The world of technology is changing at a faster rate than we can possibly fathom. Long gone are the days when we were the sole trailblazers in a human-tech relationship when the incentive resided in our hands.
The world of technology is changing at a faster rate than we can possibly fathom. Long gone are the days when we were the sole trailblazers in a human-tech relationship when the incentive resided in our hands.
 We will train a simple neural network to solve the OpenAI CartPole game using a genetic algorithm, PyTorch, and PyGAD.
We will train a simple neural network to solve the OpenAI CartPole game using a genetic algorithm, PyTorch, and PyGAD.
 Quick introduction of LightOn, aka how photonic processors will save machine learning
Quick introduction of LightOn, aka how photonic processors will save machine learning
 Image Courtesy:- Pexels.com
Image Courtesy:- Pexels.com
 Recently, when I was watching the Terminator: Dark Fate (By the way, I was disappointed with the whole reboot kind of thing, for me, Judgement Day was the ultimate Terminator movie).
Recently, when I was watching the Terminator: Dark Fate (By the way, I was disappointed with the whole reboot kind of thing, for me, Judgement Day was the ultimate Terminator movie).
 You hear it all the time. AI Is exciting, AI will change our lives, but also Terminators are coming.
You hear it all the time. AI Is exciting, AI will change our lives, but also Terminators are coming.
 The brain of a human child is spectacularly amazing. Even in any previously unknown situation, the brain makes a decision based on its primal knowledge. Depending on the outcome, it learns and remembers the most optimal choices to be taken in that particular scenario. On a high level, this process of learning can be understood as a ’trial and error’ process, where the brain tries to maximise the occurrence of positive outcomes.
The brain of a human child is spectacularly amazing. Even in any previously unknown situation, the brain makes a decision based on its primal knowledge. Depending on the outcome, it learns and remembers the most optimal choices to be taken in that particular scenario. On a high level, this process of learning can be understood as a ’trial and error’ process, where the brain tries to maximise the occurrence of positive outcomes.

 Reinforcement learning is the fastest growing branches of machine learning. Embark your RL journey by getting a soft introduction to reinforcement learning now.
Reinforcement learning is the fastest growing branches of machine learning. Embark your RL journey by getting a soft introduction to reinforcement learning now.
 The plethora of knowledge involved in Machine Learning is the most fabulous thing about the subject. The theoretical and coding balance requires a steady and disciplined approach. In this five series tutorial, we saw CNNs, where we saw various approaches to different scenarios, and then worked on word embeddings, which was our gateway to Natural Language Processing, and finally ended with Support Vector Machines(SVMs) which were as powerful as Artificial Neural Networks, during the time of their inception.
The plethora of knowledge involved in Machine Learning is the most fabulous thing about the subject. The theoretical and coding balance requires a steady and disciplined approach. In this five series tutorial, we saw CNNs, where we saw various approaches to different scenarios, and then worked on word embeddings, which was our gateway to Natural Language Processing, and finally ended with Support Vector Machines(SVMs) which were as powerful as Artificial Neural Networks, during the time of their inception.
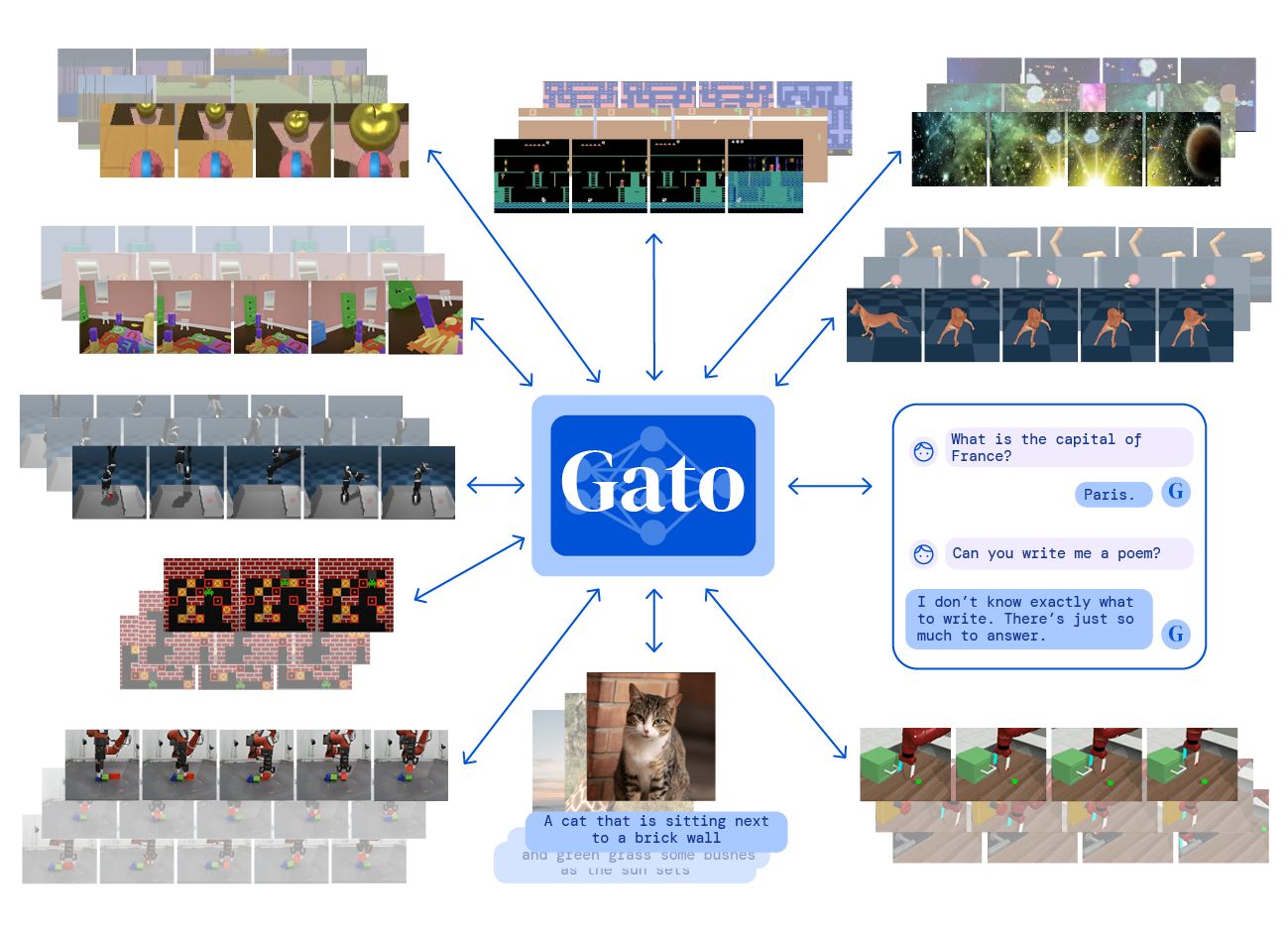
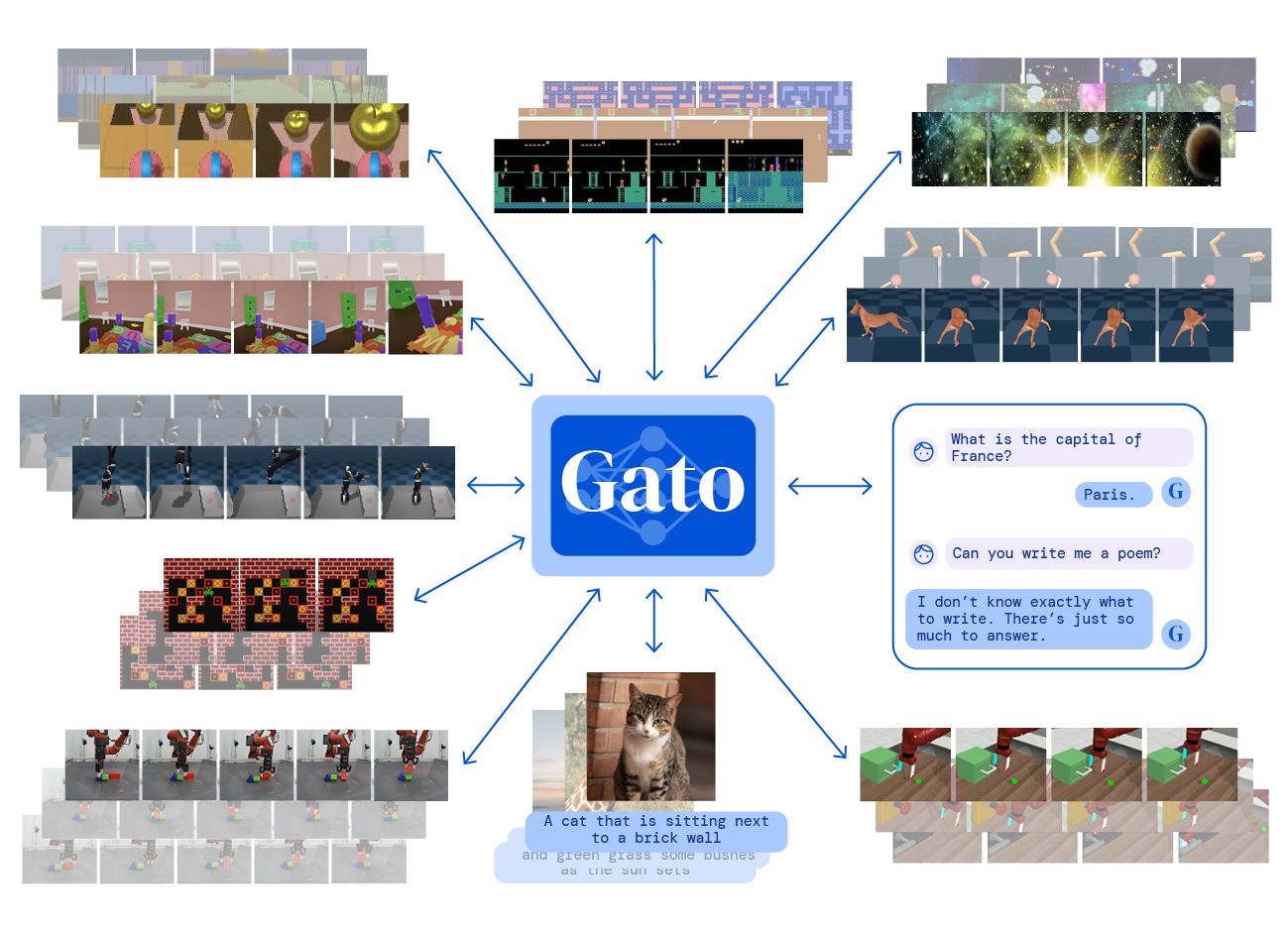 Gato from DeepMind was just published! It is a single transformer that can play Atari games, caption images, chat with people, control a real robotic arm, and more! Indeed, it is trained once and uses the same weights to achieve all those tasks. And as per Deepmind, this is not only a transformer but also an agent. This is what happens when you mix Transformers with progress on multi-task reinforcement learning agents.
Gato from DeepMind was just published! It is a single transformer that can play Atari games, caption images, chat with people, control a real robotic arm, and more! Indeed, it is trained once and uses the same weights to achieve all those tasks. And as per Deepmind, this is not only a transformer but also an agent. This is what happens when you mix Transformers with progress on multi-task reinforcement learning agents.
 SpaceBok, a quadruped robot, uses nature’s tactics for space exploration. The robot isn’t graded for space yet but is ready for some exciting experiments.
SpaceBok, a quadruped robot, uses nature’s tactics for space exploration. The robot isn’t graded for space yet but is ready for some exciting experiments.
 Chatbots are a powerful way to teach and learn, and this course shows you how to build them from scratch.
Chatbots are a powerful way to teach and learn, and this course shows you how to build them from scratch.
 The financial market has evolved from what it used to be. There are a lot of redundant pictures stuck in the heads of everyone who are not a part of it and do not know how far it has come. The financial technology sector has accelerated its development during the last two decades and has created opportunities for people to trade from all across the world utilizing either their home computers, tablets, or even smartphones.
The financial market has evolved from what it used to be. There are a lot of redundant pictures stuck in the heads of everyone who are not a part of it and do not know how far it has come. The financial technology sector has accelerated its development during the last two decades and has created opportunities for people to trade from all across the world utilizing either their home computers, tablets, or even smartphones.
 The International Conference on Learning Representations (ICLR) took place last week, and I had a pleasure to participate in it. ICLR is an event dedicated to research on all aspects of representation learning, commonly known as deep learning.
The International Conference on Learning Representations (ICLR) took place last week, and I had a pleasure to participate in it. ICLR is an event dedicated to research on all aspects of representation learning, commonly known as deep learning.
 What do a smartphone, a kick scooter and a pet have in common? When combined and powered by artificial intelligence, they become new members of the household – social companion robots. They can do a boatload of things from guarding the house and doing chores to babysitting and teaching kids to keeping company to the older adults or those with health issues.
What do a smartphone, a kick scooter and a pet have in common? When combined and powered by artificial intelligence, they become new members of the household – social companion robots. They can do a boatload of things from guarding the house and doing chores to babysitting and teaching kids to keeping company to the older adults or those with health issues.
 In this era, technology has become a basic necessity due to its compactness and handiness. This alleviation in the use of technology has also welcomed new problems. One of the most crucial issues is security. Devices contain personal and critical data which is usually misused if it is not secured. This is why the functioning of cybersecurity uses Machine language and Artificial Intelligence. It implements protection tools to create a wall between user and hacker.
In this era, technology has become a basic necessity due to its compactness and handiness. This alleviation in the use of technology has also welcomed new problems. One of the most crucial issues is security. Devices contain personal and critical data which is usually misused if it is not secured. This is why the functioning of cybersecurity uses Machine language and Artificial Intelligence. It implements protection tools to create a wall between user and hacker.
 Learning how to find the optimal q-value can produce significant improvements in a ML-algorithm's ability to learn both in terms of speed and quality.
Learning how to find the optimal q-value can produce significant improvements in a ML-algorithm's ability to learn both in terms of speed and quality.
 Data scientists have created AI that can beat the best human players in most games, thanks to a technique called reinforcement learning.
Data scientists have created AI that can beat the best human players in most games, thanks to a technique called reinforcement learning.
 In Reinforcement Learning (RL), agents are trained on a reward and punishment mechanism. The agent is rewarded for correct moves and punished for the wrong ones. In doing so, the agent tries to minimize wrong moves and maximize the right ones.
In Reinforcement Learning (RL), agents are trained on a reward and punishment mechanism. The agent is rewarded for correct moves and punished for the wrong ones. In doing so, the agent tries to minimize wrong moves and maximize the right ones.
 Codes and demo are available. This article explores what are states, actions and rewards in reinforcement learning, and how agent can learn through simulation to determine the best actions to take in any given state.
Codes and demo are available. This article explores what are states, actions and rewards in reinforcement learning, and how agent can learn through simulation to determine the best actions to take in any given state.
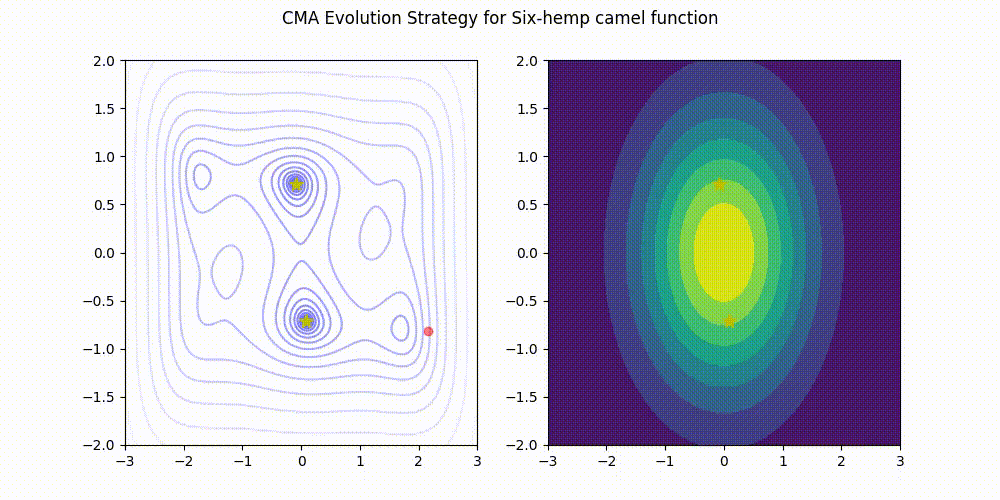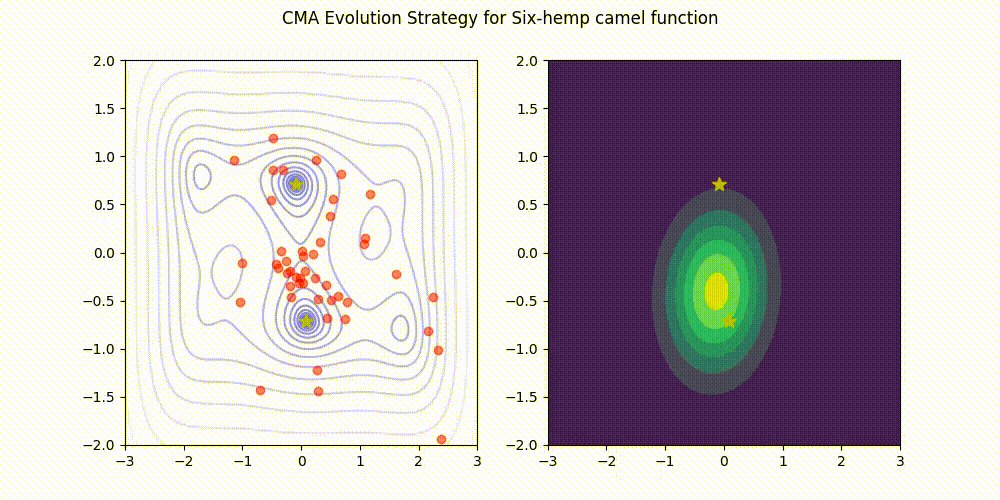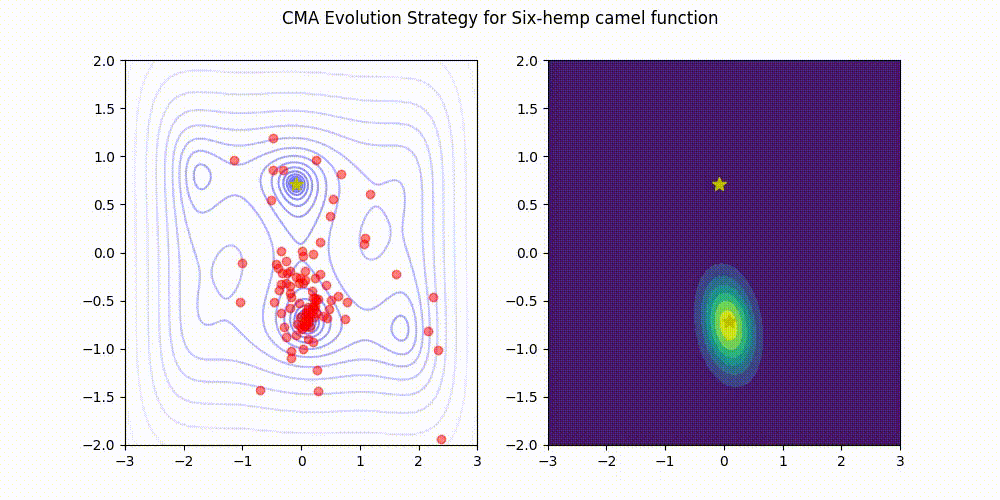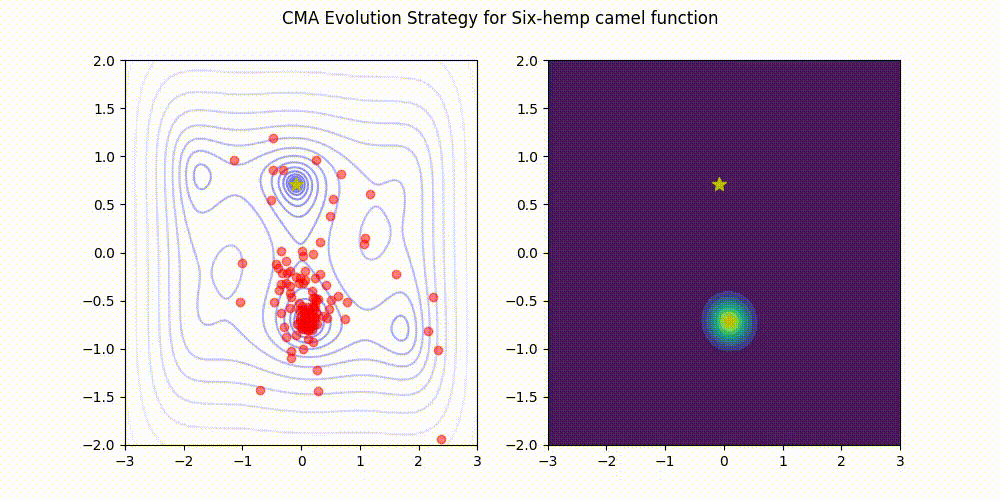 Using Optuna, the hyperparameter optimization library to search for tiny RL policies! The code used is open-source on Github.
Using Optuna, the hyperparameter optimization library to search for tiny RL policies! The code used is open-source on Github.
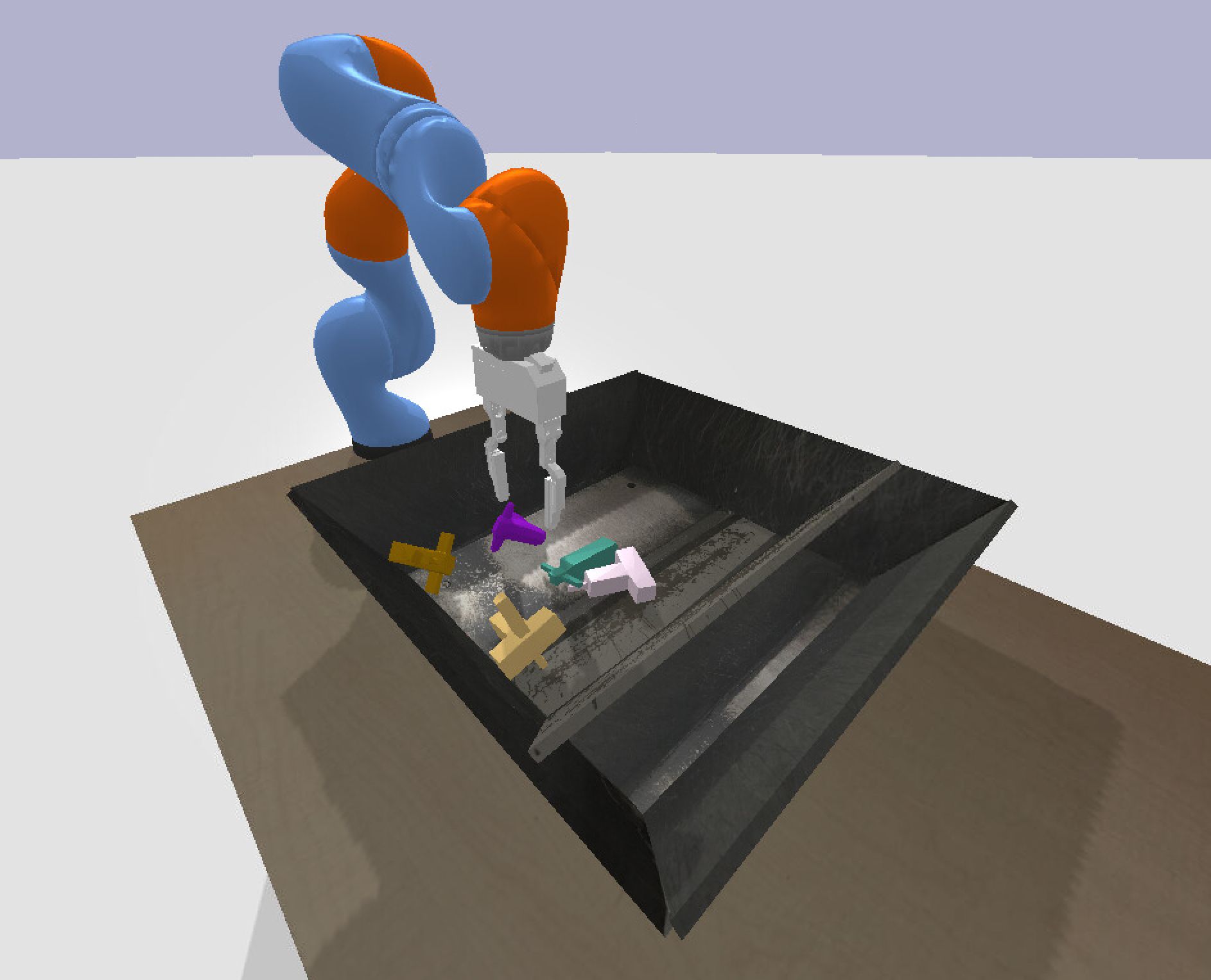 Tips and tricks to build an autonomous grasping Kuka robot
Tips and tricks to build an autonomous grasping Kuka robot
 Machine learning is quite an exciting field to study and rightly so. It is all around us in this modern world. From Facebook’s feed to Google Maps for navigation, machine learning finds its application in almost every aspect of our lives.
Machine learning is quite an exciting field to study and rightly so. It is all around us in this modern world. From Facebook’s feed to Google Maps for navigation, machine learning finds its application in almost every aspect of our lives.
 (Source: Netflix)
(Source: Netflix)
 As a logical person at the casino. you want to put your money on the machine with the maximum expected return. This is the origin of the multi-armed bandit problem. We will cover the two most basic concept here: Beta distribution and Thompson sampling.
As a logical person at the casino. you want to put your money on the machine with the maximum expected return. This is the origin of the multi-armed bandit problem. We will cover the two most basic concept here: Beta distribution and Thompson sampling.
Beta Distribution
 Let’s walk this beautiful path from the fundamentals to cutting edge reinforcement learning (RL), step-by-step, with coding examples and tutorials in Python.
Let’s walk this beautiful path from the fundamentals to cutting edge reinforcement learning (RL), step-by-step, with coding examples and tutorials in Python.
 Last week I had a pleasure to participate in the International Conference on Learning Representations (ICLR), an event dedicated to the research on all aspects of representation learning, commonly known as deep learning. The conference went virtual due to the coronavirus pandemic, and thanks to the huge effort of its organizers, the event attracted an even bigger audience than last year. Their goal was for the conference to be inclusive and interactive, and from my point of view, as an attendee, it was definitely the case!
Last week I had a pleasure to participate in the International Conference on Learning Representations (ICLR), an event dedicated to the research on all aspects of representation learning, commonly known as deep learning. The conference went virtual due to the coronavirus pandemic, and thanks to the huge effort of its organizers, the event attracted an even bigger audience than last year. Their goal was for the conference to be inclusive and interactive, and from my point of view, as an attendee, it was definitely the case!