The process used by Gulzar relies on a specific glyph naming scheme. The patent for Linotype Qalmi, which we originally used to determine our initial approach to engineering, describes the naming scheme, but I will explain it briefly here.
Rasm glyphs and nukta/diacritic glyphs are decomposed so that the dots can be more easily manipulated; for example, the "BE" and "FE" glyphs should have no dots. (See Khaled's blog for motivation.)
Each glyph which forms part of the rasm has three components in its name. The first part is the name of the letter in capitals: for example, BE, JIM, SIN. The second part identifies the form of the glyph: "i" for initial, "m" for medial, "f" for final, and "u" for isolated. The third part is a number identifying the variation. (The "BE" glyphs also have variants called "sd1" and "sd2".) For example, Gulzar has sixteen forms of the initial "lam" glyph, which I have named "LAMi1 ... LAMi16". There are separate glyphs for BE and TE, as they will be handled separately in shaping, but BE forms also handle peh etc.
The naming convention used for nukta glyphs also comes from Qalmi: single dot below is "sdb", double dot above is "dda" and so on.
There should be separate space glyphs for Latin and Urdu, called space and space.urdu. The default encoded space glyph should be space; space.urdu will be contextually substituted into Urdu runs. (See languages.fez below.) The Urdu space glyph must be categorised as a ligature glyph, for reasons we will explore when looking at the dot avoidance code.
The dot collision avoidance system moves glyphs up and down by substituting them with .one and .two glyphs, which are placed one or two "positions" higher or lower. e.g. sdb.two is two positions lower than the standard sdb (single dot below.) The anchors for these glyphs are created by the shaping rules and do not need to be specified individually, but these glyphs need to be present in the font as duplicates of the standard nukta glyphs.
As well as the collision-avoidance nukta glyphs, there are also zero-width nukta glyphs without anchors for bari ye handling, called sdb.yb, ddb.yb, etc. There is a separate collision-avoidance system for these bari ye nuktas, and so additional duplicate glyphs sdb.yb.attached / ddb.yb.attached / etc. and sdb.yb.collides/... need to be present in the font. To delimit the length of a bari-ye dot sequence, the empty mark glyph endOfBariYe is used.
We also need to make sure that the font contains glyphs to "hold" the incoming characters, even if the glyphs are empty. For example, the letter "beh" will be decomposed into two glyphs - BEu1 (all incoming characters begin their shaping journey as isolated forms) and sdb.
It is up to you how you handle this. Some people like to have an empty beh-ar glyph with mapping U+0628, which is then decomposed later into BEu1 sdb. I try to avoid having empty glyphs as much as possible, so I take a shortcut - I map BEu1 (dotless isolated beh) to U+0628 and then I substitute BEu1 by BEu1 sdb. But it doesn't really matter.
Whichever way you choose to map your glyphs, you should not have a precomposed beh-with-dot-below glyph. Rasm glyphs and ijam/tashkil glyphs should be separate as described above.
The shaping rules are written in the FEZ language. This is an alternative to Adobe's feature language which is more flexible as it allows us to write plugins to extend the language in Python. Much of the hard work of the shaping process will be performed by these shaping extensions; in fact, FEZ was created to handle this font! (Yes, this font was so complex we had to invent our own language to deal with it...)
The FEZ rules are stored in a series of files in sources/build/fez, and are compiled into Adobe feature files when the font is built. Each of the FEZ files are thoroughly commented to explain their operation. Some of the files will need to be customized for the new outlines and proportions of a different font, but many can be used without modification.
One of the key features of Nastaliq script is the multiple variants of each glyph, determined contextually based on the glyphs around it. We begin with each glyph in their "1" variant (i.e. BEi1 FEm1 REf1) and then will move along the sequence from final (leftmost) glyph to initial (rightmost), selecting the appropriate glyph based on the one preceding it. (See the Qalmi patent for more on this process.)
It is the responsibility of the designer to determine the correct connections, and so glyph selection is integrated into the Glyphs sources. We can use the Nastaliq Connection Editor script for Glyphs to specify how the forms connect together. Add the script to your Glyphs scripts directory, and make sure you have installed the "vanilla" Python module. (You can do this by opening the preferences menu, selecting the "Addons" icon from the toolbar, opening the "modules" tab, and clicking on "Install Modules".)
Open Nastaliq Connection Editor from the Script menu, and you should see a screen like the one below.
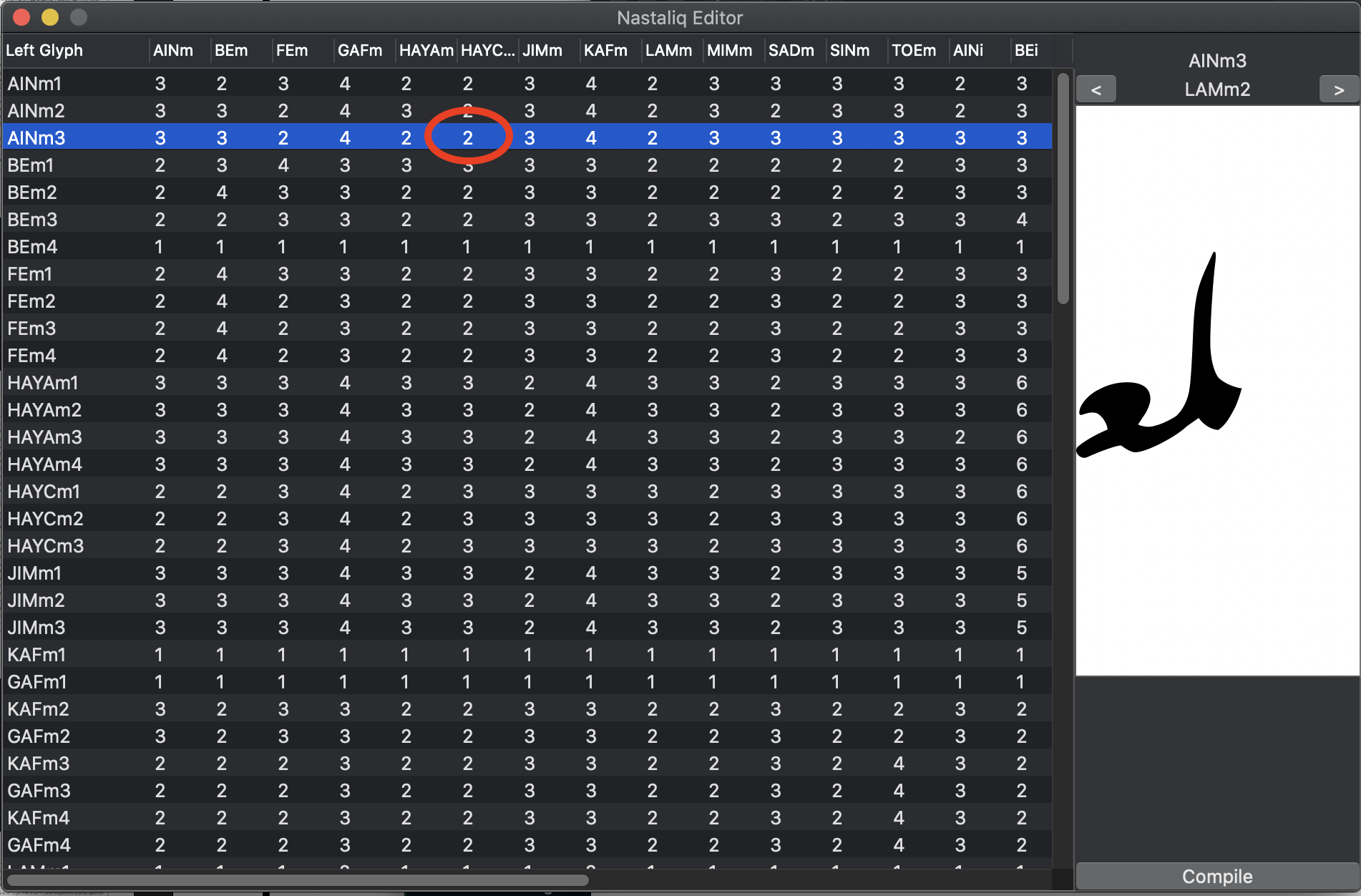
Each number represents a choice of connection between the glyph on the left column and the glyph at the top. For example, the highlighted cell shows that when we have a medial lam / medial ain sequence with an "AINm3" glyph on the left, the correct form of medial lam is variant 2 ("LAMm2"). To control the connections, click on each cell in the grid and use the arrows on the right to find the correct connecting form.
Here is a basic outline of the shaping process, in order, explaining what is covered by each FEZ file. See the comments in each file for an explanation of their operation.
shared.fez- a series of class definitions used by multiple FEZ files.languages.fez- contains language-specific substitutions.decomposition.fez- replaces incoming glyphs with decomposed forms (splitting off dots) and containsinit/medi/finafeatures.connections.fez- handles the glyph selection described above.bariye-drop.fez- replaces marks under a bari ye by.ybforms.bariye-drop2.fez- repositions.ybmarks to avoid collisions.anchor-attachment.fez- contains mark and mkmk logic as well as the dot collision avoidance code.latin-kerning.fez- loads the Latin kerning rules from the source file.kerning.fez- automated Nastaliq kerning.post-mkmk-repositioning.fez- general special-case repositioning rules.bariye-overhang.fez- adds extra space to short bari-ye sequences.
With a complex script such as Nastaliq, and given the tightness of the word images we are striving for, there are a huge number of potential interactions between glyph sequences. A change to the shaping rules to deal with one situation may have unintended consequences in other cases.
To deal with this problem, we created two additional tools: the collidoscope glyph collision detector and a system of test-driven development for OTL shaping which is now built into Google's fontbakery quality control tool.
The Makefile target test-shaping runs these tests based on files in the qa/shaping_tests directory, and reports any sequences of shaped glyphs which differ from the expectations we have set, and any sequences which cause an unexpected collision. Running make test-shaping after each substantial change to the shaping rules allows us to ensure that we have not introduced any unexpected breakage.