An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Textual Inversion is a method to train a pretrained text-to-image model to generate images of a specific unique concept, modify their appearance, or compose them in new roles and novel scenes. It does not require lots of training data, only 3-5 images of a user-provided concept. It does not update the weights of the text-to-image model to learn the new concept, but learns it through new "words" in the embedding space of a frozen text encoder. These new "words" can be composed into natural language sentences, making it plausible to generate personalized visual content.
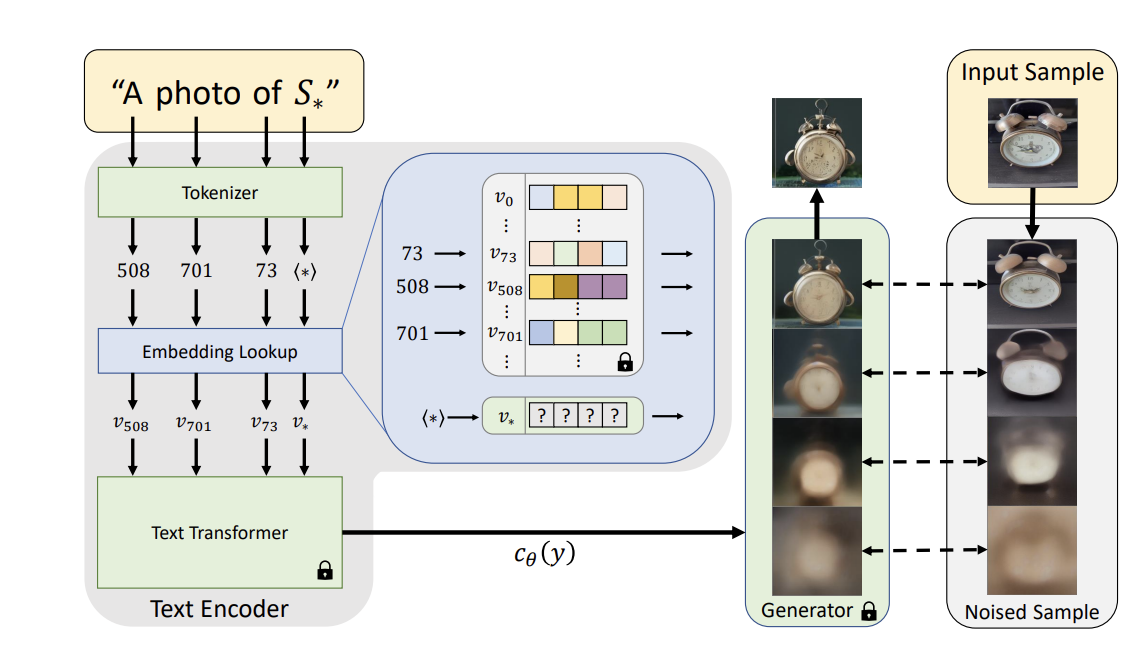
Figure 1. The Diagram of Textual Inversion. [1]
As shown above, the textual inversion method consists of the following steps:
- First, it creates a text prompt following some template like A photo of
$S_{*}$ , where$S_{*}$ is a placeholder for the new "word" to be learned. - Then, the tokenizer will assign a unique index to this placeholder. This index corresponds to a single embedding vector
$v_{*}$ in the embedding lookup table which is trainable, while all other parameters are non-trainable. - Lastly, compute the loss function of the generator (e.g., stable diffusion model) and the gradients of the single embedding vector, then update the weights in
$v_{*}$ during training steps.
Make sure the following frameworks are installed.
- mindspore 2.1.0 (Ascend 910) / mindspore 2.2.1 (Ascend 910*)
- openmpi 4.0.3 (for distributed mode)
Enter the example/stable_diffusion_xl folder and run
pip install -r requirement.txtDownload the official pre-train weights from huggingface, convert the weights from .safetensors format to Mindspore .ckpt format, and put them to ./checkpoints/ folder. Please refer to SDXL GETTING_STARTED.md for detailed steps.
Depending on the concepts that we want the finetuned model to learn, the datasets can be divided into two groups: the datasets of the same object and the datasets of the same style.
For object dataset, we use the cat-toy dataset. The dataset contains six images which are shown below.

Figure 2. The cat-toy example dataset for finetuning.
For style dataset, we use the test set of the chinese-art dataset, which contains 20 images. Some example images are shown below:

Figure 3. The example images from the test set of the chinese-art dataset
For the details of downloading chinese-art dataset, please refer to LoRA: Text-image Dataset Preparation.
The finetuning images of the same dataset should be placed under the same folder, like this:
dir-to-images
├── img1.jpg
├── img2.jpg
├── img3.jpg
├── img4.jpg
└── img5.jpg
We name the folder containing the object dataset as datasets/cat_toy, and the folder containing the test set of the chinese_art dataset as datasets/chinese_art.
The key arguments for finetuning experiments are explained as follows:
-
num_vectors: the number of trainable text embeddings for text encoder. Note that sd-xl has two text encoders. Larger value indicates larger capacity. -
total_step: the number of training steps. -
gradient_accumulation_steps: the number of gradient accumulation steps. When it equals to one, no gradient accumulation will be applied. -
placeholder_token: the token$S_{*}$ . -
learnable_property: one of ["object", "style", "face"]
The standalone training command for finetuning on the cat-toy dataset:
python train_textual_inversion.py \
--data_path datasets/cat_toy \
--save_path runs/cat_toy \
--infer_during_train True \
--gradient_accumulation_steps 4 \
--num_vectors 10 \
--total_step 3000 \
--placeholder_token "<cat-toy>" \
--learnable_property "object"The standalone training command for finetuning on the chinese-art dataset:
python train_textual_inversion.py \
--data_path datasets/chinese_art \
--save_path runs/chinese_art \
--infer_during_train True \
--gradient_accumulation_steps 4 \
--num_vectors 2 \
--total_step 2000 \
--placeholder_token "<chinese-art>" \
--learnable_property "style"Notes:
- Increasing the number of training steps
--total_stepor the number of trainable tokens--num_vectorsincreases the risk of overfitting. - By default, we use random initialization for the new learnable token embeddings. However, we also allow to initialize the new learnable token embeddings using an existing token's embedding. Check
--initializer_tokenintrain_textual_inversion.pyfor more details. - Setting
--infer_during_traintoTruewill make an inference for everyargs.infer_intervalsteps (by default 500 steps). Setting it toFalsecan save some trainig time.
Notice that the training command above gets finetuned textual inversion weights in the specified save_path. Now we could use the inference command to generate images on a given prompt. Assume that the pretrained ckpt path is checkpoints/sd_xl_base_1.0_ms.ckpt and the trained textual inversion ckpt path is runs/<dataset>/SD-XL-base-1.0_x_ti.ckpt, examples of inference command are as below.
-
Run with the cat-toy learned embedding
export MS_PYNATIVE_GE=1 python demo/sampling_without_streamlit.py \ --task txt2img \ --config configs/training/sd_xl_base_finetune_textual_inversion.yaml \ --weight checkpoints/sd_xl_base_1.0_ms.ckpt \ --textual_inversion_weight runs/cat_toy/SD-XL-base-1.0_3000_ti.ckpt \ --prompt "a <cat-toy> backpack" \ --device_target Ascend \ --num_cols 4
-
Run with the chinese-art learned embedding
export MS_PYNATIVE_GE=1 python demo/sampling_without_streamlit.py \ --task txt2img \ --config configs/training/sd_xl_base_finetune_textual_inversion.yaml \ --weight checkpoints/sd_xl_base_1.0_ms.ckpt \ --textual_inversion_weight runs/chinese_art/SD-XL-base-1.0_2000_ti.ckpt \ --prompt "a dog in <chinese-art> style" \ --device_target Ascend \ --num_cols 4
It is also recommended to run inference with an interactive app via streamlit. Please revise the VERSION2SPECS in demo/sampling.py as the example below (Note that config and textual_inversion_weight are modified):
"SDXL-base-1.0": {
"H": 1024,
"W": 1024,
"C": 4,
"f": 8,
"is_legacy": False,
"config": "configs/training/sd_xl_base_finetune_textual_inversion.yaml",
"ckpt": "checkpoints/sd_xl_base_1.0_ms.ckpt",
"textual_inversion_weight": "runs/chinese_art/SD-XL-base-1.0_2000_ti.ckpt", # or path to another textual inversion weight
},Then specify the prompt as "a dog in <chinese-art> style" in __main__ of demo/sampling.py and run:
export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python
streamlit run demo/sampling.py --server.port <your_port>The generated images using the prompt "a <cat-toy> backpack" are show below:

Figure 4. The generated images.
The generated images using the prompt "a dog in <chinese-art> style" are show below:

Figure 5. The generated images.
[1] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, Daniel Cohen-Or: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. ICLR 2023