


These instructions will lead you step by step for the workshop on introducing the NoSQL Databases technologies.
It doesn't matter if you join our workshop live or you prefer to do at your own pace, we have you covered. In this repository, you'll find everything you need for this workshop:
![]()
To get the verified badge, you have to complete the following steps:
- Complete the practice steps of this workshop as explained below. Steps 1-4 (Astra account + tabular/document/key-value databases) are mandatory, step 5 (graph database) is optional. Take a screenshot of completion of the last step for sections 2, 3 and 4 (either a CQL command output or a response in the Swagger UI). NOTE: When taking screenshots ensure NOT to copy your Astra DB secrets!
- Submit the practice here, answering a few "theory" questions and also attaching the screenshots.
- Login or Register to AstraDB and create database
- Tabular Databases
- Document Databases
- Key-Value Databases
- Graph Databases
ASTRADB is the simplest way to run Cassandra with zero operations at all - just push the button and get your cluster. No credit card required,
a monthly free credit to use, covering about 20M reads/writes and 80GB storage (sufficient to run small production workloads), all for FREE.
Click the button below to login or register on DataStax Astra DB. You can use your Github, Google accounts or register with an email.

Use the following values when creating the database (this makes your life easier further on):
| Field | Value |
|---|---|
| database name | workshops |
| keyspace | nosql1 |
| Cloud Provider | Stick to GCP and then pick an "unlocked" region to start immediately |
More info on account creation here.
You will see your new database as pending or initializing on the Dashboard.
The status will then change to Active when the database is ready: this will only take 2-3 minutes.
At that point you will also receive a confirmation email.
In a tabular database we will store ... tables! The Astra DB Service is built on Apache Cassandra™, which is tabular. Let's start with this.
Tabular databases organize data in rows and columns, but with a twist from the traditional RDBMS. Also known as wide-column stores or partitioned row stores, they provide the option to organize related rows in partitions that are stored together on the same replicas to allow fast queries. Unlike RDBMSs, the tabular format is not necessarily strict. For example, Apache Cassandra™ does not require all rows to contain values for all columns in the table. Like Key/Value and Document databases, Tabular databases use hashing to retrieve rows from the table. Examples include: Cassandra, HBase, and Google Bigtable.
At database creation you provided a keyspace, a logical grouping for tables. Let's visualize it. In Astra DB go to CQL Console to enter the following commands
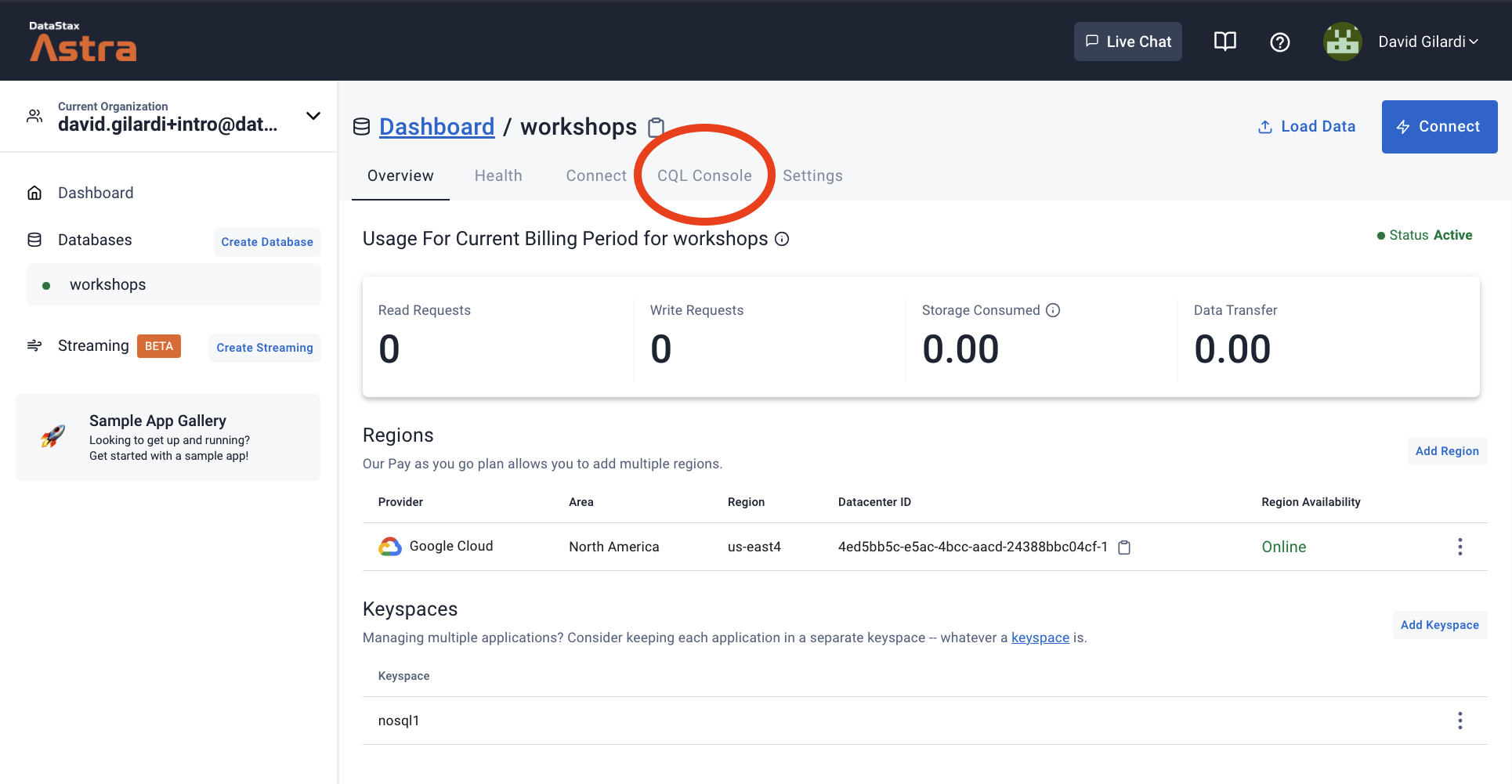
... and press Enter:
DESCRIBE KEYSPACES;
Execute the following Cassandra Query Language commands
USE nosql1;
CREATE TABLE IF NOT EXISTS accounts_by_user (
user_id UUID,
account_id UUID,
account_type TEXT,
account_balance DECIMAL,
user_name TEXT STATIC,
user_email TEXT STATIC,
PRIMARY KEY ( (user_id), account_id)
) WITH CLUSTERING ORDER BY (account_id ASC);Check keyspace contents and structure:
DESCRIBE KEYSPACE nosql1;👁️ Expected output
CREATE KEYSPACE nosql1 WITH replication = {'class': 'NetworkTopologyStrategy', 'eu-central-1': '3'} AND durable_writes = true;
CREATE TABLE nosql1.accounts_by_user (
user_id uuid,
account_id uuid,
account_balance decimal,
account_type text,
user_email text static,
user_name text static,
PRIMARY KEY (user_id, account_id)
) WITH CLUSTERING ORDER BY (account_id ASC)
AND additional_write_policy = '99PERCENTILE'
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.UnifiedCompactionStrategy'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair = 'BLOCKING'
AND speculative_retry = '99PERCENTILE';
INSERT INTO accounts_by_user(user_id, account_id, account_balance, account_type, user_email, user_name)
VALUES(
1cafb6a4-396c-4da1-8180-83531b6a41e3,
811b56c3-cead-40d9-9a3d-e230dcd64f2f,
1500,
'Savings',
'[email protected]',
'Alice'
);
INSERT INTO accounts_by_user(user_id, account_id, account_balance, account_type)
VALUES(
1cafb6a4-396c-4da1-8180-83531b6a41e3,
83428a85-5c8f-4398-8019-918d6e1d3a93,
2500,
'Checking'
);
INSERT INTO accounts_by_user(user_id, account_id, account_balance, account_type, user_email, user_name)
VALUES(
0d2b2319-9c0b-4ecb-8953-98687f6a99ce,
81def5e2-84f4-4885-a920-1c14d2be3c20,
1000,
'Checking',
'[email protected]',
'Bob'
);SELECT * FROM accounts_by_user;Such a full-table query is strongly discouraged in most distributed databases as it involves contacting many nodes to assemble the whole result dataset: here we are using it for learning purposes, not in production and on a table with very few rows!
👁️ Expected output
user_id | account_id | user_email | user_name | account_balance | account_type
--------------------------------------+--------------------------------------+-------------------+-----------+-----------------+--------------
0d2b2319-9c0b-4ecb-8953-98687f6a99ce | 81def5e2-84f4-4885-a920-1c14d2be3c20 | [email protected] | Bob | 1000 | Checking
1cafb6a4-396c-4da1-8180-83531b6a41e3 | 811b56c3-cead-40d9-9a3d-e230dcd64f2f | [email protected] | Alice | 1500 | Savings
1cafb6a4-396c-4da1-8180-83531b6a41e3 | 83428a85-5c8f-4398-8019-918d6e1d3a93 | [email protected] | Alice | 2500 | Checking
(3 rows)
Notice that all three rows are "filled with data", despite the second of the insertions above skipping the
user_emailanduser_namecolumns: this is because these are static columns (i.e. associated to the whole partition) and their value had been written already in the first insertion.
SELECT user_email, account_type, account_balance
FROM accounts_by_user
WHERE user_id=0d2b2319-9c0b-4ecb-8953-98687f6a99ce
AND account_id=81def5e2-84f4-4885-a920-1c14d2be3c20;👁️ Expected output
user_email | account_type | account_balance
-----------------+--------------+-----------------
[email protected] | Checking | 1000
(1 rows)
But data can be grouped, we stored together what should be retrieved together.
(Optional: click to expand)
SELECT account_id, account_type, account_balance
FROM accounts_by_user
WHERE account_id=81def5e2-84f4-4885-a920-1c14d2be3c20;
Yes, we know, and now let's see why.
TRACING ON;
SELECT account_id, account_type, account_balance
FROM accounts_by_user
WHERE account_id=81def5e2-84f4-4885-a920-1c14d2be3c20
ALLOW FILTERING;
TRACING OFF;
Note:
ALLOW FILTERINGis almost never to be used in production, we use it here to see what happens!
👁️ Output
account_id | account_type | account_balance
--------------------------------------+--------------+-----------------
81def5e2-84f4-4885-a920-1c14d2be3c20 | Checking | 1000
(1 rows)
But also ("Anatomy of a full-cluster scan"):
Tracing session: e97b98b0-d146-11ec-a4e5-19251c2b96e1
activity | timestamp | source | source_elapsed | client
----------------------------------------------------------------------------------------------------------------------------+----------------------------+-------------+----------------+-----------------------------------------
Execute CQL3 query | 2022-05-11 16:25:03.675000 | 10.0.63.218 | 0 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Parsing SELECT[....]_by_user\n WHERE account_id=81def5e2-84f4-4885-a920-1c14d2be3c20\n ALLOW FILTERING; [CoreThread-0] | 2022-05-11 16:25:03.676000 | 10.0.63.218 | 229 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Preparing statement [CoreThread-0] | 2022-05-11 16:25:03.676000 | 10.0.63.218 | 445 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Computing ranges to query... [CoreThread-0] | 2022-05-11 16:25:03.681000 | 10.0.63.218 | 5970 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
READS.RANGE_READ message received from /10.0.63.218 [CoreThread-9] | 2022-05-11 16:25:03.682000 | 10.0.31.189 | -- | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Submitting range requests on 25 ranges with a concurrency of 1 (0.0 rows per range expected) [CoreThread-0] | 2022-05-11 16:25:03.682000 | 10.0.63.218 | 6197 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Submitted 1 concurrent range requests [CoreThread-0] | 2022-05-11 16:25:03.682000 | 10.0.63.218 | 6312 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Sending READS.RANGE_READ message to /10.0.32.75, size=227 bytes [CoreThread-9] | 2022-05-11 16:25:03.682000 | 10.0.63.218 | 6436 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Sending READS.RANGE_READ message to /10.0.31.189, size=227 bytes [CoreThread-8] | 2022-05-11 16:25:03.682000 | 10.0.63.218 | 6436 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
READS.RANGE_READ message received from /10.0.63.218 [CoreThread-4] | 2022-05-11 16:25:03.683000 | 10.0.32.75 | -- | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Executing seq scan across 0 sstables for (min(-9223372036854775808), min(-9223372036854775808)] [CoreThread-4] | 2022-05-11 16:25:03.683000 | 10.0.32.75 | 444 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Executing seq scan across 0 sstables for (min(-9223372036854775808), min(-9223372036854775808)] [CoreThread-9] | 2022-05-11 16:25:03.684000 | 10.0.31.189 | 356 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Read 1 live rows and 0 tombstone ones [CoreThread-4] | 2022-05-11 16:25:03.684000 | 10.0.32.75 | 789 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Read 1 live rows and 0 tombstone ones [CoreThread-9] | 2022-05-11 16:25:03.684000 | 10.0.31.189 | 731 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Enqueuing READS.RANGE_READ response to /10.0.32.75 [CoreThread-4] | 2022-05-11 16:25:03.684000 | 10.0.32.75 | 897 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Enqueuing READS.RANGE_READ response to /10.0.31.189 [CoreThread-9] | 2022-05-11 16:25:03.684000 | 10.0.31.189 | 731 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Sending READS.RANGE_READ message to /10.0.63.218, size=212 bytes [CoreThread-7] | 2022-05-11 16:25:03.684000 | 10.0.32.75 | 954 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Sending READS.RANGE_READ message to /10.0.63.218, size=212 bytes [CoreThread-1] | 2022-05-11 16:25:03.684000 | 10.0.31.189 | 1098 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
READS.RANGE_READ message received from /10.0.32.75 [CoreThread-9] | 2022-05-11 16:25:03.685000 | 10.0.63.218 | 9626 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
READS.RANGE_READ message received from /10.0.31.189 [CoreThread-1] | 2022-05-11 16:25:03.702000 | 10.0.63.218 | 27526 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Processing response from /10.0.32.75 [CoreThread-0] | 2022-05-11 16:25:03.856000 | 10.0.63.218 | 181075 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Processing response from /10.0.31.189 [CoreThread-0] | 2022-05-11 16:25:03.856000 | 10.0.63.218 | 181193 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Didn't get enough response rows; actual rows per range: 0.04; remaining rows: 99, new concurrent requests: 1 [CoreThread-0] | 2022-05-11 16:25:03.856000 | 10.0.63.218 | 181384 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
Request complete | 2022-05-11 16:25:03.856560 | 10.0.63.218 | 181560 | 2898:d2d9:30d9:4a4f:acec:3e3a:3a76:4a7b
SELECT account_id, account_type, account_balance
FROM accounts_by_user
WHERE user_id=1cafb6a4-396c-4da1-8180-83531b6a41e3;👁️ Expected output
account_id | account_type | account_balance
--------------------------------------+--------------+-----------------
811b56c3-cead-40d9-9a3d-e230dcd64f2f | Savings | 1500
83428a85-5c8f-4398-8019-918d6e1d3a93 | Checking | 2500
(2 rows)
Let's do some hands-on with document database queries.
Document databases expand on the basic idea of key-value stores where “documents” are more complex, in that they contain data and each document is assigned a unique key, which is used to retrieve the document. These are designed for storing, retrieving, and managing document-oriented information, often stored as JSON. Since the Document database can inspect the document contents, the database can perform some additional retrieval processing. Unlike RDBMSs which require a static schema, Document databases have a flexible schema as defined by the document contents. Examples include: MongoDB and CouchDB. Note that some RDBMS and NoSQL databases outside of pure document stores are able to store and query JSON documents, including Cassandra.
It is not widely known, but Cassandra accepts JSON queries out of the box. You can find more information here.
Show native JSON support
Insert data into Cassandra with JSON syntax:
INSERT INTO accounts_by_user JSON '{
"user_id": "1cafb6a4-396c-4da1-8180-83531b6a41e3",
"account_id": "811b56c3-cead-40d9-9a3d-e230dcd64f2f",
"user_email": "[email protected]",
"user_name": "Alice",
"account_type": "Savings",
"account_balance": "8500"
}' ;Warning: missing fields in the provided JSON will entail explicit insertion of corresponding
nullvalues.
In the same way you can retrieve JSON out of Cassandra (more info here).
SELECT JSON account_type, account_balance
FROM accounts_by_user
WHERE user_id=1cafb6a4-396c-4da1-8180-83531b6a41e3;👁️ Output
[json]
-------------------------------------------------------
{"account_type": "Savings", "account_balance": 8500}
{"account_type": "Checking", "account_balance": 2500}
(2 rows)
This JSON support is but a wrapper around access to the same fixed-schema tables seen in the previous section ("Tabular").
We now turn to using Astra DB's Document API.
To do so, first you need to create an Astra DB token, which will be used for authentication to your database.
Create a token with "Database Administrator" privileges following the instructions here: Create an Astra DB token. (See also the official docs on tokens.)
Keep the "token" ready to use (it is the long string starting with AstraCS:.....).
⚠️ ImportantThe instructor will show you on screen how to create a token but will have to destroy to token immediately for security reasons.
The Document API can be easily accessed through a Swagger UI: go the "Connect" page, stay in the "Document API" subpage, and locate the URL under the "Launching Swagger UI" heading:

Locate the "documents" section in the Swagger UI. You are now ready to fire requests to the Document API.

- Access Create a new empty collection in a namespace
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
bodyuse
{ "name": "users" }- Click the
Executebutton
You will get an HTTP 201 - Created return code.
Note: the response you just got from actually calling the API endpoint is given under the "Server response" heading. Do not confuse it with the "Responses" found immediately after, which are simply a documentation of all possible response codes (and the return object they quote are static example JSONs).
Click to show a screenshot


- Access Create a new document
- Click
Try it outbutton - Fill with Header
X-Cassandra-TokenwithAstraCS:...[your_token]... - For
namespace-idusenosql1 - For
collection-iduseusers - For
bodyuse
{
"accounts": [
{
"balance": "1000",
"id": "81def5e2-84f4-4885-a920-1c14d2be3c20",
"type": "Checking"
}
],
"email": "[email protected]",
"id": "0d2b2319-9c0b-4ecb-8953-98687f6a99ce",
"name": "Bob"
}- Click the
Executebutton
👁️ Expected output (your documentId will be different)
{
"documentId": "137d8609-87f6-4cb7-9506-e52f338e79e9"
}Repeat with the following body, which has a different structure:
{
"accounts": [
{
"balance": "2500",
"id": "83428a85-5c8f-4398-8019-918d6e1d3a93",
"type": "Checking"
},
{
"balance": "1500",
"id": "811b56c3-cead-40d9-9a3d-e230dcd64f2f",
"type": "Savings"
}
],
"email": "[email protected]",
"id": "1cafb6a4-396c-4da1-8180-83531b6a41e3",
"name": "Alice"
}As before, the document will automatically be given an internal unique documentId.

- Access Get a document
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-iduseusers - For
document-iduse Bob'sdocumentId(e.g.137d8609-87f6-4cb7-9506-e52f338e79e9in the above sample output) - Click the
Executebutton
👁️ Expected output
{
"documentId": "137d8609-87f6-4cb7-9506-e52f338e79e9",
"data": {
"accounts": [
{
"balance": "1000",
"id": "81def5e2-84f4-4885-a920-1c14d2be3c20",
"type": "Checking"
}
],
"email": "[email protected]",
"id": "0d2b2319-9c0b-4ecb-8953-98687f6a99ce",
"name": "Bob"
}
}
- Access Search documents in a collection
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-iduseusers
Leave other fields blank (in particular, every query is paged in Cassandra).
- Click the
Executebutton
👁️ Expected output (take note of the documentIds of your output for later)
{
"data": {
"6d0aafd9-3c2c-461f-92c6-08322eaef5da": {
"accounts": [
{
"balance": "2500",
"id": "83428a85-5c8f-4398-8019-918d6e1d3a93",
"type": "Checking"
},
{
"balance": "1500",
"id": "811b56c3-cead-40d9-9a3d-e230dcd64f2f",
"type": "Savings"
}
],
"email": "[email protected]",
"id": "1cafb6a4-396c-4da1-8180-83531b6a41e3",
"name": "Alice"
},
"137d8609-87f6-4cb7-9506-e52f338e79e9": {
"accounts": [
{
"balance": "1000",
"id": "81def5e2-84f4-4885-a920-1c14d2be3c20",
"type": "Checking"
}
],
"email": "[email protected]",
"id": "0d2b2319-9c0b-4ecb-8953-98687f6a99ce",
"name": "Bob"
}
}
}The endpoint you just used can support where clauses as well,
expressed as JSON. You don't need to navigate away from it do try the
following:

- Access Search documents in a collection (you should be there already)
- Click
Try it outbutton - Fill Header
X-Cassandra-Tokenwith<your_token> - For
namespace-idusenosql1 - For
collection-iduseusers - For
whereuse{"name": {"$eq": "Alice"}} - Click the
Executebutton
👁️ Expected output
{
"data": {
"6d0aafd9-3c2c-461f-92c6-08322eaef5da": {
"accounts": [
{
"balance": "2500",
"id": "83428a85-5c8f-4398-8019-918d6e1d3a93",
"type": "Checking"
},
{
"balance": "1500",
"id": "811b56c3-cead-40d9-9a3d-e230dcd64f2f",
"type": "Savings"
}
],
"email": "[email protected]",
"id": "1cafb6a4-396c-4da1-8180-83531b6a41e3",
"name": "Alice"
}
}
}Key/Value databases are some of the simplest and yet powerful as all of the data within consists of an indexed key and a value. Key-value databases use a hashing mechanism, so that that given a key, the database can quickly retrieve the associated value. Hashing mechanisms provide constant time access, which means they maintain high performance even at large scale. The keys can be any type of object, but are typically a string. The values are generally opaque blobs (i.e. a sequence of bytes that the database does not interpret). Examples include: Redis, Amazon DynamoDB, Riak, and Oracle NoSQL database. Some tabular NoSQL databases, like Cassandra, can also service key/value needs.
Go to the CQL Console again and issue the following commands to create a new, simple table with just two columns:
USE nosql1;
CREATE TABLE users_kv (
key TEXT PRIMARY KEY,
value TEXT
);Insert into the table all the following entries. Note that all inserted values, regardless of their "true" data type, have been coerced into strings according to the table schema. Also note how the keys are structured and how some entries reference other, effectively creating a set of interconnected pieces of information on the users:
INSERT INTO users_kv (key, value) VALUES ('user:1cafb6a4-396c-4da1-8180-83531b6a41e3:name', 'Alice');
INSERT INTO users_kv (key, value) VALUES ('user:1cafb6a4-396c-4da1-8180-83531b6a41e3:email', '[email protected]');
INSERT INTO users_kv (key, value) VALUES ('user:1cafb6a4-396c-4da1-8180-83531b6a41e3:accounts', '{83428a85-5c8f-4398-8019-918d6e1d3a93, 811b56c3-cead-40d9-9a3d-e230dcd64f2f}');
INSERT INTO users_kv (key, value) VALUES ('user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:name', 'Bob');
INSERT INTO users_kv (key, value) VALUES ('user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:email', '[email protected]');
INSERT INTO users_kv (key, value) VALUES ('user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:accounts', '{81def5e2-84f4-4885-a920-1c14d2be3c20}');
INSERT INTO users_kv (key, value) VALUES ('account:83428a85-5c8f-4398-8019-918d6e1d3a93:type', 'Checking');
INSERT INTO users_kv (key, value) VALUES ('account:83428a85-5c8f-4398-8019-918d6e1d3a93:balance', '2500');
INSERT INTO users_kv (key, value) VALUES ('account:811b56c3-cead-40d9-9a3d-e230dcd64f2f:type', 'Savings');
INSERT INTO users_kv (key, value) VALUES ('account:811b56c3-cead-40d9-9a3d-e230dcd64f2f:balance', '1500');
INSERT INTO users_kv (key, value) VALUES ('account:81def5e2-84f4-4885-a920-1c14d2be3c20:type', 'Checking');
INSERT INTO users_kv (key, value) VALUES ('account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance', '1000');You can imagine an application "navigating the keys" (e.g, from an user to an account) for instance when it must update a balance. The actual update would look like:
INSERT INTO users_kv (key, value) VALUES ('account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance', '9000');Let's check:
SELECT * FROM users_kv WHERE key = 'account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance';👁️ Expected output
key | value
------------------------------------------------------+-------
account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance | 9000
(1 rows)
The same result is obtained with
UPDATE users_kv SET value = '-500' WHERE key = 'account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance';indeed, in most key-value data stores, inserting and updating are one and the same operation since the main goal is usually the highest performance (hence, row-existence checks are skipped altogether).
Thus, writing entries with the key of a pre-existing entry will simply overwrite the less recent values, enabling a very efficient and simple deduplication strategy.
Check once more what's in the table:
SELECT * FROM users_kv ;👁️ Expected output
key | value
------------------------------------------------------+------------------------------------------------------------------------------
account:81def5e2-84f4-4885-a920-1c14d2be3c20:balance | -500
user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:accounts | {81def5e2-84f4-4885-a920-1c14d2be3c20}
account:811b56c3-cead-40d9-9a3d-e230dcd64f2f:balance | 1500
user:1cafb6a4-396c-4da1-8180-83531b6a41e3:accounts | {83428a85-5c8f-4398-8019-918d6e1d3a93, 811b56c3-cead-40d9-9a3d-e230dcd64f2f}
user:1cafb6a4-396c-4da1-8180-83531b6a41e3:email | [email protected]
user:1cafb6a4-396c-4da1-8180-83531b6a41e3:name | Alice
user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:name | Bob
user:0d2b2319-9c0b-4ecb-8953-98687f6a99ce:email | [email protected]
account:83428a85-5c8f-4398-8019-918d6e1d3a93:type | Checking
account:811b56c3-cead-40d9-9a3d-e230dcd64f2f:type | Savings
account:81def5e2-84f4-4885-a920-1c14d2be3c20:type | Checking
account:83428a85-5c8f-4398-8019-918d6e1d3a93:balance | 2500
(12 rows)
Graph databases store their data using a graph metaphor to exploit the relationships between data. Nodes in the graph represent data items, and edges represent the relationships between the data items. Graph databases are designed for highly complex and connected data, which outpaces the relationship and JOIN capabilities of an RDBMS. Graph databases are often exceptionally good at finding commonalities and anomalies among large data sets. Examples of Graph databases include DataStax Graph, Neo4J, JanusGraph, and Amazon Neptune.
Astra DB does not contain yet a way to implement Graph Databases use cases. But at Datastax we do have a product called DataStax Graph that you can use for free when not in production.
For graph databases, the presenter will show a demo based on the example in the slides.
The hands-on practice for you is different. But since it cannot be done in the browser using Astra DB like the rest, it is kept separate and not included in today's curriculum.
🔥 Yet, you are strongly encouraged to try it at your own pace, on your own computer, by following the instructions given here: Graph Databases Practice. 🔥
Try it out, it's super cool!
Congratulations! You made it to the END.
See you next time!