通过合理组织数据利用CPU的缓存机制来加快内存访问速度。
我们被骗了。 他们总拿着CPU速度增长的年度报表来让人以为摩尔定律不只是历史观测的结果甚至是某种真理!我们做软件的就这么毫不费力地看着自己的程序光凭着新硬件的优势就莫名地飞奔起来!
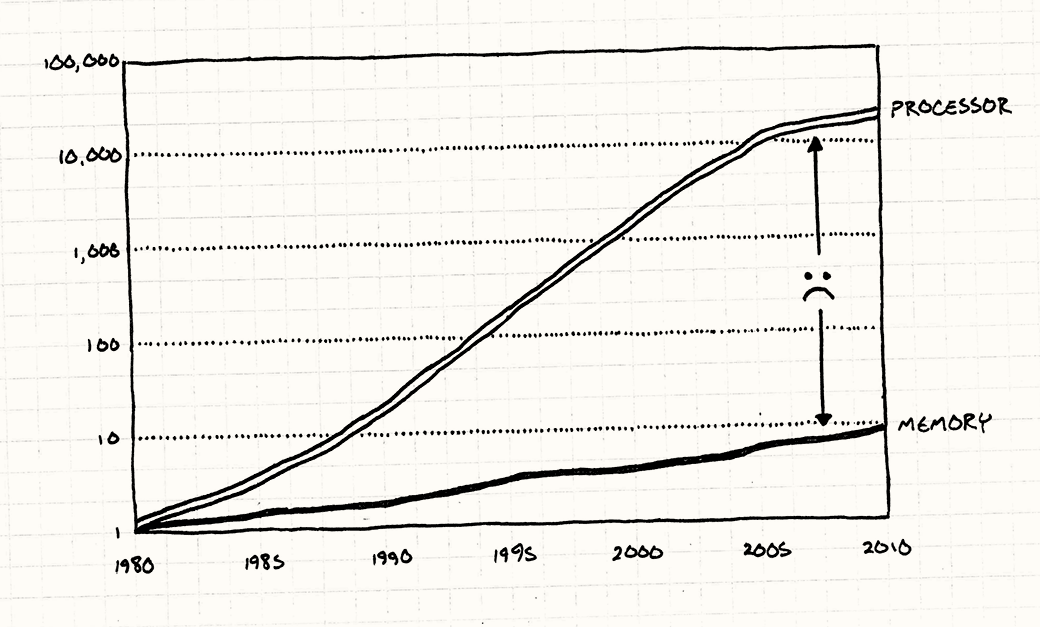
注解: 处理器和RAM的速度分别与它们在1900年的速度有关。如你所见,CPU的速度飞速增长,但RAM访问速度却增长迟缓。上图数据来自John L. Hennessy, David A. Patterson, Andrea C. Arpaci-Dusseau借由Tony Albrecht的“Pitfalls of Object-Oriented Programming”统计于《Computer Architecture: A Quantitative Approach》一书中
为使你超快的CPU进行大量的计算,实际上它需要从主存中取出数据并置入寄存器中。如你所见,RAM的存取速度远远跟不上CPU的速度,根本就没沾过边。
今天的硬件设备可能要花去数百次的循环来从RAM中获取一个字节的数据。加入许多指令需要访问数据,且每次需要数百次循环来获取这数据,要是我们的CPU在等候数据的这段时间里的99%都处于忙碌状态,该怎么办?
实际上,当今的CPU会花去惊人的时间片段来等候内存传输数据,但这也还没糟到谷底。为进行解释,让我们进行一次稍长的比喻吧...
注解: 叫它RAM(随机存储器)的原因是,不同于光盘驱动器,理论上你可以超越其他任何存储介质的速度访问到RAM中任何一块内存数据,你无需担心光盘上需要连续读取的问题——或者至少你至今这么认为。正如我们所将看到的,RAM不再是可以任意地随机访问了
#数据仓库 设想你是一个小办公室里的会计。你的工作是采集一盒子的单子并对它们进行一些核查统计或其他的计算。你需要根据一些晦涩到的会计专业逻辑来对这样的一系列打了标签的盒子进行处理。
注解:我似乎不该拿个自己完全不在行的工作来打比方...
多亏你的努力工作,出色的才能以及进取心,你可以在(比方说)一分钟内完成一个盒子里的所有任务。当然,这里有个小问题。这些盒子都被分别存放于一个一栋楼里的不同地方。为了拿到这些盒子,你必须询问仓储人员来获取这些盒子。他去开来叉车并在过道之间寻找直至找到你想要的那个盒子。
这花了他一整天的时间来取一个盒子。不像你,他很快就要在这个月结束后走人了,这意味着不论你办事效率有多高,你一天只能搞定一个盒子。而你剩余的时间,就只能坐在办公椅上思考自己怎么就干了这样一份吸食灵魂的工作。
某天,一堆工业设计师出现了。他们的任务是提高工作效率,比如提高流水线效率啥的。在观察你工作了几天之后,他们注意到以下几点:
- 往往当你完成某个盒子里的任务时,你所需要的下个盒子就放在仓储间中与这盒子所属的同个架子上。
- 开着叉车来取个小盒子真是蠢哭了。
- 其实在你的办公室角落里有一些空闲的空间。
注解:对刚访问数据的邻近数据进行访问的术语叫做引用局部性。
他们想到了一个聪明的办法。不论何时当你向仓库管理员提出一个盒子的需求时,他将取来一整车的盒子:他为你带来你所要的盒子,并将与它相邻的那些盒子也都一起带来。他并不知道你是否需要他们(当然,基于他的职业道德,能容忍一次搬这么多),他只是尽可能地让盒子填满叉车并带来给你。
他卸下这些盒子并给你。先不管工作所在地的安全性,他把叉车直接开进你的办公室并把盒子都卸到那个空闲的角落里。
现在当你需要一个新盒子时,你首先从你办公室角落的那些盒子里找。假如找到那就太棒了,你只需要几秒的时间把它拿过来然后继续算你的算数。假如一台叉车能容纳50和盒子并且碰巧你所需要的50个盒子都在其中,你就可以完成比从前多50倍的工作了!
但假如你需要的盒子不在叉车里,那你就必须把一个已经处理完的盒子退回去。由于你的办公室只能容纳一车的盒子,所以你的仓管同志会来帮你带回那个盒子并为你带来一个新的。
奇怪的是,上面的过程与当今计算机内CPU的工作原理类似。也许这不太显然,你却扮演者CPU的角色。你的桌面是CPU的寄存器,装着单子的盒子是你所要处理的数据。仓库是你机器的RAM,那个讨厌的仓管员是从主存往寄存器中拉取数据的总线。
假如我在三十年前写这一章,比喻恐怕就此结束。但随着处理器速度的飞跃(以及RAM速度的落后),硬件工程师开始寻找解决方案,而他们想到的就是CPU缓存技术。
当代计算机在其芯片内部的内存十分有限。CPU从芯片中读取数据的速度要快于它从主存中读取数据的速度。它很小,以便于嵌在芯片上,而且由于它使用更快的内存类型(静态RAM或称SRAM),所以更贵。
当代计算机有多级缓存,也就是你所听到的那些“L1”,“L2”,“L3”等等。它们的大小按照其等级递增,但速度也越来越慢。在本章中,我们并不区分缓存的层级(hierarchy),但知道还是有必要的。
这一小块内存被称为缓存(特别地,芯片上的那块叫做你的L1缓存),在我那个啰嗦的比喻里,它的角色就是那装满盒子的叉车。任何时候当你需要RAM中的数据时,它自动将一整块连续的内存(通常在64到128字节)取出来并置入缓存中。这块内存被称为缓存线cache line)。
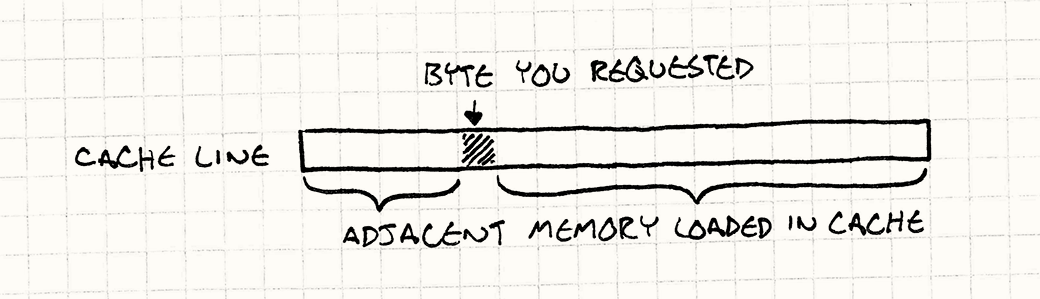
注解: 让我对比喻中的一些细节做下解释。在你的办公室里,仅有能容纳一辆叉车或者说缓存线的空间。实际中的缓存包含了一系列的缓存线。其工作原理在此超纲,但你可以搜索“缓存关联性”来脑补。
当缓存未命中时,CPU就停止运转:它因为缺少数据而无法执行下一条指令。CPU坐在地上进行几百次空循环发呆,直到取得数据。我们的任务就是避免这一情况发生。设想你正试图通过改进一些关键性的游戏代码来提高性能,比如下面这样:
for (int i = 0; i < NUM_THINGS; i++)
{
sleepFor500Cycles();
things[i].doStuff();
}对这段代码你首先可以做些啥?是的,显然循环里的函数调用开销很大。这样的调用等价于缓存未命中带来的性能损失。每次跳入主存中,就意味着往你的代码里塞了一段延时。
着手写这一章时,我花了些时间整理了一些类似游戏的小程序,他们能制造最好和最坏的缓存使用情况。我想为缓存的徒劳无功划定基准,以便能第一时间确知它究竟造成了多少性能损失。
当我对一些程序进行测试时,大为吃惊。我无法形容问题之夸张,耳听为虚眼见为实!我写了两段代码来进行相同的运算,二者唯一的差别在于它们造成的缓存未命中次数不同。而较慢者竟然在速度上比另一段代码慢了50倍!
注解: 你需要注意许多警告。尤其是,不同的计算机有不同的缓存步骤,所以我的机器可能与你的机制不同,而专用的控制台游戏与PC又有很大不同,当然在移动设备上的差别也不言而喻。总之因人而异
这真让我开了眼界。我曾经以为性能是代码的一部分,而非数据。一字节的数据并无快慢之分,它只是一个静态的事物。但由于缓存机制的存在,你组织数据的方式直接影响了性能。
现在的挑战是将上面这些转为本章节的相关内容。对缓存使用的优化是个大话题。我还从没有涉及过指令缓存。请记住,代码也是在内存中的,并且需要被载入到CPU中才能够被执行。那些更精通于这课题的人能够为此写出一整本书来。
注解: 事实上,就有人为此写了本书:Richard Fabian的Data-Oriented Design
不论你是否已经读了这本书,我这介绍一些基本的技巧,以便你在关于数据结构是如何影响程序性能这一问题上展开思考。
这些都可以归结为一件简单的事情:不论芯片何时读取多少内存,它都整块地获取缓存线。这快缓存线你的可用数据越多,程序就跑得越快。所以优化的目标就是将你的数据结构进行组织,以使需要处理的数据对象在内存中两两相邻。
注解: 这里需要一个关键性的假设:单线程。假如你在多线程中对当前数据附近的内存进行修改,如果每个线程在不同的缓存线上处理数据,那么速度会更快,但如果两个线程对同一缓存线上的数据进行改动,那么两条线程上的代码都不得不花些开销来对它们的缓存进行同步。
换句话说,假如你的代码正在处理Thing,接着Another,然后Also这三个数据,你就希望它们在内存里是这样布局的:
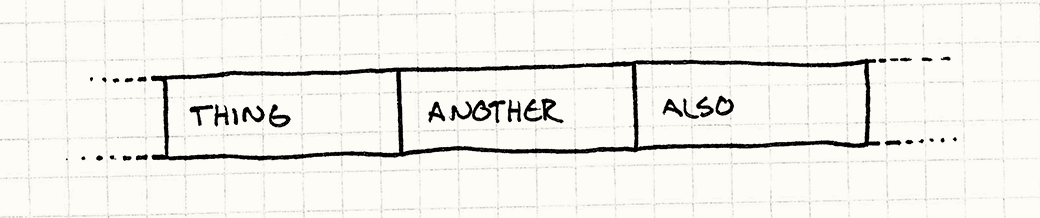
当代CPU带有多级缓存以提高内存访问速度。这一机制加快了对最近访问过的数据其邻近内存的访问速度。通过增加数据区域化来利用这一点以提高性能:保持数据位于连续的内存中以供你的程序进行处理。
如同多数优化措施,指引我们使用数据区域化模式的第一条准则就是找到出现性能问题的地方。不要在那些代码库里非频繁执行的部分浪费时间,它们不需要本模式。对那些非必要的代码进行优化将使你的人生变得艰难——因为结果总是更加复杂且笨拙的。
由于此模式的特殊性,你可能还希望确定你的性能问题是否是由缓存未命中引起的,如果不是,那么这个模式也帮不到忙。
最简单的估算办法就是人为地添加一系列的测量工具以计量一段代码执行所花费的时间,最好能够使用一些精确的计时器。为了获悉缓存的使用情况,你需要一些更复杂的手段——你希望能够确知有多少次的缓存未命中,并对它们进行定位。
幸运的是,有现成的工具来做这些工作。在正式深入你的数据结构前,些时间来架构一个这样的工具并搞懂那些统计数据的含义(相当复杂!)是值得的。
注解: 然而不幸的是这些工具多数十分昂贵。假如你在一个主机游戏开发团队里,大概你已经有这些工具的证书啦。 假如你不在这样的团队里,Cachegrind是个很不错且免费的选择。它将你的程序置于一个虚拟CPU上运行并进行分层级的缓存,最终展示这些缓存的表现。
如前所述,缓存未命中将影响到你的游戏性能。由于你无法花费大量的时间预先对缓存的使用进行优化,是该想想再设计的过程中如何让你的数据结构变得更加缓存友好。
软件架构的一大特征是抽象化。本书的很大一部分讨论的是如何将代码进行分块并对在各个块之间进行解耦,以使它们变得更易于修改。在面向对象的语言中,这往往意味着接口化。
在C++中,使用接口则意味着要通过指针或引用来访问对象。而使用指针进行访问也就是要在内存里这儿那儿地跳转,这就引发了本设计模式在极力规避的缓存未命中现象。
注解: 接口的另一个要点就是虚方法的调用。而这要求CPU检索一个对象的虚表(vtable)并找到表所指向的实际方法以进行函数调用。所以你又得追踪指针了,又要缓存未命中了。
为了做到缓存友好,你可能需要牺牲一些之前所做的抽象化。你越是在程序的数据区域上化下功夫,你就越要牺牲继承,接口以及这些手段所带来的好处。要时刻记得没有银弹(译者注:一句话说就是技术上什么包治百病且立竿见影的良药,参见这里),只有充满着挑战的牺牲与交换。当然拆东墙补西墙也是很有趣的事情!
假如你真的钻研到数据区域化优化的深处,你将发现有无数种办法,将你的数据结构拆解成片段以供CPU更好地进行处理。为了让你知道如何下手,我将在对几个最常见的组织数据的方法各做一个简单的实例。我们将在特定的游戏引擎环境下来完成它们,但(正如其他设计模式一样)要牢记只要符合条件,这一技术在任何情境中都是通用的。
让我们从一个处理一系列游戏实体的游戏循环([Game loop](./03.2-Game Loop.md))开始。每个实体通过组件模式(Component)被拆解为不同的部分:AI,物理,渲染。GameEntity类如下:
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai() { return ai_; }
PhysicsComponent* physics() { return physics_; }
RenderComponent* render() { return render_; }
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};每个组件都包含一系列相关的状态属性,或许是一些向量或矩阵,且组件具有一个更新这些状态的方法。在此其细节并不重要,但我们可以根据这些粗略设想出如下的组件结构:
注解: 正如其名,这些例子正是来自[Update Method](./03.3-Update Method.md)模式。甚至连render()方法也采用这一模式,只是换了个名字而已。
class AIComponent
{
public:
void update() { /* Work with and modify state... */ }
private:
// Goals, mood, etc. ...
};
class PhysicsComponent
{
public:
void update(){ /* Work with and modify state... */ }
private:
// Rigid body, velocity, mass, etc. ...
};
class RenderComponent
{
public:
void render() { /* Work with and modify state... */ }
private:
// Mesh, textures, shaders, etc. ...
};游戏维护一个很大的指针数组,它们包含了对游戏世界中所有实体的引用。每次游戏循环我们需要做以下工作:
1.为所有实体更新AI组件。
2.为所有实体更新其物理组件。
3.使用渲染组件对它们进行渲染。
许多游戏实体将这样进行实现:
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
entities[i]->ai()->update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
entities[i]->physics()->update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
entities[i]->render()->render();
}
// Other game loop machinery for timing...
}在你耳闻CPU缓存机制之前,上面的代码看不出什么毛病。但现在,我想你已经察觉到有些不妥了。这样的代码不仅伤害着缓存,甚至将它来回给搅成了一团浆糊。看看它都干了些啥吧:
1.数组存储着指向游戏实体的指针,因此对于数组中的每个元素而言,我们需要遍历这些指针(所指向的内存)——这就引发了缓存未命中。
2.然后游戏实体又维护着指向自己组件们的指针,再一次缓存未命中。
3.接着我们更新组件。
4.再然后我们回到步骤1,对游戏里每个实体的每个组件都这么干。
最可怕的是我们不知道这些对象在内存中的布局情况,我们完全任由内存管理器摆布。由于实体随着时间被分配、释放,堆空间会倾向于变得随机离散化。
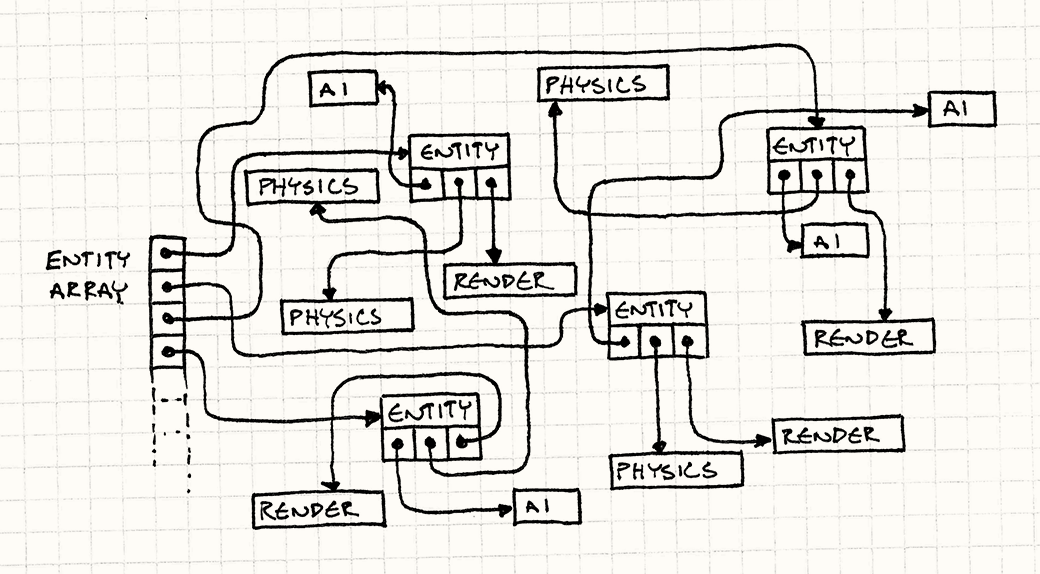
注解: 在每帧里,游戏循环需要把上图所有的箭头都跑一遍来获取它所关心的数据。
假如我们的目标是在游戏地址空间进行快速纵览(比如“256兆RAM的四晚廉价游套餐”!),那还是蛮划算的。然而我们的目标却是让游戏更快地运转,并且在整个主存中游荡可不是个理想的办法。还记得sleepFor500Cycles()这个函数吗?我们上面代码在效率上相当于无时无刻地在调用这家伙!
注解: 在遍历一系列指针上耗费时间,可以用术语”指针雕镂”(pointer chasing)来表述。然而它却没有名字上听起来那么好笑。
让我们做一些改进吧。首先可以发现的是,我们追踪游戏实体的指针是为了找到这个实体内指向其组件的指针以便访问这些组件。GameEntity类本身并没有什么要紧的状态或者方法。游戏循环仅关心这些组件。 为了对这一堆游戏实体以及散乱在地址空间各个角落的组件做改进,我们将从头来过——我们有一个容纳着各类组件的大数组:存放所有AI组件的一维数组,当然还有存放物理和渲染组件的数组,如下:
AIComponent* aiComponents =
new AIComponent[MAX_ENTITIES];
PhysicsComponent* physicsComponents =
new PhysicsComponent[MAX_ENTITIES];
RenderComponent* renderComponents =
new RenderComponent[MAX_ENTITIES];注解: 在关于使用组件模式我最反感的一点就是component这个词的长度...
这里需要强调一下,这些是存储组件的数组而非组件指针的数组。数组里直接包含了所有组件的实际数据,逐个字节地在内存中分布。游戏循环可以直接遍历它们:
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
aiComponents[i].update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
physicsComponents[i].update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
renderComponents[i].render();
}
// Other game loop machinery for timing...
}注解: 我们会注意到在新的代码里我们已经不再使用”->”操作符,假如你希望增强数据的区域性,就尽可能想办法去掉那些间接性的(尤其是指针的)操作吧。
我们抛弃了所有指针跟踪。我们采用直接对三个连续数组进行遍历的办法来取代在内存中进行跳跃性的访问。
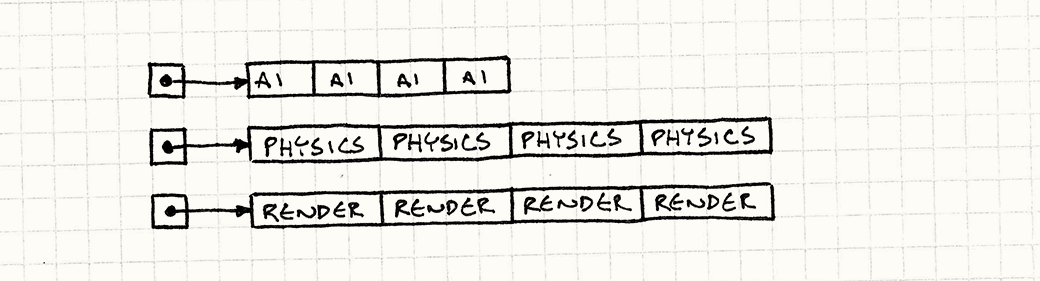
有趣的是,我们这么做并没有放弃太多的封装性。当然,现在游戏循环直接对组件进行遍历更新而不是通过遍历游戏实体,但在此之前它还是必须遍历游戏实体来确保它们是按照正确的顺序被更新的。尽管如此,每个组件本身依然具有很好的封装性。它持有自身的数据和方法。我们只是改变了使用它的方式而已。
这也并不意味着我们需要放弃GameEntity类。我们可以将它放在一边,并保持它身上对组件的那些指针。它们只是指向这三个数组而已。而当你在游戏的其他部分中需要传入一个类似游戏实体概念的对象及其所有内容时,依然可以使用它们。重要的是减少了性能开支的游戏循环避开了这些游戏实体而直接访问了其内部的数据。
假设我们在制作一个粒子系统。顺着上一部分的思路,我们将所有的粒子置入一个大的连续数组中,我们也将它做成一个类来看看:
注解:
ParticleSystem类是根据[Object Pool](./06.3-Object Pool.md)模式为某个类型的对象集合创建的类。
class Particle
{
public:
void update() { /* Gravity, etc. ... */ }
// Position, velocity, etc. ...
};
class ParticleSystem
{
public:
ParticleSystem()
: numParticles_(0)
{}
void update();
private:
static const int MAX_PARTICLES = 100000;
int numParticles_; Particle particles_[MAX_PARTICLES];
};同时粒子系统的一个简单的更新方法如下:
void ParticleSystem::update()
{
for (int i = 0; i < numParticles_; i++)
{
particles_[i].update();
}
}但实际上我们并不需要总是更新所有的粒子。粒子系统维护一个固定大小的对象池,但它们并不总是同时都被激活而在屏幕上闪烁。下面的方法会更加合适:
for (int i = 0; i < numParticles_; i++)
{
if (particles_[i].isActive())
{
particles_[i].update();
}
}我们赋予Particle类一个标志来表示其是否处于激活状态。在更新循环中,我们挨个粒子地检查其标志。这使得该标志随着对应粒子的其他数据一起被加载到缓存中。假如粒子并未被激活,那么我们就跳向下一个。这时将该粒子的其他数据加载到缓存中就是一种浪费。
活跃的粒子越少,我们就会越多次地在内存中跳转。假如粒子数组太大而活跃的粒子又太少,我们就回到了浪费缓存的起点。
将对象存入连续的数组,但我们实际处理的那些对象却并不连续时,这个办法就无效了。假如为了这些非活跃的粒子而要在内存中跳来跳去,那么我们就回到了问题的起点。
注解: 懂得底层编程的人也许能看到更多的问题。为所有的粒子执行if判断将会引发CPU的分支预测失准和流水线停顿。当代CPU中,单条指令实际上需要好几次时钟周期来完成。为了让CPU保持忙碌,指令被处理成流水线模式以便多条指令可以被并行地处理。
为实现流水线模式,CPU必须猜测哪些指令接下来将会被执行。在顺序结构的代码中这很简单,但在控制流结构中,就麻烦了。当它执行相关的if语句时,它该猜测粒子是处于激活状态继而为其调用update()方法呢,还是猜测它未被激活而跳过它呢?
为了回答这个问题,芯片就进行分支预测——它分析前一次你的代码走向,然后猜想嗯这次也该这么走。但要是这些粒子按顺序一个激活一个未激活穿插地排列,那么预测就总是失败。
当预测失败时,CPU要对先前投机执行的指令进行撤销(流水线清理)并重新执行正确的指令,这样的性能损耗在计算机运转过程中是很常见的,而这也是为什么你有时也会看到开发者们在关键代码中避开控制流语句。
再看看这小节的标题,我想你可能已经猜到了答案。我们将根据这个标志对粒子进行排序,而不是去判断这些标志。我们总是将那些被激活的例子维持在列表的前端。假如我们知道它们都处于激活状态,就根本不必去检测标志了。
我们也可以时刻跟踪被激活粒子的数目。这样我们就可以美化一下代码了:
for (int i = 0; i < numActive_; i++)
{
particles[i].update();
}现在我们不跳过任何数据。每个塞进缓存的粒子都是被激活的,也都正是我们要处理的。
当然我可没说你得在每帧对整个粒子集合进行快速排序,这样是得不偿失的。我们希望的是时刻保持数组有序。
假设数组已经排好序——并且一开始所有的粒子都处于非激活状态。数组仅当某个粒子被激活或者反激活时处于乱序状态。我们很容易就能对这两种情况进行处理:当粒子被激活时,我们通过把它与数组中第一个未激活的例子进行交换来将其移动到所有激活粒子的末端:
void ParticleSystem::activateParticle(int index)
{
// Shouldn't already be active!
assert(index >= numActive_);
// Swap it with the first inactive particle
// right after the active ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
// Now there's one more.
numActive_++;
}反激活粒子就只要反其道而行之:
void ParticleSystem::deactivateParticle(int index)
{
// Shouldn't already be inactive!
assert(index < numActive_);
// There's one fewer.
numActive_--;
// Swap it with the last active particle
// right before the inactive ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
}许多程序员(包括我在内)都很厌恶在内存中移动数据。把内存里的字节移来移去让人觉得比为指针分配内存开销更大。但当你再加上遍历指针的开销时,会发现我们的直觉有时会失灵。在某些情况下,假如你能保持缓存数据满,在内存中移动数据的开销是很小的。
注解: 这将是当你做这类决定时可以参考的一个贴士
结论就是,我们可以保持粒子依照其激活状态有序,而无需保存激活状态本身。这可以通过粒子在数组中的位置和numActive_计数器来确定。这使得我们的粒子结构变小,也就意味着缓存线上能存储更多数据,从而提高速度。
当然并非万事都称心如意。正如你从API文档中看到的,我们在此放弃了许多面向对象的思想。Particle类不再控制其自身的状态,你也无法对粒子对象调用诸如activate()之类的方法因为它确定自身在数组内的索引(即无法确定自身激活状态)。而所有与激活粒子相关的代码都必须通过粒子系统来执行。
对于这样的情况,我倒是不介意ParticleSystem和Particle之间的紧关联。概念上我将它们视为由两个物理类组成的一个整体。当然这么说来,喷射和销毁粒子都是粒子系统的工作。
这是最后一个帮助你代码变得缓存友好的技术案例。假设我们为某个游戏实体配置了AI组件,其中包含了一些状态:它当前所播放的动画,它当前所走向的目标位置,能量值等等...总之这些是它在每帧都要检查和修改的量。如下:
class AIComponent
{
public:
void update() { /* ... */ }
private:
Animation* animation_;
double energy_;
Vector goalPos_;
};而它还存储着一些并非每帧都用到的处理意外情况的量。比如存储一些关于当这家伙被开枪打死后掉落宝物的数据。掉落数据仅仅在实体的生命周期结束时才被使用,我们将其置于上面的那些状态属性之后:
class AIComponent
{
public:
void update() { /* ... */ }
private:
// Previous fields...
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};假设我们采用前述方法,当更新这些AI组件时,我们遍历一个已经包装好,且连续的数组中的数据。然而这些数据中包含着所有的掉落信息。这使得每个组件都变得更庞大,也就导致我们在一条缓存线上能放入的组件更少。我们将引发更多的缓存未命中,因为我们遍历的总内存增加了。对每帧的每个组件,其掉落物品的数据都要被置入缓存,尽管我们根本不会去碰它们。
对此问题的解决办法我们称之为”热/冷分解”。其思路为将我们的数据结构划分为两部分。第一个部分为“热数据”,也就是我们每帧需要用到的数据,另一部分为”冷数据”,也就是并不会被频繁用到的那些剩余的数据。
这里我们的热数据为主AI组件。它是我们处理的关键,所以我们不希望通过指针来访问它。冷组件可以放到一边,但我们还是需要访问它,所以就为它分配一个指针,如下:
class AIComponent
{
public:
// Methods...
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_;
};
class LootDrop
{
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};现在当我们遍历AI组件时,载入到缓存中的那些数据就是我们实际要处理的(当然指向冷数据的那部分的指针是一个小小的意外)
注解: 可以通过维护两个平行的数组分别存放冷热数据,来抛弃这个指针,接着我们可以让两个数组中同一组件的索引保持一致,以便通过热数据数组的索引来访问对应的冷数据
然而你将会开始对冷热觉得有些模糊。我这里的例子其数据的冷热之分是明显的,但实际游戏中很少有这样鲜明的划分。如果某些实体在某个模式下需要这部分数据而在其他模式下无需这些数据该怎么办?或者它们只是在某个等级阶段使用这些数据呢?
做这样的优化就像是在挖老鼠洞和黑色艺术之间徘徊。我们很容易花费大量陷在对数据与速度的测试上,但要相信你的努力总会换来收获的。
这种设计模式更适合叫做一种思维模式。它提醒着你,数据的组织方式乃是游戏性能的一个关键部分。这一块的实际拓展空间很大,你可以让你的数据区域化影响到游戏的整个架构,又或者它只是应用在一些核心模块的数据结构上。
对这一模式的应用,你最需要关心的就是该何时何地使用它。而随着这个问题我们也会看到一些新的顾虑。
注解: Noel Llopis在他的著作中称此为”面相数据的设计模式”,这让许多人开始思考如何在游戏中利用缓存。
就这一点,我们此前避开了子类进程和虚方法,并假设我们已经将同质的对象都很好地置入了数组,此时我们知道它们每个的尺寸都一样大。然而多态和方法的动态调用也是非常有用的工具,我们如何来在二者之间进行协调?
-
避开继承
最简单的方法就是避开子类化,或者说至少在你进行缓存优化的地方避开继承。软件工程中也较为排斥重度的继承。
注解: 如果想避开子类继承而保持多态的灵活性,那么可以使用[Type Object](./04.3-Type Object.md)模式。
-
这安全而容易。你知道自己正在处理什么类,而且显然所有的对象其尺度都是一样的。
-
这样速度很快。方法的动态调用意味着在vtable中寻找实际需要调用的方法,并通过指针来访问实际代码,由于此操作在不同硬件平台呈现很大的性能差异,故动态调用意味着一些开销。
注解: 当然还是那句话,反事没有绝对。在许多情况下,c++编译器需要使用间接引用来调用一个虚函数。但在某些情况下,当编译器知道调用者的确切类型时,它会进行非虚拟化来静态调用正确的方法。非虚拟化在诸如Java和JavaScript这类实时编译语言中更为常见。
- 这样灵活性差。当然,我们使用方法动态调用的原因正是在于它能够给与我们强大的对象多态能力,让对象表现出不同的行为。假如你希望游戏中的不同实体拥有各自的渲染风格或者特殊的移动与攻击等表现,虚方法正是为此而准备的。想要避免使用虚方法而做到这一点,那你可能就要维护一个庞大的switch逻辑块,很快你就会陷入混乱。
-
-
为不同的对象类型使用相互独立的数组。
我们使用多态来实现在对象类型未知的情况下调用其行为。换句话说,我们有个装着一堆对象的包,我们希望当我们一声令下时它们能够各做各的事情。但这带来的问题是,为什么从一个龙蛇混杂的背包开始,而不是维护一系列按照类型分放的集合?
-
这样的一系列集合让对象紧密地封包。由于每个数组仅包含一个类型的对象,也就不存在填充或者其他古怪了。
-
你可以进行静态的调用分发。你能按照类型将对象划分,也就不再需要多态了,你可以进行常规的,非虚的方法调用。
-
你必须时刻追踪这些集合。假如你有许多不同类型的对象,那么逐个维护这些数组集合的繁杂工作将是复杂而代价高昂的。
-
你必须注意每一个类型,由于你要维护每个类型的对象集合,你无法从这些类型集合中解耦它们。多态的一个神奇作用就在于它是可扩展的,通过使用接口来进行外部操作,多态将调用这些接口的代码从潜在的那些类型(它们均实现这一接口)中完全地解耦出来。
-
-
使用指针集合
假如你不担心缓存的性能,那么这自然是个好办法。你只需维护一个指向基类或接口的指针数组,你可以很好地利用多态性,而且对象的大小也无须一致。
-
这样做灵活性高。只要能适配接口,访问这个集合的代码就能够处理你关心的任何类型的对象。这是完全可扩展的。
-
这样做并不缓存友好。当然,我们在此讨论其他方案的原因就在于解决这样指针间接访问数据的缓存不友好局面,然而请记住,如果这些代码并不对性能苛求,使用多态是完全没问题的。
-
假如你将本模式与Component模式一起使用,你将会拥有一系列相邻的组件数组来组成你的游戏实体。游戏循环直接对组件数组进行迭代,也就是说实体本身是不重要的,当然在游戏的其他代码模块你还是可能会需要这些概念性的实体。
接下来问题是这该如何表现?实体如何跟踪自己的组件?
-
假如游戏实体通过类中的指针来索引其组件:
我们的第一个例子看起来就是如此。这是相对普通的面向对象的办法。你有一个GameEntity类,而它内部有指向其组件的指针。由于它们只是指针,故它们并不知道那些组件在内存中的确切位置或者它们是如何组织的。
-
你可以将组件存于相邻的数组中。由于游戏实体并不关心组件的存储,你可以将它们组织到一个封包过的数组中来对迭代过程进行优化。
-
对于给定实体,你可以很容易地获取它的组件。只需通过指针访问即可。
-
这样在内存中移动组件很困难。当组件被启用或禁用时,你可能会希望将这些组件进行移动以保持那些激活的组件总排在数组的前端并彼此相邻。假如你移动一个与某实体通过裸指针关联的组件,你可能一不小心就会弄坏这一指针关联。你必须确保同时对实体的相应指针进行更新。
-
-
假如游戏实体通过一系列ID来索引其组件:
- 在内存中移动指向组件的裸指针是一大挑战。你可以使用更抽象的表示来取代指针:一个能够检索到指定组件的ID或索引。
ID的实际语义以及索引的过程完全取决于你。可能是简单地为每个组件存储一个唯一ID并进行数组遍历,也可能是在一个哈希表上将ID对组件所在的数组索引进行映射。
-
这更加地复杂。你的ID系统无需做到过度复杂,但总得比直接使用指针要麻烦。你需要实现并调试它,当然用id记录也需要额外的内存空间。
-
这样做更慢。要想比遍历裸指针速度更快是很难的。通过实体获取其组件的过程将涉及到哈希查找等问题。
-
你需要访问组件管理器。最简单的想法就是用一些抽象的ID来定义组件。你可以通过它来获取到实际的组件对象。但为了做到正确索引,你必须让这些id有办法对应到组件上。这也就是存储着你组件数组的那个管理类所要做的。
使用裸指针,假如你有一个游戏实体,你就可以找到其组件。而使用ID的方法,你则需要同时对游戏实体和组件进行注册。
注解: 你可能会想,我只需要写个单例就完事了!嗯,只能说部分情况是的。你可以先点开这篇文章看看。
-
假如游戏实体本身就只是个ID
这是一些新的游戏引擎所采用的风格。一旦你将你游戏实体的所有行为和状态从主类移动到组件中,那游戏实体还剩什么呢?结果是剩不了什么,游戏实体唯一做的就是将自己与其组件绑定。它的存在就意味着其AI,物理和渲染组件构成了这个游戏世界中的实体。
这一点很重要,因为组件之间要进行交互。渲染组件需要知道实体位于何处,而这个位置信息就很可能位于其物理组件中。AI希望移动实体,于是它需要对物理组件施加一个力。在一个实体内,需要为每个组件提供一个访问其兄弟组件的办法。
某些聪明人意识到我们所需要的就是个ID。这使得组件能知道它所属的实体是哪个,而不是让实体来确定其组件位置。当AI组件需要其同属实体的物理组件时,它只需访问与自身相同实体ID的那个物理组件即可。
- 你的游戏实体类完全消失了,取而代之的是一个优雅的数值包装。
实体变得很小。当你需要传入一个实体的引用时,你只需传入一个数值。
实体类本身是空的。当然这一方法的负面是你必须把所有东西都扫出游戏实体。你不再有地方来存放那些非组件构成的实体状态和行为。这样做更加依赖于Component模式。
-
你无须管理其生命周期。由于现在实体只是某些内置类型的值,它们无需进行显式的分配或释放。实际上当某个实体的所有组件都销毁时,这个实体也就随之自动消失了。
-
检索一个实体的所有组件会很慢。这与前一个方案的问题类似,但处于相反的一面。为某个实体寻找其组件,你需要对一个对象进行ID映射,这个过程会带来开销。
-
这一次性能方面也存在着问题。组件在更新过程中频繁与其兄弟组件交互,于是你需要频繁地检索组件。一个解决方案是将实体的ID对应为其组件所在数组的索引。
假如所有的实体都包含相同的组件集,那么你的组件数组之间是完全平行的。AI组件数组中的第三个组件将与物理组件数组中的第三个组件对应着同一个实体。
请牢记,这个办法迫使你保持这些数组平行。当你希望对数组进行排序或者按照某种规则进行封包时就很难做到平行了,你的某些实体可能禁用了物理引擎,而其他的实体不可见。在保持它们平行的情况下,你无法兼顾物理组件和渲染组件来同时满足这两种情况。
- 本章节的许多内容涉及到Component模式,而此模式中的数据结构是在优化缓存使用时几乎最常用的。事实上,使用组件模式使得这一优化更加简单。因为实体一次只是更新他们的一个域(AI模块,物理模块等等),将这些模块划分为组件使得你可以将一系列实体合理地划为缓存友好的几部分。
- 但这并不意味着你只能选择组件模式实现本模式!不论何时你遇到涉及大量数据的性能问题,考虑数据的区域化都是很重要的。
- Tony Albrecht著的“Pitfalls of Object-Oriented Programming”一书大概是介绍关于游戏内数据结构设计来实现缓存友好性的材料中最被广泛阅读的了。它使得许多人(包括我!)意识到这样对数据结构的设计是多么地重要。
- 与此同时,Noel Llopis就同一话题撰写了一篇广为流传的博客。
- 本设计模式几乎完全地利用了一个同类型对象的连续数组。随着时间流逝,你将会往这个数组中添加和移除对象。[Object Pool](./06.3-Object Pool.md)模式恰恰阐释了这一内容。
- Artemis游戏引擎是首个也是最为知名的对游戏实体使用简单ID的框架。