Robustness of dimensions - varying number of ratings threshold for characters #16
Comments
|
Sort of related sanity checking: #17 If we transpose the matrix and run SVD, we see the same dimensions in terms of traits as the columns of U. |
|
|

|
Talking with Dodds
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
df_n: (800, 269)
Avg min: 42.07125
Std for n: 52.91026529358461
If 10 ratings are required for each trait for each character in order for that character to be included in the matrix, then:
newdf: (560, 236)
First dimension (first row of V^T)
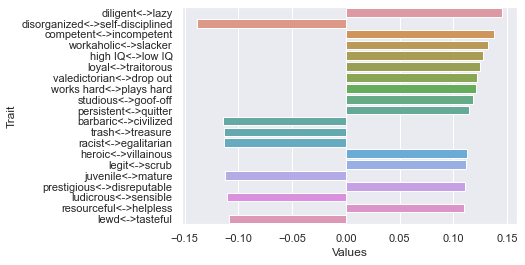
Second dimension
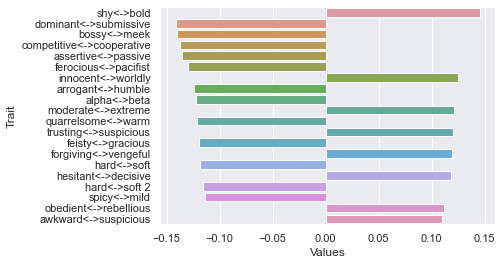
Third dimension
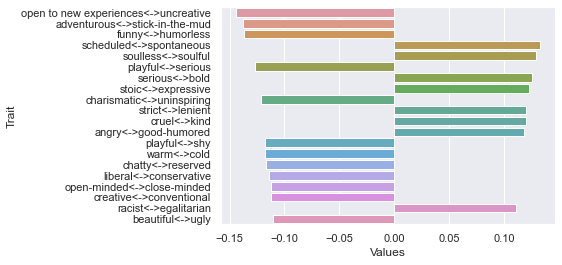
Fourth dimension
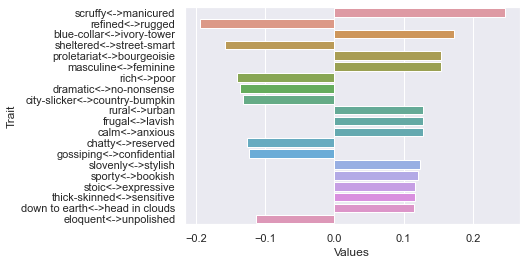
Fifth dimension
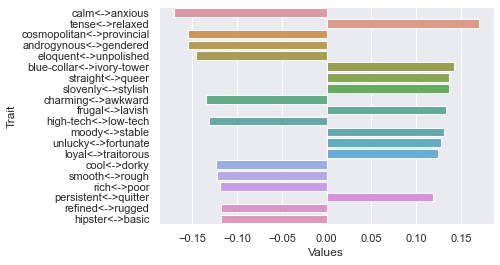
Sixth dimension
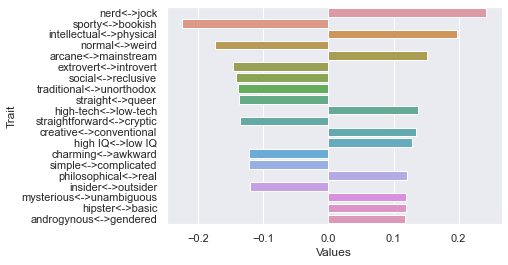
Seventh dimension
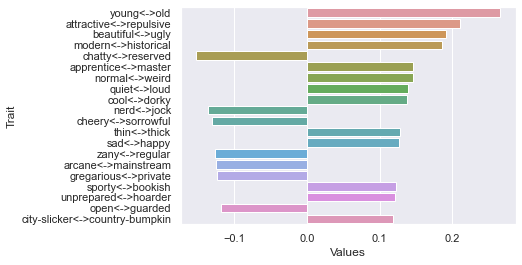
Eighth dimension
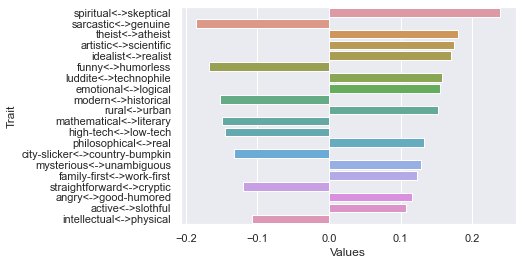
Ninth dimension
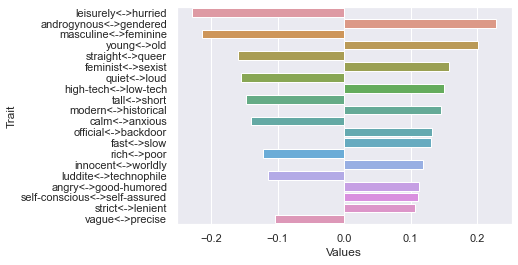
Tenth dimension
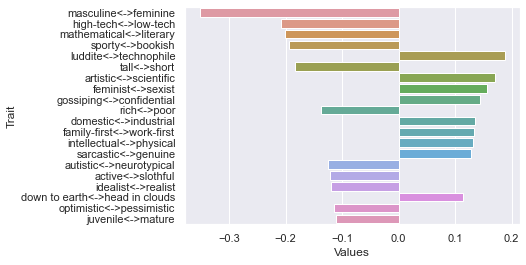
20 rating threshold: newdf: (436, 236)
First dimension
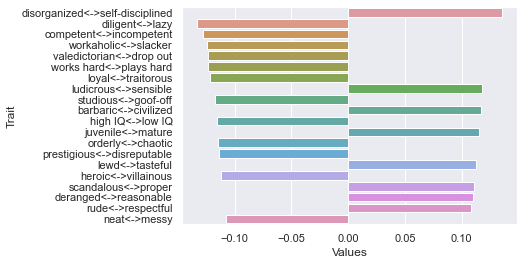
Second dimension
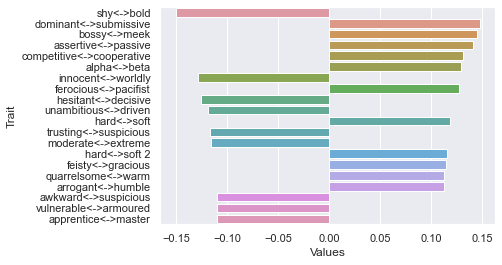
Third dimension
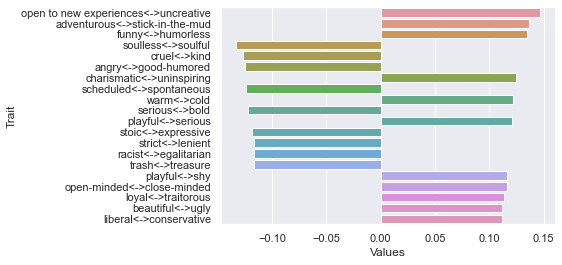
Fourth dimension
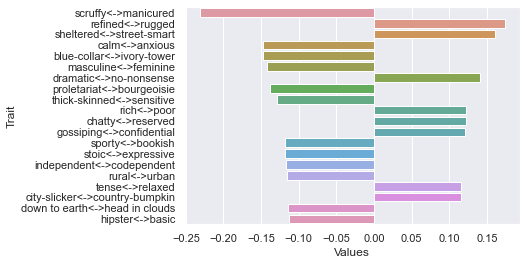
Fifth dimension
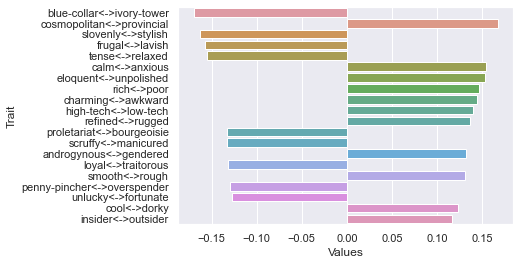
Sixth dimension
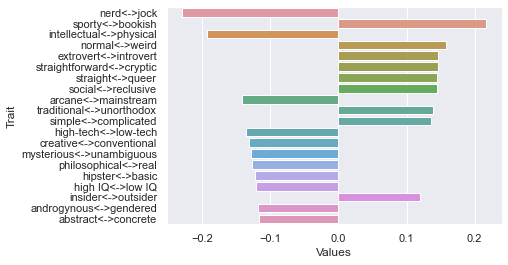
Seventh dimension
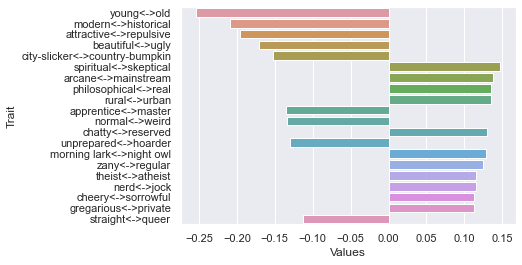
Eighth dimension
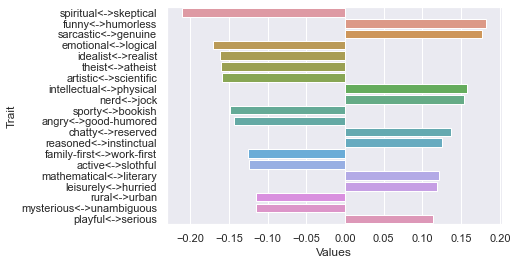
Ninth dimension
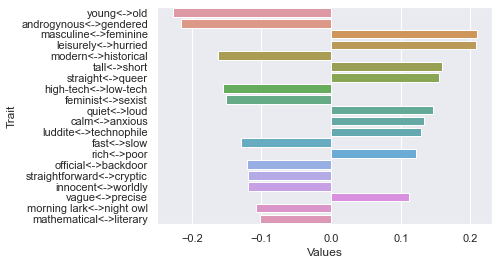
Tenth dimension
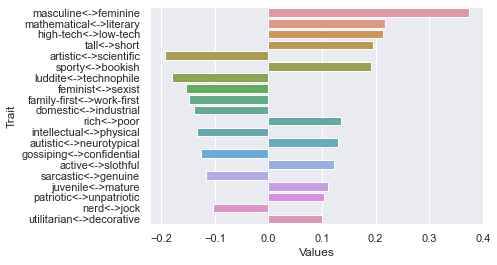
===============================
30 rating threshold: newdf: (323, 236)
First dimension
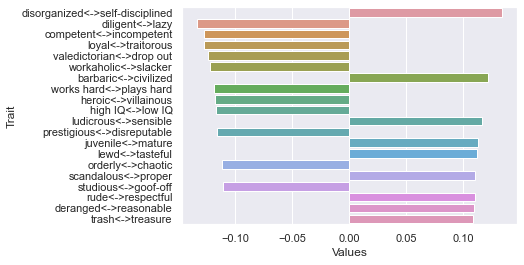
Second dimension
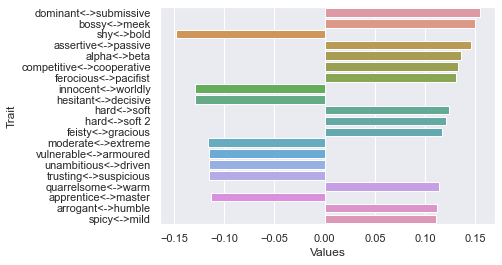
Third dimension
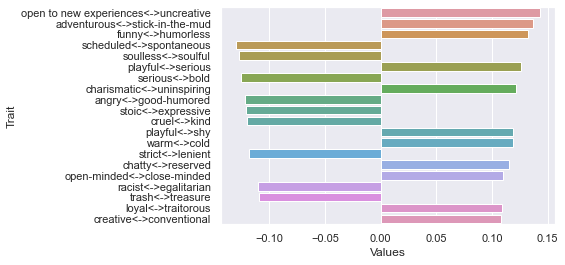
===============================
40 rating threshold: newdf: (280, 236)
First dimension
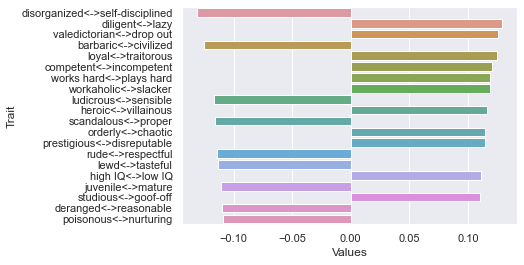
Second dimension
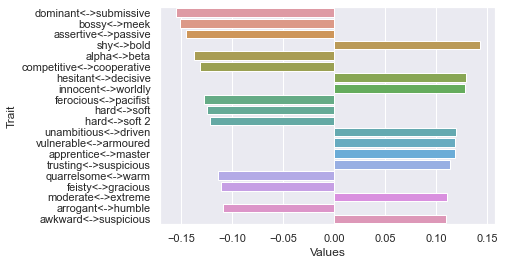
Third dimension
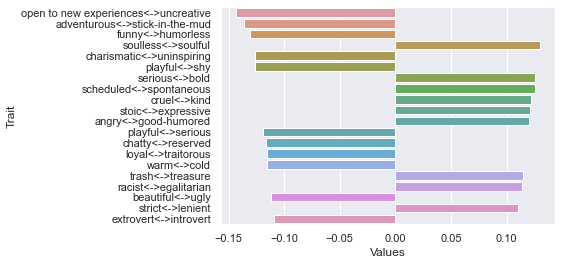
===============================
50 rating threshold: newdf: (218, 236)
First dimension
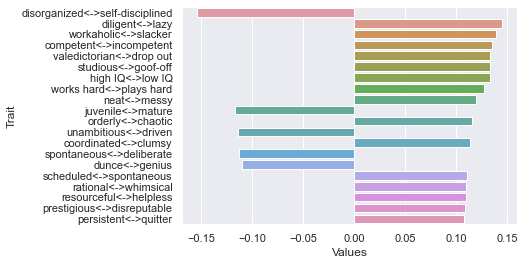
Second dimension

Third dimension
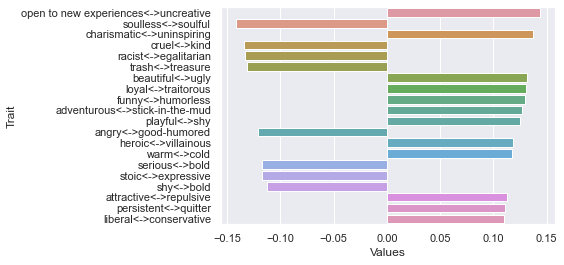
===============================
60 rating threshold: newdf: (167, 236)
First dimension
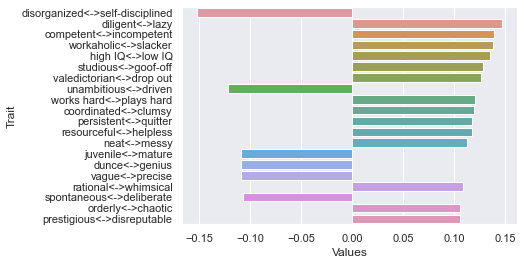
Second dimension
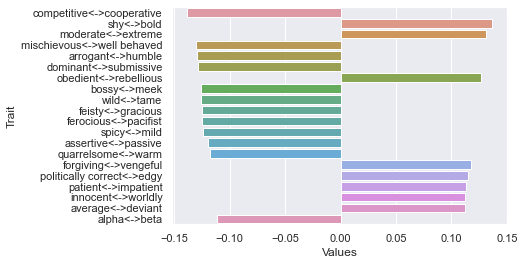
Third dimension
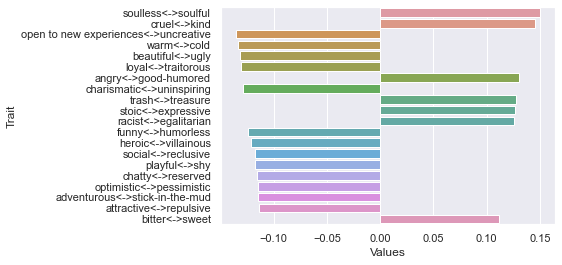
Fourth dimension
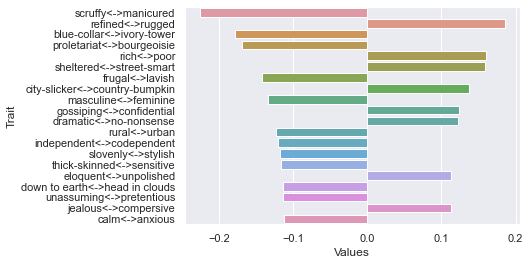
Fifth dimension
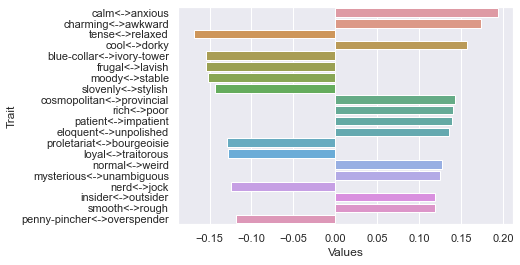
Sixth dimension
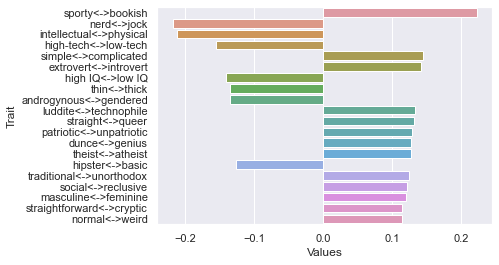
Seventh dimension
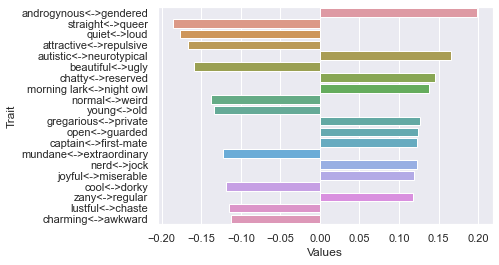
Eighth dimension
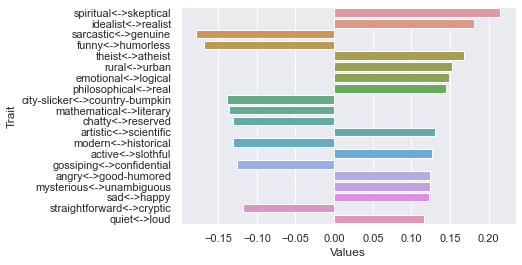
Ninth dimension
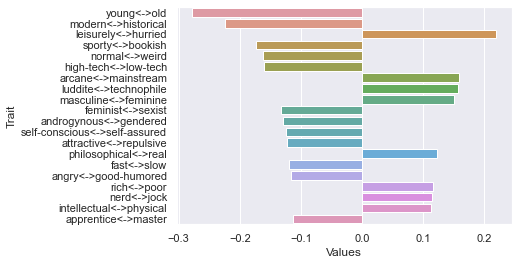
Tenth dimension
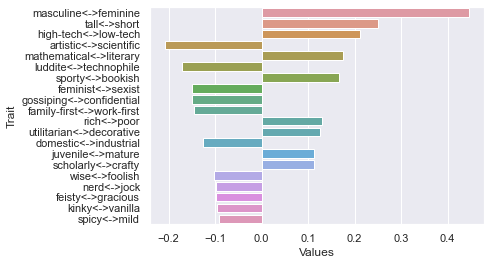
===============================
70 rating threshold: newdf: (140, 236)
First dimension
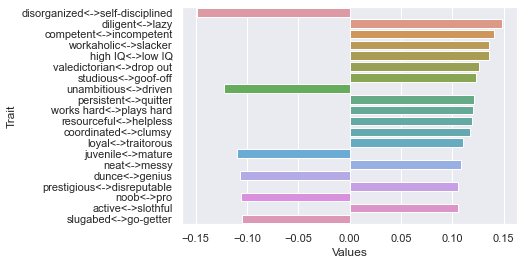
Second dimension
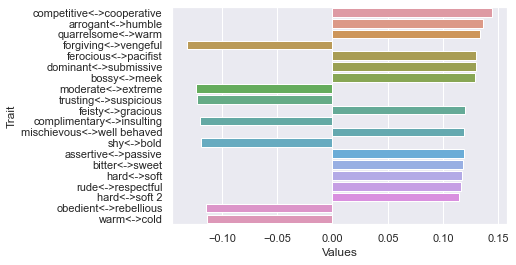
Third dimension
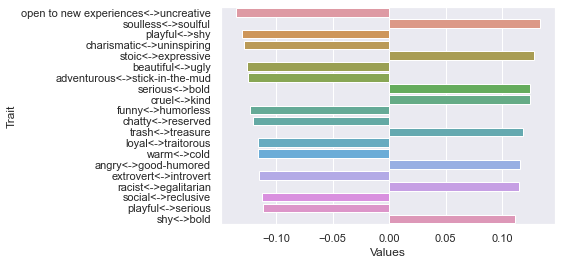
=============================
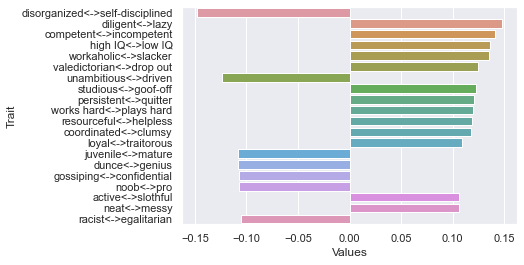
80 rating threshold: newdf: (132, 236)
First dimension
Second dimension
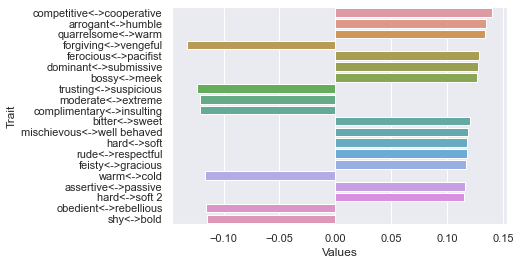
Third dimension
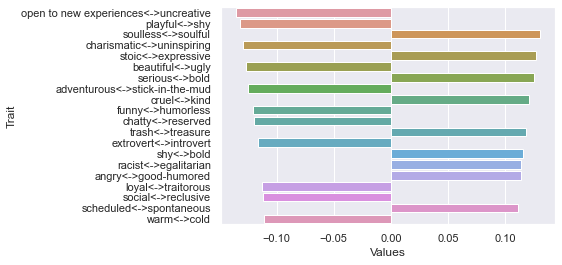
=============================
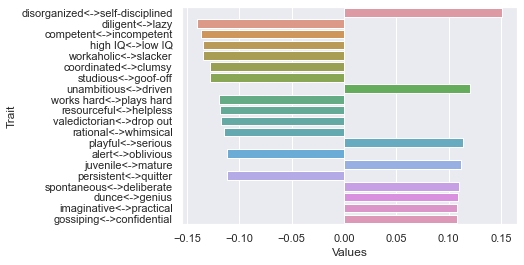
90 rating threshold: newdf: (116, 236)
First dimension
Second dimension
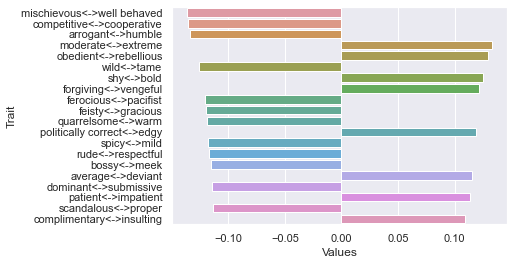
Third dimension
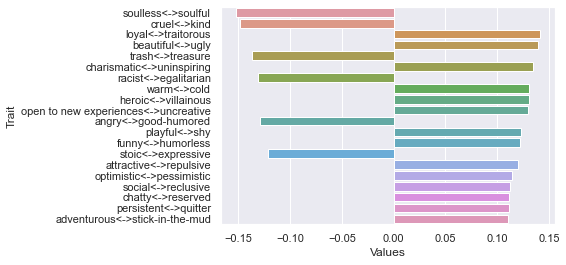
=============================
100 rating threshold: newdf: (100, 236)
First dimension
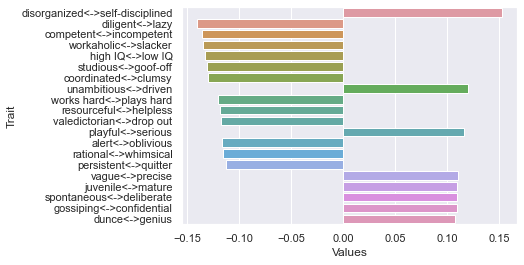
Second dimension
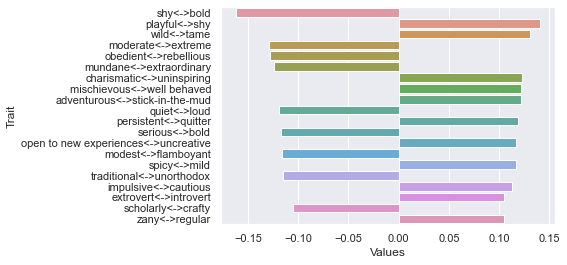
Third dimension
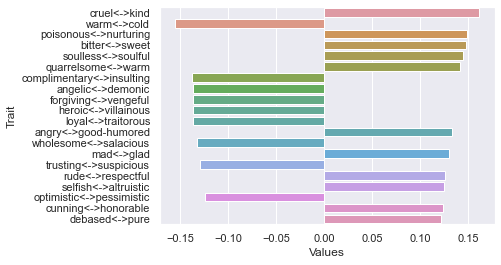
Fourth dimension
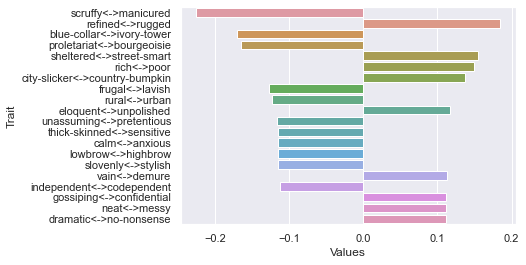
Fifth dimension
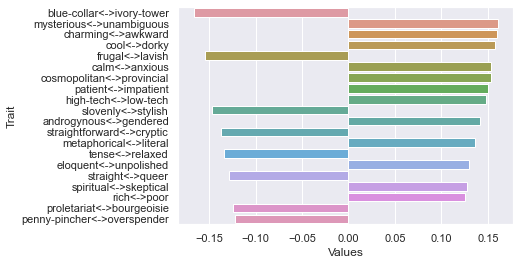
Sixth dimension
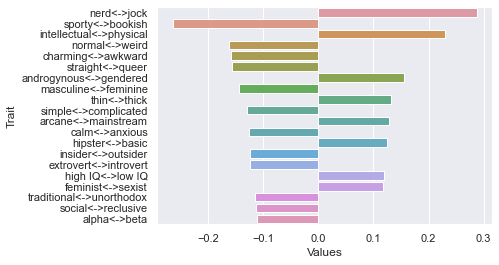
Seventh dimension
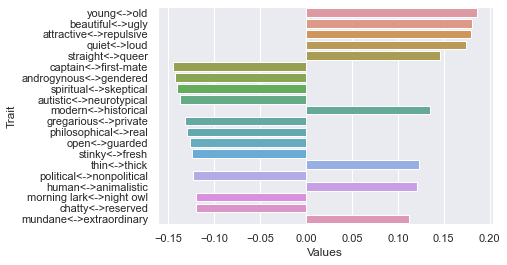
Eighth dimension
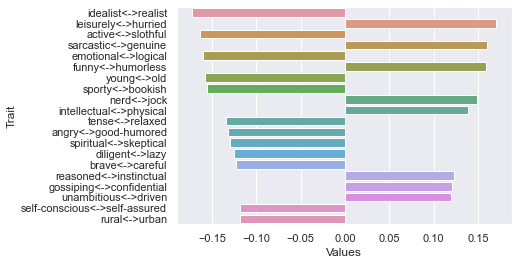
Ninth dimension
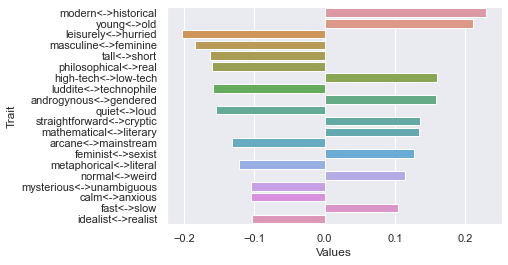
Tenth dimension
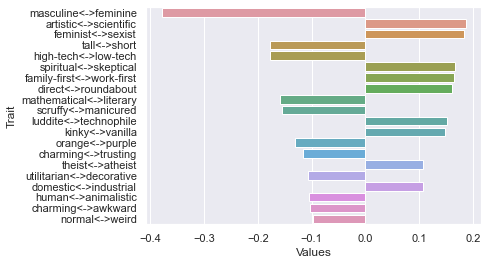
Eleventh dimension
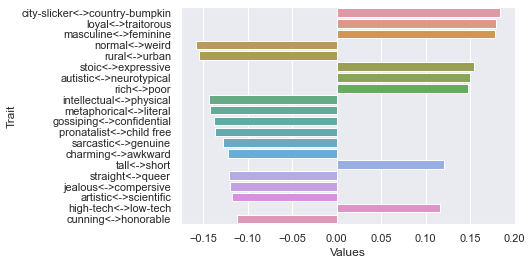
Twelfth dimension
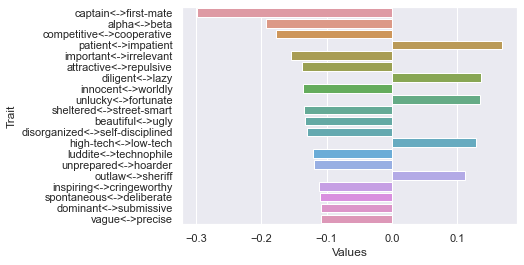
Thirteenth dimension
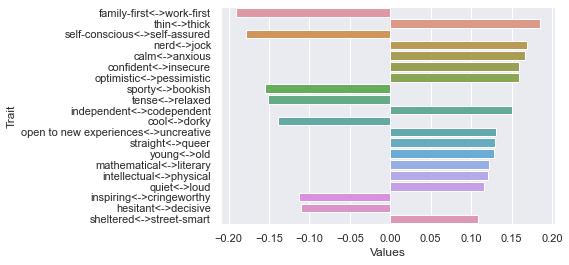
Fourteenth dimension
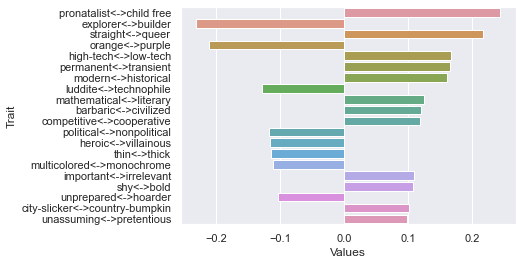
Fifteenth dimension
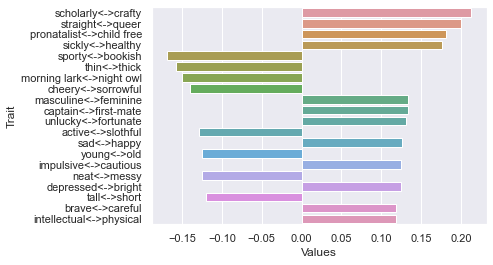
=========================
Threshold 150 ratings: newdf: (40, 236)
First dimension
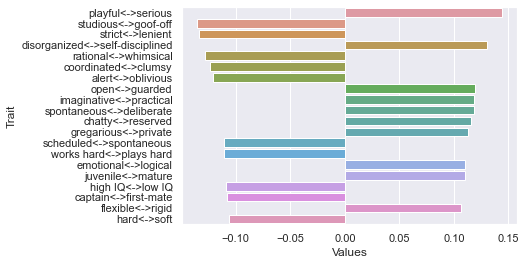
Second dimension
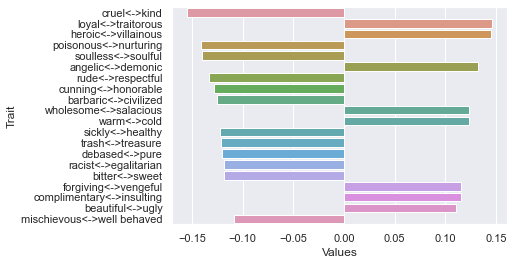
Third dimension
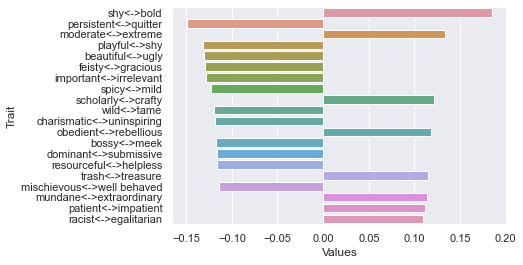
Fourth dimension
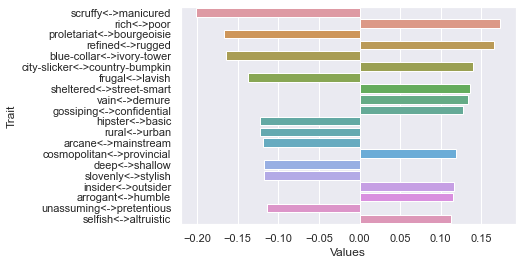
Fifth dimension
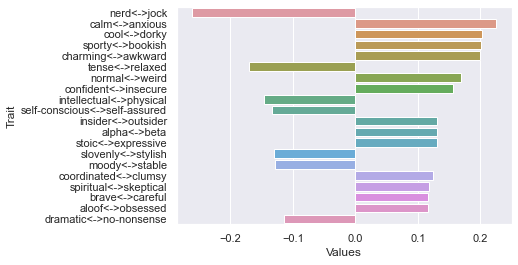
==========================
Threshold 200 ratings: newdf: (19, 236)
First dimension
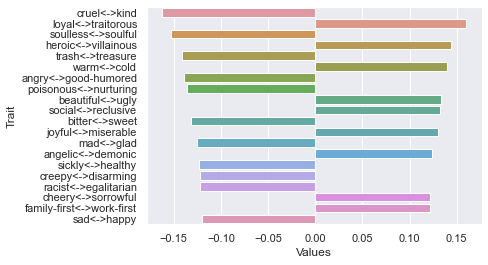
Second dimension
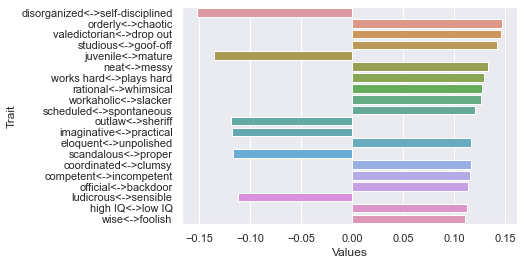
Third dimension
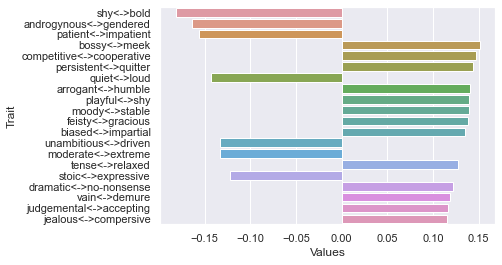
Fourth dimension
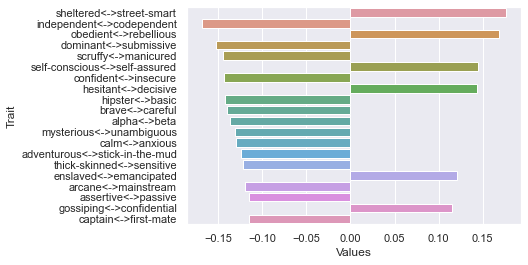
Fifth dimension
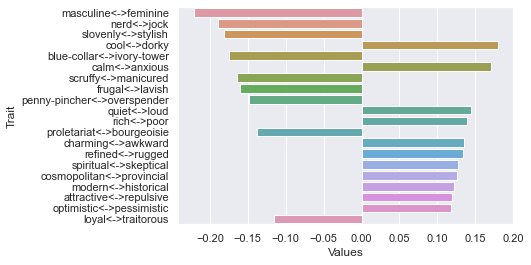
==============================
Threshold 250 ratings: newdf: (12, 236)
First dimension
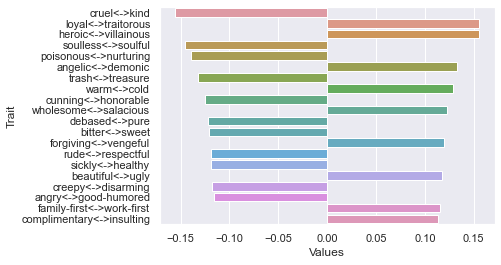
Second dimension
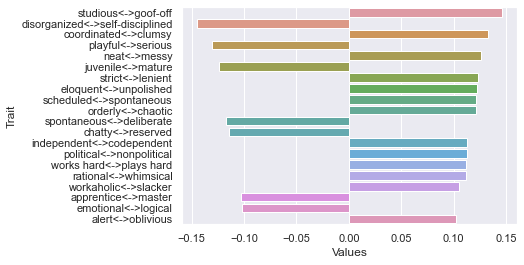
Third dimension
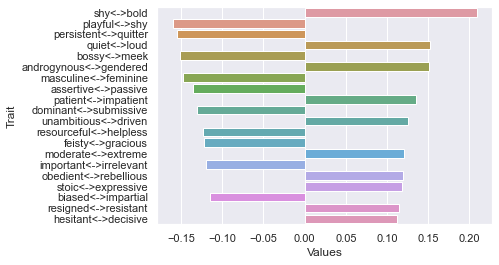
==============================
Threshold 300 ratings: newdf: (5, 236)
First d
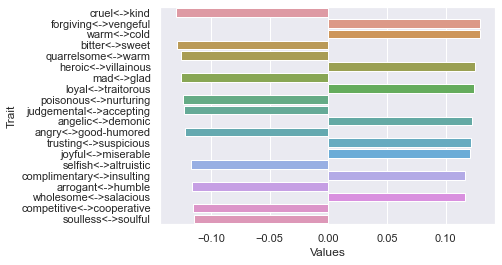
Second d
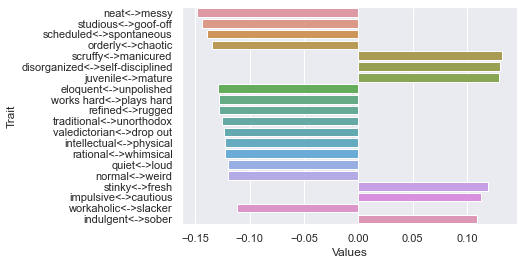
Third d
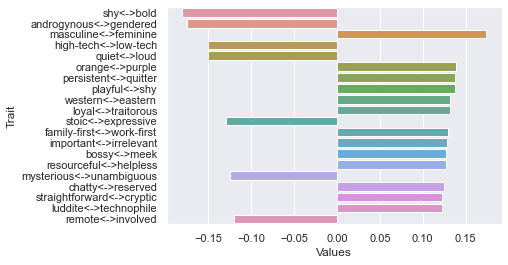
==============================
To rerun (with e.g. 10 rating threshold):
Relevant code:
The text was updated successfully, but these errors were encountered: