diff --git a/README.md b/README.md
index 64cf2320..8d5764fc 100644
--- a/README.md
+++ b/README.md
@@ -129,7 +129,7 @@ I welcome all sorts of feedback, best shared via the [Discussions](https://githu
If you notice any problems or issues, please do not hesitate to file an [Issue](https://github.com/rasbt/LLMs-from-scratch/issues).
-However, since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book.
+However, since this repository contains the code corresponding to a print book, I currently cannot accept contributions that would extend the contents of the main chapter code, as it would introduce deviations from the physical book. Keeping it consistent helps ensure a smooth experience for everyone.
diff --git a/ch01/README.md b/ch01/README.md
index 50002e6d..f938fccf 100644
--- a/ch01/README.md
+++ b/ch01/README.md
@@ -1,3 +1,12 @@
# Chapter 1: Understanding Large Language Models
There is no code in this chapter.
+
+
+As optional bonus material, below is a video tutorial where I explain the LLM development lifecycle covered in this book:
+
+
+
+
+[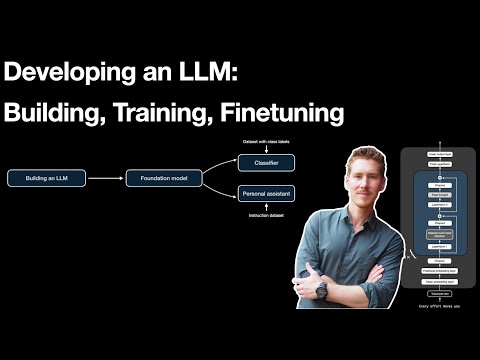](https://www.youtube.com/watch?v=kPGTx4wcm_w)
+
diff --git a/ch03/03_understanding-buffers/README.md b/ch03/03_understanding-buffers/README.md
index 092e778d..9a276c3f 100644
--- a/ch03/03_understanding-buffers/README.md
+++ b/ch03/03_understanding-buffers/README.md
@@ -4,7 +4,7 @@
-Below is a video tutorial of me explaining walking through the code:
+Below is a hands-on video tutorial I recorded to explain the code:
diff --git a/ch04/01_main-chapter-code/ch04.py b/ch04/01_main-chapter-code/ch04.py
index 75f81663..2287f5e0 100644
--- a/ch04/01_main-chapter-code/ch04.py
+++ b/ch04/01_main-chapter-code/ch04.py
@@ -62,6 +62,20 @@ def forward(self, x):
return x
+class LayerNorm(nn.Module):
+ def __init__(self, emb_dim):
+ super().__init__()
+ self.eps = 1e-5
+ self.scale = nn.Parameter(torch.ones(emb_dim))
+ self.shift = nn.Parameter(torch.zeros(emb_dim))
+
+ def forward(self, x):
+ mean = x.mean(dim=-1, keepdim=True)
+ var = x.var(dim=-1, keepdim=True, unbiased=False)
+ norm_x = (x - mean) / torch.sqrt(var + self.eps)
+ return self.scale * norm_x + self.shift
+
+
tokenizer = tiktoken.get_encoding("gpt2")
batch = []
txt1 = "Every effort moves you"
@@ -102,3 +116,12 @@ def forward(self, x):
torch.set_printoptions(sci_mode=False)
print("Mean\n:", mean)
print("Variance:\n", var)
+
+
+ln = LayerNorm(emb_dim=5)
+out_ln = ln(batch_example)
+
+mean = out_ln.mean(dim=-1, keepdim=True)
+var = out_ln.var(dim=-1, unbiased=False, keepdim=True)
+
+print("Here")
diff --git a/setup/README.md b/setup/README.md
index 91d3dd67..a91a7486 100644
--- a/setup/README.md
+++ b/setup/README.md
@@ -15,6 +15,11 @@ pip install -r requirements.txt
+# Local Setup
+
+This section provides recommendations for running the code in this book locally. Note that the code in the main chapters of this book is designed to run on conventional laptops within a reasonable timeframe and does not require specialized hardware. I tested all main chapters on an M3 MacBook Air laptop. Additionally, if your laptop or desktop computer has an NVIDIA GPU, the code will automatically take advantage of it.
+
+
## Setting up Python
If you don't have Python set up on your machine yet, I have written about my personal Python setup preferences in the following directories:
@@ -46,6 +51,14 @@ If you are using Visual Studio Code (VSCode) as your primary code editor, you ca
+# Cloud Resources
+
+This section describes cloud alternatives for running the code presented in this book.
+
+While the code can run on conventional laptops and desktop computers without a dedicated GPU, cloud platforms with NVIDIA GPUs can substantially improve the runtime of the code, especially in chapters 5 to 7.
+
+
+
## Using Lightning Studio
For a smooth development experience in the cloud, I recommend the [Lightning AI Studio](https://lightning.ai/) platform, which allows users to set up a persistent environment and use both VSCode and Jupyter Lab on cloud CPUs and GPUs.
@@ -85,6 +98,6 @@ You can optionally run the code on a GPU by changing the *Runtime* as illustrate
-## Questions?
+# Questions?
If you have any questions, please don't hesitate to reach out via the [Discussions](https://github.com/rasbt/LLMs-from-scratch/discussions) forum in this GitHub repository.
diff --git a/todo.md b/todo.md
index bcfae048..69a2ebd5 100644
--- a/todo.md
+++ b/todo.md
@@ -295,6 +295,15 @@ to discuss
To ensure that the positional embeddings are on the same device as the input indices and token embeddings, you specify device=in_idx.device when creating the positional indices tensor. This guarantees that the positional indices tensor and, consequently, the output of pos_emb will be on the correct device.
+ 3.
+
+ https://en.wikipedia.org/wiki/Rectifier_(neural_networks)
+
+ 4.
+
+ https://en.wikipedia.org/wiki/Bessel%27s_correction
+
+
### 05/08/2024 -
1. mha-implementations.ipynb from the 02_bonus_efficient-multihead-attention