diff --git a/content/blogs/2022-10-05-kestra-snowflake.md b/content/blogs/2022-10-05-kestra-snowflake.md
index 574eec5e7e..64a4586c6d 100644
--- a/content/blogs/2022-10-05-kestra-snowflake.md
+++ b/content/blogs/2022-10-05-kestra-snowflake.md
@@ -26,7 +26,7 @@ The platform enables organizations to avoid large-scale licensing costs commonly
Data warehouse workloads are typically part of a larger technological stack. To streamline operations, orchestration, and scheduling of data pipelines are crucial. This is where Kestra comes into play.
-Kestra is designed to orchestrate and schedule scalable data workflows, thereby enhancing DataOps teams' productivity. It can construct, operate, manage, and monitor a [variety of complex workflows](../docs/02.tutorial/05.flowable.md) sequentially or in parallel.
+Kestra is designed to orchestrate and schedule scalable data workflows, thereby enhancing DataOps teams' productivity. It can construct, operate, manage, and monitor a [variety of complex workflows](../docs/01.tutorial/05.flowable.md) sequentially or in parallel.
Kestra can execute workflows based on event-based, time-based, and API-based scheduling, giving complete control.
Snowflake already offers many cost optimization processes like data compression and auto-scaling. However, Kestra makes it simpler to [download](../plugins/plugin-jdbc-snowflake/tasks/io.kestra.plugin.jdbc.snowflake.Download.md), [upload](../plugins/plugin-jdbc-snowflake/tasks/io.kestra.plugin.jdbc.snowflake.Upload.md), and [query](../plugins/plugin-jdbc-snowflake/tasks/io.kestra.plugin.jdbc.snowflake.Query.md) data by integrating with Snowflake's storage and compute resources.
@@ -141,5 +141,5 @@ Kestra provides flexibility and control to data teams, it can orchestrate any ki
Kestra's Snowflake plugin makes data warehousing simple even for non-developers thanks to YAML. Your Snowflake storage pipeline can accommodates raw data from multiple sources and transforms it using ETL operations. Additionally, you can skip the transformation and directly load data into the warehouse using the [ELT pipeline](./2022-04-27-etl-vs-elt.md). Kestra can manage both workflows simultaneously. In any case, Kestra ensures that the data is readily available to perform analysis and learn valuable patterns.
Join the Slack [community](https://kestra.io/slack) if you have any questions or need assistance.
-Follow us on [Twitter](https://twitter.com/kestra_io) for the latest news.
+Follow us on [Twitter](https://twitter.com/kestra_io) for the latest news.
Check the code in our [GitHub repository](https://github.com/kestra-io/kestra) and give us a star if you like the project.
diff --git a/content/blogs/2023-02-23-techniques-kafka-streams-developer.md b/content/blogs/2023-02-23-techniques-kafka-streams-developer.md
index 15399b1fc9..6547ab9abe 100644
--- a/content/blogs/2023-02-23-techniques-kafka-streams-developer.md
+++ b/content/blogs/2023-02-23-techniques-kafka-streams-developer.md
@@ -25,7 +25,7 @@ While building Kestra, we wanted to rely only on the queue as a database for our
## Same Kafka Topic for Source and Destination
-In Kestra, we have a [Kafka topic](https://kafka.apache.org/intro#intro_concepts_and_terms) for the current flow [execution](../docs/03.concepts/02.executions.md). That topic is both the source and the destination. We update the current execution to add some information and send it back to Kafka for further processing.
+In Kestra, we have a [Kafka topic](https://kafka.apache.org/intro#intro_concepts_and_terms) for the current flow [execution](../docs/03.concepts/execution.md). That topic is both the source and the destination. We update the current execution to add some information and send it back to Kafka for further processing.
Initially, we were unsure if this design was possible with Kafka. We [asked](https://twitter.com/tchiotludo/status/1252197729406783488) Matthias J. Sax, one of the primary maintainers of Kafka Streams, who responded on [Stack Overflow](https://stackoverflow.com/questions/61316312/does-kafka-stream-with-same-sink-source-topics-with-join-is-supported).
@@ -124,7 +124,7 @@ Our first assumption was that `all()` returns an object (Flow in our case), as t
- Fetch all the data from RocksDB
- Deserialize the data from RocksDB that is stored as byte, and map it to concrete Java POJO
-So each time we call the `all()` method, all values are deserialized, which can lead to high CPU usage and latency on your stream. We are talking about all [flow revisions](../docs/03.concepts/01.flows.md#revision) on our cluster. The last revision had 2.5K flows, but we don't see people creating a lot of revisions. Imagine 100K `byte[]` to deserialize to POJO for every call. 🤯
+So each time we call the `all()` method, all values are deserialized, which can lead to high CPU usage and latency on your stream. We are talking about all [flow revisions](../docs/03.concepts/flow.md#revision) on our cluster. The last revision had 2.5K flows, but we don't see people creating a lot of revisions. Imagine 100K `byte[]` to deserialize to POJO for every call. 🤯
Since we only need the last revision in our use case, we create an in-memory Map with all the flows using the following:
diff --git a/content/docs/01.architecture.md b/content/docs/01.architecture.md
deleted file mode 100644
index 508b5fcc52..0000000000
--- a/content/docs/01.architecture.md
+++ /dev/null
@@ -1,255 +0,0 @@
----
-title: 🏗️ Architecture
----
-
-## Architecture diagram
-
-The following diagram shows the main components of the **Open-Source** and the **Enterprise Edition** of Kestra. The arrows visualize how the components interact with each other.
-
-
-
-When comparing both diagrams, the main difference between the architecture of an **Open-Source** and an **Enterprise Edition** is the data layer (_JDBC Database vs. Kafka and Elasticsearch_).
-
-Note that apart from Postgres, the JDBC setup also supports MySQL and H2 databases. Also, it's possible to use the Enterprise Edition with a JDBC database backend for smaller deployments.
-
-The **Worker** is the only component communicating with your private data sources to extract and transform data. The Worker also interacts with **Internal Storage** to persist intermediary results and store the final task run outputs.
-
-All components of the **application layer** (incl. Worker, Executor, and Scheduler) are **decoupled microservices**. They are stateless and communicate with each other through the **Queue** (Kafka/JDBC). You can deploy and scale them independently — the only exception is the Scheduler, you can have only one Scheduler component in a JDBC-based architecture. When using Kafka and Elasticsearch, you can scale the replica count for the Scheduler as well, making it highly available.
-
-The **Webserver** communicates with the (Elasticsearch/JDBC) Repository to serve data for Kestra UI and API.
-
-The **data layer** is decoupled from the application layer and provides a separation between:
-- storing your private data processing artifacts — **Internal Storage** is used to store outputs of your executions; you can think of Internal Storage as your own private S3 bucket
-- storing execution metadata — (Kafka/JDBC) **Queue** is used as the orchestration backend
-- storing logs and user-facing data — the (Elasticsearch/JDBC) **Repository** is used to store data needed to serve Kestra UI and API.
-
-The Indexer, available only in the Enterprise Edition, indexes content from Kafka topics (_such as the flows and executions topics_) to the Elasticsearch repositories. Thanks to the separation between Queue and Repository in the Enterprise Edition, even if your Elasticsearch instance experiences downtime, your executions will continue to work by relying on the Kafka backend.
-
-## Main components
-
-Kestra has three internal components:
-- The **Internal Storage** stores flow data like task outputs and flow inputs.
-- The **Queue** is used for internal communication between Kestra server components.
-- The **Repository** is used to store flows, templates, executions, logs, etc. The repository stores every internal object.
-
-These internal components are provided on multiple implementations depending on your needs and deployment architecture. You may need to install additional plugins to use some implementations.
-
-### Internal Storage
-
-Kestra uses an **Internal Storage** to handle incoming and outgoing files of varying sizes. This notion is included in the heart of Kestra. Nowadays, storage availability is backed up by many file systems. We rely on these to guarantee the scalability of Kestra. The *Kestra Internal Storage* will store all the files generated by all tasks and transmit them between different tasks if needed.
-
-By default, only the local storage is available. It uses a directory inside the host filesystem, so it is not scalable and not designed for production usage.
-
-More implementations are available as plugins.
-
-You can replace the local storage with one of the following storage implementations:
-- [Storage Minio](https://github.com/kestra-io/storage-minio) for [Minio](https://min.io/), which is compatible with [AWS S3](https://aws.amazon.com/s3/) and all other *S3 Like* storage.
-- [Storage GCS](https://github.com/kestra-io/storage-gcs) for [Google Cloud Storage](https://cloud.google.com/storage).
-- [Storage Azure](https://github.com/kestra-io/storage-azure) for [Azure Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/).
-
-### Queue
-
-The Queue, or more precisely, queues, are used internally for communication between the different Kestra server components. Kestra provides multiple queue types that must be used with their repository counterparts.
-
-There are three types of queues:
-- **In-Memory** that must be used with the In-Memory Repository.
-- **Database** that must be used with the Database Repository.
-- **Kafka** that must be used with the Elasticsearch Repository. **Only available in the [Enterprise Edition](/enterprise)**.
-
-### Repository
-
-The Repository, or more precisely, repositories, are the internal way to store data. Kestra provides multiple repository types that must be used with their queue counterparts.
-
-There exist three types of repositories:
-- **In-Memory** that must be used with the In-Memory Queue.
-- **Database** that must be used with the Database Queue.
-- **Elasticsearch** that must be used with the Kafka Queue. **Only available in the [Enterprise Edition](/enterprise)**.
-
-## Server components
-
-Kestra consists of multiple server components that can be scaled independently.
-Each server component interacts with the Kestra internal components (internal storage, queues, and repositories).
-
-### Executor
-
-The **Executor** handles all executions and [flowable tasks](./05.developer-guide/02.tasks.md#flowable-tasks). The only goal of the Executor is to receive created executions and look for the next tasks to run. There is no heavy computation required (and no capacity for it) for this server component.
-
-The Executor also handles special execution cases:
-- [Listeners](./05.developer-guide/13.listeners.md)
-- [Flow Triggers](./05.developer-guide/08.triggers/02.flow.md)
-- [Templates](./05.developer-guide/09.templates.md)
-
-You can scale Executors as necessary, but as no heavy computations are done in the Executor, this server component only requires little resources (unless you have a very high rate of executions).
-
-
-### Worker
-
-All tasks and polling triggers are executed by a **Worker**. A Worker receives and processes tasks from the Executor and polling triggers from the Scheduler. Given that tasks and polling triggers can be virtually anything (heavy computations, simple API calls, etc.), the Worker is essentially a Thread Pool where you can configure the number of threads you need.
-
-You can scale Workers as necessary and have many instances on multiple servers, each with its own Thread Pool.
-
-As the worker executes the tasks and the polling triggers, it needs access to any external services they use (database, REST services, message broker, etc.). Workers are the only server components that need access to external services.
-
-#### Worker Group (EE)
-
-::alert{type="warning"}
-This is an [Enterprise Edition](https://kestra.io/enterprise) feature.
-::
-
-A Worker Group is a set of workers that can be targeted specifically for a task execution or a polling trigger evaluation. For this, the task or the polling trigger must define the `workerGroup.key` property with the key of the worker group to target. A default worker group can also be configured at the namespace level.
-
-If the `workerGroup.key` property is not provided, all tasks and polling triggers are executed on the default worker group. That default worker group doesn't have a dedicated key.
-
-Here are common use cases in which Worker Groups can be beneficial:
-- Execute tasks and polling triggers on specific compute instances (e.g., a VM with a GPU and preconfigured CUDA drivers).
-- Execute tasks and polling triggers on a worker with a specific Operating System (e.g., a Windows server).
-- Restrict backend access to a set of workers (firewall rules, private networks, etc.).
-- Execute tasks and polling triggers close to a remote backend (region selection).
-
-::alert{type="warning"}
-Even if you are using worker groups, we strongly recommend having at least one worker in the default worker group, as there is no way to enforce that all tasks and polling triggers have a `workerGroup.key` property set.
-::
-
-There is currently no way to validate whether a worker group exists before using it in a task or polling trigger. If a task or a polling trigger defines a worker group that doesn't exist, it will wait forever, leaving the flow's Execution stuck in a pending state.
-
-A worker is part of a worker group if it is started with `--worker-group workerGroupKey`.
-
-### Scheduler
-
-The **Scheduler** will handle most of the [Triggers](./05.developer-guide/08.triggers/index.md) except the [Flow Triggers](./05.developer-guide/08.triggers/02.flow.md) which are handled by the Executor. It will continuously watch all the triggers and, if all conditions are met, will start an execution of the flow (submit the flow to the Executor).
-
-In the case of polling triggers, the Scheduler will decide (based on the configured evaluation interval) whether to execute the flow. If the polling trigger conditions are met, the Scheduler will send the execution, along with the trigger metadata, to the Worker for execution.
-
-Note that polling triggers cannot be evaluated concurrently. They also can't be reevaluated i.e. if the execution of a flow, which started as a result of the same trigger, is already in a Running state, the next execution will not be started until the previous one finishes.
-
-Internally, the Scheduler will keep checking every second whether some trigger must be evaluated.
-
-::alert{type="warning"}
-By default, Kestra will handle all dates based on your system timezone. You can change the timezone with [JVM options](./09.administrator-guide/01.configuration/05.others.md#jvm-configuration).
-::
-
-### Indexer
-
-The **Indexer** is an optional component only needed when using Kafka and Elasticsearch. It will watch for many Kafka topics (like flows and executions) and will index their content to Elasticsearch [Repositories](#the-repository).
-
-### Webserver
-
-The **Webserver** offers two main modules in the same component:
-- **API**: All the [APIs](./12.api-guide/api-oss-guide.md) that allow triggering executions for any system, and interacting with Kestra.
-- **UI**: The [User Interface](./04.user-interface-guide/index.md) (UI) is also served by the Webserver.
-
-The Webserver interacts mostly with the Repository to deliver a rich API/UI. It also interacts with the Queue to trigger new executions, follow executions in real-time, etc.
-
-
-::alert{type="info"}
-Each server component (other than the Scheduler) can continue to work as long as the Queue is up and running. The Repository is only used to help provide our rich Webserver UI, and even if the Repository is down, workloads can continue to process on Kestra.
-::
-
-## Plugins
-
-Kestra's core is not able to handle many task types by itself. We have therefore, included a [Plugins](../plugins) system that allows developing as many task types as you need.
-A wide range of plugins is already available, and many more will be delivered by the Kestra team!
-
-Plugins are also used to provide different implementations for Kestra's internal components like its Internal Storage.
-
-## Deployment architecture
-
-Kestra is a Java application that is provided as an executable. You have many deployments options:
-- [Docker](./09.administrator-guide/02.deployment/01.docker.md)
-- [Kubernetes](./09.administrator-guide/02.deployment/02.kubernetes.md)
-- [Manual deployment](./09.administrator-guide/02.deployment/03.manual.md)
-
-At its heart, Kestra has a plugin system allowing you to choose the dependency type that fits your needs.
-
-You can find three example deployment architectures below.
-
-### Small-sized deployment
-
-
-
-For a small-sized deployment, you can use Kestra standalone server, an all-in-one server component that allows running all Kestra server components in a single process. This deployment architecture has no scaling capability.
-
-In this case, a database is the only dependency. This allows running Kestra with a minimal stack to maintain. We have, for now, three databases available:
-- PostgreSQL
-- MySQL
-- H2
-
-Database configuration options are available [here](./09.administrator-guide/01.configuration/01.databases.md).
-
-
-### Medium-sized deployment
-
-
-
-For a medium-sized deployment, where high availability is not a strict requirement, you can use a database (Postgres or MySQL) as the only dependency. This allows running Kestra with a minimal stack to maintain. We have, for now, two databases available for this kind of architecture, as H2 is not a good fit when running distributed components:
-- PostgreSQL
-- MySQL
-
-All server components will communicate through the database.
-
-::alert{type="warning"}
-When using a database, you can't scale the replica count for the scheduler, and you must have only **one** instance of it for the whole cluster.
-::
-
-Database configuration options are available [here](./09.administrator-guide/01.configuration/01.databases.md).
-
-In this deployment mode, unless all components run on the same host, you must use a distributed storage implementation like Google Cloud Storage, AWS S3, or Azure Blob Storage.
-
-### High-availability deployment
-
-
-
-To support higher throughput, and full horizontal and vertical scaling of the Kestra cluster, we can replace the database with Kafka and Elasticsearch. In this case, all the server components can be scaled without any single point of failure.
-
-Kafka and Elasticsearch are available only in the **[Enterprise Edition](/enterprise)**.
-
-In this deployment mode, unless all components run on the same host, you must use a distributed storage implementation like Google Cloud Storage, AWS S3, or Azure Blob Storage.
-
-#### Kafka
-
-[Kafka](https://kafka.apache.org/) is Kestra's primary dependency in high availability mode. Each of the most important server components in the deployment must have a Kafka instance up and running. Kafka allows Kestra to be a highly scalable solution.
-
-Kafka configuration options are available [here](./09.administrator-guide/01.configuration/03.enterprise-edition/kafka.md).
-
-##### Kafka Executor
-
-With Kafka, the Executor is a heavy [Kafka Stream](https://kafka.apache.org/documentation/streams/) application. The Executor processes all events from Kafka in the right order, keeps an internal state of the execution, and merges task run results from the Worker.
-It also detects dead Workers and resubmits the tasks run by a dead Worker.
-
-As the Executor is a Kafka Stream, it can be scaled as needed (within the limits of partitions count on Kafka). Still, as no heavy computations are done in the Executor, this server component only requires a few resources (unless you have a very high rate of executions).
-
-##### Kafka Worker
-
-With Kafka, the Worker is a [Kafka Consumer](https://kafka.apache.org/documentation/#consumerapi) that will process any Task Run submitted to it. Workers will receive all tasks and dispatch them internally in their Thread Pool.
-
-It can be scaled as needed (within the limits of partitions count on Kafka) and have many instances on multiple servers, each with its own Thread Pool.
-
-With Kafka, if a Worker is dead, the Executor will detect it and resubmit their current task run to another Worker.
-
-#### Elasticsearch
-[Elasticsearch](https://www.elastic.co/) is Kestra's User Interface database in high availability mode, allowing the display, search, and aggregation of all Kestra's data (Flows, Executions, etc.). Elasticsearch is only used by the Webserver (API and UI).
-
-Elasticsearch configuration options are available [here](./09.administrator-guide/01.configuration/03.enterprise-edition/elasticsearch.md).
-
-## Multi-tenancy
-
-Multi-tenancy is a software architecture in which a single instance of software serves multiple tenants. You can think of it as running multiple virtual instances in a single physical instance.
-
-Multi-tenancy is available only in the **[Enterprise Edition](/enterprise)**.
-
-Multi-tenancy allows you to manage **multiple environments** (e.g., dev, staging, prod) in a single Kestra instance. You can also use it to **separate resources** between business units, teams, or customers.
-
-By default, multi-tenancy is disabled. See the [multi-tenancy section](./09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md) of the Administrator Guide on how to configure it.
-
-When multi-tenancy is enabled, all resources (such as flows, triggers, executions, RBAC, and more) are isolated by the tenant. This means that you can have a flow with the same identifier and the same namespace in multiple tenants at the same time.
-
-Data stored inside the internal storage is also isolated by tenants.
-
-Multi-tenancy functionality is not visible to end-users from the UI except for the tenant selection dropdown menu. That dropdown menu lists all tenants a user has access to, allowing users to switch between tenants easily. Each UI page will also include the tenant ID in the URL e.g. `https://demo.kestra.io/ui/yourTenantId/executions/namespace/flow/executionId`.
-
-
-
-The API URLs will also change to include the tenant identifier.
-For example, the URL of the API operation to list flows of the `products` namespace is `/api/v1/flows/products` when multi-tenancy is not enabled, and becomes `/api/v1/production/flows/products` for the `production` tenant when multi-tenancy is enabled. You can check the [Enterprise Edition API Guide](./12.api-guide/api-ee-guide.md) for more information.
-
-Tenants must be created upfront, and a user needs to be granted access to use a specific tenant.
\ No newline at end of file
diff --git a/content/docs/01.getting-started.md b/content/docs/01.getting-started.md
index 8d8fe6a80d..cb2688fd8d 100644
--- a/content/docs/01.getting-started.md
+++ b/content/docs/01.getting-started.md
@@ -8,7 +8,6 @@ Start Kestra using Docker Compose and create your first flow.
**Prerequisites**: Make sure that Docker is installed in your environment. We recommend [Docker Desktop](https://docs.docker.com/get-docker/).
::
----
## Start Kestra
@@ -51,7 +50,6 @@ Open [http://localhost:8080](http://localhost:8080) in your browser to launch th
If you want to extend your Docker Compose file, modify container networking, or if you have any other issues using this Docker Compose file, check the [Troubleshooting Guide](14.troubleshooting.md).
::
----
## Create Your First Flow
@@ -72,17 +70,16 @@ Click on **Save** and then on the **Execute** button to start your first executi
::next-link
-[For a more detailed introduction to Kestra, check our Tutorial](./02.tutorial/index.md)
+[For a more detailed introduction to Kestra, check our Tutorial](01.tutorial/index.md)
::
----
## Next Steps
Congrats! You've just installed Kestra and executed your first flow! :clap:
Next, you can follow the documentation in this order:
-- Check the [tutorial](./02.tutorial/index.md)
+- Check the [tutorial](01.tutorial/index.md)
- Learn core [concepts](./03.concepts/index.md)
- Read the [Developer Guide](./05.developer-guide/index.md) for an in-depth explanation of all key concepts
- Check the available [Plugins](../plugins/index.md) to integrate with external systems and start orchestrating your applications, microservices and processes
diff --git a/content/docs/02.tutorial/01.fundamentals.md b/content/docs/01.tutorial/01.fundamentals.md
similarity index 80%
rename from content/docs/02.tutorial/01.fundamentals.md
rename to content/docs/01.tutorial/01.fundamentals.md
index 06254bcfce..eea69c28d8 100644
--- a/content/docs/02.tutorial/01.fundamentals.md
+++ b/content/docs/01.tutorial/01.fundamentals.md
@@ -10,7 +10,7 @@ To install Kestra, check the [Getting Started](../01.getting-started.md) page.
## Flows
-Flows are defined in a declarative YAML syntax to keep the orchestration code portable and language-agnostic.
+[Flows](../03.concepts/flow.md) are defined in a declarative YAML syntax to keep the orchestration code portable and language-agnostic.
Each flow consists of three **required** components: `id`, `namespace` and `tasks`:
1. `id` represents the name of the flow
@@ -37,17 +37,17 @@ The combination of `id` and `namespace` serves as a **unique identifier** for a
### Namespaces
-[Namespaces](../03.concepts/01.flows.md#namespace) are used to group flows and provide structure. Keep in mind, however, that allocation of a flow to a namespace is immutable. Once a flow is created, you cannot change its namespace. If you need to change the namespace of a flow, create a new flow with the desired namespace and delete the old flow.
+[Namespaces](../03.concepts/namespace.md) are used to group flows and provide structure. Keep in mind, however, that allocation of a flow to a namespace is immutable. Once a flow is created, you cannot change its namespace. If you need to change the namespace of a flow, create a new flow with the desired namespace and delete the old flow.
### Labels
-To add another layer of organization, you can use [labels](../03.concepts/01.flows.md#labels), allowing you to group flows using key-value pairs.
+To add another layer of organization, you can use [labels](../03.concepts/labels.md), allowing you to group flows using key-value pairs.
### Description(s)
-You can optionally add a [description](../05.developer-guide/01.flow.md#document-your-flow) property to keep your flows documented. The `description` is a string that supports **markdown** syntax. That markdown description will be rendered and displayed in the UI.
+You can optionally add a [description](../03.concepts/flow.md#document-your-flow) property to keep your flows documented. The `description` is a string that supports **markdown** syntax. That markdown description will be rendered and displayed in the UI.
::alert{type="info"}
Not only flows can have a description. You can also add a `description` property to `tasks` and `triggers` to keep all components of your workflow documented.
@@ -76,7 +76,7 @@ tasks:
This task will print "Hello World!" to the logs.
```
-Learn more about flows in the [Flows section](../05.developer-guide/01.flow.md) in the Developer Guide.
+Learn more about flows in the [Flows section](../03.concepts/flow.md).
---
@@ -128,7 +128,7 @@ Let's look at supported task types.
### Internal Storage
-Tasks from the `io.kestra.core.tasks.storages` category, along with [Outputs](../05.developer-guide/05.outputs.md), are used to interact with the **internal storage**. Kestra uses internal storage to **pass data between tasks**. You can think of internal storage as an S3 bucket. In fact, you can use your private S3 bucket as internal storage. This storage layer helps avoid proliferation of connectors. For example, you can use the Postgres plugin to extract data from a Postgres database and load it to the internal storage. Other task(s) can read that data from internal storage and load it to other systems such as Snowflake, BigQuery, or Redshift, or process it using any other plugin, without requiring point to point connections between each of them.
+Tasks from the `io.kestra.core.tasks.storages` category, along with [Outputs](../03.concepts/outputs.md), are used to interact with the **internal storage**. Kestra uses internal storage to **pass data between tasks**. You can think of internal storage as an S3 bucket. In fact, you can use your private S3 bucket as internal storage. This storage layer helps avoid proliferation of connectors. For example, you can use the Postgres plugin to extract data from a Postgres database and load it to the internal storage. Other task(s) can read that data from internal storage and load it to other systems such as Snowflake, BigQuery, or Redshift, or process it using any other plugin, without requiring point to point connections between each of them.
### State Store
diff --git a/content/docs/02.tutorial/02.inputs.md b/content/docs/01.tutorial/02.inputs.md
similarity index 90%
rename from content/docs/02.tutorial/02.inputs.md
rename to content/docs/01.tutorial/02.inputs.md
index 221b9cd546..b0c8261186 100644
--- a/content/docs/02.tutorial/02.inputs.md
+++ b/content/docs/01.tutorial/02.inputs.md
@@ -6,7 +6,7 @@ Inputs allow you to make your flows more dynamic and reusable. Instead of hardco
## How to retrieve inputs
-Inputs can be accessed in any task using a special `{{ inputs.input_name }}` [variable](../05.developer-guide/03.variables/01.index.md).
+Inputs can be accessed in any task using the following [expression](../03.concepts/expression/01.index.md) `{{ inputs.input_name }}`.
---
@@ -47,7 +47,7 @@ Here are the most common input types:
| INT | It can be any valid integer number (without decimals). |
| BOOLEAN | It must be either `true` or `false`. |
-Check the [inputs documentation](../05.developer-guide/04.inputs.md) for a full list of supported input types.
+Check the [inputs documentation](../03.concepts/inputs.md) for a full list of supported input types.
---
diff --git a/content/docs/02.tutorial/03.outputs.md b/content/docs/01.tutorial/03.outputs.md
similarity index 99%
rename from content/docs/02.tutorial/03.outputs.md
rename to content/docs/01.tutorial/03.outputs.md
index 2e8f2c4c72..04c88622ca 100644
--- a/content/docs/02.tutorial/03.outputs.md
+++ b/content/docs/01.tutorial/03.outputs.md
@@ -2,7 +2,7 @@
title: Outputs
---
-Tasks can generate outputs, which can be passed to downstream tasks. These outputs can be variables or files stored in the [internal storage](../01.architecture.md#the-internal-storage).
+Tasks can generate outputs, which can be passed to downstream tasks. These outputs can be variables or files stored in the [internal storage](../03.concepts/internal-storage.md).
## How to retrieve outputs
diff --git a/content/docs/02.tutorial/04.triggers.md b/content/docs/01.tutorial/04.triggers.md
similarity index 100%
rename from content/docs/02.tutorial/04.triggers.md
rename to content/docs/01.tutorial/04.triggers.md
diff --git a/content/docs/02.tutorial/05.flowable.md b/content/docs/01.tutorial/05.flowable.md
similarity index 91%
rename from content/docs/02.tutorial/05.flowable.md
rename to content/docs/01.tutorial/05.flowable.md
index db31f149ad..2b94442c2e 100644
--- a/content/docs/02.tutorial/05.flowable.md
+++ b/content/docs/01.tutorial/05.flowable.md
@@ -2,7 +2,7 @@
title: Flowable
---
-Use [Flowable tasks](../05.developer-guide/02.tasks.md#flowable-tasks) to control the orchestration logic — run tasks in parallel, create loops, add conditional branching, and more.
+Use [Flowable tasks](../03.concepts/flowable-tasks.md) to control the orchestration logic — run tasks in parallel, create loops, add conditional branching, and more.
## Add parallelism using flowable tasks
diff --git a/content/docs/02.tutorial/06.errors.md b/content/docs/01.tutorial/06.errors.md
similarity index 95%
rename from content/docs/02.tutorial/06.errors.md
rename to content/docs/01.tutorial/06.errors.md
index 61988bff81..7db9662692 100644
--- a/content/docs/02.tutorial/06.errors.md
+++ b/content/docs/01.tutorial/06.errors.md
@@ -54,7 +54,7 @@ To get notified on a workflow failure, you can leverage Kestra's built-in notifi
- [Email](../../../plugins/plugin-notifications/tasks/mail/io.kestra.plugin.notifications.mail.mailexecution.md)
-For a centralized namespace-level alerting, we recommend adding a dedicated monitoring workflow with one of the above mentioned notification tasks and a [Flow trigger](../../05.developer-guide/08.triggers/02.flow.md). Below is an example workflow that automatically sends a Slack alert as soon as any flow in the namespace `prod` fails or finishes with warnings.
+For a centralized namespace-level alerting, we recommend adding a dedicated monitoring workflow with one of the above mentioned notification tasks and a [Flow trigger](../03.concepts/triggers/flow-trigger.md). Below is an example workflow that automatically sends a Slack alert as soon as any flow in the namespace `prod` fails or finishes with warnings.
```yaml
id: failure_alert
@@ -149,5 +149,5 @@ tasks:
```
::next-link
-[Next, let's run tasks in separate containers](./07.dockers.md)
+[Next, let's run tasks in separate containers](./07.docker.md)
::
diff --git a/content/docs/02.tutorial/07.dockers.md b/content/docs/01.tutorial/07.docker.md
similarity index 98%
rename from content/docs/02.tutorial/07.dockers.md
rename to content/docs/01.tutorial/07.docker.md
index fdfa7e38c3..b74f1bac74 100644
--- a/content/docs/02.tutorial/07.dockers.md
+++ b/content/docs/01.tutorial/07.docker.md
@@ -62,6 +62,7 @@ For more examples of running scripts in Docker containers, check the [Script tas
Congrats! :tada: You've completed the tutorial.
Next, you can dive into:
+- [Architecture](../02.architecture/index.md)
- [Key concepts](../03.concepts/index.md)
- [Developer Guide](../05.developer-guide/index.md) that includes a more detailed explanation of everything covered in this tutorial
- [Plugins](../../plugins/index.md) to integrate with external systems
diff --git a/content/docs/02.tutorial/index.md b/content/docs/01.tutorial/index.md
similarity index 100%
rename from content/docs/02.tutorial/index.md
rename to content/docs/01.tutorial/index.md
diff --git a/content/docs/02.architecture/01.main-components.md b/content/docs/02.architecture/01.main-components.md
new file mode 100644
index 0000000000..58d36274fb
--- /dev/null
+++ b/content/docs/02.architecture/01.main-components.md
@@ -0,0 +1,42 @@
+---
+title: Main components
+---
+
+Kestra has three internal components:
+- The **Internal Storage** stores flow data like task outputs and flow inputs.
+- The **Queue** is used for internal communication between Kestra server components.
+- The **Repository** is used to store flows, templates, executions, logs, etc. The repository stores every internal object.
+- The **Plugins** extend the core of Kestra with new task and trigger types, storage implementations, etc.
+
+These internal components are provided on multiple implementations depending on your needs and deployment architecture. You may need to install additional plugins to use some implementations.
+
+## Internal Storage
+
+Kestra uses the concept of **Internal Storage** for storing input and output data. Multiple storage options are available, including local storage (default), [S3 and Minio](https://github.com/kestra-io/storage-minio), [Google Cloud Storage](https://github.com/kestra-io/storage-gcs), and [Azure Blobs Storage](https://github.com/kestra-io/storage-azure).
+
+Check the [Internal Storage](../03.concepts/internal-storage.md) concept documentation for more information.
+
+## Queue
+
+The Queue, or more precisely, queues, are used internally for communication between the different Kestra server components. Kestra provides multiple queue types that must be used with their repository counterparts.
+
+There are three types of queues:
+- **In-Memory** that must be used with the In-Memory Repository.
+- **Database** that must be used with the Database Repository.
+- **Kafka** that must be used with the Elasticsearch Repository. **Only available in the [Enterprise Edition](/enterprise)**.
+
+## Repository
+
+The Repository, or more precisely, repositories, are the internal way to store data. Kestra provides multiple repository types that must be used with their queue counterparts.
+
+There exist three types of repositories:
+- **In-Memory** that must be used with the In-Memory Queue.
+- **Database** that must be used with the Database Queue.
+- **Elasticsearch** that must be used with the Kafka Queue. **Only available in the [Enterprise Edition](/enterprise)**.
+
+## Plugins
+
+Kestra's core is not able to handle many task types by itself. We have therefore, included a [Plugins' ecosystem](../../plugins) that allows developing as many task types as you need.
+A wide range of plugins is already available, and many more will be delivered by the Kestra team!
+
+Plugins are also used to provide different implementations for Kestra's internal components like its Internal Storage.
diff --git a/content/docs/02.architecture/02.server-components.md b/content/docs/02.architecture/02.server-components.md
new file mode 100644
index 0000000000..1224e74395
--- /dev/null
+++ b/content/docs/02.architecture/02.server-components.md
@@ -0,0 +1,41 @@
+---
+title: Server components
+---
+
+
+Kestra consists of multiple server components that can be scaled independently.
+Each server component interacts with the Kestra internal components (internal storage, queues, and repositories).
+
+## Executor
+
+The [Executor](../03.concepts/executor.md) oversees all executions and certain types of tasks, such as flowable tasks or flow triggers. It requires minimal resources as it doesn't perform heavy computations.
+
+Generally speaking, the Executor never touches your data. It orchestrates workflows based on the information it receives from the Scheduler and the Queue, and it defers the execution of tasks to Workers.
+
+If you have a large number of Executions, you can scale the Executor horizontally. However, this is rarely necessary as the Executor is very lightweight — all heavy computations are performed by Workers.
+
+## Worker
+
+[Workers](../03.concepts/worker.md) execute tasks (from the Executor) and polling triggers (from the Scheduler).
+
+Workers are highly configurable and scalable, accommodating a wide range of tasks from simple API calls to complex computations. Workers are the only server components that need access to external services in order to connect to databases, APIs, or other services that your tasks interact with.
+
+## Worker Group (EE)
+
+In the Enterprise Edition, [Worker Groups](../03.concepts/worker-group.md) allow tasks and polling triggers to be executed on specific worker sets. They can be beneficial in various scenarios, such as using compute instances with GPUs, executing tasks on a specific OS, restricting backend access, and region-specific execution. A default worker group is recommended per tenant or namespace.
+
+To specify a worker group for a task, use the workerGroup.key property in the task definition to point the task to a specific worker group key. If no worker group is specified, the task will be executed on the default worker group.
+
+
+## Scheduler
+
+The [Scheduler](../03.concepts/scheduler.md) manages all triggers except for Flow triggers handled by the Executor. It determines when to start a flow based on trigger conditions.
+
+## Indexer
+
+The [Indexer](../03.concepts/indexer.md) indexes content from Kafka topics (such as the flows and executions topics) to Elasticsearch repositories.
+
+
+## Webserver
+
+The [Webserver](../03.concepts/webserver.md) is the entry point for all external communications with Kestra. It handles all REST API calls made to Kestra and serves the Kestra UI.
\ No newline at end of file
diff --git a/content/docs/02.architecture/03.deployment-architecture.md b/content/docs/02.architecture/03.deployment-architecture.md
new file mode 100644
index 0000000000..b31370cafd
--- /dev/null
+++ b/content/docs/02.architecture/03.deployment-architecture.md
@@ -0,0 +1,81 @@
+---
+title: Deployment Architecture
+---
+
+
+Kestra is a Java application that is provided as an executable. You have many deployments options:
+- [Docker](../09.administrator-guide/02.deployment/01.docker.md)
+- [Kubernetes](../09.administrator-guide/02.deployment/02.kubernetes.md)
+- [Manual deployment](../09.administrator-guide/02.deployment/03.manual.md)
+
+At its heart, Kestra has a plugin system allowing you to choose the dependency type that fits your needs.
+
+You can find three example deployment architectures below.
+
+## Small-sized deployment
+
+
+
+For a small-sized deployment, you can use Kestra standalone server, an all-in-one server component that allows running all Kestra server components in a single process. This deployment architecture has no scaling capability.
+
+In this case, a database is the only dependency. This allows running Kestra with a minimal stack to maintain. We have, for now, three databases available:
+- PostgreSQL
+- MySQL
+- H2
+
+Database configuration options are available [here](../09.administrator-guide/01.configuration/01.databases.md).
+
+
+## Medium-sized deployment
+
+
+
+For a medium-sized deployment, where high availability is not a strict requirement, you can use a database (Postgres or MySQL) as the only dependency. This allows running Kestra with a minimal stack to maintain. We have, for now, two databases available for this kind of architecture, as H2 is not a good fit when running distributed components:
+- PostgreSQL
+- MySQL
+
+All server components will communicate through the database.
+
+::alert{type="warning"}
+When using a database, you can't scale the replica count for the scheduler, and you must have only **one** instance of it for the whole cluster.
+::
+
+Database configuration options are available [here](../09.administrator-guide/01.configuration/01.databases.md).
+
+In this deployment mode, unless all components run on the same host, you must use a distributed storage implementation like Google Cloud Storage, AWS S3, or Azure Blob Storage.
+
+## High-availability deployment
+
+
+
+To support higher throughput, and full horizontal and vertical scaling of the Kestra cluster, we can replace the database with Kafka and Elasticsearch. In this case, all the server components can be scaled without any single point of failure.
+
+Kafka and Elasticsearch are available only in the **[Enterprise Edition](/enterprise)**.
+
+In this deployment mode, unless all components run on the same host, you must use a distributed storage implementation like Google Cloud Storage, AWS S3, or Azure Blob Storage.
+
+### Kafka
+
+[Kafka](https://kafka.apache.org/) is Kestra's primary dependency in high availability mode. Each of the most important server components in the deployment must have a Kafka instance up and running. Kafka allows Kestra to be a highly scalable solution.
+
+Kafka configuration options are available [here](../09.administrator-guide/01.configuration/03.enterprise-edition/kafka.md).
+
+#### Kafka Executor
+
+With Kafka, the Executor is a heavy [Kafka Stream](https://kafka.apache.org/documentation/streams/) application. The Executor processes all events from Kafka in the right order, keeps an internal state of the execution, and merges task run results from the Worker.
+It also detects dead Workers and resubmits the tasks run by a dead Worker.
+
+As the Executor is a Kafka Stream, it can be scaled as needed (within the limits of partitions count on Kafka). Still, as no heavy computations are done in the Executor, this server component only requires a few resources (unless you have a very high rate of executions).
+
+#### Kafka Worker
+
+With Kafka, the Worker is a [Kafka Consumer](https://kafka.apache.org/documentation/#consumerapi) that will process any Task Run submitted to it. Workers will receive all tasks and dispatch them internally in their Thread Pool.
+
+It can be scaled as needed (within the limits of partitions count on Kafka) and have many instances on multiple servers, each with its own Thread Pool.
+
+With Kafka, if a Worker is dead, the Executor will detect it and resubmit their current task run to another Worker.
+
+### Elasticsearch
+[Elasticsearch](https://www.elastic.co/) is Kestra's User Interface database in high availability mode, allowing the display, search, and aggregation of all Kestra's data (Flows, Executions, etc.). Elasticsearch is only used by the Webserver (API and UI).
+
+Elasticsearch configuration options are available [here](../09.administrator-guide/01.configuration/03.enterprise-edition/elasticsearch.md).
diff --git a/content/docs/02.architecture/index.md b/content/docs/02.architecture/index.md
new file mode 100644
index 0000000000..d4d65695cc
--- /dev/null
+++ b/content/docs/02.architecture/index.md
@@ -0,0 +1,28 @@
+---
+title: 🏗️ Architecture
+---
+
+
+The following diagram shows the main components of the **Open-Source** and the **Enterprise Edition** of Kestra. The arrows visualize how the components interact with each other.
+
+
+
+When comparing both diagrams, the main difference between the architecture of an **Open-Source** and an **Enterprise Edition** is the data layer (_JDBC Database vs. Kafka and Elasticsearch_).
+
+Note that apart from Postgres, the JDBC setup also supports MySQL and H2 databases. Also, it's possible to use the Enterprise Edition with a JDBC database backend for smaller deployments.
+
+The **Worker** is the only component communicating with your private data sources to extract and transform data. The Worker also interacts with **Internal Storage** to persist intermediary results and store the final task run outputs.
+
+All components of the **application layer** (incl. Worker, Executor, and Scheduler) are **decoupled microservices**. They are stateless and communicate with each other through the **Queue** (Kafka/JDBC). You can deploy and scale them independently — the only exception is the Scheduler, you can have only one Scheduler component in a JDBC-based architecture. When using Kafka and Elasticsearch, you can scale the replica count for the Scheduler as well, making it highly available.
+
+The **Webserver** communicates with the (Elasticsearch/JDBC) Repository to serve data for Kestra UI and API.
+
+The **data layer** is decoupled from the application layer and provides a separation between:
+- storing your private data processing artifacts — **Internal Storage** is used to store outputs of your executions; you can think of Internal Storage as your own private S3 bucket
+- storing execution metadata — (Kafka/JDBC) **Queue** is used as the orchestration backend
+- storing logs and user-facing data — the (Elasticsearch/JDBC) **Repository** is used to store data needed to serve Kestra UI and API.
+
+The Indexer, available only in the Enterprise Edition, indexes content from Kafka topics (_such as the flows and executions topics_) to the Elasticsearch repositories. Thanks to the separation between Queue and Repository in the Enterprise Edition, even if your Elasticsearch instance experiences downtime, your executions will continue to work by relying on the Kafka backend.
+
+
+
diff --git a/content/docs/03.concepts/01.flows.md b/content/docs/03.concepts/01.flows.md
deleted file mode 100644
index 8b84ae793a..0000000000
--- a/content/docs/03.concepts/01.flows.md
+++ /dev/null
@@ -1,99 +0,0 @@
----
-title: Flow
----
-
-A [flow](../05.developer-guide/01.flow.md) is a list of tasks. You create flows in Kestra to automate your processes.
-
-A flow can have [inputs](#inputs).
-
-
-## Task
-
-A task is a single action in a flow. A task can have properties, use flow inputs and other task's outputs, perform an action, and produce an [output](#outputs).
-
-There are two kinds of tasks in Kestra:
-- Runnable Tasks
-- Flowable Tasks
-
-
-### Runnable Task
-
-[Runnable Tasks](../05.developer-guide/02.tasks.md#runnable-tasks) handle computational work in the flow. For example, file system operations, API calls, database queries, etc. These tasks can be compute-intensive and are handled by [Workers](../01.architecture.md#worker).
-
-By default, Kestra only includes a few Runnable Tasks. However, many of them are available as [plugins](../../plugins/index.md), and if you use our default Docker image, plenty of them will already be included.
-
-
-### Flowable Task
-
-[Flowable Tasks](../05.developer-guide/02.tasks.md#flowable-tasks) only handle flow logic (branching, grouping, parallel processing, etc.) and start new tasks. For example, the [Switch task](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Switch.md) decides the next task to run based on some inputs.
-
-A Flowable Task is handled by [Executors](../01.architecture.md#executor) and can be called very often. Because of that, these tasks cannot include intensive computations, unlike Runnable Tasks. Most of the common Flowable Tasks are available in the default Kestra installation.
-
-
-## Namespace
-
-You can think of a namespace as a **folder for your flows**.
-
-- Similar to folders on your file system, namespaces can be used to organize flows into logical categories.
-- And as filesystems, namespaces can be indefinitely nested.
-Using the dot `.` symbol, you can add hierarchical structure to your flow organization.
-This allows to separate not only environments, but also projects, teams and departments.
-
-This way, your **product, engineering, marketing, finance, and data teams** can all use the same Kestra instance, while keeping their flows organized and separated. They all can have their own namespaces that belong to a parent namespace indicating the **development** or **production** environment.
-
-A namespace is like a folder for flows. A namespace is composed of words and letters separated by `.`. The hierarchy depth for namespaces is unlimited. Here are some examples of namespaces:
-- `projectOne`
-- `com.projectTwo`
-- `test.projectThree.folder`
-
-Namespaces are hierarchical, which means that for our previous example, the `test.projectThree.folder` namespace is inside the `test.projectThree` namespace.
-
-## Labels
-
-[Labels](../05.developer-guide/01.flow.md#labels) are key-value pairs that you can add to flows. Labels are used to **organize** flows and can be used to **filter executions** of any given flow from the UI.
-
-## Inputs
-
-[Inputs](../05.developer-guide/04.inputs.md) are parameters sent to a flow at execution time. It's important to note that inputs in Kestra are [strongly typed](../05.developer-guide/04.inputs.md#input-types).
-
-The inputs can be declared as either optional or mandatory. If the flow has required inputs, you'll have to provide them before the execution of the flow. You can also provide default values to the inputs.
-
-Inputs can have [validation rules](../05.developer-guide/04.inputs.md#input-validation) that are enforced at execution time.
-
-Inputs of type `FILE` will be uploaded to Kestra's [internal storage](../01.architecture.md#the-internal-storage) and made available for all tasks.
-
-Flow inputs can be seen in the **Overview** tab of the **Execution** page.
-
-## Outputs
-
-Each task can produce an output that may contain multiple properties. This output is described in the plugin documentation task and can then be accessible by all the following tasks via [variables](../05.developer-guide/03.variables/02.basic-usage.md).
-
-Some outputs are of a special type and will be stored inside Kestra's [internal storage](../01.architecture.md#the-internal-storage). Successive tasks may still use them as Kestra will automatically make them available for all tasks.
-
-Tasks outputs can be seen in the **Outputs** tab of the **Execution** page. If an output is a file from the [internal storage](../01.architecture.md#the-internal-storage), it will be available to download.
-
-
-## Revision
-
-Changing the source of a flow will produce a new revision for the flow. The revision is an incremental number that will be updated each time you change the flow.
-
-Internally, Kestra will track and manage all the revisions of the flow. Think of it as version control for your flows integrated inside Kestra.
-
-You can access old revisions inside the **Revisions** tab of the **Flows** page.
-
-
-## Listeners (deprecated)
-
-[Listeners](../05.developer-guide/13.listeners.md) are special tasks that can listen to the current flow, and launch tasks *outside the flow*, meaning launch tasks that are not part of the flow.
-
-The result of listeners will not change the execution status of the flow. Listeners are mainly used to send notifications or handle special behavior outside the primary flow.
-
-
-## Triggers
-
-[Triggers](../05.developer-guide/08.triggers/index.md) are a way to start a flow from external events. For example, a trigger might initiate a flow at a scheduled time or based on external events (webhooks, file creation, message in a broker, etc.).
-
-
-## Templates (deprecated)
-
-[Templates](../05.developer-guide/09.templates.md) are lists of tasks that can be shared between flows. You can define a template and call it from other flows. Templates allow you to share a list of tasks and keep them updated without changing all flows that use them.
diff --git a/content/docs/03.concepts/03.storage.md b/content/docs/03.concepts/03.storage.md
deleted file mode 100644
index 871cae5432..0000000000
--- a/content/docs/03.concepts/03.storage.md
+++ /dev/null
@@ -1,27 +0,0 @@
----
-title: Variables and Storage
----
-
-## Variables
-
-You can use variables inside your flow definition by using a special syntax: `{{ variable_name }}`.
-
-Variables can be used on each task property that is documented as **dynamic**.
-
-Dynamic variables will be rendered, thanks to the Pebble templating engine. Pebble allows the processing of variables with filters and functions. More information on variable processing can be found in the [Developer Guide](../05.developer-guide/03.variables/01.index.md).
-
-Flows, tasks, executions, triggers, and schedules, have default variables; for example `{{ flow.id }}` allows accessing the identifier of a flow inside an execution.
-
-Flow inputs will be available as variables via `{{ inputs.input_variable }}`, and task's output attributes will be available as variables via `{{ outputs.task_id.output_attribute }}`.
-
-Most variables will be stored inside the context of the execution and directly passed from task to task. Some variables are of a special type and will be stored inside Kestra's internal storage. Those variables will be automatically fetched from the internal storage when needed.
-
-## Internal storage
-
-Kesta's internal storage allows storing arbitrary-sized files inside a dedicated storage area.
-
-If an output attribute is stored inside the internal storage, it will be retrievable from a variable named `{{ outputs.task_id.output_attribute }}`. Kestra will automatically fetch the file when the variable is used.
-
-Inputs of type `FILE` will be automatically stored inside the internal storage.
-
-On the **Outputs** tab of an execution, if an output attribute is from the internal storage, there will be a link to download it.
diff --git a/content/docs/03.concepts/backfill.md b/content/docs/03.concepts/backfill.md
new file mode 100644
index 0000000000..013a77adaf
--- /dev/null
+++ b/content/docs/03.concepts/backfill.md
@@ -0,0 +1,18 @@
+---
+title: Backfill
+---
+The concept of a backfill is the replay of a missed schedule because a flow was created after it should have been scheduled.
+
+Backfills will perform all the schedules between the defined and current dates and will start after the normal schedule.
+
+> A schedule with a backfill.
+
+```yaml
+triggers:
+ - id: schedule
+ type: io.kestra.core.models.triggers.types.Schedule
+ cron: "*/15 * * * *"
+ backfill:
+ start: 2024-02-24T14:00:00Z
+```
+
diff --git a/content/docs/05.developer-guide/concurrency.md b/content/docs/03.concepts/concurrency.md
similarity index 97%
rename from content/docs/05.developer-guide/concurrency.md
rename to content/docs/03.concepts/concurrency.md
index b5331df3cb..e595373228 100644
--- a/content/docs/05.developer-guide/concurrency.md
+++ b/content/docs/03.concepts/concurrency.md
@@ -1,5 +1,5 @@
---
-title: Flow-level concurrency control
+title: Concurrency limits
---
The flow-level `concurrency` property allows you to control the number of concurrent executions of a given flow. You can limit the number of concurrent executions of a given flow by setting the `limit` key.
diff --git a/content/docs/05.developer-guide/11.conditions.md b/content/docs/03.concepts/conditions.md
similarity index 86%
rename from content/docs/05.developer-guide/11.conditions.md
rename to content/docs/03.concepts/conditions.md
index 9808d95391..62372266d1 100644
--- a/content/docs/05.developer-guide/11.conditions.md
+++ b/content/docs/03.concepts/conditions.md
@@ -2,7 +2,7 @@
title: Conditions
---
-Conditions are used in [Triggers](./08.triggers/index.md) and [Listeners](./13.listeners.md) to limit the cases for which a task run or a flow execution is triggered.
+Conditions are used in [Triggers](./triggers/index.md) and [Listeners](./listeners.md) to limit the cases for which a task run or a flow execution is triggered.
For example:
* you can restrict a listener to only a specified status,
diff --git a/content/docs/03.concepts/errors.md b/content/docs/03.concepts/errors.md
new file mode 100644
index 0000000000..0fc9b41504
--- /dev/null
+++ b/content/docs/03.concepts/errors.md
@@ -0,0 +1,30 @@
+---
+title: Errors
+---
+
+The `errors` is a property of a flow that accepts a list of tasks that will be executed when an error occurs. You can add as many tasks as you want, and they will be executed sequentially.
+
+The example below sends a flow-level failure alert via Slack using the [SlackIncomingWebhook](../../../plugins/plugin-notifications/tasks/slack/io.kestra.plugin.notifications.slack.slackincomingwebhook.md) task defined using the `errors` property.
+
+
+```yaml
+id: unreliable_flow
+namespace: prod
+
+tasks:
+ - id: fail
+ type: io.kestra.plugin.scripts.shell.Commands
+ runner: PROCESS
+ commands:
+ - exit 1
+
+errors:
+ - id: alert_on_failure
+ type: io.kestra.plugin.notifications.slack.SlackIncomingWebhook
+ url: "{{ secret('SLACK_WEBHOOK') }}" # https://hooks.slack.com/services/xyz/xyz/xyz
+ payload: |
+ {
+ "channel": "#alerts",
+ "text": "Failure alert for flow {{ flow.namespace }}.{{ flow.id }} with ID {{ execution.id }}"
+ }
+```
\ No newline at end of file
diff --git a/content/docs/03.concepts/02.executions.md b/content/docs/03.concepts/execution.md
similarity index 96%
rename from content/docs/03.concepts/02.executions.md
rename to content/docs/03.concepts/execution.md
index 6704d689a4..a5fe9e6498 100644
--- a/content/docs/03.concepts/02.executions.md
+++ b/content/docs/03.concepts/execution.md
@@ -20,7 +20,7 @@ If retries have been configured, a task failure will generate new attempts until
Each task can generate output data that other tasks of the current flow execution can use.
-These outputs can be variables or files that will be stored inside Kestra's [internal storage](../01.architecture.md#the-internal-storage).
+These outputs can be variables or files that will be stored inside Kestra's [internal storage](../03.concepts/internal-storage.md).
Outputs are described on each task documentation page and can be seen in the **Outputs** tab of the **Execution** page.
diff --git a/content/docs/03.concepts/executor.md b/content/docs/03.concepts/executor.md
new file mode 100644
index 0000000000..52e2f42844
--- /dev/null
+++ b/content/docs/03.concepts/executor.md
@@ -0,0 +1,12 @@
+---
+title: Executor
+---
+
+The **Executor** handles all executions and [flowable tasks](flowable-tasks.md). The only goal of the Executor is to receive created executions and look for the next tasks to run. There is no heavy computation required (and no capacity for it) for this server component.
+
+The Executor also handles special execution cases:
+- [Listeners](listeners.md)
+- [Flow Triggers](triggers/flow-trigger.md)
+- [Templates](templates.md)
+
+You can scale Executors as necessary, but as no heavy computations are done in the Executor, this server component only requires little resources (unless you have a very high rate of executions).
\ No newline at end of file
diff --git a/content/docs/03.concepts/expression/01.index.md b/content/docs/03.concepts/expression/01.index.md
new file mode 100644
index 0000000000..1aed2bd8f3
--- /dev/null
+++ b/content/docs/03.concepts/expression/01.index.md
@@ -0,0 +1,19 @@
+---
+title: Expressions
+---
+
+You can use expressions inside your flow definition by using a special syntax: `{{ expression_name }}`. They can be used on each task property that is documented as **dynamic**.
+
+Dynamic expressions will be rendered, thanks to the Pebble templating engine. Pebble allows the processing of expressions with filters and functions.
+
+Flows, tasks, executions, triggers, and schedules, have default expressions; for example `{{ flow.id }}` allows accessing the identifier of a flow inside an execution.
+
+Flow inputs can be accessed using `{{ inputs.myinput }}`, and task's output attributes are available as `{{ outputs.task_id.output_attribute }}` expressions.
+
+Most expressions will be stored inside the execution context. Expressions of a FILE-type are stored inside Kestra's internal storage and fetched from there at execution time.
+
+Expressions use [Pebble Templating](https://pebbletemplates.io/) along with Kestra's execution context, allowing flexible access patterns to the data you need.
+
+The execution context encompasses flow and execution, environment variables, global variables, task defaults, flow inputs, and task outputs.
+
+
diff --git a/content/docs/05.developer-guide/03.variables/01.index.md b/content/docs/03.concepts/expression/02a.expression-types.md
similarity index 71%
rename from content/docs/05.developer-guide/03.variables/01.index.md
rename to content/docs/03.concepts/expression/02a.expression-types.md
index 5e5fb8a17e..591fd54a6f 100644
--- a/content/docs/05.developer-guide/03.variables/01.index.md
+++ b/content/docs/03.concepts/expression/02a.expression-types.md
@@ -1,38 +1,36 @@
---
-title: Variables
+title: Expression Types
---
-You can use variables to set any task property. They use the power of [Pebble Templates](https://pebbletemplates.io/) with Kestra's special context system, allowing powerful task composition inside a flow.
+There are many ways to use expressions in Kestra. This page will guide you through different types of expressions.
-Variables can use flow execution contextual information registered inside the execution context. The execution context is a set of data from different sources: flow and execution, environment variables, global variables, task defaults, flow inputs, and task outputs.
+## Flow and Execution expressions
-## Flow and Execution variables
+Flow and Execution expressions allow using the current execution context to set task properties. For example: name a file with the current date or the current execution id.
-Flow and Execution variables allow using the current execution context to set task properties. For example: name a file with the current date or the current execution id.
+The following table lists all the default expressions available on each execution.
-The following table lists all the default variables available on each execution.
+| Parameter | Description |
+| ---------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| `{{ flow.id }}` | The identifier of the flow. |
+| `{{ flow.namespace }}` | The name of the flow namespace. |
+| `{{ flow.tenantId }}` | The identifier of the tenant (EE only). |
+| `{{ flow.revision }}` | The revision of the flow. |
+| `{{ execution.id }}` | The execution ID, a generated unique id for each execution. |
+| `{{ execution.startDate }}` | The start date of the current execution, can be formatted with `{{ execution.startDate \| date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}`. |
+| `{{ execution.originalId }}` | The original execution ID, this id will never change even in case of replay and keep the first execution ID. |
+| `{{ task.id }}` | The current task ID |
+| `{{ task.type }}` | The current task Type (Java fully qualified class name). |
+| `{{ taskrun.id }}` | The current task run ID. |
+| `{{ taskrun.startDate }}` | The current task run start date. |
+| `{{ taskrun.parentId }}` | The current task run parent identifier. Only available with tasks inside a Flowable Task. |
+| `{{ taskrun.value }}` | The value of the current task run, only available with tasks wrapped in Flowable Tasks. |
+| `{{ taskrun.attemptsCount }}` | The number of attempts for the current task (when retry or restart is performed). |
+| `{{ parent.taskrun.value }}` | The value of the closest (first) parent task run, only available with tasks inside a Flowable Task. |
+| `{{ parent.outputs }}` | The outputs of the closest (first) parent task run Flowable Task, only available with tasks wrapped in a Flowable Task. |
+| `{{ parents }}` | The list of parent tasks, only available with tasks wrapped in a Flowable Task. See [Parents expressions](./02b.using-expressions.md#parents-with-flowable-task) for its usage. |
-| Parameter | Description |
-| ---------- |-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| `{{ flow.id }}` | The identifier of the flow. |
-| `{{ flow.namespace }}` | The name of the flow namespace. |
-| `{{ flow.tenantId }}` | The identifier of the tenant (EE only). |
-| `{{ flow.revision }}` | The revision of the flow. |
-| `{{ execution.id }}` | The execution ID, a generated unique id for each execution. |
-| `{{ execution.startDate }}` | The start date of the current execution, can be formatted with `{{ execution.startDate \| date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}`. |
-| `{{ execution.originalId }}` | The original execution ID, this id will never change even in case of replay and keep the first execution ID. |
-| `{{ task.id }}` | The current task ID |
-| `{{ task.type }}` | The current task Type (Java fully qualified class name). |
-| `{{ taskrun.id }}` | The current task run ID. |
-| `{{ taskrun.startDate }}` | The current task run start date. |
-| `{{ taskrun.parentId }}` | The current task run parent identifier. Only available with tasks inside a ([Flowable Task](../02.tasks.md#flowable-tasks)). |
-| `{{ taskrun.value }}` | The value of the current task run, only available with tasks inside a ([Flowable Task](../02.tasks.md#flowable-tasks)). |
-| `{{ taskrun.attemptsCount }}` | The number of attempts for the current task (when retry or restart is performed). |
-| `{{ parent.taskrun.value }}` | The value of the closest (first) parent task run [Flowable Task](../02.tasks.md#flowable-tasks), only available with tasks inside a ([Flowable Task](../02.tasks#flowable-tasks)). |
-| `{{ parent.outputs }}` | The outputs of the closest (first) parent task run [Flowable Task](../02.tasks.md#flowable-tasks), only available with tasks inside in a ([Flowable Task](../02.tasks#flowable-tasks)). |
-| `{{ parents }}` | The list of parent tasks, only available with tasks inside a ([Flowable Task](../02.tasks.md#flowable-tasks)). See [Parents variables](./02.basic-usage.md#parents-with-flowable-task) for its usage. |
-
-If a [schedule](../08.triggers/01.schedule.md) event triggers the flow, these variables are also available:
+If a [schedule](../triggers/schedule-trigger) event triggers the flow, these expressions are also available:
| Parameter | Description |
| ---------- | ----------- |
@@ -40,7 +38,7 @@ If a [schedule](../08.triggers/01.schedule.md) event triggers the flow, these va
| `{{ trigger.next }}` | The date of the next schedule. |
| `{{ trigger.previous }}` | The date of the previous schedule. |
-If a [flow](../08.triggers/02.flow.md) event triggers the flow, these variables are also available:
+If a [flow](../triggers/flow-trigger.md) event triggers the flow, these expressions are also available:
| Parameter | Description |
| ---------- | ----------- |
@@ -49,7 +47,7 @@ If a [flow](../08.triggers/02.flow.md) event triggers the flow, these variables
| `{{ trigger.flowId }}` | The ID of the flow that triggers the current flow. |
| `{{ trigger.flowRevision }}` | The revision of the flow that triggers the current flow. |
-All these variables can be used thanks to the Pebble template syntax `{{varName}}`:
+All these expressions can be accessed using the Pebble template syntax `{{expression}}`:
```yaml
id: context-example
@@ -75,7 +73,7 @@ To access an environment variable `KESTRA_FOO` from one of your tasks, you can u
## Global variables
-You can define global variables inside Kestra's configuration files and access them using `{{ globals.foo }}`, see [Variables configuration](../../09.administrator-guide/01.configuration/05.others.md#variables-configuration) for more information.
+You can define global variables inside Kestra's configuration files and access them using `{{ globals.foo }}`, see [Variables configuration](../../09.administrator-guide/01.configuration/04.others.md#variables-configuration) for more information.
## Flow variables
@@ -95,9 +93,9 @@ tasks:
format: "{{ vars.my_variable }}"
```
-## Inputs variables
+## Inputs
-You can use any flow [inputs](../04.inputs.md) using `inputs.inputName`, for example:
+You can use any flow [inputs](../inputs.md) using `inputs.inputName`, for example:
```yaml
id: context-inputs
@@ -113,7 +111,7 @@ tasks:
format: "{{inputs.myInput}}"
```
-## Secret variables
+## Secrets
You can retrieve secrets in your flow using the `secret()` function. Here is an example:
@@ -127,7 +125,7 @@ tasks:
format: "{{secret('MY_SECRET')}}"
```
-Secrets can be provided on both open-source and [Enterprise Edition](https://kestra.io/enterprise). Check the [Secrets](../10.secrets.md) documentation for more details. Also, see the [Administrator Guide](../../09.administrator-guide/01.configuration/03.enterprise-edition/secrets/index.md) for detailed instructions on Secrets Manager configuration.
+Secrets can be provided on both open-source and [Enterprise Edition](https://kestra.io/enterprise). Check the [Secrets](../secret.md) documentation for more details. Also, see the [Administrator Guide](../../09.administrator-guide/01.configuration/03.enterprise-edition/secrets/index.md) for detailed instructions on Secrets Manager configuration.
## Namespace variables (EE)
@@ -147,9 +145,9 @@ tasks:
format: "{{ namespace.my_variable }}"
```
-## Outputs variables
+## Outputs
-You can use any task [output](../05.outputs.md) attributes using `outputs.taskId.outputAttribute` where:
+You can use any task [output](../outputs.md) attributes using `outputs.taskId.outputAttribute` where:
- `taskId` is the ID of the task.
- `outputAttribute` is the attribute of the task output you want to use. Each task output can emit different attributes; refer to the task documentation for the list of output attributes.
@@ -167,19 +165,19 @@ tasks:
- id: second-example
type: io.kestra.core.tasks.debugs.Return
format: "Second return"
- - id: log-both-variables
+ - id: log-both-outputs
type: io.kestra.core.tasks.log.Log
message: "First: {{outputs.firstExample.value}}, Second: {{outputs['second-example'].value}}"
```
::alert{type="info"}
-The `Return` task has an output attribute `value` which is used by the `log-both-variables` task.
-In the `log-both-variables` task, you can see two ways to access task outputs: the dot notation (`outputs.firstExample`) and the subscript notation (`outputs['second-example']`). The subscript notation must be used when a variable contains a special character, such as `-` that is a Pebble reserved character.
+The `Return` task has an output attribute `value` which is used by the `log-both-outputs` task.
+In the `log-both-outputs` task, you can see two ways to access task outputs: the dot notation (`outputs.firstExample`) and the subscript notation (`outputs['second-example']`). The subscript notation must be used when a variable contains a special character, such as `-` that is a Pebble reserved character.
::
## Pebble templating: example
-The example below will parse the Pebble expressions within the `variables` based on the `inputs` and `trigger` values. Both variables use the [Null-Coalescing Operator](02.basic-usage.md#null-coalescing-operator) to use the first non-null value.
+The example below will parse the Pebble expressions within the `variables` based on the `inputs` and `trigger` values. Both variables use the [Null-Coalescing Operator](02b.using-expressions.md#null-coalescing-operator) to use the first non-null value.
Here, the first variable `trigger_or_yesterday` will evaluate to a `trigger.date` if the flow runs on schedule. Otherwise, it will evaluate to the yesterday's date by using the `execution.startDate` minus one day.
@@ -210,6 +208,6 @@ tasks:
## Pebble templating: deep dive
-Pebble templating offers a myriad of ways to process variables. For a deep dive, check the following section:
+Pebble templating offers a myriad of ways to parse expressions.
diff --git a/content/docs/05.developer-guide/03.variables/02.basic-usage.md b/content/docs/03.concepts/expression/02b.using-expressions.md
similarity index 85%
rename from content/docs/05.developer-guide/03.variables/02.basic-usage.md
rename to content/docs/03.concepts/expression/02b.using-expressions.md
index 5722f931de..86777322e7 100644
--- a/content/docs/05.developer-guide/03.variables/02.basic-usage.md
+++ b/content/docs/03.concepts/expression/02b.using-expressions.md
@@ -1,5 +1,5 @@
---
-title: Basic Usage
+title: Using Expressions
---
## Syntax Reference
@@ -12,14 +12,8 @@ There are two primary delimiters used within a Pebble template: `{{ ... }}` and
If needed, you can escape those delimiters and avoid Pebble templating applying on a variable thanks to the [raw](06.tag/raw.md) tag.
-## Variables
+You can use the dot (`.`) notation to access child attributes. If the attribute contains a special character, you can use the subscript notation (`[]`) instead.
-You can output variables directly inside an expression. For example, if the context contains a variable named `foo` which is a string with the value "bar", the following will output "bar":
-```twig
-{{ foo }}
-```
-
-You can use the dot (`.`) notation to access the attributes of variables. If the attribute contains a special character, you can use the subscript notation (`[]`) instead.
```twig
{{ foo.bar }} # Attribute 'bar' of 'foo'
{{ foo.bar.baz }} # Attribute 'baz' of attribute 'bar' of 'foo'
@@ -28,28 +22,28 @@ You can use the dot (`.`) notation to access the attributes of variables. If the
```
::alert{type="warning"}
-You will see a lot of tasks with hyphenated names in the documentation. When using hyphenated names, you must use the subscript notation (`[]`) to access any task variables as `-` is a Pebble special character.
+When using task, variable or output names containing a hyphen symbol `-`, make sure to use the subscript notation (`[]`) e.g. `"{{ outputs.mytask.myoutput['foo-bar'] }}"` because `-` is a special character in the Pebble templating engine.
::
-
-Additionally, if `foo` is a List, then `foo[idx]` can be used to access the element of index `idx` of the foo variable.
-
-If the value of a variable (or of an attribute) is undefined, it will throw an error and fail the task.
+If `foo` would be a List, then `foo[idx]` can be used to access the elements of index `idx` of the foo variable.
## Filters
-Expression output can be further modified with the use of filters. Filters are separated from the variable using a pipe symbol (`|`) and may have optional arguments in parentheses. Multiple filters can be chained, and the output of one filter is applied to the next.
+You can use filters in your expressions using a pipe symbol (`|`). Multiple filters can be chained, and the output of one filter is applied to the next one.
+
```twig
-{{ "If life gives you lemons, eat lemons." | upper | abbreviate(13) }}
+{{ "When life gives you lemons, make lemonade." | upper | abbreviate(13) }}
```
The above example will output the following:
+
```twig
-IF LIFE GI...
+WHEN LIFE ...
```
## Functions
-Whereas filters are intended to modify existing content/variables, functions are intended to generate new content. Similar to other programming languages, functions are invoked via their name followed by parentheses (`()`).
+Whereas filters are intended to modify existing content/variables, functions are intended to generate new content. Similar to other programming languages, functions are invoked via their name followed by parentheses `function_name()`.
+
```twig
{{ max(user.score, highscore) }}
```
@@ -222,9 +216,9 @@ In order from highest to lowest precedence:
- `or`
-### Parents with [Flowable Task](../02.tasks.md#flowable-tasks).
+### Parents with Flowable Task
-When a task is in a hierarchy of [Flowable Tasks](../02.tasks.md#flowable-tasks), it can be complex to access the
+When a task is in a hierarchy of [Flowable Tasks](../flowable-tasks.md), it can be complex to access the
`value` of any of its parents because only the `value` of the direct parent task is accessible via `taskrun.value`.
To deal with this, we have included the `parent` and the `parents` variables.
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/abbreviate.md b/content/docs/03.concepts/expression/03.filter/abbreviate.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/abbreviate.md
rename to content/docs/03.concepts/expression/03.filter/abbreviate.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/abs.md b/content/docs/03.concepts/expression/03.filter/abs.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/abs.md
rename to content/docs/03.concepts/expression/03.filter/abs.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/base64decode.md b/content/docs/03.concepts/expression/03.filter/base64decode.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/base64decode.md
rename to content/docs/03.concepts/expression/03.filter/base64decode.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/base64encode.md b/content/docs/03.concepts/expression/03.filter/base64encode.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/base64encode.md
rename to content/docs/03.concepts/expression/03.filter/base64encode.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/capitalize.md b/content/docs/03.concepts/expression/03.filter/capitalize.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/capitalize.md
rename to content/docs/03.concepts/expression/03.filter/capitalize.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/chunk.md b/content/docs/03.concepts/expression/03.filter/chunk.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/chunk.md
rename to content/docs/03.concepts/expression/03.filter/chunk.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/className.md b/content/docs/03.concepts/expression/03.filter/className.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/className.md
rename to content/docs/03.concepts/expression/03.filter/className.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/date.md b/content/docs/03.concepts/expression/03.filter/date.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/date.md
rename to content/docs/03.concepts/expression/03.filter/date.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/dateAdd.md b/content/docs/03.concepts/expression/03.filter/dateAdd.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/dateAdd.md
rename to content/docs/03.concepts/expression/03.filter/dateAdd.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/default.md b/content/docs/03.concepts/expression/03.filter/default.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/default.md
rename to content/docs/03.concepts/expression/03.filter/default.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/first.md b/content/docs/03.concepts/expression/03.filter/first.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/first.md
rename to content/docs/03.concepts/expression/03.filter/first.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/index.md b/content/docs/03.concepts/expression/03.filter/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/index.md
rename to content/docs/03.concepts/expression/03.filter/index.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/join.md b/content/docs/03.concepts/expression/03.filter/join.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/join.md
rename to content/docs/03.concepts/expression/03.filter/join.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/jq.md b/content/docs/03.concepts/expression/03.filter/jq.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/jq.md
rename to content/docs/03.concepts/expression/03.filter/jq.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/json.md b/content/docs/03.concepts/expression/03.filter/json.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/json.md
rename to content/docs/03.concepts/expression/03.filter/json.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/keys.md b/content/docs/03.concepts/expression/03.filter/keys.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/keys.md
rename to content/docs/03.concepts/expression/03.filter/keys.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/last.md b/content/docs/03.concepts/expression/03.filter/last.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/last.md
rename to content/docs/03.concepts/expression/03.filter/last.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/length.md b/content/docs/03.concepts/expression/03.filter/length.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/length.md
rename to content/docs/03.concepts/expression/03.filter/length.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/lower.md b/content/docs/03.concepts/expression/03.filter/lower.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/lower.md
rename to content/docs/03.concepts/expression/03.filter/lower.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/merge.md b/content/docs/03.concepts/expression/03.filter/merge.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/merge.md
rename to content/docs/03.concepts/expression/03.filter/merge.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/number.md b/content/docs/03.concepts/expression/03.filter/number.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/number.md
rename to content/docs/03.concepts/expression/03.filter/number.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/numberFormat.md b/content/docs/03.concepts/expression/03.filter/numberFormat.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/numberFormat.md
rename to content/docs/03.concepts/expression/03.filter/numberFormat.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/replace.md b/content/docs/03.concepts/expression/03.filter/replace.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/replace.md
rename to content/docs/03.concepts/expression/03.filter/replace.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/reverse.md b/content/docs/03.concepts/expression/03.filter/reverse.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/reverse.md
rename to content/docs/03.concepts/expression/03.filter/reverse.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/rsort.md b/content/docs/03.concepts/expression/03.filter/rsort.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/rsort.md
rename to content/docs/03.concepts/expression/03.filter/rsort.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/sha256.md b/content/docs/03.concepts/expression/03.filter/sha256.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/sha256.md
rename to content/docs/03.concepts/expression/03.filter/sha256.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/slice.md b/content/docs/03.concepts/expression/03.filter/slice.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/slice.md
rename to content/docs/03.concepts/expression/03.filter/slice.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/slugify.md b/content/docs/03.concepts/expression/03.filter/slugify.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/slugify.md
rename to content/docs/03.concepts/expression/03.filter/slugify.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/sort.md b/content/docs/03.concepts/expression/03.filter/sort.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/sort.md
rename to content/docs/03.concepts/expression/03.filter/sort.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/split.md b/content/docs/03.concepts/expression/03.filter/split.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/split.md
rename to content/docs/03.concepts/expression/03.filter/split.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/substringAfter.md b/content/docs/03.concepts/expression/03.filter/substringAfter.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/substringAfter.md
rename to content/docs/03.concepts/expression/03.filter/substringAfter.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/substringAfterLast.md b/content/docs/03.concepts/expression/03.filter/substringAfterLast.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/substringAfterLast.md
rename to content/docs/03.concepts/expression/03.filter/substringAfterLast.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/substringBefore.md b/content/docs/03.concepts/expression/03.filter/substringBefore.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/substringBefore.md
rename to content/docs/03.concepts/expression/03.filter/substringBefore.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/substringBeforeLast.md b/content/docs/03.concepts/expression/03.filter/substringBeforeLast.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/substringBeforeLast.md
rename to content/docs/03.concepts/expression/03.filter/substringBeforeLast.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/timestamp.md b/content/docs/03.concepts/expression/03.filter/timestamp.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/timestamp.md
rename to content/docs/03.concepts/expression/03.filter/timestamp.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/timestampMicro.md b/content/docs/03.concepts/expression/03.filter/timestampMicro.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/timestampMicro.md
rename to content/docs/03.concepts/expression/03.filter/timestampMicro.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/timestampNano.md b/content/docs/03.concepts/expression/03.filter/timestampNano.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/timestampNano.md
rename to content/docs/03.concepts/expression/03.filter/timestampNano.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/title.md b/content/docs/03.concepts/expression/03.filter/title.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/title.md
rename to content/docs/03.concepts/expression/03.filter/title.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/trim.md b/content/docs/03.concepts/expression/03.filter/trim.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/trim.md
rename to content/docs/03.concepts/expression/03.filter/trim.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/upper.md b/content/docs/03.concepts/expression/03.filter/upper.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/upper.md
rename to content/docs/03.concepts/expression/03.filter/upper.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/urldecode.md b/content/docs/03.concepts/expression/03.filter/urldecode.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/urldecode.md
rename to content/docs/03.concepts/expression/03.filter/urldecode.md
diff --git a/content/docs/05.developer-guide/03.variables/03.filter/urlencode.md b/content/docs/03.concepts/expression/03.filter/urlencode.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/03.filter/urlencode.md
rename to content/docs/03.concepts/expression/03.filter/urlencode.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/block.md b/content/docs/03.concepts/expression/04.function/block.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/block.md
rename to content/docs/03.concepts/expression/04.function/block.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/currentEachOutput.md b/content/docs/03.concepts/expression/04.function/currentEachOutput.md
similarity index 93%
rename from content/docs/05.developer-guide/03.variables/04.function/currentEachOutput.md
rename to content/docs/03.concepts/expression/04.function/currentEachOutput.md
index a9f821bb9d..977b39e31d 100644
--- a/content/docs/05.developer-guide/03.variables/04.function/currentEachOutput.md
+++ b/content/docs/03.concepts/expression/04.function/currentEachOutput.md
@@ -2,7 +2,7 @@
title: currentEachOutput
---
-The `currentEachOutput` function retrieves the current output of a sibling task when using an [EachSequential](../../../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachSequential.md) task. See [Lookup in sibling tasks](../../05.outputs.md#lookup-in-sibling-tasks) for background on sibling tasks.
+The `currentEachOutput` function retrieves the current output of a sibling task when using an [EachSequential](../../../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachSequential.md) task. See [Lookup in sibling tasks](../../outputs.md#lookup-in-sibling-tasks) for background on sibling tasks.
Look at the following flow:
diff --git a/content/docs/05.developer-guide/03.variables/04.function/index.md b/content/docs/03.concepts/expression/04.function/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/index.md
rename to content/docs/03.concepts/expression/04.function/index.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/json.md b/content/docs/03.concepts/expression/04.function/json.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/json.md
rename to content/docs/03.concepts/expression/04.function/json.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/max.md b/content/docs/03.concepts/expression/04.function/max.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/max.md
rename to content/docs/03.concepts/expression/04.function/max.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/min.md b/content/docs/03.concepts/expression/04.function/min.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/min.md
rename to content/docs/03.concepts/expression/04.function/min.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/now.md b/content/docs/03.concepts/expression/04.function/now.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/now.md
rename to content/docs/03.concepts/expression/04.function/now.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/parent.md b/content/docs/03.concepts/expression/04.function/parent.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/parent.md
rename to content/docs/03.concepts/expression/04.function/parent.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/range.md b/content/docs/03.concepts/expression/04.function/range.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/range.md
rename to content/docs/03.concepts/expression/04.function/range.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/read.md b/content/docs/03.concepts/expression/04.function/read.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/04.function/read.md
rename to content/docs/03.concepts/expression/04.function/read.md
diff --git a/content/docs/05.developer-guide/03.variables/04.function/secret.md b/content/docs/03.concepts/expression/04.function/secret.md
similarity index 94%
rename from content/docs/05.developer-guide/03.variables/04.function/secret.md
rename to content/docs/03.concepts/expression/04.function/secret.md
index 0f22555d02..2dc53044c4 100644
--- a/content/docs/05.developer-guide/03.variables/04.function/secret.md
+++ b/content/docs/03.concepts/expression/04.function/secret.md
@@ -29,5 +29,5 @@ The above example will:
1. retrieve the secret `GITHUB_ACCESS_TOKEN` from an environment variable `SECRET_GITHUB_ACCESS_TOKEN`
2. base64-decode it at runtime.
-See the [Secrets section](../../10.secrets.md) in the Developer Guide for more details.
+See the [Secrets section](../../secret.md) in the Developer Guide for more details.
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/comparisons.md b/content/docs/03.concepts/expression/05.operator/comparisons.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/comparisons.md
rename to content/docs/03.concepts/expression/05.operator/comparisons.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/concat.md b/content/docs/03.concepts/expression/05.operator/concat.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/concat.md
rename to content/docs/03.concepts/expression/05.operator/concat.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/contains.md b/content/docs/03.concepts/expression/05.operator/contains.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/contains.md
rename to content/docs/03.concepts/expression/05.operator/contains.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/index.md b/content/docs/03.concepts/expression/05.operator/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/index.md
rename to content/docs/03.concepts/expression/05.operator/index.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/is.md b/content/docs/03.concepts/expression/05.operator/is.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/is.md
rename to content/docs/03.concepts/expression/05.operator/is.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/logic.md b/content/docs/03.concepts/expression/05.operator/logic.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/logic.md
rename to content/docs/03.concepts/expression/05.operator/logic.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/math.md b/content/docs/03.concepts/expression/05.operator/math.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/math.md
rename to content/docs/03.concepts/expression/05.operator/math.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/not.md b/content/docs/03.concepts/expression/05.operator/not.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/not.md
rename to content/docs/03.concepts/expression/05.operator/not.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/null-coalescing.md b/content/docs/03.concepts/expression/05.operator/null-coalescing.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/null-coalescing.md
rename to content/docs/03.concepts/expression/05.operator/null-coalescing.md
diff --git a/content/docs/05.developer-guide/03.variables/05.operator/ternary-operator.md b/content/docs/03.concepts/expression/05.operator/ternary-operator.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/05.operator/ternary-operator.md
rename to content/docs/03.concepts/expression/05.operator/ternary-operator.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/block.md b/content/docs/03.concepts/expression/06.tag/block.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/block.md
rename to content/docs/03.concepts/expression/06.tag/block.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/filter.md b/content/docs/03.concepts/expression/06.tag/filter.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/filter.md
rename to content/docs/03.concepts/expression/06.tag/filter.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/for.md b/content/docs/03.concepts/expression/06.tag/for.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/for.md
rename to content/docs/03.concepts/expression/06.tag/for.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/if.md b/content/docs/03.concepts/expression/06.tag/if.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/if.md
rename to content/docs/03.concepts/expression/06.tag/if.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/index.md b/content/docs/03.concepts/expression/06.tag/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/index.md
rename to content/docs/03.concepts/expression/06.tag/index.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/macro.md b/content/docs/03.concepts/expression/06.tag/macro.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/macro.md
rename to content/docs/03.concepts/expression/06.tag/macro.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/raw.md b/content/docs/03.concepts/expression/06.tag/raw.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/raw.md
rename to content/docs/03.concepts/expression/06.tag/raw.md
diff --git a/content/docs/05.developer-guide/03.variables/06.tag/set.md b/content/docs/03.concepts/expression/06.tag/set.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/06.tag/set.md
rename to content/docs/03.concepts/expression/06.tag/set.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/defined.md b/content/docs/03.concepts/expression/07.test/defined.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/defined.md
rename to content/docs/03.concepts/expression/07.test/defined.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/empty.md b/content/docs/03.concepts/expression/07.test/empty.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/empty.md
rename to content/docs/03.concepts/expression/07.test/empty.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/even.md b/content/docs/03.concepts/expression/07.test/even.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/even.md
rename to content/docs/03.concepts/expression/07.test/even.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/index.md b/content/docs/03.concepts/expression/07.test/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/index.md
rename to content/docs/03.concepts/expression/07.test/index.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/iterable.md b/content/docs/03.concepts/expression/07.test/iterable.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/iterable.md
rename to content/docs/03.concepts/expression/07.test/iterable.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/json.md b/content/docs/03.concepts/expression/07.test/json.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/json.md
rename to content/docs/03.concepts/expression/07.test/json.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/map.md b/content/docs/03.concepts/expression/07.test/map.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/map.md
rename to content/docs/03.concepts/expression/07.test/map.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/null.md b/content/docs/03.concepts/expression/07.test/null.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/null.md
rename to content/docs/03.concepts/expression/07.test/null.md
diff --git a/content/docs/05.developer-guide/03.variables/07.test/odd.md b/content/docs/03.concepts/expression/07.test/odd.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/07.test/odd.md
rename to content/docs/03.concepts/expression/07.test/odd.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/boolean.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/boolean.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/boolean.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/boolean.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/date.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/date.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/date.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/date.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/index.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/index.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/index.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/index.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/iterations.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/iterations.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/iterations.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/iterations.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/json.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/json.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/json.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/json.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/number.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/number.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/number.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/number.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/string.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/string.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/string.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/string.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/use.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/use.md
similarity index 100%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/use.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/use.md
diff --git a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/vars.md b/content/docs/03.concepts/expression/08.deprecated-handlebars/vars.md
similarity index 70%
rename from content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/vars.md
rename to content/docs/03.concepts/expression/08.deprecated-handlebars/vars.md
index 0bfc5a6da7..4897f16c4e 100644
--- a/content/docs/05.developer-guide/03.variables/08.deprecated-handlebars/vars.md
+++ b/content/docs/03.concepts/expression/08.deprecated-handlebars/vars.md
@@ -14,7 +14,7 @@ Return the first defined variables or throw an exception if no variables are def
Evaluate a handlebars expression at runtime based on the whole context.
-Mostly useful for [Lookup in current child's tasks tree](../02.basic-usage.md#parents-with-flowable-task) and dynamic tasks.
+Mostly useful for [Lookup in current child's tasks tree](../02b.using-expressions.md#parents-with-flowable-task) and dynamic tasks.
```handlebars
@@ -25,7 +25,7 @@ Mostly useful for [Lookup in current child's tasks tree](../02.basic-usage.md#pa
First defined evaluates a handlebars expression at runtime based on the whole context or throws an exception if no variables are defined.
-Mostly useful for [Lookup in current child's tasks tree](../02.basic-usage.md#parents-with-flowable-task) and dynamic tasks.
+Mostly useful for [Lookup in current child's tasks tree](../02b.using-expressions.md#parents-with-flowable-task) and dynamic tasks.
```handlebars
@@ -40,7 +40,7 @@ Mostly useful for [Lookup in current child's tasks tree](../02.basic-usage.md#pa
* get on `object` type map, the key at `key`
* get on `object` type array, the index at `key`
-Mostly useful for [Lookup in current child's tasks tree](../02.basic-usage.md#parents-with-flowable-task) and dynamic tasks.
+Mostly useful for [Lookup in current child's tasks tree](../02b.using-expressions.md#parents-with-flowable-task) and dynamic tasks.
```handlebars
{{ get outputs 'first' }}
diff --git a/content/docs/03.concepts/flow-properties.md b/content/docs/03.concepts/flow-properties.md
new file mode 100644
index 0000000000..630fe01d89
--- /dev/null
+++ b/content/docs/03.concepts/flow-properties.md
@@ -0,0 +1,110 @@
+---
+title: Flow properties
+---
+
+This section covers the required and optional properties of a flow.
+
+## Required properties
+
+A flow **must** have:
+
+1. an `id`,
+2. a `namespace`,
+3. a list of `tasks`.
+
+Those three are the only **required** properties. All other properties are **optional**.
+
+## Optional properties
+
+The **optional properties** include:
+
+- a `description`,
+- a map of `labels`,
+- a map of `variables`,
+- a list of `inputs`,
+- a list of `triggers`,
+- a list of `taskDefaults`.
+
+## Description of all flow properties
+
+The list below describes each property in detail.
+
+- `id`: The flow identifier which represents the name of the flow. This ID must be unique within a namespace and is immutable (you cannot rename the flow ID later; you could only recreate it with a new name).
+- `namespace`: Each flow lives in one namespace. Namespaces are used to group flows and provide structure. Allocation of a flow to a namespace is immutable. Once a flow is created, you cannot change its namespace. If you need to change the namespace of a flow, create a new flow with the desired namespace and delete the old flow.
+- `tasks`: The list of tasks to be executed within the flow. By default, tasks will run sequentially one after the other. However, you can use additional [flowable tasks](https://kestra.io/docs/tutorial/flowable) to run tasks in parallel.
+- `inputs`: The list of inputs that allow you to make your flows more dynamic and reusable. Instead of hardcoding values in your flow, you can use inputs to trigger multiple Executions of your flow with different values determined at runtime. Use the syntax `{{inputs.your_input_name}}` to access specific input values in your tasks.
+- `triggers`: The list of triggers which automatically start a new execution based on events, such as a scheduled date, a new file arrival, a new message in a queue, or the completion event of another flow's execution.
+- `errors`: The list of tasks that will be executed sequentially on errors — Kestra will run those tasks anytime there is an error in the current execution.
+- `labels`: A map of custom key-value pairs that you can use to organize your flows based on your project, maintainers, or any other criteria. You can use labels to filter Executions in the UI.
+- `variables`: A map of custom key-value pairs (such as an API endpoint, table name, etc.) that you can use in your flow to avoid repetition. When you declare some variables, you can then access them in all tasks using the syntax `{{vars.your_variable_name}}`.
+- `revision`: The flow version, handled internally by Kestra, and incremented upon each modification. You should not manually set it.
+- `description`: A markdown description of the flow, providing a simple way of documenting your workflows. That description is automatically rendered on the flow's page in the UI.
+- `disabled`: Set it to true to temporarily disable any new executions of the flow. This is useful when you want to stop a flow from running (even manually) without deleting it. Once you set this property to true, nobody will be able to trigger any execution of that flow, whether from the UI or via an API call, until the flow is reenabled by setting this property back to false (default behavior) or by simply deleting this property in your flow configuration.
+- `taskDefaults`: The list of default task values, allowing you to avoid repeating the same properties on each task.
+ - `taskDefaults.[].type`: The task type is a full qualified Java class name, i.e., the task name such as `io.kestra.core.tasks.log.Log`.
+ - `taskDefaults.[].forced`: If set to `forced: true`, the `taskDefault` will take precedence over properties defined in the task (the default behavior is `forced: false`).
+ - `taskDefaults.[].values.xxx`: The task property that you want to be set as default.
+
+---
+
+## Flow example
+
+Here is an example flow. It uses a `Log` task available in Kestra core for testing purposes and demonstrates how to use `labels`, `inputs`, `variables`, `triggers` and various `descriptions`.
+
+```yaml
+id: getting_started
+namespace: dev
+
+description: |
+ # This is a flow description that will be rendered in the UI
+ Let's `write` some **markdown** - [first flow](https://t.ly/Vemr0) 🚀
+
+labels:
+ owner: rick.astley
+ project: never-gonna-give-you-up
+ environment: dev
+ country: US
+
+inputs:
+ - name: user
+ type: STRING
+ required: false
+ defaults: Rick Astley
+ description: |
+ This is an optional value. If not set at runtime,
+ it will use the default value "Rick Astley".
+
+variables:
+ first: 1
+ second: "{{vars.first}} > 2"
+
+tasks:
+ - id: hello
+ type: io.kestra.core.tasks.log.Log
+ description: this is a *task* documentation
+ message: |
+ The variables we used are {{vars.first}} and {{vars.second}}.
+ The input is {{inputs.user}} and the task was started at {{taskrun.startDate}} from flow {{flow.id}}.
+
+taskDefaults:
+ - type: io.kestra.core.tasks.log.Log
+ values:
+ level: TRACE
+
+triggers:
+ - id: monthly
+ type: io.kestra.core.models.triggers.types.Schedule
+ cron: "0 9 1 * *"
+ description: |
+ This trigger will start a new execution of the flow every first day of the month at 9am. It will use the default values defined in the taskDefaults section, as well as the default input values.
+```
+
+## Add descriptions to flows, tasks, inputs and triggers
+
+Each component of your workflow can be documented in the [Markdown](https://en.wikipedia.org/wiki/Markdown) syntax using the `description` property.
+
+All markdown descriptions will be rendered in the UI.
+
+
+
+To keep all elements of a flow documented, you can add the description to the `flow` itself, as well as to each `task`, `input` and `trigger`.
diff --git a/content/docs/03.concepts/flow.md b/content/docs/03.concepts/flow.md
new file mode 100644
index 0000000000..0b66bc4bba
--- /dev/null
+++ b/content/docs/03.concepts/flow.md
@@ -0,0 +1,164 @@
+---
+title: Flow
+---
+
+A flow is a container for `tasks`, their `inputs`, `outputs`, handling of `errors` and overall orchestration logic. It defines the **order** in which tasks are executed and **how** they are executed, e.g. **sequentially**, i**n parallel**, based on upstream task dependencies and their state, etc.
+
+**Flows** are used to implement your workload. They define all the tasks you want to perform and the order in which they will be run.
+
+You define a flow using the declarative model called [YAML](https://en.wikipedia.org/wiki/YAML).
+
+A flow must have an identifier (`id`), a `namespace`, and a list of [`tasks`](./02.tasks.md).
+
+A flow can also have [`inputs`](./inputs.md), [error handlers](./07.errors-handling.md) under the property `errors`, and [`triggers`](./triggers/index.md).
+
+## Flow sample
+
+Here is a sample flow definition. It uses tasks available in Kestra core for testing purposes.
+
+```yaml
+id: hello-world
+namespace: dev
+
+description: flow **documentation** in *Markdown*
+
+labels:
+ env: prod
+ team: engineering
+
+inputs:
+ - name: my-value
+ type: STRING
+ required: false
+ defaults: "default value"
+ description: This is a not required my-value
+
+variables:
+ first: "1"
+ second: "{{vars.first}} > 2"
+
+tasks:
+ - id: date
+ type: io.kestra.core.tasks.debugs.Return
+ description: "Some tasks **documentation** in *Markdown*"
+ format: "A log line content with a contextual date variable {{taskrun.startDate}}"
+
+taskDefaults:
+ - type: io.kestra.core.tasks.log.Log
+ values:
+ level: ERROR
+```
+
+### Task defaults
+
+You can also define `taskDefaults` in your flow. This is a list of default task properties that will be applied to each task of a certain type inside your flow. The `taskDefaults` property can be handy to avoid repeating the same values when leveraging the same task multiple times.
+
+### Variables
+
+You can set flow variables that will be accessible by each task using `{{ vars.key }}`. Flow `variables` is a map of key/value pairs.
+
+### List of tasks
+
+The most important part of a flow is the list of tasks that will be run sequentially when the flow is executed.
+
+
+## Document your flow
+
+You can add documentation to flows, tasks, etc... to explain the goal of the current element.
+
+For this, Kestra allows adding a `description` property where you can write documentation of the current element.
+The description must be written using the [Markdown](https://en.wikipedia.org/wiki/Markdown) syntax.
+
+You can add a `description` property on:
+- [Flows](./01.flow.md)
+- [Tasks](./02.tasks.md)
+- [Listeners](./listeners.md)
+- [Triggers](./triggers/index.md)
+
+All markdown descriptions will be rendered in the UI.
+
+
+
+
+## Enable or Disable a Flow
+
+By default, all flows are active and will execute whether or not a trigger has been set.
+
+You have the option to disable a Flow, which is particularly useful when you wish to prevent its execution.
+
+Enabling a previously disabled Flow will prompt it to execute any missed triggers from the period when it was disabled.
+
+
+
+
+## Task
+
+A task is a single action in a flow. A task can have properties, use flow inputs and other task's outputs, perform an action, and produce an [output](#outputs).
+
+There are two kinds of tasks in Kestra:
+- Runnable Tasks
+- Flowable Tasks
+
+
+### Runnable Task
+
+[Runnable Tasks](../05.developer-guide/02.tasks.md#runnable-tasks) handle computational work in the flow. For example, file system operations, API calls, database queries, etc. These tasks can be compute-intensive and are handled by [Workers](../03.concepts/worker.md).
+
+By default, Kestra only includes a few Runnable Tasks. However, many of them are available as [plugins](../../plugins/index.md), and if you use our default Docker image, plenty of them will already be included.
+
+
+### Flowable Task
+
+[Flowable Tasks](../03.concepts/flowable-tasks.md) only handle flow logic (branching, grouping, parallel processing, etc.) and start new tasks. For example, the [Switch task](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Switch.md) decides the next task to run based on some inputs.
+
+A Flowable Task is handled by [Executors](../03.concepts/executor.md) and can be called very often. Because of that, these tasks cannot include intensive computations, unlike Runnable Tasks. Most of the common Flowable Tasks are available in the default Kestra installation.
+
+
+## Labels
+
+Labels are key-value pairs that you can add to flows. Labels are used to **organize** flows and can be used to **filter executions** of any given flow from the UI.
+
+## Inputs
+
+Inputs are parameters sent to a flow at execution time. It's important to note that inputs in Kestra are [strongly typed](../03.concepts/inputs.md#input-types).
+
+The inputs can be declared as either optional or mandatory. If the flow has required inputs, you'll have to provide them before the execution of the flow. You can also provide default values to the inputs.
+
+Inputs can have validation rules that are enforced at execution time.
+
+Inputs of type `FILE` will be uploaded to Kestra's [internal storage](../03.concepts/internal-storage.md) and made available for all tasks.
+
+Flow inputs can be seen in the **Overview** tab of the **Execution** page.
+
+## Outputs
+
+Each task can produce an output that may contain multiple properties. This output is described in the plugin documentation task and can then be accessible by all the following tasks via [variables](../03.concepts/expression/02.basic-usage.md).
+
+Some outputs are of a special type and will be stored inside Kestra's [internal storage](../03.concepts/internal-storage.md). Successive tasks may still use them as Kestra will automatically make them available for all tasks.
+
+Tasks outputs can be seen in the **Outputs** tab of the **Execution** page. If an output is a file from the [internal storage](../03.concepts/internal-storage.md), it will be available to download.
+
+
+## Revision
+
+Changing the source of a flow will produce a new revision for the flow. The revision is an incremental number that will be updated each time you change the flow.
+
+Internally, Kestra will track and manage all the revisions of the flow. Think of it as version control for your flows integrated inside Kestra.
+
+You can access old revisions inside the **Revisions** tab of the **Flows** page.
+
+## Triggers
+
+[Triggers](../03.concepts/triggers/index.md) are a way to start a flow from external events. For example, a trigger might initiate a flow at a scheduled time or based on external events (webhooks, file creation, message in a broker, etc.).
+
+
+## Listeners (deprecated)
+
+[Listeners](../03.concepts/listeners.md) are special tasks that can listen to the current flow, and launch tasks *outside the flow*, meaning launch tasks that are not part of the flow.
+
+The result of listeners will not change the execution status of the flow. Listeners are mainly used to send notifications or handle special behavior outside the primary flow.
+
+
+## Templates (deprecated)
+
+[Templates](../05.developer-guide/03.concepts/templates.md) are lists of tasks that can be shared between flows. You can define a template and call it from other flows. Templates allow you to share a list of tasks and keep them updated without changing all flows that use them.
diff --git a/content/docs/05.developer-guide/02.tasks.md b/content/docs/03.concepts/flowable-tasks.md
similarity index 79%
rename from content/docs/05.developer-guide/02.tasks.md
rename to content/docs/03.concepts/flowable-tasks.md
index 8cee7b31c2..472c85e21a 100644
--- a/content/docs/05.developer-guide/02.tasks.md
+++ b/content/docs/03.concepts/flowable-tasks.md
@@ -1,48 +1,12 @@
---
-title: Tasks
+title: Flowable Tasks
---
-## Runnable Tasks
-
-In Kestra, workloads are executed using **Runnable Tasks**.
-
-Runnable Tasks handle computational work in the flow. For example, file system operations, API calls, database queries, etc. These tasks can be compute-intensive and are handled by [workers](../01.architecture.md#worker).
-
-Each task must have an identifier (id) and a type. The type is the task's Java Fully Qualified Class Name (FQCN).
-
-Tasks have properties specific to the type of the task; check each task's documentation for the list of available properties.
-
-Most available tasks are Runnable Tasks except special ones that are [Flowable Tasks](#flowable-tasks); those are explained later on this page.
-
-By default, Kestra only includes a few Runnable Tasks. However, many of them are available as [plugins](../../plugins/index.md), and if you use our default Docker image, plenty of them will already be included.
-
-### Task common properties
-
-The following task properties can be set.
-
-| Field | Description |
-| ---------- |---------------------------------------------------------------------------------------------------|
-|`id`| The flow identifier, must be unique inside a flow. |
-|`type`| The Java FQCN of the task. |
-|`description`| The description of the task, more details [here](./01.flow.md#document-your-flow). |
-|`retry`| Task retry behavior, more details [here](./07.errors-handling.md#retries). |
-|`timeout`| Task timeout expressed in [ISO 8601 Durations](https://en.wikipedia.org/wiki/ISO_8601#Durations). |
-|`disabled`| Set it to `true` to disable execution of the task. |
-|`workerGroup.key`|To execute this task on a specific [Worker Group (EE)](../01.architecture.md#worker-group-ee).|
-|`logLevel`| To define the log level granularity for which logs will be inserted into the backend database. By default, all logs are stored. However, if you restrict that to e.g., the `INFO` level, all lower log levels such as `DEBUG` and TRACE won't be persisted. |
-| `allowFailure` | Boolean flag allowing to continue the execution even if this task fails. |
-
-
-Task properties can be static or dynamic. Dynamic task properties can be set using [variables](./03.variables/01.index.md). To know if a task property is dynamic, read the task's documentation.
-
-
-## Flowable Tasks
-
-In Kestra, we orchestrate your workflows using **Flowable Tasks**. These tasks do not compute anything but allow us to build more complex workflows.
+Kestra orchestrates your flows using **Flowable Tasks**. These tasks do not perform any heavy computation. Instead, they control the orchestration behavior, allowing you to implement more advanced workflow patterns.
Flowable Tasks are used for branching, grouping, doing tasks in parallel, etc...
-Flowable Tasks use context [variables](./03.variables/01.index.md) to define the next tasks to run. For example, you can use the [outputs](./05.outputs.md) of a previous task in a `Switch` task to decide which task to run next.
+Flowable Tasks use context [variables](./expression/01.index.md) to define the next tasks to run. For example, you can use the [outputs](./outputs.md) of a previous task in a `Switch` task to decide which task to run next.
### Sequential
@@ -68,7 +32,7 @@ tasks:
```
::alert{type="info"}
-You can access the output of a sibling task with `{{outputs.sibling.value}}`, see [Lookup in sibling tasks](./05.outputs.md#lookup-in-sibling-tasks)
+You can access the output of a sibling task with `{{outputs.sibling.value}}`, see [Lookup in sibling tasks](./outputs.md#lookup-in-sibling-tasks)
::
::next-link
@@ -213,7 +177,7 @@ tasks:
```
::alert{type="info"}
-You can access the output of a sibling task with `{{outputs.sibling[taskrun.value].value}}`, see [Lookup in sibling tasks](./05.outputs.md#lookup-in-sibling-tasks)
+You can access the output of a sibling task with `{{outputs.sibling[taskrun.value].value}}`, see [Lookup in sibling tasks](./outputs.md#lookup-in-sibling-tasks)
::
@@ -281,7 +245,7 @@ Syntax:
```
This will execute the subflow `dev.subflow` for each batch of items.
-To pass the batch of items to a subflow, you can use [inputs](../04.inputs.md). The example above uses an input of `FILE` type called `file` that takes the URI of an internal storage file containing the batch of items.
+To pass the batch of items to a subflow, you can use [inputs](../inputs.md). The example above uses an input of `FILE` type called `file` that takes the URI of an internal storage file containing the batch of items.
::next-link
[ForEachItem Task documentation](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.ForEachItem.md)
@@ -444,7 +408,7 @@ tasks:
This task will trigger another flow. This allows you to decouple the first flow from the second and monitor each flow individually.
-You can pass flow [outputs](./05.outputs.md) as [inputs](./04.inputs.md) for the triggered subflow (those must be declared in the subflow).
+You can pass flow [outputs](./outputs.md) as [inputs](./inputs.md) for the triggered subflow (those must be declared in the subflow).
```yaml
id: subflow
@@ -591,7 +555,7 @@ For this: go to the **Gantt** tab of the **Execution** page, click on the task,
### Template
-[Templates](./09.templates.md) are lists of tasks that can be shared between flows. You can define a template and call it from other flows, allowing them to share a list of tasks and keep these tasks updated without changing your flow.
+[Templates](./templates.md) are lists of tasks that can be shared between flows. You can define a template and call it from other flows, allowing them to share a list of tasks and keep these tasks updated without changing your flow.
The following example uses the Template task to use a template.
@@ -610,5 +574,3 @@ tasks:
::next-link
[Template Task documentation](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Template.md)
::
-
-
diff --git a/content/docs/03.concepts/index.md b/content/docs/03.concepts/index.md
index 8543b92e42..c3969c45cb 100644
--- a/content/docs/03.concepts/index.md
+++ b/content/docs/03.concepts/index.md
@@ -5,20 +5,20 @@ title: 💡 Concepts
Understanding key concepts is crucial for harnessing the full potential of any tool. In this section, we will explore the fundamental concepts of Kestra, enabling you to automate your processes efficiently. For detailed information on each concept, please refer to the corresponding pages.
-[**Flow**](./01.flows.md): A flow is a sequence of tasks.
+[**Flow**](./flow.md): A flow is a sequence of tasks.
-[**Task**](./01.flows.md#task): A task represents a discrete action within a flow. Each task can have properties, utilize inputs from the flow, consume outputs generated by other tasks, execute specific actions, and produce outputs for subsequent tasks to consume.
+[**Task**](./tasks.md): A task represents a discrete action within a flow. Each task can have properties, utilize inputs from the flow, consume outputs generated by other tasks, execute specific actions, and produce outputs for subsequent tasks to consume.
-[**Namespace**](./01.flows.md#namespace): A namespace is a way to organize your flows.
+[**Namespace**](./namespace.md): A namespace is a way to organize your flows.
-[**Execution**](./02.executions.md): An execution refers to a single run of a flow.
+[**Execution**](./execution.md): An execution refers to a single run of a flow.
-[**Task Run**](./02.executions.md#task-run): A task run denotes the execution of an individual task within a flow.
+[**Task Run**](./execution.md#task-run): A task run denotes the execution of an individual task within a flow.
-[**Variables**](./03.storage.md#variables): Kestra allows you to utilize variables and process them using the [integrated Pebble language](../05.developer-guide/03.variables/01.index.md). Variables enable dynamic values, configurations, or computed results to be passed between tasks within a flow.
+[**Internal Storage**](./internal-storage): Kestra provides an internal storage mechanism that facilitates the storage of files of arbitrary sizes within a dedicated storage area.
-[**Internal Storage**](./03.storage.md#internal-storage): Kestra provides an internal storage mechanism that facilitates the storage of files of arbitrary sizes within a dedicated storage area.
+[**Expressions**](./expression/01.index.md): Kestra allows you to utilize variables and process them using the [integrated Pebble language](../03.concepts/expression/01.index.md). Variables enable dynamic values, configurations, or computed results to be passed between tasks within a flow.
-For more detailed explanations on these core concepts, please refer to the following pages:
+For a more detailed explanation on all main concepts, please refer to the following pages:
-
\ No newline at end of file
+
diff --git a/content/docs/03.concepts/indexer.md b/content/docs/03.concepts/indexer.md
new file mode 100644
index 0000000000..e0edf9bd8a
--- /dev/null
+++ b/content/docs/03.concepts/indexer.md
@@ -0,0 +1,5 @@
+---
+title: Indexer
+---
+
+The **Indexer** is an optional component only needed when using Kafka and Elasticsearch. It will watch for many Kafka topics (like flows and executions) and will index their content to Elasticsearch [Repositories](#the-repository).
\ No newline at end of file
diff --git a/content/docs/05.developer-guide/04.inputs.md b/content/docs/03.concepts/inputs.md
similarity index 96%
rename from content/docs/05.developer-guide/04.inputs.md
rename to content/docs/03.concepts/inputs.md
index 19af91eb40..a18cb4ddb9 100644
--- a/content/docs/05.developer-guide/04.inputs.md
+++ b/content/docs/03.concepts/inputs.md
@@ -80,7 +80,7 @@ Here is the list of supported data types:
- `JSON`: Must be a valid JSON string and will be converted to a typed form.
- `URI`: Must be a valid URI and will be kept as a string.
-All inputs of type `FILE` will be automatically uploaded to Kestra's [internal storage](../01.architecture.md#the-internal-storage) and accessible to all tasks. After the upload, the input variable will contain a fully qualified URL of the form `kestra:///.../.../` that will be automatically managed by Kestra and can be used as-is within any task.
+All inputs of type `FILE` will be automatically uploaded to Kestra's [internal storage](../03.concepts/internal-storage.md) and accessible to all tasks. After the upload, the input variable will contain a fully qualified URL of the form `kestra:///.../.../` that will be automatically managed by Kestra and can be used as-is within any task.
## Input Properties
@@ -182,7 +182,7 @@ inputs:
required: true
```
-You can use the value of the input `my-string` inside dynamic task properties with `{{ inputs['my-string'] }}`. See [variables basic usage](./03.variables/02.basic-usage.md).
+You can use the value of the input `my-string` inside dynamic task properties with `{{ inputs['my-string'] }}`. See more in the [using expressions](./expression/02b.using-expressions.md) section.
## Set input values at flow execution
diff --git a/content/docs/03.concepts/internal-storage.md b/content/docs/03.concepts/internal-storage.md
new file mode 100644
index 0000000000..08e415cee9
--- /dev/null
+++ b/content/docs/03.concepts/internal-storage.md
@@ -0,0 +1,22 @@
+---
+title: Internal Storage
+---
+
+Kestra uses an **Internal Storage** to handle incoming and outgoing files of varying sizes. This notion is included in the heart of Kestra. Nowadays, storage availability is backed up by many file systems. We rely on these to guarantee the scalability of Kestra. The *Kestra Internal Storage* will store all the files generated by all tasks and transmit them between different tasks if needed.
+
+By default, only the local storage is available. It uses a directory inside the host filesystem, so it is not scalable and not designed for production usage.
+
+More implementations are available as plugins.
+
+You can replace the local storage with one of the following storage implementations:
+- [Storage Minio](https://github.com/kestra-io/storage-minio) for [Minio](https://min.io/), which is compatible with [AWS S3](https://aws.amazon.com/s3/) and all other *S3 Like* storage.
+- [Storage GCS](https://github.com/kestra-io/storage-gcs) for [Google Cloud Storage](https://cloud.google.com/storage).
+- [Storage Azure](https://github.com/kestra-io/storage-azure) for [Azure Blob Storage](https://azure.microsoft.com/en-us/services/storage/blobs/).
+
+Kesta's internal storage allows storing arbitrary-sized files inside a dedicated storage area.
+
+If an output attribute is stored inside the internal storage, it will be retrievable from a variable named `{{ outputs.task_id.output_attribute }}`. Kestra will automatically fetch the file when the variable is used.
+
+Inputs of type `FILE` will be automatically stored inside the internal storage.
+
+On the **Outputs** tab of an execution, if an output attribute is from the internal storage, there will be a link to download it.
diff --git a/content/docs/03.concepts/labels.md b/content/docs/03.concepts/labels.md
new file mode 100644
index 0000000000..a728136f37
--- /dev/null
+++ b/content/docs/03.concepts/labels.md
@@ -0,0 +1,5 @@
+---
+title: Labels
+---
+
+You can add arbitrary `labels` to your flows to sort them on multiple dimensions. When you execute such flow, the labels will be propagated to the created execution. It is also possible to override and define new labels at flow execution start.
diff --git a/content/docs/05.developer-guide/13.listeners.md b/content/docs/03.concepts/listeners.md
similarity index 81%
rename from content/docs/05.developer-guide/13.listeners.md
rename to content/docs/03.concepts/listeners.md
index ddd955ece6..564119a3e5 100644
--- a/content/docs/05.developer-guide/13.listeners.md
+++ b/content/docs/03.concepts/listeners.md
@@ -37,7 +37,7 @@ listeners:
* **SubType:** ==Condition==
* **Required:** ❌
-> A list of [Conditions](./11.conditions.md) that must be validated in order to execute the listener `tasks`. If you don't provide any conditions, the listeners will always be executed.
+> A list of [Conditions](conditions.md) that must be validated in order to execute the listener `tasks`. If you don't provide any conditions, the listeners will always be executed.
### `tasks`
* **Type:** ==array==
@@ -46,7 +46,7 @@ listeners:
> A list of tasks that will be executed at the end of the flow. The status of these tasks will not impact the main execution and will not change the execution status even if they fail.
>
-> You can use every tasks you need here, even [Flowable](./02.tasks.md#flowable-tasks).
+> You can use every tasks you need here, even Flowable.
> All task `id` must be unique for the whole flow even for main `tasks` and `errors`.
@@ -54,4 +54,4 @@ listeners:
* **Type:** ==string==
* **Required:** ❌
-> Description for documentation, more details [here](./01.flow.md#document-your-flow).
+> Description for documentation.
diff --git a/content/docs/03.concepts/multi-tenancy.md b/content/docs/03.concepts/multi-tenancy.md
new file mode 100644
index 0000000000..632adc5f55
--- /dev/null
+++ b/content/docs/03.concepts/multi-tenancy.md
@@ -0,0 +1,27 @@
+---
+title: Multi-tenancy
+---
+
+## What is multi-tenancy
+Multi-tenancy is a software architecture in which a single instance of software serves multiple tenants. You can think of it as running multiple virtual instances in a single physical instance.
+
+Multi-tenancy is available only in the **[Enterprise Edition](/enterprise)**.
+
+## Benefits of multi-tenancy
+Multi-tenancy allows you to manage **multiple environments** (e.g., dev, staging, prod) in a single Kestra instance. You can also use it to **separate resources** between business units, teams, or customers.
+
+## How does multi-tenancy work in Kestra
+By default, multi-tenancy is disabled. See the [multi-tenancy section](../09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md) of the Administrator Guide on how to configure it.
+
+When multi-tenancy is enabled, all resources (such as flows, triggers, executions, RBAC, and more) are isolated by the tenant. This means that you can have a flow with the same identifier and the same namespace in multiple tenants at the same time.
+
+Data stored inside the internal storage is also isolated by tenants.
+
+Multi-tenancy functionality is not visible to end-users from the UI except for the tenant selection dropdown menu. That dropdown menu lists all tenants a user has access to, allowing users to switch between tenants easily. Each UI page will also include the tenant ID in the URL e.g. `https://demo.kestra.io/ui/yourTenantId/executions/namespace/flow/executionId`.
+
+
+
+The API URLs will also change to include the tenant identifier.
+For example, the URL of the API operation to list flows of the `products` namespace is `/api/v1/flows/products` when multi-tenancy is not enabled, and becomes `/api/v1/production/flows/products` for the `production` tenant when multi-tenancy is enabled. You can check the [Enterprise Edition API Guide](../12.api-guide/api-ee-guide.md) for more information.
+
+Tenants must be created upfront, and a user needs to be granted access to use a specific tenant.
\ No newline at end of file
diff --git a/content/docs/03.concepts/namespace.md b/content/docs/03.concepts/namespace.md
new file mode 100644
index 0000000000..1564824e3c
--- /dev/null
+++ b/content/docs/03.concepts/namespace.md
@@ -0,0 +1,19 @@
+---
+title: Namespace
+---
+
+You can think of a namespace as a **folder for your flows**.
+
+- Similar to folders on your file system, namespaces can be used to organize flows into logical categories.
+- And as filesystems, namespaces can be indefinitely nested.
+Using the dot `.` symbol, you can add hierarchical structure to your flow organization.
+This allows to separate not only environments, but also projects, teams and departments.
+
+This way, your **product, engineering, marketing, finance, and data teams** can all use the same Kestra instance, while keeping their flows organized and separated. They all can have their own namespaces that belong to a parent namespace indicating the **development** or **production** environment.
+
+A namespace is like a folder for flows. A namespace is composed of words and letters separated by `.`. The hierarchy depth for namespaces is unlimited. Here are some examples of namespaces:
+- `projectOne`
+- `com.projectTwo`
+- `test.projectThree.folder`
+
+Namespaces are hierarchical, which means that for our previous example, the `test.projectThree.folder` namespace is inside the `test.projectThree` namespace.
diff --git a/content/docs/05.developer-guide/05.outputs.md b/content/docs/03.concepts/outputs.md
similarity index 80%
rename from content/docs/05.developer-guide/05.outputs.md
rename to content/docs/03.concepts/outputs.md
index 4562262901..561f8f5e11 100644
--- a/content/docs/05.developer-guide/05.outputs.md
+++ b/content/docs/03.concepts/outputs.md
@@ -6,7 +6,7 @@ A flow can produce outputs when processing tasks. Outputs are stored in the exec
Outputs can have multiple attributes; please refer to the documentation of each task to see their output attributes.
-You can use outputs everywhere [variables](./03.variables/01.index.md) are allowed.
+You can use outputs everywhere [variables](./expression/01.index.md) are allowed.
## Using outputs
@@ -26,23 +26,22 @@ tasks:
In the example above, the first task produces an output based on the task property `format`. This output attribute is then used in the second task `message` property.
-The `use-output` task uses the templating system `{{ outputs['produce-output'].value }}` to reference the previous task output attribute. If you're not familiar with the syntax used here, please read [variables basic usage](./03.variables/02.basic-usage.md).
+The expression `{{ outputs['produce-output'].value }}` references the previous task output attribute. You can read more about the expression syntax on the [Using Expressions](./expression/02b.using-expressions.md) page.
::alert{type="info"}
-In the example above, the **Return** task produces an output attributes `value`. Every task produces different output attributes. You can look at each task outputs documentation or use the **Outputs** tab of the **Executions** page to know about specific task output attributes.
+In the example above, the **Return** task produces an output attribute `value`. Every task produces different output attributes. You can look at each task outputs documentation or use the **Outputs** tab of the **Executions** page to find out about specific task output attributes.
::
## Storage variables
-Each task can store data in Kestra's internal storage. If an output attribute is stored in the internal storage, the attribute will contain a URI that points to a file in the internal storage.
+Each task can store data in Kestra's internal storage. If an output attribute is stored in internal storage, the attribute will contain a URI that points to a file in the internal storage. This output attribute could be used by other tasks to access the stored data.
-This output attribute could be used by other tasks to access the stored data, Kestra will automatically make it accessible.
-
-The following example store the result of a BigQuery query in the internal storage, then access it in the `write-to-csv` task:
+The following example stores the query results in internal storage, then accesses it in the `write-to-csv` task:
```yaml
+id: output-sample
+namespace: dev
tasks:
-
- id: output-from-query
type: io.kestra.plugin.gcp.bigquery.Query
sql: |
@@ -57,9 +56,9 @@ tasks:
from: "{{outputs['output-from-query'].uri}}"
```
-## Dynamic variables (Each loop)
+## Dynamic variables (Each tasks)
-#### Current taskrun value
+### Current taskrun value
In dynamic flows (using "Each" loops for example), variables will be passed to task dynamically. You can access the current taskrun value with `{{ taskrun.value }}` like this:
@@ -74,9 +73,9 @@ tasks:
format: "{{task.id}} > {{taskrun.value}} > {{taskrun.startDate}}"
```
-#### Loop over object
+### Loop over object
-On loop, the `value` is always a JSON string, so the `{{ taskrun.value }}` is the current element as JSON string. If you want to access properties, you need to use the [json function](./03.variables/04.function/json.md) to have a proper object and to access each property easily.
+On loop, the `value` is always a JSON string, so the `{{ taskrun.value }}` is the current element as JSON string. If you want to access properties, you need to use the [json function](./expression/04.function/json.md) to have a proper object and to access each property easily.
```yaml
tasks:
@@ -119,7 +118,7 @@ tasks:
The `outputs.sub.s1.value` variable reaches the `value` of the `sub` task of the `s1` iteration.
-#### Previous task lookup
+### Previous task lookup
It is also possible to locate a specific dynamic task by its `value`:
@@ -139,7 +138,7 @@ tasks:
It uses the format `outputs.TASKID[VALUE].ATTRIBUTE`. The special bracket `[]` in `[VALUE]` is called the subscript notation; it enables using special chars like space or '-' in task identifiers or output attributes.
-#### Lookup in sibling tasks
+### Lookup in sibling tasks
Sometimes, it can be useful to access previous outputs on the current task tree, what is called sibling tasks.
@@ -167,7 +166,7 @@ tasks:
When there are multiple levels of [EachSequential](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachSequential.md) tasks, you can use the `parents` variable to access the `taskrun.value` of the parent of the current EachSequential. For example, for two levels of EachSequential you can use `outputs.sibling[parents[0].taskrun.value][taskrun.value].value`.
-The latter can become very complex when parents exist (multiple imbricated EachSequential). For this, you can use the special [currentEachOutput](./03.variables/04.function/currentEachOutput.md) function. No matter the number of parents, the following example will retrieve the correct output attribute: `currentEachOutput(outputs.sibling).value` thanks to this function.
+The latter can become very complex when parents exist (multiple imbricated EachSequential). For this, you can use the special [currentEachOutput](./expression/04.function/currentEachOutput.md) function. No matter the number of parents, the following example will retrieve the correct output attribute: `currentEachOutput(outputs.sibling).value` thanks to this function.
::alert{type="warning"}
Accessing sibling task outputs is impossible on [Parallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Parallel.md) or [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) as they run tasks in parallel.
diff --git a/content/docs/03.concepts/retries.md b/content/docs/03.concepts/retries.md
new file mode 100644
index 0000000000..3eb1cf3233
--- /dev/null
+++ b/content/docs/03.concepts/retries.md
@@ -0,0 +1,111 @@
+---
+title: Retries
+---
+
+## What are retries
+
+Kestra provides a task retry functionality. This makes it possible to add retry behavior for any **failed task run** based on configurations in the flow description.
+
+A retry on a task run will create a new task run attempt.
+
+### Example
+
+The following example defines a retry for the `retry-sample` task with a maximum of 5 attempts every 15 minutes:
+
+```yaml
+- id: retry-sample
+ type: io.kestra.core.tasks.log.Log
+ message: my output for task {{task.id}}
+ timeout: PT10M
+ retry:
+ maxAttempt: 5
+ type: constant
+ interval: PT15M
+```
+
+### Retry options for all retry types
+
+| name | type | description |
+| ---------- | ----------- | ----------- |
+|`type`|`string`|Retry behavior to apply. Can be one of `constant`, `exponential`, `random`.|
+|`maxAttempt`|`integer`|Number of retries performed before the system stops retrying.|
+|`maxDuration`|`Duration`|Maximum delay the execution is retried. Once passed, the task is no more processed.|
+|`warningOnRetry`|`Boolean`|Flag the execution as warning if any retry was done on this task. Default `false`.|
+
+### Duration
+
+Some options above have to be filled with a duration notation.
+Durations are expressed in [ISO 8601 Durations](https://en.wikipedia.org/wiki/ISO_8601#Durations), here are some examples:
+
+| name | description |
+| ---------- | ----------- |
+|PT0.250S|250 milliseconds delay|
+|PT2S|2 seconds delay|
+|PT1M|1 minute delay|
+|PT3.5H|3 hours and a half delay|
+
+---
+
+## Retry types
+
+
+### `constant`
+This establishes constant retry times: if the `interval` property is set to 10 minutes, it retries every 10 minutes.
+
+| name | type | description |
+| ---------- | ----------- | ----------- |
+|`interval`|`Duration`|Duration between each retry.|
+
+### `exponential`
+This establishes retry behavior that waits longer between each retry e.g. 1s, 5s, 15s, ...
+
+| name | type | description |
+| ---------- | ----------- | ----------- |
+|`interval`|`Duration`|Duration between each retry.|
+|`maxInterval`|`Duration`|Max Duration between each retry.|
+|`delayFactor`|`Double`|Multiplier for the `interval` on between retry, default is 2. For example, with an interval of 30s and a delay factor of 2, retry will append at 30s, 1m30, 3m30, ... |
+
+### `random`
+This establishes retries with a random delay within minimum and maximum limits.
+
+| name | type | description |
+| ---------- | ----------- | ----------- |
+|`minInterval`|`Duration`|Minimal duration between each retry.|
+|`maxInterval`|`Duration`|Maximum duration between each retry.|
+
+---
+
+## Retry vs. Restart vs. Replay
+
+### Automatic vs. manual
+**Retries** ensure that failed task runs are *automatically* rerun within the *same Execution*. Apart from retries, defined within your flow code, you can also *manually* rerun the flow from the Flow Execution page in the UI using the **Restart** or **Replay** buttons.
+
+
+
+### Restart vs. Replay
+While **Restart** will rerun failed tasks within the current Execution (*i.e., without creating a new execution*), a **Replay** would result in a completely new run with a different Execution ID than the initial run.
+
+
+
+When you replay an Execution, a new execution gets created for the same flow. However, you can still track which Execution triggered this new run thanks to the `Original Execution` field:
+
+
+
+Replay can be executed from any task, even if that task executed successfully.
+But note that when you trigger a replay from a specific failed task, it will still result in a new Execution running all tasks downstream of your chosen start task:
+
+
+
+When you want to rerun only failed tasks, use `Restart`.
+
+
+### Summary: Retries vs. Restart vs. Replay
+
+The table below summarizes the differences between a retry, restart and replay.
+
+| Concept | Flow or task level | Automatic or manual | Does it create a new execution? |
+| --- | --- | --- | --- |
+| Retry | Task level | Automatic | No, it only reruns a given task within the same Execution. Each retry results in a new attempt number, allowing you to see how many times a given task run was retried. |
+| Restart | Flow level | Manual | No, it only reruns all failed tasks within the same Execution. It's meant to handle unanticipated, transient failures. The UI shows a new attempt number for all task runs that were restarted. |
+| Replay | Either flow or task level | Manual | Yes. You can pick an arbitrary step from which a new execution should be triggered. If you select a task in the middle that needs outputs from a previous task, its output is retrieved from cache. |
+
diff --git a/content/docs/03.concepts/runnable-tasks.md b/content/docs/03.concepts/runnable-tasks.md
new file mode 100644
index 0000000000..f1be34dd88
--- /dev/null
+++ b/content/docs/03.concepts/runnable-tasks.md
@@ -0,0 +1,13 @@
+---
+title: Runnable Tasks
+---
+
+Runnable tasks handle computational work in the flow. For example, file system operations, API calls, database queries, etc. These tasks can be compute-intensive and are handled by [workers](worker.md).
+
+Each task must have an identifier (id) and a type. The type is the task's Java Fully Qualified Class Name (FQCN).
+
+Tasks have properties specific to the type of the task; check each task's documentation for the list of available properties.
+
+Most available tasks are Runnable Tasks except special ones that are [Flowable Tasks](flowable-tasks.md); those are explained later on this page.
+
+By default, Kestra only includes a few Runnable Tasks. However, many of them are available as [plugins](../../plugins/index.md), and if you use our default Docker image, plenty of them will already be included.
\ No newline at end of file
diff --git a/content/docs/03.concepts/scheduler.md b/content/docs/03.concepts/scheduler.md
new file mode 100644
index 0000000000..92e1a4b98d
--- /dev/null
+++ b/content/docs/03.concepts/scheduler.md
@@ -0,0 +1,15 @@
+---
+title: Scheduler
+---
+
+The **Scheduler** will handle most of the [Triggers](triggers/index.md) except the [Flow Triggers](triggers/flow-trigger.md) which are handled by the Executor. It will continuously watch all the triggers and, if all conditions are met, will start an execution of the flow (submit the flow to the Executor).
+
+In the case of polling triggers, the Scheduler will decide (based on the configured evaluation interval) whether to execute the flow. If the polling trigger conditions are met, the Scheduler will send the execution, along with the trigger metadata, to the Worker for execution.
+
+Note that polling triggers cannot be evaluated concurrently. They also can't be reevaluated i.e. if the execution of a flow, which started as a result of the same trigger, is already in a Running state, the next execution will not be started until the previous one finishes.
+
+Internally, the Scheduler will keep checking every second whether some trigger must be evaluated.
+
+::alert{type="warning"}
+By default, Kestra will handle all dates based on your system timezone. You can change the timezone with [JVM options](../09.administrator-guide/01.configuration/05.others.md#jvm-configuration).
+::
\ No newline at end of file
diff --git a/content/docs/05.developer-guide/10.secrets.md b/content/docs/03.concepts/secret.md
similarity index 93%
rename from content/docs/05.developer-guide/10.secrets.md
rename to content/docs/03.concepts/secret.md
index fa9e0f6f7a..0c02de1e38 100644
--- a/content/docs/05.developer-guide/10.secrets.md
+++ b/content/docs/03.concepts/secret.md
@@ -1,10 +1,10 @@
---
-title: Managing Secrets
+title: Secret
---
-Your [flows](./1.flow.md) often need to interact with external systems. To do that, they need to programmatically authenticate using passwords or API keys. Secrets help you securely store such variables and avoid hard-coding sensitive information within your workflow code.
+Your [flows](flow.md) often need to interact with external systems. To do that, they need to programmatically authenticate using passwords or API keys. Secrets help you securely store such variables and avoid hard-coding sensitive information within your workflow code.
-You can leverage the `secret()` function, described in the [function section](./03.variables/04.function/secret.md), to retrieve sensitive variables within your flow code.
+You can leverage the `secret()` function, described in the [function section](./expression/04.function/secret.md), to retrieve sensitive variables within your flow code.
## Secrets in the Open-Source version
diff --git a/content/docs/05.developer-guide/01b.subflows.md b/content/docs/03.concepts/subflows.md
similarity index 100%
rename from content/docs/05.developer-guide/01b.subflows.md
rename to content/docs/03.concepts/subflows.md
diff --git a/content/docs/03.concepts/task-defaults.md b/content/docs/03.concepts/task-defaults.md
new file mode 100644
index 0000000000..76ed89d34b
--- /dev/null
+++ b/content/docs/03.concepts/task-defaults.md
@@ -0,0 +1,63 @@
+---
+title: Task defaults
+---
+
+The `taskDefaults` property is a list of default task properties that will be applied to each task of a certain type within your flow. Task defaults can help avoid repeating the same value for a task property in case the same task type is used multiple times in the same flow.
+
+You can add task defaults to avoid repeating task properties on multiple occurrences of the same task in a `taskDefaults` properties. For example:
+
+```yaml
+id: api_python_sql
+namespace: dev
+
+tasks:
+ - id: api
+ type: io.kestra.plugin.fs.http.Request
+ uri: https://dummyjson.com/products
+
+ - id: hello
+ type: io.kestra.plugin.scripts.python.Script
+ docker:
+ image: python:slim
+ script: |
+ print("Hello World!")
+
+ - id: python
+ type: io.kestra.plugin.scripts.python.Script
+ docker:
+ image: python:slim
+ beforeCommands:
+ - pip install polars
+ warningOnStdErr: false
+ script: |
+ import polars as pl
+ data = {{outputs.api.body | jq('.products') | first}}
+ df = pl.from_dicts(data)
+ df.glimpse()
+ df.select(["brand", "price"]).write_csv("{{outputDir}}/products.csv")
+
+ - id: sql_query
+ type: io.kestra.plugin.jdbc.duckdb.Query
+ inputFiles:
+ in.csv: "{{ outputs.python.outputFiles['products.csv'] }}"
+ sql: |
+ SELECT brand, round(avg(price), 2) as avg_price
+ FROM read_csv_auto('{{workingDir}}/in.csv', header=True)
+ GROUP BY brand
+ ORDER BY avg_price DESC;
+ store: true
+
+taskDefaults:
+ - type: io.kestra.plugin.scripts.python.Script
+ values:
+ runner: DOCKER
+ docker:
+ image: python:slim
+ pullPolicy: ALWAYS # set it to NEVER to use a local image
+```
+
+Here, we avoid repeating Docker and Python configurations in each task by directly setting those within the `taskDefaults` property. This approach helps to streamline the configuration process and reduce the chances of errors caused by inconsistent settings across different tasks.
+
+Note that when you move some required task attributes into the `taskDefaults` property, the code editor within the UI will complain that the required task argument is missing. The editor shows this message because `taskDefaults` are resolved at runtime and the editor is not aware of those default attributes until you run your flow. As long as `taskDefaults` contains the relevant arguments, you can save the flow and ignore the warning displayed in the editor.
+
+
\ No newline at end of file
diff --git a/content/docs/03.concepts/tasks.md b/content/docs/03.concepts/tasks.md
new file mode 100644
index 0000000000..74e330189d
--- /dev/null
+++ b/content/docs/03.concepts/tasks.md
@@ -0,0 +1,35 @@
+---
+title: Tasks
+---
+
+
+## Flowable Tasks
+
+Kestra orchestrates your flows using [Flowable Tasks](flowable-tasks.md). These tasks do not perform any heavy computation. Instead, they control the orchestration behavior, allowing you to implement more advanced workflow patterns.
+
+## Runnable Tasks
+
+In Kestra, most data processing workloads are executed using [Runnable Tasks](runnable-tasks.md).
+
+In contrast to Flowable Tasks, Runnable Tasks are responsible for performing the actual work. For example, file system operations, API calls, database queries, etc. These tasks can be compute-intensive and are handled by [workers](../03.concepts/worker.md).
+
+### Task common properties
+
+The following task properties can be set.
+
+| Field | Description |
+| ---------- |-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+|`id`| The flow identifier, must be unique inside a flow. |
+|`type`| The Java FQCN of the task. |
+|`description`| The description of the task, more details [here](flow.md#document-your-flow). |
+|`retry`| Task retry behavior, more details [here](retries.md). |
+|`timeout`| Task timeout expressed in [ISO 8601 Durations](https://en.wikipedia.org/wiki/ISO_8601#Durations). |
+|`disabled`| Set it to `true` to disable execution of the task. |
+|`workerGroup.key`| To execute this task on a specific [Worker Group (EE)](worker-group.md). |
+|`logLevel`| To define the log level granularity for which logs will be inserted into the backend database. By default, all logs are stored. However, if you restrict that to e.g., the `INFO` level, all lower log levels such as `DEBUG` and TRACE won't be persisted. |
+| `allowFailure` | Boolean flag allowing to continue the execution even if this task fails. |
+
+
+Task properties can be static or dynamic. Dynamic task properties can be set using [epressions](./expression/01.index.md). To know if a task property is dynamic, check the task documentation embedded in the UI.
+
+
diff --git a/content/docs/05.developer-guide/09.templates.md b/content/docs/03.concepts/templates.md
similarity index 100%
rename from content/docs/05.developer-guide/09.templates.md
rename to content/docs/03.concepts/templates.md
diff --git a/content/docs/05.developer-guide/08.triggers/02.flow.md b/content/docs/03.concepts/triggers/flow-trigger.md
similarity index 95%
rename from content/docs/05.developer-guide/08.triggers/02.flow.md
rename to content/docs/03.concepts/triggers/flow-trigger.md
index 042018a61f..d7d5f7a2a4 100644
--- a/content/docs/05.developer-guide/08.triggers/02.flow.md
+++ b/content/docs/03.concepts/triggers/flow-trigger.md
@@ -2,7 +2,6 @@
title: Flow trigger
---
-
```yaml
type: "io.kestra.core.models.triggers.types.Flow"
```
@@ -74,9 +73,9 @@ triggers:
Check the [Flow trigger](../../../plugins/core/triggers/io.kestra.core.models.triggers.types.Flow.md) documentation for the list of all properties.
-## Variables
+## Expressions
-When another flow triggers the flow, some context variables will be injected to allow flow customization.
+When another flow triggers the flow, you'll additionally see the following execution context expressions:
| Parameter | Description |
| ---------- | ----------- |
diff --git a/content/docs/05.developer-guide/08.triggers/index.md b/content/docs/03.concepts/triggers/index.md
similarity index 68%
rename from content/docs/05.developer-guide/08.triggers/index.md
rename to content/docs/03.concepts/triggers/index.md
index da8a3e0212..00467be570 100644
--- a/content/docs/05.developer-guide/08.triggers/index.md
+++ b/content/docs/03.concepts/triggers/index.md
@@ -6,9 +6,9 @@ Kestra supports both **scheduled** and **external** events.
Kestra core provides three types of triggers:
-* [Schedule trigger](./01.schedule.md) allows you to execute your flow on a regular cadence e.g. using a CRON expression and custom scheduling conditions
-* [Flow trigger](./02.flow.md) allows you to execute your flow when another flow finishes its execution (based on a configurable list of states)
-* [Webhook trigger](./03.webhook.md) allows you to execute your flow based on an HTTP request emitted by a webhook.
+* [Schedule trigger](schedule-trigger.md) allows you to execute your flow on a regular cadence e.g. using a CRON expression and custom scheduling conditions
+* [Flow trigger](flow-trigger.md) allows you to execute your flow when another flow finishes its execution (based on a configurable list of states)
+* [Webhook trigger](webhook-trigger.md) allows you to execute your flow based on an HTTP request emitted by a webhook.
Many other triggers are available from the plugins, such as triggers based on file detection events, e.g. the [S3 trigger](https://kestra.io/plugins/plugin-aws/triggers/s3/io.kestra.plugin.aws.s3.trigger), or a new message arrival in a message queue, such as the [SQS](https://kestra.io/plugins/plugin-aws/triggers/sqs/io.kestra.plugin.aws.sqs.trigger) or [Kafka trigger](https://kestra.io/plugins/plugin-kafka/triggers/io.kestra.plugin.kafka.trigger).
@@ -16,24 +16,24 @@ Many other triggers are available from the plugins, such as triggers based on fi
Following trigger properties can be set.
-| Field | Description |
-| ----- |------------------------------------------------------------------------------------------------------|
-|`id`| The flow identifier, must be unique inside a flow. |
-|`type`| The Java FQDN of the trigger. |
-|`description`| The description of the trigger, more details [here](../01.flow.md#document-your-flow). |
-|`disabled`| Set it to `true` to disable execution of the trigger. |
-|`workerGroup.key`| To execute this trigger on a specific [Worker Group (EE)](../../01.architecture.md#worker-group-ee). |
+| Field | Description |
+| ----- |--------------------------------------------------------------------------------------------|
+|`id`| The flow identifier, must be unique inside a flow. |
+|`type`| The Java FQDN of the trigger. |
+|`description`| The description of the trigger. |
+|`disabled`| Set it to `true` to disable execution of the trigger. |
+|`workerGroup.key`| To execute this trigger on a specific [Worker Group (EE)](../worker-group.md). |
---
## Trigger variables
-Triggers allow you to access trigger metadata through [Variables](../05.developer-guide/03.variables/01.index.md) e.g. `{{ trigger.date }}` to access the current date of the [Schedule trigger](https://kestra.io/plugins/core/triggers/io.kestra.core.models.triggers.types.schedule), `{{ trigger.uri }}` to access the file or message from any file detection or message arrival event, as well as `{{ trigger.rows }}` for all Query triggers e.g. the [PostgreSQL Query](https://kestra.io/plugins/plugin-jdbc-postgres/triggers/io.kestra.plugin.jdbc.postgresql.trigger) trigger.
+Triggers allow you to access trigger metadata through [Variables](../expression/01.index.md) e.g. `{{ trigger.date }}` to access the current date of the [Schedule trigger](https://kestra.io/plugins/core/triggers/io.kestra.core.models.triggers.types.schedule), `{{ trigger.uri }}` to access the file or message from any file detection or message arrival event, as well as `{{ trigger.rows }}` for all Query triggers e.g. the [PostgreSQL Query](https://kestra.io/plugins/plugin-jdbc-postgres/triggers/io.kestra.plugin.jdbc.postgresql.trigger) trigger.
::alert{type="warning"}
Note that the above-mentioned **templated variables** are only available when the execution is created **automatically** by the trigger. You'll get an error if you try to run a flow containing such variables **manually**.
-Also, note that **you don't need an extra task to consume** the file or message from the event. Kestra downloads those automatically to the **internal storage** and makes those available in your flow using `{{ trigger.uri }}` variable. Therefore, you don't need any additional task to e.g. consume a message from the SQS queue or to download a file from S3 when using those event triggers. The trigger already consumes and downloads those, making them directly available for further processing. Check the documentation of a specific trigger and [Blueprints](../04.user-interface-guide/blueprints.md) with the **Trigger** tag for more details and examples.
+Also, note that **you don't need an extra task to consume** the file or message from the event. Kestra downloads those automatically to the **internal storage** and makes those available in your flow using `{{ trigger.uri }}` variable. Therefore, you don't need any additional task to e.g. consume a message from the SQS queue or to download a file from S3 when using those event triggers. The trigger already consumes and downloads those, making them directly available for further processing. Check the documentation of a specific trigger and [Blueprints](../../04.user-interface-guide/blueprints.md) with the **Trigger** tag for more details and examples.
::
Triggers restrict parallel execution for a given trigger ID to one active run. For instance, if an Execution from a flow with a `Schedule` trigger with ID `hourly` is still in a `Running` state, another one will not be started. However, you can still trigger the same flow manually (from the UI or API), and the scheduled Executions will not be affected.
@@ -55,9 +55,9 @@ triggers:
The following triggers are included in Kestra core:
-* [Schedule](./01.schedule.md): to trigger a flow based on a schedule.
-* [Flow](./02.flow.md): to trigger a flow after another one.
-* [Webhook](./03.webhook.md): to trigger a flow from an HTTP request.
+* [Schedule](schedule-trigger.md): to trigger a flow based on a schedule.
+* [Flow](flow-trigger.md): to trigger a flow after another one.
+* [Webhook](webhook-trigger.md): to trigger a flow from an HTTP request.
## Polling triggers
@@ -88,4 +88,4 @@ triggers:
sql: "SELECT * FROM my_table"
```
-Polling triggers can be evaluated on a specific [Worker Group (EE)](../01.architecture.md#worker-group-ee), thanks to the `workerGroup.key` property.
+Polling triggers can be evaluated on a specific [Worker Group (EE)](../worker-group.md), thanks to the `workerGroup.key` property.
diff --git a/content/docs/05.developer-guide/08.triggers/01.schedule.md b/content/docs/03.concepts/triggers/schedule-trigger.md
similarity index 84%
rename from content/docs/05.developer-guide/08.triggers/01.schedule.md
rename to content/docs/03.concepts/triggers/schedule-trigger.md
index d12fd0a970..a4b68816aa 100644
--- a/content/docs/05.developer-guide/08.triggers/01.schedule.md
+++ b/content/docs/03.concepts/triggers/schedule-trigger.md
@@ -1,5 +1,5 @@
---
-title: Schedule
+title: Schedule trigger
---
```yaml
@@ -45,24 +45,13 @@ You can use this expression to make your **manual execution work**: `{{ trigger.
## Backfill
-Kestra will optionally handle schedule backfills. The concept of a backfill is the replay of a missed schedule because a flow was created after it should have been scheduled.
-Backfills will perform all the schedules between the defined and current dates and will start after the normal schedule.
+Kestra will optionally handle schedule [backfills](../backfill.md).
-> A schedule with a backfill.
-
-```yaml
-triggers:
- - id: schedule
- type: io.kestra.core.models.triggers.types.Schedule
- cron: "*/15 * * * *"
- backfill:
- start: 2020-06-25T14:00:00Z
-```
+## Trigger expressions
-## Variables
-When the flow is scheduled, some context variables are injected to allow flow customization (such as filename, where clause in SQL query, etc.).
+When the flow is scheduled, some context expressions are injected to allow flow customization (such as filename, where clause in SQL query, etc.).
| Parameter | Description |
|--------------------------|------------------------------------|
@@ -70,7 +59,9 @@ When the flow is scheduled, some context variables are injected to allow flow cu
| `{{ trigger.next }}` | the date of the next schedule. |
| `{{ trigger.previous }}` | the date of the previous schedule. |
+
## Schedule Conditions
+
When the `cron` is not sufficient to determine the date you want to schedule your flow, you can use `scheduleConditions` to add some additional conditions, (for example, only the first day of the month, only the weekend, ...).
You **must** use the `{{ trigger.date }}` expression on the property `date` of the current schedule.
This condition will be evaluated and `{{ trigger.previous }}` and `{{ trigger.next }}` will reflect the date **with** the conditions applied.
diff --git a/content/docs/05.developer-guide/08.triggers/03.webhook.md b/content/docs/03.concepts/triggers/webhook-trigger.md
similarity index 100%
rename from content/docs/05.developer-guide/08.triggers/03.webhook.md
rename to content/docs/03.concepts/triggers/webhook-trigger.md
diff --git a/content/docs/03.concepts/webserver.md b/content/docs/03.concepts/webserver.md
new file mode 100644
index 0000000000..63a28903eb
--- /dev/null
+++ b/content/docs/03.concepts/webserver.md
@@ -0,0 +1,14 @@
+---
+title: Webserver
+---
+
+The **Webserver** offers two main modules in the same component:
+- **API**: All the [APIs](../12.api-guide/api-oss-guide.md) that allow triggering executions for any system, and interacting with Kestra.
+- **UI**: The [User Interface](../04.user-interface-guide/index.md) (UI) is also served by the Webserver.
+
+The Webserver interacts mostly with the Repository to deliver a rich API/UI. It also interacts with the Queue to trigger new executions, follow executions in real-time, etc.
+
+
+::alert{type="info"}
+Each server component (other than the Scheduler) can continue to work as long as the Queue is up and running. The Repository is only used to help provide our rich Webserver UI, and even if the Repository is down, workloads can continue to process on Kestra.
+::
diff --git a/content/docs/03.concepts/worker-group.md b/content/docs/03.concepts/worker-group.md
new file mode 100644
index 0000000000..e1fed795cc
--- /dev/null
+++ b/content/docs/03.concepts/worker-group.md
@@ -0,0 +1,26 @@
+---
+title: Worker Group
+---
+
+
+::alert{type="warning"}
+This is an [Enterprise Edition](https://kestra.io/enterprise) feature.
+::
+
+A Worker Group is a set of workers that can be targeted specifically for a task execution or a polling trigger evaluation. For this, the task or the polling trigger must define the `workerGroup.key` property with the key of the worker group to target. A default worker group can also be configured at the namespace level.
+
+If the `workerGroup.key` property is not provided, all tasks and polling triggers are executed on the default worker group. That default worker group doesn't have a dedicated key.
+
+Here are common use cases in which Worker Groups can be beneficial:
+- Execute tasks and polling triggers on specific compute instances (e.g., a VM with a GPU and preconfigured CUDA drivers).
+- Execute tasks and polling triggers on a worker with a specific Operating System (e.g., a Windows server).
+- Restrict backend access to a set of workers (firewall rules, private networks, etc.).
+- Execute tasks and polling triggers close to a remote backend (region selection).
+
+::alert{type="warning"}
+Even if you are using worker groups, we strongly recommend having at least one worker in the default worker group, as there is no way to enforce that all tasks and polling triggers have a `workerGroup.key` property set.
+::
+
+There is currently no way to validate whether a worker group exists before using it in a task or polling trigger. If a task or a polling trigger defines a worker group that doesn't exist, it will wait forever, leaving the flow's Execution stuck in a pending state.
+
+A worker is part of a worker group if it is started with `--worker-group workerGroupKey`.
\ No newline at end of file
diff --git a/content/docs/03.concepts/worker.md b/content/docs/03.concepts/worker.md
new file mode 100644
index 0000000000..de70110461
--- /dev/null
+++ b/content/docs/03.concepts/worker.md
@@ -0,0 +1,9 @@
+---
+title: Worker
+---
+
+All tasks and polling triggers are executed by a **Worker**. A Worker receives and processes tasks from the Executor and polling triggers from the Scheduler. Given that tasks and polling triggers can be virtually anything (heavy computations, simple API calls, etc.), the Worker is essentially a Thread Pool where you can configure the number of threads you need.
+
+You can scale Workers as necessary and have many instances on multiple servers, each with its own Thread Pool.
+
+As the worker executes the tasks and the polling triggers, it needs access to any external services they use (database, REST services, message broker, etc.). Workers are the only server components that need access to external services.
\ No newline at end of file
diff --git a/content/docs/04.user-interface-guide/04-executions.md b/content/docs/04.user-interface-guide/04-executions.md
index 400baf4181..8c4265ae86 100644
--- a/content/docs/04.user-interface-guide/04-executions.md
+++ b/content/docs/04.user-interface-guide/04-executions.md
@@ -15,7 +15,7 @@ An **Execution** page will allow access to the details of a flow execution, incl
### Gantt Tab
-The Gantt tab allows to see each task's durations. From this interface, you can replay a specific task, see task source code, change task status, or look at task [metrics](../03.concepts/02.executions.md#metrics) and [outputs](../03.concepts/02.executions.md#outputs).
+The Gantt tab allows to see each task's durations. From this interface, you can replay a specific task, see task source code, change task status, or look at task [metrics](../03.concepts/execution.md#metrics) and [outputs](../03.concepts/execution.md#outputs).

@@ -35,13 +35,13 @@ The Outputs tab in an execution page allows to see each task's outputs.

-The "Eval Expression" box allows to evaluate [expressions](../05.developer-guide/03.variables/01.index.md) on those task outputs. It's a great way to debug your flows.
+The "Eval Expression" box allows to evaluate [expressions](../03.concepts/expression/01.index.md) on those task outputs. It's a great way to debug your flows.
> Note: You have to select one task to be able to use the "Eval Expression" button.

-For example, you can use the "Eval Expression" feature to deep-dive into your tasks' outputs and play directly with [variable operations](../05.developer-guide/03.variables/02.basic-usage.md).
+For example, you can use the "Eval Expression" feature to deep-dive into your tasks' outputs and play directly with [variable operations](../03.concepts/expression/02.basic-usage.md).
### Metrics Tab
diff --git a/content/docs/04.user-interface-guide/09-namespaces.md b/content/docs/04.user-interface-guide/09-namespaces.md
index a7e7d8d65f..b67d4e7659 100644
--- a/content/docs/04.user-interface-guide/09-namespaces.md
+++ b/content/docs/04.user-interface-guide/09-namespaces.md
@@ -16,9 +16,9 @@ You can click on the **+** icon at the right of a namespace to create it.
After creating a namespace, you can configure it:
-- The **Variables** tab allows setting [variables](../05.developer-guide/03.variables/01.index.md#namespace-variables-ee) scoped to a namespace.
+- The **Variables** tab allows setting [variables](../03.concepts/expression/01.index.md#namespace-variables-ee) scoped to a namespace.
- The **Task defaults** tab allows setting task default scoped to a namespace.
-- The **Secrets** tab allows setting secrets accessible via the [secret function](../05.developer-guide/03.variables/04.function/secret.md).
+- The **Secrets** tab allows setting secrets accessible via the [secret function](../03.concepts/expression/04.function/secret.md).
- The **Groups**, **Roles**, and **Access** tabs allow managing role-based access control.
- The **Service accounts** tab allows managing service accounts to access Kestra as a service, and not as an end user.
- The **Audit Logs** tab allows access to the audit logs of the namespace.
diff --git a/content/docs/04.user-interface-guide/blueprints.md b/content/docs/04.user-interface-guide/blueprints.md
index e4ab952b82..869fa716a5 100644
--- a/content/docs/04.user-interface-guide/blueprints.md
+++ b/content/docs/04.user-interface-guide/blueprints.md
@@ -16,9 +16,9 @@ Community Blueprints are particularly helpful when you're getting started with a
### Where to find Blueprints
-Blueprints are accessible from two places in the UI:
+Blueprints are accessible from two places in the UI:
-1. The left navigation sidebar
+1. The left navigation sidebar
2. A dedicated tab in the code editor named "Source and blueprints", showing your source code and Blueprints side by side.

diff --git a/content/docs/05.developer-guide/01.flow.md b/content/docs/05.developer-guide/01.flow.md
deleted file mode 100644
index d6dd4e8cc8..0000000000
--- a/content/docs/05.developer-guide/01.flow.md
+++ /dev/null
@@ -1,177 +0,0 @@
----
-title: Flows
----
-
-**Flows** are used to implement your workload. They define all the tasks you want to perform and the order in which they will be run.
-
-You define a flow using the declarative model called [YAML](https://en.wikipedia.org/wiki/YAML).
-
-A flow must have an identifier (`id`), a `namespace`, and a list of [`tasks`](./02.tasks.md).
-
-A flow can also have [`inputs`](./04.inputs.md), [error handlers](./07.errors-handling.md) under the property `errors`, and [`triggers`](./08.triggers/index.md).
-
-## Flow sample
-
-Here is a sample flow definition. It uses tasks available in Kestra core for testing purposes.
-
-```yaml
-id: samples
-namespace: io.kestra.tests
-description: "Some flow **documentation** in *Markdown*"
-
-labels:
- env: prd
- country: FR
-
-inputs:
- - name: my-value
- type: STRING
- required: false
- defaults: "default value"
- description: This is a not required my-value
-
-variables:
- first: "1"
- second: "{{vars.first}} > 2"
-
-tasks:
- - id: date
- type: io.kestra.core.tasks.debugs.Return
- description: "Some tasks **documentation** in *Markdown*"
- format: "A log line content with a contextual date variable {{taskrun.startDate}}"
-
-taskDefaults:
- - type: io.kestra.core.tasks.log.Log
- values:
- level: ERROR
-```
-
-### Labels
-
-You can add arbitrary `labels` to your flows to sort them on multiple dimensions. When you execute such flow, the labels will be propagated to the created execution. It is also possible to override and define new labels at flow execution start.
-
-### Task Defaults
-
-You can also define `taskDefaults` inside your flow. This is a list of default task properties that will be applied to each task of a certain type inside your flow. Task defaults can be handy to avoid repeating the same value for a task property in case the same task type is used multiple times in the same flow.
-
-### Variables
-You can set flow variables that will be accessible by each task using `{{ vars.key }}`. Flow `variables` is a map of key/value pairs.
-
-### List of tasks
-
-The most important part of a flow is the list of tasks that will be run sequentially when the flow is executed.
-
-
-## Flow Properties
-
-The following flow properties can be set.
-
-| Field | Description |
-| ---------- |----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-|`id`| The flow identifier, must be unique inside a namespace. |
-|`namespace`| Each flow lives in one namespace, this is useful for flow organization and is mandatory. |
-|`revision`| The flow version, handled internally by Kestra, and incremented for each modification. You should not manually set it. |
-|`description`| The description of the flow, more details [here](#document-your-flow). |
-|`labels`| The list of labels which are string key/value pairs. |
-|`inputs`| The list of inputs, more details [here](./04.inputs.md). |
-|`variables`| The list of variables (such as api key, table name, URL, etc) that can be reached inside tasks with `{{ vars.name }}`. |
-|`tasks`| The list of tasks, all tasks will be run sequentially. |
-|`errors`| The list of error tasks, all listed tasks will be run sequentially only if there is an error on the current execution. More details [here](./07.errors-handling.md). |
-|`listeners`| The list of listeners, more details [here](./13.listeners.md). |
-|`triggers`| The list of triggers which are external events (such as date schedule or message presence in a broker, for example) that will launch this flow, more details [here](./08.triggers/index.md). |
-|[`taskDefaults`](#taskdefaults)| The list of default task values, this avoid repeating the same properties on each tasks. |
-|`taskDefaults.[].type`| The task type is a full qualified Java class name. |
-|`taskDefaults.[].forced`| If set to `forced: true`, the taskDefault will take precedence over properties defined in the task (default `false`). |
-|`taskDefaults.[].values.xxx`| The task property that you want to be set as default. |
-|`disabled`| Set it to `true` to disable execution of the flow. |
-|[`concurrency`](./concurrency.md)| Use it to define flow-level concurrency control. By default, flow execution concurrency is not limited |
-
-
-### `taskDefaults`
-
-You can add task defaults to avoid repeating task properties on multiple occurrences of the same task in a `taskDefaults` properties. For example:
-
-```yaml
-id: api_python_sql
-namespace: dev
-
-tasks:
- - id: api
- type: io.kestra.plugin.fs.http.Request
- uri: https://dummyjson.com/products
-
- - id: hello
- type: io.kestra.plugin.scripts.python.Script
- docker:
- image: python:slim
- script: |
- print("Hello World!")
-
- - id: python
- type: io.kestra.plugin.scripts.python.Script
- docker:
- image: python:slim
- beforeCommands:
- - pip install polars
- warningOnStdErr: false
- script: |
- import polars as pl
- data = {{outputs.api.body | jq('.products') | first}}
- df = pl.from_dicts(data)
- df.glimpse()
- df.select(["brand", "price"]).write_csv("{{outputDir}}/products.csv")
-
- - id: sql_query
- type: io.kestra.plugin.jdbc.duckdb.Query
- inputFiles:
- in.csv: "{{ outputs.python.outputFiles['products.csv'] }}"
- sql: |
- SELECT brand, round(avg(price), 2) as avg_price
- FROM read_csv_auto('{{workingDir}}/in.csv', header=True)
- GROUP BY brand
- ORDER BY avg_price DESC;
- store: true
-
-taskDefaults:
- - type: io.kestra.plugin.scripts.python.Script
- values:
- runner: DOCKER
- docker:
- image: python:slim
- pullPolicy: ALWAYS # NEVER to use a local image
-```
-
-Here, we avoid repeating Docker and Python configurations in each task by directly setting those within the `taskDefaults` property. This approach helps to streamline the configuration process and reduce the chances of errors caused by inconsistent settings across different tasks.
-
-Note that when you move some required task attributes into the `taskDefaults` property, the code editor within the UI will complain that the required task argument is missing. The editor shows this message because `taskDefaults` are resolved at runtime and the editor is not aware of those default attributes until you run your flow. As long as `taskDefaults` contains the relevant arguments, you can save the flow and ignore the warning displayed in the editor.
-
-
-
-
-## Document your flow
-
-You can add documentation to flows, tasks, etc... to explain the goal of the current element.
-
-For this, Kestra allows adding a `description` property where you can write documentation of the current element.
-The description must be written using the [Markdown](https://en.wikipedia.org/wiki/Markdown) syntax.
-
-You can add a `description` property on:
-- [Flows](./01.flow.md)
-- [Tasks](./02.tasks.md)
-- [Listeners](./13.listeners.md)
-- [Triggers](./08.triggers/index.md)
-
-All markdown descriptions will be rendered in the UI.
-
-
-
-
-## Enable or Disable a Flow
-
-By default, all flows are active and will execute whether or not a trigger has been set.
-
-You have the option to disable a Flow, which is particularly useful when you wish to prevent its execution.
-
-Enabling a previously disabled Flow will prompt it to execute any missed triggers from the period when it was disabled.
-
-
\ No newline at end of file
diff --git a/content/docs/05.developer-guide/03.scripts.md b/content/docs/05.developer-guide/03.scripts.md
index 66c07c72dc..01435e2278 100644
--- a/content/docs/05.developer-guide/03.scripts.md
+++ b/content/docs/05.developer-guide/03.scripts.md
@@ -2,9 +2,9 @@
title: Python, R, Node.js and Shell Scripts
---
-The previous sections in the Developer Guide covered [Flows](01.flow.md) and [Tasks](02.tasks.md). This section covers script tasks.
+The previous sections in the Developer Guide covered [Flows](../03.concepts/flow.md) and [Tasks](../03.concepts/tasks.md). This section covers script tasks.
-Script tasks allow you to orchestrate custom business logic written in `Python`, `R`, `Node.js`, `Powershell` and `Shell` scripts. By default, all these tasks run in individual Docker containers. You can optionally run those scripts in a local process or run them on a remote [worker group](../01.architecture.md#worker-group-ee).
+Script tasks allow you to orchestrate custom business logic written in `Python`, `R`, `Node.js`, `Powershell` and `Shell` scripts. By default, all these tasks run in individual Docker containers. You can optionally run those scripts in a local process or run them on a remote [worker group](../03.concepts/worker-group.md).
## The `Commands` and `Script` tasks
@@ -123,7 +123,7 @@ Below is a simple example of the recommended usage pattern:
2. Use `io.kestra.plugin.git.Clone` as the first child task of a `io.kestra.core.tasks.flows.WorkingDirectory` task to ensure that your repository is cloned into an empty directory. You can provide a URL and authentication credentials to any Git-based system including GitHub, GitLab, BitBucket, CodeCommit, and more.
3. Use one of the `Commands` task (e.g. `python.Commands`) to specify which scripts or modules to run, while explicitly specifying the path within the Git repository. For instance, the command `python scripts/etl_script.py` ensures you run a Python script `etl_script.py` located in the `scripts` directory of the [examples](https://github.com/kestra-io/examples) repository in the `main` branch.
1. This repository is **public**, so the repository's `url` and a `branch` name is all that's required.
- 2. If this repository were **private**, we would also had to specify `kestra-io` as the `username` and add a [Personal Access Token](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token) as the `password` property.
+ 2. If this repository were **private**, we would also had to specify `kestra-io` as the `username` and add a [Personal Access Token](https://docs.github.com/en/authentication/keeping-your-account-and-data-secure/creating-a-personal-access-token) as the `password` property.
4. Optionally, specify your **base** Docker image using the `image` argument of the `docker` property. If you don't specify the image property, the default image is used, as shown in the table above. The referenced container image should include commonly used dependencies, for example `requests`, `pandas`, `sqlalchemy`, `scikit-learn`, etc. While you can have a dedicated image for each script, Kestra supports a much simpler Python dependency management pattern using a base image with shared dependencies and installing any custom dependencies needed for a particular script at runtime using the `beforeCommands` property.
5. The `beforeCommands` property is a list of arbitrary commands that can be *optionally* executed within the container before starting the script `commands`. If your cloned Git repository includes `requirements.txt` file, you can use `pip install -r requirements.txt` to install the required `pip` packages.
1. The additional `warningOnStdErr` boolean flag can be set to `false` to avoid setting the task to a WARNING state when the installation process emits warnings to the standard error. By default, warnings during e.g. `pip` package installation will set the task state to a `WARNING` state to give you more transparency about the entire process.
@@ -308,7 +308,7 @@ tasks:
- "*.parquet"
```
-Head over to the [Secrets](10.secrets.md) section to learn more about secrets management in Kestra.
+Head over to the [Secrets](../03.concepts/secret.md) section to learn more about secrets management in Kestra.
### runner: PROCESS
@@ -329,7 +329,7 @@ tasks:
- python /Users/you/scripts/etl_script.py
```
-Running scripts in a local process is particularly beneficial when using [remote Worker Groups](../01.architecture.md#worker-group-ee). The example below ensures that a script will be picked up only by Kestra workers that have been started with the key `gpu`, effectively delegating processing of scripts that require demanding computational requirements to the right server, rather than running them directly in a local container:
+Running scripts in a local process is particularly beneficial when using [remote Worker Groups](../03.concepts/worker-group.md). The example below ensures that a script will be picked up only by Kestra workers that have been started with the key `gpu`, effectively delegating processing of scripts that require demanding computational requirements to the right server, rather than running them directly in a local container:
```yaml
id: gpuTask
@@ -458,7 +458,6 @@ tasks:
- ls -lt $(python -c "import site; print(site.getsitepackages()[0])") | head -n 20
```
-
---
## Using Kestra's prebuilt images
@@ -622,7 +621,7 @@ All tasks within the `WorkingDirectory` can use output artifacts from previous t
## Generating outputs from a script task using `{{outputDir}}`
-If you want to generate files in your script to make them available for download and use in downstream tasks, you can leverage the `outputDir` [variable](03.variables/01.index.md). Files stored in that directory will be persisted in Kestra's internal storage. Here is an example:
+If you want to generate files in your script to make them available for download and use in downstream tasks, you can leverage the `outputDir` [expression](../03.concepts/expression/01.index.md). Files stored in that directory will be persisted in Kestra's internal storage. Here is an example:
```yaml
id: outputTest
@@ -645,13 +644,13 @@ tasks:
The first task creates a file `'myfile.txt'` and the next task can access it by leveraging the syntax `{{outputs.yourTaskId.outputFiles['yourFileName.fileExtension']}}`.
-Check the [Outputs](05.outputs.md) page for more details about managing outputs.
+Check the [Outputs](../03.concepts/outputs.md) page for more details about managing outputs.
## The `LocalFiles` task to manage `inputs` and `outputs` for your script code
-The `LocalFiles` task is meant to be used inside the `WorkingDirectory` task.
+The `LocalFiles` task is meant to be used inside the `WorkingDirectory` task.
It allows you to **output files** generated in a script and **add new files inline** within the YAML workflow definition. The examples from the previous sections demonstrate how you can use **inputs** and **outputs**. The subsections below provide additional explanation and further examples.
@@ -764,7 +763,7 @@ This separation of concerns (*i.e. not mixing orchestration and business logic*)
### Managing output files: `LocalFiles.outputs`
-Using the previous example, note how the `LocalFiles` can be used to output any file as downloadable artifacts. [This script from GitHub](https://github.com/kestra-io/examples/blob/main/scripts/clean_messy_dataset.py#L12) outputs a file named `clean_dataset.csv`. However, you don't have to hardcode that specific file name. Instead, a simple [Glob](https://en.wikipedia.org/wiki/Glob_(programming)) expression can be used to define that you want to output any CSV or Parquet file generated by that script:
+Using the previous example, note how the `LocalFiles` can be used to output any file as downloadable artifacts. [This script from GitHub](https://github.com/kestra-io/examples/blob/main/scripts/clean_messy_dataset.py#L12) outputs a file named `clean_dataset.csv`. However, you don't have to hardcode that specific file name. Instead, a simple [Glob](https://en.wikipedia.org/wiki/Glob_(programming)) expression can be used to define that you want to output any CSV or Parquet file generated by that script:
```yaml
- id: output
@@ -773,7 +772,7 @@ Using the previous example, note how the `LocalFiles` can be used to output any
- "*.csv"
- "*.parquet"
```
-If any files matching that [Glob](https://en.wikipedia.org/wiki/Glob_(programming)) patterns are generated during the flow's Execution, they will be available for download from the **Outputs** tab.
+If any files matching that [Glob](https://en.wikipedia.org/wiki/Glob_(programming)) patterns are generated during the flow's Execution, they will be available for download from the **Outputs** tab.
---
@@ -796,8 +795,8 @@ This example automatically emits output metadata, such as the status `code`, fil
### Outputs and metrics in Script and Commands tasks
-The [Scripts Plugin](https://github.com/kestra-io/plugin-scripts) provides convenient methods to send outputs and metrics to the Kestra backend during flow Execution. Under the hood, Kestra tracks outputs and metrics from script tasks by searching standard output and standard error for `::{}::` or `{}` patterns that allow you to specify outputs and metrics using a JSON request payload:
-- `{}` for single-line JSON objects
+The [Scripts Plugin](https://github.com/kestra-io/plugin-scripts) provides convenient methods to send outputs and metrics to the Kestra backend during flow Execution. Under the hood, Kestra tracks outputs and metrics from script tasks by searching standard output and standard error for `::{}::` or `{}` patterns that allow you to specify outputs and metrics using a JSON request payload:
+- `{}` for single-line JSON objects
- `::{}::` for multi-line JSON objects.
> Note that `outputs` require a **dictionary**, while `metrics` expect a **list of dictionaries**.
@@ -815,7 +814,7 @@ Below is an example showing `outputs` with key-value pairs:
}
```
-Here is the representation of a `metrics` object. It's a **list of dictionaries**:
+Here is the representation of a `metrics` object. It's a **list of dictionaries**:
```json
"metrics": [
@@ -931,7 +930,7 @@ The JSON payload should be provided without any spaces.
## When to use metrics and when to use outputs?
-If you want to track task-run metadata across multiple executions of a flow, and this metadata is of an arbitrary data type (*it might be a string, a list of dictionaries, or even a file*), use `outputs` rather than `metrics`. Metrics can only be used with numerical values.
+If you want to track task-run metadata across multiple executions of a flow, and this metadata is of an arbitrary data type (*it might be a string, a list of dictionaries, or even a file*), use `outputs` rather than `metrics`. Metrics can only be used with numerical values.
### Use cases for `outputs`: results of a task of any data type
@@ -957,10 +956,10 @@ tasks:
### Use cases for `metrics`: numerical values that can be aggregated and visualized across Executions
-Metrics are intended to track custom **numeric** (metric type: `counter`) or **duration** (metric type: `timer`) attributes that you can visualize across flow executions, such as number of rows or bytes processed in a task. Metrics are expressed as numerical values of `integer` or `double` data type.
+Metrics are intended to track custom **numeric** (metric type: `counter`) or **duration** (metric type: `timer`) attributes that you can visualize across flow executions, such as number of rows or bytes processed in a task. Metrics are expressed as numerical values of `integer` or `double` data type.
-Examples of metadata you may want to track as `metrics`:
-- the **number of rows** processed in a given task (e.g. during data ingestion or transformation),
-- the **accuracy score** of a trained ML model in order to compare this result across multiple workflow runs (*e.g. you can see the average or max value across multiple executions*),
-- other pieces of **metadata** that you can track across executions of a flow (e.g. a duration of a certain function execution within a Python ETL script).
+Examples of metadata you may want to track as `metrics`:
+- the **number of rows** processed in a given task (e.g. during data ingestion or transformation),
+- the **accuracy score** of a trained ML model in order to compare this result across multiple workflow runs (*e.g. you can see the average or max value across multiple executions*),
+- other pieces of **metadata** that you can track across executions of a flow (e.g. a duration of a certain function execution within a Python ETL script).
diff --git a/content/docs/05.developer-guide/06.storage.md b/content/docs/05.developer-guide/06.storage.md
index 6a8adb1667..5239cf0830 100644
--- a/content/docs/05.developer-guide/06.storage.md
+++ b/content/docs/05.developer-guide/06.storage.md
@@ -2,7 +2,7 @@
title: Data storage and processing
---
-Kestra's primary purpose is to orchestrate data processing via [tasks](02.tasks.md), so data is central to each [flow's](01.flow.md) execution.
+Kestra's primary purpose is to orchestrate data processing via tasks, so data is central to each flow's execution.
Depending on the task, data can be stored inside the execution context or inside Kestra's internal storage. You can also manually store data inside Kestra's state store by using [dedicated tasks](../../plugins/core/tasks/states/io.kestra.core.tasks.states.Set.md).
@@ -34,7 +34,7 @@ The three `fetch`/`fetchOne`/`store` properties will do the same but using three
Data can be stored as variables inside the flow execution context. This can be convenient for sharing data between tasks.
-To do so, tasks store data as output attributes that are then available inside the flow via Pebble expressions like `{{outputs.taskName.attributeName}}`. More information about outputs can be found [here](./05.outputs.md).
+To do so, tasks store data as [output attributes](../03.concepts/outputs.md) that are then available inside the flow via Pebble expressions like `{{outputs.taskName.attributeName}}`.
Be careful that when the size of the data is significant, this will increase the size of the flow execution context, which can lead to slow execution and increase the size of the execution storage inside Kestra's repository.
@@ -69,7 +69,7 @@ tasks:
to: "/upload/file.ion"
```
-If you need to access data from the internal storage, you can use the Pebble [read](./03.variables/04.function/read.md) function to read the file's content as a string.
+If you need to access data from the internal storage, you can use the Pebble [read](./expression/04.function/read.md) function to read the file's content as a string.
Dedicated tasks allow managing the files stored inside the internal storage:
- [Concat](../../plugins/core/tasks/storages/io.kestra.core.tasks.storages.Concat.md): concat multiple files.
@@ -109,7 +109,7 @@ tasks:
## Processing data
-You can make basic data processing thanks to variables processing offered by the Pebble templating engine, see [variables basic usage](./03.variables/02.basic-usage.md).
+You can make basic data processing thanks to variables processing offered by the Pebble templating engine, see [variables basic usage](./expression/02.basic-usage.md).
But these are limited, and you may need more powerful data processing tools; for this, Kestra offers various data processing tasks like file transformations or scripts.
@@ -181,16 +181,16 @@ tasks:
type: io.kestra.core.tasks.storages.LocalFiles
inputs:
data.csv: "{{outputs['write-csv'].uri}}"
-
+
- id: pandas
type: io.kestra.plugin.scripts.python.Script
warningOnStdErr: false
- docker:
+ docker:
image: ghcr.io/kestra-io/pydata:latest
script: |
import pandas as pd
from kestra import Kestra
-
+
df = pd.read_csv("data.csv")
views = df['views'].sum()
Kestra.outputs({'views': int(views)})
diff --git a/content/docs/05.developer-guide/07.errors-handling.md b/content/docs/05.developer-guide/07.errors-handling.md
index dbd9131228..d4692dbbe0 100644
--- a/content/docs/05.developer-guide/07.errors-handling.md
+++ b/content/docs/05.developer-guide/07.errors-handling.md
@@ -7,7 +7,7 @@ Errors are special branches of your flow where you can define how to handle task
Two kinds of error handlers can be defined:
* **Global**: error handling global to a flow that must be at the root of the flow.
-* **Local**: error handling local to a [Flowable Task](./02.tasks.md#flowable-tasks), will handle errors for the flowable task and its children.
+* **Local**: error handling local to a [Flowable Task](../03.concepts/flowable-tasks.md), will handle errors for the flowable task and its children.
### Global Error Handler
@@ -64,106 +64,4 @@ tasks:
## Retries
-Kestra provides a task retry feature. This makes it possible to add retry behavior for any task **failed run** based on configurations in the flow description.
-
-A retry on a task run will create a new task attempt.
-
-### Example
-
-The following example defines a retry for the `retry-sample` task with a maximum of 5 attempts every 15 minutes:
-
-```yaml
-- id: retry-sample
- type: io.kestra.core.tasks.log.Log
- message: my output for task {{task.id}}
- timeout: PT10M
- retry:
- maxAttempt: 5
- type: constant
- interval: PT15M
-```
-
-### Retry options for all retry types
-
-| name | type | description |
-| ---------- | ----------- | ----------- |
-|`type`|`string`|Retry behavior to apply. Can be one of `constant`, `exponential`, `random`.|
-|`maxAttempt`|`integer`|Number of retries performed before the system stops retrying.|
-|`maxDuration`|`Duration`|Maximum delay the execution is retried. Once passed, the task is no more processed.|
-|`warningOnRetry`|`Boolean`|Flag the execution as warning if any retry was done on this task. Default `false`.|
-
-### Duration
-
-Some options above have to be filled with a duration notation.
-Durations are expressed in [ISO 8601 Durations](https://en.wikipedia.org/wiki/ISO_8601#Durations), here are some examples:
-
-| name | description |
-| ---------- | ----------- |
-|PT0.250S|250 milliseconds delay|
-|PT2S|2 seconds delay|
-|PT1M|1 minute delay|
-|PT3.5H|3 hours and a half delay|
-
-
-### Retry types
-
-
-#### `constant`
-This establishes constant retry times: if the `interval` property is set to 10 minutes, it retries every 10 minutes.
-
-| name | type | description |
-| ---------- | ----------- | ----------- |
-|`interval`|`Duration`|Duration between each retry.|
-
-#### `exponential`
-This establishes retry behavior that waits longer between each retry e.g. 1s, 5s, 15s, ...
-
-| name | type | description |
-| ---------- | ----------- | ----------- |
-|`interval`|`Duration`|Duration between each retry.|
-|`maxInterval`|`Duration`|Max Duration between each retry.|
-|`delayFactor`|`Double`|Multiplier for the `interval` on between retry, default is 2. For example, with an interval of 30s and a delay factor of 2, retry will append at 30s, 1m30, 3m30, ... |
-
-#### `random`
-This establishes retries with a random delay within minimum and maximum limits.
-
-| name | type | description |
-| ---------- | ----------- | ----------- |
-|`minInterval`|`Duration`|Minimal duration between each retry.|
-|`maxInterval`|`Duration`|Maximum duration between each retry.|
-
-
-## Retry vs. Restart vs. Replay
-
-### Automatic vs. manual
-**Retries** ensure that failed task runs are *automatically* rerun within the *same Execution*. Apart from retries, defined within your flow code, you can also *manually* rerun the flow from the Flow Execution page in the UI using the **Restart** or **Replay** buttons.
-
-
-
-### Restart vs. Replay
-While **Restart** will rerun failed tasks within the current Execution (*i.e., without creating a new execution*), a **Replay** would result in a completely new run with a different Execution ID than the initial run.
-
-
-
-When you replay an Execution, a new execution gets created for the same flow. However, you can still track which Execution triggered this new run thanks to the `Original Execution` field:
-
-
-
-Replay can be executed from any task, even if that task executed successfully.
-But note that when you trigger a replay from a specific failed task, it will still result in a new Execution running all tasks downstream of your chosen start task:
-
-
-
-When you want to rerun only failed tasks, use `Restart`.
-
-
-### Summary: Retries vs. Restart vs. Replay
-
-The table below summarizes the differences between a retry, restart and replay.
-
-| Concept | Flow or task level | Automatic or manual | Does it create a new execution? |
-| --- | --- | --- | --- |
-| Retry | Task level | Automatic | No, it only reruns a given task within the same Execution. Each retry results in a new attempt number, allowing you to see how many times a given task run was retried. |
-| Restart | Flow level | Manual | No, it only reruns all failed tasks within the same Execution. It's meant to handle unanticipated, transient failures. The UI shows a new attempt number for all task runs that were restarted. |
-| Replay | Either flow or task level | Manual | Yes. You can pick an arbitrary step from which a new execution should be triggered. If you select a task in the middle that needs outputs from a previous task, its output is retrieved from cache. |
-
+Retries provide a way to automatically retry a task when it fails. Check the [Retries](../03.concepts/retries.md) documentation for more details.
\ No newline at end of file
diff --git a/content/docs/05.developer-guide/12.best-practice.md b/content/docs/05.developer-guide/12.best-practice.md
index 2622a0ece6..66dac58a3c 100644
--- a/content/docs/05.developer-guide/12.best-practice.md
+++ b/content/docs/05.developer-guide/12.best-practice.md
@@ -15,7 +15,53 @@ The execution of a flow is an object that will contain:
- Theirs outputs
- Their state histories
-Here is an example of a TaskRun:
+Internally:
+- Each TaskRun on a flow will be added on the same flow execution context that contains all tasks executed on this flow.
+- Each TaskRun status change is read by the Kestra Executor (at most 3 for a task: CREATED, RUNNING then SUCCESS).
+- For each state on the Executor, we need:
+ - to fetch the serialized flow execution context over the network,
+ - to deserialize the flow execution context, find the next task or tasks and serialize the flow execution context,
+ - to send the serialized flow execution context over the network.
+- The bigger the flow execution context, the longer it will take to handle this serialization phase.
+- Depending on the Kestra internal queue and repository implementation, there can be a hard limit on the size of the flow execution context as it is stored as a single row/message. Usually, this limit is around 1MB, so this is important to avoid storing large amounts of data inside the flow execution context.
+
+## Task on the same execution
+Based on previous observations, here are some recommendations.
+
+While it is possible to code a flow with any number of tasks, it is not recommended to have a lot of tasks on the same flow.
+
+A flow can be comprised of manually generated tasks or dynamic ones. While [EachSequential](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachSequential.md) and [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) are really powerful tasks to loop over the result of a previous task, there are some drawbacks. If the task you are looping over is too large, you can easily end up with hundreds of tasks created. If, for example, you were using a pattern with Each inside Each (nested looping), it would take only a flow with 20 TaskRuns X 20 TaskRuns to reach 400 TaskRuns.
+
+::alert{type="warning"}
+Based on our observations, we have seen that in cases where there are **more than 100** tasks on a flow, we see a decrease in performance and longer executions.
+::
+
+To avoid reaching these limits, you can easily create a subflow with the [Subflow](../03.concepts/subflows.md) task, passing arguments from parent to child. In this case, since the `Subflow` task creates a new execution, the subflow tasks will be **isolated** and won't hurt performance.
+
+## Volume of data from your outputs
+Some tasks allow you to fetch results on outputs to be reused on the next tasks.
+While this is powerful, this **is not intended to be used to transport a lot of data!**
+For example, with the [Query](../../plugins/plugin-gcp/tasks/bigquery/io.kestra.plugin.gcp.bigquery.Query.md) task from BigQuery, there is a property `fetch` that allows fetching a resultset as an output attribute.
+
+Imagine a big table with many MB or even GB of data. If you use `fetch`, the output will be stored in the execution context and will need to be serialized on each task state change! This is not the idea behind `fetch`, it serves mostly to query a few rows to use it on a [Switch](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Switch.md) task for example, or an [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) task to loop over.
+
+::alert{type="info"}
+In most cases, there is an other property called `stores` that can handle a large volume of data. When an output is stored, it uses Kestra's internal storage, and only the URL of the stored file is stored in the execution context.
+::
+
+
+## Parallel Task
+Using the [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) task or the [Parallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Parallel.md) task is a convenient way to optimize flow duration, but keep in mind that, by default, **all parallel tasks are launched at the same time** (unless you specify the `concurrent` property). The only limit will be the number of worker threads you have configured.
+
+Keep this in mind, because you cannot allow parallel tasks to reach the limit of external systems, such as connection limits or quotas.
+
+
+## Duration of Tasks
+By default, Kestra **never limits the duration** (unless specified explicitly on the task's documentation) of the tasks. If you have a long-running process or an infinite loop, the tasks will never end. We can control the timeout on RunnableTask with the property `timeout` that takes a [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601) duration like `PT5M` for a duration of 5 minutes.
+
+## Task run JSON
+
+Here is an example of a TaskRun JSON object:
```json
{
"id": "5cBZ1JF8kim8fbFg13bumX",
@@ -92,47 +138,3 @@ Here is an example of a TaskRun:
}
}
```
-
-Internally:
-- Each TaskRun on a flow will be added on the same flow execution context that contains all tasks executed on this flow.
-- Each TaskRun status change is read by the Kestra Executor (at most 3 for a task: CREATED, RUNNING then SUCCESS).
-- For each state on the Executor, we need:
- - to fetch the serialized flow execution context over the network,
- - to deserialize the flow execution context, find the next task or tasks and serialize the flow execution context,
- - to send the serialized flow execution context over the network.
-- The bigger the flow execution context, the longer it will take to handle this serialization phase.
-- Depending on the Kestra internal queue and repository implementation, there can be a hard limit on the size of the flow execution context as it is stored as a single row/message. Usually, this limit is around 1MB, so this is important to avoid storing large amounts of data inside the flow execution context.
-
-## Task on the same execution
-Based on previous observations, here are some recommendations.
-
-While it is possible to code a flow with any number of tasks, it is not recommended to have a lot of tasks on the same flow.
-
-A flow can be comprised of manually generated tasks or dynamic ones. While [EachSequential](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachSequential.md) and [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) are really powerful tasks to loop over the result of a previous task, there are some drawbacks. If the task you are looping over is too large, you can easily end up with hundreds of tasks created. If, for example, you were using a pattern with Each inside Each (nested looping), it would take only a flow with 20 TaskRuns X 20 TaskRuns to reach 400 TaskRuns.
-
-::alert{type="warning"}
-Based on our observations, we have seen that in cases where there are **more than 100** tasks on a flow, we see a decrease in performance and longer executions.
-::
-
-To avoid reaching these limits, you can easily create a subflow with the [Subflow](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Subflow.md) task, passing arguments from parent to child. In this case, since the `Subflow` task creates a new execution, the subflow tasks will be **isolated** and won't hurt performance.
-
-## Volume of data from your outputs
-Some tasks allow you to fetch results on outputs to be reused on the next tasks.
-While this is powerful, this **is not intended to be used to transport a lot of data!**
-For example, with the [Query](../../plugins/plugin-gcp/tasks/bigquery/io.kestra.plugin.gcp.bigquery.Query.md) task from BigQuery, there is a property `fetch` that allows fetching a resultset as an output attribute.
-
-Imagine a big table with many MB or even GB of data. If you use `fetch`, the output will be stored in the execution context and will need to be serialized on each task state change! This is not the idea behind `fetch`, it serves mostly to query a few rows to use it on a [Switch](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Switch.md) task for example, or an [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) task to loop over.
-
-::alert{type="info"}
-In most cases, there is an other property called `stores` that can handle a large volume of data. When an output is stored, it uses Kestra's internal storage, and only the URL of the stored file is stored in the execution context.
-::
-
-
-## Parallel Task
-Using the [EachParallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.EachParallel.md) task or the [Parallel](../../plugins/core/tasks/flows/io.kestra.core.tasks.flows.Parallel.md) task is a convenient way to optimize flow duration, but keep in mind that, by default, **all parallel tasks are launched at the same time** (unless you specify the `concurrent` property). The only limit will be the number of worker threads you have configured.
-
-Keep this in mind, because you cannot allow parallel tasks to reach the limit of external systems, such as connection limits or quotas.
-
-
-## Duration of Tasks
-By default, Kestra **never limits the duration** (unless specified explicitly on the task's documentation) of the tasks. If you have a long-running process or an infinite loop, the tasks will never end. We can control the timeout on RunnableTask with the property `timeout` that takes a [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601) duration like `PT5M` for a duration of 5 minutes.
diff --git a/content/docs/05.developer-guide/13.cicd/index.md b/content/docs/05.developer-guide/13.cicd/index.md
index c55596fc10..427b4696df 100644
--- a/content/docs/05.developer-guide/13.cicd/index.md
+++ b/content/docs/05.developer-guide/13.cicd/index.md
@@ -96,7 +96,7 @@ triggers:
key: "yourSecretKey1234"
```
-While you can trigger that deployment pipeline manually using Kestra UI or API (*i.e. just like any other Kestra flow*), it's better to combine that with a `push` event emitted by your Git repository. The above flow leverages the [Webhook trigger](../08.triggers/03.webhook.md) so that your CI/CD flow runs as soon as you push changes to your Git branch.
+While you can trigger that deployment pipeline manually using Kestra UI or API (*i.e. just like any other Kestra flow*), it's better to combine that with a `push` event emitted by your Git repository. The above flow leverages the [Webhook trigger](../../03.concepts/triggers/webhook-trigger.md) so that your CI/CD flow runs as soon as you push changes to your Git branch.
To configure the webhook for your GitHub repository, go to **Settings**, and then select **Webhooks**. The URL in your browser should look as follows:
diff --git a/content/docs/05.developer-guide/15.git.md b/content/docs/05.developer-guide/15.git.md
index a6e679b8da..39450362cc 100644
--- a/content/docs/05.developer-guide/15.git.md
+++ b/content/docs/05.developer-guide/15.git.md
@@ -55,7 +55,7 @@ triggers:
You can choose to commit this flow to Git or add it from the built-in Editor in Kestra UI — this flow won't be overwritten by the Git reconciliation process.
-This flow can also be triggered anytime you push changes to Git via a [GitHub webhook](08.triggers/03.webhook.md):
+This flow can also be triggered anytime you push changes to Git via a [GitHub webhook](../03.concepts/triggers/webhook-trigger.md):
```yaml
id: sync_from_git
diff --git a/content/docs/08.kestra-editions/01.enterprise.md b/content/docs/08.kestra-editions/01.enterprise.md
index 657bd7b0a1..acb89c162f 100644
--- a/content/docs/08.kestra-editions/01.enterprise.md
+++ b/content/docs/08.kestra-editions/01.enterprise.md
@@ -4,7 +4,7 @@ title: Enterprise Edition
The Enterprise Edition is a highly-available and fault-tolerant self-hosted version of Kestra, with additional features required for enterprise use cases.
-It's meant for production workloads with high security and compliance requirements.
+It's designed for production workloads with high security and compliance requirements.

diff --git a/content/docs/08.kestra-editions/03.tenants.md b/content/docs/08.kestra-editions/03.tenants.md
index 310b532ed5..9e30be19e9 100644
--- a/content/docs/08.kestra-editions/03.tenants.md
+++ b/content/docs/08.kestra-editions/03.tenants.md
@@ -105,7 +105,7 @@ resource "kestra_tenant" "example" {
### Admin Role Assignment
-Regardless of which of the above methods you use to create a tenant, the User who creates the tenant will automatically get the [Admin Role](../../../08.kestra-editions/RBAC/02.admins.md) assigned. That role grants admin rights to that user on that tenant.
+Regardless of which of the above methods you use to create a tenant, the User who creates the tenant will automatically get the [Admin Role](RBAC/02.admins.md#admin) assigned. That role grants admin rights to that user on that tenant.
Note that there is an exception to this rule if tenant is created by a User with an [Instance Admin Role](RBAC/02.admins.md#instance-admin). In that case, the Instance Admin User will have to explicitly assign the Admin Role for that tenant to themselves or any other User, Service Account or Group.
diff --git a/content/docs/09.administrator-guide/01.configuration/01.databases.md b/content/docs/09.administrator-guide/01.configuration/01.databases.md
index b09e1b753a..a10183ef28 100644
--- a/content/docs/09.administrator-guide/01.configuration/01.databases.md
+++ b/content/docs/09.administrator-guide/01.configuration/01.databases.md
@@ -97,7 +97,7 @@ datasources:
## Connection pool size
-The total number of connections opened to the database will depend on the [deployment architecture](../../01.architecture.md#deployment-architecture) used. Each Kestra instance will open a pool of up to the `maximum-pool-size` setting of 10 by default, with a minimum size of the `minimum-idle` setting of 10 by default.
+The total number of connections opened to the database will depend on the [deployment architecture](../../02.architecture/03.deployment-architecture.md) used. Each Kestra instance will open a pool of up to the `maximum-pool-size` setting of 10 by default, with a minimum size of the `minimum-idle` setting of 10 by default.
For example:
- If you deploy Kestra as a standalone server, it will open 10 connections to the database.
diff --git a/content/docs/09.administrator-guide/01.configuration/02.storage.md b/content/docs/09.administrator-guide/01.configuration/02.storage.md
index cd9ea191b7..a155ab691e 100644
--- a/content/docs/09.administrator-guide/01.configuration/02.storage.md
+++ b/content/docs/09.administrator-guide/01.configuration/02.storage.md
@@ -2,7 +2,7 @@
title: Storage configuration
---
-Kestra needs an [internal storage](../../01.architecture.md#the-internal-storage) to store data processed by tasks. This includes files from flow inputs and data stored as task outputs.
+Kestra needs an [internal storage](../../03.concepts/internal-storage.md) to store data processed by tasks. This includes files from flow inputs and data stored as task outputs.
The default internal storage implementation is the local storage which is **not suitable for production** as it will store data inside a local folder on the host filesystem.
diff --git a/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md b/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md
index c2e2c8f40d..e623574eb3 100644
--- a/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md
+++ b/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/multi-tenancy.md
@@ -2,7 +2,7 @@
title: Multi-tenancy configuration
---
-This section dives into how you can configure multi-tenancy in your Kestra instance. For a high-level overview, check the multi-tenancy section of the [Architecture documentation](../../../01.architecture.md#multi-tenancy) or the [Tenants page](../../../08.kestra-editions/03.tenants.md).
+This section dives into how you can configure multi-tenancy in your Kestra instance. For a high-level overview, check the multi-tenancy section of the [Architecture documentation](../../../03.concepts/multi-tenancy.md) or the [Tenants page](../../../08.kestra-editions/03.tenants.md).
## Enabling multi-tenancy
diff --git a/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/workers.md b/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/workers.md
index d0ed83b7a2..4fdda1e1f9 100644
--- a/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/workers.md
+++ b/content/docs/09.administrator-guide/01.configuration/03.enterprise-edition/workers.md
@@ -4,7 +4,7 @@ title: Worker Isolation configuration
## Java security
-By default, Kestra uses a [shared worker](../../../01.architecture.md#worker) to handle workloads. This is fine for most use cases, but when you are using a shared Kestra instance between multiple teams, since the worker shares the same file system, this can allow people to access temporary files created by Kestra with powerful tasks like [Groovy](../../../../plugins/plugin-script-groovy/tasks/io.kestra.plugin.scripts.groovy.Eval.md), [Jython](../../../../plugins/plugin-script-jython/tasks/io.kestra.plugin.scripts.jython.Eval.md), etc...
+By default, Kestra uses a [shared worker](../../../03.concepts/worker.md) to handle workloads. This is fine for most use cases, but when you are using a shared Kestra instance between multiple teams, since the worker shares the same file system, this can allow people to access temporary files created by Kestra with powerful tasks like [Groovy](../../../../plugins/plugin-script-groovy/tasks/io.kestra.plugin.scripts.groovy.Eval.md), [Jython](../../../../plugins/plugin-script-jython/tasks/io.kestra.plugin.scripts.jython.Eval.md), etc...
You can use the following to opt-in to real isolation of file systems using advanced Kestra EE Java security:
diff --git a/content/docs/09.administrator-guide/01.configuration/04.others.md b/content/docs/09.administrator-guide/01.configuration/04.others.md
index 5d662c9832..de762a5631 100644
--- a/content/docs/09.administrator-guide/01.configuration/04.others.md
+++ b/content/docs/09.administrator-guide/01.configuration/04.others.md
@@ -1,5 +1,5 @@
---
-title: Others Kestra configuration
+title: Other Kestra configuration
---
## URL configuration
@@ -78,7 +78,7 @@ kestra:
```
### `kestra.variables.disable-handlebars`
-By default, [deprecated handlebars](../../05.developer-guide/03.variables/08.deprecated-handlebars/index.md) is disabled, it can be enabled by setting this option to `true`.
+By default, [deprecated handlebars](../../03.concepts/expression/08.deprecated-handlebars/index.md) is disabled, it can be enabled by setting this option to `true`.
### `kestra.variables.cache-enabled`
diff --git a/content/docs/09.administrator-guide/01.configuration/index.md b/content/docs/09.administrator-guide/01.configuration/index.md
index d4a50a90ed..9e4a8f8a94 100644
--- a/content/docs/09.administrator-guide/01.configuration/index.md
+++ b/content/docs/09.administrator-guide/01.configuration/index.md
@@ -38,6 +38,7 @@ The following queue types are available:
- Kafka that must be used with the Elasticsearch repository. Those are **only available inside the Enterprise Edition**.
To enable the PostgreSQL database queue, you need to add the following to your configuration files:
+
```yaml
kestra:
queue:
@@ -58,6 +59,7 @@ The following repository types are available:
- Elasticsearch that must be used with the Kafka queue. Those are **only available inside the Enterprise Edition**.
To enable the PostgreSQL database repository, you need to add the following to your configuration files:
+
```yaml
kestra:
repository:
@@ -69,8 +71,8 @@ Details about the database configuration can be found [here](./01.databases.md)
## Other Kestra configuration
-Other Kestra configuration options can be found [here](./05.others.md).
+Other Kestra configuration options can be found [here](./04.others.md).
## Micronaut configuration
-As Kestra is a Java-based application built with Micronaut, you can configure any Micronaut configuration options. More details [here](./04.micronaut.md).
+As Kestra is a Java-based application built with Micronaut, you can configure any Micronaut configuration options. More details [here](./06.micronaut.md).
diff --git a/content/docs/09.administrator-guide/02.deployment/01.docker.md b/content/docs/09.administrator-guide/02.deployment/01.docker.md
index 4df3bc3e94..e0917d2b07 100644
--- a/content/docs/09.administrator-guide/02.deployment/01.docker.md
+++ b/content/docs/09.administrator-guide/02.deployment/01.docker.md
@@ -19,7 +19,7 @@ Make sure you have already installed:
This will start all the dependencies with a pre-configured Kestra that is connected to everything!
-Kestra will start a *Standalone* server (all the different [servers](../../01.architecture.md) in one JVM).
+Kestra will start a *Standalone* server (all the different [servers](../../02.architecture/index.md) in one JVM).
This is clearly not meant for **production** workloads, but is certainly sufficient to test on a local computer.
The [configuration](../01.configuration/index.md) will be done inside the `KESTRA_CONFIGURATION` environment variable of the Kestra container. You can update the environment variable inside the Docker compose file, or pass it via the Docker command line argument.
diff --git a/content/docs/09.administrator-guide/02.deployment/02.kubernetes.md b/content/docs/09.administrator-guide/02.deployment/02.kubernetes.md
index 230c42077f..896d723dd0 100644
--- a/content/docs/09.administrator-guide/02.deployment/02.kubernetes.md
+++ b/content/docs/09.administrator-guide/02.deployment/02.kubernetes.md
@@ -22,7 +22,7 @@ helm install kestra kestra/kestra
## Details
You can change the default behavior and configure your cluster by changing the [default values](https://github.com/kestra-io/helm-charts/blob/master/charts/kestra/values.yaml).
-By default, the chart will only deploy one Kestra standalone [service](../../01.architecture.md) (all Kestra server components in only one pod) with only one replica.
+By default, the chart will only deploy one Kestra standalone [service](../../02.architecture/index.md) (all Kestra server components in only one pod) with only one replica.
You can also deploy each server independently, using these values:
```yaml
diff --git a/content/docs/09.administrator-guide/02.deployment/05.reverse-proxy.md b/content/docs/09.administrator-guide/02.deployment/05.reverse-proxy.md
index eac0086cbe..e6b0c7e31f 100644
--- a/content/docs/09.administrator-guide/02.deployment/05.reverse-proxy.md
+++ b/content/docs/09.administrator-guide/02.deployment/05.reverse-proxy.md
@@ -2,9 +2,9 @@
title: Kestra behind a reverse proxy
---
-If you prefer to host Kestra behind a reverse proxy, you should take care that Kestra use [Server Send Event (SSE)](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events) to display execution in real-time.
+If you want to host Kestra behind a reverse proxy, make sure to configure Kestra to use [Server Send Event (SSE)](https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events) to display executions in real-time.
-On some reverse proxy like Nginx, you need to disable buffering to enable real-time update.
+On some reverse proxies such as Nginx, you need to disable buffering to enable real-time updates.
---
diff --git a/content/docs/09.administrator-guide/03.monitoring/index.md b/content/docs/09.administrator-guide/03.monitoring/index.md
index fb0fd067e4..0216283a86 100644
--- a/content/docs/09.administrator-guide/03.monitoring/index.md
+++ b/content/docs/09.administrator-guide/03.monitoring/index.md
@@ -10,7 +10,7 @@ Failure alerts are non-negotiable. When a production workflow fails, you should
- [Email](../../../plugins/plugin-notifications/tasks/mail/io.kestra.plugin.notifications.mail.mailexecution.md)
-Technically, you can add custom failure alerts to each flow separately using the [`errors` tasks](../../02.tutorial/06.errors.md):
+Technically, you can add custom failure alerts to each flow separately using the [`errors` tasks](../../03.concepts/errors.md):
```yaml
id: onFailureAlert
@@ -36,7 +36,7 @@ errors:
However, this can lead to some boilerplate code if you start copy-pasting this `errors` configuration to multiple flows.
-To implement a centralized namespace-level alerting, we instead recommend a dedicated monitoring workflow with a notification task and a [Flow trigger](../../05.developer-guide/08.triggers/02.flow.md). Below is an example workflow that automatically sends a Slack alert as soon as any flow in a namespace `prod` fails or finishes with warnings.
+To implement a centralized namespace-level alerting, we instead recommend a dedicated monitoring workflow with a notification task and a [Flow trigger](../../03.concepts/triggers/flow-trigger.md). Below is an example workflow that automatically sends a Slack alert as soon as any flow in a namespace `prod` fails or finishes with warnings.
```yaml
id: failureAlertToSlack
@@ -190,9 +190,9 @@ Kestra exposes [Prometheus](https://prometheus.io/) metrics on the endpoint `/pr
You can leverage Kestra's internal metrics to configure custom alerts. Each metric provides multiple timeseries with tags allowing to track at least namespace & flow but also other tags depending on available tasks.
-Kestra metrics use the prefix `kestra`. This prefix can be changed using the `kestra.metrics.prefix` property in the [configuration options](../01.configuration/05.others.md#metrics-configuration).
+Kestra metrics use the prefix `kestra`. This prefix can be changed using the `kestra.metrics.prefix` property in the [configuration options](../01.configuration/04.others.md#metrics-configuration).
-Each task type can expose [custom metrics](../../03.concepts/02.executions.md#metrics) that will be also exposed on Prometheus.
+Each task type can expose [custom metrics](../../03.concepts/execution.md#metrics) that will be also exposed on Prometheus.
#### Worker
@@ -252,7 +252,7 @@ We'd love to see what dashboards you will build. Feel free to share a screenshot
## Kestra endpoints
-Kestra exposes internal endpoints on the management port (8081 by default) to provide status corresponding to the [server type](../../01.architecture.md#the-kestra-server-components):
+Kestra exposes internal endpoints on the management port (8081 by default) to provide status corresponding to the [server type](../../02.architecture/02.server-components.md):
* `/worker`: will expose all currently running tasks on this worker.
* `/scheduler`: will expose all currently scheduled flows on this scheduler with the next date.
diff --git a/content/docs/09.administrator-guide/04.servers.md b/content/docs/09.administrator-guide/04.servers.md
index e572579dab..beb3ec3b27 100644
--- a/content/docs/09.administrator-guide/04.servers.md
+++ b/content/docs/09.administrator-guide/04.servers.md
@@ -1,12 +1,12 @@
---
-title: Kestra server command
+title: Kestra server commands
---
Kestra leverages five different server components. The `kestra server` command allows to start them one by one, or run an all-inclusive standalone server.
## Separate server components
-### [Kestra Executor](../01.architecture.md#executor)
+### [Kestra Executor](../03.concepts/executor.md)
`./kestra server executor`
@@ -14,7 +14,7 @@ Kestra leverages five different server components. The `kestra server` command a
* `--skip-executions`: the list of execution identifiers to skip. Use it only for troubleshooting e.g. when an execution cannot be processed by Kestra.
-### [Kestra Indexer](../01.architecture.md#indexer)
+### [Kestra Indexer](../03.concepts/indexer.md)
`./kestra server indexer`
@@ -22,7 +22,7 @@ Kestra leverages five different server components. The `kestra server` command a
No special options for this server.
-### [Kestra Scheduler](../01.architecture.md#scheduler)
+### [Kestra Scheduler](../03.concepts/scheduler.md)
`./kestra server scheduler`
@@ -30,16 +30,16 @@ No special options for this server.
No special options for this server.
-### [Kestra Worker](../01.architecture.md#worker)
+### [Kestra Worker](../03.concepts/worker.md)
`./kestra server worker`
**Options:**
* `-t` or `--thread`: the number of threads that can handle tasks at the same time. By default, the worker will start 2 threads per CPU core available.
-* `-g` or `--worker-group`: the key of the worker group if using [Worker Group (EE)](../01.architecture.md#worker-group-ee).
+* `-g` or `--worker-group`: the key of the worker group if using [Worker Group (EE)](../03.concepts/worker-group.md).
-### [Kestra Webserver](../01.architecture.md)
+### [Kestra Webserver](../03.concepts/webserver.md)
`./kestra server webserver`
diff --git a/content/docs/10.plugin-developer-guide/02.runnable-task.md b/content/docs/10.plugin-developer-guide/02.runnable-task.md
index f4fc4b9bbc..a2fb846b54 100644
--- a/content/docs/10.plugin-developer-guide/02.runnable-task.md
+++ b/content/docs/10.plugin-developer-guide/02.runnable-task.md
@@ -2,7 +2,7 @@
title: Develop your RunnableTask
---
-Here are the instructions to develop the most common **Runnable Task**.
+Here are the instructions to develop the most common [Runnable Task](../03.concepts/runnable-tasks.md).
Here is a simple task example that reverse a string:
@@ -81,6 +81,7 @@ format: "{{outputs.previousTask.name}}"
```
You can declare as many properties as you want, all of these will be filled by Kestra executors.
+
You can use any serializable by [Jackson](https://github.com/FasterXML/jackson) for your properties (ex: Double, boolean, ...). You can create any class as long as the class is Serializable.
### Properties validation
@@ -172,7 +173,7 @@ To have a logger, you need to use this instruction, this will provide a logger f
```java
String render = runContext.render(format);
```
-In order to use [variables](../05.developer-guide/03.variables/01.index.md), you need to render the variables, aka: transform the properties with Pebble.
+In order to use [variables](../03.concepts/expression/01.index.md), you need to render the variables, aka: transform the properties with Pebble.
Just don't forget to render variables if you need to pass some output from previous variables.
You also need to add the annotation `@PluginProperty(dynamic = true)` in order to explain in the documentation that you can pass some dynamic variables.
@@ -221,7 +222,7 @@ public class ReverseString extends Task implements RunnableTask:/api/v1/executions/webhook///`. Here is an example: `http://localhost:8080/api/v1/executions/webhook/dev/hello-world/secretWebhookKey42`.
@@ -114,7 +114,7 @@ flow.execute('dev', 'hello-world', {'greeting': 'hello from Python'})
The `ForEachItem` task allows you to iterate over a list of items and run a subflow for each item, or for each batch containing multiple items. This is useful when you want to process a large list of items in parallel, e.g. to process millions of records from a database table or an API payload.
-The `ForEachItem` task is a **[Flowable](../02.tutorial/05.flowable.md)** task, which means that it can be used to define the flow logic and control the execution of the flow.
+The `ForEachItem` task is a **[Flowable](../01.tutorial/05.flowable.md)** task, which means that it can be used to define the flow logic and control the execution of the flow.
Syntax:
diff --git a/content/docs/16.faq/pebble.md b/content/docs/16.faq/pebble.md
index d0e9dd8a49..1b2ce2be90 100644
--- a/content/docs/16.faq/pebble.md
+++ b/content/docs/16.faq/pebble.md
@@ -54,14 +54,14 @@ tasks:
## How to format a date in Pebble?
-Pebble can be very useful to make small transformation on the fly - without the need to use Python or some dedicated programming language.
+Pebble can be very useful to make small transformation on the fly - without the need to use Python or some dedicated programming language.
For instance, we can use the `date` function to format date values: `'{{ inputs.my_date | date("yyyyMMdd") }}'`
-You can find more documentation on the `date` function [in the Variables section of the Developer Guide](../05.developer-guide/03.variables/03.filter/date.md)
+You can find more documentation on the `date` function on the [Expressions page](../03.concepts/expression/03.filter/date.md)
### Coalesce operator for trigger or manual execution
-Most of the time, a flow will be triggered automatically. Either on schedule or based on external events. It’s common to use the date of the execution to process the corresponding data and make the flow dependent on time.
+Most of the time, a flow will be triggered automatically. Either on schedule or based on external events. It’s common to use the date of the execution to process the corresponding data and make the flow dependent on time.
With Pebble you can use the `trigger.date` to get the date of the executed trigger.
Still, sometimes you want to manually execute a flow. Then the `trigger.date` variable won’t work anymore. For this you can use the `execution.startDate` variable that returns the execution start date.
diff --git a/content/docs/16.faq/variables.md b/content/docs/16.faq/variables.md
index ac2ec2b9ea..3af155b11f 100644
--- a/content/docs/16.faq/variables.md
+++ b/content/docs/16.faq/variables.md
@@ -4,7 +4,7 @@ title: Variables FAQ
## How to escape some block in a Pebble syntax to ensure that it won't be parsed?
-To ensure that a block of code won't be parsed by Pebble, you can use the `{% raw %}` and `{% endraw %}` [Pebble tags](../05.developer-guide/03.variables/06.tag/raw.md). For example, the following Pebble expression will return the string `{{ myvar }}` instead of the value of the `myvar` variable:
+To ensure that a block of code won't be parsed by Pebble, you can use the `{% raw %}` and `{% endraw %}` [Pebble tags](../03.concepts/expression/06.tag/raw.md). For example, the following Pebble expression will return the string `{{ myvar }}` instead of the value of the `myvar` variable:
```yaml
{% raw %}{{ myvar }}{% endraw %}
@@ -15,12 +15,12 @@ To ensure that a block of code won't be parsed by Pebble, you can use the `{% ra
## In which order are inputs and variables resolved?
-[Variables](../05.developer-guide/03.variables/01.index.md) are rendered recursively, meaning that if a variable contains another variable, the inner variable will be resolved first.
-
-[Inputs](../05.developer-guide/04.inputs.md) are resolved first, even before the execution starts. In fact, if you try to create a flow with an invalid input value, the execution will not be created.
+[Inputs](../03.concepts/inputs.md) are resolved first, even before the execution starts. In fact, if you try to create a flow with an invalid input value, the execution will not be created.
Therefore, you can use inputs within variables, but you can't use variables or Pebble expressions within inputs.
+[Variables](../03.concepts/expression/01.index.md) are rendered recursively, meaning that if a variable contains another variable, the inner variable will be resolved first.
+
When it comes to triggers, they are handled similarly to inputs as they are known before the execution starts (they trigger the execution). This means that you can't use inputs (unless they have `defaults` attached) or variables within triggers, but you can use trigger variables within `variables`.
To make it clearer, let's look at some examples.
@@ -114,7 +114,7 @@ triggers:
## Can I transform variables with Pebble expressions?
-Yes. Kestra uses [Pebble Templates](https://pebbletemplates.io/) along with the execution context to render **dynamic properties**. This means that you can use Pebble expressions (such as [filters](../05.developer-guide/03.variables/03.filter/index.md), [functions](../05.developer-guide/03.variables/04.function/index.md), and [operators](../05.developer-guide/03.variables/05.operator/index.md)) to transform [inputs](../05.developer-guide/04.inputs.md) and [variables](../05.developer-guide/03.variables/01.index.md).
+Yes. Kestra uses [Pebble Templates](https://pebbletemplates.io/) along with the execution context to render **dynamic properties**. This means that you can use Pebble expressions (such as [filters](../03.concepts/expression/03.filter/index.md), [functions](../03.concepts/expression/04.function/index.md), and [operators](../03.concepts/expression/05.operator/index.md)) to transform [inputs](../03.concepts/inputs.md) and [variables](../03.concepts/expression/01.index.md).
The example below illustrates how to use variables and Pebble expressions to transform string values in dynamic task properties:
diff --git a/content/docs/index.md b/content/docs/index.md
index e24d482122..6da371f914 100644
--- a/content/docs/index.md
+++ b/content/docs/index.md
@@ -4,7 +4,7 @@ title: 📓 Welcome to Kestra
Kestra is a universal open-source orchestrator that makes both **scheduled** and **event-driven workflows** easy. By bringing Infrastructure as Code best practices to data, process, and microservice orchestration, you can build reliable workflows and manage them with confidence.
-In just a few lines of code, you can [create a flow](./05.developer-guide/01.flow.md) directly from the UI. Thanks to the declarative YAML interface for defining orchestration logic, business stakeholders can participate in the workflow creation process. Kestra offers a versatile set of language-agnostic developer tools while simultaneously providing an intuitive user interface tailored for business professionals. The YAML definition gets automatically adjusted any time you make changes to a workflow from the UI or via an API call. Therefore, the orchestration logic is always managed declaratively in code, even if some workflow components are modified in other ways (UI, CI/CD, Terraform, API calls).
+In just a few lines of code, you can [create a flow](./03.concepts/flow.md) directly from the UI. Thanks to the declarative YAML interface for defining orchestration logic, business stakeholders can participate in the workflow creation process. Kestra offers a versatile set of language-agnostic developer tools while simultaneously providing an intuitive user interface tailored for business professionals. The YAML definition gets automatically adjusted any time you make changes to a workflow from the UI or via an API call. Therefore, the orchestration logic is always managed declaratively in code, even if some workflow components are modified in other ways (UI, CI/CD, Terraform, API calls).
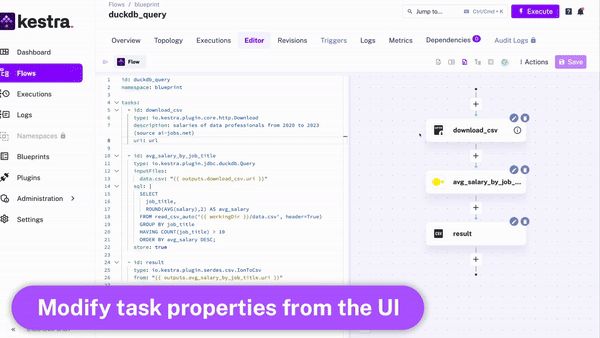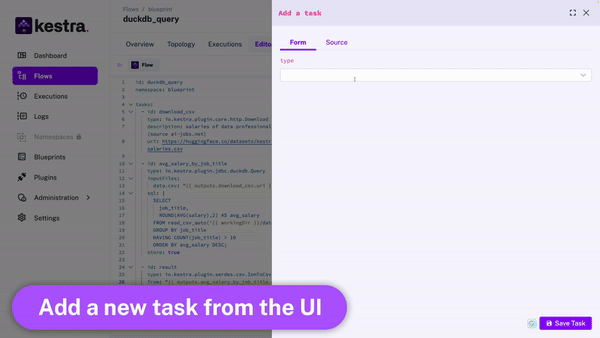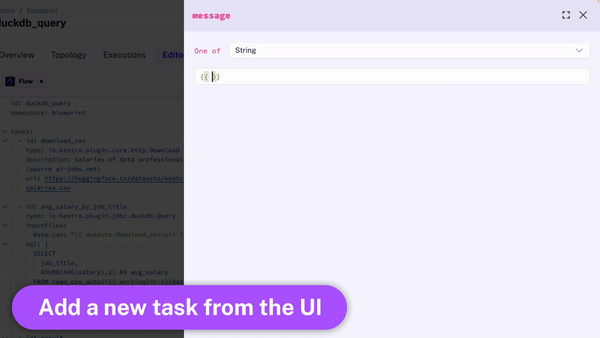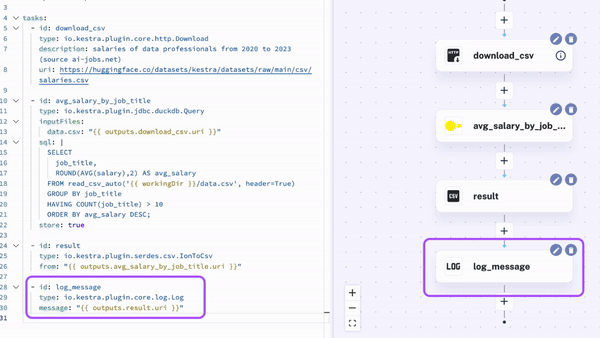
@@ -16,7 +16,7 @@ In just a few lines of code, you can [create a flow](./05.developer-guide/01.flo
**Real-time & event-driven**: Kestra is built with real-time use cases in mind. You can create flows, run them, and see all their logs in real-time. Kestra can be used along with Kafka to process a large number of events at any scale.
-**Scalable architecture as a foundation**: Kestra's [architecture](./01.architecture.md) is built with proven and time-tested technologies. The [Enterprise Edition](/enterprise) can handle millions of executions per second without breaking a sweat, thanks to a backend built on top of Kafka and Elasticsearch.
+**Scalable architecture as a foundation**: Kestra's [architecture](./02.architecture/index.md) is built with proven and time-tested technologies. The [Enterprise Edition](/enterprise) can handle millions of executions per second without breaking a sweat, thanks to a backend built on top of Kafka and Elasticsearch.
**API-first design**: Every action in Kestra is API-driven. In contrast to Python-based workflows that heavily rely on client-side implementation in a single language, Kestra's workflow definition is a config that gets sent as a payload to an API call.
- You define in a YAML config **which tasks** do you want to orchestrate, and **how**, and that config is sent to Kestra's backend via an API call.
@@ -24,11 +24,11 @@ In just a few lines of code, you can [create a flow](./05.developer-guide/01.flo
**Portability**: Kestra's workflows are programming-language agnostic. Your tasks can be written in Python, R, Node.js, Julia, Rust, Bash or Powershell. You can also extend the platform via custom plugins, triggers and tasks.
-**Declarative & imperative**: We believe that declarativeness is a spectrum and you decide about the degree of how declarative or imperative you want your workflows to be. You can write as simple or as [complex](./05.developer-guide/02.tasks.md#flowable-tasks) workflows as you wish.
+**Declarative & imperative**: We believe that declarativeness is a spectrum and you decide about the degree of how declarative or imperative you want your workflows to be. You can write as simple or as [complex](./03.concepts/tasks.md#flowable-tasks) workflows as you wish.
**Separation of orchestration and business logic**: Mixing the two can result in a complicated data platform that ties you to a specific platform. Kestra can orchestrate business logic written in any language or platform without you having to make ANY modifications to your code. No Python decorators are required, and no need to worry about breaking your orchestration system due to misaligned Python package dependencies.
-**Extensible**: Kestra is built on top of a plugins ecosystem. You can use an existing plugin from our [plugin library](../plugins/index.md) or build your [own](./10.plugin-developer-guide/index.md). You don't even need to know much of Java to build your own plugin — as long as your custom script can be packaged into a Docker container, you can use it similarly to [script plugins](https://github.com/kestra-io/plugin-scripts).
+**Extensible**: Kestra is built on top of a plugins ecosystem. You can use an existing plugin from our [plugin library](../plugins/index.md) or build your [own](./10.plugin-developer-guide/index.md). You don't even need to know much of Java to build your own plugin — as long as your custom script can be packaged into a Docker container, you can use it similarly to [script plugins](./05.developer-guide/03.scripts.md).
**Cloud-native**: Built with the cloud in mind, Kestra uses cloud-native technologies and allows you to [deploy your server anywhere](./09.administrator-guide/02.deployment/index.md).