-
+
@@ -569,7 +569,7 @@ GoodData also has a clear refresh button and methodology to refresh sources in t
-
+
diff --git a/docs/website/blog/2023-11-08-solving-ingestion.md b/docs/website/blog/2023-11-08-solving-ingestion.md
index d1d0c21b7e..88f020d7f5 100644
--- a/docs/website/blog/2023-11-08-solving-ingestion.md
+++ b/docs/website/blog/2023-11-08-solving-ingestion.md
@@ -1,7 +1,7 @@
---
slug: solving-data-ingestion-python
title: "Solving data ingestion for Python coders"
-image: /img/blog-ingestion-etl-tools-users.png
+image: https://storage.googleapis.com/dlt-blog-images/blog-ingestion-etl-tools-users.png
authors:
name: Adrian Brudaru
title: Open source data engineer
@@ -30,7 +30,7 @@ When building a data pipeline, we can start from scratch, or we can look for exi
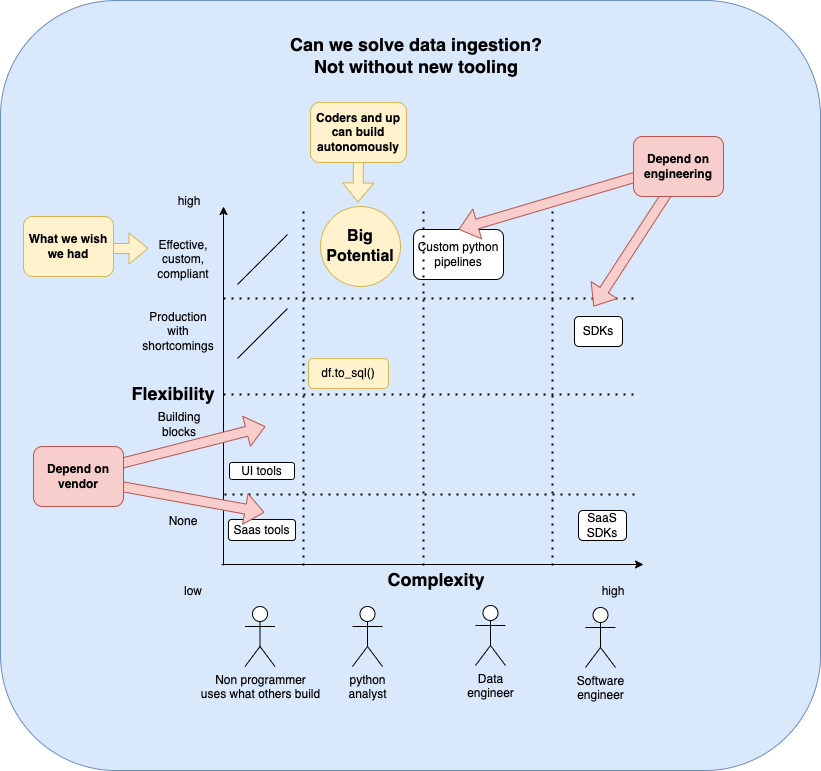
Besides the persona-tool fit, in the current tooling, there is a major trade-off between complexity. For example, SaaS tools or SaaS SDKs offer “building blocks” and leave little room for customizations. On the other hand, custom pipelines enable one to do anything they could want but come with a high burden of code, complexity, and maintenance. And classic SDKs are simply too difficult for the majority of data people.
-
+
# So how can we solve ingestion?
@@ -81,7 +81,7 @@ One-offs have their advantage: they are easy to create and can generally take a
Let’s let Drake recap for us:
-
+
So what does our desired solution look like?
diff --git a/docs/website/static/img/why-duckdb.png b/docs/website/static/img/why-duckdb.png
deleted file mode 100644
index 405f73bd535832b54140478ed25858fa735701ea..0000000000000000000000000000000000000000
GIT binary patch
literal 0
HcmV?d00001
literal 388520
zcmdRW^;cV4&?vXi;)S9u?k+9vP~0i*?(P<>f@^VtUZ6nn;ts_vcyV`6@Ia8f(EEKq
zy?@}nvsPBJ=A3
k&uY!pFjU7XwaP@AyFYINPpDwTRK_w&oI*UXE?jeY5QX`J3Fi00XcGMFvzm@
zPbBsym(3e<8(%PKW&EI}nN6T+fCIlX@5z&HS^#+t?b!g?OB8bcxvU
zG|1GUIskIFm%!R!usU1m;@va{h2Cze`|8eic&Bf*dyn6}{!oXY3UPgQOz5Nj@23P6
z%6~slB>x`=WaNkqt`D>U0!)|s<6IBiUVGznzu}^0Q=tOwv)K$J{=MD2vzIAl
zXV(f>Y4Wf~)5rY_+*ra0m5f{{Bf8(4eKCXf&tG6wgTz5pI6h=S;0A
zzs{;nODkQibp-VOK8Q5`iHfe^lR{rJ#AcV*9U&smS5>~m0ZSL$$EDP~pXoLFUznTo
zOG#J#KbL#U8IdR$@y}v}gk+@jvC+ScSbt%^c?r>?m{z7Yy5K|u7gv8_
zNb_1$1d?{G6oF?PHvxUSd~x4_sUDW)-!iVoWwBM*FOo`3jP7cDA$EwXY(wy?plm
zm`!_gze%U~L-YzkganlrX{5Ad
z_I=1f?Y|85e9qUZ?gV#@Eq}fyGyooePTzJ!x!TFAzq(ZQ#1I+Oa
zyIW`9L9qvyLYe_v6RX#ArJY~8U=depdBhsyPG0~zylHSKPJmEmUp8ky=!ZZ^z2`=<
z>1ca<#E+}>0L?qwU^Uh_Ty*!35h*~K?vZvk%?U_I8h48$Kd!;t8NOPH@2TK~xfS(~
zlwxL4ig#B5Wh|nzsRm5{-UR{_^fLDjXS|$u{?Son;^oH0kYiW)r}X4J`5XNF=g8hT
z{IKA7dOMLKA(!b|M>os5XnKD}@*hzGql2LCu%5|;+#xa%o-Rf_d!fTj9&C1kX&P!Z
z>#&kCBhEO7ZY1M!Q=(^yd|`gR@g_Fyz|e)Qz1?)eFx@7EFkmSQFXWDT9j23SPq&Am
zE=?DCr56>MsvJa|nz*ixXV(?XHd+XBp($#X_44pFAx=}(%V+tKQs4z*i&>QM#^B>b`N<_*J6hjd+^@IDu2r3qH92=BZt5Z?i+tm1N{`jx>L3d
zV0>W`aM2`nMt^gz5xA~um-z2@Iuy*JG#hU@ydItTs|FA_r2VsnBwMH%W1g>2+hs{B
zgUN!}S+)54k?op$h+_NYM^jDFV{zgltZ?dL#Ko20&kn6MOWt+QHJ*
z!4HLtciEiEfpCRFmi&I2AC8jq3aXR>gN@q*B0gF!@bfE8&ctHEVGE7okj_=#UI%#P
z@vsO!b!2E2rjT%B8acgF7I_iF^y2A#SYfEfFs0~zmwg-&1_ASl`N7OUEf+U4ujn9)
zPFiY^zv+`*iA2`**G^i2pw7@wEk@wJ(lyt>fRn{^mXKp(YuBLUy~|Bp;{tA)&`Fd!
zQ4zk*>!Lr7_ZB!Sy4PQzuq@I&?tuVxLtk6keazvUwuHxdxDLD~A*I8AbcfCQc|je8
zaF4>@v^>JVt?)A+9Mk&SZjb?w*3Dqo=BXXtg_Db=4c?COk7>2el)#ggo+ygcaf}Fs
z8LLT09-WBb!|{y{e%0!Cv_(8#n?IxEa+%2lca7(58vlf@1NdJ)?(bB5O@$rumA9EP
z`Mi>yndovrD8t$XLk4w$#bx+#HH@z@OQnJ90AF(Gv-rbYTfMy7h5B4nE`o{rK~i^*
zgC5o7K6OU0ea;)W!dhKb9LRJ0B~W&wid1B*VJ5R|F=()M+2<+;KZ+&5w7Gm
zRu=PSB2qr`;at<$6lMr7;|tLg9e-B)RJa&4EcR8D{=H*2{FF0)WDE`x0@tS3@3kS}
zshW)5AGpyIgH9*Uh`UmQ0rywl#4wpBdE28XV#VOgN^460rdX7TC+(#7SRd)wgzuN~
zSISWvqBDHA9Uvp&o{eP!cgdBdc`k&KXi1v)u;@mE*&)B9b7FaC%kHmXC6!`+5EV^i
z^SvTbDbrhqeGIlkr|OhKjfoTa$A?{e&Yxi~WVI~}5H@tjhk^`t3?JPm5T^eqo%H=x
zdQ!@`bnRtzSElfy{{0k=|FPqwu-9R7J}y3IyT@6R*vc(1A>F0rxCir+<4kdgOi=9h
zQSRvJKSroVF||Yei!ww#zN;f=-+U8A7%$$ayG$H^%e%Y3
zs;mB9HRe>^#)^U16t=^Ixh0;4epYY6Ui370nO38X0k4Y1jgtW?Ms`U&aXandKU=Ez
z#7xvulI+ibi<%%OXu_{T8;-Z~(m(9?9~gP_?fXlJl5j6pP#u%#YDey}u6M4#&r4Ax
zD@(}_$9t}|IMeM;_KF`qE%9e-Wdhv^(s?$}xv(z)!`sv|xUB1xxd4B%3;01T;p9g`){6+imc}EY^>rH&TK*IAd7yjDAfeYUb
zm4i$(>XdD|nHF#^sC#~}sq-LK4RrG*4RYjOtB(xD`zz$FivwscM<`dg&URi~($uwc
zqZ8h{m^`Z{fhP9x=wxw!j?0H~86EYk#lV#yfsg}fs^C@N55}E`kL*h5?L$WA~&nC6d|VPoO^gHI;HK$fd3!j}5TSiRCW
zG2{D<7DX73-@=~0tPGEXo}})csBLNNOQtpE>m?)-WFOeao*D^rGg;JB=*Nfv#2Ml_
zQ|CRuH=J-LC8_JUKIBb}YRnfJf@4>_9(RPTZ5o{&&6onNq~TqnA{TuV+I+fKMUi$}
zMY^g%yO2z=M@Gy5Q&8^G5yBQKB**Bz$E40SGQYA_qrC4kT`aVe$+Jy}^~nExkA`3-
zF4{z6`HS+*Yf|Cc;nUHjYl(28=52r|3DG{$vKD^nAGN%Fqs<3$7ikvYIHl0L=4&B$
zz!t?+{d8fxGj=RSQD2HGIt^DDJ~1FLl!6s#z$mNoBj=o;?6V0A$l<7!$|ZD?mRc0=
zf^QC0xBBD`)`ca09?L{vlS@m(f`xSxbPT^+);Z|@UEfuVLnic8Iw6cd3{+!lxttqN
zdvu>tE%{T`F(`iB;<^7dcTMlET2$-$2@0AM_koS=V3vyBCv!r`0-lPl*1oYMt2ff>
zp?d=e=-;3-E6mIDx2t&5H#uXt8W9_HEk&lY+fwl##N@IrNhm2wEb8{k;|8n$(M?2@iuTqs;rBV}N
zxS120wf>rJ#)AtJO+@Tu^p9fs<}aQDJ}O*Q`_?-}ngQe{{fQGRIdqN+HD86qJA1p{z7`iqSA6B^N+@?AU1is
zsmVWl9hvfi+sp(EEm#UOXfAs5w}&iTvE31rMfz2@QO?VrjH)kno7B3RYg<;LG{+bE
z>Q{Q`9!@Lkyg7w|$~OxNA82uFaqrfGyFHCf?mE9bg*+LGFS|k1#%gd#+GeE6zcyd-Kj#*`(Fn}k`d-$QlyWwl|0h4>3NR_{6
zv;MONV{yVV^=nhn7$b!+@#vt{81?gIgzB5_+Lvanz1L>BoTf-sp5QjE(P)ukM7cbC
zaidsz(o)z(Cn#lkb9OalF%6m8n!?PGkvB=u!4qRdie=21LZ`+>Y@~+R)M#|5O
zFP|!FC>r|?B;j*Hw16jJ!NP^IxiFde^rv{wFyK8%5=BUdFL)~Bagyy4;rwoQ=D!0eu>O?#<;Ew=LPCaY$cRxXkzH1wCf~5Sz_84p@8`a4*{K
zRJ5Ql6G*DVrQ*t5t8up);r|q4^6QuIy+?qlt&U5>!~Co!s&UCD+)
zg}ZDd2Gzu-Tf~qk?VmiXyJA_)RM1Z=gMY~mtU-px`UpSD;UBnD`qYqGp2xI(r`Bq_
zVw`B(XvF
zS!?jBleR>iTtbNt*d&n5YH*lLFm0uw=^$&Kc5?w4YCn_4{Sq;u<^kmV<%^g#|H2tP
z>OHol;7zYFqc#g0e9c{qx%0IBGcHl%}UGhfZ{=L75EK%6ttBwe1Ny&wU@GdqqF<
z^Zo!L&A-mFmjU(5r{t2g=kYj>n?7cT>81`B-JF=}wGiXEq%&}rf3=Q_E5V^WMFc8j
z@Ey}#H6Oy3#g}rBR(8PsSO(H_Za}xF-v^vp&lkJq{p}ji)QDASb$FdIOUNAp!HN?s
zz3PF{WYkrYk97KE@C-K^|FDR#Hp~gKSVEyuA!*p^0dYvda|M|D1PdY!%#UCvhzV+;t8chOLoxYdlll)Y3=Q0#9CF!|a>G}01
z%e{@nMa3Sb!4H<|>;znR)|uW`4pp
z?nl-y{GcW6#PhKjdG#R@SSV^1zRPJ>KqwsPK@h+rAs!)g0pJROfQ1ISLB(
zmyS!MRz;yHQ4wnf@N*ocJm`f{2lDe4#zU24X1Wc}lB4w3xq8ic&VLZyU?=}7`U*>+
zaGS=Jy`#gg)nI|jp^=~dj!rp~l>lT85`4uw$;EF9B^9E-gv#yo@qFWUMN
z`qDr4K!soTVW1kO%X7H-{d%XTM%M=e#N*wr(g1NAa
ziyN~gBI39^?vgBS352XN#Q?Q;!#ba~UYbS7Eo4GU{y{g7i!-Dxv<=xDU!=>V@J+qY
z(oX4kOlMiUXO*Sl;OL@fdQLxZ#7M|XPZ47GX3aaUKLOvTdHjCMJ(`3|nAKFMu}E_b
zBW@El&p8lVjp8rbE$J`Zxpq6c@`#ZpXouR=wWN*rDb?k(T>ajwaTO71K>q$UI1|qr
zxCnkHP0{}FCeZ|M?!kl+$l(#U(8&8f5FHSmLK1kZZX0M}Lt|lc_yNBQW;OeonC2vs^U)2XIYq9(8n*#W2P=T5DJ%NuchfWAp10$-MLkh=9>DU^*c`0X
zUr(*CSWI>oWBfp%s*&}@@M3z5nTg(G5`D}2)XarO{$
z_oI_A-myHm*8O~!72U|5FF|PXuut&0>&*RYqEk|yGS*`;SX=jvPA8frv%+@<+heo+
zuMI{rl?a#n3Qd}6AeQ2ms0rdNgS2nqN0ho
z@t&;g&|+5h>U4qY3ks3)%)&~D{Rc=kB%478&;kp
zEFeH-Kx|Bh6bNX^*sPZ>zoJ4dt+h7ZBv=(Ee^!)=EKK{5GX&(65GQl-{6+P0TWxKEv)zhI*`!-kRA;g9mOhICB$Mso-s-iX7LWv1dhg8yS9WJHVKcu
z+x)8imaMpdk_}`)$L1B3n}^OOZ8lam*qeu5VXX4#YjD$k9S)NS!ri3Ysd^__XaK+R_;AaNYSv`;Sl+^Lzz6
zf7r_D8-E*VoY1MIrlGzX5wOqvKHb)+l7=#|NNLlQ!_xcZ_bO>}f*5N?Sc*Y`SMB2n
z$Y*^6l<(`-V!qe&+sxy>YSAP93J|1%jfw85^u8&MU1|5SZiRL_Qkug_`>WxJYA5SSs+Fs^alm~oIF9pA3v;U(2
zS}cdz0uYT9|*D;o|W>v$gLhdbgn_)}K)
zDCcpukd2SVVGU!*<_~TeI7>(F28{R8C^cA2gfQy%n``bV%ngw!n*8;f=UEj?P_aE3
zXoRl=h$CJo%@`p(!@-sXCysa6$+q2?=G=8yw+(tx@2?g!y~fWLK%4#mYarD{J%8r4
zc5+ue;8imG$g^t`5WjW4P=m-RDFVE}AW2d3g;)uZzc7
znkE$_ussY6nJP4A-!c7E7YmF#l75(gYtD*4$y_z9bM$`M`r>A%6{j|VY#_q&18b%8
zV@$SlIe?j`2QGOK8+m!N?(<9V)4@=mcGVu=E&o
ztP>rGO_zbJDYvR#R+(xX9GiXx3**VwhelTxjYnS^8?z(}LppwKVD(nq1$k4#?Y3>j
zs!+elZXVEcyb9*2GDwie=)PFZPb+joQ?{NT1oBjlxNS~+n3X;@}n4g$p|A0Opb
z;%9`JEx#H1_N)&i1PqbmBex*!6Y+9sR&Pm{Ri8GZXh^xd>KaTyU1_hl-vLf&yNH69
zMLTE5YH&me0Hfqi#LT+eu?#tz=k_WRhu3~Oya4`+Y_gIvt`^Xo@!WY8$WyrFb@`>M
zf$f~G!){IKU}~~`z+2JKbXO8O>e_0`fJZfWEi|u_dyr~k0om|H`ErajtqM^GfkI@U
ztLe?{@FF
z4iDS|EG#UJl{`g$S41XD`!oHO;cR0!@0c2Qdd}gdgT~}lPb(Y4WIBJ{CQz5|=a=ui
zQ@ih7sZ}s&-ktf+*GIo&ccQTvZCr`|S2Oe4>gY?G%N5V8GB}ExE7yOMxAEizvrT4A
zX!T=vg-q|$GQXYmn~xr~>|m=}3v_DZU
zJ%+PhiCm9N+o3=n<_b+)JeAOb4TPr0rzsbfqQ@UyF4y9yS^h5pzY8E
zU|=VLhokeKMq}C-Q0m%n%03PGLVZH6Nr!cPCK}b*$@oSsh+CqcbDzI!4PXX2Pj2#E
z`vWU=ZC73{HSCQ2VL@_&S;U>5q+1$*`G%3t6F~V1+xoZmTz-%-gGqjUDlJw-l^|Vn
z5tz^*6wqRp3_T%}VSkIZ8d4rB8yUK+mb4rK0-rDzJZvW4%?o#wXRXe)TxE6|&gl=f
zG7?+DPKoMzIV_;!$aI(q{UpT>Sohil7@^hi?e@mf0ue-umOY7XkWw;KAcl
z+TPZBDN2x42DjrT26gE6)#HpWPZ#I;q@ne1&J@cyM#jcYo~z!$q-roxJof~tbb@RT
z=^Qrvs?=h>F)h%0;#@7H3Q-pkZw|h$_ukje{|*5kKMpj#>V!%$rrH$k32uIu$4HXy
z1Ff}YjzGKi`^r>?YX7$vphO(t?MRkGQ1&o-3$HEXT&zx3pZ`W-Kz#R{f7ABtb8lLq8U3!~>3CRmt@eWmuU;BHz%X95UpE|fpzbZykL-Dt
zw2p%ZdVIyaRx@i&TdSdzo!VZ`QZxwj1Mdn<=TX7DEgIb3@lX}o7V}GFoySkadi5NT
zM-ls4;dGen_-Kk;Q6{9W1O+&a=3p97U4i1+Pug!YNsr+>y-$QH#5ziQJ@KztwGsX{
zqSDy;8SS|(#!WDJ^t>RmICZ7HYSN&NuE=^?4e|>XZgV2=64KUhCpLja<3k2nnj2bf
zQbyEN4l728qZ@;A646t$8_r&F@4qIiQ@zU0r60-;xcb@)l{^%WYfhy}C2rHr(xz^)en-X~8M>L^S=1ShCLbQs}*9LdLG@7GyYJW_QK_1t5)~~KbM>u+jt_o
zo&LCQI)h(i(a5_Fj9ZGXRSW)Y_cMDgR&!fnd^bj%Ij>3R-qtY*qyNy>M74
z7kE@tc|zb??Acx0hB_(kM=$en@Qw7B_*B*>7^j2y#Ya&*G1pg-D*(&kJwuzeSJ4bu
z7a8r}+az%P9m+Drp!-FJVBDlV1Ja<6-_-Zj<}F-(!0H*O&R&j$tXpj2ShBLz7D2_M%e=T-PjZLEORiI6g|n%GHc8G$65D~VSVho0T^vYzQ>;=29Q3F9LxiGNEI=CepM
zABX%Bo;<
zVaZ=q%qqPhgV#lrer>Knq{$gmq8THULLUsbGcX%xXLSR0Q$`@74p1!R0PZm4K}Jy2)!0VdF`E}5YhCalc?_l
z(btJ_lNmY%yiA+W-o&h`gcWZ@RUpDuhSnaF>4mgLI6|ahCyepIC)_RDjEw2*?yR-S
z9TwN}&0GAzMGwZVN)YjB=oqAS%VPf3*qc#=2DzrZmmfamhdyjKB@3Hq9%2da>vw*Q
z9I^zIvm(MU%K^n0nSNjwORXh{%&4pNK@=zFp`5e!6cqSblyB{E))f(|PX)Lzk6-Rf
z@yE3VWzoqyNIGQN-x_2pf}43gF0a4Lo&xCFHzue|et%O?q?VVbQK40VWs+LDu4#A-
zvLkMTXTS11mxItkG3~SQ--)?iFE@ILH;$2+oD^W5{EUJ_H6bvB5&^#n7i+MVrQr60
zvm+X6E`)LRUQ=k7R#3zMsvR$VcrXj>_5VD6xZDDt+yvE)eMI6H_U89bCO&<4j}TCC=B?>dCmfc_Jzu+RfjxO9432Bx&IM8r
zQczGnO*aj|ADPvERZWT5Wzc8w*KA#04JJ{k%(PQn0C@8zB2xj580`{E|IT5+MTYm>=XP~cXe$%=_QI1o*^RkN0^gb`b
zJrvn=b&cz=SF-CRIlRuT8#Ph8%3Z#;vjU)4^Wj_Dv^(t;>yIERn_~(^7afl>-&pOr
ze9IiUa1lW}9?oMeZ=#540fT+!&b5PB0uhFP8H)(-Y$wb?6psiKGD|nZ)?!+rB
zShp<@wwWlYmY1w72&^#6fBBHPZmXl6asKuYcIYV-ptjep^TRFTGhU6w_&$ad?ae{P
zh>iA|#VDQz26NHiWbYeMk`JSbtJg4_*MJ@Uz4fGjfyT%CL34{M0@hNV;(klAB}R*M
z@@Fr{I*lh&KLsA6eR)flOPYjf-o%ewgPf_5N`~AtDWwTkWY{
z{hR>&>^N|d=E7KTG{$d0j;&N*XO(kAe*0$~>oEatD6q&~y+jCd64vpBFEmk{2CwJg
z1l^F%4Vwt9f0rz`og^VE@-&q#synpxEz@c|n9*iQh8~XirLA74QU%v-Z
zBmi`(sS?~bBf=Knsl-1nt5xEQrrYAVCFHv)wNjNolZj+Rk>>t-(+cmc@Y>?z6xS#$NTQ_z#M
z*PP00ySo(rcnV7IDlD~LPBYY!b@)1an9^{Ye)TrDQMRLV`W?k+m(PNN_4xXo>~k(>
zDJyjAp?f<_v%?F!3b|YImj!jjul1_vmyWF0bFF~^LBpAIwMQ%}Gm}!!Djvy={iWpI
z<~O+ru`AsR={!9!VNriloV-Yfh9G8>)uu>&#
zkAXh%u^l?^AAxf`Q<^6h;H%+CR7Usy>QfX3I5z|nOHlVoZcw~~munW44_-lud
z-0qqY2@Od!A`7qe#46}RsV$r5Q!R(v9lb<;Mwpw3kiQE1+o1-nsgZE$fEabdal)EU
z1t5Vs0Xi7cbBusgMF8tx#6sV6E#u`gWemO&c@0bbjueLLV*bfOs%b=$>kXz>DzQP?
z?g&g;Df!*&=+EdEy&*NdOtk(B+3QuKbrQlyC^yhjU!dq_USz%N6=sh~W0eC{y
z$zU<~JyG&ZGVvBgY}Mx41MS+ox#49-azVd>Wb~a=(foL;b@{Qs+@k)^=nCMZ=^H5g
zf;=o}a9DkabTs8fm<3S*l=!pj(L!81hx
zau5jAVif=KRkca|w|J@N7rMZb_H*A!$mS17SnJ;
zBU0(Q&5G65_F1p{cn_Yjvompf5Dq}bMNb;}zL=R|uuft+Lu6Os?XcBd=8-oape^fC
zq$QMG!-h%xmrK8Crs(eqTy|z3MMKW?>m2pW5@9dHsq^&|SW;fec+=<^nm7HKgw5TS
z&AC7z?%5+r6c=rJ`Z@r)p%G-+KyfQ3~p)9|XGg4_W@_&AV#u
z-p|ZJVq2qs%cUqykvGu}l|4Qu76kS~nQUj`ar=}N(G3M#(>Ss1Qr$yTWb%s)Oy@~l
zUCyMx(rj?In+VpS95j5Oo(Y=I2zm|(k=%-2Nj81VYj%G;&(fVyGbPCMQOWzKU-CVs
zMzN}irnJ=Io+2V1^z;0tX>9XHJ6x%73HasTKxZ%Hzk>gJmJBTnSC$DEa0cGN=QP%I
zKl3WEwBg_IS79Z(NJ;lE$2**JfWsPVmq;-D8q9v5W$+ZTV%h)K$6pmL!BoW75`ba*sgmLOrdCf
zqcmNCx;H~jyvGhkn(_KfL=_dE=M|-q8+HveRa~^C4hLqfXSJ>D=!&wFLe-g`Q!R+G
zsS*b_;bD*tL1+hKe_|DDCquO1n-u-S%=g%bmkZj~I*uy#a*qFYj#NdyDq{`&f@Gic
zgP{LaNI}5=ke!M^Znh`yZ4DRYkL)#8)?KS*2eAPc)uR_N?gUKmek%Sfc5u`VI$XLj
z(=SEyyEcFRLf>1A13D|4{;#3ayj)o92cxrTf~VK#
z@qBf~lCyoZ4XGxpxRD`$2fEQua^6wg9+k(oRqclaea+x(V(R}I6^2U}sXt#SFOeei
zVivu;RI#4FPq)Fp=i_UD=$Fs3p=5uR__L?JeSY8W+R1)-#wpDga!1Ev!$2Jww$07W
z%F+IKx}xL0;g)mJOEy|%
zYC0usZ6pKEV7u)w6{VbhIPqIxi^;_1UA$S^$V`)#B9C}57=oPpz1*VwOF0#;2}t>E
zSryt^h?2v;`D$%C+vgUUkG!SI#w4xUZ&>TKB9^n1vW_tute;>t{BzejA=+r~60owKp#GHh2vo|A|ZgNWY+VrR$fJs*p233*2
z13w4fohbg~nt~6gv_s#%!(3r);&{#drpVF4Cm_hl+pxZ}yHo+ik@ef=dli+~1Ejys
z5fZMX5reiYV^O>>dB8rUe?-#$yQWe-rhdsCr3acf*jjz3+Hnrfo_CpzZu-FYUZsv2
zirL2h;S)5H6%7SB&86IfJM@E~3PMnvufQ-fWBg){pfw{Y!G^ii2EJjKqBi#eMP9?8Vd
zj2r1+-=h%x#kvuV6I%7jQHte_cJH?8BrS5VC=q)_S+b*!v|*MKK7DNk9WFX8>VGZ@
z+uANKLJIUtHN^wQF9E*6GI5Ir#MPy9JaIp~(pjZn|Hp%7A>@344j-yE(a--Q?$4)m
z{=4@%2HBDOFJ?rq+<$LH`dgwy!2bUO{9hCsk$RDRjgk5w+<5ww70IJQTQCZUNcAAI
zy^y1s_RawU{g)t|aA@tyie(Q7oRC?pz?^=w(T0iu7o}tt8w;bh99Z)$|K}8ZITNWI
z2;-yQ4}Ji3sXnTNguv(a^CpNf*rY4!ud2qfg2dK$1N#7gfF?0`dk{k~3i6lxMyK<;
zK;zZb2~l{v#z;`aru+_A7=rcc#ps`vE}9*W7Gl%jmh!gcxUnpk*3zoRo3HDyxhaJL
z{r0PjlhNynTVXebuJi@Ha`EjCBdke7L3)}}z1aLKW+Ve#wR1)0b^R=f&
z9Oh7JN2IeXKlxusA~<`iDnl
zMx^-g@=mh*---Q8KM{%q+r%Kp^w4dA$H&J(wQMSy-uFw(OGgfloC4Tfmz~I{@p%H9
zuOyAD=S+&e;F>QA1%~aA|oSP$Od}clk%z{@CSE^
z6JTW)A6^5ndow~-NXW@oL(Vp=QgT|*nTx89O%fOhFl3Yz1I6;Hj_W!ExQQ{stXO8(
z*Vkv3g}JzrM)%oAYuS|0%mE^ZNAaR~_<4E%%=&kjSV=zb5|keOB5q)MlPe|3J8Bx5
zT6V{Hi6KyLZ!cnb16fk>B$O;6Ea_J*wbs$qvFw_GU-
z8hw%Yx3D9~&2H!vi;V!IL`XP`grsNl>?l4SoJ#@i*txjV%*j!Si<4P5SpWUobGeZa
zBTSHwE=qpn^Lk$7prfPXv4bP)$SAK$8{U1O-Bf_G^j#pLJ$5wcUa@rAuD-HC8_&9K
z5xiysJtCB(+d3y48^c^R5=#$ohJvN!;z4iPS5*#LDOlMntIEo%s$71SW1_s+7o`QQ
z%q-uZ%vILC>?zIqt|6|5lME(T$GlJ&&~X*Sp&&{4Ce5pvLdA(!I2_+uPg8$kVL>
z0FT8JC&U>~Ia%58h=|ogE0gM`ii#6Oaf{Q_(};MoLlJ!Uw$@ezs)=Lc)v228RNZhn
z*~lUH?A*0A$^4CTzi2X|qLl4y3R59WdX#0K{7-M+k&F7>y1jo}QCZsZ)Ow7NrRwg*
zDA3B{Z0hLl3V+ox48dYMg(%#Dx^mVWRW*w5$8(i2(lo?wfdrQ;wtd$6I=a5l(s9-2
z15wuHI+X@>0B@$ZBCZVCLZj}lnK2k
zf#^j4G93Tfx9@P{?2IhyEjekHQ+2vD%~VnnYlk)odW3F6lcQ~`(JNHc!GVE{#pCNL
z1qRO`e=(!b94RB@UbA-6$?Ja(zT~2+a{Nwlk-8;SE#8Pm*TWM
zm{9VTZ(5jPJ&5g?8?qT@#KC`=I-&Z8pl9;hPhVdu=rMY4FB}H*(+8$ZcU1jIS#Fdm`k8Gd6yZ0`2&Jq%1IFvPA~rUTZc4gR0fKY{
zr*U4t#+#C6;T7P~GS>E9(>(i4x^9QZEv2P&cnDOjRm+Vz
z!!~NUB6lNI#!^yJVDsVKOHS8y6Mgl~Yry&DYXnE#T2LivG~x@V--(j7qOk|taKy{T6+Hx?y($3)m&~aW{i>SZkky7Y@M%+!r0bZv^voo-Cn_Tc*TAF>4
zmtJ;NAs3HG;Mrt8!dSH0MntlW0^IL!lsTZq_uw{JB3-J2#Hp#LFaJP)A{5U}BOkPY
zgo4DwvPFX>QN99vpqDi4QKMH8v^xTvbzgOrh^G*4g#7-pJ(#eM`4YP01HBP@7@~Cz
zIW{aWFB=c&B?+HeSuw(k0=47wuLfS;-rjDjiMa19e1OK;)-K|gsLsyKsfx~L79;G{
zA1&SL!-F%_7hd3Wx%^K*MG}8jSHm|GLRQw-Ay1vvU0oq&|8`crrUWB6iFD~66%k8>
zIPVj96La`YjzbcHgE)VfJ2Il!)G-SB_U#+^-##E9AYfH7JefM;2bmhf;J_e4Xc1zi
zrmXDp(`T*xb+fSLvQOuyq5aD+$?i&Sf1nX%W^qGPlN{}vChE1-nPgGVK7>J#qj}@&
zD%{q(5~Zfq3wC~Vv+dJQ;}s0|
z)NlHkas+`)SaC_BFz%%43>mt&^FKg5O~DT2Kd)P
z)`RHj>61eg8ImVlRx=e#IB)Hmt0|+TT^8$^39wW<$NT#F>hB_2t4u>yz4={M-lCz{
zjd+$sr>7cs1wZa2EIQ4xqx=o$5G)F)5iorlVqJGBJOg;
z#{-1=|F;(a>3u?cypOLhPC~3zoxU9N%=>~VJ8f%gYnlFf#Vn8rpBT9KrOoS?-!|QD
z+uyOJPb9>~HVZQsv8mA!E!7cVA&vl4uif-ug0jc00Qay0dU_C9l(djeCBWxchi1g4
zuA`&l`uaNNa4!|n0BHerUc`%$%?mk~8FY^vYCNr6ZcIg7jCeC9?Vp&G$BlVZxOEJK
zmJKcUthj*63@;PSUcdU5c=@s{Dk`eGyL+mpMw!o$i2$n?EuuF#kCWgvRH
z0Rq6$VM$v6V1+jD>R?JV0J`S(cs(GQCXsyytI=b_MT=Ea&Ni`}tc?zo%&9KPiL|K6
zu+IdeC=I%wyc^Aa7UJL5B#0aVo8ML#`E%P(IO3enzm~fmOA&XElHZCC{
zKCa(31$k`O10mLm%rw!dX^7o|g@dykpFFXD4}<9t7+H1|scHu3L2^<;~Z4t`vPnAlOJXjGXr98Km+eUp-Eak}XnPA=D}@*0iv
zsxWA6Xs?Q^PQ$^=$!Q{26yfOR$}>zb3rky(
zgwJnB4Q{iu>L5J3RM|q$grppMH@gG51Ti5oF^*6(YUSQ$@0nsfw!O|rEtXvlwrV^lTChRps6G9qPjC>EkuuP|ECB|
z^x$^48REeHwg5tKXJku1T%HZda{;}UVY^Y%LB=^QZ(X#Gk501rek4b70YL`~8EyMX
zKU-@(zzp_lwLXy5dq{#vt>=6d;-4~R*bSH&bziC3a@b4
zKuM&Ayo>3)tLp=Y_rIUiJlxFGxwyzDd~^CJOCJf9d_C#vX21WZ#YN2LxcAWi
z&}Xj4E7O({3cN_{VL+v%v~?*_|T=
zfyb||JXH!mmv@;o*?0p7k|v*Wy>YUZpI?F%8Q0+9;VtWzzGP?bIvZrc#>W1t`3!=o
zw*1v7I4VoP>*Q>D-G0X*ezDHy^1<(x((i2CAlE3D+=-k@z%j3Bd`yE)
zKA{|&cy9k9+`or)NICmep@%W(jpym6y+PAMb%HufFnc888AErHwF&(2H^s+1(!VP_
zeNFJn6uNp+vn+gUa$o54a4lv}{_A$&I_6;E^V)j3M#Y}R)~5E%bY%Xnd;%b+b8thF
z6^jQVFrjm;ZhO5uJB*QY*&}De!xs*tX)V`Y9o6QW4-XG3c#%cyME89%vL1HJonEJ#
z&gJ#Z^{#i{B3wF;f)QQb`whqA<4T!)JC(Z)b6S%~aq+eLBgMY+`}gl$-z}k;fWf1qBdW)7s?etoBzThtMr}*pxAs*s
zCDz_I!|BuzF=NC1%ZXyD$FtH(TU!Y%W#!j@=G#16-@Tjs0^&Bw&KB`_xNAAx+S=S|
z=)Js{`aLl*ahc=eu)8YlcdA}~cBY|1;e9f&dVuJEk0*TeeKG-5I6TJHul=vw_STSO>_G@J3E)LQ~_K4kYk1m?r>atO46Hb
zWf}@jzy0%>SW2PItX%Nr!7R6`RXrb04+n6GatDJ!aaPwKnnoY+9-X%yua@~P_8&q-
z&0XIWsh3-sewy4FHtZx1tNr#dIpNkd{_(@!N1Jo6#KKE4?%C79No*
zG%P47Ir+y$8F6xGOmwvHML%uZK})GxO}NKAU_g~!H&dDLj^dexnQEiV7H4U+d{N88
zgGJd`%BkS>-MP5|Zc7;%83)hj9iKiq9^84|YgK8_yN!xajU%sLP(A9BEYw>&zIo&3
zrlmD@a&p2@6w1?epi|R9w4kKmbay0$Cjxw8Z}Kt_5povWYF@HY`aRzF9Jad%-4|4#
z6IUDE4yXipA5XkkjCXFi`}s^o_+h({Oi=87QOh}WxmUPPAcmo@Z^`d+G5R?qvnr*L
zXW1@sI^)Ndi6@QN-p^WIC4>Eo?z{GpV;hp;Ly`Nlr4FBfQX>tNUrn*(UZ+(}XY&kD
zfLoh*U#+mq$wmAVN=W*)Q~^ydlC|q5llyT!_wd@}QQFPy?Cm85VSJ9v+tbY-Kx~5j
z+;J_bF?{8D^rm^v7|yq~xmo|i+00Cmii(u{k2O!dzMGc?{Sa5xzSZPhZ#h#_h8hni
z-$jstAzL!;lF#9!ibyeEe(&Dzht5t0N}oSx>D*C@ip-kRts-Z#jdrtu$28E&7BCLh
z{sC}Mtni)VzF;9B2LUEAEssxeL`F%ubUaROav-cmaDH(fN|niviE*vl?6?w~a(MO~
zh*1F>LnhTpLu5(11kzIP->Zn7|7^6MkD(B9w+*UNur@c}2qiWV_S?j{iasx;47iJs
zrF!Ynb!{0cQ>ezATBnT-N}$_W;IgILagCu6^Y1ao9OR2E7>|z+dU#+RDwscYnA+mW
z{LusNx*wV`o@~^zsGivyB^UfTKlwIb`ssgc)gf12qucV+i7d
z%v)z);Ub7}i*vCSNvJv?fG{R2WORN&Wb(tOSw%r|3^lB<=sc%6+L7&If{G=?5jZE0tBwGxZ+I&0^9=V;q*Q>>fGc^+p
zy}fG;D!Z9c{XKZXs$CyiH%j+@(lI-@B+yZro9z?5({tZF+fn@laD{+B@v_VtCr?L3
zvY8h;-S(O~k3XC!q&Z^digq2Jjk}o
zhjb;3!gBL+Dd2JWe#+$j9M9kJ`o#Py@7i=f)c^77xa;P?Bj6&+#43i78}BKu|83^-
zLWk{)rK{=Rg?bHkH{tC&K4CWzdrW<_+21~nUG&g=J0=xj;o$FIJQgD$B9d*MjyOBN
z2s15GDCXkfDKhWrEiN|CrTsqqPg)JcvY@0SwOPnHXw@6!1HsfZ2_*OS_N3>@U<<&$
z10kR)k$Sc5uyg*P@drVCo#iN-aT}30MU(yfh2Gg}ETSlnyjF!ir*q2Y$MA3nmB;?V
zt5$RDg<3T}#%qKA*p1}m-21yN%aQC!&K8^ElW%WhMUJo5a(7fi%yO`h7v{8|MBLoo
zpx@l`-!;`VHECDIcNs{)_T6v4MLZL`8;>0ch;!MQnw|Y8eNjE^FXwbQB4Oc{1sqku
zDSkDLA~XCAZ~i)~D*Gukd&^i;^>&zQq-6ft|4&C=DkZ!Zgu9CDpo{9c><$=NJA&EDXcZXiWHi
zT&cI&%9if_#xo2tYcG3x)W`$AJ+t%kyWh|;es!|sBXKHx{SU!@xU#I*sQ0X)srenT
zAo!v{ttQ}I7KPjc>wUn{#t1#R^&t9KZ%!h
z&W__$pXS#m!*Weg+|Pa@@)_=e6scx9%!`sA7B=20er}90TYp`YSJevSE?(Ejz-)48QP`1Wn0n?dB
zK0(!pij3@bw{G;{SLY(u`@gF|m7#JQN&u~<^!HdPWsmgD+7EUj2<4Q7wgS1#bOXq%
zww09#UAENkSWdXmiL#k+^e0-kM(Np8UX2^cgj&haiTU|Tl`E2qo0LI`t%Zv}OHXN<
z?*Gh&+RoH__YBL%kjp2+a)miXMQhE6EDzc>@djQjXJCUqsMw*`3S^L^DttJIoIX@Y
zDXDqffIa_K7y8`_=A@Yndsc8*fYC>96sUUsotyQ^x*Dj*|Hb?l&Y
zc01kuO6{z7`Ho9Q%JUy>+;w4PUHcbBZ^A4y84Dc&*=)3P*8He%~gc3`5(xBT>IQ_MpH)#
znVFvUKRy|%Y@%@%-6*p5w)PhMqpwn^c58JYa5D!){lzx-P}!7}l!WfFKQE2RQWa+A
zxt{;snOtHCMi30e#K--z>&~(vdtS`FgA=erxJoQmyG3QOF&A-3i6))hbINKT29;t>
zW~Jy4)(k*>1YiKWu7Z=3lhr0kR(7su$_h1AiHZ6Bz>I+vk0tp@o}t>p!>+Ez#uA-@
z#AnY8#QM+AG=|E#EvNm4tp17kmZMc+-$d>5u^^S9eZP6+MO&S*7fVeiV{(PBCy9-9
z_4Qi~KA%uUIU5@p2>BcsUO53Ldd8l3`k%4CEz6^~Zf&hK3&{8zg#o
zz`qf1dWCw@tXQm$c>c##P^a412+n7@wORj;hm+H(<54ysAixC94l2@f-`JhfuH+Tr
zUK^HE003`D@0jtPM`eD=z)7;;51<36-
zEQ3%$`2m#6CRL5$tVJ2UoiM>tO=iNW{<+;<*(7^t?Ou-0!#3W-oB8Rge60J2yJ(wk)}bX4Z&yJ1Q7P4LXmz>0h_z*Q?uk5lQepp}42-k(c6IXCYepz_?M`J^
z(;C&IwEYb3)w^m?A!7zPm6+2>k^kz#-QBFqRxRr!eSQ2(gX*U6=i7%=BqX}}#xmb*
zqoQ;yEs1^WrK;4QzpPJNdfsTi*y?4qJvdc~_~pQ-k|oI7+3M})P6UxIDjf$1&$8w5
zP0Qp?`}JmKD=kPI(dK^eamI%1viRt2UzR_kL|JyYUq^>vO&Z<6>O=zD?{MQ*fO`1f
z0+I6YkcyP_=5qPII)`rfZlvunWoTphaZpE8>VV6Xg3Y+~tS=KD1~8{53;-aguB%+M
zLCcOtY>>U;-boR5T=t{w=?Romt2g)j^$<+X@
z;ZJ1)B1AX;GS}&GA_HJQqGuPWt5;v2P?C_4i2sA9#2$nKEIqB{0+LI1_TcTugX{sb
zJ0lVaj$Iz{*5AI&PRMD=R0txk1z*K-uc>
z^W)cLg;qsUn=!}(d@zwN!nijk_QT=|;#EV+Y!}?5LwnLl*H};QD5bQ)+wak`LYNV1
zonhSJeI73Ma16(znpUqu{IqSb%<;boQv(Ba({Zb^I0HSs7DJ5G<)cP`;2LISw3dgk
zB-7K=yFMf$HaE9oJ0C@fQ7&7TRbfQL!~v&$WYRtp)lwQ)TkGGx9R{3N0s^RablUYf
z|B@$w)D!5glP+U+bE>Oq9xskosP4~7b+$Hx=>vX0+#b%hoEGL9K__gQmR~uqFN9*>
zI1IPHy}ck?G8kuggLHdp{~wv)c>LP6Av&_Zq(-#kH1|Q;ZGN4h3Z0kH4B#j-Zg~iQ
zXe18aQ!R(01F(~`SuldzqebQo=MHTHeSPFWRwW>}w%q3U
z@cqgHz%#%?uJ;Y#MyFxL{0kL}mkX!UD?Na4g6P+~nC}S(1Vs1!1us9iWrlgFO0NIf
z5B{2w5z1d(U1^$L-0p{S=M8k%nN;^>iw?AAm5UD>l{M29Q%?@Ms17b(FZ@uRqm!=&
zi0AcSa^d$Fqh?157g99wGzNNlT#@T{<(fCYUv_Og1L*$U-5qdj^l~Jg_TXN+Vrmyq
zXB-+U^iqskyc=e1%9oaSI5>_5JV*a30cq6jLd2ygCifjikE^*_eKMlfyd+6qV)o}_
zbA|PAC>c|SzS?bi@2JURl1;O$#aiA!!G@If!~!&BW;pZG4Y+fpP!q(J#hK^cP=_SL82c9YF*(u-n%Q|l&$GjsM)4PrQ1q(=(AE46M=xv#hnEU!+igPjwiVFbNj?5-qwD8
z6acfFRx$RZiCIIryITxQiO;>8Q7G%s1nXY?{16KZ0JUdQQZ((JsgYDHGUFP|Ww(fZ$=QXmh3h>jBWlf@!w1rY4ccy4oGPbspP&YoDzd&0d(qiRD?KH0TjpS
zF}Ke;G{!#kk~swGyxegKP`Hh3T3KCG2!JkuKp^V%>xDZePvl&y)F%2
z-Q~xJ_fLefM-*$?6X+sRQUie7ggLbXa#)+zn&dZZ4ULR9m^SC-vLVlXRh&JYi`8EN
zi6k}Gud#Hz`3Kypa?$_1Vdm43m#J!Ex^xHv`Uu%j-|2k+B-ir~=Tt7gkBVQF=t|El
z#((jMpakPEO4p;0&_i2S*-{B}PCnoWu6nLkR<
zr9+6_?}zMj{{vLJ&c>vwwD+cFj5Xxzn%nQ{h)wK%+88uBbQolO(j{ZR@ePx$*Kqyb
zXpbj$_4{D4jb-CxA6|hVh`l<`#pinEP5NP3$aNc72$tl?hQNQNy3eRIGCW7;mX{Be
zU7Ez{LU%h2Hg3*ltAI#5=SdGuOiU~$Ygu~2hxhdS;%xZG=#$haiYCiXG{br+*5-ev
z^^yHv(7jEWFYAM;g}}OTKtQj_?ZuxK1LSk>7fGBZHCQ0=N-3Bob86+3O^5b85634L
zAilJ@PucQ9TeA}ZN0CwynVOlo9IUKiyJ7m8#{+r;I71Jf=+)SJyv~O{vQp(-ZG+Uz
z4!~9psr+vNy=~un?`S1za!1s^m-+=Km4f
zaMspZ-gLEThwrDeq&~(52%S(pdfDHuXQz|3=d@g3?+m5($f`ttSoEgmkWT>2c<+Y=
z7=C-Xe=CmE*x1PDc5IeVQX$y{pLfTeeI+I)=CTnl(h!KOKQ*)cNyY6&{
zVgrN+xT>@(^~-T^a9%4bJ7i}qa0!!3j{`iLMW-ehUfz+u7UNGbJu_3vZjzIoo12?$
zWXmVC?_O?5381aLJu(34QBdq39>)5;X8{#i3;JE3OibWY%fJ9x422)>jxh(5x#ujY
zja!y(s8(@uvbCJ-g~{R%wgn
za6bb||H?-FlYcqr=Mk&uo4EP_(Mp)Qx=--+MNf>7L=qu9D@1b8V
z!Z0QOQiFfYTRW}%-<<$%?*DqC2Q~k{cN=CJJoeu^1HSves|37R8uecm`_GfF!GB}V
zKc7L5@t02hbHC3*{`Zyt|9kuY*G=^?gdl!FNy40F9=Y=FIl2C`!ObkghS`>;FmZ8M
z2hSuhPB;*hhZl)~c*n}xeS?A>_%LDu3pVsniU4_Mhd+3ECbFo4!G8FyPe2d}kZQL(
zHFCkD2MASC{GJ~c4aOL_SErJBg!f*aXEG!IX=3Ukox)ymV)|b%fChxfbgXJ{MnX(s
z8EsJ#>E>RlyBqgG9DBZeBm&dzjLwg@-3P8|zt2v8y)sKI!sQ~A1
zvA>OPT6&#`OG9tXC(ynzTjT%M(NQDA9Nuv~UGg<(zVj_#+3U6Wv`N_Iw8*7nXG
zvC|WSkaH6N(x2To8T;Ig<$J>)H_FR9zrIwQA?oY<9@ZFL%K;izR>}3;n;My`MHD?p
zfr67+HXicF{qV%}s;AG3jvwC#<=hZ>0;-Cq(cvMlrl6XZ*XcXXTU4wE(gMc4zqd1Gsjz2}W=Xwerjf^WQG1mLrqrycbu
zl3MR!6;yH5k{~){R46M%Ms5AuQz$ZchXqWdV>?WK#*B>|d4Pr;$gxe&X^C9^2~nm=
z!(fCOA8hERSi*%4LPGRcq1+7FxkoZFDzK;01ymuLDQ0Z_AVm0J0t-_Ry6L?NI(4^$
zfs2!>Fcvh>-><`grfW60f=g2or7ZAbZ#@srB3*;dcZE%
z+>no@8BC4KPvtDJ-AP`Si-xF>3X%f>QjRBXewzmp#&eV?xxSja)vd>yfa}y`eU%n+
zqa49pcYSZ=`>(lo_fIHA>Zj!mvPUj+Z|6mBFNL+LzY|0}Yp-o?zB?JJ5xx0Um?_(*
zbrOZajr~6G?kF_1^D^M>@NsAGX1mcxnbHUT&Uq#@QI^W@W^CHc!U9R)@?pH|zUyIh
zgM}Ew(aTC9BI^{i6ot#L$3;DQh~H8?Uaj>8fZB4
zJ~i?;MwpyLp8AaOw%Oioi%C2|<@cHLx!@6E6VB6cUDUXGeR=S!DOknZ@hW6#QzXu$
z=i@q#GUG?;D|hIiA~i0j~rJ~Mg3
zAW&e|&D7SO-pZkVp2j$oF_4kCl>MRY@$zwJpUn3x!qUWN;~Gdr?xjh^dH|tX3(v{P
zY!l=c65?rWn6<+_J5N^p{Hb}44#bfZ4~<-S)w7}B+VJIC^=E=UH{FeLQq~H-B+s-!^VUCl)YBJvQ#uZ*`sa-<;y;3K6t+_5DMzZQ%zHWCC59vdA-Nr}e{K{)0!aqTzu<@%`1%%s}|`}hK#Z6>pnWdoVB(ytg$J|F_?vXm#MJw-Yg9v7^!hE7}ty5
z{(5q0tAmDuDj5x-1>qx*A`tx|6cCJfFeZ)UksJ4=;>nB2RRs_zd=dj9j=?EO_XUG<
zSG2S4VYw(4vMjbxtEXL}_Nf+%oY+Pf&@dzq>jl2#&bSY;EGfi#%xEnv?)
zqhAh#IlYF}*Dfg}6iqtNXQvRr@-S$*K+D%+Fm0N@>AhK~=(*+d)HtlEwCYN)
z8hbioylQoZ>pT+=*)lk)xsEktd{5J$bxVh}>e@+<+U?(hW!Yvg;GjyIHTZb+~u&D@=LwdHAx
zC@OQJv`7=J9|)EQ@Uvs1#lcV^Y0`1C4HA)ZOZid8hnO}>7|&-3y^Wr+60n^uo*GHf
zdhOFA!>X5)LE`;W9VZnOW-~Yi%aX3ivNchtd@-|xvOBIw5~vX{R5Tj)^aY
zvIyobX}QuJ7={`sNLTVaMnZEHKXA`YS}h+B85vg8s@zRpPJ}hfqUFS^HZ!|-NQhw1
zQT&X{yvm2&7P)rwTBk-@oQ~j4mx}DN*v8@OYv9Q!SaMl
zAmloDxyxJsVB~HL(DPblSI$ol`rrtJ;qwq`98l!)lbMg{^B=EFFgMXu`iE4Pyo%fW
z)aONv9_bVrTY|B`@od-MhsBF10!_of`5Z!}2Ml2P&2H3!(*(6w(Rr)WRn2>;XM57d
zy7@Xz4h8t~iarSZa(R_B3fJ2gEn=~UbQ&pEpkl;ZrS4kvfev+C-Rz0hiZM*)fmFo-0y*Zw7UxU$>~#_op2LDsr$(2cPD
zG~LYE!jwe%{C9zsCv(_Oq4C7OSN)mjs6kcQw_9R<{#LGkJ~QOreSN$Pu$0$l(`v>w
z@m@_ot`fR91o}7pZVS`I>6Ek+Sy_@5sK0zQlLw^@!PE$X+-W@I9dxWmxniJ_f#=Dg
z0+EFRSPY8g>deWNSx)5y$=vcUloEM{)RE-%Upn>Lz+lrNM7GcW%CcA8fl$UQPM7>Z
zqM|pVSfM1|PZkr~9iA;mgm+5txHhb~^?iUs`>PLh>{?)`XJ!l}+E_#^p4D5EycuD8
zE;BjbzoeIu6TIQa{H_|OoiM|Ly`LZs&>!3p%=|d2FV0<9F+zD_EjrSnl+p#=S$SA!
zs5%}JNs0w{30@xzo&fcX;H7v-yn4&)4QKi><%#I@
zS5cr^cLw_={mLlnXhsBU!q=yR?H(AF|FV_^G}J&e-S*rWhk2H9TqLSW;-ntNW6gL$V+m8I?3P3UxjKf0@~o49|y$z5we`Imb|l
zPLJFWl?_3FpsTvTw8hqgFkz@4oRZVi5
z;O!N3dx4khmR5(gHkE
z2(Im(X58GDT7dv+DnV#;s0yyRCJn#hj<+_Z8fw}rMp@hmmUjB91@B(DB@gM;oz;71)5PdA9I#{SX?4X64bb9hB%|$5=fv%E)o^hbXKeTSk=3H=3
zmrb%XF<6|5t&Kf?`I0s9=lKFMfw1}c`UeE+@7-jU!_M>h^JH_7VYBzfmCqqAu0yqU
z<#4o|n&AYyAybTaUbcHJ>yO&{hDP-6KsD9xzJ+{2LV;TUGRuP!)}O6O)0pXcQR>Dt
z^7+#El4ttka>c46l9DswzwS|w8ra;-TwhRZ=jfdM@EzI1ALl=jZ{8(3WZbcF$T!BN{BVIn%7B??%Gx(|)T|Jc$
z%b{EngVRPyHT=pq(<+JTm1GeHrj#`&d!}3FZx9kz{!FGEtU6pn#0Ql&K=EtKBBF-S
z25kb{z~29e{do4H^-_2$r(RNW0=g8qV!44>e{wmMktp;@SV
zeMAg7V7i&eAONZn0*0(dP_TC0pVusVZDl82XY>0%?FOW}rl!lKCzKD9Vz)k!vF-kp
z92u0eJ~Z)(9cpp%fr9&aB@1J
zDsfpNi#rkY7Q44SqwOVdt7V0LOdU#gE}k`fyW-fjd6NnGuK>^qj#L%rf>=mcQqq!f
zefivGBfiMwtBNr>lxt!o^7PfNS4~M|E_f;DGEl)InF;PWTuB?siuA`}>wUY7HVN7v
z?JjCnI}B7DO3r*~qW7Dak5d+djC2=-^}!furAmi!3i+J)9VVFGrHZW&8S`l8Gz3re
zdu%+OUs#b@aN4K@3t6oo5Rs}OlDcM&$`ayQ??ZJ$pVG5Wer918ZF=$2KZM&+0^>CM
zYds$xI>F9dBZqmUS4N=#8vERPa#F4yr^(>mdP6wvf-wZNU8^3wLV3
z=};>31|z+`Zd%nj?p;T~Rjxhhc5bJ)+t4qfb2jy7zuYTdGO96QiSlJs$D4oT`$X+k
z{e9Q_bhxFQ*x2{Fe;)3baxm9+35*ZlB_pxpH7L%>xux>9YnVzmF+?_%{CMtwA31F>
z;N4c(`BA>FO1rkbx&Jxw2*1<$iBL>K^k0c)fkM}XPM0JdNj*dWiw66^TWI>11h34v
zcT6D2Lciy@fw&{V!ovP7suP8Gr-=GXRo_80EGz*bh+k4r+&5V=qLSXM9Ysc>h#|S*
zwWaIUKKm>U{qe{l&l_vThe+f4oz83<}k7ZJ60^ukytu=lsa
zdQ;gaI5fdx2k&vS<=OX`Vm)NNwiY&)A(r%`$x;9P-(TPF)1_x-F4k=wN7s#+%P;GTT&}
z9O3_oGBBUDeV2Bjh@XJ^oOu9JJ|BbrX^^BM9l==^85>=$>S6a}
zTSXhqF>M-3=(L^(og^v(OWEUBpzorZc})}Ec?>&w+%ZG;qY73#R#ksM*kx|}cm~%=Ga|n6tf7_{(&*0r{7>M9h_VVj!ak&gy>+&jJv}tvr
zw)UXga}^X3aWhTtXw;1y+E5@2LX?qzullI*K|zj0I_U+IC53&QHko0&P!89Bx9ot3
z=0Qca2v!>%!FZx`Q@y5)hFhRWKtShioEqJ-rSMR_&2{3uQBK6ltZUd!71*k~Jx0xe
zVbvHk$fW>p7NV&T;hvA8h2{nVYx@!$wx%sKF~YHhkw)t*SB3;8@jfpVB)0cM~Y7
zM_c2Lx;d~&3doIGbQwg^8f2eG*(@~J1S2YC>)?3qrSftZu5Oy_W8>K`Ze0D6PjODZ
zkID{m3&=+;j-NV25@MgQ;S@t#%|0p{-Hgm|WXL^`gCQ;6ZWqgUnE~8>UM2cf(GJgF
z*U=dq@_64oCO+PE{c80i<1lO&@Efhpb|UAlBg>Yy;+=0$;EmC2YE>{#Ic~6>nakC$K@OKtL%-^uMgQCCAj6ZiY1LIWJ#SM(YZ1RMytZ}e0qcS>1mX6dzkmR#?
zkUE33W#3@ZK%nGE6VWNDrqu<3$uC1oW)yN+0
z4o^P8Z2iug%^5w9;~sU03rn34UnXP~CI3X-59o=Z!Fq4G
zk!x1Y?@nU|)Fcg!;P<=9CcNHcu_7np4Th0x7)W(IQ~N+k|5EJ!>}tK}0N!FqO1W#&
zivN9znWku1EhG!m5(jEM;m|ZgbG59XMxFU@-QfxuEVw#m6pO6}TQ`z8O$#ZQExeRf
zGulvR$@(fM$9`1kG7`ushcvKt;aaOq`=lNH9kEhAzT7Q+&sc6($fY`}3mN467mfr%
zbxg#R@@2msLk5ooQa$HrCFJtXOu$D%6e5#0`ugU&pF?OHnKv#j8~=r=#5w{-!VT;H
zrL{QL#f4x_)!W{r(vtl=P2M|dgP)JlmM_1u`r4S}qg1K7^rEa0sz{5rEYxu=xw^QK
zq>UPsRq0_QB@r^_zGGy1t}98RMppo&s`@jfqE$cJ`}-#!B4CIwJ8BpbSS_P*F^mdD
ztFOdvdS9s@lkK8&`dyY^)T(!~vej`m54R?Y9a0dv67IHdrRbvig4+>|n^<-HGx-a3
zDS9M4b*7bIi9gLb1SRo6AH!AAuKGmU0(N9G94FR{GQlOVcn)1MnZ{N
z8k>j3QQp6IA_x-mW0@K}`eju-oyp1V(x5I=KnHa1nWnf`5(=6{P(N#CNf`ULrqs76
zLGd{7J&LY?OhuXx_9G9
z)#CPs2Fy+nT|XWtF14Rm_A1x`+bC9WblP5_e7|s=OksfcU4`URH%X@LFMHZpG{My^
zLer6i&H8DTyyZo7{5!Hmed##g=#WY6(o$1S{4g(s30~6mfyWl_`
z(x;H+M&>d3iKz{9Bt19-M6FOig4XgG8EwicK7JK%CeV?3uv5Mq@Ys>;j25`~kxeea
zwR&W@{d_u8kp(#2QmL1+gITmCQMFWderEanb}dk^PhN-yfF?o&%)NLL8UOPvOv&?f
zcA2G?Aa;vy7$7br$Us^m>oa$0KFhcrsV}^!s<6G(?s}fzAk{LF5lUl<463Qo{T+}&lipm)ss3;VyT0I1o%}<
zZdhK^qR)~pNfD-c@~iguyl5|>1C2ygdd1f`y5upka(;8Z@=_l7VQ~tKhBT1D_>!*S^^!@G{*QbmKlubhgZ7k?9gl}UDpUchm{7Ag
z?+XhPgm=mP6bXO@J#&CFbf
zV)hLR1@QU5VP_Y;%yP=e77O51Oiy&Rb}COSa&vkj2T~|jZy84vGDb2+zAeJgo%>-?
z*RW)4f=w@%_t5fR=+Vh&!}0FNwIRIpMf>)%KsknG0EKXmWSP^xdNyIG-Etrq$l)pd
z`v-&HTCq+-bt0svK@?>doGnmJzx|XA9C1(BRjJj=@2XugM@q85g9dH^e~#N?69^^r
zwFL1hQI}XX5(jl9WJm{g(8QPM3(@fZT%-YQgn=clnD=m
zu}{<~ZC5gwAo5RbX>|zEAx|4rIZGZ%=VW;Yzs|UISh*z@iysI(o5lC2(wH9btZ9cY
zEaXLnd=Vz+(hbAf#o6jBl0|((lU%|EdLJ5kA7eWlN%SOC((s)Q21C@Bv*Mk{BdP}*
zFY^}Ts-MgoJo1CZCs)%H0cYO>v@54w{oVZiFS?7%!zsPy#J!eBNEU6L*;PDQf?z$Vao|EEQA5
zwU2hO-+w}Y-eF**VY-ye^mmi9lHN<#Vxh#F6=P!c@pRU&)f*!0o>^QLjw*vqY51c`
zUm^c4LN*(-@Ru2uR`7ID#Pq^KMiplZ7OsI-^uJ6ZYS2$B1%=(@(j$j$%74pi=%zLw
zS8rg%q3b6TQx2E-?&U``$NGXjNL~l4Z8R$G;IqtlTAZOm5V6~;yLR{=5cN1xyFJj87cm+@P)H`olkm#kXS&{?rl@nykT4ai@L`r%JsV(p`xBEFd-Z
zI!zjir7R7F4kuXL0X@sxI$hq$;M-eozzZ_y8@%@o0=86|4u6g4(Np6%Z!Ux`$xvB-
zNl0ET(~gM%fikO#CU<_?x`l!JcKDp_-OT;Gy!PJGzAZH9{*Zk11B{5<{^fJ%&~+LA
zwX@TrZPL)l2;PwPB647HJA$#|Cr6|X(6pz|rTS7M1Qra+da=Dl6H%{g^}q5W9VQxT
z+)t)3BdP3WI>`oypLuRup?C)pnzst<;tnxH743On7VgC4$|bQfFfePMDU!Exj_=8T
z!0=$B`C2cNc;t&4nCV+6>0>FuO)w{(jibW>Ma2tkB7((W}3$HCnkp1lQBfiDE
zjO7c&EUjr>74>ZXy^-}!r(cqqNzwcslpgCiYI~Xnex;v2@ZY%r-*NN;J11ny4oX)r
zz}D(!a%g!5WD1BAZ>>
zwYpyQb-QD-q{J6Covi8-L!uFT`SDcy`+>3j;$ToW^6+nDHCWoLiXAix{{3vE7~XX{
zvV8aZ$&ZGqr5u|K_f2B$3A+1Ds>gfa`>(6)6eb=L!PDorFeZ0-&YR*SST(D!9g)euyib}D+BoXCSgVvLm^64}-bOMOD3@+}{Uy^s77)-JOqo5GTj{4;7KH>HvC#CJMa@3Edr_~T-S6g#PC;4A
zllQwlxVN>;0Cf?hq$iFFHe$dU9O18XV2vbFXK9TQeG_th>UND3cwT?3%;vSiMQl@H
z)-ziq`&CI*okk35;yCERnoIC=*(yQ!`ZQ|W+v{+ZLOPB6u=tz*$ymTsKztj>lCDJ1
zWnZ|6UF|7qY$>Q|)@Ttm)YaXa891jw?N(
zX45oH{utC?Y|(rDgxOqe!F|V-im;y=0qeBU@l~Fw!VaL*%0&B|F-qk=`%~a6oe={{
zv%aT8Kt`_NDp`&jp`2?Op|rpd7wbX{7*b_nX%m3T*bS!=z1!0b?H=rBxHC7AXtYgWbdWvi+S^ss%)ZpN51_(uN
z!U3feqJ=4OD?|I=@`vv@PyVNOjEs_@xZ&}x$bPR4
zJ+WDRGXhS#c|Tue2@;zinc|Nb4JmpOaGcP3D0mdBfXW>Ol-l>Z5LF@)
z#V@}x%9}C11CKeZ*_(mInPy9a`ea4ia_T)}vxLSqrOBCf()A%oGPNWmFW&66S*HNL
zw_cB;r0M5oS0knm*N<@39bo#x+(-5XqERH!o8uSUn|ICPB$93!26bAxzKyal$X?OM
znVsFpJ^Wi(2|ExQ11{l!1KiyD3?^Ic%t5h5PS3?|`uIDw;6H=U_Xp?Z8bYt1P_^Uv
ziTujm55}3W_JGwow=Bp{G+1DRZpe5WV1u%N`f6)ikwMuO
zF7|G(el-7q*HfDnFZG8ozaXU~H-tB&!swI)t1L>VUJF*~cZ6pRlzsbe$^8miE@1(F
zM-Yb-g21GGArfMy!COaxjuAYqa`ZCMTBaFbOCVp+j<2kPAbmOS2-Pn!
ztzqETq(60sHGw2YXu?C|W~)j%<2~%o`EnlW&S?1g5HJVl$r{Xx7xbYVQin(=kodAS
zE5`uLs$}D1Gh;3Mfw57jArEb%iUV4FUziA%V{hGqxU5AH6a)Afo({4VIJaaVXtRQI$oC
zxh>1kXkOem4ezZlLk{{g06Ti&pzGG&CT4OsoBmYrDErZIB~i;lJ)-q
zg43uvC8Re*FnRISVABA`DAbjr>B99N7JTc#uaQ@xzKJ=Tc#esR#g_ogfjW&1ze7WH
zUOAgPCm}R~O3BIOi=&3hA`JDZF|hs*Rd3P#
zQi61Migb6Eq=YmG5|YxbfP|EQfb_ffzMuPke$T(KYu9<5-{U;a<0C3dH9zu-`~&0H
z{B$~GjhPZ^0HITU>JaZ+@SHX}@X@uLs}{{i#ozGE7rkf-*(b^&89DvVWInt2X#c<$
z@0IafTV4tqa(J~BRa#tbM(d9BnkPoPR2VO7W9ExQv(Wwu^xDiQc?
zY_i`~La+6@e^fFRdQe7xrqxgVCC10i>H0OBzlt)ph#m5M10i@b>Y3M{K!wP;iHUze
z<)v0^)N!34zO_;pm1~6@sC%=KuCg|?5>mWvPqoZ0=GOQA+v#D9322B>i78@|Ez$I{
zbt`!NG2li#pzY0sqX{J(iqkKINpiC$IasG6`&eBKa4jmMf?tw3JTr<{(`@6Lv8E;Aq;Wml!RfN?5d8~kwP8gwyHCOQ0a7Z5tB^ZYeym(X2aEJWM=ip6hUd}
zoM7h86;_79c;g>f5V5_DWcr;bzk$!Kh2|sYR*xQ)-sc<87_oJAo&p$UtjeVQ+|*B_
zH3~K;B}*qYxFjQi(t?C{llc>2B->oHo6zLSEHSQF$aR~M4cj?Usv!>F=kyglkIpG|
z<;xEXhljuM-&TG@eM<+BdmE~p-5^D04&m~Mh
zMT?!=?rgZ`kNlBU&{v-=9~nR_Jl+EHB6A2r`rm$mS3K<%`8W*^~
zz$9j5@CLB3;x{$}T-@9*wxTuxr{9dbQmt~FeD5yzB_z83;Mw-Mp3RS>jQr?9VkWf<
zIS^1^aJFYuWPBFM+eFLqb$HNyS5Wb^-N#zY`ks4Y@;8hpB5d3S!L7^n%R2>vk!=sv
zD}OD!zmc$Qxw*C@SHR4VWwWliN)}Wt|I0$l*M%(qY4#-abq*NFfsj}08n1=k{c7E!
z+Jf|i!e#D3s|pW{a6qH`_SOCHliqj&hNg}PsGCAU8l$Nsp9P5Y>HxoXN^#ZZlY8m%
z&+iv-k?-*>is!s%{z)Kq!|OL8tc0A}?PQEC@xy73U#jv&c+0AyA>7=r?5DZiiS@}M
zwMPSIHqy>)Or;uLrhoe8R=2fX@cCEd6ZUJIkrmg$*~?STs(&q?9gTw-J_P=I?7^TA
zs1a&ZfPc*~xx)MPn5xmD4ePfoLB8gPP8y!iX-px-H9A^V&VYUnYv#T_ROrADS;XIl
z7b~3nfVzE=u6szEhZ`g1H9tH8BQc(IE3kZIog&JQyNF%i57Um^ZO;`uRpdV
zS*j6Hq>9KO;ahekE9IBtFxDLAIF&#sS+H|^=M!6j=L_AfpE_DU34F5c`Jc;06%)+S
z{cNBBP*;apsxbqCNiBq1Q!eH0imaKv$c=J~loxWQAx{T@uu^7dt+^s*VBE?$XLH#cH()(uax92TulQ1hH(
zRP+m9!T3N}KmK}uB&l*L`XGcz;`6mo6gr7HzcuyM_uxJV-DkLrb@wpo%DWD6OdI9@
zB?w?hJjBDMJ5mSc!~5WzdjnYAoyHMg;_LM%lDDPXFL?~nI+c1_u0c8e8S
zNCf)D3OB3>@+vB&f=Xh@WuaoalO1qMPRp$W9w0%&ZzFrtG(js5>(Z@Yj`iGljUNH{
z?^BM71|E4R>wfCo8g>gSiR*Y=Mf>+(bkVl~*YR}!meU~VS!YmSk6|L^8Ks^S&o&!u
z__3<4``Bzg7c#8cXGqOh`_AlWsv^X#@8EZP4fhD3r{?AnzHp}^DI4rjW6v4{kW`j
zJ1k5nhXn2)7Ja7mzSZoj+J9`Ca6Zm5riii77(i4+6s-i}rk_MfsGF`L<#T)O<
zobkmszXo5u$@5$1621F|U48-5_dQ?h+{ta6@an%B7aowj;J+C47IA|VXs$E=%`{+w
zL)zOhaMcfzm%B{s)gai&ESE0uWbAL_f1+jJZr0Ly)a2}!{T|J{CN;i4Gnpp_?5@8;&=5g@=3Sf`pHU^$Y^
zp|$-L7>ZF0$r}rPHEsUTX0W5?fOv+MMmFE{x(F#+sf7^Yj+_$gDvEj^=?U7H6M63j
zLRrpb_1>;(9s`&7^YyS9h@HPRXyfcv6hHarn-@_^uqkT#V}M#vfzG1Z1gCcLX{?o^
zN}RY(_A7pQ{CVjC!v2lLjO{P_NC*UTj+}
zVfd^J-krKUAw@b-_zZLGkfKV&7J
z)EKI~hP)zc9;b3e!V9n0(^oDTa)d=Cf%Vxtqt4X{&kgY
z42gw_()*^k&yn&|>pf;A$QQcq!Oz6Y)wNlIGsl^f0^1I#$w@-_O_+C;Qr1#UO{m70
zIO3`!;$PhH3UUE|wP(_DE26Gv1_PtB*h@+wu`r*ui*A1;*t*Q3zEylOz
zw4vgINDu8!ZN-m8r809Cs*${EI(olfSTEOxwzo_yZbQpM0uf(;uS~(2zS;RtY;Dx)d$MuhyyNph!u!`q3e-kh*sn!zb>)7m*7tg*
zLd$=u++RoOwb%JdmGwmKY~!@YTLELhkCE0Ip=Mn)^7_hN$WDRf-_O@b25m+TuX)+f3hE@e6Nqtmy-^*wh1i*j!Vmb8|`}j?*SLr
z^3M#7BaZ0@E7N8pIsQ+FH*%sTXS}4Iqmn}UkAs8?Sf(8Lm;*|i2@-%~g-p`eLF`zK
zU%wDMwon@1BQhqOQwV!;kpKyWk`dC@Ab14oTYkGF;=M_7q++tjtNojA(^8m}VevH8
z#!h!CA915eHG?Wm6r%v5^$P22K+2i;d;|({2TU@GYGi11Aeo)Du@-;Or-VN8r
zECT_!)CD{hctb<5CkPI9cZ&sPFlj&-A%n<3_;g5A_^6$fwOmQW|1ELh!C_uXIcDSt
z0e23kPvRG}wD2KxS*}~(~$u@MT6jJhel)2VT|W`R7FI
z2d^`?efXCkKIR0beA>>i>vdiM<2S9*@KO_%<18)h$g)81iO0~4ZB=N^d+X7j=H!owVu0J}L#brZ
zvz5$Lf#*4*`9@fZ-#D62S~pfNXx$#l|Rk8
z+8Py1vB1Zo=q-3gPuHl=Y8Ni9^Fir%XAyuqabN|RY7mmiwikw3n|xWgC-4%j8Czl}
zFG%flPFks>{W@xwDD0~eYdS3|RIVh}Yq?-BC)nmiXXHiNt^iCE5?YgH$;Z#EXH>q(
zeP>rsPGxFY8;(mf-r3NGuauH@6gv~I$Z$Kh}@MixQ=p}?*
z&4UF%(qC5fl{%_T;Kh{ZX~dhY6Cf#qrO-iBziAN#L*pee
z6WxD8Fg_WOVoUmjHJK@^kcB$r&6`I$v(Cc%H(mQTLwEMiFeaNeIR(TMMmbKx|0r5Q
z6~ZJ@U~q6+syH*vpIrCpB&OkH#Uft5EaPy(@YJ9nQaa~++K~=bdK?1!4b68kVczUw
zECcxhtyE{eS^yJi=HW=S2>JOfQAVt4{TNJJAU^UmYU~}izG+xleCEx>T;D!Eqvcm>
zLO`H-O@H#nCaK)isFF)@)oR$w7qt%FOPdNI#IAbwQ*GTH%JjFpLJ|t65{f*Lvai*n
zuin<+pFjd4-`c!acp(-RJFI$A*kutJ3We*yHv)_J^e-ElyecW4p
zgu)wzzx$2KuQMh10j5f)=#WbHHJn8oe2+2S)nloLTL$0lmbQW7%D0lo?KR7iZ%@0g
zngZPC4LwQ}@Vdy^0hmY{DX<0Pg~WL;zEbbREZWR0y(IKUFy{YJ
z)|zLuS((T-CnH~YmCYTd9NGH8O~QNrMaRtwft1L?y1}S56>qlGS-2o({{QkSvbDKu
zElz&bH!uE^xA~0r=In{RR#eZMukI0dF|NYP>bDR~40qYS$uVU1KnnST7ibsCF
zgrzNm)Mg{R18U=VJ1<$K;j-MRS{YGF{3)f4$~+XV=_Ik)OsIlUWTYdXY*qi6yv$n!
z4^Zb(+Z<6%0Wa*enZUrQYjw`gh;YG&ztIu9j(Uh>NPbrAay9Xgo4WgnwhoDC%7D1!*TETkZeIYPCeR&4GNS~`e