 +
+# COMMAND ----------
+
+from databricks import agents
+import mlflow
+
+# Connect to the Unity Catalog model registry
+mlflow.set_registry_uri("databricks-uc")
+
+# Configure UC model location
+UC_MODEL_NAME = f"catalog.schema.db_docs_agent" # REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
+assert (
+ UC_MODEL_NAME != "catalog.schema.db_docs_agent"
+), "Please replace 'catalog.schema.db_docs_agent' with your actual UC catalog and schema."
+
+# Register the Llama 70b version to Unity Catalog
+uc_registered_model_info = mlflow.register_model(
+ model_uri=model_info_llama_70b.model_uri, name=UC_MODEL_NAME
+)
+# Deploy to enable the review app and create an API endpoint
+deployment_info = agents.deploy(
+ model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC # Step 5. Deploy to production and monitor
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I host my agent as a production ready, scalable service?
+# MAGIC - How do I execute tool code securely and ensure it respects my governance policies?
+# MAGIC - How do I enable telemetry or observability in development and production?
+# MAGIC - How do I monitor my agent’s quality at-scale in production? How do I quickly investigate and fix any quality issues?
+# MAGIC
+# MAGIC With Agent Framework, production deployment is the same for pre-production and production - you already have a highly scalable REST API that can be intergated in your application. This API provides an endpoint to get agent responses and to pass back user feedback so you can use that feedback to improve quality.
+# MAGIC
+# MAGIC To learn more about how monitoring works (in summary, Databricks has adapted a version of the above UIs and LLM judges for monitoring), read the documentation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/evaluating-production-traffic.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/evaluating-production-traffic)) or watch this [2 minute video](https://www.youtube.com/watch?v=ldAzmKkvQTU).
diff --git a/quick_start_demo/Mosaic AI agent demo - bring your own data.py b/quick_start_demo/Mosaic AI agent demo - bring your own data.py
new file mode 100644
index 0000000..697ffa9
--- /dev/null
+++ b/quick_start_demo/Mosaic AI agent demo - bring your own data.py
@@ -0,0 +1,681 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC # Create, evaluate, improve, and deploy an AI agent with your own data
+# MAGIC
+# MAGIC This notebook demonstrates how to use your own data with Mosaic AI to evaluate and improve the quality, cost, and latency of a tool-calling agent. It also shows you how to deploy the resulting agent to a web-based chat UI.
+# MAGIC
+# MAGIC Using Mosiac AI Agent Evaluation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/index.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/)), Agent Framework ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/build-genai-apps.html) |[Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/build-genai-apps)), MLflow ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/log-agent.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/log-agent)) and Model Serving ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/deploy-agent.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/deploy-agent)), this notebook:
+# MAGIC
+# MAGIC 1. Generates synthetic evaluation data from a document corpus.
+# MAGIC 2. Creates a tool-calling agent with a retriever tool.
+# MAGIC 3. Evaluates the agent's quality, cost, and latency across several foundational models.
+# MAGIC 4. Deploys the agent to a web-based chat app.
+# MAGIC
+# MAGIC ## Technical requirements
+# MAGIC * Use serverless compute or a cluster running Databricks Runtime 14.3 or above.
+# MAGIC * Databricks Serverless and Unity Catalog enabled.
+# MAGIC * CREATE MODEL access to a Unity Catalog schema.
+# MAGIC * Permission to create Model Serving endpoints.
+# MAGIC
+# MAGIC ## Data requirements
+# MAGIC To use this notebook, you need:
+# MAGIC 1. A Delta Table containing your parsed documents
+# MAGIC 2. A Delta Sync Managed Embedding Vector Search index with your chunked/embedded documents
+# MAGIC
+# MAGIC If you don’t have these data requirements already set up, you can run the standalone version of this notebook. The standalone version uses a sample corpus of data and doesn't require a pre-configured Vector Search index or Delta Table ([AWS](https://docs.databricks.com/generative-ai/tutorials/agent-framework-notebook.html) | [Azure](https://learn.microsoft.com/azure/databricks/generative-ai/tutorials/agent-framework-notebook)).
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+from databricks import agents
+import mlflow
+
+# Connect to the Unity Catalog model registry
+mlflow.set_registry_uri("databricks-uc")
+
+# Configure UC model location
+UC_MODEL_NAME = f"catalog.schema.db_docs_agent" # REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
+assert (
+ UC_MODEL_NAME != "catalog.schema.db_docs_agent"
+), "Please replace 'catalog.schema.db_docs_agent' with your actual UC catalog and schema."
+
+# Register the Llama 70b version to Unity Catalog
+uc_registered_model_info = mlflow.register_model(
+ model_uri=model_info_llama_70b.model_uri, name=UC_MODEL_NAME
+)
+# Deploy to enable the review app and create an API endpoint
+deployment_info = agents.deploy(
+ model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC # Step 5. Deploy to production and monitor
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I host my agent as a production ready, scalable service?
+# MAGIC - How do I execute tool code securely and ensure it respects my governance policies?
+# MAGIC - How do I enable telemetry or observability in development and production?
+# MAGIC - How do I monitor my agent’s quality at-scale in production? How do I quickly investigate and fix any quality issues?
+# MAGIC
+# MAGIC With Agent Framework, production deployment is the same for pre-production and production - you already have a highly scalable REST API that can be intergated in your application. This API provides an endpoint to get agent responses and to pass back user feedback so you can use that feedback to improve quality.
+# MAGIC
+# MAGIC To learn more about how monitoring works (in summary, Databricks has adapted a version of the above UIs and LLM judges for monitoring), read the documentation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/evaluating-production-traffic.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/evaluating-production-traffic)) or watch this [2 minute video](https://www.youtube.com/watch?v=ldAzmKkvQTU).
diff --git a/quick_start_demo/Mosaic AI agent demo - bring your own data.py b/quick_start_demo/Mosaic AI agent demo - bring your own data.py
new file mode 100644
index 0000000..697ffa9
--- /dev/null
+++ b/quick_start_demo/Mosaic AI agent demo - bring your own data.py
@@ -0,0 +1,681 @@
+# Databricks notebook source
+# MAGIC %md
+# MAGIC # Create, evaluate, improve, and deploy an AI agent with your own data
+# MAGIC
+# MAGIC This notebook demonstrates how to use your own data with Mosaic AI to evaluate and improve the quality, cost, and latency of a tool-calling agent. It also shows you how to deploy the resulting agent to a web-based chat UI.
+# MAGIC
+# MAGIC Using Mosiac AI Agent Evaluation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/index.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/)), Agent Framework ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/build-genai-apps.html) |[Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/build-genai-apps)), MLflow ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/log-agent.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/log-agent)) and Model Serving ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/deploy-agent.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/deploy-agent)), this notebook:
+# MAGIC
+# MAGIC 1. Generates synthetic evaluation data from a document corpus.
+# MAGIC 2. Creates a tool-calling agent with a retriever tool.
+# MAGIC 3. Evaluates the agent's quality, cost, and latency across several foundational models.
+# MAGIC 4. Deploys the agent to a web-based chat app.
+# MAGIC
+# MAGIC ## Technical requirements
+# MAGIC * Use serverless compute or a cluster running Databricks Runtime 14.3 or above.
+# MAGIC * Databricks Serverless and Unity Catalog enabled.
+# MAGIC * CREATE MODEL access to a Unity Catalog schema.
+# MAGIC * Permission to create Model Serving endpoints.
+# MAGIC
+# MAGIC ## Data requirements
+# MAGIC To use this notebook, you need:
+# MAGIC 1. A Delta Table containing your parsed documents
+# MAGIC 2. A Delta Sync Managed Embedding Vector Search index with your chunked/embedded documents
+# MAGIC
+# MAGIC If you don’t have these data requirements already set up, you can run the standalone version of this notebook. The standalone version uses a sample corpus of data and doesn't require a pre-configured Vector Search index or Delta Table ([AWS](https://docs.databricks.com/generative-ai/tutorials/agent-framework-notebook.html) | [Azure](https://learn.microsoft.com/azure/databricks/generative-ai/tutorials/agent-framework-notebook)).
+# MAGIC
+# MAGIC 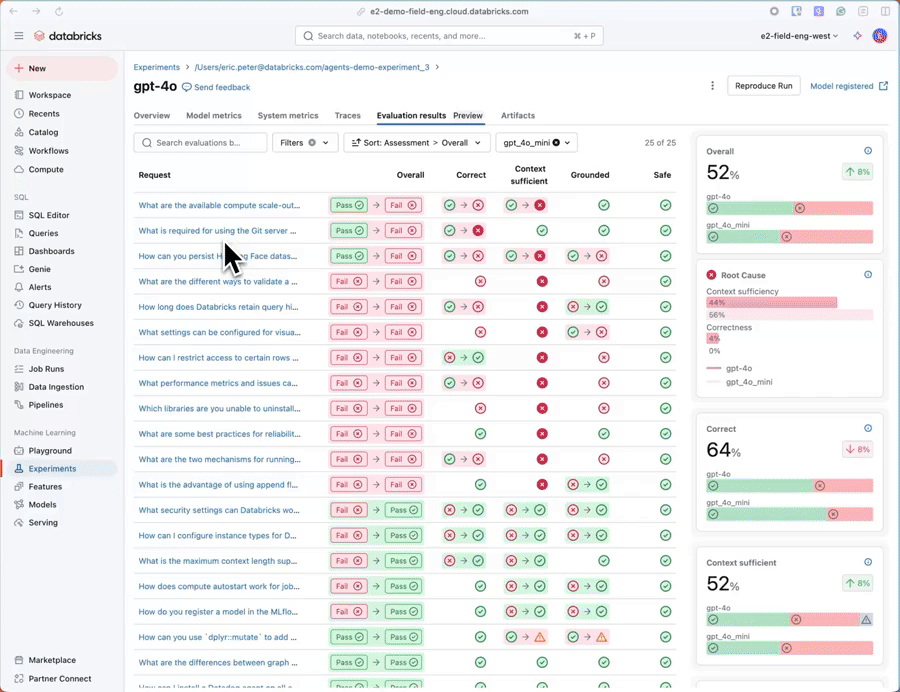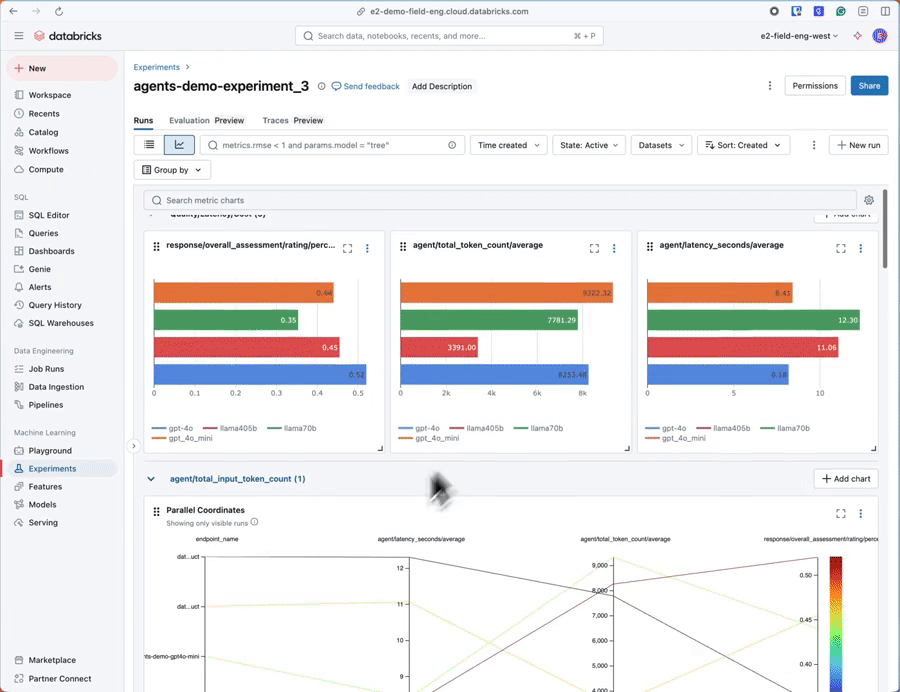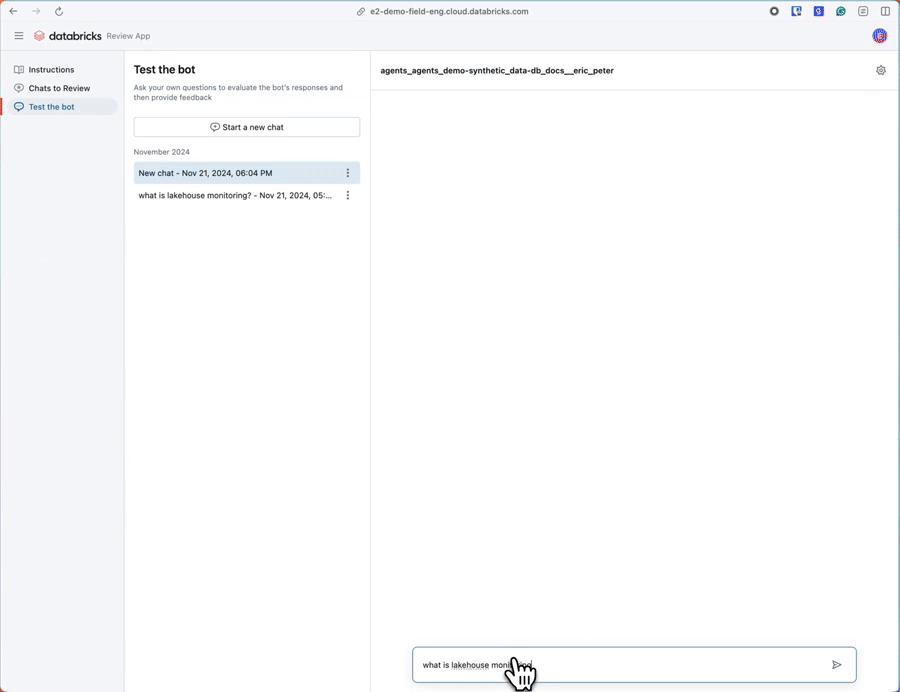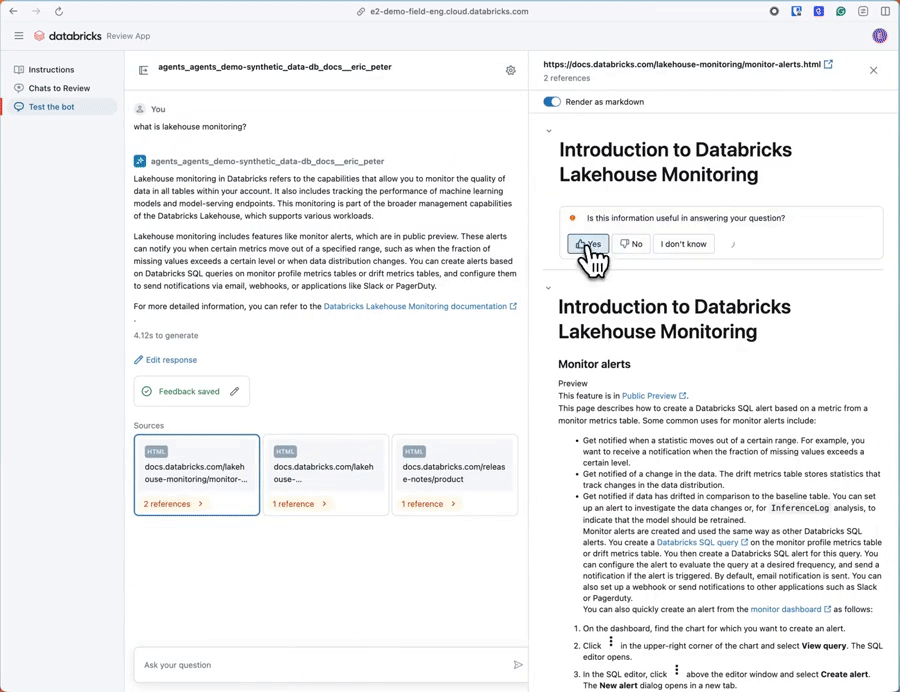 +# MAGIC
+# MAGIC For videos that go deeper into the capabilities, see this [YouTube channel](https://www.youtube.com/@EricPeter-q6o).
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Setup
+
+# COMMAND ----------
+
+# MAGIC %pip install -U -qqqq databricks-agents mlflow databricks-sdk[openai] backoff
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %reload_ext autoreload
+# MAGIC %autoreload 2
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 1. Generate synthetic evaluation data to measure quality
+# MAGIC
+# MAGIC **Challenges Addressed**
+# MAGIC 1. How to start quality evaluation with diverse, representative data without SMEs spending months labeling?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC - We pass the documents to the Synthetic API along with a `num_evals` and prompt-like `agent_description` and `question_guidelines` to tailor the generated questions for our use case. This API uses a proprietary synthetic generation pipeline developed by Mosaic AI Research.
+# MAGIC - The API produces `num_evals` questions, each coupled with the source document and a list of facts, generated based on the source document. Each fact must be present in the agent's response for it to be considered correct.
+# MAGIC
+# MAGIC *Why does the the API generates a list of facts, rather than a fully written answer. This...*
+# MAGIC - Makes SME review more efficient: by focusing on facts rather than a full response, they can review and edit more quickly.
+# MAGIC - Improves the accuracy of our proprietary LLM judges.
+# MAGIC
+# MAGIC Interested in have your SMEs review the data? Check out a [video demo of the Eval Set UI](https://youtu.be/avY9724q4e4?feature=shared&t=130).
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Load your documents
+
+# COMMAND ----------
+
+# DBTITLE 1,Parsed Documents
+PARSED_DOCS_TABLE = f"catalog.schema.db_docs" # Replace with your parsed docs.
+assert (
+ PARSED_DOCS_TABLE != "catalog.schema.db_docs"
+), "Please update `PARSED_DOCS_TABLE` with your parsed doc Delta Table's UC location"
+parsed_docs_df = spark.table(PARSED_DOCS_TABLE)
+
+# if your `PARSED_DOCS_TABLE` does not have 2 columns `content` and `doc_uri`, you can use the following code to rename the correct columns to these names.
+# parsed_docs_df = parsed_docs_df.withColumnsRenamed({"col_with_parsed_doc_text": "content", "col_with_doc_identifer": "doc_uri"})
+
+display(parsed_docs_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Call API to generate synthetic evaluation data
+
+# COMMAND ----------
+
+# Use the synthetic eval generation API to get some evals
+from databricks.agents.evals import generate_evals_df
+
+# "Ghost text" for agent description and question guidelines - feel free to modify as you see fit.
+agent_description = f"""
+The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
+"""
+question_guidelines = f"""
+# User personas
+- A developer who is new to the Databricks platform
+- An experienced, highly technical Data Scientist or Data Engineer
+
+# Example questions
+- what API lets me parallelize operations over rows of a delta table?
+- Which cluster settings will give me the best performance when using Spark?
+
+# Additional Guidelines
+- Questions should be succinct, and human-like
+"""
+
+evals = generate_evals_df(
+ docs=parsed_docs_df, # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
+ num_evals=100, # How many synthetic evaluations to generate
+ agent_description=agent_description,
+ question_guidelines=question_guidelines,
+)
+display(evals)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 2. Write the agent's code
+# MAGIC ### Function-calling agent that uses a retriever tool
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I track different versions of my agent's code or configuration?
+# MAGIC - How do I enable observability, monitoring, and debugging of my agent’s logic?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC First, create a function-calling agent with access to a retriever tool using OpenAI SDK and Python code. To keep the demo simple, the retriever is a function that performs keyword lookup rather than a vector search index.
+# MAGIC
+# MAGIC When creating your agent, you can either:
+# MAGIC 1. Generate template agent code from the AI Playground
+# MAGIC 2. Use a template from our Cookbook
+# MAGIC 3. Start from an example in popular frameworks such as LangGraph, AutoGen, LlamaIndex, and others.
+# MAGIC
+# MAGIC **NOTE: It is not necessary to understand how this agent works to understand the rest of this demo notebook.**
+# MAGIC
+# MAGIC *A few things to note about the code:*
+# MAGIC 1. The code is written to `fc_agent.py` in order to use [MLflow Models from Code](https://www.mlflow.org/blog/models_from_code) for logging, enabling easy tracking of each iteration as you tune the agent for quality.
+# MAGIC 2. The code is parameterized with an MLflow Model Configuration ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/create-agent.html#use-parameters-to-configure-the-agent) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/create-agent#agent-parameters)), enabling easy tuning of these parameters for quality improvement.
+# MAGIC 3. The code is wrapped in an MLflow [ChatModel](https://mlflow.org/docs/latest/llms/chat-model-intro/index.html), making the agent's code deployment-ready so any iteration can be shared with stakeholders for testing.
+# MAGIC 4. The code implements MLflow Tracing ([AWS](https://docs.databricks.com/en/mlflow/mlflow-tracing.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/mlflow/mlflow-tracing)) for unified observability during development and production. The same trace defined here will be logged for every production request post-deployment. For agent authoring frameworks, you can tracing with one line of code: `mlflow.framework_agent.autolog()`.
+# MAGIC
+# MAGIC ### IMPORTANT: Update the cell below to include the details of your vector index.
+
+# COMMAND ----------
+
+# MAGIC %%writefile fc_agent.py
+# MAGIC from databricks.sdk import WorkspaceClient
+# MAGIC from openai import OpenAI
+# MAGIC import openai
+# MAGIC import pandas as pd
+# MAGIC from typing import Any, Union, Dict, List, Optional
+# MAGIC from mlflow.entities import Document
+# MAGIC import mlflow
+# MAGIC from mlflow.pyfunc import ChatModel
+# MAGIC from mlflow.types.llm import ChatResponse, ChatMessage, ChatParams, ChatChoice
+# MAGIC from dataclasses import asdict
+# MAGIC import dataclasses
+# MAGIC import json
+# MAGIC import backoff # for exponential backoff on LLM rate limits
+# MAGIC
+# MAGIC VECTOR_SEARCH_INDEX = f"catalog.schema.db_docs_index" # Replace with your vector index.
+# MAGIC
+# MAGIC assert (
+# MAGIC VECTOR_SEARCH_INDEX != "catalog.schema.db_docs_index"
+# MAGIC ), "Please update `VECTOR_SEARCH_INDEX` to have your vector index's UC location."
+# MAGIC
+# MAGIC # Provide the below mapping to match your column names. This is required for Agent Evaluation to work and for the Review App to display the documents in the UI.
+# MAGIC
+# MAGIC VECTOR_SEARCH_COL_MAPPING = {
+# MAGIC 'doc_uri': 'doc_uri',
+# MAGIC 'content': 'content_chunked',
+# MAGIC 'id': 'chunk_id'
+# MAGIC }
+# MAGIC
+# MAGIC # Default configuration for the Agent.
+# MAGIC DEFAULT_CONFIG = {
+# MAGIC 'endpoint_name': "databricks-meta-llama-3-1-70b-instruct",
+# MAGIC 'temperature': 0.01,
+# MAGIC 'max_tokens': 1000,
+# MAGIC 'system_prompt': """You are a helpful assistant that answers questions using tools. Based on the user's request, select the appropiate tool to use. If needed, ask the user follow-up questions to clarify their request.""",
+# MAGIC "vector_search_parameters": {
+# MAGIC "num_results": 5,
+# MAGIC "query_type": "ann"
+# MAGIC },
+# MAGIC "vector_search_schema": VECTOR_SEARCH_COL_MAPPING,
+# MAGIC "vector_search_index": VECTOR_SEARCH_INDEX,
+# MAGIC # `vector_search_description` is the prompt that tells the LLM what type of documents are contained in your index. Tune this parameter to help the LLM know what type of documents are in your index so it can know when to retrieve from this index.
+# MAGIC "vector_search_description": "Use this tool to search for [DESCRIPTION OF YOUR CONTENT]."
+# MAGIC }
+# MAGIC
+# MAGIC assert (
+# MAGIC DEFAULT_CONFIG['vector_search_description'] != "Use this tool to search for [DESCRIPTION OF YOUR CONTENT]."
+# MAGIC ), "Please update the `DEFAULT_CONFIG['vector_search_description']` to include a description of the content in your vector search index - without this update, the LLM likely will not be able to call the retrieval tool correctly."
+# MAGIC
+# MAGIC class FunctionCallingAgent(mlflow.pyfunc.ChatModel):
+# MAGIC """
+# MAGIC Class representing a function-calling Agent that has one tool: a retriever w/ keyword-based search.
+# MAGIC """
+# MAGIC
+# MAGIC def __init__(self):
+# MAGIC """
+# MAGIC Initialize the OpenAI SDK client connected to Model Serving.
+# MAGIC Load the Agent's configuration from MLflow Model Config.
+# MAGIC """
+# MAGIC # Initialize OpenAI SDK connected to Model Serving
+# MAGIC w = WorkspaceClient()
+# MAGIC self.model_serving_client: OpenAI = w.serving_endpoints.get_open_ai_client()
+# MAGIC
+# MAGIC # Load config
+# MAGIC # When this Agent is deployed to Model Serving, the configuration loaded here is replaced with the config passed to mlflow.pyfunc.log_model(model_config=...)
+# MAGIC self.config = mlflow.models.ModelConfig(development_config=DEFAULT_CONFIG)
+# MAGIC
+# MAGIC # Configure playground & review app & agent evaluation to display / see the chunks from the retriever
+# MAGIC mlflow.models.set_retriever_schema(
+# MAGIC name=self.config.get("vector_search_index"),
+# MAGIC primary_key=self.config.get('vector_search_schema').get('id'),
+# MAGIC text_column=self.config.get('vector_search_schema').get('content'),
+# MAGIC doc_uri=self.config.get('vector_search_schema').get('doc_uri'),
+# MAGIC )
+# MAGIC
+# MAGIC
+# MAGIC # OpenAI-formatted function for the retriever tool
+# MAGIC retriever_tool_name = "retrieve_docs"
+# MAGIC self.retriever_tool_spec = [{
+# MAGIC "type": "function",
+# MAGIC "function": {
+# MAGIC "name": retriever_tool_name,
+# MAGIC "description": self.config.get("vector_search_description"),
+# MAGIC "parameters": {
+# MAGIC "type": "object",
+# MAGIC "required": ["query"],
+# MAGIC "additionalProperties": False,
+# MAGIC "properties": {
+# MAGIC "query": {
+# MAGIC "description": "query to look up in retriever",
+# MAGIC "type": "string",
+# MAGIC }
+# MAGIC },
+# MAGIC },
+# MAGIC },
+# MAGIC }]
+# MAGIC
+# MAGIC
+# MAGIC # Get workspace client to call vector search
+# MAGIC self.workspace_client = WorkspaceClient()
+# MAGIC
+# MAGIC # Identify the function used as the retriever tool
+# MAGIC self.tool_functions = {
+# MAGIC retriever_tool_name: self.retrieve_docs
+# MAGIC }
+# MAGIC
+# MAGIC @mlflow.trace(name="rag_agent", span_type="AGENT")
+# MAGIC def predict(
+# MAGIC self, context=None, messages: List[ChatMessage]=None, params: Optional[ChatParams] = None
+# MAGIC ) -> ChatResponse:
+# MAGIC """
+# MAGIC Primary function that takes a user's request and generates a response.
+# MAGIC """
+# MAGIC if messages is None:
+# MAGIC raise ValueError("predict(...) called without `messages` parameter.")
+# MAGIC
+# MAGIC # Convert all input messages to dict from ChatMessage
+# MAGIC messages = convert_chat_messages_to_dict(messages)
+# MAGIC
+# MAGIC # Add system prompt
+# MAGIC request = {
+# MAGIC "messages": [
+# MAGIC {"role": "system", "content": self.config.get('system_prompt')},
+# MAGIC *messages,
+# MAGIC ],
+# MAGIC }
+# MAGIC
+# MAGIC # Ask the LLM to call tools & generate the response
+# MAGIC output= self.recursively_call_and_run_tools(
+# MAGIC **request
+# MAGIC )
+# MAGIC
+# MAGIC # Convert response to ChatResponse dataclass
+# MAGIC return ChatResponse.from_dict(output)
+# MAGIC
+# MAGIC @mlflow.trace(span_type="RETRIEVER", name="vector_search_retriever")
+# MAGIC def retrieve_docs(self, query: str) -> List[dict]:
+# MAGIC """
+# MAGIC Performs vector search to retrieve relevant chunks.
+# MAGIC
+# MAGIC Args:
+# MAGIC query: Search query.
+# MAGIC filters: Optional filters to apply to the search. Should follow the LLM-generated filter pattern of a list of field/filter pairs that will be converted to Databricks Vector Search filter format.
+# MAGIC
+# MAGIC Returns:
+# MAGIC List of retrieved Documents.
+# MAGIC """
+# MAGIC traced_search = mlflow.trace(
+# MAGIC self.workspace_client.vector_search_indexes.query_index,
+# MAGIC name="_workspace_client.vector_search_indexes.query_index",
+# MAGIC span_type="FUNCTION",
+# MAGIC )
+# MAGIC
+# MAGIC results = traced_search(
+# MAGIC index_name=self.config.get("vector_search_index"),
+# MAGIC query_text=query,
+# MAGIC columns=list(self.config.get('vector_search_schema').values()),
+# MAGIC **self.config.get("vector_search_parameters"),
+# MAGIC )
+# MAGIC
+# MAGIC # We turn the config into a dict and pass it here
+# MAGIC doc_similarity_threshold = 0
+# MAGIC return self.convert_vector_search_to_documents(
+# MAGIC results.as_dict(), doc_similarity_threshold
+# MAGIC )
+# MAGIC
+# MAGIC @mlflow.trace(span_type="PARSER")
+# MAGIC def convert_vector_search_to_documents(
+# MAGIC self, vs_results, vector_search_threshold
+# MAGIC ) -> List[dict]:
+# MAGIC column_names = []
+# MAGIC for column in vs_results["manifest"]["columns"]:
+# MAGIC column_names.append(column)
+# MAGIC
+# MAGIC docs = []
+# MAGIC if vs_results["result"]["row_count"] > 0:
+# MAGIC for item in vs_results["result"]["data_array"]:
+# MAGIC metadata = {}
+# MAGIC score = item[-1]
+# MAGIC if score >= vector_search_threshold:
+# MAGIC metadata["similarity_score"] = score
+# MAGIC for i, field in enumerate(item[0:-1]):
+# MAGIC metadata[column_names[i]["name"]] = field
+# MAGIC # put contents of the chunk into page_content
+# MAGIC text_col_name = self.config.get('vector_search_schema').get('content')
+# MAGIC page_content = metadata[text_col_name]
+# MAGIC del metadata[text_col_name]
+# MAGIC
+# MAGIC # put the primary key into id
+# MAGIC id_col_name = self.config.get('vector_search_schema').get('id')
+# MAGIC id = metadata[id_col_name]
+# MAGIC del metadata[id_col_name]
+# MAGIC
+# MAGIC doc = Document(page_content=page_content, metadata=metadata, id=id)
+# MAGIC docs.append(asdict(doc))
+# MAGIC
+# MAGIC return docs
+# MAGIC ##
+# MAGIC # Helper functions below
+# MAGIC ##
+# MAGIC @backoff.on_exception(backoff.expo, openai.RateLimitError)
+# MAGIC def completions_with_backoff(self, **kwargs):
+# MAGIC """
+# MAGIC Helper: exponetially backoff if the LLM's rate limit is exceeded.
+# MAGIC """
+# MAGIC traced_chat_completions_create_fn = mlflow.trace(
+# MAGIC self.model_serving_client.chat.completions.create,
+# MAGIC name="chat_completions_api",
+# MAGIC span_type="CHAT_MODEL",
+# MAGIC )
+# MAGIC return traced_chat_completions_create_fn(**kwargs)
+# MAGIC
+# MAGIC def chat_completion(self, messages: List[ChatMessage]) -> ChatResponse:
+# MAGIC """
+# MAGIC Helper: Call the LLM configured via the ModelConfig using the OpenAI SDK
+# MAGIC """
+# MAGIC request = {"messages": messages, "temperature": self.config.get("temperature"), "max_tokens": self.config.get("max_tokens"), "tools": self.retriever_tool_spec}
+# MAGIC return self.completions_with_backoff(
+# MAGIC model=self.config.get("endpoint_name"), **request,
+# MAGIC
+# MAGIC )
+# MAGIC
+# MAGIC @mlflow.trace(span_type="CHAIN")
+# MAGIC def recursively_call_and_run_tools(self, max_iter=10, **kwargs):
+# MAGIC """
+# MAGIC Helper: Recursively calls the LLM w/ the tools in the prompt. Either executes the tools and recalls the LLM or returns the LLM's generation.
+# MAGIC """
+# MAGIC messages = kwargs["messages"]
+# MAGIC del kwargs["messages"]
+# MAGIC i = 0
+# MAGIC while i < max_iter:
+# MAGIC with mlflow.start_span(name=f"iteration_{i}", span_type="CHAIN") as span:
+# MAGIC response = self.chat_completion(messages=messages)
+# MAGIC assistant_message = response.choices[0].message # openai client
+# MAGIC tool_calls = assistant_message.tool_calls # openai
+# MAGIC if tool_calls is None:
+# MAGIC # the tool execution finished, and we have a generation
+# MAGIC return response.to_dict()
+# MAGIC tool_messages = []
+# MAGIC for tool_call in tool_calls: # TODO: should run in parallel
+# MAGIC with mlflow.start_span(
+# MAGIC name="execute_tool", span_type="TOOL"
+# MAGIC ) as span:
+# MAGIC function = tool_call.function
+# MAGIC args = json.loads(function.arguments)
+# MAGIC span.set_inputs(
+# MAGIC {
+# MAGIC "function_name": function.name,
+# MAGIC "function_args_raw": function.arguments,
+# MAGIC "function_args_loaded": args,
+# MAGIC }
+# MAGIC )
+# MAGIC result = self.execute_function(
+# MAGIC self.tool_functions[function.name], args
+# MAGIC )
+# MAGIC tool_message = {
+# MAGIC "role": "tool",
+# MAGIC "tool_call_id": tool_call.id,
+# MAGIC "content": result,
+# MAGIC }
+# MAGIC
+# MAGIC tool_messages.append(tool_message)
+# MAGIC span.set_outputs({"new_message": tool_message})
+# MAGIC assistant_message_dict = assistant_message.dict().copy()
+# MAGIC del assistant_message_dict["content"]
+# MAGIC del assistant_message_dict["function_call"]
+# MAGIC if "audio" in assistant_message_dict:
+# MAGIC del assistant_message_dict["audio"] # hack to make llama70b work
+# MAGIC messages = (
+# MAGIC messages
+# MAGIC + [
+# MAGIC assistant_message_dict,
+# MAGIC ]
+# MAGIC + tool_messages
+# MAGIC )
+# MAGIC i += 1
+# MAGIC # TODO: Handle more gracefully
+# MAGIC raise "ERROR: max iter reached"
+# MAGIC
+# MAGIC def execute_function(self, tool, args):
+# MAGIC """
+# MAGIC Execute a tool and return the result as a JSON string
+# MAGIC """
+# MAGIC result = tool(**args)
+# MAGIC return json.dumps(result)
+# MAGIC
+# MAGIC def convert_chat_messages_to_dict(messages: List[ChatMessage]):
+# MAGIC new_messages = []
+# MAGIC for message in messages:
+# MAGIC if type(message) == ChatMessage:
+# MAGIC # Remove any keys with None values
+# MAGIC new_messages.append({k: v for k, v in asdict(message).items() if v is not None})
+# MAGIC else:
+# MAGIC new_messages.append(message)
+# MAGIC return new_messages
+# MAGIC
+# MAGIC
+# MAGIC # tell MLflow logging where to find the agent's code
+# MAGIC mlflow.models.set_model(FunctionCallingAgent())
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Empty `__init__.py` to allow the `FunctionCallingAgent()` to be imported.
+
+# COMMAND ----------
+
+# MAGIC %%writefile __init__.py
+# MAGIC
+# MAGIC # Empty file
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Vibe check the agent
+# MAGIC Test the agent for a sample query to see the MLflow Trace.
+
+# COMMAND ----------
+
+from fc_agent import FunctionCallingAgent
+fc_agent = FunctionCallingAgent()
+
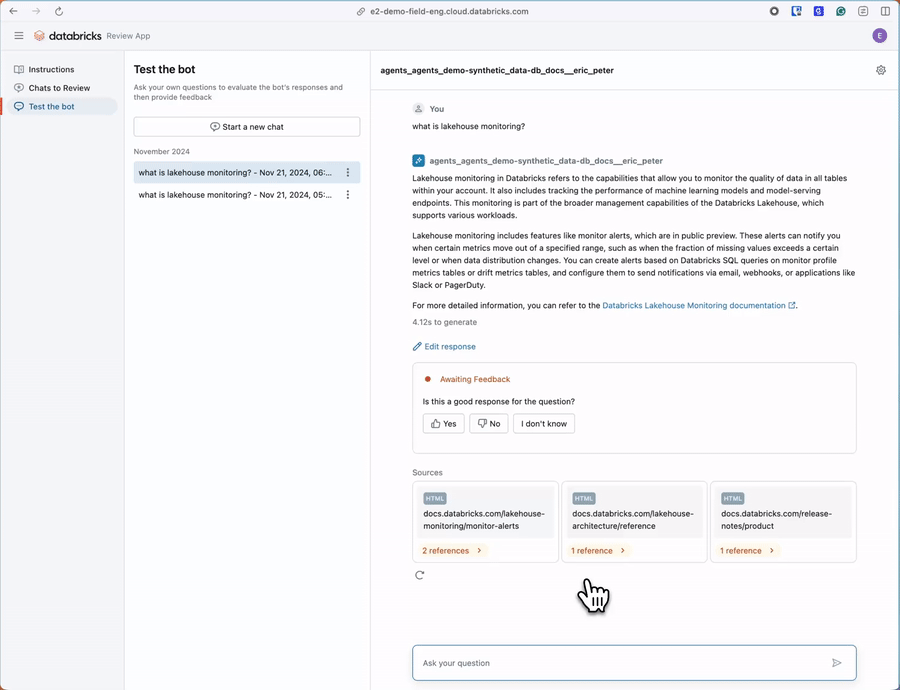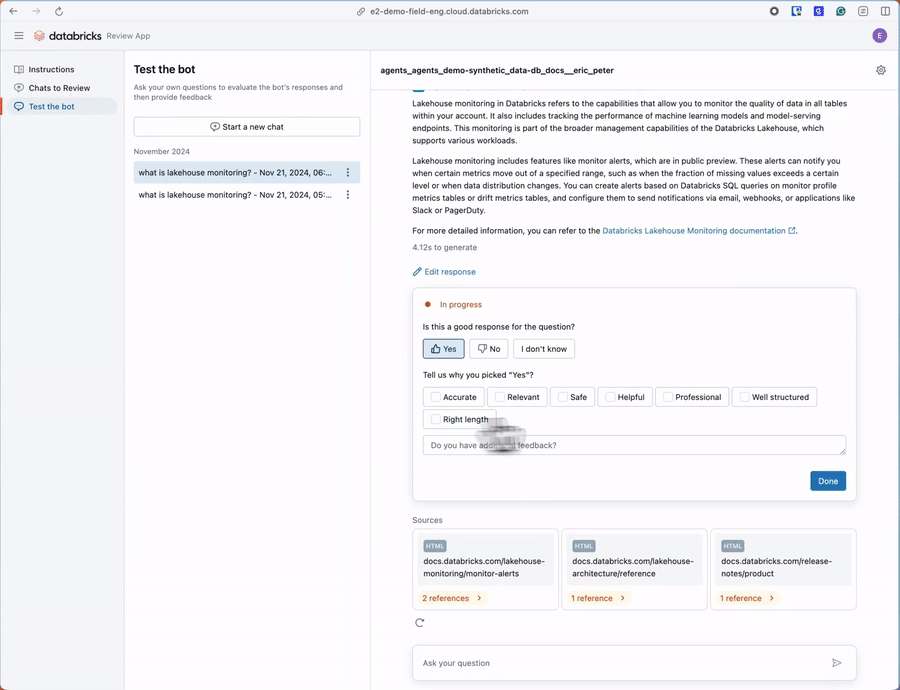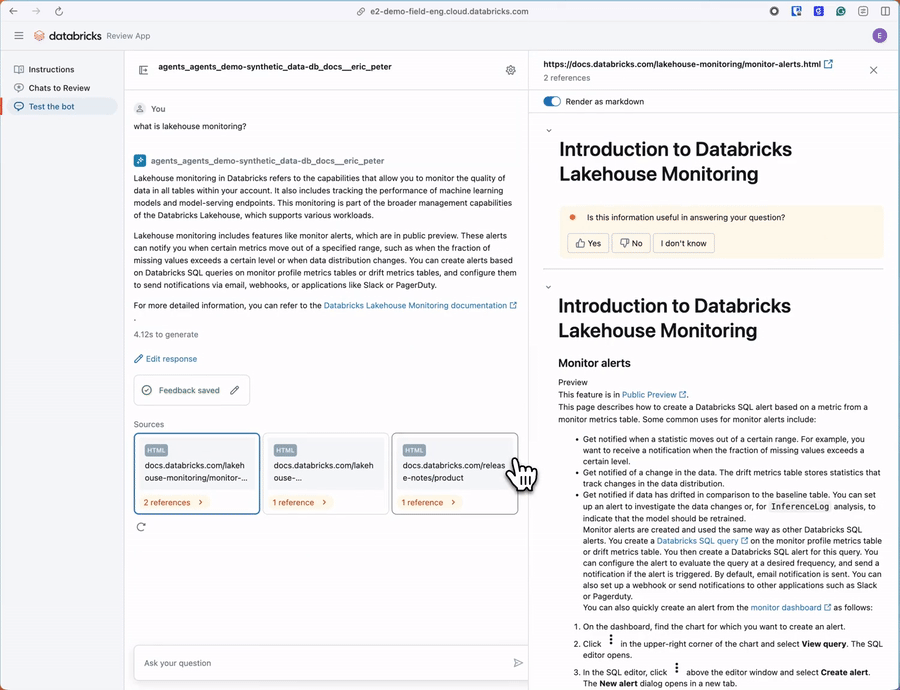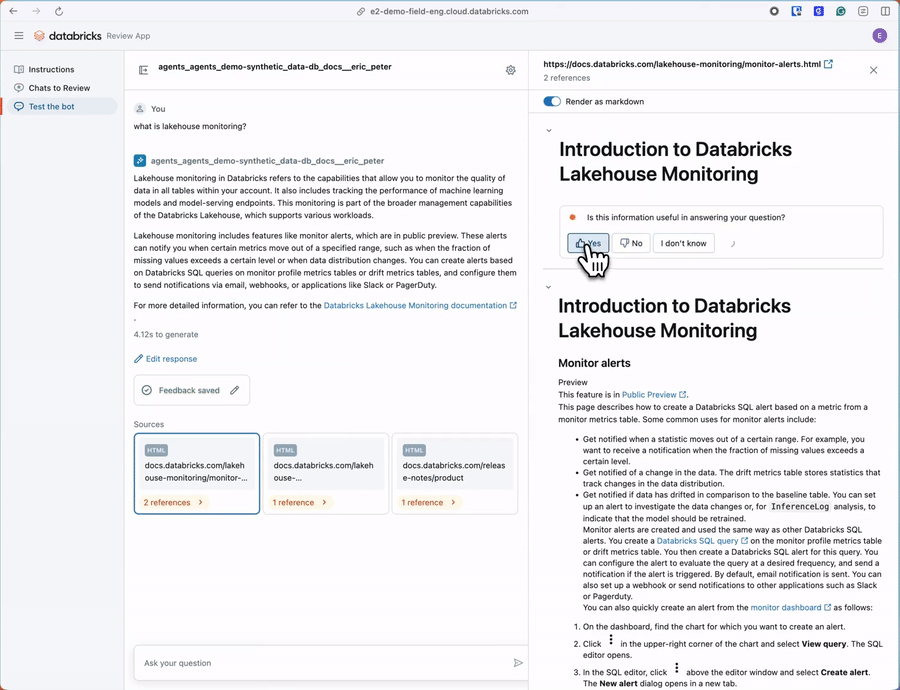
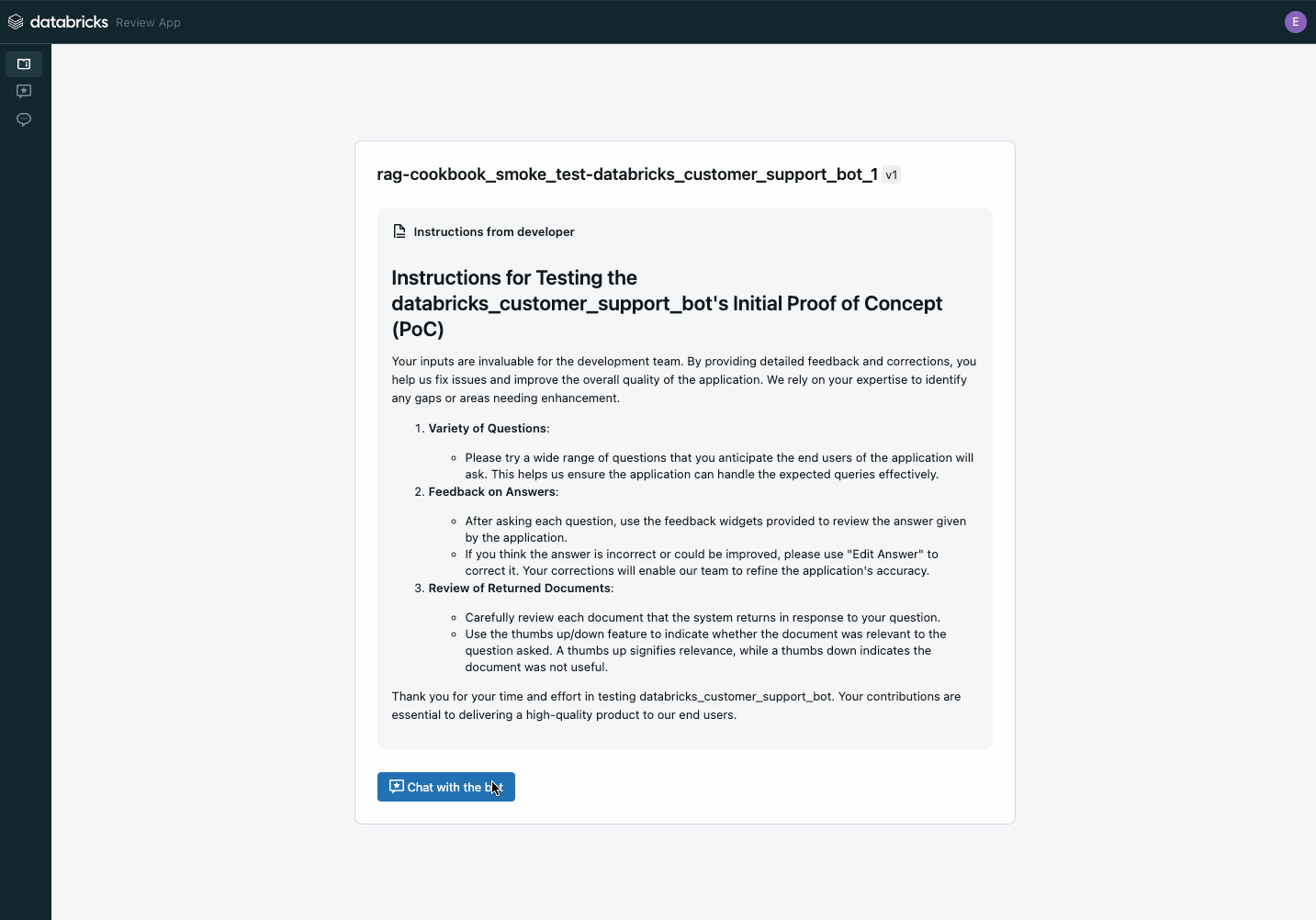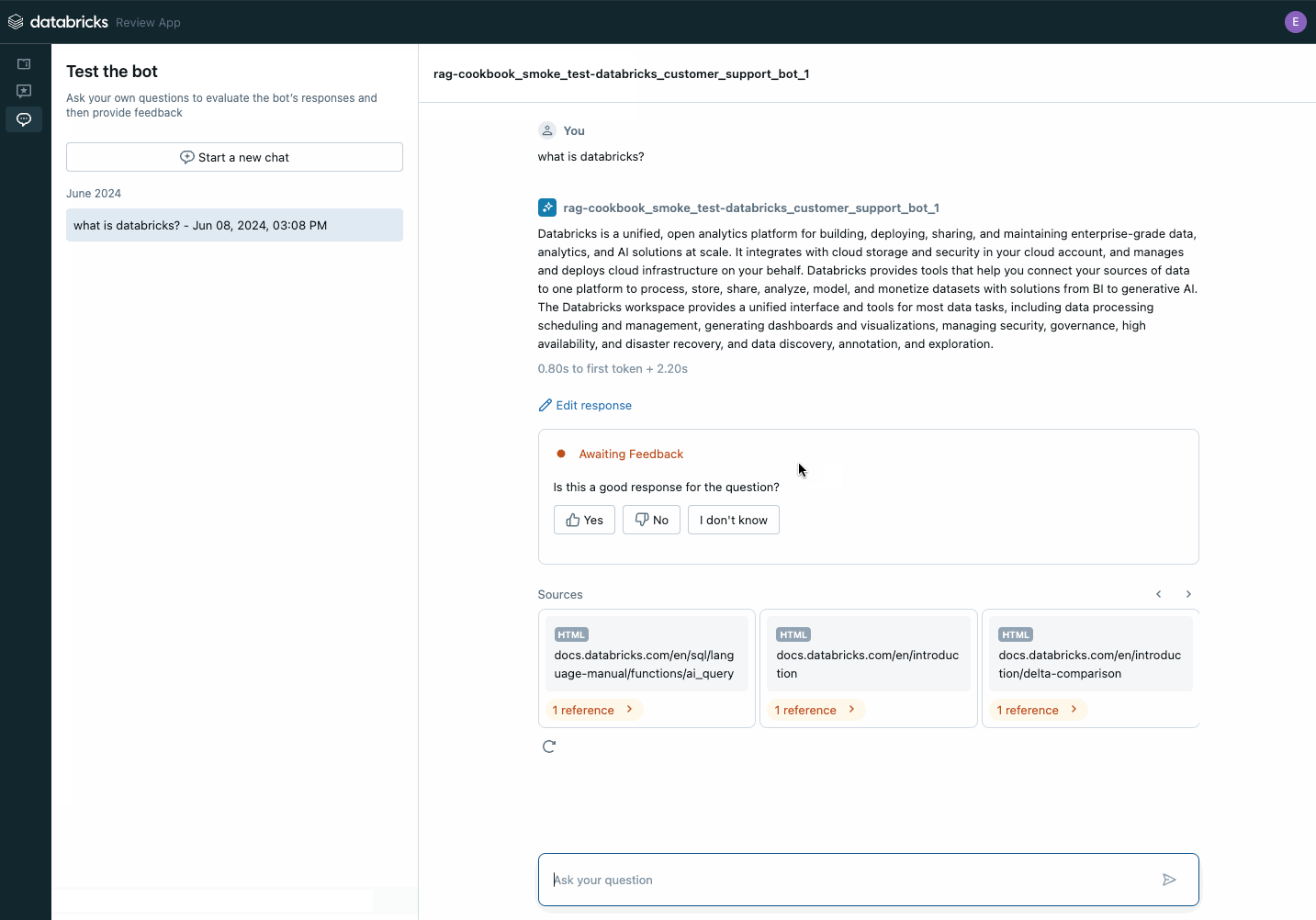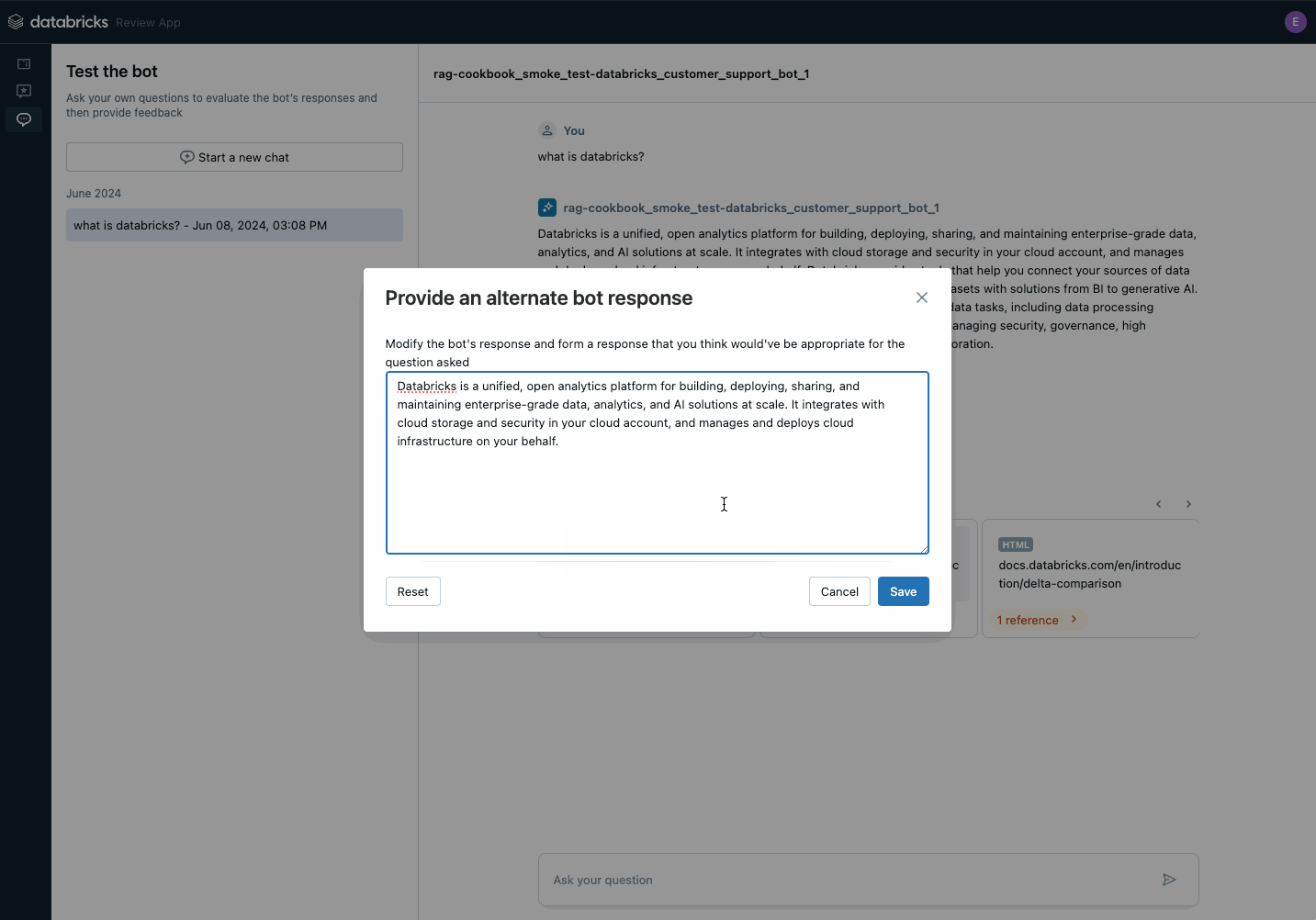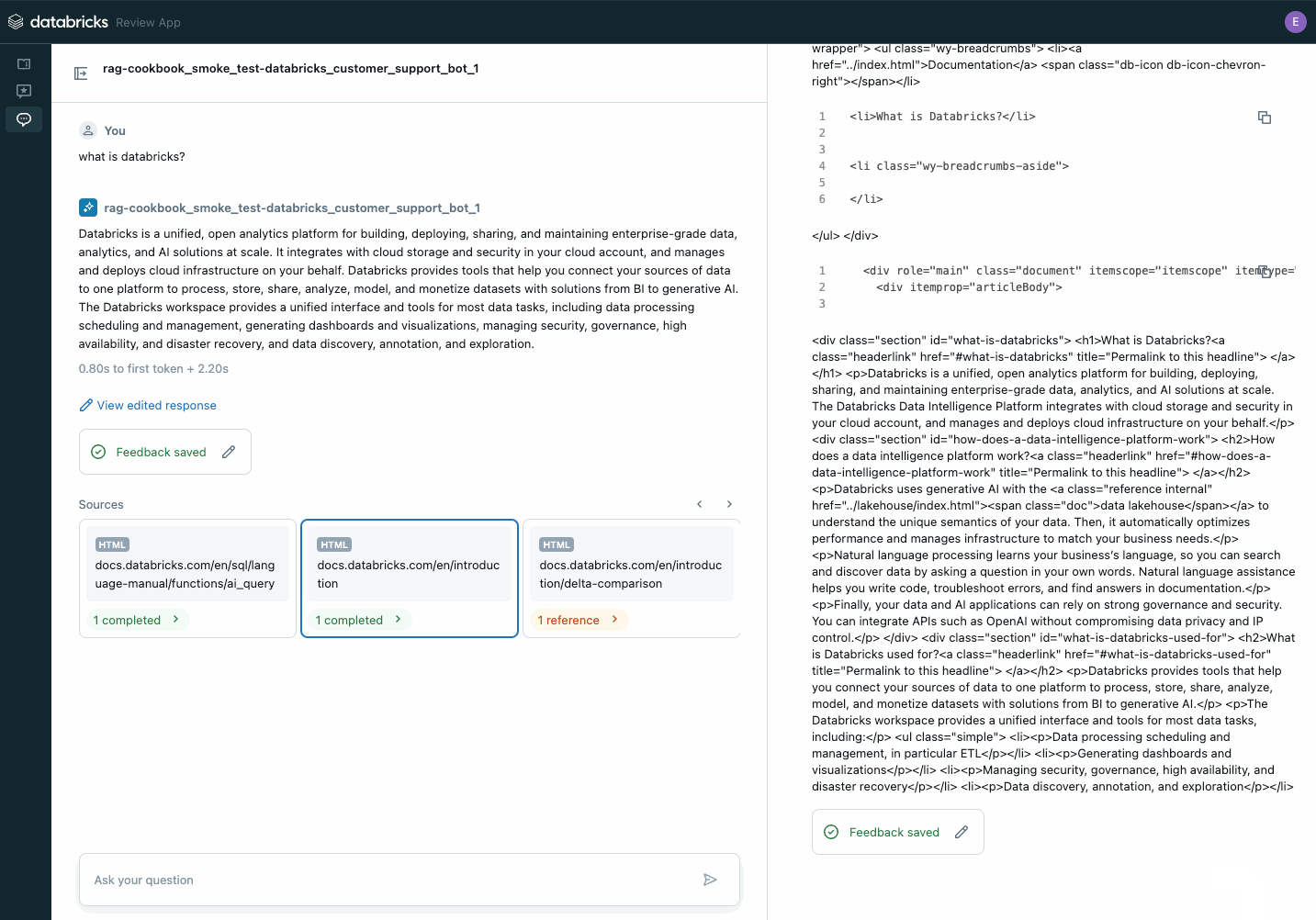
+response = fc_agent.predict(messages=[{"role": "user", "content": "What is lakehouse monitoring?"}])
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 3. Evaluate the agent
+# MAGIC ### Initial evaluation
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - What are the right metrics to evaluate quality? How do I trust the outputs of these metrics?
+# MAGIC - I need to evaluate many ideas - how do I…
+# MAGIC - …run evaluation quickly so the majority of my time isn’t spent waiting?
+# MAGIC - …quickly compare these different versions of my agent on quality, cost, and latency?
+# MAGIC - How do I quickly identify the root cause of any quality problems?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC Now, we run Agent Evaluation's proprietary LLM judges using the synthetic evaluation set to see the quality, cost, and latency of the agent and identify any root causes of quality issues. Agent Evaluation is tightly integrated with `mlflow.evaluate()`.
+# MAGIC
+# MAGIC Mosaic AI Research has invested signficantly in the quality AND speed of the LLM judges, optimizing the judges to agree with human raters. Read more [details in our blog](https://www.databricks.com/blog/databricks-announces-significant-improvements-built-llm-judges-agent-evaluation) about how our judges outperform the competition.
+# MAGIC
+# MAGIC Once evaluation runs, click `View Evaluation Results` to open the MLflow UI for this Run. This lets you:
+# MAGIC - See summary metrics
+# MAGIC - See root cause analysis that identifies the most important issues to fix
+# MAGIC - Inspect individual responses to gain intuition about how the agent is performing
+# MAGIC - See the judge outputs to understand why the responses were graded as pass or fail
+# MAGIC - Compare between multiple runs to see how quality changed between experiments
+# MAGIC
+# MAGIC You can also inspect the other tabs:
+# MAGIC - `Overview` lets you see the agent's configuration and parameters
+# MAGIC - `Artifacts` lets you see the agent's code
+# MAGIC
+# MAGIC This UIs, coupled with the speed of evaluation, help you efficiently test your hypotheses to improve quality, letting you reach the production quality bar in less time.
+# MAGIC
+# MAGIC
+# MAGIC
+# MAGIC For videos that go deeper into the capabilities, see this [YouTube channel](https://www.youtube.com/@EricPeter-q6o).
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ## Setup
+
+# COMMAND ----------
+
+# MAGIC %pip install -U -qqqq databricks-agents mlflow databricks-sdk[openai] backoff
+# MAGIC dbutils.library.restartPython()
+
+# COMMAND ----------
+
+# MAGIC %reload_ext autoreload
+# MAGIC %autoreload 2
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 1. Generate synthetic evaluation data to measure quality
+# MAGIC
+# MAGIC **Challenges Addressed**
+# MAGIC 1. How to start quality evaluation with diverse, representative data without SMEs spending months labeling?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC - We pass the documents to the Synthetic API along with a `num_evals` and prompt-like `agent_description` and `question_guidelines` to tailor the generated questions for our use case. This API uses a proprietary synthetic generation pipeline developed by Mosaic AI Research.
+# MAGIC - The API produces `num_evals` questions, each coupled with the source document and a list of facts, generated based on the source document. Each fact must be present in the agent's response for it to be considered correct.
+# MAGIC
+# MAGIC *Why does the the API generates a list of facts, rather than a fully written answer. This...*
+# MAGIC - Makes SME review more efficient: by focusing on facts rather than a full response, they can review and edit more quickly.
+# MAGIC - Improves the accuracy of our proprietary LLM judges.
+# MAGIC
+# MAGIC Interested in have your SMEs review the data? Check out a [video demo of the Eval Set UI](https://youtu.be/avY9724q4e4?feature=shared&t=130).
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Load your documents
+
+# COMMAND ----------
+
+# DBTITLE 1,Parsed Documents
+PARSED_DOCS_TABLE = f"catalog.schema.db_docs" # Replace with your parsed docs.
+assert (
+ PARSED_DOCS_TABLE != "catalog.schema.db_docs"
+), "Please update `PARSED_DOCS_TABLE` with your parsed doc Delta Table's UC location"
+parsed_docs_df = spark.table(PARSED_DOCS_TABLE)
+
+# if your `PARSED_DOCS_TABLE` does not have 2 columns `content` and `doc_uri`, you can use the following code to rename the correct columns to these names.
+# parsed_docs_df = parsed_docs_df.withColumnsRenamed({"col_with_parsed_doc_text": "content", "col_with_doc_identifer": "doc_uri"})
+
+display(parsed_docs_df)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Call API to generate synthetic evaluation data
+
+# COMMAND ----------
+
+# Use the synthetic eval generation API to get some evals
+from databricks.agents.evals import generate_evals_df
+
+# "Ghost text" for agent description and question guidelines - feel free to modify as you see fit.
+agent_description = f"""
+The agent is a RAG chatbot that answers questions about Databricks. Questions unrelated to Databricks are irrelevant.
+"""
+question_guidelines = f"""
+# User personas
+- A developer who is new to the Databricks platform
+- An experienced, highly technical Data Scientist or Data Engineer
+
+# Example questions
+- what API lets me parallelize operations over rows of a delta table?
+- Which cluster settings will give me the best performance when using Spark?
+
+# Additional Guidelines
+- Questions should be succinct, and human-like
+"""
+
+evals = generate_evals_df(
+ docs=parsed_docs_df, # Pass your docs. They should be in a Pandas or Spark DataFrame with columns `content STRING` and `doc_uri STRING`.
+ num_evals=100, # How many synthetic evaluations to generate
+ agent_description=agent_description,
+ question_guidelines=question_guidelines,
+)
+display(evals)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 2. Write the agent's code
+# MAGIC ### Function-calling agent that uses a retriever tool
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I track different versions of my agent's code or configuration?
+# MAGIC - How do I enable observability, monitoring, and debugging of my agent’s logic?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC First, create a function-calling agent with access to a retriever tool using OpenAI SDK and Python code. To keep the demo simple, the retriever is a function that performs keyword lookup rather than a vector search index.
+# MAGIC
+# MAGIC When creating your agent, you can either:
+# MAGIC 1. Generate template agent code from the AI Playground
+# MAGIC 2. Use a template from our Cookbook
+# MAGIC 3. Start from an example in popular frameworks such as LangGraph, AutoGen, LlamaIndex, and others.
+# MAGIC
+# MAGIC **NOTE: It is not necessary to understand how this agent works to understand the rest of this demo notebook.**
+# MAGIC
+# MAGIC *A few things to note about the code:*
+# MAGIC 1. The code is written to `fc_agent.py` in order to use [MLflow Models from Code](https://www.mlflow.org/blog/models_from_code) for logging, enabling easy tracking of each iteration as you tune the agent for quality.
+# MAGIC 2. The code is parameterized with an MLflow Model Configuration ([AWS](https://docs.databricks.com/en/generative-ai/agent-framework/create-agent.html#use-parameters-to-configure-the-agent) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-framework/create-agent#agent-parameters)), enabling easy tuning of these parameters for quality improvement.
+# MAGIC 3. The code is wrapped in an MLflow [ChatModel](https://mlflow.org/docs/latest/llms/chat-model-intro/index.html), making the agent's code deployment-ready so any iteration can be shared with stakeholders for testing.
+# MAGIC 4. The code implements MLflow Tracing ([AWS](https://docs.databricks.com/en/mlflow/mlflow-tracing.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/mlflow/mlflow-tracing)) for unified observability during development and production. The same trace defined here will be logged for every production request post-deployment. For agent authoring frameworks, you can tracing with one line of code: `mlflow.framework_agent.autolog()`.
+# MAGIC
+# MAGIC ### IMPORTANT: Update the cell below to include the details of your vector index.
+
+# COMMAND ----------
+
+# MAGIC %%writefile fc_agent.py
+# MAGIC from databricks.sdk import WorkspaceClient
+# MAGIC from openai import OpenAI
+# MAGIC import openai
+# MAGIC import pandas as pd
+# MAGIC from typing import Any, Union, Dict, List, Optional
+# MAGIC from mlflow.entities import Document
+# MAGIC import mlflow
+# MAGIC from mlflow.pyfunc import ChatModel
+# MAGIC from mlflow.types.llm import ChatResponse, ChatMessage, ChatParams, ChatChoice
+# MAGIC from dataclasses import asdict
+# MAGIC import dataclasses
+# MAGIC import json
+# MAGIC import backoff # for exponential backoff on LLM rate limits
+# MAGIC
+# MAGIC VECTOR_SEARCH_INDEX = f"catalog.schema.db_docs_index" # Replace with your vector index.
+# MAGIC
+# MAGIC assert (
+# MAGIC VECTOR_SEARCH_INDEX != "catalog.schema.db_docs_index"
+# MAGIC ), "Please update `VECTOR_SEARCH_INDEX` to have your vector index's UC location."
+# MAGIC
+# MAGIC # Provide the below mapping to match your column names. This is required for Agent Evaluation to work and for the Review App to display the documents in the UI.
+# MAGIC
+# MAGIC VECTOR_SEARCH_COL_MAPPING = {
+# MAGIC 'doc_uri': 'doc_uri',
+# MAGIC 'content': 'content_chunked',
+# MAGIC 'id': 'chunk_id'
+# MAGIC }
+# MAGIC
+# MAGIC # Default configuration for the Agent.
+# MAGIC DEFAULT_CONFIG = {
+# MAGIC 'endpoint_name': "databricks-meta-llama-3-1-70b-instruct",
+# MAGIC 'temperature': 0.01,
+# MAGIC 'max_tokens': 1000,
+# MAGIC 'system_prompt': """You are a helpful assistant that answers questions using tools. Based on the user's request, select the appropiate tool to use. If needed, ask the user follow-up questions to clarify their request.""",
+# MAGIC "vector_search_parameters": {
+# MAGIC "num_results": 5,
+# MAGIC "query_type": "ann"
+# MAGIC },
+# MAGIC "vector_search_schema": VECTOR_SEARCH_COL_MAPPING,
+# MAGIC "vector_search_index": VECTOR_SEARCH_INDEX,
+# MAGIC # `vector_search_description` is the prompt that tells the LLM what type of documents are contained in your index. Tune this parameter to help the LLM know what type of documents are in your index so it can know when to retrieve from this index.
+# MAGIC "vector_search_description": "Use this tool to search for [DESCRIPTION OF YOUR CONTENT]."
+# MAGIC }
+# MAGIC
+# MAGIC assert (
+# MAGIC DEFAULT_CONFIG['vector_search_description'] != "Use this tool to search for [DESCRIPTION OF YOUR CONTENT]."
+# MAGIC ), "Please update the `DEFAULT_CONFIG['vector_search_description']` to include a description of the content in your vector search index - without this update, the LLM likely will not be able to call the retrieval tool correctly."
+# MAGIC
+# MAGIC class FunctionCallingAgent(mlflow.pyfunc.ChatModel):
+# MAGIC """
+# MAGIC Class representing a function-calling Agent that has one tool: a retriever w/ keyword-based search.
+# MAGIC """
+# MAGIC
+# MAGIC def __init__(self):
+# MAGIC """
+# MAGIC Initialize the OpenAI SDK client connected to Model Serving.
+# MAGIC Load the Agent's configuration from MLflow Model Config.
+# MAGIC """
+# MAGIC # Initialize OpenAI SDK connected to Model Serving
+# MAGIC w = WorkspaceClient()
+# MAGIC self.model_serving_client: OpenAI = w.serving_endpoints.get_open_ai_client()
+# MAGIC
+# MAGIC # Load config
+# MAGIC # When this Agent is deployed to Model Serving, the configuration loaded here is replaced with the config passed to mlflow.pyfunc.log_model(model_config=...)
+# MAGIC self.config = mlflow.models.ModelConfig(development_config=DEFAULT_CONFIG)
+# MAGIC
+# MAGIC # Configure playground & review app & agent evaluation to display / see the chunks from the retriever
+# MAGIC mlflow.models.set_retriever_schema(
+# MAGIC name=self.config.get("vector_search_index"),
+# MAGIC primary_key=self.config.get('vector_search_schema').get('id'),
+# MAGIC text_column=self.config.get('vector_search_schema').get('content'),
+# MAGIC doc_uri=self.config.get('vector_search_schema').get('doc_uri'),
+# MAGIC )
+# MAGIC
+# MAGIC
+# MAGIC # OpenAI-formatted function for the retriever tool
+# MAGIC retriever_tool_name = "retrieve_docs"
+# MAGIC self.retriever_tool_spec = [{
+# MAGIC "type": "function",
+# MAGIC "function": {
+# MAGIC "name": retriever_tool_name,
+# MAGIC "description": self.config.get("vector_search_description"),
+# MAGIC "parameters": {
+# MAGIC "type": "object",
+# MAGIC "required": ["query"],
+# MAGIC "additionalProperties": False,
+# MAGIC "properties": {
+# MAGIC "query": {
+# MAGIC "description": "query to look up in retriever",
+# MAGIC "type": "string",
+# MAGIC }
+# MAGIC },
+# MAGIC },
+# MAGIC },
+# MAGIC }]
+# MAGIC
+# MAGIC
+# MAGIC # Get workspace client to call vector search
+# MAGIC self.workspace_client = WorkspaceClient()
+# MAGIC
+# MAGIC # Identify the function used as the retriever tool
+# MAGIC self.tool_functions = {
+# MAGIC retriever_tool_name: self.retrieve_docs
+# MAGIC }
+# MAGIC
+# MAGIC @mlflow.trace(name="rag_agent", span_type="AGENT")
+# MAGIC def predict(
+# MAGIC self, context=None, messages: List[ChatMessage]=None, params: Optional[ChatParams] = None
+# MAGIC ) -> ChatResponse:
+# MAGIC """
+# MAGIC Primary function that takes a user's request and generates a response.
+# MAGIC """
+# MAGIC if messages is None:
+# MAGIC raise ValueError("predict(...) called without `messages` parameter.")
+# MAGIC
+# MAGIC # Convert all input messages to dict from ChatMessage
+# MAGIC messages = convert_chat_messages_to_dict(messages)
+# MAGIC
+# MAGIC # Add system prompt
+# MAGIC request = {
+# MAGIC "messages": [
+# MAGIC {"role": "system", "content": self.config.get('system_prompt')},
+# MAGIC *messages,
+# MAGIC ],
+# MAGIC }
+# MAGIC
+# MAGIC # Ask the LLM to call tools & generate the response
+# MAGIC output= self.recursively_call_and_run_tools(
+# MAGIC **request
+# MAGIC )
+# MAGIC
+# MAGIC # Convert response to ChatResponse dataclass
+# MAGIC return ChatResponse.from_dict(output)
+# MAGIC
+# MAGIC @mlflow.trace(span_type="RETRIEVER", name="vector_search_retriever")
+# MAGIC def retrieve_docs(self, query: str) -> List[dict]:
+# MAGIC """
+# MAGIC Performs vector search to retrieve relevant chunks.
+# MAGIC
+# MAGIC Args:
+# MAGIC query: Search query.
+# MAGIC filters: Optional filters to apply to the search. Should follow the LLM-generated filter pattern of a list of field/filter pairs that will be converted to Databricks Vector Search filter format.
+# MAGIC
+# MAGIC Returns:
+# MAGIC List of retrieved Documents.
+# MAGIC """
+# MAGIC traced_search = mlflow.trace(
+# MAGIC self.workspace_client.vector_search_indexes.query_index,
+# MAGIC name="_workspace_client.vector_search_indexes.query_index",
+# MAGIC span_type="FUNCTION",
+# MAGIC )
+# MAGIC
+# MAGIC results = traced_search(
+# MAGIC index_name=self.config.get("vector_search_index"),
+# MAGIC query_text=query,
+# MAGIC columns=list(self.config.get('vector_search_schema').values()),
+# MAGIC **self.config.get("vector_search_parameters"),
+# MAGIC )
+# MAGIC
+# MAGIC # We turn the config into a dict and pass it here
+# MAGIC doc_similarity_threshold = 0
+# MAGIC return self.convert_vector_search_to_documents(
+# MAGIC results.as_dict(), doc_similarity_threshold
+# MAGIC )
+# MAGIC
+# MAGIC @mlflow.trace(span_type="PARSER")
+# MAGIC def convert_vector_search_to_documents(
+# MAGIC self, vs_results, vector_search_threshold
+# MAGIC ) -> List[dict]:
+# MAGIC column_names = []
+# MAGIC for column in vs_results["manifest"]["columns"]:
+# MAGIC column_names.append(column)
+# MAGIC
+# MAGIC docs = []
+# MAGIC if vs_results["result"]["row_count"] > 0:
+# MAGIC for item in vs_results["result"]["data_array"]:
+# MAGIC metadata = {}
+# MAGIC score = item[-1]
+# MAGIC if score >= vector_search_threshold:
+# MAGIC metadata["similarity_score"] = score
+# MAGIC for i, field in enumerate(item[0:-1]):
+# MAGIC metadata[column_names[i]["name"]] = field
+# MAGIC # put contents of the chunk into page_content
+# MAGIC text_col_name = self.config.get('vector_search_schema').get('content')
+# MAGIC page_content = metadata[text_col_name]
+# MAGIC del metadata[text_col_name]
+# MAGIC
+# MAGIC # put the primary key into id
+# MAGIC id_col_name = self.config.get('vector_search_schema').get('id')
+# MAGIC id = metadata[id_col_name]
+# MAGIC del metadata[id_col_name]
+# MAGIC
+# MAGIC doc = Document(page_content=page_content, metadata=metadata, id=id)
+# MAGIC docs.append(asdict(doc))
+# MAGIC
+# MAGIC return docs
+# MAGIC ##
+# MAGIC # Helper functions below
+# MAGIC ##
+# MAGIC @backoff.on_exception(backoff.expo, openai.RateLimitError)
+# MAGIC def completions_with_backoff(self, **kwargs):
+# MAGIC """
+# MAGIC Helper: exponetially backoff if the LLM's rate limit is exceeded.
+# MAGIC """
+# MAGIC traced_chat_completions_create_fn = mlflow.trace(
+# MAGIC self.model_serving_client.chat.completions.create,
+# MAGIC name="chat_completions_api",
+# MAGIC span_type="CHAT_MODEL",
+# MAGIC )
+# MAGIC return traced_chat_completions_create_fn(**kwargs)
+# MAGIC
+# MAGIC def chat_completion(self, messages: List[ChatMessage]) -> ChatResponse:
+# MAGIC """
+# MAGIC Helper: Call the LLM configured via the ModelConfig using the OpenAI SDK
+# MAGIC """
+# MAGIC request = {"messages": messages, "temperature": self.config.get("temperature"), "max_tokens": self.config.get("max_tokens"), "tools": self.retriever_tool_spec}
+# MAGIC return self.completions_with_backoff(
+# MAGIC model=self.config.get("endpoint_name"), **request,
+# MAGIC
+# MAGIC )
+# MAGIC
+# MAGIC @mlflow.trace(span_type="CHAIN")
+# MAGIC def recursively_call_and_run_tools(self, max_iter=10, **kwargs):
+# MAGIC """
+# MAGIC Helper: Recursively calls the LLM w/ the tools in the prompt. Either executes the tools and recalls the LLM or returns the LLM's generation.
+# MAGIC """
+# MAGIC messages = kwargs["messages"]
+# MAGIC del kwargs["messages"]
+# MAGIC i = 0
+# MAGIC while i < max_iter:
+# MAGIC with mlflow.start_span(name=f"iteration_{i}", span_type="CHAIN") as span:
+# MAGIC response = self.chat_completion(messages=messages)
+# MAGIC assistant_message = response.choices[0].message # openai client
+# MAGIC tool_calls = assistant_message.tool_calls # openai
+# MAGIC if tool_calls is None:
+# MAGIC # the tool execution finished, and we have a generation
+# MAGIC return response.to_dict()
+# MAGIC tool_messages = []
+# MAGIC for tool_call in tool_calls: # TODO: should run in parallel
+# MAGIC with mlflow.start_span(
+# MAGIC name="execute_tool", span_type="TOOL"
+# MAGIC ) as span:
+# MAGIC function = tool_call.function
+# MAGIC args = json.loads(function.arguments)
+# MAGIC span.set_inputs(
+# MAGIC {
+# MAGIC "function_name": function.name,
+# MAGIC "function_args_raw": function.arguments,
+# MAGIC "function_args_loaded": args,
+# MAGIC }
+# MAGIC )
+# MAGIC result = self.execute_function(
+# MAGIC self.tool_functions[function.name], args
+# MAGIC )
+# MAGIC tool_message = {
+# MAGIC "role": "tool",
+# MAGIC "tool_call_id": tool_call.id,
+# MAGIC "content": result,
+# MAGIC }
+# MAGIC
+# MAGIC tool_messages.append(tool_message)
+# MAGIC span.set_outputs({"new_message": tool_message})
+# MAGIC assistant_message_dict = assistant_message.dict().copy()
+# MAGIC del assistant_message_dict["content"]
+# MAGIC del assistant_message_dict["function_call"]
+# MAGIC if "audio" in assistant_message_dict:
+# MAGIC del assistant_message_dict["audio"] # hack to make llama70b work
+# MAGIC messages = (
+# MAGIC messages
+# MAGIC + [
+# MAGIC assistant_message_dict,
+# MAGIC ]
+# MAGIC + tool_messages
+# MAGIC )
+# MAGIC i += 1
+# MAGIC # TODO: Handle more gracefully
+# MAGIC raise "ERROR: max iter reached"
+# MAGIC
+# MAGIC def execute_function(self, tool, args):
+# MAGIC """
+# MAGIC Execute a tool and return the result as a JSON string
+# MAGIC """
+# MAGIC result = tool(**args)
+# MAGIC return json.dumps(result)
+# MAGIC
+# MAGIC def convert_chat_messages_to_dict(messages: List[ChatMessage]):
+# MAGIC new_messages = []
+# MAGIC for message in messages:
+# MAGIC if type(message) == ChatMessage:
+# MAGIC # Remove any keys with None values
+# MAGIC new_messages.append({k: v for k, v in asdict(message).items() if v is not None})
+# MAGIC else:
+# MAGIC new_messages.append(message)
+# MAGIC return new_messages
+# MAGIC
+# MAGIC
+# MAGIC # tell MLflow logging where to find the agent's code
+# MAGIC mlflow.models.set_model(FunctionCallingAgent())
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC Empty `__init__.py` to allow the `FunctionCallingAgent()` to be imported.
+
+# COMMAND ----------
+
+# MAGIC %%writefile __init__.py
+# MAGIC
+# MAGIC # Empty file
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Vibe check the agent
+# MAGIC Test the agent for a sample query to see the MLflow Trace.
+
+# COMMAND ----------
+
+from fc_agent import FunctionCallingAgent
+fc_agent = FunctionCallingAgent()
+
+response = fc_agent.predict(messages=[{"role": "user", "content": "What is lakehouse monitoring?"}])
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 3. Evaluate the agent
+# MAGIC ### Initial evaluation
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - What are the right metrics to evaluate quality? How do I trust the outputs of these metrics?
+# MAGIC - I need to evaluate many ideas - how do I…
+# MAGIC - …run evaluation quickly so the majority of my time isn’t spent waiting?
+# MAGIC - …quickly compare these different versions of my agent on quality, cost, and latency?
+# MAGIC - How do I quickly identify the root cause of any quality problems?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC Now, we run Agent Evaluation's proprietary LLM judges using the synthetic evaluation set to see the quality, cost, and latency of the agent and identify any root causes of quality issues. Agent Evaluation is tightly integrated with `mlflow.evaluate()`.
+# MAGIC
+# MAGIC Mosaic AI Research has invested signficantly in the quality AND speed of the LLM judges, optimizing the judges to agree with human raters. Read more [details in our blog](https://www.databricks.com/blog/databricks-announces-significant-improvements-built-llm-judges-agent-evaluation) about how our judges outperform the competition.
+# MAGIC
+# MAGIC Once evaluation runs, click `View Evaluation Results` to open the MLflow UI for this Run. This lets you:
+# MAGIC - See summary metrics
+# MAGIC - See root cause analysis that identifies the most important issues to fix
+# MAGIC - Inspect individual responses to gain intuition about how the agent is performing
+# MAGIC - See the judge outputs to understand why the responses were graded as pass or fail
+# MAGIC - Compare between multiple runs to see how quality changed between experiments
+# MAGIC
+# MAGIC You can also inspect the other tabs:
+# MAGIC - `Overview` lets you see the agent's configuration and parameters
+# MAGIC - `Artifacts` lets you see the agent's code
+# MAGIC
+# MAGIC This UIs, coupled with the speed of evaluation, help you efficiently test your hypotheses to improve quality, letting you reach the production quality bar in less time.
+# MAGIC
+# MAGIC 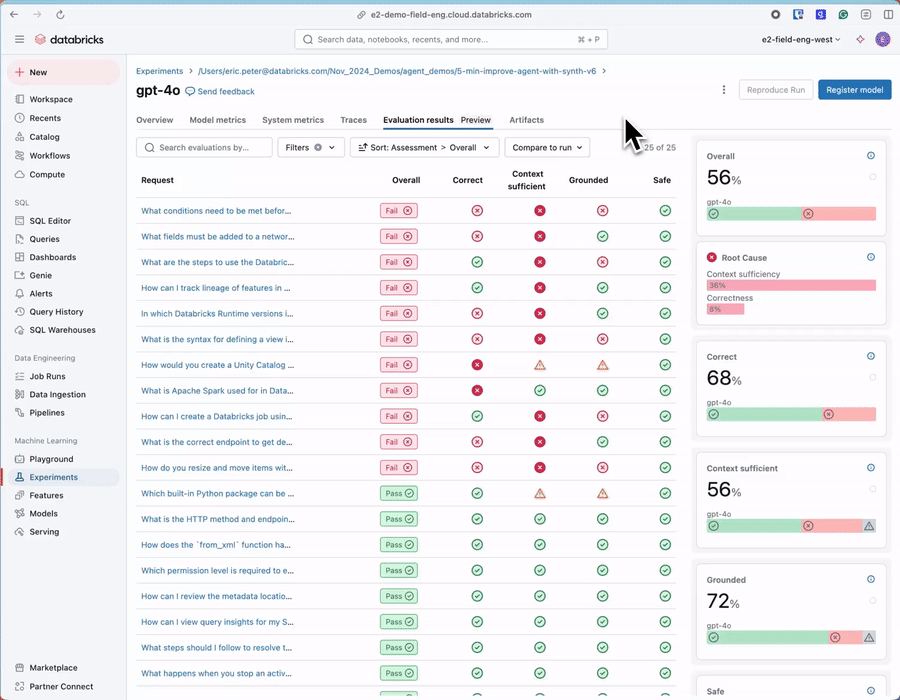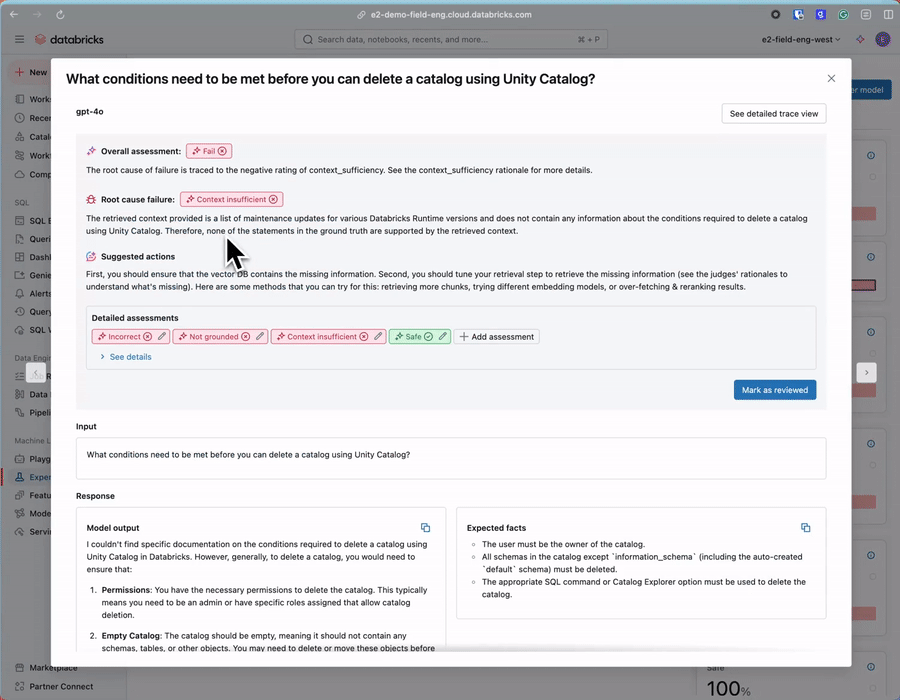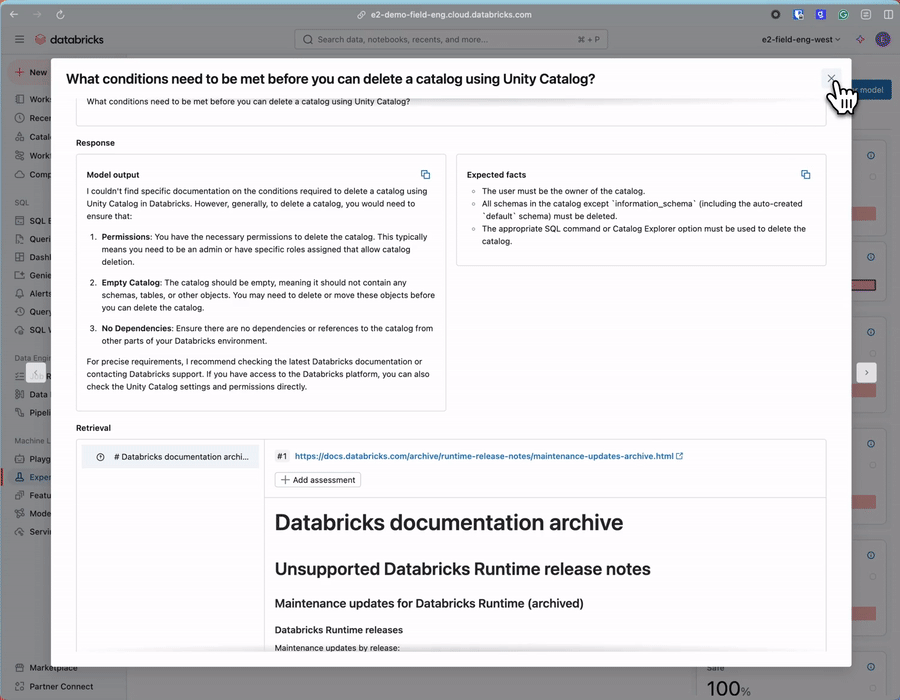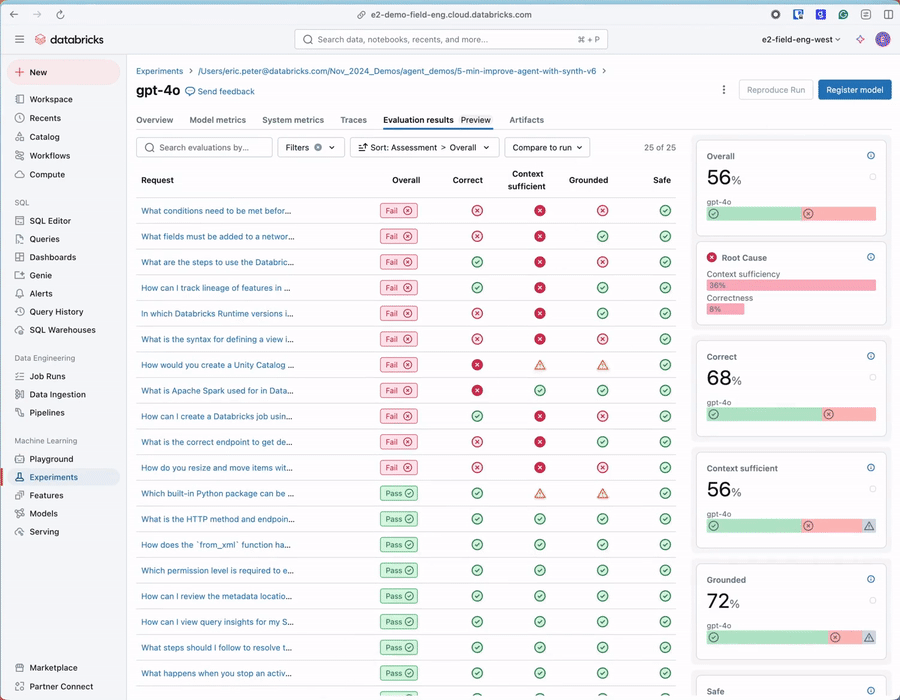 +
+# COMMAND ----------
+
+from mlflow.models.resources import DatabricksServingEndpoint, DatabricksVectorSearchIndex
+import mlflow
+from databricks.sdk import WorkspaceClient
+from databricks.sdk.service.vectorsearch import VectorIndexType
+from databricks.sdk.errors import ResourceDoesNotExist
+from fc_agent import DEFAULT_CONFIG
+
+# First, we define a helper function so we can compare the agent across multiple parameters and LLMs.
+def log_and_evaluate_agent(agent_config: dict, run_name: str):
+
+ def _get_vector_search_embedding_endpoint(vector_search_index):
+ w = WorkspaceClient()
+ index_info= w.vector_search_indexes.get_index(vector_search_index)
+ if index_info.index_type == VectorIndexType.DELTA_SYNC:
+ # Only DELTA_SYNC indexes have embedding model endpoints
+ for (
+ embedding_source_col
+ ) in index_info.delta_sync_index_spec.embedding_source_columns:
+ endpoint_name = embedding_source_col.embedding_model_endpoint_name
+ if endpoint_name is not None:
+ return [DatabricksServingEndpoint(endpoint_name=endpoint_name)]
+ else:
+ print(
+ f"Could not identify the embedding model endpoint resource for {vector_search_index}. Please manually add the embedding model endpoint to `databricks_resources`."
+ )
+ return []
+
+ # Define the databricks resources so this logged agent is deployment ready
+ resources = [DatabricksServingEndpoint(endpoint_name=agent_config["endpoint_name"]), DatabricksVectorSearchIndex(index_name=agent_config["vector_search_index"])] + _get_vector_search_embedding_endpoint(agent_config["vector_search_index"])
+
+ # Start a run to contain the agent. `run_name` is a human-readable label for this run.
+ with mlflow.start_run(run_name=run_name):
+ # Log the agent's code and configuration to MLflow
+ model_info = mlflow.pyfunc.log_model(
+ python_model="fc_agent.py",
+ artifact_path="agent",
+ model_config=agent_config,
+ resources=resources,
+ input_example={
+ "messages": [
+ {"role": "user", "content": "What is lakehouse monitoring?"}
+ ]
+ },
+ pip_requirements=["databricks-sdk[openai]", "mlflow", "databricks-agents", "backoff"],
+ )
+
+ # Run evaluation
+ eval_results = mlflow.evaluate(
+ data=evals, # Your evaluation set
+ model=model_info.model_uri, # Logged agent from above
+ model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
+ )
+
+ return (model_info, eval_results)
+
+
+# Now we call the helper function to run evaluation.
+# The configuration keys must match those defined in `fc_agent.py`
+model_info_llama_70b, eval_results = log_and_evaluate_agent(
+ agent_config=DEFAULT_CONFIG,
+ run_name="llama-3-1-70b-instruct",
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Compare multiple LLMs on quality, cost, and latency
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How to determine the foundational model that offers the right balance of quality, cost, and latency?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC Normally, you would use the evaluation results to inform your hypotheses to improve quality, iteratively implementing, evaluating, and comparing each idea to the baseline. For the purposes of the demo, we will assume that you have fixed any root causes identified above and now we want to optimize our agent for quality, cost, and latency.
+# MAGIC
+# MAGIC Here, you run evaluation for several LLMs. After the evaluation runs, click `View Evaluation Results` to open the MLflow UI for one of the runs. In the MLFLow Evaluations UI, use the **Compare to Run** dropdown to select another run name. This comparison view helps you quickly identify where the agent got better, worse, or stayed the same.
+# MAGIC
+# MAGIC Then, go to the MLflow Experiement page and click the chart icon in the upper left corner by `Runs`. Here, you can compare the models quantiatively across quality, cost, and latency metrics. The number of tokens used serves as a proxy for cost.
+# MAGIC
+# MAGIC This helps you make informed tradeoffs in partnership with your business stakeholders about quality, cost, and latency. Further, you can use this view to provide quantitative updates to your stakeholders so they can follow your progress improving quality.
+# MAGIC
+# MAGIC
+
+# COMMAND ----------
+
+from mlflow.models.resources import DatabricksServingEndpoint, DatabricksVectorSearchIndex
+import mlflow
+from databricks.sdk import WorkspaceClient
+from databricks.sdk.service.vectorsearch import VectorIndexType
+from databricks.sdk.errors import ResourceDoesNotExist
+from fc_agent import DEFAULT_CONFIG
+
+# First, we define a helper function so we can compare the agent across multiple parameters and LLMs.
+def log_and_evaluate_agent(agent_config: dict, run_name: str):
+
+ def _get_vector_search_embedding_endpoint(vector_search_index):
+ w = WorkspaceClient()
+ index_info= w.vector_search_indexes.get_index(vector_search_index)
+ if index_info.index_type == VectorIndexType.DELTA_SYNC:
+ # Only DELTA_SYNC indexes have embedding model endpoints
+ for (
+ embedding_source_col
+ ) in index_info.delta_sync_index_spec.embedding_source_columns:
+ endpoint_name = embedding_source_col.embedding_model_endpoint_name
+ if endpoint_name is not None:
+ return [DatabricksServingEndpoint(endpoint_name=endpoint_name)]
+ else:
+ print(
+ f"Could not identify the embedding model endpoint resource for {vector_search_index}. Please manually add the embedding model endpoint to `databricks_resources`."
+ )
+ return []
+
+ # Define the databricks resources so this logged agent is deployment ready
+ resources = [DatabricksServingEndpoint(endpoint_name=agent_config["endpoint_name"]), DatabricksVectorSearchIndex(index_name=agent_config["vector_search_index"])] + _get_vector_search_embedding_endpoint(agent_config["vector_search_index"])
+
+ # Start a run to contain the agent. `run_name` is a human-readable label for this run.
+ with mlflow.start_run(run_name=run_name):
+ # Log the agent's code and configuration to MLflow
+ model_info = mlflow.pyfunc.log_model(
+ python_model="fc_agent.py",
+ artifact_path="agent",
+ model_config=agent_config,
+ resources=resources,
+ input_example={
+ "messages": [
+ {"role": "user", "content": "What is lakehouse monitoring?"}
+ ]
+ },
+ pip_requirements=["databricks-sdk[openai]", "mlflow", "databricks-agents", "backoff"],
+ )
+
+ # Run evaluation
+ eval_results = mlflow.evaluate(
+ data=evals, # Your evaluation set
+ model=model_info.model_uri, # Logged agent from above
+ model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
+ )
+
+ return (model_info, eval_results)
+
+
+# Now we call the helper function to run evaluation.
+# The configuration keys must match those defined in `fc_agent.py`
+model_info_llama_70b, eval_results = log_and_evaluate_agent(
+ agent_config=DEFAULT_CONFIG,
+ run_name="llama-3-1-70b-instruct",
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC ### Compare multiple LLMs on quality, cost, and latency
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How to determine the foundational model that offers the right balance of quality, cost, and latency?
+# MAGIC
+# MAGIC **What is happening?**
+# MAGIC
+# MAGIC Normally, you would use the evaluation results to inform your hypotheses to improve quality, iteratively implementing, evaluating, and comparing each idea to the baseline. For the purposes of the demo, we will assume that you have fixed any root causes identified above and now we want to optimize our agent for quality, cost, and latency.
+# MAGIC
+# MAGIC Here, you run evaluation for several LLMs. After the evaluation runs, click `View Evaluation Results` to open the MLflow UI for one of the runs. In the MLFLow Evaluations UI, use the **Compare to Run** dropdown to select another run name. This comparison view helps you quickly identify where the agent got better, worse, or stayed the same.
+# MAGIC
+# MAGIC Then, go to the MLflow Experiement page and click the chart icon in the upper left corner by `Runs`. Here, you can compare the models quantiatively across quality, cost, and latency metrics. The number of tokens used serves as a proxy for cost.
+# MAGIC
+# MAGIC This helps you make informed tradeoffs in partnership with your business stakeholders about quality, cost, and latency. Further, you can use this view to provide quantitative updates to your stakeholders so they can follow your progress improving quality.
+# MAGIC
+# MAGIC  +
+# COMMAND ----------
+
+from fc_agent import DEFAULT_CONFIG
+
+llama405b_config = DEFAULT_CONFIG.copy()
+llama405b_config["endpoint_name"] = "databricks-meta-llama-3-1-405b-instruct"
+llama405b_config, _ = log_and_evaluate_agent(
+ agent_config=llama405b_config,
+ run_name="llama-3-1-405b-instruct",
+)
+
+# If you have an External Model, such as OpenAI, uncomment this code, and replace `
+
+# COMMAND ----------
+
+from databricks import agents
+import mlflow
+
+# Connect to the Unity Catalog model registry
+mlflow.set_registry_uri("databricks-uc")
+
+# Configure UC model location
+UC_MODEL_NAME = f"catalog.schema.db_docs_agent" # REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
+
+assert (
+ UC_MODEL_NAME != "catalog.schema.db_docs_agent"
+), "Please replace 'catalog.schema.db_docs_agent' with your actual UC catalog and schema."
+
+# Register the Llama 70b version to Unity Catalog
+uc_registered_model_info = mlflow.register_model(
+ model_uri=model_info_llama_70b.model_uri, name=UC_MODEL_NAME
+)
+# Deploy to enable the review app and create an API endpoint
+deployment_info = agents.deploy(
+ model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 5. Deploy to production and monitor
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I host my agent as a production ready, scalable service?
+# MAGIC - How do I execute tool code securely and ensure it respects my governance policies?
+# MAGIC - How do I enable telemetry or observability in development and production?
+# MAGIC - How do I monitor my agent’s quality at-scale in production? How do I quickly investigate and fix any quality issues?
+# MAGIC
+# MAGIC With Agent Framework, production deployment is the same for pre-production and production - you already have a highly scalable REST API that can be intergated in your application. This API provides an endpoint to get agent responses and to pass back user feedback so you can use that feedback to improve quality.
+# MAGIC
+# MAGIC To learn more about how monitoring works (in summary, Databricks has adapted a version of the above UIs and LLM judges for monitoring), read the documentation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/evaluating-production-traffic.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/evaluating-production-traffic)) or watch this [2 minute video](https://www.youtube.com/watch?v=ldAzmKkvQTU).
diff --git a/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html b/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html
deleted file mode 100644
index e168966..0000000
--- a/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
-
-
-
+
+# COMMAND ----------
+
+from fc_agent import DEFAULT_CONFIG
+
+llama405b_config = DEFAULT_CONFIG.copy()
+llama405b_config["endpoint_name"] = "databricks-meta-llama-3-1-405b-instruct"
+llama405b_config, _ = log_and_evaluate_agent(
+ agent_config=llama405b_config,
+ run_name="llama-3-1-405b-instruct",
+)
+
+# If you have an External Model, such as OpenAI, uncomment this code, and replace `
+
+# COMMAND ----------
+
+from databricks import agents
+import mlflow
+
+# Connect to the Unity Catalog model registry
+mlflow.set_registry_uri("databricks-uc")
+
+# Configure UC model location
+UC_MODEL_NAME = f"catalog.schema.db_docs_agent" # REPLACE WITH UC CATALOG/SCHEMA THAT YOU HAVE `CREATE MODEL` permissions in
+
+assert (
+ UC_MODEL_NAME != "catalog.schema.db_docs_agent"
+), "Please replace 'catalog.schema.db_docs_agent' with your actual UC catalog and schema."
+
+# Register the Llama 70b version to Unity Catalog
+uc_registered_model_info = mlflow.register_model(
+ model_uri=model_info_llama_70b.model_uri, name=UC_MODEL_NAME
+)
+# Deploy to enable the review app and create an API endpoint
+deployment_info = agents.deploy(
+ model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version
+)
+
+# COMMAND ----------
+
+# MAGIC %md
+# MAGIC
+# MAGIC ## Step 5. Deploy to production and monitor
+# MAGIC
+# MAGIC **Challenges addressed**
+# MAGIC - How do I host my agent as a production ready, scalable service?
+# MAGIC - How do I execute tool code securely and ensure it respects my governance policies?
+# MAGIC - How do I enable telemetry or observability in development and production?
+# MAGIC - How do I monitor my agent’s quality at-scale in production? How do I quickly investigate and fix any quality issues?
+# MAGIC
+# MAGIC With Agent Framework, production deployment is the same for pre-production and production - you already have a highly scalable REST API that can be intergated in your application. This API provides an endpoint to get agent responses and to pass back user feedback so you can use that feedback to improve quality.
+# MAGIC
+# MAGIC To learn more about how monitoring works (in summary, Databricks has adapted a version of the above UIs and LLM judges for monitoring), read the documentation ([AWS](https://docs.databricks.com/en/generative-ai/agent-evaluation/evaluating-production-traffic.html) | [Azure](https://learn.microsoft.com/en-us/azure/databricks/generative-ai/agent-evaluation/evaluating-production-traffic)) or watch this [2 minute video](https://www.youtube.com/watch?v=ldAzmKkvQTU).
diff --git a/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html b/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html
deleted file mode 100644
index e168966..0000000
--- a/quick_start_demo/Mosaic-AI-Agents-10-Minute-Demo.html
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
-
-
- -# MAGIC
-# MAGIC #### Agent Evaluation outputs in MLflow
-# MAGIC
-# MAGIC
-# MAGIC #### Agent Evaluation outputs in MLflow
-# MAGIC 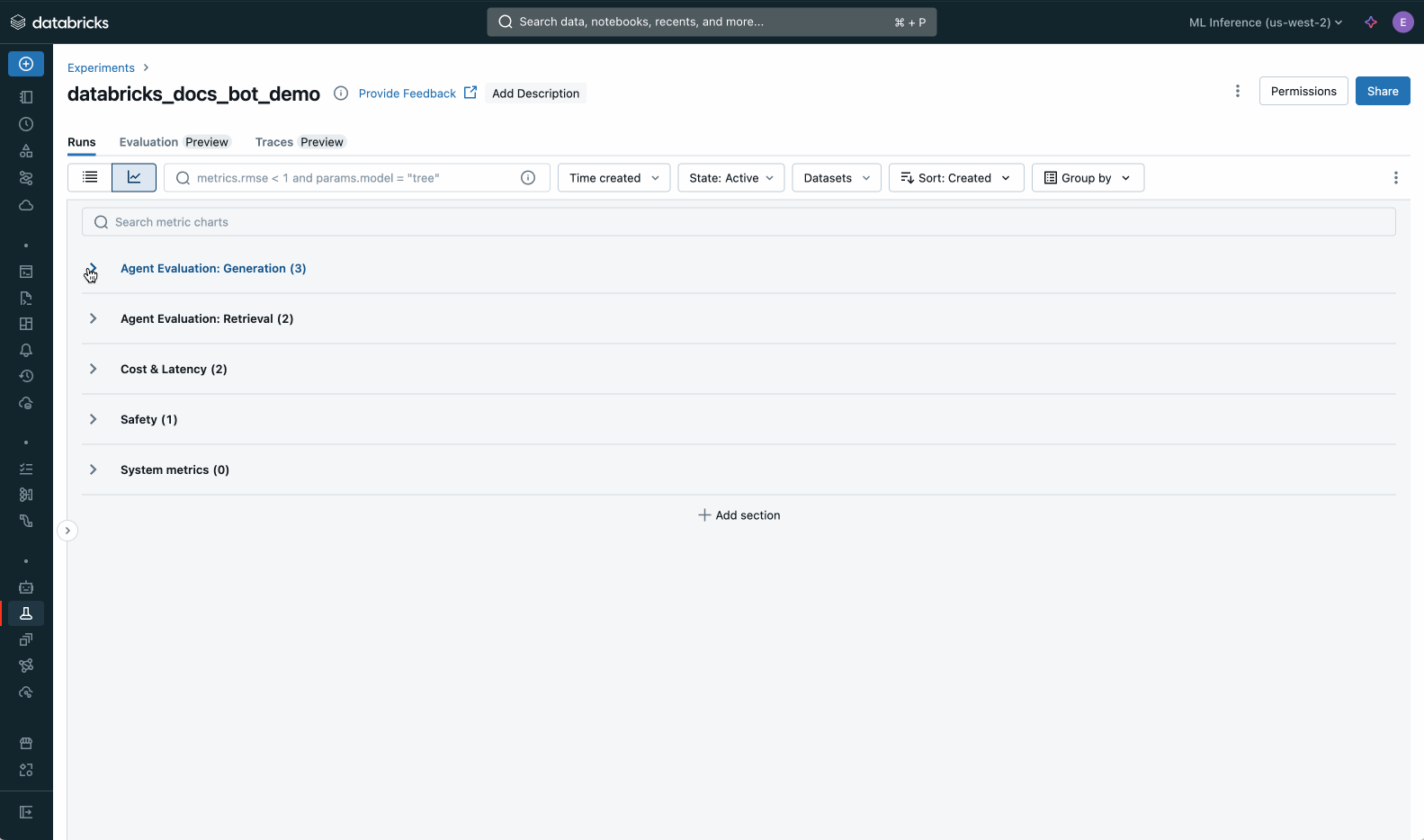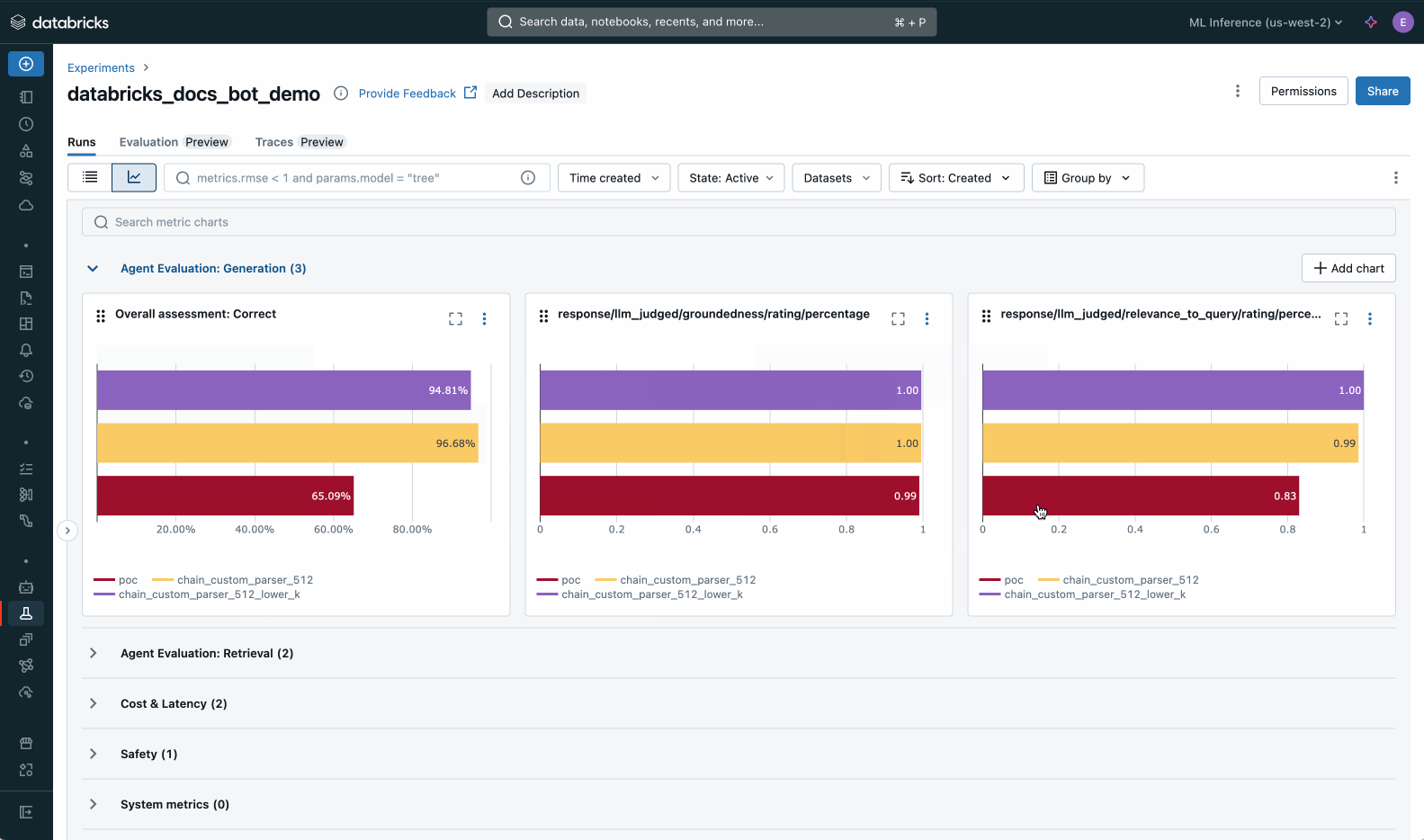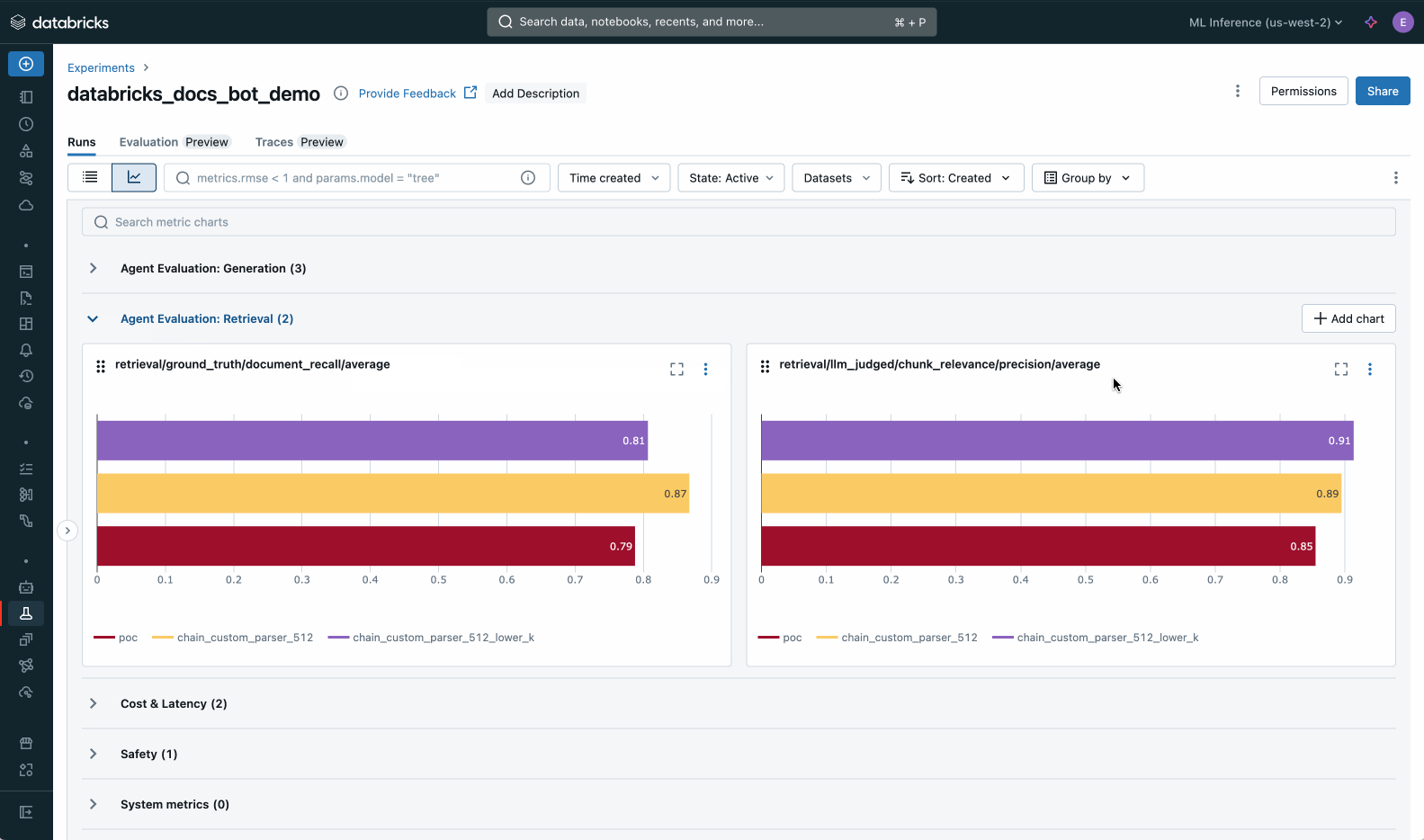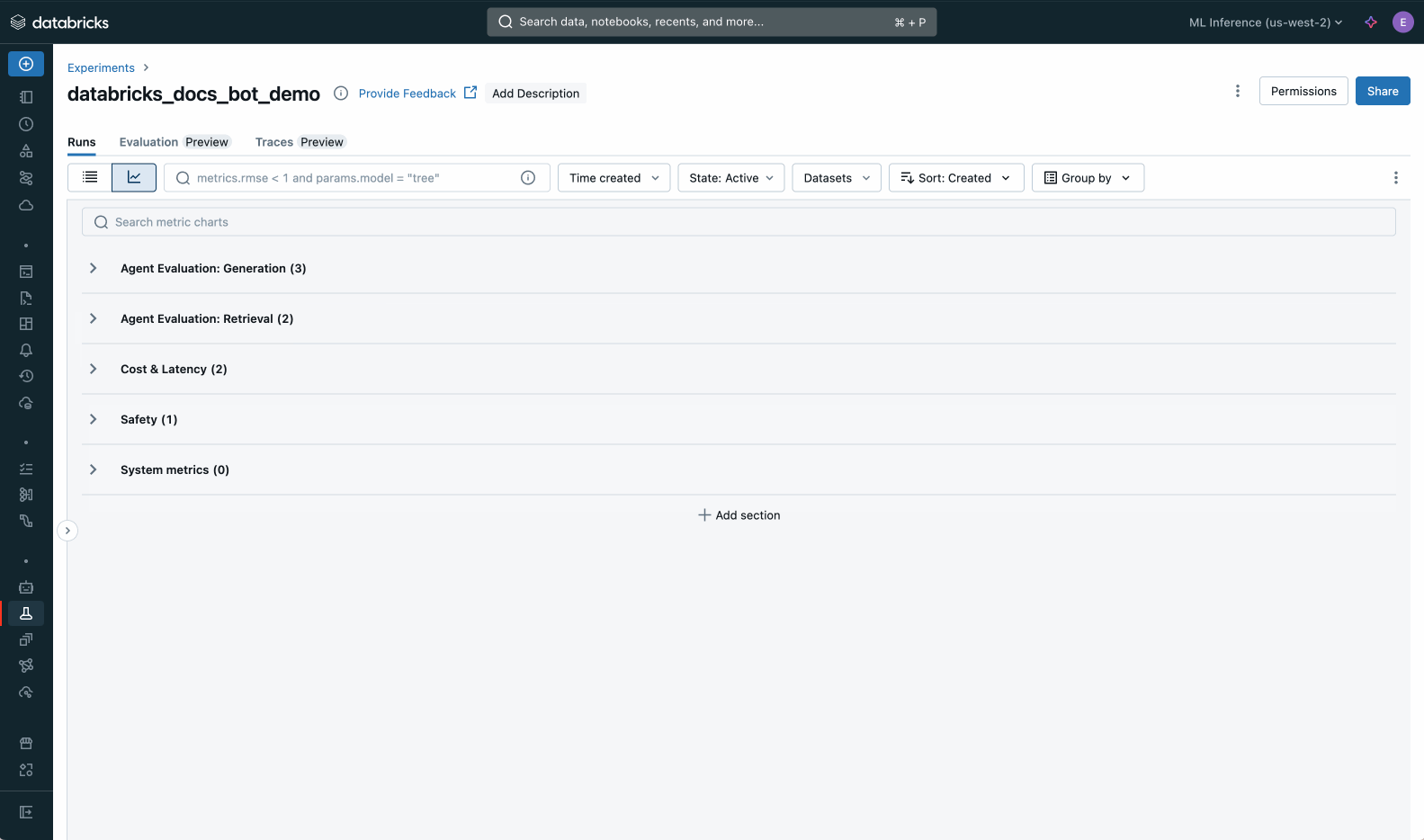 -# MAGIC
-# MAGIC #### Generative AI Cookbook
-# MAGIC
-# MAGIC
-# MAGIC #### Generative AI Cookbook
-# MAGIC 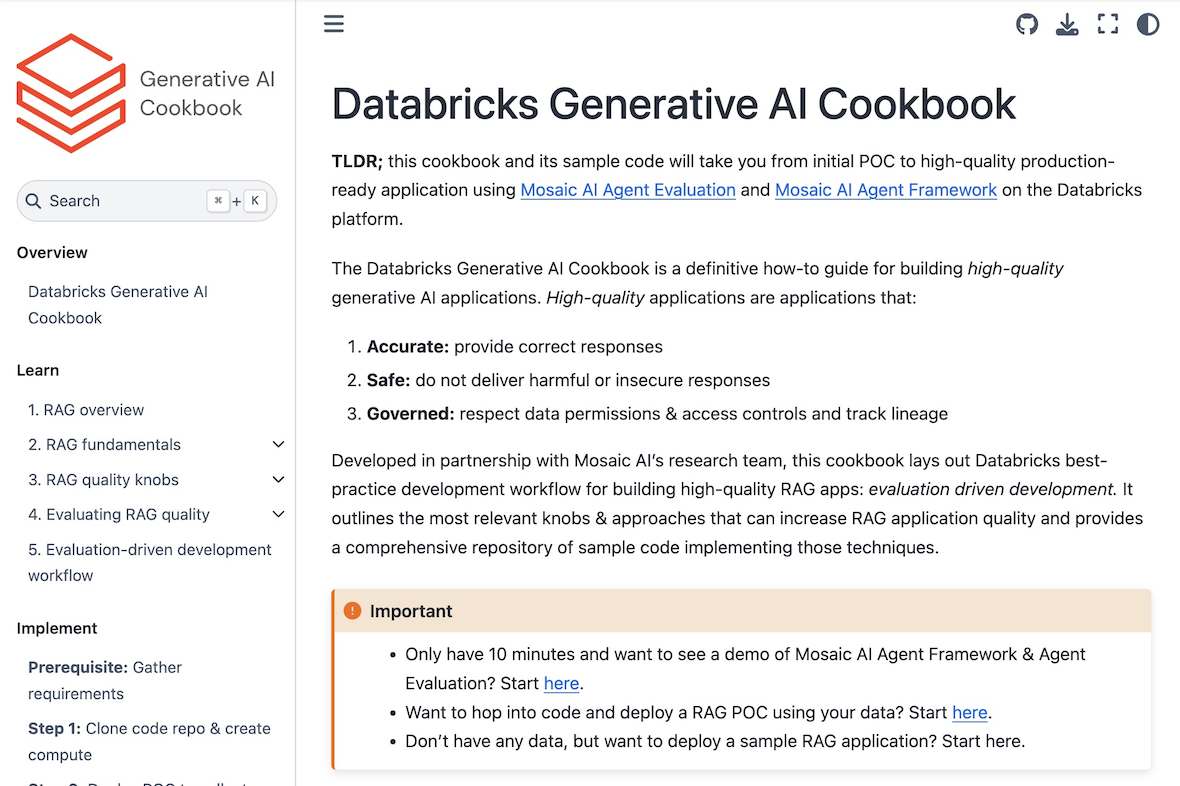 -
-# COMMAND ----------
-
-# MAGIC %pip install -U -qqqq databricks-agents mlflow mlflow-skinny databricks-vectorsearch databricks-sdk langchain==0.2.11 langchain_core==0.2.23 langchain_community==0.2.10
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-import os
-CURRENT_FOLDER = os.getcwd()
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Application configuration
-# MAGIC
-# MAGIC We've selected defaults for the following parameters based on your user name, but inspect and change if you prefer to use existing resources. Any missing resources will be created in the next step.
-# MAGIC
-# MAGIC 1. `UC_CATALOG` & `UC_SCHEMA`: [Unity Catalog](https://docs.databricks.com/en/data-governance/unity-catalog/create-catalogs.html#create-a-catalog) and a Schema where the output Delta Tables with the parsed/chunked documents and Vector Search indexes are stored
-# MAGIC 2. `UC_MODEL_NAME`: Unity Catalog location to log and store the chain's model
-# MAGIC 3. `VECTOR_SEARCH_ENDPOINT`: [Vector Search Endpoint](https://docs.databricks.com/en/generative-ai/create-query-vector-search.html#create-a-vector-search-endpoint) to host the resulting vector index
-
-# COMMAND ----------
-
-# Use the current user name to create any necesary resources
-from databricks.sdk import WorkspaceClient
-w = WorkspaceClient()
-user_name = w.current_user.me().user_name.split("@")[0].replace(".", "")
-
-# UC Catalog & Schema where outputs tables/indexs are saved
-# If this catalog/schema does not exist, you need create catalog/schema permissions.
-UC_CATALOG = f'{user_name}_catalog'
-UC_SCHEMA = f'rag_{user_name}'
-
-# UC Model name where the POC chain is logged
-UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{user_name}_agent_quick_start"
-
-# Vector Search endpoint where index is loaded
-# If this does not exist, it will be created
-VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search'
-
-# COMMAND ----------
-
-# MAGIC %md ## Check if the UC Catalog & Vector Search endpoint exist; create otherwise
-
-# COMMAND ----------
-
-# MAGIC %run ./utils
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC #### Validate UC Catalog & Schema, create if not exists
-
-# COMMAND ----------
-
-validate_catalog_and_schema_exist(UC_CATALOG, UC_SCHEMA)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC #### Validate Vector Search endpoint, create if not exists
-
-# COMMAND ----------
-
-# Create the Vector Search endpoint if it does not exist
-validate_vector_search_endpoint_exists(VECTOR_SEARCH_ENDPOINT)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Build & deploy the application
-# MAGIC
-# MAGIC Below is a high-level overview of the architecture we will deploy:
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %pip install -U -qqqq databricks-agents mlflow mlflow-skinny databricks-vectorsearch databricks-sdk langchain==0.2.11 langchain_core==0.2.23 langchain_community==0.2.10
-# MAGIC dbutils.library.restartPython()
-
-# COMMAND ----------
-
-import os
-CURRENT_FOLDER = os.getcwd()
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## Application configuration
-# MAGIC
-# MAGIC We've selected defaults for the following parameters based on your user name, but inspect and change if you prefer to use existing resources. Any missing resources will be created in the next step.
-# MAGIC
-# MAGIC 1. `UC_CATALOG` & `UC_SCHEMA`: [Unity Catalog](https://docs.databricks.com/en/data-governance/unity-catalog/create-catalogs.html#create-a-catalog) and a Schema where the output Delta Tables with the parsed/chunked documents and Vector Search indexes are stored
-# MAGIC 2. `UC_MODEL_NAME`: Unity Catalog location to log and store the chain's model
-# MAGIC 3. `VECTOR_SEARCH_ENDPOINT`: [Vector Search Endpoint](https://docs.databricks.com/en/generative-ai/create-query-vector-search.html#create-a-vector-search-endpoint) to host the resulting vector index
-
-# COMMAND ----------
-
-# Use the current user name to create any necesary resources
-from databricks.sdk import WorkspaceClient
-w = WorkspaceClient()
-user_name = w.current_user.me().user_name.split("@")[0].replace(".", "")
-
-# UC Catalog & Schema where outputs tables/indexs are saved
-# If this catalog/schema does not exist, you need create catalog/schema permissions.
-UC_CATALOG = f'{user_name}_catalog'
-UC_SCHEMA = f'rag_{user_name}'
-
-# UC Model name where the POC chain is logged
-UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{user_name}_agent_quick_start"
-
-# Vector Search endpoint where index is loaded
-# If this does not exist, it will be created
-VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search'
-
-# COMMAND ----------
-
-# MAGIC %md ## Check if the UC Catalog & Vector Search endpoint exist; create otherwise
-
-# COMMAND ----------
-
-# MAGIC %run ./utils
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC #### Validate UC Catalog & Schema, create if not exists
-
-# COMMAND ----------
-
-validate_catalog_and_schema_exist(UC_CATALOG, UC_SCHEMA)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC #### Validate Vector Search endpoint, create if not exists
-
-# COMMAND ----------
-
-# Create the Vector Search endpoint if it does not exist
-validate_vector_search_endpoint_exists(VECTOR_SEARCH_ENDPOINT)
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC
-# MAGIC # Build & deploy the application
-# MAGIC
-# MAGIC Below is a high-level overview of the architecture we will deploy:
-# MAGIC
-# MAGIC  -
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC
-# MAGIC  -# MAGIC
-# MAGIC ## 1/ Create the Vector Search Index
-# MAGIC
-# MAGIC First, we copy the sample data to a Delta Table and sync to a Vector Search index. Here, we use the [gte-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) embedding model hosted on [Databricks Foundational Model APIs](https://docs.databricks.com/en/machine-learning/foundation-models/index.html).
-
-# COMMAND ----------
-
-# UC locations to store the chunked documents & index
-CHUNKS_DELTA_TABLE = f"`{UC_CATALOG}`.`{UC_SCHEMA}`.databricks_docs_chunked2"
-CHUNKS_VECTOR_INDEX = f"`{UC_CATALOG}`.`{UC_SCHEMA}`.databricks_docs_chunked_index2"
-
-# COMMAND ----------
-
-from pyspark.sql import SparkSession
-from databricks.vector_search.client import VectorSearchClient
-
-# Workspace URL for printing links to the delta table/vector index
-workspace_url = SparkSession.getActiveSession().conf.get(
- "spark.databricks.workspaceUrl", None
-)
-
-# Vector Search client
-vsc = VectorSearchClient(disable_notice=True)
-
-# Load the chunked data to Delta Table & enable change-data capture to allow the table to sync to Vector Search
-chunked_docs_df = spark.read.parquet(
- f"file:{CURRENT_FOLDER}/chunked_databricks_docs.snappy.parquet"
-)
-chunked_docs_df.write.format("delta").saveAsTable(CHUNKS_DELTA_TABLE)
-spark.sql(
- f"ALTER TABLE {CHUNKS_DELTA_TABLE} SET TBLPROPERTIES (delta.enableChangeDataFeed = true)"
-)
-
-print(
- f"View Delta Table at: https://{workspace_url}/explore/data/{UC_CATALOG}/{UC_SCHEMA}/{CHUNKS_DELTA_TABLE.split('.')[-1]}"
-)
-
-# Embed and sync chunks to a vector index
-print(
- f"Embedding docs & creating Vector Search Index, this will take ~5 - 10 minutes.\nView Index Status at: https://{workspace_url}/explore/data/{UC_CATALOG}/{UC_SCHEMA}/{CHUNKS_VECTOR_INDEX.split('.')[-1]}"
-)
-
-index = vsc.create_delta_sync_index_and_wait(
- endpoint_name=VECTOR_SEARCH_ENDPOINT,
- index_name=CHUNKS_VECTOR_INDEX,
- primary_key="chunk_id",
- source_table_name=CHUNKS_DELTA_TABLE,
- pipeline_type="TRIGGERED",
- embedding_source_column="chunked_text",
- embedding_model_endpoint_name="databricks-gte-large-en",
-)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ## 2/ Deploy to the review application
-# MAGIC
-# MAGIC
-# MAGIC
-# MAGIC ## 1/ Create the Vector Search Index
-# MAGIC
-# MAGIC First, we copy the sample data to a Delta Table and sync to a Vector Search index. Here, we use the [gte-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) embedding model hosted on [Databricks Foundational Model APIs](https://docs.databricks.com/en/machine-learning/foundation-models/index.html).
-
-# COMMAND ----------
-
-# UC locations to store the chunked documents & index
-CHUNKS_DELTA_TABLE = f"`{UC_CATALOG}`.`{UC_SCHEMA}`.databricks_docs_chunked2"
-CHUNKS_VECTOR_INDEX = f"`{UC_CATALOG}`.`{UC_SCHEMA}`.databricks_docs_chunked_index2"
-
-# COMMAND ----------
-
-from pyspark.sql import SparkSession
-from databricks.vector_search.client import VectorSearchClient
-
-# Workspace URL for printing links to the delta table/vector index
-workspace_url = SparkSession.getActiveSession().conf.get(
- "spark.databricks.workspaceUrl", None
-)
-
-# Vector Search client
-vsc = VectorSearchClient(disable_notice=True)
-
-# Load the chunked data to Delta Table & enable change-data capture to allow the table to sync to Vector Search
-chunked_docs_df = spark.read.parquet(
- f"file:{CURRENT_FOLDER}/chunked_databricks_docs.snappy.parquet"
-)
-chunked_docs_df.write.format("delta").saveAsTable(CHUNKS_DELTA_TABLE)
-spark.sql(
- f"ALTER TABLE {CHUNKS_DELTA_TABLE} SET TBLPROPERTIES (delta.enableChangeDataFeed = true)"
-)
-
-print(
- f"View Delta Table at: https://{workspace_url}/explore/data/{UC_CATALOG}/{UC_SCHEMA}/{CHUNKS_DELTA_TABLE.split('.')[-1]}"
-)
-
-# Embed and sync chunks to a vector index
-print(
- f"Embedding docs & creating Vector Search Index, this will take ~5 - 10 minutes.\nView Index Status at: https://{workspace_url}/explore/data/{UC_CATALOG}/{UC_SCHEMA}/{CHUNKS_VECTOR_INDEX.split('.')[-1]}"
-)
-
-index = vsc.create_delta_sync_index_and_wait(
- endpoint_name=VECTOR_SEARCH_ENDPOINT,
- index_name=CHUNKS_VECTOR_INDEX,
- primary_key="chunk_id",
- source_table_name=CHUNKS_DELTA_TABLE,
- pipeline_type="TRIGGERED",
- embedding_source_column="chunked_text",
- embedding_model_endpoint_name="databricks-gte-large-en",
-)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ## 2/ Deploy to the review application
-# MAGIC
-# MAGIC  -# MAGIC
-# MAGIC Now that our Vector Search index is ready, let's prepare the RAG chain and deploy it to the review application backed by a scalable-production ready REST API on Model serving.
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ### 2.1/ Configuring our Chain parameters
-# MAGIC
-# MAGIC Databricks makes it easy to parameterize your chain with MLflow Model Configurations. Later, you can tune application quality by adjusting these parameters, such as the system prompt or retrieval settings. Most applications will include many more parameters, but for this demo, we'll keep the configuration to a minimum.
-
-# COMMAND ----------
-
-chain_config = {
- "llm_model_serving_endpoint_name": "databricks-dbrx-instruct", # the foundation model we want to use
- "vector_search_endpoint_name": VECTOR_SEARCH_ENDPOINT, # Endoint for vector search
- "vector_search_index": f"{CHUNKS_VECTOR_INDEX}",
- "llm_prompt_template": """You are an assistant that answers questions. Use the following pieces of retrieved context to answer the question. Some pieces of context may be irrelevant, in which case you should not use them to form the answer.\n\nContext: {context}""", # LLM Prompt template
-}
-
-# Here, we define an input example in the schema required by Agent Framework
-input_example = {"messages": [ {"role": "user", "content": "What is Retrieval-augmented Generation?"}]}
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ### 2.1/ Log the application & view trace
-# MAGIC
-# MAGIC We first register the chain as an MLflow model and inspect the MLflow Trace to understand what is happening inside the chain.
-# MAGIC
-# MAGIC #### MLflow trace
-# MAGIC
-# MAGIC
-# MAGIC Now that our Vector Search index is ready, let's prepare the RAG chain and deploy it to the review application backed by a scalable-production ready REST API on Model serving.
-# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ### 2.1/ Configuring our Chain parameters
-# MAGIC
-# MAGIC Databricks makes it easy to parameterize your chain with MLflow Model Configurations. Later, you can tune application quality by adjusting these parameters, such as the system prompt or retrieval settings. Most applications will include many more parameters, but for this demo, we'll keep the configuration to a minimum.
-
-# COMMAND ----------
-
-chain_config = {
- "llm_model_serving_endpoint_name": "databricks-dbrx-instruct", # the foundation model we want to use
- "vector_search_endpoint_name": VECTOR_SEARCH_ENDPOINT, # Endoint for vector search
- "vector_search_index": f"{CHUNKS_VECTOR_INDEX}",
- "llm_prompt_template": """You are an assistant that answers questions. Use the following pieces of retrieved context to answer the question. Some pieces of context may be irrelevant, in which case you should not use them to form the answer.\n\nContext: {context}""", # LLM Prompt template
-}
-
-# Here, we define an input example in the schema required by Agent Framework
-input_example = {"messages": [ {"role": "user", "content": "What is Retrieval-augmented Generation?"}]}
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ### 2.1/ Log the application & view trace
-# MAGIC
-# MAGIC We first register the chain as an MLflow model and inspect the MLflow Trace to understand what is happening inside the chain.
-# MAGIC
-# MAGIC #### MLflow trace
-# MAGIC -# MAGIC
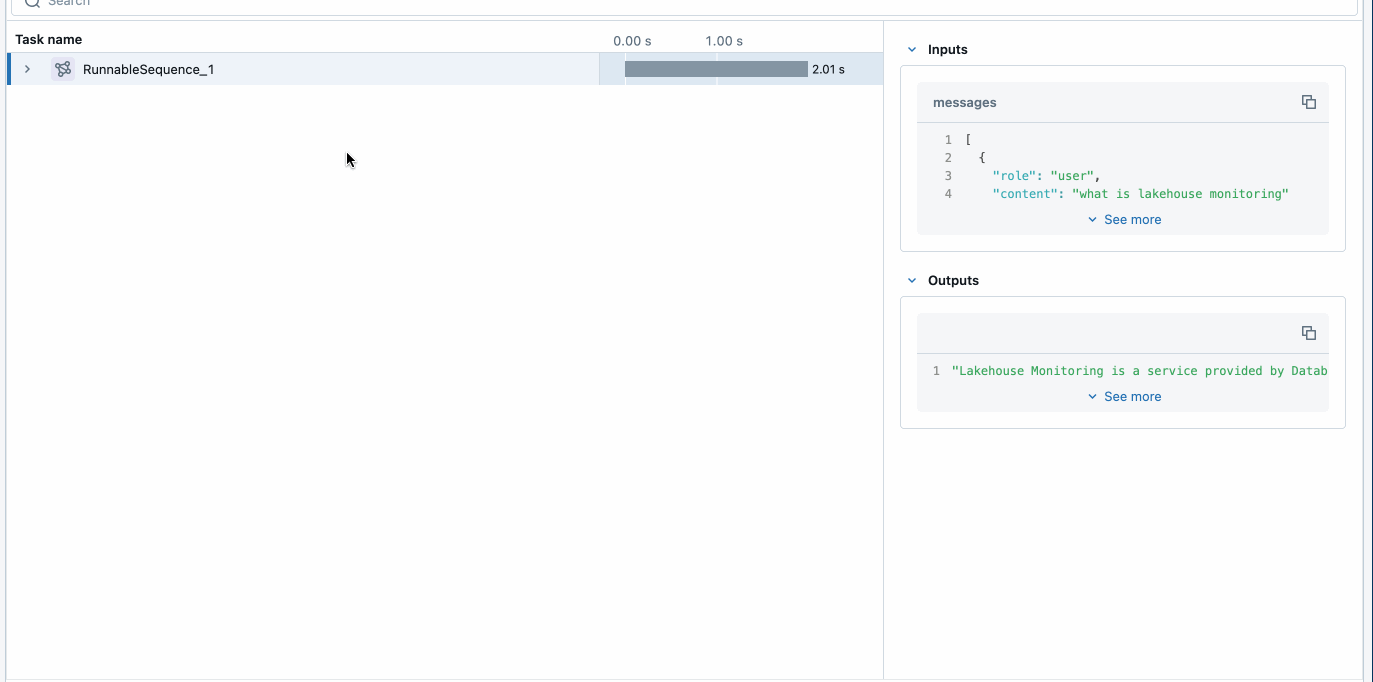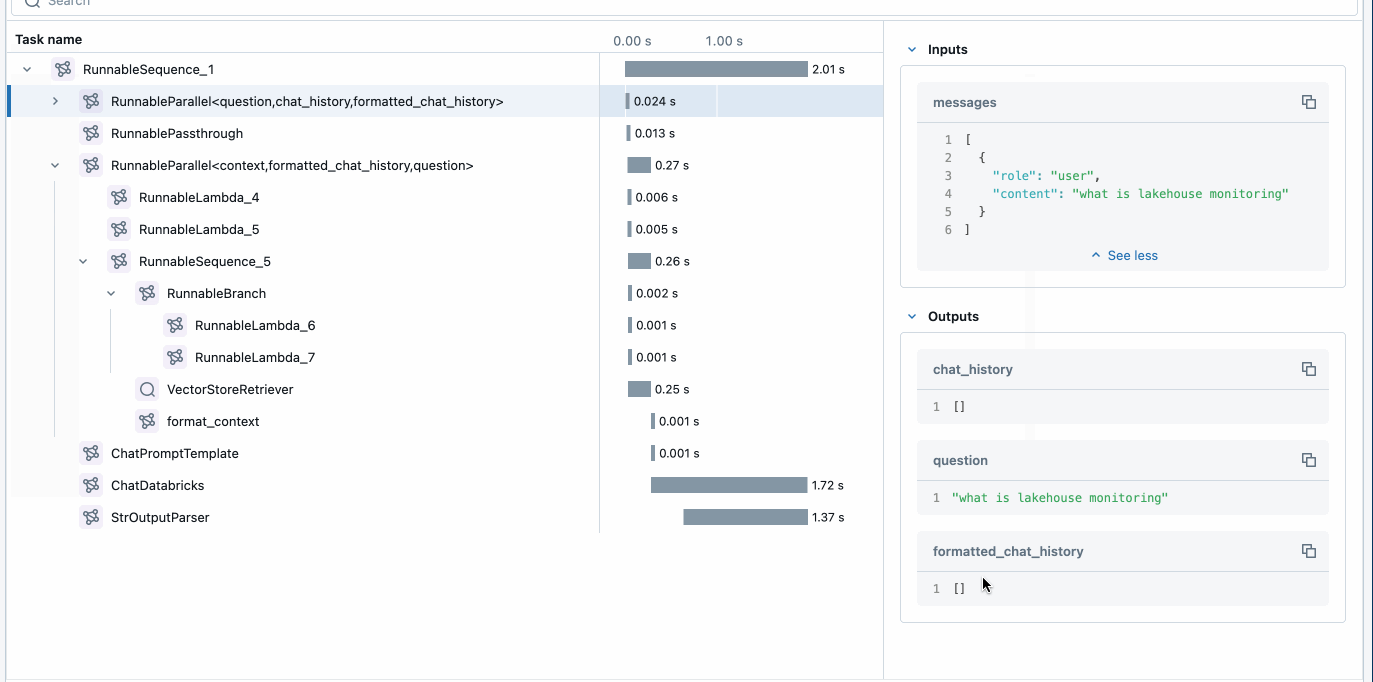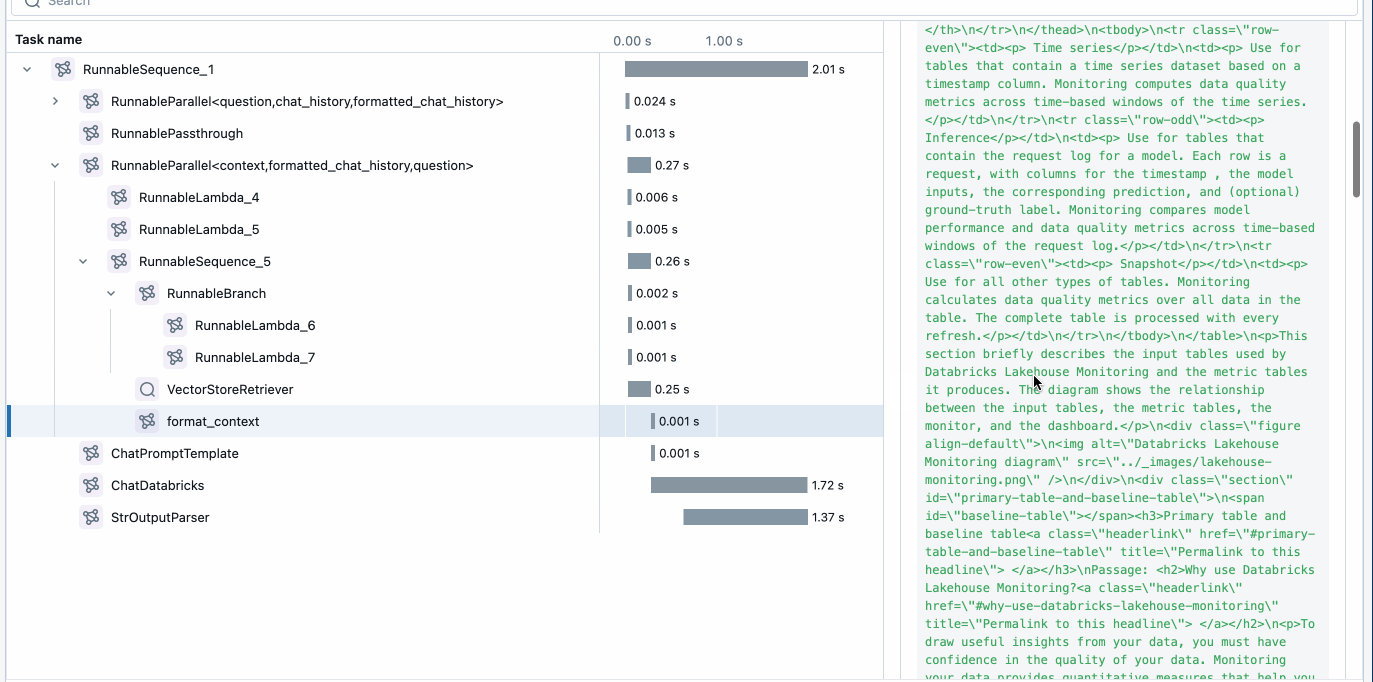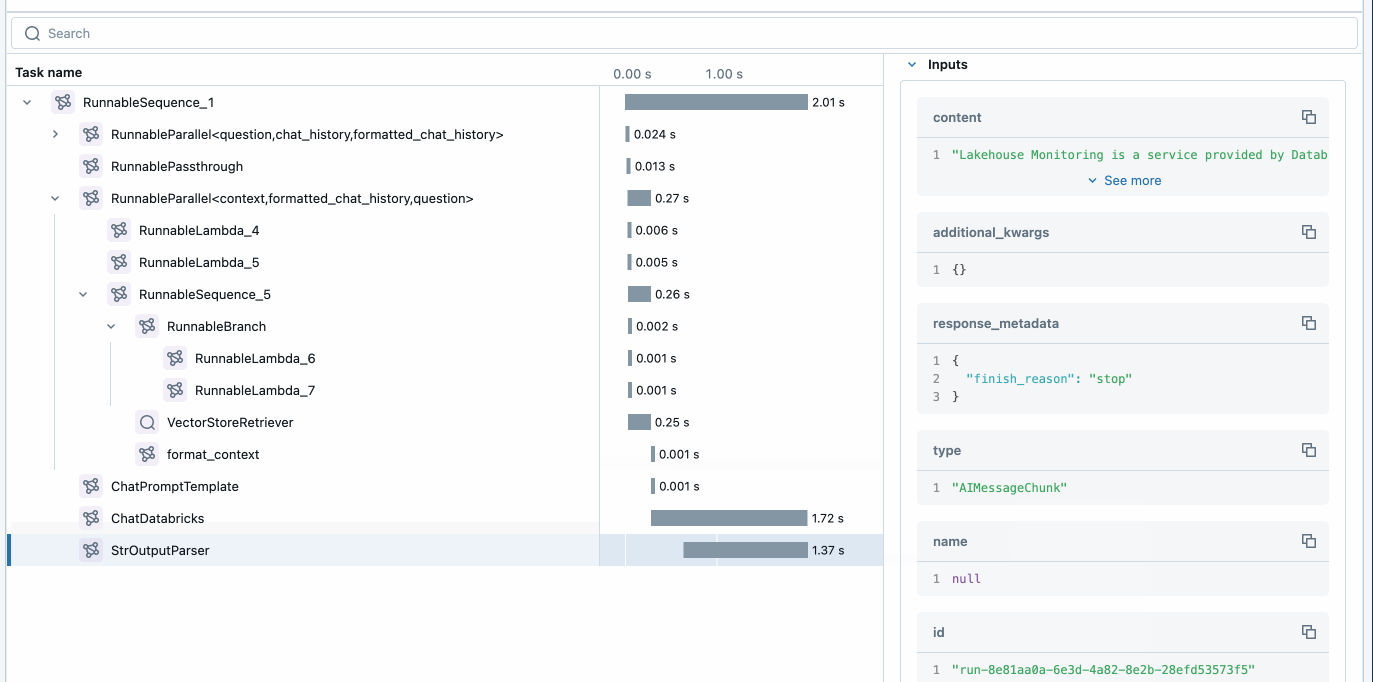 -# MAGIC
-
-# COMMAND ----------
-
-import mlflow
-
-# Log the model to MLflow
-with mlflow.start_run(run_name="databricks-docs-bot"):
- logged_chain_info = mlflow.langchain.log_model(
- lc_model=os.path.join(
- os.getcwd(),
- "sample_rag_chain",
- ), # Chain code file from the quick start repo
- model_config=chain_config, # Chain configuration set above
- artifact_path="chain", # Required by MLflow
- input_example=input_example, # Save the chain's input schema. MLflow will execute the chain before logging & capture it's output schema.
- )
-
-# Test the chain locally to see the MLflow Trace
-chain = mlflow.langchain.load_model(logged_chain_info.model_uri)
-chain.invoke(input_example)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ### 2.1/ Deploy the application
-# MAGIC
-# MAGIC Now, we:
-# MAGIC 1. Register the application in Unity Catalog
-# MAGIC 2. Use Agent Framework to deploy to the Quality Lab review application
-# MAGIC
-# MAGIC Along side the review ap, a scalable, production-ready Model Serving endpoint is also deployed.
-# MAGIC
-# MAGIC #### Agent Evaluation review application
-# MAGIC
-
-# COMMAND ----------
-
-from databricks import agents
-import time
-from databricks.sdk.service.serving import EndpointStateReady, EndpointStateConfigUpdate
-
-# Use Unity Catalog to log the chain
-mlflow.set_registry_uri('databricks-uc')
-
-# Register the chain to UC
-uc_registered_model_info = mlflow.register_model(model_uri=logged_chain_info.model_uri, name=UC_MODEL_NAME)
-
-# Deploy to enable the Review APP and create an API endpoint
-deployment_info = agents.deploy(model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version)
-
-# Wait for the Review App to be ready
-print("\nWaiting for endpoint to deploy. This can take 15 - 20 minutes.")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # 3/ Use Agent Evaluation to evaluate your application
-# MAGIC
-# MAGIC ## 3.1/ Have stakeholders chat your bot to build your evaluation dataset
-# MAGIC
-# MAGIC Normally, you would now give access to internal domain experts and have them test and review the bot. **Your domain experts do NOT need to have Databricks Workspace access** - you can assign permissions to any user in your SSO if you have enabled [SCIM](https://docs.databricks.com/en/admin/users-groups/scim/index.html)
-# MAGIC
-# MAGIC This is a critical step to build or improve your evaluation dataset: have users ask questions to your bot, and provide the bot with output answer when they don't answer properly.
-# MAGIC
-# MAGIC Your applicaation is automatically capturing all stakeholder questions and bot responses, including the MLflow Trace for each, into Delta Tables in your Lakehouse. On top of that, Databricks makes it easy to track feedback from your end user: if the chatbot doesn't give a good answer and the user gives a thumbdown, their feedback is included in the Delta Tables.
-# MAGIC
-# MAGIC Your evaluation dataset forms the basis of your development workflow to improve quality: identifying the root causes of quality issues and then objectively measuring the impact of your fixes.
-# MAGIC
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-import mlflow
-
-# Log the model to MLflow
-with mlflow.start_run(run_name="databricks-docs-bot"):
- logged_chain_info = mlflow.langchain.log_model(
- lc_model=os.path.join(
- os.getcwd(),
- "sample_rag_chain",
- ), # Chain code file from the quick start repo
- model_config=chain_config, # Chain configuration set above
- artifact_path="chain", # Required by MLflow
- input_example=input_example, # Save the chain's input schema. MLflow will execute the chain before logging & capture it's output schema.
- )
-
-# Test the chain locally to see the MLflow Trace
-chain = mlflow.langchain.load_model(logged_chain_info.model_uri)
-chain.invoke(input_example)
-
-# COMMAND ----------
-
-# MAGIC %md-sandbox
-# MAGIC ### 2.1/ Deploy the application
-# MAGIC
-# MAGIC Now, we:
-# MAGIC 1. Register the application in Unity Catalog
-# MAGIC 2. Use Agent Framework to deploy to the Quality Lab review application
-# MAGIC
-# MAGIC Along side the review ap, a scalable, production-ready Model Serving endpoint is also deployed.
-# MAGIC
-# MAGIC #### Agent Evaluation review application
-# MAGIC
-
-# COMMAND ----------
-
-from databricks import agents
-import time
-from databricks.sdk.service.serving import EndpointStateReady, EndpointStateConfigUpdate
-
-# Use Unity Catalog to log the chain
-mlflow.set_registry_uri('databricks-uc')
-
-# Register the chain to UC
-uc_registered_model_info = mlflow.register_model(model_uri=logged_chain_info.model_uri, name=UC_MODEL_NAME)
-
-# Deploy to enable the Review APP and create an API endpoint
-deployment_info = agents.deploy(model_name=UC_MODEL_NAME, model_version=uc_registered_model_info.version)
-
-# Wait for the Review App to be ready
-print("\nWaiting for endpoint to deploy. This can take 15 - 20 minutes.")
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # 3/ Use Agent Evaluation to evaluate your application
-# MAGIC
-# MAGIC ## 3.1/ Have stakeholders chat your bot to build your evaluation dataset
-# MAGIC
-# MAGIC Normally, you would now give access to internal domain experts and have them test and review the bot. **Your domain experts do NOT need to have Databricks Workspace access** - you can assign permissions to any user in your SSO if you have enabled [SCIM](https://docs.databricks.com/en/admin/users-groups/scim/index.html)
-# MAGIC
-# MAGIC This is a critical step to build or improve your evaluation dataset: have users ask questions to your bot, and provide the bot with output answer when they don't answer properly.
-# MAGIC
-# MAGIC Your applicaation is automatically capturing all stakeholder questions and bot responses, including the MLflow Trace for each, into Delta Tables in your Lakehouse. On top of that, Databricks makes it easy to track feedback from your end user: if the chatbot doesn't give a good answer and the user gives a thumbdown, their feedback is included in the Delta Tables.
-# MAGIC
-# MAGIC Your evaluation dataset forms the basis of your development workflow to improve quality: identifying the root causes of quality issues and then objectively measuring the impact of your fixes.
-# MAGIC
-# MAGIC -# MAGIC -# MAGIC
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC ## 3.2/ Run Evaluation of your Chain
-# MAGIC
-# MAGIC Now, let's use everage Agent Evaluation's specialized AI evaluators to evaluate our model performance. Agent Evaluation is integrated into `mlflow.evaluate(...)`, all you need to do is pass `model_type="databricks-agent"`.
-# MAGIC
-# MAGIC For this demo, we use a toy 10 question evaluation dataset. Read more about our [best practices](https://ai-cookbook.io/nbs/4-evaluation-eval-sets.html) on the size of your evaluation dataset.
-# MAGIC
-# MAGIC
-
-# COMMAND ----------
-
-import pandas as pd
-
-sample_eval_set = [
- {
- "request_id": "5482",
- "request": "What happens if I try to access an index that is out of bounds in an array using the [ ] operator in Databricks SQL when spark.sql.ansi.enabled is set to false?",
- "response": "If you try to access an index that is out of bounds in an array using the [ ] operator in Databricks SQL when `spark.sql.ansi.enabled` is set to false, Databricks will return `NULL` instead of raising an `INVALID_ARRAY_INDEX` error. However, if `spark.sql.ansi.enabled` is set to true, an `INVALID_ARRAY_INDEX` error will be raised.",
- "expected_retrieved_context": [
- {
- "content": "[ ] (bracket sign) operator \nApplies to: Databricks SQL Databricks Runtime \nReturns an array element or map value given an index or key. \nSyntax\nSyntax\nexpr [ keyExpr ] \nNote that the use of brackets here is as literal text and not indicating optional syntax.\n\nArguments\nArguments\nexpr: An ARRAY or MAP expression. \nkeyExpr: If expr is an ARRAY an integral numeric. Otherwise an expression matching the type of the key of the MAP.\n\nReturns\nReturns\nThe result type is the element type of the ARRAY or the value type of the MAP. \nThe first element of an ARRAY is at index 0. \nIf the keyExpr is not a valid key for the MAP expr Databricks returns null. \nIf the keyExpr is out of bound for the ARRAY expr Databricks raises a INVALID_ARRAY_INDEXerror. \nNote \nIn Databricks Runtime, if spark.sql.ansi.enabled is false, the operator returns NULL instead of an out of bounds error.\n\nExamples\nExamples\n> SELECT a[2] FROM VALUES(array(10, 20, 30)) AS T(a); 30 > SELECT m[1] FROM VALUES(map(1, 'Hello', 2, 'World')) AS T(m); Hello\n\nRelated functions\nRelated functions\narray function \narray_contains function \narray_position function \nmap function \nmap_keys function \nmap_values function",
- "doc_uri": "https://docs.databricks.com/sql/language-manual/functions/bracketsign.html",
- }
- ],
- "expected_response": "If you try to access an index that is out of bounds in an array using the [ ] operator in Databricks SQL when spark.sql.ansi.enabled is set to false, Databricks will return NULL instead of raising an error.",
- },
- {
- "request_id": "2112",
- "request": "Why is a long-running stage in my Spark job only showing one task, and how can I resolve this issue?",
- "response": "A long-running stage in a Spark job with only one task could be caused by expensive UDFs on small data, window functions without a `PARTITION BY` statement, reading from an unsplittable file type, setting the `multiLine` option when reading a JSON or CSV file, schema inference of a large file, or using `repartition(1)` or `coalesce(1)`. To diagnose this issue, you can check the Spark UI to identify the longest stage of the job and look at the Input, Output, Shuffle Read, and Shuffle Write columns. If there is only one task, it could be a sign of a problem. To resolve this issue, you can try optimizing your Spark job by avoiding the aforementioned causes. For example, you can avoid using `repartition(1)` or `coalesce(1)` unless necessary, use a splittable file type, and optimize your UDFs and window functions.",
- "expected_retrieved_context": [
- {
- "content": "One Spark task \nIf you see a long-running stage with just one task, that’s likely a sign of a problem. While this one task is running only one CPU is utilized and the rest of the cluster may be idle. This happens most frequently in the following situations: \nExpensive UDF on small data \nWindow function without PARTITION BY statement \nReading from an unsplittable file type. This means the file cannot be read in multiple parts, so you end up with one big task. Gzip is an example of an unsplittable file type. \nSetting the multiLine option when reading a JSON or CSV file \nSchema inference of a large file \nUse of repartition(1) or coalesce(1)",
- "doc_uri": "https://docs.databricks.com/optimizations/spark-ui-guide/one-spark-task.html",
- }
- ],
- "expected_response": "A long-running stage with one task in a Spark job could be due to several reasons such as:\n\n1. Expensive User Defined Functions (UDFs) on small data\n2. Window function without a PARTITION BY statement\n3. Reading from an unsplittable file type like gzip\n4. Setting the multiLine option when reading a JSON or CSV file\n5. Schema inference of a large file\n6. Use of repartition(1) or coalesce(1)\n\nTo resolve this issue, you can:\n\n1. Optimize your UDFs or replace them with built-in functions if possible.\n2. Ensure that you have a proper PARTITION BY statement in your window functions.\n3. Avoid using unsplittable file types like gzip. Instead, use splittable file types like snappy or lz4.\n4. Avoid setting the multiLine option when reading JSON or CSV files.\n5. Perform schema inference on a small sample of your data and then apply it to the entire dataset.\n6. Avoid using repartition(1) or coalesce(1) unless necessary.\n\nBy implementing these changes, you should be able to resolve the issue of a long-running stage with only one task in your Spark job.",
- },
- {
- "request_id": "5054",
- "request": "How can I represent 4-byte single-precision floating point numbers in Databricks SQL and what are their limits?",
- "response": "4-byte single-precision floating point numbers in Databricks SQL are represented using the `FLOAT` data type. The range of numbers that can be represented is from -3.402E+38 to +3.402E+38, including negative infinity, positive infinity, and NaN (not a number). The literals for `FLOAT` type can be expressed in base-10 or base-2 format, with the `F` postfix and `E` exponent being case insensitive. However, due to the base-2 representation, the literal may not be exact. For accurate representation of fractional or large base-10 numbers, it is recommended to use the `DECIMAL` data type.",
- "expected_retrieved_context": [
- {
- "content": "FLOAT type \nApplies to: Databricks SQL Databricks Runtime \nRepresents 4-byte single-precision floating point numbers. \nSyntax\nSyntax\n{ FLOAT | REAL }\n\nLimits\nLimits\nThe range of numbers is: \n-∞ (negative infinity) \n-3.402E+38 to -1.175E-37 \n0 \n+1.175E-37 to +3.402E+38 \n+∞ (positive infinity) \nNaN (not a number)\n\nLiterals\nLiterals\ndecimal_digits [ exponent ] F | [ + | - ] digit [ ... ] [ exponent ] F decimal_digits: [ + | - ] { digit [ ... ] . [ digit [ ... ] ] | . digit [ ... ] } exponent: E [ + | - ] digit [ ... ] \ndigit: Any numeral from 0 to 9. \nThe F postfix and E exponent are case insensitive.\n\nNotes\nNotes\nFLOAT is a base-2 numeric type. When given a literal which is base-10 the representation may not be exact. Use DECIMAL type to accurately represent fractional or large base-10 numbers.\n\nExamples\nExamples\n> SELECT +1F; 1.0 > SELECT 5E10F; 5E10 > SELECT 5.3E10F; 5.3E10 > SELECT -.1F; -0.1 > SELECT 2.F; 2.0 > SELECT -5555555555555555.1F -5.5555558E15 > SELECT CAST(6.1 AS FLOAT) 6.1\n\nRelated\nRelated\nTINYINT type \nSMALLINT type \nINT type \nBIGINT type \nDECIMAL type \nDOUBLE type \ncast function \nSpecial floating point values",
- "doc_uri": "https://docs.databricks.com/sql/language-manual/data-types/float-type.html",
- }
- ],
- "expected_response": "4-byte single-precision floating point numbers can be represented in Databricks SQL using the `FLOAT` or `REAL` syntax. The range of numbers that can be represented is from -3.402E+38 to +3.402E+38, including negative infinity, positive infinity, and NaN (not a number). Here are some examples of how to represent these numbers:\n\n* `+1F` represents 1.0\n* `5E10F` represents 5E10\n* `5.3E10F` represents 5.3E10\n* `-.1F` represents -0.1\n* `2.F` represents 2.0\n* `-5555555555555555.1F` represents -5.5555558E15\n* `CAST(6.1 AS FLOAT)` represents 6.1\n\nNote that `FLOAT` is a base-2 numeric type, so the representation of base-10 literals may not be exact. If you need to accurately represent fractional or large base-10 numbers, consider using the `DECIMAL` type instead.",
- },
- {
- "request_id": "2003",
- "request": "How can I identify the reason for failing executors in my Databricks workspace, and what steps can I take to resolve memory issues?",
- "response": "To identify the reason for failing executors in your Databricks workspace, you should first check the compute's Event log in the Spark UI to see if there's any explanation for why the executors failed. If you don't find any information in the event log, navigate to the Executors tab in the Spark UI to get the logs from the failed executors.\n\nThe most common reasons for executors being removed are autoscaling, spot instance losses, and executors running out of memory. If you see any failing jobs, click on them to get to their pages, scroll down to see the failed stage and a failure reason, and check the failed tasks to identify the issue.\n\nIf you suspect a memory issue, you can verify it by doubling the memory per core to see if it impacts your problem. If it takes longer to fail with the extra memory or doesn't fail at all, that's a good sign that you're on the right track. If you can fix your issue by increasing the memory, great! If it doesn't fix the issue, or you can't bear the extra cost, you should dig deeper into memory issues.",
- "expected_retrieved_context": [
- {
- "content": "Failing jobs or executors removed \nSo you’re seeing failed jobs or removed executors: \nThe most common reasons for executors being removed are: \nAutoscaling: In this case it’s expected and not an error. See Enable autoscaling. \nSpot instance losses: The cloud provider is reclaiming your VMs. You can learn more about Spot instances here. \nExecutors running out of memory \nFailing jobs\nFailing jobs\nIf you see any failing jobs click on them to get to their pages. Then scroll down to see the failed stage and a failure reason: \nYou may get a generic error. Click on the link in the description to see if you can get more info: \nIf you scroll down in this page, you will be able to see why each task failed. In this case it’s becoming clear there’s a memory issue:\n\nFailing executors\nFailing executors\nTo find out why your executors are failing, you’ll first want to check the compute’s Event log to see if there’s any explanation for why the executors failed. For example, it’s possible you’re using spot instances and the cloud provider is taking them back. \nSee if there are any events explaining the loss of executors. For example you may see messages indicating that the cluster is resizing or spot instances are being lost. \nIf you are using spot instances, see Losing spot instances. \nIf your compute was resized with autoscaling, it’s expected and not an error. See Learn more about cluster resizing. \nIf you don’t see any information in the event log, navigate back to the Spark UI then click the Executors tab: \nHere you can get the logs from the failed executors:\n\nNext step\nNext step\nIf you’ve gotten this far, the likeliest explanation is a memory issue. The next step is to dig into memory issues. See Spark memory issues.",
- "doc_uri": "https://docs.databricks.com/optimizations/spark-ui-guide/failing-spark-jobs.html",
- }
- ],
- "expected_response": "1. Identify failing executors: In your Databricks workspace, navigate to the compute's Event log to check for any explanations regarding executor failures. Look for messages indicating spot instance losses or cluster resizing due to autoscaling. If using spot instances, refer to 'Losing spot instances' documentation. For autoscaling, refer to 'Learn more about cluster resizing' documentation.\n\n2. Check executor logs: If no information is found in the event log, go to the Spark UI and click the Executors tab. Here, you can access logs from failed executors to investigate further.\n\n3. Identify memory issues: If the above steps do not provide a clear reason for failing executors, it is likely a memory issue. To dig into memory issues, refer to the 'Spark memory issues' documentation.\n\n4. Resolve memory issues: To resolve memory issues, consider the following steps:\n\n a. Increase executor memory: Allocate more memory to executors by adjusting the 'spark.executor.memory' property in your Spark configuration.\n\n b. Increase driver memory: Allocate more memory to the driver by adjusting the 'spark.driver.memory' property in your Spark configuration.\n\n c. Use off-heap memory: Enable off-heap memory by setting the 'spark.memory.offHeap.enabled' property to 'true' and allocating off-heap memory using the 'spark.memory.offHeap.size' property.\n\n d. Optimize data processing: Review your data processing workflows and optimize them for memory efficiency. This may include reducing data shuffling, using broadcast variables, or caching data strategically.\n\n e. Monitor memory usage: Monitor memory usage in your Databricks workspace to identify potential memory leaks or inefficient memory utilization. Use tools like the Spark UI, Ganglia, or Grafana to monitor memory usage.",
- },
-]
-
-eval_df = pd.DataFrame(sample_eval_set)
-display(eval_df)
-
-# COMMAND ----------
-
-with mlflow.start_run(run_id=logged_chain_info.run_id):
- # Evaluate
- eval_results = mlflow.evaluate(
- data=eval_df, # Your evaluation set
- model=logged_chain_info.model_uri, # previously logged model
- model_type="databricks-agent", # activate Mosaic AI Agent Evaluation
- )
-
-# COMMAND ----------
-
-# MAGIC %md
-# MAGIC # What's next?
-# MAGIC
-# MAGIC
-# MAGIC ## Code-based quick starts
-# MAGIC
-# MAGIC | Time required | Outcome | Link |
-# MAGIC |------ | ---- | ---- |
-# MAGIC | 🕧 10 minutes | Sample RAG app deployed to web-based chat app that collects feedback | ✅ | -# MAGIC | 🕧🕧🕧
60 minutes | POC RAG app with *your data* deployed to a chat UI that can collect feedback from your business stakeholders | [Deploy POC w/ your data](https://ai-cookbook.io/nbs/5-hands-on-build-poc.html)| -# MAGIC | 🕧🕧
30 minutes | Comprehensive quality/cost/latency evaluation of your POC app | - [Evaluate your POC](https://ai-cookbook.io/nbs/5-hands-on-evaluate-poc.html)
- [Identify the root causes of quality issues](https://ai-cookbook.io/nbs/5-hands-on-improve-quality-step-1.html) | -# MAGIC -# MAGIC ## Browse the code samples -# MAGIC -# MAGIC Open the `./genai-cookbook/agent_app_sample_code` folder that was synced to your Workspace by this notebook. Documentation [here](https://ai-cookbook.io/nbs/6-implement-overview.html). -# MAGIC -# MAGIC ## Read the [Generative AI Cookbook](https://ai-cookbook.io)! -# MAGIC -# MAGIC **TLDR;** the [cookbook]((https://ai-cookbook.io) and its sample code will take you from initial POC to high-quality production-ready application using [Mosaic AI Agent Evaluation](https://docs.databricks.com/generative-ai/agent-evaluation/index.html) and [Mosaic AI Agent Framework](https://docs.databricks.com/generative-ai/retrieval-augmented-generation.html) on the Databricks platform. -# MAGIC -# MAGIC The Databricks Generative AI Cookbook is a definitive how-to guide for building *high-quality* generative AI applications. *High-quality* applications are applications that: -# MAGIC 1. **Accurate:** provide correct responses -# MAGIC 2. **Safe:** do not deliver harmful or insecure responses -# MAGIC 3. **Governed:** respect data permissions & access controls and track lineage -# MAGIC -# MAGIC Developed in partnership with Mosaic AI's research team, this cookbook lays out Databricks best-practice development workflow for building high-quality RAG apps: *evaluation driven development.* It outlines the most relevant knobs & approaches that can increase RAG application quality and provides a comprehensive repository of sample code implementing those techniques. -# MAGIC -# MAGIC
-# MAGIC -# MAGIC
 diff --git a/quick_start_demo/sample_rag_chain.py b/quick_start_demo/sample_rag_chain.py
deleted file mode 100644
index c82c094..0000000
--- a/quick_start_demo/sample_rag_chain.py
+++ /dev/null
@@ -1,212 +0,0 @@
-# Databricks notebook source
-# MAGIC %pip install -U -qqqq databricks-agents mlflow mlflow-skinny databricks-vectorsearch langchain==0.2.11 langchain_core==0.2.23 langchain_community==0.2.10
-
-# COMMAND ----------
-
-# dbutils.library.restartPython()
-
-# COMMAND ----------
-
-from operator import itemgetter
-import mlflow
-import os
-
-from databricks.vector_search.client import VectorSearchClient
-
-from langchain_community.chat_models import ChatDatabricks
-from langchain_community.vectorstores import DatabricksVectorSearch
-
-from langchain_core.runnables import RunnableLambda
-from langchain_core.output_parsers import StrOutputParser
-from langchain_core.prompts import (
- PromptTemplate,
- ChatPromptTemplate,
- MessagesPlaceholder,
-)
-from langchain_core.runnables import RunnablePassthrough, RunnableBranch
-from langchain_core.messages import HumanMessage, AIMessage
-
-## Enable MLflow Tracing
-mlflow.langchain.autolog()
-
-
-############
-# Helper functions
-############
-# Return the string contents of the most recent message from the user
-def extract_user_query_string(chat_messages_array):
- return chat_messages_array[-1]["content"]
-
-
-# Return the chat history, which is is everything before the last question
-def extract_chat_history(chat_messages_array):
- return chat_messages_array[:-1]
-
-
-# Load the chain's configuration
-model_config = mlflow.models.ModelConfig(development_config="rag_chain_config.yaml")
-
-# Here, we define an input example in the schema required by Agent Framework
-input_example = {"messages": [ {"role": "user", "content": "What is Retrieval-augmented Generation?"}]}
-
-############
-# Connect to the Vector Search Index
-############
-vs_client = VectorSearchClient(disable_notice=True)
-vs_index = vs_client.get_index(
- endpoint_name=model_config.get("vector_search_endpoint_name"),
- index_name=model_config.get("vector_search_index"),
-)
-
-############
-# Turn the Vector Search index into a LangChain retriever
-############
-vector_search_as_retriever = DatabricksVectorSearch(
- vs_index,
- text_column="chunked_text",
- columns=[
- "chunk_id",
- "chunked_text",
- "url",
- ],
-).as_retriever(search_kwargs={"k":3})
-
-############
-# Required to:
-# 1. Enable the RAG Studio Review App to properly display retrieved chunks
-# 2. Enable evaluation suite to measure the retriever
-############
-
-mlflow.models.set_retriever_schema(
- primary_key="chunk_id",
- text_column="chunked_text",
- doc_uri="url", # Review App uses `doc_uri` to display chunks from the same document in a single view
-)
-
-
-############
-# Method to format the docs returned by the retriever into the prompt
-############
-def format_context(docs):
- chunk_template = "Passage: {chunk_text}\n"
- chunk_contents = [
- chunk_template.format(
- chunk_text=d.page_content,
- )
- for d in docs
- ]
- return "".join(chunk_contents)
-
-
-############
-# Prompt Template for generation
-############
-prompt = ChatPromptTemplate.from_messages(
- [
- ( # System prompt contains the instructions
- "system",
- model_config.get("llm_prompt_template"),
- ),
- # If there is history, provide it.
- # Note: This chain does not compress the history, so very long converastions can overflow the context window.
- MessagesPlaceholder(variable_name="formatted_chat_history"),
- # User's most current question
- ("user", "{question}"),
- ]
-)
-
-
-# Format the converastion history to fit into the prompt template above.
-def format_chat_history_for_prompt(chat_messages_array):
- history = extract_chat_history(chat_messages_array)
- formatted_chat_history = []
- if len(history) > 0:
- for chat_message in history:
- if chat_message["role"] == "user":
- formatted_chat_history.append(
- HumanMessage(content=chat_message["content"])
- )
- elif chat_message["role"] == "assistant":
- formatted_chat_history.append(
- AIMessage(content=chat_message["content"])
- )
- return formatted_chat_history
-
-
-############
-# Prompt Template for query rewriting to allow converastion history to work - this will translate a query such as "how does it work?" after a question such as "what is spark?" to "how does spark work?".
-############
-query_rewrite_template = """Based on the chat history below, we want you to generate a query for an external data source to retrieve relevant documents so that we can better answer the question. The query should be in natural language. The external data source uses similarity search to search for relevant documents in a vector space. So the query should be similar to the relevant documents semantically. Answer with only the query. Do not add explanation.
-
-Chat history: {chat_history}
-
-Question: {question}"""
-
-query_rewrite_prompt = PromptTemplate(
- template=query_rewrite_template,
- input_variables=["chat_history", "question"],
-)
-
-
-############
-# FM for generation
-############
-model = ChatDatabricks(
- endpoint=model_config.get("llm_model_serving_endpoint_name"),
- extra_params={"temperature": 0.01},
-)
-
-############
-# RAG Chain
-############
-chain = (
- {
- "question": itemgetter("messages") | RunnableLambda(extract_user_query_string),
- "chat_history": itemgetter("messages") | RunnableLambda(extract_chat_history),
- "formatted_chat_history": itemgetter("messages")
- | RunnableLambda(format_chat_history_for_prompt),
- }
- | RunnablePassthrough()
- | {
- "context": RunnableBranch( # Only re-write the question if there is a chat history
- (
- lambda x: len(x["chat_history"]) > 0,
- query_rewrite_prompt | model | StrOutputParser(),
- ),
- itemgetter("question"),
- )
- | vector_search_as_retriever
- | RunnableLambda(format_context),
- "formatted_chat_history": itemgetter("formatted_chat_history"),
- "question": itemgetter("question"),
- }
- | prompt
- | model
- | StrOutputParser()
-)
-
-## Tell MLflow logging where to find your chain.
-# `mlflow.models.set_model(model=...)` function specifies the LangChain chain to use for evaluation and deployment. This is required to log this chain to MLflow with `mlflow.langchain.log_model(...)`.
-
-mlflow.models.set_model(model=chain)
-
-# COMMAND ----------
-
-input_example = {
- "messages": [
- {
- "role": "user",
- "content": "User's first question",
- },
- {
- "role": "assistant",
- "content": "Assistant's reply",
- },
- {
- "role": "user",
- "content": "User's next question",
- },
- ]
- }
-
-# chain.invoke(input_example)
diff --git a/quick_start_demo/sample_rag_chain.py b/quick_start_demo/sample_rag_chain.py
deleted file mode 100644
index c82c094..0000000
--- a/quick_start_demo/sample_rag_chain.py
+++ /dev/null
@@ -1,212 +0,0 @@
-# Databricks notebook source
-# MAGIC %pip install -U -qqqq databricks-agents mlflow mlflow-skinny databricks-vectorsearch langchain==0.2.11 langchain_core==0.2.23 langchain_community==0.2.10
-
-# COMMAND ----------
-
-# dbutils.library.restartPython()
-
-# COMMAND ----------
-
-from operator import itemgetter
-import mlflow
-import os
-
-from databricks.vector_search.client import VectorSearchClient
-
-from langchain_community.chat_models import ChatDatabricks
-from langchain_community.vectorstores import DatabricksVectorSearch
-
-from langchain_core.runnables import RunnableLambda
-from langchain_core.output_parsers import StrOutputParser
-from langchain_core.prompts import (
- PromptTemplate,
- ChatPromptTemplate,
- MessagesPlaceholder,
-)
-from langchain_core.runnables import RunnablePassthrough, RunnableBranch
-from langchain_core.messages import HumanMessage, AIMessage
-
-## Enable MLflow Tracing
-mlflow.langchain.autolog()
-
-
-############
-# Helper functions
-############
-# Return the string contents of the most recent message from the user
-def extract_user_query_string(chat_messages_array):
- return chat_messages_array[-1]["content"]
-
-
-# Return the chat history, which is is everything before the last question
-def extract_chat_history(chat_messages_array):
- return chat_messages_array[:-1]
-
-
-# Load the chain's configuration
-model_config = mlflow.models.ModelConfig(development_config="rag_chain_config.yaml")
-
-# Here, we define an input example in the schema required by Agent Framework
-input_example = {"messages": [ {"role": "user", "content": "What is Retrieval-augmented Generation?"}]}
-
-############
-# Connect to the Vector Search Index
-############
-vs_client = VectorSearchClient(disable_notice=True)
-vs_index = vs_client.get_index(
- endpoint_name=model_config.get("vector_search_endpoint_name"),
- index_name=model_config.get("vector_search_index"),
-)
-
-############
-# Turn the Vector Search index into a LangChain retriever
-############
-vector_search_as_retriever = DatabricksVectorSearch(
- vs_index,
- text_column="chunked_text",
- columns=[
- "chunk_id",
- "chunked_text",
- "url",
- ],
-).as_retriever(search_kwargs={"k":3})
-
-############
-# Required to:
-# 1. Enable the RAG Studio Review App to properly display retrieved chunks
-# 2. Enable evaluation suite to measure the retriever
-############
-
-mlflow.models.set_retriever_schema(
- primary_key="chunk_id",
- text_column="chunked_text",
- doc_uri="url", # Review App uses `doc_uri` to display chunks from the same document in a single view
-)
-
-
-############
-# Method to format the docs returned by the retriever into the prompt
-############
-def format_context(docs):
- chunk_template = "Passage: {chunk_text}\n"
- chunk_contents = [
- chunk_template.format(
- chunk_text=d.page_content,
- )
- for d in docs
- ]
- return "".join(chunk_contents)
-
-
-############
-# Prompt Template for generation
-############
-prompt = ChatPromptTemplate.from_messages(
- [
- ( # System prompt contains the instructions
- "system",
- model_config.get("llm_prompt_template"),
- ),
- # If there is history, provide it.
- # Note: This chain does not compress the history, so very long converastions can overflow the context window.
- MessagesPlaceholder(variable_name="formatted_chat_history"),
- # User's most current question
- ("user", "{question}"),
- ]
-)
-
-
-# Format the converastion history to fit into the prompt template above.
-def format_chat_history_for_prompt(chat_messages_array):
- history = extract_chat_history(chat_messages_array)
- formatted_chat_history = []
- if len(history) > 0:
- for chat_message in history:
- if chat_message["role"] == "user":
- formatted_chat_history.append(
- HumanMessage(content=chat_message["content"])
- )
- elif chat_message["role"] == "assistant":
- formatted_chat_history.append(
- AIMessage(content=chat_message["content"])
- )
- return formatted_chat_history
-
-
-############
-# Prompt Template for query rewriting to allow converastion history to work - this will translate a query such as "how does it work?" after a question such as "what is spark?" to "how does spark work?".
-############
-query_rewrite_template = """Based on the chat history below, we want you to generate a query for an external data source to retrieve relevant documents so that we can better answer the question. The query should be in natural language. The external data source uses similarity search to search for relevant documents in a vector space. So the query should be similar to the relevant documents semantically. Answer with only the query. Do not add explanation.
-
-Chat history: {chat_history}
-
-Question: {question}"""
-
-query_rewrite_prompt = PromptTemplate(
- template=query_rewrite_template,
- input_variables=["chat_history", "question"],
-)
-
-
-############
-# FM for generation
-############
-model = ChatDatabricks(
- endpoint=model_config.get("llm_model_serving_endpoint_name"),
- extra_params={"temperature": 0.01},
-)
-
-############
-# RAG Chain
-############
-chain = (
- {
- "question": itemgetter("messages") | RunnableLambda(extract_user_query_string),
- "chat_history": itemgetter("messages") | RunnableLambda(extract_chat_history),
- "formatted_chat_history": itemgetter("messages")
- | RunnableLambda(format_chat_history_for_prompt),
- }
- | RunnablePassthrough()
- | {
- "context": RunnableBranch( # Only re-write the question if there is a chat history
- (
- lambda x: len(x["chat_history"]) > 0,
- query_rewrite_prompt | model | StrOutputParser(),
- ),
- itemgetter("question"),
- )
- | vector_search_as_retriever
- | RunnableLambda(format_context),
- "formatted_chat_history": itemgetter("formatted_chat_history"),
- "question": itemgetter("question"),
- }
- | prompt
- | model
- | StrOutputParser()
-)
-
-## Tell MLflow logging where to find your chain.
-# `mlflow.models.set_model(model=...)` function specifies the LangChain chain to use for evaluation and deployment. This is required to log this chain to MLflow with `mlflow.langchain.log_model(...)`.
-
-mlflow.models.set_model(model=chain)
-
-# COMMAND ----------
-
-input_example = {
- "messages": [
- {
- "role": "user",
- "content": "User's first question",
- },
- {
- "role": "assistant",
- "content": "Assistant's reply",
- },
- {
- "role": "user",
- "content": "User's next question",
- },
- ]
- }
-
-# chain.invoke(input_example)