次的`Feature`, `Fix`, `Performance Improvement or Breaking Changes`等类型的`commit`记录生成或更新`CHANGELOG.md`。如果你希望根据之前所有的`commit`记录生成完整的`CHANGELOG.md`,那么可以试试下面这条命令:\n\n```shell\nconventional-changelog -p angular -i CHANGELOG.md -s -r 0\n```\n\n# 工作流\n\n## 代码添加到暂存区\n\n这一步没有什么特殊,日常撸代码,然后将工作区的内容添加到暂存区。\n\n```shell\ngit add .\n```\n\n## 规范commit message\n\n> 一个规范的commit message一般分为三个部分Header,Body 和 Footer。Header包含type, scope, subject等部分,分别用于描述commit类型,影响范围,commit简述。Body则是详细描述,可以分多行写。Footer主要用于描述不兼容改动(Breaking Change)或者关闭issue(Closes #issue)。\n\n格式如下:\n\n```xml\n(): \n\n\n\n\n```\n\n举个栗子:\n\n```\nfeat(支持自动部署): 结合conventional-changelog,配合部署脚本完成部署任务\n\nconventional-changelog是一个很好的工具,用于自动生成changelog,再配上自定义的部署脚本,整个部署流程就显得更规范了\n\nBreaking Change: 比较大的更新\nCloses #315\n```\n\n其中,`Header`是必需的,`Body`和`Footer`可以省略。\n\n大致了解规范后,就可以上工具了,这里我们用到的是`commitizen`。\n\n```shell\nnpm install -g commitizen\n```\n\n接着在项目根目录运行以下命令:\n\n```shell\ncommitizen init cz-conventional-changelog --save --save-exact\n```\n\n运行成功后,`package.json`会新增如下内容:\n\n```json\n\"devDependencies\": {\n \"cz-conventional-changelog\": \"^3.1.0\"\n},\n\"config\": {\n \"commitizen\": {\n \"path\": \"./node_modules/cz-conventional-changelog\"\n }\n}\n```\n\n`git commit`这一步用`git cz替代`,`cz`就是指`commitizen`,通过交互式命令行完成`commit`操作。\n\n```shell\nPS D:\\robin\\frontend\\spa-blog-frontend> git cz\ncz-cli@4.0.3, cz-conventional-changelog@3.1.0\n\n? Select the type of change that you\'re committing: feat: A new feature\n? What is the scope of this change (e.g. component or file name): (press enter to skip) 支持自动部署\n? Write a short, imperative tense description of the change (max 86 chars):\n (37) 结合conventional-changelog,配合部署脚本完成部署任务\n? Provide a longer description of the change: (press enter to skip)\n\n? Are there any breaking changes? No\n? Does this change affect any open issues? No\n[master ee41f35] feat(支持自动部署): 结合conventional-changelog,配合部署脚本完成部署任务\n 3 files changed, 15 insertions(+), 3 deletions(-)\n```\n\n## 处理版本号,更新CHANGELOG\n\n接着我们要更新`npm`包的版本号,结合`npm version`和`conventional-changelog`使用,可以同时更新`CHANGELOG.md`。\n\n好的,我们先准备好脚本:\n\n```json\n\"scripts\": {\n \"start\": \"vue-cli-service serve\",\n \"build\": \"vue-cli-service build\",\n \"deploy\": \"node deploy\",\n \"version\": \"conventional-changelog -p angular -i CHANGELOG.md -s && git add CHANGELOG.md\",\n \"postversion\": \"npm run deploy\"\n}\n```\n\n根据实际版本情况选择更新`patch/minor/major`版本。假设我们更新的是`minor`版本号,那么操作命令如下:\n\n```shell\nnpm version minor -m \'特性版本更新\'\n```\n\n执行这条命令会更新`package.json`中的`version`字段,\n\n同时会执行`conventional-changelog -p angular -i CHANGELOG.md -s && git add CHANGELOG.md`,更新`CHANGELOG.md`。\n\n执行完这条命令后,可以看到`CHANGELOG.md`已经被修改了。\n\n\n\n## npm钩子触发部署脚本\n\n通过`postversion`钩子触发部署脚本`node deploy`,开始进行部署工作。`deploy.js`文件内容如下:\n\n```javascript\nconst { execFile } = require(\'child_process\');\n\nconst version = process.env.npm_package_version;\n\nexecFile(\'deploy.sh\', [version], { shell: true }, (err, stdout, stderr) => {\n if (err) {\n throw err;\n }\n console.log(stdout);\n});\n```\n\n这里利用了`nodejs`的 `child_process`模块执行子进程,调用了`execFile`执行了 `deploy.sh`,并将`npm`包版本号作为参数传递给了`deploy.sh`。\n\n`deploy.sh`文件内容如下:\n\n```shell\n#!/bin/bash\nnpm run build\nhtmldir=\"/usr/share/nginx/html\"\nuploadbasedir=\"${htmldir}/upgrade_blog_vue_ts\"\nappenddir=$1\nuploaddir=\"${uploadbasedir}/${appenddir}\"\nprojectdir=\"/usr/share/nginx/html/blog_vue_ts\"\nscp -r ./dist/. txcloud:${uploaddir}\nssh txcloud > /dev/null 2>&1 << eeooff\nln -snf ${uploaddir} ${projectdir}\nexit\neeooff\necho done\n```\n\n以上命令主要做的事情是:\n\n- `npm run build`执行构建任务\n- 将构建得到的`dist`文件夹中的内容通过`scp`传输到服务器,通过版本号区分各个版本。\n- `nginx`配置的是监听`80`端口,指向`/usr/share/nginx/html/blog_vue_ts`,而我通过软连接将`blog_vue_ts`再次指向到`upgrade_blog_vue_ts`下的版本目录,如`upgrade_blog_vue_ts/0.5.4`。每次发布版本时,以上脚本会修改软连接,指向目标版本,如`upgrade_blog_vue_ts/0.6.0`,完成版本过渡。\n\n我这里使用了软连接改进了之前的部署脚本,既可以在服务器保留各个历史版本文件夹,也不用考虑处理`index.html`与静态资源分离的问题。\n\n**强烈建议结合[自动化部署的一小步,前端搬砖的一大步](https://juejin.im/post/5e206168f265da3e2b2d7560)这篇文章一起看。**\n\n```shell\nlrwxrwxrwx 1 root root 47 Feb 3 21:35 blog_vue_ts -> /usr/share/nginx/html/upgrade_blog_vue_ts/0.6.0\n```\n\n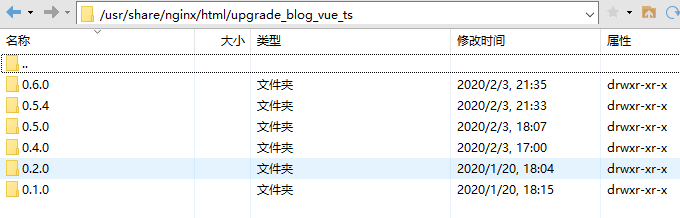\n\n如果要回退版本,也可以通过修改软连接的方式实现,还是比较方便的。\n\n## 推送到remote\n\n最后别忘了把代码`push`到远程仓库。\n\n```shell\ngit push\n```\n\n更新日志`changelog`查看也变得很方便了,修改了什么内容一目了然,并且可以直接跳转到`commit`历史,`issue`等。\n\n\n\n# 番外\n\n可以看到,我是通过`deploy.js`调用了`deploy.sh`。之前本想直接在`npm scripts`中调用`deploy.sh`并传入版本号参数的,但是试了几种写法都不行,这里也记录一下。\n\n```json\n\"deploy\": \"deploy.sh npm_package_version\"\n```\n\n```shell\n\"deploy\": \"deploy.sh $npm_package_version\"\n```\n\n看起来在`npm scripts`中调用`sh`脚本时,只能写字面量参数,传变量作为参数好像行不通。\n\n下面这种字面量参数写法是可以的,但是就有点呆呆的感觉了,而且与自动化部署的主题不符。\n\n```shell\n\"deploy\": \"deploy.sh 0.6.0\"\n```\n\n所以我目前还是选择通过`deploy.js`作为中间者来调用`deploy.sh`的。\n\n# 结语\n\n需要承认的是,我以上所述的部署流程是以我的个人项目为例说明,可能不是很规范,但是也算是通过自己的理解和摸索,完整地搞了一套部署流程,并没有借用`jenkins`等工具。有了这段自动化部署的学习经历后,相信学习和使用`jenkins`会变得更轻松。接下来我会继续优化和规范自己的部署流程,`jenkins`理所当然会出现在我的计划表中。', '2020-02-04 12:16:14', '2024-10-31 16:41:03', 1, 50, 0, '年前我也在自动化部署这方面下了点功夫,将自己的学习所得在自动化部署的一小步,前端搬砖的一大步这篇博客中做了分享。感谢两位网友@_shanks和@TomCzHen的意见,让我有了继续优化部署流程的动力。', 'https://qncdn.wbjiang.cn/自动化部署深度实践.png', 0, 0);
-INSERT INTO `article` VALUES (205, '共克时疫,https+小程序为“战疫”献上一份技术力量', '# 前言\n\n新型冠状病毒笼罩下的新年,让每个中国人都感到恐慌和揪心。我们每天为前线的白衣天使和平民英雄们的事迹感动而落泪,也为不法分子哄抬物价,无良个人以权谋私等自私自利的行为而感到痛心疾首。作为普通人,我们最大的贡献就是宅在家里,响应钟南山院士的号召,**做好个人防护,不为疫情添负担,不为他人添麻烦**。最近看到很多大佬都为“**战疫**”贡献了自己的技术力量,有的人提供了数据和接口支持,有的人做了`app`,有的人做了`webapp`。看到这些举动,我也跃跃欲试,静下心去做,总会做点东西出来,于是我做了一版微信小程序,主要是想方便自己和家人朋友们查询下最新的数据,毕竟大家都用微信。\n\n> 微信小程序的版本审核实在太慢了,昨天提交版本审核的,现在还没通过,唉,心累。\n\n# 数据获取和处理\n\n首先要感谢丁香园,数据源于丁香园-丁香医生。\n\n重点要感谢[掘金@普通程序员](https://juejin.im/user/5e2741925188254baf6c4cb1/activities)提供的数据接口能力,让我们菜鸡也有机会做一点微小的工作。\n\n为了防止给大佬的服务器增加访问压力,我每15分钟抓取一次接口数据,存储于个人服务器上,供自己和他人访问和使用。\n\n> Q: 为什么别人有提供接口,你还要再多此一举?A:我要做小程序,没有https搞不了。\n\n目前主要上线了以下接口:\n\n在线接口基地址: `https://wuhan.wbjiang.cn/api/`\n\n| 接口名 | 请求方式 | 接口描述 |\n| -------------------- | -------- | ------------------------------------------------------------ |\n| timeline | GET | 获取发生的事件,支持分页参数pageNo和pageSize |\n| stats | GET | 整体统计数据 |\n| rumour | GET | 最新辟谣 |\n| protect_wiki | GET | 最新防护知识 |\n| wiki | GET | 最新知识百科 |\n| help_links | GET | 便民信息/诊疗信息 |\n| province_stats | GET | 全国省份级患者分布数据 |\n| city_stats/:areaName | GET | 根据省份查市县疫情数据,areaName传入省级行政区的简写,如“湖南” |\n| oversea_stats | GET | 全球海外其他地区患者分布数据 |\n\n可以点击[在线访问整体统计数据](https://wuhan.wbjiang.cn/api/stats)试试看呢!\n\n```\nhttps://wuhan.wbjiang.cn/api/stats\n```\n\n该服务的源码我也上传到了`github`,欢迎访问[wuhan_best_wishes](https://github.com/cumt-robin/wuhan_best_wishes)查看,如果能顺手给个`star`那是极好的,感谢感谢!\n\n# HTTPS支持\n\n由于**微信小程序**需要调用`https`协议的接口,所以我利用`nginx`的能力和阿里云提供的`SSL`证书,对上述接口提供了`https`支持。\n\n# 服务整体框架\n\n**接口服务**:使用的是`nodejs`语言,技术框架是`express`。\n\n**应用管理**:利用`pm2`来管理`node`应用。\n\n**代理服务器**:利用`Nginx`监听`80`端口,转发到`node`服务所在的内部端口。\n\n# 小程序概述\n\n取名挺烦的,拟的名字要么是被行业限制,要么已经有人用了。最后就随便取了个名**wuhan速报**。\n\n技术方面,我暂时没有使用框架,用的是小程序原生的开发语言。为了快速出第一版效果,`UI`部分用到了我熟悉的`vant-weapp`。\n\n相关代码已开源,请访问[ncov-weapp](https://github.com/cumt-robin/ncov_weapp)查看源码。\n\n先发个小程序码,方便大家直接访问小程序(**暂时还没通过审核**,微信小程序审核速度你懂的,如果想体验一下的话,欢迎加我微信ice_lloly使用体验版)。\n\n\n\n# 小程序内容\n\n内容上,主要做了四个页面,分为**疫情地图**,**辟谣与防护**,**事件播报**,**疾病知识**等几块。\n\n> 疫情统计数据\n\n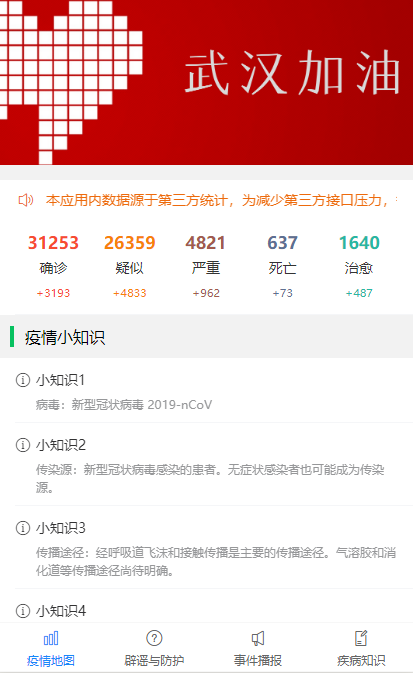\n\n> 疫情地图与趋势\n\n\n\n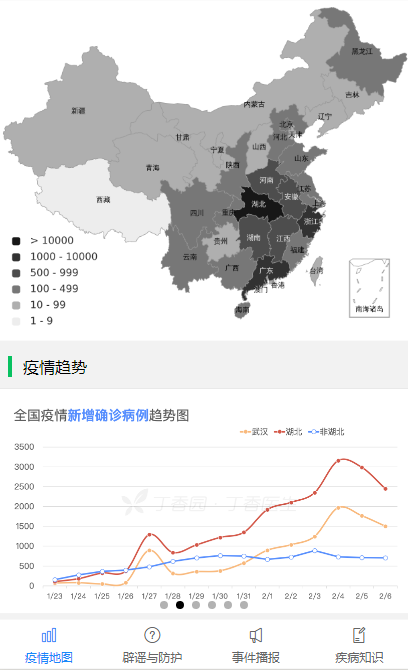\n\n> 国内省市疫情分布\n\n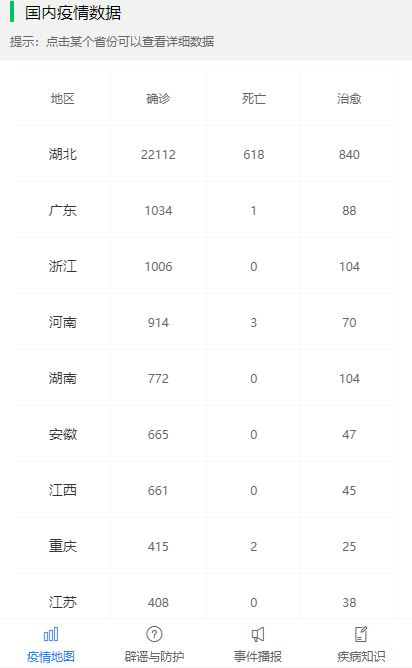\n\n> 海外疫情分布\n\n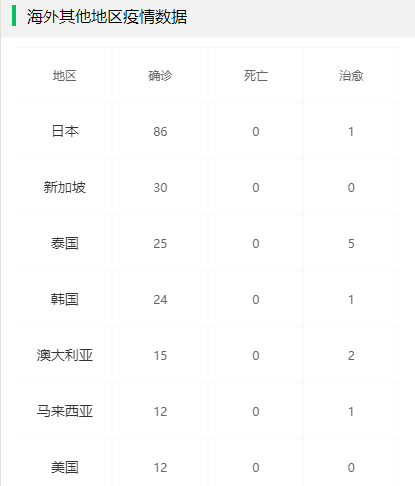\n\n> 辟谣与防护\n\n\n\n> 最新事件实时播报\n\n\n\n> 疾病知识\n\n\n\n\n\n为了快速出效果,做的时候有参考丁香园的设计,感谢丁香园技术和设计团队!\n\n# 结语\n\n由于时间有限,大概花了一天多的时间吧,所以做出来的效果是比较粗糙的。接下来我会在有余力的情况下,继续迭代更新,毕竟还是要远程办公的,大部分时间还是要聚焦于公司业务。', '2020-02-08 09:22:54', '2024-08-15 10:12:03', 1, 57, 0, '新型冠状病毒笼罩下的新年,让每个中国人都感到恐慌和揪心。作为程序员,我尽力了...', 'https://qncdn.wbjiang.cn/武汉加油.png', 0, 0);
-INSERT INTO `article` VALUES (206, '前端小微团队的Gitlab实践', '疫情期间我感觉整个人懒散了不少,慢慢有意识要振作起来了,恢复到正常的节奏。最近团队代码库从`Gerrit`迁移到了`Gitlab`,为了让前端团队日常开发工作**有条不紊**,**高效运转**,开发历史**可追溯**,我也查阅和学习了不少资料。参考业界主流的**Git工作流**,结合公司业务特质,我也梳理了一套**适合自己团队的Git工作流**,在这里做下分享。\n\n# 分支管理\n\n首先要说的是分支管理,分支管理是`git`工作流的基础,好的分支设计有助于规范开发流程,也是`CI/CD`的基础。\n\n## 分支策略\n\n业界主流的`git`工作流,一般会分为`develop`, `release`, `master`, `hotfix/xxx`, `feature/xxx`等分支。各个分支各司其职,贯穿了整个**开发,测试,部署**流程。我这里也基于主流的分支策略做了一些定制,下面用一张表格简单概括下:\n\n| 分支名 | 分支定位 | 描述 | 权限控制 |\n| ----------- | :------------- | ------------------------------------------------------------ | ----------------------------------------- |\n| develop | 开发分支 | 不可以在develop分支push代码,应新建feature/xxx进行需求开发。迭代功能开发完成后的代码都会merge到develop分支。 | Develper不可直接push,可发起merge request |\n| feature/xxx | 特性分支 | 针对每一项需求,新建feature分支,如feature/user_login,用于开发用户登录功能。 | Develper可直接push |\n| release | 提测分支 | 由develop分支合入release分支。ps: 应配置此分支触发CI/CD,部署至测试环境。 | Maintainer可发起merge request |\n| bug/xxx | 缺陷分支 | 提测后发现的bug,应基于`develop`分支创建`bug/xxx`分支修复缺陷,修改完毕后应合入develop分支等待回归测试。 | |\n| master | 发布分支 | master应处于随时可发布的状态,用于对外发布正式版本。ps: 应配置此分支触发CI/CD,部署至生产环境。 | Maintainer可发起merge request |\n| hotfix/xxx | 热修复分支 | 处理线上最新版本出现的bug | Develper可直接push |\n| fix/xxx | 旧版本修复分支 | 处理线上旧版本的bug | Develper可直接push |\n\n一般来说,`develop`, `release`, `master`分支是必备的。而`feature/xxx`, `bug/xxx`, `hotfix/xxx`, `fix/xxx`等分支纯属一种语义化的分支命名,如果要简单粗暴一点,这些分支可以不分类,都命名为`issue/issue号`,比如`issue/1`,但是要在`issue`中说明具体问题和待办事项,保证开发工作可追溯。\n\n## 保护分支\n\n利用`Protected Branches`,我们可以防止开发人员错误地将代码`push`到某些分支。对于普通开发人员,我们仅对`develop`分支提供`merge`权限。\n\n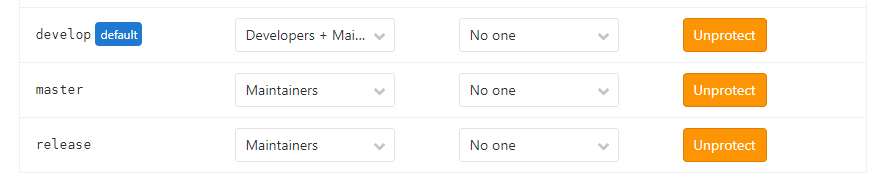\n\n具体操作案例请前往下面的**实战案例**一节查看。\n\n# issue驱动工作\n\n我们团队采用的**敏捷开发**协作平台是腾讯的[TAPD](https://www.tapd.cn/ \'TAPD\'),日常迭代需求,缺陷等都会在`TAPD`上记录。为了让`Gitlab`代码库能与迭代日常事务关联上,我决定用`Gitlab issues`来做记录,方便追溯问题。\n\n## 里程碑\n\n**里程碑Milestone**可以认为是一个**阶段性的目标**,比如是一轮迭代计划。里程碑可以设定时间范围,用来约束和提醒开发人员。\n\n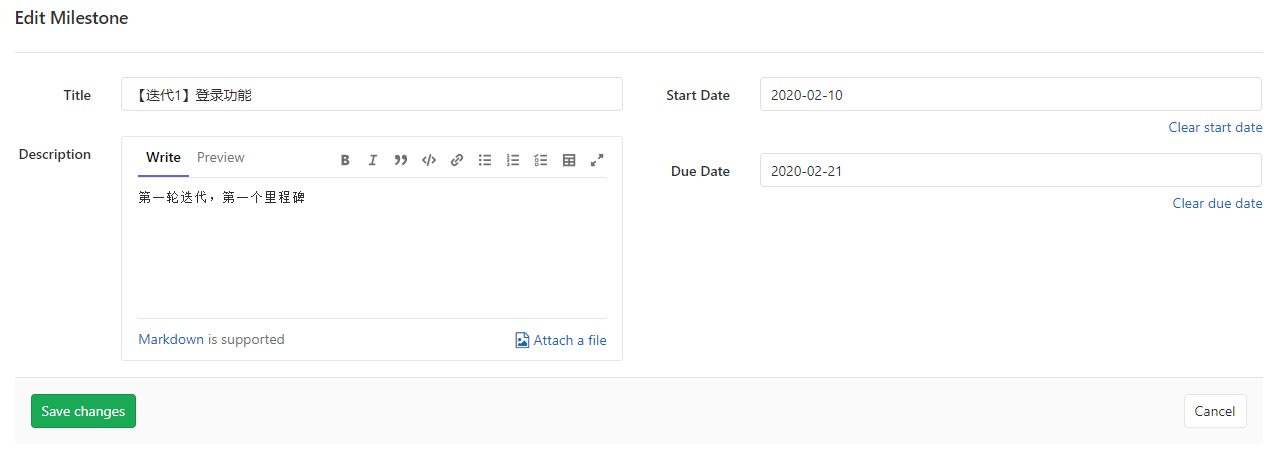\n\n里程碑可以**拆解为N个issue**,新建`issue`时可以**关联里程碑**。比如这轮迭代一共5个需求,那么就可以新建5个`issue`。在约定的时间范围内,如果一个里程碑关联的所有`issue`都`Closed`掉了,就意味着目标顺利达成。\n\n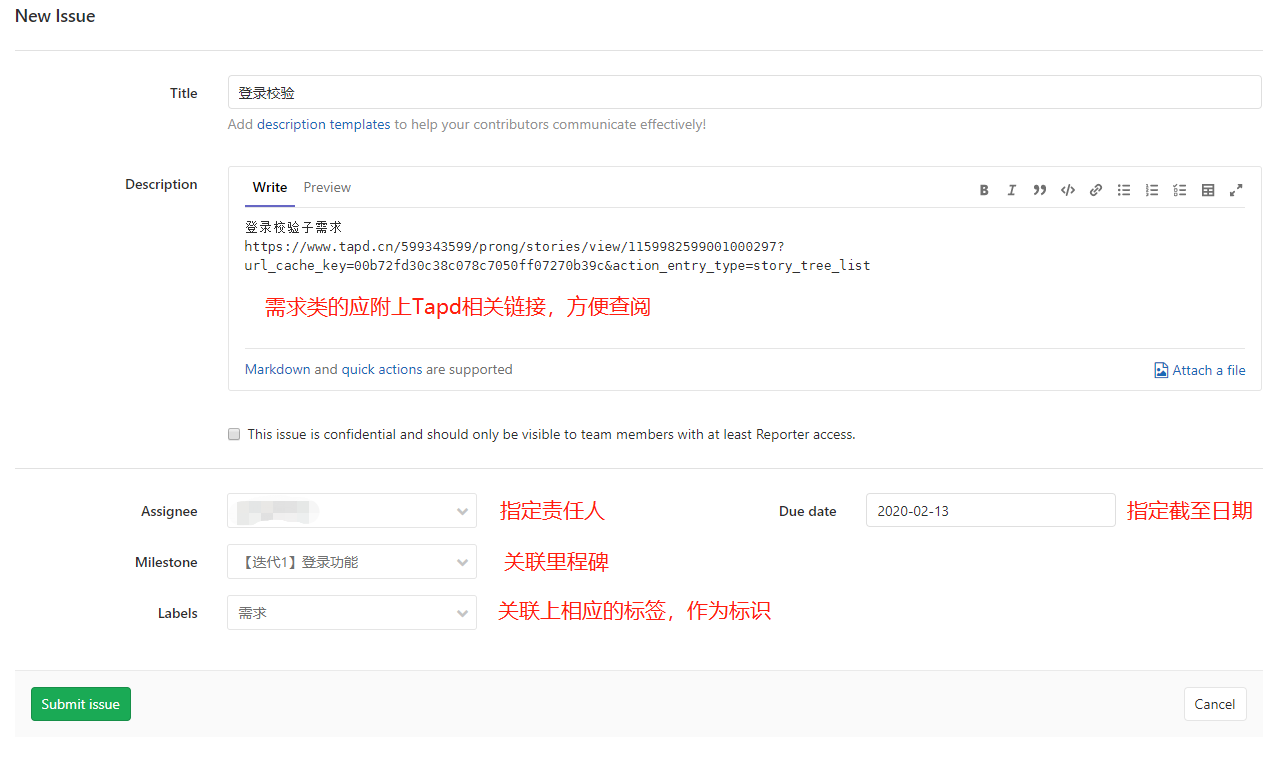\n\n## 标签\n\n`Gitlab`提供了`label`来标识和分类`issue`,我觉得这是一个非常好的功能。我这里列举了几种`label`,用来标识`issue`的**分类**和**紧急程度**。\n\n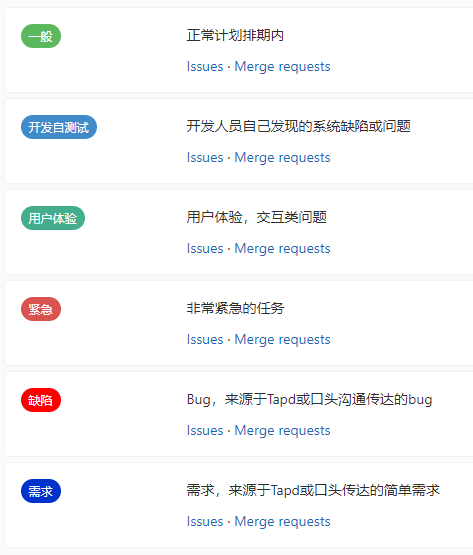\n\n## issue分类\n\n所有的开发工作应该通过`issue`记录,包括但不限于**需求**,**缺陷**,**开发自测试**,**用户体验**等范畴。\n\n### 需求&缺陷\n\n这里大概又分为两种情况,一种是`TAPD`记录在案的需求和缺陷,另一种是与产品或测试人员口头沟通时传达的简单需求或缺陷(小公司会有这种情况...)。\n\n对于`TAPD`记录的需求和缺陷,创建`issue`时应附上链接,方便查阅(上文中已有提到)。\n\n对于口头沟通的需求和缺陷,我定了个规则,要求提出人本人在`Gitlab`上创建`issue`,并将需求或缺陷简单描述清楚,否则口头沟通的开发工作我不接(也是为了避免事后扯皮)。\n\n**ps**:其实要求产品或者测试提`issue`,还不如上`Tapd`记录。我定这么个规则,其实就是借`Gitlab`找个说辞,**杜绝口头类需求或缺陷**,哈哈。\n\n### 开发自测试\n\n开发者自己发现了系统缺陷或问题,此时应该通过`issue`记录问题,并创建相应分支修改代码。\n\n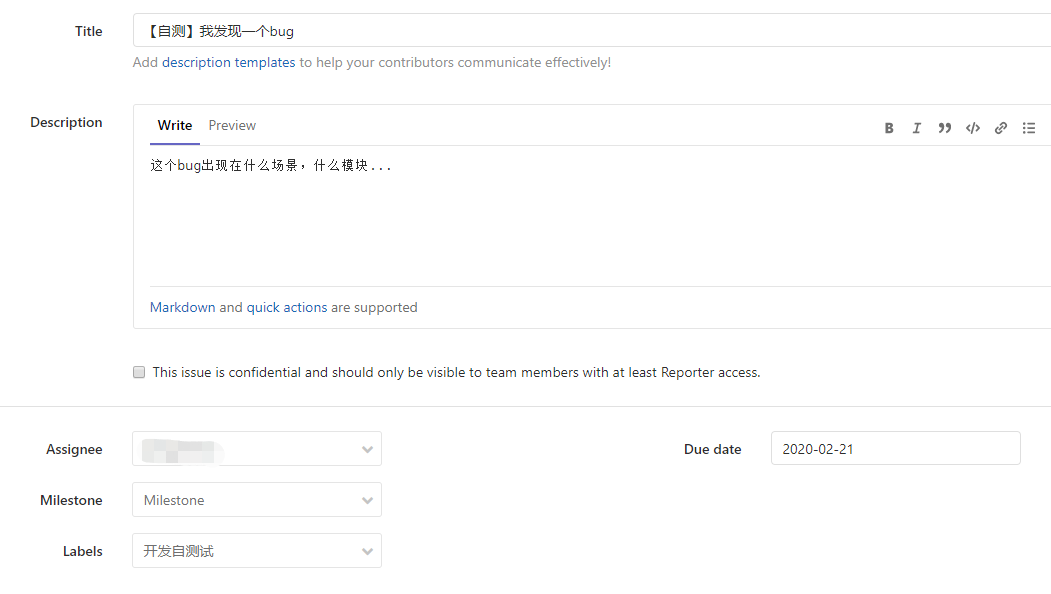\n\n# 实战案例\n\n我前面也说了,我的原则是`issue`驱动开发工作。\n\n下面用几个例子来简单说明基本的开发流程。小公司里整个流程比较简单,没有复杂的集成测试,多轮验收测试,灰度测试等。我甚至连单元测试都没做(捂脸...)。\n\n> 公共库和公共组件其实是很有必要做单元测试的,这里立个flag,后面一定补上单元测试。\n\n## 需求开发\n\n> feature/1,一个特性分支,对应issue 1\n\n### 创建需求\n\n正常的需求当然来源于产品经理等需求提出方,由于是通过示例说明,这里我自己在`TAPD`上模拟着写一个需求。\n\n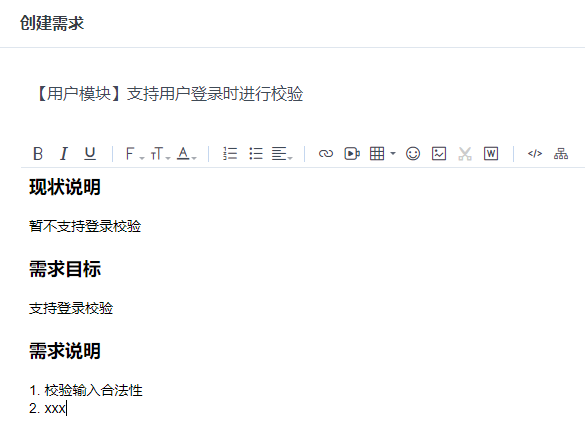\n\n### 创建issue\n\n创建`Gitlab issue`,链接到`TAPD`中的相关需求。\n\n\n\n\n\n### 创建分支&功能开发\n\n基于`develop`分支创建`feature`分支进行功能开发(要保证本地git仓库当前处于develop分支,且与远程仓库develop分支同步)。\n\n```shell\ngit checkout -b feature/1\n```\n\n或者直接以远程仓库的`develop`分支为基础创建分支。\n\n```\ngit checkout -b feature/1 origin/develop\n```\n\nps:我这里用的`feature/1`作为分支名,其实这里的`1`是用的`issue`号,并没有用诸如`feature/login_verify`之类的名字,是因为我觉得用`issue`号可以更方便地找到对应的`issue`,更容易追踪代码。\n\n接着我们开始开发新功能......\n\n\n\n### commit & push\n\n完成功能开发后,我们需要提交代码并同步到远程仓库。\n\n```\nPS D:\\projects\\gitlab\\project_xxx> git add .\nPS D:\\projects\\gitlab\\project_xxx> git cz\ncz-cli@4.0.3, cz-conventional-changelog@3.1.0\n\n? Select the type of change that you\'re committing: feat: A new feature\n? What is the scope of this change (e.g. component or file name): (press enter to skip)\n? Write a short, imperative tense description of the change (max 94 chars):\n (9) 登录校验功能\n? Provide a longer description of the change: (press enter to skip)\n\n? Are there any breaking changes? No\n? Does this change affect any open issues? Yes\n? If issues are closed, the commit requires a body. Please enter a longer description of the commit itself:\n -\n? Add issue references (e.g. \"fix #123\", \"re #123\".):\n fix #1\n\ngit push origin HEAD\n```\n\n`git cz`是利用了`commitizen`来替代`git commit`。详情请点击[前端自动化部署的深度实践](https://juejin.im/post/5e38ec1ce51d4526c932a4fb)深入了解。\n\n`fix #1`用于关闭`issue 1`。\n\n`git push origin HEAD`则代表推送到远程仓库同名分支。\n\n### 创建Merge Request\n\n开发人员发起`Merge Request`,请求将自己开发的功能特性合入`develop`分支。\n\n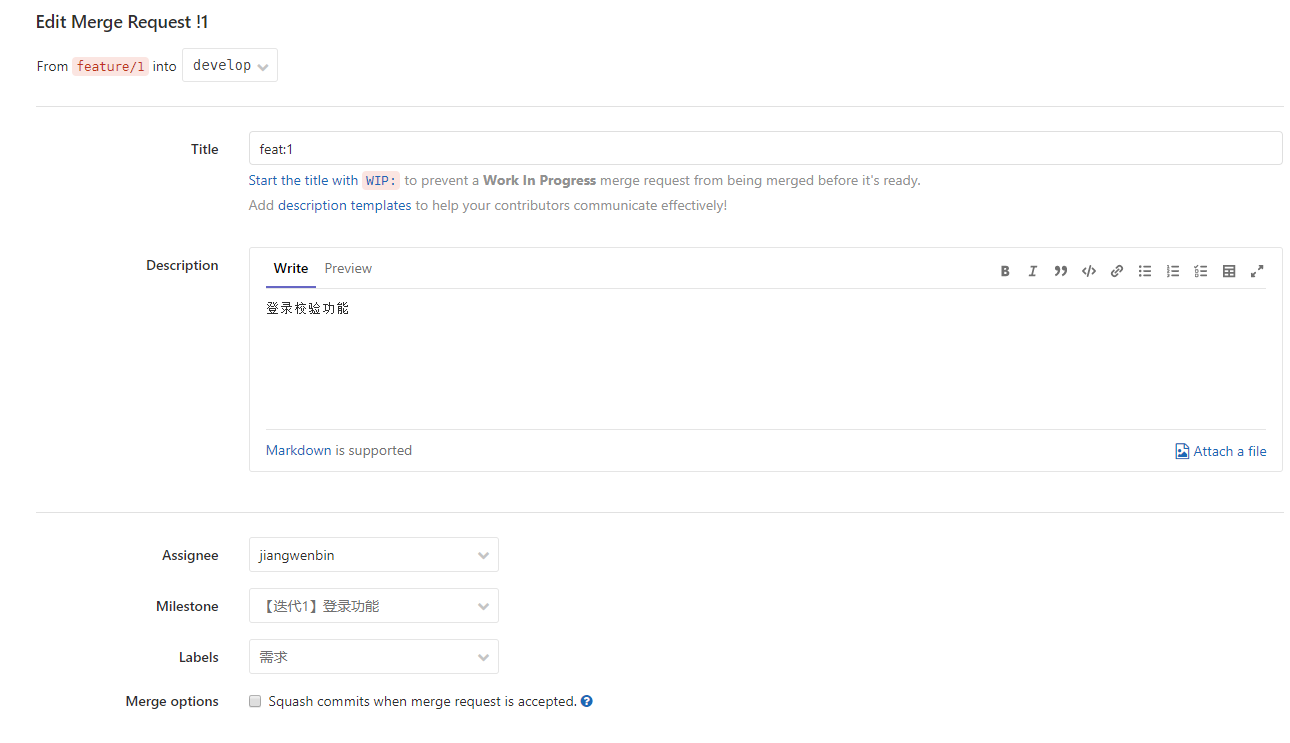\n\n接着`Maintainer`需要**Review代码**,确认无误后**同意Merge**。然后这部分代码就在远程`Git`仓库入库了,其他开发同学拉取`develop`分支就能看到了。\n\n## 版本提测\n\n> issue/2,处理更新日志,版本号等内容,对应issue 2\n\n每个团队的开发节奏都不同,有的团队会每日**持续集成**发版本提测,有的可能两天一次,这个就不深入讨论了......\n\n那么当我们准备提测时,应该怎么做呢?\n\n通过上节的了解,我们已经知道,迭代内的功能需求都会通过`feature/xxx`分支合入到`develop`分支。\n\n提测前,一般来说,还是要更新下`CHANGELOG.md`和`package.json`的版本号,可以由`Maintainer`或其他负责该项事务的同学执行。\n\n> 主要是执行npm version major/minor/patch -m \'something done\',具体操作可以参考[前端自动化部署的深度实践](https://juejin.im/post/5e38ec1ce51d4526c932a4fb#heading-7)一文。\n\n```\ngit checkout -b issue/2 origin/develop\nnpm version minor -m \'迭代1第一次提测\'\ngit push origin HEAD\n然后发起merge request合入develop分支\n```\n\n此时,应以最新的`develop`分支代码在开发环境跑一遍功能,保证版本自测通过。\n\n提测时,由`Maintainer`发起`Merge Request`,将`develop`分支代码合入`release`分支,此时自动触发`Gitlab CI/CD`,自动构建并发布至**测试环境**。\n\n版本提测后,各责任人应在`TAPD`上将相关需求和缺陷的状态变更为**“测试中”**。\n\n## 修复测试环境bug\n\n> bug/3,一个bug分支,对应issue 3\n\n这里说的是在迭代周期内由测试工程师发现的测试环境中的系统`bug`,这些`bug`会被记录在敏捷开发协作平台`TAPD`上。修复测试环境`bug`的步骤与开发需求类似,这里简单说下步骤:\n\n1. **在Gitlab上创建issue**\n\n > 创建issue,并附上TAPD上的缺陷链接,方便追溯\n\n2. **创建分支&修复缺陷**\n\n 基于`develop`分支创建分支:\n\n ```\n // 3是issue号\n git checkout -b bug/3 origin/develop\n ```\n\n 接着改代码......\n\n3. **commit & push**\n\n ```\n PS D:\\projects\\gitlab\\project_xxx> git cz\n cz-cli@4.0.3, cz-conventional-changelog@3.1.0\n \n ? Select the type of change that you\'re committing: fix: A bug fix\n ? What is the scope of this change (e.g. component or file name): (press enter to skip)\n ? Write a short, imperative tense description of the change (max 95 chars):\n (11) 修复一个测试环境bug\n ? Provide a longer description of the change: (press enter to skip)\n \n ? Are there any breaking changes? No\n ? Does this change affect any open issues? Yes\n ? If issues are closed, the commit requires a body. Please enter a longer description of the commit itself:\n -\n ? Add issue references (e.g. \"fix #123\", \"re #123\".):\n fix #3\n \n git push origin HEAD\n ```\n\n4. **发起Merge Request**\n\n 开发人员发起`Merge Request`,请求将自己修复缺陷引入的代码合入`develop`分支。\n\n 然后`Maintainer`需要**Review代码**,同意本次`Merge Request`。\n\n5. **等待回归测试**\n\n 该`bug`将在下一次`CI/CD`后,进入回归测试流程。\n\n6. **级别高的测试环境Bug**\n\n 如果是级别很高的`bug`,比如影响了系统运行,导致测试人员无法正常测试的,应以`release`分支为基础创建`bug`分支,修改完毕后合入`release`分支,再发起`cherry pick`合入`develop`分支。\n\n## 发布至生产环境\n\n经过几轮持续集成和回归测试后,一个迭代版本也慢慢趋于稳定,此时也迎来了激动人心的上线时间。我们要做的就是把通过了测试的`release`分支合入`master`分支。\n\n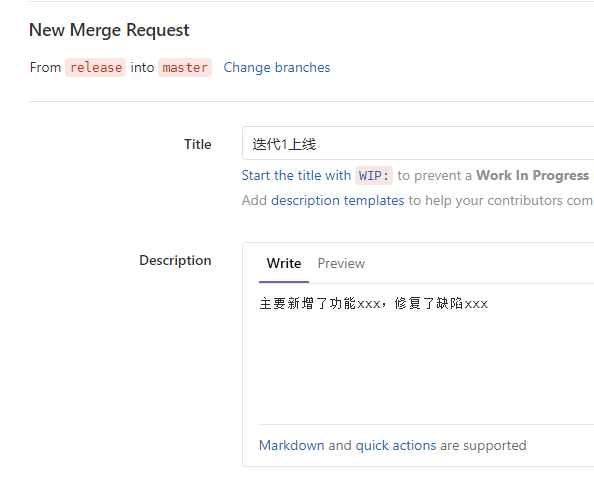\n\n这一步相对简单,但是要特别注意权限控制(**防止生产环境事故**),具体权限控制可以回头看第一章节**分支管理**。\n\n与`release`分支类似,`master`分支自动触发`Gitlab CI/CD`,自动构建并发布至**生产环境**。\n\n## 线上回滚\n\n> revert/4,一个回滚分支,对应issue 4\n\n代码升级到线上,但是发现报错,系统无法正常运行。此时如果不能及时排查出问题,那么只能先进行版本回退操作。\n\n先说说**惯性思维**下,我的版本回退做法。\n\n首先还是创建`issue`记录下:\n\n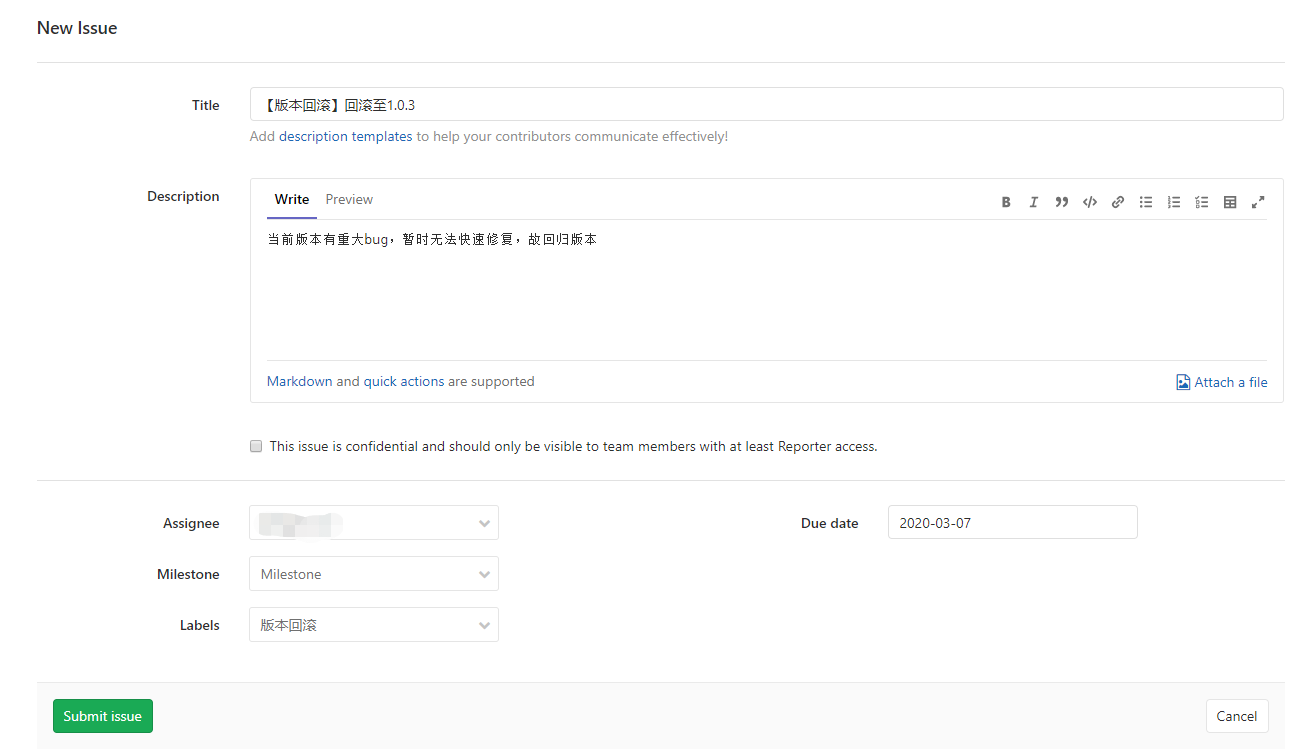\n\n基于`master`分支创建`revert/4`分支\n\n```\ngit checkout -b revert/4 origin/master\n```\n\n假设当前版本是`1.1.0`,我们想回退到上个版本`1.0.3`。那么我们需要先查看下`1.0.3`版本的信息。\n\n```\nPS D:\\tusi\\projects\\gitlab\\projectname> git show 1.0.3\ncommit 90c9170a499c2c5f8f8cf4e97fc49a91d714be50 (tag: 1.0.3, fix/1.0.2_has_bug)\nAuthor: tusi \nDate: Thu Feb 20 13:29:31 2020 +0800\n\n fix:1.0.2\n\ndiff --git a/README.md b/README.md\nindex ac831d0..2ee623b 100644\n--- a/README.md\n+++ b/README.md\n@@ -10,6 +10,8 @@\n\n 只想修改旧版本的bug,不改最新的master\n\n+1.0.2版本还是有个版本,再修复下\n+\n 特性2提交\n\n 特性3提交\n```\n\n主要是取到`1.0.3`版本对应的`commit id`,其值为`90c9170a499c2c5f8f8cf4e97fc49a91d714be50`。\n\n接着,我们根据`commit id`进行`reset`操作,再推送到远程同名分支。\n\n```\ngit reset --hard 90c9170a499c2c5f8f8cf4e97fc49a91d714be50\ngit push origin HEAD\n```\n\n接着发起`Merge Request`把`revert/4`分支合入`master`分支。\n\n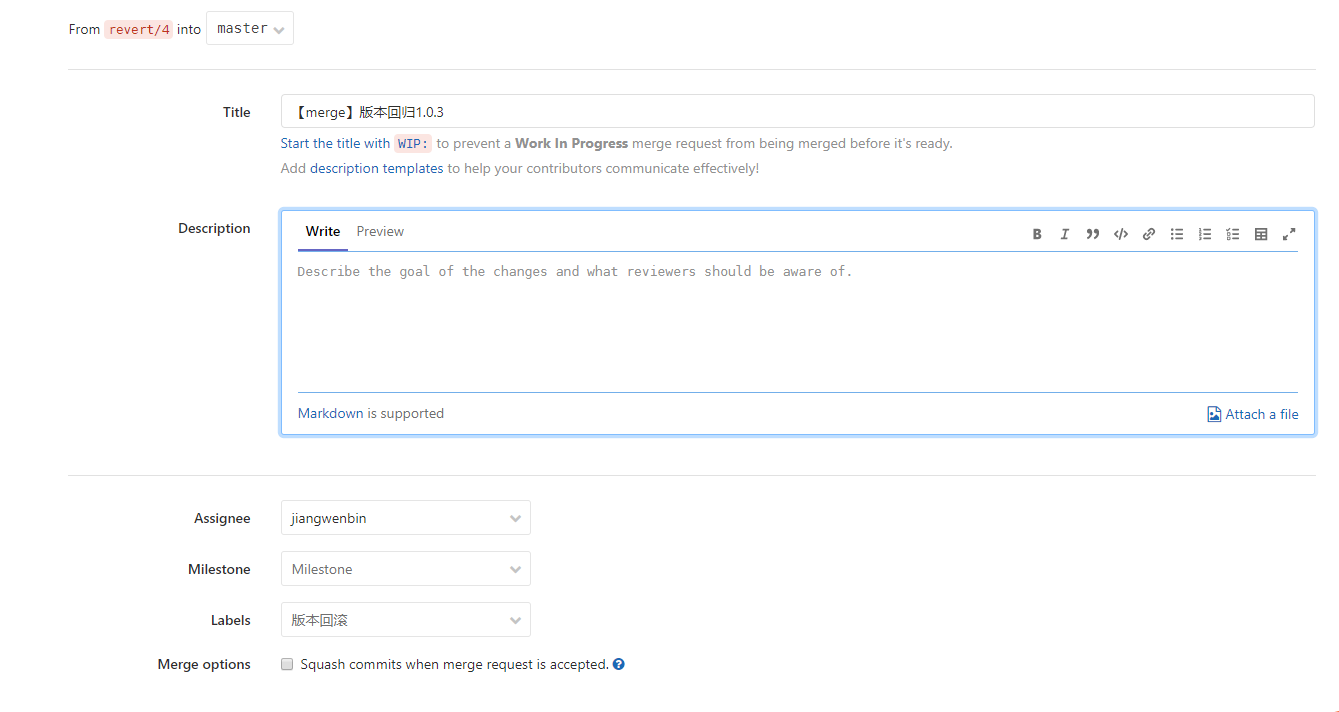\n\n一般来说,这波操作没什么问题,能解决常规的回滚问题。\n\n### 临时变通\n\n由于`master`分支是保护分支,设置了不可`push`。如果不想通过`merge`的方式回滚,所以只能先临时设置`Maintainer`拥有`push`权限,然后由`Maintainer`进行回滚操作。\n\n```\ngit checkout master\ngit pull\ngit show 1.0.3\ngit reset --hard 90c9170a499c2c5f8f8cf4e97fc49a91d714be50\ngit push origin HEAD\n```\n\n完事后,还需要记得把`master`设置为不可`push`。\n\n> Q: 为什么不让`Maintainer`一直拥有`master`的`push`权限?\n>\n> A: 主要还是为了防止出现生产环境事故,给予临时性权限更稳妥!\n\n### git reset --hard存在什么问题?\n\n如题,`git reset --hard`确实是存在问题的。`git reset --hard`属于霸道玩法,直接移动`HEAD`指针,会丢弃之后的提交记录,如果不慎误操作了也别慌,还是可以通过查询`git reflog`找到`commitId`抢救回来的;`git reset`后还存在一个隐性的问题,如果与旧的`branch`进行`merge`操作时,会把`git reset`回滚的代码重新引入。那么怎么解决这些问题呢?\n\n\n\n别慌,这个时候你必须掏出`git revert`了。\n\n> Q: `git revert`的优势在哪?\n>\n> A: 首先,`git revert`是通过一次新的commit来进行回滚操作的,HEAD指针向前移动,这样就不会丢失记录;另外,`git revert`也不会引起`merge`旧分支时误引入回滚的代码。最重要的是,`git revert`在回滚的细节控制上更加优秀,可解决部分回滚的需求。\n\n举个栗子,本轮迭代团队共完成需求`2`项,而上线后发现其中`1`项需求有致命性缺陷,需要回滚这个需求相关的代码,同时要保留另一个需求的代码。\n\n\n\n首先我们查看下日志,找下这两个需求的`commitId`\n\n```shell\nPS D:\\tusi\\projects\\test\\git_test> git log --oneline\n86252da (HEAD -> master, origin/master, origin/HEAD) 解决冲突\ne3cef4e (origin/release, release) Merge branch \'develop\' into \'release\'\nf247f38 (origin/develop, develop) 需求2\n89502c2 需求1\n```\n\n我们利用`git revert`回滚需求1相关的代码\n\n```shell\ngit revert -n 89502c2\n```\n\n这时可能要解决冲突,解决完冲突后就可以`push`到远程`master`分支了。\n\n```shell\ngit add .\ngit commit -m \'回滚需求1的相关代码,并解决冲突\'\ngit push origin master\n```\n\n感觉还是菜菜的,如果大佬们有更优雅的解决方案,求指导啊!\n\n## 修复线上bug\n\n> hotfix/5,一个线上热修复分支,对应issue 5\n\n比如线上出现了系统无法登录的`bug`,测试工程师也在`TAPD`提交了缺陷记录。那么修复线上`bug`的步骤是什么呢?\n\n1. 创建`issue`,标题可以从`TAPD`中的`Bug`单中`copy`过来,而描述就贴上`Bug`单的链接即可。\n\n2. 基于`master`分支创建分支`hotfix/5`。\n\n ```\n git checkout -b hotfix/5 origin/master\n ```\n\n3. 撸代码,修复此bug......\n\n4. 修复完此`bug`后,提交该分支代码到远程仓库同名分支\n\n ```\n git push origin HEAD\n ```\n\n5. 然后发起`cherry pick`合入到`master`和`develop`分支,并在`master`分支打上新的版本`tag`(假设当前最大的`tag`是`1.0.0`,那么新的版本`tag`应为`1.0.1`)。\n\n## 修复线上旧版本bug\n\n> fix/6,一个线上旧版本修复分支,对应issue 6\n\n某些项目产品可能会有多个线上版本同时在运行,那么不可避免要解决旧版本的`bug`。针对线上旧版本出现的`bug`,修复步骤与上节类似。\n\n1. 创建`issue`,描述清楚问题\n\n2. 假设当前版本是`1.0.0`,而`0.9.0`版本出了一个`bug`,应基于`tag 0.9.0`创建`fix`分支。\n\n ```\n git checkout -b fix/6 0.9.0\n ```\n\n3. 修复缺陷后,应打上新的`tag 0.9.1`,并推送到远程。\n\n ```\n git tag 0.9.1\n git push origin tag 0.9.1\n ```\n\n4. 如果此`bug`也存在于最新的`master`分支,则需要`git push origin HEAD`提交该`fix`分支代码到远程仓库同名分支,然后发起`cherry pick`合入到`master`,此时很大可能存在冲突,需要解决冲突。\n\n \n\n## cherry pick\n\n在了解到`cherry pick`之前,我一直认为只有`git merge`可以合并代码,也好几次遇到合入了不想要的代码的问题。有了`cherry pick`,我们就可以合并单次提交记录,解决`git merge`时合并太多不想要的内容的烦恼,在解决`bug`时特别有用。\n\n## git rebase\n\n经过这段时间的使用,我发现使用`git merge`合并分支时,会让`git log`的`Graph`图看起来有点吃力。\n\n```\nPS D:\\tusi\\projects\\gitlab\\projectname> git log --pretty --oneline --graph\n* 7f513b0 (HEAD -> develop) Merge branch \'issue/55\' into \'release\'\n|\\\n| * 1c94437 (origin/issue/55, issue/55) fix: 【bug】XXX1\n| * c84edd6 Merge branch \'release\' of host:project_repository into release\n| |\\\n| |/\n|/|\n* | 115a26c Merge branch \'develop\' into \'release\'\n|\\ \\\n| * \\ 60d7de6 Merge branch \'issue/30\' into \'develop\'\n| |\\ \\\n| | * | 27c59e8 (origin/issue/30, issue/30) fix: 【bug】XXX2\n| | | * ea17250 Merge branch \'release\' of host:project_repository into release\n| | | |\\\n| |_|_|/\n|/| | |\n* | | | 9fd704b Merge branch \'develop\' into \'release\'\n|\\ \\ \\ \\\n| |/ / /\n| * | | a774d26 Merge branch \'issue/30\' into \'develop\'\n| |\\ \\ \\\n| | |/ /\n```\n\n接着我就了解到了`git rebase`,变基,哈哈哈。由于对`rebase`了解不深,目前也不敢轻易改用`rebase`,毕竟`rebase`还是有很多隐藏的坑的,使用起来要慎重!在这里先挖个坑吧,后面搞懂了再填坑......\n\n# 注意事项\n\n1. 一般而言,自己发起的`Merge Request`必须由别的同事`Review`并同意合入,这样更有利于发现代码问题。\n2. 对了,`TAPD`还支持与`Gitlab`协同的。详情见[源码关联指引](https://www.tapd.cn/help/view#1120003271001001346 \'源码关联指引\')。\n\n# 结语\n\n实践证明,这套`Git`工作流目前能覆盖我项目开发过程中的绝大部分场景。不过要注意的是,适合自己的才是最好的,盲目采用别人的方案有时候是会水土不服的。\n\n以上所述纯属前端小微团队内部的`Gitlab`实践,必然存在着很多不足之处,如有错误之处还请指正,欢迎交流。', '2020-03-09 00:06:01', '2024-07-25 02:20:08', 1, 45, 0, 'Gitlab工作流在前端小微团队的落地,推荐收藏!', 'https://qncdn.wbjiang.cn/%E5%89%8D%E7%AB%AFgitlab%E5%B0%81%E9%9D%A2.png', 0, 0);
-INSERT INTO `article` VALUES (207, '记一次Navicat for MySQL 10060错误的解决过程', '最近加班挺多,所以也好久没远程访问自己云服务器上的`MySQL`数据库了。今天本地启动`Node`服务时连不上`MySQL`,照常用`Navicat For MySQL`连接远程数据库进行检查,结果发现突然报错了。\n\n```\n2003-Can’t connect to MySQL server on ‘XXX.XX.XX.XX’(10060)\n```\n\n# 检查网络\n\n第一反应还是检查网络是不是正常,所以就马上`ping`测试一下,然而发现并不是网络问题,可以正常`ping`通。\n\n```\nping XXX.XX.XX.XX\n\n正在 Ping XXX.XX.XX.XX 具有 32 字节的数据:\n来自 XXX.XX.XX.XX 的回复: 字节=32 时间=64ms TTL=47\n来自 XXX.XX.XX.XX 的回复: 字节=32 时间=86ms TTL=47\n```\n\n# 检查安全组\n\n然后就想着看看云服务器的安全组设置是否有问题,但是之前都没出过这个问题,讲道理安全组出现问题的可能性不大,但还是先检查下为妙。\n\n登录腾讯云后,发现实例对应的安全组设置妥妥的,没有什么问题。\n\n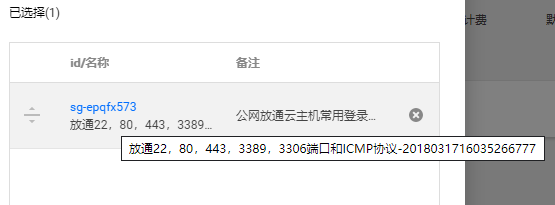\n\n# 检查下用户权限\n\n由于是我自己的服务器,所以用的都是`root`用户。需要在`xshell`中登录`MySQL`查询下`user`表。\n\n```\nmysql -uroot -p\n输入密码\nmysql> use mysql\nmysql> select host,user from user;\n+-----------+------------------+\n| host | user |\n+-----------+------------------+\n| % | root |\n| localhost | mysql.infoschema |\n| localhost | mysql.session |\n| localhost | mysql.sys |\n+-----------+------------------+\n4 rows in set (0.00 sec)\n```\n\n可以发现,`root`对应的`host`是`%`,任意的意思,也就意味着`root`用户在连接`MySQL`时不受`ip`约束。\n\n所以说也不是这里的问题啦!\n\n# 检查CentOS防火墙\n\n这是很容易忽略的一步,可能很多人都会认为安全组已经设置好了,不必再检查`CentOS`的防火墙。其实是很有必要检查防火墙的,我们应该把`3306`放通,再重启防火墙。\n\n```\n[root@VM_0_14_centos ~]# firewall-cmd --permanent --zone=public --add-port=3306/tcp\nsuccess\n[root@VM_0_14_centos ~]# firewall-cmd --reload\nsuccess\n```\n\n然后一看,很愉快,`Navicat for MySQL`连接远程数据库成功!\n\n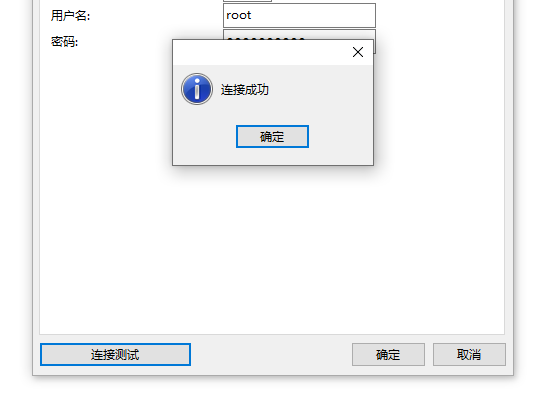', '2020-03-17 15:37:54', '2024-07-25 05:17:39', 1, 45, 0, '最近加班挺多,所以也好久没远程访问自己云服务器上的MySQL数据库了。今天本地启动Node服务时连不上MySQL,照常用Navicat For MySQL连接远程数据库进行检查,结果发现突然报错了。', 'https://s1.ax1x.com/2020/03/17/8NIffK.png', 0, 0);
-INSERT INTO `article` VALUES (208, '【读书笔记】js数据类型', '最近脑子里有冒出“多看点书”的想法,但我个人不是很喜欢翻阅纸质书籍,另一方面也是由于我能抽出来看书的时间比较琐碎,所以我就干脆用**app**看电子书了(如果有比较完整的阅读时间,还是建议看纸质书籍,排版看起来更舒服点)。考虑到平时工作遇到的大部分问题还是**javascript**强相关的,于是我选择从**《Javascript权威指南第6版》**开始。\n\n\n\n# 数据类型有哪些?\n\njavascript的数据类型分为两大类,一类是原始类型(primitive type),一类是对象类型(object type)。\n\n## 原始类型\n\n原始类型又称为基本类型,分为`Number`, `String`, `Boolean`, `Undefined`, `Null`几类。比较特殊的是,`undefined`是`Undefined`类型中的唯一一个值;同样地,`null`是`Null`类型中的唯一一个值。\n\n\n\n除此之外,`ES6`引入了一个比较特殊的原始类型`Symbol`,用于表示一个独一无二的值,具体使用方法可以看阮一峰老师的[ECMAScript6入门](https://es6.ruanyifeng.com/#docs/symbol),或者直接翻阅[MDN](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Symbol),我平时看**MDN**比较多,感觉比较权威,**API**也很完善。\n\n\n\n为什么说`Symbol`是原始类型,而不是对象类型呢?因为我们知道,大部分程序员都是没有对象的,那么要想找到女朋友,最快的办法就是`new`一个。\n\n```javascript\nconst options = {\n \'性格\': \'好\',\n \'颜值\': \'高\',\n \'对我\': \'好\'\n}\nconst gf = new GirlFriend(options) // new一个女朋友\n```\n\n\n\n好了,不皮了,回到正题,意思就是,`Symbol`是没有构造函数`constructor`的,不能通过`new Symbol()`获得实例。\n\n但是获取`symbol`值是通过调用`Symbol`函数得到的。\n\n```javascript\nconst symbol1 = Symbol(\'Tusi\')\n```\n\n## 对象类型\n\n对象类型也叫引用类型,简单地理解呢,对象就是键值对`key:value`的集合。常见的对象类型有`Object`, `Array`, `Function`, `Date`, `RegExp`等。\n\n除了这些,`Javascript`还有蛮蛮多的全局对象,具体见[JavaScript 标准内置对象](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects)。但是全局对象并不意味着它就是一种对象类型,就比如`JSON`是一个全局对象,但是它不是一种类型,这一点要搞清楚。\n\n前面说了,对象可以`new`出来,所以对象类型都有构造函数,`Object`类型对应的构造函数是`Object()`,`Array`类型对应的构造函数是`Array()`,不再赘述。\n\n```javascript\nvar obj = new Object() // 不过我们一般也不会这么写一个普通对象\nvar arr1 = new Array(1) // 创建一个length是1的空数组\nvar arr2 = new Array(1, 2) // 创建数组[1, 2]\n```\n\n\n\n## 数据类型的判断\n\n## 栈内存和堆内存\n\n原始类型的变量存储在栈内存中,其占内存大小是已知的或者是有范围的;而引用类型的变量是存在堆内存中,其占用内存大小是可变的,未知的。\n\n# 显示转换和隐式转换\n\n4\n\n## 显示转换\n\n5\n\n## 隐式转换\n\n6\n\n# toString和valueOf\n\n7\n\n## toString\n\n8\n\n## valueOf\n\n9\n\n', '2020-04-24 19:21:39', '2020-04-24 19:21:49', 1, 0, 0, '我的笔记', 'https://s1.ax1x.com/2020/04/24/JDmKaR.png', 1, 0);
-INSERT INTO `article` VALUES (209, 'js数据类型很简单,却也不简单', '最近脑子里有冒出“多看点书”的想法,但我个人不是很喜欢翻阅纸质书籍,另一方面也是因为我能抽出来看书的时间比较琐碎,所以就干脆用**app**看电子书了(如果有比较完整的阅读时间,还是建议看纸质书籍,排版看起来更舒服点)。考虑到平时工作遇到的大部分问题还是**javascript**强相关的,于是我选择从《Javascript权威指南第6版》开始。\n\n\n\n# 数据类型有哪些?\n\n`javascript`的数据类型分为两大类,一类是原始类型(primitive type),一类是对象类型(object type)。\n\n## 原始类型\n\n原始类型又称为基本类型,分为`Number`, `String`, `Boolean`, `Undefined`, `Null`几类。比较特殊的是,`undefined`是`Undefined`类型中的唯一一个值;同样地,`null`是`Null`类型中的唯一一个值。\n\n\n\n除此之外,`ES6`引入了一个比较特殊的原始类型`Symbol`,用于表示一个独一无二的值,具体使用方法可以看阮一峰老师的[ECMAScript6入门](https://es6.ruanyifeng.com/#docs/symbol \"ECMAScript6入门\"),或者直接翻阅[MDN](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Symbol \"MDN Symbol\"),我平时看**MDN**比较多,感觉比较权威,**API**也很完善。\n\n\n\n为什么说`Symbol`是原始类型,而不是对象类型呢?因为我们知道,大部分程序员都是没有对象的,那么要想找到女朋友,最快的办法就是`new`一个。\n\n```javascript\nconst options = {\n \'性格\': \'好\',\n \'颜值\': \'高\',\n \'对我\': \'好\'\n}\nconst gf = new GirlFriend(options) // new一个女朋友\n```\n\n\n\n好了,不皮了,回到正题,意思就是,`Symbol`是没有构造函数`constructor`的,不能通过`new Symbol()`获得实例。\n\n但是获取`symbol`类型的值是通过调用`Symbol`函数得到的。\n\n```javascript\nconst symbol1 = Symbol(\'Tusi\')\n```\n\n`Symbol`值是唯一的,所以下面的等式是不成立的。\n\n```javascript\nSymbol(1) === Symbol(1) // false\n```\n\n## 对象类型\n\n对象类型也叫引用类型,简单地理解呢,对象就是键值对`key:value`的集合。常见的对象类型有`Object`, `Array`, `Function`, `Date`, `RegExp`等。\n\n除了这些,`Javascript`还有蛮蛮多的全局对象,具体见[JavaScript 标准内置对象](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects \"JavaScript 标准内置对象\")。但是全局对象并不意味着它就是一种对象类型,就比如`JSON`是一个全局对象,但是它不是一种类型,这一点要搞清楚。\n\n前面说了,对象可以`new`出来,所以对象类型都有构造函数,`Object`类型对应的构造函数是`Object()`,`Array`类型对应的构造函数是`Array()`,不再赘述。\n\n```javascript\nvar obj = new Object() // 不过我们一般也不会这么写一个普通对象\nvar arr1 = new Array(1) // 创建一个length是1的空数组\nvar arr2 = new Array(1, 2) // 创建数组[1, 2]\n```\n\n## 栈内存和堆内存\n\n> 栈内存的优势是,存取速度比堆内存要快,充分考虑这一点,其实是可以优化代码性能的。\n\n### 栈内存\n\n原始类型是按值访问的,其值存储在栈内存中,所占内存大小是已知的或是有范围的;\n\n对基本类型变量的重新赋值,其本质上是进行压栈操作,写入新的值,并让变量指向一块栈顶元素(大概意思是这样,但是`v8`等引擎有没有做这方面的优化,就要细致去看了)\n\n```javascript\nvar a = 1; // 压栈,1成为栈顶元素,其值赋给变量a\na = 2; // 压栈,2成为栈顶元素,并赋值给变量a(内存地址变了)\n```\n\n### 堆内存\n\n而对象类型是按引用访问的,通过指针访问对象。\n\n指针是一个地址值,类似于基本类型,存储于栈内存中,是变量访问对象的中间媒介。\n\n而对象本身存储在堆内存中,其占用内存大小是可变的,未知的。\n\n举例如下:\n\n```javascript\nvar b = { name: \'Tusi\' }\n```\n\n运行这行代码,会在堆内存中开辟一段内存空间,存储对象`{name: \'Tusi\'}`,同时声明一个指针,其值为上述对象的内存地址,指针赋值给引用变量`b`,意味着`b`引用了上述对象。\n\n对象可以新增或删除属性,所以说对象类型占用的内存大小一般是未知的。\n\n```javascript\nb.age = 18; // 对象新增了age属性\n```\n\n那么,按引用访问是什么意思呢?\n\n我的理解是:对引用变量进行对象操作,其本质上改变的是引用变量所指向的堆内存地址中的对象本身。\n\n这就意味着,如果有两个或两个以上的引用变量指向同一个对象,那么对其中一个引用变量的对象操作,会影响指向该对象的其他引用变量。\n\n```javascript\nvar b = { name: \'Tusi\' }; // 创建对象,变量b指向该对象\nvar c = b; // 声明变量c,指向与b一致\nb.age = 18; // 通过变量b修改对象\n// 产生副作用,c受到影响\nconsole.log(c); // {name: \"Tusi\", age: 18}\n```\n\n考虑到对象操作的副作用,我们会在业务代码中经常使用深拷贝来规避这个问题。\n\n# 数据类型的判断\n\n判断数据类型是非常重要的基础设施之一,那么如何判断数据类型呢?请接着往下看。\n\n## typeof\n\n`javascript`本身提供了`typeof`运算符,可以辅助我们判断数据类型。\n\n> `typeof`操作符返回一个字符串,表示未经计算的操作数的类型。\n\n`typeof`的运算结果如下,引用自[MDN typeof](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Operators/typeof \"MDF typeof\")\n\n| 数据类型 | 运算结果 |\n| ---------------------------------------------------------- | -------------- |\n| Undefined | \"undefined\" |\n| Null | \"object\" |\n| Boolean | \"boolean\" |\n| Number | \"number\" |\n| String | \"string\" |\n| Symbol | \"symbol\" |\n| Function | \"function\" |\n| 其他对象 | \"object\" |\n| 宿主对象(由JS环境提供,如Nodejs有global,浏览器有window) | 取决于具体实现 |\n\n可以看到,`typeof`能帮我们判断出大部分的数据类型,但是要注意的是:\n\n1. `typeof null`的结果也是`\"object\"`\n2. 对象的种类很多,`typeof`得到的结果无法判断出数组,普通对象,其他特殊对象\n\n那么如何准确地知道一个变量的数据类型呢?\n\n## 结合instanceof\n\n> `instanceof` 运算符用于检测构造函数的 `prototype` 属性是否出现在某个实例对象的原型链上。\n\n利用`instanceof`,我们可以判断一个对象是不是某个构造函数的实例。那么结合`typeof`,我们可以封装一个基本的判断数据类型的函数。\n\n基本思想是:首先看`typeof`是不是返回`\"object\"`,如果不是,说明是普通数据类型,那么直接返回`typeof`运算结果即可;如果是,则需要先把`null`这个坑货摘出来,然后依次判断其他对象类型。\n\n```javascript\nfunction getType(val) {\n const type = typeof val;\n if (type === \'object\') {\n if (val === null) {\n // null不是对象,所以不能用instanceof判断\n return \'null\'\n } else if (val instanceof Array) {\n return \'array\'\n } else if (val instanceof Date) {\n return \'date\'\n } else if (// 其他对象的instanceof判断) {\n return \'xxx\'\n } else if (val instanceof Object) {\n // 所有对象都是Object的实例,所以放最后\n return \'object\'\n }\n } else {\n return type\n }\n}\n// 测试下\ngetType(Symbol(1)) // \"symbol\"\ngetType(null) // \"null\"\ngetType(new Date()) // \"date\"\ngetType([1, 2, 3]) // \"array\"\ngetType({}) // \"object\"\n```\n\n但是,要把常用的对象类型都列举出来也是有点麻烦的,所以也不算一个优雅的方法。\n\n## 终极神器toString\n\n有没有终极解决方案?当然是有的。但是,不是标题中的`toString`,而是`Object.prototype.toString`。用上它,不仅上面的数据类型都能被判断出来,而且也可以判断`ES6`引入的一些新的对象类型,比如`Map`, `Set`等。\n\n```javascript\n// 利用了Object.prototype.toString和正则表达式的捕获组\nfunction getType(val) {\n return Object.prototype.toString.call(val).replace(/\\[object\\s(\\w+)\\]/, \'$1\').toLowerCase();\n}\n\ngetType(new Map()) // \"map\"\ngetType(new Set()) // \"set\"\ngetType(new Promise((resolve, reject) => {})) // \"promise\"\n```\n\n为什么普通的调用`toString`不能判断数据类型,而`Object.prototype.toString`可以呢?\n\n因为`Object`是基类,而各个派生类,如`Date`, `Array`等在继承`Object`的时候,一般都重写(`overwrite`)了`toString`方法,用以表达自身业务,从而失去了判断类型的能力。\n\n# 装箱和拆箱\n\n> 首先解释一下什么是装箱和拆箱,把原始类型转换为对应的对象类型的操作称为装箱,反之是拆箱。\n\n## 装箱\n\n我们知道,只有对象才可以拥有属性和方法,但是我们在使用一些基本类型数据的时候,却可以直接调用它们的一些属性或方法,这是怎么回事呢?\n\n```javascript\nvar a = 1;\na.toFixed(2); // \"1.00\"\n\nvar b = \'I love study\';\nb.length; // 12\nb.substring(2, 6); // \"love\"\n```\n\n其实在读取一些基本类型数据的属性或方法时,`javascript`会创建临时对象(也称为“包装对象”),通过这个临时对象来读取属性或方法。以上代码等价于:\n\n```javascript\nvar a = 1;\nvar aObj = new Number(a);\naObj.toFixed(2); // \"1.00\"\n\nvar b = \'I love study\';\nvar bObj1 = new String(b);\nbObj1.length; // 12\nvar bObj2 = new String(b);\nbObj2.substring(2, 6); // \"love\"\n```\n\n临时对象是只读的,可以理解为它们在发生读操作后就销毁了,所以不能给它们定义新的属性,也不能修改它们现有的属性。\n\n```\nvar c = \'123\';\nc.name = \'jack\'; // 给临时对象加新属性是无效的\nc.name; // undefined\nc.length; // 3\nc.length = 2; // 修改临时对象的属性值,是无效的\nc.length; // 3\n```\n\n> 我们也可以显示地进行装箱操作,即通过`String()`, `Number()`, `Boolean()`构造函数来显示地创建包装对象。\n\n```javascript\nvar b = \'I love study\';\nvar bObj = new String(b);\n```\n\n## 拆箱\n\n对象的拆箱操作是通过`valueOf`和`toString`完成的,且看下文。\n\n# 类型的转换\n\n`javascript`在某些场景会自动执行类型转换操作,而我们也会根据业务的需要进行数据类型的转换。类型的转换规则如下:\n\n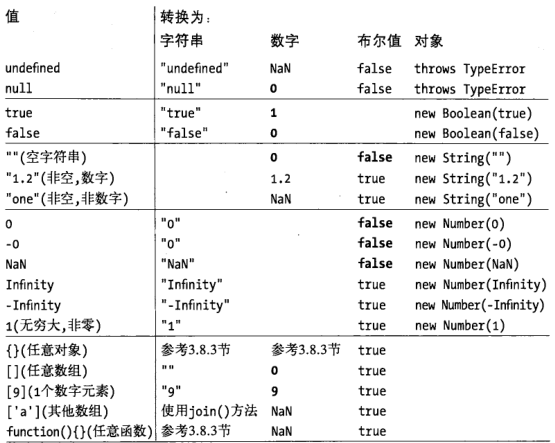\n\n## 对象到原始值的转换\n\n### toString\n\n`toString()`是默认的对象到字符串的转换方法。\n\n```javascript\nvar a = {};\na.toString(); // \"[object Object]\"\n```\n\n但是很多类都自定义了`toString()`方法,举例如下:\n\n- Array:将数组元素用逗号拼接成字符串作为返回值。\n\n```javascript\nvar a = [1, 2, 3];\na.toString(); // 1,2,3\n```\n\n- Function:返回一个字符串,字符串的内容是函数源代码。\n- Date:返回一个日期时间字符串。\n\n```javascript\nvar a = new Date();\na.toString(); // \"Sun May 10 2020 11:19:29 GMT+0800 (中国标准时间)\"\n```\n\n- RegExp:返回表示正则表达式直接量的字符串。\n\n```javascript\nvar a = /\\d+/;\na.toString(); // \"/\\d+/\"\n```\n\n### valueOf\n\n`valueOf()`会默认地返回对象本身,包括`Object`, `Array`, `Function`, `RegExp`。\n\n日期类`Date`重写了`valueOf()`方法,返回一个1970年1月1日以来的毫秒数。\n\n```javascript\nvar a = new Date();\na.toString(); // 1589095600419\n```\n\n### 对象 --> 布尔值\n\n从上表可见,对象(包括数组和函数)转换为布尔值都是`true`。\n\n### 对象 --> 字符串\n\n对象转字符串的基本规则如下:\n\n- 如果对象具有`toString()`方法,则调用这个方法。如果它返回字符串,则作为转换的结果;如果它返回其他原始值,则将原始值转为字符串,作为转换的结果。\n- 如果对象没有`toString()`方法,或`toString()`不返回原始值(不返回原始值这种情况好像没见过,一般是自定义类的`toString()`方法吧),那么`javascript`会调用`valueOf()`方法。如果存在`valueOf()`方法并且`valueOf()`方法返回一个原始值,`javascript`将这个值转换为字符串(如果这个原始值本身不是字符串),作为转换的结果。\n- 否则,`javascript`无法从`toString()`或`valueOf()`获得一个原始值,会抛出异常。\n\n### 对象 --> 数字\n\n与对象转字符串的规则类似,只不过是优先调用`valueOf()`。\n\n- 如果对象具有`valueOf()`方法,且`valueOf()`返回一个原始值,则`javascript`将这个原始值转换为数字(如果原始值本身不是数字),作为转换结果。\n- 否则,如果对象有`toString()`方法且返回一个原始值,`javascript`将这个原始值转换为数字,作为转换结果。\n- 否则,`javascript`将抛出一个类型错误异常。\n\n## 显示转换\n\n使用`String()`, `Number()`, `Boolean()`函数强制转换类型。\n\n```javascript\nvar a = 1;\nvar b = String(a); // \"1\"\nvar c = Boolean(a); // true\n```\n\n## 隐式转换\n\n在不同的使用场景中,`javascript`会根据实际情况进行类型的隐式转换。举几个例子说明下。\n\n### 加法运算符+\n\n我们比较熟悉的运算符有算术运算符`+`, `-`, `*`, `/`,其中比较特殊的是`+`。因为加法运算符`+`可以用于数字加法,也可以用于字符串连接,所以加法运算符的两个操作数可能是类型不一致的。\n\n当两个操作数类型不一致时,加法运算符`+`会有如下的运算规则。\n\n- 如果其中一个运算符是对象,则会遵循对象到原始值的转换规则,对于非日期对象来说,对象到原始值的转换基本上是对象到数字的转换,所以首先调用`valueOf()`,然而大部分对象的`valueOf()`返回的值都是对象本身,不是一个原始值,所以最后也是调用`toString()`去获得原始值。对于日期对象来说,会使用对象到字符串的转换,所以首先调用`toString()`。\n\n```javascript\n1 + {}; // \"1[object Object]\"\n1 + new Date(); // \"1Sun May 10 2020 22:53:24 GMT+0800 (中国标准时间)\"\n```\n\n- 在进行了对象到原始值的转换后,如果加法运算符`+`的其中一个操作数是字符串的话,就将另一个操作数也转换为字符串,然后进行字符串连接。\n\n```javascript\nvar a = {} + false; // \"[object Object]false\"\n\nvar b = 1 + []; // \"1\"\n```\n\n- 否则,两个操作数都将转换为数字(或者NaN),然后进行加法操作。\n\n```javascript\nvar a = 1 + true; // 2\n\nvar b = 1 + undefined; // NaN\n\nvar c = 1 + null; // 1\n```\n\n### [] == ![]\n\n还有个很经典的例子,就是`[] == ![]`,其结果是`true`。一看,是不是觉得有点懵,一个值的求反竟然还等于这个值!其实仔细分析下过程,就能发现其中的奥秘了。\n\n1. 首先,我们要知道运算符的优先级是这样的,一元运算符`!`的优先级高于关系运算符`==`。\n\n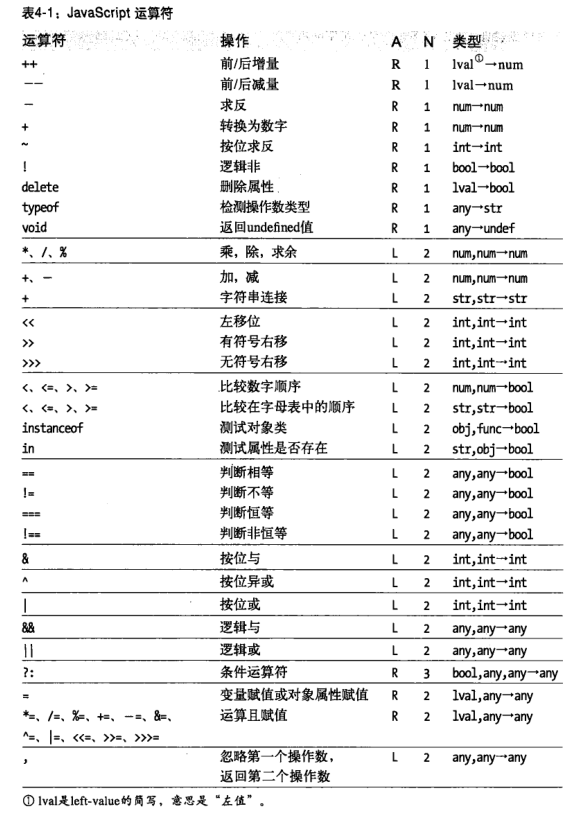\n\n2. 所以,右侧的`![]`首先会执行,而逻辑非运算符`!`会首先将其操作数转为布尔值,再进行求反。`[]`转为布尔值是`true`,所以`![]`的结果是`false`。此时的比较变成了`[] == false`。\n3. 根据比较规则,如果`==`的其中一个值是`false`,则将其转换为数字`0`,再与另一个操作数比较。此时的比较变成了`[] == 0`。\n4. 接着,再参考比较规则,如果一个值是对象,另一个值是数字或字符串,则将对象转为原始值,再进行比较。左侧的`[]`转为原始值是空字符串`\"\"`,所以此时的比较变成了`\"\" == 0`。\n5. 最后,如果一个值是数字,另一个是字符串,先将字符串转换为数字,再进行比较。空字符串会转为数字`0`,`0`与`0`自然是相等的。\n\n搞懂了这个问题,也可以分析下为什么`{} == !{}`的结果是`false`了,这个就比较简单了。\n\n看到这里,你还觉得数据类型是简答的知识点吗?有兴趣深究的朋友可以翻阅下[ES5的权威解释](http://es5.github.io/#x11.9.1 \"ES5官方注解\")。\n\n# 最后\n\n数据类型是`javascript`中非常重要的一部分,搞清楚数据类型的基本知识点,对于学习`javascript`的后续知识点多有裨益。\n\n另外,写笔记其实对思考问题很有帮助,就算只是总结很简单的基础知识,也是多有助益。\n\n以上内容是个人笔记和总结,难免有错误或遗漏之处,欢迎留言交流。', '2020-05-11 15:25:38', '2024-08-31 07:54:49', 1, 26, 0, '看似简单的东西背后却耐人寻味。每个知识点都值得再思索一番。[] == ![]背后的逻辑你清楚了吗?', 'https://s1.ax1x.com/2020/05/11/YJCmrV.jpg', 0, 0);
-INSERT INTO `article` VALUES (210, '关于数据类型的一些小疑惑', '上期在阅读《Javascript权威指南》第六版**类型转换**这一章节的时候,我虽然搞清楚了之前留下的很多疑问,比如说数据类型转换的基本规则,对象到原始值的转换规则等。但是对于书中3.8.3节(对象转换为原始值)中的一段文字存有疑惑,今天回头又看了一遍,总算是搞明白了。\n\n首先引用下这段文字。\n\n> “+”和“==”应用的对象到原始值的转换包含日期对象的一种特殊情形。日期类是JavaScript语言核心中唯一的预先定义类型,它定义了有意义的向字符串和数字类型的转换。对于所有非日期的对象来说,对象到原始值的转换基本上是对象到数字的转换(首先调用valueOf),日期对象则使用对象到字符串的转换模式,然而,这里的转换和上文讲述的并不完全一致:通过valueOf或toString返回的原始值将被直接使用,而不会被强制转换为数字或字符串。\n> \n\n> 和“==”一样,“<”运算符以及其他关系运算符也会做对象到原始值的转换,但要除去日期对象的特殊情形:任何对象都会首先尝试调用valueOf,然后调用toString。不管得到的原始值是否直接使用,它都不会进一步被转换为数字或字符串。\n> \n\n> “+”、“==”、“!=”和关系运算符是唯一执行这种特殊的字符串到原始值的转换方式的运算符。其他运算符到特定类型的转换都很明确,而且对日期对象来讲也没有特殊情况。例如“-”(减号)运算符把它的两个操作数都转换为数字。\n\n复制这么长一段文字呢,也不是为了凑字数,是我一开始真的没看明白这段。因为我一直纠结在这节内容前面说的对象转换为原始值的规则,死死地认为:\n\n1. 对象转原始值都应该按照两条路线走,一条路线是转为字符串,一条路线是转为数字。\n2. 对象转为字符串这条路线,是优先调用`toString()`方法,其次调用`valueOf()`方法,如果最后得到的原始值不是字符串,再把这个原始值转为字符串。\n3. 对象转为数字这条路线,是优先调用`valueOf()`方法,其次调用`toString()`方法,如果最后得到的原始值不是数字,再把这个原始值转为数字。\n4. 否则就抛出类型错误。\n\n这里写的转换规则比较粗略了,因为[上一篇笔记](https://juejin.im/post/5eb8e2fff265da7bb46bd8ae)中已经提到了比较详细的规则了,这里就捡重点看了。\n\n掉进这个规则里,我就产生了固化思维,觉得所有的对象转原始值的情况都应该按这个规则来。所以对上面引用的这段话就开始想不明白了。大概产生了这些疑问:\n\n1. 引文中第一段的最后一句“通过valueOf或toString返回的原始值将被直接使用,而不会被强制转换为数字或字符串。”。我的疑惑是:为什么最后不会再强制转换了?\n1. 第二段中提到的“关系运算符中对象到原始值的转换,都会首先调用valueOf,然后调用toString”。我的疑惑是:为什么日期对象又不特殊处理(首先调用toString)了呢?\n\n\n其实我上篇写到最后一小节[隐式转换](https://juejin.im/post/5eb8e2fff265da7bb46bd8ae#heading-21)的时候,已经提到了,不同运算符对于对象的转换规则是特殊的。\n\n> 在不同的使用场景中,`javascript`会根据实际情况进行类型的隐式转换。\n\n\n可能是写完之后回头看这段文字又串戏了,懵逼了。\n\n其实还是要看`javascript`到底期望什么类型的操作数。之所以`+`, `==`比较特殊,是因为`javascript`不太明确操作数的类型。\n\n就拿`+`来说吧,可能是用来做数字加法,也可能是用来拼接字符串。所以`javascript`必须把这些情况都考虑到,针对这个运算符来定个特殊的规则。\n\n而`==`是相等运算符,与恒等运算符`===`是不一样的。恒等运算符会首先判断数据类型是否一致,而`==`运算符不要求两个操作数类型一致,当两个操作数不一致时,会按照一定的规则进行操作数的隐式转换。\n\n而一些其他算术运算符,比如`-`, `*`, `/`,它们都很明确操作数的类型,希望操作数是数字。所以即使你给的操作数不是数字,它也会转为数字来运算。\n\n所以,如果其中一个操作数是对象,会发生对象到原始值的转换,然后这个原始值也会被转为数字(如果这个原始值本身不是数字)。\n\n```javascript\nvar a = {name: \'飞白\'};\na / 2; // NaN\n\nvar b = new Date();\nb / 2; // 795202699143\n```\n\n大概的思路是这个样子的,而每个运算符是怎么样的一个运算流程,还是要看去看它的官方说明。\n\n写这么一篇没什么实际内容的东西,主要还是想记录下自己的这种疑惑吧,希望自己以后不要再被这种文字绕进去了,要多想想程序这样设计到底是为了解决什么问题,这样才能更容易理解或猜到规则背后的逻辑。\n', '2020-05-30 18:02:57', '2024-08-08 09:06:30', 1, 20, 0, '上期在阅读《Javascript权威指南》第六版类型转换这一章节的时候,我虽然搞清楚了之前留下的很多疑问,比如说数据类型转换的基本规则,对象到原始值的转换规则等。但是对于书中3.8.3节(对象转换为原始值)中的一段文字存有疑惑,今天回头又看了一遍,总算是搞明白了。', 'https://qncdn.wbjiang.cn/1724ba0674616c9c', 0, 0);
-INSERT INTO `article` VALUES (211, '“入坑”自媒体写作,我有干货与你分享', '**自媒体时代**,人人都可以发声,大家都可以通过互联网发表自己的言论和观点。常见的自媒体平台有微信公众号,知乎,微博,头条,以及各个新闻博客平台等。自媒体写作与传统写作最大的不同,就是突出个性思维,只要找准自己的定位,一直坚持一个方向深耕,且不说会得到什么样的收益,但一定会提升自己的综合能力。之前也不止一次问过自己,你又不是大咖,写什么文章?质量还不高?我想,大概是兴趣驱动,写作是一种思考和沉淀的过程,于我而言是收获。\n\n借用《后浪》里的一句话:\n\n> 人与人之间的壁垒被打破,你们只凭相同的爱好,就能结交千万个值得干杯的朋友,你们拥有了我们曾经梦寐以求的权利——选择的权利。\n\n\n\n是的,我们有幸生在这个时代,自媒体已经没有职业之分了,任何职业的个体都可以在网络上发文分享自己的知识、经验、见识,也可以通过短视频这个当红的渠道快速传播。对于我们IT技术人来讲,一般会选择从技术知识写作入手,那么怎样才能写好一篇文章呢?作为一个粉丝数接近0的作者,我还是有一点**干货**与你分享。\n\n# 准备工作\n\n准备一篇有品质的文章,除了实打实的文章质量,美观的排版设计和丰富的素材也会加不少分。那么要从哪些方面入手呢?不着急,马上给您安排!\n\n## 写作方式\n\n最重要的当然是写作方式,选择一些好的编辑器往往让你事半功倍。一般而言,我们会选择**富文本**编辑器和**Markdown**编辑器两大类。\n\n### 富文本编辑器\n\n一般的写作平台都标配了富文本编辑器,所见即所得,这种感觉可能跟使用Word文档差不多。对于大多数人来说,富文本编辑器是一个非常棒的选择。下面是微信公众号的一个富文本编辑器界面:\n\n\n\n虽然有了富文本编辑器,但是写作仍然是一个伤脑筋的事情,比如找一些关注引导推荐类的素材还不够方便,所以我们还需要一个有大量可用素材模板的编辑器。\n\n有流量的地方自然有人去做,微信公众号这么一个巨大的流量通道,市面上自然少不了各种微信图文编辑器。大家可以自行去搜索下,我这里就不实名推荐了,防止广告嫌疑。\n\n\n\n这些编辑器内的素材都可以方便地复制到微信公众号的编辑器里,有的甚至做了一键导入到微信公众号的能力。\n\n当然这里不可避免会出现一些收费的素材,但是免费的基本上已经满足大众需求了,不用过于担心。\n\n### Markdown\n\n作为程序狗,自然忍不住要提一提Markdown。Markdown是一种标记语言。通过简单的标记语法,它可以使普通文本内容具有一定的格式,可以代表标题,文本,表格,图片,链接等等。\n\n你完全不用担心Markdown效果不好,虽然Markdown默认是极简风格,但是结合现在的表现层语言,它可以做得很漂亮。下面是一个简单的例子:\n\n\n\n你也不用担心不会使用Markdown,市面上已经有很多非常nice的Markdown编辑器。有了这些编辑器,你可以像写word文档一般玩转Markdown。\n\n### typora\n\n这里必须强力推荐一款编辑器**typora**了,是因为它真的很好用。\n\n在typora,你可以选择各种主题:\n\n\n\n利用这些主题,你可以专注于把控文章质量,写好之后直接复制到微信公众号,知乎等平台上的编辑器中,效果非常棒!\n\n\n\n### mdnice等在线编辑器\n\n如果不想用本地的markdown编辑器,也有在线的备选项,搜索“在线markdown编辑器”就好了。\n\n这里推荐一个[mdeditor](http://www.mdeditor.com),但是一般的在线markdown编辑器都没有主题功能,如果你需要做出个性化的效果,可能这些还不够。\n\n所以必须要推荐我现在很喜欢的一款编辑器[mdnice](https://mdnice.com/)了。mdnice可以说是把CSS的威力发挥得淋漓尽致了,支持的主题很多,也可以自行定义主题(如果你会使用CSS语言的话,可以尝试一下),下面这个主题是我自己定制的,个人觉得效果还行。\n\n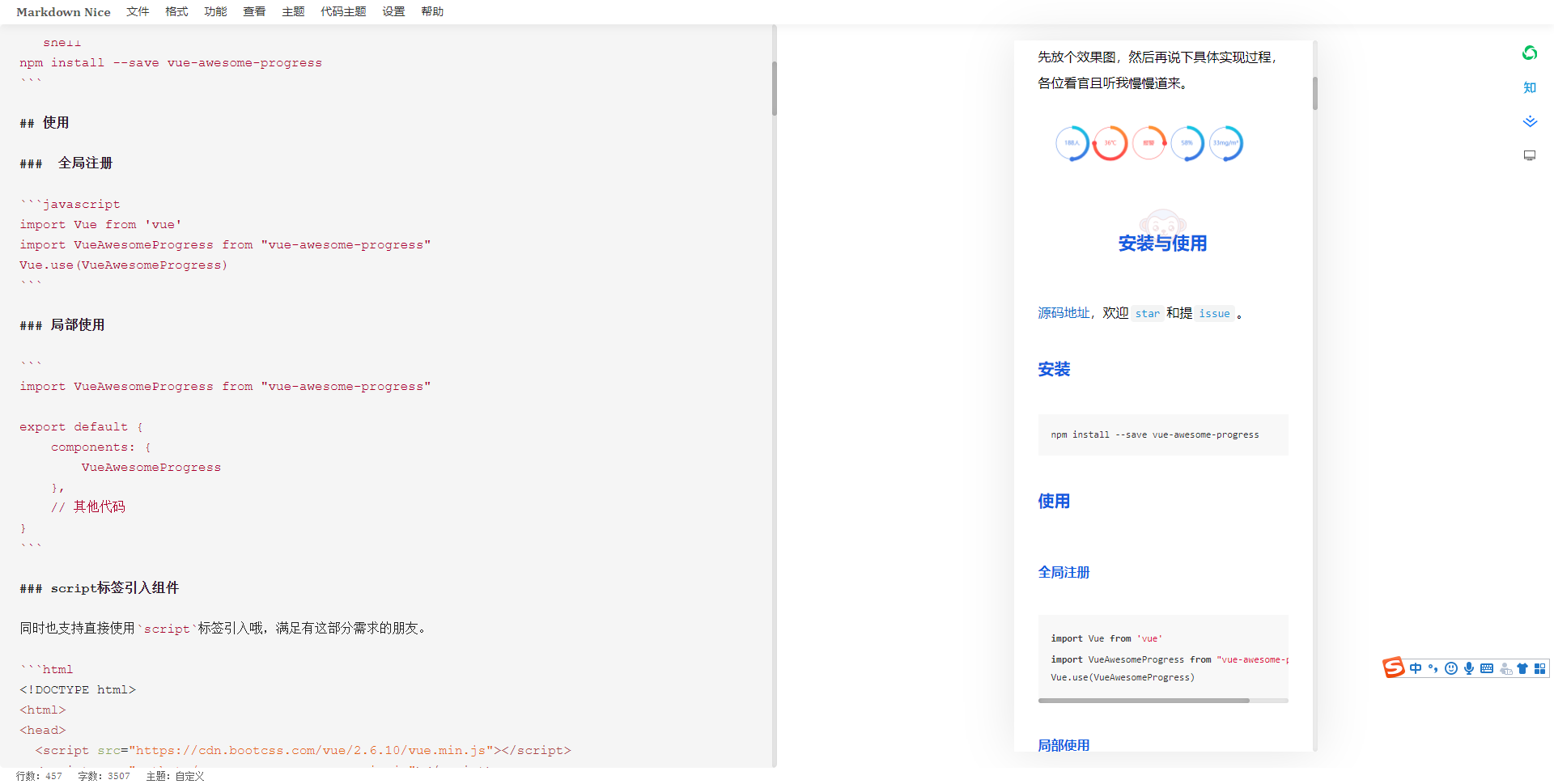\n\nmdnice也支持一键复制到微信公众号,掘金,知乎等平台,可以满足多数人的需求。\n\n并且mdnice支持缓存你的历史修改版本,这样也可以从一定程度上防止写作内容丢失了!\n\n还有一款类似的编辑器,做得也挺好的,就是主题太少了点。附上链接:[https://lab.lyric.im/wxformat/#](https://lab.lyric.im/wxformat/#)\n\n之前还用过一款md2all,不过好像停更了,链接是:[http://md.aclickall.com/](http://md.aclickall.com/)\n\n### 语雀\n\n有一次我本地用typora写作,结果系统崩了,没保存到,心态有点炸。最近我开始慢慢地在语雀上写个大概的草稿,然后可以导出markdown格式,转到typora或者mdnice再细致改改。有云同步的功能还是保险啊。\n\n我在公司写文档也基本上是用语雀的(之前还试过自己搭gitbook,不过没语雀给力),这是阿里内部孵化的很好的一款工具,强烈推荐!\n\n\n\n说了这么多编辑器,并不是说选择哪一款就可以解决所有问题,一般来说,结合起来使用,效果更棒,可以自行体会下!\n\n## 素材\n\n搞清楚了如何选择编辑器,接下来的重点就是素材的收集和处理了。灵活地运用素材,会让你的文章显得很饱满,生动有趣!\n\n### 无版权图\n\n首先要说的就是图片素材,写作的过程中,我们大部分时候会希望插入一些优质的图片,或是风景图,或是卡通,或是人物图。找图片素材自然要上一些靠谱的网站了,我这里也推荐一些,有些是否能商用要仔细看看,反正个人用途基本上没问题的。\n\n\n\n- [https://wallhaven.cc/](https://wallhaven.cc/) 这个是我用得最多的,并且支持原图在线裁剪。\n- [https://www.pexels.com/zh-tw/](https://www.pexels.com/zh-tw/)\n- [https://pixabay.com/zh/photos/](https://pixabay.com/zh/photos/)\n- [https://stocksnap.io/](https://stocksnap.io/)\n\n### 图标\n\n有时候我们可能也不需要找很大的图片素材,如果只是寻找一个小图标的话,上[iconfont](https://www.iconfont.cn/)就基本上解决了,支持导出主流的图片格式,并且可以自定义修改颜色,大小等。对了,iconfont是前端工程师日常开发中一个很重要的工具哦!\n\n\n\n### 动图\n\n如果需要录制一些GIF动图,比如操作引导之类的,就需要一个比较方便的工具了。我这里使用的是**GifCam**,如果您有更好的工具,请不吝赐教。\n\n### 录屏\n\n如果要录视频的话,可以选择**FSCapture**,除了录屏之外,还可以实现截图,滚动截图等能力哦,可谓是小而美。\n\n之前还用过一款[超级录屏](https://www.onlinedown.net/soft/518458.htm),也是不错的。\n\n当然还有一个神器**OBS Studio**,接触过直播的应该都知道(别问我为什么知道)。\n\n### 表情包\n\n有时候还是要来点表情包活跃下气氛的,除了日常搜集的表情包,我们有时候可能希望制作一些跟我们写作主题相关的表情,这个时候就要搜一下**表情包制作**了,这种工具很多,自行筛选即可。这里也简单地列举几个吧:\n\n- [https://fabiaoqing.com/diy](https://fabiaoqing.com/diy)\n- [https://app.xuty.tk/static/app/index.html](https://app.xuty.tk/static/app/index.html)\n- [https://www.52doutu.cn/diy/](https://www.52doutu.cn/diy/)\n\n### Emoji\n\n插入emoji也是个基本操作了,但是很多平台的编辑器还不支持直接识别emoji编码,直接复制上去是不行的,会被认定为普通文本。\n\n\n而**typora**编辑器是支持emoji的,只要把emoji编码复制上去,马上就呈现出来了。\n\n\n\n所以我们可以先在typora编辑器里面把emoji弄好,然后复制到其他平台上的富文本编辑器,就可以显示出来了。\n\n据我测试,大部分markdown编辑器是不支持这样做的,如果想把emoji复制到markdown编辑器上,需要先从typora复制到富文本编辑器,然后就可以把emoji表情从富文本编辑器复制到markdown编辑器上了。\n\n\n\n关于emoji的编码,这里有比较完整的一个列表。\n[https://www.webfx.com/tools/emoji-cheat-sheet/](https://www.webfx.com/tools/emoji-cheat-sheet/)\n\n### 流程图/结构图/架构图\n\n画图是一个很有用的方法,可以帮助我们把一个复杂的过程简单而直观地展示出来,极大提高了我们的效率。\n\n- 桌面端有强大的visio\n- 在线的绘图平台有ProcessOn\n\n\n\n### 思维导图\n\nProcessOn也可以画思维导图,类似的还有百度脑图。不过我还是更习惯用桌面端的**xmind**。\n\n## 资源压缩\n\n一般来说,找一些在线的压缩工具即可。但是有的要收费,要注意避坑。\n\n- 压缩图片\n\n[https://tinypng.com/](https://tinypng.com/)\n\n[https://www.tutieshi.com/compress/](https://www.tutieshi.com/compress/)\n\n[https://www.soogif.com/compress](https://www.soogif.com/compress)\n\n[https://docsmall.com/image-compress](https://docsmall.com/image-compress)\n\n- 压缩视频\n\n我几乎不用视频素材,如果要压缩视频,一般是找桌面端工具了,可以自行搜索下,或者看看这篇知乎[如何压缩视频大小?](https://www.zhihu.com/question/62583598?sort=created)\n\n## 图床\n\n我目前只用了七牛云和路过图床。\n\n- 七牛云对象存储,如果不用https的话,存图片是免费的。\n- [路过图床](https://imgchr.com/),这个是免费的,但是复制到微信公众号编辑器上,直接加载失败,头疼,估计是做了防盗链。\n- 还有一个比较好的工具[PicGo](https://picgo.github.io/PicGo-Doc/zh/guide/#%E5%BA%94%E7%94%A8%E6%A6%82%E8%BF%B0),集合了多个图床平台,有兴趣的可以试试。\n\n\n## 在线作图\n\n有时候我们要处理下封面,或者公众号首图,光有素材可能还不够的,一般人也不会使用**PS**,那么在线作图还是很重要的,可以节省很多时间。\n\n这里推荐我用过的两款:\n\n- [稿定设计](https://www.gaoding.com/):素材比较丰富,也支持同步到微信公众号素材库。\n- [Canva](https://www.canva.com/zh_cn/) 我早期用的一个在线作图工具。\n\n# 骚操作\n\n## 图片加阴影\n\n我们经常会截图作为素材,但是有时候截图的轮廓感不是很强,这个时候就要给图片来加个阴影效果了。我试过直接在mdnice上用css的`box-shadow`做阴影,但是感觉比较容易受盒子的影响,出现不太好的效果。\n\n所以我觉得还是直接改图片本身比较好,我现在使用的图片处理工具是ShareX。如果你会使用PS,那就自然不必多说。\n\n\n\n\n## typora主题定制\n\ntypora支持主题定制,首先要找到typora的主题目录。\n\n\n\n然后添加一个`css`文件,例如`feibai.css`,写下需要定制的css内容,比如:\n\n```css\nh1 {\n background: url(http://qncdn.xxx.cn/xxx.svg);\n background-size: 48px 48px;\n background-position: top center;\n background-repeat: no-repeat;\n text-align: center;\n font-size: 24px;\n}\n\nh1 > span {\n padding-top: 48px;\n display: block;\n color: #135ce0;\n}\n```\n\n接着在typora选择你刚才写的主题,就可以看到效果了。\n\n\n\n\n如果想要详细了解如何定制typora主题,可以主动联系我。\n\n# 最后\n\n做了这些准备工作,我不敢打包票说能写出很nice的文章,但至少能过得了自己眼球这一关吧。好了,本次分享结束,如果您觉得这篇文章还不错,欢迎**关注+在看+分享**鼓励一下我,也可以留言加我微信交流,谢谢!\n\n', '2020-05-30 18:11:48', '2024-08-15 23:33:53', 1, 30, 0, '自媒体时代,人人都可以发声,大家都可以通过互联网发表自己的言论和观点。作为一个粉丝数接近0的作者,我还是有一点干货与你分享。', 'https://qncdn.wbjiang.cn/wallhaven-0j26pq_1280x600.png', 0, 0);
-INSERT INTO `article` VALUES (212, '千万别小看这些运算符背后的逻辑', '# 前言\n\n最近回顾`javascript`的一些基础知识点时,引起的思考确实颠覆了我之前的一些认知。我清楚地记得曾多次在网上看到一些奇奇怪怪的表达式,它们的运算结果着实让人懵逼。就比如我在[js数据类型很简单,却也不简单](https://juejin.im/post/5eb8e2fff265da7bb46bd8ae#heading-23)这一篇笔记中提到的`[] == ![]`这样一个表达式,它的运算结果是`true`。如果你不细致地去研究它背后的运算逻辑,你只会惊呼”这是什么鬼“?相反,当你静下心来看清楚它的运算逻辑后,你会感叹“妙哉妙哉”!没错,本文的主角就是这些容易让人小觑的运算符。\n\n# 加法运算符+\n\n首先说的是加法运算符`+`,这是一个很容易被人忽视的运算符。我们知道,`+`可以用来做数字运算,也可以用作字符串拼接,但是还有一些细节可能是大家不知道的。如果`+`运算符的两个操作数类型不一致,或者说两个操作数既不是字符串也不是数字,那么它的运算规则是什么?\n\n先举几个例子,你可以先思考下这些运算结果分别是什么。\n\n```javascript\nvar a = 1 + \"1\";\nvar b = 1 + {};\nvar c = 1 + [];\nvar d = 1 + true;\nvar e = { name: \'飞白\' } + [1, 2];\nvar f = null + undefined;\nvar g = true + null;\n```\n\n其实规则很简单,我们只要简单地列举出数据类型的可能性,就几乎得到了完整的答案。\n\n1. 如果操作数都是数字,进行数字的加法运算。\n2. 如果操作数都是字符串,进行字符串的拼接。\n3. 如果操作数是对象,会转换为原始值(一般是先调用`valueOf()`,日期对象比较特殊,会调用`toString()`),得到的原始值不再被强制转换为数字或字符串。在这种约束下,对象转为原始值基本都是字符串(如果你没有重写`valuOf()`或者`toString()`方法),根据下面的第四点,会执行字符串拼接操作。\n4. 如果其中一个操作数是字符串,另一个操作数也会被转为字符串,`+`运算符执行字符串拼接操作。\n5. 如果两个操作数都不是字符串或对象,则会进行算术加法运算(非数字的操作数会被强制转为数字)。\n\n所以,不难得出上面列举的表达式的运算结果。\n\n```javascript\nvar a = 1 + \"1\"; // \"11\"\nvar b = 1 + {}; // \"1[object Object]\"\nvar c = 1 + []; // \"1\"\nvar d = 1 + true; // 2\nvar e = { name: \'飞白\' } + [1, 2]; // \"[object Object]1,2\"\nvar f = null + undefined; // NaN\nvar g = true + null; // 1\n```\n\n要记住这些规则并不简单,一个记忆技巧是:`+`运算符偏爱字符串拼接操作。\n\n# 相等运算符==\n\n这个运算符的运算规则,在[js数据类型很简单,却也不简单](https://juejin.im/post/5eb8e2fff265da7bb46bd8ae#heading-23)这篇笔记中已经简单地解释过了。其实只要记住一条规则:对于`==`运算符,如果两个操作数是`null`或`undefined`,运算结果是`true`;否则,不管操作数的类型如何转换,`==`运算符最后都是数字的比较。\n\n举几个简单的例子说明下:\n\n```javascript\nnull == undefined; // true\n[1] == 1; // true\n1 == true; // true\n1 == \"1\" // true\nnew Date(2020, 0, 1, 0, 0, 0) == 1577808000000 // false\n```\n\n# 比较运算符\n\n大于`>`,大于等于`>=`,小于`<`,小于等于`<=`,用于比较数字的大小或字符在字母表中的排序。要注意的是,在`ASCII`中,大写字母排在小写字母前面。\n\n这些比较运算符更偏爱数字的比较,除非两个操作数都是字符串。\n\n对于字符串比较的情况,如果两个字符串的第一个字符是相同的,则会比较第二个字符,以此类推。\n\n这里有一个比较特殊的`NaN`,它与任何值做比较都会返回`false`。\n\n```javascript\nNaN < 1; // false\nNaN > 1; // false\n```\n\n# 位运算符\n\n位运算符很少用到,但是弄明白它们的运算逻辑是很有必要的。位运算符主要分为与`&`、或`|`、非`~`、异或`^`以及左移`<<`、带符号右移`>>`、无符号右移`>>>`等。\n\n位运算符都是二进制的运算,并且是基于32位整数运算。所以十进制,十六进制的操作数都会先转为32位的二进制后再进行运算。这里以`0x1234 & 0x00FF = 0x0034`为例说明下流程:\n\n1. `0x123`转为二进制是`0000 0000 0000 0000 0001 0010 0011 0100`,`0x00FF`转为二进制是`0000 0000 0000 0000 0000 0000 0011 0100`。\n2. 进行按位与操作,结果是`0000 0000 0000 0000 0000 0000 0011 0100`,最后转为十六进制就是`0x0034`。\n\n## 移位运算符\n\n在复习到移位运算符这块时,我不由得提出了一个疑问:“javascript中为什么没有无符号左移运算符?”要解答这样一个疑问,首先还是要看看左移和右移分别是怎么运算的。\n\n摘取《计算机组成原理教程》书中的一段描述:\n\n> 计算机中机器数的字长往往是固定的,当机器数左移n位或右移n位时,必然会使其n位低位或n位高位出现空位。那么,对空出的空位应该添补0还是1呢?这与机器数采用有符号数还是无符号数有关。对无符号数的移位称为逻辑移位,对有符号数的移位称为算术移位。\n\n**注意**:在javascript中,移位运算符只支持移动0~31位,如果移动的位数超过了`31`位,位数会取模`MOD 32`。也就是说:\n\n```javascript\n1 << 32\n// 等价于\n1 << 0\n```\n\n### 带符号右移>>\n\n对于带符号右移(算术右移)运算而言,第一个操作数是有符号数,它的最高位代表符号位,在移位后的符号位不改变。简单总结就是“低位舍弃,高位补符号位”。\n\n```javascript\nvar a = -1;\na >> 2; // -1\n// 用负数的补码形式进行算术右移,高位补1\n```\n\n如果你自己写几个右移运算表达式做试验,你就会产生一个疑惑,为什么有的正数在带符号右移后却变成了负数,比如下面这个:\n\n```javascript\n2147483648 >> 31 // -1\n```\n\n这是因为`32`位的最大带符号正整数是231 - 1,即`2147483647`,转换为二进制是`0111 1111 1111 1111 1111 1111 1111 1111`。正数的补码与原码相同,`2147483648`相当于在此基础上加`1`,就得到补码`1000 0000 0000 0000 0000 0000 0000 0000`,而这个补码是一个非常特殊的码,它没有对应的原码和补码,代表`32`位能表示的带符号数中最小的负数231 - 1,即`-2147483648`。而`2147483648`在`32`位带符号正数中是无法表示的,其值已经溢出了。\n\n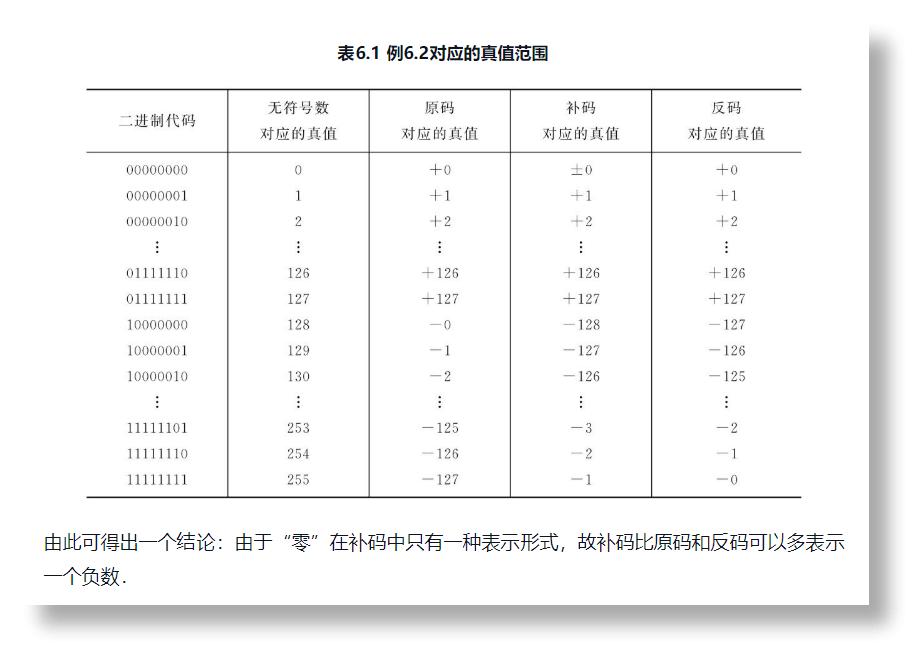\n\n计算机只理解二进制,与人类所理解的十进制之间永远存在一个精度问题,需要足够的精度才能更加准确地表示十进制,而计算机的位数永远都是有限的,这就是矛盾存在的地方,所以会出现溢出这种现象。\n\n\n\n就好比时钟一般,`23`时结束了又从`0`时开始。在带符号二进制表示法中,正数和负数首尾相连,形成一个环,在计算机可表示的范围内,溢出的那个数字在某种意义上能在另一个起点找到。\n\n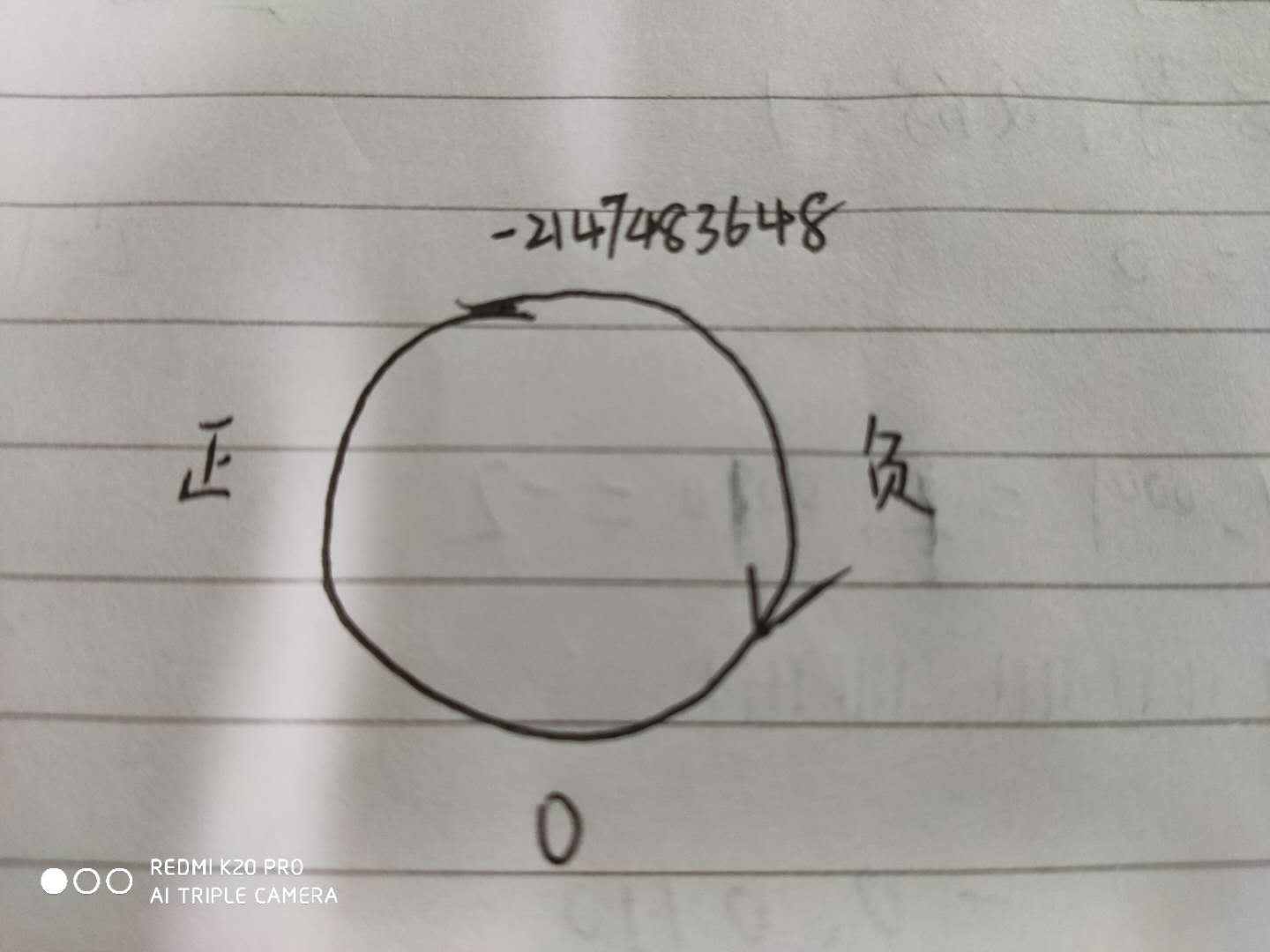\n\n所以,下面的位运算表达式也是等价的:\n\n```javascript\n2147483649 >> 1 // -1073741824\n-2147483647 >> 1 // 可以理解为:2147483649溢出的值为2,所以在位运算中,等价于第二小的负数-2147483647\n```\n\n### 无符号右移>>>\n\n无符号右移也称为逻辑右移。无符号右移的移位过程中,符号位可能会改变。因此移位后,原来的负数可能变成正数。可以简单记忆为“低位舍弃,高位补0”。\n\n```javascript\n-1 >>> 2; // 1073741823\n// 1000 0000 0000 0000 0000 0000 0000 0001 右移两位变成 0010 0000 0000 0000 0000 0000 0000 0000\n// 也就是2的30次方减去1,等于1073741823\n```\n\n### 左移<<\n\n翻阅《计算机组成原理教程》可以发现,书中有描述到算术左移和逻辑左移。也就是说,左移也分带符号左移和无符号左移。经测试,`javascript`中的左移运算符`<<`一般不会改变符号位,意味着它是算术左移(其实对比`<<`和`>>`也能知道,`<<`是带符号左移)。\n\n但是左移也要注意溢出的情况,比如:\n\n```javascript\n1 << 31; // -2147483648\n```\n\n\n\n那么为什么`javascript`中却没有逻辑左移呢?我找了一些资料,比如`es5`规范和注解,还有一些`javascript`的书籍,都没有找到解释。所以这里也没有一个权威的答案(如果有大佬知道的话,请不吝赐教)。\n\n\n\n我个人的想法是,应该是要回到移位运算的本质。\n\n> 二进制表示的机器数在相对于小数点作n位左移或右移时,其实质就是该数乘以或除以2n(n=1,2, …, n)。\n\n而在左移过程中,如果把符号位都丢了,就失去了乘以`2n`的意义了。所以不只是`javascript`,其他编程语言如`java`等也没有逻辑左移运算符。\n\n# 最后\n\n不得不说,大学课程真的很重要。如果一直都保持对计算机基础课程的关注,相信理解这些编程语言背后的本质会变得轻松很多。\n\n', '2020-06-05 11:08:09', '2024-08-13 18:52:12', 1, 31, 0, '带符号右移(算术右移)用补码运算,然后转为原码;无符号右移(逻辑右移)用原码或补码运算都可以,得到的结果真值是一样的。这是不是从另一个角度说明了逻辑运算不需要补码,补码只是为了带符号数的运算而设计?', 'http://qncdn.wbjiang.cn/wallhaven-0qx3x7_1200x500.png', 0, 0);
-INSERT INTO `article` VALUES (213, '「思维导图学前端 」一文搞懂Javascript对象,原型,继承', '# 前言\n\n去年开始我给自己画了一张知识体系的思维导图,用于规划自己的学习范围和方向。但是我犯了一个大错,我的思维导图只是一个全局的蓝图,而在学习某个知识点的时候没有系统化,知识太过于零散,另一方面也很容易遗忘,回头复习时没有一个提纲,整体的学习效率不高。意识到这一点,我最近开始用思维导图去学习和总结具体的知识点,效果还不错。试想一下,一张思维导图的某个端点是另一张思维导图,这样串起来的知识链条是多么“酸爽”!当然,YY一下就好了,我保证你没有足够的时间给所有知识点都画上思维导图,挑重点即可。\n\n\n\n# 提纲思路\n\n当我们要研究一个问题或者知识点时,关注点无非是:\n\n1. 是什么?\n\n2. 做什么?\n\n3. 为什么?\n\n很明显,搞懂“是什么”是最最基础的,而这部分却很重要。万丈高楼平地起,如果连基础都不清楚,何谈应用实践(“做什么”),更加也不会理解问题的本质(“为什么”)。\n\n而要整理一篇高质量的思维导图,必须充分利用“总-分”的思路,首先要形成一个基本的提纲,然后从各个方面去延伸拓展,最后得到一棵较为完整的知识树。分解知识点后,在细究的过程中,你可能还会惊喜地发现一个知识点的各个组成部分之间的关联,对知识点有一个更为饱满的认识。\n\n梳理提纲需要对知识点有一个整体的认识。如果是学习比较陌生的领域知识,我的策略是从相关书籍或官方文档的目录中提炼出提纲。\n\n下面以我复习`javascript`对象这块知识时的一些思路为例说明。\n\n# javascript对象\n\n在复习`javascript`对象这块知识时,我从过往的一些使用经验,书籍,文档资料中提炼出了这么几个方面作为提纲,分别是:\n\n- 对象的分类\n\n- 对象的三个重要概念:类,原型,实例\n\n- 创建对象的方法\n\n- 对象属性的访问和设置\n\n- 原型和继承\n\n- 静态方法和原型方法\n\n由此展开得到了这样一个思维导图:\n\n\n\n## 对象的分类\n\n对象主要分为这么三大类:\n\n- **内置对象**:ECMAScript规范中定义的类或对象,比如`Object`, `Array`, `Date`等。\n\n- **宿主对象**:由javascript解释器所嵌入的宿主环境提供。比如浏览器环境会提供`window`,`HTMLElement`等浏览器特有的宿主对象。Nodejs会提供`global`全局对象\n\n- **自定义对象**:由javascript开发者自行创建的对象,用以实现特定业务。就比如我们熟悉的Vue,它就是一个自定义对象。我们可以对Vue这个对象进行实例化,用于生成基于Vue的应用。\n\n## 对象的三个重要概念\n\n### 类\n\njavascript在ES6之前没有`class`关键字,但这不影响javascript可以实现面向对象编程,javascript的类名对应构造函数名。\n\n在ES6之前,如果我们要定义一个类,其实是借助函数来实现的。\n\n```javascript\nfunction Person(name) {\n this.name = name;\n}\nPerson.prototype.sayHello = function() { \n console.log(this.name + \': hello!\');\n}\n\nvar person = new Person(\'Faker\');\nperson.sayHello();\n```\n\nES6明确定义了`class`关键字。\n\n```javascript\nclass Person {\n constructor(name) {\n this.name = name;\n }\n\n sayHello() {\n console.log(this.name + \': hello!\');\n }\n}\n\nvar person = new Person(\'Faker\');\nperson.sayHello();\n```\n\n### 原型\n\n原型是类的核心,用于定义类的属性和方法,这些属性和方法会被实例继承。\n\n定义原型属性和方法需要用到构造函数的`prototype`属性,通过`prototype`属性可以获取到原型对象的引用,然后就可以扩展原型对象了。\n\n```javascript\nfunction Person(name) {\n this.name = name;\n}\nPerson.prototype.sexList = [\'man\', \'woman\'];\nPerson.prototype.sayHello = function() {\n console.log(this.name + \': hello!\');\n}\n```\n\n### 实例\n\n类是抽象的概念,相当于一个模板,而实例是类的具体表现。就比如`Person`是一个类,而根据`Person`类,我们可以实例化多个对象,可能有小明,小红,小王等等,类的实例都是一个个独立的个体,但是他们都有共同的原型。\n\n```javascript\nvar xiaoMing = new Person(\'小明\');\nvar xiaoHong = new Person(\'小红\');\n\n// 拥有同一个原型\nObject.getPrototypeOf(xiaoMing) === Object.getPrototypeOf(xiaoHong); // true\n```\n\n## 如何创建对象\n\n### 对象直接量\n\n对象直接量也称为对象字面量。直接量就是不需要实例化,直接写键值对即可创建对象,堪称“简单粗暴”。\n\n```javascript\nvar xiaoMing = { name: \'小明\' };\n```\n\n每写一个对象直接量相当于创建了一个新的对象。即使两个对象直接量看起来一模一样,它们指向的堆内存地址也是不一样的,而对象是按引用访问的,所以这两个对象是不相等的。\n\n```javascript\nvar xiaoMing1 = { name: \'小明\' };\nvar xiaoMing2 = { name: \'小明\' };\nxiaoMing1 === xiaoMing2; // false\n```\n\n### new 构造函数\n\n可以通过关键词`new`调用javascript对象的构造函数来获得对象实例。比如:\n\n1. 创建内置对象实例\n\n```javascript\nvar o = new Object();\n```\n\n2. 创建自定义对象实例\n\n```javascript\nfunction Person(name) {\n this.name = name;\n};\nnew Person(\'Faker\');\n```\n\n### Object.create\n\n`Object.create`用于创建一个对象,接受两个参数,使用语法如下;\n\n```javascript\nObject.create(proto[, propertiesObject]);\n```\n\n第一个参数`proto`用于指定新创建对象的原型;\n\n第二个参数`propertiesObject`是新创建对象的属性名及属性描述符组成的对象。\n\n`proto`可以指定为`null`,但是意味着新对象的原型是`null`,它不会继承`Object`的方法,比如`toString()`等。\n\n`propertiesObject`参数与`Object.defineProperties`方法的第二个参数格式相同。\n\n```javascript\nvar o = Object.create(Object.prototype, {\n // foo会成为所创建对象的数据属性\n foo: { \n writable:true,\n configurable:true,\n value: \"hello\" \n },\n // bar会成为所创建对象的访问器属性\n bar: {\n configurable: false,\n get: function() { return 10 },\n set: function(value) {\n console.log(\"Setting o.bar to\", value);\n }\n }\n});\n```\n\n## 属性查询和设置\n\n### 属性查询\n\n属性查询也可以称为属性访问。在javascript中,对象属性查询非常灵活,支持点号查询,也支持字符串索引查询(之所以说是“字符串索引”,是因为写法看起像数组,索引是字符串而不是数字)。\n\n通过点号加属性名访问属性的行为很像一些静态类型语言,如java,C等。属性名是javascript标识符,必须直接写在属性访问表达式中,不能动态访问。\n\n```javascript\nvar o = { name: \'小明\' };\no.name; // \"小明\"\n```\n\n而根据字符串索引查询对象属性就比较灵活了,属性名就是字符串表达式的值,而一个表达式是可以接受变量的,这意味着可以动态访问属性,这赋予了javascript程序员很大的灵活性。下面是一个很简单的示例,而这种特性在业务实践中作用很大,比如深拷贝的实现,你往往不知道你要拷贝的对象中有哪些属性。\n\n```javascript\nvar o = { chineseName: \'小明\', englishName: \'XiaoMing\' };\n[\'chinese\', \'english\'].forEach(lang => {\n var property = lang + \'Name\';\n console.log(o[property]); // 这里使用了字符串索引访问对象属性\n})\n```\n\n对了,属性查询不仅可以查询自由属性,也可以查询继承属性。\n\n```javascript\nvar protoObj = { age: 18 };\nvar o = Object.create(protoObj);\no.age; // 18,这里访问的是原型属性,也就是继承得到的属性\n```\n\n### 属性设置\n\n通过属性访问表达式,我们可以得到属性的引用,就可以据此设置属性了。这里主要注意一下只读属性和继承属性即可,细节不再展开。\n\n## 原型和继承\n\n### 原型\n\n前面也提到了,原型是实现继承的基础。那么如何去理解原型呢?\n\n首先,要明确原型概念中的三角关系,三个主角分别是构造函数,原型,实例。我这里画了一张比较简单的图来帮助理解下。\n\n\n\n原型这东西吧,我感觉“没人能帮你理解,只有你自己去试过才是懂了”。\n\n不过这里说说我刚学习原型时的疑惑,疑惑的是为什么构造函数有属性`prototype`指向原型,而实例又可以通过`__proto__`指向原型,究竟`prototype`和`__proto__`谁是原型?其实这明显是没有理解对象是按引用访问这个特点了。原型对象永远只有一个,它存储于堆内存中,而构造函数的`prototype`属性只是获得了原型的引用,通过这个引用可以操作原型。\n\n同样地,`__proto__`也只是原型的引用,但是要注意了,`__proto__`不是`ECMAScript`规范里的东西,所以千万不要用在生产环境中。\n\n至于为什么不可以通过`__proto__`访问原型,原因也很简单。通过实例直接获得了原型的访问和修改权限,这本身是一件很危险的事情。\n\n举个例子,这里有一个类`LatinDancer`,意思是拉丁舞者。经过实例化操作,得到了多个拉丁舞者。\n\n```javascript\nfunction LatinDancer(name) {\n this.name = name;\n};\nLatinDancer.prototype.dance = function() {\n console.log(this.name + \'跳拉丁舞...\');\n}\n\nvar dancer1 = new LatinDancer(\'小明\');\nvar dancer2 = new LatinDancer(\'小红\');\nvar dancer3 = new LatinDancer(\'小王\');\ndancer1.dance(); // 小明跳拉丁舞...\ndancer2.dance(); // 小红跳拉丁舞...\ndancer3.dance(); // 小王跳拉丁舞...\n```\n\n大家欢快地跳着拉丁舞,突然小王这个家伙心血来潮,说:“我要做b-boy,我要跳Breaking”。于是,他私下改了原型方法`dance()`。\n```\ndancer3.__proto__.dance = function() {\n console.log(this.name + \'跳breaking...\');\n}\n\ndancer1.dance(); // 小明跳breaking...\ndancer2.dance(); // 小红跳breaking...\ndancer3.dance(); // 小王跳breaking...\n```\n\n这个时候就不对劲了,小明和小红正跳着拉丁,突然身体不受控制了,跳起了Breaking,心里暗骂:“沃尼玛,劳资不是跳拉丁的吗?”\n\n\n\n这里只是举个例子哈,没有对任何舞种或者舞者不敬的意思,抱歉抱歉。\n\n所以,大家应该也明白了为什么不能使用`__proto__`了吧。\n\n### 原型链\n\n在javascript中,任何对象都有原型,除了`Object.prototype`,它没有原型,或者说它的原型是`null`。\n\n那么什么是原型链呢?javascript程序在查找一个对象的属性或方法时,会首先在对象本身上进行查找,如果找不到则会去对象的原型上进行查找。按照这样一个递归关系,如果原型上找不到,就会到原型的原型上找,这样一直查找下去,就会形成一个链,它的终点是`null`。\n\n还要注意的一点是,构造函数也是一个对象,也存在原型,它的原型可以通过`Function.prototype`获得,而`Function.prototype`的原型则可以通过`Object.prototype`获得。\n\n### 继承\n\n说到继承,可能大家脑子里已经冒出来“原型链继承”,“借用构造函数继承”,“寄生式继承”,“原型式继承”,“寄生组合继承”这些概念了吧。说实话,一开始我也是这么记忆,但是发现好像不是那么容易理解啊。最后,我发现,只要从原型三角关系入手,就能理清实现继承的思路。\n\n\n\n我们知道,对象实例能访问的属性和方法一共有三个来源,分别是:调用构造函数时挂载到实例上的属性,原型属性,对象实例化后自身新增的属性。\n\n很明显,第三个来源不是用来做继承的,那么前两个来源用来做继承分别有什么优缺点呢?很明显,如果只基于其中一种来源做继承,都不可能全面地继承来自父类的属性或方法。\n\n首先明确下继承中三个主体:**父类**,**子类**,**子类实例**。那么怎么才能让子类实例和父类搭上关系呢?\n\n#### 原型链继承\n\n所谓继承,简单说就是能通过子类实例访问父类的属性和方法。而利用原型链可以达成这样的目的,所以只要父类原型、子类原型、子类实例形成原型链关系即可。\n\n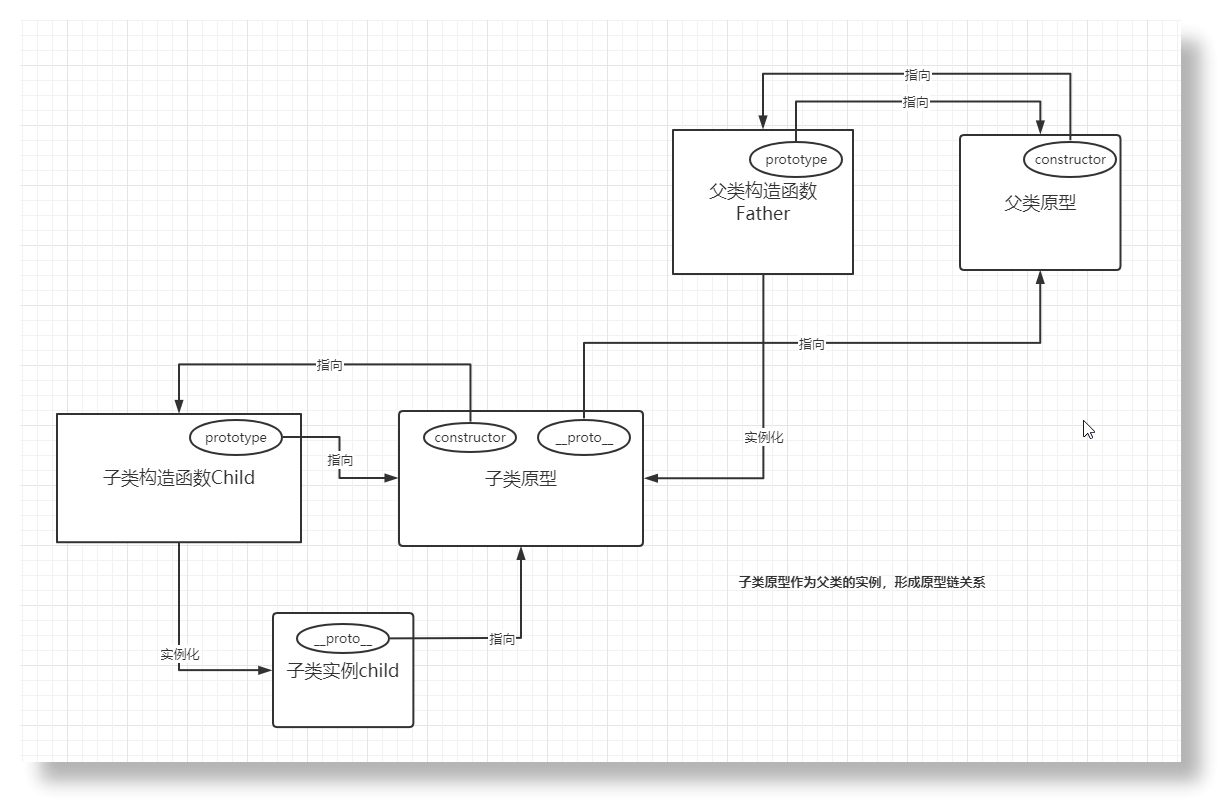\n\n代码示例:\n\n```javascript\nfunction Father() {\n this.nationality = \'Han\';\n};\nFather.prototype.propA = \'我是父类原型上的属性\';\nfunction Child() {};\nChild.prototype = new Father();\nChild.prototype.constructor = Child; // 修正原型上的constructor属性\nChild.prototype.propB = \'我是子类原型上的属性\';\nvar child = new Child();\nconsole.log(child.propA, child.propB, child.nationality); // 都可以访问到\nchild instanceof Father; // true\n```\n\n可以看到,在上述代码中,我们做了这样一个特殊处理`Child.prototype.constructor = Child;`。一方面是为了保证`constructor`的指向正确,毕竟实例由子类实例化得来,如果`constructor`指向父类构造函数也不太合适吧。另一方面是为了防止某些方法显示调用`constructor`时带来的麻烦。具体解释见[Why is it necessary to set the prototype constructor?](https://stackoverflow.com/questions/8453887/why-is-it-necessary-to-set-the-prototype-constructor#)\n\n**关键点**:让子类原型成为父类的实例,子类实例也是父类的实例。\n\n**缺点**:无法继承父类构造函数给实例挂载的属性。\n\n#### 借用构造函数\n\n在调用子类构造函数时,通过call调用父类构造函数,同时指定this值。\n\n```javascript\nfunction Father() {\n this.nationality = \'Han\';\n};\nFather.prototype.propA = \'我是父类原型上的属性\';\nfunction Child() {\n Father.call(this);\n};\nChild.prototype.propB = \'我是子类原型上的属性\';\nvar child = new Child();\nconsole.log(child.propA, child.propB, child.nationality);\n```\n\n这里的`child.propA`是`undefined`,因为子类实例不是父类的实例,无法继承父类原型属性。\n\n```javascript\nchild instanceof Father; // false\n```\n\n**关键点**:构造函数的复用。\n\n**缺点**:子类实例不是父类的实例,无法继承父类原型属性。\n\n#### 组合继承\n\n所谓组合继承,就是综合上述两种方法。实现代码如下:\n\n```javascript\nfunction Father() {\n this.nationality = \'Han\';\n};\nFather.prototype.propA = \'我是父类原型上的属性\';\nfunction Child() {\n Father.call(this);\n};\nChild.prototype = new Father();\nChild.prototype.constructor = Child; // 修正原型上的constructor属性\nChild.prototype.propB = \'我是子类原型上的属性\';\nvar child = new Child();\nconsole.log(child.propA, child.propB, child.nationality); // 都能访问到\n```\n\n一眼看上去没什么问题,但是`Father()`构造函数其实是被调用了两次的。第一次发生在`Child.prototype = new Father();`,此时子类原型成为了父类实例,执行父类构造函数`Father()`时,获得了实例属性`nationality`;第二次发生在`var child = new Child();`,此时执行子类构造函数`Child()`,而`Child()`中通过`call()`调用了父类构造函数,所以子类实例也获得了实例属性`nationality`。这样理解起来可能有点晦涩难懂,我们可以看看子类实例的对象结构:\n\n\n\n可以看到,子类实例和子类原型上都挂载了执行父类构造函数时获得的属性`nationality`。然而我们做继承的目的是很单纯的,即“让子类继承父类属性和方法”,但并不应该给子类原型挂载不必要的属性而导致污染子类原型。\n\n有人会说“这么一点副作用怕什么”。当然,对于这么简单的父类而言,这种副作用微乎其微。假设父类有几百个属性或方法呢,这种白白耗费性能和内存的行为是有必要的吗?答案显而易见。\n\n**关键点**:实例属性和原型属性都得以继承。\n\n**缺点**:父类构造函数被执行了两次,污染了子类原型。\n\n#### 原型式继承\n\n原型式继承是相对于原型链继承而言的,与原型链继承的不同点在于,子类原型在创建时,不会执行父类构造函数,是一个纯粹的空对象。\n\n```javascript\nfunction Father() {\n this.nationality = \'Han\';\n};\nFather.prototype.propA = \'我是父类原型上的属性\';\nfunction Child() {};\nChild.prototype = Object.create(Father.prototype);\nChild.prototype.constructor = Child; // 修正原型上的constructor属性\nChild.prototype.propB = \'我是子类原型上的属性\';\nvar child = new Child();\nconsole.log(child.propA, child.propB, child.nationality); // 都可以访问到\nchild instanceof Father; // true\n```\n\n在`ES5`之前,可以这样模拟`Object.create`:\n\n```javascript\nfunction create(proto) {\n function F() {}\n F.prototype = proto;\n return new F();\n}\n```\n\n**关键点**:利用一个空对象过渡,解除子类原型和父类构造函数的强关联关系。这也意味着继承可以是纯对象之间的继承,无需构造函数介入。\n\n**缺点**:无法继承父类构造函数给实例挂载的属性,这一点和原型链继承并无差异。\n\n#### 寄生式继承\n\n寄生式继承有借鉴工厂函数的设计模式,将继承的过程封装到一个函数中并返回对象,并且可以在函数中扩展对象方法或属性。\n\n```javascript\nvar obj = {\n nationality: \'Han\'\n};\nfunction inherit(proto) {\n var o = Object.create(proto);\n o.extendFunc = function(a, b) {\n return a + b;\n }\n return o;\n}\nvar inheritObj = inherit(obj);\n```\n\n这里`inheritObj`不仅继承了`obj`,而且也扩展了`extendFunc`方法。\n\n**关键点**:工厂函数,封装过程函数化。\n\n**缺点**:如果在工厂函数中扩展对象属性或方法,无法得到复用。\n\n#### 寄生组合继承\n\n用以解决组合继承过程中存在的“父类构造函数多次被调用”问题。\n\n```javascript\nfunction inherit(childType, fatherType) {\n childType.prototype = Object.create(fatherType.prototype);\n childType.prototype.constructor = childType;\n}\n\nfunction Father() {\n this.nationality = \'Han\';\n}\nFather.prototype.propA = \'我是父类原型上的属性\';\nfunction Child() {}\ninherit(Child, Father); // 继承\nChild.prototype.propB = \'我是子类原型上的属性\';\nvar child = new Child();\nconsole.log(child);\n```\n\n**关键点**:解决父类构造函数多次执行的问题,同时让子类原型变得更加纯粹。\n\n### 静态方法\n\n何谓“静态方法”?静态方法为类所有,不归属于任何一个实例,需要通过类名直接调用。\n\n```javascript\nfunction Child() {}\nChild.staticMethod = function() { console.log(\"我是一个静态方法\") }\nvar child = new Child();\nChild.staticMethod(); // \"我是一个静态方法\"\nchild.staticMethod(); // Uncaught TypeError: child.staticMethod is not a function\n```\n\n`Object`类有很多的静态方法,我学习的时候习惯把它们分为这么几类(当然,这里没有全部列举开来,只挑了常见的方法)。\n\n#### 创建和复制对象\n\n- `Object.create()`:基于原型和属性描述符集合创建一个新对象。\n\n- `Object.assign()`:合并多个对象,会影响源对象。所以在合并对象时,为了避免这个问题,一般会这样做:\n\n```javascript\nvar mergedObj = Object.assign({}, a, b);\n```\n\n#### 属性相关\n\n- `Object.defineProperty`:通过属性描述符来定义或修改对象属性,主要涉及`value`, `configurable`, `writable`, `enumerable`四个特性。\n\n- `Object.defineProperties`:是`defineProperty`的升级版本,一次性定义或修改多个属性。\n\n- `Object.getOwnPropertyDescriptor`:获取属性描述符,是一个对象,包含`value`, `configurable`, `writable`, `enumerable`四个特性。\n\n- `Object.getOwnPropertyNames`:返回一个由指定对象的所有自身属性的属性名(包括不可枚举属性但不包括Symbol值作为名称的属性)组成的数组。\n\n- `Object.keys`:会返回一个由一个给定对象的自身可枚举属性组成的数组,与`getOwnPropertyNames`最大的不同点在于:`keys`只返回`enumerable`为`true`的属性,并且会返回原型对象上的属性。\n\n#### 原型相关\n\n- `Object.getPrototypeOf`:返回指定对象的原型。\n\n```javascript\nfunction Child() {}\nvar child = new Child();\nObject.getPrototypeOf(child) === Child.prototype; // true\n```\n\n- `Object.setPrototypeOf`:设置指定对象的原型。这是一个比较危险的动作,同时也是一个性能不佳的方法,不推荐使用。\n\n#### 行为控制\n\n以下列举的这三个方式是一个递进的关系,我们按序来看:\n\n- `Object.preventExtensions`:让一个对象变的不可扩展,也就是永远不能再添加新的属性。\n\n- `Object.seal`:封闭一个对象,阻止添加新属性并将所有现有属性标记为不可配置。也就是说`Object.seal`在`Object.preventExtensions`的基础上,给对象属性都设置了`configurable`为`false`。\n\n这里有一个坑是:对于`configurable`为`false`的属性,虽然不能重新设置它的`configurable`和`enumerable`特性,但是可以把它的`writable`特性从`true`改为`false`(反之不行)。\n\n- `Object.freeze`:冻结一个对象,不能新增,修改,删除属性,也不能修改属性的原型。这里还有一个深冻结`deepFreeze`的概念,有点类似深拷贝的意思,递归冻结。\n\n#### 检测能力\n\n- `Object.isExtensible`:检测对象是否可扩展。\n\n- `Object.isSealed`:检测对象是否被封闭。\n\n- `Object.isFrozen`:检测对象是否被冻结。\n\n#### 兼容性差\n\n- `Object.entries`\n\n- `Object.values`\n\n- `Object.fromEntries`\n\n### 原型方法\n\n原型方法是指挂载在原型对象上的方法,可以通过实例调用,本质上是借助原型对象调用。例如:\n\n```javascript\nfunction Child() {}\nChild.prototype.protoMethod = function() { console.log(\"我是一个原型方法\") }\nvar child = new Child();\nchild.protoMethod(); // \"我是一个原型方法\"\n```\n\nECMAScript给`Object`定义了很多原型方法。\n\n\n\n#### hasOwnProperty\n\n该方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键),常配合`for ... in`语句一起使用,用来遍历对象自身可枚举属性。\n\n#### isPrototypeOf\n\n该方法用于测试一个对象是否存在于另一个对象的原型链上。`Object.prototype.isPrototypeOf`与`Object.getPrototypeOf`不同点在于:\n\n- `Object.prototype.isPrototypeOf`判断的是原型链关系,并且返回一个布尔值。\n\n- `Object.getPrototypeOf`是获取目标对象的直接原型,返回的是目标对象的原型对象\n\n#### PropertyIsEnumerable\n\n该方法返回一个布尔值,表示指定的属性是否可枚举。它检测的是对象属性的`enumerable`特性。\n\n#### valueOf & toString\n\n对象转原始值会用到的方法,之前写过一篇笔记,具体见[js数据类型很简单,却也不简单](https://juejin.im/post/5eb8e2fff265da7bb46bd8ae#heading-14)。\n\n#### toLocaleString\n\n`toLocaleString`方法返回一个该对象的字符串表示。此方法被用于派生对象为了特定语言环境的目的(locale-specific purposes)而重载使用。常见于日期对象。\n\n# 最后\n\n通过阅读本文,读者们可以对Javascript对象有一个基本的认识。对象是Javascript中非常复杂的部分,绝非一篇笔记或一张思维导图可囊括,诸多细节不便展开,可关注我留言交流,回复“思维导图”可获取我整理的思维导图。', '2020-06-17 17:25:34', '2024-08-16 10:09:47', 1, 47, 0, '用思维导图的方式学习javascript对象,原型,继承', 'https://qncdn.wbjiang.cn/%E4%B8%80%E6%96%87%E6%90%9E%E6%87%82%E5%AF%B9%E8%B1%A1%E5%8E%9F%E5%9E%8B%E7%BB%A7%E6%89%BF.png', 0, 0);
-INSERT INTO `article` VALUES (214, '「冲击leetcode青铜5」回文数的两种解法', '我最近也开始看看leetcode了,有时间也刷个一两题,不得不说,现在这个行业对前端工程师的要求是越来越高了,除了写业务代码,还要懂框架原理,工程化,服务端,服务器部署,就连算法也逃不了。\n\n其实也没办法抱怨,现在高校计算机相关专业出来的毕业生中,越来越大比例的同学会选择从事前端开发,这些同学在学校或多或少都接触过数据结构和算法(鸭梨山大)。除此之外,前端开发过程中确实也有越来越多的场景会涉及到算法,简单的可能有数组转二叉树,各种排序算法,甚至有贪心算法,动态规划等......\n\n\n\n为了让自己学习(保持)更多知识(竞争力),我想还是冲击下leetcode青铜五吧。\n\n# 回文数\n\n打开leetcode第一天,系统给我推荐了一题回文数。\n\n> 判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。\n\n示例 1:\n\n```\n输入: 121\n输出: true\n```\n\n示例 2:\n\n```\n输入: -121\n输出: false\n解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。\n```\n\n\n示例 3:\n\n```\n输入: 10\n输出: false\n解释: 从右向左读, 为 01 。因此它不是一个回文数。\n```\n\n看了下题干,我感觉还挺简单的啊,不愧是简单难度。\n\n\n\n## 字符串反转\n\n我假装思考了一会儿,心想,好像只要把数字转为字符串,然后再反转一波就基本搞定了啊。\n\n对了,还要先判断一下负数的情况,显得我考虑比较周全。\n\n\n\n```javascript\n/**\n * @param {number} x\n * @return {boolean}\n */\nvar isPalindrome = function(x) {\n if (x < 0) {\n return false;\n } else {\n var strNum = String(x);\n if (strNum.split(\'\').reverse().join(\'\') === strNum) {\n return true;\n }\n return false;\n }\n};\n```\n\n`split(\'\')`用于将字符串各个字符分割出来得到一个字符串数组,而`reverse()`是数组反转方法,`join(\'\')`则是将数组重新拼接为字符串。这样就实现了一个基于字符串反转得到的回文数解决方法。\n\n不出所料,测试用例执行通过。\n\n\n\n## 数字反转\n\n正当我准备提交解题代码时,我发现题目中还有这么一句话:\n\n> 进阶: 你能不将整数转为字符串来解决这个问题吗?\n\n果然,问题没有这么简单,还剩最后一点倔强的我,必须要试试。\n\n我的思路是利用取模运算符`%`依次获得最后一位数字,这样就能把数字反转过来得到一个数组。最后求值的时候只需要遍历数组,乘以对应的10次幂即可。\n\n```javascript\n/**\n * @param {number} x\n * @return {boolean}\n */\nvar isPalindrome = function(x) {\n var reverseNumList = [];\n var tempNum = x;\n while(tempNum > 0) {\n var lastNum = tempNum % 10;\n reverseNumList.push(lastNum);\n tempNum = Math.floor(tempNum / 10);\n }\n var reversedValue = 0;\n for (var i = 0, len = reverseNumList.length; i < len; i++) {\n reversedValue += reverseNumList[i] * Math.pow(10, len - 1 - i)\n }\n return reversedValue === x;\n};\n```\n\n# 最后\n\nleetcode并没有限制你的解法,不管性能优劣如何,自己能把思路用代码写出来就是成功的。最后可以再看看一些排名靠前的解法,你也许能打开新世界的大门(当然,也许你会自暴自弃,哈哈...)。', '2020-06-22 19:52:59', '2024-08-25 05:03:36', 1, 22, 0, '现在这个行业对前端工程师的要求是越来越高了,除了写业务代码,还要懂框架原理,工程化,服务端,服务器部署,就连算法也逃不了。', 'http://qncdn.wbjiang.cn/leetcode%E6%8B%8D%E4%BA%86%E6%8B%8D%E6%88%91.png', 0, 0);
-INSERT INTO `article` VALUES (215, '「冲击leetcode青铜5」妙用数组fill处理每日温度', '在老家过完粽子节,回到工作地又可以一脸开(无)心(奈)地刷leetcode了。今天的题目是每日温度,给定一个温度数组,求解的目标是算出某一天需要等待几天才能超过该天的温度。\n\n# 每日温度\n\n请根据每日气温列表,重新生成一个列表。对应位置的输出为:要想观测到更高的气温,至少需要等待的天数。如果气温在这之后都不会升高,请在该位置用`0`来代替。\n\n例如,给定一个列表`temperatures = [73, 74, 75, 71, 69, 72, 76, 73]`,你的输出应该是`[1, 1, 4, 2, 1, 1, 0, 0]`。\n\n提示:气温列表长度的范围是`[1, 30000]`。每个气温的值的均为华氏度,都是在`[30, 100]`范围内的整数。\n\n\n## 两层循环判断\n\n整体思路是,利用两层`for`循环,判断每个温度之后是否有更高的温度。要注意,第一层`for`循环到最后一个元素时,是不会进入第二层`for`循环的。此时直接通过`push`方法把`0`塞入数组。\n\n```javascript\n/**\n * @param {number[]} T\n * @return {number[]}\n */\nvar dailyTemperatures = function(T) {\n var result = [];\n for(var i = 0, len = T.length; i < len; i++) {\n if (i == len - 1) {\n result.push(0);\n } else {\n var currValue = T[i];\n var waitDay = 0;\n inner: for (var j = i + 1, len = T.length; j < len; j++) {\n if (T[j] > currValue) {\n waitDay = j - i;\n break inner;\n }\n }\n result.push(waitDay)\n }\n }\n return result;\n};\n```\n\n执行结果是:\n\n内存占用45.8M,超过100%用户?\n\n执行时间924ms,竟然只超过了20.19%的用户。\n\n## 考虑边界\n\n考虑温度的边界,如果当前温度是100,那肯定就不用进第二层循环了。\n\n```javascript\nvar dailyTemperatures = function(T) {\n var result = [];\n for(var i = 0, len = T.length; i < len; i++) {\n var currValue = T[i];\n if (currValue === 100) {\n result.push(0); \n } else if (i == len - 1) {\n result.push(0);\n } else {\n var waitDay = 0;\n inner: for (var j = i + 1, len = T.length; j < len; j++) {\n if (T[j] > currValue) {\n waitDay = j - i;\n break inner;\n }\n }\n result.push(waitDay)\n }\n }\n return result;\n};\n```\n\n## new Array & fill\n\n提交解法后,我看了一下第一名的解法,还是学到了一点东西。\n\n主要有两个地方不太一样:\n\n- 一个是使用`new Array`预先声明好数组空间,在大数组时性能表现更佳;\n- 第二个是使用了`Array.prototype.fill`预填充`0`,所以也不需要判断是否需要进第二层循环。\n\n```javascript\nvar dailyTemperatures = function(T) {\n const res = new Array(T.length).fill(0);\n for (let i = 0; i < T.length; i++) {\n for (let j = i + 1; j < T.length; j++) {\n if (T[j] > T[i]) {\n res[i] = j - i;\n break;\n } \n } \n }\n return res;\n};\n```\n\n特意对比了一下`fill`和`push`的执行时间,原来`fill`的性能挺好的。\n\n```javascript\nconsole.time(\'fill计时\');\nvar a = new Array(100).fill(0);\nconsole.timeEnd(\'fill计时\');\n// fill计时: 0.009033203125ms\n\nconsole.time(\'push计时\');\na.push(0);\na.push(0);\na.push(0);\n// 此处省略97行a.push(0);特意没有用for循环,毕竟循环也是要开销的。\nconsole.timeEnd(\'push计时\');\n// push计时: 0.02001953125ms\n```\n\n如果给数组初始化1000个值为0的元素呢?不得不说,数据量越大,`fill`性能越好。\n\n```javascript\n// fill计时: 0.01220703125ms\n// push计时: 0.136962890625ms\n```\n\n再看了看`fill`的兼容性,我只想说,在LeetCode中别怕,给我用最新的特性,IE不兼容的`fill`都可以用上。\n\n\n\n最后再把第一名的代码放上去提交一遍,尼玛,啪啪打脸。\n\n\n\n同样的代码人家执行耗时`132ms`,我这里提交就是执行耗时`872ms`。我只想问,LeetCode执行用时是怎么算出来的?\n\n不过有一说一,第一名的解法确实性能更好,写法也很优雅,值得学习。', '2020-06-29 11:34:42', '2024-07-25 10:29:07', 1, 22, 0, '节后你的状态恢复了吗?奥利给!', 'http://qncdn.wbjiang.cn/leetcode%E6%8B%8D%E4%BA%86%E6%8B%8D%E6%88%91.png', 0, 0);
-INSERT INTO `article` VALUES (216, '「前端必看」这篇Nginx反向代理技巧,助你准时下班陪女神', '最近同事小G总是闷闷不乐,让我感觉慌慌的,难道是我平时压榨小G了?我转念一想,不应该啊,工作量事先都评估好了,没道理天天加班啊。\n\n坐下来聊聊后,小G向我吐槽说,”改bug效率太低了,每天加班改bug,都不能早点下班陪女神!”\n\n我深吸一口气,“卧槽,忘记传授小G秘籍了...”\n\n在一步步提问引导下,我搞清楚了小G的问题所在......\n\n\n\n\n\n\n\n\n\n# 问题引入\n\n相信很多前端朋友在线上debug时都吐槽过`npm run dev`或`npm start`太费时的问题吧(这里提到的两条npm脚本代指启动前端dev server)。\n\n由于环境差异,开发环境和生产环境下,我们访问的后端服务域名是不一样的。那么当我们debug生产问题时,难免还是要修改下`webpack devServer`的`proxy`配置指向生产环境域名,然后重启`devServer`,这个过程一般比较缓慢。\n\n有些时候可能测试环境也能复现bug,那么只要接入测试环境也能排查问题原因。但这不是本文关注的重点,本文主要说说如何提高debug效率。\n\n# webpack-dev-server反向代理\n\n0202年了,如果作为开发者的你还不了解反向代理,那么是很有必要去关注下了。\n\n我们知道,跨域对于前端而言是一个无法逃避的问题。如果不想在开发时麻烦后端同事,前端仔必须通过自己的手段解决跨域问题。当然,你帮后端同事买包辣条,他给你通过CORS解决跨域也是可以的。\n\n还好,`webpack-dev-server`帮我们解决了这个痛点,它基于Node代理中间件`http-proxy-middleware`实现。\n\n配置起来也非常简单:\n\n```javascript\nproxy: {\n // 需要代理的url规则\n \"/api\": {\n target: \"https://dev.xxx.tech\", // 反向代理的目标服务\n changeOrigin: true, // 开启后会虚拟一个请求头Origin\n pathRewrite: {\n \"^/api\": \"\" // 重写url,一般都用得到\n }\n }\n}\n```\n\n这个时候小G打断了我,表示不理解。\n\n\n\n反向代理是个什么意思呢?举个例子,我想找马云借钱,马云是肯定不会借给我的。\n\n\n\n但是我有一个好朋友老张,我于是找老张借了1W块,但是我没想到这个朋友和马云关系不错,他从马云那里借了1W块,然后转给我。也就是说,我不知道我借到的钱实际来源于哪里,我只知道我从我朋友老张那里借到了钱,老张给我做了一层反向代理。\n\n具体到开发中就是,我前端仔要从`https://dev.xxx.tech`这个域名调用后端接口,但是我前端开发服务运行在`http://localhost:8080`,直接调用后端接口会跨域,被浏览器同源策略阻塞,所以这条路是走不通的。\n\n因此我需要从前端服务器做个代理,这样我就可以用`http://localhost:8080/api/user/login`这种形式调用接口,就好像在调前端自己的接口一样(因为我访问的是前端的url嘛)。\n\n然而实际上是前端服务器做了一层代理,把`http://localhost:8080/api/user/login`这个接口代理到`https://dev.xxx.tech/user/login`。这对前端开发者而言是无感的。\n\n\n\n简单总结就是:反向代理隐藏了真实的服务端;相反地,正向代理隐藏了真实的客户端,类似kexueshangwang这种。\n\n# debug痛点\n\n问题来了,假设我们正在`feature`分支开发需求,这个时候上头通知要即时排查和解决一个生产bug,假设生产环境域名为`https://production.xxx.tech`。\n\n我们一般会`stash`代码,然后切`fix`分支,修改`target`的值为`\"https://production.xxx.tech\"`,然后重新运行`npm start`重启开发服务器接入生产环境,静静等待,放空自己......\n\n\n\n这个时候我们就会幻想“唉,要是不用等这么久就好了!”\n\n是的,其实很多时候,一个bug并不复杂,可能解决bug只要1分钟,然而我们切换环境重新运行开发服务器就花了1分钟(大多数情况可能超过这个时间)。那么如何解决这个问题?\n\n# 代理层解耦\n\n是的,有的同学已经想到了,只要把代理服务器抽离出来,问题便可以得到解决,我不再需要把前端编译过程和服务代理目标捆绑在一起。在生产环境,这种Nginx转发对大多数人而言早已是熟门熟路,然而很少有人会尝试在开发环境中也这么做。那么不妨这样试试呢!\n\n## 下载Nginx\n\n我们照常下载[Nginx](http://nginx.org/en/download.html),选择Windows稳定版即可。\n\n## 固定前端代理\n\n为了避免在debug线上问题时需要切换proxy target而重新运行`npm start`,我们在前端层把proxy target固定下来。比如我固定访问`127.0.0.1:8090`(当然,实际上访问哪个端口可以视个人情况调整)。\n\n```javascript\nproxy: {\n \"/api\": {\n target: \"127.0.0.1:8090\", // 固定代理目标\n changeOrigin: true,\n pathRewrite: {\n \"^/api\": \"\"\n }\n }\n}\n```\n\n然后从`127.0.0.1:8090`肯定是无法访问到后端接口的,请接着往下看!\n\n## Nginx代理\n\n由于前端的接口访问已经固定为`127.0.0.1:8090`,那么剩下的工作就交给Nginx吧。我们只要在Nginx中监听本地8090端口,把请求统统转发给目标服务器即可,配置如下:\n\n```\nserver {\n listen 8090;\n server_name 127.0.0.1;\n\n location / {\n proxy_pass https://dev.xxx.tech;\n proxy_http_version 1.1;\n proxy_set_header Upgrade $http_upgrade;\n proxy_set_header Connection \"upgrade\";\n proxy_set_header Host $host;\n # proxy_set_header X-Real-IP $remote_addr;\n proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;\n }\n}\n```\n\n可以看到,我在配置中注释了X-Real-IP,而我们在生产环境下配置Nginx时,一般会保留这几项Host,X-Real-IP,X-Forwarded-For,用以保留请求的服务器域名,原始客户端和代理服务器的IP等信息。\n\n如果不注释X-Real-IP,前端访问入口的真实IP是`127.0.0.1`或`localhost`,Nginx不认可这样的本地ip,直接返回404,客户端请求不予代理到其他远程服务器。不扯了,这里具体的原因我也不知,如有大佬知道原因,还请点拨下,太感谢了。\n\n好了,回到正题,有了以上的配置,我们就可以将前端代理层和Nginx代理层解耦,前端固定通过本地`127.0.0.1:8090`访问后端接口,而具体接口是代理到开发环境、测试环境或是生产环境,由Nginx决定,只需要修改`nginx.conf`后重启即可。\n\n而Nginx热重启是非常快的,一条命令即可实现,几乎零等待时间。\n\n```\n// windows下是这个命令\nnginx.exe -s reload\n// linux是这样的\nnginx -s reload\n```\n\n## 本地域名\n\n听到这里,小G又将了我一军。\n\n\n\n还好我早有准备,没有自乱阵脚。\n\n如果真的遇到本地端口被占用的情况,最简单的办法当然是换个端口。\n\n为了杜绝这种情况,我们可以引入本地域名,兼具“装逼”效果。\n\n我们知道,域名是通过解析后才能得到真实的服务IP。而域名解析过程中也有这么一些关键节点,是我们应该知道的。\n\n- 浏览器缓存\n- 操作系统hosts文件\n- Local DNS\n- Root DNS\n- gTLD Server\n\n借用网上一张图说明下大致流程(侵删)。\n\n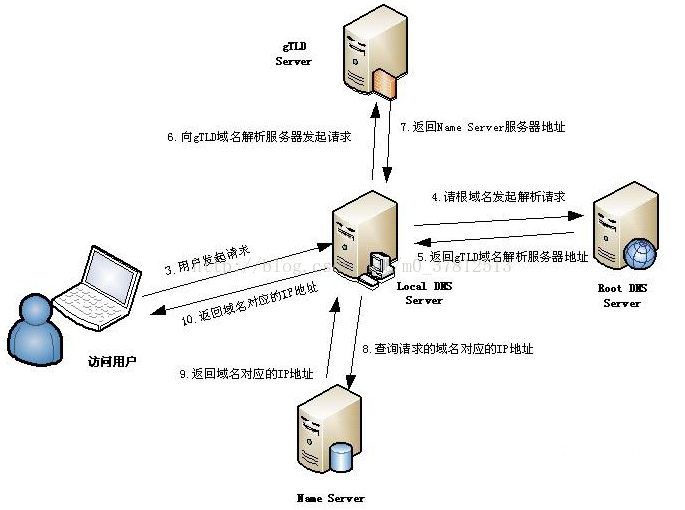\n\n上图没提到hosts文件,但是不影响我们魔改。我们只要在操作系统hosts文件这个节点动下手脚,就可以实现本地域名了。\n\n首先,我们找到`C:\\Windows\\System32\\drivers\\etc\\hosts`这个文件,打开后在最后新增一条解析记录\n\n```\n127.0.0.1 www.devtest.com\n```\n\n然后保存这个文件,保存hosts文件时需要administrator权限。\n\n这就相当于告诉本地操作系统,如果用户访问`www.devtest.com`,我就给他解析到`127.0.0.1`这个ip\n\n所以,我们在Nginx只要监听`127.0.0.1`的`80`端口即可,配置如下。\n\n```\nserver {\n listen 80;\n server_name 127.0.0.1;\n\n location / {\n proxy_pass https://dev.xxx.tech;\n proxy_http_version 1.1;\n proxy_set_header Upgrade $http_upgrade;\n proxy_set_header Connection \"upgrade\";\n proxy_set_header Host $host;\n proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;\n }\n}\n```\n\n最后,我们只要在前端工程中把代理目标设置为`www.devtest.com`即可。\n\n```javascript\nproxy: {\n \"/api\": {\n target: \"http://www.devtest.com\", // 固定代理目标\n changeOrigin: true,\n pathRewrite: {\n \"^/api\": \"\"\n }\n }\n}\n```\n\n这样前端访问的某接口`http://localhost:8080/api/user/login`就会被代理到`http://www.devtest.com/user/login`,而`www.devtest.com`被本地hosts文件解析到`127.0.0.1`,接着Nginx监听了`127.0.0.1`的`80`端口,将请求转发到真实的后端服务,完美!\n\n对了,`www.devtest.com`是我特意命名的一个无法访问的域名,所以你千万别把`www.taobao.com`这种地址解析到本地哦,不然你没法给女神买礼物别怪我。。。\n\n\n\n今天分享给大家的干货就这么多,祝愿大家准点下班陪女神!\n\n看到最后,求个关注点赞,欢迎大家加我微信交流技术,闲聊也可以哦!', '2020-07-07 09:54:05', '2024-07-25 07:34:30', 1, 34, 0, '准点下班陪女神的秘密,点开揭晓', 'http://qncdn.wbjiang.cn/%E6%88%91%E5%85%88%E4%B8%8B%E7%8F%AD%E4%BA%86.png', 0, 0);
-INSERT INTO `article` VALUES (217, '「思维导图学前端 」初中级前端值得收藏的正则表达式知识点扫盲', '本文是**思维导图学前端**系列第二篇,主题是正则表达式。首先还是想说下我的出发点,之所以自己画一遍思维导图,是因为我整理的思维导图里加入了自己的理解,更容易记忆。之前也看过很多别人整理的思维导图,虽然有点拨之用,但是要想吸收个二三分营养却也是很难。所以,建议本系列的读者在阅读文章之后,在时间允许的情况下,可以考虑自行整理知识点,便于更好地理解和吸收。\n\n推荐下同系列文章:\n\n- [「思维导图学前端」6k字一文搞懂Javascript对象,原型,继承](https://juejin.im/post/5ee9ac91f265da02aa2e751e)\n\n很多前端新手在遇到正则表达式时都望而却步,我自己初学时,也基本上是直接跳过了正则表达式这一章,除了copy网上的一些常用的正则表达式做表单校验,其余时候几乎没有去了解过如何写一个正则表达式。\n\n但是,当自己真正要去写一个适合特定业务的正则表达式时,我发现自己掌握的正则表达式知识真的是捉襟见肘。所以我这里也用思维导图整理了一些正则表达式必知必会的知识点。\n\n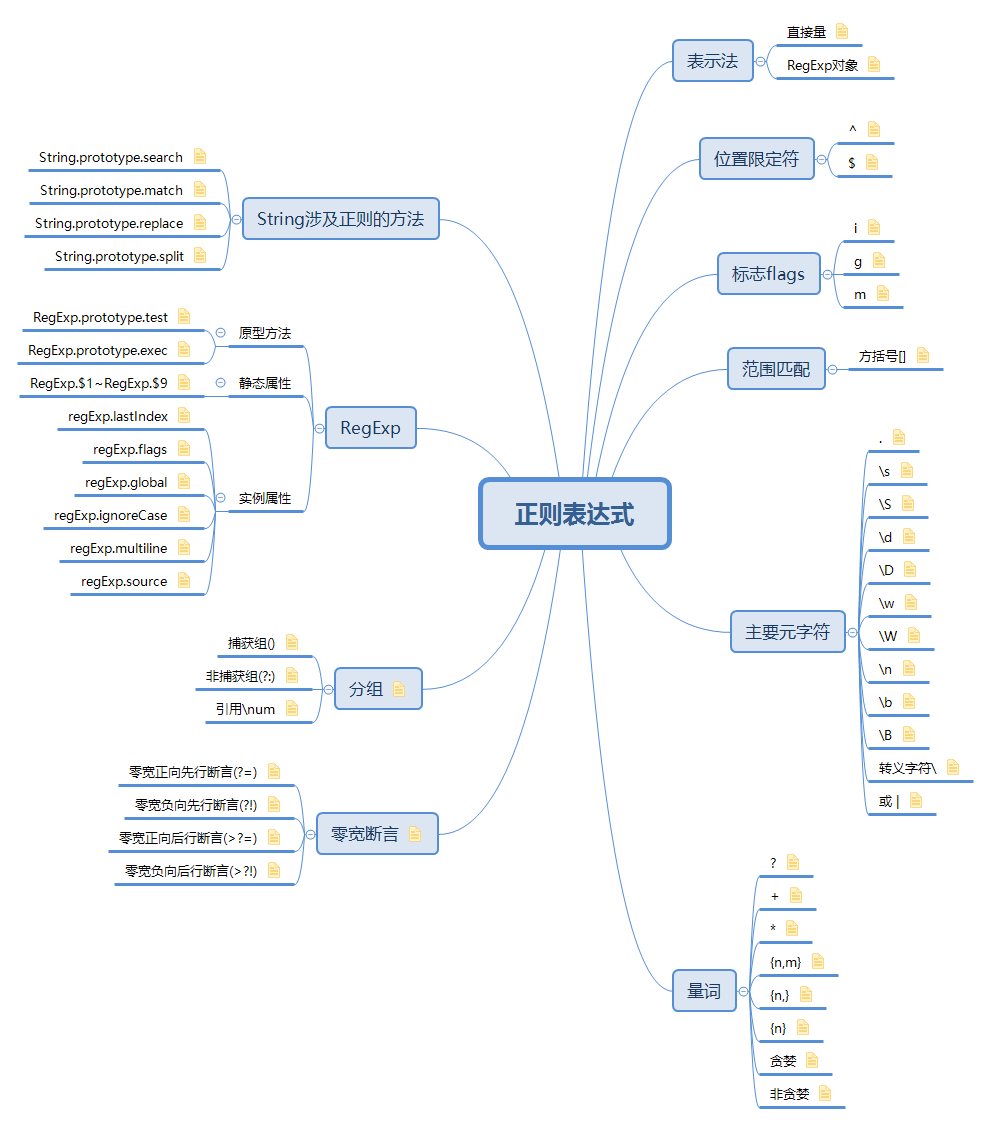\n\n# 什么是正则表达式\n\n> [正则表达式](https://baike.baidu.com/item/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F/1700215?fr=aladdin),又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。\n\n在软件开发过程中,我们或多或少会接触到正则表达式,对于前端而言,正则表达式不仅可以校验表单,文本查找和替换,还可以做语法解析器,用于AST,编辑器等领域。\n\n# 正则表示法\n\n## 直接量表示法\n\n直接量也称为字面量,写法如下:\n\n```javascript\n/^\\d+$/g\n```\n\n直接量写法的正则表达式在执行时会转换为一个新的`RegExp`对象。我想应该是因为直接量是没有调用方法的能力的,只有转为了对象,才使得调用方法成为可能。所以才有了`/^\\d+$/.test()`。\n\n当在循环中用到正则对象`lastIndex`判断终止条件时,一定不要使用直接量正则表达式写法,否则每次循环`lastIndex`都会被重置为`0`,这是因为每次执行字面量正则表达式时,都会转换为一个新的`RegExp`对象,相应的`lastIndex`当然也会变成`0`。\n\n## RegExp对象表示法\n\n```javascript\nvar pattern = new RegExp(/^\\d+$/, \'g\')\n```\n\n第一个参数可以接受正则表达式直接量,也可以接受字符串,传递字符串作为第一个参数时,首尾不需要带斜杠,字符串中如果用到特殊字符`\\`,需要在`\\`前再加一个`\\`,防止`\\`在字符串中被转义。\n\n```javascript\n\"\\s\" === \"s\" // true\n```\n\n字符串`\"\\\\s\"`才能正确地表示`\\s`\n\n第二个参数代表标志`flags`,可接受的标志有`i`, `g`, `m`等。\n\n# 标志flags\n\n## i\n\n如果启用了标志`i`,正则表达式在执行时不区分大小写。\n\n`/abc/i.test(\'abc\')`等价于`/abc/i.test(\'ABC\')`\n\n## g\n\n如果启用了标志`g`,正则表达式会执行全局匹配,匹配到一个结果后不会立刻停止匹配,直到后续没有任何符合匹配规则的字符为止。\n\n## m\n\n如果启用了标志`m`,正则表达式会执行多行匹配,`^`可以匹配每一行的开始或整个字符串的开始,而`$`可以匹配每一行的结束或整个字符串的结束。\n\n示例如下:\n\n```javascript\n/^\\d+$/.test(\'123\\n456\') // false\n/^\\d+$/m.test(\'123\\n456\') // true\n```\n\n仍然可以匹配整个字符串\n\n```javascript\n/^\\d+\\n\\d+$/m.test(\'123\\n45\') // true\n```\n\n# 位置限定符\n\n## ^\n\n匹配字符的开始。比如必须以数字开始,可以这么写:\n\n```javascript\n/^\\d/\n```\n\n## $\n\n匹配字符的结束。比如必须以数字结束,可以这么写:\n\n```javascript\n/\\d$/\n```\n\n# 范围匹配\n\n范围匹配是利用方括号`[]`实现的。\n\n方括号`[]`用于范围匹配,也就是查找某个范围内的字符。比如`[0-9]`代表匹配数字,而`[a-z]`可以匹配小写字母a到z这26个字符中的任意一个。\n\n如果要匹配不在方括号中的字符,可以在方括号中以`^`开头,比如`[^0-9]`,用于匹配非数字,等价于`\\D`。\n\n# 主要元字符\n\n## .\n\n匹配除换行符`\\n`外的任意字符,如果要匹配任意字符,应该用`/[.\\n]*/`。\n\n## \\s\n\n匹配任意空字符,包括空格` `,制表符`\\t`,垂直制表符`\\v`,换行符`\\n`,回车符`\\r`,换页符`\\f`。`\\s`等价于`[ \\t\\v\\n\\r\\f]`,注意方括号内第一个位置有空格。\n\n这里也说下换行符和回车符的区别:\n\n- 换行符`\\n`:光标下移一行,不回行首。\n- 回车符`\\r`:光标回到行首,不换行。\n\n## \\S\n\n`\\S`是`\\s`的反集\n,利用`\\s`和`\\S`的这种互为反集的关系,我们就可以匹配任意字符,写法如下:\n\n```\n/[\\s\\S]/\n```\n\n## \\d\n\n`\\d`用于匹配数字,等价于`[0-9]`。\n\n## \\D\n\n`\\D`是`\\d`的反集,也就是匹配非数字,等价于`[^0-9]`。\n\n## \\w\n\n`\\w`用于匹配单词字符,包含`0-9`,`a-z`,`A-z`以及下划线`_`,等价于`[A-Za-z0-9_]`。\n\n## \\W\n\n`\\W`是`\\w`的反集,用于匹配非单词字符,等价于`[^A-Za-z0-9_]`。\n\n## \\n\n\n`\\n`是开发中经常遇到的换行符,而上面提到的`\\s`是包含`\\n`在内的。所以,能被`\\n`匹配的字符,也一定能被`\\s`匹配。\n\n## \\b\n\n`\\b`用于匹配单词的边界,即单词的开始或结束。\n\n一开始其实我不太能理解`\\b`在正则表达式中的作用。\n\n直到我自己试了一下这个案例\n\n```javascript\n\'I love you\'.match(/love/)\n\'Iloveyou\'.match(/love/)\n```\n\n这两个表达式都能匹配到结果`\"love\"`。\n\n但是有时候我们并不希望这样的字符串`\'Iloveyou\'`被匹配,因为它没有单词间的空格。\n\n所以`\\b`有了它存在的意义。看下面的例子:\n\n```javascript\n\'I love you\'.match(/\\blove\\b/)\n\'Iloveyou\'.match(/\\blove\\b/) // null\n```\n\n第一个表达式仍然可以正常匹配到结果,而第二个就无法匹配到结果了,这符合我们的预期。\n\n有的人可能会说,那我可以用空格匹配啊。\n\n```javascript\n\'I love you\'.match(/ love /)\n```\n\n空格和`\\b`在这种场景下还是有一点不一样的,这体现在`match`的结果上。\n\n如果是用空格匹配,那么`match`的结果数组中的第一项就是`\" love \"`,是带了空格的,然而很多时候我们不希望在结果中得到空格,所以`\\b`存在的意义也就比较明显了。\n\n## \\B\n\n与`\\b`相反,代表非单词边界。也就是说,使用`\\B`匹配时,目标字符前或后不能是空格。\n\n假设`\\B`在前,比如\n\n```javascript\n/\\Babc/.test(\'111 abc\') // false\n```\n\n假设`\\B`在后,比如\n\n```javascript\n/abc\\B/.test(\'abc 111\') // false\n```\n\n## 转义字符\\\n\n由于正则表达式中很多字符有特殊含义,比如`(`, `)`, `\\`, `[`, `]`, `+`,如果你真的要匹配它们,必须加上转义符`\\`。\n\n```javascript\n/\\//.test(\'/\'); // true\n```\n\n## 或 |\n\n实现或的逻辑是比较简单的,正则表达式提供了`|`。\n\n要注意的是,`|`隔断的是其左右的整个子表达式,而不是单个普通字符。\n\n所以,\n\n```javascript\n/^ab|cd|ef$/.test(\'ab\') // true\n/^ab|cd|ef$/.test(\'cd\') // true\n/^ab|cd|ef$/.test(\'ace\') // false\n```\n\n还要注意的是,`|`具有从左到右的优先级,如果左侧的匹配上了,右侧的就被忽略了,即便右侧的匹配看起来更“完美”。\n\n`/a|ab/.exec(\'ab\')`得到的结果是\n\n```javascript\n[\"a\", index: 0, input: \"ab\", groups: undefined]\n```\n\n# 量词\n\n## ?\n\n匹配前面的子表达式零次或一次\n\n## +\n\n匹配前面的子表达式一次或多次\n\n## *\n\n匹配前面的子表达式零次或任意次\n\n## {n,m}\n\n匹配前一个普通字符或者子表达式最少n次,最多m次\n\n## {n,}\n\n匹配前一个普通字符或者子表达式最少n次\n\n## {n}\n\n匹配前一个普通字符或者子表达式n次\n\n## 贪婪\n\n贪婪匹配是尽可能多地匹配,如果能满足匹配条件,就尽可能侵占后面的匹配规则。\n\n贪婪匹配是默认的,比如`/\\d?/`会尽可能地匹配`1`个数字,`/\\d+/`和`/\\d*/`会尽可能地匹配多个数字。\n\n举个例子,\n\n```javascript\n\'123456789\'.match(/^(\\d+)(\\d{2,})$/)\n```\n\n以上结果中捕获组的第一项是`\"1234567\"`,第二项是`\"89\"`。\n\n为什么会这样呢?因为`\\d+`是贪婪匹配,尽可能地多匹配,如果没有后面的`\\d{2,}`,捕获组第一项会直接是`\"123456789\"`。但是由于`\\d{2,}`的存在,`\\d+`会给`\\d{2,}`留个面子,满足它的最小条件,即匹配2个数字,而`\\d+`自己匹配7个数字。\n\n## 非贪婪\n\n非贪婪匹配是尽可能少地匹配,一般是在量词`?`, `+`, `*`之后再加一个`?`,表示尽可能少地匹配,把机会留给后面的匹配规则。\n\n还是拿贪婪模式中那个例子举例,稍微改一下,`\\d+`换成非贪婪模式`\\d+?`。\n\n```javascript\n\'123456789\'.match(/^(\\d+?)(\\d{2,})$/)\n```\n\n捕获组的第一项是`\"1\"`,第二项变成了`\"23456789\"`。\n\n为什么会这样呢?因为在非贪婪模式下,会尽可能少匹配,把机会留给后面的匹配规则。\n\n# 分组\n\n分组在正则中是一个非常有用的神器,用圆括号`()`来包裹的内容就是一个分组,在正则中是这种表示形式:\n\n```javascript\n/(\\d*)([a-z]*)/\n```\n\n## 捕获组()\n\n利用捕获组,我们能捕获到关键字符。\n\n比如\n\n```javascript\nvar group = \'123456789hahaha\'.match(/(\\d*)([a-z]*)/)\n```\n\n分组1用于匹配任意个数字,分组2用于匹配任意个小写字母。\n\n那么我们在`match`方法的返回结果中就可以取到这两个分组匹配的结果,`group[1]`是`\"123456789\"`,`group[2]`是`\"hahaha\"`。\n\n我们还可以在`RegExp`的静态属性`$1~$9`取得前`9`个分组匹配的结果。`RegExp.$1`是`\"123456789\"`,`RegExp.$2`是`\"hahaha\"`。但是`RegExp.$1~$9`是非标准的,虽然很多浏览器都实现了,尽量不要在生产环境中使用。\n\n这种捕获组的应用在字符串的`replace`方法中也是类似,不过在调用`replace`方法时,我们需要通过`$1`, `$2`, `$n`这种形式去引用分组。\n\n```javascript\n\"123456789hahaha\".replace(/(\\d*)([a-z]*)/, \"$1\") // \"123456789\"\n```\n\n利用`$1`,我们就可以把源字符串替换为分组1匹配到的字符串,也就是`\"123456789\"`。\n\n## 非捕获组(?:)\n\n非捕获组是不生成引用的分组,它也由圆括号`()`包裹起来,不过圆括号中起头的是`?:`,也就是`/(?:\\d*)/`这种形式。\n\n还是改造下之前的例子来看下:\n\n```javascript\nvar group = \'123456789hahaha\'.match(/(?:\\d*)([a-z]*)/)\n```\n\n由于非捕获组不生成引用,所以`group[1]`是`\"hahaha\"`;同样地,`RegExp.$1`也是`\"hahaha\"`。\n\n看到这里,我不禁也产生了疑问,既然我不需要引用非捕获组,那么非捕获组的意义何在?\n\n思考了一阵后,我觉得非捕获组大概有这么一些优势和必要性:\n\n1. 与捕获组相比,非捕获组在内存上开销更小,因为它不需要生成引用\n\n2. 分组是为了方便加量词。我们虽然可以不生成引用,但是如果没有分组,就不太方便加给一组字符加量词。\n\n```javascript\n\'1a2b3c...\'.match(/(?:\\d[a-z]){2,3}(\\.+)/)\n```\n\n## 引用\\num\n\n正则表达式中可以引用前面的具有引用的分组,通过`\\1`,`\\2`这种形式可以实现引用前面的子表达式。\n\n比如,我要匹配一个字符串,要求符合这样的规则:\n\n字符串由单引号或双引号开头和结束,中间内容可以是数字,单词。\n\n那我要保证的是首尾要么是单引号,要么是双引号,所以我的pattern写法可以是:\n\n```javascript\nvar pattern = /^([\"\'])[a-z\\d]*\\1$/\npattern.test(\"\'perfect123\'\") // true\npattern.test(\'\"1perfect2\"\') // true\n```\n\n# 零宽断言\n\n说实话,一开始看零宽断言的概念和解释时,我真的完全不懂在说什么。\n\n- 零宽正向先行断言(?=)\n- 零宽负向先行断言(?!)\n- 零宽正向后行断言(?<=)\n- 零宽负向后行断言(? ES2018才支持零宽后行断言,具体见[TC39 Proposals](https://github.com/tc39/proposals/blob/master/finished-proposals.md)\n\n## 零宽负向后行断言(? 注:ES2018才支持此特性。\n\n# RegExp\n\n说到正则表达式,就不得不提到`RegExp`对象。下面我们从原型方法,静态属性,实例属性等几个方面来认识下`RegExp`对象。\n\n## 原型方法\n\n### RegExp.prototype.test\n\n`test()`是我们平时最常用的正则方法,`test()`方法执行一个检索,用来查看正则表达式与指定的字符串是否匹配,返回一个布尔值`true`或`false`。\n\n如果正则表达式设置了全局标志`g`,执行`test()`会改变`RegExp.lastIndex`属性,用于记录上次匹配到的字符的起始索引。连续执行`test()`方法,后续的执行将会从`lastIndex`处开始匹配字符串。这种情况下,如果`test()`无法匹配到结果,`lastIndex`就会重置为`0`。\n\n### RegExp.prototype.exec\n\n`exec()`相较于`test()`能得到更丰富的匹配信息,其结果是一个数组,数组的第0个元素是匹配到的字符串,第1~n个元素是圆括号`()`分组捕获的结果。\n\n结果数组是数组,数组也是对象类型数据,所以结果数组还有两个属性分别是`index`和`input`\n\n- `index`代表匹配到的字符位于原始字符串的基于0的索引值\n- `input`则代表原始字符串\n\n与`test()`一致,如果正则表达式设置了`g`标志符,那么每次执行`exec()`都会更新`lastIndex`。\n\n## 静态属性\n\n静态属性不属于任何一个实例,必须通过类名访问,这一点在上一篇[「思维导图学前端」6k字一文搞懂Javascript对象,原型,继承](https://juejin.im/post/5ee9ac91f265da02aa2e751e)已经提到过。\n\n### RegExp.`$1-$9`\n\n用于获取分组的匹配结果,`RegExp.$1`获取的是第一个分组的匹配结果,`RegExp.$9`则是第九个分组的匹配结果。\n\n具体见上文[分组-捕获组](#)一节。\n\n## 实例属性\n\n### lastIndex\n\n`lastIndex`,从语义上理解,就是上次匹配到的字符的起始索引。要注意的是,只有设置了`g`标志,`lastIndex`才有效。\n\n当还未进行匹配时,`lastIndex`自然是`0`,代表从第`0`个字符串开始匹配。\n\n`lastIndex`会随着`exec()`和`test()`的执行而更新\n\n```javascript\nvar reg = /\\d/g\nreg.lastIndex // 0\nreg.test(\'123456\')\nreg.lastIndex // 1\nreg.exec(\'123456\')\nreg.lastIndex // 2\n```\n\n`lastIndex`可以手动修改,也就是说,你可以自由控制匹配的细节。\n\n### flags\n\n`flags`属性返回一个字符串,代表该正则表达式实例启用了哪些标志。\n\n```javascript\nvar reg = /\\d/ig\nreg.flags; // \"gi\"\n```\n\n### global\n\n`global`是布尔量,表明正则表达式是否使用了`g`标志。\n\n### ignoreCase\n\n`ignoreCase`是布尔量,表明正则表达式是否使用了`i`标志。\n\n### multiline\n\n`multiline`是布尔量,表明正则表达式是否使用了`m`标志。\n\n### source\n\n`source`,意为源,是正则表达式的字符串表示,不会包含正则字面量两边的斜杠以及任何的标志字符。\n\n# String涉及正则的方法\n\n## String.prototype.search\n\n`search()`方法用正则表达式对字符串对象进行一次匹配,结果返回一个`index`,代表正则表达式在字符串中首次匹配项的索引。如果无法匹配,则返回`-1`。\n\n`search()`方法的参数必须是正则表达式,如果不是也会被`new RegExp()`默默转换为正则表达式对象。\n\n```javascript\n\"123abc\".search(/[a-z]/); // 3\n```\n\n## String.prototype.match\n\n字符串的`match`方法用于检索字符串,和正则表达式的`exec`方法是相似的。`match`方法的参数也要求是正则表达式。`match`方法返回一个数组。\n\n与`exec()`的不同点在于,如果`match`方法传入的正则表达式带了标识`g`,则将返回与完整正则表达式匹配的所有结果,但不会返回捕获组。\n\n```javascript\n\"123abc456\".match(/([a-z])/g);\n// 返回[\"a\", \"b\", \"c\"]\n\nvar reg = /([a-z])/g;\nreg.exec(\'123abc456\');\n// 返回数组[\"a\", \"a\", index: 3, input: \"123abc456\", groups: undefined]\nreg.exec(\'123abc456\');\n// 返回数组[\"b\", \"b\", index: 4, input: \"123abc456\", groups: undefined]\nreg.exec(\'123abc456\');\n// 返回数组[\"c\", \"c\", index: 5, input: \"123abc456\", groups: undefined]\n```\n\n如果`match()`方法传入的正则表达式不带标志`g`,表现与`exec()`方法一致,只会返回第一个匹配结果和分组捕获到的结果。\n\n如果此时表达式中有圆括号分组,在`match()`的结果数组中也是可以获取到这些分组匹配的结果的,这一点在捕获组中也有提到。\n\n```javascript\n\"123abc456\".match(/([a-z])/);\n// 返回[\"a\", \"a\", index: 3, input: \"123abc456\", groups: undefined]\nRegExp.$1; // \"a\"\n```\n\n## String.prototype.replace\n\n`replace()`是字符串替换方法,它不要求第一个参数必须是正则表达式。如果第一个参数是正则表达式,并且包含分组,那么在`replace()`的第二个参数中,可以通过`\"$1\"`,`\"$2\"`这种形式引用分组匹配结果。\n\n```javascript\n\"123456789hahaha\".replace(/(\\d*)([a-z]*)/, \"$1\") // \"123456789\"\n```\n\n## String.prototype.split\n\n`split()`方法是字符串分割方法,也算平时用得很多的一个方法,但是很多人不知道它可以接受正则表达式作为参数。\n\n假设我们得到这样一个不太规律的字符串`\"1,2, 3 ,4, 5\"`,然后需要分割这个字符串得到纯数字组成的数组,直接使用`split(\",\")`是不行的,而利用正则表达式作为分割条件就可以做到。\n\n```javascript\nvar str = \"1,2, 3 ,4, 5\";\nstr.split(/\\s*,\\s*/);\n// 返回 [\"1\", \"2\", \"3\", \"4\", \"5\"]\n```\n\n# 最后\n\n正则表达式是一个非常重要却容易被忽视的知识点,在面试中也是一个频繁的考点,所以必须给予它足够的重视。经过上面的知识点梳理,相信能在后续的实战中胸有成竹,不慌不忙。', '2020-07-13 13:39:40', '2024-08-04 22:54:27', 1, 29, 0, '一文搞懂正则表达式关键知识点,面试不慌', 'http://qncdn.wbjiang.cn/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%89%AB%E7%9B%B2.png', 0, 0);
-INSERT INTO `article` VALUES (218, '面试官真的会问:new的实现以及无new实例化', '面试官很忙,但我不单纯是蹭热点,今天聊的主题绝对是面试中命中率很高的知识点。我在复习javascript函数这块知识时,注意到一个有意思的点,就是构造函数显式return,并由此引发了一波头脑风暴......\n\n我们知道,如果不做特殊处理,new构造函数时会发生下面这几步。\n\n- 首先创建一个新对象,这个新对象的`__proto__`属性指向构造函数的`prototype`属性\n- 此时构造函数执行环境的`this`指向这个新对象\n- 执行构造函数中的代码,一般是通过`this`给新对象添加新的成员属性或方法。\n- 最后返回这个新对象。\n\n下面我们来验证下:\n\n```javascript\nfunction Test() {\n console.log(JSON.stringify(this));\n console.log(this.__proto__.constructor === Test);\n this.name = \'jack\';\n this.age = 18;\n console.log(JSON.stringify(this));\n}\nvar a = new Test();\n// Chrome控制台会输出以下内容\n// {}\n// true\n// {\"name\":\"jack\",\"age\":18}\n```\n\n这完全符合我们的认知,没毛病。\n\n# 实现一个new\n\n那么在认识到new实例化过程的几个关键步骤后,我们也能解答一道面试中常见的题目:如何实现一个new?\n\n实现一个new也就意味着不能用new关键字,那么要完成这么一系列步骤,当然是通过函数实现了。\n\n```javascript\n// func是构造函数,...args是需要传给构造函数的参数\nfunction myNew(func, ...args) {\n // 创建一个空对象,并且指定原型为func.prototype\n var obj = Object.create(func.prototype);\n // new构造函数时要执行函数,同时指定this\n func.call(obj, ...args);\n // 最后return这个对象\n return obj;\n}\n```\n\n以这四个关键步骤作为指导思想,我们很快就写出了代码实现。从这一点我也能体会到思路的重要性,别当工具人,代码才是工具!\n\n从实现逻辑上来看没什么问题,我们来验证下。\n\n```javascript\nfunction Test(name, age) {\n this.name = name;\n this.age = age;\n}\n\nmyNew(Test, \'小明\', 18);\n// Chrome控制台会输出以下内容\n// Test {name: \"小明\", age: 18}\n```\n\n# 构造函数显式return\n\n所谓显式return,就是在构造函数中主动return一个对象,这里说的对象不仅包括`Object`,也包含`Array`,`Date`等对象哦。\n\n我们可以试一试:\n\n```javascript\nfunction Test() {\n this.name = \'jack\';\n this.age = 18;\n return {\n content: \'我有freestyle\'\n }\n}\nnew Test();\n// Chrome控制台会输出以下内容\n// {content: \"我有freestyle\"}\n```\n\n那么return一个普通类型数据有没有用呢?比如字符串,数字?试试便知。\n\n```javascript\nfunction Test() {\n this.name = \'jack\';\n this.age = 18;\n return \'我有freestyle\'\n}\nnew Test();\n// Chrome控制台会输出以下内容\n// Test {name: \"jack\", age: 18}\n```\n\n可以看到,当我们return一个普通类型数据时,不会影响结果,依然会返回new出来的这个新对象。\n\n我们也应该知道,new构造函数就是为了创建对象,你return一个字符串之类的普通类型数据是没有任何意义的,所以我们的关注点应该是return一个特殊的对象。请接着往下看。\n\n# 无new实例化\n\n所谓“无new实例化”,就是指不通过new关键字实例化对象(当然,这里说的不通过new,只是调用层面的,底层还是用了new)。这一点我们使用jQuery的时候已经体验过了。\n\n```javascript\n// 实例化了一个jQuery对象,但是没有用到new\nvar ele = jQuery(\'freestyle
\');\n```\n\n那么这种黑科技是怎么实现的呢?\n\n前面已经提到了,我们可以在构造函数中通过显式return来返回一个自定义的对象,那么这里就有发挥的空间了。我们通过一个简单的例子来感受下:\n\n```javascript\nfunction Shadow() {\n this.name = \'jack\';\n this.age = 18;\n}\n\nfunction jQuery() {\n return new Shadow();\n}\n\nvar obj1 = jQuery();\nconsole.log(obj1)\n// Chrome控制台会输出以下内容\n// Shadow {name: \"jack\", age: 18}\n```\n\n`jQuery()`用了移花接木的障眼法完成了对象实例化,一手隐藏的`new Shadow()`让我们误以为不用`new`直接调用函数也能创建实例。\n\n我们再来试下`new jQuery()`,会发现,“卧槽,怎么跟`jQuery()`执行结果一模一样!”\n\n```javascript\nvar obj2 = new jQuery();\nconsole.log(obj2)\n// Chrome控制台会输出以下内容\n// Shadow {name: \"jack\", age: 18}\n```\n\n这是因为new构造函数显式return了`new Shadow()`,这样返回的结果也就是`new Shadow()`实例化出来的对象,而不使用`new`直接调用`jQuery()`,只是把`jQuery()`当成一个普通的函数执行,其结果不言而喻是`new Shadow()`实例化出来的对象。\n\n所以,这里`new jQuery()`和`jQuery()`是等价的。\n\n虽然jQuery已经用得越来越少,但是其设计思路非常值得我们学习。那么jQuery到底妙在哪里?可以说是很多,链式操作,插件体系这些特色都是我们耳熟能详的。不扯太多了,就让我们来简单分析下jQuery实例化的过程。\n\n我这里拿到了jQuery v1.12.4版本的代码,大概1W行,很舒服。\n\n翻啊翻啊,翻到了第71行,看到了这么一串代码:\n\n```javascript\njQuery = function( selector, context ) {\n return new jQuery.fn.init( selector, context );\n}\n```\n\n这不就是我们熟悉的移花接木技术吗?`jQuery.fn.init`似乎就是上面例子中的`Shadow`。看着有点像了,但是还是要好好研究下。\n\n## 为啥要搞个jQuery.fn?\n\njQuery.fn是jQuery.prototype的别名,是为了代码简洁的考虑。这一点参考源码第91行就可以知道。\n\n```javascript\njQuery.fn = jQuery.prototype = {\n// ......\n```\n\n## 移花接木如何保证原型指向?\n\n我们知道,如果仅仅通过`new jQuery.fn.init(selector, context)`是存在一个问题的,问题就是得到的实例不是`jQuery`的实例,而是`jQuery.fn.init`的实例。那么如何处理这个问题呢?\n\n我们翻到源码2866行,可以看到:\n\n```javascript\ninit = jQuery.fn.init = function( selector, context, root ) {\n // 创建实例的具体逻辑\n}\n```\n\n具体`init`方法怎么创建一个jQuery对象,做了哪些判断逻辑,这些都不是本文关注的重点。我们需要关注的是,jQuery是如何保证实例化的对象的原型指向是正确的?不然实例化的对象如何使用`jQuery.prototype`上面挂载的诸多方法呢,比如`this.show()`、`this.hide()`?\n\n紧接着翻到2982行,我有了答案:\n\n```javascript\ninit.prototype = jQuery.fn;\n```\n\n\n\n妙啊,这一手修改原型指向的操作,完美解决了这个问题。这样一来,`new init()`得到的实例自然也是`jQuery`的实例。\n\n```javascript\njQuery.prototype.init.prototype === jQuery.prototype; // true\nvar a = $(\'123
\')\na instanceof jQuery // true\na instanceof jQuery.fn.init // true\n```\n\n这样一来,我们可以得到一个基本的设计思路:\n\n```javascript\nfunction myModule(params) {\n return new myModule.fn.init(params);\n}\nmyModule.fn = myModule.prototype = {\n constructor: myModule\n}\nmyModule.fn.init = function(params) {\n // 可以对实例对象进行各种操作\n}\nmyModule.fn.init.prototype = myModule.prototype;\n```\n\n在这个基础上,我们可以扩展静态方法和原型方法,这个myModule模块就变得越来越丰富。\n\n# 最后\n\n妙啊,一个构造函数,让我陷入了思考......扶我起来,我还能学!\n\n', '2020-07-15 18:02:50', '2024-08-04 07:17:32', 1, 35, 0, 'new还是不new,这是一个问题', 'http://qncdn.wbjiang.cn/new%E8%BF%98%E6%98%AF%E4%B8%8Dnew.png', 0, 0);
-INSERT INTO `article` VALUES (219, '写给自己的Object和Function的3个灵魂拷问', '最近在研究函数和原型链这块内容时,我遇到了不少疑惑,对自己而言,这些疑惑可以算得上是灵魂拷问吧。在一步步探究和查证的过程中,我也许理解了一部分,也许还是什么都没懂吧,以文记之,只求能收获二三分。不知这里面有没有你遇到的疑惑呢?一起来看下吧!\n\n# Object和Function谁是谁的实例\n\n## Object instanceof Function\n\n`instanceof`检查的是右操作数的`prototype`属性是否在左操作数的原型链上。\n\n首先`Object`是一个对象类型的构造函数,而函数的构造函数是谁,当然是函数的鼻祖`Function`。所以`Object`是`Function`的实例这一点还是比较容易理解的。\n\n```javascript\nObject.__proto__ === Function.prototype;\n// true\n```\n\n其实通过下面的代码也可以侧面证明`Object`是`Function`的实例。\n\n```javascript\nObject.constructor === Function;\n// true\n```\n\n## Function instanceof Object\n\n`Function`反过来又是`Object`的实例,这又该如何理解呢?我们知道,除去`null`这种情况,原型链的顶端是`Object.prototype`,这一定程度上说明了javascript中所有的引用类型都是由`Object.prototype`构造而来。\n\n按照我们一般的思路来看,实例的原型可以通过构造函数的`prototype`属性来访问。那么这里的实例主角是谁?没错,是`Function`,那么`Function`有构造函数吗?显然,在我们认知的javascript中,`Function`本身就是函数的构造器,自然是没有`Function`的构造函数的,有的话,那也是`V8`引擎干的事了吧。\n\n那么没有构造函数就不配有原型了吗?答案是否定的。还记得我在[「思维导图学前端 」6k字一文搞懂Javascript对象,原型,继承](https://juejin.im/post/5ee9ac91f265da02aa2e751e \"「思维导图学前端 」6k字一文搞懂Javascript对象,原型,继承\")中提到的`Object.create()`方法吗?通过`Object.create()`可以直接创建一个新对象,并可以指定现有的对象作为这个新对象的原型,此过程并没有构造函数参与进来。你想啊,连`ES5`暴露给我们的API都能这么做,那么在实现`V8`等js引擎的过程当然也可以这么做。\n\n所以,`Function`也有原型,也就是`Function.__proto__`。那么`Function.__proto__`到底指向哪里?我们可以从下面这个语句中发现端倪。\n\n```javascript\nFunction.__proto__ === Function.prototype;\n// true\n```\n\n上面的表达式的结果是`true`。震惊,`Function.__proto__`竟然是`Function.prototype`!\n\n而`Function.prototype`的原型就是`Object.prototype`。这一点可以从下面的语句中得到验证!\n\n```javascript\nFunction.prototype.__proto__ === Object.prototype;\n// true\n```\n\n由于从`Function`到`Object.prototype`存在这样一段原型链关系,所以`Function instanceof Object`也是成立的。\n\n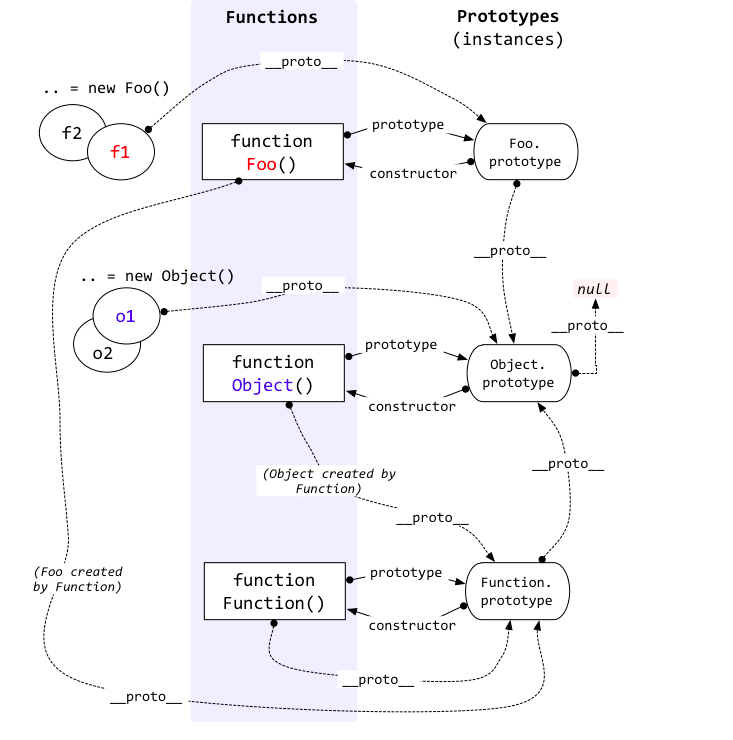\n\n## Object instanceof Object\n\n从上面我们已经知道`Object instanceof Function`和`Function instanceof Object`都是成立的。根据这些已知结果,我们很容易推断出`Object instanceof Object`也是成立的。这是因为`Object`是`Function`的实例,`Function`是`Object`的实例,显然`Object`也是`Object`的实例。\n\n```javascript\nObject instanceof Object; // true\n```\n\n## Function instanceof Function\n\n有了以上的推论过程,我们自然也能理解`Function instanceof Function`是成立的。\n\n# Function.prototype是一个函数?\n\n```javascript\nFunction.prototype;\n// ƒ () { [native code] }\n\n// 以下代码可以正常执行\nFunction.prototype();\n```\n\n`Function.prototype()`可以执行,不会报错,说明`Function.prototype`真的是一个函数。\n\n```javascript\ntypeof Function.prototype; // \"function\"\n```\n\n还有个有意思的地方,就是:\n\n```javascript\nFunction.prototype.constructor === Function;\n// true\n```\n\n666,`Function`的原型指向`Function.prototype`,而`Function.prototype`的构造器反过来又是`Function`,有内味了!\n\n> 回头想了一下,这是原型三角关系,思考这部分的时候有点被绕进去了,小题大做了。\n\n# Function和Object鸡生蛋蛋生鸡?\n\n有了上面这些复杂的关系,我们不免要问问自己,到底是先有`Object`还是`Function`?\n\n我也尝试从V8源码去找一些线索,但是恕我太菜,学校教的C++基本忘光了,从源码中完全找不到思路。[V8的官方文档](https://v8.dev/docs \"V8的官方文档\")也没有说这些东西(可能是我没找到吧)。\n\n于是我找了一些分析这个问题的文章,大概有了一些认知。重要的事情说三遍:\n\n只是认知,不是答案!\n\n只是认知,不是答案!\n\n只是认知,不是答案!\n\n毕竟我也没找到直接甩V8源码进行分析的文章,如果有大佬知道这方面资源,还望分享一下链接,感谢!\n\nOK,总体的认知是这样的,加了一些我的理解在里面,希望对你有所帮助!\n\n- V8先构造了`Object`的原型[[Prototype]],简称OP,初始化其内部属性,但不包括其行为。这里有必要猜想一下,这里说的“内部属性”应该是OP在V8引擎中的属性,因为我看`Object.prototype`基本上是没有属性的,只有方法。而行为,则代表方法。\n- 基于OP构造了`Function`的原型[[Prototype]],简称FP,初始化其内部属性,但不包括其行为。\n- 将FP的原型[[Prototype]]指向OP。\n- 创建各种内置引用类型如`Object`, `Function`, `Array`, `Date`等。\n- 将各个内置引用类型的[[Prototype]]指向FP。\n- 将`Function`的`prototype`属性指向FP。\n- 将`Object`的`prototype`属性指向OP。\n- 用`Function`实例化OP,FP,`Object`的**行为**并挂载。这里别看错了,是实例化行为,也就是把OP,FP,`Object`的方法创建好,然后挂载到相应对象上。\n- 用`Object`实例化**除了**`Object`及`Function`**之外**的其他内置引用类型的`prototype`属性对象。**除了之外**这四个字是一个要关注的重点,另一个重点就是要理解`prototype`是一个对象,所以用`Object`实例化。\n- 用`Function`实例化**除了**`Object`及`Function`**之外**的其他内置引用类型的`prototype`属性对象的行为并挂载。我们知道,`prototype`是一个对象,在上一步被创建了,`prototype`对象下会有很多方法,比如数组的`push()`方法,就是在这个时候被创建的。而方法当然是用`Function`实例化。\n- 实例化内置对象Math以及Global对象。\n\n上面说的[[Prototype]]指的是一个对象的原型,与我们所熟知的`prototype`是有区别的,`prototype`只是一个属性,是指向原型的一个引用。\n\n理清[[Prototype]]和`prototype`的关系后,再仔细去想想,你会发现上面说的这些步骤是有道理的。慢慢品味吧!\n\n所以严格上来说,`Function`和`Object`没有创建时间上的先后顺序关系,与它们相比,先出现的也是它们的原型[[Prototype]]。而在它们的原型中,先有的是`Object`的原型,后有的是`Function`的原型。\n\n`Function`和`Object`没有所谓的鸡生蛋和蛋生鸡的关系,它们之间是一种互相成就的关系。\n\n灵魂拷问总是让人难以回答,啰嗦了一番,不知道我懂了没,也不知道在座的各位懂了没......\n\n可以参考的资料有:\n\n- [ECMAScript5注解](https://es5.github.io/ \"ECMAScript5注解\")\n\n- [高能!typeof Function.prototype 引发的先有 Function 还是先有 Object 的探讨](https://segmentfault.com/a/1190000005754797 \"高能!typeof Function.prototype 引发的先有 Function 还是先有 Object 的探讨\")', '2020-07-20 09:19:50', '2024-08-14 17:29:54', 1, 57, 0, '来自对象的灵魂拷问', 'http://qncdn.wbjiang.cn/%E5%AF%B9%E8%B1%A1%E7%9A%84%E7%81%B5%E9%AD%82%E6%8B%B7%E9%97%AE.png', 0, 0);
-INSERT INTO `article` VALUES (220, '解读闭包,这次从ECMAScript词法环境,执行上下文说起', '对于x年经验的前端仔来说,项目也做了好些个了,各个场景也接触过一些。但是假设真的要跟面试官敞开来撕原理,还是有点慌的。看到很多大神都在手撕各种框架原理还是有点羡慕他们的技术实力,羡慕不如行动,先踏踏实实啃基础。嗯...今天来聊聊闭包!\n\n讲闭包的文章可能大家都看了几十篇了吧,而且也能发现,一些文章(我没说全部)行文都是一个套路,基本上都在关注两个点,什么是闭包,闭包举例,很有搬运工的嫌疑。我看了这些文章之后,一个很大的感受是:如果让我给别人讲解闭包这个知识点,我能说得清楚吗?我的依据是什么?可信度有多大?我觉得我是怀疑我自己的,否定三连估计是妥了。\n\n\n\n不同的阶段做不同的事,当有一些基础后,我们还是可以适当地研究下原理,不要浮在问题表面!那么技术水平一般的我们,应该怎么办,怎么从这些杂乱的文章中突围?我觉得一个办法是从一些比较权威的文档上去找线索,比如ES规范,MDN,维基百科等。\n\n关于**闭包**(closure),总是有着不同的解释。\n\n第一种说法是,闭包是由**函数**以及声明该函数的**词法环境**组合而成的。这个说法来源于[MDN-闭包](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Closures)。\n\n另外一种说法是,闭包是指有权访问另外一个函数作用域中的变量的函数。\n\n从我的理解来看,我认为第一个说法是正确的,闭包不是一个函数,而是函数和词法环境组成的。那么第二种说法对不对呢?我觉得它说对了一半,在闭包场景下,确实存在一个函数有权访问另外一个函数作用域中的变量,但闭包不是函数。\n\n这就完了吗?显然不是!解读闭包,这次我们刨根究底(吹下牛逼)!\n\n本文会直接从**ECMAScript5规范**入手解读JS引擎的部分内部实现逻辑,基于这些认知再来重新审视**闭包**。\n\n回到主题,上文提到的**词法环境**(Lexical Environment)到底是什么?\n\n# 词法环境\n\n我们可以看看ES5规范第十章(可执行代码和执行上下文)中的第二节[词法环境](http://es5.github.io/#x10.2)是怎么说的。\n\n> A Lexical Environment is a specification type used to define the association of Identifiers to specific variables and functions based upon the lexical nesting structure of ECMAScript code. \n\n词法环境是一种规范类型(specification type),它定义了标识符和ECMAScript代码中的特定变量及函数之间的联系。\n\n问题来了,规范类型(specification type)又是什么?specification type是Type的一种。从ES5规范中可以看到Type分为**language types**和**specification types**两大类。\n\n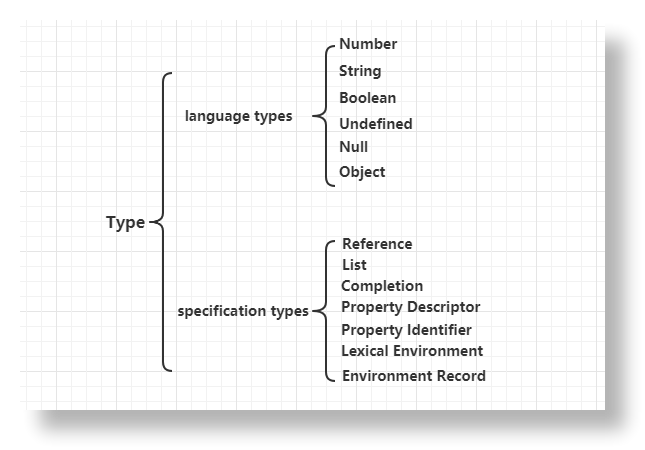\n\nlanguage types是语言类型,我们熟知的类型,也就是使用ECMAScript的程序员们可以操作的数据类型,包括`Undefined`, `Null`, `Number`, `String`, `Boolean`和`Object`。\n\n而规范类型(specification type)是一种更抽象的**元值**(meta-values),用于在算法中描述ECMAScript的语言结构和语言类型的具体语义。\n\n> A specification type corresponds to meta-values that are used within algorithms to describe the semantics of ECMAScript language constructs and ECMAScript language types.\n\n至于元值是什么,我觉得可以理解为**元数据**,而元数据是什么意思,可以简单看看这篇知乎[什么是元数据?为何需要元数据?](https://www.zhihu.com/question/20679872/answer/681988497)\n\n总的来说,**元数据是用来描述数据的数据**。这一点就可以类比于,高级语言总要用一个更底层的语言和数据结构来描述和表达。这也就是JS引擎干的事情。\n\n大致理解了规范类型是什么后,我们不免要问下:规范类型(specification type)包含什么?\n\n> The specification types are Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, and Environment Record. \n\n看到这里我好似明白了些什么,原来**词法环境**(Lexical Environment)和**环境记录**(Environment Record)都是一种**规范类型**(specification type),果然是更底层的概念。\n\n先抛开`List`, `Completion`, `Property Descriptor`, `Property Identifier`等规范类型不说,我们接着看词法环境(Lexical Environment)这种规范类型。\n\n下面这句解释了词法环境到底包含了什么内容:\n\n> A Lexical Environment consists of an Environment Record and a possibly null reference to an outer Lexical Environment.\n\n词法环境包含了一个**环境记录**(Environment Record)和一个**指向外部词法环境的引用**,而这个引用的值可能为null。\n\n一个词法环境的结构如下:\n\n```\nLexical Environment\n + Outer Reference\n + Environment Record\n```\n\nOuter Reference指向外部词法环境,这也说明了词法环境是一个链表结构。简单画个结构图帮助理解下!\n\n\n\n> Usually a Lexical Environment is associated with some specific syntactic structure of ECMAScript code such as a FunctionDeclaration, a WithStatement, or a Catch clause of a TryStatement and a new Lexical Environment is created each time such code is evaluated.\n\n通常,词法环境与ECMAScript代码的某些特定语法结构(如**FunctionDeclaration**,**WithStatement**或**TryStatement**的**Catch**子句)相关联,并且每次评估此类代码时都会创建一个新的词法环境。\n\nPS:evaluated是evaluate的过去分词,从字面上解释就是评估,而评估代码我觉得不是很好理解。我个人的理解是,评估代码代表着**JS引擎在解释执行javascript代码**。\n\n我们知道,执行函数会创建新的词法环境。\n\n我们也认同,with语句会“延长”作用域(实际上是调用了NewObjectEnvironment,创建了一个新的词法环境,词法环境的环境记录是一个对象环境记录)。\n\n以上这些是我们比较好理解的。那么catch子句对词法环境做了什么?虽然try-catch平时用得还比较多,但是关于词法环境的细节很多人都不会注意到,包括我!\n\n我们知道,catch子句会有一个错误对象`e`\n\n```javascript\nfunction test(value) {\n var a = value;\n try {\n console.log(b);\n // 直接引用一个不存在的变量,会报ReferenceError\n } catch(e) {\n console.log(e, arguments, this)\n }\n}\ntest(1);\n```\n\n在`catch`子句中打印`arguments`,只是为了证明`catch`子句不是一个函数。因为如果`catch`是一个函数,显然这里打印的`arguments`就不应该是`test`函数的`arguments`。既然`catch`不是一个函数,那么凭什么可以有一个仅限在`catch`子句中被访问的错误对象`e`?\n\n答案就是`catch`子句使用NewDeclarativeEnvironment创建了一个新的词法环境(catch子句中词法环境的外部词法环境引用指向函数test的词法环境),然后通过CreateMutableBinding和SetMutableBinding将标识符e与新的词法环境的环境记录关联上。\n\n有人会说,`for`循环中的`initialization`部分也可以通过`var`定义变量,和`catch`子句有什么本质区别吗?要注意的是,在ES6之前是没有块级作用域的。在`for`循环中通过`var`定义的变量原则上归属于所在函数的词法环境。如果`for`语句不是用在函数中,那么其中通过`var`定义的变量就是属于全局环境(The Global Environment)。\n\n**with语句和catch子句中建立了新的词法环境**这一结论,证据来源于上文中一句话“a new Lexical Environment is created each time such code is evaluated.”具体细节也可以看看[12.10 The with Statement](http://es5.github.io/#x12.10)和[12.14 The try Statement](https://es5.github.io/#x12.14)。\n\n# Environment Record\n\n了解了词法环境(Lexical Environment),接下来就说说词法环境中的**环境记录**(Environment Record)吧。环境记录与我们使用的变量,函数息息相关,可以说环境记录是它们的底层实现。\n\n规范描述环境记录的内容太长,这儿就不全部复制了,请直接打开[ES5规范第10.2.1节](https://es5.github.io/#x10.2.1)阅读。\n\n> There are two kinds of Environment Record values used in this specification: declarative environment records and object environment records. // 省略一大段\n\n从规范中我们可以看到环境记录(Environment Record)分为两种:\n\n- **declarative environment records** 声明式环境记录\n- **object environment records** 对象环境记录\n\nECMAScript规范约束了声明式环境记录和对象环境记录都必须实现环境记录类的一些公共的抽象方法,即便他们在具体实现算法上可能不同。\n\n这些公共的抽象方法有:\n\n- HasBinding(N)\n- CreateMutableBinding(N, D)\n- SetMutableBinding(N,V, S)\n- GetBindingValue(N,S)\n- DeleteBinding(N)\n- ImplicitThisValue()\n\n声明式环境记录还应该实现两个特有的方法:\n\n- CreateImmutableBinding(N)\n- InitializeImmutableBinding(N,V)\n\n关于不可变绑定(ImmutableBinding),在规范中有这么一段比较细致的场景描述:\n\n> If strict is true, then Call env’s CreateImmutableBinding concrete method passing the String \"arguments\" as the argument.按钮1 \n按钮2 \n\n// pageB.vue\n按钮3 \n按钮4 \n```\n\n很明显,每使用一次`el-button`,我就要写一个`size`属性,好烦啊!\n\n\n\n是的,确实很烦,那么怎么解决呢?答案是提供一个编程接口,去改变组件的默认值。有这方面考虑的组件设计者一般会提供一个设置默认值的接口,比如`xxx.setDefault(options)`。那么ElementUI和Ant Design有没有提供这样的能力呢?据我观察好像是没有,其实主要是因为Vue没有一个方便的途径去修改`prop`的`default`属性。但是没有方便的途径并不代表没有途径...\n\n\n\n由于本文的主题是**透传**,所以就不说那个途径(或者说方法)了,有点跑偏了。\n\n网友小王说:“好,那就硬上,封装一个组件!”\n\n好的,马上安排!基本思路是封装一个自定义组件,组件里面再调用`el-button`,并且强行给`el-button`安排上默认属性`size=\"medium\"`。\n\n```vue\n\n \n \n \n\n\n```\n\n聪明的读者一看就发现了,这个组件问题很大,除了size属性,`ElButton`的其他属性和事件怎么处理完全没有提到!\n\n小王说:“没事,您需要什么?我给安排上!”\n\n于是,这个组件最后就慢慢变成了:\n\n```vue\n\n \n \n\n\n```\n\n看起来有点糟心,这组件甚至会更冗余,更复杂,因为我这里只加了3个prop和1个event。对于稍微复杂一点的组件来说,prop加上event一共几十个是随随便便的吧!你适配得过来吗?而且,不少人还有代码洁癖吧,这简直受不了!\n\n\n\n淡定淡定!这当然是有办法解决的。强如框架的设计者尤小右自然早已想到了这个场景,所以你应该在Vue官网文档中关注到[inheritAttrs](https://cn.vuejs.org/v2/api/#inheritAttrs)。\n\n如何理解`inheritAttrs`(默认值为`true`)这个选项呢?我们知道,一个组件如果要接受父组件传来的属性,是需要先在`props`里面预定义好的。比如前面的例子,我在`MyButton`预定义了3个属性,分别是`size`, `type`, `disabled`,意思是`MyButton`这里只接受3个`prop`。\n\n那么假设父组件传了4个或者更多`prop`过来呢,会怎么样?看下面这个例子:\n\n```vue\n\n 测试\n \n```\n\n实际上,`round`和`autofocus`都不是`MyButton`组件支持的`prop`,所以反映到`HTML`上是这么一个效果:\n\n\n\n作为使用者,我们应该是希望`round`和`native-type=\"submit\"`能够传到`el-button`,产生应有的效果。然而,`round`和`native-type=\"submit\"`仅仅是挂在了根元素的`attribute`上,并没有真正起到应有的作用!\n\nPS:举个例子,`round`属性作用到`el-button`能让`button`带一个`is-round`的`class`,从而产生圆角效果!\n\n也就是说,`inheritAttrs`的作用是:使那些没有在`props`中定义的属性,直接以`attribute`的形式作用在组件的根元素上!\n\n那么`round`和`native-type=\"submit\"`如何透传下去呢?\n\n首先,不能让那些未被props标识的属性直接落到根元素上,所以需要设置`inheritAttrs`为`false`。\n\n然后,要获取到那些未被props标识的属性,并直接绑定到`el-button`。恰好,Vue提供了[attrs](https://cn.vuejs.org/v2/api/#vm-attrs)用于获取这些属性,而`v-bind`本身就能绑定一个对象,这是容易被我们忽略的!\n\n处理完属性透传,接下来我们还要处理事件,类似于`$attrs`,`$listeners`也能把父组件中对子组件的事件监听全部拿到,这样我们就能用一个`v-on`把这些来自于父组件的事件监听传递到下一级组件。\n\n看图可能会更好理解!\n\n\n\n相当于`MyButton`是一个**不赚差价的中间商**,直接透传消息!直观上看,组件代码量有一个明显的减少,更重要的是扩展性和可维护性变得更强!\n\n```vue\n\n \n \n\n\n```\n\n对于调用者来说,使用体验是完全没有被影响的,他的感觉就好像仍然在直接使用`el-button`,属性传递和事件监听的使用体验都没有任何变化!\n\n```vue\n\n \n```\n\n# 总结\n\n结合`inheritAttrs`, `v-bind`以及`v-on`,我们就实现了一个支持透传的基础组件!本文是以`Button`组件为例,做的关于透传的入门介绍。实际上,透传的应用范围远远不止`Button`组件,利用透传的技巧,我们能做更多漂亮的事情!现在,你的代码洁癖还好吗?\n\n\n', '2021-03-28 19:45:49', '2024-09-03 10:08:51', 1, 76, 0, '写优雅的代码需要慢慢修炼,一个小技巧奉上', 'https://qncdn.wbjiang.cn/danpianji.jpg', 0, 0);
-INSERT INTO `article` VALUES (226, '花半天时间,轻松打造前端CI/CD工作流', '**CI/CD** 是 Continuous Intergration/Continuous Deploy 的简称,翻译过来就是**持续集成/持续部署**。CD 也会被解释为**持续交付**(Continuous Delivery),但是对于软件工程师而言,最直接接触的应该是持续部署。\n\n我刚开始工作时,就有接触过CI的概念,那个时候主要是团队 QA(质量保证)使用 **hudson** 对工程进行质量扫描,跑一些基础的自动化测试。当时印象最深的一幕就是 QA 对我说:”你的代码静态告警了,赶紧改一下...“。\n\n现在一想,我不禁感到诧异,”咦?我们当时没有用 ESLint 吗?记不清楚了...“于是我翻了下 ESLint 的更新记录,发现那时候 ESLint 的大版本号才刚到3,VSCode 的 ESLint 插件也还是比较早期的版本,可能还没普及开吧。\n\n后面我也慢慢地听到了 Jenkins, Travis CI 这样一些名词,但是由于太菜,我一个都不会用。\n\n\n\n而且我发现,我对 CI/CD 并没有什么兴趣,为什么呢?因为我还没有使用它的动机。\n\n# 构建/部署那些事\n\n构建/部署说的简单点,就是先利用 webpack 或者 gulp 这类的工具把工程打包,然后把打包得到的文件放在服务器上某个托管静态资源的 Web 容器里,像 Java 就可以放在 Tomcat,不过现在流行用 Nginx 托管静态资源。有了 Web 容器,前端打包的那些文件(比如index.html, main.js等等)就可以被访问到了,这个相信大家都懂。\n\n16年~18年时,我还不负责打包部署这些事(另一方面也是因为前端根本没权限碰服务器啊,emmm...),所以我压根没关注打包部署这些事情。\n\n18年到19年时,我开始负责打包部署了。当时完全没这方面经验,Linux 命令都是靠着一边百度一边敲。不过我清楚地记得,之前在测试组那间办公室看他们用的是**xshell**和**xftp**,把这俩工具搞来用后,我觉得部署真是简单,我只要跑个脚本,安静地等 webpack 和 gulp 的工作流结束后,把文件通过 xftp 传到服务器就行,**只要注意不要操作出错就行了**(显然,人为操作就容易出错,这也是个隐患)。由于构建部署的频率不高,项目数量也不是很多,这一年我基本应付得过来。\n\n直到去年,我手底下有差不多5个项目,接近10个前端工程。在这种日常部署节奏下,我觉得 xshell+xftp 也救不了我,虽然这些项目不是天天都发版上线,但是测试环境还是经常发的,每天光部署这事我就够烦躁,写代码经常被打断,而且也非常浪费时间。\n\n\n\n我想着要寻求些改变了,但我还是没考虑 CI/CD 这事,因为我觉得我好像还是不太懂 CI/CD。于是我考虑先用 **shell 脚本**来做构建/部署的事情,所以后来就有了这么两篇探索性的文章:\n\n- [自动化部署的一小步,前端搬砖的一大步](https://juejin.cn/post/6844904049582538760#heading-0 \"自动化部署的一小步,前端搬砖的一大步\")\n- [前端自动化部署的深度实践](https://juejin.cn/post/6844904056498946055 \"前端自动化部署的深度实践\")\n\n靠着这一波脚本的探索,我基本上也是过渡到**半自动化**的阶段了,这种焦虑的状况基本上得到了一些缓解。但是,我发现我的电脑还是扛不住,风扇急速旋转的声音能让我自闭。。。毕竟一边跑本地开发环境,一边还可能同时跑1~2个工程的构建/部署脚本,再加上电脑运行的其他软件,这发热量你懂的!\n\n所以,构建/部署这活不应该由我的电脑来承担,它太累了。\n\n\n\n而且,我也不想手动触发部署脚本了,太累了,是时候让代码学会自己部署了。**也就是这个时候,我对 CI/CD 就有了诉求**。\n\n由于我们的代码是托管在自建的 gitlab 服务器上,所以 CI/CD 这块我直接选择了用 gitlab 自带的 CI/CD 能力。工作之余,我差不多花了两天时间去熟悉[gitlab CI/CD的文档](https://docs.gitlab.com/ee/ci/quick_start/ \"gitlab CI/CD的文档\")。\n\n然后我按照文档先把环境搭建好,接着一遍遍地调试`.gitlab-ci.yml`配置文件,我记得第一次成功跑完一个 Pipeline 前,我一共失败了大概11次,这个过程挺折磨人,有时候你就是不知道到底哪里配错了。\n\n\n\n不过调通这个流程后,你就会觉得这整个试错的过程都是值得的。Nice!\n\n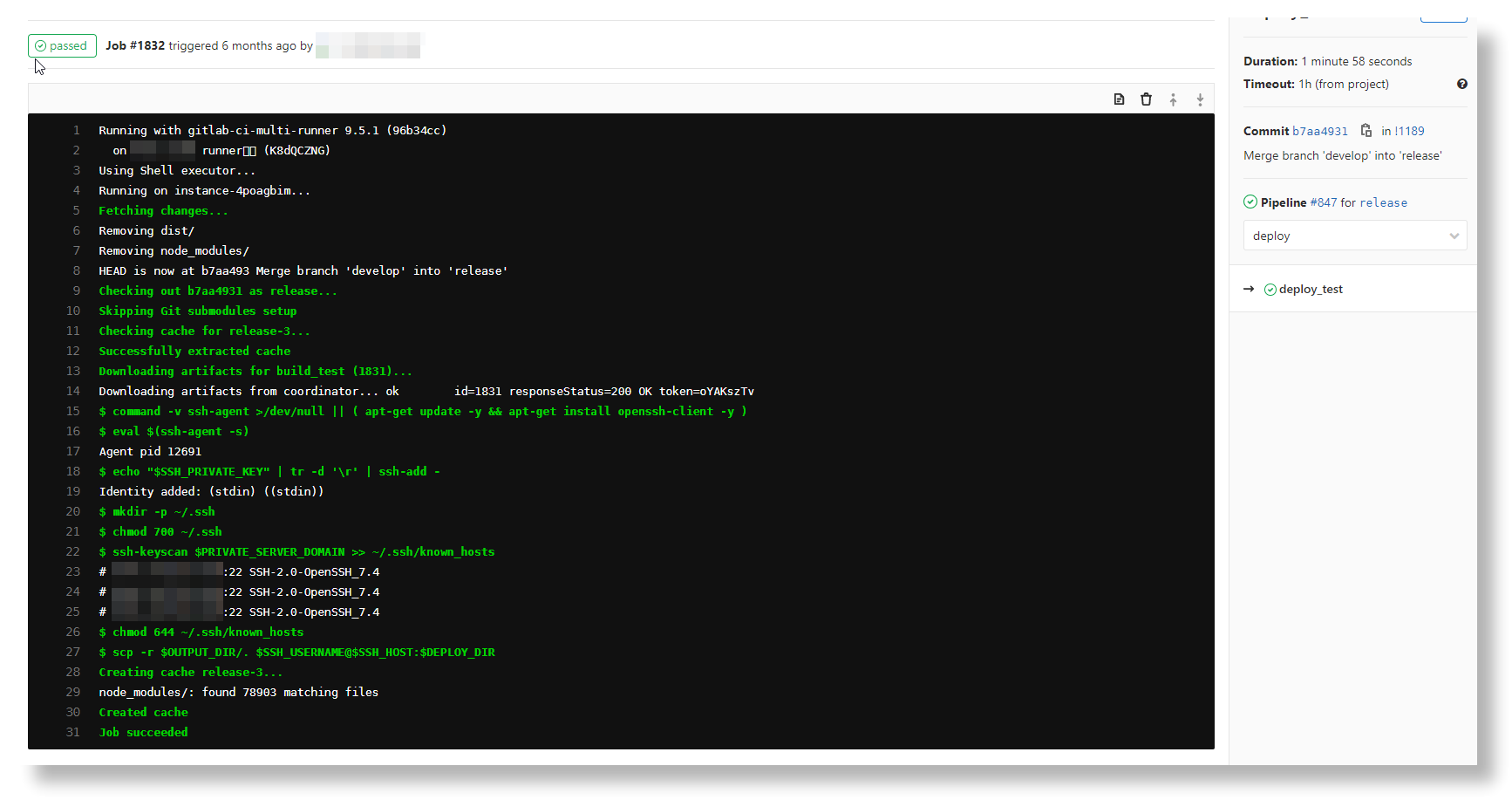\n\n# CI/CD到底干了啥?\n\n其实我前面也提到了,一个版本发布的过程,主要就是分为以下几个步骤:\n\n- **代码合并**:测试环境或生产环境都有独立的分支,等所有待发版的代码都合并到对应分支后,就可以考虑发版了。\n- **打包**:或者叫构建。以生产环境部署为例,我们切到生产环境分支并 pull 最新代码后,就可以开始打包步骤了。这一步主要是通过一些 bundler 完成的,比如 webpack。而打包命令嘛,一般都是定义在`package.json`的`scripts`中了,我这儿定义的命令是`build:prod`,所以只要运行`npm run build:prod`就行了。\n- **部署**:把打包得到的文件放在 web 容器中,而 web 容器通常在 Linux 服务器上,这涉及到远程传输文件,这个时候我们一般要借助 shell 脚本或者 xftp。\n\n而 CI/CD 做的事情就是:**用自动化技术接管流程**。\n\n# 监控Mutation\n\n我的诉求是:**当代码合并到某个分支后,gitlab能自动帮我执行完打包和部署这两个步骤。**\n\n所以,首先就必须有代码变动的监控能力。这个确实有,如果你有关注过[git hook](https://git-scm.com/book/zh/v2/%E8%87%AA%E5%AE%9A%E4%B9%89-Git-Git-%E9%92%A9%E5%AD%90 \"git hook\"),就知道这是可以实现的。\n\n而且,绝大部分代码托管平台都提供了 webhooks,能监控不少事件,比如 push 和 merge。\n\n\n\n这也就是说,即便不使用代码托管平台提供的 CI/CD 能力,开发者也有能力实现自己的 CI/CD 机制。\n\nps:当然,除了 CI/CD,做短信/邮件通知也是可行的,只要你敢去尝试,基于平台开放的能力,我们能做很多事情。自研 CI/CD 的事情我们就不去搞了,人家造的轮子已经6翻了,直接拿来用。\n\n回归主题,只要我监控到代码变动了,服务器端自动执行构建/部署脚本即可。\n\n# Gitlab CI/CD是怎么工作的\n\n软件服务于生活,也源于生活。Gitlab CI/CD 设计了很多概念,其中我觉得最有意思的是:**Pipeline 和 Runner**。\n\n## Pipeline\n\n**Pipeline是CI/CD的最上层组件**,它翻译过来是管道,其实你可以将之理解为**流水线**,每一个符合`.gitlab-ci.yml`触发规则的 CI/CD 任务都会产生一个 Pipeline。这个概念就有点像工厂中的车间流水线了,我们知道车间中有很多条流水线,不同的流水线可能会处理同一类型的生产任务,也可能处理不同类型的生产任务。当一条流水线空闲的时候,就有可能会被用来安排执行其他的生产任务。而 Gitlab 的 Pipeline 虽然没有空闲的概念,一个 Pipeline 执行结束后也不会被复用,但是会将资源让出来给其他的 Pipeline,所以和车间流水线也有异曲同工之妙。\n\n\n\n## Runner\n\n有了流水线,还必须有辛勤的工人进行生产作业,**Runner**在 Gitlab Pipeline 中就扮演着工人角色,根据我们下达的指令进行作业。\n\n### Runner的类型\n\n在 Gitlab 中,Runner 有很多种,分为**Shared Runner**, **Group Runner**, **Specific Runner**。\n\n- Shared Runner 可以理解为机动人员,他可能会在工厂的各个流水线机动作业,随时支援!在整个 Gitlab 应用中,Shared Runner 可以服务于各个 Project。\n\n\n\n- Group Runner 就比较好理解了,他只在这个组上班,别的组他是不会去的。在 Gitlab 中,我们是可以建立不同的 Group 的,比如前端一个 Group,后端一个 Group,甚至前端里面还可以分 N 个 Group。所以,Group Runner 只服务于指定的 Group。\n\n\n\n- Specific Runner 就更牛逼了,它只服务于指定的项目,也就是 Project 级别,别的项目咱都不去。\n\n\n\n### 注册Runner\n\n工人是要持证上岗的,同样地,Runner 有一个注册的过程,就相当于在工厂中入职登记的意思。具体见[Registering runners](https://docs.gitlab.com/runner/register/ \"Registering runners\")。只有合法注册的 Runner,才有资格执行 Pipeline。不过,Gitlab 好像没给 Runner 发工资啊!\n\n\n\n## .gitlab-ci.yml配置\n\n流水线和工人都安排好之后,就必须**制定车间生产规章制度**了。一条流水线到底怎么干活,总要有个规矩吧,你说呢?\n\n没错,`.gitlab-ci.yml`文件就是来制定规则的!其实我要求的 CI/CD 流程并不复杂,只要帮我把构建和部署两步搞定就行了。下面以一个简化的生产环境构建部署流程为例说明:\n\n```yml\nworkflow:\n rules:\n - if: \'$CI_COMMIT_REF_NAME == \"master\"\'\n\nstages:\n - build\n - deploy\n\nbuild_prod:\n stage: build\n cache:\n key: build_prod\n paths:\n - node_modules/\n script:\n - yarn install\n - yarn build:prod\n artifacts:\n paths:\n - dist\n \ndeploy_prod:\n stage: deploy\n script:\n - scp -r $CI_PROJECT_DIR username@host:/usr/share/nginx/html\n```\n\n首先,我希望只在 master 分支进行构建/部署作业,这个可以通过`workflow.rules`下的`if`条件约束完成。\n\n然后,我希望把整个过程分为两个阶段执行,第一个阶段是`build`,用于执行构建任务;第二个阶段是`deploy`,用于执行部署任务。这可以通过`stages`来完成定义。\n\n接着,我定义了两个`job`,第一个`job`是`build_prod`,属于`build`阶段;第二个`job`是`deploy_prod`,属于`deploy`阶段。\n\n在`buiild_prod`这个`job`中,主要是运行了`yarn install`和`yarn build:prod`两个脚本,打包生成的文件资产会根据`artifacts`的配置保存下来,供后面的`job`使用。\n\n在`deploy_prod`这个`job`中,主要是通过`scp`命令向 linux 服务器上的 nginx 目录下传输文件。\n\n这个简单的 Pipeline 配置示例其实应用的是 Basic Pipeline Architecture,只不过示例中每个 stage 只定义了一个 job。\n\n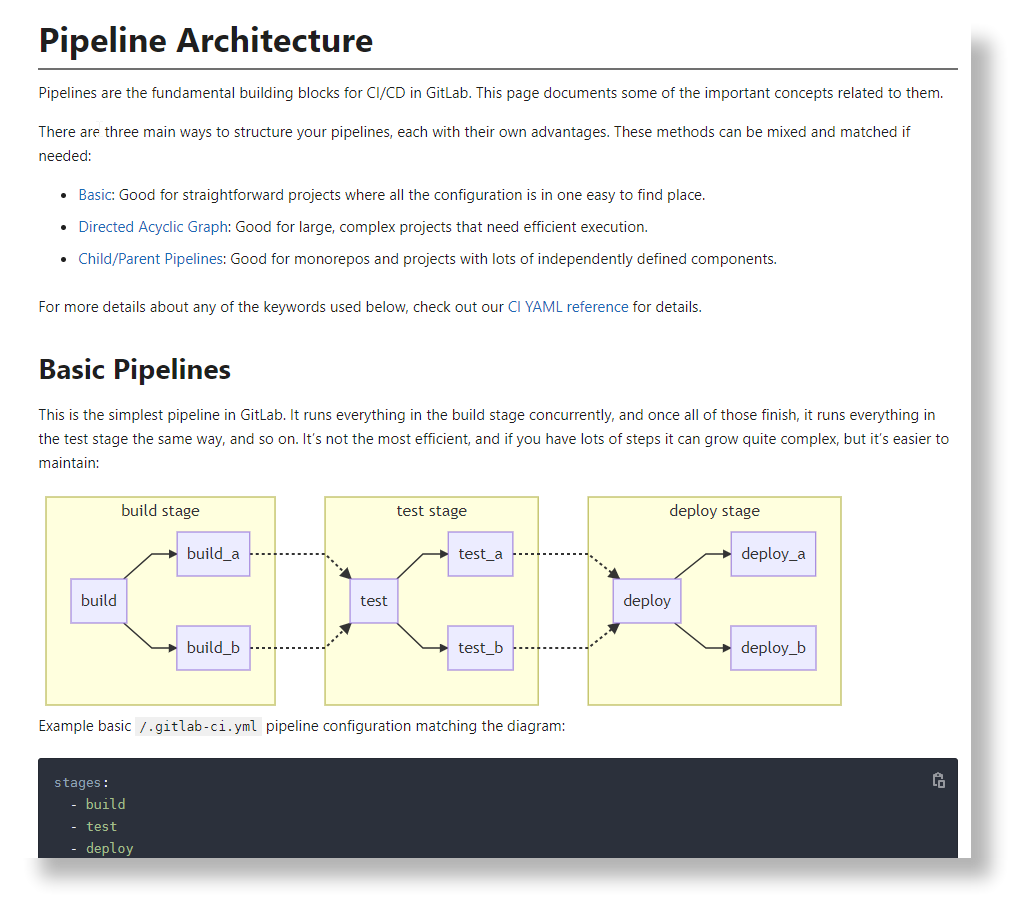\n\n## Gitlab CI/CD Variables\n\nGitlab 通过 **Variables** 为 CI/CD 提供了更多配置化的能力,方便我们快速取得一些关键信息,用来做流程决策。上述示例中的`$CI_COMMIT_REF_NAME`和`$CI_PROJECT_DIR`就是 Gitlab 的预定义变量。\n\n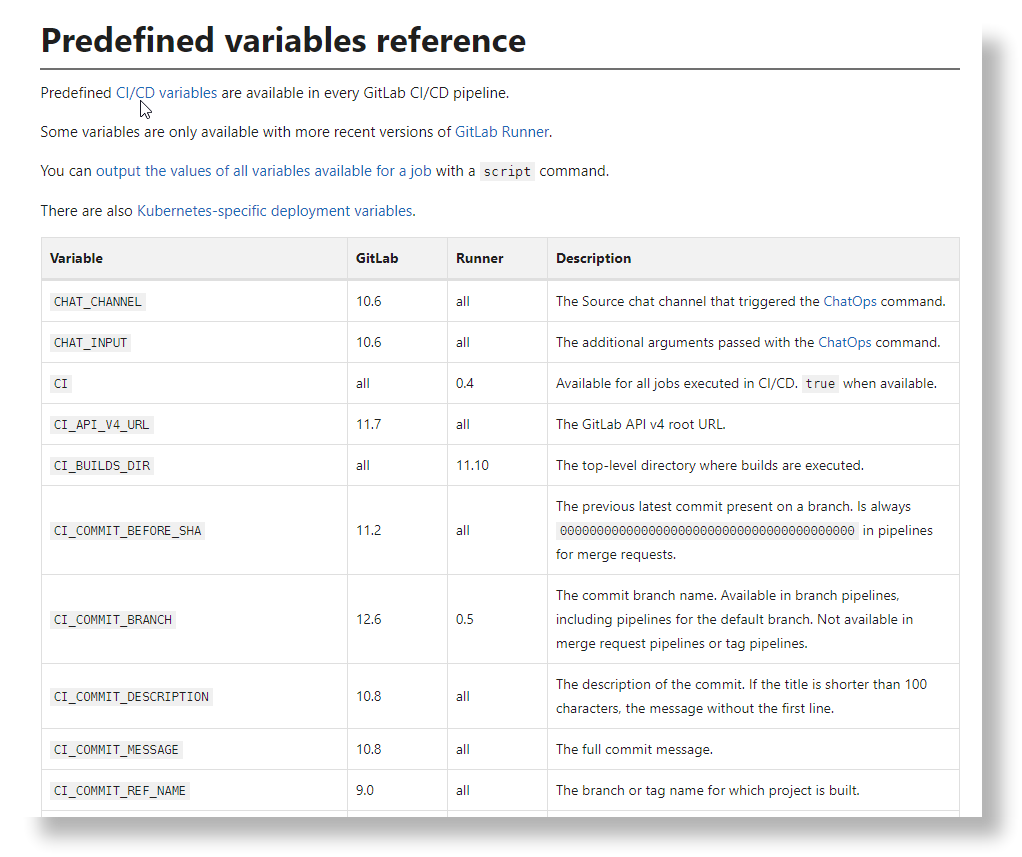\n\n除了预定义变量,我们也可以自行定义一些环境变量,比如服务器 ip,用户名等等,这样就免去了在配置文件中明文列出私密信息的风险;另一方面也方便后期快速调整配置,避免直接修改`.gitlab-ci.yml`。\n\n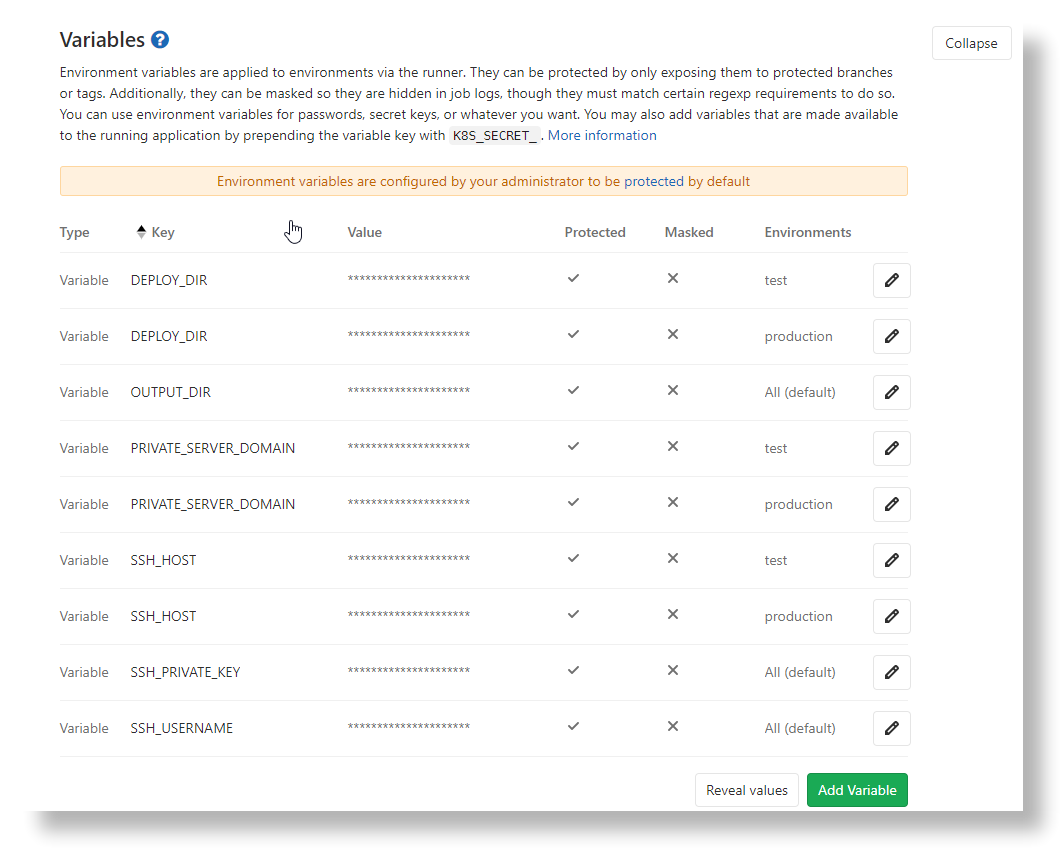\n\n## 授信问题\n\n在不同主机间通过`scp`传输文件需要建立信任关系,在 CI/CD 中最好选择免密方式,其基本原理就是把 **ssh公钥** 交给对方。而这一点我在[自动化部署的一小步,前端搬砖的一大步](https://juejin.cn/post/6844904049582538760#heading-7 \"自动化部署的一小步,前端搬砖的一大步\")这篇文章中也提到了,这里就不再赘述。\n\n## Runner独立部署\n\n由于我是将 Runner 直接部署到了 Gitlab 代码服务器上,而我司配的这台代码服务器的配置本身就不高,用来跑高 CPU 占用的构建部署 Pipeline 还是有点吃力的,有时候 Pipeline 跑起来甚至直接把 Gitlab 的 Web 服务搞崩了。\n\n队友问我:”怎么 Gitlab 白屏打不开了?“\n\n\n\n没过多久,领导那边给我发了一台 Linux 服务器,专门给前端搞日常工作用的。bingo,我就顺手把 Runner 独立部署到新机器上了,这样就不会影响队友了,而且每次发版时间直接从 8min 缩短到 2min 以内,简直 Nice!\n\n\n\n# CI/CD带来的收益\n\n直观来看,我的重复劳动被去除了大部分,多出来的这部分时间我可以用来干更多有意义的事情,或者摸鱼它不香吗?而且,每天不用手动发版,心情也是倍儿棒!\n\n此外,由于 CI/CD 采用自动化作业方式,只要脚本写对了,几乎不会出错,出生产事故的几率也就大大降低了。\n\n# 小结\n\n本文从笔者的一些亲身经历出发,回忆了笔者在构建/部署过程中遇到的痛点,并围绕一个最基础的Gitlab CI/CD案例,讲述了笔者使用 CI/CD 来解决这些痛点的过程。虽然本文的主角是Gitlab CI/CD,但它和其他代码托管平台的CI/CD在思路上是类似的,掌握了一个,触类旁通也就不难。并且,利用 Pipeline 这类工具,我们还可以做更多事情,比如**持续集成+自动化测试**。这就考验大家的想象力了,剩下的就交给聪明的读者啦!', '2021-04-21 20:30:52', '2024-08-15 13:22:42', 1, 124, 0, '讲讲我的部署亲身经历', 'https://qncdn.wbjiang.cn/cicdworkflow.png', 0, 0);
-INSERT INTO `article` VALUES (227, 'npm init @vitejs/app的背后,仅是npm CLI的冰山一角', '结尾的话说在前面。\n\n> 我有时候会得出这样的结论:**原来那些我不常用的命令或工具,都是为了解决大佬们遇到的问题而存在的!**\n\n我们每天都和**npm**打交道,但是不少人对**npm**的掌握程度还停留在一个比较浅的层面(当然这也包括我)。就比如说一个用 vite 创建 app 的命令`npm init @vitejs/app`,很多人就懵了,“`npm init`不是用来创建`package.json`文件的吗?”\n\n同样还有`npx create-react-app my-app`这样的命令,懵吗?\n\n的确,这些命令背后还有一些我们很少关注的逻辑,虽然不难,但是我们却没有系统去了解过。\n\n考虑到这些,最近我有系统地去学习**npm**,主要的学习方式是利用一些空余时间,结合我之前的**npm**使用经验,从**npm**官方文档入手去排查一些知识盲点和疑惑。顺着官方文档一块块看下来,同时对不清楚的知识点进行资料查阅和验证之后,虽然还有那么一小部分知识点我几乎没用过,但是我的确对**npm**有了更多的认识。最后我也是以思维导图的形式,把自己的一些学习所得简单记录下来。\n\n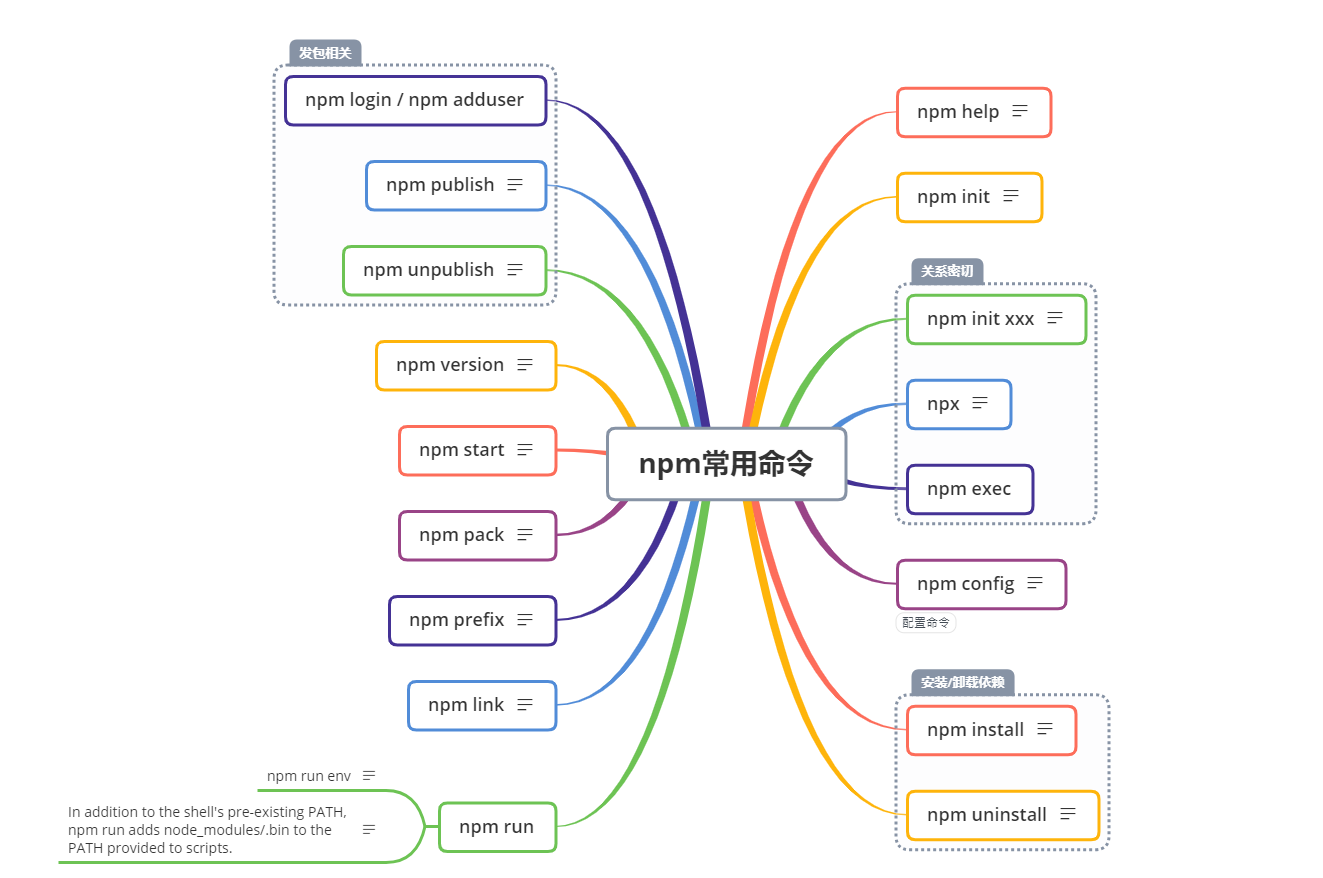\n\n\n经过这几天的学习,我发现我学习**npm**的两个大方向是`npm CLI`和`package.json`。\n\n今天我想先聊聊`npm CLI`,**CLI**就是Command Line Interface,也就是我们说的命令行接口。`npm`提供了非常多的`CLI`,具体可以参考[npm CLI commands](https://docs.npmjs.com/cli/v7/commands)。\n\n```\nUsage: npm \n\nwhere is one of:\n access, adduser, audit, bin, bugs, c, cache, ci, cit,\n clean-install, clean-install-test, completion, config,\n create, ddp, dedupe, deprecate, dist-tag, docs, doctor,\n edit, explore, fund, get, help, help-search, hook, i, init,\n install, install-ci-test, install-test, it, link, list, ln,\n login, logout, ls, org, outdated, owner, pack, ping, prefix,\n profile, prune, publish, rb, rebuild, repo, restart, root,\n run, run-script, s, se, search, set, shrinkwrap, star,\n stars, start, stop, t, team, test, token, tst, un,\n uninstall, unpublish, unstar, up, update, v, version, view,\n whoami\n\nnpm -h quick help on \nnpm -l display full usage info\nnpm help search for help on \nnpm help npm involved overview\n\nSpecify configs in the ini-formatted file:\n C:\\Users\\Tusi\\.npmrc\nor on the command line via: npm --key value\nConfig info can be viewed via: npm help config\n```\n\n命令太多,就不全部解释一遍了。我筛选出了一些基础的,同时也是我见得比较多的一些命令来简单介绍下。\n\n\n\n# npm CLI常见命令\n\n## npm help\n\n不懂就问,`npm help`是个好命令。就像我用`git --help`一样,对于有些比较模糊的命令,我都会用**help**来查一下。\n\n## npm init\n\n在我们初始化一个 npm 包,或者说创建 package.json 文件,就需要用到`npm init`。\n\n## npm init xxx\n\n虽然之前在创建vue或者react应用时,我都用到了`npm init xxx`,但我都没怎么关注`npm init xxx`背后发生了什么。\n\n比如`npm init @vitejs/app`,只知道官网说它是用来创建应用的,但很少会去想到其背后是调用了`npx @vitejs/create-app`,其实就是在执行一个`create-app`脚本。\n\n这也就是说,如果你想让别人通过`npm init xxx`命令调用你的包,就必须提供一个`create-xxx`脚本。\n\n## npx\n\nnpx 用来运行本地或远程npm包的一个命令。比如前面提到的`npx @vitejs/create-app`。\n\n如果 npx 请求的包(比如`@vitejs/create-app`)没有出现在本地项目的依赖中,npm 就会把`@vitejs/create-app`安装到全局的 npm cache 目录下。\n\n接着会执行`create-app`脚本,而这个脚本需要定义在`package.json`的`bin`配置项下。\n\n> `npm init xxx`和`npx create-xxx`也是一般`CLI`工具的常用套路。\n\n\n\n## npm config\n\n`npm config`是用来管理配置文件的,我们平时用的最多的是设置`npm`的源。\n\n```\nnpm config set registry https://registry.npm.taobao.org \n```\n\n利用`npm config list`,我们可以列出所有的配置项;利用`get`, `set`, `delete`可以执行查询,设置,删除配置项的操作。\n\n## npm install / uninstall\n\nnpm install 不指定包时,会将 package.json 列出的依赖安装到 node_modules 中,如果指定包名,则安装指定的包。主要注意:\n\n- -g是全局安装;\n\n- 如果指定了 --production ,或者 NODE_ENV 是 production,就不会安装 devDependencies 中的依赖。\n\n- `--save` 等价于 -S,安装的依赖包信息保存到 package.json中的 dependencies,这些依赖(比如vue, react)如果有进入 bundler (比如 webpack )的 Dependency Graph(依赖关系图),会被打包到项目的构建结果中;`npm install vue`会默认执行`-S`的行为,但是建议显示给出`-S`,给人的感觉会比较清晰。\n\n- `--save-dev` 等价于 -D,安装的依赖包信息保存到 devDependencies 中,这些依赖一般是开发环境的工具,比如 eslint, webpack, babel之类的,这些依赖一般不会被打包工具处理到构建结果中。\n\n**但是**,如果你使用`npm install -D vue`安装了`vue`,并且在项目中引用了`vue`依赖,那么 webpack 的 Dependency Graph 中也会有`vue`,最终`vue`也会体现到构建结果中;\n\n看到这里,是不是又懵逼了?不管是`npm install -S vue`还是`npm install -D vue`,如果项目中引用了`vue`,都会把`vue`打包进构建结果,那么`-S`和`-D`有什么区别?\n\n\n\n注意了,webpack 不关心一个依赖是`dependencies`还是`devDependencies`,只要进入 webpack 的 Dependency Graph,就会打包到结果中。\n\n所以我们不要被构建工具迷了眼,`-S`和`-D`影响的是`npm install`,而且影响的也是有限的场景。\n\n如果别人 install 你的包`package-a`,他会顺便安装`package-a`中的`dependencies`,而不会去安装`package-a`中的`devDependencies`。\n\n**分两方面来看**:\n\n- **第一种情况:生产依赖误入开发依赖**。\n\n假设你的包`package-a`通过`package.json`的`module`字段提供了一个ESM入口。\n\n```\n\"module\": \"module-entry.js\"\n```\n\n在`module-entry.js`里面又依赖了一个包,假设是`lodash-es`吧。\n\n```javascript\n// module-entry.js\nimport { cloneDeep } from \"lodash-es\"\n```\n\n但是,你没注意你是通过`npm install -D lodash-es`安装的,你在本地调试`package-a`时,没有任何问题。于是,你发布了这个`package-a`,同事小王安装了`package-a`却发现使用时报错了(因为他不会自动安装`package-a`的`devDependencies`)。\n\n- **第二种情况:开发依赖误入生产依赖**。\n\n开发环境的依赖进入了生产环境,会导致构建时多了无意义的开发依赖,打包结果变大,这常发生于开发库或组件时。\n\n```javascript\nimport VueAwesomeProgress from \"./index.vue\";\n\n// 开发组件时,不必要的vue引入;\n// 导致最终build的文件变大。\nimport Vue from \"vue\"\nconsole.log(Vue)\n\nVueAwesomeProgress.install = function(Vue) {\n Vue.component(VueAwesomeProgress.name, VueAwesomeProgress);\n};\n\nif (typeof window !== \'undefined\' && window.Vue) {\n window.Vue.use(VueAwesomeProgress)\n}\n\nexport default VueAwesomeProgress\n```\n\n实质上,我们在开发一个Vue组件时,仅仅需要把`vue`作为`devDependencies`即可。\n\n## npm start\n\n`npm start`是一个语义化的命令。通常我们会在 scripts 中自定义 start 脚本,比如:\n\n```json\n\"start\": \"npm run dev\"\n```\n\n如果没有指定自定义的 start 脚本,`npm start`默认会执行:\n\n```\nnode server.js\n```\n\n## npm run\n\n`npm run`用来运行我们定义的`scripts`,命令后直接跟脚本名称就行。在`npm run`时,我们可以调用一些特殊路径下的可执行文件或脚本,这些路径包括环境变量PATH定义的路径,也包括当前项目`node_modules`中的`./bin`。\n\n> In addition to the shell\'s pre-existing PATH, npm run adds node_modules/.bin to the PATH provided to scripts.\n\n## npm version\n\n这个命令也是值得掌握的,从语义上看,`npm version`会修改`package.json`中的`version`字段,用来管理包的版本号。\n\n你可以试着运行:\n\n```shell\nnpm version major/minor/patch -m \"reason for upgrade\"\n```\n\n**major/minor/patch**三选一,分别代表**主版本/次版本/补丁版本**。当然也可以传其他的版本参数,具体参考[npm-version](https://docs.npmjs.com/cli/v7/commands/npm-version)。\n\n通常,我们还会定义一个自定义的 version 脚本,配合`conventional-changelog`用来自动生成`CHANGELOG.md`。\n\n```json\n{\n \"scripts\": {\n \"version\": \"conventional-changelog -p angular -i CHANGELOG.md -s && git add CHANGELOG.md\"\n }\n}\n```\n\n## 发包相关\n\n### npm login/ npm adduser\n\n发布一个 npm 包的流程并不复杂。首先你必须通过命令行登录 npm,这用到了`npm adduser`,别名是`npm login`。\n\n### 确保你的代理正确\n\n有时候,考虑到国内环境,我们安装依赖时,会设置 npm 的源为淘宝镜像。但是在发布 npm 包之前,必须把源切回到 npm。\n\n```shell\nnpm config set registry http://registry.npmjs.org/\n```\n\n### npm publish\n\n发布一个npm包,发布的界限是以 version 判断的,不能发布相同的 version。即便你只是改了一个`README`,也必须修改 version 才能重新 `npm publish`。\n\n### npm unpublish\n\n与发包对应的就是**移除已发布的包**。你可以选择移除整个已发布的包,也可以针对性地下架某个版本。\n\n## npm pack\n\n将package打包成 tgz 格式。举个例子,在`vue-awesome-progress`目录下,运行 npm pack 将得到一个 vue-awesome-progress-1.9.1.tgz,其中 1.9.1 是取自 version 字段。\n\n然后通过 npm install vue-awesome-progress-1.9.1.tgz 会在当前目录的 node_moudles 目录下安装 vue-awesome-progress包及其相关依赖。\n\n## npm link\n\n`npm link`用于创建一个符号链接,类似于 Linux 软链接(`ln -s`)的效果。\n\n首先需要在待创建 link 的包目录(比如vue-awesome-progress)下运行 npm link,这会在 npm 全局文件夹下创建一个 symlink。\n\n`npm prefix -g`指向 npm 全局文件夹,我这里的值是:\n\n```shell\nPS C:\\Users\\Tusi> npm prefix -g\nC:\\Users\\Tusi\\AppData\\Roaming\\npm\n```\n\nnpm link后,`C:\\Users\\Tusi\\AppData\\Roaming\\npm\\node_modules\\`中就有一个`vue-awesome-progress`的目录了,其实是一个快捷方式。\n\n同时,如果 vue-awesome-progress 中有配置 bin 文件,也会被 link 到全局。\n\n要用到 vue-awesome-progress 的地方可以通过`npm link vue-awesome-progress`安装它,也会安装到 node_modules 下,不过是一个**全量的 vue-awesome-progress**,而非`npm publish`后的 vue-awesome-progress。\n\n个人感觉,npm link 适合在本地对两个及以上的包做调试用,这样就不用每次调试问题时,还要重新 npm run build, npm publish,省去了很多事。\n\n# 写在结尾\n\n当我们习惯了一个工具的常用功能时,很少会去想它背后发生了什么,甚至更少会去思考它还有没有其他能力。但是,当你有一定使用经验后,再去深入了解它,你会感叹:“卧槽!原来这个命令是用来解决这个问题的,大佬们果然还是考虑得全面!”\n\n就像我开头说的那样,一个人如果想在技术领域进阶,一定要给自己提出足够多的问题,带着问题去深入。至于如何带着问题深入,我觉得最好是做一个自己的产品,可以是项目,也可以是组件,或者是library,甚至是framework。遇到困惑时,如果你发现大佬们给了解决方案,你会惊喜;如果没有,**你来成为大佬!**', '2021-04-21 20:32:25', '2024-10-04 20:54:34', 1, 60, 0, '系统学习npm,从npm CLI开始', 'https://qncdn.wbjiang.cn/npm_cli.jpg', 0, 0);
-INSERT INTO `article` VALUES (228, '这还是我最熟悉的package.json吗?', '# 前言\n\n在上一篇[npm init @vitejs/app的背后,仅是npm CLI的冰山一角](https://juejin.cn/post/6950817077670182943)中,有提到我复习**npm**主要是从两个大方向来入手,所以这篇继续来讲讲`package.json`这部分知识,经过这轮复习,也发现了自己的很多不足,之前把常用的命令和配置玩熟了,却没关心**npm**已经有了更多新的玩法,而这些玩法却实实在在地在解决别人的问题。\n\nnpm 的配置还是挺多的,具体可以参考[package.json官方文档](https://docs.npmjs.com/cli/v7/configuring-npm/package-json)。通读了文档之后,我略过了一些基础的配置项,总结了一些我认为比较有用的配置项。\n\n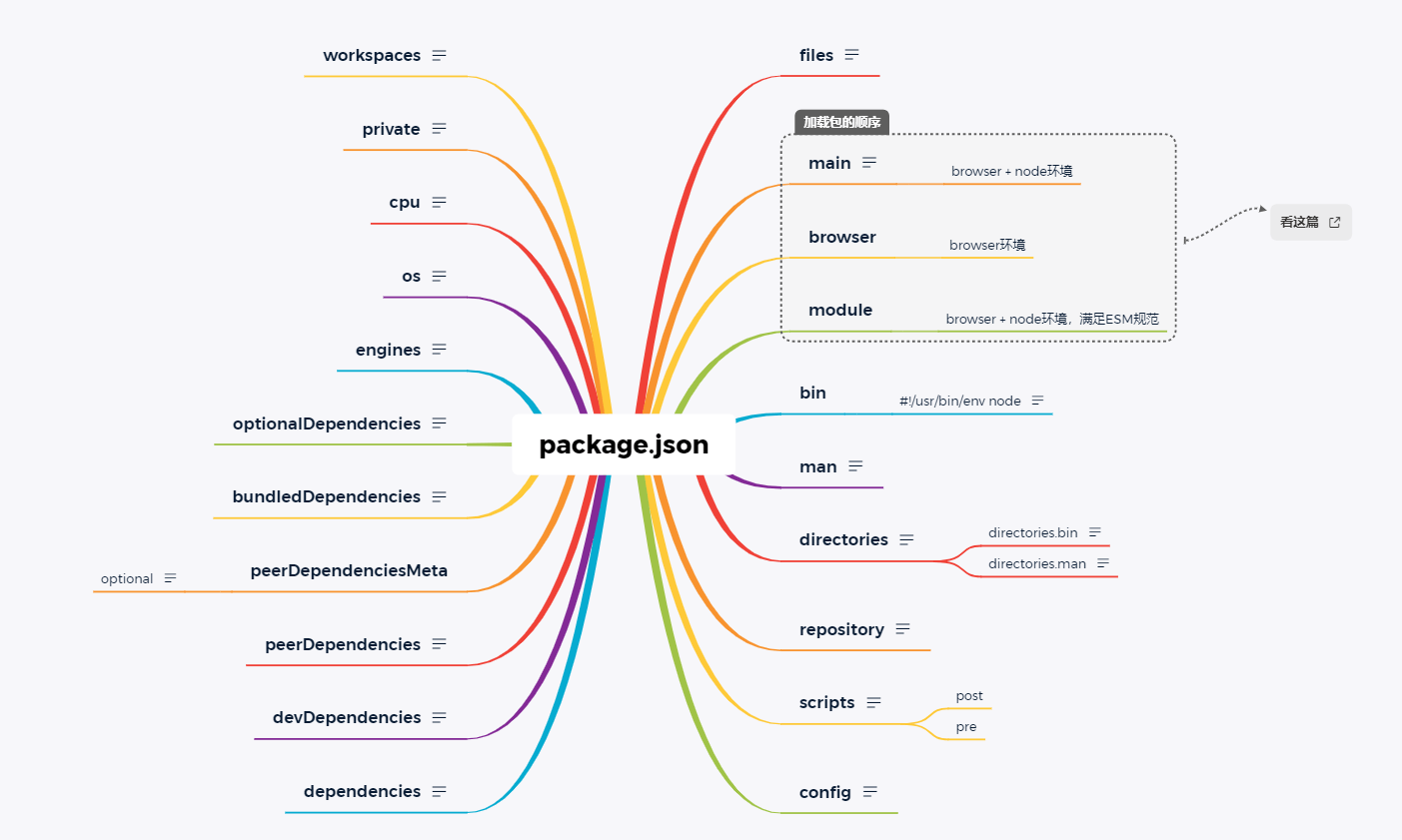\n\n# 常用配置项\n\n## files\n\n`files`定义了哪些文件应该被包括在 npm install 后的 node_modules中。\n\n当然,有些文件是自动暴露出来的,不管你是不是配置了`files`,比如:\n\n- package.json\n- README / CHANGELOG / LICENSE\n- ...\n\n很多库都定义了 files,避免一些不必要的文件暴露到 node_modules 中。\n\nvite 中是这样配置的:\n\n```json\n{\n \"files\": [ \"bin\", \"dist\", \"client.d.ts\" ]\n}\n```\n\n我之前就不知道这个配置,导致我发布的一个 npm 组件 [vue-awesome-progress](https://cumt-robin.github.io/vue-awesome-progress/) 就暴露了源码部分,虽然这也没啥影响,本来就是开源的。但是这也增加了别人的资源下载量,也是一种浪费。所以,专业点的搞法还是加上`files`配置吧。\n\n## bin\n\nbin 列出了可执行文件,表示你这个包要对外提供哪些脚本。\n\n在这个包被 install 安装时,如果是全局安装 -g,bin 列出的可执行文件会被添加到 PATH 变量(全局可执行);如果是局部安装,则会进入到 node_modules/.bin/ 目录下。\n\nbin 在一些 CLI 工具中用得很频繁,比如 Vue CLI。\n\n在开发 npm 包时,要求发布的可执行脚本要以`#!/usr/bin/env node`开头,这是为什么呢?\n\n我查了一下,原来是为了用于指明该脚本文件要使用 node 来执行。\n\n## main, browser, module\n\n这三个配置对我们的影响还是挺大的。\n\n- `main`字段决定了别人`require(\'xxx\')`时,引用的是哪个模块对象。在不设置`main`字段时,默认值是`index.js`。\n- 如果你开发的包是用于浏览器端的,那么用`browser`指定入口文件是最佳的选择。\n- `module`则代表你开发的包支持`ESM`,并指定了一个`ESM`入口。\n\n具体这三个字段怎么用,还是挺有学问的,这里推荐一篇文章[package.json中你还不清楚的browser,module,main 字段优先级](https://www.cnblogs.com/qianxiaox/p/14041717.html),讲得挺细。\n\n**长图警告!**\n\n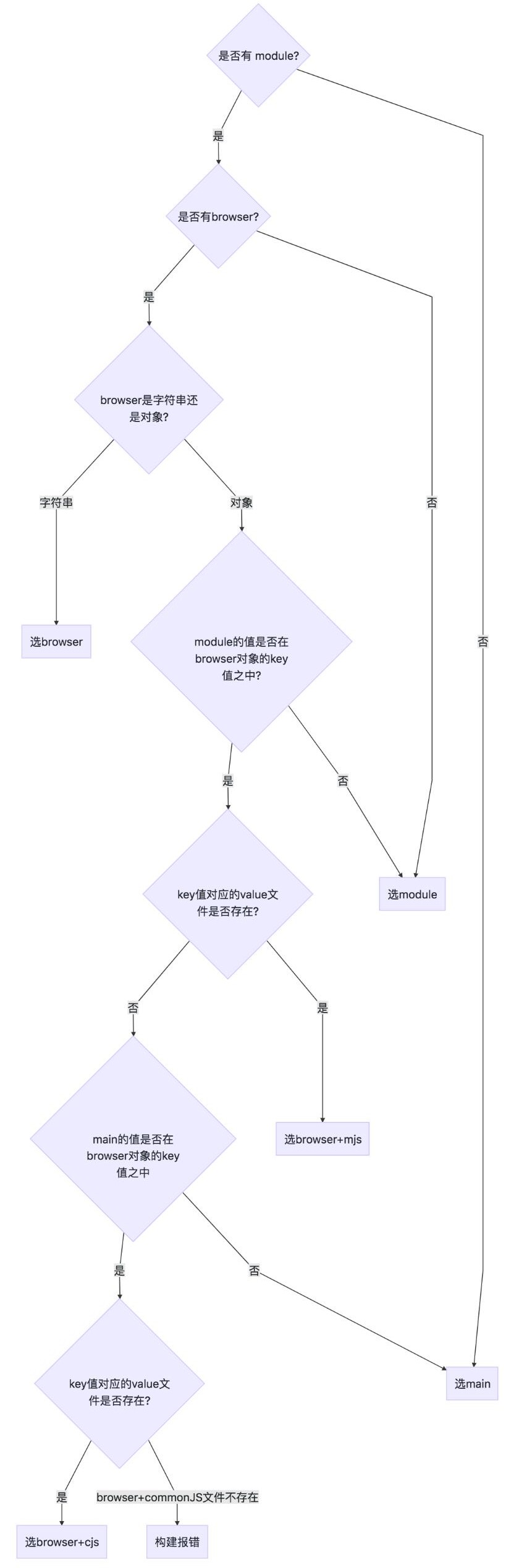\n\n## scripts\n\n`scripts`也基本上每天都用了,但是它的钩子脚本你用过吗?如果没有用过,可以试试,在组织脚本流程时非常好用!\n\n- **pre**:在一个script执行前执行,比如prebuild,可以在打包前做一些准备工作。\n- **post**:在一个script执行后执行,比如postbuild,可以在打包后做一些收尾工作。\n\n## config\n\n通过`config`配置的参数`xxx`,可以在脚本中通过`npm_package_config_xxx` 的形式引用,比如`port`。\n\n```json\n{\n \"config\": {\n \"port\": \"8080\"\n }\n}\n```\n\n## 依赖相关\n\n### dependencies\n\n`dependencies`可以理解为生产依赖,通过`npm install --save`安装的依赖包都会进入到`dependencies`中。\n\n### devDependencies\n\n`devDependencies`可以理解为开发环境依赖,通常是一些工具类的包,比如 webpack, babel等。 通过`npm install --save-dev`安装的依赖包都会进入到`devDependencies`中。\n\n但是,在结合一些构建工具使用时,我们往往会有困惑。比如我安装了一个包到`devDependencies`中,但是不小心在项目中引用了它,最后也被 webpack 打包到构建结果中了。这是怎么回事呢?\n\n建议结合[上篇文章npm install这一节](https://juejin.cn/post/6950817077670182943#heading-6)一起看。\n\n### peerDependencies\n\n> 我是**package-a**,你装我,你就必须装我的**peerDependencies**。\n\n让“调包侠”将**package-a的依赖**提升到自己的`node_modules`中,这样可以在“调包侠”和**package-a**都需要同一个依赖(比如vue)时,避免重复安装。这常见于开发组件或者库。\n\n注意,一个 npm 包的开发者如果声明了`peerDependencies`,开发环境下在该包目录`npm install`也不会在`node_modules`中安装这些依赖,所以往往还需要借助`devDependencies`。\n\n举个例子,我开发一个组件,不想发布到 npm 时包含了 vue 的代码,这就需要外部提供 vue ,所以我把 vue 定义在 peerDependencies 也无可厚非。但是,在开发组件时,一般还需要本地开发环境跑一个 demo 试试效果,这时候是依赖 vue 的,所以还需要在 devDependencies 中安装 vue 。我看了下 vue-router 就是这么做的,所以我在开发自己的组件时也学会了这招。\n\n### bundledDependencies\n\n`bundledDependencies`跟上面的依赖都不太一样,配置上不是键值对的形式,而是一个数组。\n\n```json\n{\n \"bundledDependencies\": [\n \"vue\",\n \"vue-router\"\n ]\n}\n```\n\n在运行`npm pack`时,会将对应依赖打包到`tgz`文件中。用得不多,不知道具体的细节,主要还是直接用`npm install`安装 tgz 包的场景比较少,有个概念就行。\n\n### optionalDependencies\n\n`optionalDependencies`用于配置可选的依赖,即使配了这个,代码里也要做好判断(保护),否则运行报错就不好玩了。\n\n```javascript\ntry {\n var foo = require(\'foo\')\n var fooVersion = require(\'foo/package.json\').version\n} catch (er) {\n foo = null\n}\n```\n\n# 题外话\n\n仔细读过`package.json`文档后,整体上还是解决了我的不少困惑,对我开发 npm 组件也提供了不少帮助。如果您想了解更多细节和实战,不妨打开我这个项目[vue-awesome-progress](https://cumt-robin.github.io/vue-awesome-progress/)看看,希望对您有所帮助!', '2021-04-22 14:46:30', '2024-09-03 07:27:27', 1, 137, 0, '在上一篇npm init @vitejs/app的背后,仅是npm CLI的冰山一角中,有提到我复习npm主要是从两个大方向来入手,所以这篇继续来讲讲package.json这部分知识', 'https://qncdn.wbjiang.cn/npm%E5%B0%81%E9%9D%A2.png', 0, 0);
-INSERT INTO `article` VALUES (229, '你还在为node-sass烦恼吗?快试试官方推荐的dart-sass', '众所周知,node-sass 是一个非常棒的工具,是前端工程师组织 CSS 的一个神兵利器。然而,用过的朋友都知道,node-sass 是让人既爱又恨!你爱它,因为它赋能了 CSS 工程化;你恨它,因为有时候你搞不懂它为什么又出差错了。我最近就在生产环境新踩了两次 node-sass 的坑,这让我下定决心放弃 node-sass。\n\n# 什么是node-sass?\n\n虽然 node-sass 是一个熟悉的老朋友了,但是还是有必要介绍一下。\n\n> Node-sass is a library that **provides binding for Node.js to LibSass**, the C++ version of the popular stylesheet preprocessor, Sass.\n>\n> It allows you to natively **compile .scss files to css at incredible speed and automatically via a connect middleware**.\n\n从上面的介绍可以知道,node-sass 是一个 nodejs 环境下提供的一个 Bridge,它提供了调用 LibSass 的能力(而 LibSass 是一个 C++ 实现的样式预处理器)。\n\n> ps: 可以看到,node-sass 并不完全是 javascript 实现的,而是借助了 C++ 的能力,毕竟编译型语言还是速度快啊。\n\n# Round1:安装 node-sass\n\n刚进入前端领域的朋友,可能都问过这么一个问题:**为什么我的 node-sass安装失败了?**\n\n在网上搜索这个问题,你会找到答案,其中一个是使用 cnpm,但我用过感觉怪怪的,最早是使用 Angular4 时,执行`ng eject`发生了很多错误。\n\n后面就一直用的设置 npm 淘宝镜像源的方式处理这个问题,同时这也是解决`npm install`下载卡顿或失败的一个技巧,毕竟有些包被墙了。\n\n```shell\nnpm config set registry https://registry.npm.taobao.org\n```\n\n但解决了这个问题,也不是说就万事大吉了...\n\n# Round2:node-sass和node版本不兼容\n\n一般来说,个人电脑的 NodeJS 环境安装好了后,很久都不会想着去升级。\n\n不过我前段时间去研究 Vite 的时候,发现我的 NodeJS 版本已经不满足条件了。\n\n> Compatibility Note\n> \n> Vite requires Node.js version >=12.0.0.\n\n于是乎,我就升级了 NodeJS 版本。\n\n但是,当我运行一些旧项目的时候,我发现,项目报错了。\n\n```\nModule build failed (from ./node_modules/sass-loader/dist/cjs.js):\nError: Node Sass does not yet support your current environment: Windows 64-bit with Unsupported runtime (83)\nFor more information on which environments are supported please see:\nhttps://github.com/sass/node-sass/releases/tag/v4.13.0\n```\n\n粗略一看,报错信息说的是 NodeSass 不支持当前运行时环境,我猜这肯定是跟 NodeJS 版本不匹配了。我首先检查了下我的 NodeJS 版本。\n\n```shell\nnove -v\nv14.16.0\n```\n\n嗯,是新版本没错了。\n\n于是就去 github 上查了下 node-sass,发现确实还是这么一回事,node-sass@4.13.0 版本真的不支持 node@14,惨!\n\n\n\n其实,我只要把 NodeJS 版本降低到 13,问题也能得以解决。\n\n但我觉得这还是有问题的。新项目要求高版本 NodeJS,而旧项目需要低版本 NodeJS,我本地只有一套 Node 环境,这样就出现了矛盾点,**看来开发环境也比较需要容器化**。\n\n虽然这个问题也不能完全算是 node-sass 的锅,但谁叫它不支持 node@14 呢?用着还是不爽!\n\n# Round3:node-sass: Command failed\n\n这是我上个月在生产环境跑 CI/CD 时遇到的一个问题。\n\n```\nerror /builds/coollu-r-d/coollu-fe/xkgj_web/node_modules/node-sass: Command failed.\n```\n\n后面还跟了一堆错误信息。\n\n\n\n即便我已经是在 Docker 容器里执行 build 任务了,也就是说没有上面那个和 Node 版本不兼容的问题,但还是遇到了一次又一次的报错,这谁能顶得住呢?\n\n\n\n# 使用Dart Sass\n\nDart Sass 是 Sass 官网力推的工具,它包括了基于 Dart VM 的命令行工具,以及基于 Node 的纯 Javascript 实现。前者说的 Dart VM 就是现在很火的 Flutter 选择的编程语言 Dart 的虚拟机;而后者的出现是为了能快速与 Node 环境下现有的工作流集成,比如 webpack,gulp等。Dart Sass的命令行工具是比 Javascript Library性能更好的,但是为了快速对接 webpack 等工具,我们目前一般通过`npm install --save-dev sass`直接使用 sass 的 Javascript Library。\n\n改用 Dart Sass 后,不管是安装还是兼容高版本 Node 这块,都没有什么问题,总的来说,使用体验还是非常棒!\n\n> Dart Sass 是我们对它的习惯称呼,最早它在 npm 上的确是以 dart-sass 的名字发布的,不过现在它已经更名为 sass 了。\n\n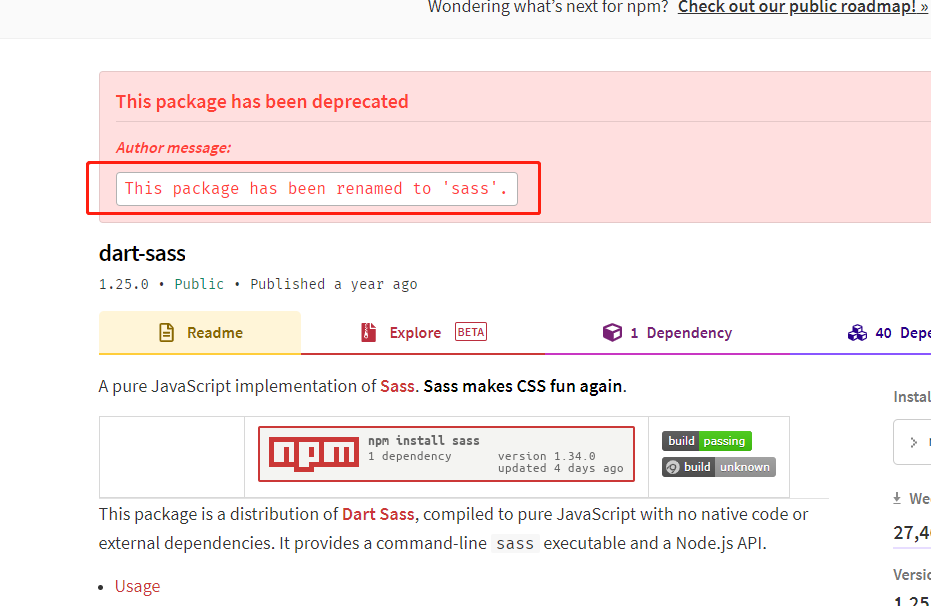\n\n# 换Dart Sass后,我要做些什么\n\n众所周知,在 Vue 项目中,scoped 样式是会通过一个哈希化的属性选择器进行隔离的(比如`[data-v-67c6b990]`),如果希望做样式穿透,在`Vue@2`中会用到`/deep/`深度选择器。\n\n> 注意,`/deep/`本身是作为一个 CSS 的提案(好像是用于解决 web components 的样式穿透问题,用 Angular 的时候简单了解过),后面又被废弃了,而 Vue 的 `/deep/`跟 CSS 的`/deep/`不是同一个概念!考虑到用户容易误解 Vue 的`/deep/`和 CSS 被废弃的`/deep/`提案是一个东西,也就会误认为 `/deep/`是一个不可用的特性,Vue 也出了 RFC 针对这块做调整,后面也就有了`::v-deep`。\n\n使用 Dart Sass 后,可能会在运行开发环境时遇到不支持`/deep/`的问题,需要改用`::v-deep`,简写就是`:deep(selector)`,比如:\n\n```css\n:deep(.foo) {\n position: relative;\n}\n```\n\n# 欢迎交流\n\n你还遇到过哪些 node-sass 的问题呢?不妨留言交流一下!', '2021-05-27 09:09:34', '2024-09-03 01:04:11', 1, 285, 0, 'node-sass 是一个非常棒的工具,是前端工程师组织 CSS 的一个神兵利器。然而,用过的朋友都知道,node-sass 是让人既爱又恨!你爱它,因为它赋能了 CSS 工程化;你恨它,因为...', 'https://qncdn.wbjiang.cn/css%E9%A2%9C%E8%89%B2%E6%A0%BC%E5%AD%90.png', 0, 0);
-INSERT INTO `article` VALUES (231, '摸索前端管理2年,这份研发流程帮到我不少', '> 在现在的公司工作也有2年多了,时间过得真快!2年的时间里,前端从单兵作战发展到现在的10人规模。如果要我说,这个过程里什么最重要?我想应该是一份**接地气的研发流程**。\n\n说到研发流程,大部分人肯定首推某某某大厂的研发流程。诚然,大厂的研发流程的确完善并且细致,然而实际上并不一定适用于其他公司或团队,比如QA、单元测试、自动化测试这些环节,我想很多公司都不会有。所以,盲目地套用别的公司或者团队的研发流程,是可能水土不服的,但是却可以给我们提供一个参考意见,去弥补自身的不足。\n\n研发流程一定不是凭空出现的,它必须紧密贴合实际的项目过程。我很重视这块,在我还是“光杆司令”的时候,我就在筹备着。我当时的想法是,等我这个组进人的时候,我一定不是手把手告诉他做项目的每一步该怎么做,而是用标准化的文档把整个大致过程记录下来,另外也是想要告诉我未来的同事,我这个团队是有思考和沉淀的,值得大家一起成长!\n\n研发流程一定不是完美的,但它一定是与时俱进的。我回顾了一下这份文档,前前后后修改了不下100次。\n\n\n\n接下来针对前端研发流程这块分享一下我们的实践,希望给有需要的朋友一点帮助!\n\n# 整体流程\n\n团队整体的一个研发流程大致如下:\n\n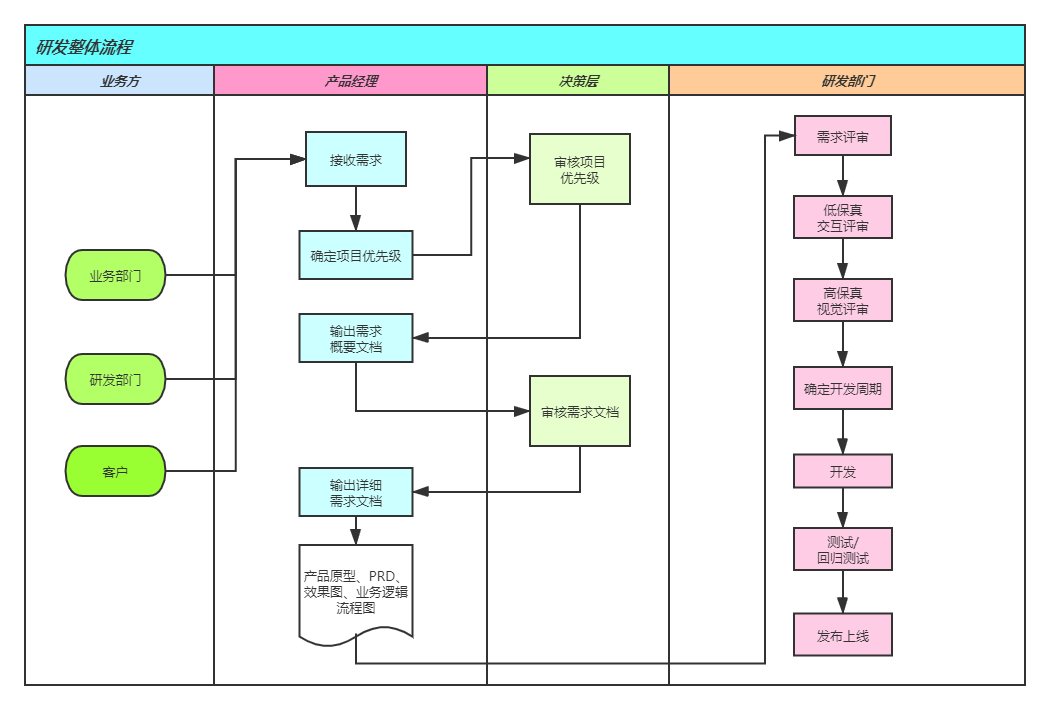\n\n这块可能大部分公司都是大同小异,没什么好细说的。实际上,可能每个环节是否执行到位也是需要打个问号的。\n\n\n\n# 前端研发流程\n\n## 系统镜像\n\n为了方便新入职同事快速进入状态,我们制作了统一的前端开发系统镜像,避免了出现电脑装机和各种环境配置出现的问题,产生一些不必要沟通而浪费时间。\n\n> 最早的时候,还是我出的一个简单的文档,告诉新同事要装什么什么软件这样子,但是发现问题还是挺多,用了镜像后,省心不少。\n\n## 前端研发流程图\n\n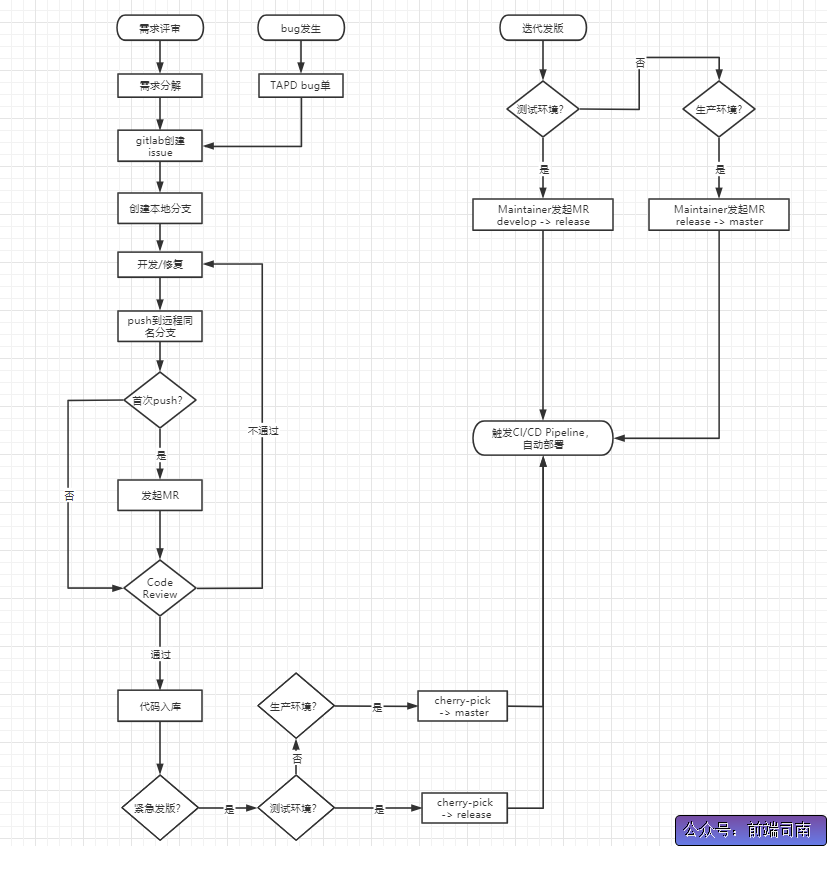\n\n这张图描述了前端日常开发的主要过程,可以花个1到2分钟好好看看。\n\n## 研发资源\n\n- 原型设计:`axure`\n- 视觉设计:蓝湖,`iconfont`\n- api文档:`swagger`\n- 敏捷协作:`TAPD`,研发日常的任务,需求,缺陷等工作都集中在[TAPD](https://www.tapd.cn/my_worktable)平台上。\n- 源码仓库:自建`Gitlab`\n- 团队文档:语雀\n\n## 处理IconFont图标\n\n在图标管理这块,我们使用的是 iconfont,包括字体图标和矢量图标都有用到,并且封装了对应的组件`icon-font`和`icon-svg`,目前主要以使用`icon-svg`为主,`icon-font`主要面向部分项目。\n\n\n\n**在 iconfont 上调整好图标后,需要重新生成链接**;\n\n- 对于字体图标组件 icon-font,生成在线的 font class 链接,替换掉项目中 index.html 中的对应链接才会生效。\n\n\n\n- 对于矢量图标组件 icon-svg,生成在线的 symbol 链接,替换掉 icon-svg 组件中引用的 js 链接才会生效。\n\n\n\n## issue驱动\n\n虽然`git log`已经提供了记录查询的能力,但是还不够便捷,直观。\n\n我们采用`issue`驱动开发,所有的代码改动都应该先在`gitlab`创建`issue`,包括但不限于需求,缺陷,自测试,优化类改动。\n\n> commit是可以自动关联和关闭issue的,这样一来,我打开每一个issue,就知道这个issue关联了哪些代码提交记录,查问题非常直观!另外,这也是众多开源项目常见的协作方式。\n\n\n\n对于需求、缺陷类型的开发任务,应在创建`issue`时附上`TPAD`相关链接,方便跳转查询。\n\n**issue应该保证原子性,一个issue只做一件事。**\n\n## 开发流程\n\n### VSCode扩展\n\n首先,安装必要的 VSCode 扩展,结合项目中配置的 Lint/Formatting 能力,达到一个高效开发的状态。\n\n\n\n\n\n\n\n\n\n### 全局依赖\n\n```javascript\n// 保证 yarn 的正常使用\nnpm install -g yarn\n// 用于规范 commit 提交\nnpm install -g commitizen\nnpm install -g conventional-changelog-cli\n```\n\n### npm/yarn代理\n\nnpm 自带的源有时候速度太慢,或者有时候根本下载不了某个包,容易导致 install 失败或停顿,请统一使用 taobao 代理。\n\n```shell\nnpm config set registry https://registry.npm.taobao.org\n\n// 部分项目使用yarn\nyarn config set registry https://registry.npm.taobao.org\n```\n\n### Nginx代理配置\n\n我们在开发者本地使用 Nginx 作为中间代理,加一层本地 Nginx 代理的目的是:\n\n- 统一项目访问的服务端口,防止误提交项目配置文件,避免不必要的代码冲突。\n- 便于切换不同环境时,实现秒级切换,不用重启 devServer。后面这里可以优化下,据我观察,ant-design-pro 实现了不重启 devServer 更新 proxy,有空研究下!\n- 如果比较反感,不强制增加本地 Nginx 这一层,可以自行指定后端 gateway 地址,但是注意不要提交 vue.config.js 文件,避免引起冲突!\n\n1. 下载windows稳定版本Nginx,链接是[http://nginx.org/en/download.html](http://nginx.org/en/download.html)\n\n\n\n2. 修改nginx/conf/nginx.conf\n\n> 一个基本的代理配置如下:\n\n```nginx\nworker_processes 1;\n\nevents {\n worker_connections 1024;\n}\n\nhttp {\n include mime.types;\n default_type application/octet-stream;\n sendfile on;\n keepalive_timeout 65;\n #gzip on;\n server {\n listen 8090;\n server_name 127.0.0.1;\n\n location / {\n proxy_pass http://xxx.xxx.tech;\n proxy_http_version 1.1;\n proxy_set_header Upgrade $http_upgrade;\n proxy_set_header Connection \"upgrade\";\n # proxy_set_header Host $host;\n proxy_set_header X-Real-IP $remote_addr;\n # proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;\n }\n }\n}\n```\n\nnginx 统一监听 127.0.0.1:port,代理请求到后端 gateway。在需要切换环境时只需要修改 proxy_pass 这一项即可。\n\n3. 前端工程默认配置 proxy 的 target 为 `http://127.0.0.1:port`,配合Nginx使用时,不要修改此项。\n\n4. 常见命令\n\n```\n#linux中\n#开机启动\nsystemctl enable nginx\n#启动\nsystemctl start nginx\n#重启\nnginx -s reload\n\n#windows中\n#启动\n直接打开nginx.exe\n#重启\n修改配置文件后重启,可以选择cmd打开根目录,然后nginx.exe -s reload\n#其他\n如果重启有问题,一般是点击了多次nginx.exe,这时候可能启动了多个nginx,算是个windows版本的bug吧,\n可以直接打开任务管理器找到所有nginx进程,然后结束掉。最后直接打开nginx.exe启动。\n```\n\n关于这一环节,我之前还写过一篇[「前端必看」这篇Nginx反向代理技巧,助你准时下班陪女神](https://juejin.cn/post/6846687599508078600),想要详细了解的朋友可以打开看看。\n\n### 项目依赖安装\n\n目前有的项目使用`npm`管理依赖,有的使用的是`yarn`。进入项目时,观察`lock`文件,如果项目根目录有`yarn.lock`,则说明使用`yarn`;如果项目有`package-lock.json`,说明使用`npm`。\n\n安装依赖时根据情况执行以下命令:\n\n- npm\n```\nnpm install\n```\n\n- yarn\n```\nyarn\n```\n\n### 需求/缺陷分配\n\n**TL**负责任务分配,将`TPAD`上的需求进行分配,指定开发责任人。\n\n> TAPD的需求分发到个人后,都要求开发人员拆分出前端子需求(不限于1个),根据自身能力和需求复杂度评估出**开发时间规模**,根据自己的排期填写预估**起始时间**和**结束时间**,项目经理会追这个事情,责任到个人。如果有逾期风险,提前向 TL 或者自己的导师反馈原因,不要拖到最后一天才暴露问题。\n\n按道理,开发时间规模应该是大家做需求评审时定下来的,但是考虑到团队的一个实际情况,这块权限是下放到开发者自行评估,但是 TL 需要起到一个监督的作用。这里大家可以结合实际情况考量。\n\n### 创建issue\n\n原则上由开发者自行创建,创建需求和 bug 类 issue 时,应附上 tapd 链接,方便查询关联事项!issue 也是分支命名的一个依据。下面我会接着说。\n\n> 有些时候,TL 或者项目 Owner 会安排一些非 TAPD 管理的组内任务,会直接以 issue 形式指给开发人员,开发人员接到 issue 后,不必再重复创建 issue,只要基于已创建的 issue 创建本地分支开发就行。\n\n### 分支权限控制\n\n在我们团队中,约定了三个重要分支,分别是:\n\n- develop:开发分支\n- release:测试分支\n- master:生产分支\n\n这三个分支被设置为 Protected Branches,通常都关联了对应环境的 CI/CD 配置。在权限控制上一般设置为:**Maintainer 拥有 Merge 权限,所有人都没有 push 权限**。\n\n实际操作时,一个基本的 Merge 方向是:\n\n\n\n根据实际情况,也可以引入预发布分支之类的分支。\n\n如果对分支权限不做控制,大家可以随意 push,就意味着潜在的灾难随时可能发生。所以这一点是非常值得关注的!\n\n### 创建分支\n\n我之前也试过分支语义化命名,但是也发现了要用有限的单词描绘出复杂的含义永远是个伪命题。我们可能会在做一个新功能时,会把相关分支命名为`feature/xxx`,而后面有优化类需求时,又会新建一个`feature/xxx-optimization`之类的分支。然而,往往一个功能会有一次又一次的优化、变更或 bug,采取这样的命名策略永远会让自己直面灵魂拷问!\n\n并且在追溯问题时,这种分支命名方式往往让人心力交瘁!\n\n那么如何命名能解决这样的问题呢?我采用了下面这种策略!\n\n`issue`本身有一个编号,或者叫`ID`,这种唯一标识让我们命名分支变得简单。假定一个`issue`的编号是`1`,那么我们在本地创建分支时,只需要将分支命名为`issue/1`即可,根据这个编号,我就能查到这个分支处理的是哪个`issue`,而打开 Gitlab 的`issue`界面,我就能知道这个`issue`与什么需求或缺陷有关,而且也能直观看到与这个`issue`关联的代码 commit 记录。这不仅给开发者带来了方便,也让管理者变得更轻松!\n\n好,下面说实际操作。以开发新特性为例:\n\n- 本地切换到`develop`分支,拉取最新`develop`分支代码\n\n```\ngit checkout develop\ngit pull\n```\n\n- 基于`develop`分支创建新的特性分支,用于开发新特性,目前统一命名为`issue/xxx`,其中`xxx`是你在`gitlab`上创建的`issue`号,如下所示:\n\n```\ngit checkout -b issue/1\n```\n\n也就是说,`issue/1`分支用于解决`gitlab`上的`issue 1`提到的问题。\n\n> 有的项目比较简单,或者还在初期阶段,这种情况下,不会设置 develop 分支,而是基于 master 分支快速开发。如果是这种情况,在上面的操作中,可以直接把 master 理解为 develop,依葫芦画瓢即可。\n\n### 提交代码\n\n**特性/缺陷分支应该保证原子性,一个分支只解决一个问题(指的是一个issue提及的问题),否则原则上不允许合入其他分支。这对敏捷迭代有关键意义!**\n\n开发完毕后,应提交到远程仓库同名分支。\n\n```javascript\ngit add .\ngit cz // 进行cz交互式命名行提交\ngit push origin HEAD // 提交到远程仓库同名分支\n```\n\n#### 提交部分代码\n\n如果一次**commit**希望提交部分文件(而不是全部修改的文件),不要用 `git add .`,可以结合 GUI 进行选择(比如VSCode自带的Git面板),进入**staged**状态的文件,就是你希望提交的。\n \n> ➕ 是进入 staged,➖ 是移出 staged,**Staged Changes** 就是你希望在这次 commit 的内容。\n> \n> 提交部分代码时,注意保管好自己未提交的代码,未入库就有丢失的可能,这一点要明确!\n\n\n\n#### git cz流程\n\n`git cz`是`commitizen`提供的能力,这块我之前简单写过一段介绍,具体见[规范commit message](https://juejin.cn/post/6844904056498946055#heading-6)。使用`git cz`的主要目的就是规范代码提交。\n\n1. 选择提交的类型,`feat`代表需求,`fix`代表修复缺陷,`docs`代表文档类变动,`style`是代码风格层面的(不是指样式...),`refactor`指的是代码重构,`perf`则是优化相关的(包括性能/体验等),`test`是单元测试之类的,`build`是构建工具相关的,`ci`是持续集成相关的,`chore`的解释各异,按`commitizen`的解释就是非`src`或`test`的其他改动,`revert`代表代码回退...\n\n2. 请准确选择改动类型!\n\n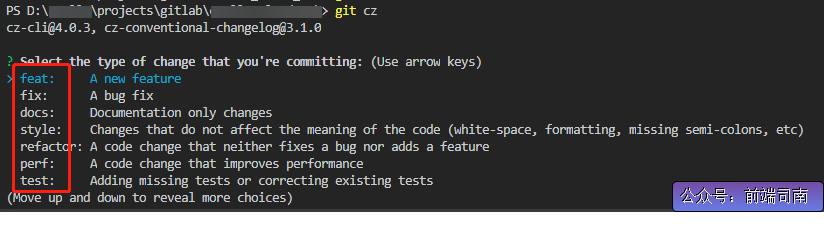\n\n3. 影响范围\n\n【按情况填写即可,如果不是过于抠细节,大部分时候可以不填】\n\n```\nWhat is the scope of this change (e.g. component or file name): (press enter to skip)\n```\n\n4. 改动描述\n\n【必填】本次代码改动的描述信息,可摘取issue的标题,或者是tapd需求或缺陷的标题,也可以自行总结。\n\n```\nWrite a short, imperative tense description of the change (max 94 chars):\n登录功能开发\n```\n\n5. 详细描述\n\n【按情况填写,如果不是过于抠细节,大部分时候可以不填】提供详细描述\n\n```\nProvide a longer description of the change: (press enter to skip)\n```\n\n6. 是否有重大变更?\n\n【一般是回车或者输入N跳过】一般来说,只有架构层面的变更才会填入y\n\n```\nAre there any breaking changes? (y/N)\n```\n\n7. 是否影响issue?\n\n【一般来说,一次commit都应该有与之关联的issue,输入y,用来关闭issue,这个是很常见的】\n\n```\nDoes this change affect any open issues? (y/N)\n```\n\n【一般可以跳过】如果关联的issue已经关闭,可以针对本次commit\n做一个信息补充。\n\n```\nIf issues are closed, the commit requires a body. Please enter a longer description of the commit itself:\n (-)\n```\n\n8. 关闭issue?\n\n```\n? Add issue references (e.g. \"fix #123\", \"re #123\".):\n```\n\n假设要关闭 issue#1,则输入:\n\n```\nfix #1\n```\n\n如果要关闭多个 issue,则输入:\n\n```\nfix #1 #2 #3\n```\n\n9. 提交至远程同名分支\n\n```\ngit push origin HEAD // 提交到远程仓库同名分支\n```\n\n#### commit 检查\n\n配合 husky 和 git hook 来实现 commit 检查。\n\n1. 防止提交不符合规范的代码。\n2. 防止`commit message`不规范。\n\n这里需要借助以下依赖:\n\n- husky\n- commitlint\n- commitizen\n- conventional-changelog-cli\n- lint-staged\n\n### 发起Merge Request\n\n`git push`到远程同名分支后,并不代表你的代码进入了主分支,你接着还需要走代码合并流程。\n\n由开发者在`gitlab`自行发起`Merge Request`,请求将代码合入`develop`分支。\n\n**TL或者有Merge权限的人**负责进行**Code Review**,审核通过后,方可合入代码。\n\n### 本地获取最新develop分支\n\n代码合入后,就可以基于`develop`分支做其他的功能开发了。\n\n```\ngit checkout develop\ngit pull\n// 进行其他的特性开发,或bug修复\n```\n\n### 继续未完成的需求\n\n如果提交代码**并被Merge**后,发现本需求并未开发完毕,此时不可再另外创建 issue,应该基于同一个 issue 继续修改;以 issue 号为 1 举例说明。\n\n首先需要在 gitlab 上 reopen issue#1。然后本地进行分支操作。\n\n```shell\ngit checkout develop\ngit pull\ngit branch -d issue/1\ngit checkout -b issue/1\n```\n\n继续开发...\n\n### 开发到中途想拉别人代码\n\n如果自己正在 issue/1 分支开发,而其他同事提交了代码,并且已经合并到 develop 分支,此时你想用他这部分代码。需要执行以下步骤。\n\n```shell\ngit checkout develop // 如果这一步如果无法执行,见下一节\ngit pull\ngit checkout issue/1\ngit merge develop\n```\n\n### 想切出去合入别人提交的最新代码却发现git checkout develop报错\n\n这种情况是因为你的 issue 分支代码与最新的 develop 分支相比,已经落后或者产生了冲突。\n\n此时如果仍希望把别人提交的最新代码合入到自己的 issue 分支继续开发,需要执行以下步骤,利用`git stash`做一个临时储存。\n\n```shell\n// 假设现在位于 issue/1 分支\ngit stash\ngit checkout develop\ngit pull\ngit checkout issue/1\ngit merge develop\ngit stash pop\n```\n\n此时一般会出现冲突,VSCode git 区域会有提示感叹号或者 C(代表 conflict)。\n\n需要解决掉冲突再继续开发,开发完毕后按正常流程提交代码。\n\n### 其他\n\n以上是以新特性开发为例进行说明。\n\n其实对于修复缺陷而言,整个操作流程也基本相同。\n\n如果是测试环境和生产环境都有的bug,通常先修复测试环境验证效果后,视情况通过 cherry-pick 进行生产环境紧急发版。紧急情况下,可优先修复生产环境。\n\n## issue和merge request规范\n\n### issue规范\n\n创建 issue 时,应清楚该 issue 用于处理什么事务。\n\n1. 如果明确 issue 处理的是 TAPD 上的需求或缺陷,必须在描述中插入 TAPD 链接,方便自己或同事查阅跟踪。选择的 Label 应该是需求或 Bug。\n\n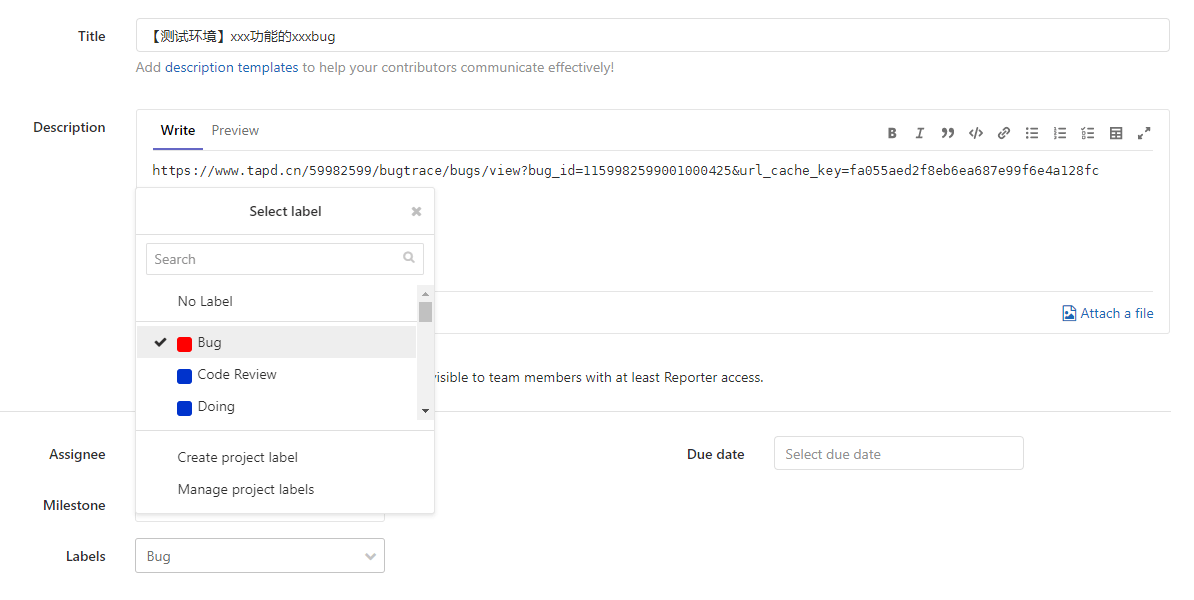\n\n2. 如果不是来源于TAPD,则在标题中简要说明主题,在描述中说明具体事项(可选),根据实际情况选择合适的Label。\n\n\n\n### Merge Request 规范\n\n1. 提交 Merge Request 时,应明确目标分支。比如需求类的,我们是基于 develop 分支创建 issue/xxx 分支,所以提交到远程同名分支后,需要请求合入到 develop 分支。\n\n2. 对于 bug,首先明确 bug 发生的环境。而对于**生产环境bug**,我们是基于 master 分支创建 issue/xxx 分支,解决完之后,是请求合入到 master 分支;**测试环境bug**的处理方式可类比;如果一个bug**在开发环境,测试环境和生产环境都有出现**,应基于develop分支新建分支,bug 处理完毕后先发起 MR 合入到 develop 分支,再通过 cherry-pick 等方式合入到 release 或者 master 分支。\n\n> 可能有人会觉得生产环境 bug 相关的代码直接合入到 master 分支不妥,这个我觉得可以看具体情况分析,如果团队的风险把控程度严一点,可以考虑安排一个预发布分支,对应一个预发布环境,尽可能模拟生产环境。\n\n3. Assignee选择审核人,一般是Mentor或其他同事(交叉评审)。\n\n\n\n4. 同时也附上Labels,表明你这次提交解决了哪些类型的问题。如同时涉及多类,则进行多选。比如,我同时解决了 bug 和需求,那我就会勾选两项,但是不推荐这样做,因为我们建议一个 issue 只做一件事,所以一次 Merge Request 也意味着只解决一个问题。\n\n5. 如果涉及发版分支(比如release和master),建议勾选下环境选项(如**测试环境**,**生产环境**),给人一目了然的感觉。\n\n\n\n### Merge Request 不通过\n\n有 Code Review 就可能存在审核不通过的情况,各种情况都有,比如业务组织方式不恰当,不符合规范,未完成功能,等等。\n\nCode Review 不通过时,我会以 Comment 的形式直接在问题代码附近进行标注。这些 Review 意见会以邮件的形式通知到责任人。\n\n\n\n针对 Code Review 不通过的情况,不用另外创建 issue,直接切到 issue 对应的分支继续修改代码并 push 就可以了,push 到 remote 后会自动反映到 MR 中,自己在 MR 的 Changes 中也能看得到你最终修改了哪些内容。\n\n\n\n当所有 Review 意见都被 Resolved 后,这个 Merge Request 才可以通过。\n\n# 发版流程\n\n由于我们团队采用了 CI/CD,所以发版流程与相关分支的代码合并是紧密关联的,项目 Owner 负责跟进发版事宜。\n\n按照我们目前的流程,发版的触发动作就是执行 Merge Request,接着对应的 Pipeline 就会自动执行,根据 CI/CD 的环境配置,部署到对应的服务器上。\n\n\n\n\n\n正常情况下发版的一个 Merge 方向是:\n\n测试环境发版:develop -> release\n\n生产环境发版:release -> master\n\n## 正常发版\n\n正常就是一个迭代进行一次生产环境发版。生产环境发版当天,要求相关责任人在场支撑!\n\n测试环境的发版可能会频繁一点,一般来说,至少一天一个版本,方便快速进行回归测试。\n\n## 非全量发版\n\n有时候会遇到这么一个情况,生产环境准备要发版了,但是突然发现测试环境某个功能存在缺陷,不能执行全量发版。但是你不可能说我就不发了吧,所以还是要把剩下的可用功能发上去。\n\n那么此时我们就不能执行 release -> master 这样一个 Merge 流程了,只能挑选出可以上线的代码,这个时候就用到 cherry-pick 了。我们可以找到可用功能的代码 Merge 到 develop 分支的记录,通过 cherry-pick 挑选合入到 master 分支,实现一个非全量上线的效果。\n\n这也是我前面强调一个 issue 只做一件事的原因,而且一次 commit 尽可能要做完一件事,方便我们进行特殊情况下的 cherry-pick。如果很多代码掺和到一起,一旦部分功能不可用,发版上线就成了一件非常痛苦的事情。\n\n## 发版成功判定依据\n\n目前已经配置了 Pipeline 邮件提醒,发版成功后,会有邮件提醒到项目组全员!\n\n注意分支和环境的对应关系,就能知道哪个环境发布了新版本!\n\n后面考虑对接一下企业微信对话机器人,会更加直观一点。\n\n# TAPD管理\n\n代码提交的流程已经在上文中描述清楚了,另外还要做的事情是`TAPD`的状态流转。\n\n## 开发优先级\n\n1. 首先遵从产品规划层面的优先级排序。\n\n2. 在此基础上拆解出前端子需求,各个子需求的优先级应视实际情况(比如后端接口完成情况)调整。\n\n3. 按高中低三个等级来看,应保证子需求分配到个人后,个人工作台只有1-3个高优先级任务,也就是可能并行开发的1-3个需求,其余需求视情况应纳入中或低优先级。待高优先级子需求开发完毕转测试后,应通知项目 Owner,Owner 再根据实际情况调整其余任务的优先级,保证高优先级的任务的最小规模,使得开发人员专注于处理高优先级任务。\n\n## 开发排期\n\n1. 迭代层面会有一个大致的排期出来,但仍不足以作为开发排期。\n\n2. 拆解子需求后,处理人应第一时间评估出开发预估耗时,方便进行迭代需求排期,按照优先级、预估耗时以及自己的任务排期情况,排好每个需求的开发起止时间。\n\n3. 如无团队协作的意外情况发生,应保证在每个需求的开发结束时间之前完成需求转测,否则应回溯原因。\n\n4. 当出现多个项目之间并行迭代发生优先级冲突时,应由项目经理组织协调,根据实际情况调整排期和优先级。\n\n## 开发中\n\n准备开发需求前,应先将`TAPD`上的相关需求的状态改为**开发中**\n\n解决缺陷前,应先将`TAPD`上的相关缺陷的状态改为**接受/处理**\n\n## 已完成\n\n开发完毕后,开发者应充分自测,如果转测试不通过,需要承担相应责任。\n\nCI/CD 自动发版完成后,开发者会收到邮件通知,此时方可在`TPAD`中进行状态流转:\n\n- 相关需求的状态改为**转测试**\n- 相关缺陷的状态改为**已解决**\n\n# 小结\n\n以上就是我在前端研发流程上的一点亲身实践,希望能给有需要的朋友带来一点帮助。总的来说,将流程形成文档之后,还是节省了我很多时间,有些重复的问题我就不必一一回答了。当然,上述文档也只是描述了研发过程中主要环节的过程,起到一个辅助的作用,还有很多细节也是需要在日常多做沟通交流的。\n\n我始终认为有效的沟通和反馈是一个团队的首要任务,只有这一块做好了,才能劲往一处使,高效出成果!', '2021-08-18 23:23:08', '2024-10-09 07:23:30', 1, 533, 0, '10人小团队,靠着它运作...', 'https://qncdn.wbjiang.cn/team_ground.jpg', 0, 0);
-INSERT INTO `article` VALUES (232, 'Vue3+TS+Node打造个人博客(总览篇)', '从 Vue3 正式发布到现在,也快过去一年了(写这行文字的时候是2021年09月08日,拖延症...)。\n\n\n\n但是就我最近招聘面试的一些经历来看,很多 Vue 技术栈的候选人依然还没有使用过 Vue3。\n\n关于他们没有选择使用 Vue3 这个事情,我觉得也是可以理解的。一方面,Vue3 直接放弃了 IE11。虽然 IE 的用户数量在持续下降,但是想让老板们直接放弃 IE11 还是有一些困难。\n\n\n\n另外就是,做项目这种事情,有时候人们的选择就是能用就行,升级 Vue3 可能并不能给项目带来太多效益。对于一些历史悠久的项目,甚至还要考虑 Vue3 新生态是否完善的问题,是不是能够支撑自己完美过渡。\n\n诚然,拥抱新技术还存在着这么一些障碍,是否选择新技术需要综合去考量。但是从做技术的角度出发,我们还是要保持一个 Open 的心态,敢于去接受新鲜事物,即便短期不能直接用在工作中,也可以自己私下感受下新框架给我们带来了什么新的体验。\n\n早些时候,我为了更深入地了解前后端完整链路,特意自己实现了个人博客。早期效果如下:\n\n\n\n之后一方面是觉得博客做得太难看,另一方面是想尝试在 Vue 项目中实践 TS,于是2020年我就立了一个 Flag 做重构,当时技术选型是 vue-class-component + vue-property-decorator,类组件 + 装饰器模式。做了一段时间,感觉开发体验也不是很好,慢慢就放弃了,等着 Vue3 的发布。\n\n最近也是借着一些业余时间完成了自己的一个Flag,虽然延期了很久,但总算是有了结果。\n\n\n\n首先分享下在线链接:[Tusi博客](https://blog.wbjiang.cn/)\n\n# 整体架构\n\n\n\n从技术选型来看,我还是选择了一些比较接地气的框架和技术。\n\n其实对于博客这种 SEO 要求高的网站,优选的方案还是 SSR,但我还是选择了 CSR 方案(毕竟是个人项目,怎么舒服怎么来),后续时间充裕的情况下再考虑下 SEO 优化。\n\nWeb 端这块,我是直接选择了 [Vue3](https://v3.cn.vuejs.org/) + [TS](https://www.typescriptlang.org/docs/) 作为一个开发骨架。作为一个代码洁癖选手,我还是非常倾向于使用 TS 的。\n\nUI 方面,我选择了 AntDesign 为主、ElementPlus 为辅的这样一个组合,这两个 UI 框架都是非常优秀的,但二者都有一些对方没实现的能力,所以我综合使用了二者。读者们也不用担心性能问题,按需加载情况下,用两套 UI 框架也没有什么压力,这一点我也是思考过的。\n\n视觉效果这块,基本上属于我自己发挥想象了,凭着自己感觉做的一个整体效果。然后我也是采用了 Mobile First 的理念,优先完成移动端视觉效果,结合 Media Query 去做一些其他屏幕的适配。\n\n在客户端这块,除了 Web 端,我早期还是做了小程序的,这个可以在微信直接搜索到,名字也是**Tusi博客**。\n\n\n\n回过头来看,如果是这种跨端的系统,我应该优选 uniapp 这类的方案,不过这个小程序我做得比较早,那会儿我几乎还不会小程序开发,也是属于一个边学习边开发的状态。\n\n后端这块,也是开发得比较早,那会儿可选的 Node 框架也不多,所以我选择了比较流行的 [Express](https://www.expressjs.com.cn/),这确实是一个易上手并且好用的框架,Express 不会给你灌输太多的设计模式,对于初次接触后端的朋友来说,是一个非常友好的选择。\n\n数据库我选择的是关系型数据库 MySQL,接入层当然首选 Nginx 啦。\n\n# 云服务器配置\n\n我买的云服务器配置是:1核 2GB 1Mbps\n\n这对于前期负载不是很高的个人项目来说,是足够的。反正现在都支持弹性伸缩,不够就加,问题不大。\n\n# 部署方式\n\n\n\n整体上采用了自动化部署的策略。Node 这块是基于PM2去做进程守护和自动化部署.\n\n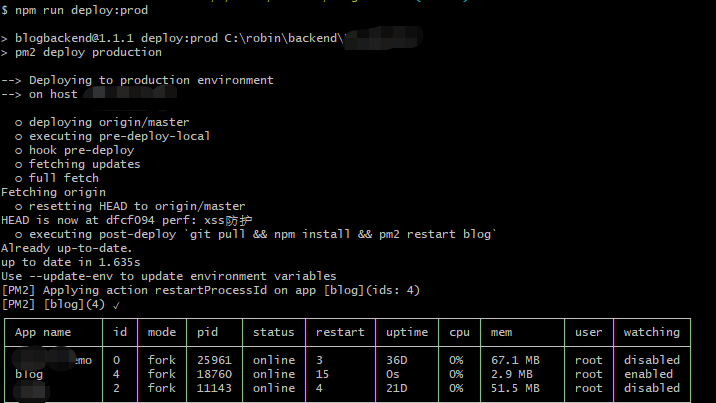\n\n前端则是基于 Github Actions 实现的CI/CD。\n\n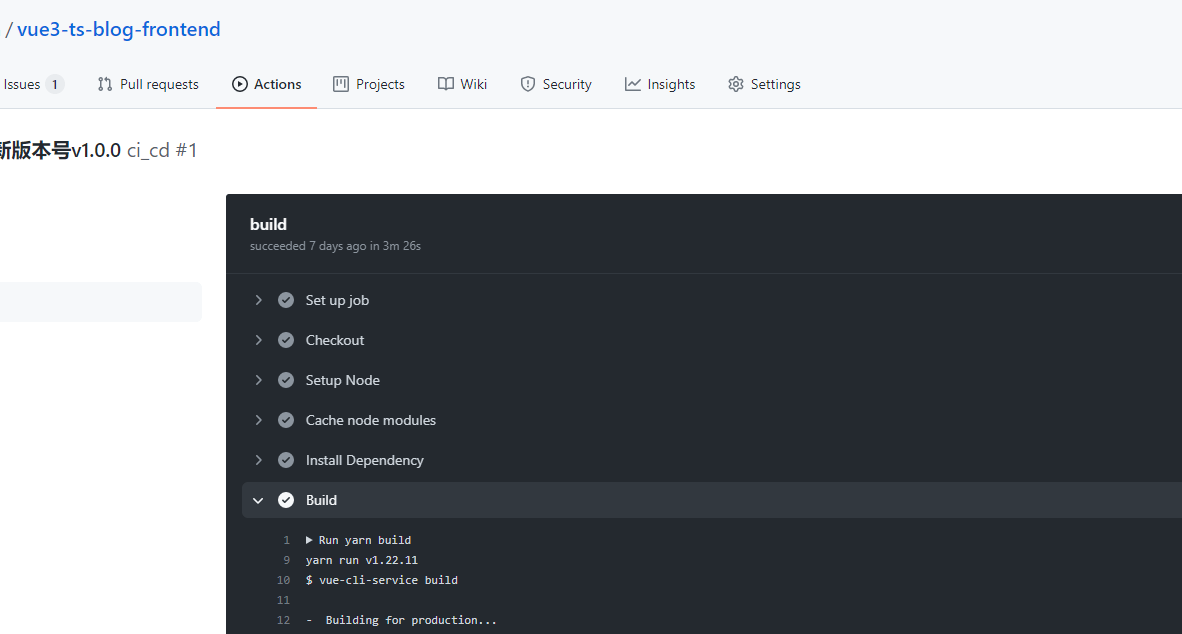\n\n我购买的云服务器配置很普通,图片资源放自己服务器上是不现实的,所以我的图片资源是放在七牛云存储。\n\n# 未完待续\n\n本文主要是对[Tusi博客](https://blog.wbjiang.cn/)做了一个总体的介绍,让大家先有个整体的印象。整个博客应用确实是比较简单,但也算是一个前后端完整的系统,应该能给朋友们带来一点帮助或思路。接下来,我将分几篇文章详细讲讲我是怎么实现这些功能的,敬请期待!\n\n# 代码,拿来吧你\n\n> 本项目代码已开源,具体见:\n>\n> 前端工程:[vue3-ts-blog-frontend](https://github.com/cumt-robin/vue3-ts-blog-frontend)\n>\n> 后端工程:[express-blog-backend](https://github.com/cumt-robin/express-blog-backend)\n>\n> 数据库初始化脚本:关注公众号[程序员白彬](https://qncdn.wbjiang.cn/%E5%85%AC%E4%BC%97%E5%8F%B7/qrcode_new.jpg),回复关键字“博客数据库脚本”,即可获取。\n\n# 系列文章\n\n**Vue3+TS+Node打造个人博客**系列文章如下,持续更新,欢迎阅读!点赞关注不迷路!😍\n\n- [Vue3+TS+Node打造个人博客(总览篇)](https://juejin.cn/post/7066966456638013477)\n- [Vue3+TS+Node打造个人博客(数据库设计)](https://juejin.cn/post/7070001585199251487)\n- [Vue3+TS+Node打造个人博客(后端架构)](https://juejin.cn/post/7072903323128594462)\n- [Vue3+TS+Node打造个人博客(前端架构)](https://juejin.cn/post/7245674094493057082)\n- [前端如何学会全栈分页开发?源码和思路都在这了](https://juejin.cn/post/7301242196888387593)\n- [一键到顶和侧边弹射效果制作,复习巩固“切图仔”基本技能](https://juejin.cn/post/7307065042004410377)\n- [一篇博客如何来到用户面前,分享前端也能看懂的文章详情页全栈设计](https://juejin.cn/spost/7363454217191325733)\n- [评论系统的全栈设计思路,学会自己也能快速上手搭建](https://juejin.cn/spost/7366972839779975218)\n- [别背八股文了,WebSocket 是什么,我劝你花几分钟让面试官惊艳!](https://juejin.cn/post/7371379258122371123)\n- [花1块钱让你的网站支持 ChatGPT](https://juejin.cn/post/7176539666210881592)\n- [前端轻松拿捏!最简全栈登录认证和权限设计](https://juejin.cn/post/7371716394302767142)\n- [前端上手全栈自动化部署,让你看起来像个“高手”](https://juejin.cn/post/7373488886461431860)\n- [小程序博客搭建分享,纯微信小程序原生实现](https://juejin.cn/post/7374410972070920228)\n- [前端不懂 Docker ?先用它换掉常规的 Vue 项目部署方式](https://juejin.cn/post/7378079761817354277)\n- [五分钟学会 Docker Registry 搭建私有镜像仓库](https://juejin.cn/post/7379803343450062888)\n- [在 CI/CD 中怎么使用 Docker 部署前端项目?](https://juejin.cn/post/7380545407729090587)\n', '2022-02-11 15:59:56', '2024-11-13 16:38:10', 1, 1923, 0, '分享一下Vue3+TS+Node打造个人博客系列文章,想了解全栈的不要错过。', 'https://qncdn.wbjiang.cn/%E5%85%AC%E4%BC%97%E5%8F%B7%E9%A6%96%E5%9B%BE/%E5%8D%9A%E5%AE%A2_%E6%80%BB%E8%A7%88%E7%AF%87_1.png', 0, 0);
-INSERT INTO `article` VALUES (233, 'Vue3+TS+Node打造个人博客(数据库设计)', '> 本项目代码已开源,具体见:\n>\n> 前端工程:[vue3-ts-blog-frontend](https://github.com/cumt-robin/vue3-ts-blog-frontend)\n>\n> 后端工程:[express-blog-backend](https://github.com/cumt-robin/express-blog-backend)\n>\n> 数据库初始化脚本:关注公众号[程序员白彬](https://qncdn.wbjiang.cn/%E5%85%AC%E4%BC%97%E5%8F%B7/qrcode_new.jpg),回复关键字“博客数据库脚本”,即可获取。\n\n一个博客系统应该有什么功能,相信大家都是非常熟悉的,其核心无非是**文章**、**分类**、**创作**。而像**标签**、**评论**、**留言**、**交流**、**后台管理**这些功能,都是锦上添花。\n\n要实现这些功能,最关键的是先梳理各个功能之间的关系。提到关系,自然就会联想到关系型数据库。\n\n\n\n在设计数据库前,需要先理清实体和实体之间的联系,这里会用到 E-R 图或者 UML 之类的建模语言来做一个概要设计。\n\n但是从我这种非专业的数据库用户的视角来看,我觉得可以不拘泥于形式,不必局限于 E-R 图或者 UML,你也可以选择用思维导图这类的图形化表述工具。因为这只是一个概要设计阶段。\n\n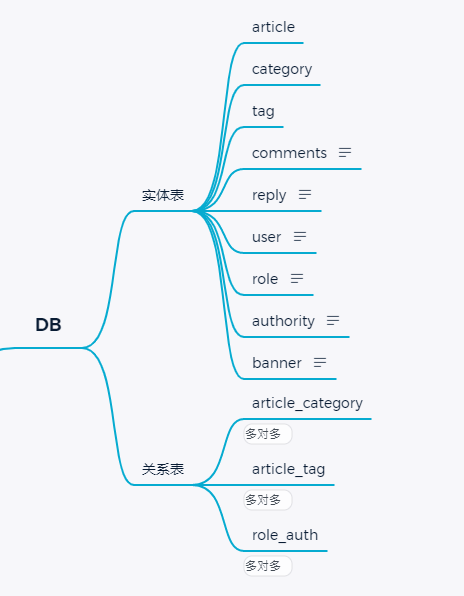\n\n如上图所示,针对我的个人博客,我做了简单的实体和实体关系设计。\n\n# 多对多关系\n\n其中文章表`article`是核心,考虑到一篇文章可能关联多个分类`category`或标签`tag`,一个分类或标签下也会有多篇文章,所以我这里设计的都是**多对多关系**,用到了关系表。\n\n关系表不会涉及很多字段。\n\n\n\n主要是关系表中设计的两个外键起到关键作用。\n\n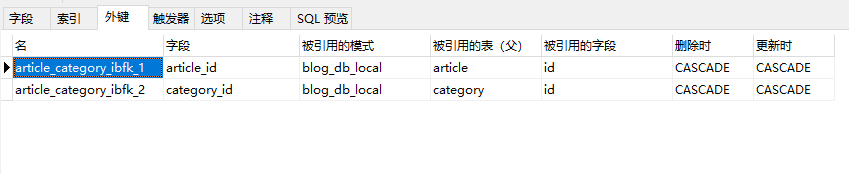\n\n根据这么一张关系表,就能完成多对多的关联关系。\n\n# 一对多关系\n\n文章下有评论,一篇文章可以有多条评论,文章`article`和评论`comment`的关系就是一对多的,这个是很好理解的。\n\n对于这种**一对多**关系,我的设计是在评论表中用一个外键`article_id`来实现关联。\n\n\n\n要查询某文章下的评论时,就可以依据条件`article_id`筛选出对应的评论数据。\n\n```\nSELECT * FROM comments WHERE article_id = 229;\n```\n\n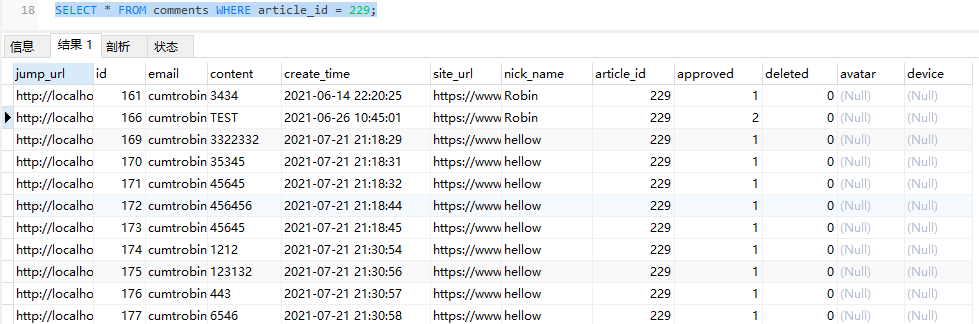\n\n# 子级关系\n\n同样地,一条评论下也会有很多回复,针对回复,我是单独设计了`reply`表。`comment`和`reply`也是一对多的关系,`reply`表中有`comment_id`外键关联到`comment`表。\n\n除了对评论做回复,还可以针对某一条回复做回复,类似于这样:\n\n\n\n而这种子级关系,就需要一个`parent_id`来做记录,根据`parent_id`串起来的关系,在业务侧我们就可以得到一棵回复树。\n\n# 状态字段\n\n很多业务都离不开状态的维护,比如数据的逻辑删除,文章的公开/私密处理,评论/回复的审核机制,这些都需要一些标志位来描述状态,同时提供一些业务接口来维护状态。\n\n\n\n# 小结\n\n本文是**Vue3+TS+Node打造个人博客(数据库设计篇)**,主要介绍了我在为博客系统设计数据库时的一些主要思路和关注点,接下来将针对一些具体的业务实现来进行更详细的剖析,敬请期待!\n\n# 系列文章\n\n**Vue3+TS+Node打造个人博客**系列文章持续更新,欢迎阅读!点赞关注不迷路!😍\n\n- 专栏导航:[Vue3+TS+Node打造个人博客(总览篇)](https://juejin.cn/post/7066966456638013477)\n', '2022-03-01 12:34:55', '2024-11-11 09:10:04', 1, 1043, 0, '一个博客系统应该有什么功能,相信大家都是非常熟悉的,其核心无非是文章、分类、创作。而像标签、评论、留言、交流、后台管理这些功能,都是锦上添花。', 'https://qncdn.wbjiang.cn/%E5%8D%9A%E5%AE%A2%E7%B4%A0%E6%9D%90/%E5%8D%9A%E5%AE%A2%E5%85%A8%E7%B3%BB%E5%88%97_%E6%95%B0%E6%8D%AE%E5%BA%93.png', 0, 0);
-INSERT INTO `article` VALUES (234, 'Vue3+TS+Node打造个人博客(后端架构)', '> 本项目代码已开源,具体见:\n>\n> 前端工程:[vue3-ts-blog-frontend](https://github.com/cumt-robin/vue3-ts-blog-frontend)\n>\n> 后端工程:[express-blog-backend](https://github.com/cumt-robin/express-blog-backend)\n>\n> 数据库初始化脚本:关注公众号[程序员白彬](https://qncdn.wbjiang.cn/%E5%85%AC%E4%BC%97%E5%8F%B7/qrcode_new.jpg),回复关键字“博客数据库脚本”,即可获取。\n\n[Express](https://www.expressjs.com.cn/) 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架。目前已经更新到 5.x 版本。\n\n我的博客后端其实开发得比较早,19年年底基本上已经完成了主体功能的开发,当时用的是 Express 4.x 版本。\n\n\n\n在使用 Express 搭建后端服务时,主要关注的几个点是:\n\n- 路由中间件和控制器\n- SQL处理\n- 响应返回体数据结构\n- 错误码\n- Web安全\n- 环境变量/配置\n\n# 路由和控制器\n\n路由基本上是按模块或功能去划分的。\n\n首先是按模块去划分一级路由,各个模块的子功能相当于是用二级路由处理。\n\n简单举个例子,`/article`路由开头的是文章模块,`/article/add`用于新增文章功能。\n\n控制器的概念其实是从其他语言中借鉴而来的,Express 并没有明确说什么是控制器,但在我看来,路由中间件的处理模块/函数就是控制器的概念。\n\n下面是本项目使用到的一些控制器。\n\n\n\n```javascript\nconst BaseController = require(\'../controllers/base\');\nconst ValidatorController = require(\'../controllers/validator\');\nconst UserController = require(\'../controllers/user\');\nconst BannerController = require(\'../controllers/banner\');\nconst ArticleController = require(\'../controllers/article\');\nconst TagController = require(\'../controllers/tag\');\nconst CategoryController = require(\'../controllers/category\');\nconst CommentController = require(\'../controllers/comment\');\nconst ReplyController = require(\'../controllers/reply\');\n\nmodule.exports = function(app) {\n app.use(BaseController);\n app.use(\'/validator\', ValidatorController);\n app.use(\'/user\', UserController);\n app.use(\'/banner\', BannerController);\n app.use(\'/article\', ArticleController);\n app.use(\'/tag\', TagController);\n app.use(\'/category\', CategoryController);\n app.use(\'/comment\', CommentController);\n app.use(\'/reply\', ReplyController);\n};\n```\n\n## BaseController\n\n其中,`BaseController`是用作第一道关卡,对所有的请求做一个基本的校验和拦截。\n\n其实主要是对一些敏感接口(比如后台维护类的)做一个权限校验。\n\n权限控制这块,我设计得还是比较简单粗暴的,因为我在数据库表中目前只预留了一个用户`Tusi`,关联的角色也是唯一用到的`admin`。毕竟目前还没考虑开放用户注册这类的能力,有一个管理用户基本上也够用了。\n\n所以我的设计是:**只要在我登录成功后的有效期内,就有权限操作敏感接口,否则就无权操作!**\n\n`BaseController`大体工作流程如下:\n\n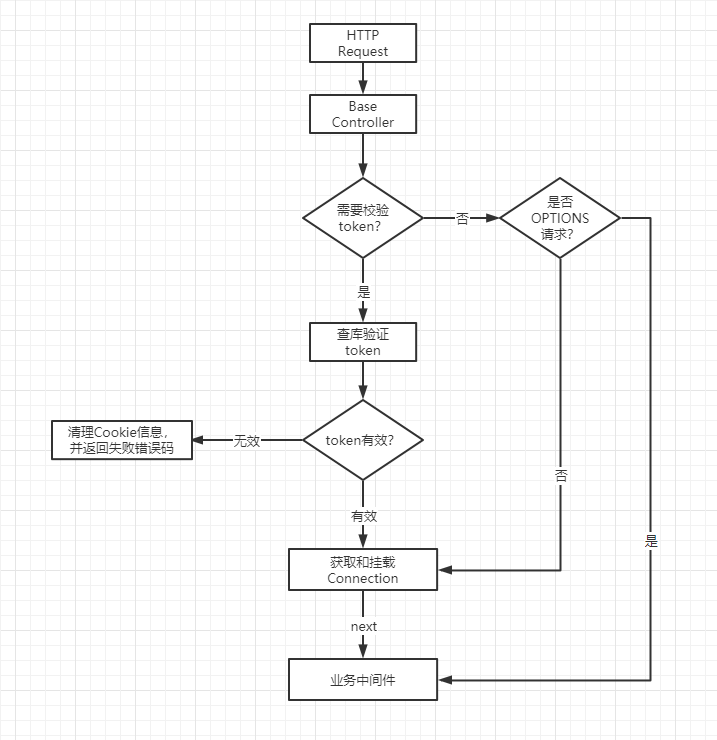\n\n`BaseController`的主体代码结构大概如下:\n\n```javascript\nrouter.use(function(req, res, next) {\n // authMap 维护了敏感接口列表\n const authority = authMap.get(req.path);\n // 首先检查是不是敏感接口\n if (authority) {\n // 需要检验身份的接口\n if (req.cookies.token) {\n // 取到 token 去做校验\n dbUtils.getConnection(function (connection) {\n req.connection = connection;\n // 这里会直接查库验明身份\n connection.query(indexSQL.GetCurrentUser, [req.cookies.token], function (error, results, fileds) {\n // 身份校验通过,才继续,否则返回错误码\n })\n })\n } else {\n return res.send({\n ...errcode.AUTH.UNAUTHORIZED\n });\n }\n } else {\n // 不是敏感接口,不校验身份\n if (req.method == \'OPTIONS\') {\n // OPTIONS 类型请求不能去连数据库,否则会导致数据库连接过多崩了\n next();\n } else {\n // 从mysql连接池取得connection\n dbUtils.getConnection(function (connection) {\n req.connection = connection;\n next();\n }, function (err) {\n return res.send({\n ...errcode.DB.CONNECT_EXCEPTION\n });\n })\n }\n }\n}\n```\n\n如注释所述,`BaseController`主要是针对敏感接口做一个身份检查,防止系统数据被一些不怀好意的 HTTP 请求给黑了。\n\n### 20220218更新\n\n按照上面的逻辑实现功能并上线后,服务运行一段时间(可能是3~5天)后,能观察到服务请求会变成无法正常响应的状态。\n\n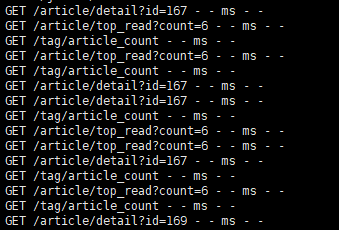\n\n其实我能感觉到可能是**mysql**连接池未合理释放导致的。\n\n但是由于我一开始采取的方案是:在**BaseController**给`req`挂载`connection`,并在具体的业务控制器执行完`sql`查询语句后再自行释放`connection`,这个基本使用过程我在后面一节也说到了。\n\n如果要完全改掉这种调用方式,代码改动还是挺大的,所以我一直拖着没改,发现问题了就通过 PM2 重启服务也能接着用。最近还是咬咬牙全部重构了,具体见[refactor: 重构sql调用部分](https://github.com/cumt-robin/express-blog-backend/commit/41628e98b2e1f2fee14289fdb8d13fe1bc0501e3)。\n\n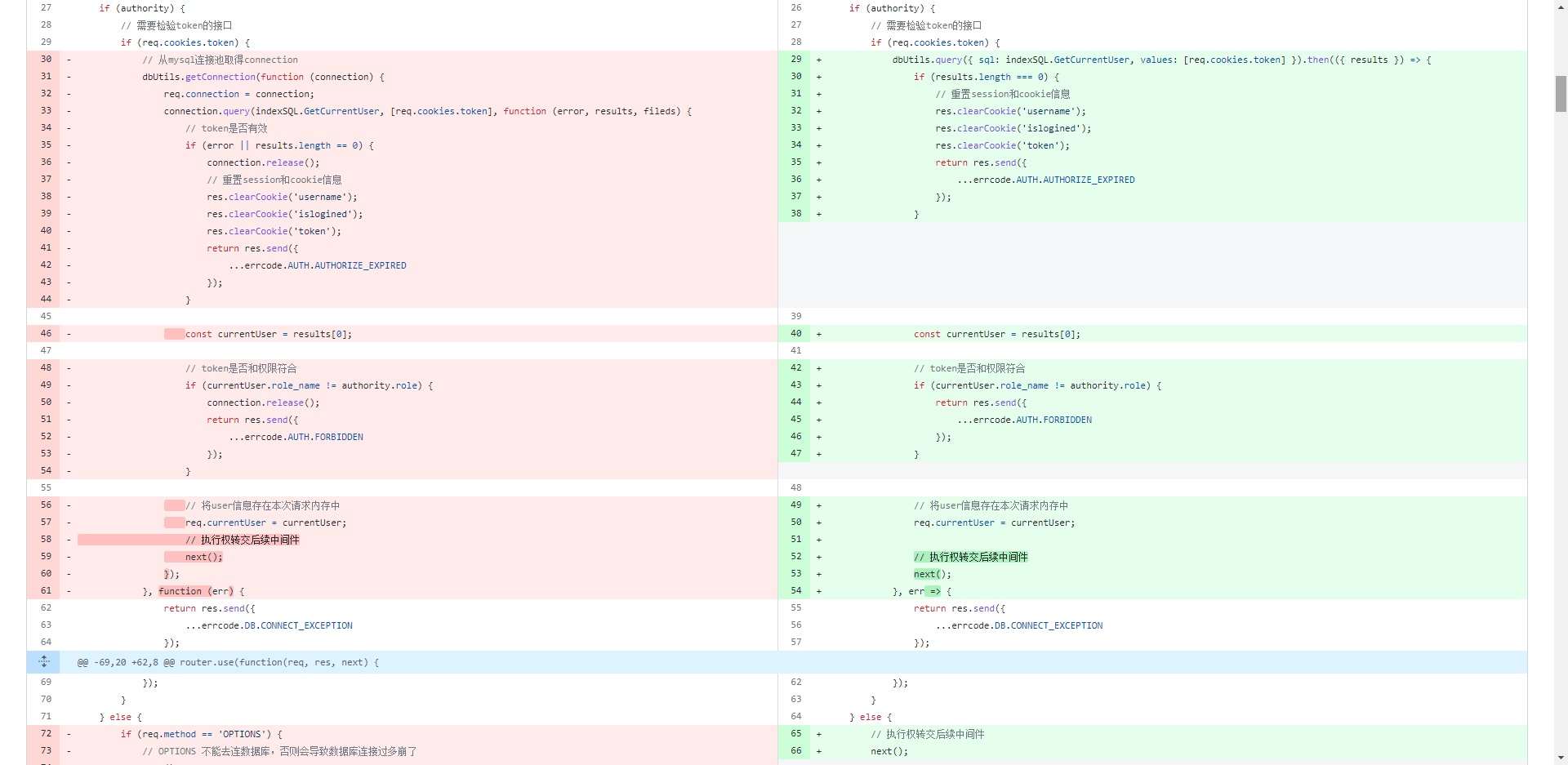\n\n## 业务Controller\n\n前端会分模块,后端自然也会。业务模块会有很多,比如文章,分类,标签,等等。这些都可以分成不同的`Controller`处理。\n\n**业务Controller**的大体结构如下,一个子路由就对应一个功能:\n\n```javascript\n/**\n * @param {Number} count 查询数量\n * @description 根据传入的count获取阅读排行top N的文章\n */\nrouter.get(\'/top_read\', function (req, res, next) {\n // 业务代码\n}\n\n/**\n * @param {Number} pageNo 页码数\n * @param {Number} pageSize 一页数量\n * @description 分页查询文章\n */\nrouter.get(\'/page\', function (req, res, next) {\n // 业务代码\n}\n\n/**\n * @param {Number} id 当前文章的id\n * @description 查询上一篇和下一篇文章的id\n */\nrouter.get(\'/neighbors\', function (req, res, next) {\n // 业务代码\n}\n```\n\n# SQL处理\n\nSQL 这块,我没有直接用 ORM 工具。因为我觉得自己的 SQL 基础并不是很好,还需要自己多写 SQL 语句练习一下,所以我只用了一个**mysql**的库。\n\n\n\n安装**mysql**依赖:\n\n```\nnpm install --save mysql\n```\n\n简单使用时,可以直接创建连接,然后执行 SQL 语句:\n\n```javascript\nvar mysql = require(\'mysql\');\nvar connection = mysql.createConnection({\n host : \'localhost\',\n user : \'me\',\n password : \'secret\',\n database : \'my_db\'\n});\n \nconnection.connect();\n \nconnection.query(\'SELECT 1 + 1 AS solution\', function (error, results, fields) {\n if (error) throw error;\n console.log(\'The solution is: \', results[0].solution);\n});\n \nconnection.end();\n```\n\n实际上,更推荐使用连接池,可以避免重复向 MySQL 申请连接,实现了连接的重用,在响应速度上也会更快!\n\n```javascript\nvar mysql = require(\'mysql\');\nvar pool = mysql.createPool(...);\n \npool.getConnection(function(err, connection) {\n if (err) throw err; // not connected!\n \n // Use the connection\n connection.query(\'SELECT something FROM sometable\', function (error, results, fields) {\n // When done with the connection, release it.\n connection.release();\n \n // Handle error after the release.\n if (error) throw error;\n \n // Don\'t use the connection here, it has been returned to the pool.\n });\n});\n```\n\n实际操作时,我是在**BaseController**中执行了`pool.getConnection`,然后把`connection`对象挂载到`req`对象上,后续的路由中间件就可以直接从`req`对象中取得`connection`,可以少嵌套一层回调,也避免了每处业务代码都写这部分重复的`getConnection`代码。\n\n**BaseController**的关键代码:\n\n```javascript\n// 从mysql连接池取得connection\ndbService.getConnection(function (connection) {\n req.connection = connection;\n next();\n}, function (err) {\n return res.send({\n ...errcode.DB.CONNECT_EXCEPTION\n });\n})\n```\n\n业务处直接从`req`获取到`connection`对象:\n\n```javascript\nrouter.get(\'/page\', function (req, res, next) {\n const connection = req.connection;\n const pageNo = Number(req.query.pageNo || 1);\n const pageSize = Number(req.query.pageSize || 10);\n connection.query(indexSQL.GetPagedArticle, [(pageNo - 1) * pageSize, pageSize], function (error, results, fileds) {\n connection.release();\n // 其他业务代码\n })\n```\n\nSQL 语句主要是以字符串的形式编写,通过`?`作为一个参数槽位,接收一些动态的值。\n\n比如一个逻辑删除的语句,我们会这样写:\n\n```javascript\n// 逻辑删除/恢复\nUpdateArticleDeleted: \'UPDATE article SET deleted = ? WHERE id = ?\',\n```\n\n第一个`?`是留给字段`deleted`的值,第二个`?`便是传具体的`id`值。\n\n而参数传值是通过`connection.query`的第二个参数携带的。\n\n注意,这个参数是一个数组,数组中的值会按照从左到右的顺序依次替换掉 SQL 字符串中的`?`,变成一个真实的可执行的 SQL 语句。\n\n```javascript\nconnection.query(indexSQL.UpdateArticleDeleted, [params.deleted, params.id], function (error, results, fileds) {})\n```\n\n`connection.query`执行回调后切记调用`connection.release`释放连接。\n\n另外要注意的一个就是 MySQL 的事务处理。对事务而言,初步要关注的是这三个 API!具体的使用场景我在后面的具体应用会再提到,这里就不展开了!\n\n```\n// 开始事务,对应 MySQL begin 语句\nconnection.beginTransaction();\n\n// 事务提交,对应 MySQL commit 语句\nconnection.commit();\n\n// 事务回滚,对应 MySQL rollback 语句\nconnection.rollback();\n```\n\n## 20220218更新\n\n为了保留在这个项目中我使用`mysql`思路的一个转变过程,前面的 mysql 调用过程,我还是按照最初的想法展开介绍的,关键的也就是这么几点。\n\n1. BaseController 统一获取 mysql pool 的 connection 对象,并挂载到 req 对象上,供后面的业务使用。\n2. 业务 Controller 与 mysql 交互时,只需要从 req 对象中取得 connection,通过 connection.query 去执行 sql 语句。\n3. 业务 Controller 执行完 sql 语句后,主动 release 释放掉 connection。\n4. 事务场景中,事务处理完毕后,统一 release 释放掉 connection,而不是每个 query 都自行释放 connection。\n\n这样的设计,虽然省去了在具体业务 Controller 执行`getConnection`(少一层回调写法),但是在`connection.release()`的把控上还存在漏洞,一旦业务调用方忘记调用`release()`,就有可能造成服务不可用。而且有的业务不需要与 mysql 交互,也必须要记得 `release()`,虽然可以用一些配置字段去规避,也并不能从根本上解决问题!\n\n所以我的修改方案是:\n\n1. 总体的原则是**高内聚,低耦合**。\n2. 封装 mysql 的查询过程,把 getConnection, query, release 等几个关键行为都放在封装的代码中控制,对外只暴露一些封装好的方法,这样就不用担心调用方忘记某些关键操作(比如`release()`)。\n3. 关键 API Promise 化,这样在一些复杂的异步过程中可以做到事半功倍,特别是涉及事务处理的时候!\n\n核心代码见[db.js](https://github.com/cumt-robin/express-blog-backend/blob/main/utils/db.js)\n\n# 响应返回体\n\n响应返回体的数据结构是需要前后端进行约定的,只有约定好规范,双方才能紧密有序地配合起来。通常来说,会涉及到错误码,信息,数据等字段。\n\n其中错误码`code`,信息`message`两个字段应该是通用的。数据部分`data`则随业务的需要,可能会有多种情况,比如数组结构,对象结构,或者是普通数据类型。\n\n```javascript\n{\n code: \"0\",\n message: \"查询成功\",\n data: {\n id: 1,\n name: \'xxx\'\n }\n}\n```\n\n# 错误码\n\n**错误码**是后端规范中必不可少的部分。错误码的设计是为了快速定位问题,也为一些业务监控系统提供了分析和统计依据。\n\n每个程序员会有自己的一些编码风格,在错误码这块,我是通过语义化的属性名去定位到错误码的。通常,一个错误码会配对一条错误信息,也就是下面的`msg`字段。\n\n```javascript\nmodule.exports = {\n DB: {\n CONNECT_EXCEPTION: {\n code: \"-1\",\n msg: \"数据库连接异常\"\n }\n },\n AUTH: {\n UNAUTHORIZED: {\n code: \"000001\",\n msg: \"对不起,您还未获得授权\"\n },\n AUTHORIZE_EXPIRED: {\n code: \"000002\",\n msg: \"授权已过期\"\n },\n FORBIDDEN: {\n code: \"000003\",\n msg: \"抱歉,您没有权限访问该内容\"\n }\n },\n}\n```\n\n错误码的设计还有一个好处,就是方便做**映射**。\n\n什么意思呢?后端返回错误码`-1`,并且通过`msg`字段告诉前端错误信息是**数据库连接异常**。但是,前端到底要不要反馈用户这么直接粗暴的信息呢?我想,有时候是不需要的,而是**通过一条委婉的提示来安抚一下用户情绪**。\n\n比如,\n\n\n\n所以,有了错误码,前端就可以收放自如,在错误提示上有更多发挥的余地,而不是直白地把后端反馈的错误信息直接暴露给用户。\n\n简单的一个映射可以是:\n\n```javascript\n// ERR_MSG\n{\n \"-1\": \"系统开了个小差,请稍后重试!\",\n}\n```\n\n那么`message`的展示逻辑就可以是:\n\n```javascript\nmessage.error(ERR_MSG[res.code])\n```\n\n# Web安全\n\n主要是考虑几个方面,XSS,CSRF,响应头。\n\nXSS,指的是 Cross-Site-Scripting 跨站脚本攻击。出现 XSS 漏洞的主要场景是用户输入,比如评论,富文本等信息,如果不加以校验,就可能会被植入恶意代码,造成数据和财产损失!\n\n针对 XSS 的校验不能光靠客户端,服务端也必须进行校验。我这里用的是`xss@1.0.9`。\n\n```\nnpm install --save xss\n```\n\n`xss`默认会处理掉常见的 XSS 风险,使用起来也非常简单。比如,在新增评论的接口处,我们可以对参数这样处理:\n\n```javascript\nconst xss = require(\"xss\");\nrouter.post(\'/add\', function (req, res, next) {\n const params = Object.assign(req.body, {\n create_time: new Date(),\n });\n // XSS防护\n if (params.content) {\n params.content = xss(params.content)\n }\n}\n```\n\n虽然我目前还没有用富文本承载评论内容,但是还是先预备一下,万一哪天想用富文本了呢!\n\n至于 CSRF(跨站请求伪造)攻击,常见的漏洞来源就是基于 Cookie 的身份验证,因为 Cookie 会在发 HTTP 请求的时候自动带上,这样一来攻击者就有了可乘之机,通过脚本注入,或者一些引诱点击,让你不知不觉就上了套,发出了意料之外的请求。\n\n不过,浏览器也是在不断完善 Cookie 安全这块,比如 Chrome 80 版本默认启用的 SameSite=Lax,也防范了很多 CSRF 的攻击场景。\n\n为了安全起见,在 Set-Cookie 时,最好带上这些属性。\n\n```\nSet-Cookie: token=74afes7a8; HttpOnly; Secure; SameSite=Lax;\n```\n\n为了防止 CSRF 攻击,还可以采用 csrf-token 方式,或者采用 JWT 认证,共同点都是避开基于 Cookie 的身份/口令认证方式。\n\n另外,设置一些必要的响应头对于 Web 安全也至关重要!\n\nExpress 推荐我们直接用上`helmet`。\n\n> Helmet 通过设置各种 HTTP 请求头,提升 Express 应用的安全性。它不是 Web 安全的银弹,但的确有所帮助!\n\n安装`helmet`:\n\n```\nnpm install --save helmet\n```\n\n使用起来也很简单,因为它就是一个中间件。\n\n```javascript\napp.use(helmet());\n```\n\n\n\n# 环境变量/配置\n\n由于后端配置文件中一般会出现一些私密性的配置,比如数据库配置,服务器配置,这些都不适合在开源项目中直接出现。所以,在[本项目](https://github.com/cumt-robin/express-blog-backend)中,我只给出了`example`示例,大家按照说明给出自己的配置文件即可。\n\n- 通用配置:config/env.example.js\n- 开发环境配置:config/dev.env.example.js\n- 生产环境配置:config/prod.env.example.js\n- PM2 deploy 配置:deploy.config.example.js\n\n数据库、邮箱配置,以及其他的参数配置,建议是给开发环境和生产环境单独配置,避免本地开发时直接影响到生产环境。\n\n所以,我们需要设置环境标识,并且根据环境标识来引用对应的参数配置。\n\n环境标识我们都不陌生了,它就是`process.env.NODE_ENV`。由于项目中用到了`pm2`,所以我是通过`pm2`来配置`NODE_ENV`的。\n\n```\nenv: {\n NODE_ENV: \"development\",\n PORT: 8002,\n},\nenv_production: {\n NODE_ENV: \'production\',\n PORT: 8002,\n},\n```\n\n所以,我们只要根据`NODE_ENV`来判断开发环境或生产环境,然后加载对应的参数配置即可。逻辑非常简单!\n\n```\n// 配置入口文件,根据环境标识导出配置\nconst baseEnv = require(\"./env\")\nconst devEnv = require(\"./dev.env\")\nconst prodEnv = require(\"./prod.env\")\n\nmodule.exports = process.env.NODE_ENV === \'production\' ? {\n ...baseEnv,\n ...prodEnv\n} : {\n ...baseEnv,\n ...devEnv\n}\n```\n\n# 小结\n\n本文是**Vue3+TS+Node打造个人博客(后端架构篇)**,从一个不太专业的视角来切入后端,主要介绍了我在为博客系统设计后端时的一些主要思路,诸多细节不便展开,可以打开[源码](https://github.com/cumt-robin/express-blog-backend)了解。\n\n有了这次全栈开发的经验,大大提高了我对前后端全链路的理解程度,这之后和后端开发们聊天也更有话题可聊了,有时候还能帮后端捋捋思路、一起排查下问题。总之非常奈斯!\n\n但是,要把后端做完善还有很多的路要走,看看 Java 那么多中间件就知道了,道阻且长,行则将至,加油吧!\n\n\n\n# 系列文章\n\n**Vue3+TS+Node打造个人博客**系列文章入口可点击下方链接,持续更新,欢迎阅读!点赞关注不迷路!😍\n\n- [Vue3+TS+Node打造个人博客(总览篇)](https://juejin.cn/post/7066966456638013477)\n', '2022-03-09 09:25:04', '2024-11-11 15:44:15', 1, 770, 0, '讲讲博客后端NodeJS的关键设计思路', 'https://qncdn.wbjiang.cn/%E5%8D%9A%E5%AE%A2%E7%B4%A0%E6%9D%90/%E5%8D%9A%E5%AE%A2%E5%85%A8%E7%B3%BB%E5%88%97_node.png', 0, 0);
-INSERT INTO `article` VALUES (235, '服务器拒绝了我的ssh免密登录', '> 众里寻他千百度,蓦然回首,答案就在眼皮子底下......\n\n正如标题所述,我遇到的问题是服务器拒绝了我的ssh免密登录,具体情况是我之前已经配置好了ssh免密登录,但是最近突发 PC ssh 登录云服务器报错,接连好些天都没找到原因。\n\nssh 免密码登录本身不是一个复杂的问题,百度 / google 上面随便都找得到教程。关键点在于:\n\n1. 基于 RSA 密钥对保障通信的安全。\n2. 将公钥传递到目标服务器的 `~/.ssh/authorized_keys` 中。\n\n```shell\n// 生成密钥\nssh-keygen -t rsa -b 4096 -C \"your comment\"\n// 将公钥发送到目标服务器\nssh-copy-id -i ~/.ssh/id_rsa.pub user@host\n// 免密登录\nssh user@host\n```\n\n我自己的一台个人服务器原本也配置好了 authorized_keys,免密登录一直用得挺好,在PC本地,remote CI/CD 中一直跑得通。\n\n然而,最近我不知道在服务器上调整了什么,或者是我的 PC 发生了什么升级,不记得了,反正现象就是在 git bash 使用 ssh 免密登录上不去了,一直提示 Permission denied (publickey) 之类的报错信息,但是在 xshell 或者 CI/CD 中都是正常的。\n\n```shell\n$ ssh txcentos\nusername@xxx.xx.xx.xx: Permission denied (publickey).\n```\n\n网上自然有各种类似问题,解决方案诸如修改 .ssh 目录权限,修改 sshd_config 配置等,或者是说你的密钥不对(然而重新生成了也一样,emm...)。\n\n- 调整了权限,发现不是权限的问题\n\n```shell\nchmod 700 ~/.ssh\nchmod 600 .ssh/authorized_keys\n```\n\n- 调整了 sshd_config 的几个关键配置,发现也不是这个问题。\n\n```\nPermitRootLogin yes\nPubkeyAuthentication yes\nPasswordAuthentication no\n\n// 调整之后重启服务\nsystemctl restart sshd.service\n// 或者\nservice sshd restart\n```\n\n其实我心里很清楚,我的问题可能不是这些情况,即使从报错信息上看还是差不多的。我抱着试试的态度,改了一遍又一遍,还是不太行,要么是提示 denied,要么是 ssh 登录时让我输入密码(这还怎么免密),有点崩溃。\n\n最终决定从 ssh 命令上 debug 看看报错信息(这是我之前忽略的,应该从这里开始查的),\n\n```\n$ ssh txcentos -v\n```\n\n找到了这么一个关键信息。\n\n\n```\ndebug1: send_pubkey_test: no mutual signature algorithm\ndebug1: No more authentication methods to try.\n```\n\n顺着`no mutual signature algorithm`这个信息查到了一些资料,由于 OpenSSH 从 8.8 版本由于安全原因开始弃用了 rsa 加密的密钥,需要在 .ssh 的 config 配置中加入这么一行:\n\n```\nPubkeyAcceptedKeyTypes +ssh-rsa\n```\n\n经测试真的管用,免密登录成功!\n\n```shell\n$ ssh xxx\nLast login: Tue Sep 6 xx:xx:47 2022 from xxx.xx.xxx.xxx\n```\n\n附上参考的博客链接 https://blog.csdn.net/q274488181/article/details/121673370\n\n同时我也检查了 PC 的 openssh 版本,确实是高于 8.8 版本的。\n\n```shell\n$ ssh -V\nOpenSSH_9.0p1, OpenSSL 1.1.1o 3 May 2022\n```\n\n接着我还是去查阅 openssh 8.8 的发行日志核实了一下,确实有关于 security 的 incompatible changes,具体与 RSA/SHA-256/512 和 RSA/SHA1 有关。\n\n详细资料可以参考 https://www.openssh.com/txt/release-8.8\n\n> 总结下来就是,本次遇到问题时,我盲目自信认为可以凭自己之前的一些经验,找之前用过的一些方法去修改测试,浪费了很多时间,同时也打击了自己的信心。正确的做法是,对于一些命令行接口,可以优先确认是否能找到 debug 或者日志信息,优先从这些信息入手查问题,就比如这次的 ssh 命令,实际上是提供了 -v 选项,也就是 verbose,能看到比较详细的日志,往往会有事半功倍之效。\n\n', '2022-09-07 09:45:03', '2024-09-24 20:57:38', 1, 68, 0, '我遇到的问题是服务器拒绝了我的ssh免密登录,具体情况是我之前已经配置好了ssh免密登录,但是最近突发 PC ssh 登录云服务器报错,接连好些天都没找到原因。', 'https://qncdn.wbjiang.cn/%E5%8D%9A%E5%AE%A2%E7%B4%A0%E6%9D%90%2Fssh%E5%85%8D%E5%AF%86%E7%99%BB%E5%BD%95%E8%A2%AB%E6%8B%92.jpg', 0, 0);
-INSERT INTO `article` VALUES (236, '基于Vite打造业务组件库(开篇介绍)', '> 本文为稀土掘金技术社区首发签约文章,14天内禁止转载,14天后未获授权禁止转载,侵权必究!\n>\n> 专栏下篇文章传送门:[组件库技术选型和开发环境搭建](https://juejin.cn/post/7153432538046791687)\n\n# 专栏介绍\n\n大家好,我是 [Tusi](https://juejin.cn/user/2752832847753085),最近在写 **基于Vite打造业务组件库** 相关专栏,欢迎读者们关注 [我的专栏](https://juejin.cn/column/7140103979697963045) 一起交流学习。\n\n我的专栏聚焦于如何搭建一个 **业务组件库**,并不会讲述怎么从 0 到 1 搭建一个类似于 **AntDesign** 或者 **ElementPlus** 这样的基础组件库,因为各个社区中这样的课程或者专栏也不少,大家从这些专栏中可以更详细地了解怎么造一些基础组件,进而掌握建设组件库的方法。\n\n同时也是因为我认为 **没必要重复造基础轮子**,在我看来,你很难做出一个`Button`组件,它会比 AntDesign 的`Button`组件的设计更完美、更好用,这并不是意味着不可能做到,只是这种投入跟最后产出的价值是不是能匹配,用圈内的话术说就是,“你做的事情,他的价值点在哪里?你是否做出了壁垒,形成了核心竞争力?你做的事情,和 AntDesign 团队的差异化在哪里?”\n\n> 🐶狗头保命\n\n没错,站在公司或者团队角度,Leader 重点关心你做的东西是不是真的对业务产生了价值。当然,这是我站在个人冲 KPI/OKR 的角度来思考这个事情的,这种造重复性基础轮子的产出,基本上很难得到 Leader 的认可,对 Leader 来说,他想的很可能是,“你为什么不直接用 AntDesign / Lodash / Dayjs 等等呢?为什么要做个差不多的东西,但是质量还没别人高?”\n\n**换个角度**,其实对个人来说,从头到尾搞一次基础设施建设,是会有很大提升和收获的。如果你想要深入某个领域,不 **彻底钻进去一探究竟** 是很难发现那些开拓者在落地的过程中都遇到了什么困难(踩了什么坑)以及解决这些难点都走了什么样的路子(也就是技术方案的演进路线)。\n\n那么什么是有价值的产出呢?我认为有这么两个方向值得我们探索。\n\n* 第一,还是造轮子,**造新的并且能落地的轮子**,新轮子是有价值的,因为它不具备重复性,暂时也没有替代物,甚至它的出现可能影响技术社区的发展。\n* 第二,**创造附加价值**。在现有轮子的基础上,塑造一个更强大的工具。我建议大家可以从一些门槛比较低的方向入手,比如基于现有的工具链,整合出一个贴近实际业务的 CLI / 可视化工具,用于提升开发效率;或者如本专栏主题一般,基于已有的三方基础组件库打造一个服务于业务开发的专用组件库。\n\n回到正题,既然本专栏讲的内容不是从 0 到 1 搭建基础组件库,那是不是意味着学习专栏过后并不能掌握搭建一个类似 AntDesign 这样大而全的组件库的核心方法呢?\n\n**答案显然是否定的**。组件库的搭建理念都是类似的,是殊途同归的,最终从输出的产物形式上看都是要满足诸如 **按需加载**、**兼容各个模块规范**、**Typescript类型支持**、**Unplugin** 这类的核心诉求,而组件的内容丰富度是其次考虑的,提供`Button`, `Icon`, `Table`, `Form` 这些组件与否,都不影响这个组件库的核心架构,即便你后续想要自行实现这些基础组件,随时都可以开始。\n\n最后,在我看来,一个采纳了业务组件库的应用,它的整体架构可能会呈现出这样一种形态:博采众长,提升效率的同时也不会束缚住开发者的手脚,不会限制开发者局限于使用某一个特定的 UI 框架,这在按需加载的支持下是可行的。\n\n\n\n在本专栏中,我会基于自己在多个项目中摸索总结得到的实战经验,带着读者一起探索组件库从设计到开发,再到自动化发布的全链路流水线。本专栏大致会围绕 **设计思路**、**组件开发实战**、**构建打包流程**、**发布流程**,**文档建设**等方面入手介绍,把组件库研发链路的一些**关键节点**讲清楚,**帮助读者掌握基于 Vite 构建现代组件库的核心方法**。\n\n# 前言\n\n**UI组件库** 对前端工程师而言,早已不是一个陌生的概念,BootStrap, Material, AntDesign, Element, Vant, iView,以及最近某些大厂开源出来的 AcroDesign, TDesign, Semi Design 等,这些名词对我们来说都应该不算陌生,甚至可以说日常工作中我们都至少需要与其中的一员打交道(大佬略过)。看多了组件库,自己动手写一两个小组件自然也不是什么难事,毫不夸张地说,**95%以上**的前端工程师都敢拍着自己的胸脯说:“我会开发组件!”\n\n我们认同组件开发简单易上手,但同时也不得不承认这一切都建立在不断繁荣发展的前端框架和工具链生态圈之上!\n\n伴随着 **前端框架**、**构建工具**、**UI/UX设计理念** 的更新换代,UI组件库的发展也是日新月异!确实,在现代前端框架的加持下,开发一个组件的门槛很低,开发者只需要使用框架提供的 **声明式** 语法,约定好 **输入** 和 **输出**,将组件内部 **逻辑** 组织好,一个组件就有了雏形。\n\n\n\n然而门槛低不代表开发组件就很简单,开发优质的组件实际上非常考验开发者的综合设计能力。\n\n# 组件设计基本原则\n\n那么开发一个组件到底要考虑什么呢?结合我自己的实战开发经验,我想大概会有这样几个方面:\n\n## 清晰明了的输入输出\n\n输入输出是由组件提供的功能决定的,它们就像是一个组件的 **用户使用手册**,决定了用户对组件产品的第一印象。开发者应该提供语义化的、简单易懂的 API,降低使用的门槛和心智负担!\n\n## 高内聚,低耦合\n\n高内聚显得很好理解,在编写组件时,我们的出发点都是把逻辑聚合到组件中,基本上是竭尽所能做到内聚,但是这也非常考验个人的逻辑抽象能力。\n\n低耦合,则体现在不要与外部产生太多的联系。用函数思维来说就是:组件尽可能是一个纯函数,不要对外部产生副作用。\n\n当你在提供通用组件时,应当尽可能不显式依赖外部状态,比如依赖 `Store`, `Context` 之类的 App 全局状态。如果实在有需要,可以尝试通过 props 或者 inject 之类的渠道注入到组件中。类似地,也不要显式依赖 `Storage`, `Cookie` 之类的浏览器存储,因为这很容易产生冲突,对 SSR 也不友好,在必要时,稍微靠谱的方法是加上命名空间。\n\n```javascript\n// bad case\nconst store = useStore(key)\n// 依赖了全局状态\nconst innerState = computed(() => store.state.xxxModule.xxxState)\n```\n\n同时,不要在组件中破坏外部状态。举个栗子,假设你为了实现某个功能而扩展出一个原型方法,直接把 Array 或者 Object 的原型给修改了,这就属于破坏外部状态了,也就是对外部产生了 **副作用**。\n\n```javascript\n// bad case\n// 为了解决这个问题,我决定给 Array 原型加一个神奇的方法\nArray.prototype.blingbling = function() {\n // balabala 一堆代码\n console.log(\"反正就是牛逼地解决了这个问题\")\n}\n```\n\n要知道,考虑到`Object.defineProperty`无法处理数组场景,即便 Vue2 为了实现数组的响应式特性,也没有直接修改`Array.prototype`上的原型方法,而是采用了一个巧妙的方式处理,具体可以看 Vue2 源码里的`core/observer/index.js`中的 **Observer** 实现以及`core/observer/array.js`中针对 Array 的特殊处理。\n\n## 可定制,可扩展\n\n一个组件要想支撑大量的业务场景,必然应该是可定制和可扩展的。我们在开发一个组件时,会预设一种最常见的场景,这种预设一般是基于大量的实际案例总结出的经验,大概意思就是:当大家想到使用这个组件时,大部分人能想到的模样就是我预设的这个样子,这就达到了一种拿来即用的效果,大部分人都基本满意。\n\n但是,满足了 80% 的使用需求,也不代表全部,你必须足够包容。用函数思维来看,就是组件跟随用户输入的条件的变化而变化。\n\n\n\n反映到组件上,最基础的做法是:可以通过`Props`接收用户的条件,然后在模板或者逻辑中,根据用户的条件呈现出不同的效果。\n\n甚至,我们可以将部分内容的渲染权限完全交给用户,在 React 中,一切皆`Props`,自定义渲染也只是通过`Props`传递过来一段渲染函数。而在 Vue 中,具体的实现可以分为插槽、作用域插槽等。使用形式并不重要,背后的原理都是相通的。\n\n## 友好的告警提示\n\n告警信息在框架源码中会很常见。当你的使用方式与框架的指导性意见不一致时,框架内部就会通过一段判断逻辑给出一些告警信息,方便你排查问题出现的原因。\n\n```javascript\n// vue源码中关于 mount 用法的告警\nif (__DEV__ && (rootContainer as any).__vue_app__) {\n warn(\n `There is already an app instance mounted on the host container.\\n` +\n ` If you want to mount another app on the same host container,` +\n ` you need to unmount the previous app by calling \\`app.unmount()\\` first.`\n )\n}\n```\n\n在组件设计中也可以采纳这种做法,如果用户错误地使用了组件的某个属性,组件内部就应该给出友好的告警提示。站在 TypeScript 的角度来看,也能通过类型做一些约束,但是如果 TypeScript 的覆盖率不是很高,也很难考虑到所有场景,同时也没法做到兼顾运行时,所以在代码中留下一些必要的告警提示还是有必要的。\n\n同时,我们可以注意到,这些告警信息都将环境信息考虑在内,仅仅会在开发环境中出现。在 Tree Shaking 时,这些不会抵达的条件分支代码,会被判定为 Dead Code 而被裁剪掉。\n\n我们之所以费这么大劲做这种告警信息,就是为了降低用户使用时的心智负担,用户很大程度上可以从告警信息中排查出问题起因。有了这些告警信息,就不用麻烦用户通过 debug 源码得以解决问题,毕竟每个人的精力都有限,阅读源码是最后的退路,非到万不得已就没必要去读源码。\n\n## 组件文档\n\n即便我们在前面做了这么多努力,也不可能完全解决用户的疑问和焦虑。此时,一份健全的使用文档则是对用户最大的安慰。文档建设本身是一项巨大的脏活累活,如何高效又全面地把文档做好,非常考验开发者的工程能力、技巧以及耐心。\n\n## 完备的TypeScript类型支持\n\n一个没有类型支持的组件,确实很难用。React 由于与 JSX 结合紧密,本身对 TypeScript 的支持度就不错,再结合 IDE 内置的 TypeScript 类型推导能力,即便我们不写太多类型声明,得到的开发体验也不会太差。\n\nVue 在这一方面相对处于劣势,SFC(单文件组件)本身就是一个新的 DSL(领域特定语言),默认情况下与 JSX 相比,其 TypeScript 支持度自然处于下风,特别在泛型组件等场景下显得更加乏力。但是,基于 `@vue/compiler-sfc` 官方提供的 parse 和 compile 能力,再配合`tsc`或者`ts-morph`之类的工具,我们也能给 SFC 提供不错的类型支持。\n\n## 配套的工具链\n\n为了更大程度提高 DX(开发者体验),组件开发者还可以根据实际情况提供一些配套工具,目的可以是提供代码的自动补全/智能提示之类的能力;也可以是提供脚手架工具,以便快速搭建起开发环境。形式上,可以选择 CLI,或者是 IDE 插件等。总之在这方面还有很大的想象空间等着大家去发掘。\n\n# 总结\n\n这是一篇 Vite 业务组件库专栏的开篇介绍,本文首先阐述了我在做专栏选题时的初衷,也简述了本专栏接下来写作的一些着重发力的方向。接着我分享了自己在做组件开发过程中总结的一些组件设计原则和经验,希望能给读者带来一些启发和帮助!如果您对我的专栏感兴趣,欢迎您[订阅关注本专栏](https://juejin.cn/column/7140103979697963045),接下来可以一同探讨和交流组件库开发过程中遇到的问题。\n\n> 专栏下篇文章传送门:[组件库技术选型和开发环境搭建](https://juejin.cn/post/7153432538046791687)\n>\n> 技术交流&闲聊:[程序员白彬](https://qncdn.wbjiang.cn/%E5%85%AC%E4%BC%97%E5%8F%B7/qrcode_new.jpg)\n', '2022-10-10 14:41:55', '2024-07-25 03:55:34', 1, 65, 0, '大家好,我是 Tusi,最近在写基于Vite打造业务组件库相关专栏,欢迎读者们关注我的专栏一起交流学习。 我的专栏聚焦于如何搭建一个业务组件库,帮助读者掌握基于Vite构建现代组件库的核心方法。', 'https://qncdn.wbjiang.cn/%E4%B8%93%E6%A0%8F1/logo_3x.png', 0, 0);
-INSERT INTO `article` VALUES (237, 'Vue3和@types/node的类型不兼容问题', '最近有个新项目启动,主体内容与先前做的一个项目相似度很高,于是我准备拿这个旧项目作为模板简单改改,就可以启动新项目的开发了。\n\n先说说现状,为了更好地拥抱云原生,部门内部的构建方案进行过升级,目前采用的是 Buildpacks 构建项目镜像,并且相关的服务器架构也做了调整,打镜像的 Runner 是部署在内网的,没有外网通道,也就是说**安装 npm 依赖时必须从企业私有的 Nexus NPM 代理走**。\n\n\n\n带来的问题就是:这个旧项目启动时还是采纳的旧版镜像构建方案,并不存在新版镜像构建方案带来的内网限制。而现在要基于这个旧项目开发新项目,对接的相关环境都是采纳的新方案,如果不将 npm registry 调整为私有的 Nexus NPM 代理,构建镜像这一步就没法走下去。\n\n\n\n所以我就必须得先把 npm registry 调整一下,重新生成 lock 文件。\n\n`.npmrc`修改成如下(已去掉敏感信息):\n\n```\nregistry=https://nexus.xxx.tech:8443/repository/npm-group/\nalways-auth=true\n_auth=xxGxxxxxxxxxxyQ0xxlGxmc=\n```\n\n`.yarnrc`也修改一下:\n\n```\nregistry \"https://nexus.xxx.tech:8443/repository/npm-group/\"\n```\n\n> npm-group 包含了 npm-proxy 和 npm-hosted,从这里既可以下载通过 npm-proxy 代理过来的公开发行的 npm 包,也可以下载通过 npm-hosted 维护的企业内部私有的 npm 包。\n\n这个项目用的是 Yarn,所以我接着删掉 `yarn.lock`,重新通过`yarn`安装依赖后生成新的 lock 文件。\n\n> 此时最好参照旧的 lock 文件,将关键依赖的版本号先锁住,再重新生成新的 lock 文件,防止在 `~`, `^` 这种约束不强的规则下,最终安装的依赖版本号发生变化的情况。\n\n生成完 lock 文件后,检查一下 dev 和 build 等场景,是不是基本上没什么问题。不出意外的话,就要出意外了!\n\n很快,我就在一段 tsx 代码上遇到了这么一个报错:\n\n```\nType \'() => void\' is not assignable to type \'MouseEvent\'.ts(2322)\nruntime-dom.d.ts(1401, 3): The expected type comes from property \'onClick\' which is declared here on type \'IntrinsicAttributes & AntdIconProps\'\n```\n\n这个报错是从 `runtime-dom.d.ts` 中抛出来的,我第一反应就是看看`@vue/runtime-dom`这个包的版本是不是变了。\n\n查了一下发现,`@vue/runtime-dom`确实是变了,从`3.2.33`变成了`3.2.40`,\n\n\n\n而这个变化是由于`vue`的版本号变化引起的,这是因为我的`vue`版本约束是`~3.2.29`,重新生成 lock 文件时会检查有没有较新的版本。\n\n\n\n好,那我就锁`vue`的版本号,就定为原来生成的`3.2.33`版本。\n\n```\n\"vue\": \"3.2.33\",\n```\n\n重新安装依赖,期待能解决问题。\n\n\n\n但是这并没有解决问题,报错依然存在。于是我尝试去锁可能影响这个问题的一些依赖的版本号,包括`typescript`, `@typescript-eslint/eslint-plugin`, `@vue/eslint-config-typescript` 等等,最终都没有解决这个问题,搞了个把小时,emo了...\n\n于是,我就尝试找问题源`runtime-dom.d.ts`有没有什么问题,先仔细观察下报错信息,\n\n```\nThe expected type comes from property \'onClick\' which is declared here ...\n```\n\n既然你说 `onClick` 未声明,那我把 `onClick` 设置为可选的行不行?\n\n```typescript\n// node_modules/@vue/runtime-dom/dist/runtime-dom.d.ts\n\nexport interface Events {\n // ...\n onClick?: MouseEvent;\n // ...\n}\n```\n\n改了之后这个报错还真的消失了!!!\n\n但是直接改 node_modules 里的代码肯定是不行的,离开自己的电脑,在其他机器安装依赖时就没法同步到这个修改。\n\n而借助 **patch-package** 可以实现**修改 node_modules 中的代码后也能让其他人安装依赖时同步到修改信息**,但是我还不想这么做。那么能不能在项目中加一个`d.ts`,把这个`interface Events`修改一下呢?\n\n考虑到`interface`有合并能力,我先尝试在`global.d.ts`中加同名的`interface Events`,\n\n```typescript\ndeclare interface Events {\n onClick?: MouseEvent;\n}\n```\n\n但是发现也并没有作用,因为`runtime-dom.d.ts`中用了`export interface Events`,这意味着`Events`接口是模块下的而不是全局的,我这样直接加在全局是合并不了的,那有没有办法合并模块下的`interface`呢?\n\n我简单尝试了一下`declare`一个同名的`module`,然后加入一个`interface Events`,也不行,这样就直接覆盖了`node_modules`里的类型声明。\n\n最后实在没办法了,我想到:既然覆盖了,那就全部覆盖吧!我干脆把`node_modules/@vue/runtime-dom/dist/runtime-dom.d.ts`整个文件抄了出来,就改了`onClick?: MouseEvent;`这一行,效果确实可以,这个问题算是临时解决了。\n\n\n\n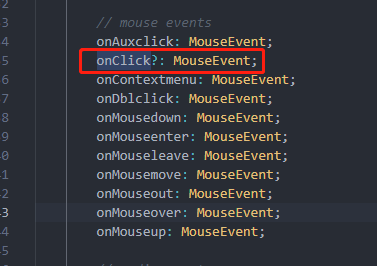\n\n福无双至,祸不单行,我就知道事情没这么简单!\n\n\n\n继续往下测试,我又遇到一个报错:\n\n\n\n这真的是搞心态啊,`@ant-design/icons-vue`不报错了,`div`又报错了。\n\n收拾好心情,发现 VSCode 右下角出现了一个提示信息。\n\n\n\n打开一看,终于找到了问题原因,这是 Volar 给出的提示。\n\n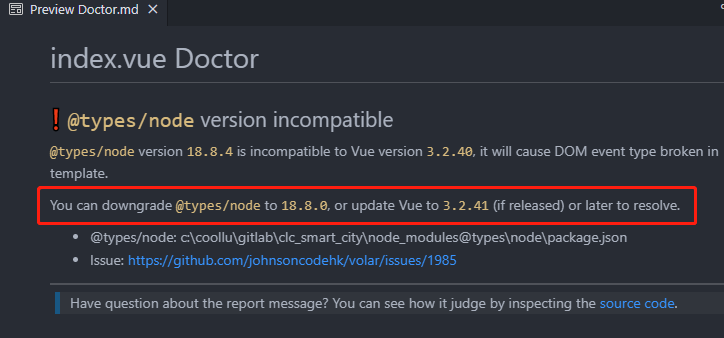\n\n原来是`@types/node@18.8.4`版本与`vue@3.2.40`版本不兼容,会造成模板中的 DOM event type 出错,解决的方法有两个:\n\n1. 降低`@types/node`版本至`18.8.0`。\n\n2. 升级 Vue 的版本号至`3.2.41`,后面还备注了(如果已发行)。\n\n于是,我去看了一下 Vue 的最新版本,发现 3.2.41 还没有发布,可能也正在解决这个问题吧!\n\n\n\n那就选择降低`@types/node`的版本号吧,最终解决了这个问题,前面改的那个`interface`相关的代码也可以删了。\n\n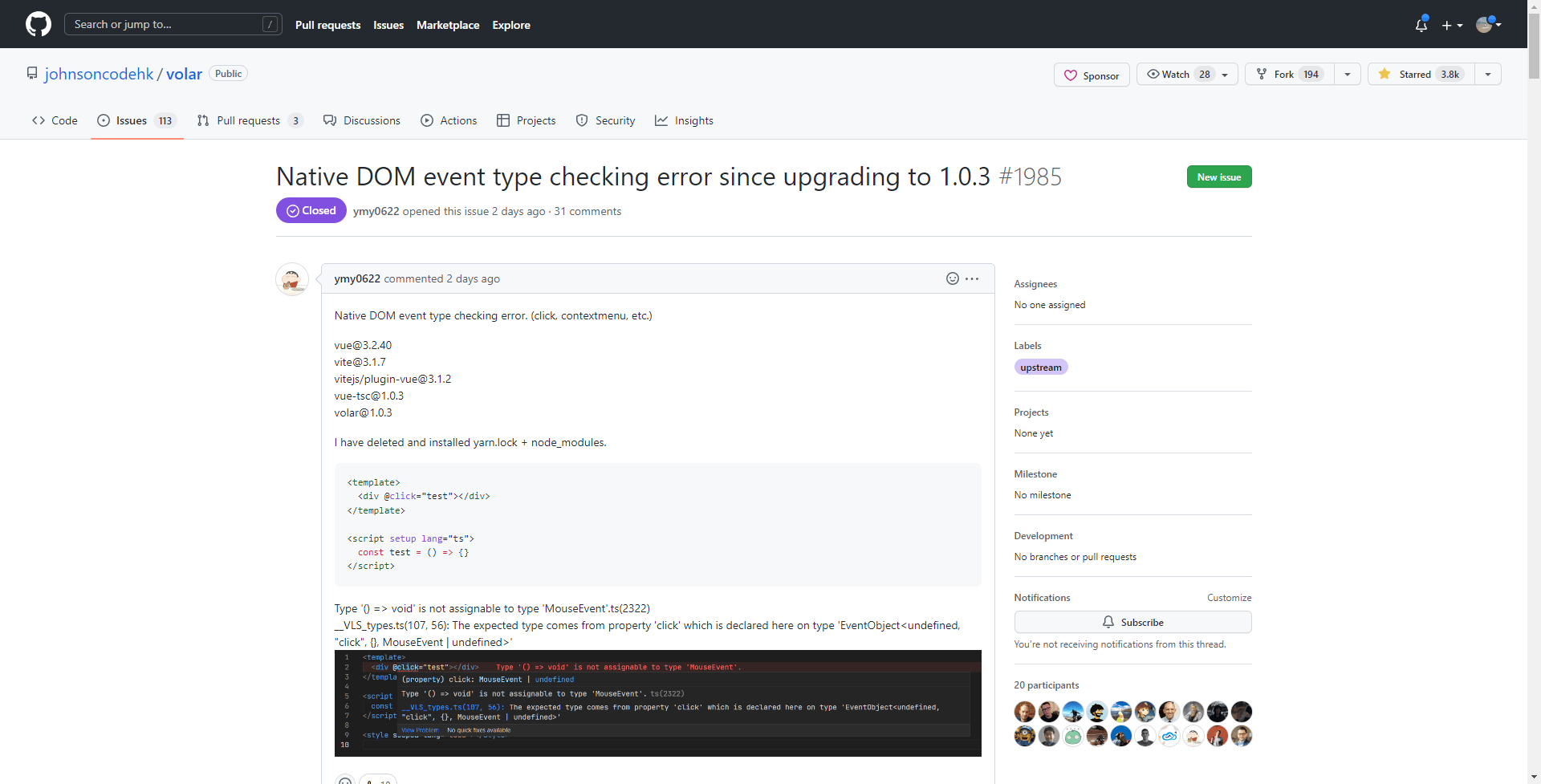\n\nVolar 仓库中相关 issue 还是 2 天前提出的,说明这个问题还是蛮新的。\n\n\n\n> 折腾了好久......为啥 Volar 不早点提示我呢?难道是因为我第一个报错是在`.tsx`中?估计是...', '2022-10-13 21:17:23', '2024-08-10 06:52:03', 1, 100, 0, 'Vue3er 最近可能会遇到的 TypeScript 问题。最近有个新项目启动,主体内容与先前做的一个项目相似度很高,于是我准备拿这个旧项目作为模板简单改改,就可以启动新项目的开发了,没想到问题来了。', 'https://qncdn.wbjiang.cn/%E5%8D%9A%E5%AE%A2%E7%B4%A0%E6%9D%90/issue%E8%AE%A8%E8%AE%BA.png', 0, 0);
-INSERT INTO `article` VALUES (238, '组件库技术选型和开发环境搭建', '> 本文为稀土掘金技术社区首发签约文章,14天内禁止转载,14天后未获授权禁止转载,侵权必究!\n>\n> 专栏上篇文章传送门:[基于Vite打造业务组件库(开篇介绍)](https://juejin.cn/post/7146022961894391821)\n>\n> 专栏下篇文章传送门:[实战案例:初探工程配置 & 图标组件热身](https://juejin.cn/post/7160549169566842893)\n>\n> 本节涉及的内容源码可在[vue-pro-components c1 分支](https://github.com/cumt-robin/vue-pro-components/tree/c1)找到,欢迎 star 支持!\n\n# 前言\n\n本文是 [基于Vite+AntDesignVue打造业务组件库](https://juejin.cn/column/7140103979697963045) 专栏第 2 篇文章【组件库技术选型和开发环境搭建】,为了让读者们沉浸式体验组件库开发,我将会手把手带着读者们搭建起一个组件库的 monorepo 开发环境,相关源码可在 [vue-pro-components](https://github.com/cumt-robin/vue-pro-components) 仓库中取得。\n\n# 为什么选择 monorepo?\n\nmonorepo 这个词大家或多或少都听过,甚至已经在项目中应用过,问题来了,你能给 monorepo 下个定义吗?\n\n\n\n别慌,我也不会,我们来看看[维基百科给出的定义](https://en.wikipedia.org/wiki/Monorepo)。\n\n> In [version control systems](https://en.wikipedia.org/wiki/Version_control \"Version control\"), a **monorepo** (\"[mono](https://en.wiktionary.org/wiki/mono-#English \"wikt:mono-\")\" meaning \'single\' and \"repo\" being short for \'[repository](https://en.wikipedia.org/wiki/Repository_\\(version_control\\) \"Repository (version control)\")\') is a software development strategy where code for many projects is stored in the same repository.\n\n可见,monorepo 的含义就是**在一个单体仓库中管理多个项目**,这种项目管理模式在一些大型项目中已经被广泛应用,比如 [Vite](https://github.com/vitejs/vite), [Vue](https://github.com/vuejs/core), [React](https://github.com/facebook/react), [Angular](https://github.com/angular/angular), [React Native](https://github.com/facebook/react-native), [Jest](https://github.com/facebook/jest), [Pinia](https://github.com/vuejs/pinia), [Vue CLI](https://github.com/vuejs/vue-cli), [Element Plus](https://github.com/element-plus/element-plus), [Modern.js](https://github.com/modern-js-dev/modern.js), [Next.js](https://github.com/vercel/next.js) 等。如果你打开这些项目仓库,你可以发现其中一个很明显的共性:它们都采用了`packages`目录来管理子包,每个子包中都包含一个`package.json`文件,也就是说子包也是一个独立的`npm`包。\n\n进一步研究这些仓库时,我们可以发现,这些项目在支撑起整个 monorepo 体系时采用的技术方案是不一样的。\n\n有的项目简单采用了 yarn workspaces,有的则使用了 Lerna,也有的用了 pnpm,还有的用了 Changesets,再卷一点的已经用上了 Turborepo。\n\n> Changesets 和 Turborepo 不能定义为 monorepo 方案,而是 monorepo 体系中强有力的配套工具。\n\n鉴于笔者还未全面使用过以上所有方案,对于这些方案中的优缺点,无法给出客观的评价,读者们可以自行去查阅更多资料。\n\n这里简单给个参考意见,帮助不了解这块的读者先有个粗略的认识,如有错误,还请评论指出:\n\n## yarn + workspaces\n\nyarn 内置的 [workspaces](https://yarnpkg.com/features/workspaces) 特性可以让子包之间的引用变得简单(其中也用到了 symbol link),在此基础上可以衍生出更多上层的能力,Lerna 就是在此基础上发展而来的工具。workspaces 支持了 monorepo 最基础的能力,但是仅靠它也显得有点单薄,因为它没有提供包的全生命周期管理能力。\n\n> Yarn workspaces aim to make working with [monorepos](https://yarnpkg.com/advanced/lexicon#monorepository) easy, solving one of the main use cases for `yarn link` in a more declarative way. In short, they allow multiple projects to live together in the same repository AND to cross-reference each other - any modification to one\'s source code being instantly applied to the others.\n\n\n\n## Lerna\n\n[Lerna](https://lerna.js.org/) 可以解决上面说的问题,它提供了包的全生命周期管理能力,包括但不限于 **新建子包** / **删除子包** / **管理子包依赖** / **发包** 等等,并且有相关的命令行支持,能较大程度上提升 monorepo 项目开发和维护效率。除此之外,Lerna 团队还竭力提升性能和开发体验,具体见 [Why Lerna?](https://lerna.js.org/docs/introduction#why-lerna)\n\n## pnpm\n\n[pnpm](https://pnpm.io/) 从设计上就天然支持了 monorepo,同时还通过 **严格的依赖结构** / **symbol link** / **hard link** 等能力解决了 **幽灵依赖**、**依赖占用大量存储空间** 等问题。pnpm 也可以搭配 Lerna 使用。\n\n## Changesets\n\n[Changesets](https://github.com/changesets/changesets) 是 pnpm 推荐的一个致力于解决变更记录集、changelog、version 等问题的工具,据说比 Lerna Version 这块的处理更科学。它有一个**生产和消费**`.changeset`的过程,用户在一些复杂版本控制场景中有一定的**自主控制权**,因为你可以对 changeset 等内容做一定调整,自由度更高。\n\n## Turborepo\n\nTurbo,涡轮增压嘛,这就是要起飞的节奏,Turborepo 内部的核心代码是基于 **Go** 来实现的,这跟 esbuild 一样,直接是降维打击啊!\n\n\n\n简单看了一些 [Turborepo](https://turborepo.org/) 官网的文档,可以发现 Turborepo是专注于提升构建性能的工具和平台,它在 Pipeline 编排、Output Caching、Remote Caching、Output Replaying 等方面做了很多努力,同样的事情不做第二次,这与 Lerna 现在的管理团队 Nrwl 研发的构建平台 [Nx](https://nx.dev/) 的发力方向有点相似。\n\n合理的 Pipeline 编排可以最大限度发挥 CPU 性能。缓存用好了真的是一把利刃,对于重复的工作,得到秒级甚至毫秒级的响应是真的香,这在 monorepo 项目中尤其重要,因为你不知道一个 monorepo 可能会演变成多大的工程!而且 Remote Caching 在 CI/CD 中也能发挥很大作用!\n\n为什么这些明星项目都不约而同选择了 monorepo 呢?背后的原因可能有这些:\n\n* 现代前端工程的复杂度在不断提升,使得**拆包成为了必然趋势**。\n* 但是把一个大型项目拆成多个仓库又让管理和联调变得十分困难,`npm link`之类的方案开发体验太差。\n* 目前最佳的方案还是在一个仓库维护,然后通过技术手段改善单体仓库的劣势,**既能保持子包之间的独立性,又能让包之间联调变得简单**。\n* 使得集成化的 CI/CD 变得更加便捷。\n* 更多亮点值得探索......\n\n# 技术选型\n\n在组件库的技术选型这块没有太多可说的,基本上是围绕项目的需求和自身的能力展开,按照开发过程中的实际需求引入相关的技术方案。这中间会存在主观意愿,仅供参考!\n\n* Monorepo: 我还是选择了保守一点的 Lerna,这个我相对熟悉一点,同时也是想多踩踩坑,知道坑在哪里,才能明白为什么要换更好的工具。\n* 前端框架:如专栏标题所述,我选择了个人更熟悉的 Vue3 生态。\n* 类型支持: TypeScript。\n* 基础 UI 组件库:AntDesignVue,继承了 AntDesign 的企业级设计风格,个人感觉 AntDesignVue 相对其他 Vue 生态的组件库更有质感,但是它也不是完美的。\n* 构建工具:Vite, Rollup, Gulp 以及相关插件生态。组件库建设是一个相对复杂的工程,很难依靠一种工具把所有事宜处理完毕,所以整合工具链是必要的。\n* CSS预处理器:Less。选择 Less 主要是考虑后续切换主题,这块 Less 比较好处理(纯属个人主观意见,毕竟还有不依赖 preprocessor 的)。\n* 发布流程工具:release-it。\n* CI/CD: Github Actions。这个没有强制要求,有很多选择。\n* 规范/约束之类的:ESLint, Prettier, StyleLint, husky, commitizen 等等。\n* 更多......\n\n# 开发环境搭建\n\n说太多概念也不太容易消化,我们来实操一下。\n\n## 创建 Lerna 工程\n\n首先我们需要新建并进入`vue-pro-components`工程目录,接着通过`npx lerna init`创建一个工程。\n\n```shell\n$ mkdir vue-pro-components && cd vue-pro-components\n$ npx lerna init\nlerna notice cli v4.0.0\nlerna info Initializing Git repository\nlerna info Creating package.json\nlerna info Creating lerna.json\nlerna info Creating packages directory\nlerna success Initialized Lerna files\n```\n\n可以发现 Lerna 为我们生成了一个 monorepo 项目的基本骨架:\n\n```shell\n$ tree\n.\n|-- lerna.json\n|-- package.json\n`-- packages\n```\n\n### package.json\n\n粗略看一下,`package.json`中的`private`字段设置为了`true`。\n\n```\n {\n \"name\": \"root\",\n \"private\": true,\n \"devDependencies\": {\n \"lerna\": \"^4.0.0\"\n }\n }\n```\n\n这代表什么意思呢?我们看看 npm 文档中关于 [private](https://docs.npmjs.com/cli/v8/configuring-npm/package-json#private) 的描述。\n\n> If you set `\"private\": true` in your package.json, then npm will refuse to publish it.\n\n当`private`设置为`true`时,就代表你不需要在`npm`公开发布这个包。看到这,有的读者可能会纳闷了,“这好像有点问题吧,组件库一般是要发布的呀!”\n\n不用慌,由于我们采用的是 monorepo 架构,具体发布的组件库其实是`packages`目录下的一个子包。而整个工程的主包则是用来组织起整个大框架,不发布到`npm`也是可以理解的。\n\n同时,这也符合 [Yarn 1.X 版本的强制要求](https://classic.yarnpkg.com/en/docs/workspaces),如果需要用到`workspaces`特性,必须声明`private`为`true`。虽然 [Yarn Modern Version](https://yarnpkg.com/features/workspaces) 已经取消了这个限制,但是迟迟没有作为 Yarn 的默认安装版本,在[升级迁移](https://yarnpkg.com/getting-started/migration)这块还有不少阻力。\n\n### lena.json\n\n我们再观察一下`lerna.json`这个文件,它通过`packages`字段约定了子包都分布在哪些目录下,这里支持 glob pattern 匹配,也可以是一个 package 的 path。\n\n {\n \"packages\": [\n \"packages/*\"\n ],\n \"version\": \"0.0.0\"\n }\n\n对于`version`字段,Lerna 提供了[两种版本策略](https://lerna.js.org/docs/features/version-and-publish#versioning-strategies)供我们选择,我们应该怎么选择呢?这里先不展开说,免得大家产生太多疑问导致不必要的焦虑。\n\n工程搭建完毕后,我们先与 remote 仓库(您需要保证远程仓库存在)关联一下,方便后续提交代码。如果您已经 fork 该仓库,请将仓库地址改成您自己的。\n\n```\n git remote add origin https://github.com/cumt-robin/vue-pro-components.git\n```\n\n## 新建组件库子包\n\n有了上面的基本框架,我们可以着手新建一个组件库子包,这个包将存放组件相关源码,这里用到了`lerna create`命令。我们可以根据交互提示填上一些必要的信息,先把子包建好,一些信息可以后续再更改,不必过于纠结。\n\n```\n $ lerna create vue-pro-components\n // 在一步步提示下,先将一个npm子包搭建起来\n package name: (vue-pro-components)\n version: (0.0.0)\n description: pro components based on vue3\n keywords: components,vue3,vite,typescript,unplugin,on demand,pro\n homepage:\n license: (ISC) MIT\n entry point: (lib/vue-pro-components.js) index.js\n git repository:\n```\n\n注意,我这里用到的 package name 是 **vue-pro-components**,这个 name 也将作为我要发布到 npm 上的包名。\n\n> 也不用担心这个包名 vue-pro-components 和整个工程的目录名相同,因为主工程是不会发布到 npm 的。\n\n这里先不急着加具体内容,因为我们需要先把大的框架理清楚,继续往下看。\n\n## 新建 playground 子包\n\nplayground 翻译过来就是游乐场,这个子包可以作为我们调试组件表现的地方,这里直接选择用 Vite 初始化一个工程。\n\n我们尝试一下不使用`lerna create`命令新建 package。\n\n cd packages && yarn create vite playground --template vue-ts\n\n用 Vite 创建的这个 playground 包默认也是 private 的,playground 本来的作用就是调试或展示组件的基本效果,可以打包后作为一个 web 应用发布到公网,但是不需要发布到 npm,所以设置为 private 符合预期。\n\n## 我该用哪种 version 策略?\n\n回到上文留下的疑问,两种版本策略,我们该怎么选?\n\n1. [Fixed/Locked mode (default)](https://lerna.js.org/docs/features/version-and-publish#fixedlocked-mode-default)\n\nFixed mode 意味着`version`字段对应着具体的版本号,比如`0.1.0`。在这种模式下,各个子包的**版本号相对集中**,一般来说可以理解为同一个版本号(也有例外),Lerna 会在执行`lerna version`命令时根据用户的选择自动更新`version`字段,同时会修改发生过代码变更的子包的`package.json`中的`version`字段。\n\n我们可以来试验一下,先把代码 commit & push 到远程,这里我用了一个新分支`c1`。\n\n```shell\n// 回到根目录\ngit checkout -b c1\ngit add .\ngit commit -m \'chore: 先将代码提交到远程,方便后续测试lerna version\'\ngit push --set-upstream origin c1\n```\n\n文档中提到,如果当前 major 版本号是 0,则认为所有变更都是破坏性的,这意味着修改任何一个包中的内容,`lerna version`都会更新所有子包的版本号。我们来试试,修改其中一个子包`vue-pro-components`的内容,在`index.js`加了一行注释,然后 commit,接着使用`lerna version`更新版本号。\n\n\n\n```shell\n$ git add .\n$ git commit -m \'chore: 测试 major 版本号为 0 时修改一个包\'\n$ lerna version\nlerna notice cli v5.3.0\nlerna info current version 0.0.0\nlerna info Assuming all packages changed\n? Select a new version (currently 0.0.0) (Use arrow keys)\n> Patch (0.0.1)\n Minor (0.1.0)\n Major (1.0.0)\n Prepatch (0.0.1-alpha.0)\n Preminor (0.1.0-alpha.0)\n Premajor (1.0.0-alpha.0)\n Custom Prerelease\n Custom Version\n```\n\n当我们选择 Patch 更新后,可以看到,两个子包的版本号都变成了 0.0.1,并且`lerna.json`中的`version`也变成了`0.0.1`。\n\n```\n Changes:\n - playground: 0.0.0 => 0.0.1 (private)\n - vue-pro-components: 0.0.0 => 0.0.1\n```\n\n我们再试试加一行注释,模拟把一个包的大版本号变成 1 的场景,可以看到两个包的版本号以及`lerna.json`中的`version`也变成了`1.0.0`。\n\n\n\n```\n Changes:\n - playground: 0.0.1 => 1.0.0 (private)\n - vue-pro-components: 0.0.1 => 1.0.0\n```\n\n此时,我们再加一行注释,模拟引入一个 feature,再发起 minor 位的版本号变更,会发现仅有一个包的`version`变成了`1.1.0`,同时`lerna.json`中的`version`也变成`1.1.0`,而另一个包的版本号没有变化,这看起来还比较合理,因为我们认为主版本号 1 以上的是相对稳定的版本,按需更新版本号是比较合理的。\n\n\n\n```\n Changes:\n - vue-pro-components: 1.0.0 => 1.1.0\n```\n\n接着,我们把两个包都改一点内容再测试一次。\n\n```\n Changes:\n - playground: 1.0.0 => 1.1.1 (private)\n - vue-pro-components: 1.1.0 => 1.1.1\n```\n\n做了这些尝试我们可以发现,`lerna version`做版本变更时,只会让我们选择一次版本,这一次选择将作用到多个包上。\n\n假设某次更新版本时,我希望一个包是 minor 更新,另一个包是 patch 更新,该怎么办呢?我们继续往下看。👀\n\n2. [Independent mode](https://lerna.js.org/docs/features/version-and-publish#independent-mode)\n\nIndependent Mode 就是采用独立的版本号控制,会在执行`lerna version`命令时逐个询问各个 package 的新版本号,我们可以通过修改`lerna.json`中的`version`字段值为`independent`打开这个模式。\n\n当我只修改其中一个包,`lerna version`会提示我选择一个版本号,这个版本号也将只作用到这个包上,其他的包不受影响。\n\n```\n $ lerna version\n lerna notice cli v5.3.0\n lerna info versioning independent\n lerna info Looking for changed packages since v2.0.0\n ? Select a new version for vue-pro-components (currently 2.0.0) Patch (2.0.1)\n \n Changes:\n - vue-pro-components: 2.0.0 => 2.0.1\n```\n\n接着我们修改两个包的内容再测试一次,Lerna 会让我们单独为每个包选择新的版本号。\n\n```\n $ lerna version\n lerna notice cli v5.3.0\n lerna info versioning independent\n lerna info Looking for changed packages since vue-pro-components@3.0.0\n ? Select a new version for playground (currently 2.0.0) Minor (2.1.0)\n ? Select a new version for vue-pro-components (currently 3.0.0) Minor (3.1.0)\n \n Changes:\n - playground: 2.0.0 => 2.1.0 (private)\n - vue-pro-components: 3.0.0 => 3.1.0\n```\n\n也就是说,Independent Mode 下,版本号是**各管各的,按需选择**。\n\n> 简单总结一下:在 Fixed Mode 下,lerna.json 中记录了各个包中最新的版本号。如果当前大版本号是 0,则修改任意一个包中的内容都会引起所有包的版本号更新;反之,仅更新变动的包的版本号。还有一个场景,就是继续选择大版本的更新,也会引起所有包的版本号更新。总的来说,Fixed Mode 下,版本号捆绑性还是很强的。而在 Independent Mode 下,各个包的版本号相对独立,需要开发者结合包的修改情况来手动选择各个包的版本号。\n\n个人建议:如果你的整个 monorepo 项目中**各个子包联系性非常紧密,目标是对外提供统一的服务**,那么 Fixed Mode 是一个不错的选择,例如 Vue CLI,就是采用了 Fixed Mode。对用户来说,他享受的是整个 Vue CLI x.x.x 版本带来的能力,而不太关心 `@vue/cli-ui` 和 `@vue/cli-service` 现在是哪个版本。如果你的 monorepo 项目中**各个子包联系性稍弱,对外提供多种能力(比如 Lint 配置、Utils 工具、通用 Hooks、UI 库等等)**,那选择 Independent Mode 则是一个不错的选择,这种做法常见于企业内部,通常 monorepo 是作为整合多种能力的一个重要工具,既能在各个子包之间实现一部分复用,又能单独对外提供输出能力。当然,任何事情都不是一成不变的,如果你对版本控制欲很强,也可以果断选择 Independent Mode。\n\n> 我这里选择的是 Independent Mode。\n\n## 子包之间的引用\n\n对版本策略有个粗略的认识后,我们给子包之间建立一点联系,感受一下 monorepo 最大的魅力。\n\n我们先在`vue-pro-components`子包写一个简单的组件`Icon`,无需真正实现图标组件,仅仅用来测试一下。\n\n```vue\n\n {{ icon }} \n \n\n\n```\n\n一个粗略的目录结构大概是这样的:\n\n\n\n由于 Vue3 组件需要用到框架依赖,我们需要在`package.json`中声明一个`peerDependencies`。\n\n```json\n\"peerDependencies\": {\n \"vue\": \"^3.2.0\"\n}\n```\n\n然后在项目根目录的`package.json`中加一个统一安装依赖的脚本。\n\n```json\n\"scripts\": {\n \"bootstrap\": \"lerna bootstrap -- --hoist\"\n}\n```\n\n接着执行这个`bootstrap`命令,\n\n```shell\nyarn bootstrap \n```\n\n我们可以发现,在根目录中出现了`node_modules`目录,而在各个子包中没有出现`node_modules`,这是`--hoist`在起作用,将依赖提升到了根目录,可以节省一部分空间。\n\n我们还注意到,`vue-pro-components`和`playground`两个包也出现在了`node_modules`目录中,实际上它们是软链接,链接的源目录是`packages`目录中对应的子包目录,这样的目录结构符合 Node 的模块加载策略,于是子包之间就可以像使用一个普通的 npm 包一样互相引用了。\n\n> 软链接就是 symbolic link,类似于 Windows 系统中**快捷方式**的概念。但是在 Windows 系统中, workspace 的具体实现并不是快捷方式,而是采用了 junction。\n\n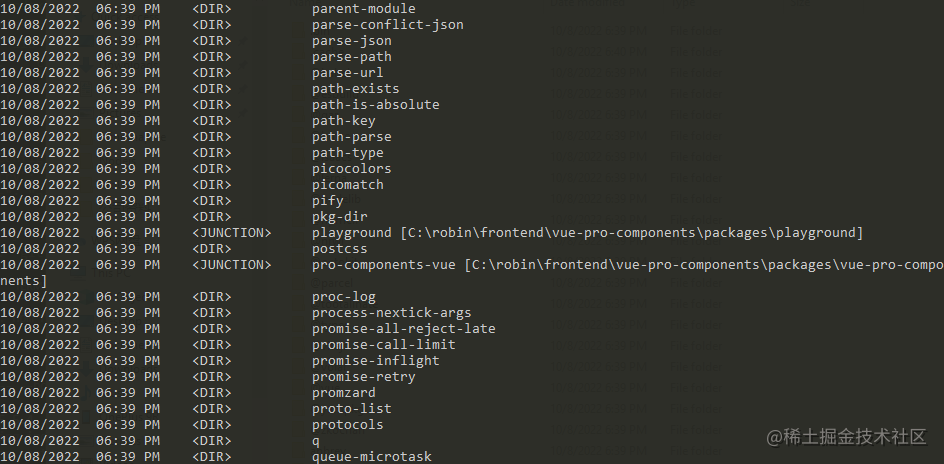\n\n> `lerna bootstrap`不仅为各个 package 安装了自身的依赖,还将各个 package 以 symlink 的方式安装到了`node_modules`中,让其他 package 拥有了引用自己的能力。\n\n接着我们试着在`playground`子包中引用一下`vue-pro-components`子包的组件 **Icon**。\n\n1. 首先需要将`vue-pro-components`作为`playground`子包的一个依赖。\n\n```shell\nlerna add vue-pro-components --scope=playground\n```\n\n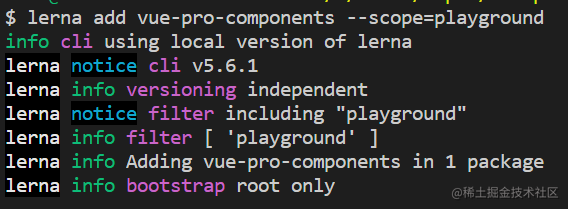\n\n2. import 引入组件并使用。\n\n```vue\n// 1. script 中引入 Icon 组件\nimport { Icon } from \"vue-pro-components\"\n\n// 2. template 中使用组件\n@types` directory even it doesn\'t contain any source code, like `@types/unist`\n // Multiple tsconfigs (Useful for monorepos)\n // use an array of glob patterns\n project: [\'tsconfig.json\', \'packages/*/tsconfig.json\'],\n },\n },\n},\n```\n\n# less\n\n我们测试一下能不能正常使用 less 开发,先把`icon.vue`的`style block`的`lang`设置为`less`试试。\n\n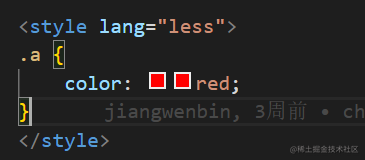\n\n由于 package `vue-pro-components`中的文件都改成 ts 了,其中也包括入口文件`index.ts`,所以我们还需要把`package.json`的`main`入口修改成`index.ts`,才能顺利调试。\n\n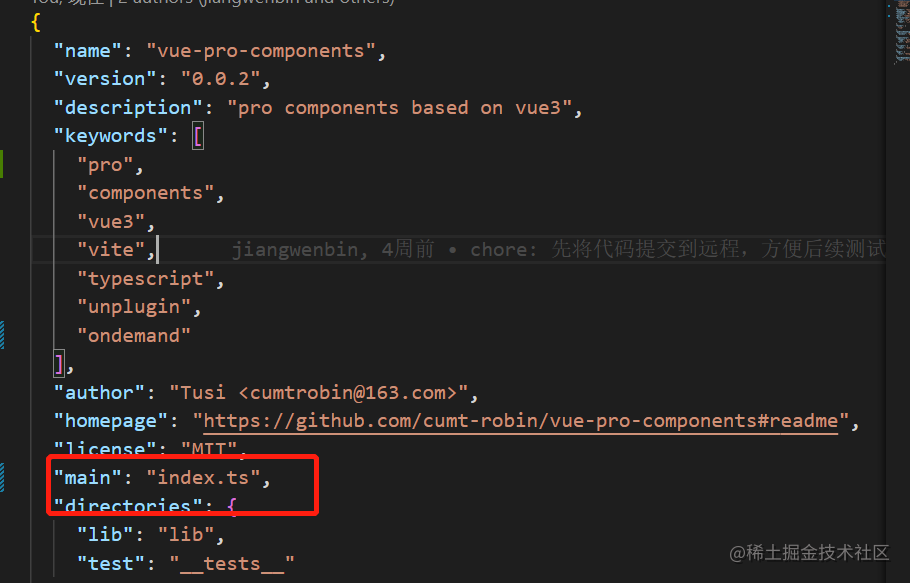\n\n但是把 dev 环境跑起来后,还是报了 less 相关的错误。\n\n\n\n由于 dev 环境是 package `playground`的,只是它引用了 package `vue-pro-components`中的`Icon`组件,所以是 package `playground`的环境中缺失`less`,我们给它安装一下`less`依赖。\n\n```\nlerna add less --scope=playground --dev\n```\n\n# 图标组件需求\n\n基本的环境准备好之后,我们来实现一个简单的 Icon 组件热热身。\n\n虽然 UI 组件库都标配了 Icon 组件,但是这些图标通常来说是不够用的,很难满足不同项目的需求,所以有必要自己实现一个 Icon 组件,能够方便地管理和使用图标。\n\n前端与 UI 设计师通常利用 iconfont 来进行图标协作,图标的表现形式有字体图标,SVG 图标等,我们就先从字体图标开始。\n\n## 准备一个 iconfont 项目\n\n每个业务项目用到的图标肯定是有差异的,我们先选一些图标做个示例,为了方便,这里直接选用了一套[阿里云官网官方图标库](https://www.iconfont.cn/collections/detail?spm=a313x.7781069.1998910419.d9df05512&cid=16472),然后把这些图标抄到自己的图标项目中。\n\n\n\n大概看了一下,图标也挺多的,一个个加到购物车手也会很累。于是我观察了一下 DOM 结构,发现可以用脚本模拟一下点击加购物车的行为,那就不浪费时间了,直接上脚本。\n\n```\n[...document.querySelector(\".collection-detail ul.block-icon-list\").children].forEach(child => {\n child.children[2].children[0].click()\n})\n```\n\n\n\n> 图标复制到项目中后发现图标的默认命名有点呆,全是 icon-test11 这样的,辨识度太低。懒得一个个改名字,最后还是换了一个图标库 [Hippo Design 官方图标库](https://www.iconfont.cn/collections/detail?spm=a313x.7781069.1998910419.d9df05512&cid=22664)。\n\n## 了解字体图标的基本原理\n\n顾名思义,字体图标本质上也是利用字体文件来展示图标的。字符的展示是依赖字符编码的,从 ASCII 到 Unicode,字符集也在不断丰富。计算机并不认识文字、符号或图标,本质上都是通过字符编码结合字体文件、排版引擎等来做渲染的。而 Unicode 预留了`E000-F8FF`范围作为私有保留区域,这个区间的 Unicode 码可以用来自定义一些内容,那么用来做字体图标显然也是非常合适,前端根据 Unicode 码就能显示对应的图标。\n\n> [PUA](https://baike.baidu.com/item/%E7%A7%81%E4%BA%BA%E4%BD%BF%E7%94%A8%E5%8C%BA/61727452?fr=aladdin),即 Private Use Areas,私人使用区相同的代码点可被分配为不同的字符,因此用户可能因安装了某种字体,看到其显示为一种形态,但使用了其他字体的用户可能看到完全不同的字符。\n>\n> 这也就是说,不同的字体文件可以重复利用这个区域的 Unicode,但是可以展示出不同的形态,这也就可以理解为什么我们能展示各种各样的图标了。\n\n然而直接用 Unicode 并不方便记忆和理解,所以我们会在 Unicode 编码基础上再封装一层,通过不同的 class 结合伪元素来表现图标,类似下面这样:\n\n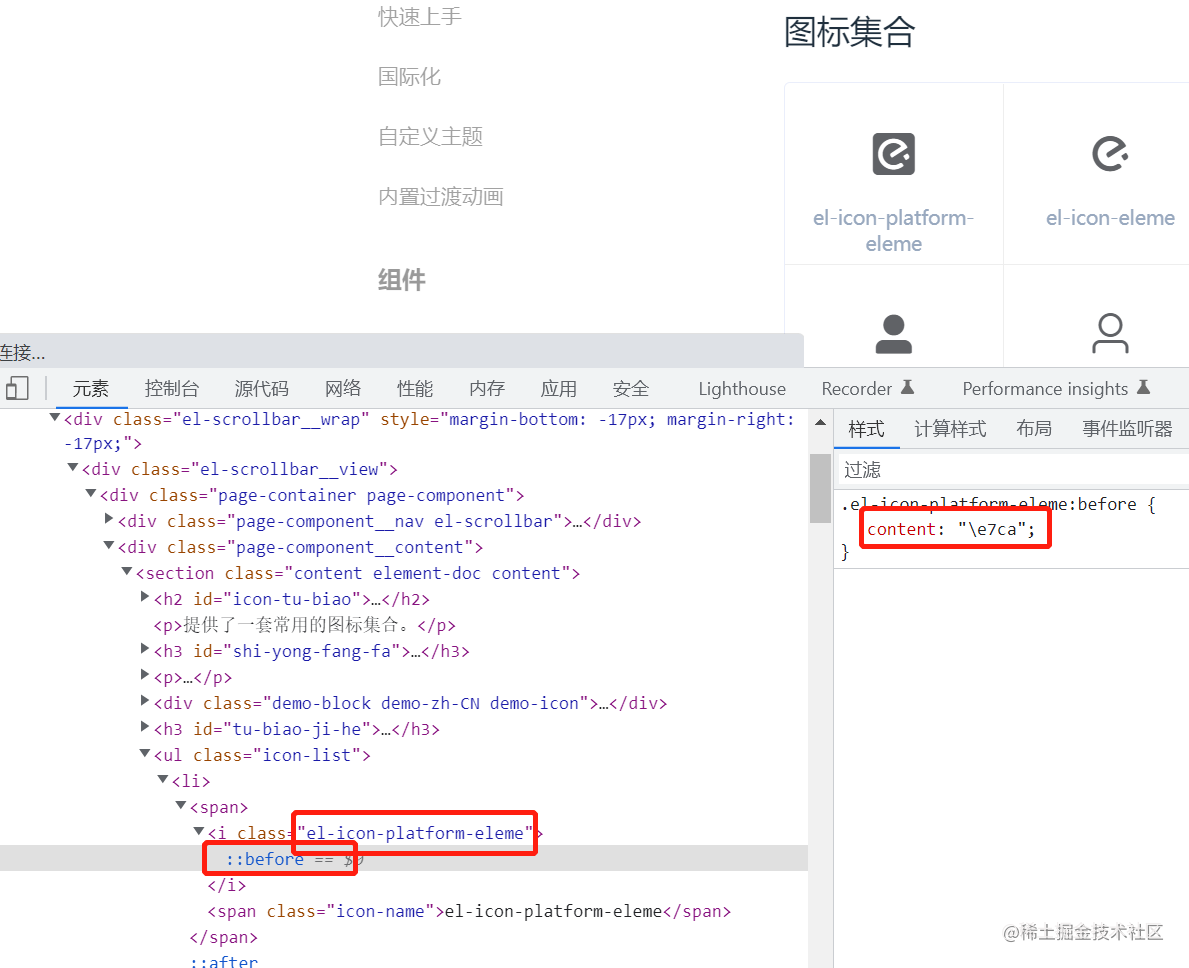\n\n## 引入字体文件\n\n接上面,你首先需要有一个图标库对应的字体文件,而这个字体文件可以来源于 iconfont。\n\n如果希望偷偷懒,或者不关注 iconfont cdn 的稳定性,你完全可以选择使用在线的 css 文件,这个 css 文件中也会引用在线的 ttf 等字体文件。\n\n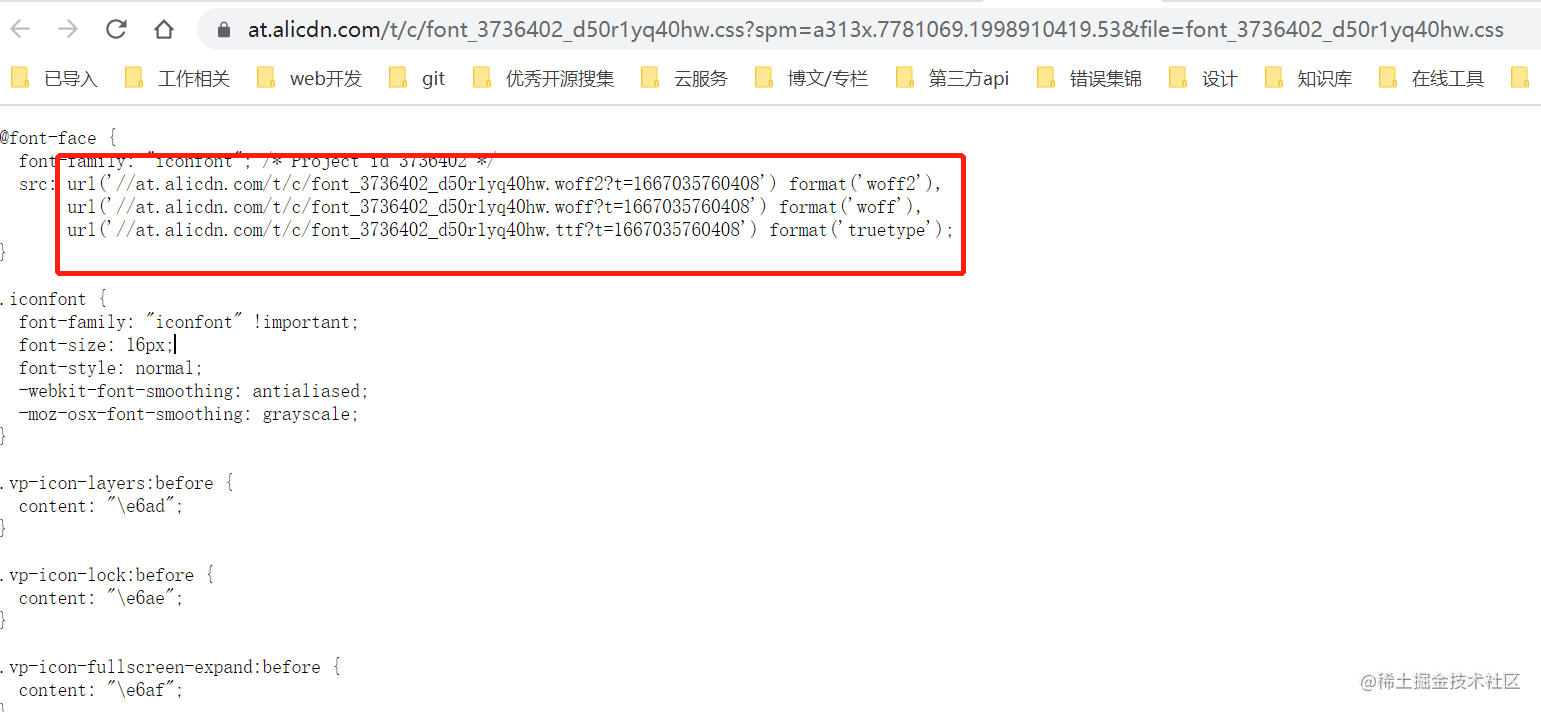\n\n如果你关注内容的稳定性,不希望因为 iconfont cdn 问题导致业务损失,那么我建议把相关资源(包括 css 文件及其关联的字体文件)下载到项目中使用。\n\n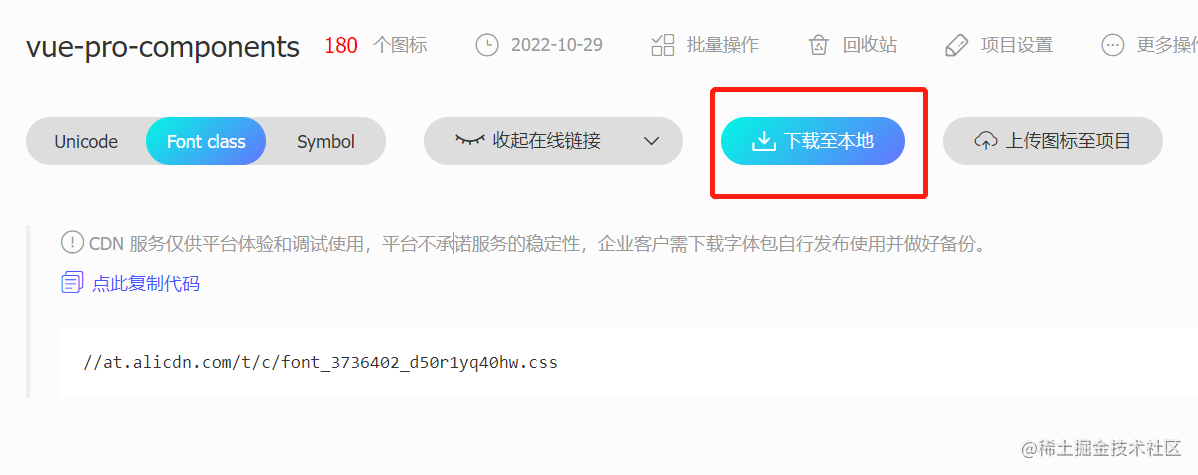\n\n还有一个要考虑的问题,字体文件这些资源放在组件库中加载合适,还是放在业务项目中加载合适?\n\n我想,应该是放在业务项目中加载字体文件等资源比较合适。因为不同的业务项目用到的图标库肯定是有差异的,如果把字体文件内置到图标组件中,就会导致图标库都是一样的,显然没法满足各个项目的需求。\n\n而在我们的 monorepo 工程中,`playground`就扮演着业务项目的角色,可以用来测试组件库的表现,所以我们先在`playground`中引入生成的在线 css 文件。\n\n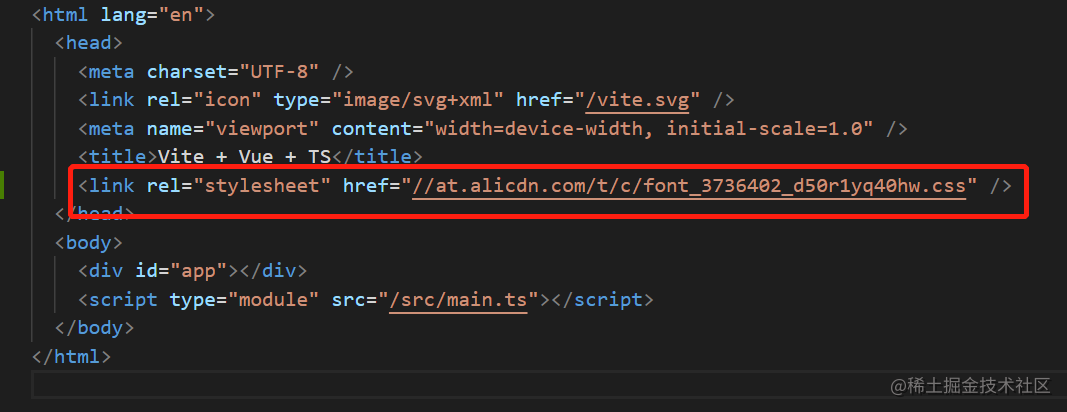\n\n## 思路整理\n\n字体等资源准备好之后,就可以思考怎么基于这些资源实现组件了。\n\n我们知道,css 文件中已经将各个图标封装成 class 了。\n\n\n\n只要我们引用这些 class,就能得到一个字体图标,我们来试试看:\n\n```\n`** element is used to define graphical template objects which can be instantiated by a [``](https://developer.mozilla.org/en-US/docs/Web/SVG/Element/use) element.\n\nsymbol 标签是用来定义图形模板对象的,但是不会直接渲染,需要通过 use 标签去实例化。\n\n\n\n上图就是 SVG symbol 的大致结构,可以发现最外层的 svg 下面是一个 defs 标签。\n\n> The **``** element is used to store graphical objects that will be used at a later time. Objects created inside a `` element are not rendered directly。\n\n在SVG 中,可复用的内容定义在 defs 下面,并不局限于 symbol。\n\n\n\n> symbol 也不强制放在 defs 下面,直接放在 svg 标签下也可以,因为它本身就是模板的含义,不会直接渲染。\n\n我们还可以发现,每个 symbol 上都有一个属性 id,而这个 id 将成为 use 标签引用的依据,`xlink:href`通过`#`加 id 的方式就可以引用对应的 symbol。\n\n\n\n了解这些知识后,我们应该清楚,要实现 SVG Sprite 组件,第一步是要生产出 symbol 内容。\n\nUI 交付给前端的一般是一个个独立的 SVG 文件,那么怎么把这些独立的 SVG 文件变成我们想要的 symbol 呢?\n\n这涉及到文件操作,如果用 nodejs 实现,必然离不开 [fs](https://nodejs.org/api/fs.html) 模块相关的 api,基本的原理就是读文件的字符串内容,然后做拼接处理,输出一个字符串,这个字符串最终可以通过 innerHTML 方式插入到 HTML 文档流中。\n\n如果你的图标类的 SVG 文件都是放在项目工程中的,那么可以选用 [svg-sprite-loader](https://www.npmjs.com/package/svg-sprite-loader)(webpack 体系)直接把这部分工作做好,剩下的事情就是封装组件。\n\n> Vite 中也可以实现类似的插件,大家按 vite svg sprite 等关键词去搜一搜就能找到很多。\n\n如果我们使用的是 iconfont,也可以直接用 iconfont 提供的脚本。通过`script`标签引入这个 js 文件后,会自动创建相关的 SVG symbol。\n\n\n\n剩下的工作就是把 use 的使用封装到组件中,让业务调用变得简单。\n\n# 编码实现 SVG 图标组件\n\n基本逻辑捋清楚了,我们来编码实现一下。\n\n> 为了和字体图标组件区分开,我们把上节中实现的字体图标组件`Icon`重新命名为`IconFont`,而本次要实现的 SVG 图标组件就叫做`IconSvg`。\n\n首先在业务项目中引入 iconfont 图标项目中的这个在线 js 文件。\n\n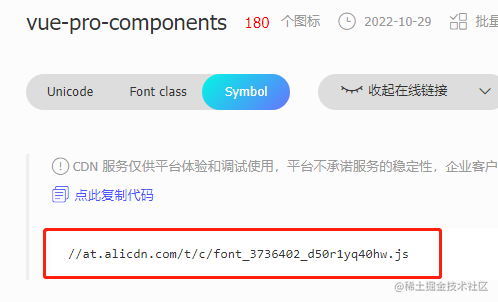\n\n按照[前一篇文章](https://juejin.cn/post/7160549169566842893#heading-10)所述,我们可以暂时把`playground`包看作是业务项目,所以直接在`playground`包中的`index.html`中引入这个 js 就可以了。\n\n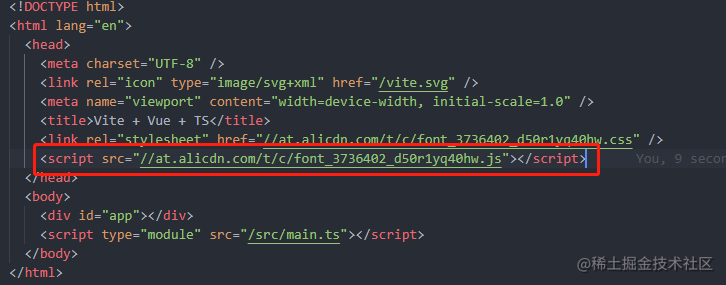\n\n引入 js 后,我们可以看到 SVG symbol 已经生成好了。\n\n\n\n> 注意:如果您担忧 cdn 的稳定性,可以考虑把 iconfont 项目中的相关资源下载到项目中直接引用,这样就不用担心哪天线上业务由于 cdn 问题受到影响。\n\n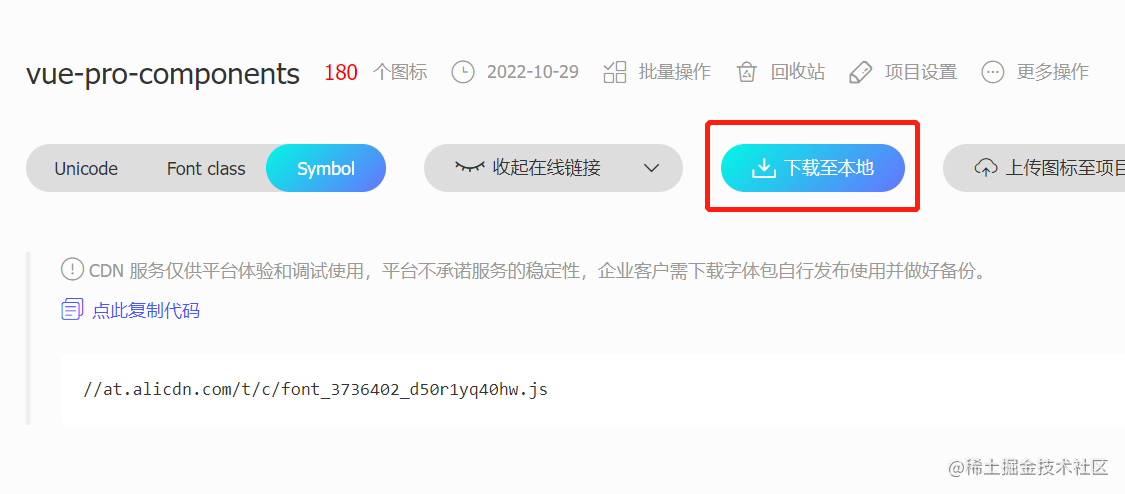\n\n接着就是在组件中把 use 的逻辑处理好。\n\n```vue\n\n \n \n \n\n\n```\n\n属性定义基本上与`IconFont`组件一致,但是具体用法有一点区别。\n\n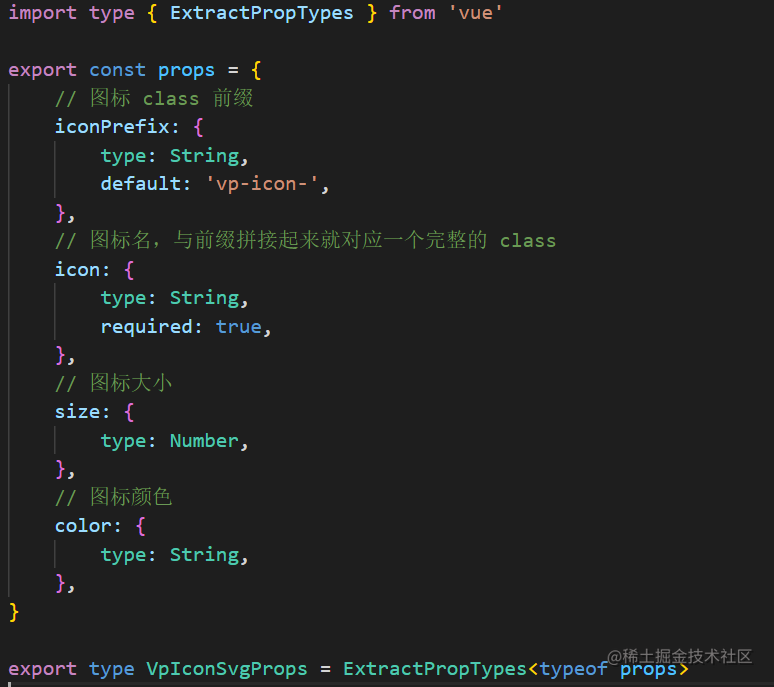\n\n组件的尺寸还是交给属性`size`控制,但是对应到 style 上是由`width`和`height`控制(因为`font-size`对 svg 无效)。\n\n组件的颜色是通过 style 的`fill`控制的(因为`color`也对 svg 无效)。\n\n我们看看目前的使用效果。\n\n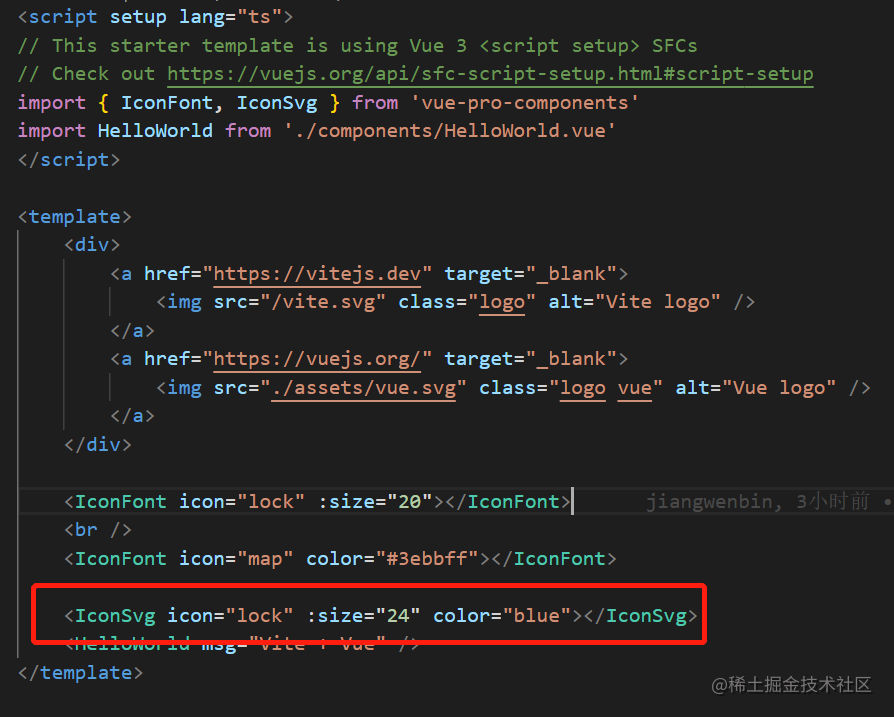\n\n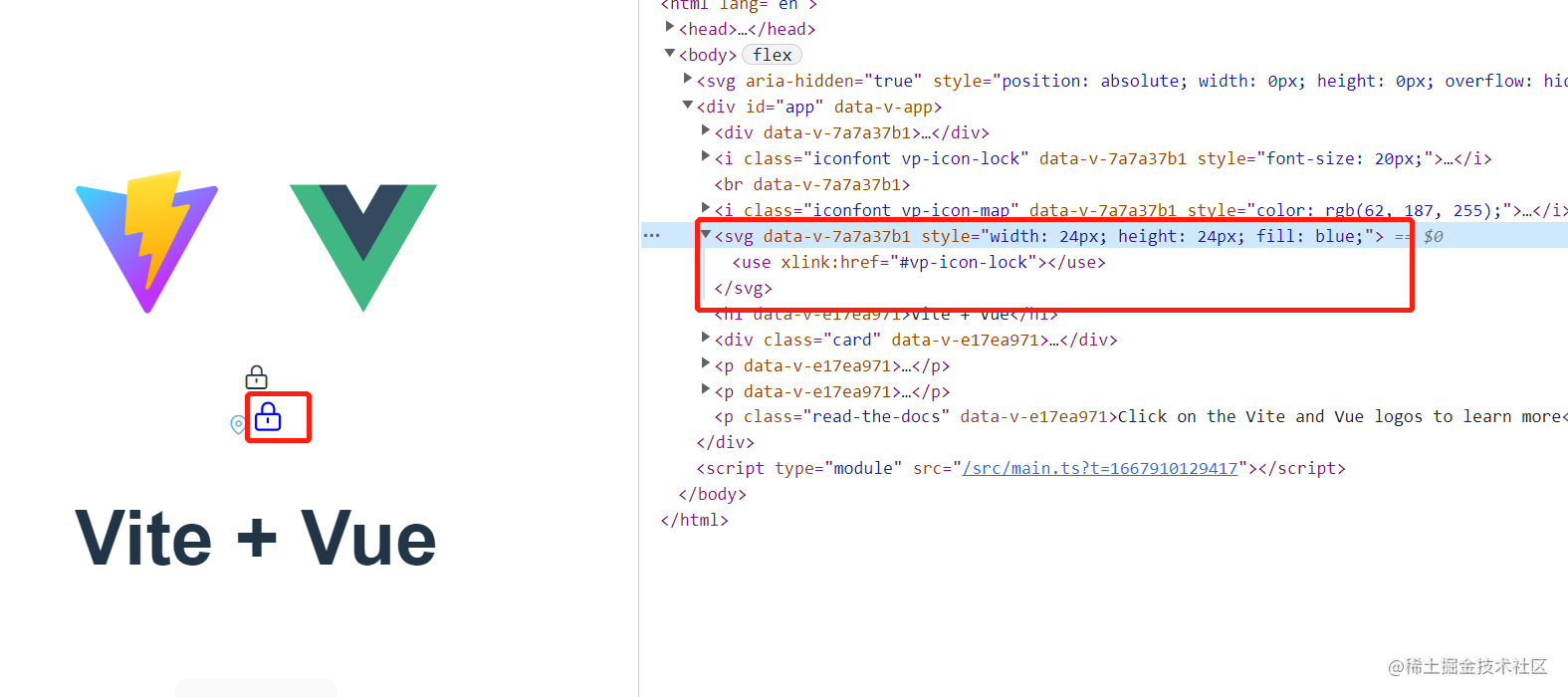\n\n基本效果出来了,但是我们发现一个问题,如果不绑定`size`和`color`属性,SVG 图标的表现不符合我们的预期。\n\n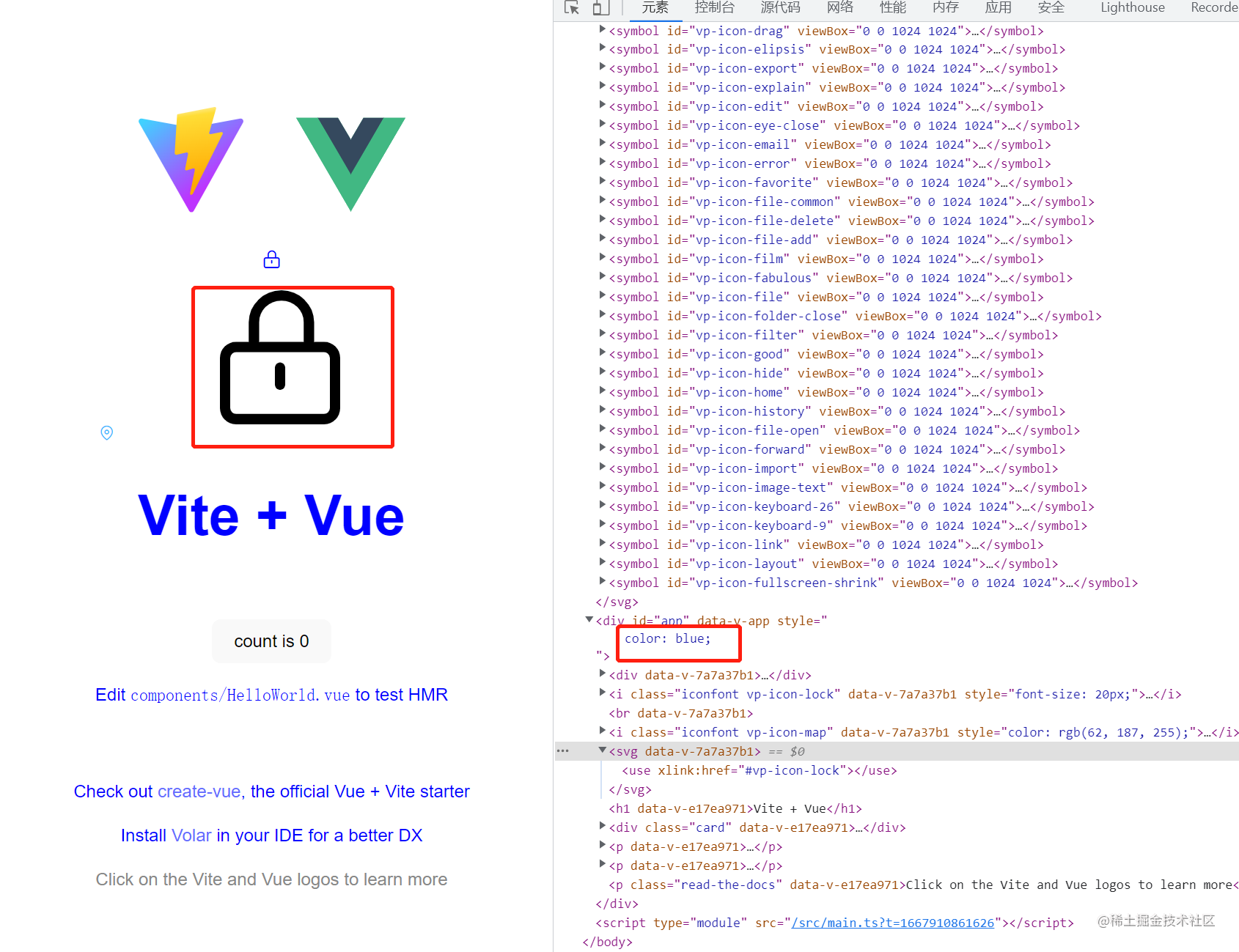\n\n默认的尺寸太大了,预期应该是和同一个块中的文字差不多大。\n\n默认的颜色也不符合预期,我们希望它能跟随父级元素的字体颜色,这样才显得协调。\n\n所以,还需要再做一些优化。我们把组件的外层包裹一个`span`标签,让`svg`的尺寸继承`span`的字体大小,让`svg`的颜色继承`span`的颜色。\n\n- 尺寸上的继承:可以设置`svg`的宽高都为`1em`,这样就可以与文本的字体大小保持一致。\n- 颜色上的继承:可以设置`svg`的`fill`属性值为[currentColor](https://developer.mozilla.org/en-US/docs/Web/CSS/color_value#currentcolor_keyword),currentColor 是一个 css 变量,它能取到当前元素的`color`属性值,这样就可以与文本颜色保持一致了。\n\n代码改造如下:\n\n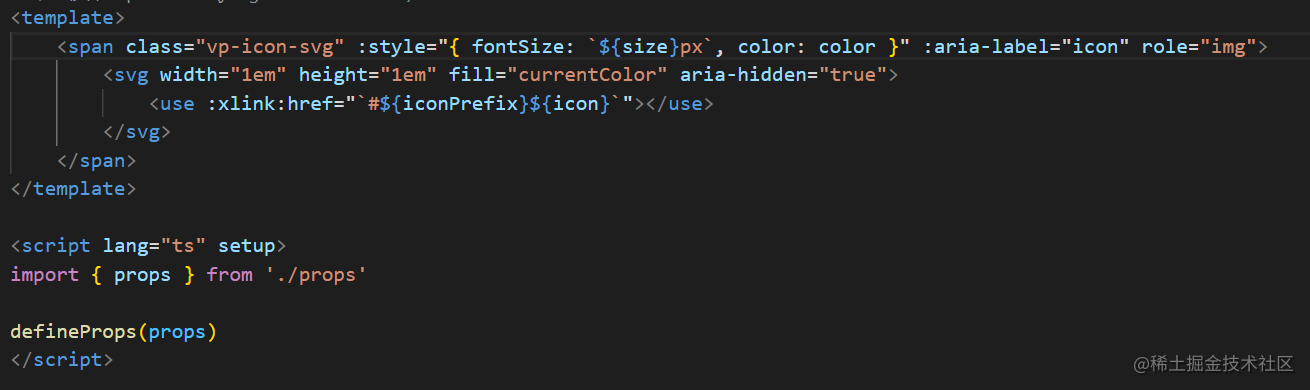\n\n其中样式部分如下:\n\n\n\n这里用到了一个`text-rendering: optimizelegibility;`,对抗锯齿、字体微调等会更友好,具体见[这篇MDN介绍](https://developer.mozilla.org/en-US/docs/Web/SVG/Attribute/text-rendering)。\n\n后面两个属性`-webkit-font-smoothing: antialiased;`和`-moz-osx-font-smoothing: grayscale;`也是对抗锯齿的优化。\n\n而`line-height`设置为`0`,可以消除行高对整个 span 尺寸的影响,使得 svg 的尺寸能准确表现出来。\n\n再次查看效果,发现不传任何属性时,SVG 图标也能与文本效果协调。\n\n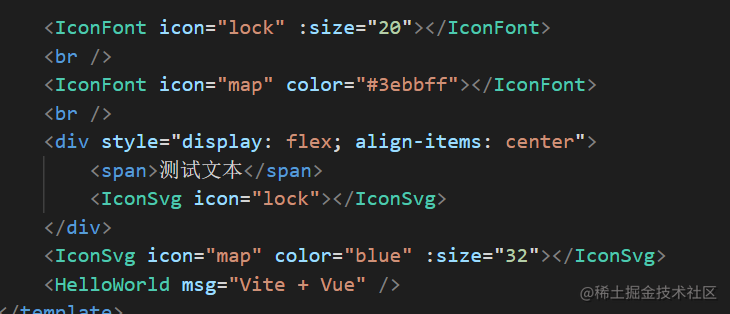\n\n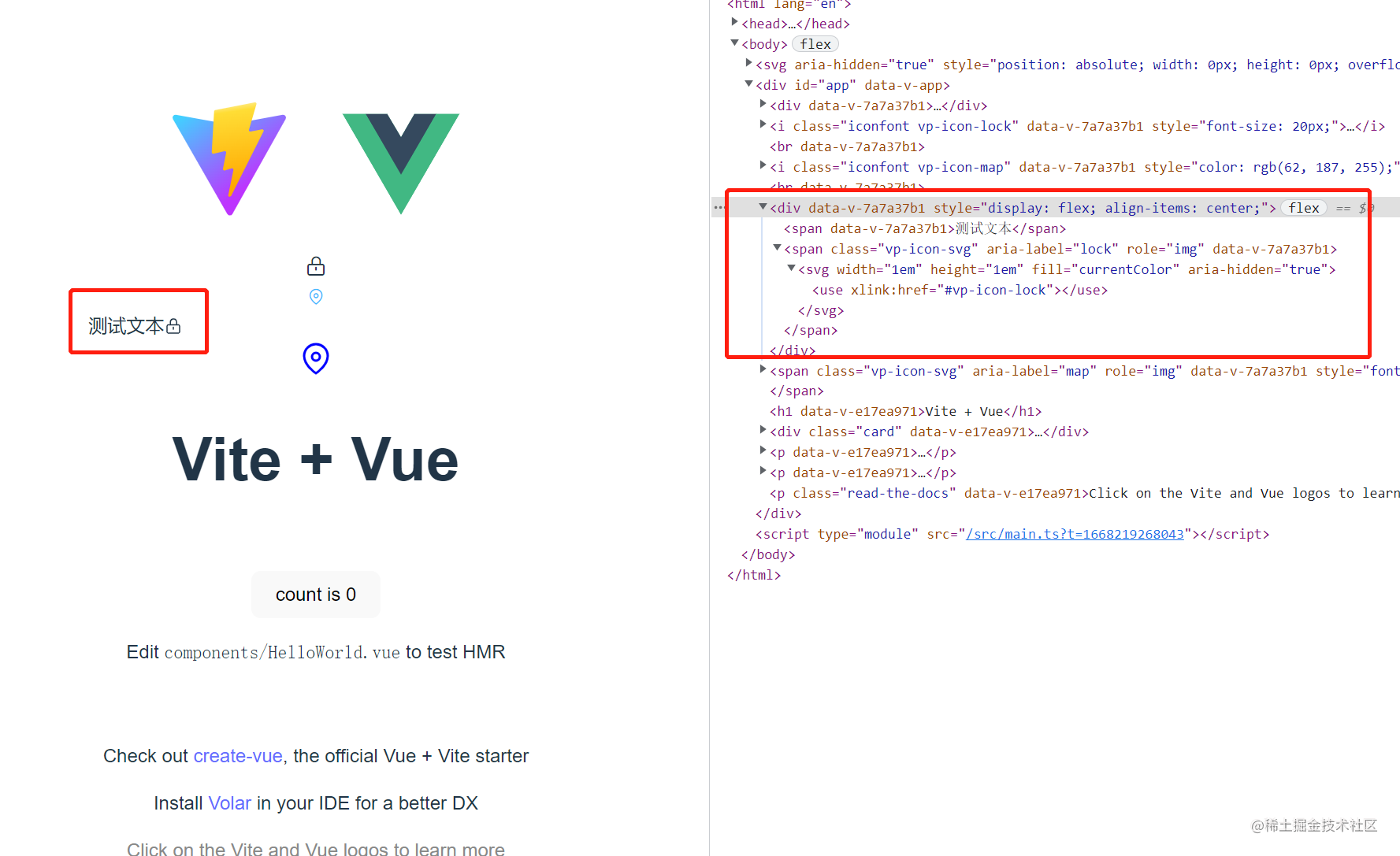\n\n至此,SVG 图标组件已经能应付大部分场景了。\n\n# 参考文献\n\n- [Computer font](https://en.wikipedia.org/wiki/Computer_font)\n- [一种笔划矢量字库的存取方法](https://patents.google.com/patent/CN101957837B/zh)\n\n# 结语\n\n在本节中,我们首先了解了一些字体相关的基础知识,以及使用 SVG 图标的一些优点,接着学习了实现 SVG 图标组件的基本思路和编码过程。本文写作过程中,我有感觉到字体是个很复杂的知识领域,若文中相关知识点叙述有误,还请指出!在实际项目中,对图标组件还会有一些拓展的需求,我们在下篇文章中会具体展开聊聊。如果您对我的专栏感兴趣,欢迎您[订阅关注本专栏](https://juejin.cn/column/7140103979697963045 \"https://juejin.cn/column/7140103979697963045\"),接下来可以一同探讨和交流组件库开发过程中遇到的问题。', '2022-11-24 19:52:15', '2024-08-15 11:00:16', 1, 40, 0, '我们接着上篇的字体图标组件实战,继续探索图标的另一个展现形式 —— SVG 。在开发 SVG 图标组件之前,还有一些问题我们必须搞清楚!', 'https://qncdn.wbjiang.cn/博客素材/994303bb7bcd44fa82f3e3263dc57001~tplv-k3u1fbpfcp-jj-mark:480:480:0:0:q75.avis', 0, 0);
-INSERT INTO `article` VALUES (241, '衍生需求:按钮集成图标组件 & 图标选择器', '> 本文为稀土掘金技术社区首发签约文章,14天内禁止转载,14天后未获授权禁止转载,侵权必究!\n>\n> 专栏上篇文章传送门:[Web 中的字体和 SVG 图标,你了解多少?](https://juejin.cn/post/7163889112364089380)\n>\n> 本节涉及的内容源码可在[vue-pro-components c4 分支](https://github.com/cumt-robin/vue-pro-components/tree/c4)找到,欢迎 star 支持!\n\n# 前言\n\n本文是 [基于Vite+AntDesignVue打造业务组件库](https://juejin.cn/column/7140103979697963045) 专栏第 5 篇文章【衍生需求:按钮集成图标组件 & 图标选择器】,聊聊实际业务中与图标组件相关的一些衍生需求,例如:\n\n- 怎么通过一个简单的`icon`属性就能在`a-button`中用上我们的图标组件?\n- 怎么实现一个可视化的图标选择器?\n\n# 按钮集成图标组件\n\n## 背景介绍\n\n按钮中搭配图标一起用,是再常见不过的场景了。ant-design-vue 的 Button 组件具备自定义图标的能力,具体是通过`icon`插槽实现的。\n\n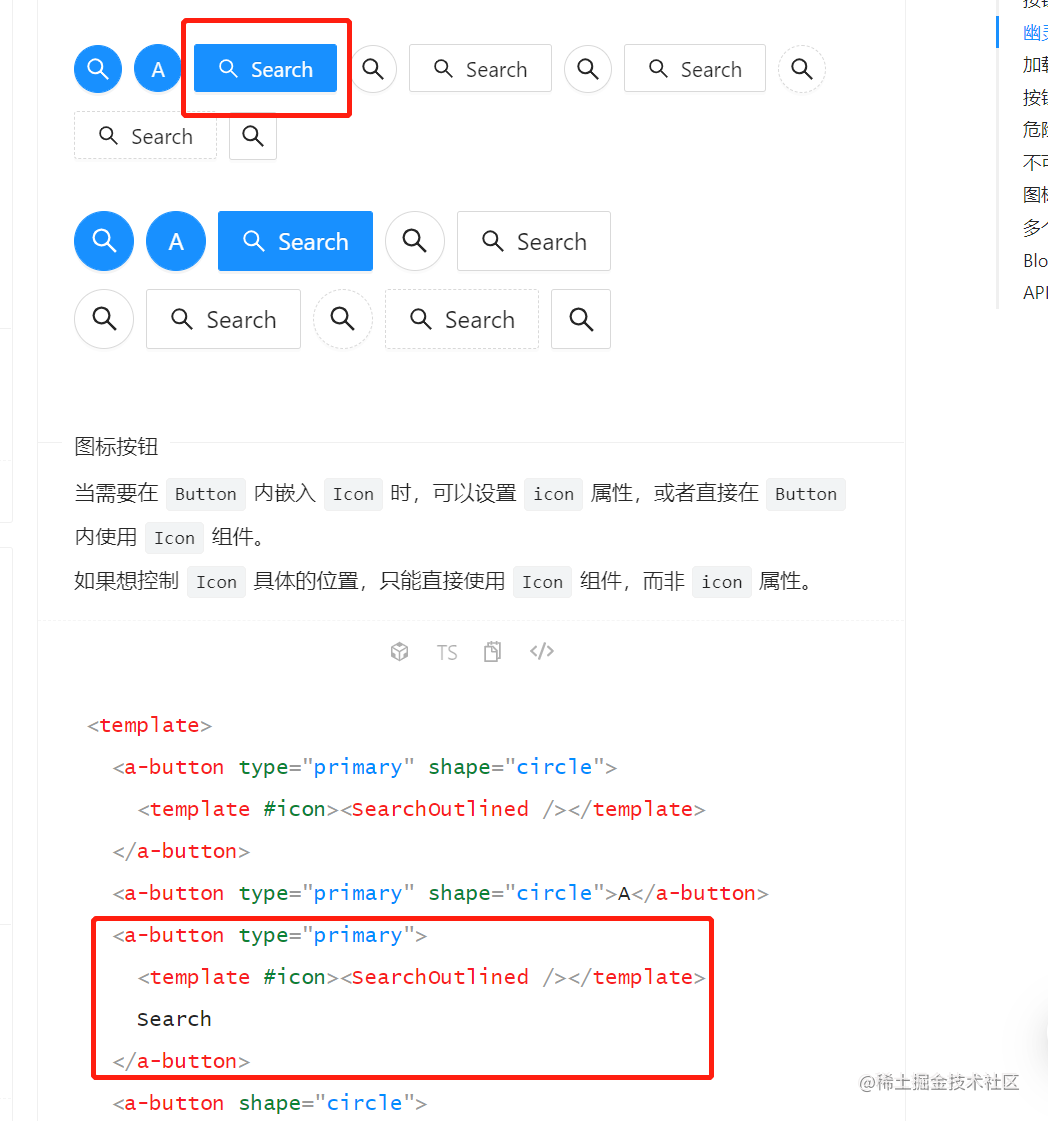\n\n虽然能实现,但是感觉写起来也挺复杂的,代码量不少,那么能不能简化成这样呢?只要通过一个`icon`属性(而不是插槽)就能把图标展示出来呢?最理想的状态是还能同时支持我们自己的业务图标。\n\n```\n// 比较理想的用法\n// 既支持\nSearch \nSearch \n```\n\n事实上,`ant-design-vue`没有支持这种能力。\n\n首先,从字符串到组件,是需要一个解析的过程,这对应`resolveComponent`,简单看下源码,`resolveComponent`内部会调用`resolveAssets`,我们发现,这需要将组件注册好,不管是注册到局部还是全局,都可以。\n\n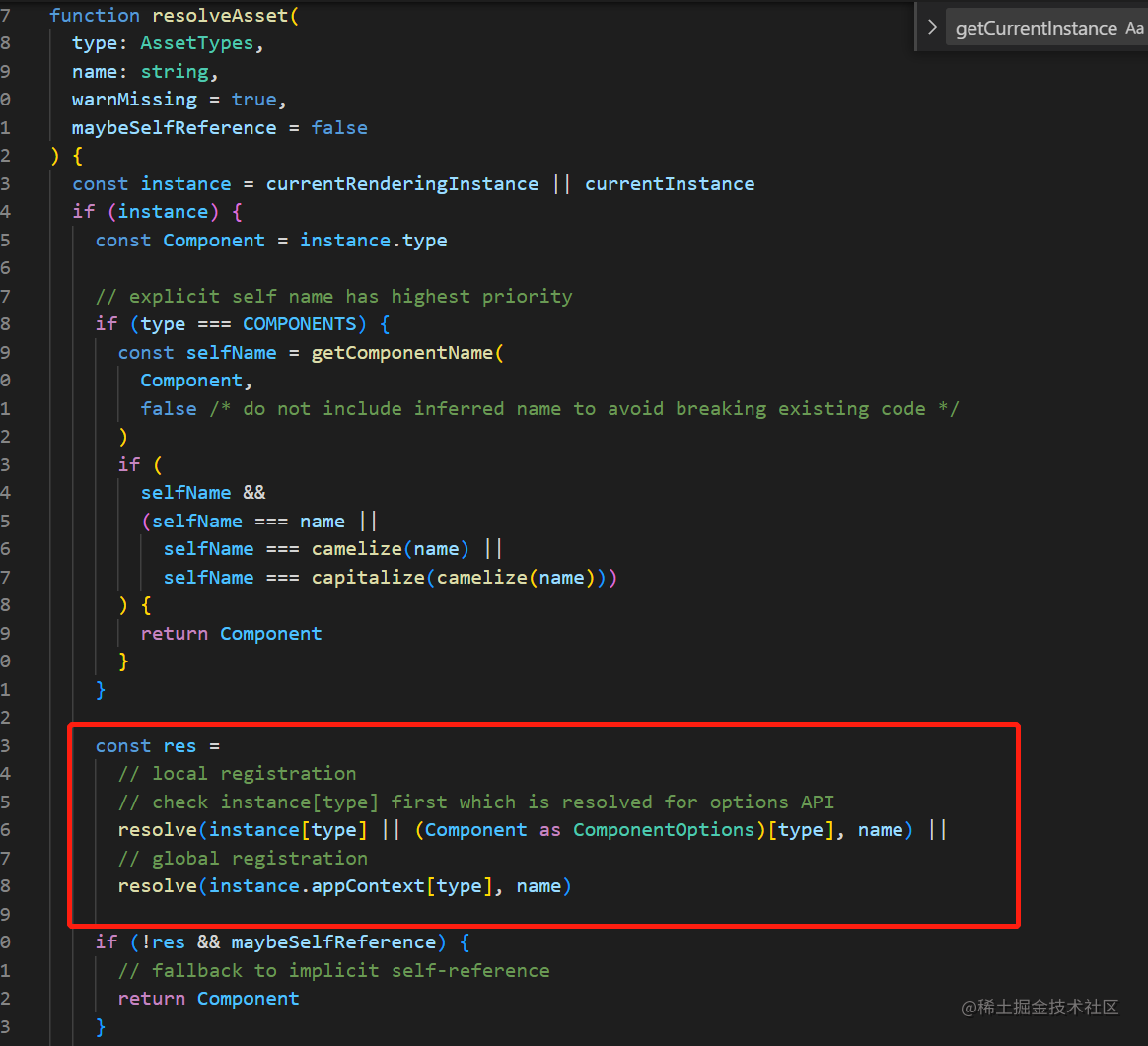\n\n而 ant-design-vue 是一个通用组件库,它提供的图标都是一个个独立的组件,这些组件都在`@ant-design/icons-vue`这个包里。如果要实现字符串到组件的解析能力,就要求把图标组件都提前注册好,这就违背了按需加载的初衷。\n\n另外, ant-design-vue 也要考虑用户自定义图标的场景,所以综合来看留个插槽算是比较合理的做法。\n\n然而,对业务方来说,通常考虑的是:\n\n- **大而全**:能力丰富,既要有原始组件本身的能力,还能增加一些定制的能力;\n- **用起来方便**:提供最简单的用法;\n- **性能过得去**:没有明显的性能负担即可。\n\n那么,我们自己来尝试实现一下这些能力。\n\n## 封装按钮组件\n\n`a-button`我们也不能改,所以,需要先做一个`vp-button`,它既有`a-button`的全部能力,还能支持使用各种图标组件,这样才不至于说封装了一个组件,却牺牲了底层的能力。\n\n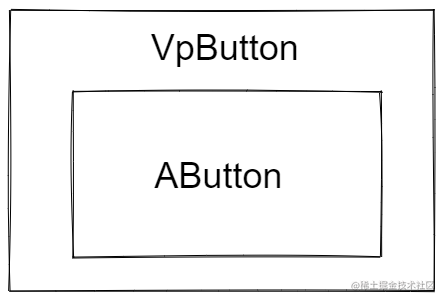\n\n我们首先要考虑的是:AButton 本身有很多属性,那么我们怎么让 VpButton 同样支持这些属性呢?\n\n有两条路子可供选择:\n\n1. 利用`v-bind=\"$attrs\"`透传属性,简单快捷。\n\n2. 将 AButton 支持的 props,都列入 VpButton 的 props 中,然后 VpButton 再原样通过属性绑定传递给 AButton,这样就能保证这些 props 的响应式依然有效。\n\n路子1虽然是最简单的,但是也存在一些问题。在 Vue2 中,因为 patch 过程中的`updateChildComponent`执行时会给`$attrs`重新赋值,这就会导致不管`$attrs`绑定的那部分属性有没有更新过,都会导致其对应的`Watcher`更新。\n\n可以用这个[codesandbox链接](https://codesandbox.io/s/relaxed-mountain-2kk5qq?file=/src/App.vue)测试一下 Vue2 的表现,打断点试试。\n\n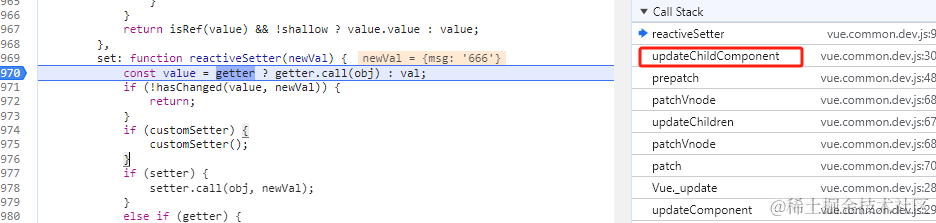\n\n在 Vue2 组件嵌套很深时,如果不合理地使用`$attrs`容易引发一些性能危机,引起某些业务逻辑不必要地执行,最终导致页面卡顿。\n\n那么 Vue3 在这方面的表现如何呢?使用`$attrs`是否也会触发不必要的更新?\n\n我们也开一个[codesandbox链接](https://codesandbox.io/s/sad-cori-2v76w3?file=/src/App.vue)测试一下。经测试,Vue3 此场景下并没有触发不必要的更新。\n\n我们在源码里寻找一下关于`$attrs`的踪迹,发现在 patch 的过程中没有直接给`$attrs`重新赋值的操作,但是有一个`hasAttrsChanged`的判断,仅当`hasAttrsChanged`为`true`时,才会执行`$attrs`的更新操作。\n\n\n\n```js\ntrigger(instance, TriggerOpTypes.SET, \'$attrs\')\n```\n\n这就仅在`$attrs`真正变化的时候才会更新组件,应当是 Vue3 针对此问题的优化。\n\n看起来 Vue3 场景下走路子1也没什么大问题,不过为了后续更方便地生成完整的组件文档,我还是倾向于使用路子2。\n\n路子2是比较靠谱的,但是使用起来很繁琐,需要将 AButton 支持的属性重复定义在 VpButton 中。此外,一旦粗心就可能会遗漏一些属性,这就会导致功能是有缺失的,那么怎么解决这些问题呢?\n\n我的思路是:\n\n1. 想办法把 AButton 的 props 定义取出来,与我们要额外扩展的属性做一个合并,统一作为 VpButton 的 props 定义。这样一来,从外部调用者的视角来看,VpButton 支持的属性就是完整的,给人的直观感觉就是:VpButton 是 AButton 的加强版,我可以放心使用。\n2. 在 VpButton 内部需要封装 AButton,同时要从所有 props 中将属于 AButton 的那部分 props 挑选出来,传递给 AButton,这样对 AButton 来说就是无感的,因为我们传给 AButton 的属性是完全符合要求的。\n\n只要我们封装的 VButton 满足了上面这两点,这个组件就是趋近完美的,它向上对调用者提供了更强大的能力,同时向下又包容了 AButton 的能力。\n\n我们来试试看,大致查阅 ant-desigin-vue 的 Button 组件源码,我们可以发现,AButton 的属性是由这些代码构造出来的。\n\n\n\n\n\n我们新建一个`button/props.ts`文件,尝试一下下面的代码,看看能不能拿到预期的 AButton 属性定义,如果能成功,那就意味着我们就不必一个一个属性地重复定义了,同时也意味着我们得到了一种扩展属性的基本方法。\n\n```\nimport buttonProps from \'ant-design-vue/es/button/buttonTypes\'\nimport { initDefaultProps } from \'ant-design-vue/es/_util/props-util\'\n\nconst _buttonProps = initDefaultProps(buttonProps(), {\n type: \'default\',\n})\n\nconsole.log(_buttonProps)\n```\n\n打印出来发现,这就是我们需要的 AButton 的属性定义:\n\n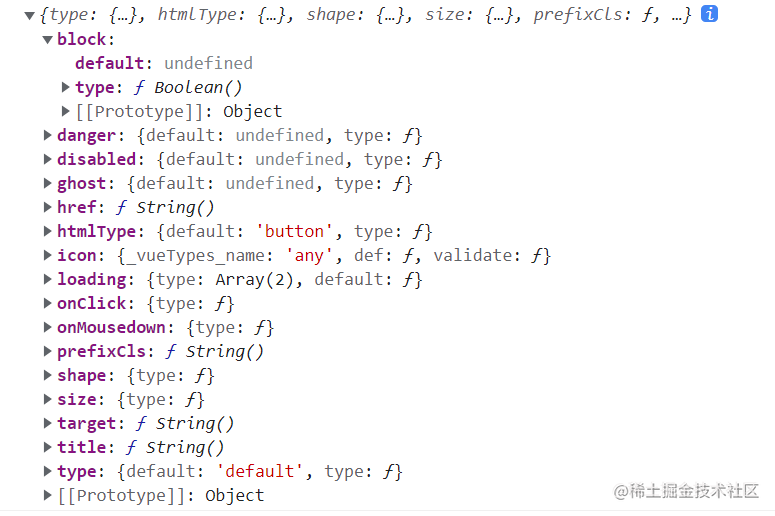\n\n接着我们用一个`enhancedProps`来定义需要扩展的属性,这里先给出以下几个属性:\n\n```typescript\nexport const enhancedProps = {\n // 对应自定义图标的名称\n ico: {\n type: String,\n },\n // 图标的大小\n icoSize: {\n type: Number,\n },\n // 图标颜色\n icoColor: {\n type: String,\n },\n // 按钮主体颜色,影响边框颜色,背景色\n primaryColor: {\n type: String,\n },\n}\n```\n\n用`ico`接收图标名称,是为了避免与`AButton`的`icon`插槽冲突。\n\n然后我们把`_buttonProps`和`enhancedProps`这两部分组成一个完整的`props`。\n\n```typescript\nexport const innerKeys = Object.keys(_buttonProps)\nexport const enhancedKeys = Object.keys(enhancedProps)\n\nexport const props = {\n ..._buttonProps,\n ...enhancedProps,\n}\n\nexport type VpButtonProps = ExtractPropTypes\n```\n\n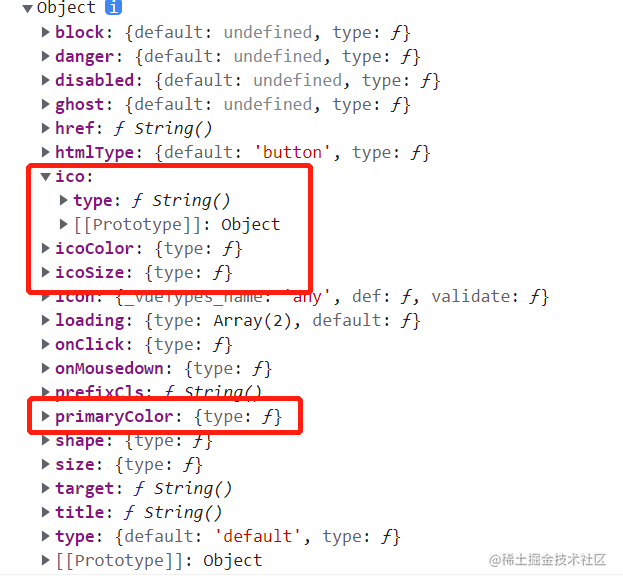\n\n可以发现属性很完整了,其中框起来的部分是我们扩展的属性,剩下的都是 AButton 支持的属性。\n\n接下来就是看怎么使用这些属性了,直接上组件主体代码,这里用了 tsx 实现。\n\n```tsx\nimport { defineComponent } from \'vue\'\nimport { Button } from \'ant-design-vue\'\nimport IconSvg from \'../icon-svg\'\nimport { innerKeys, props as buttonProps } from \'./props\'\nimport { usePickedProps } from \'../hooks/props\'\n\nexport default defineComponent({\n name: \'VpButton\',\n props: buttonProps,\n setup(props, { slots }) {\n // 把属于 AButton 的属性挑选出来,再绑定到 AButton 上\n const innerProps = usePickedProps(props, innerKeys)\n\n return () => (\n (\n <>\n {props.ico && !props.loading ?