",
}
- ```
+}
+```
+
+The fields are:
- This configuration is more flexible and allows you to specify the start and end conditions for the incremental loading.
+- `start_param` (str): The name of the query parameter to be used as the start condition. If we use the example above, it would be `"created_since"`.
+- `end_param` (str): The name of the query parameter to be used as the end condition. This is optional and can be omitted if you only need to track the start condition. This is useful when you need to fetch data within a specific range and the API supports end conditions (like `created_before` query parameter).
+- `cursor_path` (str): The JSONPath to the field within each item in the list. This is the field that will be used to track the incremental loading. In the example above, it's `"created_at"`.
+- `initial_value` (str): The initial value for the cursor. This is the value that will initialize the state of incremental loading.
+- `end_value` (str): The end value for the cursor to stop the incremental loading. This is optional and can be omitted if you only need to track the start condition. If you set this field, `initial_value` needs to be set as well.
See the [incremental loading](../../general-usage/incremental-loading.md#incremental-loading-with-a-cursor-field) guide for more details.
+If you encounter issues with incremental loading, see the [troubleshooting section](../../general-usage/incremental-loading.md#troubleshooting) in the incremental loading guide.
+
## Advanced configuration
`rest_api_source()` function creates the [dlt source](../../general-usage/source.md) and lets you configure the following parameters:
@@ -674,3 +778,92 @@ In this example, the source will ignore responses with a status code of 404, res
- `content` (str, optional): A substring to search for in the response content.
- `action` (str): The action to take when the condition is met. Currently supported actions:
- `ignore`: Ignore the response.
+
+## Troubleshooting
+
+If you encounter issues while running the pipeline, enable [logging](../../running-in-production/running.md#set-the-log-level-and-format) for detailed information about the execution:
+
+```sh
+RUNTIME__LOG_LEVEL=INFO python my_script.py
+```
+
+This also provides details on the HTTP requests.
+
+### Configuration issues
+
+#### Getting validation errors
+
+When you running the pipeline and getting a `DictValidationException`, it means that the [source configuration](#source-configuration) is incorrect. The error message provides details on the issue including the path to the field and the expected type.
+
+For example, if you have a source configuration like this:
+
+```py
+config: RESTAPIConfig = {
+ "client": {
+ # ...
+ },
+ "resources": [
+ {
+ "name": "issues",
+ "params": { # <- Wrong: this should be inside
+ "sort": "updated", # the endpoint field below
+ },
+ "endpoint": {
+ "path": "issues",
+ # "params": { # <- Correct configuration
+ # "sort": "updated",
+ # },
+ },
+ },
+ # ...
+ ],
+}
+```
+
+You will get an error like this:
+
+```sh
+dlt.common.exceptions.DictValidationException: In path .: field 'resources[0]'
+expects the following types: str, EndpointResource. Provided value {'name': 'issues', 'params': {'sort': 'updated'},
+'endpoint': {'path': 'issues', ... }} with type 'dict' is invalid with the following errors:
+For EndpointResource: In path ./resources[0]: following fields are unexpected {'params'}
+```
+
+It means that in the first resource configuration (`resources[0]`), the `params` field should be inside the `endpoint` field.
+
+:::tip
+Import the `RESTAPIConfig` type from the `rest_api` module to have convenient hints in your editor/IDE and use it to define the configuration object.
+
+```py
+from rest_api import RESTAPIConfig
+```
+:::
+
+#### Getting wrong data or no data
+
+If incorrect data is received from an endpoint, check the `data_selector` field in the [endpoint configuration](#endpoint-configuration). Ensure the JSONPath is accurate and points to the correct data in the response body. `rest_api` attempts to auto-detect the data location, which may not always succeed. See the [data selection](#data-selection) section for more details.
+
+#### Getting insufficient data or incorrect pagination
+
+Check the `paginator` field in the configuration. When not explicitly specified, the source tries to auto-detect the pagination method. If auto-detection fails, or the system is unsure, a warning is logged. For production environments, we recommend to specify an explicit paginator in the configuration. See the [pagination](#pagination) section for more details. Some APIs may have non-standard pagination methods, and you may need to implement a [custom paginator](../../general-usage/http/rest-client.md#implementing-a-custom-paginator).
+
+#### Incremental loading not working
+
+See the [troubleshooting guide](../../general-usage/incremental-loading.md#troubleshooting) for incremental loading issues.
+
+#### Getting HTTP 404 errors
+
+Some API may return 404 errors for resources that do not exist or have no data. Manage these responses by configuring the `ignore` action in [response actions](#response-actions).
+
+### Authentication issues
+
+If experiencing 401 (Unauthorized) errors, this could indicate:
+
+- Incorrect authorization credentials. Verify credentials in the `secrets.toml`. Refer to [Secret and configs](../../general-usage/credentials/configuration#understanding-the-exceptions) for more information.
+- An incorrect authentication type. Consult the API documentation for the proper method. See the [authentication](#authentication) section for details. For some APIs, a [custom authentication method](../../general-usage/http/rest-client.md#custom-authentication) may be required.
+
+### General guidelines
+
+The `rest_api` source uses the [RESTClient](../../general-usage/http/rest-client.md) class for HTTP requests. Refer to the RESTClient [troubleshooting guide](../../general-usage/http/rest-client.md#troubleshooting) for debugging tips.
+
+For further assistance, join our [Slack community](https://dlthub.com/community). We're here to help!
\ No newline at end of file
diff --git a/docs/website/docs/dlt-ecosystem/verified-sources/sql_database.md b/docs/website/docs/dlt-ecosystem/verified-sources/sql_database.md
index 36a8569a4a..ce5424d2a9 100644
--- a/docs/website/docs/dlt-ecosystem/verified-sources/sql_database.md
+++ b/docs/website/docs/dlt-ecosystem/verified-sources/sql_database.md
@@ -177,7 +177,7 @@ pipeline = dlt.pipeline(
)
def _double_as_decimal_adapter(table: sa.Table) -> None:
- """Return double as double, not decimals, this is mysql thing"""
+ """Emits decimals instead of floats."""
for column in table.columns.values():
if isinstance(column.type, sa.Float):
column.type.asdecimal = False
diff --git a/docs/website/docs/general-usage/http/overview.md b/docs/website/docs/general-usage/http/overview.md
index 94dc64eac5..2d193ceb2c 100644
--- a/docs/website/docs/general-usage/http/overview.md
+++ b/docs/website/docs/general-usage/http/overview.md
@@ -8,6 +8,10 @@ dlt has built-in support for fetching data from APIs:
- [RESTClient](./rest-client.md) for interacting with RESTful APIs and paginating the results
- [Requests wrapper](./requests.md) for making simple HTTP requests with automatic retries and timeouts
+Additionally, dlt provides tools to simplify working with APIs:
+- [REST API generic source](../../dlt-ecosystem/verified-sources/rest_api) integrates APIs using a [declarative configuration](../../dlt-ecosystem/verified-sources/rest_api#source-configuration) to minimize custom code.
+- [OpenAPI source generator](../../dlt-ecosystem/verified-sources/openapi-generator) automatically creates declarative API configurations from [OpenAPI specifications](https://swagger.io/specification/).
+
## Quick example
Here's a simple pipeline that reads issues from the [dlt GitHub repository](https://github.com/dlt-hub/dlt/issues). The API endpoint is https://api.github.com/repos/dlt-hub/dlt/issues. The result is "paginated", meaning that the API returns a limited number of issues per page. The `paginate()` method iterates over all pages and yields the results which are then processed by the pipeline.
diff --git a/docs/website/docs/general-usage/http/rest-client.md b/docs/website/docs/general-usage/http/rest-client.md
index 61af3d2057..d3a06a1d28 100644
--- a/docs/website/docs/general-usage/http/rest-client.md
+++ b/docs/website/docs/general-usage/http/rest-client.md
@@ -306,7 +306,9 @@ client = RESTClient(
### Implementing a custom paginator
-When working with APIs that use non-standard pagination schemes, or when you need more control over the pagination process, you can implement a custom paginator by subclassing the `BasePaginator` class and `update_state` and `update_request` methods:
+When working with APIs that use non-standard pagination schemes, or when you need more control over the pagination process, you can implement a custom paginator by subclassing the `BasePaginator` class and implementing `init_request`, `update_state` and `update_request` methods:
+
+- `init_request(request: Request) -> None`: This method is called before making the first API call in the `RESTClient.paginate` method. You can use this method to set up the initial request query parameters, headers, etc. For example, you can set the initial page number or cursor value.
- `update_state(response: Response) -> None`: This method updates the paginator's state based on the response of the API call. Typically, you extract pagination details (like the next page reference) from the response and store them in the paginator instance.
@@ -326,6 +328,10 @@ class QueryParamPaginator(BasePaginator):
self.page_param = page_param
self.page = initial_page
+ def init_request(self, request: Request) -> None:
+ # This will set the initial page number (e.g. page=1)
+ self.update_request(request)
+
def update_state(self, response: Response) -> None:
# Assuming the API returns an empty list when no more data is available
if not response.json():
diff --git a/docs/website/docs/general-usage/incremental-loading.md b/docs/website/docs/general-usage/incremental-loading.md
index 72957402da..b21a5779bc 100644
--- a/docs/website/docs/general-usage/incremental-loading.md
+++ b/docs/website/docs/general-usage/incremental-loading.md
@@ -29,7 +29,7 @@ using `primary_key`. Use `write_disposition='merge'`.
-
+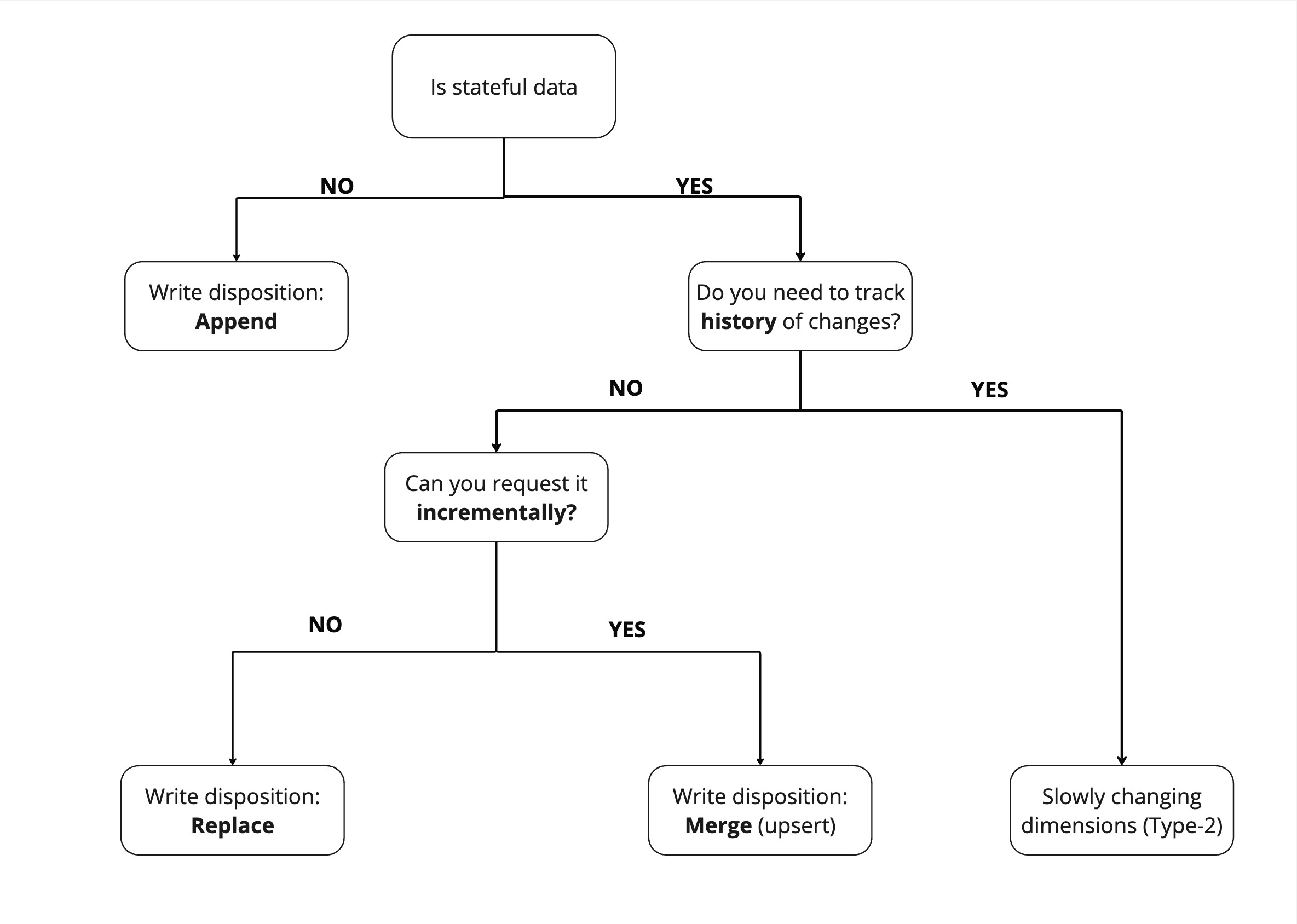
@@ -41,8 +41,9 @@ user's profile Stateless data cannot change - for example, a recorded event, suc
Because stateless data does not need to be updated, we can just append it.
-For stateful data, comes a second question - Can I extract it incrementally from the source? If not,
-then we need to replace the entire data set. If however we can request the data incrementally such
+For stateful data, comes a second question - Can I extract it incrementally from the source? If yes, you should use [slowly changing dimensions (Type-2)](#scd2-strategy), which allow you to maintain historical records of data changes over time.
+
+If not, then we need to replace the entire data set. If however we can request the data incrementally such
as "all users added or modified since yesterday" then we can simply apply changes to our existing
dataset with the merge write disposition.
@@ -505,7 +506,7 @@ def get_events(last_created_at = dlt.sources.incremental("$", last_value_func=by
```
### Using `last_value_func` for lookback
-The example below uses the `last_value_func` to load data from the past month.
+The example below uses the `last_value_func` to load data from the past month.
```py
def lookback(event):
last_value = None
@@ -981,3 +982,64 @@ def search_tweets(twitter_bearer_token=dlt.secrets.value, search_terms=None, sta
yield page
```
+
+## Troubleshooting
+
+If you see that the incremental loading is not working as expected and the incremental values are not modified between pipeline runs, check the following:
+
+1. Make sure the `destination`, `pipeline_name` and `dataset_name` are the same between pipeline runs.
+
+2. Check if `dev_mode` is `False` in the pipeline configuration. Check if `refresh` for associated sources and resources is not enabled.
+
+3. Check the logs for `Bind incremental on ...` message. This message indicates that the incremental value was bound to the resource and shows the state of the incremental value.
+
+4. After the pipeline run, check the state of the pipeline. You can do this by running the following command:
+
+```sh
+dlt pipeline -v info
+```
+
+For example, if your pipeline is defined as follows:
+
+```py
+@dlt.resource
+def my_resource(
+ incremental_object = dlt.sources.incremental("some_key", initial_value=0),
+):
+ ...
+
+pipeline = dlt.pipeline(
+ pipeline_name="example_pipeline",
+ destination="duckdb",
+)
+
+pipeline.run(my_resource)
+```
+
+You'll see the following output:
+
+```text
+Attaching to pipeline
+...
+
+sources:
+{
+ "example": {
+ "resources": {
+ "my_resource": {
+ "incremental": {
+ "some_key": {
+ "initial_value": 0,
+ "last_value": 42,
+ "unique_hashes": [
+ "nmbInLyII4wDF5zpBovL"
+ ]
+ }
+ }
+ }
+ }
+ }
+}
+```
+
+Verify that the `last_value` is updated between pipeline runs.
\ No newline at end of file
diff --git a/docs/website/sidebars.js b/docs/website/sidebars.js
index e1773cb5b3..465212cae6 100644
--- a/docs/website/sidebars.js
+++ b/docs/website/sidebars.js
@@ -46,11 +46,8 @@ const sidebars = {
type: 'category',
label: 'Integrations',
link: {
- type: 'generated-index',
- title: 'Integrations',
- description: 'dlt fits everywhere where the data flows. check out our curated data sources, destinations and unexpected places where dlt runs',
- slug: 'dlt-ecosystem',
- keywords: ['getting started'],
+ type: 'doc',
+ id: 'dlt-ecosystem/index',
},
items: [
{