\n", + "
Code repository: https://github.com/rasbt/LLMs-from-scratch\n", + "\n", + "
 \n",
+ "
\n",
+ "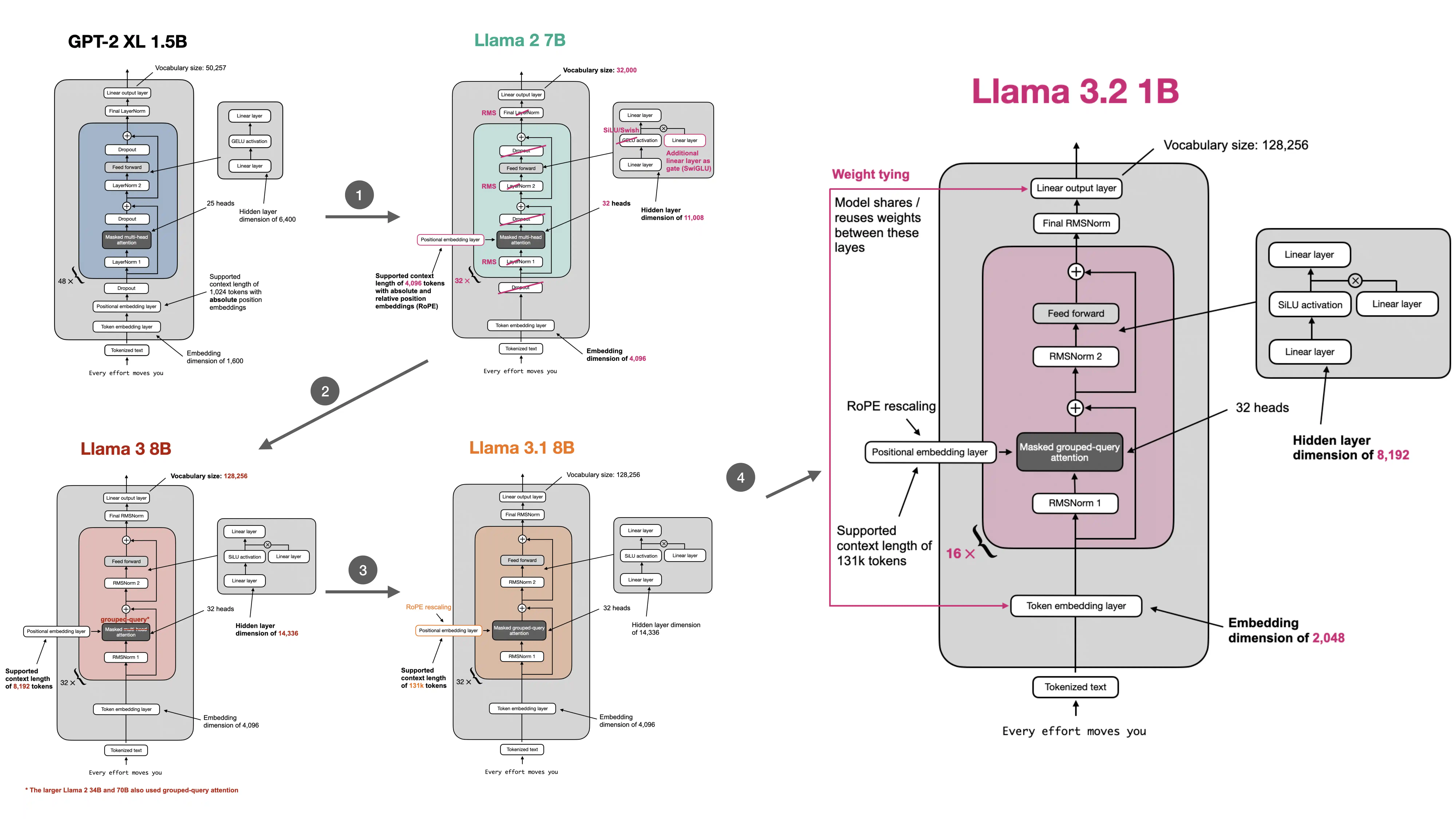 \ No newline at end of file
diff --git a/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb b/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
index 4454af0e..e8c5bf68 100644
--- a/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
+++ b/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
@@ -76,7 +76,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
- "outputId": "7ce8fe41-1c24-4f0b-a8d9-352b4af1b46b"
+ "outputId": "8118963b-3c72-43af-874b-439ffebdc94c"
},
"outputs": [
{
@@ -108,6 +108,7 @@
"id": "UJJneXpTEg4W"
},
"source": [
+ " \n",
"# 1. Convert the GPT model implementation step by step"
]
},
@@ -129,6 +130,7 @@
"id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f"
},
"source": [
+ " \n",
"## 1.1 Replace LayerNorm with RMSNorm layer"
]
},
@@ -228,6 +230,7 @@
"id": "5eb81f83-c38c-46a4-b763-aa630a32e357"
},
"source": [
+ " \n",
"## 1.2 Replace GELU with SiLU activation"
]
},
@@ -300,6 +303,7 @@
"id": "4f9b5167-1da9-46c8-9964-8036b3b1deb9"
},
"source": [
+ " \n",
"## 1.3 Update the FeedForward module"
]
},
@@ -388,6 +392,7 @@
"id": "f6b7bf4f-99d0-42c1-807c-5074d2cc1949"
},
"source": [
+ " \n",
"## 1.4 Implement RoPE"
]
},
@@ -503,6 +508,7 @@
"id": "f78127b0-dda2-4c5a-98dd-bae8f5fe8297"
},
"source": [
+ " \n",
"## 1.5 Add RoPE to MultiHeadAttention module"
]
},
@@ -578,8 +584,8 @@
" values = values.transpose(1, 2)\n",
"\n",
" ################################### NEW ###################################\n",
- " keys = compute_rope(keys, self.sin, self.cos)\n",
- " queries = compute_rope(queries, self.sin, self.cos)\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
" ###########################################################################\n",
"\n",
" # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
@@ -652,6 +658,7 @@
"id": "e5a1a272-a038-4b8f-aaaa-f4b241e7f23f"
},
"source": [
+ " \n",
"## 1.6 Update the TransformerBlock module"
]
},
@@ -727,6 +734,7 @@
"id": "ada953bc-e2c0-4432-a32d-3f7efa3f6e0f"
},
"source": [
+ " \n",
"## 1.7 Update the model class"
]
},
@@ -791,6 +799,7 @@
"id": "4bc94940-aaeb-45b9-9399-3a69b8043e60"
},
"source": [
+ " \n",
"## 2. Initialize model"
]
},
@@ -916,7 +925,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "6079f747-8f20-4c6b-8d38-7156f1101729",
- "outputId": "1ca50091-a20c-4a44-b806-9985a5e64135"
+ "outputId": "0a0eb34b-1a21-4c11-804f-b40007bda5a3"
},
"outputs": [
{
@@ -952,7 +961,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
- "outputId": "b157b5ac-d37c-4b71-f609-45a91f7ed93a"
+ "outputId": "11ced939-556d-4511-d5c0-10a94ed3df32"
},
"outputs": [
{
@@ -1029,6 +1038,7 @@
"id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34"
},
"source": [
+ " \n",
"## 3. Load tokenizer"
]
},
@@ -1085,7 +1095,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "3357a230-b678-4691-a238-257ee4e80185",
- "outputId": "7d4adc4b-53cf-4099-a45f-2fb4fd25edc4"
+ "outputId": "768ed6af-ce14-40bc-ca18-117b4b448269"
},
"outputs": [
{
@@ -1126,10 +1136,24 @@
"id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
"metadata": {
"colab": {
- "base_uri": "https://localhost:8080/"
+ "base_uri": "https://localhost:8080/",
+ "height": 153,
+ "referenced_widgets": [
+ "e6c75a6aa7b942fe84160e286e3acb3d",
+ "08f0bf9459bd425498a5cb236f9d4a72",
+ "10251d6f724e43788c41d4b7879cbfd3",
+ "53a973c0853b44418698136bd04df039",
+ "bdb071e7145a4007ae01599333e72612",
+ "6b1821a7f4574e3aba09c1e410cc81e4",
+ "8c2873eaec3445888ad3d54ad7387950",
+ "0c8f7044966e4207b12352503c67dcbb",
+ "8b5951213c9e4798a258146d61d02d11",
+ "2c05df3f91e64df7b33905b1065a76f7",
+ "742ae5487f2648fcae7ca8e22c7f8db9"
+ ]
},
"id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
- "outputId": "aa18fccc-6533-4446-f57b-546068ad518c"
+ "outputId": "c230fec9-5c71-4a41-90ab-8a34d114ea01"
},
"outputs": [
{
@@ -1143,6 +1167,20 @@
"Please note that authentication is recommended but still optional to access public models or datasets.\n",
" warnings.warn(\n"
]
+ },
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "e6c75a6aa7b942fe84160e286e3acb3d",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "tokenizer.model: 0%| | 0.00/500k [00:00\n",
+ "\n",
+ "
\ No newline at end of file
diff --git a/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb b/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
index 4454af0e..e8c5bf68 100644
--- a/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
+++ b/ch05/07_gpt_to_llama/converting-gpt-to-llama2.ipynb
@@ -76,7 +76,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
- "outputId": "7ce8fe41-1c24-4f0b-a8d9-352b4af1b46b"
+ "outputId": "8118963b-3c72-43af-874b-439ffebdc94c"
},
"outputs": [
{
@@ -108,6 +108,7 @@
"id": "UJJneXpTEg4W"
},
"source": [
+ " \n",
"# 1. Convert the GPT model implementation step by step"
]
},
@@ -129,6 +130,7 @@
"id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f"
},
"source": [
+ " \n",
"## 1.1 Replace LayerNorm with RMSNorm layer"
]
},
@@ -228,6 +230,7 @@
"id": "5eb81f83-c38c-46a4-b763-aa630a32e357"
},
"source": [
+ " \n",
"## 1.2 Replace GELU with SiLU activation"
]
},
@@ -300,6 +303,7 @@
"id": "4f9b5167-1da9-46c8-9964-8036b3b1deb9"
},
"source": [
+ " \n",
"## 1.3 Update the FeedForward module"
]
},
@@ -388,6 +392,7 @@
"id": "f6b7bf4f-99d0-42c1-807c-5074d2cc1949"
},
"source": [
+ " \n",
"## 1.4 Implement RoPE"
]
},
@@ -503,6 +508,7 @@
"id": "f78127b0-dda2-4c5a-98dd-bae8f5fe8297"
},
"source": [
+ " \n",
"## 1.5 Add RoPE to MultiHeadAttention module"
]
},
@@ -578,8 +584,8 @@
" values = values.transpose(1, 2)\n",
"\n",
" ################################### NEW ###################################\n",
- " keys = compute_rope(keys, self.sin, self.cos)\n",
- " queries = compute_rope(queries, self.sin, self.cos)\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
" ###########################################################################\n",
"\n",
" # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
@@ -652,6 +658,7 @@
"id": "e5a1a272-a038-4b8f-aaaa-f4b241e7f23f"
},
"source": [
+ " \n",
"## 1.6 Update the TransformerBlock module"
]
},
@@ -727,6 +734,7 @@
"id": "ada953bc-e2c0-4432-a32d-3f7efa3f6e0f"
},
"source": [
+ " \n",
"## 1.7 Update the model class"
]
},
@@ -791,6 +799,7 @@
"id": "4bc94940-aaeb-45b9-9399-3a69b8043e60"
},
"source": [
+ " \n",
"## 2. Initialize model"
]
},
@@ -916,7 +925,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "6079f747-8f20-4c6b-8d38-7156f1101729",
- "outputId": "1ca50091-a20c-4a44-b806-9985a5e64135"
+ "outputId": "0a0eb34b-1a21-4c11-804f-b40007bda5a3"
},
"outputs": [
{
@@ -952,7 +961,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
- "outputId": "b157b5ac-d37c-4b71-f609-45a91f7ed93a"
+ "outputId": "11ced939-556d-4511-d5c0-10a94ed3df32"
},
"outputs": [
{
@@ -1029,6 +1038,7 @@
"id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34"
},
"source": [
+ " \n",
"## 3. Load tokenizer"
]
},
@@ -1085,7 +1095,7 @@
"base_uri": "https://localhost:8080/"
},
"id": "3357a230-b678-4691-a238-257ee4e80185",
- "outputId": "7d4adc4b-53cf-4099-a45f-2fb4fd25edc4"
+ "outputId": "768ed6af-ce14-40bc-ca18-117b4b448269"
},
"outputs": [
{
@@ -1126,10 +1136,24 @@
"id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
"metadata": {
"colab": {
- "base_uri": "https://localhost:8080/"
+ "base_uri": "https://localhost:8080/",
+ "height": 153,
+ "referenced_widgets": [
+ "e6c75a6aa7b942fe84160e286e3acb3d",
+ "08f0bf9459bd425498a5cb236f9d4a72",
+ "10251d6f724e43788c41d4b7879cbfd3",
+ "53a973c0853b44418698136bd04df039",
+ "bdb071e7145a4007ae01599333e72612",
+ "6b1821a7f4574e3aba09c1e410cc81e4",
+ "8c2873eaec3445888ad3d54ad7387950",
+ "0c8f7044966e4207b12352503c67dcbb",
+ "8b5951213c9e4798a258146d61d02d11",
+ "2c05df3f91e64df7b33905b1065a76f7",
+ "742ae5487f2648fcae7ca8e22c7f8db9"
+ ]
},
"id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
- "outputId": "aa18fccc-6533-4446-f57b-546068ad518c"
+ "outputId": "c230fec9-5c71-4a41-90ab-8a34d114ea01"
},
"outputs": [
{
@@ -1143,6 +1167,20 @@
"Please note that authentication is recommended but still optional to access public models or datasets.\n",
" warnings.warn(\n"
]
+ },
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "e6c75a6aa7b942fe84160e286e3acb3d",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "tokenizer.model: 0%| | 0.00/500k [00:00\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "ws0wsUzwLH2k",
+ "metadata": {
+ "id": "ws0wsUzwLH2k"
+ },
+ "outputs": [],
+ "source": [
+ "# pip install -r requirements-extra.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "JBpQwU89ETA1",
+ "metadata": {
+ "id": "JBpQwU89ETA1"
+ },
+ "source": [
+ "- Packages that are being used in this notebook:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
+ "outputId": "e3d3d4b6-ee63-4e28-d794-e8b0bdd931fd"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "blobfile version: 3.0.0\n",
+ "huggingface_hub version: 0.24.7\n",
+ "tiktoken version: 0.8.0\n",
+ "torch version: 2.4.1+cu121\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"blobfile\", # to download pretrained weights\n",
+ " \"huggingface_hub\", # to download pretrained weights\n",
+ " \"tiktoken\", # to implement the tokenizer\n",
+ " \"torch\", # to implement the model\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "UJJneXpTEg4W",
+ "metadata": {
+ "id": "UJJneXpTEg4W"
+ },
+ "source": [
+ " \n",
+ "# 1. Convert the Llama model implementation step by step"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "v1zpfX2GHBKa",
+ "metadata": {
+ "id": "v1zpfX2GHBKa"
+ },
+ "source": [
+ "- If you are new to implementing LLM architectures, I recommend starting with [chapter 4](../../ch04/01_main-chapter-code/ch04.ipynb), which walks you through the implementation of the original GPT architecture step by step\n",
+ "- The [Converting a From-Scratch GPT Architecture to Llama 2](./converting-gpt-to-llama2.ipynb) then implements the Llama-specific components, such as RMSNorm layers, SiLU and SwiGLU activations, RoPE (rotary position embeddings), and the SentencePiece tokenizer\n",
+ "- This notebook takes the Llama 2 architecture and transforms it into Llama 3 architecture by\n",
+ " 1. modifying the rotary embeddings\n",
+ " 2. implementing grouped-query attention\n",
+ " 3. and using a customized version of the GPT-4 tokenizer\n",
+ "- Later, we then load the original Llama 3 weights shared by Meta AI into the architecture"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c14b9121-abe1-4a46-99b8-acdef71e5b41",
+ "metadata": {
+ "id": "c14b9121-abe1-4a46-99b8-acdef71e5b41"
+ },
+ "source": [
+ " \n",
+ "## 1.1 Reusing Llama 2 components"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dgDhJGJ6xR4e",
+ "metadata": {
+ "id": "dgDhJGJ6xR4e"
+ },
+ "source": [
+ "- Llama 2 is actually quite similar to Llama 3, as mentioned above and illustrated in the figure at the top of this notebook\n",
+ "- This means that we can import several building blocks from the [Llama 2 notebook](./converting-gpt-to-llama2.ipynb) using the following code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "a5bc3948-231b-4f1f-8d41-24ad0b7643d0",
+ "metadata": {
+ "id": "a5bc3948-231b-4f1f-8d41-24ad0b7643d0"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "import io\n",
+ "import nbformat\n",
+ "import types\n",
+ "\n",
+ "def import_from_notebook():\n",
+ " def import_definitions_from_notebook(fullname, names):\n",
+ " current_dir = os.getcwd()\n",
+ " path = os.path.join(current_dir, fullname + \".ipynb\")\n",
+ " path = os.path.normpath(path)\n",
+ "\n",
+ " # Load the notebook\n",
+ " if not os.path.exists(path):\n",
+ " raise FileNotFoundError(f\"Notebook file not found at: {path}\")\n",
+ "\n",
+ " with io.open(path, \"r\", encoding=\"utf-8\") as f:\n",
+ " nb = nbformat.read(f, as_version=4)\n",
+ "\n",
+ " # Create a module to store the imported functions and classes\n",
+ " mod = types.ModuleType(fullname)\n",
+ " sys.modules[fullname] = mod\n",
+ "\n",
+ " # Go through the notebook cells and only execute function or class definitions\n",
+ " for cell in nb.cells:\n",
+ " if cell.cell_type == \"code\":\n",
+ " cell_code = cell.source\n",
+ " for name in names:\n",
+ " # Check for function or class definitions\n",
+ " if f\"def {name}\" in cell_code or f\"class {name}\" in cell_code:\n",
+ " exec(cell_code, mod.__dict__)\n",
+ " return mod\n",
+ "\n",
+ " fullname = \"converting-gpt-to-llama2\"\n",
+ " names = [\"precompute_rope_params\", \"compute_rope\", \"SiLU\", \"FeedForward\", \"RMSNorm\", \"MultiHeadAttention\"]\n",
+ "\n",
+ " return import_definitions_from_notebook(fullname, names)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "d546032d-fce4-47cf-8d0e-682b78b21c61",
+ "metadata": {
+ "id": "d546032d-fce4-47cf-8d0e-682b78b21c61"
+ },
+ "outputs": [],
+ "source": [
+ "imported_module = import_from_notebook()\n",
+ "\n",
+ "# We need to redefine precompute_rope_params\n",
+ "# precompute_rope_params = getattr(imported_module, \"precompute_rope_params\", None)\n",
+ "compute_rope = getattr(imported_module, \"compute_rope\", None)\n",
+ "SiLU = getattr(imported_module, \"SiLU\", None)\n",
+ "FeedForward = getattr(imported_module, \"FeedForward\", None)\n",
+ "RMSNorm = getattr(imported_module, \"RMSNorm\", None)\n",
+ "\n",
+ "# MultiHeadAttention only for comparison purposes\n",
+ "MultiHeadAttention = getattr(imported_module, \"MultiHeadAttention\", None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f",
+ "metadata": {
+ "id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f"
+ },
+ "source": [
+ " \n",
+ "## 1.2 Modified RoPE"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "m9_oDcHCx8VI",
+ "metadata": {
+ "id": "m9_oDcHCx8VI"
+ },
+ "source": [
+ "- Llama 3 uses rotary position embeddings (RoPE) similar to Llama 2 (for a detailed explanation, please see the [RoPE paper](https://arxiv.org/abs/2104.09864))\n",
+ "- There are some subtle differences in the RoPE settings, though\n",
+ " - Llama 3 now supports up to 8,192 tokens, twice as many as Llama 2 (4,096)\n",
+ " - The base value for the so-called RoPE $\\theta$ (see equation below) was increased from 10,000 (Llama 2) to 50,000 (Llama 3) in the following equation (adapted from the [RoPE paper](https://arxiv.org/abs/2104.09864))\n",
+ "\n",
+ "$$\\Theta = \\left\\{\\theta_i = \\text{base}^{\\frac{-2(i-1)}{d}}, i \\in \\left[1, 2, ..., d/2\\right]\\right\\}$$\n",
+ "\n",
+ "- These $\\theta$ values are a set of predefined parameters that are used to determine the rotational angles in the rotary matrix, where $d$ is the dimensionality of the embedding space\n",
+ "- Increasing the base from 10,000 to 50,000 makes the frequencies (or rotation angles) decay more slowly across the dimensions, which means that higher dimensions will be associated with larger angles than before (essentially, it's a decompression of the frequencies)\n",
+ "- In addition, we introduce a `freq_config` section in the code below that adjusts the frequency; however, we won't be needing it in Llama 3 (only Llama 3.1 and Llama 3.2), so we will revisit this `freq_config` later (it's set to `None` and ignored by default)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "6Upl109OOAcu",
+ "metadata": {
+ "id": "6Upl109OOAcu"
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "def precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):\n",
+ " assert head_dim % 2 == 0, \"Embedding dimension must be even\"\n",
+ "\n",
+ " # Compute the inverse frequencies\n",
+ " inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))\n",
+ "\n",
+ " ################################ NEW ###############################################\n",
+ " # Frequency adjustments\n",
+ " if freq_config is not None:\n",
+ " low_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"low_freq_factor\"]\n",
+ " high_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"high_freq_factor\"]\n",
+ "\n",
+ " wavelen = 2 * torch.pi / inv_freq\n",
+ "\n",
+ " inv_freq_llama = torch.where(\n",
+ " wavelen > low_freq_wavelen, inv_freq / freq_config[\"factor\"], inv_freq\n",
+ " )\n",
+ "\n",
+ " smooth_factor = (freq_config[\"original_context_length\"] / wavelen - freq_config[\"low_freq_factor\"]) / (\n",
+ " freq_config[\"high_freq_factor\"] - freq_config[\"low_freq_factor\"]\n",
+ " )\n",
+ "\n",
+ " smoothed_inv_freq = (\n",
+ " (1 - smooth_factor) * (inv_freq / freq_config[\"factor\"]) + smooth_factor * inv_freq\n",
+ " )\n",
+ "\n",
+ " is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\n",
+ " inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\n",
+ " inv_freq = inv_freq_llama\n",
+ " ####################################################################################\n",
+ "\n",
+ "\n",
+ " # Generate position indices\n",
+ " positions = torch.arange(context_length)\n",
+ "\n",
+ " # Compute the angles\n",
+ " angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)\n",
+ "\n",
+ " # Expand angles to match the head_dim\n",
+ " angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\n",
+ "\n",
+ " # Precompute sine and cosine\n",
+ " cos = torch.cos(angles)\n",
+ " sin = torch.sin(angles)\n",
+ "\n",
+ " return cos, sin"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "jJBvO0YMJBXR",
+ "metadata": {
+ "id": "jJBvO0YMJBXR"
+ },
+ "source": [
+ "- To summarize, what's new so far for Llama 3 compared to Llama 2 are the context length and theta base parameter:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "56c37216-e022-4603-be16-f9d3eaeaf4a1",
+ "metadata": {
+ "id": "56c37216-e022-4603-be16-f9d3eaeaf4a1"
+ },
+ "outputs": [],
+ "source": [
+ "# Instantiate RoPE parameters\n",
+ "\n",
+ "llama_2_context_len = 4096\n",
+ "llama_3_context_len = 8192\n",
+ "\n",
+ "llama_2_theta_base = 10_000\n",
+ "llama_3_theta_base = 50_000"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "_V8v6i7MJItU",
+ "metadata": {
+ "id": "_V8v6i7MJItU"
+ },
+ "source": [
+ "- The usage remains the same as before in Llama 2:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "dae70c8a-eb18-40f9-a2e5-a6af2a57628b",
+ "metadata": {
+ "id": "dae70c8a-eb18-40f9-a2e5-a6af2a57628b"
+ },
+ "outputs": [],
+ "source": [
+ "# Settings\n",
+ "batch_size = 2\n",
+ "num_heads = 4\n",
+ "head_dim = 16\n",
+ "\n",
+ "# Instantiate RoPE parameters\n",
+ "cos, sin = precompute_rope_params(\n",
+ " head_dim=head_dim,\n",
+ " theta_base=llama_3_theta_base,\n",
+ " context_length=llama_3_context_len\n",
+ ")\n",
+ "\n",
+ "# Dummy query and key tensors\n",
+ "torch.manual_seed(123)\n",
+ "queries = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)\n",
+ "keys = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)\n",
+ "\n",
+ "# Apply rotary position embeddings\n",
+ "queries_rot = compute_rope(queries, cos, sin)\n",
+ "keys_rot = compute_rope(keys, cos, sin)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd19b75c-cf25-47b8-a010-6733fc0e9a8a",
+ "metadata": {
+ "id": "cd19b75c-cf25-47b8-a010-6733fc0e9a8a"
+ },
+ "source": [
+ " \n",
+ "## 1.3 Grouped-query attention"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "111c7d3f-fded-49e8-a617-9fe67b81dddc",
+ "metadata": {
+ "id": "111c7d3f-fded-49e8-a617-9fe67b81dddc"
+ },
+ "source": [
+ "- In this section, we replace multi-head attention (MHA) with an alternative mechanism called grouped-query attention (GQA)\n",
+ "- In short, one can think of GQA as a more compute- and parameter-efficient version of MHA\n",
+ "- In GQA, we reduce the number of key and value projections by sharing them among multiple attention heads\n",
+ "- Each attention head still has its unique query, but these queries attend to the same group of keys and values\n",
+ "- Below is an illustration of GQA with 2 key-value-groups (kv-groups):\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "ws0wsUzwLH2k",
+ "metadata": {
+ "id": "ws0wsUzwLH2k"
+ },
+ "outputs": [],
+ "source": [
+ "# pip install -r requirements-extra.txt"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "JBpQwU89ETA1",
+ "metadata": {
+ "id": "JBpQwU89ETA1"
+ },
+ "source": [
+ "- Packages that are being used in this notebook:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "34a9a440-84c2-42cc-808b-38677cb6af8a",
+ "outputId": "e3d3d4b6-ee63-4e28-d794-e8b0bdd931fd"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "blobfile version: 3.0.0\n",
+ "huggingface_hub version: 0.24.7\n",
+ "tiktoken version: 0.8.0\n",
+ "torch version: 2.4.1+cu121\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"blobfile\", # to download pretrained weights\n",
+ " \"huggingface_hub\", # to download pretrained weights\n",
+ " \"tiktoken\", # to implement the tokenizer\n",
+ " \"torch\", # to implement the model\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "UJJneXpTEg4W",
+ "metadata": {
+ "id": "UJJneXpTEg4W"
+ },
+ "source": [
+ " \n",
+ "# 1. Convert the Llama model implementation step by step"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "v1zpfX2GHBKa",
+ "metadata": {
+ "id": "v1zpfX2GHBKa"
+ },
+ "source": [
+ "- If you are new to implementing LLM architectures, I recommend starting with [chapter 4](../../ch04/01_main-chapter-code/ch04.ipynb), which walks you through the implementation of the original GPT architecture step by step\n",
+ "- The [Converting a From-Scratch GPT Architecture to Llama 2](./converting-gpt-to-llama2.ipynb) then implements the Llama-specific components, such as RMSNorm layers, SiLU and SwiGLU activations, RoPE (rotary position embeddings), and the SentencePiece tokenizer\n",
+ "- This notebook takes the Llama 2 architecture and transforms it into Llama 3 architecture by\n",
+ " 1. modifying the rotary embeddings\n",
+ " 2. implementing grouped-query attention\n",
+ " 3. and using a customized version of the GPT-4 tokenizer\n",
+ "- Later, we then load the original Llama 3 weights shared by Meta AI into the architecture"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c14b9121-abe1-4a46-99b8-acdef71e5b41",
+ "metadata": {
+ "id": "c14b9121-abe1-4a46-99b8-acdef71e5b41"
+ },
+ "source": [
+ " \n",
+ "## 1.1 Reusing Llama 2 components"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dgDhJGJ6xR4e",
+ "metadata": {
+ "id": "dgDhJGJ6xR4e"
+ },
+ "source": [
+ "- Llama 2 is actually quite similar to Llama 3, as mentioned above and illustrated in the figure at the top of this notebook\n",
+ "- This means that we can import several building blocks from the [Llama 2 notebook](./converting-gpt-to-llama2.ipynb) using the following code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "a5bc3948-231b-4f1f-8d41-24ad0b7643d0",
+ "metadata": {
+ "id": "a5bc3948-231b-4f1f-8d41-24ad0b7643d0"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import sys\n",
+ "import io\n",
+ "import nbformat\n",
+ "import types\n",
+ "\n",
+ "def import_from_notebook():\n",
+ " def import_definitions_from_notebook(fullname, names):\n",
+ " current_dir = os.getcwd()\n",
+ " path = os.path.join(current_dir, fullname + \".ipynb\")\n",
+ " path = os.path.normpath(path)\n",
+ "\n",
+ " # Load the notebook\n",
+ " if not os.path.exists(path):\n",
+ " raise FileNotFoundError(f\"Notebook file not found at: {path}\")\n",
+ "\n",
+ " with io.open(path, \"r\", encoding=\"utf-8\") as f:\n",
+ " nb = nbformat.read(f, as_version=4)\n",
+ "\n",
+ " # Create a module to store the imported functions and classes\n",
+ " mod = types.ModuleType(fullname)\n",
+ " sys.modules[fullname] = mod\n",
+ "\n",
+ " # Go through the notebook cells and only execute function or class definitions\n",
+ " for cell in nb.cells:\n",
+ " if cell.cell_type == \"code\":\n",
+ " cell_code = cell.source\n",
+ " for name in names:\n",
+ " # Check for function or class definitions\n",
+ " if f\"def {name}\" in cell_code or f\"class {name}\" in cell_code:\n",
+ " exec(cell_code, mod.__dict__)\n",
+ " return mod\n",
+ "\n",
+ " fullname = \"converting-gpt-to-llama2\"\n",
+ " names = [\"precompute_rope_params\", \"compute_rope\", \"SiLU\", \"FeedForward\", \"RMSNorm\", \"MultiHeadAttention\"]\n",
+ "\n",
+ " return import_definitions_from_notebook(fullname, names)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "d546032d-fce4-47cf-8d0e-682b78b21c61",
+ "metadata": {
+ "id": "d546032d-fce4-47cf-8d0e-682b78b21c61"
+ },
+ "outputs": [],
+ "source": [
+ "imported_module = import_from_notebook()\n",
+ "\n",
+ "# We need to redefine precompute_rope_params\n",
+ "# precompute_rope_params = getattr(imported_module, \"precompute_rope_params\", None)\n",
+ "compute_rope = getattr(imported_module, \"compute_rope\", None)\n",
+ "SiLU = getattr(imported_module, \"SiLU\", None)\n",
+ "FeedForward = getattr(imported_module, \"FeedForward\", None)\n",
+ "RMSNorm = getattr(imported_module, \"RMSNorm\", None)\n",
+ "\n",
+ "# MultiHeadAttention only for comparison purposes\n",
+ "MultiHeadAttention = getattr(imported_module, \"MultiHeadAttention\", None)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f",
+ "metadata": {
+ "id": "979c7b6d-1370-4da1-8bfb-a2b27537bf2f"
+ },
+ "source": [
+ " \n",
+ "## 1.2 Modified RoPE"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "m9_oDcHCx8VI",
+ "metadata": {
+ "id": "m9_oDcHCx8VI"
+ },
+ "source": [
+ "- Llama 3 uses rotary position embeddings (RoPE) similar to Llama 2 (for a detailed explanation, please see the [RoPE paper](https://arxiv.org/abs/2104.09864))\n",
+ "- There are some subtle differences in the RoPE settings, though\n",
+ " - Llama 3 now supports up to 8,192 tokens, twice as many as Llama 2 (4,096)\n",
+ " - The base value for the so-called RoPE $\\theta$ (see equation below) was increased from 10,000 (Llama 2) to 50,000 (Llama 3) in the following equation (adapted from the [RoPE paper](https://arxiv.org/abs/2104.09864))\n",
+ "\n",
+ "$$\\Theta = \\left\\{\\theta_i = \\text{base}^{\\frac{-2(i-1)}{d}}, i \\in \\left[1, 2, ..., d/2\\right]\\right\\}$$\n",
+ "\n",
+ "- These $\\theta$ values are a set of predefined parameters that are used to determine the rotational angles in the rotary matrix, where $d$ is the dimensionality of the embedding space\n",
+ "- Increasing the base from 10,000 to 50,000 makes the frequencies (or rotation angles) decay more slowly across the dimensions, which means that higher dimensions will be associated with larger angles than before (essentially, it's a decompression of the frequencies)\n",
+ "- In addition, we introduce a `freq_config` section in the code below that adjusts the frequency; however, we won't be needing it in Llama 3 (only Llama 3.1 and Llama 3.2), so we will revisit this `freq_config` later (it's set to `None` and ignored by default)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "6Upl109OOAcu",
+ "metadata": {
+ "id": "6Upl109OOAcu"
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "def precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):\n",
+ " assert head_dim % 2 == 0, \"Embedding dimension must be even\"\n",
+ "\n",
+ " # Compute the inverse frequencies\n",
+ " inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))\n",
+ "\n",
+ " ################################ NEW ###############################################\n",
+ " # Frequency adjustments\n",
+ " if freq_config is not None:\n",
+ " low_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"low_freq_factor\"]\n",
+ " high_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"high_freq_factor\"]\n",
+ "\n",
+ " wavelen = 2 * torch.pi / inv_freq\n",
+ "\n",
+ " inv_freq_llama = torch.where(\n",
+ " wavelen > low_freq_wavelen, inv_freq / freq_config[\"factor\"], inv_freq\n",
+ " )\n",
+ "\n",
+ " smooth_factor = (freq_config[\"original_context_length\"] / wavelen - freq_config[\"low_freq_factor\"]) / (\n",
+ " freq_config[\"high_freq_factor\"] - freq_config[\"low_freq_factor\"]\n",
+ " )\n",
+ "\n",
+ " smoothed_inv_freq = (\n",
+ " (1 - smooth_factor) * (inv_freq / freq_config[\"factor\"]) + smooth_factor * inv_freq\n",
+ " )\n",
+ "\n",
+ " is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\n",
+ " inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\n",
+ " inv_freq = inv_freq_llama\n",
+ " ####################################################################################\n",
+ "\n",
+ "\n",
+ " # Generate position indices\n",
+ " positions = torch.arange(context_length)\n",
+ "\n",
+ " # Compute the angles\n",
+ " angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)\n",
+ "\n",
+ " # Expand angles to match the head_dim\n",
+ " angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\n",
+ "\n",
+ " # Precompute sine and cosine\n",
+ " cos = torch.cos(angles)\n",
+ " sin = torch.sin(angles)\n",
+ "\n",
+ " return cos, sin"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "jJBvO0YMJBXR",
+ "metadata": {
+ "id": "jJBvO0YMJBXR"
+ },
+ "source": [
+ "- To summarize, what's new so far for Llama 3 compared to Llama 2 are the context length and theta base parameter:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "56c37216-e022-4603-be16-f9d3eaeaf4a1",
+ "metadata": {
+ "id": "56c37216-e022-4603-be16-f9d3eaeaf4a1"
+ },
+ "outputs": [],
+ "source": [
+ "# Instantiate RoPE parameters\n",
+ "\n",
+ "llama_2_context_len = 4096\n",
+ "llama_3_context_len = 8192\n",
+ "\n",
+ "llama_2_theta_base = 10_000\n",
+ "llama_3_theta_base = 50_000"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "_V8v6i7MJItU",
+ "metadata": {
+ "id": "_V8v6i7MJItU"
+ },
+ "source": [
+ "- The usage remains the same as before in Llama 2:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "dae70c8a-eb18-40f9-a2e5-a6af2a57628b",
+ "metadata": {
+ "id": "dae70c8a-eb18-40f9-a2e5-a6af2a57628b"
+ },
+ "outputs": [],
+ "source": [
+ "# Settings\n",
+ "batch_size = 2\n",
+ "num_heads = 4\n",
+ "head_dim = 16\n",
+ "\n",
+ "# Instantiate RoPE parameters\n",
+ "cos, sin = precompute_rope_params(\n",
+ " head_dim=head_dim,\n",
+ " theta_base=llama_3_theta_base,\n",
+ " context_length=llama_3_context_len\n",
+ ")\n",
+ "\n",
+ "# Dummy query and key tensors\n",
+ "torch.manual_seed(123)\n",
+ "queries = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)\n",
+ "keys = torch.randn(batch_size, llama_3_context_len, num_heads, head_dim)\n",
+ "\n",
+ "# Apply rotary position embeddings\n",
+ "queries_rot = compute_rope(queries, cos, sin)\n",
+ "keys_rot = compute_rope(keys, cos, sin)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cd19b75c-cf25-47b8-a010-6733fc0e9a8a",
+ "metadata": {
+ "id": "cd19b75c-cf25-47b8-a010-6733fc0e9a8a"
+ },
+ "source": [
+ " \n",
+ "## 1.3 Grouped-query attention"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "111c7d3f-fded-49e8-a617-9fe67b81dddc",
+ "metadata": {
+ "id": "111c7d3f-fded-49e8-a617-9fe67b81dddc"
+ },
+ "source": [
+ "- In this section, we replace multi-head attention (MHA) with an alternative mechanism called grouped-query attention (GQA)\n",
+ "- In short, one can think of GQA as a more compute- and parameter-efficient version of MHA\n",
+ "- In GQA, we reduce the number of key and value projections by sharing them among multiple attention heads\n",
+ "- Each attention head still has its unique query, but these queries attend to the same group of keys and values\n",
+ "- Below is an illustration of GQA with 2 key-value-groups (kv-groups):\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "perAYa2R_KW2",
+ "metadata": {
+ "id": "perAYa2R_KW2"
+ },
+ "source": [
+ "- The main idea behind GQA is to reduce the number of unique query groups that attend to the key-value pairs, reducing the size of some of the matrix multiplications and the number of parameters in MHA without significantly reducing modeling performance\n",
+ "- The GQA code is very similar to MHA (I highlighted the changes below via the \"NEW\" sections)\n",
+ "- In short, the main change in GQA is that each query group needs to be repeated to match the number of heads it is associated with, as implemented below"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "842aa71a-4659-424e-8830-392bd6ae86af",
+ "metadata": {},
+ "source": [
+ "- In addition, we also introduce a `SharedBuffers` class that will allow us to reuse the `mask`, `cos`, and `sin` tensors in the transformer blocks to improve efficiency (this will be crucial when working with models such as Llama 3.1 and 3.2 later, which support up to 131k input tokens)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "9b12e674-ef08-4dd7-8843-615b65b39c91",
+ "metadata": {
+ "id": "9b12e674-ef08-4dd7-8843-615b65b39c91"
+ },
+ "outputs": [],
+ "source": [
+ "import torch.nn as nn\n",
+ "\n",
+ "\n",
+ "############################# NEW #############################\n",
+ "class SharedBuffers:\n",
+ " _buffers = {}\n",
+ "\n",
+ " @staticmethod\n",
+ " def get_buffers(context_length, head_dim, rope_base, freq_config, dtype=torch.float32):\n",
+ " key = (context_length, head_dim, rope_base, tuple(freq_config.values()) if freq_config else freq_config, dtype)\n",
+ "\n",
+ " if key not in SharedBuffers._buffers:\n",
+ " # Create or fetch the buffers\n",
+ " mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)\n",
+ " cos, sin = precompute_rope_params(head_dim, rope_base, context_length, freq_config)\n",
+ " if dtype is not None:\n",
+ " cos = cos.to(dtype)\n",
+ " sin = sin.to(dtype)\n",
+ " SharedBuffers._buffers[key] = (mask, cos, sin)\n",
+ "\n",
+ " return SharedBuffers._buffers[key]\n",
+ "############################# NEW #############################\n",
+ "\n",
+ "\n",
+ "class GroupedQueryAttention(nn.Module):\n",
+ " def __init__(\n",
+ " self, d_in, d_out, context_length, num_heads,\n",
+ " num_kv_groups, # NEW\n",
+ " rope_base=10_000, # NEW\n",
+ " rope_config=None, # NEW\n",
+ " dtype=None\n",
+ " ):\n",
+ " super().__init__()\n",
+ " assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n",
+ " assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n",
+ "\n",
+ " self.d_out = d_out\n",
+ " self.num_heads = num_heads\n",
+ " self.head_dim = d_out // num_heads\n",
+ "\n",
+ " ############################# NEW #############################\n",
+ " # self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " # self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.num_kv_groups = num_kv_groups\n",
+ " self.group_size = num_heads // num_kv_groups\n",
+ " ################################################################\n",
+ "\n",
+ " self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n",
+ "\n",
+ " ############################# NEW #############################\n",
+ " # Fetch buffers using SharedBuffers\n",
+ " mask, cos, sin = SharedBuffers.get_buffers(context_length, self.head_dim, rope_base, rope_config, dtype)\n",
+ " ############################# NEW #############################\n",
+ " \n",
+ " self.register_buffer(\"mask\", mask)\n",
+ " self.register_buffer(\"cos\", cos)\n",
+ " self.register_buffer(\"sin\", sin)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " b, num_tokens, d_in = x.shape\n",
+ "\n",
+ " queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\n",
+ " keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ " values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ "\n",
+ " # Reshape queries, keys, and values\n",
+ " queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ "\n",
+ " ##################### NEW #####################\n",
+ " # keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " # values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " ################################################\n",
+ "\n",
+ " # Transpose keys, values, and queries\n",
+ " keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)\n",
+ "\n",
+ " # Apply RoPE\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
+ "\n",
+ " ##################### NEW #####################\n",
+ " # Expand keys and values to match the number of heads\n",
+ " # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ "\n",
+ " keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " # For example, before repeat_interleave along dim=1 (query groups):\n",
+ " # [K1, K2]\n",
+ " # After repeat_interleave (each query group is repeated group_size times):\n",
+ " # [K1, K1, K2, K2]\n",
+ " # If we used regular repeat instead of repeat_interleave, we'd get:\n",
+ " # [K1, K2, K1, K2]\n",
+ " ################################################\n",
+ "\n",
+ " # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
+ " # Shape: (b, num_heads, num_tokens, num_tokens)\n",
+ " attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n",
+ "\n",
+ " # Original mask truncated to the number of tokens and converted to boolean\n",
+ " mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n",
+ "\n",
+ " # Use the mask to fill attention scores\n",
+ " attn_scores.masked_fill_(mask_bool, -torch.inf)\n",
+ "\n",
+ " attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n",
+ " assert keys.shape[-1] == self.head_dim\n",
+ "\n",
+ " # Shape: (b, num_tokens, num_heads, head_dim)\n",
+ " context_vec = (attn_weights @ values).transpose(1, 2)\n",
+ "\n",
+ " # Combine heads, where self.d_out = self.num_heads * self.head_dim\n",
+ " context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n",
+ " context_vec = self.out_proj(context_vec) # optional projection\n",
+ "\n",
+ " return context_vec"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "roAXSwJs9hR8",
+ "metadata": {
+ "id": "roAXSwJs9hR8"
+ },
+ "source": [
+ "- To illustrate the parameter savings, consider the following multi-head attention example from the GPT and Llama 2 code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "b4b8f085-349e-4674-a3f0-78fde0664fac",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "b4b8f085-349e-4674-a3f0-78fde0664fac",
+ "outputId": "9da09d72-43b1-45af-d46f-6928ea4af33a"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "W_key: torch.Size([4096, 4096])\n",
+ "W_value: torch.Size([4096, 4096])\n",
+ "W_query: torch.Size([4096, 4096])\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Settings\n",
+ "batch_size = 1\n",
+ "context_len = 3000\n",
+ "max_context_len = 8192\n",
+ "embed_dim = 4096\n",
+ "num_heads = 32\n",
+ "\n",
+ "\n",
+ "example_batch = torch.randn((batch_size, context_len, embed_dim))\n",
+ "\n",
+ "mha = MultiHeadAttention(\n",
+ " d_in=embed_dim,\n",
+ " d_out=embed_dim,\n",
+ " context_length=max_context_len,\n",
+ " num_heads=num_heads\n",
+ ")\n",
+ "\n",
+ "mha(example_batch)\n",
+ "\n",
+ "print(\"W_key:\", mha.W_key.weight.shape)\n",
+ "print(\"W_value:\", mha.W_value.weight.shape)\n",
+ "print(\"W_query:\", mha.W_query.weight.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "IMQtFkcQ9sXC",
+ "metadata": {
+ "id": "IMQtFkcQ9sXC"
+ },
+ "source": [
+ "- Now, if we use grouped-query attention instead, with 8 kv-groups (that's how many Llama 3 8B uses), we can see that the number of rows of the key and value matrices are reduced by a factor of 4 (because 32 attention heads divided by 8 kv-groups is 4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "15e65d3c-7b42-4ed3-bfee-bb09578657bb",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "15e65d3c-7b42-4ed3-bfee-bb09578657bb",
+ "outputId": "69709a78-2aaa-4597-8142-2f44eb59753f"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "W_key: torch.Size([1024, 4096])\n",
+ "W_value: torch.Size([1024, 4096])\n",
+ "W_query: torch.Size([4096, 4096])\n"
+ ]
+ }
+ ],
+ "source": [
+ "gqa = GroupedQueryAttention(\n",
+ " d_in=embed_dim,\n",
+ " d_out=embed_dim,\n",
+ " context_length=max_context_len,\n",
+ " num_heads=num_heads,\n",
+ " num_kv_groups=8,\n",
+ " rope_base=llama_3_theta_base\n",
+ ")\n",
+ "\n",
+ "gqa(example_batch)\n",
+ "\n",
+ "print(\"W_key:\", gqa.W_key.weight.shape)\n",
+ "print(\"W_value:\", gqa.W_value.weight.shape)\n",
+ "print(\"W_query:\", gqa.W_query.weight.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1a5d4c88-c66a-483b-b4e2-419ff9fd60d5",
+ "metadata": {
+ "id": "1a5d4c88-c66a-483b-b4e2-419ff9fd60d5"
+ },
+ "source": [
+ "- As a side note, to make the GroupedQueryAttention equivalent to standard multi-head attention, you can set the number of query groups (`num_kv_groups`) equal to the number of heads (`num_heads`)\n",
+ "- Lastly, let's compare the number of parameters below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "58f713aa-ac00-4e2f-8247-94609aa01350",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "58f713aa-ac00-4e2f-8247-94609aa01350",
+ "outputId": "486dfd9c-9f3a-4b9e-f9a2-35fb43b9a5fb"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters:\n",
+ "MHA: 67,108,864\n",
+ "GQA: 41,943,040\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(\"Total number of parameters:\")\n",
+ "\n",
+ "mha_total_params = sum(p.numel() for p in mha.parameters())\n",
+ "print(f\"MHA: {mha_total_params:,}\")\n",
+ "\n",
+ "gqa_total_params = sum(p.numel() for p in gqa.parameters())\n",
+ "print(f\"GQA: {gqa_total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "78b60dfd-6c0f-41f7-8f0c-8e57116f07f5",
+ "metadata": {
+ "id": "78b60dfd-6c0f-41f7-8f0c-8e57116f07f5"
+ },
+ "outputs": [],
+ "source": [
+ "# Free up memory:\n",
+ "del mha\n",
+ "del gqa"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fcd8802-2859-45a2-905a-f4fe96629dd9",
+ "metadata": {
+ "id": "8fcd8802-2859-45a2-905a-f4fe96629dd9"
+ },
+ "source": [
+ " \n",
+ "## 1.4 Update the TransformerBlock module"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "KABNccft_YnR",
+ "metadata": {
+ "id": "KABNccft_YnR"
+ },
+ "source": [
+ "- Next, we update the `TransformerBlock`\n",
+ "- Here, we simply swap `MultiHeadAttention` with `GroupedQueryAttention` and add the new RoPE settings"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "f9fa8eb4-7196-4dee-aec6-0dcbc70921c4",
+ "metadata": {
+ "id": "f9fa8eb4-7196-4dee-aec6-0dcbc70921c4"
+ },
+ "outputs": [],
+ "source": [
+ "class TransformerBlock(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.att = GroupedQueryAttention( # MultiHeadAttention(\n",
+ " d_in=cfg[\"emb_dim\"],\n",
+ " d_out=cfg[\"emb_dim\"],\n",
+ " context_length=cfg[\"context_length\"],\n",
+ " num_heads=cfg[\"n_heads\"],\n",
+ " num_kv_groups=cfg[\"n_kv_groups\"], # NEW\n",
+ " rope_base=cfg[\"rope_base\"], # NEW\n",
+ " rope_config=cfg[\"rope_freq\"], # NEW\n",
+ " dtype=cfg[\"dtype\"]\n",
+ " )\n",
+ " self.ff = FeedForward(cfg)\n",
+ " self.norm1 = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.norm2 = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " # Shortcut connection for attention block\n",
+ " shortcut = x\n",
+ " x = self.norm1(x)\n",
+ " x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " # Shortcut connection for feed-forward block\n",
+ " shortcut = x\n",
+ " x = self.norm2(x)\n",
+ " x = self.ff(x.to(torch.bfloat16))\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " return x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd921ab5-c48c-4c52-bf41-b847b3b822b9",
+ "metadata": {
+ "id": "fd921ab5-c48c-4c52-bf41-b847b3b822b9"
+ },
+ "source": [
+ " \n",
+ "## 1.5 Defining the model class"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "M_tLAq_r_llN",
+ "metadata": {
+ "id": "M_tLAq_r_llN"
+ },
+ "source": [
+ "- When setting up the model class, we fortunately don't have to do much; we just update the name to `Llama3Model`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "475755d6-01f7-4e6e-ad9a-cec6f031ebf6",
+ "metadata": {
+ "id": "475755d6-01f7-4e6e-ad9a-cec6f031ebf6"
+ },
+ "outputs": [],
+ "source": [
+ "# class Llama2Model(nn.Module):\n",
+ "class Llama3Model(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " self.trf_blocks = nn.Sequential(\n",
+ " *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n",
+ "\n",
+ " self.final_norm = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False, dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " def forward(self, in_idx):\n",
+ " tok_embeds = self.tok_emb(in_idx)\n",
+ " x = tok_embeds\n",
+ " x = self.trf_blocks(x)\n",
+ " x = self.final_norm(x)\n",
+ " logits = self.out_head(x.to(torch.bfloat16))\n",
+ " return logits"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4bc94940-aaeb-45b9-9399-3a69b8043e60",
+ "metadata": {
+ "id": "4bc94940-aaeb-45b9-9399-3a69b8043e60"
+ },
+ "source": [
+ " \n",
+ "## 2. Initialize model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "HoGGRAGykQTE",
+ "metadata": {
+ "id": "HoGGRAGykQTE"
+ },
+ "source": [
+ "- Now we can define a Llama 3 config file (the Llama 2 config file is shown for comparison)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "e0564727-2d35-4f0c-b0fc-cde1e9134a18",
+ "metadata": {
+ "id": "e0564727-2d35-4f0c-b0fc-cde1e9134a18"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA2_CONFIG_7B = {\n",
+ " \"vocab_size\": 32_000, # Vocabulary size\n",
+ " \"context_length\": 4096, # Context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 11_008, # Size of the intermediate dimension in FeedForward\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "2ad90f82-15c7-4806-b509-e45b56f57db5",
+ "metadata": {
+ "id": "2ad90f82-15c7-4806-b509-e45b56f57db5"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA3_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # NEW: Larger vocabulary size\n",
+ " \"context_length\": 8192, # NEW: Larger context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # NEW: Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # NEW: The base in RoPE's \"theta\" was increased to 50_000\n",
+ " \"rope_freq\": None, # NEW: Additional configuration for adjusting the RoPE frequencies\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "FAP7fiBzkaBz",
+ "metadata": {
+ "id": "FAP7fiBzkaBz"
+ },
+ "source": [
+ "- Using these settings, we can now initialize a Llama 3 8B model\n",
+ "- Note that this requires ~34 GB of memory (for comparison, Llama 2 7B required ~26 GB of memory)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "7004d785-ac9a-4df5-8760-6807fc604686",
+ "metadata": {
+ "id": "7004d785-ac9a-4df5-8760-6807fc604686"
+ },
+ "outputs": [],
+ "source": [
+ "model = Llama3Model(LLAMA3_CONFIG_8B)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "edea6334-d1fc-427d-9cf2-4af963ff4bfc",
+ "metadata": {},
+ "source": [
+ "- The following is expected to print True to confirm buffers are reused instead of being (wastefully) recreated:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ee9625cc-9afa-4b11-8aab-d536fd170761",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Check buffers\n",
+ "print(model.trf_blocks[0].att.mask is model.trf_blocks[-1].att.mask)\n",
+ "print(model.trf_blocks[0].att.cos is model.trf_blocks[-1].att.cos)\n",
+ "print(model.trf_blocks[0].att.sin is model.trf_blocks[-1].att.sin) "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8056a521-91a6-440f-8473-591409c3177b",
+ "metadata": {},
+ "source": [
+ "- Let's now also compute the number of trainable parameters:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "6079f747-8f20-4c6b-8d38-7156f1101729",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "6079f747-8f20-4c6b-8d38-7156f1101729",
+ "outputId": "0a8cd23b-d9fa-4c2d-ca63-3fc79bc4de0d"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 8,030,261,248\n"
+ ]
+ }
+ ],
+ "source": [
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Bx14NtzWk2wj",
+ "metadata": {
+ "id": "Bx14NtzWk2wj"
+ },
+ "source": [
+ "- As shown above, the model contains 8 billion parameters\n",
+ "- Additionally, we can calculate the memory requirements for this model using the code below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
+ "outputId": "3425e9ce-d8c0-4b37-bded-a2c60b66a41a"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "float32 (PyTorch default): 68.08 GB\n",
+ "bfloat16: 34.04 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def model_memory_size(model, input_dtype=torch.float32):\n",
+ " total_params = 0\n",
+ " total_grads = 0\n",
+ " for param in model.parameters():\n",
+ " # Calculate total number of elements per parameter\n",
+ " param_size = param.numel()\n",
+ " total_params += param_size\n",
+ " # Check if gradients are stored for this parameter\n",
+ " if param.requires_grad:\n",
+ " total_grads += param_size\n",
+ "\n",
+ " # Calculate buffer size (non-parameters that require memory)\n",
+ " total_buffers = sum(buf.numel() for buf in model.buffers())\n",
+ "\n",
+ " # Size in bytes = (Number of elements) * (Size of each element in bytes)\n",
+ " # We assume parameters and gradients are stored in the same type as input dtype\n",
+ " element_size = torch.tensor(0, dtype=input_dtype).element_size()\n",
+ " total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\n",
+ "\n",
+ " # Convert bytes to gigabytes\n",
+ " total_memory_gb = total_memory_bytes / (1024**3)\n",
+ "\n",
+ " return total_memory_gb\n",
+ "\n",
+ "print(f\"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB\")\n",
+ "print(f\"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "zudd-5PulKFL",
+ "metadata": {
+ "id": "zudd-5PulKFL"
+ },
+ "source": [
+ "- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "a4c50e19-1402-45b6-8ccd-9077b2ba836d",
+ "metadata": {
+ "id": "a4c50e19-1402-45b6-8ccd-9077b2ba836d"
+ },
+ "outputs": [],
+ "source": [
+ "if torch.cuda.is_available():\n",
+ " device = torch.device(\"cuda\")\n",
+ "elif torch.backends.mps.is_available():\n",
+ " device = torch.device(\"mps\")\n",
+ "else:\n",
+ " device = torch.device(\"cpu\")\n",
+ "\n",
+ "model.to(device);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34",
+ "metadata": {
+ "id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34"
+ },
+ "source": [
+ " \n",
+ "## 3. Load tokenizer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0eb30f0c-6144-4bed-87d9-6b2bac377005",
+ "metadata": {
+ "id": "0eb30f0c-6144-4bed-87d9-6b2bac377005"
+ },
+ "source": [
+ "- In this section, we are going to load the tokenizer for the model\n",
+ "- Llama 2 used Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's BPE tokenizer based on the [Tiktoken](https://github.com/openai/tiktoken) library\n",
+ "- Llama 3, however, reverted back to using the BPE tokenizer from Tiktoken; specifically, it uses the GPT-4 tokenizer with an extended vocabulary\n",
+ "- You can find the original Tiktoken-adaptation by Meta AI [here](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py) in their official Llama 3 repository\n",
+ "- Below, I rewrote the tokenizer code to make it more readable and minimal for this notebook (but the behavior should be similar)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "5f390cbf-8f92-46dc-afe3-d90b5affae10",
+ "metadata": {
+ "id": "5f390cbf-8f92-46dc-afe3-d90b5affae10"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "\n",
+ "import tiktoken\n",
+ "from tiktoken.load import load_tiktoken_bpe\n",
+ "\n",
+ "\n",
+ "class Tokenizer:\n",
+ " def __init__(self, model_path):\n",
+ " assert os.path.isfile(model_path), f\"Model file {model_path} not found\"\n",
+ " mergeable_ranks = load_tiktoken_bpe(model_path)\n",
+ "\n",
+ " self.special_tokens = {\n",
+ " \"<|begin_of_text|>\": 128000,\n",
+ " \"<|end_of_text|>\": 128001,\n",
+ " \"<|start_header_id|>\": 128006,\n",
+ " \"<|end_header_id|>\": 128007,\n",
+ " \"<|eot_id|>\": 128009,\n",
+ " }\n",
+ " self.special_tokens.update({\n",
+ " f\"<|reserved_{i}|>\": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()\n",
+ " })\n",
+ "\n",
+ " self.model = tiktoken.Encoding(\n",
+ " name=Path(model_path).name,\n",
+ " pat_str=r\"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?\\p{L}+|\\p{N}{1,3}| ?[^\\s\\p{L}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+\",\n",
+ " mergeable_ranks=mergeable_ranks,\n",
+ " special_tokens=self.special_tokens\n",
+ " )\n",
+ "\n",
+ "\n",
+ " def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):\n",
+ " if bos:\n",
+ " tokens = [self.special_tokens[\"<|begin_of_text|>\"]]\n",
+ " else:\n",
+ " tokens = []\n",
+ "\n",
+ " tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)\n",
+ "\n",
+ " if eos:\n",
+ " tokens.append(self.special_tokens[\"<|end_of_text|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, tokens):\n",
+ " return self.model.decode(tokens)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0a1509f8-8778-4fec-ba32-14d95c646167",
+ "metadata": {
+ "id": "0a1509f8-8778-4fec-ba32-14d95c646167"
+ },
+ "source": [
+ "- Meta AI shared the original Llama 3 model weights and tokenizer vocabulary on the Hugging Face Hub\n",
+ "- We will first download the tokenizer vocabulary from the Hub and load it into the code above"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "KbnlzsbYmJU6",
+ "metadata": {
+ "id": "KbnlzsbYmJU6"
+ },
+ "source": [
+ "- Please note that Meta AI requires that you accept the Llama 3 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) repository to accept the terms\n",
+ "- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \"Settings\"\n",
+ "\n",
+ "\n",
+ "
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "perAYa2R_KW2",
+ "metadata": {
+ "id": "perAYa2R_KW2"
+ },
+ "source": [
+ "- The main idea behind GQA is to reduce the number of unique query groups that attend to the key-value pairs, reducing the size of some of the matrix multiplications and the number of parameters in MHA without significantly reducing modeling performance\n",
+ "- The GQA code is very similar to MHA (I highlighted the changes below via the \"NEW\" sections)\n",
+ "- In short, the main change in GQA is that each query group needs to be repeated to match the number of heads it is associated with, as implemented below"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "842aa71a-4659-424e-8830-392bd6ae86af",
+ "metadata": {},
+ "source": [
+ "- In addition, we also introduce a `SharedBuffers` class that will allow us to reuse the `mask`, `cos`, and `sin` tensors in the transformer blocks to improve efficiency (this will be crucial when working with models such as Llama 3.1 and 3.2 later, which support up to 131k input tokens)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "9b12e674-ef08-4dd7-8843-615b65b39c91",
+ "metadata": {
+ "id": "9b12e674-ef08-4dd7-8843-615b65b39c91"
+ },
+ "outputs": [],
+ "source": [
+ "import torch.nn as nn\n",
+ "\n",
+ "\n",
+ "############################# NEW #############################\n",
+ "class SharedBuffers:\n",
+ " _buffers = {}\n",
+ "\n",
+ " @staticmethod\n",
+ " def get_buffers(context_length, head_dim, rope_base, freq_config, dtype=torch.float32):\n",
+ " key = (context_length, head_dim, rope_base, tuple(freq_config.values()) if freq_config else freq_config, dtype)\n",
+ "\n",
+ " if key not in SharedBuffers._buffers:\n",
+ " # Create or fetch the buffers\n",
+ " mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)\n",
+ " cos, sin = precompute_rope_params(head_dim, rope_base, context_length, freq_config)\n",
+ " if dtype is not None:\n",
+ " cos = cos.to(dtype)\n",
+ " sin = sin.to(dtype)\n",
+ " SharedBuffers._buffers[key] = (mask, cos, sin)\n",
+ "\n",
+ " return SharedBuffers._buffers[key]\n",
+ "############################# NEW #############################\n",
+ "\n",
+ "\n",
+ "class GroupedQueryAttention(nn.Module):\n",
+ " def __init__(\n",
+ " self, d_in, d_out, context_length, num_heads,\n",
+ " num_kv_groups, # NEW\n",
+ " rope_base=10_000, # NEW\n",
+ " rope_config=None, # NEW\n",
+ " dtype=None\n",
+ " ):\n",
+ " super().__init__()\n",
+ " assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n",
+ " assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n",
+ "\n",
+ " self.d_out = d_out\n",
+ " self.num_heads = num_heads\n",
+ " self.head_dim = d_out // num_heads\n",
+ "\n",
+ " ############################# NEW #############################\n",
+ " # self.W_key = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " # self.W_value = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.num_kv_groups = num_kv_groups\n",
+ " self.group_size = num_heads // num_kv_groups\n",
+ " ################################################################\n",
+ "\n",
+ " self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n",
+ "\n",
+ " ############################# NEW #############################\n",
+ " # Fetch buffers using SharedBuffers\n",
+ " mask, cos, sin = SharedBuffers.get_buffers(context_length, self.head_dim, rope_base, rope_config, dtype)\n",
+ " ############################# NEW #############################\n",
+ " \n",
+ " self.register_buffer(\"mask\", mask)\n",
+ " self.register_buffer(\"cos\", cos)\n",
+ " self.register_buffer(\"sin\", sin)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " b, num_tokens, d_in = x.shape\n",
+ "\n",
+ " queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\n",
+ " keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ " values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ "\n",
+ " # Reshape queries, keys, and values\n",
+ " queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ "\n",
+ " ##################### NEW #####################\n",
+ " # keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " # values = values.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " ################################################\n",
+ "\n",
+ " # Transpose keys, values, and queries\n",
+ " keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)\n",
+ "\n",
+ " # Apply RoPE\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
+ "\n",
+ " ##################### NEW #####################\n",
+ " # Expand keys and values to match the number of heads\n",
+ " # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ "\n",
+ " keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " # For example, before repeat_interleave along dim=1 (query groups):\n",
+ " # [K1, K2]\n",
+ " # After repeat_interleave (each query group is repeated group_size times):\n",
+ " # [K1, K1, K2, K2]\n",
+ " # If we used regular repeat instead of repeat_interleave, we'd get:\n",
+ " # [K1, K2, K1, K2]\n",
+ " ################################################\n",
+ "\n",
+ " # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
+ " # Shape: (b, num_heads, num_tokens, num_tokens)\n",
+ " attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n",
+ "\n",
+ " # Original mask truncated to the number of tokens and converted to boolean\n",
+ " mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n",
+ "\n",
+ " # Use the mask to fill attention scores\n",
+ " attn_scores.masked_fill_(mask_bool, -torch.inf)\n",
+ "\n",
+ " attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n",
+ " assert keys.shape[-1] == self.head_dim\n",
+ "\n",
+ " # Shape: (b, num_tokens, num_heads, head_dim)\n",
+ " context_vec = (attn_weights @ values).transpose(1, 2)\n",
+ "\n",
+ " # Combine heads, where self.d_out = self.num_heads * self.head_dim\n",
+ " context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n",
+ " context_vec = self.out_proj(context_vec) # optional projection\n",
+ "\n",
+ " return context_vec"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "roAXSwJs9hR8",
+ "metadata": {
+ "id": "roAXSwJs9hR8"
+ },
+ "source": [
+ "- To illustrate the parameter savings, consider the following multi-head attention example from the GPT and Llama 2 code:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "b4b8f085-349e-4674-a3f0-78fde0664fac",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "b4b8f085-349e-4674-a3f0-78fde0664fac",
+ "outputId": "9da09d72-43b1-45af-d46f-6928ea4af33a"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "W_key: torch.Size([4096, 4096])\n",
+ "W_value: torch.Size([4096, 4096])\n",
+ "W_query: torch.Size([4096, 4096])\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Settings\n",
+ "batch_size = 1\n",
+ "context_len = 3000\n",
+ "max_context_len = 8192\n",
+ "embed_dim = 4096\n",
+ "num_heads = 32\n",
+ "\n",
+ "\n",
+ "example_batch = torch.randn((batch_size, context_len, embed_dim))\n",
+ "\n",
+ "mha = MultiHeadAttention(\n",
+ " d_in=embed_dim,\n",
+ " d_out=embed_dim,\n",
+ " context_length=max_context_len,\n",
+ " num_heads=num_heads\n",
+ ")\n",
+ "\n",
+ "mha(example_batch)\n",
+ "\n",
+ "print(\"W_key:\", mha.W_key.weight.shape)\n",
+ "print(\"W_value:\", mha.W_value.weight.shape)\n",
+ "print(\"W_query:\", mha.W_query.weight.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "IMQtFkcQ9sXC",
+ "metadata": {
+ "id": "IMQtFkcQ9sXC"
+ },
+ "source": [
+ "- Now, if we use grouped-query attention instead, with 8 kv-groups (that's how many Llama 3 8B uses), we can see that the number of rows of the key and value matrices are reduced by a factor of 4 (because 32 attention heads divided by 8 kv-groups is 4)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "15e65d3c-7b42-4ed3-bfee-bb09578657bb",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "15e65d3c-7b42-4ed3-bfee-bb09578657bb",
+ "outputId": "69709a78-2aaa-4597-8142-2f44eb59753f"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "W_key: torch.Size([1024, 4096])\n",
+ "W_value: torch.Size([1024, 4096])\n",
+ "W_query: torch.Size([4096, 4096])\n"
+ ]
+ }
+ ],
+ "source": [
+ "gqa = GroupedQueryAttention(\n",
+ " d_in=embed_dim,\n",
+ " d_out=embed_dim,\n",
+ " context_length=max_context_len,\n",
+ " num_heads=num_heads,\n",
+ " num_kv_groups=8,\n",
+ " rope_base=llama_3_theta_base\n",
+ ")\n",
+ "\n",
+ "gqa(example_batch)\n",
+ "\n",
+ "print(\"W_key:\", gqa.W_key.weight.shape)\n",
+ "print(\"W_value:\", gqa.W_value.weight.shape)\n",
+ "print(\"W_query:\", gqa.W_query.weight.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1a5d4c88-c66a-483b-b4e2-419ff9fd60d5",
+ "metadata": {
+ "id": "1a5d4c88-c66a-483b-b4e2-419ff9fd60d5"
+ },
+ "source": [
+ "- As a side note, to make the GroupedQueryAttention equivalent to standard multi-head attention, you can set the number of query groups (`num_kv_groups`) equal to the number of heads (`num_heads`)\n",
+ "- Lastly, let's compare the number of parameters below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "58f713aa-ac00-4e2f-8247-94609aa01350",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "58f713aa-ac00-4e2f-8247-94609aa01350",
+ "outputId": "486dfd9c-9f3a-4b9e-f9a2-35fb43b9a5fb"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters:\n",
+ "MHA: 67,108,864\n",
+ "GQA: 41,943,040\n"
+ ]
+ }
+ ],
+ "source": [
+ "print(\"Total number of parameters:\")\n",
+ "\n",
+ "mha_total_params = sum(p.numel() for p in mha.parameters())\n",
+ "print(f\"MHA: {mha_total_params:,}\")\n",
+ "\n",
+ "gqa_total_params = sum(p.numel() for p in gqa.parameters())\n",
+ "print(f\"GQA: {gqa_total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "78b60dfd-6c0f-41f7-8f0c-8e57116f07f5",
+ "metadata": {
+ "id": "78b60dfd-6c0f-41f7-8f0c-8e57116f07f5"
+ },
+ "outputs": [],
+ "source": [
+ "# Free up memory:\n",
+ "del mha\n",
+ "del gqa"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fcd8802-2859-45a2-905a-f4fe96629dd9",
+ "metadata": {
+ "id": "8fcd8802-2859-45a2-905a-f4fe96629dd9"
+ },
+ "source": [
+ " \n",
+ "## 1.4 Update the TransformerBlock module"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "KABNccft_YnR",
+ "metadata": {
+ "id": "KABNccft_YnR"
+ },
+ "source": [
+ "- Next, we update the `TransformerBlock`\n",
+ "- Here, we simply swap `MultiHeadAttention` with `GroupedQueryAttention` and add the new RoPE settings"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "f9fa8eb4-7196-4dee-aec6-0dcbc70921c4",
+ "metadata": {
+ "id": "f9fa8eb4-7196-4dee-aec6-0dcbc70921c4"
+ },
+ "outputs": [],
+ "source": [
+ "class TransformerBlock(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.att = GroupedQueryAttention( # MultiHeadAttention(\n",
+ " d_in=cfg[\"emb_dim\"],\n",
+ " d_out=cfg[\"emb_dim\"],\n",
+ " context_length=cfg[\"context_length\"],\n",
+ " num_heads=cfg[\"n_heads\"],\n",
+ " num_kv_groups=cfg[\"n_kv_groups\"], # NEW\n",
+ " rope_base=cfg[\"rope_base\"], # NEW\n",
+ " rope_config=cfg[\"rope_freq\"], # NEW\n",
+ " dtype=cfg[\"dtype\"]\n",
+ " )\n",
+ " self.ff = FeedForward(cfg)\n",
+ " self.norm1 = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.norm2 = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " # Shortcut connection for attention block\n",
+ " shortcut = x\n",
+ " x = self.norm1(x)\n",
+ " x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " # Shortcut connection for feed-forward block\n",
+ " shortcut = x\n",
+ " x = self.norm2(x)\n",
+ " x = self.ff(x.to(torch.bfloat16))\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " return x"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd921ab5-c48c-4c52-bf41-b847b3b822b9",
+ "metadata": {
+ "id": "fd921ab5-c48c-4c52-bf41-b847b3b822b9"
+ },
+ "source": [
+ " \n",
+ "## 1.5 Defining the model class"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "M_tLAq_r_llN",
+ "metadata": {
+ "id": "M_tLAq_r_llN"
+ },
+ "source": [
+ "- When setting up the model class, we fortunately don't have to do much; we just update the name to `Llama3Model`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "475755d6-01f7-4e6e-ad9a-cec6f031ebf6",
+ "metadata": {
+ "id": "475755d6-01f7-4e6e-ad9a-cec6f031ebf6"
+ },
+ "outputs": [],
+ "source": [
+ "# class Llama2Model(nn.Module):\n",
+ "class Llama3Model(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " self.trf_blocks = nn.Sequential(\n",
+ " *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n",
+ "\n",
+ " self.final_norm = RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False, dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " def forward(self, in_idx):\n",
+ " tok_embeds = self.tok_emb(in_idx)\n",
+ " x = tok_embeds\n",
+ " x = self.trf_blocks(x)\n",
+ " x = self.final_norm(x)\n",
+ " logits = self.out_head(x.to(torch.bfloat16))\n",
+ " return logits"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4bc94940-aaeb-45b9-9399-3a69b8043e60",
+ "metadata": {
+ "id": "4bc94940-aaeb-45b9-9399-3a69b8043e60"
+ },
+ "source": [
+ " \n",
+ "## 2. Initialize model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "HoGGRAGykQTE",
+ "metadata": {
+ "id": "HoGGRAGykQTE"
+ },
+ "source": [
+ "- Now we can define a Llama 3 config file (the Llama 2 config file is shown for comparison)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "e0564727-2d35-4f0c-b0fc-cde1e9134a18",
+ "metadata": {
+ "id": "e0564727-2d35-4f0c-b0fc-cde1e9134a18"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA2_CONFIG_7B = {\n",
+ " \"vocab_size\": 32_000, # Vocabulary size\n",
+ " \"context_length\": 4096, # Context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 11_008, # Size of the intermediate dimension in FeedForward\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "2ad90f82-15c7-4806-b509-e45b56f57db5",
+ "metadata": {
+ "id": "2ad90f82-15c7-4806-b509-e45b56f57db5"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA3_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # NEW: Larger vocabulary size\n",
+ " \"context_length\": 8192, # NEW: Larger context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # NEW: Larger size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # NEW: Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # NEW: The base in RoPE's \"theta\" was increased to 50_000\n",
+ " \"rope_freq\": None, # NEW: Additional configuration for adjusting the RoPE frequencies\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "FAP7fiBzkaBz",
+ "metadata": {
+ "id": "FAP7fiBzkaBz"
+ },
+ "source": [
+ "- Using these settings, we can now initialize a Llama 3 8B model\n",
+ "- Note that this requires ~34 GB of memory (for comparison, Llama 2 7B required ~26 GB of memory)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "id": "7004d785-ac9a-4df5-8760-6807fc604686",
+ "metadata": {
+ "id": "7004d785-ac9a-4df5-8760-6807fc604686"
+ },
+ "outputs": [],
+ "source": [
+ "model = Llama3Model(LLAMA3_CONFIG_8B)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "edea6334-d1fc-427d-9cf2-4af963ff4bfc",
+ "metadata": {},
+ "source": [
+ "- The following is expected to print True to confirm buffers are reused instead of being (wastefully) recreated:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ee9625cc-9afa-4b11-8aab-d536fd170761",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Check buffers\n",
+ "print(model.trf_blocks[0].att.mask is model.trf_blocks[-1].att.mask)\n",
+ "print(model.trf_blocks[0].att.cos is model.trf_blocks[-1].att.cos)\n",
+ "print(model.trf_blocks[0].att.sin is model.trf_blocks[-1].att.sin) "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8056a521-91a6-440f-8473-591409c3177b",
+ "metadata": {},
+ "source": [
+ "- Let's now also compute the number of trainable parameters:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 18,
+ "id": "6079f747-8f20-4c6b-8d38-7156f1101729",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "6079f747-8f20-4c6b-8d38-7156f1101729",
+ "outputId": "0a8cd23b-d9fa-4c2d-ca63-3fc79bc4de0d"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 8,030,261,248\n"
+ ]
+ }
+ ],
+ "source": [
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Bx14NtzWk2wj",
+ "metadata": {
+ "id": "Bx14NtzWk2wj"
+ },
+ "source": [
+ "- As shown above, the model contains 8 billion parameters\n",
+ "- Additionally, we can calculate the memory requirements for this model using the code below:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 19,
+ "id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "0df1c79e-27a7-4b0f-ba4e-167fe107125a",
+ "outputId": "3425e9ce-d8c0-4b37-bded-a2c60b66a41a"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "float32 (PyTorch default): 68.08 GB\n",
+ "bfloat16: 34.04 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def model_memory_size(model, input_dtype=torch.float32):\n",
+ " total_params = 0\n",
+ " total_grads = 0\n",
+ " for param in model.parameters():\n",
+ " # Calculate total number of elements per parameter\n",
+ " param_size = param.numel()\n",
+ " total_params += param_size\n",
+ " # Check if gradients are stored for this parameter\n",
+ " if param.requires_grad:\n",
+ " total_grads += param_size\n",
+ "\n",
+ " # Calculate buffer size (non-parameters that require memory)\n",
+ " total_buffers = sum(buf.numel() for buf in model.buffers())\n",
+ "\n",
+ " # Size in bytes = (Number of elements) * (Size of each element in bytes)\n",
+ " # We assume parameters and gradients are stored in the same type as input dtype\n",
+ " element_size = torch.tensor(0, dtype=input_dtype).element_size()\n",
+ " total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\n",
+ "\n",
+ " # Convert bytes to gigabytes\n",
+ " total_memory_gb = total_memory_bytes / (1024**3)\n",
+ "\n",
+ " return total_memory_gb\n",
+ "\n",
+ "print(f\"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB\")\n",
+ "print(f\"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "zudd-5PulKFL",
+ "metadata": {
+ "id": "zudd-5PulKFL"
+ },
+ "source": [
+ "- Lastly, we can also transfer the model to an NVIDIA or Apple Silicon GPU if applicable:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 20,
+ "id": "a4c50e19-1402-45b6-8ccd-9077b2ba836d",
+ "metadata": {
+ "id": "a4c50e19-1402-45b6-8ccd-9077b2ba836d"
+ },
+ "outputs": [],
+ "source": [
+ "if torch.cuda.is_available():\n",
+ " device = torch.device(\"cuda\")\n",
+ "elif torch.backends.mps.is_available():\n",
+ " device = torch.device(\"mps\")\n",
+ "else:\n",
+ " device = torch.device(\"cpu\")\n",
+ "\n",
+ "model.to(device);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34",
+ "metadata": {
+ "id": "5dc64a06-27dc-46ec-9e6d-1700a8227d34"
+ },
+ "source": [
+ " \n",
+ "## 3. Load tokenizer"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0eb30f0c-6144-4bed-87d9-6b2bac377005",
+ "metadata": {
+ "id": "0eb30f0c-6144-4bed-87d9-6b2bac377005"
+ },
+ "source": [
+ "- In this section, we are going to load the tokenizer for the model\n",
+ "- Llama 2 used Google's [SentencePiece](https://github.com/google/sentencepiece) tokenizer instead of OpenAI's BPE tokenizer based on the [Tiktoken](https://github.com/openai/tiktoken) library\n",
+ "- Llama 3, however, reverted back to using the BPE tokenizer from Tiktoken; specifically, it uses the GPT-4 tokenizer with an extended vocabulary\n",
+ "- You can find the original Tiktoken-adaptation by Meta AI [here](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py) in their official Llama 3 repository\n",
+ "- Below, I rewrote the tokenizer code to make it more readable and minimal for this notebook (but the behavior should be similar)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 21,
+ "id": "5f390cbf-8f92-46dc-afe3-d90b5affae10",
+ "metadata": {
+ "id": "5f390cbf-8f92-46dc-afe3-d90b5affae10"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "\n",
+ "import tiktoken\n",
+ "from tiktoken.load import load_tiktoken_bpe\n",
+ "\n",
+ "\n",
+ "class Tokenizer:\n",
+ " def __init__(self, model_path):\n",
+ " assert os.path.isfile(model_path), f\"Model file {model_path} not found\"\n",
+ " mergeable_ranks = load_tiktoken_bpe(model_path)\n",
+ "\n",
+ " self.special_tokens = {\n",
+ " \"<|begin_of_text|>\": 128000,\n",
+ " \"<|end_of_text|>\": 128001,\n",
+ " \"<|start_header_id|>\": 128006,\n",
+ " \"<|end_header_id|>\": 128007,\n",
+ " \"<|eot_id|>\": 128009,\n",
+ " }\n",
+ " self.special_tokens.update({\n",
+ " f\"<|reserved_{i}|>\": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()\n",
+ " })\n",
+ "\n",
+ " self.model = tiktoken.Encoding(\n",
+ " name=Path(model_path).name,\n",
+ " pat_str=r\"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?\\p{L}+|\\p{N}{1,3}| ?[^\\s\\p{L}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+\",\n",
+ " mergeable_ranks=mergeable_ranks,\n",
+ " special_tokens=self.special_tokens\n",
+ " )\n",
+ "\n",
+ "\n",
+ " def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):\n",
+ " if bos:\n",
+ " tokens = [self.special_tokens[\"<|begin_of_text|>\"]]\n",
+ " else:\n",
+ " tokens = []\n",
+ "\n",
+ " tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)\n",
+ "\n",
+ " if eos:\n",
+ " tokens.append(self.special_tokens[\"<|end_of_text|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, tokens):\n",
+ " return self.model.decode(tokens)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0a1509f8-8778-4fec-ba32-14d95c646167",
+ "metadata": {
+ "id": "0a1509f8-8778-4fec-ba32-14d95c646167"
+ },
+ "source": [
+ "- Meta AI shared the original Llama 3 model weights and tokenizer vocabulary on the Hugging Face Hub\n",
+ "- We will first download the tokenizer vocabulary from the Hub and load it into the code above"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "KbnlzsbYmJU6",
+ "metadata": {
+ "id": "KbnlzsbYmJU6"
+ },
+ "source": [
+ "- Please note that Meta AI requires that you accept the Llama 3 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) repository to accept the terms\n",
+ "- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \"Settings\"\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "- Then, create and copy the access token so you can copy & paste it into the next code cell\n",
+ "\n",
+ "
\n",
+ "\n",
+ "- Then, create and copy the access token so you can copy & paste it into the next code cell\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "3357a230-b678-4691-a238-257ee4e80185",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "3357a230-b678-4691-a238-257ee4e80185",
+ "outputId": "a3652def-ea7f-46fb-f293-2a59affb71a0"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "The token has not been saved to the git credentials helper. Pass `add_to_git_credential=True` in this function directly or `--add-to-git-credential` if using via `huggingface-cli` if you want to set the git credential as well.\n",
+ "Token is valid (permission: read).\n",
+ "Your token has been saved to /root/.cache/huggingface/token\n",
+ "Login successful\n"
+ ]
+ }
+ ],
+ "source": [
+ "from huggingface_hub import login\n",
+ "import json\n",
+ "\n",
+ "with open(\"config.json\", \"r\") as config_file:\n",
+ " config = json.load(config_file)\n",
+ " access_token = config[\"HF_ACCESS_TOKEN\"]\n",
+ "\n",
+ "login(token=access_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "IxGh6ZYQo0VN",
+ "metadata": {
+ "id": "IxGh6ZYQo0VN"
+ },
+ "source": [
+ "- After login via the access token, which is necessary to verify that we accepted the Llama 3 licensing terms, we can now download the tokenizer vocabulary:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
+ "outputId": "c9836ba8-5176-4dd5-b618-6cc36fdbe1f0"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import hf_hub_download\n",
+ "\n",
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Meta-Llama-3-8B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama3-files\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "F8BH1Nk0AYCS",
+ "metadata": {
+ "id": "F8BH1Nk0AYCS"
+ },
+ "source": [
+ "- Note that for using Llama 3 files, we may need the `blobfile` package, which is used when handling datasets or models stored in cloud storage solutions like Google Cloud Storage (GCS), Azure Blob Storage, or Amazon S3\n",
+ "- You can install this dependency by uncommenting and executing the `pip` command below\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "5dm6Oz7uAytV",
+ "metadata": {
+ "id": "5dm6Oz7uAytV"
+ },
+ "outputs": [],
+ "source": [
+ "# pip install blobfile"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "8b8c0ce6-a6fb-4b8a-8de2-ee7bb7646fd0",
+ "metadata": {
+ "id": "8b8c0ce6-a6fb-4b8a-8de2-ee7bb7646fd0"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "NVhmFeX3pT_M",
+ "metadata": {
+ "id": "NVhmFeX3pT_M"
+ },
+ "source": [
+ "- We can now use the `generate` function to have the Llama 3 model generate new text:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "e0a2b5cd-6cba-4d72-b8ff-04d8315d483e",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "e0a2b5cd-6cba-4d72-b8ff-04d8315d483e",
+ "outputId": "990d7b74-cb35-476b-d8bd-d544006e00f4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Output text:\n",
+ " Every effort_dead aeros Ingredients başında.extensionégor clangmissions güc như submodule.and report官方%,.Reader(\",\");\n",
+ "ामल ندار Parliamentary !!! HigginsDynamicZhgmt writeln Globalsletion 사진------\n"
+ ]
+ }
+ ],
+ "source": [
+ "from previous_chapters import generate, text_to_token_ids, token_ids_to_text\n",
+ "\n",
+ "\n",
+ "torch.manual_seed(123)\n",
+ "\n",
+ "token_ids = generate(\n",
+ " model=model,\n",
+ " idx=text_to_token_ids(\"Every effort\", tokenizer).to(device),\n",
+ " max_new_tokens=30,\n",
+ " context_size=LLAMA3_CONFIG_8B[\"context_length\"],\n",
+ " top_k=1,\n",
+ " temperature=0.\n",
+ ")\n",
+ "\n",
+ "print(\"Output text:\\n\", token_ids_to_text(token_ids, tokenizer))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93WTtAA5paYV",
+ "metadata": {
+ "id": "93WTtAA5paYV"
+ },
+ "source": [
+ "- Of course, as we can see above, the text is nonsensical since we haven't trained the Llama 3 model yet\n",
+ "- In the next section, instead of training it ourselves, which would cost tens to hundreds of thousands of dollars, we load the pretrained weights from Meta AI"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f63cc248-1d27-4eb6-aa50-173b436652f8",
+ "metadata": {
+ "id": "f63cc248-1d27-4eb6-aa50-173b436652f8"
+ },
+ "source": [
+ " \n",
+ "## 4. Load pretrained weights"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aKeN7rUfqZMI",
+ "metadata": {
+ "id": "aKeN7rUfqZMI"
+ },
+ "source": [
+ "- We are loading the [\"meta-llama/Meta-Llama-3-8B\"](https://huggingface.co/meta-llama/Meta-Llama-3-8B) base model below, which is a simple text completion model before finetuning\n",
+ "- Alternatively, you can load the instruction-finetuned and aligned [\"meta-llama/Meta-Llama-3-8B-Instruct\"](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) model by modifying the string in the next code cell accordingly\n",
+ "- Combined, the weight files are about 16 GB large"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "5fa9c06c-7a53-4b4d-9ce4-acc027322ee4",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 145,
+ "referenced_widgets": [
+ "f3788acce34f4956b0727b58d0cf38c6",
+ "6022a9426683420690d9b41a0ca4f870",
+ "e9aba3d53b4d45c485a7aad649c7b465",
+ "f1a12d7929db4309b9881853135359fc",
+ "58c9dec75a3346b1b787f88dd510d254",
+ "9492edc02dee456f840325d913fa4e4f",
+ "66dc94b23556499f985f8accbb1f89cb",
+ "7c6658cfff1a4d27af3de148184f77d9",
+ "7266a729edfb4a44b5b1c67dc79be146",
+ "76dbab4873f342019c5d7624ae2c9775",
+ "3cea4b431147441a8d9bd872811d5974",
+ "8ae98969541849efa356cf912ac39b1e",
+ "f9373112649945e3b446c3e1ec274dc1",
+ "d49791082a304ade95c185c79fae1f41",
+ "616e383bb3d442bcb6edb2721a8180b6",
+ "87f474861e54432e9d533e0a89bb77da",
+ "e805bb6dfee34dab8870f4618d8bffdb",
+ "be3e9bf271f04eb0b119659e1af3a0ea",
+ "00148825ce0248b7a23eb28e3eca6749",
+ "f1a9b0c2431640298a6c1b258298b12d",
+ "8ba9f009e92a46fcbcbb401dc444f12e",
+ "d74186bb74d142dfb683fa347b6990f7",
+ "9bb60a5a3710463ebe3a17f8d2a446be",
+ "0a08fb81165748748ccb080e6df0600f",
+ "603690f543114a7fb6aebd433c80bdc3",
+ "773b802daed942f5a11f3eab3b83be08",
+ "7989003a613e45f780d3f800e121543a",
+ "9d49589118f5432cac49650251046429",
+ "f114549fe8ce49638a791ca2fecb2d89",
+ "0aa155b794a8426aa265f4a7670f43ad",
+ "a06fbde549cc47fdaddfbdb82d35d823",
+ "172c0c6955e1428b999dcb2d133704cd",
+ "1bf7108774c34016a2193e2cd7639b7d",
+ "ed28e180d94a4b7aa548581612e31232",
+ "ff4338faded5494da1ccb660e1c441ed",
+ "b46a08cf4929422eb0f76d8d9af11249",
+ "f049eb4a50f54c34912ca959d2eaf353",
+ "80dfd3e80ceb444a83ec1fd65f9af80e",
+ "519147a10b984befbd0f255f78c1f66a",
+ "562e82438dbe41b793ff488b8447c5bf",
+ "1da83719e47c4196b06f3aa32056b560",
+ "c4a2c88326d14fbca87cfde073755a2e",
+ "f0ab5a46cbb0444c88ed137d8a95002b",
+ "f8f28ac0e149428f9fef42373c6a87d0"
+ ]
+ },
+ "id": "5fa9c06c-7a53-4b4d-9ce4-acc027322ee4",
+ "outputId": "c05118ce-9f81-41c8-a1f2-72caa932ae86"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "245443330e4d40c887a5649cc1663e98",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00\"])\n",
+ " tokens.extend(self.tokenizer.encode(message[\"role\"], bos=False, eos=False))\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|end_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(\"\\n\\n\", bos=False, eos=False))\n",
+ " return tokens\n",
+ "\n",
+ " def encode(self, text):\n",
+ " message = {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": text\n",
+ " }\n",
+ "\n",
+ " tokens = self.encode_header(message)\n",
+ " tokens.extend(\n",
+ " self.tokenizer.encode(message[\"content\"].strip(), bos=False, eos=False)\n",
+ " )\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|eot_id|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, token_ids):\n",
+ " return self.tokenizer.decode(token_ids)\n",
+ "\n",
+ "\n",
+ "chat_tokenizer = ChatFormat(tokenizer)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "M-dkSNvwDttN",
+ "metadata": {
+ "id": "M-dkSNvwDttN"
+ },
+ "source": [
+ "- The usage is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 34,
+ "id": "nwBrTGTsUNhn",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nwBrTGTsUNhn",
+ "outputId": "72a495b4-b872-429a-88ef-49a9b4577f0f"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[128006, 882, 128007, 271, 9906, 4435, 0, 128009]\n"
+ ]
+ }
+ ],
+ "source": [
+ "token_ids = chat_tokenizer.encode(\"Hello World!\")\n",
+ "print(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 35,
+ "id": "0fpmpVgYVTRZ",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 36
+ },
+ "id": "0fpmpVgYVTRZ",
+ "outputId": "bb3e819a-112a-466c-ac51-5d14a9c3475b"
+ },
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'<|start_header_id|>user<|end_header_id|>\\n\\nHello World!<|eot_id|>'"
+ ]
+ },
+ "execution_count": 35,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "tokenizer.decode(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Wo-aUGeKDvqq",
+ "metadata": {
+ "id": "Wo-aUGeKDvqq"
+ },
+ "source": [
+ "- Let's now see the Llama 3 instruction model in action:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 36,
+ "id": "ozGOBu6XOkEW",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "ozGOBu6XOkEW",
+ "outputId": "4f689c70-bed9-46f3-a52a-aea47b641283"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Output text:\n",
+ " Llamas are herbivores, which means they primarily eat plants and plant-based foods. Here are some of the things llamas like to eat:\n",
+ "\n",
+ "1. Grass: Llamas love to graze on grass, especially in the spring and summer months.\n",
+ "2. Hay: Hay is a staple in a llama's diet. They like to eat timothy hay, alfalfa hay, and other types of hay.\n",
+ "3. Grains: Llamas may also be fed grains like oats, barley, and corn. However, grains should not make up more than 10-15% of a llama's diet.\n",
+ "4. Fruits and vegetables: Llamas may enjoy fruits and vegetables as treats, such as\n"
+ ]
+ }
+ ],
+ "source": [
+ "torch.manual_seed(123)\n",
+ "\n",
+ "token_ids = generate(\n",
+ " model=model,\n",
+ " idx=text_to_token_ids(\"What do llamas eat?\", chat_tokenizer).to(device),\n",
+ " max_new_tokens=150,\n",
+ " context_size=LLAMA3_CONFIG_8B[\"context_length\"],\n",
+ " top_k=1,\n",
+ " temperature=0.\n",
+ ")\n",
+ "\n",
+ "output_text = token_ids_to_text(token_ids, tokenizer)\n",
+ "\n",
+ "\n",
+ "def clean_text(text, header_end=\"assistant<|end_header_id|>\\n\\n\"):\n",
+ " # Find the index of the first occurrence of \"<|end_header_id|>\"\n",
+ " index = text.find(header_end)\n",
+ "\n",
+ " if index != -1:\n",
+ " # Return the substring starting after \"<|end_header_id|>\"\n",
+ " return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\n",
+ " else:\n",
+ " # If the token is not found, return the original text\n",
+ " return text\n",
+ "\n",
+ "print(\"Output text:\\n\", clean_text(output_text))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2r5JKrO-ZOHK",
+ "metadata": {
+ "id": "2r5JKrO-ZOHK"
+ },
+ "source": [
+ " \n",
+ "# Llama 3.1 8B"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "QiQxX0XnP_iC",
+ "metadata": {
+ "id": "QiQxX0XnP_iC"
+ },
+ "source": [
+ "- A few months after the initial Llama 3 release, Meta AI followed up with their Llama 3.1 suite of models (see the official [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/) announcement blog post for details)\n",
+ "- Conveniently, we can reuse our previous Llama 3 code from above to implement Llama 3.1 8B\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 22,
+ "id": "3357a230-b678-4691-a238-257ee4e80185",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "3357a230-b678-4691-a238-257ee4e80185",
+ "outputId": "a3652def-ea7f-46fb-f293-2a59affb71a0"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "The token has not been saved to the git credentials helper. Pass `add_to_git_credential=True` in this function directly or `--add-to-git-credential` if using via `huggingface-cli` if you want to set the git credential as well.\n",
+ "Token is valid (permission: read).\n",
+ "Your token has been saved to /root/.cache/huggingface/token\n",
+ "Login successful\n"
+ ]
+ }
+ ],
+ "source": [
+ "from huggingface_hub import login\n",
+ "import json\n",
+ "\n",
+ "with open(\"config.json\", \"r\") as config_file:\n",
+ " config = json.load(config_file)\n",
+ " access_token = config[\"HF_ACCESS_TOKEN\"]\n",
+ "\n",
+ "login(token=access_token)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "IxGh6ZYQo0VN",
+ "metadata": {
+ "id": "IxGh6ZYQo0VN"
+ },
+ "source": [
+ "- After login via the access token, which is necessary to verify that we accepted the Llama 3 licensing terms, we can now download the tokenizer vocabulary:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 23,
+ "id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "69714ea8-b9b8-4687-8392-f3abb8f93a32",
+ "outputId": "c9836ba8-5176-4dd5-b618-6cc36fdbe1f0"
+ },
+ "outputs": [],
+ "source": [
+ "from huggingface_hub import hf_hub_download\n",
+ "\n",
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Meta-Llama-3-8B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama3-files\"\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "F8BH1Nk0AYCS",
+ "metadata": {
+ "id": "F8BH1Nk0AYCS"
+ },
+ "source": [
+ "- Note that for using Llama 3 files, we may need the `blobfile` package, which is used when handling datasets or models stored in cloud storage solutions like Google Cloud Storage (GCS), Azure Blob Storage, or Amazon S3\n",
+ "- You can install this dependency by uncommenting and executing the `pip` command below\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 24,
+ "id": "5dm6Oz7uAytV",
+ "metadata": {
+ "id": "5dm6Oz7uAytV"
+ },
+ "outputs": [],
+ "source": [
+ "# pip install blobfile"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 25,
+ "id": "8b8c0ce6-a6fb-4b8a-8de2-ee7bb7646fd0",
+ "metadata": {
+ "id": "8b8c0ce6-a6fb-4b8a-8de2-ee7bb7646fd0"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "NVhmFeX3pT_M",
+ "metadata": {
+ "id": "NVhmFeX3pT_M"
+ },
+ "source": [
+ "- We can now use the `generate` function to have the Llama 3 model generate new text:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 26,
+ "id": "e0a2b5cd-6cba-4d72-b8ff-04d8315d483e",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "e0a2b5cd-6cba-4d72-b8ff-04d8315d483e",
+ "outputId": "990d7b74-cb35-476b-d8bd-d544006e00f4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Output text:\n",
+ " Every effort_dead aeros Ingredients başında.extensionégor clangmissions güc như submodule.and report官方%,.Reader(\",\");\n",
+ "ामल ندار Parliamentary !!! HigginsDynamicZhgmt writeln Globalsletion 사진------\n"
+ ]
+ }
+ ],
+ "source": [
+ "from previous_chapters import generate, text_to_token_ids, token_ids_to_text\n",
+ "\n",
+ "\n",
+ "torch.manual_seed(123)\n",
+ "\n",
+ "token_ids = generate(\n",
+ " model=model,\n",
+ " idx=text_to_token_ids(\"Every effort\", tokenizer).to(device),\n",
+ " max_new_tokens=30,\n",
+ " context_size=LLAMA3_CONFIG_8B[\"context_length\"],\n",
+ " top_k=1,\n",
+ " temperature=0.\n",
+ ")\n",
+ "\n",
+ "print(\"Output text:\\n\", token_ids_to_text(token_ids, tokenizer))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "93WTtAA5paYV",
+ "metadata": {
+ "id": "93WTtAA5paYV"
+ },
+ "source": [
+ "- Of course, as we can see above, the text is nonsensical since we haven't trained the Llama 3 model yet\n",
+ "- In the next section, instead of training it ourselves, which would cost tens to hundreds of thousands of dollars, we load the pretrained weights from Meta AI"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f63cc248-1d27-4eb6-aa50-173b436652f8",
+ "metadata": {
+ "id": "f63cc248-1d27-4eb6-aa50-173b436652f8"
+ },
+ "source": [
+ " \n",
+ "## 4. Load pretrained weights"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aKeN7rUfqZMI",
+ "metadata": {
+ "id": "aKeN7rUfqZMI"
+ },
+ "source": [
+ "- We are loading the [\"meta-llama/Meta-Llama-3-8B\"](https://huggingface.co/meta-llama/Meta-Llama-3-8B) base model below, which is a simple text completion model before finetuning\n",
+ "- Alternatively, you can load the instruction-finetuned and aligned [\"meta-llama/Meta-Llama-3-8B-Instruct\"](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) model by modifying the string in the next code cell accordingly\n",
+ "- Combined, the weight files are about 16 GB large"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "id": "5fa9c06c-7a53-4b4d-9ce4-acc027322ee4",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 145,
+ "referenced_widgets": [
+ "f3788acce34f4956b0727b58d0cf38c6",
+ "6022a9426683420690d9b41a0ca4f870",
+ "e9aba3d53b4d45c485a7aad649c7b465",
+ "f1a12d7929db4309b9881853135359fc",
+ "58c9dec75a3346b1b787f88dd510d254",
+ "9492edc02dee456f840325d913fa4e4f",
+ "66dc94b23556499f985f8accbb1f89cb",
+ "7c6658cfff1a4d27af3de148184f77d9",
+ "7266a729edfb4a44b5b1c67dc79be146",
+ "76dbab4873f342019c5d7624ae2c9775",
+ "3cea4b431147441a8d9bd872811d5974",
+ "8ae98969541849efa356cf912ac39b1e",
+ "f9373112649945e3b446c3e1ec274dc1",
+ "d49791082a304ade95c185c79fae1f41",
+ "616e383bb3d442bcb6edb2721a8180b6",
+ "87f474861e54432e9d533e0a89bb77da",
+ "e805bb6dfee34dab8870f4618d8bffdb",
+ "be3e9bf271f04eb0b119659e1af3a0ea",
+ "00148825ce0248b7a23eb28e3eca6749",
+ "f1a9b0c2431640298a6c1b258298b12d",
+ "8ba9f009e92a46fcbcbb401dc444f12e",
+ "d74186bb74d142dfb683fa347b6990f7",
+ "9bb60a5a3710463ebe3a17f8d2a446be",
+ "0a08fb81165748748ccb080e6df0600f",
+ "603690f543114a7fb6aebd433c80bdc3",
+ "773b802daed942f5a11f3eab3b83be08",
+ "7989003a613e45f780d3f800e121543a",
+ "9d49589118f5432cac49650251046429",
+ "f114549fe8ce49638a791ca2fecb2d89",
+ "0aa155b794a8426aa265f4a7670f43ad",
+ "a06fbde549cc47fdaddfbdb82d35d823",
+ "172c0c6955e1428b999dcb2d133704cd",
+ "1bf7108774c34016a2193e2cd7639b7d",
+ "ed28e180d94a4b7aa548581612e31232",
+ "ff4338faded5494da1ccb660e1c441ed",
+ "b46a08cf4929422eb0f76d8d9af11249",
+ "f049eb4a50f54c34912ca959d2eaf353",
+ "80dfd3e80ceb444a83ec1fd65f9af80e",
+ "519147a10b984befbd0f255f78c1f66a",
+ "562e82438dbe41b793ff488b8447c5bf",
+ "1da83719e47c4196b06f3aa32056b560",
+ "c4a2c88326d14fbca87cfde073755a2e",
+ "f0ab5a46cbb0444c88ed137d8a95002b",
+ "f8f28ac0e149428f9fef42373c6a87d0"
+ ]
+ },
+ "id": "5fa9c06c-7a53-4b4d-9ce4-acc027322ee4",
+ "outputId": "c05118ce-9f81-41c8-a1f2-72caa932ae86"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "245443330e4d40c887a5649cc1663e98",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00\"])\n",
+ " tokens.extend(self.tokenizer.encode(message[\"role\"], bos=False, eos=False))\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|end_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(\"\\n\\n\", bos=False, eos=False))\n",
+ " return tokens\n",
+ "\n",
+ " def encode(self, text):\n",
+ " message = {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": text\n",
+ " }\n",
+ "\n",
+ " tokens = self.encode_header(message)\n",
+ " tokens.extend(\n",
+ " self.tokenizer.encode(message[\"content\"].strip(), bos=False, eos=False)\n",
+ " )\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|eot_id|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, token_ids):\n",
+ " return self.tokenizer.decode(token_ids)\n",
+ "\n",
+ "\n",
+ "chat_tokenizer = ChatFormat(tokenizer)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "M-dkSNvwDttN",
+ "metadata": {
+ "id": "M-dkSNvwDttN"
+ },
+ "source": [
+ "- The usage is as follows:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 34,
+ "id": "nwBrTGTsUNhn",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "nwBrTGTsUNhn",
+ "outputId": "72a495b4-b872-429a-88ef-49a9b4577f0f"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "[128006, 882, 128007, 271, 9906, 4435, 0, 128009]\n"
+ ]
+ }
+ ],
+ "source": [
+ "token_ids = chat_tokenizer.encode(\"Hello World!\")\n",
+ "print(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 35,
+ "id": "0fpmpVgYVTRZ",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 36
+ },
+ "id": "0fpmpVgYVTRZ",
+ "outputId": "bb3e819a-112a-466c-ac51-5d14a9c3475b"
+ },
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "'<|start_header_id|>user<|end_header_id|>\\n\\nHello World!<|eot_id|>'"
+ ]
+ },
+ "execution_count": 35,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "tokenizer.decode(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Wo-aUGeKDvqq",
+ "metadata": {
+ "id": "Wo-aUGeKDvqq"
+ },
+ "source": [
+ "- Let's now see the Llama 3 instruction model in action:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 36,
+ "id": "ozGOBu6XOkEW",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "ozGOBu6XOkEW",
+ "outputId": "4f689c70-bed9-46f3-a52a-aea47b641283"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Output text:\n",
+ " Llamas are herbivores, which means they primarily eat plants and plant-based foods. Here are some of the things llamas like to eat:\n",
+ "\n",
+ "1. Grass: Llamas love to graze on grass, especially in the spring and summer months.\n",
+ "2. Hay: Hay is a staple in a llama's diet. They like to eat timothy hay, alfalfa hay, and other types of hay.\n",
+ "3. Grains: Llamas may also be fed grains like oats, barley, and corn. However, grains should not make up more than 10-15% of a llama's diet.\n",
+ "4. Fruits and vegetables: Llamas may enjoy fruits and vegetables as treats, such as\n"
+ ]
+ }
+ ],
+ "source": [
+ "torch.manual_seed(123)\n",
+ "\n",
+ "token_ids = generate(\n",
+ " model=model,\n",
+ " idx=text_to_token_ids(\"What do llamas eat?\", chat_tokenizer).to(device),\n",
+ " max_new_tokens=150,\n",
+ " context_size=LLAMA3_CONFIG_8B[\"context_length\"],\n",
+ " top_k=1,\n",
+ " temperature=0.\n",
+ ")\n",
+ "\n",
+ "output_text = token_ids_to_text(token_ids, tokenizer)\n",
+ "\n",
+ "\n",
+ "def clean_text(text, header_end=\"assistant<|end_header_id|>\\n\\n\"):\n",
+ " # Find the index of the first occurrence of \"<|end_header_id|>\"\n",
+ " index = text.find(header_end)\n",
+ "\n",
+ " if index != -1:\n",
+ " # Return the substring starting after \"<|end_header_id|>\"\n",
+ " return text[index + len(header_end):].strip() # Strip removes leading/trailing whitespace\n",
+ " else:\n",
+ " # If the token is not found, return the original text\n",
+ " return text\n",
+ "\n",
+ "print(\"Output text:\\n\", clean_text(output_text))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2r5JKrO-ZOHK",
+ "metadata": {
+ "id": "2r5JKrO-ZOHK"
+ },
+ "source": [
+ " \n",
+ "# Llama 3.1 8B"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "QiQxX0XnP_iC",
+ "metadata": {
+ "id": "QiQxX0XnP_iC"
+ },
+ "source": [
+ "- A few months after the initial Llama 3 release, Meta AI followed up with their Llama 3.1 suite of models (see the official [Introducing Llama 3.1: Our most capable models to date](https://ai.meta.com/blog/meta-llama-3-1/) announcement blog post for details)\n",
+ "- Conveniently, we can reuse our previous Llama 3 code from above to implement Llama 3.1 8B\n",
+ "\n",
+ " \n",
+ "\n",
+ "- The architecture is identical, with the only change being a rescaling of the RoPE frequencies as indicated in the configuration file below\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 37,
+ "id": "X5Fg8XUHMv4M",
+ "metadata": {
+ "id": "X5Fg8XUHMv4M"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA3_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 8192, # Context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"rope_freq\": None, # Additional configuration for adjusting the RoPE frequencies\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}\n",
+ "\n",
+ "LLAMA31_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # NEW: Larger supported context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # NEW: RoPE frequency scaling\n",
+ " \"factor\": 8.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d81ee464-c112-43b0-9ee8-70df6ac942d0",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9bdbe32f-4c96-4e60-8bf4-52b5217df1e6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "xa3bpMDtTdBs",
+ "metadata": {
+ "id": "xa3bpMDtTdBs"
+ },
+ "source": [
+ "- As we've seen in the code earlier, the RoPE method uses sinusoidal functions (sine and cosine) to embed positional information directly into the attention mechanism\n",
+ "- In Llama 3.1, via the additional configuration, we introduce additional adjustments to the inverse frequency calculations\n",
+ "- These adjustments influence how different frequency components contribute to the positional embeddings (a detailed explanation is a topic for another time)\n",
+ "- Let's try out the Llama 3.1 model in practice; first, we clear out the old model to free up some GPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 38,
+ "id": "7dUtYnNUOqhL",
+ "metadata": {
+ "id": "7dUtYnNUOqhL"
+ },
+ "outputs": [],
+ "source": [
+ "# free up memory\n",
+ "del model\n",
+ "\n",
+ "gc.collect() # Run Python garbage collector\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "DbbVsll6TYWR",
+ "metadata": {
+ "id": "DbbVsll6TYWR"
+ },
+ "source": [
+ "- Next, we download the tokenizer\n",
+ "- Note that since the Llama 3.1 family is distinct from the Llama 3 family, you'd have to go to the [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\n",
+ "- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\"meta-llama/Llama-3.1-8B\"` with `\"meta-llama/Llama-3.1-8B-Instruct\"`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 39,
+ "id": "8xDk4chtPNU4",
+ "metadata": {
+ "id": "8xDk4chtPNU4"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Llama-3.1-8B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama31-files\"\n",
+ ")\n",
+ "\n",
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 40,
+ "id": "a7l21VE4Otcs",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "a7l21VE4Otcs",
+ "outputId": "3dd5cfba-bf3f-44d2-9be1-7cd42bfe4ba9"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 8,030,261,248\n"
+ ]
+ }
+ ],
+ "source": [
+ "model = Llama3Model(LLAMA31_CONFIG_8B)\n",
+ "\n",
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 41,
+ "id": "u4J7IxOvOyPM",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 145,
+ "referenced_widgets": [
+ "5bbaa046d8934c8fae0a12c3d7bd991b",
+ "e1e4125eac004bae92dc1f22f673bf0e",
+ "d5b4bb4891ec4e44be46e9815c7e10dc",
+ "4f6595a392b244bd8e887935defc06f0",
+ "100c1b15cc4046cea1147f657eb2d8d0",
+ "81458e7953a349cfafccaa213b370406",
+ "a3dc9dfadae642b4a873705596739468",
+ "f55b59efcefa4ad5955d082f4bf7c637",
+ "1b02e0c7d1604b1c87a327c4c4f8b0e7",
+ "02ad170019454fd096b37347de5c481d",
+ "c52e0f34892b4daa84c1bf61500ac399",
+ "af985cf6fa26475eb2c4dd81e0c79ff4",
+ "8659c3eddb014c3bb5931fd9e6fadad8",
+ "f5fa00d96c4c49e48e1806d23a5b8570",
+ "080c484114f64f5591fa1287a35b46c9",
+ "14dc6a3717484c55a116612e28447dbb",
+ "00d3286c9c1d4161bb777b7b65ae744d",
+ "66f27fb11edf453b8144c2dfcdc66baa",
+ "5798e5118430439fb1f6bf29e1bafe58",
+ "357f367cf74146b8825be371acd51d06",
+ "94073be250cd42d5b82e196e30cbf22e",
+ "0cd0724f825e480389a82f0c49f91e6d",
+ "dffa208978f34e6a9aae94ecda92fe67",
+ "b8a98f163ebd4ac89af08a49c0881c23",
+ "f0d9febe1a634a0ba7e8e50fa104dcc2",
+ "e23870f0c7ff40cc8fa6a1e862a4af99",
+ "87da9905a0534c26ad0712ad426ca930",
+ "b953419300604b8e86fc0ad003fdfd2f",
+ "f1865ed0fbcc40eeabdca90a43d00069",
+ "ea0128909a9d4801ba312a876b0cf183",
+ "d160986df978416c9ad91d1e10fc90fc",
+ "5e97f7c2e8f5453dafcdad0552060e60",
+ "4b3e7b8774df4b458bb6c6146fe3226d",
+ "2ffd8dbed00e46d2887b9a2590cad297",
+ "a06dcb3bdfc84905a7222066c32fe500",
+ "e7602abc26714ee890a0cf5c0c7b67e1",
+ "dc5d555099f64a998514ebde90eeb6df",
+ "ef93a2f58cc54373941f43658bb808cf",
+ "fea1e2327d2944859af3d91c216b9008",
+ "320c00a5d18c45ccae634d166f1bd810",
+ "6c857e69d5204cd3b7c3bf426993ad1f",
+ "2145e47428f1446fba3e62b3cde0a7f5",
+ "3d519ce3562c4e249bf392c7f43d04c0",
+ "cc20ffcf0c1a4656945959bf457dfd84"
+ ]
+ },
+ "id": "u4J7IxOvOyPM",
+ "outputId": "925348d7-fc69-4d1b-90f1-7029426bcfcf"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eabfde3ef38b436ea750e6fb50a02b5c",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "K0KgjwCCJ9Fb",
+ "metadata": {
+ "id": "K0KgjwCCJ9Fb"
+ },
+ "source": [
+ "- As we can see based on the figure above, the main difference between the Llama 3.1 8B and Llama 3.2 1B architectures are the respective sizes\n",
+ "- A small additional change is an increased RoPE rescaling factor, which is reflected in the configuration file below"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 43,
+ "id": "Yv_yF3NCQTBx",
+ "metadata": {
+ "id": "Yv_yF3NCQTBx"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA31_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # NEW: Larger supported context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # NEW: RoPE frequency scaling\n",
+ " \"factor\": 8.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "\n",
+ "LLAMA32_CONFIG_1B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # Context length\n",
+ " \"emb_dim\": 2048, # NEW: Half the embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 16, # NEW: Half the number of layers\n",
+ " \"hidden_dim\": 8192, # NEW: Almost half the size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # RoPE frequency scaling\n",
+ " \"factor\": 32.0, # NEW: Adjustment of the rescaling factor\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b5cd351b-d883-460d-9cdc-47e15ddb884a",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "387456c3-c6a1-46fe-8830-6e00eb46ac13",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Dl4_0EoJKKYv",
+ "metadata": {
+ "id": "Dl4_0EoJKKYv"
+ },
+ "source": [
+ "- Below, we can reuse the code from the Llama 3.1 8B section to load the Llama 3.2 1B model\n",
+ "- Again, since the Llama 3.2 family is distinct from the Llama 3.1 family, you'd have to go to the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\n",
+ "- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\"meta-llama/Llama-3.2-1B\"` with `\"meta-llama/Llama-3.2-1B-Instruct\"`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 44,
+ "id": "tCstHgyRRD2x",
+ "metadata": {
+ "id": "tCstHgyRRD2x"
+ },
+ "outputs": [],
+ "source": [
+ "# free up memory\n",
+ "del model\n",
+ "\n",
+ "\n",
+ "gc.collect() # Run Python garbage collector\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 45,
+ "id": "jt8BKAHXRCPI",
+ "metadata": {
+ "id": "jt8BKAHXRCPI"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Llama-3.2-1B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama32-files\"\n",
+ ")\n",
+ "\n",
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 46,
+ "id": "uf8KjasmRFSt",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "uf8KjasmRFSt",
+ "outputId": "4e718852-2aa1-4b5a-bec3-3d5f866a4038"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 1,498,482,688\n",
+ "\n",
+ "Total number of unique parameters: 1,235,814,400\n"
+ ]
+ }
+ ],
+ "source": [
+ "model = Llama3Model(LLAMA32_CONFIG_1B)\n",
+ "\n",
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")\n",
+ "\n",
+ "# Account for weight tying\n",
+ "total_params_normalized = total_params - model.tok_emb.weight.numel()\n",
+ "print(f\"\\nTotal number of unique parameters: {total_params_normalized:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 47,
+ "id": "9FbCIYW7RIOe",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "9FbCIYW7RIOe",
+ "outputId": "35588405-e2e1-4871-a1db-1d4bcb852e49"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "c309c56a6cdf426e8ba7967b6a21864e",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model.safetensors: 0%| | 0.00/2.47G [00:00=3.0.0
huggingface_hub>=0.24.7
-sentencepiece>=0.1.99
\ No newline at end of file
+ipywidgets>=8.1.2
+safetensors>=0.4.4
+sentencepiece>=0.1.99
diff --git a/ch05/07_gpt_to_llama/standalone-llama32.ipynb b/ch05/07_gpt_to_llama/standalone-llama32.ipynb
new file mode 100644
index 00000000..a9398a25
--- /dev/null
+++ b/ch05/07_gpt_to_llama/standalone-llama32.ipynb
@@ -0,0 +1,1069 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c",
+ "metadata": {},
+ "source": [
+ "
\n",
+ "\n",
+ "- The architecture is identical, with the only change being a rescaling of the RoPE frequencies as indicated in the configuration file below\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 37,
+ "id": "X5Fg8XUHMv4M",
+ "metadata": {
+ "id": "X5Fg8XUHMv4M"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA3_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 8192, # Context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"rope_freq\": None, # Additional configuration for adjusting the RoPE frequencies\n",
+ " \"dtype\": torch.bfloat16 # Lower-precision dtype to save memory\n",
+ "}\n",
+ "\n",
+ "LLAMA31_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # NEW: Larger supported context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # NEW: RoPE frequency scaling\n",
+ " \"factor\": 8.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d81ee464-c112-43b0-9ee8-70df6ac942d0",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9bdbe32f-4c96-4e60-8bf4-52b5217df1e6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "xa3bpMDtTdBs",
+ "metadata": {
+ "id": "xa3bpMDtTdBs"
+ },
+ "source": [
+ "- As we've seen in the code earlier, the RoPE method uses sinusoidal functions (sine and cosine) to embed positional information directly into the attention mechanism\n",
+ "- In Llama 3.1, via the additional configuration, we introduce additional adjustments to the inverse frequency calculations\n",
+ "- These adjustments influence how different frequency components contribute to the positional embeddings (a detailed explanation is a topic for another time)\n",
+ "- Let's try out the Llama 3.1 model in practice; first, we clear out the old model to free up some GPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 38,
+ "id": "7dUtYnNUOqhL",
+ "metadata": {
+ "id": "7dUtYnNUOqhL"
+ },
+ "outputs": [],
+ "source": [
+ "# free up memory\n",
+ "del model\n",
+ "\n",
+ "gc.collect() # Run Python garbage collector\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "DbbVsll6TYWR",
+ "metadata": {
+ "id": "DbbVsll6TYWR"
+ },
+ "source": [
+ "- Next, we download the tokenizer\n",
+ "- Note that since the Llama 3.1 family is distinct from the Llama 3 family, you'd have to go to the [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\n",
+ "- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\"meta-llama/Llama-3.1-8B\"` with `\"meta-llama/Llama-3.1-8B-Instruct\"`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 39,
+ "id": "8xDk4chtPNU4",
+ "metadata": {
+ "id": "8xDk4chtPNU4"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Llama-3.1-8B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama31-files\"\n",
+ ")\n",
+ "\n",
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 40,
+ "id": "a7l21VE4Otcs",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "a7l21VE4Otcs",
+ "outputId": "3dd5cfba-bf3f-44d2-9be1-7cd42bfe4ba9"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 8,030,261,248\n"
+ ]
+ }
+ ],
+ "source": [
+ "model = Llama3Model(LLAMA31_CONFIG_8B)\n",
+ "\n",
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 41,
+ "id": "u4J7IxOvOyPM",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 145,
+ "referenced_widgets": [
+ "5bbaa046d8934c8fae0a12c3d7bd991b",
+ "e1e4125eac004bae92dc1f22f673bf0e",
+ "d5b4bb4891ec4e44be46e9815c7e10dc",
+ "4f6595a392b244bd8e887935defc06f0",
+ "100c1b15cc4046cea1147f657eb2d8d0",
+ "81458e7953a349cfafccaa213b370406",
+ "a3dc9dfadae642b4a873705596739468",
+ "f55b59efcefa4ad5955d082f4bf7c637",
+ "1b02e0c7d1604b1c87a327c4c4f8b0e7",
+ "02ad170019454fd096b37347de5c481d",
+ "c52e0f34892b4daa84c1bf61500ac399",
+ "af985cf6fa26475eb2c4dd81e0c79ff4",
+ "8659c3eddb014c3bb5931fd9e6fadad8",
+ "f5fa00d96c4c49e48e1806d23a5b8570",
+ "080c484114f64f5591fa1287a35b46c9",
+ "14dc6a3717484c55a116612e28447dbb",
+ "00d3286c9c1d4161bb777b7b65ae744d",
+ "66f27fb11edf453b8144c2dfcdc66baa",
+ "5798e5118430439fb1f6bf29e1bafe58",
+ "357f367cf74146b8825be371acd51d06",
+ "94073be250cd42d5b82e196e30cbf22e",
+ "0cd0724f825e480389a82f0c49f91e6d",
+ "dffa208978f34e6a9aae94ecda92fe67",
+ "b8a98f163ebd4ac89af08a49c0881c23",
+ "f0d9febe1a634a0ba7e8e50fa104dcc2",
+ "e23870f0c7ff40cc8fa6a1e862a4af99",
+ "87da9905a0534c26ad0712ad426ca930",
+ "b953419300604b8e86fc0ad003fdfd2f",
+ "f1865ed0fbcc40eeabdca90a43d00069",
+ "ea0128909a9d4801ba312a876b0cf183",
+ "d160986df978416c9ad91d1e10fc90fc",
+ "5e97f7c2e8f5453dafcdad0552060e60",
+ "4b3e7b8774df4b458bb6c6146fe3226d",
+ "2ffd8dbed00e46d2887b9a2590cad297",
+ "a06dcb3bdfc84905a7222066c32fe500",
+ "e7602abc26714ee890a0cf5c0c7b67e1",
+ "dc5d555099f64a998514ebde90eeb6df",
+ "ef93a2f58cc54373941f43658bb808cf",
+ "fea1e2327d2944859af3d91c216b9008",
+ "320c00a5d18c45ccae634d166f1bd810",
+ "6c857e69d5204cd3b7c3bf426993ad1f",
+ "2145e47428f1446fba3e62b3cde0a7f5",
+ "3d519ce3562c4e249bf392c7f43d04c0",
+ "cc20ffcf0c1a4656945959bf457dfd84"
+ ]
+ },
+ "id": "u4J7IxOvOyPM",
+ "outputId": "925348d7-fc69-4d1b-90f1-7029426bcfcf"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "eabfde3ef38b436ea750e6fb50a02b5c",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model-00001-of-00004.safetensors: 0%| | 0.00/4.98G [00:00"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "K0KgjwCCJ9Fb",
+ "metadata": {
+ "id": "K0KgjwCCJ9Fb"
+ },
+ "source": [
+ "- As we can see based on the figure above, the main difference between the Llama 3.1 8B and Llama 3.2 1B architectures are the respective sizes\n",
+ "- A small additional change is an increased RoPE rescaling factor, which is reflected in the configuration file below"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 43,
+ "id": "Yv_yF3NCQTBx",
+ "metadata": {
+ "id": "Yv_yF3NCQTBx"
+ },
+ "outputs": [],
+ "source": [
+ "LLAMA31_CONFIG_8B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # NEW: Larger supported context length\n",
+ " \"emb_dim\": 4096, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 32, # Number of layers\n",
+ " \"hidden_dim\": 14_336, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # NEW: RoPE frequency scaling\n",
+ " \"factor\": 8.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "\n",
+ "LLAMA32_CONFIG_1B = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # Context length\n",
+ " \"emb_dim\": 2048, # NEW: Half the embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 16, # NEW: Half the number of layers\n",
+ " \"hidden_dim\": 8192, # NEW: Almost half the size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # RoPE frequency scaling\n",
+ " \"factor\": 32.0, # NEW: Adjustment of the rescaling factor\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b5cd351b-d883-460d-9cdc-47e15ddb884a",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "387456c3-c6a1-46fe-8830-6e00eb46ac13",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "Dl4_0EoJKKYv",
+ "metadata": {
+ "id": "Dl4_0EoJKKYv"
+ },
+ "source": [
+ "- Below, we can reuse the code from the Llama 3.1 8B section to load the Llama 3.2 1B model\n",
+ "- Again, since the Llama 3.2 family is distinct from the Llama 3.1 family, you'd have to go to the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository and acknowledge the license terms for your Hugging Face access token to work for the download\n",
+ "- Tip: For simplicity, we only load the base model below, but there's also an instruction-finetuned version you can use by replacing `\"meta-llama/Llama-3.2-1B\"` with `\"meta-llama/Llama-3.2-1B-Instruct\"`"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 44,
+ "id": "tCstHgyRRD2x",
+ "metadata": {
+ "id": "tCstHgyRRD2x"
+ },
+ "outputs": [],
+ "source": [
+ "# free up memory\n",
+ "del model\n",
+ "\n",
+ "\n",
+ "gc.collect() # Run Python garbage collector\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " torch.cuda.empty_cache()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 45,
+ "id": "jt8BKAHXRCPI",
+ "metadata": {
+ "id": "jt8BKAHXRCPI"
+ },
+ "outputs": [],
+ "source": [
+ "tokenizer_file_path = hf_hub_download(\n",
+ " repo_id=\"meta-llama/Llama-3.2-1B\",\n",
+ " filename=\"original/tokenizer.model\",\n",
+ " local_dir=\"llama32-files\"\n",
+ ")\n",
+ "\n",
+ "tokenizer = Tokenizer(tokenizer_file_path)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 46,
+ "id": "uf8KjasmRFSt",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "uf8KjasmRFSt",
+ "outputId": "4e718852-2aa1-4b5a-bec3-3d5f866a4038"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 1,498,482,688\n",
+ "\n",
+ "Total number of unique parameters: 1,235,814,400\n"
+ ]
+ }
+ ],
+ "source": [
+ "model = Llama3Model(LLAMA32_CONFIG_1B)\n",
+ "\n",
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")\n",
+ "\n",
+ "# Account for weight tying\n",
+ "total_params_normalized = total_params - model.tok_emb.weight.numel()\n",
+ "print(f\"\\nTotal number of unique parameters: {total_params_normalized:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 47,
+ "id": "9FbCIYW7RIOe",
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "9FbCIYW7RIOe",
+ "outputId": "35588405-e2e1-4871-a1db-1d4bcb852e49"
+ },
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "c309c56a6cdf426e8ba7967b6a21864e",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "model.safetensors: 0%| | 0.00/2.47G [00:00=3.0.0
huggingface_hub>=0.24.7
-sentencepiece>=0.1.99
\ No newline at end of file
+ipywidgets>=8.1.2
+safetensors>=0.4.4
+sentencepiece>=0.1.99
diff --git a/ch05/07_gpt_to_llama/standalone-llama32.ipynb b/ch05/07_gpt_to_llama/standalone-llama32.ipynb
new file mode 100644
index 00000000..a9398a25
--- /dev/null
+++ b/ch05/07_gpt_to_llama/standalone-llama32.ipynb
@@ -0,0 +1,1069 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e1b280ab-b61f-4d1a-bf7e-44e5f9ed3a5c",
+ "metadata": {},
+ "source": [
+ "| \n",
+ "\n",
+ "Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \n", + " Code repository: https://github.com/rasbt/LLMs-from-scratch\n", + "\n", + " | \n",
+ "\n",
+ "\n",
+ " | \n",
+ "
 \n",
+ " \n",
+ " \n",
+ "- About the code:\n",
+ " - all code is my own code, mapping the Llama 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\n",
+ " - the tokenizer code is inspired by the original [Llama 3 tokenizer code](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py), which Meta AI used to to extends the Tiktoken GPT-4 tokenizer\n",
+ " - the RoPE rescaling section is inspired by the [_compute_llama3_parameters function](https://github.com/huggingface/transformers/blob/5c1027bf09717f664b579e01cbb8ec3ef5aeb140/src/transformers/modeling_rope_utils.py#L329-L347) in the `transformers` library"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "beef121b-2454-4577-8b56-aa00961089cb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "dd1b65a8-4301-444a-bd7c-a6f2bd1df9df",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "blobfile version: 3.0.0\n",
+ "huggingface_hub version: 0.25.1\n",
+ "tiktoken version: 0.7.0\n",
+ "torch version: 2.4.0\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"blobfile\", # to download pretrained weights\n",
+ " \"huggingface_hub\", # to download pretrained weights\n",
+ " \"tiktoken\", # to implement the tokenizer\n",
+ " \"torch\", # to implement the model\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "653410a6-dd2b-4eb2-a722-23d9782e726d",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 1. Architecture code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "82076c21-9331-4dcd-b017-42b046cf1a60",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "\n",
+ "\n",
+ "class FeedForward(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.fc1 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ " self.fc2 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ " self.fc3 = nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " x_fc1 = self.fc1(x)\n",
+ " x_fc2 = self.fc2(x)\n",
+ " x = nn.functional.silu(x_fc1) * x_fc2\n",
+ " return self.fc3(x)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "4b9a346f-5826-4083-9162-abd56afc03f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):\n",
+ " assert head_dim % 2 == 0, \"Embedding dimension must be even\"\n",
+ "\n",
+ " # Compute the inverse frequencies\n",
+ " inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))\n",
+ "\n",
+ " # Frequency adjustments\n",
+ " if freq_config is not None:\n",
+ " low_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"low_freq_factor\"]\n",
+ " high_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"high_freq_factor\"]\n",
+ "\n",
+ " wavelen = 2 * torch.pi / inv_freq\n",
+ "\n",
+ " inv_freq_llama = torch.where(\n",
+ " wavelen > low_freq_wavelen, inv_freq / freq_config[\"factor\"], inv_freq\n",
+ " )\n",
+ "\n",
+ " smooth_factor = (freq_config[\"original_context_length\"] / wavelen - freq_config[\"low_freq_factor\"]) / (\n",
+ " freq_config[\"high_freq_factor\"] - freq_config[\"low_freq_factor\"]\n",
+ " )\n",
+ "\n",
+ " smoothed_inv_freq = (\n",
+ " (1 - smooth_factor) * (inv_freq / freq_config[\"factor\"]) + smooth_factor * inv_freq\n",
+ " )\n",
+ "\n",
+ " is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\n",
+ " inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\n",
+ " inv_freq = inv_freq_llama\n",
+ "\n",
+ " # Generate position indices\n",
+ " positions = torch.arange(context_length)\n",
+ "\n",
+ " # Compute the angles\n",
+ " angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)\n",
+ "\n",
+ " # Expand angles to match the head_dim\n",
+ " angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\n",
+ "\n",
+ " # Precompute sine and cosine\n",
+ " cos = torch.cos(angles)\n",
+ " sin = torch.sin(angles)\n",
+ "\n",
+ " return cos, sin\n",
+ "\n",
+ "\n",
+ "def compute_rope(x, cos, sin):\n",
+ " # x: (batch_size, num_heads, seq_len, head_dim)\n",
+ " batch_size, num_heads, seq_len, head_dim = x.shape\n",
+ " assert head_dim % 2 == 0, \"Head dimension must be even\"\n",
+ "\n",
+ " # Split x into first half and second half\n",
+ " x1 = x[..., : head_dim // 2] # First half\n",
+ " x2 = x[..., head_dim // 2 :] # Second half\n",
+ "\n",
+ " # Adjust sin and cos shapes\n",
+ " cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\n",
+ " sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\n",
+ "\n",
+ " # Apply the rotary transformation\n",
+ " rotated = torch.cat((-x2, x1), dim=-1)\n",
+ " x_rotated = (x * cos) + (rotated * sin)\n",
+ "\n",
+ " return x_rotated.to(dtype=x.dtype)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "e8169ab5-f976-4222-a2e1-eb1cabf267cb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class SharedBuffers:\n",
+ " _buffers = {}\n",
+ "\n",
+ " @staticmethod\n",
+ " def get_buffers(context_length, head_dim, rope_base, freq_config, dtype=torch.float32):\n",
+ " key = (context_length, head_dim, rope_base, tuple(freq_config.values()) if freq_config else freq_config, dtype)\n",
+ "\n",
+ " if key not in SharedBuffers._buffers:\n",
+ " # Create or fetch the buffers\n",
+ " mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)\n",
+ " cos, sin = precompute_rope_params(head_dim, rope_base, context_length, freq_config)\n",
+ " if dtype is not None:\n",
+ " cos = cos.to(dtype)\n",
+ " sin = sin.to(dtype)\n",
+ " SharedBuffers._buffers[key] = (mask, cos, sin)\n",
+ "\n",
+ " return SharedBuffers._buffers[key]\n",
+ "\n",
+ "\n",
+ "class GroupedQueryAttention(nn.Module):\n",
+ " def __init__(\n",
+ " self, d_in, d_out, context_length, num_heads,\n",
+ " num_kv_groups,\n",
+ " rope_base=10_000,\n",
+ " rope_config=None,\n",
+ " dtype=None\n",
+ " ):\n",
+ " super().__init__()\n",
+ " assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n",
+ " assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n",
+ "\n",
+ " self.d_out = d_out\n",
+ " self.num_heads = num_heads\n",
+ " self.head_dim = d_out // num_heads\n",
+ "\n",
+ " self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.num_kv_groups = num_kv_groups\n",
+ " self.group_size = num_heads // num_kv_groups\n",
+ "\n",
+ " self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n",
+ "\n",
+ " # Fetch buffers using SharedBuffers\n",
+ " mask, cos, sin = SharedBuffers.get_buffers(context_length, self.head_dim, rope_base, rope_config, dtype)\n",
+ " self.register_buffer(\"mask\", mask)\n",
+ "\n",
+ " self.register_buffer(\"cos\", cos)\n",
+ " self.register_buffer(\"sin\", sin)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " b, num_tokens, d_in = x.shape\n",
+ "\n",
+ " queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\n",
+ " keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ " values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ "\n",
+ " # Reshape queries, keys, and values\n",
+ " queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ "\n",
+ " # Transpose keys, values, and queries\n",
+ " keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)\n",
+ "\n",
+ " # Apply RoPE\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
+ "\n",
+ " # Expand keys and values to match the number of heads\n",
+ " # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " # For example, before repeat_interleave along dim=1 (query groups):\n",
+ " # [K1, K2]\n",
+ " # After repeat_interleave (each query group is repeated group_size times):\n",
+ " # [K1, K1, K2, K2]\n",
+ " # If we used regular repeat instead of repeat_interleave, we'd get:\n",
+ " # [K1, K2, K1, K2]\n",
+ "\n",
+ " # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
+ " # Shape: (b, num_heads, num_tokens, num_tokens)\n",
+ " attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n",
+ "\n",
+ " # Original mask truncated to the number of tokens and converted to boolean\n",
+ " mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n",
+ "\n",
+ " # Use the mask to fill attention scores\n",
+ " attn_scores.masked_fill_(mask_bool, -torch.inf)\n",
+ "\n",
+ " attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n",
+ " assert keys.shape[-1] == self.head_dim\n",
+ "\n",
+ " # Shape: (b, num_tokens, num_heads, head_dim)\n",
+ " context_vec = (attn_weights @ values).transpose(1, 2)\n",
+ "\n",
+ " # Combine heads, where self.d_out = self.num_heads * self.head_dim\n",
+ " context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n",
+ " context_vec = self.out_proj(context_vec) # optional projection\n",
+ "\n",
+ " return context_vec"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "457cb2f8-50c1-4045-8a74-f181bfb5fea9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class TransformerBlock(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.att = GroupedQueryAttention(\n",
+ " d_in=cfg[\"emb_dim\"],\n",
+ " d_out=cfg[\"emb_dim\"],\n",
+ " context_length=cfg[\"context_length\"],\n",
+ " num_heads=cfg[\"n_heads\"],\n",
+ " num_kv_groups=cfg[\"n_kv_groups\"],\n",
+ " rope_base=cfg[\"rope_base\"],\n",
+ " rope_config=cfg[\"rope_freq\"],\n",
+ " dtype=cfg[\"dtype\"]\n",
+ " )\n",
+ " self.ff = FeedForward(cfg)\n",
+ " self.norm1 = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.norm2 = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " # Shortcut connection for attention block\n",
+ " shortcut = x\n",
+ " x = self.norm1(x)\n",
+ " x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " # Shortcut connection for feed-forward block\n",
+ " shortcut = x\n",
+ " x = self.norm2(x)\n",
+ " x = self.ff(x.to(torch.bfloat16))\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " return x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "e88de3e3-9f07-42cc-816b-28dbd46e96c4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Llama3Model(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " self.trf_blocks = nn.Sequential(\n",
+ " *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n",
+ "\n",
+ " self.final_norm = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False, dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " def forward(self, in_idx):\n",
+ " tok_embeds = self.tok_emb(in_idx)\n",
+ " x = tok_embeds\n",
+ " x = self.trf_blocks(x)\n",
+ " x = self.final_norm(x)\n",
+ " logits = self.out_head(x.to(torch.bfloat16))\n",
+ " return logits"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be2d201f-74ad-4d63-ab9c-601b00674a48",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 2. Initialize model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "23dea40c-fe20-4a75-be25-d6fce5863c01",
+ "metadata": {},
+ "source": [
+ "- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "caa142fa-b375-4e78-b392-2072ced666f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Llama 3.2 1B\n",
+ "\n",
+ "LLAMA32_CONFIG = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # Context length\n",
+ " \"emb_dim\": 2048, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 16, # Number of layers\n",
+ " \"hidden_dim\": 8192, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # RoPE frequency scaling\n",
+ " \"factor\": 32.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "# Llama 3.2 3B\n",
+ "\n",
+ "# LLAMA32_CONFIG = {\n",
+ "# \"vocab_size\": 128_256, # Vocabulary size\n",
+ "# \"context_length\": 131_000, # Context length\n",
+ "# \"emb_dim\": 3072, # Embedding dimension\n",
+ "# \"n_heads\": 24, # Number of attention heads\n",
+ "# \"n_layers\": 28, # Number of layers\n",
+ "# \"hidden_dim\": 8192, # Size of the intermediate dimension in FeedForward\n",
+ "# \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ "# \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ "# \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ "# \"rope_freq\": { # RoPE frequency scaling\n",
+ "# \"factor\": 32.0,\n",
+ "# \"low_freq_factor\": 1.0,\n",
+ "# \"high_freq_factor\": 4.0,\n",
+ "# \"original_context_length\": 8192,\n",
+ "# }\n",
+ "# }\n",
+ "\n",
+ "LLAMA_SIZE_STR = \"1B\" if LLAMA32_CONFIG[\"emb_dim\"] == 2048 else \"3B\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34535172-797e-4dd0-84fb-65bc75ad5b06",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "a8bc2370-39d2-4bfe-b4c1-6bdd75fe101c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "156253fe-aacd-4da2-8f13-705f05c4b11e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = Llama3Model(LLAMA32_CONFIG)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19de6c2c-83ce-456d-8be9-6ec415fe9eb1",
+ "metadata": {},
+ "source": [
+ "- The following is expected to print True to confirm buffers are reused instead of being (wastefully) recreated:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "0e95db6d-2712-41a5-a5e0-86c49897f4cf",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "True\n",
+ "True\n",
+ "True\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Check buffers\n",
+ "print(model.trf_blocks[0].att.mask is model.trf_blocks[-1].att.mask)\n",
+ "print(model.trf_blocks[0].att.cos is model.trf_blocks[-1].att.cos)\n",
+ "print(model.trf_blocks[0].att.sin is model.trf_blocks[-1].att.sin) "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "364e76ca-52f8-4fa5-af37-c4069f9694bc",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 1,498,482,688\n",
+ "\n",
+ "Total number of unique parameters: 1,235,814,400\n"
+ ]
+ }
+ ],
+ "source": [
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")\n",
+ "\n",
+ "# Account for weight tying\n",
+ "total_params_normalized = total_params - model.tok_emb.weight.numel()\n",
+ "print(f\"\\nTotal number of unique parameters: {total_params_normalized:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "fd5efb03-5a07-46e8-8607-93ed47549d2b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "float32 (PyTorch default): 11.42 GB\n",
+ "bfloat16: 5.71 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def model_memory_size(model, input_dtype=torch.float32):\n",
+ " total_params = 0\n",
+ " total_grads = 0\n",
+ " for param in model.parameters():\n",
+ " # Calculate total number of elements per parameter\n",
+ " param_size = param.numel()\n",
+ " total_params += param_size\n",
+ " # Check if gradients are stored for this parameter\n",
+ " if param.requires_grad:\n",
+ " total_grads += param_size\n",
+ "\n",
+ " # Calculate buffer size (non-parameters that require memory)\n",
+ " total_buffers = sum(buf.numel() for buf in model.buffers())\n",
+ "\n",
+ " # Size in bytes = (Number of elements) * (Size of each element in bytes)\n",
+ " # We assume parameters and gradients are stored in the same type as input dtype\n",
+ " element_size = torch.tensor(0, dtype=input_dtype).element_size()\n",
+ " total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\n",
+ "\n",
+ " # Convert bytes to gigabytes\n",
+ " total_memory_gb = total_memory_bytes / (1024**3)\n",
+ "\n",
+ " return total_memory_gb\n",
+ "\n",
+ "print(f\"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB\")\n",
+ "print(f\"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "31f12baf-f79b-499f-85c0-51328a6a20f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if torch.cuda.is_available():\n",
+ " device = torch.device(\"cuda\")\n",
+ "elif torch.backends.mps.is_available():\n",
+ " device = torch.device(\"mps\")\n",
+ "else:\n",
+ " device = torch.device(\"cpu\")\n",
+ "\n",
+ "model.to(device);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78e091e1-afa8-4d23-9aea-cced86181bfd",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 3. Load tokenizer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "9482b01c-49f9-48e4-ab2c-4a4c75240e77",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "\n",
+ "import tiktoken\n",
+ "from tiktoken.load import load_tiktoken_bpe\n",
+ "\n",
+ "\n",
+ "class Tokenizer:\n",
+ " def __init__(self, model_path):\n",
+ " assert os.path.isfile(model_path), f\"Model file {model_path} not found\"\n",
+ " mergeable_ranks = load_tiktoken_bpe(model_path)\n",
+ " num_base_tokens = len(mergeable_ranks)\n",
+ "\n",
+ " self.special_tokens = {\n",
+ " \"<|begin_of_text|>\": 128000,\n",
+ " \"<|end_of_text|>\": 128001,\n",
+ " \"<|start_header_id|>\": 128006,\n",
+ " \"<|end_header_id|>\": 128007,\n",
+ " \"<|eot_id|>\": 128009,\n",
+ " }\n",
+ " self.special_tokens.update({\n",
+ " f\"<|reserved_{i}|>\": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()\n",
+ " })\n",
+ "\n",
+ " self.model = tiktoken.Encoding(\n",
+ " name=Path(model_path).name,\n",
+ " pat_str=r\"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?\\p{L}+|\\p{N}{1,3}| ?[^\\s\\p{L}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+\",\n",
+ " mergeable_ranks=mergeable_ranks,\n",
+ " special_tokens=self.special_tokens\n",
+ " )\n",
+ "\n",
+ "\n",
+ " def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):\n",
+ " if bos:\n",
+ " tokens = [self.special_tokens[\"<|begin_of_text|>\"]]\n",
+ " else:\n",
+ " tokens = []\n",
+ "\n",
+ " tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)\n",
+ "\n",
+ " if eos:\n",
+ " tokens.append(self.special_tokens[\"<|end_of_text|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, tokens):\n",
+ " return self.model.decode(tokens)\n",
+ " \n",
+ "\n",
+ "class ChatFormat:\n",
+ " def __init__(self, tokenizer):\n",
+ " self.tokenizer = tokenizer\n",
+ "\n",
+ " def encode_header(self, message):\n",
+ " tokens = []\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|start_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(message[\"role\"], bos=False, eos=False))\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|end_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(\"\\n\\n\", bos=False, eos=False))\n",
+ " return tokens\n",
+ "\n",
+ " def encode(self, text):\n",
+ " message = {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": text\n",
+ " }\n",
+ "\n",
+ " tokens = self.encode_header(message)\n",
+ " tokens.extend(\n",
+ " self.tokenizer.encode(message[\"content\"].strip(), bos=False, eos=False)\n",
+ " )\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|eot_id|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, token_ids):\n",
+ " return self.tokenizer.decode(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b771b60c-c198-4b30-bf10-42031197ae86",
+ "metadata": {},
+ "source": [
+ "- Please note that Meta AI requires that you accept the Llama 3.2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository to accept the terms\n",
+ "- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \"Settings\"\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "- Then, create and copy the access token so you can copy & paste it into the next code cell\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "8cdf801700d64fe9b2b827172a8eebcf",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "VBox(children=(HTML(value='
\n",
+ " \n",
+ " \n",
+ "- About the code:\n",
+ " - all code is my own code, mapping the Llama 3 architecture onto the model code implemented in my [Build A Large Language Model (From Scratch)](http://mng.bz/orYv) book; the code is released under a permissive open-source Apache 2.0 license (see [LICENSE.txt](https://github.com/rasbt/LLMs-from-scratch/blob/main/LICENSE.txt))\n",
+ " - the tokenizer code is inspired by the original [Llama 3 tokenizer code](https://github.com/meta-llama/llama3/blob/main/llama/tokenizer.py), which Meta AI used to to extends the Tiktoken GPT-4 tokenizer\n",
+ " - the RoPE rescaling section is inspired by the [_compute_llama3_parameters function](https://github.com/huggingface/transformers/blob/5c1027bf09717f664b579e01cbb8ec3ef5aeb140/src/transformers/modeling_rope_utils.py#L329-L347) in the `transformers` library"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "beef121b-2454-4577-8b56-aa00961089cb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/ch05/07_gpt_to_llama/requirements-extra.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "id": "dd1b65a8-4301-444a-bd7c-a6f2bd1df9df",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "blobfile version: 3.0.0\n",
+ "huggingface_hub version: 0.25.1\n",
+ "tiktoken version: 0.7.0\n",
+ "torch version: 2.4.0\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"blobfile\", # to download pretrained weights\n",
+ " \"huggingface_hub\", # to download pretrained weights\n",
+ " \"tiktoken\", # to implement the tokenizer\n",
+ " \"torch\", # to implement the model\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "653410a6-dd2b-4eb2-a722-23d9782e726d",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 1. Architecture code"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "id": "82076c21-9331-4dcd-b017-42b046cf1a60",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import torch.nn as nn\n",
+ "\n",
+ "\n",
+ "class FeedForward(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.fc1 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ " self.fc2 = nn.Linear(cfg[\"emb_dim\"], cfg[\"hidden_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ " self.fc3 = nn.Linear(cfg[\"hidden_dim\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"], bias=False)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " x_fc1 = self.fc1(x)\n",
+ " x_fc2 = self.fc2(x)\n",
+ " x = nn.functional.silu(x_fc1) * x_fc2\n",
+ " return self.fc3(x)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "4b9a346f-5826-4083-9162-abd56afc03f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "def precompute_rope_params(head_dim, theta_base=10000, context_length=4096, freq_config=None):\n",
+ " assert head_dim % 2 == 0, \"Embedding dimension must be even\"\n",
+ "\n",
+ " # Compute the inverse frequencies\n",
+ " inv_freq = 1.0 / (theta_base ** (torch.arange(0, head_dim // 2) / (head_dim // 2)))\n",
+ "\n",
+ " # Frequency adjustments\n",
+ " if freq_config is not None:\n",
+ " low_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"low_freq_factor\"]\n",
+ " high_freq_wavelen = freq_config[\"original_context_length\"] / freq_config[\"high_freq_factor\"]\n",
+ "\n",
+ " wavelen = 2 * torch.pi / inv_freq\n",
+ "\n",
+ " inv_freq_llama = torch.where(\n",
+ " wavelen > low_freq_wavelen, inv_freq / freq_config[\"factor\"], inv_freq\n",
+ " )\n",
+ "\n",
+ " smooth_factor = (freq_config[\"original_context_length\"] / wavelen - freq_config[\"low_freq_factor\"]) / (\n",
+ " freq_config[\"high_freq_factor\"] - freq_config[\"low_freq_factor\"]\n",
+ " )\n",
+ "\n",
+ " smoothed_inv_freq = (\n",
+ " (1 - smooth_factor) * (inv_freq / freq_config[\"factor\"]) + smooth_factor * inv_freq\n",
+ " )\n",
+ "\n",
+ " is_medium_freq = (wavelen <= low_freq_wavelen) & (wavelen >= high_freq_wavelen)\n",
+ " inv_freq_llama = torch.where(is_medium_freq, smoothed_inv_freq, inv_freq_llama)\n",
+ " inv_freq = inv_freq_llama\n",
+ "\n",
+ " # Generate position indices\n",
+ " positions = torch.arange(context_length)\n",
+ "\n",
+ " # Compute the angles\n",
+ " angles = positions[:, None] * inv_freq[None, :] # Shape: (context_length, head_dim // 2)\n",
+ "\n",
+ " # Expand angles to match the head_dim\n",
+ " angles = torch.cat([angles, angles], dim=1) # Shape: (context_length, head_dim)\n",
+ "\n",
+ " # Precompute sine and cosine\n",
+ " cos = torch.cos(angles)\n",
+ " sin = torch.sin(angles)\n",
+ "\n",
+ " return cos, sin\n",
+ "\n",
+ "\n",
+ "def compute_rope(x, cos, sin):\n",
+ " # x: (batch_size, num_heads, seq_len, head_dim)\n",
+ " batch_size, num_heads, seq_len, head_dim = x.shape\n",
+ " assert head_dim % 2 == 0, \"Head dimension must be even\"\n",
+ "\n",
+ " # Split x into first half and second half\n",
+ " x1 = x[..., : head_dim // 2] # First half\n",
+ " x2 = x[..., head_dim // 2 :] # Second half\n",
+ "\n",
+ " # Adjust sin and cos shapes\n",
+ " cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0) # Shape: (1, 1, seq_len, head_dim)\n",
+ " sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)\n",
+ "\n",
+ " # Apply the rotary transformation\n",
+ " rotated = torch.cat((-x2, x1), dim=-1)\n",
+ " x_rotated = (x * cos) + (rotated * sin)\n",
+ "\n",
+ " return x_rotated.to(dtype=x.dtype)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "e8169ab5-f976-4222-a2e1-eb1cabf267cb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class SharedBuffers:\n",
+ " _buffers = {}\n",
+ "\n",
+ " @staticmethod\n",
+ " def get_buffers(context_length, head_dim, rope_base, freq_config, dtype=torch.float32):\n",
+ " key = (context_length, head_dim, rope_base, tuple(freq_config.values()) if freq_config else freq_config, dtype)\n",
+ "\n",
+ " if key not in SharedBuffers._buffers:\n",
+ " # Create or fetch the buffers\n",
+ " mask = torch.triu(torch.ones(context_length, context_length), diagonal=1)\n",
+ " cos, sin = precompute_rope_params(head_dim, rope_base, context_length, freq_config)\n",
+ " if dtype is not None:\n",
+ " cos = cos.to(dtype)\n",
+ " sin = sin.to(dtype)\n",
+ " SharedBuffers._buffers[key] = (mask, cos, sin)\n",
+ "\n",
+ " return SharedBuffers._buffers[key]\n",
+ "\n",
+ "\n",
+ "class GroupedQueryAttention(nn.Module):\n",
+ " def __init__(\n",
+ " self, d_in, d_out, context_length, num_heads,\n",
+ " num_kv_groups,\n",
+ " rope_base=10_000,\n",
+ " rope_config=None,\n",
+ " dtype=None\n",
+ " ):\n",
+ " super().__init__()\n",
+ " assert d_out % num_heads == 0, \"d_out must be divisible by num_heads\"\n",
+ " assert num_heads % num_kv_groups == 0, \"num_heads must be divisible by num_kv_groups\"\n",
+ "\n",
+ " self.d_out = d_out\n",
+ " self.num_heads = num_heads\n",
+ " self.head_dim = d_out // num_heads\n",
+ "\n",
+ " self.W_key = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.W_value = nn.Linear(d_in, num_kv_groups * self.head_dim, bias=False, dtype=dtype)\n",
+ " self.num_kv_groups = num_kv_groups\n",
+ " self.group_size = num_heads // num_kv_groups\n",
+ "\n",
+ " self.W_query = nn.Linear(d_in, d_out, bias=False, dtype=dtype)\n",
+ " self.out_proj = nn.Linear(d_out, d_out, bias=False, dtype=dtype)\n",
+ "\n",
+ " # Fetch buffers using SharedBuffers\n",
+ " mask, cos, sin = SharedBuffers.get_buffers(context_length, self.head_dim, rope_base, rope_config, dtype)\n",
+ " self.register_buffer(\"mask\", mask)\n",
+ "\n",
+ " self.register_buffer(\"cos\", cos)\n",
+ " self.register_buffer(\"sin\", sin)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " b, num_tokens, d_in = x.shape\n",
+ "\n",
+ " queries = self.W_query(x) # Shape: (b, num_tokens, d_out)\n",
+ " keys = self.W_key(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ " values = self.W_value(x) # Shape: (b, num_tokens, num_kv_groups * head_dim)\n",
+ "\n",
+ " # Reshape queries, keys, and values\n",
+ " queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)\n",
+ " keys = keys.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ " values = values.view(b, num_tokens, self.num_kv_groups, self.head_dim)\n",
+ "\n",
+ " # Transpose keys, values, and queries\n",
+ " keys = keys.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.transpose(1, 2) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " queries = queries.transpose(1, 2) # Shape: (b, num_query_groups, num_tokens, head_dim)\n",
+ "\n",
+ " # Apply RoPE\n",
+ " keys = compute_rope(keys, self.cos, self.sin)\n",
+ " queries = compute_rope(queries, self.cos, self.sin)\n",
+ "\n",
+ " # Expand keys and values to match the number of heads\n",
+ " # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " keys = keys.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " values = values.repeat_interleave(self.group_size, dim=1) # Shape: (b, num_heads, num_tokens, head_dim)\n",
+ " # For example, before repeat_interleave along dim=1 (query groups):\n",
+ " # [K1, K2]\n",
+ " # After repeat_interleave (each query group is repeated group_size times):\n",
+ " # [K1, K1, K2, K2]\n",
+ " # If we used regular repeat instead of repeat_interleave, we'd get:\n",
+ " # [K1, K2, K1, K2]\n",
+ "\n",
+ " # Compute scaled dot-product attention (aka self-attention) with a causal mask\n",
+ " # Shape: (b, num_heads, num_tokens, num_tokens)\n",
+ " attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head\n",
+ "\n",
+ " # Original mask truncated to the number of tokens and converted to boolean\n",
+ " mask_bool = self.mask.bool()[:num_tokens, :num_tokens]\n",
+ "\n",
+ " # Use the mask to fill attention scores\n",
+ " attn_scores.masked_fill_(mask_bool, -torch.inf)\n",
+ "\n",
+ " attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)\n",
+ " assert keys.shape[-1] == self.head_dim\n",
+ "\n",
+ " # Shape: (b, num_tokens, num_heads, head_dim)\n",
+ " context_vec = (attn_weights @ values).transpose(1, 2)\n",
+ "\n",
+ " # Combine heads, where self.d_out = self.num_heads * self.head_dim\n",
+ " context_vec = context_vec.reshape(b, num_tokens, self.d_out)\n",
+ " context_vec = self.out_proj(context_vec) # optional projection\n",
+ "\n",
+ " return context_vec"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "457cb2f8-50c1-4045-8a74-f181bfb5fea9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class TransformerBlock(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.att = GroupedQueryAttention(\n",
+ " d_in=cfg[\"emb_dim\"],\n",
+ " d_out=cfg[\"emb_dim\"],\n",
+ " context_length=cfg[\"context_length\"],\n",
+ " num_heads=cfg[\"n_heads\"],\n",
+ " num_kv_groups=cfg[\"n_kv_groups\"],\n",
+ " rope_base=cfg[\"rope_base\"],\n",
+ " rope_config=cfg[\"rope_freq\"],\n",
+ " dtype=cfg[\"dtype\"]\n",
+ " )\n",
+ " self.ff = FeedForward(cfg)\n",
+ " self.norm1 = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.norm2 = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ "\n",
+ " def forward(self, x):\n",
+ " # Shortcut connection for attention block\n",
+ " shortcut = x\n",
+ " x = self.norm1(x)\n",
+ " x = self.att(x.to(torch.bfloat16)) # Shape [batch_size, num_tokens, emb_size]\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " # Shortcut connection for feed-forward block\n",
+ " shortcut = x\n",
+ " x = self.norm2(x)\n",
+ " x = self.ff(x.to(torch.bfloat16))\n",
+ " x = x + shortcut # Add the original input back\n",
+ "\n",
+ " return x"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "e88de3e3-9f07-42cc-816b-28dbd46e96c4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "class Llama3Model(nn.Module):\n",
+ " def __init__(self, cfg):\n",
+ " super().__init__()\n",
+ " self.tok_emb = nn.Embedding(cfg[\"vocab_size\"], cfg[\"emb_dim\"], dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " self.trf_blocks = nn.Sequential(\n",
+ " *[TransformerBlock(cfg) for _ in range(cfg[\"n_layers\"])])\n",
+ "\n",
+ " self.final_norm = nn.RMSNorm(cfg[\"emb_dim\"], eps=1e-5)\n",
+ " self.out_head = nn.Linear(cfg[\"emb_dim\"], cfg[\"vocab_size\"], bias=False, dtype=cfg[\"dtype\"])\n",
+ "\n",
+ " def forward(self, in_idx):\n",
+ " tok_embeds = self.tok_emb(in_idx)\n",
+ " x = tok_embeds\n",
+ " x = self.trf_blocks(x)\n",
+ " x = self.final_norm(x)\n",
+ " logits = self.out_head(x.to(torch.bfloat16))\n",
+ " return logits"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be2d201f-74ad-4d63-ab9c-601b00674a48",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 2. Initialize model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "23dea40c-fe20-4a75-be25-d6fce5863c01",
+ "metadata": {},
+ "source": [
+ "- The remainder of this notebook uses the Llama 3.2 1B model; to use the 3B model variant, just uncomment the second configuration file in the following code cell"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "id": "caa142fa-b375-4e78-b392-2072ced666f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Llama 3.2 1B\n",
+ "\n",
+ "LLAMA32_CONFIG = {\n",
+ " \"vocab_size\": 128_256, # Vocabulary size\n",
+ " \"context_length\": 131_072, # Context length\n",
+ " \"emb_dim\": 2048, # Embedding dimension\n",
+ " \"n_heads\": 32, # Number of attention heads\n",
+ " \"n_layers\": 16, # Number of layers\n",
+ " \"hidden_dim\": 8192, # Size of the intermediate dimension in FeedForward\n",
+ " \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ " \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ " \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ " \"rope_freq\": { # RoPE frequency scaling\n",
+ " \"factor\": 32.0,\n",
+ " \"low_freq_factor\": 1.0,\n",
+ " \"high_freq_factor\": 4.0,\n",
+ " \"original_context_length\": 8192,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "# Llama 3.2 3B\n",
+ "\n",
+ "# LLAMA32_CONFIG = {\n",
+ "# \"vocab_size\": 128_256, # Vocabulary size\n",
+ "# \"context_length\": 131_000, # Context length\n",
+ "# \"emb_dim\": 3072, # Embedding dimension\n",
+ "# \"n_heads\": 24, # Number of attention heads\n",
+ "# \"n_layers\": 28, # Number of layers\n",
+ "# \"hidden_dim\": 8192, # Size of the intermediate dimension in FeedForward\n",
+ "# \"n_kv_groups\": 8, # Key-Value groups for grouped-query attention\n",
+ "# \"rope_base\": 50_000, # The base in RoPE's \"theta\"\n",
+ "# \"dtype\": torch.bfloat16, # Lower-precision dtype to save memory\n",
+ "# \"rope_freq\": { # RoPE frequency scaling\n",
+ "# \"factor\": 32.0,\n",
+ "# \"low_freq_factor\": 1.0,\n",
+ "# \"high_freq_factor\": 4.0,\n",
+ "# \"original_context_length\": 8192,\n",
+ "# }\n",
+ "# }\n",
+ "\n",
+ "LLAMA_SIZE_STR = \"1B\" if LLAMA32_CONFIG[\"emb_dim\"] == 2048 else \"3B\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34535172-797e-4dd0-84fb-65bc75ad5b06",
+ "metadata": {},
+ "source": [
+ "- Reduce the context length so the model would work fine on a MacBook Air (if you have more RAM, feel free to comment out the lines below):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "a8bc2370-39d2-4bfe-b4c1-6bdd75fe101c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "LLAMA32_CONFIG[\"context_length\"] = 8192"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "156253fe-aacd-4da2-8f13-705f05c4b11e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model = Llama3Model(LLAMA32_CONFIG)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "19de6c2c-83ce-456d-8be9-6ec415fe9eb1",
+ "metadata": {},
+ "source": [
+ "- The following is expected to print True to confirm buffers are reused instead of being (wastefully) recreated:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "0e95db6d-2712-41a5-a5e0-86c49897f4cf",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "True\n",
+ "True\n",
+ "True\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Check buffers\n",
+ "print(model.trf_blocks[0].att.mask is model.trf_blocks[-1].att.mask)\n",
+ "print(model.trf_blocks[0].att.cos is model.trf_blocks[-1].att.cos)\n",
+ "print(model.trf_blocks[0].att.sin is model.trf_blocks[-1].att.sin) "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "364e76ca-52f8-4fa5-af37-c4069f9694bc",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Total number of parameters: 1,498,482,688\n",
+ "\n",
+ "Total number of unique parameters: 1,235,814,400\n"
+ ]
+ }
+ ],
+ "source": [
+ "total_params = sum(p.numel() for p in model.parameters())\n",
+ "print(f\"Total number of parameters: {total_params:,}\")\n",
+ "\n",
+ "# Account for weight tying\n",
+ "total_params_normalized = total_params - model.tok_emb.weight.numel()\n",
+ "print(f\"\\nTotal number of unique parameters: {total_params_normalized:,}\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "id": "fd5efb03-5a07-46e8-8607-93ed47549d2b",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "float32 (PyTorch default): 11.42 GB\n",
+ "bfloat16: 5.71 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def model_memory_size(model, input_dtype=torch.float32):\n",
+ " total_params = 0\n",
+ " total_grads = 0\n",
+ " for param in model.parameters():\n",
+ " # Calculate total number of elements per parameter\n",
+ " param_size = param.numel()\n",
+ " total_params += param_size\n",
+ " # Check if gradients are stored for this parameter\n",
+ " if param.requires_grad:\n",
+ " total_grads += param_size\n",
+ "\n",
+ " # Calculate buffer size (non-parameters that require memory)\n",
+ " total_buffers = sum(buf.numel() for buf in model.buffers())\n",
+ "\n",
+ " # Size in bytes = (Number of elements) * (Size of each element in bytes)\n",
+ " # We assume parameters and gradients are stored in the same type as input dtype\n",
+ " element_size = torch.tensor(0, dtype=input_dtype).element_size()\n",
+ " total_memory_bytes = (total_params + total_grads + total_buffers) * element_size\n",
+ "\n",
+ " # Convert bytes to gigabytes\n",
+ " total_memory_gb = total_memory_bytes / (1024**3)\n",
+ "\n",
+ " return total_memory_gb\n",
+ "\n",
+ "print(f\"float32 (PyTorch default): {model_memory_size(model, input_dtype=torch.float32):.2f} GB\")\n",
+ "print(f\"bfloat16: {model_memory_size(model, input_dtype=torch.bfloat16):.2f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "id": "31f12baf-f79b-499f-85c0-51328a6a20f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "if torch.cuda.is_available():\n",
+ " device = torch.device(\"cuda\")\n",
+ "elif torch.backends.mps.is_available():\n",
+ " device = torch.device(\"mps\")\n",
+ "else:\n",
+ " device = torch.device(\"cpu\")\n",
+ "\n",
+ "model.to(device);"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "78e091e1-afa8-4d23-9aea-cced86181bfd",
+ "metadata": {},
+ "source": [
+ " \n",
+ "# 3. Load tokenizer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "id": "9482b01c-49f9-48e4-ab2c-4a4c75240e77",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from pathlib import Path\n",
+ "\n",
+ "import tiktoken\n",
+ "from tiktoken.load import load_tiktoken_bpe\n",
+ "\n",
+ "\n",
+ "class Tokenizer:\n",
+ " def __init__(self, model_path):\n",
+ " assert os.path.isfile(model_path), f\"Model file {model_path} not found\"\n",
+ " mergeable_ranks = load_tiktoken_bpe(model_path)\n",
+ " num_base_tokens = len(mergeable_ranks)\n",
+ "\n",
+ " self.special_tokens = {\n",
+ " \"<|begin_of_text|>\": 128000,\n",
+ " \"<|end_of_text|>\": 128001,\n",
+ " \"<|start_header_id|>\": 128006,\n",
+ " \"<|end_header_id|>\": 128007,\n",
+ " \"<|eot_id|>\": 128009,\n",
+ " }\n",
+ " self.special_tokens.update({\n",
+ " f\"<|reserved_{i}|>\": 128002 + i for i in range(256) if (128002 + i) not in self.special_tokens.values()\n",
+ " })\n",
+ "\n",
+ " self.model = tiktoken.Encoding(\n",
+ " name=Path(model_path).name,\n",
+ " pat_str=r\"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\\r\\n\\p{L}\\p{N}]?\\p{L}+|\\p{N}{1,3}| ?[^\\s\\p{L}\\p{N}]+[\\r\\n]*|\\s*[\\r\\n]+|\\s+(?!\\S)|\\s+\",\n",
+ " mergeable_ranks=mergeable_ranks,\n",
+ " special_tokens=self.special_tokens\n",
+ " )\n",
+ "\n",
+ "\n",
+ " def encode(self, text, bos=False, eos=False, allowed_special=set(), disallowed_special=()):\n",
+ " if bos:\n",
+ " tokens = [self.special_tokens[\"<|begin_of_text|>\"]]\n",
+ " else:\n",
+ " tokens = []\n",
+ "\n",
+ " tokens += self.model.encode(text, allowed_special=allowed_special, disallowed_special=disallowed_special)\n",
+ "\n",
+ " if eos:\n",
+ " tokens.append(self.special_tokens[\"<|end_of_text|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, tokens):\n",
+ " return self.model.decode(tokens)\n",
+ " \n",
+ "\n",
+ "class ChatFormat:\n",
+ " def __init__(self, tokenizer):\n",
+ " self.tokenizer = tokenizer\n",
+ "\n",
+ " def encode_header(self, message):\n",
+ " tokens = []\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|start_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(message[\"role\"], bos=False, eos=False))\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|end_header_id|>\"])\n",
+ " tokens.extend(self.tokenizer.encode(\"\\n\\n\", bos=False, eos=False))\n",
+ " return tokens\n",
+ "\n",
+ " def encode(self, text):\n",
+ " message = {\n",
+ " \"role\": \"user\",\n",
+ " \"content\": text\n",
+ " }\n",
+ "\n",
+ " tokens = self.encode_header(message)\n",
+ " tokens.extend(\n",
+ " self.tokenizer.encode(message[\"content\"].strip(), bos=False, eos=False)\n",
+ " )\n",
+ " tokens.append(self.tokenizer.special_tokens[\"<|eot_id|>\"])\n",
+ " return tokens\n",
+ "\n",
+ " def decode(self, token_ids):\n",
+ " return self.tokenizer.decode(token_ids)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b771b60c-c198-4b30-bf10-42031197ae86",
+ "metadata": {},
+ "source": [
+ "- Please note that Meta AI requires that you accept the Llama 3.2 licensing terms before you can download the files; to do this, you have to create a Hugging Face Hub account and visit the [meta-llama/Llama-3.2-1B](https://huggingface.co/meta-llama/Llama-3.2-1B) repository to accept the terms\n",
+ "- Next, you will need to create an access token; to generate an access token with READ permissions, click on the profile picture in the upper right and click on \"Settings\"\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "- Then, create and copy the access token so you can copy & paste it into the next code cell\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "id": "e9d96dc8-603a-4cb5-8c3e-4d2ca56862ed",
+ "metadata": {},
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "8cdf801700d64fe9b2b827172a8eebcf",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "VBox(children=(HTML(value=' \n",
+ "\n",
+ " 1. [Converting a From-Scratch GPT Architecture to Llama 2](converting-gpt-to-llama2.ipynb)\n",
+ " 2. [Converting Llama 2 to Llama 3.2 From Scratch](converting-llama2-to-llama3.ipynb)\n",
+ " \n",
+ "- For those interested in a comprehensive guide on building a large language model from scratch and gaining a deeper understanding of its mechanics, you might like my [Build a Large Language Model (From Scratch)](http://mng.bz/orYv)\n",
+ "\n",
+ ""
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/ch05/07_gpt_to_llama/tests/tests.py b/ch05/07_gpt_to_llama/tests/tests.py
index eae1fc7e..d4725861 100644
--- a/ch05/07_gpt_to_llama/tests/tests.py
+++ b/ch05/07_gpt_to_llama/tests/tests.py
@@ -18,39 +18,45 @@
@pytest.fixture(scope="module")
def notebook():
- def import_definitions_from_notebook(fullname, names):
- # Get the directory of the current test file
- current_dir = os.path.dirname(__file__)
- path = os.path.join(current_dir, "..", fullname + ".ipynb")
- path = os.path.normpath(path)
+ def import_definitions_from_notebook(notebooks):
+ imported_modules = {}
- # Load the notebook
- if not os.path.exists(path):
- raise FileNotFoundError(f"Notebook file not found at: {path}")
+ for fullname, names in notebooks.items():
+ # Get the directory of the current test file
+ current_dir = os.path.dirname(__file__)
+ path = os.path.join(current_dir, "..", fullname + ".ipynb")
+ path = os.path.normpath(path)
- with io.open(path, "r", encoding="utf-8") as f:
- nb = nbformat.read(f, as_version=4)
+ # Load the notebook
+ if not os.path.exists(path):
+ raise FileNotFoundError(f"Notebook file not found at: {path}")
- # Create a module to store the imported functions and classes
- mod = types.ModuleType(fullname)
- sys.modules[fullname] = mod
+ with io.open(path, "r", encoding="utf-8") as f:
+ nb = nbformat.read(f, as_version=4)
- # Go through the notebook cells and only execute function or class definitions
- for cell in nb.cells:
- if cell.cell_type == "code":
- cell_code = cell.source
- for name in names:
- # Check for function or class definitions
- if f"def {name}" in cell_code or f"class {name}" in cell_code:
- exec(cell_code, mod.__dict__)
- return mod
+ # Create a module to store the imported functions and classes
+ mod = types.ModuleType(fullname)
+ sys.modules[fullname] = mod
- # Specify the notebook name and functions/classes to import
- fullname = "converting-gpt-to-llama2"
- names = ["precompute_rope_params", "compute_rope", "SiLU", "RMSNorm"]
+ # Go through the notebook cells and only execute function or class definitions
+ for cell in nb.cells:
+ if cell.cell_type == "code":
+ cell_code = cell.source
+ for name in names:
+ # Check for function or class definitions
+ if f"def {name}" in cell_code or f"class {name}" in cell_code:
+ exec(cell_code, mod.__dict__)
- # Import the required functions and classes from the notebook
- return import_definitions_from_notebook(fullname, names)
+ imported_modules[fullname] = mod
+
+ return imported_modules
+
+ notebooks = {
+ "converting-gpt-to-llama2": ["SiLU", "RMSNorm", "precompute_rope_params", "compute_rope"],
+ "converting-llama2-to-llama3": ["precompute_rope_params"]
+ }
+
+ return import_definitions_from_notebook(notebooks)
@pytest.fixture(autouse=True)
@@ -59,6 +65,9 @@ def set_seed():
def test_rope_llama2(notebook):
+
+ this_nb = notebook["converting-gpt-to-llama2"]
+
# Settings
batch_size = 1
context_len = 4096
@@ -66,15 +75,15 @@ def test_rope_llama2(notebook):
head_dim = 16
# Instantiate RoPE parameters
- cos, sin = notebook.precompute_rope_params(head_dim=head_dim, context_length=context_len)
+ cos, sin = this_nb.precompute_rope_params(head_dim=head_dim, context_length=context_len)
# Dummy query and key tensors
queries = torch.randn(batch_size, num_heads, context_len, head_dim)
keys = torch.randn(batch_size, num_heads, context_len, head_dim)
# Apply rotary position embeddings
- queries_rot = notebook.compute_rope(queries, cos, sin)
- keys_rot = notebook.compute_rope(keys, cos, sin)
+ queries_rot = this_nb.compute_rope(queries, cos, sin)
+ keys_rot = this_nb.compute_rope(keys, cos, sin)
rot_emb = LlamaRotaryEmbedding(
dim=head_dim,
@@ -93,6 +102,10 @@ def test_rope_llama2(notebook):
def test_rope_llama3(notebook):
+
+ nb1 = notebook["converting-gpt-to-llama2"]
+ nb2 = notebook["converting-llama2-to-llama3"]
+
# Settings
batch_size = 1
context_len = 8192
@@ -101,19 +114,20 @@ def test_rope_llama3(notebook):
theta_base = 50_000
# Instantiate RoPE parameters
- cos, sin = notebook.precompute_rope_params(
+ cos, sin = nb2.precompute_rope_params(
head_dim=head_dim,
context_length=context_len,
theta_base=theta_base
)
# Dummy query and key tensors
+ torch.manual_seed(123)
queries = torch.randn(batch_size, num_heads, context_len, head_dim)
keys = torch.randn(batch_size, num_heads, context_len, head_dim)
# Apply rotary position embeddings
- queries_rot = notebook.compute_rope(queries, cos, sin)
- keys_rot = notebook.compute_rope(keys, cos, sin)
+ queries_rot = nb1.compute_rope(queries, cos, sin)
+ keys_rot = nb1.compute_rope(keys, cos, sin)
rot_emb = LlamaRotaryEmbedding(
dim=head_dim,
@@ -131,16 +145,83 @@ def test_rope_llama3(notebook):
torch.testing.assert_close(queries_rot, ref_queries_rot)
+def test_rope_llama3_12(notebook):
+
+ nb1 = notebook["converting-gpt-to-llama2"]
+ nb2 = notebook["converting-llama2-to-llama3"]
+
+ # Settings
+ batch_size = 1
+ context_len = 8192
+ num_heads = 4
+ head_dim = 16
+ rope_theta = 50_000
+
+ rope_config = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+
+ # Instantiate RoPE parameters
+ cos, sin = nb2.precompute_rope_params(
+ head_dim=head_dim,
+ theta_base=rope_theta,
+ context_length=context_len,
+ freq_config=rope_config,
+ )
+
+ # Dummy query and key tensors
+ torch.manual_seed(123)
+ queries = torch.randn(batch_size, num_heads, context_len, head_dim)
+ keys = torch.randn(batch_size, num_heads, context_len, head_dim)
+
+ # Apply rotary position embeddings
+ queries_rot = nb1.compute_rope(queries, cos, sin)
+ keys_rot = nb1.compute_rope(keys, cos, sin)
+
+ hf_rope_params = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_max_position_embeddings": 8192,
+ "rope_type": "llama3"
+ }
+
+ class RoPEConfig:
+ rope_type = "llama3"
+ rope_scaling = hf_rope_params
+ factor = 1.0
+ dim: int = head_dim
+ rope_theta = 50_000
+ max_position_embeddings: int = 8192
+ hidden_size = head_dim * num_heads
+ num_attention_heads = num_heads
+
+ config = RoPEConfig()
+
+ rot_emb = LlamaRotaryEmbedding(config=config)
+ position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)
+ ref_cos, ref_sin = rot_emb(queries, position_ids)
+ ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)
+
+ torch.testing.assert_close(sin, ref_sin.squeeze(0))
+ torch.testing.assert_close(cos, ref_cos.squeeze(0))
+ torch.testing.assert_close(keys_rot, ref_keys_rot)
+ torch.testing.assert_close(queries_rot, ref_queries_rot)
+
+
def test_silu(notebook):
example_batch = torch.randn(2, 3, 4)
- silu = notebook.SiLU()
+ silu = notebook["converting-gpt-to-llama2"].SiLU()
assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))
@pytest.mark.skipif(torch.__version__ < "2.4", reason="Requires PyTorch 2.4 or newer")
def test_rmsnorm(notebook):
example_batch = torch.randn(2, 3, 4)
- rms_norm = notebook.RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)
+ rms_norm = notebook["converting-gpt-to-llama2"].RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)
rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)
assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))
diff --git a/ch05/08_memory_efficient_weight_loading/README.md b/ch05/08_memory_efficient_weight_loading/README.md
new file mode 100644
index 00000000..2b8fef08
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/README.md
@@ -0,0 +1,5 @@
+# Memory-efficient Model Weight Loading
+
+This folder contains code to illustrate how to load model weights more efficiently
+
+- [memory-efficient-state-dict.ipynb](memory-efficient-state-dict.ipynb): contains code to load model weights via PyTorch's `load_state_dict` method more efficiently
diff --git a/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb b/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb
new file mode 100644
index 00000000..8ab9d4f7
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb
@@ -0,0 +1,929 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1E_HhLEeYqFG"
+ },
+ "source": [
+ "
\n",
+ "\n",
+ " 1. [Converting a From-Scratch GPT Architecture to Llama 2](converting-gpt-to-llama2.ipynb)\n",
+ " 2. [Converting Llama 2 to Llama 3.2 From Scratch](converting-llama2-to-llama3.ipynb)\n",
+ " \n",
+ "- For those interested in a comprehensive guide on building a large language model from scratch and gaining a deeper understanding of its mechanics, you might like my [Build a Large Language Model (From Scratch)](http://mng.bz/orYv)\n",
+ "\n",
+ ""
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/ch05/07_gpt_to_llama/tests/tests.py b/ch05/07_gpt_to_llama/tests/tests.py
index eae1fc7e..d4725861 100644
--- a/ch05/07_gpt_to_llama/tests/tests.py
+++ b/ch05/07_gpt_to_llama/tests/tests.py
@@ -18,39 +18,45 @@
@pytest.fixture(scope="module")
def notebook():
- def import_definitions_from_notebook(fullname, names):
- # Get the directory of the current test file
- current_dir = os.path.dirname(__file__)
- path = os.path.join(current_dir, "..", fullname + ".ipynb")
- path = os.path.normpath(path)
+ def import_definitions_from_notebook(notebooks):
+ imported_modules = {}
- # Load the notebook
- if not os.path.exists(path):
- raise FileNotFoundError(f"Notebook file not found at: {path}")
+ for fullname, names in notebooks.items():
+ # Get the directory of the current test file
+ current_dir = os.path.dirname(__file__)
+ path = os.path.join(current_dir, "..", fullname + ".ipynb")
+ path = os.path.normpath(path)
- with io.open(path, "r", encoding="utf-8") as f:
- nb = nbformat.read(f, as_version=4)
+ # Load the notebook
+ if not os.path.exists(path):
+ raise FileNotFoundError(f"Notebook file not found at: {path}")
- # Create a module to store the imported functions and classes
- mod = types.ModuleType(fullname)
- sys.modules[fullname] = mod
+ with io.open(path, "r", encoding="utf-8") as f:
+ nb = nbformat.read(f, as_version=4)
- # Go through the notebook cells and only execute function or class definitions
- for cell in nb.cells:
- if cell.cell_type == "code":
- cell_code = cell.source
- for name in names:
- # Check for function or class definitions
- if f"def {name}" in cell_code or f"class {name}" in cell_code:
- exec(cell_code, mod.__dict__)
- return mod
+ # Create a module to store the imported functions and classes
+ mod = types.ModuleType(fullname)
+ sys.modules[fullname] = mod
- # Specify the notebook name and functions/classes to import
- fullname = "converting-gpt-to-llama2"
- names = ["precompute_rope_params", "compute_rope", "SiLU", "RMSNorm"]
+ # Go through the notebook cells and only execute function or class definitions
+ for cell in nb.cells:
+ if cell.cell_type == "code":
+ cell_code = cell.source
+ for name in names:
+ # Check for function or class definitions
+ if f"def {name}" in cell_code or f"class {name}" in cell_code:
+ exec(cell_code, mod.__dict__)
- # Import the required functions and classes from the notebook
- return import_definitions_from_notebook(fullname, names)
+ imported_modules[fullname] = mod
+
+ return imported_modules
+
+ notebooks = {
+ "converting-gpt-to-llama2": ["SiLU", "RMSNorm", "precompute_rope_params", "compute_rope"],
+ "converting-llama2-to-llama3": ["precompute_rope_params"]
+ }
+
+ return import_definitions_from_notebook(notebooks)
@pytest.fixture(autouse=True)
@@ -59,6 +65,9 @@ def set_seed():
def test_rope_llama2(notebook):
+
+ this_nb = notebook["converting-gpt-to-llama2"]
+
# Settings
batch_size = 1
context_len = 4096
@@ -66,15 +75,15 @@ def test_rope_llama2(notebook):
head_dim = 16
# Instantiate RoPE parameters
- cos, sin = notebook.precompute_rope_params(head_dim=head_dim, context_length=context_len)
+ cos, sin = this_nb.precompute_rope_params(head_dim=head_dim, context_length=context_len)
# Dummy query and key tensors
queries = torch.randn(batch_size, num_heads, context_len, head_dim)
keys = torch.randn(batch_size, num_heads, context_len, head_dim)
# Apply rotary position embeddings
- queries_rot = notebook.compute_rope(queries, cos, sin)
- keys_rot = notebook.compute_rope(keys, cos, sin)
+ queries_rot = this_nb.compute_rope(queries, cos, sin)
+ keys_rot = this_nb.compute_rope(keys, cos, sin)
rot_emb = LlamaRotaryEmbedding(
dim=head_dim,
@@ -93,6 +102,10 @@ def test_rope_llama2(notebook):
def test_rope_llama3(notebook):
+
+ nb1 = notebook["converting-gpt-to-llama2"]
+ nb2 = notebook["converting-llama2-to-llama3"]
+
# Settings
batch_size = 1
context_len = 8192
@@ -101,19 +114,20 @@ def test_rope_llama3(notebook):
theta_base = 50_000
# Instantiate RoPE parameters
- cos, sin = notebook.precompute_rope_params(
+ cos, sin = nb2.precompute_rope_params(
head_dim=head_dim,
context_length=context_len,
theta_base=theta_base
)
# Dummy query and key tensors
+ torch.manual_seed(123)
queries = torch.randn(batch_size, num_heads, context_len, head_dim)
keys = torch.randn(batch_size, num_heads, context_len, head_dim)
# Apply rotary position embeddings
- queries_rot = notebook.compute_rope(queries, cos, sin)
- keys_rot = notebook.compute_rope(keys, cos, sin)
+ queries_rot = nb1.compute_rope(queries, cos, sin)
+ keys_rot = nb1.compute_rope(keys, cos, sin)
rot_emb = LlamaRotaryEmbedding(
dim=head_dim,
@@ -131,16 +145,83 @@ def test_rope_llama3(notebook):
torch.testing.assert_close(queries_rot, ref_queries_rot)
+def test_rope_llama3_12(notebook):
+
+ nb1 = notebook["converting-gpt-to-llama2"]
+ nb2 = notebook["converting-llama2-to-llama3"]
+
+ # Settings
+ batch_size = 1
+ context_len = 8192
+ num_heads = 4
+ head_dim = 16
+ rope_theta = 50_000
+
+ rope_config = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_context_length": 8192,
+ }
+
+ # Instantiate RoPE parameters
+ cos, sin = nb2.precompute_rope_params(
+ head_dim=head_dim,
+ theta_base=rope_theta,
+ context_length=context_len,
+ freq_config=rope_config,
+ )
+
+ # Dummy query and key tensors
+ torch.manual_seed(123)
+ queries = torch.randn(batch_size, num_heads, context_len, head_dim)
+ keys = torch.randn(batch_size, num_heads, context_len, head_dim)
+
+ # Apply rotary position embeddings
+ queries_rot = nb1.compute_rope(queries, cos, sin)
+ keys_rot = nb1.compute_rope(keys, cos, sin)
+
+ hf_rope_params = {
+ "factor": 8.0,
+ "low_freq_factor": 1.0,
+ "high_freq_factor": 4.0,
+ "original_max_position_embeddings": 8192,
+ "rope_type": "llama3"
+ }
+
+ class RoPEConfig:
+ rope_type = "llama3"
+ rope_scaling = hf_rope_params
+ factor = 1.0
+ dim: int = head_dim
+ rope_theta = 50_000
+ max_position_embeddings: int = 8192
+ hidden_size = head_dim * num_heads
+ num_attention_heads = num_heads
+
+ config = RoPEConfig()
+
+ rot_emb = LlamaRotaryEmbedding(config=config)
+ position_ids = torch.arange(context_len, dtype=torch.long).unsqueeze(0)
+ ref_cos, ref_sin = rot_emb(queries, position_ids)
+ ref_queries_rot, ref_keys_rot = apply_rotary_pos_emb(queries, keys, ref_cos, ref_sin)
+
+ torch.testing.assert_close(sin, ref_sin.squeeze(0))
+ torch.testing.assert_close(cos, ref_cos.squeeze(0))
+ torch.testing.assert_close(keys_rot, ref_keys_rot)
+ torch.testing.assert_close(queries_rot, ref_queries_rot)
+
+
def test_silu(notebook):
example_batch = torch.randn(2, 3, 4)
- silu = notebook.SiLU()
+ silu = notebook["converting-gpt-to-llama2"].SiLU()
assert torch.allclose(silu(example_batch), torch.nn.functional.silu(example_batch))
@pytest.mark.skipif(torch.__version__ < "2.4", reason="Requires PyTorch 2.4 or newer")
def test_rmsnorm(notebook):
example_batch = torch.randn(2, 3, 4)
- rms_norm = notebook.RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)
+ rms_norm = notebook["converting-gpt-to-llama2"].RMSNorm(emb_dim=example_batch.shape[-1], eps=1e-5)
rmsnorm_pytorch = torch.nn.RMSNorm(example_batch.shape[-1], eps=1e-5)
assert torch.allclose(rms_norm(example_batch), rmsnorm_pytorch(example_batch))
diff --git a/ch05/08_memory_efficient_weight_loading/README.md b/ch05/08_memory_efficient_weight_loading/README.md
new file mode 100644
index 00000000..2b8fef08
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/README.md
@@ -0,0 +1,5 @@
+# Memory-efficient Model Weight Loading
+
+This folder contains code to illustrate how to load model weights more efficiently
+
+- [memory-efficient-state-dict.ipynb](memory-efficient-state-dict.ipynb): contains code to load model weights via PyTorch's `load_state_dict` method more efficiently
diff --git a/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb b/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb
new file mode 100644
index 00000000..8ab9d4f7
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/memory-efficient-state-dict.ipynb
@@ -0,0 +1,929 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "1E_HhLEeYqFG"
+ },
+ "source": [
+ "| \n",
+ "\n",
+ "Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka \n", + " Code repository: https://github.com/rasbt/LLMs-from-scratch\n", + "\n", + " | \n",
+ "\n",
+ "\n",
+ " | \n",
+ "
 "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "SxQzFoS-IXdY",
+ "outputId": "b28ebfbd-9036-4696-d95a-7f96fdf29919"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "memory_profiler version: 0.61.0\n",
+ "torch version: 2.4.1+cu121\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"torch\",\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y47iQaQKyHap"
+ },
+ "source": [
+ " \n",
+ "## 1. Benchmark utilities"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nQeOEoo6yT0X"
+ },
+ "source": [
+ "- First, let's define some utility code to track VRAM (GPU memory)\n",
+ "- Later, we will also introduce a tool to track the main system RAM (CPU memory)\n",
+ "- The purpose of these functions will become clear when we apply them later"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "id": "pEiqjYrVivgt"
+ },
+ "outputs": [],
+ "source": [
+ "import gc\n",
+ "import time\n",
+ "import torch\n",
+ "\n",
+ "\n",
+ "def start_memory_tracking():\n",
+ " \"\"\"Initialize GPU memory tracking.\"\"\"\n",
+ " if torch.cuda.is_available():\n",
+ " torch.cuda.reset_peak_memory_stats()\n",
+ " else:\n",
+ " print(\"This notebook is intended for CUDA GPUs but CUDA is not available.\")\n",
+ "\n",
+ "def print_memory_usage():\n",
+ " max_gpu_memory = torch.cuda.max_memory_allocated() / (1024 ** 3) # Convert bytes to GB\n",
+ " print(f\"Maximum GPU memory allocated: {max_gpu_memory:.1f} GB\")\n",
+ "\n",
+ "def cleanup():\n",
+ " gc.collect()\n",
+ " torch.cuda.empty_cache()\n",
+ " time.sleep(3) # some buffer time to allow memory to clear\n",
+ " torch.cuda.reset_peak_memory_stats()\n",
+ " max_memory_allocated = torch.cuda.max_memory_allocated(device) / (1024 ** 3)\n",
+ " print(f\"Maximum GPU memory allocated: {max_memory_allocated:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "z5oJwoc-kkXs"
+ },
+ "source": [
+ " \n",
+ "## 2. Model setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YfJE0vnMyr88"
+ },
+ "source": [
+ "- This code section sets up the model itself\n",
+ "- Here, we use the \"large\" GPT-2 model to make things more interesting (you may use the \"gpt2-small (124M)\" to lower the memory requirements and execution time of this notebook)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "id": "tMuhCYaVI0w7"
+ },
+ "outputs": [],
+ "source": [
+ "from previous_chapters import GPTModel\n",
+ "\n",
+ "\n",
+ "BASE_CONFIG = {\n",
+ " \"vocab_size\": 50257, # Vocabulary size\n",
+ " \"context_length\": 1024, # Context length\n",
+ " \"drop_rate\": 0.0, # Dropout rate\n",
+ " \"qkv_bias\": True # Query-key-value bias\n",
+ "}\n",
+ "\n",
+ "model_configs = {\n",
+ " \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n",
+ " \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n",
+ " \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n",
+ " \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n",
+ "}\n",
+ "\n",
+ "CHOOSE_MODEL = \"gpt2-xl (1558M)\"\n",
+ "\n",
+ "BASE_CONFIG.update(model_configs[CHOOSE_MODEL])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KWYoo1z5y8aX"
+ },
+ "source": [
+ "- Now, let's see the GPU memory functions in action:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "GK3NEA3eJv3f",
+ "outputId": "60573d6e-c603-45e7-8283-b1e92e2a0013"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "start_memory_tracking()\n",
+ "\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG)\n",
+ "device = torch.device(\"cuda\")\n",
+ "model.to(device)\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GIhwBEBxzBsF"
+ },
+ "source": [
+ "- Additionally, let's make sure that the model runs okay by passing in some example tensor"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {
+ "id": "i_j6nZruUd7g"
+ },
+ "outputs": [],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UgNb8c32zh4g"
+ },
+ "source": [
+ "- Next, imagine we were pretraining the model and saving it for later use\n",
+ "- We skip the actual pretraining here for simplicity and just save the initialized model (but the same concept applies)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {
+ "id": "wUIXjcsimXU7"
+ },
+ "outputs": [],
+ "source": [
+ "# Training code would go here...\n",
+ "\n",
+ "model.train()\n",
+ "torch.save(model.state_dict(), \"model.pth\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "s9tBS4HUzz1g"
+ },
+ "source": [
+ "- Lastly, we delete the model and example tensor in the Python session to reset the GPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "SqmTzztqKnTs",
+ "outputId": "1198afb9-2d97-4b6a-9bdb-41551f25749d"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "del model, test_input\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7EnO8beUJ6Sb"
+ },
+ "source": [
+ " \n",
+ "## 3. Weight loading"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JtAXKjsG0AVL"
+ },
+ "source": [
+ "- Now begins the interesting part where we load the pretrained model weights\n",
+ "- Let's see how much GPU memory is required to load the previously saved model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "wCrQNbSJJO9w",
+ "outputId": "9b203868-a8ef-4011-fc2b-611cc0d10994"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Then load pretrained weights\n",
+ "\n",
+ "start_memory_tracking()\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG)\n",
+ "model.to(device)\n",
+ "\n",
+ "model.load_state_dict(\n",
+ " torch.load(\"model.pth\", map_location=device, weights_only=True)\n",
+ ")\n",
+ "model.to(device)\n",
+ "model.eval();\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4AGvOrcN0KdJ"
+ },
+ "source": [
+ "- Notice that the memory is 2x as large as in the previous session\n",
+ "- This is because we have the same model in memory twice, for a short period of time:\n",
+ " - The first time via `model.to(device)`\n",
+ " - The second time via the code line `model.load_state_dict(torch.load(\"model.pth\", map_location=device, weights_only=True))`; eventually, the loaded model weights will be copied into the model, and the `state_dict` will be discarded, but for a brief amount of time, we have both the main model and the loaded `state_dict` in memory\n",
+ "- The remaining sections focus on addressing this\n",
+ "- But first, let's test the model and reset the GPU memory\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "DvlUn-nmmbuj",
+ "outputId": "11d3ab68-f570-4c1e-c631-fe5547026799"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)\n",
+ "\n",
+ "del model, test_input\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RdPnW3iLLrjX"
+ },
+ "source": [
+ " \n",
+ "## 4. Loading weights sequentially"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FYqtUON602TD"
+ },
+ "source": [
+ "- One workaround for the problem of having the model weights in GPU memory twice, as highlighted in the previous section, is to load the model sequentially\n",
+ "- Below, we:\n",
+ " - first load the model into GPU memory\n",
+ " - then load the model weights into CPU memory\n",
+ " - and finally copy each parameter one by one into GPU memory\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "DOIGTNWTmx9G",
+ "outputId": "145162e6-aaa6-4c2a-ed8f-f1cf068adb80"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.7 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "start_memory_tracking()\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG).to(device)\n",
+ "\n",
+ "state_dict = torch.load(\"model.pth\", map_location=\"cpu\", weights_only=True)\n",
+ "\n",
+ "print_memory_usage()\n",
+ "\n",
+ "# Sequentially copy weights to the model's parameters\n",
+ "with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name].to(device))\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pn9xD_xL1ZzM"
+ },
+ "source": [
+ "- As we can see above, the memory usage is much lower than before\n",
+ "- Notice that the memory increases from 6.4 to 6.7 GB because initially, we only have the model in memory, and then we have the model plus 1 parameter tensor in memory (we temporarily move the parameter tensor to the GPU so we can assign it using `\".to\"` the model)\n",
+ "- Overall, this is a significant improvement\n",
+ "- Again, let's briefly test the model and then reset the GPU memory for the next section"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "PRHnjA48nJgw",
+ "outputId": "dcd6b1b2-538f-4862-96a6-a5fcbf3326a4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)\n",
+ "\n",
+ "del model, test_input, state_dict, param\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5M92LK7usb-Z"
+ },
+ "source": [
+ " \n",
+ "## 5. Loading the model with low CPU memory"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "R45qgeB613e2"
+ },
+ "source": [
+ "- In the previous session, we reduced GPU memory use by loading the weights (`state_dict`) into CPU memory first before copying them one-by-one into the model\n",
+ "- However, what do we do if we have limited CPU memory?\n",
+ "- This section uses PyTorch's so-called `\"meta\"` device approach to load a model on machines with large GPU memory but small CPU memory\n",
+ "- But first, let's define a convenience function to monitor CPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "metadata": {
+ "id": "BrcWy0q-3Bbe"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import psutil\n",
+ "from threading import Thread\n",
+ "\n",
+ "\n",
+ "def memory_usage_in_gb(func, *args, **kwargs):\n",
+ " process = psutil.Process(os.getpid())\n",
+ "\n",
+ " # Measure the baseline memory usage before running the function\n",
+ " baseline_mem = process.memory_info().rss / 1024 ** 3 # in GB\n",
+ "\n",
+ " # Start monitoring memory in a separate thread\n",
+ " mem_usage = []\n",
+ " done = False\n",
+ "\n",
+ " def monitor_memory():\n",
+ " while not done:\n",
+ " mem_usage.append(process.memory_info().rss / 1024 ** 3) # Convert to GB\n",
+ " time.sleep(0.1)\n",
+ "\n",
+ " t = Thread(target=monitor_memory)\n",
+ " t.start()\n",
+ "\n",
+ " # Run the function\n",
+ " func(*args, **kwargs)\n",
+ "\n",
+ " # Stop monitoring\n",
+ " done = True\n",
+ " t.join()\n",
+ "\n",
+ " peak_mem_usage_gb = max(mem_usage) - baseline_mem\n",
+ " return peak_mem_usage_gb\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ayy30Ytd5hjF"
+ },
+ "source": [
+ "- To start with, let's track the CPU memory of the sequential weight loading approach from the previous section"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "rCkV6IbQtpVn",
+ "outputId": "26c0435a-1e3d-4e8f-fbe2-f9655bad61b4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.7 GB\n",
+ "-> Maximum CPU memory allocated: 6.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_sequentially():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " model = GPTModel(BASE_CONFIG).to(device)\n",
+ "\n",
+ " state_dict = torch.load(\"model.pth\", map_location=\"cpu\", weights_only=True)\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ " # Sequentially copy weights to the model's parameters\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name].to(device))\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_sequentially)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UWrmnCML5oKy"
+ },
+ "source": [
+ "- Now, suppose we have a machine with low CPU memory but large GPU memory\n",
+ "- We can trade off CPU memory and GPU memory usage by introducing PyTorch's so-called \"meta\" device\n",
+ "- PyTorch's meta device is a special device type that allows you to create tensors without allocating actual memory for their data, effectively creating \"meta\" tensors\n",
+ "- This is useful for tasks like model analysis or architecture definition, where you need tensor shapes and types without the overhead of memory allocation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "PBErC_5Yt8ly",
+ "outputId": "8799db06-191c-47c4-92fa-fbb95d685aa9"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "-> Maximum CPU memory allocated: 1.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_sequentially_with_meta():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model = model.to_empty(device=device)\n",
+ "\n",
+ " state_dict = torch.load(\"model.pth\", map_location=device, weights_only=True)\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ " # Sequentially copy weights to the model's parameters\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name])\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_sequentially_with_meta)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VpnCABp75-VQ"
+ },
+ "source": [
+ "- As we can see above, by creating the model on the meta-device and loading the weights directly into GPU memory, we effectively reduced the CPU memory requirements\n",
+ "- One might ask: \"Is the sequential weight loading still necessary then, and how does that compare to the original approach?\"\n",
+ "- Let's check the simple PyTorch weight loading approach for comparison (from the first weight loading section in this notebook):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "4f-bqBNRuR39",
+ "outputId": "f7c0a901-b404-433a-9b93-2bbfa8183c56"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "-> Maximum CPU memory allocated: 4.4 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def baseline():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ " model.to(device)\n",
+ "\n",
+ " model.load_state_dict(torch.load(\"model.pth\", map_location=device, weights_only=True))\n",
+ " model.to(device)\n",
+ " model.eval();\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(baseline)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NKAjxbX86xnb"
+ },
+ "source": [
+ "- As we can see above, the \"simple\" weight loading without the meta device uses more memory\n",
+ "- In other words, if you have a machine with limited CPU memory, you can use the meta device approach to directly load the model weights into GPU memory to reduce peak CPU memory usage"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "## 6. Using `mmap=True` (recommmended)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- As an intermediate or advanced `torch.load` user, you may wonder how these approaches compare to the `mmap=True` setting in PyTorch\n",
+ "- The `mmap=True` setting in PyTorch enables memory-mapped file I/O, which allows the tensor to access data directly from disk storage, thus reducing memory usage by not loading the entire file into RAM if RAM is limited\n",
+ "- Also, see the helpful comment by [mikaylagawarecki](https://github.com/rasbt/LLMs-from-scratch/issues/402)\n",
+ "- At first glance, it may look less efficient than the sequential approaches above:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 37,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "GKwV0AMNemuR",
+ "outputId": "e207f2bf-5c87-498e-80fe-e8c4016ac711"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "-> Maximum CPU memory allocated: 5.9 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def best_practices():\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model.load_state_dict(\n",
+ " torch.load(\"model.pth\", map_location=device, weights_only=True, mmap=True),\n",
+ " assign=True\n",
+ " )\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(best_practices)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- The reason why the CPU RAM usage is so high is that there's enough CPU RAM available on this machine\n",
+ "- However, if you were to run this on a machine with limited CPU RAM, the `mmap` approach would use less memory"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "## 7. Other methods"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- This notebook is focused on simple, built-in methods for loading weights in PyTorch\n",
+ "- The recommended approach for limited CPU memory cases is the `mmap=True` approach explained enough\n",
+ "- Alternatively, one other option is a brute-force approach that saves and loads each weight tensor separately:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "metadata": {
+ "id": "2CgPEZUIb00w"
+ },
+ "outputs": [],
+ "source": [
+ "model = GPTModel(BASE_CONFIG)\n",
+ "# Assume `model` is your trained model\n",
+ "state_dict = model.state_dict()\n",
+ "\n",
+ "# Create a directory to store individual parameter files\n",
+ "os.makedirs(\"model_parameters\", exist_ok=True)\n",
+ "\n",
+ "# Save each parameter tensor separately\n",
+ "for name, param in state_dict.items():\n",
+ " torch.save(param.cpu(), f\"model_parameters/{name}.pt\")\n",
+ "\n",
+ "del model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "gTsmtJK-b4yy",
+ "outputId": "d361e2d3-e34c-48d7-9047-846c9bfd291e"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "-> Maximum CPU memory allocated: 0.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_individual_weights():\n",
+ "\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model = model.to_empty(device=device)\n",
+ "\n",
+ " print_memory_usage()\n",
+ " param_dir = \"model_parameters\"\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " weight_path = os.path.join(param_dir, f\"{name}.pt\")\n",
+ " if os.path.exists(weight_path):\n",
+ " param_data = torch.load(weight_path, map_location=\"cpu\", weights_only=True)\n",
+ " param.copy_(param_data)\n",
+ " del param_data # Free memory\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in {param_dir}.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_individual_weights)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "gpuType": "L4",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/ch05/08_memory_efficient_weight_loading/previous_chapters.py b/ch05/08_memory_efficient_weight_loading/previous_chapters.py
new file mode 100644
index 00000000..1fb5835a
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/previous_chapters.py
@@ -0,0 +1,170 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+#
+# This file collects all the relevant code that we covered thus far
+# throughout Chapters 2-5.
+
+
+import torch
+import torch.nn as nn
+
+#####################################
+# Chapter 3
+#####################################
+
+
+class MultiHeadAttention(nn.Module):
+ def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
+ super().__init__()
+ assert d_out % num_heads == 0, "d_out must be divisible by n_heads"
+
+ self.d_out = d_out
+ self.num_heads = num_heads
+ self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
+
+ self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
+ self.dropout = nn.Dropout(dropout)
+ self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
+
+ def forward(self, x):
+ b, num_tokens, d_in = x.shape
+
+ keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
+ queries = self.W_query(x)
+ values = self.W_value(x)
+
+ # We implicitly split the matrix by adding a `num_heads` dimension
+ # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
+ keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
+ values = values.view(b, num_tokens, self.num_heads, self.head_dim)
+ queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
+
+ # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
+ keys = keys.transpose(1, 2)
+ queries = queries.transpose(1, 2)
+ values = values.transpose(1, 2)
+
+ # Compute scaled dot-product attention (aka self-attention) with a causal mask
+ attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
+
+ # Original mask truncated to the number of tokens and converted to boolean
+ mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
+
+ # Use the mask to fill attention scores
+ attn_scores.masked_fill_(mask_bool, -torch.inf)
+
+ attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
+ attn_weights = self.dropout(attn_weights)
+
+ # Shape: (b, num_tokens, num_heads, head_dim)
+ context_vec = (attn_weights @ values).transpose(1, 2)
+
+ # Combine heads, where self.d_out = self.num_heads * self.head_dim
+ context_vec = context_vec.reshape(b, num_tokens, self.d_out)
+ context_vec = self.out_proj(context_vec) # optional projection
+
+ return context_vec
+
+
+#####################################
+# Chapter 4
+#####################################
+class LayerNorm(nn.Module):
+ def __init__(self, emb_dim):
+ super().__init__()
+ self.eps = 1e-5
+ self.scale = nn.Parameter(torch.ones(emb_dim))
+ self.shift = nn.Parameter(torch.zeros(emb_dim))
+
+ def forward(self, x):
+ mean = x.mean(dim=-1, keepdim=True)
+ var = x.var(dim=-1, keepdim=True, unbiased=False)
+ norm_x = (x - mean) / torch.sqrt(var + self.eps)
+ return self.scale * norm_x + self.shift
+
+
+class GELU(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return 0.5 * x * (1 + torch.tanh(
+ torch.sqrt(torch.tensor(2.0 / torch.pi)) *
+ (x + 0.044715 * torch.pow(x, 3))
+ ))
+
+
+class FeedForward(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.layers = nn.Sequential(
+ nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
+ GELU(),
+ nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
+ )
+
+ def forward(self, x):
+ return self.layers(x)
+
+
+class TransformerBlock(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.att = MultiHeadAttention(
+ d_in=cfg["emb_dim"],
+ d_out=cfg["emb_dim"],
+ context_length=cfg["context_length"],
+ num_heads=cfg["n_heads"],
+ dropout=cfg["drop_rate"],
+ qkv_bias=cfg["qkv_bias"])
+ self.ff = FeedForward(cfg)
+ self.norm1 = LayerNorm(cfg["emb_dim"])
+ self.norm2 = LayerNorm(cfg["emb_dim"])
+ self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
+
+ def forward(self, x):
+ # Shortcut connection for attention block
+ shortcut = x
+ x = self.norm1(x)
+ x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
+ x = self.drop_shortcut(x)
+ x = x + shortcut # Add the original input back
+
+ # Shortcut connection for feed-forward block
+ shortcut = x
+ x = self.norm2(x)
+ x = self.ff(x)
+ x = self.drop_shortcut(x)
+ x = x + shortcut # Add the original input back
+
+ return x
+
+
+class GPTModel(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
+ self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
+ self.drop_emb = nn.Dropout(cfg["drop_rate"])
+
+ self.trf_blocks = nn.Sequential(
+ *[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
+
+ self.final_norm = LayerNorm(cfg["emb_dim"])
+ self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
+
+ def forward(self, in_idx):
+ batch_size, seq_len = in_idx.shape
+ tok_embeds = self.tok_emb(in_idx)
+ pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
+ x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
+ x = self.drop_emb(x)
+ x = self.trf_blocks(x)
+ x = self.final_norm(x)
+ logits = self.out_head(x)
+ return logits
diff --git a/ch05/README.md b/ch05/README.md
index 3a725194..0a446e43 100644
--- a/ch05/README.md
+++ b/ch05/README.md
@@ -1,9 +1,11 @@
# Chapter 5: Pretraining on Unlabeled Data
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code
+
## Bonus Materials
- [02_alternative_weight_loading](02_alternative_weight_loading) contains code to load the GPT model weights from alternative places in case the model weights become unavailable from OpenAI
@@ -11,4 +13,5 @@
- [04_learning_rate_schedulers](04_learning_rate_schedulers) contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping
- [05_bonus_hparam_tuning](05_bonus_hparam_tuning) contains an optional hyperparameter tuning script
- [06_user_interface](06_user_interface) implements an interactive user interface to interact with the pretrained LLM
-- [07_gpt_to_llama](07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama and loads pretrained weights from Meta AI
+- [07_gpt_to_llama](07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama 3.2 and loads pretrained weights from Meta AI
+- [08_memory_efficient_weight_loading](08_memory_efficient_weight_loading) contains a bonus notebook showing how to load model weights via PyTorch's `load_state_dict` method more efficiently
diff --git a/ch06/01_main-chapter-code/load-finetuned-model.ipynb b/ch06/01_main-chapter-code/load-finetuned-model.ipynb
index fd7e1808..f6d210d2 100644
--- a/ch06/01_main-chapter-code/load-finetuned-model.ipynb
+++ b/ch06/01_main-chapter-code/load-finetuned-model.ipynb
@@ -124,7 +124,6 @@
"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n",
"\n",
"# Initialize base model\n",
- "model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n",
"model = GPTModel(BASE_CONFIG)"
]
},
diff --git a/ch06/README.md b/ch06/README.md
index ddc28bfb..abcbb6e4 100644
--- a/ch06/README.md
+++ b/ch06/README.md
@@ -1,10 +1,11 @@
# Chapter 6: Finetuning for Classification
-
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code
+
## Bonus Materials
- [02_bonus_additional-experiments](02_bonus_additional-experiments) includes additional experiments (e.g., training the last vs first token, extending the input length, etc.)
diff --git a/ch07/README.md b/ch07/README.md
index b081489f..2a3883c0 100644
--- a/ch07/README.md
+++ b/ch07/README.md
@@ -1,9 +1,11 @@
# Chapter 7: Finetuning to Follow Instructions
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code and exercise solutions
+
## Bonus Materials
- [02_dataset-utilities](02_dataset-utilities) contains utility code that can be used for preparing an instruction dataset
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "SxQzFoS-IXdY",
+ "outputId": "b28ebfbd-9036-4696-d95a-7f96fdf29919"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "memory_profiler version: 0.61.0\n",
+ "torch version: 2.4.1+cu121\n"
+ ]
+ }
+ ],
+ "source": [
+ "from importlib.metadata import version\n",
+ "\n",
+ "pkgs = [\n",
+ " \"torch\",\n",
+ "]\n",
+ "for p in pkgs:\n",
+ " print(f\"{p} version: {version(p)}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "y47iQaQKyHap"
+ },
+ "source": [
+ " \n",
+ "## 1. Benchmark utilities"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "nQeOEoo6yT0X"
+ },
+ "source": [
+ "- First, let's define some utility code to track VRAM (GPU memory)\n",
+ "- Later, we will also introduce a tool to track the main system RAM (CPU memory)\n",
+ "- The purpose of these functions will become clear when we apply them later"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "id": "pEiqjYrVivgt"
+ },
+ "outputs": [],
+ "source": [
+ "import gc\n",
+ "import time\n",
+ "import torch\n",
+ "\n",
+ "\n",
+ "def start_memory_tracking():\n",
+ " \"\"\"Initialize GPU memory tracking.\"\"\"\n",
+ " if torch.cuda.is_available():\n",
+ " torch.cuda.reset_peak_memory_stats()\n",
+ " else:\n",
+ " print(\"This notebook is intended for CUDA GPUs but CUDA is not available.\")\n",
+ "\n",
+ "def print_memory_usage():\n",
+ " max_gpu_memory = torch.cuda.max_memory_allocated() / (1024 ** 3) # Convert bytes to GB\n",
+ " print(f\"Maximum GPU memory allocated: {max_gpu_memory:.1f} GB\")\n",
+ "\n",
+ "def cleanup():\n",
+ " gc.collect()\n",
+ " torch.cuda.empty_cache()\n",
+ " time.sleep(3) # some buffer time to allow memory to clear\n",
+ " torch.cuda.reset_peak_memory_stats()\n",
+ " max_memory_allocated = torch.cuda.max_memory_allocated(device) / (1024 ** 3)\n",
+ " print(f\"Maximum GPU memory allocated: {max_memory_allocated:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "z5oJwoc-kkXs"
+ },
+ "source": [
+ " \n",
+ "## 2. Model setup"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "YfJE0vnMyr88"
+ },
+ "source": [
+ "- This code section sets up the model itself\n",
+ "- Here, we use the \"large\" GPT-2 model to make things more interesting (you may use the \"gpt2-small (124M)\" to lower the memory requirements and execution time of this notebook)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "id": "tMuhCYaVI0w7"
+ },
+ "outputs": [],
+ "source": [
+ "from previous_chapters import GPTModel\n",
+ "\n",
+ "\n",
+ "BASE_CONFIG = {\n",
+ " \"vocab_size\": 50257, # Vocabulary size\n",
+ " \"context_length\": 1024, # Context length\n",
+ " \"drop_rate\": 0.0, # Dropout rate\n",
+ " \"qkv_bias\": True # Query-key-value bias\n",
+ "}\n",
+ "\n",
+ "model_configs = {\n",
+ " \"gpt2-small (124M)\": {\"emb_dim\": 768, \"n_layers\": 12, \"n_heads\": 12},\n",
+ " \"gpt2-medium (355M)\": {\"emb_dim\": 1024, \"n_layers\": 24, \"n_heads\": 16},\n",
+ " \"gpt2-large (774M)\": {\"emb_dim\": 1280, \"n_layers\": 36, \"n_heads\": 20},\n",
+ " \"gpt2-xl (1558M)\": {\"emb_dim\": 1600, \"n_layers\": 48, \"n_heads\": 25},\n",
+ "}\n",
+ "\n",
+ "CHOOSE_MODEL = \"gpt2-xl (1558M)\"\n",
+ "\n",
+ "BASE_CONFIG.update(model_configs[CHOOSE_MODEL])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "KWYoo1z5y8aX"
+ },
+ "source": [
+ "- Now, let's see the GPU memory functions in action:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "GK3NEA3eJv3f",
+ "outputId": "60573d6e-c603-45e7-8283-b1e92e2a0013"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "start_memory_tracking()\n",
+ "\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG)\n",
+ "device = torch.device(\"cuda\")\n",
+ "model.to(device)\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "GIhwBEBxzBsF"
+ },
+ "source": [
+ "- Additionally, let's make sure that the model runs okay by passing in some example tensor"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {
+ "id": "i_j6nZruUd7g"
+ },
+ "outputs": [],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UgNb8c32zh4g"
+ },
+ "source": [
+ "- Next, imagine we were pretraining the model and saving it for later use\n",
+ "- We skip the actual pretraining here for simplicity and just save the initialized model (but the same concept applies)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {
+ "id": "wUIXjcsimXU7"
+ },
+ "outputs": [],
+ "source": [
+ "# Training code would go here...\n",
+ "\n",
+ "model.train()\n",
+ "torch.save(model.state_dict(), \"model.pth\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "s9tBS4HUzz1g"
+ },
+ "source": [
+ "- Lastly, we delete the model and example tensor in the Python session to reset the GPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "SqmTzztqKnTs",
+ "outputId": "1198afb9-2d97-4b6a-9bdb-41551f25749d"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "del model, test_input\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "7EnO8beUJ6Sb"
+ },
+ "source": [
+ " \n",
+ "## 3. Weight loading"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "JtAXKjsG0AVL"
+ },
+ "source": [
+ "- Now begins the interesting part where we load the pretrained model weights\n",
+ "- Let's see how much GPU memory is required to load the previously saved model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 8,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "wCrQNbSJJO9w",
+ "outputId": "9b203868-a8ef-4011-fc2b-611cc0d10994"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Then load pretrained weights\n",
+ "\n",
+ "start_memory_tracking()\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG)\n",
+ "model.to(device)\n",
+ "\n",
+ "model.load_state_dict(\n",
+ " torch.load(\"model.pth\", map_location=device, weights_only=True)\n",
+ ")\n",
+ "model.to(device)\n",
+ "model.eval();\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "4AGvOrcN0KdJ"
+ },
+ "source": [
+ "- Notice that the memory is 2x as large as in the previous session\n",
+ "- This is because we have the same model in memory twice, for a short period of time:\n",
+ " - The first time via `model.to(device)`\n",
+ " - The second time via the code line `model.load_state_dict(torch.load(\"model.pth\", map_location=device, weights_only=True))`; eventually, the loaded model weights will be copied into the model, and the `state_dict` will be discarded, but for a brief amount of time, we have both the main model and the loaded `state_dict` in memory\n",
+ "- The remaining sections focus on addressing this\n",
+ "- But first, let's test the model and reset the GPU memory\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "DvlUn-nmmbuj",
+ "outputId": "11d3ab68-f570-4c1e-c631-fe5547026799"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)\n",
+ "\n",
+ "del model, test_input\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "RdPnW3iLLrjX"
+ },
+ "source": [
+ " \n",
+ "## 4. Loading weights sequentially"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "FYqtUON602TD"
+ },
+ "source": [
+ "- One workaround for the problem of having the model weights in GPU memory twice, as highlighted in the previous section, is to load the model sequentially\n",
+ "- Below, we:\n",
+ " - first load the model into GPU memory\n",
+ " - then load the model weights into CPU memory\n",
+ " - and finally copy each parameter one by one into GPU memory\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "DOIGTNWTmx9G",
+ "outputId": "145162e6-aaa6-4c2a-ed8f-f1cf068adb80"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.7 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "start_memory_tracking()\n",
+ "\n",
+ "model = GPTModel(BASE_CONFIG).to(device)\n",
+ "\n",
+ "state_dict = torch.load(\"model.pth\", map_location=\"cpu\", weights_only=True)\n",
+ "\n",
+ "print_memory_usage()\n",
+ "\n",
+ "# Sequentially copy weights to the model's parameters\n",
+ "with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name].to(device))\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ "print_memory_usage()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Pn9xD_xL1ZzM"
+ },
+ "source": [
+ "- As we can see above, the memory usage is much lower than before\n",
+ "- Notice that the memory increases from 6.4 to 6.7 GB because initially, we only have the model in memory, and then we have the model plus 1 parameter tensor in memory (we temporarily move the parameter tensor to the GPU so we can assign it using `\".to\"` the model)\n",
+ "- Overall, this is a significant improvement\n",
+ "- Again, let's briefly test the model and then reset the GPU memory for the next section"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "PRHnjA48nJgw",
+ "outputId": "dcd6b1b2-538f-4862-96a6-a5fcbf3326a4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 0.0 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "# Test if the model works (no need to track memory here)\n",
+ "test_input = torch.tensor([[1, 2, 3]]).to(device)\n",
+ "model.eval()\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " model(test_input)\n",
+ "\n",
+ "del model, test_input, state_dict, param\n",
+ "cleanup()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "5M92LK7usb-Z"
+ },
+ "source": [
+ " \n",
+ "## 5. Loading the model with low CPU memory"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "R45qgeB613e2"
+ },
+ "source": [
+ "- In the previous session, we reduced GPU memory use by loading the weights (`state_dict`) into CPU memory first before copying them one-by-one into the model\n",
+ "- However, what do we do if we have limited CPU memory?\n",
+ "- This section uses PyTorch's so-called `\"meta\"` device approach to load a model on machines with large GPU memory but small CPU memory\n",
+ "- But first, let's define a convenience function to monitor CPU memory"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "metadata": {
+ "id": "BrcWy0q-3Bbe"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import psutil\n",
+ "from threading import Thread\n",
+ "\n",
+ "\n",
+ "def memory_usage_in_gb(func, *args, **kwargs):\n",
+ " process = psutil.Process(os.getpid())\n",
+ "\n",
+ " # Measure the baseline memory usage before running the function\n",
+ " baseline_mem = process.memory_info().rss / 1024 ** 3 # in GB\n",
+ "\n",
+ " # Start monitoring memory in a separate thread\n",
+ " mem_usage = []\n",
+ " done = False\n",
+ "\n",
+ " def monitor_memory():\n",
+ " while not done:\n",
+ " mem_usage.append(process.memory_info().rss / 1024 ** 3) # Convert to GB\n",
+ " time.sleep(0.1)\n",
+ "\n",
+ " t = Thread(target=monitor_memory)\n",
+ " t.start()\n",
+ "\n",
+ " # Run the function\n",
+ " func(*args, **kwargs)\n",
+ "\n",
+ " # Stop monitoring\n",
+ " done = True\n",
+ " t.join()\n",
+ "\n",
+ " peak_mem_usage_gb = max(mem_usage) - baseline_mem\n",
+ " return peak_mem_usage_gb\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Ayy30Ytd5hjF"
+ },
+ "source": [
+ "- To start with, let's track the CPU memory of the sequential weight loading approach from the previous section"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "rCkV6IbQtpVn",
+ "outputId": "26c0435a-1e3d-4e8f-fbe2-f9655bad61b4"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.7 GB\n",
+ "-> Maximum CPU memory allocated: 6.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_sequentially():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " model = GPTModel(BASE_CONFIG).to(device)\n",
+ "\n",
+ " state_dict = torch.load(\"model.pth\", map_location=\"cpu\", weights_only=True)\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ " # Sequentially copy weights to the model's parameters\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name].to(device))\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_sequentially)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "UWrmnCML5oKy"
+ },
+ "source": [
+ "- Now, suppose we have a machine with low CPU memory but large GPU memory\n",
+ "- We can trade off CPU memory and GPU memory usage by introducing PyTorch's so-called \"meta\" device\n",
+ "- PyTorch's meta device is a special device type that allows you to create tensors without allocating actual memory for their data, effectively creating \"meta\" tensors\n",
+ "- This is useful for tasks like model analysis or architecture definition, where you need tensor shapes and types without the overhead of memory allocation"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 14,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "PBErC_5Yt8ly",
+ "outputId": "8799db06-191c-47c4-92fa-fbb95d685aa9"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "-> Maximum CPU memory allocated: 1.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_sequentially_with_meta():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model = model.to_empty(device=device)\n",
+ "\n",
+ " state_dict = torch.load(\"model.pth\", map_location=device, weights_only=True)\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ " # Sequentially copy weights to the model's parameters\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " if name in state_dict:\n",
+ " param.copy_(state_dict[name])\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in state_dict.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_sequentially_with_meta)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "VpnCABp75-VQ"
+ },
+ "source": [
+ "- As we can see above, by creating the model on the meta-device and loading the weights directly into GPU memory, we effectively reduced the CPU memory requirements\n",
+ "- One might ask: \"Is the sequential weight loading still necessary then, and how does that compare to the original approach?\"\n",
+ "- Let's check the simple PyTorch weight loading approach for comparison (from the first weight loading section in this notebook):"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 15,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "4f-bqBNRuR39",
+ "outputId": "f7c0a901-b404-433a-9b93-2bbfa8183c56"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 12.8 GB\n",
+ "-> Maximum CPU memory allocated: 4.4 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def baseline():\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ " model.to(device)\n",
+ "\n",
+ " model.load_state_dict(torch.load(\"model.pth\", map_location=device, weights_only=True))\n",
+ " model.to(device)\n",
+ " model.eval();\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(baseline)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "NKAjxbX86xnb"
+ },
+ "source": [
+ "- As we can see above, the \"simple\" weight loading without the meta device uses more memory\n",
+ "- In other words, if you have a machine with limited CPU memory, you can use the meta device approach to directly load the model weights into GPU memory to reduce peak CPU memory usage"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "## 6. Using `mmap=True` (recommmended)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- As an intermediate or advanced `torch.load` user, you may wonder how these approaches compare to the `mmap=True` setting in PyTorch\n",
+ "- The `mmap=True` setting in PyTorch enables memory-mapped file I/O, which allows the tensor to access data directly from disk storage, thus reducing memory usage by not loading the entire file into RAM if RAM is limited\n",
+ "- Also, see the helpful comment by [mikaylagawarecki](https://github.com/rasbt/LLMs-from-scratch/issues/402)\n",
+ "- At first glance, it may look less efficient than the sequential approaches above:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 37,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "GKwV0AMNemuR",
+ "outputId": "e207f2bf-5c87-498e-80fe-e8c4016ac711"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "-> Maximum CPU memory allocated: 5.9 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def best_practices():\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model.load_state_dict(\n",
+ " torch.load(\"model.pth\", map_location=device, weights_only=True, mmap=True),\n",
+ " assign=True\n",
+ " )\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(best_practices)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- The reason why the CPU RAM usage is so high is that there's enough CPU RAM available on this machine\n",
+ "- However, if you were to run this on a machine with limited CPU RAM, the `mmap` approach would use less memory"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ " \n",
+ "## 7. Other methods"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "- This notebook is focused on simple, built-in methods for loading weights in PyTorch\n",
+ "- The recommended approach for limited CPU memory cases is the `mmap=True` approach explained enough\n",
+ "- Alternatively, one other option is a brute-force approach that saves and loads each weight tensor separately:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 13,
+ "metadata": {
+ "id": "2CgPEZUIb00w"
+ },
+ "outputs": [],
+ "source": [
+ "model = GPTModel(BASE_CONFIG)\n",
+ "# Assume `model` is your trained model\n",
+ "state_dict = model.state_dict()\n",
+ "\n",
+ "# Create a directory to store individual parameter files\n",
+ "os.makedirs(\"model_parameters\", exist_ok=True)\n",
+ "\n",
+ "# Save each parameter tensor separately\n",
+ "for name, param in state_dict.items():\n",
+ " torch.save(param.cpu(), f\"model_parameters/{name}.pt\")\n",
+ "\n",
+ "del model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 16,
+ "metadata": {
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "id": "gTsmtJK-b4yy",
+ "outputId": "d361e2d3-e34c-48d7-9047-846c9bfd291e"
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "Maximum GPU memory allocated: 6.4 GB\n",
+ "-> Maximum CPU memory allocated: 0.3 GB\n"
+ ]
+ }
+ ],
+ "source": [
+ "def load_individual_weights():\n",
+ "\n",
+ " start_memory_tracking()\n",
+ "\n",
+ " with torch.device(\"meta\"):\n",
+ " model = GPTModel(BASE_CONFIG)\n",
+ "\n",
+ " model = model.to_empty(device=device)\n",
+ "\n",
+ " print_memory_usage()\n",
+ " param_dir = \"model_parameters\"\n",
+ "\n",
+ " with torch.no_grad():\n",
+ " for name, param in model.named_parameters():\n",
+ " weight_path = os.path.join(param_dir, f\"{name}.pt\")\n",
+ " if os.path.exists(weight_path):\n",
+ " param_data = torch.load(weight_path, map_location=\"cpu\", weights_only=True)\n",
+ " param.copy_(param_data)\n",
+ " del param_data # Free memory\n",
+ " else:\n",
+ " print(f\"Warning: {name} not found in {param_dir}.\")\n",
+ "\n",
+ " print_memory_usage()\n",
+ "\n",
+ "\n",
+ "peak_memory_used = memory_usage_in_gb(load_individual_weights)\n",
+ "print(f\"-> Maximum CPU memory allocated: {peak_memory_used:.1f} GB\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "gpuType": "L4",
+ "provenance": []
+ },
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.11.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}
diff --git a/ch05/08_memory_efficient_weight_loading/previous_chapters.py b/ch05/08_memory_efficient_weight_loading/previous_chapters.py
new file mode 100644
index 00000000..1fb5835a
--- /dev/null
+++ b/ch05/08_memory_efficient_weight_loading/previous_chapters.py
@@ -0,0 +1,170 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+#
+# This file collects all the relevant code that we covered thus far
+# throughout Chapters 2-5.
+
+
+import torch
+import torch.nn as nn
+
+#####################################
+# Chapter 3
+#####################################
+
+
+class MultiHeadAttention(nn.Module):
+ def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
+ super().__init__()
+ assert d_out % num_heads == 0, "d_out must be divisible by n_heads"
+
+ self.d_out = d_out
+ self.num_heads = num_heads
+ self.head_dim = d_out // num_heads # Reduce the projection dim to match desired output dim
+
+ self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
+ self.out_proj = nn.Linear(d_out, d_out) # Linear layer to combine head outputs
+ self.dropout = nn.Dropout(dropout)
+ self.register_buffer('mask', torch.triu(torch.ones(context_length, context_length), diagonal=1))
+
+ def forward(self, x):
+ b, num_tokens, d_in = x.shape
+
+ keys = self.W_key(x) # Shape: (b, num_tokens, d_out)
+ queries = self.W_query(x)
+ values = self.W_value(x)
+
+ # We implicitly split the matrix by adding a `num_heads` dimension
+ # Unroll last dim: (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
+ keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
+ values = values.view(b, num_tokens, self.num_heads, self.head_dim)
+ queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
+
+ # Transpose: (b, num_tokens, num_heads, head_dim) -> (b, num_heads, num_tokens, head_dim)
+ keys = keys.transpose(1, 2)
+ queries = queries.transpose(1, 2)
+ values = values.transpose(1, 2)
+
+ # Compute scaled dot-product attention (aka self-attention) with a causal mask
+ attn_scores = queries @ keys.transpose(2, 3) # Dot product for each head
+
+ # Original mask truncated to the number of tokens and converted to boolean
+ mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
+
+ # Use the mask to fill attention scores
+ attn_scores.masked_fill_(mask_bool, -torch.inf)
+
+ attn_weights = torch.softmax(attn_scores / keys.shape[-1]**0.5, dim=-1)
+ attn_weights = self.dropout(attn_weights)
+
+ # Shape: (b, num_tokens, num_heads, head_dim)
+ context_vec = (attn_weights @ values).transpose(1, 2)
+
+ # Combine heads, where self.d_out = self.num_heads * self.head_dim
+ context_vec = context_vec.reshape(b, num_tokens, self.d_out)
+ context_vec = self.out_proj(context_vec) # optional projection
+
+ return context_vec
+
+
+#####################################
+# Chapter 4
+#####################################
+class LayerNorm(nn.Module):
+ def __init__(self, emb_dim):
+ super().__init__()
+ self.eps = 1e-5
+ self.scale = nn.Parameter(torch.ones(emb_dim))
+ self.shift = nn.Parameter(torch.zeros(emb_dim))
+
+ def forward(self, x):
+ mean = x.mean(dim=-1, keepdim=True)
+ var = x.var(dim=-1, keepdim=True, unbiased=False)
+ norm_x = (x - mean) / torch.sqrt(var + self.eps)
+ return self.scale * norm_x + self.shift
+
+
+class GELU(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return 0.5 * x * (1 + torch.tanh(
+ torch.sqrt(torch.tensor(2.0 / torch.pi)) *
+ (x + 0.044715 * torch.pow(x, 3))
+ ))
+
+
+class FeedForward(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.layers = nn.Sequential(
+ nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
+ GELU(),
+ nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
+ )
+
+ def forward(self, x):
+ return self.layers(x)
+
+
+class TransformerBlock(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.att = MultiHeadAttention(
+ d_in=cfg["emb_dim"],
+ d_out=cfg["emb_dim"],
+ context_length=cfg["context_length"],
+ num_heads=cfg["n_heads"],
+ dropout=cfg["drop_rate"],
+ qkv_bias=cfg["qkv_bias"])
+ self.ff = FeedForward(cfg)
+ self.norm1 = LayerNorm(cfg["emb_dim"])
+ self.norm2 = LayerNorm(cfg["emb_dim"])
+ self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
+
+ def forward(self, x):
+ # Shortcut connection for attention block
+ shortcut = x
+ x = self.norm1(x)
+ x = self.att(x) # Shape [batch_size, num_tokens, emb_size]
+ x = self.drop_shortcut(x)
+ x = x + shortcut # Add the original input back
+
+ # Shortcut connection for feed-forward block
+ shortcut = x
+ x = self.norm2(x)
+ x = self.ff(x)
+ x = self.drop_shortcut(x)
+ x = x + shortcut # Add the original input back
+
+ return x
+
+
+class GPTModel(nn.Module):
+ def __init__(self, cfg):
+ super().__init__()
+ self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
+ self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
+ self.drop_emb = nn.Dropout(cfg["drop_rate"])
+
+ self.trf_blocks = nn.Sequential(
+ *[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
+
+ self.final_norm = LayerNorm(cfg["emb_dim"])
+ self.out_head = nn.Linear(cfg["emb_dim"], cfg["vocab_size"], bias=False)
+
+ def forward(self, in_idx):
+ batch_size, seq_len = in_idx.shape
+ tok_embeds = self.tok_emb(in_idx)
+ pos_embeds = self.pos_emb(torch.arange(seq_len, device=in_idx.device))
+ x = tok_embeds + pos_embeds # Shape [batch_size, num_tokens, emb_size]
+ x = self.drop_emb(x)
+ x = self.trf_blocks(x)
+ x = self.final_norm(x)
+ logits = self.out_head(x)
+ return logits
diff --git a/ch05/README.md b/ch05/README.md
index 3a725194..0a446e43 100644
--- a/ch05/README.md
+++ b/ch05/README.md
@@ -1,9 +1,11 @@
# Chapter 5: Pretraining on Unlabeled Data
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code
+
## Bonus Materials
- [02_alternative_weight_loading](02_alternative_weight_loading) contains code to load the GPT model weights from alternative places in case the model weights become unavailable from OpenAI
@@ -11,4 +13,5 @@
- [04_learning_rate_schedulers](04_learning_rate_schedulers) contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping
- [05_bonus_hparam_tuning](05_bonus_hparam_tuning) contains an optional hyperparameter tuning script
- [06_user_interface](06_user_interface) implements an interactive user interface to interact with the pretrained LLM
-- [07_gpt_to_llama](07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama and loads pretrained weights from Meta AI
+- [07_gpt_to_llama](07_gpt_to_llama) contains a step-by-step guide for converting a GPT architecture implementation to Llama 3.2 and loads pretrained weights from Meta AI
+- [08_memory_efficient_weight_loading](08_memory_efficient_weight_loading) contains a bonus notebook showing how to load model weights via PyTorch's `load_state_dict` method more efficiently
diff --git a/ch06/01_main-chapter-code/load-finetuned-model.ipynb b/ch06/01_main-chapter-code/load-finetuned-model.ipynb
index fd7e1808..f6d210d2 100644
--- a/ch06/01_main-chapter-code/load-finetuned-model.ipynb
+++ b/ch06/01_main-chapter-code/load-finetuned-model.ipynb
@@ -124,7 +124,6 @@
"BASE_CONFIG.update(model_configs[CHOOSE_MODEL])\n",
"\n",
"# Initialize base model\n",
- "model_size = CHOOSE_MODEL.split(\" \")[-1].lstrip(\"(\").rstrip(\")\")\n",
"model = GPTModel(BASE_CONFIG)"
]
},
diff --git a/ch06/README.md b/ch06/README.md
index ddc28bfb..abcbb6e4 100644
--- a/ch06/README.md
+++ b/ch06/README.md
@@ -1,10 +1,11 @@
# Chapter 6: Finetuning for Classification
-
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code
+
## Bonus Materials
- [02_bonus_additional-experiments](02_bonus_additional-experiments) includes additional experiments (e.g., training the last vs first token, extending the input length, etc.)
diff --git a/ch07/README.md b/ch07/README.md
index b081489f..2a3883c0 100644
--- a/ch07/README.md
+++ b/ch07/README.md
@@ -1,9 +1,11 @@
# Chapter 7: Finetuning to Follow Instructions
+
## Main Chapter Code
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code and exercise solutions
+
## Bonus Materials
- [02_dataset-utilities](02_dataset-utilities) contains utility code that can be used for preparing an instruction dataset