Libnetwork is a Docker project that implments network functionalities for docker container. It supports several drivers, including bridge, host, and overlay. Overlay provides multi-host container networking through VXLAN. Although libnetwork has been integrated into the docker engine and its swarm mode, libnetwork can work just by itself. Indeed, container is composed by a collection of namespaces; namespaces are independent to each other and network namespace is one of them. Since libnetwork's role is to manipulate network namespace, it certainly can live without containers.
This article demonstrates how libnetwork can be used to create isolated network namespace with virtual interfaces and establish connections between them. In particular, we focus on multi-host networking enabled by the overlay driver. The benefits of exploring libnetwork without a real container include
- Reveal the myth behind docker networking by removing other non-networking components
- Provide a lightweight approach to develop new drivers for container networking
- Help users understand how libnetwork works; all commands are sent to libnetwork code base directly, instead of through docker api
The main tool we use to achieve the goal is dnet.
docker run -d \
--name=pr_consul \
-p 8500:8500 -p 8300-8302:8300-8302/tcp \
-p 8300-8302:8300-8302/udp \
-h consul \
progrium/consul \
-server -bootstrap
or use a newer version of consul (Recommended)
docker run -d \
--name=consul \
-p 8500:8500 -p 8300-8302:8300-8302/tcp -p 8300-8302:8300-8302/udp \
-h consul consul:0.8.5
Checkout the libnetwork repository and build the dnet executable
git clone https://github.com/huikang/libnetwork.git
make build
The dnet executable is ./bin/dnet. To use the consul kv store, dnet needs a configurable file, e.g., libnetwork-dnet-consul.toml. The content of the file looks llike
title = "LibNetwork Configuration file"
[daemon]
debug = true
[cluster]
discovery = "consul://172.17.0.1:8500/custom_prefix"
Heartbeat = 10
[scopes]
[scopes.global]
[scopes.global.client]
provider = "consul"
address = "172.17.0.1:8500/custom_prefix"To form a libnetwork cluster like docker swarm, we need to create multiple libnetwork container on the same host, e.g.,
docker run -d --hostname=dnet-1-multi-consul --name=dnet-1-multi_consul \
--privileged -p 41000:2385 -e _OVERLAY_HOST_MODE \
-v /go/src/github.com/huikang/libnetwork/:/go/src/github.com/huikang/libnetwork \
-w /go/src/github.com/huikang/libnetwork \
mrjana/golang \
./bin/dnet -d -D -c ./libnetwork-dnet-consul.toml
docker run -d --hostname=dnet-2-multi-consul --name=dnet-2-multi_consul \
--privileged -p 41001:2385 -e _OVERLAY_HOST_MODE \
-v /go/src/github.com/huikang/libnetwork/:/go/src/github.com/huikang/libnetwork \
-w /go/src/github.com/huikang/libnetwork \
mrjana/golang \
./bin/dnet -d -D -c ./libnetwork-dnet-consul.tomlThe dnet process listens on port 2385 and serves requests. To avoid conflict, the above two containers expose 2385 to different port, i.e., 41000 and 41001. Therefore, client requests should be sent to 41000 for the first dnet process.
Note: if the dnets run on different hosts, port
7946needs to be exposed because port 7946 is the serf membership listening port
You can also start dnet directly on the host
./bin/dnet -d -D -H tcp://0.0.0.0:4567 -c ./cmd/dnet/libnetwork-consul.toml
Now you can run some dnet client commands to test the libnetwork cluster.
List the network
./bin/dnet -H tcp://127.0.0.1:41000 network ls
./bin/dnet -H tcp://127.0.0.1:41001 network ls
Create a test network mh1 from dnet-1 container. For now, you'd better use the test driver; otherwise the network will not be synced to other dnet instance. Later we will see how overlay driver works.
./bin/dnet -H tcp://127.0.0.1:41000 network create -d test mh1
./bin/dnet -H tcp://127.0.0.1:41001 network ls
The above commands show that the network created in one dnet process will be propagated to the libnetwork cluster.
To examine the global datastore, download cosul binary on another machine
export CONSUL_HTTP_ADDR=172.17.0.2:8500
consul kv export
Then remove the mh1 from dnet-2 to verify data is synced via consul
./bin/dnet -H tcp://127.0.0.1:41001 network rm mh1
Before experimenting the overlay driver, we must understand what network, service, and sandbox are in libnetwork.
Create service(aka., endpoint) and attach the endpoint to sandbox
./bin/dnet -H tcp://127.0.0.1:41000 network create -d test multihost
./bin/dnet -H tcp://127.0.0.1:41001 service publish svc.multihost
./bin/dnet -H tcp://127.0.0.1:41000 service ls
Create an Sandbox, which represents the network namespace of a container
./bin/dnet -H tcp://127.0.0.1:41000 container create container_0
./bin/dnet -H tcp://127.0.0.1:41000 service attach container_0 svc.multihost
List the container attached to the network
./bin/dnet -H tcp://127.0.0.1:41000 service ls
Since a service represents an endpoint, the endpoint can not be attached to another container, e.g.,
./bin/dnet -H tcp://127.0.0.1:41000 container create container_00
./bin/dnet -H tcp://127.0.0.1:41000 service attach container_00 svc.multihost
A new service or endpoint should be created
./bin/dnet -H tcp://127.0.0.1:41001 service publish newsvc.multihost
./bin/dnet -H tcp://127.0.0.1:41000 service attach container_00 newsvc.multihost
Note that service(aka., endpoint) has a global scope, so service can be created on any node. But, sandbox or container has local scope.
To test libnetwork overlay
Create an overlay network
./bin/dnet -H tcp://127.0.0.1:41000 network create -d overlay multihost
./bin/dnet -H tcp://127.0.0.1:41000 network ls
./bin/dnet -H tcp://127.0.0.1:41001 network ls
Since overlay network is a global resource, the network is visiable on all the dnet agents.
Create container/sandbox on two hosts
./bin/dnet -H tcp://127.0.0.1:41000 container create container_0
./bin/dnet -H tcp://127.0.0.1:41001 container create container_1
Create endpoint/service
./bin/dnet -H tcp://127.0.0.1:41000 service publish srv_0.multihost
./bin/dnet -H tcp://127.0.0.1:41001 service publish srv_1.multihost
Attach service/endpint to the container
./bin/dnet -H tcp://127.0.0.1:41000 service attach container_0 srv_0.multihost
./bin/dnet -H tcp://127.0.0.1:41001 service attach container_1 srv_1.multihost
Find the sandbox ID on dnet-1 by
./bin/dnet -H tcp://127.0.0.1:41000 service ls
SERVICE ID NAME NETWORK CONTAINER **SANDBOX**
1ee4cd3181d8 srv_1 multihost
692d3ab5d660 srv_0 multihost container_0 ee8de392bc41
d4cca2196e93 gateway_container_0 docker_gwbridge container_0 ee8de392bc41The outlist the service(aka., endpoint) and network name because they have global scope, while only container_0 with its sandbox is displayed. This is becuse sandbox has local scope.
The next step is to verify that the two endpoints in the two Sandboxes are connected because libnetwork puts them in the same network.
mkdir -p /var/run/netns
touch /var/run/netns/c && mount -o bind /var/run/docker/netns/[SANDBOXID] /var/run/netns/c
ip netns exec c ifconfigThe output of last command should be the NIC of the sandbox, which is different than the dnet-1 container:
eth0 Link encap:Ethernet HWaddr 02:42:0a:00:03:02
inet addr:10.0.3.2 Bcast:0.0.0.0 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:13 errors:0 dropped:0 overruns:0 frame:0
TX packets:13 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1162 (1.1 KiB) TX bytes:1162 (1.1 KiB)Ping the another container/sandbox in the same overlay network
# ip netns exec c ping 10.0.3.3
dnet's log
time="2017-02-24T16:04:10Z" level=debug msg="Watch triggered with 2 nodes" discovery=consul
time="2017-02-24T16:04:16Z" level=debug msg="2017/02/24 16:04:16 [DEBUG] memberlist: TCP connection from=172.17.0.4:58210\n"
time="2017-02-24T16:04:24Z" level=debug msg="Watch triggered with 2 nodes" discovery=consul
time="2017-02-24T16:04:25Z" level=debug msg="Miss notification, l2 mac 02:42:0a:00:03:02"
time="2017-02-24T16:04:25Z" level=debug msg="Miss notification, l2 mac 02:42:0a:00:03:03"
time="2017-02-24T16:04:30Z" level=debug msg="Watch triggered with 2 nodes" discovery=consul
time="2017-02-24T16:04:40Z" level=debug msg="2017/02/24 16:04:40 [DEBUG] memberlist: Initiating push/pull sync with: 172.17.0.4:7946\n"
time="2017-02-24T16:04:44Z" level=debug msg="Watch triggered with 2 nodes" discovery=consul
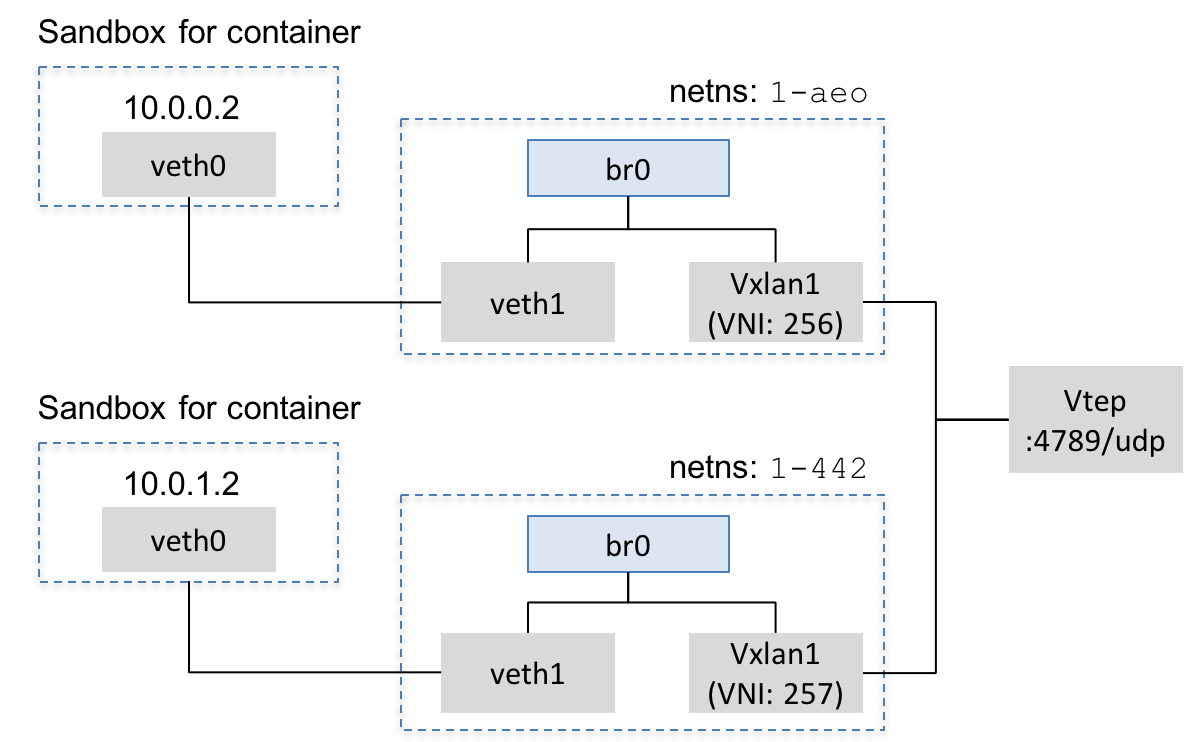
If you are curious enough, you may want to see what is the vxlan VNI created for the overlay network. In the dnet-1 container:
First, find out the netns created for the overlay network named "multihost".
# ls /var/run/docker/netns/
The netns typically start with 1-XYZ. For example, here the netns
is /var/run/docker/netns/1-ae0e5b2b78
# touch /var/run/netns/1ae
# mount -o bind /var/run/docker/netns/1-ae0e5b2b78 /var/run/netns/1ae
# ip netns exec 1ae ip -d link show dev vxlan1
6: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN mode DEFAULT group default
link/ether 0e:5f:79:4b:d4:71 brd ff:ff:ff:ff:ff:ff promiscuity 1
vxlan id 256 srcport 0 0 dstport 4789 proxy l2miss l3miss ageing 300
bridge_slave
You can see the vxlan ID is 256. Suppose you create a new overlay network, the vxlan ID will be assigned sequentially, i.e., 257, 258...
# ip netns exec 1ae bridge fdb show dev vxlan1
0e:5f:79:4b:d4:71 vlan 1 master br0 permanent
0e:5f:79:4b:d4:71 master br0 permanent
02:42:0a:00:03:03 dst 172.17.0.4 self permanent
The full architecture is illustrated in Figure xxx.