![]()
![]()
![]()


Improved pipelines for data science projects.
It has cool features, like selecting columns using Unix patterns:

or getting beautiful output column names instead of numeric indexed outputs:

or fitting a different transformer per group:
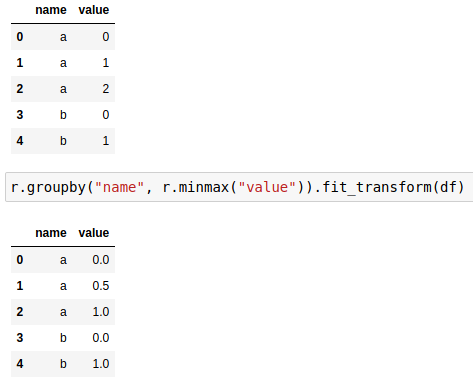
Read the tutorials and other examples to learn more.
pip install recipipe
All the dependencies will be installed automatically.
Clone the repository and run:
pip install .
Install the package in a dev environment with:
pip install -e .
All the dependencies will be installed automatically.
- Explore a notebook with a list of things you can do with Recipipe.
- Learn how to transform Titanic data.
- Learn how to use Recipipe analyzing data from weird creatures from another planet: Recipipe getting started tutorial.
Run all the test using:
pytest
Run an specific test file with:
pytest tests/<filename>
Run tests with coverage using:
coverage run --source=recipipe -m pytest
It comes from a beautiful R library called recipes and the concept of pipelines.
recipes + pipelines = recipipe
That explains the logo of a muffing (recipes) holding some pipes (pipelines).
![]()
This project is licensed under the MIT License, see the LICENSE file for details.
guiferviz, contributions are more than welcome.