Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Tune-A-Video is a method for one-shot video tuning task. This task involves finetuning a pretrained T2I (Text-to-Image) model (e.g., Stable Diffusion) on one reference video to generate an edited video based on an edited text prompt. For example, given a reference video with the text prompt "A man is skiing", as shown below, the authors finetuned the Text-to-Image model on this reference video. The resulted Text-to-Video model will generates another video based the text prompt "Spider Man is skiing on the beach, cartoon style".
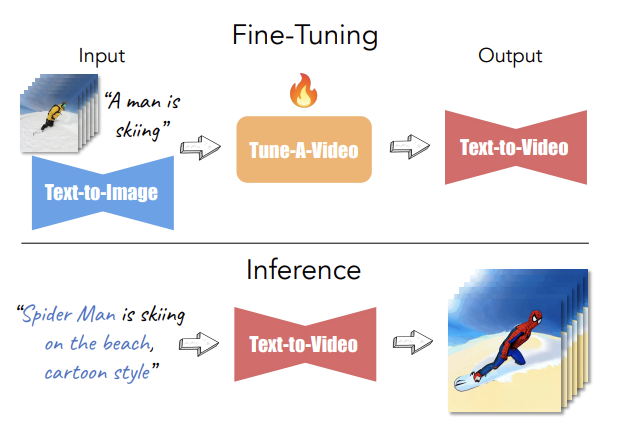
Figure 1. The diagram of one-shot video tuning task. [1]

Figure 2. The diagram of Tune-A-Video. [1]
The picture above shows the method proposed in Tune-A-Video paper. First, the authors designed a sparse spatial-temporal attention layer to model the spatial-temporal relations efficienly. They replaced the first self-attention layer in the Transformer block inside the UNet by their custom spatial-temporal attention layer (ST-Attn). They also inserted another temporal attention layer after the FeedForward layer to further learn the temporal relations. Secondly, they proposed to use DDIM inverted noise from the reference video latent features as the input to the UNet during inference. It improves the spatial-temporal consistency of the generated video compared with the reference video.
With two techniques above, Tune-A-Video achieves high flexibility and fidelity in text-based video editing task with a small computation cost.
Please make sure the following frameworks are installed.
- mindspore >= 1.9 [install] (2.0 is recommended for the best performance.)
- python >= 3.7
- opencv (for video frame loading)
- openmpi 4.0.3 (for distributed training/evaluation) [install]
Install the dependent packages by running:
pip install -r requirements.txtPlease download a video file from here. For example, we can download the man-skiing.mp4 file and place it under videos/. We will use "A man is skiing" as its text prompt.
Given the different versions of pretrained Stable Diffusion model, we recommend you to refer to configs/train/train_config_tuneavideo_v1.yaml for SD v1.5, and configs/train/train_config_tuneavideo_v2.yaml for SD v2.0 and SD v2.1. Since SD V1.5 has not been supported with Flash-Attention yet, which affect its maximum number of frames for finetuning, we mainly use SD V2(2.1) as examples in this tutorial.
Please change the three items according to your data path and the memory budget.
video_path: "videos/man-skiing.mp4"
prompt: "a man is skiing"
num_frames: 12 # use 24 (910B) or 12 (910A)Notes:
- Lower number of frames leads to less memory consumption.
- Finetuning SD V1.5 with vanilla attention instead of Flash-Attention is feasible now, as long as the user reduces the number of frames to no greater than 12 frames on 910B and 4 frames on 910A.
- Changing
version: "2.0"toversion: "2.1"intrain_config_tuneavideo_v2.yamlallows fintuning based on SD v2.1 model.
The training command for Tune-A-Video based SD v2 is:
python train_tuneavideo.py --train_config configs/train/train_config_tuneavideo_v2.yaml --output output_path/Running this commond will finetune the SD 2.0 model for 500 steps at a constant learning rate 3e-5. The resulted model will be saved in output_path/ckpt. The training script takes about 10 mins for graph compilation and 30 mins for training on a single card of 910A (30GB memory).
python inference_tuneavideo.py \
--config configs/v2-train-tuneavideo.yaml \
--version "2.0" \
--video_path "videos/man-skiing.mp4" \
--num_frames 12 \ # change to 24 if finetuned with 24 frames on 910B
--prompt "Wonderwoman is skiing" \
--ckpt_path output_path/ckpt/sd-500.ckpt \
--output_path output/We show the generated video in GIF format:

Figure 3. The generated video from the prompt "Wonderwoman is skiing".
- support Flash-Attention with SD v1.5.