В Главе 3 мы говорили об иерархических структурах подпотоков — очевидно, что в FBP есть еще один тип иерархической структуры, о котором упоминалось ранее: иерархические отношения между компонентами. Хотя все процессы в приложении FBP представляют собой небольшие основные линии, взаимодействующие на одном уровне для выполнения работы, проще построить общую структуру иерархически, с "верхней" структурой, состоящей из двух или более процессов, большинство из которых будут реализованы с использованием составных компонентов. Каждый составной компонент, в свою очередь, "разрывается" на два или более процессов и так далее, пока вы не достигнете уровня, на котором вы сможете использовать преимущества существующих компонентов, или пока вы не решите, что собираетесь писать свои собственные элементарные компоненты, а не продолжать процесс разрыва. Помимо акцента на использовании уже существующих компонентов, это, по сути, методология пошаговой декомпозиции структурированного анализа.
Применение этого подхода к FBP в значительной степени связано с покойным Уэйном Стивенсом, возникшим в результате его работы над структурным программированием и методологиями разработки приложений в целом. С точки зрения иерархии работающая программа, построенная с использованием AMPS (первого диалекта FBP), была "плоской" — она вообще не имела иерархической структуры. Люди рисовали сети приложений на больших листах чертежной бумаги и прикрепляли их к стенам своих кабинетов. Затем эти рисунки постепенно накапливали комментарии и примечания, поскольку разработчики добавляли описания потоков данных, параметризацию, DD-names и т.д. Когда пришло время реализовывать сети, разработчик просто преобразовал рисунок в список вызовов макросов.
Уэйн понял, что лучшим способом разработки этих сетей было бы использование методов декомпозиции структурного анализа, но, в отличие от традиционного программирования, "угол обзора" не надо было менять по мере перехода от проектирования к реализации. В традиционном программировании существует "разрыв" между подходом к потоку данных, используемым во время проектирования, и точкой зрения на поток управления, необходимой во время программирования, которую чрезвычайно трудно преодолеть. Таким образом, при построении DFDM мы предоставили разработчикам возможность наращивать свои системы путем поэтапной декомпозиции, но во время построения структуры иерархия "сглаживалась" до уровня обычной сети типа AMPS. Этот подход оказался очень удачным — я упоминал ранее коллегу, который построил сеть из 200 узлов, ни разу не нарисовав сети!
Таким образом, сети DFDM могут быть построены иерархически, но во время выполнения являются плоскими. Такой подход позволяет разработчикам создавать свои приложения слой за слоем. Как мы показали в некоторых примерах, вы также можете взять простой компонент и заменить его подсетью — это дает дополнительное измерение расширяемости. В DFDM мы видели, что подсети можно хранить в повторно используемых библиотеках и использовать повторно. Однако они должны храниться в интерпретируемом виде, чтобы была видна их внутренняя структура (хотя они и построены из черных ящиков). Было бы еще лучше, если бы кто-то, разрабатывающий приложение, мог бы хранить часть или всё приложение как набор подсетей-"чёрных ящиков", чтобы клиент не мог видеть внутренности подсетей. Помните, что DFDM может взять интерпретируемую сеть и преобразовать ее в непосредственно исполняемый загрузочный модуль. Должна быть возможность сделать это и с подсетью, чтобы часть приложения также хранилась как черный ящик. Однако первоначальной мотивацией для этого была производительность интерактивных систем.
Рассмотрим приложение, содержащее 200 процессов. Когда вы связываете весь код вместе в один модуль, в результате получается довольно большой загрузочный модуль. Конкретное приложение, упомянутое выше, работало под управлением IMS/DC, и сеть выполнялась один раз для каждой транзакции. Однако, когда мы начали измерять производительность, мы обнаружили, что при каждом проходе по сети, даже несмотря на то, что IMS загружает всю сеть для большинства транзакций, фактически выполняется только около 1/3 процессов для данной транзакции. Мы задались вопросом, можем ли мы создать фреймворк для и динамически загружать необходимые фрагменты логики. Преимущество здесь в том, что для загрузки приложения при каждой транзакции потребуется меньше времени, поскольку отдельные загрузочные модули будут меньше, что улучшит время отклика. Кроме того, для каждой транзакции вам потребуется только фреймворк и конкретный подгруженный фрагмент, поэтому фреймворк можно сделать "постоянным", что еще больше улучшит время отклика. Это также должно облегчить расширение приложения и даже изменение его на лету. Проблема заключалась в следующем: как запустить сеть, которая динамически модифицируется, не теряя при этом ваших данных?
Долгое время я сопротивлялся этой идее, поскольку у меня было видение сложной системы метро, подобной лондонскому, но с дополнительной сложностью, состоящей в том, что станции будут появляться и исчезать случайным образом. Каково было бы быть пассажиром в такой системе?! Я экспериментировал с динамической загрузкой отдельных компонентов в AMPS: я мог считывать или загружать фрагмент кода, обрабатывая его как чистые данные, и позволял ему перемещаться по сети, пока он не достигал "пустого" процесса (который был связан с другими процессами, но не имел назначенного ему кода — своего рода процесс "tabula rasa"), и в этот момент он должен был выполняться, поэтому я чувствовал, что динамическая модификация процесса может работать в контролируемых обстоятельствах. Уэйн Стивенс также предложил частный случай модификации динамической сети, который был проще, чем то, что мы в конечном итоге получили, но мы так и не удосужились его опробовать: его образ был инженером, ремонтирующим плотину. Вода должна продолжать течь, поэтому инженеры отводят воду по вторичному каналу. После ремонта плотины поток воды может быть восстановлен в первоначальном русле. Кажется, это хороший способ обслуживания системы FBP, которая должна работать 24 часа в сутки, как банковская система.
Я сам придумал другой и несколько более сложный подход, который, впрочем, тоже был безопасным и управляемым, а также решал описанную выше проблему размера загрузочного модуля. Уловка, которую я обнаружил, заключалась в том, чтобы "материнский" процесс загружал подсеть (в скомпилированной и связанной форме), запускал процессы в подсети, а затем переходил в спящий режим, пока все ее "дочерние" процессы не завершились. Во время запуска подсети подсчитываются дочерние узлы, поэтому работа подсети завершается, когда количество активных дочерних узлов становится равным нулю. Пока материнский процесс спит, некоторым дочерним процессам можно передать управление входными и выходными портами их материнского процесса. Не будет конфликта из-за того, кто контролирует порты, так как мать и дочери никогда не бодрствуют одновременно.
Мы назвали эти подсети в DFDM "динамическими подсетями". "Мать" представляла собой обобщенный компонент под названием "Менеджер подсети", который непрерывно повторял следующую логику:
- Получить имя подсети в IP
- Загрузить модуль загрузки подсети
- "Вшить" его в основную сеть
- Запусти и ложись спать
- Проснуться, когда все дочерние процессы завершились
- Утилизируйте модуль загрузки подсети и повторите эти шаги
В дополнение к Subnet Manager мы добавили специальные предварительно закодированные компоненты (Subnet In и Subnet Out), которые использовались для обработки ввода и вывода в подсети. Вот изображение очень простой динамической подсети (с одним входным портом данных и одним выходным портом):
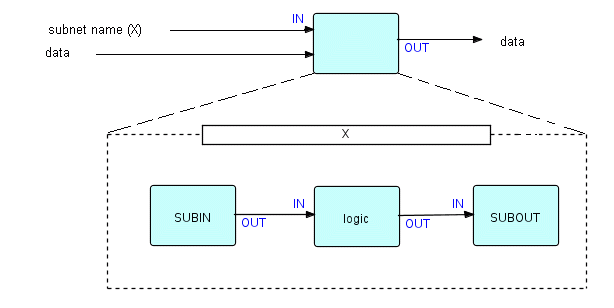
Фрагмент 7.1
Когда "X" получает управление, оно ведет себя как мини-приложение: технически SUBIN не имеет входных портов, поэтому оно инициируется. Два других процесса имеют входные порты, поэтому они не будут инициированы, пока не поступят данные. SUBIN и SUBOUT могут использовать входные и выходные порты своей матери соответственно. Они должны быть отдельными процессами, поскольку они должны быть независимо приостанавливаемыми. Таким образом, если бы мать имела два порта входных данных, подсеть должна была бы иметь два процесса SUBIN для их обработки.
Теперь мы заметили странную вещь: обычно, как только процесс завершается, его уже нельзя запустить снова. Мы увидели, что Subnet Manager должен иметь уникальную возможность перезапускать завершенные процессы. Это была единственная функция в DFDM, у которой была такая возможность, и она была в специальном готовом компоненте.
В работе, которая последовала за DFDM (упомянутой выше под названием FPE), мы поняли, что эти характеристики динамических подсетей могут быть распространены и на статические сети. Мы перенесли эту возможность в инфраструктуру (удалив порт имен подсетей), чтобы все подсети имели встроенный процесс мониторинга. Такой подход естественным образом согласовывал иерархию процессов с иерархией потоков. Кроме того, поскольку другой задачей процесса мониторинга является вшивание композита в основную сеть, теперь у нас могут быть композитные компоненты типа "черный ящик". Это средство позволит упаковать подсети в виде отдельных модулей загрузки для распространения, которые впоследствии могут быть связаны разработчиком с другими компонентами для формирования полной сети приложений. Это кажется очень привлекательным, поскольку производитель программного обеспечения сможет продавать составной компонент, не раскрывая его внутренности (как того требует DFDM)! Мы также увидим позже (в главе 20), что эти концепции дают нам интуитивно понятный способ реализации довольно сложных ситуаций, таких как создание контрольных точек для долго выполняющихся приложений.
Выше мы упоминали, что в динамических подсетях у нас есть "материнский" процесс, который следит за выполнением своих дочерних процессов и может "возродить" их после того, как они все закрылись. Однако, поскольку подсеть не может закрыться до тех пор, пока все IP не будут получены на всех входных портах, какой смысл когда-либо снова пробуждать подсеть? Что ж, если бы это было всё, что мы можем сделать, это было бы просто улучшением производительности. Тем не менее, мы придумали идею, которая, как нам казалось, довольно вписалась довольно аккуратно. Почему бы не поставить маркеры в потоке данных, чтобы внутренняя подсеть думала, что видит конец данных, и завершится, но на самом деле есть еще данные, так что подсети будут восстановлены? Мы сделали это, добавив к составным компонентам параметр, называемый чувствительностью к подпотоку. Это было реализовано в DFDM для динамических подсетей и в FPE в качестве опции для всех составных компонентов. Составные компоненты, чувствительные к подпотокам, по существу отслеживают уровни вложенности скобок на каждом из своих входных портов, и всякий раз, когда этот уровень падает до нуля для данного порта, задействованный порт закрывается, что приводит к индикации "конец данных" в следующий раз, когда дочерний процесс вычитывает данные с этого порта. По сути, подпотоки снаружи делаются похожими на потоки внутри. Поскольку вы можете вкладывать подсети в подсети, каждый уровень вложенности удаляет один уровень "брекетинга" (назовем это "луковицей приложения").
Давайте начнем только с одного порта входных данных. Предположим, у нас есть "чувствительный к подпотоку" составной компонент B, который содержит C и D, как показано ниже:
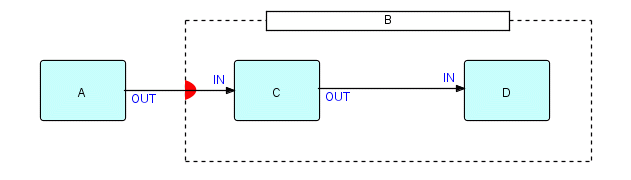
Точка, показанная жирным полукругом, является портом, чувствительным к подпотоку на Б.
(Это своего рода сокращение - жирный полукруг будет реализован как "внешний порт", который не имеет реальных входных портов, но может получить доступ к входному порту подсети.)
Фрагмент 7.2
Предположим, что A генерирует поток следующим образом:
( a b c d e f ) ( g h i ) ( j k l m ) ...
Читаем слева направо. C увидит IP a, b, c, d, e и f, а затем конец данных. В конце данных он завершается, так как у него нет вышестоящих процессов на том же уровне внутри его сети, что позволяет D также завершаться. Если бы D был Writer, он бы закрыл файл, в который писал. Однако мы знаем (а подсеть нет), что C и D "мертвы" не навсегда — когда следующая "открытая скобка" поступит на входной порт B, они оба оживут. Что касается C и D, IP от a до f составляют "всю работу", но что касается B, для него каждый подпоток, (например, от a до f) приводит к однократной активации внутренней подсети.